Министерство образования и науки РФ
Федеральное агентство по образованию ГОУ
ВПО
Всероссийский заочный
финансово-экономический институт
Филиал в г.
Барнауле
Факультет
«Учетно-статистический»
\
КОНТРОЛЬНАЯ РАБОТА
по эконометрике
вариант №4
|
Преподаватель
|
|
|
Студентка
|
|
|
Специальность
|
Бухгалтерский учет анализ и аудит
|
|
№ личного дела
|
|
|
0бразование
|
|
|
Группа
|
|
Барнаул 2008
Задача №1.
Эконометрическое моделирование
стоимости квартир в Московской области. Наименование показателей и исходных
данных для эконометрического моделирования представлены в таблице:
|
№ п.п.
|
Цена квартиры, тыс.долл.
(Y)
|
Город области, 1 – Подольск, 0 – Люберцы
(Х1)
|
Число комнат в квартире
(Х2)
|
Жилая площадь квартиры, кв. м
(Х4)
|
|
1
|
38
|
1
|
1
|
19
|
|
2
|
62,2
|
1
|
2
|
36
|
|
3
|
125
|
0
|
3
|
41
|
|
4
|
61,1
|
1
|
2
|
34,8
|
|
5
|
67
|
0
|
1
|
18,7
|
|
6
|
93
|
0
|
2
|
27,7
|
|
7
|
118
|
1
|
3
|
59
|
|
8
|
132
|
0
|
3
|
44
|
|
9
|
92,5
|
0
|
3
|
56
|
|
10
|
105
|
1
|
4
|
47
|
|
11
|
42
|
1
|
1
|
18
|
|
12
|
125
|
1
|
3
|
44
|
|
13
|
170
|
0
|
4
|
56
|
|
14
|
38
|
0
|
1
|
16
|
|
15
|
130,5
|
0
|
4
|
66
|
|
16
|
85
|
0
|
2
|
34
|
|
17
|
98
|
0
|
4
|
43
|
|
18
|
128
|
0
|
4
|
59,2
|
|
19
|
85
|
0
|
3
|
50
|
|
20
|
160
|
1
|
3
|
42
|
|
21
|
60
|
0
|
1
|
20
|
|
22
|
41
|
1
|
1
|
14
|
|
23
|
90
|
1
|
4
|
47
|
|
24
|
83
|
0
|
4
|
49,5
|
|
25
|
45
|
0
|
1
|
18,9
|
|
26
|
39
|
0
|
1
|
18
|
|
27
|
86,9
|
0
|
3
|
58,7
|
|
28
|
40
|
0
|
1
|
22
|
|
29
|
80
|
0
|
2
|
40
|
|
30
|
227
|
0
|
4
|
91
|
|
31
|
235
|
0
|
4
|
90
|
|
32
|
40
|
1
|
1
|
15
|
|
33
|
67
|
1
|
1
|
18,5
|
|
34
|
123
|
1
|
4
|
55
|
|
35
|
100
|
0
|
3
|
37
|
|
36
|
105
|
1
|
3
|
48
|
|
37
|
70,3
|
1
|
2
|
34,8
|
|
38
|
82
|
1
|
3
|
48
|
|
39
|
280
|
1
|
4
|
85
|
|
40
|
200
|
1
|
4
|
60
|
Задание:
1. Расширить матрицу парных
коэффициентов корреляции; оценить статистическую значимость коэффициентов
корреляции.
2. Построить поле корреляции
результативного признака и наиболее тесно связанного с ним фактора.
3. Рассчитать параметры линейных парных
регрессий для всех факторов Х.
4. Оценить качество каждой модели через
коэффициент детерминации, среднюю ошибку аппроксимации и F – критерия Фишера. Выбрать лучшую
модель.
5. С использованием лучшей модели осуществить
прогнозирование среднего значения показателя Y при уровне значимости α = 0,1,
если прогнозное значение фактора Х составит 80% от его максимального значения.
Представить графически и модельные значения Y, результаты прогнозирования.
6. Используя пошаговую множественную
регрессию (метод исключения или метод включения), построить модель формирования
цены квартиры за счет значимых факторов. Дать экономическую интерпретацию
коэффициентов модели регрессии.
7. Оценить качество модели. Улучшилось
ли качество модели по сравнению с однофакторной моделью? Дать оценку влияния
значимых факторов на результат с помощью коэффициента эластичности, β- и
Δ-коэффициентов.
Решение:
1. Расширить матрицу парных коэффициентов корреляции; оценить
статистическую значимость коэффициентов корреляции.
Используем Exel / сервис / анализ данных /
корреляция. Получим матрицу коэффициентов парной корреляции между всеми
имеющимися переменными:
|
|
Y
|
Х1
|
Х2
|
Х4
|
|
Y
|
1
|
|
|
|
|
Х1
|
-0,01126
|
1
|
|
|
|
Х2
|
0,751061
|
-0,0341
|
1
|
|
|
Х4
|
0,874012
|
-0,0798
|
0,868524
|
1
|
Проанализируем
коэффициенты корреляции между результирующим признаком Y и каждым из факторов Хj:
r(Y, X1) = – 0,01 < 0, значит, между переменными Y и Х1 наблюдается обратная
корреляционная зависимость: цена на квартиры выше в Люберцах.
|r(Y, X1)| = 0,01 < 0,4 – эта зависимость слабая.
r(Y, X2) = 0,75 > 0, значит, между переменными Y и Х2 наблюдается прямая
корреляционная зависимость: чем больше комнат в квартире, тем выше ее цена.
|r(Y, X2)| = 0,75 > 0,7 – эта зависимость тесная, ближе к
умеренной.
r(Y, X4) = 0,87 > 0, значит, между переменными Y и Х4 наблюдается прямая
корреляционная зависимость: чем больше жилая площадь в квартире, тем выше ее
цена.
|r(Y, X4)| = 0,87 > 0,7 – эта зависимость тесная.
Для проверки значимости
найденных коэффициентов корреляции используем критерий Стьюдента.
Для каждого коэффициента r(Y, Xj) вычислим t-статистику по формуле t = 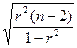 и занесем результаты
расчетов в корреляционную таблицу:
и занесем результаты
расчетов в корреляционную таблицу:
|
|
Y
|
Х1
|
Х2
|
Х4
|
t-статистики
|
|
Y
|
1
|
|
|
|
|
|
Х1
|
-0,01126
|
1
|
|
|
0,069411185
|
|
Х2
|
0,751061
|
-0,0341
|
1
|
|
7,012446419
|
|
Х4
|
0,874012
|
-0,0798
|
0,868524
|
1
|
11,08813705
|
По таблице критических
точек распределения Стьюдента при уровне значимости α = 5% и числе
степеней свободы k = n – 2 = 40 – 2 = 38 определим критическое значение tкр = 2,02 (или с помощью функции
СТЬЮДРАСПОБР).
Сопоставим фактическое
значение t с критическим tкр, и сделаем выводы в соответствии со схемой:
t(r(Y, X1)) = 0,07 < tкр = 2,02, следовательно коэффициент r(Y, X1) не является значимым. На основании выборочных данных
нет оснований утверждать, что зависимость между ценой квартиры Y и городом области Х1
существует.
t(r(Y, X2)) = 7,01 > tкр = 2,02, следовательно коэффициент r(Y, X2) значимо отличается от нуля. На уровне значимости 5%
выборочные данные позволяют сделать вывод о наличии линейной корреляционной
зависимости между признаками Y и Х2. Зависимость между ценой квартиры Y и числом комнат в квартире Х2
является достоверной.
t(r(Y, X4)) = 11,09 > tкр = 2,02, следовательно коэффициент r(Y, X4) значимо отличается от нуля. На уровне значимости 5%
выборочные данные позволяют сделать вывод о наличии линейной корреляционной
зависимости между признаками Y и Х4. Зависимость между ценой квартиры Y и жилой площадью квартиры Х4
является достоверной.
Таким образом, наиболее
тесная и значимая зависимость наблюдается между ценой квартиры Y и жилой площадью квартиры Х4.
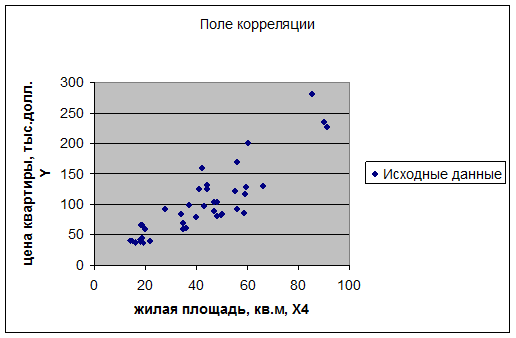
2. Построить поле корреляции результативного признака и
наиболее тесно связанного с ним фактора.
Для построения поля
корреляции используем Мастер диаграмм (точечная) – покажем исходные данные Y и значение наиболее информативного
фактора Х4. В результате получим диаграмму «поле корреляции»:
3. Рассчитать параметры линейных парных регрессий для всех
факторов Х.
Для построения парной
линейной модели Yt = a+b*X1.
используем программу РЕГРЕССИЯ. В качестве входного интервала Х покажем
значение фактора Х1.
Результаты вычислений
представлены в таблицах:
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
Множественный R
|
0,011259
|
|
|
R-квадрат
|
0,000127
|
|
|
Нормированный R-квадрат
|
-0,02619
|
|
|
Стандартная ошибка
|
58,03646
|
|
|
Наблюдения
|
40
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
16,22784
|
16,22784
|
0,004818
|
0,945026
|
|
|
Остаток
|
38
|
127992,8
|
3368,231
|
|
|
|
|
Итого
|
39
|
128009
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
Y-пересечение
|
101,8136
|
12,37341
|
8,228419
|
5,73E-10
|
76,76497
|
126,8623
|
76,76497
|
126,8623
|
|
Х1
|
-1,2803
|
18,4452
|
-0,06941
|
0,945026
|
-38,6207
|
36,06005
|
-38,6207
|
36,06005
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты модели
содержатся в третьей таблице итогов Регрессии (столбец Коэффициенты).
Таким образом, уравнение
модели (1) имеете вид:
YТ = 101,81 –
1,28*X1.
Коэффициент регрессии b = –1,28, следовательно цена
реализации квартиры в Подольске в среднем на 1,28 тыс. долл. ниже цены
реализации в Люберцах. Свободный член a = 101,81 не имеет реального смысла.
Аналогичные расчеты
проведем для построения модели зависимости цены реализации Y от числа комнат в квартире Х2:
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
Множественный R
|
0,751061
|
|
|
R-квадрат
|
0,564092
|
|
|
Нормированный R-квадрат
|
0,552621
|
|
|
Стандартная ошибка
|
38,32002
|
|
|
Наблюдения
|
40
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
72208,88
|
72208,88
|
49,1744
|
2,37E-08
|
|
Остаток
|
38
|
55800,11
|
1468,424
|
|
|
|
Итого
|
39
|
128009
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
Y-пересечение
|
7,539299
|
14,67125
|
0,513882
|
0,61031
|
-22,1611
|
37,23969
|
-22,1611
|
37,23969
|
|
Х2
|
36,03777
|
5,139115
|
7,012446
|
2,37E-08
|
25,63418
|
46,44136
|
25,63418
|
46,44136
|
Модель (2) построена, ее
уравнение имеет вид:
YТ = 7,54 +
36,04*X2.
Коэффициент регрессии b = 36,04, следовательно при
увеличении на 1 комнату в квартире в
среднем на 36,04 тыс. долл. увеличивается цена квартиры. Свободный член a = 7,54 не имеет реального смысла.
Также построим модель
зависимости цены квартиры Y от жилой площади квартиры Х4.
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная
статистика
|
|
|
Множественный R
|
0,874012
|
|
|
R-квадрат
|
0,763897
|
|
|
Нормированный R-квадрат
|
0,757684
|
|
|
Стандартная ошибка
|
28,20195
|
|
|
Наблюдения
|
40
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
97785,7
|
97785,7
|
122,9468
|
1,79E-13
|
|
Остаток
|
38
|
30223,29
|
795,3498
|
|
|
|
Итого
|
39
|
128009
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
Y-пересечение
|
-2,86485
|
10,39375
|
-0,27563
|
0,784324
|
-23,9059
|
18,17619
|
-23,9059
|
18,17619
|
|
Х4
|
2,475975
|
0,223299
|
11,08814
|
1,79E-13
|
2,023929
|
2,928021
|
2,023929
|
2,928021
|
Модель (3) построена, ее
уравнение имеет вид:
YТ = – 2,86 +
2,48*X4.
Коэффициент регрессии b = 2,48, следовательно при увеличении
жилой площади квартиры на 1 кв.
м в среднем на 2,48 тыс. долл. увеличивается цена
квартиры. Свободный член a = –2,86 не имеет
реального смысла.
4. Оценить качество каждой модели через коэффициент
детерминации, среднюю ошибку аппроксимации и F – критерия Фишера. Выбрать лучшую
модель.
Для удобства все
результаты будем заносить в сводную таблицу.
Коэффициенты детерминации
R-квадрат
определены для каждой модели программой РЕГРЕССИЯ (таблица «Регрессионная
статистика») и составляют:
|
Модель
|
R-квадрат
|
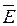 отн отн
|
F
|
|
YТ = 101,81 – 1,28*X1
(1)
|
0,000127
|
|
|
|
YТ = 7,54 + 36,04*X2 (2)
|
0,564092
|
|
|
|
YТ = – 2,86 + 2,48*X4
(3)
|
0,763897
|
|
|
Таким образом, вариация
цены квартиры Y на 0,01% объясняется по уравнению (1) изменением города области Х1;
на 56,41% по уравнению (2) вариацией числа комнат в квартире Х2; на
76,39% по уравнению (3) изменением жилой площади квартиры Х4.
Для вычисления средней
относительной ошибки аппроксимации рассмотрим остатки модели Еi = Yi – YТi, содержащиеся в столбце Остатки
итогов программы РЕГРЕССИЯ (таблица «вывод остатка»). Дополним таблицу столбцом
относительных погрешностей, которые вычислим по формуле Еотн.i = 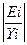
 100 с
помощью функции ABS.
100 с
помощью функции ABS.
Выполнение расчетов для
модели (1):
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
Отн. погр-ти
|
|
1
|
100,5333
|
-62,5333
|
164,5614
|
|
2
|
100,5333
|
-38,3333
|
61,62915
|
|
3
|
101,8136
|
23,18636
|
18,54909
|
|
4
|
100,5333
|
-39,4333
|
64,53901
|
|
5
|
101,8136
|
-34,8136
|
51,96065
|
|
6
|
101,8136
|
-8,81364
|
9,477028
|
|
7
|
100,5333
|
17,46667
|
14,80226
|
|
8
|
101,8136
|
30,18636
|
22,86846
|
|
9
|
101,8136
|
-9,31364
|
10,0688
|
|
10
|
100,5333
|
4,466667
|
4,253968
|
|
11
|
100,5333
|
-58,5333
|
139,3651
|
|
12
|
100,5333
|
24,46667
|
19,57333
|
|
13
|
101,8136
|
68,18636
|
40,10963
|
|
14
|
101,8136
|
-63,8136
|
167,9306
|
|
15
|
101,8136
|
28,68636
|
21,98189
|
|
16
|
101,8136
|
-16,8136
|
19,78075
|
|
17
|
101,8136
|
-3,81364
|
3,891466
|
|
18
|
101,8136
|
26,18636
|
20,4581
|
|
19
|
101,8136
|
-16,8136
|
19,78075
|
|
20
|
100,5333
|
59,46667
|
37,16667
|
|
21
|
101,8136
|
-41,8136
|
69,68939
|
|
22
|
100,5333
|
-59,5333
|
145,2033
|
|
23
|
100,5333
|
-10,5333
|
11,7037
|
|
24
|
101,8136
|
-18,8136
|
22,66703
|
|
25
|
101,8136
|
-56,8136
|
126,2525
|
|
26
|
101,8136
|
-62,8136
|
161,0606
|
|
27
|
101,8136
|
-14,9136
|
17,16184
|
|
28
|
101,8136
|
-61,8136
|
154,5341
|
|
29
|
101,8136
|
-21,8136
|
27,26705
|
|
30
|
101,8136
|
125,1864
|
55,14818
|
|
31
|
101,8136
|
133,1864
|
56,67505
|
|
32
|
100,5333
|
-60,5333
|
151,3333
|
|
33
|
100,5333
|
-33,5333
|
50,04975
|
|
34
|
100,5333
|
22,46667
|
18,26558
|
|
35
|
101,8136
|
-1,81364
|
1,813636
|
|
36
|
100,5333
|
4,466667
|
4,253968
|
|
37
|
100,5333
|
-30,2333
|
43,00616
|
|
38
|
100,5333
|
-18,5333
|
22,60163
|
|
39
|
100,5333
|
179,4667
|
64,09524
|
|
40
|
100,5333
|
99,46667
|
49,73333
|
По столбцу относительных
погрешностей найдем среднее значение отн = 54,13% (с помощью функции СРЗНАЧ).
Выполнение расчетов для
модели (2):
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
Отн. погр-ти
|
|
1
|
43,57707
|
-5,57707
|
14,6765
|
|
2
|
79,61484
|
-17,4148
|
27,99813
|
|
3
|
115,6526
|
9,347392
|
7,477914
|
|
4
|
79,61484
|
-18,5148
|
30,30252
|
|
5
|
43,57707
|
23,42293
|
34,9596
|
|
6
|
79,61484
|
13,38516
|
14,39265
|
|
7
|
115,6526
|
2,347392
|
1,989315
|
|
8
|
115,6526
|
16,34739
|
12,38439
|
|
9
|
115,6526
|
-23,1526
|
25,02985
|
|
10
|
151,6904
|
-46,6904
|
44,46703
|
|
11
|
43,57707
|
-1,57707
|
3,754925
|
|
12
|
115,6526
|
9,347392
|
7,477914
|
|
13
|
151,6904
|
18,30962
|
10,77037
|
|
14
|
43,57707
|
-5,57707
|
14,6765
|
|
15
|
151,6904
|
-21,1904
|
16,23784
|
|
16
|
79,61484
|
5,385162
|
6,335485
|
|
17
|
151,6904
|
-53,6904
|
54,7861
|
|
18
|
151,6904
|
-23,6904
|
18,50811
|
|
19
|
115,6526
|
-30,6526
|
36,06189
|
|
20
|
115,6526
|
44,34739
|
27,71712
|
|
21
|
43,57707
|
16,42293
|
27,37155
|
|
22
|
43,57707
|
-2,57707
|
6,285533
|
|
23
|
151,6904
|
-61,6904
|
68,54486
|
|
24
|
151,6904
|
-68,6904
|
82,75949
|
|
25
|
43,57707
|
1,422932
|
3,16207
|
|
26
|
43,57707
|
-4,57707
|
11,73607
|
|
27
|
115,6526
|
-28,7526
|
33,08701
|
|
28
|
43,57707
|
-3,57707
|
8,942671
|
|
29
|
79,61484
|
0,385162
|
0,481452
|
|
30
|
151,6904
|
75,30962
|
33,17605
|
|
31
|
151,6904
|
83,30962
|
35,4509
|
|
32
|
43,57707
|
-3,57707
|
8,942671
|
|
33
|
43,57707
|
23,42293
|
34,9596
|
|
34
|
151,6904
|
-28,6904
|
23,32551
|
|
35
|
115,6526
|
-15,6526
|
15,65261
|
|
36
|
115,6526
|
-10,6526
|
10,14534
|
|
37
|
79,61484
|
-9,31484
|
13,25013
|
|
38
|
115,6526
|
-33,6526
|
41,03977
|
|
39
|
151,6904
|
128,3096
|
45,82487
|
|
40
|
151,6904
|
48,30962
|
24,15481
|
По столбцу относительных
погрешностей найдем среднее значение отн = 23,46%.
Выполнение расчетов для
модели (3):
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
Отн. погр-ти
|
|
1
|
44,17867
|
-6,17867
|
16,25965
|
|
2
|
86,27023
|
-24,0702
|
38,69812
|
|
3
|
98,65011
|
26,34989
|
21,07991
|
|
4
|
83,29906
|
-22,1991
|
36,33235
|
|
5
|
43,43587
|
23,56413
|
35,17034
|
|
6
|
65,71964
|
27,28036
|
29,33372
|
|
7
|
143,2176
|
-25,2176
|
21,37089
|
|
8
|
106,078
|
25,92197
|
19,63786
|
|
9
|
135,7897
|
-43,2897
|
46,7997
|
|
10
|
113,506
|
-8,50595
|
8,100909
|
|
11
|
41,70269
|
0,297309
|
0,707878
|
|
12
|
106,078
|
18,92197
|
15,13758
|
|
13
|
135,7897
|
34,21027
|
20,12369
|
|
14
|
36,75074
|
1,249258
|
3,287521
|
|
15
|
160,5495
|
-30,0495
|
23,02641
|
|
16
|
81,31828
|
3,681716
|
4,33143
|
|
17
|
103,6021
|
-5,60206
|
5,716383
|
|
18
|
143,7128
|
-15,7128
|
12,27566
|
|
19
|
120,9339
|
-35,9339
|
42,27515
|
|
20
|
101,1261
|
58,87392
|
36,7962
|
|
21
|
46,65464
|
13,34536
|
22,24227
|
|
22
|
31,79879
|
9,201207
|
22,44197
|
|
23
|
113,506
|
-23,506
|
26,11773
|
|
24
|
119,6959
|
-36,6959
|
44,21192
|
|
25
|
43,93107
|
1,068932
|
2,375404
|
|
26
|
41,70269
|
-2,70269
|
6,929977
|
|
27
|
142,4749
|
-55,5749
|
63,95265
|
|
28
|
51,60659
|
-11,6066
|
29,01647
|
|
29
|
96,17413
|
-16,1741
|
20,21766
|
|
30
|
222,4488
|
4,551164
|
2,004918
|
|
31
|
219,9729
|
15,02714
|
6,394527
|
|
32
|
34,27477
|
5,725233
|
14,31308
|
|
33
|
42,94068
|
24,05932
|
35,90944
|
|
34
|
133,3138
|
-10,3138
|
8,385163
|
|
35
|
88,74621
|
11,25379
|
11,25379
|
|
36
|
115,9819
|
-10,9819
|
10,45898
|
|
37
|
83,29906
|
-12,9991
|
18,49085
|
|
38
|
115,9819
|
-33,9819
|
41,44138
|
|
39
|
207,593
|
72,40701
|
25,85965
|
|
40
|
145,6936
|
54,30638
|
27,15319
|
По столбцу относительных
погрешностей найдем среднее значение отн = 21,89%.
Разнесем результаты в
сводную таблицу:
|
Модель
|
R-квадрат
|
отн
|
F
|
|
YТ = 101,81 – 1,28*X1
(1)
|
0,000127
|
54,13%
|
|
|
YТ = 7,54 + 36,04*X2 (2)
|
0,564092
|
23,46%
|
|
|
YТ = – 2,86 + 2,48*X4 (3)
|
0,763897
|
21,89%
|
|
Оценим точность
построенных моделей в соответствии со схемой:

отн1 = 54,13% > 15%, отн2 = 23,46% > 15%, отн3 = 21,89% > 15%. Точность всех трех моделей неудовлетворительная.
Ближе к 15% отн модели (3).
Проверим значимость
полученных уравнений с помощью F – критерия Фишера.
F – статистики
определены программой РЕГРЕССИЯ (таблицы «Дисперсионный анализ») и составляют:
|
Модель
|
R-квадрат
|
отн
|
F
|
|
YТ = 101,81 – 1,28*X1
(1)
|
0,000127
|
54,13%
|
0,004818
|
|
YТ = 7,54 + 36,04*X2 (2)
|
0,564092
|
23,46%
|
49,1744
|
|
YТ = – 2,86 + 2,48*X4 (3)
|
0,763897
|
21,89%
|
122,9468
|
С помощью функции FРАСПОБР найдем значение Fкр = 4,1 для уровня значимости α =
5%, и чисел степеней свободы k1 = 1, k2 = 38.
Схема проверки:

F = 0,0048 < Fкр = 4,1, следовательно уравнение модели
(1) не является значимой и ее использование нецелесообразно.
F = 49,17 > Fкр = 4,1, F = 122,95 > Fкр = 4,1, следовательно, уравнения
моделей (2) и (3) являются значимыми, их использование целесообразно, зависимая
переменная Y достаточно
хорошо описывается включенной в модель (2) факторной переменной Х2 и
включенной в модель (3) факторной переменной Х4.
Вывод: на основании оценки качества моделей по коэффициенту детерминации,
средней ошибке аппроксимации и критерию Фишера наилучшей является модель (3)
зависимости цены квартиры от ее жилой площади. Однако эту модель нецелесообразно
использовать для прогнозирования в реальных условиях, поскольку ее точность
неудовлетворительная, и дальнейшие расчеты проведем в учебных целях.
5. С использованием лучшей модели осуществить прогнозирование
среднего значения показателя Y при уровне значимости α = 0,1, если прогнозное значение фактора Х
составит 80% от его максимального значения. Представить графически и модельные
значения Y, результаты прогнозирования.
Согласно условию задачи
прогнозное значение фактора Х4 составляет 80% от его максимального
значения. Максимальное значение Х4 = 91 найдем с помощью функции
МАКС. Тогда прогнозное значение Х4* = 72,8. Рассчитаем по
уравнению модели (3) прогнозное значение Y:
Y*Т = – 2,86 + 2,48* Х4*
= – 2,86 + 2,48 * 72,8 = 177,39.
Таким образом, если жилая
площадь квартиры составит 80% от ее
максимального значения и составит 72,8 кв. м, то ожидаемая цена квартиры будет составлять
около 177,39 тыс. долл.
Зададим доверительную
вероятность p = 1 – α = 1– 0,1 = 0,9 и построим доверительный прогнозный интервал
для среднего значения Y.
Для этого нужно
рассчитать стандартную ошибку прогнозирования для среднего значения
результирующего признака:
S(Y*Т) = SE * 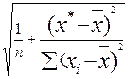 .
.
Предварительно
подготовим:
- стандартная ошибка SE = 28,2 (таблица «регрессионная
статистика» итогов РЕГРЕССИИ);
- по столбцу данных Х4
найдем среднее значение 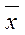 = 42,04 (функция СРЗНАЧ) и определим
= 42,04 (функция СРЗНАЧ) и определим 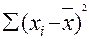 = 15950,82 (функция
КВАДРОТКЛ);
= 15950,82 (функция
КВАДРОТКЛ);
- tкр – коэффициент Стьюдента для уровня
значимости α=10% и числа степеней свободы k = 38. tкр = 1,686 (функция СТЬЮДРАСПОБР).
Следовательно,
стандартная ошибка прогнозирования для среднего значения составляет:
S(Y*Т) = 28,2 * 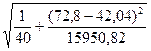 = 8,188 .
= 8,188 .
Размах доверительного
интервала для среднего значения:
U(Y*Т) = tкр * S(Y*Т) = 1,686 * 8,188 = 13,805.
Границами прогнозного
интервала будут:
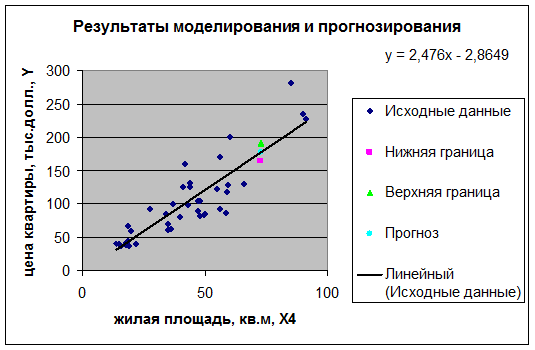
Uнижн = Y*Т – U(Y*Т) = 177,39
– 13,805 = 163,58;
Uверх = Y*Т + U(Y*Т) = 177,39
+ 13,805 = 191,19.
Таким образом, с
надежностью 90% можно утверждать, что если жилая площадь квартиры составит 80%
от ее максимального значения и составит 72,8 кв. м, то ожидаемая
средняя цена квартиры будет от 163,58 тыс. долл. до 191,19 тыс. долл.
Для построения чертежа
используем Мастер диаграмм (точечная) – покажем исходные данные (поле
корреляции). Затем с помощью опции Добавить линию тренда, построим линию модели
и покажем на графике результаты прогнозирования.
6. Используя пошаговую множественную регрессию (метод
исключения или метод включения), построить модель формирования цены квартиры за
счет значимых факторов. Дать экономическую интерпретацию коэффициентов модели
регрессии.
Методом включения
построим двух факторные модели, сохраняя в них наиболее информативный фактор
– жилую площадь квартиры (Х4).
В качестве «входного
интервала Х» укажем значения факторов Х1 и Х4, с помощью
программы РЕГРЕССИЯ получим:
|
ВЫВОД ИТОГОВ
|
|
|
|
|
Регрессионная статистика
|
|
Множественный R
|
0,875979
|
|
R-квадрат
|
0,767339
|
|
Нормированный R-квадрат
|
0,754763
|
|
Стандартная ошибка
|
28,3714
|
|
Наблюдения
|
40
|
|
|
|
|
|
Коэффициенты
|
|
Y-пересечение
|
-6,4361
|
|
Х1
|
6,692936
|
|
Х4
|
2,48928
|
Таким образом, модель (4)
зависимости цены квартиры Y от города области Х1 и жилой площади квартиры Х4
построена, ее уравнение имеет вид:
YТ = –6,44 +
6,69*X1 + 2,49*Х4.
Используем в качестве
«входного интервала Х» значения факторов Х2 и Х4, с
помощью РЕГРЕССИИ найдем:
|
ВЫВОД ИТОГОВ
|
|
|
|
|
Регрессионная статистика
|
|
Множественный R
|
0,874163
|
|
R-квадрат
|
0,76416
|
|
Нормированный R-квадрат
|
0,751412
|
|
Стандартная ошибка
|
28,56458
|
|
Наблюдения
|
40
|
|
|
Коэффициенты
|
|
Y-пересечение
|
-2,16757
|
|
Х2
|
-1,57033
|
|
Х4
|
2,556497
|
Таким образом, модель (5)
зависимости цены квартиры Y от числа комнат Х2 и жилой площади Х4
построена, ее уравнение имеет вид:
YТ = –2,17 –
1,57*X2 + 2,56*Х4.
Построим множественную
модель регрессии, учитывая все факторы (Х1, Х2, и Х4):
|
ВЫВОД ИТОГОВ
|
|
|
|
|
Регрессионная статистика
|
|
Множественный R
|
0,876218
|
|
R-квадрат
|
0,767758
|
|
Нормированный R-квадрат
|
0,748404
|
|
Стандартная ошибка
|
28,73688
|
|
Наблюдения
|
40
|
|
|
Коэффициенты
|
|
Y-пересечение
|
-5,64357
|
|
Х1
|
6,859631
|
|
Х2
|
-1,98516
|
|
Х4
|
2,591406
|
|
|
|
Таким образом,
трехфакторная модель (6) зависимости цены квартиры Y от города области Х1,
числа комнат Х2 и жилой площади Х4 построена, ее
уравнение имеет вид:
YТ = –5,67 +
6,86*Х1 – 1,99*X2 + 2,59*Х4.
Выберем лучшую из
построенных.
Для сравнения моделей с
различным количеством учтенных в них факторов используем нормированные
коэффициенты детерминации, которые содержатся в строке «нормированный R-квадрат» итогов программы РЕГРЕССИЯ.
Чем больше величина нормированного коэффициента детерминации, тем лучше модель.
|
Модель
|
Нормированный R-квадрат
|
|
YТ = –6,44 + 6,69*X1 + 2,49*Х4 (4)
|
0,754763
|
|
YТ = –2,17 – 1,57*X2 + 2,56*Х4 (5)
|
0,751412
|
|
YТ = –5,67 + 6,86*Х1 – 1,99*X2 + 2,59*Х4 (6)
|
0,748404
|
Таким образом, лучшей
является модель (4) зависимости цены квартиры Y от города области Х1 и
жилой площади квартиры Х4:
YТ = –6,44 +
6,69*X1 + 2,49*Х4.
Коэффициент регрессии b1 = 6,69, следовательно, при покупке квартиры в
Люберцах (Х1) той же жилой площади (Х4), что и в
Подольске цена квартиры (Y) увеличится в среднем на 6,69 тыс. долл.
Коэффициент регрессии b2 = 2,49, следовательно, при увеличении жилой площади (Х4)
на 1 кв. м
в одном городе (Х1), цена квартиры (Y) увеличится в среднем на 2,48 тыс.
долл.
Свободный коэффициент не
имеет экономического смысла.
7. Оценить качество модели. Улучшилось ли качество модели по
сравнению с однофакторной моделью? Дать оценку влияния значимых факторов на
результат с помощью коэффициента эластичности, β- и Δ-коэффициентов.
Для оценки качества
выбранной множественной модели (4) YТ = –6,44 + 6,69*X1 + 2,49*Х4 аналогично п.4 данной задачи
используем коэффициент детерминации R-квадрат, среднюю относительную
ошибку аппроксимации и F – критерий Фишера.
Коэффициент детерминации R-квадрат выпишем из итогов РЕГРЕССИИ
(таблица «Регрессионная статистика» для модели (4)).
R2 = 0,767, следовательно, вариация
цены квартиры Y на 76,7% объясняется по данному уравнению вариацией города области Х1
и жилой площади Х4.
Используем исходные
данные Yi и найденные программой РЕГРЕССИЯ остатки Еi (таблица «Вывод остатка» для модели
(4)). Рассчитаем относительные погрешности и найдем среднее значение отн.
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
Отн. погр-ти
|
|
1
|
47,55316
|
-9,55316
|
25,13988493
|
|
2
|
89,87092
|
-27,6709
|
44,48700502
|
|
3
|
95,62438
|
29,37562
|
23,50049523
|
|
4
|
86,88378
|
-25,7838
|
42,19931434
|
|
5
|
40,11344
|
26,88656
|
40,12920021
|
|
6
|
62,51696
|
30,48304
|
32,77746634
|
|
7
|
147,1244
|
-29,1244
|
24,68165955
|
|
8
|
103,0922
|
28,90778
|
21,89983249
|
|
9
|
132,9636
|
-40,4636
|
43,74441266
|
|
10
|
117,253
|
-12,253
|
11,66952159
|
|
11
|
45,06388
|
-3,06388
|
7,294943394
|
|
12
|
109,7852
|
15,21484
|
12,17187399
|
|
13
|
132,9636
|
37,03642
|
21,7861284
|
|
14
|
33,39238
|
4,60762
|
12,12531651
|
|
15
|
157,8564
|
-27,3564
|
20,96274499
|
|
16
|
78,19942
|
6,800579
|
8,000681624
|
|
17
|
100,6029
|
-2,60294
|
2,656062313
|
|
18
|
140,9293
|
-12,9293
|
10,10099834
|
|
19
|
118,0279
|
-33,0279
|
38,85635461
|
|
20
|
104,8066
|
55,1934
|
34,49587661
|
|
21
|
43,3495
|
16,6505
|
27,75083346
|
|
22
|
35,10676
|
5,893244
|
14,37376579
|
|
23
|
117,253
|
-27,253
|
30,28110852
|
|
24
|
116,7833
|
-33,7833
|
40,70272457
|
|
25
|
40,61129
|
4,388708
|
9,752684736
|
|
26
|
38,37094
|
0,62906
|
1,612974811
|
|
27
|
139,6846
|
-52,7846
|
60,7418157
|
|
28
|
48,32806
|
-8,32806
|
20,82015006
|
|
29
|
93,1351
|
-13,1351
|
16,41887615
|
|
30
|
220,0884
|
6,911617
|
3,044764999
|
|
31
|
217,5991
|
17,4009
|
7,40463685
|
|
32
|
37,59604
|
2,403964
|
6,009909809
|
|
33
|
46,30852
|
20,69148
|
30,88281157
|
|
34
|
137,1672
|
-14,1672
|
11,51807973
|
|
35
|
85,66726
|
14,33274
|
14,33273923
|
|
36
|
119,7423
|
-14,7423
|
14,04026449
|
|
37
|
86,88378
|
-16,5838
|
23,59001573
|
|
38
|
119,7423
|
-37,7423
|
46,02716795
|
|
39
|
211,8456
|
68,15436
|
24,34084302
|
|
40
|
149,6136
|
50,38636
|
25,19318084
|
По столбцу относительных
погрешностей найдем среднее значение 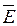 отн = 22,69% (с помощью функции СРЗНАЧ).
отн = 22,69% (с помощью функции СРЗНАЧ).
Сравнение показывает, что
22,69% > 15%. Следовательно, точность модели неудовлетворительная.
С помощью F – критерия Фишера проверим
значимость модели в целом. Для этого выпишем из итогов РЕГРЕССИИ (таблица
«дисперсионный анализ» для модели (4)) F = 61,01.
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
2
|
98226,35
|
49113,17573
|
61,01499
|
1,92E-12
|
|
Остаток
|
37
|
29782,64
|
804,9362779
|
|
|
|
Итого
|
39
|
128009
|
|
|
|
С помощью функции FРАСПОБР найдем значение Fкр = 3,25 для уровня значимости α =
5%, и чисел степеней свободы k1 = 2, k2 = 37.
F = 61,01 > Fкр = 3,25, следовательно, уравнения
модели (4) является значимым, его использование целесообразно, зависимая
переменная Y достаточно
хорошо описывается включенными в модель (4) факторными переменными Х1
и Х4.
Дополнительно с помощью t – критерия Стьюдента проверим
значимость отдельных коэффициентов модели.
t – статистики
для коэффициентов уравнения регрессии приведены в итогах программы РЕГРЕССИЯ.
Для выбранной модели (4) получены следующие значения:
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
|
Y-пересечение
|
-6,4361
|
11,51649
|
-0,558859663
|
0,579624
|
|
Х1
|
6,692936
|
9,045869
|
0,739888746
|
0,464037
|
|
Х4
|
2,48928
|
0,22536
|
11,04580516
|
2,85E-13
|
Критическое значение tкр найдено для уровня значимости α
= 5% и числа степеней свободы k = 40 – 2 – 1 = 37. tкр = 2,03 (функция СТЬЮДРАСПОБР).
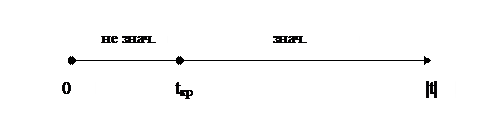
Для свободного
коэффициента a= –6,44 определена статистика t(a) = –0,56.
|t(a)| = 0,56 < tкр = 2,03, следовательно, свободный
коэффициент a = –6,44 не является значимым, его можно исключить из модели.
Для коэффициента
регрессии b1 = 6,69
определена статистика t(b1)=
0,74.
|t(b1)| = 0,74 < tкр = 2,03, следовательно, коэффициента
регрессии b1 не
является значимым, его и фактор города области можно исключить из модели.
Для коэффициента
регрессии b2=2,49
определена статистика t(b2)=
11,05.
|t(b2)| = 11,05 > tкр = 2,03, следовательно, коэффициента
регрессии b2 является
значимым, его и фактор жилой площади квартиры нужно сохранить в модели.
Выводы о значимости
коэффициентов модели сделаны на уровне значимости α = 5%. Рассматривая
столбец «P-значение», отметим, что свободный коэффициент a можно считать значимым на уровне
0,58 = 58%; коэффициент регрессии b1 – на уровне 0,46 = 46%;, а коэффициент регрессии b2 – на уровне 2,85E-13 = 0,000000000000285 =
0,000000000001%.
При добавлении в
уравнение новых факторных переменных автоматически увеличивается коэффициент
детерминации R2 и
уменьшается средняя ошибка аппроксимации, хотя при этом не всегда улучшается
качество модели. Поэтому для сравнения качества модели (3) и выбранной
множественной модели (4) используем нормированные коэффициенты детерминации.
|
Модель
|
Нормированный R-квадрат
|
|
YТ = – 2,86 + 2,48*X4 (3)
|
0,757684
|
|
YТ = –6,44 + 6,69*X1 + 2,49*Х4 (4)
|
0,754763
|
Таким образом, при
добавлении в уравнение регрессии фактора «город области» Х1 качество
модели ухудшилось, что говорит не в пользу сохранения фактора Х1 в
модели.
Дальнейшие расчеты проведем
в учебных целях.
Средние коэффициенты
эластичности в случае линейной модели определяются формулами Эj = bj * 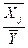 .
.
С помощью функции СРЗНАЧ
найдем: 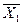 = 0,45,
= 0,45, 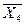 = 42,045,
= 42,045, 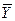 = 101,24. Тогда Э1 = 6,69 *
= 101,24. Тогда Э1 = 6,69 * 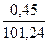 = 0,03, Э2 = 2,49 *
= 0,03, Э2 = 2,49 * 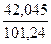 = 1,03 .
= 1,03 .
Следовательно, при
покупке квартиры в Люберцах (Х1) и неизменной жилой площади цена
квартиры увеличится в среднем на 0,03%.
Увеличение жилой площади Х4
в том же городе на 1% приводит к увеличению цены квартиры в среднем на 1,03%.
Бета-коэффициенты
определяются формулами βj = bj * 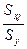 .
.
С помощью функции
СТАНДОТКЛОН найдем SX1 = 0,5; SX4 = 20,22; SY = 57,29. Тогда
β1 = 6,69 * 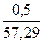 = 0,06; β2
= 2,49 *
= 0,06; β2
= 2,49 * 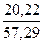 = 0,88.
= 0,88.
Таким образом, при
увеличении только фактора Х1 на одно свое стандартное отклонение
результат Y увеличивается в среднем на 0,06 своего стандартного отклонения SY, а при увеличении только фактора Х4
на одно его стандартное отклонение – увеличивается на 0,88 SY.
Дельта-коэффициенты
определяются формулами Δj = βj * 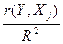 .
.
Коэффициенты парной
корреляции r(Y, X1) = – 0,01,
и r(Y, X4) = 0,87 найдены с помощью программы КОРРЕЛЯЦИЯ.
Коэффициент детерминации R2 = 0,77 определен для рассматриваемой двухфакторной модели
программой РЕГРЕССИЯ.
Вычислим
дельта-коэффициенты:
Δ1 = 0,06
* 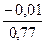 = – 0,0009; Δ2 = 0,88 *
= – 0,0009; Δ2 = 0,88 * 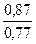 = 1,0009.
= 1,0009.
Поскольку Δ1 <
0, то факторная переменная Х1 выбрана неудачно и ее нужно исключить
из модели.
Значит, по уравнению
полученной линейной двухфакторной модели изменение результирующего фактора Y (цены квартиры) на 100% объясняется
воздействием фактора Х4 (жилой площадью квартиры).
Задача №2.
Исследование динамики
экономического показателя на основе анализа одномерного временного ряда.
В течение девяти
последовательных недель фиксировался спрос Y(t) (млн. руб.) на кредитные ресурсы
финансовой компании. Временной ряд Y(t) этого показателя приведен в таблице.
|
t
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
Y(t)
|
30
|
28
|
33
|
37
|
40
|
42
|
44
|
49
|
47
|
Задание:
1. Проверить наличие аномальных
наблюдений.
2. Построить линейную модель временного
ряда Yt = a + b * t, параметры которой оценить МНК.
3. Оценить адекватность построенной
модели, используя свойства независимости остаточной компоненты, случайности и
соответствия нормальному закону распределения.
4. Оценить точность модели на основе
использования средней относительной ошибки аппроксимации.
5. Осуществить прогноз спроса на
следующие 2 недели (прогнозный интервал рассчитать при доверительной
вероятности 70%).
6. Представить графически фактические
значения показателя, результаты моделирования и прогнозирования.
1.
Проверить наличие аномальных
наблюдений.
Используем метод Ирвина,
основанный на определении λt-статистик по формуле: λt = 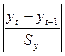 , где Sy – выборочное среднее квадратичное
(стандартное) отклонение признака Y.
, где Sy – выборочное среднее квадратичное
(стандартное) отклонение признака Y.
Подготовим Sy = 7,42 (функция СТАНДОТКЛОН) и
рассчитаем λt-статистики. Результат расчетов приведем в таблице:
|
t
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
Y(t)
|
30
|
28
|
33
|
37
|
40
|
42
|
44
|
49
|
47
|
|
λt
|
|
0,27
|
0,67
|
0,54
|
0,40
|
0,27
|
0,27
|
0,67
|
0,27
|
При n = 9 и уровне значимости α = 5%
можно использовать λкр= 1,5.
Схема проверки:

Все λt-статистики меньше λкр,
то есть аномальных наблюдений нет. Исходный ряд будем использовать для
выполнения следующих пунктов задачи.
2. Построить линейную модель временного ряда Yt = a + b * t, параметры которой оценить МНК.
С помощью программы
РЕГРЕССИЯ найдем:
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
Множественный R
|
0,971442
|
|
|
R-квадрат
|
0,9437
|
|
|
Нормированный R-квадрат
|
0,935657
|
|
|
Стандартная ошибка
|
1,883091
|
|
|
Наблюдения
|
9
|
|
|
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
416,0667
|
416,0667
|
117,333
|
1,26E-05
|
|
Остаток
|
7
|
24,82222
|
3,546032
|
|
|
|
Итого
|
8
|
440,8889
|
|
|
|
|
|
|
|
|
|
Коэффициенты
|
|
|
Y-пересечение
|
25,72222
|
|
|
t
|
2,633333
|
|
|
|
|
|
|
|
|
|
|
|
Таким образом, a = 25,72, b = 2,63. Модель построена, ее
уравнение имеет вид:
Yt = 25,72 + 2,63 * t.
Коэффициент регрессии b = 2,63 показывает, что с каждой
неделей спрос на кредитные ресурсы финансовой компании (Y) увеличивается в среднем на 2,63
млн. руб.
3. Оценить адекватность построенной модели, используя
свойства независимости остаточной компоненты, случайности и соответствия
нормальному закону распределения.
Проверка перечисленных
свойств состоит в исследовании Ряда остатков et, который содержится в таблице «Вывод
остатка» итогов РЕГРЕССИИ.
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное
Y(t)
|
Остатки
|
|
1
|
28,35556
|
1,644444
|
|
2
|
30,98889
|
-2,98889
|
|
3
|
33,62222
|
-0,62222
|
|
4
|
36,25556
|
0,744444
|
|
5
|
38,88889
|
1,111111
|
|
6
|
41,52222
|
0,477778
|
|
7
|
44,15556
|
-0,15556
|
|
8
|
46,78889
|
2,211111
|
|
9
|
49,42222
|
-2,42222
|
Для проверки свойства
независимости остаточной компоненты используем критерий Дарбина-Уотсона.
Согласно этому критерию вычислим по формуле статистику d = 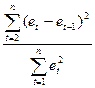 .
.
Подготовим для
вычислений:
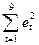 = 24,82 (функция СУММКВ);
= 24,82 (функция СУММКВ); 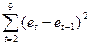 = 56,94 (функция СУММКВРАЗН).
= 56,94 (функция СУММКВРАЗН).
Таким образом, d = 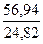 = 2,29. Поскольку d > 2, то перейдем к d’ = 4 – d = 4 – 2.29 = 1,71.
= 2,29. Поскольку d > 2, то перейдем к d’ = 4 – d = 4 – 2.29 = 1,71.
По таблице d-статистик Дарбина-Уотсона определим
критические уровни: нижний d1 = 0,82 и верхний d2 = 1,32.
Сравним полученную фактическую
величину d’ с критическими уровнями d1 и d2 и сделаем выводы согласно схеме:

d’ = 1,71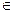 (d2 = 1,32; 2), следовательно, свойство независимости
остатков для построенной модели выполняется.
(d2 = 1,32; 2), следовательно, свойство независимости
остатков для построенной модели выполняется.
Для проверки свойства случайности
остаточной компоненты используем критерий поворотных точек (пиков), основой
которого является определение количества поворотных точек для ряда остатков. С
помощью Мастера диаграмм построим график остатков et.
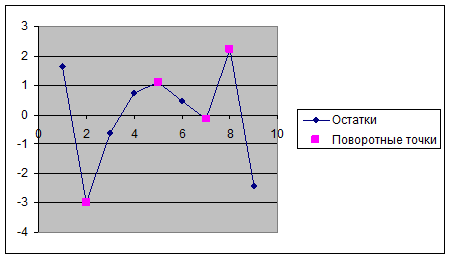
Поворотные точки –
вторая, пятая, седьмая, восьмая. Их количество p=4. По формуле pкр = 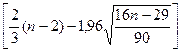 при n = 9 вычислим критическое значение pкр=
при n = 9 вычислим критическое значение pкр= 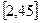 = 2.
= 2.
Сравним значения p и pкр и сделаем вывод согласно схеме:

p = 4 > pкр= 2, следовательно, свойство
случайности для ряда остатков выполняется.
Для проверки соответствия
ряда остатков нормальному закону распределения используем R/S критерий.
В соответствии с этим
критерием вычислим по формуле статистику
R/S = 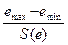 .
.
Подготовим для
вычислений:
emax =
2,21 – максимальный уровень ряда остатков (функция МАКС);
emin = –2,99
– минимальный уровень ряда остатков (функция МИН);
S(e) = 1,88 – стандартная ошибка модели
(таблица «регрессионная статистика» вывода итогов РЕГРЕССИИ).
Получим: R/S = 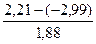 = 2,76.
= 2,76.
По таблице критических
границ отношения R/S определим критический интервал. При n = 9 можно использовать (2,67; 3,69).
Сопоставим фактическую величину R/S с критическим интервалом и сделаем выводы согласно схеме:

2,76(2,67; 3,69), значит, для построенной модели свойство
нормального распределения остаточной компоненты выполняется.
Проведенная проверка
показывает, что для построенной модели выполняются все свойства. Таким образом,
данная модель является адекватной, и ее можно использовать для построения
прогнозных оценок.
4. Оценить точность модели на основе использования средней
относительной ошибки аппроксимации.
Используем исходные
данные Yt и найденные программой РЕГРЕССИЯ остатки et (таблица «Вывод остатков»). По
формуле eотн.t = 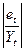 100 рассчитаем
столбец относительных погрешностей и найдем среднее значение
100 рассчитаем
столбец относительных погрешностей и найдем среднее значение 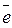 отн = 3,78%.
отн = 3,78%.
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y(t)
|
Остатки
|
Отн. погр-ти
|
|
1
|
28,35556
|
1,644444
|
5,481481
|
|
2
|
30,98889
|
-2,98889
|
10,6746
|
|
3
|
33,62222
|
-0,62222
|
1,885522
|
|
4
|
36,25556
|
0,744444
|
2,012012
|
|
5
|
38,88889
|
1,111111
|
2,777778
|
|
6
|
41,52222
|
0,477778
|
1,137566
|
|
7
|
44,15556
|
-0,15556
|
0,353535
|
|
8
|
46,78889
|
2,211111
|
4,512472
|
|
9
|
49,42222
|
-2,42222
|
5,153664
|
Сравнение показывает, что
3,78% < 5%, следовательно модель имеет высокую точность.
5. Осуществить прогноз спроса на следующие 2 недели
(прогнозный интервал рассчитать при доверительной вероятности 70%).
«Следующие 2 недели»
соответствуют периодам k1 = 1 и k2 = 2, при этом 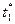 = n + k1 = 10 и
= n + k1 = 10 и 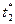 = n + k2 = 11.
= n + k2 = 11.
Согласно уравнению модели
получим точечные прогнозные оценки:
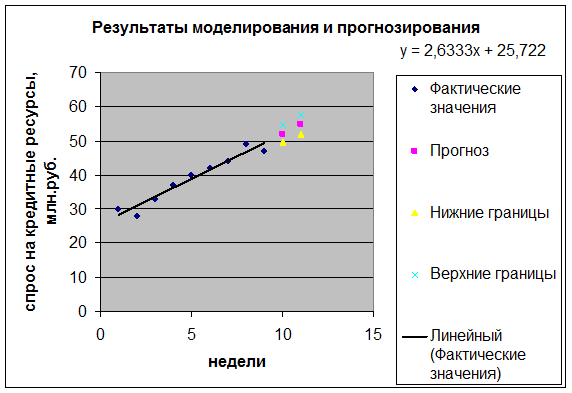
Y*10 = 25,72 + 2,63 * 10 = 52,05 и
Y*11 = 25,72 + 2,63 * 11 = 54,69.
Таким образом, ожидаемый
спрос на кредитные ресурсы финансовой компании в следующие 2 недели будут
составлять около 52,05 млн. руб. и 54,69 млн. руб. соответственно.
Для оценки точности
прогнозирования рассчитаем границы прогнозного интервала для индивидуальных
значений результирующего признака (доверительная вероятность p = 70%).
Подготовим:
tкр = 1,12 (функция СТЬЮДРАСПОБР
при α = 100 % - 70 % = 30 %, k = 9 – 2 = 7);
S(e) = 1,88 (строка «стандартная ошибка»
итогов РЕГРЕССИИ);
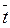 = 5 (функция СРЗНАЧ);
= 5 (функция СРЗНАЧ);
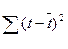 = 60 (функция КВАДРОТКЛ).
= 60 (функция КВАДРОТКЛ).
Вычислим размах
прогнозного интервала для индивидуальных значений, используя формулу: Un = 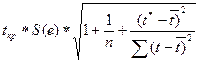 .
.
При = 10 получим U10 = 2,6 и определим границы доверительного интервала:
Uниж10= Y*10 –
U10 =
49,45; Uверх10= Y*10 +
U10 = 54,66.
При = 11 получим U11 = 2,76 и определим границы доверительного интервала:
Uниж11= Y*11 –
U11 = 51,93; Uверх11= Y*11 +
U11 = 57,45.
Таким образом, с
надежностью 70% можно утверждать, что спрос на кредитные ресурсы финансовой
компании на следующую (10-ю) неделю будет составлять от 49,45 до 54,66 млн.
руб., а через неделю (11-ю) – от 51,93 до 57,45 млн. руб.
6. Представить графически фактические значения показателя,
результаты моделирования и прогнозирования.
Для построения чертежа
используем Мастер диаграмм (точечная) – покажем исходные данные. С помощью
опции Добавить линию тренда… построим линию модели и покажем на графике результаты
прогнозирования.