|
Содержание
Введение
………………………………………………………..2
Задание №1
…………………………………………………….4
Задание №2
…………………………………………………….5
Задание №3
…………………………………………………….9
Задание №4
…………………………………………………….13
Задание №5
…………………………………………………….14
Задание №6
…………………………………………………….18
Задание №7
…………………………………………………….20
Задание №8
…………………………………………………….23
Задание №9
…………………………………………………….27
Задание №10
…………………………………………………...28
Список использованной литературы
………………………41
Введение
Теорией вероятностей называется математическая наука, изучающая закономерности в случайных явлениях. Ее предметом являются специфические закономерности, наблюдаемые в случайных явлениях.
При научном изучении и описании окружающего мира часто приходится встречаться с особого типа явлениями, которые принято называть случайными. Для них характерна большая по сравнению с другими степень неопределенности, непредсказуемости. Случайное явление — это такое явление, которое при неоднократном воспроизведении одного и того же опыта протекает каждый раз несколько по-иному.
Совершенно очевидно, что в природе нет ни одного явления, в котором не присутствовали бы в той или иной мере элементы случайности. Как бы точно и подробно ни были фиксированы условия опыта, невозможно достигнуть того, чтобы при его повторении результаты полностью и в точности совпадали. Случайные отклонения неизбежно сопутствуют каждому закономерному явлению. Тем не менее в ряде практических задач этими случайными элементами можно пренебречь, рассматривая вместо реального явления его упрощенную схему, «модель», и предполагая, что в данных условиях опыта явление протекает вполне определенным образом. По мере развития науки число учитываемых факторов становится все больше, научный прогноз — все точнее. Это — классическая схема так называемых «точных наук» — от условий опыта к его однозначному результату.
Однако для решения ряда задач такая схема оказывается плохо приспособленной. Это — те задачи, где интересующий нас результат опыта существенно зависит от столь большого числа факторов, что практически невозможно зарегистрировать и учесть их все. В этих задачах многочисленные второстепенные факторы так тесно связаны с результатом опыта, что ничтожное, на первый взгляд, их изменение может сыграть решающую роль, обусловить «успех» или «неуспех» опыта. В таких случаях классическая схема точных наук — детерминистская — оказывается непригодной.
Методы теории вероятностей не отменяют и не упраздняют случайности, непредсказуемости исхода отдельного опыта, но дают возможность предсказать, с каким-то приближением, средний суммарный результат массы однородных случайных явлений. Чем большее количество однородных случайных явлений фигурирует в задаче, тем отчетливее выявляются присущие им специфические законы, тем с большей уверенностью и точностью можно осуществлять научный прогноз.
Характерным для современного этапа развития науки является все более широкое применение вероятностных методов во всех ее областях. Это связано с двумя причинами. Во-первых, изучение явлений окружающего мира, становясь более глубоким, требует выявления не только основных закономерностей, но и возможных случайных отклонений от них. Во-вторых, наука все больше внедряется в такие области практики, где наличие и большое влияние именно случайности не подлежит сомнению, а иногда даже является определяющим.
В настоящее время нет практически ни одной области науки, в которой в той или иной степени не применялись бы вероятностные методы. В одних науках в силу специфики предмета и исторических условий эти методы находят применение раньше, в других — позднее.
Знакомство с методами теории вероятностей необходимо сегодня каждому грамотному менеджеру, и не только ему. На сегодняшний день, нет области знаний, где не могли бы сказать свое слово эти методы исследования.
Задание 1
Налоговая инспекция из общего числа N малых предприятий (x1,
x2
,…, xN
),
имеющих учетные номера 1,2,3,…N, для проверки отбирает случайным образом K предприятий, номера которых затем располагает в возрастающем порядке: x1
< x2
<,…,< xk
. Вычислить вероятность того, что под номером j в ранжированном ряду будет предприятие с учетным номером L.
Дано: N=60; K=17; J=15; L=52
Найти: Р(А)-?
Решение:
Обозначим событием А то, что под номером 15 в ранжированном ряду окажется предприятие с учетным номером 52.
Так как из общего числа исходов нас интересует число благоприятствующих исходов и поскольку налоговая служба отбирает предприятия для проверки случайным образом, то отборы равновозможны. Поэтому для определения вероятности воспользуемся классическим способом. Воспользуемся элементами комбинаторного анализа и формулой гипергеометрического распределения.
Число благоприятствующих исходов: 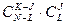
Способов выбрать К предприятий из N предприятий: 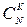
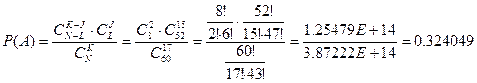
Ответ:
вероятность того, что в ранжированном ряду под номером 15 будет предприятие с учетным номером 52 равна: Р(А)=0,324049.
Задание 2
На плоскости проведены параллельные прямые, отстоящие друг от друга на расстоянии 2
h
.
На плоскость случайным образом (на удачу) бросается тонкий стержень (игла) длиной 2
l
(l
<h
).Появление центра на отрезке 2
h
в любой его точке равновозможно, как и появление любого значения угла φ
между стержнем и прямой на интервале (0
,π
).
Попадание центра стержня на отрезок 2
h
и угловая ориентация φ
стержня – события независимые. Требуется при заданных исходных данных 2
h
и 2l
:
1.Определить вероятность того, что стержень пересечёт какую-либо прямую.
2.Методом статистических испытаний определить эмпирическое значение числа π
при заданных h
,l
и числе испытаний n
≥100. Описать опыт и представить таблицу результатов испытаний.
Дано: 2h=80; 2l=62
Решение:
Обозначим:
Событие А – игла пересекла какую-либо прямую
Введем обозначение Х
– расстояние от середины иглы до ближайшей прямой
Угол φ –
угол, составленный иглой с параллелью
1.Определим вероятность Р(А)

Положение иглы полностью определяется заданием Х
и φ,
причем Х принимает значение от 0 до h, возможные значения φ
от 0 до π. Другими словами середина иглы может попасть в любую из точек прямоугольника со сторонами h и φ
.
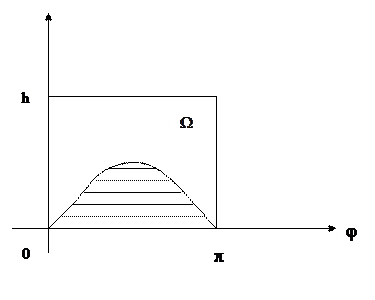 Таким образом данный прямоугольник можно рассматривать как фигуру G, точки которой представляют собой все возможные положения центра иглы. Площадь фигуры G=h*π
Найдем теперь такую фигуру g, каждая точка которой благоприятствует появлению события А, т.е.каждая точка которой может служить серединой иглы, которая пересекает ближайшую к ней параллель при условии, что
X<l*sin φ т.е.если середина попадет в любую из точек заштрихованной фигуры на рисунке.
Таким образом заштрихованную фигуру можно рассматривать как фигуру g. Найдем площадь этой фигуры:
g=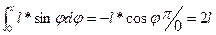
P(A)=
P(A)=0.4936
Значит, вероятность того, что игла пересечет какую-либо прямую равна 0.4936.
2.Методом статистических испытаний определим эмпирическое значение числа 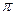 . Я буду проводить опыт с бросанием иглы 200 раз. Если игла пересечет какую-либо прямую(событие А) то вероятность данного опыта – 1, если не пересечет то вероятность данного опыта равна – 0. . Я буду проводить опыт с бросанием иглы 200 раз. Если игла пересечет какую-либо прямую(событие А) то вероятность данного опыта – 1, если не пересечет то вероятность данного опыта равна – 0.
| №
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
| А
|
0
|
1
|
1
|
0
|
1
|
0
|
1
|
0
|
1
|
0
|
| №
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
| А
|
0
|
1
|
1
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
| №
|
21
|
22
|
23
|
24
|
25
|
26
|
27
|
28
|
29
|
30
|
| А
|
0
|
0
|
0
|
1
|
1
|
0
|
1
|
1
|
1
|
1
|
| №
|
31
|
32
|
33
|
34
|
35
|
36
|
37
|
38
|
39
|
40
|
| А
|
1
|
0
|
1
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
| №
|
41
|
42
|
43
|
44
|
45
|
46
|
47
|
48
|
49
|
50
|
| А
|
1
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
| №
|
51
|
52
|
53
|
54
|
55
|
56
|
57
|
58
|
59
|
60
|
| А
|
0
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
1
|
1
|
| №
|
61
|
62
|
63
|
64
|
65
|
66
|
67
|
68
|
69
|
70
|
| А
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
0
|
1
|
| №
|
71
|
72
|
73
|
74
|
75
|
76
|
77
|
78
|
79
|
80
|
| А
|
0
|
0
|
0
|
1
|
0
|
1
|
1
|
0
|
0
|
0
|
| №
|
81
|
82
|
83
|
84
|
85
|
86
|
87
|
88
|
89
|
90
|
| А
|
1
|
1
|
1
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
| №
|
91
|
92
|
93
|
94
|
95
|
96
|
97
|
98
|
99
|
100
|
| А
|
1
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
1
|
1
|
| №
|
101
|
102
|
103
|
104
|
105
|
106
|
107
|
108
|
109
|
110
|
| А
|
0
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
| №
|
111
|
112
|
113
|
114
|
115
|
116
|
117
|
118
|
119
|
120
|
| А
|
1
|
0
|
1
|
0
|
1
|
1
|
0
|
1
|
1
|
0
|
| №
|
121
|
122
|
123
|
124
|
125
|
126
|
127
|
128
|
129
|
130
|
| А
|
0
|
0
|
1
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
| №
|
131
|
132
|
133
|
134
|
135
|
136
|
137
|
138
|
139
|
140
|
| А
|
0
|
1
|
1
|
0
|
0
|
1
|
0
|
1
|
1
|
1
|
| №
|
141
|
142
|
143
|
144
|
145
|
146
|
147
|
148
|
149
|
150
|
| А
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
1
|
1
|
1
|
| №
|
151
|
152
|
153
|
154
|
155
|
156
|
157
|
158
|
159
|
160
|
| А
|
0
|
1
|
1
|
1
|
0
|
1
|
0
|
0
|
1
|
1
|
| №
|
161
|
162
|
163
|
164
|
165
|
166
|
167
|
168
|
169
|
170
|
| А
|
0
|
0
|
1
|
0
|
1
|
1
|
0
|
1
|
0
|
1
|
| №
|
171
|
172
|
173
|
174
|
175
|
176
|
177
|
178
|
179
|
180
|
| А
|
1
|
1
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
| №
|
181
|
182
|
183
|
184
|
185
|
186
|
187
|
188
|
189
|
190
|
| А
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
| №
|
191
|
192
|
193
|
194
|
195
|
196
|
197
|
198
|
199
|
200
|
| А
|
0
|
0
|
1
|
1
|
1
|
1
|
0
|
1
|
0
|
0
|
Событие А наступило в 99 испытаниях. Статистическим способом найдем вероятность наступления события А.
Р(А)= 
Р(А)=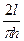 откуда откуда
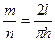 откуда откуда

Эмпирическое значение числа 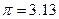
Ответ:
1. Вероятность того, что стержень пересечёт какую-либо прямую: 
2. Методом статистических испытаний эмпирическое значение числа π
при заданных h
, l
и числе испытаний n
≥100
: 
Задание 3
Структурная схема системы доведения информации об экономических угрозах до руководства некоторой фирмы имеет вид:

    
 
 
   

 
Отказы элементов при передаче информации - события независимые. Известны вероятности передачи информации об угрозе i-м элементом, Pi (i=1,…,8).
Найти вероятность доведения информации о поступившей экономической угрозе до руководства фирмы.
Дано: Р1=Р2=Р8=0.69; Р3=Р4=Р6=0.84; Р5=Р7=P9=0.79
Найти: Р(А)-?
Решение:
Обозначим событие А – исправность системы
событие А1 – безотказная работа элемента 1
событие А2 – безотказная работа элемента 2
событие А3 – безотказная работа элемента 3
событие А4 – безотказная работа элемента 4
событие А5 – безотказная работа элемента 5
событие А6 – безотказная работа элемента 6
событие А7 – безотказная работа элемента 7
событие А8 – безотказная работа элемента 8
гипотеза H1 – элементы 5 и 6 работают
гипотеза Н2 – элементы 5 и 6 не работают
гипотеза Н3 – элемент 5 работает, а 6 не работает
гипотеза Н4 – элемент 5 не работает, а 6 работает
Рассмотрим систему и бозначим ее за систему В
Используем метод разложения систему по базисному элементу, основанное на теореме о полной вероятности.
1) Пусть имеет место гипотеза Н1 и 5 и 6 элементы работают, тогда
   

 
Найдем вероятность исправности данной системы:
Р(Н1)=Р(А5)*Р(А6)=0.6636
Р(B/H1)=P[(A1+A3)*(A7+A4)*A2]*P(H1)=(P1+P3-P1*P3)*P2*(P7+P4-P7*P4)*P(H1)=(0.69+0.84-0.5796)*0.69*(0.79+0.84-0.6636)*0.6636= =0.655776*0.6413034=0.4205
2) Пусть имеет место гипотеза Н2 и 5 и 6 элемент не работают, тогда

Найдем вероятность исправности данной системы:
Р(H2)=(1-P5)*(1-P6)=0.21*0.16=0.0336
P(B/H2)=P[(P1*P2*P7)+(P3*P4)]*P(H1)=(0.69*0.69*0.79+0.84*0.84-0.69*0.69*0.79*0.84*0.84)*0.0336=0.2743
3) Пусть имеет место гипотеза Н3 и тогда 5 элемент работает и 6 элемент не работает, тогда
Найдем вероятность исправности данной системы:
P(H3)=P5*(1-P6)=0.16*0.79=0.1264
P(B/H3)=P[(P1+P3)*(P2*P7+P4)]*P(H3)=(0.69+0.84-0.5796)*(0.5451+0.84-0.4579)*0.1264=0.9504*0.9272*0.1264=0.1113
4) Пусть имеет место гипотеза Н4 и 5 элемент не работает и 6 работает, тогда

P(H4)=(1-P5)*P6=0.21*0.84=0.1344
P(B/H4)=P[(P1*P2+P3)*(P7*P4)]*P(H4)=(0.69*0.84+0.69-0.69*0.84*0.69)* *(0.79+0.69)*0.1344=(0.5796+0.69-0.39924)*(0.79+0.69-0.5451)*0.1344= 0.87036*0.9349*0.1344=0.1094
Полная группа событий:
P(B)=P(B/H1)+P(B/H2)+P(B/H3)+P(B/H4)=0.4205+0.02743+0.1113+0.1094=
=0.66863
Теперь рассмотрим систему В вместе с 8 и 9 элементом:
 
А-исправность системы
Р(А)=Р[(P8*P9)+(P *P9)]=P8*P9+ P*P9 - P8*P9* P*P9=0.5451+0.5282-0.29=0.7833 *P9)]=P8*P9+ P*P9 - P8*P9* P*P9=0.5451+0.5282-0.29=0.7833
Ответ:
Вероятность доведения информации о поступившей экономической угрозе до руководства фирмы равна 0.7833
Задание 4
Инвестор вложил капитал в ценные бумаги двух финансовых фирм. При этом он надеется получить доход в течение обусловленного времени от первой фирмы с вероятностью P1
; от второй — с вероятностью P2
. Однако есть возможность банкротства фирм независимо друг от друга, которая оценивается для первой фирмы вероятностью P3
; для второй — P4
. В случае банкротства фирмы инвестор получает только вложенный капитал. Какова вероятность того, что инвестор получит прибыль?
Дано: Р1
=0,95; Р2
=0,90; Р3
=0,09; Р4
=0,01
Найти: Р(А)-?
Решение:
Обозначим Р(А) – вероятность того, что инвестор получит прибыль.Всего 3 возможных варианта получения прибыли:
1.получение прибыли и с первого предприятия и со второго(Р1*Р2)
2.получения прибыли с первого, а со второго нет(Р1*Р4)
3.получения прибыли со второго, а с первого нет(Р2*Р3)
Используем теорему сложения вероятностей для трех совместных событий:
P(A)=P[(P1*P3)+(P2*P3)+(P1*P4)]=P1*P2+P2*P3+P1*P4-P1*P2*P2*P3-P1*P2*P1*P4-P1*P4*P2*P3+P1*P2*P2*P3*P1*P4=0.855+0.081+0.0095-0.0693-0.0082-0.0008+0.00065=0.867895
P(A)=0.8697
Ответ:
Вероятность того, что инвестор, получит прибыль равна 0,8679
Задание 5
Случайная величина  – годовой доход наугад взятого налогоплательщика. Плотность распределения вероятностей случайной величины – годовой доход наугад взятого налогоплательщика. Плотность распределения вероятностей случайной величины 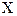 задана в виде: задана в виде:
 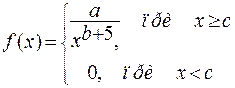
где a
– неизвестный параметр распределения, а величины b и c являются константами, значения которых заданы в таблице вариантов задания.
Требуется :
1) Определить значения параметра «а» и построить график функции f
(х).
2) Найти функцию распределения F
(х)
и построить её график.
3) Определить математическое ожидание m
x
, дисперсию D
x
и среднее квадратическое отклонение 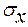 годового дохода . годового дохода .
4) Вычислить значения третьего µ
3
и четвертого µ
4
центральных моментов, и определить коэффициенты ассиметрии А
s
и эксцесса Ex
.
5) Определить размер годового дохода Х1
в тыс. у.е., не ниже которого с вероятностью Р
окажется годовой доход случайного выбранного налогоплательщика.
Дано:
с=0,7
b=0,30
P=0,55
Найти: 1) a-? f(x)-?
2) F(x)-?
3) mx
,-?; Dx
-?;  -? -?
4) µ
3
-? ; µ
4
-?
5) Х1
-?
Решение:
1)Для определения параметра «а» воспользуемся свойством плотности распределения:
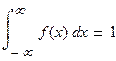
Возьмём нижний предел равным «с»:

отсюда «а» равен
а = 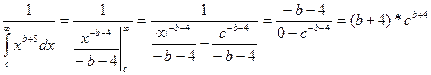
Подставим значения и получим а:
а=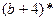 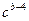 = =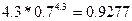
Построим график плотности распределения при вычисленном параметре а:

2) Для определения функции распределения воспользуемся формулой:

Нижним пределом также возьмем «с»:
  F(x) = 
| F(x) =
|
0,2158· (0.7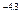 -x-4,3
), при x≥0,7 -x-4,3
), при x≥0,7
|
| 0, при x<0,7
|
3) Для нахождения математического ожидания воспользуемся формулой:

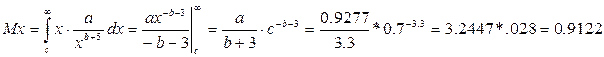


4) Центральный момент k-ого порядка вычисляется по формуле:

Начальный момент k-ого порядка определяется равенством:

Выразим центральные моменты 3 и 4 порядка через начальные моменты:
μ3
=ν3
- 3ν1
ν2
+ 2ν1
3
μ4= ν4
- 4ν1
ν3
+ 6ν1
2
ν2
- 3ν1
4
Вычислим начальный моменты 2,3,4-го порядков:



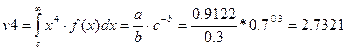
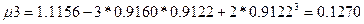
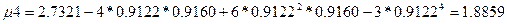
Коэффициенты ассиметрии и эксцесса расчитываются по формулам:


Подставляя известные значения получаем:


5) Для определения вероятности воспользуемся формулой для расчета вероятности попадания СВ в интервал:
P(x1≤X)=1-P(X<x1)=1-F(x1)
Подставляя известные значения получаем:

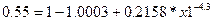
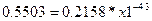
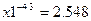

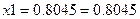
Ответ:
1) значения параметра «а» равно 0.9277.
2) функция распределения имеет вид:
| F(x) =
|
0,2158· (0.7-x-4,3
), при x≥0,7
|
| 0, при x<0,7
|
3) математическое ожидание Mx
=0,9122, дисперсия Дx
=0,0839, среднее квадратическое отклонение годового дохода равно σ =0,2897.
4) значения третьего и четвертого центральных моментов равно  3
=0,127 и 4
=1,8859 соответственно, коэффициенты ассиметрии и эксцесса равны AS
=5,222 и EC
=264,7405. 3
=0,127 и 4
=1,8859 соответственно, коэффициенты ассиметрии и эксцесса равны AS
=5,222 и EC
=264,7405.
5) размер годового дохода Х1
в тыс. у.е., не ниже которого с вероятностью Р окажется годовой доход случайного выбранного налогоплательщика равен 0,8045.
Задание 6
Производится «n
» независимых испытаний, в каждом из которых события А
может появиться с вероятностью Р
.
Требуется
:
1)Определить вероятность того, что событие А
появится при n
– испытаниях равно k
- раз.
2)Определить вероятность того, что событие А
появится при n
– испытаниях более m
- раз.
3)Определить вероятность того, что событие А
появится при n
– испытаниях не менее k
1
- раз, но не более k
2
- раз.
4)Вычислить среднее число появления события А
при n
– испытаниях и среднее квадратическое отклонение числа появлений события А
.
5)Определить с какой вероятностью должно появляться события А
в каждом из «n
» - опытов при условии, что вероятность не появления события А
ни в одном из «n
» - опытов равна Р0
.
Дано:
n=10; k=4; P=0.6; m=2; k1
=3; k2
=6; P0
=0.3; q=0.4
Найти:
1) Р(m=3)-?
2) Р(m>1)-?
3) Р(2≤m≤5)-?
4) m
x
-?;  -? -?
5) Р1
(А)-?
Решение:
Поскольку испытания независимы и р=const, то используем схему Бернулли. Обозначим Х число испытаний в которых событие А наступило. Х={1,2,..10}
X принадлежит биномиальному закону распределения.
1) Для расчёта вероятности наступления события k раз применяем формулу Бернулли

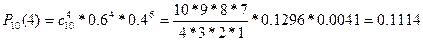
2) Для того, чтобы найти вероятность того, что событие наступит более m раз воспользуемся формулой ) Р(m>1)=1 – [Р(0)+Р(1)+Р(2)]
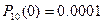
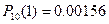
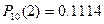

3) Для нахождения вероятности наступления события не менее m1
, но не более чем m2
раз (m1
≤m≤m2
) воспользуемся формулой
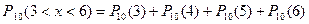

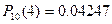

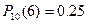

4) Так как Х принадлежит биномиальному распределению, то


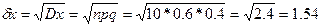
5)
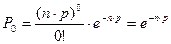

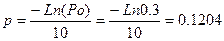
Ответ:
1) Р(k=3)=0.1114
2) Р(x>2)=0.88694
3) Р(3≤x≤6)=0.6045
4) m
x
=6;  2.4 =1.54 2.4 =1.54
5) p=0.1204
Задание 7
Дискретная двумерная случайная величина (X
,
Y
) описывается законом распределения вероятностей, заданного рядом распределения вероятностей, представленным в таблице:
|  Xi Xi
Yj
|
X1
|
X2
|
| Y1
|
P11
|
P12
|
| Y2
|
P21
|
P22
|
| Y3
|
P31
|
P32
|
Требуется:
1. Определить частные законы распределения компонент X
и Y
случайного вектора соответственно.
2. Определить условный закон распределения случайной величины X
при условии, что Y
приняла значение yj
.
3. Определить условный закон распределения случайной величины Y
при условии, что X
приняла значение xi
.
4. Вычислить математические ожидания и дисперсии компонент X
и Y
.
Дано: P11
=0,15; P12
=0,10
P21
=0,25; P22
=0,15
P31
=0,15; P32
=0,20
Yj
=Y2
Xj
=X1
Решение:
1)Определим закон распределения компонент случайного вектора X, для этого воспользуемся формулой:  , где , где 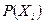 представляет собой не что иное, как вероятность того, что случайная величина X примет значение представляет собой не что иное, как вероятность того, что случайная величина X примет значение 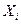 , таким образом получим ряд распределения случайной величины X. , таким образом получим ряд распределения случайной величины X.

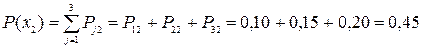
В результате получим закон распределения:
Произведем проверку, для этого сложим вероятности:
P(X) = 0,55+0,45=1;
Следовательно закон распределения Х вычислен правильно.
Определим закон распределения компонент случайного вектора Y, для этого воспользуемся формулой: 

Получим следующий закон распределения:
| Y
|
Y1
|
Y2
|
Y3
|
| P(Y)
|
0,25
|
0,40
|
0,35
|
Проверка:
P(Y) =0,25+0,40+0,35=1
2) Для того чтобы определить условный закон распределения случайной величины Х, при условии, что величина Y приняла значение Yj
, воспользуемся формулой:

где n = 1,2, а P(Yj
) - вероятность того, что Y примет значение Yj
,определенное из закона распределения компоненты Y. Подставив данные в формулу, получаем:

Проверка: 0,625+0,375=1;
Мы определили условный закон распределения случайной величины Х, при условии, что величина Y приняла значение Y2.
3) Аналогично определим условный закон распределения случайной величины Y, при условии, что величина Х приняла значение Хi
.
:
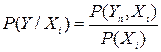
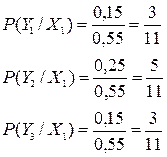
Проверка: 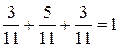
Мы определили условный закон распределения случайной величины Y, при условии, что величина X приняла значение X1.
4) Вычислим математическое ожидание компонент X и Y:

х1
=1, x2
=2 следовательно 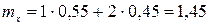
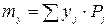
y1
=1, y2
=2, y3
=3 следовательно 
Задача №8
Случайная величина Y
связана со случайными величинами xi
(i= 1,…,3) функциональной зависимостью вида  . .
Известны математические ожидания случайных величин  и средние квадратические отклонения, и средние квадратические отклонения,  Задана также нормированная корреляционная матрица: Задана также нормированная корреляционная матрица:
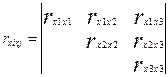
Требуется:
1. Вычислить математическое ожидание случайной величины Y
.
2. Вычислить среднее квадратическое отклонение случайной величины Y
.
3. В предположении нормального закона распределения случайных величин xi
записать выражение для плотности распределения случайной величины Y
.
Дано: а1
=-0.69; a2
=2.78; a3
=-2.61; b=8.33;
mx1
=1.33; mx2
=-0.98; mx3
=2.12;
σx1
=0.68; σx2
=1.53; σx3
=0.95;
rx1x2
=-0.15; rx1x3
=0.74; rx2x3
=0.86
Найти:
1) my
-?
2) σy
-?
3) f(y)-?
Решение:
1) Т.к. случайная величина Y является линейной функцией от аргументов X1
,X2
,X3
(Y(X1
,X2
,X3
)), то для определения
МОЖ Y воспользуемся теоремой МОЖ линейной функции:
МОЖ линейной функции равно той же линейной функции от МОЖ её аргументов:
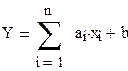
 M[Y]= M[Y]=

2) 2) Для вычисления среднего квадратического отклонения случайной величины Y,
сначала воспользуемся формулой для нахождения дисперсии Dy
линейной функции 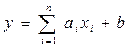


Найдем корреляционные моменты Kij
величин xi
xj
из формулы для коэффициента корреляции: 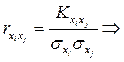 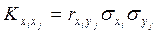 . .

Так как в задаче задано СКО, то воспользуемся формулой  : :


3) Найдем выражение для плотности распределения случайной величины Y
Плотность n
-мерного нормального закона распределения случайного вектора  имеет вид: имеет вид:

 - корреляционная матрица, которая является положительно определенной симметрической матрицей, - корреляционная матрица, которая является положительно определенной симметрической матрицей,
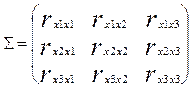 - нормированная корреляционная матрица - нормированная корреляционная матрица
Составим корреляционную матрицу вектора 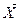

K12
=K21
=-0.156;
K13
=K31
=0.478;
K23
=K32
=1.25
Для диагонального элемента 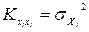
К11
=(0.68)2
=0.4624;
К22
=(1.53)2
=2.3409;
К33
=(0.95)2
=0.9025
Получаем корреляционную матрицу:
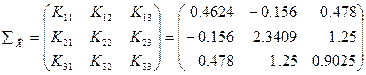
Составим матрицу коэффициентов функциональной зависимости  : :

Рассчитаем корреляционную матрицу СВ Y:


Определитель матрицы:
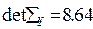
Вычислим обратную матрицу:
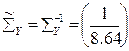
Из 1-го пункта задачи имеем:

Найдем выражение одномерной плотности распределения случайной величины Y

Ответ:
1) my
=-0.8453
2) σy
=2.433
3) 
Задание 9
Пусть Х – время задержки момента начала матчей на данном стадионе. Известно среднее значение времени задержки, которое составляет «а» минут.
Требуется:
1. Оценить вероятность того, что начало матча будет задержано не менее, чем на t минут.
2. Найти минимальное значение времени задержки начала матча t0
, при котором вероятность задержки на время не менее t0
не превышает требуемого значения Ртр
, если дополнительно известно, что среднее квадратичное отклонение времени задержки начала матчей 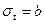 секунд. секунд.
Дано: t1
=2.5; a=1.1; Pтр
=0.4; b=52
Найти:
1) Р(t≥t1
)-?
2) t0
-?
Решение:
1) Обозначим x-время задержания начала матча
Для решения задачи применим 1-ое неравенство Чебышева, так как оно имеет смысл тогда, когда 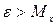 и устанавливает вероятность того, что случайная величина при произвольном законе распределения попадает на интервал ( и устанавливает вероятность того, что случайная величина при произвольном законе распределения попадает на интервал ( ;∞), ограниченная ;∞), ограниченная 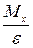
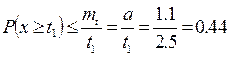
2) Воспользуемся вторым неравенством Чебышева, которое позволяет определить вероятность попадания случайной величины при произвольном законе распределения на интервал симметричный относительно математического ожидания:

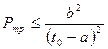

52сек.=0.86 мин.
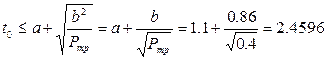
Ответ:
1) Вероятность того, что начало матча будет задержано не менее, чем на 2,5 минут равна 0.44
2) Минимальное значение времени задержки начала матча = 2.4596 минут
Задание 10
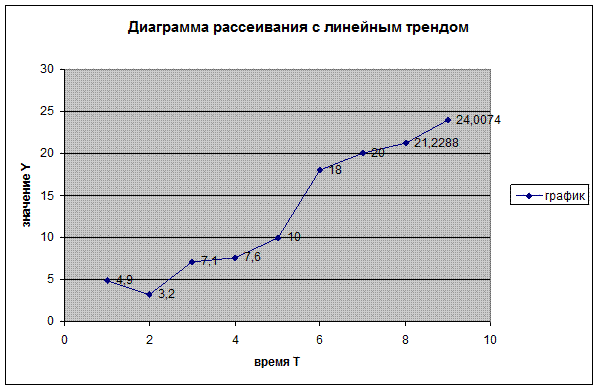
По заданному в таблице Приложения 4 временному ряду U
=
¦
(
T
)
требуется:
- построить диаграмму рассеивания, провести спецификацию модели тренда;
- провести идентификацию модели, ограничившись моделями линейного и квадратичного трендов;
-проверить адекватность построенных моделей по критериям случайности колебаний уровней остаточной последовательности (критерием серий или критерием поворотных точек), критерием соответствия распределения случайной компоненты нормальному закону распределения (критерием ассиметрии и эксцесса или критерием стьюдентизированного размаха), критерием проверки равенства математического ожидания случайной компоненты нулю, критерием проверки независимости значений уровней случайной компоненты (Дарбина-Уотсона);
- выполнить точечный прогноз значений зависимой переменной U по линейному и квадратичному тренду для Τ=8 и T=9;
- выполнить интервальный прогноз для линейного тренда;
-сформулировать выводы о качестве трендовых моделей.
Решение:
Дано:
| T
|
F(T)
|
| 1
|
4.9
|
| 2
|
3.2
|
| 3
|
7.1
|
| 4
|
7.6
|
| 5
|
10
|
| 6
|
18
|
| 7
|
20
|
1)
Суть стадии спецификации заключается в том, что подбирается математическая модель, описывающая изменение процессов во времени.
Для построения диаграммы рассеивания воспользуемся программой Excel

2)
Построим линии тренда
Линейная линия тренда используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением :  ,где b константа. ,где b константа.
Квадратичная линия тренда используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:  , ,
где  константы. константы.

R2
– величина достоверности аппроксимации
По характеру линии тренда видим, что с увеличение времени, значение переменной Y имеет тенденцию к увеличению.
Построим линию квадратичного тренда, так как парабола имеет большое доверие.

3)
Коэффициент детерминации показывает степень соответствия трендовой модели исходным данным. Его значение может лежать в диапазоне от 0 до 1. Чем ближе коэффициент к 1, тем точнее модель описывает имеющиеся данные.
Значение коэффициента детерминации линейного тренда R2
= 0.8636
Значение коэффициента детерминации квадратичного тренда R2
= 0.9507
4)
Для проверки адекватности построенных трендовых моделей воспользуемся критериями оценки моделей.
а)
Критерий поворотных точек
.
С помощью этого критерия можно проверить случайность остатков модели. В соответствии с этим критерием каждый уровень ряда сравнивается с двумя соединенными с ними. Если он больше или меньше их, то эта точка считается поворотной. Далее подсчитывается сумма поворотных точек m. В случайном ряду чисел должно выполняться строгое неравенство:
 , где N – объем выборочной совокупности. , где N – объем выборочной совокупности.
В нашем случае число поворотных точек m=1
N=7

Данное условие не выполняется, следовательно, можно утверждать, что ряд остатков моделей не является случайным.
б) Критерий асимметрии и эксцесса.
Проверка ряда остатков на нормальность осуществляется с помощью показателей асимметрии и эксцесса (если объем выборочной совокупности не превышает 50 значений). При нормальном распределении показатели асимметрии и эксцесса равны нулю.
На основании выборочных данных строятся эмпирические коэффициенты асимметрии и эксцесса по формулам:
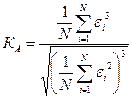 ; ;  . .
В дополнение к выборочным коэффициентам асимметрии и эксцесса определяют среднеквадратические отклонения коэффициентов:
 ; ; 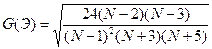
Если одновременно выполняются следующие неравенства:  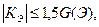 то гипотеза о нормальном характере распределения остатков принимается. то гипотеза о нормальном характере распределения остатков принимается.

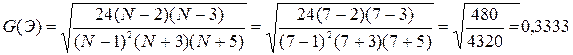
Для линейной модели
:
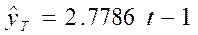

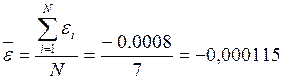
| 
|

|

|
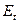
|
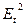
|

|

|

|
| 1
|
4,9
|
1,7786
|
3,1214
|
9,74313796
|
30,41223
|
94,928737
|
9,7438559
|
| 2
|
3,2
|
4,5572
|
-1,3572
|
1,84199184
|
-2,49995
|
3,3929339
|
1,8416797
|
| 3
|
7,1
|
7,3358
|
-0,2358
|
0,05560164
|
-0,01311
|
0,0030915
|
0,05554742
|
| 4
|
7,6
|
10,1144
|
-2,5144
|
6,32220736
|
-15,8966
|
39,970306
|
6,32162906
|
| 5
|
10
|
12,893
|
-2,893
|
8,369449
|
-24,2128
|
70,047677
|
8,36878362
|
| 6
|
18
|
15,6716
|
2,3284
|
5,42144656
|
12,6233
|
29,392083
|
5,42198211
|
| 7
|
20
|
18,4502
|
1,5498
|
2,40188004
|
3,722434
|
5,7690277
|
2,40223651
|
| Сумма
|
70,8008
|
-0,0008
|
34,1557144
|
4,135524
|
243,50386
|
34,1557143
|



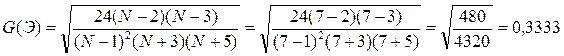

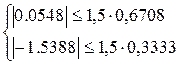 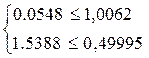
Так как второе неравенство не выполняется, то гипотеза о нормальном характере распределения остатков отклоняется.
Для квадратичной модели:


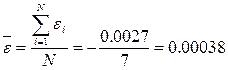
| 
|

|
|
|

|

|

|
|
| 1
|
4,9
|
4,3262
|
0,5738
|
0,32924644
|
0,188921607
|
0,108403
|
| 2
|
3,2
|
4,5571
|
-1,3571
|
1,84172041
|
-2,499398768
|
3,391934
|
3,72837481
|
| 3
|
7,1
|
5,807
|
1,293
|
1,671849
|
2,161700757
|
2,795079
|
7,02303001
|
| 4
|
7,6
|
8,0759
|
-0,4759
|
0,22648081
|
-0,107782217
|
0,051294
|
3,12900721
|
| 5
|
10
|
11,3638
|
-1,3638
|
1,85995044
|
-2,53660041
|
3,459416
|
0,78836641
|
| 6
|
18
|
15,6707
|
2,3293
|
5,42563849
|
12,63793973
|
29,43755
|
13,63898761
|
| 7
|
20
|
20,9966
|
-0,9966
|
0,99321156
|
-0,989834641
|
0,986469
|
11,06161081
|
| сумма
|
0,0027
|
12,34809715
|
8,854946062
|
40,23015
|
39,36937686
|
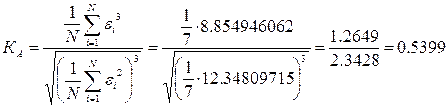


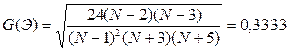

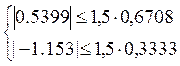 
Так как второе неравенство не выполняется, то гипотеза о нормальном характере распределения остатков отклоняется.
в)
Критерий проверки независимости значений уровней случайной компоненты (критерий Дарбина-Уотсона).
Для проверки независимости остатков используют критерий Дарбина-Уотсона, связанный с гипотезой о наличии в ряде остатков автокорреляции первого порядка, т.е. о корреляционной зависимости соседних остатков.
Наблюдаемое значение  критерия Дарбина-Уотсона: критерия Дарбина-Уотсона:
 , где , где 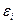 - остатки модели. - остатки модели.
Для линейной модели
:

|
|
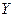
|
|

|
|
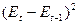
|
| 1
|
4,9
|
1,7786
|
3,1214
|
9,74313796
|
20,05785796
|
| 2
|
3,2
|
4,5572
|
-1,3572
|
1,84199184
|
1,25753796
|
| 3
|
7,1
|
7,3358
|
-0,2358
|
0,05560164
|
5,19201796
|
| 4
|
7,6
|
10,1144
|
-2,5144
|
6,32220736
|
0,14333796
|
| 5
|
10
|
12,893
|
-2,893
|
8,369449
|
27,26301796
|
| 6
|
18
|
15,6716
|
2,3284
|
5,42144656
|
0,60621796
|
| 7
|
20
|
18,4502
|
1,5498
|
2,40188004
|
54,51998776
|
| Сумма
|
-0,0008
|
34,1557144
|
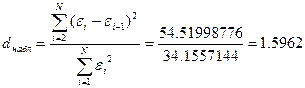
По таблице значения критерия Дарбина – Уотсона определим для числа наблюдений n=7 критические значения нижней и верхней границы:
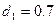 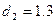
Так как фактически найденное d=1,5962 находится в пределах от d1
до 4 – d2
(0,7<d<2,7), то гипотеза об отсутствии автокорреляции принимается.
Для квадратичной модели
:
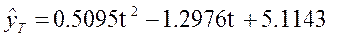

| 
|

|

|
|

|
|
| 1
|
4,9
|
4,3262
|
0,5738
|
0,32924644
|
| 2
|
3,2
|
4,5571
|
-1,3571
|
1,84172041
|
3,72837481
|
| 3
|
7,1
|
5,807
|
1,293
|
1,671849
|
7,02303001
|
| 4
|
7,6
|
8,0759
|
-0,4759
|
0,22648081
|
3,12900721
|
| 5
|
10
|
11,3638
|
-1,3638
|
1,85995044
|
0,78836641
|
| 6
|
18
|
15,6707
|
2,3293
|
5,42563849
|
13,63898761
|
| 7
|
20
|
20,9966
|
-0,9966
|
0,99321156
|
11,06161081
|
| Сумма
|
0,0027
|
12,34809715
|
31,36937686
|

При значимости α=0,05, определим по таблице значений критерия Дарбина-Уотсона для числа наблюдений n
=7 и числа независимых переменных модели k=1, критические значения d1
и d2
:
d1
=0.7
d2
=1.3
4 – dВ
=2.7
Так как фактически найденное d=2.54042 находится в пределах от dВ
до 4 – dВ
(0.7<d<2.7), то гипотеза об отсутствии автокорреляции принимается.
5) Выполним точечный прогноз значений зависимой переменной Y по линейному и квадратичному тренду для Т=8 и Т=9:
Прогноз с линейным трендом:
| T
|
Y(T)
|
| 1
|
4.9
|
| 2
|
3.2
|
| 3
|
7.1
|
| 4
|
7.6
|
| 5
|
10
|
| 6
|
18
|
| 7
|
20
|
| 8
|
21.2288
|
| 9
|
24.0074
|
Прогноз с квадратичным трендом:

| T
|
Y(T)
|
| 1
|
4.9
|
| 2
|
3.2
|
| 3
|
7.1
|
| 4
|
7.6
|
| 5
|
10
|
| 6
|
18
|
| 7
|
20
|
| 8
|
27.3415
|
| 9
|
34.7054
|
6)
Линия тренда – графическое представление направления изменения ряда данных. Линии тренда используются для анализа ошибок предсказания, что также называется регрессионным анализом. Линии тренда позволяют графически отображать тенденции данных и прогнозировать их дальнейшие изменения.
Регрессионный анализ – форма статистического анализа, используемого для прогнозов. Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения переменной из нескольких уже известных значений.
Значения R в квадрате. Число от 0 до 1, которое отражает близость значений линии тренда к фактическим данным. Линия тренда наиболее соответствует действительности, когда значение R в квадрате близко к 1. Оно также называется квадратом смешанной корреляции.
Сравнивая тренды, можно утверждать, что лидирующим по качеству отображения является квадратичный тренд. Он точнее отражает характер модели, т.к. коэффициент детерминации R2
для квадратичного тренда больше соответствующего коэффициента для линейного тренда
C
писок использованной литературы:
1. Теория вероятностей. Учебник для вузов (А.В. Печенкин.,О.И. Тескин.,Г.М. Цветкова и др.). Под ред. В.С. Зарубина., А.П. Крищенко. Изд-во МГГУ им.Н.Э. Баумана.,1999 – 456 стр.
2. Кибзун А.И. Теория вероятностей и математическая статистика, 2005г.
3. Вентцель Е.С. Те ория вероятностей. Учебник для вузов – М.: «Высшая школа», 2000г.
4. Вентцель Е.С., Овчаров Л.А. Задачи и упражнения по теории вероятностей, 2004г.
5. Вентцель Е.С., Овчаров Л.А. Теория вероятностей и её инженерные приложения, 2003г.
6. Виноградов С.А. и др. Теория вероятностей и математическая статистика. Учебно-методическое пособие для практических занятий. МО, 1998 г
|