ФЕДЕРАЛЬНОЕ
АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ
ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ ИНСТИТУТ
Аудиторная
работа
по дисциплине «Эконометрика»
студентки 3 курса специальности «Финансы и кредит»
Вариант № 4
Пенза,
2006
Имеются данные
по странам за 1997 г.:
|
Страна
|
Индекс
челове-ческого разви-тия, Y
|
Ожидаемая
продолжительность жизни при рождении в 1997 г., лет, X1,
|
Суточная
калорийность питания населения, ккал на душу, Х2
|
|
|
|
|
|
|
Австрия
|
0,904
|
77
|
3343
|
|
Австралия
|
0,922
|
78,2
|
3001
|
|
...........................................................................................................................
|
|
Япония
|
0,924
|
80
|
2905
|
Задание
1.
Постройте матрицу парных коэффициентов корреляции.
2.
Постройте парные уравнения регрессии, отобразите
результаты моделирования на графиках.
3.
Оцените статистическую значимость уравнений и их
параметров с помощью критериев Фишера и Стьюдента.
4.
Постройте уравнение множественной регрессии.
5.
Постройте график остатков.
6.
Проверьте выполнение предпосылок МНК, в том числе
проведите тестирование ошибок уравнения множественной регрессии на
гетероскедастичность.
7.
Оцените статистическую значимость уравнения
множественной регрессии. Определите, какое уравнение лучше использовать для
прогноза индекса человеческого развития:
·
парную регрессию у на х1;
·
парную регрессию у на х2;
·
множественную регрессию.
Решение
1. Для расчета матрицы парных коэффициентов корреляции используем
инструмент Корреляция (Анализ данных в Excel):
·
выберем команду Сервис => Анализ данных => Корреляция;
·
в диалоговом окне Корреляция в поле Входной интервал введем диапазон ячеек,
содержащих исходные данные. Так как введены заголовки столбцов, то установим
флажок Метки в первой строке ;
·
выберем в качестве параметра вывода Новый рабочий лист и нажмем ОК.
В результате получим матрицу парных коэффициентов корреляции
(табл.1).
Таблица
1
|
|
Y
|
X1,
|
Х2
|
|
Y
|
1
|
|
|
|
X1
|
0,949805867
|
1
|
|
|
Х2
|
0,553261358
|
0,53286729
|
1
|
2. Для построения парных уравнений регрессии применим инструмент
Регрессия (Анализ данных в Excel):
·
выберем команду Сервис => Анализ данных => Регрессия;
·
в диалоговом окне Регрессия в поле Входной интервал Y введем диапазон
ячеек, содержащих значения зависимой переменной. В поле Входной интервал Х введем диапазон ячеек, содержащих значения
независимой переменной. Так как введены заголовки столбцов, то установим флажок
Метки;
·
выберем в качестве параметра вывода Новый рабочий лист;
·
в поле Остатки
поставим флажок Остатки и График
подбора и нажмем ОК.
Результат регрессионного анализа для
модели у-х1 содержится в табл. 2-4 и на рис. 1. По результатам табл.
4 запишем полученное уравнение линейной регрессии:
у= -0,575
+ 0,019 х1.
Таблица 2
|
Регрессионная статистика
|
|
Множественный R
|
0,949805867
|
|
R-квадрат
|
0,902131184
|
|
Нормированный R-квадрат
|
0,89925269
|
|
Стандартная ошибка
|
0,032166824
|
|
Наблюдения
|
36
|
Таблица 3
|
Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
|
Регрессия
|
1
|
0,32428
|
0,324280351
|
313,403816
|
|
Остаток
|
34
|
0,03518
|
0,001034705
|
|
|
Итого
|
35
|
0,35946
|
|
|
Таблица 4
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
|
Y-пересечение
|
-0,575225283
|
0,079622
|
-7,224463516
|
|
X1
|
0,01911398
|
0,00108
|
17,70321486
|
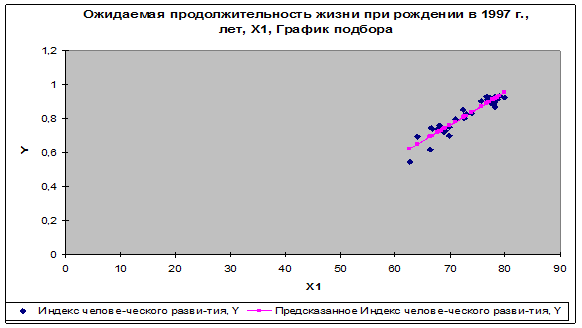
Рис. 1. Регрессионная модель
у-х1.
Результат регрессионного анализа для модели у-х2
содержится в табл. 5-7 и на рис. 2. По результатам табл. 7 запишем полученное
уравнение линейной регрессии:
у= 0,234 + 0,00019 х2.
Таблица 5
|
Регрессионная статистика
|
|
Множественный R
|
0,553261358
|
|
R-квадрат
|
0,30609813
|
|
Нормированный R-квадрат
|
0,285689251
|
|
Стандартная ошибка
|
0,085651513
|
|
Наблюдения
|
36
|
Таблица 6
|
Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
|
Регрессия
|
1
|
0,11003
|
0,110030127
|
14,99828
|
|
Остаток
|
34
|
0,24943
|
0,007336182
|
|
|
Итого
|
35
|
0,35946
|
|
|
Таблица 7
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
|
Y-пересечение
|
0,233708671
|
0,154924
|
1,508540085
|
|
Х2
|
0,000187383
|
4,84E-05
|
3,872761637
|
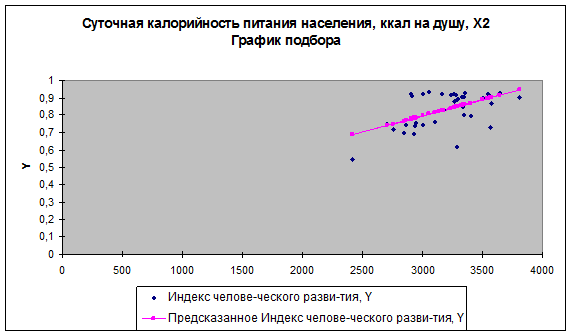
Рис. 2. Регрессионная модель
у-х2.
3. Оценку параметров
парных регрессионных моделей у-х1 и у-х2 проведем с помощью
t-критерия Стьюдента. Табличное значение t-критерия определим с помощью функции
СТЬЮДРАСПОБР (0.05,34). Табличное значение t-критерия при 5%-ном уровне
значимости и степенях свободы (36-1-1=34) составляет 2,032. Так как для всех
параметров регрессионной модели у-х1 выполняется неравенство |tрасч|>tтабл,
то все коэффициенты парного уравнения регрессии у-х1 являются
значимыми (табл. 4). Так как для коэффициента а0 в парном уравнение
у-х2 неравенство |tрасч|>tтабл не
выполняется, то данный коэффициент является незначимым, а коэффициент а1
парного уравнения регрессии у-х2 является значимым, так как для него
выполняется |tрасч|>tтабл (табл. 7).
Значимости уравнений парных регрессионных моделей у-х1 и у-х2 оценим с помощью F-критерия
Фишера. Табличное значение F-критерия определим с помощью функции FРАСПОБР
(0.05;1;34). Табличное значение F-критерия при доверительной вероятности 0,95
при v1=k=2 и v2=n-k-1=36-1-1=34 составляет 4,13. Так как для двух
уравнений регрессионных моделей у-х1 и у-х2 выполняется неравенство Fрасч>Fтабл,
то оба уравнения регрессии являются значимым (табл. 3 и табл. 6).
4. Для построения уравнения множественной регрессии, как и для
построения парных уравнений регрессии, применим инструмент Регрессия (Анализ
данных в Excel). Отличие состоит в том, что в поле Входной интервал Х введем
диапазон ячеек, содержащих значения двух независимых переменных х1 и
х2.
Результат регрессионного анализа для модели множественной регрессии
содержится в табл. 8-11. По результатам табл. 10 запишем полученное уравнение
множественной регрессии:
у= -0,594 + 0,0184 х1 + 0,0000223 х2.
Таблица 8
|
Регрессионная статистика
|
|
Множественный R
|
0,951438214
|
|
R-квадрат
|
0,905234676
|
|
Нормированный R-квадрат
|
0,899491323
|
|
Стандартная ошибка
|
0,032128705
|
|
Наблюдения
|
36
|
Таблица 9
|
Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
|
Регрессия
|
2
|
0,325396
|
0,162697967
|
157,61432
|
|
Остаток
|
33
|
0,034064
|
0,001032254
|
|
|
Итого
|
35
|
0,35946
|
|
|
Таблица 10
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
|
Y-пересечение
|
-0,59437154
|
0,081632
|
-7,281087849
|
|
X1
|
0,018408007
|
0,001274
|
14,44425507
|
|
Х2
|
0,0000223
|
2,14E-05
|
1,039579016
|
Таблица 11
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
1
|
0,897585077
|
0,006415
|
|
2
|
0,912048986
|
0,009951
|
|
3
|
0,817496694
|
0,009503
|
|
4
|
0,726517053
|
0,036483
|
|
5
|
0,905726151
|
0,017274
|
|
6
|
0,700792974
|
0,038207
|
|
7
|
0,898903157
|
0,019097
|
|
8
|
0,78661178
|
0,008388
|
|
9
|
0,900976812
|
0,005023
|
|
10
|
0,923006873
|
-0,05601
|
|
11
|
0,884022942
|
0,020977
|
|
12
|
0,699415346
|
-0,08342
|
|
13
|
0,910728369
|
-0,02773
|
|
14
|
0,611817824
|
-0,06682
|
|
15
|
0,91492281
|
-0,02092
|
|
16
|
0,923264561
|
-0,02326
|
|
17
|
0,928001747
|
0,003998
|
|
18
|
0,718898699
|
0,021101
|
|
19
|
0,753921043
|
-0,05292
|
|
20
|
0,728528888
|
0,015471
|
|
21
|
0,912279304
|
0,008721
|
|
22
|
0,917989966
|
0,00901
|
|
23
|
0,814771343
|
-0,01277
|
|
24
|
0,812752164
|
0,039248
|
|
25
|
0,69189379
|
0,055106
|
|
26
|
0,757969282
|
-0,00597
|
|
27
|
0,896888786
|
0,030111
|
|
28
|
0,755337929
|
-0,02734
|
|
29
|
0,733483976
|
-0,01248
|
|
30
|
0,884382501
|
0,028617
|
|
31
|
0,922471736
|
-0,00447
|
|
32
|
0,836818893
|
-0,00382
|
|
33
|
0,925633154
|
-0,01163
|
|
34
|
0,921116669
|
0,001883
|
|
35
|
0,650979869
|
0,04402
|
|
36
|
0,943042852
|
-0,01904
|
5. Графики остатков (зависимость еi от х1 и от х2) строятся
автоматически, так как в поле инструмента Регрессия Остатки установлен флажок
График остатков, данные графики приведены на рис. 4 и 5. Для построения графика
остатков (зависимость еi
от у) используем Мастер диаграмм Excel, полученный график приведен на рис. 3.
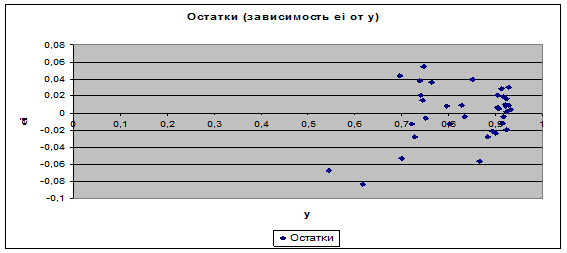
Рис. 3. График остатков (еi от у)
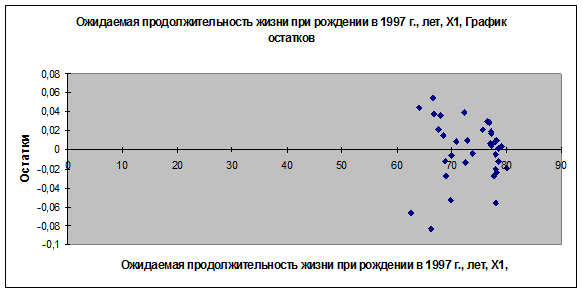
Рис. 4. График остатков (еi от х1)
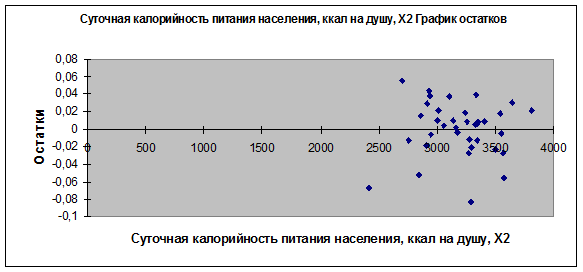
Рис. 5. График остатков (еi от х2)
6. Для проверки предпосылок МНК рассмотрим графики остатков (рис. 3, 4,
5). На графике еi
от х1 остаточная величина еi обнаруживает тенденцию к уменьшению по мере роста х1.
Это дает повод усомниться в случайности остаточной компоненты и выполнении
предпосылки о равенстве дисперсий. Проверим наличие гетероскедастичности при помощи метода Голдфельда-Квандта:
·
упорядочим все наблюдения по мере возрастания
х1;
·
разделим совокупность на 2 группы, исключив из
рассмотрения 2 центральных наблюдения, тогда в каждой группе будет по 17
наблюдений;
·
определим по каждой из групп уравнения регрессии
(применим инструмент Регрессия). Остаточные суммы квадратов для первой
регрессии S1у=0,025073, для второй – S2у=0,003735. Так
как S1у> S2у, то Fнабл= S1у / S2у=6.713.
Табличное значение F-критерия при доверительной вероятности 0,95 при
v1=n1-m=17-2=15 и v2=n-n1-m=36-17-2=15 составляет 2,308. Так как Fнабл>Fтабл,
то наличие гетероскедастичности подтверждается.
Предпосылка о равенстве математического ожидания остаточной компоненты
нулю выполняется, так как на графиках остатков (еi от хi) (рис 4,5) остатки распределены
у оси охi
симметрично.
Предпосылка о независимости остатков принимается как аксиома, так как
дана пространственная выборка.
Проверим предпосылку о нормальности ряда остатков с помощью RS-критерия.
R=εmax- εmin=0,05511-(-0,08342)=0,1385.
S=0.0312
RS=0,1385/0,0312=4,439.
Значение RS-критерия
попадает в критический интервал (3,58; 4,84) для n=35 и α=0,05, значит остатки
распределены по нормальному закону.
7. Уравнение множественной регрессии статистически
значимо, так как Fрасч>Fтабл (F(0,05;2;33)=3,285) (табл.
8). Так как для коэффициента b2
в уравнение регрессии неравенство |tрасч|>tтабл (t(0,05;33)=2,035)
не выполняется, то данный коэффициент является незначимым, а коэффициенты b0 и b1 являются значимыми,
так как для них выполняется |tрасч|>tтабл (табл. 10).
Для прогноза индекса человеческого
развития лучше всего использовать парную модель регрессии у-х1, так
как для нее высокий нормированный коэффициент детерминации и все коэффициенты
ее значимы.