Объектно-ориентированная СУБД (прототип)
МОСКОВСКИЙ
ГОСУДАРСТВЕННЫЙ
ИНСТИТУТ ЭЛЕКТРОНИКИ
И МАТЕМАТИКИ
Кафедра
Автоматизации
и Интеллектуализации
Процессов
Управления
ПОЯСНИТЕЛЬНАЯ
ЗАПИСКА
К
дипломной
работе
На
тему: «Разработка
прототипа
системы управления
объектно-ориентированной
базой данных»
Студент
Юдин Илья
Викторович
Руководитель
дипломной
работы: Нечаев
Анатолий Михайлович
Специальная
часть: Титов
Виктор Иванович
М
О С К В А
1 9 9 9
Содержание
1.
Введение Error: Reference source not found
1.1
Причины появления
объектно-ориентированных
баз данных Error: Reference source not found
1.2
Подходы в разработке
ООБД Error: Reference source not found
1.3
Краткий сравнительный
анализ постреляционных
и традиционных
баз данных Error: Reference source not found
1.4
Основания
дипломной
работы Error: Reference source not found
1.5
Анализ полученного
результата Error: Reference source not found
2.
Уточнение
методов решения
задачи Error: Reference source not found
2.1
Наследование Error: Reference source not found
2.2
Инкапсуляция Error: Reference source not found
2.3
Идентификатор
объекта Error: Reference source not found
2.4
Идентификатор
поля агрегата Error: Reference source not found
2.5
Триггеры. Ограничение
доступа Error: Reference source not found
2.6
Действие (knowhow) Error: Reference source not found
2.7
Объекты-поведения Error: Reference source not found
2.8
Принципы
взаимодействия
объектов Error: Reference source not found
2.9
Транзакции
и механизм
согласованного
управления Error: Reference source not found
3.
Разработка
структуры СУ Error: Reference source not found
3.1
Положение дел
в области
интероперабельности
систем Error: Reference source not found
3.2
Менеджер памяти Error: Reference source not found
3.3
Виртуальная
память и каналы Error: Reference source not found
3.4
Система управления
кэшированием
объектов Error: Reference source not found
3.5
Система управления
журнализацией
и восстановлением Error: Reference source not found
3.6
Принципы реализации
механизма
согласованного
управления Error: Reference source not found
4.
Представление
данных в ООБД Error: Reference source not found
4.1
Базовые объекты
системы Error: Reference source not found
4.2
Строение объекта Error: Reference source not found
4.3
Контекст транзакции Error: Reference source not found
5.
Описание операций
над объектами
в БД Error: Reference source not found
6.
Требования
к техническим
и программным
средствам Error: Reference source not found
7.
Реализация
прототипа Error: Reference source not found
7.1
Построитель Error: Reference source not found
7.2
Заголовочный
модуль для
каналов Error: Reference source not found
7.3
Менеджер виртуальной
памяти Error: Reference source not found
7.4
Система управления
хранением
объектов Error: Reference source not found
7.5
Система управления
каналами Error: Reference source not found
7.6
Работа с базовыми
объектами Error: Reference source not found
7.7
Выполнение
действий Error: Reference source not found
7.8
Кэширование
объектов Error: Reference source not found
8.
Контрольный
пример, демонстрирующий
возможности
технологии Error: Reference source not found
9.
Оценка трудоемкости
разработки
ПО с использованием
традиционного
и предлагаемого
подходов Error: Reference source not found
9.1
Табличные базы
данных с низкоуровневыми
операциями
доступа Error: Reference source not found
9.2
Реляционные
базы данных Error: Reference source not found
9.3
Объектно-ориентированные
базы данных Error: Reference source not found
9.4
Будущее применения
различных баз
данных Error: Reference source not found
10.
Литература Error: Reference source not found
1.
Введение
Причины
появления
объектно-ориентированных
баз данных
Развитие
вычислительной
техники и увеличение
объемов хранимой
информации
привело к
необходимости
выделения
технологии
баз данных в
отдельную
науку. Как правило,
базы данных
хранили множество
однотипных
данных, предоставляя
пользователю
сервис доступа
к нужной ему
информации.
На смену иерархическим
и сетевым базам
данных пришли
реляционные
базы данных.
Успех реляционных
баз данных
обусловлен
их более простой
архитектурой,
наличием
ненавигационного
языка запросов
и, главное, ясностью
математики
реляционной
алгебры.
На
этапе зарождения
технологии
баз данных при
построении
какой-либо базы
данных строилась
физическая
модель. С накоплением
опыта стало
понятно, что
нужен переход
к даталогической
модели, которая
позволяет
абстрагироваться
от конкретной
СУБД. Появилось
понятие схемы
базы данных,
описывающей
организацию
данных в СУБД.
Программы стали
работать с
базой данных
не напрямую,
а через схему
БД. Такой
подход обеспечил
возможность
менять структуру
БД без необходимости
изменять логику
программ. Появление
и стандартизация
SQL предоставила
единый
интерфейс для
работы с данными.
Иерархическая
и сетевая модели
баз данных
стали применяться
крайне редко.
Это было вызвано,
прежде всего,
трудностью
модификации
схем иерархических
и сетевых баз
данных и сильно
зависящей от
приложений
навигацией
в этих базах
данных.
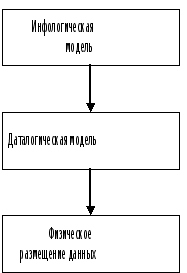
Далее,
развитие
объектно-ориентированного
анализа и
объектно-ориентированного
проектирования
как эффективных
подходов
для формализации
предметной
области,
привело к
появлению
инфологической
модели предметной
области.
Теперь, при
разработке
базы данных
составлялось
три модели
представления
информации
предметной
области: инфологическая,
даталогическая
и физическая,
не считая
локальных
пользовательских
представлений.
Рис
1: Этапы проектирования
БД
Поскольку
физическая
модель требовала
привлечения
эксперта в
области конкретной
СУБД для получения
эффективного
размещения
данных, физическая
модель стала
строиться
самой СУБД из
схемы БД, вводимой
пользователем
на основе
даталогической
модели предметной
области. Затем
появились
CASE-средства,
позволяющие
создавать
инфологическую
модель предметной
области и
транслирующие
ее в даталогическую
модель.
Казалось
бы, что цель
достигнута,
– проектировщик
работает только
с инфологической
моделью, но на
самом деле, до
тех пор, пока
работа происходит
с реляционной
базой данных,
существует
разрыв между
языком программирования
(логикой пользователя)
и языком описания
данных (представлением
данных), который
преодолевать
должен программист.
Суть разрыва
можно сформулировать
так: возможности
работы с данными
программы и
с данными СУБД
должны быть
одинаковы.
В
конце 80-х – начале
90-х годов массовое
внедрение
персональных
компьютеров
привело к развитию
мультимедиа-технологий
и настольных
САПР, структуры
данных в которых
слишком сложны
для процедурного
программирования
или же необычны
(например,
звук). Это, а также
то, что объектно-ориентированное
программирование
позволяет
существенно
снизить сложность
разработки
и обеспечить
адекватное
представлению
моделирование
предметной
области, привело
к тому, что в
области языков
программирования
произошло
слияние стилей
языков высокого
уровня. Доминирующим
подходом
стало внедрение
в них технологий
объектно-ориентированного
программирования.
Не остались
в стороне и
языки, встроенные
в СУБД. В качестве
примера вышеизложенного
можно привести
продукт Visual
FoxPro фирмы
Microsoft.
Эта СУБД обладает
объектно-ориентированным
языком программирования,
но, по сути,
является
реляционной
СУБД, поскольку
хранимые данные
представлены
в виде таблиц,
а таблицы
представляют
собой множество
кортежей, которые
содержат
атомарные
значения. Такое
несоответствие
и привело к
буму в области
разработки
постреляционных
баз данных.
Сложившаяся
ситуация хотя
чем-то и напоминает
время перехода
к реляционным
базам данных,
однако во многом
и отличается.
Прежде всего,
отсутствует
математическая
модель, которая
была бы однозначно
признана всеми
ведущими
разработчиками
постреляционных
СУБД. Нет документа,
который однозначно
определил
бы требования
к таким СУБД.
И, наконец, нет
самой системы,
которая считалась
бы эталоном
для других
систем, как
это было с СУБД
System-R фирмы
IBM.
Одним
из основных
критериев
выбора СУБД
всегда была
производительность.
Однако, несмотря
на то, что
объектно-ориентированные
базы данных
существуют
уже около 10 лет,
стандартных
тестов на
производительность
пока нет. Тому
есть несколько
причин: отсутствие
стандартного
языка запросов,
канонических
приложений,
разница в
архитектуре
и т.д.
Что
же есть? Имеется
многочисленный
опыт разработок,
например
Jasmine, POSTGRES, и
других. Три
документа,
содержащих
пожелания
относительно
возможностей
постреляционных
СУБД : [3], [12] и
[14].
1.2 Подходы
в разработке
ООБД
За
время существования
баз данных
накоплено
огромное количество
информации.
Разработано
огромное количество
приложений
для работы с
базами данных.
Это привело
к появлению
двух конкурирующих
концепций
архитектур
постреляционных
СУБД:
1.
Объектно-реляционные
базы данных
2.
Объектно-ориентированные
базы данных
Объектно-реляционные
базы данных
представляют
собой реляционные
базы данных,
дополненные
надстройкой,
представляющей
эти данные
как объекты.
Все по-прежнему
хранится в
виде таблиц.
Этот подход
позволяет
плавно перейти
от технологии
хранилища
таблиц к технологии
хранилища
объектов. Остается
возможность
выборки данных
с помощью
SQL-запросов.
Сам SQL расширен
командами
работы с объектами.
Наиболее известным
продуктом,
в котором реализован
подобный подход
является Oracle
ver.8. Комитет
ANSI X3H2, разработавший
стандарт
SQL–92, сейчас работает
над SQL3. Основными
усовершенствованиями
в SQL3 должны стать
возможность
процедурного
доступа наравне
с декларативным
и поддержка
объектов. Основным
недостатком
объектно-реляционных
СУБД является
необходимость
разбирать
объекты для
размещения
их в таблицах
и собирать их
для передачи
пользователю
из таблиц [2].
Объектно-ориентированные
базы данных
хранят объекты
целиком. Для
выборки объектов
с помощью запросов
разрабатывается
язык OQL (Object
Query Language), в
который был
включен стандарт
SQL'92. Единство
описания структуры
БД достигается
применением
языка определения
объектов ODL
(Object Definition Language), предложенного
ODMG (Object Database Management Group),
являющегося
расширением
языка IDL.
Эти
виды баз данных
обладают высокой
производительностью,
часто в несколько
раз более высокой,
чем реляционные
базы данных.
Наиболее известными
ООСУБД являются
Jasmine, ObjectStore и
POET.
Из
отечественных
разработок
в области
постреляционных
баз данных
достоверно
известно лишь
о существовании
ООСУБД ODB-Jupiter.
Похоже, она
была написана
специально
для создания
продукта ODB-Text.
По крайней
мере, ни о каких
других приложениях
написанных
на ODB-Jupiter ничего
не известно.
Также
в Internet было
обнаружено
описание
некой отечественной
объектно-ориентированной
базы данных
версии
1.2. Точнее, это
был модуль,
предоставляющий
функции
объектно-ориентированной
СУБД. Документ
даже не имел
названия. В
нем детально
рассматривалась
организация
хранения данных
и принцип работы.
Похоже, разработка
обосновывалась
лишь на принципах,
которым должна
удовлетворять
СУООБД. Наиболее
интересная
идея: назначение
строкам уникальных
идентификаторов
и удаление
строк только
при упаковке
базы. Это дает
существенный
выигрыш в сравнении
строк, так как
объекты-строки
с одинаковым
содержанием
имеют одинаковые
идентификаторы.
Краткий
сравнительный
анализ постреляционных
и традиционных
баз данных
Постреляционные
базы данных
вобрали в себя
все лучшие
черты иерархических,
сетевых и
реляционных
баз данных.
Хотя
существуют
некоторые
сходства, как,
например,
использование
указателей
и вложенная
структура
записей в сетевой
модели. Однако
надо отметить,
что СУООБД
используют
логические
указатели для
обеспечения
целостности,
а также поддерживают
иерархию классов,
наследование
и методы. Таких
средств нет
в иерархических
и сетевых
моделях [4].
Реляционные
СУБД, идеально
соответствующие
своему назначению
в традиционных
областях применения
баз данных, —
банковское
дело, системы
резервирования
и т.д. — в данном
случае оказываются
неудобными
и неэффективными
по многим
причинам.
Основное
требование
реляционной
модели — нормализация
— в случае
сложноструктурированных
данных с многочисленными
взаимосвязями
приводит
к сложным запросам
с соединением
таблиц. То есть
к тому, к чему
реляционные
СУБД не приспособлены,
поскольку не
могут обеспечить
высокую
производительность,
требуемую
интерактивным
системам.
Производительность
реляционных
СУБД в таких
случаях может
уступать СУООБД
во много раз.
Кроме того,
приложения
развиваются,
и число таблиц
увеличивается.
Небольшое
изменение в
организации
данных
может привести
к необходимости
изменить исходные
тексты программы.
При этом вносятся
дополнительные
ошибки.
Объектно-ориентированные
языки БД позволяют
достичь того
же результата
локальными
изменениями
в свойствах
и методах
интересующих
объектов. Кроме
того, методы
работы с объектами
хранятся в
базе вместе
с объектами.
1.4 Основания
дипломной
работы
В
отношении
избранных
математических
моделей
Значительная
часть этой
дипломной
работы основывается
на двух математических
моделях.
Модель
единого представления
данных поведений
и сообщений
в объектно-ориентированной
базе данных
Модель
[17]
замечательна
тем, что не только
описывает что
представляют
из себя объекты
и как они взаимодействуют
между собой,
но и является
замкнутой,
самодостаточной.
Она позволяет
описать качественно
новый вид
взаимодействия
в объектно-ориентированной
системе: алгебру
объектов. Эта
алгебра является
по своей сущности
и важности
аналогом
реляционной
алгебры в теории
реляционных
баз данных.
В этой алгебре
объектов
определяется
что представляют
из себя такие
операции, как
селекция, проекция
и другие хорошо
известные
из теории
реляционных
баз данных
операции. Таким
образом, эта
модель объединяет
два способа
получения
информации:
посылка
сообщения
объекту (что
типично для
объектно-ориентированного
программирования)
и выполнение
запроса над
совокупностью
хранимых данных
(что типично
для реляционных
баз данных).
Модель
согласованного
управления
в объектно-ориентированной
базе данных
Эта
модель [19] также
оказала значительное
влияние на
данную работу,
поскольку
дополнила
собой модель
представления
данных. Ни
одна современная
система управления
базой данных
не может обойтись
без подсистемы
транзакций.
Природа транзакций
в таких приложениях,
как CAD,
мультимедийные
базы данных,
является весьма
различной.
Эти приложения
характеризуются
совместно
выполняемыми
продолжительными
транзакциями
с произвольными
операциями.
У
продолжительных
пользовательских
транзакций
время выполнения
может быть
растянуто на
часы, а то и дни.
Это условие
приводит к
тому, что хорошо
известный,
и ставший уже
классическим
для традиционных
баз данных,
критерий
сериализуемости
становится
неприменим
непосредственно.
О
самом критерии
сериализуемости
и способах
реализации
механизма
транзакций
достаточно
подробно изложено
в [9] и
[22].
Механизм
согласованного
управления
позволяет
повысить
производительность
СУООБД за счет
составления
расписания
выполнения
транзакций,
в том числе
продолжительных,
предоставляет
транзакциям
использовать
промежуточные
результаты
других
транзакций,
учитывает
объектную
ориентированность
данных и допускает
обобщение
операций (не
только чтение
и запись).
Другие
работы, также
повлиявшие
на организацию
структуры
системы управления
В
статье [20] излагается
довольно интересная
точка зрения
на состояние
объектно-ориентированного
программирования,
а также рассказывается
о применении
несколько
отличного от
традиций
объектно-ориентированного
программирования
подхода. В
частности,
наследование
реализуется
с помощью механизмов
включения и
делегирования.
Это позволяет
решить проблему
множественного
наследования.
Вводится
понятие фильтров,
представляющих
собой продукции,
которые могут
обрабатывать
входящие
сообщения
и даже перенаправлять
их на другие
объекты, сохраняя
в теле этих
сообщений
ссылку на
первоначальный
объект, к которому
было послано
сообщение.
Причем, фильтры
могут реагировать
не только на
входящие, но
и на исходящие
от объекта
сообщения.
Принципы
журнализации
заимствованы
из системы
POSTGRES [23] и
[15].
Принципы
кэширования
взяты из [1].
В
отношении
языка реализации
Было
решено реализовывать
прототип СУООБД
на ДССП. ДССП
– диалоговая
система структурного
программирования
– была разработана
в 1980 году Н.П.Брусенцовым
в МГУ [5].
Система имеет
под собой
теоретическое
обоснование.
Принцип ДССП
«Слово есть
слово», т.е. одно
слово программы
соответствует
одному слову
кода. Принципы
управляющих
конструкций
наследуются
от троичной
вычислительной
машины Сетунь-70,
имевшей память
на магнитных
сердечниках.
Словарь и
обозначения
– от языка Ч.Мура
Forth. ДССП
превосходит
Forth по
многим параметрам.
Язык ДССП обладает
существенно
более низкой,
чем язык ассемблера
трудоемкостью
в программировании,
не уступая
ему в компактности
кода и быстродействии,
позволяет
проверять
работу подпрограмм
в интерактивном
режиме и имеет
возможность
модификации
программ
практически
без внесения
изменений
в остальные
части кода.
Основные
черты ДССП:
Обратная
польская запись
Словари
Поддержка
нисходящего
программирования
Встроенный
отладчик с
рекомпиляцией
Высокоуровневые
структуры
данных и операции
Высокоуровневый
механизм
программных
прерываний
и исключительных
ситуаций
Компактный
код
Гибкость,
мобильность,
наращиваемость
Наличие
сопрограммного
механизма
К
сожалению, при
всех этих
достоинствах,
ДССП на данный
момент является
только системой
программирования.
Она не предоставляет
сервис СУБД
и не взаимодействует
ни с одной СУБД.
Данная работа
направлена
на то, чтобы
обеспечить
ДССП возможность
обрабатывать
данные в качестве
СУБД, создав
тем самым дешевый
(Jasmine стоит
порядка $15000),
но
эффективный
инструмент,
способный
работать даже
в самых непритязательных
условиях, которые
так часто
встречаются
сейчас в России.
Разработка
не ограничивается
расширением
ДССП и способна
работать в
качестве
сервера ООБД
на файл-сервере
ЛВС.
1.5 Анализ
полученного
результата
В
результате
проделанной
работы изучена
литература
по организации
реляционных
баз данных,
подходы к
организации
объектно-ориентированных
баз данных.
Были отобраны
математические
модели, на основании
которых была
определена
архитектура
базы данных
и принципы ее
функционирования.
Программно
реализованы
подсистемы
управления
виртуальной
памятью и
кэширования
объектов. Сама
работа носит
исследовательский
характер, являясь
шагом от чистой
теории к идеям
реализации
ООБД. Обширность
тематики не
позволила
проработать
детально все
вопросы, касающиеся
организации
ООБД. В частности,
очень мало
места уделено
средствам
повышения
производительности
поиска в БД
(индексирование).
Тем не менее,
некоторые
найденные
решений, на
мой взгляд,
являются весьма
перспективными.
Это касается
организации
виртуальной
памяти, позволяющей
организовать
произвольную
степень вложенности
данных, и механизма
кэширования,
которые подробно
рассматриваются
в работе.
В
виде программного
кода реализовано:
Создание,
открытие ООБД
Менеджер
виртуальной
памяти
Система
управления
каналами
Система
управления
кэшированием
объектов
Создание
основных объектов
Клонирование
объектов
Переопределение
поведений и
действий
Изменение
данных в объектах
Журнализация
изменений в
объектах
Выполнение
действий (knowhow)
2.
Уточнение
методов решения
задачи
2.1
Наследование
Наследование
является мощным
средством
моделирования
(поскольку
кратко и точно
описывает мир)
и помогает
программисту
разрабатывать
новые версии
классов и методов,
не опасаясь
повредить
работающую
систему. Наследование
способствует
повторному
использованию
кода, потому
что каждая
программа
находится на
том уровне, на
котором ее
может использовать
наибольшее
число объектов.
Совокупности
свойств объекта
в объектно-ориентированной
базе данных
уделяется
большее внимание,
чем во многих
объектно-ориентированных
языках программирования,
поскольку они
являются также
целью запросов.
Объект=состояние+поведение.
Чаще всего
существует
только одна
иерархия
наследования.
Этот подход
перешел и в
C++. Однако, возможно
разделение
иерархий
наследования
данных и наследования
поведений.
Не всегда желательно
иметь точно
такую же иерархию
наследования
поведения,
как и иерархию
наследования
свойств. Разделение
этих двух иерархий
повышает возможности
переиспользования
(reuse) поведений.
Значение
переиспользования
поведений
Предположим,
мы имеем класс
Студент и хотим
создать класс
Аспирант. Чтобы
стать аспирантом,
человек должен
сначала получить
высшее образование
как студент.
В общем случае
экземпляры
этих классов
различны. Мы
не можем наследовать
Аспирант от
Студент, т.к.
аспирант не
является студентом.
В противном
случае, мы имели
бы право рассматривать
аспиранта как
экземпляр
класса Аспирант
и, с тем же правом,
как экземпляр
класса студент.
Тем не менее,
оба класса
обладают общими
атрибутами,
такими как:
имя, адрес,
номер_личной_карточки,
а также большинством
общих поведений.
Это обстоятельство
побуждает
создать класс
Аспирант,
унаследовав
свойства и
поведения
Студента. Однако,
хотя экземпляры
класса Аспирант
будут подмножеством
всех экземпляров
класса Студент
(т.к. все аспиранты
были студентами,
но не все студенты
стали аспирантами),
это представление
будет некорректно
с точки зрения
моделирования
ситуации в
реальном мире.
На
рисунке представлено
дерево наследования:
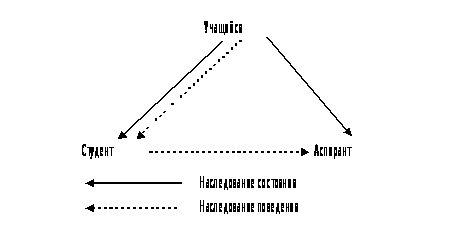
Рис.
2: Диаграмма
наследования
Свойства
классов Студент
и Аспирант
наследуются
от класса Учащийся.
Поведение
класса Аспирант
наследуется
от Студент.
Обычно подкласс
наследует все
атрибуты и
методы из
суперклассов.
В приложении
к наследованию
поведений это
означает, что
класс-ученик
(demandclass) состоит в
отношении
Переиспользовать-от
(Reuse-Of) с другим
классом, называемым
классом-учителем
(supplyclass), и класс-ученик
должен наследовать
все поведения
от класса-учителя.
Эталоны
наследования:
классы или
прототипы?
В
системе отсутствуют
классы и типы.
Роль класса
может брать
на себя любой
объект, называемый
объектом-образцом.
Такой вид
наследования
называется
наследованием
на основе
прототипов.
Как
правило, системы
с наследованием
на основе прототипов
концептуально
более просты
по сравнению
с системами
на основе классов.
Порождение
экземпляра
достигается
копированием
объекта-образца.
Копия получает
от системы
уникальный
идентификатор,
отличный от
идентификатора
любого другого
объекта в системе.
Независимо
от модели
наследования
(классы или
прототипы)
существует
две различные
стратегии
реализации
механизма
наследования:
делегирование
и конкатенация.
Способ
наследования:
делегирование
или конкатенация?
Делегирование
представляет
собой такую
форму наследования,
в которой
объединение
интерфейсов
реализовано
посредством
разделения
родительских
интерфейсов,
т.е. с использованием
ссылок. Конкатенация
достигает
аналогичного
эффекта посредством
копирования
родительских
интерфейсов
в интерфейс
порождаемого
класса или
объекта, – как
результат,
полученный
интерфейс
является
непрерывным.
В любом случае
дочерний объект
способен отвечать
как на сообщения,
определенные
в родительских
интерфейсах,
так и на сообщения,
добавленные
к интерфейсу
объекта. При
делегировании
те сообщения,
которые не
могут быть
обработаны
объектом, должны
быть направлены
родителям. При
конкатенации
каждый объект
является
самодостаточным,
и необходимость
перенаправления
сообщений
отсутствует.
Введение
идентификаторов
полей позволяет
распространить
подходы делегирования
и конкатенации
и на агрегатные
объекты.
И
конкатенация,
и делегирование
имеют свои
достоинства
и недостатки.
Делегирование
обеспечивает
возможность
гибкого распространения
изменений:
любое изменение
свойств родителя
автоматически
отражается
на потомках.
Подход, использующий
конкатенацию,
допускает
изменение
свойств родителей
и потомков
независимо
друг от друга,
что также может
быть полезно
во многих ситуациях.
Делегирование
обычно требует
меньших затрат
по памяти, в
то время как
конкатенация
является более
эффективной
по времени.
Simula и
C++ являются
примерами
языков, которые
реализуют
наследование
на основе классов
с использованием
делегирования.
В Smalltalk реализовано
наследование
на основе прототипов
с использованием
делегирования.
Обоснование
избранного
механизма
наследования
Было
решено использовать
в дипломной
работе механизм
наследования
на основе прототипов
с использованием
конкатенации,
как для состояний,
так и для поведений,
поскольку для
СУБД критично
именно время
выполнения
операций. Разделение
наследований
состояния и
поведения
позволяет
уменьшить
объем хранимой
в каждом объекте
информации.
В объект помещается
ссылка на объект,
хранящий его
интерфейс
(т.е. поведение).
Таким образом,
интерфейсы
многих объектов
с одинаковым
поведением
могут быть
сосредоточены
в одном месте.
Наследование
на основе прототипов
позволяет
управлять
конфигурацией
объектов-образцов
и обеспечивает
единство
представления
данных. Т.е.
результатом
запроса к базе
данных может
быть список
используемых
методов, их
аргументы и
другая информация,
которая в системе
с наследованием
на основе классов
скрыта в классах.
Создание экземпляра
через копирование
снимает необходимость
введения
конструктора
по умолчанию,
поскольку
содержимое
копируемого
объекта и
задает начальные
значения.
Система
поддерживает
множественное
наследование.
Необходимость
множественного
наследования
остается предметом
горячих споров.
Практика говорит
о том, что «множественное
наследование
играет роль
парашюта: в
нем нет постоянной
необходимости,
но если он вдруг
понадобился,
то большое
счастье иметь
его под рукой»
[8].
Определение
родства
Остается
важный вопрос:
как определить,
является ли
объект потомком
другого объекта?
Разделение
наследований
состояния и
поведения
приводит к
тому, что слово
«потомок объекта»
обретает
двойственное
значение. С
одной стороны,
это потомок
по данным, с
другой стороны,
это потомок
по поведению.
На
самом деле, в
чистой объектно-ориентированной
системе данные
объектов надежно
защищены от
вмешательства
пользователя
через механизм
инкапсуляции.
Доступ к данным
производится
через методы.
Таким образом,
родство объектов
следует определять
исключительно
через их интерфейсы.
В системе на
основе классов
обычно строится
дерево наследования.
В системе на
основе прототипов
с конкатенацией
определение
родства достигается
за счет операций
пересечения
интерфейсов.
Поведение
объекта составляют
методы, хранящиеся
в объекте-множестве,
а значит для
определения
родства необходимо
выполнить
операцию пересечения
множеств. Если
получившийся
в результате
пересечения
интерфейс
совпадает с
интерфейсом
одного из двух
сравниваемых
объектов, то
другой объект
– его потомок.
Фактически,
это алгоритм
определения
общего предка
двух объектов.
Использование
множеств для
хранения
интерфейсов
позволяет
взглянуть на
операцию
наследования
конкатенацией
как на операцию
слияния множеств.
2.2
Инкапсуляция
Идея
инкапсуляции
в языках программирования
происходит
от абстрактных
типов данных.
С этой точки
зрения объект
делится на
интерфейсную
часть и реализационную
часть. Интерфейсная
часть является
спецификацией
набора допустимых
над объектом
операций. Только
эта часть объекта
видима. Реализационная
часть состоит
из части данных
(состояние
объекта) и
процедурной
части (реализация
операций).
Интерпретация
этого принципа
для баз данных
состоит в том,
что объект
инкапсулирует
и программу
и данные.
Рассмотрим,
например, объект
Служащий. В
реляционной
системе служащий
представляется
кортежем. Запрос
к нему осуществляется
с помощью
реляционного
языка, а прикладной
программист
пишет программы
для изменения
этой записи,
например повышение
зарплаты служащего
или прием на
работу. Такие
программы
обычно пишутся
либо на императивном
языке программирования
с включением
в него операторов
языка манипулирования
данными или
на языке четвертого
поколения и
хранятся в
обычной файловой
системе, а не
в базе данных.
Таким образом,
при таком подходе
имеются кардинальные
различия между
программой
и данными, а
также между
языком запросов
(для незапланированных
запросов) и
языком программирования
(для прикладных
программ).
В
объектно-ориентированной
системе служащий
определяется
как объект,
который состоит
из части данных
(очень даже
вероятно, что
эта часть
практически
совпадает с
записью, определенной
для реляционной
системы) и части
операций (эта
часть состоит
из операций
повышения
зарплаты и
приема на работу
и других операций
для доступа
к данным сотрудника).
При хранении
набора сотрудников,
как данные,
так и операции
хранятся в
базе данных.
Таким образом,
имеется единая
модель данных
и операций, и
информация
может быть
скрыта. Никакие
иные операции,
кроме указанных
в интерфейсе,
не выполняются.
Это ограничение
справедливо
как для операций
изменения, так
и для операций
выборки.
Инкапсуляция
обеспечивает
что-то вроде
“логической
независимости
данных”: мы
можем изменить
реализацию
типа, не меняя
каких-либо
программ,
использующих
этот тип. Таким
образом, прикладные
программы
защищены от
реализационных
изменений на
нижних слоях
системы.
Здесь
уместно вспомнить
о “проблеме
2000 года”, возникшей
из-за того, что
в СУБД отводилось
всего два разряда
на год даты.
Чтобы исправить
возникающую
ошибку,
нужно пересмотреть
заново весь
код приложения!
В ООБД для решения
аналогичной
проблемы требуется
исправление
небольшого
количества
методов, работающих
с данными даты.
2.3
Идентификатор
объекта
Назначение
идентификатора
Объекты
в БД обладают
индивидуальностью.
Даже при изменении
структуры и
поведения
объекта, его
индивидуальность
сохраняется.
Два объекта
в системе
отличаются
своими идентификаторами.
Идентификатор
является
характеристикой
индивидуальности.
Понятие индивидуальности
ново для реляционных
баз данных. В
чисто реляционной
БД все кортежи
в пределах
одной таблицы
отличаются
между собой.
Характеристика
различия –
первичный
ключ. Многие
современные
реляционные
базы
данных допускают
существование
в пределах
одной таблицы
одинаковых
кортежей. И
потребность
в этом есть,
иначе не было
бы квалификатора
DISTINCT в
операторе SQL
SELECT.
Идентификатор
объекта в БД
позволяет
различить
между собой
два одинаковых
по значению
объекта. Фактически,
он играет роль
дескриптора
адреса объекта.
Таким образом,
пользователь
работает с
объектом не
через его адрес,
а через его
идентификатор.
Строение
идентификатора
В
современных
ООБД для ускорения
доступа к объектам
идентификаторы
наделяются
составной
структурой.
Имеются
два основных
подхода для
идентификации
объектов:
Составной
адрес состоит
из физической
части (сегмента
и номера страницы)
и логической
части (внутристраничный
индекс), которые
являются масками
фиксированной
длины и, соединяясь,
дают идентификатор.
Составные
адреса более
популярны в
современных
ООБД как более
эффективные:
за один дисковый
доступ можно
получить адрес
объекта. Использование
составного
адреса как
идентификаторов
приводит к
зависимости
от организации
физического
хранения. Это
приводит к
трудностям
при перемещении
данных для
хранения на
другое устройство.
Заменитель
– чисто логический
идентификатор,
генерируемый
по некоторому
алгоритму,
который гарантирует
уникальность.
В заменителях,
индекс (также
называется
директорией
объекта), часто
используется
для отображения
идентификаторов
в расположение
объектов.
Эффективность
операций с
базой данных
во многом
определяется
скоростью
доступа к одиночному
объекту. Часто
объекты связаны
между собой
и доступ к одному
объекту происходит
через доступ
к другому. Например,
через объект-список
происходит
доступ к его
элементам. Во
многих случаях
создание объекта
(например, глубоким
копированием)
приводит к
каскадному
созданию других
объектов,
составляющих
его содержимое.
Использование
кластеризации
помогает организации
быстрого доступа
к группе связанных
объектов. Кроме
того, размещение
объектов в
одной области
дискового
пространства
также увеличивает
быстродействие.
В
работе [16]
описан
подход к построению
идентификаторов-заменителей.
Идентификатор
состоит из
двух частей:
кода кластера
и номера в
последовательности.
Такой подход
основывается
на следующих
трех принципах:
Идентификатор
объекта должен
содержать
информацию
о кластере,
который группирует
совместно
используемые
объекты
Должны
быть допустимы
произвольные
размеры кластеров
Идентификаторы
объектов должны
подчиняться
достаточно
однообразному
представлению,
чтобы они могли
выступать в
качестве
псевдоключей
динамического
хеширования.
Есть
три признака,
по которым
СУБД могут
принимать
решение о месте
размещения
объектов:
Правила,
заданные в
схеме БД
Указание
пользователя
Статистика
доступа
В
дипломной
работе, несмотря
на заманчивость
идеи кластеризации,
принят тривиальный
подход: идентификатор
нового объекта
– это значение
максимального
идентификатора,
использующийся
в системе, плюс
один. Объекты
также хранятся
не в виде кластеров
и не вкладываются
друг в друга.
Хотя система
управления
памятью позволяет
организовать
и такой способ
хранения.
Идентичность
и эквивалентность
В
ООБД при сравнении
двух объектов
между собой
различают
идентичность
и эквивалентность
объектов.
Определение
идентичности
Два
объекта являются
идентичными,
если их идентификаторы
совпадают.
Поскольку в
системе не
может быть
двух объектов
с одинаковыми
идентификаторами,
это означает,
что это один
и тот же объект,
на который
ссылаются с
двух разных
мест. Идентичность
обозначается
так: o1
є
o2.
Определение
N-эквивалентности
Пусть
0-эквивалентность
(обозначается
»0)
то же самое,
что проверка
идентичности
є.
Тогда для любых
двух объектов
o1,
o2ОO,
o1 и
o2 n-эквивалентны
(обозначается
o1 »n
o2)
для
n > 0,
если:
Существует
атомарный
объект c,
такой,
что значение(o1)
= значение(o2)
и их
поведения
идентичны;
Существует
объект-агрегат
c, такой,
что FID
каждого поля
с
присутствует
в o1
и
o2,
а
также верно
обратное: FID
каждого
поля o1
(o2)
присутствует
в c,
значение(o1)=[A1
: x1,
…, Am
: xm]
и
значение(o2)=[A1
: y1,
…, Am
: ym],
и при этом
xi
»n-1
yi
для
1Ј
i Ј
n; или
Существует
объект-условие
c, такой,
что значение(o1)
= <x1,
x2,
x3>
и
значение(o2)
= <y1,
y2,
y3>
и
xi
»n-1
yi
для
1Ј
i Ј
3; или
Существует
объект-множество
c, такой,
что значение(o1)
= {x1,
…, xl}
и
значение(o2)
= {y1,
…, ym}
и
l
= m и
для каждого
xi(yj)
существует
один yj(xi)
: xi
»n-1
yj
для
1Ј
i,j Ј
l; или
Существует
объект-список
c, такой,
что значение(o1)
= (x1,
…, xl)
и
значение(o2)
= (y1,
…, ym)
и
l
= m и
xi
»n-1
yi
для
1Ј
i Ј
l.
Два
объекта называются
эквивалентными
(o1 »
o2)
тогда и только
тогда, когда
o1 »n
o2
для некоторого
n > 0.
2.4
Идентификатор
поля агрегата
Введение
идентификатора
поля позволяет
преодолеть
трудность
определения
размещения
данных полей
агрегатов.
Суть проблемы
заключается
в том, что если
мы наследуем
классы B и C от
класса A, а затем
наследуем
множественно
класс D от классов
B и C, то экземпляр
класса D одновременно
является экземпляром
классов A, B и C.
При этом важно,
чтобы "старый"
класс (например,
A) умел работать
с