1 Методологічні основи соціально-економічного прогнозування
Прогнозом називають науково обґрунтований висновок про майбутні події і перспективи розвитку процесів, про можливі наслідки управлінських рішень.
За специфікою об'єктів прогнози поділяють на науково-технічні, економічні, соціальні, військово-політичні тощо. Економічні прогнози класифікують за масштабністю об'єкта на глобальні, макроекономічні, структурні (міжгалузеві та міжрегіональні), регіональні, галузеві, мікроекономічні.
B світовій практиці прикладного прогнозування використовують різні методи: статистичні (прогнозна екстраполяція), функціонально-ієрархічні (прогнозні сценарії), методи структурної аналогії, імітаційного моделювання, експертні оцінки.
При прогнозуванні соціально-економічних процесів перевага віддається статистичним методам, прогнозним результатом яких є очікувані у майбутньому значення характеристик процесу, тобто статистичний прогноз завжди є умовним.
Іншою особливістю статистичного прогнозу є визначеність його в часі. Часовий горизонт прогнозу називають періодом упередження.
За тривалістю цього періоду вирізняють прогнози: короткострокові (до 1 року), середньострокові (до 5 років) і довгострокові (від 5 до 20 років і більше). Тривалість періоду упередження залежить від специфіки об'єкта прогнозування, інтенсивності динаміки, тривалості дії виявлених закономірностей та тенденцій.
Прогнозний результат на період упередження можна представити одним числом (точковий прогноз) або інтервалом значень, до якого з певною ймовірністю належить прогнозна величина (інтервальний прогноз).
Статистичні прогнози ґрунтуються на гіпотезах про стабільність значень величини, що прогнозується; закону її розподілу; взаємозв'язків з іншими величинами тощо. Основний інструмент прогнозування — екстраполяція.
Суть прогнозної екстраполяції полягає в поширенні закономірностей, зв'язків і відношень, виявлених в t
-му періоді, за його межі.
Залежно від гіпотез щодо механізму формування і подальшого розвитку процесу використовуються різні методи прогнозної екстраполяції. Їх можна об'єднати в дві групи:
- екстраполяція закономірностей динаміки — тренду і коливань;
- екстраполяція причинно-наслідкового механізму формування процесу — факторне прогнозування.
Ці методи різняться не процедурою розрахунків прогнозу, а способом описування об'єкта моделювання. Екстраполяція закономірностей розвитку ґрунтується на вивченні його передісторії, виявленні загальних і усталених тенденцій, траєкторій зміни в часі. Абстрагуючись від причин формування процесу, закономірності його розвитку розглядають як функцію часу. Інформаційною базою прогнозування слугують одномірні динамічні ряди.
При багатофакторному прогнозуванні процес розглядається як функція певної множини факторів, вплив яких аналізується одночасно або з деяким запізненням. Інформаційною базою виступає система взаємозв'язаних динамічних рядів. Оскільки фактори включаються в модель у явному вигляді, то особливого значення набуває апріорний, теоретичний аналіз структури взаємозв'язків.
Важливим етапом статистичного прогнозування є верифікація прогнозів,
тобто оцінювання їх точності та обґрунтованості. Ha етапі верифікації використовують сукупність критеріїв, способів і процедур, які дають можливість оцінити якість прогнозу.
Найбільш поширене ретроспективне оцінювання прогнозу,
тобто оцінювання прогнозу для минулого часу (ex-post прогноз). Процедура перевірки така. Динамічний ряд поділяється на дві частини: перша — для t
= 1,2,3,
...,p —
називається ретроспекцією (передісторією), друга — для t=p
+ 1
, p + 2, p + 3, ..., p +(n —р)
— прогнозним періодом.
За даними ретроспекції моделюється закономірність динаміки і на основі моделі розраховується прогноз Yp+v
,
де v
— період упередження. Ретроспекція послідовно змінюється, відповідно змінюється прогнозний період, що унаочнює рис. 1.1 (для v = 1
).

Оскільки фактичні значення прогнозного періоду відомі, то можна визначити похибку прогнозу як різницю фактичного уt
і прогнозного Yt
рівнів: et
= yt
– Yt
.
Всього буде n —р
похибок. Узагальнюючою оцінкою точності прогнозу слугує середня похибка:
абсолютна 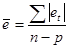 , квадратична , квадратична 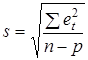 . .
Для порівняння точності прогнозів, визначених за різними моделями, використовують похибку апроксимації
(%):
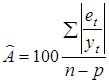
Якщо результат оцінювання точності прогнозу задовольняє визначені критерії точності, скажімо, 10%, то прогнозна модель вважається прийнятною і рекомендується для практичного використання. Очевидно, що похибка прогнозу залежить від довжини ретроспекції та горизонту прогнозування. Оптимальним співвідношенням між ними вважається 3 : 1.
При оцінюванні та порівнянні точності прогнозів використовують також коефіцієнт розбіжності Г. Тейла, який дорівнює нулю за відсутності похибок прогнозу і не має верхньої межі:
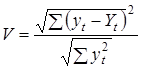
Існуючі методи верифікації прогнозів у більшості своїй ґрунтуються на статистичних процедурах, які зводяться до побудови довірчих меж прогнозу, себто до побудови інтервальних прогнозів.
2 Методи і моделі прогнозування одновимірних процесів
Ряди динаміки характеризують процеси розвитку соціально-економічних явищ. Цим процесам властиві дві взаємопов'язані риси: динамічність та інерційність, що формують закономірність розвитку.
Ряди, в яких рівні коливаються навколо постійної середньої, називаються стаціонарними. Економічні ряди, як правило, нестаціонарні. Для більшості з них характерна систематична зміна рівнів з нерегулярними коливаннями, коли піки і западини чергуються з різною інтенсивністю. Скажімо, економічні цикли (промислові, будівельні, фондового ринку тощо) повторюються з різною тривалістю і різною амплітудою коливань.
Короткострокове прогнозування на основі ковзних середніх
Досить поширеним і простим методом аналізу динаміки є згладжування ряду. Суть його полягає в заміні фактичних рівнів уt
,
середніми за певними інтервалами. Варіація середніх порівняно з варіацією рівнів первинного ряду значно менша, а тому характер динаміки проявляється чіткіше. Процедуру згладжування називають фільтруванням, а оператори, за допомогою яких вона здійснюється, — фільтрами. На практиці використовують переважно лінійні фільтри, з-поміж яких найпростіший — ковзна середня
з інтервалом згладжування m < n.
Інтервали поступово зміщуються на один елемент:
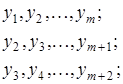
Для кожного з них визначається середня 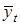 ,
яка припадає на середину інтервалу. Якщо m —
непарне число, тобто m = 2p +
1, а ваги членів ряду в межах інтервалу однакові ,
яка припадає на середину інтервалу. Якщо m —
непарне число, тобто m = 2p +
1, а ваги членів ряду в межах інтервалу однакові
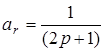 , то , то
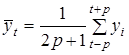
де yi
—
фактичне значення рівня в i
-й момент; i
— порядковий номер рівня в інтервалі.
При парному m
середина інтервалу знаходиться між двома часовими точками і тоді проводиться додаткова процедура центрування
(усереднення кожної пари значень).
Ковзна середня з однаковими вагами аr
при згладжуванні динамічного ряду погашає не лише випадкові, а й властиві конкретному процесу періодичні коливання. Припускаючи наявність таких коливань, використовують зважену ковзну середню, тобто кожному рівню в межах інтервалу згладжування надають певну вагу. Способи формування вагової функції різні. B одних випадках ваги відповідають членам розкладання біному 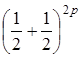 , при m=
3, скажімо, ar
=
1/4, 1/2,1/4. B інших випадках до даних інтервалу згладжування добирається певний поліном, наприклад, парабола , при m=
3, скажімо, ar
=
1/4, 1/2,1/4. B інших випадках до даних інтервалу згладжування добирається певний поліном, наприклад, парабола 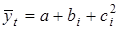 , де i
= -р, …, p.
Тоді вагова функція така: , де i
= -р, …, p.
Тоді вагова функція така:
Для m = 5 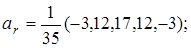
Для m = 7 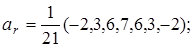 і т.д.
і т.д.
Як видно з формул, ваги симетричні відносно центра інтервалу згладжування, сума їх з урахуванням винесеного за дужки множника дорівнює 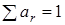 . .
Основна перевага ковзної середньої — наочність і простота тлумачення тенденції. Проте не слід забувати, що ряд ковзних середніх коротший за первинний ряд на 2p
рівнів, а отже, втрачається інформація про крайні члени ряду. I чим ширший інтервал згладжування, тим відчутніші втрати, особливо нової інформації . Окрім того, маючи спільну основу розрахунку, ковзні середні виявляються залежними, що при згладжуванні значних коливань навіть за відсутності циклів у первинному ряду може вказувати на циклічність процесу (ефект Слуцького).
У симетричних фільтрах стара і нова інформація рівновагомі, а при прогнозуванні важливішою є нова інформація. У такому разі використовують асиметричні фільтри. Найпростіший з них — ковзна середня, яка замінює не центральний, а останній член ряду (адаптивна середня):
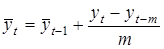 . .
У наведеній формулі перший елемент характеризує інерцію розвитку, другий — адаптує середню до нових умов. Таким чином середня 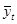 з кожним кроком ніби оновлюється. Ступінь оновлення визначається постійною вагою з кожним кроком ніби оновлюється. Ступінь оновлення визначається постійною вагою 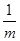 . При використанні зважених асиметричних фільтрів вагова функція формується з урахуванням ступеня новизни інформації. Такою є середня з екс-поненційно розподіленими вагами: . При використанні зважених асиметричних фільтрів вагова функція формується з урахуванням ступеня новизни інформації. Такою є середня з екс-поненційно розподіленими вагами:
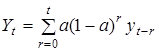 , ,
де Yt
,
— експоненційна середня,
тобто згладжене значення рівня динамічного ряду на момент t
; 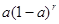 —
вага ( t - r )-
гo рівня; a
— параметр згладжування, який визначає вагу t-
гo рівня, значення його коливаються в межах від 0 до 1. —
вага ( t - r )-
гo рівня; a
— параметр згладжування, який визначає вагу t-
гo рівня, значення його коливаються в межах від 0 до 1.
Розклавши формулу за елементами суми, маємо
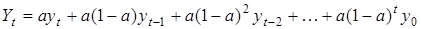 , ,
або
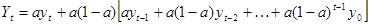
Друга складова останньої формули є не що інше, як експоненційна середня для (t-
l)-гo моменту. Отже, експоненційну середню можна представити як лінійну комбінацію фактичного рівня t-
гo моменту та експоненційної середньої (t
- l)-гo моменту: 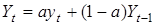 . .
Чим віддаленіший від t-
го моменту рівень ряду, тим менша його відносна вага і вклад у тенденцію. Так, при a = 0,2
ваги становлять: для t-
го моменту — 0,2
, для ( t – 1 )-
го моменту — 0,2(1 -O,2) =
0,16; для (t-2)
-ro моменту — 0,2(1 -0,2)2
= 0,128
і т. д. Надаючи більшу вагу новій інформації, експоненційна середня адаптується до нових умов, що робить її досить ефективним і надійним методом короткострокового прогнозування.
Для розрахунку експоненційної середньої Yt
,
необхідно визначити початкові умови: початкову величину Y0
і параметр а.
Як початкову величину можна використати середній рівень за минулий (до динамічного ряду) період, або за відсутності таких даних, перший рівень ряду, тобто Yo
=yt
.
Щодо параметра а,
то на практиці найчастіше використовують його значення в інтервалі від 0,1 до 0,3 . Оскільки від параметра а
залежить сума вагових коефіцієнтів 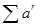 на певному часовому інтервалі m,
то можна за наперед заданим значенням цих величин орієнтовно визначити параметр а: на певному часовому інтервалі m,
то можна за наперед заданим значенням цих величин орієнтовно визначити параметр а:
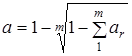
Наприклад, якщо часовий інтервал m = 10
місяців, а сума ваг 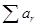 = 0,90 , то = 0,90 , то 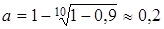 . Тобто, при a
= 0,2
десять членів динамічного ряду визначать 90% величини експоненційної середньої. . Тобто, при a
= 0,2
десять членів динамічного ряду визначать 90% величини експоненційної середньої.
При прогнозуванні процесу вдаються до багаторазового згладжування. Якщо період упередження v
= 1, то використовують подвійне згладжування. Експоненційна середня другого порядку 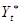 визначається за такою ж самою рекурентною формулою на основі згладженого ряду визначається за такою ж самою рекурентною формулою на основі згладженого ряду 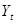 : :
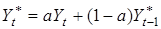 . .
Якщо припустити наявність лінійного тренда, прогнозний рівень Yt+
1
можна розрахувати за формулою :
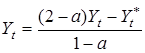
Довірчі межі прогнозного рівня визначаються традиційно:
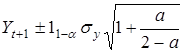
де 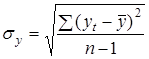 ¾ дисперсія рівнів первинного динамічного ¾ дисперсія рівнів первинного динамічного
ряду; t
— квантиль розподілу Стьюдента для ймовірності (
1 -
a
).
Очевидно, що за умови значної варіації рівнів динамічного ряду довірчі межі будуть досить широкими.
Базову модель експоненційного згладжування можна використати при моделюванні рядів, які мають сезонну компоненту.
Оцінювання сезонної компоненти
Сезонні коливання формуються під впливом не лише природно-кліматичних, але й соціально-економічних факторів. Сила і напрям дії окремих факторів формує різну конфігурацію сезонної хвилі. За своїм характером сезонна компонента може бути адитивною або мультиплікативною. Для адитивної компоненти характерні сталі коливання навколо середнього рівня чи тренда, для мультиплікативної — зростання амплітуди коливань з часом.
Кожний рівень ряду уt
,
належить до певного сезонного циклу s,
Довжина якого становить 12 місяців, або 4 квартали. Відношення Yt
до середнього рівня за цикл називається індексом сезонності:
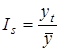 . .
За умови, що вплив несезонних факторів еліміновано, середня з iндексіву j
-го циклу становить 1, або 100 % .
У нестаціонарних рядах замість середньої використовують лі-н
'ю тренда Yt
= y(t),
яка плавно проходить через ряд динаміки і , як і середня , елімінує його нерівномірності. Сукупність індексів Се
зонності в межах циклу характеризує сезонний ритм.
Прогнозування сезонних процесів ґрунтується на декомпозиції динамічного ряду. Припускають, що у майбутньому збережеться тенденція і такий же характер коливань. За таких умов прогноз на будь-який місяць (квартал), визначений методом екстра-поляціїтренда, коригується індексом сезонності: 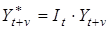 ,
де v
— період упередження. Скажімо, поквартальна динаміка обсягів імпорту пального (тис. т) за два роки (n =
8, t
1
=
-3,5, tn
= 3,5) описується трендом Yt
=
923,7 + 33,8t
, за яким теоретичний обсяг імпорту у восьмому кварталі становить 1042,0 тис.т, а в 1-му кварталі наступного року (v=
1)
передбачається Yt+v
= 1042,0 + 33,8 * 1 = 1075,8 . Якщо середній індекс сезонності 1-го кварталу It
=
1,34, то скоригований на сезонність прогнозний рівень дорівнює ,
де v
— період упередження. Скажімо, поквартальна динаміка обсягів імпорту пального (тис. т) за два роки (n =
8, t
1
=
-3,5, tn
= 3,5) описується трендом Yt
=
923,7 + 33,8t
, за яким теоретичний обсяг імпорту у восьмому кварталі становить 1042,0 тис.т, а в 1-му кварталі наступного року (v=
1)
передбачається Yt+v
= 1042,0 + 33,8 * 1 = 1075,8 . Якщо середній індекс сезонності 1-го кварталу It
=
1,34, то скоригований на сезонність прогнозний рівень дорівнює 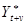 ,= 1,34 - 1075,8 = 1441,6 тис.т. ,= 1,34 - 1075,8 = 1441,6 тис.т.
Динаміка більшості показників не виявляє чітко вираженої тенденції розвитку. Через постійний перерозподіл впливу факторів, які формують динаміку процесу, змінюється інтенсивність динаміки, частота та амплітуда коливань. До таких фактичних даних більш еластичною виявляється ковзна середня, інтервал згладжування якої дорівнює сезонному циклу (4 або 12). Коригування ковзної середньої на сезонність здійснюється так само, як коригування лінійного тренда.
Ha використанні експоненційної середньої ґрунтується ceзонно-деколіпозиційна модель Холта-Вінтера,
в якій поєднуються моделі стаціонарності, лінійності та сезонності. Послідовність операцій така:
1. Визначаються індекси сезонності It
2. Ряд динаміки фільтрується від сезонних коливань діленням yt
на коефіцієнт сезонності з лагом s
; ряд ut
= yt
: It-s
називається декомпозиційним.
3. Перші різниці декомпозиційного ряду bt
= (ut
– ut-
1
)
розглядаються як характеристики лінійного тренда.
Кожна з компонент моделі згладжується за допомогою експоненційної середньої. При комбінації лінійної та сезонно-адитивної моделей тренда:
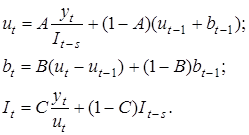
Значення параметрів згладжування A,
D
і C
в системі Statistica
за умовчування визначаються на рівні 0,1, в [10] рекомендуються: A =
0,2; B =
0,2; C =
0,5.
За умови ізольованої оцінки трьох факторів прогноз на період упередження v
визначається як скоригована на сезонність сума прогнозного рівня ut
,
і лінійного тренда:
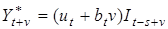 . .
При комбінації лінійного та сезонно-мультиплікативного трендів кінцевий прогноз визначається за формулою :
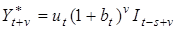 , де , де 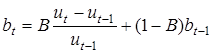 . .
Типи трендових моделей
При моделюванні динамічних процесів причинний механізм формування властивих їм особливостей у явному вигляді не враховується. Будь-який процес розглядається як функція часу. Певна річ, час не є фактором конкретного соціально-економічного процесу, змінна часу t
просто акумулює комплекс постійно діючих умов і причин, які визначають цей процес.
У моделях динаміки процес умовно поділяється на чотири складові:
- довгострокову, детерміновану часом еволюцію — трендf(t)
);
- періодичні коливання різних частот Ct
;
- сезонні коливання St
;
- випадкові коливання et
.
Зв'язок між цими складовими представляється адитивно (сумою) або мультиплікативно (добутком):
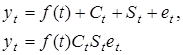
Така умовна конструкція дає змогу, залежно від мети дослідження, вивчати тренд, елімінуючи коливання, або вивчати коливання, елімінуючи тренд. При прогнозуванні здійснюється зведення прогнозів різних елементів в один кінцевий прогноз.
Характерною властивістю будь-якого динамічного ряду є залежність рівнів: значення уt
,
певною мірою залежить від попередніх значень: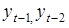 i т. д. Для оцінювання ступеня залежності рівнів ряду використовують коефіцієнти автокореляції rр
з часовим лагом p = 1, 2, ..., т. i т. д. Для оцінювання ступеня залежності рівнів ряду використовують коефіцієнти автокореляції rр
з часовим лагом p = 1, 2, ..., т.
Коефіцієнт rр
характеризує щільність зв'язку між первинним рядом динаміки і цим же рядом, зсуненим на p
моментів. У табл. 2.1 наведено зсунені ряди динаміки з лагами p - 1, 2, 3
. Як видно, із збільшенням лага p
кількість пар корельованих рівнів зменшується. Так, при p
= 1
довжина корельованих рядів менша за первинний ряд на один рівень, при p
= 2 — на два рівні і т. д. Через це на практиці при визначенні автокореляційної функції дотримуються правила, за яким кількість лапв 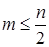 . .
Таблиця 2.1
| Змінна часу t
|
Рівень ряду у
|
р=1
|
р = 2
|
р = 3
|
| 1
|
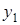
|
—
|
—
|
—
|
| 2
|
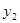
|
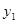
|
—
|
—
|
| З
|
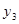
|
|
|
—
|
| …
|
…
|
…
|
…
|
…
|
| n-2
|
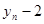
|
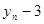
|
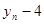
|
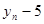
|
| n-1
|
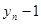
|
|
|
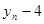
|
| n
|
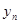
|
|
|
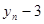
|
Значення коефіцієнта автокореляції rр
визначається величиною лага p
і не виходить за межі ±1:
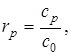
де 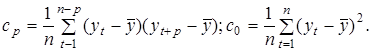
Послідовність коефіцієнтів rр
називають автокореляційною функцією
і зображують графічно у вигляді автокорелограми з абсцисою p
та ординатою rp
.
За швидкістю згасання автокореляційної функції можна зробити висновок про характер динаміки. Найчастіше використовується значення r1
.
Характеризуючи ступінь залежності двох послідовних членів ряду, коефіцієнт автокореляції є мірою неперервності цього ряду. Якщо 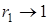 , то ряду динаміки властива тенденція розвитку, якщо , то ряду динаміки властива тенденція розвитку, якщо 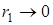 — рівні ряду незалежні. Відносно високі значення коефіцієнта автокореляції при p = k, 2k, 3k, …
свідчать про регулярні коливання. — рівні ряду незалежні. Відносно високі значення коефіцієнта автокореляції при p = k, 2k, 3k, …
свідчать про регулярні коливання.
На відміну від детермінованої складової випадкова складова не зв'язана із зміною часу. Аналіз цієї складової є основою перевірки гіпотези про адекватність моделі реальному процесу. За умови, що модель вибрано правильно, випадкова складова являє собою стаціонарний процес з математичним сподіванням M(e)
= 0 і дисперсією
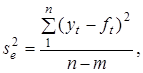
де m
— число параметрів функції.
Для оцінювання стаціонарності випадкової складової використовують циклічний коефіцієнт автокореляції першого порядку r1
.
Корелюються ряди залишкових величин: 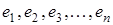 та та 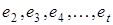
Припускаючи, що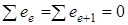 , формула розрахунку спрощується: , формула розрахунку спрощується:
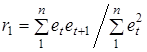 . .
Існують таблиці критичних значень циклічного коефіцієнта автокореляції для додатних і від'ємних значень (додаток 5). Якщо фактичне значення r1
менше за критичне, автокореляція вважається неістотною, а випадкова складова — стаціонарним процесом. У разі, коли фактичне значення r1
перевищує критичне, можна зробити висновок про неадекватність детермінованої складової реальному процесу.
Важливою складовою динамічних процесів є тенденція середньої, тобто основний напрям розвитку. B аналізі динамічних рядів тенденцію представляють у вигляді плавної траєкторії та описують певною функцією, яку називають трендом Yt
= f(t)
, де t= 1, 2, … , n —
змінна часу. Ha основі такої функції здійснюється вирівнювання динамічного ряду і прогнозування подальшого розвитку процесу.
Процедура вирівнювання динамічних рядів включає два етапи: обґрунтування (вибір) типу функції, яка б адекватно описувала характер динаміки, та оцінювання параметрів функції. Ha практиці переважно використовують функції, параметри яких мають конкретну інтерпретацію залежно від характеру динаміки. Найбільш поширені поліноми (многочлени), різного роду експоненти та логістичні криві. Так, параметри полінома p
-ro ступеня Yt
= a
+ bt + ct2
+ dt3
…
характеризують:
а —
рівень динамічного ряду при t
= 0;
b —
абсолютну швидкість зміни рівнів ряду (ординат);
2c
— прискорення (прирощення абсолютної швидкості);
d —
зміну прирощення тощо.
Поліном 1-го ступеня, тобто лінійний тренд Yt
= a + bt,
описує процеси, які рівномірно змінюються в часі і мають стабільні прирости ординат. Поліном 2-го ступеня (парабола) Yt
= a + bt + ct2
здатний описати процес, характерною особливістю якого є рівноприскорене зростання або зменшення ординат. Форма параболи визначається параметром c:
при c >
0 гілки параболи спрямовані вгору — парабола має мінімум, при c <
0 гілки параболи спрямовані вниз — парабола має максимум. При визначенні екстремуму (max, min) похідну параболи прирівнюють до нуля і розв'язують систему рівнянь відносно t.
Наприклад, динаміка захворювань при епідемії грипу (чол.) описується параболою Yt
= 264 + 45t - 1,5t2
. Похідна параболи 45-2,25t = 0
, a t = 20.
Максимум захворювань буде зафіксовано через 20 днів від початку відліку часу (t = 0)
і становитиме Ymах
= 264 + 45 – 20 - 1,5
×
202
= 564
чол. У полінома 3-го ступеня Yt
= a + bt + ct2
+ dt3
знак прирощення ординати може змінюватися один чи два рази.
Якщо характерною властивістю процесу є стабільна відносна швидкість (темпи приросту), такий процес описується експонентою яка може набувати різних еквівалентних форм. Основна (показникова) форма експоненти
Yt
= abt
де b
— середня відносна швидкість зміни ординати: при b > 1
ордината зростає з постійним темпом, при b <
1, навпаки, зменшується. Абсолютний приріст пропорційний досягнутому рівню. Експоненту можна представити у формі:
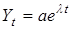 або або 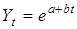
де l
= lnb
, е = 2,718
— основа натурального логарифма, lne
= 1
.
Експоненти приводяться до лінійного виду заміною yt
десятковими або натуральними логарифмами:
lgY
=lga
+ t
lgb
, |
lnY
= lna
+ l
t
lne
= lna
+ l
t
,
lnY
= lnea
+
lne
bt
=
lna
+ lnbt =
lna
+ l
t
.
Оцінювання параметрів трендових рівнянь найчастіше здійснюється методом найменших квадратів
(MHK), основною умовою якого є мінімізація суми квадратів відхилень фактичних значень yt
від теоретичних Yt
, визначених за трендовим рівнянням :
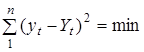 . .
Параметри поліноміального тренда визначаються безпосередньо розв'язуванням систем p +
1 нормальних рівнянь. Експонента, як показано вище, приводиться до лінійного виду логарифмуванням; розраховані параметри підлягають потенціюванню.
Виявлену тенденцію можна продовжити за межі динамічного ряду Така процедура називається екстраполяцією
тренда. Принципова можливість екстраполяції ґрунтується на припущенні, що умови, які визначали тенденцію у минулому, не зазнають істотних змін у майбутньому. Формально операцію екстраполяції можна представити як визначення функції:
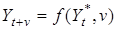 , ,
де Yt+v
— прогнозне значення на період упередження v
; 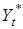 — база екстраполяції, найчастіше це останній, визначений за трендом рівень ряду. — база екстраполяції, найчастіше це останній, визначений за трендом рівень ряду.
Екстраполяція тренда дає точковий прогноз. Очевидно, що «влучення в точку» малоймовірне. Адже тренду властива невизначеність, передусім через похибки параметрів. Джерелом цих похибок є обмежена сукупність спостережень yt
,
кожне з яких містить випадкову компоненту et
,.
Зсунення періоду спостереження лише на один крок веде до зсунення оцінок параметрів. Випадкова компонента буде присутня і за межами динамічного ряду, а отже, її необхідно врахувати. Для цього визначають довірчий інтервал, який би з певною ймовірністю окреслив межі можливих значень Yt
+
v
Точковий інтервал перетворюється в інтервальний. Ширина інтервалу залежить від варіації рівнів динамічного ряду навколо тренда та ймовірності висновку (1 - а)
: 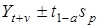
Де Sp
— середня квадратична похибка прогнозу, значення якої залежить від дисперсії тренда 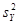 та дисперсії відхилень від тренда
та дисперсії відхилень від тренда 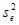 .
Зокрема, для лінійного тренда .
Зокрема, для лінійного тренда
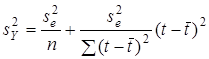 . .
Якщо база прогнозування — останній рівень ряду, то 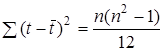 , a , a 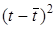 замінюється на замінюється на 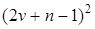 . Після нескладних алгебраїчних перетворень похибку прогнозу за лінійним трендом можна представити так: . Після нескладних алгебраїчних перетворень похибку прогнозу за лінійним трендом можна представити так:
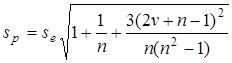
або, позначивши підкореневий вираз символом z, sp
= se
z.
Тобто похибка прогнозу залежить від залишкової дисперсії 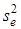 ,
довжини динамічного ряду (передісторії) n
та періоду упередження v
. Чим довший період передісторії, тим похибка менша, а збільшення періоду упередження, навпаки, веде до зростання похибки прогнозу. ,
довжини динамічного ряду (передісторії) n
та періоду упередження v
. Чим довший період передісторії, тим похибка менша, а збільшення періоду упередження, навпаки, веде до зростання похибки прогнозу.
Прогнозування повних циклів
Свої особливості має моделювання динамічних процесів з ефектом насичення, коли темпи зростання (зниження) уповільнюються і рівень наближується до певної межі (питомі витрати ресурсів, споживання продуктів харчування на душу населення тощо). Для їх описування використовують клас кривих, що мають горизонтальну асимптоту 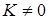 . Найпростішою з-поміж них є модифікована експонента:
. Найпростішою з-поміж них є модифікована експонента:
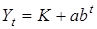
де параметр а —
різниця між ординатою Yt
,
при t =
0 та асимптотою K.
Якщо a <
0, асимптота знаходиться вище кривої, якщо a >
0 — асимптота нижче кривої. Параметр b
характеризує співвідношення послідовних приростів ординати. За умови рівномірного розподілу ординати по осі часу ці співвідношення є сталими:
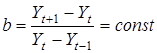 . .
Модифікована експонента описує процеси, на які діє певний обмежувальний фактор, і вплив цього фактора зростає зі зростанням Yt
.
У разі, коли обмежувальний фактор впливає лише після певного моменту, до якого процес розвивався за експоненційним законом, то такий процес найкраще апроксимується S
-подібною функцією з точкою перегину P,
в якій прискорене зростання змінюється уповільненням. Наприклад, попит на новий товар попервах незначний; потім, після визнання споживачами, він стрімко зростає, але у міру насичення ринку темпи зростання уповільнюються, згасають. Попит стабілізується на певному рівні. Аналогічні фази розвитку мають процеси нововведень і винаходів, ефективність використання ресурсів тощо. З-поміж S
-подібних кривих, що описують повний цикл розвитку, найпоширенішою є функція Перла-Ріда — логістична крива:
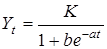 . .
Якщо показник процесу — частка, що змінюється в межах від 0 до 1, то формула логістичної функції спрощується:
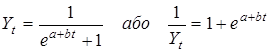 . .
У страховій і демографічній статистиці використовують іншу S-подібну функцію — криву Гомперца: 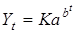 або в логарифмах
або в логарифмах
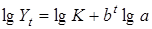 . .
Тобто крива Гомперца приводиться до модифікованої експоненти, у якої сталими є відношення приростів ординат у логарифмах.
Оцінювання параметрів функцій, які мають асимптоти, порівняно з поліномами та експонентами значно складніше. Тут можливі два варіанти.
За першим варіантом асимптота у вигляді нормативу, стандарту тощо визначається апріорі — 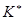 .
Тоді модифіковану експоненту можна представити так: .
Тоді модифіковану експоненту можна представити так:
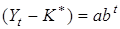 . .
Замінивши 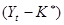 на z
і прологарифмувавши рівняння, дістанемо лінійну функцію логарифмів lgz =
lga + t
lgb.
Аналогічно приводиться до лінійного виду логістична функція на z
і прологарифмувавши рівняння, дістанемо лінійну функцію логарифмів lgz =
lga + t
lgb.
Аналогічно приводиться до лінійного виду логістична функція 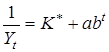 ,
яка при заміні ,
яка при заміні 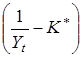 на z
у логарифмах набуває такого ж вигляду: lgz =
lga + t
lgb.
Параметри приведених до лінійного виду функцій, як і параметри поліномів, можна оцінити методом найменших квадратів. на z
у логарифмах набуває такого ж вигляду: lgz =
lga + t
lgb.
Параметри приведених до лінійного виду функцій, як і параметри поліномів, можна оцінити методом найменших квадратів.
Отже, клас моделей динаміки досить широкий, і вони описують різні процеси розвитку. Вибір типу моделі у конкретному дослідженні ґрунтується передусім на теоретичному аналізі специфіки процесу, його внутрішньої структури, взаємозв'язків з іншими процесами. Ha основі такого аналізу в загальних рисах визначається характер динаміки (рівномірний, рівноприскорений, з насиченням тощо) та окреслюється коло функцій, здатних апроксимувати цей процес. Серйозною підмогою при виборі конкретної моделі слугують формальні методи. Скажімо, для поліномів — це аналіз послідовних різниць. Рівність різниць р-го порядку розглядається як симптом того, що процес описується поліномом р-го порядку. Якщо приблизно однакові різниці 1-го порядку 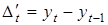 ,
використовують лінійний тренд, якщо однакові різниці 2-го порядку — ,
використовують лінійний тренд, якщо однакові різниці 2-го порядку — 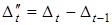 — параболу і т. д. Певні складнощі можуть виникнути при виборі експоненти. Адже S-подібна крива до точки перегину описує експоненційний тренд, а сама точка перегину може бути за межами динамічного ряду. Отже, якщо межа насичення теоретично можлива і процес у майбутньому може згасати або існують певні обмеження для процесу (правові, матеріальних ресурсів, виробничих потужностей тощо), то перевага віддається S-подібній кривій. — параболу і т. д. Певні складнощі можуть виникнути при виборі експоненти. Адже S-подібна крива до точки перегину описує експоненційний тренд, а сама точка перегину може бути за межами динамічного ряду. Отже, якщо межа насичення теоретично можлива і процес у майбутньому може згасати або існують певні обмеження для процесу (правові, матеріальних ресурсів, виробничих потужностей тощо), то перевага віддається S-подібній кривій.
Оскільки первинним рядам динаміки властива значна варіація рівнів yt
то аналіз послідовних різниць більш коректно проводити на основі рядів ковзних середніх. У табл.2.2 наведено основні характеристики такого аналізу (апріорні тести), за якими визначається конкретний тип моделі повного циклу.
Таблица 2.2
| Характеристика
|
Властивості характеристик
|
Тип трендової моделі
|
| 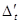
|
Приблизно однакові
|
Поліном 1-го ступеня
|
|
|
Лінійно змінюються
|
Поліном 2-го ступеня
|
| 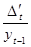
|
Приблизно однакові
|
Експонента
|
| 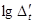
|
Лінійно змінюються
|
Модифікована експонента
|
| 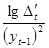
|
Лінійно змінюються
|
Логістична крива
|
| 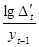
|
Лінійно змінюються
|
Крива Гомперца
|
При зворотному напрямку тенденції різниці розраховуються, починаючи з кінця. За наявності від'ємних різниць логарифмування неможливе, тому необхідно збільшити інтервал згладжування ковзних середніх.
Типи моделей взаємозв'язку
Усі явища навколишнього світу взаємопов'язані й взаємозумовлені. У складному переплетенні всеохоплюючого взаємозв'язку будь-яке з них є наслідком дії певної множини причин і водночас причиною інших явищ.
Логічний зміст і практичну значущість статистичних моделей взаємозв'язку слід розглядати саме в площині співвідношення причинності і зв'язків, що вимірюються статистичними методами. Суть причинності полягає в породженні одного явища іншим. Причина — активна основа, що примушує інше явище змінюватися. Сама по собі причина не визначає наслідку. Останній залежить і від умов, у яких діє причина. Через нерозрізненість причин і умов при моделюванні вони об'єднуються в одне поняття «фактор», а наслідок розглядається як результат дії факторів. Отже, в рамках моделі досліджується детермінованість результату факторами.
Методологічні проблеми побудови моделей взаємозв'язку можна об'єднати в дві групи:
- формування ознакової множини
моделі, себто визначення кількості факторів та їх числових еквівалентів;
- модельна специфікація —
вибір функціонального виду моделі, ідентифікація та оцінювання параметрів.
При формуванні ознакової множини моделі різноманітні прояви причинно-наслідкових зв'язків доцільно представляти візуально у вигляді спеціальних конструкцій — графів зв'язку,
елементами яких е
вершини та орієнтовані ребра (дуги). Вершини графа відповідають ознакам, а дуги показують відношення між ознаками. На рис. 2.1 ілюструється граф зв'язку чотирьох ознак. За дугами графа можна простежити систему відношень між ними: х
впливає на у
прямо, безпосередньо, z — прямо та опосередковано двома шляхами: 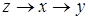 та та 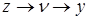 .
У такій логічній конструкції ознака у
є результатом, а х, z
і .
У такій логічній конструкції ознака у
є результатом, а х, z
і 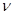 — факторами, що визначають результат. — факторами, що визначають результат.
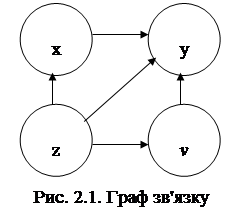 |
Граф відображує теоретично обґрунтовану систему відношень між ознаками. Кожна ланка цієї системи розглядається як окрема гіпотеза, що підлягає перевірці в подальшому аналізі на усіх етапах побудови моделі. Основна мета моделей взаємозв'язку - виявити і кількісно виміряти вплив факторів на результат. Очевидно, щоб визначити ефект впливу і-го фактора, необхідно елімінувати (усунути) вплив інших факторів, умовно зафіксувавши їх шляхом відповідних розрахунків на одному і тому ж рівні.
На етапі модельної специфікації враховується характер зв'язку та особливості наявної інформації. За своїм характером зв'язки поділяються на стохастичні,
різновидом яких є кореляційні
зв'язки, та жорстко детерміновані (функціональні).
Перші відображують стохастичний характер причинно-наслідкових відношень, Другі - адитивні чи мультиплікативні зв'язки між елементами розрахункових формул показників. Відповідно вибирається функціональна форма моделі: кореляційні зв'язки описуються переважно регресійними моделями, функціональні - балансовими або індексними. У моделях, що описують функціональні зв'язки, ступінь вільності при формуванні ознакової множини обмежена, маневрувати можна лише кількістю факторів, укрупнюючи їх чи деталізуючи. Для регресійних моделей характерна багатоваріантність як ознакової множини, так і функціональної форми моделі. Інформаційна база моделі залежить від того, як представлено об’єкт моделювання. Якщо він розглядається як сукупність елементів у просторі, то інформація подається просторовими рядами
У вигляді матриці обсягом 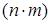 ,
де п -
обсяг сукупності, т -
кількість включених у модель факторів. Класична регресія передбачає однорідність сукупності, тобто всі одиниці сукупності мають бути однотипними щодо комплексу умов існування, а властиві їм закономірності однаковими для усіх одиниць без винятку. Якщо сукупність внутрішньо диференційована, має у своєму складі певні групи (класи) одиниць зі специфічним характером зв'язку, в моделі слід врахувати неоднорідність за принципом структурної подібності. Методи відображення неоднорідності залежать від характеру та сталості міжгрупових розбіжностей. ,
де п -
обсяг сукупності, т -
кількість включених у модель факторів. Класична регресія передбачає однорідність сукупності, тобто всі одиниці сукупності мають бути однотипними щодо комплексу умов існування, а властиві їм закономірності однаковими для усіх одиниць без винятку. Якщо сукупність внутрішньо диференційована, має у своєму складі певні групи (класи) одиниць зі специфічним характером зв'язку, в моделі слід врахувати неоднорідність за принципом структурної подібності. Методи відображення неоднорідності залежать від характеру та сталості міжгрупових розбіжностей.
Моделі, побудовані у просторовій площині, охоплюють одиничний, фіксований інтервал часу. Серія такого типу моделей за певний період дає можливість простежити динаміку взаємозв'язків, оцінити зміну потужності впливу окремих факторів, його перерозподіл.
Якщо об'єкт моделювання розглядається як первинний, неподільний елемент (галузь економіки, регіон, країна), то інформаційна база представляється багатовимірним динамічним рядом у вигляді матриці обсягом (т • Т),
де Т-
довжина динамічного ряду. В такому разі в моделі необхідно відобразити властиві процесу закономірності динаміки, як-от: тенденції, коливання, запізнення впливу тощо. За умови, що об'єкт моделювання нечисленний, а довжина динамічного ряду обмежена, просторові та динамічні ряди об'єднуються.
На практиці використовують переважно автономно побудовані моделі, тобто моделі одного показника-функції. Специфікація моделі залежить від її призначення, природи і структури взаємозв'язків, специфіки об'єкта моделювання, наявної інформації. Поєднання, комбінація усіх цих елементів визначає безліч типів моделей.
В автономних регресійних моделях (одного рівняння) відбувається складний процес елімінування впливів між включеними в модель факторами і виокремлення безпосереднього впливу кожного з них на результат. Фактичне використання такої моделі передбачає, що в разі необхідності рівні факторів можна змінювати незалежно один від одного. Проте в реальних умовах зміна одного фактора не може відбуватися за незмінності інших, вона спричиняє ланцюгову реакцію в усій системі взаємозв'язаних показників. Поряд з безпосереднім прямим впливом має місце опосередкований вплив, часом за різними напрямами, що потребує оцінювання сумарного впливу. Іноді одна й та сама змінна виступає водночас причиною і наслідком. Тоді виникає необхідність одночасного оцінювання прямого і зворотного впливів.
Складне переплетення взаємозв'язків соціально-економічних явищ потребує і складних інструментів аналізу. З-поміж таких інструментів є системи рівнянь, заміна множин висококорельованих ознак інтегральними факторами (головними компонентами) тощо. Методологічні засади модельної специфікації розглядаються за принципом «від простого до складного».
Класична регресія
Регресійна модель описує об'єктивно існуючі між явищами кореляційні зв'язки. За своїм характером кореляційні зв'язки надзвичайно складні та різноманітні. В одних випадках результат у
зі зміною фактора х,
зростає чи зменшується рівномірно, в інших — нерівномірно. Іноді зростання може змінитися зменшенням і навпаки. Простежити всі ці взаємозв'язки і встановити точний функціональний вид практично неможливо. А тому при виборі типу функції йдеться лише про апроксимацію відносно простими функціями незрівнянно більш складних за своєю природою взаємозв'язків. На практиці перевагу віддають моделям, які є лінійними або приводяться до лінійного виду шляхом перетворення змінних, наприклад логарифмуванням. Такий підхід, безперечно, містить у собі певну умовність, оскільки передбачає однаковий характер зв'язку з усіма факторами. Проте використання надто складних функцій неминуче веде до збільшення кількості параметрів, а отже, зменшує точність вимірювання та ускладнює інтерпретацію результатів.
При обґрунтуванні типу функції слід враховувати й той факт, що межі варіації корельованих ознак у конкретних умовах простору і часу, в конкретній сукупності значно вужчі за їх можливі значення, і в цих межах варіації навіть лінійна функція може задовільно апроксимувати зв'язок.
У лінійному щодо параметрів рівнянні регресії індивідуальне значення результативного показника 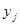 (де j — порядковий номер одиниці сукупності) записується так: (де j — порядковий номер одиниці сукупності) записується так:
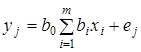 , ,
де 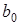 — вільний член рівняння; економічного змісту, як правило, не має, лише окреслює область існування моделі; — вільний член рівняння; економічного змісту, як правило, не має, лише окреслює область існування моделі; 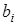 — коефіцієнт регресії
; показує, як в середньому змінюється — коефіцієнт регресії
; показує, як в середньому змінюється 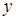 зі зміною зі зміною 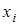 на одиницю її шкали вимірювання за незмінності інших включених в модель факторів і за інших рівних умов; на одиницю її шкали вимірювання за незмінності інших включених в модель факторів і за інших рівних умов; 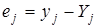 — залишкова величина. — залишкова величина.
У регресійній моделі основне навантаження покладається на коефіцієнт регресії 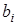 ,
він розглядається як своєрідна міра «очищеного» впливу ,
він розглядається як своєрідна міра «очищеного» впливу 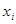 на у
і називається ефектом впливу. на у
і називається ефектом впливу.
Процедура оцінювання параметрів регресійної моделі ґрунтується на методі найменших квадратів
(МНК). Оскільки алгоритми МНК описано в математико-статистичній літературі й реалізовано в комп'ютерних програмах, наведемо лише загальну схему розрахунку статистичних характеристик моделі, акцентуючи увагу на їх змістовній інтерпретації.
Первинна інформація представляється як матриця факторних ознак X розміром (п • т)
і вектора результативної ознаки у
розміром (п •
1). Задля зручності використання алгоритмів МНК матриця X
розширюється за рахунок додатково введеної фіктивної змінної 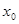 ,
вектор якої представлений одиницями. Параметри моделі — вектор ,
вектор якої представлений одиницями. Параметри моделі — вектор 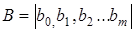 визначаються розв'язуванням системи нормальних рівнянь, яка записується так: визначаються розв'язуванням системи нормальних рівнянь, яка записується так:
X'ХВ = 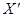 у, у,
де 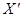 X
— матриця розміром п (т +
1). X
— матриця розміром п (т +
1).
Послідовність розрахунків включає етапи:
- обчислення матриці 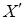 X
і вектора X
і вектора 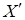 у у
- обертання матриці С =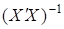 ;
;
- розрахунок параметрів 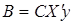 ; ;
- визначення теоретичних значень результативної ознаки
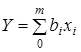 та залишків та залишків 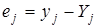 . .
Значення коефіцієнтів регресії певною мірою залежать від складу введених у модель факторів.
З розширенням ознакової множини моделі відбувається перерозподіл впливу попередньо введених факторів. Чим вагоміший вплив нововведеного фактора, тим помітніші зміни. Ілюстрацією перерозподілу впливу факторів може слугувати регресійна модель урожайності рису, ц/га [11]. У модель послідовно вводились агротехнічні фактори: 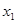 — попередник, балів; — попередник, балів; 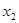 — внесення добрив під основний обробіток, центнерів поживної речовини (ц п. р.) на 1 га посіву; — внесення добрив під основний обробіток, центнерів поживної речовини (ц п. р.) на 1 га посіву; 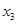 — передпосівний обробіток, та м'якої оранки; — передпосівний обробіток, та м'якої оранки; 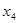 — підживлення, ц п. р.; — підживлення, ц п. р.; 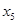 — норма висіву; — норма висіву; 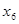 — кількість прополювань. Відповідно отримано такі рівняння регресії: — кількість прополювань. Відповідно отримано такі рівняння регресії:
1. Y=30,432 + 3,001;
2. Y= 26,208 + 2,049 + 5,995;
3. Y= 21,563 + 1,970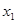 + 4,610 + 4,610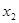 + 2,906 + 2,906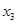 ; ;
4. Y= 22,332 + 1,321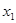 + 4,558 + 4,558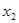 + 1,465 + 1,465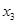 + 9,791 + 9,791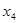 ; ;
5. Y= 18,960 + 1,342 + 4,483 + 1,347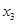 + 9,545 + 9,545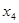 + 1,756 + 1,756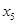 ; ;
6. Y= 19,387+ 0,965, + 3,400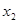 + 0,501 + 0,501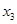 + 7,500 + 1,73 + 3,433 + 7,500 + 1,73 + 3,433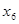 . .
Як бачимо, введення кожного нового фактора спричиняє зменшення впливу попередньо введених факторів, таку ж тенденції має й вільний член рівняння.
Оскільки факторні ознаки мають, як правило, різні одиниці вимірювання, то для порівняння ефектів їх впливу в рамках моделі використовують стандартизовані коефіцієнти регресії
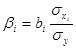 (бета-коефіцієнти) або коефіцієнти еластичності - (бета-коефіцієнти) або коефіцієнти еластичності - 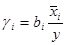 . Бета-коефіцієнт
характеризує ефект впливу . Бета-коефіцієнт
характеризує ефект впливу 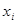 на у в середньоквадратичних відхиленнях, коефіцієнт еластичності
— в процентах. У табл. 5.2 наведено бета-коефіцієнти останнього (шостого) варіанта моделі врожайності рису. Згідно із значеннями Р, найвагоміший вплив на врожайність рису мають: прополювання ( на у в середньоквадратичних відхиленнях, коефіцієнт еластичності
— в процентах. У табл. 5.2 наведено бета-коефіцієнти останнього (шостого) варіанта моделі врожайності рису. Згідно із значеннями Р, найвагоміший вплив на врожайність рису мають: прополювання (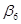 =
0,360), підживлення =
0,360), підживлення 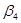 = 0,264), внесення добрив під основний обробіток ( = 0,264), внесення добрив під основний обробіток (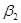 = 0,248). = 0,248).
Для оцінювання адекватності
регресійної моделі використовують:
- стандартне відхилення;
- множинні коефіцієнти детермінації та кореляції;
- частинні коефіцієнти детермінації та кореляції;
- коефіцієнти окремої детермінації;
- критерії перевірки істотності зв'язку.
Стандартне відхилення
характеризує варіацію залишкових величин
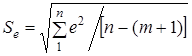 , ,
де n
— обсяг сукупності, т
— кількість коефіцієнтів регресії.
Розрахунок характеристик щільності зв'язку ґрунтується на декомпозиції (розкладанні) варіації у
за джерелами формування:
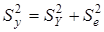 , ,
де 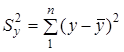 — загальна сума квадратів відхилень,
зумовлена впливом усіх можливих факторів; — загальна сума квадратів відхилень,
зумовлена впливом усіх можливих факторів; 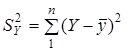 — факторна сума квадратів відхилень,
зумовлена впливом включених у модель факторних ознак — факторна сума квадратів відхилень,
зумовлена впливом включених у модель факторних ознак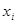 ; ; 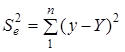 — залишкова сума квадратів відхилень,
розмір якої залежить від потужності впливу не включених у модель факторів. — залишкова сума квадратів відхилень,
розмір якої залежить від потужності впливу не включених у модель факторів.
Відношення факторної суми квадратів до загальної характеризує частку варіації у, пов'язану з варіацією включених у модель факторів, і називається множинним коефіцієнтом детермінації
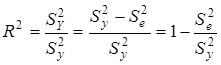 . .
За відсутності зв'язку 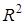 =
0. Якщо зв'язок функціональний, то =
0. Якщо зв'язок функціональний, то 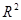 =
1. Очевидно, що пов'язаний із стандартним відхиленням =
1. Очевидно, що пов'язаний із стандартним відхиленням 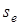 .
При зменшенні .
При зменшенні 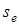 значення зростатиме і навпаки. Корінь квадратний із коефіцієнта детермінації називають коефіцієнтом кореляції значення зростатиме і навпаки. Корінь квадратний із коефіцієнта детермінації називають коефіцієнтом кореляції 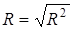 .
Для моделі врожайності рису R
= 0,8394, .
Для моделі врожайності рису R
= 0,8394, 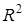 =
0,7029, тобто 70,29% варіації врожайності рису лінійно пов'язані з агротехнічними факторами, включеними в модель. =
0,7029, тобто 70,29% варіації врожайності рису лінійно пов'язані з агротехнічними факторами, включеними в модель.
Окрім названих множинних коефіцієнтів щільності зв'язку, в комп'ютерних програмах передбачено розрахунок з
урахуванням числа ступенів вільності:
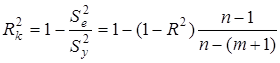 , ,
де 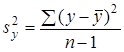 — оцінка дисперсії результативної ознаки у
; — оцінка дисперсії результативної ознаки у
; 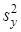 — оцінка залишкової дисперсії. — оцінка залишкової дисперсії.
Скоригований коефіцієнт множинної детермінації 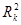 відрізняється від
відрізняється від 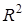 співвідношенням числа ступенів вільності дисперсій: залишкової співвідношенням числа ступенів вільності дисперсій: залишкової 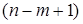 і загальної і загальної 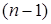 . Для розглянутої моделі це співвідношення становить (34-1) : (34-6-1) = 1,2222, а = 1-(1-0,7029) • 1,2222 = 0,6369. . Для розглянутої моделі це співвідношення становить (34-1) : (34-6-1) = 1,2222, а = 1-(1-0,7029) • 1,2222 = 0,6369.
У моделях множинної регресії поряд з оцінкою сукупного впливу всіх включених у модель факторів вимірюється кореляція між функцією у та кожним окремим фактором 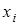 , при елімінуванні впливу інших факторів. Для цього використовують частинні коефіцієнти детермінації , при елімінуванні впливу інших факторів. Для цього використовують частинні коефіцієнти детермінації 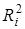 .
Схему розрахунку .
Схему розрахунку  розглянемо на прикладі фактора
розглянемо на прикладі фактора 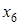 моделі врожайності рису. До введення його в модель п'ять факторів пояснювали 64,61% варіації врожайності ( моделі врожайності рису. До введення його в модель п'ять факторів пояснювали 64,61% варіації врожайності (
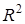 =
0,6461), не поясненими залишалися (1 - 0,6461) • 100 = 35,39% варіації. Фактор =
0,6461), не поясненими залишалися (1 - 0,6461) • 100 = 35,39% варіації. Фактор 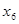 додатково пояснив 0,7029 — 0,6461 =0,0568 варіації у,
що відносно не поясненої іншими факторами варіації становить 0,0568:0,3539 = 0,1605. Це і є частинним коефіцієнтом детермінації фактора додатково пояснив 0,7029 — 0,6461 =0,0568 варіації у,
що відносно не поясненої іншими факторами варіації становить 0,0568:0,3539 = 0,1605. Це і є частинним коефіцієнтом детермінації фактора 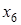 .
.
Отже, розрахунок
ґрунтується на порівнянні двох регресійних моделей: повної, з урахуванням фактора і скороченої, у якій фактор відсутній. Чисельник 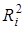 дорівнює різниці сукупних коефіцієнтів детермінації цих моделей, знаменник — одиниці мінус сукупний коефіцієнт детермінації скороченої моделі. Загальну схему його розрахунку можна представити як відношення сум квадратів: частинної
дорівнює різниці сукупних коефіцієнтів детермінації цих моделей, знаменник — одиниці мінус сукупний коефіцієнт детермінації скороченої моделі. Загальну схему його розрахунку можна представити як відношення сум квадратів: частинної 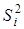 і залишкової і залишкової 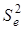 : :
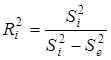 , ,
де 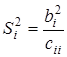 ; ; 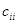 — діагональний елемент оберненої матриці. — діагональний елемент оберненої матриці.
Корінь квадратний із частинного коефіцієнта детермінації називають частинним коефіцієнтом кореляції.
Іноді для характеристики ролі кожного фактора у відтворенні варіації у
сукупний коефіцієнт детермінації розкладають на складові:
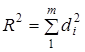 , ,
де 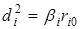 — коефіцієнт окремої детермінації,
який залежить від потужності впливу і-го фактора на y
та щільності зв'язку між ними ( — коефіцієнт окремої детермінації,
який залежить від потужності впливу і-го фактора на y
та щільності зв'язку між ними ( 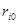 — парний коефіцієнт кореляції). — парний коефіцієнт кореляції).
Ефекти впливу факторів на врожайність рису та характеристики щільності зв'язку наведено в табл. 2.3.
Таблиця 2.3
| Фактор
|
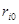
|
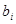
|
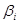
|
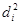
|
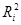
|
|
|
0,597
|
0,965
|
0,192
|
0,1146
|
0,0727
|
| 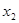
|
0,614
|
3,400
|
0,248
|
0,1521
|
0,1160
|
| 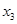
|
0,489
|
0,501
|
0,045
|
0,0221
|
0,0039
|
|
|
0,638
|
7,500
|
0,264
|
0,1687
|
0,1168
|
| 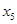
|
0,411
|
1,730
|
0,029
|
0,0119
|
0,0020
|
| 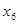
|
0,716
|
3,443
|
0,362
|
0,2335
|
0,1605
|
У таблиці для кожного фактора наведено три характеристики спільності зв'язку: парний коефіцієнт 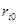 , частинний і коефіцієнт окремої детермінації , частинний і коефіцієнт окремої детермінації 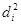 . Найбільші значення мають парні коефіцієнти кореляції. Це пояснюється тим, що фактори взаємозалежні, і парний коефіцієнт кореляції акумулює вплив інших факторів. Частинні коефіцієнти характеризують відносну зміну залишкової дисперсії за рахунок відповідного фактора; для кожного з них база порівняння інша, а тому аналітичні можливості їх обмежені. Коефіцієнти окремої детермінації, сума яких дорівнює множинному коефіцієнту детермінації . Найбільші значення мають парні коефіцієнти кореляції. Це пояснюється тим, що фактори взаємозалежні, і парний коефіцієнт кореляції акумулює вплив інших факторів. Частинні коефіцієнти характеризують відносну зміну залишкової дисперсії за рахунок відповідного фактора; для кожного з них база порівняння інша, а тому аналітичні можливості їх обмежені. Коефіцієнти окремої детермінації, сума яких дорівнює множинному коефіцієнту детермінації 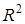 = 0,7029, упорядковуючи фактори за потужністю впливу, практично дублюють висновки, які можна зробити на основі бета-коефіцієнтів. = 0,7029, упорядковуючи фактори за потужністю впливу, практично дублюють висновки, які можна зробити на основі бета-коефіцієнтів.
Перевірка істотності зв'язку
статистичне формулюється як перевірка нульових гіпотез: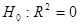 ; ; 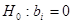 . Гіпотеза
. Гіпотеза 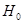 відхиляється чи визнається допустимою на основі статистичних критеріїв, зокрема дисперсійного F-критерію, статистична характеристика якого розраховується відношенням оцінок факторної і залишкової дисперсій: відхиляється чи визнається допустимою на основі статистичних критеріїв, зокрема дисперсійного F-критерію, статистична характеристика якого розраховується відношенням оцінок факторної і залишкової дисперсій:
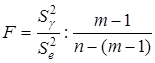 або або 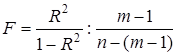 . .
Критичні значення 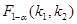 , де , де 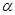 — рівень істотності, — рівень істотності, 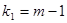 , , 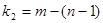 — числа ступенів вільності чисельника та знаменника, наведено в додатку 10. Оскільки F-критерій функціонально зв'язаний з коефіцієнтом детермінації — числа ступенів вільності чисельника та знаменника, наведено в додатку 10. Оскільки F-критерій функціонально зв'язаний з коефіцієнтом детермінації 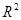 ,
то перевірку істотності зв'язку можна здійснити, використовуючи безпосередньо критичні значення ,
то перевірку істотності зв'язку можна здійснити, використовуючи безпосередньо критичні значення 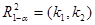 , наведені в додатку 11. , наведені в додатку 11.
Паралельно з оцінюванням адекватності моделі проводиться перевірка істотності впливу окремих факторів
, на у
за допомогою t-критерію:
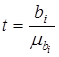 , ,
де 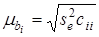 — стандартна похибка коефіцієнта регресії; — стандартна похибка коефіцієнта регресії; 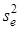 —оцінка залишкової дисперсії; —оцінка залишкової дисперсії; 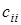 — діагональний елемент оберненої матриці С. — діагональний елемент оберненої матриці С.
Критичні значення 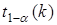 , де , де 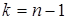 наведено в додатку 5.
Ефект впливу і-го фактора визнається істотним, якщо наведено в додатку 5.
Ефект впливу і-го фактора визнається істотним, якщо 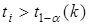 . Так, при . Так, при 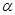 = 0,05 і = 0,05 і 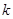 = 20 коефіцієнт в 2,15 раза перевищує стандартну похибку = 20 коефіцієнт в 2,15 раза перевищує стандартну похибку 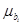 , що свідчить про його значущість (істотність). , що свідчить про його значущість (істотність).
Довірчі межі ефекту впливу визначаються за правилами вибіркового методу 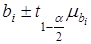 , де , де 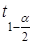 — значення двостороннього t-критерію.
— значення двостороннього t-критерію.
Рівняння регресії має такий вигляд:
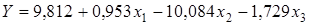 . .
Із збільшенням цукристості буряка на 1%, за умови незмінності інших факторів, вихід цукру з 1 т сировини зростає в середньому на 0,953%; щодо порушень технології зберігання та переробки сировини, то вони мають негативний вплив, особливо порушення технології зберігання. Включені в модель фактори пояснюють 84,5% варіації виходу цукру з 1 т сировини; ефекти впливу усіх факторів істотні.
3 Методи і моделі прогнозування багатовимірних процесів
Багатофакторні індексні моделі
При вивченні функціональних зв'язків між показниками широко використовуються індексні моделі. Основою індексної моделі є мультиплікативний зв'язок між певною множиною показників; один з них розглядається як результат у,
інші - як фактори :
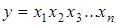 . .
Послідовність факторів у моделі не може бути довільною, вона визначається економічним змістом показників і методикою їх розрахунку. Кожний наступний фактор-множник розраховується на одиницю попереднього, а отже, добуток будь-якої кількості факторів є економічно змістовною величиною. Наприклад, прибутковість активів компанії у
є функцією прибутковості продажу продукції 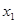 та оборотності мобільних активів та оборотності мобільних активів 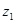 ,
тобто ,
тобто 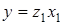 .
Оборотність мобільних активів .
Оборотність мобільних активів 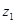 ,
в свою чергу, є функцією оборотності матеріальних запасів і частки матеріальних запасів у мобільних активах ,
в свою чергу, є функцією оборотності матеріальних запасів і частки матеріальних запасів у мобільних активах 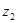 .
Отже, .
Отже, 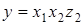 . .
Схематично послідовність розширення моделі можна представити так:
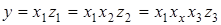 і т.д. і т.д.
Характерною рисою мультиплікативної моделі є взаємозв'язок факторів: чисельник розрахункової формули одного фактора є знаменником розрахункової формули наступного. Введення в ланцюгову схему нового фактора означає лише деталізацію функціонального зв'язку і не змінює його сутності. Ступінь деталізації залежить від мети дослідження.
При побудові індексної моделі функція 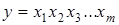 розглядається для двох періодів: базисного розглядається для двох періодів: базисного 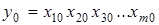 і поточного і поточного 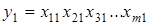 . .
Абсолютну і відносну зміну показника-функції у
можна розкласти за факторами-множниками .
Оцінювання ступеня та абсолютного розміру впливу кожного з них на динаміку функції здійснюється в рамках індексної моделі, в якій відтворюються взаємозв'язки між показниками:
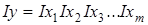
При розрахунку частинного індексу 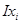 необхідно елімінувати вплив інших включених у модель факторів. Задля цього всі фактори-множники, окрім ,
фіксуються на постійному рівні. Найчастіше фактори, розміщені в ланцюгу зліва від ,
фіксуються на рівні поточного періоду, а розміщені справа від - на рівні базисного періоду. Скажімо, в моделі необхідно елімінувати вплив інших включених у модель факторів. Задля цього всі фактори-множники, окрім ,
фіксуються на постійному рівні. Найчастіше фактори, розміщені в ланцюгу зліва від ,
фіксуються на рівні поточного періоду, а розміщені справа від - на рівні базисного періоду. Скажімо, в моделі 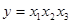 принцип послідовно-ланцюгового елімінування впливу фактора х2
реалізується таким чином: принцип послідовно-ланцюгового елімінування впливу фактора х2
реалізується таким чином:
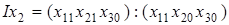 . .
За такою ж схемою визначається абсолютний вплив його на у:
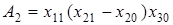 . .
Абсолютний вплив факторів можна визначити з використанням відповідних частинних індексів. При послідовному множенні (за ланцюговою схемою) базисного рівня показника-функції на індекси факторів визначаються розрахункові рівні, тобто такі рівні, які мав би показник у
під впливом і-го фактора і при незмінному рівні решти факторів. Якщо базисний його рівень позначити 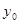 ,
розрахунковий рівень для першого фактора - у',
для другого — у"
і т. д., то порядок розрахунку абсолютного впливу і-го фактора ,
розрахунковий рівень для першого фактора - у',
для другого — у"
і т. д., то порядок розрахунку абсолютного впливу і-го фактора 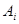 схематично можна представити так: схематично можна представити так:
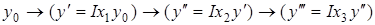 . .
Методику побудови багатофакторної індексної моделі розглянемо на прикладі взаємозв'язку показника прибутковості капіталу з індикаторами фінансового стану та платоспроможності підприємства. Для окремої компанії (фірми, корпорації) прибутковість капіталу розраховується відношенням чистого прибутку до власного капіталу. Динаміку цього показника можна розкласти за такою множиною факторів:
a —
чистий прибуток на одиницю валового обороту (реалізації продукції, послуг);
b
— оборотність поточних активів;
с
— поточна ліквідність;
d
— частка поточних пасивів у залучених коштах, (коефіцієнт заборгованості);
f
— співвідношення залучених і власних коштів.
Взаємозв'язок між ними має вигляд:
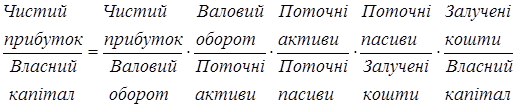
Наприклад, прибутковість капіталу умовної фірми становила: в базисному періоді - 115,1%, у поточному - 129,0%, тобто прибутковість зросла на 13,9 процентного пункту, індекс прибутковості - 1,121. Індекси включених у модель факторів - множників і розрахунок внеску кожного з них в абсолютний приріст прибутковості капіталу наведено в табл. 3.1.
Таблиця 3. 1
| Фактор
|
Індекс фактора
|
Розрахунковий рівень прибутковості
|
Абсолютний внесок фактора в приріст прибутковості
|
| а
|
1,057
|
121,7
|
+6,6
|
| b
|
0,986
|
120,0
|
-1,7
|
| с
|
1,012
|
121,4
|
+ 1,4
|
| d
|
1,025
|
124,4
|
+3,0
|
| f
|
1,037
|
129,0
|
+4,6
|
| Разом
|
X
|
X
|
+ 13,9
|
Абсолютний приріст прибутковості в розмірі 13,9 процентного пункту розкладено за факторами. Всі фактори, окрім оборотності поточних активів, мали позитивний вплив на динаміку прибутковості. З-поміж них найвагоміший вплив фактора а —
чистого прибутку на одиницю валового обороту, на другому місці фактор f
- співвідношення власних і залучених коштів, на третьому - фактор d
- коефіцієнт заборгованості.
Систему взаємозв'язаних показників можна представити у матричному вигляді. На головній діагоналі матриці за певною стратегією розміщуються т
абсолютних величин 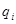 на основі яких можна визначити т(т-
1) відносних величин на основі яких можна визначити т(т-
1) відносних величин 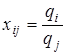 ,
де ,
де 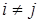 . .
Очевидно, що недіагональні елементи, симетрично розташовані щодо головної діагоналі, є оберненими одна до одної величинами, тобто 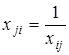 . Система взаємозв'язаних абсолютних і відносних величин утворює квадратну матрицю. Аналогічно складається матриця індексів. . Система взаємозв'язаних абсолютних і відносних величин утворює квадратну матрицю. Аналогічно складається матриця індексів.
У табл. 3.2 наведено індексно-матричну модель економічного розвитку умовної країни за певний період. На головній діагоналі розміщено індекси макропоказників (
D-національний дохід. М
-матеріальні витрати, F
-виробничі фонди, Т
-чисельність зайнятих працівників). Вони ранжовані за економічною нормаллю, згідно з якою темпи зростання кінцевих результатів мають бути вищими за темпи зростання витрат і ресурсів, тобто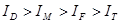 . .
Таблиця 3.2
| Показник нормалі
|
D
|
M
|
F
|
Т
|
| D
|
1,142
|
| М
|
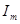 =1,005 =1,005
|
1,136
|
| F
|
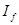 =0,935 =0,935
|
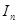 = 0,930 = 0,930
|
1,222
|
| Т
|
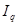 =1,І71 =1,І71
|
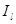 = 1,165 = 1,165
|
= 1,253
|
0,975
|
За даними таблиці економічна нормаль порушена у двох ланках: 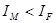 та та 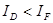 . Значення індексів свідчать про фондоємкий трудозберігаючий тип відтворення. Піддіагональні елементи матриці - це результат бінарних відношень між індексами, на перетині яких знаходиться відповідний елемент. За змістом вони характеризують динаміку показників інтенсивності та ефективності економіки: . Значення індексів свідчать про фондоємкий трудозберігаючий тип відтворення. Піддіагональні елементи матриці - це результат бінарних відношень між індексами, на перетині яких знаходиться відповідний елемент. За змістом вони характеризують динаміку показників інтенсивності та ефективності економіки: 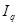 — продуктивності праці, — фондовіддачі, Іт
-— матеріаловіддачі, — продуктивності праці, — фондовіддачі, Іт
-— матеріаловіддачі, 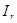 — фондоозброєності праці, — співвідношення матеріальних витрат і вартості основних фондів. Аналізуючи співвідношення цих індексів, можна виявити диспропорції У використанні живої та уречевленої праці. — фондоозброєності праці, — співвідношення матеріальних витрат і вартості основних фондів. Аналізуючи співвідношення цих індексів, можна виявити диспропорції У використанні живої та уречевленої праці.
В індексно-матричній моделі ранжування показників і ступінь їх деталізації цілковито залежить від економічної стратегії та мети дослідження.
Особливості моделювання взаємозв'язаних динамічних рядів
Якщо інформаційна база регресійної моделі представлена рядами динаміки, то виникають певні методологічні труднощі, спричинені залежністю рівнів, їх автокореляцією. Наявність останньої порушує одну з передумов регресійного аналізу —. незалежність спостережень — і призводить до викривлення його результатів.
У практиці регресійного аналізу застосовують різні способи усунення автокореляції. Найпростішим є спосіб різницевих перетворень, коли замість первинних рівнів взаємозв'язаних рядів динаміки 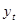 , ,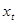 використовують абсолютні прирости (різниці). Так, різниці першого порядку
використовують абсолютні прирости (різниці). Так, різниці першого порядку 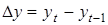 та та 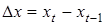 усувають лінійний тренд, однофакторна регресія набуває такого вигляду: усувають лінійний тренд, однофакторна регресія набуває такого вигляду:
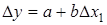 , ,
де b
інтерпретується як звичайний коефіцієнт регресії; a
— вільний член рівняння.
Якщо тенденція нелінійна, доцільно застосувати спосіб відхилень від тенденції, коли первинні рівні ,
замінюються відхиленнями від тренда
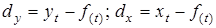 . .
Усуненню автокореляції сприяє також уведення фактора часу t
у рівняння регресії 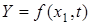 . Навантаження на змінну t
залежить від комплексу включених у модель факторів. Зміст параметрів такої моделі розглянемо на прикладі взаємозв'язку динаміки імпорту нафти і цін за барель нафти на світовому ринку. За даними табл. 3.3, обсяги імпорту нафти в країну систематично зменшувалися, що зумовлено як зміною цін, так і внутрішніми факторами. Зв'язок між цими показниками можна подати лінійною функцією . Навантаження на змінну t
залежить від комплексу включених у модель факторів. Зміст параметрів такої моделі розглянемо на прикладі взаємозв'язку динаміки імпорту нафти і цін за барель нафти на світовому ринку. За даними табл. 3.3, обсяги імпорту нафти в країну систематично зменшувалися, що зумовлено як зміною цін, так і внутрішніми факторами. Зв'язок між цими показниками можна подати лінійною функцією
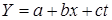 , ,
де b
— середній приріст результативної ознаки у
на одиницю приросту факторної ознаки х; с
— середній щорічний приріст у
під впливом зміни неідентифікованих факторів, які рівномірно змінюються в часі.
Таблиця 3.3
| Порядковий номер року
|
Iм порт нафти, ,млн. барелів
|
Ціна за 1 барель, ,
дол.
|
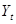
|
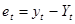
|
| 1
|
1749
|
13,48
|
1808
|
-59
|
| 2
|
1702
|
14,76
|
1743
|
-41
|
| 3
|
1769
|
18,92
|
1653
|
116
|
| 4
|
1600
|
22,97
|
1562
|
38
|
| 5
|
1431
|
30,29
|
1442
|
-11
|
| 6
|
1325
|
34,66
|
1349
|
-24
|
| 7
|
1302
|
30,77
|
1332
|
-30
|
| 8
|
1341
|
29,36
|
1292
|
49
|
| 9
|
1232
|
28,07
|
1251
|
-19
|
| 10
|
1180
|
26,40
|
1213
|
-33
|
| 11
|
1162
|
27,79
|
1147
|
15
|
| Разом
|
15793
|
х
|
15793
|
0
|
Модель імпорту нафти описується рівнянням:
Y=
1984,340-2,497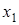 , -52,986t , -52,986t
(27,97) (-2,50) (-6,99).
Наведені в дужках значення t
-критерію перевищують критичне 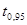 (8) = 2,31, що дає підстави з імовірністю 0,95 вважати вплив кожного фактора на обсяги імпорту істотним. Згідно із значеннями коефіцієнтів регресії підвищення ціни одного бареля нафти на 1 долар зменшує імпорт нафти в країну в середньому на 2,5 млн. барелів. За рахунок інших факторів, передусім політики енергозбереження, імпорт нафти щорічно зменшується в середньому на 53 млн. барелів. (8) = 2,31, що дає підстави з імовірністю 0,95 вважати вплив кожного фактора на обсяги імпорту істотним. Згідно із значеннями коефіцієнтів регресії підвищення ціни одного бареля нафти на 1 долар зменшує імпорт нафти в країну в середньому на 2,5 млн. барелів. За рахунок інших факторів, передусім політики енергозбереження, імпорт нафти щорічно зменшується в середньому на 53 млн. барелів.
Значення коефіцієнта детермінації 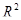 = 0,951 та дисперсійного критерію F
(2,8) = 77,48 свідчать про адекватність моделі. = 0,951 та дисперсійного критерію F
(2,8) = 77,48 свідчать про адекватність моделі.
Отже, за наявності лінійної тенденції в рядах у модель вводиться змінна часу
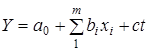
де 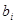 — чистий ефект впливу i
-го фактора на у
;
с
— ефект неідентифікованих факторів, які формують тенденцію ряду. — чистий ефект впливу i
-го фактора на у
;
с
— ефект неідентифікованих факторів, які формують тенденцію ряду.
У динамічній моделі можна відобразити не лише тенденцію, а й більш складні компоненти ряду, скажімо, періодичні чи сезонні коливання, перервність процесу тощо.
Особливістю регресійного аналізу динамічних рядів є оцінка автокореляції залишкових величин 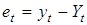 .
Якщо автокореляція істотна, значить включені в модель фактори не повністю розшифровують механізм формування процесу, модель визнається неадекватною. Перевірку істотності автокореляції можна здійснити на основі циклічного коефіцієнта першого порядку .
Якщо автокореляція істотна, значить включені в модель фактори не повністю розшифровують механізм формування процесу, модель визнається неадекватною. Перевірку істотності автокореляції можна здійснити на основі циклічного коефіцієнта першого порядку 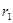 . .
У програмних засобах для перевірки істотності автокореляції частіше використовують критерій Дарбіна-Ватсона, характеристика якого в функціонально зв'язана з 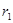 : :
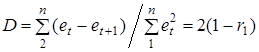 , ,
За відсутності автокореляції між суміжними членами ряду значення в становить приблизно 2, при високій додатній автокореляції в наближається до 0, при високій від'ємній автокореляції— до 4. Визначені критичні межі його значень: нижня 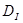 і верхня і верхня 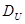 ,
на основі яких приймається або відхиляється гіпотеза про відсутність автокореляції: ,
на основі яких приймається або відхиляється гіпотеза про відсутність автокореляції: 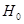 : =
0. : =
0.
При перевірці гіпотези можливі три висновки:
- в > — автокореляція відсутня;
- в < 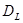 — гіпотеза про відсутність автокореляції відхиляється; — гіпотеза про відсутність автокореляції відхиляється;
- 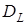 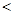 в в 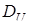 — висновок залишається невизначеним. — висновок залишається невизначеним.
Критичні межі в залежать від кількості членів ряду п
і кількості параметрів моделі т.
У додатку 8 наведено критичні значення в для додатної автокореляції при 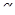 = 0,05. Перевірка від'ємної автокореляції проводиться на основі значень (4 – D). = 0,05. Перевірка від'ємної автокореляції проводиться на основі значень (4 – D).
За даними табл. 7.1 D =
1,831, що потрапляє в інтервал допустимих значень гіпотези 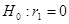 , а отже, істотність автокореляції не доведено. Аналогічний висновок дає перевірка гіпотези за допомогою циклічного коефіцієнта автокореляції, значення якого =
0,085 значно менше за критичне , а отже, істотність автокореляції не доведено. Аналогічний висновок дає перевірка гіпотези за допомогою циклічного коефіцієнта автокореляції, значення якого =
0,085 значно менше за критичне 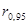 (11) =
0,353. Відсутність автокореляції залишків підтверджує адекватність моделі. Характерною рисою механізму формування варіації та динаміки соціально-економічних показників є запізнення впливу факторів, коли причина і наслідок розірвані в часі (наприклад, інвестиції в іригацію і введення в дію зрошувальних земель). Часові лаги зумовлені тривалістю виробничого циклу, інерційністю процесів, наявністю зворотного зв'язку тощо. Для оцінювання ефектів запізнення впливу i
-го фактора в модель вводиться лагова змінна (11) =
0,353. Відсутність автокореляції залишків підтверджує адекватність моделі. Характерною рисою механізму формування варіації та динаміки соціально-економічних показників є запізнення впливу факторів, коли причина і наслідок розірвані в часі (наприклад, інвестиції в іригацію і введення в дію зрошувальних земель). Часові лаги зумовлені тривалістю виробничого циклу, інерційністю процесів, наявністю зворотного зв'язку тощо. Для оцінювання ефектів запізнення впливу i
-го фактора в модель вводиться лагова змінна 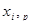 .
Фактори, що мають два і більше лагів (розподілений у часі лаг),
вводяться в модель блоками лагових змінних. Загальний вигляд моделі з розподіленими лагами: .
Фактори, що мають два і більше лагів (розподілений у часі лаг),
вводяться в модель блоками лагових змінних. Загальний вигляд моделі з розподіленими лагами:
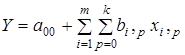
де p
= 0, 1,...,k — лаги; т
— кількість включених у модель факторів.
Теоретично модель з розподіленими лагами можна узагальнити на будь-яку кількість факторів, проте практична реалізація такої моделі натикається на непереборні труднощі, зумовлені обмеженістю динамічних рядів і складністю внутрішньої їх структури. Як правило, в модель включаються такі лагові змінні, для яких лаги обґрунтовано теоретично і перевірено емпірично. Інструментом визначення лагів слугує взаємокореляційна функція, яка являє собою множину коефіцієнтів кореляції між рядами 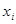 та y
зсуненими відносно один до одного на лаг р.
Зі збільшенням лага взаємокореляційна функція згасає. У табл. 3.4 наведено коефіцієнти кореляції між попитом на легкові автомобілі у
та двома факторами: середньодушовим доходом та y
зсуненими відносно один до одного на лаг р.
Зі збільшенням лага взаємокореляційна функція згасає. У табл. 3.4 наведено коефіцієнти кореляції між попитом на легкові автомобілі у
та двома факторами: середньодушовим доходом 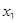 та цінами х2
. та цінами х2
.
Таблиця 3.4
| Лаг
|
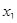
|
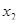
|
| 0
|
0,823
|
0,612
|
| 1
|
0,646
|
0,441
|
| 2
|
0,416
|
0,187
|
| 3
|
0,098
|
0,098
|
Для фактора істотними виявилися лаги p
= 0,1,2; для фактора х2
— лаги p
= 0,1. Модель набуває вигляду:
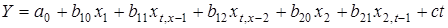 . .
де параметри 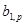 i i 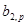 характеризують ефекти впливу факторів з відповідними лагами, параметр с
— вплив неідентифікованих факторів (мода, смаки тощо). характеризують ефекти впливу факторів з відповідними лагами, параметр с
— вплив неідентифікованих факторів (мода, смаки тощо).
Динамічна модель для сукупності об'єктів
Через обмеженість динамічних рядів соціально-економічних явищ неможливо врахувати в моделі усі особливості розвитку процесу. Аби розширити інформаційну базу моделі, практикують об'єднання просторових і динамічних рядів. Скажімо, описується залежність 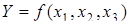 заданими по 10 об'єктах за п'ять років. Можливі різні варіанти використання такої змішаної статично-динамічної інформації. Розглянемо два з них. заданими по 10 об'єктах за п'ять років. Можливі різні варіанти використання такої змішаної статично-динамічної інформації. Розглянемо два з них.
1. Динамізація просторових моделей.
Для кожного i-го
року визначається статична модель 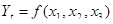 .У
нашому прикладі їх буде п'ять. Коефіцієнти регресії статичних моделей утворюють динамічні ряди. Якщо ефект впливу i
-го фактора змінюється в часі, то така зміна виявиться трендом ряду .У
нашому прикладі їх буде п'ять. Коефіцієнти регресії статичних моделей утворюють динамічні ряди. Якщо ефект впливу i
-го фактора змінюється в часі, то така зміна виявиться трендом ряду 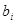 . Методом екстраполяції тренда можна визначити очікуваний ефект впливу на період упередження . Методом екстраполяції тренда можна визначити очікуваний ефект впливу на період упередження 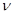 . Водночас визначається прогнозний рівень самого фактора . Водночас визначається прогнозний рівень самого фактора 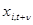 . Поєднання цих прогнозів дає прогноз функції y: . Поєднання цих прогнозів дає прогноз функції y:
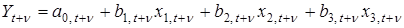 . .
За відсутності тренда коефіцієнта регресії в прогнозній моделі використовують середнє його значення. В табл. 3.5 наведено фрагменти динамічних рядів параметрів регресійної моделі продуктивності праці в цементній промисловості (тонн на одного робітника). Фактори:  — енергоозброєність праці, кВт-г; — енергоозброєність праці, кВт-г;  — продуктивність цементних печей т/г; — продуктивність цементних печей т/г; 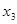 — коефіцієнт використання календарного часу роботи цементних печей. — коефіцієнт використання календарного часу роботи цементних печей.
Таблиця 3.5
| Рік
|
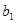
|
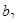
|
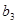
|
| 1
|
11,8
|
11,3
|
18,5
|
| 2
|
11,5
|
11,9
|
19,1
|
| 3
|
11,3
|
12,2
|
17,7
|
| 4
|
10,6
|
13,4
|
18,2
|
| 5
|
9,9
|
13,7
|
18,6
|
Як видно з даних таблиці, в цементній промисловості відбувається перерозподіл ефектів впливу факторів на продуктивність праці: зменшується вплив енергоозброєності праці (
),
збільшується вплив продуктивності устаткування (х2
) і практично незмінним залишається вплив використання календарного часу устаткування (х3
).
Прогнозування ефектів впливу факторів та їх рівнів можна здійснити у будь-який спосіб, обґрунтувавши функціональний вид прогнозної моделі. Звісно, щоб характер динаміки чітко виявився, довжина динамічного ряду має бути достатньою. Умова достатності інформації стосується і просторового ряду.
2. Модель об'єкто-періодів.
У невеликих за обсягом сукупностях просторові та динамічні ряди об'єднуються в один інформаційний масив, одиницею якого є об'єкто-період. Для 10 об'єктів і п'яти років маємо 10*5=50 об'єкто-періодів. Такий підхід до об'єднання просторово-динамічних рядів значно розширює інформаційну базу моделі, водночас наділяє її особливими властивостями. Головна особливість статично-динамічної інформації — залежність спостережень. Залежними виявляються не лише рівні динамічних рядів, але й ряди в цілому ( і просторові, і часові), оскільки належність рівнів до того чи іншого ряду фіксована. Так, залежність між рядами динаміки — це результат просторової варіації, яка через інерційність процесів зберігається певний час. Залежність просторових рядів відбиває синхронність динаміки показників по окремих об'єктах, зумовлену спільними умовами розвитку. Ігнорування цих особливостей інформаційної бази моделювання призводить до помилкових висновків.
Особливості просторової варіації враховуються в моделі за допомогою структурних змінних окремих об'єктів 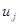 .
Властивий усім об'єктам тренд функції у фільтрується за допомогою змінної часу t.
Проте через нерівномірність розвитку окремих об'єктів сукупності поряд зі спільним трендом можуть виявитися істотними індивідуальні тренди. Для їх фільтрації можна використати змінні динамічної взаємодії:
для факторів — .
Властивий усім об'єктам тренд функції у фільтрується за допомогою змінної часу t.
Проте через нерівномірність розвитку окремих об'єктів сукупності поряд зі спільним трендом можуть виявитися істотними індивідуальні тренди. Для їх фільтрації можна використати змінні динамічної взаємодії:
для факторів — 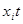 ,
для об'єктів — ,
для об'єктів — 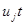 . З урахуванням усіх цих особливостей регресійну модель для сукупності об'єкто-періодів можна записати так: . З урахуванням усіх цих особливостей регресійну модель для сукупності об'єкто-періодів можна записати так:
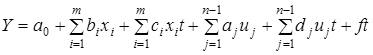 . .
Параметри моделі вимірюють:
— чистий, елімінований від взаємозв'язків у межах моделі, ефект впливу фактора ;
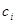 — зміну ефектів впливу
, у часі;
— зміну ефектів впливу
, у часі;
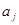 — різницю між значеннями функції на j
-му об'єкті та в ці. лому по сукупності; — різницю між значеннями функції на j
-му об'єкті та в ці. лому по сукупності;
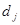 — зміну цих відмінностей у часі; — зміну цих відмінностей у часі;
f
— спільний для всіх об'єктів сукупності тренд — вплив неідентифікованих в моделі факторів;
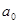 — вільний член рівняння. Для кожного j
-го об'єкта вільний член рівняння дорівнює сумі
— вільний член рівняння. Для кожного j
-го об'єкта вільний член рівняння дорівнює сумі 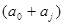 ; на відміну від сума має економічний зміст — вимірює вплив факторів, які визначають специфіку цього об'єкта. ; на відміну від сума має економічний зміст — вимірює вплив факторів, які визначають специфіку цього об'єкта.
Отже, модель об'єкто-періодів включає дві групи параметрів. Одна з них представляє оцінки ефектів впливу факторів і зміну їх у часі, друга — особливості сукупності, специфіку розвитку окремих об'єктів. Уникнути перевантаження моделі і зберегти максимум інформації для оцінки параметрів можна, скориставшись алгоритмом покрокового регресійного аналізу.
Як приклад розглянемо параметри моделі продуктивності праці в агрогосподарствах, які спеціалізуються на вирощуванні винограду та фруктів і мають власні переробні цехи. Інформаційний масив сформовано за даними 18 господарств за п'ять років. До ознакової множини моделі включено фактори: 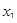 — економічна оцінка сільськогосподарських угідь, бали; х2
— частка садів і виноградників у загальній площі сільськогосподарських угідь; х3
— частка праці механізаторів у загальній кількості відпрацьованих людино-днів. Для оцінювання тенденцій ефектів впливу кожного з цих факторів введено змінні динамічної взаємодії .
Два нетипових (аномальних) господарства представлено в моделі структурними змінними — економічна оцінка сільськогосподарських угідь, бали; х2
— частка садів і виноградників у загальній площі сільськогосподарських угідь; х3
— частка праці механізаторів у загальній кількості відпрацьованих людино-днів. Для оцінювання тенденцій ефектів впливу кожного з цих факторів введено змінні динамічної взаємодії .
Два нетипових (аномальних) господарства представлено в моделі структурними змінними 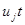 ,
а індивідуальні їх тренди — змінними динамічної взаємодії ,
а індивідуальні їх тренди — змінними динамічної взаємодії 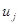 . .
Істотними виявилися ефекти впливу всіх факторів 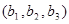 ,
параметр при змінній динамічної взаємодії другого фактора ,
параметр при змінній динамічної взаємодії другого фактора 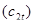 ,
параметри при структурних змінних обох господарств ,
параметри при структурних змінних обох господарств 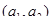 ,
параметр при змінній динамічної взаємодії другого господарства ,
параметр при змінній динамічної взаємодії другого господарства 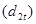 - Значення параметрів наведено в табл. 3.6. - Значення параметрів наведено в табл. 3.6.
Таблиця 3.6
| Параметр моделі
|
|
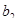
|
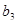
|
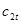
|
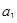
|
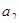
|
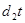
|
| Значення параметра
|
39,86
|
15.63
|
20,46
|
1,17
|
-42,65
|
56,78
|
-3,52
|
Коефіцієнти регресії інтерпретуються традиційно як чисті ефекти впливу включених у модель факторів. При цьому, як показує параметр 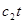 ,
ефект впливу спеціалізації (частки садів і виноградників у загальній площі сільськогосподарських угідь) на продуктивність праці щорічно збільшується в середньому на 1,17 тис. грн. Істотність параметрів ,
ефект впливу спеціалізації (частки садів і виноградників у загальній площі сільськогосподарських угідь) на продуктивність праці щорічно збільшується в середньому на 1,17 тис. грн. Істотність параметрів 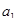 і а2
підтверджує нетиповість господарств, представлених у моделі структурними змінними. За рахунок специфічних умов функціонування цих господарств рівень продуктивності праці на першому з них нижчий за середній на 42,65 тис. грн, на другому, навпаки, на 56,78 тис. грн. вищий. Останній параметр має тенденцію до зменшення щорічно в середньому на 3,52 тис. грн. і а2
підтверджує нетиповість господарств, представлених у моделі структурними змінними. За рахунок специфічних умов функціонування цих господарств рівень продуктивності праці на першому з них нижчий за середній на 42,65 тис. грн, на другому, навпаки, на 56,78 тис. грн. вищий. Останній параметр має тенденцію до зменшення щорічно в середньому на 3,52 тис. грн.
Отже, модель об'єкто-періодів більш універсальна і повніше використовує інформацію про взаємозв'язки порівняно зі схемою динамізації просторових моделей.
4 Методи експертних оцінок
При прогнозуванні процесів, розвиток яких повністю або частково не піддається формалізації (наприклад, розвиток науки і техніки, соціально-економічні та політичні наслідки прийняття певних управлінських рішень), використовують методи експертних оцінок. Вони ґрунтуються на мобілізації професійного досвіду та інтуїції експертів, які добираються за принципом компетентності.
Характерною особливістю моделювання та прогнозування соціально-економічних процесів є багатоваріантність, тобто можливість використання різних методів, моделей, інформаційного забезпечення, критеріїв оцінювання адекватності моделі тощо. Вибір між конкуруючими варіантами базується на певній системі правил, що забезпечують надання обґрунтованих оцінок кожному варіанту. Вважається, що експерт володіє цією системою правил і може порівняти варіанти, приписуючи кожному з них числа. Найчастіше перевага чи відносна значущість варіантів встановлюється за допомогою методів ранжування, попарних порівнянь або безпосереднього оцінювання.
При ранжуванні
експерт повинен розмістити варіанти (фактори, моделі, об'єкти тощо) у порядку, який вважає раціональним, і приписати кожному з них числа натурального ряду — ранги 1, 2, ..., n.
Кількість рангів дорівнює кількості варіантів. Якщо експерт надає двом і більше варіантам однакові ранги, то кожному з цих варіантів приписується середній ранг, обчислений з відповідних чисел натурального ряду.
При обґрунтуванні складних управлінських рішень в умовах невизначеності, при довгостроковому прогнозуванні розвитку науки, техніки, економіки використовують групові експертизи. Надійність групових оцінок залежить від узгодженості думок експертів, що потребує відповідної статистичної обробки інформації.
При груповій експертизі (n
експертів) для кожного /-ro варіанта визначається сума рангів S
Rt
,
за якою упорядковуються варіанти. Скажімо, перший — найвищий — ранг надається варіанту, який набирає найменшу суму рангів, а останній — варіанту з найбільшою сумою рангів. Результати опитування експертів оформляються у вигляді матриці.
Наприклад, за даними ранжування трьох варіантів п'ятьма експертами (табл. 4.1), перший ранг надається варіанту A, для якого S
Rt
=
6, другий — варіанту B, третій — варіанту C. Слід зазначити, що ранги визначають лише місця варіантів поміж іншими, не враховуючи існуючих між ними відстаней.
Таблица 4.1
| Варіант
|
Експерт
|
Сума рангів
|
d
|
d
|
| 1
|
2
|
з
|
4
|
5
|
| А
|
2
|
1
|
1
|
1
|
1
|
6
|
-4
|
16
|
| В
|
1
|
2
|
з
|
2
|
2
|
10
|
0
|
0
|
| C
|
З
|
З
|
2
|
3
|
З
|
14
|
4
|
6
|
| Разом
|
X
|
X
|
X
|
X
|
X
|
З0
|
X
|
32
|
Статистична обробка результатів ранжування передбачає оцінювання ступеня узгодженості думок експертів. Мірою узгодженості слугує коефіцієнт конкордації W,
в основу розрахунку якого покладено відхилення d
сум рангів за окремими варіантами S
Ri
від середньої суми рангів, яка становить 1/2 n (m
+ 1)
. Коефіцієнт конкордації — це відношення суми квадратів названих відхилень S =
S
d2
до максимально можливої суми квадратів відхилень Smax
= n2
(m3
- т) / 12
. Якщо ранги не повторюються, то
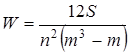
де m —
кількість варіантів; n —
кількість експертів.
При неузгодженості думок експертів W =
0. Чим вищий ступінь узгодженості, тим більше значення W
наближається до 1. За даними табл. 1.1, середня сума рангів становить 30:
3 = 10, сума квадратів відхилень S
- 32, а коефіцієнт конкордації
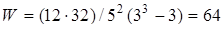 , ,
що свідчить про певні розбіжності в оцінках експертів щодо значущості варіантів.
Перевірка істотності коефіцієнта конкордації W
здійснюється за допомогою критерію c
2
з (m - 1)числом ступенів вільності (свободи).
Статистична характеристика критерію розраховується за формулоюc
2
=
Wn(m - 1)
. Для наведеного прикладу c
2
=
0,64 *
5(3 - 1)
= 6,4
, що перевищує критичне значення c
2
(2) = 5,99
(див. додаток 2). Це дає підстави стверджувати з імовірністю 0,95
, що значення W= 0,64
не випадкове і думки експертів узгоджені. При попарних порівняннях
експерти використовують дві оцінки: 0 або 1. Більш вагомому варіанту надається оцінка 1, менш вагомому — 0. Результати попарних порівнянь оформляються у вигляді матриці, елементами якої є кількості наданих переваг aij
. Діагональні елементи такої матриці представлені нулями. Одна із властивостей матриці aij
+ aji
= n,
де n —
кількість експертів.
Таблиця 4.2
| Варіант
|
А
|
В
|
C
|
Разом
|
wi
|
| А
|
0
|
4
|
5
|
9
|
0,60
|
| В
|
1
|
0
|
4
|
5
|
0,33
|
| C
|
0
|
1
|
0
|
1
|
0,07
|
| Разом
|
1
|
5
|
9
|
15
|
1,00
|
Відношення кількості наданих відповідному варіанту переваг до загальної суми елементів матриці характеризує його вагомість.
За даними табл. 4.1, найвагомішим виявився варіант A, для якого w
= 9 : 15 = 0,60.
Часто завданням експерта є не ранжування варіантів, а безпосереднє оцінювання рівнів певного явища чи окремих його властивостей, скажімо, якості продукції, конкурентоспроможності фірм тощо. У таких ситуаціях спершу визначається шкала (діапазон) оцінок, у межах якої експерт і оцінює явище (властивість) певним балом zij
,
де і
— властивість, j
— елемент сукупності.
Для певної множини m
властивостей одного явища визначається середній бал Gj
=
S
zij
/m.
Ha таких методичних засадах ґрунтується більшість рейтингових систем. Так, всесвітньо відома рейтингова система CAMEL, якою користуються органи нагляду за банківською діяльністю, має п'ятибальну шкалу оцінок: від 1 (добре) до 5 (незадовільно). Для кожного банку оцінюється достатність капіталу, якість активів, ефективність менеджменту, прибутковість і ліквідність балансу. Середній бал Gj
є рейтингом фінансового стану j
-го банку. Від його значення залежить ступінь втручання органів банківського нагляду і комплекс заходів щодо усунення недоліків.
Якщо властивості z, не рівновагомі, то рейтинг визначається як середня арифметична зважена Gj
=
S
zij
w
i
, де w
i
— вага i-
ой властивості. Саме так оцінюються комерційні, політичні ризики тощо. Наприклад, комерційний ризик, пов'язаний з інтернаціоналізацією банківської діяльності, оцінюється індексом Бері. Ознакова множина цього індексу включає 15 різновагомих показників, які характеризують політичну та економічну ситуацію в країні-партнерові. Зокрема, політична стабільність (вага 12 %), стан платіжного балансу (вага 6 %), темп економічного розвитку (вага 10 %), інші. Сума ваг становить 100 %.
Одним з популярних методів формування групової експертизи є метод Дельфи, назва якого походить від дельфійських мудреців, які славилися в давнину передбаченнями майбутнього. Основні принципи методу Дельфи: анонімність, регульованість зворотного зв'язку та узгодженість групової оцінки.
Автономне опитування експертів проводиться, як правило, в чотири тури. Кожного разу експерт виражає свою думку певною оцінкою в межах визначеної шкали. Результати опитування групи експертів упорядковуються; на основі упорядкованого ряду визначається медіана Me
й квартилі оцінок — нижній Q1
і верхній Q
3
- Медіана розглядається як узагальнююча групова оцінка процесу; для характеристики варіації оцінок використовують інтерквартильний розмах R
= Q
3
- Q1
.
Значення медіани і розмаху повідомляють усім експертам. Тим з них, чиї оцінки виявилися за межами діапазону (Q3
- Q1
)
, пропонують аргументувати свої висновки, аби ознайомити з ними решту експертів. Такий зворотний зв'язок відсікає «шуми», зменшує вплив індивідуальних і групових інтересів, не пов'язаних з проблемою.
Ітераційна процедура упорядкування та узагальнення експертних оцінок дає можливість зблизити точки зору експертів, що робить групові оцінки надійнішими за просте усереднення. Проте сама по собі процедура опитування не розв'язує всіх проблем точності прогнозів. Вирішальну роль відіграють компетентність експертів і досконалість програми опитування.
5.
Оцінювання якості прогнозів
Забезпечення адекватності регресійної моделі
Адекватність
регресійної моделі означає здатність її правильно описати реальну структуру взаємозв'язків між ознаками 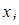 та y.
Методологічною основою вирішення проблеми адекватності є теоретичний, змістовний аналіз матеріальної природи процесу (явища) та обґрунтування типу й структури моделі, яка описує механізм його формування. Практично з метою забезпечення адекватності моделі змістовний аналіз поєднується з формальними процедурами перевірки гіпотез щодо дотримання логіко-статистичних умов використання МНК. та y.
Методологічною основою вирішення проблеми адекватності є теоретичний, змістовний аналіз матеріальної природи процесу (явища) та обґрунтування типу й структури моделі, яка описує механізм його формування. Практично з метою забезпечення адекватності моделі змістовний аналіз поєднується з формальними процедурами перевірки гіпотез щодо дотримання логіко-статистичних умов використання МНК.
Мірою адекватності моделі слугують відхилення фактичних значень від теоретичних 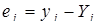 .
На величину цих відхилень впливає весь комплекс умов, зокрема: .
На величину цих відхилень впливає весь комплекс умов, зокрема:
- обсяг та однорідність сукупності;
- незалежність спостережень;
- інформативність включених у модель факторів;
- стабільність не включених у модель факторів;
- тип моделі.
Репрезентативність оцінок регресійного аналізу прямо пропорційна обсягу та однорідності сукупності. Саме недостатній обсяг сукупності та її неоднорідність вважаються найвагомішими чинниками неадекватності моделей. Тому при формуванні ознакової множини моделі слід враховувати співвідношення між обсягом вибірки і кількістю включених у модель факторів (воно має бути приблизно 8:1).
Оцінювання однорідності сукупності здійснюється на етапі розвідувального аналізу даних. Так, наявність аномальних значень, які не узгоджуються з розподілом основної маси даних, може бути наслідком помилок спостереження або результатом незвичайної комбінації причин і умов, у яких функціонує одиниця сукупності. Ідентифікація таких спостережень дає можливість Усунути помилки, а якщо це неможливо, то вилучити аномальний об'єкт з подальшого аналізу. Якщо сукупність розшарована на групи (кластери), то в моделі можна врахувати таку неоднорідність.
Інформативність включених у модель факторних ознак залежить як від соціально-економічного змісту, так і від шкали вимірювання ознаки. Якщо ознака за змістом не інформативна, то ніякий спосіб моделювання не забезпечить належних результатів. Так само результати аналізу будуть суттєво різнитися залежно від того, якою шкалою представлено одну й ту саму ознаку (метричною, ранговою чи номінальною).
Ті властивості, що безпосередньо не вимірюються або не мають єдиного вимірника, включаються в модель у вигляді інтегральних оцінок. Наприклад, погодні умови характеризуються середньодобовою температурою повітря, кількістю опадів, тривалістю сонячного світла, хмарністю і т. ін. Усі ці характеристики агрегуються в індексі погодних умов.
Важливою умовою регресійного аналізу є відсутність мультиколінеарності, яка веде до зсунення оцінок параметрів моделі та унеможливлює коректну інтерпретацію результатів. Два фактори вважаються колінеарними, якщо коефіцієнт кореляції між ними перевищує сукупний коефіцієнт кореляції, тобто 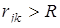 .
Найпростіший спосіб усунення мультиколінеарності — виключити одну із корельованих ознак із моделі або замінити її іншою. Часом колінеарні фактори агрегуються в одну узагальнюючу оцінку. .
Найпростіший спосіб усунення мультиколінеарності — виключити одну із корельованих ознак із моделі або замінити її іншою. Часом колінеарні фактори агрегуються в одну узагальнюючу оцінку.
Стабільність не включених у модель факторів означає, що вплив їх на варіацію у
незначний і врівноважується, він однаковий в усіх частинах сукупності.
Математичною основою дотримання цих передумов МНК слугує імовірнісний розподіл залишків 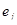 .
Передбачається, що: .
Передбачається, що:
- для кожного спостереження залишок —
випадкова величина, яка має нормальний розподіл. Умова нормальності необхідна для визначення довірчих меж коефіцієнтів регресії і для перевірки гіпотез щодо їх істотності;
- математичне сподівання залишків М(е) =
0;
- дисперсія залишків однакова в усіх частинах сукупності: 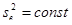 . Ця умова пов'язана з однорідністю сукупності; . Ця умова пов'язана з однорідністю сукупності;
- залишки незалежні, тобто відсутня серійна кореляція чи автокореляція даних.
Використовуючи параметри моделі, можна також оцінити потенційно можливі рівні показника-функції для кожної одиниці Окупності, визначити резерви збільшення (зменшення) показника у
за рахунок факторів, які піддаються регулюванню (суб'єктивних факторів). У нашому прикладі — це збільшення виходу цукру з 1 т сировини за рахунок зменшення витрат при зберіганні цукрового буряка і в процесі його переробки. Така оцінка, природно, орієнтована на кращі досягнення в галузі. Ефект регулювання і-го фактора на  -му об'єкті визначається за формулою -му об'єкті визначається за формулою
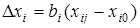 , ,
де 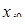 — база порівняння, — база порівняння, 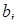 — коефіцієнт регресії і-го фактора. — коефіцієнт регресії і-го фактора.
Застосовуючи цю методику, визначимо резерв збільшення виходу цукру з 1 т сировини для -го заводу (табл. 5.1).
Таблиця 5.1
| Фактор
|
Рівень втрат, %
|
Відхилення
|
Коефіцієнт регресії
|
Ефект регулювання фактора
|
| фактичний
|
мінімальний
|
| 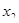
|
1,06
|
0,90
|
0,16
|
-10,084
|
-1,613
|
| 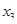
|
2,68
|
2,0
|
0,68
|
-1,729
|
-1,175
|
| Разом
|
X
|
X
|
X
|
X
|
-2,788
|
Якщо мінімальні втрати цукрового буряка при переробці — 2,0%, а на 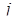 -му заводі — 2,68%, то ефект доведення втрат до мінімального рівня становить (2,68-2,0)(-1,729) = -1,175. Зменшення втрат при зберіганні цукрового буряка дає ефект (1,06--0,90)(-10,084) = -1,613. Отже, сумарний ефект за рахунок обох факторів -2,788, а потенційно можливий вихід цукру з 1 т сировини за незмінності цукристості буряка, яка є зовнішнім, об'єктивним фактором, становить 11,91 кг. Відношення фактичного рівня до потенційно можливого характеризує ступінь використання об'єктивних можливостей.
У розглянутому прикладі це відношення становить 9,13 : 11,91 =0,777, тобто ефективність використання сировини на заводі нижча за потенційно можливу на 23,3%. При визначенні резервів збільшення (зменшення) показника функції за рахунок регулювання суб'єктивних факторів базою порівняння може бути середня величина, норматив, стандарт тощо. -му заводі — 2,68%, то ефект доведення втрат до мінімального рівня становить (2,68-2,0)(-1,729) = -1,175. Зменшення втрат при зберіганні цукрового буряка дає ефект (1,06--0,90)(-10,084) = -1,613. Отже, сумарний ефект за рахунок обох факторів -2,788, а потенційно можливий вихід цукру з 1 т сировини за незмінності цукристості буряка, яка є зовнішнім, об'єктивним фактором, становить 11,91 кг. Відношення фактичного рівня до потенційно можливого характеризує ступінь використання об'єктивних можливостей.
У розглянутому прикладі це відношення становить 9,13 : 11,91 =0,777, тобто ефективність використання сировини на заводі нижча за потенційно можливу на 23,3%. При визначенні резервів збільшення (зменшення) показника функції за рахунок регулювання суб'єктивних факторів базою порівняння може бути середня величина, норматив, стандарт тощо.
Функція нормального розподілу 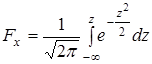 . .
Додаток 1
| z
|
00
|
11
|
22
|
23
|
44
|
55
|
66
|
77
|
88
|
99
|
| 00,0
|
500
|
504
|
508
|
512
|
516
|
520
|
524
|
528
|
532
|
536
|
| 00,1
|
540
|
544
|
548
|
552
|
556
|
560
|
564
|
567
|
571
|
575
|
| 00,2
|
580
|
583
|
587
|
591
|
595
|
599
|
603
|
606
|
610
|
614
|
| 00,3
|
618
|
622
|
626
|
629
|
633
|
637
|
641
|
644
|
648
|
652
|
| 00,4
|
655
|
659
|
663
|
666
|
670
|
674
|
677
|
681
|
684
|
688
|
| 00,5
|
691
|
695
|
698
|
702
|
705
|
709
|
712
|
716
|
719
|
722
|
| 00,6
|
726
|
729
|
732
|
736
|
739
|
742
|
745
|
749
|
752
|
755
|
| 00,7
|
758
|
761
|
764
|
767
|
770
|
773
|
776
|
779
|
782
|
785
|
| 00,8
|
788
|
791
|
794
|
797
|
800
|
802
|
805
|
808
|
811
|
813
|
| 00,9
|
816
|
819
|
821
|
824
|
826
|
829
|
831
|
834
|
836
|
839
|
| 11,0
|
841
|
844
|
846
|
849
|
851
|
853
|
855
|
858
|
860
|
862
|
| 11,1
|
864
|
867
|
869
|
871
|
873
|
875
|
877
|
879
|
881
|
883
|
| 11,2
|
885
|
887
|
889
|
891
|
893
|
894
|
896
|
898
|
900
|
901
|
| 11,3
|
903
|
905
|
907
|
908
|
910
|
911
|
913
|
915
|
916
|
918
|
| 11,4
|
919
|
921
|
922
|
924
|
925
|
926
|
928
|
929
|
931
|
932
|
| 11,5
|
933
|
934
|
936
|
937
|
938
|
939
|
941
|
942
|
943
|
944
|
| 11,6
|
945
|
946
|
947
|
948
|
950
|
951
|
952
|
953
|
954
|
954
|
| 11,7
|
955
|
956
|
957
|
958
|
959
|
960
|
961
|
962
|
962
|
963
|
| 11,8
|
964
|
965
|
966
|
966
|
967
|
968
|
969
|
969
|
970
|
971
|
| 11,9
|
971
|
972
|
973
|
973
|
974
|
974
|
975
|
976
|
976
|
977
|
| 22,0
|
977
|
978
|
978
|
979
|
979
|
980
|
980
|
981
|
981
|
982
|
| 22,1
|
982
|
983
|
983
|
983
|
984
|
984
|
985
|
985
|
985
|
986
|
| 22,2
|
986
|
986
|
987
|
987
|
987
|
988
|
988
|
988
|
989
|
989
|
| 22,3
|
989
|
990
|
990
|
990
|
990
|
991
|
991
|
991
|
991
|
992
|
| 22,4
|
992
|
992
|
992
|
992
|
993
|
993
|
993
|
993
|
993
|
994
|
| 22,5
|
994
|
994
|
994
|
994
|
994
|
995
|
995
|
995
|
995
|
995
|
| 22,6
|
995
|
995
|
996
|
996
|
996
|
996
|
996
|
996
|
996
|
996
|
| 22,8
|
997
|
998
|
998
|
998
|
998
|
998
|
998
|
998
|
998
|
998
|
| 22,9
|
998
|
998
|
998
|
998
|
998
|
998
|
998
|
999
|
999
|
999
|
Критичні значення 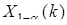
Додаток 2
| /с
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
| <х =0,10
|
2,71
|
4,61
|
6,25
|
7,78
|
9,24
|
10,64
|
12,02
|
13,36
|
14,68
|
15,99
|
17,28
|
| а =0,05
|
3,84
|
5,99
|
7,81
|
9,49
|
11,07
|
12,59
|
14,07
|
15,51
|
16,92
|
18,31
|
19,67
|
Квантилі t
-розподілу Стьюдента t1-0,05
(k)
: | t
| 1 — двосторонній критерій; t
— односторонній критерій
Додаток 3
| Іс
|
І'І
|
І
|
£
|
І'І
|
І
|
| 5
|
2,57
|
3,04
|
18
|
2,10
|
2,17
|
| 6
|
2,45
|
2,78
|
20
|
2,09
|
2,15
|
| 7
|
2,37
|
2,62
|
25
|
2,06
|
2,11
|
| 8
|
2,31
|
2,51
|
30
|
2,05
|
2,08
|
| 9
|
2,26
|
2,43
|
40
|
2,02
|
2,05
|
| 10
|
2,23
|
2,37
|
50
|
2,01
|
2,03
|
| 11
|
2,20
|
2,33
|
60
|
2,00
|
2,02
|
| 12
|
2,18
|
2,29
|
100
|
1,98
|
1,99
|
| 14
|
2,15
|
2,24
|
¥
|
1,96
|
1,96
|
| 16
|
2,12
|
2,20
|
Значення Z*
для оцінювання довірчих меж прогнозу (лінійний тренд)
Додаток 4
| n
|
V
|
n
|
v
|
| 1
|
2
|
3
|
1
|
2
|
3
|
| 5
|
1,366
|
1,524
|
1,702
|
10
|
1,211
|
1,270
|
1,335
|
| 7
|
1,309
|
1,427
|
1,558
|
11
|
1,191
|
1,239
|
1,293
|
| 8
|
1,267
|
1,358
|
1,459
|
12
|
1,174
|
1,215
|
1,260
|
| 9
|
1,236
|
1,308
|
1,389
|
Критичні значення циклічного коефіцієнта автокореляції (а = 0,05)
Додаток 5
| n
|
Додатні значення
|
Від'ємні значення
|
n
|
Додатні значення
|
Від'ємні значення
|
| 5
|
0,253
|
-0,753
|
20
|
0,299
|
-0,399
|
| 6
|
0,345
|
-0,708
|
25
|
0,276
|
-0,356
|
| 7
|
0,370
|
-0,674
|
ЗО
|
0,257
|
-0,356
|
| 8
|
0,371
|
-0,625
|
35
|
0,242
|
-0,300
|
| 9
|
0,366
|
-0,593
|
40
|
0,229
|
-0,279
|
| 10
|
0,360
|
-0,564
|
50
|
0,208
|
-0,248
|
| 11
|
0,353
|
-0,539
|
60
|
0,191
|
-0,225
|
| 12
|
0,348
|
-0,516
|
70
|
0,178
|
-0,207
|
| 13
|
0,341
|
-0,497
|
80
|
0,170
|
-0,195
|
| 14
|
0,335
|
-0,479
|
90
|
0,161
|
-0,184
|
| 15
|
0,328
|
-0,462
|
100
|
0,154
|
-0,174
|
Квантилі F-розподілу (
a
= 0,05)
Додаток 6
| k2
|
k1
|
| 1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
| 5
|
6,61
|
5,79
|
5,41
|
5,19
|
5,05
|
4,95
|
4,88
|
4,82
|
4,77
|
4,74
|
| 6
|
5,99
|
5,14
|
4,76
|
4,53
|
4,39
|
4,28
|
4,21
|
4,15
|
4,10
|
4,06
|
| 7
|
5,59
|
4,74
|
4,35
|
4,12
|
3,97
|
3,87
|
3,79
|
3,73
|
3,68
|
3,64
|
| 8
|
5,32
|
4,46
|
4,07
|
3,84
|
3,69
|
3,59
|
3,50
|
3,44
|
3,39
|
3,35
|
| 9
|
5,12
|
4,26
|
3,86
|
3,63
|
3,48
|
3,37
|
3,29
|
3,23
|
3,18
|
3,14
|
| 10
|
4,96
|
4,10
|
3,71
|
3,48
|
3,33
|
3,22
|
3,14
|
3,07
|
3,02
|
2,98
|
| 11
|
4,84
|
3,98
|
3,59
|
3,36
|
3,20
|
3,09
|
3,01
|
2,95
|
2,90
|
2,85
|
| 12
|
4,75
|
3,89
|
3,49
|
3,26
|
3,11
|
3,00
|
2,91
|
2,85
|
2,80
|
2,75
|
| 13
|
4,67
|
3,81
|
3,41
|
3,18
|
3,03
|
2,92
|
2,83
|
2,77
|
2,71
|
2,67
|
| 14
|
4,60
|
3,74
|
3,34
|
3,11
|
2,96
|
2,85
|
2,76
|
2,70
|
2,65
|
2,60
|
| 15
|
4,54
|
3,68
|
3,29
|
3,06
|
2,90
|
2,79
|
2,71
|
2,64
|
2,59
|
2,54
|
| 16
|
4,49
|
3,63
|
3,24
|
3,01
|
2,85
|
2,74
|
2,66
|
2,59
|
2,54
|
2,49
|
| 18
|
4,41
|
3,55
|
3,16
|
2,93
|
2,77
|
2,66
|
2,58
|
2,51
|
2,46
|
2,41
|
| 20
|
4,35
|
3,49
|
3,10
|
2,87
|
2,71
|
2,60
|
2,51
|
2,45
|
2,39
|
2,35
|
| 22
|
4,30
|
3,44
|
3,05
|
2,82
|
2,66
|
2,55
|
2,46
|
2,40
|
2,34
|
2,30
|
| 24
|
4,26
|
3,40
|
3,01
|
2,78
|
2,62
|
2.51
|
2,42
|
2,36
|
2,30
|
2,25
|
| 26
|
4,23
|
3,37
|
2,98
|
2,74
|
2,59
|
2,47
|
2,39
|
2,32
|
2,27
|
2,22
|
| 28
|
4,20
|
3,34
|
2,95
|
2,71
|
2,56
|
2,45
|
2,36
|
2,29
|
2,24
|
2,19
|
| 30
|
4,17
|
3,32
|
2,92
|
2,69
|
2,53
|
2,42
|
2,33
|
2,27
|
2,21
|
2,16
|
| 40
|
4,08
|
3,23
|
2,84
|
2,61
|
2,45
|
2,34
|
2,25
|
2,18
|
2,12
|
2,08
|
| 60
|
4,00
|
3,15
|
2,76
|
2,53
|
2,37
|
2,25
|
2,17
|
2,10
|
2,04
|
1,99
|
| 120
|
3,92
|
3,07
|
2,68
|
2,45
|
2,29
|
2,17
|
2,09
|
2,02
|
1,96
|
1,91
|
| ¥
|
3,84
|
3,00
|
2,60
|
2,37
|
2,21
|
2,10
|
2,01
|
1,94
|
1,88
|
1,83
|
Критичні значення коефіцієнта детермінації R2
кореляційного відношення
h2
для рівня істотності α = 0,05
Додаток 7
| k2
/k1
|
1
|
2
|
3
|
4
|
5
|
| 5
|
0,569
|
699
|
764
|
806
|
835
|
| 6
|
500
|
632
|
704
|
751
|
785
|
| 7
|
444
|
575
|
651
|
702
|
739
|
| 8
|
399
|
527
|
604
|
657
|
697
|
| 9
|
362
|
488
|
563
|
618
|
659
|
| 10
|
332
|
451
|
527
|
582
|
624
|
| 12
|
283
|
394
|
466
|
521
|
564
|
| 14
|
247
|
348
|
417
|
471
|
514
|
| 16
|
219
|
312
|
378
|
429
|
477
|
| 18
|
197
|
283
|
345
|
394
|
435
|
| 20
|
179
|
259
|
318
|
364
|
404
|
| 24
|
151
|
221
|
273
|
316
|
353
|
| 28
|
130
|
193
|
240
|
279
|
314
|
| 32
|
115
|
171
|
214
|
250
|
282
|
| 36
|
102
|
153
|
192
|
226
|
256
|
| 40
|
093
|
139
|
176
|
207
|
234
|
| 50
|
075
|
113
|
143
|
170
|
194
|
| 60
|
063
|
095
|
121
|
144
|
165
|
| 80
|
047
|
072
|
093
|
110
|
127
|
| 100
|
038
|
058
|
075
|
090
|
103
|
| 120
|
032
|
049
|
063
|
075
|
087
|
| 200
|
019
|
030
|
038
|
046
|
053
|
|