Содержание
Введение. 4
1. Архитектура базы данных MS SQL Server 2000. 5
1.1 Физическая архитектура базы данных SQL Server 2000. 5
1.1.1 Файлы данных и группы файлов. 6
1.1.2 Страничная организация файлов данных. 8
1.2 Логическая архитектура базы данных SQL Server 2000. 10
1.3 Системные базы данных SQL Server 2000. 11
2. Создание и сопровождение баз данных средствами EntepriseManager14
3. Основы программирования на языке Transact-SQL. 20
3.1 Средства языка Transact–SQL. 21
3.2 Константы, имена, идентификаторы, переменные TRANSACT–SQL. 22
3.3 Типы данных SQL Server 2000. 25
3.4 Создание и удаление баз данных, таблиц и представлений. 28
3.4.1 Создание и удаление баз данных. 28
3.4.2 Создание и удаление таблиц. 30
3.4.3 Создание представлений. 31
3.5 Создание и управление индексами. 32
3.6 Вставка, удаление и изменение данных. 34
Заключение. 38
Глоссарий. 39
Список использованных источников. 40
Список сокращений. 41
Приложение А.. 42
Приложение Б. 43
Приложение В.. 44
Приложение Г. 45
Приложение Д.. 46
Приложение Е. 47
Приложение Ж.. 48
Приложение З. 49
Введение
Система управления базами данных SQL Server 2000 предоставляет пользователям широкие возможности по разработке и сопровождению баз данных. Для этого в составе системы имеется набор графических средств (Enterprise Manager, Query Analyzer), языковых средств (язык Transact-SQL), набор хранимых процедур [1].
Основными задачами в процессе разработки и сопровождения баз данных в среде SQL Server 2000 являются создание, модификация и удаление баз данных, таблиц, а также объектов баз данных, таких как индексы, представления, запросы, хранимые процедуры и триггеры. В курсовом проекте рассматриваются физическая и логическая организация баз данных в SQL Server 2000, структурный язык запросов Transact-SQL, шаблоны команд и примеры запросов [2].
В первой главе («Архитектура баз данных SQL Server 2000»
) рассматриваются физическая и логическая организация баз данных, сотав и назначение системных баз данных сервера.
Во второй главе («Создание и сопровождение баз данных средствами Enterprise Manager»
) рассматривается создание, сопровождение, удаление иперенос базы данных на другие сервера. В качестве инструментария используетсяграфическая утилита Enterprise Manager.
Третья глава («Основы программирования на языке Transact-SQL»
) включает в себя основы структурированного языка запросов Transact-SQL, способы выполнения основных действий по созданию и сопровождению баз данных и входящих в них объектов средствами языка Transact-SQL. В данной главе приводятся шаблоны и примеры применения соответствующих команд. Более полный набор примеров по командам языка Transact-SQL.
В приложениях представлены рисунки и таблицы.
1. Архитектура базы данных MS SQL S
erver
2000
Структурой хранения данных в SQL Server 2000 является база данных (database). Вся работа SQL Server 2000 сводится к управлению базами данных. Системные данные сервера, отвечающие за его функционирование, также хранятся в базах данных. Базу данных SQL Server 2000 можно рассматривать с двух сторон: физической
и логической
.
При работе с любой базой данных SQL Server 2000 – пользовательской или системной – действуют одни и те же механизмы.
Физическая база данных
представляет собой набор файлов, расположенных на диске. С этими файлами можно выполнять любые операции, разрешенные для обычных файлов: копирование, переименование, удаление и т. д. Конечно, делать этого не стоит, но все же выполнение перечисленных операций в случае необходимости возможно. Физическая структура базы данных описывает количество файлов данных и журнала транзакций, из которых состоит база данных, их первоначальный и текущий размер, положение на диске, имя, расширение, шаг приращения и некоторые другие параметры. Эти параметры необходимы только для правильного восприятия SQL Server 2000 базы данных. Для пользователей, работающих с базой данных, в подавляющем большинстве случаев ее физическая структура не имеет значения.
Гораздо больший интерес для пользователей представляет логическая структура базы данных
, описывающая все ее объекты, их поведение ивзаимодействие друг с другом. Логическая структура базы данных включает в себясистемные и пользовательские таблицы, представления, хранимые процедуры,пользователей и роли, умолчания, ограничения целостности и другие объекты.
1.1 Физическая архитектура базы данных SQL S
erver
2000
Физическая база данных SQL Server 2000 хранится в самостоятельном, уникальном для каждой БД наборе файлов. Журнал транзакций и сами данные обязательно хранятся отдельно. Это повышает отказоустойчивость базы данных в случае сбоев системы.
1.1.1 Файлы данных и группы файлов
Для хранения базы данных предназначен набор файлов, персональный для любой базы данных. Каждый файл может принадлежать только одной базе данных. В SQL Server 2000 существует два типа файлов базы данных:
· файлы данных;
· файлы журнала транзакций.
Файлы данных
(data file)
предназначены для хранения информации, находящейся в таблицах базы данных. Кроме того, в этих файлах также размещены процедуры, ограничения, триггеры, индексы и другая информация;
В файлы журнала транзакций
(
transaction
log
file
)
SQLServer 2000 записывает информацию о ходе выполнения транзакций. В них размешается информация о состоянии данных перед началом транзакции, о выполняемых изменениях, блокированных ресурсах и другая сопутствующая информация.
Любая база данных должна содержать как минимум один файл данных и один файл журнала транзакций, т.е. минимальное количество файлов, составляющих базу данных, равно 2. При необходимости администратор может добавлять новые файлы данных или файлы журнала транзакций.
Файлы данных бывают двух типов:
· Primary File (основной, или главный, файл);
· Secondary File (вторичный, или дополнительный, файл).
Каждая база данных имеет один и только один основной или главный файл
(Primary File)
. Если база данных включает в себя только один файл данных, то этотфайл будет основным. Основной файл предназначен для хранения всех системныхтаблиц, присутствующих в любой базе данных. В основном файле хранитсяинформация о структуре базы данных, созданных в ней объектах, параметрахдополнительных файлов и файлов журнала транзакций. По умолчанию основномуфайлу базы данных присваивается расширение mdf
.
В отличие от основного файла база данных может содержать множество вторичных или дополнительных файлов
(Secondary File
) или не содержать их вовсе. В дополнительных файлах может храниться только пользовательская информация. Хранение любой системной информации не допускается. В ходе эксплуатации базы данных администратор может добавлять новые или удалять уже существующие дополнительные файлы.
Файлы журнала транзакций
бывают только одного типа – Transaction Log File
, служащего для хранения журнала транзакций. В базе данных должен быть какминимум один файл журнала транзакций. Для ускорения обработки транзакцийможно использовать несколько журналов транзакций, расположенных на разныхфизических дисках.
Для каждого файла базы данных можно задать свойство автоматического роста и шаг прироста в мегабайтах или в процентах от первоначального роста, а также максимальный размер, до которого возможен рост файла. Каждый файл, используемый в базе данных, имеет два имени:
· Logical File Name
– логическое имя файла, которое используется в командах Transact-SQL при ссылке на конкретный файл;
· OS File Name
– имя файла в операционной системе, которое используется для обращения к файлу в операционной системе.
Сложные базы данных могут иметь несколько файлов для данных и для журнала транзакций. В этом случае файлы БД объединяются в группы для упрощения администрирования базы данных. SQL Server 2000 обеспечивает создание групп следующих трех типов:
· Primary File Group
– основная группа файлов, которая включает первичный файл и все файлы, не включенные в другие группы, база данных может иметь только одну основную группу файлов;
· User-defined File Group
– пользовательская группа файлов, создаваемая командой CREATE
DATEBASE
или командой ALTER
DATABASE
, если в них используется параметр FILEGROUP,
в базе данных можно создать несколько пользовательских групп файлов с произвольным набором файлов;
· Default File Group
– группа файлов по умолчанию, в качестве которой назначается одна из групп файлов, созданных в базе данных. Только одна группа файлов может быть группой по умолчанию. Если не указано явно, группой по умолчанию становится основная группа. Если при создании объекта базы данных не указано явно, к какой группе файлов он будет принадлежать, то этот объект создается в группе файлов по умолчанию.
Когда какие-то данные записываются в группу файлов, они распределяются между файлами этой группы равномерно, т.е. производится распараллеливание записи данных. Для этих целей можно использовать и возможности файловой системы NTFS: чередующийся набор дисков с контролем четности и без него [7].
Любая группа файлов, в том числе и основная, может быть установлена в режим только для чтения, что позволяет защитить данные, записанные на файлы этой группы.
1.1.2
Страничная организация файлов данных
Основная единица хранения данных
на уровне файла базы данных – это страница
, которая участвует в операциях ввода-вывода как единое целое даже тогда, когда требуется всего одна строка. Каждая страница файла базы данных имеет объем 8192 байт. Страницы объединяются в экстенты. Экстент состоит из 8 страниц (64 Кбайт).
Первые 96 байт страницы отводятся под заголовок, в котором хранится системная информация:
· тип страницы;
· объем свободного места на странице;
· идентификационный номер таблицы или индекса – владельца страниц.
Имеется шесть типов страниц:
· Data
- в страницах этого типа хранятся собственно данные, исключая данные типа text
,
ntext
и image
;
· Index
- страницы этого типа используются для хранения информации об
индексированных таблицах;
· Text/Image
- в страницах этого типа хранятся данные типа text
, ntext
и
image
;
· Global Allocation Map
- в страницах данного типа хранится информация об использовании экстентов (групп страниц);
· Page Free Space
- в страницах этого типа хранится информация о свободном пространстве на страницах;
· Index Allocation Map
- страницы этого типа хранят информацию об экстентах, используемых таблицами или индексами.
В страницах типа Data строки записываются последовательно сразу после заголовка страницы, а их смещения записываются в обратном порядке в конце страницы.
Каждый файл данных базы имеет приблизительно одинаковую структуру. Все страницы в файле нумеруются последовательно, начиная с 0. Каждый файл имеет уникальный идентификационный номер. Комбинация этого номера и номера страницы позволяет однозначно идентифицировать любую страницу в базе данных.
На нулевой странице располагается заголовок страницы, в которых хранятся атрибуты файла. Следующая страница содержит PFC, в которой хранится информация об использовании страниц экстента. Затем располагаются битовые поля GAM
и дополнительной таблицы SGAM (Shared GAM).
Остальные страницы заняты данными или являются свободными. Страницы IAM
могут быть созданы в любом месте файла. Для многофайловой базы данных экстенты выделяются на всех файлах в равных пропорциях. Все это обеспечивает высокую скорость создания, поиска и удаления строк данных [8].
Файл журнала транзакций не имеет страниц и экстентов. Он содержит только последовательность записей транзакций, выполняемых в базе данных.
1.2
Логическая архитектура базы данных
SQL S
erver
2000
Если на физическом уровне рассматриваются структуры, используемые для хранения различной информации, то на логическом уровне необходимо рассматривать объекты, которые можно создавать в базе данных, а также различные свойства, которые влияют на работу сервера с базой данных. Под объектами здесь понимается не только собственно объект, каким является таблица, представление, хранимая процедура, но также и пользователи, роли, полнотекстовые каталоги. К логическому уровню относятся и права доступа пользователей и ролей базы данных к созданным в ней объектам. В список объектов базы данных, которые служат для хранения и обработки информации, входят:
· таблицы
(tables)
- единственный объект базы данных, предназначенный для хранения пользовательских данных;
· представления
(views)
- виртуальные таблицы
(virtual tables
), которые отображают данные, хранящиеся в других таблицах, и для пользователя во многом напоминают таблицы;
· индексы
(indexes)
- не могут существовать сами по себе и предназначены для повышения производительности работы сервера при поиске нужных данных в таблицах и представлениях, что достигается путем хранения в упорядоченном состоянии данных одного или более столбцов таблицы или представления;
· ключи
(keys)
- один из типов ограничения целостности, реализуются так же, как и другие ограничения целостности, которые связываются с таблицами, но играют достаточно важную роль в базе данных и поэтому рассматриваются как отдельные объекты;
· умолчания
(defaults)
- описывают значения, которые присваиваются столбцам таблицы, если при добавлении строки явно не было указано значение для соответствующего столбца;
· правила
(rules)
- логические условия, ограничивающие диапазон возможных значений для столбца таблицы или определяемого пользователем типа данных;
· ограничения целостности
(constraints)
- специальные управляющие конструкции, связанными с таблицами и ограничивающие диапазон возможных значений в столбце таблицы;
· хранимые процедуры
(stored procedures)
– поименованные наборы команд на языке Transact-SQL, сохраненные специальным образом и вызываемые на выполнение пользователями;
· триггеры
(triggers)
- специальный тип хранимых процедур, связываемых с таблицами и автоматически запускаемых сервером при выполнении удаления, вставки или изменения данных в конкретной таблице;
· определяемые пользователем типы данных
(UDDT)
- типы данных, создаваемые пользователями;
· определяемые пользователем функции
(user-defined function)
– набор команд Transact-SQL, сохраненных пользователем в виде функции.
1.3
Системные базы данных
SQL S
erver
2000
Система управления MS SQL Server 2000 в своей работе использует несколько системных баз данных, которые создаются автоматически при установке SQL Server 2000 и не должны удаляться. Вся информация о настройке сервера хранится в этих базах данных. Системные базы данных MS SQL SERVER 2000, создаваемые при его установке, их назначение и имена соответствующих им файлов представлены в приложении Е, таблице 1.
Все перечисленные в приложении Е, таблице 1 системные базы данных, как и пользовательские базы данных, в обязательном порядке содержат 18 системных таблиц, которые хранят информацию, определяющую структуру и организацию соответствующей базы данных. Имена всех системных таблиц начинаются с символов sys
. В приложении Ж, таблице 2 перечислены системные таблицы с кратким описанием их назначения.
Не следует напрямую работать с системными таблицами с помощью команд SQLInsert, Updateи Delete. Для изменения данных в системных таблицах в SQL Server 2000 имеется набор системных хранимых процедур, с помощью которых можно выполнить практически любые действия по администрированию сервера. Фирма Microsoft настоятельно рекомендует использовать эти хранимые процедуры, а не изменять данные непосредственно. Это связано не только с опасностью повреждения системных данных, но еще и с обеспечением совместимости. Microsoft может изменить структуру системных таблиц и назначение колонок в следующих версиях SQL Server. Если приложение напрямую изменяет системные таблицы SQL Server 2000 и при этом корректно работает, то нет никакой гарантии, что оно станет правильно работать в следующих версиях. При использовании системных хранимых процедур Microsoft обещает, что приложение будет корректно работать даже при существенных изменениях в системных базах данных.
Системная база данных master
. Эта системная база данных является главной базой данных SQL Server 2000. Остальные системные базы данных имеют второстепенное значение и их можно считать вспомогательными. В базе данных master хранится вся системная информация о параметрах конфигурации сервера, имеющихся на сервере пользовательских баз данных, пользователях, имеющих доступ к серверу, и другая системная информация.
В базе данных master имеется набор таблиц с системной информацией. Наименование таблиц базы данных master и их назначение приведены в приложении З, таблице 3. По умолчанию база данных master создается в каталоге Data установочного каталога SQL Server 2000.
Системная база данных model.
Cистемная база данных model служит шаблоном для создания новых баз данных. Технология создания новой базы данных в SQL Server 2000 построена следующим образом: сервер копирует базу данных model в указанное место и изменяет ее имя соответствующим образом. Если при создании базы данных не указаны никакие параметры, кроме ее имени, то новая база данных будет являться полной копией базы данных model. Если же размер и состав файлов создаваемой базы данных указан явно, то скопированная база данных изменяется соответствующим образом. Но в любом случае в качестве основы используется база данных model. Независимо от того, создаете ли вы базу данных с помощью интерфейса EnterpriseManagerили команд Transact-SQL, последовательность действий будет одинакова.
Изменяя параметры базы данных model, можно управлять параметрами по умолчанию создаваемых баз данных. Кроме того, базу данных model можно использовать в качестве корпоративного стандарта на содержимое и свойства базы данных.
2. Создание и сопровождение баз данных средствами
Enteprise
Manager
База данных является базовым элементом SQL Server 2000 и своего рода контейнером, в котором располагаются объекты и данные. Любой объект должен принадлежать базе данных. Каждая база данных имеет свою систему безопасности, связанную с системой безопасности SQL Server 2000. Любой пользователь при обращении к серверу работает в контексте какой-то базы данных. Каждой базе данных сопоставлен пользователь, который является ее владельцем (database owner). Этот пользователь имеет имя dbo и ему предоставлены максимальные права в базе
данных.
Создание базы данных возможно несколькими способами:
· средствами языка Transact-SQL;
· с помощью графической утилиты Enterprise Manager;
· с помощью мастера создания базы данных Create Database Wizard.
Создание базы данных заключается в том, что на уровне операционной системы будет создан набор файлов, который и станет представлять базу данных. Каждая база данных как минимум состоит из двух файлов – один для данных и один для журнала транзакций. Помимо этих двух файлов, могут быть созданы дополнительные файлы данных и журнала транзакций. Один из файлов данных является первичным
(primary
) и содержит все системные таблицы базы данных. Помимо этого, в системной таблице sysdatabases
системной базы данных master
SQL Server создается новая строка, которая описывает новую базу данных. В столбце filename
этой строки содержится полный путь и имя первичного файла базы данных. Всю остальную информацию о параметрах базы данных, в том числе о количестве и размещении файлов данных и журнала транзакций, сервер получает из системных таблиц базы данных, размещенных в первичном файле. Помимо имени первичного файла, таблица sysdatabases
содержит также идентификационный номер базы данных (столбец dbid
), идентификатор безопасности владельца базы данных (столбец sid
), дату создания (столбец crdate
), уровень совместимости (столбец cmptlevel
) и другую информацию.
В данном разделе рассмотрим создание базы данных с помощью графического интерфейса Enterprise Manager. С помощью этого инструмента можно не только создавать базы данных, но и управлять ими, а также удалять их. В общем случае использование Enterprise Manager по сравнению с непосредственным использованием команд Transact-SQL может заметно сократить время, необходимое на создание баз данных. Работа с Enterprise Manager не требует знания синтаксиса команды CREATE DATABASE, что является неоспоримым достоинством. Для управления базами данных SQL Server 2000 используется папка Databases (приложение А, рисунок 1), имеющаяся в каждой инсталляции. Непосредственно в этой папке перечисляется набор баз данных, созданных на сервере. Как видно из рисунка, в папке перечислены не только пользовательские базы данных, но и системные. Однако если не предполагается работать с системными базами данных, а также с системными объектами пользовательских баз данных и наличие их в панели Enterprise Manager только мешает работе, то можно запретить отображение этих объектов. Для этого достаточно открыть окно регистрации сервера Registered SQL
Server
Properties
(приложение Б, рисунок 2) и сбросить флажок Show
system
databases
and
system
objects
. Для открытия окна свойств сервера достаточно в контекстном меню сервера выбрать команду Edit
SQL
Server
Registration
Properties
.
Создание новой базы данных выполняется с помощью окна Database Properties (приложение В, рисунок 3). Открыть это окно можно разными способами:
· выбрав в контекстном меню папки Databases команду New Database;
· щелкнув правой кнопкой мыши на пустом пространстве правой части и выбрав в открывшемся контекстном меню команду New Database;
· нажаввпанелиинструментов Enterprise Manager кнопку New Database;
· выбрав в меню Action (Действия ) команду New Database.
Окно свойств базы данных Database Properties имеет три вкладки. Первая вкладка General предназначена для указания имени базы данных и сопоставления, которое будет использоваться для базы данных. Остальные элементы управления вкладки General предназначены для предоставления пользователю различной информации о базе данных. На момент создания базы данных этой информации еще не существует, и поэтому указываются значения Unknown (неизвестно) и None (нет).
При выборе имени базы данных, которое должно быть введено в поле Name
, следует придерживаться тех же правил, которые используются при непосредственной работе с командой Create Database. Сопоставление, которое будет иметь база данных, выбирается с помощью раскрывающегося списка Collation
name
. По умолчанию список содержит значение (Server default
), что предписывает применять для базы данных то же сопоставление, которое было указано на уровне сервера при установке SQL Server 2000. Однако можно выбрать и любое другое сопоставление.
Вкладка Data Files
(приложение Г, рисунок 4) предназначена для определения файлов данных, из которых будет состоять создаваемая база данных. В верхней части вкладки Data Files расположена таблица Database files
, с помощью которой собственно и определяются файлы базы данных. В столбце File Name
указывается логическое имя файла, в столбце Location
задается полный путь и имя файла операционной системы. Отметим, что указанный в столбце Location
файл не должен существовать на момент создания базы данных. Путь и имя файла могут быть введены вручную или выбраны с помощью окна Locate Database File
, открыть которое можно с помощью кнопки, расположенной в левой части столбца Location
.
В столбце Initial size (MB)
находится первоначальный размер, который файл будет иметь непосредственно после создания базы данных. Если отсутствует какой- либо суффикс, то подразумевается, что значение указано в мегабайтах. С помощью столбца Filegroup
можно определить группу файлов, к которой должен принадлежать файл. По умолчанию все файлы размещаются в группе файлов PRIMARY.
Помимо сведений, указываемых в таблице Database files
, файлы базы данных имеют дополнительные свойства, такие, как максимальный размер и шаг прироста. Управление этими свойствами осуществляется с помощью группы элементов управления File properties
, расположенной в нижней части вкладки Data Files
.
Вкладка Transaction Log
(приложение Д, рисунок 5) предназначена для управления файлами журнала транзакций. Эта вкладка в значительной степени напоминает вкладку Data Files. Единственное различие между ними состоит в том, что при определении файлов журнала транзакций нельзя работать с группами файлов. После того как все файлы базы данных будут определены, а также указано имя базы данных и сопоставление, остается только нажать кнопку ОК и Enterprise Manager приступит к непосредственному созданию базы данных. Для этого он сгенерирует код команды CREATE DATABASE на основе введенных пользователем значений и выполнит его. Рассмотрение создания базы данных средствами Enterprise Manager можно считать оконченным.
В процессе эксплуатации созданной базы данных возникает необходимость в изменении, как физических параметров, так и логической структуры этой базы. К управлению базой данных на физическом уровне
относится вся работа по изменению имен, размера, количества, положения файлов базы данных, усечению базы данных и журнала транзакций, созданию групп файлов, изменению группы файлов по умолчанию, изменению имени и владельца базы данных. Большинство действий по изменению конфигурации базы данных выполняется с помощью команды ALTER DATABASE. Для уменьшения размера базы данных можно также использовать команды DBCC SHRINKDATABASE, DBCC SHRINKFILE и системную хранимую процедура sp_dboption.
На логическом уровне
изменяются такие параметры, как выполнение автоматического усечения журнала транзакций, автоматическое создание и обновление статистики, возможность выполнения вложенных триггеров и т.п. – всего 22 параметра. Изменять эти параметры можно командой ALTER DATABASE с параметром SET и процедурой sp_dboption.
Для просмотра и модификации свойств базы данных в ее контекстном меню или меню Action
(Действия
) необходимо выбрать команду Proprties (Свойства
). При этом откроется окно свойств выбранной базы данных. Это окно имеет 6 вкладок, три из которых использовались при создании базы данных. Можно отметить некоторые отличия. Например, на вкладке General (Общие) при просмотре свойств созданной базы данных, поле Name (Имя) доступно только в режиме чтения. Также недоступен список Collation Name (Имя сопоставления).
На вкладке Data Files (Файлы данных) можно добавить новые файлы к базе данных или сконфигурировать существующие файлы. На этой же вкладке можно указать возможность автоматического роста размера файла и задать шаг увеличения размера файла.
На вкладке Transaction Log (Журнал транзакций) выполняется настройка файлов, используемых для хранения журнала транзакций. Конфигурирование выполняется аналогично конфигурированию файлов базы данных, за исключением того, что файлы журнала транзакций не объединяются в группы.
Список имеющихся в базе данных групп файлов содержится на вкладке Filegroups (Группы файлов). Этот список можно модифицировать удаляя и добавляя группы файлов.
С помощью вкладки Permissions (Права) администратор может раздавать пользователям и ролям базы данных права на выполнение команд Transact-SQL или разрешать создание тех или иных объектов базы данных.
На вкладке Options (Параметры) представлены разнообразные параметры конфигурирования базы данных, которые разбиты на две группы параметров: Access (Доступ) и Settings (Настройки).
Часто бывает, что по прошествии некоторого времени необходимо изменить структуру базы данных и удалить часть ее объектов. Для этого достаточно нажать клавишу Del или выбрать команду Delete (Удалить) в контекстном меню объекта. Но необходимо помнить, что удаление объекта может привести к нарушению функционирования базы данных.
Сервер позволяет отсоединять (хранимая процедура sp_detach) и присоединять (хранимая процедура sp_attach_db) до 32767 баз данных, изменять владельца (хранимая процедура sp_changedbowner), просматривать свойства (хранимая процедура sp_dboption и DATABASEPROPERTY), получать справки (хранимая процедура sp_helpdb) и т.д. Для того чтобы отсоединить базу данных от сервера в Enterprise Manager, необходимо выполнить команду Detach Database
(Отсоединить
базу данных
) из списка задач контекстного меню базы данных или меню Action
(Действия
). Для того чтобы присоединить базу данных к серверу в Enterprise Manager, необходимо выполнить команду Attach Database
(Присоединить базу
данных
) из списка задач контекстного меню базы данных или меню Action
(Действия
).
Для переноса структуры базы данных на другой сервер или для отправки ее по электронной почте SQL Server 2000 позволяет создавать сценарии объектов. Для создания сценариев объектов базы данных в контекстном меню объекта или в меню Action (Действия) из списка всех задач выбирается команда Generate SQL Script (Генерировать сценарии SQL). Открывающееся при этом окно содержит три вкладки, позволяющие выполнять настройку процесса создания сценариев. На вкладке General (Общие) можно выбрать объекты, для которых будут создаваться сценарии. На вкладке Formatting (Форматирование) выполняется настройка процесса создания сценария. На вкладке Options (Параметры) можно задать параметры кода для пользователей и ролей базы данных, определить режим создания кода для индексов, триггеров, полнотекстовых индексов, ключей, умолчаний и ограничений для таблиц, а также другие параметры.
Логическим завершением манипуляций с базой данных является ее удаление
. Для этого надо просто выбрать в списке имя базы данных, щелкнув правой кнопкой мыши, и выбрать в открывшемся контекстном меню команду Delete
. При удалении базы данных происходит удаление строки таблицы sysdatabases
, описывающей соответствующую базу данных. Так же производится и физическое удаление всех файлов, из которых состояла база данных. Тем не менее, имея резервную копию базы данных, впоследствии можно восстановить ее снова.
3. Основы программирования на языке T
ransact
-SQL
Целью любой системы управления базами данных является предоставление пользователю простых и эффективных механизмов манипулирования данными. Для этого можно использовать различные методы управления данными, одним из которых является язык структурированных запросов
(SQL
).
Язык SQL является хорошим примером использования технологии клиент- сервер. Когда пользователю требуется произвести некоторые операции с данными, он описывает действия, которые необходимо выполнить, с помощью команд языка SQL. Подготовленные команды, называемые запросом
(query
), отправляются на сервер баз данных. В соответствии с полученными инструкциями сервер осуществляет необходимые действия и отправляет клиенту лишь результат работы. Таким образом, вся работа с данными производится на сервере. В 1992 г. Американским национальным институтом стандартизации был разработан стандарт на язык SQL, названный ANSI SQL-92. Этот стандарт не только определяет основные правила использования команд, идентификаторов, переменных и других элементов, но и регламентирует работу самой системы управления базами данных. В частности, в стандарте ANSI SQL-92 были рассмотрены механизмы работы транзакций и блокировок.
Стандарт ANSI SQL-92 был хорошей попыткой зарегистрировать языки доступа к данным, используемые в различных СУБД. Однако со временем каждый из производителей начал улучшать и модернизировать возможности языка, подстраивая их под конкретную СУБД. С одной стороны, это позволяет более эффективно использовать возможности той или иной СУБД, с другой – это привело к потере совместимости продуктов. В настоящее время стандарт ANSI SQL-92 рассматривается, скорее, как общие рекомендации к построению эффективной системы управления базами данных, чем как конкретный список шагов по построению СУБД.
Корпорация Microsoft, как и многие другие производители, разработала свою версию языка SQL, назвав его Transact-SQL. Именно этот язык используется в SQL Server 2000 для доступа к данным. Он удовлетворяет требованиям ANSI SQL-92, но предлагает пользователю еще и ряд дополнительных возможностей, позволяющих более гибко и эффективно работать с данными. Язык Transact-SQL активно используется не только в программных продуктах корпорации Microsoft, но и в пакетах независимых разработчиков.
Раздел документации сервера T–SQL Help содержит описание каждой команды языка Transact–SQL и набор примеров их использования.
3
.1 Средства языка
Transact
–SQL
Язык Transact–SQL включает следующие средства:
· данные баз данных и переменных различного типа;
· константы, стандартные и ограниченные идентификаторы;
· арифметические и логические выражения, включающие в качестве операндов константы, переменные, имена столбцов таблиц, функции, подзапросы и условные выражения, а также выражения, взятые в круглые скобки;
· SQL–команды для создания, изменения и удаления баз данных и их объектов, а также для определения запросов на ввод, обработку и извлечение данных;
· управляющие программные структуры, определяющие условия и порядок выполнения команд в заданной последовательности или пакете команд;
· встроенные (системные) и определяемые пользователем функции;
· встроенные (системные) и определяемые пользователем хранимые процедуры.
В системе могут храниться, помимо функций и процедур, последовательности (пакеты) команд, которые называются скриптами. Если скрипт описывает процесс создания базы данных, или каких-либо ее объектов, то такой скрипт называется сценарием. Сценарии позволяют переносить структуру базы данных от одного сервера к другому, а также структуру таблиц и других объектов в различные базы данных. Скрипты хранятся в текстовых файлах. Функции и хранимые процедуры баз данных позволяют уменьшить объем запросов, передаваемых от клиента к серверу, что повышает общую производительность системы. Наличие исходного кода для этих объектов позволяет упростить сопровождение программных комплексов и внесение изменений в них.
Обычно все бизнес–правила и алгоритмы обработки данных реализуются на сервере баз данных и доступны конечному пользователю в виде набора функций и хранимых процедур, которые и представляют интерфейс обработки данных. Для обеспечения целостности данных, а также в целях безопасности, приложению обычно не предоставляется прямой доступ к данным. Вся работа ведется с помощью указанного интерфейса.
Подобный подход делает весьма простым изменение алгоритмов обработки данных и обеспечивает возможность расширения системы без внесения изменений в само приложение. Достаточно изменить хранимую процедуру на сервере баз данных, и сделанные изменения тотчас станут доступными всем пользователям сети.
3.2 Константы, имена, идентификаторы, переменные TRANSACT–SQL
В языке Transact–SQL имеются следующие виды констант:
· битовые: 0 и 1;
· логические: FALSE и TRUE;
· бинарные в шестнадцатеричном представлении: 0x9E70DA;
· символьные: ‘ABC’; “ABC” (если QUOTED_IDENTIFIER = OFF), N‘ABC’ или N “ABC” (Unicode);
· целые: 1; 2; 175;
· с фиксированной точкой: 12.35; - 16.753;
· с плавающей точкой: 1.75Е5; 3.84Е – 3;
· для даты: “ April 15.2003”; “4/15/2003”; “20031207”;
· для времени: 14:30; 14:30:20:999; 4am; 4pm;
· денежные: $100;?200; 2.15.
Комментарии в языке бывают двух типов: строчные, начинающиеся с двух символов минуса («--») и блочные, заключаемые символами /* и */. Все объекты базы данных должны иметь имена, которые используются в командах для ссылки на эти объекты. Любой объект базы данных должен быть уникально идентифицирован. Помимо программных имен сервер автоматически генерирует внутренние уникальные имена для идентификации объектов баз данных, например, PK_ _Table X_ _ 014543FA. Программные имена задаются идентификаторами двух типов:
стандартными идентификаторами: Table X; Key Col;
· ограниченнымиидентификаторами: [My Table]; [Order]; “My Table”; “Order”;
· (если QUOTED_IDENTIFIER = ON).
Длина идентификатора – от 1 до 128 символов. Идентификатором не может быть какое-либо зарезервированное ключевое слово языка. Стандартный идентификатор в качестве первого символа может иметь любую латинскую или русскую букву, знаки #, ##, @, @@ и знак подчеркивания _. Последующими знаками, помимо указанных знаков, могут быть еще и десятичные цифры.
Ограниченные идентификаторы могут включать и другие символы, в том числе зарезервированные слова. В этом случае они должны заключаться в квадратные скобки или двойные кавычки.
В соответствии с идеологией SQL Server 2000 каждый объект создается определенным пользователем и принадлежит той или иной базе данных. В свою очередь база данных расположена на конкретном сервере. Из имен объекта, пользователя, базы данных и сервера создается полное имя (complete name) или полностью определенное имя (full qualified name), записываемое в следующем виде:
[[[server.].[database].[owner_name].] object_name.
Варианты обращения к объектам базы данных: A.B.C.D; A.B..D; A..C.D; A..D; B.C.D; B..D; C.D; D. Чтобы сослаться на конкретный столбец таблицы или представления, необходимо в полном имени указать пятый элемент: А.В.С.D.E.
В Transact–SQL существует несколько способов передачи данных между командами. Одним из таких способов является передача данных через локальные переменные, объявляемые следующим образом:
DECLARE {@ имя локальной переменной тип данных}[,…n]
Таким образом, знак @ является признаком имени локальной переменной. Этот же знак используется для определения имен параметров функций и хранимых процедур. Часть синтаксиса [,…n] означает повторение синтаксической конструкции, взятой в фигурные скобки:
DECLARE @Ivar int или DECLARE @IBit bit.
Значения переменным можно присвоить с помощью команд SET и SELECT. Командой SET можно присвоить значение только одной переменной: SET @Ivar = 5
или SET @IBit = 0.
Для присваивания значений нескольким переменным, вычисляемых с помощью выражений, следует использовать команду SELECT, которая выводит результаты в окно Grids:
SELECT @Ivar = SUM (price) FROM titles _ _ см. окно Result.
Для вывода значений переменных следует использовать команды:
· SELECT – для вывода данных в стандартный набор строк;
· PRINT – для вывода данных как служебной информации.
Примеры команд вывода значений переменных:
· SELECT @Ivar _ _ вокно Grids утилиты Query Analyzer;
· PRINT @IBit _ _ вокно Messages утилиты Query Analyzer.
Константы, переменные и параметры функций и хранимых процедур, вызовы функций, имена столбцов и подзапросы являются операторами арифметических и логических выражений. В качестве операнда может быть также само выражение типа CFSE, NULLIFи COALESCE.
Операторами выражения могут быть унарные («+» или «-»), бинарные арифметические операторы (+, -, *, % ), оператор присваивания (=), строковая операция конкатенации (+), операторы сравнения (=, >, <, <=, >=, =, != или <>, !<, !>), логические операторы (NOT, AND, OR, ALL, ANY, BETWEEN, EXIST, IN, LIKE, SOME ) и битовые операторы (&, |, ^).
Константы, переменные, операнды и выражения используются при записи команд и программирования функций и хранимых процедур, которые, все вместе взятые, составляют основную часть системы программирования SQL Server 2000 и определяют ее выразительную мощь. Команды позволяют создавать, модифицировать и удалять базы данных и их объекты, формировать сложные запросы на ввод, обработку и извлечение данных из баз знаний, выполнять функции администрирования и обслуживания баз данных. Функции и хранимые процедуры реализуют разнообразные алгоритмы обработки данных или выполнение служебных функций сервера.
3.3 Типы данных SQL
Server
2000
При объявлении переменной с помощью команды DECLARE необходимо указать ее тип данных. Тип данных определяет, какая информация может храниться в переменной, и какие операции могут выполняться над этими данными. В общем, понятие и использование типов данных в Transact-SQL соответствуют большинству современных языков программирования.
Типы данных играют большую роль при работе с таблицами. Каждый столбец должен иметь конкретный тип данных. В одной таблице может быть множество столбцов, как с одинаковыми, так и с различными типами данных. Наконец, типы данных активно используются при работе с хранимыми процедурами, определяя вид значений, указываемых при вызове.
В SQL Server 2000 набор типов данных несколько расширен по сравнению с предыдущей версией SQL Server – добавлены типы данных bigint, table и sql_variant.
В итоге в распоряжении пользователей имеется набор из встроенных типов данных:
· binary(n) – двоичные данные фиксированной длины до 8000 байт; для n байтов выделяется n+4 байта памяти, значения задаются с помощью шестнадцатеричных чисел 0x<шестнадцатеричные цифры>;
· image – двоичные данные длиной до 231–1, место во внешней памяти выделяется в виде цепочки страниц;
· char(n) – строковый тип данных фиксированной длины без поддержки Unicode длиной до 8000 байтов, данные зависят от кодовой страницы; если для столбца не задана опция NULL, то строка при необходимости будет дополняться справа пробелами; если эта опция задана, то дополнение пробелами будет иметь место при условии ANSI_PADDING=ON, в противном случае пробелы добавляться не будут;
· varchar(n) – строковый тип, как и char(n), но не с фиксированной длиной, если ANSI_PADDING=OFF, то будет выполняться удаление конечных пробелов, если ANSI_PADDING=ON, то удаление пробелов производиться не будет;
· nchar(n) - строковый тип, как и char(n), но с поддержкой Unicode, поэтому максимальное количество символов составляет 4000, в этом случае для строковых констант надо задавать впереди букву N (например, N’ABC’);
· nvarchar(n) – строковый тип, как varchar(n), но с поддержкой Unicode;
· text – строковый тип без поддержки Unicode длиной до 2 Гбайт; память выделяется страницами по 8 Кбайт, связываемыми в цепочку;
· ntext – строковый тип как и text, но с поддержкой Unicode, поэтому длина строки не более 1 Гбайта;
· int – целый тип длиной в 4 байта и с диапазоном от –231 до 231-1;
· smalling – целый тип длиной в 2 байта с диапазоном от –215 до 215-1;
· tinyint – целый тип длиной в 1 байт и диапазоном от 0 до 255;
· bigint – целый тип длиной в 8 байт и с диапазоном от-263 до 263-1;
· decimal[(p[,s])] – десятичный двоично-кодированный тип с p десятичными разрядами, из которых s – дробных; максимальное значение p достигает 38, поэтому диапазон значений составляет от –(1038-1) до 1038-1;
· numeric[(p[,s])] – тип, аналогичныйтипу decimal[(p[,s])];
· float[(n)] – плавающий (приблизительный) тип длиной в 4 байта и с диапазоном от –1.79x10308 до 1.79x10308; значение n определяет количество бит для хранения мантиссы и может принимать значения от 1 до 53;
· real – плавающий тип, являющийся аналогом float(240);
· datetime – тип данных для хранения даты (4 первых байта) и времени (4 последних байта) в диапазоне от 1.1.1753 и до 31.12.9999 года, дата хранится в виде смещения относительно базовой даты 1.1.1753, а время является количеством миллисекунд после полуночи;
· smalldatetime – тип данных для хранения даты (первых 2 байта) и времени (последние 2 байта) в диапазоне от 1.1.1900г. до 6.6.2079г., время задается с точностью до минуты;
· money – тип данных для хранения больших денежных величин с точностью до 4 знаков после запятой в диапазоне от –922 337 203 685 477.5808 до +922 337 203 685 477.5807, для хранения данных отводится 8 байт;
· smallmoney – тип данных для хранения нормальных денежных величин с точностью до 4 знаков после запятой в диапазоне от –214 748.3648 до 214 748.3647, для хранения данных отводится 4 байта;
· bit – битовый (логический) тип со значениями 0 и 1; для хранения выделяется 1 разряд байта памяти;
· timestamp – тип данных временный штамп для учета числа изменений данных в записи (версий строки row version), значение timestamp уникально в пределах базы данных и позволяет идентифицировать конкретное значение записи;
· uniqueidentifier – тип данных для хранения глобальных уникальных идентофикаторов длиной в 16 байт, генерируемых функций NEWID и используемых для идентификации строк (записей), при генерации используется номер сетевой карты компьютера и текущее время;
· sysname – тип данных для хранения имен объектов базы данных; аналог
nvarchar (128);
· sql_variant – вариантный тип данных для хранения данных любого типа, кроме text, ntext, image, timestamp;
· table – тип таблицы для временного хранения наборов данных с использованием переменных.
На основе некоторых из базовых типов данных могут быть созданы новые типы данных, называемые пользовательскими (user-defined). Примером такого типа данных может служить тип sysname (основанный на nvarchar(l28)), активно применяемый в системных таблицах для хранения имен объектов.
Типы данных SQL Server 2000 можно разбить на следующие группы:
· целочисленные (Integers) – bigint, int, smallint и tinyint;
· нецелочисленные (Decimal) – decimal, numeric, float и real;
· денежные (Money) – money и smallmoney;
· датаивремя (Date and Time) – datetime и smalldatetime;
· двоичные (Binary) – binary, varbinary и image;
· строковые (String) – char, varchar, nchar и nvarchar;
· текстовые (Text) – text и ntext;
· специальные (Specials) – timestamp, uniqueidentifier, bit, cursor, table и sql variant.
3.4 Создание и удаление баз данных, таблиц и представлений
3.4.1 Создание и удаление баз данных
Любая пользовательская база данных может быть создана командой CREATE DATABASE. Для создания базы данных и для ее обслуживания нужно иметь соответствующие права. По умолчанию такими правами обладают члены фиксированных ролей сервера sysadmin и dbcreator. При необходимости такие права можно предоставить и другим пользователям. Лицо создающее базу данных, автоматически становится ее владельцем. Имя базы данных должно точно отражать ее назначение и создаваться по правилам построения системных идентификаторов. Длина имени не более 128 символов. Для команды CREATE DATABASE запись синтаксиса на этом метаязыке будет выглядеть следующим образом:
CREATE DATABASE database_name
[ON
[<filespec> [,…n]]
[<filegroup> [,…n]]
]
[LOG ON {<file spec> [,…n]}]
[COLLATE collation_name]
[FOR LOAD| FOR ATTACH]
<filespec> : : =
[PRIMARY]
( [NAME=Logial_file_name,]
FILENAME=’os_file_name’
[, SIZE=size]
[, MAXSIZE={MAX_SIZE|UNLIMITED}]
[, FILEGROWTH=growth_increment]) [,…n]
<filegroup> : : =
FILEGROUP filegroup_ name <filespec> [,…n]
Эта команда определяет новую базу данных и файлы для хранения данных или подключает ранее созданную базу данных, используя ее файлы.
Из определения синтаксиса команды CREATE DATABASE следует:
· для создания базы данных в ряде случаев достаточно задать лишь ее имя;
· имеется возможность задавать полные пути и имена файлов, как для данных, так и для журнала транзакций (logon);
· явно указывать первичный файл, который содержит необходимые сведения об остальных файлах;
· можно использовать группы файлов для ускорения операций ввода – вывода.
Большинство действий по изменению конфигурации базы данных выполняется с помощью команды ALTER DATABASE. Для уменьшения размера базы данных можно также использовать команды DBCC SHRINKDATABASE, DBCC SHRINKFILE. На логическом уровне изменяются такие параметры, как выполнение автоматического усечения журнала транзакций, автоматическое создание и обновление статистики, возможность выполнения вложенных триггеров и т.п. – всего 22 параметра. Изменять эти параметры можно командой ALTER DATABASE с параметром SET.
3.4.2
Создание и удаление таблиц
Пользовательская таблица создается командой Transact-SQL CREATE TABLE. При этом необходимо задать имя таблицы, перечислить имена столбцов, задать тип данных для каждого столбца, упорядоченность символов для сортировки символьных данных, значения по умолчанию, а также ограничения на столбцы или таблицу в целом.
Командой DELETE TABLE можно удалить любую таблицу. Но прежде, чем это сделать, необходимо удалить все объекты базы данных, которые ссылаются на данную таблицу, либо изменить их таким образом, чтобы они не ссылались на удаляемую таблицу.
Чтобы получить информацию о таблице, необходимо выполнить следующую хранимую процедуру: sp_help имя таблицы. После исполнения этой команды на экране появляется целый ряд информационных таблиц: таблица с общей информацией, таблица со свойствами колонок, таблица с ограничением IDENTITY, таблица с информацией о размещении на файлах, таблица с информацией об индексах, таблица с данными об ограничениях, таблица с информацией о ссылающихся таблицах.
3.4.3
Создание представлений
Представление (View) для пользователей баз данных выглядит как таблица, но при этом оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Подобно реальным таблицам представления содержат именованные столбцы и строки с данными, которые они динамически выбирают из таблиц и предлагают эти данные пользователю для просмотра. Представления часто применяются для ограничения доступа к конфиденциальным данным в таблицах баз данных. Когда в представление не включается столбец исходной таблицы, то считают, что на таблицу наложен вертикальный фильтр. Если в SQL – запросе установлено одно или несколько условий для выборки строк, то считают, что на таблицу наложен горизонтальный фильтр.
Представление может выбирать данные из других представлений, которые, в свою очередь, могут также основываться на представлениях или таблицах. Вложенность представлений не должна превышать 32. Представления можно создавать, используя базы данных одного сервера (текущего). Максимальное количество столбцов в представлении равно 1024. Представление не может ссылаться на временные таблицы. Кроме того, нельзя создавать временное представление.
Для представления нельзя определить ограничения целостности, триггеры, правила, или умолчания, а также создать обычный или полнотекстовый индекс. В основном представления используются для выборки данных. Однако с помощью представлений можно выполнять и изменение данных в таблицах, на основе которых построено представление, при этом требуется соблюдение ряда правил:
· представление должно содержать, как минимум, одну таблицу в параметре FROM команды SELECT;
· не разрешается использование функций агрегирования и др.
Как и для таблиц, для представлений можно определить следующие права доступа:
· SELECT – просмотр данных;
· INSERT – добавление данных через представления;
· UPDATE – изменение данных в исходных таблицах;
· DELETE –удаление данных в исходных таблицах.
Чтобы иметь возможность создавать представления, надо обладать правами владельца баз данных и иметь соответствующие разрешения для любых таблиц или представлений, упомянутых в запросе на создание этого представления. Для создания представления используется следующая команда Transact-SQL:
CREATE VIEW [Имя базы данных.] [имя владельца.]
Имя представления
[(Имя колонки [,... n])]
[WITH{ENCRYPITION\SHEMABINDING\
VIEW_METADATA}
AS Команда SELECT
[WITH CHECK OPTION]
Если в команде не заданы имена колонок представления, то они определяются по именам выбираемых колонок в команде SELECT. Параметр ENCRYPTION скрывает код создания этого представления, а параметр SHEMABINDING обеспечивает контроль структуры исходных объектов, к которым обращается оператор SELECT. Опция WITH CHEC OPTION не позволяет изменять строки таким образом, чтобы они исчезли при отборе командой SELECT.
Наиболее полная информация по созданию и удалению баз данных приводится в [1, 3, 5, 6, 9]
3.5
Создание и управление индексами
Создание индекса командами языка Transact – SQL производится следующим
образом:
· автоматически при создании первичного ключа, когда создается кластерный индекс (если не указан параметр NONCLUSTERED);
· автоматически при реализации ограничения целостности UNIQUE, когда создается не кластерный индекс;
· автоматически при создании таблицы, когда для столбца указываются параметры CLUSTERED или NONCLUSTERED;
· с помощью специальной команды CREATE INDEX.
Как только индексы созданы для таблицы, сервер обеспечивает их эффективное автоматическое использование при поиске запрашиваемых или модифицируемых строк. Пользователю не предоставляется никаких средств для указаний серверу, какие индексы и каким способом использовать при выполнении того или иного запроса.
Формат команды для явного создания индекса следующий:
CREATE [UNIQVE] [CLUSTERED\NONCLUSTERED] INDEX
Имяиндекса
ON {Имя индекса\Имя представления}
(column[ASC\DESC] [,…n])
[WITH [PAD_INDEX]
[[,] FILLFACTOR = Факторзаполнения]
[[,] IGNOR_DUP_KEY]
[[,] DROP_EXISTING]
[[,] STATISTICS_NORECOMPUTE]
[[,] SORT_IN_TEMP_DB]
]
[ON Имя группы файлов]
Если автоматическое создание кластерного индекса не предполагается, то перед созданием не кластерного индекса надо создать кластерный, так как некластерный индекс всегда ссылается на кластерный. Можно создать 249 некластерных индексов с использованием до 16 столбцов в каждом индекс, при этом общая длина индекса не должна превышать 900 байтов. Столбцы с типами данных text, ntext или image в индексах не допускаются. Порядок столбцов при определении ключа очень важен. Желательно их указывать в порядке возрастания длины данных. Параметры ASC и DESC определяют метод сортировки ключевых элементов – соответственно по возрастанию или по убыванию.
Параметр PAD_INDEX обеспечивает резервирование на каждой странице индекса места для вставки новых записей и используется вместе с параметром FILLFACTOR.
Параметр IGNORE_DUP_KEY не приводит к отказу транзакции при добавлении дублирующих строк, при этом сами дублирующие строки игнорируются, и сервером выдается сообщение об ошибке. Остальные параметры команды используются редко. Созданный тем или иным способом индекс, можно переименовать с помощью системной хранимой процедуры sp_rename, можно его удалить командой DROP INDEX или перестроить для упорядочивания свободного места на индексных страницах, используя команды DROP INDEX и CREATE INDEX или команду DBCC DBREINDEX. Для получения информации об индексах используется системная хранимая процедура:
sp_helpindex [@objname] ‘name’, где name – имя рассматриваемой таблицы текущей базы данных.
Для просмотра индивидуальных свойств конкретного индекса следует применять команду:
INDEXPROPERTY (table_ID, index, property), в которой table_ID = OBJECT_ID (имя таблицы) – идентификационный номер таблицы, index – имя индекса, а property – рассматриваемое свойство: Index Depth (глубина индекса), Is Clustered (кластерный), Is Unique (уникальный) и др.
Для сбора и анализа статических данных при использовании индексов используются следующие команды и процедуры: CREATE STATISTICS, UPDATE STATISTICS, sp_autostats, sp_statisticsи др.
3.6
Вставка, удаление и изменение данных
Изначально целью любой системы управления базами данных является предоставление пользователям удобных и эффективных механизмов управления данными. Любая СУБД предоставляет пользователям инструменты для ввода, изменения, удаления и выборки данных. Остальные возможности, такие, как репликация, резервное копирование, автоматическое администрирование, перенос данных и другие, являются лишь дополнительными компонентами, обеспечивающими более эффективное решение все тех же задач ввода, изменения, удаления и выборки данных.
SQL Server 2000 предлагает несколько различных механизмов управления данными. Например, вставка данных может выполняться не только средствами Transact-SQL, но и с помощью утилиты bср.ехе или служб трансформации данных (DTS, Data Transformation Services).
Для добавления данных в языке Transact-SQL используются команды INSERT и SELECT INTO, для изменения данных – команда UPDATE и для удаления строк из таблиц – команда DELETE.
Команда INSERT позволяет вставить в таблицу одну или несколько строк. Упрощенный синтаксис этой команды таков:
INSERT [INTO] имя модифицируемой таблицы
[WITH (уровень блокировки запроса)]
{[(список колонок модифицируемой таблицы)]
{VALUES (список значений новой строки)\
команда SELECT}}\
DEFAULT VALUES
Если необходимо явно вставлять значения в колонки – счетчики, имеющие свойство IDENTITY, то для модифицируемой таблицы надо выполнить команду:
SET IDENTITY_INSERT имямодифицируемойтаблицы ON
Если список столбцов не задан, то сервер будет вставлять данные последовательно во все столбцы, начиная с первого. Для каждого столбца должен быть указан аргумент, имеющий соответствующий тип. Аргументами могут быть константы, выражения соответствующего типа, значение NULL и значение по умолчанию DEFAULT. В списке столбцов можно не указывать столбцы со свойством IDENTITY, столбцы, допускающие значение NULL и столбцы типа timestamp.
Если в команде задан источник данных DEFAULT VALUES, то строка будет содержать только значения по умолчанию или значения NULL.
Если в данной команде в место имени таблицы задать имя представления, то новая строка будет вставлена в представление, а точнее, в ту исходную таблицу, на основе которой было создано представление, при этом изменение данных через представление должно быть разрешено специальной командой. Для представления невозможно задать уровень блокировки.
Если необходимо быстро создать таблицу, имеющую такую структуру, чтобы в ней можно было сохранить результат выполнения запроса, то следует использовать следующую команду:
SELECT список выбираемых колонок исходных таблиц
INTO имя автоматически создаваемой таблицы
FROM список исходных таблиц
[условия выбора значений из таблиц]
Имена колонок новой таблицы либо совпадают с именами колонок исходных таблиц, либо задаются после ключевого слова AS, следующего за именем колонки исходной таблицы. Имя создаваемой таблицы должно быть уникальным в пределах базы данных. Чаще всего эта команда используется для создания временных локальных (#) и глобальных (##) таблиц.
Для любой базы данных использование команды SELECT… INTO запрещено. Для установки разрешения на ее использование необходимо выполнить команду:
EXES sp_dboption ‘имябазыданных’, ‘select into/bulkcopy’, ‘on’
Изменение данных в таблицах или задание значений переменным производится командой UPDATE:
UPDATE имя таблицы или представления WITH блокировка
SET имя колонки или переменной = выражение…
FROM имена исходных таблиц
WHERE условия поиска
Удаление данных из таблиц производится командой DELETE:
DELETE FROM имя таблицы или представления
или
DELETE FROM имя таблицы
WHERE условие поиска OPTION (уровни блокировки).
Заключение
Направление ООБД возникло сравнительно давно. Публикации появились уже в середине 80-х гг. Однако наиболее активно это направление развивается в последние годы. С каждым годом увеличивается число публикаций и реализованных коммерческих и экспериментальных систем [4].
Возникновение направления ООБД определяется прежде всего потребностями практики: необходимостью разработки сложных информационных прикладных систем, для которых технология предшествующих систем БД не была вполне удовлетворительной.
Наиболее важным новым качеством ООБД, которого позволяет достичь объектно-ориентированный подход, является поведенческий аспект объектов. В прикладных информационных системах, основывавшихся на БД с традиционной организацией, существовал принципиальный разрыв между структурной и поведенческой частями. Структурная часть системы поддерживалась всем аппаратом БД, ее можно было моделировать, верифицировать и т.д., а поведенческая часть создавалась изолированно. В среде ООБД проектирование, разработка и сопровождение прикладной системы становится процессом, в котором интегрируются структурный и поведенческий аспекты. Конечно, для этого нужны специальные языки, позволяющие определять объекты и создавать на их основе прикладную систему [10].
В настоящее время ведется очень много экспериментальных и производственных работ в области СУБД. Уже несколько лет назад отмечалось существование, по меньшей мере, тринадцати коммерчески доступных систем ООБД. Среди них системы O2, ORION, GemStone и Iris.
Глоссарий
| №
|
Понятие
|
Содержание
|
| 1 |
2
|
3 |
| 1 |
Алгоритм
|
Именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области |
| 2 |
Атрибут
|
Именованная характеристика, определяющая свойства данной сущности (объекта) |
3
|
База данных
|
Точное предписание, определяющее вычислительный процесс, ведущий от варьируемых начальных данных к искомому результату |
4
|
Данные
|
Набор конкретных значений, параметров, характеризующих
объект, условие, ситуацию или любые другие факторы
|
5
|
Запрос
|
Команда, которая даётся СУБД и которая сообщает ей, чтобы она вела определённую информацию из таблиц |
6
|
Индекс
|
Структура данных, которая помогает СУБД быстрее обнаруживать отдельные записи в таблице, а потому позволяет сократить время выполнения запросов пользователя |
7
|
Ключ
|
Минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности |
8
|
Компонент
|
Функциональный элемент, имеющий определенные свойства и размещаемый программистом в окне формы |
| 9 |
Представления
|
Виртуальные таблицы, определяемые запросом на языке Transact-SQL |
| 10 |
Свойство
|
Специальный механизм классов, регулирующий доступ к полям |
11
|
Связь
|
Ассоциация, устанавливаемая между несколькими сущностями, и показывающая как взаимодействуют сущности между собой |
| 12 |
Система управления базами данных
|
Совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями |
| 13 |
Файл
|
Именованная область внешней памяти, в которую записывают и из которой считывают данные |
Список использованных источников
1. Бойко В.В. Проектирование баз данных информационных систем / В.В. Бойко, В.М. Савинков – М., 1989.
2. Дейт К.Дж. Введение в системы баз данных / К.Дж. Дейт. – К.;М.;СПб: Вильямс, 2001. – 1096 с.
3. Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ / Г.Джексон – М.: Мир, 1991.
4. Диго С.М. Проектирование и использование баз данных / С.М. Диго – М.: Финансы и статистика, 1995.
5. Карпова Т.С. Базы данных: модели, разработка, реализация / Т.С. Карпова. – СПб.: Питер, 2001. – 304 с.
6. Кириллов В.В. Структуризованный язык запросов (SQL) / В.В. Кириллов, Г.Ю. Громов – СПб.: ИТМО, 1994
7. Мартин Дж. Планирование развития автоматизированных систем / Дж. Мартин – М.: Финансы и статистика, 1984.
8. Мейер М. Теория реляционных баз данных / М. Мейер – М.: Мир, 1987.
9. Михеева В.Д. Microsoft Access 2002 / В.Д. Михеева, И.А. Харитонова – СПб.: БХВ, 2002.
10. Тиори Т. Проектирование структур баз данных. В 2 кн. / Т. Тиори, Дж. Фрай – М.: Мир, 1985.
Список сокращений
1. ANSI - American National Standard Institute
2. IAM - index allocation map
3. GAM - global allocation map
4. MB - мегабайт
5. MDF - master data file
6. SGAM - shared global allocation map
7. SQL - structured querylanguage
8. UDDT - user-defined data types
9. БД - базаданных
10. ООБД - объектно-ориентированные базы данных
11. СУБД - системы управления базами данных
Приложение А

Рисунок 1 - Содержимое папки Databases в SQL Server 2000
Приложение Б
Рисунок 2 - ОкнорегистрациисервераRegistered SQL Server Properties
Приложение В
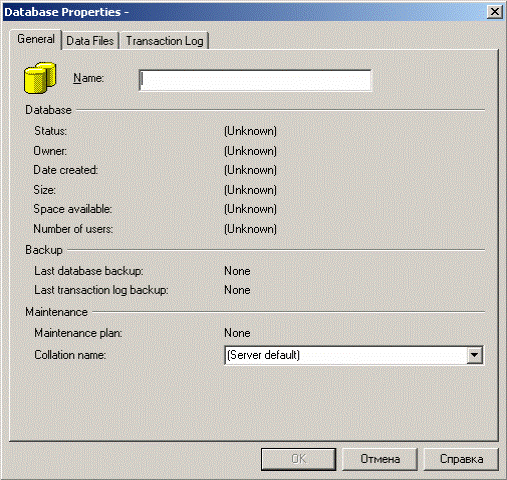
Рисунок 3 – Окно создания новой базы данных, вкладка General
Приложение Г

Рисунок 4 - Окно создания новой базы данных, вкладка Data Files
Приложение Д
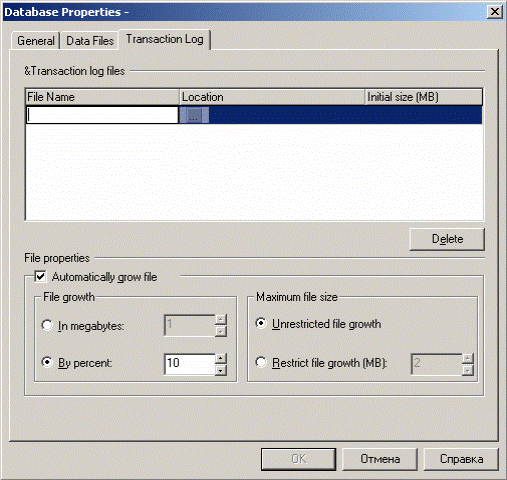
Рисунок 5 - Окно создания новой базы данных, вкладка Transaction Log
Приложение Е
Таблица 1 – Системные базы данных SQLServer 2000 и их назначение
| Название |
Назначение |
Размещение |
| master |
Хранит всю системную информацию сервера, включая учетные записи и параметры, сведения о всех базах и местонахождении их первичных файлов с данными об инициализации баз данных пользователей |
master.mdf - файл данных
(7.5 Мбайт)
mastlog.ldf-журнал транзакций (1 Мбайт)
|
| model |
Является шаблоном, задаваемым администратором и используемым для создания любых пользовательских баз данных. Содержит параметры по умолчанию, которые можно переопределять при создании соответствующей базы данных пользователя |
model.mdf - файл данных
(0.75 Мбайт)
modellog.ldf – журнал транзакций (0.75 Мбайт)
|
| tempdb |
Хранит все временные системные и пользовательские объекты: таблицы, переменные, хранимые процедуры и т д. |
tempdb.mdf – файл данных (8 Мбайт)
templog.ldf – журнал транзакций (0.5 Мбайт)
|
| msdb |
Хранит информацию, относящуюся к автоматизации администрирования и управления сервером |
msdbdata.mdf –файл
данных(3.5 Мбайт)
msdblog.ldf -журнал
транзакций (0.75 Мбайт)
|
Приложение Ж
Таблица 2 – Список и описание системных таблиц
| Название таблицы |
Описание |
| sysallocations |
Содержит сведения о размещении объектов внутри БД |
| syscolumns |
Содержит информацию о каждом столбце таблицы или представления БД, а также о каждом параметре хранимой процедуры |
| syscomments |
Содержит информацию о каждом объекте БД |
| syscontrains |
Описывает связь между ограничениями и объектами, которым они принадлежат |
| sysdepends |
Содержит ссылки на объекты, которые были использованы при определении других объектов БД |
| sysfilegroups |
Перечислены все группы файлов, принадлежащих БД |
| sysfiles |
Перечислены все файлы БД |
| sysforeignkeys |
Содержит информацию, определяющую ограничение FOREIGN KEY |
| sysfulltextcatalogs |
Перечислены все полнотекстовые каталоги, присоединенные к БД |
| sysindexes |
Используется для хранения информации об индексах и таблицах БД |
| sysindexkeys |
Хранит сведения о ключах и столбцах индексов |
| sysmembers |
Содержит информацию обо всех участниках ролей БД |
| sysobjects |
Содержит сведения обо всех объектах, создаваемых в базе данных |
| syspermissions |
Содержит информацию о предоставленных либо отклоненных правах на доступ к объектам БД для ролей, пользователей и групп пользователей |
| sysprotects |
Содержит сведения о разрешениях, которые предоставляются либо отзываются посредством команд GRANT и REVOKE |
| sysreferences |
Содержит соответствия между ограничением FOREIGN KEY и столбцами, на которые оно ссылается |
| systypes |
Содержит информацию обо всех типах данных, как встроенных, так и пользовательских |
| sysusers |
Содержит список всех пользователей БД |
Приложение З
Таблица 3 - Набор таблиц системной базы данных master
| Название таблицы |
Описание |
| sysaltfiles |
Сведения о всех файлах всех баз данных |
| syscacheobjects |
Информация об использовании кэш-памяти |
| syscharsets |
Все наборы символов сервера и порядок сортировки |
| sysconfigures |
Настройки сервера перед запуском во время работы (динамические),
производимые пользователем
|
| sysurconfigs |
Текущие значения параметров настройки сервера |
| sysdatabases |
Сведения обо всех базах данных сервера |
| sysdevices |
Сведения обо всех файлах базы данных, хранящихся на различных устройствах |
| syslanguages |
Сведения о языках сервера (кроме английского) |
| syslockinfo |
Информация обо всех блокировках |
| syslogins |
Сведения об учетной записи пользователя |
| sysmessages |
Учетные записи и пароли пользователей для связанных серверов |
| sysprocesses |
Информация о процессорах, запушенных на сервере (системных и клиентских) |
| sysremotelogins |
Сведенья о пользователях, которым разрешено вызывать удалённые хранимые процедуры |
| sysservers |
Информация о серверах, способных выступать в роли источника данных OLE DB для сервера |
|