№1................................................................................................................................................... 2
№ 2.................................................................................................................................................. 5
№3................................................................................................................................................... 6
№4................................................................................................................................................. 13
№ 5................................................................................................................................................ 17
№6................................................................................................................................................. 20
№ 7................................................................................................................................................ 23
№ 8................................................................................................................................................ 27
№9................................................................................................................................................. 29
№10............................................................................................................................................... 31
№ 11.............................................................................................................................................. 32
№ 12.............................................................................................................................................. 35
№13............................................................................................................................................... 39
№ 14.............................................................................................................................................. 41
№15............................................................................................................................................... 42
№ 16.............................................................................................................................................. 46
№17............................................................................................................................................... 50
№ 18.............................................................................................................................................. 54
№19............................................................................................................................................... 57
№20............................................................................................................................................... 60
№ 21.............................................................................................................................................. 62
№22............................................................................................................................................... 66
№ 23.............................................................................................................................................. 69
№24............................................................................................................................................... 73
№ 25.............................................................................................................................................. 75
№26............................................................................................................................................... 77
№27............................................................................................................................................... 79
№28............................................................................................................................................... 82
№29............................................................................................................................................... 84
№30............................................................................................................................................... 88
№31............................................................................................................................................... 94
№32............................................................................................................................................... 98
№33............................................................................................................................................. 104
№1
Индустрия разработки автоматизированных информационных систем управления родилась в 50-х - 60-х годах и к концу века приобрела вполне законченные формы. Не смотря на имеющиеся различия в реализации функциональных модулей данных систем, общие подходы к их разработки во многом схожи, что позволило нам объединить вопросы их проектирования в рамках одного издания.
На рынке автоматизированных систем для крупных корпораций и финансово-промышленных групп на сегодня можно выделить два основных субъекта: это ранок автоматизированных банковских систем (АБС) и рынок корпоративных информационных систем промышленных предприятий. Не смотря на сильную взаимосвязь этих двух рынков систем автоматизации, предлагаемые на них решения пока еще не достаточно интегрированы между собой, чего следует ожидать в недалеком будущем.
Устаревшие, плохо интегрированные приложения отрицательно сказываются на эффективности ведения дел, требуют больших затрат на обслуживание и уязвимы. Интерфейсы, построенные на терминалах, запутывают конечных пользователей. Трудно извлечь нужные финансовые данные, "Унаследованные" системы учета страдают отсутствием гибкости и оказываются источником постоянных конфликтов.
ERP системы, построенные в рамках имитационной концепции, повторяют (имитируют) реальное строение предприятия с выделением модулей, соответствующих отделам. Например, плановый, финансы, бухгалтерия, склад, продажи, логистика и т.п. Модули пишутся как отдельные задачи для автоматизации конкретных отделов, затем обмениваются необходимыми данными дабы увязать все в единую систему.
Задача проектирования АИС промышленных предприятий сложная, т.к. характер обрабатываемой информации еще разнороден и сложно формализуем. Однако и здесь можно выделить основную модель работы - это работа "от кода проекта". В общем случае код проекта представляет собой аналог (функциональный) лицевого счета, он имеет определенную разрядность, порядок (т.е. конкретная группа цифро-буквенного обозначения характеризует деталь, сборочную единицу, изделие и их уровень взаимосвязи). Причем конкретная часть кода характеризует технологические, конструкторские, финансовые и др. документы. Все это регламентируется соответствующими ГОСТами (аналог инструкций ЦБ для банков), поэтому может быть формализовано. При этом модульный подход к реализации АИС в этом случае еще более важен. Двойственный подход к формированию ежедневного производственного плана лег в основу т.н. "принципа дуализма" для АИС промышленных предприятий. Реализация принципа дуализма неизбежно также требовала построения АИС предприятий нового поколения в виде программных модулей, органически связанных между собой, но в то же время способных работать и автономно.
Такая многокомпонентная система обеспечивала соблюдение основополагающего принципа построения автоматизированных информационных систем - отсутствия дублирования ввода исходных данных. Информация по операциям, проведенным с применением одного из компонентов системы, могла быть использована любым другим ее компонентом. Модульность построения АИС нового поколения и принцип одноразового ввода дают возможность гибко варьировать конфигурацией этих систем. Так, в банках, имеющих разветвленную филиальную сеть и не передающих данные в режиме реального времени, установка всего СПО во всех филиалах не всегда экономически оправдано. В этих случаях возможна эксплуатация в филиалах ПО общего назначения, предназначенного для первичного ввода информации и последующей автоматизированной обработки данных в СПО, установленном в головном офисе банка. Такая структура дает возможность органически включить в АБС нового поколения компонент для создания хранилища данных, разделяя системы оперативного действия и системы поддержки принятия решения.
Вопрос автоматизации малых предприятий решается приобретением простых и дешевых программ типа "мини-бухгалтерия", то при подборе программных комплексов для автоматизации средних предприятий его решение становится достаточно трудоемким. В этом случае, как правило, приходится выбирать из тиражируемых отечественных комплексов, функциональные возможности которых наиболее полно соответствуют специфике ведения финансового учета на конкретном предприятии. Самой сложной на сегодня остается задача комплексной автоматизации крупных предприятий и фирм. Ее решение имеет целью объединение бухгалтерии с финансовыми, коммерческими и техническими службами, производством и отделами управления. При этом остро встают проблемы выбора между поставщиками принципиально различных технических решений автоматизации учета, между отечественными и зарубежными системами автоматизации, между разработкой системы силами своих программистов или ее приобретением. Разработка силами своих специалистов хотя и имеет такие преимущества, как непосредственная близость разработчиков к объекту автоматизации, глубокое знание специфики предметной области, в реальных условиях является процессом длительным и малоэффективным. Собственные отделы АСУ делают ничем не оправданные закупки новейшего оборудования и дорогих средств программирования, сильно зависят от сложившейся структуры управления на предприятии, поэтому ожидаемого снижения издержек при такой автоматизации, как правило, не происходит.
№ 2
Технология и методы проектирования информационных систем.
Методология создания ИС заключается в организации процесса построения ИС и обеспечения управления этим процессом для того, чтобы гарантировать выполнение требований как к самой системе, так и к хар-ам процесса разработки. Методология, технология и инструментальные средства проектирования составляют основу любой ИС. Методология реализуется через конкретные технологии и поддерживающие их стандарты, методики и инструментальные средства, которые обеспечивают выполнение процессов жизненного цикла ИС. Основное содержание технологии проектирования составляют технологические инструкции, состоящие из описания последовательности технологических операций, условий, в зависимости от которых выполняется та или иная операция, и описаний самих операций.
Технология проектирования может быть представлена как совокупность 3 составляющих:
- заданной последовательности выполнения технологических операций проектирования;
- критериев и правил, используемых для оценки результатов выполнения тех.операций;
- графических и текстовых средств, используемых для описания проектируемой системы.
№3
Методы структурного анализа и проектирования стремятся преодолеть сложность больших систем путем расчленения их на части ("черные ящики") и иерархической организации этих черных ящиков. Выгода в использовании черных ящиков заключается в том, что их пользователю не требуется знать, как они работают, необходимо знать лишь его входы и выходы, а также его назначение (т.е. функцию, которую он выполняет).
Первым шагом упрощения сложной системы является ее разбиение на черные ящики, при этом такое разбиение должно удовлетворять следующим критериям:
• каждый черный ящик должен реализовывать единственную функцию системы;
• функция каждого черного ящика должна быть легко понимаема независимо от сложности ее реализации (например, в системе управления ракетой может быть черный ящик для расчета места ее приземления: несмотря на сложность алгоритма, функция черного ящика очевидна – "расчет точки приземления");
• связь между черными ящиками должна вводиться только при наличии связи между соответствующими функциями системы (например, в бухгалтерии один черный ящик необходим для расчета общей заработной платы служащего, а другой для расчета налогов – необходима связь между этими черными ящиками: размер заработанной платы требуется для расчета налогов);
• связи между черными ящиками должны быть простыми, насколько это возможно, для обеспечения независимости между ними.
Второй важной идеей, лежащей в основе структурных методов, является идея иерархии. нотации, также служащие для облегчения понятия сути сложных систем.
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами. Диаграммы потоков данных известны очень давно.
ПОТОКИ ДАННЫХ являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним – двунаправленным.
Назначение ПРОЦЕССА состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, ВЫЧИСЛИТЬ МАКСИМАЛЬНУЮ ВЫСОТУ). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
ХРАНИЛИЩЕ (НАКОПИТЕЛЬ) ДАННЫХ позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет "срезы" потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
ВНЕШНЯЯ СУЩНОСТЬ (или ТЕРМИНАТОР) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ, Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке.
Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных.
Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями, что дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний:
описанием значений потоков и хранилищ, изображенных на DFD;
описанием композиции агрегатов данных, движущихся вдоль потоков, т.е. комплексных данных, которые могут расчленяться на элементарные символы (например, АДРЕС ПОКУПАТЕЛЯ содержит ПОЧТОВЫЙ ИНДЕКС, ГОРОД, УЛИЦУ и т.д.);
описанием композиции групповых данных в хранилище;
специфицированием значений и областей действия элементарных фрагментов информации в потоках данных и хранилищах;
описанием деталей отношений между хранилищами.
По типу потока в словаре содержится информация, идентифицирующая:
простые (элементарные) или групповые (комплексные) потоки; внутренние (существующие только внутри системы) или внешние (связывающие систему с другими системами) потоки; потоки данных или потоки управления; непрерывные (принимающие любые значения в пределах определенного диапазона) или дискретные (принимающие определенные значения) потоки.
Рассмотрим некоторые наиболее часто используемые методы задания спецификаций процессов.
1.Структурированный естественный язык применяется для читабельного, строгого описания спецификаций процессов. Он является разумной комбинацией строгости языка программирования и читабельности естественного языка и состоит из подмножества слов, организованных в определенные логические структуры, арифметических выражений и диаграмм.
2.Таблицы решений
Структурированный естественный язык неприемлем да некоторых типов преобразований. Например, если действие зависит от нескольких переменных, которые в совокупности могут продуцировать большое число комбинаций, то его описание будет слишком запутанным и с большим числом уровней вложенности. Для описания подобных действий традиционно используются таблицы и деревья решений.
Проектирование спецификаций процессов с помощью таблиц решений (ТР) заключается в задании матрицы, отображающей множество входных условий во множество действий.
Таблица Решений состоит из двух частей. Верхняя часть таблицы используется для определения условий. Обычно условие является ЕСЛИ-частью оператора ЕСЛИ-ТО и требует ответа "да-нет". Однако иногда в условии может присутствовать и ограниченное множество значений, например, ЯВЛЯЕТСЯ ЛИ ДЛИНА СТРОКИ БОЛЬШЕЙ, МЕНЬШЕЙ ИЛИ РАВНОЙ ГРАНИЧНОМУ ЗНАЧЕНИЮ?
Нижняя часть Таблицы Решений используется для определения действий, т.е. ТО-части оператора ЕСЛИ-ТО. Так, в конструкции ЕСЛИ ИДЕТ ДОЖДЬ, ТО РАСКРЫТЬ ЗОНТ. ИДЕТ ДОЖДЬ является условием, а РАСКРЫТЬ ЗОНТ – действием.
Левая часть Таблицы Решений содержит собственно описание условий и действий, а в правой части перечисляются все возможные комбинации условий и, соответственно, указывается, какие конкретно действия и в какой последовательности выполняются, когда определенная комбинация условий имеет место.
3. Визуальные языки проектирования базируются на основных идеях структурного программирования и позволяют определять потоки управления с помощью специальных иерархически организованных схем. Одним из наиболее известных подходов к визуальному проектированию спецификаций является подход с использованием FLOW-форм. Каждый символ FLOW-формы имеет вид прямоугольника и может быть вписан в любой внутренний прямоугольник любого другого символа. Символы помечаются с помощью предложений на естественном языке или с использованием математической нотации.
Диаграммы "сущность-связь" (ERD) предназначены для разработки моделей данных и обеспечивают стандартный способ определения данных и отношений между ними. Фактически с помощью ERD осуществляется детализация хранилищ данных проектируемой системы, а также документируются сущности системы и способы их взаимодействия, включая идентификацию объектов, важных для предметной области (сущностей), свойств этих объектов (атрибутов) и их отношений с другими объектами (связей). Эти диаграммные техники используются прежде всего для проектирования реляционных баз данных (хотя также могут с успехом применяться и для моделирования как иерархических, так и сетевых баз данных).
СУЩНОСТЬ представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, идей, предметов и т.п.), обладающих общими атрибутами или характеристиками. Любой объект системы может быть представлен только одной сущностью, которая должна быть уникально идентифицирована. При этом имя сущности должно отражать тип или класс объекта, а не его конкретный экземпляр (например, АЭРОПОРТ, а не ВНУКОВО).
ОТНОШЕНИЕ в самом общем виде представляет собой связь между двумя и более сущностями. Именование отношения осуществляется с помощью грамматического оборота глагола (ИMEET, ОПРЕДЕЛЯЕТ, МОЖЕТ ВЛАДЕТЬ и т.п.).
Спецификации управления предназначены для моделирования и документирования аспектов систем, зависящих от времени или реакции на событие. Они позволяют осуществлять декомпозицию управляющих процессов и описывают отношения между входными и выходными управляющими потоками на управляющем процессе-предке. Для этой цели обычно используются диаграммы переходов состояний (STD).
С помощью STD можно моделировать последующее функционирование системы на основе ее предыдущего и текущего функционирования. Моделируемая система в любой заданный момент времени находится точно в одном из конечного множества состояний. С течением времени она может изменить свое состояние, при этом переходы между состояниями должны быть точно определены.
Модель требований описывает то, что должна делать проектируемая система без ссылок на то, как это реализуется.
Проектирование – это фаза ЖЦ, на которой вырабатывается, как реализуются требования пользователя, которые порождены и зафиксированы на фазе анализа. На этом этапе осуществляется построение модели реализации (или физической модели), демонстрирующей как система будет удовлетворять предъявленные к ней требования. Фактически структурное проектирование является мостом между структурным анализом и реализацией.
Техника структурных карт (схем) используется на этапе проектирования для того, чтобы продемонстрировать, каким образом системные требования будут отражаться комбинацией программных структур. При этом наиболее часто применяются две техники: структурные карты Константайна, предназначенные для описания отношений между модулями, и структурные карты Джексона, предназначенные для описания внутренней структуры модулей.
Структурные карты Константайна
Базовыми строительными блоками программной системы являются модули. Все виды модулей в любом языке программирования имеют ряд общих свойств, среди которых при проектировании важны следующие:
1) модуль состоит из множества операторов языка программирования, записанных последовательно;
2) модуль имеет имя, по которому к нему можно ссылаться как к единому фрагменту;
3) модуль может принимать и/или передавать данные как параметры в вызывающей последовательности или связывать данные через фиксированные ячейки.
4) Структурные карты Константайна являются моделью отношений иерархии между программными модулями. Структурные карты Джексона
Техника структурных карт Джексона основана на методологии структурного программирования Джексона. Эта техника позволяет осуществлять проектирование нижнего уровня структуры ПО и на этом этапе является близкой к традиционным блок-схемам.
Диаграмма Джексона включает объекты следующего типа:
1) структурный блок представляет частную функцию или блок кодов с одним входом и одним выходом.
2) Процедурный блок является специальным видом структурного блока, представляющим вызов ранее определенной процедуры.
3) Библиотечный блок аналогичен процедурному и представляет вызов библиотечного модуля.
Для взаимоувязывания блоков используются связи следующих типов:
- последовательная связь;
- параллельная связь;
- условная связь;
- итерационная связь.
Характеристики хорошей модели реализации
Структурные карты сами по себе ничего не говорят о качестве модели реализации, т.к. являются всего лишь инструментом для демонстрации структуры системы и составляющих ее модулей, а также их связи друг с другом.
Один из фундаментальных принципов структурного проектирования заключается в том, что большая система должна быть расчленена на обозримые модули. При этом существенными является то, что это расчленение должно быть выполнено таким образом, чтобы модули были как можно более независимыми (так называемый критерий сцепления) и чтобы каждый модуль выполнял единственную функцию (критерий связности). Существуют и другие принципы оценки и улучшения качества проекта на основе структурных карт. Однако сцепление и связность являются основными критериями.
Сцепление
Сцепление является мерой взаимозависимости модулей. В хорошем проекте сцепления должны быть минимизированы, т.е. модули должны быть слабо зависимыми настолько, насколько это возможно.
Связность
Связность – мера прочности соединения функциональных и информационных объектов внутри одного модуля. Выделяют следующие уровни связности:
- функциональная (функционально связный модуль содержит объекты, предназначенные для выполнения единственной задачи, пример: расчет заработной платы);
- последовательная (модуль имеет последовательную связность, если его объекты охватывают подзадачи, для которых выходные данные одной из подзадач служат входными данными для следующей, пример: открыть файл – прочитать запись – закрыть файл);
- информационная (информационно связный модуль содержит объекты, использующие одни и те же входные или выходные данные);
- процедурная (процедурно связный модуль является модулем, объекты которого включены в различные подзадачи, в которых управление переходит от каждой подзадачи к последующей, пример: последовательность утренних процедур);
- временная (временно связным модулем является модуль, объекты которого включены в подзадачи, связанные временем исполнения, пример: установившаяся последовательность действий перед сном);
- логическая (модулем с логической связностью является модуль объекты которого содействуют решению общей подзадачи, для которой эти объекты отобраны во внешнем по отношению к модулю мире, пример: чем ехать до места отдыха (поехать автомобилем, поехать поездом, поплыть на корабле, полететь самолетом));
- случайная (случайно связным модулем является модуль, объекты которого соответствуют подзадачам, незначительно связанным друг с другом, пример: 1.Ремонтировать автомобиль 2.Пить пиво. 3.Смотреть телевизор).
№4
Методология структурного анализа и проектирования ПО определяет шаги работы, которые должны быть выполнены, их последовательность, правила распределения и назначения операций и методов. В настоящее время успешно используются такие методологии, как SADT (Structure Analysis and Design Technique), структурный системный анализ Гейна-Сарсона, структурный анализ и проектирование Йодана/Де Марко, развитие систем Джексона и другие.
Перечисленные структурные методологии жестко регламентируют фазы анализа требований и проектирования спецификаций и отражают подход к разработке ПО с позиций рецептов "кулинарной книги".
Несмотря на достаточно широкий спектр используемых методов и диаграммных техник, большинство методологий базируется на следующей "классической" совокупности:
- Диаграммы потоков данных в нотации Йодана/Де Марко или Гейна-Сарсона, обеспечивающие анализ требований и функциональное проектирование информационных систем;
- Расширения Хатли и Уорда-Меллора для проектирования систем реального времени, основанные на диаграммах переходов состояний, таблицах решений, картах и схемах потоков управления;
- Диаграммы "сущность-связь" (в нотации Чена или Баркера) для проектирования структур данных, схем БД, форматов файлов как части всего проекта;
- Структурные карты Джексона и/или Константайна для проектирования межмодульных взаимодействий и внутренней структуры модулей.
Методологии структурного анализа Йодана/Де Марко и Гейна-Сарсона
Обе методологии фокусируют внимание на потоках данных, их главное назначение – создание базированных на графике документов по функциональным требованиям. Методологии поддерживаются традиционными нисходящими методами проектирования спецификаций и обеспечивают один из лучших способов связи между аналитиками, разработчиками и пользователями системы. При это используются следующие средства:
DFD-диаграммы потоков данных. Являются графическими иерархическими спецификациями, описывающими систему с позиций потоков данных.
Словари данных. Являются каталогами всех элементов данных, присутствующих в DFD, включая групповые и индивидуальные потоки данных, хранилища и процессы, а также все их атрибуты.
Миниспецификации обработки, описывающие DFD-процессы нижнего уровня и являющиеся базой для кодогенерации. Фактически миниспецификации представляют собой алгоритмы описания задач, выполняемых процессами. Множество всех миниспецификаций является полной спецификацией системы.
Отметим, что DFD моделируют функции, которые система должна выполнять, но ничего (или почти ничего) не сообщают об отношениях между данными, а также о поведении системы в зависимости от времени – для этой цели методологии используют диаграммы "сущность-связь" и диаграммы переходов состояний.
Главной отличительной чертой методологии Гейна-Сарсона является наличие этапа моделирования данных, определяющего содержимое хранилищ данных (БД и файлов) в DFD в Третьей нормальной Форме.
SADT – одна из самых известных методологий анализа и проектирования информационных систем, введенная в 1973 году Россом.
С точки зрения SADT модель может основываться либо на функциях системы, либо на ее предметах (планах, данных, оборудовании, информации и т.д.). Соответствующие модели принято называть функциональными моделями и моделями данных. Функциональная модель представляет с нужной степенью подробности систему активностей, которые в свою очередь отражают свои взаимоотношения через предметы системы. Модели данных дуальны к функциональным моделям и представляют собой подробное описание предметов системы. Полная методология SADT заключается в построении моделей обеих типов для более точного описания сложной системы. Однако, в настоящее время широкое применение нашли только функциональные модели.
Методология SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Функциональная модель SADT отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями. Основные элементы этой методологии основываются на следующих концепциях:
· графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы отображает функцию в виде блока, а интерфейсы входа/выхода представляются дугами, соответственно входящими в блок и выходящими из него. Взаимодействие блоков друг с другом описываются посредством интерфейсных дуг, выражающих "ограничения", которые в свою очередь определяют, когда и каким образом функции выполняются и управляются;
· строгость и точность. Выполнение правил SADT требует достаточной строгости и точности, не накладывая в то же время чрезмерных ограничений на действия аналитика. Правила SADT включают:
· ограничение количества блоков на каждом уровне декомпозиции (правило 3-6 блоков);
· связность диаграмм (номера блоков);
· уникальность меток и наименований (отсутствие повторяющихся имен);
· синтаксические правила для графики (блоков и дуг);
Методология SADT может использоваться для моделирования широкого круга систем и определения требований и функций, а затем для разработки системы, которая удовлетворяет этим требованиям и реализует эти функции. Для уже существующих систем SADT может быть использована для анализа функций, выполняемых системой, а также для указания механизмов, посредством которых они осуществляются.
Результатом применения методологии SADT является модель, которая состоит из диаграмм, фрагментов текстов и глоссария, имеющих ссылки друг на друга. Диаграммы – главные компоненты модели, все функции ИС и интерфейсы на них представлены как блоки и дуги. Место соединения дуги с блоком определяет тип интерфейса. Управляющая информация входит в блок сверху, в то время как информация, которая подвергается обработке, показана с левой стороны блока, а результаты выхода показаны с правой стороны. Механизм (человек или автоматизированная система), который осуществляет операцию, представляется дугой, входящей в блок снизу (рисунок 1).
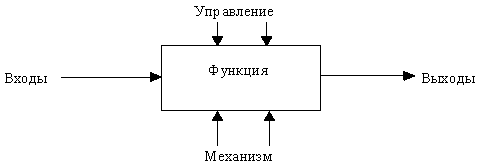
Рис. 1 Функциональный блок и интерфейсные дуги
Одной из наиболее важных особенностей методологии SADT является постепенное введение все больших уровней детализации по мере создания диаграмм, отображающих модель.
На рисунке 2, где приведены четыре диаграммы и их взаимосвязи, показана структура SADT-модели. Каждый компонент модели может быть декомпозирован на другой диаграмме. Каждая диаграмма иллюстрирует "внутреннее строение" блока на родительской диаграмме.
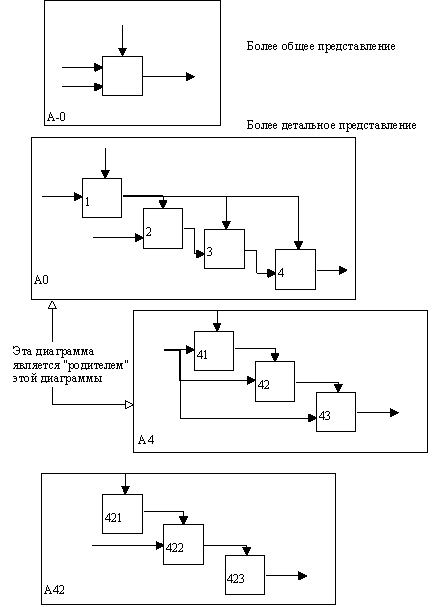
Рис. 2 Структура SADT-модели. Декомпозиция диаграмм
№ 5
Создание современных информационных систем (ИС) представляет собой сложную задачу, решение которой требует применения специальных методик и инструментов. В последнее время значительно вырос интерес к CASE (Computer-Aided Software/System Engineering) - технологиям и инструментальным CASE-средствам, позволяющим максимально систематизировать и автоматизировать все этапы разработки программного обеспечения. В качестве примера можно привести CASE-средство ERwin фирмы PLATINUM technology, S-Designer фирмы Sybase, Rational Rose компании Rational Software.
Одним из достоинств многих CASE-средств является возможность в наглядной форме моделировать предметную область, прежде чем начинать ее программную разработку, т.е. строить так называемые визуальные модели. Сложность разрабатываемых систем продолжает увеличиваться, а визуальные модели ИС позволяют обеспечивать ясность представления выбранных архитектурных решений и понять разрабатываемую систему во всей ее полноте, наладить плодотворное взаимодействие между заказчиками, пользователями и командой разработчиков.
Под термином CASE-средства понимаются программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований, проектирование прикладного ПО (приложений) и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы. CASE-средства вместе с системным ПО и техническими средствами образуют полную среду разработки ИС.
CASE-средства подразделяются на логическое проектирование БД и физическое проектирование.
Цель моделирования данных на логическом уровне состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных. Логическая модель данных может быть построена на основе другой логической модели, например модели процессов.
На логическом уровне проектирования строится так называемая визуальная модель объекта. Визуальные модели обеспечивают ясность представления выбранных архитектурных решений и позволяют понять разрабатываемую систему во всей ее полноте. Построение визуальных моделей позволяет решить сразу несколько типичных проблем. Во-первых, и это главное, технология визуального моделирования, позволяет работать со сложными и очень сложными системами и проектами.
Во-вторых, визуальные модели позволяют содержательно организовать общение между заказчиками и разработчиками.
Визуальное моделирование не способно раз и навсегда решить все проблемы, однако его использование существенно облегчает достижения таких целей как:
· повышение качества программного продукта,
· сокращение стоимости проекта,
· поставка системы в запланированные сроки.
Построение модели данных предполагает определение сущностей и атрибутов, т.е. необходимо определить, какая информация будет храниться в конкретной сущности или атрибуте. Сущность можно определить как объект, событие или концепцию, информация о которых должна сохраняться.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой. Имя связи выражает некоторое ограничение или правило и облегчает чтение диаграммы.
На физическом уровне – данные, напротив, зависят от конкретной СУБД, фактически являясь отображением системного каталога. В физической модели содержится информация обо всех объектах БД. Они подразделяются на:
Иерархические БД состоят из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного “ корневого” типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждый из которых является некоторым типом дерева). Сетевые модели создавались для мало ресурсных ЭВМ.
Сетевой подход к организации данных является расширением иерархического. В этой модели потомок может иметь любое число предков. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из наборов экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка.
Сегодня наиболее распространены реляционные (основанные на двумерных таблицах) модели данных. Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или "отношений" в терминологии СУРБД). Каждое отношение (таблица) может быть представлено в виде прямоугольного массива со следующими свойствами:
· каждая ячейка в таблице представляет точно один элемент данных; нет повторяющихся групп;
· каждая таблица имеет однородные столбцы; все элементы в любом из столбцов одного и того же вида;
· каждому столбцу назначено определенное имя;
· все строки различны; дублировать строки не разрешается;
· и строки, и столбцы не зависят от последовательности; просмотр в различной последовательности не может изменить информационное содержание отношения;
· каждая строка олицетворяет уникальный элемент данных, который ею и описывается;
· столбцы представляют собой отдельные куски информации (атрибуты данных), которые известны о данном элементе.
Объектно-ориентированные базы данных относительно новы, теория баз данных не имеет такой хорошей математической основы как реляционные или древовидные модели. Тем не менее, это не должно обязательно рассматриваться как признаки слабости, присущие данной технологии моделирования.
№6
Классификация архитектур информационных приложений
Традиционные архитектурные решения, основанных на использовании выделенных файл-серверов или серверов баз данных.
Архитектуры корпоративных информационных систем, базирующихся на технологии Internet (Intranet-приложения). Следующая разновидность архитектуры информационной системы основывается на концепции "склада данных" (DataWarehouse) - интегрированной информационной среды, включающей разнородные информационные ресурсы. Архитектура предназначена для построения глобальных распределенных информационных приложений с интеграцией информационно-вычислительных компонентов на основе объектно-ориентированного подхода.
· Файл-серверной информационной системой называют систему, которая в основном базируется на персональных компьютерах, используя в качестве внешней поддержки один или несколько файловых серверов, обеспечивающих значительные возможности управления внешней памятью, но не обладающих "интеллектом", поддерживая в основном только управление файлами. Практически во всех файл-серверных средствах и методологиях имеется тенденция к переходу к технологии "клиент-сервер". Приложения, созданные с использованием инструментальных средств программирования приложений, связанных с использованием баз данных на персональных компьютерах, занимают существенную долю файл-серверных приложений.
Новые СУБД для персональных компьютеров и соответствующие инструментальные средства разработки файл-серверных приложений обладают перечисленными ниже общими чертами.
· Визуальный характер программирования приложений особенно в части создания диалогового графического интерфейса пользователя. Это множество поддерживаемых диалоговых объектов, поддержка механизма drag-and-drop и наличие мастеров, помогающих реализовать сложные процедуры.
· Управляемость приложений в соответствии с событиями диалога и обеспечение доступа к БД позволяет строить гибкий интерфейс пользователя и поддерживать ссылочную целостность БД.
· Имеется возможность построения приложений клиент-сервер за счет реализации доступа к серверам БД напрямую или через интерфейс ODBC для открытого взаимодействия с базами данных.
· Использование объектно-ориентированного языка разработки приложений (по крайней мере в части диалога) позволяет широко использовать механизм наследования и тем самым использовать ранее произведенные программные компоненты.
· "Истинно реляционная" база данных представляет собой объединенный набор файлов, содержащий таблицы, индексы и т.п., что облегчает сопровождение БД и приложений и является основой для поддержки целостности данных.
· Поддерживается общий для информационной системы словарь данных (data dictionary), который содержит описание структуры БД, типы полей, правила поддержки ограничений целостности и т.п.
· Поддержка целостности БД (данных, ссылок и транзакций) позволяет создавать приложения с необходимым уровнем надежности и сохранности данных.
· Хранение в БД описания проекта создаваемого приложения является прообразом репозитория инструментальных средств быстрой разработки RAD и CASE-систем.
Теория графов
Граф (от греческого gr a jw - пишу) - множество V вершин и набор E неупорядоченных и упорядоченных пар вершин; обычно граф обозначают как G(V, E).
Неупорядоченная пара вершин называется ребром, упорядоченная пара - дугой.
Граф, содержащий только ребра, называется неориентированным; граф, содержащий только дуги - ориентированным (или орграфом).
Пара вершин может быть соединена двумя или более ребрами (или, соответственно, дугами одного направления), такие ребра (или дуги) называются кратными.
Дуга (или ребро) может начинаться и заканчиваться в одной и той же вершине, в этом случае соотв. дуга (или ребро) называется петлей.
Вершины, соединенные ребром или дугой, называются смежными.
Ребра, имеющие общую вершину, тоже называются смежными.
Ребро (или дуга) и любая из его вершин называются инцидентными.
Принято говорить, что ребро (u, v) соединяет вершины u и v, а дуга (u, v) начинается в вершине u и кончается в вершине v. Каждый граф можно представить в евклидовом пространстве множеством точек, соответствующих вершинам, которые соединены линиями, соответствующими ребрам (или дугам - в последнем случае направление обычно указывается стрелочками). - такое представление называется укладкой графа. Доказано, что в 3-мерном пространстве любой граф можно представить в виде укладки таким образом, что линии, соответствующие ребрам (дугам) не будут пересекаться во внутренних точках. Для 2-мерного пространства это, вообще говоря, неверно. Допускают представление в виде укладки в 2-мерном пространстве графы, называемые плоскими. Матрицей инцидентности графа G называется матрица B=||bij||, i=1, .., n; j = 1, ..., m, у которой элемент bij равен 1, если вершина vi инцидентна ребру (дуге) ej и равен 0, если не инцидентна.
Наконец, граф можно задать посредством списков. Например,
вариант 1: списком пар вершин, соединенных ребрами (или дугами);
вариант 2: списком списков для каждой вершины множества смежных с ней вершин.
Метод анализа иерархий имеет аналогии с теорией графов.
Задачи принятия решения можно рассмотреть следующим образом.
Пусть имеются:
1. несколько однотипных альтернатив (объектов, действий и т.п.),
2. главный критерий (главная цель) сравнения альтернатив,
3. несколько групп однотипных факторов (частных критериев, объектов, действий и т.п.), влияющих известным образом на отбор альтернатив.
Требуется каждой альтернативе поставить в соответствие приоритет (число) – получить рейтинг альтернатив. Причем чем более предпочтительна альтернатива по избранному критерию, тем больше ее приоритет. Принятие решений основывается на величинах приоритетов
Структура ситуации принятия решения представляется в методе анализа иерархий в виде направленного графа. Узлами графа служат: альтернативы, главный критерий рейтингования альтернатив, факторы, влияющие на рейтинг альтернатив. Направленными дугами графа являются связи, указывающие на влияния одних узлов, на приоритеты других узлов
№ 7
Применительно к системам баз данных архитектура "клиент-сервер" интересна и актуальна главным образом потому, что обеспечивает простое и относительно дешевое решение проблемы коллективного доступа к базам данных в локальной сети. В некотором роде системы баз данных, основанные на архитектуре "клиент-сервер", являются приближением к распределенным системам баз данных, конечно, существенно упрощенным приближением, но зато не требующим решения основного набора проблем действительно распределенных баз данных.
Для системы, основанной на архитектуре "клиент-сервер" актуальны программные пакеты, реализующие протоколы удаленного вызова процедур (RPC - Remote Procedure Call). При использовании таких средств обращение к сервису в удаленном узле выглядит как обычный вызов процедуры. Средства RPC, в которых, естественно, содержится вся информация о специфике аппаратуры локальной сети и сетевых протоколов, переводит вызов в последовательность сетевых взаимодействий.
Обобщенная Архитектура построения Брокеров Объектных Запросов разработана для поддержки интеграции самых разнообразных объектных систем. Спецификация CORBA устанавливает принципы создания Брокеров Объектных Запросов, которые и допускают такую интеграцию.
Собственно, идея CORBA довольно проста. Она заключается в следующем. Во-первых, в каждый объект, который должен быть включен в интегрированную объектную систему добавляется специальный программный код, обеспечивающий принципиальную возможность взаимодействия объектов. Этот код генерируется автоматически за счет использования определенного OMG языка определения объектных интерфейсов IDL (Interface Definition Language). В исходный текст программы включаются спецификации интерфейса на языке IDL. Затем этот текст должен быть обработан специальным предкомпилятором, который и генерирует дополнительный программный код. Заметим, что на сегодняшний день в документах OMG определены правила встраивания конструкций IDL в далеко не все языки программирования, но, по крайней мере, определены правила встраивания для таких популярных языков как Си и Си++.
Во-вторых, для реального взаимодействия должным образом настроенных объектов предполагается наличие специального программного обеспечения, называемого в документах OMG брокером объектных заявок (ORB - Object Request Broker). Брокер объектных заявок должен существовать и на стороне вызывающего объекта, и на стороне вызываемого объекта. Основная задача ORB состоит в том, чтобы доставить заявку на вызов метода вызываемого объекта и возвратить результаты выполнения метода вызываемому объекту.
Intranet-приложение - это корпоративная система, для организации которой используются механизмы Internet. Intranet-система может основываться на локальной сети компьютеров, собственной корпоративной глобальной сети или виртуальной корпоративной подсети Internet. Различают несколько типов Intranet-систем, для реализации каждого из которых, вообще говоря, применяются разные средства:
1. Коммуникационные Intranet-системы предназначены главным образом для связывания территориально разнесенных подразделений корпорации, уменьшая потребность в многочисленных выделенных линиях связи. При реализации систем этого типа следует обращать особое внимание на эффективность, соответствие стандартам и управляемость системы.
2. Интегрирующие Intranet-системы служат для интеграции разнородных существующих коммуникационных и обрабатывающих корпоративных подсистем. С этой точки зрения достоинством Intranet-системы является поддержка общего интерфейса доступа к "унаследованным" системам и установление связи между ними за счет понимаемого всеми гипертекстового представления информации.
3. Если от Intranet-системы требуется обеспечение широкого доступа к большим объемам информации, в частности, мультимедийной, то особое внимание требуется уделить выбору базового сервера баз данных. Нужно учитывать возможности сервера по части управления очень большими данными и поддержки сложных типов данных.
4. Intranet-системы с упрощенной для пользователей процедурой доступа обычно основываются на механизме электронной подписи. Такие системы должны быть особенно надежно защищены от внешнего мира.
Поскольку для разработки Intranet-систем используются методы и средства Internet, и главным образом, технология WWW, то и понятия и термины Internet и Intranet совпадают. Приведем некоторые из них:
HTTP (HyperText Transfer Protocol) - протокол обмена гипертекстовой информацией;
URL (Universal Resource Locator) - универсальный локатор ресурсов. Используется в качестве универсальной схемы адресации ресурсов в сети.
HTML (HyperText Markup Language) - язык гипертекстовой разметки документов. Специальная форма подготовки документов для их опубликования в World Wide Web.
CGI (Common Gateway Interface) - спецификация на формат обмена данными между сервером протокола HTTP и прикладной программой.
API (Application Program Interface) - в данном контексте это спецификация, определяющая правила обмена данными между сервером и программным модулем, который должен быть включен в состав сервера.
VRML (Virtual Reality Modeling Language) - язык описания трехмерных сцен и взаимодействия трехмерных объектов.
Javaapplets - мобильные (независимые от архитектуры "железа") программные коды, написанные на языке программирования Java.
Java - объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems и используемый в качестве основного средства мобильного программирования.
MIME (Multipurpose Internet Mail Exchange) - формат почтового сообщения Internet. В данном контексте стандарт MIME используется для установления соответствия между типом информационного файла, именем этого файла и программой просмотра этого файла.
CCI (Common Client Interface) - спецификация обмена данными меду прикладной программой и браузером Mosaic. В случае применения программного обеспечения, выполненного согласно CCI, браузер превращается в сервер-посредник для программного обеспечения пользователя.
Метод Монте-Карло (метод статистических испытаний) – численный метод решения математических задач при помощи моделирования случайных чисел. Суть метода: посредством специальной программы на ЭВМ вырабатывается последовательность псевдослучайных чисел с равномерным законом распределения от 0 до1. Затем данные числа с помощью специальных программ преобразуются в числа, распределенные по закону Эрланга, Пуассона, Релея и т.д. Полученные таким образом случайные числа используются в качестве входных параметров экономических систем. При многократном моделировании случайных чисел определяем математическое ожидание функции и, при достижении средним значением функции уравнения не ниже заданного, прекращаем моделирование.
Статистические испытания (метод Монте-Карло) характеризуются основными параметрами:
D - заданная точность моделирования;
P – вероятность достижения заданной точности;
N – количество необходимых испытаний для получения заданной точности с заданной вероятностью.
Определим необходимое число реализаций N, тогда
(1 - D) будет вероятность того, что при одном испытании результат не достигает заданной точности D;
(1 - D) N – вероятность того, что при N испытаниях мы не получим заданной точности D.
Тогда вероятность получения заданной точности при N испытаниях можно найти по формуле
![]()
Формула позволяет определить заданное число испытаний для достижения заданной точности D с заданной вероятностью Р.Случайные числа получаются в ЭВМ с помощью специальных математических программ или спомощью физических датчиков. Одним из принципов получения случайных чисел является алгоритм Неймана, когда из одного случайного числа последовательно выбирается середина квадрата. Кроме того данные числа проверяются на случайность и полученные числа заносятся в базу данных. Физические датчики разрабатываются на электронных схемах и представляют собой генераторы белого (нормального) шума, то есть когда в спектральном составе шума имеются гармоничные составляющие с частотой F ®¥. Из данного белого шума методом преобразования получаются случайные числа.
№ 8
Объектно-ориентированные CASE-средства (Rational Rose)
Rational Rose - CASE-средство фирмы Rational Software Corporation (США) - предназначено для автоматизации этапов анализа и проектирования программного обеспечения, а также для генерации кодов на различных языках и выпуска проектной документации. Rational Rose использует синтез-методологию объектно-ориентированного анализа и проектирования, основанную на подходах трех ведущих специалистов в данной области: Буча, Рамбо и Джекобсона. Разработанная ими универсальная нотация для моделирования объектов (UML - Unified Modeling Language) претендует на роль стандарта в области объектно-ориентированного анализа и проектирования. Конкретный вариант Rational Rose определяется языком, на котором генерируются коды программ (Си++, Smalltalk, PowerBuilder, Ada, SQLWindows и ObjectPro). Основной вариант - Rational Rose/Си++ - позволяет разрабатывать проектную документацию в виде диаграмм и спецификаций, а также генерировать программные коды на Си++. Кроме того, Rational Rose содержит средства реинжиниринга программ, обеспечивающие повторное использование программных компонент в новых проектах.
Структура и функции
В основе работы Rational Rose лежит построение различного рода диаграмм и спецификаций, определяющих логическую и физическую структуры модели, ее статические и динамические аспекты. В их число входят диаграммы классов, состояний, сценариев, модулей, процессов.
В составе Rational Rose можно выделить 6 основных структурных компонент: репозиторий, графический интерфейс пользователя, средства просмотра проекта (browser), средства контроля проекта, средства сбора статистики и генератор документов. К ним добавляются генератор кодов (индивидуальный для каждого языка) и анализатор для Си++, обеспечивающий реинжиниринг - восстановление модели проекта по исходным текстам программ.
Репозиторий представляет собой объектно-ориентированную базу данных. Средства просмотра обеспечивают "навигацию" по проекту, в том числе, перемещение по иерархиям классов и подсистем, переключение от одного вида диаграмм к другому и т. д. Средства автоматической генерации кодов программ на языке Си++, используя информацию, содержащуюся в логической и физической моделях проекта, формируют файлы заголовков и файлы описаний классов и объектов. Создаваемый таким образом скелет программы может быть уточнен путем прямого программирования на языке Си++. Анализатор кодов Си++ реализован в виде отдельного программного модуля. Его назначение состоит в том, чтобы создавать модули проектов в форме Rational Rose на основе информации, содержащейся в определяемых пользователем исходных текстах на Си++. В процессе работы анализатор осуществляет контроль правильности исходных текстов и диагностику ошибок. Модель, полученная в результате его работы, может целиком или фрагментарно использоваться в различных проектах. Анализатор обладает широкими возможностями настройки по входу и выходу. Например, можно определить типы исходных файлов, базовый компилятор, задать, какая информация должна быть включена в формируемую модель и какие элементы выходной модели следует выводить на экран. Таким образом, Rational Rose/Си++ обеспечивает возможность повторного использования программных компонент.
В результате разработки проекта с помощью CASE-средства Rational Rose формируются следующие документы:
· диаграммы классов;
· диаграммы состояний;
· диаграммы сценариев;
· диаграммы модулей;
· диаграммы процессов;
· спецификации классов, объектов, атрибутов и операций
· заготовки текстов программ;
· модель разрабатываемой программной системы.
№9
Реляционные системы управления базами данных являются ограниченными. Они идеально походят для таких традиционных приложений, как системы резервирования билетов или мест в гостиницах, а также банковских систем, но их применение в системах автоматизации проектирования, интеллектуальных производственных системах и других системах, основанных на знаниях, часто является затруднительным. Это, прежде всего, связано с примитивностью структур данных, лежащих в основе реляционной модели данных. Плоские нормализованные отношения универсальны и теоретически достаточны для представления данных любой предметной области. Однако в нетрадиционных приложениях в базе данных появляются сотни, если не тысячи таблиц, над которыми постоянно выполняются дорогостоящие операции соединения, необходимые для воссоздания сложных структур данных, присущих предметной области.
Другим серьезным ограничением реляционных систем являются их относительно слабые возможности по части представления семантики приложения. Самое большее, что обеспечивают реляционные СУБД – это возможность формулирования и поддержки ограничений целостности данных. Осознавая эти ограничения и недостатки реляционных систем, исследователи в области баз данных выполняют многочисленные проекты, основанные на идеях, выходящих за пределы реляционной модели данных.
В качестве других недостатков реляционных СУБД отмечаются следующие:
· негибкость структуры для развивающихся БД,
· затруднения в построении концептуальной модели для объектов с многочисленными связями “многие – ко – многим”,
· неестественность табличного представления для разреженных массивов данных.
Объектно-ориентированные базы данных относительно новы, теория баз данных не имеет такой хорошей математической основы как реляционные или древовидные модели. Тем не менее, это не должно обязательно рассматриваться как признаки слабости, присущие данной технологии моделирования. Свойства, представляющиеся общими для большинства реализаций БД, таковы:
1. Абстракция: Каждая реальная "вещь", которая хранится в БД, является членом какого-либо класса. Класс определяется как совокупность свойств, методов, общедоступных и частных структур данных, а также программы, применимых к объектам (экземплярам) данного класса. Классы представляют собой ни что иное, как абстрактные типы данных. Методы - это процедуры, которые вызываются для того, чтобы произвести какие-либо действия с объектом (например, напечатать себя или скопировать себя). Свойства - это значения данных, связанные с каждым объектом класса, характеризующие его тем или иным образом (например, цвет, возраст).
2. Инкапсуляция: Внутреннее представление данных и деталей реализации общедоступных и частных методов (программ) является частью определения класса и известно только внутри этого класса. Доступ к объектам класса разрешен только через свойства и методы этого класса или его родителей (см. ниже "наследование"), а не путем использования знания подробностей внутренней реализации.
3. Наследование (одиночное или множественное): Классы определены как часть иерархии классов. Определение каждого класса более низкого уровня наследует свойства и методы его родителя, если они только они явно не объявлены ненаследуемыми или изменены новым определением. При одиночном наследовании класс может иметь только один родительский класс (т.е. классовая иерархия имеет древовидную структуру). При множественном наследовании класс может происходить от многочисленных родителей (т.е. иерархия классов имеет структуру ориентированного нециклического графа, не обязательно древовидную).
4. Полиморфизм: Несколько классов могут иметь совпадающие имена методов и свойств, даже если они считаются различными. Это позволяет писать методы доступа, которые будут правильно работать с объектами совершенно различных классов, лишь бы соответствующие методы и свойства были в этих классах определены.
5. Сообщения: Взаимодействие с объектами осуществляется путем посылки сообщений с возможностью получения ответов.
Каждый объект, информация о котором хранится в ООБД, считается принадлежащим какому-либо классу, а связи между классами устанавливаются при помощи свойств и методов классов.
Модель ООБД находится на более высоком уровне абстракции, чем реляционные или древовидные БД, поэтому классы можно реализовать, опираясь либо на одну из этих моделей, либо на какую-нибудь еще. Поскольку в центре разработки оказываются не структуры данных, а процедуры (методы), важно, чтобы выбиралась базовая модель, которая обеспечивает достаточную прочность, гибкость и производительность обработки.
Реляционные БД с их строгим определением структуры и ограниченным набором разрешенных операций, бесспорно, не подходят в качестве базовой платформы для ООБД. Более приспособленной для использования в качестве базовой платформы для СУООБД представляется система М-языка с ее более гибкой структурой данных и более процедурным подходом к разработке.
№10
В Cache' реализована концепция Единой архитектуры данных. К одним и тем же данным, хранящимся под управлением Сервера многомерных данных Cache' есть три способа доступа: прямой, объектный и реляционный:
Cache' Direct Access - прямой доступ к данным, обеспечивает максимальную производительность и полный контроль со стороны программиста. Разработчики приложений получают возможность работать напрямую со структурами хранения. Использование этого типа доступа накладывает определенные требования на квалификацию разработчиков, но понимание структуры хранения данных в Cache' позволяет оптимизировать хранение данных приложения и создавать сверхбыстрые алгоритмы обработки данных.
Cache' SQL - реляционный доступ, обеспечивающий максимальную производительность реляционных приложений с использованием встроенного SQL. Cache' SQL соответствует стандарту SQL 92. Кроме этого, разработчик может использовать разные типы триггеров и хранимых процедур. Все это позволяет Cache' успешно конкурировать с реляционными СУБД. Даже без использования прямого и объектного доступа приложения на Cache' работают быстрее за счет высокой производительности Сервера многомерных данных.
Cache' Objects - объектный доступ, для максимальной продуктивности разработки при использовании Java, EJB, C++, а также VB и других ActiveX-совместимых средств разработки, таких как PowerBuilder и Delphi. В Cache' реализована объектная модель в соответствии с рекомендациями ODMG (Группа управления объектными базами данных – Object Database Management Group). В Cache' полностью поддерживаются наследование (в том числе и множественное), инкапсуляция и полиморфизм. При создании информационной системы разработчик получает возможность использовать объектно-ориентированный подход к разработке, моделируя предметную область в виде совокупности классов объектов, в которых хранятся данные (свойства классов) и поведение классов (методы классов). Cache', поддерживая объектную модель данных, позволяет естественным образом использовать объектно-ориентированный подход как при проектировании (в Rational Rose) предметной области, так и при реализации приложений в ОО-средствах разработки (Java, C++, Delphi, VB). Постреляционная СУБД Cache' конкурирует с объектными СУБД, значительно превосходя их по таким показателям как надежность, производительность и удобство разработки.
№ 11
а) Задача проектирования АИС промышленных предприятий сложная, т.к. характер обрабатываемой информации еще разнороден и сложно формализуем. Однако и здесь можно выделить основную модель работы - это работа "от кода проекта". В общем случае код проекта представляет собой аналог (функциональный) лицевого счета, он имеет определенную разрядность, порядок (т.е. конкретная группа цифро-буквенного обозначения характеризует деталь, сборочную единицу, изделие и их уровень взаимосвязи). Причем конкретная часть кода характеризует технологические, конструкторские, финансовые и др. документы. Все это регламентируется соответствующими ГОСТами (аналог инструкций ЦБ для банков), поэтому может быть формализовано. При этом модульный подход к реализации АИС в этом случае еще более важен. Двойственный подход к формированию ежедневного производственного плана лег в основу т.н. "принципа дуализма" для АИС промышленных предприятий. Реализация принципа дуализма неизбежно также требовала построения АИС предприятий нового поколения в виде программных модулей, органически связанных между собой, но в то же время способных работать и автономно.
Такая многокомпонентная система обеспечивала соблюдение основополагающего принципа построения автоматизированных информационных систем - отсутствия дублирования ввода исходных данных. Информация по операциям, проведенным с применением одного из компонентов системы, могла быть использована любым другим ее компонентом. Модульность построения АИС нового поколения и принцип одноразового ввода дают возможность гибко варьировать конфигурацией этих систем. Так, в банках, имеющих разветвленную филиальную сеть и не передающих данные в режиме реального времени, установка всего СПО во всех филиалах не всегда экономически оправдано. В этих случаях возможна эксплуатация в филиалах ПО общего назначения, предназначенного для первичного ввода информации и последующей автоматизированной обработки данных в СПО, установленном в головном офисе банка. Такая структура дает возможность органически включить в АБС нового поколения компонент для создания хранилища данных, разделяя системы оперативного действия и системы поддержки принятия решения.
б) Одноканальная система массового обслуживания с накопителем, многоканальная система массового обслуживания с накопителем.
Рассмотрим общую схему системы массового обслуживания для разомкнутых смешанных систем. Она состоит из обслуживающей и обслуживаемой систем. Обслуживаемая система включает совокупность источников требований и водящего потока требований. Требование -каждый отдельный запрос на выполнение какой-либо работы (на производство услуги). Источник требования - объект (человек, механизм и т.д.), который может послать в обслуживающую систему одновременно только одно требование Обслуживающая система состоит из накопителя и механизма обслуживания. Обслуживанием считается удовлетворение поступившего запроса на выполнение услуги. Механизм обслуживания состоит из нескольких обслуживаюших аппаратов. Обслуживающий аппарат - это часть механизма обслуживания. которая способна удовлетворить одновременно только одно требование (ремонтный рабочий или бригада, кран, экскаватор, пост мойки и т.д.). После окончания обслуживания требования покидают систему, образуя выходящей поток требований. Для моделирования СМОРС должны быть известны четыре ее параметра λ - плотность входящего потока, показывающая среднее число требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейший. μ -среднее число заявок обслуживаемых одним аппаратом в час (параметр разгрузки). Распределение интервалов обслуживания подчиняется показательному распределению N - чисто обслуживающих аппаратов. Будем полагать, что аппараты имеют одинаковую производительность обслуживания μ требований/час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требований поступающее в СМО в состоянии, когда буду т заняты все аппараты и все места в накопителе то требовании получает отказ в обслуживании и покидает систему массового обслуживания не обслуженным. В системе массового обслуживания постоянно протекают два случайные процесса:
- процесс загрузки обуотовтенный параметром λ
- процесс разгрузки обуотовтенный параметром μ
В результате чего СМО меняет свои состояния
Для расчета вероятностей состояний используется формула связывающая вероятности двух соседних состояний из графа состояний по следующему правилу: вероятность Рi равна вероятности предыдущего состояния Рi-1 умноженной на отношение показателя загрузки к показателю разгрузки Si-1 состояния.
![]()
Все вероятности связаны между собой, поэтому выразим их через Ро
![]()
![]()
Воспользуемся формулой:
![]()
Получим уравнение с одним неизвестным Ро. из которого и определим
![]()
№ 12
С общей позиции обработки данных можно выделить два доминирующих класса информационных систем: системы, ориентированные на операционную (транзакционную) обработку данных (On-Line Transaction Processing, OLTP-системы), часто их определяют как системы обработки данных (СОД); системы, ориентированные на аналитическую обработку данных (Decision Support Systems, DSS), или системы поддержки принятия решений (СППР).
СОД обеспечивают процессы повседневной рутинной обработки данных на конкретных рабочих местах или производственных участках.
СППР – являются вторичными по отношению к СОД и призваны осуществлять анализ результатов деятельности за различные периоды времени, оценку эффективности работы отдельных подразделений или сотрудников и другие аналитические процедуры. Дальнейшее развитие аналитических информационных систем связано с технологией оперативной аналитической обработки данных (On-Line Analytical Processing, OLAP-системы), в основе концепции которой лежит многомерное представление данных. В среде Delphi многомерные данные представляются в виде метакуба, где каждому фактору соответствует свое измерение. В конкретной ячейке, как правило, представляются агрегированные данные – сумма, среднее, максимальное значение – или новые многомерные данные (кубы)
OLAP-технология. Состав аналитической информационной системы.
Основная идея OLAP-технологии заключается в построении многомерных кубов данных, которые в дальнейшем можно использовать для реализации аналитических пользовательских запросов. Исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных, называемых также хранилищами данных (Data Warehouse). В отличие от оперативных баз данных, с которыми работают приложения ведения данных, хранилища данных предназначены исключительно для обработки и анализа информации, поэтому проектируются они таким образом, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных баз данных согласно определенному регламенту, например, раз в месяц, квартал или год. Типичная структура хранилища данных существенно отличается от структуры обычной реляционной БД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables). Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся: факты, связанные с транзакциями. Они основаны на отдельных событиях (например, телефонный звонок); факты, связанные с «моментальными снимками». Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за; факты, связанные с элементами документа. Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки); факты, связанные с событиями или состоянием объекта. Представляют возникновение события без подробностей о нем.
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений, чаще всего это целочисленные значения либо значения типа «дата/время». При этом как ключевые, так и некоторые не ключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные. Таблицы измерений содержат неизменяемые либо редко изменяемые данные Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем элемента измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации элемента измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного элемента в этой иерархии. Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов. Скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее. Одно измерение куба может содержаться как в одной таблице, так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда». Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка». Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами. Традиционно даже при наличии иерархических измерений с целью повышения скорости выполнения запросов к хранилищу данных предпочтение отдается схеме «звезда».
С общей позиции обработки данных можно выделить два доминирующих класса информационных систем: системы, ориентированные на операционную (транзакционную) обработку данных (On-Line Transaction Processing, OLTP-системы), часто их определяют как системы обработки данных (СОД); системы, ориентированные на аналитическую обработку данных (Decision Support Systems, DSS), или системы поддержки принятия решений (СППР).
СОД обеспечивают процессы повседневной рутинной обработки данных на конкретных рабочих местах или производственных участках.
СППР – являются вторичными по отношению к СОД и призваны осуществлять анализ результатов деятельности за различные периоды времени, оценку эффективности работы отдельных подразделений или сотрудников и другие аналитические процедуры. Дальнейшее развитие аналитических информационных систем связано с технологией оперативной аналитической обработки данных (On-Line Analytical Processing, OLAP-системы), в основе концепции которой лежит многомерное представление данных. В среде Delphi многомерные данные представляются в виде метакуба, где каждому фактору соответствует свое измерение. В конкретной ячейке, как правило, представляются агрегированные данные – сумма, среднее, максимальное значение – или новые многомерные данные (кубы)
OLTP-системы создаются для того, чтобы способствовать повседневной деятельности корпорации, и опираются на актуальные для текущего момента данные. OLAP-системы служат для анализа деятельности корпорации или ее компонентов и прогнозирования будущего состояния. Для этого требуется использовать многочисленные накопленные данные о деятельности корпорации в прошлом, а также внешние источники данных, формирующие контекст, в котором работала корпорация.
Система оперативной аналитической обработки данных отличается от статической системы поддержки принятия решений (DecisionSupportSystem - DSS) тем, что OLAP-система позволяет аналитику динамически формировать класс вопросов, который требуется для решаемой им текущей аналитической задачи. DSS обеспечивает выдачу отчетов в соответствии с заранее сформулированными правилами. Для удовлетворения нового запроса нужно формально его описать, запрограммировать и только потом выполнить. Данные могут иметь разные представления, а иногда могут быть даже несогласованными (например, из-за ошибки ввода в одну из баз данных).
Концепция хранилища данных:
1.Интеграция разъединенных детализированных данных (детализированных в том смысле, что описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
2.Разделение наборов данных, используемых для оперативной обработки, и наборов данных, применяемых для решения задач анализа.
Хранилище данных, содержит большие объемы разнородных данных и, обычно, большое количество “разнородных” потребителей. Для интенсификации общения специалистов, повышения эффективности анализа и сокращения сроков принятия решений, хранилище обязательно должно обладать средствами исключения семантических разрывов или минимизации времени на их преодоление. Такие системы принято называть подсистемами управления метаданными. Модель семантических разрывов может быть полезна в процессе анализа решений и проектирования подсистем управления метаданными. Семантический разрыв – это синоним непонимания информации, которая заключена в данных. Непонимание, в свою очередь, может быть полным, частичным, и … разным у разных пользователей или, например, у пользователей и “производителей” данных.
№13
Данные несут в себе сведения о событиях, произошедших в материальном мире, и являются регистрацией сигналов, возникших в результате этих событий. Однако, данные не тождественны информации. Станут ли данные информацией, зависит от того, известен ли метод преобразования данных в известные понятия.
Данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. Причем необходимо учитывать тот факт, что информация не является статичным объектом - она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных. Информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных.
Одни и те же данные могут в момент потребления представлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов. По своей природе данные являются объективными, так как это результат регистрации объективно существующих сигналах, вызванных изменениями в материальных телах или полях. Методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные людьми (субъектами).
Информация - данные, определенным образом организованные, имеющие смысл, значение и ценность для своего потребителя и необходимые для принятия им решений, а также реализации других функций и действий.
Впервые понятие "база данных" появилось в начале 60-х годов. Данные в то время обычно представлялись в виде простых последовательных файлов на магнитной ленте и зависели от программ обработки. Если менялись организация данных или тип запоминающего устройства, программисту приходилось заново переписывать программу. Существовали многочисленные версии одного и того же файла, большинство из них применялось только для одного программного продукта. Когда же появлялась необходимость в других, зачастую те же данные использовались в иной форме: создавался новый файл, содержащий аналогичную информацию. Это приводило к очень высокой степени дублирования данных, так называемой избыточности. Наличие огромного количества копий буквально пожирало машинную память и порождало ряд специфических проблем, одной из которых являлось, например, одновременное обновление дублирующихся данных, без которого возникают различные версии одной и той же информации, приводящие к противоречиям в системе. С появлением БД проблемы, связанные с зависимостью данных от программ и дублированием информации, были в основном сняты. БД можно определить как совокупность взаимосвязанных хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений; данные запоминаются так, чтобы они были независимы от программ, использующих эти данные; для добавления новых или модификации существующих данных, а также для поиска данных в БД применяется общий управляемый способ. Данные структурируются таким образом, чтобы была обеспечена возможность дальнейшего наращивания приложений.
Весьма существенный вклад в изменение подходов к обработке информации внесли системы управления базами данных (СУБД), которые предназначены для манипулирования текстовым, графическими и числовыми данными с помощью ресурсов ЭВМ. Они выполняют функции формирования наборов данных (файлов), поиска, сортировки и корректировки данных перечисленных типов.
Программное обеспечение СУБД должно отвечать достаточно сложным требованиям, предъявляемым к нему выполняющимися на той же ЭВМ прикладными программами. Основные принципы построения СУБД основаны на том, что для работы с текстовыми, числовыми и графическими данными достаточно реализовать ограниченное число часто используемых функций и определить последовательность их выполнения.
№ 14
Трехуровневая архитектура. Стандартная структура базы данных, состоящая из концептуального, внешнего и внутреннего уровней.
На концептуальном уровне выполняется концептуальное проектирование базы данных. Концептуальное проектирование базы данных включает анализ информационных потребностей пользователей и определение нужных им элементов данных. Результатом концептуального проектирования является концептуальная схема, единое логическое описание всех элементов данных и отношений между ними.
Концептуальный уровень. Структурный уровень базы данных, определяющий логическую схему базы данных.
Внешний уровень составляют пользовательские представления данных базы данных. Каждая поддающаяся определению пользовательская группа получает свое собственное представление данных в базе данных. Каждое та кое представление данных дает ориентированное на пользователя описание Элементов данных, из которых состоит представление данных, и отношений между ними. Его можно напрямую вывести из концептуальной схемы Со вокупность всех таких пользовательских представлений данных и есть внешний уровень.
Внешний уровень. Структурный уровень базы данных, определяющий пользовательские представления данных.
Внутренний уровень обеспечивает физический взгляд на базу данных: дисководы, физические адреса, индексы, указатели и т.д. За этот уровень отвечают проектировщики физической базы данных, которые решают, какие физические устройства будут хранить данные, какие методы доступа будут использоваться для извлечения и обновления данных и какие меры следует принять для поддержания или повышения быстродействия системы управления базами данных. Ни один пользователь (как пользователь) не касается этого уровня. Реализация этих трех уровней требует, чтобы СУБД «преобразовывала» или переводила с одного уровня на другой. Для того чтобы представить данные пользователям на концептуальном или внешнем уровне, система должна уметь преобразовывать адреса и указатели в соответствующие логические имена и отношения. Такой перевод может происходить и в обратном направлении — с логического уровня на физический. Цена такого перевода состоит в большой системной задержке. Выгодой же является независимость логического и физического представления данных.
№15
Модель Entity-Relationship (Сущность-Связь)
В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных.Основными понятиями ER-модели являются сущность, связь и атрибут.
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи).
Как и сущность, связь - это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
Атрибут - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязательным Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Например, связь продавца с контрактом может быть выражена следующим образом:
· продавец может получить вознаграждение за 1 или более контрактов;
· контракт должен быть инициирован ровно одним продавцом.
Первый тип связи – связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В. Например, работник и его ставка.
В концептуальной модели можно было бы наследовать от типа работник тип строчка в ведомости, где добавить свойство сумма зарплаты, тогда указав должность работника можно узнать какие зарплаты получают работники, занимающие или занимавшие эту должность.
Второй тип – связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В.
В концептуальной модели это соответствует включению.
На основе этих двух видов связей, Вы можете составить более сложные связи.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Как правило – это первичный ключ в таблице базы данных. Теперь о внешних ключах:
Если сущность С связывает сущности А и В, то она должна включать внешние ключи, соответствующие первичным ключам сущностей А и В.
Если сущность В обозначает сущность А, то она должна включать внешний ключ, соответствующий первичному ключу сущности А.
Стержневая сущность (стержень) – это независимая сущность. Например, при описании накладной, стержневой сущностью является шапка накладной.
Ассоциативная сущность (ассоциация) – это связь вида "многие-ко-многим". Например, товар в накладной – это связь с шапкой накладной и справочником наименований товара, справочником единиц измерения.
Характеристическая сущность (характеристика) – это связь вида "многие-к-одной" или "одна-к-одной" между двумя сущностями (частный случай ассоциации). Единственная цель характеристики в рамках рассматриваемой предметной области состоит в описании или уточнении некоторой другой сущности. Это что-то вроде перечисления. Например, Список поставщиков – это список указателей на отдельные записи из справочника организаций. При указании поставщика в накладной, Вы выбираете его из списка поставщиков, но реально указываете организацию из справочника организаций. Просто организация может быть и поставщиком, и покупателем, и налоговым органом, но Вам удобнее будет выбирать из более короткого списка. Обозначающая сущность или обозначение – это связь вида "многие-к-одной" или "одна-к-одной" между двумя сущностями и отличается от характеристики тем, что не зависит от обозначаемой сущности. Например, зачисление народных депутатов в разные комитеты. Один народный депутат может входить в разные комитеты.
Дискретная математика в информатике
Развитие Булева алгебра получила в виде исчисления предикатов — в котором она расширена за счет введения предметных символов, отношений между ними, кванторов существования и всеобщности. Практически каждая система искусственного интеллекта (ИИ), построенная на логическом принципе, представляет собой машину доказательства теорем. При этом исходные данные хранятся в базе данных в виде аксиом. Имеются правила логического вывода как отношения между аксиомами. Кроме того, каждая такая машина имеет блок генерации цели, и система вывода пытается доказать данную цель как теорему. Если цель доказана, то трассировка примененных правил позволяет получить цепочку действий, необходимых для реализации поставленной цели. Мощность такой системы определяется возможностями генератора целей и машиной доказательства теорем. Таким образом, было бы логично предположить, что все, что возможно реализовать на ЭВМ, можно было бы реализовать и в виде логики предикатов.
№ 16
Модели данных. Структура, операции, ограничения модели.
При описании ПО используется инфологическая модель, модель «сущность-связь». При описании данных используются соответствующие модели данных. Модель данных – это форматы данных и состав операции выполняемых над этими данными. В настоящее время существуют следующие модели данных: сетевые; иерархические; реляционные; объектно-ориентированные.
Иерархическая модель. Представляет собой взаимосвязанный набор иерархий, т.е. расположение данных в определенной последовательности и зависимости. Пример - организационная структура предприятия. Особенность иерархической модели заключается в однонаправленном движении по иерархии. Сетевая модель. Позволяет сохранять концептуальную простоту иерархического подхода и добавляет ему гибкость, позволяя ему работать со многими иерархиями одновременно. На практике примером этой модели служит модель графика строительства объекта, (движения транспорта, изготовления изделия и т.п.): выбрать котлован — заложить фундамент — поставить стены - заложить перекрытия. В иерархической модели каждое данное находится на определенном уровне, взаимосвязь можно представить в виде диаграммы. В сетевой модели допускается одновременное наличие однотипных данных на различных уровнях. Здесь каждая запись может быть связана с любой другой.
Реляционная модель. Облегчает установление связей, дает возможность легко и быстро установить новую связь, позволяет оптимальным образом осуществить доступ к данным любого уровня. Все СУБД, работающие на ПК, поддерживают эту модель. гибкость модели объясняется наличием математического аппарата нормализации отношений; наличие внешних ключей; использование языка структурированных запросов.
Структура, операции, ограничения модели
Построение структуры данных каждой конкретной модели не может выполняться произвольным образом. Это связано с ограничениями вытекающими из особенностей использующих в модели типов структуры данных и операции над данными. Исходя из вытекающего в качестве основных компонентов модели данных рассматриваются структуры данных, операции и ограничении целостности данных. Основные компоненты модели тесно взаимосвязаны между собой и в различных моделях могут быть реализованы различными способами.
Ограничения модели. Это логические ограничения, которые накладываются на данные. Ограничения могут быть явные и внутренние. Внутренние представлены в модели данных правилами композиции допустимых структур данных в конкретной схеме БД. Находят свое отражения в структурных спецификациях и в правилах выполнения операции. Это явные ограничения специфицируются явным образом с помощью специальных конструкции языки описанных данных. В современных СУБД имеются собственные аппараты по проверке непротиворечивости данных, которые в свою очередь обеспечивают целость данных.
Операции над данными. Динамические свойства модели данных выражается множеством операции над данными. Реализация любой конкретной операции над данными включает в себя селекцию, то есть выделение из всей совокупности именно технические данные над которыми должна быть выполнена операция. Условия селекции специфицируется в виде некоторого критерия отбора данных. Селекция выполняется любым способом с использованием логические позиции данного, значений данного и связей между данными. Например: выполнять селекцию из общего набора данных. Условия: в результате выборки по характеру производимого действия различают следующие виды операции: Идентификация данного и нахождение его позиции, выборка данных, включающий запись данного, удаление данного, модификация данного. По характеру способа получения результата различают: навигационные операции; спецификационные операции.
Навигационные операции: результат операции получатся путем прохождения по связям реализованным в структуре БД. Результат навигации единичный объект БД. Например: экземпляр записи.
Спецификационные операции: если определятся только требования к результату, но не задается способ его получения.
Например: Спецификация требований может выполняться с использованием формул исчисления предикатов, что имеет место в реляционной модели.
Результатом является: множество объектов БД. То есть в начале осуществляется селекция требуемых данных, затем вид операции.
Структура данных.
Структирование данных базируется на основных концепции, агрегации и обобщения. Например: в файловых системах, которое реализует модель плоский файл понимательный базис состоит из 4-х основных типов логических структур данных.
Поле, наименьшая поименованная единица данных;
Запись, поименованная совокупность полей; Файл, поименованная совокупность экземпляров записи одного типа; Набор файлов, поименованная совокупность файлов обрабатывающих в системе. В этой модели агрегация используется для компиляции полей в запись, а обобщения для представления множества экземпляров записей одного типа, одной общей структурой более высокого уровня.
Модель сети Петри является принципиально асинхронной и служит для отображения и анализа причинно-следственных связей в системе. Для привязки к определенным моментам времени тех или иных переходов в синхронных системах используются события. Переходы из состояния в состояния считаются "мгновенными". Если переход реально происходит через какие-то промежуточные состояния, а нам существенно учесть в модели эти обстоятельства, то вводятся соответствующие "подсобытия". Сеть Петри имеет четыре базовых элемента: позиции (places), переходы, дуги и метки (token). В сетях Петри события и условия отображаются абстрактными символами, называемыми переходами(вертикальными или горизонатальными полосками - "барьерами") и позициями (кружками). Условия-позиции и события-переходы связаны отношениями зависимости, которые отображаются с помощью ориентированных дуг.
В отличии от модели машины конечных состояний здесь отсутствуют комбинированные состояния типа отправитель-канал-получатель, и переходы из состояния в состояние для каждого процесса или объекта рассматриваются независимо. Если условия ни для одного из переходов не реализованы, сеть переходит в заблокированное состояние.
Аналитическое определение. Сеть Петри - набор N = (P, T, F, W, M0), где (P, T, F) - конечная сеть (множество Х = ЗuT конечно), а W: F→ N\ {O} (знак \ здесь означает разность множеств) и M0: P→N - две функции, называемые кратностью дуг и начальной пометкой. Первая ставит в соответствие каждой дуге число N>0 (кратность дуги). Если N>0, то при графическом представлении сети число N выписывается рядом с короткой чертой, пересекающей дугу. Дуги с кратностью 1 не помечаются. Каждой позиции p ставится в соответствие некоторое число M0(p) N (пометка позиции).
Формально работа сети Петри описывается множеством последовательностей срабатываний и множеством реализуемых разметок позиций.
Для сетей Петри существует удобная алгебраическая нотация. Каждому переходу ставится в соответствие правило грамматики. Каждое правило специфицирует входную и выходную позиции. Текущее состояние сети Петри характеризуется неупорядоченным набором позиций. Каждая позиция присутствует в этом наборе столько раз, сколько меток она имеет.
Диаграммы деятельности, которые используются в современных технологиях создания программного обеспечения заимствуют идеи из нескольких различных методов, в частности, метода моделирования состояний SDL и сетей Петри. Эти диаграммы особенно полезны в описании поведения, включающего большое количество параллельных процессов. Диаграммы деятельности являются также полезными при параллельном программировании, поскольку можно графически изобразить все ветви и определить, когда их необходимо синхронизировать.
Диаграммы деятельности можно применять для описания потоков событий в вариантах использования. С помощью текстового описания можно достаточно подробно рассказать о потоке событий, но в сложных и запутанных потоках с множеством альтернативных ветвей будет трудно понять логику событий. Диаграммы деятельности предоставляют ту же информацию, что и текстовое описание потока событий, но в наглядной графической форме.
№17
Сетевая модель данных базируется на графовой форме представления данных. Вершина графа используется для интерпретации типов сущностей., а дуги – типов связей.
При реализации моделей в различных СУБД , можно применять различные способы представления в памяти системы данных, описывающих связи м/у сущностями.
Доминирующее влияние на развитие СМД в соответствии со стандартами СУБД оказала группа Кодасил (стандарт ISO) Модель Кодасил постоянно развивается , по мере совершенствования вычислительной техники. По мере появления новой версии, появляется новый стандарт.
Основная конструкция сетевой модели данных КОДАСИЛ - набор.
Набор - это поименованное двухуровневое дерево, которое реализует связь между записями двух типов: владельцем набора и членом набора. Разрешаются только связи 1 : М или М : 1 , но связи M : N в явном виде не поддерживаются. Для каждого набора, устанавливающего связь между предком P и потомком C должны выполняться два условия:
1. Каждый экземпляр Р является предком только в одном экземпляре набора;
2. Каждый экземпляр C является потомком не более чем в одном экземпляре набора.
Основные свойства набора:
· набор имеет имя,
· в каждом наборе только один владелец,
· в каждом наборе 0, 1 или несколько членов,
· набор существует, только если существует запись - владелец.
· поскольку набор имеет имя, то два экземпляра записи могут быть в разных наборах,
· экземпляр записи может входить только в один экземпляр набора данного типа.
· в общем случае каждый набор - это вход в БД;
С помощью наборов можно строить многоуровневые деревья и простые сетевые структуры. Так как роль записи жестко не фиксируется, то в одном наборе запись (файл) может быть членом, а в другом владельцем, поэтому такая модель и называется моделью с равноправными файлами.
Типы наборов
В зависимости от способа физического хранения различают одночленные, многочленные и сингулярные наборы. Одночленный набор включает только один файл - член. Многочленные наборы состоят из трех и более файлов, сингулярный набор - это особый набор, в котором владельцем является система. В каждом сингулярном наборе всего один экземпляр. Сингулярные наборы чаще всего применяются, чтобы получить доступ ко всем записям файла - владельца, а также чтобы объединить записи, не имеющие владельца.
Реляционная модель
Концепция реляционной модели данных была впервые выдвинута в пятидесятые годы, но первые реализации появились только в семидесятых, а широкую популярность эта модель завоевала лишь в восьмидесятые. СУБД реляционного типа освобождает пользователя от всех ограничений, связанных с организацией хранения данных и спецификой аппаратуры. Изменение физической структуры базы данных не влияет на работоспособность прикладных программ, работающих с нею.
Современные реляционные СУБД предоставляют пользователю мощные средства работы с данными и автоматически выполняют такие системные функции, как восстановление после сбоя и одновременный доступ нескольких пользователей к разделяемым данным. Такой подход избавляет пользователя от необходимости знать форматы хранения данных, методы доступа и методы управления памятью.
Преимущества реляционных моделей данных заключаются в следующем:
· в распоряжение пользователя предоставляется простая структура данных — они рассматриваются как таблицы;
· пользователь может не знать, каким образом его данные структурированы в базе — это обеспечивает независимость данных;
· возможно использование простых непроцедурных языков запросов.
В то же время у реляционной модели данных есть одно уязвимое место — организовать работу с такой БД достаточно сложно, поскольку не существует способов организации быстрого доступа пользователя к данным. Однако эта проблема решается путем применения специализированных аппаратных средств и заданием вспомогательных путей, поскольку традиционно в реляционной модели пути доступа к данным заранее не определяются и при обработке запросов приходится просматривать практически всю базу. На вычислительной системе обычной структуры такой поиск требует слишком много времени, поэтому в современных реляционных СУБД допускается задание вспомогательных описаний путей доступа, т.е. организация индексации.
В реляционных БД имеется механизм блокировки, предотвращающий переход системы в противоречивое состояние в результате одновременного доступа двух или более запросов к одному и тому же элементу данных.
Реляционные модели данных достаточно просты. Они собирают данные в унифицированные таблицы и позволяют работать с ними, не вдаваясь в подробности механизма их хранения. Пользователь может:
· заносить в базу новые данные;
· создавать и уничтожать таблицы;
· добавлять строки и столбцы к ранее созданным таблицам;
· создавать и уничтожать индексы;
· определять и отменять представления хранимых данных;
· изменять привилегии различных пользователей.
Способ описания и представления данных пользователю, принятый в реляционных системах, радикально отличается от принятых в иерархических и сетевых моделях. Манипулирование данными осуществляется при помощи операций, порождающих таблицы. Комбинируя таблицы, выбирая отдельные столбцы и строки, пользователь может одной операцией сформировать новые таблицы для отображения на экране терминала, дальнейшей обработки или записи на хранение. Табличная организация позволяет неопытному пользователю быстрее освоиться с системой. Каждая строка в таблице соответствует записи в файле, которую столбцы таблицы разбивают на поля.
Теория игр - теория математических моделей принятия решений в условиях неопределенности, в условиях столкновения, конфликтных ситуациях, когда принимающий решение субъект (игрок), располагает информацией лишь о множестве возможных ситуаций, в одной из которых он в действительности находится, о множестве решений, которые он может принять, и о количественной мере того выигрыша, который он мог бы получить, выбрав в данной ситуации данную стратегию.
Игры двух лиц с нулевой суммой
Игра двух лиц с нулевой суммой в матричной форме занимает центральное место в современной теории игр, так как теория таких игр разработана практически до конца.
Итак, пусть имеется два игрока. В распоряжении первого игрока имеется всего n возможных ходов i=1,2,3,...,n; в распоряжении второго игрока имеется m возможных ходов j=1,2,3,...,n. Эти возможные ходы называются чистыми стратегиями игроков.
Оба игрока делают одновременно по одному ходу, после чего партия считается законченной. Если первый игрок делает ход i, а второй - ход j,
то первый игрок получает выигрыш, равный
![]() ,
очевидно, что выигрыш второго игрока равен
,
очевидно, что выигрыш второго игрока равен ![]() .
.
Эти данные можно записать в виде матрицы
 ,
,
в которой строки соответствуют ходу первого игрока, а столбцы - ходу второго игрока. Основное содержание современной теории игр - это так называемая матричная форма игры. В этом случае считается, что каждый игрок делает всего лишь один ход, причем все ходы делаются одновременно. После этого каждому игроку выплачивается выигрыш (или берётся проигрыш) в зависимости от того, какие ходы были сделаны им и другими игроками. Игра в позиционной форме может быть сведена к игре в матричной форме, однако для реальных игр это сведение настолько сложно, что практически невыполнимо даже для современных ЭВМ. Однако вполне возможно, что в будущем такое сведение будет иметь и практический смысл. Таким образом, оказывается, что случайный выбор хода повышает наши шансы на успех, хотя бы в среднем. И это является одной из основных идей теории игр - выбирать свой ход случайно. Подобный случайный выбор хода получил название смешанной стратегии. Случайный выбор хода - смешанная стратегия - имеет право на существование, даже в реальной жизни. Когда не знаешь, как действовать - выбирай свой ход случайным образом! Иногда помогает. По крайней мере, никто не разгадает стратегии твоего поведения и не предугадает твоего хода
№ 18
Операции над отношениями
В число определенных Коддом операций входят перестановка (permutation), проекция (projection), соединение (join), связывание (tie) и композиция (composition) (в статье 1970-го г. добавлена операция ограничения (restriction), которую я описываю здесь для удобства). Интересно заметить, что определения ограничения и соединения отличаются от тех, которые используются сегодня, а операции связывания и композиции теперь редко принимаются во внимание. В том, что следует ниже, символы X, Y, ... (и т.д.) по мере необходимости обозначают либо индивидуальные атрибуты, либо комбинации атрибутов. Кроме того, по причинам, которые скоро будут понятны, определение соединения откладывается до конца раздела.
Перестановка. Переупорядочение атрибутов отношения слева направо.
Проекция. Понималась более или менее так же, как и сегодня (хотя синтаксис был другим; далее будем использовать синтаксис R{X} для обозначения проекции R на X). Замечание: название "проекция" происходит из того факта, что отношение степени n можно рассматривать как представление точек в n-мерном пространстве, и к проекции этого отношения на m его атрибутов (m<=n) можно относиться как к проекции этих точек на соответствующие m осей.
Связывание. Для данного отношения A{X1,X2,...,Xn} связывание A - это ограничение A до тех строк, в которых A.Xn = A.X1 (если использовать термин "ограничение" в его современном смысле, а не в специальном смысле, определяемом ниже.)
Композиция. Для данных отношений A{X,Y} и B{Y,Z} композицией A c B называется проекция на X и Z соединения (a join) A с B (причина, по которой я говорю "a join", а не "the join", объясняется ниже). Замечание: естественная композиция - это проекция на X и Z естественного соединения.
Ограничение. Для данных отношений A{X,Y} и B{Y} ограничение A по B определяется как максимальное подмножество A такое, что A{Y} является подмножеством -- не обязательно точным -- B.
Для данных отношений A{X,Y} и B{Y,Z} соединение A с B в статье определяется как любое отношение C{X,Y,Z} такое, что C{X,Y} = A и C{Y,Z} = B. Заметим, что следовательно A и B можно соединить (или они "соединяемы"), только если их проекции на Y идентичны -- т.е. только если A{Y} = B{Y}, условие, которое вряд ли удовлетворяется на практике. Также заметим, что если A и B соединяемы, то могут существовать различные соединения (в общем случае). Хорошо известное естественное соединение -- называемое в статье линейным естественным соединением, чтобы отличить его от другого вида, именуемого циклическим соединением -- это важный частный случай, но не единственно возможный.
Имитационное моделирование.
Поддержка имитационного моделирования позволяет эффективно решать проблемы, возникающие при моделировании больших систем, и позволяет обеспечить как точный анализ, так и визуальное представление альтернативных вариантов. Кроме того, проведение экспериментов с имитационными моделями позволило проводить не только анализ их характеристик, но и решать задачи синтеза таких систем, т.е. эффективнее решать задачи автоматизации построения моделей, используя количественные оценки альтернатив, полученные в ходе имитации.
Задача имитации функционирования системы на ее объектной модели приводит к необходимости моделирования различных функциональных (аналитических, логических и т.д.) зависимостей. Для решения данной задачи в рамках проекта по созданию инструмента UFO - toolkit разработан специальный язык сценариев ( scripting language ), а также компилятор и интерпретатор для него. Данный язык позволяет описывать и визуализировать поведение УФО-элементов на этапе имитационного моделирования.
Метод Монте-Карло (метод статистических испытаний) – численный метод решения математических задач при помощи моделирования случайных чисел. Суть метода: посредством специальной программы на ЭВМ вырабатывается последовательность псевдослучайных чисел с равномерным законом распределения от 0 до1. Затем данные числа с помощью специальных программ преобразуются в числа, распределенные по закону Эрланга, Пуассона, Релея и т.д. Полученные таким образом случайные числа используются в качестве входных параметров экономических систем. При многократном моделировании случайных чисел определяем математическое ожидание функции и, при достижении средним значением функции уравнения не ниже заданного, прекращаем моделирование.
Статистические испытания (метод Монте-Карло) характеризуются основными параметрами:
D - заданная точность моделирования;
P – вероятность достижения заданной точности;
N – количество необходимых испытаний для получения заданной точности с заданной вероятностью.
Определим необходимое число реализаций N, тогда
(1 - D) будет вероятность того, что при одном испытании результат не достигает заданной точности D;
(1 - D) N – вероятность того, что при N испытаниях мы не получим заданной точности D.
Тогда вероятность получения заданной точности при N испытаниях можно найти по формуле
![]()
Формула (19) позволяет определить заданное число испытаний для достижения заданной точности D с заданной вероятностью Р.Случайные числа получаются в ЭВМ с помощью специальных математических программ или спомощью физических датчиков. Одним из принципов получения случайных чисел является алгоритм Неймана, когда из одного случайного числа последовательно выбирается середина квадрата. Кроме того данные числа проверяются на случайность и полученные числа заносятся в базу данных. Физические датчики разрабатываются на электронных схемах и представляют собой генераторы белого (нормального) шума, то есть когда в спектральном составе шума имеются гармоничные составляющие с частотой F ®¥. Из данного белого шума методом преобразования получаются случайные числа.
№19
Каждая сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. При этом любой атрибут может быть определен как ключевой.
Детализация сущности осуществляется с использованием диаграмм атрибутов, которые раскрывают ассоциированные сущностью атрибуты. Диаграмма атрибутов состоит из детализируемой сущности, соответствующих атрибутов и доменов, описывающих области значений атрибутов. На диаграмме каждый атрибут представляется в виде связи между сущностью и соответствующим доменом, являющимся графическим представлением множества возможных значений атрибута. Все атрибутные связи имеют значения на своем окончании. Для идентификации ключевого атрибута используется подчеркивание имени атрибута. Разработка ERD включает следующие этапы:
Идентификация сущностей, их атрибутов, а также первичных и альтернативных ключей. Идентификация отношений между сущностями и указаний типов отношений.
Разрешение неспецифических отношений (отношений n*m).
Этап 1 является определяющим при построении модели, его исходной информацией служит содержимое хранилищ данных определяемое входящими и выходящими в/из него потоками данных. Первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища, описание структур данных, содержащихся во входных и выходных потоках.
Затем, если полученная схема обладает избыточностью, то происходит упрощение схемы путем нормализации (удаления повторяющихся групп). Концепции и методы нормализации были разработаны Коддом, установившим существование трех типов нормализованных схем, называемых в порядке уменьшения сложности первой, второй и третьей нормальной формой (1НФ, 2НФ, 3НФ).
Пример НФ. Рассмотрим все три нормальные формы на примере Группы Студентов. У Студента ключом является реквизит Номер (№ личного дела), к описательным реквизитам относятся: Фамилия (Фамилия студента), Имя (Имя студента), Отчество (Отчество студента), Дата (Дата рождения), Группа (N группы). Если отсутствует реквизит Номер, то для однозначного определения характеристик конкретного студента необходимо использование составного ключа из трех реквизитов: Фамилия + Имя + Отчество.
Первая нормальная форма
Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые (далее неделимы). Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа.
Например, отношение Студент=(Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой нормальной форме.
Вторая нормальная форма
Чтобы рассмотреть вопрос приведения отношений ко второй нормальной форме, необходимо дать пояснения к таким понятиям, как функциональная зависимость и полная функциональная зависимость.
Описательные реквизиты информационного объекта логически связаны с общим для них ключом, эта связь носит характер функциональной зависимости реквизитов.
Функциональная зависимость реквизитов – зависимость, при которой в экземпляре сущности (в нашем случае, сущность – это студент) определенному значению ключевого реквизита соответствует только одно значение описательного реквизита.
Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты.
В случае составного ключа вводится понятие функционально полной зависимости.
Функционально полная зависимость неключевых атрибутов заключается в том, что каждый неключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.
Отношение будет находиться во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально полно зависит от составного ключа.
Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой и во второй нормальной форме одновременно, так как описательные реквизиты однозначно определены и функционально зависят от ключа Номер. Отношение Успеваемость = (Номер, Фамилия, Имя, Отчество, Дисциплина, оценка) находится в первой нормальной форме и имеет составной ключ Номер+Дисциплина. Это отношение не находится во второй нормальной форме, так как атрибуты Фамилия, Имя, Отчество не находятся в полной функциональной зависимости с составным ключом отношения.
Третья нормальная форма
Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита.
Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Пример. Если в состав описательных реквизитов Студент включить фамилию старосты группы (Староста), которая определяется только номером группы, то одна и та же фамилия старосты будет многократна повторяться в разных экземплярах Студентов. В этом случае наблюдаются затруднения в корректировке фамилии старосты в случае назначения нового старосты, а также неоправданный расход памяти для хранения дублированной информации.
Для устранения транзитивной зависимости описательных реквизитов необходимо провести "расщепление" исходной сущности. В результате расщепления часть реквизитов удаляется из исходной сущности и включается в состав другой (возможно, вновь созданных) сущности.
Пример. Студент группы представляется в виде совокупности правильно структурированных информационных объектов (Студент и Группа), реквизитный состав которых тождественен исходному объекту. Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится одновременно в первой, второй и третьей нормальной форме.
3НФ является наиболее простым способом представления данных, отражающим здравый смысл. Построив 3НФ, мы фактически выделяем базовые сущности предметной области.
№20
Иерархические СУБД
В основе иерархических СУБД лежит довольно простая модель данных, которую можно представить себе в виде дерева — ациклического ориентированного графа особого вида. Дерево состоит из вершин, каждая из которых, кроме одной, имеет единственную родительскую вершину и несколько (в том числе ни одной) дочерних. Вершина, не имеющая родительской, называется корнем дерева. Вершины, не имеющие дочерних, называются листьями. Остальные вершины являются ветвями.
Иерархические базы данных наиболее пригодны для моделирования структур, по своей природе являющихся иерархическими. В качестве примеров можно привести воинские подразделения или сложные механизмы, состоящие из более простых узлов, которые в вою очередь тоже можно подвергнуть декомпозиции.
Тем не менее существует значительное количество структур, не сводящихся к простой иерархии. Например, всем известное генеалогическое дерево, которое на самом деле не является деревом в строгом смысле, поскольку у большинства людей по два родителя. О более сложных структурах и говорить не приходится.
Сетевые СУБД
Подобно иерархической, сетевую модель также можно представить себе в виде ориентированного графа. Но в этом случае граф может содержать циклы, т.е. вершина может иметь несколько родительских. Такая структура намного гибче и выразительнее предыдущей и пригодна для моделирования гораздо более широкого класса задач. В этой модели вершины представляют собой сущности, а соединяющие их ребра – отношения между ними.
Сетевые СУБД имели гораздо больший успех и долго господствовали на рынке СУБД. В немалой степени их успеху способствовала энергичная деятельность Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL). Эта организация тщательно проработала спецификации сетевой модели и ее архитектуру, что позволило создать ряд успешных коммерческих продуктов, не последнее место среди которых занимал некогда весьма популярный COBOL.
Сетевые СУБД весьма прочно укрепились на рынке, и реляционной модели пришлось с боем завоевывать свое место под солнцем. В истории информатики навечно останется «Великий Спор», который на самом деле явился решающим сражением сетевой и реляционной моделей.
Реляционные СУБД
Реляционные СУБД являются в настоящий момент самыми распространенными. Их реализации существуют на всех мало-мальски пригодных для этого платформах (от персональных компьютеров до мэйнфреймов), для всех операционных систем и для всех применений – от простейших продуктов, предназначенных для ведения картотек индивидуального пользования, до сложнейших распределенных многопользовательских систем. С виду эта модель довольно проста: база данных выглядит как простой набор взаимосвязанных таблиц. Но за внешней простотой кроется мощный и вместе с тем изящный математический аппарат реляционной алгебры, которая в свою очередь базируется на целом ряде математических дисциплин, среди которых – логика, исчисление предикатов, теория множеств.
Немалую роль в успехе реляционных СУБД играет также язык SQL, разработанный специально для запросов к реляционным БД. Это достаточно простой и в то же время выразительный язык, при помощи которого можно выполнять достаточно изощренные запросы к базе.Разумеется, предшествующие СУБД также имели языки описания данных (ЯОД) и языки манипулирования данными (ЯМД). SQL объединил в себе обе эти функции. Но самой привлекательной его особенностью, особенно для пользователей-непрофессионалов в программировании, является то, что можно строить запросы на основе непроцедурного подмножества SQL. Это означает, что в формулировке запроса указывается, что должно содержаться в результате, а не как его получить. Имеются, правда, и процедурные элементы языка, например, операторы организации ветвления и циклов, но их применения зачастую удается избежать. При работе же с сетевыми БД программист был вынужден использовать навигационные процедуры, отвлекаясь при этом от решения самой задачи.
Как следует из определения ссылочной целостности при наличии в ссылочных полях двух таблиц различного представления данных происходит нарушение ссылочной целостности, такое нарушение делает информацию в базе данных недостоверной. Чтобы предотвратить потерю ссылочной целостности, используется механизм каскадных изменений (который чаще всего реализуется специальными объектами СУБД - триггерами). Данный механизм состоит в следующей последовательсности действий:
· при изменении поля связи в записи родительской таблицы следует синхронно изменить значения полей связи в соответствующих записях дочерней таблицы;
· при удалении записи в родительской таблицы следует удалить соответствующие записи и в дочерней таблице.
№ 21
Любая ИС может считаться эффективной если выборка данных осуществляется быстро, качественно и в требуемом объёме. Наиболее эффективным решением этой проблемы является возможность построения запросов средствами команд SQL. Язык SQL в отличии от существующих команд языка СУБД является множественно-ориентированным языком и направлен на получение готовых таблиц с результатами запроса. Особенности SQL:
команда SQL работает с данными на уровне машинного представления поэтому скорость обработки возрастает в сотни раз по сравнению с традиционными командами СУБД.
Ком. SQL самостоятельно выполняют создание индексов и ключей при необходимости, это экономит место на диске и затраты ресурсов на поддержание целостности структуры индексов.
Каждая СУБД имеет свой собственный диалект по SQL, который отличается полнотой поддержки стандарта и некоторыми незначительными отличиями синтаксиса.
Для построения запроса в диалоговом режиме может быть использован конструктор запросов. Где генерируется тело команды SQL и создаётся файл с .qpr. Этот файл можно выполнить используя команду
DO имя запроса .QPR. Сгенерировать код команды SQL возможно также в дизайнере представлений, однако в том и другом случае в дизайнерах не могут быть реализованы все сложные синтаксические конструкции SQL , поэтому один из вариантов может быть следующим: в конструкторе создаётся тело SQL и вручную дополняются тонкие настройки.
Обобщённый алгоритм построения запроса ---- Описание полей данных в результате---- Список источников данных----Условия связи между различными источниками данных----*Усл. отбора данных-----*Усл. Суммирования данных
*Задание порядка записей в результате
* - необязательные блоки алгоритма
Т.о Select SQL является наиболее мощной и удобной командой для получения выборок. Позволяет выполнить запрос к одной или более таблицам, направляя при этом результат в курсор или таблицу, в график, на принтер. Команда Select SQL поддерживает функции агрегирования.
Элементарной конъюнкцией называется произвольная конъюнкция переменных, которая содержит либо саму переменную, либо ее отрицание. Элементарной дизъюнкцией называется произвольная дизъюнкция переменных, которая содержит либо саму переменную, либо ее отрицание.
Дизъюнктивные нормальные формы (ДНФ)
Конъюнктивные нормальные формы (КНФ)
Элементарной конъюнкцией (ЭК) называется выражение вида
X1a1 X2a2…Xnan
Элементарной конъюнкцией (ЭК) называется выражение вида
X1a1 X2a2…Xnan
ЭК называется правильной, если все входящие в неё переменные различны.
Правильная ЭК называется полной относительно данного набора переменных, если в неё входят все эти переменные.
Для элементарных дизъюнкций (ЭД) – аналогичный набор определений.
ЭД – выражение вида
X1a1 V X2a2 V…V Xnan
ДНФ – дизъюнкция разных правильных элементарных конъюнкций.
__
X1 V X1X2 V X1X2X3 – ДНФ.
ДНФ называется совершенной (СДНФ), если все входящие в неё элементарные конъюнкции полны относительно данного набора переменных.
ДНФ называется совершенной (СДНФ), если все входящие в неё элементарные конъюнкции полны относительно данного набора переменных.
Дизъюнктивной нормальной формой (ДНФ) называется произвольная дизъюнкция элементарных конъюнкций. Конъюнктивной нормальной формой (КНФ) называется произвольная конъюнкция элементарных дизъюнкция. СКНФ – совершенная КНФ. У нее все ЭД полны.
СКНФ – совершенная КНФ. У нее все ЭД полны.
Алгоритм представления функции в виде СДНФ.
1. Выписываем носитель функции.
2. Для каждого вектора из носителя выписываем конъюнкцию соответствующих переменных. (если координата равна нулю, переменную пишем с отрицанием, если единице – без отрицания). Это и будут все полные ЭК.
3. Выписываем дизъюнкцию всех этих ЭК.
Алгоритм представления функции в виде СКНФ.
1. Выписываем носитель функции
2. Для каждого вектора из носителя выписываем дизъюнкцию соответствующих переменных. (если координата равна нулю, переменную пишем без отрицания, . если единице – с отрицанием). Это и будут все полные ЭД.
4. Выписываем конъюнкцию всех этих ЭД.
Булевы функции
Множество M с двумя введенными бинарными операциями (& V), одной унарной операцией (*) и двумя выделенными элементами называется булевой алгеброй, если выполнены следующие свойства (аксиомы булевой алгебры).
1. X & Y = Y&X, X V Y = Y V X – коммутативность.
2. (X & Y) & Z = X & (Y & Z), (X V Y) V Z = X V (Y V Z) – ассоциативность.
3. (X V Y) & Z = (X & Z) V (Y & Z), (X & Y) V (Y & Z) = (X V Z) & (Y & Z) – дистрибутивность.
4. Поглощение – X & X = X, X V X = X.
5. Свойства констант
X & 0 = 0
X & I = X, где I – аналог универсального множества.
6. Инвальтивность (X*)* = X
7. Дополнимость X V X* = I, X & X* = 0.
8. Законы двойственности – (X & Y)* = X* V Y*, (X V Y)* = X* & Y
Применение дискретной математики в информатике
Нечеткая логика – надмножество Булевой логики, которая была расширена с целью обработки концепции частичной правды - значения истинности между «полностью истинным» и «полностью ложным».
Основным отличием нечеткой логики от классической, как явствует из названия, является наличие не только двух классических состояний (значений) – истина и ложь, но и промежуточных:
F = {0…1}
Соответственно, вводятся расширения базовых операций логического умножения, сложения и отрицания (сравните с соответствующими операциями теории вероятностей):
Нечеткая экспертная система - экспертная система, которая для вывода решения использует место Булевой логики совокупность нечетких функций принадлежности и правил.
Антецедент правила (предпосылка правила) описывает, когда правило применяется, в то время как заключение (следствие правила) назначает функцию принадлежности к каждому из выведенных значений переменных. Большинство инструментальных средств, работающих с нечеткими экспертными системами позволяют применять в правиле несколько заключений. Совокупность правил в нечеткой экспертной системе известна как база знаний. В общем случае вывод решения происходит за три (или четыре) шага.
№22
Криптостойкость алгоритма RSA основывается на предположении, что исключительно трудно определить секретный ключ по известному, поскольку для этого необходимо решить задачу о существовании делителей целого числа. Данная задача является NP-полной, и, как следствие этого факта, не допускает cейчас эффективного (полиноминального) решения. Более того, сам вопрос существования эффективных алгоритмов решения NP-полных задач является до настоящего времени открытым. Если Вы используете числа, состоящие из 200 цифр(такие и надо использовать при шифровании данных), для несанкционированной расшифровки придется генерировать огромное число операций (около 10^23).
Процедура шифрования
Понятия:
Простое число - делится только на 1 и на само себя;
Взаимно простым- не имеют ни одного общего делителя, кроме 1;
Результат операции i mod j - остаток от целочисленного деления i на j.
Чтобы использовать алгоритм RSA, надо сначала сгенерировать открытый и секретные ключи выполнив следующие шаги:
1) Выберем два очень больших простых числа p and q.
2) Определим n, как результат умножения p on q (n= p*q).
3) Выберем большое случайное число, которое назовем d. Это число должно быть взаимно простым с результатом умножения (p-1)*(q-1).
4) Определим такое число е, для которого является истинным следующее соотношение (e*d) mod ((p-1)*(q-1))=1.
5) Hазовем открытым ключем числа e и n, а секретным ключом - чмсла d и n.
Теперь, чтобы зашифровать данные по известному ключу {e,n}, необходимо сделать следующее:
- разбить шифруемый текст на блоки, каждый из которых может быть представлен в виде числа M(i)=0,1,2..., n-1( т.е. только до n-1).
- зашифровать текст, рассматриваемый как последовательность чисел M(i) по формуле C(i)=(M(I)^e)mod n.
Чтобы расшифровать эти данные, используя секретный ключ {d,n}, необходимо выполнить следующие вычисления: M(i) = (C(i)^d) mod n. В результате будет получено множество чисел M(i), которые представляют собой исходный текст.
Приведем пример:
Зашифруем и расшифруем сообщение "САВ" по алгоритму RSA. Для простоты буду использовать маленькие числа(на практике - нужно брать намного большие).
1) Выберем p=3 and q=11.
2)Определим n= 3*11=33.
3) Hайдем (p-1)*(q-1)=20. Следовательно, d будет равно, например, 3: (d=3).
4) Выберем число е по следующей формуле: (e*3) mod 20=1. Значит е будет равно, например, 7: (e=7).
5) Представим шифруемое сообщение как последовательность чисел в диапозоне от 0 до 32 (незабывайте, что кончается на n-1). Буква А =1, В=2, С=3.
Теперь зашифруем сообщение, используя открытый ключ {7,33}
C1 = (3^7) mod 33 = 2187 mod 33 = 9;
C2 = (1^7) mod 33 = 1 mod 33 = 1;
C3 = (2^7) mod 33 = 128 mod 33 = 29;
Теперь расшифруем эти данные, используя закрытый ключ {3,33}.
M1=(9^3) mod 33 =729 mod 33 = 3(С);
M2=(1^3) mod 33 =1 mod 33 = 1(А);
M3=(29^3) mod 33 = 24389 mod 33 = 2(В);
Все, данные расшифрованы.
Электронная подпись - это вставка в данные фрагмента инородной зашифрованной информации. Сама передаваемая информация при этом никак не защищается, т. е. остается открытой и доступной для ознакомления теми лицами, через которых она передается (например, администраторами и инспекторами почтовых узлов связи). Инородная зашифрованная информация формируется с использованием двух методов: хэшфункции для подсчета контрольной суммы и шифрования результатов с открытым ключом.
Контрольная сумма
Подсчет контрольной суммы данных весьма эффективно используется во многих сферах, например при передаче информации по протоколу XMODEM. Это весьма удобное средство для контроля целостности передаваемых даных, принцип которого заключается в том, что на выходе информации по определенному алгоритму вычисляется некое значение. Это значение (контрольная сумма) передается вместе с данными. На входе по тому же алгоритму высчитывается контрольная сумма и сопоставляется с той, которая была подсчитана на выходе.
Шифрование с открытым ключом
В электронных подписях может использоваться симметричное шифрование, однако по сложившейся традиции почти все системы ЭП базируются на шифровании с открытым ключом. Шифрование с открытым ключом называется так потому, что для работы с зашифрованной и передаваемой информацией используются два ключа, один из которых приватный (закрытый), а второй - публичный (открытый). Публичный ключ находится у всех ваших корреспондентов, закрытый же - у вас. Алгоритм работает таким образом, что для зашифровки данных вы используете ваш приватный ключ. Дешифровать же данные можно только с помощью вашего же публичного ключа.
№ 23
Существует множество определений Виртуальной Частной Сети (VNP), однако главной отличительной чертой данной технологии является использование сети Internet в качестве магистрали для передачи корпоративного IP-трафика. Сети VPN предназначены для решения задач подключения конечного пользователя к удаленной сети и соединения нескольких локальных сетей. Структура VPN включает в себя каналы глобальной сети, защищенные протоколы и маршрутизаторы.
Для объединения удаленных локальных сетей в виртуальную сеть корпорации используются так называемые виртуальные выделенные каналы. Для создания подобных соединений используется механизм туннелирования. Инициатор туннеля инкапсулирует пакеты локальной сети (в том числе, пакеты немаршрутизируемых протоколов) в новые IP-пакеты, содержащие в своем заголовке адрес этого инициатора туннеля и адрес терминатора туннеля. На противоположном конце терминатором туннеля производится обратный процесс извлечения исходного пакета. При осуществлении подобной передачи требуется учитывать вопросы конфиденциальности и целостности данных, которые невозможно обеспечить простым туннелированием. Для достижения конфиденциальности передаваемой корпоративной информации необходимо использовать некоторый алгоритм шифрования, причем одинаковый на обоих концах туннеля.
Для того чтобы была возможность создания VPN на базе оборудования и программного обеспечения от различных производителей необходим некоторый стандартный механизм. Таким механизмом построения VPN является протокол Internet Protocol Security (IPSec). IPSec описывает все стандартные методы VPN. Этот протокол определяет методы идентификации при инициализации туннеля, методы шифрования, используемые конечными точками туннеля и механизмы обмена и управления ключами шифрования между этими точками. Из недостатков этого протокола можно отметить то, что он ориентирован на IP.
Другими протоколами построения VPN являются протоколы PPTP (Point-to-Point Tunneling Protocol), разработанный компаниями Ascend Communications и 3Com, L2F (Layer-2 Forwarding) - компании Cisco Systems и L2TP (Layer-2 Tunneling Protocol), объединивший оба вышеназванных протокола. Однако эти протоколы, в отличие от IPSec, не являются полнофункциональными (например, PPTP не определяет метод шифрования).
Говоря об IPSec, нельзя забывать о протоколе IKE (Internet Key Exchange), Существуют различные варианты построения VPN. При выборе решения требуется учитывать факторы производительности средств построения VPN. Например, если маршрутизатор и так работает на пределе мощности своего процессора, то добавление туннелей VPN и применение шифрования/дешифрования информации могут остановить работу всей сети из-за того, что этот маршрутизатор не будет справляться с простым трафиком, не говоря уже о VPN.
Варианты построения VPN.
VPN на базе брандмауэров
Брандмауэры большинства производителей поддерживают туннелирование и шифрование данных. Все подобные продукты основаны на том, что если уж трафик проходит через брандмауэр, то почему бы его заодно не зашифровать. К программному обеспечению собственно брандмауэра добавляется модуль шифрования. Недостатком данного метода можно назвать зависимость производительности от аппаратного обеспечения, на котором работает брандмауэр. При использовании брандмауэров на базе ПК надо помнить, что подобное решение можно применять только для небольших сетей с небольшим объемом передаваемой информации.
VPN на базе маршрутизаторов
Другим способом построения VPN является применение для создания защищенных каналов маршрутизаторов. Так как вся информация, исходящая из локальной сети, проходит через маршрутизатор, то целесообразно возложить на этот маршрутизатор и задачи шифрования. Ярким примером оборудования для построения VPN на маршрутизаторах является оборудование компании Cisco Systems. Помимо простого шифрования проходящей информации Cisco поддерживает и другие функции VPN, такие как идентификация при установлении туннельного соединения и обмен ключами.
Для построения VPN Cisco использует туннелирование с шифрованием любого IP-потока. При этом туннель может быть установлен, основываясь на адресах источника и приемника, номера порта TCP(UDP) и указанного качества сервиса (QoS).
Для повышения производительности маршрутизатора может быть использован дополнительный модуль шифрования ESA (Encryption Service Adapter).
VPN на базе программного обеспечения
Следующим подходом к построению VPN являются чисто программные решения. При реализации такого решения используется специализированное программное обеспечение, которое работает на выделенном компьютере и в большинстве случаев выполняет роль proxy-сервера. Компьютер с таким программным обеспечением может быть расположен за брандмауэром. Положительными качествами являются простота установки и удобство управления. Минусами данной системы можно считать нестандартную архитектуру (собственный алгоритм обмена ключами) и низкую производительность.
Угрозы безопасности для информационной системы
Угрозы безопасности информации и программного обеспечения возникают как в процессе их эксплуатации, так и при создании этих систем, что особенно характерно для процесса разработки ПО, баз данных и других информационных компонентов КС.
Наиболее уязвимы с точки зрения защищенности информационных ресурсов являются так называемые критические компьютерные системы. Под критическими компьютерными системами понимают сложные компьютеризированные организационно-технические и технические системы. В настоящее время одним из наиболее опасных средств информационного воздействия на компьютерные системы являются программы - вирусы или компьютерные вирусы. В последние 10-15 лет компьютерные вирусы нанесли значительный ущерб, как отдельным средствам вычислительной техники, так и сложным телекоммуникационным системам различного назначения.
В качестве основных средств вредоносного (деструктивного) воздействия на КС необходимо, наряду с другими средствами информационного воздействия, рассматривать алгоритмические и программные закладки.
Под алгоритмической закладкой будем понимать преднамеренное завуалированное искажение какой-либо части алгоритма решения задачи, либо построение его таким образом, что в результате конечной программной реализации этого алгоритма в составе программного компонента или комплекса программ, последние будут иметь ограничения на выполнение требуемых функций, заданных спецификацией, или вовсе их не выполнять при определенных условиях протекания вычислительного процесса, задаваемого семантикой перерабатываемых программой данных. Кроме того, возможно появление у программного компонента функций, не предусмотренных прямо или косвенно спецификацией, и которые могут быть выполнены при строго определенных условиях протекания вычислительного процесса.
Под программной закладкой будем понимать совокупность операторов и (или) операндов, преднамеренно в завуалированной форме включаемую в состав выполняемого кода программного компонента на любом этапе его разработки. Программная закладка реализует определенный несанкционированный алгоритм с целью ограничения или блокирования выполнения программным компонентом требуемых функций при определенных условиях протекания вычислительного процесса, задаваемого семантикой перерабатываемых программным компонентом данных, либо с целью снабжения программного компонента не предусмотренными спецификацией функциями, которые могут быть выполнены при строго определенных условиях протекания вычислительного процесса.
Несанкционированное считывание информации, осуществляемое в автоматизированных системах, направлено на:
· считывание паролей и их отождествление с конкретными пользователями;
· получение секретной информации;
· идентификацию информации, запрашиваемой пользователями;
· подмену паролей с целью доступа к информации;
· контроль активности абонентов сети для получения косвенной информации о взаимодействии пользователей и характере информации, которой обмениваются абоненты сети.
Несанкционированная модификация информации является наиболее опасной разновидностью воздействий программных закладок, поскольку приводит к наиболее опасным последствиям. В этом классе воздействий можно выделить следующие:
· разрушение данных и кодов исполняемых программ внесение тонких, трудно обнаруживаемых изменений в информационные массивы;
· внедрение программных закладок в другие программы и подпрограммы (вирусный механизм воздействий);
· искажение или уничтожение собственной информации сервера и тем самым нарушение работы сети;
· модификация пакетов сообщений.
№24
Автоматизация бухгалтерского учета - объективная необходимость. Работа бухгалтера все больше становится творческой, и внедрение компьютерных технологий повышает эффективность, беря на себя, кроме всего прочего, всю рутинную работу. Однако, автоматизация вызывает необходимость построения технологии решения бухгалтерских задач с учетом ряда следующих требований:
- ограничение допуска к первичной и систематизированной информации путем введения паролей (ключей секретности) и недопущения несанкционированного доступа;
- сохранности учетной информации на необходимый срок;
- диалогового (запросного) режима работы пользователей с вычислительными техническими средствами;
- возможности выдачи информации фрагментно, то есть в любом сочетании, удобном для пользователя;
- возможности принудительного ввода данных для оперативного управления и обеспечения при этом автоматического контроля за выполнением управленческих решений.
Классификация информационных систем
По масштабам применения современные АС подразделяются на три основные класса:
1.Настольные - для работы одного человека. К ним следует отнести Автоматизированное Рабочее Место (АРМ) бухгалтера малого предприятия, АРМ кассира, АРМ расчетчика заработной платы и.т.д. Внедрение таких программ не вызывает особых трудностей и для хороших систем может исчисляться днями.
Основные проблемы возникают при объединении информации с разных участков учета - так как рабочие данные специалистов хранятся на разных компьютерах, и возникает много рассогласований. Например, один и тот же объект (материал, товар, изделие) на разных АРМах может иметь разные коды.
2.Офисные - для работы отдела. К такого рода системам следует отнести сетевые бухгалтерские программы, программы автоматизации торгового зала, сетевые складские программы и.т.д. Сотрудники всего отдела могут одновременно работать с единой базой данных, выполняя отдельную функцию управления предприятием. Внедрение систем этого класса значительно сложнее настольных : требуется упорядочение плана счетов, составление общего справочника поставщиков и потребителей, настройка на учетную политику предприятия, обучение персонала и т.д. Но настоящие проблемы возникают при попытках обеспечения информационного безбумажного взаимодействия между сбытом, бухгалтерией, снабжением и производством.
Корпоративные - для работы целого предприятия или даже нескольких предприятий. Корпоративные системы охватывают, как правило, всю финансово-хозяйственную и производственную деятельность предприятия, в т.ч. имеющего филиалы и дочерние фирмы, входящего в холдинговые компании и концерны. Рассмотрим корпоративные системы, которые только в настоящее время стали появляться на нашем рынке, и в скором времени неизбежно станут столь же популярны, как и на Западе. Может показаться, что корпоративные системы нужны только крупным предприятиям. На самом деле те проблемы, которые в них решаются, актуальны для любой фирмы.
САБУ от "1С" реализованы для разных программных и аппаратных платформ: DOS, Windows, Windows 95, Macintosh (с начала 1996 г.), Power Macintosh (с лета 1996 г.). Существует несколько модификаций системы: базовая, профессиональная (для решения более сложных бухгалтерских задач, включающих элементы анализа хозяйственной деятельности предприятий), сетевая (с весны 1996 г. реализована технология клиент/сервер). Наиболее распространенная современная версия "1С:Бухгалтерия Проф. 6.0" под Windows является, на наш взгляд, лучшей из представленных на российском рынке. В базовый комплект поставки входят одна или две дискеты, руководство пользователя и регистрационная анкета. Для установки и эксплуатации программы достаточно иметь 3 - 5 Мбайт свободного места на диске.
САБУ "БОСС-Бухгалтер" может применяться на предприятиях любой формы собственности и функционировать как автономно, так и в составе системы управления "БОСС-Компания" или "БОСС-Корпорация". САБУ фирмы "Инфософт" До недавнего времени отличительной чертой продуктов фирмы "Инфософт" было наличие модулей, предназначенных для автоматизации отдельных участков бухгалтерского учета.
№ 25
Автоматизация бухгалтерского учета основывается на едином взаимосвязанном технологическом процессе обработки документации по всем разделам учета начиная от сбора первичных учетных данных до получения бухгалтерской отчетности. Информация справочного характера вводится в ЭВМ в начале работы. Текущая учетная информация - с первичных документов либо со специальных регистраторов учетных данных производится по специальным программам, в соответствии с которыми полученная учетная информация может храниться, поступать в обработку, выдаваться на экран или печать по запросу.
В условиях комплексной автоматизации бухгалтерского учета данные синтетического и аналитического учета формируются в базах данных используемого программного комплекса и ежемесячно выводятся на бумажные носители - выходные формы документов (мемориальные ордера, карточки, ведомости, главная книга, отчет и т.п.). Учетным регистром, получаемым с ЭВМ, может быть любой документ, содержащий систематическую или хронологическую запись. При этом содержание показателей в выходных формах документов должно соответствовать требованиям, предусмотренным законодательством для регистров бухгалтерского учета.
Наряду с выпуском полного комплекта бухгалтерской и налоговой отчетности, одной из важнейших задач автоматизированной системы бухгалтерского учета является максимальная автоматизация расчетных процедур, решающих возникающие проблемы.
Автоматизация бухгалтерского учета - объективная необходимость. Работа бухгалтера все больше становится творческой, и внедрение компьютерных технологий повышает эффективность, беря на себя, кроме всего прочего, всю рутинную работу. Однако, автоматизация вызывает необходимость построения технологии решения бухгалтерских задач с учетом ряда следующих требований:
- ограничение допуска к первичной и систематизированной информации путем введения паролей (ключей секретности) и недопущения несанкционированного доступа;
- сохранности учетной информации на необходимый срок;
- диалогового (запросного) режима работы пользователей с вычислительными техническими средствами;
- возможности выдачи информации фрагментно, то есть в любом сочетании, удобном для пользователя;
- возможности принудительного ввода данных для оперативного управления и обеспечения при этом автоматического контроля за выполнением управленческих решений.
Из всего сказанного можно сделать вывод, что все предприятия обязаны вести бухгалтерский учет своего имущества и хозяйственных процессов в обобщенном денежном выражении путем сплошного, непрерывного, документального и взаимосвязанного их отражения. Но при этом следует отметить, что предприятию при организации и осуществлении бухгалтерского учета разрешается:
· вносить в рекомендуемые Минфином РФ регистры бухгалтерского учета и методы его ведения изменения, исходя из конкретных условий хозяйствования, при соблюдении общих методологических принципов;
· устанавливать формы организации бухгалтерской работы;
· разрабатывать систему внутрипроизводственного учета и контроля;
· вводить отчетность, необходимую предприятию.
№26
Матричная модель позволяет символически выразить технологию подготовки и маршруты движения документов, алгоритмы формирования показателей, а также взаимосвязь между всеми рабочими группами данного подразделения, подразделениями предприятия и внешней средой. Она служит основным, завершающим обследование документом, отражающим в наглядной форме деятельность как любого подразделения (отдела), так и всей системы управления в целом. Основное назначение матричной модели в том, что она характеризует существующие потоки информации, необходимые для проектирования системы обработки данных. Она должна по возможности содержать все без исключения сведения, отражающие процесс планово-управленческой деятельности и сопровождающий его документооборот.
Принципиальная схема матричной информационной модели
Матричная информационная модель представляет собой шахматную таблицу, которая позволяет в единой форме отразить связи между подразделениями предприятия и процессы выработки новых сведений. Это модель выявленных потоков информации системы или любого его подразделения, выражающая количественно и качественно все их внешние и внутренние характеристики.
Закон Литтла
Производительность λ и среднее время ответа U связаны между собой зависимостью
![]()
которая
называется формулой Литтла и является
фундаментальным законом теории массового обслуживания. В системе, состоящей из N устройств, загрузка которых равна ![]() ,
среднее число задач m, выполняемых одновременно в
мультипрограммном режиме, равно суммарной загрузке устройств:
,
среднее число задач m, выполняемых одновременно в
мультипрограммном режиме, равно суммарной загрузке устройств:
![]()
Остальные
![]() задач находятся в состоянии ожидания. Число одновременно выполняемых задач,
определяемое, называется коэффициентом
мультипрограммирования и равно отношению производительности системы в
мультипрограммном режиме λ к производительности в однопрограммном режиме
задач находятся в состоянии ожидания. Число одновременно выполняемых задач,
определяемое, называется коэффициентом
мультипрограммирования и равно отношению производительности системы в
мультипрограммном режиме λ к производительности в однопрограммном режиме ![]() ,
если затраты ресурсов на организацию мультипрограммирования возрастают
пропорционально числу одновременно выполняемых задач, т. е.
,
если затраты ресурсов на организацию мультипрограммирования возрастают
пропорционально числу одновременно выполняемых задач, т. е.
![]()
Таким образом, коэффициент мультипрограммирования m является показателем увеличения производительности системы за счет мультипрограммирования. Из
![]() следует, что коэффициент
мультипрограммирования
следует, что коэффициент
мультипрограммирования
![]()
где N – число устройств системы, способных функционировать параллельно с каждым из N–1 остальных устройств. При этом предполагается, что система работает без отказов. Общим правилом работы с новым программным обеспечением математического характера является его тестирование на задачах с известным решением (предпочтительно аналитическим).
№27
Запрос - команда которую вы даете вашей программе базы данных, и которая сообщает ей чтобы она вывела определенную информацию из таблиц в память. Эта информация обычно посылается непосредственно на экран компьютера или терминала которым вы пользуетесь, хотя, в большинстве случаев, ее можно также послать принтеру, сохранить в файле ( как объект в памяти компьютера ), или представить как вводную информацию для другой команды или процесса.
Все запросы в SQL состоят из одиночной команды. Структура этой команды обманчиво проста, потому что вы должны расширять ее так чтобы выполнить высоко сложные оценки и обработки данных. Эта команда называется - SELECT(ВЫБОР). КОМАНДА SELECT В самой простой форме, команда SELECT просто инструктирует базу данных чтобы извлечь информацию из таблицы.
Другими словами, эта команда просто выводит все данные из таблицы. Большинство программ будут также давать заголовки столбца как выше, а некоторые позволяют детальное форматирование вывода, но это уже вне стандартной спецификации. Имеется объяснение каждой части этой команды: SELECT Ключевое слово которое сообщает базе данных что эта команда - запрос. Все запросы начинаются этим словом, сопровождаемым пробелом. snum, sname Это - список столбцов из таблицы которые выбираются запросом. Любые столбцы не перечисленные здесь не будут включены в вывод команды. Это, конечно, не значит что они будут удалены или их информация будет стерта из таблиц, потому что запрос не воздействует на информацию в таблицах; он только показывает данные. FROM FROM - ключевое слово, подобно SELECT, которое должно Salespeople быть представлено в каждом запросе. Оно сопровождается пробелом и затем именем таблицы используемой в качестве источника информации. В данном случае - это таблица Продавцов(Salespeople). ; Точка с запятой используется во всех интерактивных командах SQL чтобы сообщать базе данных что команда заполнена и готова выполниться. С тех пор как SQL использует точку с запятой чтобы указывать конец команды, большинство программ SQL обрабатывают возврат (через нажим Возврат или клавишу ENTER ) как пробел. В общем случае, команда SELECT начинается с ключевого слова SELECT, сопровождаемого пробелом. После этого должен следовать список имен столбцов которые вы хотите видеть, отделяемые запятыми. Если вы хотите видеть все столбцы таблицы, вы можете заменить этот список звездочкой (*). Ключевое слово FROM следующее далее, сопровождается пробелом и именем таблицы запрос к которой делается. В заключение, точка с запятой ( ; ) должна использоваться чтобы закончить запрос и указать что команда готова к выполнению.
По длительности ЖЦ АЭИС разделяется на два класса:
- системы с малой длительностью эксплуатации, предназначенные для получения конкретных результатов вычислений. Они относительно невелики (до 10 тысяч команд), разрабатываются, как правило, одним специалистом или небольшой группой, не предназначены для тиражирования и передачи для последующего использования, преобладают в научных организациях и ВУЗах;
- Системы с большой длительностью эксплуатации создаются для
регулярной обработки экономической информации. Размеры их колеблются в широких размерах (от 10 до 1000 тыс. команд), они могут подвергаться модернизации в процессе их длительного сопровождения, допускается большой объем их тиражирования, они снабжаются документацией, как промышленные изделия, преобладают в проектных и отраслевых организациях. Проектирование занимает особое место в жизненном цикле информационной системы. Специалистами установлено, что стоимость выявления и исправления на более поздних стадиях жизненного цикла ошибок, допущенных при проектировании и его отдельных фазах, возрастает в десятки раз. Поэтому большие усилия направлены на совершенствование специальных языков проектирования и трансляторов, на развитие методов формализованной отладки, на создание простейших систем автоматизации программирования и проектирования для отдельных типов ЭВМ, включая персональные, т.е. на наиболее формализованных этапах технологического процесса создания информационных систем. Одновременно постоянно развивается и совершенствуется теория и практика спецификаций систем, позволяющие формализовать начальные этапы создания АЭИС.
Методологическая поддержка включает набор стандартов, инструкций и методик, определяющих правила создания систем и регламентирующие построение объекта разработки и процесса его создания. В методиках и инструкциях конкретизируются языки проектирования систем, правила использования символов и обозначений, правила структурного построения аппаратных и программных компонент и
их взаимодействия и другие важнейшие методические принципы организации вычислительных и информационных систем. Сюда могут быть отнесены и документы, содержащие методические основы процесса создания систем: правила программирования, принципы отладки компонент систем, порядок их испытания, способы оценки качества и т.д.
На базе государственных и отраслевых стандартов, содержащих методические основы проектирования систем, для разработки конкретной АЭИС или группы систем одного класса создаются стандарты предприятия и руководящие указания по проектированию. В совокупности эти документы отражают отражают различные аспекты методологии создания конкретных АЭИС. Средства поддержки:
Технологическая поддержка детализирует документы методологической поддержки, регламентирующие технологию обеспечения жизненного цикла систем.
Инструментальная поддержка. Состоит из программных средств и средств вычислительной техники, связи и тиражирования, обеспечивающих автоматизацию процесса создания АЭИС (комплекса программ).
№28
Обработка экономической информации стала самостоятельным научно-техническим направлением с большим разнообразием идей и методов. Отдельные компоненты процесса обработки достигли высокой степени организации и взаимосвязи, что позволяет объединить все средства обработки информации на конкретном экономическом объекте понятием «экономическая информационная система» (ЭИС). Детальное изучение ЭИС опирается на понятия «информация» и «система». Выделяются три фазы существования информации:
1. Ассимилированная информация-представление сообщений в сознании человека, наложенное на систему его понятий и оценок.
2. Документированная информация - сведения, зафиксированные в знаковой форме на каком-то физическом носителе.
3. Передаваемая информация - сведения, рассматриваемые в момент передачи информации от источника к приемнику. Основная масса информации собирается, передается и обрабатывается с помощью знаков. Знаки - это сигналы, которые могут передавать информацию при наличии соглашения об их смысловом содержании между источниками и приемниками информации. Набор знаков, для которых существует указанное соглашение, называется знаковой системой. Многие знаковые системы, нельзя четко ограничить, однако при обработке информации на электронных вычислительных машинах наличие точного перечня знаков обязательно. Для обработки экономической информации характерны сравнительно простые алгоритмы, преобладание логических операций (упорядочение, выборка, корректировка) над арифметическими, табличная форма представления исходных и результатных данных. К важнейшим признакам, по которым обычно осуществляется классификация циркулирующей экономической информации, относятся:
1. Отношение к данной управляющей системе. Этот признак позволяет разделить сообщения на входные, внутренние и выходные;
2. Признак времени. Относительно времени сообщения делятся на перспективные (о будущих событиях) и ретроспективные. К первому классу относится плановая и прогнозная информация, ко второму - учетные данные. По времени поступления разделяются периодические и непериодические сообщения;
3. Функциональные признаки. Формируется классификация по функциональным подсистемам экономического объекта. Например, информация о трудовых ресурсах, производственных процессах, финансах и т.п., в другом разрезе - на данные планирования, нормирования, контроля, учета и отчетности. Создание АЭИС с использованием ПЭВМ позволяет: обеспечивать работников управленческой сферы и финансово-экономических служб оперативной информацией вместо обезличенного представления информации функциональному подразделению в целом; - получать комплексную информацию на основе данных всех подсистем управления хозяйственной и коммерческой деятельностью;
- создать многоуровневый интегрированный банк данных и обеспечить диалоговый режим общения пользователя с системой через автоматизированные рабочие места (АРМ);
- снизить объем выходных бумажных документов (так называемых машинограмм) в три-четыре раза;
- сократить время поиска информации в системе, а также ее
обработки, подготовки и выпуска различной организационно-распорядительной документации;
- автоматизировать функции контроля исполнения на всех уровнях управления и экономической деятельности;
- автоматизировать ведение локальной информации конечных пользователей и создавать локальные базы данных;
- дать возможность пользователям работать с имеющейся в банке данных информацией как в составе общей сети, так и автономно.
Между модульной структурой и структурами данных существует связь, которая может быть проиллюстрирована примером отладки системе на уровне языка проектирования. При этом могут быть использованы две технологии:
просмотр проектирования, который используется для проверки
корректности проекта; автоматизация этого процесса может быть
осуществлена с помощью эмулятора просмотра; технология просмотра
достаточно проста, если система построена на модульной основе и
каждый модуль разбит на относительно несложные процедуры;
выверка потока данных, которая проверяет правильность обработки информации в системе; для этого используются диаграммы потока данных, управляющие и контролирующие правильность прохода данных через систему. Существуют несколько способов организации данных. Простейшая структура данных, состоящая из нескольких элементов, называется списком. Данные запоминаются в последовательности, соответствующей списку (таким же способом, каким они создаются или генерируются).
№29
ИИ - это научно-исследовательское направление создающие модели и соответствующие программные средства, позволяющие с помощью ЭВМ решать задачи творческого, не вычислительного характера, которые в процессе решения требуют обращения к семантике (проблеме смысла). Исследования в области ИИ проводятся в течение 30 лет.
Началом работ в области ИИ считают создание ЭВМ, которая должна была имитировать процесс человеческого мышления. Разработка Розенблата. Машина-персептрон имела два вида нейтронов, которые образовывали нейтронную сеь.
Исследования в области ИИ разделились на два подхода:
1)Конекционистский
2)Символьный
В конце 60-х изменилась методология решения задач ИИ, т.е. вместо моделирования способов мышления человека началась разработка программ способных решать человеческие задачи, но на базе Эффективных машинно-ориентированных методов. Исследовательским полигоном этого периода явились головоломки и игры. Это объясняется замкнутостью пространства поиска решений и возможностью моделирования очень сложной стратегии поиска решения. В то же время делаются попытки перенести ИИ из искусственной среды в реальную. Возникает проблема моделирования внешнего мира. Это привело к появлению интегральных роботов, которые изначально должны были выполнять определенные операции в технологических процессах, работать в опасных для человека средах. С появлением роботов большое внимание уделяется реализации функции формирования действий, восприятие ими информации о внешней среде. Появление роботов считают вторым этапом исследований в ИИ.
В начале 70-х акценты в ИИ сместились на создание человеко-машинных систем, позволяющих комплексно на основе эвристических методов вырабатывать решения в рамках конкретных предметных областей на основе символьного подхода. В это же время стали развиваться бурными темпами экспертные системы (ЭС). ЭС - позволяет выявлять, накапливать и корректировать знания из различных областей и на основе этих знаний формировать решения, которые считаются если не оптимальными, то достаточно эффективными в определенных ситуациях. Распознавание образов - эта область очень важна для конструирования промышленных роботов, а в области персональных компьютеров на ней целиком строится технология программ оптического распознавания символов - именно благодаря алгоритмам искусственного интеллекта компьютер может теперь почти без ошибок «читать» сканированный текст.
Стандартные модели знаний (МЗ):
1 - продукционная модель знаний (системы продукции)
2 - логическая МЗ
3 - фреймовая МЗ
4 - реляционная МЗ
Продукционная модель (ПМ) знаний и ее использование в ЭС.
ПМ или системы продукции используют для представления знаний два понятия:
1 - “объект-атрибут-значение”
2 - “правило продукции”
С помощью (1) описываются декларативные знания в базе. Такое представление позволяет при формировании БЗ упорядочить описание объектов, соблюдая их определенную иерархию. Если к таким упорядоченным объектам в процессе логического вывода применять правила, то можно организовать обращение отдельно к объекту, отдельно к атрибуту и отдельно к значению.
Правило продукции представляет собой средство описания процедурных знаний в виде MG->MD
MG описывает определенную ситуацию в предметной области
MD описывает собой одно действие или соволкупность действий, которые необходимо выполнить в случае обнаружения соответствующей ситуации в предметной области
Применеие каждого текущего правила изменяет ситуацию на обьекте, поэтому нужно в следующем цикле проверить весь набор правил, пока не встретится условие останова. И левая и правая часть правила строится на основе знаний в виде “объект-атрибут-значение” или более сложных конструкций, построенных на их базе.
Продукционные системы используют модульный принцип организации знаний (этим они отличаются от традиционных систем, т.к. те используют модульный принцип организации алгоритмов). В продукционных моделях предполагается полная независимость правил друг от друга, т.е. на одном уровне иерархии одно правило не может вызвать другое. Продукционные модели обладают высокой степенью модифицируемости значений, дают возможность четко отделить метазнания от предметных знаний, что позволяет даже врамках одной системы использовать разные стратегии вывода. В продукционных системах можно выделить два подхода , исп. при выводе решений:
1 — безвозвратный
2 — пробный
В (1) выбранное для выбранное для исполнения правило используется необратимо, т.е. без возможности дальнейшего пересмотра. В (2) применимое к конкретной ситуации правило также выполняется , но предусматривает возможность вернуться к этой ситуации, чтобы применить другое правило. Для этого режима предусматривается точка возврата и если на последующих этапах невозможно получить результат, то управление передается в последнюю точку возврата.
В основе логической модели знаний лежит понятие формальной теории и отношения, которые существуют между единицами знаний можно описывать только с помощью синтаксических правил, допустимых в рамках этой теории.
Формальная теория задается всегда четверкой символов S=<B, F, A, R>, где
В - конечное множество базовых символов, иначе - алфавит теории S;
F - подмножество выражений теории S, называемых формулами теории. Обычно имеется эффективная процедура, которая представляет собой совокупность правил, позволяющих из элементов множества В строить синтаксически правильные выражения.
А - выделенное множество правил, называемых аксиомами теории, т. е. множество априорно истинных формул.
R - конечное множество отношений { r1, r2, ... , rn } между формулами, называемыми правилами вывода. Для любого ri существует целое положительное число j, такое, что для каждого множества, состоящего из j формул, и для каждой формулы F эффективно решается вопрос о том, находятся ли эти j-формулы в отношении ri с формулой F. Если ri выполняется, то F называют непосредственным следствием F-формул по правилу ri.
Следствием (выводом) формулы в теории S называется такая последовательность правил, что для любого из них представленная формула явл-ся либо аксиомой теории S, либо непосредственным следствием.
Правила вывода, которые разрабатываются проектировщиками, позволдяют расширить множество формул, которые явл-ся аксиомами теории.
Формальная теория наз. разрешимой, если существует эффективная процедура, позволяющая узнать для любой заданной формулы, существует ли её вывод в теории S.
Формальная теория S наз. Непротиаворечивой, если не существует такой формулы А, что и А, и не А выводимы в данной теории.
Наиболее распространенной формальной теорией, используемой в системах искусственного интеллекта явл-ся исчисление предикатов, то есть функций, которые могут принимать только 2 значения.
К достоинствам логической модели относят:
- наличие стандартной типовой процедуры логического вывода (доказательства теорем). Однако такое единообразие влечет за собой основной недостаток модели - сложность использования в процессе логического вывода эвристик, отражающих специфику ПО.
К другим недостаткам логической модели относят:
- “монотонность”;
- “комбинаторный взрыв”;
- слабость структурированности описаний.
Фреймовые модели представления знаний
Особенности представления знаний с помощью фреймов
Представление знаний с помощью фреймов явл. альтернативным по отнош. к системам продукции и лог. моделям. Оно дает возможность хранить родовидовую иерархию в явной форме.
Фрейм — составная структурная единица, предназначенная для описания относящихся к стереотипной ситуации на объекте
Осн. элемент единиц фрейма явл. слот, кот. исп. для хранения единичного знания. Станд. стр-ра слота след.:
{ имя слота; <f1> <S1>;...<fm> <Sm>; <q1> <q2>...<qn>.}
fi — имя атрибута, характерного для слота
Si — значение атрибута
qi — ссылки на другие слоты или фреймы
Стр-ра слота след-я:
имя файла
имя слота1 значение слота1
имя слота n значение слота n
Если структура знаний позволяет, то при описании нужно использовать простые слоты, т.е. слоты, кот. имеют одно значение. Значением слота м.б. не т. константа или ссылка на др. фрейм , но и функция, кот. требует определенной детализации в процессе решения. Т. функции получили название фасет. Основной операцией при работе с фреймами явл. поиск по образцу. В рамках фреймовой модели образец — это фрейм, в которых заполнены не все стр. единицы, а т. те, кот. б. использованы в качестве ключа для реализации действий в конкретных фреймах.
Логическая МЗ
Реляционная МЗ
№30
В начале 70-х акценты в ИИ сместились на создание человеко-машинных систем, позволяющих комплексно на основе эвристических методов вырабатывать решения в рамках конкретных предметных областей на основе символьного подхода. В это же время стали развиваться бурными темпами экспертные системы (ЭС). ЭС - позволяет выявлять, накапливать и корректировать знания из различных областей и на основе этих знаний формировать решения , которые считаются если не оптимальными, то достаточно эффективными в определенных ситуациях.
ЭС используют знания группы экспертов в рамках определенной предметной области. В качестве экспертов используются конкретные специалисты, которые могут быть не достаточно знакомы с ЭВМ. В настоящее время в общем объеме доля ЭС составляет до 90%. Области применения по количеству созданных образцов:
1. Медицинская диагностика, обучение, консультирование.
2. Проектирование ЭС.
3. Оказание помощи пользователям по решению задач в разных областях.
4. Автоматическое программирование. Проверка и анализ качества ПО.
5. Проектирование сверхбольших интегральных схем.
6. Техническая диагностика и выработка рекомендаций по ремонту оборудования.
7. Планирование в различных предметных областях и анализ данных, в том числе и на основе статистических методов. Интерпретация геологических данных и выработка рекомендаций по обнаружению полезных ископаемых.
В проектировании ЭС есть существенное отличие от проектирования традиционных информационных систем. Это объясняется тем, что в ЭС используется понятие “знание”, а в традиционной системе - “данные”. В ЭС отсутствует понятие жесткого алгоритма, а всевозможные действия задаются в виде правил, которые являются эвристиками, т.е. эмпирическими правилами или упрощениями. В процессе работы системы производится построение динамического плана решения задачи с помощью специального аппарата логического вывода понятий.
Проектирование ЭС имеет существенное отличие от проектирования традиционных информационных систем в силу того, что постановка задач, решаемых экспертной системой может уточняться во время всего цикла проектирования. Вследствие этого возникает потребность модифицировать принципы и способы построения базы знаний и аппарата логического вывода в ходе проектирования по мере того, как увеличивается объем знаний разработчиков о предметной области.
В силу отмеченных особенностей при проектировании ЭС-м применяется концепция “быстрого прототипа”. Ее суть: разработчики не пытаются сразу построить законченный продукт. На начальном этапе создается прототип, которыйрый должен удовлетворять двум условиям:
1) он должен решать типичные задачи предметной области;
2) с другой стороны трудоемкость его разработки должна быть очень незначительной.
Для удовлетворения этих условий при создании прототипа используются инструментальные средства, позволяющие ускорить процесс программирования ЭС (скелетные языки, оболочки ЭС). В случае успеха прототип должен расширяться дополнительными знаниями из предметной области. При неудаче может потребоваться разработка нового прототипа или проектировщики могут прийти к выводу о непригодности методов искуственного интеллекта для данного приложения.
По мере увеличения знаний о предметной области прототип может достичь такого состояния, когда он успешно решает все требуемые задачи в рамках предметной области. В этом случае требуется преобразование прототипа в конечный продукт путем его перепрограммирования на языках “низкого уровня”, что обеспечит увеличение быстродействия и эффективности программного продукта.
Примеры широко известных и эффективно используемых (или использованных в свое время) экспертных систем:
DENDRAL - ЭС для распознавания структуры сложных органических молекул по результатам их спектрального анализа (считается первой в мире экспертной системой). MOLGEN - ЭС для выработке гипотез о структуре ДНК на основе экспериментов с ферментами. XCON - ЭС для конфигурирования (проектирования) вычислительных комплексов VAX-11 в корпорации DEC в соответствии с заказом покупателя.
MYCIN - ЭС диагностики кишечных заболеваний.
PUFF - ЭС диагностики легочных заболеваний.
MACSYMA - ЭС для символьных преобразований алгебраических выражений.
YES/MVS - ЭС для управления многозадачной операционной системой MVS больших ЭВМ корпорации IBM. PROSPECTOR - ЭС для консультаций при поиске залежей полезных ископаемых.
POMME - ЭС для выдачи рекомендаций по уходу за яблоневым садом.
Набор экспертных систем для управления планированием, запуском и полетом космических аппаратов типа «челнок».
ЭСПЛАН - ЭС для планирования производства на Бакинском нефтеперерабатывающем заводе.
МОДИС - ЭС диагностики различных форм гипертонии.
Основные этапы разработки ЭС
1. Идентификация.
2. Концептуализация.
3. Формализация.
4. Выполнение.
6. Тестирование.
a. Переформулирование
b. Переконструирование
c. Усовершенствование
d. Завершение
В состав функций этапа 1 входит:
1) определение команды проектировщиков, их роли, а также формы взаимоотоношений;
2) определение целей разработок и ресурсов;
3) описание общих характеристик проблемы, входных данных, предполагаемого вида решения, ключевых понятий и отношений.
Типичные ресурсы этого этапа: источники знаний, время разработки, вычислительные ресурсы, объем финансирования.
На этапе 2 эксперт и инженер по знаниям формализуют ключевые понятия, отношения и характеристики, которые выявлены на предыдущем этапе. Данный этап призван решить следующие вопросы:
определить типы данных, выводимые понятия, используемые стратегии и гипотезы, виды взаимосвязей между объектами, типы ограничений, накладываемых на процесс решения задачи, состав знаний, которые используются для выработки и обоснования решений.
Опыт показывает, что для успешного решения вопросов этого этапа целесообразно составлять протокол действий и рассуждений экспертов в процессе проектирования. Такой протокол обеспечивает инженера по знаниям словарем терминов и вто же время заставляет эксперта осмысленно относиться к своим словам.
На этом этапе не требуется добиваться полной определенности и корректности всех заключений, а следует наметить лишь основные типовые направления решения проблемы.
На этапе 3 производится описание всех ключевых понятий и отношений на формальном языке. Инженер по знаниям производит анализ инструментальных систем и определяет их пригодность для конкретного приложения. Выходом данного этапа является формальное описание всего процесса решения жадачи на уровне декларативных и процедурных знаний. Инженер по знаниям определяет структуру пространства поиска решений, выбирает и обосновывает модель знаний, определяет состав метазнаний, которые затем могут быть положены в механизм логического вывода. При работе со знаниями изучается степень их достоверности, согласованность и избыточность, реализуется функция принадлежности различных оценочных показателей (например, коэффициентов уверенности), а также закладывается определенная интерпретация знаний в формальных структурах.
Этап 4 заключается в разработке одного или нескольких прототипов. Этот этап выполняется программистом и заключается в наполнении базы знаний инструментальной системы конкретными знаниями, а также программировании отдельных компонент системы. Обычная ошибка программиста заключается в том, что процесс наполнения базы знаний реальными знаниями откладывается до окончания программирования. Если база знаний заполняется с начала разработки прототипа, то это позволяет своевременно уточнить структуру знаний и быстро изменить программные компоненты.
Первый прототип должен быть готов уже через 2 месяца. При работе с ним программист доказывает, что выбранные структуры и методы пригодны для данного приложения и могут быть в дальнейшем расширены. При этом он совсем не заботится об эффективности машинной реализации. После завершения первого прототипа круг задач расширяется и на этой основе формируется следующий прототип. После достижения достаточно эффективного функционирования ЭС на базе прототипов, совершенствуются структуры декларативных и процедурных знаний, а также процедуры логического вывода. Основная трудность состоит в том, что очень часто в системе имеются громоздкие правила или много похожих правил. Неверно выбранные управляющие стратегии, в которых порядок выбора и анализа понятий существенно отличается от технологии эксперта. На этом этапе очень важно посвящать эксперта во все проблемы, связанные с получением решений, и внимательно проводить анализ мнения эксперта о недостатках системы.
Этап 5 оценивает пригодность ЭС для конечного пользователя. При этом разработчики стараются привлечь как можно больше пользователей различной квалификации, которые могут обращаться к системе для реализации разнообразных запросов. Для того, чтобы не дискредитировать систему в глазах пользователя, разработчики перед этим этапом должны устранить все ошибки в работе системы, даже мелкие технические ошибки. Пользователь анализирует систему с точки зрения полезности (возможность системы в ходе диалога определить потребности пользователя, выявить и устранить причины его неудач в работе) и удобства (настраиваемость на уровень квалификации пользователя, а также устойчивость к ошибкам).
По результатам 5-го этапа может понадобиться не только модификация программного обеспечения, но и идеологии разработки интерфейса.
Этап 6. Призван осуществлять оценку системы в целом. Тут необходимо особое внимание уделить подбору тестовых примеров. В них должны найти отражение следующие случаи:
* неверно сформулированные вопросы пользователя;
* присутствие неопределенности в вопросах пользователя;
* доступность для пользователя лексики системы;
* доступность для пользователя объяснений, которые выдает система;
* противоречивость и неполнота правил;
* согласование контекстов действия правил.
По результатам 6-го этапа осуществляется модификация системы. Наиболее простым её видом являетсяся усовершенствование прототипов. Этот вид затрагивает только этапы 4 и 6. Более серьёзным видом модификации являетсяся переконструирование представлений. Этот вид модификации необходим в том случае, если обнаруживается, что желаемое поведение системы не достигнуто. Предполагается возврат на этап формализации и далее осуществляется весь цикл проектирования. Если проблемы функционирования системы еще более серьёзны, то приходится возвращаться на этапы 2 и 1 для переформулирования требований к системе и основных понятий.
Структура экспертных систем
База знаний предназначена для хранения экспертных знаний о предметной области, используемых при решении задач экспертной системой.
База данных предназначена для временного хранения фактов или гипотез, являющихся промежуточными решениями или результатом общения системы с внешней средой, в качестве которой обычно выступает человек, ведущий диалог с экспертной системой.
Машина логического вывода – механизм рассуждений, оперирующий знаниями и данными с целью получения новых данных из знаний и других данных, имеющихся в рабочей памяти. Для этого обычно используется программно реализованный механизм дедуктивного логического вывода (какая-либо его разновидность) или механизм поиска решения в сети фреймов или семантической сети.
Машина логического вывода может реализовывать рассуждения в виде:
· дедуктивного вывода (прямого, обратного, смешанного);
· нечеткого вывода;
· вероятностного вывода;
· унификации (подобно тому, как это реализовано в языке Пролог);
· поиска решения с разбиением на последовательность подзадач;
· поиска решения с использованием стратегии разбиения пространства поиска с учетом уровней абстрагирования решения или понятий, с ними связанных;
· монотонного или немонотонного рассуждения,
· рассуждений с использованием механизма аргументации;
· ассоциативного поиска с использованием нейронных сетей;
· вывода с использованием механизма лингвистической переменной.
Подсистема общения служит для ведения диалога с пользователем, в ходе которого ЭС запрашивает у пользователя необходимые факты для процесса рассуждения, а также, дающая возможность пользователю в какой-то степени контролировать и корректировать ход рассуждений экспертной системы.
Подсистема объяснений необходима для того, чтобы дать возможность пользователю контролировать ход рассуждений и, может быть, учиться у экспертной системы. Если нет этой подсистемы, экспертная система выглядит для пользователя как «вещь в себе», решениям которой можно либо верить либо нет.
Подсистема приобретения знаний служит для корректировки и пополнения базы знаний. В простейшем случае это – интеллектуальный редактор базы знаний, в более сложных экспертных системах – средства для извлечения знаний из баз данных, неструктурированного текста, графической информации и т.д.
№31
С появлением ЭС появилась новая научная дисциплина - инженерия знаний, которая занимается исследованиями в области представления и формализации знаний, их обработки и использования в ЭС. В настоящее время под термин ЭС попадает очень большой круг систем, которые можно отнести к ЭС только по используемым моделям и методам проектирования. Поэтому делается попытка более строгой классификации систем ИИ символьного направления.
![]() В настоящее время при широком использовании символьного подхода усилилось
внимание к использованию нейтронных сетей. Это объясняется тем, что предложены
очень мощные модели нейтронных сетей и алгоритмы их обучения (метод обратного
распространения ошибок).
В настоящее время при широком использовании символьного подхода усилилось
внимание к использованию нейтронных сетей. Это объясняется тем, что предложены
очень мощные модели нейтронных сетей и алгоритмы их обучения (метод обратного
распространения ошибок).
Нейтронные сети используются в медицинской диагностике, управлении самолетом, налоговых и почтовых службах США.
Одной из составляющих успеха нейтронных сетей явилась совместная разработка компании Intel и корпорации Nestor микросхемы с архитектурой нейтронных сетей.
Тенденции развития средств вычислительной техники:
1. Развитие вычислительной базы: параллельные, нейтронные и оптические технологии, которые будут способны к распределенному представлению информации, параллельной ее обработки, обучению и самоорганизации.
2. Развитие теоретической основы для информационной обработки основанный на понятии ‘Softlogic’, поддерживающий как логический, так и интуитивный вывод понятий.
3. Разработка для реальных приложений системы когнетивных функций, таких как речь, звуковые эффекты, когнетивная графика и т.п.
Основным элементом БЗ являются знания о предметной области, в которой должна функционировать ЭС.
Знание - это совокупность сведений, образующих целостное описание соответствующее определенному уровню осведомленности об описываемой проблеме.
Основное отличие знаний от данных в том, что данные описывают лишь конкретное состояние объектов или группы объектов в текущий момент времени, а знания кроме данных содержат сведения о том как оперировать этими данными.
В БЗ ЭС знания должны быть обязательно структурированы и описаны терминами одной из модели знаний. Выбор модели знаний - это наиболее сложный вопрос в проектировании ЭС, так как формальное описание знаний оказывает существенное влияние на конечные характеристики и свойства ЭС.
В рамках одной БЗ все знания должны быть однородно описаны и простыми для понимания. Однородность описания диктуется тем, что в рамках ЭС должна быть разработана единая процедура логического вывода, которая манипулирует знаниями на основе стандартных типовых подходов. Простота понимания определяется необходимостью постоянных контактов с экспертами предметной области, которые не обладают достаточными знаниями в компьютерной технике.
Знания подразделяются с точки зрения семантики на факты и эвристики. Факты как правило указывают на устоявшиеся в рамках предметной области обстоятельства, а эвристики основываются на интуиции и опыте экспертов предметной области.
По степени обобщенности описания знания подразделяются на:
1) Поверхностные - описывают совокупности причинно- следственных отношений между отдельными понятиями предметной области.
2) Глубинные - относят абстракции, аналогии, образцы, которые отображают глубину понимания всех процессов происходящих в предметной области.
Введение в базу глубинных представлений позволяет сделать систему более гибкой и адаптивной, так как глубинные знания являются результатом обобщения проектировщиком или экспертом первичных примитивных понятий.
По степени отражения явлений знания подразделяются на:
1) Жесткие - позволяют получить однозначные четкие рекомендации при задании начальных условий.
2) Мягкие - допускают множественные расплывчатые решения и многовариантные рекомендации.
Тенденции развития ЭС.
![]()
М,Ж - мягкие, жесткие знания.
П,Г - поверхностные, глубинные знания.
I - медицина, управление
II - психодиагностика, планирование
III - диагностика неисправностей разного вида
IV - проектирование различных видов устройств
Обычно при проектировании БЗ проектировщик старается пользоваться стандартной моделью знаний (МЗ):
5 - продукционная модель знаний (системы продукции)
6 - логическая МЗ
7 - фреймовая МЗ
8 - реляционная МЗ
По форме описания знания подразделяются на:
1) Декларативные (факты) - это знания вида “А есть А”.
2) Процедурные - это знания вида “Если А, то В”.
Декларативные знания подразделяются на объекты, классы объектов и отношения.
Объект - это факт, который задается своим значением.
Класс объектов - это имя, под которым объединяется конкретная совокупность объектов-фактов.
Отношения - определяют связи между классами объектов и отдельными объектами, возникшие в рамках предметной области.
К процедурным знаниям относят совокупности правил, которые показывают, как вывести новые отличительные особенности классов или отношения для объектов. В правилах используются все виды декларативных знаний, а также логические связки. При обработке правил следует отметить рекурсивность анализа отношений, т.е. одно правило вызывает глубинный поиск всех возможных вариантов объектов БЗ.
Граница между декларативными и процедурными знаниями очень подвижна, т.е. проектировщик может описать одно и то же как отношение или как правило.
Во всех видах моделей выделен еще один вид знаний - метазнания, т.е. знания о данных. Метазнания могут задавать способы использования знаний, свойства знаний и т.д., т.е. все, что необходимо для управления логическим выводом и обучением ЭС.
В ЭС применяется стратегия вывода в виде прямой и обратной цепочек рассуждения. Прямая стратегия ведет от фактов к гипотезам, а обратная пытается найти данные для доказательства или опровержения гипотезы.
В современных ЭС применяются комбинированные стратегии, которые на одних этапах используют прямую, а на других обратную цепочки рассуждения.
№32
Существуют различные подходы к построению систем ИИ.
Практически каждая система ИИ, построенная на логическом принципе, представляет собой машину доказательства теорем. При этом исходные данные хранятся в базе данных в виде аксиом. Имеются правила логического вывода как отношения между аксиомами. Кроме того, каждая такая машина имеет блок генерации цели, и система вывода пытается доказать данную цель как теорему. Если цель доказана, то трассировка примененных правил позволяет получить цепочку действий, необходимых для реализации поставленной цели. Мощность такой системы определяется возможностями генератора целей и машиной доказательства теорем.
Добиться большей выразительности логическому подходу позволяет такое сравнительно новое направление, как нечеткая логика, которую мы рассмотрим ниже.
Для большинства логических методов характерна большая трудоемкость, поскольку во время поиска доказательства возможен полный перебор вариантов. Поэтому данный подход требует эффективной реализации вычислительного процесса, и хорошая работа обычно гарантируется при сравнительно небольшом размере базы данных.
Несмотря на этот недостаток, логический подход является, наряду с искусственными нейронными сетями, основным подходом к построению ИИ.
Под структурным подходом мы подразумеваются попытки построения ИИ путем моделирования структуры человеческого мозга. Одной из первых таких попыток был перцептрон Френка Розенблатта. Основной моделируемой структурной единицей в перцептронах (как и в большинстве других вариантов моделирования мозга) является нейрон.
Позднее возникли и другие модели, которые известны под термином «нейронные сети» (НС). Эти модели различаются по строению отдельных нейронов, по топологии связей между ними и по алгоритмам обучения. Среди наиболее известных сейчас вариантов НС можно назвать НС с обратным распространением ошибки, сети Хопфилда, стохастические нейронные сети.
НС наиболее успешно применяются в задачах распознавания образов, в том числе сильно зашумленных, однако имеются и примеры успешного применения их для построения собственно систем ИИ.
Для моделей, построенных по мотивам человеческого мозга характерна не слишком большая выразительность, легкое распараллеливание алгоритмов, и связанная с этим высокая производительность параллельно реализованных НС. Также для таких сетей характерно одно свойство, которое очень сближает их с человеческим мозгом — нейронные сети работают даже при условии неполной информации об окружающей среде, то есть как и человек, они на вопросы могут отвечать не только «да» и «нет» но и «не знаю точно, но скорее да».
Довольно большое распространение получил и эволюционный подход. При построении систем ИИ по данному подходу основное внимание уделяется построению начальной модели, и правилам, по которым она может изменяться (эволюционировать). Причем модель может быть составлена по самым различным методам, это может быть и НС и набор логических правил и любая другая модель. После этого мы включаем компьютер и он, на основании проверки моделей отбирает самые лучшие из них, на основании которых по самым различным правилам генерируются новые модели, из которых опять выбираются самые лучшие и т. д.
В принципе можно сказать, что эволюционных моделей как таковых не существует, существует только эволюционные алгоритмы обучения, но модели, полученные при эволюционном подходе, имеют некоторые характерные особенности, что позволяет выделить их в отдельный класс.
Такими особенностями являются перенесение основной работы разработчика с построения модели на алгоритм ее модификации и то, что полученные модели практически не сопутствуют извлечению новых знаний о среде, окружающей систему ИИ, то есть она становится как бы вещью в себе.
Еще один широко используемый подход к построению систем ИИ — имитационный. Данный подход является классическим для кибернетики с одним из ее базовых понятий — «черным ящиком» (ЧЯ). ЧЯ — устройство, программный модуль или набор данных, информация о внутренней структуре и содержании которых отсутствуют полностью, но известны спецификации входных и выходных данных. Объект, поведение которого имитируется, как раз и представляет собой такой «черный ящик». Нам не важно, что у него и у модели внутри и как он функционирует, главное, чтобы наша модель в аналогичных ситуациях вела себя точно так же.
Таким образом, здесь моделируется другое свойство человека — способность копировать то, что делают другие, не вдаваясь в подробности, зачем это нужно. Зачастую эта способность экономит ему массу времени, особенно в начале его жизни.
Основным недостатком имитационного подхода также является низкая информационная способность большинства моделей, построенных с его помощью.
Важнейшим инструментом реализации логического подхода является технология логического программирования.
Логическое программирование – программирование, основанное на использовании механизма доказательства теорем в логике, который позволяет выяснить, является ли противоречивым некоторое множество логических формул. При этом программа рассматривается как набор логических формул, описывающих предметную область, совместно с теоремой, которая должна быть доказана. Логическое программирование избавляет программиста от необходимости определения точной последовательности шагов выполнения вычислений.
Наиболее известные языки логического программирования – РЕФАЛ и ПРОЛОГ. Рассмотрим язык ПРОЛОГ, как наиболее популярный из языков логического программирования. Этот язык используется для решения задач в различных областях, включающих:
· математическую логику;
· решение абстрактных задач;
· понимание естественного языка;
· автоматизацию проектирования;
· символьное решение уравнений;
· анализ биохимических структур.
Как мы видим, перечень областей использования ПРОЛОГа вполне соответствует сфере применения искусственного интеллекта.
ПРОЛОГ является не процедурным, а декларативным языком. В качестве типовых данных ПРОЛОГ использует элементарные единицы данных, так называемые атомы – строки символов и числа. Из атомов составляются списки и бинарные деревья. Сама «программа» строится из последовательности фактов и правил, и затем формулируется утверждение, которое ПРОЛОГ будет пытаться доказать с помощью введенных правил. Таким способом можно описывать очень сложные проблемы, которые будут решаться самим ПРОЛОГом автоматически (человек лишь описывает структуру задачи, а внутренний «мотор» сам ищет решение.) Это происходит с помощью метода сопоставления и рекурсивного поиска. Опишем кратко синтаксис языка ПРОЛОГ.
Программа на языке ПРОЛОГ – набор утверждений, составляющих базу фактов и базу правил, к которым допустимо обращение с запросами, касающимися их содержимого. Запросы называются также целевыми утверждениями.
Утверждение языка ПРОЛОГ – линейная конструкция из термов, заканчивающаяся точкой.
Терм языка ПРОЛОГ – это либо константа, либо переменная, либо структура. Константами являются атомы и числа.
Константы используются для обозначения (именования) конкретных объектов предметной области и конкретных отношений между ними.
Атом языка ПРОЛОГ – это
- последовательность букв, цифр и знака подчеркивания, обязательно начинающаяся со строчной буквы;
- последовательности специальных знаков «:-» , «?-», «=», «>» и других.
Переменная языка ПРОЛОГ – последовательность букв, цифр и знака подчеркивания, обязательно начинающаяся с прописной буквы.
Структура языка ПРОЛОГ – конструкция из функтора и компонент, имеющая следующий вид
<функтор>(<компонент-1>,<компонент-2>, ... ,<компонент-n>) ,
где в качестве функтора должен выступать атом, а компонентом может быть любой терм (в том числе и структура).
База фактов в языке ПРОЛОГ – последовательность утверждений, описывающих факты предметной области в виде структур, функторами которых являются атомы – имена отношений (предикатные буквы), а компонентами - предметные константы.
Каждый факт представляет собой элементарную формулу (предикат) исчисления предикатов первого порядка и является дизъюнктом Хорна, состоящим из одного (положительного) литерала.
При описании фактов переменные не используются.
Дизъюнкт Хорна – правильно построенное предложение, имеющее следующий общий вид записи P0 \/ ~P1 \/ ~P2 \/ ... \/ ~Pn, n >= 0, где Pi - атомарная формула (предикат), все переменные которой связаны не указанными явно кванторами всеобщности, областью действия которых является весь дизъюнкт.
Эквивалентной, но более удобной для человека, формой представления дизъюнкта является Р1 & Р2 &...& Рn -> P0. Следует отметить, что существует формальная процедура приведения произвольных правильно построенных формул к стандартному виду - совокупности коньюктивно связанных дизъюнктов Хорна. Однако в большинстве случаев человеку не составляет труда описать свою предметную область аксиомами непосредственно в стандартном виде, используя импликативную интерпретацию диэъюнктов.
База правил – совокупность правил в программе на языке ПРОЛОГ.
Правило представляет собой дизьюнкт Хорна, содержащий один положительный литерал и несколько отрицательных, и записывается следующим образом
<структура-0>:-<структура-1>, ... ,<структура-N>.
Здесь каждая структура представляет собой предикат, областью действия переменных является все правило. Предикат, стоящий слева от атома «:-», называется заголовком правила, все остальные предикаты образуют его тело.
Правило может трактоваться следующим образом: предикат, являющийся заголовком правила доказан (удовлетворен), когда доказан каждый предикат тела правила.
В качестве предикатов, составляющих тело правила, могут выступать
· предикаты, фигурирующие в базе фактов;
· предикаты, совпадающие с заголовком других правил;
· встроенные предикаты систем программирования ПРОЛОГ.
Встроенный предикат – предикат, выводимость (согласованность) которого устанавливается непосредственно системой программирования ПРОЛОГ.
Запрос на языке ПРОЛОГ – утверждение, рассматриваемое в качестве целевого, имеющее следующий вид:
?-<структура-1>, ...,<структура-N>.
Конкретизация переменной – связывание переменной языка ПРОЛОГ с конкретным значением.
Конкретизация переменной обеспечивает возврат искомых значений переменных по запросам.
Выполнение запроса в языке ПРОЛОГ – процесс доказательства выводимости всех подцелей целевого утверждения методом резолюции с использовании линейной по входу стратегии.
Получив запрос, состоящий из нескольких предикатов, интерпретатор выбирает первый в последовательности запроса предикат и делает попытку (если этот предикат не встроенный) согласовать его с утверждениями, составляющими базы фактов и правил, для чего выполняется сопоставление этого предиката со всеми фактами и заголовками этих правил в простом линейном порядке до тех пор, пока оно не даст положительного результата. Если этого не происходит, ответом на запрос будет "Нет". В ходе согласования возможна конкретизация переменных значениями.
Если в ходе просмотра произошло сравнение с заголовком правила, то тело правила рекурсивно рассматривается в качестве нового целевого утверждения, доказательство которого реализуется с помощью рассматриваемой здесь процедуры.
Удовлетворив один предикат (подцель) запроса, интерпретатор переходит к соседнему справа, обрабатывая его аналогичным образом.
Запрос считается выполненным после удовлетворения его последней (крайней справа) подцели. Если же какая-либо подцель (но не первая) не может быть удовлетворена (согласована), то в работу включается механизм бэктрекинга, который заставляет интерпретатор, передвигаясь по предикатам целевого утверждения справа налево, вновь согласовывать эти предикаты, но уже на новых утверждениях программы. Если попытка пересогласовать какой-либо предикат (подцель) удается, то интерпретатор продолжает рассмотрение подцелей от данной в обычном порядке (слева направо).
Применение ПРОЛОГа для решения интеллектуальных задач, в частности в экспертных системах удачно настолько, что породило мнение, что ПРОЛОГ не является языком программирования в чистом виде. Его можно считать и оболочкой экспертной системы, и реализацией интеллектуальной база данных (не реляционной).
Машинная реализация языка предиката первого порядка имеет ряд серьезных проблем, которые связаны с универсальностью аппарата логического вывода. 1-я проблема — монотонность рассуждений (в процессе логического вывода нельзя отказаться от промежуточного заключения, если становятся известными дополнительные факты, которые свидетельствуют о том, что полученные на основе этого заключения решения не приводят к желаемому результату. 2-я проблема — комбинаторный взрыв ( в процессе логического вывода невозможно применять оценочные критерии для выбора очередного правила. Безсистемное применение правил в расчете на случайное доказательство приводит к тому, что возникает много лишних цепочек ППФ , активных в определенный момент времени. Это чаще всего приводит к переполнению рабочей памяти.
№33
Для выхода на новый уровень в использовании Интернет, в первую очередь, необходим переход к семантически значимому представлению информации в сети. Анализ как реально действующих в Интернет систем, так и исследовательских прототипов, ориентированных на представление информации в виде знаний, позволяет утверждать, что лидирующим направлением для реализации приложений в этой области являются агентные технологии и мультиагентные системы.
Машины поиска и извлечения информации, такие как "Yahoo!", "Lycos", "Infoseek", используют механизм поиска по ключевым словам и не учитывают контекст, в котором существует информация. Вот почему результатом работы таких систем могут быть сотни тысяч ссылок. Современные версии поисковых систем ("Metacrawler", "WebSeek" и.т.п.) адресуют запрос пользователя сразу к множеству машин поиска, и составляют индексные мета-каталоги и базы данных. Но так как они остаются в рамках поиска, основанного на ключевых словах, то полученные индексы связывают информацию с терминами, учитывая только актуальный для данного запроса лексический или синтаксический контекст. Аналогичные претензии можно адресовать и к тематическим каталогам, составленным вручную. Кроме того, что для их создания и сопровождения необходимо слишком много времени, существует диссонанс между критериями классификации понятий автора и пользователей. Подход к решению проблемы интеллектуализации Интернет заключается в дополнении специальными семантическими тегами стандартного HTML для того, чтобы "внести знания" прямо в страницы. Такие модифицированные HTML-документы несут информацию о взаимосвязях понятий и их семантических атрибутах в HTML-подобном формате, то есть не требуют внутреннего языка представления знаний. Идея создания расширенного HTML нашла воплощение в таком стандарте, как разработанный в W3С (интернациональный всемирный Web консорциум) язык XML (Extensible Markup Language) [URL1]. XML - язык для разметки синтаксической структуры документов, позволяющий благодаря спецификации синтаксиса, использовать такие документы множеству агентов, для которых данный формат является общим. Для того, чтобы аннотировать документы с помощью XML, разработан формат описания ресурсов RDF (Resource Description Framework) [URL2]. Мета-информация, определяемая форматом RDF, размещается как дополнительная страница или блок внутри каждой web-страницы (элементы web страницы не могут быть аннотированы прямо в тексте исходного документа, а должны быть повторены с дополнительной мета-информацией). Такой способ влечет за собой много трудностей из-за дублирования информации.
Также предлагается расширить HTML с целью получения семантических индексов к информации, организованной в виде так называемых Lightweight Deductive Databases, где связи между отдельными страницами определяются гипертекстовыми ссылками с атрибутами. Дедуктивные базы данных являются расширением реляционных за счет применения правил логического программирования для более сложного представления данных. В последнее время серьезное развитие получила потенциальная база знаний. Для работы со знаниями в сети нужны специальные методы представления и обработки знаний, интерпретации запросов и т.д. Задача здесь прежде всего в том, чтобы адаптировать методы и средства, разработанные в ИИ для систем, основанных на знаниях, в новую проблемную область. По определению онтология - это спецификация концептуализации, которая состоит из словаря и теории. Онтологии включают абстрактное описание как очень общих, так и специфичных для конкретной предметной области терминов. Одной из сильных сторон онтологий являются их потенциальные свойства для решения таких важных задач как разделение знаний и их повторное использование. Это заключение основывается на предположении о том, что если общая схема (представления и использования знаний), - то есть онтология, - явно определена для работающих с ней агентов как общий ресурс, то этот ресурс возможно разделять между агентами и многократно использовать.
Вовлечение систем, основанных на знаниях на Web, компонентом которых являются онтологии, позволяет рассматривать всемирную паутину как организованное и структурированное пространство знаний, что, возможно, приведет к использованию информации в сети на новом уровне.