ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ
ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ ИНСТИТУТ
КАФЕДРА СТАТИСТИКИ
О Т Ч Е Т
о результатах выполнения
компьютерной лабораторной работы 2
Автоматизированный
корреляционно-регрессионный анализ взаимосвязи статистических данных в среде MS
Excel
Вариант № 322
Выполнил:
Проверила:
1.
Постановка задачи статистического исследования
Корреляционно-регрессионный анализ взаимосвязи
признаков является составной частью проводимого статистического исследования
деятельности 30-ти предприятий и частично использует результаты ЛР-1.
В ЛР-2 изучается взаимосвязь между факторным признаком
Среднегодовая стоимость основных производственных
фондов
(признак Х) и результативным
признаком Выпуск продукции (признак Y),
значениями которых являются исходные данные ЛР-1 после исключения из них
аномальных наблюдений.
|
|
Таблица 1
|
|
Исходные данные
|
|
|
Номер предприятия
|
Среднегодовая стоимость основных
производственных фондов, млн.руб.
|
Выпуск продукции, млн. руб.
|
|
1
|
17486,00
|
16686,00
|
|
2
|
20564,00
|
18306,00
|
|
3
|
21212,00
|
20412,00
|
|
4
|
22346,00
|
22680,00
|
|
5
|
14570,00
|
11340,00
|
|
6
|
23480,00
|
19440,00
|
|
7
|
24128,00
|
26244,00
|
|
8
|
18134,00
|
17820,00
|
|
9
|
22184,00
|
20898,00
|
|
10
|
25586,00
|
26082,00
|
|
12
|
28016,00
|
27540,00
|
|
13
|
21374,00
|
21708,00
|
|
14
|
23480,00
|
23652,00
|
|
15
|
26882,00
|
28674,00
|
|
16
|
30770,00
|
30780,00
|
|
17
|
22994,00
|
20736,00
|
|
18
|
25424,00
|
24624,00
|
|
19
|
20240,00
|
15390,00
|
|
20
|
25748,00
|
21060,00
|
|
21
|
28664,00
|
28350,00
|
|
22
|
19754,00
|
16038,00
|
|
23
|
15704,00
|
15066,00
|
|
24
|
26234,00
|
24138,00
|
|
25
|
23480,00
|
21060,00
|
|
26
|
21860,00
|
19926,00
|
|
27
|
17000,00
|
12960,00
|
|
28
|
22832,00
|
20250,00
|
|
29
|
26396,00
|
22194,00
|
|
31
|
25100,00
|
21060,00
|
|
32
|
18458,00
|
18792,00
|
В процессе статистического
исследования необходимо решить ряд задач.
1. Установить наличие статистической
связи между факторным признаком Х
и результативным признаком Y
графическим методом.
2. Установить наличие корреляционной
связи между признаками Х и Y методом аналитической группировки.
3. Оценить тесноту связи признаков Х и
Y на основе эмпирического
корреляционного отношения η.
4. Построить однофакторную
линейную регрессионную модель связи признаков Х и Y, используя
инструмент Регрессия надстройки Пакет анализа, и оценить тесноту связи признаков Х и Y на основе линейного
коэффициента корреляции r.
5. Определить адекватность и
практическую пригодность построенной линейной регрессионной модели, оценив:
а) значимость и
доверительные интервалы коэффициентов а0,
а1;
б) индекс детерминации R2 и его значимость;
в) точность регрессионной модели.
6. Дать экономическую
интерпретацию:
а) коэффициента регрессии а1;
б) коэффициента эластичности
КЭ;
в) остаточных величин εi.
7. Найти наиболее адекватное
нелинейное уравнение регрессии с помощью средств инструмента Мастер диаграмм.
2. Выводы по результатам
выполнения лабораторной работы[1]
Задача 1. Установление наличия статистической
связи между факторным признаком Х
и результативным признаком Y графическим методом.
Статистическая
связь является разновидностью стохастической (случайной) связи, при которой с
изменением факторного признака X закономерным образом изменяется
какой–либо из обобщающих статистических показателей распределения
результативного признака Y.
Вывод:
Точечный график
связи признаков (диаграмма
рассеяния, полученная в ЛР-1 после удаления аномальных наблюдений) позволяет
сделать вывод, что имеет место
статистическая связь. Предположительный вид связи – линейная прямая.
Задача 2. Установление наличия корреляционной
связи между признаками Х и Y методом аналитической группировки.
Корреляционная
связь – важнейший частный случай стохастической статистической связи, когда под
воздействием вариации факторного признака Х
закономерно
изменяются от группы к группе средние групповые значения 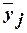 результативного
признака Y (усредняются результативные значения
результативного
признака Y (усредняются результативные значения 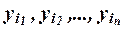 , полученные под воздействием фактора
, полученные под воздействием фактора 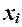 ). Для выявления наличия корреляционной связи используется
метод аналитической группировки.
). Для выявления наличия корреляционной связи используется
метод аналитической группировки.
Вывод:
Результаты выполнения аналитической группировки
предприятий по факторному признаку Среднегодовая
стоимость основных производственных фондов даны в табл. 2.2 Рабочего файла,
которая показывает, что с увеличением значений факторного признака Х закономерно увеличиваются средние групповые
значения результативного признака
. Следовательно,
между признаками Х и Y существует корреляционная
связь.
Задача 3.Оценка тесноты связи признаков Х и
Y на основе эмпирического
корреляционного отношения.
Для анализа
тесноты связи между факторным и результативным признаками рассчитывается
показатель η – эмпирическое корреляционное отношение, задаваемое
формулой
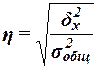 ,
,
где 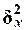 и
и 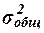 - соответственно
межгрупповая и общая дисперсии результативного признака Y - Выпуск продукции (индекс х дисперсии означает, что
оценивается мера влияния признака Х
на Y).
- соответственно
межгрупповая и общая дисперсии результативного признака Y - Выпуск продукции (индекс х дисперсии означает, что
оценивается мера влияния признака Х
на Y).
Для качественной оценки тесноты связи на основе
показателя эмпирического корреляционного отношения служит шкала Чэддока:
|
Значение η
|
0,1 – 0,3
|
0,3 – 0,5
|
0,5 – 0,7
|
0,7 – 0,9
|
0,9 – 0,99
|
|
Сила связи
|
Слабая
|
Умеренная
|
Заметная
|
Тесная
|
Весьма тесная
|
Результаты выполненных расчетов представлены в табл. 2.4 Рабочего
файла.
Вывод:
Значение коэффициента η =0,9028,
что в соответствии с оценочной шкалой Чэддока говорит о весьма тесной степени
связи изучаемых признаков.
Задача 4. Построение однофакторной линейной регрессионной модели связи
изучаемых признаков с помощью инструмента Регрессия надстройки Пакет
анализа и оценка тесноты связи на
основе линейного коэффициента корреляции r.
4.1. Построение
регрессионной модели заключается в нахождении аналитического выражения связи
между факторным признаком X и результативным признаком Y.
Инструмент Регрессия на основе исходных данных (xi , yi), производит расчет параметров а0 и а1 уравнения однофакторной линейной регрессии 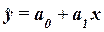 , а также вычисление ряда показателей, необходимых для
проверки адекватности построенного уравнения исходным (фактическим) данным.
, а также вычисление ряда показателей, необходимых для
проверки адекватности построенного уравнения исходным (фактическим) данным.
Примечание. В результате работы инструмента Регрессия получены четыре
результативные таблицы (начиная с заданной ячейки А75). Эти таблицы выводятся
в Рабочий файл без нумерации, поэтому необходимо присвоить им номера табл.2.5 –
табл.2.8 в соответствии с их порядком.
Вывод:
Рассчитанные в табл.2.7
(ячейки В91 и В92) коэффициенты а0
и а1 позволяют
построить линейную регрессионную модель связи изучаемых признаков в виде
уравнения 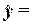 -3565,4820+1,0894х
-3565,4820+1,0894х
4.2. В случае линейности функции связи для оценки тесноты
связи признаков X и Y, устанавливаемой по
построенной модели, используется линейный коэффициент корреляции r.
Значение
коэффициента корреляции r приводится в табл.2.5 в
ячейке В78 (термин "Множественный R").
Вывод:
Значение коэффициента
корреляции r =0,9132,
что в соответствии с оценочной шкалой Чэддока говорит о весьма тесной степени
связи изучаемых признаков.
Задача 5. Анализ адекватности и практической пригодности построенной линейной
регрессионной модели.
Анализ
адекватности регрессионной модели преследует цель оценить, насколько
построенная теоретическая модель взаимосвязи признаков отражает фактическую
зависимость между этими признаками, и тем самым оценить практическую
пригодность синтезированной модели связи.
Оценка
соответствия построенной регрессионной модели исходным (фактическим) значениям
признаков X и Y
выполняется в 4 этапа:
1)
оценка
статистической значимости коэффициентов уравнения а0, а1
и определение их доверительных интервалов для заданного уровня надежности;
2)
определение
практической пригодности построенной модели на основе оценок линейного
коэффициента корреляции r и индекса детерминации R2;
3)
проверка
значимости уравнения регрессии в целом по F-критерию Фишера;
4) оценка
погрешности регрессионной модели.
5.1.
Оценка статистической
значимости коэффициентов уравнения а0, а1 и определение
их доверительных интервалов
Так как коэффициенты уравнения а0 , а1 рассчитывались, исходя из значений признаков
только для 30-ти пар (xi , yi), то полученные значения коэффициентов являются лишь приближенными
оценками фактических параметров связи а0 , а1. Поэтому необходимо:
1.
проверить
значения коэффициентов на неслучайность (т.е. узнать, насколько они типичны для
всей генеральной совокупности предприятий отрасли);
2.
определить (с
заданной доверительной вероятностью 0,95
и 0,683) пределы, в которых могут
находиться значения а0, а1 для генеральной совокупности предприятий.
Для анализа коэффициентов а0, а1 линейного уравнения регрессии используется табл.2.7, в которой:
– значения коэффициентов а0, а1 приведены в ячейках В91 и В92 соответственно;
– рассчитанный уровень значимости
коэффициентов уравнения приведен в ячейках Е91
и Е92;
– доверительные интервалы коэффициентов с
уровнем надежности Р=0,95 и Р=0,683 указаны в диапазоне ячеек F91:I92.
5.1.1. Определение значимости
коэффициентов уравнения
Уровень
значимости – это величина α=1–Р, где Р – заданный
уровень надежности (доверительная вероятность).
Режим
работы инструмента Регрессия
использует по умолчанию уровень надежности Р=0,95. Для этого уровня надежности уровень значимости равен α
= 1 – 0,95 = 0,05. Этот уровень значимости
считается заданным.
В
инструменте Регрессия надстройки Пакет анализа для каждого из
коэффициентов а0 и
а1 вычисляется уровень его значимости αр,
который указан в результативной
таблице (табл.2.7 термин
"Р-значение"). Если рассчитанный для коэффициентов а0, а1 уровень значимости αр,
меньше заданного уровня значимости α= 0,05, то этот коэффициент признается неслучайным (т.е. типичным для
генеральной совокупности), в противном случае – случайным.
Примечание. В случае, если признается случайным свободный член а0,
то уравнение регрессии целесообразно построить заново без свободного члена а0.
В этом случае в диалоговом окне Регрессия необходимо
задать те же самые параметры за исключением лишь того, что следует
активизировать флажок Константа-ноль (это означает, что модель будет
строиться при условии а0=0). В лабораторной работе такой шаг не предусмотрен.
Если
незначимым (случайным) является коэффициент регрессии а1, то взаимосвязь между признаками X и
Y в принципе
не может аппроксимироваться линейной моделью.
Вывод:
Для свободного члена а0 уравнения регрессии рассчитанный уровень значимости есть αр
=0,1026 Так как он больше
заданного уровня значимости α=0,05,
то коэффициент а0
признается случайным.
Для коэффициента
регрессии а1 рассчитанный
уровень значимости есть αр
=1,9760 Так как он больше
заданного уровня значимости α=0,05,
то коэффициент а1
признается случайным.
5.1.2.
Зависимость доверительных интервалов коэффициентов уравнения от заданного
уровня надежности
Доверительные интервалы коэффициентов а0, а1
построенного уравнения регрессии при уровнях надежности Р=0,95 и Р=0,683 представлены в табл.2.7, на
основе которой формируется табл.2.9.
Таблица 2.9
Границы
доверительных интервалов коэффициентов уравнения
|
Коэффициенты
|
Границы доверительных
интервалов
|
|
Для уровня надежности Р=0,95
|
Для уровня надежности Р=0,683
|
|
нижняя
|
верхняя
|
нижняя
|
верхняя
|
|
а0
|
-7893,0932
|
762,1293
|
-5717,9652
|
-1412,9987
|
|
а1
|
0,9012
|
1,2776
|
0,9957
|
1,183
|
Вывод:
В генеральной
совокупности предприятий значение коэффициента
а0 следует
ожидать с надежностью Р=0,95 в
пределах 7893,0932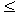 а0762,1293,
значение коэффициента а1 в
пределах 0,9012а11,2776. Уменьшение
уровня надежности ведет к сужению доверительных интервалов коэффициентов
уравнения.
а0762,1293,
значение коэффициента а1 в
пределах 0,9012а11,2776. Уменьшение
уровня надежности ведет к сужению доверительных интервалов коэффициентов
уравнения.
Определение
практической пригодности построенной регрессионной модели.
Практическую
пригодность построенной модели 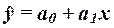 можно охарактеризовать по величине линейного коэффициента корреляции r:
можно охарактеризовать по величине линейного коэффициента корреляции r:
· близость  к единице
свидетельствует о хорошей аппроксимации исходных (фактических) данных с помощью
построенной линейной функции связи ;
к единице
свидетельствует о хорошей аппроксимации исходных (фактических) данных с помощью
построенной линейной функции связи ;
· близость  к нулю означает, что
связь между фактическими данными Х и Y нельзя аппроксимировать как
построенной, так и любой другой линейной моделью,
и, следовательно, для моделирования связи следует использовать какую-либо
подходящую нелинейную модель.
к нулю означает, что
связь между фактическими данными Х и Y нельзя аппроксимировать как
построенной, так и любой другой линейной моделью,
и, следовательно, для моделирования связи следует использовать какую-либо
подходящую нелинейную модель.
Пригодность построенной регрессионной модели для
практического использования можно оценить и по величине индекса
детерминации R2,
показывающего, какая часть общей вариации признака Y объясняется в
построенной модели вариацией фактора
X.
В основе такой оценки лежит
равенство R
= r (имеющее место
для линейных моделей связи), а также шкала Чэддока, устанавливающая качественную характеристику тесноты
связи в зависимости от величины r.
Согласно шкале Чэддока высокая степень тесноты связи
признаков достигается лишь при 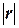 >0,7, т.е. при
>0,7, т.е. при 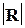 >0,7.
Для индекса детерминации R2
это означает выполнение
неравенства R2 >0,5.
>0,7.
Для индекса детерминации R2
это означает выполнение
неравенства R2 >0,5.
При недостаточно тесной
связи признаков X, Y (слабой, умеренной,
заметной) имеет место неравенство 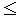 0,7, а следовательно, и неравенство
0,7, а следовательно, и неравенство 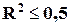 .
.
С учетом вышесказанного,
практическая пригодность построенной модели связи оценивается по
величине R2 следующим образом:
·
неравенство R2 >0,5 позволяет
считать, что построенная модель пригодна для практического применения, т.к. в
ней достигается высокая степень тесноты связи признаков X и Y, при
которой более 50% вариации признака Y объясняется влиянием фактора Х;
·
неравенство означает, что
построенная модель связи практического значения не имеет ввиду недостаточной
тесноты связи между признаками X и Y, при которой менее 50% вариации признака Y объясняется влиянием фактора Х,
и, следовательно, фактор Х влияет на вариацию Y в значительно меньшей степени, чем другие (неучтенные в модели)
факторы.
Значение
индекса детерминации R2 приводится в табл.2.5 в ячейке В79
(термин "R - квадрат").
Вывод:
Значение линейного
коэффициента корреляции r и значение индекса детерминации R2 согласно табл. 2.5 равны: r =0,9132, R2 =0,8339.
Поскольку 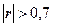 и
и 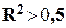
 , то построенная линейная регрессионная модель связи пригодна для практического использования.
, то построенная линейная регрессионная модель связи пригодна для практического использования.
Общая оценка адекватности регрессионной модели по F-критерию Фишера
Адекватность построенной регрессионной
модели фактическим данным (xi, yi) устанавливается по критерию Р.Фишера, оценивающему
статистическую значимость (неслучайность) индекса детерминации R2.
Рассчитанная для уравнения регрессии
оценка значимости R2
приведена в табл.2.6 в ячейке F86 (термин "Значимость F"). Если
она меньше заданного уровня значимости α=0,05, то величина R2 признается
неслучайной и, следовательно, построенное уравнение регрессии может быть использовано как модель связи между
признаками Х и Y для генеральной
совокупности предприятий отрасли.
Вывод:
Рассчитанный уровень значимости αр индекса детерминации R2 есть αр=1,9760. Так как он больше заданного уровня
значимости α=0,05, то
значение R2
признается случайным и модель связи между признаками Х и Y 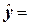 -3565,4820+1,0894х неприменима для генеральной совокупности предприятий отрасли в
целом.
-3565,4820+1,0894х неприменима для генеральной совокупности предприятий отрасли в
целом.
Оценка погрешности регрессионной модели
Погрешность
регрессионной модели можно оценить по величине стандартной ошибки 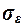 построенного
линейного уравнения регрессии . Величина ошибки оценивается как среднее
квадратическое отклонение по совокупности отклонений
построенного
линейного уравнения регрессии . Величина ошибки оценивается как среднее
квадратическое отклонение по совокупности отклонений 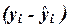 исходных (фактических)
значений yi признака Y от его теоретических значений
исходных (фактических)
значений yi признака Y от его теоретических значений 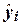 , рассчитанных по построенной модели.
, рассчитанных по построенной модели.
Погрешность регрессионной
модели выражается в процентах и рассчитывается как величина 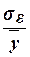 .100.
.100.
В адекватных
моделях погрешность не должна превышать 12%-15%.
Значение 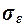 приводится в
выходной таблице "Регрессионная статистика"
(табл.2.5) в
ячейке В81 (термин "Стандартная
ошибка"), значение
приводится в
выходной таблице "Регрессионная статистика"
(табл.2.5) в
ячейке В81 (термин "Стандартная
ошибка"), значение 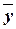 – в таблице описательных
статистик (ЛР-1, Лист
1, табл.3, столбец 2).
– в таблице описательных
статистик (ЛР-1, Лист
1, табл.3, столбец 2).
Вывод:
Погрешность линейной
регрессионной модели составляет .100=1938,6660/21130,2*100=9,1749%, что подтверждает
адекватность построенной модели -3565,4820+1,0894х
Задача 6. Дать экономическую интерпретацию:
1) коэффициента регрессии а1;
3) остаточных величин 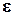 i.
i.
2) коэффициента эластичности КЭ;
6.1. Экономическая интерпретация коэффициента регрессии а1
В случае линейного уравнения регрессии 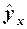 =a0+a1x
величина коэффициента регрессии a1 показывает, на
сколько в среднем (в абсолютном выражении) изменяется значение
результативного признака Y при
изменении фактора Х на единицу его
измерения. Знак при a1 показывает направление этого
изменения.
=a0+a1x
величина коэффициента регрессии a1 показывает, на
сколько в среднем (в абсолютном выражении) изменяется значение
результативного признака Y при
изменении фактора Х на единицу его
измерения. Знак при a1 показывает направление этого
изменения.
Вывод:
Коэффициент
регрессии а1 =1,0894
показывает, что при увеличении факторного признака Среднегодовая
стоимость основных производственных фондов на
1 млн руб. значение результативного признака Выпуск продукции увеличивается
в среднем на 1,0894млн руб.
6.2. Экономическая интерпретация коэффициента
эластичности.
С целью расширения возможностей
экономического анализа явления используется коэффициент эластичности 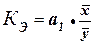 , который
измеряется в процентах и показывает, на
сколько процентов изменяется в среднем результативный признак при
изменении факторного признака на 1%.
, который
измеряется в процентах и показывает, на
сколько процентов изменяется в среднем результативный признак при
изменении факторного признака на 1%.
Средние значения 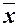 и
и 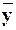 приведены в таблице
описательных статистик (ЛР-1, Лист 1, табл.3).
приведены в таблице
описательных статистик (ЛР-1, Лист 1, табл.3).
Расчет коэффициента эластичности:
=1,0894*(22670/21130,2) =1,1688%
Вывод:
Значение коэффициента
эластичности Кэ=1,1688 показывает, что при увеличении факторного признака Среднегодовая стоимость основных
производственных фондов на 1%
значение результативного признака Выпуск
продукции увеличивается в среднем на 1,1688%.
6.3. Экономическая интерпретация остаточных величин
εi
Каждый их остатков 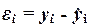 характеризует
отклонение фактического значения
yi от теоретического значения
характеризует
отклонение фактического значения
yi от теоретического значения 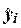 , рассчитанного по построенной регрессионной модели и
определяющего, какого среднего значения
, рассчитанного по построенной регрессионной модели и
определяющего, какого среднего значения 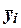 следует ожидать,
когда фактор Х принимает значение xi.
следует ожидать,
когда фактор Х принимает значение xi.
Анализируя остатки, можно
сделать ряд практических выводов, касающихся выпуска продукции на
рассматриваемых предприятиях отрасли.
Значения остатков i (таблица остатков из
диапазона А98:С128) имеют как положительные, так и отрицательные
отклонения от ожидаемого в среднем объема выпуска продукции (которые в
итоге уравновешиваются, т.е.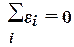 ).
).
Экономический
интерес представляют наибольшие расхождения между
фактическим объемом выпускаемой продукции yi и ожидаемым усредненным
объемом 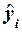 .
.
Вывод:
Согласно таблице остатков максимальное превышение
ожидаемого среднего объема выпускаемой
продукции имеют три
предприятия - с номерами 20,27,6, а
максимальные отрицательные отклонения - три предприятия с номерами 24,8,26.
.Именно эти шесть предприятий подлежат дальнейшему экономическому анализу для
выяснения причин наибольших отклонений объема выпускаемой ими продукции от
ожидаемого среднего объема и выявления резервов роста производства.
Задача 7. Нахождение наиболее
адекватного нелинейного уравнения регрессии с помощью средств
инструмента Мастер диаграмм.
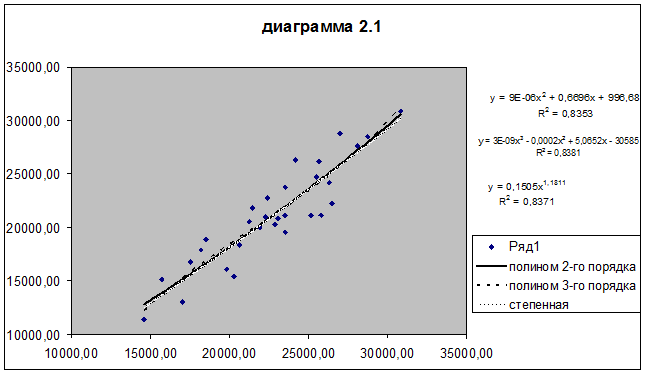
Уравнения регрессии и их графики построены для 3-х
видов нелинейной зависимости между признаками и представлены на диаграмме 2.1 Рабочего
файла.
Уравнения регрессии и соответствующие им индексы
детерминации R2 приведены в табл.2.10 (при заполнении данной
таблицы коэффициенты уравнений необходимо указывать не в компьютерном формате,
а в общепринятой десятичной форме чисел).
Таблица 2.10
Регрессионные модели связи
|
Вид уравнения
|
Уравнение регрессии
|
Индекс
детерминации R2
|
|
Полином
2-го порядка
|
9Е-06х2+0,6696х+996,68
|
0.8353
|
|
Полином
3-го порядка
|
3Е-09х3-0,0002х2+5,0652х-30585
|
0.8381
|
|
Степенная
функция
|
0.1505х1.1811
|
0.8371
|
Выбор наиболее адекватного уравнения регрессии
определяется максимальным значением индекса детерминации R2: чем ближе значение R2
к
единице, тем более точно регрессионная модель соответствует фактическим данным.
Вывод:
Максимальное значение индекса детерминации R2 =0,8381. Следовательно, наиболее адекватное
исходным данным нелинейное уравнение регрессии имеет вид 3Е-09х3-0,0002х2+5,0652х-30585
ПРИЛОЖЕНИЕ
Результативные таблицы и графики
|
|
Таблица 2.1
|
|
Исходные данные
|
|
Номер предприятия
|
Среднегодовая стоимость основных
производственных фондов, млн.руб.
|
Выпуск продукции, млн. руб.
|
|
5
|
14570,00
|
11340,00
|
|
23
|
15704,00
|
15066,00
|
|
27
|
17000,00
|
12960,00
|
|
1
|
17486,00
|
16686,00
|
|
8
|
18134,00
|
17820,00
|
|
32
|
18458,00
|
18792,00
|
|
22
|
19754,00
|
16038,00
|
|
19
|
20240,00
|
15390,00
|
|
2
|
20564,00
|
18306,00
|
|
3
|
21212,00
|
20412,00
|
|
13
|
21374,00
|
21708,00
|
|
26
|
21860,00
|
19926,00
|
|
9
|
22184,00
|
20898,00
|
|
4
|
22346,00
|
22680,00
|
|
28
|
22832,00
|
20250,00
|
|
17
|
22994,00
|
20736,00
|
|
6
|
23480,00
|
19440,00
|
|
14
|
23480,00
|
23652,00
|
|
25
|
23480,00
|
21060,00
|
|
7
|
24128,00
|
26244,00
|
|
31
|
25100,00
|
21060,00
|
|
18
|
25424,00
|
24624,00
|
|
10
|
25586,00
|
26082,00
|
|
20
|
25748,00
|
21060,00
|
|
24
|
26234,00
|
24138,00
|
|
29
|
26396,00
|
22194,00
|
|
15
|
26882,00
|
28674,00
|
|
12
|
28016,00
|
27540,00
|
|
21
|
28664,00
|
28350,00
|
|
16
|
30770,00
|
30780,00
|
|
|
|
|
Таблица 2.2
|
|
Зависимость выпуска
продукции от среднегодовой стоимости основных фондов
|
|
Номер группы
|
Группы предприятий по стоимости
основеных фондов
|
Число предприятий
|
Выпуск продукции
|
|
Всего
|
В среднем
на одно
предприятие
|
|
1
|
14570-17810
|
4
|
56052,00
|
14013,00
|
|
2
|
17810-21050
|
5
|
86346,00
|
17269,20
|
|
3
|
21050-24290
|
11
|
237006,00
|
21546,00
|
|
4
|
24290-27530
|
7
|
167832,00
|
23976,00
|
|
5
|
27530-30770
|
3
|
547236,00
|
182412,00
|
|
Итого
|
|
30
|
1094472,00
|
36482,40
|
|
|
|
Таблица 2.3
|
|
Показатели внутригрупповой
вариации
|
|
Номер группы
|
Группы предприятий по стоимости
основеных фондов
|
Число предприятий
|
Внутригрупповая дисперсия
|
|
1
|
14570-17810
|
4
|
4126869,00
|
|
2
|
17810-21050
|
5
|
1748900,16
|
|
3
|
21050-24290
|
11
|
3559640,73
|
|
4
|
24290-27530
|
7
|
6733460,57
|
|
5
|
27530-30770
|
3
|
1895400,00
|
|
Итого
|
|
30
|
|
|
|
|
Таблица 2.4
|
|
Показатели дисперсии
и эмпирического корреляционного отношения
|
|
Общая дисперсия
|
Средняя из внутригрупповых
дисперсия
|
Межгрупповая дисперсия
|
Эмпирическое корреляционное
отношение
|
|
21120617,16
|
3907614,96
|
17213002,2
|
0,902765617
|
|
Выходные
таблицы
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ВЫВОД
ИТОГОВ
|
|
|
|
|
|
|
|
|
|
Таблица
2.5
|
|
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
|
|
Множественный
R
|
0,91318826
|
|
|
|
|
|
|
|
|
R-квадрат
|
0,833912798
|
|
|
|
|
|
|
|
|
Нормированный
R-квадрат
|
0,827981112
|
|
|
|
|
|
|
|
|
Стандартная
ошибка
|
1938,666019
|
|
|
|
|
|
|
|
|
Наблюдения
|
30
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2.6
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
|
|
Регрессия
|
1
|
528382588,7
|
528382588,7
|
140,5861384
|
1,97601E-12
|
|
|
|
|
Остаток
|
28
|
105235926,1
|
3758425,934
|
|
|
|
|
|
|
Итого
|
29
|
633618514,8
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2.7
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 68,3%
|
Верхние 68,3%
|
|
Y-пересечение
|
-3565,481952
|
2112,671466
|
-1,687665125
|
0,10258589
|
-7893,093213
|
762,129309
|
-5717,965198
|
-1412,998706
|
|
Переменная
X 1
|
1,089355181
|
0,09187519
|
11,85690257
|
1,97601E-12
|
0,901157387
|
1,277552975
|
0,995748668
|
1,182961694
|
|
|
|
|
|
|
|
|
|
|
ВЫВОД
ОСТАТКА
|
|
|
|
|
Таблица
2.8
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
1
|
12306,42303
|
-966,4230343
|
|
2
|
13541,75181
|
1524,24819
|
|
3
|
14953,55612
|
-1993,556124
|
|
4
|
15482,98274
|
1203,017258
|
|
5
|
16188,8849
|
1631,115101
|
|
6
|
16541,83598
|
2250,164022
|
|
7
|
17953,64029
|
-1915,640292
|
|
8
|
18483,06691
|
-3093,06691
|
|
9
|
18836,01799
|
-530,0179889
|
|
10
|
19541,92015
|
870,0798538
|
|
11
|
19718,39569
|
1989,604315
|
|
12
|
20247,8223
|
-321,8223034
|
|
13
|
20600,77338
|
297,2266179
|
|
14
|
20777,24892
|
1902,751079
|
|
15
|
21306,67554
|
-1056,675539
|
|
16
|
21483,15108
|
-747,1510786
|
|
17
|
22012,5777
|
-2572,577697
|
|
18
|
22012,5777
|
1639,422303
|
|
19
|
22012,5777
|
-952,5776966
|
|
20
|
22718,47985
|
3525,520146
|
|
21
|
23777,33309
|
-2717,33309
|
|
22
|
24130,28417
|
493,7158317
|
|
23
|
24306,75971
|
1775,240292
|
|
24
|
24483,23525
|
-3423,235247
|
|
25
|
25012,66186
|
-874,6618649
|
|
26
|
25189,1374
|
-2995,137404
|
|
27
|
25718,56402
|
2955,435978
|
|
28
|
26953,8928
|
586,1072026
|
|
29
|
27659,79495
|
690,2050454
|
|
30
|
29953,97697
|
826,0230343
|
[1] Все статистические показатели необходимо представить в таблицах с
точностью до 4-х знаков после запятой. Таблицы и пробелы в формулировках
выводов заполнять вручную. В выводах при выборе альтернативного
варианта ответа ненужный вариант вычеркивается.