Анализ и оптимизация цифровой системы связи
связей
между m и n нет. Существуют только верхние и нижние оценки, которые
устанавливают связь между максимально возможным минимальным расстоянием
корректирующего кода и его избыточностью.
Так, граница Плоткина даёт верхнюю
границу кодового расстояния dmin
при заданном числе разрядов n в кодовой комбинации и числе информационных разрядов
m, и для двоичных кодов:
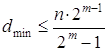 (1.38)
(1.38)
или
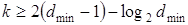 при
при 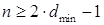 .(1.39)
.(1.39)
Верхняя граница Хемминга
устанавливает максимально возможное число разрешённых кодовых комбинаций (2m) любого помехоустойчивого кода при заданных
значениях n и dmin:
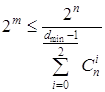 ,(1.40)
,(1.40)
где 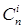 -
число сочетаний из n элементов по i элементам.
-
число сочетаний из n элементов по i элементам.
Отсюда можно получить выражение для
оценки числа проверочных символов:
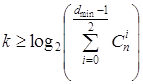 .(1.41)
.(1.41)
Для значений (dmin/n) ≤ 0,3 разница между
границей Хемминга и границей Плоткина сравнительно невелика.
Граница Варшамова-Гильберта для
больших значений n определяет нижнюю границу для числа проверочных разрядов,
необходимого для обеспечения заданного кодового расстояния:
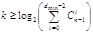 .(1.42)
.(1.42)
Все приведенные выше оценки дают
представление о верхней границе числа dmin при фиксированных значениях n и m или оценку снизу числа проверочных символов k при заданных m и dmin.
Из изложенного можно сделать вывод,
что с точки зрения внесения постоянной избыточности в кодовую комбинацию
выгодно выбирать длинные кодовые комбинации, так как с увеличением n относительная пропускная способность
R = V/B = m/n(1.43)
увеличивается, стремясь к пределу,
равному 1.
В реальных каналах связи действуют
помехи, приводящие к появлению ошибок в кодовых комбинациях. При обнаружении
ошибки декодирующим устройством в системах с РОС производится переспрос группы
кодовых комбинаций. Во время переспроса полезная информация не передается,
поэтому скорость передачи информации уменьшается.
Можно показать, что в этом случае
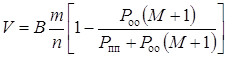 ,(1.44)
,(1.44)
где
Poo - вероятность
обнаружения ошибки декодером (вероятность переспроса):
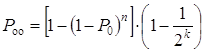 ;(1.45)
;(1.45)
Рпп
- вероятность правильного приема (безошибочного приема) кодовой комбинации 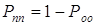 ;
;
М
- емкость накопителя передатчика в числе кодовых комбинаций
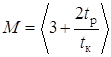 ,(1.46)
,(1.46)
где
tp - время распространения сигнала по каналу связи, с;
tк
– время передачи кодовой комбинации из n
разрядов, с.
Знак
< > означает, что при расчете М следует брать большее ближайшее целое
значение.
Время
распространения сигнала по каналу связи и время передачи кодовой комбинации
рассчитываются в соответствии с выражениями
tp = (L/с);
tк = (n/B),
где
L - расстояние между оконечными станциями, км;
с
- скорость распространения сигнала по каналу связи, км / с (с = 3х105);
В
- скорость модуляции, Бод.
При
наличии ошибок в канале связи величина R является функцией Р0, n,
k, В, L, с. Следовательно, существует оптимальное n
(при заданных Р0, В, L, с), при котором относительная пропускная
способность будет максимальной.
Для
вычисления оптимальных величин n,
k, m
удобнее всего воспользоваться программным пакетом математического
моделирования, таким как MathLab
или MathCAD, построив в нем
график зависимости R(n).
Оптимальное значение будет в том случае, когда R(n)
– максимально. При определении величин n,
k, m
необходимо также обеспечить выполнение условия:
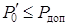 ,(1.47)
,(1.47)
где
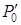 - эквивалентная вероятность
ошибки приема единичного разряда при применении помехоустойчивого кодирования с
РОС.
- эквивалентная вероятность
ошибки приема единичного разряда при применении помехоустойчивого кодирования с
РОС.
Величину
можно определить
воспользовавшись соотношением, что при передаче без применения
помехоустойчивого кодирования вероятность ошибочной регистрации кодовой
комбинации Р0кк длины n
равна
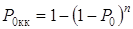 .(1.48)
.(1.48)
В
тоже время при применении помехоустойчивого кодирования
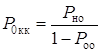 ,(1.49)
,(1.49)
где 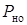 - вероятность необнаруженных ошибок
- вероятность необнаруженных ошибок
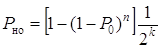 ;(1.50)
;(1.50)
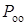 - вероятность обнаруженных ошибок
- вероятность обнаруженных ошибок
.(1.51)
Дополнительно к выполнению условия (1.47)
необходимо обеспечить
V ³ Ht. (1.52)
Из казанного выше следует, что
процесс поиска значений В, n, m, k является итерационным и его удобнее всего оформить в виде
таблицы, образец которой приведен в табл. 1.2
Таблица 1.2
| Ht = , Pдоп = . |
| to |
n |
m |
K |
|
В |
V |
| 1 |
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
| … |
|
|
|
|
|
|
Для обнаружения ошибок выбираем
циклический код. Из всех известных помехоустойчивых кодов циклические коды
являются наиболее простыми и эффективными. Эти коды могут быть использованы как
для обнаружения и исправления независимых ошибок, так и, в особенности, для
обнаружения и исправления серийных ошибок. Основное их свойство состоит в том,
что каждая кодовая комбинация может быть получена путём циклической
перестановкой символов комбинаций, принадлежащей этому же коду.
Циклические коды значительно упрощают
описание линейного кода, поскольку для них вместо задания 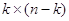 элементов двоичной матрицы Ρ требуется задать (n-k+1) двоичных коэффициентов многочлена g(D). Кроме того, они упрощают процедуру кодирования и
декодирования для обнаружения ошибок. Действительно, для осуществления
кодирования достаточно выполнить перемножение полиномов, что реализуется с
помощью линейного регистра, содержащего k ячеек памяти и имеющего обратные связи, соответствующие многочлену
h(D) [4].
элементов двоичной матрицы Ρ требуется задать (n-k+1) двоичных коэффициентов многочлена g(D). Кроме того, они упрощают процедуру кодирования и
декодирования для обнаружения ошибок. Действительно, для осуществления
кодирования достаточно выполнить перемножение полиномов, что реализуется с
помощью линейного регистра, содержащего k ячеек памяти и имеющего обратные связи, соответствующие многочлену
h(D) [4].
Циклический код гарантированно
обнаруживает ошибки кратностью 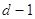 и исправляет
и исправляет 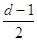 . Поэтому в системах с решающей обратной связью
применяется кодирование циклическим кодом.
. Поэтому в системах с решающей обратной связью
применяется кодирование циклическим кодом.
При
обнаружении ошибки на приемной стороне по обратному каналу связи посылается
запрос на блок, в котором она была обнаружена, и тогда этот блок передаётся
повторно. Так продолжается до тех пор, пока данный блок не будет принят без
обнаруженной ошибки. Такая система называется системой с решающей обратной
связью (РОС), поскольку решение о приёме блока или о его повторной передаче
производится на приёмной стороне. Система с РОС являются эффективным способом
повышения помехоустойчивости передачи информации.
При описании процедуры кодирования и
декодирования циклическим кодом удобно использовать математический аппарат,
основанный на сопоставлении множества кодовых слов с множеством степенных
полиномов. Этот аппарат позволяет выявить для циклического кода более простые
операции кодирования и декодирования.
Среди всех полиномов, соответствующих
кодовым словам циклического кода, имеется ненулевой полином P(x) наименьшей степени. Этот полином полностью определяет соответствующий
код и поэтому называется порождающим.
Степень порождающего полинома P(x) равна n - m, свободный член всегда равен
единице.
Порождающий полином является
делителем всех полиномов, соответствующих кодовым словам циклического кода.
Нулевая комбинация обязательно
принадлежит любому линейному циклическому коду и может быть записана как (xn Å 1) mod (xn Å 1) = 0. Следовательно, порождающий полином
Р(x) должен быть делителем бинома xn Å 1.
Это даёт конструктивную возможности
построения циклического кода заданной длины n: любой полином, являющийся делителем бинома xn Å 1, можно использовать в качестве
порождающего.
При построении циклических кодов,
пользуются таблицами разложения биномов xn Å 1 на неприводимые полиномы, т.е.
полиномы, которые нельзя представить в виде произведения двух других полиномов
(см. приложение А).
Любой неприводимый полином, входящий
в разложение бинома xn Å 1, а также любое произведение неприводимых полиномов
может быть выбрано в качестве порождающего полинома, что дает соответствующий
циклический код.
Для построения систематического
циклического кода используется следующее правило построения кодовых слов
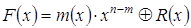 ,
,
где R(x) – остаток от
деления m(x)×xn-m
на Р(x).
Степень R(x), очевидно,
меньше (n - m), а потому в кодовом слове первые m, символов будут совпадать с
информационными, а последние n - m символов будут проверочными.
В основу процедуры декодирования
циклических кодов может быть положено свойство их делимости без остатка на порождающий
полином Р(x).
В режиме обнаружения ошибок, если
принятая последовательность делится без остатка на Р(x), делается вывод, что ошибки нет или она не обнаруживается.
В противном случае комбинация бракуется.
В режиме исправления ошибок декодер
вычисляет остаток R(x) от деления принятой
последовательности F¢(x) на P(x).
Этот остаток называют синдромом. Принятый полином F¢(x) представляет
собой сумму по модулю два переданного слова F(x) и вектора
ошибок Eош(x):
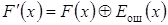 .
.
Тогда синдром S(x) = F¢(x) mod P(x), так как по определению циклического кода F(x) mod P(x) = 0.
Определенному синдрому S(x) может быть поставлен в соответствие
определенный вектор ошибок Eош(x). Тогда переданное слово F(x) находят,
складывая 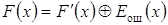 .
.
Однако один и тот же синдром может
соответствовать 2m
различным векторам ошибок. Положим, синдром S1(x) соответствует
вектору ошибок E1(x). Но и все векторы ошибок, равные сумме E1(x) Å F(x), где F(x) любое кодовое слово, будут давать
тот же синдром. Поэтому, поставив в соответствие синдрому S1(x)
вектор ошибок E1(x), мы
будем осуществлять правильное декодирование в случае, когда действительно
вектор ошибок равен E1(x), во всех остальных 2m- 1
случаях декодирование будет ошибочным.
Для уменьшения вероятности ошибки
декодирования из всех возможных векторов ошибок, дающих один и тот же синдром,
следует выбирать в качестве исправляемого наиболее вероятный в заданном канале.
Например, для ДСК, в котором
вероятность P0 ошибочного приёма двоичного символа много меньше
вероятности (1 - P0) правильного приема, вероятность появления векторов
ошибок уменьшается с увеличением их веса i. В этом случае следует исправлять в первую очередь вектор
ошибок меньшего веса.
Если кодом могут быть исправлены
только все векторы ошибок веса i и
меньше, то любой вектор ошибки веса от i + 1
до n, будет приводить к ошибочному декодированию.
Вероятность ошибочного декодирования
будет равна вероятности Pn(>i) появления векторов ошибок веса i + 1 и больше в заданном канале. Для ДСК эта вероятность
будет равна
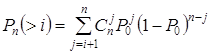 .
.
Общее число различных векторов
ошибок, которые может исправлять циклический код, равно числу ненулевых
синдромов – 2n-m - 1.
В курсовом проекте необходимо на
основании вычисленного в предыдущем пункте значения k выбрать образующий полином по таблице приведенной в приложении
А. По выбранному образующему полиному необходимо разработать схему кодера и
декодера для случая обнаружения ошибки.
1.5
Показатели эффективности цифровой системы связи
Цифровые системы связи
характеризуются качественными показателями, одним из которых является верности
(правильность) передачи.
Для оценки эффективности системы
связи вводят коэффициент использования канала связи за мощностью 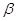 (энергетическая эффективность) и
коэффициент использования канала по полосе частот
(энергетическая эффективность) и
коэффициент использования канала по полосе частот 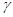 (частотная эффективность):
(частотная эффективность):
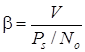 , (1.53)
, (1.53)
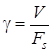 , (1.54)
, (1.54)
где V – скорость передачи информации;
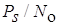 — отношения сигнал/шум на входе демодулятора
— отношения сигнал/шум на входе демодулятора
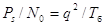 ; (1.55)
; (1.55)
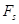 - ширина полосы частот, которую занимает сигнал
- ширина полосы частот, которую занимает сигнал
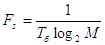 , (1.56)
, (1.56)
где М – число позиций сигнала.
Обобщенной характеристикой есть коэффициент использования
канала по пропускной способности (информационная эффективность):
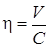 . (1.57)
. (1.57)
Для непрерывного канала связи с учетом формулы Шеннона
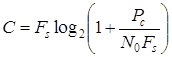
получаем следующее выражение
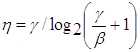 . (1.58)
. (1.58)
Соответственно теоремам Шеннона при h=1 можно получить зависимость между b и g:
b=g/(2g - 1), (1.59)
которая имеет название границы
Шеннона, что отображает наилучший обмен между b и g в непрерывном канале. Эту зависимость удобно изобразить в виде кривой на
плоскости b - g (рис.1.6).
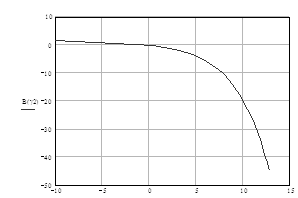
Рисунок 1.6 - Граница Шеннона
Эффективность системы может быть
повышена за