Всероссийский заочный финансово-экономический институт
Контрольная
работа
по дисциплине «Эконометрика»
Вариант № 13
Выполнил:
Проверил:
Тула, 2006 г.
Задание
I.
Исходные данные:
|
Показатель
|
Номер
наблюдения
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
X(t)
|
12
|
17
|
20
|
21
|
25
|
27
|
24
|
28
|
31
|
1) определить
наличие тренда Y(t);
2) построить
линейную модель Y(t)=a0+a1t, параметры которой оценить с помощью
МНК;
3) оценить
адекватность построенных моделей на основе исследования:
- случайности остаточной
компоненты по критерию пиков;
- независимости уровней ряда
остатков по d-критерию
(в качестве критических используйте уровни d1=1,08 и d2=1,36) или по первому коэффициенту корреляции,
критический уровень которого r(1)=0,36;
- нормальности распределения
остаточной компоненты по R/S-критерию с критическими
уровнями 2,7-3,7;
4) для оценки точности модели
используйте среднеквадратическое отклонение и среднюю по модулю относительную
ошибку;
5)
построить точечный и интервальный прогнозы на два шага вперед (для вероятности P=70% используйте коэффициент
t=1,11)
Все
расчеты проводились с использованием программы «Статэксперт», результаты
которых представлены в виде таблиц и графиков.
1) Определение
наличия тренда.
Определим
статистики временного ряда:
|
Cтатистики временного ряда - Показатель-A
|
|
|
|
|
|
|
Базисные
характеристики
|
|
|
|
|
Наблюдение
|
Абс.
прирост
|
Темп
роста
|
Темп
прироста
|
|
2
|
5.000
|
141.667
|
41.667
|
|
3
|
8.000
|
166.667
|
66.667
|
|
4
|
9.000
|
175.000
|
75.000
|
|
5
|
13.000
|
208.333
|
108.333
|
|
6
|
15.000
|
225.000
|
125.000
|
|
7
|
12.000
|
200.000
|
100.000
|
|
8
|
16.000
|
233.333
|
133.333
|
|
9
|
19.000
|
258.333
|
158.333
|
|
Цепные
характеристики
|
|
|
|
|
Наблюдение
|
Абс.
прирост
|
Темп
роста
|
Темп
прироста
|
|
2
|
5.000
|
141.667
|
41.667
|
|
3
|
3.000
|
117.647
|
17.647
|
|
4
|
1.000
|
105.000
|
5.000
|
|
5
|
4.000
|
119.048
|
19.048
|
|
6
|
2.000
|
108.000
|
8.000
|
|
7
|
-3.000
|
88.889
|
-11.111
|
|
8
|
4.000
|
116.667
|
16.667
|
|
9
|
3.000
|
110.714
|
10.714
|
|
Средние
характеристики
|
|
|
Характеристика
|
Значение
|
|
Среднее
арифметическое
|
22.778
|
|
Средний
темп роста (%)
|
112.596
|
|
Средний
темп прироста (%)
|
12.596
|
|
Средний
абсолютный прирост
|
2.375
|
Результаты
проверки гипотезы об отсутствии тренда приведены в таблице:
|
Гипотеза
об отсутствии тренда
|
|
Метод проверки
|
Результат
|
|
Метод
Форстера-Стюарта
|
Нет
|
|
Метод
сравнения средних
|
Нет
|
|
Вывод:
гипотеза отвергается
|
|
Приведем графики.
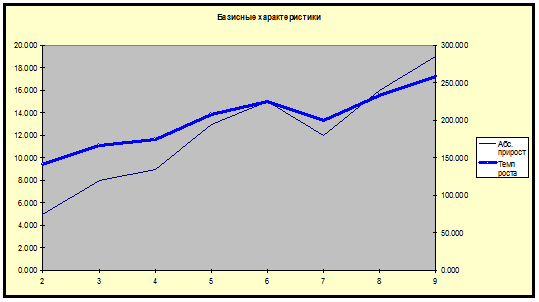
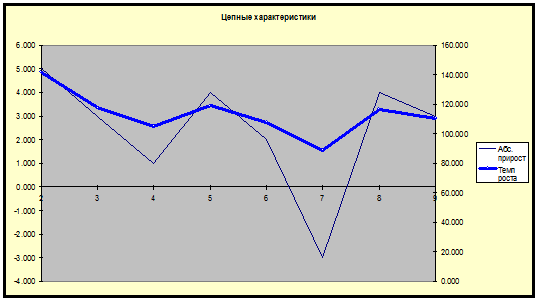
2) Построим
линейную модель.
Рассмотрим
уравнение вида 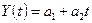 , где t
– время. С помощью данной функции будем аппроксимировать функцию, заданную
таблично с помощью метода наименьших квадратов, т.е. сумма квадратов отклонений
между теоретическими и эмпирическими уровнями:
, где t
– время. С помощью данной функции будем аппроксимировать функцию, заданную
таблично с помощью метода наименьших квадратов, т.е. сумма квадратов отклонений
между теоретическими и эмпирическими уровнями: 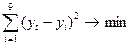 (1).
(1).
Параметры
модели 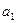 ,
, 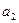 согласно методу наименьших квадратов находятся из решения
системы уравнений из преобразования (1):
согласно методу наименьших квадратов находятся из решения
системы уравнений из преобразования (1):
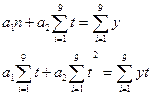
Решая эту систему, получим:
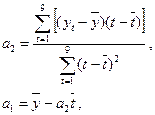
где 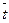 и
и 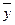 - средние значения
соответственно моментов наблюдения и уровней ряда.
- средние значения
соответственно моментов наблюдения и уровней ряда.
|
Параметры
моделей
|
|
|
|
Модель
|
a1
|
a2
|
|
Y(t)=+12.528+2.050*t
|
12.528
|
2.050
|
3) Оценим адекватность, точность и
качество построенной модели.
|
Проверка
однородности данных
|
|
Аномальные
наблюдения не обнаружены
|
|
Автокорреляционная
функция
|
|
|
|
Лаг
|
Исходный
ряд
|
Разностный
ряд (d=1)
|
|
1
|
0.512
|
-0.177
|
|
2
|
0.219
|
-0.337
|
|
Cтандартные
отклонения = +0.4244, +0.3785
|
|
|
Частная
автокорреляционная функция
|
|
|
Лаг
|
Исходный
ряд
|
Разностный
ряд (d=1)
|
|
1
|
0.542
|
-0.244
|
|
2
|
-0.058
|
-0.380
|
|
Cтандартные
отклонения = +0.3333, +0.3780
|
|
|
Таблица
кривых роста
|
|
|
|
Функция
|
Критерий
|
Эластич
ность
|
|
Y(t)=+12.528+2.050*t
|
3.915
|
0.450
|
|
Выбрана
функция Y(t)=+12.528+2.050*t
|
|
|
Характеристики
базы моделей
|
|
|
|
Модель
|
Адекват
ность
|
Точность
|
Качество
|
|
Y(t)=+12.528+2.050*t
|
70.984
|
47.770
|
53.573
|
|
Лучшая
модель Y(t)=+12.528+2.050*t
|
|
|
4) Приведем
характеристики остатков.
|
Таблица
остатков
|
|
|
|
|
|
|
номер
|
Факт
|
Расчет
|
Ошибка
абс.
|
Ошибка
относит.
|
|
1
|
12.000
|
14.578
|
-2.578
|
|
-21.481
|
|
2
|
17.000
|
16.628
|
0.372
|
|
2.190
|
|
3
|
20.000
|
18.678
|
1.322
|
|
6.611
|
|
4
|
21.000
|
20.728
|
0.272
|
|
1.296
|
|
5
|
25.000
|
22.778
|
2.222
|
|
8.889
|
|
6
|
27.000
|
24.828
|
2.172
|
|
8.045
|
|
7
|
24.000
|
26.878
|
-2.878
|
|
-11.991
|
|
8
|
28.000
|
28.928
|
-0.928
|
|
-3.314
|
|
9
|
31.000
|
30.978
|
0.022
|
|
0.072
|
|
Характеристики
остатков
|
|
|
Характеристика
|
Значение
|
|
Среднее
значение
|
0.000
|
|
Дисперсия
|
3.045
|
|
Приведенная
дисперсия
|
3.915
|
|
Средний
модуль остатков
|
1.419
|
|
Относительная
ошибка
|
7.099
|
|
Критерий
Дарбина-Уотсона
|
1.632
|
|
Коэффициент
детерминации
|
0.994
|
|
F
- значение ( n1 = 1, n2 = 7)
|
1257.087
|
|
Критерий
адекватности
|
70.984
|
|
Критерий
точности
|
47.770
|
|
Критерий
качества
|
53.573
|
|
Уравнение
значимо с вероятностью 0.95
|
5) Построим прогноз на 3 шага вперёд
|
Таблица
прогнозов (p = 80%)
|
|
|
|
|
|
Упреждение
|
Прогноз
|
Нижняя
граница
|
Верхняя
граница
|
|
1
|
33.028
|
30.990
|
35.066
|
|
|
2
|
35.078
|
32.712
|
37.443
|
|
|
3
|
37.128
|
34.426
|
39.830
|
|
Приведем
график прогноза:
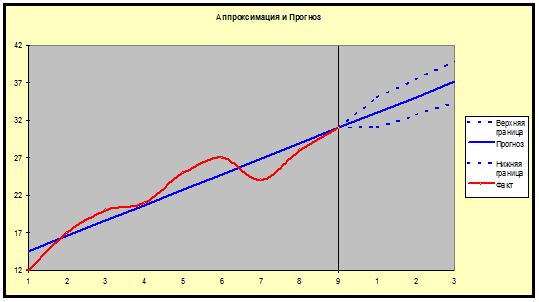
Построим
графики абсолютной и относительной ошибок:
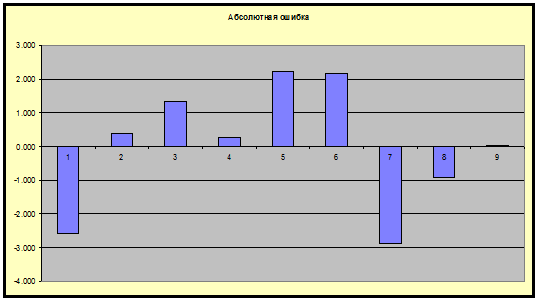
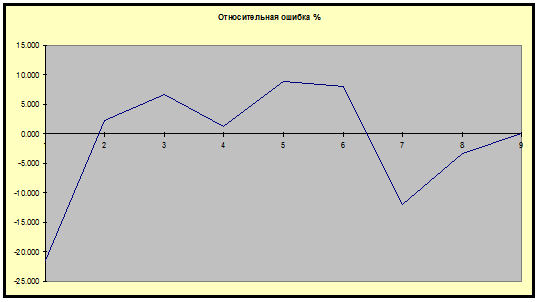
Задание II.
1)
построить матрицу коэффициентов парной корреляции Y(t) с X1(t) и X2(t) и выбрать фактор, наиболее
тесно связанный с зависимой переменной Y(t).
Исходя из следующих данных:
|
Y(t)
|
X1(t)
|
X2(t)
|
|
12
|
20
|
25
|
|
17
|
22
|
30
|
|
20
|
24
|
36
|
|
21
|
26
|
41
|
|
25
|
25
|
38
|
|
27
|
29
|
43
|
|
24
|
35
|
47
|
|
28
|
38
|
45
|
|
31
|
43
|
50
|
С помощью Excel рассчитаем матрицу парных
коэффициентов корреляции переменных. Для этого воспользуемся стандартной
функцией:
1) в главном меню последовательно
выбираем пункты Вставка / Функция;
2) в открывшемся окне Мастер функций выбираем Категория: Статистические / Функция: КОРРЕЛ;
3) заполняем Массив1 и Массив2
необходимым множеством данных (Y(t) и X1(t), Y(t) и X2(t), X1(t) и X2(t));
4) результаты вычислений –
матрица коэффициентов парной корреляции – представлены на рис.2.1.
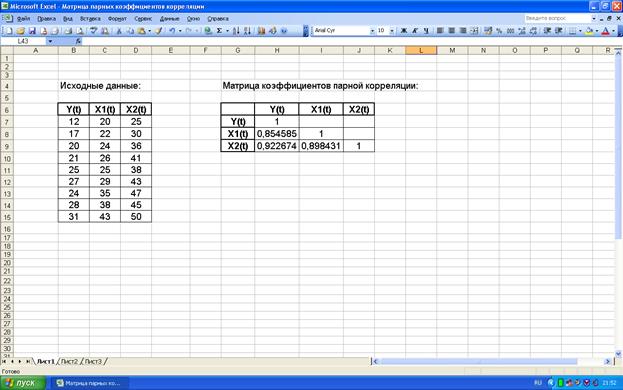
Рис. 2.1. Матрица
коэффициентов парной корреляции
Коэффициент
корреляции также можно вычислить по следующей формуле:
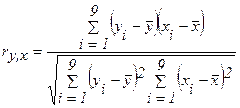 ;
;
Для удобства вычисления
коэффициента корреляции ry,x1 предварительные расчеты сведем в таблицу:
|
Наблюдение
|
Y(t)
|
X1(t)
|
(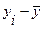 ) )
|
()2
|
(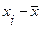 ) )
|
()2
|
()()
|
|
1
|
12
|
20
|
-10,778
|
116,1605
|
-9,111
|
83,0123
|
98,1975
|
|
2
|
17
|
22
|
-5,778
|
33,3827
|
-7,111
|
50,5679
|
41,0864
|
|
3
|
20
|
24
|
-2,778
|
7,7160
|
-5,111
|
26,1235
|
14,1975
|
|
4
|
21
|
26
|
-1,778
|
3,1605
|
-3,111
|
9,6790
|
5,5309
|
|
5
|
25
|
25
|
2,222
|
4,9383
|
-4,111
|
16,9012
|
-9,1358
|
|
6
|
27
|
29
|
4,222
|
17,8272
|
-0,111
|
0,0123
|
-0,4691
|
|
7
|
24
|
35
|
1,222
|
1,4938
|
5,889
|
34,6790
|
7,1975
|
|
8
|
28
|
38
|
5,222
|
27,2716
|
8,889
|
79,0123
|
46,4198
|
|
9
|
31
|
43
|
8,222
|
67,6049
|
13,889
|
192,9012
|
114,1975
|
|
Сумма
|
205
|
262
|
|
279,5556
|
|
492,8889
|
317,2222
|
|
Среднее зн.
|
22,778
|
29,111
|
|
|
|
|
|
В итоге при подстановке значений вычисляем ry,x1:
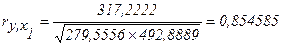
По аналогии расчета коэффициента ry,x1 вычисляем коэффициент парной корреляции ry,x2 и rx1,x2:
|
Наблюдение
|
Y(t)
|
X2(t)
|
()
|
()2
|
()
|
()2
|
()()
|
|
1
|
12
|
25
|
-10,778
|
116,1605
|
-14,444
|
208,6420
|
155,6790
|
|
2
|
17
|
30
|
-5,778
|
33,3827
|
-9,444
|
89,1975
|
54,5679
|
|
3
|
20
|
36
|
-2,778
|
7,7160
|
-3,444
|
11,8642
|
9,5679
|
|
4
|
21
|
41
|
-1,778
|
3,1605
|
1,556
|
2,4198
|
-2,7654
|
|
5
|
25
|
38
|
2,222
|
4,9383
|
-1,444
|
2,0864
|
-3,2099
|
|
6
|
27
|
43
|
4,222
|
17,8272
|
3,556
|
12,6420
|
15,0123
|
|
7
|
24
|
47
|
1,222
|
1,4938
|
7,556
|
57,0864
|
9,2346
|
|
8
|
28
|
45
|
5,222
|
27,2716
|
5,556
|
30,8642
|
29,0123
|
|
9
|
31
|
50
|
8,222
|
67,6049
|
10,556
|
111,4198
|
86,7901
|
|
Сумма
|
205
|
355
|
|
279,5556
|
|
526,2222
|
353,8889
|
|
Среднее зн.
|
22,778
|
39,444
|
|
|
|
|
|

|
Наблюдение
|
X1(t)
|
X2(t)
|
()
|
()2
|
()
|
()2
|
()()
|
|
1
|
20
|
25
|
-9,111
|
83,0123
|
-14,444
|
208,6420
|
131,6049
|
|
2
|
22
|
30
|
-7,111
|
50,5679
|
-9,444
|
89,1975
|
67,1605
|
|
3
|
24
|
36
|
-5,111
|
26,1235
|
-3,444
|
11,8642
|
17,6049
|
|
4
|
26
|
41
|
-3,111
|
9,6790
|
1,556
|
2,4198
|
-4,8395
|
|
5
|
25
|
38
|
-4,111
|
16,9012
|
-1,444
|
2,0864
|
5,9383
|
|
6
|
29
|
43
|
-0,111
|
0,0123
|
3,556
|
12,6420
|
-0,3951
|
|
7
|
35
|
47
|
5,889
|
34,6790
|
7,556
|
57,0864
|
44,4938
|
|
8
|
38
|
45
|
8,889
|
79,0123
|
5,556
|
30,8642
|
49,3827
|
|
9
|
43
|
50
|
13,889
|
192,9012
|
10,556
|
111,4198
|
146,6049
|
|
Сумма
|
262
|
355
|
|
492,8889
|
|
526,2222
|
457,5556
|
|
Среднее зн.
|
29,111
|
39,444
|
|
|
|
|
|
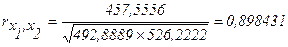
Полученные значения коэффициентов парной корреляции сведем в
следующую таблицу:
|
Y(t)
|
X1(t)
|
X2(t)
|
|
Y(t)
|
1
|
0,854585
|
0,922674
|
|
X1(t)
|
0,854585
|
1
|
0,898431
|
|
X2(t)
|
0,922674
|
0,898431
|
1
|
Из таблицы
видно, что значения коэффициентов парной корреляции указывают на весьма тесную
связь переменной Y(t) с
коэффициентом X2(t). Но в то
же время коэффициент rx1,x2 также имеет тесную межфакторную связь, которая
превышает тесноту связи X1(t) с Y(t). В связи с этим для улучшения
данной модели можно исключить из нее фактор X1(t) как малоинформативный, недостаточно статистически
надежный.
2) Построить линейную однопараметрическую модель регрессии Y(t)=а0+а1
X(t).
Для проведения регрессионного анализа воспользуемся EXCEL:
1) в главном меню последовательно выбираем пункты Сервис / Анализ данных;
2) в открывшемся окне Анализ
данных выбираем Инструменты анализа:
Регрессия;
3) заполняем Входной
интервал Y и Входной интервал X множеством данных Y(t) и X2(t);
4) отмечаем флажком Метки;
5) в поле Остатки отмечаем флажком Остатки, График остатков, График
подбора;
6) результат регрессионного анализа представлен в табл.
2.1-2.3;
Таблица
2.1
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
|
Y-пересечение
|
-3,7489
|
4,2679
|
-0,8784
|
|
X2(t)
|
0,6725
|
0,1062
|
6,3311
|
Во втором столбце табл.2.1
содержатся коэффициенты уравнения регрессии а0,
а1. В третьем столбце
содержатся стандартные ошибки коэффициентов уравнения регрессии, а в четвертом t-статистика, используемая
для проверки значимости коэффициентов уравнения регрессии.
Уравнение регрессии зависимости Y(t) от X2(t) имеет
вид: Y(t)=
-3,7489+0,6725 ∙ X(t)
Таблица 2.2
Расчеты по модели
регрессии
|
ВЫВОД ОСТАТКА
|
|
Наблюдение
|
Предсказанное Y(t)
|
Остатки
|
|
1
|
13,0638
|
-1,0638
|
|
2
|
16,4263
|
0,5737
|
|
3
|
20,4614
|
-0,4614
|
|
4
|
23,8239
|
-2,8239
|
|
5
|
21,8064
|
3,1936
|
|
6
|
25,1689
|
1,8311
|
|
7
|
27,8590
|
-3,8590
|
|
8
|
26,5139
|
1,4861
|
|
9
|
29,8765
|
1,1235
|
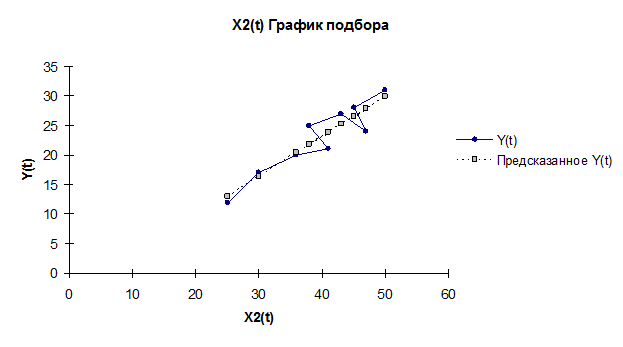
Оценка параметров
модели без ПЭВМ.
Построим линейную однопараметрическую модель регрессии для X2(t).
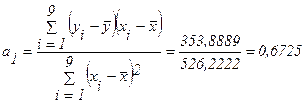

Y(t)=
-3,7489+0,6725 ∙ X(t).
3) Оценить качество построенной модели, исследовав ее адекватность и
точность;
Оценим
качество построенной модели, исследуя адекватность.
Модель
является адекватной, если математическое ожидание значений остаточного ряда
близко или равно нулю и если значения остаточного ряда случайны, независимы и
подчинены нормальному закону распределения.
а) при проверке независимости (отсутствия
автокорреляции) определяется отсутствие в ряду остатков систематической
составляющей (с помощью d-критерия
Дарбина-Уотсона).
Таблица 2.3
Данные для вычисления
d-критерия
|
Наблюдение
|
Y(t)
|
Y-расчетное
|
Отклонение E(t)
|
E(t)-E(t-1)
|
(E(t)-E(t-1))2
|
E(t)2
|
|
1
|
12
|
13,0638
|
-1,0638
|
|
|
1,1317
|
|
2
|
17
|
16,4263
|
0,5737
|
1,6375
|
2,6814
|
0,3291
|
|
3
|
20
|
20,4614
|
-0,4614
|
-1,0351
|
1,0714
|
0,2129
|
|
4
|
21
|
23,8239
|
-2,8239
|
-2,3625
|
5,5814
|
7,9744
|
|
5
|
25
|
21,8064
|
3,1936
|
6,0175
|
36,2103
|
10,1991
|
|
6
|
27
|
25,1689
|
1,8311
|
-1,3625
|
1,8564
|
3,3529
|
|
7
|
24
|
27,8590
|
-3,8590
|
-5,6901
|
32,3772
|
14,8919
|
|
8
|
28
|
26,5139
|
1,4861
|
5,3451
|
28,5701
|
2,2085
|
|
9
|
31
|
29,8765
|
1,1235
|
-0,3626
|
0,1315
|
1,2623
|
|
Сумма
|
|
|
|
|
108,4798
|
41,5627
|
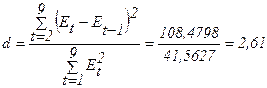 ;
; 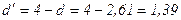
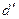 попало в интервал от d2 до 2, значит модель уровня ряда остатков
независима, автокорреляции нет, свойство независимости выполняется. Модель по
этому критерию адекватна.
попало в интервал от d2 до 2, значит модель уровня ряда остатков
независима, автокорреляции нет, свойство независимости выполняется. Модель по
этому критерию адекватна.
б) проверку случайности уровней ряда остатков проведем на основе
критерия поворотных точек.
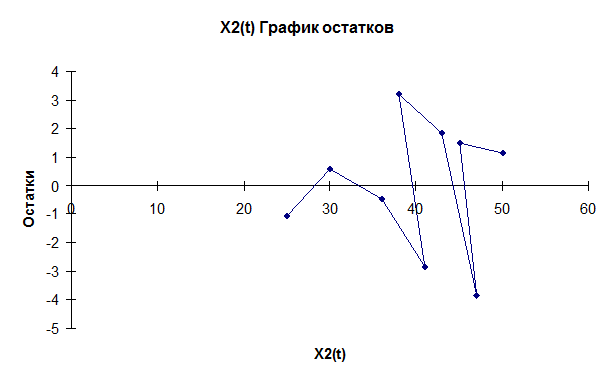
В случайном ряду чисел должно выполняться строгое
неравенство:
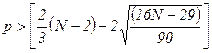 . Количество поворотных точек равно 5 (график остатков).
. Количество поворотных точек равно 5 (график остатков).
в)
соответствие ряда остатков нормальному закону распределения определим при
помощи RS-критерия.
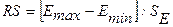 ,
,
где 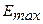 -максимальный уровень ряда остатков, равный 3,1936;
-максимальный уровень ряда остатков, равный 3,1936;
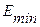 - минимальный уровень ряда остатков, равный -3,8590;
- минимальный уровень ряда остатков, равный -3,8590;
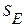 -среднеквадратическое отклонение,
-среднеквадратическое отклонение,
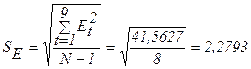 ,
,
Тогда:
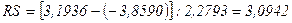
Расчетное
значение попадает в интервал (2,7…3,7), следовательно, свойство нормальности
распределения выполняется. Модель по этому критерию адекватна.
г) проверка
равенства нулю математического ожидания уровней ряда остатков осуществляется с
использованием t-критерия
Стьюдента.
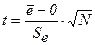 ,
,
где 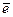 -среднее значение уровней остаточного ряда;
-среднее значение уровней остаточного ряда;
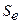 -среднеквадратическое отклонение уровней остаточного ряда.
-среднеквадратическое отклонение уровней остаточного ряда.
В нашем случае =0, поэтому гипотеза о равенстве математического ожидания значений
остаточного ряда нулю выполняется.
Для
расширенной характеристики модели регрессии вычислим несколько дополнительных
показателей: коэффициент детерминации R2 и
коэффициент множественной корреляции R:
|
Регрессионная статистика
|
|
Множественный R
|
0,9227
|
|
R-квадрат
|
0,8513
|
|
Нормированный R-квадрат
|
0,8301
|
|
Стандартная ошибка
|
2,4367
|
|
Наблюдения
|
9
|
Коэффициент детерминации:
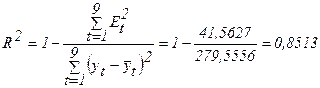
R2
показывает долю вариации результативного признака под воздействием изучаемых
факторов. Следовательно, более 85,1 % вариации зависимой переменной учтено в
модели и обусловлено влиянием включенного фактора.
R –
коэффициент множественной корреляции. R=0,9227 показывает
тесноту связи зависимой переменной Y с факторами X, включенными в модель.
4) Для модели регрессии рассчитать коэффициент эластичности и
β-коэффициент.
а) Расчет коэффициента
эластичности.
Он показывает,
на сколько процентов в среднем по совокупности изменится результат Y от своей средней величины
при изменении фактора Х на 1% от своего среднего значения:
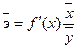
Для линейной
модели производная по функции равна коэффициенту при Х, т.е. а1.
Тогда получим:
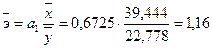
Следовательно,
при изменении Х на 1% от своего среднего значения величина Y в среднем изменится на 1,16%.
б) Расчет β-коэффициента.
β-коэффициент
показывает, на какую часть сигмы изменяется результативный признак, при
изменении факторного признака на величину его сигмы. Сравнение
β-коэффициентов при различных факторах дает возможность оценить силу их
воздействия на результативный признак. Он вычисляется по формуле:
 ,
,
Дисперсии
определим по формулам:
 ,
,
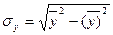
Все
необходимые вычисления сведем в таблицу:
|
Наблюдение
|
Y(t)
|
X2(t)
|
Y(t)2
|
X2(t)2
|
|
1
|
12
|
25
|
144
|
625
|
|
2
|
17
|
30
|
289
|
900
|
|
3
|
20
|
36
|
400
|
1296
|
|
4
|
21
|
41
|
441
|
1681
|
|
5
|
25
|
38
|
625
|
1444
|
|
6
|
27
|
43
|
729
|
1849
|
|
7
|
24
|
47
|
576
|
2209
|
|
8
|
28
|
45
|
784
|
2025
|
|
9
|
31
|
50
|
961
|
2500
|
|
Сумма
|
205
|
355
|
4949
|
14529
|
|
Среднее зн.
|
22,778
|
39,444
|
549,8889
|
1614,3333
|
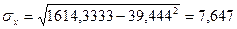 ,
,
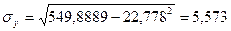
Тогда:
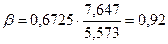 - при изменении факторного признака на величину его сигмы
результативный признак изменяется на 0,92 сигмы.
- при изменении факторного признака на величину его сигмы
результативный признак изменяется на 0,92 сигмы.
5) Построить точечный и
интервальный прогнозы на два шага вперед по модели регрессии (для вероятности Р
= 70 % используйте коэффициент v = 1,11). Прогнозные оценки фактора X(t) на два шага вперед получить на основе
среднего прироста от фактически достигнутого уровня).
Для вычисления
прогнозных оценок Y на основе построенной модели
необходимо получить прогнозные оценки фактора X.
Получим
прогнозные оценки фактора на основе величины его среднего абсолютного прироста САП.
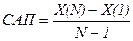 ;
;
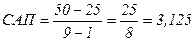 ;
;
Построим прогноз на 2 шага вперед. Для этого определим
значение X на первом и втором шагах соответственно:
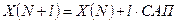 ;
;
l=1;
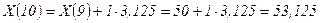 ;
;
l=2;
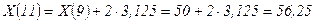 .
.
Для получения прогнозных оценок
зависимой переменной подставим в модель:
Y(t)= -3,7489+0,6725 ∙ X(t)
найденные прогнозные значения фактора X:
Y(10)=
-3,7489+0,6725 ∙ X(10)= -3,7489+0,6725 ∙53,125=31,98
Y(11)=
-3,7489+0,6725 ∙ X(11)= -3,7489+0,6725 ∙56,25=34,08
Определим доверительный интервал
прогноза, который будет иметь следующие границы:
- верхняя граница прогноза: Y(N+l) + U(l);
- нижняя граница прогноза: Y(N+l) – U(l).
Величина U(l) имеет вид:
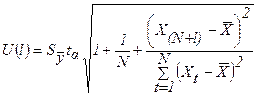 ,
,
где  - стандартная ошибка.
Значение ошибки было определено при исследовании модели на точность и
адекватность (
- стандартная ошибка.
Значение ошибки было определено при исследовании модели на точность и
адекватность (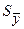 = 2,4367).
= 2,4367).
Необходимые вычисления для определения доверительного
интервала сведем в таблицу:
|
Наблюдение
|
X2(t)
|
()
|
()2
|
|
1
|
25
|
-14,444
|
208,6420
|
|
2
|
30
|
-9,444
|
89,1975
|
|
3
|
36
|
-3,444
|
11,8642
|
|
4
|
41
|
1,556
|
2,4198
|
|
5
|
38
|
-1,444
|
2,0864
|
|
6
|
43
|
3,556
|
12,6420
|
|
7
|
47
|
7,556
|
57,0864
|
|
8
|
45
|
5,556
|
30,8642
|
|
9
|
50
|
10,556
|
111,4198
|
|
Сумма
|
355
|
|
526,2222
|
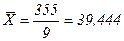
Для прогноза на два шага имеем:
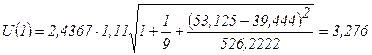
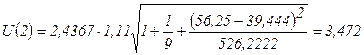
Результаты прогнозных оценок по модели регрессии представим
в таблице:
|
Время
|
Шаг
|
Прогноз
|
Нижняя граница
|
Верхняя граница
|
|
10
|
1
|
31,98
|
28,704
|
35,256
|
|
11
|
2
|
34,08
|
30,608
|
37,552
|
Отобразим на графике фактические данные, результаты расчетов
и прогнозирования.
