Лабораторная
работа № 2
Автоматизированный
корреляционно-регрессионный анализ взаимосвязи статистических данных в среде MS Excel
Задание 1.
Построение аналитической группировки для
выявления
корреляционной
зависимости результативного признака от факторного и оценка тесноты взаимосвязи
признаков
Задание 2. Построение
однофакторной линейной регрессионной модели связи изучаемых признаков с помощью
инструмента Регрессия надстройки Пакет анализа
Задание 3. Построение
однофакторных нелинейных регрессионных моделей связи признаков с помощью
инструмента Мастер диаграмм и выбор наиболее адекватного уравнения
регрессии
Порядок выполнения лабораторной
работы
Для выполнения Лабораторной работы №2 выделяется Лист 2 рабочего файла,
сформированного в персональной папке студента при выполнении Лабораторной
работы №1, и используется следующая информация из Лабораторной работы №1:
·
исходные данные – Таблица 1, полученная после удаления аномальных
значений (А4:С33);
·
интервальный ряд распределения единиц совокупности по факторному
признаку Х – Среднегодовая стоимость основных производственных фондов из табл. 7 (А102:В106);
·
диаграмма рассеяния, расположенная начиная с ячейки F4.
I. Подготовительный этап
На данном этапе студент должен скопировать необходимую
информацию из Лабораторной работы №1 на Лист 2 рабочего файла персональной папки ФИО.
На Листе 2 рабочего файла
персональной папки студента заготовлены макеты таблиц, используемые при
выполнении Лабораторной работы №2.
Для записи
необходимой информации в рабочий и отчетный
файлы персональной папки необходимо скопировать данные из Листа 1 в Лист
2 рабочего файла в соответствии с нижеследующей таблицей:
Лист 1
Лист 2
|
Номер
таблицы
|
Содержимое
таблицы
|
Адресация
содержимого
|
|
Номер
таблицы
|
Содержимое
таблицы
|
Адресация
содержимого
|
|
Табл. 1
|
Исходные данные
|
A4:С33
|
|
Табл. 2.1
|
Исходные данные
|
A4:С33
|
|
 – –
|
Диаграмма рассеяния
копируется дважды
|
Начиная с ячейки F4
|
Копировать в
|
–
|
Диаграмма рассеяния
|
Начиная с ячейки Е4 и Е20
|
|
Табл. 7
|
Интервальный ряд
распределения факторного признака Х
|
А102: В106
|

|
Табл. 2.2
и
табл. 2.3
|
Интервальный ряд
распределения факторного признака Х
|
B41:C45
и
B52:C56
|
Расположение
макетов результативных таблиц в рабочем файле на Листе 2 персональной папки студента
|
A
|
B
|
C
|
D
|
E
|
|
1
|
|
|
Таблица 2.1
|
|
|
|
2
|
Исходные данные
|
|
|
|
3
|
Номер
предприятия
|
Среднегодовая
стоимость основных производственных фондов, млн. руб.
|
Выпуск
продукции, млн. руб.
|
|
|
|
4
|
|
|
|
|
|
|
5
|
|
|
|
|
|
|
6
|
|
|
|
|
|
|
7
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
9
|
|
|
|
|
|
|
10
|
|
|
|
|
|
|
11
|
|
|
|
|
|
|
12
|
|
|
|
|
|
|
13
|
|
|
|
|
|
|
14
|
|
|
|
|
|
|
15
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
17
|
|
|
|
|
|
|
18
|
|
|
|
|
|
|
19
|
|
|
|
|
|
|
20
|
|
|
|
|
|
|
21
|
|
|
|
|
|
|
22
|
|
|
|
|
|
|
23
|
|
|
|
|
|
|
24
|
|
|
|
|
|
|
25
|
|
|
|
|
|
|
26
|
|
|
|
|
|
|
27
|
|
|
|
|
|
|
28
|
|
|
|
|
|
|
29
|
|
|
|
|
|
|
30
|
|
|
|
|
|
|
31
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
33
|
|
|
|
|
|
|
34
|
|
|
|
|
|
|
35
|
|
|
|
|
|
|
36
|
|
|
|
|
|
|
A
|
B
|
C
|
D
|
E
|
|
37
|
|
|
|
|
Таблица 2.2
|
|
39
|
Зависимость выпуска продукции от среднегодовой
стоимости основных фондов
|
|
39
|
Номер группы
|
Группы
предприятий по среднегодовой стоимости основных производственных фондов, млн.
руб.
|
Число
предприятий
|
Выпуск
продукции, млн. руб.
|
|
40
|
Всего
|
В среднем
на одно
предприятие
|
|
41
|
1
|
|
|
СУММ()
|
D41/C41
|
|
42
|
2
|
|
|
СУММ()
|
D42/C42
|
|
43
|
3
|
|
|
СУММ()
|
D43/C43
|
|
44
|
4
|
|
|
СУММ()
|
D44/C44
|
|
45
|
5
|
|
|
СУММ()
|
D45/C45
|
|
46
|
Итого
|
|
СУММ(C41:C45)
|
СУММ(D41:D45)
|
D46/C46
|
|
47
|
|
|
|
|
|
|
48
|
|
|
|
|
|
|
49
|
|
|
|
Таблица 2.3
|
|
|
50
|
Показатели внутригрупповой вариации
|
|
|
51
|
Номер группы
|
Группы
предприятий по среднегодовой стоимости основных производственных фондов, млн.
руб.
|
Число
предприятий
|
Внутригрупповая
дисперсия
|
|
|
52
|
1
|
|
|
ДИСПР()
|
|
|
53
|
2
|
|
|
ДИСПР()
|
|
|
54
|
3
|
|
|
ДИСПР()
|
|
|
55
|
4
|
|
|
ДИСПР()
|
|
|
56
|
5
|
|
|
ДИСПР()
|
|
|
57
|
Итого
|
|
СУММ(C52:C56)
|
СУММ(D52:D56)
|
|
|
58
|
|
|
|
|
|
|
59
|
|
|
|
|
|
|
60
|
|
|
|
Таблица 2.4
|
|
|
61
|
Показатели дисперсии и эмпирического
корреляционного отношения
|
|
|
62
|
Общая дисперсия
|
Средняя из
внутригрупповых дисперсий
|
Межгрупповая
дисперсия
|
Эмпирическое
корреляционное отношение
|
|
|
63
|
ДИСПР(C4:C33)
|
СУММПРОИЗВ
(D52:D56,C52:C56)/C46
|
A63-B63
|
C63/A63
|
|
|
64
|
|
|
|
|
|
|
65
|
|
|
|
|
|
|
66
|
|
|
Таблица 2.5
|
|
|
|
67
|
Линейный коэффициент корреляции признаков
|
|
|
|
68
|
|
Столбец1
|
Столбец2
|
|
|
|
69
|
Столбец1
|
|
|
|
|
|
70
|
Столбец2
|
|
|
|
|
|
71
|
|
|
|
|
|
|
72
|
|
|
|
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
|
73
|
Выходные
таблицы
|
|
|
|
|
74
|
|
|
|
|
|
|
|
75
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
76
|
|
|
|
|
|
|
|
77
|
Регрессионная
статистика
|
|
|
|
|
|
78
|
Множественный
R
|
|
|
|
|
|
|
79
|
R-квадрат
|
|
|
|
|
|
|
80
|
Нормированный
R-квадрат
|
|
|
|
|
|
|
81
|
Стандартная
ошибка
|
|
|
|
|
|
|
82
|
Наблюдения
|
|
|
|
|
|
|
83
|
|
|
|
|
|
|
|
84
|
Дисперсионный
анализ
|
|
|
|
|
|
|
85
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
86
|
Регрессия
|
|
|
|
|
|
|
87
|
Остаток
|
|
|
|
|
|
|
88
|
Итого
|
|
|
|
|
|
|
89
|
|
|
|
|
|
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
|
90
|
|
Коэффициенты
|
Стандарт-ная ошибка
|
t-ста-тис-тика
|
P-Зна-чение
|
Нижние 95%
|
Верхние 95%
|
Нижние 68,3%
|
Верхние 68,3%
|
|
91
|
Y-пересечение
|
|
|
|
|
|
|
|
|
|
92
|
Переменная X 1
|
|
|
|
|
|
|
|
|
|
93
|
|
|
|
|
|
|
|
|
|
|
94
|
|
|
|
|
|
|
|
|
|
|
95
|
|
|
|
|
|
|
|
|
|
|
96
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
|
|
97
|
|
|
|
|
|
|
|
|
|
|
98
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
|
|
|
|
|
|
99
|
|
|
|
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
II. Этап
выполнения статистических расчетов.
Задание
1
Построение аналитической
группировки для выявления корреляционной зависимости результативного признака
от факторного и оценка тесноты взаимосвязи признаков
Выполнение
Задания 1 заключается в решении трех
задач:
1. Построение аналитической
группировки предприятий по факторному признаку Среднегодовая стоимость основных производственных фондов.
2. Оценка тесноты связи
изучаемых признаков на основе эмпирического корреляционного отношения.
3. Оценка тесноты связи
изучаемых признаков на основе линейного коэффициента корреляции (в
предположении, что взаимосвязь признаков линейная).
Алгоритмы выполнения Задания 1
Задача 1. Построение аналитической группировки предприятий по признаку Среднегодовая стоимость основных
производственных фондов.
Этап 1.
Ранжирование единиц совокупности по возрастанию факторного признака Среднегодовая стоимость основных
производственных фондов.
Алгоритм 1.1.
Ранжирование исходных данных.
1. Выделить исходные данные
(вместе с заголовком) табл. 2.1 (А3:С33);
2. Данные => Сортировка;
3. Сортировать по <= заголовок столбца (Среднегодовая
стоимость основных производственных фондов), по которому выполняется
сортировка;
4. по возрастанию/по убыванию – устанавливается в
положение по возрастанию;
5. Затем и В последнюю очередь по – не
активизируются;
6. Идентифицировать поля по подписям/обозначениям столбцов листа – устанавливается в
положение подписям;
7. ОК.
В результате указанных действий в таблице 2.1
размещаются данные, ранжированные по возрастанию признака Среднегодовая стоимость
основных производственных фондов.
Этап 2. Распределение
предприятий по группам.
Алгоритм 1.2.
Выделение групп предприятий с помощью заливки контрастным цветом.
1. Из всего диапазона
отсортированных данных A4:C33 выделить мышью диапазон ячеек первой
группы,
для чего необходимо отсчитать в ранжированном ряду количество строк,
соответствующее числу предприятий первой группы (графа 3 табл.2.2),
2. Нажать на панели
инструментов кнопку  ;
;
3. Выбрать цвет по собственному
усмотрению;
4. Выполнить действия 1–3 для всех
групп, выбирая контрастные цвета для цветовой заливки очередной группы.
Результат работы алгоритмов
1.1 и 1.2 для демонстрационного примера дан в табл.2.1–ДП.
Таблица
2.1–ДП
Исходные
данные
|
А
|
В
|
С
|
|
3
|
Номер предприятия
|
Среднегодовая стоимость основных
производственных фондов, млн. руб.
|
Выпуск продукции, млн. руб.
|
|
4
|
1
|
94,00
|
110,00
|
|
5
|
2
|
107,00
|
101,00
|
|
6
|
3
|
134,00
|
120,00
|
|
7
|
4
|
157,00
|
81,00
|
|
8
|
5
|
163,00
|
80,00
|
|
9
|
6
|
167,00
|
114,00
|
|
10
|
29
|
167,00
|
114,00
|
|
11
|
7
|
173,00
|
161,00
|
|
12
|
8
|
173,00
|
90,00
|
|
13
|
9
|
177,00
|
178,00
|
|
14
|
10
|
179,00
|
107,00
|
|
15
|
11
|
200,00
|
125,00
|
|
16
|
12
|
201,00
|
108,00
|
|
17
|
13
|
205,00
|
133,00
|
|
18
|
30
|
205,00
|
133,00
|
|
19
|
14
|
208,00
|
124,00
|
|
20
|
15
|
212,00
|
201,00
|
|
21
|
16
|
213,00
|
161,00
|
|
22
|
17
|
214,00
|
151,00
|
|
23
|
18
|
216,00
|
169,00
|
|
24
|
19
|
218,00
|
149,00
|
|
25
|
20
|
230,00
|
180,00
|
|
26
|
21
|
234,00
|
148,00
|
|
27
|
22
|
237,00
|
162,00
|
|
28
|
23
|
241,00
|
166,00
|
|
29
|
24
|
248,00
|
168,00
|
|
30
|
32
|
260,00
|
224,00
|
|
31
|
26
|
276,00
|
171,00
|
|
32
|
27
|
290,00
|
191,00
|
|
33
|
28
|
298,00
|
220,00
|
Этап 3. Расчет
суммарных и средних групповых значений результативного признака Y – Выпуск продукции.
Алгоритм 1.3.
Расчет суммарных групповых значений результативного признака.
1. В ячейке (D41),
выделенной для суммарного значения результативного признака Выпуск продукции первой
группы,
перед формулой поставить знак равенства «=»;
2. В качестве аргумента функции указать диапазон
ячеек из табл. 2.1 с результативными значениями уi первой группы (визуально легко определяется
по цвету заливки диапазона);
3.
Enter;
4. Выполнить действия 1–3
поочередно для всех групп, используя цветовые заливки диапазонов.
Алгоритм 1.4.
Расчет средних групповых значений результативного признака.
В таблице 2.2 приведены
формулы для расчета средних групповых значений результативного признака Выпуск продукции.
Для выполнения вычислений
следует перед формулой поставить знак равенства «=».
Для расчета
итоговых сумм в табл. 2.2 (в ячейках C46, D46 и E46) перед формулами необходимо
поставить знак равенства «=».
Результат работы алгоритмов
1.3 и 1.4 для демонстрационного примера дан в табл. 2.2–ДП.
Таблица
2.2–ДП
Зависимость выпуска продукции от
среднегодовой стоимости основных фондов
|
A
|
B
|
C
|
D
|
E
|
|
39
|
Номер группы
|
Группы предприятий по стоимости
основных фондов млн. руб.
|
Число предприятий
|
Выпуск продукции млн. руб.
|
|
40
|
Всего
|
В среднем
на одно
предприятие
|
|
41
|
1
|
94 – 134,8
|
3
|
331,00
|
110,33
|
|
42
|
2
|
134,8 – 175,6
|
6
|
640,00
|
106,67
|
|
43
|
3
|
175,6 – 216,4
|
11
|
1590,00
|
144,55
|
|
44
|
4
|
216,4 – 257,2
|
6
|
973,00
|
162,17
|
|
45
|
5
|
257,2 – 298
|
4
|
806,00
|
201,50
|
|
46
|
Итого
|
|
30
|
4340,00
|
144,67
|
|
|
|
|
|
|
|
Задача 2. Оценка тесноты связи изучаемых признаков на основе эмпирического корреляционного
отношения.
Алгоритм 2.1.
Расчет внутригрупповых дисперсий результативного признака.
1. В ячейке, выделенной для
внутригрупповых дисперсий первой группы (D52),
перед формулой поставить знак равенства «=»;
2. В качестве аргумента функции указать диапазон
ячеек из табл. 2.1 со значениями yi первой группы – визуально легко
определяется по цвету заливки диапазона;
3. Enter;
4. Выполнить действия 1–3
поочередно для всех групп, используя цветовые заливки диапазонов.
Для расчета итоговой суммы в
табл. 2.3 (в ячейке C57) перед формулой необходимо
поставить знак равенства «=».
Результат работы алгоритма
2.1 для демонстрационного примера дан в табл.2.3–ДП.
Таблица
2.3–ДП
Показатели внутригрупповой вариации
|
A
|
B
|
C
|
D
|
|
51
|
Номер группы
|
Группы предприятий по стоимости
основных фондов млн. Руб.
|
Число предприятий
|
Внутригрупповая дисперсия
|
|
52
|
1
|
94 – 134,8
|
3
|
60,22
|
|
53
|
2
|
134,8 – 175,6
|
6
|
784,56
|
|
54
|
3
|
175,6 – 216,4
|
11
|
821,16
|
|
55
|
4
|
216,4 – 257,2
|
6
|
123,47
|
|
56
|
5
|
257,2 – 298
|
4
|
472,25
|
|
57
|
Итого
|
|
30
|
|
Алгоритм 2.2.
Расчет общей, средней из внутригрупповых и факторной дисперсий
В ячейках для общей
дисперсии (А63), для средней из
внутригрупповых дисперсий (В63) и
для значения факторной дисперсии (С63)
перед формулами необходимо поставить знак равенства «=».
Примечание. В случае, если вычисления в
ячейке В63 не выполняются то знак «,» между диапазонами заменить на знак
«;».
Алгоритм 2.3. Расчет эмпирического корреляционного отношения.
В ячейке, выделенной для
эмпирического корреляционного отношения (D63), перед формулой поставить
знак равенства «=».
В результате работы алгоритмов 2.2 – 2.3 Excel
осуществляет вывод результатов расчета показателей (для демонстрационного
примера табл.2.4–ДП).
Таблица 2.4–ДП
Показатели дисперсии и эмпирического
корреляционного отношения
|
A
|
B
|
C
|
D
|
|
62
|
Общая дисперсия
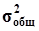
|
Средняя из внутригрупповых
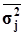
|
Факторная дисперсия
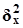
|
Эмпирическое корреляционное отношение
η
|
|
63
|
1450,288889
|
551,6853535
|
898,6035354
|
0,787148735
|
Задача 3. Оценка тесноты связи изучаемых признаков на основе линейного
коэффициента корреляции.
Алгоритм 3.1.
Расчет линейного коэффициента корреляции.
1. Сервис => Анализ данных => Корреляция => ОК;
2. Входной интервал <= диапазон ячеек табл. 2.1 со значениями факторного и
результативного признаков (В4:С33);
3. Группирование – по столбцам;
4. Метки в первой строке – не активизировать;
5. Выходной интервал – адрес ячейки заголовка
первого столбца выходной табл. 2.5 (А68);
6. Новый рабочий лист и Новая рабочая книга – не
активизировать;
7. ОК.
В результате работы
алгоритма 3.1 Excel выдает оценку тесноты связи
факторного и результативного признаков (для демонстрационного примера табл. 2.5–ДП).
Таблица
2.5–ДП
Линейный коэффициент корреляции
признаков
|
|
A
|
B
|
C
|
|
68
|
|
Столбец1
|
Столбец2
|
|
69
|
Столбец1
|
1
|
|
|
70
|
Столбец2
|
0,753661673
|
1
|
Задание
2
Построение однофакторной линейной
регрессионной модели связи изучаемых признаков с помощью инструмента Регрессия
надстройки Пакет анализа
Алгоритмы выполнения Задания 2
Алгоритм 1. Расчет параметров уравнения линейной
регрессии и проверка его адекватности фактическим данным.
1.
Сервис => Анализ данных
=> Регрессия => ОК;
2. Входной интервал Y <= диапазон ячеек
таблицы со значениями признака Y – Выпуск продукции (С4:С33);
3. Входной интервал X – диапазон ячеек таблицы со значениями признака X – Стоимость основных фондов (В4:В33);
4. Метки в первой строке/Метки в первом столбце – не активизировать;
5. Уровень надежности <= 68,3;
6. Константа–ноль – не активизировать;
7. Выходной интервал <= адрес ячейки заголовка первого столбца первой
выходной результативной таблицы (А75);
8. Новый рабочий лист и Новая рабочая книга – не
активизировать;
9. Остатки – активизировать;
10.
Стандартизованные остатки – не активизировать;
11.
График остатков – не активизировать;
12.
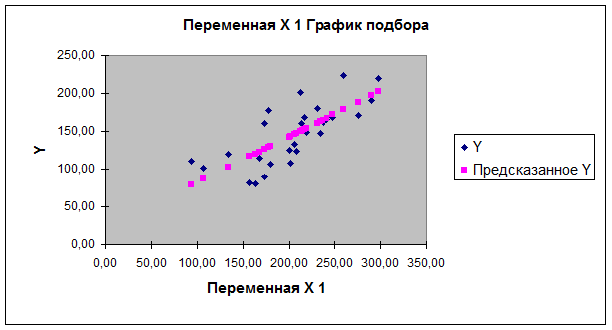
График подбора – активизировать;
13.
График нормальной
вероятности – не
активизировать;
14.
ОК.
Полученный
график необходимо расположить после выходных таблиц.
В результате указанных действий
осуществляется вывод в заданный диапазон рабочего файла четырех выходных таблиц
и одного графика, начиная с ячейки, указанной в поле Выходной интервал (для демонстрационного примера они имеют
следующий вид).
|
|
А
|
В
|
|
77
|
Регрессионная статистика
|
|
78
|
Множественный R
|
0,753661673
|
|
79
|
R–квадрат
|
0,568005917
|
|
80
|
Нормированный R-квадрат
|
0,552577557
|
|
81
|
Стандартная ошибка
|
25,90882817
|
|
82
|
Наблюдения
|
30
|
|
|
А
|
B
|
C
|
D
|
E
|
F
|
|
84
|
Дисперсионный
анализ
|
|
85
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
86
|
Регрессия
|
1
|
24713,1801
|
24713,1801
|
36,81570256
|
1,52606E-06
|
|
87
|
Остаток
|
28
|
18795,48657
|
671,2673773
|
|
|
|
88
|
Итого
|
29
|
43508,66667
|
|
|
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
|
90
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 68,3%
|
Верхние
68,3%
|
|
91
|
Y-пересечение
|
21,64454934
|
20,81975413
|
1,039615992
|
0,307412837
|
-21,0028
|
64,29193
|
0,432468
|
42,85664
|
|
92
|
Переменная
X 1
|
0,605324507
|
0,099763508
|
6,067594462
|
1,52606E-06
|
0,400968
|
0,809681
|
0,503681
|
0,706968
|
|
|
A
|
B
|
C
|
|
96
|
ВЫВОД ОСТАТКА
|
|
97
|
|
|
98
|
Наблюдение
|
Предсказанное
Y
|
Остатки
|
|
99
|
1
|
78,54505301
|
31,45494699
|
|
100
|
2
|
86,4142716
|
14,5857284
|
|
101
|
3
|
102,7580333
|
17,24196671
|
|
102
|
4
|
116,680497
|
-35,68049696
|
|
|
…
|
…
|
…
|
|
128
|
30
|
202,0312525
|
17,96874754
|
Задание
3
Построение
однофакторных нелинейных регрессионных моделей связи признаков с помощью
инструмента Мастер диаграмм и выбор наиболее адекватного уравнения
регрессии
Алгоритмы выполнения Задания 3
Алгоритм 1. Построение уравнений регрессионных моделей для различных видов зависимости признаков с
использованием средств инструмента Мастер диаграмм.
1.
Выделить мышью диаграмму рассеяния, расположенную начиная с ячейки Е4, и увеличить масштаб диаграммы на
весь экран;
2.
Диаграмма => Добавить
линию тренда;
3.
Выбрать вкладку Тип, задать
вид регрессионной модели – полином 2-го
порядка;
4.
Выбрать вкладку Параметры и
выполнить действия:
1.
Переключатель Название
аппроксимирующей кривой: автоматическое/другое – установить в положение автоматическое;
2.
Поле Прогноз вперед на – не
активизировать;
3.
Поле Прогноз назад на – не
активизировать;
4.
Флажок Пересечение кривой с осью
Y в точке – не активировать;
5.
Флажок Показывать уравнение на
диаграмме – активизировать;
6.
Флажок Поместить на диаграмму
величину достоверности аппроксимации R2 – активизировать;
7.
ОК;
8.
Установить курсор на линию регрессии и щелкнуть правой клавишей мыши;
9.
В появившемся диалоговом окне Формат
линии тренда выбрать тип, цвет и толщину линии;
10.
ОК;
11.
Вынести уравнение и индекс детерминации R2 за корреляционное поле. При необходимости уменьшить размер шрифта.
5.
Действия 2 – 4 (в п.4 –шаги 1–11) выполнить
поочередно для следующих видов регрессионных моделей:
– полином 3-го
порядка,
– степенная.
Переместить Диаграмму 2.1 в
конец рабочего файла.
В результате указанных действий для выбранных
видов моделей регрессии осуществляется вывод на диаграмму рассеяния 4-х
уравнений регрессии, их графиков и значений соответствующих индексов
детерминации R2 (для демонстрационного примера Диаграмма
2.1–ДП приведена на Рис. 2.1).
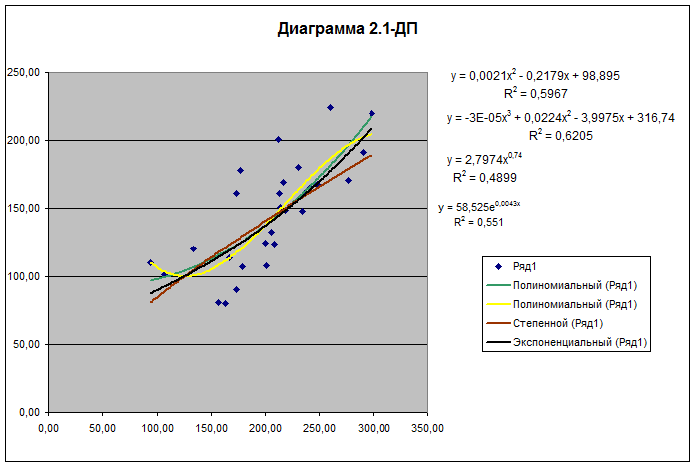 Рис
2.1. Уравнения регрессии и их
графики
Рис
2.1. Уравнения регрессии и их
графики
Алгоритм 2.
Построение наиболее адекватного уравнения регрессии.
1. Путем визуального анализа
значений R2 выбрать по максимальной
величине R2 наиболее адекватное уравнение регрессии;
2. Выделить диаграмму
рассеяния, расположенную с ячейки Е20;
3. Диаграмма => Добавить линию тренда;
4. Выбрать вкладку Тип и задать вид наиболее адекватной
нелинейной регрессионной модели;
5. Выбрать вкладку Параметры:
1. Переключатель Название аппроксимирующей кривой:
автоматическое/другое – установить в положение автоматическое;
2. Поле Прогноз вперед на – не активизировать;
3. Поле Прогноз назад на – не активизировать;
4. Флажок Пересечение кривой с осью Y в точке – не активировать;
5. Флажок Показывать уравнение на диаграмме – активизировать;
6. Флажок Поместить на диаграмму величину достоверности аппроксимации R2 – активизировать;
7. ОК.
Переместить Диаграмму 2.2 в
конец рабочего файла.
В результате указанных действий
осуществляется вывод на диаграмму рассеяния уравнения регрессии для выбранной
наиболее адекватной модели регрессии, ее графика и значения индекса
детерминации R2 (для демонстрационного примера Диаграмма
2.2–ДП приведена на Рис. 2.2).
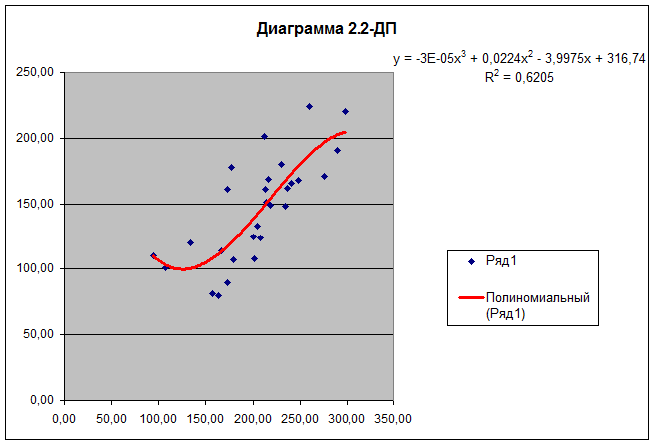 Рис.2.2. Наиболее адекватное уравнение
регрессии и его график
Рис.2.2. Наиболее адекватное уравнение
регрессии и его график