МИНИСЕРСТВО
ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ВСЕРОССИЙСКИЙ
ЗАОЧНЫЙ ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ ИНСТИТУТ
КОНТРОЛЬНАЯ
РАБОТА
Дисциплина «Эконометрика»
На тему:
«9
вариант»
Выполнила Зенченко
Маргарита Олеговна
Студентка 3 курса,
вечер
Специальность Бух.учёт и аудит
№ зач.книжки 06убб00979
Преподаватель Бакальчук М.В.
Брянск
2009 г.
ЗАДАНИЕ
9
По предприятиям легкой промышленности
региона получена информация, характеризующая зависимость объема выпускаемой
продукции (Y, млн. руб.) от объема капиталовложений (X, млн.
руб.):
|
№ предприятия
|
X
|
Y
|
|
1
|
12
|
21
|
|
2
|
4
|
10
|
|
3
|
18
|
26
|
|
4
|
27
|
33
|
|
5
|
26
|
34
|
|
6
|
29
|
37
|
|
7
|
1
|
9
|
|
8
|
13
|
21
|
|
9
|
26
|
32
|
|
10
|
5
|
14
|
Требуется:
1.
Найти параметры
уравнения линейной регрессии, дать экономическую интерпретацию углового
коэффициента регрессии.
2.
Вычислить
остатки; найти остаточную сумму квадратов; определить стандартную ошибку
регрессии; построить график остатков.
3.
Проверить
выполнение предпосылок метода наименьших квадратов.
4.
Осуществить
проверку значимости параметров уравнения регрессии с помощью t-критерия
Стьюдента (уровень значимости a=0,05).
5.
Вычислить
коэффициент детерминации R2;
проверить значимость уравнения регрессии с помощью F-критерия Фишера (уровень значимости a=0,05); найти среднюю относительную ошибку аппроксимации. Сделать вывод о
качестве модели.
6.
Осуществить
прогнозирование значения показателя Y при уровне значимости a=0,1,
если прогнозное значения фактора Х
составит 80 % от его максимального значения.
7.
Представить
графически: фактические и модельные значения Y, точки прогноза.
8. Составить уравнения нелинейной регрессии:
·
логарифмической;
·
степенной;
·
показательной.
Привести
графики построенных уравнений регрессии.
9. Для указанных моделей найти коэффициенты детерминации
и средние относительные ошибки аппроксимации.
Сравнить модели по этим характеристикам и сделать вывод.
РЕШЕНИЕ
Для решения задачи используется
табличный процессор EXCEL.
1. С помощью надстройки «Анализ данных» проводим регрессионный анализ и определяем параметры
уравнения линейной регрессии 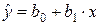 (меню «Сервис»
® «Анализ данных…» ® «Регрессия»):
(меню «Сервис»
® «Анализ данных…» ® «Регрессия»):
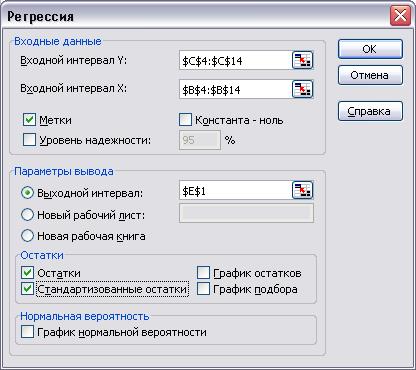
(Для копирования снимка окна в буфер
обмена данных WINDOWS используется комбинация клавиш Alt+Print Screen.)
В результате этого уравнение регрессии
будет иметь вид:
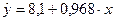 (прил. 1).
(прил. 1).
Угловой
коэффициент b1=0,968 показывает, что при увеличении объема капиталовложений
X на 1 млн. руб. объем выпускаемой продукции Y возрастает в среднем
на 0,968 млн. руб.
2. При
проведении регрессионного анализа в EXCEL
одновременно были определены остатки регрессии 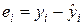 (i=1, 2, …, n,
где n=10 — число наблюдений значений переменных X и Y) (см. «Вывод остатка» в прил. 1) и рассчитана остаточная сумма квадратов
(i=1, 2, …, n,
где n=10 — число наблюдений значений переменных X и Y) (см. «Вывод остатка» в прил. 1) и рассчитана остаточная сумма квадратов
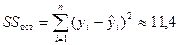 (см. «Дисперсионный анализ» в прил. 1).
(см. «Дисперсионный анализ» в прил. 1).
Стандартная ошибка линейной парной
регрессии Sрег определена
там же:
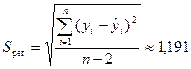 млн. руб.
млн. руб.
(см.
«Регрессионную статистику» в прил. 1).
Стандартная ошибка регрессии Sрег показывает, что
фактические значения объема выпускаемой
продукции Y отличается от расчетных значений в среднем
на 1,191 млн. руб.
График остатков ei от предсказанных уравнением
регрессии значений результата  (i=1, 2, …, n) строим с помощью «Мастера диаграмм». Предварительно в «Выводе остатка» в прил. 1
выделяются блоки ячеек «Предсказанное Y» и «Остатки» вместе с заголовками, а затем выбирается пункт меню
«Вставка» ® «Диаграмма…»
® «Точечная»:
(i=1, 2, …, n) строим с помощью «Мастера диаграмм». Предварительно в «Выводе остатка» в прил. 1
выделяются блоки ячеек «Предсказанное Y» и «Остатки» вместе с заголовками, а затем выбирается пункт меню
«Вставка» ® «Диаграмма…»
® «Точечная»:
3. Проверим выполнение предпосылок
обычного метода наименьших квадратов.
1) Случайный характер остатков.
Визуальный анализ графика остатков не
выявляет в них какой-либо явной закономерности.
Проверим
исходные данные на наличие аномальных наблюдений (выбросов) объема
выпускаемой продукции Y. С этой целю сравним абсолютные
величины стандартизированных остатков
(см. «Вывод остатка» в прил. 1)
с табличным значением t-критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы 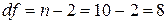 , которое составляет tтаб=2,306 (см. Справочные таблицы).
, которое составляет tтаб=2,306 (см. Справочные таблицы).
Видно,
что ни один из стандартизированных остатков не превышает по абсолютной величине табличное значение t-критерия Стьюдента. Это свидетельствует об отсутствии выбросов.
2) Нулевая средняя величина остатков. Данная
предпосылка всегда выполняется для линейных моделей со свободным коэффициентом b0, параметры которых оцениваются обычным методом
наименьших квадратов. В нашей модели алгебраическая сумма остатков и,
следовательно, их среднее, равны нулю: 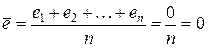 (см. прил. 1).
(см. прил. 1).
Для
вычисления суммы и среднего значений остатков использовались встроенные функции
«СУММ» и «СРЗНАЧ».
3) Одинаковая дисперсия (гомоскедастичность) остатков. Выполнение
данной предпосылки проверим методом Глейзера в предположении линейной
зависимости среднего квадратического отклонения случайной составляющей
регрессионной модели от
значений факторов. Для этого рассчитывается коэффициент корреляции  между абсолютными
величинами остатков
между абсолютными
величинами остатков  и значениями (i=1, 2, …, n) с помощью выражения,
составленного из встроенных функций:
и значениями (i=1, 2, …, n) с помощью выражения,
составленного из встроенных функций:
=КОРРЕЛ(ABS(Остатки);Предсказанное_Y)
Коэффициент корреляции оказался равным  (см. прил. 1).
(см. прил. 1).
Критическое
значение коэффициента корреляции для уровня значимости a=0,05 и числа степеней свободы составляет rкр=0,632 (см.
Справочные
таблицы).
Так
как коэффициент корреляции не превышает по абсолютной величине
критическое значение, то
статистическая гипотеза об одинаковой дисперсии остатков не отклоняется на
уровне значимости a=0,05.
4) Отсутствие
автокорреляции в остатках. Выполнение
данной предпосылки проверяем методом Дарбина–Уотсона. Предварительно ряд
остатков упорядочивается в зависимости от последовательно возрастающих значений
результата Y, предсказанных уравнением регрессии. Для этой цели в
«Выводе остатка» в прил. 1 выделяется любая ячейка в
столбце «Предсказанное
Y», и
на панели инструментов нажимается кнопка « » («Сортировка по возрастанию»). По
упорядоченному ряду остатков рассчитываем d‑статистику Дарбина–Уотсона
» («Сортировка по возрастанию»). По
упорядоченному ряду остатков рассчитываем d‑статистику Дарбина–Уотсона
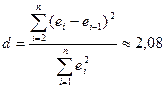 (см. прил. 1).
(см. прил. 1).
Для расчета d‑статистики использовалось выражение, составленное из встроенных
функций EXCEL:
=СУММКВРАЗН(«Остатки 2, …, n»; «Остатки 1, …, n–1»)/СУММКВ(«Остатки 1, …,n»)
Критические
значения d‑статистики для числа
наблюдений n=10, числа факторов p=1 и уровня значимости a=0,05 составляют: d1=0,88; d2=1,32 (см. Справочные
таблицы).
Так
как выполняется условие
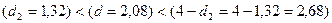 ,
,
статистическая гипотеза об отсутствии
автокорреляции в остатках не отклоняется на уровне значимости a=0,05.
Примечание:
· если
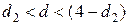 , то остатки признаются независимыми (некоррелированными);
, то остатки признаются независимыми (некоррелированными);
· если
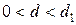 — имеется
положительная автокорреляция;
— имеется
положительная автокорреляция;
· если
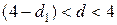 — существует
отрицательная автокорреляция;
— существует
отрицательная автокорреляция;
· если
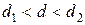 или
или 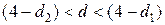 , то это указывает на неопределенность ситуации.
, то это указывает на неопределенность ситуации.
Проверим
отсутствие автокорреляции в остатках также и по коэффициенту автокорреляции
остатков первого порядка
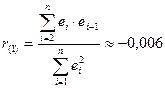 (см. прил. 1).
(см. прил. 1).
(ряд остатков упорядочен в той же самой
последовательности).
Для
расчета коэффициента автокорреляции использовалось выражение, составленное из встроенных функций:
=СУММПРОИЗВ(«Остатки 2, …, n»; «Остатки 1, …, n–1»)/СУММКВ(«Остатки 1, …,n»)
Критическое
значение коэффициента автокорреляции для числа наблюдений n=10 и уровня
значимости a=0,05
составляет r(1)кр=0,632 (см. Справочные таблицы). Так как коэффициент
автокорреляции остатков первого порядка не превышает по абсолютной величине
критическое значение, то это еще раз указывает на отсутствие автокорреляции в
остатках.
5) Нормальный закон распределения
остатков. Выполнение этой предпосылки
проверяем с помощью R/S-критерия, определяемого по формуле
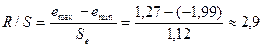 ,
,
где emax=1,27;
emin=(–1,99)
— наибольший и наименьший остатки соответственно (определялись с помощью
встроенных функций «МАКС» и «МИН»; см. прил. 1); 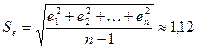 — стандартное
отклонение ряда остатков (определено с помощью встроенной функции «СТАНДОТКЛОН»; см. прил. 1).
— стандартное
отклонение ряда остатков (определено с помощью встроенной функции «СТАНДОТКЛОН»; см. прил. 1).
Критические границы R/S-критерия для числа
наблюдений n=10 и уровня значимости a=0,05 имеют значения: (R/S)1=2,67 и (R/S)2=3,69 (см. Справочные таблицы).
Так как расчетное значение R/S-критерия попадает в интервал между критическими границами,
то статистическая гипотеза о нормальном
законе распределения остатков не отклоняется на уровне
значимости a=0,05.
Проведенная
проверка показала, что выполняются все пять предпосылок обычного метода
наименьших квадратов. Это свидетельствует об адекватности регрессионной модели
исследуемому экономическому явлению.
4. Проверим статистическую значимость
коэффициентов b0 и b1 уравнения
регрессии. Табличное значение t-критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы остатка линейной парной
регрессии  составляет tтаб=2,306 (см. Справочные таблицы).
составляет tтаб=2,306 (см. Справочные таблицы).
t-статистики
коэффициентов
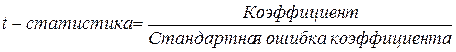 ,
,
были определены при проведении регрессионного анализа
в EXCEL: tb0»11,41; tb1»25,81 (см. прил. 1). Их анализ показывает, что по абсолютной
величине все они превышают табличное значение t-критерия Стьюдента. Это свидетельствует о
статистической значимости обоих коэффициентов.
Статистическая
значимость углового коэффициента b1 дает
основание говорить о существенном (значимом) влиянии изменения объема
капиталовложений X на изменение объема выпускаемой продукции Y.
5. Коэффициент детерминации R2 линейной
модели также был определен при проведении регрессионного анализа:

(см. «Регрессионную
статистику» в прил. 1).
Значение R2
показывает, что линейная модель объясняет 98,8 % вариации объема выпускаемой
продукции Y.
F-статистика линейной модели имеет значение
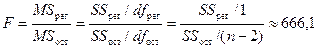
(см. «Дисперсионный
анализ» в прил. 1).
Табличное
значение F-критерия Фишера для уровня значимости a=0,05 и чисел степеней свободы 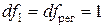 и
и 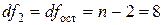 составляет Fтаб=5,32 (см.
Справочные
таблицы). Так как F-статистика превышает табличное значение F-критерия Фишера, то это свидетельствует о
статистической значимости уравнения регрессии в целом.
составляет Fтаб=5,32 (см.
Справочные
таблицы). Так как F-статистика превышает табличное значение F-критерия Фишера, то это свидетельствует о
статистической значимости уравнения регрессии в целом.
Среднюю относительную ошибку аппроксимации определяем по приближенной
формуле
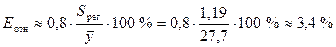 ,
,
где 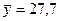 млн. руб. — средний
объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ» (см. «Исходные данные» в прил. 1).
млн. руб. — средний
объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ» (см. «Исходные данные» в прил. 1).
Значение Еотн
показывает, что предсказанные уравнением регрессии значения объема выпускаемой
продукции Y отличаются от фактических значений в среднем на 3,4
%. Линейная модель имеет высокую точность (при 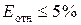 — точность модели
высокая, при
— точность модели
высокая, при 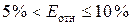 — точность хорошая,
при
— точность хорошая,
при 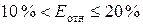 — удовлетворительная,
при
— удовлетворительная,
при 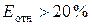 — неудовлетворительная).
— неудовлетворительная).
По
результатам проверок, проведенных в пунктах 3 — 5, можно сделать вывод о
достаточно хорошем качестве линейной модели и возможности ее использования для
целей анализа и прогнозирования объема выпускаемой продукции.
6. Спрогнозируем объем
выпускаемой продукции Y, если прогнозное значение объема
капиталовложений X составит 80 % от своего максимального значения
в исходных данных:
·
максимальное
значение X — xmax=29 млн.
руб. (см. «Исходные данные» в прил. 1);
·
прогнозное
значение X — 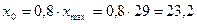 млн. руб.
млн. руб.
Среднее
прогнозируемое значение объема выпускаемой продукции
(точечный
прогноз) равно
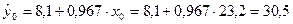 млн. руб.
млн. руб.
Стандартная
ошибка прогноза фактического значения объема выпускаемой продукции y0 рассчитывается по формуле
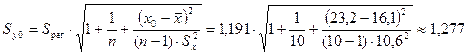 млн. руб.,
млн. руб.,
где 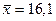 млн. руб. — средний
объем капиталовложений;
млн. руб. — средний
объем капиталовложений; 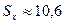 млн. руб. —
стандартное отклонение объема капиталовложений (определены с помощью встроенных
функций «СРЗНАЧ» и «СТАНДОТКЛОН»; см. «Исходные данные» в прил. 1).
млн. руб. —
стандартное отклонение объема капиталовложений (определены с помощью встроенных
функций «СРЗНАЧ» и «СТАНДОТКЛОН»; см. «Исходные данные» в прил. 1).
Интервальный
прогноз фактического значения объема выпускаемой продукции y0 с надежностью (доверительной вероятностью) g=0,9 (уровень значимости
a=0,1) имеет вид:
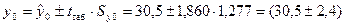 млн.руб.,
млн.руб.,
где
tтаб=1,860 — табличное значение t-критерия Стьюдента при уровне значимости a=0,1
и числе степеней свободы (см. Справочные таблицы).
Таким
образом, объем выпускаемой продукции Y с вероятностью 90 %
будет находиться в интервале от 28,1 до 32,9 млн. руб.
7. График, на котором изображены фактические и предсказанные уравнением
регрессии значения Y строим с помощью «Мастера диаграмм» (меню «Вставка»
® «Диаграмма…» ® «Точечная»).
Далее строим линию линейного тренда (меню «Диаграмма»
® «Добавить линию тренда…» ® «Линейная»),
и устанавливаем вывод на диаграмме уравнения регрессии и коэффициента детерминации
R2:

Точки
точечного и интервального прогнозов наносим на график вручную (прил.
3).
8. Логарифмическую, степенную и
показательную модели также строим с помощью «Мастера диаграмм» (меню «Вставка»
® «Диаграмма…» ® «Точечная»).
Далее последовательно строим соответствующие линии тренда (меню «Диаграмма» ® «Добавить
линию тренда…»), и устанавливаем вывод на диаграмме уравнения регрессии и
коэффициента детерминации R2:
Графики линий регрессии, уравнения
регрессии и значения R2 приведены в прил. 4.
Рассмотрим последовательно каждую модель.
1)
Логарифмическая модель:
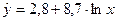 .
.
Значение параметра b1=8,7 показывает,
что при увеличении объема капиталовложений X на 1 % объем
выпускаемой продукции Y возрастает в среднем на 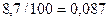 млн. руб.
млн. руб.
Коэффициент
детерминации R2»0,856 показывает, что логарифмическая модель объясняет
85,6 % вариации объема выпускаемой продукции Y.
Стандартная ошибка логарифмической
регрессии также рассчитывается через коэффициент детерминации R2:
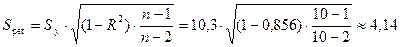 млн. руб.,
млн. руб.,
где 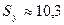 млн. руб. —
стандартное отклонение объема выпускаемой продукции, определенное с помощью
встроенной функции «СТАНДОТКЛОН» (см.
«Исходные данные» в прил. 1).
млн. руб. —
стандартное отклонение объема выпускаемой продукции, определенное с помощью
встроенной функции «СТАНДОТКЛОН» (см.
«Исходные данные» в прил. 1).
Среднюю относительную ошибку аппроксимации определяем по приближенной
формуле
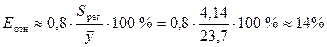 .
.
Предсказанные уравнением логарифмической регрессии
значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 4,14
млн. руб. или на 14 %. Логарифмическая модель имеет удовлетворительную точность.
2) Степенная модель:
 .
.
Показатель степени b1=0,4531
показывает, что при увеличении объема капиталовложений X на 1 % объем выпускаемой продукции
Y возрастает в среднем на 0,4531 %.
Коэффициент
детерминации R2»0,928 показывает, что степенная модель объясняет 92,8
% вариации объема выпускаемой продукции Y.
Стандартная ошибка степенной регрессии
равна
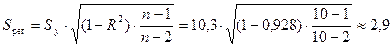 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации имеет значение
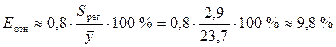 .
.
Предсказанные уравнением степенной регрессии значения
объема выпускаемой продукции Y отличаются от фактических значений в среднем на 2,9
млн. руб. или на 9,8 %. Степенная модель имеет хорошую точность.
3)
Показательная (экспоненциальная) модель:
 ,
,
где
е=2,718… — основание натуральных логарифмов; 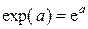 — функция экспоненты
(в EXCEL встроенная функция
«EXP»).
— функция экспоненты
(в EXCEL встроенная функция
«EXP»).
Параметр b1=1,0474 показывает, что при увеличении объема
капиталовложений X на 1 млн. руб. объем выпускаемой продукции Y возрастает в
среднем в 1,0474 раза, то есть на 1,4 %.
Коэффициент
детерминации R2»0,941 показывает, что показательная модель объясняет
94,1 % вариации объема выпускаемой продукции Y.
Стандартная ошибка показательной
регрессии:
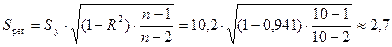 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации:
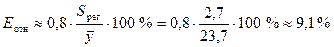 .
.
Предсказанные уравнением показательной регрессии
значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 2,7
млн. руб. или на 9,1 %. Показательная модель имеет хорошую точность.
Сравнивая
между собой коэффициенты детерминации R2
четырех построенных моделей (линейной, логарифмической, степенной и показательной),
можно придти к выводу, что лучшей моделью является показательная модель, так
как она имеет самое большое значение R2.
ПРИЛОЖЕНИЕ: компьютерные распечатки на 4 листах.