Методы внутренней сортировки. Обменная сортировка. Сравнение с другими методами сортировки
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ
РОССИЙСКОЙ
ФЕДЕРАЦИИ
КУРСОВАЯ
РАБОТА
по
дисциплине
«Алгоритмическое
обеспечение
ЭВС»
на тему «Методы
внутренней
сортировки.
Обменная сортировка.
Сравнение
с другими методами
сортировки»
2010
г.
Содержание
Введение
1.
Сортировка
включением
2.
Сортировка
Шелла
3.
Обменная сортировка
4.
Сортировка
выбором
5.
Сортировка
разделением
6.
Сравнение
методов
Заключение
Приложение
Литература
Введение
Целью
данной курсовой
работы является
изучения основных
алгоритмов
внутренней
сортировки
массивов данных,
сравнение
сложности их
реализации
и производительности.
Более подробно
рассмотрен
метод обменной
сортировки.
Если
обратиться
к литературе,
то можно обнаружить
два крайних
подхода к
представлению
материала.
Некоторые
авторы любят
излагать материал
на высоком
теоретическом
уровне. Например,
для того, чтобы
ввести понятие
типа данных
и предложить
классификацию
возможных
типов, используются
развитые механизмы
абстрактной
алгебры; при
описании алгоритмов
в обязательном
порядке приводятся
асимптотические
оценки их сложности.
Другой подход
состоит в
максимальном
приближении
к практике.
Обычно выбирается
некоторый
конкретный
язык программирования,
и все описываемые
структуры
данных и алгоритмы
представляются
на этом языке.
1.
Сортировка
включением
Одним
из наиболее
простых и
естественных
методов внутренней
сортировки
является сортировка
с простыми
включениями.
Идея алгоритма
очень проста.
Пусть имеется
массив ключей
a[1], a[2], ..., a[n]. Для каждого
элемента массива,
начиная со
второго, производится
сравнение с
элементами
с меньшим индексом
(элемент a[i]
последовательно
сравнивается
с элементами
a[i-1], a[i-2] ...) и до тех пор,
пока для очередного
элемента a[j]
выполняется
соотношение
a[j] > a[i], a[i] и a[j] меняются
местами. Если
удается встретить
такой элемент
a[j], что a[j] <= a[i], или
если достигнута
нижняя граница
массива, производится
переход к обработке
элемента a[i+1] (пока
не будет достигнута
верхняя граница
массива).
Легко
видеть, что в
лучшем случае
(когда массив
уже упорядочен)
для выполнения
алгоритма с
массивом из
n элементов
потребуется
n-1 сравнение и
0 пересылок. В
худшем случае
(когда массив
упорядочен
в обратном
порядке) потребуется
n?(n-1)/2 сравнений
и столько же
пересылок.
Таким образом,
можно оценивать
сложность
метода простых
включений как
O(n2).
Можно
сократить число
сравнений,
применяемых
в методе простых
включений, если
воспользоваться
тем фактом, что
при обработке
элемента a[i] массива
элементы a[1], a[2],
..., a[i-1] уже упорядочены,
и воспользоваться
для поиска
элемента, с
которым должна
быть произведена
перестановка,
методом двоичного
деления. В этом
случае оценка
числа требуемых
сравнений
становится
O(n?log n). Заметим, что
поскольку при
выполнении
перестановки
требуется
сдвижка на один
элемент нескольких
элементов, то
оценка числа
пересылок
остается O(n2).
Таблица 1.1
Пример сортировки
методом простого
включения
| Начальное
состояние
массива |
8 23 5 65 44 33 1 6 |
| Шаг 1 |
8 23 5 65 44 33 1 6 |
| Шаг 2 |
8 5 23 65 44 33 1 6
5 8 23 65 44 33 1 6
|
| Шаг 3 |
5 8 23 65 44 33 1 6 |
| Шаг 4 |
5 8 23 44 65 33 1 6 |
| Шаг 5 |
5 8 23 44 33 65 1 6
5 8 23 33 44 65 1 6
|
| Шаг 6 |
5 8 23 33 44 1 65 6
5 8 23 33 1 44 65 6
5 8 23 1 33 44 65 6
5 8 1 23 33 44 65 6
5 1 8 23 33 44 65 6
1 5 8 23 33 44 65 6
|
| Шаг 7 |
1 5 8 23 33 44 6 65
1 5 8 23 33 6 44 65
1 5 8 23 6 33 44 65
1 5 8 6 23 33 44 65
1 5 6 8 23 33 44 65
|
2.
Сортировка
Шелла
Дальнейшим
развитием
метода сортировки
с включениями
является сортировка
методом Шелла,
называемая
по-другому
сортировкой
включениями
с уменьшающимся
расстоянием.
Мы не будем
описывать
алгоритм в
общем виде, а
ограничимся
случаем, когда
число элементов
в сортируемом
массиве является
степенью числа
2. Для массива
с 2n элементами
алгоритм работает
следующим
образом. На
первой фазе
производится
сортировка
включением
всех пар элементов
массива, расстояние
между которыми
есть 2(n-1). На второй
фазе производится
сортировка
включением
элементов
полученного
массива, расстояние
между которыми
есть 2(n-2). И так
далее, пока мы
не дойдем до
фазы с расстоянием
между элементами,
равным единице,
и не выполним
завершающую
сортировку
с включениями.
Применение
метода Шелла
к массиву,
используемому
в наших примерах,
показано в
таблице 2.2.
Таблица1.2.
Пример сортировки
методом Шелл
| Начальное
состояние
массива |
8 23 5 65 44 33 1 6 |
| Фаза 1 (сортируются
элементы,
расстояние
между которыми
четыре) |
8 23 5 65 44 33 1 6
8 23 5 65 44 33 1 6
8 23 1 65 44 33 5 6
8 23 1 6 44 33 5 65
|
| Фаза 2 (сортируются
элементы,
расстояние
между которыми
два) |
1 23 8 6 44 33 5 65
1 23 8 6 44 33 5 65
1 23 8 6 5 33 44 65
1 23 5 6 8 33 44 65
1 6 5 23 8 33 44 65
1 6 5 23 8 33 44 65
1 6 5 23 8 33 44 65
|
| Фаза 3 (сортируются
элементы,
расстояние
между которыми
один) |
1 6 5 23 8 33 44 65
1 5 6 23 8 33 44 65
1 5 6 23 8 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
В
общем случае
алгоритм Шелла
естественно
переформулируется
для заданной
последовательности
из t расстояний
между элементами
h1, h2, ..., ht, для которых
выполняются
условия h1 = 1 и
h(i+1) < hi. Дональд
Кнут показал,
что при правильно
подобранных
t и h сложность
алгоритма Шелла
является O(n(1.2)),
что существенно
меньше сложности
простых алгоритмов
сортировки.
3.
Обменная
сортировка
Простая
обменная сортировка
(в просторечии
называемая
"методом пузырька")
для массива
a[1], a[2], ..., a[n] работает
следующим
образом. Начиная
с конца массива
сравниваются
два соседних
элемента (a[n] и
a[n-1]). Если выполняется
условие a[n-1] > a[n],
то значения
элементов
меняются местами.
Процесс продолжается
для a[n-1] и a[n-2] и т.д.,
пока не будет
произведено
сравнение a[2]
и a[1]. Понятно, что
после этого
на месте a[1] окажется
элемент массива
с наименьшим
значением. На
втором шаге
процесс повторяется,
но последними
сравниваются
a[3] и a[2]. И так далее.
На последнем
шаге будут
сравниваться
только текущие
значения a[n] и
a[n-1]. Понятна аналогия
с пузырьком,
поскольку
наименьшие
элементы (самые
"легкие") постепенно
"всплывают"
к верхней границе
массива. Пример
сортировки
методом пузырька
показан в таблице
2.3.
Таблица
1.3. Пример
сортировки
методом Пузырька
| Начальное
состояние
массива |
8 23 5 65 44 33 1 6 |
| Шаг 1 |
8 23 5 65 44 33 1 6
8 23 5 65 44 1 33 6
8 23 5 65 1 44 33 6
8 23 5 1 65 44 33 6
8 23 1 5 65 44 33 6
8 1 23 5 65 44 33 6
1 8 23 5 65 44 33 6
|
| Шаг 2 |
1 8 23 5 65 44 6 33
1 8 23 5 65 6 44 33
1 8 23 5 6 65 44 33
1 8 23 5 6 65 44 33
1 8 5 23 6 65 44 33
1 5 8 23 6 65 44 33
|
| Шаг 3 |
1 5 8 23 6 65 33 44
1 5 8 23 6 33 65 44
1 5 8 23 6 33 65 44
1 5 8 6 23 33 65 44
1 5 6 8 23 33 65 44
|
| Шаг 4 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 5 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 6 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 7 |
1 5 6 8 23 33 44 65 |
Для
метода простой
обменной сортировки
требуется число
сравнений
nx(n-1)/2, минимальное
число пересылок
0, а среднее и
максимальное
число пересылок
- O(n2).
Метод
пузырька допускает
три простых
усовершенствования.
Во-первых, как
показывает
таблица 3, на
четырех последних
шагах расположение
значений элементов
не менялось,
(массив оказался
уже упорядоченным).
Поэтому, если
на некотором
шаге не было
произведено
ни одного обмена,
то выполнение
алгоритма можно
прекращать.
Во-вторых, можно
запоминать
наименьшее
значение индекса
массива, для
которого на
текущем шаге
выполнялись
перестановки.
Очевидно, что
верхняя часть
массива до
элемента с этим
индексом уже
отсортирована,
и на следующем
шаге можно
прекращать
сравнения
значений соседних
элементов при
достижении
такого значения
индекса. В-третьих,
метод пузырька
работает
неравноправно
для "легких"
и "тяжелых"
значений. Легкое
значение попадает
на нужное место
за один шаг, а
тяжелое на
каждом шаге
опускается
по направлению
к нужному месту
на одну позицию.
На
этих наблюдениях
основан метод
шейкерной
сортировки
(ShakerSort). При его применении
на каждом следующем
шаге меняется
направление
последовательного
просмотра. В
результате
на одном шаге
"всплывает"
очередной
наиболее легкий
элемент, а на
другом "тонет"
очередной самый
тяжелый. Пример
шейкерной
сортировки
приведен в
таблице 2.4.
Таблица
4. Пример шейкерной
сортировки
| Начальное
состояние
массива |
8 23 5 65 44 33 1 6 |
| Шаг 1 |
8 23 5 65 44 33 1 6
8 23 5 65 44 1 33 6
8 23 5 65 1 44 33 6
8 23 5 1 65 44 33 6
8 23 1 5 65 44 33 6
8 1 23 5 65 44 33 6
1 8 23 5 65 44 33 6
|
| Шаг 2 |
1 8 23 5 65 44 33 6
1 8 5 23 65 44 33 6
1 8 5 23 65 44 33 6
1 8 5 23 44 65 33 6
1 8 5 23 44 33 65 6
1 8 5 23 44 33 6 65
|
| Шаг 3 |
1 8 5 23 44 6 33 65
1 8 5 23 6 44 33 65
1 8 5 6 23 44 33 65
1 8 5 6 23 44 33 65
1 5 8 6 23 44 33 65
|
| Шаг 4 |
1 5 6 8 23 44 33 65
1 5 6 8 23 44 33 65
1 5 6 8 23 44 33 65
1 5 6 8 23 33 44 65
|
| Шаг 5 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
Шейкерная
сортировка
позволяет
сократить число
сравнений (по
оценке Кнута
средним числом
сравнений
является (n2 -
n?(const + ln n)), хотя порядком
оценки по-прежнему
остается n2. Число
же пересылок,
вообще говоря,
не меняется.
Шейкерную
сортировку
рекомендуется
использовать
в тех случаях,
когда известно,
что массив
"почти упорядочен".
4. Сортировка
выбором
При
сортировке
массива a[1], a[2], ...,
a[n] методом простого
выбора среди
всех элементов
находится
элемент с наименьшим
значением a[i],
и a[1] и a[i] обмениваются
значениями.
Затем этот
процесс повторяется
для получаемых
подмассивов
a[2], a[3], ..., a[n], ... a[j], a[j+1], ..., a[n] до тех
пор, пока мы не
дойдем до подмассива
a[n], содержащего
к этому моменту
наибольшее
значение. Работа
алгоритма
иллюстрируется
примером в
таблице 2.5.
Таблица
5. Пример сортировки
простым выбором
| Начальное
состояние
массива |
8 23 5 65 44 33 1 6 |
| Шаг 1 |
1 23 5 65 44 33 8 6 |
| Шаг 2 |
1 5 23 65 44 33 8 6 |
| Шаг 3 |
1 5 6 65 44 33 8 23 |
| Шаг 4 |
1 5 6 8 44 33 65 23 |
| Шаг 5 |
1 5 6 8 33 44 65 23 |
| Шаг 6 |
1 5 6 8 23 44 65 33 |
| Шаг 7 |
1 5 6 8 23 33 65 44 |
| Шаг 8 |
1 5 6 8 23 33 44 65 |
Для метода
сортировки
простым выбором
требуемое число
сравнений -
nx(n-1)/2. Порядок
требуемого
числа пересылок
(включая те,
которые требуются
для выбора
минимального
элемента) в
худшем случае
составляет
O(n2). Однако порядок
среднего числа
пересылок есть
O(n?ln n), что в ряде
случаев делает
этот метод
предпочтительным.
5. Сортировка
разделением
(Quicksort)
Метод
сортировки
разделением
был предложен
Чарльзом Хоаром
(он любит называть
себя Тони) в
1962 г. Этот метод
является развитием
метода простого
обмена и настолько
эффективен,
что его стали
называть "методом
быстрой сортировки
- Quicksort".
Основная
идея алгоритма
состоит в том,
что случайным
образом выбирается
некоторый
элемент массива
x, после чего
массив просматривается
слева, пока не
встретится
элемент a[i] такой,
что a[i] > x, а затем
массив просматривается
справа, пока
не встретится
элемент a[j] такой,
что a[j] < x. Эти два
элемента меняются
местами, и процесс
просмотра,
сравнения и
обмена продолжается,
пока мы не дойдем
до элемента
x. В результате
массив окажется
разбитым на
две части - левую,
в которой значения
ключей будут
меньше x, и правую
со значениями
ключей, большими
x. Далее процесс
рекурсивно
продолжается
для левой и
правой частей
массива до тех
пор, пока каждая
часть не будет
содержать в
точности один
элемент. Понятно,
что как обычно,
рекурсию можно
заменить итерациями,
если запоминать
соответствующие
индексы массива.
Проследим этот
процесс на
примере нашего
стандартного
массива (таблица
2.6).
Таблица
6. Пример быстрой
сортировки
| Начальное
состояние
массива |
8 23 5 65 |44| 33 1 6 |
| Шаг 1 (в качестве
x выбирается
a[5]) |
|--------|
8 23 5 6 44 33 1 65
|---|
8 23 5 6 1 33 44 65
|
| Шаг 2 (в подмассиве
a[1], a[5] в качестве
x выбирается
a[3]) |
8 23 |5| 6 1 33 44
65
|--------|
1 23 5 6 8 33 44 65
|--|
1 5 23 6 8 33 44 65
|
| Шаг 3 (в подмассиве
a[3], a[5] в качестве
x выбирается
a[4]) |
1 5 23 |6| 8 33 44
65
|----|
1 5 8 6 23 33 44 65
|
| Шаг 4 (в подмассиве
a[3], a[4] выбирается
a[4]) |
1 5 8 |6| 23 33 44
65
|--|
1 5 6 8 23 33 44 65
|
Алгоритм
недаром называется
быстрой сортировкой,
поскольку для
него оценкой
числа сравнений
и обменов является
O(n?log n). На самом деле,
в большинстве
утилит, выполняющих
сортировку
массивов,
используется
именно этот
алгоритм.
6. Сравнение
методов
Для
сравнения
методов сортировки
была написана
программа,
позволяющая
выполнить
сортировку
пятью способами,
по возрастанию
или убыванию.
Заполнение
массива производится
случайными
данными.
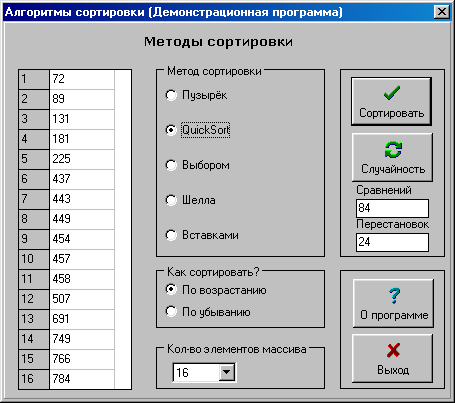
Рис
1. Интерфейс
программы.
После
выполнения
сортировки
программа
выводит количество
сравнений и
перестановок.
При сравнении
заполнялась
таблица зависимости
числа перестановок
и числа сравнений
от размера
массива.
Таблица
7
| Метод |
Сравнений |
Перестановок |
| Кол-во |
16 |
32 |
64 |
128 |
256 |
16 |
32 |
64 |
128 |
256 |
| Пузырёк |
135 |
527 |
2079 |
8255 |
32895 |
69 |
201 |
1150 |
3644 |
14648 |
| QuickSort |
70
|
223 |
486 |
1228
|
2771
|
20 |
70 |
160 |
399 |
887 |
| Выбором |
120 |
496 |
2016 |
8128 |
32640 |
11
|
29
|
58
|
124
|
249
|
| Шелла |
73 |
186
|
484
|
1348 |
3771 |
19 |
54 |
200 |
756 |
2537 |
| Вставками |
74 |
315 |
1177 |
4819 |
17525 |
46 |
257 |
1056 |
4566 |
17018 |
На основании
данных таблицы
были построены
графики.
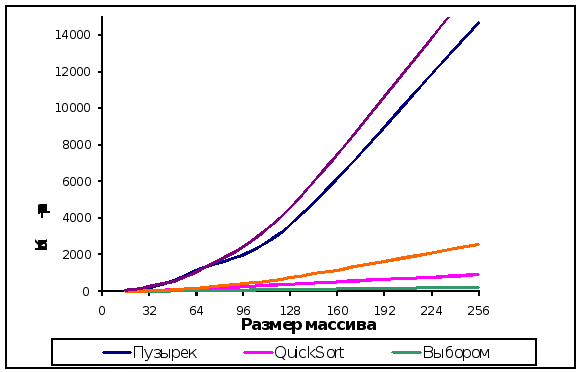
Рис
2. Зависимость
числа перестановок
от размера
массива
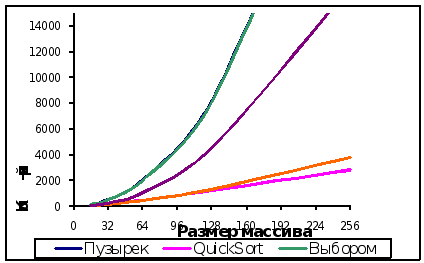
Рис
3. Зависимость
числа сравнений
от размера
массива.
Выводы
По
результатам
замеров производительности
методов можно
сделать следующие
выводы:
Наиболее
универсальным
методом, является
метод быстрой
сортировки
(«QuickSort»), он
показывает
стабильно
высокие результаты
на любых размерах
массивов. На
втором месте
находится
метод Шелла.
Его использование
может быть
обосновано
большее простым
алгоритмом
с точки зрения
программиста.
Метод
вставки эффективен,
при условии
большого времени
выполнения
операций
перестановки,
так как он является
абсолютным
лидером по
количеству
перестановок,
проигрывая
при этом по
количеству
сравнений.
При
использовании
небольших
массивов данных
нет большой
разницы по
скорости между
методами сортировки,
поэтому целесообразнее
применять
метод Пузырька
или метод вставок.
Исследование
проводилось
на массивах
с большой степенью
неупорядоченности.
Для массивов,
которые уже
являются почти
отсортированными,
наиболее применим
метод сортировки
вставками.
Приложение
Блок
схемы.
Обменная
сортировка.
Сортировка
выбором.
Сортировка
вставкой.