ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ
ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ ИНСТИТУТ
КОНТРОЛЬНАЯ РАБОТА
по предмету "Эконометрика"
Выполнил:
Обаленская Татьяна Николаевна
Студенческий № 05ффд60032
специальность:
Финансы и кредит
группа № 9/1
Проверил:
Половников Виктор Антонович
МОСКВА
2006
ВАРИАНТ № 32
I
Таблица 1. Исходные данные.
|
t
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
Y
|
26
|
30
|
32
|
30
|
35
|
33
|
35
|
38
|
40
|
На
основании данных, приведенных в табл. 1. Требуется:
1) Определить наличие тренда Y(t)
2) построить линейную модель Y(t) = ao + a1t, параметры которой оценить с помощью
МНК;
3) оценить адекватность построенной
модели на основе исследования:
-
случайности
остаточной компоненты по критерию пиков;
-
независимости
уровней ряда остатков по d-критерию
(в качестве критических значений следует
использовать уровни d1 =
1,08 и d2 = 1,36) и по
первому коэффициенту корреляции,
критический уровень которого r(1) =
0,36;
-
нормальности
распределения остаточной компоненты по R/S-критерию
с критическими уровнями 2,7 – 3,7;
4) для оценки точности модели
используйте среднеквадратическое отклонение и среднюю по модулю относительную
ошибку;
5) построить точечный и интервальный прогнозы на два шага
вперед (для вероятности
Р= 70% используйте коэффициент = 1,12);
5) отобразить на графике фактические
данные, результаты расчетов и прогнозирования.
РЕШЕНИЕ
1.1.ОПРЕДЕЛЕНИЕ
НАЛИЧИЯ ТРЕНДА Y(t)
Таблица 1.1
|
t
|
Y(t)
|
U(t)
|
l(t)
|
S(t)
|
d(t)
|
|
1
|
26
|
-
|
-
|
-
|
-
|
|
2
|
30
|
1
|
0
|
1
|
1
|
|
3
|
32
|
1
|
0
|
1
|
1
|
|
4
|
30
|
0
|
0
|
0
|
0
|
|
5
|
35
|
1
|
0
|
1
|
1
|
|
6
|
33
|
0
|
0
|
0
|
0
|
|
7
|
35
|
0
|
0
|
0
|
0
|
|
8
|
38
|
1
|
0
|
1
|
1
|
|
9
|
40
|
1
|
0
|
1
|
1
|
|
ИТОГО
|
299
|
|
|
5
|
5
|
1)
Сравним каждый
уровень временного ряда со всеми предыдущими уму уровнями ряда
U(t) =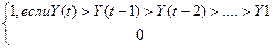
l(t) = 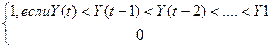
2)
Вычислим значения S и d и занесем значения в таблицу 1.1
S(t) = U(t) + l(t)
d(t) = U(t) – l(t)
3)
Для величин S и d вычислим значения статистики t – критерия Стьюдента
Табличные
значения:
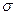 1 = 1,288
1 = 1,288
2 = 1,964
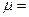 3,858
3,858
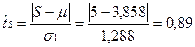
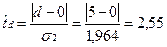
 <
tтабл (1,383) ⇒ тенденции
в дисперсии временного ряда не наблюдается.
<
tтабл (1,383) ⇒ тенденции
в дисперсии временного ряда не наблюдается.
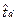 > tтабл (1,383) ⇒ тренд есть.
> tтабл (1,383) ⇒ тренд есть.
1.2. оценка
параметров модели.
Ввод
исходных данных
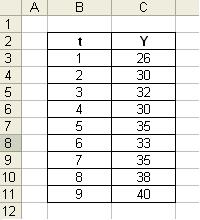
рис 1.2.1 Таблица с исходными данными.
1.2.1. Оценка
параметров модели с помощью надстройки EXCEL Анализ
данных.
Построим линейную однопараметрическую модель регрессии
Y от t. Для
проведения регрессионного анализа выполните следующие действия:
·
Выберите команду Сервис Þ Анализ данных.
·
В диалоговом окне
Анализ данных
выберите инструмент Регрессия (рис. 1.2.2), а затем щелкните на кнопке ОК.
·
В диалоговом окне
Регрессия в поле Входной интервал Y введите
адрес одного диапазона ячеек, который
представляет зависимую переменную. В поле Входной интервал Х введите адрес диапазона, который содержат значения
независимой переменной t (рис. 1.2.3).
·
Если выделены и
заголовки столбцов, то установить флажок Метки в первой строке.
·
Выберите
параметры вывода. В данном примере Новая рабочая книга.
·
В поле График подбора поставьте
флажок.
·
В поле Остатки поставьте необходимые флажки и нажмите кнопку ОК.
Рис. 1.2.2.
Выбран инструмент анализа Регрессия
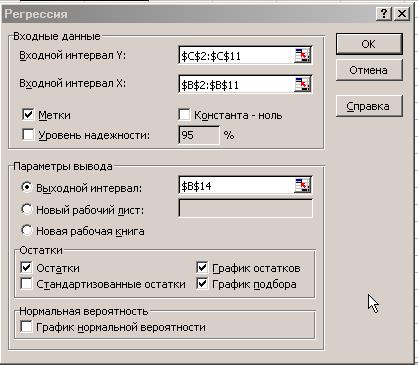
Рис. 1.2.3. Ввод исходных данных для Регрессии
Результат регрессионного анализа
содержится в нижеприведенных таблицах.
|
Таблица 1.2.1
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
|
|
Множественный R
|
0,94
|
|
|
|
|
|
|
|
|
R-квадрат
|
0,88
|
|
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,87
|
|
|
|
|
|
|
|
|
Стандартная ошибка
|
1,58
|
|
|
|
|
|
|
|
|
Наблюдения
|
9,00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 1.2.2
Дисперсионный анализ
|
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
|
|
Регрессия
|
1,00
|
132,02
|
132,02
|
52,69
|
0,00
|
|
|
|
|
Остаток
|
7,00
|
17,54
|
2,51
|
|
|
|
|
|
|
Итого
|
8,00
|
149,56
|
|
|
|
|
|
|
|
Таблица 1.2.3
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
Y-пересечение
|
а
|
25,81
|
1,15
|
22,44
|
0,00
|
23,09
|
28,52
|
23,09
|
28,52
|
|
t
|
b
|
1,48
|
0,20
|
7,26
|
0,00
|
1,00
|
1,97
|
1,00
|
1,97
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 1.2.4
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
|
|
|
|
|
|
1
|
27,29
|
-1,29
|
|
|
|
|
|
|
|
2
|
28,77
|
1,23
|
|
|
|
|
|
|
|
3
|
30,26
|
1,74
|
|
|
|
|
|
|
|
4
|
31,74
|
-1,74
|
|
|
|
|
|
|
|
5
|
33,22
|
1,78
|
|
|
|
|
|
|
|
6
|
34,71
|
-1,71
|
|
|
|
|
|
|
|
7
|
36,19
|
-1,19
|
|
|
|
|
|
|
|
8
|
37,67
|
0,33
|
|
|
|
|
|
|
|
9
|
39,16
|
0,84
|
|
|
|
|
|
|
В третьем столбце табл. 1.2.3
содержатся коэффициенты уравнения регрессии a, b, в четвертом столбце – стандартные ошибки
коэффициентов уравнения регрессии, а в
пятом – t-статистика, используемая для проверки значимости коэффициентов уравнения регрессии.
Уравнение регрессии зависимости Yt,
от tt (время) имеет вид:
Y(t) =25,81+1,48t
При вычислении
«вручную» по методу наименьших квадратов получаем те же результаты:
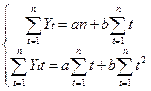
Таблица 1.2.5
|
|
t
|
Y
|
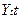
|
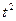
|
|
|
1
|
26
|
26
|
1
|
|
|
2
|
30
|
60
|
4
|
|
|
3
|
32
|
96
|
9
|
|
|
4
|
30
|
120
|
16
|
|
|
5
|
35
|
175
|
25
|
|
|
6
|
33
|
198
|
36
|
|
|
7
|
35
|
245
|
49
|
|
|
8
|
38
|
304
|
64
|
|
|
9
|
40
|
360
|
81
|
|
Сумма
|
45
|
299
|
1584
|
285
|
|
Среднее
|
5
|
43
|
|
|
Подставляя полученные в таблице 1.2.5. результаты в форму
получим:
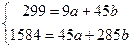
a =
25,81 b = 1,48
1.3. оценка АДЕКВАТНОСТИ
построенной модели.
Модель является адекватной, если математическое
ожидание значений остаточного ряда близко или равно нулю, и если значения
остаточного ряда случайны, независимы и подчинены нормальному закону распределения.
·
Проверку случайности уровней ряда остатков
проведем на основе критерия пиков:
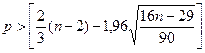
Количество поворотных точек равно 4 (рис. 1.2.4).
Неравенство выполняется (4>2,4). Следовательно, свойство случайности
выполняется. Модель по этому критерию адекватна.
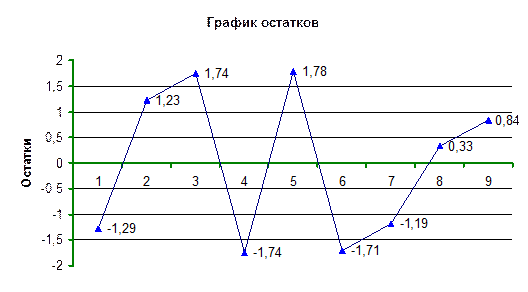
Рис. 1.3.1. График
остатков
·
При проверке случайности определяется
отсутствием в ряду остатков систематической составляющей, например, с помощью
d-критерия Дарбина–Уотсона:
Таблица1.3.1.
|
Наблюдение
|
Предсказанное Y
|
Остатки 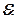
|
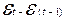
|
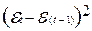
|
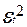
|
|
1
|
27,29
|
-1,29
|
|
|
1,66
|
|
2
|
28,77
|
1,23
|
2,52
|
6,33
|
1,51
|
|
3
|
30,26
|
1,74
|
0,52
|
0,27
|
3,04
|
|
4
|
31,74
|
-1,74
|
-3,48
|
12,13
|
3,02
|
|
5
|
33,22
|
1,78
|
3,52
|
12,37
|
3,16
|
|
6
|
34,71
|
-1,71
|
-3,48
|
12,13
|
2,91
|
|
7
|
36,19
|
-1,19
|
0,52
|
0,27
|
1,41
|
|
8
|
37,67
|
0,33
|
1,52
|
2,30
|
0,11
|
|
9
|
39,16
|
0,84
|
0,52
|
0,27
|
0,71
|
|
СУММА
|
|
|
|
46,07
|
17,54
|
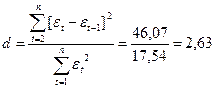
d'= 4 -2,63=1,37
Так
как d' попало в
интервал от d2 до 2 (рис. 1.3.2), значит модель отвечает критерию независимости. Модель по этому
критерию адекватна.
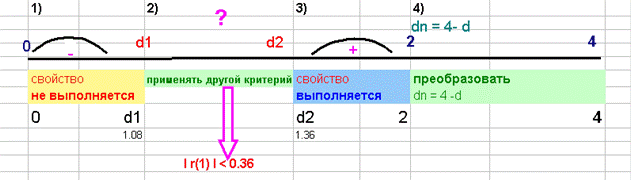 Рис. 1.3.2.
Рис. 1.3.2.
·
Соответствие ряда остатков нормальному
закону распределения определим при
помощи RS-критерия:
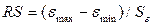
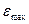 – максимальный уровень ряда остатков, = 1,78;
– максимальный уровень ряда остатков, = 1,78;
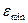 – минимальный уровень ряда остатков,
= – 1,74;
– минимальный уровень ряда остатков,
= – 1,74;
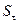 – среднеквадратичное отклонение,
– среднеквадратичное отклонение,
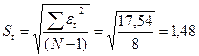
RS=[1,78–(-1,74)] / 1,48= 2,38.
Расчетное значение не попадает в интервал (2,7–3,7),
следовательно, гипотеза о нормальном распределении остаточной компоненты не
принимается. Модель по этому критерию не
адекватна.
В табл. 1.3.2. собраны данные анализа
ряда остатков.
Таблица 1.3.2. Анализ ряда остатков
|
Проверяемое
свойство
|
Используемые статистики
|
Граница
|
Вывод
|
|
наименование
|
значение
|
нижняя
|
верхняя
|
|
Случайность
|
Критерий пиков (поворотных
точек)
|
4 > 2,4
|
-
|
адекватна
|
|
Независимость
|
d-критерий
Дарбина–Уотсона
|
d=1,37
|
1,36
|
2
|
адекватна
|
|
Нормальность
|
RS-критерий
|
RS=2,38
|
2,6
|
3,7
|
не адекватна
|
|
Вывод: Модель
статистически не адекватна
|
1.4.
ОЦЕНКА ТОЧНОСТИ ПОСТРОЕННОЙ МОДЕЛИ
(используя среднеквадратическое отклонение и среднюю по модулю относительную
ошибку)
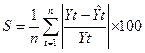
Таблица 1.4.1
|
t
|
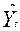
|
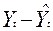
|
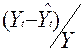
|
|
1
|
27,29
|
-1,29
|
-0,050
|
|
2
|
28,77
|
1,23
|
0,041
|
|
3
|
30,26
|
1,74
|
0,055
|
|
4
|
31,74
|
-1,74
|
-0,058
|
|
5
|
33,22
|
1,78
|
0,051
|
|
6
|
34,71
|
-1,71
|
-0,052
|
|
7
|
36,19
|
-1,19
|
-0,034
|
|
8
|
37,67
|
0,33
|
0,009
|
|
9
|
39,16
|
0,84
|
0,021
|
|
СУММА
|
|
|
-0,017
|
Для расчета воспользуемся данными таблицы 1.4.1
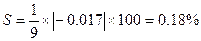
Так как S < 5% модель
считается точной.
1.5. Построить
точечный и интервальный прогнозы на два шага вперед (для вероятности 70%
использовать t = 1,12):
Y(t) =25,81+1,48t
Y10= a0
+ a1t =25,81 + 1,48t = 25,81 + 1,48 x 10 = 40,61;
Y11= a0
+ a1t =25,81 + 1,48t = 25,81 + 1,48 x 11 = 42,09;
Для построения интервального прогноза рассчитаем
доверительный интервал. Примем значение уровня значимости α = 0,3,
следовательно, доверительная вероятность равна 70%, а критерий Стьюдента при 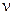 = n –2 =7 равен
1,12. Ширину доверительного интервала вычислим по формуле (3.10):
= n –2 =7 равен
1,12. Ширину доверительного интервала вычислим по формуле (3.10):
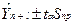 ;
; 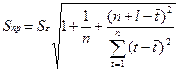
где
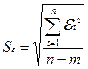 =
= 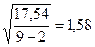 , m = 2,
, m = 2,  = 1,12,
= 1,12, 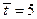 ,
,
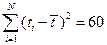 (находим из табл. 1.4.1),
(находим из табл. 1.4.1),
Далее
вычисляем верхнюю и нижнюю границы прогноза (табл. 1.5.1):
Таблица 1.5.1.
|
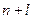
|
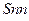
|
Прогноз 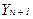
|
Формула
|
Верхняя граница
|
Нижняя граница
|
|
10
|
1,95
|
40,61
|
|
42,79
|
38,43
|
|
11
|
2,07
|
42,09
|
|
44,4
|
39,77
|
1.6. Отобразить на графике фактические данные, результаты
расчетов и прогнозирования.
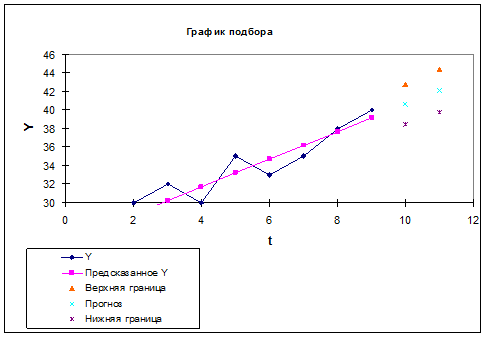
Рис 1.6.1. График подбора
II
1 – построить матрицу коэффициентов парной корреляции Y(t) с
X1(t) и X2(t) и выбрать
фактор, наиболее тесно связанный с зависимой переменной Y(t);
2 – построить линейную
однопараметрическую модель регрессии Y(t) = ao + a1 X(t);
3 – оценить качество построенной модели, исследовав ее адекватность
и точность;
4 – для модели регрессии рассчитать коэффициент эластичности и бета-коэффициент;
5 -
построить точечный и интервальный
прогнозы на два шага вперед по модели регрессии (для вероятности Р = 70%
используйте коэффициент 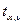 = 1,11) (прогнозные оценки фактора X(t) на два шага вперед получить на основе
среднего прироста от фактически достигнутого уровня).
= 1,11) (прогнозные оценки фактора X(t) на два шага вперед получить на основе
среднего прироста от фактически достигнутого уровня).
Таблица 2 Исходные
данные.
|
ФАКТОРЫ
|
|
Y
|
X1
|
X2
|
|
26
|
62
|
18
|
|
30
|
67
|
21
|
|
32
|
80
|
24
|
|
30
|
81
|
26
|
|
35
|
85
|
25
|
|
33
|
87
|
29
|
|
35
|
84
|
34
|
|
38
|
88
|
38
|
|
40
|
91
|
41
|
РЕШЕНИЕ
2.1. Ввод исходных данных. Результат
показан на рис. 2.1.1.
Рис. 2.1.1. Исходные данные введены в Excel
2.2. ПОСТРОЕНИЕ
СИСТЕМЫ ПОКАЗАТЕЛЕЙ (ФАКТОРОВ). АНАЛИЗ МАТРИЦЫ КОЭФФИЦИЕНТОВ ПАРНОЙ КОРРЕЛЯЦИИ.
ВЫБОР НАИБОЛЕЕ СУЩЕСТВЕННОГО ФАКТОРА Х T..
Для того чтобы выбрать фактор
наиболее тесно связанный с зависимой переменной, оценим величину влияния
факторов при помощи коэффициента корреляции.
Для проведения корреляционного анализа с помощью EXCEL выполните
следующие действия:
1)
Данные для
корреляционного анализа должны располагаться в смежных диапазонах ячеек.
2)
Выберите команду
СервисÞАнализ данных.
3)
В диалоговом окне
Анализ данных выберите инструмент Корреляция
(рисунок 2.2.1.), а затем щелкните на кнопке
ОК.
4)
В диалоговом окне
Корреляция в поле Входной интервал необходимо ввести диапазон ячеек,
содержащих исходные данные. Если выделены и заголовки столбцов, то установить
флажок Метки в первой строке (рисунок 2.2.2.).
5)
Выберите
параметры вывода.
6)
ОК.
Рис 2.2.1.
Рис. 2.2.2.
Таблица 2.2.1.
|
Результат корреляционного анализа
|
|
|
|
|
|
|
|
|
Y
|
X1
|
X2
|
|
Y
|
1
|
|
|
|
X1
|
0,874078
|
1
|
|
|
X2
|
0,920169
|
0,832068
|
1
|
Анализ матрицы коэффициентов парной
корреляции показывает, что зависимая переменная Yt имеет более тесную связь с x2t.
вычисление коэффициентов
корреляции без ПЭВМ.
Коэффициент корреляции определяется по формуле
(используем данные таблицы 2.2.2):
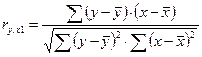 =
= 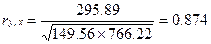
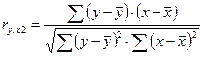 =
= 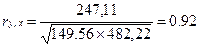
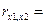 =
= 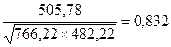
Аналогично вычисляются
остальные коэффициенты корреляции.
Таблица 2.2.2.
|
Y
|
X1
|
|
|
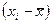
|
2
|
*
|
|
26
|
62
|
-7,22
|
52,16
|
-18,56
|
344,31
|
134,01
|
|
30
|
67
|
-3,22
|
10,38
|
-13,56
|
183,75
|
43,68
|
|
32
|
80
|
-1,22
|
1,49
|
-0,56
|
0,31
|
0,68
|
|
30
|
81
|
-3,22
|
10,38
|
0,44
|
0,20
|
-1,43
|
|
35
|
85
|
1,78
|
3,16
|
4,44
|
19,75
|
7,90
|
|
33
|
87
|
-0,22
|
0,05
|
6,44
|
41,53
|
-1,43
|
|
35
|
84
|
1,78
|
3,16
|
3,44
|
11,86
|
6,12
|
|
38
|
88
|
4,78
|
22,83
|
7,44
|
55,42
|
35,57
|
|
40
|
91
|
6,78
|
45,94
|
10,44
|
109,09
|
70,79
|
|
|
|
0,00
|
149,56
|
0,00
|
766,22
|
295,89
|
Yср =
33,22
X1ср = 80,56
Таблица 2.2.3.
|
Y
|
X2
|
|
|
|
2
|
*
|
|
26
|
18
|
-7,22
|
52,16
|
-10,44
|
109,09
|
75,43
|
|
30
|
21
|
-3,22
|
10,38
|
-7,44
|
55,42
|
23,99
|
|
32
|
24
|
-1,22
|
1,49
|
-4,44
|
19,75
|
5,43
|
|
30
|
26
|
-3,22
|
10,38
|
-2,44
|
5,98
|
7,88
|
|
35
|
25
|
1,78
|
3,16
|
-3,44
|
11,86
|
-6,12
|
|
33
|
29
|
-0,22
|
0,05
|
0,56
|
0,31
|
-0,12
|
|
35
|
34
|
1,78
|
3,16
|
5,56
|
30,86
|
9,88
|
|
38
|
38
|
4,78
|
22,83
|
9,56
|
91,31
|
45,65
|
|
40
|
41
|
6,78
|
45,94
|
12,56
|
157,64
|
85,10
|
|
|
|
0,00
|
149,56
|
0,00
|
482,22
|
247,11
|
Yср =
33,22
X2ср = 28,44
Таблица 2.2.4.
|
X1
|
X2
|
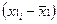
|
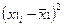
|
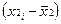
|
2
|
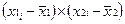
|
|
62
|
18
|
-18,56
|
344,31
|
-10,44
|
109,09
|
193,80
|
|
67
|
21
|
-13,56
|
183,75
|
-7,44
|
55,42
|
100,91
|
|
80
|
24
|
-0,56
|
0,31
|
-4,44
|
19,75
|
2,47
|
|
81
|
26
|
0,44
|
0,20
|
-2,44
|
5,98
|
-1,09
|
|
85
|
25
|
4,44
|
19,75
|
-3,44
|
11,86
|
-15,31
|
|
87
|
29
|
6,44
|
41,53
|
0,56
|
0,31
|
3,58
|
|
84
|
34
|
3,44
|
11,86
|
5,56
|
30,86
|
19,14
|
|
88
|
38
|
7,44
|
55,42
|
9,56
|
91,31
|
71,14
|
|
91
|
41
|
10,44
|
109,09
|
12,56
|
157,64
|
131,14
|
|
|
|
0,00
|
766,22
|
0,00
|
482,22
|
505,78
|
Выбираем фактор X2, так как у этого фактора
значение парной корреляции по модулю больше.
2.3. оценка параметров модели.
Оценка
параметров модели с помощью надстройки EXCEL Анализ данных.
Построим линейную однопараметрическую модель регрессии
Y от X. Для проведения регрессионного анализа выполните
следующие действия:
·
Выберите команду Сервис Þ Анализ данных.
·
В диалоговом окне
Анализ данных
выберите инструмент Регрессия (рис. 2.3.1.), а затем щелкните на кнопке ОК.
·
В диалоговом окне
Регрессия в поле Входной интервал Y введите
адрес одного диапазона ячеек, который
представляет зависимую переменную. В поле Входной интервал Х введите адрес диапазона, который содержат значения независимой
переменной t (рис. 2.3.2.).
·
Если выделены и
заголовки столбцов, то установить флажок Метки в первой строке.
·
Выберите
параметры вывода. В данном примере Новая рабочая книга.
·
В поле График подбора поставьте
флажок.
·
В поле Остатки поставьте необходимые флажки и нажмите кнопку ОК
Рис. 2.3.1 Выбран
инструмент анализа Регрессия
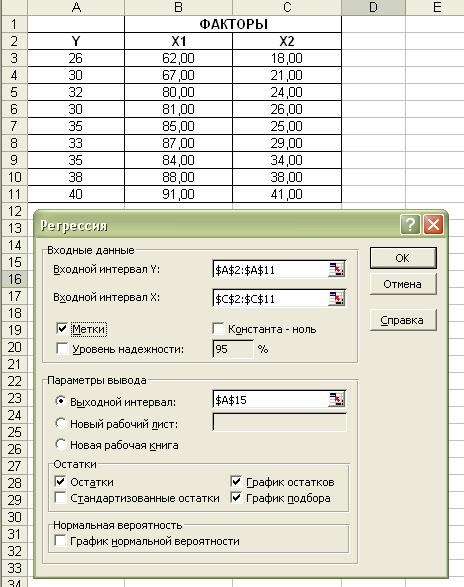
Рис. 2.3.2. Ввод исходных
данных для Регрессии
Результат регрессионного анализа
содержится в нижеприведенных таблицах.
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
|
|
|
Таблица 2.3.1
|
|
|
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
|
|
Множественный R
|
0,9202
|
|
|
|
|
|
|
|
|
R-квадрат
|
0,8467
|
|
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,8248
|
|
|
|
|
|
|
|
|
Стандартная ошибка
|
1,8097
|
|
|
|
|
|
|
|
|
Наблюдения
|
9,0000
|
|
|
|
|
|
|
|
|
Таблица 2.3.2 Дисперсионный анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
|
|
Регрессия
|
1,0000
|
126,6302
|
126,6302
|
38,6651
|
0,0004
|
|
|
|
|
Остаток
|
7,0000
|
22,9253
|
3,2750
|
|
|
|
|
|
|
Итого
|
8,0000
|
149,5556
|
|
|
|
|
|
|
|
Таблица
2.3.3.
|
|
|
|
|
|
|
|
|
Переменная
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
Y-пересечение
|
a0
|
18,6461
|
2,4205
|
7,7034
|
0,0001
|
12,9225
|
24,3697
|
12,9225
|
24,3697
|
|
X1
|
a1
|
0,5124
|
0,0824
|
6,2181
|
0,0004
|
0,3176
|
0,7073
|
0,3176
|
0,7073
|
|
Таблица 2.3.4. ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
|
|
|
|
|
|
1
|
27,87
|
-1,87
|
|
|
|
|
|
|
|
2
|
29,41
|
0,59
|
|
|
|
|
|
|
|
3
|
30,94
|
1,06
|
|
|
|
|
|
|
|
4
|
31,97
|
-1,97
|
|
|
|
|
|
|
|
5
|
31,46
|
3,54
|
|
|
|
|
|
|
|
6
|
33,51
|
-0,51
|
|
|
|
|
|
|
|
7
|
36,07
|
-1,07
|
|
|
|
|
|
|
|
8
|
38,12
|
-0,12
|
|
|
|
|
|
|
|
9
|
39,66
|
0,34
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Во втором столбце табл. 2.3.3.
содержатся коэффициенты уравнения регрессии a0, a1, в третьем столбце – стандартные ошибки коэффициентов уравнения
регрессии, а в четвертом – t-статистика,
используемая для проверки
значимости коэффициентов уравнения регрессии.
Уравнение регрессии зависимости Yt,
(прибыль коммерческого банка) от tt
(время) имеет вид:
Y(X) = 18,65 + 0,51X
При вычислении
«вручную» по формуле (3.4) получаем те же результаты:
2.4.оценка качества
построенной модели. Для этого исследуем
адекватность модели. Модель является адекватной, если математическое ожидание
значений остаточного ряда близко или равно нулю, и если значения остаточного
ряда случайны, независимы и подчинены нормальному закону распределения.
·
При проверке независимости (отсутствие
автокорреляции) определяется отсутствие в ряду остатков систематической
составляющей, например, с помощью d-критерия
Дарбина–Уотсона:
Таблица 2.4.1.
|
Наблюдение
|
Предсказанное Y
|
|
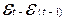
|
|
|
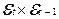
|
|
1
|
27,87
|
-1,87
|
|
|
3,50
|
|
|
2
|
29,41
|
0,59
|
2,46
|
6,06
|
0,35
|
-1,11
|
|
3
|
30,94
|
1,06
|
0,46
|
0,21
|
1,11
|
0,63
|
|
4
|
31,97
|
-1,97
|
-3,02
|
9,15
|
3,88
|
-2,08
|
|
5
|
31,46
|
3,54
|
5,51
|
30,39
|
12,55
|
-6,98
|
|
6
|
33,51
|
-0,51
|
-4,05
|
16,40
|
0,26
|
-1,80
|
|
7
|
36,07
|
-1,07
|
-0,56
|
0,32
|
1,14
|
0,54
|
|
8
|
38,12
|
-0,12
|
0,95
|
0,90
|
0,01
|
0,13
|
|
9
|
39,66
|
0,34
|
0,46
|
0,21
|
0,12
|
-0,04
|
|
СУММА
|
|
|
|
63,65
|
22,93
|
-10,71
|
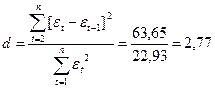
d'= 4 -2,77=1,23
Так
как d' попало в интервал от d1 до d2, значит окончательного решения о том,
что модель уровня ряда остатков независима сделать нельзя. Требуется
привлечение других критериев. Используем распределение коэффициента автокорреляции
при 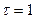
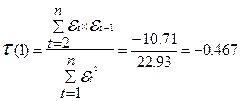
Так как 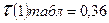 , сравнивая получим что
, сравнивая получим что 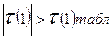 , следовательно модель по данному критерию не адекватна.
, следовательно модель по данному критерию не адекватна.
Рис. 2.4.1.
·
Проверку случайности уровней ряда остатков
проведем на основе критерия поворотных точек.
В случайном
ряду чисел должно выполняться строгое неравенство:
Количество поворотных точек равно 4 (рис. 2.4.2).
Неравенство выполняется (4>2,4). Следовательно, свойство случайности
выполняется. Модель по этому критерию адекватна.
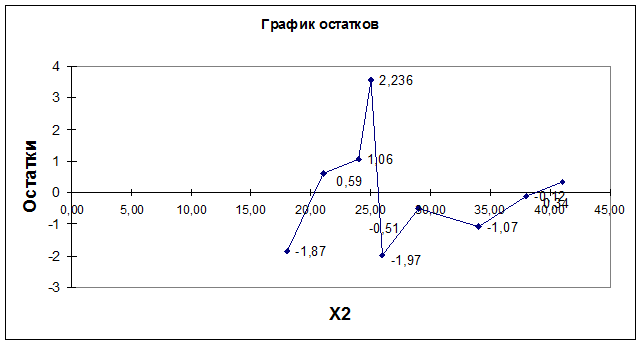
Рис. 2.4.2. График
остатков
·
Соответствие ряда остатков нормальному
закону распределения определим при
помощи RS-критерия:
– максимальный уровень ряда остатков, = 3,54;
– минимальный уровень ряда остатков,
= – 1,97;
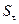 – среднеквадратичное отклонение,
– среднеквадратичное отклонение,
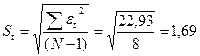
RS=[3,54 – (-1,97)] / 1,69= 3,26.
Расчетное значение попадает в интервал (2,7–3,7),
следовательно, гипотеза о нормальном распределении остаточной компоненты принимается.
Модель по этому критерию адекватна.
Для расширенной
характеристики модели регрессии вычислим несколько дополнительных показателей:
коэффициент детерминации R2
и коэффициент множественной корреляции R. Эти характеристики приведены в
таблице 2.3.1. протокола ЕХСЕL.
Таблица 2.4.2.
|
Множественный R
|
0,9202
|
|
R-квадрат
|
0,8467
|
|
Нормированный R-квадрат
|
0,8248
|
|
Стандартная ошибка
|
1,8097
|
|
Наблюдения
|
9,0000
|
Коэффициент детерминации:
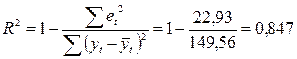
R2 показывает долю вариации результативного
признака под воздействием изучаемых факторов. Следовательно, более 84,7 %
вариации зависимой переменной учтено в модели и обусловлено влиянием
включенного фактора.
R - коэффициент множественной
корреляции. R = 0.92 показывает
тесноту связи зависимой Y c факторами Х,
включенными в модель. в случае
однофакторной модели R совпадает с ryx1.
В табл. 2.4.3. собраны данные анализа ряда остатков.
Таблица 2.4.3. Анализ ряда остатков
|
Проверяемое
свойство
|
Используемые статистики
|
Граница
|
Вывод
|
|
наименование
|
значение
|
нижняя
|
верхняя
|
|
Независимость
|
d-критерий
Дарбина–Уотсона
|
dn
=4 -2,77=1,23
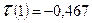
|
1,36
|
2
|
не адекватна
|
|
Случайность
|
Критерий пиков (поворотных
точек)
|
4 > 2,4
|
2
|
адекватна
|
|
Нормальность
|
RS-критерий
|
3,26
|
2,6
|
3,7
|
адекватна
|
|
Вывод: Модель статистически не адекватна
|
|
|
|
|
|
|
|
2.5.ОПРЕДЕЛИМ КОЭФФИЦИЕНТ ЭЛАСТИЧНОСТИ И β-КОЭФФИЦИЕНТ
2.5.1. Коэффициент
эластичности показывает, на сколько процентов изменится Y если X2 изменится на
1%.
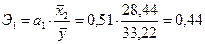 %
%
Таким образом, при изменении X2 на 1% Y изменится на 0,44%
2.5.2. β-коэффициент показывает, на какую долю в
среднем изменится среднеквадратическое отклонение зависимой переменной Y при изменении X2 на одно свое среднеквадратическое отклонение при
фиксированных значениях остальных объясняющих переменных.
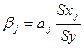 ;
; 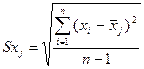
β2= 0,92
2.6.ОПРЕДЕЛИМ ТОЧЕЧНЫЕ И ИНТЕРВАЛЬНЫЕ ПРОГНОЗНЫЕ ОЦЕНКИ ПРИБЫЛИ КОММЕРЧЕСКОГО
БАНКА НА ДВА КВАРТАЛА ВПЕРЕД (T0,7 = 1,11 для n-2= 9-2 =7).
Для
вычисления прогнозных оценок Y на основе построенной модели необходимо получить
прогнозные оценки фактора Х.
Получим прогнозные оценки фактора на основе
величины его среднего абсолютного прироста Ux
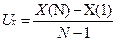 ;
;
Ux = (41-18)/(9-1) =2.88
Xp(N+l)
= X(N) + l ∙ Ux;
l=1
Xp(10) = Х(9) +2.88 ∙ 1 = 41 +2.88 ∙ 1 =43.88
l=2
Xp(11) = Х(9) +2.88 ∙ 2 =41+2.88
∙ 2 =46.76;
Подставляя расчетное значение Х в уравнение Y(X) = 18,65 + 0,51X получим
прогнозное значение Y:
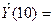 18,65 + 0,51*43,88 = 41,03
18,65 + 0,51*43,88 = 41,03
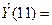 18,65 + 0,51*46,76 = 42,50
18,65 + 0,51*46,76 = 42,50
Для получения прогнозных оценок зависимой
переменной воспользуемся следующей формулой:
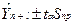
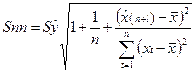 ;
; 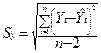
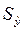 - стандартная ошибка - эта
характеристика приведена в таблице
протокола ЕХСЕL и равна 1,8097;
- стандартная ошибка - эта
характеристика приведена в таблице
протокола ЕХСЕL и равна 1,8097;
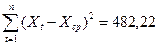
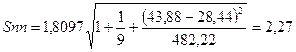
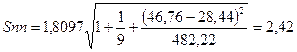
ta -является
табличным значением критерия Стьюдента для уровня значимости a и для числа
степеней свободы, равного N-2. В нашем
примере t0,7
= 1,11;
Таблица
2.6.1.
|
|
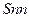
|
Прогноз 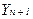
|
Формула
|
Верхняя граница
|
Нижняя граница
|
|
10
|
2,27
|
41,03
|
|
43,55
|
38,53
|
|
11
|
2,43
|
42,50
|
|
45,20
|
39,80
|
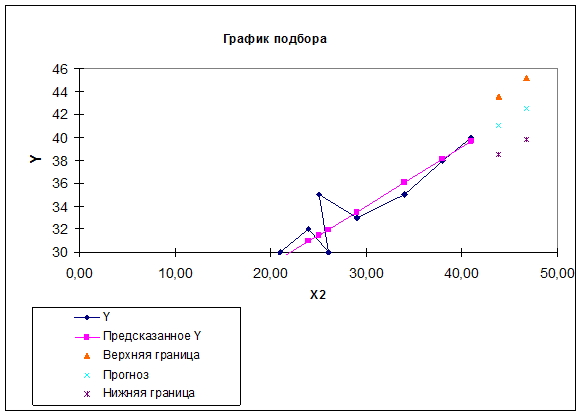
2.7.Отобразить на графике
фактические данные, результаты расчетов и прогнозирования.
Рис. 2.7.1. Результаты моделирования и прогнозирования