СОДЕРЖАНИЕ
ВВЕДЕНИЕ 3
Общие сведения 4
Множественная регрессия и корреляция 10
Двухмерная линейная модель корреляционного и
регрессионного анализа 19
Проверка адекватности регрессионной модели 20
ЗАКЛЮЧЕНИЕ 26
СПИСОК ЛИТЕРАТУРЫ 27
ВВЕДЕНИЕ
В экономических исследованиях часто
решают задачу выявления факторов, определяющих уровень и динамику
экономического процесса. Такая задача чаще всего решается методами
корреляционного, регрессионного, факторного и компонентного анализа.
Все многообразие факторов, которые
воздействуют на изучаемый процесс, можно разделить на две группы: главные
(определяющие уровень изучаемого процесса) и второстепенные. Последние часто
имеют случайный характер, определяя специфические и индивидуальные особенности
каждого объекта исследования.
Взаимодействие главных и второстепенных
факторов и определяет колеблемость исследуемого процесса. В этом взаимодействии
синтезируется как необходимое, типическое, определяющее закономерность
изучаемого явления, так и случайное, характеризующее отклонение от этой
закономерности. Случайные отклонения неизбежно сопутствуют любому закономерному
явлению.
Для достоверного отображения объективно
существующих в экономике процессов необходимо выявить существенные взаимосвязи
и не только выявить, но и дать им количественную оценку. Этот подход требует
вскрытия причинных зависимостей. Под причинной зависимостью понимается такая
связь между процессами, когда изменение одного из них является следствием
изменения другого.
Не
все факторы, влияющие на экономические процессы, являются случайными величинами.
Поэтому при анализе экономических Явлений обычно рассматриваются связи между
случайными и неслучайными величинами. Такие связи называются регрессионными, а
метод математической статистики, их
изучающий, называется регрессионным анализом.
Общие сведения
С целью математического описания конкретного вида
зависимостей с использованием регрессионного анализа подбирают класс функций, связывающих
результативный показатель y и аргументы x1, x2,…,хk , отбирают наиболее информативные аргументы,
вычисляют оценки неизвестных значений параметров уравнения связи и анализируют
точность полученного уравнения.
Функция f(x1, x2,…,хk ), описывающая зависимость условного среднего значения результативного
признака у от заданных значений аргументов, называется функцией
(уравнением) регрессии.
Термин "регрессия" (лат. - "regression" - отступление, возврат к
чему-либо) введен английским психологом и антропологом Ф.Гальтпном и связан
только со спецификой одного из первых конкретных примеров, в котором это понятие было использовано.
Обрабатывая
статистические данные в связи с вопросом о наследственности роста,
Ф.Гальтон нашел, что если отцы отклоняются от среднего роста всех
отцов на x дюймов, то их сыновья отклоняются от среднего роста всех сыновей меньше,
чем на x дюймов. Выявленная тенденция была названа «регрессией к среднему
состоянию»[1].
Термин регрессия широко используется в
статистической литературе, хотя во многих случаях он недостаточно точно
характеризует понятие статистической зависимости.
Для точного
описания уравнения регрессии
необходимо знать условный закон распределения результативного показателя у.
В статистической практике такую информацию получить обычно не удается,
поэтому ограничиваются поиском подходящих аппроксимаций для функции f( x1, x2,…,хk ), основанных на исходных статистических
данных.
В рамках отдельных модельных допущений о типе распределения
вектора показателей (у, x1, x2,…,хk ) может быть получен общий вид
уравнения регрессии f(x)=M(y/x) x=( x1, x2,…,хk )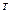 .
Например, в предложении, что исследуемая совокупность показателей подчиняется (k + 1) - мерному нормальному закону распределения с вектором
математических ожиданий
.
Например, в предложении, что исследуемая совокупность показателей подчиняется (k + 1) - мерному нормальному закону распределения с вектором
математических ожиданий
M =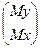 ,
,
где Mx =  , my = MY
, my = MY
и ковариационной матрицей
S = 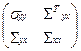 ,
,
где syy = s2y = M (y-My) ;
;
S yx =  ; S xx =
; S xx = 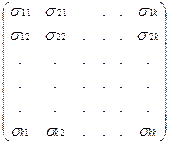 ;
;
s ij = M (xi –
Mxi);(xj – Mxj); sjj = sj = M (xj – Mxj).
Из этого следует, что уравнение
регрессии (условное математическое ожидание) имеет вид:
M(y/x) = my + 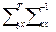 (x - Mx).Таким образом, если многомерная случайная величина (у,
x1, x2,…,хk ) подчиняется (k +1)-мерному нормальному закону распределения, то
уравнение регрессии результативного
показателя у по объясняющим
переменным x1, x2,…,хk имеет
линейный по х вид.
(x - Mx).Таким образом, если многомерная случайная величина (у,
x1, x2,…,хk ) подчиняется (k +1)-мерному нормальному закону распределения, то
уравнение регрессии результативного
показателя у по объясняющим
переменным x1, x2,…,хk имеет
линейный по х вид.
Однако в
статистической практике обычно приходится
ограничиваться поиском подходящих
аппроксимаций для неизвестной истинной функции регрессии f(x), так как исследователь не располагает точным знанием
условного закона распределения вероятностей анализируемого результатирующего показателя у при заданных эначениях аргументов х=х.
Рассмотрим взаимоотношение между истиной f(х)= M(y/x),
модельной у и оценкой у регрессии.
Пусть
результативный показатель у связан с аргументом х соотношением::
y =  + e ,
+ e ,
где e -
случайная величина, имеющая нормальный закон распределения, причем М e = 0 и
D e = 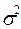 .
.
Истинная
функция регрессии в этом случае имеет вид:
F(x) = M(y/x) = 2x .
.
Предположим,
что точный вид истинного уравнения регрессии нам не известен, но мы
располагаем девятъю наблюдениями над двумерной случайной величиной,
связанной соотношением уi = 2x+ ei, и предcтавленной на рисунке:
 у
у

70

 60
60
 50
50
40
 30
30
20
 10
10

0
0 2 4 6 8 10 Рис.1 - Вид уравнения
Взаимное
расположение истинной f(x) и теоритической у модели регрессии.
Расположение точек на рисунке позволяет
ограничиться классом линейных зависимостей вида: у = b0 + b1 x.
С помощью
метода наименьших квадратов найдем оценку уравнения регрессии
у = b0 +b1 x.
Дли сравнения на рисунке
приводятся графики истинной функции регрессии f{х) =2x, теоретической
аппроксимирующей функции регрессии
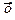 = b0 + b1 x. К последней сходится по вероятности оценка
уравнения регрессии при
неограниченном увеличении объема выборки (n
= b0 + b1 x. К последней сходится по вероятности оценка
уравнения регрессии при
неограниченном увеличении объема выборки (n 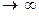 ).
).
Поскольку мы ошиблись в
выборе класса функции регрессии, что, к сожалению, достаточно часто встречается
в практике статистических исследований, то наши статистические выводы и оценки
не будут обладать свойством состоятельности, т.е., как бы мы не увеличивали объем наблюдений, наша выборочная оценка не будет сходиться к
истинной функции регрессии f(х).
Если бы мы правильно выбрали класс
функций регрессии, то неточность в описании f(x) с помощью объяснялась бы
только ограниченностью выборки и, следовательно, она могла бы быть сделана
сколько угодно малой при n .
С целью наилучшего
восстановления по исходным статистическим данным условного значения
результатирующего показателя у(х) и неизвестной функции регрессии f(x) = M(y/x) наиболее часто используют следующие критерии
адекватности (функции потерь).
1. Метод наименьших
квадратов, согласно которому минимизируется квадрат отклонения наблюдаемых
значений результативного показателя yi(i=1,2,…,n) от модельных значений 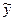 i = f(xi, b), где b = (b0, b1,…,bk)-
коэффициенты уравнения регрессии, xi – значение вектора аргументов в i-м наблюдении:
i = f(xi, b), где b = (b0, b1,…,bk)-
коэффициенты уравнения регрессии, xi – значение вектора аргументов в i-м наблюдении:
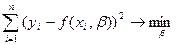 .
.
Решается задача отыскания оценки вектора b. Получаемая регрессия называется среднеквадратической[2].
2. Метод наименьших модулей,
согласно которому минимизируется сумма абсолютных отклонений наблюдаемых
значений результативного показателя от модульных значений 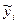 = f(xi,
b), т.е.
= f(xi,
b), т.е.
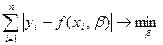 .
.
Получаемая регрессия называется среднеабсолютной
(медианой).
3. Метод минимакса сводится к
минимизации максимума модуля отклонения наблюдаемого значения результативного
показателя yi от модельного значения f(xi,
b), т.е.
 .
.
Получаемая при этом регрессия называется
минимаксной.
В практических положениях часто
встречаются задачи, в которых изучается случайная величина у, зависящая
от некоторого множества переменных x1, x2,…,хk и неизвестных параметров bj(j=0,1,2,…,k). Будем рассматривать (у, x1, x2,…,хk ) как
(k +1) – мерную генеральную совокупность, из которой взята
случайная выборка объемов n, где (уi,xi1,xi2,…,xik) результат i-го наблюдения i=1,2,…,n. Требуется по результатам наблюдений оценить
неизвестные параметры bj(j=0,1,2,…,k).
Описанная выше задача
относится к задачам регрессионного анализа.
Регрессионным анализом называется метод статистического
анализа зависимости случайной величины у от переменных xj(j=1,2,…,k), рассматриваемых в регрессионном анализе как
неслучайные величины, независимо от истинного закона распределения xj.
Обычно предполагается, что
случайная величина у имеет нормальный закон распределения с условным
математическим ожиданием , являющимся функцией от аргументов xj(j=1,2,…,k) и постоянной, не зависящей от аргументов
дисперсий  , т.е. следует помнить, что требование нормальности закона
распределения необходимо лишь для проверки значимости уравнения регрессии и его
параметров bj, а также для интервального оценивания регрессии и его
параметров bj. Для получения точечных оценок bj(j=0,1,2,…,k) этого условия не требуется.
, т.е. следует помнить, что требование нормальности закона
распределения необходимо лишь для проверки значимости уравнения регрессии и его
параметров bj, а также для интервального оценивания регрессии и его
параметров bj. Для получения точечных оценок bj(j=0,1,2,…,k) этого условия не требуется.
В общем виде линейная
модель регрессионного анализа имеет вид:
у =  ,
,
где jj
– некоторая функция его переменных x1,
x2,…,хk ;
e - случайная величина с нулевым математическим ожиданием и
дисперсией s
В
регрессионном анализе под линейной моделью подразумевает модель, линейно
зависящую о неизвестных параметров bj.
Собственно линейной будем называть модель, линейно зависящую как от
параметров bj, так и от переменных хj.
В регрессионном методе вид уравнения регрессии выбирают исходя из анализа
физической сущности изучаемого явления и результатов наблюдения.
Наиболее часто встречаются следующие виды уравнений регрессии:
·
собственно
линейное многомерное
= 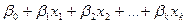 ;
;
·
полиномиальное
= 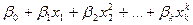 ;
;
·
гиперболическое
=  ;
;
·
степенное
= 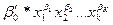 .
.
Путем логарифмирования степенные уравнения регрессии
могут быть преобразованы в линейные уравнения относительно параметров bj.
Логарифмируя, получим:
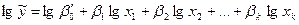 .
.
Пусть lg xj = uj для j=1,2,…,k; 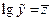 и
и  , тогда после подстановки будем иметь собственно линейные
уравнения регрессии:
, тогда после подстановки будем иметь собственно линейные
уравнения регрессии:
 =
= 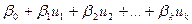 .
.
Путем подстановок 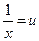 и
и 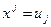 гиперболическое и
полиномиальное уравнения могут быть преобразованы в собственно линейные, теория
которых разработана наиболее полно.
гиперболическое и
полиномиальное уравнения могут быть преобразованы в собственно линейные, теория
которых разработана наиболее полно.
Оценки неизвестных параметров уравнения регрессии
находят обычно методом наименьших квадратов и свойствах оценок, найденных этим
методом.
Множественная регрессия и
корреляция
Множественная
регрессия может дать хороший результат при моделировании, только лишь в том
случае, если влиянием других факторов, воздействующих на объект исследования,
можно пренебречь.
Включение в уравнение множественной
регрессии того или иного набора факторов связано прежде всего с представлением
исследователя о природе взаимосвязи моделируемого показателя с другими
экономическими явлениями. Факторы включаемые в множественную регрессию, должны
отвечать следующим требованиям:
1 Они должны быть количественно
измеримы. Если необходимо включить в модель качественный фактор, не имеющий
количественного измерения, то ему нужно придать количественную определенность.
2 Факторы не должны быть
интеркоррелированы и тем более находиться в точной функциональной связи.
Коэффициенты интеркореляции (т.е.
корреляции между объясняющими переменными) позволяют исключать из модели
дублирующие факторы. Считается, что две модели явно коленеарны, т.е. находятся
между собой в линейной зависимости, если rXiXj>0,7.
Коэффициенты
«чистой» регрессии – характеризуют среднее изменение результата с изменением
соответствующего фактора на единицу при неизменном значении других факторов,
закрепленных на среднем уровне.
Практическая значимость уравнения
множественной регрессии оценивается с помощью показателя множественной
корреляции и его квадрата – коэффициента детерминации.
Независимо от формы связи показатель
множественной корреляции может быть найден как индекс множественной корреляции:
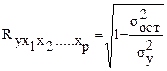
где 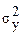 - общая дисперсия результирующего признака;
- общая дисперсия результирующего признака;
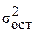 - остаточная дисперсия для уравнения у=f(х1,х2,…..,хр).
- остаточная дисперсия для уравнения у=f(х1,х2,…..,хр).
Формула
индекса множественной корреляции для линейной регрессии получила название
линейного коэффициента множественной корреляции, или, что то же самое,
совокупного коэффициента корреляции.
R=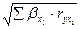
Частные
коэффициенты (или индексы) корреляции – характеризуют тесноту связи между
результатом и соответствующим фактором при устранении влияния других факторов,
включенных в уравнение регрессии. Показатели частной регрессии представляют
собой отношение сокращения остаточной дисперсии за счет дополнительного
включения в анализ нового фактора к остаточной дисперсии, имевшей место до
введения его в модель.
Объектом
статистического изучения в социальных науках являются сложные системы.
Измерение тесноты связей между переменными, построение изолированных уравнений
регрессии недостаточно для описания таких систем и объяснения механизма
функционирования. При использовании отдельных уравнений регрессии, в большинстве
случаев предполагается, что аргументы (факторы) можно изменять независимо друг
от друга. Однако это предположение является очень грубым: практически изменение
одной переменной, как правило, не может происходить при абсолютной неизменности
других. Ее изменение повлечет за собой изменение во всей системе
взаимосвязанных признаков. Следовательно, отдельно взятое уравнение
множественной регрессии не может характеризовать истинные влияния отдельных
признаков на вариацию результирующей переменной[3].
Система независимых уравнений – каждая
зависимая переменная (у) рассматривается как функция одного и того же набора
факторов (х):
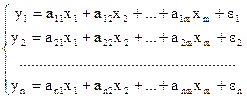
Наибольшее распространение в
эконометрических исследованиях получила система взаимозависимых уравнений. Она
получила название системы совместных, одновременных уравнений, в ней одни и те
же зависимые переменные в одних уравнениях входят в левую часть, а в других
уравнениях - в правую часть системы. Тем
самым подчеркивается, что в системе одни и те же переменные (у) одновременно
рассматриваются как зависимые в одних уравнениях и как независимые в других. В
эконометрике это система уравнений называется также структурной формой модели.
В отличии от предыдущих систем каждое уравнение системы одновременных уравнений
не может рассматриваться самостоятельно, и для нахождения его параметров
традиционный МНК неприменим. С этой целью используются специальные приемы
оценивания.
Система совместных, одновременных
уравнений (или структурная форма модели) обычно содержит эндогенные и
экзогенные переменные.
Эндогенные переменные – это зависимые
переменные, число которых равно числу уравнений в системе.
Экзогенные переменные – это
предопределенные переменные, влияющие на эндогенные переменные, но не зависящие
от них.
Приведенная форма модели - представляет собой систему линейных функций
эндогенных переменных от экзогенных:
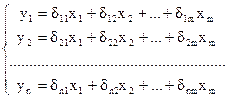
где δi – коэффициенты приведенной формы модели.
Коэффициенты приведенной формы модели
представляют собой нелинейные функции структурной формы модели.
При переходе от приведенной формы модели
к структурной исследователь сталкивается с проблемой идентификации.
Индетификация – это единственность соответствия между приведенной и структурной
формами модели.
С позиции идентификацируемости структурные
модели можно подразделить на три вида:
·
идентифицируемые;
·
неидентифицируемые;
·
сверхидентифицируемые.
Модель
идентифицируема, если все структурные ее коэффициенты определяются однозначно,
единственным образом по коэффициентам приведенной модели, т.е. если число
параметров структурной модели равно числу параметров приведенной формы модели.
Модель неидентифицируема, если число
приведенных коэффициентов меньше числа структурных коэффициентов, и в
результате структурные коэффициенты не могут быть оценены через коэффициенты
приведенной формы модели.
Модель сверхидентифицируема, если число
приведенных коэффициентов больше числа структурных коэффициентов.
Структурная модель всегда представляет
собой систему совместных уравнений, каждое из которых требуется проверить на
идентификацию. Модель считается идентифицируемой, если каждое уравнение системы
идентифицируемо[4].
Коэффициенты структурной модели могут
быть оценены разными способами в зависимости от вида системы одновременных
уравнений. Наибольшее распространение в литературе получили следующие методы
оценивания коэффициентов структурной модели:
·
косвенный метод
наименьших квадратов;
·
двухшаговый
метод наименьших квадратов;
·
трехшаглвый
метод наименьших квадратов;
·
метод
максимального правдоподобия с полной информацией;
·
метод
максимального правдоподобия при ограниченной информации.
Под
системой эконометрических уравнений
обычно понимается система одновременных, совместных уравнений. Ее применение
имеет ряд сложностей, которые связаны с ошибками спецификации модели. В виду
большого числа факторов, влияющих на экономические переменные, исследователь,
как правило, не уверен в точности предполагаемой модели для описания
экономических процессов.
Временной
ряд – это совокупность значений какого – либо показателя за несколько
последовательных моментов или периодов времени. Каждый уровень временного ряда
формируется по воздействием большого числа факторов, которые условно можно
подразделить на три группы:
·
факторы,
формирующие тенденцию ряда;
·
факторы, формирующие
циклические колебания ряда;
·
случайные
факторы.
Аддитивная модель временного ряда – это
модель, в которой временной ряд представлен как сумма перечисленных компонент.
Мультипликативная модель – модель, в
которой временной ряд представлен как произведение перечисленных компонент.
Автокорреляция уровней ряда –
корреляционная зависимость между последовательными уровнями временного ряда.
Лаг – число периодов, по которым
рассчитывается коэффициент автокорреляции.
Свойства коэффициента автокорреляции:
·
Он строится по
аналогии с линейным коэффициентом корреляции и таким образом характеризует
тесноту только линейной связи текущего и предыдущего уровней ряда.
·
По знаку
коэффициента автокорреляции нельзя делать вывод о возрастающем или убывающей
тенденции в уровнях ряда.
Последовательность
коэффициента автокорреляции уровней первого, второго и т.д. порядков называют
автокорреляционной функцией временного порядка. График зависимости ее значений
от величины лага называется коррелограммой.
Аналитическое
выравнивание временного ряда – это построение аналитической функции,
характеризующей зависимость уровней ряда от времени, или тренда.
Кусочно-линейные
модели регрессии – разделение исходной совокупности на две подсовокупности (до
времени t* и после момента t*) и
построить отдельно по каждой подсовокупности уравнения линейной регрессии.
Для того
чтобы получить коэффициенты корреляции, характеризующие причино – следственную
связь между изучаемыми рядами, следует избавиться от так называемой ложной
корреляции, вызванной наличием тенденции
в каждом ряду.
Методы
исключения:
·
Методы,
основанные на преобразовании уровней исходного ряда в новые переменные, не
содержащие тенденции. Эти методы предполагают непосредственное устранение
трендовой компоненты Т из каждого уровня временного ряда. Два основных метода в
данной группе – метод последовательной разности и метод отклонения от трендов;
·
Методы,
основанные на изучении взаимосвязи исходных уровней временных рядов при
элиминировании воздействия фактора времени на зависимую и независимые
переменные модели. В первую очередь это метод включения в модель регрессии по
временным рядам фактора времени.
Методы
автокорреляции остатков:
Первый
метод – построение графика зависимости остатков от времени и визуальное
определение наличия или отсутствия автокорреляции.
Второй
метод – использование критерия Дарбина – Уотсона и расчет величины
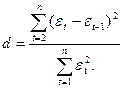
Модель
регрессии по скользящим средним – модель, где определяемые средние за два
периода уровни каждого ряда, а затем по полученным усредненным уровням обычным
МНК рассчитываем параметры а и b:
(yt+yt-1)/2=a+b(xt+xt-1)/2+ut/2
Коинтеграция
– причино-следственная зависимость в уровнях двух (или более) временных рядов,
которая выражается в совпадении или противоположенной направленности их
тенденции и случайной колеблемости.
Можно
выделить два основных типа динамических эконометрических моделей. К модели
первого типа относятся модели авторегрессии и модели с распределенным лагом, в
которых значения переменной за прошлые периоды времени непосредственно включены
в модель. Модели второго типа учитывают динамическую информацию в неявном виде.
Лаг – это
величина, характеризующая запаздывание в воздействии фактора на результат.
Лаговая
переменная – временной ряд самой факторной переменной, сдвинутый на один или
более моментов времени.
Краткосрочный
мультипликатор – коэффициент регрессии bo при переменной хt характеризует абсолютное изменение yt при изменении хt на 1
ед. своего измерения в некоторой фиксированный момент времени t, без учета воздействия лаговых значений фактора х.
Промежуточный
мультипликатор – в момент (t+1)
совокупное воздействие факторной переменной хt на результат yt составит (b0+b1)
усл. ед., (t+2) это воздействие можно
охарактеризовать суммой (b0+b1+b2) и
т.д.
Величина b – это долгосрочный мультипликатор. Но показывает
абсолютное изменение в долгосрочным периоде t+1 результата у под влиянием изменения на 1 ед.
фактора х.
Задачи
корреляционного анализа сводятся к измерению тесноты известной связи
между варьирующими признаками, определению неизвестных причинных связей
(причинный характер которых должен быть выяснен с помощью теоретического
анализа) и оценки факторов, оказывающих наибольшее влияние на результативный
признак[5].
Задачами
регрессионного анализа являются выбор типа модели (формы связи),
установление степени влияния независимых переменных на зависимую и определение
расчётных значений зависимой переменной (функции регрессии). Решение всех
названных задач приводит к необходимости комплексного использования этих методов.
Исследование
связей в условиях массового наблюдения и действия случайных факторов
осуществляется, как правило, с помощью экономико-статистических моделей. В
широком смысле модель – это аналог, условный образ (изображение, описание,
схема, чертёж и т.п.) какого-либо объекта, процесса или события, приближенно
воссоздающий «оригинал». Модель представляет собой логическое или
математическое описание компонентов и функций, отображающих существенные
свойства моделируемого объекта или процесса, даёт возможность установить
основные закономерности изменения оригинала. В модели оперируют показателями,
исчисленными для качественно однородных массовых явлений (совокупностей).
Выражение и модели в виде функциональных уравнений используют для расчёта
средних значений моделируемого показателя по набору заданных величин и для
выявления степени влияния на него отдельных факторов.
По
количеству включаемых факторов модели могут быть однофакторными и многофакторными
(два и более факторов).
В
зависимости от познавательной цели статистические модели подразделяются на структурные,
динамические и модели связи.
Двухмерная линейная модель корреляционного и
регрессионного анализа
Наиболее
разработанной в теории статистики является методология так называемой парной
корреляции, рассматривающая влияние вариации факторного анализа х на результативный признак у и представляющая собой
однофакторный корреляционный и регрессионный анализ. Овладение теорией и
практикой построения и анализа двухмерной модели корреляционного и регрессионного
анализа представляет собой исходную основу для изучения многофакторных
стохастических связей.
Важнейшим
этапом построения регрессионной модели (уравнения регрессии) является
установление в анализе исходной информации математической функции. Сложность заключается
в том, что из множества функций необходимо найти такую, которая лучше других
выражает реально существующие связи между анализируемыми признаками. Выбор
типов функции может опираться на теоретические знания об изучаемом явлении,
опят предыдущих аналогичных исследований, или осуществляться эмпирически –
перебором и оценкой функций разных типов и т.п.
При
изучении связи экономических показателей производства (деятельности) используют
различного вида уравнения прямолинейной и криволинейной связи. Внимание к
линейным связям объясняется ограниченной вариацией переменных и тем, что в
большинстве случаев нелинейные формы связи для выполнения расчётов преобразуют
(путём логарифмирования или замены переменных) в линейную форму. Уравнение
однофакторной (парной) линейной корреляционной связи имеет вид:
ŷ = a0
+ a1x
где
ŷ - теоретические значения
результативного признака, полученные по уравнению регрессии;
a0 , a1 - коэффициенты (параметры) уравнения регрессии.
Поскольку
a0 является
средним значением у в
точке х=0, экономическая
интерпретация часто затруднена или вообще невозможна.
Коэффициент
парной линейной регрессии a1 имеет смысл показателя силы связи
между вариацией факторного признака х
и вариацией результативного признака у.
Вышеприведенное уравнение показывает среднее значение изменения результативного
признака у при изменении
факторного признака х на одну
единицу его измерения, то есть вариацию у,
приходящуюся на единицу вариации х.
Знак a1 указывает
направление этого изменения.
Параметры
уравнения a0 ,
a1 находят методом
наименьших квадратов.
Определив
значения a0 ,
a1 и подставив их в уравнение связи ŷ
= a0 + a1x, находим значения ŷ , зависящие только от
заданного значения х.
Проверка адекватности регрессионной модели
Для
практического использования моделей регрессии большое значение имеет их
адекватность, т.е. соответствие фактическим статистическим данным.
Корреляционный
и регрессионный анализ обычно (особенно в условиях так называемого малого и
среднего бизнеса) проводится для ограниченной по объёму совокупности. Поэтому
показатели регрессии и корреляции – параметры уравнения регрессии, коэффициенты
корреляции и детерминации могут быть искажены действием случайных факторов.
Чтобы проверить, насколько эти показатели характерны для всей генеральной
совокупности, не являются ли они результатом стечения случайных обстоятельств,
необходимо проверить адекватность построенных статистических моделей.
При
численности объектов анализа до 30 единиц возникает необходимость проверки
значимости (существенности) каждого коэффициента регрессии. При этом выясняют
насколько вычисленные параметры характерны для отображения комплекса условий:
не являются ли полученные значения параметров результатами действия случайных
причин.
Значимость
коэффициентов простой линейной регрессии (применительно к совокупностям, у
которых n<30) осуществляют с помощью t-критерия Стьюдента. При этом
вычисляют расчетные (фактические) значения t-критерия
для параметра a0 :
для
параметра a1 :
где n
- объём выборки;
- среднее квадратическое отклонение
результативного признака от выравненных значений ŷ ;
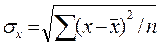 или
или 
- среднее квадратическое отклонение
факторного признака x от общей средней  .
.
Вычисленные по вышеприведенным формулам
значения сравнивают с критическими t , которые определяют по таблице Стьюдента с учетом принятого уровня
значимости α и числом степеней свободы вариации 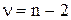 . В социально-экономических исследованиях уровень значимости α
обычно принимают равным 0,05. Параметр признаётся значимым (существенным) при
условии, если tрасч> tтабл .
В таком случае практически невероятно, что найденные значения параметров
обусловлены только случайными совпадениями.
. В социально-экономических исследованиях уровень значимости α
обычно принимают равным 0,05. Параметр признаётся значимым (существенным) при
условии, если tрасч> tтабл .
В таком случае практически невероятно, что найденные значения параметров
обусловлены только случайными совпадениями.
Проверка адекватности регрессионной
модели может быть дополнена корреляционным анализом.
Для этого необходимо определить тесноту
корреляционной
связи между переменными х и у. Теснота корреляционной связи, как и
любой другой, может быть измерена эмпирическим корреляционным отношением
ηэ ,
когда δ2
(межгрупповая дисперсия) характеризует отклонения групповых средних
результативного признака от общей средней: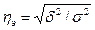 .
.
Говоря о корреляционном отношении как о
показателе измерения тесноты зависимости, следует отличать от эмпирического
корреляционного отношения – теоретическое.
Теоретическое корреляционное
отношение η представляет собой относительную величину,
получающуюся в результате сравнения среднего квадратического отклонения
выравненных значений результативного признака
δ, то есть
рассчитанных по уравнению регрессии, со средним квадратическим отношением
эмпирических (фактических) значений результативности признака σ:
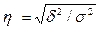 ,
,
где 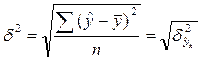 ;
; 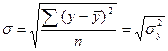 .
.
Тогда 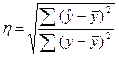 .
.
Изменение значения η объясняется влиянием факторного
признака.
В основе расчёта корреляционного
отношения лежит правило сложения дисперсий, то есть 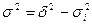 , где
, где  - отражает вариацию у за счёт всех остальных факторов, кроме х, то есть являются остаточной дисперсией:
- отражает вариацию у за счёт всех остальных факторов, кроме х, то есть являются остаточной дисперсией:
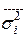
 .
.
Тогда формула теоретического
корреляционного отношения примет вид:
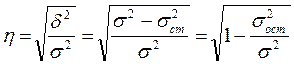 ,
,
или 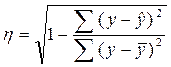 .
.
Подкоренное
выражение корреляционного выражения представляет собой коэффициент
детерминации (мера определенности, причинности).
Коэффициент
детерминации показывает долю вариации результативного признака под влиянием
вариации признака-фактора.
Теоретическое
корреляционное выражение применяется для измерения тесноты связи при линейной и
криволинейной зависимостях между результативным и факторным признаком.
Как
видно из вышеприведенных формул корреляционное отношение может находиться от 0
до 1. Чем ближе корреляционное отношение к 1, тем связь между признаками
теснее.
Кроме того, при линейной форме уравнения
применяется другой показатель тесноты связи – линейный коэффициент
корреляции:
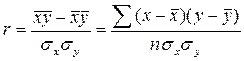 ,
,
где
n – число
наблюдений.
Для
практических вычислений при малом числе наблюдений (n≤20÷30) линейный коэффициент корреляции
удобнее исчислять по следующей формуле:
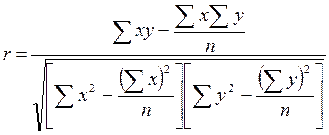 .
.
Значение
линейного коэффициента корреляции важно для исследования
социально-экономических явлений и процессов, распределение которых близко к
нормальному. Он принимает значения в интервале: -1≤ r ≤ 1.
Отрицательные
значения указывают на обратную связь, положительные – на прямую. При r = 0 линейная связь отсутствует. Чем ближе коэффициент
корреляции по абсолютной величине к единице, тем теснее связь между признаками.
И, наконец, при r = ±1 –
связь функциональная.
Квадрат
линейного коэффициента корреляции r2 называется линейным коэффициентом детерминации.
Из определения коэффициента детерминации очевидно, что его числовое значение
всегда заключено в пределах от 0 до 1, то есть 0 ≤ r2 ≤
1. Степень тесноты связи полностью соответствует теоретическому корреляционному
отношению, которое является более универсальным показателем тесноты связи по
сравнению с линейным коэффициентом корреляции.
Факт
совпадений и несовпадений значений теоретического корреляционного отношения η и линейного коэффициента
корреляции r используется
для оценки формы связи.
Выше
отмечалось, что посредством теоретического корреляционного отношения измеряется
теснота связи любой формы, а с помощью линейного коэффициента корреляции –
только прямолинейной. Следовательно, значения η и r
совпадают только при наличии прямолинейной связи. Несовпадение этих величин
свидетельствует, что связь между изучаемыми признаками не прямолинейная, а
криволинейная. Установлено, что если разность квадратов η и r не
превышает 0,1 , то гипотезу о
прямолинейной форме связи можно считать подтвержденной. В моем случае
наблюдается примерное совпадение линейного коэффициента детерминации и
теоретического корреляционного отношения, что дает мне основание считать связь
между капиталом банков и их работающими активами прямолинейной.
Показатели
тесноты связи, исчисленные по данным сравнительно небольшой статистической
совокупности, могут искажаться действием случайных причин. Это вызывает
необходимость проверки их существенности, дающей возможность распространять
выводы по результатам выборки на генеральную совокупность.
Для
оценки значимости коэффициента корреляции r используют t-критерий Стьюдента,
который применяется при t-распределении,
отличном от нормального.
При
линейной однофакторной связи t-критерий
можно рассчитать по формуле:
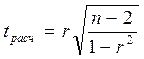 ,
,
где
(n - 2) – число степеней свободы при заданном уровне
значимости α и объеме выборки n.
Полученное значение tрасч сравнивают с табличным значением t-критерия (для α = 0,05 и 0,01). Если
рассчитанное значение tрасч превосходит табличное значение критерия tтабл, то практически невероятно, что найденное значение обусловлено только
случайными колебаниями (то есть отклоняется гипотеза о его случайности).
Корреляционные связи оцениваются по
среднему значению всей совокупности результативного признака, такт как для
одного и того же значения факторного признака возможны различные значения
результативного признака.
ЗАКЛЮЧЕНИЕ
Рассмотренный метод анализа используется
в исследовании связей в условиях массового наблюдения и действия случайных
факторов осуществляется, как правило, с помощью экономико-статистических
моделей. Модель представляет собой логическое или математическое описание компонентов
и функций, отображающих существенные свойства моделируемого объекта или
процесса, даёт возможность установить основные закономерности изменения
оригинала. В модели оперируют показателями, исчисленными для качественно
однородных массовых явлений (совокупностей). Данный метод используется во
многих областях экономики (банковская деятельность, производственная и т.д) в
следствии использования статистики.
СПИСОК
ЛИТЕРАТУРЫ
1. Гранберг А.Г. Математические модели
социалистической экономики. – М.: Экономика, 1988 – 291с.
2. Лотов А.В. Введение в
экономико-математическое моделирование. – М.: Наука, 1984 – 298 с.
3. Магнус Я.Р., Катышев П.К.,«Эконометрика
начальный курс» М.: изд-во «Дело» 2000 – 215с.
4.
Экономико-математические
методы и прикладные модели, под ред. Федосеева В.В., Москва «Юнити»,2001г –
257с.
5.
Эконометрика
под ред. И.И.Елисеевой М.: изд-во «Финансы и кредит», 2003 – 310с.
[1] Магнус Я.Р., Катышев П.К.,«Эконометрика начальный курс»
М.: изд-во «Дело» 2000 – 215с[56 стр.].
[2] Магнус Я.Р., Катышев П.К.,«Эконометрика
начальный курс» М.: изд-во «Дело» 2000 – 215с [57 cтр.].
[3] Эконометрика под ред. И.И.Елисеевой М.:
изд-во «Финансы и кредит», 2003 – 310с [105 стр.].
[4] Эконометрика под ред.
И.И.Елисеевой М.: изд-во «Финансы и кредит», 2003 – 310с [108 стр.].
[5] Эконометрика под ред.
И.И.Елисеевой М.: изд-во «Финансы и кредит», 2003 – 310с [107 стр.].