| Анотація
В курсовій роботі був розроблений транслятор з вхідної мови програмування, заданої завданням, на мову асемблер, з подальшою компіляцією отриманого коду і створення виконавчого файлу. Даний транслятор виконує лексичний аналіз, синтаксичний і семантичний, при наявності помилок у вхідному тексті програми створює список помилок і попереджень. У курсовій роботі створений лексичний аналізатор на базі скінченного автомата, а синтаксичний аналізатор на основі низхідного методу з використанням рекурсивного спуску.
Транслятор був розроблений за допомогою технології C# в середовищі MS Visual Studio 2010.
Зміст
Анотація……………………………………………………………………………………2
Зміст………………………………………………………………………………………3
Завдання на курсову роботу……………………………………………………………..4
Вступ………………………………………………………………………………………5
1. Огляд методів та способів проектування трансляторів………………………….7
2. Формальний опис вхідної мови програмування………………………………….8
2.1.
Деталізований опис вхідної мови в термінах розширеної нотації
Бекуса-Наура…………………………………………………………………………………….8
2.2.
Опис термінальних символів та ключових слів……………………………………..
10
3. Розробка транслятора вхідної мови програмування……………………………12
3.1. Вибір технології програмування………………………………………………………
12
3.2.
Проектування
таблиц
ь
транслятор
а та вибір структур даних………………
13
3.3. Розробка лексичного аналізатора……………………………………………………
16
3.3.1. Розробка граф-схеми алгоритму…………………………………………
17
3.3.2. Опис програми реалізації лексичного аналізатора…………………..
17
3.4. Розробка синтаксичного та семантичного аналізатора……………………….
19
3.4.1. Розробка дерев граматичного розбору…………………………………
20
3.4.2. Розробка граф-схеми алгоритму…………………………………………
21
3.4.3.
Опис програми реалізації синтаксичного та
семантичного аналізатора…………………………………………………………………..
22
3.5.
Розробка генератора коду…………………………………………………………….
23
3.5.1. Розробка граф-схеми алгоритму…………………………………………
23
3.5.2. Опис програми реалізації генератора коду…………………………….
24
4. Опис інтерфейсу та інструкції користувача……………………………………..25
5. Відлагодження та тестування програми…………………………………………27
5.1. Виявлення лексичних помилок………………………………………………………….
27
5.2. Виявлення синтаксичних помилок…………………………………………………….
28
5.3. Виявлення семантичних помилок……………………………………………………..
29
5.4. Загальна перевірка коректності роботи транслятора…………………………
30
Висновки…………………………………………………………………………………31
Список літератури……………………………………………………………………..32
Додатки………………………………………………………………………………….33
А. Лістинг програм
……………………………………………………………………………
33
Завдання на курсову роботу
Тема: Розробка транслятора з вхідної мови програмування.
- типи даних: INT32_t, BOOLEAN, const string;
- оператор вводу: READ;
- оператор виводу: WRITE;
- блок тіла програми: START, FINISH
- оператор: WHILE DO (Паскаль);
- регістр ключових слів: Up;
- регістр ідентифікаторів: Low2 ;
- операції арифметичні: ADD, SUB, MUL, DIV,MOD;
- операції порівняння: =, <>, LE, GE
- операції логічні: !, &, |;
- коментар: $$...
- ідентифікатори змінних, числові константи, рядкові константи;
- оператор присвоєння: >>;
Для отримання виконавчого файлу з вихідного асемблерного коду потрібно використовувати ml.ex (MASM32) вбудований в MS Visual Studio 2010.
Вступ
Транслятор – програма або технічний засіб, що виконує трансляцію програми. Транслятор зазвичай виконує також діагностику помилок, формує словники ідентифікаторів, видає для друку тексти програми і т. д.
Трансляція програми – перетворення програми, представленої на одній з мов програмування, в програму на іншій мові, в певному сенсі, рівносильну з першою. Мова, на якій представлена вхідна програма, називається вихідним мовою, а сама програма – вихідним кодом. Вихідна мова називається цільовою мовою або об'єктним кодом.
Поняття трансляції відноситься не тільки до мов програмування, але і до інших комп'ютерних мов, на зразок мов розмітки, аналогічних HTML, і до природних мов, на зразок англійської або російської
Транслятори поділяються на:
- Адресний.
- Діалоговий.
- Багатопрохідної.
- Зворотний. (детранслятор).
- Однопрохідної.
- Оптимізуючий.
- Синтаксично-орієнтований (синтаксично-керований).
- Тестовий.
Мова процесорів (машинний код) зазвичай є низькорівневою. Існують платформи, які використовують в якості машинної мову високого рівня (наприклад, iAPX-432), але вони є винятком із правила через складність і високу вартість. Транслятор, який перетворює програми в машинну мову, який приймає і виконуваний безпосередньо процесором, називається компілятором.
Процес компіляції як правило складається з декількох етапів: лексичного, синтаксичного та семантичного аналізів (англ. Semantic analysis), генерації проміжного коду, оптимізації та генерації результуючого машинного коду. Крім цього, програма як правило залежить від сервісів, наданих операційною системою і сторонніми бібліотеками (наприклад, файловий ввід-висновок або графічний інтерфейс), і машинний код програми необхідно пов'язати з цими сервісами. Для зв'язування зі статичними бібліотеками виконується редактор зв'язків або компонувальник (який може представляти із себе окрему програму або бути частиною компілятора), а з операційною системою і динамічними бібліотеками зв'язування виконується на початку виконання програми завантажувача.
1. Огляд методів та способів проектування трансляторів
Є такі методи створення компіляторів:
1. Прямий метод- цільовою мовою і мовою реалізації є асемблер.
2. Метод розкрути- саме цей метод і використовується у даній курсовій роботі, тобто вибирається інструмент (в даній курсовій це мова асемблер), для якого вже існує компілятор.
3.Використання крос-трансляторів.
4.З використанням віртуальних машин–дає спосіб отримати переносимо програму.
5. Компіляція на ходу.
В даній курсовій роботі згідно із завданням для парних варіантів необхідно реалізувати низхідний метод граматичного розбору. Низхідний розбір — один з методів визначення приналежності вхідного рядка деякій формальній мові, описаній LL(k)-граматикою.
Для кожного нетермінального символу K будується функція, яка для будь-якого вхідного слова x робить дві речі:
· Знаходить найбільший початок z слова x, здатний бути початком виводжуваного з K слова
· Визначає, чи є початок z виводжуваним з K
Така функція має задовольняти наступні критерії:
· зчитувати із ще необробленого вхідного потоку максимальний початок A, який є початком деякого слова, виводжуваного з K
· визначати чи є A вивідним з K або просто невивідним початком виводжуваного з K слова
У випадку, якщо такий початок зчитати не вдається (і коректність функції для нетермінала K доведена), тоді вхідні дані не відповідають мові, і потрібно зупинити розбір.Розбір містить у собі виклики описаних вище функцій. Якщо для зчитаного нетермінала є складене правило, тоді при його розборі будуть викликані інші функції для розбору терміналів, що входять в нього. Дерево викликів, починаючи із самої«верхньої» функції еквівалентно дереву розбору.
Низхідний метод аналізу реалізується на основі контекстно-вільних граматик.
Контекстно-вільна граматика G
це четвірка (N
,T
,P
,S
):
· 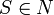
· N
та T
скінченні множини, що не перетинаються
· P
скінченна підмножина 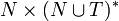
При цьому, використовують наступні назви: N
— множина нетермінальних символів, T
— множина термінальних символів, P
— множина правил виводу S
початковий символ. Правила (α,β)єP записують як α→β.
В лівій частині правила виводу має знаходитись одна змінна (нетермінальний символ). Формально, має виконуватись 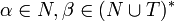 , wobei , wobei 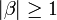 . .
LL аналізатор це алгоритм синтаксичного аналізу методом рекурсивного спуску для підмножини контекстно-вільних граматик. Він обробляє вхід зліва направо (тому перша буква означає Left), та будує ліворекурсивне виведення рядка (тому його порівнюють з LR аналізатором ). Клас граматик, що розпізнаються цим аналізатором називається LL граматиками.
Далі описується табличний аналізатор — альтернатива алгоритму рекурсивного спуску, який зазвичай кодується вручну (хоча не завжди, дивіться наприклад ANTLR для генератора аналізаторів LL(*) граматик методом рекурсивного спуску).
LL аналізатори називаються LL(k) аналізаторами, якщо вони дивляться на k токенів вперед протягом аналізу виразу. Якщо такий аналізатор існує та може розпізнавати вирази граматики без бектрекінгу, тоді граматика називається LL(k) граматикою. З цих граматик найпопулярнішою граматикою є граматика LL(1), бо незважаючи на її обмеженість, вона має дуже простий аналізатор. Мови, що відповідають LL(k) граматикам з великим k вважаються такими, що важко аналізуються, хоча сьогодні це не зовсім вірно через доступність та поширеність генераторів синтаксичних аналізаторів, що підтримують LL(k) граматики.
LL аналізатор називається LL(*) аналізатором, якщо він не обмежений скінченним числом токенів для попереднього перегляду, а може приймати рішення визначаючи чи належать вхідні токени регулярній мові (наприклад використовуючи ДСкА).
Існує конкуренція між «європейською школою» проектування мов, яка віддає перевагу LL граматикам, та «американською», яка частіше використовує LR-граматики. Це багато в чому завдяки традиціям викладання та детальному опису методів та інструментів в літературі. Інший вплив іде від досліджень Ніклауса Вірта в вищій технічній школі Цюріха, які описували багато способів оптимізації LL(1) мов, та компіляторів.
Аналізатор працює на рядках з певної контекстно вільної граматики.
Аналізатор складається з
· вхідного буфера, в якому зберігається вхідний рядок
· стека в якому зберігають термінальні та нетермінальні символи з граматики, що аналізується.
· таблицю аналізу яка каже яке ( якщо існує ) правило граматики застосувати залежно від символів на вершині стеку, та наступного вхідного токена.
Аналізатор застосовує правило з таблиці, яке відповідає символу на вершині стеку (рядок таблиці) та символу з вхідного потоку (стовпець).
2. Формальний опис вхідної мови програмування
2.1. Деталізований опис вхідної мови в термінах розширеної нотації Бекуса-Наура.
<program>::=PROGRAM<name>VAR<VAR_blok>START<code_blok>FINISH.
<VAR_blok> ::=<declarations> [{;<declarations>} ];.
<declarations>::=INT32_t<declaration_i> [{,<declaration_i>}] | BOOLEAN <declaration_b> [{,<declaration_b>}] .
.<declaration_i> ::= <ident> [ << <const_i>] .
<declaration_b> ::= <ident> [ << <const_b>] .
<ident> ::= <letter>[<l _or_n>].
<l_or_n> ::= <letter>|<number> .
<letter>::=a|b|c|d|e|f|g|h|i|j|k|l|n|m|o|p|q|r|s|t|u|v|w|x|y|z .
<number> ::= 0|1|2|3|4|5|6|7|8|9 .
<const_i> ::= [-]<number>[{number}] .
<const_b> ::=TRUE|FALSE
<code_blok> ::= <statement> [{<statement>}] .
<statement> ::= <equation>|<cycle>|<READ>|<WRITE> .
<equation> ::= <ident> [>> <expression_i>|<expression_b>]; .
<expression_i>::= <term> [{ADD <term> | SUB <term>}].
<term>::=<ident>|<const_i>|<factor>.
<factor>::=[{MUL <term> | DIV <term>| MOD <term> | <brackets>}].
<brackets>::=(<expression_i>).
<expression_b>::= <term_b> [{== <term_b> | != <term_b> | LE<term_b>| GE <term_b>}].
<term_b>::=<ident>|<const_b>|<factor_b>.
<factor_b>::=<term_b> [{ |<term_b> | <and> |<not>|<brackets_b>}].
<and>::= [{ &<term_b>}]
<not>::=!<factor_b>
<brackets_b>::=(<expression_b>).
<cycle> ::= WHILE (<expression_b>|<ident>) START <code_blok> FINISH.
<READ> ::= READ(<ident>); .
<WRITE> ::= WRITE(<expression_i>|<string>|<expression_b>); .
<string> ::= “<l_or_n>[{<l_or_n>}]” .
2.2. Термінальні символи та ключові слова.
PROGRAMM – початок тексту програми, наступним описується ім’я програми;
VAR - блок опису змінних;
START – початок тіла програми (циклу);
FINISH – кінець тіла програми (циклу);
WRITE– оператор виводу (змінних і рядкових констант)
READ – оператор вводу змінних;
>> - оператор присвоєння;
WHILE – початок умовного уиклу
DO – початок тіла умовного циклу
ADD – операція додавання
SUB – операція віднімання
MUL – операція множення
DIV – операція ділення
MOD – операція знаходження залишку від ділення;
= – операція перевірки на рівність;
<> – перевірка на нерівність;
LE – перевірка чи менше;
GE – перевірка чи більше/рівно;
! – операція логічного заперечення;
& – кон’юнкція;
| – диз’юнкція;
INT32_t – 32‑ох розрядні знакові цілі;
BOOLEAN – однобайтні логічні змінні;
$$ – рядковий коментар
“ – початок/завершення рядкової константи при операції виводу;
,– розділювач між деклараціями змінних;
; – ознака кінця оператора;
(– відкриваюча дужка;
) – закриваюча дужка;
Як термінальні символи використовуються також усі арабські цифри (0–9), латинські букви (a-z, A-Z), символи табуляції, символ переходу на нову стрічку, пробіл.
3. Розробка транслятора вхідної мови програмування
3.1. Вибір технології програмування.
Для виконання курсової роботи була вибрана об’єктно-орієнтована технологія програмування. Обєктно орієнтоване програмування (надалі ООП) - парадигма програмування, в якій основними концепціями є поняття об'єктів і класів.
Клас - це тип, що описує будову об'єктів. Поняття "клас" має на увазі деяка поведінка і спосіб представлення. Поняття "об'єкт" має на увазі щось, що має певну поведінку і спосіб представлення. Говорять, що об'єкт - це екземпляр класу. Клас можна порівняти з кресленням, згідно з яким створюються об'єкти. Зазвичай класи розробляють так, щоб їх об'єкти відповідали об'єктам предметної області.
Структура даних "клас" є об'єктним типом даних. При цьому елементи такої структури (члени класу) можуть самі бути не лише даними, але і методами (тобто процедурами або функціями). Таке об'єднання називається інкапсуляцією.
Наявність інкапсуляції достатня для объектности мови програмування, але ще не означає його об'єктної орієнтованості - для цього потрібно наявність наслідування.
Але навіть наявність інкапсуляції і наслідування не робить мову програмування повною мірою об'єктною з точки зору ООП. Основні переваги ООП проявляються тільки у тому випадку, коли в мові програмування реалізований поліморфізм.
Абстракція - це надання об'єкту характеристик, які відрізняють його від усіх інших об'єктів, чітко визначаючи його концептуальні межі. Основна ідея полягає в тому, щоб відокремити спосіб використання складених об'єктів даних від деталей їх реалізації у вигляді простіших об'єктів, подібно до того, як функціональна абстракція розділяє спосіб використання функції і деталей її реалізації в термінах примітивніших функцій, таким чином, дані обробляються функцією високого рівня за допомогою виклику функцій низького рівня.
Такий підхід є основою об'єктно-орієнтованого програмування. Це дозволяє працювати з об'єктами, не вдаючись особливо їх реалізації. У кожному конкретному випадку застосовується той або інший підхід: інкапсуляція, поліморфізм або наслідування. Наприклад, при необхідності звернутися до прихованих даних об'єкту, слід скористатися інкапсуляцією, створивши, так звану, функцію доступу або властивість.
Інкапсуляція - це принцип, згідно з яким будь-який клас повинен розглядатися як чорний ящик, - користувач класу повинен бачити і використовувати тільки інтерфейсну частину класу (т. е. список декларованих властивостей і методів класу) і не вникати в його внутрішню реалізацію. Тому дані прийнято інкапсулювати в класі так, щоб доступ до них по читанню або запису здійснювався не безпосередньо, а за допомогою методів. Принцип інкапсуляції (теоретично) дозволяє мінімізувати число зв'язків між класами і, відповідно, спростити незалежну реалізацію і модифікацію класів.
Приховання даних - невід'ємна частина ООП, що управляє зонами видимості. Є логічним продовженням інкапсуляції. Метою приховання є неможливість для користувача дізнатися або зіпсувати внутрішній стан об'єкту.
Наслідуванням називається можливість породжувати один клас від іншого із збереженням усіх властивостей і методів класу-предка (прародителя, іноді його називають суперкласом) і додаючи, при необхідності, нові властивості і методи. Набір класів, пов'язаних відношенням спадкоємства, називають ієрархією. Спадкоємство покликане відобразити таку властивість реального світу, як ієрархічність.
Поліморфізмом називають явище, при якому функції (методу) з одним і тим же ім'ям відповідає різний програмний код (поліморфний код) залежно від того, об'єкт якого класу використовується при виклику цього методу. Поліморфізм забезпечується тим, що в класі-нащадку змінюють реалізацію методу класу-предка з обов'язковим збереженням сигнатури методу. Це забезпечує збереження незмінним інтерфейсу класу-предка і дозволяє здійснити зв'язування імені методу в коді з різними класами - з об'єкту якого класу здійснюється виклик, з того класу і береться метод з цим ім'ям. Такий механізм називається динамічним (чи пізнім) зв'язуванням - на відміну від статичного (раннього) зв'язування, здійснюваного на етапі компіляції.
Концепція віртуальних методів з'явилася як засіб забезпечити виконання потрібних методів при використанні поліморфних змінних, тобто, по суті, як спроба розширити можливості виклику методів для реалізації частини функціональності, що забезпечується механізмом обробки повідомлень.
NET Framework 3.0 - це модель програмування керованого коду корпорації Microsoft. Вона є розширенням .NET Framework 2.0, яке об'єднує компоненти попередньої платформи з новими технологіями створення застосувань, що відрізняються привабливим призначеним для користувача інтерфейсом, надійними і безпечними засобами підключення і можливістю моделювання широкого ряду бізнес-процесів
Microsoft Windows Forms - це основна платформа розробки для створення інтелектуальних клієнтських застосувань. Класи Windows Forms, що містяться в .NET Framework, призначені для використання при створенні графічних інтерфейсів користувача. З їх допомогою можна легко створювати командні вікна, кнопки, меню, панелі інструментів і інші елементи.
3.2. Проектування таблиць транслятора.
Для реалізації лексичного аналізу створюємо таблицю, в яку поміщаємо всі лексеми (ArrayList lexems = new ArrayList()), і таблицю (Hashtable identy = new Hashtable()) для ідентифікаторів, які будуть введені користувачем. Ім’я програми в цю таблицю не заноситься. Для реалізації таблиці лексем описаний тнаступний клас Lexem:
| id
|
lex
|
comment
|
type
|
| зберігання номера лексеми
|
зберігання лексеми
|
зберігання класу до якого належить лексема
|
зберігання коду лексеми
|
public class Lexem
{
private int id=0;
private string lex = "";
private string comments = "";
private int type = 0;
public int Id
{ get { return id; }
set { id = value; } }
public int Type
{ get { return type; }
set { type = value; } }
public string Lex
{ get { return lex; }
set { lex = value; }}
public string Comments
{ get { return comments; }
set { comments = value; }}
}
Сама таблиця лексем є масивом таких структур.
Лексеми мають такі класи:
- клас лексем блоку
- клас операторів вводу виводу
- клас операторів присвоєння
- клас математичних операторів
- клас операторів порівняння
- клас логічних операторів
- клас ідентифікаторів
- клас операторів циклу
- клас лексем оголошення
- клас лексем опису і аргументів виводу
- клас констант
Атрибути лексем з використовуються при синтаксичному аналізі. Лексеми мають наступні коди:
Нерозпізнана лексема - -1
Ключові слова - 0
Ідентифікатори - 1
Числові константи - 2
Рядкові константи - 3
Коментарі - 4
= - 5
! - 6
& - 7
| - 8
<> - 9
>> - 10
; - 11
, - 12
) - 13
( - 14
Ключові слова мають такі коди:
PROGRAMM - 15
VAR - 16
START - 17
FINISH - 18
INT32_t - 19
BOOLEAN - 20
READ - 21
WRITE - 22
ADD - 23
SUB - 24
TRUE - 25
FALSE - 26
WHILE -27
DO - 28
MUL - 29
DIV -30
MOD - 31
LE - 32
GE -33
Атрибути використовуються генератором коду для формування відповідних процедур мовою асемблер.
Для зберігання таблиці ідентифікаторів використовується Hashtable identy = new Hashtable()
Полем таблиці є клас Iden_info він містить наступні поля:
| id
|
type
|
Id_value
|
| зберігання ідентифікаторів
|
зберігання типу змінної
|
зберігання значення змінної
|
public class Iden_info
{
private string id="";
private string type = "";
private string Id_value = "";
public string Id
{
get { return id; }
set { id = value; }
}
public string Type
{
get { return type; }
set { type = value; }
}
public string Value
{
get { return Id_value; }
set { Id_value = value; }
}
}
Для запам’ятовування виразу в постфікс ній формі використовується ArrayList.
3.3. Розробка лексичного аналізатора.
Лексичний аналіз – перша фаза трансляції, призначена для групування символів вхідного ланцюга в більш крупні конструкції, що називаються лексемами. З кожною лексемою зв’язано два поняття:
Клас лексеми
, що визначає загальну назву для категорії елементів, що мають спільні властивості (наприклад, ідентифікатор, ціле число, рядок символів і т. д.).
Значення лексеми
, що визначає підрядок символів вхідного ланцюга, що відповідають розпізнаному класу лексеми. В залежності від класу, значення лексеми може бути перетворено у внутрішнє представлення вже на етапі лексичного аналізу. Так, наприклад, роблять з числами, перетворюючи їх в машинне двійкове представлення, що забезпечує більш компактне зберігання і перевірку правильності діапазону на ранній стадії аналізу.
3.3.1. Розробка граф-схеми алгоритму
При розробці алгоритму роботи лексичного аналізатора використовується скінченний автомат.
Особливостями цього алгоритму є те, що розбір виконується відносно кількості символів з яких складаються лексеми. За даним алгоритмом всі лексеми поділяються на односимвольні (!, &, |, ; ) дво символьні (>>, <>, ==) та багатосимвольні. Для кожного класу багатосимвольної лексеми розроблена функція, яка виділяє лексему, або констатує що дана лексема не відноситься до жодного з заданих класів лексем.
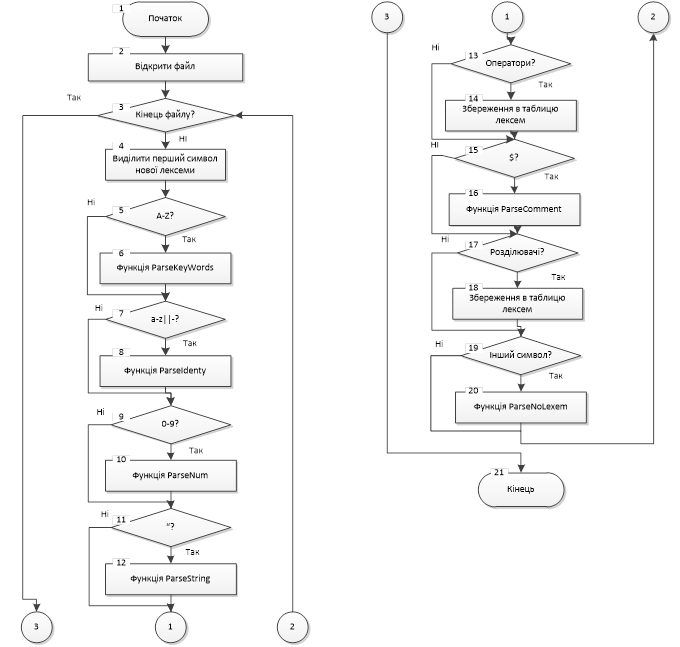
Рис 1.Граф-схема роботи лексичного аналізатора
Блок 1 – Початок роботи лексичного аналізатора
Блок 2 – Відкриття і порядкове читання вхідного файлу з текстом програми
Блок 3 – Перевірка чи не досягнутий кінець файлу
Блок 4 – Виділення першого символу нової лексеми
Блок 5 – Перевіряє чи перший символ A-Z
Блок 6 – Виконання функції ParseKeyWords()
Блок 7 – Перевіряє чи перший символ a-z
Блок 8 – Виконання функції ParseIdent()
Блок 9 – Перевіряє чи перший символ 0-9
Блок 10 – Виконання функції ParseNum()
Блок 11 – Перевіряє чи перший символ “
Блок 12 – Виконання функції ParseString()
Блок 13 – Перевіряє чи символ є оператор
Блок 14 – Зберігання до таблиці лексем
Блок 15 – Перевіряє чи перший символ є $
Блок 16 – Виконання функції ParseComments()
Блок 17 – Перевіряє чи символ є розділювач
Блок 18 – Зберігання до таблиці лексем
Блок 19 – Якщо перший символ не є жодним з вищеперечислених
Блок 20 – Виконання функції ParseNoLex()
Блок 21 – Якщо файл прочитано, завершення роботи лексичного аналізатора
3.3.2Опис програми реалізації лексичного аналізатора

Програма по рядках читає вхідний файл. Прочитаний рядок передає як параметр функції Parse класу Parser. В лексичному аналізаторі для розпізнання використовуються наступні функції:
- Функція Parse() аналізує перший символ нової лексеми:
якщо перший символ A-Z, то запускається функція ParseKeyWords()
якщо перший символ a-z, то запускається функція ParseIdent()
якщо перший символ 0-9 або -, то запускається функція ParseNum()
якщо перший символ =,<,>,!,&,|,;, , ,(,) відбувається збереження лексеми
якщо перший символ $, то запускається функція ParseComments()
якщо перший символ “,то запускається функція ParseString()
якщо перший символ не є жодним з вищезгаданих то запускається процедура ParseNoLex()
- Функція ParseKeyWords() виділяє послідовність символі, які можуть містити ключові слова і перевіряє чи ця послідовність символів є ключовим словом і якщо це ключове слово зберігає його, як лексему
- Функція ParseIdent()виділяє послідовність символі, які можуть містити ідентифікатори і зберігає ідентифікатор
- Функція ParseNum()виділяє послідовність символі, які можуть містити числові константи і зберігає лексему
- Функція ParseComments() перевіряє чи 2 символ теж $, то всі символи до кінця рядка вважає коментарем
- Функція ParseString() шукає символ завершення рядка і всі символи між початком і кінцем рядка вважає рядковою константою
- Функція ParseNoLex() шукає розділювач і вважає що всі символи, які вона виділила є нерозпізнаною лексемою
3.4.Розробка синтаксичного аналізатора
Синтаксичний розбір (розпізнавання) є першим етапом синтаксичного аналізу. Саме при його виконанні здійснюється підтвердження того, що вхідний ланцюжок символів є програмою, а окремі підланцюжки складають синтаксично правильні програмні об'єкти. Вслід за розпізнаванням окремих підланцюжків здійснюється аналіз їх семантичної коректності на основі накопиченої інформації. Потім проводиться додавання нових об'єктів в об'єктну модель програми або в проміжне представлення.
Розбір призначений для доказу того, що аналізований вхідний ланцюжок, записаний на вхідній стрічці, належить або не належить безлічі ланцюжків породжуваних граматикою даної мови. Виконання синтаксичного розбору здійснюється розпізнавачами, тому даний процес також називається розпізнаванням вхідного ланцюжка. Мета доказу в тому, щоб відповісти на питання: чи належить аналізований ланцюжок безлічі правильних ланцюжків заданої мови. Відповідь «так» дається, якщо така приналежність встановлена. Інакше дається відповідь «ні». Отримання відповіді «ні» пов'язано з поняттям відмови. Єдина відмова на будь-якому рівні веде до загальної відмови.
Щоб одержати відповідь «так» щодо всього ланцюжка, треба його одержати для кожного правила, що забезпечує розбір окремого підланцюжка. Аналізатор вибирає перший символ з сукупності лексем аналізуючи його визначає, яку функцію треба запустити щоб виконати перевірку заданого підланцюжка. Цей метод називається методом рекурсивного спуску, аналіз проводиться від кореня до листків.
Основним завданням семантичного аналізатора є перевірка типів. Також семантичний аналізатор повинен знаходити вирази, що використовуються без присвоєння та видавати попередження.
Сама програма перевірки типів базується на інформації про синтаксичні конструкції мови, представлення типів і правилах присвоєння типів конструкціям мови.
3.4.1
.
Розробка дерева граматичного розбору
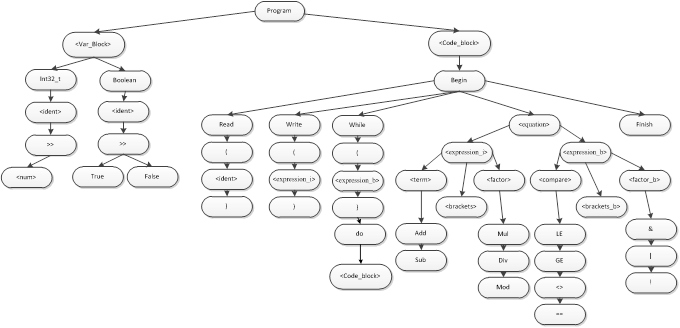
Дерево граматичного розбору розроблено згідно правил, даних у формі розширеної нотації Бекуса-Наура, та оформлено згідно правил ЄСКД.
3.4.2 Розробка граф-схеми алгоритму
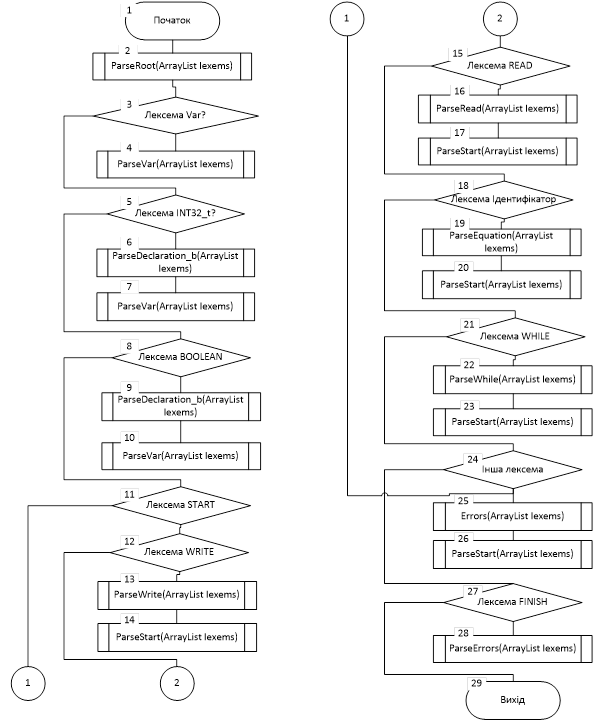
Рис
2
.Граф-схема роботи синтаксичного аналізатора
Блок 1 – Початок синтаксичного аналізатора
Блок 2 – Основна функція аналізатора
Блок 3 – Перевіряє чи наступний символ Var
Блок 4 – Виконання функції ParseVAR()
Блок 5 - Перевіряє чи наступний символ INT32_t
Блок 6 - Виконання функції ParseDeclar_i()
Блок 7 - Виконання функції ParseVAR()
Блок 8 - Перевіряє чи наступний символ BOOLEAN
Блок 9 - Виконання функції ParseDeclar_b()
Блок 10 - Виконання функції ParseVAR()
Блок 11 - Перевіряє чи наступний символ START
Блок 12 - Перевіряє чи наступний символ WRITE
Блок 13 - Виконання функції ParseWRITE()
Блок 14 - Виконання функції ParseSTART()
Блок 15 - Перевіряє чи наступний символ READ
Блок 16 - Виконання функції ParseREAD()
Блок 17 - Виконання функції ParseSTART()
Блок 18 - Перевіряє чи наступний символ <ident>
Блок 19 - Виконання функції ParseEqution()
Блок 20 - Виконання функції ParseSTART()
Блок 21 - Перевіряє чи наступний символ WHILE
Блок 22 - Виконання функції ParseWHILE()
Блок 23 - Виконання функції ParseSTART()
Блок 24 – Якщо інший символ?
Блок 25 – Функція Error();
Блок 26 - Виконання функції ParseSTART()
Блок 27 - Перевіряє чи наступний символ FINISH
Блок 28 – Якщо не фініш виконання функції Error();
Блок 29 - Завершення Синтаксичного аналізатора
3.4.3 Опис програми реалізації синтаксичного та семантичного аналізатора
На вхід синтаксичного аналізатора подається таблиця лексем, створена на етапі лексичного аналізу.
В синтаксичному аналізі використовуються функції для робору всіх конструкції вхідної мови, вони рекурсивно викликають одна одну відповідно до заданих правил. Для кожного нетерміналу розроблена функція, яка перевіряє правило, яке відповідає даному нетерміналові. Також додатково описані функції Infix_to_Postfix() і Infix_to_Postfix_b() і функція isDeclaredVariable() яка виконує семантичний аналіз, тобто перевіряє чи змінна оголошена, чи вона відповідно до контексту має правельний тип і чи має значення.
3.5.Розробка генератора коду
3.5.1 Розробка граф-схеми алгоритму
Так як генерація коду тісно пов’язана з синтаксичним аналізом, тобто код конструкції генерується відразу після розпізнавання.
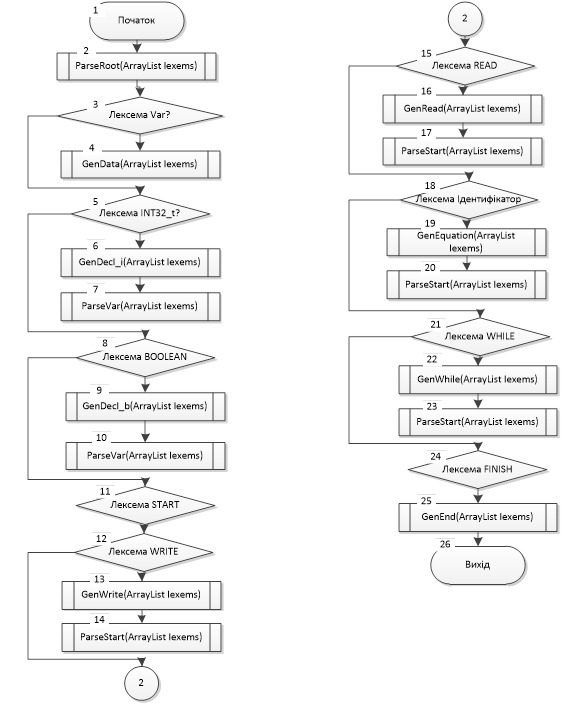
Рис
3
.Граф-схема роботи
генератора коду
Блок 1 – Початок синтаксичного аналізатора
Блок 2 – Основна функція аналізатора
Блок 3 – Перевіряє чи наступний символ Var
Блок 4 – Генерація блоку даних
Блок 5 - Перевіряє чи наступний символ INT32_t
Блок 6 – Генерація 4-х байтних хмінних
Блок 7 - Виконання функції ParseVAR()
Блок 8 - Перевіряє чи наступний символ BOOLEAN
Блок 9 – Генерація однобайтних змінних
Блок 10 - Виконання функції ParseVAR()
Блок 11 - Перевіряє чи наступний символ START
Блок 12 - Перевіряє чи наступний символ WRITE
Блок 13 – Генерація процедури виводу
Блок 14 - Виконання функції ParseSTART()
Блок 15 - Перевіряє чи наступний символ READ
Блок 16 - Генерація процедури вводу
Блок 17 - Виконання функції ParseSTART()
Блок 18 - Перевіряє чи наступний символ <ident>
Блок 19 - Генерація виразів
Блок 20 - Виконання функції ParseSTART()
Блок 21 - Перевіряє чи наступний символ WHILE
Блок 22 – Генерація блоку While
Блок 23 - Виконання функції ParseSTART()
Блок 24 – Перевіряє чи наступний символ FINISH
Блок 25 – Генерація завершення програми
Блок 26 - Завершення Синтаксичного аналізатора
3.5.2 Опис програми реалізації генератора коду
Програма починає по черзі перебирати лексеми із таблиці лексем. У відповідності до коду знайденої лексеми у проміжне представлення програми буде вставлено відповідний еквівалентний асемблерний текст. Наприклад, при зустрічі ключового слова Program, в асемблерний файл вставляється текст з описом моделі та сегментів, а при зустрічі ключового слова Var, вставляється опис сегменту даних.
Реакція на лексеми розроблена так, що пустий код не буде включений в асемблерний файл. Для того щоб уникнути помилок, імена ідентифікаторів, дані у вхідній програмі користувачем, вносяться у асемблерний файл із змінами. Наприклад, невідомо, як буде працювати згенерований код, якщо у ньому будуть зустрічатись створені користувачем змінні end, loop.
В даному трансляторі генератор коду послідовно викликає окремі функції, які записують у вихідний файл частини коду. Для кожного ланцюжка вхідної мови існує окрема функція, яка враховуючи послідовність лексем створює відповідний вихідний код.
4. Опис інтерфейсу та інструкції користувачеві
Програма NotepadProg можна запустити з виконавчого файлу NotepadProg.exe, або вибрати пункт меню Пуск/Виконати і ввести шлях до файлу і назву програми. NotepadProg є програмою, яка працює на платформі .NET і є візуальною програмою, тому для її запуску повинна бути встановлена платформа net framework не нижче версії 2.0. NotepadProg містить редактор тексту і транслятор. Редактор тексту дозволяє відкривати файли з розширенням *.prog.

Рис
4
.
Вікно редактора тексту
В редакторі присутні наступні функції:
- Ведення і редагування тексту
- Відкриття нового файл
- Збереження файлу
- Закриття файлу
- Копіювання тексту
- Зміна шрифту програми
- Зміна режимів розташування вікон редактора (каскадний, горизонтальний, вертикальний)
Після введення тексту програми код потрібно з транслювати. Під час першого запуску програми потрібно задати шлях до папки masm32 щоб в згенерований код транслятор коректо додав адресу бібліотек Win32. Щоб задати шлях потрібно виконати команду tools/Folders
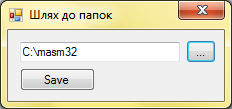
Рис
5
.
Вікно введення шляху до папки
masm
32
Після цього можна запустити транслятор вхідної мови це можна зробити за допомогою пункту меню Build/Run (F5). Вікно транслятора складається з 5 вкладок:
- Таблиця лексем
- Таблиця Ідентифікаторів
- Таблиця рядкових констант
- Таблиця помилок
- Файл Асемблерного коду

Рис 6.Вікно транслятора
Щоб отримати виконавчий файл потрібно згенерований код скомпілювати за допомогою ml.exe який вбудований в MS Visual Studio 2010.
5. Відлагодження та тестування програми
Відлагодження програми відбувається на основі спеціально створених тестів за допомогою автоматизованого відлагоджувача який присутній в середовищі Ms Visual Studio 2010, в покроковому режимі перевіряється значення потрібних змінних і вмістиме потрібних структур даних. За допомогою breakpoints відбувається запинка виконання програми в тих місцях де відбулася логічна помилка або в місцях визначених студентом.
5.1. Виявлення лексичних помилок.
До помилок виявлених на етапі лексичного аналізу відносить тільки одна помилка – виявлення нерозпізнаної лексеми. Якщо було виявлено нерозпізнану лексему – в таблицю лексем заноситься поле з коментарем «нерозпізнана лексема», і їй присвоюється код -1, і на етапі синтаксичного аналізу буде згенерована помилка пов’язана з цією лексемою.Приклад виявлення нерозпізнаної наведений на рис. 7:
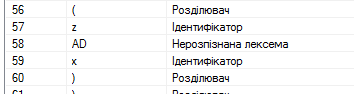
Рис
7
.
Виявлення помилок на етапі лексичного аналізу
5.2. Виявлення синтаксичних помилок.
На етапі синтаксичного аналізу виявляється основна кількість помилок. Ці помилки пов’язані з невірними записами конструкцій вхідної мови. Всі помилки виявленні на етапі синтаксичного аналізу заносяться в таблицю помилок, Таблиця помилок містить лексему яка спричинила помилку, коментар і рядок в якому виникла помилка. Приклад таблиці помилок наведений на рис. 8:

Рис
8
.
Виявлення помилок на етапі синтаксичного аналізу
5.3. Виявлення семантичних помилок.
Суттю виявлення семантичних помилок є перевірка числових констант на відповідність типу INT32_t , тобто знаковому цілому числу з відповідним діапазоном значень і перевірку на коректність використання змінних INT32_t і BOOLEAN у цілочисельних і логічних виразах. Результат роботи семантичного аналізу наведений на рис. 9:

Рис
9
.
Виявлення помилок на етапі семантичного аналізу
5.4. Загальна перевірка коректності роботи транслятора.
Загальна перевірка полягає в транслюванні завідомо коректної вхідної програми з використанням всіх можливостей мови в асемблерний код та перевірці на правильність виконання програми попередньо скомпільованої та злінкованої за допомогою ml.exe
Текст програми:
PROGRAMM n1
VAR
INT32_t a >> 665, b >> 664, z>>4, x>> 3,y;
BOOLEAN в >> TRUE,f >> FALSE, e>>TRUE;
INT32_t c1 >> 678;
START
c1 >> (aSUB548)MUL((fSUBb)MUL(zADDx));
d >> f & в | e;
WRITE(c1);
WHILE(a LE b)START
WRITE("z = ");
READ(z);
WHILE(f)START
WRITE(c1);
FINISH;
WRITE("New message");
WRITE("Hello");
b >> b ADD 1;
FINISH;
a ADD b;
FINISH
Результати роботи програми:

Висновки
Підчас виконання курсової роботи:
1. Складено формальний опис мови програмування Prog у формі розширеної нотації Бекуса-Наура, дано опис усіх символів та ключових слів.
2. Створено транслятор мови програмування Prog, а саме:
2.1.1. Розроблено лексичний аналізатор, здатний розпізнавати лексеми, що є описані в формальному описі мови програмування, та додані під час безпосереднього використання транслятора.
2.1.2. Розроблено синтаксичний аналізатор на основі рекурсивного спуску. Дерево виклику функцій згідно правил записаних в нотації у формі Бекуса-Наура.
2.1.3. Розроблено генератор коду, який починає свою роботу під час коректного виявлення кожної конструкції і генерує код який відповідає кожній конструкції вхідної мови. Проміжним кодом генератора є програма на мові Assembler(i586). Вихідним кодом є машинний код, що міститься у виконуваному файлі
3. Проведене тестування транслятора за допомогою тестових програм за наступними пунктами: Виявлення лексичних помилок. Виявлення синтаксичних помилок. Загальна перевірка роботи компілятора. Тестування не виявило помилок в роботі компілятора, а всі помилки в тестових програмах мовою prog були виявлені і дано попередження про їх наявність. В результаті виконання даної курсової роботи було успішно засвоєно методи розробки та реалізації компонент системного програмного забезпечення.
Список використаної літератури
1. Ахо и др. Компиляторы: принципы, технологии и инструменты.: Пер с англ. – М.: Издательський дом «Вильямс». 2003. – 768 с.: ил. Парал. тит. англ.
2. Шильдт Г. С#. – Санкт-Петербург: BXV, 2002. – 688 с.
3. Компаниец Р.И., Маньков Е.В., Филатов Н.Е. Системное программирование. Основы построения трансляторов. – СПб.: КОРОНА принт, 2004. – 256 с.
4. Б. Керниган, Д. Ритчи «Язык программирования Си». – Москва «Финансы и статистика», 1992. – 271 с.
5. Л. Дао. Программирование микропроцессора 8088. Пер.с англ.‑М. «Мир», 1988.
6. Ваймгартен Ф. Трансляция языков программирования. – М.: Мир, 1977.
За деталями звертатись -> Моя сторінка
|