Реферат: Применение MS Excel для решения статистических задач
|
Название: Применение MS Excel для решения статистических задач Раздел: Рефераты по информатике Тип: реферат | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
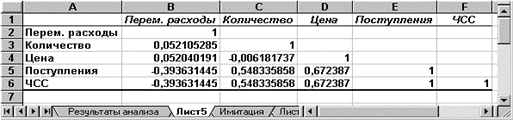
Введение В современном обществе к статистическим методам проявляется повышенный интерес как к одному из важнейших аналитических инструментариев в сфере поддержки процессов принятия решений. Статистикой пользуются все- от политиков, желающих предсказать исход выборов, до предпринимателей, стремящихся оптимизировать прибыль при тех или иных вложениях капитала. Большим шагом вперёд к развитию статистической науки послужило применение экономико-математических методов и использование компьютерной техники в анализе социально-экономических явлений. Программа обработки электронных таблиц MSExcel- мощная и достаточно простая в использовании программа, предназначенная для решения широкого круга планово-экономических, учетно-статистических, научно-технических и других задач, в которых числовая, текстовая или графическая информация с некоторой регулярной, повторяющейся структурой представлена в табличном виде. Программа MSExcel предоставляет богатые возможности создания и изменения таблиц, которые могут содержать числа, тексты, даты, денежные единицы, графику, а также математические и иные формулы для выполнения вычислений. Предусмотрены средства представления числовых данных в виде диаграммы, создания, сортировки и фильтрации списков, статического анализа данных и решения оптимизационных задач. В данной работе я постараюсь показать, какие возможности для обработки статистических данных имеет программа MSExcel. Объектом исследования данной работы являются возможности табличного процессора. Предметом исследования является применение программы MSExcel для решения статистических задач. Актуальность работы обусловлена недостаточной реализацией возможностей MSExcel для решения статистических задач. Цель настоящего исследования заключается в формированииустойчивых знаний о возможностях MSExcel для решения статистических задач. Для достижения поставленной цели потребовалось решить следующие задачи : 1. Раскрыть сущность возможностей MSExcel. 2. Определить способы применения этих возможностей при решении задач статистики. В качестве гипотезы выдвигается следующее: Использование возможностей программы MSExcel облегчает и ускоряет решения задач статистики. Глава 1. Применение Microsoft Excel для решения статистических задач.1.1. Работа с даннымиВ состав Microsoft Excel входит набор средств анализа данных (так называемый пакет анализа), предназначенный для решения сложных статистических и инженерных задач. Для проведения анализа данных с помощью этих инструментов следует указать входные данные и выбрать параметры; анализ будет проведен с помощью подходящей статистической или инженерной макрофункции, а результат будет помещен в выходной диапазон. Другие средства позволяют представить результаты анализа в графическом виде. Графические изображения используются, прежде всего, для наглядного представления статистических данных, благодаря ним существенно облегчается их восприятие и понимание. Существенна их роль и тогда, когда речь идет о контроле полноты и достоверности исходного статистического материала, используемого для обработки и анализа. Статистические данные приводятся в виде длинных и сложных статистических таблиц, поэтому бывает весьма трудно обнаружить в них имеющиеся неточности и ошибки. В процессе анализа данных, как правило, присутствуют следующие основные этапы: 1. Ввод данных Введенные данные обычно отражаются в форме электронной таблицы или матрицы данных, где столбцы представляют различные переменные (например, рост, вес), а строки - измерение значений этих переменных, произведенные в различных условиях, в различное время, у различных объектов и т.п. 2. Преобразование данных Данные в электронной таблице можно просмотреть и скорректировать методами ручного редактирования или же полуавтоматического преобразования к виду, адекватному выбранному методу анализа. Здесь может быть использован широкий набор алгебраических, матричных, структурных преобразований, а также комбинирование этих операций в требуемой последовательности. 3. Визуализация данных На данные обязательно следует просто посмотреть, чтобы составить общее (в том числе и интуитивное) представление о характере их изменения, специфических особенностях и закономерностях, что очень важно при выборе стратегии и тактики дальнейшего анализа. Для этого можно использовать как исходное числовое представление, так и различные формы графического изображения. 4. Статистический анализ Собственно выбор метода, анализ данных и интерпретация результатов. 5. Представление результатов Для наглядности производимых выводов полученные результаты желательно представлять в виде адекватных, убедительных и эффектных графиков. Для успешного применения процедур анализа необходимы начальные знания в области статистических и инженерных расчетов, для которых эти инструменты были разработаны В экономических исследованиях часто решают задачу выявления факторов, определяющих уровень и динамику экономического процесса. Такая задача чаще всего решается методами корреляционного и дисперсионного анализа. При машинной обработке исходной информации на ЭВМ, оснащенных пакетами стандартных программ ведения анализов, вычисление параметров применяемых математических функций является быстро выполняемой счетной операцией. Возможность использования формул и функций является одним из важнейших свойств программы обработки электронных таблиц. Это, в частности, позволяет проводить статистический анализ числовых значений в таблице. Текст формулы, которая вводится в ячейку таблицы, должен начинаться со знака равенства (=), чтобы программа Excel могла отличить формулу от текста. После знака равенства в ячейку записывается математическое выражение, содержащее аргументы, арифметические операции и функции. В качества аргументов в формуле обычно используются числа и адреса ячеек. Для обозначения арифметических операций могут использоваться следующие символы: + (сложение); - (вычитание); * (умножение); / (деление). Формула может содержать ссылки на ячейки, которые расположены на другом рабочем листе или даже в таблице другого файла. Однажды введенная формула может быть в любое время модифицирована. Встроенный Менеджер формул помогает пользователю найти ошибку или неправильную ссылку в большой таблице. Кроме этого, программа Excel позволяет работать со сложными формулами, содержащими несколько операций. Для наглядности можно включить текстовый режим, тогда программа Excel будет выводить в ячейку не результат вычисления формулы, а собственно формулу. Программа Excel интерпретирует вводимые данные либо как текст (выравнивается по левому краю), либо как числовое значение (выравнивается по правому краю). Для ввода формулы необходимо ввести алгебраическое выражение, которому должен предшествовать знак равенства (=). [7] Ввод формул можно существенно упростить, используя маленький трюк. После ввода знака равенства следует просто щелкнуть мышью по первой ячейке, затем ввести операцию деления и щелкнуть по второй ячейке. 1.2. Инструменты пакета анализа в MicrosoftExcelДисперсионный анализПакет анализа включает в себя три средства дисперсионного анализа. Выбор конкретного инструмента определяется числом факторов и числом выборок в исследуемой совокупности данных. [6] Однофакторный дисперсионный анализОднофакторный дисперсионный анализ используется для проверки гипотезы о сходстве средних значений двух или более выборок, принадлежащих одной и той же генеральной совокупности. Этот метод распространяется также на тесты для двух средних (к которым относится, например, t-критерий).Двухфакторный дисперсионный анализ с повторениями.Представляет собой более сложный вариант однофакторного анализа, включающий более чем одну выборку для каждой группы данных. Рассмотрим пример применения данной функции MicrosoftExcel. Требуется при уровне α=0,05 выяснить, влияют ли на урожайность пшеницы вид удобрений и способ химической обработки почвы. Выборочные данные об урожайности пшеницы, выращенной на участках, на которые вносились различные виды удобрений и которые подвергались различной химической обработке, приведены в таблице ниже.
Рассматриваемый в задаче эксперимент представляет собой факторный эксперимент типа 4×4, при котором четыре вида удобрений(фактор А) пересекаются с использованием четырёх способов химической обработки почвы(фактор В). Таким образом, в плане эксперимента имеется 16 условий. Но здесь каждому условию соответствует не одно, а три значения(3 участка земли, засеянных пшеницей).Для решения задачи используем режим работы «Двухфакторный дисперсионный анализ с повторениями». Значения параметров, установленных в одноименном диалоговом окне, и рассчитанные в данном режиме показатели представлены в таблице, расположенной ниже .
Так как Выборочный коэффициент детерминации для фактора А |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
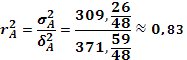
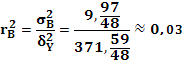
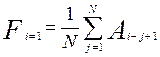
| B | C | D | |
| 21 | Номер предприятия | Уставный капитал, млн. руб. Х | Число выставленных акций Y |
Продолжение таблицы 1
| 22 | 1 | 2954 | 856 |
| 23 | 2 | 1605 | 930 |
| 24 | 3 | 4102 | 1563 |
| 25 | 4 | 2350 | 682 |
| 26 | 5 | 2625 | 616 |
| 27 | 6 | 1795 | 495 |
| 28 | 7 | 2813 | 815 |
| 29 | 8 | 1751 | 858 |
| 30 | 9 | 1700 | 467 |
| 31 | 10 | 2264 | 661 |
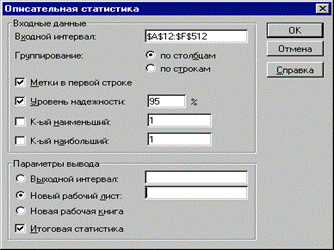
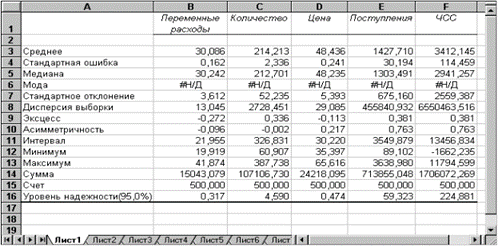
Для решения задачи используем режим работы «Ранг и персентиль». Результаты выполнения данного режима приведены ниже в таблице.
| B | C | D | E | F | G | H | I | ||
| 35 | Точка | Столбец1 | Ранг | Процент | Точка | Столбец1 | Ранг | Процент | |
| 36 | 3 | 4102 | 1 | 100,00 | 3 | 1563 | 1 | 100,00 | |
| 37 | 1 | 2954 | 2 | 88,80 | 2 | 930 | 2 | 88,80 | |
| 38 | 7 | 2813 | 3 | 77,70 | 8 | 858 | 3 | 77,70 | |
| 39 | 5 | 2625 | 4 | 66,60 | 1 | 856 | 4 | 66,60 | |
| 40 | 4 | 2350 | 5 | 55,50 | 7 | 815 | 5 | 55,50 | |
| 41 | 10 | 2264 | 6 | 44,40 | 4 | 682 | 6 | 44,40 | |
| 42 | 6 | 1795 | 7 | 33,30 | 10 | 661 | 7 | 33,30 | |
| 43 | 8 | 1751 | 8 | 22,20 | 5 | 616 | 8 | 22,20 | |
| 44 | 9 | 1700 | 9 | 11,10 | 6 | 495 | 9 | 11,10 | |
| 45 | 2 | 1605 | 10 | 11,10 | 9 | 467 | 10 | 11,10 | |
По данным этой сгенерированной таблицы заполняем в следующей таблице графы Ранг
![]() и Ранг
и Ранг
![]() , на основании которых производим вычисления квадратов разности рангов
, на основании которых производим вычисления квадратов разности рангов ![]() .
.
| B | C | D | E | F | G | |
| 21 | Номер предприятия | Уставный капитал, млн. руб. Х | Число выставленных акций Y | Ранг |
Ранг |
Квадрат разности рангов
|
| 22 | 1 | 2954 | 856 | 2 | 4 | 4 |
| 23 | 2 | 1605 | 930 | 10 | 2 | 64 |
| 24 | 3 | 4102 | 1563 | 1 | 1 | 0 |
| 25 | 4 | 2350 | 682 | 5 | 6 | 1 |
| 26 | 5 | 2625 | 616 | 4 | 8 | 16 |
| 27 | 6 | 1795 | 495 | 7 | 9 | 4 |
| 28 | 7 | 2813 | 815 | 3 | 5 | 4 |
| 29 | 8 | 1751 | 858 | 8 | 3 | 25 |
| 30 | 9 | 1700 | 467 | 9 | 10 | 1 |
| 31 | 10 | 2264 | 661 | 6 | 7 | 1 |
| 32 | 120 |
Заключительным этапом решения задачи является вычисление коэффициента Спирмена по формуле
![]() ,
,
подставляя в которую исходные данные и рассчитанные данные задачи получим
![]() .
.
Значение коэффициента Спирмена ![]() свидетельствует о слабой связи между рассматриваемыми признаками. [9]
свидетельствует о слабой связи между рассматриваемыми признаками. [9]
Регрессия
Регрессионный анализ называют основным методом современной математической статистики для выявления неявных и завуалированных связей между данными наблюдений. Электронные таблицы делают такой анализ легко доступным. Таким образом, регрессионные вычисления и подбор хороших уравнений - это ценный, универсальный исследовательский инструмент в самых разнообразных отраслях деловой и научной деятельности (маркетинг, торговля, медицина и т. д.). Усвоив технологию использования этого инструмента, можно применять его по мере необходимости, получая знание о скрытых связях, улучшая аналитическую поддержку принятия решений и повышая их обоснованность.
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. [8]
Выборка
Создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. [5]
Двухвыборочный z-тест для средних
Двухвыборочный z-тест для средних с известными дисперсиями используется для проверки гипотезы о различии между средними двух генеральных совокупностей.
1.5. Статистические функции
FРАСП Возвращает F-распределение вероятности. Эту функцию можно использовать, чтобы определить, имеют ли два множества данных различные степени плотности. Например, можно исследовать результаты тестирования мужчин и женщин, окончивших высшую школу, и определить отличается ли разброс результатов для мужчин и женщин.[10]
FРАСПОБР Возвращает обратное значение для F-распределения вероятности
БЕТАОБР Возвращает обратную функцию к интегральной функции плотности бета-вероятности
БЕТАРАСП Возвращает интегральную функцию плотности бета-вероятности
БИНОМРАСП Возвращает отдельное значение биномиального распределения
ВЕЙБУЛЛ Возвращает распределение Вейбулла
ВЕРОЯТНОСТЬ Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов
ГАММАНЛОГ Возвращает натуральный логарифм гамма функции
ГАММАОБР Возвращает обратное гамма-распределение
ГАММАРАСП Возвращает гамма-распределение
ГИПЕРГЕОМЕТ Возвращает гипергеометрическое распределение
ДОВЕРИТ Возвращает доверительный интервал для среднего значения по генеральной совокупности
КВАРТИЛЬ Возвращает квартиль множества данных
КВПИРСОН Возвращает квадрат коэффициента корреляции Пирсона
КРИТБИНОМ Возвращает наименьшее значение, для которого биномиальная функция распределения меньше или равна заданному значению
ЛГРФПРИБЛ Возвращает параметры экспоненциального тренда
ЛИНЕЙН Возвращает параметры линейного тренда
ЛОГНОРМОБР Возвращает обратное логарифмическое нормальное распределение
ЛОГНОРМРАСП Возвращает интегральное логарифмическое нормальное распределение
МАКСА Возвращает максимальное значение из списка аргументов, включая числа, текст и логические значения
МИНА Возвращает минимальное значение из списка аргументов, включая числа, текст и логические значения
НАИБОЛЬШИЙ Возвращает k-ое наибольшее значение из множества данных
НАИМЕНЬШИЙ Возвращает k-ое наименьшее значение в множестве данных
НАКЛОН Возвращает наклон линии линейной регрессии
НОРМАЛИЗАЦИЯ Возвращает нормализованное значение
НОРМОБР Возвращает обратное нормальное распределение
НОРМРАСП Возвращает нормальную функцию распределения
НОРМСТОБР Возвращает обратное значение стандартного нормального распределения
ОТРБИНОМРАСП Возвращает отрицательное биномиальное распределение
ОТРЕЗОК Возвращает отрезок, отсекаемый на оси линией линейной регрессии
ПЕРЕСТ Возвращает количество перестановок для заданного числа объектов
ПИРСОН Возвращает коэффициент корреляции Пирсона
ПРОЦЕНТРАНГ Возвращает процентную норму значения в множестве данных
ПУАССОН Возвращает распределение Пуассона
РОСТ Возвращает значения в соответствии с экспоненциальным трендом
СРГАРМ Возвращает среднее гармоническое
СРГЕОМ Возвращает среднее геометрическое
СРЗНАЧ Возвращает среднее арифметическое аргументов
СРЗНАЧА Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения.
СРОТКЛ Возвращает среднее абсолютных значений отклонений точек данных от среднего
СТАНДОТКЛОН Оценивает стандартное отклонение по выборке
СТАНДОТКЛОНА Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения
СТАНДОТКЛОНП Вычисляет стандартное отклонение по генеральной совокупности
СТАНДОТКЛОНПА Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения
СТЬЮДРАСП Возвращает t-распределение Стьюдента
СТЬЮДРАСПОБР Возвращает обратное t-распределение Стьюдента
СЧЁТЗ Подсчитывает количество значений в списке аргументов
ТЕНДЕНЦИЯ Возвращает значения в соответствии с линейным трендом
ТТЕСТ Возвращает вероятность, соответствующую критерию Стьюдента
УРЕЗСРЕДНЕЕ Возвращает среднее внутренности множества данных
ФИШЕР Возвращает преобразование Фишера
ФИШЕРОБР Возвращает обратное преобразование Фишера
ФТЕСТ Возвращает результат F-теста
ХИ2ОБР Возвращает обратное значение односторонней вероятности распределения хи-квадрат
ХИ2РАСП Возвращает одностороннюю вероятность распределения хи-квадрат
ХИ2ТЕСТ Возвращает тест на независимость
ЧАСТОТА Возвращает распределение частот в виде вертикального массива
ЭКСПРАСП Возвращает экспоненциальное распределение
1.6 Применение графических возможностей Excel
Графические изображения уже давно нашли широкое применение в самых разнообразных видах человеческой деятельности. Но, пожалуй, ни в одной области знаний и практической деятельности графические изображения не играют такой исключительной роли, как в статистике и экономике, имеющих дело с обработкой и анализом огромных массивов информации о социально- экономических явлениях и процессах. Всесторонний и глубокий анализ этой информации, так называемых статистических данных, предполагает использование различных специальных методов, важное место среди которых занимают графические изображения статистических данных.
Графические изображения широко используются, прежде всего, для наглядного представления статистических данных, благодаря ним существенно облегчается их восприятие и понимание.
Огромные возможности для автоматического построения различных видов графических изображений статистических данных представляет программа обработки электронных таблиц MicrosoftExcel.
Статистическая диаграмма- это особый способ наглядного представления и изложения с помощью геометрических знаков и других графических средств статистической информации с целью её обобщения и анализа. Основным и наиболее важным свойством статистических диаграмм является их наглядность. Непосредственная наглядность статистических диаграмм делает их более выразительными и наглядными. [11]
При анализе статистических данных диаграммы могут использоваться для решения таких задач:
· Отображать распределение единиц статистической совокупности по значениям или разновидностям исследуемого признака;
· Характеризовать развитие изучаемых явлений во времени, их общую тенденцию развития, сезонность колебаний, абсолютную и относительную скорость их развития и изменения;
· Сравнивать размеры различных явлений, их разных частей, а также тенденцию их развития и изменения во времени и пространстве;
· Выявлять структуру изучаемых явлений и её изменения, т.е. структурные сдвиги;
· Устанавливать взаимозависимость между явлениями или их признаками, а также степень тесноты существующей между ними связи;
· Отображать степень распространения изучаемых явлений по той или иной территории и интенсивности этого распространения.
Статистические диаграммы являются очень ценным средством при проведении разного рода сравнений статистических данных.
Графические изображения статистических данных осуществляются в основном посредством геометрических плоскостных знаков- точек, линий, плоскостей, фигур, различного сочетания и их расположения. Графические изображения, как плоскостные, так и объёмные, бывают разнообразными, но почти каждое из них состоит из одних и тех, же основных элементов: поле диаграммы, графического образа, пространственных и масштабных ориентиров, экспликации диаграммы.
В Excel вместо понятия «поле диаграмм» применяются такие понятия, как область построения диаграммы и область диаграммы.
Область построения диаграмма - это область, в которой отображается только координатные оси и сама диаграмма, а область диаграммы - это область, в которой кроме координатных осей и самой диаграммы, заголовок диаграммы, обозначение единиц измерения координатных осей, легенда.
Каждый элемент диаграммы можно выделить, активизировать, а потом осуществлять с ним различные преобразования, как-то: изменять размеры, редактировать, форматировать (оформлять). [5]
С помощью перетаскивания можно перемещать область диаграммы и область построения диаграммы и область диаграммы, кроме того, можно изменять их размеры, а, следовательно, и размеры самой диаграммы и отдельных её элементов.
Кроме того, Excel позволяет изменять внешний вид области построения диаграммы и области диаграммы, т.е. изменять форму линий рамки обрамления, цвет и узор заполнения их внутренних частей.
Графический образ- это совокупность геометрических или графических знаков, с помощью которых отображаются статистические данные.
Графические средства Excel позволяют в качестве графического образа использовать различные знаки – символы, в том числе и рисунки. Точнее говоря, Excel автоматически заменяет геометрические знаки негеометрическими.
Изобразительные диаграммы, которые строятся с помощью негеометрических знаков, широко используется для пропаганды и популяризации статистических данных.
Excel имеет многочисленный арсенал средств для построения и оформления основных элементов диаграммы: линии могут быть разноцветными (существует 56 вариантов цветов) или иметь различную форму (тип) – сплошные, штриховые, точечные, штрих – пунктирные, а также разную толщину – тонкие, средние, полутолстые (полужирные) и толстые(жирные); точки данных могут быть изображены в виде маленьких кружков, квадратиков, треугольников, ромбов и других геометрических знаков с разными узорами. Excel предлагает 48 видов штриховки, а также позволяет изменять цвета, узоры, обрамления основных элементов диаграммы, в том числе, самых больших её частей – области построения диаграммы и области диаграммы. [5]
В Excel вместо понятия графического образа используется термин маркер данных. Вид символа маркера зависит от вида диаграммы: на гистограмме это (обычно) прямоугольники, на круговой диаграмме – сектора и т.п.
Пространственные ориентиры – это элементы диаграммы, определяющие порядок размещения графических знаков в поле диаграммы. Такой порядок задаётся определённой системой координат – совокупностью элементов, определяющих положение точки на прямой или кривой линии, на плоскости и в пространстве. При построении статистических диаграмм обычно применяются прямоугольная или декартова, полярная, треугольная или тригональная системы координат.
Прямоугольная система координат чаще всего применяется для статистических диаграмм по причине простоты её построения и наилучшей выразительности различных соотношений и зависимостей между изображаемыми статистическими величинами. Прямоугольная система координат образуется совокупностью двух пересекающихся перпендикулярных прямых, называемых осями координат. [11]
Для облегчения построения и чтения диаграммы её поля в пределах осей координат покрывают параллельными горизонтальными и вертикальными линиями, которые в совокупности образуют так называемую координатную сетку.
В Excel координатная сетка на плоскостных диаграммах наносится на область построения диаграммы, а на объёмных диаграммах, которые имеют две стенки и основания на них.
Графические средства Excel позволяют наносить линии координатной сетки либо на одну из осей, причём линии сетки могут проходить или через основные деления – основные линии, или через промежуточные деления – промежуточные линии.
Excel по умолчанию автоматически строит и размещает координатные оси в нужном месте диаграммы, используя встроенные установки для типа осевых линий, делений и размещений меток деления. Но все эти параметры можно изменять, а также управлять вводом, выводом и удалением координатных осей.
Можно задать нужный тип линий координатных осей и настроить её деления и метки делений.
Экспликация диаграммы – это пояснение содержания диаграммы и её основных элементов.
Экспликация включает общий заголовок диаграммы, подписи вдоль масштабных шкал и пояснительные надписи, раскрывающие смысл отдельных элементов графического образа. [5]
Excel располагает множеством инструментов, позволяющих выполнить экспликацию диаграммы, при этом каждый из элементов экспликации может быть отформатирован (оформлен) различными способами в зависимости от типа и вида диаграммы.
При построении диаграммы Excel по умолчанию, т.е. автоматически, размещает заголовок диаграммы в центре верхней области построения диаграммы, а надписи координатных осей возле каждой оси.
Отметим, что Excel имеет несколько инструментов, которые позволяют просто и быстро отформатировать любой текст т числа, имеющиеся на диаграмме. Они позволяют выбрать типы шрифтов и их размеры, способы выравнивания текста, оформления его жирным шрифтом, курсивом и подчеркиванием, а также добавить к нему рамки, узоры и цвет.
Excel позволяет выравнивать на диаграмме выделенный текст по горизонтали и вертикали, а также менять ориентацию текста, т.е. выравнивать его под определённым углом.
Кроме ввода, редактирования и форматирования заголовка диаграммы и надписей осей, Excel позволяет просто и быстро поместить на саму диаграмму дополнительные надписи, так называемые ярлыки, поясняющие её смысл и значение отдельных элементов. Этот дополнительный текст можно поместить в любое место диаграммы, изменить его размеры и отформатировать.
Excel позволяет форматировать имеющиеся на диаграмме объекты, в частности стрелки и надписи.
Специальное пояснение к маркерам или элементам, используемым в диаграмме, носит название легенды. Excel автоматически создаёт легенду из названий. Но также позволяет самостоятельно создавать легенду и перемещать её в нужное место.
1.7 Классификация статистических диаграмм
Диаграммы, применяемые для изображения статистических данных, очень разнообразны и имеют ряд особенностей, что обуславливает необходимость их классификации.
Классификация статистических диаграмм имеет чрезвычайное значение для их правильного построения и изучения. Она облегчает понимание отличительных особенностей различных типов и видов диаграмм, их возможностей в решении конкретных задач статистического исследования.
В Excel классификация диаграмм осуществлена по форме графического образа. По этому признаку выделено 14 основных, встроенных, или, как их принято называть, стандартных типов диаграмм, и 20 дополнительных, нестандартных, или специальных типов диаграмм. Каждый тип диаграмм представлен несколькими видами (форматами) как плоскостных, так и объёмных диаграмм, которые могут быть применены к данному типу диаграммы. Кроме того, Excel предоставляет пользователю возможность построения собственных типов диаграмм. [5]
Помимо основных, стандартных, типов диаграмм предлагает большое количество нестандартных, специальных, типов диаграмм. Основой нестандартных диаграмм являются стандартные типы диаграмм. Некоторые встроенные нестандартные типы диаграмм подобны стандартным типам. Вместе с тем они содержат дополнительные графические средства, которые расширяют не только наглядные, но и познавательные и аналитические возможности. В частности, они содержат такие встроенные графические элементы: легенду, координатную сетку, логарифмическую шкалу, объяснительные надписи; они имеют, скажем, более привлекательный вид, поскольку их форматирование выполнено с помощью специальных приёмов.
Кроме использования стандартных и нестандартных типов диаграмм, Excel предоставляет пользователю возможность создавать собственные типы диаграмм, сохранять и применять таким же образом, как и любые другие типы диаграмм. [5]
Чтобы создать собственный тип диаграммы, необходимо располагать диаграммой, которая будет служить основой для создания собственного типа диаграммы, при этом в качестве основы можно взять любой тип и вид уже построенной диаграммы, поскольку в любой момент графические средства Excel позволяют изменить его или создать диаграмму требуемого вида и типа.
Заключение
В развитых странах практически любое решение: политическое, финансовое, техническое, научно-исследовательское и даже бытовое решение принимается только после всестороннего анализа данных. Поэтому изучение прикладной статистики и методов анализа данных является неотъемлемым компонентом образования на всех уровнях, а компьютерные пакеты для аналитических исследований и прогнозирования являются настольным рабочим инструментом любого специалиста, так или иначе связанного с информационной сферой.
Таким образом, обработка статистических данных уже давно применяется в самых разнообразных видах человеческой деятельности. Вообще говоря, трудно назвать ту сферу, в которой она бы не использовалась. Но, пожалуй, ни в одной области знаний и практической деятельности обработка статистических данных не играет такой исключительно большой роли, как в экономике, имеющей дело с обработкой и анализом огромных массивов информации о социально-экономических явлениях и процессах. Всесторонний и глубокий анализ этой информации, так называемых статистических данных, предполагает использование различных специальных методов, важное место среди которых занимают возможности табличного процессора MSExcel.
Представление экономических и других данных в электронных таблицах в наши дни стало простым и естественным. Оснащение же электронных таблиц средствами анализа способствует тому, что из группы сложных, глубоко научных и потому редко используемых, почти экзотических методов, статистический анализ превращается для специалиста в повседневный, эффективный и оперативный аналитический инструмент. Электронные таблицы делают такой анализ легко доступным.
Усвоив технологию использования табличного процессора MSExcel, можно применять его по мере необходимости, получая знание о скрытых связях, улучшая аналитическую поддержку принятия решений и повышая их обоснованность.
В данной работе я показала, что табличный процессор MSExcel обладает огромными возможностями для решения задач статистики, облегчая работу специалистов, работающих в этой области.
Список литературы
1. Бернс Дж., Берроуз Э. ,Секреты Excel 97. – М.:Веста, 1999.
2. Фигурнов В. Э. ,IBMPC для пользователя. – М.:ИНФРА, 1998.
3. А. Гончаров «MicrosoftExcel 7.0 в примерах» - С.-П.:Питер, 1996
4. Пробитюк А., Excel 7.0 для Windows 95 в бюро. – К.:BHV, 1996
5. Лаврёнов С.М.,Excel: сборник примеров и задач-М: финансы и статистика,2000.-336с.
6. Макарова Н.В.,Трофимец В.Я., Статистика в Excel:учеб. пособие.-М.:финансы и статистика,2003.-386с.
7. Сидоров М.Г., Обработка данных в Excel //информатика и образование.-2000.-№6.-с. 25-36.
8. Гутовская Г.В., Использование Excel для решения финансово-экономических задач//информатика и образование.-2003.-№3.-с. 15-21.
9. Ивинская Н.Л., решение прикладных задач в Excel//информатика и образование.-2003.-№6.-с.62-64.
10. Кирей Е.А., Базовый курс Excel для учащихся профильных экономических классов//информатика и образование.-2004.-№5.-с.39-41.
11. Андрусенко Н.Е., Использование стандартных функций Excel для поиска и связи данных в таблице//информатика и образование.-2003.-№11.-с.7-12.
12. [Электронный ресурс]. – Режим доступа:http://www.realcoding.net/article/view/3961