Министерство образования и науки РФ
Федеральное агентство по образованию ГОУ ВПО
Всероссийский заочный финансово – экономический
институт
Омский филиал
Контрольная работа по дисциплине
«Эконометрика»
Вариант №3
Выполнила:
Омск
Задача 1. Эконометрическое
моделирование стоимости квартир в Московской области.
Даны следующие исходные данные:
|
Y-цена квартиры, тыс. долл.
|
X1 (город области)
|
X2 (число комнат в квартире)
|
X4 (жилая площадь квартиры), кв.м.
|
|
115
|
0
|
4
|
51,4
|
|
85
|
1
|
3
|
46
|
|
69
|
1
|
2
|
34
|
|
57
|
1
|
2
|
31
|
|
184,6
|
0
|
3
|
65
|
|
56
|
1
|
1
|
17,9
|
|
85
|
0
|
3
|
39
|
|
265
|
0
|
4
|
80
|
|
60,65
|
1
|
2
|
37,8
|
|
130
|
0
|
4
|
57
|
|
46
|
1
|
1
|
20
|
|
115
|
0
|
3
|
40
|
|
70,96
|
0
|
2
|
36,9
|
|
39,5
|
1
|
1
|
20
|
|
78,9
|
0
|
1
|
16,9
|
|
60
|
1
|
2
|
32
|
|
100
|
1
|
4
|
58
|
|
51
|
1
|
2
|
36
|
|
157
|
0
|
4
|
68
|
|
123,5
|
1
|
4
|
67,5
|
|
55,2
|
0
|
1
|
15,3
|
|
95,5
|
1
|
3
|
50
|
|
57,6
|
0
|
2
|
31,5
|
|
64,5
|
1
|
2
|
34,8
|
|
92
|
1
|
4
|
46
|
|
100
|
1
|
3
|
52,3
|
|
81
|
0
|
2
|
27,8
|
|
65
|
1
|
1
|
17,3
|
|
110
|
0
|
3
|
44,5
|
|
42,1
|
1
|
1
|
19,1
|
|
135
|
0
|
2
|
35
|
|
39,6
|
1
|
1
|
18
|
|
57
|
1
|
2
|
34
|
|
80
|
0
|
1
|
17,4
|
|
61
|
1
|
2
|
34,8
|
|
69,6
|
1
|
3
|
53
|
|
250
|
1
|
4
|
84
|
|
64,5
|
1
|
2
|
30,5
|
|
125
|
0
|
2
|
30
|
|
152,3
|
0
|
3
|
55
|
(Х1 – город области; 1 – Подольск, 0 -
Люберцы).
Задание:
1.
Рассчитайте матрицу парных коэффициентов
корреляции; оцените статистическую значимость коэффициентов корреляции.
2.
Постройте поле корреляции результативного
признака и наиболее тесно связанного с ним фактора.
3.
Рассчитайте параметры линейной парной
регрессии для всех факторов Х.
4.
Оцените качество каждой модели через
коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера.
Выберите лучшую модель.
5.
Для лучшей модели осуществите прогнозирование
среднего значения показателя 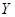 при уровне значимости
при уровне значимости 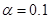 , если прогнозное значение фактора составит 80% от его
максимального значения. Представьте графически: фактические и модельные
значения, точки прогноза.
, если прогнозное значение фактора составит 80% от его
максимального значения. Представьте графически: фактические и модельные
значения, точки прогноза.
6.
Используя пошаговую множественную регрессию
(метод исключения или метод включения), постройте модель формирования цены
квартиры за счёт значимых факторов. Дайте экономическую интерпретацию
коэффициентов модели регрессии.
7.
Оцените качество построенной модели.
Улучшилось ли качество модели по сравнению с однофакторной моделью? Дайте
оценку влияния значимых факторов на результат с помощью коэффициентов
эластичности, 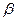 - и
- и 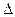 - коэффициентов.
- коэффициентов.
Решение:
При решении данной задачи
расчеты и построение графиков и диаграмм будем вести с использованием настройки
Excel Анализ
данных.
1. Рассчитаем матрицу парных коэффициентов корреляции и оценим
статистическую значимость коэффициентов корреляции.
Чтобы рассчитать матрицу парных коэффициентов корреляции скопируем
таблицу с исходными данными в Excel.
Далее воспользуемся инструментом Корреляция, входящим в настойку Анализ данных.
В диалоговом
окне Корреляция в поле Входной интервал вводим
диапазон ячеек, содержащих исходные данные. Так как мы выделили и заголовки
столбцов, то устанавливаем флажок Метки в первой строке.
Получили
следующие результаты:
Таблица 1.1. Матрица парных коэффициентов корреляции:
|
|
Y (цена квартиры), тыс. долл.
|
X4(жилая площадь квартиры), кв.м
|
X2 (число комнат в квартире)
|
X1 (город области)
|
|
Y (цена квартиры), тыс. долл.
|
1
|
|
|
|
|
X4(жилая площадь квартиры), кв.м
|
0,826
|
1
|
|
|
|
X2 (число комнат в квартире)
|
0,688
|
0,919
|
1
|
|
|
X1 (город области)
|
-0,403
|
-0,107
|
-0,155
|
1
|
Анализ матрицы
коэффициентов парной корреляции показывает, что зависимая переменная Y, т.е. цена квартиры имеет более
тесную связь с Х4 (жилая площадь квартиры). Коэффициент корреляции равен 0,826. Это означает, что на 82,6% зависимая
переменная Y (цена квартиры) зависит от показателя Х4 (жилая площадь квартиры). Также зависимая переменная Y (цена квартиры) имеет среднюю связь
68,8% с Х2 (число комнат в квартире) и слабую связь с Х1 (город области).
Статистическая значимость коэффициентов корреляции определим с помощью t-критерия Стьюдента. Табличное значение
сравниваем с расчетными значениями.
Вычислим табличное значение с помощью функции СТЬЮДРАСПОБР.
tтабл.=1,686
при доверительной вероятности равной 0,9 и степенью свободы (n-2).
Статистическим значимым является
фактор Х4.
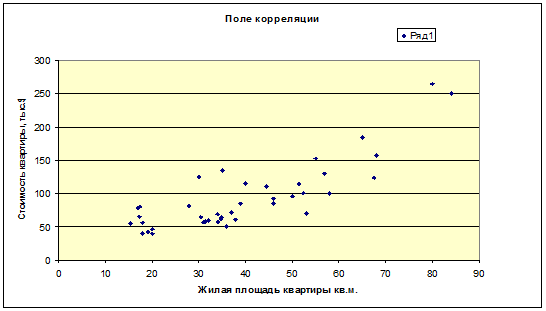
2. Построим поле корреляции результативного признака (стоимости квартиры)
и наиболее тесно связанного с ним фактора (жилой площади квартиры).
Для этого воспользуемся инструментом построения точечной
диаграммы программы Excel.
В результате получаем поле корреляции цены квартиры, тыс.
долл. и жилой площади квартиры, кв.м. (рисунок 1.1.).
Рисунок 1.1.
3. Рассчитаем параметры линейной парной регрессии для каждого фактора Х.
Для расчета параметров линейной парной регрессии воспользуемся инструментом
Регрессия, входящим в настойку Анализ данных.
В диалоговом
окне Регрессия в поле Входной
интервал Y вводим адрес диапазона ячеек, которые представляет зависимую
переменную, т.е. стоимость квартир. В поле Входной интервал Х вводим адрес
диапазона, который содержит значения независимых переменных (город области,
жилая площадь квартиры, число комнат в квартире). Выполним поочередно
вычисления параметры парной регрессии для каждого фактора Х.
Для Х4
получили следующие данные, представленные в таблице 1.2:
Таблица 1.2
|
|
Коэффициенты
|
|
Y-пересечение
|
-1,30173
|
|
X4 - жилая площадь квартиры, кв.м
|
2,396718
|
Уравнение регрессии
зависимости цены квартиры от жилой площади квартиры имеет вид: 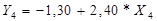
Для Х2
получили следующие данные, представленные в таблице 1.3:
Таблица 1.3
|
|
Коэффициенты
|
|
Y-пересечение
|
13,21194
|
|
X2-число комнат в квартире
|
33,51596
|
Уравнение регрессии
зависимости цены квартиры от числа комнат в квартире имеет вид: 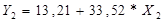
Для Х1
получили следующие данные, представленные в таблице 1.4:
Таблица 1.4
|
|
Коэффициенты
|
|
Y-пересечение
|
117,5035
|
|
X1 – город области
|
-41,484
|
Уравнение регрессии
зависимости цены квартиры от города области имеет вид:
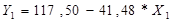
4. Оценим качество каждой модели через коэффициент детерминации, среднюю
ошибку аппроксимации и F-критерий Фишера. Установим, какая модель является
лучшей.
Коэффициент детерминации,
среднюю ошибку аппроксимации мы получили в результате расчетов, проведенных в
пункте 3. Полученные данные представлены в следующих таблицах:
Данные по Х4:
Таблица 1.5а
|
Регрессионная статистика
|
|
Множественный R
|
0,82639
|
|
R-квадрат
|
0,682921
|
|
Нормированный R-квадрат
|
0,674577
|
|
Стандартная ошибка
|
29,37418
|
|
Наблюдения
|
40
|
Таблица 1.5б
|
Дисперсионный
анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
70618,39
|
70618,39
|
81,84389
|
5,12E-11
|
|
Остаток
|
38
|
32788,02
|
862,8426
|
|
|
|
Итого
|
39
|
103406,4
|
|
|
|
Данные по Х2:
Таблица 1.6а
|
Регрессионная статистика
|
|
Множественный R
|
0,68821
|
|
R-квадрат
|
0,473634
|
|
Нормированный R-квадрат
|
0,459782
|
|
Стандартная ошибка
|
37,84653
|
|
Наблюдения
|
40
|
Таблица 1.6б
|
Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
48976,74
|
48976,74
|
34,19305
|
9,22E-07
|
|
Остаток
|
38
|
54429,67
|
1432,36
|
|
|
|
Итого
|
39
|
103406,4
|
|
|
|
Данные по Х1:
Таблица 1.7а
|
Регрессионная статистика
|
|
Множественный R
|
0,403334
|
|
R-квадрат
|
0,162678
|
|
Нормированный R-квадрат
|
0,140644
|
|
Стандартная ошибка
|
47,73403
|
|
Наблюдения
|
40
|
Таблица 1.7б
|
Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
16821,99
|
16821,99
|
7,3828
|
0,009861
|
|
Остаток
|
38
|
86584,43
|
2278,538
|
|
|
|
Итого
|
39
|
103406,4
|
|
|
|
А) Коэффициент
детерминации определяет, какая доля вариации признака У учтена в модели и
обусловлена влиянием на него фактора Х. Чем больше значение коэффициента
детерминации, тем теснее связь между признаками в построенной математической
модели.
В программе Excel обозначается R-квадрат.
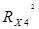 = 0,683
= 0,683
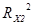 = 0,474
= 0,474
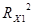 = 0,163
= 0,163
Исходя из данного
критерия наиболее адекватной является модель уравнения регрессии зависимости
цены квартиры от жилой площади квартиры (Х4).
Б)
Среднюю ошибку аппроксимации рассчитаем по формуле:
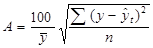 , где числитель – сумма квадратов отклонения расчетных
значений от фактических. В таблицах она находится в столбце SS, строке Остатки.
, где числитель – сумма квадратов отклонения расчетных
значений от фактических. В таблицах она находится в столбце SS, строке Остатки.
Среднее
значение цены квартиры 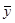 рассчитаем в Excel с помощью функции СРЗНАЧ.
рассчитаем в Excel с помощью функции СРЗНАЧ. 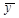 = 93,65025 тыс. долл.
= 93,65025 тыс. долл.
При проведении
экономических расчетов модель считается достаточно точной, если средняя ошибка
аппроксимации меньше 5%, модель считается приемлемой, если средняя ошибка
аппроксимации меньше 15%.
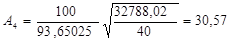
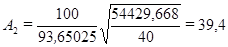
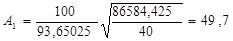
По данному критерию,
наиболее адекватной является математическая модель для уравнения регрессии
зависимости цены квартиры от жилой площади квартиры (Х4).
В) Для проверки
значимости модели регрессии используется F-тест. Для этого выполняется
сравнение  и критического (табличного)
и критического (табличного) значений F-критерия Фишера.
значений F-критерия Фишера.
Расчетные значения приведены в таблицах 1.5б, 1.6б, 1.7б (обозначены буквой F).
Табличное значение F-критерий Фишера рассчитаем в Excel с помощью функции FРАСПОБР. Вероятность возьмем равной 0,05.
Получили:
= 4,10
Расчетные значения F-критерий Фишера для каждого фактора
сравним с табличным значением:
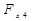 = 81,84 > = 4,10 модель по данному критерию адекватна.
= 81,84 > = 4,10 модель по данному критерию адекватна.
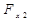 = 34,19 >= 4,10 модель по данному критерию адекватна.
= 34,19 >= 4,10 модель по данному критерию адекватна.
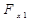 = 7,38 > = 4,10 модель по данному критерию адекватна.
= 7,38 > = 4,10 модель по данному критерию адекватна.
Проанализировав данные по всем трем критериям, можно сделать вывод, что
наиболее лучшей является математическая модель, построена для фактора жилая площадь квартиры, которая описана
линейным уравнением 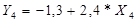 .
.
5. Для выбранной модели зависимости цены квартиры от жилой площади
квартиры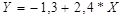 осуществим
прогнозирование среднего значения показателя при уровне
значимости , если прогнозное значения фактора составит 80% от его
максимального значения. Представим графически: фактические и модельные
значения, точки прогноза.
осуществим
прогнозирование среднего значения показателя при уровне
значимости , если прогнозное значения фактора составит 80% от его
максимального значения. Представим графически: фактические и модельные
значения, точки прогноза.
Рассчитаем прогнозное значение Х, по условию оно составит 80% от
максимального значения.
Рассчитаем Хmax в Excel с
помощью функции МАКС.
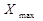 = 84кв.м
= 84кв.м
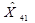 =0,8 *84 = 67,2 кв.м
=0,8 *84 = 67,2 кв.м
Для получения прогнозных
оценок зависимой переменной подставим полученное значение независимой
переменной в линейное уравнение:
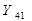 = -1,3+2,4*67,2 =
159,98 тыс.долл.
= -1,3+2,4*67,2 =
159,98 тыс.долл.
Определим доверительный интервал прогноза, который будет иметь следующие
границы:
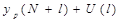
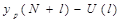
Для вычисления доверительного интервала для прогнозного значения
рассчитываем величину отклонения от линии регрессии. Для модели парной
регрессии величина отклонения рассчитывается:
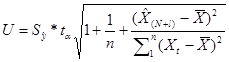
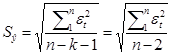 , т.е.
значение стандартной ошибки из таблицы 1.5а.
, т.е.
значение стандартной ошибки из таблицы 1.5а.
(Так как число степеней
свободы равно единицы, то знаменатель будет равен n-2).
 = 29,37
= 29,37
Для расчета коэффициента  воспользуемся функцией
Excel
СТЬЮДРАСПОБР, вероятность возьмем равную 0,1, число степеней свободы 38.
воспользуемся функцией
Excel
СТЬЮДРАСПОБР, вероятность возьмем равную 0,1, число степеней свободы 38.
= 1,686
Значение 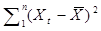 рассчитаем с помощью Excel, получим 12294.
рассчитаем с помощью Excel, получим 12294.
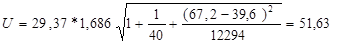
Определим верхнюю и нижнюю границы интервала.
159,98+51,63= 211,61
159,98-51,63= 108,35
Таким образом, прогнозное значение  = 159,98
тыс.долл., будет находиться между нижней границей, равной 108,35 тыс.долл. и верхней границей, равной 211,61 тыс.долл.
= 159,98
тыс.долл., будет находиться между нижней границей, равной 108,35 тыс.долл. и верхней границей, равной 211,61 тыс.долл.
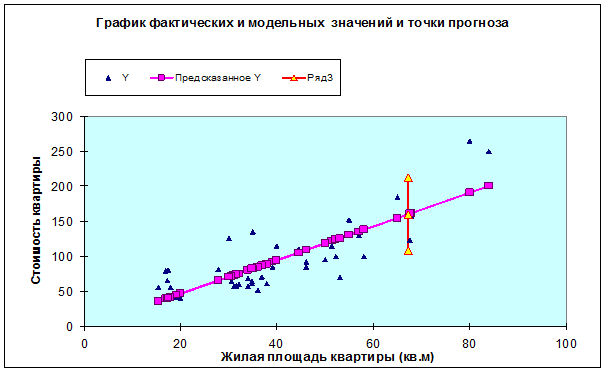
Фактические и модельные значения, точки прогноза представлены графически
на рисунке 1.2.
Рисунок 1.2.
6. Используя пошаговую множественную регрессию (метод исключения), построим
модель формирования цены квартиры за счёт значимых факторов.
Для построения множественной регрессии воспользуемся функцией Регрессия
программы Excel,
включив в нее все факторы. В результате получаем результативные таблицы, из
которых нам необходим t-критерий
Стьюдента.
Таблица 1.8.а.
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
|
Y-пересечение
|
30,45
|
10,14617717
|
3,001135
|
0,004862638
|
|
X4
(жилая площадь квартиры)
|
3,849
|
0,499544248
|
7,704503
|
3,99877E-09
|
|
X2
(число комнат в квартире)
|
-28,532
|
8,441863622
|
-3,379775
|
0,00175709
|
|
X1
(город области)
|
-36,176
|
7,070149312
|
-5,116777
|
1,05101E-05
|
Таблица 1.8.б.
|
Регрессионная статистика
|
|
Множественный R
|
0,913962927
|
|
R-квадрат
|
0,835328231
|
|
Нормированный R-квадрат
|
0,821605584
|
|
Стандартная ошибка
|
21,74863765
|
|
Наблюдения
|
40
|
Таблица 1.8.в.
|
Дисперсионный
анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
3
|
86378,29447
|
28792,76482
|
60,87223598
|
3,55864E-14
|
|
Остаток
|
36
|
17028,11663
|
473,0032397
|
|
|
|
Итого
|
39
|
103406,4111
|
|
|
|
Получаем модель вида:
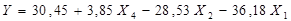 .
.
Поскольку < 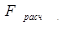 (4,10 < 60,87),
уравнение регрессии следует признать адекватным.
(4,10 < 60,87),
уравнение регрессии следует признать адекватным.
Выберем наименьшее по модулю значение t-критерия Стьюдента, оно равно
│-3,38│, сравниваем его с табличным значением, которые рассчитываем
в Excel,
уровень значимости берем равным 0,10, число степеней свободы n-m-1=40-4=36: 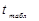 =1,688.
=1,688.
Поскольку │-3,38│> 1,688
модель следует признать адекватной.
Коэффициент парной
корреляции независимых переменных X2 (число комнат в квартире) и X4 (жилая площадь квартиры) 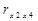 = 0,92. Так как это больше 0,8, следовательно в исходных
данных имеется мультиколлинеарность. Чтобы избавиться от мультиколлинеарности
из переменных X2 (число комнат в квартире) и X4 (жилая площадь квартиры) оставим в
модели X4, так как он в большей степени связан с зависимой переменной Y(цена
квартиры).
= 0,92. Так как это больше 0,8, следовательно в исходных
данных имеется мультиколлинеарность. Чтобы избавиться от мультиколлинеарности
из переменных X2 (число комнат в квартире) и X4 (жилая площадь квартиры) оставим в
модели X4, так как он в большей степени связан с зависимой переменной Y(цена
квартиры).
Вычисляем
новую математическую модель.
Таблица 1.9.а.
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
|
Y-пересечение
|
21,44848618
|
11,0838945
|
1,935103784
|
0,060649342
|
|
X4
(жилая площадь квартиры)
|
2,297644203
|
7,921039863
|
10,28689171
|
0,000196621
|
|
X1(город области)
|
-32,73940067
|
0,223356507
|
-4,133220036
|
2,11022E-12
|
Таблица 1.9.б.
|
Регрессионная статистика
|
|
Множественный R
|
0,884916669
|
|
R-квадрат
|
0,783077511
|
|
Нормированный R-квадрат
|
0,771351971
|
|
Стандартная ошибка
|
24,62210392
|
|
Наблюдения
|
40
|
Таблица 1.9.в.
|
Дисперсионный
анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
2
|
80975,23504
|
40487,61752
|
66,78391916
|
5,26787E-13
|
|
Остаток
|
37
|
22431,17605
|
606,2480015
|
|
|
|
Итого
|
39
|
103406,4111
|
|
|
|
Получаем модель вида: 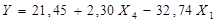 .
.
Поскольку < 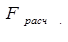 (4,10 < 66,78),
уравнение регрессии следует признать адекватным.
(4,10 < 66,78),
уравнение регрессии следует признать адекватным.
Выберем
наименьшее по модулю значение t-критерия
Стьюдента, оно равно │-4,13│, сравниваем его с табличным значением,
которые рассчитываем в Excel, уровень
значимости берем равным 0,10, число степеней свободы n-m-1=40-3=37: = 1,687.
Поскольку │-4,13│> 1,687 модель следует
признать адекватной.
Мультиколлинеарность
отсутствует.
7. Оцените качество построенной модели.
а) Для модели коэффициент
детерминации составил 0,78, для модели он составил 0,683,
поскольку чем больше значение коэффициента детерминации, тем теснее связь между
признаками в построенной математической модели, то первая модель является
лучшей по данному критерию.
б)
Рассчитаем среднюю ошибку аппроксимации:
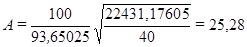
Для
предыдущей модели она составила 30,57.
в) Рассчитаем табличное
значение F-критерия
Фишера при вероятности 0,05:
=3,25
= 66,78
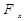 = 66,78 >=3,25 модель по данному критерию адекватна.
= 66,78 >=3,25 модель по данному критерию адекватна.
Для оценки значимого фактора полученной математической
модели, рассчитаем коэффициенты эластичности, 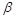 и
и 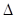 - коэффициенты.
- коэффициенты.
Коэффициент эластичности
показывает, насколько процентов изменится результативный признак при изменении
факторного признака на 1%:
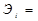
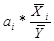 .
.
Э X4 = 2,29 *(39,62/93,65) = 1%.
Э X1 =
(-32,74) * (0,58/93,65) = - 0,2 %.
То есть с ростом общей
площади квартиры на 1% стоимость квартиры в среднем возрастает на 1%.
А при изменении города
Люберцы на Подольск при неизменной общей площади квартиры величина стоимости
квартиры уменьшится в среднем на 0,2%.
То есть наибольшее
воздействие на цену квартиры оказывает величина жилой площади (X4), а
наименьшее - X1 (город области).
-коэффициент показывает на какую часть величины
среднего квадратического отклонения меняется среднее значение зависимой
переменной с изменением независимой переменной на одно среднеквадратическое
отклонение.
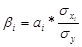
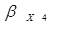 = 2,29* (17,755/51,492) = 0,79.
= 2,29* (17,755/51,492) = 0,79.
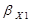 = (-32,74) * (0,5/51,492) = - 0,32.
= (-32,74) * (0,5/51,492) = - 0,32.
Данные средних
квадратических отклонений взяты из таблиц, полученных с помощью инструменты
Описательная статистика.
Таблица
1.11.
Описательная статистика (Y)
|
Y-цена квартиры, тыс. руб.
|
|
Среднее
|
93,65025
|
|
Стандартная ошибка
|
8,141631
|
|
Медиана
|
79,45
|
|
Мода
|
115
|
|
Стандартное отклонение
|
51,4922
|
|
Дисперсия выборки
|
2651,446
|
|
Эксцесс
|
3,611985
|
|
Асимметричность
|
1,805953
|
|
Интервал
|
225,5
|
|
Минимум
|
39,5
|
|
Максимум
|
265
|
|
Сумма
|
3746,01
|
|
Счет
|
40
|
Таблица
1.12.
Описательная статистика (Х4)
|
X4(жилая площадь квартиры), кв.м
|
|
Среднее
|
39,6175
|
|
Стандартная ошибка
|
2,807241
|
|
Медиана
|
35,5
|
|
Мода
|
46
|
|
Стандартное отклонение
|
17,75455
|
|
Дисперсия выборки
|
315,224
|
|
Эксцесс
|
-0,044
|
|
Асимметричность
|
0,671167
|
|
Интервал
|
68,7
|
|
Минимум
|
15,3
|
|
Максимум
|
84
|
|
Сумма
|
1584,7
|
|
Счет
|
40
|
Таблица1.13.
Описательная статистика (X1)
|
X1 (город области)
|
|
Среднее
|
0,575
|
|
Стандартная ошибка
|
0,079158
|
|
Медиана
|
1
|
|
Мода
|
1
|
|
Стандартное отклонение
|
0,500641
|
|
Дисперсия выборки
|
0,250641
|
|
Эксцесс
|
-2,0034
|
|
Асимметричность
|
-0,31539
|
|
Интервал
|
1
|
|
Минимум
|
0
|
|
Максимум
|
1
|
|
Сумма
|
23
|
|
Счет
|
40
|
- коэффициент определяет долю влияния фактора в суммарном
влиянии всех факторов: 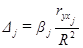
Для расчета коэффициентов
парной корреляции вычисляем матрицу парных коэффициентов корреляции в программе Excel с помощью инструмента Корреляция
настройки Анализа данных.
Таблица 1.14.
|
|
Х4 - жилая
площадь квартиры,кв. м
|
X1 - город области
|
Y-цена
квартиры, тыс. руб.
|
|
X4
- жилая площадь квартиры, кв. м
|
1
|
|
|
|
X1
- город области
|
-0,10732
|
1
|
|
|
Y-цена
квартиры, тыс. руб.
|
0,82639
|
-0,40333
|
1
|
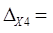 (0,79*0,826) / 0,78 = 0,84.
(0,79*0,826) / 0,78 = 0,84.
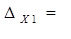 (-0,32*(-0,403))/0,78 = 0,16.
(-0,32*(-0,403))/0,78 = 0,16.
Из полученных расчетов можно сделать вывод, что
результативный признак Y (цена квартиры) имеет большую зависимость от фактора X4 (общая площадь
квартиры) (на 84 %), чем от фактора X1 (город области) (16 %).
Задача 2. Исследовать
динамику экономического показателя на основе анализа одномерного временного
ряда.
В течение
девяти последовательных недель фиксировался спрос Y(t) (млн. р.) на кредитные ресурсы
финансовой компании. Временной ряд Y(t)
этого показателя приведен ниже в таблице:
|
Номер наблюдения (t = 1,2,…,9)
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
3
|
7
|
10
|
11
|
15
|
17
|
21
|
25
|
23
|
Требуется:
1) Проверить наличие аномальных наблюдений.
2) Построить линейную модель 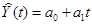 , параметры которой
оценить МНК (
, параметры которой
оценить МНК (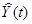 - расчетные,
смоделированные значения временного ряда).
- расчетные,
смоделированные значения временного ряда).
3) Оценить адекватность построенных моделей, используя
свойства независимости остаточной компоненты, случайности и соответствия
нормальному закону распределения (при использовании R/S-критерия взять табулированные
границы 2,7—3,7).
4) Оценить точность моделей на основе использования средней
относительной ошибки аппроксимации.
5) Осуществить прогноз спроса на
следующие две недели (доверительный интервал прогноза рассчитать при доверительной
вероятности р = 70%).
6) Фактические значения показателя, результаты моделирования
и прогнозирования представить графически.
Решение:
1) Проверим наличие аномальных
наблюдений.
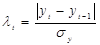
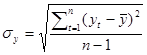 =7,52
=7,52
Результаты расчетов приведены в таблице 2.1.
Таблица 2.1
|
t
|
yt
|
y-yt-1
|
|y-yt-1|
|
yt-y-
|
(yt-y-)2
|
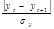
|
|
1
|
3
|
|
|
-11,667
|
136,111
|
|
|
2
|
7
|
4
|
4
|
-7,667
|
58,778
|
0,532
|
|
3
|
10
|
3
|
3
|
-4,667
|
21,778
|
0,399
|
|
4
|
11
|
1
|
1
|
-3,667
|
13,444
|
0,133
|
|
5
|
15
|
4
|
4
|
0,333
|
0,111
|
0,532
|
|
6
|
17
|
2
|
2
|
2,333
|
5,444
|
0,266
|
|
7
|
21
|
4
|
4
|
6,333
|
40,111
|
0,532
|
|
8
|
25
|
4
|
4
|
10,333
|
106,778
|
0,532
|
|
9
|
23
|
-2
|
2
|
8,333
|
69,444
|
0,266
|
|
сумма
|
132
|
|
24
|
|
452
|
|
Сравним расчетное значение 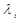 с табличным значением
(
с табличным значением
(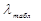 =1,5). Все расчетные значения меньше , следовательно аномальных значений во временном ряду нет.
=1,5). Все расчетные значения меньше , следовательно аномальных значений во временном ряду нет.
2) Построим линейную модель
Рассчитаем коэффициенты
линейной модели с помощью инструмента Регрессия программы Excel. В качестве входного интервала Y берем значения спроса на кредитные
ресурсы финансовой компании в качестве входного интервала Х – номера
наблюдений.
Результаты приведены в
таблице:
Таблица 2.2а
|
Регрессионная статистика
|
|
Множественный
R
|
0,983716989
|
|
R-квадрат
|
0,967699115
|
|
Нормированный
R-квадрат
|
0,963084703
|
|
Стандартная
ошибка
|
1,444200224
|
|
Наблюдения
|
9
|
Таблица 2.2б
|
Дисперсионный
анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1
|
437,4
|
437,4
|
209,712329
|
2E-06
|
|
Остаток
|
7
|
14,6
|
2,085714286
|
|
|
|
Итого
|
8
|
452
|
|
|
|
Таблица 2.2в
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
|
Y-пересечение
|
1,17
|
1,04918714
|
1,111971949
|
0,30287593
|
|
t
|
2,7
|
0,18644545
|
14,48144774
|
1,7853E-06
|
Таблица 2.2г
|
ВЫВОД
ОСТАТКА
|
|
|
|
Наблюдение
|
Предсказанное Y
|
Остатки
|
|
1
|
3,866667
|
-0,86667
|
|
2
|
6,566667
|
0,433333
|
|
3
|
9,266667
|
0,733333
|
|
4
|
11,96667
|
-0,96667
|
|
5
|
14,66667
|
0,333333
|
|
6
|
17,36667
|
-0,36667
|
|
7
|
20,06667
|
0,933333
|
|
8
|
22,76667
|
2,233333
|
|
9
|
25,46667
|
-2,46667
|
Уравнение линейной модели
будет иметь вид: 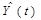 = 1,17+2,7t
= 1,17+2,7t
3) Оценим
адекватность построенных моделей, используя свойства независимости остаточной
компоненты, случайности и соответствия нормальному закону распределения.
Модель является
адекватной, если математическое ожидание значений остаточного ряда близко или
равно нулю, и если значения остаточного ряда случайны, независимы и подчинены
нормальному закону распределения.
а) При проверке независимости (отсутствия
автокорреляции) определяется отсутствие в ряду остатков систематической
составляющей (с помощью d-критерия Дарбина-Уотсона).
Таблица 2.3а. Таблица для вычисления d-критерия.
|
|
t
|
yt
|
уt
расчетное
|
Отклонение
Е(t)
|
Е(t)-Е(t-1)
|
(Е(t)-Е(t-1))2
|
Е(t)2
|
|
1
|
3
|
3,867
|
-0,867
|
|
|
0,752
|
|
2
|
7
|
6,567
|
0,433
|
1,300
|
1,69
|
0,187
|
|
3
|
10
|
9,267
|
0,733
|
0,300
|
0,09
|
0,537
|
|
4
|
11
|
11,967
|
-0,967
|
-1,700
|
2,89
|
0,935
|
|
5
|
15
|
14,667
|
0,333
|
1,300
|
1,69
|
0,111
|
|
6
|
17
|
17,367
|
-0,367
|
-0,700
|
0,49
|
0,135
|
|
7
|
21
|
20,067
|
0,933
|
1,300
|
1,69
|
0,870
|
|
8
|
25
|
22,767
|
2,233
|
1,300
|
1,69
|
4,986
|
|
9
|
23
|
25,467
|
-2,467
|
-4,700
|
22,09
|
6,086
|
|
сумма
|
45
|
132
|
|
0,00
|
|
32,32
|
14,600
|
|
среднее значение
|
5
|
14,667
|
|
|
|
|
|
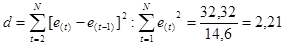
Зададим уровень
значимости равной 0,05. По таблицам значений критерия Дарбина-Уотсена для числа
n=9 и числа
независимых переменных модели k=1 критическое значение d1=0,82 и d2=1,32
Так как d попало в интервал от 2 до 4, то
вычисляем 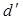 :
:
4- 2,21 = 1,79
попало в интервал от d2<d’<2, по данному
критерию модель адекватна.
б) Проверку случайности уровней ряда остатков
проведем на основе критерия поворотных точек.
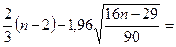 В случайном ряду чисел должно
выполняться строгое неравенство:
В случайном ряду чисел должно
выполняться строгое неравенство:
2
Количество
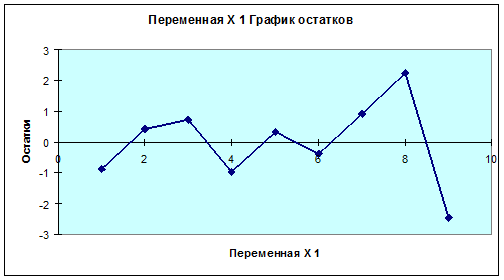
поворотных точек равно 5 (Рисунок 2.1.). Правая часть неравенства равна 2.
Неравенство выполняется (5>2), следовательно, свойство случайности
выполняется. Модель по этому критерию адекватна.
Таблица 2.3б
|
Отклонение Е(t)
|
поворотные
точки
|
|
-0,867
|
|
|
|
0,433
|
-0,39
|
0
|
|
0,733
|
0,51
|
1
|
|
-0,967
|
2,21
|
1
|
|
0,333
|
0,91
|
1
|
|
-0,367
|
0,91
|
1
|
|
0,933
|
-1,69
|
0
|
|
2,233
|
6,11
|
1
|
|
-2,467
|
|
|
Рисунок 2.1
в)
Соответствие ряда остатков нормальному закону распределения определим при
помощи RS-критерия. RS=[Emax
–Emin] : SE
Emax – максимальный уровень ряда остатков = 2,233;
Emin – минимальный уровень ряда остатков = - 2,467;
SE – среднее квадратичное отклонение
SE =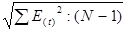 =
= 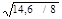 = 1,351
= 1,351
RS=[2,233–(-2,467)]/ 1,351= 3,48
Расчетное
значение попадает в интервал (2,7 - 3,7), следовательно, свойство нормальности
распределения выполняется. Модель по
этому критерию адекватна.
4) Оценим точность моделей на основе использования средней
относительной ошибки аппроксимации.
Среднюю относительную ошибку аппроксимации рассчитаем по
формуле:
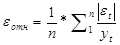 *100%
*100%
Построим расчетную таблицу:
Таблица 2.5.
|
t
|
yt
|
E(t)
|
|E(t)|
|
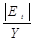
|
|
1
|
3
|
-0,867
|
0,867
|
0,289
|
|
2
|
7
|
0,433
|
0,433
|
0,062
|
|
3
|
10
|
0,733
|
0,733
|
0,073
|
|
4
|
11
|
-0,967
|
0,967
|
0,088
|
|
5
|
15
|
0,333
|
0,333
|
0,022
|
|
6
|
17
|
-0,367
|
0,367
|
0,022
|
|
7
|
21
|
0,933
|
0,933
|
0,044
|
|
8
|
25
|
2,233
|
2,233
|
0,089
|
|
9
|
23
|
-2,467
|
2,467
|
0,107
|
|
Итого
|
|
|
|
0,797
|
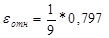 *100%= 8,85 %
*100%= 8,85 %
Данную модель можно
считать приемлемой, так как рассчитанное значение средней относительной ошибки
аппроксимации меньше 15%.
5) Осуществим прогноз
спроса на следующие две недели.
Рассчитаем прогнозные
значения для 10 и 11 недели, подставив соответствующие значения в ранее
полученное уравнение регрессии= 1,17+2,7t:
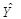 (10)= 1,17+2,7*10= 28,17
(10)= 1,17+2,7*10= 28,17
(11)= 1,17+2,7*11= 30,87
Доверительные интервалы для прогнозных значений рассчитаем по формуле:
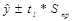 , где
, где
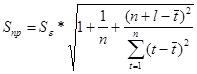
Среднее значения параметра t
равно:
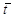 =
=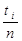 =
=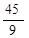 =5
=5
Рассчитаем знаменатель дроби, находящейся под корнем. Для этого построим
расчетную таблицу:
Таблица 2.6.
|
t
|
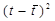
|
|
1
|
16,00
|
|
2
|
9,00
|
|
3
|
4,00
|
|
4
|
1,00
|
|
5
|
0,00
|
|
6
|
1,00
|
|
7
|
4,00
|
|
8
|
9,00
|
|
9
|
16,00
|
|
Итого
|
60,00
|
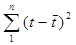 =60
=60
Из таблицы 2.2а берем значение стандартной ошибки оценки: 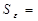 1,444
1,444
Рассчитаем Sпр для
каждой недели:
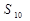 =1,444*
=1,444*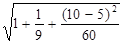 = 1,785
= 1,785
 =1,444*
=1,444*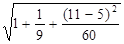 = 1,889
= 1,889
Рассчитаем t-критерий
Стьюдента с помощью формулы СТЬЮДРАСПОБР, при доверительной вероятности равной
70%: t=1,119
Рассчитаем доверительные интервалы:
Для 10-ой недели:
28,17+1,119*1,785=
30,167
28,17-1,119*1,785= 26,173
Для 11-ой недели
30,87+1,119*1,889=32,983
30,87-1,119*1,889= 28,756
6) Представим графически фактические значения показателя,
результаты моделирования и прогнозирования.
Рисунок 2.2.