Всероссийский заочный
финансово-экономический институт
Филиал в г. Барнауле
Кафедра Математики и Информатики
Контрольная работа по Эконометрике
Вариант 5
|
Исполнитель:
|
|
Факультет:
|
|
Специальность:
|
|
Группа:
|
|
Руководитель:
|
Барнаул
2008
Задача 1
По предприятиям легкой промышленности региона получена информация,
характеризующая зависимость объема выпуска продукции (Y, млн. руб.) от объема
капиталовложений (X, млн. руб.).
|
X
|
31
|
23
|
38
|
47
|
46
|
49
|
4120
|
32
|
46
|
24
|
|
Y
|
38
|
26
|
40
|
45
|
51
|
49
|
34
|
35
|
42
|
24
|
Требуется:
1.
Найти параметры уравнения линейной регрессии, дать
экономическую интерпретацию коэффициента регрессии.
2.
Вычислить остатки; найти остаточную сумму квадратов;
оценить дисперсию остатков 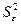 ; построить график остатков.
; построить график остатков.
3.
Проверить выполнение предпосылок МНК.
4.
Осуществить проверку значимости параметров уравнения
регрессии с помощью t-критерия Стьюдента (α=0,05).
5.
Вычислить коэффициент детерминации, проверить
значимость уравнения регрессии с помощью F- критерия Фишера (α=0,05), найти среднюю относительную ошибку
аппроксимации. Сделать вывод о качестве модели.
6.
Осуществить прогнозирование среднего значения показателя
Y при уровне значимости α=0,1 если прогнозное
значение фактора X составит 80% от его максимального значения.
7.
Представить графически: фактические и модельные
значения Y, точки прогноза.
8. Составить
уравнения нелинейной регрессии:
-
гиперболической;
-
степенной;
-
показательной.
Привести графики
построенных уравнений регрессии.
9. Для
указанных моделей найти коэффициенты детерминации и средние относительные
ошибки аппроксимации. Сравнить модели по этим характеристикам и сделать вывод.
Решение:
1.
Уравнение линейной регрессии имеет вид: 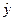 = а0 + а1x.
= а0 + а1x.
Построим линейную модель.
Для удобства выполнения расчетов предварительно упорядочим
всю таблицу исходных данных по возрастанию факторной переменной Х (Данные => Сортировка). ( рис. 1).

Рис. 1. Сортировка данных.
Используем программу
РЕГРЕССИЯ и найдем коэффициенты модели.
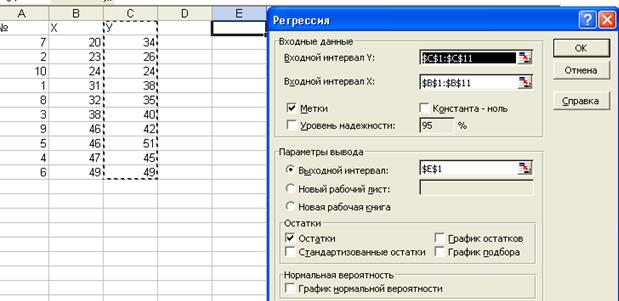 Результаты вычислений представлены в таблицах
2-5.
Результаты вычислений представлены в таблицах
2-5.
Таблица 2.
|
|
ВЫВОД
ИТОГОВ
|
|
|
|
|
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
|
|
|
Множественный
R
|
0,891531
|
|
|
|
|
R-квадрат
|
0,794827
|
|
|
|
|
Нормированный
R-квадрат
|
0,76918
|
|
|
|
|
Стандартная
ошибка
|
4,304314
|
|
|
|
|
Наблюдения
|
10
|
|
|
Таблица 3.
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
574,183
|
574,183
|
30,99148
|
0,00053
|
|
|
Остаток
|
8
|
148,217
|
18,52712
|
|
|
|
|
Итого
|
9
|
722,4
|
|
|
|
|
Таблица 4.
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
|
Y-пересечение
|
12,70755
|
4,811671
|
2,640984
|
0,029668
|
1,611806
|
23,80329
|
1,611806
|
23,80329
|
|
|
Х
|
0,721698
|
0,129639
|
5,567
|
0,00053
|
0,422751
|
1,020645
|
0,422751
|
1,020645
|
|
Таблица 5.
|
ВЫВОД
ОСТАТКА
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное У
|
Остатки
|
|
1
|
27,14151
|
6,858491
|
|
2
|
29,3066
|
-3,3066
|
|
3
|
30,0283
|
-6,0283
|
|
4
|
35,08019
|
2,919811
|
|
5
|
35,80189
|
-0,80189
|
|
6
|
40,13208
|
-0,13208
|
|
7
|
45,90566
|
-3,90566
|
|
8
|
45,90566
|
5,09434
|
|
9
|
46,62736
|
-1,62736
|
|
10
|
48,07075
|
0,929245
|
Коэффициенты модели содержатся в таблице 4 (столбец Коэффициенты). Таким образом, модель
построена и ее уравнение имеет вид Yт = 2,70755+0,721698Х.
Коэффициент регрессии b=0,721698, следовательно, при
увеличении времени разговора с продавцом (Х) на 1 минуту сумма покупки (Y) увеличивается в среднем на 0,721698
ден. ед.
Свободный член а=12,70755, в данном уравнении не имеет
реального смысла.
2. Вычислить остатки; найти остаточную
сумму квадратов; оценить дисперсию остатков S²e; построить график остатков.
Остатки модели Ei=уi-уti содержатся в столбце Остатки итогов программы РЕГРЕССИЯ (таблица 5).
Программой РЕГРЕССИЯ найдены также остаточная сумма квадратов
SSост=148,217 и
дисперсия остатков MS=18,52712 (таблица 3).
Для построения графика остатков нужно выполнить следующие
действия:
·
Вызвать
Матер Диаграмм, выбрать тип диаграммы Точечная (с соединенными точками).
·
Для
указания данных для построения диаграммы зайти во вкладку Ряд, нажать кнопку Добавить;
в качестве значений Х указать исходные данные Х (таблица 1);значения Y - остатки ( таблица 5).
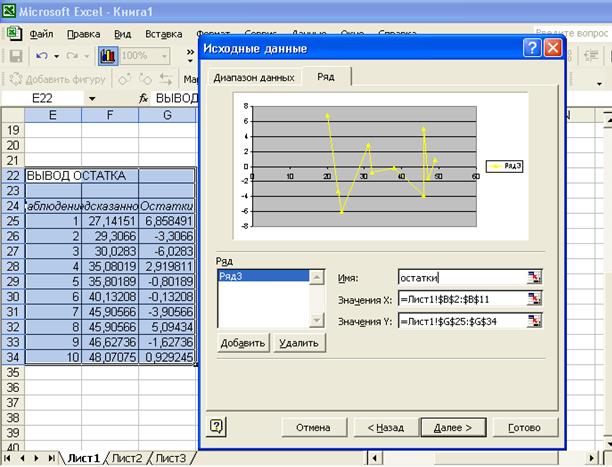
В результате получим график
остатков.
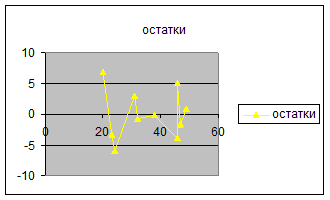
3. Проверить выполнение предпосылок МНК.
Предпосылками построения классической линейной регрессионной
модели являются четыре условия, известные как условия Гаусса-Маркова.
·
В
уравнении линейной модели Y=a+b*X+ε слагаемое ε -
случайная величина, которая выражает случайный характер результирующей
переменной Y.
·
Математическое
ожидание случайного члена в любом наблюдении равно нулю, а дисперсия постоянна.
·
Случайные члены
для любых двух разных наблюдений независимы (некоррелированы).
·
Распределение
случайного члена является нормальными.
1) Проведем проверку
случайности остаточной компоненты по критерию повторных точек.
Количество повторных точек
определим по графику остатков: p=5
Вычислим критическое значение
по формуле:
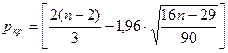 . При
. При 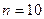 найдем
найдем 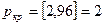
Схема критерия:

Сравним 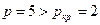 , следовательно, свойство случайности для ряда остатков
выполняется.
, следовательно, свойство случайности для ряда остатков
выполняется.
1.
Равенство нулю
математического ожидания остаточной компоненты для линейной модели,
коэффициенты которой определены по МНК, выполняется автоматически. С помощью
функции СРЗНАЧ для ряда остатков можно проверить: 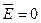 .
.
Свойство постоянства дисперсии остаточной компоненты проверим по
критерию Гольдфельда–Квандта.
В упорядоченных по возрастанию переменной X исходных данных
() выделим первые 4 и последние 4 уровня, средние 2 уровня не
рассматриваем.
С помощью программы РЕГРЕССИЯ построим модель по первым четырем
наблюдениям (регрессия-1), для этой модели остаточная сумма квадратов 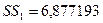 .
.
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
107,7894737
|
107,7894737
|
15,67347
|
0,15751
|
|
|
Остаток
|
1
|
6,877192982
|
6,877192982
|
|
|
|
|
Итого
|
2
|
114,6666667
|
|
|
|
|
С помощью программы РЕГРЕССИЯ построим модель по последним четырем
наблюдениям (регрессия-2), для этой модели остаточная сумма квадратов 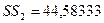 .
.
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
4,166666667
|
4,166666667
|
0,186916
|
0,707647
|
|
|
Остаток
|
2
|
44,58333333
|
22,29166667
|
|
|
|
|
Итого
|
3
|
48,75
|
|
|
|
|
Рассчитаем статистику критерия: 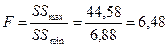 .
.
Критическое значение при уровне значимости 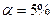 и числах степеней свободы
и числах степеней свободы 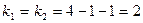 составляет
составляет 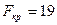 .
.
Схема критерия:

Сравним 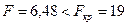 , следовательно, свойство постоянства дисперсии остатков
выполняется, модель гомоскедастичная.
, следовательно, свойство постоянства дисперсии остатков
выполняется, модель гомоскедастичная.
2.
Для проверки независимости
уровней ряда остатков используем критерий Дарбина–Уотсона
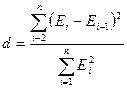 .
.
Предварительно по столбцу остатков с помощью функции СУММКВРАЗН
определим 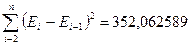 ; используем найденную программой РЕГРЕССИЯ сумму
квадратов остаточной компоненты
; используем найденную программой РЕГРЕССИЯ сумму
квадратов остаточной компоненты 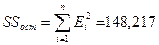 .
.
Таким образом,
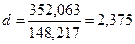
Схема критерия:

Полученное
значение d=2,375, что свидетельствует об отрицательной корреляции. Перейдем
к d’=4-d=1,62 и сравним ее с двумя критическими уровнями d1=0,88 и d2=1,32.
D’=1,62
лежит в интервале от d2=1,32 до 2, следовательно, свойство независимости остаточной
компоненты выполняются.
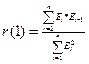 . С помощью функции
СУММПРОИЗВ найдем для остатков
. С помощью функции
СУММПРОИЗВ найдем для остатков 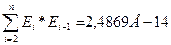 , следовательно r(1)=2,4869Е-14/148,217=1,67788Е-16.
, следовательно r(1)=2,4869Е-14/148,217=1,67788Е-16.
Критическое значение
для коэффициента автокорреляции определяется как отношение 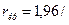 Ön и составляет для данной задачи
Ön и составляет для данной задачи 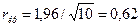
Сравнения показывает,
что çr(1)= 1,67788Е-16<0,62,
следовательно, ряд остатков некоррелирован.
4) Соответствие ряда остатков нормальному закону распределения
проверим с помощью 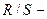 критерия:
критерия:
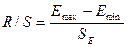 .
.
С помощью функций МАКС и МИН для ряда остатков определим 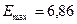 ,
, 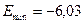 . Стандартная ошибка модели найдена программой РЕГРЕССИЯ и
составляет
. Стандартная ошибка модели найдена программой РЕГРЕССИЯ и
составляет 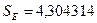 . Тогда:
. Тогда:
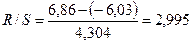
Критический интервал определяется по таблице критических границ
отношения  и при составляет (2,67;
3,57).
и при составляет (2,67;
3,57).
Схема критерия:
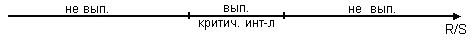
2,995 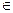 (2,67; 3,57), значит,
для построенной модели свойство нормального распределения остаточной компоненты
выполняется.
(2,67; 3,57), значит,
для построенной модели свойство нормального распределения остаточной компоненты
выполняется.
Проведенная проверка предпосылок регрессионного анализа показала,
что для модели выполняются все условия Гаусса–Маркова.
4. Осуществить проверку
значимости параметров уравнения регрессии с помощью t–критерия
Стьюдента (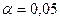 ).
).
t–статистика
для коэффициентов уравнения приведены в таблице 4.
Для свободного коэффициента 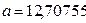 определена статистика
определена статистика 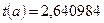 .
.
Для коэффициента регрессии 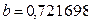 определена статистика
определена статистика 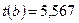 .
.
Критическое значение 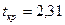 найдено для уравнения
значимости и числа степеней
свободы
найдено для уравнения
значимости и числа степеней
свободы 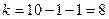 с помощью функции СТЬЮДРАСПОБР.
с помощью функции СТЬЮДРАСПОБР.
Схема критерия:

Сравнение показывает:
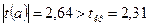 , следовательно, свободный коэффициент a является значимым.
, следовательно, свободный коэффициент a является значимым.
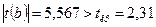 , значит, коэффициент регрессии b является значимым.
, значит, коэффициент регрессии b является значимым.
5. Вычислить коэффициент детерминации, проверить значимость
уравнения регрессии с помощью F–критерия
Фишера (), найти среднюю относительную ошибку аппроксимации. Сделать
вывод о качестве модели.
Коэффициент детерминации R–квадрат определен программой РЕГРЕССИЯ и составляет 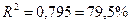 .
.
Таким образом, вариация объема выпуска продукции Y на 79,5%
объясняется по полученному уравнению вариацией объема капиталовложений X.
Проверим значимость полученного уравнения с помощью F–критерия Фишера.
F–статистика
определена программой РЕГРЕССИЯ (таблица 3)
и составляет 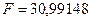 .
.
Критическое значение 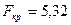 найдено для
уровня значимости и чисел степеней свободы
найдено для
уровня значимости и чисел степеней свободы 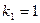 ,
, 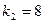 .
.
Схема критерия:

Сравнение показывает: 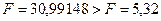 ; следовательно, уравнение модели является значимым, его
использование целесообразно, зависимая переменная Y достаточно
хорошо описывается включенной в модель факторной переменной Х.
; следовательно, уравнение модели является значимым, его
использование целесообразно, зависимая переменная Y достаточно
хорошо описывается включенной в модель факторной переменной Х.
Для вычисления средней относительной ошибки аппроксимации рассчитаем
дополнительный столбец относительных погрешностей, которые вычислим по формуле 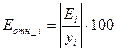 с помощью функции ABS
(таблица 6).
с помощью функции ABS
(таблица 6).
|
ВЫВОД ОСТАТКА
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
Отн. Погр-ти
|
|
1
|
27,14150943
|
6,858490566
|
20,17%
|
|
2
|
29,30660377
|
-3,306603774
|
12,72%
|
|
3
|
30,02830189
|
-6,028301887
|
25,12%
|
|
4
|
35,08018868
|
2,919811321
|
7,68%
|
|
5
|
35,80188679
|
-0,801886792
|
2,29%
|
|
6
|
40,13207547
|
-0,132075472
|
0,33%
|
|
7
|
45,90566038
|
-3,905660377
|
9,30%
|
|
8
|
45,90566038
|
5,094339623
|
9,99%
|
|
9
|
46,62735849
|
-1,627358491
|
3,62%
|
|
10
|
48,07075472
|
0,929245283
|
1,90%
|
По столбцу относительных погрешностей найдем среднее значение 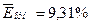 (функция СРЗНАЧ).
(функция СРЗНАЧ).
Схема проверки:

Сравним: 9,31% < 15%, следовательно, модель является точной.
Вывод: на основании
проверки предпосылок МНК, критериев Стьюдента и Фишера и величины коэффициента
детерминации модель можно считать полностью адекватной. Дальнейшее
использование такой модели для прогнозирования в реальных условиях целесообразно.
6. Осуществить прогнозирование среднего значения показателя Y при уровне
значимости 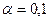 , если прогнозное значение фактора X составит
80% от его максимального значения.
, если прогнозное значение фактора X составит
80% от его максимального значения.
Согласно условию задачи прогнозное значение факторной переменной Х
составит 80% от 49, следовательно, 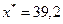 . Рассчитаем по уравнению модели прогнозное значение
показателя У:
. Рассчитаем по уравнению модели прогнозное значение
показателя У:
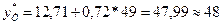 .
.
Таким образом, если объем капиталовложений составит 39,2 млн.
руб., то ожидаемый объем выпуска продукции составит около 48 млн. руб.
Зададим доверительную вероятность 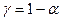 и построим
доверительный прогнозный интервал для среднего значения Y.
и построим
доверительный прогнозный интервал для среднего значения Y.
Для этого нужно рассчитать стандартную ошибку прогнозирования:
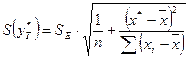
Предварительно подготовим:
- стандартную ошибку
модели (Таблица 2);
- по столбцу исходных
данных Х найдем среднее значение 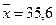 (функция СРЗНАЧ) и
определим
(функция СРЗНАЧ) и
определим 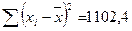 (функция КВАДРОТКЛ).
(функция КВАДРОТКЛ).
Следовательно,
стандартная ошибка прогнозирования для
среднего значения составляет:
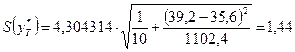
При 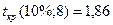 размах доверительного
интервала для среднего значения
размах доверительного
интервала для среднего значения
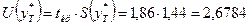
Границами прогнозного интервала будут
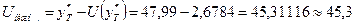
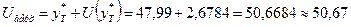
Таким образом, с надежностью 90% можно утверждать, что если объем
капиталовложений составит 39,2 млн. руб., то ожидаемый объем выпуска продукции
будет от 45,3 млн. руб. до 50,67 млн. руб.
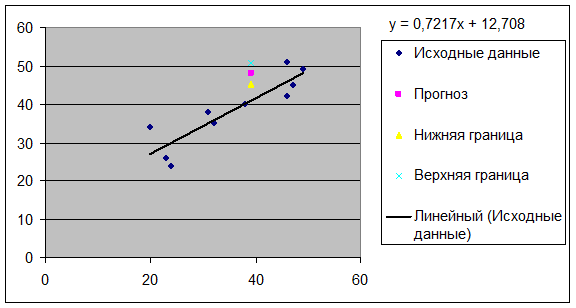
7. Представить графически фактические
и модальные значения Y точки прогноза.
Для построения чертежа используем Мастер диаграмм (точечная) – покажем исходные данные (поле
корреляции).
Затем с помощью опции Добавить линию тренда… построим линию
модели:
тип → линейная; параметры → показывать уравнение
на диаграмме.
Покажем на графике
результаты прогнозирования. Для
этого в опции Исходные данные добавим ряды:
Имя → прогноз; значения
 ; значения
; значения  ;
;
Имя → нижняя граница; значения
; значения  ;
;
Имя → верхняя граница; значения
; значения 
8. Составить уравнения нелинейной регрессии: гиперболической;
степенной; показательной.
Гиперболическая модель 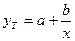 не является
стандартной.
не является
стандартной.
Для ее построения выполним линеаризацию: обозначим 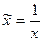 и получим вспомогательную
модель
и получим вспомогательную
модель 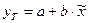 . Вспомогательная модель является линейной. Ее можно построить
с помощью программы РЕГРЕССИЯ, предварительно подготовив исходные данные:
столбец значений
. Вспомогательная модель является линейной. Ее можно построить
с помощью программы РЕГРЕССИЯ, предварительно подготовив исходные данные:
столбец значений 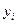 (остается без изменений) и столбец преобразованных значений (таблица 7).
(остается без изменений) и столбец преобразованных значений (таблица 7).
Таблица 7
|
Y
|
Х
|
1/Х
|
|
34
|
20
|
0,050
|
|
26
|
23
|
0,043
|
|
24
|
24
|
0,042
|
|
38
|
31
|
0,032
|
|
35
|
32
|
0,031
|
|
40
|
38
|
0,026
|
|
42
|
46
|
0,022
|
|
51
|
46
|
0,022
|
|
45
|
47
|
0,021
|
|
49
|
49
|
0,020
|
С помощью программы РЕГРЕССИЯ получим:
|
|
Коэффициенты
|
|
Y-пересечение
|
60,24808165
|
|
1/Х
|
-704,4773077
|
Таким образом, 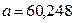 ;
; 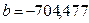 , следовательно, уравнение гиперболической модели
, следовательно, уравнение гиперболической модели 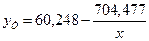 .
.
С помощью полученного
уравнения рассчитаем теоретические
значения 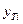 для каждого уровня
исходных данных
для каждого уровня
исходных данных 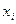 .
.
Покажем линию гиперболической модели на
графике. Для этого добавим
к ряду исходных данных 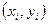 , ряд теоретических
значений
, ряд теоретических
значений
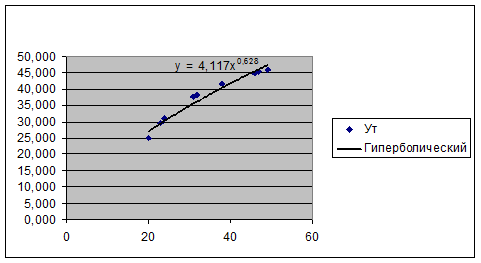
Степенная модель 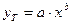 является стандартной.
Для ее построения используем Мастер
диаграмм: исходные данные покажем с помощью точечной диаграммы, затем
добавим линию степенного тренда и выведем на диаграмму уравнение модели.
является стандартной.
Для ее построения используем Мастер
диаграмм: исходные данные покажем с помощью точечной диаграммы, затем
добавим линию степенного тренда и выведем на диаграмму уравнение модели.
