Содержание
Часть 1. Информационно-поисковые системы Интернета....................... 3
1.1. Структура Интернета..................................................................... 3
1.2. Семиуровневая модель Интернета................................................. 4
1.2.1. Уровень 1, физический............................................................. 5
1.2.2. Уровень 2, канальный.............................................................. 6
1.2.3. Уровень 3, сетевой................................................................... 6
1.2.4. Уровень 4, транспортный........................................................ 7
1.2.5. Уровень 5, сеансовый............................................................... 7
1.2.6. Уровень 6, уровень представления......................................... 7
1.2.7. Уровень 7, прикладной............................................................ 8
1.3. Услуги Internet................................................................................ 8
1.4. Возможности сети Internet.............................................................. 9
1.5. Доступ к информационным ресурсам........................................... 9
1.6. Адресация и протоколы в Интернет............................................ 10
1.7. Поисковые системы....................................................................... 12
1.7.1 Как работают механизмы поиска........................................... 12
1.7.2 Сравнительный обзор поисковых систем.............................. 16
1.8. Поисковые роботы........................................................................ 19
Часть 2. Интернет страницы по
теме «Отечественные грузовые
автомобили»............................................................................. 24
2.1. Сайт компании «ТЕХИНКОМ».................................................. 24
2.2. Сайт компании «Автодин»........................................................... 25
2.3. Сайт компании «Карамазов - Авто»............................................ 26
2.4. Сайт «Автомобили КамАЗ в Москве»......................................... 26
2.5. Итоговое сравнение сайтов.......................................................... 27
Используемая литература....................................................................... 28
Часть 1. Информационно-поисковые системы Интернета
1.1. Структура Интернета
Основные протоколы, используемые в Интернет (в дальнейшем
также Сеть), не обеспечены достаточными встроенными функциями поиска, не говоря
уже о миллионах серверах, находящихся в ней. Протокол HTTP, используемый в
Интернет, хорош лишь в отношении навигации, которая рассматривается только как
средство просмотра страниц, но не их поиска. То же самое относится и к
протоколу FTP, который даже более примитивен, чем HTTP. Из-за быстрого роста
информации, доступной в Сети, навигационные методы просмотра быстро достигают
предела их функциональных возможностей, не говоря уже о пределе их
эффективности. Не указывая конкретных цифр, можно сказать, что нужную
информацию уже не представляется возможным получить сразу, так как в Сети
сейчас находятся миллиарды документов и все они в распоряжении пользователей
Интернет, к тому же сегодня их количество возрастает согласно экспоненциальной
зависимости. Количество изменений, которым эта информация подвергнута, огромно
и, самое главное, они произошли за очень короткий период времени. Основная
проблема заключается в том, что единой полной функциональной системы обновления
и занесения подобного объема информации, одновременно доступного всем
пользователям Интернет во всем мире, никогда не было. Для того, чтобы
структурировать информацию, накопленную в сети Интернет, и обеспечить ее
пользователей удобными средствами поиска необходимых им данных, были созданы
поисковые системы.
Internet является старейшей глобальной сетью. Internet предоставляет
различные способы взаимодействия удаленных компьютеров и совместного
использования распределенных услуг и информационных ресурсов.
Internet
работает по протоколу TCP/IP. Основным «продуктом»,
который вы можете найти в Internet,
является информация. Эта информация собрана в файлы, которые хранятся на хост-компьютерах, и она может быть представлена в различных
форматах. Формат данных зависит от того, каким сетевым сервисом вы
воспользовались, и какие возможности по отображению информации есть на ПК.
Любой компьютер, который поддерживает протоколы TCP/IP, может выступать в качестве хост-компьютера.
Ключом к получению информации в Internet являются адреса ресурсов. Вам придется использовать
почтовые адреса (mail addresses)
при пересылке сообщений по электронной почте своим коллегам и адреса хост-компьютеров (host names) для соединения с ними и для получения файлов с
информацией.
Одним из недостатков передачи данных по сети Internet является
недостаточная защита информации.
1.2. Семиуровневая модель Интернета
Эталонная модель OSI, иногда называемая стеком OSI представляет
собой 7-уровневую сетевую иерархию (рис. 1) разработанную Международной
организацией по стандартам (International Standardization Organization -
ISO). Эта модель содержит в себе по сути 2 различных модели:
·
горизонтальную модель на базе протоколов,
обеспечивающую механизм взаимодействия программ и процессов на различных
машинах
·
вертикальную модель на основе услуг,
обеспечиваемых соседними уровнями друг другу на одной машине
В горизонтальной модели двум программам требуется общий
протокол для обмена данными. В вертикальной - соседние уровни обмениваются
данными с использованием интерфейсов API.
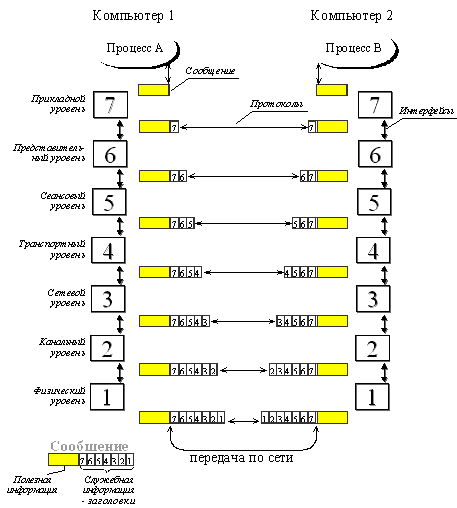
Рисунок 1 Модель OSI
1.2.1.
Уровень 1, физический
Физический уровень получает пакеты данных от вышележащего
канального уровня и преобразует их в оптические или электрические сигналы,
соответствующие 0 и 1 бинарного потока. Эти сигналы посылаются через среду
передачи на приемный узел. Механические и электрические/оптические свойства
среды передачи определяются на физическом уровне и включают:
·
Тип кабелей и разъемов
·
Разводку контактов в разъемах
·
Схему кодирования сигналов для значений 0 и 1
К числу наиболее распространенных спецификаций физического
уровня относятся:
·
EIA-RS-232-C, CCITT V.24/V.28 -
механические/электрические характеристики несбалансированного последовательного
интерфейса.
·
EIA-RS-422/449, CCITT V.10 - механические,
электрические и оптические характеристики сбалансированного последовательного
интерфейса.
·
IEEE 802.3 -- Ethernet
·
IEEE 802.5 -- Token ring
1.2.2.
Уровень 2, канальный
Канальный уровень обеспечивает создание, передачу и прием
кадров данных. Этот уровень обслуживает запросы сетевого уровня и использует
сервис физического уровня для приема и передачи пакетов. Спецификации IEEE
802.x делят канальный уровень на два подуровня: управление логическим каналом
(LLC) и управление доступом к среде (MAC). LLC обеспечивает обслуживание
сетевого уровня, а подуровень MAC регулирует доступ к разделяемой физической
среде.
Наиболее часто используемые на уровне 2 протоколы включают:
·
HDLC для последовательных соединений
·
IEEE 802.2 LLC (тип I и тип II) обеспечивают MAC
для сред 802.x
·
Ethernet
·
Token ring
·
FDDI
·
X.25
·
Frame relay
1.2.3. Уровень 3, сетевой
Сетевой уровень отвечает за деление пользователей на группы.
На этом уровне происходит маршрутизация пакетов на основе преобразования
MAC-адресов в сетевые адреса. Сетевой уровень обеспечивает также прозрачную
передачу пакетов на транспортный уровень.
Наиболее часто на сетевом уровне используются протоколы:
·
IP - протокол Internet
·
IPX - протокол межсетевого обмена
·
X.25 (частично этот протокол реализован на
уровне 2)
·
CLNP - сетевой протокол без организации
соединений
1.2.4.
Уровень 4, транспортный
Транспортный уровень делит потоки информации на достаточно
малые фрагменты (пакеты) для передачи их на сетевой уровень.
Наиболее распространенные протоколы транспортного уровня
включают:
·
TCP - протокол управления передачей
·
NCP - Netware Core Protocol
·
SPX - упорядоченный обмен пакетами
·
TP4 - протокол передачи класса 4
1.2.5.
Уровень 5, сеансовый
Сеансовый уровень отвечает за организацию сеансов обмена
данными между оконечными машинами. Протоколы сеансового уровня обычно являются
составной частью функций трех верхних уровней модели.
1.2.6.
Уровень 6, уровень представления
Уровень представления отвечает за возможность диалога между
приложениями на разных машинах. Этот уровень обеспечивает преобразование данных
(кодирование, компрессия и т.п.) прикладного уровня в поток информации для
транспортного уровня. Протоколы уровня представления обычно являются составной
частью функций трех верхних уровней модели.
1.2.7.
Уровень 7, прикладной
Прикладной уровень отвечает за доступ приложений в сеть.
Задачами этого уровня является перенос файлов, обмен почтовыми сообщениями и
управление сетью.
К числу наиболее распространенных протоколов верхних уровней
относятся:
·
FTP - протокол переноса файлов
·
TFTP - упрощенный протокол переноса файлов
·
X.400 - электронная почта
·
Telnet
·
SMTP - простой протокол почтового обмена
·
CMIP - общий протокол управления информацией
·
SNMP - простой протокол управления сетью
·
NFS - сетевая файловая система
·
FTAM - метод доступа для переноса файлов
1.3. Услуги Internet.
·
Передача файлов по протоколу FTP. Информационный сервис, основанный
на передаче файлов с использованием протокола FTP (протокол
передачи файлов).
·
Поиск файлов с помощью системы Archie. Archie – первая поисковая система
необходима для нахождения нужной информации, разбросанной по Internet.
·
Электронная почта. ЭП – это вид сетевого
сервиса. ЭП предусматривает передачу сообщений от одного пользователя, имеющего
определенный компьютерный адрес, к другому. Она позволяет быстро связаться друг
с другом.
·
Списки рассылки. Список рассылки – это средство,
предоставляющее возможность вести дискуссию группе пользователей, имеющих общие
интересы.
·
Телеконференции. Телеконференции в Internet предоставляют
возможность вести дискуссии (при помощи сообщений) по тысячам размещенных тем.
1.4. Возможности сети Internet.
Интернет представляет собой глобальную компьютерную сеть,
содержащую гигантский объем информации по любой тематике, доступной на
коммерческой основе для всех желающих, и предоставляющую большой спектр
информационных услуг. В настоящее время Интернет представляет собой объединение
более 40 000 различных локальных сетей, за что она получила название сеть
сетей. Каждая локальная сеть называется узлом или сайтом, а юридическое лицо,
обеспечивающее работу сайта – провайдером. Сайт состоит из нескольких
компьютеров – серверов, каждый из которых предназначен для хранения информации
определенного типа и в определенном формате. Каждый сайт и сервер на сайте
имеют уникальные имена, посредствам которых они идентифицируются в Интернет.
Для подключения в Интернет пользователь должен заключить
контракт на обслуживание с одним из провайдеров в его регионе.
1.5. Доступ к информационным ресурсам.
Имеется несколько видов информационных ресурсов в Интернет,
различающихся характером информации, способом ее организации, методами работы с
ней. Каждый вид информации хранится на сервере соответствующего типа,
называемых по типу хранимой информации. Для каждой информационной системы
существуют свои средства поиска необходимой информации во всей сети Интернет по
ключевым словам. В Интернет работают следующие информационные системы:
World Wide Web (WWW) – Всемирная информационная паутина. Эта система в
настоящее время является наиболее популярной и динамично развивающейся.
Информация в WWW
состоит из страниц (документов). Страницы могут содержать графику,
сопровождаться анимацией изображений и звуком, воспроизводимым непосредственно
в процессе поступления информации на экран пользователя. Информация в WWW организована в форме
гипертекста. Это означает, что в документе существуют специальные элементы –
текст или рисунки, называемые гипертекстовыми ссылками (или просто ссылками),
щелчок мышью на которых выводит на экран другой документ, на который указывает
данная ссылка. При этом новый документ может храниться на совершенно другом
сайте, возможно, расположенном в другом конце земного шара.
Gopher-система. Эта система
является предшественником WWW
и сейчас утрачивает свое значение, хотя пока и поддерживается в Интернет.
Просмотр информации на Gopher-сервере
организуется с помощью древовидного меню, аналогичного меню в приложениях Windows или аналогично дереву
каталогов (папок) файловой системы. Меню верхнего уровня состоит из перечня
крупных тем, например, экономика, культура, медицина и др. Меню следующих
уровней детализируют выбранный элемент меню предыдущего уровня. Конечным
пунктом движения вниз по дереву (листом дерева) служит документ аналогично
тому, как конечным элементом в дереве каталогов является файл.
FTP (File Transfer Protocol) – система, служащая для пересылки файлов.
Работа с системой аналогична работе с системой NC. Файлы становятся доступными для
работы (чтение, исполнения) только после копирования на собственный компьютер.
Хотя пересылка файлов может быть выполнена с помощью WWW,
FTP-системы
продолжают оставаться весьма популярными ввиду их быстродействия и простоты
использования.
1.6. Адресация и протоколы в Интернет.
Компьютер, подключенный к Интернет, и использующий для связи
с другими компьютерами сети специальный протокол TCP/IP, называется хостом. Для идентификации каждого хоста в
сети имеются следующие два способа
адресации, всегда действующие совместно.
Первый способ адресации, называемый IP-адресом, аналогичен телефонному
номеру. IP-адрес хоста
назначается провайдером, состоит из четырех групп десятичных цифр (четырех
байтов), разделенных точками, заканчивается точкой.
Аналогично телефонам, каждый компьютер в Интернет должен
иметь уникальный IP-адрес.
Обычно пользователь свой IP-адрес
не использует. Неудобство IP-адреса
состоит в его безликости, отсутствии смысловой характеристики хоста и потому
трудной запоминаемости.
Второй способ идентификации компьютеров называется системой
доменных имен, именуемой DNS
(Domain Naming System).
DNS-имена
назначаются провайдером и, например, имеет вид:
win.smtp.dol.ru.
Приведенное выше доменное имя состоит из четырех,
разделенных точками, простых доменов (или просто доменов). Число простых
доменов в полном доменном имени может быть произвольным. Каждый из простых
доменов характеризует некоторое множество компьютеров. Домены в имени вложены
друг в друга, так что любой домен (кроме последнего) представляет собой подмножество
домена, следующего за ним справа. Так, в приведенном примере DNS-имени домены имеют следующий смысл:
ru – домены
страны, в данном случае обозначает все домены в России;
dol – домен
провайдера, в данном случае обозначает компьютеры, локальной сети российской
фирмы Demos;
smtp – домен группы
серверов Demos,
обслуживающих систему электронной почты;
win – имя
конкретного компьютера из группы smtp.
Таким образом, по всей организации и внутренней структуре DNS-система напоминает полный
путь к конкретному файлу в дереве каталогов и файлов. Одно из различий состоит
в том, что домен более высокого уровня в DNS-имени находится правее. Так же, как и IP-адрес, DNS-имя должно однозначно
идентифицировать компьютер в Интернет. Полное доменное имя должно заканчиваться
точкой.
Протокол Frame Relay (FR).
Frame Relay
– это протокол, который описывает интерфейс доступа к сетям быстрой коммутации
пакетов. Он позволяет эффективно передавать крайне неравномерно распределенный
по времени трафик и обеспечивает высокие скорости прохождения информации через
сеть, малые времена задержек и рациональное использование полосы пропускания.
По сетям FR
возможна передача не только собственно данных, но и также оцифрованного голоса.
Согласно семиуровневой модели взаимодействия открытых систем
OSI, FR – протокол второго уровня. Однако он
не выполняет некоторых функций, обязательных для протоколов этого уровня, но
выполняет функции протоколов сетевого уровня. В то же время FR позволяет
устанавливать соединение через сеть, что в соответствии с OSI, относится к функции протоколов
третьего уровня.
1.7. Поисковые системы
Поисковые системы обычно состоят из трех компонент:
·
агент (паук или кроулер),
который перемещается по Сети и собирает информацию;
·
база данных, которая содержит всю информацию,
собираемую пауками;
·
поисковый механизм, который люди используют как
интерфейс для взаимодействия с базой данных.
1.7.1
Как работают механизмы поиска
Средства поиска и структурирования, иногда называемые
поисковыми механизмами, используются для того, чтобы помочь людям найти
информацию, в которой они нуждаются. Средства поиска типа агентов, пауков, кроулеров и роботов используются для сбора информации о
документах, находящихся в Сети Интернет. Это специальные программы, которые
занимаются поиском страниц в Сети, извлекают гипертекстовые ссылки на этих
страницах и автоматически индексируют информацию, которую они находят для
построения базы данных. Каждый поисковый механизм имеет собственный набор
правил, определяющих, как собирать документы. Некоторые следуют за каждой
ссылкой на каждой найденной странице и затем, в свою очередь, исследуют каждую
ссылку на каждой из новых страниц, и так далее. Некоторые игнорируют ссылки,
которые ведут к графическим и звуковым файлам, файлам мультипликации; другие игнорируют
ссылки к ресурсам типа баз данных WAIS; другие проинструктированы, что нужно
просматривать прежде всего наиболее популярные страницы.
·
Агенты - самые "интеллектуальные" из
поисковых средств. Они могут делать больше, чем просто искать: они могут выполнять
даже транзакции от Вашего имени. Уже сейчас они могут искать cайты специфической тематики и возвращать списки cайтов, отсортированных по их посещаемости. Агенты могут
обрабатывать содержание документов, находить и индексировать другие виды
ресурсов, не только страницы. Они могут также быть запрограммированы для
извлечения информации из уже существующих баз данных. Независимо от информации,
которую агенты индексируют, они передают ее обратно базе данных поискового
механизма.
·
Общий поиск информации в Сети осуществляют
программы, известные как пауки. Пауки сообщают о содержании найденного
документа, индексируют его и извлекают итоговую информацию. Также они
просматривают заголовки, некоторые ссылки и посылают проиндексированную
информацию базе данных поискового механизма.
·
Кроулеры просматривают
заголовки и возвращают только первую ссылку.
·
Роботы могут быть запрограммированы так, чтобы
переходить по различным ссылкам различной глубины вложенности, выполнять
индексацию и даже проверять ссылки в документе. Из-за их природы они могут
застревать в циклах, поэтому, проходя по ссылкам, им нужны значительные ресурсы
Сети. Однако, имеются методы, предназначенные для того, чтобы запретить роботам
поиск по сайтам, владельцы которых не желают, чтобы они были проиндексированы.
Агенты извлекают и индексируют различные виды информации.
Некоторые, например, индексируют каждое отдельное слово во встречающемся
документе, в то время как другие индексируют только наиболее важных 100 слов в
каждом, индексируют размер документа и число слов в нем, название, заголовки и
подзаголовки и так далее. Вид построенного индекса определяет, какой поиск
может быть сделан поисковым механизмом и как полученная информация будет
интерпретирована.
Агенты могут также перемещаться по Интернет и находить
информацию, после чего помещать ее в базу данных поискового механизма.
Администраторы поисковых систем могут определить, какие сайты или типы сайтов
агенты должны посетить и проиндексировать. Проиндексированная информация
отсылается базе данных поискового механизма так же, как было описано выше.
Люди могут помещать информацию прямо в индекс, заполняя
особую форму для того раздела, в который они хотели бы поместить свою
информацию. Эти данные передаются базе данных.
Когда кто-либо хочет найти информацию, доступную в Интернет,
он посещает страницу поисковой системы и заполняет форму, детализирующую
информацию, которая ему необходима. Здесь могут использоваться ключевые слова,
даты и другие критерии. Критерии в форме поиска должны соответствовать
критериям, используемым агентами при индексации информации, которую они нашли
при перемещении по Сети.
База данных отыскивает предмет запроса, основанный на
информации, указанной в заполненной форме, и выводит соответствующие документы,
подготовленные базой данных. Чтобы определить порядок, в котором список
документов будет показан, база данных применяет алгоритм ранжирования. В
идеальном случае, документы, наиболее релевантные пользовательскому запросу
будут помещены первыми в списке. Различные поисковые системы используют
различные алгоритмы ранжирования, однако, основные принципы определения
релевантности следующие:
1.
Количество слов запроса в текстовом содержимом
документа (т.е. в html-коде).
2.
Тэги, в которых эти слова располагаются.
3.
Местоположение искомых слов в документе.
4.
Удельный вес слов, относительно которых определяется
релевантность, в общем количестве слов документа.
Эти принципы применяются всеми поисковыми системами. А
представленные ниже используются некоторыми, но достаточно известными (вроде AltaVista, HotBot).
5.
Время - как долго страница находится в базе поискового
сервера. Поначалу кажется, что это довольно бессмысленный принцип. Но, если
задуматься, как много существует в Интернете сайтов, которые живут максимум
месяц! Если же сайт существует довольно долго, это означает, что владелец
весьма опытен в данной теме и пользователю больше подойдет сайт, который пару
лет вещает миру о правилах поведения за столом, чем тот, который появился
неделю назад с этой же темой.
6.
Индекс цитируемости - как много ссылок на данную
страницу ведет с других страниц, зарегистрированных в базе поисковика.
База данных выводит ранжированный подобным образом список
документов с HTML и возвращает его человеку, сделавшему запрос. Различные
поисковые механизмы также выбирают различные способы показа полученного списка
- некоторые показывают только ссылки; другие выводят ссылки с первыми
несколькими предложениями, содержащимися в документе или заголовок документа
вместе с ссылкой.
Когда Вы щелкаете на ссылке к одному из документов, который
вас интересует, этот документ запрашивается у того сервера, на котором он
находится.
1.7.2 Сравнительный обзор поисковых систем
Lycos. В Lycos используется следующий механизм индексации:
·
слова в <title> заголовке
имеют высший приоритет;
·
слова в начале страницы;
·
слова в ссылках;
·
если в его базе индекса есть сайты, ссылка с
которых указывает на индексируемый документ - релевантность этого документа
возрастает.
Как и большинство систем, Lycos
дает возможность применять простой запрос и более изощренный метод поиска. В
простом запросе в качестве поискового критерия вводится предложение на
естественном языке, после чего Lycos производит
нормализацию запроса, удаляя из него так называемые stop-слова, и только после
этого приступает к его выполнению. Почти сразу выдается информация о количестве
документов на каждое слово, а позже и список ссылок на формально релевантные
документы. В списке против каждого документа указывается его мера близости
запросу, количество слов из запроса, попавших в документ, и оценочная мера
близости, которая может быть больше или меньше формально вычисленной. Пока
нельзя вводить логические операторы в строке вместе с терминами, но
использовать логику через систему меню Lycos
позволяет. Такая возможность применяется для построения расширенной формы
запроса, предназначенной для искушенных пользователей, уже научившихся работать
с этим механизмом. Таким образом, видно, что Lycos
относится к системе с языком запросов типа "Like
this", но намечается его расширение и на другие
способы организации поисковых предписаний.
AltaVista.
Индексирование в этой системе осуществляется при помощи робота. При этом робот
имеет следующие приоритеты:
·
слова содержащиеся в теге <title> имеют высший приоритет; ключевые фразы в <Meta> тэгах;
·
ключевые фразы, находящиеся в начале странички;
·
ключевые фразы в ALT - ссылках
·
ключевые фразы по количеству вхождений \ присутствия
слов \ фраз;
Если тэгов на странице нет, использует первые 30 слов,
которые индексирует и показывает вместо описания (tag
description)
Наиболее интересная возможность AltaVista
- это расширенный поиск. Здесь стоит сразу оговориться, что, в отличие от
многих других систем AltaVista поддерживает
одноместный оператор NOT. Кроме этого, имеется еще и оператор NEAR, который
реализует возможность контекстного поиска, когда термины должны располагаться
рядом в тексте документа. AltaVista разрешает поиск
по ключевым фразам, при этом она имеет довольно большой фразеологический
словарь. Кроме всего прочего, при поиске в AltaVista
можно задать имя поля, где должно встретиться слово: гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К
сожалению, подробно процедура ранжирования в документации по системе не
описана, но видно, что ранжирование применяется как при простом поиске, так и
при расширенном запросе. Реально эту систему можно отнести к системе с
расширенным булевым поиском.
Yahoo. Данная
система появилась в Сети одной из первых, и сегодня Yahoo
сотрудничает со многими производителями средств информационного поиска, а на
различных ее серверах используется различное программное обеспечение. Язык Yahoo достаточно прост: все слова следует вводить через
пробел, они соединяются связкой AND либо OR. При выдаче не указывается степень
соответствия документа запросу, а только подчеркиваются слова из запроса,
которые встретились в документе. При этом не производится нормализация лексики
и не проводится анализ на "общие" слова. Хорошие результаты поиска
получаются только тогда, когда пользователь знает, что в базе данных Yahoo информация есть наверняка. Ранжирование производится
по числу терминов запроса в документе. Yahoo
относится к классу простых традиционных систем с ограниченными возможностями
поиска.
OpenText.
Информационная система OpenText представляет собой
самый коммерциализированный информационный продукт в
Сети. Все описания больше похожи на рекламу, чем на информативное руководство
по работе. Система позволяет провести поиск с использованием логических коннекторов, однако размер запроса ограничен тремя
терминами или фразами. В данном случае речь идет о расширенном поиске. При
выдаче результатов сообщается степень соответствия документа запросу и размер
документа. Система позволяет также улучшить результаты поиска в стиле традиционного
булевого поиска. OpenText можно было бы отнести к
разряду традиционных информационно-поисковых систем, если бы не механизм
ранжирования.
Infoseek. В этой
системе индекс создает робот, но он индексирует не весь сайт, а только
указанную страницу. При этом робот имеет такие приоритеты:
·
слова в заголовке <title>
имеют наивысший приоритет;
·
слова в теге keywords,
description и частота вхождений \ повторений в самом
тексте;
·
при повторении одинаковых слов рядом выбрасывает
из индекса
·
Допускает до 1024 символов для тега keywords, 200 символов для тэга description;
·
Если тэги не использовались, индексирует первые
200 слов на странице и использует как описание;
Система Infoseek обладает довольно
развитым информационно-поисковым языком, позволяющим не просто указывать, какие
термины должны встречаться в документах, но и своеобразно взвешивать их.
Достигается это при помощи специальных знаков "+" - термин обязан
быть в документе, и "-" - термин должен отсутствовать в документе.
Кроме этого, Infoseek позволяет проводить то, что
называется контекстным поиском. Это значит, что используя специальную форму
запроса, можно потребовать последовательной совместной встречаемости слов.
Также можно указать, что некоторые слова должны совместно встречаться не только
в одном документе, а даже в отдельном параграфе или заголовке. Имеется
возможность указания ключевых фраз, представляющих собой единое целое, вплоть
до порядка слов. Ранжирование при выдаче осуществляется по числу терминов
запроса в документе, по числу фраз запроса за вычетом общих слов. Все эти
факторы используются как вложенные процедуры. Подводя краткое резюме, можно
сказать, что Infoseek относится к традиционным
системам с элементом взвешивания терминов при поиске.
WAIS. WAIS является одной из наиболее изощренных
поисковых систем Internet. В ней не реализованы лишь
поиск по нечетким множествам и вероятностный поиск. В отличие от многих
поисковых машин, система позволяет строить не только вложенные булевы запросы,
считать формальную релевантность по различным мерам близости, взвешивать
термины запроса и документа, но и осуществлять коррекцию запроса по
релевантности. Система также позволяет использовать усечения терминов,
разбиение документов на поля и ведение распределенных индексов. Не случайно
именно эта система была выбрана в качестве основной поисковой машины для
реализации энциклопедии "Британика" на Internet.
1.8. Поисковые роботы
За последние годы Всемирная паутина стала настолько
популярной, что сейчас Интернет является одним из основных средств публикации
информации. Когда размер Сети вырос из нескольких серверов и небольшого числа
документов до огромных пределов, стало ясно, что ручная навигация по
значительной части структуры гипертекстовых ссылок больше не представляется
возможной, не говоря уже об эффективном методе исследования ресурсов.
Эта проблема побудила исследователей Интернет на проведение
экспериментов с автоматизированной навигацией по Сети, названной
"роботами". Веб-робот - это программа,
которая перемещается по гипертекстовой структуре Сети, запрашивает документ и
рекурсивно возвращает все документы, на которые данный документ ссылается. Эти
программы также иногда называют "пауками", " странниками",
или " червями" и эти названия, возможно, более привлекательны,
однако, могут ввести в заблуждение, поскольку термин "паук" и
"странник" создает ложное представление, что робот сам перемещается,
а термин "червь" мог бы подразумевать, что робот еще и размножается
подобно интернетовскому вирусу-червю. В действительности, роботы реализованы как
простая программная система, которая запрашивает информацию из удаленных
участков Интернет, используя стандартные сетевые протоколы.
Роботы могут использоваться для выполнения множества
полезных задач, таких как статистический анализ, обслуживание гипертекстов,
исследования ресурсов или зазеркаливания страниц.
Рассмотрим эти задачи подробнее.
Статистический Анализ. Первый робот был создан для
того, чтобы обнаружить и посчитать количество веб-серверов
в Сети. Другие статистические вычисления могут включать среднее число
документов, приходящихся на один сервер в Сети, пропорции определенных типов
файлов на сервере, средний размер страницы, степень связанности ссылок и т.д.
Обслуживание гипертекстов. Одной из главных
трудностей в поддержании гипертекстовой структуры является то, что ссылки на
другие страницы могут становиться " мертвыми ссылками" в случае,
когда страница переносится на другой сервер или совсем удаляется. На
сегодняшний день не существует общего механизма, который смог бы уведомить
обслуживающий персонал сервера, на котором содержится документ с ссылками на
подобную страницу, о том, что она изменилась или вообще удалена. Некоторые
серверы, например, CERN HTTPD, будут регистрировать неудачные запросы,
вызванные мертвыми ссылками наряду с рекомендацией относительно страницы, где
обнаружена мертвая ссылка, предусматривая что данная проблема будет решаться
вручную. Это не очень практично, и в действительности авторы документов
обнаруживают, что их документы содержат мертвые ссылки лишь тогда, когда их
извещают непосредственно, или, что бывает очень редко, когда пользователь сам
уведомляет их по электронной почте.
Робот типа MOMSPIDER, который проверяет ссылки, может помочь
автору документа в обнаружении подобных мертвых ссылок, и также может помогать
в обслуживании гипертекстовой структуры. Также роботы могут помочь в
поддержании содержания и самой структуры, проверяя соответствующий
HTML-документ, его соответствие принятым правилам, регулярные модернизации, и
т.д., но это обычно не используется. Возможно, данные функциональные
возможности должны были бы быть встроены при написании окружающей среды
HTML-документа, поскольку эти проверки могут повторяться в тех случаях, когда
документ изменяется, и любые проблемы при этом могут быть решены немедленно.
Зазеркаливание. Зазеркаливание - популярный механизм поддержания FTP
архивов. Зеркало рекурсивно копирует полное дерево каталогов по FTP, и затем
регулярно перезапрашивает те документы, которые
изменились. Это позволяет распределить загрузку между несколькими серверами,
успешно справиться с отказами сервера и обеспечить более быстрый и более
дешевый локальный доступ, так же как и автономный доступ к архивам. В Сети
Интернет зазеркаливание может быть осуществлено с
помощью робота, однако на время написания этой статьи никаких сложных средств
для этого не существовало. Конечно, существует несколько роботов, которые
восстанавливают поддерево страниц и сохраняют его на локальном сервере, но они
не имеют средств для обновления именно тех страниц, которые изменились. Вторая
проблема - это уникальность страниц, которая состоит в том, что ссылки в
скопированных страницах должны быть перезаписаны там, где они ссылаются на
страницы, которые также были зазеркалены и могут
нуждаться в обновлении. Они должны быть изменены на копии, а там, где
относительные ссылки указывают на страницы, которые не были зазеркалены,
они должны быть расширены до абсолютных ссылок. Потребность в механизмах зазеркаливания по причинам показателей производительности
намного уменьшается применением сложных кэширующих серверов, которые предлагают
выборочную модернизацию, что может гарантировать, что кэшированный документ не
обновился, и в значительной степени самообслуживается.
Однако, ожидается, что средства зазеркаливания в
будущем будут развиваться должным образом.
Исследование ресурсов. Возможно, наиболее
захватывающее применение роботов - использование их при исследовании ресурсов.
Там, где люди не могут справиться с огромным количеством информации, довольно
возможность переложить всю работу на компьютер выглядит довольно
привлекательно. Существует несколько роботов, которые собирают информацию в
большей части Интернет и передают полученные результаты базе данных. Это
означает, что пользователь, который ранее полагался исключительно на ручную
навигацию в Сети, теперь может объединить поиск с просмотром страниц для
нахождения нужной ему информации. Даже если база данных не содержит именно
того, что ему нужно, велика вероятность того, что в результате этого поиска
будет найдено немало ссылок на страницы, которые, в свою очередь, могут
ссылаться на предмет его поиска.
Второе преимущество состоит в том, что эти базы данных могут
автоматически обновляться за определенный период времени так, чтобы мертвые
ссылки в базе данных были обнаружены и удалены, в отличие от обслуживания
документов вручную, когда проверка часто является спонтанной и не полной.
Использование роботов для исследования ресурсов будет обсуждаться ниже.
Комбинированное использование. Простой робот может
выполнять более чем одну из вышеупомянутых задач. Например робот RBSE Spider выполняет статистический анализ запрошенных
документов и обеспечивает ведение базы данных ресурсов. Однако, подобное
комбинированное использование встречается, к сожалению, весьма редко.
Часть 2. Интернет страницы по теме «Отечественные
грузовые автомобили»
Первые страницы со ссылками по теме «Отечественные грузовые
автомобили», в разных поисковых системах будут следующими.
В ИПС «Яндекс» (http://www.yandex.ru) начальная страница
с первыми ссылками будет иметь вид:
Откроем некоторые из найденных ссылок.
2.1. Сайт компании
«ТЕХИНКОМ»
На этом сайте каждом продаваемом автомобиле представлена
такая информация, как:
·
фото;
·
страна изготовитель;
·
год выпуска;
·
пробег;
·
полная масса автомобиля;
·
грузоподъемность
·
цена
Переход от одного типа автомобиля к другому осуществляется
посредствам меню, которое расположено с левой стороны всех страниц.

2.2. Сайт компании «Автодин»
На главной странице сайта компании «Автодин», занимающейся
продажей автомобилей марок МАЗ и КамАЗ, а также тракторов, спецтехники и
запчастей представлены отдельные ссылки для перехода к разделам сайта,
посвященным каждому из перечисленных выше типов техники.
Также сразу можно получить информацию о компании, вакансиях
и партнерах.
Ещё одной важной чертой этого сайта является ссылка для
перехода к его английской версии.
Имеется опрос посетителей сайта об используемых в их
организации автомобилях.
Начальная страница сайта имеет вид:
2.3. Сайт компании «Карамазов - Авто»
Компания «Карамазов - Авто» занимается комиссионной продажей
транспортных средств.
На главной странице сайта в разделе «Грузовики в продаже»
можно просмотреть перечень продаваемых автомобилей, отсортированных по марке
или по типу.
Можно перейти в разделы сайта, касающиеся предоставляемым услугам
по приему грузовых а/м на комиссию, покупке подержанных грузовиков, продаже
автомобилей в лизинг и т.д.
Главная страница сайта имеет вид:
2.4. Сайт «Автомобили КамАЗ в Москве»
На первой странице этого сайта представлена краткая
информация о истории Торгового Дома КАМА XXI век.
Приведен список продаваемых автомобилей по моделям.
Имеются ссылки для перехода в разделы «О компании»,
«Контакты» и «Цены».
Также есть последние новости компании.
Первая страница сайта имеет вид:
2.5. Итоговое сравнение сайтов
На основание приведенным выше данным по возможностям сайтов,
занимающихся торговлей грузовых автомобилей составим следующую сводную таблицу:
|
Наименование компании
|
Англий-ская версия
|
Информация о компании
|
Быстрый переход по разделам
|
Полнота информации
|
Опрос посетителей
|
|
ТЕХИНКОМ
|
Нет
|
Есть
|
В виде меню
|
Все параметры и фото каждого автомобиля
|
Нет
|
|
Автодин
|
Есть
|
Есть
|
С главной страницы
|
Только марки автомобилей
|
Есть
|
|
Карамазов – Авто
|
Нет
|
Нет
|
В виде меню
|
Информация о комиссии и фото автомобилей
|
Нет
|
|
Автомобили КамАЗ в Москве
|
Нет
|
Есть
|
С главной страницы
|
Список всех автомобилей с краткой характеристикой
каждого
|
Нет
|
Вывод: наиболее полно информация о компании и о товаре
представлена на сайте компании «Автодин», хотя по удобству использования, и,
следовательно, удобству заключения сделок все рассматриваемые сайты
приблизительно равны.
Используемая литература
1.
А.А. Козырев. Самоучитель работы на персональном
компьютере. Издание второе переработанное и дополненное. Издательство Михайлова
В.А. Санкт-Петербург, 2000 г.
2.
Крол Эд. Всё об Internet.-Киев.- Торгово-издательское бюро BHV.-1995г.
3.
Нэш К. Война браузеров.-Сети.-1997г.-№1.
4.
Леонтьев В.П. Новейшая энциклопедия персонального компьютера
2003. М., ОЛМА-ПРЕСС, 2003. – 920 с.:
ил.
5.
Лазовский Л.Ш., Ратновский Л.А. Интернет
– это интересно. Москва, ИНФРА-М, 2003
6.
Олифер В.Г., Олифер Н.А. Сетевые
операционные системы (учебник). Издательство «Питер», 2001. – 544 с.