Государственное образовательное учреждение
высшего профессионального образования
Кубанский государственный технологический университет
Армавирский механико-технологический институт
Кафедра внутризаводского электрооборудования и автоматики
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
к курсовому проекту
по дисциплине: Теория языков программирования
на тему:
«Распознавание слов
естественного языка с использованием нейросетей»
ЗАДАНИЕ
на курсовой проект
Студенту
специальности 230105(2204) «Программное обеспечение вычислительной техники и автоматизированных систем»
Тема проекта: «Распознавание слов естественного языка с использованием нейросетей»
Содержание задания:
1. Настройка и обучение нейросети.
2. Лексический анализ текста, формирование таблицы лексем.
3. Распознавание типа слов.
Требования: язык программирования C#, объектный метод проектирования, класс выполняющий распознавание, оформить в виде библиотечного компонента, составить тесты и написать программу для тестирование своих библиотечных классов.
Объем работы:
Пояснительная записка 30 – 35 листов
Графическая часть 2-3 листа формата А3
Рекомендуемая литература:
1. Комарцова Л.Г., Максимов А.В.. Нейрокомпьютеры Учебное пособие для вузов. – М.: Изд-во МГТУ им. Н.Э.Баумана,2002.
2. Осовский С. Нейронные сети для обработки информации.-М.:Финансы и статистика, 2004.
3. Уоссермен Ф. Нейрокомпьютерная техника: теория и практика. — М.: Мир, 1992.
4. Ключко В.И., Ермоленко В.В. Нейрокомпьютерные системы. Базы знаний. Учеб. пособие Изд-во КубГТУ,1999.-100с.
ГОСТ Р ИСО 9001-2001 Системы менеджмента качества. Требования.
ГОСТ 7.1-2003 СИБИД. Библиографическая запись. Библиографическое описание. Общие требования и правила составления.
ГОСТ 19.101-77 ЕСПД. Виды программ и программных документов.
ГОСТ 19.102-77 ЕСПД. Стадии разработки.
ГОСТ 19.103-77 ЕСПД. Обозначение программ и программных документов.
ГОСТ 19.105-78 ЕСПД. Общие требования к программным документам
ГОСТ 19.202-78 ЕСПД. Спецификация. Требования к содержанию и оформлению.
ГОСТ 19.404-79 ЕСПД. Пояснительная записка Требования к содержанию и оформлению.
ГОСТ 19.701-90 ЕСПД. Схемы алгоритмов, программ, данных и систем. Обозначения условные и правила выполнения.
Реферат
Пояснительная записка к курсовому проекту содержит 17 рисунков, 4 литературных источников, 3 приложения. К пояснительной записке прилагается 1 диск с готовой программой и материалами к ней, а также графическая часть, состоящая из трех листов.
ЛЕКСЕМА, НЕЙРОННАЯ СЕТЬ, ВХОДНОЙ СЛОЙ, СКРЫТЫЙ СЛОЙ, ВЫХОДНОЙ СЛОЙ, ОБУЧАЮЩАЯ ВЫБОРКА, ТЕСТОВАЯ ВЫБОРКА, ХЕШ-ТАБЛИЦА, ТАБЛИЦА ЛЕКСЕМ
Объект: лексический анализатор слов естественного языка с использованием нейросети.
Цель: закрепление теоретических знаний по дисциплине «Теория языков программирование и методов трансляции», получить практические навыки проектирования и разработки элементов транслятора.
Произведен выбор нейросети, рассмотрен ее алгоритм, представлена программная реализация на языке C# в библиотеке классов и написана тестирующая программа.
Содержание
Введение
1. Анализ нейронных сетей
1.1 Выбор разновидности сети
1.2 Модель многослойного персептрона с обучением по методу обратного распространения ошибки
1.3 Постановка задачи
2. Проектирование библиотеки классов для реализации нейросети и тестовой программы
2.1 Программная реализация нейросети обратного распространения ошибки
2.2 Класс перевода текста в двоичный вид
2.3 Класс хеш-таблицы и методов работы с ней
2.4 Класс разбиения текста на лексемы и распознавания
2.5 Описание тестирующей программы
2.6 Результаты тестирования
3. Руководство программисту
Заключение
Список используемой литературы
Приложени
я
Введение
Цель данного проекта: применение нейронной сети в лексическом анализе слов естественного языка.
Задачи: смоделировать, программно реализовать, настроить и обучить нейросеть для лексического анализа слов естественного языка.
Входной информацией являются параметры нейросети, файлы с обучающей выборкой.
Выходной информацией является таблица лексем.
Результатом курсового проекта должна быть программа-анализатор слов естественного языка с использованием нейросети.
1.
Анализ нейронных сетей
1.1 Выбор разновидности сети
Искусственные нейронные сети — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса. Впоследствии, после разработки алгоритмов обучения, получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
Искусственные нейронные сети представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи.
Существует много разновидностей нейронных сетей, но наиболее распространенными являются сети Кохонена, Хопфилда, обратного распространения ошибки.
Недостатками сети Кохонена является ее сложность и проблемы при классификации похожих образов. Сеть Хопфилда также может стать нестабильной, если обучающие примеры являются слишком похожими. Данные недостатки являются существенными, т.к. сходные по написанию слова естественного могут относиться к разным частям речи. Соответственно, для реализации лексического анализатора наиболее подходящей является сеть обратного распространения ошибки. Обратное распространение - первый эффективный алгоритм обучения многослойных нейронных сетей. Один из самых популярных алгоритмов обучения, с его помощью были решены и решаются многочисленные практические задачи.
1.2 Модель многослойного персептрона с обучением по методу обратного распространения ошибки
Когда в сети только один слой, алгоритм ее обучения с учителем очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны, и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного персептрона. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двух или более слойный персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС.
Ф. Розенблаттом использовал в своем персептроне не дифференцируемую ступенчатую функцию активации. Возможно, именно это помешало ему найти эффективный алгоритм обучения, хотя сам термин Back Propagation восходит к его попыткам обобщить свое правило обучения одного нейрона на многослойную сеть.
Разберем этот ключевой для нейрокомпьютинга метод несколько подробнее.
Алгоритм обратного распространения - это итеративный градиентный алгоритм, который используется с целью минимизации среднеквадратичного отклонения текущего выхода многослойного персептрона и желаемого выхода.
Алгоритм обратного распространения используется для обучения многослойных нейронных сетей с последовательными связями. Нейроны в таких сетях делятся на группы с общим входным сигналом - слои. На каждый нейрон первого слоя подаются все элементы внешнего входного сигнала. Все выходы нейронов m-го слоя подаются на каждый нейрон слоя m+1. Нейроны выполняют взвешенное суммирование элементов входных сигналов. К сумме элементов входных сигналов, помноженных на соответствующие синаптические веса, прибавляется смещение (порог) нейрона. Над результатом суммирования выполняется нелинейное преобразование - функция активации (передаточная функция). Значение функции активации есть выход нейрона.
На рисунке 1 показана укрупненная схема многослойной сети (многослойного персептрона). Нейроны представлены кружками, связи между нейронами - линиями со стрелками.
 
Рисунок 1 - Многослойный персептрон
Обозначим входы n-го слоя нейронов  , весовые коэффициенты wij
. Нейроны этого слоя вычисляют соответствующие линейные комбинации ai
: , весовые коэффициенты wij
. Нейроны этого слоя вычисляют соответствующие линейные комбинации ai
:
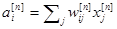 (1) (1)
и передают их на следующий слой, пропуская через нелинейную функцию активации:
 . (2) . (2)
Нелинейная функция f называется активационной и может иметь различный вид, как показано на рисунке 2. Одной из наиболее распространенных является нелинейная функция с насыщением, так называемая логистическая функция или сигмоид (т.е. функция S-образного вида):
 (3) (3)
При уменьшении a сигмоид становится более пологим, в пределе при a=0 вырождаясь в горизонтальную линию на уровне 0.5, при увеличении a сигмоид приближается по внешнему виду к функции единичного скачка с порогом T в точке x=0. Из выражения для сигмоида очевидно, что выходное значение нейрона лежит в диапазоне [0,1]. Одно из ценных свойств сигмоидной функции – простое выражение для ее производной.
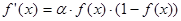

Рисунок 2 - а) функция единичного скачка; б) линейный порог (гистерезис); в) гиперболический тангенс; г) сигмоид
Следует отметить, что сигмоидная функция дифференцируема на всей оси абсцисс, что используется в некоторых алгоритмах обучения. Кроме того она обладает свойством усиливать слабые сигналы лучше, чем большие, и предотвращает насыщение от больших сигналов, так как они соответствуют областям аргументов, где сигмоид имеет пологий наклон.
Для построения алгоритма обучения необходимо знать производную ошибки по каждому из весов сети:
 . (4) . (4)
Таким образом, вклад в общую ошибку каждого веса вычисляется локально, простым умножением невязки нейрона  на значение соответствующего входа. (Из-за этого, в случае, когда веса изменяют по направлению скорейшего спуска на значение соответствующего входа. (Из-за этого, в случае, когда веса изменяют по направлению скорейшего спуска  , такое правило обучения называют дельта-правилом.) , такое правило обучения называют дельта-правилом.)
Входы каждого слоя вычисляются последовательно от первого слоя к последнему во время прямого распространения сигнала:
 , (5) , (5)
а невязки каждого слоя вычисляются во время обратного распространения ошибки от последнего слоя (где они определяются по выходам сети) к первому:
 . (6) . (6)
Области применения многослойных персептронов, с обучением по методу обратного распространения:
- распознавание образов;
- классификация;
- прогнозирование;
- экспертные системы.
Рассмотрим алгоритм сети обратного распространения ошибки подробнее.
Входной набор данных, на котором сеть должна быть обучена, подается на входной слой сети (рисунок3), и сеть функционирует в нормальном режиме (т.е. вычисляет выходные данные).
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
| прямое распространение сигнала
|
|
 |
Рисунок 3 - Прямое распространение сигнала
Полученные данные сравниваются с известными выходными данными для рассматриваемого входного набора. Разница между полученными и известными (опытными) данными - вектор ошибки.
Вектор ошибки используется для модифицирования весовых коэффициентов выходного слоя с тем, чтобы при повторной подаче (рисунок 4) того же набора входных данных вектор ошибки уменьшался.
Рисунок 4 - Модифицирование весовых коэффициентов выходного слоя (обратное распространение ошибки)
Затем таким же образом модифицируются весовые коэффициенты скрытого слоя, на этот раз сравниваются выходные сигналы нейронов скрытого слоя и входные сигналы нейронов выходного слоя (рисунок 5), целью данного сравнения является формирование вектора ошибки для скрытого слоя.

Рисунок 5 - Модифицирование весовых коэффициентов скрытого слоя (обратное распространение ошибки)
Если в сети существует входной слой (именно слой, а не ряд входных значений), то проводятся аналогичные действия и с ним.
Следует заметить, что ошибка может быть распространена на любой желаемый уровень (т.е. в нейронной сети может быть неограниченное количество скрытых слоев, для которых рассчитывается вектор ошибки по одной и той же схеме).
Сеть обучается путем предъявления каждого входного набора данных и последующего распространения ошибки. Этот цикл повторяется много раз. Например, для распознавания цифры от 0 до 9, сначала обрабатывается символ "0", символ "1" и так далее до "9", затем весь цикл повторяется много раз. Не следует поступать иначе, а именно, обучать сеть по отдельности сначала символу "0" (n-ое количество раз), потом "1", потом "2" и т.д., т.к. сеть вырабатывает очень "четкие" весовые коэффициенты для последнего входного набора (то есть для "9"), "забывая" предыдущие. Например, к тысячному повтору обучения символу "1" теряются весовые коэффициенты для распознавания символа "0". Повторяя весь цикл для всего набора входных данных, мы предполагаем, что каждый символ оказывает равноправное влияние на значения весовых коэффициентов.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Инициализировать пороговые значения и весовые коэффициенты небольшими случайными величинами (не более 0.4).
2.Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам.
3.Вычислить ошибки для выходного слоя. При этом используем следующую формулу для каждого i-ого значения выходного слоя:
Ei
= (ti
- ai
).ai
.(1 - ai
) (7)
Здесь Ei
- ошибка для i-ого узла выходного слоя,
ai
- активность данного узла,
ti
- требуемая активность для него же (т.е. требуемое выходное значение).
Используем значения ошибок выходного слоя для определения ошибок в скрытом слое. Формула практически та же, но теперь не определены желаемые выходные значения. Вычислить взвешенную сумму значений ошибок выходного слоя по формуле:
Ei
= ai
. (1 - ai
). Σj
Ej
.wij
(8)
Смысл переменных по сравнению с формулой (9) изменился незначительно. индекс i используется для нейронов скрытого слоя (а не выходного), Ei
, следовательно, значение ошибки для нейрона скрытого слоя, и ai
- сигнал на выходе нейрона. Индекс j относится к нейронам выходного слоя: wij - вес (весовой коэффициент) связи между i-ым скрытым нейроном и j-ым выходным нейроном, а Ej
- значение ошибки для выходного нейрона j. Суммирование проводится для всех весов связей между отдельно взятым i-ым нейроном и всеми нейронами выходного слоя.
Обратим внимание, что сумма включает в себя взвешенные связи только между рассматриваемым в данный момент нейроном скрытого слоя и всеми нейронами выходного слоя.
Полученные значения ошибок для выходного слоя будем использовать для изменения весовых коэффициентов между скрытым и выходным слоями. Вычислить все значения ошибок до модификации весовых коэффициентов, так как в формуле присутствуют и старые значения весов.
Применяем уравнение:
new wij
= old wij
+ ηδj
.xi
(9)
где wij
- вес связи между нейроном i скрытого слоя и нейроном j выходного;
δj
- приращение ошибки для выходного нейрона j;
xi
- сигнал на выходе скрытого нейрона i;
η - константа.
Константа используется для того, чтобы обучение не проводилось слишком быстро, то есть весовые коэффициенты не изменялись слишком сильно за один шаг обучения (что является причиной прыжков сходимости при обучении сети).
Пороговые уровни нейронов также инициализируются небольшими случайными числами и нуждаются в обучении. Пороговые уровни трактуются так же, как и весовые коэффициенты, за исключением того, что входные значения для них всегда равны -1 (знак минуса - т.к. уровни вычитаются во время функционирования сети):
new threshold = old threshold + ηδj
.(-1) (10)
или (в более удобном виде):
new threshold = old threshold - ηδj
(11)
1.3 Постановка задачи
Задачей данного курсового проекта является создание программы распознавания слов естественного языка с использованием нейросетей. Для ее выполнения была выбрана нейронная сеть обратного распространения ошибки, которая будет реализована на языке программирования C# в виде класса. Класс будет содержать конструктор, на который будут подаваться значения следующих параметров:
- обучающая выборка;
- тестовая выборка;
- количество нейронов скрытого слоя;
- коэффициент обучения;
- момент;
- количество эпох обучения.
Для перевода обучающих и тестовых слов в двоичный вид, а также сохранения слов-исключений в хеш-таблице будут предусмотрены отдельные классы.
Также будет создан класс, производящий разбиение текста на отдельные лексемы и их распознавание средствами нейросети и хеш-таблицы.
Соответственно, для решения поставленной задачи необходимо создание четырех классов:
- класс нейросети и средств ее обработки;
- класс перевода текста в двоичный вид;
- класс хеш-таблицы и методов работы с ней;
- класс разбиения текста на лексемы и распознавания.
Созданные классы будут оформлены в виде библиотечного компонента.
Для тестирования созданного класса будет создано Windows-приложение с использованием визуальных компонентов. Тестирующая программа должна осуществлять ввод текстовой информации из файла и с клавиатуры, а также ввод параметров нейросети: количество эпох обучения, количество нейронов скрытого слоя, момент и коэффициент обучения.
2. Проектирование библиотеки классов для реализации нейросети и тестовой программы
2.1 Программная реализация нейросети обратного распространения ошибки
Алгоритм был реализован в виде класса NeuroNetwork. UML диаграмма класса представленна на рисунке 6.
| Класс NeuroNetwork |
| Закрытые поля |
| string filename; |
| double[,] INP_PATTERNS; |
| double[,] OUT_PATTERNS; |
| int MAX_INP; |
| int MAX_HID; |
| int MAX_OUT; |
| int MAX_PAT; |
| double[] test_pat; |
| double[] desired; |
| neuron_type[] ipl; |
| neuron_type[] hl; |
| neuron_type[] ol; |
| double BETA; |
| double M; |
| int num_cycles; |
| Закрытые методы |
| private double sigmoid(double x) |
| private void run_input_layer() |
| private void run_hidden_layer() |
| private void run_output_layer() |
| private void run_the_network() |
| private void display_the_results(out string[] outp) |
| private void AddWeightsToFile() |
| private void blank_changes() |
| private void calculate_output_layer_errors() |
| private void calculate_hidden_layer_errors() |
| private void calculate_input_layer_errors() |
| private void weight_change() |
| private void back_propagate() |
| private void ExtractWeights() |
| Открытые методы |
| public void random_weights() |
| public void get_test_pattern(double[] tests) |
| public void train_the_network() |
| public string[] test_the_network(double[] test) |
| Public NeuroNetwork(double[,] INP_PATTERNS1, double[,] OUT_PATTERNS1, int Max_inp, int N_HID, int Max_pat, double beta, double m,int Epoch,string name,bool indicate) |
Рисунок 6 – UML-диаграмма класса NeuroNetwork
Параметры конструктора:
- обучающая выборка - INP_PATTERNS;
- желаемый выход - OUT_PATTERNS;
- момент - M;
- коэффициент обучения - BETA;
- количество нейронов скрытого слоя - N_HID;
- количество нейронов входного слоя - Max_inp;
- количество образцов, содержащихся в обучающей выборке - Max_par;
- количество эпох обучения - Epoch;
- имя файла с обучающей выборкой - name;
- логическая пременная indicate, сигнализирующая о необходимости обучения сети.
Ввод тестируемой выборки производится посредствам метода get_test_pattern(double[] tests).
Для описания нейрона была создана структура neuron_type, содержащая следующие поля:
- список весовых коэффициентов для связей между данным нейроном и всеми нейронами предыдущего слоя (или входными данными, если нейрон находится во входном слое). Каждый весовой коэффициент - действительное число (по 1 весовому коэффициенту на нейрон предыдущего слоя);
- пороговый уровень;
- значение ошибки, используется только на стадии обучения;
- изменение ошибки, также используется только во время обучения.
Описание нейрона привидено ниже:
struct neuron_type
{
public double[] w; //весовые коэффициенты
public double[] change;//модификация весовых коэффициентов используется в процессе обучения
public double threshold, a; //а-сигнал на выходе нейрона,threshold-значение порога
public double t_change; //модификация порога используется в процессе обучения
public double E; //значениеошибки
}
Выходной сигнал нейрона хранится в поле a (так называемая активность нейрона). Нейрон должен отреагировать на входной сигнал, поступающий по взвешенным связям, вычислив при этом выходной сигнал. Для трансформации входных сигналов в выходные необходима функция.
Ниже приведена декларация узлов с помощью закрытых переменных. Постоянные обозначают количество нейронов во входном, скрытом и выходном слое:
int MAX_INP; //Количество нейронов в входном слое
int MAX_HID; //Количество нейронов в скрытом слое
int MAX_OUT; //Количество нейронов в выходном слое
neuron_type[] ipl; //Входной слой
neuron_type[] hl; //Скрытый слой
neuron_type[] ol; //Выходной слой Функция активации (2) была реализована в открытом методе sigmoid. В данном метода используется формула (3). Код на С# для этого метода:private double sigmoid(double x)
{ return 1 / (1 + Math.Exp(-x)); }
Однако функция Exp приводит к ошибке в программе, если входное значение выходит из промежутка -39..38. К счастью, эти значения настолько далеко отстоят от начала координат, что мы можем считать: при аргументе < -39 значение функции равно 0, при аргументе > 38, - значение функции равно 1. Для предотвращения ошибки добавим несколько строчек:
private double sigmoid(double x)
{ if (Math.Abs(x) < 38) //проверка условия нахождения функции в интервале -39..38
{ return 1 / (1 + Math.Exp(-x)); }
else
{ if (x >= 38)
{ return 1; }
else { return 0; } } }
Биологические нейроны не срабатывают (не выдают выходной сигнал) до тех пор, пока уровень входного сигнала не достигнет некоторого порогового значения, т.е. на вход нейрона поступает сумма взвешенных сигналов минус некоторая величина. Полученное значение проходит через активационную функцию.
Каждая активность нейрона предыдущего слоя умножается на соответствующий весовой коэффициент, результаты умножения суммируются (1), вычитается пороговое значение, вычисляется значение сигмоидной функции (5). Вот пример на С#:
Вычисление суммы взвешенных сигналов для входного набора данных
private void run_input_layer()
{ double sum = 0;
for (int i = 0; i < MAX_INP; i++)
{ sum = 0;
for (int j = 0; j < MAX_INP; j++)
{ sum = sum + ipl[i].w[j] * test_pat[j];//(1) }
ipl[i].a = sigmoid(sum - ipl[i].threshold);//(5) } }
Вычисление суммы взвешенных сигналов для скрытого и выходного слоев (методы run_hidden_layer и run_output_layer) производится аналогично.
Каждый слой нейронов базируется на выходе предыдущего слоя (за исключением входного слоя, базирующегося непосредственно на предъявляемых сети входных данных (в коде - массив test_pat). Это значит, что значения входного слоя должны быть полностью рассчитаны до вычисления значений скрытого слоя, которые в свою очередь, должны быть рассчитаны до вычисления значений выходного слоя.
Выходы нейронной сети - значения активностей (поле a) нейронов выходного слоя. Программа, симулирующая работу нейронной сети, в процессе обучения будет сравнивать их со значениями, которые должны быть на выходе сети.
Полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Инициализировать пороговые значения и весовые коэффициенты небольшими случайными величинами (не более 0.4). Инициализация весовых коэффициентов случайными вещественными значениями с помощью класса Random производится в функции random_weights. 2. Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Метод run_the_networ.
3. Вычислить ошибки для выходного слоя (calculate_output_layer_errors). При этом используем формулу (7) для каждого i-ого значения выходного слоя. Ниже представлена соответствующая функция:
private void calculate_output_layer_errors()
{ for (int j = 0; j < MAX_OUT; j++)
{ ol[j].E = (desired[j] - ol[j].a) * ol[j].a * (1 - ol[j].a); } }
Вычислениеошибкидляскрытогоивходногослоевпроизводитсяметодами calculate_input_layer_errors и calculate_hidden_layer_errors поформуле (8). Кодсоответствеющейфункциидлявходногослояпредтсавленниже:
private void calculate_input_layer_errors()
{
double sum;
for (int i = 0; i < MAX_INP; i++)
{
sum = 0; // {Сумма ошибок скрытого слоя}
for (int j = 1; j < MAX_HID; j++)
{ sum = sum + hl[j].E * hl[j].w[i]; }
ipl[i].E = ipl[i].a * (1 - ipl[i].a) * sum;
}
}
Используя формулы (9), (10), (11) получим функцию, обучающую весовые коэффициенты и пороговые уровни:
private void weight_change()
{ //i обозначает нейрон скрытого слоя, j - выходного
for (int j = 0; j < MAX_OUT; j++) //выходнойслой
{ for (int i = 0; i < MAX_HID; i++) //Подстройка}
{ ol[j].change[i] = BETA * ol[j].E * hl[i].a + M * ol[j].change[i];
ol[j].w[i] = ol[j].w[i] + ol[j].change[i]; }
//Подстройказначенияпорога
ol[j].t_change = BETA * ol[j].E * 1 + M * ol[j].t_change;
ol[j].threshold = ol[j].threshold + ol[j].t_change; // }
//Модифицируем веса между входным слоем и скрытым слоем
…
//Модифицируем веса между входами и входным слоем
… } }
Далее объединим вышеуказанные функции в одном методе back_propogate().
В общем виде функция обучения сети будет выглядеть следующим образом:
public void train_the_network()
{ blank_changes();//Очисткапредыдущихзначений changes}
for (int loop = 0; loop < num_cycles; loop++)
{ for (int pat = 0; pat < MAX_PAT; pat++)
{ for (int i = 0; i < MAX_INP; i++) //Копированиевходногообраза}
{ test_pat[i] = INP_PATTERNS[pat, i]; } /вмассив 'test_pat'
for (int i = 0; i < MAX_OUT; i++) //Копированиевыходногообраза
{ desired[i] = OUT_PATTERNS[pat, i]; } //вмассив'desired'
run_the_network();//Определение выходов сети
back_propagate(); } }
AddWeightsToFile(); }
Для очистки предыдущих значений используется функция blank_changes.
Для упрощения временной сложности работы сети полученные весовые коэффициенты будем записывать в отдельные файлы (метод AddWeightsToFile()), имена которым даются программой автоматически Для считывания сохраненных параметров будет применяться метод ExtractWeights().
2.2 Класс перевода текста в двоичный вид
Данный класс предназначен для бинаризации исходных данных (слов), т.е. перевода слов с естественного языка в набор единиц и нулей. Данная процедура является необходимой, т.к. нейронная сеть обратного распространения ошибки работает только с двоичными данными. UML диаграмма класса Binarization представлена на рисунке 7.
| Класс Binarization |
| Закрытые поля |
| string[] sLetter; |
| int iLengthPattern; |
| Закрытые методы |
| private string DecToBin(string value) |
| Открытые методы |
| public double[] GetBinarizeWord(string sWord) |
| public double[,] GetBinarizeText(out double[,] OUT_PATTERNS, out int max_pat, out int iLengthPattern1) |
| public Binarization(string[] sLetter1) |
Рисунок 7 –UML-диаграмма класса Binarization
Параметром конструктора является массив строк для перевода в двоичный вид.
Алгоритм работы методов GetBinarizeWord и GetBinarizeText данного класса в общем состоит из следующих этапов:
- кодировка слова: суммирование произведений ASCII-кодов букв на i+4, где i – номер буквы в слове;
- перевод полученного десятичного числа в двоичный вид при помощи метода DecToBin;
- обработка полученных данных.
2.3 Класс хеш-таблицы и методов работы с ней
Некоторые слова невозможно четко классифицировать, т.к. они относятся либо к неизменяемым частям речи (наречия, деепричастия и.т.д), либо схожи по некоторым признакам со словами других частей речи. (существительное кровать оканчивается как глагол на ать). Слова определенных классов имеются в достаточно ограниченных количествах (союзы и.т.д) и создание для их распознавания нейросети является неоправданным. Для работы с такого рода словами и предназначен данный класс. UML диаграмма класса Hash представленна на рисунке 8.
| Класс Hash |
| Закрытые поля |
| Dictionary<int, string> predlog = new Dictionary<int, string>(); |
| Dictionary<int, string> narechie = new Dictionary<int, string>(); |
| Dictionary<int, string> deepr = new Dictionary<int, string>(); |
| Dictionary<int, string> soyuz = new Dictionary<int, string>(); |
| Dictionary<int, string> mest = new Dictionary<int, string>(); |
| Dictionary<int, string> iskl = new Dictionary<int, string>(); |
| string[] sConstant = { "predlog", "narechie", "deepr", "soyuz", "mest", "iskl" }; |
| Закрытые методы |
| private int HashFunction(string sInfo) |
| Открытые методы |
| public bool CheckHash(string sInfo, string sHash_name) |
| public void AddLetterInHashAndFile(string sLetter, string sClass,bool Flag) |
| public void AddToHash(string sInfo, string sHash_name) |
| public void ReadFileInHash(string sNamefile) |
| public void WriteWordInFile(string sInfo, string sNamefile) |
| public Hash() |
Рисунок 8 – UML диаграмма класса Hash
Полями данного класса являются хеш-таблицы – predlog (содержит предлоги), narechie (наречия), deepr (деепричастия), soyuz (союзы), mest (местоимения), iskl (существительные, глаголы, прилагательные сложные для распознавания).
Класс также содержит методы:
- HashFunction – значение хеш-функции для текущего слова;
- CheckHash – проверка наличия записи в хеш-таблице;
- AddLetterInHashAndFile – классификация и добавление нового слова в хеш-таблицу, а также запись в файл;
- AddToHash – добавление слова в хеш-таблицу;
- ReadFileInHash и WriteWordInHash – чтение слов из файла и запись слова в файл соответственно.
2.4 Класс разбиения текста на лексемы и распознавания
Данный класс является главным. Его задача – вычленение лексем из текста и их дальнейшее распознавание. В нем используются объекты всех вышеописанных классов. UML-диаграмма класса Analization представлена на рисунке 9.
| Класс Analization |
| Закрытые поля |
| List<Results> results = new List<Results>(); |
| bool flag_oy = false; |
| bool flag_om = false; |
| bool flag_im = false; |
| bool flag_em = false; |
| Bool flag_ie=false; |
| bool flag_mi=false; |
| Закрытые методы |
| private void AddEtalonLetter() |
| private string GetNeuroResult(string sLetter, string sFileName, int N_HID, double beta, double m, int Epoch, bool flag) |
| private string Scaning(string sLetter, int N_HID, double beta, double m, int Epoch, bool flag) |
| Открытые методы |
| public static void AddToFile(string sLetter, string sFile) |
| public string BigToSmall(string letter) |
| public Analization(string sText, int N_HID, double beta, double m, int Epoch, bool flag) |
| public List<Results> GetResult() |
Рисунок 9 – UML-диаграмма класса Analization
Параметрами конструктора являются:
- текст для анализа – sText;
- параметры нейросети N_HID, beta, m, Epoch;
- индикатор необходимости обучения нейросети – flag.
Из всех вышеперечисленных методов наиболее важными являются: конструктор, Scaning и GetNeuroResult.
Анализируемый текст сначала подается в конструктор. Там он разбивается на отдельные лексемы, тип которых либо определяется сразу (если это знак препинания или имя собственное), либо посредством метода Scaning. Кодданногометодапредставленниже:
private string Scaning(string sLetter, int N_HID, double beta, double m, int Epoch, bool flag)
{ Hash hash = new Hash();
string result = "существительное";//результат
string[] znaks = { "с", "п", "г" };
for (int i = 0; i < znaks.Length; i++)//поиск существительных, прилагательных и глаголов-исключений, сохраненных в хеш-таблице
{ if (hash.CheckHash(sLetter + znaks[i].ToString(), "iskl") == true)
{ switch (znaks[i])
{ case "с": result = "существительное";//если в конце слова буква с – возвращаем результат
return result;
case "п": result = "прилагательное";
return result;
case "г": result = "глагол";
return result; } } }
if (hash.CheckHash(sLetter, "predlog") == true)//проверяем, являетсялисловопредлогом (ищемвсоответствующейхеш-таблице
{ result = "предлог";//если слово есть в хеш-таблице – возвращаем результат
return result; }
//Для местоимений, союзов, деепричастий и наречий аналогично
…
if (String.Compare(sLetter, "не") == 0 || String.Compare(sLetter, "бы") == 0)
{ result = "частица";
return result; }
if (sLetter.Length < 2)
{ return "предлог"; }
//--------------------------------------------------------------------
string[] pril = {"ий","ый","ая","яя","го","ую","ое","их","ых","ым"};//массивокончанийприлагательных
string[] glagol = {"ит","ат","ят","ут","ют","ул","ял","ал","ли","ла","ег","ел","сь","ыл","ил"};//глаголов
string[] prich = {"вший","шими","вшая","вшем","вшие","ящий","ящая","ящие","щими","ющий","ющая","ющие","ущий","ущая","ущие","ащий","ащая","ащие","шего","щего"};//окончанийисуффиксовпричастий
string okonchanie= (sLetter[sLetter.Length - 2].ToString() + sLetter[sLetter.Length - 1].ToString());
if (Array.IndexOf(pril,okonchanie)!=-1)//если окончание слова содержится в массиве окончаний прилагательных переходим к проверке суффикса
{string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString() + okonchanie;
if (Array.IndexOf(prich,ok_i_suff)!= -1)//ищем в массиве суффиксов и окончаний причастий
{ return "причастие"; //если есть – результат причастие }
return "прилагательное"; //если нет - прилагательное }
else
…
if (String.Compare(okonchanie, "ом") == 0)//еслиокончание -ом
{ string res= GetNeuroResult(sLetter,"-ом",N_HID,beta,m,Epoch,flag_om);//распознаемсловонейросетью
flag_om = true;//при повторном поступлении слова на –ом нейросеть повторно обкчаться не будет
return res; }
else
//Аналогично для –ем, -им, -ой, -ие, -ми.
….}
Метод Scaning логически можно разделить на 3 блока:
- поиск слова в хеш-таблицах;
- идентификация слова по окончанию и определение его типа;
- идентификация слова по окончанию и проведение углубленного анализа с помощью нейронной сети.
Во втором блоке подразумевается определение типа слова по окончанию (последние две буквы) при помощи условных операторов:
- при помощи метода IndexOf класса Array определяется наличие в соответствующем массиве (массиве окончаний глаголов - glagol, прилагательных - pril) данного окончания;
- если это окончание прилагательного или -ся то критерий поиска изменяется до идентификации по паре суффикс-окончание: определяется наличие данной пары в массиве prich (причастие);
- после проведения вышеуказанных операций функция возвращает тип лексемы: глагол, прилагательное или причастие;
- в случае, если окончание не найдено ни в одном из массивов, то тип лексемы определяется как существительное;
- если слово оканчивается на -ие, -ми, -ем, -им, -ом то переходим к третьему блоку.
В третьем блоке в зависимости от окончания слова производится вызов функции private string GetNeuroResult(string sLetter, string sFileName, int N_HID, double beta, double m, int Epoch, bool flag) параметрами:
- sLetter – лексема,
- sFileName – имя файла с обучающей выборкой,
- N_HID – количество скрытых нейронов,
- beta – коэффициент обучения,
- m – момент,
- Epoch – количество эпох обучения,
- flag – логическая переменная, в значении «истина» означающая, что анализ будет производиться без обучения;
Код данной функции представлен ниже:
private string GetNeuroResult(string sLetter, string sFileName, int N_HID, double beta, double m, int Epoch, bool flag)
{ string[] techears = File.ReadAllLines(sFileName+".txt");
Binarization binar = new Binarization(techears);//проводимбинаризацию
double[,] inp = new double[1, 1], outp = new double[1, 1]; double[] test = new double[1]; //обучающаявыборка, выходы, тестоваявыборка
int max_inp, max_pat;//кол-во нейронов и выборок
inp = binar.GetBinarizeText(out outp, out max_pat, out max_inp);//получаем обучающую выборкув закодированном виде
test = binar.GetBinarizeWord(sLetter);//получаем тестовую выборку в закодированном виде
NeuroNetwork neuro = new NeuroNetwork(inp, outp, max_inp, N_HID, max_pat, beta, m, Epoch, sFileName, flag);//создаем объект нейросеть
if (flag == false)//если она не обучена
{ neuro.random_weights();//инициализируем весовые коэффициенты случайными числами
neuro.train_the_network(); //обучаемнейросеть}
string[] m_resultat = neuro.test_the_network(test);
string res1="",res2="";
switch (sFileName)
{ //в зависимости от имени файла с обучающей выборкой возможны определенные комбинации возвращаемых результатов
case "-ой":
res1 = "существительное";
res2 = "прилагательное";
break;
… }
//анализируем полученные значения нейросети и возвращаем результат
if (double.Parse(m_resultat[0]) < 0.5 && double.Parse(m_resultat[1]) < 0.5 && double.Parse(m_resultat[2]) < 0.5)
{ return res1; }
if (double.Parse(m_resultat[0]) < 0.5 && double.Parse(m_resultat[1]) < 0.5 && double.Parse(m_resultat[2]) > 0.5)
{ return res2; }
return "неизвестно"; }
Алгоритм данной функции можно разделить на следующие этапы:
- извлечение обучающей выборки из файла,
- ее бинаризация при помощи класса Binarization,
- если flag==false – обучение нейронной сети,
- получение результата,
- определение по полученному результату типа лексемы.
2.5 Описание тестирующей программы
Программа выполнена в виде Windows-приложения в среде Microsoft Visual Studio и имеет оконный интерфейс.
Принцип работы программы заключается в совеместном использовании для распознавания слов хеш-таблицы и нейросети. В зависимости от сложности, тип слова определяется либо с помощью сравнения окончания с использованием простых условных операторов, либо поиском слова в хеш-таблице, либо при помощи нейросети (для случая с одинаковыми окончаниями в разных частях речи).
Приложение состоит из трех окон:
- окно ввода текста для анализа (рисунок 13);
- окно анализа текста (рисунок 14);
- окно добавления лексемы в хеш-таблицу или в обучающую выборку (рисунок 15).
Текст для анализа загружается из файла или вводится с клавиатуры в richTextBox. Результат анализа (лексема и класс) выводится в dataGridView (рисунок 10)

Рисунок 10 – электронная таблица dataGridView
2.6 Результаты тестирования
Программа запускается из файла KursP.exe. В интерфейсе окна ввода текста (рисунок 11) присутствуют две кнопки: “Загрузить из файла” – загрузка текста для анализа, «Далее» - перейти к анализу. Текст для анализа можно вводить и вручную.

Рисунок 11 – Окно ввода текста
При нажатии кнопки «Далее» на экране появится окно анализа текста (рисунок 12). В окне анализа текста имеются кнопки «Анализ» и «Обучение». Первая используется для анализа текста без обучения нейросети, вторая – соответственно с обучение. Кнопка «Анализ» становится активной только при наличии файлов с весовыми коэффициентами для всех нейросетей. Результаты анализа выводятся в таблицу лексем.

Рисунок 12 – Окно анализа текста
При необходимости можно добавить слово в хеш-таблицу или в обучающую выборку при нажатии на кнопки “Добавить слово в хеш-таблицу” и «Добавить слово на –ой, -им, -ем». После нажатия данных кнопок перед пользователем появится окно добавления слова (рисунок 13). Далее пользователю необходимо ввести слово и класс и нажать кнопку «Добавить».

Рисунок 13 – Окно добавления лексемы в хеш-таблицу или в обучающую выборку
Для тестирования программы будем использовать отрывок из произведения Л.Н. Толстого «Война и мир»:
«В штабе Кутузова ожидали вестей от командующего австрийской армией Мака. В это время в штаб неожиданно прибыл незнакомый генерал, которого адъютанты не захотели пропустить к Кутузову. Главнокомандующий вышел в приемную и узнал в прибывшем генерала Мака, который подтвердил слухи о поражении австрийцев под Ульмом и о сдаче всей армии. Князь Андрей понимал, что русская армия оказалась в очень тяжелом положении, что ей предстоит трудное сражение с французами. С одной стороны, он был рад этому, так как представилась наконец возможность принять участие в бое, с другой стороны – опасался поражения русской армии, понимая, что в данной ситуации преимущество на стороне Бонапарта.»
При тестировании будем использовать нейросеть со следующими параметрами:
- эпох – 6000;
- нейронов в скрытом слое – 15;
- момент – 0,7
- коэффициент обучения – 0,7.
При анализе полученного результата была выявлена ошибка (рисунок 14).

Рисунок 14 – Окно программы с результатом анализа с ошибкой
Данной ошибки можно избежать, добавив слово «Французами» в файл с тестовой выборкой.
После внесения соответствующих изменений в нейросеть был получен следующий результат (рисунок 15):

Рисунок 15 – Окно программы с результатом анализа с без ошибки
3. Руководство п
рограммисту
Используемые в тестирующей программе классы содержатся в библиотеке классов NeuroLibrary. Соответствующий библиотечный файл NeuroLibrary.dll содержится в одной директории с исполняемым файлом программы (файл KursP.exe).
Рассмотрим процедуру создания библиотеки классов. Для этого необходимо создать в VisualStudio проект типа ClassLibrary (рисунок 16).

Рисунок 16 – Создание проекта «Библиотека классов» в VisualStudio
После создания всех необходимых классов в библиотеке, необхлодимо произвести компиляцию проекта. В случае отсутствия ошибок в коде в папке NeuroLibrary/Debug/bin будет создан библиотечный файл.
Далее подключаем библиотеку классов к тестирующей программе. Для этого необходимо в окне «Обозреватель решений» (правый верхний угол) выбрать пункт «Ссылки», вызвать контекстное меню и выбрать пункт «Добавить ссылку». В появившемся окне (рисунок 17) необходимо открыть вкладку «Обзор» и указать путь к библиотечному файлу и нажать ОК. Выбранный файл будет автоматически добавлен в папку с испольняемым файлом программы.

Рисунок 17 – Окно добавления ссылки
Далее необходимо подключить соответсвующее пространство имен NeuroLibrary с помощью директивы using и классы данной библиотеки станут доступны.
В тестирующей программе для получения результата достаточно создать объект класса Analization и вызвать свойство GetResult. Все необходимые действия будут произведены в конструкторе класса. GetResult необходим для получения результата в виде списка объектов типа string.
Для возможности влиять на работу анализатора понадобится использование класса Hash. С помощью методов данного класса можно добавить слово-исключение в хеш-таблицу. Содержимое хеш-таблиц хранится в папке с исполняемым файлом программы в текстовых файлах: narechie, predlog, soyuz, deepr, iskl, mest.
Для возможности добавления слова в обучающую выборку нейросети предусмотрен статический метод AddToFile класса Analization. Обучающие выборки нейросети хранятся в текстовых файлах: -ом, -ем, -им, -ми, -ие, -ой.
Как было сказано в подразделе 2.1, нейросеть производит запись весовых коэффициентов в текстовые файлы, хранящиеся в одном каталоге с исполняемым файлом программы. Их имена формируются по следующему принципу: имя файла с обучающей выборкой + наименование слоя сети (ip – входной, hl – скрытый, ol – выходной. Пример омip – весовые коэффициенты входного слоя сети для слов с окончанием ом.
Системные требования:
- Для корректной работы приложения необходимо наличие на компьютере программы Microsoft.NET Framework 2.0
- Операционныесистемы: Windows 2000 Service Pack 3; Windows 98; Windows 98 Second Edition; Windows ME; Windows Server 2003; Windows XP Service Pack 2
- Требуемое программное обеспечение: установщик Windows 3.0 (кроме ОС Windows 98/ME, для которых требуется Установщик Windows 2.0 или более поздней версии). Рекомендуется Установщик Windows 3.1 или более поздней версии. Обозреватель IE 5.01 или более поздней версии: Для установки.NET Framework требуется обозреватель Microsoft Internet Explorer 5.01 или более поздней версии.
Заключение
В данном курсовом проекте была разработана программа-анализатор слов естественного языка с использованием нейросети.
В ходе выполнения данного курсового проекта была разработана библиотека, содержащая классы для лексического анализа слов естественного языка с использованием нейросети (для решения поставленной задачи была выбрана нейросеть обратного распространения ошибки), была написана тестирующая программа, подготовлены тесты. При тестировании, после соответствующей настройки, программа не допустила ни одной ошибки.
Данный программный продукт может быть использован специалистами в области филолигии.
Список используемой литературы
5. Комарцова Л.Г., Максимов А.В.. Нейрокомпьютеры Учебное пособие для вузов. – М.: Изд-во МГТУ им. Н.Э.Баумана,2002.
6. Осовский С. Нейронные сети для обработки информации.-М.:Финансы и статистика, 2004.
7. Уоссермен Ф. Нейрокомпьютерная техника: теория и практика. — М.: Мир, 1992.
8. Ключко В.И., Ермоленко В.В. Нейрокомпьютерные системы. Базы знаний. Учеб. пособие Изд-во КубГТУ,1999.-100с.
Приложение А. Листинг
класса NeuroNetwork
class NeuroNetwork
{
struct neuron_type
{
public double[] w;//=new double[MAX_INP]; // {весовыекоэффициенты}
public double[] change;//=new double[MAX_INP];//{модификациявесовыхкоэффициентовиспользуетсявпроцессеобучения}
public double threshold, a; // {а-сигналнавыходенейрона,threshold-значениепорога}
public double t_change; // {модификация порога используется в процессе обучения}
public double E; // {значениеошибки}
}
double[,] INP_PATTERNS;
double[,] OUT_PATTERNS;
int MAX_INP; //{Количество нейронов в входном слое}
int MAX_HID; //{Количество нейронов в скрытом слое}
int MAX_OUT; // {Количество нейронов в выходном слое
int MAX_PAT; // {Количество образов для обучения}
double[] test_pat;
double[] desired;
neuron_type[] ipl; // {Входнойслой}
neuron_type[] hl; // {Скрытыйслой}
neuron_type[] ol; // {Выходнойслой }
double BETA = 0.8; // {Коэффициентобучения}
double M = 0.8; //{момент}
int num_cycles = 1000;
string filename;
public NeuroNetwork(double[,] INP_PATTERNS1/*выборка*/, double[,] OUT_PATTERNS1/*желаемыйвыход*/, int Max_inp/*кол-восимволоввслове*/, int N_HID, int Max_pat/*максмальноекол-вовыборок, double beta, double m, int Epoch, string name, bool indicate)
{
filename = name;
num_cycles = Epoch;
// elemKolvo = elemKol;
BETA = beta; M = m;
MAX_INP = Max_inp; //{Количество нейронов в входном слое}
MAX_HID = N_HID; //{Количество нейронов в скрытом слое}
MAX_OUT = 3; //int IPi;
MAX_PAT = Max_pat;
INP_PATTERNS = INP_PATTERNS1;
OUT_PATTERNS = OUT_PATTERNS1;
test_pat = new double[MAX_INP];
desired = new double[MAX_OUT];
ipl = new neuron_type[MAX_INP]; // {Входнойслой}
hl = new neuron_type[MAX_HID]; // {Скрытыйслой}
ol = new neuron_type[MAX_OUT];
if (indicate == true)
{
try { ExtractWeights(); }
catch { }
}
}
private double sigmoid(double x) // {функцияактивации}
{
if (Math.Abs(x) < 38) // {проверка условия нахождения функции в интервале -39..38}
{ return 1 / (1 + Math.Exp(-x)); }
else
{
if (x >= 38)
{ return 1; }
else { return 0; }
}
}
//{Вычисление суммы взвешенных сигналов для входного набора данных}
private void run_input_layer()
{
double sum = 0;
for (int i = 0; i < MAX_INP; i++)
{
sum = 0;
for (int j = 0; j < MAX_INP; j++)
{ sum = sum + ipl[i].w[j] * test_pat[j]; }
ipl[i].a = sigmoid(sum - ipl[i].threshold);
}
}
//{Вычисление суммы взвешенных сигналов для скрытого слоя}
private void run_hidden_layer()
{
double sum;
for (int i = 0; i < MAX_HID; i++)
{
sum = 0;
for (int j = 0; j < MAX_INP; j++)
{ sum = sum + hl[i].w[j] * ipl[j].a; }
hl[i].a = sigmoid(sum - hl[i].threshold);
}
}
//{Вычисление суммы взвешенных сигналов для выходного слоя}
private void run_output_layer()
{
double sum;
for (int i = 0; i < MAX_OUT; i++)
{
sum = 0;
for (int j = 0; j < MAX_HID; j++)
{ sum = sum + ol[i].w[j] * hl[j].a; }
ol[i].a = sigmoid(sum - ol[i].threshold);
}
}
private void run_the_network()
{
run_input_layer();
run_hidden_layer();
run_output_layer();
}
//{Процедура выводит на экран результаты теста}
private void display_the_results(out string[] outp)
{
outp = new string[ol.Length];
for (int i = 0; i < MAX_OUT; i++)
{ outp[i] = ol[i].a.ToString() + " "; }
}
// {Процедуры для тестирования сети до и после обучения}
public void get_test_pattern(double[] tests)
{
test_pat = tests;
}
public string[] test_the_network(double[] test)
{
test_pat = test;
Console.WriteLine();
Console.WriteLine("Процедура тестирования сети");
Console.WriteLine();
string[] str;
run_the_network();
display_the_results(out str);
return str;
}
// {Процедуры обучения сети}
private void calculate_output_layer_errors()
{
for (int j = 0; j < MAX_OUT; j++)
{ ol[j].E = (desired[j] - ol[j].a) * ol[j].a * (1 - ol[j].a); }
}
private void calculate_hidden_layer_errors()
{
double sum;
for (int i = 0; i < MAX_HID; i++)
{
sum = 0; // {Сумма ошибок выходного слоя}
for (int j = 0; j < MAX_OUT; j++)
{ sum = sum + ol[j].E * ol[j].w[i]; }
hl[i].E = hl[i].a * (1 - hl[i].a) * sum;
}
}
private void calculate_input_layer_errors()
{
double sum;
for (int i = 0; i < MAX_INP; i++)
{
sum = 0; // {Сумма ошибок скрытого слоя}
for (int j = 1; j < MAX_HID; j++)
{ sum = sum + hl[j].E * hl[j].w[i]; }
ipl[i].E = ipl[i].a * (1 - ipl[i].a) * sum;
}
}
private void weight_change()
{
for (int j = 0; j < MAX_OUT; j++) //{выходнойслой}
{
for (int i = 0; i < MAX_HID; i++) //{Подстройка}
{
ol[j].change[i] = BETA * ol[j].E * hl[i].a + M * ol[j].change[i];
ol[j].w[i] = ol[j].w[i] + ol[j].change[i];
}
// {Подстройказначенияпорога}
ol[j].t_change = BETA * ol[j].E * 1 + M * ol[j].t_change;
//--------------------
ol[j].threshold = ol[j].threshold + ol[j].t_change;
//----------------------------
}
// {Модифицируем веса между входным слоем и скрытым слоем}
// {i -нейрон входного слоя, j -скрытого}
for (int j = 0; j < MAX_HID; j++)
{
for (int i = 0; i < MAX_INP; i++)
{
hl[j].change[i] = BETA * hl[j].E * ipl[i].a + M * hl[j].change[i];
hl[j].w[i] = hl[j].w[i] + hl[j].change[i];
}
hl[j].t_change = BETA * hl[j].E * 1 + M * hl[j].t_change;
//-------------------------------------
hl[j].threshold = hl[j].threshold + hl[j].t_change;
}
// {Модифицируем веса между входами и входным слоем }
// {i -входной образ, j - нейроны входного слоя}
for (int j = 0; j < MAX_INP; j++)
{
for (int i = 0; i < MAX_INP; i++)
{
ipl[j].change[i] = BETA * ipl[j].E * test_pat[i] + M * ipl[j].change[i];
ipl[j].w[i] = ipl[j].w[i] + ipl[j].change[i];
}
ipl[j].t_change = BETA * ipl[j].E * 1 + M * ipl[j].t_change;
ipl[j].threshold = ipl[j].threshold + ipl[j].t_change;
}
}
//{Выполнениеалгоритма back propagation }
private void back_propagate()
{
calculate_output_layer_errors();
calculate_hidden_layer_errors();
calculate_input_layer_errors();
weight_change();
}
//{Инициализация весовых коэффициентов и порогов}
public void random_weights()
{
Random rnd = new Random();
for (int i = 0; i < MAX_INP; i++)
{
ipl[i].w = new double[MAX_INP]; // {весовыекоэффициенты}
ipl[i].change = new double[MAX_INP];
}
for (int i = 0; i < MAX_HID; i++)
{
hl[i].w = new double[MAX_INP]; // {весовыекоэффициенты}
hl[i].change = new double[MAX_INP];
}
for (int i = 0; i < MAX_OUT; i++)
{
ol[i].w = new double[MAX_HID]; // {весовыекоэффициенты}
ol[i].change = new double[MAX_HID];
}
for (int i = 0; i < MAX_INP; i++)
{
for (int j = 0; j < MAX_INP; j++)
{ ipl[i].w[j] = (double)rnd.Next(1000) / 1000; }
ipl[i].threshold = (double)rnd.Next(1000) / 1000;
}
for (int i = 0; i < MAX_HID; i++)
{
for (int j = 0; j < MAX_INP; j++)
{ hl[i].w[j] = (double)rnd.Next(1000) / 1000; }
hl[i].threshold = (double)rnd.Next(1000) / 1000;
}
for (int i = 0; i < MAX_OUT; i++)
{
for (int j = 0; j < MAX_HID; j++)
{ ol[i].w[j] = (double)rnd.Next(1000) / 1000; }
ol[i].threshold = (double)rnd.Next(1000) / 1000;
}
}
private void ExtractWeights()
{
for (int i = 0; i < MAX_INP; i++)
{
ipl[i].w = new double[MAX_INP]; // {весовыекоэффициенты}
ipl[i].change = new double[MAX_INP];
}
for (int i = 0; i < MAX_HID; i++)
{
hl[i].w = new double[MAX_INP]; // {весовыекоэффициенты}
hl[i].change = new double[MAX_INP];
}
for (int i = 0; i < MAX_OUT; i++)
{
ol[i].w = new double[MAX_HID]; // {весовыекоэффициенты}
ol[i].change = new double[MAX_HID];
}
if (File.Exists(filename + "ip.txt") == true && File.Exists(filename + "ol.txt") == true && File.Exists(filename + "hl.txt") == true)
{
StreamReader streamreader = new StreamReader(filename + "ip.txt");
for (int i = 0; i < ipl.Length; i++)
{
ipl[i].a = double.Parse(streamreader.ReadLine());
ipl[i].threshold = double.Parse(streamreader.ReadLine());
for (int j = 0; j < ipl[i].w.Length; j++)
{
ipl[i].w[j] = double.Parse(streamreader.ReadLine());
}
}
streamreader.Close();
streamreader = new StreamReader(filename + "ol.txt");
for (int i = 0; i < ol.Length; i++)
{
ol[i].a = double.Parse(streamreader.ReadLine());
ol[i].threshold = double.Parse(streamreader.ReadLine());
for (int j = 0; j < ol[i].w.Length; j++)
{
ol[i].w[j] = double.Parse(streamreader.ReadLine());
}
}
streamreader.Close();
streamreader = new StreamReader(filename + "hl.txt");
for (int i = 0; i < hl.Length; i++)
{
hl[i].a = double.Parse(streamreader.ReadLine());
hl[i].threshold = double.Parse(streamreader.ReadLine());
for (int j = 0; j < hl[i].w.Length; j++)
{
hl[i].w[j] = double.Parse(streamreader.ReadLine());
}
}
streamreader.Close();
}
else
{
File.Create(filename + "ip.txt");
File.Create(filename + "ol.txt");
File.Create(filename + "hl.txt");
}
}
//-------------------------------------------------------------
private void AddWeightsToFile()
{
StreamWriter streamwriter = new StreamWriter(filename + "ip.txt");
for (int i = 0; i < ipl.Length; i++)
{
streamwriter.WriteLine(ipl[i].a.ToString());
streamwriter.WriteLine(ipl[i].threshold.ToString());
for (int j = 0; j < ipl[i].w.Length; j++)
{
streamwriter.WriteLine(ipl[i].w[j].ToString());
streamwriter.Flush();
}
streamwriter.Flush();
}
streamwriter.Close();
streamwriter = new StreamWriter(filename + "hl.txt");
for (int i = 0; i < hl.Length; i++)
{
streamwriter.WriteLine(hl[i].a.ToString());
streamwriter.WriteLine(hl[i].threshold.ToString());
for (int j = 0; j < hl[i].w.Length; j++)
{
streamwriter.WriteLine(hl[i].w[j].ToString());
streamwriter.Flush();
}
streamwriter.Flush();
}
streamwriter.Close();
streamwriter = new StreamWriter(filename + "ol.txt");
for (int i = 0; i < ol.Length; i++)
{
streamwriter.WriteLine(ol[i].a.ToString());
streamwriter.WriteLine(ol[i].threshold.ToString());
for (int j = 0; j < ol[i].w.Length; j++)
{
streamwriter.WriteLine(ol[i].w[j].ToString());
streamwriter.Flush();
}
streamwriter.Flush();
}
streamwriter.Close();
}
private void blank_changes()
{
for (int j = 0; j < MAX_INP; j++)
{
for (int i = 0; i < MAX_INP; i++)
{ ipl[j].change[i] = 0; }
ipl[j].t_change = 0;
}
for (int j = 0; j < MAX_HID; j++)
{
for (int i = 0; i < MAX_INP; i++)
{ hl[j].change[i] = 0; }
hl[j].t_change = 0;
}
for (int j = 0; j < MAX_OUT; j++)
{
for (int i = 0; i < MAX_HID; i++)
{ ol[j].change[i] = 0; }
ol[j].t_change = 0;
}
}
public void train_the_network()
{
blank_changes(); // {Очисткапредыдущихзначений changes}
for (int loop = 0; loop < num_cycles; loop++)
{
for (int pat = 0; pat < MAX_PAT; pat++)
{
for (int i = 0; i < MAX_INP; i++) //{Копированиевходногообраза}
{ test_pat[i] = INP_PATTERNS[pat, i]; } //{вмассив 'test_pat' }
for (int i = 0; i < MAX_OUT; i++) //{Копированиевыходногообраза}
{ desired[i] = OUT_PATTERNS[pat, i]; } //{ вмассив'desired' }
run_the_network(); //{Определение выходов сети}
back_propagate();
}
}
AddWeightsToFile();
}
}
Приложение Б. Листинг класса Analization
public class Analization
{
List<Results> results = new List<Results>();
public static void AddToFile(string sLetter, string sFile)
{
FileStream filestream = File.Open(sFile + ".txt", FileMode.Append, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
streamwriter.WriteLine(sLetter);
streamwriter.Close();
filestream.Close();
}
private void AddEtalonLetter()
{
string[] im = { "смотрим@", "носим@", "ходим@", "бродим@", "катим@", "синим#", "большим#", "тугим#", "крайним#" };
if (File.Exists("-им.txt") == false)
{
FileStream filestream = File.Open("-им.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < im.Length; i++)
{
streamwriter.WriteLine(im[i]);
}
streamwriter.Close();
filestream.Close();
}
string[] om = { "столом@", "стулом@", "ковром@", "городом@", "селом@", "красном#", "туманном#", "тяжелом#", "легком#" };
if (File.Exists("-ом.txt") == false)
{
FileStream filestream = File.Open("-ом.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < om.Length; i++)
{
streamwriter.WriteLine(om[i]);
}
streamwriter.Close();
filestream.Close();
}
string[] oy = { "ручкой@", "краской@", "бумагой@", "оградой@", "каймой@", "большой#", "небольшой#", "тугой#", "малой#" };
if (File.Exists("-ой.txt") == false)
{
FileStream filestream = File.Open("-ой.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < oy.Length; i++)
{
streamwriter.WriteLine(oy[i]);
}
streamwriter.Close();
filestream.Close();
}
string[] em = { "кидаем@", "бросаем@", "стережем@", "бережем@", "блюдем@", "гребнем#", "камнем#", "ставнем#", "гравием#" };
if (File.Exists("-ем.txt") == false)
{
FileStream filestream = File.Open("-ем.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < em.Length; i++)
{
streamwriter.WriteLine(em[i]);
}
streamwriter.Close();
filestream.Close();
}
string[] ie = { "большие@", "синие@", "маленькие@", "хорошие@", "плохие@", "хождение#", "мероприятие#", "становление#", "украшение#" };
if (File.Exists("-ие.txt") == false)
{
FileStream filestream = File.Open("-ие.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < ie.Length; i++)
{
streamwriter.WriteLine(ie[i]);
}
streamwriter.Close();
filestream.Close();
}
string[] mi = { "красными@", "зелеными@", "хорошими@", "плохими@", "трудными@", "стульями#", "столами#", "ставнями#", "карандашами#" };
if (File.Exists("-ми.txt") == false)
{
FileStream filestream = File.Open("-ми.txt", FileMode.CreateNew, FileAccess.Write);
StreamWriter streamwriter = new StreamWriter(filestream);
for (int i = 0; i < mi.Length; i++)
{
streamwriter.WriteLine(mi[i]);
}
streamwriter.Close();
filestream.Close();
}
}
public string BigToSmall(string letter)
{
switch (letter)
{
case "А": return "а";
case "Б": return "б";
case "В": return "в";
case "Г": return "г";
case "Д": return "д";
case "Е": return "е";
case "Ё": return "ё";
case "Ж": return "ж";
case "З": return "з";
case "И": return "и";
case "Й": return "й";
case "К": return "к";
case "Л": return "л";
case "М": return "м";
case "Н": return "н";
case "О": return "о";
case "П": return "п";
case "Р": return "р";
case "С": return "с";
case "Т": return "т";
case "У": return "у";
case "Ф": return "ф";
case "Х": return "х";
case "Ц": return "ц";
case "Ч": return "ч";
case "Ш": return "ш";
case "Щ": return "щ";
case "Ъ": return "ъ";
case "Ы": return "ы";
case "Ь": return "ь";
case "Э": return "э";
case "Ю": return "ю";
case "Я": return "я";
}
return "ё";
}
public Analization(string sText, int N_HID, double beta, double m, int Epoch, bool flag)
{
AddEtalonLetter();
Results res;
string sLetter = "";
for (int i = 0; i < sText.Length; i++)
{
if (sText[i] == ' ' || sText[i] == '.' || sText[i] == ',' || sText[i] == '!' || sText[i] == '?' || sText[i] == '-' || sText[i] == ':' || sText[i] == ';')
{
if (sLetter == "")
{
goto k;
}
if ((Char.ConvertToUtf32(sLetter, 0) >= 1040 && Char.ConvertToUtf32(sLetter, 0) <= 1071))
{
if (i - sLetter.Length + 1 == 1)
{
string ch = BigToSmall(sLetter[0].ToString());
sLetter = ch + sLetter.Substring(1, sLetter.Length - 1);
goto m;
}
else
if (sText[i - sLetter.Length - 1] == ' ' && sText[i - sLetter.Length - 2] == '.')
{
string ch = BigToSmall(sLetter[0].ToString());
sLetter = ch + sLetter.Substring(1, sLetter.Length - 1);
goto m;
}
res.Class = "существительное";
res.letter = sLetter;
results.Add(res);
sLetter = "";
goto k;
}
m:
res.letter = sLetter;
res.Class = Scaning(sLetter, N_HID, beta, m, Epoch, flag);
results.Add(res);
if (sText[i] == '.')
{
res.Class = "точка";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == ',')
{
res.Class = "запятая";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == '!')
{
res.Class = "восклицательныйзнак";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == '?')
{
res.Class = "вопросительныйзнак";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == '-')
{
res.Class = "тире";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == ':')
{
res.Class = "двоеточие";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
if (sText[i] == ';')
{
res.Class = "точка с запятой";
res.letter = sText[i].ToString();
results.Add(res);
goto k;
}
k: sLetter = "";
}
else
{
sLetter = sLetter + sText[i].ToString();
}
}
}
public List<Results> GetResult()
{
return results;
}
bool flag_oy = false, flag_om = false, flag_im = false, flag_em = false, flag_ie = false, flag_mi = false;
private string GetNeuroResult(string sLetter, string sFileName, int N_HID, double beta, double m, int Epoch, bool flag)
{
string[] techears = File.ReadAllLines(sFileName + ".txt");
Binarization binar = new Binarization(techears);//проводимбинаризацию
double[,] inp = new double[1, 1], outp = new double[1, 1]; double[] test = new double[1]; //обучающаявыборка, выходы, тестоваявыборка
int max_inp, max_pat;//кол-во нейронов и выборок
inp = binar.GetBinarizeText(out outp, out max_pat, out max_inp);
test = binar.GetBinarizeWord(sLetter);
NeuroNetwork neuro = new NeuroNetwork(inp, outp, max_inp, N_HID, max_pat, beta, m, Epoch, sFileName, flag);//нейросеть
if (flag == false)
{
neuro.random_weights();
neuro.train_the_network();
}
string[] m_resultat = neuro.test_the_network(test);
string res1 = "", res2 = "";
switch (sFileName)
{
case "-ой":
res1 = "существительное";
res2 = "прилагательное";
break;
case "-им":
res1 = "глагол";
res2 = "прилагательное";
break;
case "-ем":
res1 = "глагол";
res2 = "существительное";
break;
case "-ом":
res1 = "существительное";
res2 = "прилагательное";
break;
case "-ие":
res1 = "прилагательное";
res2 = "существительное";
break;
case "-ми":
res1 = "прилагательное";
res2 = "существительное";
break;
}
if (double.Parse(m_resultat[0]) < 0.5 && double.Parse(m_resultat[1]) < 0.5 && double.Parse(m_resultat[2]) < 0.5)
{
return res1;
}
if (double.Parse(m_resultat[0]) < 0.5 && double.Parse(m_resultat[1]) < 0.5 && double.Parse(m_resultat[2]) > 0.5)
{
return res2;
}
return "неизвестно";
}
private string Scaning(string sLetter, int N_HID, double beta, double m, int Epoch, bool flag)
{
Hash hash = new Hash();
string result = "существительное";//результат
string[] znaks = { "с", "п", "г" };
for (int i = 0; i < znaks.Length; i++)
{
if (hash.CheckHash(sLetter + znaks[i].ToString(), "iskl") == true)
{
switch (znaks[i])
{
case "с": result = "существительное";
return result;
case "п": result = "прилагательное";
return result;
case "г": result = "глагол";
return result;
}
}
}
if (hash.CheckHash(sLetter, "predlog") == true)
{
result = "предлог";
return result;
}
if (hash.CheckHash(sLetter, "mest") == true)
{
result = "местоимение";
return result;
}
if (hash.CheckHash(sLetter, "narechie") == true)
{
result = "наречие";
return result;
}
if (hash.CheckHash(sLetter, "deepr") == true)
{
result = "деепричастие";
return result;
}
if (hash.CheckHash(sLetter, "soyuz") == true)
{
result = "союз";
return result;
}
if (String.Compare(sLetter, "не") == 0 || String.Compare(sLetter, "бы") == 0)
{
result = "частица";
return result;
}
if (sLetter.Length < 2)
{ return "предлог"; }
//--------------------------------------------------------------------
string[] pril = { "ий", "ый", "ая", "яя", "го", "ую", "ое", "их", "ых", "ым" };
string[] glagol = { "ит", "ат", "ят", "ут", "ют", "ул", "ял", "ал", "ли", "ла", "ег", "ел", "сь", "ыл", "ил" };
string[] prich = { "вший", "шими", "вшая", "вшем", "вшие", "ящий", "ящая", "ящие", "щими", "ющий", "ющая", "ющие", "ущий", "ущая", "ущие", "ащий", "ащая", "ащие", "шего", "щего" };
string okonchanie = (sLetter[sLetter.Length - 2].ToString() + sLetter[sLetter.Length - 1].ToString());
if (Array.IndexOf(pril, okonchanie)!= -1)
{
string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString() + okonchanie;
if (Array.IndexOf(prich, ok_i_suff)!= -1)
{
return "причастие";
}
return "прилагательное";
}
else
if (Array.IndexOf(glagol, okonchanie)!= -1)
{
return "глагол";
}
else
if (Array.IndexOf(glagol, okonchanie)!= -1)
{
return "глагол";
}
else
if (String.Compare(okonchanie, "ся") == 0)
{
string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString();
if (Array.IndexOf(pril, ok_i_suff)!= -1)
{
return "причастие";
}
else
{
return "глагол";
}
}
else
if (String.Compare(okonchanie, "ть") == 0)
{
char ok_i_suff = sLetter[sLetter.Length - 3];
if (ok_i_suff == 'а' || ok_i_suff == 'я' || ok_i_suff == 'ю' || ok_i_suff == 'у' || ok_i_suff == 'е' || ok_i_suff == 'и')
{
return "глагол";
}
else
{
return "существительное";
}
}
else
if (String.Compare(okonchanie, "ом") == 0)
{
string res = GetNeuroResult(sLetter, "-ом", N_HID, beta, m, Epoch, flag_om);
flag_om = true;
return res;
}
else
if (String.Compare(okonchanie, "ем") == 0)
{
string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString() + okonchanie;
if (Array.IndexOf(prich, ok_i_suff)!= -1)
{
return "причастие";
}
string res = GetNeuroResult(sLetter, "-ем", N_HID, beta, m, Epoch, flag_em);
flag_em = true;
return res;
}
else
if (String.Compare(okonchanie, "им") == 0)
{
string res = GetNeuroResult(sLetter, "-им", N_HID, beta, m, Epoch, flag_im);
flag_im = true;
return res;
}
else
if (String.Compare(okonchanie, "ой") == 0)
{
string res = GetNeuroResult(sLetter, "-ой", N_HID, beta, m, Epoch, flag_oy);
flag_oy = true;
return res;
}
else
if (String.Compare(okonchanie, "ие") == 0)
{
string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString() + okonchanie;
if (Array.IndexOf(prich, ok_i_suff)!= -1)
{
return "причастие";
}
string res = GetNeuroResult(sLetter, "-ие", N_HID, beta, m, Epoch, flag_ie);
flag_ie = true;
return res;
}
else
if (String.Compare(okonchanie, "ми") == 0)
{
string ok_i_suff = sLetter[sLetter.Length - 4].ToString() + sLetter[sLetter.Length - 3].ToString() + okonchanie;
if (Array.IndexOf(prich, ok_i_suff)!= -1)
{
return "причастие";
}
string res = GetNeuroResult(sLetter, "-ми", N_HID, beta, m, Epoch, flag_mi);
flag_mi = true;
return res;
}
else
{
return "существительное";
}
}
}
ПриложениеВ. Листингкласса Binaryzation
class Binarization
{
string[] sLetter;
int iLengthPattern;
public Binarization(string[] sLetter1)
{
sLetter = sLetter1;
}
private string DecToBin(string value)
{
value.Trim(); // очищаем строку от пробелов
char[] array = null; /* массив для хранения двоичных чисел ввиде символов */
int degree = Convert.ToInt32(value) / 255; /* получаем степень возведения для отображения количества 0 в массиве */
if (degree <= 255 && Convert.ToInt32(value) <= 255) /* если степень входит в стандартный диапазон 8 цифр */
array = new char[8];
else /* иначе вычисляем наш диапазон цифр */
{
if (degree == 1) /* если оставить 1, то получится первое условие, а нам надо чтобы выполнилось второе */
degree++;
array = new char[8 * degree];
}
int position = array.Length - 1; /* двоичные цифры считаются с конца в начало, соответственно писать мы их будем, тоже с конца в начало */
int nextValue = Convert.ToInt32(value); /* здесь будет хранится наше значение, которое мы будем делить на 2 и проверять есть ли остаток от деления */
for (int i = 0; i < array.Length; i++) /* в этом цикле мы будем заполнять наш массив значениями */
{
if ((Convert.ToInt32(nextValue) % 2)!= 0) /* проверяем есть ли остаток от деления */
{
nextValue /= 2; /* в любом случае записываем результат, для дальнейших расчетов */
array[position] = '1'; /* устанавливаем 1 если остаток есть */
}
else
{
nextValue /= 2; /* в любом случае записываем результат, для дальнейших расчетов */
array[position] = '0'; /* устанавливаем 0 если остатка нет */
}
position--; /* уменьшаем итератор */
}
string ret = ""; // пустая строка для хранения результата
for (int i = 0; i < array.Length; i++) /* в этом цикле уже записываем в нашу строку, наше двоичное число, с начала и до конца */
ret += array[i].ToString();
return ret;
}
public double[] GetBinarizeWord(string sWord)
{
int iSum = 0; string sBuf = ""; int k = 0;
for (int j = 0; j < sWord.Length; j++)
{
iSum = iSum + (j + 5) * Char.ConvertToUtf32(sWord[j].ToString(), 0);
}
sBuf = DecToBin(iSum.ToString());
k = 0;
while (sBuf[k]!= '1')
{
k++;
}
sBuf = sBuf.Substring(k, sBuf.Length - 1 - k);
double[] test = new double[iLengthPattern];
for (int j = 0; j < iLengthPattern; j++)
{
if (sBuf.Length <= j)
{
test[j] = 0;
}
else
if (sBuf[j] == '1')
{
test[j] = 1;
}
}
return test;
}
public double[,] GetBinarizeText(out double[,] OUT_PATTERNS, out int max_pat, out int iLengthPattern1)
{
max_pat = sLetter.Length;
OUT_PATTERNS = new double[sLetter.Length, 3];
int iSum = 0; string sBuf; int k = 0; iLengthPattern1 = 0; string[] sBigBuf = new string[sLetter.Length];
for (int i = 0; i < sLetter.Length; i++)
{
iSum = 0;
for (int j = 0; j < sLetter[i].Length - 1; j++)
{
iSum = iSum + (j + 5) * Char.ConvertToUtf32(sLetter[i][j].ToString(), 0);
}
switch (sLetter[i][sLetter[i].Length - 1])
{
case '@': OUT_PATTERNS[i, 0] = 0; OUT_PATTERNS[i, 1] = 0;
OUT_PATTERNS[i, 2] = 0;
break;
case '#': OUT_PATTERNS[i, 0] = 0; OUT_PATTERNS[i, 1] = 0;
OUT_PATTERNS[i, 2] = 1;
break;
case '*': OUT_PATTERNS[i, 0] = 0; OUT_PATTERNS[i, 1] = 1;
OUT_PATTERNS[i, 2] = 0;
break;
case '(': OUT_PATTERNS[i, 0] = 0; OUT_PATTERNS[i, 1] = 1;
OUT_PATTERNS[i, 2] = 1;
break;
case '-': OUT_PATTERNS[i, 0] = 1; OUT_PATTERNS[i, 1] = 0;
OUT_PATTERNS[i, 2] = 0;
break;
case '/': OUT_PATTERNS[i, 0] = 1; OUT_PATTERNS[i, 1] = 0;
OUT_PATTERNS[i, 2] = 1;
break;
case '+': OUT_PATTERNS[i, 0] = 1; OUT_PATTERNS[i, 1] = 1;
OUT_PATTERNS[i, 2] = 0;
break;
}
sBuf = DecToBin(iSum.ToString());
k = 0;
while (sBuf[k]!= '1')
{
k++;
}
sBuf = sBuf.Substring(k, sBuf.Length - 1 - k);
if (sBuf.Length > iLengthPattern1)
{
iLengthPattern1 = sBuf.Length;
}
sBigBuf[i] = sBuf;
}
double[,] inp = new double[sLetter.Length, iLengthPattern1];
for (int i = 0; i < sLetter.Length; i++)
{
for (int j = 0; j < iLengthPattern1; j++)
{
if (sBigBuf[i].Length <= j)
{
inp[i, j] = 0;
}
else
if (sBigBuf[i][j] == '1')
{
inp[i, j] = 1;
}
}
}
iLengthPattern = iLengthPattern1;
return inp;
}
}
|