БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИНФОРМАТИКИ И РАДИОЭЛЕКТРОНИКИ
кафедра РЭС
реферат на тему:
«Основные параметры помехоустойчивого кодирования. Основные параметры помехоустойчивых кодов»
МИНСК, 2009
ОСНОВНЫЕ ПРИНЦИПЫ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ
Кодирование с исправлением ошибок, по существу, представляет собой метод обработки сигналов, предназначенный для увеличения надежности передачи по цифровым каналам. Хотя различные схемы кодирования очень непохожи друг на друга и основаны на различных математических теориях, всем им присущи два общих свойства. Одно из них - использование избыточности. Закодированные цифровые сообщения всегда содержат дополнительные, или избыточные, символы. Эти символы используют для того, чтобы подчеркнуть индивидуальность каждого сообщения. Их всегда выбирают так, чтобы сделать маловероятной потерю сообщением его индивидуальности из-за искажения при воздействии помех достаточно большого числа символов. Второе свойство состоит в усреднении шума. Эффект усреднения достигается за счет того, что избыточные символы зависят от нескольких информационных символов. Для понимания процесса кодирования полезно рассмотреть каждое из этих свойств отдельно.
Рассмотрим вначале двоичный канал связи с помехами, приводящими к тому, что ошибки появляются независимо в каждом символе и средняя вероятность ошибки равна Р=0,01. Если требуется рассмотреть произвольный блок из 10 символов на выходе канала, то весьма трудно выявить символы, которые являются ошибочными. Вместе с тем если считать, что такой блок содержит не более трех ошибок, то мы будем неправы лишь два раза на миллион блоков. Кроме того, вероятность, что мы окажемся правы, возрастает с увеличением длины блока. При увеличении длины блока доля ошибочных символов в блоке стремится к средней частоте ошибок в канале, а также, что очень важно, доля блоков, число ошибок в которых существенно отличается от этого среднего значения, становится очень малой. Простые вычисления помогают понять, насколько верным является это утверждение. Рассмотрев, например, тот же канал, вычислим вероятность того, что доля ошибочных символов превышает значение p, и построим график этой функции для нескольких значений длины блока.

Рис. 1. Вероятность того, что доля ошибочных символов e/N в блоке длиной N превышает р при вероятности Р e
=0,01
Кривые на рис.1 показывают, что при обработке символов блоками, а не одного за другим можно уменьшить общую частоту ошибок. При этом потребуется, чтобы существовала схема кодирования, нечувствительная к ошибкам в некоторой доле символов блока и не приводящая при этом к потере сообщением своей индивидуальности, т. е. не приводящая к ошибочному блоку. Из графиков для различных длин блоков видно, какую именно долю ошибок нужно исправлять, чтобы получить заданную вероятность ошибки блока. Он показывает также, что при фиксированной вероятности ошибки блока доля ошибок, которые нужно исправлять, уменьшается при возрастании длины блока. Сказанное свидетельствует о резервах улучшения характеристик при усреднении шума и о том, что эти резервы возрастают при увеличении длины блока. Таким образом, длинные блоковые коды эффективнее коротких. После того как установлена целесообразность исправления ошибок в символах, возникает следующий логичный вопрос: как это сделать? Ключ лежит в избыточности. После некоторых размышлений читатель поймет, что при исправлении ошибок в сообщении, представляемом последовательностью из n двоичных символов, очень важно учесть, чтобы не все 2n
возможных последовательностей представляли сообщения. В самом деле, когда каждая из возможных принятых последовательностей n символов представляет некоторое сообщение, нет никаких оснований считать, что одна последовательность является более правильной, чем любая другая. Продолжая рассуждать таким же способом, можно ясно увидеть, что для исправления всех наборов из t или менее ошибок необходимо и достаточно, чтобы каждая последовательность, представляющая сообщение, отличалась от последовательности, представляющей любое другое сообщение, не менее чем в 2t+1 местах. Например, для исправления всех одиночных или всех двойных ошибок в символах нужно, чтобы каждые две последовательности, представляющие разные сообщения, отличались не менее чем в пяти символах. Каждая принятая последовательность, содержащая два ошибочных символа и, следовательно, отличающаяся от посланной последовательности ровно в двух местах, будет всегда отличаться от всех других последовательностей, представляющих сообщения, не менее чем в трех местах. Число позиций, в которых две последовательности отличаются друг от друга, будем называть расстоянием Хемминга в между этими двумя последовательностями. Наименьшее значение в для всех пар кодовых последовательностей называется кодовым расстоянием и обозначается dmin
. Поскольку dmin
всегда должно быть на единицу больше удвоенного числа исправляемых ошибок, можно написать t=[(dmin
-l)/2], где [ ] обозначает целую часть. Параметр t указывает, что все комбинации из t или менее ошибок в любой принятой последовательности могут быть исправлены.Имеются модели каналов, в которых значение t может быть больше указанного.
Пример. Рассмотрим код, состоящий из четырех кодовых слов 00000, 00111,11100 и 11011. Каждое кодовое слово используется для представления одного из четырех возможных сообщении. Поскольку код включает лишь небольшую долю всех 32 возможных последовательностей из пяти символов, мы можем выбрать кодовые слова таким образом, чтобы каждые два из них отличались друг от друга не менее чем в трех позициях. Таким образом, кодовое расстояние равно трем и код может исправлять одиночную ошибку в любой позиции. Чтобы провести процедуру декодирования при этом коде, каждой из 28 недопустимых последовательностей нужно поставить в соответствие ближайшую к ней допустимую последовательность. Этот процесс ведет к созданию таблицы декодирования, которая строится следующим образом. Вначале под каждым кодовым словом выписываем все возможные последовательности, отличающиеся от него в одной позиции. В результате получаем часть табл. 1, заключенную между штриховыми линиями. Заметим, что после построения этой части осталось воcемь последовательностей. Каждая из этих последовательностей отличается от каждого кодового слова не менее чем в двух позициях. Однако в отличие от других последовательностей эти восемь последовательностей нельзя однозначно разместить в таблице. Например, последовательностью можно поместить либо в первый, либо в четвертый столбец. При использовании этой таблицы в процессе декодирования нужно найти столбец, в котором содержится принятая последовательность, и а качестве выходной последовательности декодера взять кодовое слово, находящееся в верхней строке этого столбца.
Таблица 1. Таблица декодирования для кода с четырьмя словами
00000
10000
01000
00100
00010
00001
|
11100
01100
10100
11000
11110
11101
|
00111
10111
01111
00011
00101
00110
|
11011
01011
10011
11111
11001
11010
|
10001
10010
|
01101
01110
|
10110
10101
|
01010
01001
|
Причина, по которой таблица декодирования должна строиться именно таким образом, очень проста. Вероятность появления фиксированной комбинации из i ошибок равна Рt
e
(1 -Рe
)5-i
Заметим что при Рe<1/2
(1 -Рe
)5
Pe
(1 -Рe
)4
Рe
2
(1 -Рe
)3
...
Таким образом, появление фиксированной одиночной ошибки более вероятно, чем фиксированной комбинации двух ошибок, и т. д. Это значит, что декодер, который декодирует каждую принятую последовательность в ближайшее к ней по расстоянию Хемминга кодовое слово, выбирает в действительности то кодовое слово, вероятность передачи которого максимальна (в предположении, что все кодовые слова равновероятны). Декодер, реализующий это правило декодирования, является декодером максимального правдоподобия, и в указанных предположениях он минимизирует вероятность появления ошибки декодирования принятой последовательности. В этом смысле такой декодер является оптимальным. Это понятие очень важно, поскольку декодеры максимального правдоподобия часто используются для коротких кодов. Кроме того, параметры декодера максимального правдоподобия могут служить эталоном, с которым сравниваются параметры других, неоптимальных декодеров. Если декодирование ведется с помощью таблицы декодирования, то элементы таблицы можно расположить так, чтобы получить декодирование по максимуму правдоподобия. К сожалению, объем таблицы растет экспоненциально с ростом длины блока, так что использование таблицы декодирования для длинных кодов нецелесообразно. Однако таблица декодирования часто оказывается полезной для выяснения важных свойств блоковых кодов.
Множество кодовых слов в таблице декодирования является подмножеством (первой строкой таблицы декодирования) множества всех 2n
последовательностей длиной n. В процессе построения таблицы декодирования множество всех последовательностей длиной n разбивается на непересекающиеся подмножества (столбцы таблицы декодирования). В случае когда код исправляет t ошибок, число Ne
последовательностей длиной n в каждом подмножестве удовлетворяет неравенству
Ne
>=1+n+Cn
2
+...+Cn
t
, (2)
где Cn
i
- i-й биномиальный коэффициент.
Неравенство (2) следует непосредственно из того, что имеется ровно n различных последовательностей, отличающихся от данной последовательности в одной позиции, Cn
2
последовательностей, отличающихся в двух позициях, и т. д. Как и в приведенном выше простом примере, после размещения всех последовательностей, отличающихся от кодовых в t или менее позициях, почти всегда остаются неразмещенные последовательности [отсюда неравенство в (2)]. Теперь можно связать избыточность кода c числом ошибок, которые им исправляются Заметим сначала, что число всех возможных последовательностей равно 2n
. Каждый столбец таблицы декодирования содержит Ne
таких последовательностей, поэтому общее число кодовых слов должно удовлетворять неравенству
Ne
<=<2n
/(1+n+Cn
2
+...+Cn
t
), (3)
Это неравенство называется границей Хемминга или границей сферической упаковки. Равенство в (3) достигается только для так называемых совершенных кодов. Эти коды исправляют все наборы из t или менее ошибок и не исправляют никаких других наборов. Число известных совершенных кодов очень невелико, так что равенство в (1.3) достигается в очень редких случаях.
Процесс кодирования состоит в том, что наборы k информационных символов отображаются в кодовые последовательности, состоящие из n символов. Любое такое отображение будем называть (n, k)-кодом, хотя обычно такое название применяется только к линейным кодам (которые обсуждаются позже). Поскольку число последовательностей длиной k равно 2k
, неравенство (3) можно переписать следующим образом:
2k
<=2n
/(1+n+Cn
2
+...+Cn
t
), (4)
Мера эффективности кода определяется отношением R=k/n (5)
и называется скоростью кода. Доля избыточно передаваемых символов равна 1-R.
Отображение, возникающее при кодировании, можно задавать таблицей кодирования. Например, код с четырьмя кодовыми словами задается табл. 2.
Таблица 2. Таблица поиска при декодировании
| Входная последовательность |
Кодовая последовательность |
00
01
10
11
|
00100
01111
11011
10000
|
Часть кодовой последовательности, заключенная между штриховыми линиями, совпадает с входной последовательностью. Поэтому каждой кодовой последовательности, легко однозначно сопоставить входную последовательность. Не все блоковые коды обладают этим свойством. Те, которые им обладают, называются систематическими кодами. Понятие избыточных символов для систематических кодов становится абсолютно ясным, и избыточными символами в табл. 1 являются символы на позициях 1, 4 и 5. Коды, не обладающие указанным свойством, называются несистематическими.
Существует много хороших конструктивных методов кодирования, позволяющих исправлять кратные ошибки и приводящих к заметному уменьшению частоты появления ошибочных символов. Эти коды легко строятся и с помощью современных полупроводниковых устройств относительно просто декодируются. Например, существует блоковый код длиной 40, содержащий 50% избыточных символов и позволяющий исправлять четыре случайные ошибки. На рис. 1 показано, что при Рe
=0,01 этот код имеет вероятность ошибки блока, меньшую 10-4
. Если этого недостаточно, разработчик увеличивает избыточность, чтобы исправлять большее число ошибок, или переходит к кодам с большей длиной блока и получает выигрыш за счет большего усреднения. В каждом случае нужно принимать во внимание возникающие дополнительные затраты. Однако обе указанные возможности допустимы и могут представлять практически приемлемые альтернативы. Прежде чем идти дальше, сделаем небольшое отступление, которое не имеет большого практического значения, но привлекает внимание специалистов по теории кодирования в течение многих лет. Форма кривых, изображенных на рис. 1, позволяет предположить, что если имеется схема, исправляющая фиксированную долю t/n ошибочных символов в блоке (в нашем случае t/n незначительно превышает 0,01), то, выбирая длину блока достаточно большой, можно сделать долю ошибок сколь угодно малой. К сожалению, это оказывается очень трудной задачей. Большинство конструктивных процедур может обеспечить постоянное отношение t/n лишь при возрастающей доле избыточных символов (другими словами, R->0 при n->oo). Таким образом, потеря эффективности возникает из-за того, что доля полезных сообщений становится очень малой при большой длине блока. Частично эта задача была решена Юстесеном в 1972 г. Юстесен показал, что можно построить класс асимптотически хороших (в указанном здесь смысле) кодов и указать для них процедуру декодирования. Однако, насколько известно, эти коды не применялись ни в одной из существующих систем связи.
Основные параметры помехоустойчивых кодов
Проблема повышения верности обусловлена не соответствием между требованиями, предъявляемыми при передачи данных и качеством реальных каналов связи. В сетях передачи данных требуется обеспечить верность не хуже 10-6
- 10-9
, а при использовании реальных каналов связи и простого (первичного) кода указанная верность не превышает 10-2
- 10-5
.
Одним из путей решения задачи повышения верности в настоящее время является использование специальных процедур, основанных на применении помехоустойчивых (корректирующих) кодов.
Простые коды характеризуются тем, что для передачи информации используются все кодовые слова (комбинации), количество которых равно N=qn
(q - основание кода, а n - длина кода). В общем случае они могут отличаться друг от друга одним символом (элементом). Поэтому даже один ошибочно принятый символ приводит к замене одного кодового слова другим и, следовательно, к неправильному приему сообщения в целом.
Помехоустойчивыми называются коды, позволяющие обнаруживать и (или) исправлять ошибки в кодовых словах, которые возникают при передаче по каналам связи. Эти коды строятся таким образом, что для передачи сообщения используется лишь часть кодовых слов, которые отличаются друг от друга более чем в одном символе. Эти кодовые слова называются разрешенными. Все остальные кодовые слова не используются и относятся к числу запрещенных.
Применение помехоустойчивых кодов для повышения верности передачи данных связанно с решением задач кодирования и декодирования.
Задача кодирования заключается в получении при передаче для каждой k - элементной комбинации из множества qk
соответствующего ей кодового слова длиною n из множества qn
.
Задача декодирования состоит в получении k - элементной комбинации из принятого n - разрядного кодового слова при одновременном обнаружении или исправлении ошибок.
Основные параметры помехоустойчивых кодов:
Длина кода - n;
Длина информационной последовательности - k;
Длина проверочной последовательности - r=n-k;
Кодовое расстояние кода - d0
;
Скорость кода - R=k/n;
Избыточность кода - R;
Вероятность обнаружения ошибки (искажения) - РОО
;
Вероятность не обнаружения ошибки (искажения) - РНО
.
Кодовое расстояние между двумя кодовыми словами (расстояние Хэмминга) - это число позиций, в которых они отличаются друг от друга.
Кодовое расстояние кода - это наименьшее расстояние Хэмминга между различными парами кодовых слов.
Основные зависимости между кратностью обнаруживаемых ошибок t0
, исправляемых ошибок tu
, исправлением стираний tc
и кодовым расстоянием d0
кода:
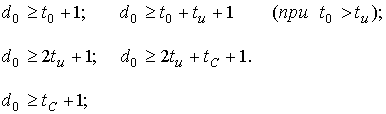
Стиранием называется "потеря" значения передаваемого символа в некоторой позиции кодового слова, которая известна.
Код, в котором каждое кодовое слово начинается с информационных символов и заканчивается проверочными символами, называется систематическим.
Граничные соотношения между параметрами помехоустойчивых кодов
Одной из важнейших задач построения помехоустойчивых кодов с заданными характеристиками является установление соотношения между его способностью обнаруживать или исправлять ошибки и избыточностью.
Существуют граничные оценки, связывающие d0
, n и k.
Граница Хэмминга, которая близка к оптимальной для высоко скоростных кодов, определяется соотношениями:
для q-ного кода 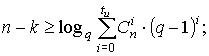
для двоичного кода 
Граница Плоткина, которую целесообразно использовать для низкоскоростных кодов определяется соотношениями:
для q-ного кода 
для двоичного кода 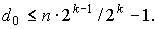
Границы Хэмминга и Плоткина являются верхними границами для кодового расстояния при заданных n и k, задающими минимальную избыточность, при которой существует помехоустойчивый код, имеющий минимальное кодовое расстояние и гарантийно исправляющий tu
- кратные ошибки.
Граница Варшамова-Гильберта (нижняя граница), определяемая соотношениями:  и и 
показывает, при каком значении n-k определено существует код, гарантийно исправляющий ошибки кратности tu
.
ЛИТЕРАТУРА
1. Лидовский В.И. Теория информации. - М., «Высшая школа», 2002г. – 120с.
2. Метрология и радиоизмерения в телекоммуникационных системах. Учебник для ВУЗов. / В.И.Нефедов, В.И.Халкин, Е.В.Федоров и др. – М.: Высшая школа, 2001 г. – 383с.
3. Цапенко М.П. Измерительные информационные системы. - . – М.: Энергоатом издат, 2005. - 440с.
4. Зюко А.Г. , Кловский Д.Д., Назаров М.В., Финк Л.М. Теория передачи сигналов. М: Радио и связь, 2001 г. –368 с.
5. Б. Скляр. Цифровая связь. Теоретические основы и практическое применение. Изд. 2-е, испр.: Пер. с англ. – М.: Издательский дом «Вильямс», 2003 г. – 1104 с.
|