РАЛЬФ ВИНС
Математика
управления капиталом
Методы
анализа риска для трейдеров и портфельных менеджеров
Оглавление
Посвящение
Введение
Обзор
книги
Некоторые распространенные ложные
концепции
Сценарии и стратегия худшего
случая
Система математических обозначений
Синтетические конструкции в этой
книге
Оптимальное количество для
торговли и оптимальное f
Глава 1 Эмпирические методы
Какой
долей счета торговать?
Основные концепции
Серийный тест
Корреляция
Обычные ошибки в отношении
зависимости
Математическое ожидание
Реинвестировать торговые прибыли
или нет
Измерение степени пригодности
системы для реинвестирования посредством среднего геометрического
Как лучше всего реинвестировать
Торговля оптимальной фиксированной
долей
Формулы Келли
Поиск оптимального f c помощью среднего
геометрического
Средняя геометрическая сделка
Почему необходимо знать
оптимальное f вашей системы
Насколько может быть серьезен
проигрыш
Современная теория портфеля
Модель Марковица
Стратегия среднего геометрического
портфеля
Ежедневные процедуры
при использовании оптимальных
портфелей
Сумма весов систем в портфеле,
превышающая 100%
Как разброс результатов
затрагивает геометрический рост
Фундаментальное уравнение торговли
Глава 2
Характеристики торговли фиксированной долей
и полезные методы
Оптимальное
f для начинающих трейлеров
с небольшими капиталами
Порог геометрической торговли
Один комбинированный денежный счет
по сравнению с отдельными
денежными счетами
Рассматривайте каждую игру как
бесконечно повторяющуюся
Потеря эффективности при
одновременных ставках
или торговле портфелем
Время, необходимое для достижения
определенной цели,
и проблема дробного f
Сравнение торговых систем
Слишком большая чувствительность к
величине наибольшего проигрыша
Приведение оптимального f к
текущим ценам
Усреднение цены при покупке и
продаже акций
Законы арксинуса и случайное
блуждание
Время, проведенное в проигрыше
Глава 3
Параметрическое оптимальное f
при нормальном распределении
Основы
распределений вероятности
Величины, описывающие
распределения
Моменты распределения
Нормальное распределение
Центральная предельная теорема
Работа с нормальным распределением
Нормальные вероятности
Последующие производные
нормального распределения
Логарифмически нормальное
распределение
Параметрическое оптимальное f
Распределение торговых прибылей и
убытков (P&L)
Поиск оптимального f пo нормальному распределению
Алгоритм расчета
Глава4 Параметрические методы для других
распределений
Тест
Колмогорова-Смирнова (К-С)
Создание характеристической функции
распределения
Подгонка параметров распределения
Использование параметров для
поиска оптимального f
Проведение тестов «что если»
Приведение f к текущим ценам
Оптимальное f для других
распределений
и настраиваемых кривых
Планирование сценария
Поиск оптимального f пo ячеистым данным
Какое оптимальное f лучше?
Глава 5
Введение в методы управления капиталом
с использованием параметрического подхода
при одновременной торговле
по нескольким позициям
Расчет
волатильности
Банкротство, риск и реальность
Модели ценообразования опционов
Модель ценообразования европейских
опционов
для всех распределений
Одиночная длинная позиция по
опциону и оптимальное f
Одиночная короткая позиция по
опциону
Одиночная позиция по базовому
инструменту
Торговля по нескольким позициям
при наличии причинной связи
Торговля по нескольким
позициям при наличии случайной связи
Глава 6
Корреляционные
связи
и выведение
эффективной границы
Определение проблемы
Решение систем линейных уравнений
с использованием матриц-строк
Интерпретация результатов
1лава7 Геометрия портфелей
Линии
рынка капитала
Геометрическая эффективная граница
Неограниченные портфели
Оптимальное f и оптимальные
портфели
Порог геометрической торговли для
портфелей
Подведение итогов
Глава 8 Управление риском
Размещение
активов
Переразмещение: четыре метода
Зачем переразмещать?
Страхование портфеля—четвертый
метод переразмещения
Необходимые залоговые средства
Ротация рынков
Резюме
Несколько слов о торговле акциями
Заключительный комментарий
Посвящение
Благоприятный прием книги «Формулы управления портфелем» превысил мои самые большие
ожидания. Я написал ее, чтобы популяризировать концепцию оптимального f и объяснить читателям ее взаимосвязь с теорией портфеля.
Книга «Формулы управления портфелем» принесла
мне много друзей, кроме того, для меня стал сюрпризом огромный интерес
читателей к математическим методам управления капиталом. Все это послужило
причиной появления книги, которую вы держите в руках. Я многим обязан Карлу
Веберу, Уэнди Грау и другим в компании John Wiley&Sons,
кто предоставил мне свободу действий, необходимую для написания этой
книги. Есть много
других людей, с кем я так или иначе общался, кто сделал свой вклад, помог мне
или повлиял на материал в этой книге. Среди них Флоренс Бо-бек, Хьюго Бурасса,
Джо Бристор, Саймон Дэвис, Ричард Файерстоун, Фред Гем (с ним мне повезло
поработать некоторое время), Моника Мэйсон, Гордон Николе и Майк Паскаул. Мне
также хочется поблагодарить Фрэна Бартлетта из компании G&H Soho,
чья мастерская работа превратила мою гору хаотических идей и энтузиазма в
законченный продукт, который вы держите в своих руках. Приведенный список
далеко не полный, так как есть и многие другие, кто так или иначе помог мне. Эта
книга полностью истощила меня, и я думаю, что она будет последней. Учитывая
это, мне бы хотелось посвятить ее трем людям, которые оказали наибольшее
влияние на меня: Реджине, моей маме, за то, что научила меня высоко ценить
живое воображение; Ларри, моему отцу, за то, что он в раннем возрасте научил
меня «играть» с числами; Арлин, моей жене, партнеру и лучшему другу Эта книга
посвящается вам троим. Ваше влияние видно во всей книге.
Введение
Обзор книги
В первом предложении пролога книги «Формулы управления
портфелем», предыстории этой книги, я написал, что она посвящена
математическим инструментам. Эта книга — о механизмах.
Мы
возьмем инструменты и построим более усовершенствованные, более мощные
инструменты — механизмы, где целое больше, чем сумма частей, и попытаемся
понять устройство этих механизмов, иначе они были бы просто «черными ящиками».
При этом мы воздержимся от детального рассмотрения всех так или иначе связанных
тем (что сделало бы эту книгу невозможной). Например, рассуждение о том, как
построить реактивный двигатель, может быть довольно подробным без необходимости
преподавать вам химию, чтобы знать, как работает реактивное топливо. То же
можно сказать и об этой книге, которая полностью полагается на многие области,
особенно статистику, и затрагивает вычислительные методы. Я не пытаюсь
преподавать математику, кроме необходимого для понимания текста. Однако я
попытался написать книгу таким образом, что если вы знаете вычислительные
методы (или статистику), то для вас она будет полностью понятна, а если вы не
знаете эти дисциплины, то будет небольшая, если будет вообще, потеря смысла, и
вы все еще сможете использовать и понимать (в большей части) материал,
раскрываемый в книге, без ощутимых потерь.
Время
от времени в статистике используются определенные математические функции. Эти
функции, например, гамма-функции и неполные гамма-функции, а также бета и
неполные бета-функции, часто называются функциями математической физики и
находятся за границами рассматриваемого материала. Раскрытие их до глубины
находится вне обзора данной книги, и даже далеко от ее направления. Помните,
что эта книга об управлении счетами трейдеров, а не математическая физика. Для
тех, кто действительно хочет знать «химию реактивного топлива», я предлагаю
книгу «Числовые рецепты» (Numerical Recipes), на которую есть ссылка в разделе рекомендованной
литературы. Я попытался осветить материал настолько глубоко, насколько возможно
учитывая, что вы не обязательно должны знать вычислительные методы или функции
математической физики, чтобы быть хорошим трейдером или управляющим деньгами.
Мое мнение таково: между умом и зарабатыванием денег на рынках нет прямой
зависимости. Этим я не хочу сказать, что чем глупее вы являетесь, тем выше ваши
шансы на успех в торговле. Я имею в виду, что один только ум является очень
небольшой составляющей в уравнении, которое определяет хорошего трейлера. В
отношении того, что же по моему мнению делает хорошего трейлера, могу сказать, что это ментальная прочность и
дисциплина, которые намного перевешивают ум. Каждый успешный трейдер, которого
я когда-либо встречал или о котором слышал, имел, по крайней мере. один опыт
огромного убытка. Общим знаменателем, характеристикой, которая отделяет
хорошего трейдера от остальных, является то, что хороший трейдер поднимает
телефонную трубку и размещает ордер, когда ситуация находится в самом мрачном
состоянии. Это требует от человека намного больше, чем может дать знание
вычислительных методов или статистики. Одним словом, я написал эту книгу, чтобы
ее использовали трейдеры на реальных рынках. Я не академик. Мой интерес в
реальном использовании, и он превыше академической высоты. Более того, я
попытался предоставить больше базовой информации, чем требуется для книги, в
надежде, что читатель будет исследовать концепции глубже, чем это сделал я.
Меня всегда интриговала архитектура музыки, теория музыки. Мне нравится читать
и узнавать о ней, однако я не музыкант. Чтобы быть музыкантом, нужна
определенная дисциплина, чего не может дать простое понимание основ музыкальной
теории. То же можно сказать про торговлю. Управление деньгами может быть в
корне здравой торговой программой, но простое понимание управления деньгами не
сделает из вас успешного трейдера. Эта книга о музыкальной теории, а не
инструкция игры на инструменте. Она не о победе над рынками, и вы не найдете в
ней ни одного ценового графика. Эта книга посвящена математическим концепциям и
делает важный шаг от теории к практике, но она не наделит вас способностью
переносить эмоциональную боль, которую торговля неизбежно припасла для вас. Эта
книга не является продолжением книги «Формулы управления портфелем». Наоборот,
книга «Формулы управления портфелем» заложила основу для тем, раскрываемых
здесь. Эта книга глубже и серьезнее предыдущей. Для тех, кто не читал книгу
«Формулы управления портфелем», глава 1 раскроет основные ее концепции.
Включение этих концепций делает книгу, которую вы держите в руках, независимой
от моей предыдущей книги. Многие идеи, раскрытые здесь, уже применяются на
практике профессиональными управляющими капиталом. Однако идеи, которые
распространены среди профессиональных управляющих капиталом, обычно недоступны
частным инвесторам. Так как здесь замешаны деньги, то все стараются держать в
тайне методы управления портфелем. Поиск такой информации — это как попытка
найти информацию об атомных бомбах. Я крайне признателен многим библиотекарям,
которые помогли мне разобраться в бесчисленных лабиринтах профессиональных
журналов и заполнить пробелы, чтобы создать эту книгу. Чтобы использовать инструменты,
которые здесь описываются, не обязательно применять механическую объективную
торговую систему. Другими словами, тот, кто, например, использует волны
Эллиотта для принятия торговых решений, также может применять оптимальное f. Однако методы, описанные в этой книге, как и те, которые
освещены в книге «Формулы управления портфелем», требуют, чтобы сумма ваших
ставок была положительным результатом. Другими словами, эти методы дадут вам
многое, но они
не
сделают чуда. Грамотное управление деньгами не превратит ваши убытки в прибыли.
Вы изначально должны иметь выигрышный подход.
Большинство методов, рассматриваемых в этой книге,
эффективны при долгосрочных стратегиях. На протяжении всей книги вы будете
встречать термин «асимптотический смысл», что означает возможный результат
чего-либо, осуществленного бесконечное число раз, когда вероятность
приближается к определенности при увеличении количества попыток. Другими
словами, что-то, в чем мы можем быть почти уверены с течением времени. Смысл
этого выражения содержится в математическом термине «асимптота», которая
является прямой и ограничивает кривую линию в том понимании, что расстояние
между двигающейся точкой кривой и прямой линией приближается к нулю, когда
точка удаляется на бесконечное расстояние от начала координат.
Торговля никогда не была легким занятием. Когда трейдеры
изучают эти концепции, то часто приобретают ложное чувство силы. Я говорю
«ложное», так как складывается впечатление, будто что-либо, что очень трудно
сделать, на самом деле очень легко, если понять механику процесса. Когда вы
будете читать эту книгу, помните, что в ней нет ничего, что может сделать вас
лучшим трейдером, ничего, что может улучшить ваш фактор времени входа на рынок
и выхода с него, ничего, что улучшит ваш торговый выбор. Эти трудные задачи
так и останутся трудными, даже после того, как вы прочтете и поймете эту
книгу.
После издания книги «Формулы управления портфелем» меня не
раз спрашивали, почему я решился ее написать. Обычный аргумент против такого
шага состоит в том, что рынок — это конкурентная арена, и когда вы пишете
книгу, это аналогично тому, что вы делитесь информацией со своими
противниками.
Мало кто представляет, насколько обширны сегодня рынки. Да,
рынки — это игра, где деньги переходят от одного участника к другому. Но в силу
их огромного размера, вы, читатель, не являетесь моим соперником.
Чаще всего я сам и являюсь своим главным врагом. Это верно
не только в отношении моей торговли на рынках, но и вообще в жизни. Другие
трейдеры не представляют мне такой угрозы, какую представляю для себя я сам. Я
не думаю, что одинок в этом, и полагаю, что большинство трейдеров согласятся со
мной. В середине 1980-х годов, когда компьютер стал основным инструментом трейдеров,
появилось большое количество торговых программ, которые открывали позицию по
стоп-ордеру, и размещение этих стоп-ордеров часто зависело от текущей
волатильности на данном рынке. Эти системы некоторое время работали прекрасно.
Затем,* к концу десятилетия, такие виды систем почти перестали использовать. В
лучшем случае они приносили только малую долю прибылей, по сравнению с
несколькими годами ранее. Большинство трейдеров, применявших эти системы,
впоследствии перестали их использовать, заявляя, что «раз все ими пользуются,
то как они могут работать?» .
Большинство этих систем применяли на рынке фьючерсов на
казначейские облигации. Давайте рассмотрим теперь размер рынка, лежащего в
основе фьючерсного рынка. Когда цены на рынке спот и фьючерсном рынке
расходятся (обычно не более чем на несколько тиков), в игру вступают
арбитражеры, покупая менее дорогостоящий из двух инструментов и продавая более
дорогостоящий. В результате расхождение между ценой спот-рынка и ценой
фьючерсного рынка достаточно быстро исчезает. Разница между ценой на спот-рынке
и фьючерсном рынке может действительно сильно измениться, только когда внешний
шок (какие-либо неожиданные события или новости) ведет цены к большему
расхождению, чем это бывает при обычном процессе арбитража. Такие разрывы
происходят обычно в течение очень короткого времени и встречаются довольно
редко. Арбитражеры зарабатывает на ценовых различиях, тем самым сглаживая их. В
результате этого процесса, рынок фьючерсов казначейских облигаций внутренне
привязан к огромному спот-рьшку казначейских обязательств. Фьючерсный рынок
отражает, по крайней мере, до нескольких тиков то, что происходит на гигантском
спот-рынке, который никогда не был ведомым системными трейдерами, скорее
наоборот.
Вернемся теперь к нашему спору. Маловероятно, чтобы
трейдеры на спот-рынке и на фьючерсном рынке начали торговать по одной системе
в одно и то же время! Также маловероятно, чтобы участники спот-рынка решили
вступить в сговор против тех, кто процветает на фьючерсном рынке. Тот факт, что
многие фьючерсные трейдеры торговали с помощью этих систем, не является действительной
причиной того, что системы перестали работать, поскольку это также означало бы,
что крупный участник на любом небольшом по объему рынке был бы обречен на
неудачу. Таким же образом глупо было бы полагать, что, как только выйдет в
свет моя книга по концепциям управления счетом, все сливки с рынка будут
моментально сняты.
Победа над рынком требует больше, чем понимание концепций
управления деньгами. Она требует дисциплины, чтобы вынести эмоциональную боль,
которую 19 из 20 людей не могут вынести. Этому вы не научитесь ни с помощью
этой, ни с помощью любой другой книги. Тот, кто заявляет, что он заинтригован
«интеллектуальным вызовом рынков», — не трейдер. Рынки так же интеллектуальны,
как и кулачный бой. Лучший совет, который я могу дать, — это всегда закрывать
свой подбородок и челюсть. Проиграете вы или выиграете, все равно будут
значительные удары. В действительности на рынках мало что относится к
интеллектуальному вызову; в конечном счете, торговля — это упражнение на
самообладание и выносливость. Эта книга пытается детально объяснить стратегию
кулачного боя, и ее следует использовать только тому, кто уже обладает необходимой
ментальной прочностью.
Некоторые
распространенные ложные концепции
В этой книге мы оспорим некоторые распространенные
концепции. Например:
- потенциальная прибыль является линейной
функцией потенциального риска, то есть: чем больше вы рискуете, тем больше ваша
возможность выиграть;
- ваше положение в спектре риска зависит от типа того
инструмента, которым вы торгуете;
- диверсификация уменьшает убытки (она может это сделать, но только до определенной степени — намного
меньше, чем считает большинство трейдеров);
- цена ведет себя рациональным способом.
Последней из этих ложных концепций, касающейся
рационального поведения цены, вероятно, менее всего придается значения, хотя ее
последствия могут быть особенно разрушительными. Под «рациональным способом»
подразумевается, что, когда происходит торговля на определенном ценовом уровне,
цена двигается обычным образом (по тикам), вверх или вниз. Таким образом
считается, что если цена двигается из одной точки в другую, то можно заключить
сделку в любой точке между ними. Большинство людей расплывчато осознают, что
цена не ведет себя таким образом, и тем не менее развивают торговые
методологии, которые допускают, что цена действует именно таким упорядоченным
способом.
Цена является искусственно воспринимаемой величиной и
поэтому не изменяется таким рациональным способом. Цена временами может делать
очень большие скачки, когда переходит с одного уровня на другой, полностью
минуя все цены между этими значениями. Цена может делать гигантские скачки, и
намного чаще, чем считает большинство трейдеров. Ошибка при выборе направления
позиции может быть разрушительным опытом, полностью уничтожающим счет трейдера.
Зачем упоминать здесь об этом? Потому что основа любой
эффективной игровой стратегии (а управление деньгами, в конечном счете,
является игровой стратегией) — надеяться
на лучшее и готовиться к худшему.
Сценарии
и стратегия худшего случая
С частью «надейся на лучшее» справиться довольно легко.
Подготовиться же к худшему психологически довольно сложно, и большинство
трейдеров предпочитает просто не думать о таком развитии событий. Это касается
не только торговли, но и других сфер человеческой деятельности. Когда сценарии
худшего случая имеют очень маленькую вероятность, то ими можно пренебречь. В
нашем же случае надо быть готовым к худшему, и это должно быть одной из
составляющих стратегии управления деньгами.
Вы увидите, что мы всегда будем продумывать стратегию,
исходя из сценария худшего случая. Мы всегда будем включать его в
математический метод, чтобы просчитать ситуации, которые предполагают
осуществление худшего случая.
Наконец,
необходимо учитывать следующую аксиому. Если
вы играете в игру с неограниченной ответственностью, то обанкротитесь с
вероятностью, которая приближается к уверенности, когда длина игры приближается
к бесконечности. Не очень приятная перспектива, не правда ли? Поясним
сказанное на примере: если вы можете умереть от удара молнией, то в конце
концов это произойдет. Если вы торгуете инструментом с неограниченной
ответственностью (таким, как фьючерсы), то в итоге понесете убыток такой
величины, что потеряете все. Вероятность того, что вас поразит молния именно
сегодня, чрезвычайно мала, И чрезвычайно мала для вас в течение следующих
пятидесяти лет. Однако эта вероятность существует, и если вам суждено прожить
достаточно долго, то в конце ' концов эта микроскопическая вероятность
реализуется. Таким же образом вероятность понести огромный убыток по позиции
сегодня может быть чрезвычайно мала (но намного больше, чем умереть сегодня от
молнии). Однако если вы торгуете достаточно долго, то в конце концов эта
вероятность также будет реализована. Существуют три подхода, которые вы можете
использовать. Первый — это торговать только теми инструментами, где
ответственность ограничена (например, длинная позиция по опционам). Второй —
не торговать бесконечно долгий период времени. Большинство трейдеров умрут
прежде, чем разорятся (или прежде, чем их поразит молния). Вероятность
огромного выигрыша также существует, и одна из приятных сторон торговли
заключается в том, что вам не обязательно сразу получить гигантский выигрыш,
достаточно многих маленьких побед. Поэтому если вы не собираетесь торговать
финансовыми инструментами с ограниченной ответственностью и не собираетесь
умирать, то пообещайте себе, что прекратите торговлю, когда баланс вашего счета
достигнет некоторой заранее установленной цели. Если когда-нибудь вы достигнете
этой цели, уходите с рынка и никогда не возвращайтесь. Мы рассматривали
сценарии худшего случая и то, как избежать или, по крайней мере, уменьшить
вероятность его появления. Представьте, что сегодня вы получили-таки огромный
проигрыш, ваш счет опустошен, брокерская фирма хочет знать, что вы будете
делать с этим большим дебетом на счете. Вы не ожидали, что это произойдет
сегодня. Те, кто попадает в такую ситуацию, чаще всего не готовы к ней. Теперь
попытайтесь представить, как бы вы себя чувствовали в такой ситуации. Затем
попытайтесь понять, что бы вы сделали в этом случае. Запишите на листок бумаги
план ваших действий: кому позвонить, чтобы получить юридическую помощь, и так
далее. Сделайте список настолько подробным, насколько возможно. Сделайте все
сейчас, чтобы, когда худшее произойдет, вам не пришлось к этому возвращаться.
Есть ли какие-то вопросы, которые вы можете решить сейчас, чтобы защитить себя
до возможного ужасающего убытка? Вы уверены, что не хотите торговать
инструментом с ограниченной ответственностью? Если вы собираетесь торговать
средством с неограниченной ответственностью, на каком заработке вы
остановитесь? Запишите, какой уровень прибыли вам подходит. Не читайте пока
книгу, закройте ее и некоторое время подумайте над этими вопросами. Именно с
этой точки мы и двинемся дальше. Задача книги состоит не в том, чтобы сделать
вас фаталистом. Это будет антипродуктивно, так как для эффективной торговли на
рынках с вашей стороны потребуется большой оптимизм, чтобы пройти через все
неизбежные затяжные периоды убытков. Цель книги — заставить вас задуматься о
сценарии худшего случая и заранее продумать план действий на тот случай, если
такой сценарий произойдет. Теперь возьмите листок бумаги с вашим планом на
крайний случай (и с суммой счета, при которой вы перестанете торговать) и
положите его в верхний ящик стола. Теперь, если начнет вырисовываться сценарий
худшего случая, вам не придется прыгать из окна. Надейтесь на лучшее, но готовьтесь
к худшему. Если вы не сделали эти приготовления, тогда закройте эту книгу и не
открывайте ее. Ничто не поможет вам, если вы не создадите себе фундамент, на
который будете опираться.
Система
математических обозначений
Так как
эта книга полна математических уравнений, я попытался сделать математические
обозначения легкими для понимания, причем настолько легкими, чтобы их можно
было взять из текста и перенести на экран компьютера. Умножение всегда будет
обозначаться звездочкой (*), а возведение в степень будет обозначаться
поднятым знаком вставки (^). Поэтому квадратный корень числа будет обозначаться
так: ^(1/2). Вы никогда не встретите знак корня. Деление в большинстве случаев
выражено черточкой (/). При использовании знака корня и средства выражения
деления с помощью горизонтальной линии длинные подкоренные выражения, а также
выражения в числителе и знаменателе дроби, часто не берутся в скобки. При
переводе такого выражения в компьютерный код может возникнуть путаница, мы
избежим ее с помощью этих условных обозначений для деления и возведения в
степень. Скобки будут единственным оператором группировки, и они могут быть использованы
для ясности выражения, даже если в них математически нет необходимости. В
качестве оператора группировки также могут использоваться фигурные скобки.
Большинство математических функций, используемых в книге, довольно просты
(например, функция абсолютного значения и функция натурального логарифма).
Есть одна функция, которая может быть знакома не всем читателям, — это
экспоненциальная функция, обозначаемая в книге ЕХР(). Математически она чаще
выражается как постоянная е, равная 2,7182818285, возведенная в степень. Таким
образом:
ЕХР(Х) = е ^ Х = 2,7182818285 ^Х
Мы
будем использовать обозначение ЕХР(Х), поскольку в большинстве компьютерных
языков в той или иной форме есть эта функция. Так как большая часть математики
книги может быть перенесена в компьютер, предложенная система обозначений
оптимальна.
Синтетические
конструкции в этой книге
Когда
вы будете читать книгу, то увидите, что в ней достаточно много геометрии.
Однако для того, чтобы добраться до этой геометрии, нам придется создать определенные
синтетические конструкции. Для начала мы переведем торговые прибыли и убытки в
«прибыль за период удержания позиции» (holding period returns), или, вкратце, HPR. Таким образом,
сделке, которая принесла 10% прибыли, соответствует HPR = 1 + 0,10 = 1,10.
Аналогично, сделке, по которой получился убыток 10%, соответствует HPR = 1 +
(-0,10) = 0,90. В большинстве книг при ссылке на прибыль за период удержания
позиции единица не прибавляется к проценту выигрыша или проигрыша. Однако в
этой книге, когда упоминается HPR, мы всегда прибавляем единицу к проценту
проигрыша или выигрыша.
Еще одна синтетическая конструкция, которую мы будем
использовать, — это рыночная система.
Она является определенным торговым подходом на данном рынке (подход не
обязательно должен быть механической торговой системой). Предположим, мы
используем два различных подхода, чтобы торговать на двух рынках; один из наших
подходов является системой, основанной на пересечении графика цены и простой
скользящей средней, другой подход основывается на интерпретации волн Эллиотта.
Далее предположим, что мы торгуем на двух рынках, например казначейскими облигациями
и мазутом. У нас получается четыре различные рыночные системы: система
скользящей средней на рынке облигаций, система волн Эллиотта на рынке
облигаций, система скользящей средней на рынке мазута и волн Эллиотта на рынке
мазута.
Рыночная система может быть далее дифференцирована другими
факторами, одним из которых является зависимость. Например, в системе
скользящей средней мы обнаруживаем (посредством методов, описанных в этой
книге), что прибыльные сделки порождают убыточные, и наоборот. Мы разбиваем
нашу систему скользящей средней на две рыночные системы. Одна из рыночных
систем будет торговать только после проигрыша (учитывая природу такой
зависимости, эта система лучше), другая рыночная система будет работать только
после выигрыша. Возвращаясь к торговле по системе скользящей средней на рынке
казначейских облигаций и мазута и используя метод торговли по волнам Эллиотта,
мы теперь имеем шесть рыночных систем: система скользящей средней после
проигрыша по облигациям, система скользящей средней после выигрыша по
облигациям, метод, основанный на волнах Эллиотта на рынке облигаций, система
скользящей средней после выигрыша на рынке мазута, система скользящей средней
после проигрыша на рынке мазута, и метод, основанный на волнах Эллиотта на
рынке мазута.
Торговля, основанная на пирамидальном подходе (прибавление
контрактов во время торговли), рассматривается, в смысле управления капиталом,
как несколько последовательных рыночных систем. Если вы применяете торговый метод,
основанный на пирамиде, то должны считать первоначальный вход на рынок одной
рыночной системой. Каждый дополнительный контракт при увеличении пирамиды
создает еще одну рыночную систему. Допустим, торговый метод требует, чтобы вы
добавляли контракты каждый раз, когда зарабатываете 1000 долларов. Если
торговля успешна, то следует прибавлять больше и больше контрактов, когда цена
будет переходить через уровни прибыли в 1000 долларов. Каждый добавленный
контракт должен считаться отдельной рыночной системой. В этом есть большой плюс,
он состоит в том, что рассматриваемые в этой книге методы дадут вам количество
контрактов для определенной рыночной системы в зависимости от уровня баланса
на счете. Обращаясь с каждым добавленным контрактом как с отдельной рыночной
системой, вы сможете использовать рассматриваемые методы, чтобы узнать
оптимальное количество контрактов, которое надо добавить при текущем уровне
баланса.
Еще одной очень важной синтетической конструкцией, которую
мы будем использовать, является концепция единицы.
HPR, которые вы будете рассчитывать для отдельных рыночных
систем, должны рассчитываться на основе «одной единицы». Другими словами, если
это фьючерсные контракты или опционы, то каждая сделка будет основываться на 1
контракте. Если это акции, то вы должны заранее решить, какой будет эта
единица, она может равняться 100 акциям или 1 акции. При торговле на
спот-рынках или на рынке FOREX вы также должны решить, какой
будет единица. Используя результаты, основанные на торговле одной единицей,
применяя методы из этой книги, вы сможете получить выходные результаты,
основанные на одной единице. То есть, вы будете знать, какое количество
контрактов или акций необходимо использовать в определенной сделке. Неважно,
какое количество вы выберете для единицы, так как это гипотетическая
конструкция, необходимая только для того, чтобы произвести расчеты. Для каждой
рыночной системы вы должны рассчитать, какой будет единица. Например, если вы
торгуете на рынке FOREX, то можете выбрать в качестве единицы 1 миллион
долларов. Если вы трейдер на фондовом рынке, то оптимальным числом может быть
100 акций.
И, наконец, необходимо решить, будете ли вы торговать
дробными единицами. Например, если вы торгуете на товарном рынке и единица
равна 1 контракту, то торговать дробными единицами невозможно. Если вы
работаете на фондовом рынке и .единица равна 1 акции, то также не сможете
торговать дробной единицей, однако если 1 единица — это 100 акций, то можно
работать с дробной единицей, если есть желание торговать нестандартным лотом.
Если вы торгуете фьючерсами, то можно взять за единицу 1
мини-контракт и не допускать дробные единицы. Теперь допустим, что 2
мини-контракта соответствуют 1 обычному контракту, и с помощью методов,
описанных в этой книге, вы приходите к выводу, что надо торговать 9 единицами,
— это будет означать, что вам следует торговать 9 мини-контрактами. Так как
при делении 9 на 2 получается 4,5, то следует торговать 4 обычными контрактами
и 1 мини-контрактом. Вообще, с точки зрения управления деньгами считается, что
торговля дробными единицами дает определенное преимущество, но, как правило,
этот выбор не играет большой роли. Посмотрим на двух трейдеров на рынке акций.
У одного единица — это 1 акция и он не может торговать дробными единицами, у
другого единица — 100 акций и он может торговать дробными единицами. Допустим,
что сегодня оптимальное количество для первого трейдера составляет 61 единица
(т.е. 61 акция), а для второго трейдера в тот же день 0,61 единицы (снова 61
акция).
Многие
справедливо полагают: чтобы стать хорошим учителем, нужно довести материал до
уровня, который мог бы понять ученик. Один из способов — провести аналогию
между концепцией, которую нужно объяснить, и чем-то знакомым. Поэтому в тексте
вы найдете много аналогий. Несмотря на то, что аналогии могут быть весьма
полезны и в споре, и при обучении, я отношусь к ним настороженно, так как они
привносят нечто чуждое и вынуждают (часто совершенно несправедливо)
рассматривать новую концепцию с точки зрения логики уже известного. Например:
Квадратный корень из 6 равен 3, так как квадратный корень 4
составляет 2, а 2+2 будет 4.
Поскольку 3 + 3 = 6, то квадратный корень из б должен быть равен 3.
Аналогии объясняют, но они ничего не решают. Наоборот,
аналогия делает априорное предположение о том, что некоторое суждение истинно,
и это «объяснение» затем считается доказательством. Заранее прошу прощение за
использование аналогий в книге, я использую их только для наглядности.
Оптимальное
количество для торговли и оптимальное f
Современная теория управления портфелем, возможно, являясь
вершиной концепции управления капиталом при торговле акциями, не была принята
остальным торговым миром. Фьючерсные трейдеры, чьи технические торговые идеи
обычно считаются родственными торговым идеям фондового рынка, не желали
принимать методы из мира торговли акциями. Вследствие этого современная теория
портфеля никогда в действительности не использовалась фьючерсными трейдерами.
В то время как современная теория портфеля определяет
оптимальный вес составляющих портфеля (для достижения наименьшей дисперсии при
заданном доходе или наоборот), она не затрагивает идею оптимального количества.
Речь идет о том, что для данной рыночной системы есть оптимальное количество,
которое можно использовать в торговле при данном уровне баланса счета, чтобы
максимизировать геометрический рост. Это количество мы и будем называть
оптимальным f. Данная книга предлагает, чтобы современная теория
портфеля использовалась трейдерами на любых рынках, а не только на фондовом.
Однако мы должны породнить современную теорию портфеля (которая дает нам
оптимальный вес) с идеей оптимального количества (оптимальное f), чтобы
добиться действительно оптимального портфеля. Именно этот оптимальный портфель
может и должен использоваться трейдерами на любых рынках, включая фондовые.
При
торговле без заемных средств (т.е. без «рычага»), например при управлении
портфелем акций, вес и количество являются синонимами, но в ситуации с рычагом
(например портфель фьючерсных торговых систем) вес и количество отличаются. В
этой книге вы познакомитесь с концепцией, которая впервые была освещена в книге
«Формулы управления портфелем»,
заключающейся в том, что необходимо знать оптимальное торговое количество,
которое является функцией оптимального взвешивания.
Как только
мы изменим современную теорию портфеля и отделим вес от количества, то сможем
вернуться к торговле акциями с этим теперь уже переработанным инструментом. Мы
увидим, как почти любой портфель акций без рычага можно улучшить, превратив его
в портфель с рычагом, соединив с безрисковым активом. В дальнейшем все станет
вам интуитивно очевидно. Степень риска (или консервативности) является в таком
случае функцией рычага, который трейдер желает применить к своему портфелю. Это
означает, что положение данного трейдера в спектре «неприятия риска» зависит не
от используемого инструмента, а от рычага, который он выбирает для торговли.
Если говорить коротко, то книга научит вас управлению
риском. Мало трейдеров имеют представление о том, что такое управление риском.
Это не полное упразднение риска, поскольку тогда вы полностью упразднили бы
выигрыш, и не просто вопрос максимизации потенциального дохода по отношению к
потенциальному риску. Управление риском
относится к стратегии принятия решений, которая имеет целью максимизацию
отношения потенциальной прибыли к потенциальному риску при определенном
приемлемом уровне риска. Чтобы понять это, мы должны сначала познакомиться
с оптимальным f, компонентом уравнения, выражающим оптимальное количество для
сделки. Затем мы должны научиться комбинировать оптимальное f с оптимальным
взвешиванием портфеля. Такой портфель будет максимизировать потенциальную
прибыль по отношению к потенциальному риску. Сначала мы раскроем эти концепции
с эмпирической точки зрения (вкратце повторим книгу «Формулы управления портфелем»), затем изучим их с более мощной
точки зрения, параметрической. В отличие от эмпирического подхода, который
использует прошлые данные, параметрический подход использует прошлые данные и
некоторые параметры. Затем эти
параметры используются в модели,
дающей преимущественно те же ответы, что и эмпирический подход. Сильной
стороной параметрического подхода является то, что вы можете изменить значения
параметров, чтобы посмотреть, как изменится результат. Эмпирический подход не
позволяет этого сделать. Однако эмпирические методы также имеют сильные
стороны. Они в основном проще с точки зрения математики, поэтому их легче
использовать на практике. По этой причине сначала рассматриваются эмпирические
методы. В конце нашего исследования мы увидим, как применять данные концепции
при заданном пользователем уровне риска, и узнаем стратегии, которые максимизируют
рост. В книге рассмотрено очень много тем. Я попытался сделать ее настолько сжатой,
насколько это вообще возможно. Некоторый материал может быть не совсем вам
понятен, и, возможно, он поднимет больше вопросов, чем даст ответов. Если так
оно и есть, значит я добился одной из целей этой книги. Большинство книг имеет
одно «сердце», одну центральную концепцию, из которой проистекает вся книга.
Эта книга отличается тем, что у нее несколько таких концепций. Некоторые
посчитают ее трудной, если подсознательно ищут книгу с одним «сердцем». Я не
приношу за это извинений; это не ослабляет логики книги, наоборот, обогащает
ее. Чтобы полностью понять материал, изложенный в книге, может быть, вам
придется прочитать ее два или даже три раза. Одной из особенностей книги
является более широкая трактовка концепции
принятия решений в среде, характеризуемой геометрическими следствиями.
Среда геометрического следствия — это среда, где количество, с которым вы
должны работать сегодня, является функцией предыдущих результатов. Я думаю, что
это освещает большую часть среды, в которой мы живем! Оптимальное f— это регулятор роста в такой среде, а побочные продукты
оптимального f говорят о скорости роста в данной среде. Из этой книги вы
узнаете, как определять оптимальное 1И его побочные продукты для любой формы
распределения. Это статистический инструмент, который применим к различным
сферам в бизнесе и науке. Надеюсь, что вы попытаетесь использовать описанные
инструменты, чтобы найти оптимальные 1не только для рынков, но и для других
областей. Много лет торговое сообщество обсуждало концепцию «управления деньгами».
Однако в итоге управление деньгами характеризовалось пестрым набором правил,
многие из которых были некорректны. Я надеюсь, что эта книга даст трейдерам
точность в сфере управления капиталом.
Глава
1
Эмпирические
методы
Эта
глава является кратким изложением книги «Формулы управления портфелем». Цель
главы — довести уровень читателей, которые не знакомы с эмпирическими методами,
до уровня тех, кто уже знаком с ними.
Какой долей
счета торговать?
Когда вы начинаете торговлю, то должны принять два решения:
какую позицию открыть, длинную или короткую, и каким количеством торговать.
Решение о количестве всегда зависит
от баланса на вашем счете. При счете в 10 000 долларов приобретение 100
контрактов на золото будет слишком рискованным. Если на вашем счету 10
миллионов долларов, разве не очевидно, что приобретение одного контракта на
золото почти никак не отразится на счете? Признаем мы это или нет, решение
относительно того, каким количеством контрактов в определенный момент времени
торговать, зависит от уровня баланса на счете. Если мы будем использовать
определенную долю счета в каждой сделке (другими словами, когда будем
торговать количеством, соотносимым с размером нашего счета), то добьемся более
быстрого прироста капитала. Количество зависит не только от баланса на нашем
счете, а является также функцией некоторых других переменных: нашего
предполагаемого убытка наихудшего случая в следующей сделке; скорости, с
которой мы хотим, чтобы рос наш счет; зависимости от прошлых сделок. Доля
счета, которую следует использовать для торговли, будет зависеть от многих
переменных, и мы попытаемся собрать все эти переменные, включая уровень
баланса счета, чтобы в итоге принять достаточно субъективное решение
относительно того, сколькими контрактами или акциями торговать. Из этой главы
вы узнаете, как принимать математически верные решения в отношении количества и
не основывать свои действия на субъективном и, возможно, ошибочном суждении.
Вы увидите, что если использовать неправильное количество, то придется
заплатить чрезмерную цену, и эта цена возрастет с течением времени.
Большинство трейдеров не уделяет должного внимания проблеме выбора количества.
Они считают, что этот выбор в значительной мере случаен, и не имеет значения,
какое количество использовать, важно только то, насколько они правы в отношении
направления торговли. Более того, возникает ошибочное впечатление, что
существует прямая зависимость между тем, сколько контрактов открывать, и тем,
сколько можно выиграть или проиграть с течением времени. Это неверно. Как мы увидим,
отношение между потенциальным выигрышем и количеством не выражается прямой
линией. Это кривая. У этой кривой есть пик, и именно на этом пике мы достигнем
максимального потенциального выигрыша. Из этой книги вы узнаете, что решение о
количестве, используемом в определенной сделке, также важно, как и решение о
длинной или короткой позиции. Мы опровергнем ложное мнение большинства
трейдеров и покажем, что уровень счета зависит от правильного выбора количества
контрактов не в меньшей степени, чем от правильного направления торговли. Не вы управляете ценами, и не от вас
зависит, будет следующая сделка прибыльной или убыточной. Однако количество контрактов, которые вы
открываете, зависит только от вас. Поэтому ваши ресурсы будут использованы с
большей отдачей, если сконцентрироваться на верном количестве. При любой
сделке вы хотя бы приблизительно предполагаете, каким может быть убыток
наихудшего случая. Можно даже не осознавать этого, но, когда вы начинаете
торговлю, у вас есть ощущение, пусть даже подсознательное, что может произойти
в худшем случае. Восприятие худшего случая вместе с уровнем баланса на вашем
счете формирует решение о том, сколькими контрактами торговать.
Таким
образом, мы можем сказать, что существует некий делитель (число между 0 и 1)
наибольшего предполагаемого убытка для определения количества контрактов.
Например, если при счете в 50 000 долларов вы ожидаете, в худшем случае, убыток
5000 долларов на контракт, и открыто 5 контрактов, то делителем будет 0,5, так
как:
50 000/(5000/0,5) =5
Другими
словами, у вас есть 5 контрактов на счет в 50 000 долларов, т. е. 1 контракт
на каждые 10000 долларов баланса. Вы ожидаете в худшем случае потерять 5000
долларов на контракт, таким образом, вашим делителем будет 0,5. Если бы у вас
был один контракт, то делителем в этом случае было бы число 0,1, так как:
50 000/(5000/0,1)=1
Этот делитель мы назовем переменной f. Таким образом, сознательно или подсознательно при любой
сделке вы выбираете значение f, когда решаете, сколько контрактов или акций приобрести.
Теперь посмотрите на рисунок 1-1. На нем представлена игра,
где у вас 50% шансов выиграть 2 доллара против 50% шансов потерять 1 доллар в
каждой игре. Отметьте, что здесь оптимальное f составляет 0,25, когда TWR составляет 10,55 после 40 ставок (20 последовательностей
+2, -1). TWR — это «относительный конечный капитал» (Terminal Wealth Relative), он представляет доход по вашим ставкам в виде
множителя. TWR = 10,55 означает, что вы увеличили бы в 10,55 раз ваш
первоначальный счет, или получили бы 955% прибыли. Теперь посмотрите, что
произойдет, если вы отклонитесь всего лишь на 0,15 от оптимального f= 0,25. Когда f равно 0,1 или 0,4, ваш TWR = 4,66. Это не
составляет даже половины того, что будет при 0,25, причем вы отошли только на
0,15 от оптимального значения и сделали только 40 ставок!
О какой сумме в долларах мы говорим? При f = 0,1 вы ставите
1 доллар на каждые 10 долларов на счете. При f=
0,4 вы ставите 1 доллар на каждые 2,50 долларов на счете. В обоих случаях мы
получаем TWR = 4,66. При f= 0,25 вы ставите 1 доллар на каждые
4 доллара на счете. Отметьте, что если вы ставите 1 доллар на каждые 4 доллара
на счете, то выигрываете в два раза больше после 40 ставок, чем в случае ставки
одного доллара на каждые 2,50 доллара на вашем счете! Очевидно, что не стоит
излишне увеличивать ставку. При ставке 1 доллар на каждые 2,50 доллара вы
получите тот же результат, что и в случае ставки четверти этой суммы, то есть 1
доллар на каждые 10 долларов на вашем счете! Отметьте, что в игре 50/50, где вы
выигрываете вдвое больше, чем проигрываете, при f=
0,5 вы только «остаетесь при своих»! При f
больше 0,5 вы проигрываете в этой игре, и теперь окончательное разорение — это
просто вопрос времени! Другими словами, если f (в игре 50/50, 2:1) на 0,25
отклоняется от оптимального, вы будете банкротом с вероятностью, которая
приближается к определенности, если продолжать играть достаточно долго. Таким
образом, нашей целью будет объективный поиск пика кривой f для данной
торговой системы.
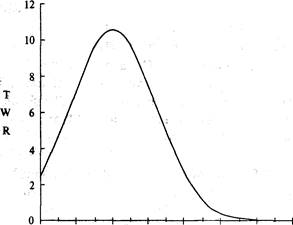
0,05 0,15
0,25 0,35 0,45
0,55 0,65 0,75 значения f
Рисунок 1-1 20 последовательностей +2, -1
В этой книге определенные концепции освещаются с позиции
азартных игр. Основное отличие азартной игры от спекуляции заключается в том,
что азартная игра создает риск (и
отсюда многие настроены против нее), в то время как спекуляция является переходом уже существующего риска
(предположительного) от одной стороны к другой. Иллюстрации азартных игр
используются для наглядного примера излагаемых концепций. Математика управления
капиталом и принципы, используемые в торговле и азартных играх, довольно
похожи. Основная разница состоит в том, что в математике азартных игр мы обычно
имеем дело с бернуллиевыми результатами (только два возможных исхода), в то
время как в торговле мы сталкиваемся со всем распределением результатов,
которые только могут быть в реальной сделке.
Основные
концепции
Вероятность
задается числом от 0 и 1, которое определяет, насколько вероятен результат,
где 0 — это полное отсутствие вероятности происхождения определенного события,
а 1 означает, что рассматриваемое событие определенно произойдет. Процесс
независимых испытаний (отбор с замещением) является последовательностью
результатов, где значение вероятности постоянно от одного события к другому
Бросок монеты является примером такого процесса. Каждый бросок имеет вероятность
50/50 независимо от результата предыдущего броска. Даже если последние 5 раз
выпадал орел, вероятность того, что при следующем броске выпадет орел, все
равно не изменяется и составляет 0,5.
Другой
тип случайного процесса характеризуется тем, что результат предыдущих событий
влияет на значение вероятности, и, таким образом, значение вероятности
непостоянно от одного события к другому Эти виды событий называются процессами
зависимых испытаний (отбор без замещения). Игра «21 очко» является примером
такого процесса. После того как вытаскивают карту, состав колоды изменяется.
Допустим, что новая колода перемешивается и одна карта удалена, скажем,
бубновый туз. До удаления этой карты вероятность вытянуть туза была 4/52, или
0,07692307692. Теперь, когда туза вытащили из колоды и не вернули обратно,
вероятность вытянуть туза при следующем ходе составляет 3/51, или
0,05882352941.
Различие
между независимыми и зависимыми испытаниями состоит в том, что вероятность или
фиксирована (независимые попытки), или меняется (зависимые попытки) от одного
события к другому, в зависимости от предыдущих результатов. Фактически это и
есть единственное различие.
Серийный
тест
Когда в
случае с колодой карт мы проводим отбор без замещения, можно путем проверки
определить, существует ли зависимость. Для определенных событий (таких, как
поток прибыли и убытков по сделкам), где зависимость не может быть определена
путем проверки, мы будем использовать серийный тест. Серийный тест подскажет
нам, имеет ли наша система больше (или меньше) периодов последовательных
выигрышей и проигрышей, чем случайное распределение.
Цель
серийного теста — найти счет Z для периодов
выигрышей и проигрышей в системной торговлеe.
Счет Z означает, на сколько стандартных отклонений вы удалены от
среднего значения распределения. Таким образом, счет Z = 2,00 означает, что вы
на 2,00 стандартных отклонения удалились от среднего значения (ожидание
случайного распределения периодов выигрышей и проигрышей).
Счет Z — это просто число стандартных отклонений, на которое
данные отстоят от среднего значения нормального распределения вероятности.
Например, счет Z
в 1,00 означает, что данные,
которые вы тестируете, отклонены на 1 стандартное отклонение от среднего
значения.
Счет Z
затем переводится в доверительную
границу, которая иногда также называется степенью достоверности. Площадь под кривой нормального распределения
вероятности шириной в 1 стандартное отклонение с каждой стороны от среднего
значения равна 68% всей площади под этой кривой. Преобразуем счет Z в
доверительную границу. Связь счета Z и доверительной границы следующая: счет Z
является числом стандартных отклонений от среднего значения, а доверительная
граница является долей площади под кривой, заполненной при таком числе
стандартных отклонений.
|
Доверительная Счет Z
граница(%)
|
|
99,73
3,00
99
2,58
98
2,33
97 2,17
96 2,05
95,45 2,00
95 1,96
90 1,64
|
При минимальном количестве 30 закрытых сделок мы можем
рассчитать счет Z. Попытаемся узнать, сколько периодов выигрышей (проигрышей)
можно ожидать от данной системы? Соответствуют ли периоды выигрыша (проигрыша)
тестируемой системы ожидаемым? Если нет, существует ли достаточно высокая доверительная
граница, чтобы допустить, что между сделками существует зависимость, т.е.
зависит ли результат текущей сделки от результата предыдущих сделок? Ниже
приведено уравнение серийного теста. Счет Z для торговой системы равен:
(1.01)
Z=(N*(R-0,5)-Х)/((Х*(Х-N))/(N-1))^(1/2), где
N = общее число сделок в последовательности;
R = общее число серий выигрышных или проигрышных сделок;
X=2*W*L;
W = общее число
выигрышных сделок в последовательности;
L = общее число проигрышных сделок в последовательности.
Этот расчет можно провести следующим образом:
1. Возьмите данные по вашим сделкам:
A) Общее число сделок, т.е. N.
Б) Общее число выигрышных сделок и общее число проигрышных
сделок.
Теперь рассчитайте X.
Х = 2 * (Общее число
выигрышей) * (Общее число проигрышей).
B) Общее число серий в последовательности, т.е. R.
2. Предположим, что произошли следующие сделки:
-3, +2, +7, -4, +1, -1, +1, +6, -1, 0, -2, +1.
Чистая прибыль составляет +7. Общее число сделок 12,
поэтому N = 12. Теперь нас интересует не то, насколько велики выигрыши и проигрыши, а то, сколько было выигрышей и проигрышей, а также серий. Поэтому мы
можем переделать наш ряд сделок в простую последовательность плюсов и минусов.
Отметьте, что сделка с нулевой прибылью считается проигрышем. Таким образом:
- + + - +-++---+
Как видно, последовательность состоит из 6 прибылей и 6
убытков, поэтому X =2 * 6 * 6 = 72. В последовательности есть 8 серий, поэтому
R = 8. Мы называем серией каждое
изменение символа, которое встречается при чтении последовательности слева
направо (т.е. хронологически).
1. Последовательность будет выглядеть следующим образом:- +
+ - +-++---+ т.е. 1 2 3 4 5 6 7 8
2. Вычислите значение выражения:
N*(R-0,5)-X
Для нашего примера:
12* (8 -0, 5) -72
12*7,5-72
90 - 72
18
3. Вычислите значение выражения:
(X*(X-N))/(N-1) Для нашего примера:
(72* (72-12))/(12-1)
(72* 60)/11
4320/11
392,727272
4. Возьмите квадратный корень числа, полученного в пункте
3. В нашем примере:
392,727272 ^(1/2) = 19,81734777
5. Разделите ответ из пункта 2 на ответ из пункта 4. Это и
есть счет Z. В нашем примере:
18/19,81734777 = 0,9082951063
6. Теперь преобразуйте ваш счет Z в доверительную границу.
Распределение периодов является биномиальным распределением. Однако когда
рассматриваются 30 или больше сделок, мы можем использовать нормальное распределение,
как близкое к биномиальному. Таким образом, если вы используете 30 или более
сделок, вы просто можете преобразовать ваш счет Z в доверительную границу,
основываясь на уравнении (3.22) для нормального распределения.
Серийный тест подскажет вам, содержит ли ваша
последовательность выигрышей и проигрышей больше или меньше полос (серий
выигрышей или проигрышей), чем можно было бы ожидать от действительно
случайной последовательности, в которой нет зависимости между испытаниями. Так
как в нашем случае мы находимся на уровне относительно низкой доверительной
границы, то можно допустить, что между сделками в этой последовательности нет
зависимости.
Если счет Z имеет отрицательное значение, то при расчете
доверительной границы просто возьмите его абсолютное значение. Отрицательный
счет Z говорит о положительной зависимости, то есть полос меньше, чем при
нормальном распределении вероятности, и следовательно, выигрыши порождают
выигрыши, а проигрыши порождают проигрыши. Положительный счет Z говорит об
отрицательной зависимости, то есть полос больше, чем при нормальном распределении
вероятности, и следовательно, выигрыши порождают проигрыши, а проигрыши
порождают выигрыши.
Какой уровень доверительной границы считать приемлемым?
Статистики, как правило, рекомендуют доверительную границу не менее 90%.
Некоторые рекомендуют доверительную границу свыше 99%, чтобы быть уверенными,
что зависимость существует, другие рекомендуют менее строгий минимум 95,45% (2
стандартных отклонения).
Очень
редко система демонстрирует доверительную границу свыше 95,45%, чаще всего она
менее 90%. Даже если вы найдете систему с доверительной границей от 90 до
95,45, это не будет золотым самородком. Чтобы убедиться в зависимости, на
которой можно хорошо заработать, вам нужно как минимум 95,45%. Пока
зависимость находится на приемлемой доверительной границе, вы можете изменить
систему, чтобы улучшить торговые решения, даже если вы не понимаете основной
причины зависимости. Если вы узнаете причину, то сможете оценить, когда
зависимость действовала, а когда нет, а также когда можно ожидать изменение
степени зависимости. До настоящего момента мы смотрели на зависимость только с
точки зрения того, была ли последняя сделка выигрышем или проигрышем. Теперь мы
попытаемся определить, есть ли в последовательности выигрышей и проигрышей
зависимость или нет. Серийный тест на наличие зависимости автоматически принимает
в расчет процент выигрышей и проигрышей. Однако серийный тест по периодам
выигрышей и проигрышей учитывает последовательность
выигрышей и проигрышей, но не их размер.
Для того чтобы получить истинную независимость, не только сама
последовательность выигрышей и проигрышей должна быть независимой, но и размеры
выигрышей и проигрышей в последовательности также должны быть независимыми.
Выигрыши и проигрыши могут быть независимыми, однако их размеры могут зависеть
от результатов предыдущей сделки (или наоборот). Возможным решением является
проведение серийного теста только с выигрышными сделками. При этом полосы
выигрышей следует разделить на длинные (по сравнению со средним значением
распределения вероятности) и менее длинные. Только затем надо искать
зависимость между размером выигрышных сделок, после этого необходимо провести
ту же процедуру с проигрышными сделками.
Корреляция
Есть другой, и, может быть, лучший способ определения
зависимости между размерами выигрышей и проигрышей. Этот метод позволяет
рассмотреть размеры выигрышей и проигрышей с совершенно другой стороны, и когда
он используется вместе с серийным f тестом, то
взаимосвязь сделок измеряется с большей глубиной. Для количественной оценки
зависимости или независимости данный метод использует коэффициент линейной
корреляции г, который иногда называют пирсоновским r. Посмотрите на рисунок 1-2. На нем
изображены две абсолютно коррелированные последовательности. Мы называем это положительной корреляцией.
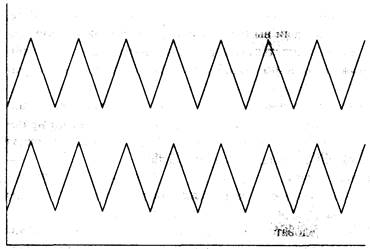
Рисунок 1-2 Положительная корреляция (r =1,00)
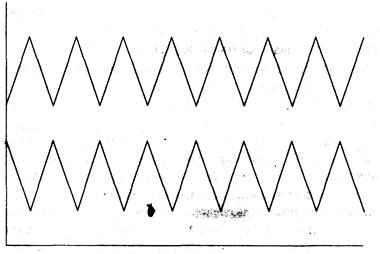
Рисунок 1-3 Отрицательная
корреляция (r = -1,00)
Теперь
посмотрите на рисунок 1-3. Он показывает две последовательности, которые
находятся точно в противофазе. Когда одна линия идет вверх, другая следует вниз
(и наоборот). Мы называем это отрицательной
корреляцией.
Формула
для коэффициента линейной корреляции г двух последовательностей Х и Y такова (черта над переменной обозначает среднее
арифметическое значение):
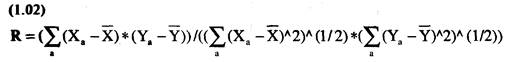
Расчет следует производить следующим образом:
1. Вычислите среднее Х и Y (т.е. X и Y )•
2. Для каждого периода найдите разность между Х и средним
X, а также Y и средним Y.
3. Теперь рассчитайте числитель. Для этого
для каждого периода перемножьте ответы из шага 2, другими словами, для каждого
периода умножьте разность между Х и средним X, на разность между Y и средним
Y.
4. Сложите результаты, полученные в шаге 3, за все периоды.
Это и есть числитель.
5. Теперь найдите знаменатель. Для этого возьмите результаты
шага 2 для каждого периода, как для разностей X, так и для разностей Y, и возведите
их в квадрат (теперь они будут положительными значениями).
6. Сложите возведенные в квадрат разности Х за все периоды.
Проделайте ту же операцию с возведенными в квадрат разностями Y.
7. Извлеките квадратный корень из суммы возведенных в
квадрат разностей X, которые найдены в шаге 6. Теперь проделайте то же с Y,
взяв квадратный корень суммы возведенных в квадрат разностей Y.
8. Умножьте два результата, которые вы нашли в шаге 7, то
есть умножьте квадратный корень суммы возведенных в квадрат разностей Х на
квадратный корень суммы возведенных в квадрат разностей Y. Это и есть
знаменатель.
9. Разделите числитель, который вы нашли в шаге 4, на
знаменатель, который вы нашли в шаге 8. Это и будет коэффициент линейной
корреляции г.
Значение г всегда будет между +1,00 и -1,00. Значение 0
указывает, что корреляции нет.
Теперь
посмотрите на рисунок 1-4. Он представляет следующую последовательность из 21
сделки:
Чтобы
понять, есть ли какая-либо зависимость между предыдущей и текущей сделкой, мы
можем использовать коэффициент линейной корреляции. Для значений Х в формуле
для г возьмем P&L
по каждой сделке. Для значений Y в формуле для г
возьмем ту же самую последовательность P&L, только смещенную на одну
сделку. Другими словами, значение Y — это предыдущее значение X. (См. рисунок
1-5.).
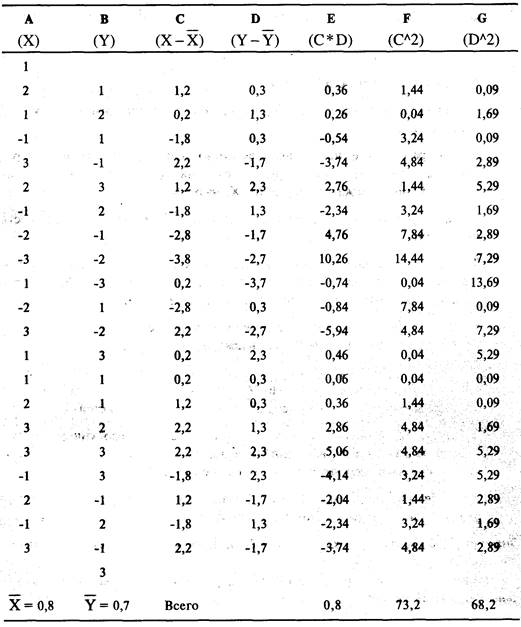
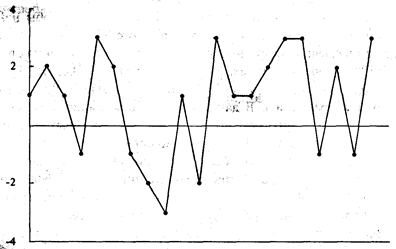
Рисунок 1-4 Отдельные результаты 21 сделки
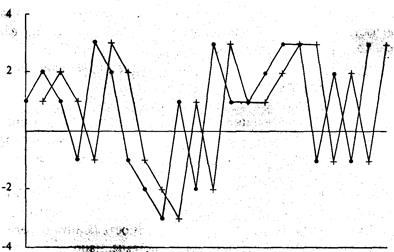
Рисунок
1-5 Отдельные результаты 21 сделки,
сдвинутые на 1 сделку
Средние
значения различаются, потому что вы усредняете только те Х и Y, которые частично перекрывают друг друга, поэтому
последнее значение Y (3) не вносит вклад в среднее Y, а первое значение Х (1)
не вносит вклад в среднее X. Числитель является суммой всех значений из столбца
Е (0,8). Чтобы найти знаменатель, мы извлечем квадратный корень из итогового
значения столбца F, то есть 8,555699, затем извлечем
квадратный корень из итогового значения столбца G,
то есть 8,258329, и перемножим их, что даст в результате 70,65578. Теперь
разделим числитель 0,8 на знаменатель 70,65578 и получим 0,011322. Это наш коэффициент
линейной корреляции г. В данном случае коэффициент линейной корреляции 0,011322
едва ли о чем-то говорит, но для многих торговых систем он может достигать
больших значений. Высокая положительная корреляция (по крайней мере, 0,25)
говорит о том, что большие выигрыши редко сменяются большими проигрышами, и
наоборот. Отрицательные значения коэффициента корреляции (между -0,25 и -0,30)
подразумевают, что после больших проигрышей следуют большие выигрыши, и
наоборот. Для заданного количества сделок с помощью метода, известного как «Трансформация Z Фишера», коэффициент корреляции можно преобразовать в
доверительный уровень. Эта тема рассматривается в приложении С. Отрицательную
корреляцию так же, как и положительную, можно использовать в своих интересах.
Например, если обнаружена отрицательная корреляция и система показала большой
проигрыш, то в следующей сделке можно ожидать большой выигрыш и таким образом
открыть больше контрактов, чем обычно. Если и эта сделка принесет убыток, то он
не должен быть очень большим (из-за отрицательной корреляции).
Наконец,
при определении зависимости вы должны провести тесты по разным сегментам
данных. Для этого разбейте ваши данные на две или более частей. Если вы увидите
зависимость в первой части, тогда посмотрите, существует ли эта зависимость во
второй части, и так далее. Это поможет исключить случаи, где появляется
кажущаяся зависимость, но фактически ее нет. Использование этих двух
инструментов (серийный тест и коэффициент линейной корреляции) поможет
ответить на многие вопросы, однако только в том случае, если у вас есть
достаточно высокая доверительная граница и/или достаточно высокий коэффициент
корреляции. Большую часть времени эти инструменты вряд ли будут вам полезны,
так как слишком часто во фьючерсных торговых системах зависимость отсутствует.
Если вы получите данные, указывающие на зависимость, то следует обязательно
воспользоваться этим обстоятельством в торговле, вернуться и включить новое
правило в торговую логику, чтобы использовать зависимость. Другими словами, вы
должны вернуться и изменить логику торговой системы, чтобы она учитывала эту
зависимость (минуя определенные сделки или разбивая систему на две различные
системы, например, одна для сделок после выигрышей и одна для сделок после
проигрышей). Таким образом, можно утверждать, что, если в сделках появляется
зависимость, вы не максимизировали систему. Зависимость, если она найдена,
надо использовать (для этого измените правила системы), пока она не исчезнет.
Первой ступенью в управлении деньгами является
использование и, следовательно, удаление любой зависимости в сделках.
Чтобы узнать о зависимости больше, прочитайте приложение С: «Подробнее о
зависимости: разворотные точки и тест длины фазы». Мы рассмотрели зависимость в
отношении торговых прибылей и убытков. Можно также поискать зависимость между
индикатором и последующей сделкой или между любыми двумя переменными. Чтобы
узнать больше об этих концепциях, посмотрите приложение В, а именно: раздел
«Биномиальное распределение», посвященный статистической оценке торговой
системы.
Обычные
ошибки в отношении зависимости
Будучи трейдерами, мы должны исходить из того, что в
большинстве рыночных систем зависимости не существует. То есть, при торговле в
данной рыночной системе, мы находимся в среде, где результат следующей сделки
не предсказуем на основе результата (результатов) предыдущих сделок. Это не значит,
что в рыночных системах никогда не бывает зависимости между сделками. Речь
идет о том, что нам следует действовать так, как будто зависимости не
существует, пока не будет убедительных доказательств обратного. Это произойдет
в случае, если счет Z и коэффициент линейной корреляции
указывают на зависимость на рынке даже с оптимизированными параметрами системы.
Если мы посчитаем, что зависимость есть, когда нет убедительных доказательств,
то обманем сами себя и не получим хороших торговых результатов. Даже если
система показала зависимость при доверительной границе 95% для всех значений
параметра, это не достаточно высокая доверительная граница, чтобы с
уверенностью говорить, что на определенном рынке или в определенной системе
зависимость между сделками существует.
Первая ошибка заключается в том, что мы можем отвергнуть
гипотезу, которую следует принять. Если, однако, мы принимаем гипотезу, когда
ее следует отвергнуть, то совершаем другую ошибку. Не зная заранее, верна или
нет гипотеза, мы должны решить, какую цену мы готовы заплатить за первую
ошибку, а какую за вторую. Иногда одна ошибка серьезнее, чем другая, и в таких
случаях мы должны решить, принимать или отвергать неподтвержденную гипотезу,
выбирая меньшее из двух зол.
Допустим, вы хотите использовать определенную торговую
систему, но не уверены, будет ли она работать при торговле в режиме реального
времени. Здесь гипотеза состоит в том, что торговая система будет хорошо
работать в режиме реального времени. Вы решаете принять гипотезу и торговать с
помощью этой системы. Если гипотеза не подтвердится, то вы совершите вторую
ошибку и заплатите за нее проигрышами. С другой стороны, если вы решите не
торговать по системе, которая на самом деле окажется прибыльной, то совершите
первую из рассмотренных нами ошибок. В этом случае цена, которую вы заплатите,
— это упущенные прибыли. Что лучше? Ясно, что упущенная прибыль. Хотя из этого
примера можно сделать вывод, что если вы собираетесь торговать по системе в режиме
реального времени, то ей, конечно, надо быть прибыльной на прошлых данных, но
есть и другой мотив для использования этого примера. Если мы допустим, что
зависимость есть, когда фактически ее нет, то совершим вторую ошибку. Цена,
которую мы заплатим, — реальный убыток. Однако если мы допустим, что
зависимости нет, а она на самом деле есть, то совершим первую ошибку и упустим
прибыль. Согласитесь, что лучше упустить прибыль, чем понести реальные убытки.
Поэтому, пока не будет убедительного доказательства зависимости, вам лучше
исходить из того, что прибыли и убытки в торговле (неважно, по механической
системе или нет) не зависят от предыдущих результатов. Здесь, как может показаться,
существует некий парадокс. Во-первых, если существует зависимость в сделках, то
система подоптимальна. Однако о зависимости никогда нельзя говорить с полной
уверенностью. Если мы будем действовать, как будто зависимость есть (когда
фактически ее нет), мы совершим более дорогостоящую ошибку, чем если бы
действовали, как будто зависимости нет (когда фактически она есть). Допустим,
что в системе с историей из 60 сделок на основе серийного теста обнаружена
зависимость с доверительным уровнем 95%. Мы хотим, чтобы наша система была
оптимальной, поэтому соответствующим образом изменяем ее правила, чтобы
использовать замеченную зависимость. Предположим, после этого у нас остается 40
сделок, и зависимости больше нет, в результате, мы приходим к выводу, что
правила системы оптимальны. Теперь при 40 сделках мы получаем более высокое
оптимальное f, чем при 60 (более подробно об оптимальном f — далее в этой главе). Если вы будете торговать по этой
системе с новыми правилами, использующими зависимость, применяя более высокое
сопутствующее оптимальное f, а зависимости на самом деле нет, то результат
будет ближе к 60 сделкам, чем к 40 сделкам, в которых были показаны лучшие
результаты. Таким образом, f, которое вы выбрали, будет сдвинуто вправо, что
выразится в потерях, которые вы понесете из-за того, что предположили
зависимость. Если зависимость присутствует, тогда вы будете ближе к пику
кривой f, допускающей, что зависимость существует. Если бы вы решили, что
зависимости нет, когда фактически она есть, то вы были бы слева от пика кривой
f, и ваша система была бы подоптимальной (но вы потеряете меньше, чем если бы
были справа от пика).
Короче говоря, ищите зависимость. Если она обнаружится с
достаточно высокой вероятностью, тогда измените правила системы, чтобы
использовать эту зависимость. В противном случае, при отсутствии убедительного
статистического доказательства зависимости, считайте, что ее не существует (и
вы понесете меньшие потери, если фактически зависимость все же существует).
Математическое
ожидание
Таким же образом, вам лучше не торговать, пока не будет
убедительных доказательств того, что рыночная система, по которой вы
собираетесь торговать, прибыльна, то есть пока вы не будете уверены, что
рыночная система имеет положительное математическое ожидание. Математическое
ожидание является суммой, которую вы можете заработать или проиграть, в
среднем, по каждой ставке. На языке азартных игроков это иногда называется «преимуществом игрока» (если оно
положительно для игрока) или «преимуществом
казино» (если оно отрицательно для игрока):
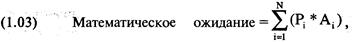
где Р = вероятность
выигрыша или проигрыша;
А = выигранная или проигранная сумма;
N = количество возможных результатов.
Математическое ожидание — это сумма произведений каждого
возможного выигрыша или проигрыша и вероятности такого выигрыша или проигрыша.
Давайте
рассмотрим математическое ожидание игры, где у вас есть 50% шансов выиграть 2
доллара и 50% шансов проиграть 1 доллар:
Математическое ожидание =
(0,5 * 2) + (0,5 * (-1)) =1+(-0.5) =0,5
В таком случае ваше математическое ожидание — выигрыш 50
центов, в среднем, забросок.
Рассмотрим ставку на один номер в рулетке. В этом случае
ваше математическое ожидание составит:
МО =((1/38)* 35)+((37/38) *(-1)) = (0,02631578947 * 35) +
(0,9736842105 * (-1)) = (0,9210526315) + (-0,9736842105) = -0,05263157903
Если вы поставите 1 доллар на номер в рулетке (американский
двойной ноль), то можете ожидать проигрыш, в среднем, 5,26 центов на один круг.
Если вы поставите 5 долларов, то можете ожидать проигрыш, в среднем, 26,3
цента
на один круг. Отметьте, что различные
ставки имеют различное математическое ожидание в денежном выражении, но в
процентном отношении от ставки оно всегда одинаково. Ожидание серии ставок
является суммой значений ожиданий отдельных ставок. Поэтому если при игре в
рулетку вы ставите 1 доллар на число, затем 10 долларов на число, затем 5
долларов на число, то вашим общим ожиданием будет:
МО = (-0,0526 * 1) + (-0,0526 *10) +
(-0,0526 *5) =0,0526 - 0,526 -
0,263 = -0,8416
Таким образом, следует ожидать проигрыш 84,16 цента. Этот
принцип объясняет, почему системы, в которых пытаются изменить размер ставок в
зависимости от того, сколько проигрышей или выигрышей было (допуская процесс
независимых испытаний), считаются проигрышными. Сумма отрицательных ожиданий
по ставкам всегда является отрицательным ожиданием!
В
отношении управления капиталом очень важно понимать, что при игре с отрицательным ожиданием нет схемы управления деньгами,
которая может сделать вас победителем. Если вы продолжаете играть, то
независимо от способа управления деньгами
вы проиграете весь ваш счет, каким бы большим он ни был в начале.
Эта аксиома верна не только для игры с отрицательным
ожиданием, она истинна также для игры с равными шансами. Поэтому единственный
случай, когда у вас есть шанс выиграть в долгосрочной перспективе, — это игра с
положительным математическим ожиданием. Кроме того, вы можете выиграть только
в двух случаях. Во-первых, при использовании ставки одинакового размера,
во-вторых, используя ставки при f, меньшем значения f, соответствующего точке, в которой среднее геометрическое HPR становится
равным или меньшим 1.
Эта аксиома истинна только при отсутствии верхнего
поглощающего барьера. Например, азартный игрок, который начинает со 100
долларов, прекратит играть, если его счет вырастет до 101 доллара. Эта верхняя
цель (101 доллар) называется поглощающим барьером. Допустим, игрок всегда
ставит 1 доллар на красный цвет рулетки. Таким образом, у него небольшое
отрицательное математическое ожидание. У игрока больше шансов увидеть, как его
счет вырастет до 101 доллара и он прекратит играть, чем то, что его счет
уменьшится до нуля, и он будет вынужден прекратить играть. Если он будет
повторять этот процесс снова и снова, то окажется в отрицательном
математическом ожидании. Если сыграть в такую игру только раз, то аксиома
неизбежного банкротства, конечно же, не применима. Различие между отрицательным
ожиданием и положительным ожиданием — это различие между жизнью и смертью. Не
имеет значения, насколько положительное или насколько отрицательное ожидание;
важно только то, положительное оно или отрицательное. Поэтому до рассмотрения
вопросов управления капиталом вы должны найти игру с положительным ожиданием.
Если у вас такой игры нет, тогда никакое управление
деньгами в мире не спасет вас.1 С другой
стороны, если у вас есть положительное ожидание, то можно, посредством
правильного управления деньгами, превратить его в функцию экспоненциального
роста. Не имеет значения, насколько мало это положительное ожидание! Другими
словами, не имеет значения, насколько прибыльна торговая система на основе 1
контракта. Если у вас есть система, которая выигрывает 10 долларов на контракт
в одной сделке (после вычета комиссионных и проскальзывания), можно
использовать методы управления капиталом таким образом, чтобы сделать ее более
прибыльной, чем систему, которая показывает среднюю прибыль 1000 долларов за
сделку (после вычета комиссионных и проскальзывания). Имеет значение не то,
насколько прибыльна ваша система была, а то, насколько определенно можно
сказать, что система покажет, по крайней мере, минимальную прибыль в будущем.
Поэтому наиболее важное приготовление, которое может сделать трейдер, — это
убедиться в том, что система покажет положительное математическое ожидание в
будущем. Для того чтобы иметь положительное математическое ожидание в будущем,
очень важно не ограничивать степени свободы вашей системы. Это достигается не
только упразднением или уменьшением количества параметров, подлежащих
оптимизации, но также и путем сокращения как можно большего количества правил
системы. Каждый параметр, который вы добавляете, каждое правило, которое вы
вносите, каждое мельчайшее изменение, которое вы делаете в системе, сокращает
число степеней свободы. В идеале, вам нужно построить достаточно примитивную и
простую систему, которая постоянно будет приносить небольшую прибыль почти на
любом рынке. И снова важно, чтобы вы поняли, — не имеет значения, насколько
прибыльна система, пока она прибыльна. Деньги, которые вы заработаете в
торговле, будут заработаны посредством эффективного управления деньгами. Торговая
система — это просто средство, которое дает вам положительное математическое
ожидание, чтобы можно было использовать управление деньгами. Системы, которые
работают (показывают, по крайней мере, минимальную прибыль) только на одном или
нескольких рынках или имеют различные правила или параметры для различных
рынков, вероятнее всего, не будут работать в режиме реального времени
достаточно долго. Проблема большинства технически ориентированных трейдеров
состоит в том, что они тратят слишком много времени и усилий на оптимизацию
различных правил и значений параметров торговой системы. Это дает совершенно
противоположные результаты. Вместо того, чтобы тратить силы и компьютерное
время на увеличение прибылей торговой системы, направьте энергию на увеличение
уровня надежности получения минимальной прибыли.
Реинвестировать
торговые прибыли или нет
Давайте назовем следующую систему «Система А». Она состоит
из 2 сделок: первая выигрывает 50%, вторая проигрывает 40%. Если мы не
реинвестируем прибыль, то выигрываем 10%, если реинвестируем, та же
последовательность сделок дает проигрыш 10%.

Теперь давайте посмотрим на систему В (выигрыш 15% и
проигрыш 5%), которая так же, как и система А, приносит 10% за 2 сделки при
отсутствии реинвестирования. Но посмотрите на результаты системы В при
реинвестировании:
в отличие
от системы А она зарабатывает деньги.

Важно понимать, что при
торговле с реинвестированием выигрышная система может превратиться в
проигрышную систему, но не наоборот! Выигрышная система превращается в
проигрышную систему при торговле с реинвестированием, если доходы недостаточно
последовательны.
Изменение порядка
или последовательности сделок не влияет на окончательный результат. Это не только верно при отсутствии реинвестирования, но и
при реинвестировании (хотя многие ошибочно полагают, что это не так).
Очевидно, что последовательность сделок не
влияет на окончательный результат, неважно, используем мы реинвестирование или
нет. Одним из плюсов при торговле на основе реинвестирования является то, что
проигрыши обычно сглаживаются. Когда система входит в период проигрышей, за
каждой проигрышной сделкой следует сделка с меньшим количеством контрактов.
На первый взгляд кажется, что лучше торговать без
реинвестирования, так как в этом случае вероятность выигрыша больше. Однако это
неправильное утверждение, так как в реальной торговле мы не забираем все
прибыли и не покрываем все наши убытки, добавляя средства на счет. Более того,
природа инвестирования или торговли основана на смешивании исходных и полученных
в результате торговли средств. Если мы не производим этого смешивания (как в
случае отсутствия реинвестирования), то не можем надеется на значительное
увеличение капитала.
Если система достаточно эффективна, то прибыли, полученные
на основе реинвестирования, будут намного больше прибылей, полученных без
инвестирования.
Изменение
степени пригодности системы для реинвестирования посредством среднего
геометрического.
До настоящего момента мы видели,
как систему можно разрушить, благодаря отсутствию стабильности от сделки к
сделке. Не означает ли это, что мы должны прекратить торговлю и положить деньги
в банк?
Теперь,
если мы действительно стремимся к последовательности, рассмотрим банковский
депозит, абсолютно стабильный инструмент (по сравнению с торговлей),
выплачивающий 1 пункт за определенный период. Назовем эту серию системой С.
Наша цель — максимизировать прибыли при торговле с реинвестированием. С этой
точки зрения наша лучшая реинвестиционная последовательность имеет место при
использовании системы В. Как выбрать наилучшую систему при наличии информации
только о торговле без реинвестирования? По проценту выигрышных сделок? По общей
сумме заработка? По средней сделке? Ответом на эти вопросы будет «нет», так как
ответив «да», мы должны торговать по системе А (и именно это решение примет
большинство фьючерсных трейдеров). Что если принять решение, исходя из
наибольшей стабильности (то есть исходя из наибольшего отношении средняя
сделка / стандартное отклонение или исходя из самого низкого стандартного
отклонении)? Как насчет самого высокого отношения риск / выигрыш или самого
низкого проигрыша? Это тоже не поможет нам с правильным ответом. Если мы будем
выбирать систему по этим признакам, то лучше положить деньги в банк и забыть о
торговле.
Система
В обладает хорошим сочетанием прибыльности и стабильности. Системы А и С не
обладают этими качествами. Вот почему система В работает лучше всего при
торговле с реинвестированием. Каков наилучший способ измерения этого «хорошего
сочетания»? Данную проблему можно решить с помощью среднего геометрического.
Это просто корень N-й степени из относительного конечного капитала (TWR), где N является количеством периодов (сделок). TWR для
этих рассматриваемых трех систем будут следующими:

Так как в
каждой такой системе по 4 сделки, то, чтобы получить среднее геометрическое,
возьмем корень четвертой степени TWR.

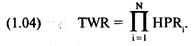
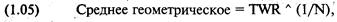
где N = общее
количество сделок;
HPR = прибыль за определенный период
(единица плюс уровень до хода,
например HPR =1,10 означает 10% прибыль за данный период, ставку или сделку);
TWR =количество долларов на конец серии периодов / ставок /
сделок на доллар первоначальной инвестиции.
Далее представлен другой способ выражения этих переменных:
(1.06) TWR = (конечное состояние счета) /
(начальное состояние счета) Среднее геометрическое (G)
равно вашему фактору роста за игру, или:
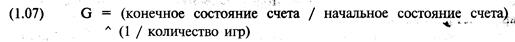
Как мы уже сказали, среднее геометрическое — это фактор
роста вашего счета за игру. Система с наибольшим средним геометрическим
является системой, которая принесет наибольшую прибыль, если торговать на
основе реинвестирования доходов. Среднее геометрическое меньше единицы
означает, что система будет терять деньги, если вы будете торговать на основе
реинвестирования.
Эффективность инвестиций часто оценивается с точки зрения
дисперсии доходов. Коэффициенты Шарпа, Трейнора, Дженсена, Вами и так далее,
пытаются соотнести эффективность инвестирования с дисперсией. Среднее
геометрическое можно рассматривать как одну из таких величин. Однако в отличие
от других коэффициентов среднее геометрическое измеряет эффективность
инвестирования по отношению к дисперсии в той же математической форме, в
которой задается баланс вашего счета.
Уравнение (1.04) можно прокомментировать следующим образом.
Если HPR = 0, то вы полностью выйдете из игры, так как все, что умножается на
ноль, равно нулю. Любая большая проигрышная сделка будет иметь самое
неблагоприятное влияние на TWR, так как эта функция мультипликативна, а не аддитивна.
Как лучше всего
реинвестировать
До этого момента речь шла о реинвестировании 100% средств
со счета. И хотя нам известно, что для максимизации потенциально прибыльной
системы мы должны реинвестировать, использование в каждой сделке 100% капитала
вряд ли разумно.
Рассмотрим
игру (50/50) с броском монеты. Предположим, вам платят 2 доллара, если вы
выигрываете, и теряете 1 доллар, если проигрываете. Математическое ожидание
составляет 0,5. Другими словами, следует ожидать выигрыша 50 центов в среднем
за бросок. Это верно для первого броска и для всех последующих бросков при
условии, что вы не увеличиваете сумму ставки. Но в процессе независимых
испытаний именно это и следует делать. Когда вы выигрываете, то должны
увеличивать ставку при каждом броске.
Допустим,
вы начинаете игру с одного доллара, выигрываете при первом броске и
зарабатываете два доллара. При следующем броске вы также ставите весь счет (3
доллара), однако на этот раз проигрываете и теряете 3 доллара. Вы проиграли
первоначальную сумму в 1 доллар и 2 доллара, которые ранее выиграли. Если вы
выигрываете при последнем броске, то зарабатываете 6 долларов, так как сделали
3 ставки по 1 доллару. Дело в том, что если вы используете 100% счета, то
выйдете из игры, как только столкнетесь с проигрышем, что является неизбежным
событием. Если бы мы могли переиграть предыдущий сценарий и вы делали бы ставки
без реинвестирования, то выиграли бы 2 доллара при первой ставке и проиграли 1
доллар при второй. Теперь ваша чистая прибыль 1 доллар, а счет равен 2
долларам. Где-то между этими двумя сценариями находится оптимальный выбор ставок
при положительном ожидании. Однако сначала мы должны рассмотреть оптимальную
стратегию ставок для игры с отрицательным ожиданием. Когда вы знаете, что игра
имеет отрицательное математическое ожидание, то лучшей ставкой будет отсутствие
ставки. Помните, что нет стратегии управления деньгами, которая может
превратить проигрышную игру в выигрышную. Однако если вы должны сделать ставку
в игре с отрицательным ожиданием, то наилучшей стратегией будет стратегия максимальной смелости. Другими
словами, вам надо сделать как можно меньше ставок (в противоположность игре с
положительным ожиданием, где следует ставить как можно чаще). Чем больше попыток,
тем больше вероятность, что при отрицательном ожидании вы проиграете. Поэтому
при отрицательном ожидании меньше возможности для проигрыша, если длина игры
укорачивается (то есть когда число попыток приближается к 1). Если вы играете в
игру, где есть шанс 49% выиграть 1 доллар и 51% проиграть 1 доллар, то лучше
всего сделать только одну попытку. Чем больше ставок вы будете делать, тем
больше вероятность, что вы проиграете (с вероятностью проигрыша,
приближающейся к уверенности, когда игра приближается к бесконечности). Это не
означает, что вы достигаете положительного ожидания при одной попытке, но вы,
по крайней мере, минимизируете вероятность проигрыша, совершая только одну
попытку. Теперь вернемся к игре с положительным ожиданием. Мы решили в начале
этой дискуссии, что в любой сделке количество контрактов, которое открывает
трейдер, определяется фактором f (число между 0 и
1), что представляет собой количество контрактов, зависящее как от
предполагаемого проигрыша
в
следующей сделке, так и от общего баланса счета. Если вы знаете, что обладаете
преимуществом при N ставках, но не знаете, какие из этих N будут выигрышами (и
на какую сумму), а какие из них будут проигрышами (и на какую сумму), то лучше
всего на большом отрезке времени рисковать одной и той же долей вашего счета.
Этот метод, основанный на использовании фиксированной доли вашего счета, и
является лучшей системой ставок. Если в ваших сделках есть зависимость, где
выигрыши порождают выигрыши, а проигрыши порождают проигрыши, или наоборот,
тогда все равно лучше ставить определенную долю вашего общего счета, но эта
доля уже не будет фиксированной. В этом случае доля счета должна отражать
действие зависимости (если вы не «отпугнули» зависимость от системы, создав системные
правила для ее использования).
«Подождите, — скажете вы. — Разве не бесполезны все эти
системы ставок? Разве они преодолевают преимущество казино? Они только
отдаляют момент полного разорения!» Это абсолютная правда для ситуации с отрицательным
математическим ожиданием. Когда ожидание положительное, трейдер/азартный игрок
стоит перед вопросом, как наилучшим образом использовать это положительное
ожидание.
Торговля оптимальной фиксированной долей
Все, о чем мы говорили выше, подготовило основу для этого
раздела. Мы теперь знаем, что перед тем, как обсуждать величину ставок на
данном рынке или в системе, надо понять, есть ли у вас положительное
математическое ожидание. Мы увидели, что так называемая «хорошая система»
(когда математическое ожидание имеет положительное значение) фактически может
быть не такой уж и хорошей при реинвестировании доходов, если реинвестировать
слишком высокий процент выигрышей по отношению к разбросу результатов системы.
Если в действительности есть положительное математическое ожидание, каким бы
маленьким оно ни было, используйте его с максимальной отдачей. При независимых
испытаниях это достигается посредством реинвестирования фиксированной доли вашего
общего счета.1
Как нам
найти это оптимальное f? В последние десятилетия азартными игроками
использовалось множество систем, самая известная и точная из которых — «Система
ставок Келли, являющаяся продолжением математической идеи, выдвинутой в начале
1956 года Джоном Л. Келли младшим.
Из
критерия Келли следует, что мы должны использовать фиксированную долю счета (f), которая максимизирует функцию роста G (f):
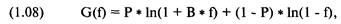
где f =
оптимальная фиксированная доля;
Р = вероятность выигрышной ставки или сделки;
В = отношение выигранной суммы по выигрышной ставке к проигранной
сумме по проигрышной ставке;
1n() = функция натурального логарифма.
Оказывается,
что для систем с двумя возможными исходами это оптимальное f можно довольно
легко найти с помощью формул Келли.
Формулы Келли
Начиная
с конца 1940-х годов, инженеры компании Bell System работали над проблемой передачи
данных по международным линиям. Проблема, стоящая перед ними, заключалась в
том, что линии были подвержены случайному, неизбежному «шуму», который мешал
передаче данных. Инженерами компании было предложено несколько довольно
оригинальных решений. Как это ни странно, наблюдались большие сходства между
проблемой передачи данных и проблемой геометрического роста, которая относится
к управлению деньгами в азартных играх (так как обе проблемы являются продуктом
случайной среды). Так появилась первая формула Келли.
Первое уравнение выглядит следующим образом:
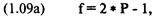
или
(1.09б) f=P-Q,
где f =
оптимальная фиксированная доля;
Р = вероятность выигрышной ставки или сделки;
Q = вероятность проигрыша (1 - Р).
Обе формы уравнения (1.09) эквивалентны.
Уравнения (1.09а) или (1.096) для оптимального f дадут
правильный ответ при условии, что выигрыши и проигрыши будут одинаковые по
величине. В качестве примера рассмотрим следующий поток ставок:
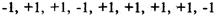
Есть 10 ставок, 6 из них выигрышных, отсюда:
f=(0,6*2)-l =1,2-1=0,2
Если
выигрыши и проигрыши не были бы одинакового размера, то эта формула не дала бы
правильного ответа. Примером служит бросок монеты в игре «два к одному», где
все выигрыши — 2 единицы, а проигрыши — 1 единица.В этом случае формула Келли
будет выглядеть следующим образом:
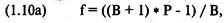
где t = оптимальная фиксированная доля;
Р = вероятность выигрышной ставки или сделки;
В = отношение выигранной суммы по выигрышной ставке к
проигранной сумме по проигрышной ставке.
В нашем примере с броском монеты в игре «два к одному»:
f=((2+l)*0,5-1)/2 =(3*0,5-1)/2 =0,5/2 = 0,25
Эта формула даст правильный ответ для оптимального f при
условии, что все выигрыши между собой всегда одинаковы и все проигрыши между
собой всегда одинаковы. Если это не так, формула не даст правильного ответа.
Формулы Келли
применимы только к результатам, которые имеют распределение Бернулли (распределение с двумя возможными исходами). Торговля, к
сожалению, не так проста. Применение формул Келли к иному распределению
является ошибкой и не даст нам оптимального f.
Более подробно о распределении Бернулли рассказано в приложении В.
Поиск
оптимального f с помощью
среднего геометрического.
В
реальной торговле размер проигрышей и выигрышей будут постоянно меняться.
Поэтому формулы Келли не могут дать нам правильное оптимальное f. Как корректно с математической точки зрения найти
оптимальное f, которое позволит нам определить количество контрактов
для торговли? Попытаемся ответить на этот вопрос. Для начала мы должны изменить
формулу для поиска HPR, включив в нее f:
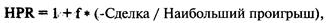
где
-Сделка= прибыль или убыток в этой сделке (с противоположным знаком,
чтобы убыток стал положительным числом, а прибыль — отрицательным);
Наибольший проигрыш = наибольший убыток за сделку (это
всегда отрицательное число).
TWR — это произведение всех HPR, а среднее геометрическое (G) — это корень N-й степени TWR.
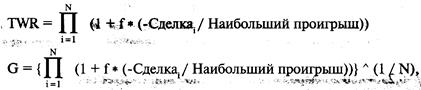
где -
Сделкаi = прибыль или убыток по сделке i
(с противоположным знаком, чтобы убыток был положительным числом, а прибыль —
отрицательным);
Наибольший проигрыш = результат сделки, которая дала
наибольший убыток (это всегда должно быть отрицательное число);
N = общее количество сделок;
G = среднее геометрическое HPR.
Просмотрев
значения/от 0,01 до 1, мы найдем/, которое даст наивысшее TWR. Это значение f позволит получить максимальную прибыль при
торговле фиксированной долей. Мы можем также сказать, что оптимальное f
позволяет получить наивысшее среднее геометрическое. Не имеет значения, что мы
ищем: наивысшее TWR или среднее геометрическое, так как обе величины
максимальны при одном и том же значении f.
Описанную выше процедуру достаточно легко осуществить с
помощью компьютера, перебирая f от 0,01 до 1,00. Как только вы получите TWR,
которое меньше предыдущего, то знайте, что f, относящееся к предыдущему TWR, является
оптимальным f, поскольку графики TWR
и среднего геометрического имеют один пик. Чтобы облегчить процесс поиска
оптимального f диапазоне от 0 до 1, можно использовать разные алгоритмы.
Один из самых быстрых способов расчета оптимального f — это метод
параболической интерполяции, который детально описан в книге «Формулы
управления портфелем».
Мы увидели, что лучшей торговой системой является система с
наивысшим средним геометрическим. Для расчета среднего геометрического необходимо
знать f. Итак, давайте поэтапно опишем наши действия.
1.
Возьмите историю сделок в данной рыночной системе.
2. Найдите оптимальное f, просмотрев различные значения f
от 0 до 1. Оптимальное f соответствует наивысшему значению TWR.
3. После того, как вы найдете f, возьмите корень N-й
степени TWR (N — общее количество сделок). Это и
есть ваше среднее геометрическое для данной рыночной системы. Теперь можно
использовать полученное среднее геометрическое, чтобы сравнивать эту систему с
другими. Значение f подскажет вам, сколькими контрактами торговать в данной
рыночной системе. После того, как найдено
f, его можно перевести в денежный эквивалент, разделив наибольший проигрыш на
отрицательное оптимальное/. Например, если наибольший проигрыш равен 100
долларам, а оптимальное f = 0,25, тогда -100 долларов / -0,25 = 400 долларов.
Другими словами, следует ставить 1 единицу на каждые 400 долларов счета. Для
простоты можно все рассчитывать на основе единиц (например одна 5-долларовая
фишка или один фьючерсный контракт, или 100 акций). Количество долларов,
которое следует отвести под каждую единицу, можно рассчитать, разделив ваш
наибольший убыток на отрицательное оптимальное f. Оптимальное f — это результат равновесия прибыльности системы (на основе
1 единицы) и ее риска (на основе 1 единицы). Многие думают, что оптимальная
фиксированная доля — это процент счета, который отводится под ваши ставки. Это
совершенно неверно. Должен быть еще один шаг. Оптимальное f само по себе
не является процентом вашего счета, который отводится под торговлю, это делитель
наибольшего проигрыша. Частным этого деления является величина, на которую
надо разделить общий счет, чтобы выяснить, сколько ставок сделать или сколько
контрактов открыть на рынке.
Необходимо отметить, что залог под открытые позиции не имеет ничего общего с тем, какое
математически оптимальное количество контрактов надо открывать. Залог не
так важен, поскольку размеры отдельных прибылей и убытков не являются продуктом
залоговых средств. Прибыли и убытки зависят от выигрыша и убытка в расчете на
одну открытую единицу (один фьючерсный контракт). Для управления деньгами залог
не имеет значения, так как размер убытка не ограничивается только залоговыми
средствами. Многие ошибочно полагают, что f является линейной функцией, и чем
большей суммой рисковать, тем больше можно выиграть, так как по мнению
сторонников такого подхода положительное математическое ожидание является зеркальным
отражением отрицательного ожидания, то есть если увеличение общего оборота в
игре с отрицательным ожиданием в результате приносит более быстрый проигрыш,
то увеличение общего оборота в игре с положительным ожиданием в результате
принесет более быстрый выигрыш. Это неправильно. В некоторой точке в ситуации с
положительным ожиданием дальнейшее увеличение общего оборота работает против
вас. Эта точка является функцией как прибыльности системы, так и ее
стабильности (то есть ее средним геометрическим), так как вы реинвестируете
прибыли обратно в систему. Когда два человека сталкиваются с одной и той же
последовательностью благоприятных ставок или сделок, и один использует
оптимальное f, а другой использует любую другую систему управления
деньгами, математическим фактом является то, что отношение счета держащего пари
на основе оптимального f к счету другого человека будет увеличиваться с течением
времени с все более высокой вероятностью. Через бесконечно долгое время
держащий пари на основе оптимального f будет иметь бесконечно большее состояние,
чем его оппонент, использующий любую другую систему управления деньгами, с
вероятностью, приближающейся к 1. Более того, если участник пари ставит своей
целью достижение определенного капитала, и он стоит перед серией благоприятных
ставок или сделок, то ожидаемое время достижения этой цели будет короче с
оптимальным f, чем с любой другой системой ставок.
Давайте
вернемся и рассмотрим последовательность ставок (сделок):
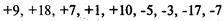
Мы уже знаем, что формула Келли не применима к этой
последовательности, так как величины выигрышей и проигрышей отличаются. Ранее в
этой главе мы усреднили выигрыши и проигрыши и использовали эти средние
значения в формуле Келли (так ошибочно поступают многие трейдеры). В
результате, мы получили значение f= 0,16. Было
отмечено, что применение формулы Келли в данном случае некорректно и не дает нам
оптимального f. Формула Келли работает только при постоянных выигрышах и
проигрышах. Вы не можете усреднить торговые выигрыши и проигрыши и получить
истинное оптимальное f, используя формулы Келли. Наибольшее значение TWR при такой последовательности ставок (сделок) достигается
при 0,24 (т.е. 1 доллар на каждые 71 доллар на счете). Это оптимальный
геометрический рост, которого можно достичь при данной последовательности
ставок (сделок) при торговле фиксированной долей. Давайте посмотрим, как
меняется TWR при повторении этой последовательности ставок от 1 до 100 при f =
0,16 и f = 0,24. Мы видим, что использование значения f, которое ошибочно
получено из формулы Келли, дало только 37,5% дохода, полученного при
оптимальном f = 0,24 после 900 ставок или сделок (100 циклов из серий по 9
сделок). Другими словами, оптимальное f= 0,24,
которое только на 0,08 отличается от 0,16 (смещено от оптимального на 50%),
принесло почти на 167% прибыли больше, чем f = 0,16 за 900 ставок!
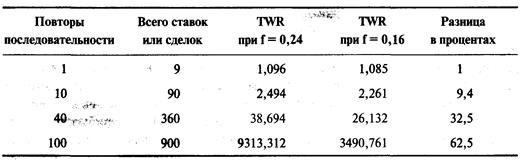
Давайте повторим эту последовательность сделок еще 11 раз,
чтобы в общей сложности получить 999 сделок. Теперь TWR
для f=0,16 составляет 8563,302 (даже меньше, чем при f= 0,24 за 900 сделок), а TWR для f==0,24
составляет 25451,045. При 999 сделках эффективность при f= 0,16 составляет только 33,6% от f=
0,24, то есть прибыль при f== 0,24 на 197%
больше, чем при f= 0,16!
Как видите, использование оптимального f не дает большого
преимущества на коротком временном отрезке, но с течением времени оптимальное f
оказывает все большее влияние. Дело в том, что при торговле с оптимальным f
надо дать программе время, а не ждать чуда на следующий день. Чем больше
времени (то есть ставок или сделок) проходит, тем больше становится разница
между стратегией оптимального f и любой другой стратегией управления деньгами.
Средняя
геометрическая сделка
Трейдеру может быть интересно рассчитать свою среднюю
геометрическую сделку (то есть среднюю прибыль, полученную на контракт за
сделку), допуская, что прибыли реинвестируются, и торговать можно дробными
контрактами. Это и есть математическое ожидание, когда торговля ведется на
основе фиксированной доли. В
действительности это приблизительный доход системы за сделку при использовании
фиксированной доли счета. (На самом деле средняя геометрическая сделка
является математическим ожиданием в долларах на контракт за сделку. Вычитая из
среднего геометрического единицу, вы получите математическое ожидание. Среднее
геометрическое 1,025 соответствует математическому ожиданию в 2,5% за сделку).
Многие трейдеры смотрят только на среднюю сделку рыночной системы, чтобы
понять, стоит ли торговать по этой системе. Однако при принятии решения следует
обращать внимание именно на среднюю геометрическую сделку (GAT).
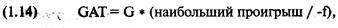
где G = среднее
геометрическое - 1;
f = оптимальная фиксированная доля.
(Разумеется, наибольший убыток всегда будет отрицательным
числом).
Допустим,
что система имеет среднее геометрическое 1,017238, наибольший проигрыш
составляет 8000 долларов и оптимальное f
= 0,31. Наша геометрическая средняя сделка будет равна:
GAT = (1,017238 - 1) * (-$8 000 /-0,31) = 0,017238 * $25
806,45= $444,85
Почему необходимо
знать оптимальное f вашей системы
График на рисунке 1-6 еще раз демонстрирует важность
использования оптимального f в торговле фиксированной долей. Вспомните f для игры с
броском монеты 2:1 (рисунок 1-1).
Давайте увеличим выигрыш с 2 до 5 единиц (рисунок 1-6). В
этом случае оптимальное f = 0,4, то есть ставка в 1 доллар на каждые 2,50
доллара на счете. После 20 последовательностей +5,-1 (40 ставок) ваш счет в
2,50 доллара вырастет до 127,482 доллара, и все благодаря оптимальному f.
Теперь посмотрим, что произойдет, если вы ошибетесь с оптимальным f на 0,2. При значениях f= 0,6 и f= 0,2 вы не
заработаете даже десятой части того, что заработаете при 0,4. Эта ситуация
(50/50, 5 к 1) имеет математическое ожидание (5 * 0,5) + (1 * (-0,5)) = 2,
однако если вы будете делать ставки, используя значение f больше 0,8, то
потеряете деньги.
Здесь надо отметить два момента. Первый состоит в том, что
когда мы обсуждаем TWR, то допускаем использование дробных
контрактов. Например, вы можете торговать 5,4789 контрактами, если именно это
требуется в какой-либо момент. Расчет TWR допускает дробные контракты, чтобы
его значение всегда было одинаково для данного набора торговых результатов вне
зависимости от их последовательности. Вы можете усомниться в правильности
такого подхода, поскольку при реальной торговле это невыполнимо. В реальной
жизни вы не можете торговать дробными контрактами. Этот аргумент правильный.
Однако мы оставим подобный расчет TWR, потому что таким образом мы представим
средний TWR для всех возможных начальных счетов. Если вы хотите, чтобы размеры
всех ставок были целыми числами, тогда становится важна величина начального
счета. Однако если бы вы должны были усреднить TWR со всех значений возможных
начальных счетов, используя только ставки в целых числах, то достигли бы того
же значения TWR, которое мы рассчитали при дробных ставках. Поэтому значение
TWR, которое рассчитано здесь, более реально, чем то, которое мы рассчитывали
бы при ставках в целых числах, так как оно представляет огромное количество
результатов с различными начальными счетами. Разумеется, чем выше баланс счета,
тем ближе будут результаты торговли целыми и дробными контрактами. Пределом
здесь является счет с бесконечным капиталом, где ставка в целых числах и
дробная ставка в точности равны.
Таким образом, чем ближе вы находитесь к оптимальному f, тем лучше. Также можно сказать, что чем больше счет, тем
больше будет эффект от оптимального f. Так как оптимальное f позволяет счету
расти с максимально возможной скоростью, мы можем заявить, что оптимальное f
будет работать все лучше и лучше при увеличении вашего счета.
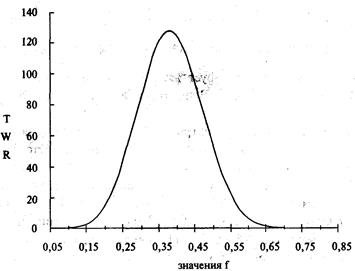
Рисунок
1-6 20 последовательностей +5, -1
Графики (рисунки 1-1 и 1-6) имеют несколько других
интересных особенностей. Во-первых, ни
при какой другой фиксированной доле вы не заработаете больше денег, чем при
оптимальном/. Другими словами, в предыдущем примере с игрой 5:1 не стоит
ставить, например, 1 доллар на каждые 2 доллара на счете. Вы заработаете
больше, если будете ставить 1 доллар на каждые 2,50 доллара на счете. Не стоит рисковать больше, чем позволяет
оптимальное/, — это может дорого обойтись.
Очевидно, что чем больше капитализация счета, тем более
точно вы сможете придерживаться оптимального f, так как сумма в долларах,
требуемая под один контракт, составит меньший процент от общего баланса.
Допустим, что оптимальное f для данной рыночной системы соответствует 1
контракту на каждые 5000 долларов на счете. Если счет равен 10 000 долларов,
то надо будет выиграть (или проиграть) 50% до того момента, когда изменение
количества контрактов для текущей торговли станет возможным. Сравните это со
счетом в 500 000 долларов, где надо будет регулировать количество контрактов
после изменения баланса в 1%. Ясно, что при большом счете можно лучше
воспользоваться плюсами, предоставляемыми оптимальным f,
чем при меньшем счете. Теоретически оптимальное f
допускает, что вы можете торговать бесконечно делимыми частями, чего в реальной
жизни не бывает, где наименьшим количеством, которым вы можете торговать,
является один контракт. В асимптотическом смысле это не имеет значения. Но в
реальной жизни со ставками в целых числах в торговую систему необходимо ввести
такой вариант, который потребует настолько малый процент баланса счета,
насколько только возможно, особенно для небольших счетов. Помните, что сумма,
требуемая для открытия контракта, в реальной торговле больше первоначальных
залоговых требований и суммы, отводимой под контракт оптимальным f.
Чем чаще вы сможете изменять размер позиций для
соответствия оптимальному f, тем лучше, поэтому имеет смысл торговать на
рынках с недорогими контрактами. Кукуруза может показаться не таким интересным
рынком, как S&P. Однако для некоторых трейдеров
рынок кукурузы может стать чрезвычайно волнующим, если они будут открывать на
нем несколько сотен контрактов.
Трейдеры, торгующие акциями или форвардными контрактами
(например на рынке форекс), имеют огромное преимущество. Так как следует
рассчитывать оптимальное f из финансовых результатов (P&Ls) на основе 1 контракта (1 единицы), то надо сначала
решить, какой будет 1 единица в акциях или в валюте. Например, трейдер с
фондового рынка может выбрать в качестве 1 единицы 100 акций. Для определения
оптимального Гон будет использовать поток P&L, созданный торговлей 100 акциями. Если система торговли
потребует использовать 2,39 контракта или единицы, то это будет выполнимо.
Таким образом, имея возможность торговать дробной частью 1 единицы, вы можете
эффективнее воспользоваться преимуществом оптимального f. Таким же образом
надо поступать и трейдерам с рынка форекс, которые должны сначала решить, каким
будет 1 контракт или единица. Для трейдера с рынка форекс 1 единицей может
быть, например, один миллион долларов США или один миллион швейцарских франков.
Насколько может
быть серьезен проигрыш
Здесь важно отметить, что проигрыш, который может произойти
при торговле фиксированной долей (в процентах от вашего счета), исторически
может быть такой же, как f. Другими словами, если f равно 0,55, то проигрыш
может составить 55% от вашего баланса. Если вы торгуете с оптимальным f, то
ваш наибольший проигрыш будет эквивалентен f. Допустим, что f для системы
составляет 0,55; при торговле 1 контрактом на каждые 10 000 долларов это
означает, что вашим наибольшим убытком будет 5500 долларов. Когда вы
встречаете наибольший проигрыш (снова мы говорим о том, что может произойти),
можно потерять 5500 долларов по каждому открытому контракту, и если у вас 1 контракт
на каждые 10 000 долларов на счете, то в этой точке проигрыш составит 55%
вашего баланса. Более того, полоса проигрышей может продолжиться: следующая
сделка или серия сделок могут уменьшить счет еще больше. Чем лучше
система,
тем выше f. Чем выше f, тем больше
возможный проигрыш, так как максимальный проигрыш (в процентах) не меньше f.
Парадокс ситуации заключается в том, что если система способна создать
достаточно высокое оптимальное f, тогда проигрыш для такой системы также будет
достаточно высоким. С одной стороны, оптимальное f позволяет вам получить
наибольший геометрический рост, с другой стороны, оно создает для вас ловушку,
в которую можно легко попасться.
Мы знаем, что если при торговле фиксированной долей
использовать оптимальное f, то можно ожидать значительных проигрышей (в
процентах от баланса). Оптимальное f подобно плутонию — оно дает огромную
силу, однако и чрезвычайно опасно. Эти значительные проигрыши — большая
проблема, особенно для новичков, потому что торговля на уровне оптимального f
создает опасность получить огромный проигрыш быстрее, чем при обычной торговле.
Диверсификация может сильно сгладить проигрыш. Плюсом диверсификации является то, что она позволяет делать много
попыток (проводить много игр) одновременно, тем самым увеличивая общую прибыль.
Справедливости ради следует отметить, что диверсификация, хотя обычно она и
является лучшим способом для сглаживания проигрышей, не обязательно уменьшает
их и в некоторых случаях может даже увеличить убытки!
Существует ошибочное представление, что проигрышей можно
полностью избежать, если провести достаточно эффективную диверсификацию. До некоторой
степени верно, что проигрыши можно смягчить посредством эффективной
диверсификации, но их никогда нельзя полностью исключить. Не вводите себя в
заблуждение. Не имеет значения, насколько хороша применяемая система, не имеет
значения, как эффективно вы проводите диверсификацию, вы все равно будете
сталкиваться со значительными проигрышами. Причина этого не во взаимной
корреляции ваших рыночных систем, поскольку бывают периоды, когда большинство
или все рыночные системы портфеля работают против вас, когда, по вашему мнению,
этого не должно происходить. Попробуйте найти портфель с пятилетними
историческими данными, чтобы все торговые системы работали бы при оптимальном f
и при этом максимальный убыток был бы менее 30%! Это будет непросто. Не имеет
значения, сколько при этом рыночных систем используется. Если вы хотите все
сделать математически правильно, то надо быть готовым к проигрышу от 30 до 95%
от баланса счета. Необходима строжайшая дисциплина, и далеко не все могут ее
соблюдать.
Как только трейдер отказывается от торговли постоянным
количеством контрактов, он сталкивается с проблемой, каким количеством
торговать. Это происходит всегда независимо от того, признает трейдер данную
проблему или нет. Торговля постоянным количеством контрактов не является
решением, так как таким образом никогда нельзя добиться геометрического роста.
Поэтому, нравится вам это или нет, вопрос о том, каким количеством торговать в
следующей сделке, будет неизбежен для всех. Простой выбор случайного количества
может привести к серьезной ошибке. Оптимальное f
является единственным математически верным решением.
Современная
теория портфеля
Вспомните ситуацию с оптимальным f и проигрышем рыночной
системы. Чем лучше рыночная система, тем выше значение f. Однако если вы
торгуете с оптимальным f, проигрыш (исторически) никогда не может быть меньше
f. Вообще говоря, чем лучше рыночная система, тем больше будут промежуточные
проигрыши (в процентах от баланса счета), если торговать при оптимальном f.
Таким образом, если вы хотите достичь наибольшего геометрического роста, то
должны быть готовы к серьезным проигрышам на своем пути.
Эффективная
диверсификация, путем включения в портфель других рыночных систем, является
лучшим способом, которым можно смягчить этот проигрыш и преодолеть его, все
еще оставаясь близко к пику кривой f (то есть не уменьшая f, скажем, до f/2). Когда одна рыночная система приносит убыток, другая
приносит прибыль, тем самым смягчая проигрыш первой. Это также оказывает
большое влияние на весь счет. Рыночная система, которая только что испытала
проигрыш (и теперь возвращается к хорошей работе), будет иметь не меньше
средств, чем до убытка (благодаря тому, что другая рыночная система аннулировала
проигрыш). Диверсификация не будет сдерживать прирост системы (наоборот,
движение вверх будет быстрее, так как после проигрыша вы не начнете с меньшего
числа контрактов), при этом она смягчает понижение баланса (но только до очень
ограниченной степени). Можно рассчитать оптимальный портфель, состоящий из
различных рыночных систем с соответствующими оптимальными f. Хотя мы не можем
быть полностью уверены, что оптимальный в прошлом портфель будет оптимальным и
в будущем, это все же более вероятно, чем то, что прошлые оптимальные параметры
системы будут оптимальными или приблизительно оптимальными в будущем. В то
время как оптимальные параметры системы с течением времени меняются довольно
быстро, веса отдельных систем в оптимальном портфеле меняются очень медленно
(как и значения оптимальных f). Вообще, корреляция между рыночными системами
достаточно стабильна. Эта новость будет еще более приятна для трейдера, если он
уже нашел такой оптимально смешанный портфель.
Модель Марковица
Основные концепции современной теории портфеля изложены в
монографии, написанной доктором Гарри Марковицем. Первоначально Марковиц предположил,
что управление портфелем является проблемой структурного, а не индивидуального
выбора акций, что обычно практикуется. Марковиц доказывал, что диверсификация эффективна только тогда, когда корреляция между
включенными в портфель рынками имеет отрицательное значение. Если у нас есть
портфель, составленный из одного вида акций, то наилучшая диверсификация достигается
в том случае, если мы выберем другой вид акций, которые имеют минимально
возможную корреляцию с ценой первой акции. В результате этого. портфель в целом
(если он состоит из этих двух видов акций с отрицательной корреляцией) будет
иметь меньшую дисперсию, чем любой вид акций, взятый отдельно. Марковиц
предположил, что инвесторы действуют рациональным способои и при наличии выбора
предпочитают портфель с меньшим риском при равном уровне прибыльности или выбирают
портфель с большей прибылью, при одинаковом риске. Далее Марковиц утверждает,
что для данного уровня риска есть оптимальный портфель с наивысшей
доходностью, и таким же образом для данного уровня доходности есть оптимальный
портфель с наименьшим риском. Портфель, доходность которого может быть
увеличена без сопутствующего увеличения риска или портфель, риск которого
можно уменьшить без сопутствующего уменьшения доходности, согласно Марковицу, неэффективны.
Рисунок
1-7 показывает все имеющиеся портфели, рассматриваемые в данном примере. Если у
вас портфель С, то лучше заменить его на портфель А, где прибыль такая же, но
с меньшим риском, или на портфель В, где вы получите большую прибыль при том
же риске. Описывая эту ситуацию, Марковиц ввел понятие «эффективная граница» (efficient frontier). Это набор
портфелей, которые находятся в верхней левой части графика, то есть портфели,
прибыль которых больше не может быть увеличена без увеличения риска, и риск
которых не может быть уменьшен без уменьшения прибыли. Портфели, находящиеся
на эффективной границе, называются эффективными
портфелями (см. Рисунок 1-8). Портфели, которые находятся вверху справа и внизу
слева, в целом недостаточно диверсифицированы по сравнению с другими
портфелями. Те же портфели, которые находятся в середине эффективной границы,
обычно очень хорошо диверсифицированы. Выбор портфеля инвестором зависит от
степени неприятия риска инвестором — иначе говоря, от желания взять на себя
риск. В модели Марковица любой портфель, который находится на эффективной
границе, является хорошим выбором, но какой именно портфель выберет инвестор —
это вопрос личного предпочтения (позднее мы увидим, что есть точное оптимальное
расположение портфеля на эффективной границе для всех инвесторов).
Модель
Марковица первоначально была представлена для портфеля акций, который инвестор
будет держать достаточно долго. Поэтому основными входными данными были
ожидаемые доходы по акциям (определяется как ожидаемый прирост цены акции плюс
дивиденды), ожидаемые дисперсии этих доходов и корреляции доходов между
различными акциями. Если бы мы
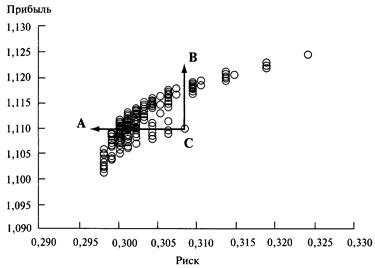
Рисунок 1-7 Современная теория портфеля
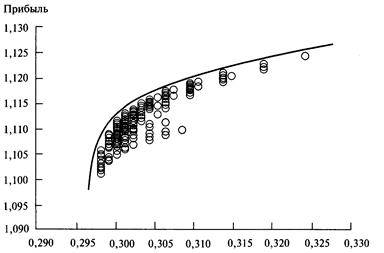
Рисунок
1-8 Эффективная граница
перенесли
эту концепцию на фьючерсы, то было бы разумным (так как по фьючерсам не
выплачивают дивидендов) измерять ожидаемое повышение цены, дисперсию и
корреляции различных фьючерсов. Возникает вопрос: «Если мы измеряем корреляцию
цен, то что произойдет при включении в портфель двух систем с отрицательной
корреляцией, работающих на одном и том же рынке?» Допустим, у нас есть системы
А и В с отрицательной корреляцией. Когда А в проигрыше, В в выигрыше, и
наоборот. Разве это не идеальная диверсификация? Действительно, мы хотим измерить не корреляции цен рынков, на
которых работаем, а корреляции изменений ежедневных балансов различных рыночных
систем. И все-таки это является сравнением яблок и апельсинов. Скажем, две
рыночные системы, корреляции которых мы собираемся измерить, работают на одном
и том же рынке, и одна из систем имеет оптимальное f,
соответствующее 1 контракту на каждые 2000 долларов на счете, а другая система
имеет оптимальное f, соответствующее 1 контракту на каждые 10 000 долларов на
счете. Чтобы понять суть торговли фиксированной долей в портфеле из нескольких
систем, мы переведем изменения ежедневного баланса для данной рыночной системы
в ежедневные HPR. HPR в этом контексте означает, сколько
заработано или проиграно в данный день на основе 1 контракта в зависимости от
оптимального f для этой
системы. Рассмотрим пример. Скажем, рыночная система с оптимальным f в 2000
долларов за день заработала 100 долларов. Тогда HPR для этой рыночной системы
составит 1,05. Дневное HPR можно найти следующим образом:

где А =
сумма в долларах, выигранная или проигранная
за этот день;
В = оптимальное f в долларах.
Для рассматриваемых рыночных систем преобразуем дневные
выигрыши и проигрыши в дневные HPR, тогда мы получим значение, не зависящее от
количества контрактов. В указанном примере, где дневное HPR составляет 1,05, вы
выиграли 5%. Эти 5% не зависят от того, был у вас 1 контракт или 1000
контрактов. Теперь можно сравнивать разные портфели. Мы будем сравнивать все
возможные комбинации портфелей, начиная с портфелей, состоящих из одной
рыночной системы (для каждой рассматриваемой рыночной системы), заканчивая
портфелями из N рыночных систем. В качестве примера рассмотрим рыночные системы
А, В и С, их комбинации будут выглядеть следующим образом:
А
В
С
АВ
АС
ВС
АВС
Но не будем останавливаться на этом. Для каждой комбинации
рассчитаем веса рыночных систем в портфеле. Для этого необходимо задать
минимальный процентный вес системы (или минимальное изменение веса). В
следующем примере (портфель из систем А, В, С) этот минимальный вес системы
равен 10% (0,10):
|
А
|
100%
|
|
|
В
|
100%
|
|
|
С
|
100%
|
|
|
АВ
|
90%
|
10%
|
|
|
80%
70%
|
20% 30%
|
|
|
60%
|
40%
|
|
|
50%
|
50%
|
|
|
40%
|
60%
|
|
|
30%
|
70%
|
|
|
20%
|
80%
|
|
|
10%
|
90%
|
|
АС
|
90%
|
10%
|
|
|
80%
|
20%
|
|
|
70%
|
30%
|
|
|
60%
|
40%
|
|
|
50%
|
50%
|
|
|
40%
|
60%
|
|
|
30%
|
70%
|
|
|
20%
|
80%
|
|
|
10%
|
90%
|
|
ВС
|
90%
|
10%
|
|
|
80%
|
20%
|
|
|
70%
|
30%
|
|
|
|
60%
|
40%
|
|
|
|
50%
|
50%
|
|
|
|
40%
|
60%
|
|
|
|
30%
|
70%
|
|
|
|
20%
|
80%
|
|
|
|
10%
|
90%
|
|
|
АВС
|
80%
|
10%
|
10%
|
|
|
70%
|
20%
|
10%
|
|
|
70%
|
10%
|
20%
|
|
|
10%
|
30%
|
60%
|
|
|
10%
|
20%
|
70%
|
|
|
10%
|
10%
|
80%
|
Введем понятие КСП (комбинация систем в портфеле). Теперь
для каждой КСП рассчитаем совокупное HPR для отдельного
дня. Совокупное HPR для данного дня будет суммой HPR
каждой рыночной системы для этого дня, умноженных на процентные веса систем.
Например, для систем А, В и С мы рассматриваем процентные веса 10%, 50%, 40%
соответственно. Далее допустим, что отдельные HPR для этих рыночных систем в
тот день были 0,9, 1,4 и 1,05 соответственно. Тогда совокупное HPR для этого
дня будет:
Совокупное HPR = (0,9 *
0,1) + (1,4 * 0,5) + (1,05 * 0,4) = 0,09 + 0,7 + 0,42 =1,21
Теперь нанесем дневные HPR для каждой КСП на ось Y В модели Марковица это соответствует получаемому доходу.
На оси Х отложим стандартное отклонение дневных HPR для каждой КСП. В модели
Марковица это соответствует риску. Современную теорию портфеля часто называют Теорией Е -V, что соответствует
названиям осей. Вертикальную ось часто называют Е — ожидаемая прибыль (expected return), а
горизонтальную ось называют V — дисперсия ожидаемой прибыли (variance in expected returns). После этого
можно найти эффективную границу. Мы включили различные рынки, системы и факторы
f и теперь можем количественно
определить лучшие КСП (то есть КСП, которые находятся вдоль эффективной
границы).
Стратегия среднего геометрического портфеля
В какой
именно точке на эффективной границе вы будете находиться (то есть какова
эффективная КСП), является функцией вашего собственного неприятия риска, по
крайней мере, в соответствии с моделью Марковица. Однако есть оптимальная
точка на эффективной границе, и с помощью математических методов можно найти
эту точку. Если вы выберете КСП с наивысшим средним геометрическим HPR, то достигнете оптимальной КСП! Мы можем рассчитать
среднее геометрическое из среднего арифметического HPR и стандартного
отклонения HPR (обе эти величины у нас уже есть, так как они являются осями Х и
Y модели Марковица!) Уравнения (1.16а) и (1.166) дают нам
формулу для оценочного среднего геометрического EGM
(estimated geometric mean). Данный расчет очень близок (обычно до четвертого или
пятого знака после запятой) к реальному среднему геометрическому, поэтому можно
использовать оценочное среднее геометрическое вместо реального среднего
геометрического.
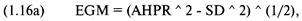
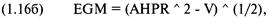
где EGM ==
оценочное среднее геометрическое;
AHPR = среднее арифметическое HPR, или координата, соответствующая доходу по портфелю;
SD = стандартное отклонение HPR, или координата, соответствующая риску по портфелю;
V =
дисперсия HPR, равная SD ^ 2. Обе формы
уравнения (1.16) эквивалентны.
При КСП с
наивысшим средним геометрическим рост стоимости портфеля будет максимальным;
более того, данная КСП позволит достичь определенного уровня баланса за
минимальное время.
Ежедневные
процедуры при использовании оптимальных портфелей
Посмотрим
на примере, как применять вышеописанный подход на ежедневной основе. Допустим,
что оптимальное КСП соответствует трем различным рыночным системам.
Предположим, что процент размещения составляет 10%, 50% и 40%. Если бы вы
рассматривали счет в 50 000 долларов, то он был бы «разделен» на три субсчета в
5000, 25 000 и 20 000 долларов для каждой рыночной системы (А, В и С)
соответственно. Затем для баланса по субсчету каждой рыночной системы
вычислите, сколькими контрактами торговать. Скажем, фактор f дал следующие
величины:
Рыночная система А: 1 контракт на $5000 баланса счета.
Рыночная система В: 1 контракт на $2500 баланса счета.
Рыночная система С: 1 контракт на $2000 баланса счета.
Тогда вы будете торговать 1 контрактом для рыночной системы
А ($5000 / $5000), 10 контрактами для рыночной системы В ($25 000 / $2500) и 10
контрактами для рыночной системы С ($20 000 / $2000). Каждый день, когда общий
баланс счета изменяется, все субсчета перерассчитываются. Допустим, что счет в
50 000 долларов на следующий день понизился до 45000 долларов. Так как мы
каждый день заново перераспределяем средства по субсчетам, то получаем 4500
долларов для рыночной системы А, 22 500 долларов для рыночной системы В, и 18
000 долларов для рыночной системы субсчета С. На следующий день мы будем
торговать нулевым количеством контрактов по рыночной системе А ($4500 / $5000
= 0,9, или, так как мы всегда основываемся на целых числах, 0), 9 контрактами
для рыночной системы В ($22 500 / $2500), и 9 контрактами для рыночной системы
С ($18 000 / $2000). Перерассчитывайте субсчета ежедневно, независимо от того,
что вы получили: прибыль или убыток. Помните, субсчета, использованные здесь,
являются условной конструкцией.
Есть
более простой для понимания способ, дающий те же самые ответы, — деление
оптимального f рыночной системы на ее процентный вес. Это даст сумму в
долларах, на которую мы затем разделим общий баланс счета, чтобы узнать,
сколькими контрактами торговать. Так как баланс счета изменяется ежедневно, мы
перерассчитываем субсчета также ежедневно для получения нового общего баланса
счета. В рассмотренном примере рыночная система А, при значении f в 1 контракт
на 5000 долларов баланса счета и процентном весе 10%, соответствует 1
контракту на 50 000 долларов общего баланса счета ($5000 / 0,10). Рыночная
система В, при значении ib 1
контракт на 2500 долларов баланса счета и процентном весе 50%, соответствует 1
контракту на 5000 долларов общего баланса счета ($2500 / 0,50). Рыночная
система С, при значении ib 1
контракт на 2000 долларов баланса счета и процентном весе 40%, соответствует 1
контракту на 5000 долларов общего баланса счета ($2000 / 0,40). Таким образом,
если бы у нас было 50 000 долларов на счете, мы бы торговали 1 контрактом в
рыночной системе А, 10 контрактами в рыночной системе В и 10 контрактами в
рыночной системе С. На следующий день процедура повторяется. Скажем, наш общий
баланс счета повысился до 59 000 долларов. В этом случае разделим 59 000
долларов на 50 000 долларов и получим 1,18 (или округляя до целого числа 1),
поэтому завтра мы бы торговали 1 контрактом в рыночной системе А, 11
контрактами ($59 000 / $5000 =11,8, что ближе к целому числу 11) в рыночной
системе В и 11 контрактами в рыночной системе С. Предположим, в рыночной
системе С со вчерашнего дня у нас открыта длинная позиция на 10 контрактов.
Нам не следует добавлять сегодня до 11 контрактов. Суммы, которые мы
рассчитываем с использованием баланса, рассчитываются только для новь1х
позиций. Поэтому завтра (если было открыто 10 контрактов, но мы закрыли
позицию, т.е. зафиксировали прибыль) нам следует открыть 11 контрактов, если мы
посчитаем это целесообразным. Расчет оптимального портфеля с использованием
ежедневных HPR означает, что нам следует
входить на рынок и изменять позиции на ежедневной основе, а не от сделки к
сделке; но это не обязательно делать, если вы будете торговать по долгосрочной
системе, поскольку вам будет невыгодно регулировать размер позиции на
ежедневной основе из-за высоких накладных расходов. Вообще говоря, вам следует
изменять позиции на ежедневной основе, но в реальной жизни вы можете изменять
их от сделки к сделке с малой потерей точности. Применение правильных дневных
позиций не является большой проблемой. Вспомните, что при поиске оптимального
портфеля мы использовали в качестве вводных данных дневные HPR. Поэтому нам
следовало бы изменять размер позиции ежедневно (если бы мы могли изменять
каждую позицию по цене, по которой она закрылась вчера). В действительности это
становится непрактично, так как издержки на трансакции начинают перевешивать
прибыли от ежедневного изменения позиций. С другой стороны, если мы открываем
позицию, которую собираемся удерживать в течение года, нам следует
пересматривать ее чаще, чем раз в год (т.е. в конце срока, когда мы откроем
другую позицию). Вообще, в подобных долгосрочных системах нам лучше
регулировать позицию каждую неделю, а не каждый день. Аргументация здесь
такова: потери из-за не совсем правильных дневных позиций могут быть меньше,
чем дополнительные издержки по сделкам для ежедневного изменения позиций. Вы
должны определить, основываясь на используемой торговой стратегии, какие из
потерь будут для вас меньше. Какой объем исторических данных необходим для
расчета оптимальных портфелей? Этот вопрос можно сформулировать несколько
иначе: «Какой объем исторических данных необходим для определения оптимального f данной рыночной системы?» Точного ответа не существует.
Вообще, чем больше исторических данных вы используете, тем лучше должен быть
результат (то есть оптимальные портфели в будущем будут напоминать нынешние
оптимальные портфели, рассчитанные по историческим данным). Однако соотношения
изменяются, хотя и медленно. Одна из проблем при использовании данных за
слишком большой период времени заключается в том, что возникает тенденция к
использованию в портфеле рынков, которые были активны в прошлом. Например,
если бы вы создавали портфель в 1983 году на 5 годах прошлых данных, то,
вероятнее всего, один из драгоценных металлов оказался бы частью оптимального
портфеля. Однако торговые системы по драгоценным металлам работали в
большинстве своем очень плохо на протяжении нескольких лет после 1980-1981
годов. Поэтому, как видите, при определении будущего оптимального портфеля
между использованием слишком большого количества исторических данных и
использованием слишком малого количества данных нужно найти золотую середину. И,
наконец, возникает вопрос, как часто следует повторять всю процедуру поиска
оптимального портфеля. По большому счету вы должны делать это постоянно.
Однако в реальной жизни достаточно тестировать портфель каждые 3 месяца. И даже
если производить эту операцию каждые 3 месяца, все еще есть высокая
вероятность, что вы придете к тому же составу портфеля или очень сходному с
тем, что создали ранее.
Сумма
весов систем в портфеле, превышающая 100%
До настоящего момента мы ограничивали сумму процентных
весов 100 процентами. Однако возможно, что сумма процентных размещений для
портфеля, который будет иметь наивысший геометрический рост, превысит 100%. Рассмотрим,
например, две рыночные системы, А и В, которые идентичны во всех отношениях, за
тем исключением, что у них отрицательная корреляция (R
< 0). Допустим, что оптимальное f в долларах для
каждой из этих рыночных систем составляет 5000 долларов. Допустим, что
оптимальный портфель на основе самого высокого среднего геометрического — это
портфель, который размещает 50% в каждую из двух рыночных систем. Это означает,
что вам следует торговать 1 контрактом на каждые 10 000 долларов баланса для
рыночной системы А, и для системы В. Однако когда есть отрицательная
корреляция, можно показать, что оптимальный рост счета в действительности
будет достигнут при торговле 1 контрактом для баланса, меньшего 10 000
долларов для рыночной системы А и/или рыночной системы В. Другими словами,
когда есть отрицательная корреляция, сумма процентных весов может превышать
100%. Более того, возможно, что процентные размещения в рыночные системы могут
по отдельности превысить 100%.
Интересно рассмотреть случай, когда корреляция между двумя
рыночными системами приближается к -1,00. В этом случае сумма для финансирования
сделок по рыночным системам стремится стать бесконечно малой. Дело в том, что в
таком портфеле почти не будет проигрышных дней, так как проигранная в данный
день одной рыночной системой сумма возмещается суммой, выигранной другой
рыночной системой в тот же день. Поэтому с помощью диверсификации возможно
получить оптимальный портфель, который размещает меньшую долю f (в долларах) в
данную рыночную систему, чем при торговле только в этой рыночной системе. Для
этого для каждой рыночной системы вы можете разделить оптимальное f в долларах на количество рыночных систем, в которых
работаете. В нашем примере, вместо того чтобы выбрать 5000 долларов в качестве
оптимального f для рыночной системы А,
нам следует использовать 2500 долларов (разделив 5000 долларов, оптимальное f, на
2, количество рыночных систем, в которых мы собираемся торговать), и таким же
образом следует поступить с рыночной системой В. Теперь, когда мы используем
данную процедуру для определения оптимального среднего геометрического
портфеля, который состоит из 50% для А и 50% для В, это означает, что нам
следует торговать 1 контрактом на каждые 5000 долларов на балансе для рыночной
системы А ($2500 / 0,5) и аналогично для В. В качестве еще одной рыночной
системы вы можете использовать систему беспроцентного вклада. Это активы, не
приносящие дохода, с HPR = 1,00 каждый день. Допустим, в
нашем предыдущем примере оптимальный рост получен при 50% для системы А и 40%
для системы В. Другими словами, следует торговать 1 контрактом на каждые 5000
долларов на балансе для рыночной системы А и 1 контрактом на каждые 6250
долларов для В ($2500 / 0,4). При использовании беспроцентного вклада в
качестве другой рыночной системы это была бы одна из комбинаций (оптимальный
портфель, который на 10% в деньгах). Если ваш портфель, найденный с помощью
этой процедуры, не содержит систему беспроцентного вклада в качестве одной из
составляющих, тогда вы должны повысить используемый фактор и разделить
оптимальные f в долларах, используемые в качестве вводных данных. Возвращаясь
к нашему примеру, допустим, мы использовали беспроцентный вклад и две рыночные
системы, А и В. Далее предположим, что наш итоговый оптимальный портфель не
содержит систему беспроцентного вклада. Пусть оптимальный портфель оказался на
60% в рыночной системе А, на 40% в рыночной системе В (возможна любая другая
процентная комбинация, веса которой в сумме дают 100%) и на 0% в системе
беспроцентного вклада. Если бы мы разделили наши оптимальные f в долларах на
два, то этого было бы недостаточно. Мы должны разделить их на число, больше 2.
Итак, мы вернемся и разделим наши оптимальные f в долларах на 3 или 4, пока не
получим оптимальный портфель, который включает систему беспроцентного вклада.
Конечно, в реальной жизни это не означает, что мы должны размещать какую-либо
часть нашего торгового капитала в беспроцентные вклады. Беспроцентные активы
стоит использовать для того, чтобы определить оптимальную сумму средств на 1
контракт в каждой рыночной системе при сравнении нескольких рыночных систем. Вы
должны знать, что сумма процентных весов портфеля, при которых достигался
наибольший геометрический рост в прошлом, может быть выше 100%. Этого можно
достичь, разделив оптимальное f в долларах для каждой рыночной системы на
некое целое число (которое обычно является числом рыночных систем), включив
беспроцентный вклад (то есть рыночную систему с HPR = 1,00 каждый день) в
качестве еще одной рыночной системы. Корреляции различных рыночных систем
могут оказать серьезное воздействие на портфель. Важно понимать, что портфель
может быть больше, чем сумма его частей (если корреляции его составляющих
частей достаточно низки). Также возможно, что портфель будет меньше, чем сумма
его частей (если корреляции слишком высоки). Рассмотрим снова игру с броском
монеты, где вы выигрываете 2 доллара, когда выпадает лицевая сторона, и
проигрываете 1 доллар, когда выпадает обратная сторона. Каждый бросок имеет
математическое ожидание (арифметическое) пятьдесят центов. Оптимальное f составляет 0,25, то есть надо ставить 1 доллар на каждые 4
доллара на счете, а среднее геометрическое составляет 1,0607. Теперь рассмотрим
вторую игру, где сумма, которую вы можете выиграть при броске монеты,
составляет 0,90 долларов, а сумма, которую вы можете проиграть, — 1,10
долларов. Такая игра имеет отрицательное математическое ожидание -0,10 доллара,
таким образом, здесь нет оптимального f и соответственно нет и среднего геометрического.
Посмотрим, что произойдет, когда мы будем играть в обе игры одновременно. Если
корреляция этих игр равна 1,0 (то есть мы выигрываем при выпадении лицевой
стороны, а монеты всегда падают либо на лицевые стороны, либо на обратные
стороны), тогда результаты были бы следующими: мы выигрываем 2,90 доллара при
выпадении лицевой стороны или проигрываем 2,10 доллара при выпадении обратной.
Такая игра имеет математическое ожидание 0,40 доллара, оптимальное f= 0,14 и среднее геометрическое 1,013. Очевидно, что это
худший подход к торговле с положительным математическим ожиданием. Теперь
допустим, что игры имеют отрицательную корреляцию. То есть, когда монета в игре
с положительным математическим ожиданием выпадает на лицевую сторону, мы
теряем 1,10 доллара в игре с отрицательным ожиданием, и наоборот. Таким
образом, результатом двух игр будет выигрыш 0,90 доллара в одном случае и
проигрыш -0,10 доллара в другом случае. Математическое ожидание все еще 0,40
доллара, однако оптимальное f= 0,44, что дает
среднее геометрическое 1,67. Вспомните, что среднее геометрическое является
фактором роста вашего счета в среднем за одну игру.. Это означает, что в такой
игре в среднем можно ожидать выигрыша в 10 раз больше, чем в уже рассмотренной
одиночной игре с положительным математическим ожиданием. Однако этот результат
получен с помощью игры с положительным математическим ожиданием и ее комбинирования
с игрой с отрицательным ожиданием. Причина большой разницы в результатах
возникает из-за отрицательной корреляции между двумя рыночными системами. Мы
рассмотрели пример, когда портфель больше, чем сумма его частей.
Важно
помнить, что исторически ваш проигрыш может быть такой же большой, как и
процент f (в смысле возможного уменьшения баланса). В действительности вам
следует ожидать, что в будущем он будет выше,
чем данное значение. Это означает, что комбинация двух рыночных систем, даже
если они имеют отрицательную корреляцию, может привести к уменьшению баланса на
44%. Это больше, чем в системе с положительным математическим ожиданием, в
которой оптимальное f= 0,25, и поэтому максимальный
исторический проигрыш уменьшит баланс только на 25%. Мораль такова: диверсификация, если она произведена
правильно, является методом, который повышает прибыли. Она не обязательно
уменьшает проигрыши худшего случая, что абсолютно противоречит популярному
представлению. Диверсификация смягчает многие мелкие проигрыши, но она не
уменьшает проигрыши худшего случая. При оптимальном f
максимальные проигрыши могут быть существенно больше, чем думают многие.
Поэтому, даже если вы хорошо диверсифицировали портфель, следует быть готовым
к значительным уменьшениям баланса. Однако давайте вернемся и посмотрим на
результаты, когда коэффициент корреляции между двумя играми равен 0. В такой
ситуации, какими бы ни были результаты одного броска, они не влияют на
результаты другого броска. Таким образом, есть четыре возможных результата:
|
Игра 1
|
Игра2
|
Итого
|
|
Результат
|
Сумма
|
Результат
|
Сумма
|
Результат
|
Сумма
|
|
Выигрыш
|
$2,0
|
Выигрыш
|
$9,0
|
Выигрыш
|
$2,90
|
|
Выигрыш
|
$2,0
|
Проигрыш
|
-$1,10
|
Выигрыш
|
$0,90
|
|
Проигрыш
|
-$1,00
|
Выигрыш
|
$0,90
|
Проигрыш
|
-$0,10
|
|
Проигрыш
|
-$1,00
|
Проигрыш
|
-$1,10
|
Проигрыш
|
-$2,10
|
Математическое ожидание равно:
МО = 2,9 * 0,25 + 0,9 * 0,25 - 0,1 * 0,25 - 2,1 * 0,25 =
0,725 + 0,225 - 0,025 - 0,525 =0,4
Математическое ожидание равно 0,40 доллара. Оптимальное f в
этой последовательности составляет 0,26, или 1 ставка на каждые 8,08 доллара
на балансе счета (так как наибольший проигрыш здесь равен -2,10 доллара). Таким
образом, максимальный исторический проигрыш может быть 26% (примерно такой же,
что и в простой игре с положительным математическим ожиданием). Однако в этом
примере происходит сглаживание уменьшении баланса. Если бы мы просто рассматривали
игру с положительным ожиданием, то третья последовательность принесла бы нам
максимальный проигрыш. Так как мы комбинируем две системы, третья
последовательность более ровная. Это единственный плюс. Среднее
геометрическое
здесь равно 1,025, то есть скорость роста в два раза меньше, чем при простой
игре с положительным математическим ожиданием. Мы делаем 4 ставки (когда могли
бы сделать только 2 ставки в простой игре с положительным ожиданием), а больше
не зарабатываем:
1,0607^2= 1,12508449
1,025^4= 1,103812891
Очевидно, что при диверсификации вы должны использовать такие рыночные системы, которые имеют самую
низкую корреляцию прибылей друг к другу, и желательно отрицательную
корреляцию. Вы должны понимать, что уменьшение баланса худшего случая едва ли
будет смягчено диверсификацией, хотя вы сможете смягчать многие более слабые
уменьшения баланса. Наибольшая польза
диверсификации состоит в улучшении среднего геометрического. Метод поиска
оптимального портфеля путем рассмотрения чистых дневных HPR упраздняет необходимость смотреть за тем, сколько сделок
в каждой рыночной системе произошло. Использование этого метода позволит вам
наблюдать только за средним геометрическим независимо от частоты сделок. Таким
образом, среднее геометрическое становится единственной статистической оценкой
того, насколько прибыльным является портфель. Главная цель диверсификации — это
получение наивысшего среднего геометрического.
Как
разброс результатов затрагивает геометрический рост
После того как мы признали тот факт, что, хотим мы того или
нет, сознательно или нет, количество для торговли определяется по уровню
баланса на счете, можно рассматривать HPR, а не денежные суммы. Таким образом,
мы придадим управлению деньгами определенность и точность. Мы сможем проверить
наши стратегии управления деньгами, составить правила и сделать определенные
выводы. Посмотрим, как связан геометрический рост и разброс результатов (HPR).
В этой дискуссии мы для простоты будем использовать пример
азартной игры. Рассмотрим две системы: систему А, которая выигрывает 10%
времени и имеет отношение выигрыш/проигрыш 28 к 1, и систему В, которая
выигрывает 70% времени и имеет отношение выигрыш/проигрыш 1,9 к 1. Наше
математическое ожидание на единицу ставки для А равно 1,9, а для В равно 0,4.
Поэтому мы можем сказать, что для каждой единицы ставки система А выиграет, в
среднем, в 4,75 раз больше, чем система В. Но давайте рассмотрим торговлю
фиксированной долей. Мы можем найти оптимальные f,
разделив математическое ожидание на отношение выигрыш/проигрыш. Это даст нам
оптимальное f = 0,0678 для А и 0,4 для В. Средние геометрические для каждой
системы при соответствующих значениях оптимальных f составят:
А= 1,044176755
В= 1,0857629
Как видите, система В, несмотря на то что ее математическое
ожидание примерно в четыре раза меньше, чем системы А, приносит почти в два
раза больше за ставку (доходность 8,57629% за ставку, когда вы реинвестируете с
оптимальным f), чем система А (которая приносит 4,4176755% за ставку,
когда вы реинвестируете с оптимальным f).
|
Система
|
%
Выигрышей
|
Выигрыш:
Проигрыш
|
МО
|
f
|
Среднее
геометрическое
|
|
А
|
10
|
28:
1
|
1,9
|
0,0678
|
1,0441768
|
|
В
|
70
|
1,9:1
|
0,4
|
0,4
|
1,0857629
|
Проигрыш 50% по балансу потребует 100% прибыли для
возмещения; 1,044177 в степени Х будет равно 2,0, когда Х приблизительно равно
16,5, то есть для возмещения 50% проигрыша для системы А потребуется более 16
сделок. Сравним с системой В, где 1,0857629 в степени Х будет равно 2,0, когда
Х приблизительно равно 9, то есть для системы В потребуется 9 сделок для
возмещения 50% проигрыша.
В чем
здесь дело? Не потому ли все это происходит, что система В имеет процент
выигрышных сделок выше? Истинная причина, по которой В функционирует лучше А,
кроется в разбросе результатов и его влиянии на функцию роста. Большинство
трейдеров ошибочно считают, что функция роста TWR
задается следующим образом:
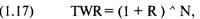
где R = процентная ставка за период (например, 7% = 0,07);
N = количество периодов.
Так как 1 + R то же, что и HPR,
большинство ошибочно полагает, что функция роста1
TWR равна:
(1.18) TWR = HPR ^N
Эта
функция верна только тогда, когда прибыль (то есть HPR)
постоянна, чего в торговле не бывает. Реальная функция роста в торговле (или
любой другой среде, где HPR не является постоянной) — это произведение всех
HPR. Допустим, мы торгуем кофе, наше оптимальное f
составляет 1 контракт на каждую 21 000 долларов на балансе счета и прошло 2
сделки, одна из которых принесла убыток 210 долларов, а другая выигрыш 210
долларов. В этом примере HPR равны 0,99 и 1,01 соответственно. Таким образом, TWR равно:
TWR = 1,01 * 0,99 = 0,9999
Дополнительную информацию можно получить, используя
оценочное среднее геометрическое (EGM):
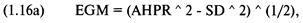
или
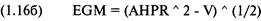
Теперь возведем уравнение (1.16а) или (1.166) в степень N, чтобы рассчитать TWR Оно будет близко к
«мультипликативной» функции роста, действительному TWR
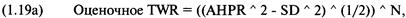
или
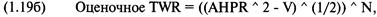
где
N = количество периодов;
АНPR = среднее арифметическое HPR;
SD = стандартное отклонение значений HPR;
V = дисперсия значений HPR.
Оба уравнения (1.19) эквивалентны.
Полученная
информация говорит, что найден компромисс между увеличением средней
арифметической торговли (HPR) и дисперсией HPR, и становится ясна причина, по
которой система (1,9:1 ; 70%) работает лучше, чем система (28:1; 10%)!
Нашей
целью является максимизация коэффициента этой функции, т.е. максимизация
следующей величины:
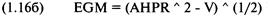
Показатель оценочного TWR,
т.е. N, сам о себе позаботится. Увеличение N не является
проблемой, так как мы можем расширить количество рынков или торговать в более
краткосрочных типах систем.
Расчет дисперсии и стандартного отклонения (V и SD соответственно) может оказаться трудным для большинства
людей, не знакомых со статистикой. Вместо этих величин многие используют среднее абсолютное отклонение, которое
мы назовем М. Чтобы найти М, надо просто взять среднее абсолютное значение
разности самой величины и ее среднего значения.
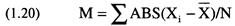
При колоколообразном распределении (как почти всегда бывает
с распределением прибылей и убытков торговой системы) среднее абсолютное
отклонение примерно равно 0,8 стандартного отклонения (в нормальном
распределении оно составляет 0,7979). Поэтому мы можем сказать:
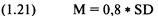
и
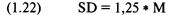
Обозначим среднее арифметическое HPR
переменной А, а среднее геометрическое HPR
переменной G. Используя уравнение (1.166), мы можем выразить оценочное
среднее геометрическое следующим образом:
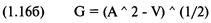
Из этого уравнения получим:
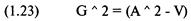
Теперь вместо дисперсии подставим стандартное отклонение
[как в (1.16а)]:
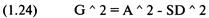
Из этого уравнения мы можем выделить каждую переменную, а
также выделить ноль, чтобы получить фундаментальные соотношения между средним
арифметическим, средним геометрическим и разбросом, выраженным здесь как SD ^
2:
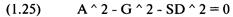
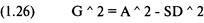
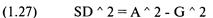
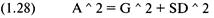
В этих уравнениях значение SD^2 можно записать как V или
как (1,25 * М) ^2. Это подводит нас к той точке, когда мы можем описать
существующие взаимосвязи. Отметьте, что последнее из уравнений — это теорема
Пифагора: сумма квадратов катетов равна квадрату гипотенузы! Но здесь
гипотенуза это А, а мы хотим максимизировать одну из ее сторон, G. При увеличении G любое повышение D («катет» дисперсии, равный SD
или V^(1/2), или 1,25 * М) приведет к увеличению А. Когда D равно нулю, тогда А
равно G, этим самым соответствуя ложно толкуемой функции роста TWR = (1 + R)^ N. Действительно,
когда D равно нулю, тогда А равно G в соответствии с уравнением (1.26).
Мы можем сказать, что повышение А^ 2 оказывает на G то же
воздействие, что и аналогичное понижение величины (1,25 * М) ^ 2.
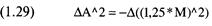
Чтобы понять это, рассмотрим изменение А от 1,1 до 1,2:
|
А
|
SD
|
М
|
G
|
А^2
|
SD ^ 2 = (1, 25 * М)^ 2
|
|
|
1,1
|
0,1
|
0,08
|
1,095445
|
1,21
|
0,01
|
|
|
1,2
|
0,4899
|
0,39192
|
1,095445
|
1.44
|
0.24
|
|
|
|
|
|
|
|
0,23 =
|
0,23
|
|
|
|
|
|
|
|
|
|
|
|
|
Когда A=l,l,ToSD=0,l. Когда А = 1,2, то, чтобы получить эквивалентное G, SD
должно быть равно 0,4899, согласно уравнению (1.27). Так как М = = 0,8 * SD,ToM=0,3919. Если мы возведем в квадрат
значения А и SD и рассчитаем разность, то получим 0,23 в соответствии с
уравнением (1.29). Рассмотрим следующую таблицу:
|
А
|
|
SD
|
М
|
G
|
А^2
|
SD ^ 2 = (1,25 * М) ^ 2
|
|
|
1,1
|
|
0,25
|
0,2
|
1,071214
|
1, 21
|
|
0,0625
|
|
1,2
|
|
0,5408
|
0,4327
|
1,071214
|
1, 44
|
|
0.2925
|
|
|
|
|
|
|
0, 23
|
=
|
0,23
|
|
|
|
|
|
|
|
|
|
Отметьте, что в предыдущем примере, где мы начали с меньших
значений разброса (SD или М), требовалось их большее повышение, чтобы достичь
того же G. Таким образом, можно
утверждать, что чем сильнее вы уменьшаете дисперсию, тем легче дается больший
выигрыш. Это экспоненциальная функция, причем в пределе, при нулевой
дисперсии, G равно А. Трейдер, который торгует на фиксированной долевой
основе, должен максимизировать G, но не обязательно А. При максимизации G надо
понимать, что стандартное отклонение SD затрагивает G в
той же степени, что и А в соответствии с теоремой Пифагора! Таким образом,
когда трейдер уменьшает стандартное отклонение (SD) своих сделок, это
эквивалентно повышению арифметического среднего HPR
(т.е. А), и наоборот!
Фундаментальное
уравнение торговли
Мы можем получить гораздо больше, чем просто понимание того
факта, что уменьшение размера проигрышей улучшает конечный результат. Вернемся
к уравнению (1.19а):
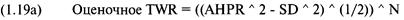
Подставим А вместо AHPR
(среднее арифметическое HPR). Далее, так как (X ^Y)
^ Z = Х ^ (Y * Z), мы можем еще больше упростить уравнение:
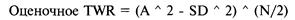
Это последнее уравнение мы назовем фундаментальным уравнением торговли, так как оно описывает, как
различные факторы: А, SD и N — влияют на результат торговли. Очевидны
несколько фактов. Во-первых, если А меньше или равно единице, тогда при любых
значениях двух других переменных, SD и N,
наш результат не может быть больше единицы. Если А меньше единицы, то при N,
стремящемся к бесконечности, наш результат приближается к нулю. Это означает,
что, если А меньше или равно 1 (математическое ожидание меньше или равно нулю,
так как математическое ожидание равно А - 1), у нас нет шансов получить прибыль.
Фактически, если А меньше 1, то наше разорение — это просто вопрос времени (то
есть достаточно большого N).
При
условии, что А больше 1, сростом N увеличивается наша прибыль. Например,
система показала среднее арифметическое 1,1 и стандартное отклонение 0,25.
Таким образом:
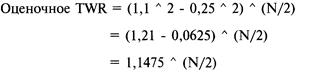
В нашем примере, где коэффициент равен 1,1475; 1,1475 ^
(1/2) = 1,071214264. Таким образом, каждая следующая сделка, каждое увеличение
N на единицу
соответствует
умножению нашего конечного счета на
1,071214264. Отметьте, что это число является средним геометрическим. Каждый
раз, когда осуществляется сделка и когда N увеличивается на единицу,
коэффициент умножается на среднее геометрическое. В этом и состоит
действительная польза диверсификации, выраженная математически фундаментальным
уравнением торговли. Диверсификация позволяет
вам как бы увеличить N (т.е. количество сделок) за определенный период времени.
Есть еще одна важная деталь, которую необходимо отметить при рассмотрении
фундаментального уравнения торговли: хорошо, когда вы уменьшаете стандартное
отклонение больше, чем арифметическое среднее HPR.
Поэтому следует быстро закрывать убыточные позиции (использовать маленький stop-loss). Но уравнение также
демонстрирует, что при выборе слишком жесткого стопа вы можете больше потерять.
Вас выбьет с рынка из-за слишком большого количества сделок с маленьким
проигрышем, которые позднее оказались бы прибыльными, поскольку А уменьшается в
большей степени, чем SD. Вместе с тем, и уменьшение больших
выигрышных сделок поможет вашей системе, если это уменьшает SD больше, чем
уменьшает А. Во многих случаях этого можно достичь путем включения в вашу
торговую программу опционов. Позиция по опционам, которая направлена против
позиции базового инструмента (покупка опциона или продажа соответствующего
опциона), может оказаться весьма полезной. Например, если у вас длинная позиция
по какой-либо акции (или товару), покупка пут-опциона (или продажа
колл-опциона) может уменьшить ваше SD по совокупной позиции в большей степени,
чем уменьшить А. Если вы получаете прибыль по базовому инструменту, то будете
в убытке по опциону. При этом убыток опциону лишь незначительно уменьшит общую
прибыль. Таким образом, вы уменьшили как ваше SD, так и А. Если вы не получаете
прибыль по базовому инструменту, вам надо увеличить А и уменьшить SD. Надо
стремиться уменьшить SD в большей степени, чем уменьшить А.
Конечно,
издержки на трансакции при такой стратегии довольно значительны, и они всегда
должны приниматься в расчет. Чтобы воспользоваться такой стратегией, ваша
программа не должна быть ориентирована на очень короткий срок. Все
вышесказанное лишь подтверждает, что различные стратегии и различные торговые
правила должны рассматриваться сточки зрения фундаментального уравнения
торговли. Таким образом, мы можем оценить влияние этих факторов на уровень
возможных убытков и понять, что именно необходимо сделать для улучшения
системы.
Допустим,
в долгосрочной торговой программе была использована вышеупомянутая стратегия
покупки пут-опциона совместно с длинной позицией по базовому инструменту, в
результате мы получили большее оценочное TWR.
Ситуация, когда одновременно открыты длинная позиция по базовому инструменту и
позиция по пут-опциону, эквивалентна просто длинной позиции по колл-опциону. В
том случае лучше просто купить колл-опцион, так как издержки на трансакции
будут существенно ниже1, чем при наличии длинной позиции по
базовому инструменту и длинной позиции по пут-опциону. Продемонстрируем это на
примере рынка индексов акций в 1987 году. Допустим, мы покупаем базовый
инструмент — индекс ОЕХ. Система, которую мы будем использовать, является
простым 20-дневным прорывом канала. Каждый день мы рассчитываем самый высокий
максимум и самый низкий минимум последних 20 дней. Затем, в течение дня, если
рынок повышается и касается верхней точки, мы покупаем. Если цены идут вниз и
касаются низшей точки, мы продаем. Если дневные открытия выше или ниже точек
входа в рынок, мы входим при открытии. Такая система подразумевает постоянную
торговлю на рынке:
|
Дата
|
Позиция
|
Вход
|
P&L
|
Полный капитал
|
Волатильность
|
|
870106
|
Длинная
|
241,07
|
0
|
0
|
0,1516987
|
|
870414
|
Короткая
|
276,54
|
35,47
|
35,47
|
0,2082573
|
|
870507
|
Длинная
|
292,28
|
-15,74
|
19,73
|
0,2182117
|
|
870904
|
Короткая
|
313,47
|
21,19
|
40,92
|
0,1793583
|
|
871001
|
Длинная
|
320,67
|
-7,2
|
33,72
|
0,1848783
|
|
871012
|
Короткая
|
302,81
|
-17,86
|
15,86
|
0,2076074
|
|
871221
|
Длинная
|
242,94
|
59,87
|
75,73
|
0,3492674
|
Если определять оптимальное f no этому потоку сделок, мы найдем, что
соответствующее среднее геометрическое (фактор роста на нашем счете за игру) равно
1,12445.
Теперь мы возьмем те же сделки, только будем использовать
модель оценки фондовых опционов Блэка-Шоулса (подробно об этом будет рассказано
в главе 5), и преобразуем входные цены в теоретические цены опционов. Входные
данные для ценовой модели будут следующими: историческая волатильность,
рассчитанная на основе 20 дней (расчет исторической волатильности также
приводится в главе 5), безрисковая ставка 6% и 260,8875 дней (это среднее число
рабочих дней в году). Далее мы допустим, что покупаем опционы, когда остается
ровно 0,5 года до даты их исполнения (6 месяцев), и что они «при деньгах». Другими
словами, существуют цены исполнения, в точности соответствующие цене входа на
рынок. Покупка колл-опциона, когда система в длинной позиции по базовому
инструменту, и пут-опциона, когда система в короткой позиции по базовому
инструменту, с учетом параметров упомянутой модели оценки опционов, даст в
результате следующий поток сделок:
|
Дата
|
Позиция
|
Вход
|
P&L
|
Полный капитал
|
Базовый инструмент
|
Действие
|
|
870106
|
Длинная
|
9,623
|
0
|
0
|
241,07
|
Длинный колл
|
|
870414
|
Фиксация
|
35,47
|
25,846
|
25,846
|
276,54
|
|
|
870414
|
Длинная
|
15,428
|
0
|
25,846
|
276,54
|
Длинный пут
|
|
870507
|
Фиксация
|
8,792
|
-6,637
|
19,21
|
292,28
|
|
|
870507
|
Длинная
|
17,116
|
0
|
19,21
|
292,28
|
Длинный колл
|
|
870904
|
Фиксация
|
21,242
|
4,126
|
23,336
|
313,47
|
|
|
870904
|
Длинная
|
14,957
|
0
|
23,336
|
313,47
|
Длинный пут
|
|
871001
|
Фиксация
|
10,844
|
-4,113
|
19,223
|
320,67
|
|
|
871001
|
Длинная
|
15,797
|
0
|
19,223
|
320,67
|
Длинный колл
|
|
871012
|
Фиксация
|
9,374
|
-6,423
|
12,8
|
302,81
|
|
|
871012
|
Длинная
|
16,839
|
0
|
12,8
|
302,81
|
Длинный пут
|
|
871221
|
Фиксация
|
61,013
|
44,173
|
56,974
|
242,94
|
|
|
871221
|
Длинная
|
23
|
0
|
56,974
|
242,94
|
Длинный колл
|
Если рассчитать оптимальное f
по этому потоку сделок, мы придем к выводу, что соответствующее среднее
геометрическое (фактор роста на нашем счете за игру) равно 1,2166. Сравните его
со средним геометрическим при оптимальном f для базового инструмента 1,12445.
Разница огромная. Так как мы получили всего б сделок, то можно возвести каждое
среднее геометрическое в 6-ую степень для определения TWR.
Это даст TWR по базовому инструменту 2,02 против TWR по опционам 3,24. Преобразуем TWR в процент прибыли от
нашего начального счета. Мы получим 102% прибыли при торговле по базовому
инструменту и 224% прибыли при торговле опционами. Опционы в рассмотренном случае
предпочтительнее, что подтверждается фундаментальным уравнением торговли.
Длинные
позиции по опционам могут быть менее эффективными, чем длинные позиции по
базовому инструменту. Чтобы не сделать здесь ошибку, торговые стратегии (а
также выбор серии опционов) необходимо рассматривать с точки зрения
фундаментального уравнения торговли.
Как
видите, фундаментальное уравнение торговли можно использовать для улучшения
торговли. Улучшения могут заключаться в изменении жесткости приказов на
закрытие убыточных позиций (stop-loss приказов), в установлении целей и так далее. Эти изменения
могут быть вызваны неэффективностью текущей торговли, а также неэффективностью
торговой методологии.
Надеюсь, вы теперь понимаете, что компьютер
неверно используется большинством трейдеров. Оптимизация, поиск систем и
значений параметров, которые бы заработали больше всего денег на прошлых
данных,— по сути пустая трата времени. Вам надо получить систему, которая будет
прибыльна в будущем. С помощью грамотного управления капиталом вы сможете
«выжать» максимум из системы, которая лишь минимально прибыльна. Прибыльность
системы в большей степени определяется управлением капиталом, которое вы
применяете к системе, чем самой системой. Вот почему вы должны строить свои системы
(или торговые методы, если вы настроены против механических систем), будучи
уверенными в том, что они останутся прибыльными (даже если только минимально
прибыльными) в будущем. Помните, что этого нельзя достичь путем ограничения
степеней свободы системы или метода. При разработке вашей системы или метода
помните также о фундаментальном уравнении торговли. Оно будет вести вас в
верном направлении в отношении эффективности системы или метода. Когда оно
будет использоваться вместе с принципом «неограничения степеней свободы», вы
получите метод или систему и сможете применить различные техники управления
деньгами. Использование этих методов управления деньгами, будь они
эмпирическими, которые описываются в этой главе, или параметрическими (ими мы
займемся в главе 3), определит степень прибыльности вашего метода или системы.
Глава
2
Характеристики торговли фиксированной
долей и полезные методы
Мы видели,
что оптимальный рост счета достигается посредством оптимального f. Это верно независимо от инструмента, используемого в
торговле. Работаем ли мы на рынке фьючерсов, акций или опционов, управляем ли
группой трейдеров, при оптимальном f достигается
оптимальный рост, а поставленная цель — в кратчайшее время. Мы также узнали,
как с эмпирической точки зрения объединить различные рыночные системы на их
оптимальных уровнях f в оптимальный портфель, то есть как скомбинировать
оптимальное f и теорию портфеля, используя прошлые данные для определения весов
компонентов в оптимальном портфеле. Далее мы рассмотрим важные характеристики
торговли фиксированной долей.
Оптимальное F для начинающих трейдеров с небольшими
капиталами
Каким образом при небольшом счете, который дает возможность
торговать только 1 контрактом, использовать подход оптимального f? Одно из предложений заключается в том, чтобы торговать 1
контрактом, учитывая не только оптимальное ib долларах (наибольший проигрыш / -f), но также проигрыш и
маржу (залог). Сумма средств, отведенная под первый контракт, должна быть
больше суммы оптимального ib долларах
или маржи плюс максимальный исторический проигрыш (на основе 1 единицы):
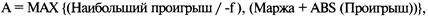
где А =сумма в
долларах, отведенная под первый контракт;
f =оптимальное f (от 0 до 1);
Маржа =первоначальная спекулятивная маржа для данного
контрак та (залоговые средства,
необходимые для открытия одного контракта);
Проигрыш =максимальный исторический совокупный проигрыш;
МАХ {} = максимальное значение выражения в скобках;
ABS() = функция абсолютного значения.
При такой процедуре вы сможете пережить максимальный
проигрыш и все еще иметь достаточно денег для следующей попытки. Хотя мы не
можем быть уверены, что в будущем проигрыш наихудшего случая не превысит
исторический проигрыш наихудшего случая, маловероятно, чтобы мы начали торговлю
сразу с нового исторического проигрыша. Трейдер, использующий эту технику,
каждый день должен вычитать сумму, полученную с помощью уравнения (2.01), из
своего баланса. Остаток следует разделить на величину (наибольший проигрыш /
-f). Полученный ответ следует округлить в меньшую сторону и прибавить единицу,
таким образом, мы получим число контрактов для торговли.
Прояснить
ситуацию поможет пример. Допустим, у нас есть система, где оптимальное f= 0,4, наибольший исторический проигрыш равен -3000
долларов, максимальный совокупный проигрыш был -6000 долларов, а залог равен
2500 долларов. Используя уравнение (2.01), мы получим:
А = МАХ {(-$3000 / 0,4),
($2500 + ABS(-$6000))}
= MAX {($7500), ($2500 + $6000)}
= МАХ {$7500, $8500} == $8500
Таким
образом, нам следует отвести 8500 долларов под первый контракт. Теперь
допустим, что на нашем счете 22 500 долларов. Поэтому мы вычтем сумму под
первый контракт из баланса: $22 500 - $8500 = $14 000 Затем разделим эту сумму на оптимальное f в долларах: $14 000/$7500 =1,867 Округлим полученный
результат в меньшую сторону до ближайшего целого числа: INT (1,867)=1 Затем добавим 1 к полученному результату (1
контракт уже обеспечен 8500 долларами, которые мы вычли из баланса):1+1=2 Таким
образом, мы будем торговать 2 контрактами. Если бы мы торговали на уровне оптимального
f ($7500 на 1 контракт), то торговали бы 3 контрактами (22 500 / 7500). Как
видите, этот метод можно использовать независимо от того, насколько велик
баланс счета (однако чем больше баланс, тем ближе будут результаты). Более
того, чем больше баланс, тем менее вероятно, что вы в конце концов получите
проигрыш, после которого сможете торговать только 1 контрактом. Трейдерам с
небольшими счетами или тем, кто только начинает торговать, следует
использовать этот подход.
Порог
геометрической торговли
Существует еще один хороший подход для трейдеров, которые
только начинают торговать, правда, если вы не используете только что упомянутый
метод. При таком подходе используется еще один побочный продукт оптимального f — порог
геометрической торговли. Мы уже знаем такие побочные продукты оптимального
f, как TWR, среднее геометрическое и т.д.; они были получены из оптимального
f и дают нам информацию о системе. Порог геометрической торговли — это еще
один из таких побочных расчетов. По существу, порог геометрической торговли говорит нам, в какой точке следует
переключиться на торговлю фиксированной долей, предполагая, что мы начинаем
торговать фиксированным количеством контрактов. Вспомните пример с броском
монеты, где мы выигрываем 2 доллара, если монета падает на лицевую сторону, и
проигрываем 1 доллар, если она падает на обратную сторону. Мы знаем, что
оптимальное f= 0,25, т.е. 1 ставка на каждые 4 доллара баланса счета.
Если мы торгуем на основе постоянного количества контрактов, то в среднем
выигрываем 0,50 долларов за игру. Однако если мы начнем торговать фиксированной
долей счета, то можем ожидать выигрыша в 0,2428 доллара на единицу за одну игру
(при геометрической средней торговле). Допустим, мы начинаем с первоначального
счета в 4 доллара и поэтому делаем 1 ставку за одну игру. В конце концов, когда
счет увеличивается до 8 долларов, следует делать 2 ставки за одну игру. Однако
2 ставки, умноженные на геометрическую среднюю торговлю 0,2428 доллара, дадут в
итоге 0,4856 доллара. Не лучше ли придерживаться 1 ставки при уровне баланса 8
долларов, так как нашим ожиданием за одну игру все еще будет 0,50 доллара?
Ответ — «да». Причина в том, что оптимальное f
рассчитывается на основе контрактов, которые бесконечно делимы, чего в реальной
торговле не бывает.
Мы
можем найти точку, где следует перейти к торговле двумя контрактами,
основываясь на формуле порога геометрической торговли Т:
Т = ААТ / GAT * Наибольший
убыток / -f,
где
Т = порог геометрической торговли;
ААТ = средняя арифметическая сделка;
GAT = средняя геометрическая сделка;
f= оптимальное f (от 0 до 1). Для нашего
примера с броском монеты (2 к I): Т=0,50 / 0,2428*-1 / -0,25 =8,24
Поэтому следует переходить на торговлю двумя контрактами,
когда счет увеличится до 8,24 доллара, а не до 8,00 долларов. Рисунок 2-1
иллюстрирует порог геометрической торговли для игры с 50% шансов выигрыша 2
долларов и 50% шансов проигрыша 1 доллара. Отметьте, что дно кривой порога
геометрической торговли соответствует оптимальному f. Порог геометрической
торговли является оптимальным уровнем баланса для перехода от торговли одной
единицей к торговле двумя единицами. Поэтому если вы используете оптимальное
f, то сможете перейти к геометрической торговле при минимальном уровне баланса
счета. Теперь возникает вопрос: «Можем ли мы использовать подобный подход,
чтобы узнать, когда переходить от 2 к 3 контрактам?», а также: «Почему в самом
начале размер единицы не может быть 100 контрактов, если вы начинаете с
достаточно большого счета, а не такого, который позволяет торговать лишь одним
контрактом?» Разумеется, можно использовать этот метод при работе с размером
единицы, большим 1. Однако это корректно в том случае, если вы не уменьшите
размер единицы до перехода к геометрическому способу торговли. Дело в том, что
до того, как вы перейдете на геометрическую торговлю, вы должны будете
торговать постоянным размером единицы.
Допустим,
вы начинаете со счета в 400 единиц в игре с броском монеты 2 к 1. Оптимальное f в долларах предполагает торговлю 1 контрактом (1 ставка)
на каждые 4 доллара на счете. Поэтому начинайте торговать 100 контрактами
(сделав 100 ставок) в первой сделке. Ваш порог геометрической торговли равен
8,24 доллара, и поэтому следует торговать 101 контрактом на уровне баланса
404,24 доллара. Вы можете преобразовать порог геометрической торговли, который
соответствует переходу с 1 контракта к 2 следующим образом:
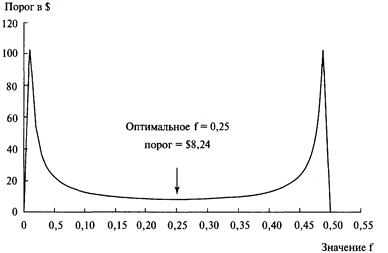
Рисунок
2-1 Порог геометрической торговли
для броска монеты 2 к 1
Преобразованное Т = EQ
+ Т - (Наибольший проигрыш / -f),
где EQ =
начальный уровень баланса счета;
Т = порог геометрической торговли для перехода с одного
контракта к двум;
f=
оптимальное f (от 0 до 1).
Преобразованное Т = 400 + 8,24 - (-1 / -0,25) = 400 + 8,24
- 4 = 404,24
Таким
образом, вы перейдете к торговле 101 контрактом (101 ставке), только когда
баланс счета достигнет 404,24 доллара. Допустим, вы торгуете постоянным
количеством контрактов, пока баланс счета не достигнет 404,24 доллара, где вы
начнете применять геометрический подход. Пока баланс счета не достигнет 404,24
доллара, вы будете торговать 100 контрактами в последующих сделках независимо
от суммы счета. Если после того, как вы пересечете порог геометрической
торговли (то есть после того, как баланс счета достигнет 404,24 доллара), вы
понесете убыток и баланс упадет ниже 404,24 доллара, вы вернетесь снова к
торговле на основе 100 контрактов и будете так торговать до тех пор, пока снова
не пересечете геометрический порог. Невозможность уменьшения количества
контрактов при уменьшении счета, когда вы находитесь ниже геометрического
порога, является недостатком при использовании этой процедуры, когда контрактов
больше 2. Если вы торгуете только 1 контрактом, геометрический порог является
реальным методом для определения того, на каком уровне баланса начать торговать
2 контрактами (так как вы не можете торговать менее чем 1 контрактом при
понижении баланса). Однако этот метод не работает, когда речь идет о переходе
от 2 контрактов к 3, так как метод базируется на том, что вы начинаете торговлю
с постоянного количества контрактов. То есть, если вы торгуете 2 контрактами,
метод не будет работать (за исключением случая, когда вы откажетесь от
возможности понизить количество контрактов до одного при падении уровня
баланса). Таким образом, начиная торговлю со 100 контрактов, вы не можете
перейти к торговле меньшим числом контрактов. Если вы не будете уменьшать
количество контрактов, которыми в настоящее время торгуете, при понижении
баланса, то порог геометрической торговли или его преобразованная версия из
уравнения (2.03) будет уровнем баланса, достаточным для добавления следующего
контракта. Проблема этой операции (не уменьшать при понижении) состоит в том,
что вы заработаете меньше (TWR будет меньше) в
асимптотическом смысле. Вы не выиграете столько, сколько бы выиграли при
торговле полным оптимальным f. Более того, ваши
проигрыши будут больше, и риск банкротства увеличится. Поэтому порог
геометрической торговли будет эффективен, если вы начнете с наименьшего размера
ставки (1 контракт) и повысите его до 2. Оптимально, если средняя
арифметическая сделка более чем в два раза превышает среднюю геометрическую
сделку. Предложенный метод следует использовать, когда вы не можете торговать
дробными единицами.
Один
комбинированный денежный счет по сравнению с отдельными денежными счетами
Прежде чем мы обсудим параметрические методы, необходимо
рассмотреть некоторые очень важные вопросы в отношении торговли фиксированной
долей. Во-первых, при одновременной торговле более чем в одной рыночной системе
вы получите лучшие результаты в асимптотическом смысле, если будете использовать
только один комбинированный денежный счет. Рассчитывать количество контрактов
для торговли следует не для каждого отдельно взятого денежного счета, а для
этого единого комбинированного счета.
По этой причине необходимо ежедневно «соединять» подсчета
при изменении их балансов. Сравним две похожие системы: систему А и систему Б.
Обе системы имеют 50% шанс выигрыша и обе имеют отношение выигрыша 2:1.
Поэтому оптимальное f диктует, чтобы мы ставили 1 доллар на
каждые 4 доллара баланса. Первый пример описывает ситуацию, когда эти две
системы имеют положительную корреляцию. Мы начинаем со 100 долларов и
разбиваем их на 2 подсчета по 50 долларов каждый. После регистрации сделки для
этой системы изменится только столбец «Полный капитал», так как каждая система
имеет свой собственный отдельный счет. Размер денежного счета каждой системы
используется для определения ставки для последующей игры:
|
Таблица
I
|
|
Сделка
|
Система
А P&L Полный капитал
|
Сделка
|
Система
Б P&L Полный капитал
|
|
|
50,00
|
|
|
50,00
|
|
|
2
|
25,00
|
75,00
|
2
|
25,00
|
75,00
|
|
-1
|
-18,75
|
56,25
|
-1
|
-18,75
|
56,25
|
|
2
|
28,13
|
84,38
|
2
|
28,13
|
84,38
|
|
-1
|
-21,09
|
63,28
|
-1
|
-21,09
|
63,28
|
|
2
|
31,64
|
94,92
|
2
|
31,64
|
94,92
|
|
-1
|
-23,73
|
71,19
|
-1
|
-23,73
|
71,19
|
|
|
|
-50.00
|
|
|
-50.00
|
|
Чистая прибыль
|
21,19140
|
|
|
21,19140
|
|
Итоговая чистая прибыль по двум счета =
|
$42,38
|
Теперь мы рассмотрим комбинированный счет в 100 единиц.
Вместо того чтобы ставить 1 доллар на каждые 4 доллара на комбинированном счете
для каждой системы, мы будем ставить 1 доллар на каждые 8 долларов
комбинированного счета. Каждая сделка для любой системы затрагивает
комбинированный счет, и именно комбинированный счет используется для
определения размера ставки для последующей игры (Таблица II).
Отметьте, что в случае комбинированного счета и в случае
отдельных счетов прибыль одна и та же: $42,38. Мы рассматривали положительную
корреляцию между двумя системами. Теперь рассмотрим случай с отрицательной
корреляцией между теми же системами, для двух отдельных денежных счетов (Таблица III):
|
Таблица
II
|
|
Система А Сделка P&L
|
Система Б Сделка P&L
|
Комбинированный счет
|
|
|
|
|
|
100,00
|
|
2
|
25,00
|
2
|
25,00
|
150,00
|
|
-1
|
-18,75
|
-1
|
-18,75
|
112,50
|
|
2
|
28,13
|
2
|
28,13
|
168,75
|
|
-1
|
-21,09
|
-1
|
-21,09
|
126,56
|
|
2
|
31,64
|
2
|
31,64
|
189,84
|
|
-1
|
-23,73
|
-1
|
-23,73
|
142,38
|
|
|
|
|
|
-100.00
|
|
Итоговая чистая прибыль по комбинированному
счету=
|
$42,38
|
|
Таблица
Ш
|
|
Сделка
|
Система А P&L
Полный капитал
|
Сделка
|
Система Б P&L Полный капитал
|
|
|
|
50,00
|
|
|
50,00
|
|
2
|
25,00
|
75,00
|
-1
|
-12,50
|
37,50
|
|
-1
|
-18,75
|
56,25
|
2
|
18,75
|
56,25
|
|
2
|
28,13
|
84,38
|
-1
|
-14,06
|
42,19
|
|
-1
|
-21,09
|
63,28
|
2
|
21,09
|
63,28
|
|
2
|
31,64
|
94,92
|
-1
|
-15,82
|
47,46
|
|
-1
|
-23,73
|
71,19
|
2
|
23,73
|
71,19
|
|
|
|
-50.00
|
|
|
-50.00
|
|
Чистая прибыль
|
|
21,19140
|
|
|
21,19140
|
|
Итоговая чистая прибыль по двум счетам =
|
$42,38
|
Как
видите, при работе с отдельными денежными счетами обе системы выигрывают ту же
сумму независимо от корреляции. Однако при комбинированном счете:
|
Таблица
IV
|
|
Система А Сделка P&L
|
Система Б Сделка P&L
|
Комбинированный счет
|
|
|
|
|
|
100,00
|
|
2
|
25,00
|
-1
|
-12,50
|
112,50
|
|
-1
|
-14,06
|
2
|
28,12
|
126,56
|
|
2
|
31,64
|
-1
|
-15,82
|
142,38
|
|
-1
|
-17,80
|
2
|
35,59
|
160,18
|
|
2
|
40,05
|
-1
|
-20,02
|
180,20
|
|
-1
|
-22,53
|
2
|
45,00
|
202,73
|
|
|
|
|
|
-100.00
|
|
Итоговая чистая прибыль по комбинированному
счету=
|
$102,73
|
При использовании комбинированного счета результаты гораздо
лучше. Таким образом, торговать
фиксированной долей следует на основе одного комбинированного счета.
Рассматривайте
каждую игру как бесконечно повторяющуюся
Следующая аксиома, касающаяся торговли фиксированной долей,
относится к максимизации текущего события, как будто оно должно быть
осуществлено бесконечное количество раз в будущем. Мы определили, что для
процесса независимых испытаний вы должны всегда использовать оптимальное и
постоянное f, но при наличии зависимости оптимальное f уже не будет
постоянной величиной.
Допустим, в нашей системе существует зависимость, в
соответствии с которой подобное порождает подобное, а доверительная граница
достаточно высока. Для наглядности мы будем использовать уже знакомую нам игру
2:1. Система показывает, что если последняя игра выигрышная, то следующая игра
имеет 55% шанс выигрыша. Если последняя игра проигрышная, то следующая игра
имеет 45% шанс проигрыша. Таким образом, если последняя игра была выигрышная,
то исходя из формулы Келли, уравнение (1.10) для поиска оптимального f (так как
результаты игры имеют бернуллиево распределение), получим:
(1.10)
f =((2+1)* 0,55-1)/2 =(3*0,55-
1)/2=0,65/2=0,325
После проигрышной игры наше оптимальное f равно:
f =((2+1)* 0,45-1)/2
=(3*0,45-1) /2 =0,35/2 =0,175
Разделив наибольший проигрыш системы (т.е. -1) на
отрицательные оптимальные f, мы получим 1 ставку на каждые 3,076923077 единицы
на счете после выигрыша и 1 ставку на каждые 5,714285714 единицы на счете
после проигрыша. Таким образом мы максимизируем рост в долгосрочной
перспективе.
Отметьте, что в этом примере ставки как после выигрышей,
так и после проигрышей все еще имеют положительное математическое ожидание. Что
произойдет, если после проигрыша вероятность выигрыша будет равна 0,3? В таком
случае математическое ожидание имеет отрицательное значение и оптимального f
не существует, таким образом, вам не следует использовать эту игру:
(1.03) М0=(0,3*2)+(0,7*-1) =0,6-0,7 =-0,1
В этом случае следует использовать оптимальное количество
только после выигрыша и не торговать после проигрыша. Если зависимость
действительно существует, вы должны изолировать сделки рыночной системы,
основанные на зависимости, и обращаться с изолированными сделками как с
отдельными рыночными системами. Принцип, состоящий в том, что асимптотический рост максимизируется, когда
каждая игра осуществляется бесконечное количество раз в будущем, также
применим к нескольким одновременным играм (или торговле портфелем).
Рассмотрим две системы ставок, А и Б. Обе имеют отношение
выигрыша к проигрышу 2:1, и обе выигрывают 50% времени. Допустим, что
коэффициент корреляции между двумя системами равен 0. Оптимальные f для обеих
систем (при раздельной, а не одновременной торговле) составляют 0,25 (т.е. одна
ставка на каждые 4 единицы на балансе). Оптимальные f при одновременной
торговле в обеих системах составляют 0,23 (т.е. 1 ставка на каждые 4,347826087
единицы на балансе счета). В случае, когда система Б торгует только две трети
времени, некоторые трейдеры разорятся, если обе системы не будут торговать
одновременно. Первая последовательность показана при начальном комбинированном
счете в 1000 единиц, и для каждой системы оптимальное f
соответствует 1 ставке на каждые 4,347826087 единицы:
|
|
А
|
|
Б
|
Комбинированный счет
|
|
|
|
|
|
1 000,00
|
|
-1
|
- 230,00
|
|
|
770,00
|
|
2
|
354,20
|
-1
|
-177,10
|
947,10
|
|
-1
|
-217,83
|
2
|
435,67
|
1 164,93
|
|
2
|
535,87
|
|
|
1 700,80
|
|
-1
|
-391,18
|
-1
|
-391,18
|
918,43
|
|
2
|
422,48
|
2
|
422,48
|
1 763,39
|
Рассмотрим теперь ситуацию, когда А торгует отдельно от Б.
В этом случае мы делаем 1 ставку на каждые 4 единицы на комбинированном счете
для системы А (так как это оптимальное f для
одной игры). В игре с одновременными ставками мы все равно ставим 1 единицу на
каждые 4,347826087 единицы на балансе счета как для А, так и для Б. Отметьте,
что независимо от того, отдельная это ставка или одновременная ставка по А и
Б, мы применяем то оптимальное f, которое увеличивает доход при бесконечном
повторении ставок.
|
|
А
|
|
Б
|
Комбинированный счет
|
|
|
|
|
|
1 000,00
|
|
-1
|
- 250,00
|
|
|
750,00
|
|
2
|
345,20
|
-1
|
-172,50
|
922,50
|
|
-1
|
-212,17
|
2
|
424,35
|
1 134,67
|
|
2
|
567,34
|
|
|
1 702,01
|
|
-1
|
-391,46
|
-1
|
-391,46
|
919,09
|
|
2
|
422,78
|
2
|
422,78
|
1 764,65
|
Как видите, с помощью этого метода мы получаем небольшой
выигрыш, и чем больше сделок проходит, тем больше этот выигрыш. Тот же принцип
применяется к торговле портфелем, где не все компоненты портфеля находятся на
рынке в определенный момент времени. Вам следует торговать на оптимальных
уровнях для комбинации компонентов (или одного компонента), чтобы получить в
итоге оптимальный рост, как будто этой комбинацией компонентов (или одним
компонентом) придется торговать бесконечное количество раз в будущем.
Потеря
эффективности при одновременных ставках или торговле портфелем
Давайте вернемся к нашей игре с броском монеты 2:1.
Допустим, мы собираемся одновременно сыграть в две игры: А и Б, — и существует
нулевая корреляция между результатами этих двух игр. Оптимальные f для такого
случая соответствуют ставке в 1 единицу на каждые 4,347826 единицы на балансе
счета, когда игры проводятся одновременно. Отметьте, что при начальном счете в
100 единиц мы заканчиваем с результатом в 156,86 единицы:
|
Таблица
V
|
|
Система А Сделка P&L
|
Система Б
|
|
Сделка
|
P&L
|
Счет
|
|
Оптимальное f соответствует 1 единице на каждые 4,347826 единицы на счете:
|
|
|
100,00
|
|
-1 -23,00
|
-1
|
-23,00
|
54,00
|
|
2 24,84
|
-1
|
-12,42
|
66,42
|
|
-1 -15,28
|
2
|
30,55
|
81,70
|
|
2 37,58
|
2
|
37,58
|
156,86
|
Теперь давайте рассмотрим систему В. Она будет такой же,
как система А и Б, только мы будем играть в эту игру без одновременного ведения
другой игры. Мы сыграем 8 раз, но не 2 игры по 4 раза, как в прошлом примере.
Теперь наше оптимальное f - это ставка 1 единицы на каждые 4 единицы на балансе
счета. Мы, как и прежде, имеем те же 8 сделок, но лучший конечный результат (Таблица VI). Мы
получили лучший конечный результат не потому, что оптимальные f немного
отличаются (оба значения f находятся на соответствующих оптимальных уровнях), а
потому, что есть небольшая потеря эффективности при одновременных ставках. Неэффективность является результатом
невозможности изменения структуры вашего счета (т.е. рекапитализации) после
каждой отдельной ставки, как в игре только по одной рыночной системе. В
случае с двумя одновременными
ставками
вы можете рекапитализировать счет только 3 раза, в то время как в случае с 8
отдельными ставками вы рекапитализируете счет 7 раз. Отсюда возникает потеря
эффективности при одновременных ставках (или при торговле портфелем рыночных
систем).
Система В Счет
|
Сделка
|
P&L
|
100, 00
|
|
-1
|
-25
|
75
|
|
2
|
37, 5
|
112, 5
|
|
-1
|
-28, 13
|
84, 38
|
|
2
|
42, 19
|
126, 56
|
|
2
|
63, 28
|
189, 84
|
|
2
|
94, 92
|
284, 77
|
|
-1
|
-71, 19
|
213, 57
|
|
-1
|
-53, 39
|
160, 18
|
Оптимальное f соответствует
единице на каждые 4 единице на счете
Мы
рассмотрели случай, когда одновременные ставки не были коррелирова-ны. Давайте
посмотрим, что произойдет при положительной корреляции (+1,00):
|
Таблица
VII
|
|
Система А
|
|
Система Б
|
|
|
|
Сделка
|
P&L
|
|
Сделка
|
P&L
|
|
Счет
|
|
|
|
|
|
|
|
|
100,00
|
|
|
-1
|
-12,50
|
|
-1
|
-12,50
|
|
75,00
|
|
|
2
|
18,75
|
|
2
|
18,75
|
|
112,50
|
|
|
-1
|
-14,06
|
|
-1
|
-14,06
|
|
84,38
|
|
|
2
|
21,09
|
|
2
|
21,09
|
|
126,56
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Оптимальное f соответствует
единице на каждые 8 единице на счете
Отметьте,
что после 4 одновременных игр при корреляции между рыночными системами +1,00 мы
увеличили первоначальный счет 100 единиц до 126,56. Это соответствует TWR = 1,2656, или среднему геометрическому (даже если это комбинированные
игры) 1,2656 ^ (1/4) =1,06066. Теперь вернемся к случаю с одной ставкой.
Обратите внимание, что после 4 игр мы получим 126,56 при начальном счете в 100
единиц. Таким образом, среднее геометрическое равно 1,06066. Это говорит о том,
что скорость роста такая же, как и при торговле с оптимальными долями на
абсолютно коррелированных рынках. Как только коэффициент корреляции опускается
ниже +1,00, скорость роста повышается. Таким
образом, мы можем утверждать, что при комбинировании рыночных систем ваша
скорость роста никогда не будет меньше, чем в случае одиночной ставки по каждой
системе, независимо от того, насколько высоки корреляции, при условии, что
добавляемая рыночная система имеет положительное арифметическое математическое
ожидание. Вспомним первый пример из этого раздела, когда 2 рыночные системы
имели нулевой коэффициент корреляции. Эта рыночная система увеличила счет 100
единиц до 156,86 после 4 игр при среднем геометрическом (156,86/ / 100) ^ (1/4)
= 1,119. Теперь давайте рассмотрим случай, когда коэффициент корреляции равен
-1,00. Так как при таком сценарии никогда не бывает проигрышной игры,
оптимальная сумма ставки является бесконечно большой суммой (другими словами,
следует ставить 1 единицу на бесконечно малую сумму баланса счета). Для
примера мы сделаем 1 ставку на каждые 4 единицы на счете и посмотрим на
полученные результаты:
|
Таблица
VIII
|
|
Система А
|
Система Б
|
|
Сделка
|
P&L
|
Сделка
|
P&L
|
Счет
|
|
Оптимальное f соответствует 1 единице на каждые 0,00 на балансе (показана 1
единица на каждые 4):
|
|
|
|
|
|
100,00
|
|
-1
|
-12,50
|
2
|
25,00
|
112,50
|
|
2
|
28,13
|
-1
|
-14,06
|
126,56
|
|
-1
|
-15,82
|
2
|
31,64
|
142,38
|
|
2
|
35,60
|
-1
|
-17,80
|
160,18
|
Из этого раздела можно сделать два вывода. Первый состоит в
том, что при одновременных ставках или торговле портфелем существует небольшая
потеря эффективности, вызванная невозможностью рекапитализировать счет после
каждой отдельной игры. Второй заключается в том, что комбинирование рыночных
систем, при условии, что они имеют положительные математические ожидания (даже
если они положительно коррелированы), никогда не уменьшит ваш общий рост за
определенный период времени. Однако когда вы продолжаете добавлять все больше
и больше рыночных систем, эффективность уменьшается. Если у вас есть, скажем,
10 рыночных систем, и все они одновременно несут убытки, совокупный убыток
может уничтожить весь счет, так как вы не сможете уменьшить размер каждого
проигрыша, как в случае последовательных сделок. Таким образом, при добавлении
новой рыночной системы в портфель польза будет только в двух случаях: когда
рыночная система имеет коэффициент корреляции меньше 1 и положительное
математическое ожидание или же когда система имеет отрицательное ожидание, но
достаточно низкую корреляцию с другими составляющими портфеля, чтобы
компенсировать отрицательное ожидание. Каждая добавленная рыночная система
вносит постепенно уменьшающийся вклад в среднее геометрическое. То есть каждая
новая рыночная система улучшает среднее геометрическое все в меньшей и меньшей
степени. Более того, когда вы добавляете новую рыночную систему, теряется общая
эффективность из-за одновременных, а не последовательных результатов. В некоторой
точке добавление еще одной рыночной системы принесет больше вреда, чем пользы.
Время,
необходимое для достижения определенной цели, и проблема дробного f
Допустим, мы знаем среднее арифметическое HPR и среднее геометрическое HPR
для данной системы. Мы можем определить стандартное отклонение HPR из формулы
для расчета оценочного среднего геометрического:
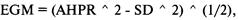
где AHPR = среднее арифметическое HPR;
SD = стандартное отклонение значений HPR.
Поэтому мы можем рассчитать стандартное отклонение SD
следующим образом:
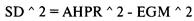
Возвращаясь к нашей игре с броском монеты 2:1, где
математическое ожидание 0,50 долларов и оптимальное f- ставка в 1 доллар на
каждые 4 доллара на счете, мы получим среднее геометрическое 1,06066. Для
определения среднего арифметического HPR можно использовать уравнение (2.05):
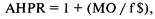
где AHPR = среднее арифметическое HPR;
МО = арифметическое математическое ожидание в единицах;
f$= наибольший проигрыш/-f
f = оптимальное f (от 0 до 1).
Таким образом, среднее арифметическое HPR равно:
AHPR =1+(0,5/(-1/-0,25))
=1+(0,5/4) =1+0,125 =1,125
Теперь, так как у нас есть AHPR и EGM,
мы можем использовать уравнение (2.04) для определения оценочного стандартного
отклонения HPR:
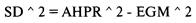
=1,125 ^2-
1,06066 ^62
=
1,265625-1,124999636 =0,140625364
Таким образом, SD ^ 2, то есть дисперсия HPR, равна 0,140625364. Извлекая квадратный
корень из этой суммы, мы получаем стандартное отклонение HPR =0,140625364
^(1/2) =0,3750004853. Следует отметить, что это оценочное стандартное
отклонение, так как при его расчете используется оценочное среднее геометрическое.
Это не совсем точный расчет, но вполне приемлемый для наших целей. Предположим,
мы хотим преобразовать значения для стандартного отклонения (или дисперсии),
арифметического и среднего геометрического HPR, чтобы отражать торговлю не
оптимальным f, а некоторой его частью. Эти преобразования даны далее:
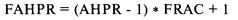
(2.07) FSD = SD * FRAC
(2.08) FGHPR= (FAHPR ^ 2 - FSD ^ 2) А^(1/2),
где FRAC = используемая дробная часть оптимального f;
АН PR= среднее арифметическое HPR при
оптимальном f;
SD = стандартное отклонение HPR
при оптимальном f;
FAHPR== среднее арифметическое HPR при дробном f;
FSD = стандартное отклонение HPR при дробном f;
FGHPR = среднее геометрическое HPR при дробном f.
Например, мы хотим посмотреть, какие значения приняли бы FAHPR, FGHPR и FSD в игре с броском монеты 2:1 при половине
оптимального f (FRAC = 0,5). Мы знаем, что AHPR= 1,125 и SD = 0,3750004853.
Таким образом:
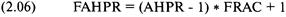
=(1,125- 1)*0,5+ 1
=0,125* 0,5 + 1 = 0,0625 + 1 = 1,0625
(2.07) FSD = SD * FRAC
=0,3750004853*0,5 =
0,1875002427
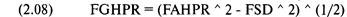
= (1,0625 ^ 2 - 0,1875002427 ^2) ^
(1/2) = (1,12890625 - 0,03515634101) ^
(1/2) =1,093749909 ^ (1/2) = 1,04582499
Для оптимального f= 0,25 (1 ставка на
каждые 4 доллара на счете) мы получаем значения 1,125, 1,06066 и 0,3750004853
для среднего арифметического, среднего геометрического и стандартного
отклонения HPR соответственно. При дробном (0,5) f =0,125 (1 ставка на каждые 8
долларов на счете) мы получаем значения 1,0625, 1,04582499 и 0,1875002427 для
среднего арифметического, среднего геометрического и стандартного отклонения
HPR соответственно. Посмотрим, что происходит, когда мы используем стратегию
дробного f. Мы уже знаем, что при дробном f заработаем меньше, чем при
оптимальном f. Более того, мы определили, что проигрыши и дисперсии прибылей
будут меньше при дробном f. Что произойдет со временем, необходимым для
достижения определенной цели?
Мы
можем определить только ожидаемое количество сделок, необходимое для
достижения определенной цели. Это не то же самое, что ожидаемое время,
требуемое для достижения определенной цели, но, так как наши измерения
производятся в сделках, мы будем считать время и количество сделок синонимами.
(2.09) N = 1п(Цель) /
1n(Среднее геометрическое),
где N = ожидаемое количество сделок для достижения цели;
Цель = цель в виде множителя первоначального счета, т.е. TWR;
1n() = функция натурального логарифма.
Вернемся к нашему примеру с броском монеты 2:1. При
оптимальном f среднее геометрическое равно 1,06066, а при половине f оно
составляет 1,04582499. Теперь давайте рассчитаем ожидаемое количество сделок,
необходимое для удвоения нашего счета (Цель = 2). При полном f:
N=ln(2)/ln( 1,06066) =0,6931471/0,05889134 =11,76993
Таким образом, в игре с броском монеты 2:1 при полном f
следует ожидать 11,76993 сделок для удвоения нашего счета. При половине f
получаем:
N=ln(2)/ln( 1,04582499) =0,6931471/0,04480602 = 15,46996
Таким образом, при половине f мы ожидаем, что потребуется
15,46996 сделок для удвоения счета. Другими словами, чтобы достичь цели при
торговле на уровне f/ /2, от нас понадобится на 31,44% сделок больше. Ну
что же, это звучит не так уж плохо. Проявляя терпение для достижения
поставленной цели, мы потратим времени на 31,44% больше, но сократим худший
проигрыш и дисперсию наполовину. Согласитесь, половина — это довольно много.
Чем меньшую часть оптимального f вы будете использовать, тем более гладкую
кривую счета получите, и тем меньшее время вы будете в проигрыше. Теперь
посмотрим на эту ситуацию с другой стороны. Допустим, вы открываете два счета:
один для торговли с полным f и один для торговли с половиной f. После 12 игр
ваш счет с полным f увеличится в 2,02728259 в 12 раза. После 12 сделок (с
половиной f) он вырастет в 1,712017427 (1,04582499 ^ 12) раза. С
половиной f первоначальный счет увеличится в 2,048067384 (1,04582499 ^
16) раза при 16 сделках. Поэтому, торгуя на одну треть дольше, вы
достигнете той же цели, что и при полном оптимальном f, но при активности,
меньшей наполовину. Однако к 16 сделке счет с полным f будет в 2,565777865
(1,06066 ^ 16) раза больше вашего первоначального счета. Полное f
продолжает увеличивать счет. К 100 сделке ваш счет с половиной f увеличится в
88,28796546 раз, но полное f увеличит его в 361,093016 раз!
Единственный
минус торговли с дробным f— это большее время, необходимое для достижения
определенной цели. Все дело во времени. Мы можем вложить деньги в казначейские
обязательства и достичь-таки заданной цели через определенное время с
минимальными промежуточными падениями баланса и дисперсией! Время — это суть
проблемы.
Сравнение
торговых систем
Мы увидели, что две торговые системы можно сравнивать на
основе их средних геометрических при соответствующих оптимальных f. Далее, мы
можем сравнивать системы, основываясь на том, насколько высокими являются их
оптимальные f, поскольку более высокие оптимальные f соответствуют более
рискованным системам. Это связано с тем, что исторический проигрыш может
понизить счет, по крайней мере, на процент f. Поэтому существуют две основные
величины для сравнения систем: среднее геометрическое при оптимальном f, где
более высокое среднее геометрическое предпочтительнее, и само оптимальное f,
где более низкое оптимальное f лучше. Таким образом, вместо одной величины для
измерения эффективности системы мы получаем две; эффективность должна
измеряться в двухмерном пространстве, где одна ось является средним
геометрическим, а другая — значением f. Чем
выше среднее геометрическое при оптимальном f, тем лучше система. Также чем ниже оптимальное f, тем
лучше система.
Среднее
геометрическое ничего не скажет нам о проигрыше. Высокое среднее геометрическое
не означает, что проигрыш системы большой (или, наоборот, незначительный).
Среднее геометрическое имеет отношение только к прибыли. Оптимальное f является
мерой минимального ожидаемого исторического проигрыша как процентное понижение
баланса. Более высокое оптимальное f не говорит о более высоком (или низком)
доходе. Мы можем также использовать эти положения для сравнения определенной
системы при дробном значении f с другой системой при полном значении оптимального
f. При рассмотрении систем вам следует учитывать, насколько
высоки средние геометрические и каковы оптимальные f. Например, у нас есть
система А, которая имеет среднее геометрическое 1,05 и оптимальное f= 0,8. Также у нас есть система В, которая имеет среднее
геометрическое 1,025 и оптимальное f=0,4. Система А при
половине уровня f будет иметь то же минимальное историческое падение баланса
худшего случая (проигрыш) в 40%, как и система В при полном f, но среднее геометрическое системы А при половине f вce равно будет выше, чем среднее
геометрическое системы В при полном значении f. Поэтому система А лучше
системы В. «Минутку, — можете возразить вы, — разве не является самым
важным то обстоятельство, что среднее геометрическое больше 1, и системе
необходимо быть только минимально прибыльной, чтобы (посредством грамотного
управления деньгами) заработать желаемую сумму!» Так оно и есть. Скорость, с
которой вы зарабатываете деньги, является функцией среднего геометрического на
уровне используемого f. Ожидаемая дисперсия зависит от того, насколько большое
f вы используете. Вы, безусловно, должны
иметь систему с оптимальным f и со средним геометрическим, большим 1 (то есть
с положительным математическим ожиданием). С такой системой вы можете заработать
практически любую сумму через соответствующее количество сделок. Скорость роста
(количество сделок, необходимое для достижения определенной цели) зависит от
среднего геометрического при используемом значении f. Дисперсия на пути к этой
цели также является функцией используемого значения f. Хотя
важность среднего геометрического и применяемого f вторична по сравнению с тем
фактом, что вы должны иметь положительное математическое ожидание, эти
величины действительно полезны при сравнении двух систем или методов, которые
имеют положительное математическое ожидание и равную уверенность в их работе в
будущем.
Слишком большая
чувствительность к величине наибольшего проигрыша
Недостаток
подхода, основанного на оптимальном f, заключается в том, что f слишком зависит
от величины наибольшего проигрыша, что является серьезной проблемой для многих
трейдеров, и они доказывают, что количество контрактов, которые вы открываете
сегодня, не должно быть функцией одной неудачной сделки в прошлом.
Для устранения этой сверхчувствительности к наибольшему
проигрышу были разработаны разнообразные алгоритмы. Многие из этих алгоритмов
заключаются в изменении наибольшего проигрыша в большую или меньшую сторону,
чтобы сделать наибольший проигрыш функцией текущей волатильности рынка. Эта
связь, как утверждают некоторые, квадратичная, то есть абсолютное значение
наибольшего проигрыша, по всей видимости, увеличивается с большей скоростью,
чем волатильность. Волатильность чаще всего определяется как средний дневной
диапазон цен за последние несколько недель или как среднее абсолютное дневное
изменение за последние несколько недель. Однако об этой зависимости нельзя
говорить с полной уверенностью. То, что волатильность сегодня составляет X, не
означает, что наш наибольший проигрыш будет
Х ^ Y. Можно говорить лишь о том, что он обычно
где-то около Х ^ Y.
Если бы мы могли заранее определить
сегодняшний наибольший проигрыш, то, безусловно, могли бы лучше использовать
методы управления деньгами1. Это тот
самый случай, когда мы должны рассмотреть сценарий худшего случая и
отталкиваться от него. Проблема состоит в том, что мы не знаем точно, каким
будет сегодня наибольший проигрыш. Алгоритмы, которые могут спрогнозировать
это, не очень эффективны, так как они часто дают ошибочные результаты.
Предположим,
в течение торгового дня произошло событие, вызвавшее на рынке шок, и до этого
шока волатильность была достаточно низкой. Затем рынок находился не на вашей
стороне несколько следующих дней. Или, допустим, на следующий день рынок
открылся с огромным разрывом не в вашу пользу. Эти события так же стары, как
сама торговля товарами и акциями. Они могут произойти и происходят, и о них не всегда предупреждает заранее
повышающаяся волатильность. Таким образом, лучше не «сокращать»
ваш наибольший исторический проигрыш для отражения текущего рынка с низкой
волатильностью. Более того, есть реальная
возможность испытать в будущем проигрыш больший, чем наибольший исторический
проигрыш. Наибольший проигрыш, который вы получили в прошлом, может оказаться
наибольшим проигрышем, который вы испытаете сегодня, и не зависеть от текущей
волатильности1. Проблема
состоит в том, что с эмпирической точки зрения f,
оптимальное в прошлом, является функцией наибольшего проигрыша в прошлом. С
этим ничего не поделаешь. Однако мы увидим, когда перейдем к параметрическим
методам, что можно предусмотреть больший проигрыш в будущем. При этом мы будем
готовы к появлению почти неизбежного большого проигрыша. Вместо подгонки
наибольшего проигрыша к текущей ситуации на рынке, чтобы эмпирическое
оптимальное f отражало нынешнюю ситуацию, лучше изучить параметрические
методы. Следующий метод является возможным решением данной проблемы
и может применяться вне зависимости от того, рассчитываем мы оптимальное f
эмпирически или параметрически.
Приведение оптимального f к текущим ценам
Оптимальное f даст наибольший геометрический рост при
большом количестве сделок. Это математический факт. Рассмотрим гипотетический
поток сделок:
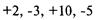
Из этого потока сделок мы найдем, что оптимальное f= 0,17 (ставка 1 единицы на каждые 29,41 доллара на
балансе). Такой подход при данном потоке даст нам наибольший рост счета.
Представьте
себе, что этот поток выражает прибыли и убытки при торговле одной акцией.
Оптимально следует покупать одну акцию на каждые 29,41 доллара на балансе
счета, несмотря на текущую цену акции. Предположим, что текущая цена акции
равна 100 долларам. Более того, допустим, что при первых двух сделках акция
стоила 20 долларов, а при двух последних сделках — 50 долларов.
Для наших
первых двух сделок, которые произошли при цене акции в 20 долларов, выигрыш в
2 доллара соответствует выигрышу в 10%, а проигрыш 3 долларов соответствует
проигрышу в 15%. Для двух последних сделок при цене акции 50 долларов выигрыш
10 долларов соответствует выигрышу в 20%, а проигрыш в 5 долларов соответствует
проигрышу в 10%.
Формулы
преобразования необработанных торговых P&L в процент выигрыша и проигрыша для длинных и коротких
позиций следующие:
(2. 10а) P&L% = Цена выхода / Цена входа — 1 (для длинных)
(2.106) , P&L% = Цена входа / Цена выхода - 1 (для коротких),
или мы можем использовать следующую формулу для
преобразования как длинных, так и коротких:
(2.10в) P&L% =
P&L в пунктах / Цена входа
Таким образом, для наших 4 гипотетических сделок мы получим
следующий поток процентных выигрышей и проигрышей (с точки зрения длинных
позиций):
Мы
назовем этот новый поток преобразованных P&L приведенными данными,
так как при торговле они приводятся к цене базового инструмента.
Чтобы
учесть комиссионные и проскальзывание, вы должны уменьшить цену выхода в
уравнении (2.10а) на сумму комиссионных и проскальзывания. Таким же образом вам
следует увеличить цену выхода в (2.106). Если вы используете (2.10в), то
должны вычесть сумму комиссионных и проскальзывания (в пунктах) из числителя
(P&L в пунктах). Затем мы определим оптимальное f
по этим процентным выигрышам и проигрышам. Оптимальное f будет равно 0,09.
Преобразуем это оптимальное f= 0,09 в денежный
эквивалент, основываясь на текущей цене акции, с помощью формулы:
(2.11) f$ = Наибольший процентный проигрыш * Текущая цена * ($ за пункт/ -f)
Таким образом, так как наш наибольший процентный проигрыш
был -0,15, текущая цена равна 100 долларам за акцию, а количество долларов на
пункт равно 1 (так как мы имеем дело с покупкой только 1 акции), можно
определить f$ следующим образом:
f$ =-0,15*100*1/-0,09 =-15/-0,09 = 166,67
Следует покупать 1 акцию на каждые 166,67 долларов баланса
счета. Если бы мы выбрали 100 акций в качестве единицы, единственной
переменной, затронутой этим изменением, было бы количество долларов за полный
пункт, которое стало бы равно 100. В результате, f$
было бы 16 666,67 доллара баланса на каждые 100 акций.
Теперь допустим, что цена акции упала до 3 долларов. Наше
уравнение для f$ будет таким же, но текущая станет
равна 3. Таким образом, сумма для финансирования 1 акции изменится:
f$=-0,15*3* 1/-0,09 = -0,45 /
-0,09=5
Теперь следует покупать 1 акцию на каждые 5 долларов
баланса счета.
Отметьте, что оптимальное f не изменяется с текущей ценой
акции. Оно остается на уровне 0,09. Однако f$
меняется постоянно, так как меняется цена акции. Это не означает, что вы должны
обязательно изменить позицию, которую уже открыли в этот день, но если бы вы
так поступили, то это пошло бы на пользу торговле. Например, если вы
открываете длинную позицию по какой-либо акции и ее цена падает, количество
денег, которое вам следует разместить под 1 единицу (100 акций в этом случае),
также уменьшится (если оптимальное f получено из
приведенньк данных). Если ваше оптимальное f получено из необработанных данных,
то количество денег, необходимое для 1 единицы, не уменьшится. В обоих случаях
ваш дневной баланс понижается. Использование приведенного оптимального f делает
более вероятным, что ежедневное изменение размера позиции пойдет вам на пользу
Использование приведенных данных для оптимального f неизбежно влечет за собой
изменение побочных продуктов1. Мы
знаем, что и оптимальное f, и среднее геометрическое (и отсюда TWR) изменятся. Средняя арифметическая сделка также
изменится, потому что все сделки в прошлом должны быть пересчитаны, как если бы
они происходили при текущей цене. Таким образом, в нашем предполагаемом потоке
результатов по 1 акции (+2,-3,+10и-5) мы получим среднюю сделку, равную 1 доллару.
Когда мы используем процентные выигрыши и проигрыши (+0,1; -0,15; +0,2 и
-0,1), то получаем среднюю сделку (в процентах) +0,5. При цене 100 долларов за
акцию мы получим среднюю сделку 100 * 0,05, или 5 долларов за сделку. При цене
3 доллара за акцию средняя сделка становится равной 0,15 доллара (3 * 0,05).
Средняя
геометрическая сделка также изменится. Вспомните уравнение (1.14) для средней
геометрической сделки:
(1.14) GAT = G * (Наибольший проигрыш /-f),
где G = (среднее
геометрическое) -1;
f=оптимальная фиксированная доля. (Разумеется, наш
наибольший проигрыш всегда является отрицательным числом.)
Это уравнение эквивалентно следующему:
GAT = (среднее геометрическое - 1) * f$
Мы получили новое среднее геометрическое на основе
приведенных данных. Переменная f$, которая была
постоянной, когда прошлые данные не приводились, теперь изменится, так как она
является функцией текущей цены. Таким образом, наша средняя геометрическая
сделка меняется, когда меняется цена базового инструмента.
Порог геометрической торговли также должен измениться.
Вспомните уравнение (2.02) для порога геометрической торговли:
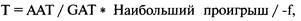
где Т = порог
геометрической торговли;
ААТ = средняя арифметическая сделка;
GAT =средняя
геометрическая сделка;
f= оптимальное
f (от 0 до 1). Это уравнение также можно
переписать следующим образом:
Т = ААТ/GAT* f$
Наконец, при сведении в единый портфель нескольких рыночных
систем мы должны рассчитать ежедневные HPR.
Это также функция f$:
(2.12) Дневное HPR = D$ / f$
+ 1,
где D$ = долларовое изменение цены 1
единицы по сравнению с прошлым днем, т. е. (закрытие сегодня - закрытие вчера)
* (доллары за пункт);
f$= текущее оптимальное f в долларах, рассчитанное из
уравнения (2.11). Здесь текущей ценой является закрытие последнего дня.
Предположим, некая акция сегодня вечером закрылась на
уровне 99 долларов. На прошлой сессии ее цена была 102 доллара. Наибольший
процентный проигрыш равен -15. Если f= 0,09, тогда f$ равно:
f$ =-0,15*102*1/-0,09 =-15,3/-0,09 =
170
Так как мы имеем дело только с одной акцией, цена одного
пункта составляет 1 доллар. Мы можем теперь определить сегодняшнее дневное HPR
из уравнения (2.12):
(2.12) Дневное
HPR = (99 -102) * 1 / 170 + 1 =-3/170+1
= -0,01764705882 + 1 = 0,9823529412
Теперь вернемся к началу нашей дискуссии. При потоке
торговых P&L оптимальное f
позволит получить наибольший геометрический рост (при условии, что
арифметическое математическое ожидание положительное)'. Мы используем поток
торговых P&L в качестве образца распределения возможных результатов в
следующей сделке. Если привести к текущей цене поток прошлых прибылей и
убытков, то мы сможем получить более правдоподобное распределение потенциальных
прибылей и убытков для следующей сделки. Таким образом, нам следует
рассчитывать оптимальное f из этого измененного распределения прибылей и
убытков. Это не означает, что, используя оптимальное f, рассчитанное на основе
приведенных данных, мы выиграем больше. Как видно из следующего примера, все
выглядит несколько иначе:
|
P&L
|
Процент Цена f$ базового инструмента
|
Количество акций
|
Полный капитал
|
|
При f= 0,09 (торговля приведенным методом):
|
$10000
|
|
+2
|
0,1
|
20
|
$33,33
|
300
|
$10600
|
|
-3
|
-0,15
|
20
|
$33,33
|
318
|
$9646
|
|
+10
|
0,2
|
50
|
$83,33
|
115,752
|
$10803,52
|
|
-5
|
-0,1
|
50
|
$83,33
|
129,642
|
$10155,31
|
|
P&L
|
Процент Цена f$ базового инструмента
|
Количество акций
|
Полный капитал
|
|
При f= 0,17 (торговля неприведенным методом):
|
$10000
|
|
+2
|
0,1
|
20
|
$29,41
|
340,02
|
$10680,04
|
|
-3
|
-0,15
|
20
|
$29,41
|
363,14
|
$9 590,61
|
|
+10
|
0,2
|
50
|
$29,41
|
326,1
|
$12851,61
|
|
-5
|
-0,1
|
50
|
$29,41
|
436,98
|
$10666,71
|
Однако если бы все сделки были рассчитаны на основе текущей
цены (скажем, 100 долларов за акцию), приведенное оптимальное f позволило бы
выиграть больше, чем необработанное оптимальное f.
Что лучше использовать? Следует ли нам определять
оптимальное f (и его побочные продукты) на основе приведенных данных
или лучше действовать обычным способом? Это больше вопрос ваших предпочтений.
Все зависит от того, что более важно в инструменте, которым вы торгуете:
процентные изменения или абсолютные изменения. Будет ли движение в 2 доллара
по акции в 20 долларов то же, что и движение в 10 долларов по акции в 100
долларов? Посмотрим, например, на торги по доллару и немецкой марке. Будет ли
движение в 0,30 пункта при 0,4500 то же, что и движение в 0,40 пункта при
0,6000? На мой взгляд, лучше использовать приведенные данные. С этим, однако,
можно поспорить. Например, если акция с 20 долларов выросла до 100 долларов, и
мы хотим определить оптимальное f, нам, возможно, потребуется использовать
только текущие данные. Сделки, которые происходили при цене в 20 долларов за
акцию, относятся к рынку, значительно отличающемуся от существующего в настоящий
момент.
Лучше не использовать данные, когда базовый инструмент был
на совершенно другом ценовом уровне, так как состояние рынка могло существенно
измениться В этом смысле оптимальное f на основе необработанных данных и
оптимальное f, получаемое из приведенных данных, будут почти идентичны, когда
все сделки происходят при ценах, близких к текущей цене базового инструмента.
Если действительно большое значение имеет то
обстоятельство, приводите вы данные или нет, значит вы используете слишком
много исторических данных. На самом деле, нет большой разницы, используете ли
вы приведенные или необработанные данные, если нет вышеописанной проблемы,
поэтому следует пользоваться приведенными данными. Это не означает, что
оптимальное f, рассчитанное из приведенных данных, было оптимальным в прошлом.
Оно могло таковым и не быть. Оптимальное f, рассчитанное из необработанных
данных, могло быть оптимальным в прошлом. Однако оптимальное f, рассчитанное из
приведенных данных, имеет больше смысла, так как приведенные данные являются
более справедливым представлением распределения возможных результатов по
следующей сделке.
Уравнения с (2. 10а) по (2. 10в) дают разные ответы в
зависимости от того, какая была открыта позиция: длинная или короткая.
Например, если акция куплена за 80, а продана за 100, выигрыш составит 25%.
Однако если акция продана по 100, а закрыта по 80, то выигрыш составит только
20%. В обоих случаях позицию открыли по 80 и закрыли по 100. Таким образом,
последовательность — хронология трансакций — должна приниматься во внимание.
Так как хронология трансакций затрагивает распределение процентных выигрышей и
проигрышей, мы допускаем, что будущая хронология скорее всего будет подобна
прошлой. Конечно, мы можем игнорировать хронологию сделок (используя 2.10в для
длинных позиций и цену выхода в знаменателе 2.10в для коротких позиций), но это
означало бы уменьшение информации в исторических данных. Более того,
риск
торговли является функцией хронологии торговли, и этот факт мы были бы
вынуждены игнорировать.
Усреднение
цены при покупке и продажа акций
Это старая, мало используемая техника управления деньгами,
которая является идеальным инструментом для работы в ситуациях, когда у вас
мало информации. Рассмотрим пример: Джо Пуцивакян каждую неделю заливает в
свою машину бензина на 20 долларов, независимо от цены бензина в эту неделю.
Он всегда заправляется на 20 долларов и каждую неделю использует только 20 долларов.
Когда цена бензина выше, это вынуждает его быть более экономным при вождении.
Джо Пуцивакян покупает больше бензина, когда он дешевле, и
меньше, когда он дороже. Поэтому всю свою жизнь он платит за галлон бензина
цену ниже средней. Другими словами, если вы усредните стоимость галлона бензина
за все недели, когда Джо водил автомобиль, среднее значение будет выше, чем
платил Джо.
У Джо есть двоюродный брат, Сесил Пуцивакян. Когда ему
нужен бензин, он просто наполняет бак и сетует на высокую цену. В результате,
Сесил использует постоянное количество топлива каждую неделю и поэтому платит
среднюю цену всю свою автомобильную жизнь.
Предположим, вы ищите долгосрочную инвестиционную
программу. В итоге вы решаете вложить деньги во взаимный фонд, чтобы
обеспечить себе достойную старость. Вы полагаете, что, когда уйдете на пенсию,
акции взаимного фонда будут стоить намного дороже, чем сегодня, то есть, в
асимптотическом смысле, инвестиции во взаимный фонд принесут деньги (с другой
стороны, в асимптотическом смысле, и молния дважды ударит в одно и то же
место). Однако вы не знаете, какова будет стоимость этих вложений в следующем
месяце или в следующем году. У вас нет информации о краткосрочной тенденции цен
акций взаимного фонда.
Чтобы решить эту проблему, вы можете усреднить цену покупки
акций взаимного фонда. Скажем, вы хотите купить акции взаимного фонда на
определенную сумму в течение двух лет. Для инвестирования у вас есть 36 000
долларов. Поэтому каждый месяц в течение следующих 24 месяцев из этих 36 000
долларов вы будете инвестировать в фонд по 1500 долларов. Таким образом, вы
вложите деньги в фонд ниже средней цены. Под «средней» имеется в виду средняя
цена за 24 месяца, в течение которых вы инвестируете. Это не обязательно
означает, что вы получите цену, которая меньше, чем в случае разовой
инвестиции 36 000 долларов, и не гарантирует, что в конце этих 24 месяцев вы
получите прибыль на вложенные 36 000 долларов. Сумма, которую вы инвестировали
в акции фонда, к этому времени может быть меньше 36 000 долларов. Все
вышесказанное означает только то, что если вы войдете в какой-то произвольной
точке в течение 24 месяцев с 36 000 долларов, то сможете купить меньше акций
фонда и, следовательно, заплатите более высокую цену, чем при усреднении.
Похожим
образом следует поступать, когда вы собираетесь выйти из взаимного фонда,
только теперь это относится к усреднению цены продаж акций, а не к усреднению
цены покупки. Скажем, вы уходите на пенсию с 1000 акций этого взаимного фонда.
Вы не знаете, пришло время выходить из фонда или нет, поэтому решаете продавать
акции в течение 2 лет (24 месяца), чтобы усреднить цену выхода. Вот как следует
действовать. Возьмите общее количество акций (1000) и разделите их на
количество периодов, за которое хотите выйти (24 месяца). Так как 1000 / 24 =
41,67, то последующие 24 месяца вы будете продавать 41,67 акций каждый месяц.
Таким образом, вы продадите свои акции по более высокой цене, чем средняя цена
за эти 24 месяца. Конечно, нет гарантии, что вы продадите их по более высокой
цене, чем сегодняшняя, и совсем необязательно, что вы продадите акции по более
высокой цене, чем через 24 месяца. Вы получите более высокую цену, чем средняя
цена за период времени, когда вы усредняетесь. Это вам гарантировано. Те же принципы
можно применять к торговому счету. В противоположность «одному решительному
шагу» в какой-то точке в течение выбранного отрезка времени входите на рынок по
лучшей «средней цене». При отсутствии информации о том, каким будет
краткосрочное изменение баланса на счете, вам лучше усредняться. Не полагайтесь
только на свою выдержку и интуицию, используйте методы измерения зависимости
ежемесячных изменений баланса торговой программы (см. главу 1). Попытайтесь
понять, есть ли зависимость в ежемесячных изменениях баланса. Если зависимость
существует при достаточно высоком доверительном уровне, чтобы вы могли
полностью войти в благоприятной точке, тогда так и делайте. Однако если нет
достаточно высокой уверенности относительно зависимости в ежемесячных изменениях
баланса, тогда усредняйтесь. Таким образом, у вас будет преимущество в асимптотическом
смысле. То же верно в случае снятия денег со счета. Аналогично усреднению при
покупке (неважно, торгуете вы акциями или товарами) следует принять решение о
дате начала усреднения, а также о том, насколько долгий период времени
необходим для усреднения. В тот день, когда вы собираетесь начать усреднение,
разделите баланс счета на 100. Это даст вам стоимость «I акции». Теперь
разделите 100 на количество периодов, по прошествии которых вы закончите
усреднение. Скажем, вы хотите снять все деньги со счета в течение следующих 20
недель. Разделив 100 на 20, вы получите 5. Поэтому вы будете снимать со своего
счета 5 «акций» в неделю. Умножьте величину, которую вы вычислили как 1
«акцию», на 5, чтобы знать, сколько денег снять с торгового счета в эту неделю.
Теперь вы должны отслеживать, сколько «акций» у вас осталось. Так как вы взяли
5 долей на прошлой неделе, у вас осталось 95. Когда подойдет время для второго
снятия, разделите баланс на вашем счете на 95 и умножьте на 5. Это даст вам
стоимость 5 «акций», которые вы «переведете в наличные» на этой неделе.
Следуйте этой стратегии, пока у вас не закончатся «акции». Таким образом,
средняя цена продажи будет лучше, чем цена в произвольной точке в течение этих
20 недель.
Этот
принцип усреднения настолько прост, что остается только поражаться, почему мало
кто ему следует. Я всегда использую этот принцип в торговле, однако не встречал
никого, кто следовал бы моему примеру. Причина проста. Эта достаточно
эффективная концепция требует дисциплины и времени для проработки, и при этом
точно те же составляющие необходимы для использования концепции оптимального f. Посоветуйтесь с Джо Пуцивакяном. Понять концепции и
поверить в них — только полдела. Самое важное — следовать им.
Законы
арксинуса и случайное блуждание
Давайте поговорим о проигрышах, но сначала скажем несколько
слов о первом и втором законах арксинуса. Эти принципы относятся к случайному
блужданию. Поток торговых P&L в некоторых
случаях может быть неслучайным, хотя обычно большинство потоков торговых
прибылей и убытков почти случайны, что можно подтвердить серийным тестом и
коэффициентом линейной корреляции. Законы арксинуса предполагают, что вы
заранее знаете сумму, которую можно выиграть или проиграть, и допускают, что
сумма, которую можно выиграть, равна сумме, которую можно проиграть, и эта
сумма постоянна. В нашей дискуссии мы допустим, что сумма, которую вы можете
выиграть или проиграть, — это 1 доллар за каждую игру. Законы арксинуса также
допускают, что у вас есть 50% шанс выигрыша и 50% шанс проигрыша. Таким
образом, законы арксинуса предполагают игру, где математическое ожидание
составляет 0. Эти предположения относятся к играм, которые значительно проще,
чем торговля. Однако первый и второй законы арксинуса в точности относятся к
только что описанной игре. Конечно, напрямую они не применимы к реальной торговле,
но для наглядности мы не будем различать игру и торговлю. Представим себе
действительно случайную последовательность, такую, как бросок монеты1, где мы получаем 1 единицу, когда
выигрываем, и теряем 1 единицу, когда проигрываем. Если бы мы строили кривую
баланса за Х число бросков, то наносили бы точки с координатами (X, Y), где Х представляет собой номер броска, а Y — наш общий
выигрыш или проигрыш после этого броска.
Введем
понятие положительной области, когда
кривая баланса находится выше оси Х или на оси X, если предыдущая точка была
выше X. Таким же образом мы определим отрицательную
область, когда кривая баланса находится ниже оси Х или на оси X, если
предыдущая точка была ниже X. Логично предположить, что общее количество точек
в положительной области будет примерно равно общему количеству точек в
отрицательной области. На самом деле это не так. Если бросить монету N раз, то
вероятность (Prob) осуществления К событий в положительной области
составит:
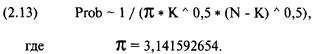
Символ ~ означает, что обе части стремятся к
равенству в пределе. В этом случае, так как или К, или (N - К) стремятся к бесконечности, обе части уравнения будут
стремиться к равенству.
Таким образом, если бросить монету 10 раз (N = 10), мы получим следующие вероятности
нахождения в положительной области:
|
К
|
Вероятность2
|
|
о
|
0,14795
|
|
1
|
0,1061
|
|
2
|
0,0796
|
|
3
|
0,0695
|
|
4
|
0,065
|
|
5
|
0,0637
|
|
6
|
0,065
|
|
7
|
0,0695
|
|
8
|
0,0796
|
|
9
|
0,1061
|
|
10
|
0,14795
|
Можно
ожидать попадания в положительную область 5-ти из 10-ти бросков, но это
наименее вероятный результат!
Наиболее вероятным результатом будет нахождение в
положительной области при всех бросках или ни при одном!
Этот принцип формально описывается в первом законе арксинуса, который гласит:
Для фиксированного А (0 < А < 1), когда N стремится к
бесконечности, время, проведенное в положительной области (т.е., когда К / N
< А), будет определяться следующим образом:
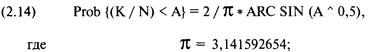
N = количество бросков;
К = количество бросков в положительной области.
Даже при N = 20 вы получите очень хорошее
приближение для вероятности.
Уравнение (2.14), то есть первый закон арксинуса, говорит
нам, что с вероятностью 0,1 кривая баланса счета проведет 99,4% времени в
одной области (положительной или отрицательной). С вероятностью 0,2 кривая
баланса будет находиться в той же области 97,6% времени. С вероятностью 0,5
кривая баланса счета проведет в одной области более 85,35% времени. Настолько
упряма кривая баланса простой монетки!
Существует также второй
закон арксинуса, который основан на уравнении (2.14) и дает те же
вероятности, что и первый закон арксинуса, но применяется к другому случаю,
максимуму или минимуму кривой баланса. Второй закон арксинуса гласит, что
максимальная (или минимальная) точка кривой баланса вероятнее всего будет при
начальном или конечном бросках, чем в середине игры. Распределение будет таким
же, как и в случае со временем, проведенным в одной области!
Если вы бросаете монету N раз, вероятность достижения
максимума (или минимума) в точке К на кривой баланса также описывается
уравнением (2.13):
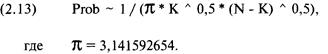
Таким образом, если бросить монету 10 раз (N = 10), мы получим следующие вероятности максимума (или
минимума) при К бросках:
|
к
|
Вероятность
|
|
о
|
0,14795
|
|
1
|
0,1061
|
|
2
|
0,0796
|
|
3
|
0,0695
|
|
4
|
0,065
|
|
5
|
0,0637
|
|
6
|
0,065
|
|
7
|
0,0695
|
|
8
|
0,0796
|
|
9
|
0,1061
|
|
10
|
0,14795
|
Второй закон арксинуса говорит о том, что максимум (или
минимум) вероятнее всего будет рядом с крайними точками кривой баланса.
Время, проведенное в проигрыше
Вспомните первоначальные предположения в законах арксинуса.
Законы арксинуса допускают 50% шанс выигрыша и 50% шанс проигрыша. Более того,
они допускают, что вы выигрываете или проигрываете одинаковые суммы, а поток
сделок случаен. Торговля является значительно более сложной игрой. Таким
образом, в чистом виде законы арксинуса не применимы к торговле. Законы
арксинуса верны при нулевом арифметическом математическом ожидании. Таким
образом, согласно первому закону, мы можем интерпретировать процент времени,
проведенного с любой стороны нулевой линии, как процент времени с любой стороны
арифметического математического ожидания. Так же обстоит дело и со вторым
законом, где вместо того, чтобы искать абсолютный максимум и минимум, мы поищем
максимум выше математического ожидания и минимум ниже его. Минимум ниже
математического ожидания может быть больше, чем максимум выше него, если
минимум был позднее, и арифметическое математическое ожидание было
повышающейся линией (как в торговле), а не горизонтальной линией на нулевом
уровне. Таким образом, мы можем считать, что общая идея законов арксинуса применима
к торговле. Однако вместо горизонтальной линии на нулевом уровне следует
начертить линию, направленную вверх со скоростью арифметической средней
торговли (если торговля ведется постоянным количеством контрактов). Если мы
используем
торговлю фиксированной долей, то линия будет направлена вверх, становясь более
крутой со скоростью среднего геометрического. Мы можем интерпретировать первый
закон арксинуса следующим образом: наша система будет находиться с одной
стороны линии математического ожидания большее число сделок, чем с другой
стороны этой линии. В отношении второго закона арксинуса можно сказать, что
максимальные отклонения от линии математического ожидания (выше или ниже ее)
будут чаще встречаться рядом с начальной или конечной точкой кривой баланса и
реже в середине. Отметим еще одну характеристику, которая очень важна при
торговле с оптимальным f. Эта характеристика касается времени,
которое вы проводите между двумя пиками баланса. Если вы торгуете на уровне
оптимального f (в одной рыночной системе или портфелем рыночных систем), период
самого длительного проигрыша1 (не
обязательно наибольшего) может составить от 35 до 55% времени, на протяжении
которого ведется торговля. Это справедливо независимо от того, какой временной
период вы рассматриваете! (Время здесь измеряется в сделках).
Это правило не жесткое. Скорее, это возможное проявление
сути законов арксинуса в реальной жизни.
Данный
принцип справедлив независимо от того, насколько длинный или короткий период
времени вы рассматриваете. Мы можем находиться в проигрыше приблизительно от
35 до 55% времени за весь период работы торговой программы! Это верно
независимо от того, используем мы одну рыночную систему или портфель. Поэтому
надо быть готовыми к периодам проигрыша 35-55% времени торговой программы,
тогда мы сможем психологически подготовиться к торговле в эти периоды.
Собираетесь
ли вы управлять чьим-то счетом, отдать деньги в управление или торговать со
своего собственного счета, вы должны помнить о законах арксинуса и знать, что
может произойти с кривой баланса, а также помнить правило 35-55%. Таким
образом, вы будете готовы к тому, что может произойти в будущем. Мы достаточно подробно изучили эмпирические
подходы. Кроме того, мы обсудили многие характеристики торговли фиксированной
долей и узнали некоторые полезные методы, которые будут использоваться в
дальнейшем. Мы увидели, что при торговле на оптимальных уровнях следует
ожидать не только значительных падений баланса счета, но и длительного периода
времени, необходимого для того, чтобы снова заработать проигранные деньги. В
следующей главе мы поговорим о параметрических подходах.
Глава
3
Параметрическое оптимальное f при нормальном распределении
Теперь, когда мы закончили рассмотрение
эмпирических методов, а также характеристик торговли фиксированной долей, мы
изучим параметрические методы. Эти методы отличаются от эмпирических тем, что
в них не используется прошлая история в качестве данных, с которыми придется
работать. Мы просто наблюдаем за прошлой историей для создания математического
описания распределения исторических данных. Это математическое описание
основывается на том, что произошло в прошлом, а также на том, что, как мы
ожидаем, произойдет в будущем. В параметрических методах мы имеем дело с этими
математическими описаниями, а не с самой прошлой историей. Математические
описания, используемые в параметрических методах, называются распределениями
вероятности. Чтобы использовать параметрические методы, мы должны сначала изучить
распределения вероятности. Затем мы перейдем к изучению очень важного типа
распределения, нормального распределения. Мы узнаем, как найти оптимальное/и
его побочные продукты при нормальном распределении.
Основы
распределений вероятности
Представьте себе, что вы находитесь на ипподроме и ведете
запись мест, на которых лошади финишируют в забегах. Вы записываете, какая
лошадь пришла первой, какая второй и так далее для каждого забега. Учитываются
только первые десять мест. Если лошадь пришла после десятой, то вы запишете ее
на десятое место. Через несколько дней вы соберете достаточное количество
информации и увидите распределение финишных мест для каждой лошади. Теперь вы
можете взять полученные данные и нанести на график. По горизонтальной оси будут
отмечаться места, на которых лошадь финишировала, слева на оси будет наихудшее
место (десятое), а справа наилучшее (первое). На вертикальной оси мы будем
отмечать, сколько раз беговая лошадь финишировала в позиции, отмеченной на
горизонтальной оси. Вы увидите, что построенная кривая будет иметь
колоколообразную форму.
При таком сценарии есть десять возможных финишных мест для
каждого забега. Мы будем говорить, что в этом распределении — десять ячеек (bins). Посмотрим, что
произойдет, если вместо десяти мы будем использовать пять ячеек. Первая ячейка
будет для первого и второго места, вторая ячейка для третьего и четвертого
места и так далее. Как это отразится на результатах?
Использование меньшего количества ячеек при том же наборе
данных в результате дало бы распределение вероятности с тем же профилем, что и
при большом количестве ячеек. То есть графически они бы выглядели примерно
одинаково. Однако использование меньшего количества ячеек уменьшает
информационное содержание распределения, и наоборот, использование большего
количества ячеек повышает информационное содержание распределения. Если вместо
финишных позиций лошадей в каждом забеге мы будем записывать время, за которое
пробежала лошадь, округленное до ближайшей секунды, то получим не десять
ячеек, а больше, и, таким образом, информационное содержание распределения
увеличится.
Если бы мы записали точное время финиша, а не округленное
до секунд, то могли бы построить непрерывное
распределение. При непрерывном распределении нет ячеек. Представьте
непрерывное распределение как серию бесконечно малых ячеек (см. рисунок 3-1).
Непрерывное распределение отличается от дискретного,
которое является ячеистым распределением. Хотя создание ячеек уменьшает
информационное содержание распределения, в реальной жизни это единственно
возможный подход для обработки ячеистых данных, поэтому на практике приходится
жертвовать частью информации, сохраняя при этом профиль распределения. И
наконец, вы должны понимать, что можно взять непрерывное распределение и
сделать его дискретным путем создания ячеек, но невозможно дискретное
распределение переделать в непрерывное.
Когда мы имеем дело с торговыми прибылями и убытками, то чаще
всего рассматриваем непрерывное распределение. Сделка может иметь множество
исходов (хотя мы можем округлить цены до ближайшего цента). Для того чтобы
работать с
таким
распределением, потребуется разбить данные на ячейки, например шириной 100
долларов. Такое распределение имело бы отдельную ячейку для сделок, прибыли
которых оказались ниже 99,99 доллара, другую ячейку для сделок от 100 до 199,99
доллара и так далее. При таком подходе будет определенная потеря информации, но
профиль распределения торговых прибылей и убытков не изменится.
Рисунок
3-1 Непрерывное распределение
является серией бесконечно малых ячеек.
Величины,
описывающие распределения
Многие из вас наверняка знакомы со средним, или, если
говорить точнее, средним арифметическим (arithmetic
mean). Это просто сумма значений, соответствующих точкам
распределения, деленная на количество точек данных:
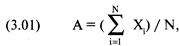
где А = среднее арифметическое;
X. =
значение, соответствующее точке i;
N =
общее число точек данных в распределении.
Среднее арифметическое является самым распространенным из
набора величин, оценивающих расположение
(location) или центральную тенденцию (central tendency) тела данных распределения. Однако вы должны знать, что
среднее арифметическое является не единственным доступным измерением
центральной тенденции, и зачастую не самым лучшим. Среднее арифметическое
обычно оказывается плохим выбором, когда распределение имеет широкие хвосты (tails1 ).
Если при исследовании распределения с очень широкими хвостами вы случайным
образом будете выбирать точки данных для расчета среднего, то, проделав это
несколько раз подряд, увидите, что средние арифметические, полученные таким
способом, заметно отличаются друг от друга. Еще одной важной величиной,
определяющей расположение распределения, является медиана (median). Медиана описывает
среднее значение, когда данные расположены по порядку в соответствии с их
величиной. Медиана делит распределение вероятности на две половины таким
образом, что площадь под кривой одной половины равна площади под кривой другой
половины. В некоторых случаях медиана лучше задает центральную тенденцию, чем
среднее арифметическое. В отличие от среднего арифметического медиана не
искажается крайними случайными значениями. Более того, медиану можно
рассчитать даже для распределения, в котором все значения выше заданной ячейки
попадают в определенную ячейку. Примером такого распределения является
рассмотренный выше забег лошадей. Любое финишное место после десятого
записывается в десятое место. Медиана широко используется в Бюро Переписи США.
Третьей величиной, определяющей центральную тенденцию, является мода (mode) — наиболее часто
повторяющееся событие (или значение данных). Мода — это пик кривой
распределения. В некоторых распределениях нет моды, а иногда есть более чем
одна мода. Как и медиана, мода в некоторых случаях может лучше всего описывать
центральную тенденцию. Мода никак не зависит от крайних случайных значений, и
ее можно рассчитать быстрее, чем среднее арифметическое или медиану. Мы
увидели, что медиана делит распределение на две равные части. Таким же образом
распределение можно разделить тремя квартилями
(quartiles), чтобы получить
четыре области равного размера или вероятности, или девятью децилями (deciles), чтобы получить
десять областей равного размера или вероятности, или 99 перцентилями (percentiles) (чтобы получить 100
областей равного размера или вероятности), 50-й перцентиль является медианой и
вместе с 25-м и 75-м перцентилями дает нам квартили. И наконец, еще один
термин, с которым вы должны познакомиться, — это квантиль (quantile). Квантиль — это
некоторое число N-1, которое делит общее поле данных на
N равных частей. Теперь вернемся к среднему. Мы обсудили среднее
арифметическое, которое измеряет центральную тенденцию распределения. Есть и другие
виды средних, они реже встречаются, но в определенных случаях также могут
оказаться предпочтительнее. Одно из них — это среднее геометрическое (geometric mean), расчет которого дан
в первой главе. Среднее геометрическое является корнем степени N из произведения
значений, соответствующих точкам распределения.
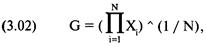
где G = среднее геометрическое;
Х = значение, соответствующее точке i;
N = общее число точек данных в распределении.
Среднее геометрическое не может быть рассчитано, если хотя
бы одна из переменных меньше или равна нулю.
Мы знаем, что арифметическое математическое ожидание
является средним арифметическим результатом каждой игры (на основе 1 единицы)
минус размер ставки. Таким же образом можно сказать, что геометрическое
математическое ожидание является средним геометрическим результатом каждой игры
(на основе 1 единицы) минус размер ставки.
Еще одним видом среднего является среднее гармоническое (harmonic mean). Это обратное
значение от среднего обратных значений точек данных.
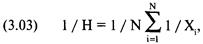
где
Н = среднее гармоническое;
Х = значение, соответствующее точке i;
N = общее число точек данных в распределении.
Последней величиной, определяющей центральную тенденцию,
является среднее квадратическое (quadratic mean), или среднеквадратический
корень (root mean square).
где
R = среднеквадратический корень;
Х = значение, соответствующее точке i;
N = общее число точек данных в распределении.
Вы должны знать, что среднее арифметическое (А) всегда
больше или равно среднему геометрическому (G), а среднее геометрическое всегда
больше или равно среднему гармоническому (Н):
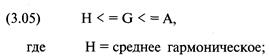
G = среднее геометрическое;
А = среднее арифметическое.
Моменты
распределения
Центральное значение, или расположение распределения, —
первое, что надо знать о группе данных. Следующая величина, которая
представляет интерес, — это изменчивость данных, или «ширина» относительно
центрального значения. Мы назовем значение центральной тенденции первым моментом распределения.
Изменчивость точек данных относительно центральной тенденции называется вторым моментом распределения.
Следовательно, второй момент измеряет разброс распределения относительно
первого момента.
Как и в случае с центральной тенденцией, существует много
способов измерения разброса. Далее мы рассмотрим семь из них, начиная с наименее
распространенных вариантов и заканчивая самыми распространенными.
Широта (range) распределения — это просто разность между самым высоким и
самым низким значением распределения. Таким же образом широта перцентиля 10-90 является разностью между 90-й и 10-й
точками. Эти первые две величины измеряют разброс по крайним точкам. Остальные
пять измеряют отклонение от центральной тенденции (т.е. измеряют половину
разброса).
Семи-интерквартильная
широта (sem-interquartile range), или квартальное отклонение (quartile deviation), равна половине
расстояния между первым и третьим квартилями (25-й и 75-й перцентили). В
отличие от широты перцентиля 10-90, здесь широта делится на два.
Полуширина (half-width) является наиболее распространенным способом измерения
разброса. Сначала надо найти высоту распределения в его пике (моде), затем
найти точку в середине высоты и провести через нее горизонтальную линию
перпендикулярно вертикальной линии. Горизонтальная линия пересечет кривую
распределения в одной точке слева и в одной точке справа. Расстояние между этими
двумя точками называется полушириной.
Среднее абсолютное
отклонение (mean absolute deviation), или просто среднее отклонение, является средним
арифметическим абсолютных значений разности значения каждой точки и среднего
арифметического значений всех точек. Другими словами (что и следует из
названия), это среднее расстояние, на которое значение точки данных удалено от
среднего. В математических терминах:
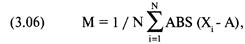
где М = среднее
абсолютное отклонение;
N = общее число точек данных;
X. = значение, соответствующее точке i;
А =
среднее арифметическое значений точек данных;
ABS() = функция абсолютного значения.
Уравнение (3.06) дает нам совокупное среднее абсолютное отклонение. Вам следует знать, что
можно рассчитать среднее абсолютное отклонение по выборке. Для расчета среднего абсолютного отклонения выборки
замените 1 / N в уравнении (3.06) на 1 / (N
- 1). Используйте эту версию, когда расчеты ведутся не по всей совокупности
данных, а по некоторой выборке.
Самыми
распространенными величинами для измерения разброса являются дисперсия и
стандартное отклонение. Как и в случае со средним абсолютным отклонением, их
можно рассчитать для всей совокупности и для выборки. Далее показана версия для
всей совокупности данных, которую можно легко переделать в выборочную версию,
заменив l/NHal/(N-l). Дисперсия (variance) чем-то напоминает среднее абсолютное отклонение, но при
расчете дисперсии каждая разность значения точки данных и среднего значения
возводится в квадрат. В результате, нам не надо брать абсолютное значение
каждой разности, так как мы автоматически получаем положительный результат,
независимо от того, была эта разность отрицательной или положительной. Кроме
того, так как в квадрат возводится каждая из этих величин, крайние выпадающие
значения оказывают большее влияние на дисперсию, а не на среднее абсолютное
отклонение. В математических терминах:
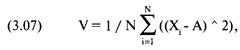
где
V = дисперсия;
N = общее число точек данных;
X. = значение, соответствующее точке i;
А = среднее
арифметическое значений точек данных.
Стандартное
отклонение (standard deviation) тесно связано с
дисперсией (и, следовательно, со средним абсолютным отклонением). Стандартное отклонение является квадратным
корнем дисперсии.
Третий момент распределения называется асимметрией (skewness), и он описывает
асимметричность распределения относительно среднего значения (рисунок 3-2). В
то время как первые два момента распределения имеют размерные величины (то есть те же единицы измерения, что и
измеряемые параметры), асимметрия определяется таким способом, что получается безразмерной. Это просто число, которое
описывает форму распределения.
Положительное
значение асимметрии означает, что хвосты больше с положительной стороны
распределения, и наоборот. Совершенно симметричное распределение имеет нулевую
асимметрию.
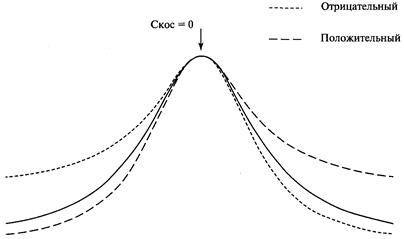
Рисунок 3-2 Асимметрия
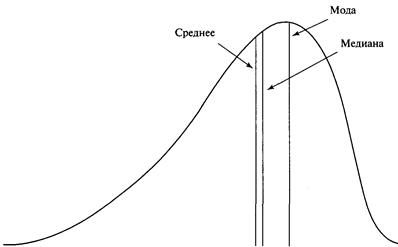
Рисунок 3-3 Асимметричное распределение
В
симметричном распределении среднее, медиана и мода имеют одинаковое значение.
Однако когда распределение имеет ненулевое значение асимметрии, оно может
принять вид, показанный на рисунке 3-3. Для асимметричного распределения (любого
распределения с ненулевой асимметрией) верно равенство:
(3.08) Среднее -
Мода = 3 * (Среднее - Медиана)
Есть много способов для расчета асимметрии, и они часто
дают различные ответы. Ниже мы рассмотрим несколько вариантов:
(3.09) S == (Среднее - Мода) / Стандартное отклонение
(3.10) S = (3 *
(Среднее - Медиана)) / Стандартное отклонение
Уравнения (3.09) и (3.10) дают нам первый и второй
коэффициенты асимметрии Пирсона. Асимметрия также часто определяется следующим
образом:
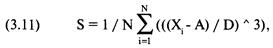
где S = асимметрия;
N = общее число
точек данных;
Х = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных;
D = стандартное отклонение значений точек данных.
И наконец, четвертый
момент распределения, эксцесс (kurtosis) (см. рисунок 3-4), измеряет, насколько у распределения
плоская или острая форма (по сравнению с нормальным распределением). Как и
асимметрия, это безразмерная величина. Кривая, менее остроконечная, чем
нормальная, имеет эксцесс отрицательный, а кривая, более остроконечная, чем
нормальная, имеет эксцесс положительный. Когда пик кривой такой же, как и у
кривой нормального распределения, эксцесс равен нулю, и мы будем говорить, что
это распределение с нормальным эксцессом.
Как и
предыдущие моменты, эксцесс имеет несколько способов расчета. Наиболее
распространенными являются:
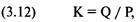
где К = эксцесс;
Q ==
семи-интерквартильная широта;
Р = широта перцентиля 10-90.
(3.13) К = (1 / N (∑ (((X - Аi) / D)^ 4))) - 3,
где К = эксцесс;
N = общее число точек данных;
Х = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных;
D = стандартное отклонение значений точек данных.
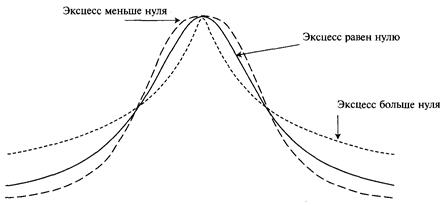
Рисунок 3-4 Эксцесс
Наконец, необходимо отметить, что «теория», связанная с
моментами распределения, намного серьезнее, чем то, что представлено здесь.
Для более глубокого понимания вам следует просмотреть книги по статистике,
упомянутые в списке рекомендованной литературы. Для наших задач изложенного
выше вполне достаточно.
До
настоящего момента рассматривалось распределение данных в общем виде. Теперь мы
изучим нормальное распределение.
Нормальное
распределение
Часто нормальное распределение называют распределением
Гаусса, или Муавра, в честь тех, кто, как считается, открыл его — Карл Фридрих
Гаусс (1777-1855) и, веком ранее, что не так достоверно, Авраам де Муавр
(1667-1754). Нормальное распределение считается наиболее ценным
распределением, благодаря тому, что точно моделирует многие явления. Давайте
рассмотрим приспособление, более известное как доска Галтона (рисунок 3-5).
Это вертикально установленная доска в форме равнобедренного треугольника. В
доске расположены колышки, один в верхнем ряду, два во втором, и так далее.
Каждый последующий ряд имеет на один колышек больше. Колышки в сечении
треугольные, так что, когда падает шарик, у него есть вероятность 50/50 пойти
вправо или влево. В основании доски находится серия желобов для подсчета
попаданий каждого броска.
Рисунок 3-5 Доска Галтона
Шарики, падающие через доску Галтона и достигающие желобов,
начинают формировать нормальное распределение. Чем «глубже» доска (то есть чем
больше рядов она имеет) и чем больше шариков бросается, тем ближе конечный
результат будет напоминать нормальное распределение.
Нормальное распределение интересно еще и потому, что оно
является предельной формой многих других типов распределений. Например, если Х
распределено биномиально, а N стремится к бесконечности, то Х стремится к нормальному
распределению. Более того, нормальное распределение также является предельной
формой многих других ценных распределений вероятности, таких как Пуассона,
Стьюдента (или t-распределения). Другими словами, когда количество данных (N), используемое в этих распределениях, увеличивается, они
все более напоминают нормальное распределение.
Центральная
предельная теорема
Одно из наиболее важных применений нормального
распределения относится к распределению средних значений. Средние значения
выборок заданного размера, взятые таким образом, что каждый элемент выборки
отобран независимо от других, дадут распределение, которое близко к нормальному
Это чрезвычайно важный факт, так как он означает, что вы можете получить
параметры действительно случайного процесса из средних значений, рассчитанных
на основе выборочных данных.
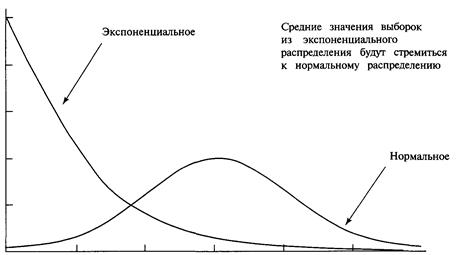
Рисунок 3-6 Экспоненциальное распределение и нормальное
распределение
Таким образом, мы можем сформулировать, что если N случайных выборок извлекаются из
совокупности всех данных, тогда суммы (или средние значения) выборок будут
приблизительно нормально распределяться независимо от распределения совокупности,
из которой взяты эти выборки. Близость к нормальному распределению
увеличивается, когда N (число выборок) возрастает. В качестве примера
рассмотрим распределение чисел от 1 до 100. Это равномерное распределение, где все элементы (в данном случае
числа) встречаются только раз. Например, число 82 встречается один раз, так же
как и 19, и так далее. Возьмем выборку из пяти элементов и среднее значение
этих пяти элементов (мы можем также взять их сумму). Теперь поместим полученные
пять элементов обратно, возьмем другую выборку и рассчитаем среднее. Если мы
будем продолжать этот процесс дальше, то увидим, что полученные
средние нормально распределяются, даже если совокупность, из которой они взяты,
распределена равномерно.
Все
вышесказанное верно независимо от
того, как распределена совокупность данных! Центральная предельная теорема
позволяет нам обращаться с распределением средних значений выборок, как с
нормальным, без необходимости знать распределение совокупности. Это чрезвычайно
удобный факт для многих областей исследований. Если совокупность
нормально распределена, то распределение средних значений выборок будет точно
(а не приблизительно) нормальным. Кроме того, скорость, с которой распределение
средних значений выборок приближается к нормальному при повышении N, зависит от того, насколько близко совокупность находится
к нормальному распределению. Общее практическое правило следующее: если совокупность
имеет унимодальное (одновершинное) распределение
(любой тип распределения, где есть концентрация частоты вокруг одной моды и
уменьшение частот с любой стороны моды, например, выпуклость) или равномерно
распределяется, то можно использовать N = 20 (это считается достаточным) и N =
10 (это считается достаточным с большой вероятностью). Однако если совокупность
распределена экспоненциально (рисунок 3-6), тогда может потребоваться и N =
100.
Центральная
предельная теорема, этот поразительно простой и красивый факт, подтверждает
важность нормального распределения.
Работа
с нормальным распределением
При использовании нормального распределения часто требуется
найти долю площади под кривой распределения в данной точке на кривой. На
математическом языке это называется интегралом функции, задающей кривую. Таким
же образом функция, которая задает кривую, является производной площади под
кривой. Если у нас есть функция N(X), которая представляет процент площади под кривой в точке
X, мы можем говорить, что производная этой функции N'(X) является функцией самой кривой в точке X.
Мы начнем с формулы самой кривой N' (X). Данная функция
выглядит следующим образом:
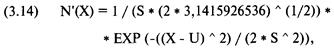
где U = среднее значение
данных;
S =стандартное отклонение данных;
Х = наблюдаемая точка данных;
ЕХР () =
экспоненциальная функция.
Эта
формула даст нам значение для оси Y, или высоту кривой,
при любом данном значении X.
Часто мы будем говорить о точке на кривой, ссылаясь на ее
координату X, и будем смотреть, на сколько стандартных отклонений она удалена
от среднего. Таким образом, точка данных, которая удалена на одно стандартное
отклонение от среднего, считается смещенной на одну стандартную единицу (standard units) от среднего.
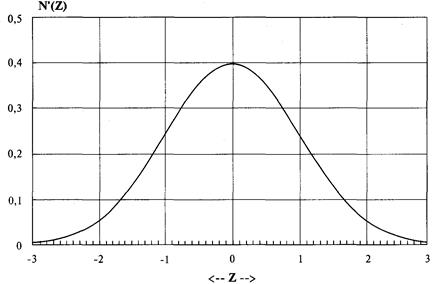
Рисунок 3- 7 Функция плотности нормального распределения
вероятности
Более того, часто имеет смысл из всех точек данных вычесть
среднее. При этом центр распределения сместится в начало координат. В этом
случае точка данных, которая смещена на одно стандартное отклонение вправо от
среднего, имеет значение 1 на оси X.
Если мы вычтем среднее из точек данных, а затем разделим
полученные значения на стандартное отклонение точек данных, то преобразуем
распределение в нормированное нормальное
(standardized normal). Это нормальное
распределение со средним, равным 0, и дисперсией, равной 1. Теперь N'(Z) даст нам значение на оси Y (высота
кривой) для любого значения Z:
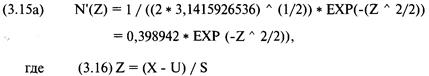
U = среднее значение данных;
S = стандартное отклонение данных;
Х = наблюдаемая точка данных;
ЕХР() = экспоненциальная функция.
Уравнение (3.16) дает нам число стандартных единиц, которым соответствует точка данных; другими
словами, число стандартных отклонений, на которое точка данных смещена от
среднего. Когда уравнение (3.16) равно 1, оно называется стандартным нормальным отклонением (standard normal deviate) от среднего значения.
Стандартное отклонение, или стандартная единица, иногда называется сигмой (sigma). Таким образом,
когда говорят о событии, которое было «событием пяти сигма», то речь идет о
событии, вероятность которого находится за пределами пяти стандартных
отклонений.
Рисунок 3-7 показывает нормальную кривую, заданную
предедущим уравнением. Отметьте, что высота стандартной нормальной кривой
составляет 0,39894, поскольку из уравнения (3.15а) мы получаем:

Отметьте, что кривая непрерывна
(в ней нет «разрывов»), когда она переходит из отрицательной области слева в
положительную область справа. Отметьте также, что кривая симметрична: сторона
справа от пика является зеркальным отражением стороны слева. Предположим,
у нас есть группа данных, где среднее равно 11, а стандартное отклонение равно
20. Чтобы увидеть, где точка данных будет отображена на кривой, рассчитаем ее
в стандартных единицах. Предположим, что рассматриваемая точка данных имеет
значение -9. Чтобы рассчитать число стандартных единиц, мы сначала должны
вычесть среднее из этой точки данных: -9- 11 =-20
Затем надо разделить полученный результат на стандартное
отклонение:
-20/20=-1
Теперь мы можем сказать, что, когда точка данных равна -9,
среднее равно 11, а стандартное отклонение составляет 20, число стандартных
единиц равно -1. Другими словами, мы находимся на одно стандартное отклонение
от пика кривой, и, так как это значение отрицательно, оно находится слева от
пика. Чтобы увидеть, где это будет на самой кривой (то есть насколько высока
кривая при одном стандартном отклонении слева от центра, или чему равно
значение кривой на оси Y для значения -1 на оси X), надо
подставить полученное значение в уравнение (3.15а):
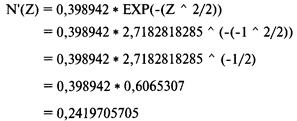
Таким образом, высота кривой при Х=-1 составляет
0,2419705705. Функция N'(Z)
также часто выражается как:
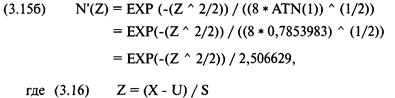
и ATN() = функция
арктангенса;
U = среднее значение данных;
S = стандартное отклонение данных;
Х = наблюдаемая точка данных;
ЕХР() =
экспоненциальная функция.
Не искушенные в статистике люди часто находят концепцию
стандартного отклонения (или квадрата ее величины, дисперсии) трудной для представления. Среднее абсолютное отклонение (mean absolute deviation), которое можно
преобразовать в стандартное отклонение, гораздо проще для понимания. Среднее
абсолютное отклонение полностью отвечает своему названию: среднее данных
вычитается из каждой точки данных, затем абсолютные значения каждой из этих
разностей суммируются, и данная сумма делится на число точек данных. В
результате у вас получается среднее расстояние каждой точки данных до среднего
значения. Преобразование среднего абсолютного отклонения в стандартное
отклонение, и наоборот, представлены далее:
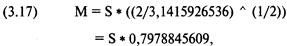
где М = среднее
абсолютное отклонение;
S = стандартное
отклонение.
Можно
сказать, что при нормальном распределении среднее абсолютное отклонение равно
стандартному отклонению, умноженному на 0,7979.
(3.18) S = М * 1 / 0,7978845609
=М* 1,253314137, где
S = стандартное отклонение;
М = среднее абсолютное отклонение.
Мы можем также сказать, что при нормальном распределении
стандартное отклонение равно среднему абсолютному отклонению, умноженному на
1,2533. Так как дисперсия всегда является стандартным отклонением в квадрате
(а стандартное отклонение является квадратным корнем дисперсии), мы можем задать
преобразование между дисперсией и средним абсолютным отклонением.
(3.19)
М = V
^ (1/2) * ((2 / 3,1415926536)^ (1/2))
= V ^ (1/2)* 0,7978845609,
где М = среднее
абсолютное отклонение;
V = дисперсия.
(3.20)
V = (М * 1,253314137)^
2,
где V =дисперсия;
М = среднее абсолютное отклонение.
Так как стандартное отклонение в стандартной нормальной
кривой равно 1, мы можем сказать, что среднее абсолютное отклонение в
стандартной нормальной кривой равно 0,7979. Более того, в
колоколообразной кривой, подобной нормальной, семи-интер-квартильная широта
равна приблизительно 2/3 стандартного отклонения, и поэтому стандартное
отклонение примерно в 1,5 раза больше семи-интерквартильной широты. Это
справедливо для большинства колоколообразных распределений, а не только для
нормальных, как и в случае с преобразованием среднего абсолютного отклонения в
стандартное отклонение.
Нормальные
вероятности
Теперь мы знаем, как преобразовывать наши необработанные
данные в стандартные единицы и как построить кривую N'(Z) (т.е. как найти высоту кривой, или координату Y, для данной стандартной единицы), а также N'(X) (из уравнения (3.14), т.е. саму
кривую без первоначального преобразования в стандартные единицы). Для
практического использования нормального распределения вероятности нам надо
знать вероятность определенного результата. Это определяется не высотой кривой,
а площадью под кривой. Эта площадь задается интегралом функции N'(Z), которую мы до настоящего момента
изучали. Теперь мы займемся N(Z), интегралом N'(Z), чтобы найти площадь под кривой (т.е. вероятности)1.
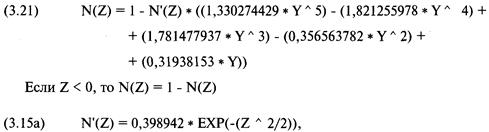
где Y=1/(1+2316419*ABS(Z))
и ABSQ = функция абсолютного значения;
ЕХР() =
экспоненциальная функция.
При расчете вероятности мы всегда будем преобразовывать
данные в стандартные единицы. То есть вместо функции N(X) мы будем использовать функцию
N(Z), где:
(3.16) Z=(X-U)/S,
где U = среднее значение данных;
S = стандартное отклонение данных;
Х = наблюдаемая точка данных.
Теперь обратимся к уравнению (3.21). Допустим, нам надо
знать, какова вероятность события, не превышающего +2 стандартных единицы (Z = +2).
Y=
1/(1 +2316419*ABS(+2)) =1/1,4632838 =0,68339443311
(3.15a) N'(Z) = 0,398942
* ЕХР(-(+2^2/2))
=
0,398942 *ЕХР (-2)=0,398942*0,1353353=0,05399093525
Заметьте, мы можем найти высоту кривой при +2 стандартных
единицах. Подставляя полученные значения вместо Y
и N'(Z) в уравнение (3.21), мы можем
получить вероятность события, не превышающего +2 стандартных единицы:
N(Z) = 1 - N'(Z) *
((1,330274429 * Y^ 5) -
- (1,821255978 * Y^4) +
(1,781477937 * Y^ 3) -
- (0,356563782 * Y ^ 2) + (0,31938153 * Y))
= 1-0,05399093525* ((1,330274429* 0,68339443311^5)-
- (1,821255978 * 0,68339443311 ^
4 + 1,781477937 * 0,68339443311^ 3) - - (0,356563782 * 0,68339443311 ^2) +
0,31938153 * 0,68339443311))
= 1 - 0,05399093525 * (1,330274429 * 0,1490587) -
- (1,821255978 * 0,2181151 + (1,781477937 * 0,3191643)-
-
(0,356563782 * 0,467028 + 0,31938153 - 0,68339443311))
1-
0,05399093525 * (0,198288977 - 0,3972434298 + 0,5685841587 -
-0,16652527+0,2182635596)
= 1 - 0,05399093525 * 0,4213679955 = 1 - 0,02275005216=
0,9772499478
Таким образом, можно ожидать, что 97,72% результатов в
нормально распределенном случайном процессе не попадают за +2 стандартные
единицы. Это изображено на рисунке 3-8.
Чтобы узнать, какова вероятность события, равного или
превышающего заданное число стандартных единиц (в нашем случае +2), надо
просто изменить уравнение (3.21) и не использовать условие «Если Z < 0, то N(Z) = 1 - N(Z)». Поэтому вторая с конца строка в последнем расчете
изменится с
= 1 - 0,02275005216 на 0,02275005216
Таким
образом, с вероятностью 2,275% событие в нормально распределенном случайном
процессе будет равно или превышать +2 стандартные единицы. Это показано на
рисунке 3-9.
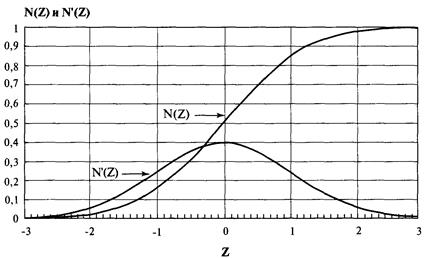
Рисунок
3-8 Уравнение (3.21) для
вероятности Z=+2
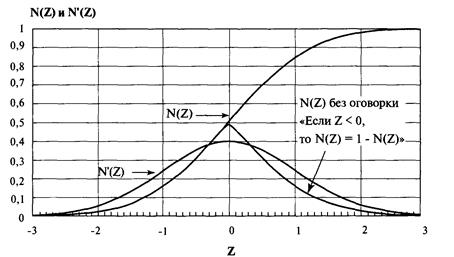
Рисунок 3-9 Устранение
оговорки «Если Z < 0, то N(Z) = 1 - N(Z)» в уравнении (3.21)
До сих
пор мы рассматривали площади под кривой 1-хвостых распределений вероятности. То
есть до настоящего момента мы отвечали на вопрос: «Какова вероятность события,
которое меньше (больше) заданного количества стандартных единиц от среднего?»
Предположим, теперь нам надо ответить на такой вопрос: «Какова вероятность
события, которое находится в интервале между
определенным количеством стандартных единиц от среднего?» Другими словами, мы
хотим знать, как подсчитать 2-хвостые вероятности. Посмотрим на рисунок 3-10.
Он представляет вероятности события в интервале двух стандартных единиц от
среднего. В отличие от рисунка 3-8 этот расчет вероятности не включает крайнюю
область левого хвоста, область меньше -2 стандартных единиц. Для расчета
вероятности нахождения в диапазоне Z стандартных единиц
от среднего вы должны сначала рассчитать 1-хвостую вероятность абсолютного
значения Z с помощью уравнения (3.21), а затем полученное значение подставить
в уравнение (3.22), которое дает 2-хвостые вероятности (то есть вероятности
нахождения в диапазоне ABS(Z)
стандартных единиц от среднего):
(3.22) 2-хвостая
вероятность =1-((1- N(ABS(Z))) * 2)
Если мы рассматриваем вероятности наступления события в
диапазоне 2 стандартных отклонений (Z = 2), то из уравнения (3.21) найдем, что
N(2) = 0,9772499478 и можно использовать полученное значение
для уравнения (3.22):
2-хвостая вероятность
=1-((1- 0,9772499478) * 2) =1-(0,02275005216*2) = 1 - 0,04550010432 = 0,9544998957
Таким образом, из этого уравнения следует, что при
нормально распределенном случайном процессе вероятность события, попадающего в
интервал 2 стандартных единиц от среднего, составляет примерно 95,45%.
Как и в
случае с уравнением (3.21), можно убрать первую единицу в уравнении (3.22),
чтобы получить (1 - N(ABS(Z))) * 2, что представляет вероятности события вне ABS(Z) стандартных единиц от среднего. Это
отображено на рисунке 3-11. Для нашего примера, где Z = 2, вероятность события
при нормально распределенном случайном процессе вне 2 стандартных единиц составляет:
2-хвостая вероятность
(вне) = (1 - 0,9772499478) * 2 =0,02275005216*2 =0,04550010432
Наконец, мы рассмотрим случай, когда надо найти вероятности
(площадь под кривой N'(Z))
для двух различных значений Z.
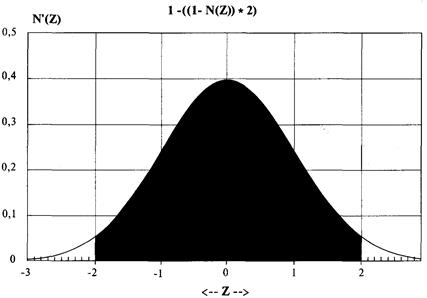
Рисунок
3-10 2-хвостая вероятность события между +2 и -2 сигма
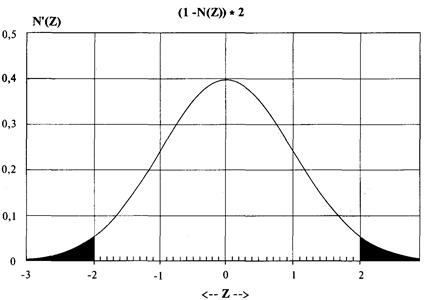
Рисунок
3-11 2-хвостая вероятность события, находящегося вне 2 сигма
Допустим,
нам надо найти площадь под кривой N'(Z) между -1 стандартной единицей и +2 стандартными
единицами. Есть два способа расчета. Мы можем рассчитать вероятность,
не превышающую +2 стандартные единицы, при помощи уравнения (3.21) и вычесть
вероятность, не превышающую -1 стандартную единицу (см. рисунок 3-12). Это
даст нам:
0,9772499478 - 0,1586552595 = 0,8185946883
Рисунок
3-12 Площадь между -1 и +2 стандартными единицами
Другой способ: из единицы, представляющей всю площадь под
кривой, надо вычесть вероятность, не превышающую -1 стандартную единицу, и
вероятность, превышающую 2 стандартные единицы:
= 1 - (0,022750052 + 0,1586552595) = 1 -0,1814053117
=0,8185946883
С помощью рассмотренных в этой главе математических
подходов вы сможете рассчитывать любые вероятности событий для случайных
процессов, имеющих нормальное распределение.
Последующие
производные нормального распределения
Иногда требуется знать вторую производную функции N(Z). Так как функция N(Z) дает нам значение площади под кривой
при Z, а функция N'(Z) дает нам высоту самой кривой при значении Z, тогда
функция N"(Z) дает нам мгновенный наклон (instantaneous slope) кривой при данном значении Z:
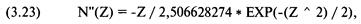
где ЕХР() =
экспоненциальная функция.
Найдем наклон кривой N'(Z) при +2 стандартных отклонениях:
N"(Z) = -2 I 2,506628274
* ЕХР(-(+2^ 2) / 2) = -2 / 2,506628274 * ЕХР(-2) = -2 / 2,506628274 * 0,1353353 =-0,1079968336
Теперь мы знаем, что мгновенная скорость изменения функции N'(Z) при Z = +2 равна-0,1079968336. Это
означает повышение/понижение за период, поэтому, когда Z = +2, кривая N'(Z) повышается на -0,1079968336. Эта ситуация
показана на рисунке 3-13.
Последующие
производные даются далее для справки. Они не будут использоваться в оставшейся
части книги и представлены для полноты освещения темы:
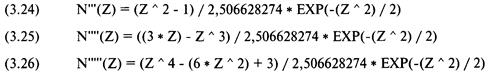
В качестве последнего дополнения к сказанному о нормальном
распределении стоит заметить, что на самом деле это распределение не такое
остроконечное, как на графиках, представленных в данной главе. Реальная форма
нормального распределения показана на рисунке 3-14. Отметьте, что здесь
масштабы двух осей одинаковы, в то время как в других графических примерах они
отличаются для придания более вытянутой формы.
Логарифмически
нормальное распределение
Для торговли многие приложения требуют небольшой, но важной
модификации нормального распределения.
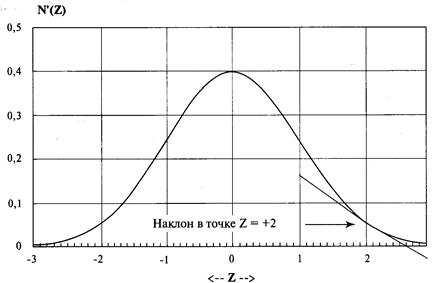
Рисунок
3-13 N"(Z) дает наклон касательной к N'(Z) при Z = +2

Рисунок
3-14 Реальная форма нормального распределения
С
помощью этой модификации нормальное распределение преобразуется в логарифмически
нормальное распределение. Цена любого свободно котируемого инструмента имеет
нулевое значение в качестве нижнего предела1.
Поэтому когда цена этого инструмента падает и приближается к нулю, то,
теоретически, цене инструмента должно быть все труднее понизиться. Рассмотрим
некую акцию стоимостью 10 долларов. Если бы акция упала на 5 долларов до 5
долларов за акцию (50% понижение), то в соответствии с нормальным
распределением она может также легко упасть с 5 долларов до 0 долларов. Однако
при логарифмически нормальном распределении подобное падение на 50% с цены в 5
долларов за акцию до цены 2,50 долларов за акцию будет примерно таким же
вероятным, как и падение с 10 долларов до 5 долларов за акцию.
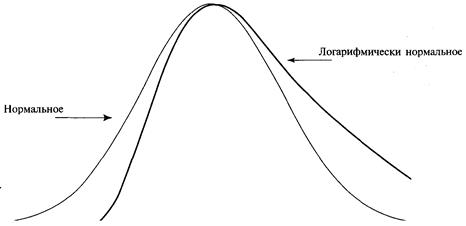
Рисунок
3-15 Нормальное и логарифмически нормальное распределения
Логарифмически нормальное распределение, рисунок 3-15,
работает точно так же, как и нормальное распределение, за тем исключением, что
при логарифмически нормальном распределении мы имеем дело с процентными
изменениями, а не абсолютными. Теперь рассмотрим движение вверх. В
соответствии с логарифмически нормальным распределением движение с 10 долларов
за акцию до 20 долларов за акцию аналогично движению с 5 долларов до 10
долларов за акцию, так как оба эти движения представляют повышение на 100%. Это
не означает, что мы не будем использовать нормальное распределение. Мы просто
познакомимся с логарифмически нормальным распределением, покажем его отличие
от нормального (логарифмически нормальное распределение использует процентные,
а не абсолютные изменения цены) и увидим, что обычно именно оно используется
при обсуждении ценовых движений или в том случае, когда нормальное
распределение ограничено снизу нулем. Для использования логарифмически
нормального распределения необходимо преобразовывать данные, с которыми вы
работаете, в натуральные логарифмы1.
Преобразованные данные будут нормально распределяться, если
необработанные данные распределялись логарифмически нормально. Если мы
рассматриваем распределение изменений цены и оно логарифмически нормальное, то
можно использовать нормальное распределение. Сначала мы должны разделить
каждую цену закрытия на предыдущую цену закрытия. Допустим, мы рассматриваем
распределение ежемесячных цен закрытия (можно использовать любой временной
период: часовой, дневной, годовой и т.д.). Предположим, цены закрытия
последних пяти месяцев — 10 долларов, 5 долларов, 10 долларов, 10 долларов и
20 долларов. Это соответствует понижению на 50% во втором месяце, повышению на
100% в третьем месяце, повышению на 0% в четвертом месяце и повышению на 100% в
пятом месяце. Соответственно мы получим частные 0,5; 2; 1 и 2 по ежемесячным
изменениям цен со второго по пятый месяцы. Это то же, что и HPR нашей последовательности. Теперь мы должны преобразовать
их в натуральные логарифмы, чтобы изучить полученное распределение на основе
математического аппарата нормального распределения. Таким образом, натуральный
логарифм 0,5 равен -0,6931473, ln(2) =0,6931471 и
ln(1) = 0. Теперь к распределению этих преобразованных данных мы можем применять
математические методы, относящиеся к нормальному распределению.
Параметрическое
оптимальное f
Мы немного познакомились с математикой нормального и
логарифмически нормального распределения и теперь посмотрим, как находить
оптимальное f по нормально распределенным результатам. Формула
Келли является примером параметрического оптимального f,
где f является функцией двух параметров. В формуле Келли
вводные параметры — это процент выигрышных ставок и отношение выигрыша к
проигрышу. Однако формула Келли даст вам оптимальное f только тогда, когда
возможные результаты имеют бернуллиево распределение. Другими словами, формула
Келли даст правильное оптимальное f, когда есть только два возможных
результата, в противном случае, как, например, в нормально распределенных
результатах, формула Келли не даст вам правильное оптимальное f2.
Параметрические
методы гораздо мощнее эмпирических. Рассмотрим ситуацию, которую можно
полностью описать бернуллиевым распределением. Мы можем рассчитать оптимальное
f либо из формулы Келли, либо с помощью эмпирического метода. Допустим, мы
выигрываем 60% времени. Предположим, мы бросаем несимметричную монету, и при
долгой последовательности 60% бросков будут приходиться на лицевую сторону.
Поэтому мы каждый раз ставим на то, что монета будет выпадать на лицевую
сторону, и выигрыш составляет 1:1. Из формулы Келли следует, что надо ставить
0,2 нашего счета. Также допустим, что из прошлых 20 бросков 11 выпали лицевой
стороной, а 9 обратной. Если бы мы использовали эти 20 сделок в качестве
вводных данных для эмпирического метода расчета f, результатом было бы то, что
следует рисковать 0,1 нашего счета при каждой следующей ставке. Какое
значение правильно, 0,2, полученное параметрическим методом (формула Келли с
бернуллиевым распределением), или 0,1, найденное эмпирически на основе 20
последних бросков? Правильным ответом является значение 0,2, найденное с
помощью параметрического метода. Причина в том, что каждый последующий бросок
имеет 60% вероятность выпасть лицевой стороной, а не 55% вероятность, что
следует из результатов 20 последних бросков. Хотя мы рассматриваем только 5%
отклонение в вероятности, то есть 1 бросок из 20, результаты после применения
разных значений f будут сильно отличаться. Вообще параметрические методы
внутренне более точны, чем эмпирические (при условии, что мы знаем
распределение результатов). Это первое преимущество параметрического метода.
Самый большой недостаток параметрических методов состоит в том, что мы должны
знать, каким распределение результатов будет в течение длительного времени. Второе
преимущество состоит в том, что для эмпирического метода требуются исторические данные, в то время как для параметрического
в этом нет необходимости. Кроме того, эта история должна быть довольно
протяженной. В только
что
рассмотренном примере можно предположить, что, если бы у нас была история 50
бросков, мы бы получили эмпирическое оптимальное f
ближе к 0,2. При истории 1000 бросков оно было бы еще ближе. Тот
факт, что эмпирические методы требуют довольно большого объема исторических
данных, свел все их использование к механическим торговым системам. Тот, кто в
торговле использует что-либо отличное от механических торговых систем, будь то
волны Эллиотта или фундаментальные данные, практически не имеет возможности
использовать метод оптимального f. С параметрическими методами дело обстоит
иначе. Например, тот, кто желает слепо следовать какому-нибудь рыночному гуру,
имеет теперь возможность использовать оптимальное f. В этом состоит третье
преимущество параметрического метода — он может использоваться любым трейдером на любом рынке. В
том случае, когда не используется механическая торговая система, следует
помнить о важном допущении. Оно состоит в том, что будущее распределение
прибылей и убытков будет напоминать распределение в прошлом (поэтому мы и
рассчитываем оптимальное f), это может оказаться менее вероятным, чем в случае использования механической системы.
Все
вышесказанное заставляет по-иному взглянуть на ожидаемую работу любого не
полностью механического метода. Даже профессионалы («фундамента-листы»,
последователи Ганна или Эллиотта и т.п.), использующие такие методы, обречены
на неудачу, если они находятся далеко справа от пика кривой f. Если они слишком
далеко слева от пика, то получат геометрически более низкие прибыли, чем их
опыт и навыки в этой области позволяют. Более того, практики не полностью
механических методов должны понимать, что все сказанное об оптимальном f и
чисто механических методах будет иметь прямое отношение и к их системам. Это
надо учитывать при использовании подобных методов. Помните, что проигрыши могут
быть значительными, но это не означает, что метод не следует применять.
Четвертое
и, возможно, наибольшее преимущество параметрического метода определения
оптимального f состоит в том, что параметрический метод позволяет создавать
модели «что если». Например, вы решили торговать по рыночной системе, которая
работала достаточно успешно, но хотите подготовиться к ситуации, когда эта
рыночная система прекратит хорошо работать. Параметрические методы позволяют
варьировать ваши вводные параметры для отражения возможных изменений, и
благодаря этому показать, когда рыночная система прекратит хорошо работать. Еще
раз повторюсь: параметрические методы намного мощнее эмпирических.
Зачем
вообще использовать эмпирические методы? Они интуитивно более очевидны, чем
параметрические. Следовательно, эмпирические методы необходимо изучать до
перехода к параметрическим. Мы уже достаточно подробно рассмотрели эмпирический
подход и поэтому готовы изучать параметрические методы.
Распределение
торговых прибылей и убытков (P&L)
Рассмотрим следующую последовательность 232 торговых
прибылей и убытков в пунктах. Не имеет значения, к какому товару или системе
относится этот поток данных — это может быть любая система на любом рынке.
|
№ сделки P&L
|
№ сделки P&L
|
№ сделки P&L
|
№ сделки
|
P&L
|
|
1. 0,18
|
25. 0,15
|
49. 0,17
|
73.
|
0,22
|
|
2. -1,11
|
26. 0,15
|
50. -1,53
|
74.
|
0,92
|
|
3. 0,42
|
27. -1,14
|
51. 0,15
|
75.
|
0,32
|
|
4. -0,83
|
28. 1,12
|
52. -0,93
|
76.
|
0,17
|
|
5. 1,42
|
29. -1,88
|
53. 0,42
|
77.
|
0,57
|
|
6. 0,42
|
30. 0,17
|
54. 2,77
|
78.
|
0,17
|
|
7. -0,99
|
31. 0,57
|
55. 8,52
|
79.
|
1,18
|
|
8. 0,87
|
32. 0,47
|
56. 2,47
|
80.
|
0,17
|
|
9. 0,92
|
33. -1,88
|
57. -2,08
|
81.
|
0,72
|
|
10. -0,4
|
34. 0,17
|
58. -1,88
|
82.
|
-3,33
|
|
11. -1,48
|
35. -1,93
|
59. -1,88
|
83.
|
-4,13
|
|
12. 1,87
|
36. 0,92
|
60. 1,67
|
84.
|
-1,63
|
|
13. 1,37
|
37. 1,45
|
61. -1,88
|
85.
|
-1,23
|
|
14. -1,48
|
38. 0,17
|
62. 3,72
|
86.
|
1,62
|
|
15. -0,21
|
39. 1,87
|
63. 2,87
|
87.
|
0,27
|
|
16. 1,82
|
40. 0,52
|
64. 2,17
|
88.
|
1,97
|
|
17. 0,15
|
41. 0,67
|
65. 1,37
|
89.
|
-1,72
|
|
18. 0,32
|
42. -1,58
|
66. 1,62
|
90.
|
1,47
|
|
19. -1,18
|
43. -0,5
|
67. 0,17
|
91.
|
-1,88
|
|
20. -0,43
|
44. 0,17
|
68. 0,62
|
92.
|
1,72
|
|
21. 0,42
|
45. 0,17
|
69. 0,92
|
93.
|
1,02
|
|
22. 0,57
|
46. -0,65
|
70. 0,17
|
94.
|
0,67
|
|
23. 4,72
|
47. 0,96
|
71. 1,52
|
95.
|
0,67
|
|
24. 12,42
|
48. -0,88
|
72. -1,78
|
96.
|
-1,18
|
|
|
|
|
Продолжение
|
|
№ сделки
|
P&L
|
№ сделки
|
P&L
|
№ сделки
|
P&L
|
№ сделки P&L
|
|
97.
|
3,22
|
126.
|
-1,83
|
155.
|
0,37
|
184. 0,57
|
|
98.
|
-4,83
|
127.
|
0,32
|
156.
|
0,87
|
185. 0,35
|
|
99.
|
8,42
|
128.
|
1,62
|
157.
|
1,32
|
186. 1,57
|
|
100.
|
-1,58
|
|
|
158.
|
0,16
|
187. -1,73
|
|
101.
|
-1,88
|
130.
|
1,02
|
159.
|
0,18
|
188. -0,83
|
|
102.
|
1,23
|
131.
|
-0,81
|
160.
|
0,52
|
189. -1,18
|
|
103.
|
1,72
|
132.
|
-0,74
|
161.
|
-2,33
|
190. -0,65
|
|
104.
|
1,12
|
133.
|
1,09
|
162.
|
1,07
|
191. -0,78
|
|
105.
|
-0,97
|
134.
|
-1,13
|
163.
|
1,32
|
192. -1,28
|
|
106.
|
-1,88
|
135.
|
0,52
|
164.
|
1,42
|
193. 0,32
|
|
107.
|
-1,88
|
136.
|
0,18
|
165.
|
2,72
|
194. 1,24
|
|
108.
|
1,27
|
137.
|
0,18
|
166.
|
1,37
|
195. 2,05
|
|
109.
|
0,16
|
138.
|
1,47
|
167.
|
-1,93
|
196. 0,75
|
|
110.
|
1,22
|
139.
|
-1,07
|
168.
|
2,12
|
197. 0,17
|
|
111.
|
-0,99
|
140.
|
-0,98
|
169.
|
0,62
|
198. 0,67
|
|
112.
|
1,37
|
141.
|
1,07
|
170.
|
0,57
|
199. -0,56
|
|
113.
|
0,18
|
142.
|
-0,88
|
171.
|
0,42
|
200. -0,98
|
|
114.
|
0,18
|
143.
|
-0,51
|
172.
|
1,58
|
201. 0,17
|
|
115.
|
2,07
|
144.
|
0,57
|
173.
|
0,17
|
202. -0,96
|
|
116.
|
1,47
|
145.
|
2,07
|
174.
|
0,62
|
203. 0,35
|
|
117.
|
4,87
|
146.
|
0,55
|
175.
|
0,77
|
204. 0,52
|
|
118.
|
-1,08
|
147.
|
0,42
|
176.
|
0,37
|
205. 0,77
|
|
119.
|
1,27
|
148.
|
1,42
|
177.
|
-1,33
|
206. 1,10
|
|
120.
|
0,62
|
149.
|
0,97
|
178.
|
-1,18
|
207. -1,88
|
|
121.
|
-1,03
|
150.
|
0,62
|
179.
|
0,97
|
208. 0,35
|
|
122.
|
1,82
|
151.
|
0,32
|
180.
|
0,70
|
209. 0,92
|
|
123.
|
0,42
|
152.
|
0,67
|
181.
|
1,64
|
210. 1,55
|
|
124.
|
-2,63
|
153.
|
0,77
|
182.
|
0,57
|
211. 1,17
|
|
125.
|
-0,73
|
154.
|
0,67
|
183.
|
0,24
|
212. 0,67
|
|
|
|
|
Продолжение
|
|
№ сделки P&L
|
№ сделки
|
P&L
|
№ сделки
|
P&L
|
№ сделки P&L
|
|
213. 0,82
|
218.
|
0,25
|
223.
|
-1,30
|
228.
|
1,80
|
|
214. -0,98
|
219.
|
0,14
|
224.
|
0,37
|
229.
|
2,12
|
|
215. -0,85
|
220.
|
0,79
|
225.
|
-0,51
|
230.
|
0,77
|
|
216. 0,22
|
221.
|
-0,55
|
226.
|
0,34
|
231.
|
-1,33
|
|
217. -1,08
|
222.
|
0,32
|
227.
|
-1,28
|
232.
|
1,52
|
Если мы хотим определить приведенное параметрическое
оптимальное f, нам придется преобразовать эти торговые прибыли и убытки
в процентные повышения и понижения (основываясь на уравнениях с (2.10а) по
(2.10в)). Затем мы преобразуем эти процентные прибыли и убытки, умножив их на
текущую цену базового инструмента. Например, P&L № 1 составляет 0,18.
Допустим, что цена входа в эту сделку была 100,50. Таким образом, процентное
повышение по этой сделке будет 0,18/100,50 = 0,001791044776. Теперь
предположим, что текущая цена базового инструмента составляет 112,00. Умножив
0,001791044776 на 112,00, мы получаем приведенное P&L = 0,2005970149. Чтобы
получить полные приведенные данные, необходимо проделать эту процедуру для всех
232 торговых прибылей и убытков.
Независимо от того, будем мы проводить расчеты, используя
приведенные данные, или нет (в этой главе мы не будем использовать приведенные
данные), мы все равно должны рассчитать среднее (арифметическое) и стандартное
отклонение совокупности этих 232 торговых прибылей и убытков. В нашем случае
это 0,330129 и 1,743232 соответственно (если бы мы проводили операции на приведенной
основе, нам бы понадобилось определять среднее и стандартное отклонение по
приведенным торговым P&L). Теперь мы можем использовать уравнение (3.16),
чтобы преобразовать каждую отдельную торговую прибыль и убыток в стандартные
единицы.
(3.16) Z=(X-U)/S,
где U = среднее значение данных;
S = стандартное отклонение данных;
Х = наблюдаемая точка данных.
Для сделки № 1 преобразуем прибыль 0,18 в стандартные
единицы:
Z= (0,18-0,330129)/1,743232
=-0,150129/1,743232 =-0,08612106708
Таким
же образом следующие три сделки -1,11; 0,42 и -0,83 преобразовываются в
-0,8261258398; 0,05155423948 и -0,6655046488 стандартных единицы. После
того, как мы преобразуем все торговые прибыли и убытки в стандартные единицы,
можно собрать в ячейки теперь уже нормированные данные. Вспомните, что при
наличии ячеек теряется часть информации о распределении (в нашем случае о
распределении отдельных сделок), но характер распределения остается тем же. Допустим,
мы помещаем эти 232 сделки в 10 ячеек. Количество ячеек выбрано произвольно —
мы могли бы выбрать 9 или 50 ячеек.
Рисунок 3-16 232 сделки в
10 ячейках от -2 до +2 сигмы и нормальное распределение
Когда мы размещаем данные в ячейки, то должны выбрать
интервал значений, в котором расположены ячейки. Мы выберем интервал от -2 до
+2 сигмы. Это означает, что у нас будет 10 одинаковых ячеек между -2
стандартными единицами и +2 стандартными единицами. Так как между -2 и +2 4
стандартных единицы и мы делим этот диапазон на 10 равных частей, то получаем 4
/ 10 = 0,4 стандартных единицы в качестве размера или «ширины» каждой ячейки.
Поэтому наша первая ячейка будет содержать те сделки, которые были в диапазоне
от -2 до -1,6 стандартных единиц, следующая ячейка будет содержать сделки
от-1,6 до-1,2, затем от -1,2 до -0,8, и так далее, пока последняя ячейка не
вместит сделки между 1,6 и 2 стандартными единицами. В нашем случае те сделки,
которые менее –2 стандартных единиц или больше +2 стандартных единиц, не
будут размещены в ячейки, и мы их проигнорируем. Если бы мы пожелали, то
включили бы их в крайние ячейки, разместив точки данных менее -2 в ячейку от -2
до -1,6, и таким же образом поступили бы в отношении тех точек данных, которые
больше 2. Конечно, мы могли бы выбрать более широкий диапазон, но эти сделки
находятся за пределами выбранных ячеек, и мы их не учитываем. Другими словами,
мы не рассматриваем сделки, P&L в которых меньше, чем 0,330129 - (1,743232 * 2) = =
-3,1563, или больше, чем 0,330129 + (1,743232 * 2) = 3,816593. Мы
сейчас создали распределение торговых P&L системы. Распределение содержит
10 точек данных, так как мы решили работать с 10 ячейками. Каждая точка данных
отражает число сделок, которые попадают в эту ячейку Каждая сделка не может попасть
более чем в 1 ячейку и если сделка находится за пределами 2 стандартных единиц
с любой стороны среднего (P&L < -3,156335 или > 3,816593), тогда она
не будет представлена в этом распределении. Рисунок 3-16 показывает
распределение, которое мы только что рассчитали. Может показаться,
что распределение P&L торговой системы должно всегда быть смещено вправо
за счет больших выигрышей. Наше распределение 232 торговых P&L представляет
систему, которая в основном приносит небольшие прибыли. Многие трейдеры имеют
ошибочное мнение, что распределение P&L должно быть смещено вправо для
всех торговых систем. Это не всегда верно, что и подтверждает рисунок 3-16.
Разные рыночные системы имеют различные распределения, и вам не следует
ожидать, что все они будут одинаковыми. Также на рисунке 3-16
показано нормальное распределение для 232 торговых P&L, если бы они были
нормально распределены. Это было сделано для того, чтобы вы могли графически
сравнить торговые P&L для полученного и нормального распределения. Сначала
нормальное распределение рассчитывается для границ каждой ячейки. Для самой
левой ячейки это Z =-2 и Z=-1,6. Теперь
подставим полученные значения Z в уравнение (3.21), чтобы рассчитать
вероятность. В нашем примере это соответствует 0,02275 для Z = -2 и 0,05479932
для Z = -1,6. Затем возьмем абсолютное значение разности этих двух значений,
которое в нашем примере будет ABS(0,02275 -
0,05479932) = = 0,03204932. Затем умножим полученный ответ на
количество точек данных, то есть на 232 (мы все еще должны использовать 232
сделки, хотя некоторые исключаются, так как находятся вне диапазона выбранных
ячеек). Таким образом, если бы данные были нормально распределены и размещены в
10 ячеек равной ширины между -2 и +2 сигма, тогда самая левая ячейка содержала
бы 0,03204932 * 232 = 7,43544224 элемента. Если сделать расчет для каждой из 10
ячеек, мы получим нормальную кривую, показанную на рисунке 3-16.
Поиск
оптимального f пo нормальному распределению
Сейчас
мы разработаем метод поиска оптимального f
по нормально распределенным данным. Как и формула Келли, это способ относится
к параметрическим методам. Однако он намного мощнее, так как формула Келли
отражает только два возможных результата события, а этот метод позволяет
получить полный спектр результатов (при условии, что результаты нормально
распределены). Удобство нормально распределенных результатов (кроме того
факта, что в реальности они часто являются пределом многих других
распределений) состоит в том, что их можно описать двумя параметрами. Формулы
Келли дадут вам оптимальное f для бернуллиевых результатов, если известны два
параметра: отношение выигрыша к проигрышу и вероятность выигрыша.
Метод расчета оптимального f, о котором мы сейчас расскажем, также требует
только два параметра — среднее значение и стандартное отклонение результатов. Вспомним,
что нормальное распределение является непрерывным распределением. Для того,
чтобы использовать этот метод, необходимо дискретное распределение. Далее
вспомним, что нормальное распределение является неограниченным распределением. Первые
два шага, которые мы должны сделать для нахождения оптимального f по нормально
распределенным данным, — это определить, (1) на сколько сигма от среднего
значения мы усекаем распределение и (2) на сколько равноотстоящих точек данных
мы разделим интервал между двумя крайними точками, найденными в (1). Например,
мы знаем, что 99,73% всех точек данных находятся между плюс и минус 3 сигма от
среднего, поэтому можно использовать 3 сигма в качестве параметра для (1).
Другими словами, мы рассматриваем нормальное распределение только между минус 3
сигма и плюс 3 сигма от среднего значения. Таким образом, мы охватываем 99,73%
всей активности в пределах нормального распределения. Вообще, для этого
параметра лучше использовать значение от 3 до 5 сигма. Что касается числа
равноотстоящих точек данных (шаг 2), мы будем использовать число, как минимум,
в десять раз большее количества стандартных отклонений, которое используется в
(1). Если мы выберем 3 сигма для (1), тогда возьмем, по крайней мере, 30
равноотстоящих точек данных для (2). Это означает, что на горизонтальной оси
следует отметить отрезок от минус 3 сигма до плюс 3 сигма и нанести на нем 30
равноотстоящих точек. Так как между минус 3 сигма и плюс 3 сигма находится 6
сигма и нам надо разместить на этом отрезке 30 равноотстоящих точек, мы должны
разделить 6 на 30 - 1, или 29. Это даст нам 0,2068965517. Первой точкой данных
будет минус 3. Затем мы будем добавлять 0,2068965517 к каждой предыдущей точке,
пока не достигнем плюс 3. И так нанесем 30 равноотстоящих точек данных между
минус 3 и плюс 3. Нашей второй точкой данных будет -3 + 0,2068965517
=-2,793103448, третьей точкой данных будет 2,79310344 + 0,2068965517 =
-2,586206896, и так далее. Таким образом, мы зададим 30 точек на горизонтальной
оси. Чем больше точек данных вы используете, тем лучше будет разрешение
нормальной кривой. Использование количества точек в десять раз больше числа
стандартных отклонений не является строгим правилом определения минимального
числа точек данных. Нормальное распределение является непрерывным распределением. Однако мы должны сделать его дискретным, чтобы по нему найти
оптимальное f. Чем большее число равноотстоящих точек данных мы используем, тем
ближе наша дискретная модель будет к реальному непрерывному распределению. Почему
не следует использовать слишком большое число точек данных? Чем больше точек
данных вы будете использовать в нормальной кривой, тем больше времени
понадобится для поиска оптимального f. Даже если вы
будете использовать компьютер для поиска оптимального f,
при большом количестве точек данных расчет займет достаточно много времени.
Более того, каждая дополнительная точка данных увеличивает разрешение в меньшей
степени, чем предыдущая точка. Мы будем называть описанные выше два вводных
параметра ограничивающими параметрами (bounding parameters). Третий и четвертый шаги позволят определить среднюю
арифметическую сделку и стандартное отклонение для рыночной системы, с которой
вы работаете. Если у вас нет механической системы, можно получить эти числа из
брокерских отчетов. Один из реальных плюсов рассматриваемого метода состоит в
том, что для его использования не обязательно работать по механической системе,
вам даже не нужны брокерские отчеты или торговые результаты в бумажной форме.
Метод можно использовать, рассчитав два вводных параметра: среднюю
арифметическую сделку (в пунктах или долларах) и стандартное отклонение сделок
(в пунктах или долларах, в зависимости от того, что вы используете для средней
арифметической сделки). Если стандартное отклонение сложно рассчитать, тогда
просто попытайтесь понять, насколько, в среднем, сделка будет отличаться от
средней сделки. Рассчитав среднее абсолютное отклонение, вы можете
использовать уравнение (3.18) для преобразования оценочного среднего
абсолютного отклонения в оценочное стандартное отклонение:
(3.18) S=M* 1/0,7978845609
=М* 1,253314137,
где S = стандартное отклонение;
М = среднее абсолютное отклонение.
Эти два параметра, среднее арифметическое средней сделки и
стандартное отклонение сделок, мы будем называть действительными вводными параметрами. Теперь нам надо взять все
равноотстоящие точки данных из шага (2) и найти их соответствующие ценовые
значения, основываясь на среднем арифметическом значении и стандартном
отклонении. Вспомним, что наши равноотстоящие точки данных выражены в
стандартных единицах. Теперь для каждой из этих равноотстоящих точек данных мы
найдем соответствующую цену:
(3.27) D =
U + (S * Е),
где D = ценовое
значение, соответствующее значению стандартной единицы;
Е = значение стандартной единицы;
S = стандартное отклонение;
U= среднее арифметическое.
После того как мы определили все ценовые значения,
соответствующие каждой точке данных, мы можем сказать, что сконструировали
распределение, к которому, как ожидается, будут
стремиться точки данных.
Однако
данный метод позволяет сделать намного больше. Мы можем включить два
дополнительных параметра, которые позволят нам рассмотреть типы сценариев «что
если». Эти параметры, которые мы назовем параметрами
«что если», позволяют увидеть влияние изменения нашей средней сделки, или
изменения дисперсии (стандартного отклонения) сделок.
Первый
из этих параметров, называемый сжатием (shrink), затрагивает среднюю сделку. Сжатие — это просто множитель
нашей средней сделки. Вспомните, что когда мы находим оптимальное f, то попутно получаем другие величины, которые являются
полезными побочными продуктами оптимального f. Такие расчеты включают среднее
геометрическое, TWR и среднюю геометрическую сделку.
Сжатие является величиной, на которую мы умножаем среднюю сделку еще до того,
как осуществляем поиск оптимального f. Следовательно, сжатие позволяет нам
рассчитать оптимальное f для того случая, когда средняя сделка затронута
сжатием, а также рассчитать новые побочные продукты. Предположим, вы торгуете в
системе, которая в последнее время работала очень эффективно. Вы знаете, что
рано или поздно система прекратит работать так же успешно, поэтому хотите
знать, что произойдет, если средняя сделка будет уменьшена наполовину.
Используя значение сжатия 0,5 (так как сжатие является множителем, то средняя
сделка, умноженная на 0,5, будет равна половине средней сделки), вы можете
найти оптимальное f, когда средняя сделка уменьшается наполовину. Вы сможете
увидеть, как такие изменения затрагивают геометрическую среднюю сделку и другие
величины. Используя значение сжатия 2, вы также сможете увидеть последствия удвоения
средней сделки. Другими словами, параметр сжатия может также использоваться
для увеличения вашей средней сделки. Более того, он позволяет вам взять
неприбыльную систему (то есть систему со средней сделкой меньше нуля) и,
используя отрицательное значение сжатия, посмотреть, что произойдет, если эта
система станет прибыльной. Допустим, у вас есть система, которая показывает
среднюю сделку -100 долларов. Если вы будете использовать значение сжатия -0,5,
то получите оптимальное f для этого распределения со средней
сделкой 50 долларов, так как -100 * * -0,5 = 50. Если бы мы использовали фактор
сжатия -2, то получили бы распределение со средней сделкой 200 долларов.
Следует крайне аккуратно использовать параметры «что если», так как они легко
могут привести к неправильным результатам. Уже было упомянуто, что вы можете
превратить систему с отрицательной арифметической средней сделкой в прибыльную
систему. Это может привести к проблемам, если, например, в будущем, у вас
по-прежнему будет отрицательное ожидание. Другой параметр «что если»
называется растяжением (stretch), но он не противоположен сжатию, как можно было бы
подумать. Растяжение является множителем стандартного отклонения. Вы можете
использовать этот параметр для определения влияния разброса на f и его
побочные продукты. Растяжение всегда должно быть положительным числом, в то
время как сжатие может быть положительным или отрицательным (пока средняя
сделка, умноженная на сжатие, имеет положительное значение). Если вы хотите
увидеть, что произойдет, когда ваше стандартное отклонение удвоится, просто
используйте значение 2 для растяжения. Чтобы увидеть, что произойдет, если
разброс уменьшится, используйте значение меньше 1.При использовании этого
метода вы заметите, что, когда растяжение стремится к нулю, значения побочных
продуктов увеличиваются, и, в результате, вы получаете более оптимистичную
оценку будущего, и наоборот. Сжатие работает противоположным образом, так как
при сжатии, стремящемся к нулю, мы получаем более пессимистичные оценки
будущего, и наоборот. После того как мы зададим значения, которые будем
использовать для растяжения и сжатия (сейчас и для одного, и для другого мы
будем использовать единицу, то есть оставим действительные параметры без
изменения), можно изменить уравнение (3.27):
(3.28) D = (U * Сжатие) + (S
* E * Растяжение),
где D = значение
цены, соответствующее значению стандартной единицы;
Е = значение стандартной единицы;
S = стандартное
отклонение;
U = среднее
арифметическое.
Подведем итоги. Первые два шага определяют ограничительные
параметры (число сигма с каждой стороны от среднего, а также количество
равноотстоящих точек данных, которое мы собираемся использовать в этом
интервале).
Следующие
два шага — это нахождение действительных вводных параметров (средней
арифметической сделки и стандартного отклонения). Мы можем получить эти
параметры эмпирически из результатов торговой системы или из брокерских
отчетов. Можно также получить эти величины оценочным путем, но помните, что
результаты в этом случае будут настолько точны, насколько точны ваши оценки.
Пятый и шестой шаги позволяют определить факторы, которые надо использовать для
растяжения и сжатия, если вы собираетесь использовать сценарий «что если», в
противном случае просто используйте единицу как для растяжения, так и для
сжатия. Седьмым шагом будет использование уравнения (3.28) для преобразования
равноотстоящих точек данных из стандартных значений либо в пункты, либо в
доллары (в зависимости от того, что вы использовали в качестве вводных данных
для средней арифметической сделки и стандартного отклонения).
Восьмой шаг позволит найти вероятность, ассоциированную (associated) (находящуюся во взаимно однозначном соответствии) с
каждой из равноотстоящих точек данных. Эта вероятность определяется уравнением
3.21):

Мы будем использовать уравнение (3.21) без оговорки «если Z < 0, тогда N(Z) = 1 - N(Z)», так как нам надо знать, какова вероятность события, равного
или превышающего заданное количество стандартных единиц.
Каждая точка данных имеет стандартное значение,
определяемое как параметр Z в уравнении (3.21), а также значение, выраженное в
долларах или пунктах. Существует еще одна переменная, соответствующая каждой
равноотстоящей точке данных, — ассоциированная вероятность.
Алгоритм
расчета
Алгоритм будет продемонстрирован на торговом примере, уже
рассмотренном в этой главе. Так как наши 232 сделки выражены в пунктах, нам
следует преобразовать их в соответствующие долларовые значения. Какой именно
рынок
рассматривается, нам неизвестно, поэтому зададим произвольное значение в 1000
долларов за пункт. Таким образом, средняя сделка 0,330129 преобразуется в
0,330129 * 1000 долларов, или в 330,13 доллара. Стандартное отклонение
1,743232, умноженное на 1000 долларов за пункт, станет равно 1743,23 доллара.
Теперь построим матрицу. Сначала мы должны определить диапазон (количество
сигма от среднего), в который попадают данные. В нашем примере мы выберем 3
сигма, что означает диапазон от минус 3 сигма до плюс 3 сигма. Отметьте, что
следует использовать одинаковое количество сигма слева и справа от среднего.
Далее следует определиться с тем, на сколько равноотстоящих точек данных
разделить полученный интервал. Выбрав 61, мы получим точку данных на каждой
десятой части стандартной единицы. Таким образом, мы зададим столбец
стандартных значений.
Теперь
мы должны определить среднее арифметическое, которое будем использовать в качестве
вводного данного. Мы определим его эмпирически из 232 сделок, в нашем случае
оно равно 330,13 доллара. Далее мы найдем стандартное отклонение, которое
также определим эмпирически из 232 сделок, оно будет равно 1743,23 доллара.
Теперь рассчитаем столбец ассоциированных P&L, то есть определим P&L для каждого стандартного значения. Но до того как
определять столбец ассоциированных P&L, мы должны задать значения для
растяжения и сжатия. Так как сейчас мы не собираемся рассматривать сценарии
«что если», то возьмем единицу как для растяжения, так и для сжатия.
Среднее арифметическое = 330,13
Стандартное отклонение = 1743,23
Растяжение = 1
Сжатие = 1
С помощью уравнения (3.28) можно рассчитать столбец
ассоциированных P&L. Для этого возьмите каждое стандартное значение и
подставьте в уравнение (3.28):
(3.29) D = (U * Сжатие) + (S
* E * Растяжение),
где D = значение
цены, соответствующее значению стандартной единицы;
Е = значение стандартной единицы;
S = стандартное отклонение;
U=среднее арифметическое.
При стандартном значении -3 ассоциированное P&L
составляет:
D = (U * Сжатие) + (S * E * Растяжение) = (330,129 * 1) + (1743,232 * (-3) * 1) =
330,129 + (-5229,696) = 330,129 - 5229,696 = -4899,567
Таким образом, ассоциированное P&L при стандартном значении -3 равно -4899,567. Теперь нам
надо определить ассоциированное P&L для следующего стандартного значения,
которое составляет -2,9, для чего решим то же уравнение (3.29), только на этот
раз возьмем Е = -2,9. Теперь определим столбец ассоциированной вероятности. Ее
можно рассчитать, используя стандартное значение в качестве вводного данного
для Z в уравнении (3.21) без оговорки «если Z < О, тогда N(Z) = 1 - N(Z)». При стандартном значении -3 (Z = -3) получаем:
N(Z) = N'(Z) *
((1,330274429 * Y^ 5) - (1,821255978 * Y^ 4) +
+ (1,781477937 * Y ^
3) - (0,356563782 * Y^ 2 + (0,31938153 * Y))) Если Z < 0, тогда N(Z) = 1 - N(Z), где Y =1/(1+0,2316419 *ABS(Z));
ABS() = функция абсолютного значения;
V N'(Z) = 0,398942 * EXP (- (Z^2/2));
ЕХР() = экспоненциальная функция. Таким образом:
N'(-3) = 0,398942 * EXP
(- ((-3)^2/2)) = 0,398942 * ЕХР(- (9/2)) = 0,398942 * EXP (-4,5)
=0,398942*0,011109 =0,004431846678 Y = 1 / (1 + 0,2316419 * ABS(-3)) = I/(1+0,2316419*3) =1/(1+ 0,6949257) =1/1,6949257 =
0,5899963639
N(-3)
= 0,004431846678 * ((1,330274429 * 0,5899963639 ^ 5) -
- (-1,821255978 * 0,5899963639^ 4) + +
(1,781477937 * 0,5899963639^3) -
- (0,356563782 * 0,589996363^ 2) + +
(0,31938153 * 0,5899963639)) = 0,004431846678 * ((1,330274429 * 0,07149022693)
-
- (1,821255978 * 0,1211706) + (1,781477937 * 0,2053752) -
- (0,356563782 * 0,3480957094) + (0,31938153 *
0,5899963639)) = 0,004431846678 * (0,09510162081- 0,2206826796+ 0,3658713876 -
-0,1241183226 + 0,1884339414)
=0,004431846678*0,3046059476 =0,001349966857
Отметьте, если Z имеет отрицательное
значение (Z = -3), нам не надо менять N(Z) на N(Z)
= 1 - N(Z). Теперь для каждого
значения в столбце стандартных значений будут соответствующие значения в
столбце ассоциированных P&L
и в столбце ассоциированной вероятности. Это показано в следующей таблице.
После того как вы заполните эти три столбца, можно начать поиск оптимального f и его побочных продуктов.
|
Стандартное значение
|
Ассоциированные P&L
|
Ассоциированная вероятность
|
Ассоциированное значение HPR при f= 0,01
|
|
-3,0
|
($4899,57)
|
0,001350
|
0,9999864325
|
|
-2,9
|
($4725,24)
|
0,001866
|
0,9999819179
|
|
-2,8
|
($4550,92)
|
0,002555
|
0,9999761557
|
|
-2,7
|
($4376,60)
|
0,003467
|
0,9999688918
|
|
-2,6
|
($4202,27)
|
0,004661
|
0,9999598499
|
|
-2,5
|
($4027,95)
|
0,006210
|
0,9999487404
|
|
-2,4
|
($3853,63)
|
0,008198
|
0,9999352717
|
|
-2,3
|
($3679,30)
|
0,010724
|
0,9999191675
|
|
-2,2
|
($3504,98)
|
0,013903
|
0,9999001875
|
|
Продолжение
|
|
Стандартное значение
|
Ассоциированные P&L
|
Ассоциированная вероятность
|
Ассоциированное значение HPR при f= 0,01
|
|
-2,1
|
($3330,66)
|
0,017864
|
0,9998781535
|
|
-2,0
|
($3156,33)
|
0,022750
|
0,9998529794
|
|
-1,9
|
($2982,01)
|
0,028716
|
0,9998247051
|
|
-1,8
|
($2807,69)
|
0,035930
|
0,9997935316
|
|
-1,7
|
($2633,37)
|
0,044565
|
0,9997598578
|
|
-1,6
|
($2459,04)
|
0,054799
|
0,9997243139
|
|
-1,5
|
($2284,72)
|
0,066807
|
0,9996877915
|
|
-1,4
|
($2110,40)
|
0,080757
|
0,9996514657
|
|
-1,3
|
($1936,07)
|
0,096800
|
0,9996168071
|
|
-1,2
|
($1761,75)
|
0,115070
|
0,9995855817
|
|
-1,1
|
($1587,43)
|
0,135666
|
0,999559835
|
|
-1,0
|
($1413,10)
|
0,158655
|
0,9995418607
|
|
-0,9
|
($1238,78)
|
0,184060
|
0,9995341524
|
|
-0,8
|
($1064,46)
|
0,211855
|
0,9995393392
|
|
-0,7
|
($890,13)
|
0,241963
|
0,999560108
|
|
-0,6
|
($715,81)
|
0,274253
|
0,9995991135
|
|
-0,5
|
($541,49)
|
0,308537
|
0,9996588827
|
|
-0,4
|
($367,16)
|
0,344578
|
0,9997417168
|
|
-0,3
|
($192,84)
|
0,382088
|
0,9998495968
|
|
-0,2
|
($18,52)
|
0,420740
|
0,9999840984
|
|
-0,1
|
$155,81
|
0,460172
|
1,0001463216
|
|
0,0
|
$330,13
|
0,500000
|
1,0003368389
|
|
0,1
|
$504,45
|
0,460172
|
1,0004736542
|
|
0,2
|
$678,78
|
0,420740
|
1,00058265
|
|
0,3
|
$853,10
|
0,382088
|
1,0006649234
|
|
0,4
|
$1027,42
|
0,344578
|
1,0007220715
|
|
0,5
|
$1201,75
|
0,308537
|
1,0007561259
|
|
Продолжение
|
|
Стандартное значение
|
Ассоциированные P&L
|
Ассоциированная вероятность
|
Ассоциированное значение HPR при f= 0,01
|
|
0,6
|
$1376,07
|
0,274253
|
1,0007694689
|
|
0,7
|
$1,550,39
|
0,241963
|
1,0007647383
|
|
0,8
|
$1724,71
|
0,211855
|
1,0007447264
|
|
0,9
|
$1899,04
|
0,184060
|
1,0007122776
|
|
1,0
|
$2073,36
|
0,158655
|
1,0006701921
|
|
1,1
|
$2247,68
|
0,135666
|
1,0006211392
|
|
1,2
|
$2422,01
|
0,115070
|
1,0005675842
|
|
1,3
|
$2596,33
|
0,096800
|
1,0005117319
|
|
1,4
|
$2770,65
|
0,080757
|
1,0004554875
|
|
1,5
|
$2944,98
|
0,066807
|
1,0004004351
|
|
1,6
|
$3119,30
|
0,054799
|
1,0003478328
|
|
1,7
|
$3293,62
|
0,044565
|
1,0002986228
|
|
1,8
|
$3,467,95
|
0,035930
|
1,0002534528
|
|
1,9
|
$3642,27
|
0,028716
|
1,0002127072
|
|
2,0
|
$3816,59
|
0,022750
|
1,0001765438
|
|
2,1
|
$3990,92
|
0,017864
|
1,000144934
|
|
2,2
|
$4165,24
|
0,013903
|
1,0001177033
|
|
2,3
|
$4339,56
|
0,010724
|
1,0000945697
|
|
2,4
|
$4513,89
|
0,008198
|
1,0000751794
|
|
2,5
|
$4688,21
|
0,006210
|
1,0000591373
|
|
2,6
|
$4862,53
|
0,004661
|
1,0000460328
|
|
2,7
|
$5036,86
|
0,003467
|
1,0000354603
|
|
2,8
|
$5211,18
|
0,002555
|
1,0000270338
|
|
2,9
|
$5385,50
|
0,001866
|
1,0000203976
|
|
3,0
|
$5559,83
|
0,001350
|
1,0000152327
|
Побочные продукты при f= 0,01:
TWR= 1,0053555695
Сумма вероятностей =
7,9791232176
Среднее геометрическое
= 1,0006696309
GAT = $328,09 доллара.
Оптимальное f надо искать
следующим образом. Сначала вы должны определиться с методом поиска f. Можно
просто перебрать числа от 0 до 1 с определенным шагом (например 0,01),
используя итерационный метод, или применить метод параболической интерполяции,
описанный в книге «Формулы управления портфелем». Вам
следует определить, какое значение f (между 0 и 1) позволит получить наибольшее
среднее геометрическое. После того как вы определитесь с методом поиска,
следует найти ассоциированное P&L наихудшего случая. В нашем примере это значение P&L,
соответствующее -3 стандартным единицам, то есть -4899,57.
Для
того чтобы найти средние геометрические для значений f, которые вы будете
перебирать в поиске оптимального, нужно преобразовать каждое значение
ассоциированных P&L и вероятность в HPR.
Уравнение (3.30) позволяет рассчитать HPR:
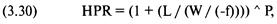
где L = ассоциированное значение P&L;
W = ассоциированное
значение P&L наихудшего случая (это всегда отрицательное значение);
f= тестируемое значение f;
Р = ассоциированная
вероятность.
Для f=0,01 найдем ассоциированное HPR при
стандартном значении-3. Ассоциированное P&L наихудшего случая составляет
-4899,57. Поэтому HPR равно:
HPR = (1 + (-4899,57 / (-4899,57 /
(-0,01))))^ 0,001349966857 = (1 +
(-4899,57/489957))^ 0,001349966857 = (1 + (-0,01))^ 0,00139966857 =
0,99^ 0,001349966857 = 0,9999864325
После
того как мы найдем ассоциированные HPR для тестируемого f (0,01 в нашем примере), можно рассчитать TWR. TWR — это произведение всех HPR для
данного значения f:
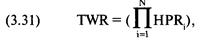
где N = общее
число равноотстоящих точек данных;
HPR = HPR из уравнения (3.30), соответствующее
точке данных i. Поэтому для нашего тестируемого значения f= 0,01 TWR равно:
TWR = 0,9999864325 * 0,9999819179 * ... * 1,0000152327 =
1,0053555695
Мы можем легко преобразовать TWR в среднее геометрическое,
возведя TWR в степень, равную единице, поделенной на сумму всех ассоциированных
вероятностей.
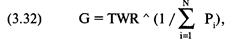
где N == число
равноотстоящих точек данных;
R = ассоциированная вероятность точки данных i.
Если мы просуммируем значения столбца, который включает 61
ассоциированную вероятность, получим 7,979105. Поэтому среднее геометрическое
при f= 0,01 равно:
G = 1,0053555695 ^ (1/7,979105) =
1,00535555695 ^ 0,1253273393 = 1,00066963
Мы можем также рассчитать среднюю геометрическую сделку (GAT). Это сумма, которую вы бы заработали в среднем на
контракт за сделку, если бы торговали при этом распределении результатов и при
данном значении f.
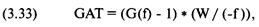
где G(f) =
среднее геометрическое для данного значения f;
W = ассоциированное P&L наихудшего случая.
GAT = (1,00066963
- 1) * (-4899,57 / (-0,01)) = 0,00066963 * 489957 = 328,09
Таким
образом, в среднем на контракт можно ожидать выигрыша в 328,09 доллара. Теперь
перейдем к следующему значению f, которое должно тестироваться
в соответствии с выбранной процедурой поиска оптимального f. В нашем случае мы
проверяем значения f от 0 до 1 с шагом 0,01, так что следующим тестируемым
значением f будет 0,02. Рассчитаем новый столбец ассоциированных HPR, а также найдем TWR и среднее
геометрическое. Значение f, которое в результате даст наивысшее среднее
геометрическое, является оптимальным (для вводных параметров, которые мы
использовали). Если бы для данного примера мы продолжили поиск оптимального f,
то получили бы f= 0,744 (при расчете оптимального f
используется шаг 0,001). Среднее геометрическое в этом случае равно 1,0265.
Соответствующая средняя геометрическая сделка составит 174,45 доллара.
Следует
отметить, что само по себе значение TWR не столь важно. Когда мы рассчитываем
среднее геометрическое параметрически, как в этом примере, TWR просто является
промежуточным шагом для получения этого среднего геометрического. Теперь мы
можем рассчитать, каким было бы наше TWR после Х сделок, возведя среднее
геометрическое в степень X. Поэтому если мы хотим рассчитать TWR для 232 сделок
при среднем геометрическом 1,0265, то следует возвести 1,0265 в степень 232,
что даст 431,79. В таком случае, при торговле с оптимальным f =0,744 можно
ожидать прибыль 43079% ((431,79 - 1) * 100) после 232 сделок. Еще
одним побочным продуктом, который мы рассчитаем, будет порог геометрической
торговли (2.02):
Порог
геометрической торговли =
330,13/174,45 * -4899,57 / -0,744 = 12462,32
Отметьте,
что значение средней арифметической сделки 330,13 доллара не является
результатом, полученным с помощью этого метода, а используется как один из
вводных параметров.
Мы можем преобразовать оптимальное f в количество
контрактов для торговли с помощью уравнения:
(3.34) K=E/Q,
где
К = число контрактов для торговли;
Е = текущий баланс счета.
(3.35)
Q=W/(-f),
где W = ассоциированное P&L наихудшего случая;
Отметьте,
что переменная Q представляет собой число, на которое
вы должны разделить баланс счета, чтобы узнать сколькими контрактами торговать,
при этом баланс должен ежедневно корректироваться. Возвращаясь к нашему
примеру: Q = -4899,57 / -0,744 = $6585,44
Следовательно,
мы будем торговать 1 контрактом на каждые 6585,44 доллара на балансе счета. Для
счета размером в 25 000 долларов это означает, что мы будем торговать:
К =25
000/6585,44 = 3,796253553
Так как
мы не можем торговать дробными контрактами, то должны округлить это число
3,796253553 вниз до ближайшего целого числа. Поэтому для счета в 25 000
долларов мы будем торговать 3 контрактами. Причина, по которой мы всегда будем
округлять вниз, а не вверх, состоит в том, что плата за нахождение ниже
оптимального f меньше, чем плата за нахождение выше.
Отметьте,
насколько чувствительна торговля оптимальным числом контрактов к наихудшему
убытку. Наихудший убыток зависит только от того, на сколько стандартных
отклонений вы отходите влево от среднего. Данный ограничительный параметр,
интервал, выраженный в количестве стандартных отклонений, очень важен. В нашем
расчете мы выбрали три сигма. Это означает, что мы допускаем проигрыш в три
сигма. Однако проигрыш за пределами трех сигма может сильно нам повредить,
если он выйдет слишком далеко за это значение. Поэтому вам следует быть очень
осторожными с выбором этого ограничительного параметра. От величины интервала
зависит очень многое. Заметьте, что для простоты изложения мы не учитывали
комиссионные и проскальзывание. Если учитывать комиссионные и проскальзывание,
то следует вычесть Х долларов комиссионных и проскальзывания из каждой сделки
в самом начале. Затем следует рассчитать среднюю арифметическую сделку и
стандартное отклонение на основе 232 измененных сделок и далее выполнить уже
известную процедуру. Теперь рассмотрим сценарий «что если». Допустим, мы хотим
посмотреть, что произойдет, если прибыль в средней сделке уменьшится вдвое
(сжатие = 0,5). Далее предположим, что рынок становится очень волатильным и
дисперсия увеличивается на 60% (растяжение = 1,6). Подставляя эти параметры в
систему, мы можем посмотреть, как они влияют на оптимальное f, и
скорректировать нашу торговлю до того,
как эти изменения произойдут на самом деле. Таким образом, оптимальное f будет
равно 0,262, что соответствует торговле 1 контрактом на каждые 31 305,92
доллара на балансе счета (так как P&L наихудшего случая сильно за-
висит
от растяжения и сжатия). Среднее геометрическое упадет до 1,0027, средняя
геометрическая сделка уменьшится до 83,02 доллара, a TWR за 232 сделки будет равно 1,869.
Такие изменения вызваны уменьшением средней сделки на 50% и увеличением
стандартного отклонения на 60%, что вполне может произойти на практике. Также
возможно, что будущее будет более благоприятно, чем прошлое. Мы можем
проанализировать другую ситуацию. Допустим, мы хотим посмотреть, что
произойдет, если наша средняя прибыль увеличится на 10%. Для этого следует
ввести значение сжатия 1,1. Параметры «что если», растяжение и сжатие, крайне
важны в управлении капиталом.
Чем ближе ваше распределение торговых P&L к нормальному, тем лучше будет
работать метод. Проблема почти всех методов управления деньгами состоит в том,
что следует учитывать определенный «коэффициент ухудшения». Здесь ухудшение — это разница между нормальным
распределением и распределением, которое вы реально получаете. Разница между
ними и есть коэффициент ухудшения, и чем больше этот коэффициент, тем менее
эффективным становится метод.
С помощью вышеописанного метода мы определили, что торговля
1 контрактом на каждые 6585,44 доллара на балансе счета оптимальна. Однако
если бы мы совершили эти сделки на практике и определили оптимальное f эмпирически, то оптимальным был бы 1 контракт на каждые
7918,04 доллара на балансе счета. Как можно видеть, использование нормального
распределения сместило нас слегка вправо вдоль кривой f и привело к торговле
несколько большим числом контрактов, чем предлагает эмпирический метод.
Однако, как мы увидим позже, многое говорит в пользу того,
что будущее распределение цен будет нормальным. Когда мы покупаем или продаем
опцион, предположение, что будущее распределение изменений цены базового инструмента
будет нормальным, уже заложено в цену опциона. Точно так же можно сказать, что
трейдеры, не использующие механические системы, получат в будущем результаты,
которые нормально распределены.
В методе, описанном в этой главе, используются
неприведенные данные. При использовании приведенных данных метод будет
выглядеть следующим образом:
1. До того как данные нормированы, их следует привести к
текущим ценам путем преобразования всех торговых прибылей и убытков в
процентные прибыли и убытки с помощью уравнений с (2.10а) по (2.10в). Затем
эти процентные прибыли и убытки следует умножить на текущую цену
2. Когда вы перейдете к нормированию этих данных,
нормируйте приведенные данные, используя среднее и стандартное отклонение
приведенных данных.
3. Далее, определите оптимальное f, среднее
геометрическое и TWR. Средняя геометрическая сделка, средняя арифметическая
сделка и порог геометрической торговли справедливы только для текущей цены
базового инструмента. Когда цена базового инструмента изменяется, процедура
должна быть проведена заново. Когда вы перейдете к повторному проведению процедуры
с другой ценой базового инструмента, вы получите то же оптимальное f, среднее геометрическое и TWR.
Однако средняя арифметическая сделка, средняя геометрическая сделка и порог
геометрической торговли будут другими в зависимости от новой цены базового
инструмента.
4. Количество контрактов для торговли, рассчитываемое с
помощью уравнения (3.34), соответствующим образом изменится. P&L наихудшего случая, переменная W, используемая в уравнении (3.34), также изменится.
Из этой главы, мы узнали, как найти оптимальное f по
распределению вероятности. Мы использовали нормальное распределение, так как
оно описывает многие естественно происходящие процессы. Кроме того, с ним
легче работать, чем со многими другими распределениями, так как можно
рассчитать интеграл функции нормального распределения с помощью уравнения
(3.21)1.
Однако нормальное распределение зачастую является неполной моделью для
распределения торговых прибылей и убытков. Какая модель будет приемлемой для
наших целей? В следующей главе мы ответим на этот вопрос и будем полагаться на
методы из главы 3 при работе с любым видом распределения вероятности
независимо от того, существует интеграл функции распределения или нет.
Глава 4
Параметрические методы для других
распределений
Из предыдущей главы мы узнали, как найти
оптимальное f
и его побочные продукты при нормальном распределении. Тот же метод применим к
любому другому распределению, где известна функция распределения вероятности
(то есть интеграл плотности распределения вероятности). О многих известных
распределениях и об их функциях распределения вероятности рассказано в
приложении В.
К сожалению, большинство распределений
торговых P&L плохо описываются
функциями нормального и других распределений. В этой главе мы сначала обратимся
к проблеме неопределенной природы распределения торговых P&L и далее изучим
метод планирования сценария — естественное продолжение идеи оптимального/.
Этот метод широко применяется и позволяет находить оптимальное f по ячеистым
распределениям. Далее мы перейдем к следующей главе, посвященной опционам и
одновременной торговле по нескольким позициям. Прежде чем смоделировать
реальное распределение торговых P&L, мы должны найти метод сравнения двух
распределений.
Тест
Колмогорова-Смирнова (К-С)
Хи-квадрат тест, без сомнения, является наиболее популярным
из всех методов сравнения двух распределений. Так как многие ориентированные на
рынок приложения, помимо рассматриваемых в этой главе, часто используют
хи-квадрат тест, то он описан в Приложении А. Однако для наших целей наилучшим
методом будет тест К-С. Этот очень эффективный тест применим к неячеистым распределениям, которые
являются функцией одной независимой переменной (в нашем случае, прибыль за одну
сделку).
Все
функции распределения вероятности имеют минимальное значение 0 и максимальное
значение 1. То, как они ведут себя между ними, и отличает их. Тест К-С измеряет
очень простую переменную D, которая определяется как
максимальное абсолютное значение разности между двумя функциями распределения
вероятности. Тест К-С достаточно прост. N объектов (в нашем случае
сделок) нормируются (вычитается среднее значение, и полученная разность делится
на стандартное отклонение) и сортируются в порядке возрастания. Когда мы
проходим эти отсортированные и нормированные сделки, накопленная вероятность
рассматриваемого количества сделок делится на N. Когда мы берем первую сделку
в отсортированной последовательности с наименьшим стандартным значением, функция распределения вероятности (cumulative
density function, далее — ФРВ) равна
1/N. Для каждого стандартного значения, которое мы проходим,
приближаясь к наибольшему стандартному значению, к числителю прибавляется
единица. В конце последовательности наша ФРВ будет равна N/N, или 1. Для каждого
стандартного значения мы можем рассчитать теоретическое распределение. Таким
образом, мы можем сравнить фактическую функцию распределения вероятности с
любой теоретической функцией распределения вероятности. Переменная D, или
статистика К-С (К-С statistic), равна наибольшему расстоянию
между значением нашей фактической функции распределения вероятности и значением
теоретического распределения ФРВ при этом же стандартном значении. При
сравнении фактической ФРВ для данного стандартного значения с теоретической
ФРВ для этого же стандартного значения мы должны также сравнить теоретическую
ФРВ предыдущего стандартного значения с фактической ФРВ текущего стандартного
значения.
Для
того чтобы прояснить эту ситуацию, посмотрим на рисунок 4-1. Отметьте. что в
точке А фактическая кривая находится выше теоретической. Поэтому мы сравниваем
текущее значение фактической ФРВ с текущим теоретическим значением для
нахождения наибольшей разности. Однако в точке В фактическая кривая находится
ниже теоретической. Поэтому мы сравниваем предыдущее фактическое значение с
текущим теоретическим значением. Идея состоит в том, что в результате мы
выберем наибольшую разность.
Для
каждого стандартного значения нам надо взять абсолютное значение разности
между текущим значением фактической ФРВ и текущим значением теоретической ФРВ.
Нам также надо взять абсолютное значение разности между предыдущим значением
фактической ФРВ и текущим значением теоретической ФРВ. Повторив эту операцию
для всех стандартных значений точек, где фактическая ФРВ делает скачок вверх на
1/N, и взяв наибольшую разность, мы определим переменную D.
Рисунок
4-1 Тест К-С
Чем ниже
значение D, тем больше похожи два распределения. Мы можем преобразовать
значение D в уровень значимости с помощью следующей формулы:

где SIG = уровень
значимости для данного D и N;
D =
статистика К-С;
N =
количество сделок, по которым определена статистика К-С;
% =
оператор, означающий остаток после деления. Здесь J%2
дает остаток после деления J на 2;
ЕХР() =
экспоненциальная функция.
Нет необходимости суммировать
значения J от 1 до бесконечности. Уравнение сходится (обычно очень
быстро) к определенному значению. После того как предел достигнут (согласно
допуску, установленному пользователем), нет необходимости продолжать
суммирование значений.
Рассмотрим
уравнение (4.01) на примере. Допустим, у нас есть 100 сделок, а значение
статистики К-С равно 0,04:
J1 = (1 % 2) * 4 -
2 * ЕХР(-2 * 1^2 * (100^(1/2) * 0,04) л 2) =1*4-2* ЕХР(-2 * ^ 2 *
(10 * 0,04)^ 2) = 2 * ЕХР(-2 * 1^2 * 0,^ 2) = 2*ЕХР(-2*1*0,16) = 2 * ЕХР(-0,32)
= 2 * 0,726149 = 1,452298
Таким
образом, нашим первым значением является 1,452298. Теперь прибавим следующее
значение:
J2 = (2 % 2) * 4 - 2 * ЕХР(-2 * 2^ 2 * (100^ (1/2) *
0,04)^2) =0*4-2* ЕХР(-2 * 2^ 2 * (10 * 0,04)^ 2) = -2 * ЕХР(-2 * 2^ 2 * 0,4^ 2)
= -2*ЕХР(-2*4*0,16) = -2*ЕХР(-1,28) = -2 * 0,2780373 = -0,5560746
Прибавив -0,5560746 к нашей текущей сумме 1,452298, мы
получим новую текущую сумму 0,8962234. Затем снова увеличим J на 1, теперь оно
будет равно 3, и решим уравнение. Получившееся значение прибавим к текущей
сумме 0,8962234. Следует поступать таким образом и дальше, пока текущая сумма в
пределах допуска не перестанет изменяться. В нашем примере предельное значение
будет равно 0,997. Этот ответ означает, что при 100 сделках и значении статистики
К-С 0,04 мы можем быть уверены на 99,7%, что фактическое распределение
генерировано функцией теоретического распределения. Другими словами, мы можем
быть на 99,7% уверены, что функция теоретического распределения представляет
фактическое распределение. В данном случае это очень хороший уровень
значимости.
Создание
характеристической функции распределения
Нормальное
распределение вероятности далеко не всегда является хорошей моделью
распределения торговых прибылей и убытков. Более того, ни одно из распространенных
распределений вероятности не является идеальной моделью. Поэтому мы должны
сами создать функцию для моделирования распределения наших торговых прибылей и
убытков.
Распределение изменений цены в общем случае относится к
распределениям Парето (см. приложение В). Распределение торговых P&L можно считать трансформацией распределения цен. Эта трансформация является результатом
торговых методов, когда трейдеры пытаются понизить свои убытки и увеличить
прибыли, следовательно, распределение торговых P&L можно отнести к
распределениям Парето. Однако распределение, которое мы будем изучать, не
является распределением Парето. Распределение Парето, как и все другие функции
распределения, моделирует определенное вероятностное явление. Оно моделирует
распределение сумм независимых, идентично распределенных случайных переменных.
Функция распределения, которую мы будем изучать, не моделирует конкретное
вероятностное явление. Она моделирует многие унимодальные функции распределения.
Поэтому она может повторить форму и плотность вероятности распределения Парето,
а также любого другого унимодального распределения.
Теперь
мы создадим эту функцию. Для начала рассмотрим следующее уравнение:
(4.02)
Y=1/(X^ 2+1)
График этого уравнения — обычная колоколообразная кривая,
симметричная относительно оси Y, как показано на
рисунке 4-2.
Таким
образом, мы будем строить свои рассуждения, используя это общее уравнение.
Переменную Х можно представить как число стандартных единиц с каждой стороны
от среднего, т.е. от оси Y. Мы можем использовать первый момент этого
«распределения», расположение его среднего значения, добавив значение для
изменения расположения на оси X. Уравнение изменится следующим образом:
(4.03) Y=1/(X-LOC^2+1),
где Y = ордината
характеристической функции;
Х = количество стандартных отклонений;
LOC = переменная, задающая
расположение среднего значения, первый момент распределения.
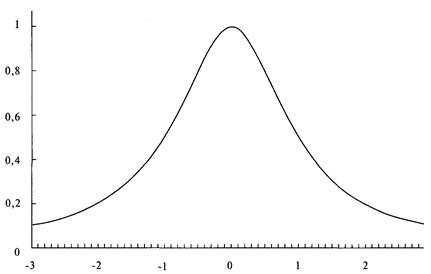
Рисунок 4-2 LOC = 0 SCALE = I SKEW = 0 KURT = 2
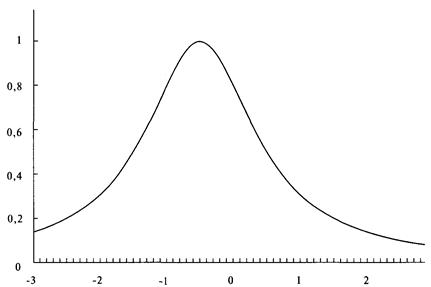
Рисунок 4-3 LOC =0,5, SCALE = 1, SKEW = 0, KURT= 2
Таким
образом, если бы мы хотели изменить расположение, передвинув график влево на
0,5 единицы, мы бы установили LOC на -0.5. Этот
график изображен на рисунке 4-3.
Таким же образом, если бы мы хотели сместить кривую вправо,
то использовали бы положительное значение для переменной LOC. LOC с нулевым значением не будет
смещать график, как показано на рисунке 4-2.
Показатель в знаменателе влияет на эксцесс. До настоящего
момента эксцесс был равен 2, но мы можем изменить его, изменив значение
показателя. Теперь формулу нашей характеристической функции можно записать
следующим образом:
(4.04) Y = 1 / ((X - LOC)^ KURT + 1),
где Y == ордината
характеристической функции;
Х = количество стандартных отклонений;
LOC = переменная,
задающая расположение среднего значения, первый момент распределения;
KURT = переменная, задающая эксцесс, четвертый момент
распределения.
Рисунки 4-4 и 4-5 показывают влияние эксцесса на нашу
характеристическую функцию. Отметьте: чем выше показатель, тем более
плосковерхое и тонкохвостое распределение (эксцесс меньше нормального), и чем
меньше показатель, тем более острый верх и тем толще хвосты распределения
(эксцесс больше нормального). Чтобы не получить иррациональное число, когда
KURT < 1, мы будем использовать абсолютное значение коэффициента в знаменателе.
Это не повлияет на форму кривой. Таким образом, мы можем переписать уравнение
(4.04) следующим образом:
(4.04) Y = 1/(ABS(X - LOC)^ KURT + 1)
Мы можем добавить множитель в знаменателе, чтобы
контролировать ширину, второй момент распределения. Характеристическая функция
будет выглядеть следующим образом:
(4.05)
Y = 1 / (ABS((X - LOC)
* SCALE)^ KURT + 1),
где Y = ордината характеристической функции;
X = количество
стандартных отклонений;
LOC = переменная,
задающая расположение среднего значения, первый момент распределения;
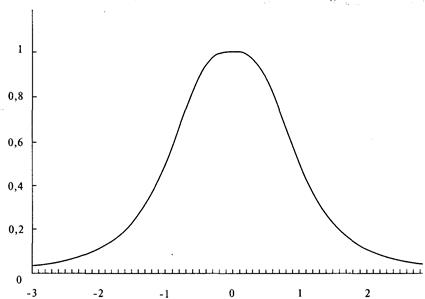
Рисунок 4-4 LOC=0, SCALE =1, SKEW = 0, KURT = 3

Рисунок 4-5 LOG = 0,
SCALE = 1, SKEW = О, KURT = 1
KURT
= переменная, задающая эксцесс, четвертый момент распределения;
SCALE = переменная, задающая ширину, второй момент распределения.
Рисунки 4-6 и 4-7 иллюстрируют изменение параметра ширины.
Действие этого параметра можно представить как движение горизонтальной оси
вверх или вниз Когда ось сдвигается вверх (при уменьшении ширины), график
расширяется (см рисунок 4-6), как будто мы смотрим на его верхнюю часть. На
рисунке 4-7 показана обратная ситуация, когда горизонтальная ось сдвигается
вниз и кривая распределения сжимается. Теперь у нас есть характеристическая
функция распределения, с помощью которой мы контролируем три из четырех
моментов распределения Сейчас распределение симметрично. Для этой функции нам
необходимо добавить коэффициент асимметрии, третий момент распределения.
Характеристическая функция тогда будет выглядеть следующим образом:
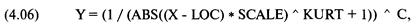
где С = показатель асимметрии, рассчитанный
следующим образом:
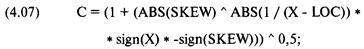
Y
= ордината характеристической функции;
Х=
количество стандартных отклонений;
LOC=
переменная, задающая расположение среднего значения, первый момент
распределения;
KURT =
переменная, задающая эксцесс,
четвертый
момент распределения;
SCALE = переменная, задающая ширину, второй момент распределения;
SKEW=
переменная, задающая асимметрию, третий момент распределения;
sign()
= функция знака, число 1 или -1. Знак Х рассчитывается как X/ ABS(X) для X, не равного 0. Если Х равно
нулю, знак будет считаться положительным;
Рисунки 4-8 и 4-9 показывают действие переменной асимметрии
на распределение. Отметим несколько важных особенностей параметров LOC, SCALE, SKEW
и KURT. За исключением переменной LOC (которая выражена как число стандартных
значений для смещения распределения), другие три
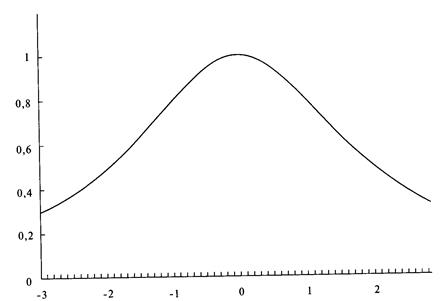
Рисунок 4-6
LOC=0, SCALE =0,5, SKEW = 0, KURT=2
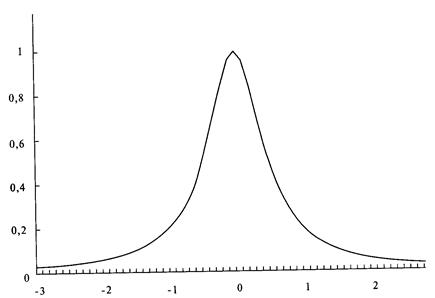
Рисунок 4-7 LOC=0, SCALE =
2, SKEW = 0, KURT=2,
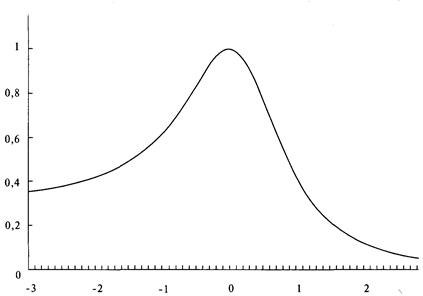
Рисунок 4-8 LOC=0, SCALE
=1, SKEW =-0,5, KURT = 2.
Рисунок 4-9 LOG = 0, SCALE = 1, SKEW = +0,5,
KURT = 2.
переменные
являются безразмерными, то есть их значения являются числами, которые
характеризуют форму распределения и относятся только к этому распределению.
Значения параметров будут другими, если вы примените стандартные измерительные
методы, детально описанные в разделе «Величины, описывающие распределения»
главы 3. Например, если вы определите один из коэффициентов асимметрии Пирсона
на наборе данных, он будет отличаться от значения переменной SKEW для распределений, рассматриваемых здесь. Значения четырех
переменных уникальны для рассматриваемого распределения и имеют смысл только
в данном контексте. Крайне важен интервал возможных значений этих переменных.
Переменная SCALE всегда должна быть положительной, кроме того, она не
ограничена сверху. То же самое верно для переменной KURT.
На практике, однако, лучше использовать значения от 0,5 до 3, в крайнем случае,
от 0,05 до 5. Вы можете использовать значения и за пределами этих крайних
точек при условии, что они больше нуля.
Переменная
LOC может быть положительной, отрицательной или нулем. Параметр
SKEW должен быть больше или равен -1, и меньше или равен +1.
Когда SKEW равен +1, вся правая сторона распределения (справа от
пика) равна пику. Когда SKEW равен -1, пику равна вся левая
сторона распределения. Интервалы значений переменных в общем виде таковы:
(4.08) -
бесконечность < LOC < + бесконечность
(4.09) SCALE > 0
(4.10) -1<=SKEW<=+1
(4.11) KURT > О
Рисунки с 4-2 по 4-9 показывают, как легко изменяется
распределение. Мы можем подогнать эти четыре параметра таким образом, чтобы
получившееся в результате распределение было похоже на любое другое
распределение.
Подгонка
параметров распределения
Как и в процедуре, описанной в главе 3, по поиску оптимального
f при нормальном распределении, мы должны преобразовать
необработанные торговые данные в стандартные единицы. Сначала мы вычтем
среднее из каждой сделки, а затем разделим полученное значение на стандартное
отклонение. Далее мы будем работать с данными в стандартных единицах. После
того как
мы
приведем сделки к стандартным значениям, можно отсортировать их в порядке
возрастания. На основе полученных данных мы сможем провести тест К-С. Нашей
целью является поиск таких значений LOC, SCALE, SKEW и KURT,
которые наилучшим образом подходят для фактического распределения сделок. Для
определения «наилучшего приближения» мы полагаемся на тест К-С. Рассчитаем
значения параметров, используя «метод грубой силы двадцатого века». Мы
просчитаем каждую комбинацию для KURT от 3 до 0,5 с шагом -0,1 (мы можем также
взять интервал от 0,5 до 3 с шагом 0,1, так как направление не имеет значения).
Далее просчитаем каждую комбинацию для SCALE от 3 до 0,5 с шагом -0,1. Пока оставим LOC и SKEW
равными 0. Таким образом, нам надо обработать следующие комбинации:
|
LOC
|
SCALE
|
SKEW
|
KURT
|
|
0
|
3
|
0
|
3
|
|
о
|
3
|
0
|
2,9
|
|
о
|
3
|
0
|
2,8
|
|
о
|
3
|
0
|
2,7
|
|
о
|
3
|
0
|
2,6
|
|
о
|
3
|
0
|
2,5
|
|
о
|
3
|
0
|
2,4
|
|
о
|
3
|
0
|
2,3
|
|
о
|
3
|
0
|
2,2
|
|
о
|
3
|
0
|
2,1
|
|
о
|
3
|
0
|
2
|
|
о
*
*
*
|
3
*
*
*
|
0
*
*
*
|
1,9
*
*
*
|
|
о
|
2,9
|
0
|
3
|
|
о
*
*
*
|
2,9
*
*
*
|
0
*
*
*
|
2,9
*
*
*
|
|
о
|
0,5
|
0
|
0,6
|
|
о
|
0,5
|
0
|
0,5
|
Для
каждой комбинации проведем тест К-С. Комбинацию, которая даст наименьшую
статистику К-С, будем считать оптимальной для параметров SKALE и KURT (на данный момент). Чтобы провести
тест К-С для каждой комбинации, нам необходимо как фактическое распределение,
так и теоретическое распределение (определяемое параметрами тестируемого
характеристического распределения). Мы уже знаем, как создать функцию
распределения вероятности X/N, где N является общим числом сделок, а Х является рангом
(от 1 до N) данной сделки. Теперь нам надо рассчитать ФРВ для
теоретического распределения при данных значениях параметров LOC, SCALE, SKEW
и KURT. У нас есть характеристическая функция регулируемого распределения, она
задается уравнением (4.06). Чтобы получить ФРВ из характеристической функции,
необходимо найти интеграл характеристической функции. Мы обозначаем интеграл,
т.е. площадь под кривой характеристической функции в точке X, как N(X). Таким образом, так как уравнение
(4.06) дает первую производную интеграла, мы обозначим уравнение (4.06) как N'(X). В большинстве случаев вы не сможете
вывести интеграл функции, даже если вы опытный математик. Поэтому вместо
интегрирования функции (4.06) мы будем использовать другой метод. Этот метод потребует
больших усилий, но он применим к любой функции.
Вероятность
для любой точки на графике характеристической функции можно оценить, если
распределение представить себе как последовательность узких прямоугольников.
Тогда для любого данного прямоугольника в распределении вы можете рассчитать
вероятность, ассоциированную с этим прямоугольником, как отношение суммы
площадей всех прямоугольников слева от вашего прямоугольника (включая площадь
вашего прямоугольника) к сумме площадей всех прямоугольников в распределении.
Чем больше прямоугольников вы используете, тем более точными будут полученные
вероятности. Если бы вы использовали бесконечное число прямоугольников, то ваш
расчет был бы точным. Рассмотрим процедуру поиска площадей под кривой
характеристического распределения на примере. Допустим, мы хотим найти
вероятности, ассоциированные с каждым отрезком длиной 0,1 в интервале от -3 до
+3 сигма. Отметьте, что в таблице (с. 183) рассмотрен интервал от -5 до +5
сигма. Дело в том, что лучше выйти на 2 сигмы за ограничительные параметры (-3
и +3 сигма в нашем случае), чтобы получить более точные результаты. Отметьте,
что Х — это число стандартных единиц, на которое мы смещены от среднего
значения. Далее идут значения четырех параметров. Следующий столбец — это
столбец N'(X), который отражает высоту кривой в
точке Х при этих значениях параметров. N'(X) рассчитывается из уравнения (4.06). Воспользуемся
уравнением (4.06). Допустим, нам надо рассчитать N'(X) для Х= -3 со значениями параметров 0,02, 2,76, 0 и 1,78
для LOC, SCALE, SKEW
и KURT соответственно. Сначала рассчитаем показатель асимметрии
для уравнения (4.06). Формула для расчета С задается уравнением (4.07):
|
Х
|
LOG
|
SCALE
|
SKEW
|
KURT
|
N'(X) Ур. (4.06)
|
Накопленная сумма
|
N(X)
|
|
-5,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0092026741
|
0,0092026741
|
0,000388
|
|
-4,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0095350519
|
0,018737726
|
0,001178
|
|
-4,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0098865117
|
0,0286242377
|
0,001997
|
|
-4,7
|
0,02
|
2,76
|
0
|
1,78
|
0,01025857
|
0,0388828077
|
0,002847
|
|
-4,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0106528988
|
0,0495357065
|
0,003729
|
|
-4,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0110713449
|
0,0606070514
|
0,004645
|
|
-4,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0115159524
|
0,0721230038
|
0,005598
|
|
-4,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0119889887
|
0,0841119925
|
0,006590
|
|
-4,2
|
0,02
|
2,76
|
0
|
1,78
|
0,0124929748
|
0,0966049673
|
0,007622
|
|
-4,1
|
0,02
|
2,76
|
0
|
1,78
|
0,0130307203
|
0,1096356876
|
0,008699
|
|
-4,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0136053639
|
0,1232410515
|
0,009823
|
|
-3,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0142204209
|
0,1374614724
|
0,010996
|
|
-3,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0148798398
|
0,1523413122
|
0,012224
|
|
-3,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0155880672
|
0,1679293795
|
0,013509
|
|
-3,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0163501266
|
0,184279506
|
0,014856
|
|
-3,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0171717099
|
0,2014512159
|
0,016270
|
|
-3,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0180592883
|
0,2195105042
|
0,017756
|
|
-3,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0190202443
|
0,2385307485
|
0,019320
|
|
-3,2
|
0,02
|
2,76
|
0
|
1,78
|
0,0200630301
|
0,2585937786
|
0,020969
|
|
-3,1
|
0,02
|
2,76
|
0
|
1,78
|
0,0211973606
|
0,2797911392
|
0,022709
|
|
-3,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0224344468
|
0,302225586
|
0,024550
|
|
-2,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0237872819
|
0,3260128679
|
0,026499
|
|
-2,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0252709932
|
0,3512838612
|
0,028569
|
|
-2,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0269032777
|
0,3781871389
|
0,030770
|
|
-2,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0287049446
|
0,4068920835
|
0,033115
|
|
-2,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0307005967
|
0,4375926802
|
0,035621
|
|
Продолжение
|
|
X
|
LOG
|
SCALE
|
SKEW
|
KURT
|
N'(X) Ур. (4.06)
|
Накопленная сумма
|
N(X)
|
|
-2,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0329194911
|
0,4705121713
|
0,038305
|
|
-2,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0353966362
|
0,5059088075
|
0,041186
|
|
-2,2
|
0,02
|
2,76
|
0
|
1,78
|
0,0381742015
|
0,544083009
|
0,044290
|
|
-2,1
|
0,02
|
2,76
|
0
|
1,78
|
0,041303344
|
0,5853863529
|
0,047642
|
|
-2,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0448465999
|
0,6302329529
|
0,051276
|
|
-1,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0488810452
|
0,6791139981
|
0,055229
|
|
-1,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0535025185
|
0,7326165166
|
0,059548
|
|
-1,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0588313292
|
0,7914478458
|
0,064287
|
|
-1,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0650200649
|
0,8564679107
|
0,069511
|
|
-1,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0722644105
|
0,9287323213
|
0,075302
|
|
-1,4
|
0,02
|
2,76
|
0
|
1,78
|
0,080818341
|
1,0095506622
|
0,081759
|
|
-1,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0910157581
|
1,1005664203
|
0,089007
|
|
-1,2
|
0,02
|
2,76
|
0
|
1,78
|
0,1033017455
|
1,2038681658
|
0,097204
|
|
-1,1
|
0,02
|
2,76
|
0
|
1,78
|
0,1182783502
|
1,322146516
|
0,106550
|
|
-1,0
|
0,02
|
2,76
|
0
|
1,78
|
0,1367725028
|
1,4589190187
|
0,117308
|
|
-0,9
|
0,02
|
2,76
|
0
|
1,78
|
0,1599377464
|
1,6188567651
|
0,129824
|
|
-0,8
|
0,02
|
2,76
|
0
|
1,78
|
0,1894070001
|
1,8082637653
|
0,144560
|
|
-0,7
|
0,02
|
2,76
|
0
|
1,78
|
0,2275190511
|
2,0357828164
|
0,162146
|
|
-0,6
|
0,02
|
2,76
|
0
|
1,78
|
0,2776382822
|
2,3134210986
|
0,183455
|
|
-0,5
|
0,02
|
2,76
|
0
|
1,78
|
0,3445412618
|
2,6579623604
|
0,209699
|
|
-0,4
|
0,02
|
2,76
|
0
|
1,78
|
0,4346363128
|
3,0925986732
|
0,242566
|
|
-0.3
|
0,02
|
2,76
|
0
|
1,78
|
0,5550465747
|
3,6476452479
|
0,284312
|
|
-0,2
|
0,02
|
2,76
|
0
|
1,78
|
0,7084848615
|
4,3561301093
|
0,337609
|
|
-0,1
|
0,02
|
2,76
|
0
|
1,78
|
0,8772840491
|
5,2334141584
|
0,404499
|
|
0,0
|
0,02
|
2,76
|
0
|
1,78
|
1
|
6,2334141584
|
0,483685
|
|
0,1
|
0,02
|
2,76
|
0
|
1,78
|
0,9363557429
|
7,1697699013
|
0,565363
|
|
0,2
|
0,02
|
2,76
|
0
|
1,78
|
0,776473162
|
7,9462430634
|
0,637613
|
|
Продолжение
|
|
X
|
LOG
|
SCALE
|
SKEW
|
KURT
|
N'(X) Ур. (4.06)
|
Накопленная сумма
|
N(X)
|
|
0,3
|
0,02
|
2,76
|
0
|
1,78
|
0,6127219404
|
8,5589650037
|
0,696211
|
|
0,4
|
0,02
|
2,76
|
0
|
1,78
|
0,4788099392
|
9,0377749429
|
0,742253
|
|
0,5
|
0,02
|
2,76
|
0
|
1,78
|
0,377388991
|
9,4151639339
|
0,778369
|
|
0,6
|
0,02
|
2,76
|
0
|
1,78
|
0,3020623672
|
9,7172263011
|
0,807029
|
|
0,7
|
0,02
|
2,76
|
0
|
1,78
|
0,2458941852
|
9,9631204863
|
0,830142
|
|
0,8
|
0,02
|
2,76
|
0
|
1,78
|
0,2034532796
|
10,1665737659
|
0,849096
|
|
0,9
|
0,02
|
2,76
|
0
|
1,78
|
0,1708567846
|
10,3374305505
|
0,864885
|
|
1,0
|
0,02
|
2,76
|
0
|
1,78
|
0,1453993995
|
10,48282995
|
0,878225
|
|
1,1
|
0,02
|
2,76
|
0
|
1,78
|
0,1251979811
|
10,6080279311
|
0,889639
|
|
1,2
|
0,02
|
2,76
|
0
|
1,78
|
0,1089291462
|
10,7169570773
|
0,899515
|
|
1,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0956499316
|
10,8126070089
|
0,908145
|
|
1,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0846780659
|
10,8972850748
|
0,915751
|
|
1,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0755122067
|
10,9727972814
|
0,922508
|
|
1,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0677784099
|
11,0405756913
|
0,928552
|
|
1,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0611937787
|
11,10176947
|
0,933993
|
|
1,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0555414402
|
11,1573109102
|
0,938917
|
|
1,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0506530744
|
11,2079639847
|
0,943396
|
|
2,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0463965419
|
11,2543605266
|
0,947490
|
|
2,1
|
0,02
|
2,76
|
0
|
1,78
|
0,0426670018
|
11,2970275284
|
0,951246
|
|
2,2
|
0,02
|
2,76
|
0
|
1,78
|
0,0393804519
|
11,3364079803
|
0,954707
|
|
2,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0364689711
|
11,3728769515
|
0,957907
|
|
2,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0338771754
|
11,4067541269
|
0,960874
|
|
2,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0315595472
|
11,4383136741
|
0,963634
|
|
2,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0294784036
|
11,4677920777
|
0,966209
|
|
2,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0276023341
|
11,4953944118
|
0,968617
|
|
2,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0259049892
|
11,5212994011
|
0,970874
|
|
2,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0243641331
|
11,5456635342
|
0,972994
|
|
Продолжение
|
|
X
|
LOG
|
SCALE
|
SKEW
|
KURT
|
N'(X) Ур. (4.06)
|
Накопленная сумма
|
N(X)
|
|
3,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0229608959
|
11,5686244301
|
0,974990
|
|
3,1
|
0,02
|
2,76
|
0
|
1,78
|
0,0216791802
|
11,5903036102
|
0,976873
|
|
3,2
|
0,02
|
2,76
|
0
|
1,78
|
0,0205051855
|
11,6108087957
|
0,978653
|
|
3,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0194270256
|
11,6302358213
|
0,980337
|
|
3,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0184344179
|
11,6486702392
|
0,981934
|
|
3,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0175184304
|
11,6661886696
|
0,983451
|
|
3,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0166712734
|
11,682859943
|
0,984893
|
|
3,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0158861285
|
11,6987460714
|
0,986266
|
|
3,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0151570063
|
11,7139030777
|
0,987576
|
|
3,9
|
0,02
|
2,76
|
0
|
1,78
|
0,014478628
|
11,7283817056
|
0,988826
|
|
4,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0138463263
|
11,742228032
|
0,990020
|
|
4,1
|
0,02
|
2,76
|
0
|
1,78
|
0,0132559621
|
11,7554839941
|
0,991164
|
|
4,2
|
0,02
|
2,76
|
0
|
1,78
|
0,012703854
|
11,7681878481
|
0,992259
|
|
4,3
|
0,02
|
2,76
|
0
|
1,78
|
0,0121867187
|
11,7803745668
|
0,993309
|
|
4,4
|
0,02
|
2,76
|
0
|
1,78
|
0,0117016203
|
11,7920761871
|
0,994316
|
|
4,5
|
0,02
|
2,76
|
0
|
1,78
|
0,0112459269
|
11,8033221139
|
0,995284
|
|
4,6
|
0,02
|
2,76
|
0
|
1,78
|
0,0108172734
|
11,8141393873
|
0,996215'
|
|
4,7
|
0,02
|
2,76
|
0
|
1,78
|
0,0104135298
|
11,8245529171
|
0,997110
|
|
4,8
|
0,02
|
2,76
|
0
|
1,78
|
0,0100327732
|
11,8345856903
|
0,997973
|
|
4,9
|
0,02
|
2,76
|
0
|
1,78
|
0,0096732643
|
11,8442589547
|
0,998804
|
|
5,0
|
0,02
|
2,76
|
0
|
1,78
|
0,0093334265
|
11,8535923812
|
0,999606
|

Затем подставляем С = 1 в
уравнение (4.06):

Таким образом, в точке Х = -3 N'(X) = 0,02243444681 (отметьте, что мы рассчитываем значения
в столбце N'(X) для каждого значения X).
Рассчитаем очередной столбец, текущую сумму N'(X), накапливающуюся с ростом X. Это
сделать достаточно просто. Далее рассчитаем столбец N(X) для вероятности, ассоциированной с каждым значением Х
при данных значениях параметров. Формула для расчета N(X) выглядит следующим образом:
где С = текущее
количество точек X;
М = общее количество точек X.
Уравнение (4.12) означает, что при каждом изменении Х
необходимо добавить текущую сумму при данном значении Х к текущей сумме
предыдущего значения X, затем разделить полученную сумму на 2. Далее полученный
результат следует разделить на последнее значение в столбце текущей суммы N'(X) (накопленная сумма значений N'(X)). Это даст нам вероятность для
значения Х при данных значениях параметров.
Таким образом, для Х = -3 текущая сумма N(X) = 0,302225586, а для предыдущего
значения Х = -3,1 текущая сумма равна 0,2797911392. Сумма двух этих величин
равна 0,5820167252. При делении на 2 мы получаем 0,2910083626. Разделив эту
величину на последнее значение в столбце накопленной суммы N'(X), равное 11,8535923812, мы получаем
0,02455022522. Это и есть вероятность N(X) при стандартном значении Х = -3.
После того как мы вычислили накопленные вероятности для
каждой сделки в фактическом распределении и вероятности для каждого приращения
стандартного значения в нашем характеристическом распределении, мы можем осуществить
тест К-С для значений параметров характеристического распределения, которые
используются в настоящий момент. Однако сначала рассмотрим два важных момента.
В примере с таблицей накопленных вероятностей, показанной
ранее для нашего регулируемого распределения, мы рассчитывали вероятности с приращением
стандартных значений 0,1. Это было сделано для наглядности. На практике вы
можете получить большую степень точности, используя меньший шаг приращения.
Приращение 0,01 в большинстве случаев является вполне приемлемым.
Скажем несколько слов о том, как для регулируемого
распределения выбрать ограничительные параметры, то есть количество сигма с
каждой стороны от среднего. В нашем примере мы использовали 3 сигма, но в
действительности следует использовать абсолютное значение самой отдаленной
точки от среднего. Для нашего примера с 232 сделками крайнее левое (самое
меньшее) стандартное значение составляет -2,96 стандартной единицы, а крайнее
правое (самое большое) составляет 6,935321 стандартной единицы. Так как 6,93
больше, чем ABS(-2,96), мы должны взять 6,935321. Теперь добавим еще 2
сигма к этому значению для надежности и найдем вероятности для распределения
от -8,94 до +8,94 сигма. Так как нам нужна хорошая точность, мы будем
использовать приращение 0,01. Рассчитаем вероятности для стандартных значений:
|
-8,94
|
|
-8,93
|
|
-8,92
|
|
-8,91
*
*
*
|
|
+8,94
|
Последнее, что мы должны сделать, прежде чем провести тест
К-С, — это округлить фактические стандартные значения отобранных сделок с
точностью 0,01 (так как мы используем 0,01 в качестве шага для теоретического
распределения). Например, значение 6,935321 не будет иметь соответствующей
теоретической вероятности, ассоциированной с ним, так как оно находится между
значениями 6,93 и 6,94. Так как 6,94 ближе к 6,935321, мы округляем 6,935321
до 6,94. Прежде чем начать процедуру оптимизирования наших параметров регулируемого
распределения путем применения теста К-С, мы должны округлить фактические
отсортированные нормированные сделки в соответствии с выбранным шагом. Вместо
округления стандартных значений сделок до ближайшего десятичного Х можно
использовать линейную интерполяцию по таблице накопленных вероятностей, чтобы
вычислить вероятности, соответствующие фактическим стандартным значениям
сделок. Чтобы больше узнать о линейной интерполяции, посмотрите хорошую книгу
по статистике, например «Управление деньгами на товарном рынке» Фреда Гема.
Другие интересные книги указаны в списке рекомендованной литературы. До
настоящего момента мы оптимизировали только параметры KURT
и SCALE. Может показаться, что при нормировании данных параметр LOC должен быть приравнен к 0, а параметр SCALE — к 1. Это не совсем верно, так как реальное расположение
распределения может не совпадать со средним арифметическим, а оптимальное
значение ширины отличаться от единицы. Значения KURT и SCALE сильно связаны друг с другом. Таким образом, мы сначала
попытаемся приблизительно определить оптимальные значения параметров KURT и SCALE. Для наших 232 сделок получаем SCALE =2,7, а KURT =1,9. Теперь попытаемся найти наиболее подходящие значения
параметров. Этот процесс займет достаточно много времени, даже если у вас
хороший компьютер. Мы проведем цикл, изменяя параметр LOC от 0,1 до -0,1 по
-0,05, параметр SCALE от 2,6 до 2,8 по 0,05, параметр SKEW от 0,1 до -0,1 по -0,05 и параметр KURT от 1,86 до 1,92 по
0,02. Результаты этого цикла дают оптимальное (самое низкое значение статистики
К-С) при LOC = О, SCALE = 2,8, SKEW
=0 и KURT =1,86. Затем мы осуществим третий цикл. На этот раз будем
просматривать LOC от 0,04 до -0,04 по -0,02, SCALE от 2,76 до 2,82 по 0,02, SKEW от 0,04 до -0,04
по -0,02 и KURT от 1,8 до 1,9 по 0,02. Результаты третьего цикла дают
оптимальные значения LOC = 0,02, SCALE = 2,76, SKEW = 0 и KURT = 1,8. Мы нашли оптимальную окрестность, в
которой параметры дают наилучшее приближение регулируемой характеристической
функции к распределению реальных данных. Для последнего цикла мы будем
просматривать LOC от 0 до 0,03 по 0,01, SCALE от 2,76 до 2,73 по -0,01, SKEW от 0,01 до -0,01
и KURT от 1,8 до 1,75 по -0,01. Результаты этого последнего прохода дают
следующие оптимальные параметры для наших 232 сделок: LOC = 0,02, SCALE =2,76, SKEW = 0 и KURT =1,78.
Использование
параметров для поиска оптимального f
Теперь, когда найдены наиболее подходящие значения
параметров распределения, рассчитаем оптимальное f для этого распределения. Мы
можем применить процедуру, которая была использована в предыдущей главе для
поиска оптимального f при нормальном распределении.
Единственное отличие состоит в том, что вероятности для каждого стандартного
значения (значения X) рассчитываются с помощью уравнений (4.06) и (4.12). При
нормальном распределении мы находим столбец ассоциированных вероятностей
(вероятностей, соответствующих определенному стандартному значению), используя
уравнение (3.21). В нашем случае, чтобы найти ассоциированные вероятности,
следует выполнить процедуру, детально описанную ранее:
1. Для данного стандартного значения Х рассчитайте его
соответствующее N'(X)
с помощью уравнения (4.06).
2. Для каждого стандартного значения Х рассчитайте
накопленную сумму значений N'(X), соответствующих всем предыдущим X.
3. Теперь, чтобы найти N(X), т.е. итоговую вероятность для данного X, прибавьте
текущую сумму, соответствующую значению X, к текущей сумме, соответствующей
предыдущему значению X. Разделите полученную величину на 2. Затем разделите
полученное частное на общую сумму всех N'(X), т.е. последнее число в столбце текущих сумм. Это новое
частное является ассоциированной 1-хвостой вероятностью для данного X.
Так как теперь у нас есть метод поиска ассоциированных
вероятностей для стандартных значений Х при данном наборе значений параметров,
мы можем найти оптимальное f. Процедура в
точности совпадает с той, которая применяется для поиска оптимального f при
нормальном распределении. Единственное отличие состоит в том, что мы рассчитываем
столбец ассоциированных вероятностей другим способом. В
нашем примере с 232 сделками значения параметров, которые получаются при самом
низком значении статистики К-С, составляют 0,02, 2,76, О и 1,78 для LOC, SCALE, SKEW
и KURT соответственно. Мы получили эти значения параметров,
используя процедуру оптимизации, описанную в данной главе. Статистика К-С == 0,0835529 (это означает, что в своей
наихудшей точке два распределения удалены на 8,35529%) при уровне значимости
7,8384%. Рисунок 4-10 показывает функцию распределения для тех значений
параметров, которые наилучшим образом подходят для наших 232 сделок. Если
мы возьмем полученные параметры и найдем оптимальное f по этому распределению,
ограничивая распределение +3 и -3 сигма, используя 100 равноотстоящих точек
данных, то получим f= 0,206, или 1 контракт на каждые 23
783,17 доллара. Сравните это с эмпирическим методом, который покажет, что
оптимальный рост достигается при 1 контракте на каждые 7918,04 доллара на
балансе счета. Этот результат мы получаем, если ограничиваем распределение
3 сигма с каждой стороны от среднего. В действительности, в эмпирическом
потоке сделок у нас был проигрыш наихудшего случая 2,96 сигма и выигрыш
наилучшего случая 6,94 сигма. Теперь, если мы вернемся и ограничим распределение
2,96 сигма слева от среднего и 6,94 сигма справа (и на этот раз будем
использовать 300 равноотстоящих точек данных), то получим оптимальное f = 0,954, или 1 контракт на каждые 5062,71 доллара на
балансе счета. Почему оно отличается от эмпирического оптимального f= 7918,04?
Проблема состоит в «грубости» фактического распределения.
Вспомните, что уровень значимости наших наилучшим образом подходящих параметров
был только 7,8384%. Давайте возьмем распределение 232 сделок и поместим в 12
ячеек от -3 до +3 сигма.
|
Ячейки
|
Количество сделок
|
|
-3,0
|
-2,5
|
2
|
|
-2,5
|
-2,0
|
1
|
|
-2,0
|
-1,5
|
2
|
|
-1,5
|
-1,0
|
24
|
|
-1,0
|
-0,5
|
39
|
|
,sr„. -0,5
|
0,0
|
43
|
|
ь -' 0,0
|
0,5
|
69
|
|
0,5
|
1,0
|
38
|
|
1,0
|
1,5
|
7
|
|
1,5
|
2,0
|
2
|
|
2,0
|
2,5
|
0
|
|
2,5
|
3,0
|
2
|
Отметьте, что на хвостах распределения находятся пробелы,
т.е. области, или ячейки, где нет эмпирических данных. Эти области
сглаживаются, когда мы приспосабливаем наше регулируемое распределение к
данным, и именно эти сглаженные области вызывают различие между параметрическим
и эмпирическим оптимальным f. Почему же наше характеристическое распределение
при всех возможностях регулировки его формы не очень хорошо приближено к
фактическому распределению? Причина состоит в том, что наблюдаемое
распределение имеет слишком много точек
перегиба. Параболу можно направить ветвями вверх или вниз. Однако
вдоль всей параболы направление вогнутости или выпуклости не изменяется. В
точке перегиба направление вогнутости изменяется. Парабола имеет 0 точек
перегиба, 
Рисунок
4-10 Регулируемое распределение для 232 сделок
Рисунок
4-11 Точки перегиба колоколообразного распределения
так как
направление вогнутости никогда не изменяется. Объект, имеющий форму буквы S, лежащий на боку, имеет одну точку перегиба, т.е. точку,
где вогнутость изменяется. Рисунок 4-11 показывает нормальное распределение.
Отметьте, что в колоколообразной кривой, такой как нормальное распределение,
есть две точки перегиба. В зависимости от значения SCALE наше регулируемое распределение может иметь ноль точек перегиба (если SCALE очень низкое) или две точки перегиба. Причина, по которой
наше регулируемое распределение не очень хорошо описывает фактическое
распределение сделок, состоит в том, что реальное распределение имеет слишком
много точек перегиба. Означает ли это, что полученное характеристическое
распределение неверно? Скорее всего нет. При желании мы могли бы создать
функцию распределения, которая имела бы больше двух точек перегиба. Такую
функцию можно было бы лучше подогнать к реальному распределению. Если бы мы
создали функцию распределения, которая допускает неограниченное количество
точек перегиба, то мы бы точно подогнали ее к наблюдаемому распределению.
Оптимальное f, полученное с помощью такой кривой, практически совпало бы
с эмпирическим. Однако чем больше точек перегиба нам пришлось бы добавить к
функции распределения, тем менее надежной она была бы (т.е. она хуже
представляла бы будущие сделки). Мы не пытаемся в точности подогнать
параметрическое ik наблюдаемому,
а стараемся лишь определить, как распределяются наблюдаемые данные, чтобы
можно было предсказать с большой уверенностью будущее оптимальное 1(если данные
будут распределены так же, как в прошлом). В регулируемом распределении, подогнанном
к реальным сделкам, удалены ложные точки
перегиба.
Поясним
вышесказанное на примере. Предположим, мы используем доску Галтона. Мы знаем,
что асимптотически распределение шариков, падающих через доску, будет
нормальным. Однако мы собираемся бросить только 4 шарика. Можем ли мы ожидать,
что результаты бросков 4 шариков будут распределены нормально? Как насчет 5
шариков? 50 шариков? В асимптотическом смысле мы ожидаем, что наблюдаемое
распределение будет ближе к нормальному при увеличении числа сделок. Подгонка
теоретического распределения к каждой точке перегиба наблюдаемого распределения
не даст нам большую степень точности в будущем. При большом количестве сделок
мы можем ожидать, что наблюдаемое распределение будет сходиться с ожидаемым и
многие точки перегиба будут заполнены сделками, когда их число стремится к
бесконечности. Если наши теоретические параметры точно отражают распределение
реальных сделок, то оптимальное f, полученное на основе теоретического распределения,
при будущей последовательности сделок будет точнее, чем оптимальное f,
рассчитанное эмпирически из прошлых сделок. Другими словами, если наши 232
сделки представляют распределение сделок в будущем, тогда мы можем ожидать, что
распределение сделок в будущем будет ближе к нашему «настроенному»
теоретическому распределению, чем к наблюдаемому, с его многочисленными точками
перегиба и «зашумленностью» из-за конечного количества сделок. Таким образом,
мы можем ожидать, что будущее оптимальное f
будет больше похоже на оптимальное f, полученное из
теоретического распределения, чем на оптимальное f, полученное эмпирически из
наблюдаемого распределения.
Итак, лучше всего в этом случае использовать не
эмпирическое, а параметрическое оптимальное f. Ситуация аналогична
рассмотренному случаю с 20 бросками монеты в предыдущей главе. Если мы ожидаем
60% выигрышей в игре 1:1, то оптимальное f=
0,2. Однако если бы у нас были только эмпирические данные о последних 20
бросках, 11 из которых были выигрышными, наше оптимальное f составило бы 0,1.
Мы исходим из того, что параметрическое оптимальное f ($5062,71 в этом случае)
верно, так как оно оптимально для функции, которая «генерирует» сделки. Как и
в случае только что упомянутой игры с броском монеты, мы допускаем, что
оптимальное f для следующей сделки определяется параметрической генерирующей
функцией, даже если параметрическое f отличается от эмпирического оптимального
f.
Очевидно, что ограничительные параметры оказывают большое
влияние на оптимальное f. Каким образом выбирать эти ограничительные параметры?
Посмотрим, что происходит, когда мы отодвигаем верхнюю границу. Следующая
таблица составлена для нижнего предела 3 сигма с использованием 100
равноотстоящих точек данных и оптимальных параметров для 232 сделок:
|
Верхняя граница
|
f
|
f$
|
|
3 Sigmas
|
0,206
|
$23783,17
|
|
4 Sigmas
|
0,588
|
$8332,51
|
|
5 Sigmas
|
0,784
|
$6249,42
|
|
6 Sigmas
|
0,887
|
$5523,73
|
|
7 Sigmas
|
0,938
|
$5223,41
|
|
8 Sigmas
*
*
*
|
0,963
*
*
*
|
$5087,81
*
*
*
|
|
100 Sigmas
|
0,999
|
$4904,46
|
Отметьте, что при постоянной нижней границе, чем выше мы
отодвигаем верхнюю границу, тем ближе оптимальное f к 1. Таким образом, чем больше мы отодвигаем
верхнюю границу, тем ближе оптимальное f в
долларах будет к нижней границе (ожидаемый проигрыш худшего случая). В том
случае, когда наша нижняя граница находится на -3 сигма, чем больше мы
отодвигаем верхнюю границу, тем ближе в пределе оптимальное f в долларах будет к нижней границе, т.е. к $330,13
-(1743,23 * 3) = = -$4899,56. Посмотрите, что происходит, когда
верхняя граница не меняется (3 сигма), а мы отодвигаем нижнюю границу
Достаточно быстро арифметическое математическое ожидание такого процесса
оказывается отрицательным. Это происходит потому, что более 50% площади под
характеристической функцией находится слева от вертикальной оси. Следовательно,
когда мы отодвигаем нижний ограничительный параметр, оптимальное f стремится к
нулю. Теперь посмотрим, что произойдет, если мы одновременно начнем отодвигать
оба ограничительных параметра. Здесь мы используем набор оптимальных параметров
0,02, 2,76, 0 и 1,78 для распределения 232 сделок и 100 равноотстоящих точек
данных:
|
Верхняя и нижняя граница
|
F f$
|
|
3 Sigmas
|
0,206
|
$23783,17
|
|
4 Sigmas
|
0,158
|
$42 040,42
|
|
5 Sigmas
|
0,126
|
$66 550,75
|
|
6 Sigmas
|
0,104
|
$97 387,87
|
|
*
*
*
|
*
*
*
|
*
*
*
|
|
100 Sigmas
|
0,053
|
$322625,17
|
Отметьте, что оптимальное f приближается к 0, когда мы
отодвигаем оба ограничительных параметра. Более того, так как проигрыш
наихудшего случая увеличивается и делится на все меньшее оптимальное f, наше f$, т.е. сумма финансирования 1 единицы, также приближается
к бесконечности.
Проблему наилучшего выбора ограничительных параметров можно
сформулировать в виде вопроса: где могут произойти в будущем наилучшие и наихудшие
сделки (когда мы будем торговать в этой рыночной системе)? Хвосты распределения
в действительности стремятся к плюс и минус бесконечности, и нам следует
финансировать каждый контракт на бесконечно большую сумму (как в последнем
примере, где мы раздвигали обе границы). Конечно, если мы собираемся торговать
бесконечно долгое время, наше оптимальное f в долларах будет бесконечно
большим. Но мы не собираемся торговать в этой рыночной системе вечно.
Оптимальное f, при котором мы собираемся торговать в этой
рыночной системе, является функцией предполагаемых наилучших и наихудших
сделок. Вспомните, если мы бросим монету 100 раз и запишем, какой
будет самая длинная полоса решек подряд, а затем бросим монету еще 100 раз, то
полоса решек после 200 бросков будет скорее всего больше, чем после 100
бросков. Таким же образом, если проигрыш наихудшего случая за нашу историю 232
сделок равнялся 2,96 сигма (для удобства возьмем 3 сигма), тогда в будущем мы
должны ожидать проигрыш больше 3 сигма. Поэтому вместо того, чтобы ограничить
наше распределение прошлой историей сделок (-2,96 и +6,94 сигма), мы ограничим
его -4 и +6,94 сигма. Нам, вероятно, следует ожидать, что в будущем именно
верхняя, а не нижняя граница будет нарушена. Однако это обстоятельство мы не
будем принимать в расчет по нескольким причинам. Первая состоит в том, что
торговые системы в будущем ухудшают свою результативность по сравнению с
работой на исторических данных, даже если они не используют оптимизируемых
параметров. Все сводится к принципу, что эффективность
механических торговых систем постепенно
снижается. Во-вторых, тот факт, что мы платим меньшую цену за ошибку в
оптимальном f при смещении влево, а не вправо от пика кривой f,
предполагает, что следует быть более консервативными в прогнозах на будущее. Мы
будем рассчитывать параметрическое оптимальное f при ограничительных
параметрах -4 и +6,94 сигма, используя 300 равноотстоящих точек данных. Однако
при расчете вероятностей для каждой из 300 равноотстоящих ячеек данных важно,
чтобы мы рассмотрели распределение на 2 сигмы до и после выбранных
ограничительных параметров. Поэтому мы будем определять ассоциированные
вероятности, используя ячейки в интервале от -6 до +8,94 сигма, даже если
реальный интервал -4 — +6,94 сигма. Таким образом, мы увеличим точность
результатов. Использование оптимальных параметров 0,02, 2,76, 0 и 1,78 теперь
даст нам оптимальное f =0,837, или 1 контракт на каждые 7936,41 доллара. Пока
ограничительные параметры не нарушаются, наша модель точна для выбранных
границ. Пока мы не ожидаем проигрыша больше 4 сигма ($330,13 -(1743,23 * 4)
=-$6642,79) или прибыли больше 6,94 сигма ($330,13 + + (1743,23 * 6,94) = $12
428,15), можно считать, что границы распределения будущих сделок выбраны
точно. Возможное расхождение между созданной моделью и реальным
распределением является слабым местом такого подхода, то есть оптимальное f,
полученное из модели, не обязательно будет оптимальным. Если наши выбранные
параметры будут нарушены в будущем, f может перестать быть оптимальным. Этот
недостаток можно устранить с помощью опционов, которые позволяют ограничить
возможный проигрыш заданной суммой. Коль скоро мы обсуждаем слабость
данного метода, необходимо указать на последний его недостаток. Следует иметь в
виду, что реальное распределение торговых прибылей и убытков является
распределением, где параметры постоянно изменяются, хотя и медленно. Следует
периодически повторять настройку по торговым прибылям и убыткам рыночной
системы, чтобы отслеживать эту динамику.
Проведение тестов «что если»
После того как найдено параметрическое оптимальное f, можно реализовывать сценарии «что если» с помощью
полученной функции распределения. Для этого нужно варьировать параметры функции
распределения LOC, SCALE, SKEW и KURT для моделирования различных
ожидаемых результатов (различных распределений, которые могут быть в будущем).
Мы знаем, как применять процедуру растяжения и сжатия в нормальном
распределении, и похожим образом можем работать с параметрами LOC, SCALE, SKEW
и KURT регулируемого распределения.
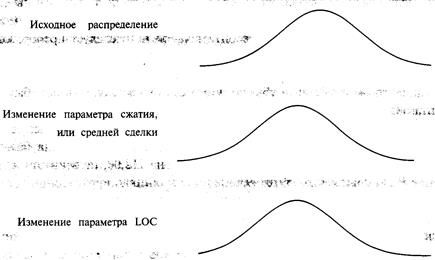
Рисунок
4-12 Изменение параметра расположения распределения
Сценарии «что если» при параметрическом подходе помогают
смоделировать изменения фактического распределения торговых P&L. Параметрические методы позволяют
увидеть воздействие изменений на распределение фактических торговых прибылей и
убытков до того, как они произойдут.
Когда
вы работаете с параметрами, следует помнить о важной детали. При поиске оптимального
f вместо того, чтобы изменять LOC,
т.е. расположение распределения, лучше изменять долларовую арифметическую
среднюю сделку, используемую в качестве входного данного. Это видно из рисунка
4-12. Отметьте (см. рисунок 4-12), что изменение параметра расположения
LOC передвигает распределение вправо или влево в «окне» ограничительных параметров,
но сами ограничительные параметры при этом не двигаются. Таким образом,
изменение параметра LOC также затрагивает количество равноотстоящих точек
данных слева и справа от моды распределения. Если изменить фактическое среднее
арифметическое (или использовать переменную сжатия при поиске f в нормальном
распределении), «окно» ограничительных параметров передвинется. Когда вы
изменяете арифметическую среднюю сделку или изменяете переменную сжатия в
механизме нормального распределения, у вас остается то же число равноотстоящих
точек данных справа и слева от моды распределения.
Приведение f к
текущим ценам
В методе, описанном в этой главе, были использованы неприведенные
данные. Мы можем использовать тот же подход для приведенных данных. Если
необходимо определить приведенное параметрическое оптимальное f, то следует
преобразовать необработанные торговые прибыли и убытки в процентные повышения и
понижения, основываясь на уравнениях с (2.10а) по (2.10в). Затем надо
преобразовать полученные процентные прибыли и убытки, умножив их на текущую
цену базового инструмента. Например, P&L номер 1 составляет 0,18. Допустим, что цена входа в этой
сделке равна 100,50, тогда процентное повышение для этой сделки равно
0,18/100,50=0,001791044776. Теперь допустим, что текущая цена базового
инструмента равна 112,00. Умножив 0,001791044776 на 112,00, получим приведенное
значение P&L, равное 0,2005970149. Если мы хотим
использовать приведенные данные, то следует провести аналогичную операцию со
всеми 232 торговыми прибылями и убытками. Затем следует рассчитать среднее
арифметическое и стандартное отклонение по приведенным сделкам и использовать
уравнение (3.16) для нормирования данных. Далее необходимо найти набор
оптимальных параметров LOC, SCALE, SKEW и KURT по приведенным данным так же, как
было показано в этой главе для неприведенных данных. Процедура
определения оптимального f, среднего геометрического и TWR
аналогична уже рассмотренной нами. Побочные продукты: средняя геометрическая
сделка, средняя арифметическая сделка и порог геометрической торговли —
действительны только для текущей цены базового инструмента. Если цена базового
инструмента изменится, расчет следует повторить, вернувшись к первому шагу,
умножив процентные прибыли и убытки на новую цену базового инструмента. Когда
вы перейдете к этой процедуре с другой ценой базового инструмента, то получите
такое же оптимальное f, среднее геометрическое и TWR. Однако средняя арифметическая сделка, средняя
геометрическая сделка и порог геометрической торговли будут другими в
зависимости от новой цены базового инструмента.
Количество контрактов для торговли, определяемое уравнением
(3.34), также должно измениться. Ассоциированное P&L наихудшего случая (переменная W
из уравнения (3.35)) будет другим в уравнении (3.34) в результате изменений,
вызванных приведением данных к другой текущей цене.
Оптимальное F для
других распределений и настраиваемых кривых
Существует много других способов, с помощью которых можно
определить параметрическое оптимальное f. В предыдущей главе мы рассмотрели
процедуру поиска оптимального f для нормально распределенных данных. Итак, у
нас есть процедура, которая дает оптимальное f для любого нормально распределенного
явления. Та же процедура используется для
поиска оптимального/в любом распределении, если существует функция
распределения (подобные функции описаны для многих других распространенных
распределений в приложении В). Когда
функции распределения не существует (т.е. когда функция плотности вероятности
не интегрируется), оптимальное f можно найти с помощью численного метода,
описанного в этой главе, приблизительно рассчитав функцию распределения.
Данная
глава посвящена моделированию фактического распределения сделок с помощью
регулируемого распределения, то есть поиску функции и ее подходящих
параметров, которые моделируют фактическую функцию плотности вероятности
торговых P&L с двумя точками перегиба. Вы можете использовать уже известные
функции и методы, например, полиномиальную интерполяцию или экстраполяцию,
интерполяцию и экстраполяцию рациональной функции (частные многочленов), или
использовать сплайн-интерполяцию. После того как теоретическая функция
найдена, можно определить ассоциированные вероятности тем же методом расчета
интеграла, который использовался при поиске ассоциированных вероятностей
регулируемого распределения, или рассчитать интеграл с помощью методов
математического анализа.
Одна из целей этой книги — позволить трейдерам,
использующим немеханические системы, применять те же методы управления счетом,
что и трейдерам, использующим механические системы. Регулируемое распределение
требует расчета параметров, они относятся к первым четырем моментам распределения.
Именно эти моменты — расположение, масштаб, асимметрия и эксцесс — описывают
распределение. Таким образом, кто-либо, торгующий по немеханическому методу,
например по волнам Эллиотта, может рассчитать параметры и получить оптимальное
f и побочные продукты. Наличие прошлой истории сделок не
является необходимым условием для расчета данных параметров. Если бы вы
использовали другие упомянутые выше методы подгонки, вам также не обязательно
было бы знать исторические данные, но значения параметров такой подгонки не
обязательно относились бы к моментам распределения. Эти методы могут лишить
вас возможности посмотреть, что произойдет, если увеличится эксцесс или
изменится асимметрия, изменится масштаб и т.д. Наше регулируемое распределение
является логичным выбором теоретической функции, которая хорошо описывает
фактическое распределение, так как параметры не только задают моменты
распределения, они дают нам контроль над этими моментами при прогнозировании
будущих изменений в распределении. Более того, рассчитать параметры
рассматриваемого здесь регулируемого распределения легче, чем подогнать
какую-либо произвольную функцию.
Планирование
сценария
Специалисты,
которые в силу своей профессии занимаются прогнозированием (экономисты,
аналитики фондового рынка, метеорологи, правительственные чиновники и т.д.),
довольно часто ошибаются, но надо признать, что большинство решений, которые
человек должен принять в жизни, обычно требуют прогноза.
Здесь есть две ловушки. Во-первых, люди делают слишком
оптимистичные предположения о будущем. Большинство из нас уверены, что в этом
месяце мы скорее выиграем в лотерею, чем погибнем в автокатастрофе, даже если
вероятность последнего выше. Это верно не только на уровне отдельного лица, но
и на уровне группы. Когда люди работают вместе, они стремятся видеть благоприятный
результат как наиболее вероятный результат (иначе не было бы смысла работать,
пока, конечно, все мы не стали автоматами, безрассудно надрывающимися на
«тонущих кораблях»).
Вторая и более пагубная ловушка состоит в том, что мы
делаем прямые прогнозы, например пытаемся предсказать цену галлона бензина
через два года или пытаемся предсказать, что произойдет с нашей карьерой, кто
будет следующим президентом, каким будет следующий стиль, и так далее. Что бы
мы ни говорили о будущем, мы стремимся думать о единственном, наиболее
вероятном результате. Таким образом, когда необходимо принять решение или
самостоятельно, или коллективно, мы принимаем его, основываясь на том, что
прогноз есть единственный наиболее вероятный результат. В итоге, мы часто
получаем неприятные сюрпризы.
Планирование сценария отчасти решает эту проблему. Сценарий
просто является возможным прогнозом, одним из путей, по которому могут
развиваться события. Планирование сценария предполагает набор сценариев для
покрытия возможного спектра исходов. Конечно, полный спектр никогда не будет
получен, но вы можете рассмотреть столько сценариев, сколько сочтете нужным.
Таким образом, в противоположность прямому прогнозу наиболее вероятного
результата вы можете подготовиться к будущему. Более того, планирование сценария
подготовит вас к тому, что может быть в противном случае неожиданным событием.
Допустим, вы занимаетесь долгосрочным планированием для
компании, которая производит некий продукт. Вместо того, чтобы сделать один
наиболее вероятный прямой прогноз, используйте метод планирования сценария. Методом
«мозгового штурма» вместе с коллегами определите возможные пути развития
событий. Что будет, если вы не сможете получить достаточно сырья, чтобы произвести
этот продукт? Как изменится ситуация, если один из ваших конкурентов
обанкротится? Как будут развиваться события, если на рынке появится новый
конкурент? Что произойдет, если вы серьезно недооцените спрос на этот продукт?
Что будет, если где-либо начнется война? А если начнется ядерная война? Так
как каждый сценарий возможен, его нужно рассматривать серьезно. Теперь надо
понять, что вы будете делать после того, как определите эти сценарии. Вы
должны определить цель, которую хотите достичь при том или ином сценарии. В
зависимости от сценария цель не обязательно должна быть положительной.
Например, при пессимистическом сценарии это могут быть просто
ремонтно-восстановительные работы на предприятии. После того как вы определите
цель для данного сценария, надо составить план на случай непредвиденных
ситуаций, относящихся к этому сценарию, для достижения необходимой цели.
Например, как уже было сказано, при невероятно мрачном сценарии вашей целью
могут быть ремонтно-восстановительные работы, и вам надо иметь план, чтобы
минимизировать ущерб. Помимо всего прочего, планирование сценария даст вам
алгоритм, которому надо следовать, если определенный сценарий реализуется.
Существует тесная связь между планированием сценария и оптимальным f. Оптимальное f позволяет разместить оптимальное количество
ресурсов при определенном наборе возможных сценариев. На самом деле,
реализуется только один сценарий, даже если мы планируем их несколько.
Планирование сценария ставит нас в ситуацию, когда необходимо принять решение,
какое количество ресурсов размещать сегодня при возможных сценариях на завтра.
Эта количественная оценка последствий — поистине «сердце» планирования
сценария.
Чтобы
определить, сколько ресурсов разместить при наличии определенного набора сценариев,
мы можем использовать еще один параметрический метод поиска оптимального f.
Сначала следует описать каждый сценарий. Далее мы должны оценить вероятность
(это число между 0 и 1) реализации каждого сценария. Сценарии с вероятностью 0
мы не будем рассматривать. Отметьте, что вероятность каждого сценария
уникальна. Допустим, вы принимаете решения в производственной корпорации АБВ.
Два сценария (из нескольких) выглядят следующим образом. При одном сценарии
корпорация АБВ подает документы на банкротство с вероятностью 0,15, в другом
сценарии АБВ уходит с рынка из-за напряженной конкуренции с иностранными
корпорациями с вероятностью 0,07. Теперь мы должны понять, включает ли первый
сценарий заявление о банкротстве из-за второго сценария, т.е. напряженной конкуренции.
Если это так. то вероятность первого сценария не учитывает вероятность второго
сценария, и мы должны уменьшить вероятность первого сценария до 0,08 (0,15 --
0,07). Отметьте также, что уникальность вероятности важна для каждого сценария,
чтобы сумма вероятностей всех рассматриваемых сценариев была равна в точности
1, а не 1,01 или 0,99.
Для каждого сценария мы определяем вероятность его
осуществления. Следует также определить конечный результат, то есть численное
значение. Оно может быть в долларах или лотах — в чем угодно. Однако ваши
выходные данные должны быть в тех же единицах, что и входные данные. Чтобы
использовать этот метод, вы должны обязательно иметь, по крайней мере, один
сценарий с отрицательным результатом. Если вы хотите знать размер ресурса,
который следует разместить сегодня при возможных сценариях на завтра, и не
имеете отрицательного сценария, тогда следует разместить 100% этого ресурса.
Без сценария с отрицательным результатом маловероятно, что данный набор
сценариев реалистичен.
Последнее условие использования этого метода состоит в том,
что математическое ожидание, сумма всех результатов, умноженных на их
соответствующие вероятности, должно быть больше нуля.
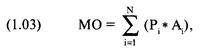
где Р =
вероятность сценария i;
А = результат сценария i;
N == общее число рассматриваемых сценариев.
Если математическое ожидание равно нулю или отрицательное,
метод нельзя использовать. Это не означает, что нельзя использовать само
планирование сценария. Можно и нужно. Однако оптимальное f может быть получено только в том случае, если
математическое ожидание больше нуля. Когда математическое ожидание равно нулю
или отрицательное, мы не должны размещать ресурсы.
И наконец, вы должны рассмотреть максимально возможный
спектр результатов. Другими словами, следует рассмотреть 99% возможных
исходов. Многие сценарии можно сделать шире, так что вам не надо будет
расписывать 10 000 сценариев, чтобы охватить 99% спектра. При расширении
сценариев не следует
слишком
упрощать ситуацию, выбрав только три сценария: оптимистический,
пессимистический и нейтральный. В этом случае полученные ответы будут слишком
грубы, чтобы иметь какую-либо практическую ценность. Захотите ли вы искать
оптимальное f
для торговой системы по трем сделкам?
Какое количество сценариев оптимально? Используйте то
количество, с которым вы справитесь. Здесь хорошим помощником будет компьютер.
Допустим, речь идет о компании АБВ и о размещении ее нового продукта на рынке
отсталой далекой страны. Рассмотрим пять возможных сценариев (в действительности
сценариев должно быть больше, но мы возьмем пять для примера). Эти пять
сценариев отражают то, что может произойти в данной стране в будущем, — то
есть вероятность определенных событий и прибыль или убыток от инвестирования.
|
Сценарий
|
Вероятность
|
Результат
|
|
Война
|
0,1
|
-$500 000
|
|
Кризис
|
0,2
|
-$200 000
|
|
Застой
|
0,2
|
0
|
|
Мир
|
0,45
|
$500 000
|
|
Процветание
|
0,05
|
$1000000
|
|
|
Сумма 1,00
|
|
Таким образом, сумма вероятностей равна 1. Обратите
внимание, что у нас есть 1 сценарий с отрицательным результатом, но
математическое ожидание больше нуля:
(0,1 * -$500 000) + (0,2 * -$200 000) +... = $185 000
С таким набором сценариев мы можем использовать данный
метод. Отметьте, что если бы мы использовали метод наиболее вероятного
результата, то пришли бы к заключению, что в этой стране скорее всего будет
мир, и действовали бы, исходя из этой единственной возможности, только
расплывчато осознавая наличие других исходов.
Рассчитаем
оптимальное f. Как мы уже знаем, оптимальное f (это число между О и 1)
максимизирует среднее геометрическое:
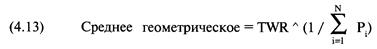
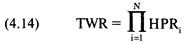
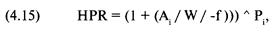
поэтому

Далее, мы можем рассчитать фактическое TWR:
(4.17) TWR= Среднее геометрическое^X,
где N= число сценариев;
TWR= относительный конечный капитал;
HPR= прибыль за период удержания позиции для сценария i;
А = результат сценария i;
Р.= вероятность сценария i;
W= наихудший результат среди всех сценариев N;
Х= число, характеризующее повторение этого сценария, когда
мы инвестируем Х раз.
TWR, полученное из уравнения (4.14), является промежуточным
значением для расчета среднего геометрического. После того как мы найдем
среднее геометрическое, фактическое TWR можно получить с помощью уравнения
(4.17).
Мы
можем произвести расчеты по этим уравнениям следующим образом. Сначала выберем
схему оптимизации, то есть способ поиска f,
максимизирующего уравнение. Можно сделать это с помощью подбора Ют 0,01 до 1,
используя метол итераций или параболическую интерполяцию. Затем мы должны
определить наихудший возможный результат для всех рассматриваемых сценариев независимо от того, насколько малы
вероятности подобных сценариев. В примере с корпорацией АБВ наихудшие
ожидаемые потери — это -500 000 долларов. Теперь для каждого сценария мы должны
сначала разделить наихудший возможный результат на отрицательное f. В примере с
корпорацией АБВ мы собираемся просмотреть значения Ют 0,01 до 1. Начнем со
значения f=0,01. Теперь, если мы разделим наихудший возможный
результат рассматриваемых сценариев на отрицательное значение f, то получим:
-$500 000 / -0,01 = $50 000 000
Для каждого сценария разделим его результат на полученное
только что значение. Так как исход первого сценария является наихудшим с
убытком 500 000 долларов, то:
-$500 000 / $50 000 000 =
-0,01
Теперь
прибавим это значение к 1:
1 + (-0,01) = 0,99
Наконец, возведем полученный ответ в степень вероятности
осуществления данного сценария (в нашем примере 0,1):
0,99^0,1=0,9989954713
Затем перейдем к следующему сценарию под названием «Кризис»
с вероятностью 0,2 проигрыша 200 000 долларов. Наш результат наихудшего случая
все еще -$500 000. Значение f,
с которым мы работаем, по-прежнему 0,01, поэтому число, на которое надо
разделить результат этого сценария, составляет 50 000 000 долларов:
-$200 000/$50 000 000 = -0,004
Проведем
дальнейшие вычисления для получения HPR:
1 + (-0,004) = 0,996 0,99^0,2 = 0,9991987169
Если мы рассмотрим остальные сценарии при тестируемом
значении f=0,01, то найдем три значения HPR, соответствующие
последним 3 сценариям:
Застой 1,0
Мир 1,004487689
Процветание 1,000990622
После того как найдены все HPR для данного значения f,
необходимо перемножить полученные HPR:
0,9989954713*0,9991987169*1,0*1,004487689 * 1,000990622=1,003667853
Мы получили промежуточное TWR
= 1,003667853. Следующим шагом будет возведение этого значения в степень,
равную единице, деленной на сумму вероятностей. Так как сумма вероятностей
составляет 1, то, чтобы получить среднее геометрическое, TWR возведем в степень 1. Таким образом, среднее
геометрическое равно в этом случае TWR, то есть 1,003667853. Если, однако,
убрать ограничение. что каждый сценарий должен иметь уникальную вероятность, то
можно получить сумму вероятностей больше 1. В таком случае, чтобы получить
среднее геометрическое, надо возвести TWR в степень, равную единице, деленной
на эту сумму вероятностей.
Ответ, полученный в нашем примере, является средним
геометрическим. соответствующим значению f=
0,01. Теперь перейдем к значению f= 0,02 и повторим
весь процесс, пока не найдем среднее геометрическое, соответствующее этому f. Мы будем продолжать, пока не дойдем до такого значения f, которое даст наивысшее среднее геометрическое.
В нашем примере наивысшее среднее геометрическое
достигается при f=0,57 и равно 1,1106. Разделив
возможный результат наихудшего сценария (-$500 000) на отрицательное
оптимальное f, мы получим 877 192,35 доллара. Другими словами, если корпорации
АБВ надо разместить на рынке новый продукт в этой далекой стране, следует
инвестировать именно эту сумму. С течением времени и развитием событий, когда
изменятся возможные исходы и вероятности, изменится также и сумма f. Чем чаще
корпорация АБВ будет учитывать эти изменения, тем более правильными будут ее
решения. Отметьте. что если корпорация АБВ инвестирует в этот проект меньше 877
192,35 доллара. тогда она находится левее пика кривой f. Это аналогично
ситуации, когда у трейдера открыто слишком мало контрактов (по сравнению с
оптимальным f). Если корпорация АБВ вкладывает в проект большую сумму, это
аналогично ситуации, когда у трейдера открыто слишком много позиций.
Количество, рассмотренное здесь, является количеством
денег, но это могут быть не только деньги, и метод будет работать. Данный
подход можно использовать для любого количественного решения в среде
благоприятной неопределенности .
Если вы создадите различные сценарии для фондового рынка,
оптимальное f. полученное с помощью этого метода, даст вам процент средств,
которые надо в данный момент инвестировать в акции. Например, если f= 0,65, то 65% вашего баланса должно быть на рынке, а
оставшиеся 35%, например, в деньгах. Этот подход даст вам наибольший
геометрический рост капитала. Конечно, результат будет зависеть от того, какие
входные данные вы использовали в системе (сценарии. их вероятности
осуществления, выигрыши и проигрыши, издержки). Все сказанное ранее об
оптимальном f применимо здесь, и это означает также, что ожидаемые проигрыши
могут достигать 100%. Если вы осуществляете планирование сценария для
размещения активов, то должны ожидать, что около 100% активов. размещенных в
соответствии с рассматриваемым сценарием, могут быть потеряны в какое-либо
время в будущем. Например, вы используете данный метод, чтобы определить сумму
средств, предназначенных для инвестирования в акции. Допустим, вы приходите к
выводу, что 65% средств должно быть инвестировано в акции, а оставшиеся 35% в
безрисковые активы. Следует ожидать, что проигрыш в будущем может достичь 100%
суммы, размещенной на фондовом рынке. Другими словами, вы должны быть готовы,
что в какой-либо точке в будущем почти 100% активов от ваших 65%, размещенных в
акции, будут проиграны. Однако именно таким образом вы достигнете максимального
геометрического роста. Ту же процедуру можно использовать для альтернативного
параметрического метода определения оптимального f
в торговле. Допустим, вы принимаете торговые решения, основываясь на
фундаментальных данных. Вы намечаете различные сценарии, которые могут
произойти в процессе торговли. Чем больше сценариев и чем точнее сценарии, тем
лучше будут полученные результаты. Предположим, вы решили купить муниципальные
облигации, но при этом не планируете удерживать их до срока погашения. Вы
можете рассмотреть множество сценариев будущих событий и использовать эти
сценарии для определения оптимального размера инвестиций.
Концепцию
планирования сценария для определения оптимального f можно использовать во
многих областях: от военных стратегий до определения оптимального уровня
участия в подписке на акции или оптимальной предоплаты за дом. Этот метод,
вероятно, является лучшим и уже точно самым легким для тех, кто не использует
механические решения при входе и выходе с рынка. Трейдеры, которые торгуют по
фундаментальным данным, графикам, волнам Эллиотта или с помощью любого другого
метода, требующего субъективного суждения, могут найти оптимальные f с помощью
этого подхода — он намного проще, чем поиск значений параметров распределения.
Арифметическое среднее HPR группы сценариев можно рассчитать
следующим образом:
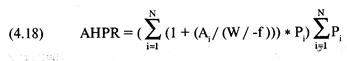
где N = число
сценариев;
А = результат (выигрыш или проигрыш) сценария i;
Р = вероятность
сценария i;
W= наихудший результат среди всех сценариев.
AHPR будет важно позднее, при поиске эффективной границы
совокупности нескольких рыночных систем, когда необходимо будет определить
ожидаемую прибыль (арифметическую) данной рыночной системы. Эта ожидаемая
прибыль равна AHPR-1. Рассмотренный метод не обязательно должен быть основан
на параметрическом подходе. Возможен и эмпирический подход. Другими словами,
мы можем взять отчет о сделках данной рыночной системы и использовать каждую из
этих сделок в качестве сценария, который может произойти в будущем. Величина
прибыли или убытка будет выходным результатом данного сценария. В этом случае
каждый сценарий (сделка) имеет равную вероятность осуществления — 1/N, где N — общее число сделок (сценариев). В результате мы
получим эмпирическое оптимальное f. Когда есть
несколько решений на основе нескольких сценариев, выбор того. чье среднее
геометрическое, соответствующее оптимальному f, самое большое. максимизирует
решение в асимптотическом смысле. Зачастую это будет происходить вопреки
общепринятым правилам принятия решения, таким как Правило Гурвица, максимакс,
минимакс, минимаксная потеря (minimax regret) и наивысшее математическое ожидание. Предположим, мы
должны выбрать одно их двух возможных решений, которые назовем «белым» и
«черным». Белое решение представляет следующие возможные сценарии:
|
Белое
решение
|
|
Сценарий
|
Вероятность
|
Результат
|
|
А
|
0,3
|
-20
|
|
В
|
0,4
|
0
|
|
С
|
0,3
|
30
|
|
Математическое
|
ожидание = $3,00
|
|
|
Оптимальное f =
|
0, 17
|
|
|
Среднее геометрическое = 1,0123
|
Черное решение
представляет следующие сценарии:
|
Черное
решение
|
|
Сценарий
|
Вероятность
|
Результат
|
|
А
|
0,3
|
-10
|
|
В
|
0,4
|
5
|
|
С
|
0,15
|
6
|
|
D
|
0,15
|
20
|
Математическое ожидание = $2,90
Оптимальное f=0,31
Среднее геометрическое = 1,0453
Многие
выбрали бы белое решение, так как оно имеет большее математическое ожидание.
При белом решении вы можете ожидать «в среднем» выигрыш в 3 доллара против
выигрыша черного решения в 2,90 доллара. Однако выбор черного решения будет
более правильным, так как оно дает наибольшее среднее геометрическое. При
черном решении можно ожидать «в среднем» выигрыш в 4,53% (1,0453 - 1) против
выигрыша белого решения в 1,23%. При реинвестировании черное решение, в
среднем, выиграет в три раза больше, чем белое решение! Вы можете возразить,
отметив, что мы не реинвестируем по тому же сценарию каждый раз, и можно
добиться большего, если всегда выбирать наивысшее арифметическое
математическое ожидание для каждого представленного набора. Мы будем принимать
решение, основываясь на большем арифметическом математическом ожидании, только
в том случае, если не собираемся реинвестировать вообще. Но так как почти
всегда деньги, которыми мы рискуем сегодня, будут снова с риском вложены в
будущем, а деньги, выигранные или проигранные в прошлом, влияют на то, чем мы
можем рисковать сегодня (среда геометрических следствий), для максимизации
долгосрочного роста капитала мы должны принимать решения, исходя из среднего
геометрического. Даже если сценарии, которые будут представлены завтра, не
будут такими же, как сегодня, используя наибольшее среднее геометрическое, мы
всегда максимизируем наши решения. Это аналогично процессу зависимых попыток,
например игре в «очко». Каждая раздача изменяет вероятности, поэтому
оптимальная ставка изменяется, чтобы максимизировать долгосрочный рост.
Помните, чтобы максимизировать долгосрочный рост, мы должны рассматривать текущую игру как неограниченную во времени.
Другими словами, следует рассматривать каждую отдельную ставку, как будто она повторяется бесконечное число
раз, если необходимо максимизировать рост в течение долгой последовательности
ставок в нескольких играх. Давайте обобщим все вышесказанное: когда
результат события оказывает влияние на результат(ы) последующего события(ий),
нам следует выбирать наибольшее геометрическое ожидание. В редких случаях,
когда результат не влияет на последующие события, следует выбирать наибольшее
арифметическое ожидание. Математическое ожидание (арифметическое) не учитывает
зависимость результатов внутри каждого сценария и поэтому может привести к
неверному заключению, когда рассматривается реинвестирование в геометрической
среде. Использование предложенного метода в планировании сценария поможет вам
правильно выбрать сценарий, оценить его результаты и вероятности их
осуществления. Этот метод внутренне более консервативен, чем размещение на
основе наибольшего арифметического математического ожидания. Уравнение (3.05)
показывает, что среднее геометрическое никогда не может быть больше среднего
арифметического. Таким образом, этот метод никогда не будет более рискованным,
чем метод наибольшего арифметического математического ожидания. В
асимптотическом смысле (долгосрочном) это не только лучший метод размещения,
так как вы получаете наибольший геометрический рост, он также более безопасен,
чем размещение по наибольшему арифметическому математическому ожиданию, которое
неизменно смещает вас вправо от пика кривой f.
Так как
реинвестирование почти всегда имеет место в реальной жизни (до того дня, когда
вы уйдете на пенсию),1 то есть
вы снова будете использовать деньги, которые использовали сегодня, мы должны
принимать решения, исходя из того, что такая возможность представится тысячи
раз, для того чтобы максимизировать рост. Мы должны принимать решения таким
образом, чтобы максимизировать геометрическое ожидание. Более того, так как
результаты большинства событий влияют на результаты последующих событий, нам
следует принимать решения и размещать средства, основываясь на максимальном
геометрическом ожидании, что может привести к решениям, которые не всегда
очевидны.
Поиск
оптимального f по ячеистым данным
Теперь мы
рассмотрим поиск оптимального f и его побочных продуктов по ячеистым данным.
Этот подход также является гибридом параметрического и эмпирического метода и
аналогичен процессу поиска оптимального f по различным сценариям; только на
этот раз мы будем использовать среднюю точку ячейки. Для каждой ячейки у нас
будет ассоциированная вероятность, рассчитанная как общее число элементов
(сделок) в этой ячейке, деленное на общее число элементов (сделок) во всех
ячейках. Для каждой ячейки у нас будет ассоциированный результат, рассчитанный
по центральной точке ячейки. Например, у нас есть 3 ячейки и
10 сделок. Первую ячейку мы определим для P&L от -1000 долларов до -100
долларов. В этой ячейке будет два элемента. Следующая
ячейка предназначена для сделок от -100 до 100 долларов, она вмещает 5 сделок. Наконец, в третью ячейку попадут 3 сделки, которые имеют P&L от 100 до 1000
долларов.
|
Ячейка
|
Ячейка
|
Сделки
|
Ассоциированная
|
Ассоциированный
|
|
|
|
|
вероятность
|
результат
|
|
-1000
|
-100
|
2
|
0,2
|
-550
|
|
-100
|
100
|
5
|
0,5
|
0
|
|
100
|
1000
|
3
|
0,3
|
550
|
Теперь нам нужно решить уравнение (4.16), где каждая ячейка
представляет отдельный сценарий. Таким образом, для случая с 3 ячейками
оптимальное f составляет 0,2, или 1 контракт на каждые 2750 долларов на
счете (наш проигрыш наихудшего случая будет средней точкой первой ячейки, или
(-$1000 + -$100) / /2 =-$550). Этот метод можно использовать в
реальной торговле, хотя он и недостаточно точен, поскольку допускает, что
наибольший проигрыш находится в середине наихудшей ячейки, а это не совсем
верно. Часто полезно иметь одну лишнюю ячейку, чтобы включить проигрыш
наихудшего случая. Допустим, как и в примере с 3 ячейками, у нас была сделка с
проигрышем в 1000 долларов. Такая сделка попадает в ячейку -1000 до -100
долларов и поэтому будет записана как 550 долларов (средняя точка ячейки), но
мы можем разместить в ячейки те же данные следующим образом:
|
Ячейка
|
Ячейка
|
Сделки
|
Ассоциированная
вероятность
|
Ассоциированный
результат
|
|
-1000
|
-1000
|
1
|
0,1
|
-1000
|
|
-999
|
-100
|
1
|
0,1
|
-550
|
|
-100
|
100
|
5
|
0,5
|
0
|
|
100
|
1000
|
3
|
0,3
|
550
|
Теперь оптимальное f составляет 0,04, или 1 контракт на
каждые 25 000 долларов на счете. Вы видите, насколько приблизителен этот
метод? Поэтому, хотя этот метод даст нам оптимальное f для ячеистых данных,
надо понимать, что потеря информации при размещении данных в ячейки может
сделать результаты настолько неточными, что они станут бесполезными. Если бы у
нас было больше точек данных и больше ячеек, метод был бы намного точнее.
Фактически, если бы у нас было бесконечное количество данных и бесконечное число
ячеек, метод был бы абсолютно точным (если бы данные в каждой из ячеек были
равны средним точкам соответствующих ячеек, то этот метод также был бы точным). Другой
недостаток предлагаемого метода заключается в том, что среднее значение ячейки
не обязательно расположено в центре ячейки. В реальности среднее значение
элементов в ячейке будет ближе к моде всего распределения, чем к средней точке
ячейки. Следовательно, полученная дисперсия будет больше, чем есть на самом
деле. Существуют способы корректировки, но и они могут быть неточными. Проблему
можно было бы преодолеть, и результаты были бы точными при бесконечном
количестве элементов (сделок) и бесконечном количестве ячеек. Если
у вас есть достаточно большое количество сделок и достаточно большое количество
ячеек, вы можете использовать этот метод с большей уверенностью. Вы также
можете провести тесты «что если», изменяя число элементов в различных ячейках,
чтобы получить более точное приближение.
Какое оптимальное
f
лучше?
Мы знаем, что можно найти оптимальное f, используя
эмпирический подход, а также используя некоторые параметрические методы как для
ячеистых, так и для неячеистых данных. Мы также знаем, что можно привести
данные к текущей цене. Какое оптимальное f действительно оптимально —
полученное по приведенным или неприведенным данным?
Неприведенное эмпирическое оптимальное f рассчитывается на
прошлых данных. Эмпирический метод для нахождения оптимального f, описанный в
главе 1, даст оптимальное f, которое реализовало бы наивысший геометрический
рост по прошлому потоку результатов. Однако нам надо определить, какое значение
оптимального f использовать в будущем (особенно в следующей сделке), учитывая,
что у нас нет достоверной информации об исходе следующей сделки. Мы точно не
знаем, будет это прибыль (тогда оптимальное f будет 1) или убыток (тогда
оптимальное f будет 0). Мы можем выразить результат следующей сделки только распределением вероятности. Лучшим
подходом для трейдеров, применяющих механическую систему, будет расчет f путем
использования параметрического метода с помощью регулируемой функции
распределения, описанной в этой главе, с приведенными или неприведенными
данными. Если есть значительное различие в использовании приведенных данных по
сравнению с неприведенными, тогда, вероятно, расчеты сделаны по слишком большой
истории сделок, или же данных на уровне текущих цен недостаточно. Для
несистемных трейдеров лучшим может оказаться подход планирования сценария.
Теперь вы имеете
представление как об эмпирических, так и параметрических методах, а также о
некоторых гибридных методах поиска оптимального f. В следующей главе мы рассмотрим проблему поиска
оптимального f
(параметрическим способом) для случая, когда одновременно открыто несколько
позиций.
Глава
5
Введение в методы управления капиталом с
использованием параметрического подхода при одновременной торговле по
нескольким позициям
В этой книге уже
упоминалось об использовании опционов отдельно или совместно с позицией по
базовому инструменту для улучшения торговых результатов. Покупка пут-опциона
вместе с длинной позицией по базовому инструменту (или просто покупка
колл-оп-циона), а иногда даже продажа (короткая продажа) колл-опциона совместно
с длинной позицией по базовому инструменту могут ускорить асимптотический
геометрический рост. Это происходит потому, что очень часто (но не всегда)
использование опционов уменьшает дисперсию в большей степени, чем уменьшает
арифметический средний доход. В результате, исходя из фундаментального
уравнения торговли, мы получаем большее оценочное TWR. Опционы можно
использовать как самостоятельные инструменты, так и вместе с позициями по
базовому инструменту для управления риском. В будущем, так как трейдеры все
больше концентрируются на управлении риском, опционы, вероятно, будут играть
еще большую роль. В книге «Формулы
управления портфелем» была рассмотрена взаимосвязь оптимального/и опционов. *
В этой главе мы продолжим начатую дискуссию и обсудим торговлю по нескольким
позициям, а также поговорим об опционах. Настоящая глава посвящена еще одному методу поиска оптимального/для
немеханических торговых систем. Параметрические методы, рассмотренные до этого
момента, могут использовать те, кто не применяет механические системы.
Допустим, вы не используете механическую систему и применяете метод, описанный
в главе 4. Если вы захотите рассчитать эксцесс, то сделать это будет не очень
легко (по крайней мере, точное значение эксцесса быстро получить, скорее всего,
не удастся). Данная глава предназначена прежде всего для тех, кто использует
немеханические методы принятия решений об открытии и закрытии позиций. Трейдерам,
использующим эти методы, надо будет рассчитывать не параметры распределения
сделок, а значения для волатильности базового инструмента и прогнозируемой цены
базового инструмента. Трейдеру, не использующему механическую, объективную систему,
будет намного легче получить именно эти величины, чем рассчитать параметры для
распределения сделок, которые еще не произошли.
Обсуждение оптимального/и его побочных
продуктов для тех трейдеров, которые не используют механическую, объективную
систему, мы начнем с рассмотрения ситуации, когда одновременно открыто
несколько позиций. Означает ли это, что тот, кто использует механические методы
для открытия и закрытия позиций, не может использовать описанные подходы? Нет.
В Главе 6 предложен метод поиска оптимальных, одновременно открытых позиций
независимо от того, использует трейдер механическую систему или нет. В этой
главе рассмотрена ситуация, когда одновременно открыто несколько позиций (с
использованием опционов или без), и применяется немеханический подход.
Расчет
волатильности
Один из важных параметров, который трейдер, желающий
использовать описываемые в этой главе концепции, должен ввести, — это
волатильность. Существует два способа определения волатильности. Первый —
использование оценки на основе рыночных данных — дает подразумеваемую волатильность. Модели ценообразования опционов, представленные
в этой главе, используют волатильность в качестве одного из своих входных
параметров для получения справедливой теоретической цены опциона.
Подразумеваемая волатильность основывается на предположении, что рыночная цена
опциона эквивалентна его справедливой теоретической цене. Волатильность,
которая дает справедливую теоретическую цену, равную рыночной цене, и есть
подразумеваемая волатильность. Второй метод расчета волатильности
основывается на использовании исторических данных. Полученная таким образом историческая волатильность определяется
фактической ценой базового инструмента. Хотя волатильность в качестве входного
данного в модели ценообразования опционов выражается в годовых процентах, при
ее определении используется более короткий временной отрезок, обычно 10-20
дней, а получившийся в результате ответ переводится в годовое значение.
Ниже
показан расчет 20-дневной годовой исторической волатильности.
Шаг 1. Разделите сегодняшнее закрытие на предыдущее
закрытие рыночного дня.
Шаг 2. Возьмите натуральный логарифм
частного, полученного в шаге 1. Для примера рассчитаем годовую историческую
волатильность японской йены на март 1991 года. При написании даты будем
использовать формат (год/месяц/день). Закрытие 910225, равное 74,52, разделим
на закрытие 910222, равное 75,52.
74,82 / 75,52 = 0,9907309322 Натуральный логарифм 0,9907309322 равен 0,009312258.
Шаг 3. По истечении 21 дня у вас будет 20
значений для шага 2. Теперь рассчитайте 20-дневную скользящую среднюю значений
из шага 2.
Шаг 4. Найдите 20-дневную дисперсию выборки
данных из шага 2. Для этого необходима 20-дневная скользящая средняя (см. шаг
3). Далее, для каждого из 20 последних дней вычтем скользящую среднюю из значений
шага 2. Теперь возведем в квадрат полученные значения, чтобы преобразовать все
отрицательные ответы в положительные. После этого сложим все
значения за последние 20 дней. Наконец, разделим найденную сумму на 19 и
получим дисперсию по выборке данных за последние 20 дней. 20-дневная
дисперсия для 901226 составляет 0,00009. Подобным образом вы можете рассчитать
20-дневную дисперсию для любого дня.
Шаг 5. После того как вы определили
20-дневную дисперсию для конкретного дня, необходимо преобразовать ее в
20-дневное стандартное отклонение. Это легко сделать путем извлечения
квадратного корня из дисперсии. Таким образом, для 901226 квадратный корень
дисперсии (которая, как было показано, равна 0,00009) даст нам 20-дневное
стандартное отклонение 0,009486832981.
Шаг 6. Теперь преобразуем полученные данные
в «годовые». Так как мы используем дневные данные и исходим из того, что по
йене в году 252 торговых дня (примерно), умножим ответы из шага 5 на квадратный
корень 252, то есть на 15,87450787. Для 901226 20-дневное стандартное
отклонение по выборке составляет 0,009486832981. Умножив его на 15,87450787,
получаем 0,1505988048. Это значение является исторической волатильностью, в
нашем случае — 15,06%, и оно может быть использовано в качестве входного значения
волатильности в модели ценообразования опционов Блэка-Шоулса.
Следующая
таблица показывает шаги, необходимые для нахождения 20-дневной «годовой»
исторической волатильности. Заметьте, что промежуточные шаги для определения
дисперсии, которые были показаны в предыдущей таблице, сюда не включены.
|
А
Дата
|
В
Закрытие
|
С
LN изменений
|
D 20-дневная средняя
|
Е 20-дневная дисперсия
|
F
20-дневное стандартное отклонение
|
G
Годовое значение F * 15,87451
|
|
901127
|
77,96
|
|
|
|
|
|
|
901128
|
76,91
|
-0,0136
|
|
|
|
|
|
901129
|
74,93
|
-0,0261
|
|
|
|
|
|
901130
|
75,37
|
0,0059
|
|
|
|
|
|
901203
|
74,18
|
-0,0159
|
|
|
|
|
|
901204
|
74,72
|
0,0073
|
|
|
|
|
|
901205
|
74,57
|
-0,0020
|
|
|
|
|
|
901206
|
75,42
|
0,0113
|
|
|
|
|
|
901207
|
76,44
|
0,0134
|
|
|
|
|
торгуете
без опционов и рассматриваете торговлю как не
ограниченную во времени, ваш реальный риск банкротства равен 1. При таких
условиях вы неминуемо разоритесь, что вполне согласуется с уравнениями риска
банкротства, поскольку в них в качестве входных переменных используются
эмпирические данные, то есть входные данные в уравнениях риска банкротства
основываются на ограниченных наборах
сделок. Утверждение о гарантированном банкротстве при бесконечно долгой
игре с неограниченной ответственностью делается с позиций параметрического
подхода. Параметрический подход учитывает большие проигрышные сделки, которые
расположены в левом хвосте распределения, но еще не произошли, поэтому они не
являются частью ограниченного набора, используемого в качестве входных данных
в уравнениях риска банкротства. Для примера представьте себе торговую
систему, в которой применяется постоянное количество контрактов. В каждой
сделке используется 1 контракт. Чтобы узнать, каким может стать баланс через Х
сделок, мы просто умножим Х на среднюю сделку. Таким образом, если система
имеет среднюю сделку 250 долларов и мы хотим знать, каким может стать баланс
через 7 сделок, мы $250 умножим на 7 и получим $1750. Отметьте, что кривая
арифметического математического ожидания задается линейной функцией. Любая
сделка может принести убыток, который отбросит нас назад (временно) от
ожидаемой линии. В такой ситуации есть предел проигрыша по сделке. Так как наша
линия всегда выше, чем самая большая сумма, которую можно проиграть за сделку,
мы не можем обанкротиться сразу. Однако длинная проигрышная полоса может
отбросить нас достаточно далеко от этой линии, и мы не сможем продолжить
торговлю, то есть обанкротимся. Вероятность подобного развития событий
уменьшается с течением времени, когда линия ожидания становится выше. Уравнение
риска банкротства позволяет рассчитать вероятность банкротства еще до того, как
мы начнем торговать по выбранной системе. Если бы мы торговали
в такой системе на основе фиксированной доли счета, линия загибалась бы вверх,
становясь после каждой сделки все круче. Однако проигрыш всегда сопоставим с
тем, насколько высоко мы находимся на линии. Таким образом, вероятность
банкротства не уменьшается с течением времени. В теории, однако, риск
банкротства при торговле фиксированной долей счета можно сделать равным нулю,
если торговать бесконечно делимыми единицами. К реальной торговле это не
применимо. Риск банкротства при торговле фиксированной долей счета всегда
немного выше, чем в этой же системе при торговле на основе постоянного
количества контрактов.
В действительности, нет верхнего предела
суммы, которую вы можете проиграть за одну сделку; кривые состояния счета
могут снизиться до нуля за одну сделку независимо от того, насколько высоко они
расположены. Таким образом, если мы торгуем бесконечно долгий период времени
инструментом с неограниченной ответственностью, постоянным количеством
контрактов или фиксированной долей счета, риск банкротства составляет 1.
Банкротство гарантировано. Единственный способ избежать такого развития
событий — поставить ограничение на максимальный проигрыш. Этого можно достичь,
используя опционы, когда позиция относится в дебет (если трейдер платит за
премию больше, чем получает, то разница между уплаченной и полученной суммами
называется «дебет»)1.
Модели
ценообразования опционов
Представьте
себе базовый инструмент (акция, облигация, валюта, товар и т.д.), цена которого
движется вверх или вниз на 1 тик каждую последующую сделку Если мы будем
измерять возможную стоимость акции через 100 тиков и рассмотрим большое
количество вариантов, то обнаружим, что полученное распределение результатов —
нормальное. Поведение цены в данном случае будет напоминать падение шарика
через доску Галтона. Если рассчитать цену опциона, исходя из того принципа, что
прибыль при покупке или продаже опционов должна быть равна нулю, мы получим биномиальную модель ценообразования опционов
(или, коротко, биномиальную модель). Ее иногда также называют моделью Кокса-Росса-Рубинштейна в честь
ее разработчиков. Такая цена опциона основывается на его ожидаемой стоимости
(его арифметическом математическом ожидании), с тем расчетом, что вы не
получаете прибыль, покупая или продавая опцион и удерживая его до истечения
срока. В этом случае говорят, что опцион справедливо
оценен.
Мы не
будем углубляться в математику биномиальной модели, а рассмотрим модель
фондовых опционов Блэка-Шоулса и модель опционов на фьючерсы Блэ-ка. Вам
следует знать, что кроме вышеперечисленных трех моделей есть другие действующие
модели ценообразования опционов, которые мы не будут рассматривать, хотя
концепции, описанные в этой главе, применимы ко всем моделям ценообразования
опционов. Для более подробного изучения математической основы моделей я могу
порекомендовать книгу Шелдона Нейтенберга (Volatility and Pricing Strategies by Sheldon Natenberg). Математика модели
фондовых опционов Блэка-Шоулса и модели опционов на фьючерсы Блэка, которые мы
будем рассматривать, взята из книги Нейтенберга. Тем читателям, которые желают
больше узнать о концепции оптимального f
и опционах, я советую прочитать фундаментальный труд Нейтенберга.
Давайте
обсудим модель ценообразования фондовых опционов Блэка-Шоулса (далее
Блэк-Шоулс). Модель названа в честь ее создателей: Фишера Блэка из Чикагского
университета и Мирона Шоулса из M.I.T; впервые она была описана в 1973 году
(May — June 1973 Journal of Political Economy). Блэк-Шоулс
считается предельной формой биномиальной модели. В биномиальной модели нужно задать
число тиков, определяющее движение вверх или вниз, прежде чем будет зафиксировано
возможное значение цены. Далее следует небольшая диаграмма, которая поясняет
эту мысль.

Текущая цена на первом шаге может пойти в 2-х направлениях.
На втором шаге в 4-х направлениях. В биномиальной модели для расчета
справедливой цены опциона вы должны заранее определить, сколько всего периодов
использовать. Блэк-Шоулс считается предельной формой биномиальной модели,
так как допускает бесконечное число периодов (в теории), то есть Блэк-Шоулс
подразумевает, что эта небольшая диаграмма будет расширяться до бесконечности.
Если вы определите справедливую цену опциона по Блэку-Шоулсу, то получите тот
же ответ, что и в случае с биномиальной моделью, если число периодов, используемых
в биномиальной модели, будет стремиться к бесконечности. (Тот факт, что
Блэк-Шоулс является предельной формой биномиальной модели, подразумевает, что
биномиальная модель появилась первой, но на самом деле сначала появилась
именно модель Блэка-Шоулса). Справедливая стоимость фондового
колл-опциона по Блэку-Шоулсу рассчитывается следующим образом:
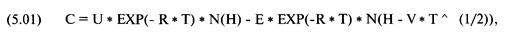
а пут-опциона:
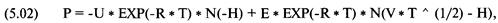
где С = справедливая стоимость колл-опциона;
Р =
справедливая стоимость пут-опциона;
U = цена базового инструмента;
Е = цена исполнения опциона;
Т = доля года, оставшаяся до истечения срока исполнения
выраженная десятичной дробью1;
V= годовая волатильность в процентах;
R = безрисковая ставка;
1п() = функция натурального логарифма;
N() = кумулятивная нормальная функция распределения
вероятностей, задаваемая уравнением (3.21).
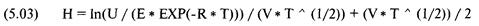
Для акций, по которым выплачиваются дивиденды, необходимо
скорректировать переменную U и отразить текущую цену базового инструмента с
учетом стоимости ожидаемых дивидендов:
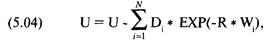
где Ц = ожидаемая выплата дивиденда 1;
W. = время (доля года, выраженная десятичной дробью) до
выплаты L
Модель Блэка-Шоулса позволяет точно
рассчитать дельту, то есть первую производную цены опциона. Это мгновенная
скорость изменения опциона по отношению к изменению U (цены базового
инструмента):
(5.05) Дельта
колл-опциона = N(H)
(5.06) Дельта
пут-опциона = -N(-H)
Эти коэффициенты будут очень важны в Главе 7, когда мы
будем рассматривать страхование портфеля.
.
Блэк
сделал модель применимой к опционам на фьючерсы, механизм операций с которыми
аналогичен операциям с акциями1. Модель
ценообразования опционов на фьючерсы Блэка аналогична модели фондовых опционов
Блэка-Шоулса за исключением переменной Н:
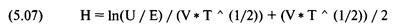
При использовании модели для фьючерсов коэффициент дельта
рассчитывается следующим образом:
(5.08) Дельта
колл-опциона = EXP(-R * Т) * N(H)
(5.09) Дельта
пут-опциона = -EXP(-R * Т) * N(-H)
Для примера рассмотрим опцион, который имеет цену исполнения
600. Текущая рыночная цена базового инструмента равна 575, а годовая
волатильность составляет 25%. Мы будем использовать модель опционов на
фьючерсы, 252-дневный год и безрисковую ставку 0%. Далее мы допустим, что дата
истечения опциона — 15 сентября 1991 года (910915), а текущая дата — 1 августа
1991 года (910801).
Сначала рассчитаем переменную Т, а затем преобразуем 910801
и 910915 в их юлианские эквиваленты. Для этого мы должны использовать следующий
алгоритм.
1. Задайте переменные 1, 2 и 3, которые будут определять
год, месяц и день, соответственно. Для нашего примера — это 1991, 8 и 1.
2. Если переменная 2 меньше 3 (январь или февраль), тогда
переменная 1 будет равна значению года минус 1, а переменная 2 будет равна
значению месяца плюс 13.
3. Если значение переменной 2 больше, чем 2 (март или
дальше), тогда переменная 2 будет равна значению месяца плюс 1.
4. Задайте переменную 4, которая будет рассчитываться
следующим образом:
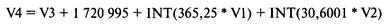
5.
Задайте переменную 5, которая будет равна целой части произведения числа 0,01
и переменной 1:
Математически:
V5=INT(0,01*V1)
6. Рассчитаем юлианскую дату:
Юлианская дата = V4 + 2 - V5 + INT(0,25 * V5) Преобразуем дату
910901 в юлианскую:
Шаг 1. VI = 1991, V2 = 8, V3 = 1.
Шаг 2. Так как наш месяц в этом примере идет за январем и
февралем, то этот шаг не применяется.
Шаг 3. Так как этот
месяц идет за январем и февралем, то получим:
V2 = 8 + 1 = 9. Шаг 4. Теперь найдем V4:
V4 = V3 + 1 720 995 +
INT(365,25 * VI) + INT(30,6001 * V2) = 1 + 1 720 995 + INT(365,25 * 1991) + INT(30,6001
* 9) = 1 + 1 720 995 + INT(727 212,75) + INT(275,4009) =1+1720 995 + 727 212 + 275 = 2 448 483 Шаг 5. Далее найдем V5:
V5=INT(0,01*V1)
=INT(0,01*1991) = INT(19,91) = 19 Шаг 6. Теперь получим юлианскую дату:
Юлианская дата = V4 + 2 - V5 + INT(0,25
* V5)
= 2 448 483 + 2 - 19 + INT(0,25
* 19) = 2 448 483 + 2 - 19 + INT(4,75) = 2 448 483
+ 2 - 19 + 4 = 2 448 470
Таким
образом, юлианская дата 1 августа 1991 года равна 2448470. Если мы преобразуем
дату истечения опциона 15 сентября 1991 года в юлианскую, то получим 2448515.
Если использовать 365-дневный год (или точнее 365,2425-дневный по григорианскому
календарю), то, чтобы найти время, оставшееся до истечения срока, необходимо
рассчитать разность между двумя юлианскими датами, затем вычесть единицу и полученное
значение разделить на 365 (или 365,2425). Однако мы будем
использовать не 365-дневный год, а 252-дневный, чтобы учесть только те дни,
когда открыта биржа (будние дни минус праздники). Просмотрим каждый день между
двумя юлианскими датами, чтобы понять, является он рабочим днем или нет. Мы
можем определить, каким днем недели является юлианская дата, прибавив к ее
значению единицу, разделив на 7 и взяв остаток. Остаток будет значением от 0
до 6, соответствуя дню недели от воскресенья до субботы. Таким образом, для 1
августа 1991 года, когда юлианская дата равна 2448470:
День недели = ((2 448 470 + 1) / 7) % 7 =2448471/% 7 =
((2 448 471/7) - INT(2 448 471 / 7)) * 7 =(349
781,5714-349 781)* 7 =0,5714*7 =4
Так как 4 соответствует четвергу, мы можем утверждать, что
1 августа 1991 года является четвергом.
Теперь
просмотрим все дни до даты истечения срока опциона. Если мы учтем все рабочие
дни между этими двумя датами, то придем к выводу, что между (и включая) 1
августа 1991 года и 15 сентября 1991 года 32 рабочих дня. Из полученного значения
следует вычесть единицу, так как мы считаем первым днем 2 августа 1991 года.
Таким образом, между 910801 и 910915 31 рабочий день. Теперь
мы должны вычесть праздники, когда биржа закрыта. В США 2 сентября 1991 года
является Днем Труда. Даже если вы живете в другой стране, биржа, где идет
торговля по этому опциону, может находиться в США, и 2 сентября она будет
закрыта, поэтому мы вычтем 1 из последнего результата. Таким образом, мы получим
30 торговых дней до истечения срока опциона. Разделим количество
торговых дней до истечения срока на число дней в году. Так как мы используем
252-дневный год, то 30/252=0,119047619. Это и есть доля года, выраженная
десятичной дробью, т.е. переменная Т.
Определим
переменную Н, необходимую для модели ценообразования. Так как мы используем
модель для фьючерсов, то должны рассчитать Н по формуле (5.07):

Уравнение (3.21) для расчета N используется два раза.
Первый раз, когда мы находим N(H), второй, когда находим N(H - V * Т^(1/2)). Мы знаем, что V * Т ^ (1/2) =
0,0862581949, поэтому Н - V* Т ^ (1/2) = -0,4502688281 -
-
0,0862581949 = -0,536527023. Таким
образом, мы должны использовать уравнение (3.21) со следующими вводными
значениями переменной Z:
-0,4502688281
и-0,536527023. Из уравнения (3.21) получим 0,3262583 и 0,2957971 соответственно
(уравнение (3.21) описано в главе 3, поэтому мы не будем повторять его здесь).
Отметьте, что сейчас мы получили коэффициент дельта, мгновенную скорость
изменения цены опциона по отношению к изменению цены базового инструмента.
Таким образом, дельта для этого опциона составляет 0,3262583. Теперь
у нас есть все входные данные, необходимые для определения теоретической цены
опциона. Подставив полученные значения в уравнение (5.01), получим:


Таким образом, в соответствии с моделью Блэка для фьючерсов
справедливая стоимость колл-опциона с ценой исполнения 600, сроком исполнения
15 сентября 1991 года, при цене базового инструмента на 1 августа 1991 года
575, при вола-тильности 25%, с учетом 252-дневного года и R = 0 составляет 10,1202625. Интересно отметить
связь между опционами и базовыми инструментами, используя вышеперечисленные
модели ценообразования. Мы знаем, что 0 является наименьшей ценой опциона, но
верхняя цена — это цена самого базового инструмента. Модели демонстрируют, что
теоретическая справедливая цена опциона приближается к верхнему значению
(стоимости базового инструмента U) при росте любой
или всех трех переменных Т, R или V Это означает, что если мы, например,
увеличим Т (время до срока истечения опциона) до бесконечно большого значения,
тогда цена опциона будет равна цене базового инструмента. В этой связи мы можем
сказать, что все базовые инструменты в
действительности эквивалентны опционам с бесконечным Т. Таким образом, все
сказанное верно не только для опционов, но и для базовых инструментов, как
будто они являются опционами с бесконечным Т. Модель фондовых
опционов Блэка-Шоулса и модель опционов на фьючерсы Блэка построены на
определенных допущениях. Разработчики этих моделей исходили из трех
утверждений. Несмотря на недостатки этих утверждений, предложенные модели
все-таки довольно точны, и цены опционов будут стремиться к значениям,
полученным из моделей.
Первое из этих утверждений состоит в том, что
опцион не может быть исполнен до истечения срока. Это приводит к недооценке опционов американского типа, которые
могут исполняться до истечения срока. Второе утверждение предполагает, что мы
знаем будущую волатильность базового инструмента, и она будет оставаться постоянной
в течение срока действия опциона. На самом деле это не так (т.е. волатильность изменится). Кроме того,
распределение изменений волатильности логарифмически нормально, и эту проблему
модели не учитывают1. Еще
одно допущение модели состоит в том, что безрисковая процентная ставка остается
постоянной в течение времени действия опциона. Это также не обязательно. Более
того, краткосрочные ставки логарифмически нормально распределены. То
обстоятельство, что, чем выше краткосрочные ставки, тем выше будут цены
опционов, и утверждение относительно неизменности краткосрочных ставок может
привести к еще большей недооценке опциона по отношению к ожидаемой цене (его
правильному арифметическому математическому ожиданию). Еще
одно утверждение (возможно наиболее важное), которое может привести к
недооценке стоимости опциона, рассчитанной с помощью модели, по отношению к
действительно ожидаемой стоимости, состоит в том, что логарифмы изменений цены
распределяются нормально. Если бы опционы характеризовались не числом дней до
даты истечения срока, а числом тиков вверх или вниз до истечения, а цена за
один раз могла бы изменяться только на 1 тик и он был бы статистически
независим от предыдущего тика, то мы могли бы допустить существование
нормального распределения. В нашем случае логарифмы изменений цены не имеют
таких характеристик. Тем не менее теоретические справедливые цены, полученные с
помощью моделей, используются профессионалами на рынке. Даже если некоторые
трейдеры применяют модели, которые отличаются от показанных здесь, большинство
из них дадут похожие теоретические справедливые цены. Когда реальные цены
расходятся с теоретическими до такой степени, что спекулянты могут получить
прибыль, цены начинают снова сходиться к так называемой «теоретической справедливой
цене». Тот факт, что мы можем спрог-нозировать с достаточной степенью точности,
какой будет цена опциона при наличии различных входных данных (время истечения,
цена базового инструмента и т.д.), позволяет нам произвести расчеты
оптимального f и его побочных продуктов по опционам и смешанным позициям.
Читатель должен помнить, что все эти методы основаны на утверждениях, которые
только что были изложены.
Модель
ценообразования европейских опционов для всех распределений
Мы можем создать собственную модель ценообразования,
лишенную каких-либо предположений относительно распределения изменений цены.
Сначала
необходимо определить термин «теоретически справедливый», относящийся к цене
опционов. Мы будем говорить, что опцион справедливо оценен, если арифметическое математическое ожидание цены
опциона к моменту истечения, выраженное на основе его текущей стоимости, не
принимает во внимание возможного направленного движения цены базового
инструмента. Смысл определения таков: «Какова стоимость данного опциона для
меня сегодня как для покупателя опционов»?
Математическое
ожидание (арифметическое) определяется из уравнения (1.03):
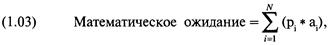
где рi =
вероятность выигрыша или проигрыша попытки i;
ai= выигранная или проигранная сумма попытки i;
N =количество возможных исходов (попыток).
Математическое ожидание представляет собой сумму
произведений каждого возможного выигрыша или проигрыша и вероятности этого
выигрыша или проигрыша. Когда сумма вероятностей рi больше 1, уравнение 1.03 необходимо разделить на сумму
вероятностей рi.
Рассмотрим все дискретные изменения цены, которые имеют
вероятность осуществления, большую или равную 0,001 в течение срока действия
контракта, и по ним определим арифметическое математическое ожидание.
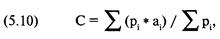
где С =
справедливая с теоретической точки зрения стоимость опциона, или
арифметическое математическое ожидание;
рi = вероятность
цены i по истечении срока опциона;
аi = внутренняя
стоимость опциона (для кол-опциона: рыночная цена инструмента минус цена
исполнения опциона;
для
пут-опциона: цена исполнения минус рыночная цена инструмента), соответствующая
базовому инструменту при цене i.
Использование этой модели подразумевает, что, начиная с
текущей цены, мы будем двигаться вверх по 1 тику, суммируя значения как в
числителе, так и в знаменателе до тех пор, пока вероятность i-ой цены (т.е.
р.) не будет меньше 0,001 (вы можете использовать меньшее число, но я считаю,
что 0,001 вполне достаточно). Затем, начиная со значения, которое на 1 тик
ниже текущей цены, мы будем двигаться вниз по 1 тику, суммируя значения как в
числителе, так и в знаменателе, пока вероятность i-ой цены (т.е. рi) не будет меньше 0,001. Отметьте, что вероятности, которые
мы используем, являются 1-хвостыми, т.е., если вероятность больше чем 0,5, мы
вычитаем это значение из 1. Интересно отметить, что значения
вероятности рi можно менять в зависимости от
того, какое распределение применяется, и оно не обязательно должно быть
нормальным, то есть пользователь может получить теоретическую справедливую цену
опциона для любой формы
распределения! Таким образом, эта модель дает возможность использовать
устойчивое распределение Парето, t-распределение, распределение Пуассона,
собственное регулируемое распределение или любое другое распределение, с
которым, по нашему мнению, согласовывается цена при определении справедливой
стоимости опционов.
Необходимо изменить модель таким образом, чтобы она
выражала арифметическое математическое ожидание на дату истечения срока
опциона как следующую величину:
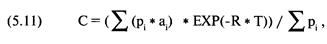
где С = справедливая с теоретической точки
зрения стоимость опциона, или текущее значение арифметического математического
ожидания при данном значении Т;
pi = вероятность цены i
по истечении срока опциона;
аi =внутренняя стоимость опциона, соответствующая базовому инструменту
при цене i;
R = текущая безрисковая ставка;
Т = доля года, оставшаяся до истечения срока исполнения,
выраженная десятичной дробью.
Уравнение (5.11) является моделью ценообразования опционов
для всех распределений и дает текущее значение арифметического математического
ожидания опциона на дату истечения1.
Отметьте, что модель можно использовать и для пут-опционов, имея в виду, что
значения а. при каждом приросте цены i будут другими. Когда
необходимо учесть дивиденды, используйте уравнение (5.04) для корректировки
текущей цены базового инструмента. При определении вероятности цены i на дату истечения используйте именно эту измененную текущую
цену. Далее следует пример использования уравнения (5.11).
Допустим, мы обнаружили, что приемлемой моделью, описывающей распределение
логарифмов изменений цены товара, опционы на который мы хотим купить, является
распределение Стьюдента2. Для
определения оптимального числа степеней
свободы распределения Стьюдента мы использовали тест К-С и пришли к
выводу, что наилучшее значение равно 5. Допустим, мы хотим
определить справедливую цену колл-опциона на 911104 (дата истечения срока
опциона — 911220). Цена базового инструмента равна 100, цена исполнения опциона
также равна 100. Предположим, годовая волатильность составляет 20%, безрисковая
ставка 5% и год равен 260,8875 дням (мы не учитываем праздники, которые
выпадают на рабочий день, например День Благодарения в США). Далее допустим,
что минимальный тик по этому предполагаемому товару равен 0,10. Используя
уравнения (5.01), (5.02) и (5.07) для переменной Н, мы найдем, что справедливая
цена равна 2,861 как для колл-опциона, так и для пут-опциона с ценой исполнения
100. Таким образом, эти цены опционов являются справедливыми ценами в
соответствии с моделью товарных опционов Блэка, которая допускает
логарифмически нормальное распределение цен. Если мы будем использовать
уравнение (5.11), то должны сначала рассчитать значения pg. Их можно получить из фрагмента программы, написанной на
языке Бейсик и представленной в приложении В. Отметьте, что необходимо знать
стандартное значение, т.е. переменную Z,
и число степеней свободы, т.е. переменную DEGFDM. Прежде чем мы обратимся к этой программе, преобразуем
цену i в стандартное значение по следующей формуле:
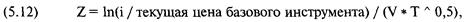
где i = цена,
соответствующая текущему состоянию процесса суммирования;
V = годовая волатильность, выраженная стандартным
отклонением;
Т = доля года, оставшаяся до истечения срока исполнения,
выраженная десятичной дробью;
1п() = функция натурального логарифма.
Уравнение
(5.12), написанное на БЕЙСИКе, будет выглядеть следующим образом:

Переменная
U представляет собой текущую цену базового инструмента (с
учетом дивидендов, если это необходимо). Вероятность для распределения Стьюдента, найденная с
помощью программы из приложения В, является 2-хвостой. Нам надо сделать ее
1-хвостой и выразить как вероятность отклонения от текущей цены (то есть
ограничить ее 0 и 0,5). Это можно сделать с помощью двух строк на БЕЙСИКе:

Таким образом, для 5 степеней свободы справедливая цена
колл-опциона равна 3,842, а справедливая цена пут-опциона равна 2,562. Эти
величины отличаются от значений, полученных с помощью более традиционных
моделей. Причин здесь несколько.
Во-первых, более толстые хвосты распределения Стьюдента с 5
степенями свободы дадут более высокую справедливую стоимость колл-опциона.
Вообще, чем толще хвосты распределения, тем больше получается цена
колл-опциона. Если бы мы использовали 4 степени свободы, то получили бы еще
большую цену колл-опциона.
Стоимость пут-опциона и стоимость колл-опциона значительно
отличаются, в то время как в традиционных моделях стоимость пут-опциона и
колл-опциона эквивалентна. Этот момент требует некоторого пояснения.
Справедливую стоимость пут-опциона можно найти из цены
колл-опциона с той же ценой исполнения и датой истечения (или наоборот) по
формуле пут-колл паритета:
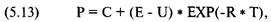
где Р =
справедливая цена пут-опциона;
С = справедливая цена колл-опциона;
Е = цена исполнения;
U = текущая цена базового инструмента;
R = безрисковая ставка;
Т = доля года, оставшаяся до истечения срока исполнения,
выраженная десятичной дробью.
Когда
равенство (5.13) не выполняется, появляется возможность арбитража. Из (5.13) мы
видим, что цены, полученные из традиционных моделей, эквивалентны, когда Е - U = 0.
Давайте заменим переменную U
в уравнении (5.13) ожидаемой ценой базового инструмента на дату истечения
срока опциона. Ожидаемая стоимость базового инструмента может быть определена
с помощью уравнения (5.10) с учетом того, что в этом случае а. просто равно i. В нашем примере с DEGFDM = 5 ожидаемая стоимость базового инструмента равна
101,288467. Это происходит потому, что минимальная цена инструмента равна 0, в
то время как ограничения цены сверху не существует. Движение цены со 100 до 50
так же вероятно, как и движение со 100 до 200. Следовательно, стоимость
колл-опционов будет выше, чем стоимость пут-опционов. Неудивительно, что
ожидаемая стоимость базового инструмента на дату истечения должна быть больше,
чем его текущая цена, — это вполне согласуется с предположением об инфляции.
Когда в уравнении (5.13) мы заменим значение U (текущую цену базового инструмента)
на значение ожидаемой стоимости на дату истечения, мы сможем рассчитать
справедливую стоимость пут-опциона:
Р = 3,842 + (100 - 101,288467) *
ЕХР(-0,05 * 33/260,8875) = 3,842+-1,288467 *ЕХР(-0,006324565186) = 3,842 +
-1,288467 * 0,9936954 = 3,842 +
1,280343731 =2,561656269
Это значение согласуется со стоимостью пут-опциона,
полученной из уравнения (5.11).
Остается одна проблема: если пут-опционы и колл-опционы с
одной ценой исполнения и сроком истечения оценены согласно уравнению (5.11),
тогда существует возможность арбитража. На самом деле LJ в (5.13) является
текущей ценой базового инструмента, а не ожидаемым значением базового
инструмента на дату истечения. Другими словами, если текущая цена равна 100 и
декабрьский колл-опцион с ценой исполнения, равной 100, стоит 3,842, а
пут-опцион с ценой исполнения, равной 100, стоит 2,561656269, то существует
возможность арбитража, исходя из (5.13).
Отсутствие паритета «пут-колл» при наличии наших заново
полученных цен опционов предполагает, что вместо покупки колл-опциона за 3,842
нам следует открыть эквивалентную позицию, купив пут-опцион за 2,562 и базовый
инструмент.
Проблема решится, если мы сначала рассчитаем ожидаемую
стоимость базового инструмента по уравнению (5.10) с учетом того, что аi просто равно i (в нашем примере с DEGFDM = 5 ожидаемая стоимость базового инструмента равна
101,288467), и вычтем текущую цену базового инструмента из полученного
значения: 101,288467 - 100= 1,288467. Теперь, если мы вычтем это значение из
каждого значения а., т.е. внутренней стоимости из (5.11), и примем любые получившиеся
значения менее 0 равными 0, тогда уравнение (5.11) даст нам теоретические
значения, которые согласуются с (5.13). Таким образом, арифметическое
математическое ожидание по базовому инструменту заменит текущую цену базового
инструмента. В нашем примере (распределение Стьюдента с 5 степенями свободы)
мы получим стоимость пут-опциона и колл-опциона с ценой исполнения 100, равную
3,218. Таким образом, наш ответ согласуется с уравнением (5.13), и возможность
арбитража между этими двумя опционами и их базовыми инструментами отсутствует.
Когда мы используем распределение, которое основано на значениях
арифметического математического ожидания базового инструмента на дату истечения
и значение этого ожидания отличается от текущей стоимости базового инструмента,
мы должны вычесть разность (ожидание - текущая стоимость) из внутренней
стоимости опциона и приравнять нулю значения меньше нуля. Таким образом, для
любой формы распределения уравнение (5.11) дает нам арифметическое математическое ожидание опциона на дату истечения, при
условии, что арифметическое математическое ожидание по базовому инструменту
равно его текущей цене (то есть направленное движение цены базового
инструмента не предполагается).
Одиночная
длинная позиция по опциону и оптимальное f
Рассмотрим обычную покупку колл-опциона. Вместо того чтобы
для нахождения оптимального f использовать полную историю сделок по опционам
данной рыночной системы, мы рассмотрим все возможные изменения цены данного
опциона за время его существования и взвесим каждый результат вероятностью его
осуществления. Этот взвешенный по вероятностям результат является HPR, соответствующим цене покупки опциона. Мы рассмотрим весь
спектр результатов (т.е. среднее геометрическое) для каждого значения f и таким
образом найдем оптимальное значение. Почти во всех
моделях ценообразования опционов вводными переменными, имеющими наибольшее
влияние на теоретическую цену опциона, являются: (а) время, оставшееся до
истечения срока, (б) цена исполнения, (в) цена базового инструмента и (г)
волатильность. Некоторые модели могут иметь и другие вводные данные, но именно
эти четыре переменные больше всего влияют на теоретическое значение. Из этих
переменных две — время, оставшееся до истечения срока, и цена базового
инструмента — переменные величины. Волатильность тоже может изменяться, однако
редко в той же степени, что цена базового инструмента или время до истечения
срока. Цена исполнения не изменяется.
С
помощью нашей модели можно найти теоретическую цену для всех значений цен
базового инструмента и времени, оставшегося до истечения срока. Таким образом, HPR для опциона является функцией не только цены базового
инструмента, но и функцией времени, оставшегося до даты истечения опциона:
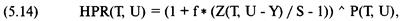
где f = тестируемое значение
f;
S = текущая цена опциона;
Z(T, U
- Y) = теоретическая цена опциона, когда цена базового инструмента
равна U - Y, а время, оставшееся до срока истечения, равно Т. Эту цену можно
определить с помощью любой модели ценообразования, которую пользователь
посчитает подходящей;
Р(Т, U) =
1-хвостая вероятность того, что цена базового инструмента равна U, когда время,
оставшееся до истечения срока исполнения, равно Т. Это значение можно определить
из любой формы распределения, которую пользователь посчитает подходящей;
Y = разность между арифметическим математическим ожиданием
базового инструмента (согласно уравнению (5.10)) и текущей ценой.
С помощью этой формулы можно рассчитать HPR (взвешенное по
вероятности результата) по сделке с опционом, при условии, что через время Т
цена базового инструмента будет равна U. В данном уравнении
переменная Т представляет собой долю года (выраженную десятичной дробью),
оставшуюся до истечения срока опциона. Поэтому на дату истечения Т = 0. Если до
истечения срока остается один год, то Т = 1. Переменная Z(T, U
- Y) зависит от модели ценообразования, которую вы используете. Единственная
переменная, которую вам надо рассчитать, — это Р(Т, U), т.е. вероятность того,
что базовый инструмент будет равен U при заданном Т (т.е. времени, оставшемся
до конца действия опциона). Если использовать модель Блэка-Шоулса
или модель товарных опционов Блэка, то можно рассчитать Р(Т, U) следующим
образом:
если U < или = О:
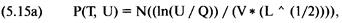
если U > Q:
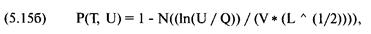
где U = рассматриваемая цена;
Q = текущая цена базового инструмента;
V= годовая волатильность базового инструмента;
Е=доля года, выраженная десятичной дробью, прошедшая с тех
пор, когда опцион был приобретен;
N() = функция нормального распределения (уравнение (3.21));
ln() = функция натурального логарифма.
В итоге мы получим взвешенное по вероятности HPR для каждого исхода. Возможен широкий диапазон результатов,
но, к сожалению, эти результаты не непрерывны. Например, время до истечения
срока не задается непрерывной функцией. До истечения срока всегда остается
целое число; то же верно и для цены базового инструмента. Если цена акции
равна, например, 35, а минимальное изменение цены равно 1/8, то между 30 и 40
находится 81 возможное значение. Зная время, через которое мы
собираемся продать опцион, можно рассчитать взвешенные по вероятности HPR для
всех возможных цен на этот рыночный день. В нормальном распределении
вероятности 99,73% всех результатов попадают в интервал трех стандартных
отклонений от среднего, которое в нашем случае является текущей ценой базового
инструмента. Поэтому нам необходимо рассчитать HPR для определенного рыночного
дня и каждой дискретной цены между - 3 и + 3 стандартными отклонениями. Можно
использовать 4, 5, 6 или больше стандартных отклонений, но ответ от этого не
станет значительно точнее. Не следует также сокращать ценовое окно до 2 или 1
стандартного отклонения. Выбор 3 стандартньк отклонений, конечно, не является
твердым правилом, но в большинстве случаев оно приемлемо. Если
мы используем модель Блэка-Шоулса или модель опционов на фьючерсы Блэка, то
можно узнать, какому изменению цены базового инструмента U соответствует 1
стандартное отклонение:
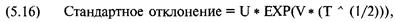
где U = текущая цена базового инструмента;
V = годовая волатильность базового инструмента;
Т = доля года, выраженная десятичной дробью, прошедшая с
тех пор. когда опцион был приобретен;
ЕХР() = экспоненциальная функция.
Отметьте,
что стандартное отклонение является функцией времени, прошедшего с момента
открытия позиции.
Для точки, которая на Х стандартных отклонений выше текущей
цены базового инструмента, получаем:
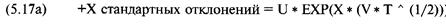
Для
точки, которая на Х стандартных отклонений ниже текущей цены базового
инструмента, получаем:
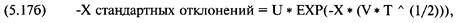
где U =текущая цена базового инструмента;
V =годовая
волатильность базового инструмента;
Т =доля года, выраженная десятичной дробью, прошедшая с
тех пор, когда опцион был приобретен;
EXPQ = экспоненциальная функция;
Х =число
стандартных отклонений от среднего, для которых вы хо тите определить вероятности.
Далее следует описание процедуры поиска оптимального f для
данного опциона.
Шаг
1. Решите, закроете ли вы позицию по
опциону в какой-то конкретный день. Если нет, тогда в дальнейших расчетах
используйте дату истечения срока опциона.
Шаг 2. Определите, сколько дней вы будете удерживать позицию.
Затем преобразуйте это число дней в долю года, выраженную десятичной дробью.
Шаг 3. Для дня из шага 1 рассчитайте точки, которые находятся
между +3 и -3 стандартными отклонениями.
Шаг 4. Преобразуйте диапазоны цен из шага 3 в дискретные
значения. Другими словами, используя приращения по 1 тику, определите все
возможные цены диапазона, включая крайние значения.
Шаг 5. Для каждого из полученных результатов рассчитайте Z(T, U
- Y) и Р(Т, U), то есть рассчитайте теоретическую цену
опциона, а также вероятность того, что базовый инструмент к рассматриваемым
датам будет равен определенной цене.
Шаг 6. После того, как вы выполните шаг 5, у вас будут все
входные данные, необходимые для расчета взвешенного по вероятности HPR.
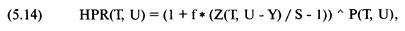
где f = тестируемое значение f;
S = текущая цена опциона;
Z(T, U
- Y) = теоретическая
цена опциона, когда цена базового инструмента равна U
- Y, а время, оставшееся до срока истечения, равно Т. Эту цену можно
определить с помощью любой модели ценообразования, которую пользователь
посчитает подходящей;
Р(Т, U) =
1-хвостая вероятность того, что цена базового инструмента равна U, когда
время, оставшееся до истечения срока исполнения, равно Т. Это значение можно
определить из любой формы распределения, которую пользователь посчитает
подходящей;
Y = разность
между арифметическим математическим ожиданием базового инструмента (согласно
уравнению (5.10)) и текущей ценой.
Необходимо отметить, что форма распределения, используемого
для Р(Т, U), не обязательно должна быть такой же, как и в модели
ценообразования, применяемой для определения значений Z(T, U - Y). Например, вы используете модель
фондовых опционов Блэка-Шоулса для определения значений Z(T, U
- Y). Эта модель предполагает логарифмически нормальное распределение изменений
цены, однако для определения соответствующего Р(Т, U) вы можете использовать
другую форму распределения.
Шаг 7. Теперь мы можем начать поиск оптимального f с помощью
метода итераций, перебирая все возможные значения f между 0 и 1, или с помощью
метода параболической интерполяции, или любого другого одномерного алгоритма
поиска. Подставляя тестируемые значения f в HPR
(у вас уже есть HPR для каждого из возможных приращений
цены между + 3 и - 3 стандартными отклонениями на дату истечения срока или
указанную дату выхода), вы можете найти среднее геометрическое для данного
тестируемого значения f. Для этого надо перемножить все HPR, и полученное
произведение возвести в степень единицы, деленной на сумма вероятностей:
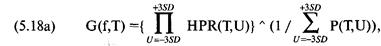
поэтому
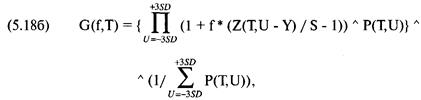
где G(f, T)
= среднее геометрическое HPR для данного тестируемого значения f;
f = тестируемое значение f;
S = текущая цена опциона;
Z(T, U
- Y) = теоретическая цена опциона, когда цена базового инструмента
равна U - Y, а время, оставшееся до срока истечения, равно Т. Эту цену можно
определить с помощью любой модели ценообразования, которую пользователь
посчитает подходящей;
Р(Т, U) = вероятность того, что базовый инструмент равен U,
когда время, оставшееся до истечения срока исполнения, равно Т. Это значение
можно определить из любой формы распределения, которую пользователь посчитает
подходящей;
Y = разность между арифметическим математическим ожиданием
базового инструмента (согласно уравнению (5.10)) и текущей ценой.
Значение f, которое в результате даст наибольшее среднее
геометрическое, является оптимальным.
Мы можем оптимизировать f, определив оптимальную дату
выхода. Другими словами, мы можем найти значение оптимального f для данного опциона на каждый день между
текущим днем и днем истечения. Запишем оптимальные f и средние геометрические
для каждой указанной даты выхода. Когда мы завершим эту процедуру, мы сможем
найти ту дату выхода, которая даст наивысшее среднее геометрическое. Таким
образом, мы получим день, когда должны выйти из позиции по опциону для того,
чтобы математическое ожидание было наивысшим (т.е. среднее геометрическое было
наивысшим). Мы также узнаем, какое оптимальное количество контрактов следует
купить.
Теперь у нас есть математический метод, с помощью которого
можно выходить из позиции по опциону и покупать опцион при положительном
математическом ожидании. Если мы выйдем из позиции в день, когда среднее
геометрическое максимально и оно больше 1,0, то следует покупать число
контрактов, исходя из оптимального f,
которое соответствует наивысшему среднему геометрическому. Математическое
ожидание, о котором мы говорим, — это геометрическое
ожидание. Другими словами, среднее геометрическое (минус 1,0) является
математическим ожиданием, когда вы реинвестируете прибыли (арифметическое
положительное математическое ожидание будет, конечно же, выше, чем
геометрическое).
После
того как вы найдете оптимальное f для
данного опциона, можно преобразовать полученное значение в число контрактов,
которое следует покупать:
(5.19) K=INT(E/(S/f)),
где К =
оптимальное число опционных контрактов для покупки;
f= значение оптимального Г(от 0 до 1);
S = текущая цена опциона;
Е = общий баланс счета;
1NT() = функция целой части.
Для расчета TWR следует знать,
сколько раз мы хотели бы воспроизвести эту же сделку в будущем. Другими
словами, если наше среднее геометрическое составляет 1,001 и необходимо найти
TWR, которое соответствует этой же игре 100 раз подряд, то TWR будет 1,001^100 = 1,105115698. Поэтому можно ожидать заработка
в 10,5115698%, если провести эту сделку 100 раз. Формула для преобразования
среднего геометрического в TWR задается уравнением (4.18):
(4.18) TWR = Среднее геометрическое ^ X,
где TWR =
относительный конечный капитал;
Х = число раз, которое мы «повторяем» эту игру.
Мы можем определить и другие побочные продукты, например,
геометрическое математическое ожидание (среднее геометрическое минус 1). Если
мы возьмем наибольший возможный проигрыш (стоимость самого опциона), разделим
его на оптимальное f и умножим на геометрическое математическое ожидание, то
получим среднюю геометрическую сделку. Как вы уже заметили, при использовании
метода оптимального f в торговле опционами появляется еще один побочный продукт
— оптимальная дата выхода. Мы рассматривали позиции по опционам
при отсутствии направленного движения цены базового инструмента. Для указанной
даты выхода точки, смещенные на 3 стандартных отклонения выше и ниже,
рассчитываются из текущей цены, таким образом, мы ничего не знаем о будущем
направлении цены базового инструмента. В соответствии с математическими
моделями ценообразования мы не получим положительное арифметическое
математическое ожидание, если будем удерживать позицию по опциону до срока
истечения. Однако, как мы уже видели, можно достичь положительного
геометрического математического ожидания, если закрыть позицию в определенный
день до срока истечения.
Если вы предполагаете определенное изменение цены базового
инструмента, его можно учесть. Допустим, мы рассматриваем опционы на базовый
инструмент, который в настоящее время стоит 100. Далее предположим, что на основе
анализа рынка выявлен тренд, который предполагает цену 105 к дате истечения, и
эта дата отстоит на 40 рыночных дней от сегодняшней даты. Мы ожидаем, что цена
повысится на 5 пунктов за 40 дней. Если исходить из линейного изменения цены,
то цена должна расти в среднем на 0,125 пунктов в день. Поэтому для завтрашнего
дня (как дня выхода) мы возьмем значение U,
равное 100,125. Для следующей даты выхода возьмем U, равное 100,25. К тому
времени, когда указанная дата выхода станет датой истечения срока опциона, U
будет равно 105. Если базовым инструментом является акция, то вы должны вычесть
дивиденды из U, воспользовавшись уравнением (5.04). Тренд можно учитывать,
если изменять каждый день значение U, исходя из сделанного прогноза. Так как
уравнения (5.17а) и (5.176) изменятся, значения U повлияют на оптимальные f и побочные продукты. Отметьте, что в
уравнениях (5.17а) и (5.176) используются новые значения U, т.е. происходит
автоматическое приведение данных, следовательно, полученные оптимальные f будут основаны на данных, приведенных к текущей цене.
Когда вы будете использовать вышеописанную технику работы с
оптимальным f, то заметите, что его значение каждый день меняется.
Предположим, сегодня вы купили опцион и рассчитали оптимальную дату выхода.
Послезавтра цена опциона может измениться, и если вы опять проведете процедуру
расчета оптимального f, то также можете получить положительное математическое
ожидание, но уже. другую дату выхода. Что это означает?
Ситуация аналогична лошадиным бегам, где можно делать
ставки после начала скачки и до их завершения. Шансы постоянно меняются, и вы
в любой момент можете обменять купленный билет на деньги. Скажем, до начала
скачек вы ставите 2 доллара на определенную лошадь, основываясь на
положительном математическом ожидании, и лошадь после первого крута прибегает
предпоследней. Предположим, ваш билет, купленный за 2 доллара, стоит теперь
только 1,50 доллара. Вы по-прежнему считаете, что математическое ожидание в
пользу вашей лошади, исходя из результатов прошлых скачек и нынешних шансов. Вы
решаете, что текущая цена билета в 1,50 доллара на 10% занижена. Можно
получить деньги по билету, купленному до начала скачек за 2 доллара (сейчас он
стоит 1,50 доллара), и можно также купить билет за 1,50 доллара, чтобы сделать
еще одну ставку. Таким образом, вы получаете положительное математическое ожидание,
но на основе билета за 1,50 доллара, а не за 2 доллара. Та
же аналогия применима и к опционам, позиция по которым в настоящий момент
немного убыточна, но имеет положительное математическое ожидание на основе новой цены. Вы должны использовать другое
оптимальное f для новой цены, регулируя текущую позицию (если это необходимо),
и закрывать ее, исходя из новой оптимальной даты выхода. Таким образом, вы
используете последнюю ценовую информацию о базовом инструменте, что иногда
может заставить вас удерживать позицию до истечения срока опциона. Возможность
получения положительного математического ожидания при работе с опционами,
которые теоретически справедливо оценены, сначала может показаться парадоксом
или просто шарлатанством. Мы знаем, что теоретические цены
опционов, найденные с помощью моделей, не позволяют получить положительное
математическое ожидание (арифметическое) ни покупателю, ни продавцу. Модели
теоретически справедливы с поправкой «если удерживаются до истечения срока».
Именно эта отсутствующая поправка позволяет опциону быть справедливо оцененным
согласно моделям и все-таки иметь положительное ожидание. Помните,
что цена опциона уменьшается со скоростью квадратного корня времени,
оставшегося до истечения срока. Таким образом, после первого дня покупки
опциона его премия должна упасть в меньшей степени, чем в последующие дни.
Рассмотрим уравнения (5.17а) и (5.176) для цен, соответствующих смещению на 4-
Х и - Х стандартных величин по истечении времени Т. Окно цен каждый день
расширяется, но все медленнее и медленнее, в первый день скорость расширения
максимальна. Таким образом, в первый день падение премии по опциону
будет минимальным, а окно Х стандартных отклонений будет расширяться быстрее
всего. Чем меньше времени пройдет, тем с большей вероятностью мы будем иметь
положительное ожидание по длинной позиции опциона, и чем шире окно Х
стандартных отклонений, тем вероятнее, что мы будем иметь положительное
ожидание, так как убыток ограничен ценой опциона, а возможная прибыль не ограничена.
Между окном Х стандартных отклонений, которое с каждым днем становится все шире
и шире (хотя со все более медленной скоростью), и премией опциона (падение
которой с каждым днем происходит все быстрее и быстрее) происходит «перетягивание
каната».
В
первый день математическое ожидание максимально, хотя оно может и не быть
положительным. Другими словами, математическое ожидание (арифметическое и
геометрическое) самое большое после того, как вы продержали опцион 1 день (оно
в действительности самое большое в тот момент, когда вы приобретаете опцион, и
далее постепенно понижается, но мы рассматриваем дискретные величины). Каждый
последующий день ожидание понижается, но все медленнее и медленнее. Следующая
таблица иллюстрирует понижение ожидания по длинной позиции опциона. Этот пример
уже упоминался в данной главе. Колл-опцион имеет цену исполнения
100, базовый инструмент стоит также 100; дата истечения — 911220. Волатильность
составляет 20%, а сегодняшняя дата 911104. Мы используем формулу товарных опционов
Блэка (Н определяется из уравнения (5.07), R
= 5%) и 260,8875-дневный год. Возьмем 8 стандартных отклонений для расчета
оптимального f, а минимальный шаг тика примем равным
0,1.

Значения столбца «AHPR» являются
средними арифметическими HPR (расчет будет рассмотрен позднее в
этой главе), a GHPR является средним
геометрическим HPR. Столбец «f» представляет оптимальные f, из которых
находятся значения столбцов AHPR и GHPR. Арифметическое математическое
ожидание равно AHPR - 1, а геометрическое математическое ожидание равно GHPR - 1. Отметьте, что наибольшие
математические ожидания (необязательно положительные ожидания, как в этом
примере) возникают в день после приобретения опциона. Каждый последующий день
ожидания уменьшаются, причем скорость уменьшения с течением времени
замедляется. После 911106 математические ожидания (HPR
- 1) становятся отрицательными. ' Если бы нам пришлось торговать по этой
информации, мы могли бы войти сегодня (911104) и выйти при закрытии завтра
(911105). Справедливая цена опциона равна 2,861. Если мы допустим, что он
котируется по цене 100 долларов за полный пункт, цена опциона составит 2,861 *
$100 ^ $286,10. Разделив эту цену на оптимальное f=
0,0806, мы найдем, что следует торговать одним опционом на каждые 3549,63 доллара
на балансе счета. Если бы мы держали опцион до закрытия 911106 (последний
день), когда он все еще имеет положительное математическое ожидание, то открыв
позицию сегодня, используя для дня выхода (911106) соответствующее оптимальное
f= 0,0016, торговали бы 1 контрактом на каждые 178 812,50
доллара на балансе счета ($286,10 / 0,0016). Отметьте, что при этом ожидание
намного ниже, чем в случае торговли 1 контрактом на каждые 3549,63 доллара на
балансе счета и выхода по цене закрытия завтра (911105).
Скорость изменения
между двумя функциями: уменьшением премии с течением времени и расширением окна
Х стандартных отклонений, может создать положительное математическое ожидание
для длинной позиции по опциону. Это ожидание имеет наибольшее значение в момент
открытия позиции и после этого понижается с уменьшающейся скоростью. Таким образом, справедливо оцененный опцион (на основе
вышеизложенных моделей) может иметь положительное математическое ожидание,
если позицию по нему закрыть в начале периода падения премии. В следующей
таблице рассматривается тот же колл-опцион с ценой исполнения 100, но на этот
раз используются окна различного размера (различные значения стандартных
отклонений):
|
Число
стандартных отклонений
|
|
|
2
|
3
|
5
|
8
|
10
|
|
AHPR
|
1,000102
|
1,000379
|
1,000409
|
1,000409
|
1,000409
|
|
GHPR
|
1,000047
|
1,00018
|
1,000195
|
1,000195
|
1,000195
|
|
f
|
0,043989
|
0,0781
|
0,0806
|
0,0806
|
0,0806
|
|
Дата выхода
|
911105
|
911105
|
911106
|
911106
|
911106
|
AHPR и GHPR — это арифметические и геометрические HPR при оптимальном f для дня закрытия 911105 (самая
благоприятная дата выхода, так как она имеет наивысшие AHPR и GHPR). f соответствует оптимальному f для 911105. Значения строки «Дата выхода» —
это последние даты, когда еще существует положительное ожидание (т.е. когда
AHPR и GHPR больше 1).
Интересно отметить, что AHPR, GHPR, f
и Дата выхода сходятся к определенным значениям, когда мы увеличиваем число
стандартных отклонений. За пределами 5 стандартных отклонений эти значения едва
заметно изменяются, за пределами 8 стандартных отклонений они практически
вообще не изменяются. Недостатком использования большого числа стандартных
отклонений является необходимость в значительном компьютерном времени. В нашем
примере это не так важно, но когда мы будем рассматривать одновременную
торговлю по нескольким позициям, вы увидите, что каждая дополнительная позиция
экспоненциально увеличивает необходимое компьютерное время. Для одной позиции 8
стандартных отклонений более чем достаточно, однако для нескольких позиций,
открытых одновременно, необходимо уменьшить число стандартных отклонений.
Следует отметить, что правило 8 стандартных отклонений применимо только тогда,
когда логарифмы изменений цены распределены нормально.
Одиночная
короткая позиция по опциону
Все сказанное по поводу одиночной длинной опционной позиции
остается верным и для одиночной короткой опционной позиции. Единственное
отличие заключается в ином написании уравнения (5.14):
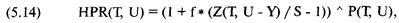
где HPR(T, U) =
НРR для данного тестируемого значения Т и U;
f = тестируемое значение
f;
S = текущая цена опциона;
Z(T, U
- Y) = теоретическая цена опциона, когда цена базового инструмента
равна U - Y, а время, оставшееся до срока истечения, равно Т,
Р(Т, U) = вероятность того, что базовый инструмент равен U,
когда время, оставшееся до истечения срока исполнения, равно Т;
Y = разность между арифметическим математическим ожиданием
базового инструмента (согласно уравнению (5.10)) и текущей ценой.
Для одиночной короткой опционной позиции это уравнение
преобразуется в:
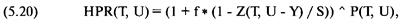
где HPR(T, U)
== HPR для данного тестируемого значения Т и U;
f= тестируемое значение f;
S =
текущая цена опциона;
Z(T, U
- Y)= теоретическая цена опциона, когда цена базового
инструмента равна U - Y, а время, оставшееся до срока истечения, равно Т;
Р(Т, U)
= вероятность того, что базовый инструмент равен U, когда время, оставшееся до
истечения срока исполнения,
равно Т,
Y = разность
между арифметическим математическим ожиданием базового инструмента (согласно
уравнению (5.10)) и текущей ценой.
Обратите внимание, что единственным отличием уравнения
(5.14) для одиночной длинной опционной позиции от уравнения (5.20) для
одиночной короткой позиции является выражение (Z(T, U-Y)/S-1), которое заменяется на (1-Z(T, U - Y) / S). Все остальное в отношении одиночной длинной опционной
позиции верно и для одиночной опционной короткой позиции.
Одиночная
позиция по базовому инструменту
В главе 3 мы подробно рассмотрели математику поиска
оптимального f параметрическим способом. Теперь мы можем использовать тот же
метод и для
одиночной
длинной опционной позиции с учетом нового HPR,
которое рассчитывается по уравнению (3.30):
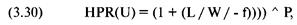
где HPR(U) = HPR для данного U;
L= ассоциированное P&L;
W = ассоциированное P&L худшего случая (это всегда
отрицательное значение);
f == тестируемое значение f;
Р =
ассоциированная вероятность.
Для длинной позиции переменная L,
т.е. ассоциированное P&L, определяется как разность между ценой базового
инструмента U и ценой S.
(5.21 а) L для
длинной позиции = U - S
Для короткой позиции ассоциированное P&L рассчитывается
наоборот:
(5.216) L для
короткой позиции = S - U,
где S = текущая
цена базового инструмента;
U = цена базового
инструмента для данного HPR.
Мы можем также рассчитать оптимальное f для одиночной
позиции по базовому инструменту, используя уравнение (5.14). При этом надо
иметь в виду, что оптимальное f может получиться больше 1.
Пусть цена базового инструмента равна 100, и мы ожидаем
пять результатов:
|
Результат
|
Вероятность
|
P&L
|
|
110
|
0,15
|
10
|
|
105
|
0,30
|
5
|
|
100
|
0,50
|
0
|
|
95
|
0,25
|
-5
|
|
90
|
0,10
|
-10
|
Отметьте, что исходя из уравнения (5.10) наше
арифметическое математическое ожидание по базовому инструменту составляет
100,576923077. Это означает, что переменная Y
для (5.14) равна 0,576923077, так как 100,576923077-100= = 0,576923077. Если
рассчитать оптимальное f, используя столбец P&L и уравнение (3.30), мы получим f= 1,9, что соответствует 1 единице на каждые 52,63 доллара
на счете. Если в уравнении (5.14) использовать данные из столбца
«Результат», тогда переменная S равна 100. В этом
случае мы не вычитаем значение Y
(арифметическое математическое ожидание базового инструмента минус его текущая
цена) из U при определении переменной Z(T, U - Y), и получаем оптимальное f около 1,9, что
соответствует 1 единице на каждые 52,63 доллара на счете, так как
100 /1,9=52,63.
Если
вычесть значение Y в выражении Z(T, U - Y), являющемся элементом уравнения
(5.14), мы получим математическое ожидание по базовому инструменту, равное его
текущему значению, и поэтому f не будет оптимальным. Тем не менее нам следует
вычесть значение Y в Z(T,
U - Y) для того, чтобы соответствовать расчетам цен
опционов, а также формуле «пут-колл» паритета. Если мы будем
использовать уравнение (3.30) вместо уравнения (5.14), тогда из каждого
значения U в (5.21а) и (5.216) следует вычесть значение Y, то есть надо вычесть
Y из каждого P&L, что опять же создает ситуацию, когда нет положительного
математического ожидания, и поэтому нет оптимального значения f. Все
вышесказанное означает, что если мы откроем позицию по базовому инструменту,
не имея никаких представлений о направлении движения его цены, то не получим
положительного математического ожидания (как происходит с некоторыми опционами)
и поэтому не найдем оптимального f. Мы можем получить оптимальное f только в
том случае, когда математическое ожидание положительное. Это произойдет, если
базовый инструмент «в тренде».
Теперь
у нас есть методология, позволяющая определить оптимальное f (и его побочные продукты) для опционов и базового
инструмента (разными способами). Отметьте, что используемые в этой
главе методы определения оптимальных f и побочных продуктов для опционов или
базового инструмента не требуют обязательного применения механической системы.
Вспомним, что эмпирический метод поиска оптимального f основан на эмпирическом
потоке P&L, созданном механической системой. Из главы 3 мы узнали о
параметрическом методе поиска оптимального f на основе данных, которые имеют
нормальное распределение. Тот же метод можно использовать для поиска
оптимального f при любом распределении данных, если существует функция распределения.
Из главы 4 мы познакомились с параметрическим методом поиска оптимального f для распределений торговых P&L, которые не имеют
функций распределения (для механической или немеханической системы) и с
методом планирования сценария.
В этой
главе мы изучили метод поиска оптимального f
для немеханических систем. Обратите внимание, все расчеты допускают, что вы в
некоторый момент времени «слепо» открываете позицию, причем направленного
движения цены базового инструмента не ожидается. Таким образом, предложенный
метод лишен какого-либо прогноза относительно цены базового инструмента. Мы
увидели, что можно учесть ценовой прогноз, изменяя каждый день значение
базового инструмента в уравнениях 5.17а и 5.176. Даже слабый тренд значительно
меняет функцию ожидания. Оптимальная дата выхода может не быть теперь рыночным днем сразу после дня входа, более того,
оптимальная дата выхода может стать датой истечения срока. В таком случае опцион
будет иметь положительное математическое ожидание, даже если его держать до
даты истечения. При небольшом тренде цены базового инструмента значительно
изменится не только функция ожидания, но и оптимальные f, AHPR и GHPR.
Проиллюстрируем вышесказанное на следующем примере. Пусть
цена исполнения колл-опциона равна 100 и он истекает 911120, цена базового
инструмента равна также 100. Волатильность составляет 20%, а сегодняшняя дата
911104. Мы будем использовать формулу товарных опционов Блэка (Н находим из
уравнения (5.07), R = 5%) и 260,8875-дневный год. Для 8
стандартных отклонений рассчитаем оптимальные f (чтобы соответствовать прошлым
таблицам, которые не учитывают тренд по базовому инструменту), и используем
минимальное приращение тика 0,1. В данном случае мы будем учитывать тренд, при
котором цена базового инструмента растет на 0,01 пункта (одну десятую тика) в
день:
|
Дата выхода
|
AHPR
|
GHPR
|
f
|
|
Вторник 911105
|
1,000744
|
1,000357
|
0,1081663
|
|
Среда 911106
|
1,000149
|
1,000077
|
0,0377557
|
|
Четверг 911107
|
1,000003
|
1,000003
|
0,0040674
|
|
Пятница 911108
|
<1
|
<1
|
0
|
Отметьте, как небольшой тренд (0,01 пункта в день) меняет
результаты. Наша оптимальная дата выхода остается 911105, но оптимальное f= 0,1081663, что соответствует 1 контракту на каждые 2645
долларов на балансе счета (2,861* * 100 / 0,1081663). Кроме того, для этого
опциона ожидание положительно все время до 911107. Если тренд будет сильнее,
результаты изменятся еще больше. Последнее, что необходимо учесть, —
это размер комиссионных. Цена опциона из уравнения (5.14) (значение переменной
Z(T, U
- Y)) должна быть уменьшена на размер комиссионных (если с вас
берут комиссионные и при открытии позиции, то вы должны увеличить значение
переменной S из уравнения (5.14) на размер комиссионных).
Мы рассмотрели поиск оптимального f и его побочных
продуктов, когда механическая система не используется. Теперь перейдем к
изучению одновременной торговли по нескольким позициям.
Торговля
по нескольким позициям при наличии причинной связи
Прежде чем начать обсуждение одновременной торговли по
нескольким позициям, необходимо пояснить разницу между причинными связями и
корреляционными связями. В случае с причинной связью существует фактическое,
связующее объяснение корреляции между двумя или более событиями, т. е.
причинная связь — это такое отношение, где есть корреляция, и ее можно
объяснить логически. Обычная корреляционная связь подразумевает, что есть
зависимость, но этому нет причинного объяснения. В качестве примера причинной
связи давайте рассмотрим пут-опционы и колл-опционы на акции IBM. Очевидно, что корреляция между пут и колл-опционами IBM составляет -1 (или находится очень близко к этому
значению), но эта связь означает больше, чем просто корреляция. Мы знаем, что,
когда по колл-опционам IBM возникает давление вверх,
появляется давление и вниз по пут-опционам (все остальное считается постоянным,
включая волатильность). Описанное логическое связующее отношение означает, что
между пут и колл-опционами IBM существует
причинная связь.
Когда существует корреляция, но нет причины, мы просто
говорим, что есть корреляционная связь (в противоположность причинной связи).
Обычно при корреляционной связи коэффициент корреляции (по абсолютной величине)
меньше 1, как правило, абсолютное значение коэффициента корреляции ближе к 0.
Например, цены на кукурузу и соевые бобы в большинстве случаев движутся
параллельно. Хотя их коэффициенты корреляции не равны точно 1, существует
причинная связь, так как оба рынка реагируют на события, которые затрагивают
зерновые. Если мы рассматриваем колл-опционы IBM
и пут-опционы компании Digital Equipment (или колл-опционы), мы не можем сказать, что между ними
существует четкая причинная связь. Что-то от причинной связи в этом случае
безусловно есть, так как оба вида базового инструмента (акции) входят в
компьютерную группу, но только потому, что цена IBM
растет (или падает), акции Digital Equipment не обязательно должны расти или падать. Как видите, нет
четкой грани, которая разделяет причинные и корреляционные связи.
Невозможность четкого определения вида связи создает
некоторые проблемы в работе. Сначала мы рассмотрим только причинные связи, или
те, которые, как мы полагаем, являются причинными. В следующей главе мы обсудим
корреляционные связи, которые включают также и причинные связи. Вы должны
понимать, что методы, упомянутые в следующей главе в отношении корреляционных
связей, применимы и для причинных связей. Обратное не всегда верно. Применение
методов, используемых для причинных связей, в случае, когда связи просто
корреляционны, является ошибкой. Причинная связь подразумевает, что
коэффициенты корреляции между ценами
двух объектов составляют 1 или -1. Для упрощения будем считать, что
причинная связь затрагивает два инструмента (акция, товар, опцион и т.д.),
имеющих один базовый инструмент. Это могут быть спрэды, стредлы, «покрытая
продажа» или любая другая позиция, когда вы используете базовый инструмент
совместно с одним или более опционами или один или несколько опционов по
одному базовому инструменту, даже если у
вас нет позиции по этому базовому инструменту.
Простейшим примером одновременных позиций является
комбинация опционов (т.е. позиция по базовому инструменту отсутствует), когда
совокупная позиция заносится в дебет и можно использовать уравнение (5.14).
Таким образом, вы можете определить оптимальное f для всей позиции, а также
побочные продукты (включая оптимальную дату выхода). В этом случае переменная S выражает общие затраты на сделку, а переменная Z(T, U
- Y) выражает «общую» цену всех одновременных позиций при цене
базового инструмента U, когда время, оставшееся до истечения срока исполнения,
равно Т. Когда совокупная позиция заносится в кредит, можно определить
оптимальное f с помощью уравнения (5.20). Как и в предыдущем случае, мы
должны изменить переменные S и Z(T, U - Y) для отражения «чистой» цены всех
позиций. Например, мы рассматриваем возможность открытия длинного стредла
(покупка пут-опциона и колл-опциона по одному базовому инструменту с одинаковой
ценой исполнения и датой истечения). Допустим, что полученное с помощью этого
метода оптимальное f соответствует 1 контракту на каждые 2000 долларов. Таким
образом, на каждые 2000 долларов на счете мы должны покупать 1 стредл (1
пут-опцион и 1 колл-опцион).
Оптимальное f, полученное с помощью данного метода, относится к финансированию
1 единицы для всей позиции. Этот факт
касается всех методов, рассмотренных в данной главе. Ниже
представлено уравнение для одновременных позиций, причем не имеет значения,
используется позиция по базовому инструменту или нет. Мы будем применять эту
обобщенную форму для одновременных позиций с причинной связью:
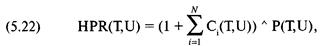
где N =
число «ног» (число составляющих сложной позиции);
HPR(T, U)
= HPR
для тестируемых значений Т и U;
C(T, U) = коэффициент i-ой «ноги» при данном значении U, когда время, оставшееся до истечения срока, равно Т.
Для опционных «ног», занесенных в дебет, или длинной
позиции по базовому инструменту:
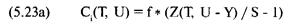
Для
опционных «ног», занесенных в кредит, или короткой позиции по базовому
инструменту:
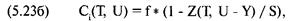
где f = тестируемое значение f;
S = текущая цена опциона или базового инструмента;
Z(T, U
- Y) = теоретическая цена опциона, когда цена базового
инструмента равна U - Y, а время, оставшееся до срoка истечения, равно Т;
Р(Т, U) = вероятность того, что базовый инструмент равен U,
когда время, оставшееся до истечения срока исполнения, равно Т;
Y = разность между арифметическим математическим ожиданием базового инструмента (согласно
уравнению (5.10)) и текущей ценой.
Уравнение (5.22) следует использовать, когда речь идет об
одновременно используемых «ногах», и вам необходимо найти оптимальное f и
оптимальную дату выхода по всей позиции (т.е. когда речь идет об одновременной
торговле по нескольким позициям).
Для каждого значения U вы можете найти HPR с помощью уравнения (5.22), а для каждого значения f вы
можете найти среднее геометрическое, составленное из всех HPR, с помощью
уравнения (5.18а):
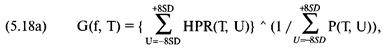
где
G(f, Т) = среднее геометрическое HPR для
данного тестируемого значения f и для данного времени, остающегося до
истечения срока от указанной даты выхода. Значения f и Т, которые дают
наивысшее среднее геометрическое, являются значениями, которые следует
использовать для всего набора одновременных позиций.
Подведем
итог. Нам надо найти оптимальное f для каждого дня
(между текущим днем и днем истечения) как дня выхода. Для каждой даты выхода
необходимо определить цены между плюс и минус Х стандартных отклонений (обычно
Х будет равно 8) от базовой цены базового инструмента. Базовая цена может быть
текущей ценой базового инструмента, или же она может быть скорректирована для
учета ценового тренда. Теперь вам надо найти значение для f между 0 и 1,
которое даст наибольшее среднее геометрическое HPR,
используя HPR для цен между плюс и минус Х стандартных отклонений от
базовой цены для указанной даты выхода. Таким образом, для каждой даты выхода
у вас будет оптимальное f и соответствующее среднее геометрическое. Дата
выхода, которая дает наибольшее среднее геометрическое, является оптимальной
датой выхода из позиции, и f, соответствующее этому среднему геометрическому,
является оптимальным f. Структура этой процедуры следующая:
Для каждой даты выхода между текущей датой и датой
истечения
Для каждого значения f (пока не будет найдено оптимальное)
Для каждой рыночной системы
Для каждого тика между +8 и -8 стандартными отклонениями
Определите HPR
Следует отметить, что мы можем определить оптимальную дату
выхода, т.е. дату, когда следует закрыть всю позицию. Можно применить эту же
процедуру для нахождения оптимальной даты выхода для каждой «ноги» (отдельной
позиции), что, правда, геометрически увеличит число расчетов. Тогда процедура
несколько изменится и будет выглядеть следующим образом:
Для каждой рыночной системы
Для каждой даты выхода между текущей датой и датой
истечения
Для каждого значения f (пока не будет найдено оптимальное)
Для каждой рыночной системы
Для каждого тика между +8 и -8 стандартными отклонениями
Определите HPR
Итак, мы рассмотрели одновременную торговлю по нескольким
позициям при наличии причинной связи. Теперь рассмотрим ситуацию, когда связь
случайна.
Торговля по
нескольким позициям при наличии случайной связи
Вы должны знать, что, как и в случае с причинной связью,
методы, упомянутые в следующей главе, посвященной корреляционным связям,
применимы и для случайных связей. Но не наоборот. Неправильно применять методы
для случайных связей к корреляционным связям (когда коэффициенты корреляции не
равны 0). При случайной связи
коэффициент корреляции между ценами двух инструментов всегда равен 0.
Случайная связь между двумя торгуемыми инструментами
(акции, фьючерсы, опционы и т.д.) имеет место в том случае, если их цены не зависят друг от друга, т.е.
коэффициент корреляции цен равен нулю, или ожидается, что он будет равен нулю в
асимптотическом смысле.
Когда коэффициент корреляции двух составляющих равен О, HPR для совокупной позиции рассчитывается следующим образом:

где N =
число «ног» позиции;
HPR(T, U)
= HPR для данного тестируемого значения Т и U;
С. (Т, U) =
коэффициент i-ой «ноги» при данном значении U, когда время, оставшееся до
истечения срока, равно Т.
Для опционных «ног», занесенных в дебет, или длинной
позиции по базовому инструменту:
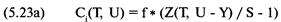
Для опционных «ног», занесенных в кредит, или короткой
позиции по базовому инструменту:
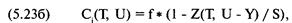
где f = тестируемое
значение f;
S = текущая цена опциона;
Z(T, U
- Y) = теоретическая цена опциона, когда цена базового инструмента
равна U - Y, а время, оставшееся до срока истечения, равно Т;
Pj(T, U)
= вероятность того, что базовый инструмент равен U, когда время, оставшееся до
истечения срока исполнения, равно Т;
Y = разность между арифметическим математическим ожиданием
базового инструмента (согласно уравнению (5.10)) и текущей ценой.
Теперь мы можем рассчитать среднее геометрическое HPR для случайной связи:
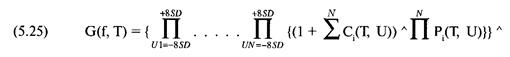
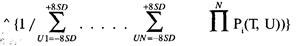
где G(f,
Т) = среднее геометрическое HPR для данного тестируемого значения f и данного времени Т, остающегося до истечения срока от
указанной даты выхода. Значения f и Т, которые дают наибольшее среднее
геометрическое, оптимальны. Структура этой процедуры такая же, как и в случае с
причинной связью:
Для каждой даты выхода между текущей датой и датой
истечения
Для каждого значения f (пока не будет найдено оптимальное)
Для каждой рыночной системы
Для каждого тика между +8 и -8 стандартными отклонениями
Определите HPR
Единственное различие между процедурой нахождения среднего
геометрического для случайных связей и процедурой для причинных связей состоит
в том, что показатель степени для каждого HPR при случайной связи
рассчитывается путем умножения вероятностей того, что «ноги» будут находиться
на данной цене определенного HPR. Все эти суммы вероятностей, используемые в
качестве показателей степени для каждого HPR, сами по себе также суммируются,
так что, когда все HPR перемножены для получения промежуточного TWR, его можно возвести в степень единицы, деленной на сумму
показателей степени, используемых в HPR. И снова процедуру можно изменить,
чтобы найти оптимальные даты выхода для каждой составляющей позиции.
Несмотря на всю сложность, уравнение (5.25) все-таки не
решает проблему ненулевого коэффициента линейной корреляции между ценами двух
компонентов. Как видите, определение оптимальных весов компонентов является довольно
сложной задачей! В следующих нескольких главах вы увидите, как найти правильные
веса для каждой составляющей позиции, будь то акция, товар, опцион или любой
другой инструмент, независимо от связи (причинная, случайная или
корреляционная). Входные данные, которые нам потребуются, следующие: (1)
коэффициенты корреляции средних дневных HPR
позиций в портфеле на основе 1 контракта, (2) арифметические среднее HPR и
стандартные отклонения HPR.
Уравнения (5.14) и (5.20) показывают, как находить HPR для
длинных и коротких позиций по опционам. Уравнение (5.18) показывает, как находить
среднее геометрическое. Мы можем также определить среднее арифметическое:
Для длинных опционных позиций, т.е. отнесенных в дебет:
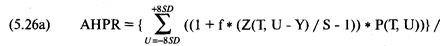
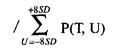
Для коротких опционных позиций, т.е. отнесенных в кредит:
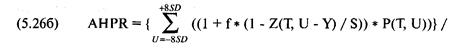
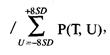
где AHPR = среднее арифметическое HPR;
f= оптимальное f (от 0 до 1);
S= текущая цена опциона;
Z(T, U
- Y)= теоретическая цена опциона, когда цена базового инструмента
равна U - Y, а время, оставшееся до срока истечения, равно Т;
Р(Т, U) = вероятность, что базовый инструмент равен U,
когда время, оставшееся до истечения срока исполнения, равно Т;
Y= разность между арифметическим математическим ожиданием
базового инструмента (согласно уравнению (5.10)) и текущей ценой.
Зная среднее геометрическое HPR и среднее арифметическое
HPR, можно определить стандартное отклонение значений HPR:
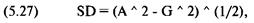
где А =
арифметическое среднее HPR;
G = геометрическое среднее HPR;
SD = стандартное отклонение значений HPR.
В этой главе мы познакомились еще с одним способом расчета
оптимального f. Предложенный метод подходит для несистемных трейдеров. В
виде входного параметра здесь используется распределение результатов по
базовому инструменту к определенной дате в будущем. Данный подход позволяет
найти оптимальное f как для отдельных опционных позиций, так и для сложных
позиций. Существенным недостатком метода является то, что связи между всеми
позициями должны быть случайными или причинными.
Означает ли вышесказанное, что мы не можем использовать
методы поиска оптимального f, рассмотренные в предыдущих главах, для нескольких
одновременно открытых позиций или опционов? Нет, вы всегда можете выбрать
наиболее эффективный с вашей точки зрения подход. Методы, детально описанные в
этой главе, имеют как определенные недостатки, так и достоинства (например возможность
расчета оптимального времени выхода). В следующей главе мы будем изучать темы,
касающиеся построения оптимального портфеля, что позднее поможет нам в
управлении капиталом при одновременной торговле по нескольким позициям.
Цель этой книги — изучить портфели рыночных систем,
использующих различные инструменты с различных рынков. В данной главе мы
достаточно подробно рассмотрели теоретические цены опционов и теперь перейдем
к созданию оптимального портфеля.
Глава
6
Корреляционные связи и выведение
эффективной границы
Мы узнали несколько способов поиска
оптимального количества при торговле фьючерсами, акциями и опционами (по
отдельности или совместно с другими инструментами), когда существует либо
случайная, либо причинная связь между ценами инструментов. Можно определить
оптимальный набор, когда коэффициент линейной корреляции двух любых элементов
портфеля равен 1, - 1 или 0. Однако связи между двумя элементами портфеля,
рассматриваем ли мы корреляцию цен (в немеханической торговой системе) или
изменений баланса (в механической системе), редко дают такие удобные значения
коэффициентов линейной корреляции. В этой главе описан способ определения
эффективной границы портфелей рыночных систем, когда коэффициенты линейной корреляции
любых двух компонентов рассматриваемого портфеля принимают произвольные
значения между -1 и 1 включительно. Далее описан метод, применяемый
профессионалами для расчета оптимальных портфелей акций. В следующей главе мы
адаптируем его для использования любых инструментов. Данная глава основана на важном предположении, которое заключается в
том, что распределения, генерирующие последовательность сделок (распределения
прибылей), имеют конечную дисперсию. Предложенные методы эффективны только
тогда, когда используемые входные данные имеют конечную дисперсию1.
Определение
проблемы
На некоторое время оставим саму идею оптимального f (мы вернемся к нему позже). Легче всего понять
параметрическое выведение эффективной границы, если рассмотреть портфель акций.
Будем исходить из того, что эти акции находятся на денежном счете и полностью
оплачены, т.е. они куплены не за счет кредита, полученного от брокерской фирмы
(не на маржинальном счете). С учетом этого ограничения мы выведем эффективную
границу портфелей, т.е. из предложенных акций создадим комбинацию, которая
будет иметь наименьший уровень ожидаемого риска для данного уровня ожидаемого
выигрыша. Эти уровни задаются степенью неприятия риска инвестором. Теория
Марковица (или Современная теория портфеля) часто называется теорией Е— V
(Expected return (ожидаемая
прибыль) —Variance of return (дисперсия прибыли)). Отметьте, что входные параметры
основаны на данных по прибыли, таким образом, входные данные для выведения
эффективной границы — это прибыли, которые мы ожидаем по данной акции, и
дисперсия, которая ожидается от этих прибылей. Прибыли по акциям определяются
как дивиденды, ожидаемые за определенный период времени, плюс повышение
рыночной стоимости акций (или минус уменьшение) за этот же период, выраженные
в процентах. Рассмотрим четыре потенциальные инвестиции, три из которых — в
акции, а одна — в сберегательный счет с процентной ставкой 8 1/2% в год.
Отметьте, что в этом примере продолжительность периода инвестирования (когда мы
измеряем прибыли и их дисперсии) — 1 год:
|
Инвестиция Ожидаемая прибыль
|
Ожидаемая дисперсия прибыли
|
|
Toxico
|
9,5%
|
10%
|
|
Incubeast Corp.
|
13%
|
25%
|
|
LA Garb
|
21%
|
40%
|
|
Сберегательный счет
|
8,5%
|
0%
|
Если прибавить к значению ожидаемой прибыли единицу, мы
получим HPR. Также мы можем
извлечь квадратный корень из значения ожидаемой дисперсии прибыли и получить
ожидаемое стандартное отклонение прибыли.
Используемый
временной горизонт не имеет значения при условии, что он одинаковый для всех
рассматриваемых компонентов. Если речь идет о прибыли, неважно, что мы
используем: год, квартал, 5 лет или день, — пока ожидаемые прибыли и
стандартные отклонения для всех рассматриваемых компонентов имеют одни и те же
временные рамки.
|
Инвестиция
|
Ожидаемая прибыль (HPR)
|
Ожидаемое стандартное отклонение
прибыли
|
|
Toxico
|
1,095
|
0,316227766
|
|
Incubeast Corp.
|
1,13
|
0,5
|
|
LA Garb
|
1,21
|
0,632455532
|
|
Сберегательный счет
|
1,085
|
0
|
Ожидаемая
прибыль — это то же самое, что и потенциальная
прибыль, а дисперсия (или стандартное отклонение) ожидаемых прибылей ~ то
же самое, что и потенциальный риск.
Отметьте, что данная модель двумерная. Мы можем сказать, что модель
представлена правым верхним квадрантом декартовой системы координат (см.
рисунок 6-1), где по вертикали (ось Y) откладывается
ожидаемая прибыль, а по горизонтали (ось X) откладывается ожидаемая дисперсия,
или стандартное отклонение прибылей.
Рисунок 6-1 Правый
верхний квадрант декартовой системы координат
Есть и
другие аспекты потенциального риска, такие как потенциальный риск (вероятность)
катастрофического убытка, который теория Е — V не рассматривает отдельно от
дисперсии прибылей. Мы не будем изучать эту концепцию в данной главе, а будем
обсуждать теорию Е — V в классическом
варианте. Марковиц также утверждал, что портфель, полученный из теории Е — V,
оптимален только в том случае, если полезность, т.е. «удовлетворение»
инвестора, является лишь функцией ожидаемой прибыли и дисперсии ожидаемой
прибыли. Марковиц указал, что инвестор может использовать и более высокие
моменты распределения, а не только первые два (на которых основана теория Е —
V), например асимметрию и эксцесс ожидаемых прибылей.
Потенциальный риск — очень емкое понятие, он является
функцией гораздо большего числа переменных и включает более высокие моменты
распределений. Тем не менее мы будем определять потенциальный риск как
дисперсию ожидаемых прибылей. Не следует, однако, полагать, что этим риск
полностью определен. Риск намного шире, и его реальная природа плохо поддается
количественной оценке.
Первое, что должен сделать инвестор, желающий использовать
теорию Е — V, это придать количественный смысл своим предположениям относительно
ожидаемых прибылей и дисперсий прибылей рассматриваемых ценных бумаг на
определенном временном горизонте (периоде удержания). Эти параметры можно получить эмпирически. Инвестор может рассмотреть
прошлую историю ценных бумаг и рассчитать прибыли и их дисперсии за определенные
периоды. Как уже было отмечено, термин «прибыли»
означает не только дивиденды по ценной бумаге, но и любые повышения стоимости
ценной бумаги (в процентах). Дисперсия
является статистической дисперсией процентных прибылей. Для определения
ожидаемой прибыли в период удержания можно использовать линейную регрессию по
прошлым прибылям. Дисперсия как входной параметр определяется путем расчета
дисперсии каждой прошлой точки данных на основе ее спрогнозированного значения
(а не на основе линии регрессии, рассчитанной для прогнозирования следующей
ожидаемой прибыли). Вместо того чтобы определять эти значения эмпирическим
способом, инвестор может оценить значения будущих прибылей и дисперсий1. Возможно, наилучшим способом
нахождения параметров является комбинация обоих подходов. Инвестору следует
использовать эмпирический подход (т.е. использовать исторические данные),
затем, если это необходимо, можно учесть прогноз относительно будущих значений
ожидаемых прибылей и дисперсий. Следующими параметрами, которые должен
знать инвестор для использования данного метода, являются коэффициенты линейной
корреляции прибылей. Эти параметры можно получить эмпирически, путем оценки или
с помощью комбинации обоих подходов.
При
определении коэффициентов корреляции важно использовать точки данных того же
временного периода, который был использован для определения ожидаемых прибылей
и дисперсий. Другими словами, если вы используете годовые данные для
определения ожидаемых прибылей и дисперсии прибылей (т.е. ведете расчеты на
годовой основе), следует использовать годовые данные и при определении
коэффициентов корреляции. Если вы используете дневные данные для определения
ожидаемых прибьыей и дисперсии прибылей (т.е. ведете расчеты на дневной
основе), тогда вам следует использовать дневные данные для определения
коэффициентов корреляции. Вернемся к нашим четырем инвестициям — Toxico, Incubeast Corp., LA Garb
и сберегательному счету. Присвоим им символы Т, 1, L
и S соответственно. Ниже приведена таблица их коэффициентов
линейной корреляции:
|
|
I
|
L
|
S
|
|
Т
|
-0,15
|
0,05
|
о
|
|
I
|
|
0,25
|
о
|
|
L
|
|
|
о
|
На основе полученных параметров мы можем рассчитать ковариацию между двумя ценными
бумагами:

Стандартные отклонения Sa и Sб можно найти, взяв
квадратный корень дисперсии ожидаемых прибылей для ценных бумаг а и б.
Вернемся к нашему примеру. Мы можем определить ковариацию между Toxico (Т) и Incubeast (I)
следующим образом:

Зная
ковариацию и стандартные отклонения, мы можем рассчитать коэффициент линейной
корреляции:

Отметьте, что ковариация ценной бумаги самой к себе
является дисперсией, так как коэффициент линейной корреляции ценной бумаги
самой к себе равен 1:

Теперь можно создать таблицу ковариаций для нашего примера
с четырьмя инвестиционными альтернативами:
|
|
Т
|
I
|
L
|
S
|
|
Т
|
0,1
|
-
0,0237
|
0,01
|
0
|
|
I
|
-
0,0237
|
0,25
|
0,079
|
0
|
|
L
|
0,01
|
0,079
|
0,4
|
0
|
|
S
|
0
|
0
|
0
|
0
|
Мы собрали необходимую параметрическую информацию и теперь
попытаемся сформулировать основную проблему. Во-первых, сумма весов ценных
бумаг, составляющих портфель, должна быть равна 1, так как операции ведутся на
денежном счете, и каждая ценная бумага полностью оплачена:
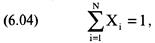
где N == число ценных бумаг, составляющих
портфель;
Х = процентный вес ценной бумаги L
Важно отметить, что в уравнении (6.04) каждое значение Х
должно быть неотрицательным числом.
Следующее равенство относится к ожидаемой прибыли всего
портфеля — это Е в теории Е — V. Ожидаемая прибыль портфеля является суммой
прибылей его компонентов, умноженных на соответствующие веса:
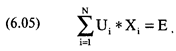
где Е =
ожидаемая прибыль портфеля;
N = число
ценных бумаг, составляющих портфель;
Xi =
процентный вес ценной бумаги i;
Ui=
ожидаемая прибыль ценной бумаги i. И наконец, мы подошли к параметру V, т. е
дисперсии ожидаемых прибылей:


Нашей
целью является поиск значений Х (причем их сумма равна единице), которые дают
наименьшее значение V для определенного значения Е. Максимизировать (или
минимизировать) функцию Н(Х, Y) при наличии
условия или ограничения G(X,
Y) можно с помощью метода Лагранжа. Для этого зададим
функцию Лагранжа F(X,
Y, L):
(6.07) F(X,Y,L) = H(X,Y) + L * G(X,Y)
Обратите внимание на форму уравнения (6.07). Новая функция F(X,Y,L) равна множителю Лагранжа L (его значение мы пока не
знаем), умноженному на ограничительную функцию G(X,Y), плюс первоначальная функция H(X,Y),
экстремум которой мы и хотим найти.
Решение этой системы из трех уравнений даст точки (X1Y1) относительного экстремума:
FxX,Y,L)
= О Fy(X,Y,L) = О FL(X,Y,L)
= О
Допустим, мы хотим максимизировать произведение двух чисел
при условии, что их сумма равна 20. Пусть Х и Y два числа. Таким образом, H(X,Y)
= Х * Y является функцией, которая должна быть максимизирована при наличии
ограничительной функции G(X,Y) = Х + Y - 20 = 0.
Зададим функцию Лагранжа:
F(X,Y,L)
= Х * Y + L * (X + Y- 20) Fx(X,Y,L)=Y+L Fy(X,Y,L)=X+L FL(X,Y,L)=
X
+Y-20
Теперь приравняем F^(X,Y,L)
и Fy(X,Y,L) нулю и решим каждое из них для получения L:
Y+L=0 Y=-L
и
X+L=0 X=-L
Теперь, приняв FL(X,Y,L)
= 0, мы получим Х + Y - 20 = 0.
Наконец, заменим Х и Y эквивалентными выражениями, содержащими L:
(-L) + (-L) - 20 = О 2 * -L - 20 L=-10
Так как Y = -L, то Y = 10 и Х = 10.
Максимальное произведение: 10*10= 100.
Метод
множителей Лагранжа был продемонстрирован для двух переменных и одной
01раничительной функции. Метод можно также применять, когда есть более чем две
переменные и более чем одна ограничительная функция. Далее для примера следует
форма для поиска экстремума, когда есть три переменные и две ограничительные
функции:
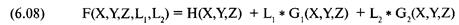
В этом случае, чтобы определить точки относительных
экстремумов, вам надо решить систему из пяти уравнений с пятью неизвестными.
Позже мы покажем, как это сделать.
Сформулируем
проблему несколько иначе: необходимо минимизировать V, т.е. дисперсию всего
портфеля, с учетом двух следующих ограничений:
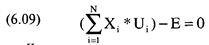
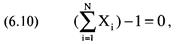
где N= число ценных бумаг, составляющих портфель;
Е = ожидаемая прибыль портфеля;
Х = процентный вес ценной бумаги i;
U. = ожидаемая прибыль ценной бумаги i.
Минимизация ограниченной функции многих переменных может
быть проведена путем введения множителей Лагранжа и частного дифференцирования
по каждой переменной. Поэтому мы сформулируем поставленную задачу в терминах
функции Лагранжа, которую назовем Т:
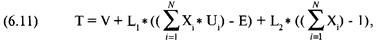
где V= дисперсия ожидаемых прибылей портфеля из уравнения
(6.06);
N = число ценных бумаг, составляющих портфель;
Е = ожидаемая прибыль портфеля;
X. =
процентный вес ценной бумаги i;
U. = ожидаемая прибыль ценной бумаги i;
L, = первый множитель Лагранжа;
L = второй множитель Лагранжа.
Мы получим портфель с минимальной дисперсией (т.е.
минимальным риском), приравняв к нулю частные производные функции Т по всем
переменньм.
Давайте снова вернемся к нашим четырем инвестициям: Toxico, Incubeast Corp., LA Garb
и сберегательному счету. Если мы возьмем первую частную производную Т по Х1,
то получим:
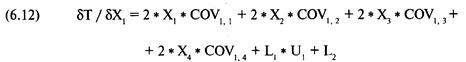
Приравняв это выражение нулю и разделив обе части уравнения
на 2, получим:
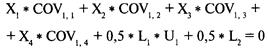
Таким же образом:
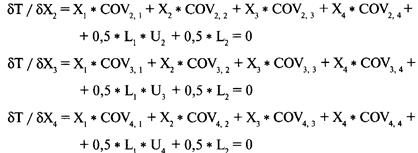

Таким образом, проблему минимизации V при данном Е для
портфеля с N компонентами можно решить с помощью системы N + 2 уравнений с N +
2 неизвестными. Для случая с четырьмя компонентами обобщенная форма будет
иметь следующий вид:
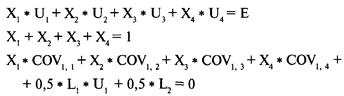
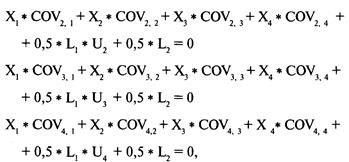
где Е = ожидаемая прибыль портфеля;
Хi = процентный вес ценной бумаги i;
Ui = ожидаемая прибыль по ценной бумаге i;
COV А, Б =
ковариация между ценными бумагами А и Б;
L1 = первый
множитель Лагранжа;
12 = второй множитель Лагранжа.
Обобщенную форму можно использовать для любого числа
компонентов. Например, если речь идет о трех компонентах (т.е. N = 3), система
уравнений будет выглядеть следующим образом:
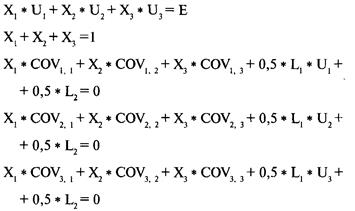
Прежде чем решать систему уравнений, необходимо задать
уровень ожидаемой прибыли Е. Решением будет комбинация весов, которая даст
искомое Е при наименьшей дисперсии. После того как вы определитесь с выбором Е,
у вас будут все входные переменные, необходимые для построения матрицы коэффициентов.
Переменная
Е в правой части первого уравнения — это значение прибыли. для которой вы
хотите определить комбинацию ценных бумаг в портфеле. Первое уравнение говорит
о том, что сумма всех ожидаемых прибылей, умноженных на
соответствующие
веса, должна равняться заданному Е. Второе уравнение отражает тот факт, что
сумма весов должна быть равна 1. Была показана матрица для случая с тремя
ценными бумагами, но вы можете использовать обобщенную форму для N ценных
бумаг.
Возьмем ожидаемые прибыли и ковариации из уже известной
таблицы ковариаций и подставим коэффициенты в обобщенную форму. Таким образом
из коэффициентов обобщенной формы можно создать матрицу. В случае четырех компонентов
(N = 4) мы получим 6
рядов (N + 2):
|
X1
|
X2
|
X3
|
X4
|
L1
|
L2
|
Ответ
|
|
0,095
|
0,13
|
0,21
|
0,085
|
|
|
Е
|
|
1
|
1
|
1
|
1
|
|
|
1
|
|
0,1
|
- 0,0237
|
0,01
|
0
|
0,095
|
1
|
0
|
|
- 0,0237
|
0,25
|
0,079
|
0
|
0,13
|
1
|
0
|
|
0,01
|
0,079
|
0,4
|
0
|
0,21
|
1
|
0
|
|
0
|
0
|
0
|
0
|
0,085
|
1
|
0
|
Отметьте, что мы получили 6 столбцов коэффициентов. Если
добавить столбец свободных членов к
матрице коэффициентов, мы получим расширенную
матрицу.
Заметьте, что коэффициенты в матрице соответствуют нашей
обобщенной форме:
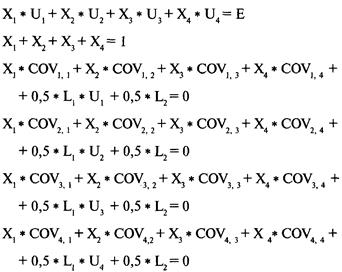
Матрица является удобным представлением этих уравнений.
Чтобы решить систему уравнений, необходимо задать Е. Ответы, полученные при
решении этой
системы
уравнений, дадут оптимальные веса, минимизирующие дисперсию прибыли всего
портфеля для выбранного уровня Е.
Допустим, мы хотим найти решение для Е = 0,14, что
соответствует прибыли в 14%. Подставив в матрицу 0,14 для Е и нули для
переменных L1 и L2 в первых двух строках, мы получим
следующую матрицу:
|
X1
|
X2
|
Х3
|
X4
|
L1
|
L2
|
Ответ
|
|
0,095
|
0,13
|
0,21
|
0,085
|
0
|
0
|
0,14
|
|
1
|
1
|
1
|
1
|
0
|
0
|
1
|
|
0,1
|
- 0,0237
|
0,01
|
0
|
0,095
|
1
|
0
|
|
- 0,0237
|
0,25
|
0,079
|
0
|
0,13
|
1
|
0
|
|
0,01
|
0,079
|
0,4
|
0
|
0,21
|
1
|
0
|
|
0
|
0
|
0
|
0
|
0,085
|
1
|
0
|
Необходимо найти N + 2 неизвестных с помощью N + 2
уравнений.
Решение
систем линейных уравнений с использованием матриц-строк.
Многочлен — это алгебраическое выражение, которое является суммой
определенного количества элементов. Многочлен с одним элементом называется одночленом, с двумя элементами — двучленом, с тремя — трехчленом и т.д. Выражение 4 * А ^ 3 +
А ^ 2 +А+2 является многочленом, имеющим четыре члена. Члены отделены знаком
(+).
Многочлены
имеют различные степени. Степень
многочлена определяется значением наибольшей степени любого из элементов.
Степенью элемента является сумма показателей переменных, содержащихся в
элементе. Показанное выше выражение является многочленом третьей степени, так
как элемент 4 * А^ 3 имеет третью степень, и это наивысшая степень среди всех
элементов многочлена. Если бы элемент был равен 4*A^З*B^62*C, мы бы получили
многочлен шестой степени, так как сумма показателей переменных (3+2+1) равна 6.
Многочлен
первой степени называется также линейным
уравнением и графически задается прямой линией. Многочлен второй степени
называется квадратным уравнением и
на графике представляет собой параболу. Многочлены третьей, четвертой и пятой степени
называются соответственно кубическим
уравнением, уравнением четвертой степени, уравнением пятой степени и т.д.
Графики многочленов третьей степени и выше довольно сложны. Многочлены могут
иметь любое число элементов и любую степень, мы будем работать только с
линейными уравнениями, т.е. многочленами первой степени. Решить
систему линейных уравнений можно с помощью процедуры
Гаусса-Жордана, или, что то же самое, метода
гауссовского исключения. Чтобы использовать этот метод, мы
должны сначала создать расширенную матрицу, объединив матрицу коэффициентов и
столбец свободных членов. Затем следует произвести элементарные преобразования для получения единичной матрицы. С помощью элементарных преобразований мы
получаем более простую, но эквивалентную первоначальной, матрицу. Элементарные
преобразования производятся посредством построчных
операций (мы опишем их ниже). Единичная матрица является квадратной
матрицей коэффициентов, где все элементы равны нулю, кроме диагональной линии
элементов, которая начинается в верхнем левом углу. Для матрицы коэффициентов
«шесть на шесть» единичная матрица будет выглядеть следующим образом:
|
1
|
0
|
0
|
0
|
0
|
о
|
|
0
|
1
|
0
|
0
|
0
|
о
|
|
0
|
0
|
1
|
0
|
0
|
о
|
|
0
|
0
|
0
|
1
|
0
|
о
|
|
0
|
0
|
0
|
0
|
1
|
о
|
|
0
|
0
|
0
|
0
|
о
|
1
|
Матрица, где число строк равно числу столбцов, называется квадратной матрицей. Благодаря
обобщенной форме задачи минимизации V
для данного Е, мы всегда будем иметь дело с квадратными матрицами
коэффициентов. Единичная матрица, полученная с помощью построчных
операций, эквивалентна первоначальной матрице коэффициентов. Ответы для нашей
системы уравнений можно получить из крайнего правого вектора-столбца. Единица в
первой строке единичной матрицы соответствует переменной X,, поэтому значение
на пересечении крайнего правого столбца и первой строки будет ответом для X1
Таким же образом на пересечении крайнего правого столбца и второй строки
содержится ответ для Х2 так как единица во второй строке
соответствует Х2 Используя построчные операции, мы можем совершать
элементарные преобразования в первоначальной матрице, пока не получим
единичную матрицу. Из единичной матрицы можно получить ответы для весов X1
... ХN—компонентов портфеля. Найденные веса дадут портфель с
минимальной дисперсией V для данного уровня ожидаемой прибыли Е1.
.
Можно
проводить три типа построчных операций:
1. Поменять местами любые две строки.
2. Умножить любую строку на ненулевую постоянную.
3. Любую строку умножить на ненулевую постоянную и
прибавить к любой другой строке.
С помощью этих трех операций мы попытаемся преобразовать
исходную матрицу коэффициентов в единичную матрицу
В расширенной матрице проведем элементарное преобразование
номер 1, используя правило номер 2 построчных операций. Мы возьмем значение на
пересечении первой строки и первого столбца (оно равно 0,095) и преобразуем
его в единицу. Для этого умножим первую строку на 1/0,095. В результате,
значение на пересечении первой строки и первого столбца станет равно единице.
Остальные значения в первой сроке изменятся соответствующим образом.
Проведем элементарное преобразование номер 2. Для этого
задействуем правило номер 3 построчных операций (для всех строк, кроме
первой). Предварительно для всех строк проведем элементарное преобразование
номер 1, преобразовав число, стоящее в первом столбце каждой строки, в единицу.
Затем все числа матрицы, кроме чисел первой строки, умножим на -1. После этого
можно перейти к непосредственному применению правила номер 3. Для этого
прибавим первую строку к каждой строке матрицы: первое число первой строки
прибавим к первому числу второй строки, второе число первой строки ко второму
числу второй строки и так далее. После этого преобразования мы получим нули в
первом столбце (во всех строках, кроме первой).
Теперь первый столбец уже является столбцом единичной
матрицы. С помощью элементарного преобразования номер 3, используя правило
номер 2 построчных операций, преобразуем значения на пересечении второй строки
и второго столбца в единицу. Посредством элементарного преобразования 4,
используя правило номер 3 построчных операций, преобразуем в нули значения
второго столбца (для всех строк, кроме второй).
Таким образом, с помощью правила номер 2 и правила номер 3
построчных операций мы преобразуем значения по диагонали в единицы и получим
единичную матрицу. Столбец с правой стороны будет содержать решение.

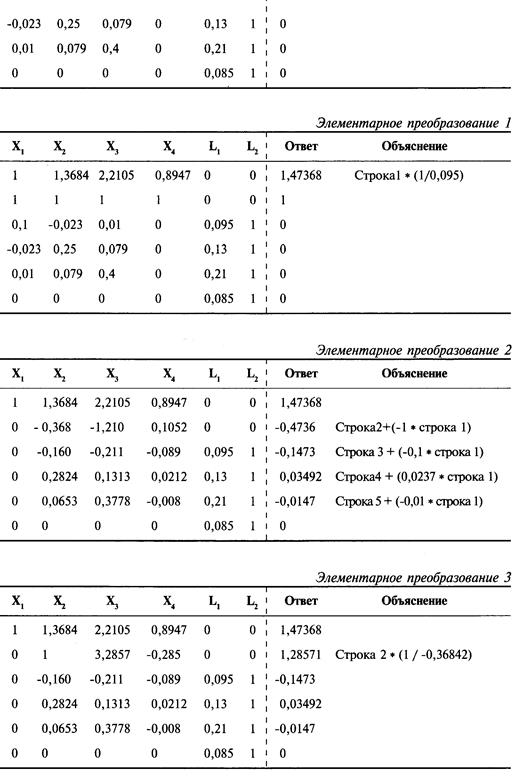
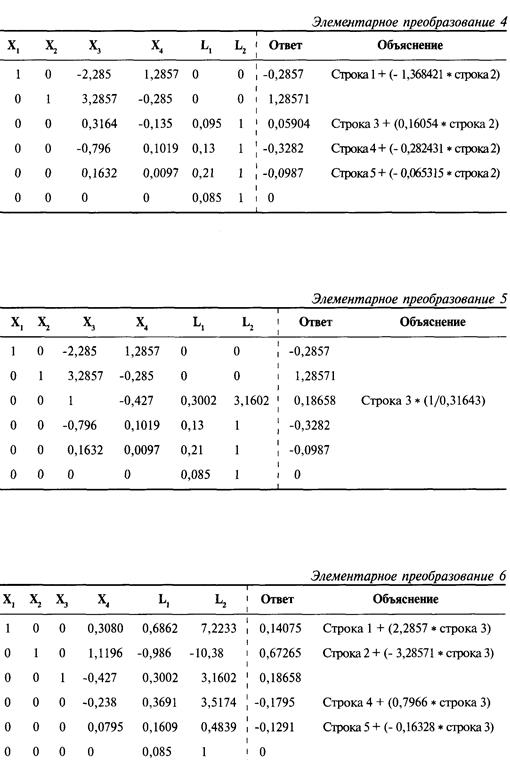
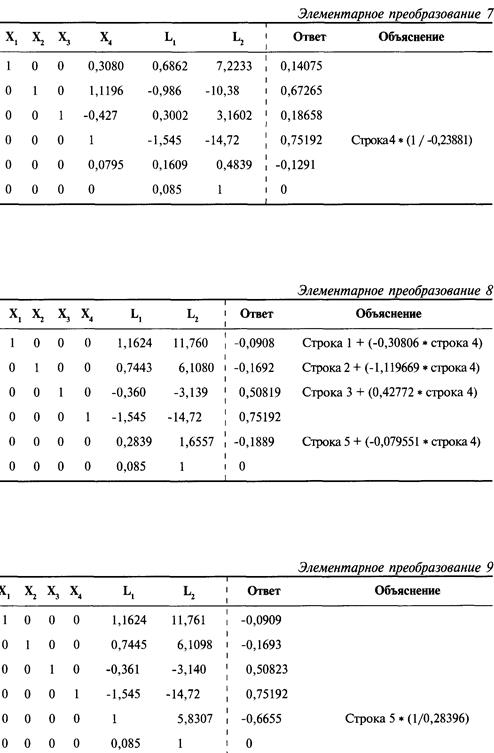

Интерпретация
результатов
После того как найдена единичная матрица, следует
интерпретировать полученные результаты. В данном случае при наличии входных
данных об ожидаемых прибылях и дисперсии прибылей по всем рассматриваемым
компонентам, при наличии коэффициентов линейной корреляции каждой пары
компонентов и ожидаемой отдаче 14% наше решение является оптимальным. Слово «оптимальный» означает, что полученное
решение дает самую низкую дисперсию при ожидаемой прибыли 14%. Мы можем
определить это значение дисперсии, но сначала интерпретируем результаты.
Первые четыре значения, от X1 до Х4
дают нам веса, т.е. доли инвестируемых средств, для получения оптимального
портфеля с 14%-ой ожидаемой прибылью. Нам следует инвестировать 12,391% в Toxico, 12,787% в Incubeast, 38,407% в LA Garb и 36,424% в
сберегательный счет. Если мы хотим инвестировать 50 000 долларов, то получим:
|
Акция
|
Процент
|
(* 50000 =) сумма инвестиций
|
|
Toxico
|
0,12391
|
$6195,50
|
|
Incubeast
|
0,12787
|
$6393,50
|
|
LA Garb
|
0,38407
|
$19 203,50
|
|
Сберегательный счет
|
0,36424
|
$18212,00
|
Таким образом, в Incubeast мы бы
инвестировали 6393,50 доллара. Теперь допустим, что Incubeast котируется по цене 20 долларов за акцию, т.е. следует
купить 319,675 акции (6393,5 / 20). На самом деле мы не можем купить дробное
число акций, поэтому купим либо 319, либо 320 акций. Следует также отметить,
что небольшой лот из 19 или 20 акций, остающийся после покупки первых 300
акций, будет стоить дороже. Нестандартные, малые лоты обычно стоят несколько
дороже, поэтому мы переплатим за 19 или 20 акций, а это коснется ожидаемой
прибыли по нашей позиции в Incubeast и в свою
очередь затронет оптимальную комбинацию портфеля. В
некоторых случаях следует ограничиться только стандартным лотом (в нашем случае
— это 300 акций). Как видите, необходимо учитывать некоторый коэффициент
ухудшения. Мы можем определить оптимальный портфель с точностью до дробной
части акции, но реальная торговля все равно внесет свои коррективы. Естественно,
чем больше ваш счет, тем ближе будет реальный портфель к теоретическому.
Допустим, вместо 50 000 долларов вы оперируете пятью миллионами долларов. Вы
хотите инвестировать 12,787% в Incubeast (если речь
идет только об этих четырех инвестиционных альтернативах) и поэтому будете инвестировать
5 000 000*0,12787 =$639 350. При цене 20 долларов за акцию вы бы купили
639350/20=31967,5 акций. Учитывая круглый лот, вы купите 31900 акций,
отклоняясь от оптимального значения примерно на 0,2%. Когда для инвестирования
у вас есть только 50 000 долларов, вы купите 300 акций вместо оптимального
количества 319,675 и таким образом отклонитесь от оптимального значения
примерно на 6,5%.

Подставим значения в уравнение (6.06a) (стр. 281):
Таким
образом, при Е = 0,14 самое низкое значение V = 0,0725872809.
Если мы
захотим протестировать значение Е = 0,18, то снова начнем с расширенной
матрицы, только на этот раз правая верхняя ячейка будет равна 0.18.
|
Xi
|
|
Xj
|
|
COVi, j
|
|
|
0,12391
|
*
|
0,12391
|
*
|
0,1
|
0,0015353688
|
|
0,12391
|
*
|
0,12787
|
*
|
-0,0237
|
-0,0003755116
|
|
0,12391
|
*
|
0,38407
|
*
|
0,01
|
0,0004759011
|
|
0,12391
|
*
|
0,36424
|
*
|
0
|
0
|
|
0,12787
|
*
|
0,12391
|
*
|
-0,0237
|
-0,0003755116
|
|
0,12787
|
*
|
0,12787
|
*
|
0,25
|
0,0040876842
|
|
0,12787
|
*
|
0,38407
|
*
|
0,079
|
0,0038797714
|
|
0,12787
|
*
|
0,36424
|
*
|
0
|
0
|
|
0,38407
|
*
|
0,12391
|
*
|
0,01
|
0,0004759011
|
|
0,38407
|
*
|
0,12787
|
*
|
0,079
|
0,0038797714
|
|
0,38407
|
*
|
0,38407
|
*
|
0,4
|
0,059003906
|
|
0,38407
|
*
|
0,36424
|
*
|
0
|
0
|
|
0,36424
|
*
|
0,12391
|
*
|
0
|
0
|
|
0,36424
|
*
|
0,12787
|
*
|
0
|
0
|
|
0,36424
|
*
|
0,38407
|
*
|
0
|
0
|
|
0,36424
|
*
|
0,36424
|
*
|
0
|
0
|
|
|
|
|
|
|
0,0725872809
|
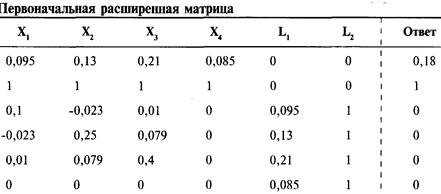
С помощью построчных операций
получим единичную матрицу:
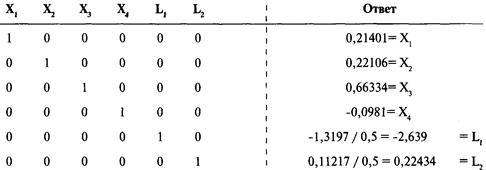
На этот раз в четвертой ячейке столбца ответов мы получили
отрицательный результат. Это означает, что нам следует инвестировать
отрицательную сумму в размере 9,81% капитала в сберегательный счет. Чтобы
решить проблему отрицательного Xi (т.е. когда значение на
пересечении строки i и крайнего правого столбца меньшее
или равно нулю), мы должны удалить из первоначальной расширенной матрицы
строку i + 2 и столбец i и решить задачу для новой расширенной матрицы. Если
значения последних двух строк крайнего правого столбца меньше или равны нулю,
нам не о чем беспокоиться, поскольку они соответствуют множителям Лагранжа и
могут принимать отрицательные значения. Так как отрицательное значение
переменной соответствует отрицательному весу четвертого компонента, мы удалим
из первоначальной расширенной матрицы четвертый столбец и шестую строку. Затем
используем построчные операции для проведения элементарных преобразований,
чтобы получить единичную матрицу:
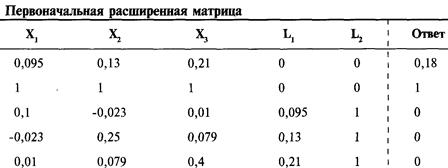
С
помощью построчных операций получим единичную матрицу:

Когда вы удаляете строки и столбцы, важно помнить, какие
строки каким переменным соответствуют, особенно когда таких строк и столбцов
несколько. Допустим, нам надо найти веса в портфеле при Е = 0,1965. Единичная
матрица, которую мы сначала получим, будет содержать отрицательные значения
для весов Toxico (X1) и сберегательного счета (Х4). Поэтому вернемся
к нашей первоначальной расширенной матрице:
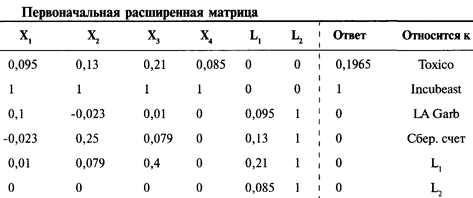
Теперь
удалим строку 3 и столбец 1 (они относятся к Toxico), а также удалим строку 6 и столбец 4 (они относятся к
сберегательному счету):
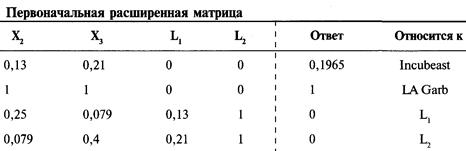
Итак, мы будем работать со
следующей матрицей:
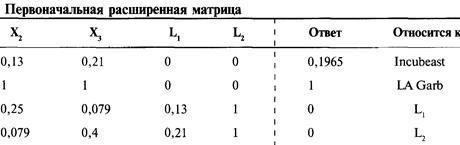
С помощью построчных операций
получим единичную матрицу:

Решить
матрицу можно также с помощью обратной
матрицы коэффициентов. Обратная матрица при умножении на первоначальную матрицу
дает единичную матрицу.
В матричной алгебре матрица часто обозначается
выделенной заглавной буквой. Например, мы можем обозначить матрицу
коэффициентов буквой С. Обратная матрица помечается верхним индексом -1.
Обратная матрица к С обозначается как С-1.Чтобы использовать этот
метод, необходимо определить обратную матрицу для матрицы коэффициентов. Для
этого добавим к матрице коэффициентов единичную матрицу. В примере с 4 акциями:
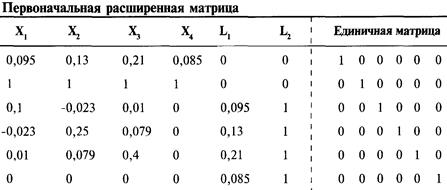
Используя построчные операции,
преобразуем матрицу коэффициентов в единичную матрицу. Так как каждая
построчная операция, проведенная слева, будет проведена и справа, мы
преобразуем единичную матрицу справа в обратную матрицу С-1.
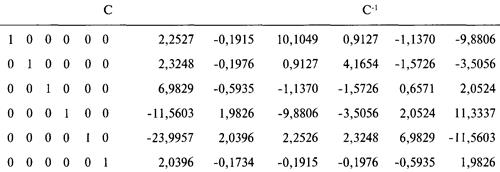
Теперь
мы можем умножить обратную матрицу С-1 на первоначальный крайний правый столбец, который в нашем
случае выглядит следующим образом:
При
умножении матрицы на вектор-столбец мы умножаем все элементы первого столбца
матрицы на первый элемент вектора, все элементы второго столбца матрицы на
второй элемент вектора, и так далее. Если бы вектор был вектор-строка, мы бы
умножили все элементы первой строки матрицы на первый элемент вектора, все
элементы второй строки матрицы на второй элемент вектора, и так далее. Так как речь
идет о векторе-столбце и последние четыре элемента нули, нам надо умножить
первый столбец обратной матрицы на Е (ожидаемая прибыль портфеля) и второй
столбец обратной матрицы на S (сумма весов). Мы
получим следующий набор уравнений, в которые можно подставить значения Е и S и
получить оптимальные веса.
Матричная алгебра
включает в себя гораздо больше тем и приложений, чем было рассмотрено в этой
главе. Существуют и другие методы матричной алгебры для решения систем
линейных уравнений. Часто вы встретите ссылки на правило Крамера,
симплекс-метод или симплексную таблицу. Эти методы сложнее, чем методы,
описанные в этой главе. Существует множество применений матричной алгебры в
бизнесе и науке, мы же затронули ее настолько, насколько необходимо для наших
целей. Для более подробного изучения матричной алгебры и ее применений в
бизнесе и науке рекомендую прочитать книгу «Множества, матрицы и линейное
программирование» Роберта Л. Чилдресса (Sets, Matrices, and Linear Programming, by Robert L. Childress). Следующая
глава посвящена методам, уже рассмотренным в этой главе, применительно к
любому торгуемому инструменту с использованием оптимального f и механических
систем.
Глава 7
Геометрия
портфелей
Мы уже познакомились с несколькими способами
расчета оптимального f для рыночных систем. Также мы знаем, как найти эффективную
границу. В этой главе мы покажем, как объединить идею оптимального f и идею
эффективной границы для получения действительно эффективного портфеля,
геометрический рост которого максимален. Мы также коснемся геометрии портфеля.
Линии рынка капитала (Capital Market
Lines — CMLs)
Из предыдущей главы мы узнали, как параметрически вывести
эффективную границу. Мы можем улучшить любой портфель путем инвестирования
определенной его доли в наличные (или, что то же самое, в беспроцентный вклад).
Рисунок 7-1 демонстрирует эту ситуацию графически.
На рисунке 7-1 точка А отражает прибыль по безрисковым
активам. Мы будем считать, что это прибыль по 91-дневным казначейским
обязательствам. Так как риск в данном случае (стандартное отклонение прибылей)
отсутствует, точка А находится на нуле по горизонтальной оси.
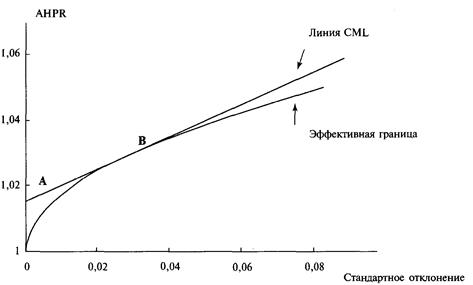
Рисунок 7-1 Увеличение прибылей с помощью безрисковых
активов
Точка В соответствует касательному портфелю. Это
единственный портфель, лежащий на эффективной границе, которого коснется
линия, проведенная из точки с координатой: безрисковая ставка прибыли на
вертикальной оси и ноль на горизонтальной оси. Любая точка на отрезке АВ
соответствует портфелю из точки В в комбинации с безрисковыми активами. В точке
В все средства вложены только в портфель, а в точке А только в безрисковые
активы. Любая точка между А и В соответствует определенной комбинации, когда
часть активов находится в портфеле, а часть в безрисковых активах. Отметьте,
что портфель на отрезке АВ более выгоден, чем любой портфель на эффективной
границе при том же уровне риска, так как, находясь на отрезке АВ, он имеет
более высокую прибыль при том же
уровне
риска. Таким образом, инвестору, который хочет получить менее рискованный
портфель, чем портфель В, следует инвестировать средства в портфель В и в
безрисковые активы, а не смещаться по эффективной границе в точку с меньшим
риском. Линия, выходящая из точки А безрискового уровня на
вертикальной оси и нуля на горизонтальной оси и касающаяся в одной точке
эффективной границы, называется линией
рынка капитала (CML). Справа от точки В линия CML представляет портфели, где инвестор занимает средства для
инвестирования в портфель В. Отметьте, что инвестору, который хочет получить
большую прибыль, чем дает портфель В, следует поступить именно таким образом,
поскольку портфели на линии CML справа от точки В дают более высокую прибыль,
чем портфели на эффективной границе при том же уровне риска. Как правило, В —
очень хорошо диверсифицированный портфель. Большинство портфелей, расположенных
справа сверху и слева снизу на эффективной границе, имеют очень мало компонентов,
портфели в середине эффективной границы, где проходит касательная, достаточно
хорошо диверсифицированы. Традиционно считается, что все
разумные инвесторы хотят получить максимальную прибыль при данном риске и
принять наименьший риск при заданной прибыли. Таким образом, все инвесторы
хотят быть где-то на линии CML. Другими словами, все инвесторы хотят держать
один и тот же портфель, но с различной долей заемных средств. Данное различие
между инвестиционным решением и инвестированием с использованием заемных
средств известно как теорема разделения. Мы
будем исходить из того, что вертикальная шкала (Е в теории Е — V) выражает
арифметическое среднее HPR (AHPR)
для портфелей, а горизонтальная шкала (V) отражает стандартное отклонение HPR.
Для заданной безрисковой ставки мы можем определить, где находится касательный
портфель на нашей эффективной границе, так как его координаты (AHPR, V)
максимизируют следующую функцию:
(7.0 la) Касательный
портфель = MAX{(AHPR - (1 + RFR))
/ SD},
где МАХ{} = максимальное значение;
AHPR
=арифметическое среднее HPR, т. е. координата Е данного портфеля на эффективной
границе;
SD =
стандартное отклонение HPR, т. е. координата V данного портфеля на эффективной
границе;
RFR==
безрисковая ставка (risk-free rate).
В
уравнении (7.0la) формула внутри скобок ({}) представляет собой отношение
Шарпа. Отношение Шарпа для портфеля — это отношение ожидаемых избыточных
значений прибыли к стандартному отклонению. Портфель с наибольшим отношением
Шарпа является портфелем, где линия CML касается
эффективной границы при данном значении RFR.
Следующая таблица показывает, как использовать уравнение (7.01а).
В первых двух столбцах указаны координаты различных портфелей на эффективной
границе. Координаты даны в формате (AHPR, SD), что соответствует осям Y
и Х рисунка 7-1. В третьем столбце представлены данные, полученные из
уравнения (7.01а), при безрисковой ставке 1,5% (AHPR=
1,015). Мы исходим из того, что HPR имеют квартальные
значения, таким образом, квартальная безрисковая ставка 1,5% примерно равна
годовой безрисковой ставке 6%. Например, для третьего набора координат (1,002;
0,00013) получим:
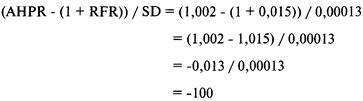
Проведем данный расчет для каждой точки на эффективной
границе. Максимальное значение уравнения (7.01а) 0,502265 соответствует
координатам (1,03;
0,02986),
они задают точку, которая соответствует точке В на рисунке 7-1, где линия CML
касается эффективной границы. Точка касания соответствует определенному
портфелю на эффективной границе. Отношение Шарпа определяет наклон CML, причем
самым крутым наклоном обладает касательная к эффективной границе.
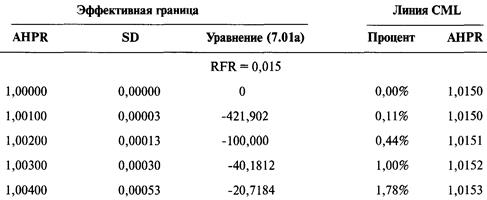
|
Продолжение
|
|
AHPR
|
Эффективная граница SD Уравнение (7.01а)
|
Линия CML Процент AHPR
|
|
1,00500
|
0,00083
|
-12,0543
|
2,78%
|
1,0154
|
|
1,00600
|
0,00119
|
-7,53397
|
4,00%
|
1,0156
|
|
1,00700
|
0,00163
|
-4,92014
|
5,45%
|
1,0158
|
|
1,00800
|
0,00212
|
-3,29611
|
7,11%
|
1,0161
|
|
1,00900
|
0,00269
|
-2,23228
|
9,00%
|
1,0164
|
|
1,01000
|
0,00332
|
-1,50679
|
11,11%
|
1,0167
|
|
1,01100
|
0,00402
|
-0,99622
|
13,45%
|
1,0170
|
|
1,01200
|
0,00478
|
-0,62783
|
16,00%
|
1,0174
|
|
1,01300
|
0,00561
|
-0,35663
|
18,78%
|
1,0178
|
|
1,01400
|
0,00650
|
-0,15375
|
21,78%
|
1,0183
|
|
1,01500
|
0,00747
|
0
|
25,00%
|
1,0188
|
|
1,01600
|
0,00849
|
0,117718
|
28,45%
|
1,0193
|
|
1,01700
|
0,00959
|
0,208552
|
32,12%
|
1,0198
|
|
1,01800
|
0,01075
|
0,279036
|
36,01%
|
1,0204
|
|
1,01900
|
0,01198
|
0,333916
|
40,12%
|
1,0210
|
|
1,02000
|
0,01327
|
0,376698
|
44,45%
|
1,0217
|
|
1,02100
|
0,01463
|
0,410012
|
49,01%
|
1,0224
|
|
1,02200
|
0,01606
|
0,435850
|
53,79%
|
1,0231
|
|
1,02300
|
0,01755
|
0,455741
|
58,79%
|
1,0238
|
|
1,02400
|
0,01911
|
0,470873
|
64,01%
|
1,0246
|
|
1,02500
|
0,02074
|
0,482174
|
69,46%
|
1,0254
|
|
1,02600
|
0,02243
|
0,490377
|
75,12%
|
1,0263
|
|
1,02700
|
0,02419
|
0,496064
|
81,01%
|
1,0272
|
|
1,02800
|
0,02602
|
0,499702
|
87,12%
|
1,0281
|
|
1,02900
|
0,02791
|
0,501667
|
93,46%
|
1,0290
|
|
1,03000
|
0,02986
|
0,502265 (пик)
|
100,02%
|
1,0300
|
|
1,03100
|
0,03189
|
0,501742
|
106,79%
|
1,0310
|
|
Продолжение
|
|
AHPR
|
Эффективная граница SD
|
Уравнение (7.01а)
|
Линия CML Процент AHPR
|
|
1,03200
|
0,03398
|
0,500303
|
113,80%
|
1,0321
|
|
1,03300
|
0,03614
|
0,498114
|
121,02%
|
1,0332
|
|
1,03400
|
0,03836
|
0,495313
|
128,46%
|
1,0343
|
|
1,03500
|
0,04065
|
0,492014
|
136,13%
|
1,0354
|
|
1,03600
|
0,04301
|
0,488313
|
144,02%
|
1,0366
|
|
1,03700
|
0,04543
|
0,484287
|
152,13%
|
1,0378
|
|
1,03800
|
0,04792
|
0,480004
|
160,47%
|
1,0391
|
|
1,03900
|
0,05047
|
0,475517
|
169,03%
|
1,0404
|
|
1,04000
|
0,05309
|
0,470873
|
177,81%
|
1,0417
|
|
1,04100
|
0,05578
|
0,466111
|
186,81%
|
1,0430
|
|
1,04200
|
0,05853
|
0,461264
|
196,03%
|
1,0444
|
|
1,04300
|
0,06136
|
0,456357
|
205,48%
|
1,0458
|
|
1,04400
|
0,06424
|
0,451416
|
215,14%
|
1,0473
|
|
1,04500
|
0,06720
|
0,446458
|
225,04%
|
1,0488
|
|
1,04600
|
0,07022
|
0,441499
|
235,15%
|
1,0503
|
|
1,04700
|
0,07330
|
0,436554
|
245,48%
|
1,0518
|
|
1,04800
|
0,07645
|
0,431634
|
256,04%
|
1,0534
|
|
1,04900
|
0,07967
|
0,426747
|
266,82%
|
1,0550
|
|
1,05000
|
0,08296
|
0,421902
|
277,82%
|
1,0567
|
Следующий столбец «Процент» отражает процент активов,
которые необходимо инвестировать в касательный портфель, если вы находитесь на
линии CML при определенном значении стандартного отклонения. Другими словами,
последняя строка в таблице (при стандартном отклонении 0,08296) соответствует
наличию 277,82% ваших активов в касательном портфеле (основная сумма инвестиций
и заем еще 1,7782 доллара на каждый инвестированный доллар для дальнейшего
инвестирования). Процентное значение можно рассчитать, если знать стандартное
отклонение касательного портфеля:
(7.02) P=SX/ST,
где SX = координата
стандартного отклонения определенной точки на линии CML;
ST = координата стандартного отклонения касательного
портфеля;
Р= процент активов, которые необходимо инвестировать в
касательный портфель, чтобы быть на линии CML для данного значения SX.
Таким образом, если значение стандартного отклонения точки
на линии CML (0,08296) из последней строки таблицы разделить на значение
стандартного отклонения касательного портфеля (0,02986), мы получим 2,7782,
что соответствует 277,82%.
В последнем столбце таблицы показано AHPR линии CML при данной координате стандартного отклонения.
Оно рассчитывается следующим образом:
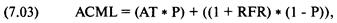
где ACML = AHPR линии CML при данной координате риска, или соответствующем
проценте, рассчитанном из (7.02);
AT =значение AHPR касательной точки, полученное из (7.01а);
Р= процент
в касательном портфеле, рассчитанный из (7.02);
RFR= безрисковая ставка.
Стандартное отклонение определенной точки на линии CML для
данного AHPR рассчитывается следующим образом:
(7.04) SD=P*ST,
где SD = стандартное отклонение в данной точке на линии CML при
определенном проценте Р, соответствующем данному AHPR;
Р =
процент в касательном портфеле, рассчитанный из (7.02);
ST = значение
стандартного отклонения касательного портфеля.
Геометрическая
эффективная граница
Особенность рисунка 7-1 состоит в том, что он отображает
арифметическое среднее HPR. Если прибыли реинвестируются, то
для координаты эффективной границы по оси Y
правильнее рассматривать геометрическое среднее HPR. Такой
подход
многое меняет. Формула для преобразования точки на эффективной границе из
арифметического HPR в геометрическое такова:
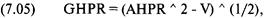
где GHPR = геометрическое среднее HPR;
AHPR = арифметическое среднее HPR;
V= координата дисперсии (она равна координате стандартного отклонения в квадрате).
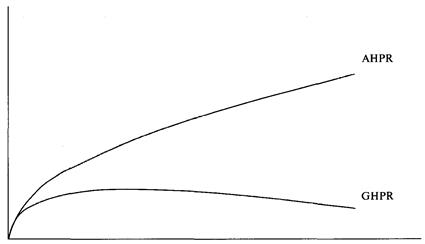
Рисунок 7-2 Эффективная граница с реинвестированием и
без реинвестирования
На рисунке 7-2 показана эффективная граница,
соответствующая арифметическим средним HPR, и граница, соответствующая
геометрическим средним HPR. Посмотрите, что происходит с эффективной границей
при реинвестировании.
Построив
линию GHPR, можно определить, какой портфель является геометрически оптимальным
(наивысшая точка на линии GHPR). Вы можете найти этот портфель, преобразовав
AHPR и V каждого портфеля на эффективной границе AHPR в GHPR с помощью
уравнения (7.05) и выбрав максимальное значение GHPR. Однако, зная AHPR и V
портфелей, лежащих на эффективной границе AHPR, можно еще проще определить
геометрический оптимальный портфель, он должен удовлетворять следующему
уравнению:
(7.06a) AHPR-1-V=0,
где АН PR = арифметическое среднее HPR,
т.е. координата Е данного портфеля на эффективной границе;
V= дисперсия HPR, т.е. координата V данного портфеля на
эффективной границе. Она равна стандартному отклонению в квадрате.
Уравнение (7.06a) также можно представить следующим
образом:
(7.06б) AHPR - 1 = V
(7.06в) AHPR-V=1
(7.06г) AHPR=V+1
Необходимо сделать небольшое замечание по геометрическому
оптимальному портфелю. Дисперсия в портфеле в общем случае имеет положительную
корреляцию с наихудшим проигрышем. Более высокая дисперсия обычно соответствует
портфелю с более высоким возможным проигрышем. Так как геометрический
оптимальный портфель является портфелем, для которого Е и V равны (при E=AHPR- 1), мы можем допустить, что
геометрический оптимальный портфель будет иметь высокие проигрыши. Фактически,
чем больше GHPR геометрического оптимального портфеля (т.е. чем больше
зарабатывает портфель), тем больше может быть его текущий проигрыш (откат по
балансу счета), так как GHPR положительно коррелирован с AHPR. Здесь мы видим
некий парадокс. С одной стороны нам следует использовать геометрический
оптимальный портфель, с другой — чем выше среднее геометрическое портфеля, тем
большими будут откаты по балансу счета в процентном выражении. Мы знаем также,
что при диверсификации следует выбирать портфель с наивысшим средним
геометрическим, а не с минимальным проигрышем, но эти величины стремятся в
противоположных направлениях! Геометрический оптимальный портфель — это
портфель, который расположен в точке, где линия, прочерченная из (0, 0) с
наклоном 1, пересекает эффективную границу AHPR.
Рисунок
7-2 показывает эффективные границы на основе одной сделки. Мы можем
преобразовать геометрическое среднее HPR в TWR
с помощью уравнения:
(7.07) GTWR = GHPR^ N,
где GTWR =
значение вертикальной оси, соответствующее данному GHPR после N сделок;
N - число сделок, которые мы хотим использовать.
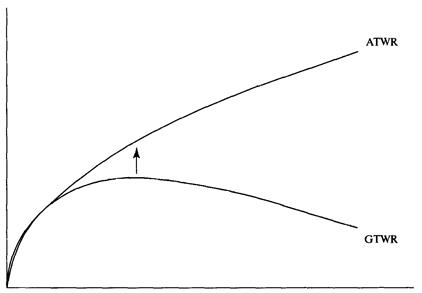
Рисунок 7-3 Эффективная граница с реинвестированием и
без реинвестирования
Рисунок 7-4 Эффективная граница с реинвестированием и
без реинвестирования
Пусть
нашей целью будет AHPR при значении V, которое
соответствует геометрическому оптимальному портфелю. В знаменателе (2.09а) мы
используем среднее геометрическое геометрического оптимального портфеля.
Теперь мы можем определить, сколько сделок необходимо для того, чтобы привести
наш геометрический оптимальный портфель к одной сделке арифметического
портфеля:
N=ln(l,031)/ln(l,01542) =0,035294/0,0153023 = 1,995075
Таким образом, можно ожидать, что через 1,995075, или
приблизительно через 2 сделки, оптимальное GHPR
достигнет соответствующего (при том же V) AHPR для одной сделки. Здесь
возникает проблема, которая заключается в том, что ATWR
должно отражать тот факт, что прошли две сделки. Другими словами, когда GTWR приближается к ATWR, ATWR двигается вверх, хотя и с постоянной скоростью (в отличие
от GTWR, которое ускоряется). Можно решить эту проблему с помощью уравнений
(7.07) и (7.08) для расчета геометрического и арифметического TWR:
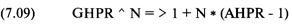
Так как мы знаем, что, когда N = 1, G всегда меньше А, можно перефразировать вопрос: «При
скольких N G будет равно А?» Математически это будет выглядеть таким образом:
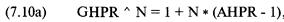
что можно представить следующим образом:
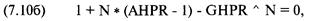
или
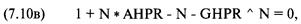
или
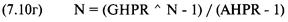
N в уравнениях с (7.10а) по (7. 10г) представляет собой
количество сделок, которое необходимо для того, чтобы геометрическое HPR стало равно арифметическому. Все три уравнения
эквивалентны. Решение можно получить методом итераций. Зная для
нашего геометрического оптимального
портфеля GHPR= 1,01542 и соответствующее AHPR= 1,031 и решая любое уравнение с (7.10а) по (7. 10г), мы
находим, что N = 83,49894. Таким образом, после того, как пройдет 83,49894
сделки, геометрическое TWR догонит арифметическое. Полученный
результат справедлив для тех TWR, которые соответствуют координате дисперсии
геометрического оптимального портфеля.Так же, как и AHPR,
GHPR имеет свою линию CML. Рисунок
7-5 показывает как AHPR, так и GHPR с линиями CML, рассчитанными на основе
безрисковой ставки.
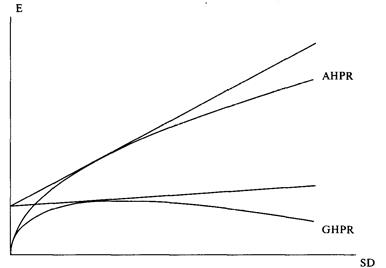
Рисунок 7-5 AHPR, GHPR и их линии CML
Зная CML для AHPR, можно рассчитать CML для GHPR следующим
образом:
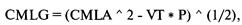
CMLG = координата Е (по вертикали) линии CML для GHPR при
данной координате V, соответствующей Р;
CMLA= координата Е (по вертикали) линии CML для AHPR при данной
координате V, соответствующей Р;
Р = процент в
касательном портфеле, рассчитанный из (7.02);
VT = координата дисперсии касательного портфеля.
Следует иметь в виду, что для данной безрисковой ставки
касательный портфель и геометрический оптимальный портфель в общем случае не
одинаковы. Портфели будут идентичными при выполнении следующего равенства:
(7.12) RFR=GHPROPT-1,
где RFR = безрисковая ставка;
GHPROPT = среднее геометрическое HPR
геометрического оптимального портфеля, т.е. координата Е портфеля на эффективной
границе.
Только когда разность GHPR
геометрического оптимального портфеля и единицы равна безрисковой ставке,
геометрический оптимальный портфель и касательный портфель будут одинаковыми.
Если RFR > GHPROPT - 1, тогда
геометрический оптимальный портфель будет слева (т.е. иметь меньшую дисперсию,
чем касательный портфель). Если RFR < GHPROPT - 1, тогда касательный портфель будет слева (т.е. иметь
меньшую дисперсию, чем геометрический оптимальный портфель). Во всех случаях
касательный портфель, конечно же, никогда не будет иметь более высокое GHPR,
чем геометрический оптимальный портфель.
Отметьте
также, что точки касания CML к GHPR и CML
к AHPR имеют одну координату SD.
Мы можем использовать уравнение (7.01а) для поиска касательного портфеля GHPR,
заменив в (7.01а) AHPR на GHPR. В результате получится следующее уравнение:
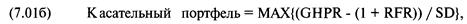
где МАХ{}=
максимальное значение;
GHPR =
геометрическое среднее HPR, т.е. координата Е
данного портфеля на эффективной границе;
SD =
стандартное отклонение HPR, т.е. координата SD данного портфеля на эффективной
границе;
RFR =
безрисковая ставка.
Неограниченные портфели
В этом разделе мы увидим, что можно поднять прибыли выше
линии GCML, если снять ограничение на сумму весов. Давайте вернемся к
геометрическим оптимальным портфелям. Если мы попробуем составить
геометрический оптимальный портфель из наших четырех рыночных систем — Toxico, Incubeast, LA Garb и сберегательного счета, то с
помощью уравнений с (7.0ба) по (7.06г) найдем, что он является таковым при Е,
равном 0,1688965, и V, равном 0,1688965. Среднее геометрическое такого портфеля
будет равно 1,094268, а состав портфеля будет иметь вид:
Toxico
18,89891%
Incubeast
19,50386%
LA Garb 58,58387%
Сберегательный
счет 0,03014%
При решении уравнений с (7.06а) по (7.06г) необходимо
использовать метод итераций, т.е. выбирать тестируемое значение для Е и решать
матрицу для этого Е. Если полученное значение дисперсии больше значения Е, это
означает, что тестируемое значение Е слишком высокое и в следующей попытке
следует его понизить. Вы можете определить дисперсию портфеля, используя одно
из уравнений с (6.06а) по (6.06г). Повторяйте процесс, пока не будет выполняться
любое из равенств с (7.06а) по (7.06г). Таким образом вы получите
геометрический оптимальный портфель (отметьте, что все рассмотренные портфели
на эффективной границе AHPR или на эффективной границе GHPR определяются с учетом того, что сумма весов равна 100%,
или 1,00). Вспомните уравнение (6.10), используемое в первоначальной
расширенной матрице для поиска оптимальных весов портфеля, уравнение отражает
тот факт, что сумма весов равна 1:
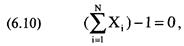
где N = количество ценных бумаг,
составляющих портфель;
X. = процентный вес ценной бумаги L
Уравнение также можно представить следующим образом:
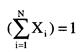
Мы
можем найти неограниченный оптимальный портфель, если левую часть этого
уравнения приравнять к числу больше 1. Для этого добавим еще одну рыночную систему,
называемую беспроцентным вкладом (non-interest-bearing cash (NIC)),
в первоначальную расширенную матрицу Данная рыночная система будет иметь
дневное среднее арифметическое HPR= 1,0, а
стандартное отклонение, дисперсию и ковариацию дневных HPR равными 0. Коэффициенты корреляции NIC с любой другой
рыночной системой всегда равны 0.
Теперь установим ограничение суммы весов на некоторое
произвольное число, большее единицы. Хорошим первоначальным значением будет
количество используемых рыночных систем (без NIC), умноженное на три. Так как
мы имеем 4 рыночные системы (не учитывая NIC), то ограничим сумму весов 4*3=12.
Отметьте, что мы просто устанавливаем ограничение на
произвольное значение, большее единицы. Разность между этим выбранным
значением и суммой полученных весов будет весом системы NIC.
На самом деле, мы не собираемся инвестировать в NIC. Это
просто дополнительная переменная, с помощью которой мы создадим матрицу для
получения
неограниченных
весов рыночных систем. Теперь возьмем параметры наших четырех рыночных систем
из главы 6 и добавим NIC:

Ковариации
рыночных систем, включая NIC, будут следующими:
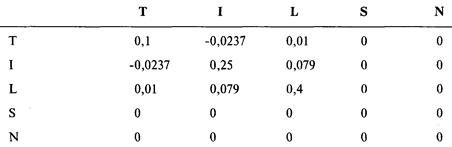
Добавив NIC, мы получим 5 рыночных систем, и обобщенная
форма первоначальной расширенной матрицы будет выглядеть следующим образом:
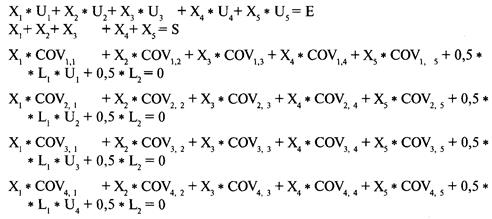
неограниченных весов рыночных
систем. Теперь возьмем параметры наших четырех рыночных систем из главы 6 и
добавим NIC:
|
Инвестиция
|
Ожидаемая прибыль в виде HPR
|
Ожидаемое стандартное отклонение
прибыли
|
|
Toxico
|
1,095
|
0,316227766
|
|
Incubeast Corp.
|
1,13
|
0,5
|
|
LA Garb
|
1,21
|
0,632455532
|
|
Сберегательный
счет
|
1,085
|
0
|
|
Беспроцентный
вклад
|
1,00
|
0
|
Ковариации рыночных систем, включая NIC, будут следующими:
|
|
Т
|
I
|
L
|
S
|
N
|
|
Т
|
0,1
|
-0,0237
|
0,01
|
0
|
0
|
|
I
|
-0,0237
|
0,25
|
0,079
|
0
|
0
|
|
L
|
0,01
|
0,079
|
0,4
|
0
|
0
|
|
S
|
0
|
0
|
0
|
0
|
0
|
|
N
|
0
|
0
|
0
|
0
|
0
|
Добавив NIC, мы получим 5 рыночных систем, и обобщенная
форма первоначальной расширенной матрицы будет выглядеть следующим образом:
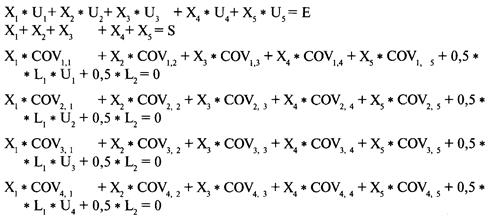
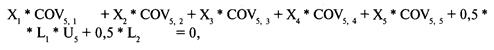

После
включения NIC первоначальная расширенная матрица приобретет вид:
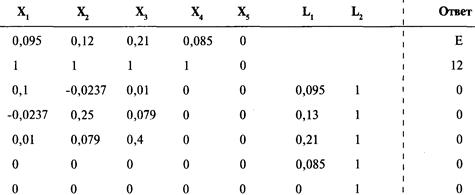
Отметьте, что значение на пересечении столбца ответов и
второй строки, т.е. ограничение суммы весов, равно количеству рыночных систем
(не включая NIC), умноженному на 3. С помощью элементарных преобразований,
описанных в главе 6, получим единичную матрицу. Теперь вы можете определить
эффективную границу AHPR и эффективную границу GHPR для портфеля с неограниченными весами. Эффективная граница
AHPR для портфеля с неограниченными весами соответствует использованию рычага
(заемного капитала) без реинвестирования.
Эффективная
граница GHPR соответствует использованию рычага и реинвестированию прибылей.
Наша цель — найти оптимальный неограниченный геометрический портфель, который в
результате даст наибольший геометрический рост. Можно использовать уравнения с
(7.Оба) по (7.06г) для нахождения на эффективной границе геометрического
оптимального портфеля. В нашем случае, независимо от того, какое значение мы
пытаемся найти для Е (значение на пересечение столбца ответов и первой строки),
мы получаем один и тот же портфель, состоящий только из сберегательного счета,
поднятого рычагом для достижения желаемого значения Е. В этом случае мы
получаем самое низкое V (т. е. 0) для любого Е.
Удалим из матрицы сберегательный счет и повторим процедуру.
На этот раз мы рассмотрим только четыре рыночные системы (Toxico, Incubeast, LA Garb и NIC)
и ограничим сумму весов числом 9. Мы должны поступить таким образом, потому
что, как только в матрице появляется компонент с нулевой дисперсией и AHPR большим 1, мы получаем оптимальный портфель, состоящий из
одного компонента, а для соответствия требуемому Е будет меняться только рычаг
этого компонента.
Решив матрицу, мы увидим, что уравнения с (7.06а) по
(7.06г) удовлетворяются при Е, равном 0,2457. Так как это геометрический
оптимальный портфель, V также равно 0,2457. Получившееся среднее геометрическое
равно 1,142833. Портфель будет выглядеть следующим образом:
Toxico 102,5982%
Incubeast 49,00558%
LA Garb 40,24979%
NIC 708,14643%
Возникает резонный вопрос: «Каким образом сумма весов
компонентов может быть больше 100%?» Мы ответим на этот вопрос, но несколько
позже.
Если
NIC не является одним из компонентов геометрического оптимального портфеля, то
следует поднять ограничение суммы весов S
до уровня, когда NIC станет одним из компонентов геометрического оптимального
портфеля. Вспомните, что если в портфеле есть только два компонента, причем коэффициент
корреляции между ними равен -1 и оба компонента имеют положительное
математическое ожидание, тогда от вас потребуется финансирование бесконечного
числа контрактов, поскольку такой портфель никогда не будет проигрывать.
Следует также отметить, что чем ниже коэффициенты корреляции между компонентами
в портфеле, тем выше процент, требуемый для инвестирования в эти компоненты.
Разность между инвестированными процентными долями и ограничением суммы весов S
должна быть заполнена NIC. Если NIC отсутствует среди компонентов
геометрического оптимального портфеля, значит портфель работает при
ограниченном S и поэтому не может считаться неограниченным геометрическим
оптимальным портфелем. Так как вы не будете в действительности инвестировать в
NIC, то не имеет значения, каков его вес, пока он является частью
геометрического оптимального портфеля.
Оптимальное f и оптимальные портфели
Из главы 6 мы узнали, что для каждого компонента портфеля
необходимо определить ожидаемую прибыль (в процентах) и ожидаемую дисперсию
прибылей. В общем случае, ожидаемые прибыли (и дисперсии) рассчитываются на
основе текущей цены акции. Затем для каждого компонента определяется его оптимальный
процент (вес). Далее, для расчета суммы инвестиций в тот или иной компонент,
баланс на счете умножается на вес компонента, и затем для определения
количества акций для покупки эта сумма в долларах делится на текущую цену одной
акции.
Так в общих чертах можно описать современную стратегию
создания портфеля. Но это не совсем оптимальный вариант, и в этом состоит одна
из основных идей книги. Вместо определения ожидаемой прибыли и дисперсии прибыли
на основе текущей цены компонента, ожидаемая прибыль и дисперсия прибылей для
каждого компонента должны определяться на основе долларового оптимального f.
Другими словами, в качестве входных данных вы должны использовать
арифметическое среднее HPR и дисперсию HPR. Используемые HPR должны быть
привязаны не к количеству сделок, а к фиксированным интервалам времени (дни,
недели, месяцы, кварталы или годы), как в главе 1 для уравнения (1.15).
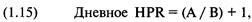
где А = сумма в долларах, выигранная или проигранная в этот день;
В =
оптимальное f в долларах.
Не
обязательно использовать дневные данные, можно использовать любой временной
период, при условии, что он одинаковый для всех компонентов портфеля (тот же
временной период должен использоваться для определения коэффициентов
корреляции между HPR различных компонентов). Скажем, рыночная система с
оптимальным f= 2000 долларов за день заработала 100 долларов. Тогда для
такой рыночной системы дневное HPR = 1,05.
Если вы рассчитываете оптимальное f на основе приведенных
данных, то для получения дневных HPR следует использовать уравнение (2.12);
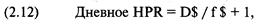
где D$ = изменение цены 1 единицы в
долларах по сравнению с прошлым днем, т.е. (закрытие сегодня - закрытие вчера)
* доллары за пункт;
f$
= текущее оптимальное f в долларах, рассчитанное из уравнения
(2.11). Здесь текущей ценой является закрытие последнего дня.
После того как вы определите оптимальное f в долларах для 1
единицы компонента, надо взять дневные изменения баланса на основе 1 единицы и
преобразовать их в HPR с помощью уравнения (1.15). Если вы
используете приведенные данные, воспользуйтесь уравнением (2.12). Когда вы
комбинируете рыночные системы в портфеле, все они должны иметь одинаковый
формат, т.е. если данные приведены к текущим ценам, то оптимальные f и
побочные продукты также должны быть приведенными.
Вернемся к арифметическому среднему HPR. Вычитая единицу из
арифметического среднего, мы получим ожидаемую прибыль компонента. Дисперсия
дневных (недельных, месячных и т.д.) HPR даст исходную дисперсию для матрицы.
Наконец, для каждой пары рассматриваемых рыночных систем рассчитаем
коэффициенты корреляции между дневными HPR.
Теперь можно сделать важное заключение. Портфели, параметры которых (ожидаемые
прибыли, дисперсия ожидаемых прибылей и коэффициенты корреляции ожидаемых
прибылей) выбраны на основе текущей цены компонента, не будут истинно
оптимальными портфелями. Для определения истинно оптимального портфеля следует
использовать входные параметры, основанные на торговле 1 единицей при
оптимальном/для каждого компонента. Вы не можете быть ближе к пику кривой
оптимального f, чем само оптимальное f. Рассчитывая параметры из текущей рыночной
цены компонента, вы выбираете параметры произвольно, следовательно, они не
обязательно оптимальны.
Вернемся к вопросу о том, каким образом возможно
инвестировать больше 100% в определенный компонент. Одно из основных
утверждений этой книги состоит в том, что вес и количество не одно и то же.
Вес, который вы получаете при нахождении геометрического оптимального портфеля,
должен быть отражен в оптимальных f компонентов портфеля. Для этого следует
разделить оптимальное f каждого компонента на его соответствующий вес.
Допустим, у нас есть следующие оптимальные f (в долларах):
Toxico $2500
Incubeast $4750
LA Garb $5000
(Отметьте,
что если вы приводите данные к текущей цене и, следовательно, получаете
приведенное оптимальное f и побочные
продукты, тогда ваше оптимальное f в долларах будет меняться каждый день в
зависимости от цены закрытия предыдущего дня на основании уравнения [2.11].)
Теперь
разделим f на соответствующие веса:
Toxico $2500 / 1,025982 = $2436,69
Incubeast $4750 / 0,4900558 =
$9692,77
LA Garb $5000 / 0,4024979 = $12
422,43
Таким образом, используя новые
«отрегулированные» значения f, мы получаем геометрический оптимальный портфель. Допустим, Toxico представляет
определенную рыночную систему. Торгуя 1 контрактом в этой рыночной системе на
каждые 2436,69 долларов на счете (и поступая таким же образом с новыми
отрегулированными значениями f других рыночных систем), мы будем торговать
геометрическим оптимальным неограниченным портфелем. Если Toxico является акцией и мы считаем 100 акций «I контрактом», то
следует торговать 100 акциями Toxico на каждые
2436,99 доллара на балансе счета. Пока мы не будем учитывать залоговые
средства. В следующей главе мы рассмотрим проблему требований к залоговым
средствам.
«Минутку, — можете возразить вы. — Если мы изменим
оптимальный портфель посредством оптимального f, будет ли он оптимальным. Если
новые значения относятся к другому портфелю, то ему соответствует другая
координата прибыли, и он может не оказаться на эффективной границе».
Заметьте, мы не изменяем значения f. Мы просто сокращаем
расчеты, и это выглядит так, как будто значения f изменяются. Мы создаем оптимальные
портфели, основываясь на ожидаемых прибылях и дисперсии прибылей при торговле
одной единицей каждого компонента, а также на коэффициентах корреляции. Таким
образом, мы получаем оптимальные веса (оптимальный процент счета для торговли
каждым компонентом). Поэтому, если рыночная система имеет оптимальное f = 2000
долларов и ее вес в оптимальном портфеле равен 0,5, мы должны использовать для
этой рыночной системы 50% счета при полном оптимальном f= 2000 долларов. Это то же самое, что торговать 100% нашего
счета при оптимальном f, деленном на оптимальный вес, т.е. ($2000 /0,5) =
$4000. Другими словами, торговать оптимальным f=
2000 долларов на 50% счета, по сути, то же самое, что и торговать измененным f= 4000 долларов на 100% счета.
AHPR и SD, которые вы вводите в матрицу,
определяются из значений оптимального f в долларах. Если речь идет об акциях,
то можно рассчитать значения AHPR, SD и оптимального f на основе одной акции или, например, 100
акций, вы сами определяете размер одной единицы.
В ситуации, когда нет рычага (например, портфель акций без
заемных средств), вес и количество одно и то же. Однако в ситуации с рычагом
(например, портфель фьючерсных рыночных систем), вес и количество отличаются.
Идея, которая была впервые изложена в книге «Формулы
управления портфелем», состоит в том, что мы пытаемся найти оптимальное
количество, и оно является функцией
оптимальных весов. Когда мы рассчитываем коэффициенты корреляции HPR двух рыночных систем с положительными арифметическими
математическими ожиданиями, то чаще всего получаем положительные значения. Это
происходит потому, что кривые баланса рыночных систем (совокупная текущая сумма
дневных изменений баланса) стремятся вверх и вправо. Проблема решается
следующим образом: для каждой кривой баланса надо определить линию регрессии
методом наименьших квадратов (до приведения к текущим ценам, если оно применяется)
и рассчитать разность кривой баланса и ее линии регрессии в каждой точке. Затем
следует преобразовать уже лишенную тренда кривую баланса в простые дневные
изменения баланса. После этого вы можете привести данные к текущим ценам
(когда это необходимо). Далее, рассчитайте корреляцию по этим уже обработанным
данным. Предложенный метод работает в том случае, если вы используете
корреляцию дневных изменений баланса, а не цен. Если вы будете использовать
цены, то можете получить искаженную картину, хотя очень часто цены и дневные
изменения баланса взаимосвязаны (например, в системе пересечения долгосрочной
скользящей средней). Метод удаления тренда следует всегда применять аккуратно.
Разумеется, дневное AHPR и стандартное отклонение HPR
должны всегда рассчитываться по данным, из которых не удален тренд.
Последняя
проблема, которая возникает, когда вы удаляете тренд из данных, касается
систем, в которых сделки совершаются достаточно редко. Представьте себе две
торговые системы, каждая из которых инициирует одну сделку в неделю, причем в
разные дни. Коэффициент корреляции между ними может быть только незначительно
положительным. Однако когда мы лишаем данные тренда, то получаем очень высокую
положительную корреляцию, поскольку их линии регрессии немного повышаются
каждый день, хотя большую часть времени изменение баланса равно нулю. Поэтому
разность будет отрицательной. Преобладание дней с незначительной отрицательной
разностью между кривой баланса и линией регрессии в обеих рыночных системах в
результате дает неоправданно высокую положительную корреляцию.
Порог
геометрической торговли для портфелей
Теперь обратимся к проблеме нахождения порога
геометрической торговли для данной комбинации оптимального портфеля. Проблема
легко решается, если разделить порог геометрической торговли для каждого
компонента на его вес в оптимальном портфеле так же, как мы делили оптимальные f компонентов на их соответствующие веса для получения
нового значения, справедливого для компонентов оптимального портфеля.
Допустим, порог геометрической торговли для Toxico составляет 5100 долларов. Разделив данное значение на его
вес в оптимальном портфеле, т.е. на 1,025982, мы получим новый измененный
порог геометрической торговли:
Порог
=$5100/1,025982= $4970,85
Так как вес для Toxico больше 1, то
его оптимальное f и порог геометрической торговли
уменьшатся, поскольку мы делим их значения на этот вес. Если нельзя торговать
дробной единицей Toxico, мы перейдем на 2 единицы, когда
баланс повысится до 4970,85 доллара. Вспомните, что наше
новое измененное значение f в оптимальном
портфеле для Toxico равно 2436,69 доллара ($2500 / 1,025982). Так как данная
сумма, умноженная на два, равна 4873,38 доллара, нам следует перейти на
торговлю двумя контрактами в этой точке. Однако порог геометрической торговли,
который больше чем в два раза превышает величину f
в долларах, говорит о том, что не стоит переходить на торговлю 2 единицами до
тех пор, пока баланс не достигнет порога геометрической торговли, равного
4970,85 доллара.
Если вы
приводите данные к текущим ценам и получаете приведенное оптимальное f и его
побочные продукты, включая порог геометрической торговли, тогда оптимальное f в
долларах и порог геометрической торговли будут меняться ежедневно в зависимости
от цены закрытия предыдущего дня на основании уравнения (2.11).
Подведение
итогов
Отметим важный факт: структура
неограниченного портфеля (для которого сумма весов больше 1, a NIC является частью
портфеля) неизменна для любого уровня Е; единственным отличием является
величина заемных средств (величина рычага). Для портфелей, лежащих на
эффективной границе, когда сумма весов ограничена, это не так. Другими
словами, для любой точки на неограниченных эффективных границах (AHPR или GHPR) отношения весов различных рыночных
систем всегда одинаковы.
Например, можно рассчитать отношения весов между различными
рыночными системами в геометрическом оптимальном портфеле. Отношение Toxico к Incubeast составляет: 102,5982% /
49,00558% = 2,0936. Таким же образом мы можем определить отношения всех
компонентов в портфеле друг к другу:
Toxico / Incubeast = 2,0936
Toxico / LA Garb = 2,5490
Incubeast / LA Garb = 1,2175
Теперь вернемся к неограниченному портфелю и найдем веса
для различных значений Е. Далее следуют веса компонентов неограниченных
портфелей, которые имеют самые низкие дисперсии для данных значений Е.
Заметьте, что отношения весов компонентов одинаковы:
|
|
E=0,1
|
Е=0,3
|
|
Toxico
|
0,4175733
|
1,252726
|
|
Incubeast
|
0,1994545
|
0,5983566
|
|
LA Garb
|
0,1638171
|
0,49145
|
Таким образом, мы можем утверждать, что эффективные границы портфелей с
неограниченной суммой весов содержат одинаковые портфели с разным уровнем заемных
средств (с разным плечом). Портфель, в котором меняется величина плеча для
получения заданного уровня прибыли Е, когда снято ограничение суммы весов,
будет иметь второй множитель Лагранжа, равный нулю, при сумме весов, равной 1.
Теперь мы можем достаточно просто определить, каким будет наш неограниченный
геометрический оптимальный портфель. Сначала найдем портфель, который имеет
нулевое значение для второго множителя Лагранжа, когда сумма весов ограничена
1,00. Одним из способов поиска такого портфеля является процесс итераций.
Получившийся в результате портфель поднимается (или опускается) рычагом в
зависимости от выбранного Е для неограниченного портфеля. Значение Е,
удовлетворяющее любому уравнению с (7.06а) по (7.06г), и будет тем значением,
которое соответствует неограниченному геометрическому оптимальному портфелю.
Для выбора геометрического оптимального портфеля на эффективной границе AHPR для портфелей с неограниченными весами, можно использовать
первый множитель Лагранжа, который определяет положение портфеля на
эффективной границе. Вспомните (см. главу 6), что одним из побочных продуктов
при определении состава портфеля методом элементарных построчных
преобразований является первый множитель Лагранжа. Он выражает мгновенную
скорость изменения дисперсии по отношению к ожидаемой прибыли (с обратным
знаком). Первый множитель Лагранжа, равный - 2, означает, что в этой точке
дисперсия изменяется по отношению к ожидаемой прибыли со скоростью 2. В
результате, мы получим портфель, который геометрически оптимален.
(7.06д) L1 = - 2,
где L1
= первый множитель Лагранжа данного портфеля на эффективной границе AHPR для
портфелей с неограниченной суммой весов1.
Теперь
объединим эти концепции вместе. Портфель,
который с помощью рычага перемещается вдоль эффективных границ (арифметических
или геометрических) портфелей с неограниченной суммой весов, является
касательным портфелем к линии CML, выходящей из RFR == 0, когда сумма
весов ограничена 1,00 и NIC не используется.
Итак, мы можем найти неограниченный геометрический оптимальный портфель путем
поиска касательного портфеля для RFR = 0, когда сумма весов ограничена 1,00, а
затем поднять рычагом полученный портфель до точки, где он становится
геометрическим оптимальным. Но как определить, насколько повысить данный ограниченный
портфель, чтобы сделать его эквивалентным неограниченному геометрическому
оптимальному портфелю?
Вспомните,
что касательный портфель находится на эффективной границе (арифметической или
геометрической) портфелей с ограниченной суммой весов в точке с наивысшим
отношением Шарпа (уравнение (7.01)). Мы просто повысим рычагом этот портфель и
умножим веса каждого из его компонентов на переменную, называемую q, которую можно получить следующим образом:
(7.13) q=(E-RFR)/V,
где Е = ожидаемая
прибыль (арифметическая) касательного портфеля;
RFR = безрисковая
ставка, по которой вы можете занять или дать взаймы;
V= дисперсия касательного портфеля.
Уравнение (7.13) является достаточно хорошим приближением
реального оптимального q.
Следующий пример может проиллюстрировать роль оптимального
q. Вспомните, что наш неограниченный геометрический оптимальный портфель выглядит
так:
|
Компонент
|
Вес
|
|
Toxico
|
1,025955
|
|
Incubeast
|
0,4900436
|
|
LA Garb
|
0,4024874
|
Портфель имеет AHPR= 1,245694 и
дисперсию 0,2456941. В оставшейся части нашего обсуждения мы будем исходить из
того, что RFR = 0 (в данном случае отношение Шарпа этого портфеля, (AHPR-(1 + RFR)) / SD, равно 0,49568).
Теперь,
если мы введем те же прибыли, дисперсии и коэффициенты корреляции компонентов в
матрицу и рассчитаем, какой портфель находится в точке касания при RFR = 0, когда сумма весов ограничена 1,00 и при отсутствии NIC, то получим следующий портфель:
|
Компонент
|
Вес
|
|
Toxico
|
0,5344908
|
|
Incubeast
|
0,2552975
|
|
LA Garb
|
0,2102117
|
Этот портфель имеет AHPR
= 1,128, дисперсию 0,066683 и отношение Шарпа 0,49568. Отметьте, что отношение Шарпа касательного портфеля, для
которого сумма весов ограничена 1,00, при отсутствии NIC, в точности равно
отношению Шарпа для нашего неограниченного геометрического оптимального портфеля.
Вычитая единицу из полученных AHPR, мы получаем арифметическую среднюю прибыль
портфеля. Далее заметим: чтобы для ограниченного касательного портфеля
получить прибыль, равную прибыли неограниченного геометрического оптимального
портфеля, мы должны умножить веса первого на 1,9195.
0,245694/0,128=1,9195
Теперь, если мы умножим каждый из весов ограниченного
касательного портфеля, то получим портфель, идентичный неограниченному
геометрическому оптимальному портфелю:
|
Компонент
|
Вес *
|
1,9195 =
|
Вес
|
|
Toxico
|
0,5344908
|
|
1,025955
|
|
Incubeast
|
0,2552975
|
|
0,4900436
|
|
LA Garb
|
0,2102117
|
|
0,4035013
|
Множитель 1,9195 получен в результате деления прибыли
неограниченного геометрического оптимального портфеля на прибьыь ограниченного
касательного портфеля. Как правило, нам надо найти неограниченный
геометрический оптимальный портфель, зная только ограниченный касательный
портфель. Именно здесь и используется оптимальное q. Если мы допускаем, что RFR = 0, то можно
определить
оптимальное q по нашему
ограниченному касательному портфелю следующим образом:
(7.13) q=(E-RFR)/V=(0,128-0)/0,066683 =
1,919529715
Несколько замечаний по поводу RFR. Когда речь идет о
фьючерсных контрактах, следует приравнять RFR к нулю, так как в
действительности мы не занимаем и не ссужаем средства для увеличения или
уменьшения активов портфеля. С акциями ситуация иная, и RFR следует принимать
во внимание.
Вы
часто будете использовать AHPR и дисперсию для
портфелей на основе дневных HPR компонентов. В
таких случаях необходимо применять не годовую, а дневную ставку RFR. Это
довольно простая задача. Сначала необходимо убедится, что годовая ставка
является эффективной годовой процентной
ставкой. Процентные ставки обычно указываются в годовых процентах, но часто
они представляют собой номинальную
годовую процентную ставку. Если процентная ставка складывается из
полугодовых, квартальных, месячных ставок и т.д., то ставка, заработанная за
год, будет больше, чем просто годовая ставка (номинальная). Когда процент
суммируется, эффективная годовая процентная ставка может быть определена из
номинальной процентной ставки. Полученную эффективную годовую процентную
ставку мы и будем использовать в расчетах. Для преобразования номинальной
ставки в эффективную ставку следует использовать формулу:
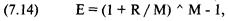
где Е =
эффективная годовая процентная ставка;
R = номинальная годовая процентная ставка;
М == число периодов сложения за год.
Предположим, номинальная годовая процентная ставка
составляет 9%, и доход по ней пересчитывается каждый месяц по формуле сложного
процента. Соответствующая эффективная процентная ставка будет равна:
(7.14) Е = (1+0,09/12)^ 12-1 = (1 + 0,0075)^12-1
==1,0075^12- 1 = 1,093806898 = 0,093806898
Таким
образом, наша эффективная годовая процентная ставка будет немногим больше
9,38%. Теперь, чтобы рассчитать HPR на основе рабочих
дней, мы должны найти среднее число рабочих дней 365,2425 /7*5= 260,8875.
Разделив 0,093806898 на 260,8875, мы получим дневное RFR
= 0,0003595683887.
Если мы на самом деле будем привлекать средства, чтобы
получить из ограниченного касательного портфеля неограниченный геометрический
оптимальный портфель, необходимо ввести значение RFR в отношение Шарпа,
уравнение (7.01), и оптимальное q, уравнение (7.13).
Подведем итог. Допустим, RFR для вашего портфеля не равно
0, и необходимо найти геометрический оптимальный портфель, не рассчитывая
ограниченный касательный портфель для этого RFR. Можете ли вы перейти прямо к
матрице, установить сумму весов на какое-либо произвольно высокое значение, добавить
NIC и найти неограниченный геометрический оптимальный
портфель, когда RFR больше О? Да, если вычесть RFR из ожидаемых прибылей
каждого компонента, но не из NIC (т.е. ожидаемая прибыль для NIC остается
нулевой, что соответствует среднему арифметическому HPR=
1,00). Теперь, решив матрицу, мы получим неограниченный геометрический
оптимальный портфель, когда RFR больше 0.
Так как эффективная граница для портфелей с неограниченной
суммой весов дает один и тот же портфель с различной величиной рычага, линия CML не может пересекаться или касаться эффективной границы
портфелей с неограниченной суммой весов, если же сумма весов ограничена (т.е.
равна 1) — это возможно.
Мы рассмотрели
несколько способов определения геометрического оптимального портфеля. Например,
мы можем рассчитать его эмпирически, что было продемонстрировано в книге «Формулы управления портфелем» и повторено в первой главе этой книги. В данной главе мы узнали, как с
помощью параметрического метода рассчитать портфель при любом значении безрисковой
ставки.
Теперь, когда мы
знаем, как определить геометрический оптимальный портфель, рассмотрим его
использование в реальной жизни. Геометрический оптимальный портфель даст нам
максимально возможный геометрический рост. В следующей главе мы рассмотрим
способы использования этого портфеля при заданных рисковых ограничениях.
Глава
8
Управление
риском
Мы познакомились
с различными методами расчета оптимального портфеля, с геометрией портфелей и
взаимосвязью оптимального количества и оптимального веса. Если торговать
портфелем базового инструмента на геометрическом оптимальном уровне и при этом
реинвестировать прибыли, то отношение ожидаемого дохода к ожидаемому риску
будет максимальным. В этой главе мы поговорим о построении геометрических оптимальных
портфелей при заданном уровне риска. Речь пойдет о том, что, какими бы
инструментами мы ни торговали, можно выбрать область в спектре риска и добиться
максимального геометрического роста для этого уровня риска.
Размещение
активов
Следует иметь в виду, что оптимальный портфель, полученный
с помощью параметрического метода, будет почти таким же, как и портфель,
полученный с помощью эмпирического метода (он подробно рассматривался в главе
1).
В этом случае возможны
большие проигрыши по портфелю (т.е. значительные колебания баланса), и
единственная возможность избежать значительных убытков — «разбавить» портфель,
т.е. добавить к геометрическому оптимальному портфелю какой-либо безрисковый
актив. Вышеописанную процедуру мы назовем размещением
активов (asset allocation). Степень риска и надежность любой инвестиции является
функцией не объекта инвестиций самого по себе, а функцией размещения активов.
Даже портфели, состоящие из акций голубых фишек (blue-chip stocks), находящиеся на уровне неограниченного геометрического
оптимального портфеля, могут показать значительные проигрыши. Однако этими
акциями следует торговать именно на
таких уровнях для максимизации отношения потенциального геометрического
выигрыша к дисперсии (риску), чтобы обеспечить достижение цели за наименьшее
время. С этой точки зрения торговля голубыми фишками является такой же
рискованной, как и торговля контрактами на свинину, а торговля свининой не
менее консервативна, чем торговля надежными акциями. То же можно сказать о
портфеле фьючерсов или облигаций.
Наша цель заключается в достижении желаемого уровня
потенциального геометрического выигрыша, исходя из данной дисперсии (риска),
путем комбинирования безрискового актива с торгуемым инструментом, будь то
портфель голубых фишек, облигаций или портфель фьючерсных торговых систем.
Когда вы торгуете портфелем с неограниченной суммой весов,
используя дробное f, то находитесь на эффективной границе
GHPR для портфелей с неограниченной суммой весов, но слева от
геометрической оптимальной точки, которая удовлетворяет любому уравнению с
(7.06а) по (7.06д). Таким образом, ваш потенциальный выигрыш по отношению к
риску меньше, чем в геометрической оптимальной точке. Это один из способов, с
помощью которого вы можете комбинировать портфель с безрисковым активом.
Другой способ размещения активов — разделение вашего счета
на два подсчета, активный и неактивный. Они не являются двумя реальными
отдельными счетами — это условное разделение. Метод работает следующим
образом. Определите первоначальное соотношение двух подсчетов. Допустим, вы
хотите создать подсчет, который соответствует f/2,
т.е. первоначальное соотношение долей составит 0,5/0,5, таким образом,
половина баланса вашего счета будет относиться к неактивному подсчету, а
половина к активному подсчету. Допустим, вы начинаете со счета 100 000
долларов, причем 50 000 долларов относятся к неактивному счету, а 50 000
долларов к активному счету, и именно баланс активного подсчета следует
использовать для определения количества контрактов для торговли. Подсчета
являются гипотетической конструкцией, которая создается для того, чтобы более
эффективно управлять деньгами, и в этом случае следует использовать полные
оптимальные f. Каждый день из общего баланса счета следует вычитать
неактивную сумму (которая остается постоянной каждый день), полученное
значение будет соответствовать активному балансу, и именно по нему следует
рассчитывать количество контрактов для торговли при полном f.
Теперь
допустим, что оптимальное f для рыночной системы А соответствует 1 контракту на
каждые 2500 долларов на балансе счета. В первый день активный баланс равен 50
000 долларов, и вы можете торговать 20 контрактами. Если бы вы использовали
стратегию, основанную на f/2, то в первый день задействовали это
же количество контрактов ($2500/0,5), но при общем балансе счета в 100 000 долларов.
Поэтому при стратегии, основанной на f/ 2, в этот день следует также торговать
20 контрактами. Когда изменяется баланс, число контрактов, которыми следует
торговать, тоже изменяется. Предположим, вы заработали 5000 долларов, увеличив
общий баланс счета до 105 000 долларов. При стратегии половинного f вам следует
торговать 21 контрактом. Однако при использовании метода разделения баланса вы
должны вычесть постоянную неактивную сумму 50 000 долларов из общего баланса
105 000 долларов. В результате вы получите активную часть баланса в 55 000
долларов и уже на основе этого определите количество контрактов при уровне
оптимального f (1 контракт на каждые 2500 долларов на счете). Таким образом,
при использовании метода разделения счета вам следует торговать 22 контрактами.
Похожая
ситуация возникает и при падении баланса вашего счета. Метод разделения счета
уменьшает количество контрактов с большей скоростью, чем это делает стратегия
половинного f. Допустим, вы потеряли 5000 долларов в первый день торговли и
общий баланс счета уменьшился до 95 000 долларов. При стратегии дробного f вам
следует торговать 19 контрактами ($95 000/$5000). Однако при использовании
метода разделения баланса активный счет будет равен 45 000 долларов, и вам
следует торговать 18 контрактами ($45 000/$2500).
Отметьте,
что при использовании метода разделения счета доля оптимального f изменяется
вместе с балансом. Сначала определяется доля баланса, которая будет задействована
в торговле (в нашем примере мы использовали первоначальную долю 0,5). При
повышении баланса доля оптимального f повышается, приближаясь в пределе к 1,
когда баланс счета стремится к бесконечности. При падении баланса доля f
приближается в пределе к 0, а общий баланс счета при этом стремится к
неактивной части. Тот факт, что страхование портфеля встроено в метод
разделения баланса, является огромным преимуществом, и об этой особенности мы
еще поговорим позже. Так как метод разделения счета использует изменяющееся
дробное f, мы назовем такой подход стратегией динамического дробного f, в противоположность стратегии статического дробного f.
Стратегия
статического дробного f смещает вас по линии CML
влево от оптимального портфеля, если вы используете ограниченный портфель, и
при любых изменениях баланса счет будет оставаться у этой точки на линии CML.
Если вы используете неограниченный портфель (что является лучшим подходом), то
будете на эффективной границе для портфелей с неограниченной суммой весов (так
как нет линий CML для неограниченных портфелей) слева от оптимального портфеля.
Когда баланс счета изменяется, вы остаетесь в той же точке на неограниченной
эффективной границе. Если речь идет об использовании динамического дробного f
для ограниченного или неограниченного портфеля, вы начинаете у тех же точек,
но, когда баланс счета повышается, портфель сдвигается вправо вверх, а когда
баланс понижается, портфель сдвигается влево вниз. Правая граница находится у
пика кривой, где доля f равна 1, а левая — у точки, где доля f равна 0.
При
размещении активов с помощью метода статического f дисперсия не меняется, так
как используемая доля оптимального f постоянна, но в случае с динамическим
дробным f дисперсия — переменная величина. В этом случае, когда баланс счета
увеличивается, увеличивается также и дисперсия, поскольку возрастает
используемая доля оптимального f. Верхней границы дисперсия достигает при
полном f, когда баланс счета приближается к бесконечности. При падении баланса
счета дисперсия быстро уменьшается по мере приближения используемой доли
оптимального f к нулю, когда общий баланс счета приближается к балансу
неактивного подсчета, и в этом случае нижняя граница дисперсии равна нулю.
Метод
динамического дробного f аналогичен методу, основанному на полном оптимальном
f, когда первоначальный размер торгового счета равен активной части баланса.
Итак, есть два способа размещения активов: с помощью статического дробного и с
помощью динамического дробного f. Динамическое дробное f дает динамическую
дисперсию, что является недостатком, но такой подход также обеспечивает
страхование портфеля (об этом позднее). Хотя эти два метода имеют много общего,
они все-таки серьезно отличаются. Какой же из них лучше? Рассмотрим систему,
где дневное среднее арифметическое HPR= 1,0265.
Стандартное отклонение дневных HPR составляет
0,1211, поэтому среднее геометрическое равно 1,019. Теперь посмотрим на
результаты торговли при статических дробных оптимальных 0, If и 0,2f. Для этого
используем уравнения с (2.06) по (2.08):

где FRAC = используемая
дробная часть оптимального f;
AHPR
= среднее арифметическое HPR при оптимальном f;
SD
= стандартное отклонение HPR при оптимальном f;
FAHPR = среднее арифметическое HPR при дробном f;
FSD
= стандартное отклонение HPR при дробном f;
FGHPR = среднее геометрическое HPR при дробном f. Результаты будут
следующими:
|
|
Полное f
|
0,2 f
|
0,1 f
|
|
AHPR
|
1,0265
|
1,0053
|
1,00265
|
|
SD
|
0,1211
|
0,02422
|
0,01211
|
|
GHPR
|
1,01933
|
1,005
|
1,002577
|
Теперь вспомним уравнение (2.09а) — ожидаемое время для
достижения определенной цели:
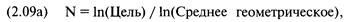
где N = ожидаемое количество сделок для
достижения определенной цели;
Цель =
цель в виде множителя первоначального счета, т.е. TWR;
1n() = функция натурального логарифма.
Сравним
торговлю при статическом дробном 0,2f при среднем
геометрическом 1,005 с торговлей, основанной на стратегии динамического
дробного 0,2f (первоначальный активный счет составляет 20% от общего)
при дневном среднем геометрическом 1,01933. Время (так как средние
геометрические имеют дневные значения, время измеряется в днях), требуемое для
удвоения счета при статическом дробном f, можно найти с помощью уравнения
(2.09а):
1n(2)/1n( 1,005) =138,9751
Для
удвоения счета при динамическом дробном f
значение цели надо приравнять шести, потому что если вы располагаете 20%
активньм балансом и начинаете с общего счета 100 000 долларов, то первоначально
в работе будет 20 000 долларов. Ваша задача увеличить активный баланс до 120
000 долларов. Так как неактивный баланс остается на уровне 80 000 долларов, то
на общем счете в итоге должно оказаться 200 000 долларов. Таким образом, рост
счета с 20 000 долларов до 120 000 долларов соответствует TWR = 6, поэтому для удвоения счета при динамическом дробном
0,2 f Цель должна быть равна 6.
ln(6) / 1n(1,01933) = 93,58634
Отметьте, что для динамического дробного f необходимо 93
дня вместо 138 дней для статического дробного f. Рассмотрим торговлю
при 0, If. Число дней, ожидаемое для удвоения баланса счета при
статическом методе, равно:
ln(2)
/ 1n(1,002577) = 269,3404
Сравните
с удвоением баланса счета при динамическом дробном 0, 1 f. Вам необходимо достичь TWR=
11, поэтому число дней при стратегии динамического дробного f равно:
1n(11)/1n(1,01933)=
125,2458
Для
удвоения баланса счета при 0, If необходимо 269
дней при статическом варианте и 125 дней при динамическом варианте. Чем меньше доля/, тем быстрее динамический
метод «обгонит» статический метод.
Посмотрим,
сколько времени потребуется, чтобы при 0,2f
увеличить счет в три раза. Число дней для статического метода будет равно:
1n(3)/1n(
1,005)= 220,2704 Сравним с динамическим методом, при котором:
1n(11)/1n(1,01933)=
125,2458 дней Чтобы получить прибыль в 400% (TWR = 5) при статическом 0,2f:
ln(5)
/ 1n( 1,005) = 322,6902 дней при динамическом подходе:
ln(21)
/ 1n(1,01933) = 159,0201 дней
Обратите
внимание, что в этом примере при динамическом подходе для достижения цели 400%
необходимо почти в два раза меньше времени, чем при статическом подходе.
Однако если вы возьмете число дней, за которое увеличился баланс счета при
статическом подходе (322,6902 дня), и подставите его в формулу расчета TWR для
динамического метода, то получите:
TWR
= 0,8 + (1,01933^ 322,6902) * 0,2 = 0,8 + 482,0659576 * 0,2 = 97,21319
Выигрыш
составит более 9600%, в то время как статический подход даст лишь 400%.
Теперь
мы можем изменить уравнение (2.09а), приспособив его как к статической, так и
к динамической стратегиям дробного f, для определения
ожидаемого времени, необходимого для достижения цели, выраженной TWR. Для
статического дробного f мы получим уравнение (2.096):
(2.096) N=ln(Цель)/ln(A),
где N = ожидаемое число сделок для достижения
определенной цели;
Цель =
цель в виде множителя начального счета, т.е. TWR;
А =
измененное среднее геометрическое, полученное из уравнения (2.08), при данном
статическом дробном f;
1п() =
функция натурального логарифма. Для динамического дробного f получим уравнение
(2.09в):
(2.09в) N = 1п(((Цель - 1) / ACTV) + 1) / 1п(Среднее геометрическое), где N = ожидаемое число сделок для достижения
определенной цели;
Цель =
цель в виде множителя начального счета, т.е. TWR;
ACTV =
доля активного счета;
Среднее
геометрическое = исходное среднее геометрическое (оно не меняется, как в случае
с уравнением (2.096));
ln()
= функция натурального логарифма.
Проиллюстрируем
уравнение (2.09в). Допустим, нам надо определить время, необходимое для
удвоения счета (т.е. TWR = 2), при активном счете 10% от общего счета и среднем
геометрическом 1,01933.
(2.09в) N = 1n(((Цель - 1) / ACTV) + 1) / ln(Среднее геометрическое) • =1n(((2-1)/0,1)+1)/1n(1,01933)
=1n((1/0,1)+1)/1n(1,01933)
=ln(10+ 1)/ln(l,01933)
=ln(ll)/ln(l,01933) = 2,397895273 / 0,01914554872 = 125,2455758
Таким образом, если среднее геометрическое определено на
дневной основе, мы можем ожидать удвоения примерно через 125 1/4 дня. Если
среднее геометрическое основано на сделках, мы можем ожидать удвоения примерно
через 125 1/4 сделки.
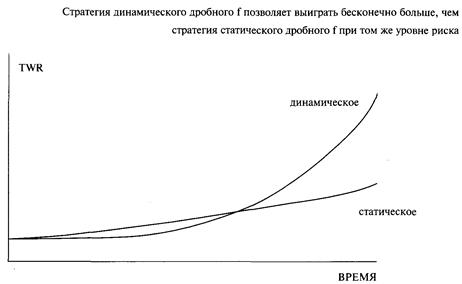
Рисунок
8-1 Сравнение статического и
динамического дробного/
Рисунок 8-1 демонстрирует отличие стратегии статического Ют
стратегии динамического дробного f. Чем больше времени
проходит, тем заметнее становится разница между стратегией статического
дробного f и стратегией динамического дробного f. Асимптотически, стратегия
динамического дробного f позволяет выиграть бесконечно больше, чем ее
статический аналог.
Если вы настроены
торговать долго, лучше размещать активы с помощью метода динамического
дробного f. Для этого определите долю
активного подсчета (остаток будет неактивным счетом). Ежедневные изменения
баланса будут касаться только активной части, неактивная часть меняться не
должна. Каждый день вычитайте неактивный баланс из вашего общего баланса
счета, и именно на основе активной части рассчитывайте
количество для торговли, основываясь на уровнях оптимального f. Если ваша торговля успешна, активная часть со временем
может значительно превысить неактивную часть, и у вас возникнет проблема
высокой дисперсии и большого потенциального проигрыша, как и в случае полного
оптимального f. Ниже мы рассмотрим четыре способа решения этой «проблемы».
Следует отметить, что четких границ, разделяющих эти четыре метода, не
существует, и можно сочетать их в зависимости от ваших потребностей.
Переразмещение:
четыре метода
Сначала скажем несколько слов о безрисковых активах. В
данной главе под безрисковыми активами мы будем понимать или денежные
средства, или близкий к деньгам эквивалент, например казначейские обязательства
Безрисковым активом может быть также любой актив, который, по мнению инвестора,
лишен риска, или риск настолько незначителен, что им можно пренебречь. Это
могут быть долгосрочные правительственные или корпоративные облигации, или,
например, купонные или дисконтные облигации. Во многих торговых
программах в качестве безрискового актива используются бескупонные облигации.
Разность между номинальной стоимостью облигации и ее рыночной ценой — это
прибыль, которую принесет облигация за время работы системы. Если при торговле
вы проиграете все деньги, облигации все равно будут погашены по номинальной стоимости. Тот
же принцип может применять любой трейдер. Не обязательно использовать
бескупонные дисконтные облигации, можно задействовать любой актив, приносящий
доход. Безрисковый актив не должен быть просто «мертвой» наличностью, он
должен быть инвестиционной программой, предназначенной приносить реальную
прибыль, которую можно использовать для возмещения ваших потенциальных
убытков. Как определить соотношение активного и неактивного
подсчетов для первоначального размещения, а затем и для переразмещения? Первым
и, возможно, самым грубым способом является метод
полезности инвестора. Его можно также назвать методом безбоязненного ощущения. Если мы можем позволить себе проигрыш
50%, под активный счет следует отвести 50%. Таким же образом, если мы можем себе
позволить проигрыш 10%, то следует разделить счет на активный (10%) и
неактивный (90%). Одним словом, при использовании метода полезности инвестора
отводите под активный баланс такую часть средств, которой вы готовы рискнуть. Возможно,
в некоторый момент времени трейдер потеряет активную часть счета, необходимую
для дальнейшей торговли, и, чтобы продолжить торговлю, ему необходимо будет
решить, какой процент оставшихся средств на счете (на неактивном подсчете)
отвести под новый активный счет. Этот новый активный счет
может быть также проигран, поэтому важно помнить с самого начала, что
первоначальный активный счет не
определяет максимальную сумму, которую можно потерять. Следует иметь в виду,
что в любой торговле, где есть вероятность неограниченного проигрыша по
позиции (например, фьючерсная торговля), риску подвергается весь счет, более
того, активы трейдера вне счета также подвергаются риску! Читателю не следует
ошибочно полагать, что он или она не встретятся с чередой дней, когда рынок
будет стоять на ценовых лимитах и не будет возможности закрыть убыточную
позицию. При открытии рынка могут происходить резкие скачки цены, которые могут
уничтожить весь счет, независимо от размера его «активной» части.
Если
падение баланса на 25% является максимумом, который трейдер изначально может
себе позволить, следует разделить счет соответствующим образом. Допустим,
трейдер начинает с 100 000-долларового счета, поэтому 25 000 долларов будут
активные и 75 000 долларов неактивные. Теперь допустим, что счет повышается до
200 000 долларов. Трейдер все еще располагает 75 000 долларов на неактивном
подсчете, но теперь активная часть повышается до 125 000 долларов. Если при
счете в 125 000 долларов торговать полным значением f,
возникает опасность проигрыша существенной части счета (или даже всего счета),
если исторический проигрыш произойдет именно в этой точке. Если общее значение
счета опустилось бы до неактивных 75 000 долларов, то проигрыш был бы больше
25%, несмотря на то что доля первоначального баланса, которую вы могли себе
позволить проиграть, составляла 25%. Счет с низким
процентным содержанием активного баланса можно переразмещать чаще, чем счет с
высоким процентным содержанием активного баланса. Поскольку счет с небольшим
процентным содержанием активного баланса изначально имеет более низкий
потенциальный проигрыш, то, переразмещая активы, неудачные соотношения
активного и неактивного балансов (допуская повышение баланса) будут быстрее
исправляться, чем в случае с высоким первоначальным активным балансом. Независимо
от того, используете ли вы простой метод полезности инвестора или один из
более сложных методов, которые вскоре будут описаны, необходимо решить, когда
производить переразмещение. Вы должны заранее определить, в какой точке счета (как
при росте, так и при падении) производить переразмещение. Например, вы можете
сделать это, получив 100%-ую прибыль. Таким же образом вы должны заранее
решить, в какой точке произвести переразмещение при убытках. Обычно в этом
случае либо не остается активного баланса, либо оставшийся активный баланс
настолько мал, что не позволяет вам приобрести даже 1 контракт в любой из
используемых рыночных систем. Необходимо заранее решить, стоит ли продолжать
торговлю по достижении этого нижнего предела, и если да, то какой процент
снова выделить под активный баланс. Также вы можете привязать
переразмещение к определенной дате. Эта техника может быть особенно интересна
для профессионально управляемых счетов. Например, вы можете переразмещать
средства каждый квартал, а если активная часть будет полностью исчерпана, то
вы просто прекратите торговать до окончания квартала. В начале следующего
квартала средства на счете переразмещаются, таким образом, Х% попадает в
активный баланс, а 100 - Х% в неактивный баланс. Нет смысла
слишком часто производить переразмещение. В идеале, вам вообще не следует
производить переразмещение, позволив используемой доле оптимального f приблизиться к единице при росте баланса счета. В
действительности, в некоторый момент времени вы, вероятно, проведете
переразмещение, но не следует делать это слишком часто. Рассмотрим
случай, когда переразмещение проводится после каждой сделки или в конце каждого
дня. Так, например, происходит в случае торговли при статическом дробном f.
Вспомним уравнение (2.09а) для расчета времени, необходимого для достижения
определенной цели.
Давайте
вернемся к нашей уже знакомой системе с активной частью 0,2, со средним
геометрическим 1,01933 и сравним ее с системой со статическим дробным 0,2f, где среднее геометрическое равно 1,005. Если мы начнем со
счета 100 000 долларов и решим произвести переразмещение на уровне 110 000
долларов, то число дней (так как в этом случае средние геометрические
определяются на дневной основе) при статическом дробном 0,2f будет равно:
1n(1,1)/1n( 1,005)= 19,10956
Сравним с использованием 20 000 долларов из общего баланса
100 000 долларов при полном 1для повышения общего счета до 110 000 долларов,
что аналогично увеличению счета 20 000 долларов в 1,5 раза:
1n(1,5)/1n(1,01933)= 21,17807
При низких целях стратегия статического дробного тдает
результаты быстрее, чем стратегия динамического дробного f. С течением времени
динамическая стратегия обгоняет статическую. Рисунок 8-1 показывает соотношение
между статическими и динамическими дробными f. Частое
переразмещение хуже стратегии статического дробного f, но если вы собираетесь
торговать долго, при размещении активов лучше всего использовать подход
динамического дробного f. Следует переразмещать средства между активным и
неактивным подсчетами как можно реже. Оптимально задать соотношение между
подсчетами один раз, в начале торговли. Вообще, динамическое
дробное f даст вам преимущество перед статическим аналогом тем быстрее, чем
ниже доля первоначального активного счета. Другими словами, портфель с
первоначальным активным балансом 0,1 опередит свой статический аналог быстрее,
чем портфель с первоначальным активным балансом 0,2. При первоначальном
активном балансе в 100% (1,0) динамическое f
никогда не обгонит статическое дробное f (они будут расти с
одинаковой скоростью). Скорость, с которой динамическое дробное f опережает
статическое, также зависит от среднего геометрического портфеля: чем выше
среднее геометрическое, тем скорее динамическое f опередит статическое f. При
среднем геометрическом 1,0 динамическое f никогда не обгонит статическое f.
Второй
метод определения первоначального соотношения активного и неактивного счетов и
переразмещения называется методом
планирования сценария. В этом случае первоначальное размещение является
функцией результатов различных сценариев и их вероятностей осуществления.
Расчет можно повторять через определенные интервалы времени. Данная техника
является уже знакомым нам методом планирования сценария, описанным в главе 4.
Рассмотрим
три сценария, которые, как мы полагаем, могут произойти в течение следующего
квартала:
|
Сценарий
|
Вероятность
|
Результат
|
|
Проигрыш
|
50%
|
- 100%
|
|
Нет выигрыша
|
25%
|
0%
|
|
Хороший рост
|
25%
|
+300%
|
Столбец результатов относится к результатам по активному
балансу счета. Таким образом, существует 50% вероятность полной потери
активного счета, 25% вероятность того, что активный баланс останется тем же, и
25% вероятность того, что прибыль по активному счету составит 300%. В реальной
торговле, разумеется, следует использовать не три сценария, а намного больше,
но для наглядности мы ограничимся этим минимумом. Рассмотрим три сценария,
вероятности их осуществления и результаты в процентных пунктах. Результаты
должны отражать ваше мнение относительно исхода каждого сценария при полном
оптимальном f.
В
данном случае оптимально использовать 0,1 If.
He путайте полученное оптимальное f с оптимальными f
компонентов портфеля. Здесь оптимальное f относится к планированию сценария, и,
таким образом, в асимптотическом смысле для активного счета лучше использовать
11%, а для неактивного счета 89%. В начале следующего квартала следует
повторить эту процедуру. Так как переразмещение в данном квартале является
функцией размещения прошлого квартала, то лучше всего использовать
соответствующее значение оптимального f, так как при этом достигается
наибольший геометрический рост (при
условии,
что ваши входные данные — сценарии, их вероятности и соответствующие
результаты — точны). Предложенный метод планирования сценария для размещения
активов эффективен тогда, когда необходимо принять решение, исходя из
прогнозов нескольких консультантов. В нашем примере вместо выбора трех
сценариев вы можете учесть мнения трех консультантов. Столбец вероятностей
выражает ваше доверие к каждому консультанту. Первый сценарий, с вероятностью
50% проигрыша всего активного счета, — это мнение «медвежьего» консультанта, и
такому прогнозу вы считаете нужным придать вес вдвое больший, чем прогнозам
двух других консультантов. Вспомним метод усреднения цены при продаже акций (см. главу 2). Мы можем
использовать этот подход для переразмещения. Таким образом, мы получим метод,
который систематически снимает прибыли и выводит нас из убыточной программы.
В
соответствии с этой программой следует регулярно (каждый месяц, квартал или
любой другой период времени) снимать часть денег с общего счета (активный счет
+ неактивный счет). Помните, что периоды должны быть достаточно долгими, чтобы
получить выигрыш, хотя бы небольшой, от динамического дробного f. Значение N, удовлетворяющее
уравнению (8.01), — это минимальная длина периода, при которой динамическое
дробное f дает нам преимущество:
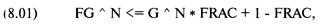
где FG
= среднее геометрическое при дробном f, полученное из уравнения (2.08);
N =
длина периода (G и FG рассчитаны на основе 1 единицы
периода);
G =
среднее геометрическое при оптимальном f;
FRAC
= доля активного счета.
Если мы используем 20-процентный активный счет (т.е. FRAC =
0,2), тогда FG рассчитывается на основе 0,2f.
Таким образом, когда среднее геометрическое при полном оптимальном f составляет
1,01933, а при 0,2fFG = 1,005, мы получим неравенство:
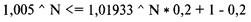
Для оптимального f мы рассчитаем среднее геометрическое G,
а для дробного f— среднее геометрическое FG. Расчеты ведутся на дневной основе.
Теперь посмотрим, является ли один квартал достаточной длиной периода. Так как
в квартале примерно 63 торговых дня, посмотрим, достаточно ли будет N = 63,
чтобы
воспользоваться
преимуществом динамического дробного f. Для этого
проверим, выполняется ли неравенство (8.01) при N = 63:
1,005 ^ 63 <= 1,01933 ^ 63 * 0,2 + 1 - 0,2
1,369184237 <=
3,340663933 * 0,2 + 1 - 0,2
1,369184237 <= 0,6681327866 +1-0,2
1,369184237 <= 1,6681327866 - 0,2
1,369184237 <= 1,4681327866
Неравенство соблюдается, так как левая его часть меньше
правой. Таким образом, если при данных значениях переразмещать активы на
ежеквартальной основе, лучше использовать динамическое дробное f.
Что следует делать, если баланс растет? В начале каждого
периода рассчитывайте общее значение счета и переводите определенное
количество средств с активного на неактивный баланс. Таким образом будет
происходить переразмещение. Рассмотрим 100 000-долларовый счет, где 20 000
долларов — активная сумма, причем усреднение происходит на ежеквартальной
основе, а ежеквартальный процент переводимых средств составляет 2%. Допустим,
в начале квартала счет все еще равен 100 000 долларов, из которых 20 000
долларов составляют активный баланс. Следует перевести 2% общего баланса счета
из активного на неактивный баланс. Таким образом, счет в 100 000 долларов будет
состоять теперь из 18 000 долларов для активного баланса и 82 000 долларов для
неактивного баланса.
Следует стремиться к тому, чтобы торговая программа
опережала периодические снятия со счета. Допустим, в нашем последнем примере
счет, равный 100000 долларов, к концу квартала повышается до 110000 долларов.
Теперь, когда мы перейдем к переразмещению на основе 2%, то снимем 2200
долларов с активного счета ($30 000) и переведем их на неактивный счет ($80
000). Таким образом, мы получим 27 800 долларов на активном счете и 82 200
долларов на неактивном счете. Так как активный баланс после переразмещения
больше, чем в начале предыдущего периода, мы можем сказать, что программа
опережает переразмещение.
С другой стороны, если программа проигрывает деньги, то предложенный
метод со временем переведет весь баланс счета в неактивный баланс, и, в конце
концов, вы автоматически прекратите использовать убыточную программу.
Естественно, возникают два вопроса. Первый: «Какую сумму
следует снимать со счета, чтобы программа автоматически прекратила работу (т.е.
активный баланс стал бы равен нулю), если баланс счета не растет в течение N
снятий с активного счета?» Ответ можно получить из уравнения:
(8.02) Р = 1 - неактивный ^ (1 / N),
где Р = доля общего баланса счета, которая
периодически переводится с активного
на неактивный баланс;
неактивный
= неактивная доля баланса счета;
N = число периодов, через которое
программа прекратит работу, если баланс не будет расти.
Таким
образом, если раз в квартал переводить часть средств с активного на неактивный
баланс (причем первоначальный неактивный баланс составляет 80% от общего) и мы
хотим, чтобы программа прекратила работать через 2,5 года (10 кварталов, т.е. N
= 10), то квартальная доля может быть найдена следующим образом:
Р=
1-0,8^(1/10) =1-0,8 ^0,1 = 1 - 0,9779327685=0,0220672315
Мы
видим, что каждый квартал следует переводить 2,20672315% общего баланса с
активного на неактивный счет.
Второй вопрос звучит так: «Если мы снимаем определенный
процент средств со счета, сколько должно пройти времени, чтобы активный баланс
стал равен О?» Другими словами, если мы снимаем Р% каждый период (в нашем
случае период равен кварталу) и баланс счета не растет, через сколько периодов
N активный баланс обнулится? Ответ можно получить из уравнения:
(8.03) N =
1n(неактивный) / 1n(1 - Р),
где Р = доля
общего баланса счета, которая периодически переводится с активного на
неактивный баланс;
неактивный = неактивная доля баланса счета;
N = число периодов, через которое программа прекратит
работу, если баланс не будет расти.
Допустим,
первоначальный неактивный баланс составляет 80% от общего баланса, и вы
ежеквартально снимаете 2,20672315%. Число периодов (в нашем случае кварталов),
необходимое для прекращения работы программы (при условии, что баланс не
растет), равно:
N = ln(0,8) / ln(l - 0,0220672315)
= ln(0,8) / ln(0,9779327685) =-0,223143/-0,0223143 =10, т.е. программа прекратит работу через 10 периодов.
Усреднение
при продаже акций выведет нас из портфеля по цене выше средней, а усреднение
при покупке позволит нам приобрести портфель по цене ниже средней. Многие же
поступают как раз наоборот: входят на рынок и выходят с рынка по ценам ниже
средних. Как правило, трейдеры после открытия торгового счета сразу переводят
на него все деньги и начинают торговать. Когда трейдер хочет добавить средства,
то почти всегда вносит их одной суммой, а не равными долями в течение
определенного времени.
В большинстве случаев, трейдер, который живет за счет
доходов от торговли, периодически снимает деньги со счета для покрытия
расходов независимо от того, какой процент счета это составляет. Данный подход
неправильный. Предположим, расходы трейдера постоянны каждый месяц и он снимает
со счета определенную сумму, которая составляет больший процент средств, когда
баланс счета понижается, и меньший процент, когда баланс счета повышается,
т.е. трейдер постепенно выходит из портфеля (или его части) по цене ниже
средней.
Разумнее снимать каждый месяц сумму, представляющую собой
постоянный процент общего баланса
счета (активный плюс неактивный). Полученные средства следует размещать на
дополнительном счету до востребования и уже с этого дополнительного счета
каждый месяц снимать фиксированную сумму «на жизнь». Если бы трейдер обошел
предлагаемый дополнительный счет и снимал постоянную сумму непосредственно с
торгового счета, то идеи усреднения работали бы против него.
Из главы 2 мы узнали, что при торговле на уровне
оптимального f время, проведенное в проигрыше, может составить от 35% до
55% рассматриваемого периода. Многие трейдеры к этому не готовы, большинство
из них, естественно, хотели бы видеть более гладкую кривую баланса. Принцип
«35-55%» справедлив как для полного оптимального f, так и для динамического
дробного f, но он не работает в случае статического дробного f.
Создание буферного счета до востребования позволяет
торговать математически оптимальным способом (при динамическом оптимальном f),
кроме того, такой подход позволяет осуществлять переразмещение методом
усреднения, когда деньги переводятся на буферный счет, и регулярно снимать
определенную сумму со счета. Разумеется, сумма, которую мы
периодически будем снимать с буферного счета, должна быть меньше, чем
наименьшая сумма, переведенная с торгового счета на буферный. Например, если
мы используем счет 500 000 долларов и снимаем 1% в месяц, начиная с 20%-ого
активного счета, тогда наименьшее снятие с торгового счета должно быть 0,01 *
500 000 * (1 - 0,2) = 0,01 * 500 000 * 0,8 = 4000 долларов. Таким образом,
сумма, которую мы будем снимать с буферного счета, должна быть меньше 4000
долларов. Отметим, что в качестве буферного счета может использоваться
неактивный счет.
Прежде
чем перейти к четвертому методу размещения активов, скажем еще несколько слов
об особенностях переразмещения. При торговле оптимальной фиксированной долей,
когда баланс увеличивается, увеличивается и количество контрактов, при падении
баланса количество контрактов уменьшается. Такой подход позволяет добиться
максимального геометрического роста.
Зачем
переразмещать?
Переразмещение,
как может показаться, противоречит нашим устремлениям, поскольку оно приводит
к уменьшению баланса после выигрыша и к увеличению баланса активной части после
периода проигрыша по счету. Переразмещение является компромиссом между теорией
и практикой, а рассматриваемые методы позволяют нам использовать этот
компромисс максимально эффективно.
В
идеале вообще не следует проводить переразмещение. Ваш небольшой счет в 10 000
долларов может вырасти до 10 миллионов долларов без переразмещения, и вы вполне
могли бы пересидеть проигрыш, который понизил бы счет 10 миллионов до 50 000
долларов перед новым скачком до 20 миллионов долларов. Если бы активный баланс
уменьшился до 1 доллара, вы все еще смогли бы торговать дробным контрактом
(«микроконтрактом»). В теории все это возможно, но на практике следует
производить переразмещение по достижении некоторой точки вверху или внизу
баланса. При переразмещении вы как бы начинаете торговать заново (но
с другим уровнем баланса). В дальнейшем, благодаря динамическому дробному f, в промежутках между переразмещениями торговля сама будет
«двигать» дробное f.
Страхование
портфеля — четвертый метод переразмещения
Предположим, вы управляете фондом акций. Рисунок 8-2
демонстрирует типичную стратегию страхования портфеля, также известную как динамическое хеджирование. Пусть
текущая стоимость портфеля равна 100 долларам за акцию. Стандартный портфель,
он изображен прямой линией, в точности следует за рынком акций. Застрахованный
портфель изображен пунктирной линией. Отметьте, что
пунктирная
линия проходит ниже прямой линии, когда портфель находится на уровне или выше
своей первоначальной стоимости (100). Величина, на которую пунктирная линия
ниже прямой линии, отражает стоимость страхования портфеля. Когда стоимость
портфеля уменьшается, страхование портфеля ограничивает падение на некотором
уровне (в данном случае 100) за вычетом расходов на осуществление стратегии.
Страхование портфеля соответствует покупке пут-опциона по
портфелю. Допустим, фонд, которым вы управляете, состоит только из 1 акции
стоимостью 100 долларов. Покупка пут-опциона на эту акцию с ценой исполнения
100 долларов при цене опциона 10 долларов соответствует пунктирной линии на
рисунке 8-2. Худшее, что может произойти в данном случае с портфелем (1 акция
и 1 пут-опцион), состоит в том, что по истечении опциона вы продадите акцию за
100 долларов, но потеряете 10 долларов (стоимость этого опциона). Таким
образом, минимальная стоимость портфеля будет 90 долларов, независимо от того,
насколько упадет базовая акция. При росте вы понесете некоторые убытки из-за
того, что стоимость портфеля уменьшится на стоимость опциона.
Если сопоставить рисунок 8-2 с фундаментальным уравнением
торговли и оценочным TWR из уравнения (1.19в), становится
ясно, что в асимптотическом смысле застрахованный портфель лучше
незастрахованного. Другими словами, если вы умны настолько, насколько глупа
ваша худшая ошибка, то, застраховав портфель, вы ограничите последствия такой
ошибки.
Обратите внимание, что длинная позиция по колл-опциону дает
тот же результат, что и длинная позиция по базовому инструменту совместно с
длинной позицией по пут-опциону с той же ценой исполнения и датой истечения,
что и у колл-опциона. Когда мы говорим о том же результате, имеются в виду
эквивалентные соотношения риск/выигрыш разных портфелей. Таким образом,
пунктирная линия на рисунке 8-2 может также представлять длинную позицию по
колл-опциону с ценой исполнения 100.
Посмотрим, как работает динамическое хеджирование при
страховании портфеля. Допустим, вы, как управляющий фондом, приобретаете 100
акций по цене 100 долларов за акцию. Давайте смоделируем колл-опцион по этой акции.
Сначала определим минимальный ценовой уровень рассматриваемой акции. Например,
установим его на 100. Далее определим дату истечения этого гипотетического
опциона. Пусть дата истечения будет последним днем текущего квартала.
Теперь рассчитаем дельту колл-опциона при цене исполнения
100 и выбранной дате истечения. Вы можете использовать уравнение (5.05) для
поиска дельты фондового колл-опциона (можно использовать дельту для любой
модели опционов, мы же будем использовать модель фондовых опционов
Блэка-Шоулса). Допустим, дельта равна 0,5, т. е. в данный актив следует
инвестировать 50% счета. Таким образом, вам следует купить только 50 акций, а
не 100 акций, которые вы
бы
купили, если бы не страховали портфель. Если цена акции будет расти, то же
будет происходить с дельтой и количеством акций. Верхняя граница дельты равна
единице, что соответствует инвестированию 100% средств. Если цена акции будет
понижаться, то же будет происходить с дельтой и размером позиции по акциям.
Нижняя граница дельты равна 0 (при этом дельта пут-опциона равна -1), и в этой
точке следует полностью закрыть позицию по акциям.
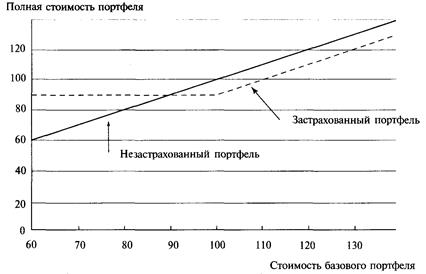
Рисунок 8-2 Страхование портфеля
На практике портфельные менеджеры используют неагрессивные методы динамического
хеджирования, что предполагает отсутствие торговли самими ценными бумагами
портфеля. Стоимость портфеля зависит от текущей дельты и модели и регулируется
с помощью фьючерсов, а иногда пут-опционов. Плюсом использования фьючерсов
является низкая стоимость трансакций. Короткая продажа фьючерсов против
портфеля эквивалентна продаже части портфеля. При падении портфеля продается
больше фьючерсных контрактов, когда же стоимость портфеля растет, эти короткие
позиции закрываются. Потери по портфелю, когда приходится закрывать короткие
фьючерсные позиции при росте цен на акции, являются издержками по страхованию
портфеля и эквивалентны стоимости гипотетических смоделированных опционов.
Преимущество динамического хеджирования состоит в том, что оно позволяет с
самого начала точно рассчитать издержки. Менеджерам, применяющим такую стратегию,
это позволяет сохранить весь портфель ценных бумаг, в то время как размещение
активов регулируется посредством фьючерсов и/или опционов. Предложенный
неагрессивный метод, основанный на использовании фьючерсов и/или опционов,
позволяет разделить размещение активов и активное управление портфелем. При
страховании вы должны постоянно регулировать портфель с учетом текущей дельты,
т. е. с определенной периодичностью, например, каждый день вы должны вводить в
модель ценообразования опционов текущую стоимость портфеля, время до даты
истечения, уровень процентной ставки и волатильность портфеля для определения
дельты моделируемого пут-опциона. Если к дельте, которая может принимать
значения 0 и -1 прибавить единицу, то вы получите соответствующую дельту
колл-опциона, которая будет коэффициентом хеджирования, т.е. долей вашего
счета, которую следует инвестировать в фонд. Допустим,
коэффициент хеджирования в настоящий момент составляет 0,46. Размер фонда,
которым вы управляете, эквивалентен 50 фьючерсным контрактам S&P. Так как вы хотите инвестировать
только 46% средств, вам надо изъять остальные 54%, т.е. 27 контрактов. Поэтому
при текущей стоимости фонда, при данных уровнях процентной ставки и
волатильности фонд должен иметь короткие позиции по 27 контрактам S&P
одновременно с длинной позицией по акциям. Так как необходимо постоянно
перерассчитывать дельту и регулировать портфель, метод называется стратегией динамического хеджирования. Одна
из проблем, связанная с использованием фьючерсов, состоит в том, что рынок
фьючерсов в точности не следует за рынком спот. Кроме того, портфель. против которого
вы продаете фьючерсы, может в точности не следовать за индексом рынка спот,
лежащего в основе рынка фьючерсов. Подобные ошибки могут добавляться к расходам
по страхованию портфеля. Более того, когда ваш моделируемый опцион подходит
очень близко к дате истечения, а стоимость портфеля приближается к цене
исполнения, гамма моделируемого опциона астрономически возрастает. Гамма — это
мгновенная скорость изменения дельты, т.е. коэффициента хеджирования. Другими
словами, гамма является дельтой дельты. Если дельта изменяется очень быстро (т.
е. моделируемый опцион имеет высокую гамму), страхование портфеля становится
крайне обременительным. Существует множество путей обхода этой проблемы, и
некоторые из них довольно сложны. Один из самых простых способов заключается в
том, чтобы совместно использовать фьючерсы и опционы для изменения как дельты,
так и гаммы моделируемого опциона. Большое значение гаммы, как правило, создает
проблемы только тогда, когда подходит дата истечения, а стоимость портфеля и цена
исполнения моделируемого опциона сближаются. Существует
интересная связь между оптимальным f и страхованием портфеля.
Можно сказать, что при открытии позиции вы инвестируете f процентов средств.
Рассмотрим азартную игру, где оптимальное f=0,5,
наибольший проигрыш равен -1 и вы располагаете 10 000 долларов. В таком случае
следует ставить 1 доллар на каждые 2 доллара на счете, так как, разделив -1
(наибольший
проигрыш) на -0,5 (отрицательное оптимальное f),
мы получим 2. Разделив 10000 долларов на 2, мы получим 5000 долларов, поэтому
следует ставить 5000 долларов, что соответствует доле f, т.е. 50% ваших денежных
средств. Если умножить 10 000 долларов на f=
0,5, мы получим тот же результат, 5000 долларов, т.е. вам следует задействовать
f процентов имеющихся денежных средств. Аналогично, если ваш
наибольший проигрыш равен 250 долларам, а все остальное остается без
изменений, то следует ставить 1 доллар на каждые 500 долларов вашего счета (так
как -$250 / -0,5 = $500). Разделив 10 000 долларов на 500 долларов, мы найдем,
что ставка равна 20 долларам. Так как максимальный проигрыш по одной ставке
составляет 250 долларов, вы, таким образом, рискуете долей счета f, т.е. 50%,
или 5000 долларов ($250 * 20). Мы можем сказать, что f равно доле вашего
счета, которая подвержена риску, или f равно коэффициенту хеджирования. Так
как f применимо только к активной части портфеля, при стратегии динамического
дробного f коэффициент хеджирования портфеля равен:
(8.04а) H=f*A/E,
где Н =
коэффициент хеджирования портфеля;
f= оптимальное Г(от 0 до 1);
А = активная часть средств счета;
Е = общий баланс счета.
Уравнение (8.04а) дает нам коэффициент хеджирования для
портфеля при стратегии динамического дробного f. Страхование портфеля также
работает при статическом дробном f, только коэффициент А/Е становится равным
единице, а оптимальное f умножается на соответствующий коэффициент. Таким
образом, при стратегии статического дробного f коэффициент хеджирования равен:
(8.046) H=f*FRAC,
где Н = коэффициент
хеджирования портфеля;
f = оптимальное f (от 0 до 1);
FRAC = используемая доля оптимального f.
Как
правило, счет используется для работы в нескольких рыночных системах. В этом
случае переменная f в уравнении (8.04а) или (8.046)
должна рассчитываться следующим образом:
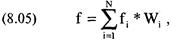
где f = f (от 0 до
1), используемое в уравнении (8.04а) или (8.046);
N = общее число рыночных систем в портфеле;
W. = вес компонента i
в портфеле (из единичной матрицы);
f i = фактор f (от 0 до 1) компонента i в
портфеле.
Можно сказать, что при торговле на основе динамического
дробного f мы проводим страхование портфеля. При этом минимально допустимый
уровень стоимости портфеля равен: первоначальный неактивный баланс плюс стоимость проведения страхования.
Далее для простоты будем считать, что нижняя граница счета равна
первоначальному неактивному балансу.
Обратите внимание, что уравнения (8.04а) и (8.046)
позволяют получить дельту моделируемого колл-опциона. Разделение счета на
неактивный и активный подсчета (для использования стратегии динамического
дробного f) эквивалентно покупке пут-опциона, цена исполнения которого больше
текущей стоимости базового актива, а дата истечения наступает не скоро. Мы
можем также сказать, что торговля с использованием стратегии динамического дробного
f аналогична покупке колл-опциона, цена исполнения которого меньше текущей
стоимости базового актива. Данное свойство страхования портфеля справедливо для
любой стратегии динамического дробного f, независимо от того, используем мы
усреднение по акциям, планирование сценария или полезность инвестора.
Можно использовать страхование портфеля в качестве метода
переразмещения. Сначала следует определить значение минимального ценового
уровня, затем для выбранной модели опциона вы должны определить дату
истечения, уровень волатильности и другие входные параметры, которые позволят
рассчитать дельту. После того как будет найдена дельта, вы можете определить
величину активного баланса. Так как дельта для счета (переменная Н в уравнении
(8.04а)) равна дельте моделируемого колл-опциона, мы можем заменить Н в
уравнении (8.04а) на D:
D=f*A/E
или
(8.06) D / f=
А / Е, если D < f (в противном случае А / Е = 1),
где D =
коэффициент хеджирования моделируемого опциона;
f = f (от 0 до 1) из уравнения (8.05);
А = активная часть средств счета;
Е = общий баланс счета.
Так как
отношение А/Е равно доле активного счета, можно сказать, что отношение
активного баланса к общему балансу равно отношению дельты колл-опциона к f из уравнения (8.05). Заметьте, если D > f, тогда предполагается,
что вы размещаете больше 100% баланса счета в активный баланс. Так как это
невозможно, для активного баланса существует верхняя граница — 100%. Вы можете
использовать уравнение (5.05) для поиска дельты колл-опциона на акции или
уравнение (5.08) для поиска дельты колл-опциона на фьючерсы.
Проблема использования страхования портфеля в качестве
метода переразмещения состоит в том, что переразмещение уменьшает
эффективность стратегии динамического дробного f, которая асимптотически
способна дать большую прибыль, чем стратегия статического дробного f. Таким
образом, страхование портфеля как стратегия переразмещения на основе
динамического дробного f является не самым лучшим подходом
Теперь рассмотрим реальный пример страхования портфеля.
Вспомним геометрический оптимальный портфель Toxico, Incubeast и LA Garb, который достигается при V= 0,2457. Преобразуем дисперсию портфеля в значение
волатильности для модели ценообразования опционов. Волатильность задается
годовым стандартным отклонением. Уравнение (8.07) показывает зависимость между
дисперсией портфеля и оценочной волатильностью для опциона по портфелю:
(8.07) OV=V'0.5)*ACTV*YEARDAYS^0.5,
где OV
= волатильность для опциона по портфелю;
V =
дисперсия портфеля;
ACTV
= текущая активная часть баланса счета;
YEARDAYS = число рыночных дней в году.
Если мы
исходим из того, что в году 251 рыночный день и доля активного баланса равна
100% (1,00), то:
OV= (0,2457 ^ 0,5) * 1 * 251 ^ 0,5 = 0,4956813493
* 15,84297952 = 7,853069464
Полученное значение соответствует волатильности свыше 785%!
Поскольку речь идет о торговле на уровне оптимального f при 100% активном
балансе, значение волатильности настолько велико. Так как мы собираемся
использовать страхование портфеля в качестве метода переразмещения, то ACTV= 1,00.
Уравнение
(5.05) позволяет рассчитать дельту колл-опциона:
(5.05) Дельта колл-опциона = N(H) Значение Н для (5.05) найдем из
уравнения (5.03):
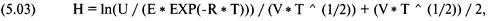
где U = цена базового инструмента;
Е = цена исполнения опциона;
Т = доля года, оставшаяся до истечения срока исполнения,
выраженная десятичной дробью;
V = годовая волатильность в процентах;
R = безрисковая ставка;
1n() = функция натурального логарифма;
N() = кумулятивная нормальная функция распределения
вероятностей, задаваемая уравнением (3.21).
Отметьте,
что мы используем модель ценообразования фондовых опционов. Для волатильности
будем использовать значение OV. Если безрисковая
ставка R = 6% и доля года, оставшаяся до истечения срока, Т = 0,25, то из
(5.03) получим:

Полученное
значение подставим в уравнение (5.05). Теперь для расчета дельты колл-опциона
решим уравнение (3.21):


Подставим значения Y
и N'(1,967087528) в уравнение (3.21) для получения дельты
колл-опциона, в соответствии с уравнением (5.05):


Таким образом, когда цена портфеля равна 100, цена
исполнения 100, доля года, оставшаяся до истечения срока исполнения, составляет
0,25, безрисковая ставка равна 6%, а волатильность портфеля 785,3069464%,
дельта нашего гипотетического колл-опциона равна 0,9754135259. Сумма
весов геометрического оптимального портфеля, состоящего из Toxico, Incubeast и LA Garb, найденная из уравнения (8.05),
составляет 1,9185357. Таким образом, принимая во внимание уравнение (8.06), при
страховании портфеля мы можем переразмещать до 50,84156244% (0,9754135359/
/1,9185357). Во сколько обходится страхование? Все зависит от
волатильности в течение срока действия смоделированного опциона. Например, если
за время действия смоделированного опциона баланс на счете не колеблется
(волатильность равна 0), цена смоделированного опциона, т.е. стоимость
страхования, равна нулю. В этом заключается большое преимущество страхования
портфеля по сравнению с реальной покупкой пут-опциона (если этот пут-опцион по
портфелю существует). Мы платим теоретическую цену опциона, исходя из той
волатильности, которой реально подвержен портфель, а не той, которая
существовала на рынке до открытия позиции, как бывает при покупке пут-опциона.
Кроме того, реальная покупка пут-опциона (опять же, если пут-опцион по нашему
портфелю существует) влечет за собой расходы, связанные со спредом
покупки/продажи. При моделировании опциона таких расходов не возникает.
Необходимые
залоговые средства
Мы видели, что при добавлении рыночной системы портфель
улучшается, если коэффициент линейной корреляции изменений дневного баланса
между этой рыночной системой и другой рыночной системой в портфеле меньше +1,
поскольку в этом случае повышается среднее геометрическое дневных HPR. Таким образом, логично использовать как можно больше
рыночных систем. Естественно, на каком-то этапе может возникнуть проблема с
залоговыми средствами.
Проблема, связанная с нехваткой залоговых
средств, может возникнуть даже в том случае, если вы используете только одну
рыночную систему. Как правило, оптимальное долларовое f
меньше первоначальных залоговых требований для данного рынка. Если же доля f
очень высока (неважно, используете вы стратегию статического или динамического
дробного f), вы можете столкнуться с требованием довнесения залога (margin call), в противном
случае позиция будет принудительно закрыта. Если вы используете
портфель рыночных систем, требование дополнительного внесения залога
становится еще более вероятным. В неограниченном портфеле сумма весов часто
значительно больше 1. Когда вы используете только одну рыночную систему, вес
де-факто равен единице. Если сумма весов рыночных систем равна, например, трем,
тогда вероятность требования внесения залога в три раза выше, чем в случае
торговли только на одном рынке. Оптимальный портфель следует создавать
с учетом минимально необходимых залоговых средств для компонентов портфеля. Это
достаточно легко сделать: надо определить, какую долю f вы можете использовать в качестве верхней границы U; ее можно найти с помощью уравнения (8.08):
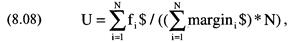
где U = верхняя
граница дробного f, при которой можно торговать оптимальным портфелем без
риска получения требования довнесения залога;
f$= оптимальное долларовое f для рыночной системы i;
margin $ = первоначальный залог для рыночной системы i;
N = общее число рыночных систем в портфеле.
Если U
больше единицы, то приравняйте U к единице. Например, у нас есть портфель из
трех рыночных систем со следующими оптимальными долларовыми f и первоначальными
минимальными залоговыми требованиями (примечание:
f$ являются оптимальными долларовыми f для каждой рыночной
системы портфеля, они представляют собой оптимальные f рыночных систем,
деленные на соответствующие веса в портфеле):
|
Рыночная
система
|
f$
|
Первоначальный
залог
|
|
А
|
$2500
|
$2000
|
|
В
|
$2000
|
$2000
|
|
С
|
$3000
|
$2000
|
|
Суммы
|
$7500
|
$6000
|
В
соответствии с уравнением (8.08) мы возьмем сумму всех f$
(7500 долларов) и разделим ее на сумму первоначальных залоговых требований
(6000 долларов), умноженную на число рынков N:
U = $7500 / ($6000 * 3) =7500/18000 =0,4167
Таким
образом, доля f не должна превышать 41,67% (если мы применяем стратегию
динамического дробного f), т. е. следует производить
переразмещение, когда отношение активного баланса к общему балансу больше или
равно 0,4167.
Если вы
все-таки применяете стратегию статического дробного f (несмотря на все ее
недостатки), тогда максимальное значение используемой доли должно быть равно
0,4167. Такой подход сместит вас по геометрической эффективной границе
портфелей с неограниченной суммой весов влево от оптимального портфеля, но вы
будете настолько близко к нему, насколько только возможно, чтобы не столкнуться
при этом с требованием довнесения залога. Для примера
рассмотрим счет в 100 000 долларов. Если доля f равна 0,4167, то для каждой
рыночной системы получим:
|
Рыночная
система
|
f$
|
/0,4167=
|
Новое И
|
|
А
|
$2500
|
|
$6000
|
|
В
|
$2000
|
|
$4800
|
|
С
|
$3000
|
|
$7200
|
При счете в 100 000 долларов мы будем торговать 16
контрактами рыночной системы А (100 000/6000), 20 контрактами рыночной системы
В (100 000/4800) и 13 контрактами рыночной системы С (100 000/7200). Итоговое
требование к залогу для такого портфеля равно:
16 *
$2000 = $32 000 20 * 2000 = 40 000 13 * 2000 = 26 000
Первоначальное
требование залога $98 000
Отметьте,
что с помощью формулы (8.08) вы получите максимально допустимую долю f (без риска сразу же столкнуться с требованием довнесения
залога), при этом отношения рыночных систем друг к другу останутся без
изменений. Следовательно, уравнение (8.08) задает разбавленный неограниченный
оптимальный портфель, в котором отсутствует риск получения требования довнесения
залога. Заметьте, если торговать на основе стратегии дробного f,
значение, полученное из уравнения (8.08), является максимальной долей f,
которую вы можете использовать (без риска сразу же столкнуться с требованием
довнесения залога). Вернемся к нашему счету в 100 000 долларов. Предположим,
когда вы открыли счет, на нем было 70 000 долларов. Далее, из этих
первоначальных 70 000 долларов вы отвели 58 330 долларов под неактивный счет.
Таким образом, вы начали торговлю с отношения между неактивным и активным
балансом приблизительно 83 к 17 и далее торговали активной частью при полных
значениях оптимального f. Теперь, когда счет равен 100 000 долларов, а неактивный
баланс — 58 330 долларам, активный счет составляет 41 670 долларов, т.е. 0,4167
от общего баланса. Полученное значение задает максимальную долю, которую вы
можете использовать (максимальное отношение активного баланса к общему
балансу), без риска столкнуться с требованием довнесения залога. Вспомните, что
вы торгуете полным f, т.е. 16 контрактами рыночной системы А (41 670/2500), 20
контрактами рыночной системы В (41 670/2000) и 13 контрактами рыночной системы
С (41 670/3000). Итоговое требование залога для такого портфеля составляет:
16 *
$2000 = $32 000 20 * 2000 = 40 000 13 * 2000 = 26000 Первоначальное требование
залога $98 000
Как мы
уже знаем (см. главу 2), добавление рыночных систем увеличивает среднее
геометрическое по портфелю в целом. Однако возникает проблема:
каждая
следующая рыночная система вносит все меньший и меньший вклад в среднее
геометрическое и все больше ухудшает его, понижая эффективность из-за
одновременных, а не последовательных результатов. Поэтому не следует торговать
слишком большим числом рыночных систем. Более того, реальное применение теоретически
оптимальных портфелей осложняется из-за залоговых требований. Другими словами,
вам лучше торговать 3 рыночными системами при полном оптимальном f, чем 300
рыночными системами при значительно пониженных уровнях, согласно уравнению (8.08).
Скорее всего вы придете к выводу, что оптимальное число рыночных систем для
торговли должно быть невелико. Особенно это обстоятельство важно, когда у вас
много ордеров к исполнению и увеличивается вероятность ошибок. Если
одна или несколько рыночных систем в портфеле имеют оптимальные веса больше
единицы, может возникнуть еще одна проблема. Рассмотрим рыночную систему с
оптимальным f=0,8 и наибольшим проигрышем, составляющим 4000 долларов.
Для этой рыночной системы f$ = 5000 долларов.
Давайте предположим, что оптимальный вес данного компонента в портфеле равен
1,25, поэтому вы будете торговать одной единицей компонента на каждые 4000
долларов ($5000/1,25) баланса счета. Как только компонент столкнется с
наибольшим проигрышем, весь активный баланс на счете будет обнулен, если
прибылей в других рыночных системах не хватит для сохранения активного баланса. Рассмотренная
проблема наиболее актуальна для систем, которые редко генерируют сделки. Если
бы у нас были две рыночные системы с отрицательной корреляцией и положительным
ожиданием, необходимо было бы открывать бесконечное количество контрактов на
рынке. Когда один из компонентов проигрывает, другой выигрывает равную или
большую сумму. Таким образом, мы получаем прибыль в каждой игре, однако только
в том случае, когда рыночные системы ведут игру одновременно. Рассматриваемая
же торговля аналогична гипотетической ситуации, когда один из компонентов в
игре не активен, но используется другая рыночная система с бесконечным числом
контрактов. Проигрыш может быть катастрофическим. Проблему можно
решить следующим образом: разделите единицу на наибольший вес компонента
портфеля и используйте полученное значение в качестве верхней границы
активного баланса, если оно меньше, чем значение, найденное из уравнения (8.08).
В таком случае, если в будущем произойдет проигрыш той же величины, что и
наибольший проигрыш (на основе которого рассчитано f),
мы не потеряем все деньги. Например, наибольший вес компонента в нашем
портфеле составляет 1,25. Если значение из уравнения (8.08) будет больше 1 /
1,25 = 0,8, следует использовать 0,8 в качестве верхней границы для доли
активного баланса. Если первоначальная доля активного баланса небольшая,
вышеописанная проблема может и не возникнуть, однако более агрессивному трейдеру
следует всегда принимать ее во внимание. Альтернативное решение состоит в
введении дополнительных ограничений в матрице портфеля (например, для каждой рыночной
системы можно ограничить максимальные веса единицей и ввести дополнительные
ограничения по залоговым средствам). Подобные дополнительные ограничения
линейного программирования могут помочь агрессивному трейдеру. но решить такую
матрицу будет достаточно сложно. Для заинтересованных читателей делаю ссылку
на Чилдресса.
Ротация рынков
Профессиональные трейдеры, как правило, отслеживают большое
количество рынков, выбирая те, которые, по их мнению, являются в настоящий
момент наиболее подходящими для данных систем. Например, некоторые трейдеры
отслеживают волатильность по всем фьючерсным рынкам и торгуют только на тех,
где волатильность превышает некоторое значение. Иногда имеет смысл торговать на
нескольких рынках, иногда вообще прекратить торговлю. Рынки постоянно изменяются,
что создает дополнительные проблемы для портфельных менеджеров. Каким образом
можно реагировать на эти изменения, сохраняя ваш портфель оптимальным? Ответ,
на самом деле, довольно прост: каждый раз, когда рынок добавляется в портфель
или удаляется из него, необходимо рассчитывать новый неограниченный
геометрический оптимальный портфель (алгоритм расчета показан в этой главе).
Также необходимо принимать во внимание любые изменения размеров существующих
позиций и учитывать новые добавленные или удаленные рыночные системы. Таким
образом, следует использовать портфель, в котором компоненты постоянно
меняются. Целью портфельного менеджера в этом случае будет создание
неограниченного геометрического оптимального портфеля и поддержка постоянной
величины неактивного баланса. Именно такой подход будет оптимальным в
асимптотическом смысле.
Если вы используете подобную технику, может
возникнуть еще одна проблема. Возьмем два высоко коррелированных рынка,
например золото и серебро. Теперь представьте, что ваша система торгует так
редко, что сделок на двух рынках в один и тот же день не происходит. Когда вы
будете определять коэффициенты корреляции дневных изменений баланса, может
оказаться, что коэффициент корреляции между золотом и серебром близок к нулю.
Однако если в будущем вы будете торговать на обоих рынках одновременно, они, скорее
всего, будут иметь высокую положительную корреляцию. Для
решения вышеописанной проблемы следует корректировать коэффициенты корреляции,
причем их следует изменять в большую, а не меньшую сторону Допустим, вы
получили коэффициент корреляции между облигациями и соевыми бобами, равный
нулю, но чувствуете, что он должен быть ниже (например - 0,25). Не следует
уменьшать коэффициенты корреляции, так как более низкие значения приводят к
увеличению размера позиции. Одним словом, если уж ошибаться в коэффициентах
корреляции, то в большую сторону Ошибка, связанная с увеличением коэффициентов
корреляции, сместит портфель влево от пика кривой f,
в то время как уменьшение сместит его вправо. Некоторые трейдеры в
своих рыночных системах используют фильтры, благодаря которым в определенный
момент сделки совершаются только на одном рынке. Если фильтр работает и
понижает проигрыш на основе одной единицы, тогда f
(оптимальное для отфильтрованных сделок) для всей серии сделок до фильтрования
будет выше (a f$ ниже). Если
трейдер использует оптимальное f, полученное по неотфильтрованным сделкам, для
отфильтрованных сделок, он окажется на уровне дробного f по отфильтрованным
сериям и, следовательно, не сможет получить геометрический оптимальный
портфель. С другой стороны, если трейдер применяет оптимальное f по
отфильтрованным сериям, он может получить геометрический оптимальный портфель,
но столкнуться с проблемой больших проигрышей при оптимальном f.
С точки зрения управления капиталом фильтры не всегда
эффективны. Фильтры работают (уменьшают
проигрыш на основе одной единицы) только потому, что они позволяют трейдеру
находиться на уровне дробного оптимального f.
Можно утверждать, что фильтры дают преимущество, если ответ
из фундаментального уравнения торговли по отфильтрованным сделкам с использованием
оптимального f, полученного по всем сделкам, больше значения, полученного по
всем сделкам с использованием того же оптимального f; при этом следует иметь в
виду, что отфильтрованных сделок меньше (N
меньше), чем неотфильтрованных.
Резюме
Торговля фиксированной долей счета дает наибольшую отдачу в
асимптотическом смысле, т.е. максимизирует отношение потенциальной прибыли к
потенциальному убытку Когда известно значение оптимального f, можно
преобразовать дневные изменения баланса на основе одной единицы в HPR, определить арифметическое среднее HPR и стандартное
отклонение полученных HPR, а также рассчитать коэффициенты корреляции HPR между
любыми двумя рыночными системами. Далее мы должны использовать эти параметры для
определения оптимальных весов оптимального портфеля (когда используется рычаг
(leverage), вес и количество не одно и то же). Затем значения f
следует разделить на соответствующие веса. В результате, мы получаем новые
значения f, которые позволяют добиться наибольшего геометрического роста,
принимая во внимание веса и взаимные корреляции рыночных систем. Наибольший
геометрический рост достигается при использовании весов, сумма которых не
ограничена, причем разность среднего арифметического HPR и стандартного
отклонения HPR, возведенного в квадрат, должна быть равна единице [Уравнение
(7.06в)]. Вместо «разбавления» (которое сдвигает нас влево на неограниченной
эффективной границе), как в случае стратегии статического дробного f, можно
использовать портфель при полном f, задей-ствуя только часть средств счета.
Такой метод называется стратегией динамического
дробного f. Оставшаяся часть средств (неактивный баланс) в торговле не
используется. Так как торговля активной частью происходит на оптимальных
уровнях f, активный баланс может довольно сильно колебаться. В
результате, при некотором значении баланса или в некоторый момент времени, вы,
вероятно, захотите (возможно, просто под воздействием эмоций) переразместить
средства между активной и неактивной частями. Мы рассмотрели четыре метода
переразмещения, хотя, конечно же, могут использоваться и другие методы,
возможно, более подходящие для вас:
1. Полезность инвестора.
2. Планирование сценариев.
3. Усреднение.
4. Страхование портфеля.
Четвертый метод, страхование портфеля, или динамическое
хеджирование, присущ любой стратегии динамического дробного f, но его можно
также использовать и как метод переразмещения.
При торговле неограниченным геометрическим оптимальным
портфелем можно столкнуться с требованием довнесения залога. Подобную проблему
можно решить, задав верхний предел отношения используемого активного баланса к
общему балансу счета.
Несколько
слов о торговле акциями
Методы, описанные в этой книге, могут использоваться не
только фьючерсными трейдерами, но и трейдерами, работающими на любом рынке. Даже тем, кто торгует
голубыми фишками, принципы, рассмотренные в этой книге, будут весьма полезны.
Мы знаем, что для портфеля голубых фишек существует оптимальный рычаг, когда
отношение потенциальных выигрышей к потенциальным проигрышам максимально,
правда, при этом падения баланса могут быть довольно значительными, поэтому
портфель необходимо разбавлять, используя стратегию динамического дробного f. Для
того чтобы использовать методы, описанные в этой книге, в торговле акциями, мы
будем считать, что акция является фьючерсной рыночной системой. Предположим,
текущая цена Toxico равна 40 долларам. Следовательно, стоимость 100 акций Toxico составляет 4000 долларов. Лот из 100 акций можно считать
1 контрактом рыночной системы Toxico. Таким
образом, если работать с наличным счетом, то в уравнении (8.08) следует
заменить переменную залогi $ на цену 100 акций Toxico (в нашем случае 4000 долларов). Далее, мы можем определить
верхнюю границу доли f. Помните, что мы моделируем ситуацию с рычагом, но на
самом деле не занимаем и не ссужаем денежные средства, поэтому в любых
формулах, где есть RFR (например, отношение Шарпа),
следует использовать RFR = 0. Если в случае с Toxico используется маржевой счет и первоначальный залог
составляет 50%, то в уравнении (8.08) залог$ = $2000. Традиционно
управляющие фондами акций использовали портфели, в которых сумма весов
ограничена единицей. Состав портфеля выбирался таким образом, чтобы при данном
уровне арифметической прибыли дисперсия была минимальной. Получившийся в
результате портфель задавался весами или долями торгового счета для каждого
компонента портфеля.
Сняв
ограничение по сумме весов и выбрав геометрически оптимальный портфель, мы
получим оптимальный портфель с рычагом. Здесь веса и количества отличаются.
Разделим оптимальное количество для финансирования одной единицы каждого
компонента на его соответствующий вес и получим оптимальный рычаг для каждого
компонента портфеля. Теперь разбавим портфель, включив в него безрисковый
актив. Можно разбавить портфель до точки, где рычаг как бы исчезает, т.е. рычаг
применяется к активной части портфеля, но активный баланс портфеля в
действительности использует беспроцентные деньги из неактивной части баланса. Таким
образом мы получим портфель, в котором регулируются позиции при изменении
баланса счета, что позволяет получить наибольший геометрический рост.
Предложенный метод максимизирует отношение потенциального геометрического роста
к потенциальному проигрышу и допускает заранее известный максимальный
проигрыш. Для управления портфелем ценных бумаг описанный метод является
наилучшим. Наиболее распространенный в настоящее время метод выведения
эффективной границы в действительности не позволяет получить эффективную
границу и, тем более, геометрический оптимальный портфель (геометрический
оптимальный портфель всегда находится на эффективной границе), который можно
найти только с помощью оптимального f. Кроме того,
традиционный метод позволяет получить портфель на основе статического f, а не
динамического f, которое в асимптотическом смысле предпочтительнее.
Заключительный
комментарий
В настоящее время исследования, подобные изложенным в этой
книге, представляют большой интерес. С середины 1950-х годов постоянно
появляются новые концепции. Много замечательных идей, основанных на модели Е —
V, пришло к нам из академического сообщества. Среди предложенных концепций
есть, например, модель Е — S, где риск
измеряется не дисперсией, а полудисперсией. Полудисперсия — это дисперсия
некоторого уровня прибыли, который может
быть
ожидаемой прибылью, нулевой прибылью или любым другим фиксированным уровнем
прибыли. Когда заданный уровень прибьши равен ожидаемой прибыли и
распределение прибылей симметрично (без асимметрии), эффективная граница Е — S совпадает с эффективной границей Е — V.
Существуют модели портфелей, использующие вместо дисперсии
прибылей другие способы выражения риска, а также более высокие моменты
распределения прибылей. Большой интерес в этом отношении представляют методы стохастического доминирования, которые
учитывают все распределения прибылей и могут считаться предельным случаем
многомерного анализа портфеля, когда число используемых моментов стремится к
бесконечности. Подобный подход может быть особенно полезен в том случае, когда
дисперсия прибылей бесконечна или не определена.
И снова повторюсь — я не академик — это ни хвастовство, ни
извинение, я такой же академик, как чревовещатель или телевизионный
проповедник. Академикам необходима модель для объяснения того, как работают
рынки, мне же не так важно, как они работают. Многие представители
академического сообщества утверждают, что гипотеза об эффективной границе
неверна, так как не существует понятия «рациональный инвестор». Сторонники
такого подхода утверждают, что люди не ведут себя рационально, поэтому
традиционные модели портфелей, такие как теория Е — V (и ее варианты) и модель
оценки доходности финансовых активов, являются неудовлетворительными моделями
работы рынков. Я согласен, что инвесторы не всегда ведут себя рационально, но
это не означает, что нам следует вести себя подобным образом. Нельзя
утверждать, что мы не можем получить выгоду из рационального поведения. Когда
дисперсия прибылей конечна, мы можем получить преимущество, находясь на
эффективной границе.
В последнее время традиционные модели портфелей
подвергаются серьезной критике, поскольку считается, что ценовые изменения
лучше всего описываются распределением Парето с бесконечной (или
неопределенной) дисперсией. Однако многие исследования доказывают, что рынки в
последние годы стали ближе к нормальному распределению (т.е. к ограниченной
дисперсии и независимости результатов), на чем и основаны критикуемые модели
портфелей. В моделях портфелей используется распределение прибылей, а не
распределение изменений цен. Несмотря на то что распределение прибылей является
трансформированным распределением
изменений цены (в результате закрытия проигрышных сделок и максимально долгого
удержания выигрышных позиций), эти распределения, как правило, отличаются.
Распределение прибылей не обязательно относится к классу распределений Парето,
поэтому в главе 4 мы моделировали распределение P&L с помощью регулируемого распределения. Более того,
существуют производные инструменты, например, опционы, которые имеют
ограниченную полудисперсию или дисперсию. Например вертикальный опционный спред
в дебете гарантирует ограниченную дисперсию прибылей. Я не пытаюсь оспаривать
разумную критику современных моделей портфелей. Модели следует использовать
при условии, что мы осознаем их недостатки. Разумеется, необходимы более
совершенные модели портфелей. Я не заявляю, что современные модели адекватны, а
говорю лишь о том, что входные данные для моделей портфелей, нынешних или
будущих, должны основываться на торговле одной единицей на оптимальном уровне
— или на том уровне, который, как мы полагаем, будет оптимальным. Например,
если мы применяем теорию Е — V (модель Марковица), входными данными являются
ожидаемая прибыль, дисперсия прибылей и корреляции прибылей между рыночными
системами. Входные данные должны определяться на основе торговли одной единицей
по каждой рыночной системе на уровне оптимального f.
Модели портфелей, отличные от Е — V, могут потребовать других входных
параметров, но и их для каждой рыночной системы все равно следует рассчитывать
на основе торговли одной единицей на уровне оптимального f. Модели портфелей
являются лишь одной составляющей управления капиталом, и эта книга не может
ответить на все вопросы. Кроме того, постоянно появляются новые,
усовершенствованные модели. Скорее всего, мы никогда не получим абсолютно
совершенной модели, но это только будет стимулировать дальнейшие поиски.
1
Это
правило применимо к торговле только в одной рыночной системе. Когда вы
начинаете торговать более чем в одной рыночной системе, то вступаете в иную
среду. Например, можно включить рыночную систему с отрицательным математическим
ожиданием для одного из рынков и в действительности получить более высокое
математическое ожидание, чем просто математическое ожидание группы до
включения системы с отрицательным ожиданием! Более того, возможно, что
математическое ожидание для группы с включением рыночной системы с
отрицательным математическим ожиданием будет выше, чем математическое ожидание
любой отдельной рыночной системы! В настоящее время мы рассматриваем только
одну рыночную систему, и для того, чтобы методы управления деньгами работали,
необходимо иметь положительное математическое ожидание.
1 Для процесса зависимых испытаний,
как и для процесса независимых испытаний, ставка части вашего общего счета
также максимально использует положительное математическое ожидание. Однако при
зависимых испытаниях ставки будут меняться; точная доля каждой отдельной ставки
будет определяться вероятностями и выигрышами по каждой отдельной ставке.
1 Многие
ошибочно используют среднее арифметическое HPR в уравнении HPR ^ N. Как здесь
показано, это не даст истинное TWR после N игр. Вы должны использовать
геометрическое, а не арифметическое среднее HPR ^ N. Это даст истинное TWR. Если стандартное отклонение HPR
равно 0, тогда арифметическое среднее HPR и геометрическое среднее HPR
эквивалентны, и не имеет значения, какое из них вы используете.
1 Здесь есть еще один плюс,
который сразу может быть и не виден. Он состоит в том, что мы заранее знаем
проигрыш худшего случая. Учитывая, насколько чувствительно уравнение
оптимального f к наибольшему проигрышу, такая стратегия может приблизить нас к
пику кривой f и показать, каким может быть наибольший проигрыш. Во-вторых,
проблема проигрыша в 3 стандартных отклонениях (или больше) с более высокой
вероятностью, чем подразумевает нормальное распределение, будет устранена.
Именно гигантские проигрыши более 3 стандартных отклонений разоряют большинство
трейдеров. Опционные стратегии могут полностью упразднить такие проигрыши.
1 Именно в этом
случае использование опционов в торговой стратегии столь полезно. Покупка пут
или колл-опциона в обратном направлении от позиции по базовому инструменту для
ограничения проигрыша либо торговля опционами вместо базового инструмента дадут
вам заранее известный максимальный проигрыш, что очень пригодится в управлении
деньгами, особенно при оптимальном f. Более того, если
вы знаете заранее, каким будет ваш максимальный проигрыш (например, при дневной
торговле), тогда вы всегда сможете точно определить величину f в долларах для каждой сделки как следующую дробь: риск в долларах на
единицу/оптимальное f. Например, дневной трейдер
знает, что его оптимальное f =0,4. Его стоп (stop-loss)
сегодня на основе 1 единицы равен 900 долларам. Поэтому оптимально торговать 1
единицей на каждые 2250 долларов ($900 / 0,4)
на балансе счета.
1 Разумный подход требует, чтобы
мы использовали наибольший проигрыш, по крайней мере, такой же величины, как и
в прошлом. С течением времени мы получаем все большее количество данных и
большие периоды проигрышей. Например, если бросить монету 100 раз, она может
12 раз подряд выпасть на обратную сторону. Если бросить ее 1000 раз, то,
вероятно, можно получить еще больший период, когда монета выпадет обратной
стороной. Тот же принцип работает и в торговле. Мы не только должны ожидать
более длинные полосы проигрышных сделок в будущем, следует также ожидать
большую проигрышную сделку наихудшего случая.
1 Уравнения риска разорения, хотя они напрямую и не
упомянуты в этой книге, должны также изменяться при использовании приведенных
данных. Вообще в качестве вводных данных для уравнений риска разорения
используют необработанные данные P&L. Однако когда вы используете приведенные данные,
новый поток процентных выигрышей и проигрышей должен умножаться на текущую
цену базового инструмента, и далее надо использовать именно этот получившийся
поток. Таким образом, при текущей цене инструмента 100 долларов поток
процентных выигрышей и проигрышей 0,1; -0,15; 0,2; -0,1 преобразуется в поток
10; -15; 20; -10. Этот новый поток и следует использовать для уравнений риска
разорения.
1 Хотя
эмпирические тесты показывают, что бросок монеты не является истинно случайной
последовательностью из-за некоторого несовершенства используемой монеты, мы
будем считать, что монета идеальная с точным шансом 0,5 выпадения на лицевую
или обратную сторону.
2
Отметьте, что в уравнении (2.13) ни К, ни (N — К) не могут быть
равными 0. Мы можем вычислить вероятности, соответствующие К = 0 и К = N, если
вычтем сумму вероятностей от К = 1 до К = N — 1 из единицы. Разделив полученное
значение на 2, мы получим вероятность при К = 0 и К = N.
1 Под самым
длительным проигрышем здесь подразумевается измеряемое в сделках время между
моментом достижения пика баланса и моментом, когда этот пик снова достигнут или
превзойден.
1 Область больших отклонении. — Прим. ред
1 На самом деле, интеграл
плотности нормального распределения вероятности нельзя
pассчитать точно, но его можно с большой степенью
точности получить с помощью
уравнения (3.21).
1 Предположение, что самой низкой ценой, по которой может
торговаться инструмент, является ноль, не всегда верно. Например, во время
краха фондового рынка в 1929 году и последующего медвежьего рьшка акционеры
многих обанкротившихся банков понесли ответственность перед вкладчиками этих
банков. Акционеры таких банков не только потеряли инвестированные в акции
деньги, но также понесли убытки сверх этого
1 Различие
между десятичным и натуральным логарифмом следующее. Десятичный логарифм — это
логарифм, который имеет в основании 10, в то время как натуральный логарифм
имеет в основании число е, где е = 2,7182818285. Десятичный логарифм Х
математически обозначается log(X), в то время как натуральный
логарифм обозначается 1п(Х). Натуральный логарифм может быть преобразован в
десятичный путем умножения натурального логарифма на 0,4342917. Таким же
образом мы можем преобразовать десятичный логарифм в натуральный путем
умножения десятичного логарифма на 2,3026.
2 Здесь мы
говорим о формулах Келли в единственном числе, хотя, фактически, есть две
версии формулы Келли: одна для случая, когда отношение выигрыша к проигрышу
составляет 1:1, а другая для случая, когда отношение выигрыша к проигрышу произвольно.
В этой главе мы исходим из отношения 1:1, поэтому не имеет значения, какую
именно формулу Келли мы используем.
1 Интеграл
функции, описывающей нормальное распределение, в действительности нельзя точно
рассчитать, но его можно получить с большой степенью точности с помощью
уравнения (3.21), чего нельзя сказать о многих других распределениях
1 В
некоторых случаях лучшим выбором будет именно наибольшее арифметическое
математическое ожидание, а не геометрическое. Например, когда трейдер торгует
постоянным количеством контрактов и желает перейти к работе «фиксированной
долей» в какой-то благоприятной точке в будущем. Эта благоприятная точка —
порог геометрической торговли, где арифметическая средняя сделка, которая
используется в качестве входного данного, рассчитывается как арифметическое
математическое ожидание (сумма результатов каждого сценария, умноженных на
вероятность их появления), поделенное на сумму вероятностей всех сценариев. Так
как сумма вероятностей всех сценариев обычно равна 1, мы можем говорить, что
арифметическая средняя сделка равна арифметическому математическому ожиданию
1 Позднее в этой
главе мы увидим, что базовые инструменты идентичны колл-опционам с
неограниченным сроком истечения. Поэтому, если у нас открыта длинная позиция по
базовому инструменту, мы можем сказать, что проигрыш наихудшего случая является
полной стоимостью инструмента. В большинстве случаев проигрыш такой величины и
является катастрофическим проигрышем. Короткая позиция по базовому инструменту
аналогична короткой позиции по колл-опциону с неограниченным сроком истечения,
и в такой ситуации ответственность действительно не ограничена.
1 Чаще всего только рыночные дни
используются при расчете этой переменной. Число рабочих дней в году
(григорианское) можно определить следующим образом: 365,2424 / 7*5= 260,8875.
Из-за выходных реальное число торговых дней в году обычно составляет от 250 до
252. Поэтому, если мы используем 252-дневный год и осталось 50 торговых дней до
истечения срока, то доля года, выраженная десятичной дробью, т.е. Т, будет 50 /
/252=0,1984126984
1 При торговле
фьючерсами не требуется немедленной уплаты денежных средств за базовый актив,
хотя необходимо уплатить залог. Кроме того, все прибыли и убытки реализуются
немедленно, даже когда позиция не ликвидирована. Эти пункты находятся в прямом
противоречии с механизмом сделок по акциям. При торговле акциями покупка
требует полной и немедленной оплаты, а прибыли (или убытки) не реализуются,
пока позиция не ликвидирована.
1 Тот факт,
что распределение изменений волатильности логарифмически нормально, не так
часто принимается во внимание. Чрезвычайная чувствительность цен опционов к
волатильности базового инструмента делает покупку опциона (пут-опциона или
колл-опциона) еще более привлекательной в смысле математического ожидания.
1 Уравнение (5.11)
не учитывает разницу между фондовыми опционами и товарными опционами. Согласно
общепринятому подходу, в цену фондового опциона включается доход по простой
бескупонной облигации, которая будет погашена в момент истечения срока опциона
и номинал которой равен цене исполнения. Опционы на товарные фьючерсы, как
считается, имеют процентную ставку 0. Мы же не учитываем это обстоятельство.
Если ценная бумага и товар имеют абсолютно одинаковое распределение ожидаемых
результатов, т.е. их арифметические математические ожидания равны, то разумный
инвестор выберет более дешевый инструмент. Эту ситуацию хорошо иллюстрирует
пример, когда вы рассматриваете покупку одного из двух одинаковых домов, и один
из них оценен выше только потому, что продавец платил более высокую процентную
ставку по ипотечному кредиту
2 Распределение
Стьюдента далеко не лучшая модель, описывающая распределение изменений цены.
Однако, так как единственным параметром, кроме волатильности (годового стандартного
отклонения), который необходимо рассматривать при использовании распределения
Стьюдента, является число степеней свободы, а ассоциированные вероятности
легко находятся (см. приложение В), мы будем использовать распределение
Стьюдента для наглядности.
1 Для получения дополнительной
информации прочитайте Fama, Eugene E, «Portfolio Analysis in a
Stable Paretian Market», Management Science 11, pp. 404 — 419, 1965. Фама
продемонстрировал параметрические методы поиска эффективной границы для стабильно
распределенных ценных бумаг (распределения которых обладают одинаковым
характеристическим показателем А), когда прибыли компонентов зависят от одного
индекса основного рынка. Существует и другая работа, посвященная выведению
эффективной границы в условиях бесконечной дисперсии прибылей компонентов
портфеля. Эти методы не рассматриваются в данной книге, но для заинтересованных
читателей есть ссылки на соответствующие статьи. О распределении Парето вы
сможете узнать из приложения В. Несколько слов о бесконечной дисперсии сказано
в разделе «Распределение Стьюдента» в приложении В.
1 Расчет
дисперсии может оказаться довольно сложным. Более легким способом является
расчет среднего абсолютного отклонения, которое следует умножить на 1,25 для
получения стандартного отклонения. Если возвести это значение в квадрат, мы
получим оценку дисперсии.
1 Веса, при которых мы получаем портфель с минимальным
V для данного Е, будут точны настолько, насколько точны значения входных данных
Е и V компонентов и коэффициенты линейной корреляции каждой возможной пары
компонентов
1 Таким образом, мы можем
утверждать, что геометрический оптимальный портфель — это портфель, в котором
второй множитель Лагранжа равен 0, когда сумма весов ограничена единицей, а в
том случае, когда сумма весов не ограничена, первый множитель Лагранжа равен -
2. Такой портфель, при снятии ограничений на сумму весов, также будет иметь
второй множитель Лагранжа, равный 0.