1. ПОНЯТИЕ О ФИЗИЧЕСКОЙ ВЕЛИЧИНЕ. МЕЖДУНАРОДНАЯ СИСТЕМА ЕДИНИЦ ФИЗИЧЕСКИХ ВЕЛИЧИН СИ
Под физической величиной
понимают характеристику физических объектов или явлений материального мира, общую в качественном отношении для множества объектов или явлений, но индивидуальную для каждого из них в количественном отношении. Например, масса – физическая величина. Она является общей характеристикой физических объектов в качественном отношении, но в количественном отношении для различных объектов имеет свое индивидуальное значение.
Под значением
физической величины
понимают ее оценку, выражаемую произведением отвлеченного числа на принятую для данной физической величины единицу. Например, в выражении для давления атмосферного воздуха р
= 95,2 кПа, 95,2 – отвлеченное число, представляющее числовое значение давления воздуха, кПа – принятая в данном случае единица давления.
Под единицей физической величины
понимают физическую величину, фиксированную по размеру и принятую в качестве основы для количественной оценки конкретных физических величин. Например, в качестве единиц длины применяют метр, сантиметр и др.
Одной из важнейших характеристик физической величины является ее размерность. Размерность физической величины
отражает связь данной величины с величинами, принятыми за основные в рассматриваемой системе величин.
Система величин, которая определяется Международной системой единиц СИ и которая принята в России, содержит семь основных системных величин, представленных в Табл.1.1.
Существуют две дополнительные единицы СИ – радиан и стерадиан, характеристики которых представлены в Табл.1.2.
Из основных и дополнительных единиц СИ образованы 18 производных единиц СИ, которым присвоены специальные, обязательные к применению наименования. Шестнадцать единиц названы в честь ученых, остальные две – люкс и люмен (см. Табл.1.3).
Специальные наименования единиц могут быть использованы при образовании других производных единиц. Производными единицами, не имеющими специального обязательного наименования являются: площадь, объем, скорость, ускорение, плотность, импульс, момент силы и др.
Наравне с единицами СИ допускается применять десятичные кратные и дольные от них единицы. В Табл.1.4 представлены наименования и обозначения приставок таких единиц и их множители. Такие приставки называются приставками СИ.
Выбор той или иной десятичной кратной или дольной единицы прежде всего определяется удобством ее применения на практике. В принципе выбирают такие кратные и дольные единицы, при которых числовые значения величин находятся в диапазоне от 0,1 до 1000. Например, вместо 4000000 Па лучше применять 4 МПа.
Таблица 1.1. Основные единицы СИ
| Величина |
Единица |
Обозначения рекомендуемых кратных и дольных единиц
|
| Наименование |
Размерность |
Рекомендуемое обозначение |
Наименование |
Обозначение |
Определение |
| международное |
русское |
| Длина |
L |
l
|
метр |
m |
м |
Метр равен расстоянию, проходимому в вакууме плоской электромагнитной волной за 1/299792458 долей секунды |
км, см, мм, мкм, нм |
| Масса |
М |
m
|
килограмм |
kg |
кг |
Килограмм равен массе международного прототипа килограмма |
Мг, г, мг, мкг |
| Время |
Т |
t
|
секунда |
s |
с |
Секунда равна 9192631770 периодам излучения при переходе между двумя сверхтонкими уровнями основного состояния атома цезия-133 |
кс, мс, мкс, нс |
| Сила электрического тока |
I |
I
|
ампер |
А |
А |
Ампер равен силе изменяющегося тока, который при прохождении по двум параллельным проводникам бесконечной длины и ничтожно малой площади кругового поперечного сечения, расположенным в вакууме на расстоянии 1 м один от другого, вызвал бы на каждом участке проводника длиной 1 м силу взаимодействия 2·10-7
Н |
кА, мА, мкА, нА, пА |
| Термодинамическая температура |
|
T
|
кельвин* |
К |
К |
Кельвин равен 1/273,16 части термодинамической температуры тройной точки воды |
МК, кК, мК, мкК |
| Количество вещества |
N |
n;
n |
моль |
mol |
моль |
Моль равен количеству вещества системы, содержащей столько же структурных элементов, сколько содержится атомов в углероде-12 массой 0,012 кг |
кмоль, ммоль, мкмоль |
| Сила света |
J |
J
|
кандела |
cd |
кд |
Кандела равна силе света в заданном направлении источника, испускающего монохроматическое излучение частостей 540·1012
Гц, сила излучения которого в этом направлении составляет 1/683 Вт/ср |
* Кроме температуры Кельвина (обозначение Т
) допускается применять также температуру Цельсия (обозначение t
), определяемую выражением t
= Т
– 273,15 К. Температура Кельвина выражается в кельвинах, а температура Цельсия – в градусах Цельсия (°С). Интервал или разность температур Кельвина выражают только в кельвинах. Интервал или разность температур Цельсия допускается выражать как в кельвинах, так и в градусах Цельсия.
Таблица 1.2
Дополнительные единицы СИ
| Величина |
Единица |
Обозначения рекомендуемых кратных и дольных единиц |
| Наименование |
Размерность |
Рекомендуемое обозначение |
Определяющее уравнение |
Наименование |
Обозначение |
Определение |
| международное |
русское |
| Плоский угол |
1 |
a, b, g, q, n, j |
a = s
/r
|
радиан |
rad |
рад |
Радиан равен углу между двумя радиусами окружности, длина дуги между которыми равна радиусу |
мрад, мкрад |
| Телесный угол |
1 |
w, W |
W = S
/r
2
|
стерадиан |
sr |
ср |
Стерадиан равен телесному углу с вершиной в центре сферы, вырезающему на поверхности сферы площадь, равную площади квадрата со стороной, равной радиусу сферы |
Таблица 1.3
Производные единицы СИ, имеющие специальные наименования
| Величина |
Единица |
| Наименование |
Размерность |
Наименование |
Обозначение |
| международное |
русское |
| Частота |
Т-1
|
герц |
Hz |
Гц |
| Сила, вес |
LMT-2
|
ньютон |
N |
Н |
| Давление, механическое напряжение, модуль упругости |
L-1
MT-2
|
паскаль |
Pa |
Па |
| Энергия, работа, количество теплоты |
L2
MT-2
|
джоуль |
J |
Дж |
| Мощность, поток энергии |
L2
MT-3
|
ватт |
W |
Вт |
| Электрический заряд (количество электричества) |
ТI |
кулон |
С |
Кл |
| Электрическое напряжение, электрический потенциал, разность электрических потенциалов, электродвижущая сила |
L2
MT-3
I-1
|
вольт |
V |
В |
| Электрическая емкость |
L-2
M-1
T4
I2
|
фарад |
F |
Ф |
| Электрическое сопротивление |
L2
MT-3
I-2
|
ом |
|
Ом |
| Электрическая проводимость |
L-2
M-1
T3
I2
|
сименс |
S |
См |
| Поток магнитной индукции, магнитный поток |
L2
MT-2
I-1
|
вебер |
Wb |
Вб |
| Плотность магнитного потока, магнитная индукция |
MT-2
I-1
|
тесла |
Т |
Тл |
| Индуктивность, взаимная индуктивность |
L2
MT-2
I-2
|
генри |
Н |
Гн |
| Световой поток |
J |
люмен |
lm |
лм |
| Освещенность |
L-2
J |
люкс |
lx |
лк |
| Активность нуклида в радиоактивном источнике |
T-1
|
беккерель |
Bq |
Бк |
| Поглощенная доза излучения, керма |
L2
T-2
|
грей |
Gy |
Гр |
| Эквивалентная доза излучения |
L2
T-2
|
зиверт |
Sv |
Зв |
Таблица 1.4
Наименования и обозначения приставок СИ для образования десятичных кратных и дольных единиц и их множители
| Наименование приставки |
Обозначение приставки |
Множитель |
| международное |
русское |
| экса |
E |
Э |
1018
|
| пета |
P |
П |
1015
|
| тера |
T |
Т |
1012
|
| гига |
G |
Г |
109
|
| мега |
M |
М |
106
|
| кило |
k |
к |
103
|
| гекто* |
h |
г |
102
|
| дека* |
da |
да |
101
|
| деци* |
d |
д |
10-1
|
| санти* |
c |
с |
10-2
|
| милли |
m |
м |
10-3
|
| микро |
|
мк |
10-6
|
| нано |
n |
н |
10-9
|
| пико |
p |
п |
10-12
|
| фемто |
f |
ф |
10-15
|
| атто |
a |
а |
10-18
|
* Приставки "гекто", "дека", "деци" и "санти" допускается применять только для единиц, получивших широкое распространение, например: дециметр, сантиметр, декалитр, гектолитр.
МАТЕМАТИЧЕСКИЕ ОПЕРАЦИИ С ПРИБЛИЖЕННЫМИ ЧИСЛАМИ
В результате измерений, а также при проведении многих математических операций получаются приближенные значения искомых величин. Поэтому необходимо рассмотреть ряд правил вычислений с приближенными значениями. Эти правила позволяют уменьшить объем вычислительной работы и исключить дополнительные погрешности. Приближенные значения имеют такие величины, как , логарифмы и т. п., различные физические постоянные, результаты измерений.
Как известно, любое число записывают с помощью цифр: 1, 2, …, 9, 0; при этом значащими цифрами считают 1, 2, …, 9. Нуль может быть как значащей цифрой, если он стоит в середине или конце числа, так и незначащей, если он стоит в десятичной дроби с левой стороны и указывает лишь разряд остальных цифр.
При записи приближенного числа следует учитывать, что цифры, составляющие его, могут быть верными, сомнительными и неверными. Цифра верна
, если абсолютная погрешность числа меньше одной единицы разряда этой цифры (слева от нее все цифры будут верными). Сомнительной
называют цифру, стоящую справа от верной цифры, а цифры справа от сомнительной неверные
. Неверные цифры необходимо отбросить не только в результате, но и в исходных данных. Округлять число при этом не нужно. Когда погрешность числа не указана, то следует считать, что абсолютная погрешность его равна половине единицы разряда последней цифры. Разряд старшей цифры погрешности показывает разряд сомнительной цифры в числе. В качестве значащих цифр могут быть только верные и сомнительные цифры, но если погрешность числа не указана, то все цифры значащие.
Следует применять следующее основное правило записи приближенных чисел (в соответствии со СТ СЭВ 543-77): приближенное число должно быть записано с таким числом значащих цифр, которое гарантирует верность последней значащей цифры числа, например:
1) запись числа 4,6 означает, что верны только цифры целых и десятых (истинное значение числа может быть 4,64; 4,62; 4,56);
2) запись числа 4,60 означает, что верны и сотые доли числа (истинное значение числа может быть 4,604; 4,602; 4,596);
3) запись числа 493 означает, что верны все три цифры; если за последнюю цифру 3 ручаться нельзя, это число должно быть записано так: 4,9·102
;
4) при выражении плотности ртути 13,6 г/см3
в единицах СИ (кг/м3
) следует писать 13,6·103
кг/м3
и нельзя писать 13600 кг/м3
, что означало бы верность пяти значащих цифр, в то время как в исходном числе приведены только три верные значащие цифры.
Результаты экспериментов записывают только значащими цифрами. Запятую ставят сразу после отличной от нуля цифры, а число умножают на десять в соответствующей степени. Нули, стоящие в начале или конце числа, как правило, не записывают. Например, числа 0,00435 и 234000 записываются так 4,35·10-3
и 2,34·105
. Подобная запись упрощает вычисления, особенно в случае формул, удобных для логарифмирования.
Округление числа (в соответствии со СТ СЭВ 543-77) представляет собой отбрасывание значащих цифр справа до определенного разряда с возможным изменением цифры этого разряда.
При округлении последняя сохраняемая цифра не изменяется, если:
1) первая отбрасываемая цифра, считая слева направо, меньше 5;
2) первая отбрасываемая цифра, равная 5, получилась в результате предыдущего округления в большую сторону.
При округлении последняя сохраняемая цифра увеличивается на единицу, если
1) первая отбрасываемая цифра больше 5;
2) первая отбрасываемая цифра, считая слева направо, равна 5 (при отсутствии предыдущих округлений или при наличии предыдущего округления в меньшую сторону).
Округление следует выполнять сразу до желаемого числа значащих цифр, а не по этапам, что может привести к ошибкам.
ОБЩАЯ ХАРАКТЕРИСТИКА И КЛАССИФИКАЦИЯ НАУЧНЫХ ЭКСПЕРИМЕНТОВ
Каждый эксперимент представляет собой совокупность трех составных частей: исследуемого явления (процесса, объекта), условий и средств проведения эксперимента. Эксперимент проводится в несколько этапов:
1) предметно-содержательное изучение исследуемого процесса и его математическое описание на основе имеющейся априорной информации, анализ и определение условий и средств проведения эксперимента;
2) создание условий для проведения эксперимента и функционирования исследуемого объекта в желаемом режиме, обеспечивающем наиболее эффективное наблюдение за ним;
3) сбор, регистрация и математическая обработка экспериментальных данных, представление результатов обработки в требуемой форме;
4) содержательный анализ и интерпретация результатов эксперимента;
5) использование результатов эксперимента, например коррекция физической модели явления или объекта, применение модели для прогноза, управления или оптимизации и др.
В зависимости от типа исследуемого объекта (явления) выделяют несколько классов экспериментов: физические, инженерные, медицинские, биологические, экономические, социологические и др. Наиболее глубоко разработаны общие вопросы проведения физических и инженерных экспериментов, в которых исследуются естественные или искусственные физические объекты (устройства) и протекающие в них процессы. При их проведении исследователь может неоднократно повторять измерения физических величин в сходных условиях, задавать желаемые значения входных переменных, изменять их в широких масштабах, фиксировать или устранять влияние тех факторов, зависимость от которых в настоящий момент не исследуется.
Классификацию экспериментов можно провести по следующим признакам:
1) степени близости используемого в эксперименте объекта к объекту, в отношении которого планируется получение новой информации (натурный, стендовый или полигонный, модельный, вычислительный эксперименты);
2) цели проведения – исследование, испытание (контроль), управление (оптимизация, настройка);
3) степени влияния на условия проведения эксперимента (пассивный и активный эксперименты);
4) степени участия человека (эксперименты с использованием автоматических, автоматизированных и неавтоматизированных средств проведения эксперимента).
Результатом эксперимента в широком смысле является теоретическое осмысление экспериментальных данных и установление законов и причинно-следственных связей, позволяющих предсказывать ход интересующих исследователя явлений, выбирать такие условия, при которых удается добиться требуемого или наиболее благоприятного их протекания. В более узком смысле под результатом эксперимента часто понимается математическая модель, устанавливающая формальные функциональные или вероятностные связи между различными переменными, процессами или явлениями.
ОБЩИЕ СВЕДЕНИЯ О СРЕДСТВАХ ПРОВЕДЕНИЯ ЭКСПЕРИМЕНТА
Исходная информация для построения математической модели исследуемого явления добывается с помощью средств проведения эксперимента, представляющих собой совокупность средств измерений различных типов (измерительных устройств, преобразователей и принадлежностей к ним), каналов передачи информации и вспомогательных устройств для обеспечения условий проведения эксперимента. В зависимости от целей эксперимента иногда различают измерительные информационные (исследование), измерительные контролирующие (контроль, испытание) и измерительные управляющие (управление, оптимизация) системы, которые различаются как составом оборудования, так и сложностью обработки экспериментальных данных. Состав средств измерений в существенной степени определяется математической моделью описываемого объекта.
В связи с возрастанием сложности экспериментальных исследований в состав современных измерительных систем включаются вычислительные средства различных классов (ЭВМ, программируемые микрокалькуляторы). Эти средства выполняют как задачи сбора и математической обработки экспериментальной информации, так и задачи управления ходом эксперимента и автоматизации функционирования измерительной системы. Эффективность применения вычислительных средств при проведении экспериментов проявляется в следующих основных направлениях:
1) сокращение времени подготовки и проведении эксперимента в результате ускорения сбора и обработки информации;
2) повышение точности и достоверности результатов эксперимента на основе использования более сложных и эффективных алгоритмов обработки измерительных сигналов, увеличении объема используемых экспериментальных данных;
3) сокращение числа исследователей и появление возможности создания автоматических систем;
4) усиление контроля за ходом проведения эксперимента и повышение возможностей его оптимизации.
Таким образом, современные средства проведения эксперимента представляют собой, как правило, измерительно-вычислительные системы (ИВС) или комплексы, снабженные развитыми вычислительными средствами. При обосновании структуры и состава ИВС необходимо решить следующие основные задачи:
1) определить состав аппаратной части ИВС (средств измерения, вспомогательного оборудования);
2) выбрать тип ЭВМ, входящей в состав ИВС;
3) установить каналы связи между ЭВМ, устройствами, входящими в аппаратную часть ИВС, и потребителем информации;
4) разработать программное обеспечение ИВС.
2. ПЛАНИРОВАНИЕ ЭКСПЕРИМЕНТА И СТАТИСТИЧЕСКАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Большинство исследований проводят для установления с помощью эксперимента функциональных или статистических связей между несколькими величинами или для решения экстремальных задач. Классический метод постановки эксперимента предусматривает фиксирование на принятых уровнях всех переменных факторов, кроме одного, значения которого определенным образом изменяют в области его определения. Этот метод составляет основу однофакторного эксперимента (такой эксперимент часто называют пассивным
). При однофакторном эксперименте, варьируя один фактор и стабилизируя все прочие на выбранных уровнях, находят зависимость исследуемой величины только от одного фактора. Производя большое число однофакторных экспериментов при изучении многофакторной системы, получают частотные зависимости, представленные многими графиками, имеющими иллюстративный характер. Найденные таким образом частные зависимости невозможно объединить в одну большую. В случае однофакторного (пассивного) эксперимента статистические методы применяют после окончания экспериментов, когда данные уже получены.
Использование однофакторного эксперимента для всестороннего исследования многофакторного процесса требует постановки очень большого числа опытов. Для их выполнения в ряде случаев необходимо значительное время, в течение которого влияние неконтролируемых факторов на результаты опытов может существенно измениться. По этой причине данные большого числа опытов оказываются несопоставимыми. Отсюда следует, что результаты однофакторных экспериментов, полученные при исследовании многофакторных систем, часто малопригодны для практического использования. Кроме того, при решении экстремальных задач данные значительного числа опытов оказываются ненужными, так как получены они для области, далекой от оптимума. Для изучения многофакторных систем наиболее целесообразным является применение статистических методов планирования эксперимента.
Под планированием эксперимента понимают процесс определения числа и условий проведения опытов, необходимых и достаточных для решения поставленной задачи с требуемой точностью.
Планирование эксперимента – это раздел математической статистики. В нем рассматриваются статистические методы планирования эксперимента. Эти методы позволяют во многих случаях при минимальном числе опытов получать модели многофакторных процессов.
Эффективность использования статистических методов планирования эксперимента при исследовании технологических процессов объясняется тем, что многие важные характеристики этих процессов являются случайными величинами, распределения которых близко следуют нормальному закону.
Характерными особенностями процесса планирования эксперимента являются стремление минимизировать число опытов; одновременное варьирование всех исследуемых факторов по специальным правилам – алгоритмам; применение математического аппарата, формализующего многие действия исследователя; выбор стратегии, позволяющей принимать обоснованные решения после каждой серии опытов.
При планировании эксперимента статистические методы применяются на всех этапах исследования и, прежде всего, перед постановкой опытов, разрабатывая схему эксперимента, а также в ходе эксперимента, при обработке результатов и после эксперимента, принимая решения о дальнейших действиях. Такой эксперимент называют активным
и он предполагает планирование эксперимента
.
Основные преимущества активного эксперимента связаны с тем, что он позволяет:
1) минимизировать общее число опытов;
2) выбирать четкие логически обоснованные процедуры, последовательно выполняемые экспериментатором при проведении исследования;
3) использовать математический аппарат, формализующий многие действия экспериментатора;
4) одновременно варьировать всеми переменными и оптимально использовать факторное пространство;
5) организовать эксперимент таким образом, чтобы выполнялись многие исходные предпосылки регрессионного анализа;
6) получать математические модели, имеющие лучшие в некотором смысле свойства по сравнению с моделями, построенными из пассивного эксперимента;
7) рандомизировать условия опытов, т. е. многочисленные мешающие факторы превратить в случайные величины;
8) оценивать элемент неопределенности, связанный с экспериментом, что дает возможность сопоставлять результаты, получаемые разными исследователями.
Чаще всего активный эксперимент ставят для решения одной из двух основных задач. Первую задачу называют экстремальной
. Она заключается в отыскании условий процесса, обеспечивающих получение оптимального значения выбранного параметра. Признаком экстремальных задач является требование поиска экстремума некоторой функции (*проиллюстрировать графиком*). Эксперименты, которые ставят для решения задач оптимизации, называют экстремальными
.
Вторую задачу называют интерполяционной
. Она состоит в построении интерполяционной формулы для предсказания значений изучаемого параметра, зависящего от ряда факторов.
Для решения экстремальной или интерполяционной задачи необходимо иметь математическую модель исследуемого объекта. Модель объекта получают, используя результаты опытов.
При исследовании многофакторного процесса постановка всех возможных опытов для получения математической модели связана с огромной трудоемкостью эксперимента, так как число всех возможных опытов очень велико. Задача планирования эксперимента состоит в установлении минимально необходимого числа опытов и условий их проведения, в выборе методов математической обработки результатов и в принятии решений.
ОСНОВНЫЕ ЭТАПЫ И РЕЖИМЫ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
1. Содержательный анализ эксперимента, построение априорной вероятностной математической модели источника экспериментальных данных.
2. Составление плана эксперимента, в частности, определение значений независимых переменных, выбор тестовых сигналов, оценка объема наблюдений. Предварительное обоснование и выбор методов и алгоритмов статистической обработки экспериментальных данных.
3. Проведение непосредственно экспериментальных исследований, сбор экспериментальных данных, их регистрация и ввод в ЭВМ.
4. Предварительная статистическая обработка данных, предназначенная, в первую очередь, для проверки выполнения предпосылок, лежащих в основе выбранного статистического метода построения стохастической модели объекта исследований, а при необходимости – для коррекции априорной модели и изменения решения о выборе алгоритма обработки.
5. Составление детального плана дальнейшего статистического анализа экспериментальных данных.
6. Статистическая обработка экспериментальных данных (вторичная, полная, итоговая обработка), направленная на построение модели объекта исследования, и статистический анализ ее качества. Иногда на этом же этапе решаются и задачи использования построенной модели, например: оптимизируются параметры объекта.
7. Формально-логическая и содержательная интерпретация результатов экспериментов, принятие решения о продолжении или завершении эксперимента, подведение итогов исследования.
Статистическая обработка экспериментальных данных может быть осуществлена в двух основных режимах.
В первом режиме сначала производится сбор и регистрация полного объема экспериментальных данных и лишь затем они обрабатываются. Этот вид обработки называют off-line-обработкой, апостериорной обработкой, обработкой данных по выборке полного (фиксированного) объема. Достоинством этого режима обработки является возможность использования всего арсенала статистических методов анализа данных и, соответственно, наиболее полное извлечение из них экспериментальной информации. Однако оперативность такой обработки может не удовлетворять потребителя, кроме того, управление ходом эксперимента почти невозможно.
Во втором режиме обработка наблюдений производится параллельно с их получением. Этот вид обработки называют on-line-обработкой, обработкой данных по выборке нарастающего объема, последовательной обработкой данных. В этом режиме появляется возможность экспресс-анализа результатов эксперимента и оперативного управления его ходом.
ОБЩИЕ СВЕДЕНИЯ ОБ ОСНОВНЫХ СТАТИСТИЧЕСКИХ МЕТОДАХ
При решении задач обработки экспериментальных данных используются методы, основанные на двух основных составных частях аппарата математической статистики: теории статистического оценивания неизвестных параметров, используемых при описании модели эксперимента, и теории проверки статистических гипотез о параметрах или природе анализируемой модели.
1. Корреляционный анализ.
Его сущность состоит в определении степени вероятности связи (как правило, линейной) между двумя и более случайными величинами. В качестве этих случайных величин могут выступать входные, независимые переменные. В этот набор может включаться и результирующая (зависимая переменная). В последнем случае корреляционный анализ позволяет отобрать факторы или регрессоры (в регрессионной модели), оказывающие наиболее существенное влияние на результирующий признак. Отобранные величины используются для дальнейшего анализа, в частности при выполнении регрессионного анализа. Корреляционный анализ позволяет обнаруживать заранее неизвестные причинно-следственные связи между переменными. При этом следует иметь в виду, что наличие корреляции между переменными является только необходимым, но не достаточным условием наличия причинных связей.
Корреляционный анализ используется на этапе предварительной обработки экспериментальных данных.
2. Дисперсионный анализ.
Этот метод предназначен для обработки экспериментальных данных, зависящих от качественных факторов, и для оценки существенности влияния этих факторов на результаты наблюдений.
Его сущность состоит в разложении дисперсии результирующей переменной на независимые составляющие, каждая из которых характеризует влияние того или иного фактора на эту переменную. Сравнение этих составляющих позволяет оценить существенность влияния факторов.
3. Регрессионный анализ.
Методы регрессионного анализа позволяют установить структуру и параметры модели, связывающей количественные результирующую и факторные переменные, и оценить степень ее согласованности с экспериментальными данными. Этот вид статистического анализа позволяет решать главную задачу эксперимента в случае, если наблюдаемые и результирующие переменные являются количественными, и в этом смысле он является основным при обработке этого типа экспериментальных данных.
4. Факторный анализ.
Его сущность состоит в том, что "внешние" факторы, используемые в модели и сильно взаимосвязанные между собой, должны быть заменены другими, более малочисленными "внутренними факторами, которые трудно или невозможно измерить, но которые определяют поведение "внешних" факторов и тем самым поведение результирующей переменной. Факторный анализ делает возможным выдвижение гипотез о структуре взаимосвязи переменных, не задавая эту структуру заранее и не имея о ней предварительно никаких сведений. Эта структура определяется по результатам наблюдений. Полученные гипотезы могут быть проверены в ходе дальнейших экспериментов. Задачей факторного анализа является нахождение простой структуры, которая бы достаточно точно отражала и воспроизводила реальные, существующие зависимости.
4. ОСНОВНЫЕ ЗАДАЧИ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
Конечной целью предварительной обработки экспериментальных данных является выдвижение гипотез о классе и структуре математической модели исследуемого явления, определение состава и объема дополнительных измерений, выбор возможных методов последующей статистической обработки. Для этого необходимо решить некоторые частные задачи, среди которых можно выделить следующие:
1. Анализ, отбраковка и восстановление аномальных (ошибочных) или пропущенных измерений, так как экспериментальная информация обычно неоднородна по качеству.
2. Экспериментальная проверка законов распределения полученных данных, оценка параметров и числовых характеристик наблюдаемых случайных величин или процессов. Выбор методов последующей обработки, направленной на построение и проверку адекватности математической модели исследуемому явлению, существенно зависит от закона распределения наблюдаемых величин.
3. Сжатие и группировка исходной информации при большом объеме экспериментальных данных. При этом должны быть учтены особенности их законов распределения, которые выявлены на предыдущем этапе обработки.
4. Объединение нескольких групп измерений, полученных, возможно, в различное время или в различных условиях, для совместной обработки.
5. Выявление статистических связей и взаимовлияния различных измеряемых факторов и результирующих переменных, последовательных измерений одних и тех же величин. Решение этой задачи позволяет отобрать те переменные, которые оказывают наиболее сильное влияние на результирующий признак. Выделенные факторы используются для дальнейшей обработки, в частности, методами регрессионного анализа. Анализ корреляционных связей делает возможным выдвижение гипотез о структуре взаимосвязи переменных и, в конечном итоге, о структуре модели явления.
Для предварительной обработки характерно итерационное решение основных задач, когда повторно возвращаются к решению той или иной задачи после получения результатов на последующем этапе обработки.
1. КЛАССИФИКАЦИЯ ОШИБОК ИЗМЕРЕНИЯ.
Под измерением
понимают нахождение значения физической величины экспериментальным путем с помощью специальных технических средств. Измерения могут быть как прямыми
, когда искомую величину находят непосредственно из опытных данных, так и косвенными
, когда искомую величину определяют на основании известной зависимости между этой величиной и величинами, подвергаемыми прямым измерениям. Значение величины, найденное измерением, называют результатом измерения
.
Несовершенство измерительных приборов и органов чувств человека, а часто и природа самой измеряемой величины приводят к тому, что при любых измерениях результаты получаются с определенной точностью, т. е. эксперимент дает не истинное значение измеряемой величины, а лишь ее приближенное значение. Под действительным значением
физической величины понимают ее значение, найденное экспериментально и настолько приближающееся к истинному значению, что для данной цели может быть использовано вместо него.
Точность измерения определяется близостью его результата к истинному значению измеряемой величины. Точность прибора определяется степенью приближения его показаний к истинному значению искомой величины, а точность метода – физическим явлением, на котором он основан.
Ошибки
(погрешности
) измерений
характеризуются отклонением результатов измерений от истинного значения измеряемой величины. Ошибка измерения, как и истинное значение измеряемой величины, обычно неизвестна. Поэтому одной из основных задач статистической обработки результатов эксперимента и является оценка истинного значения измеряемой величины по полученным опытным данным. Другими словами, после неоднократного измерения искомой величины и получения ряда результатов, каждый из которых содержит некоторую неизвестную ошибку, ставится задача вычисления приближенного значения искомой величины с возможно меньшей ошибкой.
Ошибки измерений делят на грубые
ошибки (промахи), систематические
и случайные
.
Грубые ошибки
. Грубые ошибки возникают вследствие нарушения основных условий измерения или в результате недосмотра экспериментатора. При обнаружении грубой ошибки результат измерения следует сразу отбросить и повторить измерение. Внешним признаком результата, содержащего грубую ошибку, является его резкое отличие по величине от остальных результатов. На этом основаны некоторые критерии исключения грубых ошибок по их величине (будут рассмотрены далее), однако самым надежным и эффективным способом браковки неверных результатов является браковка их непосредственно в процессе самих измерений.
Систематические ошибки.
Систематической является такая погрешность, которая остается постоянной или закономерно изменяется при повторных измерениях одной и той же величины. Систематические погрешности появляются из-за неправильной регулировки приборов, неточности метода измерения, какого-либо упущения экспериментатора, использования для вычисления неточных данных.
Систематические ошибки возникают также при проведении сложных измерений. Экспериментатор может и не догадываться о них, хотя они могут быть очень большими. Поэтому в таких случаях нужно тщательно проанализировать методику измерений. Такие ошибки можно обнаружить, в частности, проведя измерения искомой величины другим методом. Совпадение результатов измерений обоими методами служит определенной гарантией отсутствия систематических погрешностей.
При измерениях необходимо сделать все возможное, чтобы исключить систематические погрешности, так как они могут быть так велики, что сильно исказят результаты. Выявленные погрешности устраняют введением поправок.
Случайные ошибки.
Случайной ошибкой является составляющая погрешности измерения, которая изменяется случайным образом, т. е. это ошибка измерения, остающаяся после устранения всех выявленных систематических и грубых ошибок. Случайные ошибки вызываются большим числом как объективных, так и субъективных факторов, которые нельзя выделить и учесть в отдельности. Поскольку причины, приводящие к случайным ошибкам, не одинаковы, в каждом эксперименте и не могут быть учтены, исключить такие ошибки нельзя, можно лишь оценить их значение. С помощью методов теории вероятностей можно учесть их влияние на оценку истинного значения измеряемой величины со значительно меньшей ошибкой, чем ошибки отдельных измерений.
Поэтому, когда случайная погрешность больше погрешности измерительного прибора, необходимо многократно повторять одно и то же измерение для уменьшения ее значения. Это позволяет минимизировать случайную погрешность и сделать ее сравнимой с погрешностью прибора. Если же случайная ошибка меньше погрешности прибора, то уменьшать ее не имеет смысла.
Кроме этого, ошибки делят на абсолютные
, относительные
и инструментальные
. Абсолютной ошибкой считают погрешность, выраженную в единицах измеряемой величины. Относительной ошибкой является отношение абсолютной ошибки к истинному значению измеряемой величины. Составляющую ошибки измерения, которая зависит от погрешности применяемых средств измерения, называют инструментальной погрешностью измерения.
2. ПОГРЕШНОСТИ ПРЯМЫХ РАВНОТОЧНЫХ ИЗМЕРЕНИЙ. ЗАКОН НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ.
Прямые измерения
– это такие измерения, когда значение изучаемой величины находят непосредственно из опытных данных, например снимая показания прибора, измеряющего значение искомой величины. Для нахождения случайной погрешности измерение необходимо провести несколько раз. Результаты таких измерений имеют близкие значения погрешностей и называются равноточными
.
Пусть в результате n
измерений величины х
, проведенных с одинаковой точностью, получен ряд значений: х
1
, х
2
, …, х
n
. Как показано в теории ошибок, наиболее близким к истинному значению х
0
измеряемой величины х
является среднее арифметическое значение
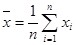 . (2.1) . (2.1)
Среднее арифметическое значение рассматривают только как наиболее вероятное значение измеряемой величины. Результаты отдельных измерений в общем случае отличаются от истинного значения х
0
. При этом абсолютная погрешность i
-го измерения составляет
Dxi
'
= х
0
– xi
4
и может принимать как положительные, так и отрицательные значения с равной вероятностью. Суммируя все погрешности, получаем
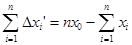 , ,
Откуда
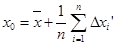 . (2.2) . (2.2)
В этом выражении второе слагаемое в правой части при большом n
равно нулю, так как всякой положительной погрешности можно поставить в соответствие равную ей отрицательную. Тогда х
0
=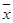 . При ограниченном числе измерений будет лишь приближенное равенство х
0 . При ограниченном числе измерений будет лишь приближенное равенство х
0
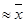 . Таким образом, можно назвать действительным значением. . Таким образом, можно назвать действительным значением.
Во всех практических случаях значение х
0
неизвестно и есть лишь определенная вероятность того, что х
0
находится в каком-то интервале вблизи и требуется определить этот интервал, соответствующий этой вероятности. В качестве оценки абсолютной погрешности отдельного измерения используют Dxi
= – xi
.
Она определяет точность данного измерения.
Для ряда измерений определяют среднюю арифметическую погрешность
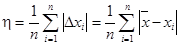 . .
Она определяет пределы, в которых лежит более половины измерений. Следовательно, х
0
с достаточно большой вероятностью попадает в интервал от –h до +h. Результаты измерений величины х
записывают тогда в виде:
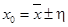 . .
Величина х
измерена тем точнее, чем меньше интервал, в котором находится истинное значение х
0
.
Абсолютная погрешность результатов измерений Dx
сама по себе еще не определяет точности измерений. Пусть, например, точность некоторого амперметра составляет 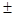 0.1а
. Были проведены измерения силы тока в двух электрических цепях. При этом получили следующие значения: 320.1а
и 0.20.1а
. Из примера видно, что, хотя абсолютная погрешность измерений одинакова, точность измерений различна. В первом случае измерения достаточно точны, а во втором – позволяют судить лишь о порядке величины. Следовательно, при оценке качества измерения необходимо сравнивать погрешность с измеренным значением, что дает более наглядное представление о точности измерений. Для этого вводится понятие относительной погрешности 0.1а
. Были проведены измерения силы тока в двух электрических цепях. При этом получили следующие значения: 320.1а
и 0.20.1а
. Из примера видно, что, хотя абсолютная погрешность измерений одинакова, точность измерений различна. В первом случае измерения достаточно точны, а во втором – позволяют судить лишь о порядке величины. Следовательно, при оценке качества измерения необходимо сравнивать погрешность с измеренным значением, что дает более наглядное представление о точности измерений. Для этого вводится понятие относительной погрешности
dx
= Dx
/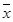 . (2.3) . (2.3)
Относительную погрешность обычно выражают в процентах.
Так как в большинстве случаев измеряемые величины имеют размерность, то и абсолютные погрешности размерны, а относительные ошибки безразмерны. Поэтому с помощью последних можно производить сравнение точности измерений разнородных величин. Наконец, эксперимент должен быть поставлен таким образом, чтобы относительная погрешность оставалась постоянной во всем диапазоне измерений.
Следует отметить, что при правильных и тщательно выполненных измерениях средняя арифметическая погрешность их результата близка к погрешности измеряемого прибора.
Если измерения искомой величины х
проведены много раз, то частоты появления того или иного значения х
i
можно представить в виде графика, имеющего вид ступенчатой кривой – гистограммы (см. рис. 1), где у
– число отсчетов; Dxi
= х
i
– xi
+1
(i
изменяется от –n
до +n
). С увеличением числа измерений и уменьшением интервала Dxi
гистограмма переходит в непрерывную кривую, характеризующую плотность распределения вероятности того, что величина xi
окажется в интервале Dxi
.
Под распределением случайной величины
понимают совокупность всех возможных значений случайной величины и соответствующих им вероятностей. Законом распределения случайной величины
называют всякое соответствие случайной величины возможным значениям их вероятностей. Наиболее общей формой закона распределения является функция распределения Р
(х
).
Тогда функция р
(х
) = Р'
(х
) – плотность распределения вероятности
или дифференциальная функция распределения. График плотности распределения вероятностей называется кривой распределения.
Функция р
(х
) характерна тем, что произведение р
(х
)dx
есть вероятность оказаться отдельному, случайно выбранному значению измеряемой величины в интервале (х
,x
+ dx
).
В общем случае эта вероятность может определяться различными законами распределений (нормальный (Гаусса), Пуассона, Бернулли, биномиальный, отрицательный биномиальный, геометрический, гипергеометрический, равномерный дискретный, отрицательный экспоненциальный). Однако чаще всего вероятность появления величины xi
в интервале (х
,x
+ dx
) в физических экспериментах описывают нормальным законом распределения – законом Гаусса (см. рис. 2):
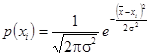 , (2.4) , (2.4)
где s2
- дисперсия генеральной совокупности. Генеральной совокупностью
называют все множество возможных значений измерений xi
или возможных значений погрешностей Dxi
.
Широкое использование закона Гаусса в теории ошибок объясняется следующими причинами:
1) равные по абсолютному значению погрешности встречаются одинаково часто при большом числе измерений;
2) малые по абсолютному значению погрешности встречаются чаще, чем большие, т. е. вероятность появления погрешности тем меньше, чем больше ее абсолютное значение;
3) погрешности измерений принимают непрерывный ряд значений.
Однако, эти условия никогда строго не выполняются. Но эксперименты подтвердили, что в области, где погрешности не очень велики, нормальный закон распределения хорошо согласуется с опытными данными. С помощью нормального закона можно найти вероятность появления погрешности того или иного значения.
Распределение Гаусса характеризуется двумя параметрами: средним значением случайной величины и дисперсией s2
. Среднее значение определяется абсциссой (х
=) оси симметрии кривой распределения, а дисперсия показывает, как быстро уменьшается вероятность появления погрешности с увеличением ее абсолютного значения. Кривая имеет максимум 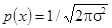 при х
=. Следовательно, среднее значение является наиболее вероятным значением величины х
. Дисперсия определяется полушириной кривой распределения, т. е. расстоянием от оси симметрии до точек перегиба кривой. Она является средним квадратом отклонения результатов отдельных измерений от их среднего арифметического значения по всему распределению. Если при измерении физической величины получают только постоянные значения х
=, то s2
= 0. Но если значения случайной величины х
принимают значения, не равные , то ее дисперсия не равна нулю и положительна. Дисперсия, таким образом, служит мерой флуктуации значений случайной величины. при х
=. Следовательно, среднее значение является наиболее вероятным значением величины х
. Дисперсия определяется полушириной кривой распределения, т. е. расстоянием от оси симметрии до точек перегиба кривой. Она является средним квадратом отклонения результатов отдельных измерений от их среднего арифметического значения по всему распределению. Если при измерении физической величины получают только постоянные значения х
=, то s2
= 0. Но если значения случайной величины х
принимают значения, не равные , то ее дисперсия не равна нулю и положительна. Дисперсия, таким образом, служит мерой флуктуации значений случайной величины.
Мера рассеяния результатов отдельных измерений от среднего значения должна выражаться в тех же единицах, что и значения измеряемой величины. В связи с этим в качестве показателя флуктуации результатов измерений гораздо чаще используют величину
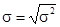 , ,
называемую средней квадратичной погрешностью
.
Она является важнейшей характеристикой результатов измерений и остается постоянной при неизменности условий эксперимента.
Значение этой величины определяет форму кривой распределения.
Так как при изменении sплощадь под кривой, оставаясь постоянной (равной единице), меняет свою форму, то с уменьшением sкривая распределения вытягивается вверх вблизи максимума при х
=, и сжимаясь в горизонтальном направлении.
С увеличением sзначение функции р
(х
i
) уменьшается, и кривая распределения растягивается вдоль оси х
(см. рис. 2).
Для нормального закона распределения средняя квадратическая погрешность отдельного измерения
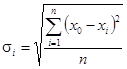 , (2.5) , (2.5)
а средняя квадратическая погрешность среднего значения
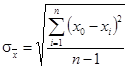 . (2.6) . (2.6)
Средняя квадратическая погрешность более точно характеризует погрешности измерений, чем средняя арифметическая погрешность, так как она получена достаточно строго из закона распределения случайных величин погрешностей. Кроме того, непосредственная связь ее с дисперсией, вычисление которой облегчается рядом теорем, делает среднюю квадратическую погрешность очень удобным параметром.
Наряду с размерной погрешностью sиспользуют и безразмерную относительную погрешность ds
=s/, которая, как и dx
, выражается либо в долях единицы, либо в процентах. Окончательный результат измерений записывают в виде:
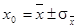 , , 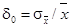 . (2.7) . (2.7)
Однако, на практике невозможно провести слишком много измерений, поэтому нельзя построить нормальное распределение, чтобы точно определить истинное значение х
0
. В этом случае хорошим приближением к истинному значению можно считать , а достаточно точной оценкой ошибки измерений – выборочную дисперсию 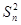 , вытекающую из нормального закона распределения, но относящуюся к конечному числу измерений. Такое название величины объясняется тем, что из всего множества значений х
i
, т. е. генеральной совокупности выбирают (измеряют) лишь конечное число значений величины х
i
(равное n
), называемых выборкой
. Выборка характеризуется уже выборочным средним значением и выборочной дисперсией. , вытекающую из нормального закона распределения, но относящуюся к конечному числу измерений. Такое название величины объясняется тем, что из всего множества значений х
i
, т. е. генеральной совокупности выбирают (измеряют) лишь конечное число значений величины х
i
(равное n
), называемых выборкой
. Выборка характеризуется уже выборочным средним значением и выборочной дисперсией.
Тогда выборочная средняя квадратическая погрешность отдельного измерения (или эмпирический стандарт)
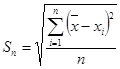 , (2.8) , (2.8)
а выборочная средняя квадратическая погрешность ряда измерений
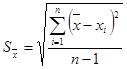 . (2.9) . (2.9)
Из выражения (2.9) видно, что, увеличивая число измерений, можно сделать сколь угодно малой среднюю квадратическую погрешность 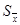 . При n
> 10 заметное изменение величины достигается лишь при весьма значительном числе измерений, поэтому дальнейшее увеличение числа измерений нецелесообразно. К тому же, невозможно полностью исключить систематические погрешности, и при , меньшей систематической ошибки дальнейшее увеличение числа опытов также не имеет смысла. . При n
> 10 заметное изменение величины достигается лишь при весьма значительном числе измерений, поэтому дальнейшее увеличение числа измерений нецелесообразно. К тому же, невозможно полностью исключить систематические погрешности, и при , меньшей систематической ошибки дальнейшее увеличение числа опытов также не имеет смысла.
Таким образом, задача нахождения приближенного значения физической величины и его погрешности решена. Теперь необходимо определить надежность найденного действительного значения. Под надежностью измерений понимают вероятность попадания истинного значения в данный доверительный интервал. Интервал (– e,+ e), в котором находится с заданной вероятностью истинное значение х
0
, называют доверительным интервалом
. Допустим, что вероятность отличия результата измерений х
от истинного значения х
0
на величину, большую, чем e, равна 1 – a, т. е.
p
(– e< х
0
<+ e) = 1 – a. (2.10)
В теории ошибок обычно под eпонимают величину 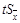 . Поэтому . Поэтому
p
(– 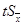 < х
0
<+ ) = Ф(t
), (2.11) < х
0
<+ ) = Ф(t
), (2.11)
где Ф(t
) – интеграл вероятности (или функция Лапласа), а также нормальная функция распределения:
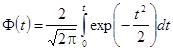 , (2.12) где , (2.12) где 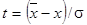 . .
Таким образом, чтобы охарактеризовать истинное значение, требуется знать как погрешность, так и надежность. Если доверительный интервал увеличивается, то возрастает надежность того, что истинное значение х
0
попадает в данный интервал. Высокая степень надежности необходима при ответственных измерениях. Это означает, что в таком случае нужно выбирать большой доверительный интервал или вести измерения с большей точностью (т. е. уменьшить величину 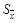 ), что можно сделать, например, многократным повторением измерений. ), что можно сделать, например, многократным повторением измерений.
Под доверительной вероятностью
понимается вероятность того, что истинное значение измеряемой величины попадает в данный доверительный интервал. Доверительный интервал характеризует точность измерения данной выборки, а доверительная вероятность – достоверность измерения.
В подавляющем большинстве экспериментальных задач доверительная вероятность составляет 0.9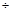 0.95 и более высокая надежность не требуется. Так при t
= 1 согласно формулам (2.10 –2.12) 1 – a= Ф(t
) = 0.683, т. е. более 68 % измерений находится в интервале (– 0.95 и более высокая надежность не требуется. Так при t
= 1 согласно формулам (2.10 –2.12) 1 – a= Ф(t
) = 0.683, т. е. более 68 % измерений находится в интервале (–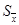 ,+). При t
= 2 1 – a= 0.955, а при t
= 3 параметр 1 – a= 0.997. Последнее означает, что в интервале (– ,+). При t
= 2 1 – a= 0.955, а при t
= 3 параметр 1 – a= 0.997. Последнее означает, что в интервале (–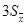 ,+) находятся почти все измеренные значения. Из данного примера видно, что интервал ,+) находятся почти все измеренные значения. Из данного примера видно, что интервал 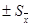 действительно содержит большинство измеренных значений, т. е. параметр aможет служить хорошей характеристикой точности измерений. действительно содержит большинство измеренных значений, т. е. параметр aможет служить хорошей характеристикой точности измерений.
До сих пор предполагалось, что число измерений хотя и конечно, но достаточно велико. В действительности же число измерений почти всегда бывает небольшим. Более того, как в технике, так и в научных исследованиях нередко используют результаты двух-трех измерений. В этой ситуации величины 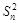 и и 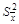 в лучшем случае могут определить лишь порядок величины дисперсии. Существует корректный метод для определения вероятности нахождения искомого значения в заданном доверительном интервале, основанный на использовании распределения Стьюдента (предложенного в 1908 г. английским математиком В.С. Госсетом). Обозначим через в лучшем случае могут определить лишь порядок величины дисперсии. Существует корректный метод для определения вероятности нахождения искомого значения в заданном доверительном интервале, основанный на использовании распределения Стьюдента (предложенного в 1908 г. английским математиком В.С. Госсетом). Обозначим через 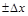 интервал, на который может отклоняться среднее арифметическое значение от истинного значения х
0
, т. е. Dx
= х
0
–. Иными словами, мы хотим определить значение интервал, на который может отклоняться среднее арифметическое значение от истинного значения х
0
, т. е. Dx
= х
0
–. Иными словами, мы хотим определить значение
 . .
Тогда
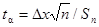 , (2.13) , (2.13)
где Sn
определяется формулой (2.8). Эта величина подчиняется распределению Стьюдента. Распределение Стьюдента характерно тем, что не зависит от параметров х
0
и sнормальной генеральной совокупности и позволяет при небольшом числе измерений (n
< 20) оценить погрешность Dx
= – х
i
по заданной доверительной вероятности aили по заданному значению Dx
найти надежность измерений. Это распределение зависит только от переменной t
a
и числа степеней свободы l
= n
– 1.
Распределение Стьюдента справедливо при n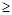 2 и симметрично относительно t
a
= 0 (см. рис. 3). С ростом числа измерений t
a
-распределение стремится к нормальному распределению (фактически при n
> 20).
2 и симметрично относительно t
a
= 0 (см. рис. 3). С ростом числа измерений t
a
-распределение стремится к нормальному распределению (фактически при n
> 20).
Доверительную вероятность при заданной погрешности результата измерений получают из выражения
p
(–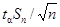 < х
0
< < х
0
<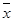 +) = 1 – a. (2.14) +) = 1 – a. (2.14)
При этом величина t
a
аналогична коэффициенту t
в формуле (2.11). Величину t
a
называют коэффициентом Стьюдента
, его значения приводятся в справочных таблицах. Используя соотношения (2.14) и справочные данные можно решить и обратную задачу: по заданной надежности aопределить допустимую погрешность результата измерений.
Распределение Стьюдента позволяет также установить, что с вероятностью, как угодно близкой к достоверности, при достаточно большом n
среднее арифметическое значение будет как угодно мало отличаться от истинного значения х
0
.
Предполагалось, что закон распределения случайной погрешности известен. Однако часто при решении практических задач не обязательно знания закона распределения, достаточно лишь изучить некоторые числовые характеристики случайной величины, например среднее значение и дисперсию. При этом вычисление дисперсии позволяет оценить доверительную вероятность даже в случае, когда закон распределения погрешности неизвестен или отличается от нормального.
В случае, если проведено всего одно измерение, точность измерения физической величины (если оно проведено тщательно) характеризуется точностью измерительного прибора.
3. ПОГРЕШНОСТИ КОСВЕННЫХ ИЗМЕРЕНИЙ
Часто при проведении эксперимента встречается ситуация, когда искомые величины и
(х
i
) непосредственно определить невозможно, однако можно измерить величины х
i
.
Например, для измерения плотности rчаще всего измеряют массу m
и объем V
, а значение плотности рассчитывают по формуле r= m
/V
.
Величины х
i
содержат, как обычно, случайные погрешности, т. е. наблюдают величины xi
'
= xi
Dxi
. Как и ранее, считаем, что xi
распределены по нормальному закону.
1. Пусть и
= f
(х
) является функцией одной переменной. В этом случае абсолютная погрешность
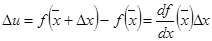 . (3.1) . (3.1)
Относительная погрешность результата косвенных измерений
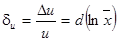 . (3.2) . (3.2)
2. Пусть и
= f
(х
, у
) является функцией двух переменных. Тогда абсолютная погрешность
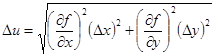 , (3.3) , (3.3)
а относительная погрешность составит
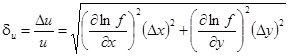 . (3.4) . (3.4)
3. Пусть и
= f
(х
, у
, z
, …) является функцией нескольких переменных. Тогда абсолютная погрешность по аналогии
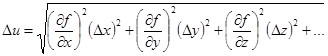 (3.5) (3.5)
и относительная погрешность
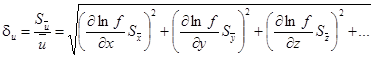 , (3.6) , (3.6)
где 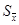 , ,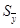 и и 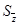 определяются согласно формуле (2.9). определяются согласно формуле (2.9).
В таблице 2 приводятся формулы для определения погрешностей косвенных измерений для некоторых часто встречающихся формул.
Таблица 2
| Функция u
|
Абсолютная погрешность Du
|
Относительная погрешность du
|
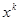 |
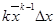 |
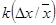 |
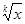 |
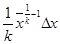 |
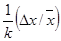 |
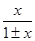 |
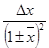 |
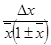 |
| ex
|
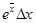 |
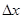 |
| ln x
|
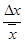 |
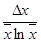 |
| sin x
|
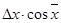 |
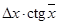 |
| cos x
|
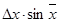 |
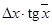 |
| tg x
|
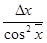 |
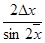 |
| ctg x
|
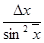 |
|
| x
y
|
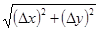 |
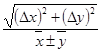 |
| xy
|
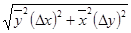 |
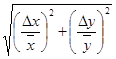 |
| x
/y
|
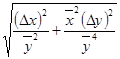 |
|
4. ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Все приведенные выше доверительные оценки как средних значений, так и дисперсий основаны на гипотезе нормальности закона распределения случайных ошибок измерения и поэтому могут применяться лишь до тех пор, пока результаты эксперимента не противоречат этой гипотезе.
Если результаты эксперимента вызывают сомнение в нормальности закона распределения, то для решения вопроса о пригодности или непригодности нормального закона распределения нужно произвести достаточно большое число измерений и применить одну из описанных ниже методик.
Проверка по среднему абсолютному отклонению (САО).
Методика может использоваться для не очень больших выборок (n
< 120). Для этого вычисляется САО по формуле:
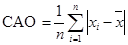 . (4.1) . (4.1)
Для выборки, имеющий приближенно нормальный закон распределения, должно быть справедливо выражение
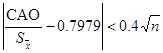 . (4.2) . (4.2)
Если данное неравенство (4.2) выполняется, то гипотеза нормальности распределения подтверждается.
Проверка по критерию соответствия
c2
("хи-квадрат") или критерию согласия Пирсона.
Критерий основан на сравнении эмпирических частот с теоретическими, которые можно ожидать при принятии гипотезы о нормальности распределения. Результаты измерений после исключения грубых и систематических ошибок группируют по интервалам таким образом, чтобы эти интервалы покрывали всю ось и чтобы количество данных в каждом интервале было достаточно большим (не менее пяти). Для каждого интервала (хi
–1
, хi
) подсчитывают число т
i
результатов измерения, попавших в этот интервал. Затем вычисляют вероятность попадания в этот интервал при нормальном законе распределения вероятностей р
i
:
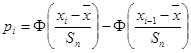 , (4.3) , (4.3)
Далее вычисляют сумму
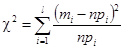 , (4.4) , (4.4)
где l
– число всех интервалов, n
– число всех результатов измерений (n
= т
1
+ т
2
+…+ тl
).
Если сумма, рассчитанная по данной формуле (4.4) окажется больше критического табличного значения c2
, определяемого при некоторой доверительной вероятности р
и числе степеней свободы k
= l
– 3, то с надежностью р
можно считать, что распределение вероятностей случайных ошибок в рассматриваемой серии измерений отличается от нормального. В противном случае для такого вывода нет достаточных оснований.
Проверка по показателям асимметрии и эксцесса.
Данный метод дает приближенную оценку. Показатели асимметрии А
и эксцесса Е
определяются по следующим формулам:
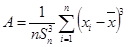 , (4.5) , (4.5)
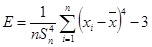 . (4.6) . (4.6)
Если распределение нормально, то оба эти показателя должны быть малы. О малости этих характеристик обычно судят по сравнению с их средними квадратическими ошибками. Коэффициенты сравнения рассчитываются соответственно:
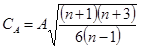 , (4.7) , (4.7)
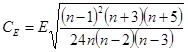 . (4.8) . (4.8)
Распределение можно считать нормальным, если коэффициенты СА
и СЕ
не превышают величины 2…3.
5. МЕТОДЫ ИСКЛЮЧЕНИЯ ГРУБЫХ ОШИБОК
При получении результата измерения, резко отличающегося от всех других результатов, возникает подозрение, что допущена грубая ошибка. В этом случае необходимо сразу же проверить, не нарушены ли основные условия измерения. Если же такая проверка не была сделана вовремя, то вопрос о целесообразности браковки резко отличающихся значений решается путем сравнения его с остальными результатами измерений. При этом применяются различные критерии, в зависимости от того, известна или нет средняя квадратическая ошибка si
измерений (предполагается, что все измерения производятся с одной и той же точностью и независимо друг от друга).
Метод исключения при известной
s
i
.
Сначала определяется коэффициент t
по формуле
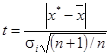 , (5.1) , (5.1)
где x
* – резко выделяющееся значение (предполагаемая ошибка). Значение 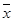 определяется по формуле (2.1) без учета предполагаемой ошибки x
*. определяется по формуле (2.1) без учета предполагаемой ошибки x
*.
Далее задаются уровнем значимости a, при котором исключаются ошибки, вероятность появления которых меньше величины a. Обычно используют один из трех уровней значимости: 5 % уровень (исключаются ошибки, вероятность появления которых меньше 0.05); 1 % уровень (соответственно меньше 0.01) и 0.1 % уровень (соответственно менее 0.001).
При выбранном уровне значимости aвыделяющееся значение x
* считают грубой ошибкой и исключают его из дальнейшей обработки результатов измерений, если для соответствующего коэффициента t
, рассчитанного по формуле (5.1), выполняется условие: 1 – Ф(t
) < a.
Метод исключения при неизвестной
s
i
.
Если средняя квадратическая ошибка отдельного измерения si
заранее неизвестна, то она оценивается приближенно по результатам измерений посредством формулы (2.8). Далее применяется тот же алгоритм, что и при известной si
с той лишь разницей, что в формуле (5.1) вместо si
используется величина Sn
, рассчитанная по формуле (2.8).
Правило трех сигм.
Так как выбор надежности доверительной оценки допускает некоторый произвол, в процессе обработки результатов эксперимента широкое распространение получило правило трех сигм: отклонение истинного значения измеряемой величины не превосходит среднего арифметического значения результатов измерений не превосходит утроенной средней квадратической ошибки этого значения.
Таким образом, правило трех сигм представляет собой доверительную оценку в случае известной величины s
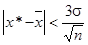 (5.2) (5.2)
или доверительную оценку
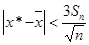 (5.3) (5.3)
в случае неизвестной величины s.
Первая из этих оценок имеет надежность 2Ф(3) = 0.9973 независимо от количества измерений.
Надежность второй оценки существенно зависит от количества измерений n
.
Зависимость надежности р
от количества измерений n
для оценки грубой ошибки в случае неизвестной величины sуказана в
Таблица 4
| n |
5 |
6 |
7 |
8 |
9 |
10 |
14 |
20 |
30 |
50 |
150 |
 |
| р(х) |
0.960 |
0.970 |
0.976 |
0.980 |
0.983 |
0.985 |
0.990 |
0.993 |
0.995 |
0.996 |
0.997 |
0.9973 |
6. ПРЕДСТАВЛЕНИЕ РЕЗУЛЬТАТОВ ИЗМЕРЕНИЙ
Результаты измерений можно представить в виде графиков и таблиц. Последний способ наиболее прост. В ряде случаев результаты исследований можно представлять только в виде таблицы. Но таблица не дает наглядного представления о зависимости одной физической величины от другой, поэтому во многих случаях строят график. Им можно пользоваться для быстрого нахождения зависимости одной величины от другой, т. е. по измеренным данным находят аналитическую формулу, связывающую величины х
и у
. Такие формулы называют эмпирическими. Точность нахождения функции у
(х
) по графику определяется корректностью построения графика. Следовательно, когда не требуется большой точности, графики удобнее таблиц: они занимают меньше места, по ним быстрее проводить отсчеты, при построении их сглаживаются выбросы в ходе функции из-за случайных погрешностей измерений. Если требуется особо высокая точность, результаты эксперимента предпочтительнее представлять в виде таблиц, а промежуточные значения находить по интерполяционным формулам.
Математическая обработка результатов измерений экспериментатором не ставит задачу раскрыть истинный характер функциональной зависимости между переменными, а лишь дает возможность наиболее простой формулой описать результаты эксперимента, что позволяет использовать интерполирование и применить к наблюдаемым данным методы математического анализа.
Графический метод.
Чаще всего для построения графиков используют прямоугольную систему координат. Чтобы облегчить построение, можно использовать миллиметровую бумагу. При этом отсчеты расстояний на графиках следует делать только по делениям на бумаге, а не при помощи линейки, так как длина делений может быть различной по вертикали и горизонтали. Предварительно нужно выбрать разумные масштабы по осям так, чтобы точность измерения соответствовала точности отсчета по графику и график не был растянут или сжат вдоль одной из осей, так как это ведет к увеличению погрешности отсчета.
Далее на график наносят точки, представляющие результаты измерений. Для выделения разных результатов их наносят различными значками: кружками, треугольниками, крестиками и т. п. Так как в большинстве случаев погрешности значений функции больше погрешностей аргумента, то наносят только погрешность функции в виде отрезка длиной, равной удвоенной погрешности в данном масштабе. При этом экспериментальная точка находится в середине этого отрезка, который с обоих концов ограничивается черточками. После этого проводят плавную кривую так, чтобы она проходила возможно ближе ко всем экспериментальным точкам и примерно одинаковое число точек находилось по обеим сторонам кривой. Кривая должна (как правило) лежать в пределах погрешностей измерений. Чем меньше эти погрешности, тем лучше кривая совпадает с экспериментальными точками. Важно отметить, что лучше провести плавную кривую вне пределов погрешности, чем допустить излом кривой вблизи отдельной точки. Если одна или несколько точек лежат далеко от кривой, то это часто свидетельствует о грубой ошибке при вычислении или измерении. Кривые на графиках чаще всего строят с помощью лекал.
Не следует брать очень много точек при построении графика плавной зависимости и только для кривых с максимумами и минимумами необходимо в области экстремума наносить точки более часто.
При построении графиков часто используют прием, называемый способом выравнивания или способом натянутой нити. Он основан на геометрическом подборе прямой "на глаз".
Если этот прием не удается, то во многих случаях преобразование кривой в прямую достигается применением одной из функциональных шкал или сеток. Чаще всего применяются логарифмическая или полулогарифмическая сетки. Этот прием полезен и в тех случаях, когда нужно растянуть или сжать какой-либо участок кривой. Так, логарифмический масштаб удобно использовать для изображения изучаемой величины, изменяющейся на несколько порядков в пределах измерений. Этот метод рекомендуется для нахождения приближенных значений коэффициентов в эмпирических формулах или для измерений с невысокой точностью данных. Прямой линией при использовании логарифмической сетки изображается зависимость типа 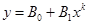 , а при использовании полулогарифмической сетки – зависимость типа , а при использовании полулогарифмической сетки – зависимость типа 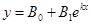 . Коэффициент В
0
в некоторых случаях может быть равен нулю. Однако, при использовании линейного масштаба все значения на графике отсчитывают с одинаковой абсолютной точностью, а при использовании логарифмического масштаба – с одинаковой относительной точностью. . Коэффициент В
0
в некоторых случаях может быть равен нулю. Однако, при использовании линейного масштаба все значения на графике отсчитывают с одинаковой абсолютной точностью, а при использовании логарифмического масштаба – с одинаковой относительной точностью.
Следует также заметить, что часто бывает трудно по имеющемуся ограниченному участку кривой (особенно, если не все точки лежат на кривой) судить о том, какого типа функцию необходимо использовать для приближения. Поэтому переводят экспериментальные точки на ту или иную координатную сетку и уже потом смотрят, на какой из них полученные данные ближе всего совпадают с прямой, и в соответствии с этим выбирают эмпирическую формулу.
Подбор эмпирических формул.
Хотя нет общего метода, который давал бы возможность подобрать наилучшую эмпирическую формулу для любых результатов измерений, все же можно найти эмпирическое соотношение, наиболее точно отражающее искомую зависимость. Не следует добиваться полного совпадения между экспериментальными данными и искомой формулой, так как интерполяционный многочлен или другая аппроксимирующая формула будет повторять все погрешности измерений, а коэффициенты не будут иметь физического смысла. Поэтому, если не известна теоретическая зависимость, то выбирают такую формулу, которая лучше совпадает с измеренными значениями и содержит меньше параметров. Для определения подходящей формулы экспериментальные данные изображают графически и сравнивают с различными кривыми, которые строят по известным формулам в том же масштабе. Изменяя параметры в формуле, можно в определенной степени менять вид кривой. В процессе сравнения необходимо учитывать имевшиеся экстремумы, поведение функции при различных значениях аргумента, выпуклость или вогнутость кривой на разных участках. Подобрав формулу, определяют значения параметров так, чтобы различие между кривой и экспериментальными данными было не больше погрешностей измерений.
На практике наиболее часто используются линейная, показательная и степенная зависимости.
7. НЕКОТОРЫЕ ЗАДАЧИ АНАЛИЗА ОПЫТНЫХ ДАННЫХ
Интерполирование.
Под интерполированием
понимают, во-первых, нахождение значений функции для промежуточного значений аргумента, отсутствующих в таблице и, во-вторых, замену функции интерполирующим многочленом, если аналитическое выражение ее неизвестно, а функция должна подвергаться определенным математическим операциям. Наиболее простые способы интерполирования – линейное и графическое. Линейное интерполирование можно применять тогда, когда зависимость у
(х
) выражается прямой линией или кривой, близкой к прямой, для которой такое интерполирование не приводит к грубым погрешностям. В некоторых случаях можно проводить линейное интерполирование и при сложной зависимости у
(х
), если оно ведется в пределах настолько малого изменения аргумента, что зависимость между переменными можно считать линейной без заметных погрешностей. При графическом интерполировании неизвестную функцию у
(х
) заменяют ее приближенным графическим изображением (по экспериментальным точкам или табличным данным), из которого определяют значения у
при любых х
в пределах измерений. Однако точное графическое построение сложных кривых иногда оказывается очень трудным, например кривой с резкими экстремумами, поэтому графическое интерполирование имеет ограниченное применение.
Таким образом, во многих случаях невозможно применить ни линейного, ни графического интерполирования. В связи с этим были найдены интерполирующие функции, позволяющие вычислить значения у
с достаточной точностью для любой функциональной зависимости у
(х
) при условии, что она является непрерывной. Интерполирующая функция имеет вид
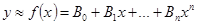 , (7.1) , (7.1)
где B
0
,B
1
, … Bn
– определяемые коэффициенты. Так как данный многочлен (7.1) изображается кривой параболического типа, то такая интерполяция называется параболической.
Коэффициенты интерполирующего многочлена находят, решая систему из (l
+ 1) линейных уравнений, получающихся при подстановке в уравнение (7.1) известных значений у
i
и х
i
.
Наиболее просто производится интерполирование, когда интервалы между значениями аргумента постоянны, т. е.
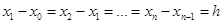 , (7.2) , (7.2)
где h
– постоянная величина, называемая шагом. В общем случае
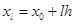 . (7.3) . (7.3)
При использовании интерполяционных формул приходится иметь дело с разностями значений у
и разностями этих разностей, т. е. разностями функции у
(х
) различных порядков. Разности любого порядка вычисляются по формуле
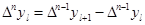 . (7.4) . (7.4)
Например,
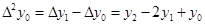 и и 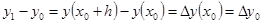 . .
При вычислении разностей их удобно располагать в виде таблицы (см. Табл. 4), в каждом столбце которой разности записывают между соответствующими значениями уменьшаемого и вычитаемого, т. е. составляется таблица диагонального типа. Обычно разности записывают в единицах последнего знака.
Таблица 4
Разности функции у
(х
)
| x |
y |
Dy |
D2
y |
D3
y |
D4
y |
| x0
|
у0
|
Dу0
Dу1
Dу2
Dу3
|
D2
у0
D2
у1
D2
у2
|
| x1
|
у1
|
D3
у0
D3
у1
|
| x2
|
у2
|
D4
у0
|
| x3
|
у3
|
| х4
|
у4
|
Так как функция у
(х
) выражается многочленом (7.1) n
-ой степени относительно х
, то разности также являются многочленами, степени которых понижаются на единицу при переходе к последующей разности. N
-я разность многочлена n
-ой степени является постоянным числом, т. е. содержит х
в нулевой степени. Все разности более высокого порядка равны нулю. Это определяет степень интерполирующего многочлена.
Преобразовав функцию (7.1), можно получить первую интерполяционную формулу Ньютона:
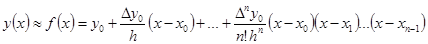 . (7.5) . (7.5)
Она используется для нахождения значений у
при любых х
в пределах измерений. Представим эту формулу (7.5) в несколько ином виде:
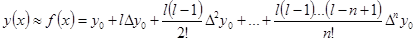 . (7.6) . (7.6)
Последние две формулы иногда называют интерполяционными формулами Ньютона для интерполирования вперед. В эти формулы входят разности, идущие по диагонали вниз, и их удобно использовать в начале таблицы экспериментальных данных, где разностей достаточно.
Вторая интерполяционная формула Ньютона, выведенная из того же уравнения (7.1), выглядит следующим образом:
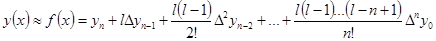 . (7.7) . (7.7)
Данную формулу (7.7) принято называть интерполяционной формулой Ньютона для интерполирования назад. Она используется для определения значений у
в конце таблицы.
Теперь рассмотрим интерполяцию при неравноотстоящих значениях аргумента.
Пусть по-прежнему функция у
(х
) задается рядом значений хi
и уi
, но интервалы между последовательными значениями хi
неодинаковы. Использовать вышеприведенные формулы Ньютона нельзя, так как они содержат постоянный шаг h
. В задачах такого рода необходимо вычислить приведенные разности:
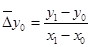 ; ; 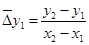 и т. д. и т. д.
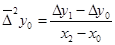 ; ; 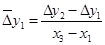 и т. д. (7.8) и т. д. (7.8)
Разности более высоких порядков вычисляются аналогично. Как и для случая равноотстоящих значений аргумента, если f
(х
) – многочлен n
-ой степени, то разности n
-го порядка постоянны, а разности более высокого порядка равны нулю. В простых случаях таблицы приведенных разностей имеют вид, аналогичный таблицам разностей при равноотстоящих значениях аргумента.
Помимо рассмотренных интерполяционных формул Ньютона часто применяют интерполяционную формулу Лагранжа:
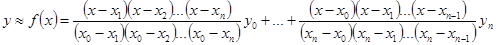 . (7.9) . (7.9)
В этой формуле каждое из слагаемых представляет собой многочленn
-ой степени и все они равноправны. Поэтому до окончания вычислений нельзя пренебрегать какими-либо из них.
Обратное интерполирование.
На практике иногда бывает необходимо найти значение аргумента, которому соответствует определенное значение функции. В этом случае интерполируют обратную функцию и следует иметь в виду, что разности функции не постоянны и интерполирование нужно проводить для неравноотстоящих значений аргумента, т. е. использовать формулу (7.8) или (7.9).
Экстраполирование.
Экстраполированием
называют вычисление значений функции у
за пределами интервала значений аргумента х
, в котором были проведены измерения. При неизвестном аналитическом выражении искомой функции экстраполирование нужно проводить весьма осторожно, так как не известно поведение функции у
(х
) за пределами интервала измерений. Экстраполяция допускается, если ход кривой плавный и нет причин ждать резких изменений в исследуемом процессе. Тем не менее экстраполирование должно проводиться в узких пределах, например в пределах шага h
. В более далеких точках можно получить неверные значения у
. Для экстраполирования применяются те же формулы, что и для интерполирования. Так, первая формула Ньютона используется при экстраполировании назад, а вторая формула Ньютона – при экстраполировании вперед. Формула Лагранжа применяется в обоих случаях. Надо также иметь в виду, что экстраполирование приводит к большим погрешностям, чем интерполирование.
Численное интегрирование.
Формула трапеций.
Формулу трапеций обычно применяют в том случае, если значения функции измерены для равноотстоящих значений аргумента, т. е. с постоянным шагом. По правилу трапеций в качестве приближенного значения интеграла
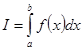 (7.10) (7.10)
принимают величину
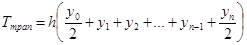 , (7.11) , (7.11)
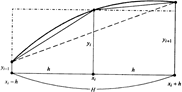
Рис. 7.1. Сравнение методов численного интегрирования
т. е. полагают 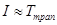 . Геометрическая интерпретация формулы трапеций (см. рис. 7.1) следующая: площадь криволинейной трапеции заменяется суммой площадей прямолинейных трапеций. Полная ошибка вычисления интеграла по формуле трапеций оценивается как сумма двух ошибок: ошибки усечения, вызванной заменой криволинейной трапеции прямолинейными, и ошибки округления, вызванной ошибками измерения значений функции. Ошибка усечения для формулы трапеций составляет . Геометрическая интерпретация формулы трапеций (см. рис. 7.1) следующая: площадь криволинейной трапеции заменяется суммой площадей прямолинейных трапеций. Полная ошибка вычисления интеграла по формуле трапеций оценивается как сумма двух ошибок: ошибки усечения, вызванной заменой криволинейной трапеции прямолинейными, и ошибки округления, вызванной ошибками измерения значений функции. Ошибка усечения для формулы трапеций составляет
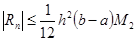 , где , где 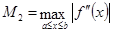 . (7.12) . (7.12)
Формулы прямоугольников.
Формулы прямоугольников, как и формулу трапеций применяют также в случае равноотстоящих значений аргумента. Приближенная интегральная сумма определяется по одной из формул
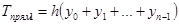 , (7.13) , (7.13)
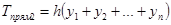 . (7.14) . (7.14)
Геометрическая интерпретация формул прямоугольников дана на рис. 7.1. Погрешность формул (7.13) и (7.14) оценивается неравенством
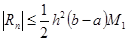 , где , где 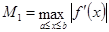 . (7.15) . (7.15)
Формула Симпсона.
Приближенно интеграл определяется по формуле
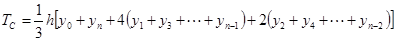 , (7.16) , (7.16)
где n
– четное число. Ошибка формулы Симпсона оценивается неравенством
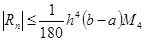 , где , где 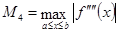 . (7.17) . (7.17)
Формула Симпсона приводит к точным результатам для случая, когда подынтегральная функция является многочленом второй или третьей степени.
Численное интегрирование дифференциальных уравнений.
Рассмотрим обыкновенное дифференциальное уравнение первого порядка у
' = f
(х
, у
) с начальным условием у
= у
0
при х
= х
0
. Требуется найти приближенно его решение у
= у
(х
) на отрезке [х
0
, х
k
].
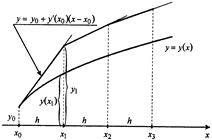
Рис. 7.2. Геометрическая интерпретация метода Эйлера
Для этого данный отрезок делится на n
равных частей длиной (х
k
– х
0
)/n
. Поиск приближенных значений у
1
, у
2
, … , у
n
функции у
(х
) в точках деления х
1
, х
2
, … , х
n
= х
k
осуществляется различными методами.
Метод ломаных Эйлера.
При заданном значении у
0
= у
(х
0
) остальные значения у
i
 у
(х
i
) последовательно вычисляются по формуле у
(х
i
) последовательно вычисляются по формуле
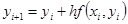 , (7.18) , (7.18)
где i
= 0, 1, …, n
– 1.
Графически метод Эйлера представлен на рис. 7.1, где график решения уравнения у
= у
(х
) приближенно представляется ломаной (откуда и происходит название метода). Метод Рунге-Кутта.
Обеспечивает более высокую точность по сравнению с методом Эйлера. Искомые значения у
i
последовательно вычисляются по формуле
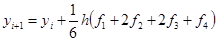 , (7.19), где , (7.19), где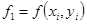 , ,
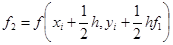 , , 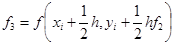 , , 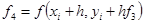 . .
ОБЗОР НАУЧНОЙ ЛИТЕРАТУРЫ
Обзор литературы – обязательная часть всякого отчета об исследовании. Обзор должен полно и систематизированно излагать состояние вопроса, позволять объективно оценивать научно-технический уровень работы, правильно выбирать пути и средства достижения поставленной цели и оценивать как эффективность этих средств, так и работы в целом. Предметом анализа в обзоре должны быть новые идеи и проблемы, возможные подходы к решению этих проблем, результаты предыдущих исследований, данные экономического характера, возможные пути решения задач. Противоречивые сведения, содержащиеся в различных литературных источниках, должны быть проанализированы и оценены с особой тщательностью.
Из анализа литературы должно быть видно, что в этом узком вопросе известно вполне достоверно, что сомнительно, спорно; какие задачи в поставленной технической проблеме первоочередные, ключевые; где и как стоит искать их решения.
Затраты времени на обзор складываются примерно так:
| выписки из справочников, чтение и конспектирование основных монографий |
3 – 5 % |
| составление рабочего плана обзора |
1 – 2 % |
| поиск периодики (и составление картотеки или списка литературы) |
5 – 8 % |
| чтение и конспектирование периодики |
30 – 40 % |
| отбор материала из конспектов, его сопоставление и анализ |
20 – 30 % |
| написание обзора |
10 – 20 % |
| правка текста |
10 – 15 % |
| переписка и изготовление рисунков |
5 – 6 % |
Исследование всегда имеет узкую конкретную цель. В заключении обзора обоснованы выбор цели и метода. Обзор должен подготовить это решение. Отсюда следует его план и отбор материала. В обзоре рассматривают только такие узкие вопросы, которые могут прямо повлиять на решение задачи, но настолько полно, чтобы охватить практически всю современную литературу по этому вопросу.
ОРГАНИЗАЦИЯ СПРАВОЧНО–ИНФОРМАЦИОННОЙ ДЕЯТЕЛЬНОСТИ
В нашей стране в основу информационной деятельности положен принцип централизованной обработки научных документов, позволяющий с наименьшими затратами достичь полного охвата источников информации, наиболее квалифицированно их обобщить и систематизировать. В результате такой обработки подготавливаются различные формы информационных изданий. К ним относятся:
1) реферативные журналы
(РЖ) – основное информационное издание, содержащее преимущественно рефераты (иногда аннотации и библиографические описания) источников, представляющих наибольший интерес для науки и практики. Реферативные журналы, оповещающие о появившейся научно-технической литературе, позволяют осуществлять ретроспективный поиск, преодолевать языковые барьеры, дают возможность следить за достижениями в смежных областях науки и техники;
2) бюллетени сигнальной информации
(СИ), включающие в себя библиографические описания литературы, выходящей по определенной отрасли знаний и являющиеся по существу библиографическими указателями. Их основной задачей является оперативное информирование о всех новинках научной и технической литературы, так как появляется эта информация значительно раньше, чем в реферативных журналах;
3) экспресс-информация
– информационные издания, содержащие расширенные рефераты статей, описание изобретений и других публикаций и позволяющие не обращаться к первоисточнику. Задача экспресс-информации – быстрое и достаточно полное ознакомление специалистов с новейшими достижениями науки и техники;
4) аналитические обзоры
– информационные издания, дающие представление о состоянии и тенденциях развития определенной области (раздела, проблемы) науки и техники;
5) реферативные обзоры
– преследующие ту же цель, что и аналитические обзоры, и в то же время носящие более описательный характер. Авторы реферативных обзоров не дают собственной оценки содержащихся в них сведений;
6) печатные библиографические карточки
, т. е. полное библиографическое описание источника информации. Относятся к числу сигнальных изданий и выполняют функции оповещения о новых публикациях и возможностях создания каталогов и картотек, необходимых каждому специалисту, научному работнику;
7) аннотированные печатные библиографические карточки
;
8) библиографические указатели
.
Большая часть этих изданий распространяется и по индивидуальной подписке. Подробные сведения о них можно найти в издаваемых ежегодно "Каталогах изданий органов научно-технической информации".
|