Содержание
Введение.. 3
1. Функциональные зависимости.. 5
2. Статистические (корреляционные)
зависимости. 7
3. Линейная корреляция.. 8
3.1
Парный линейный коэффициент корреляции. 8
3.2
Понятие о частной и множественной корреляции. 9
4. Линейная регрессия.. 11
4.1
Суть метода наименьших квадратов. 11
4.2
Интерпретация коэффициента регрессии. 13
4.3
Коэффициент детерминации. 13
4.4
Случай двух независимых переменных. Простейший случай множественной регрессии. 14
4.5
Интерпретация коэффициентов уравнения множественной регрессии. 15
5. Нелинейная регрессия и нелинейная
корреляция.. 17
5.1
Построение уравнений нелинейной регрессии. 17
5.2
Измерение тесноты связи при криволинейной зависимости. 19
6. Оценка значимости параметров взаимосвязи.. 21
Заключение.. 23
Литература.. 26
Введение
Анализ взаимосвязей, присущих
изучаемым процессам и явлениям, является важнейшей задачей статистических
исследований. В тех случаях, когда речь идет о явлениях и процессах, обладающих
сложной структурой и многообразием свойственных им связей, такой анализ
представляет собой сложную задачу. Прежде всего необходимо установить наличие
взаимосвязей и их характер. Вслед за этим возникает вопрос о тесноте
взаимосвязей и степени воздействия различных факторов (причин) на интересующий
исследователя результат. Если черты и свойства изучаемых объектов могут быть измерены
и выражены количественно, то анализ взаимосвязей может вестись на основе
применения математических методов. Использование этих методов позволяет
проверить гипотезу о наличии или отсутствии взаимосвязей между теми или иными
признаками, выдвигаемую на основе содержательного анализа. Далее, лишь
посредством математических методов можно установить тесноту и характер
взаимосвязей или выявить силу (степень) воздействия различных факторов на
результат.
Наиболее разработанными в
математической статистике методами анализа взаимосвязей являются корреляционный
и регрессионный анализ.
Анализ статистической, или
корреляционной, связи предполагает выявление формы связи, а также оценку
тесноты связи. Первая задача решается методами регрессионного анализа, вторая —
методами корреляционного анализа. Регрессионный анализ сводится к описанию
статистической связи с помощью подходящей функциональной зависимости.
Корреляционный анализ позволяет оценивать тесноту связи посредством специальных
показателей, причем выбор их зависит от вида функциональной зависимости,
пригодной для адекватного описания рассматриваемой статистической взаимосвязи. [1]
Один из важных вопросов,
возникающих в изучении связей,— установление «направления» зависимости. Пусть
для простоты рассматривается связь между двумя признаками y и х. Какой из этих
признаков следует считать подверженным влиянию, или результативным (зависимой
переменной), какой — оказывающим влияние, или факторным (независимой
переменной)?
Первостепенное значение в решении
этого вопроса имеет содержательный анализ. Положим, мы рассматриваем связь
между производительностью труда рабочих и стажем их работы. По-видимому,
результативным признаком следует признать производительность труда, а факторным
— стаж рабочего. Не всегда «направление» связи проявляется столь очевидно.
Тогда при решении вопроса о выборе результативного признака на первый план
выступает постановка содержательной проблемы, для исследования которой
используется изучение взаимосвязей.
1. Функциональные зависимости
Функциональная зависимость двух
количественных признаков или переменных состоит в том, что каждому значению
одной переменной всегда соответствует одно определенное значение другой
переменной.
Например, при строительстве
железных дорог на километр пути приходится вполне определенное количество
уложенных рельсов. Поэтому рассматривая статистические данные по таким
количественным признакам: у— длина уложенного железнодорожного пути (в км),
х—количество истраченного на строительстве рельсового проката (в тоннах), мы будем
иметь дело с функциональной зависимостью вида y=kx. Такая зависимость
называется прямой пропорциональной
зависимостью.
Прямая пропорциональная зависимость
представляет собой частный случай линейной зависимости, которая характеризуется
уравнением
y=kx+b
Графическим изображением линейной
зависимости служит прямая линия.
Линейная зависимость является
наиболее простой и в определенном смысле универсальной формой связи многих
явлений. Ее универсальность состоит в том, что более сложные зависимости часто можно
рассматривать «в первом приближении» как линейные.
Непосредственно функциональные зависимости в
чистом виде редко встречаются в общественных явлениях. Связи обычно носят
гораздо более сложный характер. Однако их описание во всей сложности часто затруднительно,
да и нецелесообразно. Поэтому их рассматривают как соответствующие тем или иным
видам функциональной зависимости. Простейшей формой функциональной связи
является линейная зависимость, которая широко используется в регрессионном и
особенно в корреляционном анализе. Гипотеза о линейной связи между исследуемыми
признаками получила широкое распространение в анализе взаимосвязей. Лишь в том
случае, если результаты применения гипотезы о линейной зависимости оказываются
неудачными или имеются веские основания против линейной связи, используют более
сложные функциональные зависимости.
Отметим наиболее употребительные
формы функциональной зависимости, применяемые в статистическом анализе.
В случае если
прямая линия не соответствует характеру используемых данных, можно использовать
параболу. Аналитическое выражение ее имеет вид: y=a0+a1
x+a2
x2
В том случае, когда мы имеем дело с
затуханием роста или падения, удобно использовать гиперболические либо
логарифмические зависимости:
y=k/x; y=a
lgx
Процессы демографического и
экономического роста описываются экспоненциальными зависимостями вида:
y=keλx.
Подбор подходящей функциональной
зависимости на основе графического и логического анализа является важным этапом
исследования взаимосвязей, особенно в тех случаях, когда линейная связь
оказалась неприемлемой.
2.
Статистические (корреляционные) зависимости.
Функциональная зависимость между
признаками предполагает их изолированность, она действует, так сказать, «при
прочих равных условиях». В общественной жизни такие ситуации бывают крайне
редко. Как правило, воздействие одной переменной (причины) на другую не
изолировано от остальных факторов, а происходит, таким образом, что на
изучаемую связь прямо или косвенно влияют многие другие факторы. Здесь налицо
зависимость особого вида. Для описания и изучения такого рода зависимостей в
науке используется понятие статистический, или корреляционной, связи.[2]
В отличие от функциональной
зависимости, когда каждому значению одного признака всегда соответствует
определенное значение другого, при статистической зависимости одному и тому же
значению одного признака могут соответствовать различные значения другого. Это
происходит в силу того, что при статистической зависимости связь
устанавливается между признаками (двумя, тремя и т. д.), которые изменяются не
только в силу взаимодействия между собой, но и под воздействием множества
различных неучтенных факторов. В результате множественного воздействия взаимно
переплетающихся факторов связь между признаками существует и проявляется не в
каждом отдельном случае, как при функциональной связи, а только в тенденции, «в
среднем». Поэтому здесь установить наличие взаимосвязи и определить ее
количественную меру можно не на основе единичных наблюдений, а лишь
применительно к определенной совокупности объектов, т. е. в среднем по
отношению к тем или иным массовым объектам или явлениям. Характеризующие эти
объекты количественные показатели в источниковедении и в статистике называются
массовыми данными.
3. Линейная корреляция
Одной из основных мер связи в
корреляционном анализе является линейный коэффициент корреляции.
3.1 Парный линейный
коэффициент корреляции.
С помощью парного линейного
коэффициента корреляции измеряется теснота связи между двумя признаками.
Линейный коэффициент корреляции чаще всего рассчитывается по формуле:
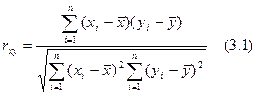
где xi и yi
— значения признаков х и у соответственно для i-ro объекта, i=1, .., n; n —
число объектов; 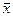 и
и 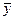 — средние арифметические значения признаков х и у
соответственно.[3]
— средние арифметические значения признаков х и у
соответственно.[3]
Линейный коэффициент корреляции
изменяется в пределах от —1 до +1. Равенство коэффициента нулю свидетельствует
об отсутствии линейной связи. Равенство коэффициента —1 или +1
показывает наличие функциональной связи. Знак «+» указывает на связь прямую
(увеличение или уменьшение одного признака сопровождается аналогичным
изменением другого признака), знак «—» — на связь обратную (увеличение или
уменьшение одного признака сопровождается противоположным по направлению
изменением другого признака).
Линейный коэффициент корреляции
является показателем взаимной связи между признаками и не дает представления о
том, какой из признаков является факторным, а какой — результативным (в формуле
(3.1) признаки х и у совершенно равноправны).
3.2 Понятие о частной
и множественной корреляции.
С помощью парного линейного
коэффициента корреляции выявляется связь между двумя признаками, один из
которых можно рассматривать как результативный, другой — как факторный. Но в
действительности на результат воздействуют несколько факторов. В связи с этим
возникают два типа задач: задачи измерения комплексного влияния на
результативную переменную нескольких переменных и задачи определения тесноты
связи между двумя переменными при фиксированных значениях остальных переменных.
Задачи первого типа решаются с помощью множественных коэффициентов корреляции,
задачи второго типа — с помощью частных коэффициентов корреляции.
Частный, или чистый, коэффициент
корреляции между двумя признаками при исключении влияния третьего признака
(обозначим его символом r12.3) рассчитывается по формуле:
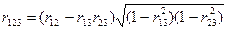 ,
,
где индексы при r показывают
номера признаков, связь между которыми оценивается.
Частный коэффициент корреляции
первого и второго признаков при исключении влияния третьего оценивает тесноту
линейной корреляционной связи между первым и вторым признаками при
фиксированном значении третьего признака. Другими словами, он оценивает влияние
на результативный (первый) признак изменения лишь второго признака.
Значения частных коэффициентов
корреляции заключаются в тех же пределах от —1 до +1, что и значения парных
коэффициентов корреляции, и так же интерпретируются.
Множественный, или совокупный,
коэффициент корреляции для случая трех признаков, один из которых —
результативный (с номером 1) и два —факторных (с порядковыми номерами 2 и 3)
рассчитывается по формуле:
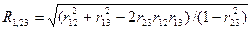
Множественный коэффициент
корреляции является показателем тесноты линейной связи между результативным
признаком и совокупностью факторных признаков.
Множественный коэффициент
корреляции изменяется в пределах от 0 до 1. Равенство его нулю говорит об
отсутствии линейной связи, равенство единице — о функциональной связи. Указаний
на то, является ли связь прямой или обратной, коэффициент не дает.
3.3 Понятие о коэффициенте
детерминации.
Линейный коэффициент корреляции
оценивает тесноту взаимосвязи между признаками и показывает, является ли связь
прямой или обратной. Но понятие тесноты взаимосвязи часто может быть
недостаточным при содержательном анализе взаимосвязей. В частности, коэффициент
корреляции не показывает степень воздействия факторного признака на
результативный. Таким показателем является коэффициент детерминации (обозначим
его D), для случая линейной связи представляющий собой квадрат парного
линейного коэффициента корреляции (D=r2) или квадрат
множественного коэффициента корреляции. Его значение определяет долю (в
процентах) изменений, обусловленных влиянием факторного признака, в общей
изменчивости результативного признака.
4. Линейная регрессия
Регрессионный анализ позволяет
приближенно определить форму связи между результативным и факторными
признаками, а также решить вопрос о том, значима ли эта связь. Вид функции, с
помощью которой приближенно выражается форма связи, выбирают заранее, исходя из
содержательных соображений или визуального анализа данных. Математическое
решение задачи основано на методе наименьших квадратов.
4.1 Суть метода наименьших
квадратов.
Пусть имеются данные о значениях
результативного признака у, соответствующие некоторым значениям факторного признака х. Попытаемся представить
интересующую нас зависимость с помощью прямой линии. Разумеется, такая линия
может дать только приближенное представление о форме реальной статистической
связи. Постараемся сделать это приближение наилучшим. Оно будет тем лучше, чем
меньше исходные данные будут отличаться от соответствующих точек, лежащих на
линии. Степень близости может быть выражена величиной суммы квадратов
отклонении, реальных значений от расположенных на прямой. Использование
квадратов отклонений позволяет суммировать отклонения различных знаков без их
взаимного погашения и дополнительно обеспечивает сравнительно большее внимание,
уделяемое большим отклонениям. Именно этот критерий (минимизация суммы
квадратов отклонений) положен в основу метода наименьших квадратов.
В вычислительном аспекте метод
наименьших квадратов сводится к составлению и решению системы так называемых
нормальных уравнений. Исходным этапом для этого является подбор вида функции,
отображающей статистическую связь.
Тип функции в каждом конкретном
случае можно подобрать путем прикидки на графике исходных данных подходящей, т.
е. достаточно хорошо приближающей эти данные, линии. В нашем случае связь может
быть изображена с помощью прямой линии и
записана в виде:
у=а0 +
а1 х,
где ao и a1
— параметры уравнения, которые могут быть найдены методом наименьших квадратов.
Для нахождения искомых параметров
нужно составить систему уравнений, которая в данном случае будет иметь вид:
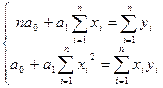
Полученная система может быть
решена известным из школьного курса методом Гаусса. Искомые параметры системы
из двух нормальных уравнений можно вычислить и непосредственно с помощью
последовательного использования нижеприведенных формул:
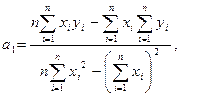
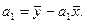
где yi — i-e
значение результативного признака; xi — i-e значение
факторного признака; и — средние арифметические результативного и факторного
признаков соответственно; n— число значений признака yi,
или, что то же самое, число значений признака xi.
4.2 Интерпретация коэффициента
регрессии.
Уравнение регрессии не только
определяет форму анализируемой связи, но и показывает, в какой степени
изменение одного признака сопровождается изменением другого признака.
Коэффициент а1 при х, называемый коэффициентом
регрессии, показывает, на какую величину в среднем изменяется
результативный признак у при изменении факторного признака х на
единицу.
4.3 Коэффициент детерминации.
Когда уравнение регрессии уместно
поставить уточняющий вопрос — какая часть вариации результативного признака
может быть объяснена влиянием факторного признака.
Рассмотрим отношение:
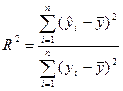
Оно показывает долю разброса,
учитываемого регрессией, в общем разбросе результативного признака и носит
название коэффициента детерминации. Этот показатель, равный отношению факторной
вариации к полной вариации признака, позволяет судить о том, насколько «удачно»
выбран вид функции (Отметим,
что по смыслу коэффициент детерминации в регрессионном анализе соответствует
квадрату корреляционного отношения для корреляционной таблицы). Проведя расчеты, основанные на одних и тех же
исходных данных, для нескольких типов функций, мы можем из них выбрать такую,
которая дает наибольшее значение R2 и, следовательно, в
большей степени, чем другие функции, объясняет вариацию результативного
признака. Действительно, при расчете R2 для одних и тех же
данных, но разных функций знаменатель выражения для R2 остается
неизменным, а числитель показывает ту часть вариации результативного признака,
которая учитывается выбранной функцией. Чем больше R2, т. е.
чем больше числитель, тем больше изменение факторного признака объясняет
изменение результативного признака и тем, следовательно, лучше уравнение
регрессии, лучше выбор функции.
Наконец, отметим, что введенный
ранее, при изложении методов корреляционного анализа, коэффициент детерминации
совпадает с определенным здесь показателем, если выравнивание производится по
прямой линии. Но последний показатель (R2) имеет более
широкий спектр применения и может использоваться в случае связи, отличной от
линейной.
4.4 Случай двух независимых
переменных. Простейший случай множественной регрессии.
В предыдущем изложении
регрессионного анализа мы имели дело с двумя признаками — результативным и
факторным. Но на результат действует обычно не один фактор, а несколько, что
необходимо учитывать для достаточно полного анализа связей.
Регрессия называется
множественной, если число независимых переменных, учтенных в ней, больше или
равно двум. В математической
статистике разработаны методы множественной регрессии, позволяющие
анализировать влияние на результативный признак нескольких факторных. [4]
Пусть результативный признак у
зависит от двух факторных признаков х1 и х2.
В этом случае резонны такие вопросы. Насколько обе независимые переменные
определяют значение результативного признака? Какая из переменных оказывает
определяющее влияние на результативный признак? Попытаемся ответить на эти
вопросы.
После добавления второй независимой
переменной уравнение регрессии будет выглядеть так:
у=а0
+ а1 х1 + а2х2
где а0, а1,
а2 — параметры, подлежащие определению.
Для нахождения числовых значений
искомых параметров, как и в случае одной независимой переменной, пользуются
методом наименьших квадратов. Он сводится к составлению и решению системы
нормальных уравнений, которая имеет вид:
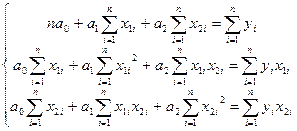
Когда система состоит из трех и
более нормальных уравнений, решение ее усложняется. Существуют стандартные
программы расчета неизвестных параметров регрессионного уравнения на ЭВМ. При
ручном счете можно воспользоваться известным из школьного курса методом Гаусса.
4.5 Интерпретация коэффициентов уравнения множественной регрессии.
Коэффициент при независимой
переменной в уравнении простой регрессии отличается от коэффициента при
соответствующей переменной в уравнении множественной регрессии тем, что в
последнем элиминировано влияние всех учтенных в данном уравнении признаков.
Коэффициенты уравнения
множественной регрессии поэтому называются частными или чистыми коэффициентами
регрессии.
Частный коэффициент множественной
регрессии а1 при х1
показывает, что с увеличением значения х1 на 1 ед. и при
фиксированном значении х2 значение у вырастает в
среднем на а1 ед. Частный коэффициент а2 при
x2 показывает, что при фиксированном значении х1
значение у вырастает в среднем на а2 ед.
Введение переменной х2 в
уравнение позволяет уточнить коэффициент при х1. Однако выводы,
полученные в результате анализа коэффициентов регрессии, не являются пока
корректными, поскольку, во-первых, не учтена разная масштабность факторов,
во-вторых, не выяснен вопрос о значимости коэффициента a2.
Величина коэффициентов регрессии
изменяется в зависимости от единиц измерения, в которых представлены
переменные. Если переменные выражены в разном масштабе измерения, то
соответствующие им коэффициенты становятся несравнимыми. Для достижения
сопоставимости коэффициенты регрессии исходного уравнения стандартизуют, взяв
вместо исходных переменных их отношения к собственным средним квадратическим
отклонениям. Тогда уравнение
множественной регрессии приобретает вид:
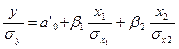 .
.
Сравнивая полученное уравнение с
уравнением у=а0 + а1
х1 + а2х2, определяем стандартизованные
частные коэффициенты уравнения, так называемые бета-коэффициенты,
по формулам:
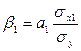 ,
, 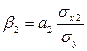
где β1 и β2—бета-коэффициенты;
а1 и а2—коэффициенты регрессии исходного
уравнения; σу, σх1 и σх2
— средние квадратические отклонения переменных у, х1
и х2 соответственно.
Вычислив бета-коэффициенты,делаем
следующий вывод: если β1 больше, чем β2, то
фактор х1 оказывает на
результат у большее влияние, чем фактор х2.
5. Нелинейная регрессия и нелинейная корреляция
5.1 Построение уравнений
нелинейной регрессии.
Не всегда связь между признаками
может быть достаточно хорошо представлена линейной функцией. Иногда для
описания существующей связи более пригодными, а порой и единственно возможными
являются более сложные нелинейные функции.
Одним из простейших видов
нелинейной зависимости является парабола, которая в общем виде может быть
представлена функцией:
у = а0+а1х+а2х2
Неизвестные параметры а0,
а1, а2 находятся в результате решения следующей системы
уравнений:
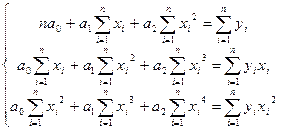
На практике для изучения связей используются
полиномы более высоких порядков (3-го и 4-го порядков). Составление системы, ее
решение, а также решение вопроса о полезности повышения порядка функции для
этих случаев аналогичны описанным. При этом никаких принципиально новых
моментов не возникает, но существенно увеличивается объем расчетов.
Кроме класса парабол для анализа
нелинейных связей можно применять и другие виды функций. Для расчета
неизвестных параметров этих функций рекомендуется использовать метод наименьших
квадратов, как наиболее мощный и широко применяемый.
Однако метод наименьших квадратов
не универсален, поскольку он может использоваться только при условии, что
выбранные для выравнивания функции линейны по отношению к своим параметрам. Не
все функции удовлетворяют этому условию, но большинство применяемых на практике
с помощью специальных преобразований могут быть приведены к стандартной форме
функции с линейными параметрами.
Рассмотрим некоторые простейшие
способы приведения функций с нелинейными параметрами к виду, который позволяет
применять к ним метод наименьших квадратов.
Функция
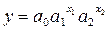
не является линейной относительно своих параметров.
Прологарифмировав
обе части приведенного равенства, получаем: 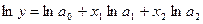
и, переобозначив
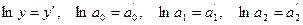
получим функцию, линейную
относительно своих новых параметров:
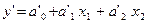
Кроме логарифмирования для
приведения функций к нужному виду используют обратные величины.
Например, функция
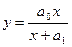
с помощью следующих переобозначений:
 y’=1/y, x’=1/x, 1/a0=a’0, a1/a0=a’1
y’=1/y, x’=1/x, 1/a0=a’0, a1/a0=a’1
может быть приведена к виду
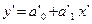
Подобные преобразования расширяют
возможности использования метода наименьших квадратов, увеличивая число
функций, к которым этот метод применим.[5]
5.2 Измерение тесноты
связи при криволинейной зависимости.
Рассмотренные ранее линейные
коэффициенты корреляции оценивают тесноту взаимосвязи при линейной связи между
признаками. При наличии криволинейной связи указанные меры связи не всегда
приемлемы.
Для измерения тесноты связи при
криволинейной зависимости используется индекс корреляции, вычисляемый по
формуле:
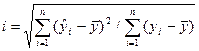
где уi—i-e
значение результативного признака; ŷi—i-e выравненное
значение этого признака;—среднее арифметическое значение результативного признака.
Числитель формулы индекса
корреляции характеризует разброс выравненных значений результативного признака.
Поскольку изменения выравненных, т. е. вычисленных по уравнению регрессии,
значений признака происходят только в результате изменения факторного признака
х, то числитель измеряет разброс результативного признака, обусловленный
влиянием на него факторного признака. Знаменатель же измеряет разброс
признака-результата, который определен влиянием на него всех факторов, в том
числе и учтенного. Таким образом, индекс корреляции оценивает участие данного
факторного признака в общем действии всего комплекса факторов, вызывающих
колеблемость результативного признака, тем самым определяя тесноту зависимости
признака у от признака х. При этом, если признак х не вызывает никаких
изменений признака у, то числитель и, следовательно, индекс корреляции равны 0.
Если же линия регрессии полностью совпадает с фактическими данными, т. е.
признаки связаны функционально, то индекс корреляции равен 1. В случае линейной
зависимости между х и у индекс корреляции численно равен линейному коэффициенту
корреляции г. Квадрат индекса корреляции совпадает с введенным ранее коэффициентом детерминации. Если же вопрос о
форме связи не ставится, то роль коэффициента детерминации играет квадрат
корреляционного отношения.
6. Оценка значимости параметров взаимосвязи
Получив
оценки корреляции и регрессии, необходимо проверить их на соответствие истинным
параметрам взаимосвязи.
Существующие
программы для ЭВМ включают, как правило, несколько наиболее распространенных
критериев. Для оценки значимости коэффициента парной корреляции рассчитывают
стандартную ошибку коэффициента корреляции:
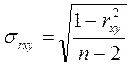
В
первом приближении нужно, чтобы  . Значимость rxy проверяется его
сопоставлением с
. Значимость rxy проверяется его
сопоставлением с 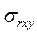 , при этом получают
, при этом получают
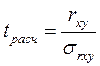
где
tрасч – так называемое расчетное значение t-критерия.
Если
tрасч больше теоретического (табличного) значения критерия
Стьюдента (tтабл) для заданного уровня вероятности и (n-2)
степеней свободы, то можно утверждать, что rxy значимо.
Подобным
же образом на основе соответствующих формул рассчитывают стандартные ошибки
параметров уравнения регрессии, а затем и t-критерии для каждого параметра.
Важно опять-таки проверить, чтобы соблюдалось условие tрасч >
tтабл. В противном случае доверять полученной оценке параметра
нет оснований.
Вывод
о правильности выбора вида взаимосвязи и характеристику значимости всего
уравнения регрессии получают с помощью F-критерия, вычисляя его расчетное
значение:
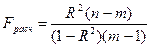
где n – число наблюдений; m – число параметров
уравнения регрессии.
Fрасч также должно быть больше Fтеор
при v1 = (m-1) и v2 = (n-m) степенях
свободы. В противном случае следует пересмотреть форму уравнения, перечень
переменных и т.д.
Заключение
Исследуя
природу, общество, экономику, необходимо считаться со взаимосвязью наблюдаемых
процессов и явлений. При этом полнота описания так или иначе определяется
количественными характеристиками причинно-следственных связей между ними.
Оценка наиболее существенных из них, а также воздействия одних факторов на
другие является одной из основных задач статистики.
Формы
проявления взаимосвязей весьма разнообразны. В качестве двух самых общих их
видов выделяют функциональную (полную) и корреляционную (неполную) связи. В
первом случае величине факторного признака строго соответствует одно или
несколько значений функции.
Корреляционная
связь (которую также называют неполной, или статистической) проявляется в
среднем, для массовых наблюдений, когда заданным значениям зависимой переменной
соответствует некоторый ряд вероятных значений независимой переменной. Объяснение
тому – сложность взаимосвязей между анализируемыми факторами, на взаимодействие
которых влияют неучтенные случайные величины. Поэтому связь между признаками
проявляется лишь в среднем, в массе случаев. При корреляционной связи каждому
значению аргумента соответствуют случайно распределенные в некотором интервале
значения функции.
По
направлению связи бывают прямыми, когда зависимая переменная растет с
увеличением факторного признака, и обратными, при которых рост последнего
сопровождается уменьшением функции. Такие связи также можно назвать
соответственно положительными и отрицательными.
Относительно
своей аналитической формы связи бывают линейными и нелинейными. В первом
случае между признаками в среднем проявляются линейные соотношения. Нелинейная
взаимосвязь выражается нелинейной функцией, а переменные связаны между собой в
среднем нелинейно.
.
Если характеризуется связь двух признаков, то ее принято называть парной. Если
изучаются более чем две переменные – множественной.
По
силе различаются слабые и сильные связи. Эта формальная характеристика
выражается конкретными величинами и интерпретируется в соответствии с
общепринятыми критериями силы связи для конкретных показателей.
В
наиболее общем виде задача статистики в области изучения взаимосвязей состоит в
количественной оценке их наличия и направления, а также характеристике силы и
формы влияния одних факторов на другие. Для ее решения применяются две группы
методов, одна из которых включает в себя методы корреляционного анализа, а
другая – регрессионный анализ. В то же время ряд исследователей объединяет эти
методы в корреляционно-регрессионный анализ, что имеет под собой некоторые
основания: наличие целого ряда общих вычислительных процедур, взаимодополнения
при интерпретации результатов и др.
Задачи
собственно корреляционного анализа сводятся к измерению тесноты связи между
варьирующими признаками, определению неизвестных причинных связей и оценке
факторов оказывающих наибольшее влияние на результативный признак.
Задачи
регрессионного анализа лежат в сфере установления формы зависимости,
определения функции регрессии, использования уравнения для оценки неизвестных
значении зависимой переменной.
Решение
названных задач опирается на соответствующие приемы, алгоритмы, показатели,
применение которых дает основание говорить о статистическом изучении
взаимосвязей.
Следует
заметить, что традиционные методы корреляции и регрессии широко представлены в
разного рода статистических пакетах программ для ЭВМ. Исследователю остается
только правильно подготовить информацию, выбрать удовлетворяющий требованиям
анализа пакет программ и быть готовым к интерпретации полученных результатов.
Алгоритмов вычисления параметров связи существует множество, и в настоящее
время вряд ли целесообразно проводить такой сложный вид анализа вручную.
Вычислительные процедуры представляют самостоятельный интерес, но знание
принципов изучения взаимосвязей, возможностей и ограничений тех или иных
методов интерпретации результатов является обязательным условием исследования.
Таковы основные принципы и условия,
методика и техника применения корреляционного и регрессионного анализа. Их
подробное рассмотрение обусловлено тем, что они являются высокоэффективными и
потому очень широко применяемыми методами анализа взаимосвязей в объективном мире
природы и общества.
Литература
1.
Гришин А.Ф. Статистика: Учеб. Пособие. – М.:
Финансы и статистика, 2003.
2.
Ефимова М.Р., Петрова Е.В., Румянцев В.Н.
Общая теория статистики: Учебник.-М.:ИНФРА – М., 1996.
3.
Ефремова М.Р. «Общая теория статистики»; М.:
«Инфра-М», 1996.
4.
Переяслова И.Г., Колбачев Е.Б., Переяслова О.Г. Статистика.
Серия «Высшее образование». – Ростов н/Д: «Феникс», 2003.
5.
Экономическая статистика (под. ред. Ю.Н. Иванова)
М.:ИНФРА-М, 1998.
[1] Гришин А.Ф. Статистика: Учеб.
Пособие. – М.: Финансы и статистика, 2003, стр.134.
[2]
Гришин А.Ф. Статистика: Учеб. Пособие. – М.:
Финансы и статистика, 2003, стр.148.
[3]
Переяслова И.Г., Колбачев
Е.Б., Переяслова О.Г. Статистика. Серия «Высшее образование». – Ростов н/Д: «Феникс», 2003,
стр.74.
[4]
Ефремова М.Р. «Общая теория статистики»; М.:
«Инфра-М», 1996, стр.98.
[5]
Переяслова И.Г., Колбачев
Е.Б., Переяслова О.Г. Статистика. Серия «Высшее образование». – Ростов н/Д: «Феникс», 2003,
стр.96.