Итоговый контроль. Контрольное задание
При выполнении контрольного задания Вы должны сделать вторичную перегруппировку для несложного примера (пример выбрать самостоятельно) и объяснить, как и при выполнении каких условий справедлив такой перерасчет. При использовании компьютерных программ и более сложного примера указать также эффект и особенности применения ИТ.
В письменном ответе на задание Вы должны:
- Объяснить связь между формулой сложения дисперсий и корреляционным отношением, разъяснить его статистический смысл.
- Выполнить сравнение вариации для двух различных распределений с различными средними, объяснить условия сопоставимости при различии средних.
- Дать наиболее полное объяснение смысла предельной ошибки, связать с понятием репрезентативности выборки и ее необходимым объемом.
- Объяснить соотношение оценивания неизвестных параметров по МНК и проверку значимости полученных результатов по критериям проверки статистических гипотез.
Если группировка первичного статистического материала не удовлетворяет целям исследования либо с точки зрения числа групп, либо в отношении сопоставимости данных, прибегают ко вторичной группировке. Различают два способа образования новых групп:
1. Изменение интервалов первичной группировки.
2. Выделение определенной доли единиц совокупности
Также вторичная группировка используется для приведения к сопоставимому виду группировок с различными интервалами с целью их сравнения.
Как пример:
| Группы магазинов по размеру товарооборота за IV квартал, тыс.руб.
|
Число магазинов
|
Товарооборот за IV квартал, тыс.руб.
|
| До 10 |
15 |
93 |
| 10 — 15 |
8 |
112 |
| 15 — 20 |
13 |
200 |
| 20 — 30 |
3 |
68 |
| 30 — 50 |
9 |
378 |
| 50 — 60 |
7 |
385 |
| 60 — 70 |
3 |
180 |
| 70 — 100 |
8 |
600 |
| 100 — 200 |
22 |
2400 |
| Свыше 200 |
12 |
3744 |
| Итого
|
100 |
8160 |
Приведенная группировка недостаточно наглядна, потому что не показывает четкой и строгой закономерности в изменении товарооборота по группам.
Уплотним ряды распределения, образовав шесть групп. Новые группы образованы путем суммирования первоначальных групп.
| Группы магазинов по размеру товарооборота за IV квартал, тыс.руб.
|
Число магазинов
|
Товарооборот за IV квартал, тыс.руб.
|
Товарооборот в среднем на 1 магазин, тыс.руб.
|
| До 10 |
15 |
93 |
6,2 |
| 10 — 20 |
21 |
312 |
14,8 |
| 20 — 50 |
12 |
446 |
37,1 |
| 50 — 100 |
18 |
1165 |
64,8 |
| 100 — 200 |
22 |
2400 |
109,0 |
| Свыше 200 |
12 |
3744 |
312,0 |
| Итого
|
100 |
8160 |
81,6 |
Совершенно четко видно, чем крупнее магазины, тем выше уровень товарооборота.
Еще пример: Имеются следующие данные о распределении колхозов по числу дворов
№
п/п
|
Группы колхозов по числу дворов
|
Удельный вес колхозов группы в процентах к итогу
|
Группы колхозов по числу дворов
|
Удельный вес колхозов группы в % к итогу
|
| 1 |
До 100 |
4,3 |
до 50 |
1,0 |
| 2 |
100 — 200 |
18,4 |
50 - 70 |
1,0 |
| 3 |
200 — 300 |
19,5 |
70 - 100 |
2,0 |
| 4 |
300 — 500 |
28,1 |
100 - 150 |
10,0 |
| 5 |
Свыше 500 |
29,7 |
150 - 250 |
18 |
| 250 - 400 |
21 |
| 400 - 500 |
23 |
| свыше 500 |
24 |
| Итого
|
100 |
Итого
|
100 |
Эти данные не позволяют провести сравнение распределения колхозов в 2-х районах по числу дворов, так как в этих районах имеется различное число групп колхозов. Необходимо ряды распределения привести к сопоставимому виду.
За основу сравнения необходимо взять распределение колхозов 1 района. Следовательно, по второму району надо произвести вторичную группировку, чтобы образовать такое же число групп и с теми же интервалами, как и в первом районе. Получим следующие данные.
| Группы колхозов по числу дворов
|
Удельный вес колхозов группы в % к итогу
|
Расчеты
|
| I район
|
II район
|
| до 100 |
4,3 |
4,0 |
1+1+2=4 |
| 100 - 200 |
18,4 |
19,0 |
10+9=19 |
| 200 - 300 |
19,5 |
16,0 |
9+7=16 |
| 300 - 500 |
28,1 |
37,0 |
21-7=14, 14+23=37 |
| свыше 500 |
29,7 |
24,0 |
24 |
| Итого
|
100,0 |
100,0 |
Для определения числа колхозов, которые надо взять из пятой группы во вновь образованную, условно примем, что это число колхозов должно быть пропорционально удельному весу отобранных дворов в группе.
Определяем удельный вес 50 дворов в пятой группе.
(50 * 18) / (250 - 150) = 9
Определяем удельный вес 50 дворов в шестой группе.
(50 * 21) / (400 - 250) = 7 и т.д.
1.
Объяснить связь между формулой сложения дисперсий и корреляционным отношением, разъяснить его статистический смысл.
В статистическом исследовании очень часто бывает необходимо не только изучить вариации признака по всей совокупности, но и проследить количественные изменения признака по однородным группам совокупности, а также и между группами.
Следовательно, помимо общей средней для всей совокупности необходимо просчитывать и частные средние величины по отдельным группам.
Различают три вида
дисперсий:
· общая;
· средняя внутригрупповая;
· межгрупповая.
Общая дисперсия :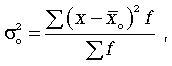
где – 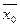 общая средняя арифметическая всей исследуемой совокупности. общая средняя арифметическая всей исследуемой совокупности.
Средняя внутригрупповая дисперсия :
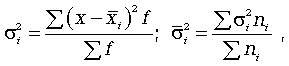
где ni
- число единиц в группе
Межгрупповая дисперсия: 
где -  средняя величина по отдельной группе. средняя величина по отдельной группе.
Все три вида дисперсии связаны между собой: общая дисперсия равна сумме средней внутригрупповой дисперсии и межгрупповой дисперсии:
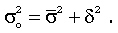
Данное соотношение отражает закон, который называют
правилом сложения дисперсий. Согласно этому закону (правилу), общая дисперсия, которая возникает под влиянием всех факторов, равна сумме дисперсий, которые появляются как под влиянием признака-фактора, положенного в основу группировки, так и под влиянием других факторов. Благодаря правилу сложения дисперсий можно определить, какая часть общей дисперсии находится под влиянием признака-фактора, положенного в основу группировки.
Важнейшей целью статистики является изучение объективно существующих связей между явлениями. В ходе статистического исследования этих связей необходимо выявить причинно-следственные зависимости между показателями, т.е. насколько изменение одних показателей зависит от изменения других показателей.
Существует две категории зависимостей (функциональная и корреляционная) и две группы признаков (признаки-факторы и результативные признаки). В отличие от функциональной связи, где существует полное соответствие между факторными и результативными признаками, в корреляционной связи отсутствует это полное соответствие.
Корреляционная связь - это связь, где воздействие отдельных факторов проявляется только как тенденция (в среднем) при массовом наблюдении фактических данных. Примерами корреляционной зависимости могут быть зависимости между размерами активов банка и суммой прибыли банка, ростом производительности труда и стажем работы сотрудников.
Важнейшая задача - измерение тесноты зависимости - для всех форм связи может быть решена при помощи вычисления эмпирического корреляционного отношения 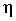 : :
 (8.7) (8.7)
где - 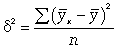 дисперсия в ряду выровненных значений результативного показателя дисперсия в ряду выровненных значений результативного показателя 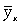 ; ;  - дисперсия в ряду фактических значений у. - дисперсия в ряду фактических значений у.
2.
Выполнить сравнение вариации для двух различных распределений с различными средними, объяснить условия сопоставимости при различии средних.
Для сравнения вариации признаков в разных совокупностях или для сравнения вариации разных признаков в одной совокупности используются относительные показатели, базой служит средняя арифметическая.
1. Относительный размах вариации.
2. Относительное линейное отклонение
3. Коэффициент вариации.
Данные показатели дают не только сравнительную оценку, но и образуют однородность совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33%.
Для оценки интенсивности вариации, а также для сравнения ее величины в разных совокупностях или по разным признакам используют относительные показатели вариации, которые рассчитываются как отношение абсолютных показателей вариации к средней величине признака: относительный размах вариации (коэффициент осцилляции), относительное линейное отклонение и др.
В результате обобщения итогов выборочного бюджетного обследования населения города N
построен вариационный ряд, отражающий распределения жителей города по величине среднедушевого дохода.
| Среднедушевой денежный доход в среднем за месяц, тыс. руб
|
Число жителей. Чел. (f)
|
Накопленные частности (S) В % к итогу
|
Середина интервала
|
xf
|
xw
|
| До 0,5 |
26 |
0,9 |
0,9 |
0,25 |
6,5 |
0,225 |
| 0,5 - 1,0 |
463 |
16,5 |
17,4 |
0,75 |
347,25 |
12,375 |
| 1,0 - 1,5 |
690 |
24,6 |
42,0 |
1,25 |
862,5 |
30,75 |
| 1,5 - 2,0 |
528 |
18,8 |
60,8 |
1,75 |
924,0 |
32,9 |
| 2,0 - 2,5 |
434 |
15,4 |
76,2 |
2,25 |
976,5 |
34,65 |
| 2,5 - 3,0 |
350 |
12,5 |
88,7 |
2,75 |
962,5 |
34,375 |
| 3,0 и более |
318 |
11,3 |
100,0 |
3,25 |
1033,5 |
36,725 |
| Итого
|
2809 |
100,0 |
- |
- |
5112,75 |
182,0 |
В рассматриваемом примере используется ряд с равными интервалами, величина которых 0,5 тыс. руб. Тогда условная нижняя граница первого интервала будет равна: 0,5 тыс. руб. - 0,5 тыс. руб. = 0, а середина - 0,25 тыс. руб., условная верхняя граница последнего интервала: 3,0 тыс. руб. + 0,5 тыс. руб. = 3,5 тыс. руб., а середина - 3,25 тыс. руб.
Расчет средней величины месячного среднедушевого денежного дохода:
х = = 5112,75/2809 = 1,82 тыс. руб.
Месячный среднедушевой доход составляет 1820 руб.
Можно при расчете средней величины в качестве весов использовать частости распределения (w). Величина средней от этого не меняется.
х = 182,0/100 = 1,82 тыс. руб.
Рассчитаем модальное значение признака:
Мо = 1,0 + 0,5*((24,6 - 16,5)/(24,6 - 16,5) + (24,6 - 18,8)) = 1,29 тыс. руб.
Таким образом, величина среднедушевого дохода составляет 1290 руб.
По данным таблицы находим интервал, сумма накопленных частот в котором превышает 50%. Это интервал от 1,5 до 2,0 тыс. руб. (S = 60,8%), он и является медианным.
Ме = 1,5 + 0,5 * ((0,5*(100 + 1) - 42,0)/18,8) = 1,72 тыс. руб.
Следовательно, половина жителей города в нашем примере имеет месячный среднедушевой доход меньше 1720 руб., а половина - больше этой суммы.
Расчет медианного значения по частостям распределения даст аналогичный результат:
Ме = 1,5 + 0,5* ((0,5*(2809 + 1) - 1179)/528) = 1,72 тыс. руб.,
где 1179 - сумма накопленных частот в домедианом интервале.
Соотношение х>Ме>Мо (1820 руб. > 1720 руб. > 1290 руб.), характерное для правосторонней асимметрии, что подтверждается графиками - гистограммой и полигоном распределения. Наличие правосторонней асимметрии свидетельствует о том, что большая часть жителей города имела месячный среднедушевой доход выше, чем его модальное значение (1290 руб.).
Для нашего примера первая дециль попадает в интервал от 0,5 до 1,0 тыс. руб. (сумма накопленных в этом интервале составляет 17,4%, что превышает 10%), девятая дециль - в интервал от 3,0 тыс. руб. и более (в этом интервале находится 10% населения с наибольшими доходами). Найдем величину соответствующих децилей.
D1 = 0,5 + 0,5*((0,1*100 - 0,9)/(16,5)) = 0,776 тыс. руб.
Следовательно, максимальная величина месячного среднедушевого дохода у 10% наименее обеспеченных жителей составляла 776 руб.
D9 = 3,0 + 0,5*((0,9*100 - 88,7)/(11,3)) = 3,058 тыс. руб.
Минимальная величина месячного среднедушевого дохода у 10% наиболее обеспеченного населения города составляла 3058.
Коэффициент децильной дифференциации доходов населения:
КD = 3058/776 = 3,9.
Это означает, что минимальный месячный среднедушевой доход 10% наиболее обеспеченного населения превышал максимальный доход 10% наименее обеспеченного населения в 3,9 раза.
Определим среднее линейное, среднее квадратическое отклонение и дисперсии для распределения жителей города по величине месячного среднедушевого дохода.
| Среднедушевой денежный доход в среднем за месяц, тыс. руб.
|
Число жителей, в % к итогу (fi)
|
Середина интервала (xi)
|
х - х
(х=1,82)
|
х - х f
|
(х - х) f
|
| До 0,5 |
0,9 |
0,25 |
1,57 |
1,413 |
2,218 |
| 0,5 - 1,0 |
16,5 |
0,75 |
1,07 |
17,655 |
18,891 |
| 1,0 - 1,5 |
24,6 |
1,25 |
0,57 |
14,022 |
7,993 |
| 1,5 - 2,0 |
18,8 |
1,75 |
0,07 |
1,316 |
0,092 |
| 2,0 - 2,5 |
15,4 |
2,25 |
0,43 |
6,622 |
2,847 |
| 2,5 - 3,0 |
12,5 |
2,75 |
0,93 |
11,625 |
10,811 |
| 3,0 и более |
11,3 |
3,25 |
1,43 |
16,159 |
23,107 |
| Итого
|
100,0 |
- |
- |
68,812 |
65,959 |
Среднее линейное отклонение:
d = 68,812/100 = 0,688 тыс. руб.;
Дисперсия:
= 65,959/100 = 0,660;
Среднее квадратическое отклонение:
= 0,660 = 0,812 тыс. руб.
Среднее линейное и среднее квадратическое отклонения показывают, на сколько в среднем величина месячного среднедушевого дохода жителей города отличалась от среднего дохода по городу. По формуле среднего линейного отклонения это отличие составляло + 688 руб., по формуле среднего квадратического отклонения + 812 руб.
Коэффициент составляет:
V = (812/1820)*100% = 44,6%, что говорит о средней колеблемости признака и, следовательно, о средней однородности совокупности жителей города по величине среднедушевых доходов.
3.
Дать наиболее полное объяснение смысла предельной ошибки, связать с понятием репрезентативности выборки и ее необходимым объемом.
Предельная ошибка выборки связана со средней ошибкой выборки
связана со средней ошибкой выборки  отношением: отношением:
 . .
При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки.
Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам:
 , ,  . .
Предельная ошибка выборки при повторном отборе определяется по формуле:
 , , 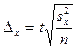 . .
Выборочной совокупностью или просто выборкой называется множество числовых значений некоторого признака всех объектов, случайным образом отобранных из всей совокупности рассматриваемых объектов.
Если же изучать не срок службы, а, например, вес лампочек, что тоже может иметь практическое значение, то та же совокупность объектов будет приводить к другим генеральной совокупности и выборке.
недвусмысленно известно, о каком признаке идет речь, под «генеральной совокупностью» и под «выборкой» будем понимать саму совокупность изучаемых объектов.
Основную задачу математической статистики можно сформулировать как задачу получения обоснованных выводов о неизвестных свойствах генеральной совокупности по известным свойствам извлеченной из нее выборки.
Различают выборки с возвращением и без возвращения.
Если после фиксирования значения параметра объект возвращается в генеральную совокупность и, таким образом, он может многократно повторяться в выборке, то говорят о выборке с возвращением или с повторением.
Если же раз отобранный объект обратно не возвращается и он не может больше одного раза повторяться в выборке, то такая выборка называется выборкой без возвращения или без повторения.
Когда объем выборки намного меньше объема генеральной совокупности, то различие между выборкой с возвращением и без возвращения практически исчезает.
Говорят, что выборка репрезентативна (представительна), если она достаточно полно представляет изучаемые признаки генеральной совокупности.
Важным условием обеспечения репрезентативности выборки является соблюдение случайности отбора, Т.
все объекты генеральной совокупности должны иметь равные вероятности попасть в выборку.
С целью обеспечения репрезентативности выборки в зависимости от конкретных условий применяются различные способы отбора: простой, типический, механический, серийный.
Например, если детали изготовляются разными цехами, то для обеспечения репрезентативности выборки отбор производится случайным образом с соблюдением пропорций из продукции каждого цеха.
Например, если резец заменяется после тридцати обработанных деталей, то нельзя составлять выборку, отбирая каждую десятую или пятнадцатую деталь.
Тогда в выборку попадут объекты из различных моментов периода ритма.
4.
Объяснить соотношение оценивания неизвестных параметров по МНК и проверку значимости полученных результатов по критериям проверки статистических гипотез.
Регрессии, нелинейные по оцениваемым параметрам:
· степенная 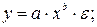
· показательная 
· экспоненциальная 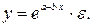
Построение уравнения регрессии сводится к оценке её параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квадратов (МНК
). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака y
от расчетных значений 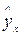 , найденных по уравнению регрессии, была минимальной, т.е. суть МНК заключается в минимизации суммы квадратов остатков: , найденных по уравнению регрессии, была минимальной, т.е. суть МНК заключается в минимизации суммы квадратов остатков:

Для линейных уравнений и нелинейных уравнений, приводимых к линейным уравнениям, решается следующая система относительно a
и b
:
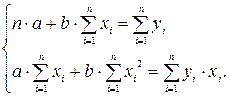
Можно воспользоваться готовыми формулами, которые являются решением этой системы:

Тесноту связи изучаемых явлений оценивает линейныйкоэффициент парной корреляции 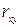 для линейной регрессии: для линейной регрессии:
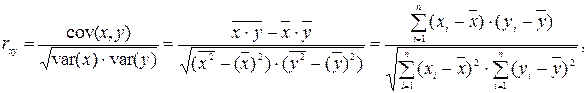 где n
– объём выборки; где n
– объём выборки;  - выборочные средние. - выборочные средние.
Для оценки статистической значимости коэффициента регрессииb
, постоянной а
и коэффициента корреляции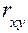 рассчитываются фактические значения t
- критерия Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза рассчитываются фактические значения t
- критерия Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза 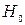 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости показателей с помощью t - критерия Стьюдента проводится путём сопоставления значения показателей с величиной их стандартных ошибок, т.е. определяются фактические значения t - критерия Стьюдента: о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости показателей с помощью t - критерия Стьюдента проводится путём сопоставления значения показателей с величиной их стандартных ошибок, т.е. определяются фактические значения t - критерия Стьюдента:

Стандартные ошибки коэффициента регрессии, константы и коэффициента корреляции рассчитываются по формулам:
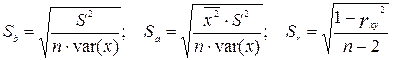 , ,
где 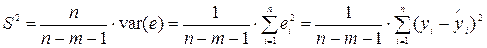 , m
– число параметров при независимой переменной x
. Величина S
называется стандартной ошибкой регрессии и служит мерой разброса зависимой переменной (результата) вокруг линии регрессии. , m
– число параметров при независимой переменной x
. Величина S
называется стандартной ошибкой регрессии и служит мерой разброса зависимой переменной (результата) вокруг линии регрессии.
Сравнивая фактическое значение t
– статистики с критическим (табличным) значением при определенном уровне значимости (обычно  =0,05) и числе степеней свободы (n-2), делаем соответствующие выводы. =0,05) и числе степеней свободы (n-2), делаем соответствующие выводы.
Если 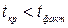 , то отклоняется, т.е. , то отклоняется, т.е. 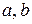 и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора x
. и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора x
.
Если  , то принимается и признается случайная природа формирования или . , то принимается и признается случайная природа формирования или .
Для парной линейной регрессии связь между F – критерием Фишера иt - критерием Стьюдента выражается равенством:  . .
Для расчёта доверительного интервала определяем предельную ошибку для каждого показателя: 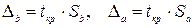 . .
Формулы для расчёта доверительных интервалов имеют вид:

Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается равным нулю, так как он не может одновременно принимать и положительное и отрицательное значения.
Прогнозное значение 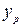 определяется путем подстановки в уравнение регрессии определяется путем подстановки в уравнение регрессии  соответствующего (прогнозного) значения соответствующего (прогнозного) значения  . Вычисляется стандартная ошибка прогноза: . Вычисляется стандартная ошибка прогноза:
 . .
Доверительный интервал для действительного значения  определяется выражением: определяется выражением:  , ,
где 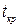 - критическое значение t
– статистики при заданном уровне значимости (обычно =0,05) и числе степеней свободы (n-2), n
- объём выборки (число наблюдаемых значений). - критическое значение t
– статистики при заданном уровне значимости (обычно =0,05) и числе степеней свободы (n-2), n
- объём выборки (число наблюдаемых значений).
|