| 1.
2. Исторические развития М.П. Основные понятия М.Г.
В 1959 г. инженеры фирмы “Texas Instruments” разработали способ, как разместить внутри одного полупроводникового кристалла несколько транзисторов и соединить их между собой – родилась первая интегральная микросхема (ИМС). По сравнению с функционально теми же устройствами, собранными из отдельных транзисторов, резисторов и т.п., ИМС обладает значительными преимуществами: меньшими габаритами, более высокой надежностью и т.д. Неудивительно, что количество выпускаемых микросхем стало быстро возрастать, а их ассортимент неуклонно расширяться. Последнее обстоятельство создавало ряд трудностей для потребителей. Важно даже не столько то, что стремительно возраставшее количество типов ИМС затрудняло ориентацию в море наименований. Значительно большим недостатком была узкая специализация ИМС, из-за которой объем их выпуска не мог быть большим, а значит стоимость одной микросхемы оставалась высокой. Улучшить ситуацию позволило бы создание универсальной логической ИМС, специализация которой определялась бы не заложенной на заводе внутренней структурой, а заданной непосредственно самим потребителем программой работы.
Таким образом, оказывается, что первые микропроцессоры (МП) появились совсем не для миниатюризации ЭВМ, а в целях создания более дешевой логической микросхемы, легко адаптируемой к потребностям пользователя.
Основные понятия
Микропроцессор - это программно управляемое устройство предназначенное для
обработки цифровой информации и управления процессами этой обработки,
выполненной в виде одной или нескольких интегральных схем с высокой степенью
интеграции электронных компонентов.
Микропроцессорный комплект - это набор микросхем необходимых для реализации
одного функционально завершённого вычислительного устройства.
Архитектура МП - это совокупность аппаратных, микропрограммных и программных
средств, определяющая технические, эксплутационные характеристики.
Микропроцессорная система - это управляемая и контрольно - измерительная
система, обрабатывающим элементом в которой является микропроцессор.*
В состав микропроцессорной системы входит микропроцессор (центральный
элемент), который может быть реализован в виде одной СБИС либо в виде одной
платы на которой микропроцессор будет собран из БИС, входящих в единый
микропроцессорный комплект. Микропроцессор МПС выполняет две функции:
1 - служит центральным устройством управления
2 - выполняет арифметико - логическое преобразование данных.
Память МПС имеет иерархическую структуру. Она делится на внутреннюю (ОЗУ, ПЗУ
и КЭШ-память) и внешнюю (накопители на магнитных носителях, на магнитных
лентах, жёсткие диски, флоппи диски).
Устройство ввода - для передачи информации из вне в регистры МП или память
(клавиатура, различные датчики)
Устройство вывода - принимающее информацию из регистра МП или памяти МПС.
Все устройства, входящие в состав МПС имеют стандартный интерфейс, через
который они подключаются к магистрали. Стандартный интерфейс во всех узлах
представлен следующими магистралями: МУ - магисталь управления, МА -
магистраль адреса, МД - магистраль данных.
2.Электрические сигналы. Свойства информации. Обработка цифровых сигналов.
1. Аналоговый сигнал
— сигнал, принимающий бесконечное число сколь угодно близких значений из непрерывного множества значений. В отличие от дискретных сигналов, аналоговые сигналы описываются непрерывными функциями времени. Поэтому аналоговый сигнал иногда называют непрерывным сигналом
2. Цифровой сигнал
— представляет собой последовательность нулей и единиц. Цифровой сигнал легче передавать на большие расстояния, чем аналоговый сигнал, так как нет проблем с усилением и в несколько раз легче бороться с помехами.
3. Релейный сигнал или элемент, минимальная совокупность деталей и связей между ними, имеющая релейную характеристику
, т. е. скачкообразно изменяющая воздействие на выходе (выходах) при поступлении фиксированных воздействий на вход (входы). При построении дискретных управляющих устройств (например, релейных, см. Реле
) Релейный элемент рассматривается как их наиболее простая составная часть.
4. Импульсный сигнал
представляет собой сигнал с кратковременным изменением установившегося состояния, характеризующийся малым интервалом времени по сравнению с временными характеристиками установившегося процесса.
Информация — совокупность данных, зафиксированных на материальном носителе, сохранённых и распространённых во времени и пространстве.
Основные виды информации
по ее форме представления, способам ее кодирования и хранения, что имеет наибольшее значение для информатики, это:
- графическая или изобразительная
— первый вид, для которого был реализован способ хранения информации об окружающем мире в виде наскальных рисунков, а позднее в виде картин, фотографий, схем, чертежей на бумаге, холсте, мраморе и др. материалах, изображающих картины реального мира;
- звуковая
— мир вокруг нас полон звуков и задача их хранения и тиражирования была решена с изобретение звукозаписывающих устройств в 1877 г. (см., например, историю звукозаписи на сайте — ее разновидностью является музыкальная информация — для этого вида был изобретен способ кодирования с использованием специальных символов, что делает возможным хранение ее аналогично графической информации;
- текстовая
— способ кодирования речи человека специальными символами — буквами, причем разные народы имеют разные языки и используют различные наборы букв для отображения речи; особенно большое значение этот способ приобрел после изобретения бумаги и книгопечатания;
- числовая
— количественная мера объектов и их свойств в окружающем мире; особенно большое значение приобрела с развитием торговли, экономики и денежного обмена; аналогично текстовой информации для ее отображения используется метод кодирования специальными символами — цифрами, причем системы кодирования (счисления) могут быть разными;
- видеоинформация
— способ сохранения «живых» картин окружающего мира, появившийся с изобретением кино.
- Объективность информации
. Объективный – существующий вне и независимо от человеческого сознания. Информация – это отражение внешнего объективного мира. Информация объективна, если она не зависит от методов ее фиксации, чьего-либо мнения, суждения.
Пример. Сообщение «На улице тепло» несет субъективную информацию, а сообщение «На улице 22°С» – объективную, но с точностью, зависящей от погрешности средства измерения.
Объективную информацию можно получить с помощью исправных датчиков, измерительных приборов. Отражаясь в сознании конкретного человека, информация перестает быть объективной, так как, преобразовывается (в большей или меньшей степени) в зависимости от мнения, суждения, опыта, знаний конкретного субъекта.
- Достоверность информации
. Информация достоверна, если она отражает истинное положение дел. Объективная информация всегда достоверна, но достоверная информация может быть как объективной, так и субъективной. Достоверная информация помогает принять нам правильное решение. Недостоверной информация может быть по следующим причинам:
- преднамеренное искажение (дезинформация) или непреднамеренное искажение субъективного свойства;
- искажение в результате воздействия помех («испорченный телефон») и недостаточно точных средств ее фиксации.
- Полнота информации
. Информацию можно назвать полной, если ее достаточно для понимания и принятия решений. Неполная информация может привести к ошибочному выводу или решению.
- Точность информации
определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т. п.
- Актуальность информации
– важность для настоящего времени, злободневность, насущность. Только вовремя полученная информация может быть полезна.
- Полезность (ценность) информации
. Полезность может быть оценена применительно к нуждам конкретных ее потребителей и оценивается по тем задачам, которые можно решить с ее помощью.
Цифрова́я обрабо́тка сигна́лов
— преобразование сигналов, представленных в цифровой форме.
Обработка сигналов во временной области широко используется в современной электронной осциллографии и в цифровых осциллографах. А для представления сигналов в частотной области используются цифровые анализаторы спектра. Для изучния математических аспектов обработки сигналов импользуются пакеты расширения (чаще всего под именем Signal Processing) систем компьютерной математики MATLAB, Mathcad, Mathematica, Maple и др.
3. Арифметические основы микропроцессорной техники. Логические основы микропроцессорной техники.
- Одноразрядное двоичное бинарное (двухоперандное) АЛУ с бинарным (двухразрядным) выходом может выполнять до
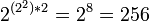 двоичных бинарных (двухоперандных) функций (операций) с бинарным (двухразрядным) выходом. двоичных бинарных (двухоперандных) функций (операций) с бинарным (двухразрядным) выходом.
- Одноразрядное троичное бинарное (двухоперандное) АЛУ с унарным (одноразрядным) выходом (полуАЛУ) может выполнять до
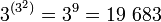 троичных бинарных (двухоперандных) функций (операций) с унарным (одноразрядным) выходом. троичных бинарных (двухоперандных) функций (операций) с унарным (одноразрядным) выходом.
- Одноразрядное троичное бинарное (двухоперандное) АЛУ с бинарным (двухразрядным) выходом может выполнять до
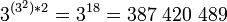 троичных бинарных (двухоперандных) функций (операций) с бинарным (двухразрядным) выходом. троичных бинарных (двухоперандных) функций (операций) с бинарным (двухразрядным) выходом.
3.Арифметические и логические основы МП.
Арифметическо-логическое устройство в зависимости от выполнения функций можно разделить на две части:
- микропрограммное устройство (устройство управления), задающее последовательность микрокоманд (команд);
- операционное устройство (АЛУ), в котором реализуется заданная последовательность микрокоманд (команд).
В состав арифметическо-логического устройства, условно, для примера на картинке, включается регистры Рг1 — Рг7, которые служат для обработки информации, поступающей из оперативной или пассивной памяти N1, N2, …NS и логические схемы, которые используются для обработки слов по микрокомандам, поступающим из устройства управления. Различают два вида микрокоманд: внешние — такие микрокоманды, которые поступают в АЛУ от внешних источников и вызывают в нём преобразование информации (на рисунке 2 это микрокоманды А1,А2,…,Аn) и внутренние — те, которые генерируются в АЛУ и оказывают влияние на микропрограммное устройство, изменяя таким образом нормальный порядок следования команд. р1, p2,…, pm на рисунке 2 — это и есть микрокоманды. А результаты вычислений из АЛУ передаются в ОЗУ по кодовым шинам записи у1, у2, …, ys.
Функции регистров, входящих в арифметическо-логическое устройство
- Рг1 — сумматор (или сумматоры) — главный регистр АЛУ, в котором образуется результат вычислений;
- Рг2,Рг3 — регистры операндов (слагаемого/сомножителя/делителя/делимого и др.) в зависимости от выполняемой операции;
- Рг4 — регистр адреса (или адресные регистры), предназначенные для запоминания (бывает что формирования) адреса операндов результата;
- Рг6 — k индексных регистров, содержимое которых используется для формирования адресов;
- Рг7 — l вспомогательных регистров, которые по желанию программиста могут быть аккумуляторами, индексными регистрами или использоваться для запоминания промежуточных результатов.
Часть операционных регистров могут быть адресованы в команде для выполнения операций с их содержимым и их называют программно-доступными. К таким регистрам относятся: сумматор, индексные регистры и некоторые вспомогательные регистры. Остальные регистры нельзя адресовать в программе, то есть они являются программно-недоступными.
4.Элементы памяти. Элементы преобразования логической информации.
Памятью
компьютера называется совокупность устройств для хранения программ, вводимой информации, промежуточных результатов и выходных данных. Классификация памяти представлен на рисунке:
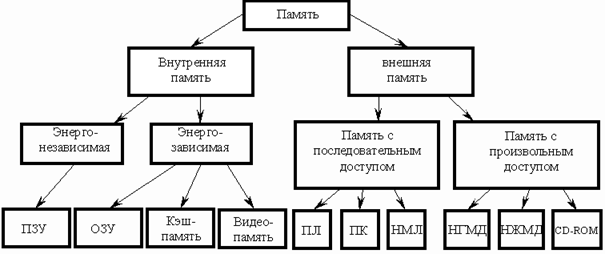
Внутренняя память
предназначена для хранения относительно небольших объемов информации при ее обработке микропроцессором.
Внешняя память
предназначена для длительного хранения больших объемов информации независимо от того включен или выключен компьютер.
Логические элементы
— устройства, предназначенные для обработки информации в цифровой форме (последовательности сигналов высокого — «1» и низкого — «0» уровней в двоичной логике, последовательность "0", "1" и "2" в троичной логике, последовательности "0", "1", "2", "3", "4", "5", "6", "7", "8"и "9" в десятичной логике). Физически логические элементы могут быть выполнены механическими, электромеханическими (на электромагнитных реле), электронными (на диодах и транзисторах), пневматическими, гидравлическими, оптическими и др.
Логические операции (булева функция) своё теоретическое обоснование получили в алгебре логики.
Логические операции с одним операндом называются унарными
, с двумя — бинарными
, с тремя — тернарными
(триарными
, тринарными
) и т. д.
Из 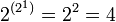 возможных унарных операций с унарным выходом интерес для реализации представляют операции отрицания и повторения, причём, операция отрицания имеет большую значимость, чем операция повторения, так как повторитель может быть собран из двух инверторов, а инвертор из повторителей не собрать. возможных унарных операций с унарным выходом интерес для реализации представляют операции отрицания и повторения, причём, операция отрицания имеет большую значимость, чем операция повторения, так как повторитель может быть собран из двух инверторов, а инвертор из повторителей не собрать.
Отрицание, НЕТ, НЕ
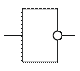
Инвертор
| A
|
|
| 0
|
1
|
| 1
|
0
|
Повторение, ДА

Повторитель (буфер)
Преобразование информации требует выполнения операций с группами знаков, простейшей из которых является группа из двух знаков. Оперирование с большими группами всегда можно разбить на последовательные операции с двумя знаками.
Из 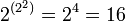 возможных бинарных логических операций с двумя знаками c унарным выходом интерес для реализации представляют 10 операций, приведённых ниже. возможных бинарных логических операций с двумя знаками c унарным выходом интерес для реализации представляют 10 операций, приведённых ниже.
Конъюнкция (логическое умножение). Операция 2И

2И
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
0
|
| 1
|
0
|
0
|
| 0
|
1
|
0
|
| 1
|
1
|
1
|
Мнемоническое правило для конъюнкции с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда на всех
входах действуют «1»,
· "0" тогда и только тогда, когда хотя бы на одном
входе действует «0»
Дизъюнкция (логическое сложение). Операция 2 ИЛИ

2ИЛИ
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
0
|
| 1
|
0
|
1
|
| 0
|
1
|
1
|
| 1
|
1
|
1
|
Мнемоническое правило для дизъюнкции с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда хотя бы на одном
входе действует «1»,
· "0" тогда и только тогда, когда на всех
входах действуют «0»
Инверсия функции конъюнкции. Операция 2 И-НЕ (штрих Шеффера)
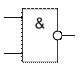
2И-НЕ
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
1
|
| 0
|
1
|
1
|
| 1
|
0
|
1
|
| 1
|
1
|
0
|
Мнемоническое правило для И-НЕ с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда хотя бы на одном
входе действует «0»,
· "0" тогда и только тогда, когда на всех
входах действуют «1»
Инверсия функции дизъюнкции. Операция 2 ИЛИ-НЕ (стрелка Пирса)
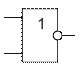
2ИЛИ-НЕ
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
1
|
| 0
|
1
|
0
|
| 1
|
0
|
0
|
| 1
|
1
|
0
|
Мнемоническое правило для ИЛИ-НЕ с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда на всех
входах действуют «0»,
· "0" тогда и только тогда, когда хотя бы на одном
входе действует «1»
Эквивалентность (равнозначность), 2 ИСКЛЮЧАЮЩЕЕ_ИЛИ-НЕ
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
1
|
| 0
|
1
|
0
|
| 1
|
0
|
0
|
| 1
|
1
|
1
|
Мнемоническое правило эквивалентности с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда на входа действует четное
количество «1»,
· "0" тогда и только тогда, когда на входа действует нечетное
количество «1»,
Сложение по модулю 2 (2 Исключающее_ИЛИ, неравнозначность). Инверсия равнозначности.

В англоязычной литературе 2XOR.
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
0
|
| 0
|
1
|
1
|
| 1
|
0
|
1
|
| 1
|
1
|
0
|
Мнемоническое правило для суммы по модулю 2 с любым количеством входов звучит так: На выходе будет:
· "1" тогда и только тогда, когда на входа действует нечётное
количество «1»,
· "0" тогда и только тогда, когда на входа действует чётное
количество «1»,
Импликация от A к B (инверсия декремента)
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
1
|
| 0
|
1
|
1
|
| 1
|
0
|
0
|
| 1
|
1
|
1
|
Импликация от B к A (инверсия инкремента)
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
1
|
| 0
|
1
|
0
|
| 1
|
0
|
1
|
| 1
|
1
|
1
|
Декремент. Запрет импликации по B. Инверсия импликации от A к B
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
0
|
| 0
|
1
|
0
|
| 1
|
0
|
1
|
| 1
|
1
|
0
|
Инкремент. Запрет импликации по A. Инверсия импликации от B к A
| A
|
B
|
f
(AB
)
|
| 0
|
0
|
0
|
| 0
|
1
|
1
|
| 1
|
0
|
0
|
| 1
|
1
|
0
|
Примечание 1
. Элементы импликаций не имеют промышленных аналогов для функций с количеством входов, не равным 2.
Примечание 2
. Элементы импликаций не имеют промышленных аналогов.
Этими простейшими логическими операциями (функциями), и даже некоторыми их подмножествами, можно выразить любые другие логические операции. Такой набор простейших функций называется функционально полным логическим базисом
. Таких базисов 4:
· И, НЕ (2 элемента)
· ИЛИ, НЕ (2 элемента)
· И-НЕ (1 элемент)
· ИЛИ-НЕ (1 элемент).
Для преобразования логических функций в один из названых базисов необходимо применять Закон (правило) де-Моргана
5.Структура микропроцессорной системы. Принцип программного управления Неймана.
Гарвардская архитектура.
Базовая структура микропроцессорной системы имеем вид
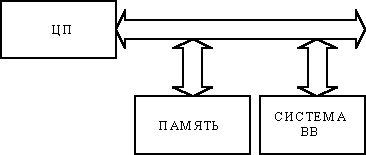
Задача управления системой возлагается на центральный процессор
(ЦП), который связан с памятью
и системой ввода-вывода
через каналы памяти и ввода-вывода соответственно. ЦП считывает из памяти команды, которые образуют программу и декодирует их. В соответствии с результатом декодирования команд он осуществляет выборку данных из памяти м портов ввода, обрабатывает их и пересылает обратно в память или порты вывода. Существует также возможность ввода-вывода данных из памяти на внешние устройства и обратно, минуя ЦП. Этот механизм называется прямым доступом к памяти
(ПДП). Каждая составная часть микропроцессорной системы имеет достаточно сложную внутреннюю структуру.
С точки зрения пользователя при выборе микропроцессора целесообразно располагать некоторыми обобщенными комплексными характеристиками возможностей микропроцессора. Разработчик нуждается в уяснении и понимании лишь тех компонентов микропроцессора, которые явно отражаются в программах и должны быть учтены при разработке схем и программ функционирования системы. Такие характеристики определяются понятием архитектуры микропроцессора.
Архитектура микропроцессора
- это его логическая организация, рассматриваемая с точки зрения пользователя; она определяет возможности микропроцессора по аппаратной и программной реализации функций, необходимых для построения микропроцессорной системы. Понятие архитектуры микропроцессора отражает:
- его структуру, т.е. совокупность компонентов, составляющих микропроцессор, и связей между ними; для пользователя достаточно ограничиться регистровой моделью микропроцессора;
- способы представления и форматы данных;
- способы обращения ко всем программно-доступным для пользователя элементам структуры ( адресация к регистрам, ячейкам постоянной и оперативной памяти, внешним устройствам);
- набор операций, выполняемых микропроцессором;
- характеристики управляющих слов и сигналов, вырабатываемых микропроцессором и поступающих в него извне;
- реакцию на внешние сигналы ( система обработки прерываний и т.п.).
По способу организации пространства памяти микропроцессорной системы различают два основных типа архитектур.
Организация, при которой для хранения программ и данных используется одно пространство памяти, называется фон Неймановской архитектурой
(по имени математика, предложившего кодирование программ в формате, соответствующем формату данных). Программы и данные хранятся в едином пространстве, и нет никаких признаков, указывающих на тип информации в ячейке памяти. Преимуществами такой архитектуры являются более простая внутренняя структура микропроцессора и меньшее количество управляющих сигналов.
Организация, при которой память программ CSEG (Code Segment) и память данных DSEG (Data Segment) разделены и имеют свои собственные адресные пространства и способы доступа к ним, называется Гарвардской архитектурой
( по имени лаборатории Гарвардского Университета, предложившей ее). Такая архитектура является более сложной и требует дополнительных управляющих сигналов. Однако, она позволяет осуществлять более гибкие манипуляции информации, реализовывать компактно кодируемый набор машинных команд и, в ряде случаев, ускорять работу микропроцессора. Представителями такой архитектуры являются микроконтроллеры семейства MCS-51 фирмы Intel.
6.Представление числовой информации. Представление текстовой информации.
Обработка информации.
В ЭВМ используются три вида чисел: с фиксированной точкой (запятой), с плавающей точкой (запятой) и двоично-десятичное представление. Точка (запятая) - это подразумеваемая граница целой и дробной частей числа.
У чисел с фиксированной точкой в двоичном формате предполагается строго определенное место точки (запятой). Обычно это место определяется или перед первой значащей цифрой числа, или после последней значащей цифрой числа. Если точка фиксируется перед первой значащей цифрой, то это означает, что число по модулю меньше единицы. Диапазон изменения значений чисел определяется неравенством
 . .
Если точка фиксируется после последней значащей цифры, то это означает, что п-
разрядные двоичные числа являются целыми. Диапазон изменения их значений составляет:

Перед самым старшим из возможных разрядов двоичного числа фиксируется его знак. Положительные числа имеют нулевое значение знакового разряда, отрицательные - единичные.
Другой формой представления чисел является представление их в виде чисел с плавающей точкой (запятой). Числа с плавающей точкой представляются в виде мантиссы т
a
и порядка р
a
,
иногда это представление называют полулогарифмической формой числа. Например, число A10
= 373 можно представить в виде 0.373 • 103, при этом т =
0.373, р
= 3, основание системы счисления подразумевается фиксированным и равным десяти. Для двоичных чисел А
2
в этом представлении также формируется т
a
и порядок р
a
при основании системы счисления равным двум.
что соответствует записи

Порядок числа р
a
определяет положение точки (запятой) в двоичном числе. Значение порядка лежит в диапазоне -р
a
max
<=р
a
<=р
a
max
,
где величина pa
mах
определяется числом разрядов к,
отведенных для представления порядка
Положительные и отрицательные значения порядка значительно усложняют обработку вещественных чисел. Поэтому во многих современных ЭВМ используют не прямое значение р
a
, а модифицированное р
'a
приведенное к интервалу

Значение р
'a
носит название “характеристика числа”. Обычно под порядок (модифицированный порядок - характеристику) выделяют один байт. Старший разряд характеристики отводится под знак числа, а семь оставшихся разрядов обеспечивают изменение порядка в диапазоне

Модифицированный порядок р
'
a
вычисляется по зависимости
Этим самым значения р'
a
формируются в диапазоне положительных чисел

Мантисса числа ma
представляется двоичным числом, у которого точка фиксируется перед старшим разрядом, т. е.

где k -
число разрядов, отведенных для представления мантиссы.
Если

то старший значащий разряд мантиссы в системе счисления с основанием N
отличен от нуля. Такое число называется нормализованным. Например, A2
=(100;0.101101)2
-нормализованное число А
2
=
1011.01 или А
10
=
11.25, а то же самое число А
2
= (101 ;0.0101101) - число ненормализованное, так как старший разряд мантиссы равен нулю.
Диапазон представления нормализованных чисел с плавающей точкой определяется

где r
и k -
соответственно количество разрядов, используемых для представления порядка и мантиссы.
Третья форма представления двоичных чисел - двоично-десятичная. Ее появление объясняется следующим. При обработке больших массивов десятичных чисел (например, больших экономических документов) приходится тратить существенное время на перевод этих чисел из десятичной системы счисления в двоичную для последующей обработки и обратно -для вывода результатов. Каждый такой перевод требует выполнения двух - четырех десятков машинных команд. С включением в состав отдельных ЭВМ специальных функциональных блоков или спецпроцессоров десятичной арифметики появляется возможность обрабатывать десятичные числа напрямую, без их преобразования, что сокращает время вычислений. При этом каждая цифра десятичного числа представляется двоичной тетрадой. Например, A10
=3759, A2-10
=
0011 0111 0101 1001. Положение десятичной точки (запятой), отделяющей целую часть от дробной, обычно заранее фиксируется. Значение знака числа отмечается кодом, отличным от кодов цифр. Например, “+” имеет значение тетрады “1100”, а “-” - “1101”.
ЭВМ первых двух поколений могли обрабатывать только числовую информацию, полностью оправдывая свое название вычислительных машин. Лишь переход к третьему поколению принес изменения: к этому времени уже назрела настоятельная необходимость использования текстов.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&"
и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Каждый символ хранится в виде двоичного кода, который является номером символа. Можно сказать, что компьютер имеет собственный алфавит, где весь набор символов строго упорядочен. Количество символов в алфавите также тесно связано с двоичным представлением и у всех ЭВМ равняется 256
. Иными словами, каждый символ всегда кодируется 8 битами
, т.е. занимает
ровно один байт
.
Как видите, хранится не начертание буквы, а ее номер. Именно по этому номеру воспроизводится вид символа на экране дисплея или на бумаге. Поскольку алфавиты в различных типах ЭВМ не полностью совпадают, при переносе с одной модели на другую может произойти превращение разумного текста в "абракадабру". Такой эффект иногда получается даже на одной машине в различных программных средах: например, русский текст, набранный в MS DOS, нельзя без специального преобразования прочитать в Windows. Остается утешать себя тем, что задача перекодировки текста из одной кодовой таблицы в другую довольно проста и при наличии программ машина сама великолепно с ней справляется.
Наиболее стабильное положение в алфавитах всех ЭВМ занимают латинские буквы, цифры и некоторые специальные знаки. Это связано с существованием международного стандарта ASCII
(American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Русские же буквы не стандартизированы и могут иметь различную кодировку.
Желающие могут в качестве примера ознакомится с таблицей стандартной части алфавита ЭВМ - символы с шестнадцатиричными кодами с 20 до 7F.
7. Структурная схема микропроцессора.
Главным устройством любой ЭВМ является центральный процессор. Он выбирает из памяти команды программы и выполняет их. Обычный цикл работы центрального процессора выглядит так: он читает первую команду из памяти, декодирует ее для определения ее типа и операндов, выполняет команду, затем считывает, декодирует и выполняет последующие команды. Таким образом, осуществляется выполнение программ. Пример выполнения команд процессором можно посмотреть здесь
.
Ранее было отмечено, что каждый процессор характеризуется набор команд
, который он в состоянии выполнить. Например, процессор Pentium фирмы не может обработать программы, написанные для процессора SPARC фирмы Sun, а SPARC не может выполнить программы, написанные для Pentium.
Укрупненную структурную схему типичного процессора можно представить в виде трех основных блоков: управляющего блока УБ, операционного блока ОБ и интерфейсного блока ИБ. Управляющий блок выполняет функции выборки, декодирования и вычисления адресов операндов, а так же генерирует последовательности микрокоманд, реализующих команды процессора. Он содержит устройство управления, прерывания, синхронизации. Операционный блок служит для обработки данных. Он объединяет арифметико-логическое устройство АЛУ, регистры общего назначения РОН и специальные регистры. АЛУ выполняет арифметические (сложение, вычитание и т.п.) и логические (логическое И, ИЛИ и т.п.) операции. Регистры являются своего рода памятью ОБ, предназначенной для хранения промежуточных результатов и некоторых команд управления, информацию о состоянии процессора. Информация из них считываются и записываются очень быстро, поскольку они находятся внутри процессора. Регистров может быть от несколько десятков до нескольких сотен штук в зависимости от типа процессора. Большим количеством регистров характеризуются RISC - процессоры
, а небольшим - CISC - процессоры
Интерфейсный блок ИБ
позволяет подключить память и периферийные устройства к процессору. ИБ выполняет также функции канала прямого доступа к памяти. Интерфейс процессора содержит информационные шины данных ШД, адресов ША и управления ШУ. Надо заметить, что такое распределение аппаратных блоков процессора между функциональными частями весьма условно и приводится для примера.
Процессор выполняет каждую команду за несколько шагов:
1. вызывает следующую команду из памяти и переносит ее в регистр команд;
2. меняет положение счетчика команд, который теперь должен указывать на следующую команду;
3. определяет тип вызванной команды;
4. если команда использует данные из памяти, определяет место нахождение данных;
5. переносит данные в регистр процессора;
6. выполняет команду;
7. переходит к 1 шагу, что бы начать выполнение следующей команды.
Эта последовательность шагов (выборка – декодирование – исполнение) является основой работы для всех процессоров.
Упрощенная структурная схема типичного процессора изображена на следующем рисунке.
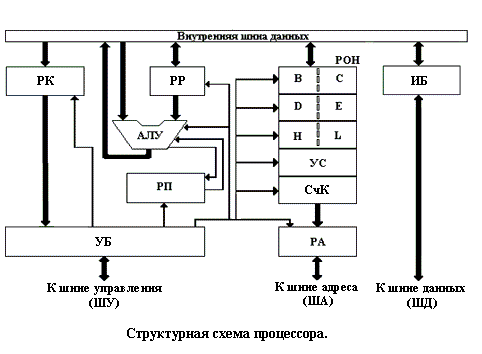
Кроме регистров общего назначения РОН, используемых для хранения переменных и временных результатов, большинство процессоров имеют несколько специальных регистров, также доступных для программиста. Один из них называется счетчиком команд СчК, в котором содержится адрес следующей, стоящей в очереди на выполнение команды. После того как команда выбрана из памяти, регистр команд корректируется и указатель переходит к следующей команде. Регистр процессора, служащий для организации стековой памяти, называется указателем стека УС. Он содержит адрес вершины стека в памяти. Стек содержит по одному фрейму (области данных) для каждой процедуры, которая уже начала выполняться, но еще не закончена. В стековом фрейме процедуры хранятся ее входные параметры, а также локальные и временные переменные, не хранящиеся в регистрах.
Первый байт любой команды поступает из ОЗУ по шине данных на регистр команд РК. Этот первый байт подается в управляющий блок УБ, который определяет вид операции. В частности, он определяет, является ли команда однобайтовой, или она состоит из большего числа байтов. В последнем случае дополнительные байты передаются по шинам данных из ОЗУ и принимаются или в регистр адреса РА данных, или в один из регистров РОН
Регистр адреса данных РА содержит адрес операнда для команд, обращающихся к памяти, адрес порта для команд ввода/вывода или адрес следующей команды для команд перехода. Регистры РОН могут содержать операнды для всех команд, работающих с данными. Среди РОН есть специальный регистр результата РР или аккумулятор, участвующий во всех арифметических и логических операциях. В частности, он содержит один из операндов перед выполнением операции и получает результат после ее завершения. Все арифметические и логические операции выполняются в арифметико – логическом устройстве АЛУ. Результаты из АЛУ передаются либо в РР, либо в какой-то из регистров РОН.
Процессор имеет регистр признаков РП
, содержащий в своих разрядах значения, которые отражают результаты выполнения некоторых команд процессора, приоритет текущей программы, режим работы процессора (пользовательский или режим ядра). Также РП содержит другую служебную информацию. Обычно пользовательские программы могут читать весь регистр РП целиком, но изменять могут только некоторые из его полей. Регистр РП играет важную роль в системных вызовах и операциях ввода-вывода.
В управляющем блоке УБ дешифрируется и анализируется код команды, поступающий из РК. В УБ из АЛУ и от триггера переноса поступают сигналы, по которым определяются условия для передачи управления. Все остальные компоненты процессора получают от УБ управляющие и синхронизирующие сигналы, необходимые для выполнения команды.
Операционная система должна знать все обо всех регистрах. При временном мультиплексировании центрального процессора операционная система часто останавливает работающую программу для запуска (или перезапуска) другой программы, например, обслуживающей периферийное устройство. Каждый раз при таком процессе, называемом прерыванием
, операционная система должна сохранять значения тех регистров процессора, которые будут востановленны позже, для того чтобы прерванная программа продолжила свою работу без потери данных, с того места, где она была прервана.
В целях улучшения характеристик центральных процессоров их разработчики давно отказались от простой модели, в которой за один такт может быть считана, декодирована и выполнена только одна команда. Многие современные процессоры обладают возможностями выполнения нескольких команд одновременно. Например, у процессора могут быть раздельные модули, занимающиеся выборкой, декодированием и выполнением команд, и во время выполнения команды с номером n он может декодировать команду с номером n + 1 и считывать команду с номером n + 2. Подобная организация процесса называется конвейером.
Более передовым по сравнению с конвейерной конструкцией является суперскалярный процессор. В этой структуре присутствует множество выполняющих узлов: один для целочисленных арифметических операций, второй - для операций с плавающей точкой и еще один - для логических операций. За один такт считывается две или более команды, которые декодируются и сбрасываются в буфер хранения, где они ждут своей очереди на выполнение. Когда выполняющее устройство освобождается, оно заглядывает в буфер хранения, интересуясь, есть ли там команда, которую оно может обработать, и если да, то забирает ее и выполняет. В результате команды часто исполняются не в порядке их следования. В большинстве случаев аппаратура должна гарантировать, что результат совпадет с тем, который выдала бы последовательная конструкция
Большинство процессоров, используемых в современных ЭВМ, имеют два режима работы: режим ядра и пользовательский режим. Обычно режим задается битом РП или слова состояния процессора. Если процессор запущен в режиме ядра, он может выполнять все команды из набора инструкций и использовать все возможности аппаратуры. Операционная система работает в режиме ядра, предоставляя доступ ко всему оборудованию.
В противоположность этому программы пользователей работают в пользовательском режиме, разрешающем выполнение подмножества команд и делающем доступным лишь часть аппаратных средств. Как правило, все команды, включая ввод-вывод данных и защиту памяти, запрещены в пользовательском режиме. Установка бита режима ядра в регистре признаков РП пользовательском режиме естественно, недоступна.
Для связи с операционной системой пользовательская программа должна сформировать системный вызов, который обеспечивает переход в режим ядра и активизирует функции операционной системы. После завершения работы управление возвращается к пользовательской программе, к команде, следующей за системным вызовом.
Стоит отметить, что в компьютерах, помимо инструкций для выполнения системных вызовов, есть и другие прерывания
. Большинство этих прерываний вызываются аппаратно для предупреждения об исключительных ситуациях, таких как попытка деления на ноль или переполнение при операциях с плавающей точкой. Во всех подобных случаях управление переходит к операционной системе, которая должна решать, что делать дальше. Иногда нужно завершить программу с сообщением об ошибке. В других случаях ошибку можно проигнорировать (например, при потере значимости числа его можно принять равным нулю). Наконец, если программа объявила заранее, что требуется обработать некоторые виды условий, управление может вернуться назад к программе, позволяя ей самой разрешить появившуюся проблему.
8. Основные параметры и классификация МП.
Микропроцессор как функциональное устройство ЭВМ обеспечивает эффективное автоматическое выполнение операций обработки цифровой информации в соответствии с заданным ал-горитмом. Для решения широкого круга задач в различных облас-тях применений микропроцессор должен обладать алгоритмически полной системой команд (операций).
Теоретически показано, что минимальная алгоритмически полная система команд процессора состоит из одной или несколь-ких универсальных команд. Однако использование процессоров с минимальными по числу операций системами команд ведет к не-экономичному использованию информационных емкостей памяти и значительным затратам времени на выполнение «длинных» про-грамм. Поэтому обычно в МП встраиваются аппаратурные средст-ва, позволяющие реализовать многие десятки и сотни команд. Та-кие развитые системы команд дают возможность обеспечить ком-пактную запись алгоритмов и соответственно эффективные про-граммы.
При проектировании МП решаются задачи определения на-боров команд, выполняемых программным или аппаратурным способом на основе заданной системы микрокоманд. Аппаратур-ная реализация сложных команд дает возможность увеличить бы-стродействие микропроцессора, но требует значительных аппара-турных ресурсов кристалла интегральной схемы МП. Программ-ная реализация сложных команд позволяет обеспечивать програм-мирование сложных задач, изменять количество и особенности исполнения сложных команд. Однако скорость исполнения программных команд ниже скорости исполнения аппаратурно-реализованных команд.
Практически во всех современных МПС используются сложные развитые системы команд. Их ядро, состоящее из набора универсальных команд, реализуется аппаратурным способом в центральном МП. Кроме того, специализированные части наборов системы команд реализуются вспомогательными или периферий-ными микропроцессорами. Эти расширяющие возможности обра-ботки данных специальные арифметические или логические МП позволяют ускорить выполнение определенных команд и тем са-мым сократить время исполнения программ.
Для описания МП как функциональных устройств необхо-димо охарактеризовать формат обрабатываемых данных и команд, количество, тип и гибкость команд, методы адресации данных, число внутренних регистров общего назначения и регистров ре-зультата, возможности организации и адресации стека, параметры виртуальной памяти и информационную емкость прямо адресуе-мой памяти. Большое значение имеют средства построения систе-мы прерываний программ, построения эффективных систем ввода — вывода данных и развитого интерфейса.
МП могут быть реализованы на различной физической ос-нове: на электронной, оптоэлектронной, оптической, биологиче-ской и даже на пневматической или гидравлической.
По назначению различают универсальные и специализиро-ванные микропроцессоры.
Универсальные МП предназначены для решения широкого круга задач. При этом их эффективная производительность слабо зависит от проблемной специфики решаемых задач В системе ко-манд МП заложена алгоритмическая универсальность, означаю-щая, что выполняемый машиной состав команд позволяет полу-чить преобразование информации в соответствии с любым задан-ным алгоритмом.
К универсальным МП относятся и секционные микропро-цессоры, поскольку для них система команд может быть оптими-зирована в каждом частном проекте создания секционного микро-процессора.
Эта группа МП наиболее многочисленна, в нее входят та-кие комплекты как К580, Z80, Intel 80?86, К582, К587, К1804, К1810 и др.
Специализированные МП предназначены для решения оп-ределенного класса задач, а иногда только для решения одной конкретной задачи. Их существенными особенностями являются простота управления, компактность аппаратурных средств, низкая стоимость и малая мощность потребления.
Специализированные МП имеют ориентацию на ускорен-ное выполнение определенных функций, что позволяет резко уве-личить эффективную производительность при решении только оп-ределенных задач.
Среди специализированных микропроцессоров можно вы-делить различные микроконтроллеры, ориентированные на вы-полнение сложных последовательностей логических операций; математические МП, предназначенные для повышения производи-тельности при выполнении арифметических операций за счет, на-пример матричных методов их выполнения; МП для обработки данных в различных областях применений и т. д.
С помощью специализированных МП можно эффективно решать новые сложные задачи параллельной обработки данных. Например, они позволяют осуществить более сложную математи-ческую обработку сигналов, чем широко используемые методы корреляции, дают возможность в реальном масштабе времени на-ходить соответствие для сигналов изменяющейся формы путем сравнения их с различными эталонными сигналами для эффектив-ного выделения полезного сигнала на фоне шума и т.д.
По виду обрабатываемых входных сигналов различают цифровые и аналоговые микропроцессоры.
Сами МП являются цифровыми устройствами обработки информации. Однако в ряде случаев они могут иметь встроенные аналого-цифровые и цифро-аналоговые преобразователи. Поэтому входные аналоговые сигналы передаются в МП через преобразова-тель в цифровой форме, обрабатываются и после обратного преоб-разования в аналоговую форму поступают на выход.
С архитектурной точки зрения такие микропроцессоры представляют собой аналоговые функциональные преобразователи сигналов. Они выполняют функции любой аналоговой схемы (например, производят генерацию колебаний, модуляцию, смеще-ние, фильтрацию, кодирование и декодирование сигналов в реаль-ном масштабе времени и т. д., заменяя сложные схемы, состоящие из операционных усилителей, катушек индуктивности, конденса-торов и т.д.). При этом применение аналогового МП значительно повышает точность обработки аналоговых сигналов и их воспро-изводимость, а также расширяет функциональные возможности за счет программной “настройки” цифровой части микропроцессора на различные алгоритмы обработки сигналов.
Обычно в составе однокристальных аналоговых МП имеет-ся несколько каналов аналого-цифрового и цифро-аналогового преобразования. В аналоговом микропроцессоре разрядность об-рабатываемых данных достигает 24 бит и более. Большое значение уделяется увеличению скорости выполнения арифметических опе-раций.
Отличительная черта аналоговых МП - это способность к переработке большого объема числовых данных, т. е. к выполне-нию операций сложения и умножения с большой скоростью, при необходимости даже за счет отказа от операций прерываний и пе-реходов. Аналоговый сигнал, преобразованный в цифровую фор-му, обрабатывается в реальном масштабе времени и передается на выход обычно в аналоговой форме через цифро-аналоговый пре-образователь. При этом согласно теореме Котельникова частота квантования аналогового сигнала должна вдвое превышать верх-нюю частоту сигнала.
Одним из направлений дальнейшего совершенствования аналоговых МП является повышение их универсальности и гибко-сти. Поэтому вместе с повышением скорости обработки большого объема цифровых данных будут развиваться средства обеспечения развитых вычислительных процессов обработки цифровой инфор-мации за счет реализации аппаратурных блоков прерывания про-грамм и программных переходов.
По количеству выполняемых программ различают одно- и многопрограммные микропроцессоры.
В однопрограммных МП выполняется только одна про-грамма. Переход к выполнению другой программы происходит после завершения текущей программы.
В много- или мультипрограммных МП одновременно вы-полняется несколько (обычно несколько десятков) программ. Ор-ганизация мультипрограммной работы микропроцессорных управ-ляющих систем, например, позволяет осуществить контроль за со-стоянием и управлением большим числом источников или прием-ников информации.
9.Запоминающие устройства. Основные параметры и классификация.
Запоминающее устройство
— носитель информации, предназначенный для записи и хранения данных. В основе работы запоминающего устройства может лежать любой физический эффект, обеспечивающий приведение системы к двум или более устойчивым состояниям.
По устойчивости записи
и возможности перезаписи ЗУ делятся на:
- Постоянные ЗУ (ПЗУ), содержание которых не может быть изменено конечным пользователем (например, BIOS). ПЗУ в рабочем режиме допускает только считывание информации.
- Записываемые ЗУ (ППЗУ), в которые конечный пользователь может записать информацию только один раз (например, CD-R).
- Многократно перезаписываемые ЗУ (ПППЗУ) (например, CD-RW).
- Оперативные ЗУ (ОЗУ) обеспечивает режим записи, хранения и считывания информации в процессе её обработки. Быстрые, но дорогие ОЗУ (SRAM) строят на триггерах, более медленные, но дешёвые разновидности ОЗУ — динамические ЗУ (DRAM) строят на конденсаторах. В обоих видах ЗУ информация исчезает после отключения от источника тока.
По типу доступа
ЗУ делятся на:
- Устройства с последовательным доступом (например, магнитные ленты).
- Устройства с произвольным доступом (RAM) (например, оперативная память).
- Устройства с прямым доступом (например, жесткие магнитные диски).
- Устройства с ассоциативным доступом (специальные устройства, для повышения производительности БД)
По геометрическому исполнению
:
- дисковые (магнитные диски, оптические, магнитооптические);
- ленточные (магнитные ленты, перфоленты);
- барабанные (магнитные барабаны);
- карточные (магнитные карты, перфокарты, флэш-карты, и др.)
- печатные платы (карты DRAM, картриджи).
По физическому принципу
:
- перфорационные (с отверстиями или вырезами)
- с магнитной записью
- ферритовые сердечники
- магнитные диски
- Жёсткий магнитный диск
- Гибкий магнитный диск
- магнитные ленты
- магнитные карты
- оптические
- CD
- DVD
- HD-DVD
- Blu-ray Disc
- магнитооптические:
- использующие накопление электростатического заряда в диэлектриках (конденсаторные ЗУ, запоминающие электроннолучевые трубки);
- использующие эффекты в полупроводниках (EEPROM, флэш-память)
- звуковые и ультразвуковые (линии задержки);
- использующие сверхпроводимость (криогенные элементы);
- другие.
По форме записанной информации выделяют аналоговые и цифровые запоминающие устройства.
Цифровые запоминающие устройства
— устройства, предназначенные для записи, хранения и считывания информации, представленной в цифровом коде.
К основным параметрам ЗУ относятся информационная ёмкость (бит), потребляемая мощность, время хранения информации, быстродействие.
Самое большое распространение запоминающие устройства приобрели в компьютерах (компьютерная память). Кроме того, они применяются в устройствах автоматики и телемеханики, в приборах для проведения экспериментов, в бытовых устройствах (телефонах, фотоаппаратах, холодильниках, стиральных машинах и т. д.), в пластиковых карточках, замках
- Магнитные ЗУ в пластиковых картах
- Флеш-память: USB-накопители, карты памяти в телефонах и фотоаппаратах, SSD
- Оптические диски: CD, DVD, Blu-Ray и др.
- Жёсткие диски (НЖМД)
- Микросхемы SDRAM (DDR и XDR)
Некоторые типы запоминающих устройств оформлены как компактные, носимые человеком устройства, приспособленные для переноса информации. В частности:
- Флеш-память
- Переносной жёсткий диск:
- Mobile Rack
- Контейнеры для жёстких дисков
- ZIV
10. Адресная, стековая и ассоциативная память. Стековая память. Полупроводниковая память.
Память - совокупность отдельных устройств, которые запоминают, хранят, выдают информацию. Отдельные устройства памяти называют запоминающими устройствами. Производительность вычислительных систем в значительной мере определяется составом и характеристиками отдельных запоминающих устройств, которые различают по принципу действия, техническим характеристикам, назначениям. Основные операции с памятью - процедура записи, процедура чтения (выборки). Процедуры записи и чтения также называют обращением к памяти. За одно обращение к памяти "обрабатывается" для различных устройств различные единицы данных (байт, слово, двойное слово, блок).
Основные технические характеристики памяти
Одними из основных характеристик памяти является емкость и быстродействие (время обращения к запоминающему устройству).
Время обращения к устройству зависит от типа памяти.
В некоторых запоминающих устройствах считывание данных сопровождается их разрушением. В этом случае цикл обращения к памяти всегда должен содержать регенерацию данных (ЗУ динамического типа). Этот цикл состоит из трех шагов:
- время от начала операции обращения до того момента, как данные станут доступны (время доступа);
- считывание;
- регенерация.
Основные технические характеристики процедуры записи:
- время доступа;
- время подготовки (приведение в исходное состояние поверхности магнитного диска при записи);
- запись.
Максимальная длительность чтения-записи называется временем обращения к памяти.
По физическим основам все запоминающие устройства разделяются: полупроводниковые, магнитно-оптические и т.д.
Организация полупроводниковой памяти
С точки зрения функционального построения, любое запоминающее устройство такого типа представляет собой некоторый массив элементов памяти. Структурные элементы памяти образуют ячейки памяти. Ширина ячеек - ширина выборки из памяти. Структура модуля памяти определяется способом организации памяти (способ адресации).
Существует 3 разновидности организации памяти:
- адресная память
- память со стековой организацией
- ассоциативная память
Random Access Memory - запоминающие устройства с произвольной выборкой
В адресной памяти, размещение и поиск информации в массиве запоминания, базируется на основе номера (адреса). Массив запоминания элементов содержит N n-разрядных слов, которые пронумерованы (0...N-1). Электронное обрамление включает в себя регистры для хранения адреса памяти, регистр информации (само слово), схемы адресной выборки (адресации), разрядные усилители для чтения и записи.
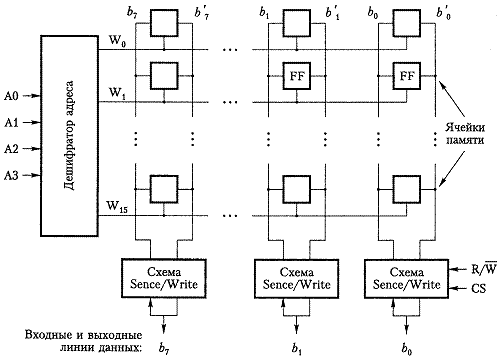
Рис. 8.1.
Цикл обращения таких устройств не зависит от того, в каком физическом месте ЗУ находятся требуемые данные. Такой способ доступа характерен для полупроводниковых ЗУ. Число записанных одновременно битов данных за одно обращение называют шириной выборки (доступа).
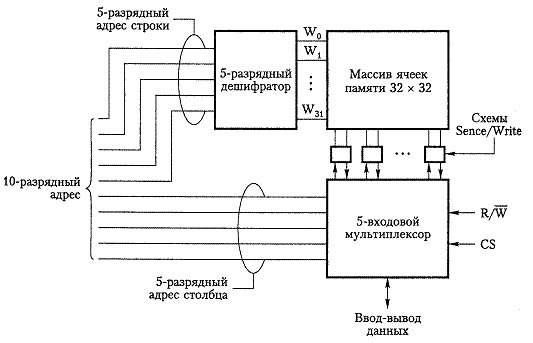
Рис. 8.2.
Основная память современных компьютеров реализуется на микросхемах статических и динамических RAM.
Статическая память
Память на основе микросхем, которые могут сохранять свое состояние лишь тех пор, пока к ним подключено питание, называется статической (Static RAM, SRAM). Может быть реализована на триггерах. Микросхемы статических SRAM имеют малое время доступа и не требуют циклов регенерации.
Статическая RAM работает быстро, но стоит очень дорого, поскольку каждая ее ячейка содержит несколько транзисторов. Вот почему выпускается еще и более дешевая память с более простой конструкцией ячеек. Однако эти ячейки не способны бесконечно долго сохранять свое состояние, поэтому такая память называется динамической (Dynamic RAM, DRAM).
Динамическая память
В ячейке динамической памяти информация хранится в форме заряда на конденсаторе, и этот заряд может сохраняться всего несколько десятков миллисекунд. Поскольку ячейка памяти должна хранить информацию гораздо дольше, ее содержимое должно периодически обновляться путем восстановления заряда на конденсаторе.
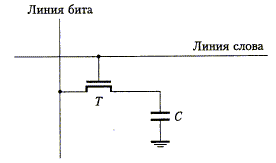
Рис. 8.3.
Ячейка динамической памяти, состоим из конденсатора С и транзистора Т. Для записи информации в эту ячейку включается транзистор Т и на линию бита подается соответствующее напряжение. В результате на конденсаторе образуется определенный заряд.
После выключения транзистора конденсатор начинает разряжаться. Это происходит из-за его собственного тока утечки, а также из-за того, что после выключения сопротивление транзистора велико, но все же конечно, поэтому он продолжает проводить ток. Полученная информация не содержит ошибок лишь в том случае, если она считывается из ячеек до того, как заряд конденсатора падает ниже определенного порогового значения. Операция чтения производится, когда транзистор выбранной ячейки включен. Соединенный с линией бита усилитель считывания определяет, превышает ли заряд конденсатора пороговое значение. Если да, он подает на линию бита напряжение, соответствующее значению 1. В результате конденсатор заряжается до напряжения, также соответствующего 1. Если заряд на конденсаторе ниже порогового значения, усилитель считывания снижает напряжение на линии бита до уровня "земли", обеспечивая тем самым отсутствие заряда (логическое значение 0) на конденсаторе. Таким образом, в процессе считывания содержимое ячейки автоматически обновляется (регенерируется). Все ячейки выбранной строки считываются одновременно, в результате чего обновляется содержимое всей строки.
Ко всем строкам всех микросхем DRAM основной памяти компьютера должны производиться периодические обращения в пределах определенного временного интервала порядка 10:60 наносекунд. Это требование кроме всего прочего означает, что система основной памяти компьютера оказывается иногда недоступной процессору, так как она вынуждена рассылать сигналы регенерации каждой микросхеме. Разработчики DRAM стараются поддерживать время, затрачиваемое на регенерацию, на уровне менее 5% общего времени. Обычно контроллеры памяти включают в свой состав аппаратуру для периодической регенерации DRAM.
В процессе развития DRAM с ростом их емкости основным вопросом стоимости таких микросхем был вопрос о количестве адресных линий и стоимости соответствующего корпуса. Было принято решение о необходимости мультиплексирования адресных линий, позволившее сократить наполовину количество контактов корпуса, необходимых для передачи адреса. Поэтому обращение к DRAM обычно происходит в два этапа: первый этап начинается с выдачи сигнала RAS - row-access strobe (строб адреса строки), который фиксирует в микросхеме поступивший адрес строки, второй этап включает переключение адреса для указания адреса столбца и подачу сигнала CAS - column-access stobe (строб адреса столбца), который фиксирует этот адрес и разрешает работу выходных буферов микросхемы. Названия этих сигналов связаны с внутренней организацией микросхемы, которая как правило представляет собой прямоугольную матрицу, к элементам которой можно адресоваться с помощью указания адреса строки и адреса столбца.
Емкость DRAM по грубым оценкам в 4 - 8 раз превышает емкость SRAM, но SRAM имеют в 8 - 16 раз меньшую длительность цикла и большую стоимость. По этим причинам в основной памяти практически любого компьютера используется полупроводниковые микросхемы DRAM (для построения кэш-памяти при этом применяются SRAM). Естественно были и исключения, например, в оперативной памяти суперкомпьютеров компании Cray Research использовались микросхемы SRAM.
Стековая память
Стековая память является безадресной. Все ячейки памяти организованы по принципу "первым вошел - последним вышел" (LIFO). Реализовано это таким образом, что для операций с памятью доступна только 0-я ячейка.
Каждая операция записи, инициируемая сигналом обращения к памяти, приводит к тому, что записанные данные помещаются в 0 ячейку памяти. При этом все ранние записи в памяти слова автоматически сдвигаются на 1 адрес ниже. Операция чтения, инициируемая сигналом обращения, приводит к тому, что на выходе памяти формируется значение слова, находящиеся в 0 ячейке памяти. При этом все имеющиеся слова сдвигаются на одно слово вверх. Счетчик стека нужен только для контроля заполнения и очищения стека. Техническая реализация стековой памяти оказывается сложнее адресной памяти. Стековая память используется достаточно широко. Чаще всего применяется не стековая память, а адресное поле, которое функционирует по принципу стека.
Ассоциативная память.
Исторически последняя. Является представителем многофункциональных запоминающих устройств (возможна обработка данных без процессора в памяти). Отличительная особенность - поиск любой информации в ЗМ производится не по адресу, а по ассоциативным признакам (признакам опроса). Поиск производится одновременно по всем ячейкам ЗМ.
С точки зрения структуры, любая основная память компьютера может быть построена, как одноблочная, либо как многоблочная (сейчас одноблочная память практически не используется). Многоблочную память строят из однотипных блоков.
Иерархия памяти
В основе реализации иерархии памяти современных компьютеров лежат два принципа: принцип локальности обращений и соотношение стоимость/производительность. Принцип локальности обращений говорит о том, что большинство программ к счастью не выполняют обращений ко всем своим командам и данным равновероятно, а оказывают предпочтение некоторой части своего адресного пространства.
Иерархия памяти современных компьютеров строится на нескольких уровнях, причем более высокий уровень меньше по объему, быстрее и имеет большую стоимость в пересчете на байт, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и так далее, пока мы не достигнем основания иерархии.
Иерархия памяти обычно состоит из многих уровней, но в каждый момент времени мы имеем дело только с двумя близлежащими уровнями. Минимальная единица информации, которая может либо присутствовать, либо отсутствовать в двухуровневой иерархии, называется блоком. Размер блока может быть либо фиксированным, либо переменным. Если этот размер зафиксирован, то объем памяти является кратным размеру блока.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание - есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate) или коэффициент попаданий (hit ratio) есть доля обращений, найденных на более высоком уровне. Иногда она представляется процентами. Доля промахов (miss rate) есть доля обращений, которые не найдены на более высоком уровне.
Поскольку повышение производительности является главной причиной появления иерархии памяти, частота попаданий и промахов является важной характеристикой. Время обращения при попадании (hit time) есть время обращения к более высокому уровню иерархии, которое включает в себя, в частности, и время, необходимое для определения того, является ли обращение попаданием или промахом. Потери на промах (miss penalty) есть время для замещения блока в более высоком уровне на блок из более низкого уровня плюс время для пересылки этого блока в требуемое устройство (обычно в процессор). Потери на промах далее включают в себя две компоненты: время доступа (access time) - время обращения к первому слову блока при промахе, и время пересылки (transfer time) - дополнительное время для пересылки оставшихся слов блока. Время доступа связано с задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между устройствами памяти двух смежных уровней.
Чтобы описать некоторый уровень иерархии памяти надо ответить на следующие четыре вопроса:
- Где может размещаться блок на верхнем уровне иерархии? (размещение блока).
- Как найти блок, когда он находится на верхнем уровне? (идентификация блока).
- Какой блок должен быть замещен в случае промаха? (замещение блоков).
- Что происходит во время записи? (стратегия записи).
Организация кэш-памяти
Сегодня кэш-память имеется практически в любом классе компьютеров, а в некоторых компьютерах - во множественном числе.
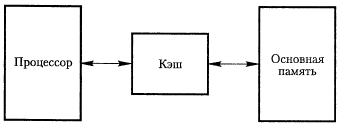
Рис. 8.4.
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
- Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока.
- Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative).
- Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше.
- Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative).
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. На попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха.
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
Общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
- сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
- запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
При промахе во время записи имеются две дополнительные возможности:
- разместить запись в кэш-памяти (write allocate) (называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении.
- не размещать запись в кэш-памяти (называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Принципы организации основной памяти в современных ЭВМ
Основная память представляет собой уровень иерархии памяти. Основная память удовлетворяет запросы кэш-памяти и служит в качестве интерфейса ввода/вывода, поскольку является местом назначения для ввода и источником для вывода. Для оценки производительности основной памяти используются два основных параметра: задержка и полоса пропускания.
Задержка памяти традиционно оценивается двумя параметрами: временем доступа (access time) и длительностью цикла памяти (cycle time). Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Согласование производительности современных процессоров со скоростью основной памяти вычислительных систем остается на сегодняшний день одной из важнейших проблем. Методы повышения производительности за счет увеличения размеров кэш-памяти и введения многоуровневой организации кэш-памяти могут оказаться не достаточно эффективными с точки зрения стоимости систем. Поэтому важным направлением современных разработок являются методы повышения полосы пропускания или пропускной способности памяти за счет ее организации, включая специальные методы организации DRAM. При увеличении полосы пропускания памяти возможно увеличение размера блоков кэш-памяти без заметного увеличения потерь при промахах.
Основными методами увеличения полосы пропускания памяти являются:
- увеличение разрядности или "ширины" памяти,
- использование расслоения памяти,
- использование независимых банков памяти,
- обеспечение режима бесконфликтного обращения к банкам памяти,
- использование специальных режимов работы динамических микросхем памяти.
Виртуальная память и организация защиты памяти
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего, к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем.
В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче, тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами.
Страничная организация памяти
В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера, и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов (TLB translation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
Сегментация памяти
Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных (сегменты стека являются частным случаем сегментов данных). Из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной, и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие - как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние - номер страницы внутри сегмента, а младшие - номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель (дескриптор) сегмента (поля базы, границы и индикаторов режима доступа). При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница - длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница - число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов (базу и границу), причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница - длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
В описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область (домен) защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств.
11. Динамические ОЗУ (Dynamic RAM)
)
Экономичный вид памяти. Для хранения разряда (бита или трита) используется схема, состоящая из одного конденсатора и одного транзистора (в некоторых вариациях конденсаторов два). Такой вид памяти решает, во-первых, проблему дороговизны (один конденсатор и один транзистор дешевле нескольких транзисторов) и во-вторых, компактности (там, где в SRAM размещается один триггер, то есть один бит, можно уместить восемь конденсаторов и транзисторов). Есть и свои минусы. Во-первых, память на основе конденсаторов работает медленнее, поскольку если в SRAM изменение напряжения на входе триггера сразу же приводит к изменению его состояния, то для того чтобы установить в единицу один разряд (один бит) памяти на основе конденсатора, этот конденсатор нужно зарядить, а для того чтобы разряд установить в ноль, соответственно, разрядить. А это гораздо более длительные операции (в 10 и более раз), чем переключение триггера, даже если конденсатор имеет весьма небольшие размеры. Второй существенный минус — конденсаторы склонны к «стеканию» заряда; проще говоря, со временем конденсаторы разряжаются. Причём разряжаются они тем быстрее, чем меньше их ёмкость. За то, что разряды в ней хранятся не статически, а «стекают» динамически во времени память на конденсаторах получила своё название динамическая память. В связи с этим обстоятельством, дабы не потерять содержимое памяти, заряд конденсаторов для восстановления необходимо «регенерировать» через определённый интервал времени. Регенерация выполняется центральным микропроцессором или контроллером памяти, за определённое количество тактов считывания при адресации по строкам. Так как для регенерации памяти периодически приостанавливаются все операции с памятью, это значительно снижает производительность данного вида ОЗУ.
12. Массочные ПЗУ. Программируемые ПЗУ. Перепрограмируемые ПЗУ.
К масочным относятся ПЗУ, информация в которые записывается непосредственно в процессе их изготовления. Само название данного подкласса устройств связано с технологическим процессом их изготовления. Известно, что нанесение «рисунка» структуры на исходный полупроводниковый материал выполняется при помощи нескольких последовательных циклов фотолитографии (проецирование рисунка через фотошаблон называемый маской) При этом отдельные элементы формируемых полупроводниковых приборов выполняются с использованием различных масок, например, коллекторные и эмиттерные переходы биполярных или выводы стока и истока полевых транзисторов.
Первоначально изготавливаются все фотошаблоны, обеспечивающие соединение всех ША с ШД. В этом случае по всем адресам из ПЗУ считывается одинаковый сигнал, например лог. 1. Далее один из шаблонов заменяют другим, в котором отсутствуют некоторые области приборов (например, коллекторные переходы транзисторов), расположенные согласно таблице истинности между шинами в тех местах, где соединение должно отсутствовать. Данный метод позволяет для изготовления ПЗУ с различной информацией заменять только один из фотошаблонов, что существенно ускоряет и удешевляет процесс производства.
Как следует из описания, масочные ПЗУ имеют простую и регулярную структуру, что предполагает выполнение ИС, способных хранить большие объемы информации.
При производстве небольших партий ПЗУ изготовление по заказу потребителя даже одной маски может оказаться слишком дорогостоящим, а время выполнения заказа – слишком большим. Поэтому многие предприятия выпускают ПЗУ, программируемые пользователем. В ПЗУ этого типа потребитель может сам записать требуемую ему информацию. Существует много видов ПЗУ, программируемых пользователем. ПЗУ, в которое информацию можно записать только однократно (навсегда), называется программируемым ПЗУ (ППЗУ).
Перепрограммируемое ПЗУ в процессе функционирования цифрового устройства используется как ПЗУ. Оно отличается от ПЗУ тем, что допускает обновление однажды занесенной информации, т.е. в нем предусматривается режим записи. Однако в отличие от ОЗУ запись информации требует отключения ППЗУ от цифрового устройства, производится с использованием специальных предназначенных для записи устройств (программаторов) и занимает длительное время, достигающее десятков минут. Перепрограммируемые ПЗУ дороже ПЗУ, и их применяют в процессе отладки программы, после чего их можно заменить более дешевым ПЗУ.
13.Внешние запоминающие устройства МП систем. Гибкие магнитные диски. Жесткие диски. Оптические носители информации. Магнитооптические диски. (см. 9 и 10)
14.Переферийные устройства МПС.
Сама передача данных между ЭВМ и периферийными устройствами происходит быстро, но обеспечение правильной передачи занимает намного больше времени. Типичная операция ввода происходит следующим образом:
1. Периферийное устройство сигнализирует ЦП о том, что имеются новые данные. Устройство ввода-вывода должно соответствующим образом сформировать сигнал и держать его до тех пор. пока ЦП его не примет;
2. Периферийное устройство посылает данные в ЦП. Устройство ввода-вывода должно хранить их до тех пор, пока ЦП не будет готов их считать;
3. Центральный процессор считывает данные. Устройство ввода-вывода должно иметь блок дешифрирования, который выбирает определенную часть УВВ (или порт
). Считывание данных должно снять сигнал, свидетельствующий о том, что данные имеются; результатом этого может быть также подтверждение, посланное периферийному устройству, о том что оно может посылать новые данные.
Операции вывода во многом похожи на операции ввода. Периферийное устройство оповещает ЦП, что оно готово принять данные. После этого ЦП направляет данные вместе с сигналом (стробом), который указывает периферийному устройству. что данные имеются. Устройство ввода-вывода
формирует соответствующим образом данные и сигналы управления и сохраняет данные в течение времени, необходимого для их использования периферийным устройством. Данные вывода должны храниться намного дольше, чем данные ввода. так как механические устройства, отображающие их, реагируют намного медленнее, чем ЭВМ.
Устройство ввода-вывода
должно выполнять множество задач простого интерфейса. Оно должно придать сигналам подходящий формат как для управляющего, так и для периферийного устройства. Центральному процессору требуются сигналы с определенными уровнями напряжения. периферийные устройства могут использовать много различных типов сигналов, включая непрерывные (аналоговые) сигналы различного тока и напряжения. Для сигналов, идущих на большие расстояния или работающих на большие нагрузки, требуются усилители.
Устройство ввода-вывода
может также выполнять некоторые функции, которые выполняет ЦП. Эти функции включают в себя преобразование данных из последовательного кода в параллельный, включение или исключение специальных символов, отмечающих начало или конец передачи данных. а также преобразование кодов обнаружения ошибок таких как проверка на четность.
Устройство ввода-вывода
может выполнить эти задачи аппаратными средствами быстрее, чем ЦП может выполнить их программными методами. Устройство ввода-вывода
ЭВМ может быть программируемым и даже содержать процессор для реализации его некоторых задач.
Адресная шина передает адрес порта ввода или вывода, который нужен для использования ЦП. Сигнал ввода-вывода определяет направление передачи. По шине данных осуществляется передача информации между устройствами. Шина управления передает сигналы, указывающие, что данные готовы и что передача завершена. Что касается шин между ЦП и ЗУ, то некоторые из них могут быть одними и теми же, но разделенными во времени для выполнения различных операций.
Более того, шины могут соединять ЦП как с памятью, так и с УВВ. Одна линия управления может определять назначение блоков. Действительно, некоторые ЭВМ (например, Motorola 6800) полностью совмещают по адресному полю память и УВВ; они обращаются к устройствам ввода или вывода так же, как к ячейкам памяти.
Современные ЭВМ имеют прямую связь межу памятью и УВВ, что позволяет осуществлять передачу данных к периферийным устройствам и обратно без участия ЦП. Этот метод передачи данных называется прямым доступом к памяти
(ПДП). Преимуществом ПДП является то, что скорость передачи обеспечивается только временем доступа к памяти (обычно менее 1 мкс). Для передачи данных через ЦП требуется несколько команд, и на это уходит в 10-20 раз больше времени. Прямой доступ к памяти применяется с быстродействующими периферийными устройствами, такими как магнитные диски, быстродействующие линии связи или дисплеи.
15. Понятие архитектуры и основные элементы
Основные понятия и характеристики архитектуры микропроцессоров
Микропроцессор
(МП) - это программно управляемое устройство, которое предназначено для обработки цифровой информации и управления процессом этой обработки и выполнено в виде одной или нескольких больших интегральных схем (БИС).
Понятие большая интегральная схема
в настоящее время четко не определено. Ранее считалось, что к этому классу следует относить микросхемы, содержащие более 1000 элементов на кристалле. И действительно, в эти параметры укладывались первые микропроцессоры. Например, 4-разрядная процессорная секция микропроцессорного комплекта К584, выпускавшегося в конце 1970-х годов, содержала около 1500 элементов. Сейчас, когда микропроцессоры содержат десятки миллионов транзисторов и их количество непрерывно увеличивается, под БИС будем понимать функционально сложную интегральную схему.
Микропроцессорная система
(МПС) представляет собой функционально законченное изделие, состоящее из одного или нескольких устройств, основу которой составляет микропроцессор.
Микропроцессор характеризуется большим количеством параметров и свойств, так как он является, с одной стороны, функционально сложным вычислительным устройством, а с другой - электронным прибором, изделием электронной промышленности. Как средство вычислительной техники он характеризуется прежде всего своей архитектурой
, то есть совокупностью программно-аппаратных свойств, предоставляемых пользователю. Сюда относятся система команд, типы и форматы обрабатываемых данных, режимы адресации, количество и распределение регистров, принципы взаимодействия с оперативной памятью и внешними устройствами (характеристики системы прерываний, прямой доступ к памяти и т. д.). По своей архитектуре микропроцессоры разделяются на несколько типов (рис. 1.1).
Универсальные микропроцессоры
предназначены для решения задач цифровой обработки различного типа информации от инженерных расчетов до работы с базами данных, не связанных жесткими ограничениями навремя выполнения задания. Этот класс микропроцессоров наиболее широко известен. К нему относятся такие известные микропроцессоры, как МП ряда Pentium фирмы Intel и МП семейства Athlon фирмы AMD.

Рис. 1.1.
Классификация микропроцессоров
Характеристики универсальных микропроцессоров:
- разрядность: определяется максимальной разрядностью целочисленных данных, обрабатываемых за 1 такт, то есть фактически разрядностью арифметико-логического устройства (АЛУ);
- виды и форматы обрабатываемых данных;
- система команд, режимы адресации операндов;
- емкость прямоадресуемой оперативной памяти: определяется разрядностью шины адреса;
- частота внешней синхронизации. Для частоты синхронизации обычно указывается ее максимально возможное значение, при котором гарантируется работоспособность схемы. Для функционально сложных схем, к которым относятся и микропроцессоры, иногда указывают также минимально возможную частоту синхронизации. Уменьшение частоты ниже этого предела может привести к отказу схемы. В то же время в тех применениях МП, где не требуется высокое быстродействие, снижение частоты синхронизации - одно из направлений энергосбережения. В ряде современных микропроцессоров при уменьшении частоты он переходит в <спящий режим>, при котором сохраняет свое состояние. Частота синхронизации в рамках одной архитектуры позволяет сравнить производительность микропроцессоров. Но разные архитектурные решения влияют на производительность гораздо больше, чем частота;
- производительность: определяется с помощью специальных тестов, при этом совокупность тестов подбирается таким образом, чтобы они по возможности покрывали различные характеристики микроархитектуры процессоров, влияющие на производительность.
Универсальные микропроцессоры принято разделять на CISC
- и RISC-микропроцессоры.
CISC-микропроцессоры
(Completed Instruction Set Computing - вычисления с полной системой команд) имеют в своем составе весь классический набор команд с широко развитыми режимами адресации операндов. Именно к этому классу относятся, например, микро процессоры типа Pentium. В то же время RISC-микропроцессоры
(reduced instruction set computing - вычисления с сокращенной системой команд) используют, как следует из определения, уменьшенное количество команд и режимов адресации. Здесь прежде всего следует выделить такие микропроцессоры, как Alpha 21x64, Power PC. Количество команд в системе команд - наиболее очевидное, но на сегодняшний день не самое главное различие в этих направлениях развития универсальных микропроцессоров. Другие различия мы будем рассматривать по мере изучения особенностей их архитектуры.
Однокристальные микроконтроллеры
(ОМК или просто МК) предназначены для использования в системах промышленной и бытовой автоматики. Они представляют собой большие интегральные схемы, которые включают в себя все устройства, необходимые для реализации цифровой системы управления минимальной конфигурации: процессор (как правило, целочисленный), ЗУ команд, ЗУ данных, генератор тактовых сигналов, программируемые устройства для связи с внешней средой (контроллер прерывания, таймеры-счетчики, разнообразные порты ввода/вывода), иногда аналого-цифровые и цифро-аналоговые преобразова- тели и т. д. В некоторых источниках этот класс микропроцессоров назы- вается однокристальными микро-ЭВМ (ОМЭВМ).
В настоящее время две трети всех производимых микропроцессорных БИС в мире составляют МП этого класса, причем почти две трети из них имеет разрядность, не превышающую 16 бит. К классу однокристальных микроконтроллеров прежде всего относятся микропроцессоры серии MCS-51 фирмы Intel и аналогичные микропроцессоры других производителей, архитектура которых де-факто стала стандартом.
Отличительные особенности архитектуры однокристальных микроконтроллеров:
- физическое и логическое разделение памяти команд и памяти данных (гарвардская архитектура), в то время как в классической неймановской архитектуре программы и данные находятся в общем запоминающем устройстве и имеют одинаковый механизм доступа;
- упрощенная и ориентированная на задачи управления система команд: в МК, как правило, отсутствуют средства обработки данных с плавающей точкой, но в то же время в систему команд входят команды, ориентированные на эффективную работу с датчиками и исполнительными устройствами, например, команды обработки битовой информации;
- простейшие режимы адресации операндов.
Основные характеристики микроконтроллеров
(в качестве примера численные значения представлены для MK-51):
- Разрядность (8 бит).
- Емкость внутренней памяти команд и памяти данных, возможности и пределы их расширения:
- внутренняя память команд - 4 Кбайт (в среднем команда имеет длину 2 байта, таким образом, во внутренней памяти может быть размещена программа длиной около 2000 команд); возможность наращивания за счет подключения внешней памяти до 64 Кбайт;
- память данных на кристалле 128 байт (можно подключить внешнюю память общей емкостью до 64 Кбайт).
- Тактовая частота:
- внешняя частота 12 МГц;
- частота машинного цикла 1 МГц.
- Возможности взаимодействия с внешними устройствами: количество и назначение портов ввода-вывода, характеристики системы прерывания, программная поддержка взаимодействия с внешними устройствами.
Наличие и характеристики встроенных аналого-цифровых преобразователей (АЦП) и цифро-аналоговых преобразователей (ЦАП) для упрощения согласования с датчиками и исполнительными устройствами системы управления.
Секционированные микропроцессоры
(другие названия: микропрограммируемые и разрядно-модульные) - это микропроцессоры, предназначенные для построения специализированных процессоров. Они представляют собой микропроцессорные секции относительно небольшой (от 2 до 16) разрядности с пользовательским доступом к микропрограммному уровню управления и средствами для объединения нескольких секций.
Такая организация позволяет спроектировать процессор необходимой разрядности и со специализированной системой команд. Из-за своей малой разрядности микропроцессорные секции могут быть построены с использованием быстродействующих технологий. Совокупность всех этих факторов обеспечивает возможность создания процессора, наилучшим образом ориентированного на заданный класс алгоритмов как по системе команд и режимам адресации, так и по форматам данных.
Одним из первых комплектов секционированных микропроцессоров были МП БИС семейства Intel 3000. В нашей стране они выпускались в составе серии К589 и 585. Процессорные элементы этой серии представляли собой двухразрядный микропроцессор. Наиболее распространенным комплектом секционированных микропроцессоров является Am2900, основу которого составляют 4-разрядные секции. В нашей стране аналог этого комплекта выпускался в составе серии К1804. В состав комплекта входили следующие БИС:
- разрядное секционное АЛУ;
- блок ускоренного переноса;
- разрядное секционное АЛУ с аппаратной поддержкой умножения;
- типа схем микропрограммного управления;
- контроллер состояния и сдвига;
- контроллер приоритетных прерываний.
Основным недостатком микропроцессорных систем на базе секционированных микропроцессорных БИС явилась сложность проектирования, отладки и программирования систем на их основе. Использование специализированной системы команд приводило к несовместимости разрабатываемого ПО для различных микропроцессоров. Возможность создания оптимального по многим параметрам специализированного процессора требовала труда квалифицированных разработчиков на протяжении длительного времени. Однако бурное развитие электронных технологий привело к тому, что за время проектирования специализированного процессора разрабатывался универсальный микропроцессор, возможности которого перекрывали гипотетический выигрыш от проектирования специализированного устройства. Это привело к тому, что в настоящее время данный класс микропроцессорных БИС практически не используется.
Процессоры цифровой обработки сигналов,
или цифровые сигнальные процессоры
, представляют собой бурно развивающийся класс микропроцессоров, предназначенных для решения задач цифровой обработки сигналов - обработки звуковых сигналов, изображений, распознавания образов и т. д. Они включают в себя многие черты однокристальных микро контроллеров: гарвардскую архитектуру, встроенную память команд и данных, развитые возможности работы с внешними устройствами. В то же время в них присутствуют черты и универсальных МП, особенно с RISC-архитектурой: конвейерная организация работы, программные и аппаратные средства для выполнения операций с плавающей запятой, аппаратная поддержка сложных специализированных вычислений, особенно умножения.
16. МП – комплекты.
Микропроцессорные средства включают: МПК БИС, однокристальные и одноплатные микропроцессоры, микро-ЭВМ, микроконтроллеры, устройства ввода-вывода, хранения, отображения, коммутации информации и т. п. Основой построения МПС являются: МПК БИС, микросхемы запоминающих устройств и преобразования вида информации (АЦП, ЦАП).
Микропроцессорный комплект БИС представляет собой набор электрически совместимых цифровых БИС, достаточный для построения различных МПУ. Существующие МПК БИС можно разделить на две группы: с фиксированной системой команд и секционированные. Основное различие этих комплектов заключается в способе реализации устройства управления. В первом случае оно реализовано на комбинационных схемах и конструктивно объединено с арифметическим устройством в одной БИС. Это объединение представляет собой функционально законченный микропроцессор с фиксированной системой команд, ориентированной на широкий круг решаемых задач. Такие МПК обычно имеют стандартные отладочные средства и относительно развитое программное обеспечение, что обеспечивает их широкое применение.
Примером однокристального микропроцессора является центральный процессорный элемент КР580ИК.80. Особенности построения и реализации арифметического и управляющего устройств делают недоступным программисту микропрограммный уровень управления. Он оперирует командами, которые не может изменить. Вместе с тем проектирование конструктивно встраиваемых в РЭА МПУ предполагает их специализацию в соответствии с реализуемым алгоритмом. Кроме того, как .будет показано в гл. 2, одним из основных требований, предъявляемых к МПУ, является реальный масштаб времени вычислений решаемых алгоритмов. Необходимость специализации системы команд и структуры проектируемых МПУ ограничивает применение однокристальных микропроцессоров в РЭА.
Основной элементной базой конструктивно встраиваемых в РЭА МПУ являются секционированные МПК БИС, у которых в отличие от однокристальных микропроцессоров управляющее устройство реализовано на принципах микропрограммного управления. Такой подход обеспечивает доступ разработчика к уровню микрокоманд, что позволяет изменять команды и соответствующие им микропрограммы исходя из решаемых алгоритмов. Секционированные МПК имеют различные системы команд, разрядность, типы интерфейса ввода-вывода и т. п. Проектируемые на основе секционированных МПК МПУ обладают большой гибкостью, так как расширение функциональных возможностей обеспечивается изменением отдельных микрокоманд или заменой всей памяти микропрограмм.
Построение арифметического устройства требуемой разрядности осуществляется объединением 4-, 8- или 16-разрядных процессорных секций. Микропрограммное устройство управления выполняется на одной или нескольких БИС. Соединив между собой несколько БИС микропрограммного управления, можно увеличить объем микропрограммной памяти. Объединение арифметического и управляющего устройств позволяет получить базовую структуру микропроцессора. Подключение к ней специализированных БИС ввода-вывода, вспомогательных аппаратных микропроцессоров и других специализированных микросхем приводит к повышению производительности МПУ.
Использование секционируемых МПК обеспечивает гибкость проектирования как по аппаратным решениям, так и по реализации требуемой системы команд. Однако при этом предполагается, что разработчик знает возможности и особенности всех микросхем, входящих в состав МПК, принципы объединения их в уст-ройство, организацию синхронизации в устройстве; владеет методами разработки и отладки микропрограмм. Вместе с тем работа на микропрограммном уровне создает и определенные трудности. Микропрограммный уровень определяется конкретными схемными решениями, поэтому программирование на этом уровне требует от разработчика знаний аппаратных особенностей МПК, учета временных соотношений и т. п. Кроме того, разработка оригинальной .системы команд приведет к необходимости проектирования дополнительных аппаратных средств и программного обеспечения, предназначенного для отладки программ. Это обуславливает увеличение сроков [разработки и повышение стоимости МПУ, проектируемых «а основе секционируемых МПК БИС.
Микропроцессорные комплекты БИС отличаются своими характеристиками, основными из которых являются: число БИС в комплекте, число внутренних магистралей, разрядность, система микрокоманд, число регистров общего назначения, число уровней прерывания, быстродействие, число буферных регистров (портов) ввода-вывода (Явв, ЯВЫв) и др.
Число БИС в комплекте во многом определяет функциональные возможности МПК. Наличие в составе комплекта разнообразных специализированных БИС позволяет проектировать функционально законченные МПУ при минимальном использовании микросхем средней и малой степени интеграции. Если число специали-зированных БИС в МПК ограничено, то некоторые функциональные узлы приходится проектировать на (микросхемах малой и средней степени интеграция, что снижает плотность упаковки МПУ и ухудшает его конструктивные параметры. Кроме того, использование специализированных БИС для аппаратной реализации некоторых сложных (с вычислительной точки зрения) функций повышает производительность МПУ.
Как было показано в § 1.1, число внутренних магистралей микропроцессорных БИС колеблется от одной до трех. При выборе МПК необходимо учитывать, что уменьшение числа магистралей снижает процент использования площади кристалла под магистрали, а также быстродействие этих микросхем.
Большинство современных МПК имеют разрядность 4, 8 или 16 бит. Ограничение разрядности обусловлено размерами кристалла и технологическими допусками изготовления логических элементов. Биполярные секционированные МПК обычно имеют разрядность 4 и 8 бит. Разрядность МПК, выполненных по МОП-тех-нологии, достигает 16 бит.
Система микрокоманд (как и число БИС) определяет функциональные возможности МПК. Системы микрокоманд распространенных МПК БИС, их (форматы, разрядность, особенности реализации подробно рассмотрены в [6 - 12]. Отметим, что при выборе типа МПК необходимо, чтобы его система микрокоманд соот-ветствовала решаемому алгоритму. При этом особое значение приобретают микрокоманды, реализующие специальные функции, например умножение, деление, нормализацию чисел и т. п. Эти функции могут быть реализованы аппаратно на специализированных БИС, либо программно, например в МПК БИС КМ1804 [12]. Для ряда применений, не требующих высоких скоростей обработки информации, программная реализация специальных функций может оказаться предпочтительней, так как не требует дополнительных аппаратных затрат.
Число регистров общего назначения (РОН) определяет емкость внутренней сверхоперативной памяти МП и колеблется от 2 до 16. Увеличение числа РОН в МПК дает возможность хранить в них большее число исходных данных и промежуточных результатов вычислений. При этом в микропрограмме вычислений будут шире использоваться микрокоманды типа регистр-регистр, а следовательно, уменьшится число обращений к ЗУ. Быстродействие выполнения такой микропрограммы будет выше.
Прерывание представляет собой процедуру обмена данными с внешними устройствами. При этом инициатором обмена является внешнее устройство, которое посылает сигнал «Запрос на прерывание». Получив этот сигнал, МП приостанавливает выполнение основной программы и переходит к реализации специальной подпрограммы обмена, называемой подпрограммой обработки прерываний. Эта подпрограмма выключает ряд действий, описание которых можно найти в [10, 13]. Число уровней прерывания определяет число внешних устройств, способных обращаться к микропроцессору и обмениваться с ним информацией. Этот параметр имеет особое значение при использовании МПК для построения систем сбора и распределения данных, характеризующихся большим числом датчиков информации, имеющих различный приоритет.
Параметром, характеризующим быстродействие МПК, обычно является время цикла выполнения простейшей микрооперации. Поскольку микрокоманды состоят из последовательности микроопераций различной длины, то время цикла выполнения микроопераций дает очень относительное представление о реальном времени реализации микрокоманд. Один из методов определения времени выполнения микрокоманд приведен в Приложении. При совместном включении нескольких арифметических и управляющих устройств с различным быстродействием такт работы всего МПУ определяется длительностью такта устройства, обладающего меньшим быстродействием.
Число буферных регистров (портов) ввода-вывода является параметром, характеризующим структуру МПК БИС. Для секционированных МПК характерно использование многопортовых структур (обычно двух-трех). Увеличение числа портов ввода-вывода приводит к уменьшению длительности цикла выполнения микро-команды, упрощает построение МПУ, реализованных по «конвейерной» структуре. Остальные параметры МПК такие же, как и у Других цифровых микросхем. Это прежде всего уровни напряжений логических сигналов (U0 и U'), потребляемая мощность, устойчивость к изменениям напряжения питания, коэффициент объединения по входу, коэффициент разветвления по выходу (нагрузочная способность), помехоустойчивость и др.
Функциональная сложность МПК БИС определяется максимальными размерами полупроводниковых кристаллов, изготовление которых может обеспечить современный уровень развития технологии. Небольшие размеры кристаллов (до 50 мм2) требуют упрощения структур и ограничения разрядности БИС. Для опреде-ления содержимого внутренних регистров МП требуются специальные программы, обеспечивающие вывод содержимого регистров из МП. Большее число выводов БИС упрощает разработку МПУ. Однако корпуса, имеющие большее число выводов, занимают большую площадь на плате. Ограниченное число внешних вы-водов приводит к необходимости использования одних и тех же выводов для нескольких целей, например для ввода и вывода данных.
При построении МПУ необходимо обеспечить электрическое сопряжение между микросхемами МПК БИС. Условиями правильного сопряжения являются одинаковые представления логических О и 1 (U°, U1) и обеспечение допустимой нагрузки на каждый выход. При построении МПУ на одном или электрически совместимых МПК БИС первое условие выполняется и задача электрического сопряжения сводится к обеспечению допустимой нагрузки на каждый выход. Для МПК, выполненных по биполярной технологии, это условна может быть записано в виде неравенства [4]
I1 макс
Умножитель параллельный (8X8) КР1802ВРЗ 2206.42 - 2 tу=200 не; Рп = 3 Вт
Умножитель параллельный (12X12) КР1802ВР4 2136.64 - 1 tу=200 не; Рп=4 Вт Пвв=2; Пвыв=1
Умножитель параллельный (16X16) КР1802ВР5 2136.64 - 1 ty=200 не; Рп=5 Вт Пвв=2; ПвыВ=1
Сумматор на четыре входа К.Р1802ИМ1 2207.48 - 1 tс = 150 не Пвв=4; Пвыв=1
4-разрядная процессорная секция КМ1804ВС1 Серия КМ1804 2123.40 - 6 Uв=5 В±10%; Гц = 110 не.
Разрядность - кратная 4. Система команд по ОСТ 11.305.909 - 82 Аналог Ат2901
Схема формирования ускоренного переноса КМ1804ВР1 201.16 - 16
Аналог Ат2902
Схема управления последовательностью мк КМ1804ВУ1, КМ1804ВУ2 2121.28 - 1 2121.28 - 1
Аналоги: Ат2909 Ат2911
Схема выбора адреса следующей мк КМ1804ВУЗ 201.16 - 16 16 инструкций Ат2918
Параллельный 4-разрядный регистр КМ1804ИР1 201.16 - 16 Гц=20 не; Рп=0,65 Вт Ат2918
4-разрядная процессорная секция КМ1804ВС2 2123.40 - 6 Число РОН 16 Ат2903
Схема управления состоянием и сдвигами КМ1804ВР2 2123.40 - 6 t3 - 60 не. Число шин 2 Ат2904
Схема управления микропрограммой КМ1804ВУ4 2123.40 - 6 Гц=95 не; Рп=1,7 Вт Ат2910
Микропроцессорный комплект БИС К1800 выполнен по ЭСЛ-функционально-технологическому принципу. Микросхемы отличаются повышенными быстродействием и потребляемой мощностью. Архитектура МПК К1800, как и предыдущих, обеспечивает наращивание разрядности, микропрограммное управление, конвейерную организацию вычислений. Отличительной особенностью ЭСЛ-комплекта является ограниченный функциональный состав БИС, что затрудняет построение законченных МПУ только на МПК К1800. Комплект БИС К1800 электрически совместим с цифровыми микросхемами серий К500, К1500. Наличие в составе комплекта двунаправленного транслятора К1800ВА4 позволяет использовать совместно с К1800 МПК БИС ТТЛШ, например КР1802, КМ1804. При построении МПК К1800 использовался ряд схемо-технических и конструктивно-технологических особенностей построения быстродействующих микросхем, что позволило достигнуть степени интеграции до 1000 логических элементов (ЛЭ) на кристалле, снизить потребляемую мощность до 4 - 5 мВт на один ЛЭ и обеспечить время задержки 1 - 1,5 не на один ЛЭ [16].
1.3. Функциональная схема операционного устройства, построенного на МПК БИС К.Р1802
Микропроцессорный комплект БИС К588 выполнен по КМОП-функцианально-технологичесшму принципу. Важнейшей отличительной особенностью таких микросхем является низкая потребляемая мощность. В статическом режиме потребляемая мощность на один ЛЭ примерно в 100 раз меньше, чем у ТТЛ ЛЭ. В дина-мическом режиме (мощность, потребляемая КМОП-ехемами, увеличивается при повышении тактовой частоты. При тактовой частоте 1 - 2 МГц она всего в 5 - 10 раз меньше мощности, потребляемой ТТЛ-схемами. Комплект БИС К588 имеет несколько меньшее быстродействие, чем ТТЛШ МПК. Однако МПК К588 обеспечивает построение МПУ РЭА с ограниченным потреблением энергии.
Рассмотрим несколько примеров построения различных аппаратных средств на базе рассмотренных МПК БИС.
Пример 1.1. На рис. 1.3 приведена схема 16-разрядного операционного устройства МП [17]. Операционное устройство выполняет арифметические и логические операции над битами, полями битов, 16-разрядными словами; сдвиг 16-разрядных слов на один разряд вправо и влево. Управление работой операционного устройства осуществляется по шине микрокоманд (ШМК) и шине адреса (ШАД). Передача операндов осуществляется по шинам А и В, результат операции выдается на шину А.
Синхронизация считывания информации из регистров и записи результата в регистр выполняется синхроимпульсом (СИ), импульсами чтения (Чт), импульсами записи (Зп). Результат операции сопровождается выдачей признаков равенства нулю (ПН) результата, переполнения разрядной сетки (ПП) и расширения (ПР). Арифметическое устройство выполнено на двух БИС КР1802ВС1 (Dl, D2). Сверхоперативная память данных и результата выполнена на четырех БИС РОН КР1802ИР1 (D3 - D6). Емкость памяти 16X16.
Пример 1.2. Процессор микро-ЭВМ общего назначения. На рис. 1.4 приведена функциональная схема процессора с системой команд и интерфейсом микро-ЭВМ «Электроника-60» [18]. Процессор предназначен для применения в МПУ с жестко ограниченными энергетическими ресурсами и быстродействием до 400 тыс. коротких операций. При этом может быть использовано математическое обеспечение микро-ЭВМ «Электроника-60». Процессор выполнен на БИС МПК К588: К588ВС2 (D6), К588ВУ2 (D1 - D5), К588ВГ1 (D7). Каждая БИС управляющей памяти (D1 - D5) отличается информационным содержанием.
1.4. Функциональная схема микропроцессора, построенного на МПК БИС К588
Данные адреса и команды передаются по 16-разрядной совмещенной магистрали данных-адреса ДА0 - ДА15. Эта магистраль соединена с каналом К1 D6 и регистрами команд управляющей памяти (Dl - D5).
Четыре БИС (Dl - D4) формируют микрокоманды, управляющие работой ДУ (D6). 12-разрядные МК объединяются по схеме «проводное И» и подключаются к регистру микрокоманд АУ. Системный контроллер (СК) К588ВП управляется 5-разрядной МК, формируемой D5. Свободные разряды МК (МК5 - МКИ) вырабатывают сигналы разрешения прерывания по запросам ППРО - ППР4, ППРТ и сигнал «Останов». Поскольку длина микропрограмм, записанных в Dl - D5, различная, синхронизация приема кода команды осу-ществляется по сигналам «Конец команды», объединенным по схеме «Про» водное И».
Таблица 1.3
Новер линии Обозначение линий системной магистрали Назначение линий системной магистрали
1 - 5 СИА, Ввод, Вывод, СИП, Байт Линии сигналов синхронизации активного уст-ройства, ввода, вывода, синхронизации пассивного устройства и вывода байта
6 Останов Линия сигнала аппаратного останова
7 ПИТН Линия сигнала источника питания, сигнализи-рующая о нормальном уровне напряжения
питания
8 - 10 ТПДП, ППДП,
ппд Линии сигналов требования, представления и подтверждения захвата системной магистрали внешним устройством для ПДП
11, 12 Пуск 0, Пуск 1 Линии начального запуска процессора соединены с входами R0 и R1
13 - 17 ТПРО - ТПР4 Линии требования прерывания внешними уст-ройствами
18 ТПРТ Сброс Линия сигнала требования прерывания от таймера
19
Линия сигнала инициализации внешних устройств
20 - 24 ППРО - ППР4 Линии разрешения прерывания по запросам ТПРО - ТПР4
25, 26 ППРТ, Останов Линии разрешения прерывания по запросам ТПРТ и Останов
27, 28 а, С2 Линии управления магистральными приемо-передатчиками (активные уровни сигналов - низкие). При активном С1 направление передачи - от процессора, при активном С2- - к процессору. При пассивных уровнях - состояние «отключено»
29, 30 ТПР, ППР Линии сигналов требования и разрешения пре-рываний
31-46 ДАО - ДА 15 Двунаправленные линии передачи данных, адреса и команд
Внутри и внепроцессорный обмен информацией осуществляется по асинхронному принципу с помощью сигналов «Выдано» (В) и «Принято (Я). При этом сигналы «Принято» всех БИС объединены, а «Выдано» соединяются следующим образом: В1 СК и В АУ, В2 СК и В D1 - D3, ВЗ СК и В D4 и DS, При таком соединении сигналов синхронизации обеспечивается разделение во времени приема данных и команд и запрещение приема команды в D1 - DS при наличии разрешенного прерывания. Соединением выводов С и Ф1 АУ и СК с соответствующими выводами управляющей памяти обеспечивается синхронизация передачи-приема МК.
Код состояния АУ выдается в канал К2 и далее поступает в канал К2 D1 - D3. В регистр состояния (канал K2) D4 и DS поступают сигналы прерывания СК Лр1 - Пр4.
Сигналы R0 и Rl D1 - D5 предназначены для начального запуска процессора. При ошибочном обращении к магистрали СК вырабатывает сигнал Я, который переводит D1 - D5 в режим формирования микропрограммы прерывания, вызванной этим ошибочным обращением к магистрали.
Интерфейс системной магистрали процессора включает 46 линий (табл. 1.3), 30 из которых (1 - 10, 18, 19, 29-46) по назначению совпадает с соответствующими линиями интерфейса микро-ЭВМ «Электроника-60». Остальные линии (11 - 17, 20 - 28) являются дополнительными.
Система команд процессора включает все команды микро-ЭВМ «Электроника-60», а также команды расширенной арифметики с фиксированной точкой. Для повышения производительности процессора в микропрограммах применено совмещение во времени отдельных этапов выполнения команд: считывание последующей команды совмещено с выполнением текущей, считывание данных из памяти - с не зависящими от него операциями. Применяемый в процессоре МПК БИС К588 электрически совместим с микросхемами серий 564 (при напряжении питания 5 В) и микросхемами серии 530 (при подключении не более двух нагрузок). Для повышения нагрузочной способности выводов внешнего интерфейса БИС процессора их можно подключать к системной магистрали через приемопередатчик К588ВА1, обеспечивающий согласование с 20 ТТЛШ-нагрузками и работу на емкостную нагрузку до 300 пФ. Потребляемая процессором мощность в динамическом режиме около 100 мВт.
Развитие МПК ведется в направлениях, указанных в 1.1, а также путем [совершенствования технологии МОП-структур, что постепенно выдвигает КМОП БИС и СБИС в первые ряды не только по малой потребляемой мощности, но и по быстродействию
17.Регистры МП и способы их использования. Счетчик команд.
Регистр является устройством временного хранения данных и используется с целью облегчения арифметических, логических и пересылочных операций. Регистры МП 80386 являются расширением регистров прежних МП 8086, 80186, 80286. Все 16-разрядные регистры МП предыдущих поколений содержатся внутри 32-разрядной архитектуры. Микропроцессор 80386 включает шесть непосредственно доступных программисту регистров селекторов сегментов, которые содержат указатели сегментов. Значения этих селекторов могут быть загружены при исполнении программы и являются специфичными для задачи. Это значит, что регистры сегментов перезагружаются автоматически при переключении МП 80386 на другую задачу. За регистрами селекторов сегментов стоят реальные регистры кэш-памяти сегментов, которые содержат описания сегментов, указываемых селектором. Это сделано на аппаратном уровне для того, чтобы избежать дополнительной выборки из памяти в случае, когда требуется описание сегмента.
Регистры общего назначения
Восемь регистров общего назначения имеют длину в 32 бит и содержат адреса или данные. Они поддерживают операнды-данные длиной 1, 8, 16, 32 и 64 бит: битовые поля от 1 до 32 бит: операнды-адреса длиной 16 и 32 бит. Эти регистры называются ЕАХ, ЕВХ, ЕСХ, EDX, ESI, EDI, ЕВР, ESP. Доступ к младшим 16 бит этих регистров выполняется независимо. Это делается в большинстве ассемблеров при использовании 16-разрядных имен регистров: АХ, ВХ, СХ, DX, Sl, Dl, BP,SP.
Регистр системных флагов
Регистр EFLAGS управляет вводом-выводом, маскируемыми прерываниями, отладкой, переключением задач и включением исполнения в режиме виртуального МП 8086 в защищенной многозадачной среде - все это в дополнение к флагам состояния, которые отражают результат исполнения команды. Младшие 16 бит его представляют собой 16-разрядный регистр флагов и состояния МП 80286, называемый FLAGS, который наиболее полезен при исполнении программ для МП 8086 и 80286.
Регистры сегментов
Шесть 16-разрядных регистров содержат значения селекторов сегментов, которые указывают на текущие адресуемые сегменты памяти. Ниже перечислены эти регистры. Регистр сегмента программы (CS) - указывает на сегмент, который содержит текущую последовательность исполняемых команд. Процессор выбирает все команды из этого сегмента, используя содержимое счетчика команд как относительный адрес. Содержимое CS изменяется в результате выполнения внутрисегментных команд управления потоком, прерываний и исключений. Он не может быть загружен явным способом. Регистр сегмента стека (SS). Вызовы подпрограмм, записи параметров и активизация процедур обычно требуют области памяти, резервируемой под стек. Все операции со стеком используют регистр SS при обращении к стеку. В отличие от регистра CS регистр SS может быть загружен явно с помощью команды программы. Остальные четыре регистра являются регистрами сегментов данных (DS, ES, FS, GS), каждый из которых адресуется текущей исполняемой программой. Доступ к четырем раздельным областям данных имеет целью повысить эффективность программ, позволяя им обращаться к различным типам структур данных. Содержимое этих регистров может быть заменено под управлением программы.
Регистры управления сегменированной памятью
Регистр таблицы глобальных дескрипторов (GDTR). Содержит 32-разрядный линейный адрес и 16-разрядную границу таблицы глобальных дескрипторов. Регистр таблицы локальных дескрипторов (LDTR). Содержит 16-разрядный селектор для таблицы локальных дескрипторов. Так как эта таблица является специфичным для задачи сегментом, то она определяется значением селектора, хранимым в регистрах системного сегмента. Регистр дескриптора сегмента, связанный с этой таблицей, программно недоступен. Регистр таблицы дескрипторов прерываний (IDTR). Указывает на таблицу точек входа в программы обработки прерываний. Регистр содержит 32-разрядный линейный базовый адрес и 16-разрядную границу таблицы дескрипторов прерываний (IDT). Регистр задачи (TR). Указывает на информацию, необходимую процессору для определения текущей задачи. Регистр TR содержит 16-разрядный селектор дескриптора сегмента состояния задачи. Поскольку этот сегмент специфичен для задачи, то он определяется значениями селекторов, хранящихся в регистрах системного сегмента.
Указатель команд
Расширенный указатель команд (EIP) является 32-разрядным регистром. Он содержит относительный адрес следующей команды, подлежащей выполнению. Относительный адрес отсчитывается от начала сегмента текущей программы. Указатель команд непосредственно не доступен программисту, но он управляется явно командами управления потоком, прерываниями и исключениями. Младшие 16 бит регистра EIP называются IP и могут быть использованы процессором независимо. Это свойство полезно при исполнении команд МП 8086 и 80286, которые имеют только регистр IP.
Регистры управления
Микропроцессор 80386 имеет три 32-разрядных регистра управления (CRO, CR2 и CR3, a CR1 зарезервированы фирмой Intel), в которых хранятся состояния машины или глобальные состояния. Глобальное состояние - это такое состояние, к которому может получить доступ любой из логических блоков системы или которое управляет этими блоками. Вместе с регистрами системных адресов эти регистры хранят информацию о состоянии машины, которая влияет на все задачи в системе. Для доступа к регистрам управления определены команды их загрузки и сохранности содержимого. Системным программистам регистры управления доступны только через варианты команды MOV, которые позволяют их загружать или сохранять в регистрах общего назначения.
Регистры отладки
Шесть доступных программисту регистров отладки (DRO-DR3, DR6 и DR7) расширяют возможности отладки в МП 80386, они устанавливают точки останова по данным и позволяют устанавливать точки останова по командам без модификации сегментов программ. Регистры DRO-DR3 предназначены для четырех линейных точек останова. Регистры DR4 и DR5 зарезервированы фирмой Intel для будущих разработок. Регистр DR6 показывает текущее состояние точек останова, а регистр DR7 используется
Счетчик команд
— регистр процессора, содержащий адрес текущей выполняемой команды. В зависимости от архитектуры содержит либо адрес инструкции, которая будет выполняться, либо той, которая выполняется в данный момент.
В большинстве процессоров, после выполнения команды, если она не нарушает последовательности команд (например, команда перехода), счетчик автоматически увеличивается (постинкремент). Понятие счётчика команд сильно связано с фон Неймановской архитектурой, одним из принципов которой является выполнение команд друг за другом в определенной последовательности.
19.Система команд. Классификация команд
Материал из Википедии — свободной энциклопедии
 Текущая версия
(не проверялась) Текущая версия
(не проверялась)
Перейти к: навигация, поиск
Система команд
— соглашение о предоставляемых архитектурой средствах программирования, а именно: определённых типах данных, инструкций, системы регистров, методов адресации, моделей памяти, способов обработки прерываний и исключений, методов ввода и вывода.
Система команд представляется спецификацией соответствия (микро)команд наборам кодов (микро)операций, выполняемых при вызове команды, определяемых (микро)архитектурой системы. (При этом, на системах с различной (микро)архитектурой может быть реализована одна и та же система команд. Например, Intel Pentium и AMD Athlon имеют почти идентичные версии системы команд x86, но имеют радикально различный внутренний дизайн.)
Базовыми командами являются, как правило, следующие:
- арифметические, например «сложения» и «вычитания»;
- битовые, например «логическое и», «логическое или» и «логическое не»;
- присваивание данных, например «переместить», «загрузить», «выгрузить»;
- ввода-вывода, для обмена данными с внешними устройствами;
- управляющие инструкции, например «переход», «условный переход», «вызов подпрограммы», «возврат из подпрограммы».
Оптимальными в различных ситуациях являются разные способы построения системы команд.
- Если объединить наиболее часто используемую последовательность микроопераций под одной микрокомандой, то надо будет обеспечивать меньше микрокоманд. Такое построение системы команд носит название CISC (Complex Instruction Set Computer), в распоряжении имеется небольшое число составных команд.
- С другой стороны, это объединение уменьшает гибкость системы команд. Вариант с наибольшей гибкостью — наличие множества близких к элементарным операциям команд. Это RISC (Reduced Instruction Set Computer), в распоряжении имеются усечённые, простые команды.
- Еще большую гибкость системы команд можно получить используя MISC подход, построенный на уменьшении количества команд до минимального и упрощении вычислительного устройства обработки этих команд.
19. Структура и форматы команд.
Знание структуры и форматов команд ЭВМ является необходимой предпосылкой для программирования на языке ассемблера на данной ЭВМ. Структура команд ЭВМ в общем случае зависит от функций, которые она должна выполнять. Эти функции в свою очередь определяются классом задач, для решения которых предназначена ЭВМ и принципов, заложенных при ее реализации. Функциональные требования, как правило, определяют те параметры, которые влияют на структуру команд. В перечень этих параметров обычно включают: способы представления данных, список операций над этими данными, способы адресации данных, режимы работы ЭВМ, организацию системы прерываний и др.
Классификация команд
процессора обычно производится по функциональным признакам.
Выбранная структура команд определяет их форматы. Под форматом команды понимается управляющее слово, разделенное на поля определенного назначения и определенной длины (разрядности). В формате любой команды можно указать две основные части, одна из которых определяет действие, а другая определяет данные, над которыми будет произведено это действие. Обязательным полем в формате команды является поле кода операции КО, определяющей действия над данными, которые называют операндами. Операнды могут задаваться неявно, когда код операции предопределяет их. При явном указании операндов они либо присутствуют в самой команде, либо представлены своими адресами в так называемых адресных полях. Команды с операндами в своих полях практически не используются. В адресной части команды, служащей для указания местонахождение операндов, содержатся адреса ячеек ОП или номера регистров общего назначения (РОН).
Например, команда, состоящая из двух полей, имеет вид:
Поле КО в виде двоичного кода задает тип операции (например, сложение) и тип данных, например, сложение целых чисел или сложение чисел с плавающей запятой. Различные операции, с различными типами данных имеют различный код КО. В адресной части команды, в полях А указываются адреса операндов. k
и m
- количество разрядов, отводимых под код операции КО и под адресную часть А, соответственно. Значение определяется количеством всех команд в системе команд. Значение зависит от способов адресации, количества операндов, разрядности и количества РОН, предполагаемого объема памяти.
Адресная часть А может содержать несколько полей, каждое из которых определяет операнд. Количество адресных полей и их длина зависят от различных факторов. Например, для двуместных операций типа сложение (вычитание, умножение, и т.п.) адресная часть команды может содержать три адресных поля:
Схема выполнения трехадресной команды: [А3]:=[А1]*[А2]. Содержимое ячейки с адресом А1 - [А1] (первый операнд) и содержимое ячейки с адресом А2 - [А2] (второй операнд), извлеченные из памяти, вступают в операцию *, заданную полем КО, и результат операции пересылается (записывается) в ячейку памяти с адресом А3. В общем случае, в зависимости от количества адресных полей, принято различать команды: безадресные, одноадресные, двухадресные, трехадресные.
Кроме того, в процессорах применяют команды различных форматов в зависимости от уровней памяти, т.е. в зависимости от того, адрес какого типа указан в адресной части команды - адрес типа R, в котором указывается номер РОН, или адрес типа А – номер ячейки ОП. Отсюда различные типы форматов: RR – команды типа регистр-регистр, RM – команды типа регистр-память, MM - команды типа память-память.
Примеры двухадресных команд типов RR (1), RM (2), MM (3) :
Надо отметить, что количество разрядов k
для адресации РОН, меньше количества разрядов m
для адресации ячейки памяти А, т.к. количесво РОН значительно меньше количества ячеек памяти.
Все возможные преобразования, дискретной информации могут быть сведены к четырем основным видам:
- передача информации в пространстве (из одного блока ЭВМ в другой);
- передача информации во времени (хранение);
- логические (поразрядные) операции;
- арифметические операции.
ЭВМ, являющаяся универсальным преобразователем дискретной информации, выполняет указанные виды преобразований.
Обработка информации (решение задач) в ЭВМ осуществляется автоматически путем программного управления. Программа представляет собой алгоритм обработки информации (решение задачи), записанный в виде последовательности команд, которые должны быть выполнены машиной для получения результата.
Команда представляет собой код, определяющий операцию и данные, участвующие в операции. Команда содержит также в явной или не явной форме информацию об адресе, по которому помещается результат операции, и об адресе следующей команды.
По характеру выполняемых операций различают следующие основные группы команд:
а) команды арифметических операций над числами с фиксированной и плавающей точками;
б) команды десятичной арифметики;
в) команды логических операций;
г) команды передачи кодов;
д) команды операций ввода-вывода;
е) команды передачи управления;
ж) команды задания режима работы машины и др.
В команде, как правило, содержатся не сами операнды, а информация об адресах ячеек памяти или регистрах, в которых они находятся.
Команда в общем случае состоит из операционной и адресной частей (рис.2.2,а).
В свою очередь, эти части, что особенно характерно для адресной части, могут состоять из нескольких полей.
Структуры команд: а) обобщенная; б) четырех-; в) трех-;
г) двух -; д) одно -; е) безадресная
Операционная часть содержит код операции (КОП), который задает вид операции (сложение, умножение и др.). Адресная часть содержит информацию об адресах операндов и результате операции, а в некоторых случаях -информацию об адресе следующей команды.
Структура команды определяется составом, назначением и расположением полей в команде.
Форматом команды называют ее структуру с разметкой номеров разрядов (бит), определяющих границы отдельных полей команды, или с указанием числа бит в определенных полях.
Важной и сложной проблемой при проектировании ЭВМ является выбор структуры и форматов команды, т.е. ее длины, назначения и размерности отдельных ее полей. Естественно стремление разместить в команде в возможно более полной форме информацию о предписываемой командой операции. Однако в условиях, когда в современных ЭВМ значительно возросло число выполняемых различных операций и соответственно команд (в компьютерах с CISC-архитектурой более 200 команд) и значительно увеличилась емкость адресуемой основной памяти (32, 64 Мб), это приводит к недопустимо большой длине формата команды.
Действительно, число двоичных разрядов, отводимых под код операции, должно быть таким, чтобы можно было представить все выполняемые машинные операции. Если ЭВМ выполняет М различных операций, то число разрядов в коде операции
nком > log 2 M, например, при М=200, пкоп = 8.
Если основная память содержит S адресуемых ячеек (байт), то для явного представления только одного адреса необходимо в команде иметь адресное поле для одного операнда с числом разрядов
nA > log2S, например, при S = 64 Мб, nA = 26.
Вместе с тем для упрощения аппаратуры и повышения быстродействия ЭВМ длина формата команды должна быть согласована с выбираемой, исходя из требований к точности вычислений, длиной обрабатываемых машиной слов (операндов), составляющей для большинства применений 32 бита с тем, чтобы для операндов и команд можно было эффективно использовать одни и те же память и аппаратные средства обработки информации. Формат команды должен быть по возможности короче, укладываться в машинное слово или полуслово, а для ЭВМ с коротким словом (8-16 бит) должен быть малократным машинному слову. Решение проблемы выбора формата команды значительно усложняется в микропроцессорах, работающих с коротким словом.
Отмечавшиеся ранее характерные для процесса развития ЭВМ расширение системы (наборы) команд и увеличение емкости основной памяти, а особенно создание микроЭВМ с коротким словом, потребовали разработки методов сокращения длины команды. При решении этой проблемы существенно видоизменилась структура команды, получили развитие различные способы адресации информации.
Проследим изменения классических структур команд.
Чтобы команда содержала в явном виде всю необходимую информацию о задаваемой операции, она должна, как это показано на рис. 2.2,6, содержать следующую информацию:
А1 , А2; - адреса операндов, А3 - адрес результата, А4 _ адрес следующей команды (принудительная адресация команд).
Такая структура приводит к большей длине команды (например, при S = 200, S = 32 Мб длина команды - 108 бит) и неприемлема для прямой адресации операндов основной памяти. В компьютерах с RISC-архитектурой четырехадресные команды используются для адресации операндов, хранящихся в регистровой памяти процессора.
Можно установить, как это принято для большинства машин, что после выполнения данной команды, расположенной по адресу К (и занимающей L ячеек), выполняется команда из (К+L)-й ячейки. Такой порядок выборки команды называется естественным. Он нарушается только специальными командами (передачи управления). В таком случае отпадает необходимость указывать в команде в явном виде адрес следующей команды.
В трехадресной команде первый и второй адреса указывают ячейки памяти, в которых расположены операнды, а третий определяет ячейку, в которую помещается результат операции.
Можно условиться, что результат операции всегда помещается на место одного из операндов, например первого. Получим двухадресную команду т.е. для результата используется подразумеваемый адрес.
В одноадресной команде (подразумеваемые адреса имеют уже и результат операции и один из операндов. Один из операндов указывается адресом в команде, в качестве второго используется содержимое регистра процессора, называемого в этом случае регистром результата или аккумулятором (Akk). Результат операции записывается в тот же регистр:
Akk :=Аkk*ОП[А1].
Наконец, в некоторых случаях возможно использование безадресных команд (рис. 2.2,е), когда подразумеваются адреса обоих операндов и результата операции, например, при работе со стековой памятью.
С точки зрения программиста, наиболее естественны и удобны трехадресные команды. Однако из-за необходимости иметь большее число разрядов для представления адресов основной памяти и кода операции длина трехадресной команды становится недопустимо большой, и ее не удается разместить в машинном слове. Следует отметить, что очень часто в качестве операндов используются результаты предыдущих операций, хранимые в регистрах машины. По указанным причинам в современных ЭВМ применяют трехадресные команды для адресации регистров.
Способ расширения кодов операции
В машинах с коротким словом практически невозможно в одном формате команды, т.е. при фиксированном назначении ее полей, кодировать большое число различных операций и одновременно иметь гибкую форму адресации операндов. Это противоречие в машинах с коротким словом преодолевается расширением кодов операций в команде. Для задания небольшой группы основных операций (арифметических и др.) используется короткий код операции, а получаемая при этом сравнительно большая адресная часть команды позволяет реализовать гибкую, например двухадресную с многими модификациями, адресацию. Для задания других операций используются более длинные (расширяемые) коды операций, при этом сокращаемая адресная часть оставляет возможность лишь для более простой, например одноадресной адресации операндов. В пределе расширяемый код операции занимает весь формат команды (безадресная команда).
Обычно в ЭВМ используется несколько структур и форматов команд разной длины.
структуры команд достаточно схематичны. В действительности адресные поля команд большей частью содержат не сами адреса, а только информацию, позволяющую определить действительные (исполнительные) адреса операндов в соответствии с используемыми в командах способами адресации.
20. Команды пересылки. Арифметические команды. Логические операции.
Для удобства практического применения и отражения их специфики команды данной группы удобнее рассматривать в соответствии с их функциональным назначением, согласно которому их можно разбить на следующие группы команд:
•пересылки данных общего назначения
•ввода-вывода в порт
•работы с адресами и указателями
•преобразования данных
•работы со стеком
Команды пересылки данных общего назначения
К этой группе относятся следующие команды:
mov <операнд назначения>,<операнд-источник>
xchg <операнд1>,<операнд2>
mov - это основная команда пересылки данных
. Она реализует самые разнообразные варианты пересылки.
Отметим особенности применения этой команды:
!!! командой mov нельзя осуществить пересылку из одной области памяти в другую. Если такая необходимость возникает, то нужно использовать в качестве промежуточного буфера любой доступный в данный момент регистр общего назначения.
К примеру, рассмотрим фрагмент программы для пересылки байта из ячейки fls в ячейку fld:
masm
model small
.data
fls db 5
fld db ?
.code
start:
...
mov al,fls
mov fld,al
...
end start
!!! нельзя загрузить в сегментный регистр значение непосредственно из памяти. Поэтому для выполнения такой загрузки нужно использовать промежуточный объект. Это может быть регистр общего назначения или стек. В начале сегмента кода две команды mov, выполняющие настройку сегментного регистра ds. При этом из-за невозможности загрузить впрямую в сегментный регистр значение адреса сегмента, содержащееся в предопределенной переменной @data, приходится использовать регистр общего назначения ax;
!!! нельзя переслать содержимое одного сегментного регистра в другой сегментный регистр. Это объясняется тем, что в системе команд нет соответствующего кода операции. Но необходимость в таком действии часто возникает. Выполнить такую пересылку можно, используя в качестве промежуточных все те же регистры общего назначения. Вот пример инициализации регистра es значением из регистра ds:
mov ax,ds
mov es,ax
Но есть и другой, более красивый способ выполнения данной операции — использование стека и команд push и pop:
push ds ;поместить значение регистра ds в стек
pop es ;записать в es число из стека
!!! нельзя использовать сегментный регистр cs в качестве операнда назначения. Причина здесь простая. Дело в том, что в архитектуре микропроцессора пара cs:ip всегда содержит адрес команды, которая должна выполняться следующей. Изменение командой mov содержимого регистра cs фактически означало бы операцию перехода, а не пересылки, что недопустимо.
MOV
(
MOVe
operand
)
Пересылка операнда
Схема команды: mov приемник,источник
Назначение: пересылка данных между регистрами или регистрами и памятью.
Алгоритм работы: копирование второго операнда в первый операнд.
Состояние флагов после выполнения команды: !!
выполнение команды не влияет на флаги
Применение:
Команда mov применяется для различного рода пересылок данных, при этом, несмотря на всю простоту этого действия, необходимо помнить о некоторых ограничениях и особенностях выполнения данной операции:
•направление пересылки в команде mov всегда справа налево, то есть из второго операнда в первый;
•значение второго операнда не изменяется;
•оба операнда не могут быть из памяти (при необходимости можно использовать цепочечную команду movs);
•лишь один из операндов может быть сегментным регистром;
•желательно использовать в качестве одного из операндов регистр al/ax/eax, так как в этом случае TASM генерирует более быструю форму команды mov.
mov al,5
mov bl,al
mov bx,ds
MOV (MOVe operand to/from system registers)
Пересылка операнда в системные регистры (или из них)
Схема команды: mov приемник,источник
Назначение: пересылка данных между регистрами или регистрами и памятью.
Алгоритм работы: копирование второго операнда в первый.
Состояние флагов после выполнения команды:
11 07 06 04 02 00
OF SF ZF AF PF CF
? ? ? ? ? ?
Применение:
Команда mov применяется для обмена данными между системными регистрами. Это одна из немногих возможностей доступа к содержимому этих регистров. Данную команду можно использовать только на нулевом уровне привилегий либо в реальном режиме работы микропроцессора.
.286
;переключение микропроцессора в защищенный
режим36:
mov eax,cr0
bts eax,0
mov cr0,eax
XCHG (eXCHanGe) Обмен
Для двунаправленной пересылки данных применяют команду xchg
. Для этой операции можно, конечно, применить последовательность из нескольких команд mov, но из-за того, что операция обмена используется довольно часто, разработчики системы команд микропроцессора посчитали нужным ввести отдельную команду обмена xchg.
Схема команды: xchg операнд_1,операнд_2
Назначение: обмен двух значений между регистрами или между регистрами и памятью.
Алгоритм работы: обмен содержимого операнд_1 и операнд_2.
Состояние флагов после выполнения команды: выполнение команды не влияет на флаги
Применение:
Команду xchg можно использовать для выполнения операции обмена двух операндов с целью изменения порядка следования байт, слов, двойных слов или их временного сохранения в регистре или памяти. Альтернативой является использование для этой цели стека.
!! операнды должны иметь один тип.
!! Не допускается (как и для всех команд ассемблера) обменивать между собой содержимое двух ячеек памяти.
Пример 1
xchg ax,bx ;обменять содержимое регистров ax и bx
xchg ax,word ptr [si] ;обменять содержимое регистра ax
;и слова в памяти по адресу в [si]
Пример 2
;поменять порядок следования байт в слове
ch1 label byte
dw 0f85ch
...
mov al,ch1
xchg ch1+1,al
mov ch1,al
В наборе команд имеются следующие арифметические операции: сложение, сложение с учетом флага переноса, вычитание с заемом, инкременирование, декременирование, сравнение, десятичная коррекция, умножение и деление.
В АЛУ производятся действия над целыми числами без знака. В двухоперандных операциях: сложение (ADD), сложение с переносом (ADDC) и вычитание с заемом (SUBB) аккумулятор является первым операндом и принимает результат операции. Вторым операндом может быть рабочий регистр выбранного банка рабочих регистров, регистр внутренней памяти данных с косвенно-регистровой и прямой адресацией или байт непосредственных данных. Указанные операции влияют на флаги: пеполнения, переноса, промежуточного переноса и флаг четности в слове состояния процессора (PSW).
Использование разряда переноса позволяет многократно повысить точность при операциях сложения (ADDC) и вычитания (SUBB).
Выполнение операций сложения и вычитания с учетом знака может быть осуществлено с помощью программного управления флагом переполнения (OV) регистра PSW. Флаг промежуточного переноса (АС) обеспечивает выполнение арифметических операций в двоично-десятичном коде.
Операции инкременирования и декременирования на флаги не влияют.
Операции сравнения не влияют ни на операнд назначения, ни на операнд источника, но они влияют на флаги переноса.
Существуют три арифметические операции, которые выполняются только на аккумуляторе: две команды проверки содержимого аккумулятора А (JZ, JNZ), и команда десятичной коррекции при сложении двоично-десятичных кодов.
При операции умножения содержимое аккумулятора А умножается на содержимое регистра В и результат размещается следующим образом: младший байт в регистре В, старший - в регистре А.
В случае выполнения операции деления целое от деления помещается в аккумулятор А, остаток от деления - в регистр В.
В эту группу входят такие команды, как: ADD (сложение), ADC (сложение с переносом), INC (инкремент), AAA (коррекция кода ASCII при сложении), DAA (десятичная коррекция при сложении), SUB (вычитание), SBB (вычитание с заемом), DEC (декремент), NEG (отрицание), СМР (сравнение), AAS (коррекция кода ASCII при вычитании), DAS (десятичная коррекция при вычитании), MUL (умножение), IMUL (умножение целых чисел), ААМ (коррекция кода ASCII при умножении), DIV (деление), IDIV (деление целых чисел), AAD (коррекция кода ASCII при делении), CBW (перевод байта в слово), CWD (перевод слова в двойное слово).
К логическим операциям относятся операция логического И (&&) и операция логического ИЛИ (||). Операнды логических операций могут быть целого типа, плавающего типа или типа указателя, при этом в каждой операции могут участвовать операнды различных типов.
Операнды логических выражений вычисляются слева направо. Если значения первого операнда достаточно, чтобы определить результат операции, то второй операнд не вычисляется.
Логические операции не вызывают стандартных арифметических преобразований. Они оценивают каждый операнд с точки зрения его эквивалентности нулю. Результатом логической операции является 0 или 1, тип результата int.
Операция логического И (&&) вырабатывает значение 1, если оба операнда имеют нулевые значения. Если один из операндов равен 0, то результат также равен 0. Если значение первого операнда равно 0, то второй операнд не вычисляется.
Операция логического ИЛИ (||) выполняет над операндами операцию включающего ИЛИ. Она вырабатывает значение 0, если оба операнда имеют значение 0, если какой-либо из операндов имеет ненулевое значение, то результат операции равен 1. Если первый операнд имеет ненулевое значение, то второй операнд не вычисляется.
| Отрицание (инверсия)
, от латинского inversio
-переворачиваю
:
· соответствует частице НЕ, словосочетанию НЕВЕРНО, ЧТО;
· обозначение: не A, A, -A;
· таблица истинности:
Инверсия логической переменной истинна, если сама переменная ложна, и, наоборот, инверсия ложна, если переменная истинна.
- пример: A = {На улице идет снег}.
A={Не верно, что
на улице идет снег}
A={На улице не
идет снег};
- логическая схема (инвертор):
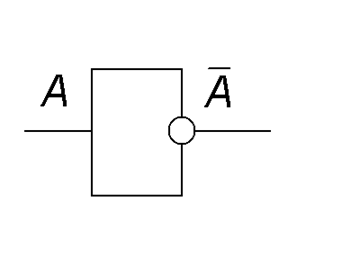
Логическое сложение (дизъюнкция)
, от латинского disjunctio - различаю
:
- соответствует союзу ИЛИ;
- обозначение: +, или, or, V;
- таблица истинности:
| A
|
B
|
F
|
| 0
|
0
|
0
|
| 0
|
1
|
1
|
| 1
|
0
|
1
|
| 1
|
1
|
1
|
Дизъюнкция ложна
тогда и только тогда, когда оба высказывания ложны
.
- пример: F={На улице светит солнце или
дует сильный ветер};
- логическая схема (дизъюнктор)
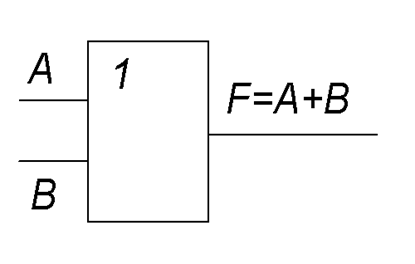
Логическое умножение (конъюкция)
, от латинского conjunctio -связываю
:
· соответствует союзу И
(в естественном языке: и А, и В
как А, так и В
А вместе с В
А, не смотря на В
А, в то время как В);
· обозначение: Ч, •, &, и, ^, and;
· таблица истинности:
| A
|
B
|
F
|
| 0
|
0
|
0
|
| 0
|
1
|
0
|
| 1
|
0
|
0
|
| 1
|
1
|
1
|
Конъюкция истинна
тогда и только тогда, когда оба высказывания истинны
.
· пример: F={На улице светит солнце и
дует сильный ветер};
· логическая схема (конъюктор):
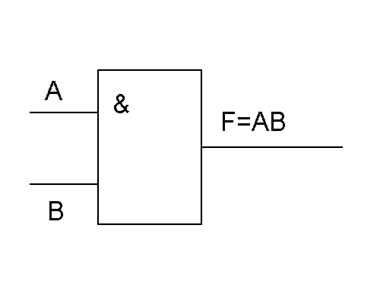
Любое сложное высказывание можно записать с помощью основных логических операций И, ИЛИ , НЕ.
С помощью логических схем И, ИЛИ, НЕ можно реализовать логическую функцию, описывающую работу различных устройств компьютера.
21. Выполнение команд процессором
|
|
|