Базы данных
1.
Понятие файловой системы. Организация доступа к файлу на диске..................... 2
2. Понятие базы данных. Модели данных: иерархическая, реляционная,
сетевая, объектная........................................................................................................................ 5
3. Распределенные базы данных. Сеть Интернет как средство создания
распределенных баз данных.......................................................................................... 9
4. Понятие базы данных. Реляционная модель данных. Таблицы, запросы, поля.
Понятие типа данных................................................................................................... 10
5. Реляционные базы данных. Таблицы, типы связей между таблицами.
Первичный ключ. Внешний ключ................................................................................................... 13
6. Реляционная модель данных. Виды связей между таблицами. Нормализация.
Нормальные формы..................................................................................................... 16
7. Характеристика СУБД MS Access. Создание базы данных. Редактирование
свойств, таблиц, полей, связей. Создание схемы данных........................................... 20
8. Характеристика СУБД MS Access. Создание интерфейса на основании ранее
созданной базы данных и её схемы. Основные управляющие элементы форм........ 22
9. Характеристика СУБД MS Access. Понятие макросов и программ.
Использование макросов и программ для реализации алгоритмов пользовательского
интерфейса 27
10. Роль программного обеспечения СУБД в создании информационной системы
предприятия.................................................................................................................. 29
1. Понятие файловой
системы. Организация доступа к файлу на диске
Операционная система состоит из многих подсистем, каждая
из которых решает определенную задачу. Одна из важнейших – организация хранения
информации в компьютере и доступа к ней. Эту задачу решает файловая система.
Она поддерживает определенную структуру на всевозможных накопителях информации
в компьютере (винчестере, дискетах и пр.) Накопители имеют разный объем,
используют разные методы записи и хранения.
Файловая
система вводит небольшое количество стандартных логических понятий, которые
позволяют человеку работать с информацией, не вдаваясь в детали работы
устройств, хранящих информацию.
Основные
логические понятия файловой системы
Самой важное понятие – это файл. Вся информация, которую
мы храним на дисках, должна быть доступна нам и опознаваема. Каждой группе
байтов, несущих какую-либо законченную информацию, присваивается определенное
обозначение – имя.
Файлом
называется целостная по именования (т.е. имеющая имя) совокупность информации
на внешнем носителе информации.
С
точки зрения файловой системы файл состоит из данных и некоторой служебной
информации. Файловая система рассматривает файл как единое целое и позволяет
выполнять над файлами несколько стандартных операций: создавать, копировать,
переименовывать файлы.
Файлы
могут содержать программы, исходные данные для их выполнения, иллюстрации,
тексты, электронные таблицы и прочее. Каждый файл при создании получает имя.
Имя состоит из собственного имени и расширения (в Windows). Расширение
отделяется от собственного имени точкой. Оно показывает на принадлежность файла
к какой-либо группе, определяет тип файла.
Примеры:
·
com., .exe – программы, готовые к выполнению
·
.bat – командные файлы, содержащие команды ОС
·
.bas – тексты программ на Бейсике;
.bmp —
графические файлы
.dbf —
файлы без данных
Имя
файла может быть набрано в любом регистре, заглавными или маленькими буквами.
Могут быть использованы цифры и некоторые символы. В ОС MS DOS на имена файлов
накладывались жесткие ограничения: количество символов в имени не должно было
превышать 8, расширение не должно было содержать более 3 символов, нельзя было
использовать русские буквы, точки, пробелы. В ОС Windows'95/98 многие из этих
ограничений сняты, длина имени может достигать 255 символов, но нельзя
использовать в имени такие символы как *, ?, / и некоторые другие.
Файловая
система позволяет хранить файлы не в общей куче, а в виде иерархической
структуры каталогов , вложенных друг в друга.
Каталогом
или папкой называется специальный файл, в котором регистрируются другие файлы.
На каждом носителе информации, например, на диске, создается главный каталог.
Он создается при форматировании диска, хранится во вполне определенной области
дисковой памяти, имеет ограниченный размер и не может быть удален никакими
средствами. Корневой каталог включает в себя файлы и подкаталоги. Получается
иерархическая древовидная структура каталогов или дерево каталогов.
Каждый
файл регистрируется всегда только в одном каталоге. Так как каталог – тоже
файл, он может быть зарегистрирован в другом каталоге, по отношению к которому
он будет называться подкаталогом. Каталог более низкого уровня вложенности
называется надкаталогом по отношению к любому каталогу, который в нем
зарегистрирован. На имена каталогов распространяются те же правила, что и на
имена файлов, только расширение для них не используют.
Файлы
физически хранятся на носителях, размещенных в различных устройствах. Носителем
может быть магнитный или оптический диск, размещенные в дисководе, магнитная
лента, размещенная в специальном магнитофоне – стримере. Некоторые устройства
предусматривают оперативную смену носителей, дискет. Чтобы указать расположение
файла, используется имя устройства или носителя. Предполагается, что нужный
носитель заранее установлен на устройство.
Традиционно в системах Windows имена устройств
однобуквенные c добавлением двоеточия. Обычно дисководы гибких дисков называют
A: и B:, первый жесткий диск – С:. Если в компьютере есть другие дисководы, то
их имена будут D:, E: и т.д.
Большая
часть ОС позволяет на базе одного физического устройства организовать
программным путем несколько логических устройств. Физический винчестер нередко
разбивается на логические диски. На устройстве С: могут быть организованы
логические устройства D: и E:. После этого файловая система будет работать с
устройствами D: и E:, как они реально существовали. Для любого файла
непременным атрибутом является имя логического диска, на котором он запсан.
Диск и каталог, с которыми в настоящие время работает пользователь, называются
текущими или рабочими. Таким образом, чтобы указать файл на современном
компьютере, нужно задать следующую информацию: имя устройства,
последовательность имен вложенных каталогов и имя файла. Последовательность из
имен каталогов, ведущих к файлу, называется путем.
Полное
имя файла состоит из следующих частей:
имя
логического устройства
путь,
т.е каталоги, разделенные знаком \
имя
файла с расширением, если оно имеется.
Примеры
путей к файлу: Пример полного имени файла: С:\SCHOOL\CLASS\FLAG.BMP
Примеры
путей к файлу:
·
CLASS\IMAGES\
·
\SCHOOL\CLASS (путь от корневого каталога)
·
..\..\CLASS\ ("подъем" вверх по дереву
каталогов)
Если
компьютер работает в сети, то путь к файлу из общей сетевой папки должен
начинаться двумя косыми черточками.
2. Понятие базы
данных. Модели данных: иерархическая, реляционная, сетевая, объектная
Часто,
говоря о базе данных, имеют в виду просто некоторое автоматизированное
хранилище данных. Такое представление не вполне корректно.
Действительно,
в узком смысле слова, база данных – это некоторый набор данных, необходимых для
работы (актуальные данные). Однако данные – это абстракция; никто никогда не
видел "просто данные"; они не возникают и не существуют сами по себе.
Данные суть отражение объектов реального мира. Пусть, например, требуется
хранить сведения о деталях, поступивших на склад. Как объект реального мира –
деталь – будет отображена в базе данных? Для того, чтобы ответить на этот
вопрос, необходимо знать, какие признаки или стороны детали будут актуальны,
необходимы для работы. Среди них могут быть название детали, ее вес, размеры,
цвет, дата изготовления, материал, из которого она сделана и т.д. В традиционной
терминологии объекты реального мира, сведения о которых хранятся в базе данных,
называются сущностями – entities (пусть это слово не пугает читателя – это
общепринятый термин), а их актуальн7ые признаки – атрибутами (attributes).
Каждый
признак конкретного объекта есть значение атрибута. Так, деталь
"двигатель" имеет значение атрибута "вес", равное
"50", что отражает тот факт, что данный двигатель весит 50
килограммов.
Было
бы ошибкой считать, что в базе данных отражаются только физические объекты. Она
способна вобрать в себя сведения об абстракциях, процессах, явлениях – то есть
обо всем, с чем сталкивается человек в своей деятельности. Так, например, в
базе данных можно хранить информацию о заказах на поставку деталей на склад
(хотя он – не физический объект, а процесс). Атрибутами сущности
"заказ" будут название поставляемой детали, количество деталей,
название поставщика, срок поставки и т.д.
Объекты реального мира связаны друг с другом множеством
сложных зависимостей, которые необходимо учитывать в информационной
деятельности. Например, детали на склад поставляются их производителями.
Следовательно, в число атрибутов детали необходимо включить атрибут
"название фирмы-производителя". Однако этого недостаточно, так как
могут понадобиться дополнительные сведения о производителе конкретной детали –
его адрес, номер телефона и т.д. Значит, база данных должна содержать не только
информацию о деталях и заказах на поставку, но и сведения об их производителях.
Более того, база данных должна отражать связи между деталями и производителями
(каждая деталь выпускается конкретным производителем) и между заказами и
деталями (каждый заказ оформляется на конкретную деталь). Отметим, что в базе
данных нужно хранить только актуальные, значимые связи.
Таким
образом, в широком смысле слова база данных – это совокупность описаний
объектов реального мира и связей между ними, актуальных для конкретной
прикладной области. В дальнейшем мы будем исходить из этого определения,
уточняя его по ходу изложения.
Разнообразие моделей связано также и с различием
используемых парадигм моделирования. С этой точки зрения, различаются
реляционные, сетевые, иерархические, объектные, объектно-реляционные,
функциональные и многие другие виды моделей данных и, соответственно, описываемые
их средствами схемы баз данных.
Иерархическая
модель данных стала применяться в системах управления базами данных в начале
60-х годов. Она представляет собой совокупность элементов, расположенных в
порядке их подчинения от общего к частному и образующих перевернутое дерево.
Иерархическая
модель данных строится по принципу иерархии типов объектов, то есть один тип
объекта является главным, а остальные, находящиеся на низших уровнях иерархии,
- подчиненными. Между главным и подчиненными объектами устанавливается
взаимосвязь "один ко многим".
Иерархические
базы данных по существу являются навигационными, т.е. доступ возможен только с
помощью заранее определенных связей.
Достоинство
иерархической базы данных состоит в том, что ее навигационная природа обеспечивает
очень быстрый доступ при следовании вдоль заранее определенных связей. Однако
негибкость модели данных и, в частности, невозможность наличия у объекта
нескольких родителей, а также отсутствие прямого доступа к данным делают ее
непригодной в условиях частого выполнения запросов, не запланированных заранее.
Еще одним недостатком иерархической модели данных является то, что
информационный поиск из нижних уровней иерархии нельзя направить по вышележащим
узлам.
Чтобы
устранить ограничения, свойственные иерархической модели данных, в начале 60-х
годов, задолго до появления компьютерных сетей, проектировщики баз данных
создают сетевую модель данных, описывающую сети связей между данными.
В
сетевой модели данных понятия главного и подчиненных объектов несколько
расширены. Любой объект может быть и главным, и подчиненным (в сетевой модели
главный объект обозначается термином "владелец набора", а подчиненный
- термином "член набора"). Один и тот же объект может одновременно
выступать и в роли владельца, и в роли члена набора. Это означает, что каждый
объект может участвовать в любом числе взаимосвязей.
Сетевая
модель базы данных похожа на иерархическую, однако характер отношений основных
ее составляющих принципиально иной. В сетевой модели принято свободная связь
между элементами разных уровней, т.е. она допускает связи "многие ко
многим". В качестве примера СУБД, поддерживающей принципы сетевой модели
данных, можно привести СУБД "Cronos Plus".
Понятие «реляционная модель» ввел в 1970 г.
Э.Ф. Кодд. В реляционной модели данных объекты и взаимосвязи между ними
представляются с помощью таблиц. Взаимосвязи также рассматриваются в качестве
объектов. Каждая таблица представляет один объект и состоит из строк и
столбцов. В реляционной базе данных каждая таблица должна иметь первичный ключ
(ключевой элемент) - поле или комбинацию полей, которые единственным образом
идентифицируют каждую строку в таблице. Благодаря своей простоте и
естественности представления реляционная модель получила наибольшее
распространение среди СУБД для персональных компьютеров.
Название
"реляционная" (relational) связано с тем, что каждая запись в такой
базе данных содержит информацию, относящуюся (related) только к конкретному
объекту. Кроме того, с данными двух типов можно работать как с единым целым,
основанным на значениях связанных между собой данных.
Преимуществом
реляционной модели перед другими моделями является простая и удобная для
пользователя схема данных, представляемая в виде таблиц.
Физическая
независимость реляционной модели состоит в том, что модель данных не включает
никаких физических описаний. В действительности физическое представление
отношений и путей доступа описывается независимо от описания логической схемы
отношений.
Недостатком
реляционной модели данных является избыточность по полям (из-за создания
связей).
В
качестве примера можно привести реляционные СУБД Microsoft Access и Borland
Paradox.
Объектно-ориентированная
модель данных отличается от вышеописанных моделей, в которых информация и
процедуры хранились раздельно, данные и связи между ними - в базе данных, а
процедуры – в прикладной программе. Объектно-ориентированная модель позволяет
хранить процедуры обработки сущностей вместе с данными. Такое совместное
хранение считается шагом вперед в методах управления данными. Но
объектно-ориентированные базы данных являются навигационными, что является
шагом назад.
Объектно-ориентированная
модель непосредственно поддерживает связи типа "многие ко многим".
3. Распределенные
базы данных. Сеть Интернет как средство создания распределенных баз данных
Основная
задача систем управления распределенными базами данных состоит в обеспечении
средства интеграции локальных баз данных, располагающихся в некоторых узлах
вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети,
имел доступ ко всем этим базам данных как к единой базе данных.
При этом должны обеспечиваться: простота использования
системы; возможности автономного функционирования при нарушениях связности сети
или при административных потребностях; высокая степень эффективности.
Возможны
однородные и неоднородные распределенные базы данных. В однородном случае
каждая локальная база данных управляется одной и той же СУБД. В неоднородной
системе локальные базы данных могут относиться даже к разным моделям данных.
Сетевая интеграция неоднородных баз данных – это актуальная, но очень сложная
проблема. Многие решения известны на теоретическом уровне, но пока не удается
справиться с главной проблемой – недостаточной эффективностью интегрированных
систем.
Заметим,
что более успешно практически решается промежуточная задача – интеграция
неоднородных SQL-ориентированных систем. Понятно, что этому в большой степени
способствует стандартизация языка SQL и общее следование производителей СУБД
принципам открытых систем.
WWW
– это пример глобальной информационной системы.
Устройства
внешней памяти, на которых хранятся БД, должны иметь высокую информационную
емкость и малое время доступа к хранимой информации. Для хранения БД может
использоваться как один компьютер, так и множество взаимосвязанных компьютеров.
Если
различные части одной базы данных хранятся на множестве компьютеров,
объединенных между собой сетью, то такая БД называется распределенной базой
данных. Очевидно, информацию в сети Интернет, объединенную паутиной WWW, можно
рассматривать как распределенную базу данных. Распределенные БД создаются также
и в локальных сетях.
4. Понятие базы
данных. Реляционная модель данных. Таблицы, запросы, поля. Понятие типа данных
База данных – это
совокупность описаний объектов реального мира и связей между ними, актуальных
для конкретной прикладной области. В дальнейшем мы будем исходить из этого
определения, уточняя его по ходу изложения.
Одним
из основных преимуществ реляционного подхода к организации баз данных (БД) является
то, что пользователи реляционных БД получают возможность эффективной работы в
терминах простых и наглядных понятий таблиц, их строк и столбцов без
потребности знания реальной организации данных во внешней памяти.
Реляционная
модель данных, содержащая набор четких предписаний к базовой организации любой
реляционной системы управления базами данных (СУБД), позволяет пользователям
работать в ненавигационной манере, т.е. для выборки информации из БД человек
должен всего лишь указать список интересующих его таблиц и те условия, которым
должны удовлетворять выбираемые данные. СУБД скрывает от пользователя
выполняемые ей последовательные просмотры таблиц, выполняя их наиболее
эффективным образом. Очень важная особенность реляционных систем состоит в том,
что результатом выполнения любого запроса к таблицам БД является также таблица,
которую можно сохранить в БД и/или по отношению к которой можно выполнять новые
запросы.
Базовым
требованием к реляционным СУБД является наличие мощного и в тоже время простого
языка, позволяющего выполнять все необходимые пользователям операции.
В
базах данных используются таблицы, запросы, поля.
Таблицы
– это основные объекты любой базы данных. Во-первых, в таблицах хранятся все
данные, имеющиеся в базе, а во-вторых, таблицы хранят и структуру базы (поля,
их типы и свойства).
Запросы.
Эти объекты служат для извлечения данных из таблиц и предоставления их
пользователю в удобном виде. С помощью запросов выполняют такие операции как
отбор данных, их сортировку и фильтрацию. С помощью запросов можно выполнять
преобразования данных по заданному алгоритму, создавать новые таблицы,
выполнять автоматическое наполнения таблиц данными, импортированными из других
источников, выполнять простейшие вычисления в таблицах и многое другое.
Поля
базы данных не просто определяют структуру базы – они еще определяют групповые
свойства данных, записываемых в ячейки, принадлежащие каждому из полей. Ниже
перечислены основные свойства полей таблиц баз данных на примере СУБД Microsoft
Access.
Имя
поля – определяет, как следует обращаться к данным этого поля при
автоматических операциях с базой (по умолчанию имена полей используются в
качестве заголовков столбцов таблиц).
Тип
поля – определяет тип данных, которые могут содержаться в данном поле.
Размер
поля – определяет предельную длину (в символах) данных, которые могут
размещаться в данном поле.
Формат
поля – определяет способ форматирования данных в ячейках, принадлежащих полю.
Маска
ввода – определяет форму, в которой вводятся данные а поле (средство автоматизации
ввода данных).
Подпись
– определяет заголовок столбца таблицы для данного поля (если подпись не
указана, то в качестве заголовка столбца используется свойство Имя поля).
Значение
по умолчанию – то значение, которое вводится в ячейки поля автоматически
(средство автоматизации ввода данных).
Условие
на значение – ограничение, используемое для проверки правильности ввода данных
(средство автоматизации ввода, которое используется, как правило, для данных,
имеющих числовой тип, денежный тип или тип даты).
Сообщение
об ошибке – текстовое сообщение, которое выдается автоматически при попытке
ввода в поле ошибочных данных.
Обязательное
поле – свойство, определяющее обязательность заполнения данного поля при
наполнении базы.
Пустые
строки – свойство, разрешающее ввод пустых строковых данных (от свойства
Обязательное поле отличается тем, что относится не ко всем типам данных, а лишь
к некоторым, например к текстовым).
Индексированное
поле – если поле обладает этим свойством, все операции, связанные с поиском или
сортировкой записей по значению, хранящемуся в данном поле, существенно
ускоряются. Кроме того, для индексированных полей можно сделать так, что
значение в записях будут проверяться по этому полю на наличие повторов, что
позволяет автоматически исключить дублирование данных.
Поскольку
в разных полях могут содержаться данные разного типа, то и свойства у полей
могут различаться в зависимости от типа данных. Так, например, список
вышеуказанных свойств полей относится в основном к полям текстового типа. Поля
других типов могут иметь или не иметь эти свойства, но могут добавлять к ним и
свои. Например, для данных, представляющих действительные числа, важным
свойством является количество знаков после десятичной запятой. С другой
стороны, для полей, используемых для хранения рисунков, звукозаписей, видео
клипов и других объектов OLE, большинство вышеуказанных свойств не имеют
смысла.
Понятие тип данных в реляционной модели данных
полностью адекватно понятию типа данных в языках программирования. Обычно в
современных реляционных БД допускается хранение символьных, числовых данных,
битовых строк, специализированных числовых данных (таких как
"деньги"), а также специальных "темпоральных" данных (дата,
время, временной интервал). Достаточно активно развивается подход к расширению
возможностей реляционных систем абстрактными типами данных (соответствующими
возможностями обладают, например, системы семейства Ingres/Postgres).
5. Реляционные базы
данных. Таблицы, типы связей между таблицами. Первичный ключ. Внешний ключ
Реляционная
база данных – это совокупность отношений, содержащих всю информацию, которая
должна храниться в БД. Однако пользователи могут воспринимать такую базу данных
как совокупность таблиц.
1.
Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2.
Строки имеют фиксированное число полей (столбцов) и значений (множественные
поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции
таблицы на пересечении строки и столбца всегда имеется в точности одно значение
или ничего.
3.
Строки таблицы обязательно отличаются друг от друга хотя бы единственным
значением, что позволяет однозначно идентифицировать любую строку такой
таблицы.
4.
Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются
однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5.
Полное информационное содержание базы данных представляется в виде явных
значений данных и такой метод представления является единственным. В частности,
не существует каких-либо специальных "связей" или указателей,
соединяющих одну таблицу с другой.
6.
При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в
любом порядке безотносительно к их информационному содержанию. Этому
способствует наличие имен таблиц и их столбцов, а также возможность выделения
любой их строки или любого набора строк с указанными признаками (например,
рейсов с пунктом назначения "Париж" и временем прибытия до 12 часов).
Предложив
реляционную модель данных, Э.Ф.Кодд создал и инструмент для удобной работы с
отношениями – реляционную алгебру. Каждая операция этой алгебры использует одну
или несколько таблиц (отношений) в качестве ее операндов и продуцирует в
результате новую таблицу, т.е. позволяет "разрезать" или
"склеивать" таблицы (рис. 1).
Рис. 1 Некоторые
операции реляционной алгебры
Созданы
языки манипулирования данными, позволяющие реализовать все операции реляционной
алгебры и практически любые их сочетания. Среди них наиболее распространены SQL
(Structured Query Language – структуризованный язык запросов) и QBE
(Quere-By-Example – запросы по образцу). Оба относятся к языкам очень высокого
уровня, с помощью которых пользователь указывает, какие данные необходимо
получить, не уточняя процедуру их получения.
С
помощью единственного запроса на любом из этих языков можно соединить несколько
таблиц во временную таблицу и вырезать из нее требуемые строки и столбцы
(селекция и проекция).
Ключ или возможный ключ – это минимальный набор
атрибутов, по значениям которых можно однозначно найти требуемый экземпляр
сущности. Минимальность означает, что исключение из набора любого атрибута не
позволяет идентифицировать сущность по оставшимся. Каждая сущность обладает
хотя бы одним возможным ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать
предпочтение несоставным ключам или ключам, составленным из минимального числа
атрибутов. Нецелесообразно также использовать ключи с длинными текстовыми
значениями (предпочтительнее использовать целочисленные атрибуты). Так, для идентификации
студента можно использовать либо уникальный номер зачетной книжки, либо набор
из фамилии, имени, отчества, номера группы и может быть дополнительных
атрибутов, так как не исключено появление в группе двух студентов (а чаще
студенток) с одинаковыми фамилиями, именами и отчествами. Плохо также
использовать в качестве ключа не номер блюда, а его название, например, "
Закуска из плавленых сырков "Дружба" с ветчиной и соленым
огурцом" или "Заяц в сметане с картофельными крокетами и салатом из
красной капусты".
Не
допускается, чтобы первичный ключ стержневой сущности (любой атрибут,
участвующий в первичном ключе) принимал неопределенное значение. Иначе
возникнет противоречивая ситуация: появится не обладающий индивидуальностью, и,
следовательно не существующий экземпляр стержневой сущности. По тем же причинам
необходимо обеспечить уникальность первичного
ключа.
Теперь
о внешних ключах:
·
Если сущность С связывает сущности А и В, то она
должна включать внешние ключи, соответствующие первичным ключам сущностей А и
В.
·
Если сущность В обозначает сущность А, то она должна
включать внешний ключ, соответствующий первичному ключу сущности А.
Связь
между первичными и внешними ключами сущностей иллюстрируется рис.2.
Рис. 2.
Структуры: а - ассоциации; б - обозначения (характеристики)
Здесь
для обозначения любой из ассоциируемых сущностей (стержней, характеристик,
обозначений или даже ассоциаций) используется новый обобщающий термин
"Цель" или "Целевая сущность".
6. Реляционная модель данных. Виды связей между таблицами.
Нормализация. Нормальные формы
Традиционно
все СУБД классифицируются в зависимости от модели данных, которая лежит в их
основе. Принято выделять иерархическую, сетевую и реляционную модели данных.
Иногда к ним добавляют модель данных на основе инвертированных списков.
Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД
на базе инвертированных списков.
По распространенности и популярности реляционные СУБД
сегодня – вне конкуренции. Они стали фактическим промышленным стандартом, и
поэтому отечественному пользователю придется столкнуться в своей практике
именно с реляционной СУБД. Кратко рассмотрим реляционную модель данных, не
вникая в ее детали.
Она
была разработана Коддом еще в 1969-70 годах на основе математической теории отношений
и опирается на систему понятий, важнейшими из которых являются таблица,
отношение, строка, столбец, первичный ключ, внешний ключ.
Реляционной
считается такая база данных, в которой все данные представлены для пользователя
в виде прямоугольных таблиц значений данных, и все операции над базой данных
сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и
имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта
реального мира (сущность), а каждая ее строка – конкретный объект. Так, таблица
Деталь содержит сведения о всех деталях, хранящихся на складе, а ее строки
являются наборами значений атрибутов конкретных деталей. Каждый столбец таблицы
– это совокупность значений конкретного атрибута объекта. Так, столбец Материал
представляет собой множество значений "Сталь", "Олово",
"Цинк", "Никель" и т.д. В столбце Количество содержатся
целые неотрицательные числа. Значения в столбце Вес – вещественные числа,
равные весу детали в килограммах.
Эти
значения не появляются из воздуха. Они выбираются из множества всех возможных
значений атрибута объекта, которое называется доменом (domain). Так, значения в
столбце материал выбираются из множества имен всех возможных материалов –
пластмасс, древесины, металлов и т.д. Следовательно, в столбце Материал
принципиально невозможно появление значения, которого нет в соответствующем
домене, например, "вода" или "песок".
Каждый
столбец имеет имя, которое обычно записывается в верхней части таблицы (рис.
3). Оно должно быть уникальным в таблице, однако различные таблицы могут иметь
столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один
столбец; столбцы расположены в таблице в соответствии с порядком следования их
имен при ее создании. В отличие от столбцов, строки не имеют имен; порядок их
следования в таблице не определен, а количество логически не ограничено.
Рис. 3
Основные понятия базы данных
Так
как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции –
среди них не существует "первой", "второй", "последней".
Любая таблица имеет один или несколько столбцов, значения в которых однозначно
идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов)
называется первичным ключом (primary key). В таблице Деталь первичный ключ – это
столбец Номер детали. В нашем примере каждая деталь на складе имеет
единственный номер, по которому из таблицы Деталь извлекается необходимая
информация. Следовательно, в этой таблице первичный ключ – это столбец Номер
детали. В этом столбце значения не могут дублироваться – в таблице Деталь не
должно быть строк, имеющих одно и то же значение в столбце Номер детали. Если
таблица удовлетворяет этому требованию, она называется отношением (relation).
Взаимосвязь
таблиц является важнейшим элементом реляционной модели данных. Она
поддерживается внешними ключами (foreign key). Рассмотрим пример, в котором
база данных хранит информацию о рядовых служащих (таблица Служащий) и
руководителях (таблица Руководитель) в некоторой организации (рис.4). Первичный
ключ таблицы Руководитель – столбец Номер (например, табельный номер). Столбец
Фамилия не может выполнять роль первичного ключа, так как в одной организации
могут работать два руководителя с одинаковыми фамилиями. Любой служащий
подчинен единственному руководителю, что должно быть отражено в базе данных.
Таблица Служащий содержит столбец Номер руководителя, и значения в этом столбце
выбираются из столбца Номер таблицы Руководитель (рис.4). Столбец Номер
Руководителя является внешним ключом в таблице Служащий.
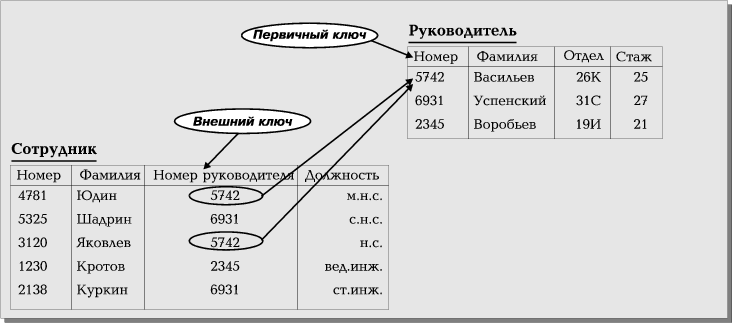 Рис.
4. Взаимосвязь таблиц базы данных
Рис.
4. Взаимосвязь таблиц базы данных
Таблицы
невозможно хранить и обрабатывать, если в базе данных отсутствуют "данные
о данных", например, описатели таблиц, столбцов и т.д. Их называют обычно
метаданными. Метаданные также представлены в табличной форме и хранятся в словаре
данных (data dictionary).
Помимо
таблиц, в базе данных могут храниться и другие объекты, такие как экранные
формы, отчеты (reports), представления (views) и даже прикладные программы,
работающие с базой данных.
Для
пользователей информационной системы недостаточно, чтобы база данных просто
отражала объекты реального мира. Важно, чтобы такое отражение было однозначным
и непротиворечивым. В этом случае говорят, что база данных удовлетворяет
условию целостности (integrity).
Для
того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на
базу данных накладываются некоторые ограничения, которые называют ограничениями
целостности (data integrity constraints).
Существует
несколько типов ограничений целостности. Требуется, например, чтобы значения в
столбце таблицы выбирались только из соответствующего домена. На практике
учитывают и более сложные ограничения целостности, например, целостность по
ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не
может быть указателем на несуществующую строку в таблице.
7. Характеристика
СУБД MS Access. Создание базы данных. Редактирование свойств, таблиц,
полей, связей. Создание схемы данных
Запуск Access. Пуск –
Программа - Microsoft Access.
После
запуска появится первичное окно
В нем поставить точку перед надписью «Новая база данных»
и нажать мышкой ОК.
Появится следующее окно. В нем в поле «Имя файла» надо
набрать имя файла, в котором будет храниться Новая база данных, и щелкнуть
мышкой по кнопке «Создать».
После
этого появится основное окно Access. В нем горизонтальным (или вертикальным)
рядом указаны основные объекты, которые могут быть созданы в базе данных. Это
таблицы, запросы , формы, отчеты и пр.
Объекты базы данных
Создание таблицы базы данных Создание
базы данных начинается с создания таблиц. Создание таблицы состоит из двух
этапов: первый этап - создание структуры таблицы, второй – заполнение таблицы.
Создание
структуры таблицы в режиме конструктора
Для
создания таблицы нужно выделить объект таблица и щелкнуть мышкой по кнопке
создать. Появится диалоговое окно, в котором надо выделить «Конструктор» и
щелкнуть мышью по кнопке ОК.
После этого мы попадаем в окно конструктора, в котором задаем
структуру таблицы: состав полей, их имена, последовательность размещения полей,
тип данных каждого поля, размер поля, подпись, ключи и другие свойства полей. В
верхней части окна конструктора указывается название поля и тип данных, в
нижней части –размер поля, надпись и т.п.
8. Характеристика
СУБД MS Access. Создание интерфейса на основании ранее созданной базы
данных и её схемы. Основные управляющие элементы форм
Microsoft Access в настоящее время является одной из
самых популярных среди настольных (персональных) программных систем управления
базами данных Среди причин такой популярности следует отметить:
-
высокую степень универсальности и продуманности
интерфейса, который рассчитан на работу с пользователями самой различной
квалификации. В частности, реализована система управления объектами базы
данных, позволяющая гибко и оперативно переходить из режима конструирования в
режим их непосредственной эксплуатации;
-
глубоко развитые возможности интеграции с другими
программными продуктами, входящими в состав Microsoft Office, а также с любыми
программными продуктами, поддерживающими технологию OLE;
-
богатый набор визуальных средств разработки.
Нельзя
не отметить, что существенной причиной такого широкого распространения MS
Access является и мощная рекламная поддержка, осуществляемая фирмой Microsoft.
В процессе разработки данного продукта на рынок представлялись его различные
версии. Наиболее известными (в некотором смысле этапными) стали Access 2.0,
Access 7.0 (он впервые был включен в состав программного комплекса MS Office
95). Позже появились версии Access 97 (в составе MS Office 97 и Access 2000 (в
составе MS Office 2000).
Очевидно,
что отправной точкой в процессе работы с любой СУБД является создание файла
(или группы файлов) базы данных.
На
рис. 1 показано окно, которое появляется после создания новой базы.
Основные разделы
главного окна соответствуют типам объектов, которые может содержать база данных
Access. Это Таблицы, Запросы, Отчеты, Макросы и Модули. Заголовок окна содержит
имя файла базы данных. В данном случае он называется TradeTest.
Интерфейс
работы с объектами базы данных унифицирован. По каждому из них предусмотрены
стандартные режимы работы:
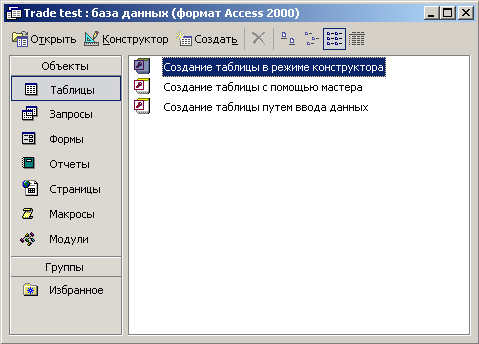
Рис. 1.
Главное окно базы данных в Access
Рис. 7.6.
Панель инструментов конструктора таблиц
Создать
- предназначен для создания структуры объектов;
Конструктор
- предназначен для изменения структуры объектов;
Открыть
(Просмотр, Запуск) - предназначен для работы с объектами базы данных.
Важным средством,
облегчающим работу с Access для начинающих пользователей, являются мастера -
специальные программные надстройки, предназначенные для создания объектов базы
данных в режиме последовательного диалога. Для опытных и продвинутых
пользователей существуют возможности более гибкого управления ресурсами и
возможностями объектов СУБД в режиме конструктора.
Специфической
особенностью СУБД Access является то, что вся информация, относящаяся к одной
базе данных, хранится в едином файле. Такой файл имеет расширение *.mdb. Данное
решение, как правило, удобно для непрофессиональных пользователей, поскольку
обеспечивает простоту при переносе данных с одного рабочего места на другое.
Внутренняя организация данных в рамках mdl формата менялась от версии к версии,
но фирма Microsoft поддерживала их ее вместимость снизу вверх, то есть базы
данных из файлов в формате ранних вер сии Access могут быть конвертированы в
формат, используемый в версиях боле поздних.
Форма – это всего лишь графическая оболочка,
рамочка. Все, что необходимо разработать, – это графические элементы, которые
будут храниться в макете формы. Даже если назвать эти картинки элементами
управления, суть не изменится. Кроме создания картинок, кнопок, полей и окон,
нужно также придумать и написать поясняющий текст (подписи к полям и кнопкам).
Основная
часть данных, представленных в форме, берется из таблиц или запросов, которые
уже разработаны, или из тех, которые будут специально разработаны для
информационной поддержки той или иной формы
В
конструктор форм Access встроены такие элементы управления, как надпись, поле,
кнопка, флажок, переключатель, список, набор вкладок и др. Помимо этого к форме
можно подключать специальные (дополнительные) элементы управления OLE, что
значительно расширяет возможности развития интерфейса управления данными.
Окно
Свойств текущего элемента управления, предназначенное для изменения его
атрибутов и настроек, например, цвета, шрифта, размера и т. п.
Рис. 3.
Форма Бумаги в режиме конструктора
В режиме Конструктор явно видна структура формы. Она
состоит из трех частей: Заголовок формы, Область данных и Примечание формы. Как
нетрудно догадаться, такая структура в первую очередь ориентирована на
возможности представления таблично организованных данных. Заметим, что как сама
форма, так и ее разделы также рассматриваются как элементы управления,
обладающие некоторыми настраиваемыми наборами свойств.
В
качестве иллюстрации возможностей конструктора по изменению интерфейса
ввода/вывода проведем следующие манипуляции над формой Бумаги:
1
Удалим фоновый рисунок: очистим свойство Рисунок, когда текущим выбранном
элементом является вся форма.
2.
Изменим цвет фона: выберем элемент ОбластьДанных и изменим у нее атрибут Цвет
фона (рис. 4).
3.
Изменим внешний вид полей: выделим группу полей (поля выбираются с помощью мыши
при нажатой клавише Shift) и в окне свойств изменим значение атрибута
Оформление на Утопленное.
4.
Отредактируем подписи полей и несколько изменим их расположение друг
относительно друга: для этого достаточно воспользоваться возможностями
визуального редактирования элементов.
5.
Добавим разделительную линию после поля НаимБум (наименование бумаги): для
этого следует воспользоваться элементом Линия.
6.
Добавим кнопку завершения работы с формой: в большинстве ситуаций эту и
подобные операции проще и удобнее делать в режиме мастера (нажата
соответствующая кнопка на панели Элементы управления). В этом случае от
пользователя требуется лишь ввести минимальное количество параметров для
добавляемого программного компонента.
В
общем, формы – это универсальное средство для работы с информацией в БД.
Большое разнообразие элементов управления позволяет конструировать
(программировать) служебные формы с расширенной функциональностью. Формы
облегчают ввод информации и широко используются для ее визуализации.
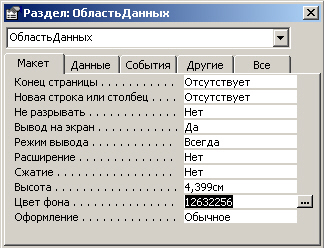
Рис. 4.
Окно свойств элемента управления
В
результате отредактированная форма Бумаги примет вид, показанный на рис.5.
Рис. 5.
Форма Бумаги после редактирования
9. Характеристика
СУБД MS Access. Понятие макросов и программ. Использование макросов и
программ для реализации алгоритмов пользовательского интерфейса
Access,
как и любая другая развитая программная система, обладает средствами разработки
программных приложений, ориентированных на конечных пользователей. Эти средства
базируются на инструментах двух типов: макросах и модулях. Само понятие макроса
подразумевает наличие набора некоторых стандартных команд системы, или
макрокоманд (допустим, таких, как открытие формы, выполнение запроса, вывод
отчета), из которых и конструируется сам макрос.
Макрос
может быть как собственно макросом, состоящим из последовательности
макрокоманд, так и группой макросов. Группой макросов называют их набор,
сохраняемый под общим именем. В некоторых случаях для решения, должна ли в
запущенном макросе выполняться определенная макрокоманда, может применяться
условное выражение.
Особый
интерес вызывает механизм вызова макросов в Access. Для этого существует две
принципиальных возможности:
-
вызов макроса по команде пользователя (либо
непосредственно из раздела Макросы главного окна базы данных, либо с помощью
меню или панели инструментов, с которыми он также может быть ассоциирован);
-
вызов макроса по некоторому системному событию
(открытие или закрытие формы, изменение управляющего элемента и т. п.).
Весьма
полезной представляется возможность организовать автоматическое выполнение ряда
действий при открытии базы данных. Для этого они должны быть описаны в
специальном макросе с именем Autoexec.
Возможности
применения макросов при работе в среде СУБД Access можно наглядно
продемонстрировать на следующем примере. Предположим, что в ранее созданную
форму Бумаги мы хотим добавить процедуру дополнительного контроля вводимых
значений дат эмиссии ценных бумаг, которая должна будет выдавать
предупреждающее сообщение, если вводится слишком "ранняя" дата.
Допустим, что к таковым относятся даты, предшествующие 1 января 1991 года.
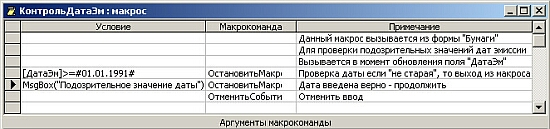
Рис. 1.
Создание макроса
Технически решение представляется удобным
реализовать в виде макроса, вызываемого по событию "до обновления",
ассоциированному с полем ДатаЭм в форме Бумаги.
На
рис. 1 показан процесс разработки данного макроса (ему дано имя
КонтрольДатаЭм). Из него видно, что макрос содержит три макрокоманды:
-
Первая, ОстановитьМакрос - прерывает работу, если
введена дата более поздняя, чем 1 января 1991 года.
-
Вторая, ОстановитьМакрос - выполняется, если
пользователь считает, что несмотря на сделанное предупреждение введенная дата
является верной. Для вывода предупреждения используется встроенная функция
MsgBox.
-
Третья - отменяет событие ввода данных, если они после
предупреждения признаются ошибочными.
Хорошим
стилем разработки макросов является снабжение их комментариями, располагаемыми
в соответствующей колонке.
Рис. 2.
"Привязка" макроса к событию
На рис. 2 показана привязка разработанного макроса к
событию "до обновления" поля ДатаЭм формы Бумаги.
10. Роль
программного обеспечения СУБД в создании информационной системы предприятия
Важную роль при создании БД играет выбор
программного обеспечения или, по терминологии информатики, системы управления
базой данных (далее - СУБД). Выбор конкретной СУБД из большого множества
разработанных программных продуктов определяется прежде всего характером
организации данных и потребностями работы с базой данных. Важными для
пользователя характеристиками СУБД являются: дружественный интерфейс, уровень
реляционности, возможность обмена данными с другими системами, средства
создания прикладных систем.
Требования
к СУБД информационной системы предприятия высоки и разнообразны, а порой и
противоречивы. Данные за годы деятельности фирмы должны быть надежно сохранены,
доступ к ним – строго разграничен. С другой стороны, должна быть возможность
обращаться к любому документу за любой период времени – т.е. производительность
и оперативность работы очень важны. Огромную роль играют масштабируемость и
стоимость продукта.