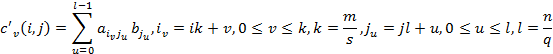Реферат: Параллельные методы умножения матрицы на вектор
|
Название: Параллельные методы умножения матрицы на вектор Раздел: Рефераты по информатике Тип: реферат | ||||||||||
ФЕДЕРАЛЬНОЕ АГЕНСТВО ПО ОБРАЗОВАНИЮ ГОУВПО “ПЕРМСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ” Кафедра прикладной математики и информатики Параллельные методы умножения матрицы на вектор ( лаба №1 )
Пермь 2010 Цель лабораторной работы. Реализация последовательного и параллельных алгоритмов умножения матрицы на вектор при использовании 2-х ядерной вычислительной системы с общей памятью. Постановка задачи. В результате умножения матрицы
Тем самым получение результирующего вектора Общее количество необходимых скалярных операций есть величина
void SerialResultCalculation(double* pMatrix, double* pVector, double* pResult, int Size) { int i, j; // Loop variables for (i=0; i<Size; i++) { pResult[i]=0; for (j=0; j<Size; j++) pResult[i] += pMatrix[i*Size+j]*pVector[j]; } }
Базовая подзадача - скалярное умножение одной строки матрицы на вектор. После завершения вычислений каждая базовая подзадача определяет один из элементов вектора результата c . В общем виде схема информационного взаимодействия подзадач в ходе выполняемых вычислений показана на рис.1. Количество вычислительных операций для получения скалярного произведения одинаково для всех базовых подзадач.
Рисунок 1 . Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы по строкам. Каждый поток параллельной программы использует только «свои» данные, ему не требуются данные, которые в данный момент обрабатывает другой поток, нет обмена данными между потоками, не возникает необходимости синхронизации. Т.е. практически нет накладных расходов на организацию параллелизма (за исключением расходов на организацию и закрытие параллельной секции), и можно ожидать линейного ускорения. Однако, как будет видно из представленных результатов, ускорение далеко от линейного. Время решения задачи одним потоком складывается из времени, когда процессор непосредственно выполняет вычисления, и времени, которое тратится на чтение необходимых для вычислений данных из ОП в кэш. При этом время, необходимое на чтение данных, может в несколько раз превосходить время счета. Процесс выполнения последовательного алгоритма умножения матрицы на вектор может быть представлен диаграммой, изображенной на рис.2.
Рисунок 2. Диаграмма состояний процесса выполнения последовательного алгоритма умножения матрицы на вектор. Время выполнения последовательного алгоритма складывается из времени вычислений и времени доступа к памяти:
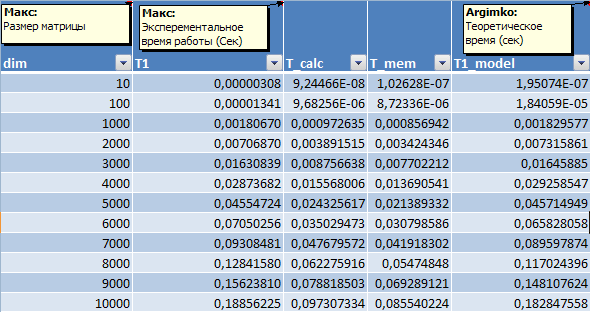
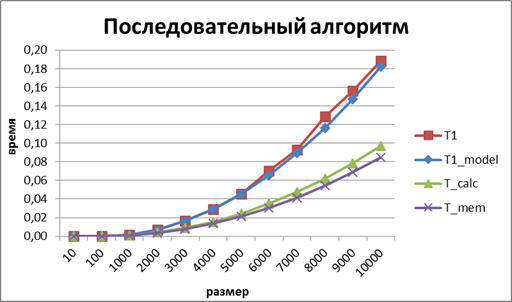
Таким образом, Для оценки Получим Тогда Теперь, оценим В таблице 1 и на рис.3 представлено сравнение реального времени последовательного алгоритма умножения матрицы на вектор и теоретического. Таблица 1. Сравнение экспериментального и теоретического времени выполнения последовательного алгоритма умножения матрицы на вектор.
Рисунок 3. График зависимости экспериментального и теоретического времени выполнения последовательного алгоритма от объема исходных данных (ленточное разбиение матрицы по строкам В многоядерных процессорах Intel архитектуры Core 2 Duo ядра процессоров разделяют общий канал доступа к памяти. Т.е., несмотря на то, что вычисления могут выполняться ядрами параллельно
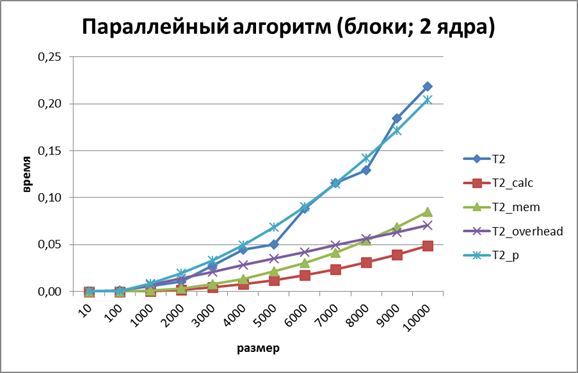
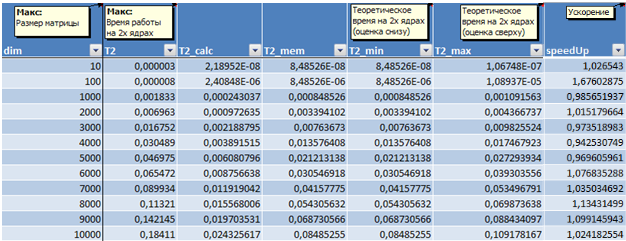
, доступ к памяти осуществляется строго последовательно. Следовательно, время void ParallelResultCalculation_rows (double* pMatrix, double* pVector, double* pResult, int Size) { int i, j; // Loop variables #pragma omp parallel private (i,j) #pragma omp for for (i=0; i<Size; i++) { for (j=0; j<Size; j++) pResult[i] += pMatrix[i*Size+j]*pVector[j]; } } Результаты вычислительных экспериментов приведены в таблице 2. Времена выполнения алгоритмов указаны в секундах. Ускорение есть результат деления времени работы последовательного алгоритма на время работы параллельного. Таблица 2. Результаты вычислительных экспериментов для параллельного алгоритма умножения матрицы на вектор при ленточной схеме разделении данных по строкам.
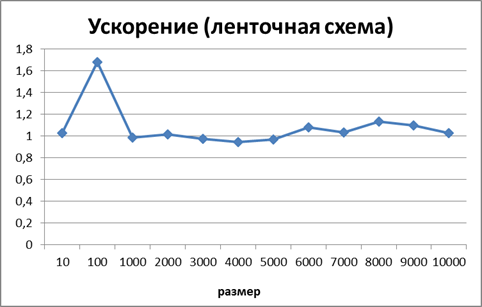
Рисунок 4. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на ленточном горизонтальном разбиении матрицы
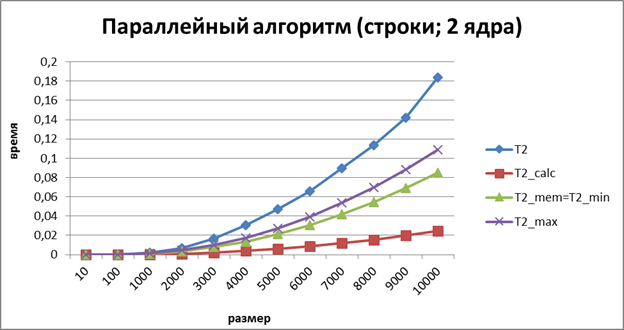
Рисунок 5. График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объема исходных данных при использовании двух потоков (ленточное разбиение матрицы по строкам) ВЫВОД: Замедление работы программы при использовании параллельного алгоритма (библиотека OpenMP) можно объяснить следующим отчётом профилировщика (см. Рисунок 6).
Рисунок 6. Сравнение данных профилировщика последовательной и параллельной программ Как видно, значительное время при выполнении программы затрачивается в библиотеке libiomp 5 md . dll . 2. Умножение матрицы на вектор при разделении данных по столбцам. Базовая подзадача - операция умножения столбца матрицы Каждая базовая задача
Рисунок 7. Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор с использованием разбиения матрицы по столбцам. При выполнении параллельного алгоритма умножения матрицы на вектор, основанного на вертикальном разделении матрицы, выполняется больше арифметических операций, т.к. на каждой итерации внешнего цикла после вычисления каждым потоком своей частичной суммы необходимо выполнить редукцию полученных результатов. Сложность выполнения операции редукции – На выполнение подкачек данных в кэш тоже тратится некоторое время. Пусть Таким образом, время выполнения параллельного алгоритма умножения матрицы на вектор, основанного на вертикальном разделении матрицы, может быть вычислено по формуле:
void ParallelResultCalculation_columns(double* pMatrix, double* pVector, double* pResult, int Size) { int i, j; // Loop variables double IterGlobalSum = 0; for (i=0; i<Size; i++) { IterGlobalSum = 0; #pragma omp parallel for reduction(+:IterGlobalSum) for (j=0; j<Size; j++) IterGlobalSum += pMatrix[i*Size+j]*pVector[j]; pResult[i] = IterGlobalSum; } } Результаты вычислительных экспериментов приведены в таблице. Таблица 3. Результаты вычислительных экспериментов для параллельного алгоритма умножения матрицы на вектор при ленточной схеме разделении данных по столбцам.
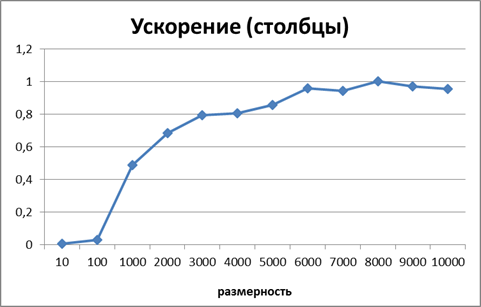
Рисунок 8. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на ленточном вертикальном разбиении матрицы Для нахождения Будем минимизировать величину Таким образом, получаем
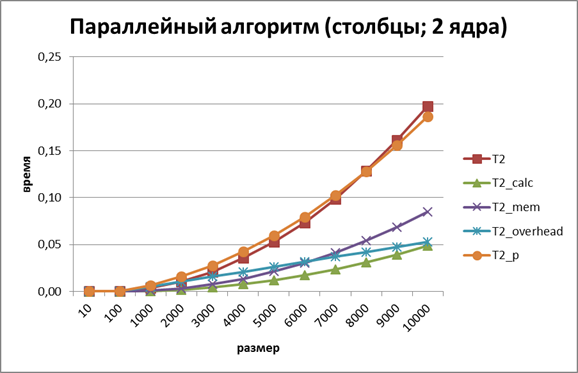
Рисунок 9. График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объёма исходных данных при использовании двух потоков (ленточное разбиение матрицы по столбцам)
При блочном разделении матрица делится на прямоугольные наборы элементов – при этом, как правило, используется разделение на непрерывной основе. Пусть количество процессоров (ядер) составляет После перемножения блоков матрицы A и вектора b каждая подзадача (i,j) будет содержать вектор частичных результатов c'(i,j), определяемый в соответствии с выражениями:
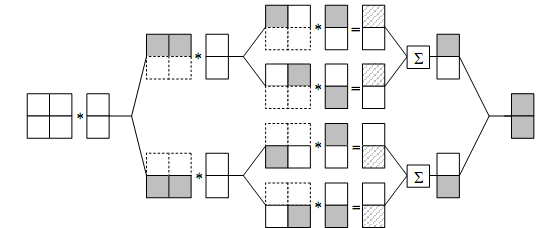
Рисунок 10. Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор с использованием блочного разделения данных. Будем предполагать, что число блоков матрицы А совпадает по горизонтали и вертикали, т.е. s=q. Для обозначения числа потоков будем использовать переменную π=q2 . Для эффективного выполнения алгоритма число базовых подзадач должно совпадать с числом выделенных потоков. Возьмём число потоков π=4. Воспользуемся алгоритмом вычисления, основанном на использовании функций библиотеки OpenMP. В данном алгоритме используется вложенный параллелизм. Для задания количества потоков будет использоваться переменная NestedThreadsNum. void ParallelResultCalculation_blocks(double* pMatrix, double* pVector, double* pResult, int Size) { int NestedThreadsNum = 2; omp_set_num_threads(NestedThreadsNum); omp_set_nested(true); #pragma omp parallel for for (int i=0; i<Size; i++) { double ThreadResult = 0; #pragma omp parallel for reduction(+:ThreadResult) for (int j=0; j<Size; j++) ThreadResult += pMatrix[i*Size+j]*pVector[j]; pResult[i] = ThreadResult; } } При анализе эффективности данного алгоритма воспользуемся следующими формулами. Время выполнения вычислений ограничено сверху величиной: (количество вычислительных элементов совпадает с числом потоков, т.е. p=π)
При выполнении вычислений, «внутренние» параллельные секции создаются и закрываются много раз, кроме того, дополнительное время тратится на синхронизацию и выполнение операции редукции. Каждый поток создаёт параллельные секции
Результаты вычислительных экспериментов при блочном разделении данных приведены в таблице 5. Таблица 5. Результаты вычислительных экспериментов для параллельного алгоритма умножения матрицы на вектор при блочной схеме разделении данных.
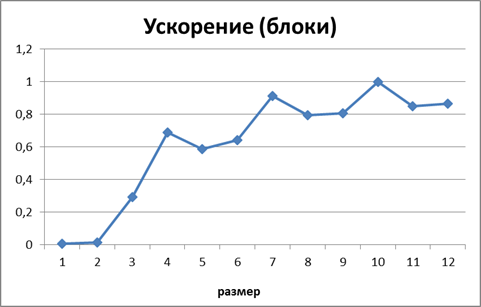
Рисунок 11. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на блочном разбиении матрицы
Рисунок 12 . График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объема исходных данных при использовании четырёх потоков при блочном разбиении матрицы Вывод
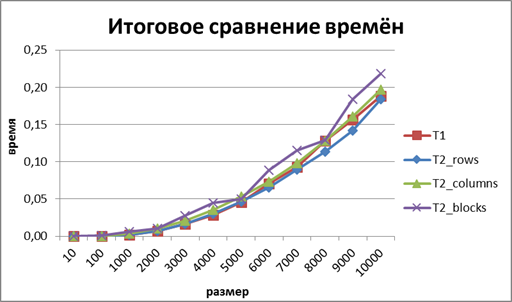
В результате проделанной работы, мы пришли к выводу, что среди параллельных алгоритмов умножения матрицы на вектор, самым быстрым оказался алгоритм, основанный на разделении матрицы по строкам. Однако существенного ускорения за счёт распараллеливания достигнуть не удалось. Это связано с тем, что значительное время расходуется на ожидания внутри библиотек OpenMP. |




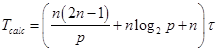 .
.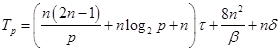 .
.