Реферат: Математическая статистика
|
Название: Математическая статистика Раздел: Рефераты по математике Тип: реферат | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
математическая статистика1. Генеральная совокупность и выборка В предыдущем разделе нас интересовала распределение признака в некоторой совокупности элементов. Совокупность, которая объединяет все элементы, имеющая этот признак, называется генеральный. Если признак человеческий (национальность, образование, коэффициент IQ т.п.), то генеральная совокупность — все население земли. Это очень большая совокупность, то есть число элементов в совокупности n велико. Число элементов называется объемом совокупности. Совокупности могут быть конечными и бесконечными. Генеральная совокупность – все люди хотя и очень большая, но, естественно, конечная. Генеральная совокупность – все звезды, наверное, бесконечно. Если исследователь проводит измерение некоторой непрерывной случайной величины X, то каждый результат измерения можно считать элементом некоторой гипотетической неограниченной генеральной совокупности. В этой генеральной совокупности бесчисленная количество результатов распределены по вероятности под влиянием погрешностей в приборах, невнимательности экспериментатора, случайных помех в самом явлении и др. Если мы проведем n повторных измерений случайной величины Х, то есть получим n конкретных различных численных значений Естественно считать, что действительным значением измеряемой величины является среднее арифметическое от результатов Можно проводить измерения и дискретной случайной величины. Пусть измерение случайной величины Х представляет собой бросание правильной однородной треугольной пирамиды, на гранях которой написаны числа 1, 2, 3, 4. Дискретная, случайная величина Х имеет простое равномерное распределение:
Эксперимент можно производить неограниченное число раз. Гипотетической теоретической генеральной совокупностью является бесконечная совокупность, в которой имеются одинаковые доли (по 0.25) четырех разных элементов, обозначенных цифрами 1, 2, 3, 4. Серия из n повторных бросаний пирамиды или одновременное бросание n одинаковых пирамид можно рассматривать как выборку объема n из этой генеральной совокупности. В результате эксперимента имеем n чисел Важнейшими числовыми характеристиками распределений являются вероятности Рi
, математическое ожидание М, дисперсия D. Статистиками для вероятностей Рi
являются относительные частоты
которая называется выборочным средним. Выборочная дисперсия
соответствует генеральной дисперсии D. Относительная частота любого события
У этого распределения математическое ожидание равно 0.25 (не зависит от n), а среднее квадратическое отклонение равно Допустим, мы выполнили
Наш результат оказался весьма маловероятным; в серии из двадцати четырех кратных бросаний он встречается примерно один раз. В биологии такой результат обычно считается практически невозможным. В этом случае у нас появится сомнение: является пирамида правильной и однородной, справедливо ли при одном бросании равенство Чтобы разрешить сомнение, надо выполнить еще один раз четырехкратное бросание. Если снова появится результат Нам можно было и не заниматься проверкой правильности и однородности пирамиды, а считать априори пирамиду правильной и однородной, и, следовательно, правильным выборочное распределение. Далее следует выяснить, что дает знание выборочного распределения для исследования генеральной совокупности. Но поскольку установление выборочного распределения является основной задачей статистического исследования, подробное описание экспериментов с пирамидой можно считать оправданным. Будем считать, что выборочное распределение верное. Тогда экспериментальные значения относительной частоты Если бы пирамида оказалась направильной и неоднородной, то выборочные распределения для различных (i=1,2,3,4) имели бы отличные математические ожидания (разные Отметим, что полученные здесь биномиальные выборочные распределения при больших n ( Продолжим случайный эксперимент — бросание правильной, однородной, треугольной пирамиды. Случайная величина Х, связанная с этим опытом, имеет распределение. Математическое ожидание здесь равно
Проведем n бросаний, что эквивалентно случайной выборке объема n из гипотетической, бесконечной, генеральной совокупности, содержащей равные доли (0.25) четырех разных элементов. Получим n выборочных значений случайной величины Х (
Поэтому статистика
Таким образом, теоретическое выборочное распределение имеет тоже математическое ожидание, что и у исходного распределения, дисперсия уменьшена в n раз. Напомним, что
Математическая, абстрактная бесконечная выборка, связанная с выборкой объема n из генеральной совокупности и с введенной статистикой будет содержать в нашем случае Среднее значение будет иметь максимальную вероятность. С ростом n экспериментальные результаты будут теснее группироваться около среднего значения. То обстоятельство, что среднее выборочного среднего Если выполнить расчеты вероятностей в выборочном распределении с Для оценки генеральной дисперсии Выше мы попытались представить первые шаги исследователя, пытающегося провести простой статистический анализ повторных экспериментов с правильной однородной треугольной призмой (тетраэдром). В этом случае нам известно исходное распределение. Можно в принципе теоретически получить и выборочные распределения относительной частоты, выборочного среднего и выборочной дисперсии в зависимости от числа повторных опытов n. При больших n все эти выборочные распределения будут приближаться к соответствующим нормальным распределениям, так как они представляют собой законы распределения сумм независимых случайных величин (центральная предельная теорема). Таким образом, нам известны ожидаемые результаты. Повторные эксперименты или выборки дадут оценки параметров выборочных распределений. Мы утверждали, что экспериментальные оценки будут правильными. Мы не выполняли эти эксперименты и даже не приводили результаты опытов, полученные другими исследователями. Можно подчеркнуть, что при определении законов распределений теоретические методы используются чаще, чем прямые эксперименты. 2. Анализ вариационных рядовСтатистическое исследование может быть полным и выборочным. При полном исследовании измерение интересующего вас признака производится у каждого элемента совокупности. При этом определяется точное распределение признака. Например, декан получил точное распределение оценок на экзамене по математике у всех 230 студентов. Он может определить точные доли отличников и не успевающих, процент успеваемости, процент качества обучения и т.п. Но это не "настоящая" статистика. Статистика решает задачу как, обследовав элементы выборки из генеральной совокупности, получить необходимую информацию о генеральной совокупности. Первое, что должен решить статистик — это как провести выборку, чтобы она наилучшим образом соответствовала генеральной совокупности, то есть, чтобы выборка была репрезентативной. Выборка будет репрезентативной, если отбор элементов в выборку производится случайно. Это означает, что все элементы генеральной совокупности имеют одинаковую вероятность попасть в выборку. Один из способов получения случайной выборки состоит в том, что каждому элементу генеральной совокупности присваивается номер; билеты с номерами помещаются в шляпу или шарики с номерами в барабан; случайно извлекается билет или шарик, а затем выбирается соответствующий элемент. В настоящее время случайные числа выдают ЭВМ. Обеспечить случайность выборки не так просто как кажется. Ни в коем случае не следует полагаться на свою интуицию, следует подчеркнуть: если выборка окажется не репрезентативной (ее называют смещенной), то с ростом ее объема может уменьшаться точность или могут появляться ошибочные выводы. Закон больших чисел сработает наоборот. По видимому, по этой причине Дизраэли пошутил: "На свете есть ложь наглая, ложь и статистика". Раздел статистики, в котором изучаются виды выборок, разрабатываются методики, обеспечивающие репрезентативность выборок, изучается влияние объема выборки на получаемые результаты и др., называется теорией выборки. Очевидна ее важная роль в планировании статистического исследования. 2.1 Дискретный вариационный рядДопустим, произведено n измерений случайной дискретной величины Х и получено k различных значений Полученные результаты удобно представить в виде таблицы.
Вторая строка таблицы представляет собой вариационный ряд для частот, третья — для относительных частот, четвертая — для кумулятивных относительных частот. Если число вариант k не очень велико, то для того, чтобы получить более наглядное представление о распределение случайной величины Х строят полигоны или кумуляты. Для этого на оси абсцисс откладывают значения вариант Эмпирическая функция распределения определена на всей числовой оси. Ясно, что Рассмотрим пример. Пусть в результате обследования получены следующие значения вариант:
Все значения (
3. Интервальный вариационный рядКак уже отмечалось выше, для непрерывной случайной величины всю область ее возможных значений нужно разделить на интервалы, которые называют классами. Обычно ширины всех классов выбирают одинаковыми. Ширину интервалов ΔX определяют формулой
где Xmax и Xmin — наибольшее и наименьшее значение признака в выборке, а k— количество классов. Оптимальное число классов зависит от объема выборки. При этом используют таблицу
Количество вариант в классе есть частота попадания в данный класс. Все классы кроме последнего представляют собой полуоткрытые справа интервалы (например
Здесь ai – границы классовых интервалов. Если на оси абсцисс отложить классовые интервалы и над ними построить прямоугольники с высотами, равными соответствующим плотностям fi
относительной частоты, то площадь каждого прямоугольника будет равна относительной частоте Интервальный вариационный ряд можно построить и для дискретной случайной величины, если объем выборки достаточно большой. Нужно, чтобы в каждом классе было не менее трех вариант. В этом случае мы как бы совершаем переход от дискретной случайной величины к непрерывной. Рассмотрим пример. Измерена частота пульса Xi
(число сокращений сердца за минуту) у 1060 студентов (
На основании этих результатов строим гистограмму и эмпирическую функцию распределения. Так как мы перешли от дискретной случайной величины к непрерывной, то мы считаем плотность вероятности постоянной внутри каждого интервала, а функция распределения на каждом интервале будет возрастать линейно от начального до конечного ее значения на интервале. На рис. представлена гистограмма, которая почти симметрична относительно вертикали
Убеждаемся, что центральная предельная теорема выполняется. На рис. представлена эмпирическая функция распределения — кумулята pi
. Эта функция приближенно выражается через функцию Лапласа (или интеграл вероятностей)
по формуле
При 4. Точечные оценки параметров распределения признака Построение графиков эмпирических функций плотности вероятности гистограммы и функции распределения (кумяляты) дают общее представление о распределении случайной величины. Для уточнения деталей распределения по данным выборки статистики разработаны специальные методы. Очень помогают исследования, если удается определить тип закона распределения признака в генеральной совокупности (нормальный, биноминальный и др.). Очевидно, что благодаря центральной предельной теореме распределение генеральной совокупности часто является нормальным. И, следовательно, для уточнения модели остается точнее определить численные значения математического ожидания и дисперсии. Поэтому были точно рассчитаны распределения различных статистик для выборок из генеральной нормальной совокупности (c2 , Стьюдента, Фишера). Теория статистики, построена на расположении о нормальности исходного распределения, была первой. Ее можно назвать Гауссовской статистикой. Раздел статистики, в которой изучается проблема получения информации о генеральной совокупности по выборочным данным, называется статистические выводы. Этот раздел можно разделить на два отдела: оценивания параметров и проверка гипотез. Для оценивания параметра распределения можно использовать несколько выборочных статистик. Например, оценка генерального среднего может служить и выборное среднее Иногда становится важным и такое свойство оценки как простота вычислений, малое время обработки. Можно выбрать такую оценку вместо более эффективной, но и более дорогой и длительной. Обычно оценку случайний величины (статистику) обозначают большими латинскими буквами ( Признаки каждого объекта выборки объема n можно считать независимыми случайными величинами Хi (i=1,2,…,n) имеющими одинаковые законы распределения (одинаковые параметры m и s). Точечной оценкой математического ожидания будет статистика
Случайную величину
Если данные выборки сгруппировать в вариационный ряд, то
где xi — значение варианты для дискретного вариационного ряда или средина классового интервала для интервального вариационного ряда; mi – частота варианта или классовая частота. Точечной оценкой дисперсии s2 признака, при неизвестной величине математического ожидания m является статистика
Значение этой статистики s2 для конкретной выборки равно
Удобно пользоваться формулой
где Точечной оценкой стандартного отклонения (среднего квадратического отклонения) s является статистика
Точечной оценкой стандартного отклонения выборочной средней
Значение этой статистики для конкретной выборки равно
Подчеркнем, что s является характеристикой отдельного измерения, а Если данные выборки представлены интервальным вариационным рядом, то для большего объема n и малого числа классов k. Оценка дисперсии признака является завышенной на величину
где Dx— ширина классового интервала. Если объем генеральной совокупности N, а объём выборки n соизмерим с N (
Рассмотрим пример. Результаты измерения признака Х из элементов выборки объёма
По формуле находим выборочное среднее
Из расчета видно, что поправка Шеппарда незначительна. По формуле определяем стандартное отклонение выборочной средней Такие величины как выборочные мода и медиана также могут служить для оценки среднего генеральной совокупности (особенно если генеральное распределение симметрично). Разность выборочного среднего Для двухмерной случайной величины выборка объёма n состоит из последовательности n пар чисел
Для коэффициента корреляции точечной оценкой служит выражение
Для нахождения точечной оценки неизвестного параметра используется также метод наибольшего правдоподобия. Он состоит в том, что в качестве наиболее правдоподобного значения параметра Q берут то его значение Q, при котором вероятность получить в n опытах данную выборку
Эта функция имеет максимум при
Пусть
Уравнение для определения l имеет вид
решение которого даёт известный результат математический дисперсия выборка дискретный
|
 . Эта функция от n результатов измерений называется статистикой, и она сама является случайной величиной, имеющей некоторое распределение называемая выборочным распределением. Определение выборочного распределения той или иной статистики — важнейшая задача статистического анализа. Ясно, что это распределение зависит от объема выборки n и от распределения случайной величины Х гипотетической генеральной совокупности. Выборочное распределение статистики
. Эта функция от n результатов измерений называется статистикой, и она сама является случайной величиной, имеющей некоторое распределение называемая выборочным распределением. Определение выборочного распределения той или иной статистики — важнейшая задача статистического анализа. Ясно, что это распределение зависит от объема выборки n и от распределения случайной величины Х гипотетической генеральной совокупности. Выборочное распределение статистики 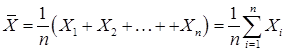 ,
, ,
,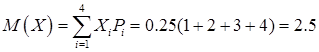 .
. .
.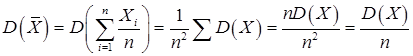 .
.


 . Понятно, что линия, которая идет по оси абсцисс, затем огибает гистограмму и затем снова идет по оси абсцисс является графиком эмпирической функции плотности вероятности.
. Понятно, что линия, которая идет по оси абсцисс, затем огибает гистограмму и затем снова идет по оси абсцисс является графиком эмпирической функции плотности вероятности.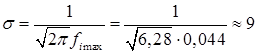 , то есть к кривой
, то есть к кривой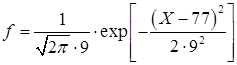 .
. ,
,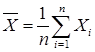 .
.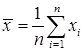 .
.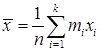 ,
,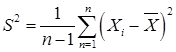 .
. .
.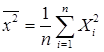 или
или 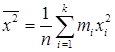 .
. .
.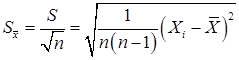
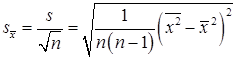 .
.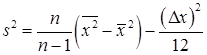 ,
,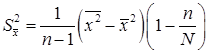 .
.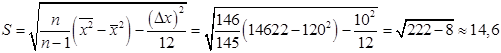
 . Тогда
. Тогда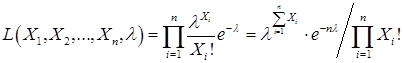 ,
,
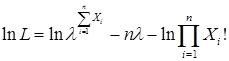 .
. ,
,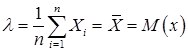 .
.