Понятие архитектуры ЭВМ. Классическая архитектура ЭВМ и принципы фон Неймана. Архитектура персональных компьютеров
Общие принципы построения современных ЭВМ:
построения всех современных ЭВМ является программное управление. В его основе представление решение любой задачи в виде программы вычислений.
Алгоритм-
это конечный набор предписаний, определяющий решение задач по средствам конечного количества операций.
Программы
– это упорядоченная последовательность команд, подлежащая обработке.
Все вычисления, предписанные решения, задачи, должны быть представлены виде программы, состоящие из последовательности управляющих слов – команд.
Каждая команда содержит указания на конкретную выполняющую операцию, место нахождения операндов, и ряд служебных признаков.
Операнды- переменные значения которые участвуют в операции преобразования данных.
Архитектура ЭВМ
совокупность общих принципов организации аппаратно-программных средств и их основных характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих типов задач.
Структура
- совокупность элементов и их связей. Различают структуры технических, программных и аппаратурно-программных средств.
Отличие архитектуры от структуры: структура определяет его текущий состав и описывает связи внутри средства, архитектура определяет основные правила взаимодействия составных элементов вычислительного средства, описание которых выполняется в той мере, в какой необходимо для формирования правил их взаимодействия.
Общие принципов построения ЭВМ, которые относятся к архитектуре:
• структура памяти ЭВМ;
• способы доступа к памяти и внешним устройствам;
• возможность изменения конфигурации компьютера;
• система команд;
• форматы данных;
• организация интерфейса. Из этого следует:
«Архитектура
- это наиболее общие принципы построения ЭВМ, реализующие программное управление работой и взаимодействием основных ее функциональных узлов
».
Классическая архитектура ЭВМ и принципы Фон Неймана
Основы учения об архитектуре вычислительных машин заложил выдающийся американский математик Джон фон Нейман
. Он работал с первой ламповой ЭВМ ENIAC
в 1944 г.
Классические принципы построения архитектуры ЭВМ были предложены в 40-ч годах ХХ века к этим принципам относятся:
Использование двоичной системы представления данных
ЭВМ стали обрабатывать и нечисловые виды информации — текстовую, графическую, звуковую и другие. Двоичное кодирование данных по-прежнему составляет информационную основу компьютера.
Принцип программного управления
. программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности.
Принцип однородности памяти
Программы и данные хранятся в одной и той же памяти. Поэтому ЭВМ не различает, что хранится в данной ячейке памяти — число, текст или команда.
Принцип хранимой программы
программа задавалась путем установки перемычек на специальной коммутационной панели. Нейман предложил сохранять программу в той же самой памяти, что и обрабатываемые ею числа. Отсутствие принципиальной разницы между программой и данными дало возможность ЭВМ самой формировать для себя программу в соответствии с результатами вычислений. Фон Нейман выдвинул основополагающие принципы логического устройства ЭВМ,и предложил ее структуру которая воспроизводилась в течение первых двух поколений ЭВМ. Схема устройства такой ЭВМ представлена на рис. 4.10.
Внешняя память отличается от устройства ввода и вывода тем, что данные в нее заносятся в виде, удобном компьютеру, но недоступном для непосредственного восприятия человеком. Так, накопитель на магнитных дисках - внешняя память, а клавиатура - устройство ввода, дисплей и печать - устройства вывода.
Устройство управления (УУ) и арифметико-логическое устройство (АЛУ) в современных компьютерах объединены в один блок — процессор, являющийся преобразователем информации, поступающей из памяти и внешних устройств. Память (ЗУ) хранит информацию (данные) и программы. Запоминающее устройство у современных компьютеров "многоярусно" и включает оперативное запоминающее устройство (ОЗУ) и внешние запоминающие устройства(ВЗУ). ОЗУ- это устройство, хранящее ту информацию, с которой компьютер работает непосредственно в данное время ВЗУ-устройства гораздо большей емкости, чем ОЗУ, но существенно более медленны. На ОЗУ и ВЗУ классификация устройств памяти не заканчивается - определенные функции выполняют и СОЗУ (сверхоперативное запоминающее устройство), и ПЗУ (постоянное запоминающее устройство), и другие подвиды компьютерной памяти.
В построенной по описанной схеме ЭВМ происходит последовательное считывание команд из памяти и их выполнение. Номер ячейки памяти из которой извлекается следующая команда программы, указывается- счетчиком команд в УУ.
Принцип адресности
Структурно основная память состоит из пронумерованных ячеек. Процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к запомненным в них значениям можно было бы впоследствии обращаться или менять их в процессе выполнения программы с использованием присвоенных имен.
Принцип последовательного выполнения операций.
Разработанные фон Нейманом основы получили название «фон-неймановской архитектуры». Исключение составляют отдельные разновидности систем для параллельных вычислений (примерами могут служить потоковая и редукционная вычислительные машины).
Отклонение от фон-неймановской архитектуры произойдет в результате развития идеи машин пятого поколения, в основе обработки информации в которых лежат не вычисления, а логические выводы.
Архитектура персонального компьютера
Архитектура персонального компьютера
— компоновка его основных частей, таких как процессор, ОЗУ, видеоподсистема, дисковая система, периферийные устройства и устройства ввода-вывода.
Появление третьего поколения ЭВМ произошло усложнение структуры за счет разделения процессов ввода-вывода информации и её обработки. Связанные устройства АЛУ и УУ получили название – процессор.
В схеме ЭВМ появились дополнительные устройства: процессоры ввода-вывода, устройства управления обменом информацией, каналы ввода-вывода (КВВ). Тенденция к децентрализации управления и параллельной работе отдельных устройств, резко повысила быстродействие ЭВМ в целом.
В персональных ЭВМ, относящихся к ЭВМ четвертого поколения, произошло дальнейшее изменение структуры (рис. 1.3). Они унаследовали ее от мини-ЭВМ.
Соединение всех устройств в единую машину обеспечивается с помощью общей шины, представляющей собой линии передачи данных, адресов, сигналов управления и питания. Все передачи данных по шине осуществляются под управлением сервисных программ. Ядро ПЭВМ образуют процессор и основная память (ОП), состоящая из оперативной памяти и постоянного запоминающего устройства (ПЗУ). ПЗУ предназначается для записи и постоянного хранения наиболее часто используемых программ управления. Подключение всех внешних устройств (ВнУ), дисплея, клавиатуры, внешних ЗУ и других обеспечивается через соответствующие адаптеры - согласователи скоростей работы сопрягаемых устройств или контроллеры - специальные устройства управления периферийной аппаратурой. Контроллеры в ПЭВМ играют роль каналов ввода-вывода. В качестве особых устройств следует выделить таймер - устройство измерения времени и контроллер прямого доступа к памяти (КПД) - устройство, обеспечивающее доступ к ОП, минуя процессор.
Все приведенные структуры не выходят за пределы классической структуры Ф.Неймона.
Из рисунка рис. 4.11 для связи между отдельными функциональными узлами ЭВМ используется общая шина Шина состоит из трех частей:
• шина данных, по которой передается информация;
• шина адреса, определяющая, куда передаются данные;
• шина управления, регулирующая процесс обмена информацией.
Описанную схему модно пополнить новыми устройствами - это свойство называют открытостью архитектуры. На рис. 4.11 представлен вид памяти - видео-ОЗУ (видеопамять). Видео память появилась с устройства вывода - дисплея. Дисплей является «очень быстрым» устройством отображения информации. Поэтому для ЭВМ третьего и четвертого поколений он является неотъемлемой частью.
Для получения картинки существует видеопамять. Объем видеопамяти зависит от числа цветов изображения. она показана пунктиром).
При описании магистральной структуры, все устройства взаимодействуют через общую шину. Такая структура применяется только для ЭВМ с небольшим числом внешних устройств. В состав ЭВМ могут вводиться одна или несколько дополнительных шин. Одна шина-для обмена с памятью, вторая -для связи с «медленными» внешними устройствами.
Характерные тенденций в развитии ЭВМ:
расширяется и совершенствуется набор внешних устройств
вычислительные машины перестают быть однопроцессорными, могут быть процессоры для вычисления с плавающей запятой, видеопроцессоры для ускорения вывода информации на экран дисплея и т.п.
машины не только для вычислений, но и для логического анализа информации.
Особенностью развития современных ЭВМ является возрастание роли межкомпьютерных коммуникаций, большее количество компьютеров объединяются в сети и обрабатывают имеющуюся информацию совместно.
Внутренняя структура вычислительной техники постоянно совершенствовалась и будет совершенствоваться.,
Все приведенные структуры не выходят за пределы классической структуры фон Неймана. Их объединяют следующие Традиционные признаки:
ядро ЭВМ образует процессор - единственный вычислитель в структуре, дополненный каналами обмена информацией и памятью;
линейная организация ячеек всех видов памяти фиксированного размера;
одноуровневая адресация ячеек памяти, стирающая различия между всеми типами информации;
внутренний машинный язык низкого уровня, при котором команды содержат элементарные операции преобразования простых операндов;
последовательное централизованное управление вычислениями;
достаточно примитивные возможности устройств ввода-вывода.
Недостатки классических структур:
плохо развитые средства обработки нечисловых данных (структуры, символы, предложения, графические образы, звук, очень большие массивы данных и др.);
несоответствие машинных операций операторам языков высокого уровня;
примитивная организация памяти ЭВМ;
низкая эффективность ЭВМ при решении задач, допускающих параллельную обработку.
Исчерпаны структурные методы производительности ЭВМ.
В ЭВМ будущих поколений, с использованием в них “встроенного искусственного интеллекта”, предполагается дальнейшее усложнение структуры.
Определение и назначение экспертной системы, ее состав. Система продукций. Этапы проектирования и участники процесса проектирования экспертной системы
Экспертные системы – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие эти знания для консультаций менее квалифицированных пользователей.
Цель
исследований по ЭС состоит в разработке программ, которые при решении задач, трудных для эксперта-человека, получают результаты, не уступающие по качеству и эффективности решениям, получаемым экспертом.
Важность экспертных систем состоит в следующем:
технология экспертных систем существенно расширяет круг практически значимых задач, решаемых на компьютерах, решение которых приносит значительный экономический эффект;
технология ЭС является важнейшим средством в решении глобальных проблем традиционного программирования: длительность и, следовательно, высокая стоимость разработки сложных приложений;
высокая стоимость сопровождения сложных систем, которая часто в несколько раз превосходит стоимость их разработки; низкий уровень повторной используемости программ и т.п.;
объединение технологии ЭС с технологией традиционного программирования добавляет новые качества к программным продуктам за счет: обеспечения динамичной модификации приложений пользователем, а не программистом; большей "прозрачности" приложения (например, знания хранятся на ограниченном ЕЯ, что не требует комментариев к знаниям, упрощает обучение и сопровождение); лучшей графики; интерфейса и взаимодействия.
По мнению ведущих специалистов, в недалекой перспективе ЭС найдут следующее применение:
ЭС будут играть ведущую роль во всех фазах проектирования, разработки, производства, распределения, продажи, поддержки и оказания услуг;
технология ЭС, получившая коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей.
ЭС предназначены для так называемых неформализованных задач, т.е. ЭС не отвергают и не заменяют традиционного подхода к разработке программ, ориентированного на решение формализованных задач.
Неформализованные задачи обычно обладают следующими особенностями:
ошибочностью, неоднозначностью, неполнотой и противоречивостью исходных данных;
ошибочностью, неоднозначностью, неполнотой и противоречивостью знаний о проблемной области и решаемой задаче;
большой размерностью пространства решения, т.е. перебор при поиске решения весьма велик;
динамически изменяющимися данными и знаниями.
Следует подчеркнуть, что неформализованные задачи представляют большой и очень важный класс задач. Многие специалисты считают, что эти задачи являются наиболее массовым классом задач, решаемых ЭВМ.
Экспертные системы и системы искусственного интеллекта отличаются от систем обработки данных тем, что в них в основном используются символьный (а не числовой) способ представления, символьный вывод и эвристический поиск решения (а не исполнение известного алгоритма).
в настоящее время технология экспертных систем используется
для решения различных типов задач (интерпретация, предсказание, диагностика, планирование, конструирование, контроль, отладка, инструктаж, управление) в самых разнообразных проблемных областях, таких, как финансы, нефтяная и газовая промышленность, энергетика, транспорт, фармацевтическое производство, космос, металлургия, горное дело, химия, образование, целлюлозно-бумажная промышленность, телекоммуникации и связь и др.
Обобщенная структура состав
Обобщенная структура экспертной системы представлена на рис. 2.4.
Обычно она состоит из следующих взаимосвязанных между собой модулей:
База знаний
– ядро экспертной системы, совокупность знаний предметной области, записанная на машинном носителе в форме, понятной эксперту и пользователю.
Интеллектуальный редактор базы знаний
– программа, представляющая инженеру-когнитологу и программисту возможность создавать базу знаний в диалоговом режиме. Включает в себя системы вложенных меню, шаблонов языка представления знаний, подсказок (help – режим) и других сервисных средств, облегчающих работу с базой знаний.
Интерфейс пользователя
– комплекс программ, реализующих диалог пользователя с экспертной системой на стадии как ввода информации, так и получения результатов.
Решатель
– программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в базе знаний. Существуют синонимы: дедуктивная машина, блок логического вывода.
Подсистема объяснений
– программа, позволяющая пользователю получать ответы на вопросы: «Как была получена та или иная рекомендация ?» и «Почему система приняла такое решение ?» Ответ на вопрос «как ?» – это трассировка всего процесса получения решения с указанием исполняющих фрагментов базы знаний, т.е. всех шагов цепи умозаключений. Ответ на вопрос «почему ?» – ссылка на умозаключение, непосредственно предшествовавшее полученному решению, т.е. отход на один шаг назад.
В коллектив разработчиков экспертной системы входит
: эксперт; инженер-когнитолог; программист; пользователь.
Возглавляет коллектив инженер-когнитолог. Это ключевая фигура при разработке систем, основанных на знаниях. Обычно это руководитель проекта, в задачу которого входит организация всего процесса создания экспертной системы. С одной стороны, он должен быть специалистом в области искусственного интеллекта, а с другой – разбираться в предметной области, общаться с экспертом, извлекая и формализуя его знания, передавать их программисту, кодирующему и помещающему их в базу знаний экспертной системы. Процесс обучения экспертной системы может производиться автоматически с помощью обучающего алгоритма либо путем вмешательства инженера-когнитолога, выполняющего роль учителя.
Экспертная система работает в двух режимах:
приобретения знаний и решения задач или консультаций.
В режиме приобретения знаний
происходит формирование базы знаний.
В режиме решения задач
общение с экспертной системой осуществляет конечный пользователь.
Системы продукций -
это набор правил, используемый как база знаний, поэтому его еще называют базой правил. В Стэндфордской теории фактор уверенности CF (certainty factor) принимает значения от +1 (максимум доверия к гипотезе) до -1 (минимум доверия). Продукционная система - способ представления знаний в виде:
- неупорядоченной совокупности продукционных правил;
- рабочей памяти; и
- механизма логического вывода
Этапы и технология разработки
В процессе разработки экспертные системы проходят определенные стадии, в результате которых создаются различные версии, называемые прототипами:
Демонстрационный прототип
– экспертная система, которая решает часть требуемых задач, демонстрируя жизнеспособность метода инженерии знаний. Демонстрационный прототип работает имея в базе знаний всего 50 – 100 правил. Время разработки такой экспертной системы – от 1 месяца до 1 года.
Исследовательский прототип
– экспертная система, которая решает все требуемые задачи, но неустойчива в работе и не полностью проверена. База знаний содержит 200 – 500 правил. Разработка занимает 3 – 6 месяцев.
Действующий прототип
– надежно решает все задачи, но для решения сложных задач может потребоваться много времени и памяти. Количество правил – 500 – 1000. Время разработки этапа – 6 – 12 месяцев.
Промышленная экспертная
система обеспечивает высокое качество решения всех задач при минимуме времени и памяти, что достигается переписыванием программ с использованием более совершенных инструментальных средств и языков низкого уровня. База знаний содержит 1000 – 1500 правил. Время разработки – 1-1,5 года.
Коммерческая экспертная
система отличается от промышленной тем, что помимо собственного использования она может продаваться различным потребителям. База знаний содержит 1500 – 3000 правил. Время разработки – 1,5 – 3 года. Стоимость – 0,3 – 5 млн. дол.
В настоящее время уже сложилась определенная технология разработки экспертных систем, которая состоит из следующих этапов, схематически изображенных
на рис. 2.5:
1. Идентификация (постановка задачи).
На этапе устанавливаются задачи, которые подлежат решению, выявляются цели разработки, требования к экспертной системе, ресурсы, используемые понятия и их взаимосвязи, определяются методы решения задач. Цель этапа – сформулировать задачу и охарактеризовать поддерживающую ее базу знаний и таким образом обеспечить начальный импульс для развития базы знаний.
2. Концептуализация.
Проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач.
3. Формализация
. Определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, оценивается адекватность целям системы зафиксированных понятий, методов решения, средств представления и манипулирования знаниями.
4. Выполнение.
Осуществляется наполнение экспертом базы знаний. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном экспертной системе. Из-за эвристического характера знаний их приобретение является весьма трудоемким.
5. Тестирование.
Эксперт и инженер по знаниям в интерактивном режиме, используя диалоговые и объяснительные средства, проверяют компетентность экспертной системы. Процесс тестирования продолжается до тех пор, пока эксперт не решит, что система достигла требуемого уровня компетентности.
6. Опытная эксплуатация.
Проверяется пригодность экспертной системы для конечных пользователей. По результатам этого этапа может потребоваться модификация экспертной системы.
7. Модификация.
В ходе создания экспертной системы почти постоянно производится ее модификация: переформулирование понятий и требований, переконструирование представления знаний и усовершенствование прототипа.
Приведенная последовательность разработки экспертных систем предложена Э.А.Поповым в [14]. Данная технология отражает опыт разработки и внедрения многочисленных экспертных систем широкого назначения.
Классификация сетей (глобальные, региональные, локальные). Архитектура сетей (модель OSI). Топология и методы доступа локальных сетей, популярные технологии
Компьютерная (вычислительная) сеть
- это совокупность компьютеров и периферийного оборудования, соединенных с помощью каналов связи в единую систему так, что они могут связываться между собой и совместно использовать ресурсы сети.
Классификации вычислительных сетей:
1)
по степени территориальной
рассредоточенности элементов (глобальные, региональные, локальные, корпоративные.
- глобальные сети
(WAN - Wide Area Network);
- региональные сети
(MAN - Metropolitan Area Network);
- локальные сети
(LAN – Local Area Network).
Отдельный класс: корпоративные
вычислительные сети -
сеть некоторой корпорации.
Глобальная вычислительная сеть объединяет абонентов, расположенных в различных странах, континентах. Взаимодействие с помощью радиосвязи, спутниковой связи, телефонной линии. Из глобальных - сеть Internet. Основными ячейками Internet являются локальные вычислительные сети.
Региональная вычислительная сеть связывает абонентов внутри города, региона, страны.
Локальнаявычислительная сеть связывает абонентов, расположенных в пределах небольшой территории.
Локальные сети могут входить как компоненты в состав региональных сетей, региональные - в глобальные и, наконец, глобальные сети могут образовывать сложные структуры.
2)
по способу управления
телекомунникационных вычислительных сетей:
-Сети с централизованными
-Децентрализованными
-смешанные
3) по организации передачи
информации:
-маршрутизация информации (не сколькой путей)
- сети с селекционной информацией (выборка)
4) по типу организации передачи данных
.
-маршрутизация информации(коммутация цепей, сообщений, пакетов)
-патология-конфигурация элементов(широковещательные, пользовательские)
Архитектура сетей (модель OSI)
Эталонная модель OSI (стек OSI) это 7-уровневая сетевая иерархия (рис. 1) разработанную Международной организацией по стандартам (International Standardization Organization - ISO). Эта модель содержит 2 модели:
- горизонтальную модель на базе протоколов, обеспечивающую механизм взаимодействия программ и процессов на различных машинах
- вертикальную модель на основе услуг, обеспечиваемых соседними уровнями друг другу на одной машине
В горизонтальной модели двум программам требуется общий протокол для обмена данными. В вертикальной - соседние уровни обмениваются данными с использованием интерфейсов API.
| Модель OSI |
| Тип данных |
Уровень |
Функции |
Протоколы |
| Данные |
7. Прикладной уровень |
Доступ к сетевым службам |
HTTP, gopher, Telnet, SMTP, SNMP, CMIP, FTP, TFTP, SSH, IRC, AIM, NFS, NNTP, NTP, SNTP, XMPP, FTAM, APPC, X.400, X.500, AFP, LDAP, SIP, ITMS, Modbus TCP, BACnet IP, IMAP |
| 6. Уровень представления |
Представление и кодирование данных |
HTTP/HTML, ASN.1, XML, TDI, XDR, SNMP, FTP, Telnet, SMTP, NCP, AFP |
| 5. Сеансовый уровень |
Управление сеансом связи |
ASP, ADSP, DLC, Named Pipes, NBT, NetBIOS, NWLink, Printer Access Protocol, ZIP |
| Сегменты |
4. Транспортный |
Прямая связь между конечными пунктами и надежность |
TCP, UDP, NetBEUI, AEP, ATP, IL, NBP, RTMP, SMB, SPX, SCTP, RTP, STP, TFTP |
| Пакеты |
3. Сетевой |
Определение маршрута и логическая адресация |
IP, ICMP, IPX, NWLink, NetBEUI, DDP, IPSec, ARP, RARP, DHCP, BootP |
| Кадры |
2. Канальный |
Физическая адресация |
ARCnet, ATM, Ethernet, FDDI, Frame Relay, LocalTalk, Token ring, PPP, StarLan, WiFi |
| Биты |
1. Физический уровень |
Работа со средой передачи, сигналами и двоичными данными |
RS-232, RS-422, RS-423, RS-449, RS-485, ITU-T, DSL, ISDN, T-carrier (T1, E1), модификации стандарта Ethernet: 10BASE-T, 10BASE2, 10BASE5, 100BASE-TX, 100BASE-FX, 100BASE-T, 1000BASE-T, 1000BASE-TX, 1000BASE-SX |
Рисунок 1 Модель OSI
Уровень 1, физический получает пакеты данных от вышележащего канального уровня и преобразует их в оптические или электрические сигналы, соответствующие 0 и 1 бинарного потока. Эти сигналы посылаются через среду передачи на приемный узел. Механические и электрические/оптические свойства среды передачи определяются на физическом уровне и включаются:
Тип кабелей и разъемов
Разводку контактов в разъемах
Схему кодирования сигналов для значений 0 и 1
Уровень 2, канальный обеспечивает создание, передачу и прием кадров данных. Этот уровень обслуживает запросы сетевого уровня и использует сервис физического уровня для приема и передачи пакетов. Спецификации IEEE 802.x делят канальный уровень на 2 подуровня: управление логическим каналом (LLC обеспечивает обслуживание сетевого уровня) и управление доступом к среде (MAC регулирует доступ к разделяемой физической среде).
Уровень 3, сетевой отвечает за деление пользователей на группы. На этом уровне происходит маршрутизация пакетов на основе преобразования MAC-адресов в сетевые адреса. Сетевой уровень обеспечивает также прозрачную передачу пакетов на транспортный уровень.
Уровень 4, транспортный делит потоки информации на достаточно малые фрагменты (пакеты) для передачи их на сетевой уровень.
Уровень 5, сеансовый отвечает за организацию сеансов обмена данными между оконечными машинами. Протоколы сеансового уровня обычно являются составной частью функций трех верхних уровней модели.
Уровень 6, уровень представления отвечает за возможность диалога между приложениями на разных машинах. Этот уровень преобразовывает данные (кодирование, компрессия и т.п.) прикладного уровня в поток информации для транспортного уровня.
Уровень 7, прикладной отвечает за доступ приложений в сеть. Задачами этого уровня является перенос файлов, обмен почтовыми сообщениями и управление сетью.
МОДЕЛЬ TCP/IP
Её возможность – объединение различных сетей. Это модель сети с коммутацией пакетов, в основе лежит не имеющий соединений межсетевой уровень. Уровни модели
TCP/IP:
1)Уровень приложений:
а) протокол виртуального терминала, позволяет регистрацию на удалённом сервере и работать с ним;
б) протокол переноса файлов;
в) протокол электронной почты;
г) протокол службы имён-доменов;
д) протокол передачи новостей;
2)Транспортный уровень – создан для поддержки связи между приёмными и передающими хостами. На нём реализуются два сквозных протокола TCP и UDP;
3) Межсетевой уровень – обеспечивает возможность каждого хоста посылать пакеты сообщений независимо друг от друга для перемещения их адресатов. Межсетевой уровень определяет формат пакета и протокол (IP протокол). Задача в доставке IP пакета адресату, определение маршрута пакета и недопущение затора транспортной передачи;
4) Канальный уровень (хост-сетевой) – реализует протоколы, которые обеспечивают соединение машины сети и позволяет посылать IP пакеты. Протоколы этого уровня точно не определены, не стандартизированы и меняются от сети к сети.
Топология сети Узел сети
представляет собой компьютер, либо коммутирующее устройство сети. Ветвь сети
- это путь, соединяющий два смежных узла. Узлы сети бывают трёх типов:
оконечный узел - расположен в конце только одной ветви;
промежуточный узел - расположен на концах более чем одной ветви;
смежный узел - такие узлы соединены по крайней мере одним путём, не содержащим никаких других узлов.
Топология сети
– геометрическая форма и физическое расположение компьютеров по отношению к друг другу. Топология позволяет сравнивать и классифицировать различные сети. Различают три основных вида топологии: 1) Звезда; 2) Кольцо; 3) Шина.
ШИННАЯ ТОПОЛОГИЯ компьютер присоединяется к общему кабелю, на концах которого устанавливаются терминаторы. Сигнал проходит по сети через все компьютеры, отражаясь от конечных терминаторов.
Шина проводит сигнал из одного конца сети к другому, при этом каждая рабочая станция проверяет адрес послания, и, если он совпадает с адресом рабочей станции, она его принимает. Если же адрес не совпадает, сигнал уходит по линии дальше.
Плюсы: отказ любой из рабочих станций не влияет на работу всей сети; простота и гибкость соединений; недорогой кабель и разъемы; необходимо небольшое количество кабеля; прокладка кабеля не вызывает особых сложностей. Минусы: разрыв кабеля, может исключить нормальную работу всей сети; ограниченная длина кабеля и количество рабочих станций; трудно обнаружить дефекты соединений; невысокая производительность; при большом объеме передаваемых данных главный кабель может не справляться с потоком информации, что приводит к задержкам.
|

ТОПОЛОГИЯ «КОЛЬЦО» последовательное соединение компьютеров, когда последний соединён с первым. Сигнал проходит от компьютера к компьютеру. Каждый компьютер работает как повторитель, усиливая сигнал и передавая его дальше. Сбой одного из них приводит к нарушению работы всей сети.
|

ТОПОЛОГИЯ «ЗВЕЗДА» компьютер подсоединяется к сети при помощи отдельного соединительного кабеля. Один конец кабеля соединяется с гнездом сетевого адаптера, другой подсоединяется к центральному устройству. Рабочая группа, может функционировать независимо или может быть связана с другими рабочими группами. Плюсы: подключение новых рабочих станций; возможность мониторинга сети; хорошая расширяемость и модернизация. Минусы: отказ от центрального устройства приводит к отключению от сети всех рабочих станций; требуется большое количество кабеля.
|
Комбинированные топологии

1. «Звезда-Шина» - несколько сетей с топологией звезда объединяются при помощи магистральной линейной шины.
|

2. Древовидная структура
|
5. «Снежинка»
|

5. «Каждый с каждым»
|
4. Пересекающиеся кольца
|
Локальные сети при разработке, как правило, имеют симметричную топологию, глобальные—неправильную.
Методы доступа и протоколы сетей
В различных сетях применяются различные сетевые протоколы для обмена данными между рабочими станциями. В 1980 году в Международном институте инженеров (Institute of Electronics Engineers–IEEE). Комитет 802 разработал семейство стандартов IЕЕЕ802. x, которые содержат рекомендации по проектированию нижних уровней локальных сетей.
Стандарты семейства IЕЕЕ802.x охватывают 2 уровня модели OSI – физический и канальный, именно они отражают специфику локальных сетей. Старшие уровни, сетевой, имеют общие черты, как для локальных, так и глобальных сетей.
К наиболее распространенным методам доступа относятся: Ethernet, ArcNet и Token Ring, которые реализованы соответственно в стандартах IЕЕЕ802.3, IЕЕЕ802.4 и IЕЕЕ802.5. Для локальных сетей, работающих на оптическом волокне, институтом ASNI был разработан стандарт FDDI, обеспечивающий скорость передачи данных 100 Мбит/с.
В канальный уровень разделяется подуровня, которые называются уровнями:
- управление логическим каналом (LCC - Logical Link Control),
-управление доступом к среде (MAC - Media Access Control).
Уровень управления доступом к среде передачи данных (MAC) появился, так как в локальных сетях используется разделяемая среда передачи данных.
Методы доступа к среде передачи данных (методы доступа к каналам связи)
В локальных сетях, использующих среду передачи данных (топологией шина и физическая звезда), актуальным является доступ рабочих станций к этой среде, если два ПК начинают одновременно передавать данные, то в сети происходит столкновение.
Для того чтобы избежать этих столкновений необходим Шинный арбитраж
- это механизм решающий проблему столкновений. Он определяет правила, когда среда свободна, и можно передавать данные. Существуют два метода шинного арбитража в локальных сетях:
- обнаружение столкновений (компьютер сначала слушает, а потом передает)
- передача маркера (чтобы передать данные, компьютер сначала должен получить разрешение)
Прослушивание канала до передачи называется “прослушивание несущей
” (carrier sense), а прослушивание во время передачи — обнаружение столкновений (collision detection). Компьютер, поступающий таким образом, использует метод, называющийся “обнаружение столкновений с прослушиванием несущей”, сокращенно CSCD.
Марке должен “поймать” циркулирующий в сети пакет данных специального вида, называемый маркером. Маркер перемещается по замкнутому кругу, минуя поочередно каждый сетевой компьютер.
Каждый раз, когда компьютер должен послать сообщение, он ловит и держит маркер у себя. Как только передача закончилась, он посылает новый маркер в путешествие дальше по сети. Такой подход дает гарантию, что любой компьютер рано или поздно получит право поймать и удерживать маркер до тех пор, пока его собственная передача не закончится.
Классификация сетей (глобальные, региональные, локальные). Архитектура сетей (модель OSI). Топология и методы доступа локальных сетей, популярные технологии
Компьютерная (вычислительная) сеть
- это совокупность компьютеров и периферийного оборудования, соединенных с помощью каналов связи в единую систему так, что они могут связываться между собой и совместно использовать ресурсы сети.
Классификации вычислительных сетей:
1)
по степени территориальной
рассредоточенности элементов (глобальные, региональные, локальные, корпоративные.
- глобальные сети
(WAN - Wide Area Network);
- региональные сети
(MAN - Metropolitan Area Network);
- локальные сети
(LAN – Local Area Network).
Отдельный класс: корпоративные
вычислительные сети -
сеть некоторой корпорации.
Глобальная вычислительная сеть объединяет абонентов, расположенных в различных странах, континентах. Взаимодействие с помощью радиосвязи, спутниковой связи, телефонной линии. Из глобальных - сеть Internet. Основными ячейками Internet являются локальные вычислительные сети.
Региональная вычислительная сеть связывает абонентов внутри города, региона, страны.
Локальнаявычислительная сеть связывает абонентов, расположенных в пределах небольшой территории.
Локальные сети могут входить как компоненты в состав региональных сетей, региональные - в глобальные и, наконец, глобальные сети могут образовывать сложные структуры.
2)
по способу управления
телекомунникационных вычислительных сетей:
-Сети с централизованными
-Децентрализованными
-смешанные
3) по организации передачи
информации:
-маршрутизация информации (не сколькой путей)
- сети с селекционной информацией (выборка)
4) по типу организации передачи данных
.
-маршрутизация информации(коммутация цепей, сообщений, пакетов)
-патология-конфигурация элементов(широковещательные, пользовательские)
Архитектура сетей (модель OSI)
Эталонная модель OSI (стек OSI) это 7-уровневая сетевая иерархия (рис. 1) разработанную Международной организацией по стандартам (International Standardization Organization - ISO). Эта модель содержит 2 модели:
- горизонтальную модель на базе протоколов, обеспечивающую механизм взаимодействия программ и процессов на различных машинах
- вертикальную модель на основе услуг, обеспечиваемых соседними уровнями друг другу на одной машине
В горизонтальной модели двум программам требуется общий протокол для обмена данными. В вертикальной - соседние уровни обмениваются данными с использованием интерфейсов API.
| Модель OSI |
| Тип данных |
Уровень |
Функции |
Протоколы |
| Данные |
7. Прикладной уровень |
Доступ к сетевым службам |
HTTP, gopher, Telnet, SMTP, SNMP, CMIP, FTP, TFTP, SSH, IRC, AIM, NFS, NNTP, NTP, SNTP, XMPP, FTAM, APPC, X.400, X.500, AFP, LDAP, SIP, ITMS, Modbus TCP, BACnet IP, IMAP |
| 6. Уровень представления |
Представление и кодирование данных |
HTTP/HTML, ASN.1, XML, TDI, XDR, SNMP, FTP, Telnet, SMTP, NCP, AFP |
| 5. Сеансовый уровень |
Управление сеансом связи |
ASP, ADSP, DLC, Named Pipes, NBT, NetBIOS, NWLink, Printer Access Protocol, ZIP |
| Сегменты |
4. Транспортный |
Прямая связь между конечными пунктами и надежность |
TCP, UDP, NetBEUI, AEP, ATP, IL, NBP, RTMP, SMB, SPX, SCTP, RTP, STP, TFTP |
| Пакеты |
3. Сетевой |
Определение маршрута и логическая адресация |
IP, ICMP, IPX, NWLink, NetBEUI, DDP, IPSec, ARP, RARP, DHCP, BootP |
| Кадры |
2. Канальный |
Физическая адресация |
ARCnet, ATM, Ethernet, FDDI, Frame Relay, LocalTalk, Token ring, PPP, StarLan, WiFi |
| Биты |
1. Физический уровень |
Работа со средой передачи, сигналами и двоичными данными |
RS-232, RS-422, RS-423, RS-449, RS-485, ITU-T, DSL, ISDN, T-carrier (T1, E1), модификации стандарта Ethernet: 10BASE-T, 10BASE2, 10BASE5, 100BASE-TX, 100BASE-FX, 100BASE-T, 1000BASE-T, 1000BASE-TX, 1000BASE-SX |
Рисунок 1 Модель OSI
Уровень 1, физический получает пакеты данных от вышележащего канального уровня и преобразует их в оптические или электрические сигналы, соответствующие 0 и 1 бинарного потока. Эти сигналы посылаются через среду передачи на приемный узел. Механические и электрические/оптические свойства среды передачи определяются на физическом уровне и включаются:
Тип кабелей и разъемов
Разводку контактов в разъемах
Схему кодирования сигналов для значений 0 и 1
Уровень 2, канальный обеспечивает создание, передачу и прием кадров данных. Этот уровень обслуживает запросы сетевого уровня и использует сервис физического уровня для приема и передачи пакетов. Спецификации IEEE 802.x делят канальный уровень на 2 подуровня: управление логическим каналом (LLC обеспечивает обслуживание сетевого уровня) и управление доступом к среде (MAC регулирует доступ к разделяемой физической среде).
Уровень 3, сетевой отвечает за деление пользователей на группы. На этом уровне происходит маршрутизация пакетов на основе преобразования MAC-адресов в сетевые адреса. Сетевой уровень обеспечивает также прозрачную передачу пакетов на транспортный уровень.
Уровень 4, транспортный делит потоки информации на достаточно малые фрагменты (пакеты) для передачи их на сетевой уровень.
Уровень 5, сеансовый отвечает за организацию сеансов обмена данными между оконечными машинами. Протоколы сеансового уровня обычно являются составной частью функций трех верхних уровней модели.
Уровень 6, уровень представления отвечает за возможность диалога между приложениями на разных машинах. Этот уровень преобразовывает данные (кодирование, компрессия и т.п.) прикладного уровня в поток информации для транспортного уровня.
Уровень 7, прикладной отвечает за доступ приложений в сеть. Задачами этого уровня является перенос файлов, обмен почтовыми сообщениями и управление сетью.
МОДЕЛЬ TCP/IP
Её возможность – объединение различных сетей. Это модель сети с коммутацией пакетов, в основе лежит не имеющий соединений межсетевой уровень. Уровни модели
TCP/IP:
1)Уровень приложений:
а) протокол виртуального терминала, позволяет регистрацию на удалённом сервере и работать с ним;
б) протокол переноса файлов;
в) протокол электронной почты;
г) протокол службы имён-доменов;
д) протокол передачи новостей;
2)Транспортный уровень – создан для поддержки связи между приёмными и передающими хостами. На нём реализуются два сквозных протокола TCP и UDP;
3) Межсетевой уровень – обеспечивает возможность каждого хоста посылать пакеты сообщений независимо друг от друга для перемещения их адресатов. Межсетевой уровень определяет формат пакета и протокол (IP протокол). Задача в доставке IP пакета адресату, определение маршрута пакета и недопущение затора транспортной передачи;
4) Канальный уровень (хост-сетевой) – реализует протоколы, которые обеспечивают соединение машины сети и позволяет посылать IP пакеты. Протоколы этого уровня точно не определены, не стандартизированы и меняются от сети к сети.
Топология сети Узел сети
представляет собой компьютер, либо коммутирующее устройство сети. Ветвь сети
- это путь, соединяющий два смежных узла. Узлы сети бывают трёх типов:
оконечный узел - расположен в конце только одной ветви;
промежуточный узел - расположен на концах более чем одной ветви;
смежный узел - такие узлы соединены по крайней мере одним путём, не содержащим никаких других узлов.
Топология сети
– геометрическая форма и физическое расположение компьютеров по отношению к друг другу. Топология позволяет сравнивать и классифицировать различные сети. Различают три основных вида топологии: 1) Звезда; 2) Кольцо; 3) Шина.
ШИННАЯ ТОПОЛОГИЯ компьютер присоединяется к общему кабелю, на концах которого устанавливаются терминаторы. Сигнал проходит по сети через все компьютеры, отражаясь от конечных терминаторов.

Шина проводит сигнал из одного конца сети к другому, при этом каждая рабочая станция проверяет адрес послания, и, если он совпадает с адресом рабочей станции, она его принимает. Если же адрес не совпадает, сигнал уходит по линии дальше.
Плюсы: отказ любой из рабочих станций не влияет на работу всей сети; простота и гибкость соединений; недорогой кабель и разъемы; необходимо небольшое количество кабеля; прокладка кабеля не вызывает особых сложностей. Минусы: разрыв кабеля, может исключить нормальную работу всей сети; ограниченная длина кабеля и количество рабочих станций; трудно обнаружить дефекты соединений; невысокая производительность; при большом объеме передаваемых данных главный кабель может не справляться с потоком информации, что приводит к задержкам.
|
ТОПОЛОГИЯ «КОЛЬЦО» последовательное соединение компьютеров, когда последний соединён с первым. Сигнал проходит от компьютера к компьютеру. Каждый компьютер работает как повторитель, усиливая сигнал и передавая его дальше. Сбой одного из них приводит к нарушению работы всей сети.
|
ТОПОЛОГИЯ «ЗВЕЗДА» компьютер подсоединяется к сети при помощи отдельного соединительного кабеля. Один конец кабеля соединяется с гнездом сетевого адаптера, другой подсоединяется к центральному устройству. Рабочая группа, может функционировать независимо или может быть связана с другими рабочими группами. Плюсы: подключение новых рабочих станций; возможность мониторинга сети; хорошая расширяемость и модернизация. Минусы: отказ от центрального устройства приводит к отключению от сети всех рабочих станций; требуется большое количество кабеля.
|
Комбинированные топологии

1. «Звезда-Шина» - несколько сетей с топологией звезда объединяются при помощи магистральной линейной шины.
|

2. Древовидная структура
|

5. «Снежинка»
|
5. «Каждый с каждым»
|
4. Пересекающиеся кольца
|
Локальные сети при разработке, как правило, имеют симметричную топологию, глобальные—неправильную.
Методы доступа и протоколы сетей
В различных сетях применяются различные сетевые протоколы для обмена данными между рабочими станциями. В 1980 году в Международном институте инженеров (Institute of Electronics Engineers–IEEE). Комитет 802 разработал семейство стандартов IЕЕЕ802. x, которые содержат рекомендации по проектированию нижних уровней локальных сетей.
Стандарты семейства IЕЕЕ802.x охватывают 2 уровня модели OSI – физический и канальный, именно они отражают специфику локальных сетей. Старшие уровни, сетевой, имеют общие черты, как для локальных, так и глобальных сетей.
К наиболее распространенным методам доступа относятся: Ethernet, ArcNet и Token Ring, которые реализованы соответственно в стандартах IЕЕЕ802.3, IЕЕЕ802.4 и IЕЕЕ802.5. Для локальных сетей, работающих на оптическом волокне, институтом ASNI был разработан стандарт FDDI, обеспечивающий скорость передачи данных 100 Мбит/с.
В канальный уровень разделяется подуровня, которые называются уровнями:
- управление логическим каналом (LCC - Logical Link Control),
-управление доступом к среде (MAC - Media Access Control).
Уровень управления доступом к среде передачи данных (MAC) появился, так как в локальных сетях используется разделяемая среда передачи данных.
Методы доступа к среде передачи данных (методы доступа к каналам связи)
В локальных сетях, использующих среду передачи данных (топологией шина и физическая звезда), актуальным является доступ рабочих станций к этой среде, если два ПК начинают одновременно передавать данные, то в сети происходит столкновение.
Для того чтобы избежать этих столкновений необходим Шинный арбитраж
- это механизм решающий проблему столкновений. Он определяет правила, когда среда свободна, и можно передавать данные. Существуют два метода шинного арбитража в локальных сетях:
- обнаружение столкновений (компьютер сначала слушает, а потом передает)
- передача маркера (чтобы передать данные, компьютер сначала должен получить разрешение)
Прослушивание канала до передачи называется “прослушивание несущей
” (carrier sense), а прослушивание во время передачи — обнаружение столкновений (collision detection). Компьютер, поступающий таким образом, использует метод, называющийся “обнаружение столкновений с прослушиванием несущей”, сокращенно CSCD.
Марке должен “поймать” циркулирующий в сети пакет данных специального вида, называемый маркером. Маркер перемещается по замкнутому кругу, минуя поочередно каждый сетевой компьютер.
Каждый раз, когда компьютер должен послать сообщение, он ловит и держит маркер у себя. Как только передача закончилась, он посылает новый маркер в путешествие дальше по сети. Такой подход дает гарантию, что любой компьютер рано или поздно получит право поймать и удерживать маркер до тех пор, пока его собственная передача не закончится.
Классификация сетей (глобальные, региональные, локальные). Адресация в глобальных сетях, сервисы глобальных сетей
Компьютерная (вычислительная) сеть
- это совокупность компьютеров и периферийного оборудования, соединенных с помощью каналов связи в единую систему так, что они могут связываться между собой и совместно использовать ресурсы сети.
Классификации вычислительных сетей:
1)
по степени территориальной
рассредоточенности элементов (глобальные, региональные, локальные, корпоративные.
- глобальные сети
(WAN - Wide Area Network);
- региональные сети
(MAN - Metropolitan Area Network);
- локальные сети
(LAN – Local Area Network).
Отдельный класс: корпоративные
вычислительные сети -
сеть некоторой корпорации.
Глобальная вычислительная сеть объединяет абонентов, расположенных в различных странах, континентах. Взаимодействие с помощью радиосвязи, спутниковой связи, телефонной линии. Из глобальных - сеть Internet. Основными ячейками Internet являются локальные вычислительные сети.
Региональная вычислительная сеть связывает абонентов внутри города, региона, страны.
Локальнаявычислительная сеть связывает абонентов, расположенных в пределах небольшой территории.
Локальные сети могут входить как компоненты в состав региональных сетей, региональные - в глобальные и, наконец, глобальные сети могут образовывать сложные структуры.
2)
по способу управления
телекомунникационных вычислительных сетей:
-Сети с централизованными
-Децентрализованными
-смешанные
3) по организации передачи
информации:
-маршрутизация информации (не сколькой путей)
- сети с селекционной информацией (выборка)
4) по типу организации передачи данных
.
-маршрутизация информации(коммутация цепей, сообщений, пакетов)
-патология-конфигурация элементов(широковещательные, пользовательские)
Адресация в глобальных сетях
Internet берет свое начало с 1969 года с создания системы ARPANET (Advanced Research Projects Net - сеть передовых исследовательских проектов). Физически структуру Internet составляют устройства разных типов. Те из них, которые подключены постоянно и участвуют в передаче данных между другими участниками сети, называют узлами. В телекоммуникационном обмене участвуют:
- Клиент
- это компьютер, программа, включенный в телекоммуникационный обмен - потребитель услуг сети, основной участник телекоммуникационного обмена;
- Сервер
- это программный комплекс, предоставляющая удаленный доступ к своим ресурсам с целью обмена информацией. Программы, обрабатывающие запросы клиентов-программные сервера (server). А компьютеры, на которых установлены программные сервера, называются физическими серверами;
- Узел
- это компьютер, служащий для обеспечения связи между серверами и клиентами.
Основа функционирования Internet - работа узлов. Каждый узел использует стандартные протоколы передачи данных - TCP/IP (Transmission Control Protocol/Internet Protocol). TCP разбивает данные на пакеты при передаче и соединяет пакеты воедино при приеме. IP - система адресации, указывающая, откуда и куда пакет идёт.
Работа протокола TCP/IP: каждый компьютер, подключенный к Internet, имеет свой уникальный номер- IP-адрес. Он состоит из 32 битов (4 байта) и записывается как четыре десятичных числа разделенных точками, например 192.168.22.11 или 217.198.0.34. Информация через Internet передается в виде коротких пакетов. Если пересылаем сообщение, то оно разбивается на несколько пакетов, каждый пакет содержит адрес отправителя, получателя и служебную информацию. Когда пакеты поступают к получателю, из них формируется исходное сообщение- это коммутация пакетов. Протокол TCP/IP регламентирует, как следует разбивать длинное сообщение на пакеты, как должны быть устроены пакеты, как контролировать прибытие пакетов к месту назначения, что делать в случае ошибок и другие детали.
DNS
(Domain Name System). DNS распределённая иерархическая база данных, поддерживающаяся DNS-серверами, каждый из которых отвечает за свою зону. DNS-сервера преобразуют символьные доменные имена в IP-адреса. Пример, набирая доменное имя web-сервера, пользователь получает доступ к нему, как если бы набрал IP-адрес.
| В доменном имени названия доменов отделяют точкой: |
www.support.nchti.ru |
www - имя компьютера (web-сервер);
support - название подразделения;
nchti - название организации;
ru - географическое положение (страна).
|
Имя домена, стоящее справа принято называть доменом первого уровня.
Доменные имена первого уровня это:
|
com (для коммерческих организаций)
.net (для сетевых организаций)
.org (для
некоммерческих организаций)
|
.mil (для военных организаций)
.gov (для правительственных организаций)
.edu (для образовательных организаций)
|
| Региональные домены первого уровня: |
ru (для России)
.ua (для Украины)
.us (для США)
.uk (для Великобритании) и т.д.
|
Каждая страна имеет свое доменное имя первого уровня.
Примеры доменных имен второго уровня: ibm.com, php.net, gazeta.ru, site.ua и т.д.
Примеры доменных имен третьего уровня: www.tourkz.com, send.site.kz, smtp.mail.ru.
Сервисы глобальных сетей
Сети Internet интересны способностью предоставлять конкретные виды ресурсов, поэтому на базе основного протокола TCP/IP действуют несколько протоколов более высокого уровня, а именно HTTP, FTP, SMTP, POP3, IMAP4 и др.
Электронная почта (E-mail) использует протоколы SMTP (для отправки), POP3 или IMAP4 (для получения) электронной корреспонденции. E-mail предусматривает передачу текстовых сообщений от одного пользователя, имеющего электронный адрес, к другому. E-mail может быть использована также для того, чтобы пересылать двоичные файлы, но они должны быть перекодированы в ASCII-формат, поскольку E-mail в Internet может оперировать только информацией в ASCII-формате.
Адрес e-mail имеет следующий формат:
<имя_пользователя>@<имя_домена>
Например: info@nchti.ru
World Wide Web
Web разработана в 1989 году в (CERN). Web основана на технологии, гипертекста, которая организовывает- текстовую информацию нелинейным способом, используя связи внутри документа и между ними.
Гипертекст
- это термин, который впервые был использован американцем Тедом Нельсоном в 1960 году для описании. Язык гипертекстовой разметки HTML (HyperText Markup Language) служит для оформления электронных документов и их связи между собой. Язык состоит из тегов (указателей). Между тегами вставляется содержимое документа. Теги служат для указания, как выводить содержимое, например цвет, размер, таблицы, вставка рисунков и т.д. Главным преимуществом HTML перед другими подобными системами является возможность связывать документы между собой.
В сети находится огромное количество серверов, на которых хранится информация в формате HTML. Такие сервера называются Web-серверами. Любой пользователь сети, имея программу для работы с WWW, может получить доступ к подобным ресурсам. Программы для работы с WWW называются браузерами (browser). СамыЙ популярный - MS Internet Explorer, Netscape Navigator, Opera.
Адреса в WWW. Доступ к ресурсам Internet осуществляется через универсальные локаторы ресурсов (URL). URL состоит из 3-х элементов: названия протокола передачи, имени хоста. название протокола и имя хоста разделены двоеточием и 2-мя косыми чертами (://). Путевое имя начинается с одной косой черты (/):
<протокол_передачи>://<имя_хоста>/<путевое_имя>
Например: http://support.nchti.ru:80/proxy.pac
FTP (File Transfer Protocol). Для передачи файлов по сети Internet, представляют собой файловые архивы. Содержимое ftp-серверов представляет собой часть файловой системы сервера, к которой предоставлен доступ через сеть. Адреса ftp архивов подчиняются тем же правилам, что и адреса www сайтов, только указывается другое имя протокола. Например: ftp://mp3.int.ru
Для доступа к таким серверам необходимо знать login и пароль, которые нужно ввести на запрос ftp-клиента (браузера) или использовать url вида:
ftp://:@<доменное_имя_ftp_сервера>
Предпочтение следует отдавать первому способу, т.к. пользовательские регистрационные данные, передаваемые в строке url могут быть легко перехвачены при передаче по сети.
Информатика как наука. Предмет и объект прикладной информатики. Системы счисления
Инфоpматика
— это основанная на использовании компьютерной техники дисциплина, изучающая структуру и общие свойства информации, а также закономерности и методы её создания, хранения, поиска, преобразования, передачи и применения в различных сферах человеческой деятельности.
Инфоpматика
— научная дисциплина с широчайшим диапазоном применения.
Её основные направления:
pазpаботка вычислительных систем и пpогpаммного обеспечения;
теоpия инфоpмации, изучающая процессы, связанные с передачей, приёмом, преобразованием и хранением информации;
методы искусственного интеллекта, позволяющие создавать программы для решения задач, требующих определённых интеллектуальных усилий при выполнении их человеком (логический вывод, обучение, понимание речи, визуальное восприятие, игры и др.);
системный анализ, заключающийся в анализе назначения проектируемой системы и в установлении требований, которым она должна отвечать;
методы машинной графики, анимации, средства мультимедиа;
средства телекоммуникации, в том числе, глобальные компьютерные сети, объединяющие всё человечество в единое информационное сообщество;
разнообразные пpиложения, охватывающие производство, науку, образование, медицину, торговлю, сельское хозяйство и все другие виды хозяйственной и общественной деятельности.
Термином информатика обозначают совокупность дисциплин, изучающих свойства информации, а также способы представления, накопления, обработки и передачи информации с помощью технических средств.
Информационная технология
есть совокупность конкретных технических и программных средств, с помощью которых мы выполняем разнообразные операции по обработке информации во всех сферах нашей жизни и деятельности.
Информатика является комплексной, междисциплинарной отраслью научного знания.
ПРЕДМЕТОМ ИНФОРМАТИКИ ЯВЛЯЕТСЯ ЗНАНИЕ. ОБЪЕКТОМ ИНФОРМАТИКИ ЯВЛЯЕТСЯ СИСТЕМА ЧЕЛОВЕК-ВМ
знание исторически
всегда подразумевает человека, а не ВМ. Этому можно возразить так: ВМ используется человеком и для человека непосредственно или в конечном счете. слова «мыслить», «думать» и «знать», примененные к ВМ, начинают применяться без кавычек: ВМ мыслит, ВМ думает и ВМ знает.
Системы счисления
Для записи информации о количестве объектов используются числа. Числа записываются с использованием особых знаковых систем, которые называются системами счисления
. Алфавит системы счисления состоит из символов, которые называются цифрами.
Система счисления
- это знаковая система, в которой числа записываются по определенным правилам с помощью символов некоторого алфавита, называемых цифрами.
Все системы счисления делятся на две большие группы: позиционные и непозиционные
.
В позиционных системах количественное значение цифры зависит от ее положения в числе, а в непозиционных — не зависит.
Непозиционные системы
счисления. Система записи чисел называется единичной
, так как любое число в ней образуется путем повторения одного знака, символизирующего единицу. Примером непозиционной системы: римская система счисления в её основе лежат знаки I (один палец) для числа 1, V (раскрытая ладонь) для числа 5, X (две сложенные ладони) для числа 10. При записи чисел в римской системе счисления есть правило: каждый меньший знак, поставленный слева от большего, вычитается из него, в остальных случаях знаки складываются. Недостатком непозиционных систем, является отсутствие арифметических действий над ними.
Позиционные системы счисления.
Для записи чисел используется отличных друг от друга знаки. Число таких знаков называется основанием системы счисления.
Пример некоторых позиционных систем: двоичная, троичная, четверичная, пятеричная, восьмеричная, десятичная, двенадцатеричная (0,1,2,3,4,5,б,7,8,9,А,В), шестнадцатеричная (0,1,2,3,4,5,6,7,8,9,A.B,D,E,F)
В позиционной системе счисления, число может быть представлено в виде суммы произведений коэффициентов на степени основания системы счисления:
AnAn-1An-2 … A1,A0,A-1,A-2 =
АnВn + An-1Bn-1 +... + A1B1 + А0В0 + A-1B-1 + А-2В-2 +...
(знак «точка» отделяет целую часть числа от дробной; знак «звездочка» здесь и ниже используется для обозначения операции умножения). Таким образом, значение каждого знака в числе зависит от позиции, которую занимает знак в записи числа. Именно поэтому такие системы счисления называют позиционными. Примеры (десятичный индекс внизу указывает основание системы счисления): 23,43(10) = 2*101 + З*10° + 4*10-1 + З*10-2
(в данном примере знак «З» в первом случае число единиц, а в другом - число сотых долей единицы);
692(10) = 6* 102 + 9*101 + 2.
(«Шестьсот девяносто два» с формальной точки зрения представляется в виде «шесть умножить на десять в степени два, плюс девять умножить на десять в степени один, плюс два»).
1101(2)= 1*23 + 1*22+0*21+ 1*2°;
A1F4(16) = A*162 + 1*161 + F*16° + 4*16-1.
При работе с компьютерами используется несколько позиционных систем счисления, большое значение имеют перевод чисел из одной системы счисления в другую. Р
езультат является десятичным числом.
Двоичная система счисления
В двоичной системе внутреннее представление информации является двоичным, т.е. описываемым наборами только из двух знаков (0 и 1).
Целая и дробная части переводятся порознь. Для перевода просто целого числа необходимо разделить ее на основание системы счисления и продолжать делить частные от деления до тех пор, пока частное не станет равным 0. Получившиеся остатки, взятые в обратной последовательности, образуют двоичное число. Например:
Остаток
25: 2 = 12 (1),
12: 2 = 6 (0),
6: 2 = 3 (0),
3: 2 = 1 (1),
1: 2 = 0 (1).
Таким образом 25(10)=11001(2).
Для перевода дробной части (или числа, у которого «0» целых) надо умножить ее на 2. Целая часть произведения будет первой цифрой числа в двоичной системе. Затем, отбрасывая у результата целую часть, вновь умножаем на 2 и т.д.
Заметим, что конечная десятичная дробь при этом вполне может стать бесконечной {периодической) двоичной. Например:
0,73 • 2 = 1,46 (целая часть 1),
0,46 • 2 = 0,92 (целая часть 0),
0,92 • 2 = 1,84 (целая часть 1),
0,84 • 2 = 1,68 (целая часть 1) и т.д.
В итоге 0,73(10) =0,1011...(2).
Над числами, записанными в любой системе счисления, можно; производить различные арифметические операции. Так, для сложения и умножения двоичных чисел необходимо использовать табл. 1.5.
Таблица 1.5. Таблицы сложения и умножения в двоичной системе

Заметим, что при двоичном сложении 1 + 1 возникает перенос единицы в старший разряд - точь-в-точь как в десятичной арифметике:
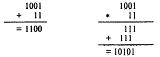
Восьмеричная и шестнадцатеричная системы счисления
Перевод чисел из десятичной системы счисления в восьмеричную производится с помощью делений и умножений на 8. Например, переведем число 58,32(10):
58: 8 = 7 (2 в остатке),
7: 8 = 0 (7 в остатке).
0,32 • 8 = 2,56,
0,56 • 8 = 4,48,
0,48-8=3,84,...
Таким образом, 58,32(10) =72,243... (8)
Для перевода целого двоичного числа в восьмеричное необходимо разбить его справа налево на группы по 3 цифры (самая левая группа может содержать менее трех двоичных цифр), а затем каждой группе поставить в соответствие ее восьмеричный эквивалент. Например:
11011001= 11011001, т.е. 11011001(2) =331(8).
Заметим, что группу из трех двоичных цифр часто называют «двоичной триадой».
Перевод целого двоичного числа в шестнадцатеричное производится путем разбиения данного числа на группы по 4 цифры - «двоичные тетрады»:
1100011011001 = 1 1000 1101 1001, т.е. 1100011011001(2)= 18D9(16).
Для перевода дробных частей двоичных чисел в восьмеричную или шестнадцатиричную системы аналогичное разбиение на триады или тетрады производится от точки вправо (с дополнением недостающих последних цифр нулями):
0,1100011101(2) =0,110 001 110 100 = 0,6164(8),
0,1100011101(2) = 0,1100 0111 0100 = 0,C74(16).
Перевод восьмеричных (шестнадцатиричных) чисел в двоичные производится обратным путем - сопоставлением каждому знаку числа соответствующей тройки (четверки) двоичных цифр.
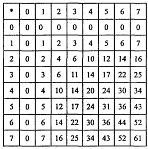
Таблица 1.6 Соответствие чисел в различных системах счисления
| Десятичная |
Шестн-чная |
Восьмеричная |
Двоичная |
| 0 |
0 |
0 |
0 |
| 1 |
1 |
1 |
1 |
| 2 |
2 |
2 |
10 |
| 3 |
3 |
3 |
11 |
| 4 |
4 |
4 |
100 |
| 5 |
5 |
5 |
101 |
| 6 |
6 |
6 |
110 |
| 7 |
7 |
7 |
111 |
| 8 |
8 |
10 |
1000 |
| 9 |
9 |
11 |
1001 |
| 10 |
А |
12 |
1010 |
| 11 |
В |
13 |
L011 |
| 12 |
С |
14 |
1100 |
| 13 |
D |
15 |
1101 |
| 14 |
E |
16 |
1110 |
| 15 |
F |
17 |
1111 |
Преобразования чисел из двоичной в восьмеричную и шестнадцатиричную системы и наоборот столь просты (по сравнению с операциями между этими тремя системами и привычной нам десятичной) потому, что числа 8 и 16 являются целыми степенями числа 2.
Арифметические действия с числами в восьмеричной и шестнадцатиричной системах счисления выполняются по аналогии с двоичной и десятичной системами. Для этого необходимо воспользоваться соответствующими таблицами. Для примера табл. 1.7 иллюстрирует сложение и умножение восьмеричных чисел.
Есть еще способ перевода чисел из одной позиционной системы счисления в другую - метод вычитания степеней
. В этом случае из числа вычитается максимально допустимая степень, умноженная на максимально возможный коэффициент, меньший основания; этот коэффициент и является значащей цифрой числа в новой системе.
Например, число 114(10):
114 - 26 = 114 – 64 = 50,
50 - 25 = 50 – 32 = 18,
18 - 24 = 2,
2 - 21 = 0.
Таким образом, 114(10) = 1110010(2).
114 – 1 ∙ 82 = 114 – 64 = 50,
50 – 6 ∙ 81 = 50 – 48 = 2,
2 – 2 ∙ 8° = 2 – 2 = 0.
Итак, 114(10)= 162(8).
Таблица 1.7 Таблицы сложения и умножения в восьмеричной системе
Сложение
 Умножение Умножение
Производственная функция, издержки производства
Производственная функция
, также функция производства — экономико-математическая количественная зависимость между величинами выпуска (количество продукции) и факторами производства, (затраты ресурсов, уровень технологий и др.)
Агрегированная производственная функция может описывать объёмы выпуска народного хозяйства в целом.
В зависимости от анализа влияния факторов производства на объём выпуска в определённый момент времени или в разные промежутки времени производственные функции делятся на статические: P = f(x1,x2,...,xn) и динамические: P = f(x1(t),...,xk(t),...,xn).
Линейные

функция производства
— экономико-математическое уравнение, связывающее переменные величины затрат (ресурсов) с величинами продукции (выпуска).
Издержки производства
— затраты, связанные с производством и обращением произведенных товаров. В бухгалтерской и статистической отчетности отражаются в виде себестоимости. Включают в себя: материальные затраты, амортизационные отчисления, расходы на оплату труда, проценты за кредиты, расходы, связанные с продвижением товара на рынок и его продажей.
Количество товара, которое предприятие может предложить на рынке, зависит от уровня издержек (затрат) на его производство и цены, по которой товар будет продаваться на рынке.
Из этого следует, что знание издержек на производство и реализацию товара является одним из важнейших условий эффективного хозяйствования предприятия.
Издержки
- это денежное выражение затрат производственных факторов, необходимых для осуществления предприятием своей производственной и коммерческой деятельности.
Они могут быть представлены в показателях себестоимости продукции, характеризующей в денежном измерении все материальные затраты и затраты на оплату труда, которые необходимы для производства и реализации продукции.
Существует несколько классификаций издержек
1. Бухгалтерские издержки - это реальные расходы фирмы по приобретению сырья, необходимого оборудования; затраты на заработную плату рабочим и аренду помещения, территории и т.д.
2. Внутренние издержки представляют собой доход, который мог бы быть получен в результате более рационального использования имеющихся ресурсов. Очень часто фирма имеет в собственности и помещение, и землю, и собственный капитал. В этом случае фирма не имеет постоянных затрат на эти факторы производства, для нее они являются «бесплатными».
3. Экономические издержки включают бухгалтерские и внутренние. При принятии экономических решений должны учитываться все ресурсы, вовлеченные в процесс производства, и расходы по ним. Это способствует их более эффективному использованию.
4. Частные издержки представляют собой все расходы фирмы по оплате нужных ресурсов.
5. Общественные издержки оцениваются с точки зрения общества с учетом положительных и отрицательных внешних эффектов.
6. Возвратные издержки - это все расходы фирмы, которая
она способна вернуть после очередного производственного цикла или по окончании своего функционирования.
7. Невозвратные издержки не имеют альтернативного использования. Это единовременные затраты по регистрации предприятия, его страхованию, изготовлению вывески.
В зависимости от объема выпускаемой продукции фирмы в краткосрочном периоде издержки подразделяются на две большие группы:
1) постоянные издержки, которые не зависят от объема производства в релевантном периоде. Они включают арендную плату, оплату электроэнергии и оклад рабочих;
2) переменные издержки, которые зависят от количества произведенного продукта, так как идут на покупку сырья и рабочей силы.
Постоянные и переменные издержки в сумме дают общие валовые. По мере развития предприятия и роста производства меняются средние и предельные издержки. Средние издержки представляют собой расходы на единицу произведенного продукта, в то время как предельные зависят от каждой дополнительно созданной единицы. Заметим, что в долгосрочном периоде все издержки фирмы являются переменными.
Кодирование числовой, текстовой, графической и др. информации
Языки программирования высокого уровня.
Кодирование текстовой информации
Информация передается в виде сообщений.
Дискретная информация записывается в виде конечного набора знаков- букв. Буква- элемент некоторого конечного набора отличных друг от друга знаков. Множество знаков, в котором определен их порядок, - алфавитом.
Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом
. Саму процедуру преобразования сообщения называют перекодировкой
. Устройства, обеспечивающие кодирование и декодирование, называют кодировщиком и декодировщиком. На рис. 1.5 приведена схема, процесс передачи сообщения в случае перекодировки, и воздействия помех (см. следующий пункт).

Рис. 1.5. Процесс передачи сообщения от источника к приемнику
кодирования-декодирования следует пользоваться равномерными кодами, т.е. двоичными группами равной длины.
Системы «байтового» кодирования.
Наиболее распространены две такие системы: EBCDIC (Extended Binary Coded Decimal Interchange Code) и ASCII (American Standard Information Interchange).
Первая
- исторически тяготеет к «большим» машинам, вторая
чаще используется на мини- и микро-ЭВМ (включая персональные компьютеры).
ASCII, в 1963 г. это - система семибитного кодирования. Она ограничивалась одним алфавитом (английским), цифрами и набором различных символов. Примеры на клавиатуре компьютера: DEL - знак удаления символа.
В следующей версии фирма IBM перешла на 8-битную кодировку. В ней первые 128 символов совпадают с исходными и имеют коды со старшим битом равным нулю.
Одним из достоинств
этой системы кодировки русских букв является упорядочениеномера букв стоят как в русском алфавите.
Кодирование числовой информации
Сходство в кодировании числовой и текстовой информации состоит в следующем: чтобы можно было сравнивать данные этого типа, у разных чисел (как и у разных символов) должен быть различный код. Основное отличие числовых данных от символьных заключается в том, что над числами кроме операции сравнения производятся разнообразные математические операции: сложение, умножение, извлечение корня, вычисление логарифма и пр. Правила выполнения этих операций в математике подробно разработаны для чисел, представленных в позиционной системе счисления. Многовековая история развития математики показывает, что именно позиционный принцип позволяет использовать эти правила как универсальные алгоритмы, справедливые для системы счисления с любым основанием: 2,3, 8, 10, 16, 60 и пр.
Кодирование графической информации
Языки программирования
Исполнитель алгоритма
— это некоторая абстрактная или реальная система, способная выполнить действия, предписываемые алгоритмом. Исполнителя хаpактеpизуют:
сpеда;
элементаpные действия;
cистема команд;
отказы.
Сpеда
— это "место обитания" исполнителя.
Система команд
. Каждый исполнитель может выполнять команды только из некотоpого стpого заданного списка — системы команд исполнителя. Для каждой команды должны быть заданы условия пpименимости (в каких состояниях сpеды может быть выполнена команда) и описаны pезультаты выполнения команды. Напpимеp, команда Pобота "ввеpх" может быть выполнена, если выше Pобота нет стены. Ее pезультат — смещение Pобота на одну клетку ввеpх.
После вызова команды исполнитель совеpшает соответствующее элементаpное действие
.
Отказы
исполнителя возникают, если команда вызывается пpи недопустимом для нее состоянии сpеды. Обычно исполнитель ничего не знает о цели алгоpитма. Он выполняет все полученные команды, не задавая вопросов "почему" и "зачем".
В информатике универсальным исполнителем алгоритмов является компьютер.
При записи алгоритма в словесной форме, в виде блок-схемы или на псевдокоде допускается определенный произвол при изображении команд. Вместе с тем такая запись точна настолько, что позволяет человеку понять суть дела и исполнить алгоритм. Исполнителем алгоритма является компьютер, поэтому алгоритмы должны быть написаны на понятное ему язык. Язык для записи алгоритмов должен быть формализован.
Такой язык принято называть языком программирования,
а запись алгоритма на этом языке — программой для компьютера.
Любой алгоритм выполняется за конечное число шагов, переходим от исходных данных к конечному результату
. От степени детализации предписаний определяется уровень языка программирования — чем меньше детализация, тем выше уровень языка.
По этому критерию можно выделить следующие уровни языков программирования:
машинные;
машинно-оpиентиpованные (ассемблеpы);
машинно-независимые (языки высокого уровня).
Машинные языки и машинно-ориентированные языки
— это языки низкого уровня
, указать мекие детали обработки данных. Языки же высокого уровня
имитируют естественные языки, используют общепринятые математические символы и разговорный язык.
Языки высокого уровня делятся на:
процедурные (алгоритмические)
(Basic, Pascal, C
и др.), предназначены:
для однозначного описания алгоритмов;
для решения задачи процедурные языки требуют в той или иной форме явно записать процедуру ее решения;
логические
(Prolog, Lisp и др.), которые ориентированы на систематическое и формализованное описание задачи с тем, чтобы решение следовало из составленного описания;
объектно-ориентированные
(Object Pascal, C++, Java и др.), в основе лежит понятие объекта, сочетающего в себе данные и действия над нами.
Программа на объектно-ориентированном языке, решая некоторую задачу, по сути описывает часть мира, относящуюся к этой задаче.
Описание действительности в форме системы взаимодействующих объектов естественнее, чем в форме взаимодействующих процедур.
Основные преимущества алгоритмических языков перед машинными таковы:
алфавит алгоритмического языка значительно шире алфавита машинного языка, что существенно повышает наглядность текста программы;
набор операций, допустимых для использования, не зависит от набора машинных операций, а выбирается из соображений удобства формулирования алгоритмов решения задач определенного класса;
формат предложений достаточно гибок и удобен для использования, что позволяет с помощью одного предложения задать достаточно содержательный этап обра ботки данных;
требуемые операции задаются с помощью общепринятых математических обозначений;
данным в алгоритмических языках присваиваются индивидуальные имена, выбираемые программистом;
в языке может быть предусмотрен значительно более широкий набор типов данных по сравнению с набором машинных типов данных.
Алгоритмические языки в значительной мере являются машинно-независимыми, они облегчают работу программиста и повышают надежность создаваемых программ.
Алгоритмический язык (как и любой другой язык) образуют три его составляющие: алфавит, синтаксис и семантика.
Алфавит
— это фиксированный набор основных символов, из которых должен состоять любой текст на этом языке.
Синтаксис
— это правила построения фраз. Позволяет определить правильность написания фразы. Синтаксис языка представляет собой набор правил, устанавливающих, какие комбинации символов являются осмысленными предложениями на этом языке.
Семантика
-определяет смысловое значение предложений языка. Являясь системой правил истолкования отдельных языковых конструкций. Семантика устанавливает, какие последовательности действий описываются теми или иными фразами языка и, в конечном итоге, какой алгоритм определен данным текстом на алгоритмическом языке.
Каждое понятие алгоритмического языка подразумевает некоторую синтаксическую единицу (конструкцию) и определяемые ею свойства программных объектов или процесса обработки данных.
Понятие языка определяется во взаимодействии синтаксических и семантических правил. Синтаксические правила показывают, как образуется данное понятие из других понятий и букв алфавита, а семантические правила определяют свойства данного понятия
Основными понятиями в алгоритмических языках обычно являются следующие.
1. Имена
(идентификаторы) — употpебляются для обозначения объектов пpогpаммы (пеpеменных, массивов, функций и дp.).
2. Опеpации
. Типы операций:
аpифметические
опеpации +, —, *, / и дp.;
логические
опеpации и, или, не;
опеpации отношения
<, >, <=, >=, =, <>;
опеpация сцепки
(иначе, "присоединения", "конкатенации") символьных значений дpуг с другом с образованием одной длинной строки; изображается знаком "+".
3. Данные
— величины, обpабатываемые пpогpаммой.
Имеется тpи основных вида данных: константы, пеpеменные и массивы
.
Константы
— это данные, которые зафиксированы в тексте программы и не изменяются в процессе ее выполнения. Пpимеpы констант: -числовые
7.5, 12; -логические да
(истина), нет
(ложь); -символьные
(содержат ровно один символ) "А", "+"; -литеpные
(содержат произвольное количество символов) "a0", "Мир", "" (пустая строка).
Пеpеменные
обозначаются именами и могут изменять свои значения в ходе выполнения пpогpаммы. Пеpеменные бывают целые, вещественные, логические, символьные и литерные
.
Массивы — последовательности однотипных элементов, число которых фиксировано и которым присвоено одно имя.
Положение элемента в массиве однозначно определяется его индексами (одним, в случае одномерного массива, или несколькими, если массив многомерный). Иногда массивы называют таблицами.
4. Выpажения —
пpедназначаются для выполнения необходимых вычислений, состоят из констант, пеpеменных, указателей функций (напpимеp, exp(x)), объединенных знаками опеpаций.
Выражения записываются в виде линейных последовательностей символов
(без подстрочных и надстрочных символов, "многоэтажных" дробей и т.д.), что позволяет вводить их в компьютер, последовательно нажимая на соответствующие клавиши клавиатуры.
Различают выражения арифметические, логические и строковые.
Арифметические выражения
служат для определения одного числового значения. Например, (1+sin(x))/2. Значение этого выражения при x=0 равно 0.5, а при x=p/2 — единице.
Логические выражения
описывают некоторые условия, которые могут удовлетворяться или не удовлетворяться. Таким образом, логическое выражение может принимать только два значения — "истина"
или "ложь"
(да
или нет
). Рассмотрим в качестве примера логическое выражение x*x + y*y < r*r, определяющее принадлежность точки с координатами (x, y) внутренней области круга радиусом r c центром в начале координат. При x=1, y=1, r=2 значение этого выражения — "истина"
, а при x=2, y=2, r=1 — "ложь".
Cтроковые (литерные) выражения, значениями которых являются текcты
. В строковые выражения могут входить литерные и строковые константы, литерные и строковые переменные, литерные функции, разделенные знаками операции сцепки. Например, А + В означает присоединение строки В к концу строки А. Если А = "куст ", а В = "зеленый", то значение выражения А + В есть "куст зеленый".
5. Операторы
(команды). Оператор — это наиболее крупное и содержательное понятие языка: каждый оператор представляет собой законченную фразу языка и определяет вполне законченный этап обработки данных. В состав опеpатоpов входят:
ключевые слова;
данные;
выpажения и т.д.
Операторы подpазделяются на исполняемые и неисполняемые.
Неисполняемые
служат описания данных и стpуктуpы пpогpаммы, а исполняемые
— для выполнения pазличных действий (напpимеp, опеpатоp пpисваивания, опеpатоpы ввода и вывода, условный оператор).
При решении различных задач с помощью компьютера бывает необходимо вычислить логарифм или модуль числа, синус угла и т.д. Вычисления часто употребляемых функций осуществляются посредством подпрограмм, называемых стандартными функциями
, которые заранее запрограммированы и встроены в транслятор языка.
Примеры функций:
| Название и математическое обозначение функции |
Указатель функции |
| Абсолютная величина (модуль) |
| х | |
abs(x) |
| Корень квадратный |
 |
sqrt(x) |
| Синус (угол в радианах) |
sin x |
sin(x) |
| Косинус (угол в радианах) |
cos x |
cos(x) |
Каждый язык программирования имеет свой набор стандартных функций.
Арифметические выражения записываются по следующим правилам:
Нельзя опускать знак умножения между сомножителями и ставить рядом два знака операций.
Индексы элементов массивов записываются в квадратных (школьный АЯ, Pascal) или круглых (Basic) скобках.
Для обозначения переменных используются буквы латинского алфавита.
Операции выполняются в порядке старшинства
: сначала вычисление функций, затем возведение в степень, потом умножение и деление и в последнюю очередь — сложение и вычитание.
Операции одного старшинства выполняются слева направо
. Однако, в школьном АЯ есть одно исключение
из этого правила: операции возведения в степень выполняются справа налево. Так, выражение 2**(3**2) в школьном АЯ
вычисляется как 2**(3**2) = 512. В языке QBasic аналогичное выражение 2^3^2 вычисляется как (2^3)^2 = 64. А в языке Pascal
вообще не предусмотрена операция возведения в степень, в Pascal x^y записывается как exp(y*ln(x)), а x^y^z как exp(exp(z*ln(y))*ln(x)).
| Математическая запись |
Запись на школьном алгоритмическом языке |
 |
x * y / z |
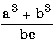 |
(a**3 + b**3) / (b*c) |
В записи логических выражений помимо арифметических операций
сложения, вычитания, умножения, деления и возведения в степень используются операции отношения
< (меньше), <= (меньше или равно), > (больше), >= (больше или равно), = (равно), <> (не равно), а также логические операции и, или, не.
| Условие |
Запись на школьном алгоритмическом языке |
| Целое число a — четное |
mod(a, 2) = 0 |
| Целое число a — нечетное |
mod(a, 2) = 1 |
| Каждое из чисел a, b положительно |
(a>0) и (b>0) |
| Только одно из чисел a, b положительно |
((a>0) и (b<=0)) или
((a<=0) и (b>0))
|
| Хотя бы одно из чисел a, b, c является отрицательным |
(a<0) или (b<0) или (c<0) |
| Число x удовлетворяет условию a < x < b |
(x>a) и (x<b) |
| Хотя бы одна из логических переменных F1 и F2 имеет значение да |
F1 или F2 |
| Обе логические переменые F1 и F2 имеют значение да |
F1 и F2 |
| Обе логические переменые F1 и F2 имеют значение нет |
не F1 и не F2 |
| Логическая переменная F1 имеет значение да, а логическая переменная F2 имеет значение нет |
F1 и не F2 |
| Только одна из логических переменных F1 и F2 имеет значение да |
(F1 и не F2) или (F2 и не F1) |
Алгоритм и его свойства, способы записи алгоритма; стандартные типы данных; представление основных структур: следование, ветвление, повторение
Алгоритмом
называется точная инструкция исполнителю, определяющая процесс достижения поставленной цели на основе имеющихся исходных данных за конечное число шагов.
Основными свойствами алгоритмов
являются:
Универсальность (массовость) - применимость алгоритма к различным наборам исходных данных.
Дискретность - процесс решения задачи по алгоритму разбит на отдельные действия.
Однозначность - правила и порядок выполнения действий алгоритма имеют единственное толкование.
Конечность - каждое из действий и весь алгоритм в целом обязательно завершаются.
Результативность - по завершении выполнения алгоритма обязательно получается конечный результат.
Выполнимость - результата алгоритма достигается за конечное число шагов.
Алгоритм считается правильным, если его выполнение дает правильный результат.
Выделяют три крупных класса алгоритмов
:
- вычислительные алгоритмы
, работают с простыми видами данных: числа и матрицы, хотя сам процесс вычисления может быть долгим и сложным;
- информационные алгоритмы
- набор простых процедур, работающих с большими объемами информации (алгоритмы баз данных);
- управляющие алгоритмы
, генерирующие различные управляющие воздействия на основе данных, полученных от внешних процессов, которыми алгоритмы управляют.
Виды алгоритмов:
Разветвляющийся алгоритм
- действия выполняются в зависимости от условия (можно ответить "да" или "нет"). Каждая такая последовательность действий называется ветвью алгоритма.
Линейный алгоритм
- действия следуют друг за другом.
Циклический алгоритм
-действия повторяются. Вложенным называется цикл, находящийся внутри тела другого цикла. Различают циклы с предусловием и послеусловием: Итерационным
называется цикл, число повторений определяется в ходе выполнения цикла. Одно повторение цикла называется итерацией
.
Разнообразие же алгоритмов определяется тем, что любой алгоритм распадается на части, фрагменты и каждый фрагмент представляет собой алгоритм одного из трех указанных видов.
Способы записи алгоритмов
Распространены следующие формы представления алгоритмов:
словесная
(запись на естественном языке);
графическая
(изображения из графических символов);
псевдокоды
(включающие в себя элементы языка программирования, и фразы естественного языка)
программная
(тексты на языках программирования).
Общепринятыми способами записи являются графическая запись с помощью блок-схем и символьная запись - алгоритмического языка.
Описание алгоритма
с помощью блок схем осуществляется рисованием последовательности геометрических фигур. Порядок действий указывается стрелками. Написание алгоритмов с помощью блок-схем регламентируется ГОСТом.
Cловесный способ
- описание последовательных этапов обработки данных. Алгоритм задается в произвольном изложении на естественном языке.
Словестный способ
не имеет широкого распространения, так как такие описания:
строго не формализуемы;
страдают многословностью записей;
допускают неоднозначность толкования отдельных предписаний.
Псевдокод
- система обозначений и правил предназначена для единообразной записи алгоритмов. Псевдокод
занимает промежуточное место между естественным и формальным языками. Алгоритмы могут на нем записываться и читаться как обычный текст. В псевдокоде не приняты строгие синтаксические правила для записи команд, что облегчает запись алгоритма на стадии его проектирования. В псевдокоде, есть служебные слова, смысл которых определен. Они выделяются в печатном тексте жирным шрифтом, а в рукописном тексте подчеркиваются.
Графически
алгоритм изображается в виде последовательности связанных между собой функциональных блоков, каждый из которых соответствует выполнению одного или нескольких действий (операторов). Такое графическое представление называется схемой алгоритма или блок-схемой.
В блок-схеме каждому типу действий соответствует геометрическая фигура, представленная в виде блочного символа. Эти символы соединяются линиями переходов, определяющими очередность выполнения действий.
В таблице приведены наиболее часто употребляемые символы.
| Название символа |
Обозначение и пример заполнения |
Пояснение |
| Процесс |
 |
Вычислительное действие или последовательность действий |
| Решение |
 |
Проверка условий |
| Модификация |
 |
Начало цикла |
| Предопределенный процесс |
 |
Вычисления по подпрограмме, стандартной подпрограмме |
| Ввод-вывод |
 |
Ввод-вывод в общем виде |
| Пуск-останов |
 |
Начало, конец алгоритма, Вход и выход в подпрограмму |
Стандартные типы данных;
Целочисленный тип - содержит числовые значения, целые числа. Числа упорядочены по возрастанию:..., -2, -1, 0, 1, 2, 3..
Логический тип - содержит всего 2 значения - True, False, которые тоже упорядочены: False, True (следует из соответствия False - 0, True - 1).
Символьный тип - символы кодовой таблицы. Поскольку каждому символу соответствует свой код, то символы расположены в порядке увеличения кода.
Из того, что перечисленных типы данных упорядочены, следует, что все значения образуют конечную последовательность.
Целочисленные типы.
позволяют хранить целые числа. Они хранят числа положительные или отрицательные, а некоторые хранят только положительные. Чем больше значений содержит тип, тем больше он памяти занимает. Рассмотрим целочисленные типы данных.
Сначала рассмотрим беззнаковые типы
- хранят только положительные числа и ноль:
Byte
- значения 0..255
- занимает в памяти 1
байт.
Word
- значения 0..65535
- 2
байта.
LongWord
- значения 0..4294967295
- 4
байта.
Теперь типы со знаком
(отрицательные "-" впереди, неотрицательные "+", так и без него):
ShortInt
- значения -128..127
- 1
байт.
SmallInt
- значения -32768..32767
- 2
байта.
LongInt
- значения -2147483648..2147483647
- 4
байта.
Int64
- значения -2^53..2^53-1
- 8
байт.
Рекомендуется использовать именно эти типы, т.к. компилятор создаёт более быстрый код:
Integer
- значения -2147483648..2147483647
- 4
байта.
Cardinal
- значения 0..4294967295
- 4
байта.
Целые числа представляются как в десятичной, так шестнадцатеричной системе счисления, $xxxxxxxx, где x - один из символов 0, 1,..E, F. Все цвета представляются в виде шестнадцатеричных чисел.
Логические типы.
Существуют следующие логические типы: Boolean
, принимает значение True и False, ByteBool, WordBool и LongBool
, Последние для обеспечения совместимости с другими языками и системами программирования. Используется только Boolean. Логическое значение в памяти занимает 1
байт.
Символьные типы.
Обеспечивают хранение отдельных символов. Основной тип данных - Char
, который содержит символы с кодами 0..255
. Существуют ещё типы AnsiChar
и WideChar
. Тип AnsiChar
эквивалентен типу Char
. Занимает в памяти 1
байт.
Для кодирования используется код ANSI
(American National Standards Institute). Тип WideChar
кодируется международным кодом Unicode
и занимает в памяти 2
байта. Таблица Unicode
включает символы практически всех языков мира.
Вещественные типы.
Для хранения вещественных- действительных чисел. Отличаются, числом цифр после запятой. Вот эти типы:
Real
(он же Double
) - значения от 5.0x10^-324
до 1.7x10^308
, точность - 15-16
цифр, занимает в памяти 8
байт.
Real48
- значения от 2.9x10^-39
до 1.7x10^38
, точность - 11-12
цифр, 6
байт памяти.
Single
- значения от 1.7x10^-45
до 3.4x10^38
, точность - 7-8
цифр, 4
байта.
Extended
- от 3.6x10^-4951
до 1.1x10^4932
, точность - 19-20
цифр, 10
байт памяти.
Comp
- от -2x10^63+1
до 2x10^63-1
, точность - 19-20
цифр, 8
байт.
Currency
- от -922337203685477.5808
до 922337203685477.5807
, точность - 19-20
цифр, в памяти занимает 8
байт.
Перед вещественными числами может стоять знак "+" или "-". Возможны 2 записи вещественных чисел - с фиксированной точкой и с плавающей.
С фиксированной точкой
целая и дробная части отделяются точкой или запятой.
С плавающей точкой
, запись которая отделяется от самого числа буквой "E". Например, запись 1.5e2 означает число 1.5 с порядком +2, т.е. это 1.5x10^2 = 150.
Типы Comp
и Currency
служат для точных денежных расчётов. Comp
, хранит целые числа, при задании чисел с дробной частью они преобразуются в целое число.
Интервальные типы данных.
(ограниченные) получаются из имеющихся типов путём ограничения диапазона значений. Интервал задаётся двумя константами - начальной и конечной границей
. При присвоении значения переменной выполняется проверка нового значения. Если значение не попадает в диапазон, выдаётся сообщение об ошибке. Ограниченный тип данных задается на основе простого упорядоченного типа. Значение правой границы должно быть больше значения левой границы.
Ограниченные типы данных также описывают в разделе type
, между константами-границами ставятся две точки.
Например, мы хотим в программе работать с датами. Можно создать ограниченные типы данных для значений дня, месяца и года
type
TDay = 1..31;
TMonth = 1..12;
TYear = 1900..2100;
Составные (структурированные) типы данных
Структуры данных хранят сразу несколько значений, некоторые не имеют ограничения на количество значений - редел определяется объёмом памяти.
Представление основных структур: следование, ветвление, повторение.
Алгоритмы можно представлять как некоторые структуры, состоящие из отдельных базовых элементов.
Логическая структура любого алгоритма может быть представлена комбинацией трех базовых структур: следование; ветвление; цикл.
Базовая структура Следование
Образуется из последовательности действий, следующих одно за другим:
|
 |
Базовая структура Ветвление.
Обеспечивает в зависимости от результата проверки условия (да или нет) выбор одного из альтернативных путей работы алгоритма.
Структура ветвление существует в четырех основных вариантах:
1. если - то

|
2. если - то - иначе

|
3. выбор

|
4. выбор - иначе

|
Базовая структура цикл.
Обеспечивает многократное выполнение некоторой совокупности действий, которая называется телом цикла.
Основные разновидности цикла:
Цикл пока

|
Цикл для.

|
Общее равновесие, эффективность и благосостояние
Общее равновесие -
это система взаимосвязанных цен, обеспечивающая одновременное равенство спроса и предложения на всех рынках. Общее экономическое равновесие - это такое состояние экономики, когда все рынки одновременно находятся в равновесии, а каждый субъект максимизирует свою целевую функцию.
Эффективность производства -
это такая ситуация, в которой при данных производственных ресурсах и существующем уровне знаний нельзя произвести больший объем одного блага, не жертвуя при этом возможностью производства некоторого объема другого блага. Понятие эффективности производства, как и более широкое понятие экономической эффективности, включает в себя избежание ущерба.
Эффективность производства достигается тогда, когда ресурсы распределяются таким образом, чтобы обеспечить максимально возможный чистый выигрыш от их применения. Эффективность производства выступает критерием успеха хозяйственной деятельности людей, применяющих ресурсы. Если достигнута эффективность производства, то никакое изменение методов производства или дальнейший обмен благами не приведет к дополнительному выигрышу.
В качестве инструмента в анализе производства и распределения ресурсов в экономике, которые отвечают критерию эффективности производства, используется диаграмма (ящик, коробка) Эджуорта.
Считается, что при данном предложении благ потребление является экономически эффективным, если уровень благосостояния одного лица можно улучшить только посредством понижения уровня благосостояния другого лица.
Считается, что при данном предложении ресурсов наблюдается эффективное их размещение, если невозможно увеличить выпуск одного блага, не сократив одновременно выпуск другого блага.
Благосостояние
— обеспечение населения государства, социальной группы или класса, семьи, отдельной личности необходимыми для жизни материальными, социальными и духовными благами. Б. находится в прямой зависимости от уровня развития производительных сил и характера экономических отношений. Чем выше уровень развития производительных сил, тем быстрее повышается Б. населения. В еще большей степени Б. связано с эффективностью социально-экономической политики в данном обществе.
Информатика как наука. Предмет и объект прикладной информатики. Системы счисления
Инфоpматика
— это основанная на использовании компьютерной техники дисциплина, изучающая структуру и общие свойства информации, а также закономерности и методы её создания, хранения, поиска, преобразования, передачи и применения в различных сферах человеческой деятельности.
Инфоpматика
— научная дисциплина с широчайшим диапазоном применения.
Её основные направления:
pазpаботка вычислительных систем и пpогpаммного обеспечения;
теоpия инфоpмации, изучающая процессы, связанные с передачей, приёмом, преобразованием и хранением информации;
методы искусственного интеллекта, позволяющие создавать программы для решения задач, требующих определённых интеллектуальных усилий при выполнении их человеком (логический вывод, обучение, понимание речи, визуальное восприятие, игры и др.);
системный анализ, заключающийся в анализе назначения проектируемой системы и в установлении требований, которым она должна отвечать;
методы машинной графики, анимации, средства мультимедиа;
средства телекоммуникации, в том числе, глобальные компьютерные сети, объединяющие всё человечество в единое информационное сообщество;
разнообразные пpиложения, охватывающие производство, науку, образование, медицину, торговлю, сельское хозяйство и все другие виды хозяйственной и общественной деятельности.
Термином информатика обозначают совокупность дисциплин, изучающих свойства информации, а также способы представления, накопления, обработки и передачи информации с помощью технических средств.
Информационная технология
есть совокупность конкретных технических и программных средств, с помощью которых мы выполняем разнообразные операции по обработке информации во всех сферах нашей жизни и деятельности.
Информатика является комплексной, междисциплинарной отраслью научного знания.

ПРЕДМЕТОМ ИНФОРМАТИКИ ЯВЛЯЕТСЯ ЗНАНИЕ.
ОБЪЕКТОМ ИНФОРМАТИКИ ЯВЛЯЕТСЯ СИСТЕМА ЧЕЛОВЕК-ВМ.
знание исторически
всегда подразумевает человека, а не ВМ. Этому можно возразить так: ВМ используется человеком и для человека непосредственно или в конечном счете. слова «мыслить», «думать» и «знать», примененные к ВМ, начинают применяться без кавычек: ВМ мыслит, ВМ думает и ВМ знает.
Системы счисления
Для записи информации о количестве объектов используются числа. Числа записываются с использованием особых знаковых систем, которые называются системами счисления
. Алфавит системы счисления состоит из символов, которые называются цифрами.
Система счисления
- это знаковая система, в которой числа записываются по определенным правилам с помощью символов некоторого алфавита, называемых цифрами.
Все системы счисления делятся на две большие группы: позиционные и непозиционные
.
В позиционных системах количественное значение цифры зависит от ее положения в числе, а в непозиционных — не зависит.
Непозиционные системы
счисления. Система записи чисел называется единичной
, так как любое число в ней образуется путем повторения одного знака, символизирующего единицу. Примером непозиционной системы: римская система счисления в её основе лежат знаки I (один палец) для числа 1, V (раскрытая ладонь) для числа 5, X (две сложенные ладони) для числа 10. При записи чисел в римской системе счисления есть правило: каждый меньший знак, поставленный слева от большего, вычитается из него, в остальных случаях знаки складываются. Недостатком непозиционных систем, является отсутствие арифметических действий над ними.
Позиционные системы счисления.
Для записи чисел используется отличных друг от друга знаки. Число таких знаков называется основанием системы счисления.
Пример некоторых позиционных систем: двоичная, троичная, четверичная, пятеричная, восьмеричная, десятичная, двенадцатеричная (0,1,2,3,4,5,б,7,8,9,А,В), шестнадцатеричная (0,1,2,3,4,5,6,7,8,9,A.B,D,E,F)
В позиционной системе счисления, число может быть представлено в виде суммы произведений коэффициентов на степени основания системы счисления:
AnAn-1An-2 … A1,A0,A-1,A-2 =
АnВn + An-1Bn-1 +... + A1B1 + А0В0 + A-1B-1 + А-2В-2 +...
(знак «точка» отделяет целую часть числа от дробной; знак «звездочка» здесь и ниже используется для обозначения операции умножения). Таким образом, значение каждого знака в числе зависит от позиции, которую занимает знак в записи числа. Именно поэтому такие системы счисления называют позиционными. Примеры (десятичный индекс внизу указывает основание системы счисления): 23,43(10) = 2*101 + З*10° + 4*10-1 + З*10-2
(в данном примере знак «З» в первом случае число единиц, а в другом - число сотых долей единицы);
692(10) = 6* 102 + 9*101 + 2.
(«Шестьсот девяносто два» с формальной точки зрения представляется в виде «шесть умножить на десять в степени два, плюс девять умножить на десять в степени один, плюс два»).
1101(2)= 1*23 + 1*22+0*21+ 1*2°;
A1F4(16) = A*162 + 1*161 + F*16° + 4*16-1.
При работе с компьютерами используется несколько позиционных систем счисления, большое значение имеют перевод чисел из одной системы счисления в другую. Р
езультат является десятичным числом.
Двоичная система счисления
В двоичной системе внутреннее представление информации является двоичным, т.е. описываемым наборами только из двух знаков (0 и 1).
Целая и дробная части переводятся порознь. Для перевода просто целого числа необходимо разделить ее на основание системы счисления и продолжать делить частные от деления до тех пор, пока частное не станет равным 0. Получившиеся остатки, взятые в обратной последовательности, образуют двоичное число. Например:
Остаток
25: 2 = 12 (1),
12: 2 = 6 (0),
6: 2 = 3 (0),
3: 2 = 1 (1),
1: 2 = 0 (1).
Таким образом 25(10)=11001(2).
Для перевода дробной части (или числа, у которого «0» целых) надо умножить ее на 2. Целая часть произведения будет первой цифрой числа в двоичной системе. Затем, отбрасывая у результата целую часть, вновь умножаем на 2 и т.д.
Заметим, что конечная десятичная дробь при этом вполне может стать бесконечной {периодической) двоичной. Например:
0,73 • 2 = 1,46 (целая часть 1),
0,46 • 2 = 0,92 (целая часть 0),
0,92 • 2 = 1,84 (целая часть 1),
0,84 • 2 = 1,68 (целая часть 1) и т.д.
В итоге 0,73(10) =0,1011...(2).
Над числами, записанными в любой системе счисления, можно; производить различные арифметические операции. Так, для сложения и умножения двоичных чисел необходимо использовать табл. 1.5.
Таблица 1.5. Таблицы сложения и умножения в двоичной системе

Заметим, что при двоичном сложении 1 + 1 возникает перенос единицы в старший разряд - точь-в-точь как в десятичной арифметике:
Восьмеричная и шестнадцатеричная системы счисления
Перевод чисел из десятичной системы счисления в восьмеричную производится с помощью делений и умножений на 8. Например, переведем число 58,32(10):
58: 8 = 7 (2 в остатке),
7: 8 = 0 (7 в остатке).
0,32 • 8 = 2,56,
0,56 • 8 = 4,48,
0,48-8=3,84,...
Таким образом, 58,32(10) =72,243... (8)
Для перевода целого двоичного числа в восьмеричное необходимо разбить его справа налево на группы по 3 цифры (самая левая группа может содержать менее трех двоичных цифр), а затем каждой группе поставить в соответствие ее восьмеричный эквивалент. Например:
11011001= 11011001, т.е. 11011001(2) =331(8).
Заметим, что группу из трех двоичных цифр часто называют «двоичной триадой».
Перевод целого двоичного числа в шестнадцатеричное производится путем разбиения данного числа на группы по 4 цифры - «двоичные тетрады»:
1100011011001 = 1 1000 1101 1001, т.е. 1100011011001(2)= 18D9(16).
Для перевода дробных частей двоичных чисел в восьмеричную или шестнадцатиричную системы аналогичное разбиение на триады или тетрады производится от точки вправо (с дополнением недостающих последних цифр нулями):
0,1100011101(2) =0,110 001 110 100 = 0,6164(8),
0,1100011101(2) = 0,1100 0111 0100 = 0,C74(16).
Перевод восьмеричных (шестнадцатиричных) чисел в двоичные производится обратным путем - сопоставлением каждому знаку числа соответствующей тройки (четверки) двоичных цифр.
Таблица 1.6 Соответствие чисел в различных системах счисления
| Десятичная |
Шестн-чная |
Восьмеричная |
Двоичная |
| 0 |
0 |
0 |
0 |
| 1 |
1 |
1 |
1 |
| 2 |
2 |
2 |
10 |
| 3 |
3 |
3 |
11 |
| 4 |
4 |
4 |
100 |
| 5 |
5 |
5 |
101 |
| 6 |
6 |
6 |
110 |
| 7 |
7 |
7 |
111 |
| 8 |
8 |
10 |
1000 |
| 9 |
9 |
11 |
1001 |
| 10 |
А |
12 |
1010 |
| 11 |
В |
13 |
L011 |
| 12 |
С |
14 |
1100 |
| 13 |
D |
15 |
1101 |
| 14 |
E |
16 |
1110 |
| 15 |
F |
17 |
1111 |
Преобразования чисел из двоичной в восьмеричную и шестнадцатиричную системы и наоборот столь просты (по сравнению с операциями между этими тремя системами и привычной нам десятичной) потому, что числа 8 и 16 являются целыми степенями числа 2.
Арифметические действия с числами в восьмеричной и шестнадцатиричной системах счисления выполняются по аналогии с двоичной и десятичной системами. Для этого необходимо воспользоваться соответствующими таблицами. Для примера табл. 1.7 иллюстрирует сложение и умножение восьмеричных чисел.
Есть еще способ перевода чисел из одной позиционной системы счисления в другую - метод вычитания степеней
. В этом случае из числа вычитается максимально допустимая степень, умноженная на максимально возможный коэффициент, меньший основания; этот коэффициент и является значащей цифрой числа в новой системе.
Например, число 114(10):
114 - 26 = 114 – 64 = 50,
50 - 25 = 50 – 32 = 18,
18 - 24 = 2,
2 - 21 = 0.
Таким образом, 114(10) = 1110010(2).
114 – 1 ∙ 82 = 114 – 64 = 50,
50 – 6 ∙ 81 = 50 – 48 = 2,
2 – 2 ∙ 8° = 2 – 2 = 0.
Итак, 114(10)= 162(8).
Таблица 1.7 Таблицы сложения и умножения в восьмеричной системе
Сложение
Умножение
Производственная функция, издержки производства
Производственная функция
, также функция производства — экономико-математическая количественная зависимость между величинами выпуска (количество продукции) и факторами производства, (затраты ресурсов, уровень технологий и др.)
Агрегированная производственная функция может описывать объёмы выпуска народного хозяйства в целом.
В зависимости от анализа влияния факторов производства на объём выпуска в определённый момент времени или в разные промежутки времени производственные функции делятся на статические: P = f(x1,x2,...,xn) и динамические: P = f(x1(t),...,xk(t),...,xn).
Линейные
функция производства
— экономико-математическое уравнение, связывающее переменные величины затрат (ресурсов) с величинами продукции (выпуска).
Издержки производства
— затраты, связанные с производством и обращением произведенных товаров. В бухгалтерской и статистической отчетности отражаются в виде себестоимости. Включают в себя: материальные затраты, амортизационные отчисления, расходы на оплату труда, проценты за кредиты, расходы, связанные с продвижением товара на рынок и его продажей.
Количество товара, которое предприятие может предложить на рынке, зависит от уровня издержек (затрат) на его производство и цены, по которой товар будет продаваться на рынке.
Из этого следует, что знание издержек на производство и реализацию товара является одним из важнейших условий эффективного хозяйствования предприятия.
Издержки
- это денежное выражение затрат производственных факторов, необходимых для осуществления предприятием своей производственной и коммерческой деятельности.
Они могут быть представлены в показателях себестоимости продукции, характеризующей в денежном измерении все материальные затраты и затраты на оплату труда, которые необходимы для производства и реализации продукции.
Существует несколько классификаций издержек.
1. Бухгалтерские издержки - это реальные расходы фирмы по приобретению сырья, необходимого оборудования; затраты на заработную плату рабочим и аренду помещения, территории и т.д.
2. Внутренние издержки представляют собой доход, который мог бы быть получен в результате более рационального использования имеющихся ресурсов. Очень часто фирма имеет в собственности и помещение, и землю, и собственный капитал. В этом случае фирма не имеет постоянных затрат на эти факторы производства, для нее они являются «бесплатными».
3. Экономические издержки включают бухгалтерские и внутренние. При принятии экономических решений должны учитываться все ресурсы, вовлеченные в процесс производства, и расходы по ним. Это способствует их более эффективному использованию.
4. Частные издержки представляют собой все расходы фирмы по оплате нужных ресурсов.
5. Общественные издержки оцениваются с точки зрения общества с учетом положительных и отрицательных внешних эффектов.
6. Возвратные издержки - это все расходы фирмы, которая
она способна вернуть после очередного производственного цикла или по окончании своего функционирования.
7. Невозвратные издержки не имеют альтернативного использования. Это единовременные затраты по регистрации предприятия, его страхованию, изготовлению вывески.
В зависимости от объема выпускаемой продукции фирмы в краткосрочном периоде издержки подразделяются на две большие группы:
1) постоянные издержки, которые не зависят от объема производства в релевантном периоде. Они включают арендную плату, оплату электроэнергии и оклад рабочих;
2) переменные издержки, которые зависят от количества произведенного продукта, так как идут на покупку сырья и рабочей силы.
Постоянные и переменные издержки в сумме дают общие валовые. По мере развития предприятия и роста производства меняются средние и предельные издержки. Средние издержки представляют собой расходы на единицу произведенного продукта, в то время как предельные зависят от каждой дополнительно созданной единицы. Заметим, что в долгосрочном периоде все издержки фирмы являются переменными.
Процедуры, функции; записи; файлы. Программирование рекурсивных алгоритмов
Подпрограмма
представляет собой набор операторов, команд, оформленных специальным образом.
Типы подпрограмм.
Все подпрограммы делятся на процедуры и функции. Функция - это подпрограмма, результатом работы которой является какое-либо значение (одно единственное). Это позволяет использовать функции как обычные переменные, т.е. как операнды в выражениях. Просто значения будут вычисляться "на лету". Процедуры - это подпрограммы, которые не возвращают никакого значения в результате своей работы. Тем не менее, процедуры могут использоваться для передачи в основную программу каких-либо данных, причём передаваться может не одно значение, а несколько. Но в общем и целом процедуру следует понимать просто как ярлычок на выполнение указанных действий.
Описание процедуры начинается
с заголовка, который является обязательным. Заголовок состоит из служебного слова Procedure, за которым следует имя процедуры и, в круглых скобках, список формальных параметров. В конце заголовка ставиться точка с запятой. После заголовка могут идти те же разделы, что и в программе.
Общий вид описания процедуры:
Procedure Имя [Список формальных параметров];
Описательная часть
Begin
Тело процедуры
End;
При вызове процедуры ее формальные параметры заменяются соответствующими фактическими.
Фактические параметры – это параметры, которые передаются процедуре при ее вызове.
Количество и типы формальных и фактических параметров должны в точности совпадать.
Формальные параметры описываются в заголовке процедуры и определяют тип и место подстановки фактических параметров. Формальные параметры делятся на 2 вида: параметры-переменные и параметры-значения.
Параметры переменные отличаются тем, что перед ними стоит служебное слово Var. Они используются тогда, когда необходимо, чтобы изменения в теле процедуры значений формальных параметров приводили к изменению соответствующих фактических параметров.
Параметры-значения отличаются тем, что перед ними слово Var не ставится. Внутри процедуры можно производить любые действия с параметрами-значениями, но все изменения никак не отражаются на значениях соответствующих фактических параметров, то есть какими они были до вызова процедуры, такими же и останутся после завершения ее работы.
Все переменные программы делятся на глобальные и локальные. Глобальные переменные объявляются в разделе описаний основной программы. Локальные переменные объявляются в процедурах и функциях.
Таким образом, локальные переменные «живут» только во время работы подпрограммы.
Функции
Заголовок функции состоит из слова Function, за которым указывается имя функции, затем в круглых скобках записывается список формальных параметров, далее ставиться двоеточие и указывается тип результата функции.
В теле функции обязательно должен быть хотя бы один оператор присваивания, в левой части которого стоит имя функции, а в правой – ее значение. Иначе значение функции не будет определено.
Таким образом общий вид описания функции следующий:
Function Имя [Список формальных параметров]:
Тип результата;
Описательная часть
Begin
Тело функции, в котором обязательно должно быть присваивание
Имя функции:=значение
Запись
представляет собой совокупность ограниченного числа логически связанных компонент, принадлежащих к разным типам. Компоненты записи называются полями, каждое из которых определяется именем. Поле записи содержит имя поля, вслед за которым через двоеточие указывается тип этого поля. Поля записи могут относиться к любому типу, допустимому в языке Паскаль, за исключением файлового типа.
Описание записи в языке Паскаль осуществляется с помощью служебного слова record, вслед за которым описываются компоненты записи. Завершается описание записи служебным словом end.
Например, телефонный справочник содержит фамилии и номера телефонов, поэтому отдельную строку в таком справочнике удобно представить в виде следующей записи:
type TRec = Record
FIO: String[20];
TEL: String[7]
end;
var rec: TRec;
Описание записей возможно и без использования имени типа, например:
var rec: Record
FIO: String[20];
TEL: String[7]
end;
Обращение к записи в целом допускается только в операторах присваивания, где слева и справа от знака присваивания используются имена записей одинакового типа. Во всех остальных случаях оперируют отдельными полями записей. Чтобы обратиться к отдельной компоненте записи, необходимо задать имя записи и через точку указать имя нужного поля, например:
rec.FIO, rec.TEL
Такое имя называется составным
. Компонентой записи может быть также запись, в таком случае составное имя будет содержать не два, а большее количество имен.
Обращение к компонентам записей можно упростить, если воспользоваться оператором присоединения with.
Он позволяет заменить составные имена, характеризующие каждое поле, просто на имена полей, а имя записи определить в операторе присоединения:
with rec do оператор;
Здесь rec - имя записи, оператор - оператор, простой или составной. Оператор представляет собой область действия оператора присоединения, в пределах которой можно не использовать составные имена. Например для нашего случая:
with rec do begin
FIO:='Иванов А.А.';
TEL:='2223322';
end;
Такая алгоритмическая конструкция полностью идентична следующей:
rec.FIO:='Иванов А.А.';
rec.TEL:='2223322';
Инициализация записей может производиться с помощью типизированных констант:
type
RecType = Record
x,y: Word;
ch: Char;
dim: Array[1..3] of Byte
end;
const
Rec: RecType = (x: 127;
y: 255;
ch: 'A';
dim: (2, 4, 8));
Особой разновидностью записей являются записи с вариантами, которые объявляются с использованием зарезервированного слова case. С помощью записей с вариантами вы можете одновременно сохранять различные структуры данных, которые имеют большую общую часть, одинаковую во все структурах, и некоторые небольшие отличающиеся части.
Например, сконструируем запись, в которой мы будем хранить данные о некоторой геометрической фигуре (отрезок, треугольник, окружность).
ype
TFigure = record
type_of_figure: string[10];
color_of_figure: byte;
...
case integer of
1: (x1,y1,x2,y2: integer);
2: (a1,a2,b1,b2,c1,c2: integer);
3: (x,y: integer; radius: word);
end;
var figure: TFigure;
Таким образом, в переменной figure мы можем хранить данные как об отрезке, так и о треугольнике или окружности. Надо лишь в зависимости от типа фигуры обращаться к соответствующим полям записи.
Заметим, что индивидуальные поля для каждого из типов фигур занимают тем не менее одно адресное пространство памяти, а это означает, что одновременное их использование невозможно.
В любой записи может быть только одна вариантная часть. После окончания вариантной части в записи не могут появляться никакие другие поля. Имена полей должны быть уникальными в пределах той записи, где они объявлены.
Введение файлового типа
в язык Паскаль вызвано необходимостью обеспечить возможность работы с периферийными (внешними) устройствами ЭВМ, предназначенными для ввода, вывода и хранения данных.
Файловый тип данных или файл определяет упорядоченную совокупность произвольного числа однотипных компонент.
Понятие файла достаточно широко. Это может быть обычный файл на диске, коммуникационный порт ЭВМ, устройство печати, клавиатура или другие устройства.
При работе с файлами выполняются операции ввода - вывода. Операция ввода означает перепись данных с внешнего устройства (из входного файла) в основную память ЭВМ, операция вывода - это пересылка данных из основной памяти на внешнее устройство (в выходной файл).
Файлы на внешних устройствах часто называют физическими файлами. Их имена определяются операционной системой. В программах на языке Паскаль имена файлов задаются с помощью строк. Например, имя файла на диске может иметь вид:
'LAB1.DAT'
'c:\ABC150\pr.txt'
'my_files'
Турбо Паскаль поддерживает три файловых типа:
текстовые файлы;
типизированные файлы;
нетипизированные файлы.
Доступ к файлу в программе происходит с помощью переменных файлового типа. Переменную файлового типа описывают одним из трех способов:
file of тип - типизированный файл (указан тип компоненты);
text - текстовый файл;
file - нетипизированный файл.
Примеры описания файловых переменных:
var
f1: file of char;
f2: file of integer;
f3: file;
t: text;
Стандартные процедуры и функции файлов:
- Любые дисковые файлы становятся доступными программе после связывания их с файловой переменной, объявленной в программе. Все операции в программе производятся только с помощью связанной с ним файловой переменной.
Assign(f, FileName)
связывает файловую переменную f с физическим файлом, полное имя которого задано в строке FileName. Установленная связь будет действовать до конца работы программы, или до тех пор, пока не будет сделано переназначение.
После связи файловой переменной с дисковым именем файла в программе нужно указать направление передачи данных (открыть файл). В зависимости от этого направления говорят о чтении из файла или записи в файл.
- Reset(f)
открывает для чтения файл, с которым связана файловая переменная f. После успешного выполнения процедуры Reset файл готов к чтению из него первого элемента. Процедура завершается с сообщением об ошибке, если указанный файл не найден.
Если f - типизированный файл, то процедурой reset он открывается для чтения и записи одновременно.
- Rewrite(f)
открывает для записи файл, с которым связана файловая переменная f. После успешного выполнения этой процедуры файл готов к записи в него первого элемента. Если указанный файл уже существовал, то все данные из него уничтожаются.
- Close(f)
закрывает открытый до этого файл с файловой переменной f. Вызов процедуры Close необходим при завершении работы с файлом. Если по какой-то причине процедура Close не будет выполнена, файл все-же будет создан на внешнем устройстве, но содержимое последнего буфера в него не будет перенесено.
- EOF(f): boolean
возвращает значение TRUE, когда при чтении достигнут конец файла. Это означает, что уже прочитан последний элемент в файле или файл после открытия оказался пуст.
- Rename(f, NewName)
позволяет переименовать физический файл на диске, связанный с файловой переменной f. Переименование возможно после закрытия файла.
- Erase(f)
уничтожает физический файл на диске, который был связан с файловой переменной f. Файл к моменту вызова процедуры Erase должен быть закрыт.
- IOResult
возвращает целое число, соответствующее коду последней ошибки ввода - вывода. При нормальном завершении операции функция вернет значение 0. Значение функции IOResult необходимо присваивать какой-либо переменной, так как при каждом вызове функция обнуляет свое значение. Функция IOResult работает только при выключенном режиме проверок ошибок ввода - вывода или с ключом компиляции {$I-}.
Типизированный файл - это последовательность компонент любого заданного типа (кроме типа "файл"). Доступ к компонентам файла осуществляется по их порядковым номерам. Компоненты нумеруются, начиная с 0. После открытия файла указатель (номер текущей компоненты) стоит в его начале на нулевом компоненте. После каждого чтения или записи указатель сдвигается к следующему компоненту.
Текстовый файл - это совокупность строк, разделенных метками конца строки. Сам файл заканчивается меткой конца файла. Доступ к каждой строке возможен лишь последовательно, начиная с первой. Одновременная запись и чтение запрещены.
Нетипизированные файлы - это последовательность компонент произвольного типа.
Понятие множества
в языке Паскаль основывается на математическом представлении о конечных множествах: это ограниченная совокупность различных элементов. Для построения конкретного множественного типа используется перечисляемый или интервальный тип данных. Тип элементов, составляющих множество, называется базовым типом.
Множественный тип описывается с помощью служебных слов Set of, например:
type M = Set of B;
Здесь М - множественный тип, В - базовый тип.
Пример описания переменной множественного типа:
type
M = Set of 'A'..'D';
var
MS: M;
Принадлежность переменных к множественному типу может быть определена прямо в разделе описания переменных:
var C: Set of 0..7;
Константы множественного типа записываются в виде заключенной в квадратные скобки последовательности элементов или интервалов базового типа, разделенных запятыми, например:
['A', 'C'] [0, 2, 7] [3, 7, 11..14]
Константа вида [ ] означает пустое подмножество. Количество базовых элементов не должно превышать 256. Инициализация величин множественного типа может производиться с помощью типизированных констант:
const seLit: Set of 'A'..'D'= [];
Порядок перечисления элементов базового типа в константах безразличен.
Значение переменной множественного типа может быть задано конструкцией вида [T], где T - переменная базового типа. Например, вполне допустима конструкция:
type T = set of char;
Множество включает в себя набор элементов базового типа, все подмножества данного множества, а также пустое подмножество. Так, переменная Т множественного типа
var T: Set of 1..3;
может принимать восемь различных значений:
[ ] [1] [2] [3] [1,2] [1,3] [2,3] [1,2,3]
К переменным и константам множественного типа применимы операции присваивания(:=), объединения(+), пересечения(*) и вычитания(-):
['A','B'] + ['A','D'] даст ['A','B','D']
['A','D'] * ['A','B','C'] даст ['A']
['A','B','C'] - ['A','B'] даст ['C'].
Результат выполнения этих операций есть величина множественного типа.
К множественным величинам применимы операции: тождественность (=), нетождественность (<>), содержится в (<=), содержит (>=). Результат выполнения этих операций имеет логический тип, например:
['A','B'] = ['A','C'] даст FALSE
['A','B'] <> ['A','C'] даст TRUE
['B'] <= ['B','C'] даст TRUE
['C','D'] >= ['A'] даст FALSE.
Кроме этих операций для работы с величинами множественного типа в языке ПАСКАЛЬ используется операция in, проверяющая принадлежность элемента базового типа, стоящего слева от знака операции, множеству, стоящему справа от знака операции. Результат выполнения этой операции - булевский. Операция проверки принадлежности элемента множеству часто используется вместо операций отношения, например:
'A' in ['A', 'B'] даст TRUE,
2 in [1, 3, 6] даст FALSE.
Рекурсия — метод
определения класса объектов или методов предварительным заданием одного или нескольких (обычно простых) его базовых случаев или методов, а затем заданием на их основе правила построения определяемого класса.
Другими словами, рекурсия — частичное определение объекта через себя, определение объекта с использованием ранее определённых. Рекурсия используется, когда можно выделить самоподобие задачи.
В программировании рекурсия — вызов функции или процедуры из неё же самой (обычно с другими значениями входных параметров), непосредственно или через другие функции (например, функция А вызывает функцию B, а функция B — функцию A). Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
Мощь рекурсивного определения объекта в том, что такое конечное определение способно описывать бесконечно большое число объектов. С помощью рекурсивной программы же возможно описать бесконечное вычисление, причём без явных повторений частей программы.
Имеется специальный тип рекурсии, называемый «хвостовой рекурсией». Интерпретаторы и компиляторы функциональных языков программирования, поддерживающие оптимизацию кода (исходного и/или исполняемого), выполняют хвостовую рекурсию в ограниченном объёме памяти при помощи итераций.
Следует избегать избыточной глубины рекурсии, так как это может вызвать переполнение стека вызовов.
Если процедура или функция в ходе выполнения вызывает саму себя, то мы имеем дело с рекурсией. Такой вызов процедур или функций может возникнуть либо вследствие рекурсивного описания, либо вследствие рекурсивного обращения. Рекурсивное описание предполагает, что в исполняемой части блока процедуры или функции присутствует обращение к ней самой. Примером рекурсивного описания может служить функция вычисления факториала:
Function Factorial (N: Integer): Integer;
Begin
if N = 1 Then Factorial:= 1
Else Factorial:= N*Factorial(N -1)
End;
Здесь Factorial(N) определяется через значение Factorial(N-1), которое определяется через Factorial(N-2), и т.д. до сведения к значению Factorial(0), которое определено явно и равно 1. Любое рекурсивное описание должно содержать явное определение для некоторых значений аргумента (или аргументов), так как иначе процесс сведения оказался бы бесконечным. Таким образом при рекурсивном описании необходимо наличие базовой части описания, которая обеспечивала бы завершение рекурсивных вызовов функции (процедуры).
Рекурсивное обращение можно рассмотреть на примере вычисления определенного двойного интеграла по формуле трапеций. Точность этого приближения тем выше, чем больше число участков разбиения n. Увеличивая число n, можно достигнуть заданной точности. Если, допустим, функция TRAP вычисляет интеграл по методу трапеций при заданном числе интервалов N и А, В - пределы интегрирования, а FN - функция вычисления подынтегрального выражения, вычисление двойного интеграла можно осуществить с помощью следующего рекурсивного обращения к функции TRAP: J:= TRAP (N1, A1, B1, TRAP (N2, A2, B2, FN));
Ниже приведена рекурсивная функция, предназначенная для вычисления наибольшего общего делителя двух целых чисел N1 и N2.
Пример.
Function HighFactor(N1,N2:lnteger):lnteger;
Var P: Integer;
Begin
lf N1 > N2 Then P:=HighFactor(N1,N2)
Else
If N2<=0 Then p:= N1 {нерекурсивное решение}
Else P:=HighFactor(N2,N1 Mod N2);
HighFactor:= P
End;
Для того чтобы выполнение рекурсивной программы завершалось, необходимо существование в наиболее простых случаях нерекурсивного решения. В противном случае не исключено зацикливание.
Некоторые алгоритмы гораздо проще описать, используя рекурсию, нежели итерацию. Это относится в первую очередь к алгоритмам, работающим с разного рода списковыми структурами.
Использование рекурсивных процедур и функций делает программу в целом более гибкой и наглядной, но не всегда эффективной, так как работает такая программа, как правило, медленнее и требуют больше памяти. Дело в том, что при каждом вызове рекурсивной процедуры или функции отводится память под локальные переменные.
При сравнении итерационных методов решения и методов, использующих рекурсию, часто эффективными оказываются первые. Таким образом, рекурсию следует применять только там, где нет очевидного итерационного решения. Уровень вложенности рекурсий может быть ограничен в конкретных реализациях языка.
Различают прямую и косвенную рекурсию. Функция HighFactor является характерным примером прямой рекурсии. Косвенная рекурсия возникает тогда, когда один блок вызывает второй, а второй, в свою очередь, первый.
Динамические структуры данных; списки: основные виды и способы реализации. Технологии программирования
Способы конструирования программ
Динамические структуры данных
– сложные, организованные определенным образом данные, которые могут менять размер и/или свою структуру во время работы программы. Т
Типичными динамическими структурами являются массивы, стеки, очереди, списки, деревья. Универсальными способами организации таких структур является использование указателей.
Указатели
– переменные, содержащие не сами данные, а адреса памяти.
Стек
– линейная динамическая структура, у которой в каждый момент времени доступным является последний ее элемент. Стеки упорядочены, неоднородны (элементы стэка могут относиться к разным типам).
Previous
– указатель на тип элемента stack
Массивы
– последовательность упорядоченных, индексированных значений одного типа.
Количество элементов динамических массивов можно изменять во время работы.
| Stack Item |
Queue Item |
List Item |
| Data |
Data |
Data |
| Previous |
Next |
Pointes |
Описание динам. массива
: TypeName = Array of BaseType
Очередь – линейная динамическая структура. Отличается от стэка тем, что при добавлении элемент помещается в конец очереди.
Список
– линейная динамическая структура связанных элементов.
Для списка определены следующие операции:
Вставка элемента в список;
Удаление элемента из списка;
Перемещение элемента по списку;
Извлечение данных элемента списка;
Поиск элемента и сортировка (дополнительно).
Pointes
– указатели для перемещения по списку.
Если каждый элемент имеет указатель на один соседний элемент, то список однонаправленный. Перемещение производится в одну сторону. Если на 2 элемента, то двунаправленный.
Списки представляют собой структуру последовательного доступа, так как в каждый момент времени доступен только текущий элемент. Для доступа к остальным необходимо последовательное перемещение по списку с помощью указателей на соседний элемент.
Для реализации двунаправленного списка элемент должен содержать данные data
и указатели previous и next
на предыдущий и последующий элемент соответственно. Перемещение по списку осуществляется простыми перемещениями указателя Current
на предыдущий и последующий элемент.
В языках программирования (Pascal, C, др.) существует и другой способ выделения памяти под данные, который называется динамическим
. В этом случае память под величины отводится во время выполнения программы. Такие величины будем называть динамическими
. Раздел оперативной памяти, распределяемый статически, называется статической памятью
; динамически распределяемый раздел памяти называется динамической памятью (динамически распределяемой памятью)
.
Использование динамических величин предоставляет программисту ряд дополнительных возможностей. Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных. Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. В-третьих, использование динамической памяти позволяет создавать структуры данных переменного размера.
Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа
. Величины, имеющие ссылочный тип, называют указателями
.
Указатель
содержит адрес поля в динамической памяти, хранящего величину определенного типа. Сам указатель располагается в статической памяти.
Адрес величины
— это номер первого байта поля памяти, в котором располагается величина. Размер поля однозначно определяется типом.
Далее будем более подробно обсуждать указатели и действия с ними в языке Pascal.
В версиях Турбо-Паскаля, работающих под операционной системой MS DOS, под данные одной программы выделяется 64 килобайта памяти (или, если быть точнее, 65520 байт). Это и есть статическая область памяти. При необходимости работать с большими массивами информации этого может оказаться мало. Размер динамической памяти — много больше (сотни килобайт). Поэтому использование динамической памяти позволяет существенно увеличить объем обрабатываемой информации.
Следует отчетливо понимать, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему — величина. Как это часто бывает, действует "закон сохранения неприятностей": выигрыш в памяти компенсируется проигрышем во времени.
Технология программирования
- это совокупность методов и средств разработки (написания) программ и порядок применения этих методов и средств. Основные походы:
Операциональный подход
. В эпоху ЭВМ 1 - го и 2-го поколений основным требованием к алгоритму была его узко понимаемая эффективность:
1) минимальные требования в отношении оперативной памяти компьютера - программа должна была использовать наименьшее возможное число ячеек оперативной памяти компьютера;
2) минимальное время исполнения (минимальное число операций). При этом программы составлялись из команд, непосредственно или почти непосредственно исполнявшихся компьютером (точнее говоря, процессором):
* операции присваивания;
* простейших арифметических операций;
* операций сравнения чисел;
* операторов безусловного и условных переходов (изменяющих порядок вычисления команд в программе);
* операторов вызова подпрограмм (вспомогательных алгоритмов).
Такой подход в программировании (создании алгоритмов), ориентированный на непосредственно выполняемые компьютером операции, можно назвать операциональным. Программа созданная в таком подходе малоэффективная. Много времени. Линейная.
Структурное программирование
– это методология программирования, основанная на иерархическом решении задач. Основная цель – это дисциплинированность программирования. Принципы:
Принцип абстракции – рассмотрение решаемой задачи в целом, без учета деталей ее реализации.
Принцип нисходящего проектирования – исходная задача разбивается на несколько подзадач, которые разбиваются на еще более мелкие подзадачи до тех пор, пока алгоритм решения подзадач не станет легко реализуемым.
Принцип модульности – каждая из подзадач реализуется в отдельном модуле.
Модуль – независимая часть программы, которая может быть разработана, отлажена и откомпилирована отдельно от основной программы. Каждый модуль может ссылаться на другие модули. Количество используемых модулей называется размахом (шириной) модуля, который не должен превышать 7. Использование модулей имеет следующие преимущества:
1) возможность создания программы несколькими программистами;
2) простота проектирования и последующих модификаций программы;
3) упрощение отладки программы - поиска и устранения в ней ошибок;
4) возможность использования готовых библиотек наиболее употребительных модулей.
Стандарты СП:
разбивать программы на модули (задачииподзадачи),
использовать стандартные алгоритмические конструкции,
использовать значимые имени,
использовать префиксы для родственных имен.
не допускать вложенности условных конструкций (ифов) – не более трех,
не использовать выражения с неочевидной семантикой (смыслом).
Объектно-ориентированное программирование
(ООП) - методология, которая основана на представлении программ в виде набора объектов отражающая части модели и определение способов взаимодействия между ними (парадигма программирования, в которой основными концепциями являются понятия объектов и классов). Цель методологии разработки программ: дисциплинированность программирования и эффективность разработки программ. Принципы ООП:
Принцип модульности – программа состоит из модулей, в каждом модуле реализованы объекты родственных классов, модули могут быть разработаны отдельно.
Инкапсуляция (encapsulation) заключается в объединении данных и методов обработки данных в одной структуре (объекте) и обеспечения скрытия данных и контролирования данных (доступ к своим данным контролирует сам объект).
Наследование (inheritance) – способность порождать новые классы объектов от уже существующих. Класс, от которого порождается новый, называется базовым классом или родительским или предок (ancestor).Порождаемый класс называется наследником или потомком (descendant).Потомок наследует все свойства и методы предка, а также может вводить свои новые свойства и методы или изменять родительские. В свою очередь от наследника могут порождаться новые классы. Причем от 1го класса могут быть порождены несколько наследников или от нескольких классов 1н наследник (множественное наследование).
Полиморфизм(polymorphism) – способность объектов разных, но родственных классов, выполнять одинаковые действия по-своему. Для решения задачи в рамках ООП должна быть разработана иерархия классов необходимых для реализации модели решаемой задачи.
Основные признаки (свойства) ООП:
- абстрагирование – это процесс выделения абстракции предметной области задачи. Это совокупность существующих характеристик некоторого объекта. Эти характеристики отличают его от других объектов.
- ограничение доступа – это сокрытие отдельных элементов абстракции.
- модульность – это принцип разработки программной системы предполагающей реализацию его отдельных частей модулей.
- иерархия – это ранжирование, упорядочение систем абстракции.
- типизация – ограничения, которые накладываются на свойства объекта и препятствующие взаимоотношению абстракции разных типов. Тип может связываться с объектом статически (раннее связывание на стадии компиляции) либо динамически (позднее связывание).
- параллелизм – это свойство нескольких объектов одновременно находящихся в активном состоянии и выполняют некоторые действия. В основном реализуют только в многопроцессорных машинах.
- устойчивость – это свойство абстракции существует во времени не зависимо от процесса, его породившего. Различают: * временные объекты (промежуточное); * локальные объекты (существуют только в том блоке, в котором описаны); * глобальные объекты (существует во время работы основной программы); * сохраненные в файлах;
Язык считается ООП, если в нем реализованы хотя бы 1-4 признака: С++, Паскаль с версии 5.5 и выше, Delphi и др.
Объект –
сложная структура, включающая данные и действия над ними. Данные определяют свойства объекта (его внутреннее состояние). Действие определяет функциональность объекта, в том числе способы взаимодействия с другими объектами. Класс – это сложный структурированный тип данных, вкл. описания набора данных и методов их обработки, а также взаимодействия с другими классами. Переменная типа класс, это объект.
Таким образом в структурном программировании на 1е место поставлена логика выполнения решаемой задачи т.е логика алгоритма определяет структуру программы. В ООП на 1е место поставлена структура данных необходимых для решения задач т.е структура программы определена данными. На практике эти подходы сочетаются.
Введение в базы данных. Основные понятия: банк данных, база данных, система управления базами данных, информационные системы. Классификация БД
Введение в базы данных.
На начальном этапе развития Базы данных били представлены как файловые системы, которые выполняют для пользователей некоторые операции. Программа расчета операций.
В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС). Автоматизированными называют ИС, в которых применяют технические средства, в частности ЭВМ. Большинство существующих ИС являются автоматизированными, поэтому для краткости просто будем называть их ИС.
В широком понимании под определение ИС подпадает любая система обработки информации.
По области применения ИС можно разделить на системы, используемые в производстве, образовании, здравоохранении, и других отраслях.
По целевой функции ИС можно условно разделить на следующие основные категории: управляющие, информационно-справочные, поддержки принятия решений.
Узкая трактовка понятия ИС как совокупности аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. В организации, например, могут существовать информационные системы, на которых соответственно возложены следующие задачи: учет кадров и материально-технических средств, расчет с поставщиками и заказчиками, бухгалтерский учет и т. п.
Банк данных
является разновидностью ИС, в которой реализованы функции централизованного хранения и накопления обрабатываемой информации, организованной в одну или несколько баз данных.
Банк данных (БнД)
в общем случае состоит из следующих компонентов: базы данных, системы управления базами данных, словаря данных, администратора, вычислительной системы и обслуживающего персонала.
База данных (БД)
представляет собой совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области.
Логическую структуру хранимых в базе данных называют моделью представления данных.
Основные модели представления данных относятся следующие: иерархическая, сетевая, реляционная, постреляционная, многомерная и объектно-ориентированная.
Система управления базами данных
(СУБД) — это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями. Обычно СУБД различают по используемой модели данных.
Одними из первых СУБД являются следующие системы: IMS (IBM, 1968 г.), IDMS (Cullinet, 1971 г.), ADABAS (Software AG, 1969 г.) и ИНЭС (ВНИИСИ АН СССР, 1976 г.). Количество современных систем управления базами данных исчисляется тысячами.
Приложение
представляет собой программу или комплекс программ, обеспечивающих автоматизацию обработки информации для прикладной задачи. Приложения могут создаваться в среде или вне среды СУБД — с помощью системы программирования, использующей средства доступа к БД, к примеру Delphi или С++ Builder. Приложения, разработанные в среде СУБД, часто называют приложениями СУБД,
а приложения, разработанные вне СУБД, — внешними приложениями
.
Словарь данных
(СД) представляет собой подсистему БнД, предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления, принадлежности данных пользователям, кодах зашиты и разграничения доступа и т. п. Функционально СД присутствует во всех БнД, чаще всего функции СД выполняются СУБД и вызываются из основного меню системы.
Администратор базы данных
(ЛБД) есть лицо или группа лиц, отвечающих за выработку требований к БД, ее проектирование, создание, эффективное использование и сопровождение. А БД обычно следит за функционированием информационной системы, обеспечивает защиту от несанкционированного доступа, контролирует избыточность, непротиворечивость, сохранность и достоверность хранимой в БД информации. В вычислительной сети АБД, как правило, взаимодействует с администратором сети. Администратор сети осуществляет контроль за функционированием аппаратно-программных средств сети, реконфигурация сети, восстановление программного обеспечения после сбоев и отказов оборудования, профилактические мероприятия и обеспечение разграничения доступа.
Вычислительная система
(ВС) представляет собой совокупность взаимосвязанных и согласованно действующих ЭВМ или процессоров и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителям. Поскольку основными функциями БнД являются хранение и обработка данных, то используемая ВС, наряду с приемлемой мощностью центральных процессоров (ЦП) должна иметь достаточный объем оперативной и внешней памяти прямого доступа.
Обслуживающий персонал
выполняет функции поддержания технических и программных средств в работоспособном состоянии. Он проводит профилактические, регламентные, восстановительные работы по планам.
Классификация БД:
по форме представления (визуальная, аудиосистемы, мултьимедиа)
по характеру организации данных (неструктурированная БД в виде семантических сетей, частично – в виде текста и гипертекста, структурированная – иерархические, сетевые, реляционные). Структурированные сисемы поддерживают уровень поля, записи, файла. Поле
– наим. ед. информации. Совокупность полей – запись
, а множество записей – файл
.
по типу хранимой информации: документальные (библиографические, реферативные, полнотекстовые БД форм документов), фактографические и лексикографические.
по характеру организации хранения: локальные, общие (интегрированные, распределенные).
Классификация СУБД. Архитектура БД: внешняя, концептуальная, физическая. Компоненты СУБД. Основные функции СУБД
Система управления базами данных
(СУБД) — это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями. Обычно СУБД различают по используемой модели данных.
Одними из первых СУБД являются следующие системы: IMS (IBM, 1968 г.), IDMS (Cullinet, 1971 г.), ADABAS (Software AG, 1969 г.) и ИНЭС (ВНИИСИ АН СССР, 1976 г.). Количество современных систем управления базами данных исчисляется тысячами.
Классификационные признаки: вид программы, характер использования, модель данных. Признаки влияют на целевой выбор СУБД и эффективность использования разрабатываемой информационной системы.
Классификация СУБД:
-
По типу моделей данных(иерархические, сетевые, реляционные, объектно-ориентированные)
По языкам общения (открытые, замкнутые, смешанные)
По числу уровней в архитектуре (1,2,3), (архитектурный уровень – это механизм поддержки некоторого уровня абстракции)
По выполняемым функциям (информационные, операционные)
По сфере возможного применения (универсальные, проблемно-ориентированные)
По мощности (настольные, корпоративные)
По ориентации на категорию пользователей (разработчиков, конечных пользователей)
Архитектура БД:
Внешняя (точка зрения на БД отдельных приложений)
Концептуальная (обобщенная модель предметной области, для которой создавалась БД, содержит объекты и их атрибуты, связи между объектами, ограничения, семантическую информацию о данных, обеспечение безопасности)
Физическая (описывает физическую реализацию БД и предназначена для достижения оптимальной производительности)

Рис. 5.6 Трехуровневая архитектура ANSI-SPARC
Внутренний уровень
наиболее близок к физическим структурам хранимой информации. Именно внутренний уровень учитывает методы доступа операционной системы для манипулирования данными на физическом уровне, что в некоторой степени снижает независимость операций обработки данных от технических средств, однако, в идеале СУБД может располагать внутренним уровнем, который бы не опирался на средства ОС.
Внешний уровень
является уровнем пользователей СУБД, т.к. он является уровнем восприятия каждого пользователя. В принципе для каждого пользователя создается свой внешний уровень (схема - модель с соответствующим языком описания данных). Типичным воплощением внешнего уровня является использование представлений (VIEW) в языке SQL [3].
Концептуальный уровень
является обобщением локальных представлений пользователей, т.е. является общим глобальным описанием предметной области в терминах (концептах) конкретной СУБД. Важно отметить, что концептуальный уровень исполняет роль некоторого стандарта пользователей, согласуя их представление о предметной области в единое целое.
Компоненты СУБД:
Ядро СУБД
– отвечает за управление данными во внешней памяти, управляет буферами, транзакциями и производит журнализацию. Ядро в свою очередь состоит из менеджера данных, менеджера буферов, менеджера транзакций, менеджера журналов. Ядро СУБД обладает собственным интерфейсом и не доступно пользователям напрямую, но используется в программах компилятором и утилитами. В память загружается только резидентная часть ядра. В архитектуре клиент-сервер ядро представляет серверную часть системы.
Процессор запросов
– преобразует запросы низкоуровневых конструкций.
Компилятор языка
– преобразует команды процессора запросов в набор таблиц, которые сохраняются в системном каталоге.
Процессор языка манипулирования данными
– преобразует операторы прикладного языка в стандартные функции базового языка.
Контроллер
– управляет доступом к системному каталогу.
Контроллер файлов манипулирования-
предназначен для хранения файлами, отвечает за дисковое пространство.
Контроллер БД
-взаимодействует с прикладными программами и запросами. Компоненты: контроль прав доступа, процессор команд, средство контроля целостности, оптимизатор запросов, контроллер транзакций, планировщик конструктивного восстановления БД.
Основные функции СУБД:
Управление данными во внешней памяти
Управление транзакциями
Вспомогательные функции
Восстановление БД
Поддержка языков БД
Словарь данных
Управление параллельным доступом
Управление буфером ОП
Контроль доступа к данным
Поддержка обмена данными
Поддержка целостности данных
Поддержка независимости от данных
Пользователи банков данных. Основные функции группы администратора БД. Модели данных, основные понятия. Классификация моделей данных, характеристика моделей. Инфологическая модель. Виды связей. ER-диаграммы
Пользователи Банков данных:
Админстраторы данных – управление данными, разработка и сопровождение стандартов
Разработчики БД (разработчики логической БД, разработчики физической БД) – рез-т работы: спроектированная БД
Прикладные программисты – используют языки 3-го и 4-го уровня
Пользователи.
Основные функции группы администратора БД:
Анализ предметной области
Проектирование структуры БД
Задание ограничения целостности
Первоначальная загрузка
Защита данных
Обеспечение восстановления данных
Анализ обращений пользователей
Анализ эффективности функционирования
Работа с конечными пользователями
Подготовка и поддержание системных средств
Организационно-методическая работа
Модели данных, основные понятия
Основная концепция БД- является понятие модели данных и данных.
Данные –
набор конкретных значений, характеризующих объект, условие, ситуацию или другие факторы. Сами по себе они не несут информацию.
Модель данных
– абстракция, которая будучи приложена к конкретным данным позволяет пользователям и разработчикам трактовать данные как информацию, т.е. сведения содержащие не только данные, но и взаимосвязи между ними.
Назначение моделей данных
:
Определить границу между логическими и физическими аспектами управления БД (независимость данных).
Обеспечить конечным пользователям и программистам возможность и средства общего понимания смысла данных.
Определить языковые понятия высокого уровня, которые позволили бы выполнять однотипные операции над большими совокупностями записей, причем эта совокупность рассматривается как единая операция.
Классификация моделей данных, характеристика моделей.
Существует 3 уровня моделей:
Инфологическая модель: диаграммы Зхмана, модель сущность-связь
Даталогическая модель: документальные (ориентированы на формат документа, дескрипторные модели, трезаусные модели) и фактографические (иерархически сетевые, теоретико-множественные модели, объектно-ориентированные)
Физическая модель: основанные на файловых структурах, основаны на странично-сигментной организации,.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, которые используются в данной операционной среде.
Отдельная категория множественные модели
(религиозные модели, модели бинарных ассоциаций).
Инфологическая модель
Инфологическая модель. Цель
инфологического моделирования – отображает информацию о предметной области в удобном для пользователя виде. Инфологическая модель представляет собой информационно-логический уровень абстрагирования, на котором фиксируются объекты предметной области, их свойства и взаимосвязи.
Инфологическая модель
сущность-связь была предложена П. Ченом и представляет собой инфологическую модель симантически определяющую сущности и связи.
Существует 3 обязательных элемента для данной модели:
Сущность
– объект, информация о котором должна быть представлена в БД (соответствует существительному:студент). Экземпляр сущности
– информация о конкретном представителе объекта(группа).
Связь
– соединение между двумя или более сущностями (соответствует глаголу).
Атрибут
– свойство сущности или связи. Ключ сущности
– атрибут или набор атрибутов, используемый для однозначной идентификации экземпляра сущности. Каждый экземпляр связи определяется набором ключей сущности
соединенных этой связью.
Виды связей.
Связь между сущностями имеет 2 характеристики:
1)степень связи (1:1-каждый экземпляр этой сущности может быть связан только с 1 экземпляром 1 сущности и наоборот, 1:М-каждый экземпляр 1 сущности может быть связан с несколькими экземплярами 2 сущности, но каждый экземпляр 2 сущности может быть связан только с 1 экземпляром 2 сущности, М:М-каждый экземпляр 1 сущности может быть связан с несколькими экземплярами 2 сущности и наоборот)
2)класс принадлежности сущности связи. (может быть обязательным и необязательным). При обязательном - каждый экземпляр сущности должен быть связан с другой сущностью. При необязательном –не требуется чтобы каждый экземпляр сущности был связан с другой сущностью.
Правила построения ER-диаграмм:
Рассмотрим формулировки шести правил формирования отношений.
Правило 1. Если степень связи 1: 1 и класс принадлежности обеих сущностей обязательный, то формируется одно отношение. Первичным ключом этого отношения может быть ключ любой из двух сущностей.
Правило 2. Если степень связи 1: 1 и класс принадлежности одной сущности обязательный, а второй – необязательный, то под каждую из сущностей формируется по отношению с первичными ключами, являющимися ключами соответствующих сущностей. Далее к отношению, сущность которого имеет обязательный КП, добавляется в качестве атрибута ключ сущности с необязательным КП.
Правило 3. Если степень связи 1: 1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать три отношения. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными ключами в этих отношениях. Третье отношение является связным между первыми двумя, поэтому его ключ объединяет ключевые атрибуты связываемых отношений.
Правило 4. Если степень связи 1: М (или М: 1) и класс принадлежности М-связной сущности обязательный, то достаточно формирование двух отношений (по одному на каждую сущность). При этом первичными ключами этих отношений являются ключи их сущностей. Кроме того, ключ 1-связной сущности добавляется как атрибут (внешний ключ) в отношение, соответствующее М-связной сущности.
Правило 5. Если степень связи 1: М (или М: 1) и класс принадлежности М-связной сущности необязательный, то необходимо формирование трех отношений. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя (его ключ объединяет ключевые атрибуты связываемых отношений).
Правило 6. Если степень связи М: М, то независимо от класса принадлежности сущностей формируются три отношения. Два отношения соответствуют связываемым сущностям и их ключи являются первичными ключами этих отношений. Третье отношение является связным между первыми двумя, а его ключ объединяет ключевые атрибуты связываемых отношений.
связь.
Должность СОСТОИТ в отделе.
Графически связь изображается линией, соединяющей две сущности:
Характер связей между сущностями не ограничивается перечисленными. Существуют и более сложные связи:
множество связей между одними и теми же сущностями
(пациент, имея одного лечащего врача, может иметь также несколько врачей-консультантов; врач может быть лечащим врачом нескольких пациентов и может одновременно консультировать несколько других пациентов);
тренарные связи
(врач может назначить несколько пациентов на несколько анализов, анализ может быть назначен несколькими врачами нескольким пациентам и пациент может быть назначен на несколько анализов несколькими врачами);
связи более высоких порядков, семантика (смысл) которых иногда очень сложна.
Каждая связь может иметь одну из двух модальностей связи
:
Реляционная модель данных. Базовые понятия. Степень отношения. Ключи отношения. Связанные отношения. Условия целостности данных. Типы связей между таблицами. Свойства таблиц реляционной БД, индексы
Реляционная модель данных.
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом в 1970 г. Данная модель помогла решить проблему независимости представления и описания данных от прикладных программ.
Плюсами
данной модели являются: наличие большого набора абстракций, что упрощает моделирование большей части предметных областей; наличие мощного математического аппарата; возможность манипулирования данными.
Минусами
реляционной модели являются: ограниченность применения в нетрадиционных областях; недостаточная эффективность при больших размерах БД.
Реляционная модель
данных (РМД) в некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними.
Базовые понятия:
Отношение
– любая взаимосвязь между объектами и/или их свойствами. Отношение задается именем и списком его атрибутов. Student (ФИО, Год рождения, Группа).
Тип данных
– полностью эквивалентен типу данных в алгоритмических языках. Набор типов данных зависит от используемой СУБД, но все СУБД поддерживают целочисленные, строковые, вещественные, денежные, временные и типы двоичных объектов.
Домен
– множество атомарных значений одного и того же типа, т.е. домен – допустимое значение. Атомарное (неделимое) значение данных – наименьшая единица данных в реляционной модели.
Данные можно сравнивать в том случае если они относятся к одному домену.
Столбцы
- атрибуты им присваиваются имена, которые с помощью имен к ним обращаются.
Числом атрибутов
- степень отношения.
Схема БД
- множество наименованных схем отношений.
Атрибут
– столбец, которому присваивается уникальное имя.
Степень отношения
– число атрибутов в отношении. Схема БД – множество именованных схем отношений.
Отношение
– это множество, которое не содержит одинаковых элементов – кортежей.
Картеж
– множество пар, содержащее только одно вхождение каждого атрибута. Альтернативные значения – строка, таблица, столбец, файл, запись, поле.
Ключ отношения
. В множестве не может быть совпадающих значений, в картеже так же не может быть совпадающих значений в любой момент времени. В отношений должна присутствовать группа атрибутов, которая определяет каждый кортеж и определяет столб. Такой атрибут – первичный ключ отношений.
Отношение представляет собой множество, в котором не может быть совпадающих значений. Первичный ключ
– атрибут или группа атрибутов, однозначно определяющий картеж и обеспечивающий уникальность данных строк. Если есть R (A1, A2,…,An), то множество атрибутов K (Ai, Ai+1,…, An) является первичным ключом тогда и только тогда когда выполняются 2 условия:
Уникальности – ни один из атрибутов отношения R не имеет одного и того же значения;
Минимальности – ни один из атрибутов K не может быть исключен без нарушения целостности R.
В зависимости от количества атрибутов ключи бывают простые (состоят из одного атрибута) и составные (из нескольких).
В реляционной модели данные представляются в виде совокупностей взаимосвязанных отношений.
Внешний ключ
– атрибут или набор атрибутов одного отношения, являющийся ключом использования для установления связи. Связь между таблицами устанавливается с помощью внешнего ключа первой таблицы с ключом значений второй таблицы. Внешние ключи используются для установления логических связей между отношениями. Внешний ключ бывает простым и составным.
Ключи обычно используют для достижения следующих целей:
Исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются).
Упорядочение кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а так же смешанное упорядочение (по одним – возрастание, а по другим - убывание)
Ускорение работы к кортежам отношения
Организации связывания таблиц
Связанные отношения
Чаще всего в реляционной модели данные предоставляются в виде совокупности отношений.
Поскольку не всякой таблице можно поставить в соответствие отношение, приведем условия, выполнение которых позволяет таблицу считать отношением.
Все строки таблицы должны быть уникальны, то есть не может быть
строк с одинаковыми первичными ключами.
Имена столбцов таблицы должны быть различны, а значения их простыми, то есть недопустима группа значений в одном столбце одной строки.
Все строки одной таблицы должны иметь одну структуру, соответствующую именам и типам столбцов.
Порядок размещения строк в таблице может быть произвольным.
Условие целостности данных
.
Информация в базе данных однозначна и непротиворечива в реляционной модели накладываются ограничительные услуги – это правила операции возможными значениями данных. Обеспечивают логическую основу для поддержания корректных данных.
Для того чтобы информация не была противоречивой, в реляционной модели накладываются ограничительные условия. Ограничениями целостности являются:
Категорийная целостность – строка не может быть занесена в БД пока не будут определены все атрибуты первичного ключа.
Ссылочная целостность – если две таблицы связаны между собой, то внешний ключ содержит только те значения, которые определены атрибутом, по которому осуществляется связь.
При установлении связей между таблицами одна становится главной, а вторая подчиненной. В главной доступны все записи, а в подчиненной только записи соответствующие текущей. У главной таблицы может быть несколько подчиненных, у подчиненной только одна главная. В реляционной модели существует 4 типа связей: 1:1, 1:М, М:1, М:М.
Современные СУБД поддерживают категорийную и ссылочную целостность. Труднее соблюдать ссылочную целостность. Она наблюдается при удалении данных
Три подхода к удалению картежа:
Запрещается производить удаление картежей на которые существуют ссылки. Надо удалить ссылки потом картежи.
При удалении картежей на который имеется ссылка, имеются ссылающие кортежи, то значение ключа не определено.
Каскадное удаление. При удалении картежа на которые имеются ссылки, то удаляется все ссылающееся. В СУБД можно выбрать любой способ модернизации целостности.
Типы связей между таблицами.
Одна из таблиц главная, вторая подчинённая. В главной все записи, а в подчиненной доступны только те записи, которые соответствуют текущим.
Различают 4 типа связи между таблицами:
один ко одному (1:1)
один ко многим (1:М)
многие ко многим (М:М.)
многие ко одному (1:М)
Свойства таблиц реляционной модели
:
отношения имеют реляционную модель данных, таблица является отношениями и свойства этих таблиц являются отношениями. Каждая таблица имеет уникальное имя и состоит из однотипных строк.
Строки имеют фиксированное число полей и значений
Все строки отличаются друг от друга и имеют хотя бы одно значение.
Все столбцы имеют уникальные названия. В каждом столбце храниться данные первого и того же типа. При работе с таблицей её строки и столбцы могут срабатывать в любом порядке
Каждая таблица имеет уникальное имя и состоит из однотипных строк;
Строки имеют фиксированное число полей и значений;
Все строки отличны друг от друга;
Все столбцы имеют уникальные названия;
В одном и том же столбце хранятся данные одного и того же типа;
При работе строки и столбцы обрабатываются в любом порядке.
Индекс
– указатель на данные, размещенные в таблице для упрощения поиска информации и поддержания целостности данных. Индексы бывают простые и составные.
Простые
строятся на основе одного столбца,
составные
– по 2-м или более столбцам.
Уникальные индексы
- не допускают ввода дублированных значений и используются не только с целью поиска данных но и для поддержки целостности дынных.
При назначении составного ключа должны выполняться следующие условия:
Первым должен быть столбец, содержащий ограниченные значения;
Первым должен быть столбец, который наиболее часто задается в условиях поиска.
Не стоит индексировать по столбцам данные, которые постоянно меняются, а также столбцы, имеющие пустые значенияи большие размеры.
Аномалии данных. Нормализация данных. Нормальные формы (примеры). Языки баз данных. Язык SQL. Основные операторы языка. Оператор выбора. Формирование запросов. Операторы манипулирования данными. Агрегатные операторы
Аномалии данных
Аномалия обновления
– связана с избыточностью данных. Аномалии
неадекватность модели данных предметной области, (что говорит на самом деле о том, что логическая модель данных попросту неверна!) или как необходимости дополнительных усилий для реализации всех ограничений определенных в предметной области (дополнительный программный код в виде триггеров или хранимых процедур).
Аномалии ввода
– возникает при добавлении новых записей в таблицу на некоторые поля, которые заданно ограничение not/noll.
Аномалии вставки (INSERT)
нельзя вставить данные о сотруднике, который пока не участвует ни в одном проекте
Аномалии обновления (UPDATE)
Фамилии сотрудников, наименования проектов, номера телефонов повторяются во многих кортежах отношения. Поэтому если сотрудник меняет фамилию, или проект меняет наименование, или меняется номер телефона Для поддержания отношения в целостном состоянии необходимо написать триггер, который при обновлении одной записи корректно исправлял бы данные и в других местах.
Аномалии удаления (DELETE)
При удалении некоторых данных может произойти потеря другой информации.
Нормализация данных
Процесс реорганизации дынных путем ликвидации повторяющихся групп и их противоречий с целью привлечения таблицы к виду позволяющему осуществлять противоречивое корректирование дынных.
Избыточность данных
Обновление-----аномалия
Удаление--------аномалия при удалении некоторых данных из БД
Ввода
Теория нормализации основана на концепции нормальных форм. Каждой характерной форме соответствует некоторый набор ограничений. Набор находится в некоторой нормальной форме если оно удовлетворяет свойствам набора данных.
Основные свойства нормальных форм:
Каждая следующая лучше предыдущей
При переходе к следующей нормальной форме свойства предыдущей сохраняются
1НФ
Отношения находятся в первой нормальной форме, если значения атрибутов атомарные.
2НФ
Отношения находятся во второй нормальной форме, в том случае если оно находятся в 1НФ,
и не нормальный ключевой атрибут находится от ключевого ключа.
-определить на какие части можно разбить первый ключ, так чтобы некоторые из неключевых полей зависили только от этих полей
-создать новую таблицу для каждой части ключа и групп зависящих полей, и переместить их в эту таблицу. Часть бывшего первичного ключа, становится первичным ключом новой таблицы.
-удалить их исходной таблиц, поля перемещенные таблицей, кроме тех полей, которые станут внешними ключами
R1: (ФИО, должность, оклад, стаж, должность стажера, кафедра, предмет, группа, вид занятия)
R2: (ФИО, должность, оклад, стаж, должность, кафедра)
Частичная зависимость, поэтому эта зависимость от атрибутами можно удалить в третью нормальную форму)
3НФ
Отношения находятся в третьей нормальной форме, если они находятся во 2НФ
и каждый не ключевой атрибут нетривиально зависят от первичного ключа. Чтобы отсутствовала физическая зависимость между не ключевыми атрибутами.
Чтобы перейти от 2НФ к 3НФ
нужно:
1)определить формы полей, от которых зависят другие поля
2)создать новую таблицу для каждого такого типа поля и группы зависящих полей, и переместить их в эту таблицу. Поле или группа полей будет являться первым ключом
3)удалить перемещаемые поля, оставив только те которые станут внешними ключами.
R3 (должность, оклад) а (код_д, должность, окдад)
R4 (стаж, доплата за стаж) а (код_с, стаж, доплата за стаж)
R5 (кафедры) а (код_к, кафедры)
Нормальная форма Бойса — Кодда (BCNF) –
если оно находится в третьей нормальной форме и в нем отсутствует зависимость ключей от неключевых атрибутов.
Методы нормальных форм:
разрешается при проектировании БД - это нормализация её отношений.
1НФ (Первая Нормальная Форма)
- это обычное отношение. Любое отношение автоматически уже находится в 1НФ. свойства отношений (это и будут свойства 1НФ): В отношении нет одинаковых кортежей, Кортежи не упорядочены, Атрибуты не упорядочены и различаются по наименованию, Все значения атрибутов атомарны.
2НФ (Вторая Нормальная Форма)
Отношение находится во второй нормальной форме
(2НФ
) тогда и только тогда, когда отношение находится в 1НФ и нет неключевых атрибутов, зависящих от части сложного ключа. (Неключевой атрибут
- это атрибут, не входящий в состав никакого потенциального ключа).
3НФ (Третья Нормальная Форма)
Атрибуты называются взаимно независимыми
, если ни один из них не является функционально зависимым от другого. Отношение находится в третьей нормальной форме
(3НФ
) тогда и только тогда, когда отношение находится в 2НФ и все неключевые атрибуты взаимно независимы и полностью зависят от первичного ключа.
Алгоритм нормализации (приведение к 3НФ)
Шаг 1 задается одно или несколько отношений, отображающих понятия предметной области. По модели предметной области выписываются обнаруженные функциональные зависимости. Все отношения автоматически находятся в 1НФ. Шаг 2 Если в некоторых отношениях обнаружена зависимость атрибутов от части сложного ключа, то проводим декомпозицию этих отношений: те атрибуты, которые зависят от части сложного ключа выносятся в отдельное отношение вместе с этой частью ключа.
Нормальная форма Бойса — Кодда (BCNF)
Это модификация третьей нормальной формы. Таблица находится в BCNF, если она находится в 3NF, и при этом отсутствуют функциональные зависимости атрибутов первичного ключа от неключевых атрибутов. Таблица может находиться в 3NF, но не в BCNF, только в одном случае: если она имеет, помимо первичного ключа, ещё по крайней мере один возможный ключ. Все зависимые от первичного ключа атрибуты должны быть потенциальными ключами отношения. Если это условие не выполняется, для них создаётся отдельное отношение. Чтобы сущность соответствовала BCNF, она должна находиться в третьей нормальной форме. Любая сущность с единственным возможным ключом, соответствующая требованиям третьей нормальной формы, автоматически находится в BCNF.
Четвёртая нормальная форма (4NF)
Таблица находится в 4NF, если она находится в BCNF и не содержит нетривиальных многозначных зависимостей. Многозначная зависимость не является функциональной, она существует в том случае, когда из факта, что в таблице содержится некоторая строка X, следует, что в таблице обязательно существует некоторая определённая строка Y. То есть, таблица находится в 4NF, если все ее многозначные зависимости являются функциональными.
Пятая нормальная форма (5NF)
Таблица находится в 5NF, если она находится в 4NF. Пятая нормальная форма в большей степени является теоретическим исследованием и практически не применяется при реальном проектировании баз данных.
Шестая нормальная форма (6NF)
Таблица находится в 6NF, если она находится в 5NF и удовлетворяет требованию отсутствия нетривиальных зависимостей.
Языки баз данных
Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных DDL
используется для описания структуры базы данных, языка управления данными DML
. для чтения и обновления самой базы данных. Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках программирования высокого уровня, как COBOL, Fortran, Pascal, Ada или С. В этом случае язык высокого уровня принято называть базовым языком (host language).
Язык управления данными DML
- язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными. К операциям управления данными относятся: вставка в базу данных новых сведений; модификация сведений, хранимых в базе данных; извлечение сведений, содержащихся в базе данных; удаление сведений из базы данных.
Языки 4GL.
"язык четвертого поколения"(Fourth-Generation Language). Выделяют следующие типы языков четвертого поколения: языки представления информации, например языки запросов или генераторы отчетов; специализированные языки, например языки электронных таблиц и баз данных; генераторы приложений, которые при создании приложений обеспечивают определение, вставку, обновление или извлечение сведений из базы данных; языки очень высокого уровня, предназначенные для генерации кода приложений. В качестве примеров языков четвертого поколения можно указать упоминавшиеся выше языки SQL и QBE.
Язык SQL.
Структурированный Язык Запросов. Это - язык, который дает Вам возможность создавать и работать в реляционных базах данных, являющихся наборами связанной информации, сохраняемой в таблицах. SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (Международной Организацией по Стандартизации).
Состав языка SQL
Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде.
Поэтому, в язык SQL в качестве составных частей входят различные команды одного языка:
язык манипулирования данными (Data Manipulation Language, DML)
язык определения данных (Data Definition Language, DDL)
язык управления данными (Data Control Language, DCL).
Основные операторы языка.
Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
| SELECT |
(выбрать) |
| INSERT |
(вставить) |
| UPDATE |
(обновить) |
| DELETE |
(удалить) |
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются:
| CREATE DATABASE |
(создать базу данных) |
| CREATE TABLE |
(создать таблицу) |
| CREATE VIEW |
(создать виртуальную таблицу) |
| CREATE INDEX |
(создать индекс) |
| CREATE TRIGGER |
(создать триггер) |
| CREATE PROCEDURE |
(создать сохраненную процедуру) |
| ALTER DATABASE |
(модифицировать базу данных) |
| ALTER TABLE |
(модифицировать таблицу) |
| ALTER VIEW |
(модифицировать виртуальную таблицу) |
| ALTER INDEX |
(модифицировать индекс) |
| ALTER TRIGGER |
(модифицировать триггер) |
| ALTER PROCEDURE |
(модифицировать сохраненную процедуру) |
| DROP DATABASE |
(удалить базу данных) |
| DROP TABLE |
(удалить таблицу) |
| DROP VIEW |
(удалить виртуальную таблицу) |
| DROP INDEX |
(удалить индекс) |
| DROP TRIGGER |
(удалить триггер) |
| DROP PROCEDURE |
(удалить сохраненную процедуру) |
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде. Более точно его можно назвать "язык управления доступом". Он состоит из двух основных команд:
| GRANT |
(дать права) |
| REVOKE |
(забрать права) |
С точки зрения прикладного интерфейса существуют две разновидности команд SQL:
интерактивный SQL
встроенный SQL.
Интерактивный SQL
используется в специальных утилитах (типа WISQL или DBD), позволяющих в интерактивном режиме вводить запросы с использованием команд SQL, посылать их для выполнения на сервер и получать результаты в предназначенном для этого окне. Встроенный SQL
используется в прикладных программах, позволяя им посылать запросы к серверу и обрабатывать полученные результаты, в том числе комбинируя set-ориентированный и record-ориентированный подходы.
Типы данных
Строковые: символьные строки функциональной длины а символьные строки переменной длины
Числовые типы: целочислительные, вещественные.
Типы с функциональной длиной: вещественные
Типы с плавающей точкой: двоичные
Типы представляющие дату и время.
Оператор выбора.
Реляционные операции. Команды языка манипулирования данными
SELECT
Начнем с базовых операций реляционных баз данных. Таковыми являются:
выборка
(Restriction)
проекция
(Projection)
соединение
(Join)
объединение
(Union)
Операция выборки позволяет получить все строки (записи) либо часть строк одной таблицы.
SELECT * FROM country
Получить все строки таблицы Country
Эти примеры иллюстрируют общую форму команды SELECT в языке SQL (для одной таблицы):
| SELECT |
(выбрать) специфицированные поля |
| FROM |
(из) специфицированной таблицы |
| WHERE |
(где) некоторое специфицированное условие является истинны |
Операция соединения позволяет соединять строки из более чем одной таблицы (по некоторому условию) для образования новых строк данных.
Операция объединения позволяет объединять результаты отдельных запросов по нескольким таблицам в единую результирующую таблицу. Таким образом, предложение UNION объединяет вывод двух или более SQL-запросов в единый набор строк и столбцов.
Формирование запросов.
Статические и динамические запросы.
Статические –задаются в процессе разработки приложения. При запуске отображается два поля. В процессе запрос можно заменить другими запросами. Данные компонента qvery представляется виде таблицы.
Динамические запросы - является запрос когда меняются отдельные его составляющие, и его отдельные параметры запроса.
Под параметром запроса понимается имя запроса перед которым стоит двоеточие без пробела. В компоненте qvery имеется свойство в которое записывается имя параметра
Операторы манипулирования данными
Агрегатные операторы.
Языки баз данных
Язык SQL.
Основные операторы языка. Оператор выбора.
Формирование запросов. Операторы манипулирования данными.
Агрегатные операторы
Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных DDL и языка управления данными DML. языка определения данных DDL (Data Definition Language) и языка управления данными DML (Data Ma-nipulation Language). Язык DDL используется для описания структуры базы данных, а язык DML - для чтения и обновления самой базы данных. Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках программирования высокого уровня, как COBOL, Fortran, Pascal, Ada или С. В этом случае язык высокого уровня принято называть базовым языком (host language). Помимо механизма внедрения, для большинства подъязыков данных также предоставляются средства интерактивного выполнения их операторов, вводимых пользователем непосредственно со своего терминала.
Схема базы данных состоит из набора определений, выраженных на специальном языке определения данных - DDL. Язык DDL используется как для определения новой схемы, так и для модификации уже существующей. Этот язык нельзя использовать для управления данными. Результатом компиляции DDL-операторов является набор таблиц, хранимый в особых файлах, называемых системным каталогом. В системном каталоге интегрированы метаданные - т.е. данные, которые описывают объекты базы данных, а также позволяют упростить способ доступа к ним и управления ими. Метаданные включают определения записей, элементов данных, а также другие объекты, представляющие интерес для пользователей или необходимые для работы СУБД. Перед доступом к реальным данным СУБД обычно обращается к системному каталогу. Для обозначения системного каталога также используются термины словарь данных и каталог данных, хотя первый из них (словарь данных) обычно относится к программному обеспечению более общего типа, чем просто каталог СУБД.
Язык управления данными DML
- язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными. К операциям управления данными относятся: вставка в базу данных новых сведений; модификация сведений, хранимых в базе данных; извлечение сведений, содержащихся в базе данных; удаление сведений из базы данных.
Таким образом, одна из основных функций СУБД заключается в поддержке языка манипулирования данными, с помощью которого пользователь может создавать выражения для выполнения перечисленных выше операций с данными. Понятие манипулирования данными применимо как к внешнему и концептуальному уровням, так и к внутреннему уровню. Однако на внутреннем уровне для этого необходимо определить очень сложные процедуры низкого уровня, позволяющие выполнять доступ к данным весьма эффективно. На более высоких уровнях акцент переносится в сторону большей простоты использования и основные усилия направляются на обеспечение эффективного взаимодействия пользователя с системой.
Языки DML отличаются базовыми конструкциями извлечения данных. Следует различать два типа языков DML: процедурный и непроцедурный. Основное отличие между ними заключается в том, что процедурные языки указывают, как можно получить результат оператора языка DML, тогда как непроцедурные языки описывают, какой результат будет получен. Как правило, в процедурных языках записи рассматриваются по отдельности, тогда как непроцедурные языки оперируют с целыми наборами записей.
С помощью процедурного языка DML пользователь, а точнее - программист, указывает на то, какие данные ему необходимы и как их можно получить. Это значит, что пользователь должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой процедурный язык DML позволяет извлечь запись, обработать ее и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Языки DML сетевых и иерархических СУБД обычно являются процедурными
Непроцедурные языки DML позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. С помощью непроцедурных языков DML пользователь указывает, какие данные ему нужны, без определения способа их получе-ния. СУБД транслирует выражение на языке DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей. Данный подход освобождает пользователя от необходимости знать детали внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. Непроцедурные языки часто также называют декларативными языками. Реляционные СУБД в той или иной форме обычно включают поддержку непроцедурных языков манипулирования данными - чаще всего это бывает язык структурированных запросов SQL (Structured Query Language) или язык запросов по образцу QBE (Query-by-Example). Непроцедурные языки обычно проще понять и использовать, чем процедурные языки DML, поскольку пользователем выполняется меньшая часть работы, а СУБД - большая. Часть непроцедурного языка DML, которая отвечает за извлечение данных, называется языком запросов. Язык запросов можно определить как высокоуровневый узкоспециализированный язык, предназначенный для удовлетворения различных требований по выборке информации из базы данных. В этом смысле термин "запрос" зарезервирован для обозначения оператора извлечения данных, выраженного с помощью языка запросов.
Языки 4GL.
Аббревиатура "4GL" представляет собой сокращенный английский вариант написания термина "язык четвертого поколения"(Fourth-Generation Language). He существует четкого определения этого понятия, хотя, по сути, речь идет о некотором стенографическом варианте языка программирования. Если для организации некоторой операции с данными на языке третьего поколения (3GL) типа COBOL потребуется написать сотни строк кода, то для реализации этой же операции на языке четвертого поколения будет достаточно нескольких строк.
В то время как языки третьего поколения являются процедурными, языки 4GL выступают как непроцедурные. Предполагается, что реализация языков четвертого поколения будет в значительной мере основана на использовании компонентов высокого уровня, которые часто называют "инструментами четвертого поколения". Пользователю не потребуется определять все этапы выполнения программы, необходимые для решения поставленной задачи, а достаточно будет лишь определить нужные параметры, на основании которых упомянутые выше инструменты автоматически осуществят генерацию прикладного приложения. Выделяют следующие типы языков четвертого поколения:
языки представления информации, например языки запросов или генераторы отчетов;
специализированные языки, например языки электронных таблиц и баз данных;
генераторы приложений, которые при создании приложений обеспечивают определение, вставку, обновление или извлечение сведений из базы данных;
языки очень высокого уровня, предназначенные для генерации кода приложений.
В качестве примеров языков четвертого поколения можно указать упоминавшиеся выше языки SQL и QBE.
Язык SQL
SQL (обычно произносимый как "СИКВЭЛ" или "ЭСКЮЭЛЬ") символизирует собой Структурированный Язык Запросов. Это - язык, который дает Вам возможность создавать и работать в реляционных базах данных, являющихся наборами связанной информации, сохраняемой в таблицах.
Стандарт SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (Международной Организацией по Стандартизации). Однако, большинство коммерческих программ баз данных расширяют SQL без уведомления ANSI, добавляя различные особенности в этот язык, которые, как они считают, будут весьма полезны. Иногда они несколько нарушают стандарт языка, хотя хорошие идеи имеют тенденцию развиваться и вскоре становиться стандартами "рынка" сами по себе в силу полезности своих качеств.
На данном уроке мы будем, в основном, следовать стандарту ANSI, но одновременно иногда будет показывать и некоторые наиболее общие отклонения от его стандарта.
Точное описание особенностей языка приводится в документации на СУБД, которую Вы используете. SQL системы InterBase 4.0 соответствует стандарту ANSI-92 и частично стандарту ANSI-III.
Состав языка SQL
Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде.
Поэтому, в язык SQL в качестве составных частей входят:
язык манипулирования данными (Data Manipulation Language, DML)
язык определения данных (Data Definition Language, DDL)
язык управления данными (Data Control Language, DCL).
Подчеркнем, что это не отдельные языки, а различные команды одного языка. Такое деление проведено только лишь с точки зрения различного функционального назначения этих команд.
Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
| SELECT |
(выбрать) |
| INSERT |
(вставить) |
| UPDATE |
(обновить) |
| DELETE |
(удалить) |
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются:
| CREATE DATABASE |
(создать базу данных) |
| CREATE TABLE |
(создать таблицу) |
| CREATE VIEW |
(создать виртуальную таблицу) |
| CREATE INDEX |
(создать индекс) |
| CREATE TRIGGER |
(создать триггер) |
| CREATE PROCEDURE |
(создать сохраненную процедуру) |
| ALTER DATABASE |
(модифицировать базу данных) |
| ALTER TABLE |
(модифицировать таблицу) |
| ALTER VIEW |
(модифицировать виртуальную таблицу) |
| ALTER INDEX |
(модифицировать индекс) |
| ALTER TRIGGER |
(модифицировать триггер) |
| ALTER PROCEDURE |
(модифицировать сохраненную процедуру) |
| DROP DATABASE |
(удалить базу данных) |
| DROP TABLE |
(удалить таблицу) |
| DROP VIEW |
(удалить виртуальную таблицу) |
| DROP INDEX |
(удалить индекс) |
| DROP TRIGGER |
(удалить триггер) |
| DROP PROCEDURE |
(удалить сохраненную процедуру) |
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде. Более точно его можно назвать "язык управления доступом". Он состоит из двух основных команд:
| GRANT |
(дать права) |
| REVOKE |
(забрать права) |
С точки зрения прикладного интерфейса существуют две разновидности команд SQL:
интерактивный SQL
встроенный SQL.
Интерактивный SQL используется в специальных утилитах (типа WISQL или DBD), позволяющих в интерактивном режиме вводить запросы с использованием команд SQL, посылать их для выполнения на сервер и получать результаты в предназначенном для этого окне. Встроенный SQL используется в прикладных программах, позволяя им посылать запросы к серверу и обрабатывать полученные результаты, в том числе комбинируя set-ориентированный и record-ориентированный подходы.
Реляционные операции. Команды языка манипулирования данными
Наиболее важной командой языка манипулирования данными является команда SELECT
Начнем с базовых операций реляционных баз данных. Таковыми являются:
выборка
(Restriction)
проекция
(Projection)
соединение
(Join)
объединение
(Union)
Операция выборки позволяет получить все строки (записи) либо часть строк одной таблицы.
SELECT * FROM country
Эти примеры иллюстрируют общую форму команды SELECT в языке SQL (для одной таблицы):
| SELECT |
(выбрать) специфицированные поля |
| FROM |
(из) специфицированной таблицы |
| WHERE |
(где) некоторое специфицированное условие является истинны |
Операция соединения позволяет соединять строки из более чем одной таблицы (по некоторому условию) для образования новых строк данных.
Операция объединения позволяет объединять результаты отдельных запросов по нескольким таблицам в единую результирующую таблицу. Таким образом, предложение UNION объединяет вывод двух или более SQL-запросов в единый набор строк и столбцов.
Для справки, приведем общую форму команды SELECT, учитывающую возможность соединения нескольких таблиц и объединения результатов:
| SELECT |
[DISTINCT] список_выбираемых_элементов (полей) |
| FROM |
список_таблиц (или представлений) |
| [WHERE |
предикат] |
| [GROUP BY |
поле (или поля) [HAVING предикат]] |
| [UNION |
другое_выражение_Select] |
| [ORDER BY |
поле (или поля) или номер (номера)]; |
Рис. 2: Общий формат команды SELECT
Отметим, что под предикатом понимается некоторое специфицированное условие (отбора), значение которого имеет булевский тип. Квадратные скобки означают необязательность использования дополнительных конструкций команды. Точка с запятой является стандартным терминатором команды. Отметим, что в WISQL и в компоненте TQuery ставить конечный терминатор не обязательно. При этом там, где допустим один пробел между элементами, разрешено ставить любое количество пробелов и пустых строк - выполняя желаемое форматирование для большей наглядности.
Команда SELECT
Простейшие конструкции команды SELECT
Итак, начнем с рассмотрения простейших конструкций языка SQL. После такого рассмотрения мы научимся:
назначать поля, которые должны быть выбраны
назначать к выборке "все поля"
управлять "вертикальным" и "горизонтальным" порядком выбираемых полей
подставлять собственные заголовки полей в результирующей таблице
производить вычисления в списке выбираемых элементов
использовать литералы в списке выбираемых элементов
ограничивать число возвращаемых строк
формировать сложные условия поиска, используя реляционные и логические операторы
устранять одинаковые строки из результата.
Список выбираемых элементов может содержать следующее:
имена полей
*
вычисления
литералы
функции
агрегирующие конструкции
Список полей
SELECT first_name, last_name, phone_no
FROM phone_list
получить список имен, фамилий и служебных телефонов всех работников предприятия
Все поля
SELECT *
FROM phone_list
получить список служебных телефонов всех работников предприятия со всей необходимой информацией
Все поля в произвольном порядке
SELECT first_name, last_name, phone_no,
location, phone_ext, emp_no
FROM phone_list
получить список служебных телефонов всех работников предприятия со всей необходимой информацией, расположив их в требуемом порядке
Вычисления
SELECT emp_no, salary, salary * 1.15
FROM employee
получить список номеров служащих и их зарплату, в том числе увеличенную на 15%
Порядок вычисления выражений подчиняется общепринятым правилам: сначала выполняется умножение и деление, а затем - сложение и вычитание. Операции одного уровня выполняются слева направо. Разрешено применять скобки для изменения порядка вычислений.
Литералы
Литералы - это строковые константы, которые применяются наряду с наименованиями столбцов и, таким образом, выступают в роли "псевдостолбцов". Строка символов, представляющая собой литерал, должна быть заключена в одинарные или двойные скобки.
SELECT first_name, "получает", salary,
"долларов в год"
FROM employee
получить список сотрудников и их зарплату
Конкатенация
Имеется возможность соединять два или более столбца, имеющие строковый тип, друг с другом, а также соединять их с литералами. Для этого используется операция конкатенации (||).
SELECT "сотрудник " || first_name || " " ||
last_name
FROM employee
получить список всех сотрудников
Использование квалификатора AS
Для придания наглядности получаемым результатам наряду с литералами в списке выбираемых элементов можно использовать квалификатор AS. Данный квалификатор заменяет в результирующей таблице существующее название столбца на заданное. Это наиболее эффективный и простой способ создания заголовков (к сожалению, InterBase, как уже отмечалось, не поддерживает использование русских букв в наименовании столбцов).
SELECT count(*) AS number
FROM employee
подсчитать количество служащих
Работа с датами
Внутренне дата в InterBase содержит значения даты и времени. Внешне дата может быть представлена строками различных форматов, например: "October 27, 1995" Кроме абсолютных дат, в SQL-выражениях можно также пользоваться относительным заданием дат: "yesterday" – вчера,"today" – сегодня, "now" - сейчас (включая время), "tomorrow" - завтра
Дата может неявно конвертироваться в строку (из строки), если:
строка, представляющая дату, имеет один из вышеперечисленных форматов;
выражение не содержит неоднозначностей в толковании типов столбцов.
Агрегатные функции
К агрегирующим функциям относятся функции вычисления суммы (SUM), максимального (SUM) и минимального (MIN) значений столбцов, арифметического среднего (AVG), а также количества строк, удовлетворяющих заданному условию (COUNT).
SELECT count(*), sum (budget), avg (budget),
min (budget), max (budget)
FROM department
WHERE head_dept = 100
вычислить: количество отделов, являющихся подразделениями отдела 100 (Маркетинг и продажи), их суммарный, средний, мини- мальный и максимальный бюджеты
Предложение FROM команды SELECT
В предложении FROM перечисляются все объекты (один или несколько), из которых производится выборка данных (рис.2). Каждая таблица или представление, о которых упоминается в запросе, должны быть перечислены в предложении FROM.
Ограничения на число выводимых строк
Число возвращаемых в результате запроса строк может быть ограничено путем использования предложения WHERE, содержащего условия отбора (предикат, рис.2). Условие отбора для отдельных строк может принимать значения true, false или unnown. При этом запрос возвращает в качестве результата только те строки (записи), для которых предикат имеет значение true.
Типы предикатов, используемых в предложении WHERE:
сравнение с использованием реляционных операторов
= равно
<> не равно
!= не равно
> больше
< меньше
>= больше или равно
<= меньше или равно
BETWEEN
IN
LIKE
CONTAINING
IS NULL
EXIST
ANY
ALL
Операции сравнения
Рассмотрим операции сравнения. Реляционные операторы могут использоваться с различными элементами. При этом важно соблюдать следующее правило: элементы должны иметь сравнимые типы. Если в базе данных определены домены, то сравниваемые элементы должны относиться к одному домену.
Элементом сравнения может выступать:
значение поля
литерал
арифметическое выражение
агрегирующая функция
другая встроенная функция
значение (значения), возвращаемые подзапросом.
BETWEEN
задает диапазон значений, для которого выражение принимает значение true. Разрешено также использовать конструкцию NOT BETWEEN.
Предикат BETWEEN с отрицанием NOT (NOT BETWEEN) позволяет получить выборку записей, указанные поля которых имеют значения меньше нижней границы и больше верхней границы.
Предикат IN проверяет, входит ли заданное значение, предшествующее ключевому слову "IN" (например, значение столбца или функция от него) в указанный в скобках список. Если заданное проверяемое значение равно какому-либо элементу в списке, то предикат принимает значение true. Разрешено также использовать конструкцию NOT IN.
LIKE
используется только с символьными данными. Он проверяет, соответствует ли данное символьное значение строке с указанной маской. В качестве маски используются все разрешенные символы (с учетом верхнего и нижнего регистров), а также специальные символы:
% - замещает любое количество символов (в том числе и 0),
_ - замещает только один символ.
CONTAINING
аналогичен предикату LIKE, за исключением того, что он не чувствителен к регистру букв. Разрешено также использовать конструкцию NOT CONTAINING.
IS NULL
значение столбца неизвестно. Поисковые условия, в которых значение столбца сравнивается с NULL, всегда принимают значение unknown (и, соответственно, приводят к ошибке), в противоположность true или false, т.е. Предикат IS NULL принимает значение true только тогда, когда выражение слева от ключевых слов "IS NULL" имеет значение null (пусто, не определено). Разрешено также использовать конструкцию IS NOT NULL, которая означает "не пусто", "имеет какое-либо значение".
Логические операторы
К логическим операторам относятся известные операторы AND, OR, NOT, позволяющие выполнять различные логические действия: логическое умножение (AND, "пересечение условий"), логическое сложение (OR, "объединение условий"), логическое отрицание (NOT, "отрицание условий"). В наших примерах мы уже применяли оператор AND. Использование этих операторов позволяет гибко "настроить" условия отбора записей.
Оператор AND
означает, что общий предикат будет истинным только тогда, когда условия, связанные по "AND", будут истинны.
Оператор OR
означает, что общий предикат будет истинным, когда хотя бы одно из условий, связанных по "OR", будет истинным.
Оператор NOT
означает, что общий предикат будет истинным, когда условие, перед которым стоит этот оператор, будет ложным.
Преобразование типов (CAST)
В SQL имеется возможность преобразовать значение столбца или функции к другому типу для более гибкого использования операций сравнения. Для этого используется функция CAST.
Изменение порядка выводимых строк (ORDER BY)
Порядок выводимых строк может быть изменен с помощью опционального (дополнительного) предложения ORDER BY в конце SQL-запроса. Это предложение имеет вид:
ORDER BY <порядок строк> [ASC | DESC]
Порядок строк может задаваться одним из двух способов:
именами
столбцов
номерами
столбцов.
Способ упорядочивания определяется дополнительными зарезервированными словами ASC и DESC. Способом по умолчанию - если ничего не указано - является упорядочивание "по возрастанию" (ASC). Если же указано слово "DESC", то упорядочивание будет производиться "по убыванию".
Подчеркнем еще раз, что предложение ORDER BY должно указываться в самом конце запроса.
Устранение дублирования (модификатор DISTINCT)
Дублированными являются такие строки в результирующей таблице, в которых идентичен каждый столбец.
Иногда (в зависимости от задачи) бывает необходимо устранить все повторы строк из результирующего набора. Этой цели служит модификатор DISTINCT. Данный модификатор может быть указан только один раз в списке выбираемых элементов и действует на весь список.
Соединение (JOIN)
Операция соединения используется в языке SQL для вывода связанной информации, хранящейся в нескольких таблицах, в одном запросе. В этом проявляется одна из наиболее важных особенностей запросов SQL - способность определять связи между многочисленными таблицами и выводить информацию из них в рамках этих связей. Именно эта операция придает гибкость и легкость языку SQL.
После изучения этого раздела мы будем способны:
соединять данные из нескольких таблиц в единую результирующую таблицу;
задавать имена столбцов двумя способами;
записывать внешние соединения;
создавать соединения таблицы с собой.
Операции соединения подразделяются на два вида - внутренние и внешние. Оба вида соединений задаются в предложении WHERE запроса SELECT с помощью специального условия соединения. Внешние соединения (о которых мы поговорим позднее) поддерживаются стандартом ANSI-92 и содержат зарезервированное слово "JOIN", в то время как внутренние соединения (или просто соединения) могут задаваться как без использования такого слова (в стандарте ANSI-89), так и с использованием слова "JOIN" (в стандарте ANSI-92).
Связывание производится, как правило, по первичному ключу одной таблицы и внешнему ключу другой таблицы - для каждой пары таблиц. При этом очень важно учитывать все поля внешнего ключа, иначе результат будет искажен. Соединяемые поля могут (но не обязаны!) присутствовать в списке выбираемых элементов. Предложение WHERE может содержать множественные условия соединений. Условие соединения может также комбинироваться с другими предикатами в предложении WHERE.
Внутренние соединения
Внутреннее соединение возвращает только те строки, для которых условие соединения принимает значение true.
GROUP BY
Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во FROM таблицы по группам, каждая из которых имеет одинаковые значения в столбце, указанном в GROUP BY. В рассматриваемом примере строки таблицы Поставки группируются так, что в одной группе содержатся все строки для продукта с ПР = 1, в другой – для продукта с ПР = 2 и т.д. (см. рис. 2.3.б). Далее к каждой группе применяется фраза SELECT. Каждое выражение в этой фразе должно принимать единственное значение для группы, т.е. оно может быть либо значением столбца, указанного в GROUP BY, либо арифметическим выражением, включающим это значение, либо константой, либо одной из SQL-функций, которая оперирует всеми значениями столбца в группе и сводит эти значения к единственному значению (например, к сумме).
SELECT ПР, SUM(К_во)
FROM Поставки
GROUP BY ПР;
HAVING
Фраза HAVING (рис.2.3) играет такую же роль для групп, что и фраза WHERE для строк: она используется для исключения групп, точно так же, как WHERE используется для исключения строк. Эта фраза включается в предложение лишь при наличии фразы GROUP BY, а выражение в HAVING должно принимать единственное значение для группы.
Например, выдать коды продуктов, поставляемых более чем двумя поставщиками:
SELECT *
FROM Поставки
GROUP BY ПС
HAVING COUNT(*) > 2;
Введение в понятие «хранилище данных». Концепция хранилища данных. Преимущества технологии хранилища данных. Сравнение OLTP-систем и хранилищ данных. Интерактивная аналитическая обработка данных (OLAP).Многомерная OLAP-технология. Многомерные базы данных
Хранилище данных
- предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки управления.
Уильям Инмон, считающийся основателем нового направления развития технологии БД, дал классическое определение информационного хранилища в 1990 г. Он охарактеризовал его как специальным образом администрируемую базу данных, содержимое которой имеет следующие свойства:
Предметная ориентация
Интегрированность данных
Инвариантность во времени
Неразрушаемость - cтабильность информации
Минимизация избыточности информации
Предметно ориентированное хранилище данных
- организованно в субъектных организациях(клиенты, продажи) а не вокруг области дейтельности (контроль за запасами) Хранить данные предназначенные для поддержки, а не прикладные данные.
Интегрированность
- данные поступают из разных источников и могут иметь разный формат, поэтому для предоставления пользователя необходимо создать интегрированный источник, который бы обеспечивал этот источник БД.
Привязка во времени
-данные будут точными если они будут привязаны к какому-то времени.
В основе концепции хранилища данных лежат две основные идеи:
(1) Интеграция разъединенных детализированных данных (они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
(2) Разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа.
Основные компоненты информационного хранилища
ПО промежуточного слоя Обеспечивает сетевой доступ и доступ к базам данных.
Транзакционные БД и внешние источники информации Базы данных OLTP-систем исторически предназначались для эффективной обработки структур данных в относительно небольшом числе четко определенных транзакций.
Уровень доступа к данным Относящееся сюда ПО обеспечивает общение конечных пользователей с информационным хранилищем и загрузку требуемых данных из транзакционных систем.
Загрузка и предварительная обработка Этот уровень включает в себя набор средств для загрузки данных из OLTP-систем и внешних источников.
Информационное хранилище Представляет собой ядро всей системы - один или несколько серверов БД. Метаданные Играют роль справочника, содержащего сведения об источниках первичных данных, алгоритмах обработки, которым исходные данные были подвергнуты, и т. д.
Уровень информационного доступа Обеспечивает непосредственное общение пользователя с данным DW посредством стандартных систем манипулирования, анализа и предоставления данных типа MS Excel, MS Access, Lotus 1-2-3 и др.
Уровень управления (администрирования) Отслеживает выполнение процедур, необходимых для обновления информационного хранилища или поддержания его состояния.
Преимущества технологии хранилища данных
Потенциально высокая отдача от инвестиций
Повышение конкурентно способности
Повышение лиц труда за принятие решения
Сравнение OLTP-систем и хранилищ данных.
| OLAP |
ХРАНИЛИЩЕ |
| Содержит все время обновляющиеся данные |
Не обновляется, исторические данные, агрегированные сведения |
| Хранит подробные сведения |
Хранит значительно обобщенные сведения |
| Данные динамические |
Данные статические |
| Высокая интенсивность обработки транзакций |
Средняя и низко обобщенная транзакция |
| Предсказуемый способ использования данных |
Не предсказуемый |
| для обработки транзакций |
Для проведения анализа |
| Поддержка принятия повседневных решений |
Поддержка приятия стратегических решений |
| Обслуживает большое количество работников |
Обслуживает малое количество работников, руководящее звено |
Интерактивная аналитическая обработка данных (OLAP).
- динамический синтаксис, анализ и консолидация объема многомерных данных
Термин OLAP-
это системы которые обеспечивают выборку данных в разных разрядах.
OLAP-включает в себя поддержку нескольких пользователей редактирующих БД, функции: моделирования., вычислительные механизмы получения производных результатов, прогнозирование выявление транзакций, статистический анализ. Для таких систем требуется многомерная модель БД.
С помощью технологии OLAP (On-Line Analytical Processing - оперативная аналитическая обработка). Этот метод позволяет аналитикам, менеджерам и руководителям "проникнуть в суть" накопленных данных за счет быстрого и согласованного доступа к широкому спектру представлений информации. Исходные данные преобразуются таким образом, чтобы наглядно отразить структуру деятельности предприятия.
При этом конечному пользователю предоставляется ряд аналитических и навигационных функций:
расчеты и вычисления по нескольким измерениям, иерархиям и/или членам;
анализ трендов;
выборка подмножеств данных для просмотра на экране;
углубление в данные (drill down), для просмотра информации на более детализированном уровне;
переход к детальным данным, лежащим в основе анализа;
поворот таблицы отображаемых данных.
Многомерная OLAP-технология
Средства OLAP часто реализуются в виде набора многопользовательских приложений с Web-поддержкой, дают быстрый доступ к любому элементу базы вне зависимости от объема и сложности данных. Часто это достигается за счет использования OLAP-сервера - мощного многопользовательского инструмента для работы с многомерными структурами данных. Конструкция сервера и структура данных оптимизируются таким образом, чтобы можно было выполнять нерегламентированные запросы, а также быстрые, гибкие вычисления и преобразования исходных данных.
С помощью OLAP сервера может быть организовано физическое хранение обработанной многомерной информации, что позволяет быстро выдавать ответы на запросы пользователя. Кроме того, предусматривается преобразование данных из реляционных и других баз в многомерные структуры в режиме реального времени.
В таблице 3 приведены сравнительные характеристики различных моделей управления данными:
Таблица 3
| Характеристики |
Реляционные СУБД OLTP |
Реляционные СУБД СППР/Хранилища данных |
Многомерные СУБД OLAP |
| Типовая операция |
Обновление |
Отчет |
Анализ |
| Уровень аналитических требований |
Низкий |
Средний |
Высокий |
| Экраны |
Неизменяемые |
Определяемые пользователем |
Определяемые пользователем |
| Объем данных на транзакцию |
Небольшой |
От малого до большого |
Большой |
| Уровень данных |
Детальные |
Детальные и суммарные |
В основном суммарные |
| Сроки хранения данных |
Только текущие |
Исторические и текущие |
Исторические, текущие и прогнозируемые |
| Структурные элементы |
Записи |
Записи |
Массивы |
В архитектуре, одновременно использующей реляционные и многомерные системы, данные хранятся на OLAP-сервере или OLAP-структуры используются в качестве кэша для реляционных данных.
Многомерные базы данных
Появились равномерно с реляционными подходом. Реально многомерных СУБД очень мало. Полчком послужило 12 требований кода и систем класса OLAP. Многомерная СУБД является усреднено специальной и предназначены для интерактивной аналитической обработки данных.
Агригируемость
- рассмотрение информации на различных уровнях её обобщения (аналитик, оператор, руководитель)
Историчность
- предполагается высокий уровень статичности не изменяемости данных и их привязка ко времени.
Прогнозируемость
- задания функции прогнозирования и применения к различным интревалам
Многомерность
- модели данных означает не многомерность реализации данных, а многомерное логическое представление структуры информации. Многомерное более наглядно и информировано чем простая модель. Её размерность более 2, то визуализация в гиперкубах и мегаразмерах. Пользователю удобнее иметь дело с многомерной моделью. Данные представляются в виде вырезок из многомерной модели.
Основные понятия: измерение
-множество однозначных данных образующих график гипер куба. Показатель
-ячейка-поле значения которого однозначно определяется фиксированным набором. Тип поля
-числовой. В зависимости от того как формируется значение ячейки, она может быть переменной. Значения могут загружаться их переменных источников, либо может быть формула: гиперкубическая, полекубическая. Полекубическая
-может быть применено несколько гипер кубов, с различной размерностью и с различным измерением разности грани.
Гипер кубическая схема
-все показатели определяются 1 и тем же набором измерений: средой, вращением, агрегацией, детализацией.
Среда-подмножество гипер куба, полученное в результате фиксации 1 или нескольких измерений.
Вращение- применяется при 2 мерном представлении данных и заключается в измененном порядке измерений
Агрегация-переход к большому общему
Дотализация- переход к большому детальному представлению информации.
Назначение хранилищ данных — предоставление пользователям информации для статистического анализа и принятия управленческих решений.
Хранилища данных должны обеспечивать высокую скорость получения данных, возможность получения и сравнения так называемых срезов данных, а также непротиворечивость, полноту и достоверность данных.
OLAP (On-Line Analytical Processing) является ключевым компонентом построения и применения хранилищ данных. Эта технология основана на построении многомерных наборов данных — OLAP-кубов, оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные.
Приложения с OLAP-функциональностью должны предоставлять пользователю результаты анализа за приемлемое время, осуществлять логический и статистический анализ, поддерживать многопользовательский доступ к данным, осуществлять многомерное концептуальное представление данных и иметь возможность обращаться к любой нужной информации.
Документальные информационно-поисковые системы. Информационно-поисковые языки. Система индексирования
Информационно-поисковая система (ИПС)
- автоматизированная поисковая система, реализованная на средствах вычислительной техники и предназначенная для нахождения и выдачи ее пользователям информации по заданным критериям.
ИПС представляет собой совокупность информационно-поискового языка, программных средств и правил перевода текстов на этот язык (индексирования), а также обеспечения поиска необходимых документов и/или данных.
Поисковый образ документа получается в результате процесса индексирования, который состоит из двух этапов: выявление смысла документа
и описание смысла на специальном информационно-поисковом языке
(ИПЯ). Поиск документа состоит в сравнении множества хранящихся в системе ПОД и текущего поискового образа запроса (ПОЗ), в результате чего пользователю выдается требуемый документ или отказ. Состоит из:
Банк данных
- автоматизированная информационная система централизованного хранения и коллективного использования данных.
Информационный запрос
- в широком смысле - текст, выражающий информационную потребность.
Поиск информации
- в узком смысле - процесс выявления в массиве информации записей, удовлетворяющих заранее определенному условию поиска (запросу).
Информационно-поисковые системы делятся на два типа.
Фактографическая информационная поисковая система -э
то система, где, объектом или сущностью есть то, что представляет интерес (сотрудник, договор, изделие и т.п.). хранятся не документы, а факты, относящиеся к какой-либо предметной области.
Документальные (документографические) ИПС
объектом сохранения и обработки есть собственно документы.. Хранимые документы индексируются некоторым специальным образом. Каждому документу (статье, отчету, протоколу и т.п.) присваивается индивидуальный код, составляющий поисковый образ документа. Поиск идет не по самим документам, а по их поисковым образам, которые содержат информацию (адрес) о местонахождении документа.
Компоненты
:
• массив документов (текстов) или фактов, выступающих в качестве объектов хранения и поиска;
• информационно-поисковый язык, предназначенный для отображения содержания документов и операций над ними, в том числе и запросов для поиска документов;
• правила, алгоритмы, методы индексирования и поиска документов, позволяющие описывать документы и операция над ними на информационно-поисковом языке;
• комплекс программных и аппаратных средств, с помощью которых реализуются процессы накопления, хранения и поиска документов;
• обслуживающий персонал, включающий администраторабанка документов, системных аналитиков, программистов и индексаторов.
Банки документов работают обычно в двух режимах:
1) избирательного распределения информации, информирование пользователей банка о новых поступлениях документов;2) ретроспективного поиска информации по разовым запросам во всем массиве документов.
Важнейший этап обработки слагается из следующих действий:
1) выявления основного смыслового содержания документа (с учетом точки зрения автора документа и информационных потребностей пользователя системы);
2) описания смыслового содержания документа на информационно-поисковом языке (ИПЯ) и получения соответствующего поискового образа документа (ПОД).
Информационно-поисковые языки (ИПЯ),
которые используются в настоящее время, можно разделить на три большие группы: • классификационные языки;•дескрипторные;• комбинированные.
Языки классификационного типа: • ИПЯ иерархической структуры;• ИПЯ фасетной структуры;• эмпирические (неиерархические) языки.
Классификационные системы.
В иерархических классификационных системах лексические единицы (термины) находятся между собой в отношениях включения. При записи они располагаются в порядке постепенного перехода от общих к более частным.
Дескрипторные информационно-поисковые языки.
Дескрипторные информационно-поисковые языки основаны на методе координатного индексирования, сущность которого сводится к тому, что смысловое содержание документа может быть с достаточной точностью и полнотой выражено списком ключевых слов, содержащихся в тексте
Различают языки описания (декларативные языки),
которые в свою очередь подразделяются на языки предкоординатные (классификационные) и посткоординатные (координатные), а
также - процедурные языки (языки запросов и манипулирования данными).
Каждый тип языковых средств включает в себя: алфавит и микро синтаксис (графические средства представления данных), лексику с парадигматикой (отражаемых словарями) и синтаксис,
который для языков описания может быть представлен в виде наборов форматов.
По области или по сфере применения информационно-поисковых языков можно выделить:
1. Коммуникативные (общесистемные) ИПЯ -
предназначенные для обеспечения взаимодействия между различными (информационными, библиотечными и др.) системами (в т.ч. распределенными по государственной, ведомственной или территориальной принадлежности);
2. Локальные (внутренние) ИПЯ -
предназначенные для использования в рамках отдельной системы;
3. Внешние ИПЯ
- используемые в других системах и предназначенные для взаимодействия только с ними.
ИНДЕКСИРОВАНИЕ -
Процесс выбора и присвоения документам, их частям, данным и/или отдельным понятиям (терминам) индексов
- лексических единиц ИПЯ
(в том числе - цифровых или символьных кодов, если они предусмотрены).
В зависимости от характера используемого ИПЯ различают предкоординатное индексирование и координатное (посткоординатное) индексирование, в т.ч. свободное индексирование (разновидность координатного индексирования производимого ключевыми словами, т.е. без использования какого-либо словаря). В зависимости от полноты учета разнородных признаков индексируемого материала (объекта индексирования) различают "одноаспектное" и "многоаспектное" индексирование (см. ниже).
Процесс индексирования включает:
1. Анализ
содержания индексируемого материала и выбор из него т.н. номинативных лексических единиц, существенных для его понимания;
2.
Формирование перечня ключевых слов, используемых при свободном индексировании;
3.
Нормализацию ключевых слов по форме и содержанию при помощи словаря используемого ИПЯ пред- или посткоординатного типа;
4. Избыточное индексирование
(см. ниже);
5.
Заполнение рабочего листа
с введением в него грамматических средств.
В зависимости от объекта и содержания процесса индексирования его результатами являются: поисковый образ документа (ПОД), поисковый образ лексической единицы (ПОЛЕ), поисковый образ запроса (ПОЗ) или поисковое предписание (ПП).
Фактографические информационные системы. Модели данных. Моделирование данных методом ERD («сущность-связь»)
Фактогрофическая информационная система -
система, где, объектом или сущностью есть то, что представляет для проблемной сферы многосторонний интерес (сотрудник, договор, изделие и т.п.). Хранятся не документы, а факты, относящиеся к какой-либо предметной области. Хранимые факты могут быть извлечены из различных документов. В базе фактов они связываются между собой системой разнообразных отношений. Запросы, поступающие в фактографические ИПС, используют тезаурус для поиска ответов на запросы. Поиск осуществляется методом поиска по образцу.
Модели данных
Успешность работы компании на рынке зависит от многих факторов – диапазона предлагаемых услуг, насыщенности рынка, маркетинговой политики и т. п.
Бизнес-процесс
– это логичный, последовательный, взаимосвязанный набор мероприятий, который потребляет ресурсы производителя, создает ценность и выдает результат потребителю.
Моделирование бизнес-процессов
-это эффективное средство поиска путей оптимизации деятельности компании, средство прогнозирования и минимизации рисков, возникающих на различных этапах реорганизации предприятия.
Под методологией создания модели бизнес-процесса
понимается совокупность способов, при помощи которых объекты реального мира и связи между ними представляются в виде модели. Любая методология включает три основные составляющие:
теоретическая база;
описание шагов, необходимых для получения заданного результата;
рекомендации по использованию как отдельно, так и в составе группы методик.
Основное в методологии – дать пользователю последовательность шагов, которые приводят к заданному результату. Способность получать результат с заданными параметрами и характеризует ее эффективность.
Объект модели отражает некоторый реальный объект так называемой предметной области (организации), люди, документы, машины и оборудование, программное обеспечение и т. д.
Связи предназначены для описания взаимоотношений объектов друг с другом. К числу таких взаимоотношений могут относиться: последовательность выполнения во времени, связь при помощи потока информации, использование другим объектом и т. д.
История развития методологий моделирования бизнес-процессов
Основу многих современных методологий моделирования бизнес-процессов составили методология SADT (Structured Analysis and Design Technique – метод структурного анализа и проектирования) и алгоритмические языки, применяемые для разработки программного обеспечения.
Основные типы методологий моделирования и анализа бизнес-процессов
В настоящее время для описания, моделирования и анализа бизнес-процессов используются несколько типов методологий. К числу наиболее распространенных типов относятся следующие методологии:
моделирования бизнес-процессов (Business Process Modeling);
описания потоков работ (Work Flow Modeling);
описания потоков данных (Data Flow Modeling).
Методологии моделирования бизнес-процессов (Business Process Modeling)
Наиболее широко используемая методология описания бизнес-процессов - стандарт США IDEF0. С момента разработки стандарт не претерпел существенных изменений
Методологии описания потоков работ (Work Flow Modeling)
Вторая важнейшая методология описания процессов – IDEF3, предназначенная для описания рабочих процессов или, иными словами, потоков работ.
Методологии описания потоков данных (Data Flow Modeling)
Еще одна группа методологий, активно используемых на практике, – нотации DFD (Data Flow Diagramming), предназначенные для описания потоков данных. Они позволяют отразить последовательность работ, выполняемых по ходу процесса
Прочие методологии
бизнес-процессы предприятия могут быть представлены при помощи стандартных блок-схем, которые, по сути, основаны на идеологии нотации IDEF3, но при этом содержат некоторые дополнительные специальные графические объекты. Использование этих объектов позволяет сделать блок-схемы процессов более наглядными и понятными для исполнителей.
Метод ERD
Цель моделирования данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных.
Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных. Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера.
Первый шаг
моделирования - извлечение информации из интервью и выделение сущностей.
Сущность (Entity)
- реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению (рисунок 2.18).
Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами: *каждая сущность должна иметь уникальное имя, *сущность обладает одним или несколькими атрибутами; *сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности; *каждая сущность может обладать любым количеством связей с другими сущностями модели.
Второй шаг моделирования является идентификация связей.
Связь (Relationship)
- поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, экземпляр сущности-потомка может существовать только при существовании сущности родителя. Должно даваться имя, помещаемое возле линии связи. Имя должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка. Степень связи и обязательность графически изображаются следующим образом.
Атрибут
- любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Экземпляр атрибута
- это определенная характеристика отдельного элемента множества.
Уникальный идентификатор
- это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рисунок 2.24).
Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Подтипы и супертипы:
одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 2.26).
Взаимно исключающие связи:
каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей
Рекурсивная связь:
сущность может быть связана сама с собой (рисунок 2.28).
Неперемещаемые (non-transferrable) связи:
экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 2.29).
Жизненный цикл программного обеспечения информационных систем. Модели жизненного цикла. Каноническое проектирование информационных систем. Типовое проектирование информационных систем
Понятие жизненного цикла
Методология проектирования информационных систем описывает процесс создания и сопровождения систем в виде жизненного цикла (ЖЦ) ИС, представляя его как некоторую последовательность стадий и выполняемых на них процессов. Для каждого этапа определяются состав и последовательность выполняемых работ, получаемые результаты, методы и средства, необходимые для выполнения работ, роли и ответственность участников и т.д. Такое формальное описание ЖЦ ИС позволяет спланировать и организовать процесс коллективной разработки и обеспечить управление этим процессом.
Понятие жизненного цикла Жизненный цикл ИС
можно представить как ряд событий, происходящих с системой в процессе ее создания и использования. Модель жизненного цикла отражает различные состояния системы, начиная с момента возникновения необходимости в данной ИС и заканчивая моментом ее полного выхода из употребления.
Модель жизненного цикла
- структура, содержащая процессы, действия и задачи, которые осуществляются в ходе разработки, функционирования и сопровождения программного продукта в течение всей жизни системы, от определения требований до завершения ее использования.
Структура жизненного цикла основывается на трех группах процессов:
+основные процессы жизненного цикла (приобретение, поставка, разработка, эксплуатация, сопровождение);
+ вспомогательные процессы, обеспечивающие выполнение основных процессов (документирование, управление конфигурацией, обеспечение качества, верификация, аттестация, оценка, аудит, разрешение проблем);
+ организационные процессы (управление проектами, создание инфраструктуры проекта, определение, оценка и улучшение самого жизненного цикла, обучение).
Основные процессы жизненного цикла
Среди основных процессов жизненного цикла наибольшую важность разработка, эксплуатация и сопровождение.
Разработка
является одним из важнейших процессов жизненного цикла информационной системы и, как правило, включает в себя стратегическое планирование, анализ, проектирование и реализацию (программирование).
Эксплуатация делится
на подготовительные и основные. К подготовительным
относятся:+ конфигурирование базы данных и рабочих мест пользователей;+ обеспечение пользователей эксплуатационной документацией;+ обучение персонала. Основные
эксплуатационные работы включают; + непосредственно эксплуатацию;+ локализацию проблем и устранение причин их возникновения;+ модификацию программного обеспечения;+ подготовку предложений по совершенствованию системы;+ развитие и модернизацию системы.
Сопровождение
Службы технической поддержки играют весьма заметную роль в жизни любой корпоративной информационной системы.
Вспомогательные процессы
управление конфигурацией- процесс, поддерживающих основные процессы жизненного цикла информационной системы, прежде всего процессы разработки и сопровождения. Управление конфигурацией позволяет организовывать, систематически учитывать и контролировать внесение изменений в различные компоненты информационной системы на всех стадиях ее жизненного цикла.
Организационные процессы.
Планирования и организации работ, создания коллективов разработчиков и контроля за сроками и качеством выполняемых работ. Проверка — это процесс определения соответствия параметров разработки исходным требованиям..
Модели жизненного цикла- структура, определяющая последовательность выполнения и взаимосвязи процессов, действий и задач, выполняемых на протяжении жизненного цикла. В настоящее время известны и используются следующие модели жизненного цикла:
Задачная модель
При разработке системы "снизу-вверх" от отдельных задач ко всей системе (задачная модель) единый поход к разработке неизбежно теряется, возникают проблемы при информационной стыковке отдельных компонентов. Однако в отдельных случаях такая технология может оказаться целесообразной: Крайняя срочность
Каскадная модель
(характерна для периода 1970-1985 гг.) Предусматривает последовательное выполнение всех этапов проекта в строго фиксированном порядке. Переход на следующий этап означает полное завершение работ на предыдущем этапе. Плюсы
подхода заключаются в следующем: *на каждом этапе формируется законченный набор проектной документации; *выполняемые в логичной последовательности этапы работ позволяют планировать сроки завершения всех работ и соответствующие затраты.
Недостатки:
реальный процесс создания систем никогда полностью не укладывался в такую жесткую схему, *потребность в возврате к предыдущим.* существенное запаздывание с получением результатов. Данная модель основным достоинством имеет системность разработки, а основные недостатки - медленно и дорого.
Поэтапная модель с промежуточным контролем
Разработка ИС ведется итерациями с циклами обратной связи между этапами. Межэтапные корректировки позволяют учитывать реально существующее взаимовлияние результатов разработки на различных этапах; время жизни каждого из этапов растягивается на весь период разработки.
Спиральная модель
(характерна для периода после 1986.г.). На каждом витке спирали выполняется создание очередной версии продукта, уточняются требования проекта, определяется его качество и планируются работы следующего витка. Особое внимание уделяется начальным этапам разработки - анализу и проектированию, где реализуемость тех или иных технических решений проверяется и обосновывается посредством создания прототипов (макетирования).
Основная проблема спирального цикла - определение момента перехода на следующий этап. Для ее решения необходимо ввести временные ограничения на каждый из этапов жизненного цикла.
На практике наибольшее распространение получили две основные модели жизненного цикла: каскадная модель, спиральная модель.
Каноническое проектирование ИС
Каноническое проектирование ориентировано на использование каскадной модели жизненного цикла ИС.Стадии и этапы создания ИС описаны в стандарте ГОСТ 34.601-90, выполняются организациями-участниками, прописываются в договорах
и технических заданиях
на выполнение работ:
СТАДИИ И ЭТАПЫ РАБОТЫ:
Стадия 1.
Формирование требований к ИС.
обследование объекта и обоснование необходимости создания ИС;
формирование требований пользователей к ИС;
оформление отчета о выполненной работе и тактико-технического задания на разработку.
Стадия 2.
Разработка концепции ИС.
изучение объекта автоматизации;
проведение необходимых научно-исследовательских работ;
разработка вариантов концепции ИС, удовлетворяющих требованиям пользователей;
оформление отчета и утверждение концепции.
Стадия 3.
Техническое задание.
разработка и утверждение технического задания на создание ИС.
Стадия 4.
Эскизный проект.
разработка предварительных проектных решений по системе и ее частям;
разработка эскизной документации на ИС и ее части.
Стадия 5.
Технический проект.
разработка проектных решений по системе и ее частям;
разработка документации на ИС и ее части;
разработка и оформление документации на поставку комплектующих изделий;
разработка заданий на проектирование в смежных частях проекта.
Стадия 6.
Рабочая документация.
разработка рабочей документации на ИС и ее части;
разработка и адаптация программ.
Стадия 7.
Ввод в действие.
подготовка объекта автоматизации;
подготовка персонала;
комплектация ИС поставляемыми изделиями (программными и техническими средствами, программно-техническими комплексами, информационными изделиями);
строительно-монтажные работы;
пусконаладочные работы;
проведение предварительных испытаний;
проведение опытной эксплуатации;
проведение приемочных испытаний.
Стадия 8.
Сопровождение ИС.
выполнение работ в соответствии с гарантийными обязательствами;
послегарантийное обслуживание.
OБСЛЕДОВАНИЕ:
- это изучение и диагностический анализ организационной структуры предприятия, его деятельности и существующей системы обработки информации.
Материалы, полученные в результате обследования, используются для:
обоснования разработки и поэтапного внедрения систем;
составления технического задания на разработку систем;
разработки технического и рабочего проектов систем.
Этап
обследования
надо выделить две составляющие:
определение стратегии внедрения ИС
детальный анализ деятельности организации.
Задачи: обследования
- оценка реального объема проекта, его целей и задач на основе выявленных функций и информационных элементов автоматизируемого объекта высокого уровня. взаимодействия
- получить полное и однозначное понимание требований заказчика. Как правило, нужная информация может быть получена в результате интервью, бесед или семинаров с руководством, экспертами и пользователями. Результатом этапа
- является документ (технико-экономическое обоснование проекта), где четко сформулировано, что получит заказчик, когда он получит готовый продукт (график выполнения работ), сколько будет стоить (для крупных проектов должен быть составлен график финансирования на разных этапах работ).
Содержание документа:
ограничения, риски, критические факторы, которые могут повлиять на успешность проекта;
совокупность условий, при которых предполагается эксплуатировать будущую систему: архитектура системы, аппаратные и программные ресурсы, условия функционирования, обслуживающий персонал и пользователи системы;
сроки завершения отдельных этапов, форма приемки/сдачи работ, привлекаемые ресурсы, меры по защите информации;
описание выполняемых системой функций;
возможности развития системы;
информационные объекты системы;
интерфейсы и распределение функций между человеком и системой;
требования к программным и информационным компонентам ПО, требования к СУБД;
что не будет реализовано в рамках проекта.
Этап детального анализа
деятельности организации.
Задачи:
обеспечивают реализацию функций управления, организационная структура, штаты и содержание работ по управлению предприятием, а также характер подчиненности вышестоящим органам управления
На этом этапе выявляют:
инструктивно-методические и директивные материалы, на основании которых определяются состав подсистем и перечень задач;
возможности применения новых методов решения задач.
Аналитики собирают и фиксируют информацию в двух взаимосвязанных формах:
функции - информация о событиях и процессах, которые происходят в бизнесе;
сущности - информация о вещах, имеющих значение для организации и о которых что-то известно.
При изучении функциональной задачи управления определяются:
наименование задачи; сроки и периодичность ее решения;
степень формализуемости задачи;
источники информации, необходимые для решения задачи;
показатели и их количественные характеристики;
порядок корректировки информации;
действующие алгоритмы расчета показателей и возможные методы контроля;
действующие средства сбора, передачи и обработки информации;
действующие средства связи;
принятая точность решения задачи;
трудоемкость решения задачи;
действующие формы представления исходных данных и результатов их обработки в виде документов;
потребители результатной информации по задаче.
Главная задача
- описание документооборота организации, составляется схема маршрута движения документов, которая должна отразить:
количество документов;
место формирования показателей документа;
взаимосвязь документов при их формировании;
маршрут и длительность движения документа;
место использования и хранения данного документа;
внутренние и внешние информационные связи;
объем документа в знаках.
Детальный анализ деятельности организации:
Результат
- перечень задач управления, решение которых целесообразно автоматизировать, и очередность их разработки.
Типовое проектирование информационных систем.
Типовое проектирование информационных систем (ИС)
Это создание системы из готовых типовых элементов. Основополагающее требование для применения методов типового проектирования - возможность декомпозиции проектируемой ИС на множество составляющих компонентов (подсистем, комплексов задач, программных модулей и т.д.). Для реализации выделенных компонентов выбираются имеющиеся на рынке типовые проектные решения, которые настраиваются на особенности конкретного предприятия.
Типовое проектное решение (ТПР)
Это тиражируемое (пригодное к многократному использованию) проектное решение.
Классы ТПР:
элементные ТПР
- типовые решения по задаче или по отдельному виду обеспечения задачи (информационному, программному, техническому, математическому, организационному);
подсистемные ТПР
- в качестве элементов типизации выступают отдельные подсистемы, разработанные с учетом функциональной полноты и минимизации внешних информационных связей;
объектные ТПР
- типовые отраслевые проекты, которые включают полный набор функциональных и обеспечивающих подсистем ИС. Каждое типовое решение предполагает наличие документации с детальным описанием ТПР и процедур настройки в соответствии с требованиями разрабатываемой системы (кроме функциональных элементов (программных или аппаратных).
Элементарные ТПРРеализация
- библиотеки методо-ориентированных программ;Достоинства:
обеспечивается применение модульного подхода к проектированию и документированию ИС; Недостатки:
большие затраты времени на сопряжение разнородных элементов вследствие информационной, программной и технической несовместимости; большие затраты времени на доработкуТПР отдельных элементов.
Подсистемные ТПРРеализация:
пакеты прикладных программ; Достоинства:
достигается высокая степень интеграции элементов ИС; позволяют осуществлять: модульное проектирование; параметрическую настройку программных компонентов на различные объекты управления; обеспечивают: сокращение затрат на проектирование и программирование взаимосвязанных компонентов; хорошее документирование отображаемых процессов обработки информации. Недостатки:
адаптивность ТПР недостаточна с позиции непрерывного инжиниринга деловых процессов возникают проблемы в комплексировании разных функциональных подсистем, особенно в случае использования решений нескольких производителей программного обеспечения
Объектные ТПРРеализация
- отраслевые проекты ИС;Достоинства:
комплексирование всех компонентов ИС за счет методологического единства и информационной, программной и технической совместимости; открытость архитектуры — позволяет устанавливать ТПР на разных программно-технических платформах; масштабируемость — допускает конфигурацию ИС для переменного числа рабочих мест; конфигурируемость — позволяет выбирать необходимое подмножество компонентов;
Недостатки:
проблемы привязки типового проекта к конкретному объекту управления, что вызывает в некоторых случаях даже необходимость изменения организационно-экономической структуры объекта автоматизации.
Подходы для реализации типового проектирования
параметрически-ориентированное; модельно-ориентированное проектирование.
Этапы параметрически-ориентированного проектирования
определение критериев оценки пригодности пакетов прикладных программ (ППП) для решения поставленных задач; анализ и оценка доступных ППП по сформулированным критериям; выбор и закупка наиболее подходящего пакета; настройка параметров (доработка) закупленного ППП.
Группы критериев оценки ППП*
назначение и возможности пакета; *отличительные признаки и свойства пакета; *требования к техническим и программным средствам; *документация пакета; *факторы финансового порядка; *особенности установки пакета;
особенности эксплуатации пакета; *помощь поставщика по внедрению и поддержанию пакета; *оценка качества пакета и опыт его использования; *перспективы развития пакета.
Внутри каждой группы критериев выделяется некоторое подмножество частных показателей, детализирующих каждый из десяти выделенных аспектов анализа выбираемых ППП. Числовые значения показателей для конкретных ППП устанавливаются экспертами по выбранной шкале оценок (например, 10-балльной). На их основе формируются групповые оценки и комплексная оценка пакета (путем вычисления средневзвешенных значений). Нормированные взвешивающие коэффициенты также получаются экспертным путем.
Модельно-ориентированное проектирование
Заключается в адаптации состава и характеристик типовой ИС в соответствии с моделью объекта автоматизации. Предполагает, построение модели объекта автоматизации с использованием специального программного инструментария (SAP Business Engineering Workbench (BEW), BAAN Enterprise Modeler). Возможно также создание системы на базе типовой модели ИС из репозитория, который поставляется вместе с программным продуктом и расширяется по мере накопления опыта.
Репозиторий содержит
базовую (ссылочную) модель ИС, типовые (референтные) модели определенных классов ИС, модели конкретных ИС предприятий.
Базовая модель ИС
в репозитории содержит описание бизнес-функций, бизнес-процессов, бизнес-объектов, бизнес-правил, организационной структуры, которые поддерживаются программными модулями типовой ИС.
Типовые модели
описывают конфигурации информационной системы для определенных отраслей или типов производства.
Модель конкретного предприятия
строится либо путем выбора фрагментов основной или типовой модели в соответствии со специфическими особенностями предприятия, либо путем автоматизированной адаптации этих моделей в результате экспертного опроса (SAP Business Engineering Workbench). Построенная модель предприятия в виде метаописания хранится в репозитории и при необходимости может быть откорректирована.
Бизнес-правила
определяют условия корректности совместного применения различных компонентов ИС и используются для поддержания целостности создаваемой системы.
Модель бизнес-функций
представляет собой иерархическую декомпозицию функциональной деятельности предприятия.
Модель бизнес-процессов
отражает выполнение работ для функций самого нижнего уровня модели бизнес-функций
Модели бизнес-объектов
используются для интеграции приложений, поддерживающих исполнение различных бизнес-процессов.
Модель организационной структуры
предприятия представляет собой традиционную иерархическую структуру подчинения подразделений.Внедрение типовой информационной системы начинается с анализа требований к конкретной ИС, которые выявляются на основе результатов предпроектного обследования объекта автоматизации
Реализация типового проекта предусматривает выполнение следующих операций:
установку глобальных параметров системы;
задание структуры объекта автоматизации;
определение структуры основных данных;
задание перечня реализуемых функций и процессов;
описание интерфейсов;
описание отчетов;
настройку авторизации доступа;
настройку системы архивирования.
Типовое проектирование ИС
Методы типового проектирования ИС достаточно подробно рассмотрены в литературе [10]. В данной книге приведены основные определения и представлено задание для разработки проекта ИС методом типового проектирования (кейс "Проектирование ИС предприятия оптовой торговли лекарственными препаратами").
Типовое проектирование ИС предполагает создание системы из готовых типовых элементов.Основополагающим требованием для применения методов типового проектирования является возможность декомпозиции проектируемой ИС на множество составляющих компонентов (подсистем, комплексов задач, программных модулей и т.д.). Для реализации выделенных компонентов выбираются имеющиеся на рынке типовые проектные решения, которые настраиваются на особенности конкретного предприятия.
Типовое проектное решение (ТПР)- это тиражируемое (пригодное к многократному использованию) проектное решение.
Принятая классификация ТПР основана на уровне декомпозиции системы. Выделяются следующие классы ТПР:
элементные ТПР - типовые решения по задаче или по отдельному виду обеспечения задачи (информационному, программному, техническому, математическому, организационному);
подсистемные ТПР - в качестве элементов типизации выступают отдельные подсистемы, разработанные с учетом функциональной полноты и минимизации внешних информационных связей;
объектные ТПР - типовые отраслевые проекты, которые включают полный набор функциональных и обеспечивающих подсистем ИС.
Каждое типовое решение предполагает наличие, кроме собственно функциональных элементов (программных или аппаратных), документации с детальным описанием ТПР и процедур настройки в соответствии с требованиями разрабатываемой системы.
Основные особенности различных классов ТПР приведены в таблице 3.3.
| Таблица 3.3. Достоинства и недостатки ТПР |
| Класс ТПР Реализация ТПР |
Достоинства |
Недостатки |
| Элементные ТПР Библиотеки методо-ориентированных программ |
обеспечивается применение модульного подхода к проектированию и документированию ИС |
большие затраты времени на сопряжение разнородных элементов вследствие информационной, программной и технической несовместимости
большие затраты времени на доработкуТПР отдельных элементов
|
| Подсистемные ТПР Пакеты прикладных программ |
достигается высокая степень интеграции элементов ИС
позволяют осуществлять: модульное проектирование; параметрическую настройку программных компонентов на различные объекты управления
обеспечивают: сокращение затрат на проектирование и программирование взаимосвязанных компонентов; хорошее документирование отображаемых процессов обработки информации
|
адаптивность ТПР недостаточна с позиции непрерывного инжиниринга деловых процессов
возникают проблемы в комплексировании разных функциональных подсистем, особенно в случае использования решений нескольких производителей программного обеспечения
|
| Объектные ТПР Отраслевые проекты ИС |
комплексирование всех компонентов ИС за счет методологического единства и информационной, программной и технической совместимости
открытость архитектуры — позволяет устанавливатьТПР на разных программно-технических платформах
масштабируемость — допускает конфигурацию ИС для переменного числа рабочих мест
конфигурируемость — позволяет выбирать необходимое подмножество компонентов
|
проблемы привязки типового проекта к конкретному объекту управления, что вызывает в некоторых случаях даже необходимость изменения организационно-экономической структуры объекта автоматизации |
Для реализации типового проектирования используются два подхода: параметрически-ориентированное и модельно-ориентированное проектирование.
Параметрически-ориентированное проектированиевключает следующие этапы: определение критериев оценки пригодности пакетов прикладных программ (ППП) для решения поставленных задач, анализ и оценка доступных ППП по сформулированным критериям, выбор и закупка наиболее подходящего пакета, настройка параметров (доработка) закупленного ППП.
Критерии оценки ППП делятся на следующие группы:
назначение и возможности пакета;
отличительные признаки и свойства пакета;
требования к техническим и программным средствам;
документация пакета;
факторы финансового порядка;
особенности установки пакета;
особенности эксплуатации пакета;
помощь поставщика по внедрению и поддержанию пакета;
оценка качества пакета и опыт его использования;
перспективы развития пакета.
Внутри каждой группы критериев выделяется некоторое подмножество частных показателей, детализирующих каждый из десяти выделенных аспектов анализа выбираемых ППП. Достаточно полный перечень показателей можно найти в литературе [10].
Числовые значения показателей для конкретных ППП устанавливаются экспертами по выбранной шкале оценок (например, 10-балльной). На их основе формируются групповые оценки и комплексная оценка пакета (путем вычисления средневзвешенных значений). Нормированные взвешивающие коэффициенты также получаются экспертным путем.
Функционально-ориентированный и объектно-ориентированный подходы к проектированию информационных систем. Методология функционального моделирования IDEF0 (SADT). Методология построения диаграмм потоков данных DFD. Универсальный язык моделирования UML
Функционально-ориентированный и объектно-ориентированный подходы к проектированию ИС
Процесс бизнес - моделирования может быть реализован в рамках различных методик, отличающихся прежде всего своим подходом к тому, что представляет собой моделируемая организация. В соответствии с различными представлениями об организации методики принято делить на объектные и функциональные
(структурные).
Объектные методики
рассматривают моделируемую организацию как набор взаимодействующих объектов – производственных единиц. Объект как реальность – предмет или явление, имеющие четко определяемое поведение. Целью применения данной методики является выделение объектов, составляющих организацию, и распределение между ними ответственностей за выполняемые действия.
Функциональные методики
, наиболее известной из которых является методика IDEF, рассматривают организацию как набор функций, преобразующий поступающий поток информации в выходной поток. Процесс преобразования информации потребляет определенные ресурсы. Основное отличие от объектной методики заключается в четком отделении функций (методов обработки данных) от самих данных.
Преимущества. Объектный подход позволяет построить более устойчивую к изменениям систему, лучше соответствует существующим структурам организации. Функциональное моделирование хорошо показывает себя в тех случаях, когда организационная структура находится в процессе изменения или вообще слабо оформлена. Подход от выполняемых функций интуитивно лучше понимается исполнителями при получении от них информации об их текущей работе
Методология функционального моделирования IDEF0
Методологию IDEF0O можно считать следующим этапом развития хорошо известного графического языка описания функциональных систем SADT. Исторически IDEF0 разработан в 1981 году в рамках программы автоматизации промышленных предприятий ICAM. Семейство стандартов IDEF унаследовало свое обозначение от названия этой программы (IDEF=Icam DEFinition), в декабре 1993 года Национальным Институтом по Стандартам и Технологиям США (NIST).
Целью: построение функциональной схемы исследуемой системы, описывающей все необходимые процессы с точностью, достаточной для однозначного моделирования деятельности системы.
В основе методологии лежат четыре основных понятия: функциональный блок, интерфейсная дуга, декомпозиция, глоссарий.
Функциональный блок
(Activity Box) представляет собой некоторую конкретную функцию в рамках рассматриваемой системы. Название в глагольном наклонении (например, «производить услуги»). На диаграмме функциональный блок изображается прямоугольником. Каждая из четырех сторон функционального блока имеет свое определенное значение (роль), при этом: Рис. 6.1. Функциональный блок
верхняя сторона имеет значение «Управление» (Control);
левая сторона имеет значение «Вход» (Input);
правая сторона имеет значение «Выход» (Output);
нижняя сторона имеет значение «Механизм» (Mechanism).
Интерфейсная дуга
(Arrow) отображает элемент системы, который обрабатывается функциональным блоком или оказывает иное влияние на функцию, представленную данным функциональным блоком. С помощью их отображают различные объекты, в той или иной степени определяющие процессы, В зависимости от сторон функционального блока подходит данная интерфейсная дуга, она носит название «входящей», «исходящей» или «управляющей».Наличие управляющих интерфейсных дуг является одним из главных отличий стандарта IDEF0 от других методологий классов DFD (Data Flow Diagram) и WFD (Work Flow Diagram).
Декомпозиция
(Decomposition) является основным понятием стандарта IDEF0. Принцип декомпозиции применяется при разбиении сложного процесса на составляющие его функции. Декомпозиция позволяет постепенно и структурированно представлять модель системы в виде иерархической структуры отдельных диаграмм, что делает ее легко усваиваемой.
Глоссарий
(Glossary). Для каждого из элементов IDEF0 существующий стандарт подразумевает создание и поддержание набора соответствующих определений, которые характеризуют объект, отображенный данным элементом. Этот набор называется глоссарием и является описанием сущности данного элемента. Глоссарий гармонично дополняет наглядный графический язык, снабжая диаграммы необходимой дополнительной информацией.
Стандарт IDEF0 содержит набор процедур, позволяющих разрабатывать и согласовывать модель большой группой людей, принадлежащих к разным областям деятельности моделируемой системы. Обычно процесс разработки является итеративным и состоит из следующих условных этапов:
Создание модели группой специалистов, относящихся к различным сферам деятельности предприятия. Эта группа в терминах IDEF0 называется авторами (Authors).
Методология построения диаграмм потоков данных DFD.
Целью: построение модели рассматриваемой системы в виде диаграммы потоков данных (Data Flow Diagram — DFD), обеспечивающей правильное описание выходов при заданном воздействии на вход системы. Диаграммы потоков данных являются основным средством моделирования функциональных требований к проектируемой системе. Существуют основные четыре понятия
: *потоки данных, *процессы (работы) *преобразования входных потоков данных в выходные, *внешние сущности, *накопители данных (хранилища).
Потоки данных
являются абстракциями, использующимися для моделирования передачи информации из одной части системы в другую. Потоки на диаграммах изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Процесс
(работы) состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Имя процесса должно содержать глагол в неопределенной форме. Каждый процесс имеет уникальный номер для ссылок. Процесс на диаграмме потоков данных изображается, как показано на рисунке 2.15.
Хранилище
(накопитель) данных позволяет на указанных участках определять данные, которые будут сохраняться в памяти между процессами. Имя хранилища должно определять его содержимое и быть существительным.
Внешняя сущность
представляет собой материальный объект вне контекста системы, являющейся источником или приемником системных данных. Ее имя существительное-«склад товаров». Предполагается, что объекты, представленные как внешние сущности, не должны участвовать ни в какой обработке.
Внешняя сущность обозначается квадратом (рисунок 2.13), расположенным как бы "над" диаграммой и бросающим на нее тень, для того, чтобы можно было выделить этот символ среди других обозначений:
Системы и подсистемы
При построении модели сложной ИС она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы как единого целого, либо может быть декомпозирована на ряд подсистем.
Подсистема (или система) на контекстной диаграмме изображается следующим образом (рисунок 2.14).
Номер подсистемы служит для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Накопители данных
Накопитель данных представляет собой абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных идентифицируется буквой "D" и произвольным числом.
В состав DFD входят словари данных и миниспецификации.
Словари данных
являются каталогами всех элементов данных, присутствующих в DFD, включая групповые и индивидуальные потоки данных, хранилища и процессы, а также все их атрибуты.
Миниспецификации обработки
— описывают DFD-процессы нижнего уровня. Фактически миниспецификации представляют собой алгоритмы описания задач, выполняемых процессами: множество всех миниспецификаций является полной спецификацией системы.
Процесс построения DFD начинается с создания так называемой основной диаграммы типа «звезда», на которой представлен моделируемый процесс и все внешние сущности. Внешние сущности выделяются по отношению к основному процессу. Для всех внешних сущностей строится таблица событий, описывающая их взаимодействие с основным потоком.
Декомпозиция завершается, когда процесс становится простым, т.е.:
процесс имеет два-три входных и выходных потока;
процесс может быть описан в виде преобразования входных данных в выходные;
процесс может быть описан в виде последовательного алгоритма.
Для простых процессов строится миниспецификация
– формальное описание алгоритма преобразования входных данных в выходные.
Следующим шагом после определения полной таблицы событий выделяются потоки данных, которыми обмениваются процессы и внешние сущности.
После построения потоков данных диаграмма должна быть проверена на полноту и непротиворечивость.
Преимущества методики DFD относятся:
возможность однозначно определить внешние сущности, анализируя потоки информации внутри и вне системы;
возможность проектирования сверху вниз, что облегчает построение модели «как должно быть»;
наличие спецификаций процессов нижнего уровня, что позволяет преодолеть логическую незавершенность функциональной модели и построить полную функциональную спецификацию разрабатываемой системы.
Недостатки модели отнесем
:
необходимость искусственного ввода управляющих процессов, поскольку управляющие воздействия (потоки) и управляющие процессы с точки зрения DFD ничем не отличаются от обычных;
отсутствие понятия времени, т.е. отсутствие анализа временных промежутков при преобразовании данных (все ограничения по времени должны быть введены в спецификациях процессов).
Универсальный язык моделирования UML.
Собственно с UML началось в 1994 году. Первая версия UML была принята консорциумом OMG (Object Management Group) в январе 1997 года. Авторы UML представляют его как язык для определения, представления, проектирования и документирования программных систем, бизнес-систем и других систем различной природы.
Универсальный язык объектного моделирования UML не зависит от языков программирования и, вследствие этого, может поддерживать любой объектно-ориентированный язык программирования. Он является открытым и позволяет расширять ядро.
Визуальные модели в технологиях управления проектированием систем. В практике эксплуатации программных информационных систем постоянно приходится решать такие задачи как перераспределение вычислений и данных, обеспечение проведения параллельных вычислений,.
Языки и методы моделирования состоят, как правило, из следующих составных частей:
1. Концепции моделирования, их семантика. - это элементы модели
2. Визуальное представление элементов моделирования - нотация
3. Правила применения элементов моделирования. - принципы использования
Плюсы
: *одной из решаемых проблем, является все возрастающая сложность систем и проектов.*упрощение общения заказчика и разработчика. Это связано как с повышенной наглядностью модели, так и с ее гибкостью и динамичностью. *Решаются вопросы уменьшения времени, затрачиваемого на разработку проекта, его стоимости и повышения качества.
Синтаксис и семантика основных объектов UML
Классы
базовые элементы любой объектно-ориентированной системы. Классы представляют собой описание совокупностей однородных объектов с присущими им свойствами — атрибутами, операциями, отношениями и семантикой.
Атрибут — это свойство класса, которое может принимать множество значений. Операция — реализация функции, которую можно запросить у любого объекта класса. изображение класса «Заказ» в нотации UML.
В языке UML определены три уровня видимости: public
(общий) — любой внешний класс, который «видит» данный, может пользоваться его общими свойствами. Обозначаются знаком «+» перед именем атрибута или операции; protected
(защищенный) — только любой потомок данного класса может пользоваться его защищнными свойствами. Обозначаются знаком «#»; private
(закрытый) — только данный класс может пользоваться этими свойствами. Обозначаются символом «-». Область действия свойства
указывает, будет ли оно проявлять себя по-разному в каждом экземпляре класса, или одно и то же значение свойства будет совместно использоваться всеми экземплярами:
instance (экземпляр) — у каждого экземпляра класса есть собственное значение данного свойства;
classifier (классификатор) — все экземпляры совместно используют общее значение данного свойства (выделяется на диаграммах подчеркиванием).
Декомпозиция систем
При проектировании сложных информационных систем требуется, для обеспечения наглядности и во избежание потери управления, разбиение системы на части, которые затем рассматриваются отдельно. Различают два вида декомпозиции
:
· Структурная
- в виде блок-схем, где узлы - это функции, а связи между ними изображают движение данных
· Объектная
- в системе выделяются объекты, взаимодействующие между собой по принципу 'клиент-сервер Вот в этом случае и применяется UML для моделирования систем.
Диаграммы в UML
основные типы диаграмм, представленные в UML:
Диаграммы использования
- описывают функциональность системы. Это изображается в виде так называемых случаев использования (use case), которые определяют взаимодействие пользователя с системой. Они рисуются в виде овалов.
Диаграммы классов
- представляют статическую структуру классов, изображаются на диаграммах классов, которые позволяют описать систему в статическом состоянии — определить типы объектов системы и различного рода статические связи между ними.
Диаграммы последовательностей
для точного определения логики сценария выполнения прецедента. Диаграммы последовательностей отображают типы объектов, взаимодействующих при исполнении прецедентов
Диаграммы компонентов
Диаграммы компонентов позволяют изобразить модель системы на физическом уровне. Элементами диаграммы являются компоненты — физические замещаемые модули системы.
Диаграммы поведения
- формирование программного кода на заданном языке программирования.
Диаграммы реализации
- описывают динамику системы
Пакеты UML
Пакеты представляют собой универсальный механизм организации элементов в группы. В пакет можно поместить диаграммы различного типа и назначения. В отличие от компонентов, существующих во время работы программы, пакеты носят чисто концептуальный характер, то есть существуют только во время разработки. Изображается пакет в виде папки с закладкой, содержащей, как правило, только имя и иногда — описание содержимого.
Методы проектирования с использованием UML
В Microsoft Visual Studio 6.0 реализованы несколько видов нотации для изображения диаграмм классов, как 'старые' - нотации Буча и ОМТ, так и новая - UML. Генерация программного кода производится на языках C++, Visual Basic, Java. Код содержит определения классов и их взаимодействия, но не методы. Это метод прямого проектирования. При использовании обратного проектирования диаграмма классов строится по готовому программному коду. UML - это лишь нотация, которая требует стандартизирования и она уже является стандартом. Методологии же невозможно привести к единому стандарту, да и вряд ли это необходимо. Нотацию UML можно использовать в рамках различных методологий.
Мировые информационные ресурсы. Виды информационных ресурсов (ИР). ИР как форма представления знаний
Мировые информационные ресурсы
Ресурс
–запас, источник чего-нибудь (Ожегов)
В индустриальном обществе, где усилия направлены на материальное производство, определены следующие виды ресурсов:
Материальные ресурсы
-предметы труда
Природные ресурсы
-объекты, процессы и условия труда, используемые для удовлетворения потребностей людей
Трудовые ресурсы
-люди с общеобразовательными и профессиональными знаниями для работы
Финансовые ресурсы
- денежные средства
Энергетические ресурсы
– уголь, нефть, газ, электроэнергия.
Информационные ресурсы
в экономике – это отдельные документы и отдельные массивы документов, документы и массивы, входящие в информационные системы (архивы, фонды, банки данных)В документах представлены знания людей.
Информационные ресурсы
– это знания, подготовленные для использования в обществе и зафиксированные на материальном носителе.
Информационные ресурсы страны должны рассматриваться как стратегические ресурсы, аналогичные по значимости запасам сырья. Знания материализовались в виде документов, баз данных, баз знаний, алгоритмов, компьютерных программ, произведений искусства.
Информационные ресурсы
- это совокупность данных, организованных для получения достоверной информации в самых разных областях знаний и практической деятельности. Ресурсы определяют как запасы, источники чего-либо.
Информационные ресурсы подразделяются по классам собираемой информации.
К первично с
обираемой информации, которая отражает специфику ее источника, области или сферы создания, по этому признаку информационные ресурсы можно классифицировать как естественные, производственные, социально-экономические.
Другой класс информационного ресурса в процессе научно-исследовательской деятельности, а также любой творческой работы. К этому же классу относятся и объекты, создаваемые как авторские произведения в области литературы, искусства. Информация, получаемая в результате интеллектуальной деятельности человека.
Выделяется вторичная
информация, возникающая на основе переработки уже имеющейся информации, и новая, фиксирующая то, что человечество до сих пор не знало. Сюда относятся открытия, прогнозы в области различных социальных и природных процессов.
Развитие мировых информационных ресурсов позволило:
Превратить деятельность по оказанию информационных услуг в глобальную человеческую деятельность;
Сформировать мировой и внутригосударственный рынок информационных услуг;
Образовать базы данных ресурсов регионов и государств, к которым возможен сравнительно недорогой доступ;
Повысить обоснованность и оперативность принимаемых решений в фирмах, банках, биржах, промышленности, торговли и др. за счет своевременного использования необходимой информации.
По существующей классификации: государственными и негосударственными и как элемент состава имущества находятся в собственности граждан, органов государственной власти, органов местного самоуправления, организаций и общественных объединений.
Особенности информационных ресурсов (ИР):
1.В отличие от других видов ресурса ИР неисчерпаем
2. По мере использования ИР не исчезают, а сохраняются и даже растут
3. ИР не самостоятелен, сам по себе имеет потенциальное значение
4. Эффективность применения ИР связана с эффектом повторного производства знания.
5. ИР является формой включения науки в производительные силы.
6. ИР возникает в результате не просто умственного труда, а его творческой части.
7. Превращение знаний в информационный ресурс зависит от их кодирования, распределения и передачи.
Существуют две формы ИР:
пассивной форме относят книги, статьи, патенты, банки данных.
активной форме относят модель, алгоритм, проект, программу базу знаний.
ИР являются базой для создания информационных продуктов.
Информационный продукт
– совокупность данных, сформированная для распространения в вещественной или невещественной форме.
Информационный продукт распространяется с помощью услуг.
Информационная услуга
– получение и предоставление в распоряжение пользователя информационного продукта.
База данных
– совокупность связанных данных с общими принципами описания, хранения и манипулирования данными.
Виды информационных ресурсов (ИР).
Виды информационных ресурсов
В настоящее время существуют:
1) Средства массовой информации. (новостные и семантические сайты) -высокий уровень посещаемости, быстрая смена информации, наличие видеоряда на сайте.
2) Электронные библиотеки.- распределенная информационная система, позволяющая надежно сохранять и эффективно использовать разнородные коллекции электронных документов через глобальные сети передачи данных в удобном для конечного пользователя виде.
3) Электронные базы данных. - это набор надписей и файлов, специальным образом организованных. 1 тип документы, сгруппированные по темам. 2 тип - это файлы с электронными таблицами.
4) Сайты. Корпоративны сайт- это Интернет-ресурс, посвященный какой-то организации, фирме, предприятию. Персональный и любительский сайт, домашнюю страничку. Они отличаются полнотой представляемой информации и профессионализмом исполнения.
5) Сервисы - это группа сайтов, предоставляет услуги: электронным почтовым ящиком, блогом Информационный портал
- это веб-сайт, организованный как многоуровневое объединение различных ресурсов и сервисов, обновление которого происходит в реальном времени
Можно говорить также о делении информационных ресурсов по другим признакам.
По целевому предназначению
: личные, корпоративные, СМИ, бизнес, образовательные, политика, учреждения и организации, сервисы и услуги, доски объявлений, культура, чаты, хранилища ПО, спорт, отдых, изображения и фото, развлекательные порталы
По способу представления
: Web-страниц, Базы данных, Файловые серверы, Телеконференции
По виду носителя
твердая копия (книга, газета, рукопись и т.д.), на машиночитаемых носителях (кино- фотопленка, аудио-, дискете, CD, флэш и т.д.), на канале связи (TV, радио)
По способу организации хранения и использования
документы на традиционных носителях (книги, газеты, журналы), массив документов, фонд документов, архив, автоматизированные формы,
По форме собственности
общероссийское национальное достояние, государственная собственность, собственность субъектов РФ (в том числе муниципальная), частная (личная, корпоративная) собственность, По содержанию
Тематическая информация, Научные публикации, Рекламная информация, Справочная информация, Новости,Вторичная (библиографическая) информация,
По национально-территориальному признаку.
По языковому признаку
. Основным языком в сети Интернет является английский, но практически все основные языки мира представлены в Сети.
По географическому признаку
. Информационный ресурс в большинстве случаев принадлежит какой-либо организации, расположенной и осуществляющей свою деятельность на определенной территории, подчиняющейся ее законам.
ИР как форма представления знаний.
Информационные ресурсы – это знания, подготовленные людьми для социального использования в обществе и зафиксированные на материальном носителе.
Если речь идет об информационных ресурсах страны, региона, организации, то они должны рассматриваться как стратегические ресурсы. Если информационные ресурсы рассматриваются как совокупность информационных ресурсов различных государств, то такие информационные ресурсы принято называть мировыми информационными ресурсами.
Разделить мировые информационные ресурсы на определенные виды (категории) весьма сложно, но можно выделить несколько критериев, по которым можно проводить разбиение на виды.
Первый критерий
– по форме представления, в каком виде зафиксирована или представлена информация: текстовая форма; графическая форма; мультимедиа и т.д.
Второй критерий
– по ограничению доступа или защите, здесь можно выделить три вида информационных ресурсов: сведения, составляющие государственную тайну; персональные данные; сведения, составляющие коммерческую тайну. Чтобы отнести тот или иной документ к одной из выше перечисленных групп следует опираться на законодательство, во всех странах приняты практически одинаковые критерии, имеются лишь небольшие расхождения.
Третий критерий
– разбивка по тематике, самый сложный критерий, так как те или иные информационные ресурсы можно отнести к сразу нескольким видам. Классификации информационных образовательных ресурсов, как правило, проводят по следующим основаниям: по целевому назначению, по уровням образования, по целевой аудитории, предметные, классификации по типу ИР.
Основные проблемы и классификация ИР. Знание как национальное достояние. Форма представления знаний
Основные проблемы и классификация ИР
Опыт обслуживания в автоматизированном режиме позволил выявить ряд проблем организации доступа к информационным массивам в целом и к электронным документам в частности. Во-первых, это неавторизованное использование компьютерного времени, превышающее нормативное, а также использование БД без разрешения персонала. Следующим проблемным моментом является “копирование” большего обьема результатов поиска, чем предусмотрено нормами. Безусловно, вызывает опасение использование дискет, зараженных компьютерными вирусами, для копирования результатов поиска, что ведет к разрушению действующих программ.
Информационные ресурсы
- это совокупность данных, организованных для получения достоверной информации в самых разных областях знаний и практической деятельности. Ресурсы определяют как запасы, источники чего-либо.
Классификация ИР:
Информационные ресурсы подразделяются по классам собираемой информации.
К первично с
обираемой информации, которая отражает специфику ее источника, области или сферы создания, по этому признаку информационные ресурсы можно классифицировать как естественные, производственные, социально-экономические.
Другой класс информационного ресурса в процессе научно-исследовательской деятельности, а также любой творческой работы. К этому же классу относятся и объекты, создаваемые как авторские произведения в области литературы, искусства. Информация, получаемая в результате интеллектуальной деятельности человека.
Выделяется вторичная
информация, возникающая на основе переработки уже имеющейся информации, и новая, фиксирующая то, что человечество до сих пор не знало. Сюда относятся открытия, прогнозы в области различных социальных и природных процессов.
По целевому предназначению
: личные, корпоративные, СМИ, бизнес, образовательные, политика, учреждения и организации, сервисы и услуги, доски объявлений, культура, чаты, хранилища ПО, спорт, отдых, изображения и фото, развлекательные порталы
По способу представления
: Web-страниц, Базы данных, Файловые серверы, Телеконференции
По виду носителя
твердая копия (книга, газета, рукопись и т.д.), на машиночитаемых носителях (кино- фотопленка, аудио-, дискете, CD, флэш и т.д.), на канале связи (TV, радио)
По способу организации хранения и использования
документы на традиционных носителях (книги, газеты, журналы), массив документов, фонд документов, архив, автоматизированные формы,
По форме собственности
общероссийское национальное достояние, государственная собственность, собственность субъектов РФ (в том числе муниципальная), частная (личная, корпоративная) собственность, По содержанию
Тематическая информация, Научные публикации, Рекламная информация, Справочная информация, Новости,Вторичная (библиографическая) информация,
По национально-территориальному признаку.
По языковому признаку
. Основным языком в сети Интернет является английский, но практически все основные языки мира представлены в Сети.
По географическому признаку
. Информационный ресурс в большинстве случаев принадлежит какой-либо организации, расположенной и осуществляющей свою деятельность на определенной территории, подчиняющейся ее законам.
Знание как национальное достояние
Мировое сообщество начала третьего тысячелетия характеризуется рядом особенностей, к которым следует, прежде всего, отнести возросшую значимость интеллектуального труда, ориентированного на использование информационного ресурса глобального масштаба и потребность в осуществлении оперативной коммуникации между отдельными специалистами, социально-профессиональными группами, сообществами людей, общественными организациями и государствами. Роль информации и коммуникаций в развитии общества всегда была значительной, а прорыв, совершенный в сфере информационно-телекоммуникационных технологий, позволил объединить компьютеры, находящиеся в различных точках мира в единую Сеть.
В результате общество приступило к созданию единого мирового информационного пространства, или, мировых информационных ресурсов. Важнейшими элементами электронной части мирового информационного пространства являются профессиональные базы, деловые ресурсы Интернет, электронные библиотеки. Возрастание роли информационного продукта как тенденция развития информационного общества определяет потребность в обработке все возрастающих объемов информации, потребность в различных формах восприятия информации, а также потребность в актуальности и точности информации.
Форма представления знаний
Информационные ресурсы – это знания, подготовленные людьми для социального использования в обществе и зафиксированные на материальном носителе.
Если речь идет об информационных ресурсах страны, региона, организации, то они должны рассматриваться как стратегические ресурсы. Если информационные ресурсы рассматриваются как совокупность информационных ресурсов различных государств, то такие информационные ресурсы принято называть мировыми информационными ресурсами.
Разделить мировые информационные ресурсы на определенные виды (категории) весьма сложно, но можно выделить несколько критериев, по которым можно проводить разбиение на виды.
Первый критерий
– по форме представления, в каком виде зафиксирована или представлена информация: текстовая форма; графическая форма; мультимедиа и т.д.
Второй критерий
– по ограничению доступа или защите, здесь можно выделить три вида информационных ресурсов: сведения, составляющие государственную тайну; персональные данные; сведения, составляющие коммерческую тайну. Чтобы отнести тот или иной документ к одной из выше перечисленных групп следует опираться на законодательство, во всех странах приняты практически одинаковые критерии, имеются лишь небольшие расхождения.
Третий критерий
– разбивка по тематике, самый сложный критерий, так как те или иные информационные ресурсы можно отнести к сразу нескольким видам. Классификации информационных образовательных ресурсов, как правило, проводят по следующим основаниям: по целевому назначению, по уровням образования, по целевой аудитории, предметные, классификации по типу ИР.
Методы представления знаний
Продукционные правила
Продукционная система состоит из трех основных компонентов, схематично изображенных на рис.
Первый из них – это база знаний, состоящих из правил.
Следующим компонентом является рабочая память, в которой хранятся исходные данные к задаче и выводы, полученные в ходе работы системы.
Третьим компонентом является механизм логического вывода, использующий правила в соответствии с содержимым рабочей памяти.
Продукционная модель – это наиболее часто используемый способ представления знаний в современных экспертных системах. Основными преимуществами продукционной модели являются: наглядность, высокая модульность, легкость внесения изменений и дополнений, простота механизма логического вывода.
Фреймы
Фрейм – это модель абстрактного образа, минимально возможное описание сущности какого-либо объекта, явления, события, ситуации, процесса. Фрейм состоит из имени и отдельных единиц, называемых слотами, и имеет однородную структуру:
ИМЯ ФРЕЙМА
Имя 1-го слота: значение 1-го слота.
Имя 2-го слота: значение 2-го слота.
Имя N-го слота: значение N-го слота.
Если одно и тоже свойство указывается в нескольких связанных между собой фреймах, то приоритет отдается нижестоящему фрейму. Так, возраст фрейма «Студент» не наследуется из вышестоящих фреймов.
Основным является наглядность и гибкость в употреблении. Кроме того, фреймовая структура согласуется с современными представлениями о хранении информации в памяти человека.
Семантические сети
В основе этого способа представления знаний лежит идея о том, что любые знания можно представить в виде совокупности понятий (объектов) и отношений (связей). Семантическая сеть представляет собой ориентированный граф, вершинами которого являются понятия, а дугами – отношения между ними. Сам термин семантическая означает смысловая.
Основным преимуществом этой модели является наглядность представления знаний, а также соответствие современным представлениям об организации долговременной памяти человека. Недостаток – сложность поиска вывода, а также сложность корректировки: удаление и дополнение сети новыми знаниями.
Математический нейрон, его уравнения и реализация простейших логических функций. Персептрон и его обучение на примере распознавания цифр и букв. Правила Хебба
Математический нейрон, его уравнения и реализация простейших логических функций.
Нейронные сети и нейрокомпьютеры
– это одно из направлений компьютерной индустрии, в основе которого лежит идея создания искусственных интеллектуальных устройств по образу и подобию человеческого мозга. Дело в том, что компьютеры, выполненные по схеме машины фон Неймана, по своей структуре и свойствам весьма далеки от нашего естественного компьютера – человеческого мозга.
1. Мозг человека состоит из белого и серого вещества: белое – это тела нейронов, а серое – соединяющие их нервные волокна. Каждый нейрон состоит из трех частей: тела клетки, дендритов и аксона.
2. Каждый нейрон может существовать в двух состояниях – возбужденном и невозбужденном. В возбужденном состоянии нейрон сам посылает электрический сигнал другим, соединенным с ним нейронам.
3. Нейроны взаимодействуют между собой посредством коротких серий импульсов продолжительностью несколько микросекунд.
4. Известно, что общее число нейронов в течение жизни человека практически не изменяется, т.е. мозг ребенка и мозг взрослого человека содержат приблизительно одинаковое число нейронов.
Математический нейрон Мак-Каллока – Питтса
в 1943 г. статью Уоррена Мак-Каллока и Вальтера Питтса. Ее авторы выдвинули гипотезу математического нейрона – устройства, моделирующего нейрон мозга человека.
Математический нейрон тоже имеет несколько входов и один выход. Через входы, которых обозначим  , математический нейрон принимает входные сигналы , математический нейрон принимает входные сигналы  , которые суммирует, умножая каждый входной сигнал на некоторый весовой коэффициент , которые суммирует, умножая каждый входной сигнал на некоторый весовой коэффициент  : :  . (3.1) . (3.1)
Выходной сигнал нейрона  может принимать одно из двух значений – ноль или единицу, которые формируются следующим образом: может принимать одно из двух значений – ноль или единицу, которые формируются следующим образом:
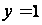 , если , если 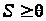 , (3.2) , (3.2)
 , если , если  , (3.3) , (3.3)
где  – порог чувствительности нейрона. – порог чувствительности нейрона.
Таким образом, математический нейрон, как и его биологический прототип, существует в двух состояниях. Если взвешенная сумма входных сигналов  меньше некоторой пороговой величины , то математический нейрон не возбужден и его выходной сигнал равен нулю. Если же входные сигналы достаточно интенсивны и их сумма достигает порога чувствительности, то нейрон переходит в возбужденное состояние, и на его выходе образуется сигнал . Весовые коэффициенты , имитируют электропроводность нервных волокон – силу синаптических связей между нейронами. Чем они выше, тем больше вероятность перехода нейрона в возбужденное состояние. Логическая функция (3.2) – (3.3) называемая активационной функцией нейрона, графически изображена на рис. 3.2. меньше некоторой пороговой величины , то математический нейрон не возбужден и его выходной сигнал равен нулю. Если же входные сигналы достаточно интенсивны и их сумма достигает порога чувствительности, то нейрон переходит в возбужденное состояние, и на его выходе образуется сигнал . Весовые коэффициенты , имитируют электропроводность нервных волокон – силу синаптических связей между нейронами. Чем они выше, тем больше вероятность перехода нейрона в возбужденное состояние. Логическая функция (3.2) – (3.3) называемая активационной функцией нейрона, графически изображена на рис. 3.2.
Таким образом, математический нейрон представляет собой пороговый элемент с несколькими входами и одним выходом. Одни из входов математического нейрона оказывают возбуждающее действие, другие – тормозящее. Каждый математический нейрон имеет свое определенное значение порога.
Математический нейрон обычно изображают кружочком, возбуждающий вход – стрелкой, а тормозящий – маленьким кружочком. Рядом может записываться число, показывающее значение порога . Как показано на рис. 3.4, математические нейроны могут реализовывать различные логические функции. Так, математический нейрон, имеющий два входа с единичными силами синаптических связей  , согласно формулам (3.1) –(3.3) реализует функцию логического умножения «И» при , согласно формулам (3.1) –(3.3) реализует функцию логического умножения «И» при 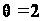 и функцию логического сложения «ИЛИ» при и функцию логического сложения «ИЛИ» при  . Нейрон с одним входом, у которого . Нейрон с одним входом, у которого 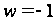 , реализует логическую функцию «НЕТ» при , реализует логическую функцию «НЕТ» при 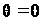 . .
Персептрон и его обучение на примере распознавания цифр и букв. Правила Хебба.
Персептрон Розенблатта и правило Хебба
Мак-Каллок и Питтс предложили конструкцию сети из математических нейронов и показали, что такая сеть может выполнять числовые и логические операции. Далее они высказали идею о том, что сеть из математических нейронов в состоянии обучаться, распознавать образы, обобщать, т.е. она обладает свойствами человеческого интеллекта.
Идея Мак-Каллока – Питтса была материализована в 1958 г. Фрэнком Розенблаттом в виде электронного устройства, моделирующего человеческий глаз. Это устройство, имеющее в качестве элементной базы модельные нейроны Мак-Каллока – Питтса и названное персептроном, удалось обучить решению сложнейшей интеллектуальной задачи – распознаванию букв латинского алфавита. Таким образом, удалось проверить основные гипотезы функционирования человеческого мозга и сам механизм его обучаемости. «Нельзя сказать, что мы точно воспроизводим работу человеческого мозга, – признавал Розенблатт, – но пока персептрон ближе всего к истине».
Разберем принцип действия персептрона для классификации цифр на четные и нечетные. Представим себе матрицу из 12 фотоэлементов, расположенных в виде четырех горизонтальных рядов по три фотоэлемента в каждом ряду. На матрицу фотоэлементов накладывается карточка с изображением цифры – это цифра «4»). Если на фотоэлемент попадает какой-либо фрагмент цифры, то данный фотоэлемент вырабатывает сигнал в виде двоичной единицы, в противном случае – ноль.
Первый фотоэлемент выдает сигнал  , второй фотоэлемент – , второй фотоэлемент –  и т.д. и т.д.
Персептронный нейрон выполняет суммирование входных сигналов , помноженных на синаптические веса , первоначально заданные датчиком случайных чисел. После этого сумма сравнивается с порогом чувствительности , также заданным случайным образом. Цель обучения
персептрона состоит в том, чтобы выходной сигнал был = 1, если на карточке была изображена четная цифра, и 0, если цифра была нечетной.
Эта цель достигается путем обучения персептрона, заключающемся в корректировке весовых коэффициентов . Если, например, на вход персептрона была предъявлена карточка с цифрой «4», и выходной сигнал случайно оказался =1, означающей четность, то корректировать веса не нужно, так как реакция персептрона правильна. Однако, если выход неправилен и  , то следует увеличить веса тех активных входов, которые способствуют возбуждению нейрона. В данном случае увеличению подлежат , то следует увеличить веса тех активных входов, которые способствуют возбуждению нейрона. В данном случае увеличению подлежат  ,, ,, и др. и др.
Иитерационный алгоритм корректировки весовых коэффициентов:
ШАГ 1. Подать входной образ и вычислить выход персептрона .
ШАГ 2,а. Если выход правильный, то перейти на шаг 1.
ШАГ 2,б. Если выход неправильный и равен нулю, то увеличить веса активных входов, например, добавить все входы к соответствующим им весам: 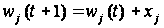 . называют первым правилом Хебба . называют первым правилом Хебба
ШАГ 2,в. Если выход неправильный и равен единице, то уменьшить веса активных входов, например, вычесть каждый вход из соответствующего ему веса: 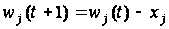 . вторым правилом Хебба . вторым правилом Хебба
ШАГ 3. Перейти на шаг 1 или завершить процесс обучения.
всегда ли алгоритм обучения персептрона приводит к желаемому результату: Если существует множество значений весов, которые обеспечивают конкретное различение образов, то в конечном итоге алгоритм обучения персептрона приводит либо к этому множеству, либо к эквивалентному ему множеству, такому, что данное различение образов будет достигнуто.
Проблемы и возможности применения сетей персептронного типа в промышленности, экономике, политологии, социологии, криминалистике, медицине и др. Проблемы проектирования и обучения нейросетей. 13-я проблема Гильберта и теорема Арнольда-Колмогорова. Гиперразмерность интерпретация обучения нейросетей: проблемы локальных минимумов, оврагов и способы их преодоления
Проблемы и возможности применения сетей персептронного типа в промышленности, экономике, политологии, социологии, криминалистике, медицине и др.
Ограниченность однослойного персептрон
Следующий период истории персептронов начался с появления книги Минского и Пайперта «Персептроны» В этой книге математически строго было доказано, что использовавшиеся в то время однослойные персептроны в принципе не способны решать многие простые задачи. Одну из таких задач, заключающуюся в реализации логической операции «Исключающее ИЛИ», мы рассмотрим подробно
«Исключающее ИЛИ» – это булева функция двух аргументов, каждый из которых может иметь значение «истинно» либо «ложно». Сама она принимает значение «истинно», когда только один из аргументов имеет значение «истинно». Во всех остальных случаях функция принимает значение «ложно»: значит, что какие бы значения ни придавались весам и порогу, рассмотренный персептрон в принципе не способен воспроизвести соотношение между входами и выходом, требуемое для представления функции «Исключающее ИЛИ».
Многослойный персептрон и алгоритм обратного распространения ошибки
проблему «Исключающего ИЛИ» можно решить с помощью двухслойного персептрона, изображенного на рис. 3.12.Советским ученым С.О.Мкртчяном был разработан специальный математический аппарат, позволяющий без обучения строить многослойные персептроны, моделирующие любые булевы функции.
Эффективный алгоритм обучения многослойных персептроново в 1986 г. благодаря работе Румельхарта, Хилтона и Вильямса. Рассмотрим идею алгоритма обратного распространения ошибки, попытавшись обобщить дельта-правило на случай обучения двухслойного персептрона, имеющего  входов, входов,  выходов и скрытый слой из нейронов Идея авторов рассматриваемого алгоритма состояла в том, чтобы в качестве этой ошибки использовать суммарные ошибки с выходного слоя, помноженные на силы соответствующих синаптических связей, т.е. выходов и скрытый слой из нейронов Идея авторов рассматриваемого алгоритма состояла в том, чтобы в качестве этой ошибки использовать суммарные ошибки с выходного слоя, помноженные на силы соответствующих синаптических связей, т.е.
ШАГ 1. Инициализация синаптических весов и смещений.
ШАГ 2. Представление из обучающей выборки очередного входного вектора
ШАГ 3. Прямой проход.
ШАГ 4. Обратный проход.
ШАГ 5. Повторение шагов 2 – 4 необходимое количество раз.
Таким образом персептрон, несмотря на помехи и искажения входного образа, выдаст правильное заключение о его принадлежности к тому или иному классу. Свойство персептрона правильно реагировать на входные образы, которых не было в обучающей выборке, называется свойством обобщения.
Возможности и области применения персептронов
Диагностика в медицине
В средствах информации имеются сообщения об удачном опыте применения нейросетей в задачах медицинской диагностики. Рассмотрим, как строятся и обучаются такие сети. Прежде всего он выясняет и записывает имя, возраст, пол, место В результате у врача накапливается от 20 до 100 и более параметров, характеризующих пациента и его состояние здоровья. Это и есть исходные параметры, обработав которые с помощью своих медицинских знаний и опыта, врач делает заключение о заболевании пациента – ставит диагноз его болезни.Персептрон должен уметь обобщать переданный ему опыт на новые точки предметной области – ставить диагнозы болезней новым, не встречавшимся ранее пациентам.
Диагностика неисправностей сложных технических устройств
Специалисты, занимающиеся этой проблемой, устанавливают датчики, измеряющие параметры работы авиадвигателей во время полетов. Файл данных полетного мониторинга обычно содержит следующие параметры: номер полета, дату полета. Задача инженера-диагноста состоит в том, чтобы, используя данные мониторинга, выявить дефекты двигателя до его профилактической разборки. Традиционно эта задача решается путем применения методик, основанных на физических закономерностях: каждый дефект вызывает определенные отклонения тех или иных полетных параметров работы двигателя, поэтому, анализируя их характер изменения, можно сделать предположения о появлении дефектов, вызывающих эти изменения.
Нейросетевой детектор лжи
Правду ли говорит ребенок, обычно легко определить по выражению его лица, движению глаз, покраснению кожи. Со взрослым человеком значительно труднее. Если измерять давление крови, то можно выяснить, что у одних людей, говорящих неправду, оно повышается, а у других – наоборот, понижается. То же самое может происходить с пульсом.
Входные параметры: дыхание, частота биения сердца, температура тела. Выходные параметры: да, нет. Выборка: есть определение правильных выходных параметров 0:1.
Нейросеть–антихакер
Прежде всего отметим, что поведение хакера, пытающегося взломать компьютерную программу, несколько отличается от поведения обычного законопослушного пользователя. Иногда хакер чаще, чем обычный пользователь, ударяет по одной и той же кнопке клавиатуры. Поэтому, измерив параметры, характеризующие стиль работы различных пользователей, можно сформировать обучающую выборку соответствующих примеров и обучить нейросеть реагировать на различные сетевые отклонения, т.е. выявлять аномалии сетевой активности. В качестве параметров, характеризующих стиль работы пользователей, их портрет, может быть: количество загружаемых одновременно программ, скорость ударов по клавиатуре и мыши в единицу времени, частота повторения ударов по одним и тем же клавишам, характер пользования мышью и др. Количество этих параметров определяет размер входного вектора  и, соответственно, количество нейронов входного слоя персептрона. На выходе персептрона целесообразно оставить один нейрон, значение которого и, соответственно, количество нейронов входного слоя персептрона. На выходе персептрона целесообразно оставить один нейрон, значение которого  будет означать, что за компьютером находится обычный пользователь, а будет означать, что за компьютером находится обычный пользователь, а 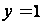 – что пользователь хакер. Теперь необходимо создать достаточный для обучения персептрона набор портретов хакеров и обычных пользователей. Далее следуют обычные действия по проектированию и обучению персептрона. Естественно, что качество нейросети–антихакера будет зависеть от того, насколько высокой окажется квалификация хакеров, приглашенных для создания обучающих примеров. – что пользователь хакер. Теперь необходимо создать достаточный для обучения персептрона набор портретов хакеров и обычных пользователей. Далее следуют обычные действия по проектированию и обучению персептрона. Естественно, что качество нейросети–антихакера будет зависеть от того, насколько высокой окажется квалификация хакеров, приглашенных для создания обучающих примеров.
Нейросети в банковском деле
Банкротство фирм, кредитуемых банками, невозможность возврата ими кредитных средств не раз являлись причиной кризисов и банкротств весьма солидных банков. Поэтому вопрос о том, какова степень кредитного риска, каким клиентами опасно выдавать кредиты, а каким нет, для любого банка является одним из самых главных вопросов стабильности его существования.
Входные: сколько можно дать, возраст, платеже способность, Выходные макс, минт. Выборка: поданным клиента
Прогнозирование валютных курсов и котировок ценных бумаг
Прогнозирование – это одна из самых востребованных задач, возникающих в самых различных областях человеческой деятельности. Задача прогнозирования в общем случае состоит в получении оценки будущих значений упорядоченных во времени данных на основе анализа уже имеющихся данных.
13-я проблема Гильберта
Вопрос о том, можно ли любую функцию многих переменных представить в виде суперпозиции функций меньшего количества переменных на Всемирном конгрессе Давидом Гильбертом были сформулированы 23 проблемы, которые он предложил решать математикам начинающегося XX века. Одна из этих проблем, под номером тринадцать, декларировала невозможность такого представления.
Однако последующие исследования показали, что 13-я проблема Гильберта имеет иное решение. А.Н.Колмогоровым и его учеником В.И.Арнольдом принципиальной возможности представления непрерывных функций нескольких переменных в виде суперпозиции функций меньшего числа переменных.
Теорема. Для любого множества пар отличных между собой входных и выходных векторов произвольной размерности существует двухслойный персептрон с сигмоидными передаточными функциями и с конечным числом нейронов, который для каждого входного вектора  формирует соответствующий ему выходной вектор формирует соответствующий ему выходной вектор  . Таким образом, была доказана принципиальная возможность построения нейросети, выполняющей преобразование, заданное любой обучающей выборкой различающихся между собой примеров, и установлено, что такой универсальной нейросетью является двухслойный персептрон. . Таким образом, была доказана принципиальная возможность построения нейросети, выполняющей преобразование, заданное любой обучающей выборкой различающихся между собой примеров, и установлено, что такой универсальной нейросетью является двухслойный персептрон.
Для определения необходимого количества нейронов в скрытых слоях персептрона была предложена формула, являющаяся следствием теорем Арнольда – Колмогорова
– Хехт-Нильсена:
 , (3.44) , (3.44)
где  – размерность выходного сигнала; – размерность выходного сигнала;  – число элементов обучающей выборки; – число элементов обучающей выборки;  – необходимое число синаптических весов; – необходимое число синаптических весов;  – размерность входного сигнала. Оценив с помощью этой формулы необходимое число синаптических весов, можно рассчитать число нейронов в скрытых слоях. Например, число нейронов скрытого слоя двухслойного персептрона – размерность входного сигнала. Оценив с помощью этой формулы необходимое число синаптических весов, можно рассчитать число нейронов в скрытых слоях. Например, число нейронов скрытого слоя двухслойного персептрона
 . (3.45) . (3.45)
Гиперразмерность – слишком много нейронов на скрытом слое.
С несколькими нейронами (гиперразмерность)
С 2 персептронами – с одним пересечением
С одним персептроном – прямая
Однако поверхность ошибок имеет более сложный характер. Так, на рис. 3.19, б, изолинии поверхности ошибок имеют вид эллипсов, а сама поверхность вблизи минимальной точки имеет форму оврага
. В этом случае траектория градиентного спуска представляет собой ломаную линию, каждый отрезок которой ортогонален к линии уровня в той точке поверхности ошибок, из которой производится очередной шаг.
Проблемы проектирования и обучения нейросете
Общая формулировка задач оптимизации и различия геометрической интерпретации, различных способов минимизации целевых функций.
Поверхность ошибок (рисунок купола с точкой на дне)
 средняя квадратичная ошибка средняя квадратичная ошибка
Задачи оптимизации: глобальные(найти самый минимальный min), локальные.
Проблемы и методы обучения
Как было показано в предыдущих подразделах, изобретение алгоритма обратного распространения ошибки открыло путь широкому практическому применению многослойного персептрона. Вместе с тем, с расширением фронта научных исследований обнаружились и недостатки этого алгоритма.
Прежде всего отметим, что алгоритм обратного распространения ошибки в его первоначальном изложении реализовывал метод наискорейшего спуска, который является далеко не самым лучшим градиентным методом теории оптимизации
Если бы изолинии поверхности ошибок нейросети представляли собой концентрические окружности, то направление антиградиента указывало бы на точное расположение точки минимума целевой функции. Однако поверхность ошибок имеет более сложный характер. изолинии поверхности ошибок имеют вид эллипсов, а сама поверхность вблизи минимальной точки имеет форму оврага
. В этом случае траектория градиентного спуска представляет собой ломаную линию, каждый отрезок которой ортогонален к линии уровня в той точке поверхности ошибок, из которой производится очередной шаг.
В настоящее время основная проблема обучения персептронов состоит в том, что поверхность функции ошибок обычно имеет очень сложную форму со множеством локальных минимумов. методы обычно приводят к одному из локальных минимумов, лежащих в окрестности начальной точки обучения. Если после нахождения такого минимума погрешность обучения нейросети признается неудовлетворительной, то сеть «встряхивают», давая весовым коэффициентам случайные приращения, и продолжают процесс обучения из другой точки.
В связи с этим, актуальным является развитие методов глобальной оптимизации, т.е. таких, которые позволяют найти глобальный минимум многоэкстремальной целевой функции. Среди множества возможных подходов наиболее успешным признается идея генетических алгоритмов. Эта идея, впервые предложенная Дж.Холландом в 70-х годах XX в. [58], состоит в имитации природных оптимизационных процессов, происходящих при эволюции живых организмов.
Таким образом, символьные модели искусственного интеллекта — это формальные системы, основанные на использовании языка алгоритмов и представлении данных по принципу "сверху вниз" (top-down), а нейронные сети — это параллельные распределенные процессоры, обладающие естественной способностью к обучению и работающие по принципу "снизу вверх" (bottom-up). Поэтому при решении когнитивных задач целесообразно создавать структурированные модели на основе связей (structured connectionist models) или гибридные системы (hybrid system), объединяющие оба подхода. Это обеспечит сочетание свойств адаптивности, робастности и единообразия, присущих нейронным сетям, с представлениями, умозаключениями и универсальностью систем искусственного интеллекта [293], [1108]. Для реализации этого подхода были разработаны методы извлечения правил из обученных нейронных сетей [61]. Эти результаты не только позволяют интегрировать нейронные сети с интеллектуальными машинами, но и обеспечивают решение следующих задач.
Верификация нейросетевых компонентов в программных системах. Для этого внутреннее состояние нейронной сети переводится в форму, понятную пользователям.
Улучшение обобщающей способности нейронной сети за счет выявления областей входного пространства, не достаточно полно представленных в обучающем множестве, а также определения условий, при которых обобщение невозможно.
Выявление скрытых зависимостей на множестве входных данных.
Интеграция символьного и коннекционистского подходов при разработке интеллектуальных машин.
Обеспечение безопасности систем, для которых она является критичной.
Данные и знания. Модели представления знаний. Представление знаний с помощью фреймов и семантических сетей. Экспертные системы и их области применения. Преимущества и недостатки технологии экспертных систем по отношению к нейросетевым технологиям
Данные
– это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства
При обработке на ЭВМ данные трансформируются, последовательно проходя следующие этапы:
 данные, существующие как результат измерений и наблюдений; данные, существующие как результат измерений и наблюдений;
данные на материальных носителях информации – в таблицах, протоколах, справочниках;
структуры данных в виде диаграмм, графиков, функций;
данные в компьютере на языке описания данных;
базы данных.
Знания
связаны с данными, основываются на них, но представляют собой результат мыслительной деятельности человека, обобщают его опыт, полученный в ходе практической деятельности. Знания
– это выявленные закономерности предметной области.
При обработке на ЭВМ знания трансформируются аналогично данным:
знания, существующие в памяти человека как результат обучения, воспитания, мышления;
знания, помещенные на материальных носителях: учебниках, инструкциях, методических пособиях, книгах;
знания, описанные на языках представления знаний и помещенные в компьютер;
базы знаний.
Знания могут быть классифицированы по следующим категориям:
поверхностные – знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области;
глубинные – абстракции, аналогии, схемы, отображающие структуру и процессы в предметной области.
Кроме того, знания можно разделить на процедурные и декларативные.
первичными были процедурные знания, т.е. знания, растворенные в алгоритмах. Они управляли данными. Для их изменения требовалось изменять программы.
Рассмотрим, например, фрагмент программы на Паскале.
Pi:= 3.14
R:= 20
S:= Pi * R * R
WRITELN (‘Площадь круга S=’, S)
Первые два оператора представляют собой данные, третий оператор – знание. Оно является результатом интеллектуальной деятельности древних геометров и представляет собой закон, выражающий площадь круга через его радиус.
Способы представления декларативных знаний Классам:
продукционные;
фреймы;
семантические сети.
Методы представления знаний
Продукционная система состоит из трех основных компонентов, схематично изображенных на рис. 2.1. Первый из них – это база знаний, состоящих из правил типа: Если (условие), то (действие). «Если» холодно, «то» одеть шубу. «Если» идет дождь, «то» взять зонтик. И т.п.
Следующим компонентом является рабочая память, в которой хранятся исходные данные к задаче и выводы, полученные в ходе работы системы.
Третьим компонентом является механизм логического вывода, использующий правила в соответствии с содержимым рабочей памяти.
Рассмотрим конкретный пример.
В базе правил экспертной системы имеются два правила:
Правило 1.
ЕСЛИ «намерение – отдых» и
«дорога ухабистая»
ТО «использовать джип»
Правило 2.
ЕСЛИ «место отдыха – горы»
ТО «дорога ухабистая»
Допустим, что в рабочую память поступили исходные данные:
«намерения – отдых»
«место отдыха – горы»
Правило 3.
ЕСЛИ «намерение – отдых»
ТО «нужна скорость»
Кроме того, введем условие останова системы: появление в рабочей памяти образца «использовать джип».
Фреймы
Фрейм
– это модель абстрактного образа, минимально возможное описание сущности какого-либо объекта, явления, события, ситуации, процесса. Фрейм состоит из имени и отдельных единиц, называемых слотами, и имеет однородную структуру:
ИМЯ ФРЕЙМА
Имя 1-го слота: значение 1-го слота.
Имя 2-го слота: значение 2-го слота.
Имя N-го слота: значение N-го слота.
Например, на схеме рис. 2.2 фрейм «Студент» имеет ссылки на вышестоящие фреймы: «Человек» и «Млекопитающее». Поэтому, на вопрос: «Может ли студент мыслить ?», ответ будет положительным, так как этим свойством обладает вышестоящий фрейм «Человек».
Основным преимуществом фреймов, как способа представления знаний, является наглядность и гибкость в употреблении. Кроме того, фреймовая структура согласуется с современными представлениями о хранении информации в памяти человека.
Семантические сети
В основе этого способа представления знаний лежит идея о том, что любые знания можно представить в виде совокупности понятий (объектов) и отношений (связей). Семантическая сеть представляет собой ориентированный граф, вершинами которого являются понятия, а дугами – отношения между ними. Сам термин семантическая означает смысловая.
На рис. 2.3 приведен пример семантической сети.
Основным преимуществом этой модели является наглядность представления знаний, а также соответствие современным представлениям об организации долговременной памяти человека. Недостаток – сложность поиска вывода, а также сложность корректировки: удаление и дополнение сети новыми знаниями.
Экспертные системы и их области применения.
Диапазон областей применения ЭС очень широк. И образование не является исключением. В последнее время сформировалось и развивается направление в исследованиях – искусственный интеллект в обучении, под которым понимается новая методология психологических, дидактических и педагогических исследований по моделированию поведения человека в процессе обучения, опирающаяся на методы инженерии знаний.
в настоящее время технология экспертных систем используется
для решения различных типов задач (интерпретация, предсказание, диагностика, планирование, конструирование, контроль, отладка, инструктаж, управление) в самых разнообразных проблемных областях, таких, как финансы, нефтяная и газовая промышленность, энергетика, транспорт, фармацевтическое производство, космос, металлургия, горное дело, химия, образование, целлюлозно-бумажная промышленность, телекоммуникации и связь и др.
Преимущества и недостатки технологии экспертных систем по отношению к нейросетевым технологиям.
Машинное обучение может включать два совершенно разных способа обработки информации: индуктивный (inductive) и дедуктивный (deductive). При индуктивной обработке информации общие шаблоны и правила создаются на основании практического опыта и потоков данных. При дедуктивной обработке информации для определения конкретных фактов используются общие правила.
сравнить модели нейронных сетей с символьными системами искусственного интеллекта.
1. Уровень объяснения Классические системы искусственного интеллекта основаны на символьном представлении.
С точки зрения познания AI предполагает существование ментального представления, в котором познание осуществляется как последовательная обработка символьной информации.
В центре внимания нейронных сетей находятся модели параллельной распределенной обработки предполагается, что обработка информации происходит за счет взаимодействия большого количества нейронов, каждый из которых передает сигналы возбуждения и торможения другим нейронам сети
2. Стиль обработки. В классических системах искусственного интеллекта обработка происходит последовательно как и в традиционном программировании. операции все равно выполняются пошагово.
В нейронных сетях принцип параллелизма, который является источником их гибкости. Кроме того, можно дополнительно повысить робастность сети, представляя каждое свойство группой нейронов.
3. Структура представления. В классических системах искусственного интеллекта в качестве модели выступает язык мышления, поэтому символьное представление имеет структуру подобно фразам обычного в нейронных сетях природа и структура представления являются ключевыми проблемами. нейронные сети не удовлетворяют двум основным критериям процесса познания: природе мысленного представления и мыслительных процессом.
символьные модели искусственного интеллекта — это формальные системы, основанные на использовании языка алгоритмов и представлении данных по принципу "сверху вниз" (top-down), а нейронные сети — это параллельные распределенные процессоры, обладающие естественной способностью к обучению и работающие по принципу "снизу вверх" (bottom-up).
Поэтому при решении когнитивных задач целесообразно создавать структурированные модели на основе связей или гибридные системы, объединяющие оба подхода. Это обеспечит сочетание свойств адаптивности, робастности и единообразия, присущих нейронным сетям, с представлениями, умозаключениями и универсальностью систем искусственного интеллекта
|