1.
Устройство обнаружения сигналов в условиях априорной неопределённости.
1.1.
Проблема обнаружения сигналов в условиях априорной неопределённости. Основные понятия и определения.
Обработка сигналов в информационной системе реализуется с помощью совокупности математических операций (алгоритмов), которые необходимо выполнить для получения того или иного результата. Типичными задачами, возлагаемыми на систему обработки радиотехнической информации, являются:
- обнаружение сигналов с заданными допустимыми вероятностями ошибочных решений, обусловленных помехами;
- измерение (оценка) параметров сигналов с заданными допустимыми погрешностями;
- разрешение сигналов, т.е. обнаружение (с заданными вероятностями ошибок) одного сигнала и оценку (с заданными погрешностями) его параметров, при наличии других сигналов;
- распознавание сигналов, т.е. отнесение их, с заданными вероятностями ошибок, к тому или иному классу.
Перечисленные операции в той или иной форме присущи многим информационным системам, поэтому методы, рассматриваемые в нашем курсе, могут иметь широкое применение. Однако для конкретности и наглядности мы будем рассматривать радиолокационную систему, на которую возложен контроль ситуации в некоторой области пространства. (Другим возможным примером может служить аппаратура потребителя спутниковой радионавигационной системы).
В современной теории обзорная радиолокационная система рассматривается как система массового обслуживания, на вход которой воздействует случайный поток целей, а также помех искусственного и естественного происхождения, статистические характеристики которых могут быть априори неизвестны и изменяться в ходе наблюдения
. Отсутствие полной информации о свойствах полезных сигналов и помех является существенной особенностью рассматриваемых систем,что дает основание для выделения задач обработки сигналов в условиях априорной неопределенности в самостоятельный раздел курса.
Будем в дальнейшем полагать, что информация, подлежащая  обработке, представляет собой выборку из сигнала на выходе приемника, который может быть представлен в виде обработке, представляет собой выборку из сигнала на выходе приемника, который может быть представлен в виде , где , где 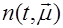 - составляющая, обусловленная воздействием помех, характеризуемых вектором параметров - составляющая, обусловленная воздействием помех, характеризуемых вектором параметров 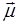 , часть которых может быть неизвестна; , часть которых может быть неизвестна; 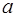 – дискретный параметр, ассоциируемый с наличием ( – дискретный параметр, ассоциируемый с наличием (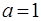 ) или отсутствием ( ) или отсутствием (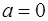 ) сигнала; ) сигнала; 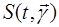 - известная функция времени, представляющая ожидаемый (отраженный) сигнал и зависящая от вектора - известная функция времени, представляющая ожидаемый (отраженный) сигнал и зависящая от вектора 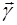 неизвестных параметров, которые могут быть детерминизированными или случайными и рассматриваться как измеряемые или мешающие. Под измеряемым мы будем понимать параметр, значение которого представляет для наблюдателя самостоятельный интерес. Мешающий параметр такого интереса не представляет. неизвестных параметров, которые могут быть детерминизированными или случайными и рассматриваться как измеряемые или мешающие. Под измеряемым мы будем понимать параметр, значение которого представляет для наблюдателя самостоятельный интерес. Мешающий параметр такого интереса не представляет.
Примером измеряемого (информативного) параметра может служить задержка радиолокационного сигнала, несущая информацию о дальности до цели, примером неинформативного (мешающего) – начальная фаза сигнала. Отметим, что в зависимости от постановки задачи один и тот же параметр сигнала может рассматриваться и как измеряемый и как мешающий. Примером может служить доплеровский сдвиг частоты отраженного сигнала, который является информативным, если ставится задача оценки радиальной скорости цели, и мешающим, если такая оценка не требуется.
В общем случае оптимальный алгоритм обработки информации состоит в фильтрации вектора 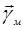 , т.е. в получении массива текущих значений апостериорной вероятности (А.В.
) , соответствующих всем возможным сочетаниям параметров целей. Такой алгоритм является наилучшим в том смысле, что сохраняет всю информацию, содержащуюся в наблюдаемом сигнале. Однако на практике такой алгоритм реализовать не удается, по крайней мере, на современном уровне вычислительной технике, хотя работы в этом направлении ведутся. , т.е. в получении массива текущих значений апостериорной вероятности (А.В.
) , соответствующих всем возможным сочетаниям параметров целей. Такой алгоритм является наилучшим в том смысле, что сохраняет всю информацию, содержащуюся в наблюдаемом сигнале. Однако на практике такой алгоритм реализовать не удается, по крайней мере, на современном уровне вычислительной технике, хотя работы в этом направлении ведутся.
Широко применяемое в настоящее время упрощение оптимального алгоритма состоит в его разбиении на ряд этапов, причем для обработки на каждый последующий этап передается только часть информации, относящаяся к тем областям пространства параметров, которым соответствуют максимумы (“пики”) АВ
. Очевидно, что такая селекция, с одной стороны, устраняет значительную часть избыточной информации, с другой – может привести к утере части полезной информации, что необходимо учитывать при разбиении процесса обработки на этапы.
Общепринятым в настоящее время является деление процесса обработки радиолокационной информации на три этапа:
- первичную обработку, которая включает в себя обнаружение целей на фоне помех, измерение их координат, разрешение целей, а также кодирование полученных данных и их преобразование в стандартные сообщения для передачи на последующие этапы обработки;
- вторичную обработку, включающую в себя обнаружение траекторий целей по совокупности единичных замеров, а также идентификацию вновь появившихся целей, обнаружение маневров целей, сглаживание и экстраполяцию траекторий;
- третичную обработку, т.е. объединение информации, полученной от разных источников, например РЛС, образующих радиолокационное поле.
Очевидно, что наибольший объем информации и скорость ее поступления характерны для этапа обнаружения сигнала. Необходимость обеспечения большого быстродействия требует создания специальных устройств обработки информации, которые и являются предметом данного курса.
Прежде чем перейти к его изложению, введем и обсудим ряд необходимых понятий и определений.
Каждая выборка  , т.е. совокупность случайных чисел представляет точку в к –мерном пространстве. Совокупность всех возможных комбинаций результатов наблюдений образуют некоторую область , т.е. совокупность случайных чисел представляет точку в к –мерном пространстве. Совокупность всех возможных комбинаций результатов наблюдений образуют некоторую область 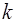 –мерного пространства, называемую пространством выборок
. Поскольку шум (а, возможно, и часть параметров сигнала) являются случайными, задача обнаружения носит вероятностный характер и трактуется как проверка статистических гипотез
: гипотеза –мерного пространства, называемую пространством выборок
. Поскольку шум (а, возможно, и часть параметров сигнала) являются случайными, задача обнаружения носит вероятностный характер и трактуется как проверка статистических гипотез
: гипотеза 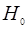 предполагает отсутствие сигнала (), альтернативная гипотеза предполагает отсутствие сигнала (), альтернативная гипотеза 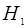 - его наличие ( - его наличие (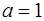 ). Статистические свойства выборок полностью описываются совместными условными распределениями ). Статистические свойства выборок полностью описываются совместными условными распределениями 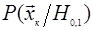 . Мы будем рассматривать непрерывные распределения, для которых существует производная – плотность вероятности . Мы будем рассматривать непрерывные распределения, для которых существует производная – плотность вероятности
 .Функции .Функции  ; ; 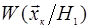 являются количественной мерой вероятности (правдоподобия) появления значений при справедливости каждой из гипотез, поэтому их называют функциями правдоподобия. Гипотезы ; называются простыми
, если соответствующие им функции правдоподобия полностью известны, т.е. не содержат неизвестных параметров, в противном случае гипотезы являются сложными
. являются количественной мерой вероятности (правдоподобия) появления значений при справедливости каждой из гипотез, поэтому их называют функциями правдоподобия. Гипотезы ; называются простыми
, если соответствующие им функции правдоподобия полностью известны, т.е. не содержат неизвестных параметров, в противном случае гипотезы являются сложными
.
Изложенная трактовка задачи различения статистических гипотез в условиях априорной неопределенности называется параметрической
, поскольку она предполагает, что функциональный вид
распределений
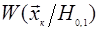 , задан. Гипотезы
и
в такой постановке формулируются относительно параметров
функций правдоподобия; априорная неопределенность (при сложных гипотезах) также сводится к отсутствию информации о тех или иных параметрах этих функций. Возложен иной подход, когда функции правдоподобия считаются не известными, определены только их некоторые свойства, например, непрерывность, унимодальность и т.п. Методы обнаружения сигналов при такой непараметрической постановке рассматриваются в других курсах.
, задан. Гипотезы
и
в такой постановке формулируются относительно параметров
функций правдоподобия; априорная неопределенность (при сложных гипотезах) также сводится к отсутствию информации о тех или иных параметрах этих функций. Возложен иной подход, когда функции правдоподобия считаются не известными, определены только их некоторые свойства, например, непрерывность, унимодальность и т.п. Методы обнаружения сигналов при такой непараметрической постановке рассматриваются в других курсах.
Основной задачей теории обнаружения является отыскание решающего правила
 , устанавливающего соответствие между возможными результатами наблюдений и возможными решениями , устанавливающего соответствие между возможными результатами наблюдений и возможными решениями 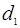 . Иными словами, решающее правило представляет собой дискретный функционал наблюдаемой выборки . Иными словами, решающее правило представляет собой дискретный функционал наблюдаемой выборки 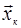 , принимающий значения , принимающий значения 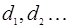 . В простейшем случае задача состоит в том, чтобы на основе выборки принять решение о наличие или отсутствии полезного сигнала . В простейшем случае задача состоит в том, чтобы на основе выборки принять решение о наличие или отсутствии полезного сигнала 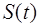 . При этом возможны два решения: . При этом возможны два решения: 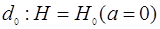 и и 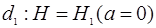 . Это означает, что все пространство выборок разделено на две непересекающиеся области . Это означает, что все пространство выборок разделено на две непересекающиеся области  и и  ; правило принятия решения устанавливает соответствие между попаданием выборки в одну из этих областей и принятием решения в пользу одной из гипотез. Следует подчеркнуть, что правило принятия решения (разбиение выборочного пространства на области и ) устанавливается до начала наблюдения. ; правило принятия решения устанавливает соответствие между попаданием выборки в одну из этих областей и принятием решения в пользу одной из гипотез. Следует подчеркнуть, что правило принятия решения (разбиение выборочного пространства на области и ) устанавливается до начала наблюдения.
Вышеизложенный подход, предполагает только вынесение решения в пользу одной из гипотез и не предусматривает никаких либо решений в отношении самой процедуры наблюдения. Наряду с ним известен класс решающих правил, называемых последовательными
, для которых множество решений кроме 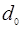 и содержит еще один компонент: решение и содержит еще один компонент: решение  о продолжении наблюдения. Этому решению сопоставляется область выборочного пространства о продолжении наблюдения. Этому решению сопоставляется область выборочного пространства 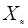 , попадание в которую выборки не позволяет с требуемой надежностью принять или отклонить любую из гипотез или (“область неопределенности”). Таким образом, в последовательных решающих правилах реализуется обратная связь
между результатами наблюдения и его дальнейшим ходом. Последовательные правила обладают рядом преимуществ, поэтому в дальнейшем им будет уделено значительное внимание. , попадание в которую выборки не позволяет с требуемой надежностью принять или отклонить любую из гипотез или (“область неопределенности”). Таким образом, в последовательных решающих правилах реализуется обратная связь
между результатами наблюдения и его дальнейшим ходом. Последовательные правила обладают рядом преимуществ, поэтому в дальнейшем им будет уделено значительное внимание.
Рассмотренные решающие правила относятся к классу детерминированных
(нерандомизированных), поскольку они устанавливают однозначную связь между попаданием выборки в область или и принятием соответствующего решения или . В принципе возможен другой подход, когда принятие того или иного решения связывается не только с попаданием выборки в соответствующую область, но и с результатом некоторого случайного
дополнительного
эксперимента,
не
связанного
с
результатами
наблюдения
. Такой подход иногда упрощает анализ и синтез решающих правил, однако на практике он не применяется, поскольку доказана теорема, что любому рандомизированному решающему правилу может быть сопоставлено нерандомизированное правило, по меньшей мере не уступающее ему в эффективности. Следует обратить внимание, что хотя при последовательном анализе решение о продолжении или завершении наблюдения зависит от случайного
результата наблюдения, последовательные правила не являются рандомизированными т.к. последние, как уже указывалось, предполагают проведение дополнительного эксперимента, не
связанного
с результатами наблюдения.
1.2. Критерии оптимальности решающих правил.
Проектирование устройств обработки обычно начинается с поиска оптимального алгоритма
, который обеспечивает наилучшие показатели качества, с точки зрения некоторого задаваемого разработчиком системы критерия
, учитывающего (с тем или иным весом) затраты на получение информации, ее достоверность, объем и другие факторы. Однако оптимальный алгоритм может быть найден не всегда, кроме того, его реализация может оказаться неприемлемо сложной. В таких случаях ставится задача поиска квазиоптимального алгоритма
и оценки его качества.
Выбор критерия оптимальности при анализе и синтезе устройств обработки информации, вообще говоря, зависит от точки зрения разработчика на назначение системы и особенности, возложенных на нее задач и не может быть строго регламентирован. Тем не менее, существуют общепринятые критерии, которые правильно отражают существенные стороны функционирования систем, допускают однозначную математическую формулировку, и в то же время достаточно наглядны и соответствуют здравому смыслу.
Применительно к проблеме фильтрации сигнала на фоне шумов в качестве критерия оптимальности часто принимаютмаксимум отношения сигнал/помеха на выходе соответствующего устройства. Этот критерий может считаться адекватным для устройств детектирования, дискретизации и накопления сигнала. Однако с точки зрения задач, решаемых на основании выходных данных этих устройств – обнаружения сигнала и оценки их параметров – критерий максимума отношения сигнал/шум является слишком “грубым” т.к. не учитывает ряд существенных особенностей этих задач.
1.3. Байесовский критерий оптимальности.
Среди используемых в современной теории обнаружения наиболее общим является критерий минимума среднего (байесовского) риска, в основу которого положены следующие рассуждения.
Вследствие случайного характера помех, а также возможных флуктуаций параметров сигналов, вынесение абсолютно достоверного решения при конечном времени наблюдения невозможно, т.е. решения и могут быть как правильными, так и ошибочными. Возможны следующие комбинации фактических ситуаций и принимаемых решений:
- ; - правильное обнаружение; ; – пропуск сигнала;
- ; – правильное не обнаружение; ; - ложная тревога.
Перечисленные ситуации образуют полную группу событий, сумма вероятностей которых =1:
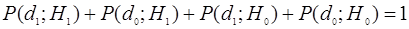 . .
Сопоставим каждому ошибочному решению некоторую стоимость (риск) 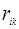 , стоимостью правильных решений примем равной нулю. Средний (байесовский) риск при этом равен: , стоимостью правильных решений примем равной нулю. Средний (байесовский) риск при этом равен:
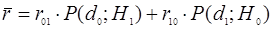 . .
Оптимальным считается решающее правило, обеспечивающее минимум среднего риска (байесовский критерий оптимальности). Правило, обладающее таким свойством, называют байесовским
.
Подчеркнем, что для расчета величины байесовского риска необходима полная
априорная информация о совместных вероятностях 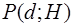 и стоимостях ошибочных решений. Обоснованный выбор указанных величин, особенно в задачах с априорной неопределенностью, по меньшей мере, затруднителен. Поэтому характеристики байесовского решающего правила в теории обнаружения обычно рассматриваются как потенциальные при сравнении квазиоптимальных алгоритмов. Далее рассматриваются более удобные с точки зрения практического применения критерии, не требующие столь исчерпывающей информации. и стоимостях ошибочных решений. Обоснованный выбор указанных величин, особенно в задачах с априорной неопределенностью, по меньшей мере, затруднителен. Поэтому характеристики байесовского решающего правила в теории обнаружения обычно рассматриваются как потенциальные при сравнении квазиоптимальных алгоритмов. Далее рассматриваются более удобные с точки зрения практического применения критерии, не требующие столь исчерпывающей информации.
|