Введение
Информатика
– это техническая наука, систематизирующая приемы создания хранения, воспроизведения, обработки и передачи данных средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.
Основной задачей
информатики является систематизация приемов и методов работы с аппаратными и программными средствами вычислительной техники. Цель
систематизации состоит в выделении, внедрении и развитии передовых, наиболее эффективных технологий, в автоматизации этапов работы с данными, а также в методическом обеспечении новых технологических исследований.
Кардинальным отличием информатики от других технических дисциплин является тот факт, что ее предметная область изменяется чрезвычайно динамично.
Единство законов обработки информации в системах различной природы является фундаментальной основой теории информационных процессов, определяющей ее общезначимость и специфичность. Объектом изучения этой теории является информация.
Информатика рассматривает информацию как связанные между собой сведения, данные, понятия, изменяющие наши представления о явлении или объекте окружающего мира. Наряду с информацией в информатике часто употребляется понятие данные.
Данные могут рассматриваться как признаки или записанные наблюдения, которые по каким-то причинам не используются, а только хранятся. В том случае, если появляется возможность использовать эти данные для уменьшения неопределенности о чем-либо, данные превращаются в информацию. Поэтому можно утверждать, что информацией являются используемые данные.
Суть всех компьютерных программ состоит в том, что они описывают преобразование некоторых начальных данных в конечные. Какие-то данные программа может использовать как промежуточные. Прежде чем выполнить какие-либо операции, надо иметь объекты, к которым данные будут применяться, и четко представлять себе структуру объектов, которые будут получены.
Развитие вычислительной техники и программирования сопровождалось эволюцией представлений о роли данных и их организации. Одним из свойств компьютеров является способность хранить огромные объемы информации и данных, обеспечивать легкий доступ к ним. Решая конкретную задачу, необходимо выбрать множество данных, представляющих реальную ситуацию. Затем надлежит выбрать способ представления этой информации. Представление данных определяется исходя из средств и возможностей, допускаемых компьютером и его программным обеспечением.
Однако очень важную роль играют и свойства самих данных, операции, которые должны выполняться над ними. С развитием вычислительной техники и программирования, средства и возможности представления данных получили большое развитие и теперь позволяют использовать как простейшие неструктурированные данные, так и данные более сложных типов, полученные с помощью комбинации простейших данных.
В заключение следует отметить, что такие параметры информации, как содержательность, достаточность, устойчивость, доступность, актуальность, достоверность непосредственно влияют на качественную и количественную структуру компьютерных данных, а также на их дальнейшую обработку и конечные преобразования.
1. Данные, их структура и типы
Данныенесут в себе информациюо событиях, произошедших в материальном мире, так как они являются регистрацией сигналов, возникших в результате этих событий. Однако данные не тождественны информации.
Данные
– диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и характера химических связей, изменение состояния электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов.
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены,то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая
и табличная.
a) Линейные структуры
– это списки. Список –это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы.
Таким образом, линейные структуры данных (списки) – это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
б) Табличные структуры
– это такие структуры, у которых элементы данных определяются адресом ячейки. Он состоит не из одного параметра, как в списках, а из нескольких.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между элементами, принадлежащими одной строке, и другой разделитель для отделения строк.
Таким образом, табличные структуры данных (матрицы)– это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Рисунок 1. Пример представления табличной структуры данных
в) Иерархические структуры данных –
это структуры, которые содержат в себенерегулярные данные, которые трудно представить в виде списка или таблицы. В иерархической структуре адрес каждого элемента определяется путем доступа, ведущим от вершины структуры к данному элементу. Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения.

Рисунок 2. Пример представления иерархической структуры данных
В современной информационной системе выделяются два основных типа данных, это простые (неструктурированные)
и более сложные – структурированные
.
a) Простые (неструктурированные) типы данных
В математике принято классифицировать величины в соответствии с их характеристиками. Различают целые, вещественные, комплексные и логические величины, представляющие собой отдельные значения, множества значений или множества множеств. Аналогично и в информатике.
Целые числа, используемые компьютером, имеют те же свойства, что и целые числа в арифметике. Все вычисления с ними выполняются абсолютно точно (не приближенно). Имеется только одно отличие в свойствах компьютерных целых чисел – ограниченность диапазона: для каждой компьютерной системы имеется самое большое допустимое в ней целое число и самое малое, отрицательное. Это свойство компьютерных чисел связано с особенностями их кодирования в ячейках памяти компьютера.
Над действительными (или вещественными) числами могут быть выполнены операции сложения, вычитания, умножения и деления, так же, как и над математическими действительными числами. Однако все операции над действительными числами выполняются с точностью, не превосходящей некоторого фиксированного значения, вследствие того, что представления чисел в памяти компьютера имеют ограниченную длину, зависящую от конкретного компьютера и используемой системы программирования.
Главным свойством литерных (символьных) данных является их упорядоченность, то есть свойство быть сравнимыми. Обычным признаком значения символьной или текстовой величины являются кавычки. Каждый символ имеет определенный числовой код (например, код символа латинской буквы 'А' в большинстве кодировок 63) и упорядочение происходит в соответствии с этими числовыми кодами. Как правило, имеются функции, позволяющие получить по символу его код и символ по коду.
К логическим данным, способным принимать значения «истина» или «ложь». Иногда можно использовать операции импликации («если»), эквиваленции («если и только если») и тому подобное.
б) Структурированные типы данных
Значительно большие возможности заключают в себе структурированные данные, по сравнению с простыми.
Структурированные типы данных классифицируют по следующим основным признакам: однородная – неоднородная, упорядоченная – неупорядоченная, прямой доступ – последовательный доступ, статическая – динамическая. Эти признаки противостоят друг другу лишь внутри пары, а вне этого могут сочетаться.
Структуру называют упорядоченной,
если между ее элементами определен порядок следования. Наличие индекса в записи элементов структуры уже указывает на ее упорядоченность.
По способу доступа упорядоченные структуры бывают прямого и последовательного доступа.
При прямом доступе каждый элемент структуры доступен пользователю в любой момент независимо от других элементов.
Если у структуры размер (длина, количество элементов) не может быть изменен по ходу действия, а фиксирован заранее, то такую структуру называют статической.
Программные средства информатики иногда позволяют не фиксировать размер структуры, а устанавливать его по ходу решения задачи и менять при необходимости, что бывает очень удобно. Такую структуру называютдинамической.
Самым традиционным и широко известным из структурированных типов данных является массив
(иначе называемый регулярным типом) – однородная упорядоченная статическая структура прямого доступа.
Массивом называют однородный набор величин одного и того же типа, называемых компонентами массива, объединенных одним общим именем и идентифицируемых вычисляемым индексом. Компонентами массива могут быть не только простейшие данные, но и структурные, в том числе массивы.
Обобщением массива является комбинированный тип данных – запись
, являющаяся неоднородной упорядоченной статической структурой прямого доступа. Запись есть набор именованных компонент – полей (часто разного типа), объединенных одним общим именем и идентифицируемых (адресуемых) с помощью как имени записи, так и имен полей.
Очередь
есть линейно упорядоченный набор следующих друг за другом компонент, доступ к которым происходит по следующим правилам:
1) новые компоненты могут добавляться лишь в хвост очереди;
2) значения компонент могут читаться (извлекаться) лишь в порядке следования компонент от головы к хвосту очереди.
Размер очереди заранее не оговаривается и теоретически может считаться бесконечным. Для запоминания (хранения) компонент очереди часто используют внешне запоминающие устройства большой емкости – магнитные диски и ленты. Отсюда другое название очереди – файл.
2. Проводимые операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных и всевозможных методов. Компьютерная обработка данных включает в себя множество различных операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие основные:
• сбор данных –
накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация данных –
приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация данных –
отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка данных
– упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
• архивация данных –
организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита данных –
комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка данных –
прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером,
а потребителя – клиентом;
• преобразование данных –
перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя: например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку.
Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. Например, для транспортировки цифровых потоков данных по каналам телефонных сетей необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства – телефонные модемы.
3. Кодирование данных
Система кодирования применяется для замены названия объекта на условное обозначение (код) в целях обеспечения удобной и более эффективной обработки информации.
Система кодирования
– совокупность правил кодового обозначения объектов.
Кодирование и хранение данных в компьютере должно обеспечивать не только надежное декодирование, но и защиту инфоpмации от разного pода сбоев, помех, вирусов, несанкционированного доступа и тому подобному.
Помехоустойчивое кодирование связано обычно с введением в кодовые комбинации двоичных символов избыточной инфоpмации, необходимой для обнаружения сбоев.

 Рисунок 3. Процесс передачи сообщения от источника к приёмнику Рисунок 3. Процесс передачи сообщения от источника к приёмнику
Помехоустойчивое кодирование связано обычно с введением в кодовые комбинации двоичных символов избыточной инфоpмации, необходимой для обнаружения сбоев.
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления – для этого обычно используется прием кодирования,
то есть выражение данных одного типа через данные другого типа.
Кодирование данных двоичным кодом
В вычислительной технике существует своя система кодирования – она называется двоичным кодированиемоснована на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами или сокращенно бит.
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и тому подобное). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия.
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе.
Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто – достаточно взять целое число и делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанная справа налево вместе с последним остатком, и образует двоичный аналог десятичного числа.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65535, а 24 бита – уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму.
Первая часть числа называется мантиссой, а вторая – характеристикой. Большую часть из 80 бит отводят для хранения мантиссы и некоторое фиксированное количество разрядов отводят для хранения характеристики.
Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число, то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы.
Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной.Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов – этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Кодирование графических данных
Любое черно-белое графическое изображение, напечатанное в газете или книге, состоит из мельчайших точек, образующих характерный узор, называемый растром.

Рисунок 4. Пример чёрно-белого рисунка с видимым растром
Растр
– это метод кодирования графической информации, издавна принятый в полиграфии.
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции
произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный, зеленый и синий. На практике считается (хотя теоретически это не совсем так), что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов.
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается.
Кодирование звуковой информации
Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Первый метод основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природезвуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП).
Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи
. При таких преобразованиях неизбежны потери информации, связанные с методом кодирования.
Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
4. Измерение информации и единицы хранения данных
Существует много различных систем и единиц измерения данных. Каждая научная дисциплина и каждая область человеческой деятельности может, использовав свои, наиболее удобные или традиционно устоявшиеся единицы. В информатике для измерения данных используют тот факт, что разные типы данных имеют двоичное представление и потому вводят свои единицы данных, основанные на нем.
Наименьшей единицей измерения является байт. Поскольку одним байтом, правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объему в символах.
Более крупная единица измерения – килобайт (Кбайт). Условно можно считать, что 1 Кбайт примерно равен 1000 байт. Условность связана с тем, что для вычислите ной техники, работающей с двоичными числами, более удобно представление чисел в виде степени двойки и потому на самом деле 1 Кбайт равен 210
байт (1024 байт). Однако всюду, где это не принципиально не включают 24 байта. В килобайтах измеряют сравнительно небольшие объемы данных. Условно можно считать, что одна страница неформатированного машинописного текста составляет около 2 Кбайт.
Более крупные единицы измерения данных образуются добавлением префиксов мега -, гига -, тера –
в более крупных единицах пока нет практической надобности.
1 байт = 8 (23
) бит
1 Кбайт =1024 байт =210
байт
1 Мбайт = 1024 Кбайт = 220
байт
1 Гбайт = 1024 Мбайт = 230
байт
1 Тбайт = 1024 Гбайт = 240
байт
При переходе к более крупным единицам «инженерная» погрешность, связанная с округлением, накапливается и становится недопустимой, поэтому на старших единицах измерения округление производится реже.
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ. Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, а при этом образуется высокая нагрузка в виде адресных данных. Без них нельзя получить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные тоже имеют размер и тоже подлежат хранению, хранить данные в виде мелких единиц, таких как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и тому подобному), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения. В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл
– это последовательность произвольного числа байтов, обладающая уникальным собственным именем.
Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла.
Поскольку в определении файла нет ограничений на размер, можно представить себе файл, имеющий 0 байтов (пустой файл),и файл, имеющий любое число байтов. Имя файла фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией из-за отсутствия метода доступа к ним. Кроме функций, связанных с адресацией, имя файла может хранить и сведения о типе данных, заключенных в нем. Для автоматических средств работы с данными это важно, поскольку по имени файла они могут автоматически определить адекватный метод извлечения информации из файла.
Практическая часть
Вариант 16
В течение текущего дня в салоне сотовой связи проданы мобильные телефоны, код, модель и цена которых указаны в таблице на рис. 16.1. В таблице на рис. 16.2 указан код и количество проданных телефонов различных моделей.
1. В итоговой таблице (рис. 16.3) обеспечит автоматическое заполнение данными столбцов «Модель мобильного телефона», «Цена, руб.», «Продано, шт.», используя исходные данные таблиц на рис. 16.1 и 16.2, а также функции ЕСЛИ(), ПРОСМОТР. Рассчитать сумму, полученную от продаж каждой моделей, итоговую сумму продаж.
2. Сформировать ведомость продаж мобильных телефонов на текущую дату.
3. Представить графически данные о продаже мобильных телефонов за текущий день.
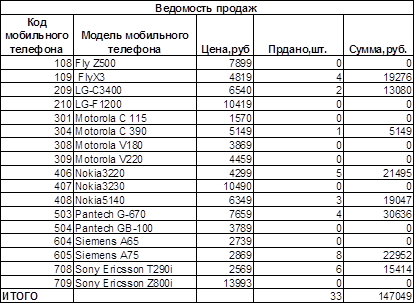
Рис. 16.3. Табличные данные ведомости продаж

Диаграмма 1. Данные о продаже мобильных телефонов за текущий день
Заключение
В современном мире компьютер считают универсальным преобразователем информации. Тексты на естественных языках и числа, математические и специальные символы – одним словом все, что в быту или в профессиональной деятельности может быть необходимо человеку, должно иметь возможность быть введенным в компьютер.
В силу безусловного приоритета двоичной системы счисления при внутреннем представлении информации в компьютере кодирование «внешних» символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования следует пользоваться двоичными группами равной длины.
Проанализировав информационные структуры и технологии, можно сделать вывод о том, что данные
– это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
• данные как результат измерений и наблюдений;
• данные на материальных носителях информации (таблицы, протоколы, справочники);
• модели (структуры) данных в виде диаграмм, графиков, функций;
• данные в компьютере на языке описания данных;
• базы данных на машинных носителях.
Для хранения данных используются базы данных, для них характерны большой объем и относительно небольшая удельная стоимость информации.
Процесс кодирования любого вида информации фактически представляет собой его преобразование тем или иным способом в числовую форму.
В памяти машины не существует принципиального различия между закодированной информацией различных типов. Над всеми видами данных, включая дополнительно и саму программу, процессор способен производить арифметические, логические и прочие операции, которые содержатся в системе его команд.
Список литературы
1. «Информатика» под ред. Профессора Н.В. Макаровой. Москва, «Финансы и статистика», 2001 г.
2. «Информатик» Базовый курс под ред. С.В. Симоновича. «Питер», 2004 г.
3. Касаткин В.Н. Информация, алгоритмы, ЭВМ. М.: Просвещение, 1991, 192 с.
4. Математический энциклопедический словарь. / Гл. ред. Ю.В. Прохоров. М.: Сов. энциклопедия, 1988, 847 с.
5. Компьютерные технологии обработки информации. / Под. ред. С.В. Назарова. – М.: Финансы и статистика, 1995.
6. Леонтьев В.П. Новейшая энциклопедия персонального компьютера 2003. – М.: Олма-пресс, 2003.
7. Миньков С.Л. Информатика: учебное пособие. – Томск, 2000.
8. Фигурнов В.Э. IBMPC для пользователей. 7-е изд., прераб. И доп. – М.: ИНФА – М, 2002.
9. Пекелис В. Кибернетика от А до Я.М., 1990.
10. Дмитриев В. Прикладная теория информации. М., 1989.
|