МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ, МЕХАНИКИ И ОПТИКИ
Гуманитарный факультет
Кафедра прикладной экономики и маркетинга
Лабораторная работа
Обработка статистической информации с использованием SPSS
Для выявления спроса на услуги столовой в студенческом общежитии
Студент:
Группа: 4070
Преподаватель:
Санкт-Петербург
2011
Цель работы: На основании знаний теоретического материала по дисциплинам «Маркетинг», «Статистика» и других смежных дисциплин провести самостоятельную обработку маркетингового исследования.
Исходные данные: анкетные данные на тему «Столовые в общежитиях студгородка ЛТА»
Описание последовательности выполнения работы:
В ходе работы был проведен анализ данных с помощью методов статистики:
· Анализ частоты распределения, модальной частоты выборки
· Определение медианы
· Расчет дисперсии
· Выделение тенденции
· Построение таблицы сопряженности
· Выделение корреляционной зависимости и построение корреляционной диаграммы
· Регрессионный анализ
· Содержательный анализ
· Построение диаграмм
1. Ввод данных

Рисунок 1. Окно редактора данных
На рисунке 1 мы видим окно редактора данных, в данное окно вручную вводятся анкетные данные. Данные представлены в программе в качестве переменных:
· Необходимость – вопрос нужна ли столовая в общежитии № 2 студгородка ЛТА;
· Частота – вопрос о частоте посещения столовой в неделю;
· Время – время посещения столовой;
· Цена – сумма денег, которую опрашиваемый респондент готов потратить в этой столовой за один раз;
· Доп_ислед – какие дополнительные услуги готова предоставить столовая;
· Посещение – будет ли опрашиваемый респондент посещать столовую, если она действительно откроется;
· Возраст – возраст опрашиваемого респондента.
Каждая переменная обладает следующими реквизитами:
>
Name
(Имя);
>
Туре
(Тип);
>
Width
(Разрядность);
>
Decimals
(Количество знаков после запятой);
> Label
(Метка);
>
Values
(Значение);
>
Missing
(Утерянные (пропущенные) данные);
>
Columns
(Количество столбцов);
>
Align
(Выравнивание- слева, справа, по центру);
>
Measure
(Мера- шкала, столбцовая или круговая диаграмма).
После того, как характеристики переменных определены, вводятся анкетные данные:

Рисунок 2. Окно ручного ввода данных
Анкетные данные содержали следующие показатели:
1. Частота посещения столовой и время дня. Эти показатели позволяют определить возможное количество посещений одного студента столовой за определенный период. Показатель важен для оценки прогнозируемого объема продаж.
2. Сумма денежных средств, которую студент готов оплатить за услуги столовой при одном посещении.
3. Дополнительные услуги. Позволяет выявить, что студентам было бы еще интересно видеть в столовой.
4. Показатель посещаемости при открытии позволяет определить действительный спрос на услугу.
2. Работа с файлами
2.1 Агрегация данных
Агрегация данных позволяет объединять группы наблюдений в обобщенные наблюдения и создавать новый файл данных. Наблюдения агрегируются на основе значений одной или нескольких агрегирующих переменных: в данном случае по значениям переменных «время» и «цена». Таким образом, мы можем видеть, в какое время ходило больше всех посетителей, и какая для каждого более удобная цена.

Рисунок 3. Агрегация данных по значениям переменных «время» и «цена»
2.2 Описательная статистика. Отображение частот.
 Рисунок 4. Отображение частот Рисунок 4. Отображение частот
Из данной таблицы можно сделать следующие выводы:
- В среднем респонденты готовы тратить на услугу 3,2 долларов
- Диапазон цен находится от 2 до 5 долларов (за одно посещение столовой)
- Медиана выборки равна 3 долларов (серединное значение)
- Среднее значение равно 3
Далее, представлено количественное отображение данных по частотам и гистограмма частот (рис. 5, 6).

Рисунок 5. Количественное отображение данных по частотам
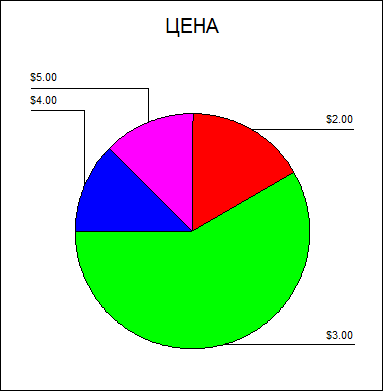
Рисунок 6.Гистограмма частот
2.3 Описательные статистические параметры

Рисунок 7
Процедура Description (описательные) отображает итоговую статистику для переменных в одной таблице и вычисляет стандартизированные значения Z- множества (1):

Где, Xi – текущее значение переменной, Xo – среднее (Mean); S- среднеквадратическое отклонение (Std.Deviation).
Из данной таблицы (рис. 7) видно, что средний возраст опрашиваемых -19 лет.
2.4 Описательная статистика исследования

Рисунок 8
Из представленной таблицы (рис. 8) видно, что средняя сумма равна 3,2 долларов, минимальная сумма равна 2 долларов, максимальная – 5 рубля. Разница между минимальной и максимальной ценой – 3 долларов.
Далее представлены гистограммы различных показателей цен, указанных респондентами (рис. 9, 10).

Рисунок 9
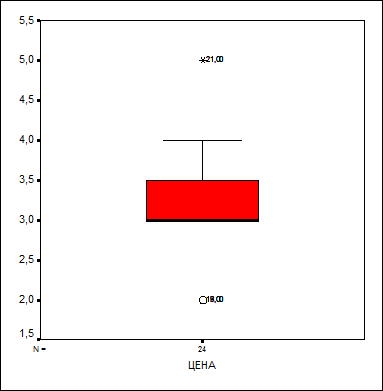
Рисунок 10
На представленных гистограммах отображена зависимость суммы от возраста. Отклонения небольшие, но они существуют в размере 0,88. Средняя сумма равна 3,2.
2.5 Таблицы сопряженности

Рисунок 10
В данной таблице анализ, проведен по трем параметрам: частота, время и посещения. Поэтому эту таблицу можно назвать трехмерной. Данная таблица показывает число людей, обладающих сочетанием данных свойств.
2.6 Корреляционная зависимость
Корреляция – это понятие, характеризующее взаимную зависимость двух случайных величин.
Взаимосвязь между двумя факторами, выраженная в явном виде, может быть названа регрессионной. Регрессионная функция чаще всего упоминается как линия регрессии. Линия регрессии представляет собой математическое ожидание взаимосвязи, а отклонение от нее – случайные величины, как правило, с незначительной дисперсией и нулевым математическим ожиданием.

Рисунок 11
На данной диаграмме (рис. 11) представлена корреляция в виде облака рассеяния точек, образующих две выборки.
Чтобы определить тесноту связи между переменными необходимо определить коэффициент корреляции.

Рисунок 12. Таблица корреляции по критерию Пирсона

Рисунок 13. Таблица корреляции по критериям Кендалла и Сипермена
В таблицах представлены матрицы взаимных парных коэффициентов корреляции, которая охватывает все возможные парные сочетания показателей возраст и сумма.
Можно отметить среднюю степень корреляции по всем трем критериям, она положительна, т.е. с ростом одного показателя возрастет и другой.
При двустороннем распределением корреляция считается значимой при уровне вероятности, составляющем 0,01. В нашем случае данный уровень по Пирсону равен 0,001, по Кендалу – 0,002, по Сипермену 0,001. Т.е. нулевая гипотеза, предполагающая, что корреляция является случайной, должна быть принята, и следовательно, корреляция случайна и незначима.
2.7 Парная линейная регрессия

Рисунок 17
Значение Т-статистики для коэффициентов и двусторонний уровень значимости Т-критерия = 0,000 и 0,616.
Стандартные ошибки = 0,925; 0,278.
Ненормированный коэффициент при зависимых переменных = 1,021.
Константа = 16,058.
2.8 Нелинейная регрессия
Подгонка кривых предназначена, в первую очередь, для вычисления парной нелинейной регрессии.

Рисунок 18
 Рисунок 19 Рисунок 19
Были исследованы следующие модели: логарифмическая, квадратичная, кубическая, гиперболическая – для того, чтобы определить, какая из них обеспечивает наилучшее приближение к облаку рассеивания.
Сравнение кривых показывает, что наилучшее приближение к множеству исходных точек дает кубическая модель.
Вывод
Используя исходные данные опросной анкеты, с помощью программы SPSS, было выявлено мнение целевой аудитории о необходимости открытия столовой в общежитии №2 студгородка ЛТА.
Следуя методическим указаниям и выполнив работу, мы получили следующее:
- Частоты распределения для переменной «цена» составили:
2 доллара – 4
3 доллара – 14
5 долларов - 3
- Средняя сумма равна 3,2
- Среднее значение равно 3
- Медиана выборки равна 3
- Дисперсия:
· Стандартное отклонение 0,88
· Вариация 2,144
· Диапазон изменений 0,087
· Минимум - 2 долларов
· Максимум – 5 доллара
· Стандартные ошибки = 0,918.
В результате исследований мы выяснили, что наиболее подходящая цена 3 доллара для одного посещения столовой. При этом диапазон цен располагает от 2 до 5 долларов.
В результате исследований было определено, как часто смогли бы студенты ходить в столовую. Наиболее предпочтительным оказалось раз в день утром.
Был проведен анализ статистической зависимости между переменными возраст и цена. Анализ показал, что зависимости слабая.
|