министерство образования российской федерации
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНДУСТРИАЛЬНЫЙ УНИВЕРСИТЕТ
Курсовая работа
«Оперативка»
Выполнил:
Москва 2004
Оглавление
| Введение …………………………………………………………………………………………………………
|
3
|
| Глава 1.
Как работает память?
|
| 1.1 Элементная база логики ………………………………………………….....................................
|
5
|
| 1.2 Быстродействие и производительность памяти…………………………………………………
|
5
|
| Глава
2
.
Чипы памяти
|
| 2.
1 Память типа
DRAM
……………………………………………………………………………..
|
7
|
| 2.2.1 FPM……………………………………………………………………………………………..
|
9
|
| 2.2.2 EDO ………………………………………………….…………………………………………
|
10
|
| 2.2.3 BEDO……………………………………………….…………………………………………...
|
12
|
| 2.2.4 VRAM ……………………………………………………………………………………….....
|
13
|
| 2.2.5 SDRAM …………………………………………………………………………………………
|
13
|
| 2.2.6 Enhanced SDRAM ……………………………………………………………………………
|
15
|
| 2.2.7 SGRAM …………………………………………………………………………………………
|
15
|
| 2.2.8 DDR SDRAM ………………………………………………………………………………….
|
15
|
| 2.2.9 RDRAM ………………………………………………………………………………………...
|
17
|
| 2.2 Память типа
SRAM
………………………………………………………………………………
|
18
|
| Глава 3. Разъёмы:
|
| 3.1 DIP ………………………………………………………………………………………………….
|
20
|
| 3.2 SIPP ………………………………………………………………………………………………...
|
21
|
| 3.3 SIMM, DIMM и RIMM………………………………………………………………………….....
|
21
|
| Глава 4. Сравнительная характеристика основных типов памяти
|
23
|
| Глава 5. Что нас ждёт в будущем?
|
| 5.1 FeRAM……………………………………………………………………………………………...
|
25
|
| 5.2 Голографическая память……………………………………………………………………….....
|
29
|
| 5.3 Молекулярная память……………………………………………………………………………..
|
31
|
| 5.4 Наноструктуры…………………………………………………………………………………….
|
33
|
| Заключение……………………………………………………………………………………………………….
|
35
|
| Список литературы………………………………………………………………………………………..……..
|
36
|
Введение
Оперативная память является одним из важнейших элементов компьютера. Именно из нее процессор берет программы и исходные данные для обработки, в нее он записывает полученные результаты. Название «оперативная» эта память получила потому, что она работает очень быстро, так что процессору практически не приходится ждать при чтении данных из памяти или записи в память.
Оперативная память - это энергозависимая среда, в которую загружаются и в которой находятся прикладные программы и данные в момент, пока с ними работают. Когда работа закончена, информация удаляется из оперативной памяти. Если необходимо обновление соответствующих дисковых данных, они перезаписываются. Это может происходить автоматически, но часто требует команды от пользователя. При выключении компьютера вся информация из оперативной памяти теряется.
В связи с этим трудно недооценить все значение оперативной памяти. Однако до недавнего времени эта область компьютерной индустрии практически не развивалась (по сравнению с другими направлениями). Взять хотя бы видео-, аудиоподсистемы, производительность процессоров и. т. д. Усовершенствования были, но они не соответствовали темпам развития других компонентов и касались лишь таких параметров, как время выборки, был добавлен кэш непосредственно на модуль памяти, конвейерное исполнение запроса, изменен управляющий сигнал вывода данных, но технология производства оставалась прежней, исчерпавшей свой ресурс. Память становилась узким местом компьютера, а, как известно, быстродействие всей системы определяется быстродействием самого медленного ее элемента. И вот несколько лет назад волна технологического бума докатилась и до оперативной памяти. Быстрое усовершенствование оперативной памяти позволило кроме ее усовершенствования, значительно снизить цену на нее.
Хотя память значительно подешевела, модернизировать приходится ее намного чаще, чем несколько лет назад. В настоящее время новые типы памяти разрабатываются намного быстрее, и вероятность того, что в новые компьютеры нельзя будет устанавливать память нового типа, как никогда велика.
От количества установленной в компьютере оперативной памяти напрямую зависит возможность, какими программами вы сможете на нем работать. При недостаточном количестве оперативной памяти многие программы либо вовсе не будут работать, либо станут работать крайне медленно.
Часто для оперативной памяти используют обозначение RAM (Random Access Memory), то есть память с произвольным доступом. Это означает, что обращение к данным, хранящимся в оперативной памяти, не зависит от порядка их расположения в памяти. Когда говорят о памяти компьютера, обычно подразумевают оперативную память, прежде всего микросхемы памяти или модули, в которых хранятся активные программы и данные, используемые процессором.
Полупроводниковая оперативная память в настоящее время делится на статическое ОЗУ (SRAM) и динамическое ОЗУ (DRAM).

Классификация ОЗУ
Глава 1. Как работает память?
1.1 Элементная база логики.
 Триггером называют элемент на транзисторах, который может находиться в одном из двух устойчивых состояний (0 и 1), а по внешнему сигналу он способен менять состояние. Таким образом, триггер может служить ячейкой памяти, хранящей один бит информации. Любой триггер можно создать из трех основных логических элементов: И, ИЛИ, НЕ. Поэтому все, что относится к элементной базе логики, относится и к триггерам. Сама же память, основанная на триггерах, называется статической (SRAM). Триггером называют элемент на транзисторах, который может находиться в одном из двух устойчивых состояний (0 и 1), а по внешнему сигналу он способен менять состояние. Таким образом, триггер может служить ячейкой памяти, хранящей один бит информации. Любой триггер можно создать из трех основных логических элементов: И, ИЛИ, НЕ. Поэтому все, что относится к элементной базе логики, относится и к триггерам. Сама же память, основанная на триггерах, называется статической (SRAM).
1. РТЛ —резистивно-транзисторна логика. Исторически является первой элементной базой логики, работающей на ЭВМ второго поколения. Обладает большой рассеивающей мощностью (свыше 100 мВт на логический элемент). Не применялась уже в ЭВМ третьего поколения.
2. ТТЛ, или Т2
Л —транзисторно-транзисторна логика. Реализована на биполярных транзисторах. Использовалась в интегральных схемах малой и средней степени интеграции. Обладает временем задержки сигнала в логическом элементе 10— нс, а потребляемая мощность на элемент —10 мВт.
3. ТТЛ-Шотки —это модификация ТТЛ с использованием диода Шотки. Обладает меньшим временем задержки (3 нс) и высокой рассеиваемой мощностью (20 мВт).
4. ИИЛ, или И2
Л —интегральная инжекторная логика. Это разновидность ТТЛ, базовым элементом которой являются не биполярные транзисторы одного рода (pnp или npn), а горизонтально расположенного pnp транзистора и вертикально расположенного npn транзистора. Это позволяет создать высокую плотность элементов на БИС и СБИС. При этом потребляемая мощность равна 50 мкВт на элемент и время задержки сигнала – 10 нс.
5. 
ЭСЛ —логические элементы с эмитерными связями. Эта логика также построена на биполярных транзисторах. Время задержки в них —0,5 —2 нс, потребляема мощность —25 —50 мВт. 6. Элементы на МДП (МОП) —транзисторах. Это схемы, в которых биполярные транзисторы заменены на полевые. Время задержки таких элементов составляет от 1 до 10 нс, потребляемая мощность — от 0,1 до 1,0 мВт
7. КМОП —логика (комплементарная логика.) В этой логике используются симметрично включенные n-МОП и p-МОП транзисторы. Потребляема мощность в статическом режиме —50 мкВт, задержка —10 —50 нс.
Как видно из этого обзора, логика на биполярных транзисторах самая быстрая, но одновременно самая дорогая и обладает высокой мощностью рассеяния . При прочих равных условиях логика на полевых транзисторах более медленная, но обладает меньшим электропотреблением и меньшей стоимостью.
1.2 Быстродействие и производительность памяти
Быстродействие памяти определяется временем выполнения операций записи и считывания данных. Основными параметрами любых элементов памяти является минимальное время доступа и длительность цикла обращения. Время доступа (access time) определяется как задержка появления действительных данных на выходе памяти относительно начала цикла чтения. Длительность цикла определяется как минимальный период следующих друг за другом обращений к памяти, причем циклы чтения и записи могут требовать различных затрат времени. В цикл обращения кроме активной фазы самого доступа входит и фаза восстановления (возврата памяти к исходному состоянию), которая соизмерима по времени с активной фазой. Временные характеристики самих запоминающих элементов определяются их принципом действия и используемой технологией изготовления.
Производительность памяти можно характеризовать как скорость потока записываемых или считываемых данных и измерять в мегабайтах в секунду. Производительность подсистемы памяти наравне с производительностью процессора существенным образом определяет производительность компьютера. Выполняя определенный фрагмент программы, процессору придется, во-первых, загрузить из памяти соответствующий программный код, а во-вторых, произвести требуемые обмены данными, и чем меньше времени потребуется подсистеме памяти на обеспечение этих операций, тем лучше.
Производительность памяти, как основной, так и кэша второго уровня, обычно характеризуют длительностью пакетных циклов чтения (Memory Burst Read Cycle). Пакетный режим обращения является основным для процессоров, использующих кэш (486 и выше); циклы чтения выполняются гораздо чаще, чем циклы записи (хотя бы потому, что процессору приходится все время считывать инструкции из памяти). Эта длительность выражается в числе тактов системной шины, требуемых для передачи очередной порции данных в пакете. Обозначение вида 5-3-3-3 для диаграммы пакетного цикла чтения соответствует пяти тактам на считывание первого элемента в цикле и трем тактам на считывание каждого из трех последующих элементов. Первое число характеризует латентность (latency) памяти — время ожидания данных, последующие — скорость передачи. При этом, конечно же, оговаривается и частота системной шины. По нынешним меркам хорошим результатом является цикл 5-1-1-1 для частоты шины 100 или 133 МГц. Однако для процессоров Pentium 4, у которых за каждый такт синхронизации системной шины передается по четыре 64-битных слова данных, возможно, будет иной способ выражения производительности памяти.
Производительность подсистемы памяти зависит от типа и быстродействия применяемых запоминающих элементов, разрядности шины памяти и некоторых «хитростей» архитектуры.
Разрядность шины памяти — это количество байт (или бит), с которыми операция чтения или записи может быть выполнена одновременно. Разрядность основной памяти обычно согласуется с разрядностью внешней шины процессора (1 байт - для 8088; 2 байта - для 8086, 80286, 3865Х; 4 байта - для 386DХ, 486; 8 байт — для Pentium и выше). Вполне очевидно, что при одинаковом быстродействии микросхем или модулей памяти производительность блока с большей разрядностью будет выше, чем у малоразрядного. Именно с целью повышения производительности у 32-битных (по внутренним регистрам) процессоров Реntium и выше внешняя шина, связывающая процессор с памятью, имеет разрядность 64 бита. Желание производителей процессоров и системных плат сэкономить на разрядности памяти всегда приводит к снижению производительности: компьютеры на процессорах с полноразрядной шиной (8086, 386DХ) более чем на 50 % обгоняют своих «младших братьев» (8088, 3865Х) при одинаковой тактовой частоте. Одно время выпускались чипсеты, работающие с 32-битной памятью даже для Pentium, но эффективность подобной экономии сомнительна.
Банком памяти называют комплект микросхем или модулей (а также их посадочных мест — «кроваток» для микросхем, слотов для SIММ или DIMM), обеспечивающий требуемую для данной системы разрядность хранимых данных. Работоспособным может быть только полностью заполненный банк. Внутри одного банка практически всегда должны применяться одинаковые (по типу и объему) элементы памяти.
В компьютерах на 486-х процессорах банком является один SIMM-72 или четверка SIMM-30. В компьютерах на процессорах 5-6 (а для АМD и 7-го) поколений банком может быть пара SIMM-72 или один модуль DIMM или RIММ (эти модули могут содержать и несколько банков). На платы с чипсетом i850 для процессора Pentium 4 требуется установка пар RIMM (чтобы обеспечить производительность памяти, достойную новой микроархитектуры).
Если устанавливаемый объем памяти набирается несколькими банками, появляется резерв повышения производительности за счет чередования банков (bank interleaving). Идея чередования заключается в том, что смежные блоки данных (разрядность такого блока данных соответствует разрядности банка) располагаются поочередно в разных банках. Тогда при весьма вероятном последовательном обращении к данным банки будут работать поочередно, причем активная фаза обращения к одному банку может выполняться во время фазы восстановления другого банка, то есть применительно к обоим банкам не будет простоя во время фазы восстановления. Частота передачи данных в системе с чередованием двух банков может быть удвоенной по отношению к максимальной частоте paботы отдельного банка. Для реализации чередования чипсет должен обеспечивать возможность перекоммутации адресных линий памяти в зависимости от установленного количества банков и иметь для них (банков) раздельные линии управляющих сигналов. Чем больше банков участвуют в чередовании, тем выше (теоретически) предельная производительность. Чаще всего используется чередование двух или трех банков (two way interleaving, three way interleaving). В чередовании может участвовать и большее число банков. Из разбиения на мелкие банки можно извлечь и другую выгоду. Поскольку современные процессоры; способны параллельно выставлять несколько запросов на транзакции с памятью, скрытые фазы обработки запросов, обусловленные необходимым временем доступа, относящихся к разным банкам, могут выполняться одновременно.
Глава 2. Чипы памяти.
Динамическая оперативная память ( Dynamic RAM – DRAM) используется в большинстве систем оперативной памяти персональных компьютеров. Основное преимущество этого типа памяти состоит в том, что ее ячейки упакованы очень плотно, т.е. в небольшую микросхему можно упаковать много битов, а значит, на их основе можно построить память большей емкости.
Ячейки памяти в микросхеме DRAM – это крошечные конденсаторы, которые удерживают заряды. Проблемы, связанные с памятью этого типа, вызваны тем, что она динамическая, т.е. должна постоянно регенерироваться, так как в противном случае электрические заряды в конденсаторах памяти будут “стекать”, и данные будут потеряны. Регенерация в микросхеме происходит одновременно по всей строке матрицы при обращении к любой из ее ячеек. Максимальный период обращения к каждой строке TRF
(refresh time) для гарантированного сохранения информации у современной памяти лежит в пределах 8-64 мс. В зависимости от объема и организации матрицы для однократной регенерации всего объема требуется 512, 1024, 2048 или 4096 циклов обращений. При распределенной регенерации
(distributed refresh) одиночные циклы регенерации выполняются равномерно с периодом tRF
,
который для стандартной памяти принимается равным 15,6 мкс. Период этих циклов называют «refresh rate», хотя такое название больше подошло бы к обратной величине — частоте циклов f=l/tRF
. Для памяти с расширенной регенерацией (extended refresh) допустим период циклов до 125 мкс. Возможен также и вариант пакетной регенерации
(burst refresh), когда все циклы регенерации собираются в пакет,
во время которого обращение к памяти по чтению и записи блокируется. При количестве циклов 1024 эти пакеты будут периодически занимать шину памяти примерно на 130 мкс, что далеко не всегда допустимо. По этой причине, как правило, выполняется распределенная регенерация, хотя возможен и промежуточный вариант — пакетами по несколько циклов.
Некоторые системы позволяют изменить параметры регенерации с помощью программы установки параметров CMOS, но увеличение времени между циклами регенерации может привести к тому, что в некоторых ячейках памяти заряд “стечет”, а это вызовет сбой памяти. В большинстве случаев надежнее придерживаться рекомендуемой или заданной по умолчанию частоты регенерации.
В устройствах DRAM для хранения одного бита используется только транзистор и конденсатор, поэтому они более вместительны, чем микросхемы других типов памяти. Транзистор для каждого однозарядного регистра DRAM использует для чтения состояния смежного конденсатора. Если конденсатор заряжен, в ячейке записана 1; если заряда нет – записан 0. Заряды в крошечных конденсаторах все время стекают, вот почему память должна постоянно регенерироваться. Даже мгновенное прерывание подачи питания или какой-нибудь сбой в циклах регенерации приведет к потере заряда в ячейке DRAM, а следовательно, к потере данных.
Каждая ячейка способна хранить только один бит. Если конденсатор ячейки заряжен, то это означает, что бит включен, если разряжен – выключен. Если необходимо запомнить один байт данных, то понадобится 8 ячеек (1 байт = 8 битам). Ячейки расположены в матрицах и каждая из них имеет свой адрес, 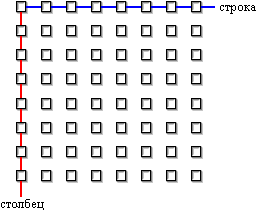 состоящий из номера строки и номера столбца. состоящий из номера строки и номера столбца.
Теперь рассмотрим, как происходит чтение. Сначала на все входы подается сигнал RAS (Row Address Strobe) – это адрес строки. После этого, все данные из этой строки записываются в буфер. Затем на регистр подается сигнал CAS (Column Address Strobe) – это сигнал столбца и происходит выбор бита с соответствующим адресом. Этот бит и подается на выход. Но во время считывания данные в ячейках считанной строки разрушаются и их необходимо перезаписать, взяв из буфера.
Теперь запись. Подается сигнал WR (Write) и информация поступает на шину столбца не из регистра, а с информационного входа памяти через коммутатор, определенный адресом столбца. Таким образом, прохождение данных при записи определяется комбинацией сигналов адреса столбца и строки и разрешения записи данных в память. При записи данные из регистра строки на выход не поступают.
Следует учесть то, что матрицы с ячейками расположены вот таким вот образом:
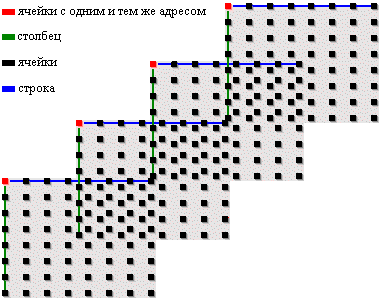
Это означает, что за один раз будет считан не один бит, а несколько. Если параллельно расположено 8 матриц, то сразу считан будет один байт. Это называется разрядностью. Количество линий, по которым будут передаваться данные от (или на) параллельных матриц, определяется разрядностью шины ввода/вывода микросхемы.
Важнейшей характеристикой DRAM является быстродействие, а проще говоря, продолжительность цикла + время задержки + время доступа, где продолжительность цикла – время, затраченное на передачу данных, время задержки – начальная установка адреса строки и столбца, а время доступа – время поиска самой ячейки. Измеряется в наносекундах.
Сейчас уже не актуально использовать 66-МГц шины памяти. Разработчики DRAM нашли возможность преодолеть этот рубеж и извлекли некоторые дополнительные преимущества путем осуществления синхронного интерфейса.
С асинхронным интерфейсом процессор должен ожидать, пока DRAM закончит выполнение своих внутренних операций, которые обычно занимают около 60 нс. С синхронным управлением DRAM происходит защелкивание информации от процессора под управлением системных часов. Триггеры запоминают адреса, сигналы управления и данных, что позволяет процессору выполнять другие задачи. После определенного количества циклов данные становятся доступны, и процессор может считывать их с выходных линий.
Другое преимущество синхронного интерфейса заключается в том, что системные часы задают только временные границы, необходимые DRAM. Это исключает необходимость наличия множества стробирующих импульсов. В результате упрощается ввод, т. к. контрольные сигналы адреса данных могут быть сохранены без участия процессора и временных задержек. Подобные преимущества также реализованы и в операциях вывода.
2.1.1
FPM
FPM (Fast Page Mode) DRAM — Динамическое ОЗУ, работающее в режиме ускоренного страничного обмена
Тип динамической памяти с произвольным доступом, которая обеспечивает более высокую производительность, чем обычное динамическое ОЗУ.
Двоичные разряды хранятся в ячейках памяти, организованных в виде матрицы, состоящей из строк и столбцов. Подобно всем остальным видам динамического ОЗУ, у ИС памяти данного типа имеется лишь половина всех выводов, необходимых для указания адреса чтения или записи данных. При этом цикл памяти начинается с указания в первую очередь адреса строки, для чего требуется половина разрядов адреса, а затем и адреса столбца данных, который составляет другую половину адреса. Затем выполняется чтение или запись данных.
Режим ускоренного страничного обмена позволяет адресовать следующий столбец, который соответствует следующему по порядку адресу памяти, без повторного указания строки. Это дает возможность сократить время доступа к нескольким следующим по порядку ячейкам памяти при условии, что при этом еще не достигнут конец строки, увеличивая тем самым производительность.
Время цикла памяти FPM DRAM составляет 50нс, что позволяет поддерживать доступ к памяти с частотой 30 миллионов раз в секунду или 30 МГц. Этого вполне достаточно для шины памяти с тактовой частотой 60 или 66 МГц, типичной для процессора Pentium. Следовательно, для доступа к памяти требуется не один цикл памяти, причем это делается в пакетном режиме, поэтому адреса памяти отнюдь не обязательно указывать при каждом доступе. Это возможно потому, что доступ к памяти обычно осуществляется в виде обращения к расположенным по порядку ячейкам памяти, а если это не так, то дополнительный доступ к памяти не используется либо данные игнорируются. Доступ к памяти в пакетном режиме обычно обозначается формулой 6-3-3-3, которая означает, что для первого обращения к памяти требуется 6 тактовых циклов, поскольку при этом необходимо полностью указать адрес, а для каждого из трех последующих обращений требуется лишь 3 тактовых цикла. Как правило, тактовые циклы выполняются с быстродействием шины памяти процессора. Зачастую это соответствует тактовой частоте 60 или 66 МГц при внутренней тактовой частоте процессора соответственно 120 или 133 МГц.

Рис. 2.1.1.1 Временная диаграмма
FPM
режима
В этом способе при считывании данных со строки памяти сигнал RAS удерживается, пока все столбцы не считаются.
Сигнал CAS снимается и выставляется каждый раз после установки очередного адреса столбца С2
, С3
, С4
, при этом после очередной установки сигнала CAS данные появляются на выходе, в этом сокращение времени достигается за счёт того, что сигнал RAS выставляется один раз в начале страницы, а столбцы выбираются сигналом RAS. Этот режим даёт выигрыш лишь при страничной организации.
Память FPM была распространена в ПК в 1995 году. Более быстродействующим типом памяти является динамическое ОЗУ EDO DRAM.
2
.1.2 EDO
Начиная с 1995 года, в компьютерах на основе Pentium используется новый тип оперативной памяти – EDO ( Extended Data Out). Это усовершенствованный тип памяти FPM; его иногда называют Hyper Page Mode. Память типа EDO была разработана и запатентована фирмой Micron Tehnology. Память EDO собирается из специально изготовленных микросхем, которые учитывают перекрытие синхронизации между очередными операциями доступа.
Не смотря на небольшие конструктивные различия, и FPM, и EDO RAM делаются по одной и той же технологии, поэтому скорость работы должна быть одна и та же. Действительно, и FPM, и EDO RAM имеют одинаковое время считывания первой ячейки — 60 —70 нс. Однако в EDO RAM применен метод считывания последовательных ячеек. При обращении к EDO RAM активизируется не только первая, но и последующие ячейки в цепочке. Поэтому, имея то же время при обращении к одной ячейке, EDO RAM обращается к следующим ячейкам в цепочке значительно быстрее. Поскольку обращение к последовательно следующим друг за другом областям памяти происходит чаще, чем к ее различным участкам (если отсутствует фрагментация памяти), то выигрыш в суммарной скорости обращения к памяти значителен.
Регистр прозрачен для данных, когда сигнал CAS находится в рабочем состоянии (низком уровне).
Выходные данные защёлкиваются подъёмом сигнала CAS и удерживаются.
Стандартное Z-состояние обеспечивается либо снятием сигнала OE (CS), либо одновременным снятием сигналов RAS и CAS, либо сигналом WE, при наличии RAS и CAS.
Наличие выходного буфера позволяет укорачивать цикл CAS и уменьшать время доступа в пределах страницы.
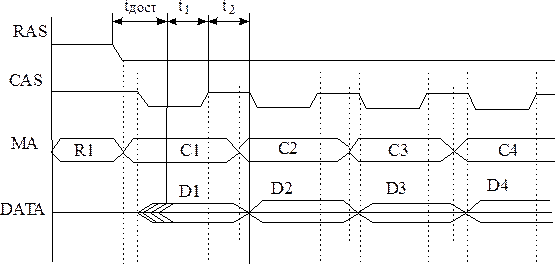
Рис 2.1.2.2 2 Диаграмма работы памяти
EDO
В отличие от стандартного режима снятие сигнала CAS может осуществляться даже раньше, чем появляются действительные данные на выходе, это соответствует: Т1
 0. 0.
За счёт защёлкивания данных в выходном регистре и удерживаются до очередного установления сигнала CAS и удерживаются до очередного Т2
. Это позволяет сократить цикл CAS и, соответственно, уменьшить время доступа.
В EDO в страничном режиме быстродействие увеличивается на 40%. В межстраничном режиме время доступа обычное.
Использование памяти EDO, вместо стандартной, может вызывать конфликт, обусловленный тем, что выход в пределах страничного режима не удерживается в Z-состоянии.
Для согласования со стандартным режимом может использоваться сигнал WE.
В режиме считывания сигнал WE переводит буфер в Z-состояние так же, как сигналы RAS и CAS.
Режим использования сигнала OE практически не используется.

Рис 2.1.2.2 Диаграмма работы памяти
EDO
с использованием режима
WE
Для обеспечения стандартного режима, при смене адреса столбцов временно устанавливается сигнал WE, который переводит выход Data в Z-состояние (стрелка-1
).
После снятия сигнала WE выход переходит опять в нормальное состояние, после считывания всей страницы сигналы CAS и RAS снимаются и выходы переходят в Z-состояние (стрелки 2
и 3
).
Однако даже для EDO RAM существует предел частоты, на которой она может работать. Несмотря ни на какие ухищрения, модули SIMM не могут работать на частоте локальной шины PCI, превышающей 66 МГц.
2.1.3
BEDO
Двукратное увеличение производительности было достигнуто в BEDO DRAM (Burst EDO). Добавив в микросхему генератор номера столбца, конструкторы ликвидировали задержку CAS Delay, сократив время цикла до 15 нс. После обращения к произвольной ячейке микросхема BEDO автоматически, без указаний со стороны контроллера, увеличивает номер столбца на единицу, не требуя его явной передачи. По причине ограниченной разрядности адресного счетчика (конструкторы отвели под него всего лишь два бита) максимальная длина пакета не могла превышать четырех ячеек (22=4).
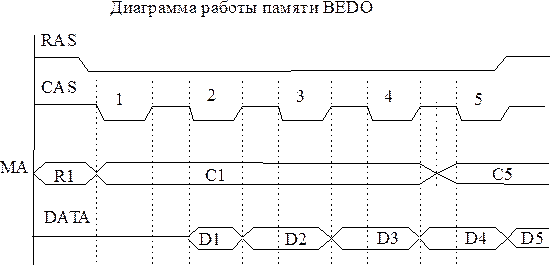
Рис. 2.1.3.1 Диаграмма работы памяти
BEDO
Независимо от порядка обращения к данным, BEDO всегда работает на максимально возможной скорости и для частоты 66 Мгц ее формула выглядит так: 5-1-1-1, что на ~40% быстрее EDO-DRAM!
Все же, несмотря на свои скоростные показатели, BEDO оказалась не конкурентоспособной и не получила практически никакого распространения. Просчет состоял в том, что BEDO, как и все ее предшественники, оставалась асинхронной памятью. Это накладывало жесткие ограничения на максимально достижимую тактовую частоту, ограниченную 60 - 66 (75) мегагерцами. Действительно, пусть время рабочего цикла составляет 15 нс. (1 такт в 66 MHz системе). Однако, поскольку "часы" контроллера памяти и самой микросхемы памяти не синхронизованы, нет никаких гарантий, что начало рабочего цикла микросхемы памяти совпадет с началом такового импульса контроллера, вследствие чего минимальное время ожидания составляет два такта. Вернее, если быть совсем точным, рабочий цикл микросхемы памяти никогда не совпадает с началом тактового импульса. Несколько наносекунд уходит на формирование контроллером управляющего сигнала RAS или CAS, за счет чего он уже не совпадет с началом тактирующего импульса. Еще несколько наносекунд требуется для стабилизации сигнала и "осмысления" его микросхемой, причем, сколько именно времени потребуется заранее определить невозможно, т.к. на результат влияет и температура, и длина проводников, и помехи на линии, и т.д.
2.1.
4
VRAM
VRAM (Video Random Access Memory) — ВидеоОЗУ. Память, специально адаптированная для использования в видеоадаптерах. Двухпортовая память — ПК может записывать данные (для изменения изображения) в то время, когда видеоадаптер непрерывно считывает содержимое VRAM для прорисовки его на экране. Обычно необходимость в памяти такого типа возникает при работе с высокими разрешениями (более 1024 х 768 пикселов) в "глубоком" цвете (более 65536 цветов) и высокой частотой кадровой развертки (более 85 Гц). "Оконное" ОЗУ (WRAM - Window RAM) также является двухпортовой, однако поддерживает более эффективную схему буферизации и другие усовершенствования, позволяющие повысить производительность на
25% по сравнению с VRAM. Оба описанных типа ОЗУ производительнее и дороже EDO.
2.1.
5
SDRAM
 SDRAM (Synchronous Dynamic Random Access Memory) – это синхронизированная динамическая память с произвольным порядком выборки. Одним словом, синхронная динамическая оперативная память. SDRAM состоит из физических ячеек, которые собраны в страницы. Размер страницы может быть от 512 байт до нескольких килобайт. Каждая страница разбита на два банка: в одном банке ячейки с нечетными адресами строк, а в другом – с четными. Каждая ячейка имеет свой адрес, состоящий из номера (адреса) строки и номера (адреса) столбца. Сначала передается номер строки, затем номер столбца. По сути дела, номер – это набор электрических сигналов, которые надо сгенерировать, передать и обработать. На все это необходимо затратить время. В страничном режиме, передав номер строки можно получить доступ к нескольким ячейкам с разными номерами столбцов, то есть, не надо для каждой из них передавать номер строки, достаточно только номера столбца. Экономия времени налицо. Двигаемся дальше, строки можно разделить на четные и нечетные. Получается два банка: один – с четными строками, а другой – с нечетными. В то время, когда происходит обращение к одному банку, в другом происходит выборка адреса или еще что. Опять же экономия времени. Такой режим иногда называют расслоением. SDRAM (Synchronous Dynamic Random Access Memory) – это синхронизированная динамическая память с произвольным порядком выборки. Одним словом, синхронная динамическая оперативная память. SDRAM состоит из физических ячеек, которые собраны в страницы. Размер страницы может быть от 512 байт до нескольких килобайт. Каждая страница разбита на два банка: в одном банке ячейки с нечетными адресами строк, а в другом – с четными. Каждая ячейка имеет свой адрес, состоящий из номера (адреса) строки и номера (адреса) столбца. Сначала передается номер строки, затем номер столбца. По сути дела, номер – это набор электрических сигналов, которые надо сгенерировать, передать и обработать. На все это необходимо затратить время. В страничном режиме, передав номер строки можно получить доступ к нескольким ячейкам с разными номерами столбцов, то есть, не надо для каждой из них передавать номер строки, достаточно только номера столбца. Экономия времени налицо. Двигаемся дальше, строки можно разделить на четные и нечетные. Получается два банка: один – с четными строками, а другой – с нечетными. В то время, когда происходит обращение к одному банку, в другом происходит выборка адреса или еще что. Опять же экономия времени. Такой режим иногда называют расслоением.
Для того чтобы увеличить скорость доступа к памяти, разработали пакетный режим (burst) доступа. Принцип состоит в том, что после установки строки и столбца ячейки, происходит обращение к следующим трем смежным адресам без дополнительных состояний ожидания. Схема пакетного режима будет выглядеть так: x-y-y-y, где х – время выполнения первой операции доступа состоящей из продолжительности цикла и времени ожидания, а y – это число циклов, необходимое для выполнения каждой последующей операции. Например, для SDRAM схема будет выглядеть так: 5-1-1-1.

Рис.2.1.5.1 Временная диаграмма
SDRAM
По отдельной линии передается синхронизирующий сигнал, по шине управления передается команда, скажем на считывание. После этого формируется адрес и по шине адреса передается в память. Затем начинается передача информации по шине данных. В этот момент может быть сформирован и передан новый адрес. И так постоянно.

Рис.2.1.5.2. Модуль SDRAM на 256Мбайт

Рис.2.1.5.3
Стандартный модуль памяти SDRAM PC100
Выпустив чипсет 440BX с официальной поддержкой тактовой частоты системной шины до 100 МГц, Intel сделала оговорку, что модули памяти SDRAM неустойчиво работают на такой скорости. После заявления Intel представила новую спецификацию, описывающую все тонкости, SDRAM PC100.
Данной спецификации отвечают только 8-нс чипы, а 10-нс чипы, по мнению Intel, неспособны устойчиво работать на частоте 100 МГц.
Введение стандарта PC100 в некоторой степени можно считать рекламной уловкой, но все известные производители памяти и системных плат поддержали эту спецификацию, а с появлением следующего поколения памяти переходят на его производство.
Спецификация PC100 является очень критичной, одно описание с дополнениями занимает больше 70 страниц.
Для комфортной работы с приложениями, требующими высокого быстродействия, разработано следующее поколение синхронной динамической памяти - SDRAM PC133. Продвижением данного стандарта на рынок занимается уже не Intel, а их главный конкурент на рынке процессоров AMD. Intel же решила поддерживать память от Rambus, мотивируя это тем, что она лучше сочетается с шиной AGP 4x.
133-МГц чипы направлены на использование с новым семейством микропроцессоров, работающих на частоте системной шины 133 МГц, и полностью совместимы со всеми PC100 продуктами. Такими производителями, как VIA Technologies, Inc., Acer Laboratories Inc. (ALi), OPTi Inc., Silicon Integrated Systems (SiS) и Standard Microsystems Corporation (SMC), разработаны чипсеты, поддерживающие спецификацию PC133.
2.1.6
Enhanced
SDRAM
(
ESDRAM
)
Enhanced SDRAM (ESDRAM - улучшенная SDRAM) - более быстрая версия SDRAM, сделанная в соответствии со стандартом JEDEC компанией Enhanced Memory Systems. С точки зрения времени доступа производительность ESDRAM в два раза выше по сравнению со стандартной SDRAM. В большинстве приложений ESDRAM, благодаря более быстрому времени доступа к массиву SDRAM и наличию кэша, обеспечивает даже большую производительность, чем DDR SDRAM.
Более высокая скорость работы ESDRAM достигается за счет дополнительных функций, которые используются в архитектуре этой памяти. ESDRAM имеет строку кэш-регистров (SRAM), в которых хранятся данные, к которым уже было обращение. Доступ к данным в строке кэша осуществляется быстрее, чем к ячейкам SDRAM, со скоростью 12 ns, т.к. не требуется обращаться к данным в строке через адрес в колонке. При этом скорость работы ячеек ESDRAM составляет 22 ns в отличие от стандартной скорости работы ячеек SDRAM, имеющей значения 50 - 60 ns.
При этом стоит заметить, что память ESDRAM полностью совместима со стандартной памятью JEDEC SDRAM на уровне компонентов и модулей, по количеству контактов и функциональности. Однако чтобы использовать все преимущества этого типа памяти, необходимо использовать специальный контроллер (чипсет).
Увеличение производительности при использовании ESDRAM достигается за счет применения двухбанковой архитектуры, которая состоит из массива SDRAM и SRAM строчных регистров (кэш). Строчные регистры вместе с быстрым массивом SDRAM обеспечивают более быстрый доступ для чтения и записи данных по сравнению со стандартной SDRAM. ESDRAM может работать в режиме "упреждающего обращения" к массиву SDRAM, в результате следующий цикл записи или чтения может начаться в момент, когда выполнение текущего цикла не завершено. Возможность использовать такой режим напрямую зависит от центрального процессора, управляющего работой конвейера адресации.
2.1.7 SGRAM
Это аббревиатура для Синхронной графической памяти со случайным доступом (Synchronous Graphic Random Access Memory), типа DRAM, всё в большей степени используемом в видеоадаптерах и графических акселераторах. Как и SDRAM, SGRAM способна самосинхронизироваться с частотой шины процессора вплоть до частот около 100 МГц. Вдобавок к этому, SGRAM использует некоторые другие технологии, такие как шаблонная и блочная запись, для увеличения пропускной способности для интенсивно работающих с графикой приложений
2.1.8
DDR
SDRAM
(
SDRAM
II
)
DDR SDRAM (Double Data Rate Synchronous Dynamic Random Access Memory) – динамическая синхронизированная память с произвольным порядком выборки и удвоенной передачей данных. Появился этот тип памяти где-то в 1998 году и был сразу взят на вооружение производителями видеокарт. Затем DDR широко распространилась и на материнские платы. На сегодняшний день, этот тип памяти, пожалуй, наиболее применяемый в персональных компьютерах. Ведь DDR сочетает в себе приемлемую скорость и при этом относительную дешевизну.

Рис.2.1.8.1 Стандартный модуль
DDR
SDRAM
Принцип работы DDR SDRAM очень схож с обычной SDRAM (отсюда и второе название DDR SDRAM – SDRAM 2). Память разбита на страницы, каждая страница разбита на банки. Работа памяти синхронизирована с тактовым генератором системной платы. Основное отличие заключается в том, что за один цикл происходит два обращения к данным: по фронту и срезу импульса тактового сигнала системной шины. Говоря простым языком, чтение/запись происходит два раза за один такт. Кроме того, частота работы повышается за счет применения интерфейсных логических схем с еще более пониженным уровнем питания. Если для SDRAM обычно используются схемотехнические решения на базе LVTTL (Low Volt Transistor-to-Transistor Logic) с напряжением питания 3,3 В, то в DDR SDRAM - на базе SSTL (Stub Series Terminated Logic) с напряжением 2,5 В (а в перспективе и SSTL-2 с напряжением 1,25 В).
DDR SDRAM управляется инверсными тактовыми сигналами. Управляющие и адресные сигналы регистрируются по положительному фронту тактового сигнала, точнее при переходе сигнала с низкого уровня напряжения на более высокий, а вот данные передаются по обоим фронтам сигнала. Такая схема работы требует более четкой синхронизации. Для этого введен дополнительный стробовый сигнал DQS. Говоря просто, этот сигнал необходим для согласования передачи данных при чтении из памяти и контроллером при записи в память. До кучи, следует отметить, что при передаче данных по фронту и срезу сигнала синхронизации критичным будет лишь время задержки распространения сигнала. Вот и пришлось использовать этот строб-сигнал.

Рис.2.1.5.2 Временная диаграмма
DDR
SDRAM
При тактовой частоте системной шины 100 МГц скорость передачи данных будет равна 1600 Мбайт/сек, а при 133 МГц – 2100 Мбайт/сек. Отсюда следуют названия памяти DDR – РС1600 и РС2100. Максимальная же пропускная способность при результирующей частоте в 400 Мгц может достигать 3,2 Гбайт/сек.
Следует упомянуть тот факт, что микросхемы SDRAM и DDR физически не совместимы: в первом случае микросхемы имеют 168 контактов, во втором – 184. Отсюда несколько разное расположение ключа. Кроме этого, не все чипсеты поддерживают тот или иной тип памяти.
В ближайшее время на рынке должна появится DDR 2. В этом типе памяти данные будут передаваться не 2 раза, а 4, что позволит повысить максимальную пропускную способность до 6,4 Гбайт/сек, и это позволит продлить жизнь DDR в мире инфотехнологий.
2.1.9
RDRAM
(
Rambus
DRAM
)
Direct Rambus DRAM - это высокоскоростная динамическая память с произвольным доступом, разработанная Rambus, Inc. Она обеспечивает высокую пропускную способность по сравнению с большинством других DRAM. Direct Rambus DRAMs представляет интегрированную на системном уровне технологию.
Технология Direct Rambus представляет собой третий этап развития памяти RDRAM. Впервые память RDRAM появилась в 1995 г., работала на частоте 150 МГц и обеспечивала пропускную способность 600 Мбайт/с. Она использовалась в станциях SGI Indigo2 IMPACTtm, в приставках Nintendo64, а также в качестве видеопамяти. Следующее поколение RDRAM появилось в 1997 г. под названием Concurrent RDRAM. Новые модули были полностью совместимы с первыми. Но за год до этого события в жизни компании произошло не менее значимое событие. В декабре 1996 г. Rambus, Inc. и Intel Corporation объявили о совместном развитии памяти RDRAM и продвижении ее на рынок персональных компьютеров. Вопреки распространенному мнению, ее архитектура довольно прозаична и не блещет новизной. Основных отличий от памяти предыдущих поколений всего три:
а) увеличение тактовой частоты за счет сокращения разрядности шины,
б) одновременная передача номеров строки и столба ячейки,
в) увеличение количества банков для усиления параллелизма.
Повышение тактовой частоты вызывает резкое усиление всевозможных помех и в первую очередь электромагнитной интерференции, интенсивность которой в общем случае пропорциональна квадрату частоты, а на частотах свыше 350 мегагерц вообще приближается к кубической. Это обстоятельство налагает чрезвычайно жесткие ограничения на топологию и качество изготовления печатных плат модулей микросхемы, что значительно усложняет технологию производства и себестоимость памяти. С другой стороны, уровень помех можно значительно понизить, если сократить количество проводников, т.е. уменьшить разрядность микросхемы. Именно по такому пути компания Rambus и пошла, компенсировав увеличение частоты до 400 MHz (с учетом технологии DDR эффективная частота составляет 800 MHz) уменьшением разрядности шины данных до 16 бит (плюс два бита на ECC).

Рис.2.1.
9
.1 Модули памяти
RDRAM
Второе (по списку) преимущество RDRAM - одновременная передача номеров строки и столбца ячейки при ближайшем рассмотрении оказывается вовсе не преимуществом, конструктивной особенностью. Это не уменьшает латентности доступа к произвольной ячейке (т.е. интервалом времени между подачей адреса и получения данных), т.к. она, латентность, в большей степени определяется скоростью ядра, а RDRAM функционирует на старом ядре.
Большое количество банков позволяет (теоретически) достичь идеальной конвейеризации запросов к памяти, несмотря на то, что данные поступают на шину лишь спустя 40 нс. после подачи запроса (что соответствует 320 тактам в 800 MHz системе), сам поток данных непрерывен.
Емкость серийно выпускаемых модулей Rambus DRAM составляет 64, 128 и 256 Мб, в дальнейшем ожидаются изделия по 1 Гб. Так как использование 9-го бита на каждый байт данных оставлено на усмотрение производителя, одни фирмы вводят функцию ЕСС, другие увеличивают емкость чипов. В последнем случае получаются модули емкостью 72, 144 или 288 Мб.
Недостатком можно посчитать придуманные производителем режимы управления питанием модулей. Если напряжение питания 2,5 В стало практически стандартом для всех новых технологий памяти DRAM, то режимы работы Асtive (активный), Standby (ожидания), NAP ("спящий") и PowerDown (отключение питания) - собственное изобретение Rambus. Самое интересное, что микросхема, не обменивающаяся в текущий момент данными с контроллером, автоматически переводится в режим ожидания, иначе возможен перегрев системы, так как тактовые частоты весьма высоки. На переключение же из режима Standby в активное состояние требуется 100 нс.
Хочется отметить, что реальная пропускная способность RDRAM существенно ниже заявленных Rambus значений. После появления системного набора Intel 820 с поддержкой DR DRAM были проведены сравнительные тесты с другими типами памяти. Оказалось, что на большинстве реальных задач RDRAM уступает даже SDRАМ, работающим на частоте 133 МГц. В значительной мере это объясняют более узкой шиной данных канала Rambus (16 бит) по сравнению с 64-битной шиной SDРАМ. С появлением чипсета VIА Ароllo Рго2бб, поддерживающего DDR DRАМ, картина для Rambus и Intel становится вовсе безрадостной.
Существует тип памяти, совершенно отличный от других - статическая оперативная память (Static RAM – SRAM). Она названа так потому, что, в отличии от динамической оперативной памяти, для сохранения ее содержимого не требуется периодической регенерации. Но это не единственное ее преимущество. SRAM имеет более высокое быстродействие, чем динамическая оперативная память, и может работать на той же частоте, что и современные процессоры.
Время доступа SRAM не более 2 нс, это означает, что такая память может работать синхронно с процессорами на частоте 500 МГц или выше. Однако для хранения каждого бита в конструкции SRAM используется кластер из 6 транзисторов. Использование транзисторов, без каких либо конденсаторов означает, что нет необходимости в регенерации. Пока подается питание, SRAM будет помнить то, что сохранено.

Рис.2.
2.1
Ячейка SRAM
Микросхемы SRAM не используются для всей системной памяти потому, что по сравнению с динамической оперативной памятью быстродействие SRAM намного выше, но плотность ее намного ниже, а цена довольно высокая. Более низкая плотность означает, что микросхемы SRAM имеют большие габариты, хотя их информационная емкость намного меньше. Большое число транзисторов и кластиризованное их размещение не только увеличивает габариты SRAM, но и значительно повышает стоимость технологического процесса по сравнению с аналогичными параметрами для микросхем DRAM.
Несмотря на это, разработчики все-таки применяют память типа SRAM для повышения эффективности РС. Но во избежание значительного увеличения стоимости устанавливается только небольшой объем высокоскоростной памяти SRAM, которая используется в качестве кэш-памяти. Кэш-память работает на тактовых частотах, близких или даже равных тактовым частотам процессора, причем обычно именно эта память используется процессором при чтении и записи.
В переводе слово «cache» (кэш) означает «тайный склад», «тайник» («заначка»). Тайна этого склада заключается в его «прозрачности» — адресуемой области памяти для программы он не добавляет. Кэш является дополнительным быстродействующим хранилищем копий блоков информации из основной памяти, вероятность обращения к которым в ближайшее время велика. Кэш не может хранить копию всей основной памяти, поскольку его объем во много раз меньше объема основной памяти. Он хранит лишь ограниченное количество блоков данных и каталог
(cache directory) — список их текущего соответствия областям основной памяти. Кроме того, кэшироваться может и не вся оперативная память, доступная процессору: во-первых, из-за технических ограничений может быть ограничен максимальный объем кэшируемой памяти; во-вторых, некоторые области памяти могут быть объявлены некэшируемыми (настройкой регистров чипсета или процессора). Если установлено оперативной памяти больше, чем возможно кэшировать, обращение к некэшируемой области ОЗУ будет медленным. Таким образом, увеличение объема ОЗУ, теоретически всегда благотворно влияющее на производительность, может снизить скорость работы определенных компонентов, попавших в некэшируемую память. В ОС Windows память распределяется, начиная с верхних адресов физической памяти, в результате чего в некэшируемую область может попасть ядро ОС.
При каждом обращении к памяти контроллер кэш-памяти по каталогу проверяет, есть ли действительная копия затребованных данных в кэше. Если она там есть, то это случай кэш-попадания
(cache hit) и данные берутся из кэшпамяти. Если действительной копии там нет, это случай кэш-промаха
(cache miss), и данные берутся из основной памяти. В соответствии с алгоритмом кэширования блок данных, считанный из основной памяти, при определенных условиях заместит один из блоков кэша. От интеллектуальности алгоритма замещения зависит процент попаданий и, следовательно, эффективность кэширования. Поиск блока в списке должен производиться достаточно быстро, чтобы «задумчивостью» в принятии решения не свести на нет выигрыш от применения быстродействующей памяти. Обращение к основной памяти может начинаться одновременно с поиском в каталоге, а в случае попадания — прерываться (архитектура Look aside). Это экономит время, но лишние обращения к основной памяти ведут к увеличению энергопотребления. Другой вариант: обращение к основной памяти начинается только после фиксации промаха (архитектура Look Through), при этом теряется, по крайней мере, один такт процессора, зато экономится энергия.
Кэш в современных компьютерах строится по двухуровневой, а иногда и трехуровневой схеме.
Первичный кэш,
или L
1
Cache
(Level 1 Cache), — кэш 1 уровня, внутренний (Internal, Integrated) кэш процессоров класса 486 и выше, а также некоторых моделей 386.
Вторичный кэш,
или L
2
Cache
(Level 2 Cache), — кэш 2 уровня. Для процессоров вплоть до Pentium (и аналогичных) это внешний
(External) кэш, установленный на системной плате. В Р6 и более мощных процессорах вторичный кэш расположен в одном корпусе с процессором, и для таких процессоров дополнительный кэш на системную плату уже не устанавливается.
Кэшем третьего уровня
оказывается кэш, установленный на системной плате с сокетом 7, когда в него устанавливают процессор AMD K6-3, обладающий встроенным двухуровневым кэшем.
Объем первичного кэша невелик (8-128 Кбайт); чтобы повысить его эффективность, для данных и команд часто используется раздельный кэш (так называемая Гарвардская архитектура — противоположность Принстонской с общей памятью для команд и данных). В процессорах Pentium 4 первичный кэш устроен уже иначе.
Кэш-контроллер должен обеспечивать когерентность
(coherency) — согласованность данных кэш-памяти обоих уровней с данными в основной памяти при том условии, что обращение к этим данным может производиться не только процессором, но и другими активными (bus-master) адаптерами, подключенными к шинам (PCI, VLB, ISA и т. д.). Следует также учесть, что процессоров может быть несколько, и у каждого может быть свой внутренний кэш.
Контроллер кэша оперирует строками
(cache line) фиксированной длины. Строка может хранить копию блока основной памяти, размер которого, естественно, совпадает с длиной строки. С каждой строкой кэша связана информация об адресе скопированного в нее блока основной памяти и ее состоянии. Строка может быть действительной
(valid) — это означает, что в текущий момент времени она достоверно отражает соответствующий блок основной памяти, или недействительной.
Информация о том, какой именно блок занимает данную строку (то есть старшая часть адреса или номер страницы) и о ее состоянии, называется тегом
(tag) и хранится в связанной с данной строкой ячейке специальной памяти тегов
(tag RAM). В операциях обмена с основной памятью обычно строка участвует целиком (несекторированный кэш), для процессоров 486 и выше длина строки совпадает с объемом данных, передаваемых за один пакетный цикл (для 486 — это 4x4 = 16 байт, для Pentium — 4 х 8 = 32 байт). Возможен и вариант секторированного (sectored) кэша, при котором одна строка содержит несколько смежных ячеек — секторов,
размер которых соответствует минимальной порции обмена данных кэша с основной памятью. При этом в записи каталога, соответствующей каждой строке, должны храниться биты действительности для каждого сектора данной строки. Секторирование позволяет экономить память, необходимую для хранения каталога при увеличении объема кэша, поскольку большее количество бит каталога отводится под тег и выгоднее использовать дополнительные биты действительности, чем увеличивать глубину индекса (количество элементов) каталога.
SRAM различается по принципу работы. Существует три типа:
1. Async SRAM (Asynchronous Static Random Access Memory) - асинхронная статическая память с произвольным порядком выборки;
2. SyncBurst SRAM (Synchronous Burst Random Access Memory) – синхронная пакетная статическая память с произвольным порядком выборки;
3. PipBurst SRAM (Pipelined Burst Random Access Memory) – конвейерная пакетная статическая память с произвольным порядком выборки;
Async SRAM – это устаревший тип памяти, асинхронный интерфейс которой схож с интерфейсом DRAM и включает в себя шины адреса, данных и управления. SyncBurst SRAM – этот тип памяти синхронизирован с системной шиной и лучше всего подходит для выполнения пакетных операций. Ну а интерфейс PipBurst SRAM схож с интерфейсом SyncBurst SRAM, но позволяет получать данные без тактов ожидания.
Глава 3. Разъёмы
3.1 DIP.
DIP-корпус —это исторически сама древняя реализация DRAM. DIP-корпус соответствует стандарту IC. Обычно это маленький черный корпус из пластмассы, по обеим сторонам которого располагаются металлические контакты (см. рисунок B.3.1.).

Рис.3.1.1
Стандартный
DIP
-корпус
Микросхемы динамического ОЗУ устанавливаются так называемыми банками
. Банки бывают на 64, 256 Кбайт, 1 и 4 Мбайт. Каждый банк состоит из девяти отдельных одинаковых чипов. Из них восемь чипов предназначены для хранени информации, а девятый чип служит для проверки четности остальных восьми микросхем этого банка.
Чипы памяти бывают одно и четырехразрядными, и иметь емкость 64 Кбит, 256 Кбит, 1 и 4 Мбит. Обозначение разновидностей микросхем памяти в DIP-корпусах показано в таблице.
Следует отметить, что памятью с DIP-корпусами комплектовались персональные компьютеры с микропроцессорами i8086/88, i80286 и, частично, i80386SX/DX. Установка и замена этого вида памяти была нетривиальной задачей. Мало того, что приходилось подбирать чипы для банков памяти одинаковой разрядности и емкости. Приходилось прилагать усилия и смекалку, чтобы чипы правильно устанавливались в разъемы. К тому же необходимо было не разрушить контакты механически, не повредить их инструментом, статическим электричеством, грязью и т.п. Поэтому уже в компьютерах с процессором i80386DX эти микросхемы стали заменять памяти SIPP и SIMM.
3.2 SIPP
Одной из незаслуженно забытых конструкций модулей памяти являются SIPP-модули. Эти модули представляют собой маленькие платы с несколькими напаянными микросхемами DRAM.

Рис.3.2.1
Стандартный
SIPP
-корпус
SIPP является сокращением слов Single Inline Package. SIPP-модули соединяются с системной платой с помощью контактных штырьков. Под контактной колодкой находятся 30 маленьких штырьков (смотри рисунок B.3.3.), которые вставляются в соответствующую панель системной платы.
Модули SIPP имели определенные вырезы, которые не позволяли вставить их в разъемы неправильным образом. По мнению автора, этот вид модулей лидировал по простоте их установки на системную плату.
3.3
SIMM, DIMM
и
RIMM
В большинстве современных компьютеров вместо отдельных микросхем памяти используются модули SIMM или DIMM, представляющие собой небольшие платы, которые устанавливаются в специальные разъемы на системной плате или плате памяти. Отдельные микросхемы так припаены к плате модуля SIMM или DIMM, что выпаить и заменить их практически невозможно. При появлении неисправности приходится заменять весь модуль. По существу, модуль SIMM или DIMM можно считать одной большой микросхемой.
В РС совместимых компьютерах применяются в основном два типа модулей SIMM: 30-контактные (9разрядов) и 72-контактные (36 разрядов). Первые из них меньше по размерам. Микросхемы в модулях SIMM могут устанавливаться как на одной, так и на обеих сторонах платы. Использование 30-контактных модулей неэффективно, поскольку для заполнения одного банка памяти новых 64-разрядных систем требуется восемь таких модулей.
72-пиновые разъемы SIMM ожидает та же участь, которая несколькими годами раньше постигла их 30-пиновых предшественников: те уже давно не производятся. Им на смену в 1996 г. пришел новый разъем DIMM со 168 контактами, а после и разъем RIMM. Если на SIMM реализовывались FPM и EDO RAM, то на DIMM более современная технология SDRAM. В системную плату модули SIMM необходимо было вставлять только попарно, а DIMM можно выбрать по одному, что связано с разрядностью внешней шины данных процессоров Pentium. Такой способ установки предоставляет больше возможностей для варьирования объема оперативной памяти.
Первоначально материнские платы поддерживали оба разъема, но уже довольно продолжительное время они комплектуются исключительно разъемами DIMM. Это связано с упомянутой возможностью устанавливать их по одному модулю и тем, что SDRAM обладает большим быстродействием по сравнению с FPM и EDORAM.
Если для FPM и EDO памяти указывается время чтения первой ячейки в цепочке (время доступа), то для SDRAM указывается время считывания последующих ячеек. Цепочка - несколько последовательных ячеек. На считывание первой ячейки уходит довольно много времени (60-70 нс) независимо от типа памяти, а вот время чтения последующих сильно зависит от типа.
В качестве оперативной памяти также используются модули RIMM, SO-DIMM и SO-RIMM. Все они имеют разное количество контактов. Модули SIMM сейчас встречаются только в старых моделях материнских плат, а им на смену пришли 168-контактные DIMM. Модули SO-DIMM и SO-RIMM, имеющие меньшее количество контактов, чем стандартные DIMM и RIMM, широко используются в портативных устройствах.

Рис.3.3.1
Модуль памяти SO-DIMM
При установке совпадение форм-факторов модуля и разъема не всегда стопроцентно гарантирует работоспособность модуля. Для сведения к минимуму риска использования неподходящего устройства применяются так называемые ключи. В модулях памяти такими ключами являются один или несколько вырезов. Этим вырезам на разъеме соответствуют специальные выступы. Так в модулях DIMM используется два ключа. Один из них (вырез между 10 и 11 контактами) отвечает за буферизованность модуля (модуль может быть буферизованным или небуферизованным), а второй (вырез между 40 и 41 контактами) - за рабочее напряжение (может быть 5 В или 3,3 В).

Рис.3.3.2
Модуль памяти DDR DIMM
Использование модулей памяти с покрытием контактов, отличным от покрытия контактов разъема также допускается. Хотя утверждают, что материал, используемый для покрытия модулей и разъемов, должен совпадать. Мотивируется это тем, что при различных материалах возможно появление гальванической коррозии, и, как следствие, разрушение модуля. Хотя такое мнение не лишено оснований, но, как показывает опыт, использование модулей и разъемов с разным покрытием никак не сказывается на работе компьютера.
Также не всегда бывает, что после установки в компьютер модуля SIMM большей емкости он нормально работает. Модули большой емкости можно использовать только в том случае, если их поддерживает системная плата. Допустимую емкость и необходимое быстродействие модулей SIMM можно выяснить в документации к компьютеру.
Модули RIMM (Rambus Interface Memory Module), по форме похожие на обычные модули памяти, специально предназначены для памяти RDRAM. У них 30-проводная шина проходит вдоль модуля слева направо, и на эту шину без ответвлений напаиваются микросхемы RDRAM в корпусах BGA. Модуль RIMM содержит до 16 микросхем RDRAM, которые всеми выводами (кроме двух) соединяются параллельно. Микросхемы памяти закрыты пластиной радиатора. В отличие от SIMM и DIMM, у которых объем памяти кратен степени числа 2, модули RIMM могут иметь более равномерный ряд объемов — в канал RDRAM память можно добавлять хоть по одной микросхеме.

Рис.3.3.3
Модуль памяти
RIMM
Существует много фирм, производящих чипы и модули памяти. Их можно разделить на brand-name и generic-производителей.

Рис.3.3.4 4 - модуля памяти, вставленные в материнскую плату
При покупке (особенно на рынках) хорошо бы лишний раз убедиться в правильности предоставляемой продавцом информации (как говорится, доверяй, но проверяй). Произвести такую проверку можно расшифровав имеющуюся на чипе строку букв и цифр (как правило, самую длинную) с помощью соответствующего databook и материалов, находящихся на сайте производителя. Но часто бывает, что необходимой информации не оказывается под рукой. И все же своей цели можно добиться, т. к. большинство производителей придерживаются более или менее стандартного вида предоставления информации (исключение составляют Samsung и Micron). По маркировке чипа можно узнать производителя, тип памяти, рабочее напряжение, скорость доступа, дату производства и др.
Глава 4. Сравнительная характеристика основных типов памяти
С точки зрения пользователя PC главная характеристика памяти - это скорость или, выражаясь другими словами, ее быстродействие. Казалось, что может быть проще, чем измерять быстродействие? Достаточно подсчитать количество информации, выдаваемой памятью в единицу времени и это будет ошибкой. Ведь, время доступа к памяти непостоянно и в зависимости от ряда обстоятельств варьируется в очень широких пределах. Наибольшая скорость достигается при последовательном чтении, а наименьшая - при чтении в разброс.
Условимся измерять максимально достижимое быстродействие памяти по скорости последовательного считывания ячеек. Конечно, это будет несколько идеализированная характеристика, ощутимо завышающая реальную производительность, но тут не обходится без тонкостей.
Современные модули памяти имеют несколько независимых банков и потому могут обрабатывать более одного запроса одновременно. Таким образом, несмотря на то, что выполнение каждого отдельно взятого запроса по-прежнему будут занимать весьма внушительное время, запросы могут следовать непрерывно. А раз так, непрерывно будут приходить и ответы.
Теоретически все так и есть, но на практике возникает множество затруднений. Основной камень преткновения - фундаментальная проблема зависимости по данным. Рассмотрим следующую ситуацию. Пусть ячейка N 1 хранит указатель на ячейку N 2, содержащую обрабатываемые данные. До того, как мы получим содержимое ячейки N 1, мы не сможем послать запрос на чтение ячейки N 2, поскольку, еще не знаем ее адрес. Следовательно, производительность памяти в данном конкретном случае будет определяться не пропускной способностью, а ее латентностью, т.е. полным временем доступа к одной ячейке.
Причем, описываемый случай отнюдь не является надуманным, скорее наоборот. Это типичная ситуация. Базовые структуры данных имеют ярко выраженную зависимость по данным, т.к. объединяют свои элементы именно посредством указателей, что сводит на нет весь выигрыш от параллелизма. Большинство функции штатных библиотек Си/Си++ также имеют зависимость по данным и не могут обрабатывать их параллельно.
Маскировать латентность позволяют лишь очень немногие алгоритмы, да и то не без помощи специальных команд предвыборки. Команды предвыборки, во-первых, отсутствуют в микропроцессорах Pentium младшего поколения. Во-вторых, они чрезвычайно аппаратно зависимы и требуют реализовать код как минимум в двух вариантах отдельно для процессоров Pentium и отдельно для процессоров K6/K7, причем, реализация для PentiumIII будет весьма не оптимальна для Pentium4 и, соответственно, наоборот. Наконец, в-третьих, команды предвыборки до сих пор не поддерживаются ни одним оптимизатором, и вряд ли будут поддерживаться в ближайшем будущем. Ручная же оптимизация слишком сложна и трудоемка, чтобы стать массовой.
Короче говоря, теоретическая пропускная способность памяти, заявленная производителями, совсем не то же самое, что и реальная производительность. Отбросив параллелизм (который все равно не ускоряет работу подавляющего большинства существующих на данный момент приложений) попробуем подсчитать максимально достижимую пропускную способность при обработке зависимых данных. Используем для этого следующую формулу:
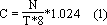
здесь: C - пропускная способность (Мегабайт/c), N - разрядности памяти (бит), T - полное время доступа (нс.).
Сравнив полученные результаты с теоретической пропускной способностью (см. рис. 4.1), мы увидим, что, во-первых, расхождение между ними чрезвычайно велико и к тому же неуклонно увеличивается по мере совершенствования памяти. Во-вторых, при обработке зависимых данных эффективная производительность SDRAM и DDR-SDRAM практически неразличима, а Direct RDRAM и вовсе идет на уровне памяти начала девяностых. Причем, фактическая производительность всех типов памяти будет еще ниже, чем рассчитанная по формуле (1). Это объясняется тем, что, во-первых, современные процессоры обмениваются с памятью не отдельными ячейками, а блоками по 32 и ли 128 байт (в зависимости от длины кэш-линеек), вследствие чего издержки на хаотичный доступ чрезвычайно велики. Во-вторых, приведенная выше формула не учитывает ни латентности контроллера памяти, ни штрафа за асинхронность, ни времени регенерации памяти, ни...
Фактически, разница в реальной и заявленной производительности отличается приблизительно в десять раз для DDR-SDRAM и в пятьдесят для Direct-Rambus.
Откуда же такая разница? А всё дело в том, что разработчики аппаратного обеспечения перегнали прогресс, заставив телегу бежать впереди лошади. Программистский мир к такому развитию событий оказался не готов и новые, замечательные возможности параллельной обработки памяти до сих пор остаются не востребованными и вряд ли будут востребованы в обозримом будущем.
Как минимум потребуется разработать принципиально новые алгоритмы обработки данных, обеспечить соответствующую поддержку параллелизма со стороны компилятора и/или штатных библиотек.
Короче говоря, "официальная" пропускная способность - это абстракция чистейшей воды, интересная скорее с маркетинговой точки зрения, но абсолютно бесполезная для конечного пользователя... 
Рис.4.1 Максимально достижимая пропускная способность основных типов памяти при наличии зависимости по данным и при отсутствии таковой.
Глава 5. Что нас ждёт в будущем?
5.1
FeRAM
Развитие оперативной памяти, пожалуй, бесконечный процесс, целью которого является увеличение частоты работы, ширины шины, а также уменьшение времени доступа, а, в некоторых случаях, и увеличение устойчивости к воздействиям извне, например, радиации. В настоящий момент требования к памяти не изменились, но к перечисленным добавились новые, удовлетворить которые намного сложнее, чем это было ранее. Среди них одним из важнейших является энергонезависимость и возможность встраивать память огромного объема в процессоры. Движение в этом направлении начато уже достаточно давно, и его результатом стало появление таких перспективных технологий, как флэш-память, FeRAM, а также MRAM. Каждая из них имеет свои преимущества и недостатки. Флэш-память позволяет практически бесконечно хранить записанную информацию без необходимости проведения циклов регенерации, которые необходимы для DRAM. MRAM, новый вид магниторезистивной памяти, продвигаемый на рынок фирмой Infineon Technologies AG, направлен на продвижение энергонезависимой памяти в компьютерах и мобильных устройствах. Это может принести пользователям многочисленные преимущества, вплоть до моментальной загрузки операционной системы после включения питания компьютера. Принцип действия этого вида памяти основан на зависимости сопротивления материала от приложенного магнитного поля. Все эти и многие другие преимущества вобрал в себя новый вид ферроэлектрической памяти. FeRAM умело сочетает простоту и надежность в эксплуатации DRAM, энергонезависимость MRAM и времена хранения информации флэш-памяти. Поскольку она включает практически все преимущества перечисленных видов памяти, то по праву может называться будущим современных технологий памяти, на чем, собственно, и делают акцент производители.
Процесс производства в настоящее время отличается тем, что от момента разработки технологии до момента массового выпуска продуктов проходит очень маленький период времени. Единственным и, пожалуй, главным движущим фактором в этом процессе является выпуск на рынок конкурентоспособного продукта. В этом стремлении выигрывает тот игрок, который быстрее своих конкурентов выпустит на рынок готовый продукт, удовлетворяющий требованиям потребителей по доступным ценам. FeRAM не является исключением в этой гонке. Производители ферроэлектрической памяти разделились на два конкурирующих между собой лагеря. Одна часть, возглавляемая постоянными партнерами в производстве памяти Infineon Technologies AG и Toshibа, разрабатывает технологию памяти, основанную на производственном процессе 1T/1C (1 транзистор / 1 конденсатор) для рынка мобильных устройств, персональных компьютеров и PDA. Производство основано на классе материалов PZT (Provskite lead zirconate titanate), которые были лицензированы фирмой Toshiba у фирмы Ramtron. Infineon также имеет кросслицензионные соглашения с Ramtron относительно использования разработанной этой фирмой технологии производства FeRAM. Технологию PZT у Ramtron также лицензировали фирмы Hitachi и Rohm. Второй фирмой, которая занималась разработкой ферроэлектрической памяти на основе оксида стронциума-висмута-танталум (strontium-bismuth-tantalum oxide) и оксида стронциума-висмута-ниобия (strontium-bismuth-niobium oxide), была Symetrix. Далее лицензионные соглашения были заключены между Symetrix и фирмами Matsushita, NEC, Siemens, Motorola, Hynix и Micron. Эти фирмы, главным образом, занимаются разработкой конкурентоспособных продуктов со встроенной FeRAM для рынка процессоров и микроконтроллеров. Основные игроки этой группы - это NEC и Matsushita, которые ведут разработки на основе технологического процесса 2T/2C. Это более ресурсоемкая технология производства памяти по сравнению с 1T/1C. Введение дополнительного транзистора и конденсатора в ячейку памяти обуславливает большую стабильность работы, но, в то же время, увеличивает площадь микросхемы той же конфигурации и поднимает цену продуктов, произведенных по такому процессу.
Сначала давайте рассмотрим наиболее простой процесс 1T/1C, по которому производится львиная доля современной памяти.
Ячейка ферроэлектрической памяти похожа на 1T/1C ячейку DRAM. Единственное отличие заключается в том, что в DRAM одна из обкладок конденсатора заземлена, а в FeRAM она подключена к передающей линии (driveline).

Рис.5.1.1 Ячейки DRAM и FeRAM
Запись в ячейку памяти DRAM происходит следующим образом: на линию данных (bitline) выставляется значение сигнала, который следует записать в конденсатор. Для записи 1 на линию данных подается положительное напряжение питания Vdd
. После этого на управляющую линию (wordline) подается сигнал, который открывает полевой транзистор. Конденсатор заряжается, и мы имеем сохраненный бит информации. В ячейке FeRAM запись 1 происходит другим образом. Для этого на передающую линию подается положительное напряжение питания, линия данных заземляется, а полевой транзистор находится в открытом состоянии. Бинарной "1" соответствует точка 1 на графике петли гистерезиса (Рис. 2).
Запись "0" происходит подобным образом. В DRAM линия данных подключается к земле, а транзистор открывается. В этом случае конденсатор полностью разряжается, что и соответствует бинарному "0". В FeRAM запись 0 (положительное значение поляризации материала, точка 3 на графике петли гистерезиса, см. Рис. 2) происходит после подачи положительного напряжения питания на линию данных. В этом случае передающая линия подключается к земле, а транзистор держится в открытом состоянии.
Подводя итог под различиями в работе ячеек DRAM и FeRAM, можно сказать, что иной принцип работы ячейки ферромагнитной памяти является результатом того, что бинарным "1" и "0" соответствуют отрицательное и положительное значения поляризации, а не нулевой и единичный заряд конденсатора, как это происходит в случае с DRAM.
Значение ячейки памяти FeRAM можно определить после подачи положительного напряжения питания Vdd
на передающую линию. Если начальная поляризация ферромагнетика негативная (позитивная), то чтение ячейки возвращает маленькое (большое) значения сигнала на линии данных. Одним из негативных свойств ячейки ферромагнитной памяти является то, что, после чтения содержимого, данные в ней перестают сохраняться. То есть, после чтения ячейки, в ней необходимо обновить значение поляризации.
Ячейка ферромагнитной памяти, производимая по схеме 2T/2C, состоит из двух ячеек 1T/1C (Рис. 4). Также как и ячейка 1T/1C, ячейка 2T/2C имеет управляющую линию (WordLine) и передающую линию (PlateLine), но данные с конденсаторов считываются через раздельные линии данных (BitLine и Complement BitLine). За счет этого достигается большая надежность хранения информации. А становится возможным это благодаря тому, что данные, хранящиеся в двух конденсаторах всегда противоположные. При этом напряжение между шиной данных (BitLine) и комплиментарной ей (Complement BitLine) всегда будет либо V0
- V1
, либо V1
- V0
, где

- напряжения на линии данных и комплиментарной ей, C0
и C1
- емкости конденсаторов, из которых состоит ячейка, CBitLine
- паразитная емкость шины данных, а Vdd
- положительное напряжение питания. Значения напряжения между линиями зависит от того, где хранится "1" в C0
или C1
. Сигнал с конденсаторов подается на усилитель, после которого считывается значение ячейки 2T/2C. Использование усилителя, а также дополнительной ячейки 1T/1C значительно увеличивает цену такой памяти. Существенное увеличение размеров ячейки 2T/2C также играет немаловажную роль. Это приводит к тому, что в настоящий момент не может быть достигнуто высокой интеграции такой памяти. Наибольшие структуры, произведенные по такой технологии, имеют объем 1 мегабит.

Рис.5.1.2 Схема 2T/2C
С другой стороны, повышенная надежность таких систем позволяет с успехом использовать их в нечеловеческих условиях, в условиях космоса. Даже маленькому ребенку известно, что для того, чтобы система могла работать в космосе, она должна выдерживать изрядные доли радиации. FeRAM прекрасно зарекомендовала себя в таких условиях, что открывает неизведанные горизонты для использования этой технологии. Энергонезависимость, а, следовательно, и малое потребление энергии становятся серьезным козырем FeRAM в борьбе за лидерство на рынке технологий для космоса. Я не оговорился: именно на рынке космических технологий, так как сейчас мы наблюдаем процесс коммерциализации космических исследований, суть которого заключается не только в запуске коммерческих космических аппаратов, но и в участии транснациональных корпораций в национальных космических программах.
Итак, о продуктах, выпущенных на рынок производителями. Toshiba совместно с Infineon Technologies выпустила прототип 8-мегабитной микросхемы памяти FeRAM. 32-мегабитная микросхема ожидается в начале 2002 года. По заявлению Шизуо Савада (Shizuo Sawada), менеджера передовых устройств памяти фирмы Toshiba, массовое производство памяти начнется в 2003 году. В настоящий момент ведутся разработки 64-мегабитных и 128-мегабитных микросхем памяти. 32-мегабитные кристаллы будут производится по 0.25-микронному процессу, с последующим переходом на 0.20-микронный процесс. 8-мегабитные кристаллы имеют площадь 76 квадратных миллиметров и цикл записи информации от 100 до 160 нс.
Фирмы NEC и Fujitsu, занимающиеся разработками встраиваемой FeRAM для процессоров и микроконтроллеров по процессу 2T/2C, достигли не таких значительных успехов на пути увеличения объема памяти, как фирмы Infineon и Toshiba. Это и не странно, поскольку они ставят перед собой немного другие цели. Последние достижения NEC в этой области - это 1-мегабитная структура, которая, как ожидается, будет встраиваться в смарт карты. Структура будет производиться по 0.35-микронному процессу и иметь площадь 18.7 квадратных миллиметра. Это не значит, что NEC существенно отстала в процессе производства от своих конкурентов, просто размеры ячейки 2T/2C, значительно (практически, в 2 раза) превосходят размеры ячейки 1T/1C, на основе которых производят память Toshiba и Infineon Technologies.
Подводя итог всему вышесказанному, можно выделить то, что FeRAM имеет неоспоримые преимущества над существующими технологиями. Более того, как потомок современных технологий памяти, она взяла лучшее от своих предков. С другой стороны, память имеет ряд существенных недостатков. Большинство из них (старение и усталость материала, предпочтение диэлектриком значения сигнала и релаксация) - это результат особых свойств ферромагнитных материалов, и от них в настоящий момент достаточно сложно избавиться.
Увеличившаяся сложность производства ферроэлектрической памяти объясняется, скорее, особенностью хранения информации в FeRAM в отличие от DRAM. Производственный процесс 2T/2C позволяет достичь большей надежности памяти, которая может быть применима в условиях космоса, однако в несколько раз усложняет производство памяти по такому процессу и увеличивает цену FeRAM. Проблемы увеличения плотности массива памяти - это временные проблемы.
5
.
2
Голографическая память
Широкие перспективы в этом плане открывает технология оптической записи, известная как голография: она позволяет обеспечить очень высокую плотность записи при сохранении максимальной скорости доступа к данным. Это достигается за счет того, что голографический образ (голограмма) кодируется в один большой блок данных, который записывается всего за одно обращение. А когда происходит чтение, этот блок целиком извлекается из памяти. Для чтения или записи блоков голографически хранимых на светочувствительном материале (за основной материал принят ниобат лития, LiNbO3) данных ("страниц") используются лазеры. Теоретически, тысячи таких цифровых страниц, каждая из которых содержит до миллиона бит, можно поместить в устройство размером с кусочек сахара. Причем теоретически ожидается плотность данных в 1TБ на кубический сантиметр (TB/sm3). Практически же исследователи ожидают достижения плотности порядка 10GB/sm3, что тоже весьма впечатляет, если сравнивать с используемым сегодня магнитным способом порядка нескольких MB/sm2, это без учета самого механизма устройства. При такой плотности записи оптический слой, имеющий толщину около 1cm, позволит хранить около 1ТВ данных. А если учесть, что такая запоминающая система не имеет движущихся частей, и доступ к страницам данных осуществляется параллельно, можно ожидать, что устройство будет характеризоваться плотностью в 1GB/sm3 и даже выше.
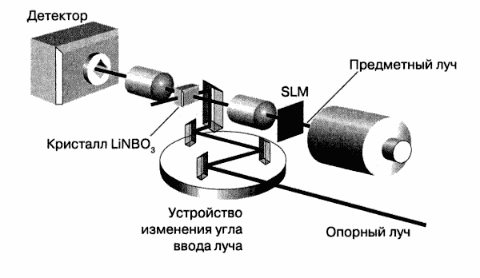
Рис.5.2.1Голографическая установка
Необычайные возможности топографической памяти заинтересовали ученых многих университетов и промышленных исследовательских лабораторий. Этот интерес уже довольно давно вылился в две научно-исследовательские программы. Одна из них - программа PRISM (Photorefractive Information Storage Material), целью которой является поиск подходящих светочувствительных материалов для хранения голограмм и исследование их запоминающих свойств. Вторая научно-исследовательская программа - HDSS (Holographic Data Storage System). Так же, как и PRISM, она предусматривает ряд фундаментальных исследований, и ее участниками являются те же компании. В то время как целью PRISM является поиск подходящих сред для хранения голограмм, HDSS ориентирована на разработку аппаратных средств, необходимых для практической реализации голографических запоминающих систем.
Функционирование системы голографической памяти происходит следующим образом. На начальном этапе в этом устройстве происходит разделение луча сине-зеленого аргонового лазера на две составляющие - опорный и предметный лучи (последний является носителем самих данных). Предметный луч подвергается расфокусировке, чтобы он мог полностью освещать пространственный световой модулятор (SLM - Spatial Light Modulator), который представляет собой просто жидкокристаллическую (LCD) панель, на которой страница данных отображается в виде матрицы, состоящей из светлых и темных пикселей (двоичные данные).
Оба луча направляются внутрь светочувствительного кристалла, где и происходит их взаимодействие. В результате этого взаимодействия образуется интерференционная картина, которая и является основой голограммы и запоминается в виде набора вариаций показателя преломления или коэффициента отражения внутри этого кристалла. При чтении данных кристалл освещается опорным лучом, который, взаимодействуя с хранимой в кристалле интерференционной картиной, воспроизводит записанную страницу в виде образа "шахматной доски" из светлых и темных пикселей (голограмма преобразует опорную волну в копию предметной). Затем этот образ направляется в матричный детектор, основой для которого служит прибор с зарядовой связью (CCD - Charge-Coupled Device или ПЗС), захватывающее всю страницу данных. При чтении данных опорный луч должен падать на кристалл под тем же самым углом, при котором производилась запись этих данных, и допускается изменение этого угла не более чем на градус. Это позволяет получить высокую плотность данных: изменяя угол опорного луча или его частоту, можно записать дополнительные страницы данных в том же самом кристалле.
Однако дополнительные голограммы изменяют свойства материала (а таких изменений может быть только фиксированное количество), в результате образы голограмм становятся тусклыми, что может привести к искажению данных при чтении. Этим и объясняется ограничение объема реальной памяти, которой обладает материал. Динамическая область среды определяется количеством страниц, которые она может реально вмещать, поэтому участники PRISM и занимаются исследованием ограничений на светочувствительность материалов.
Используемая в трехмерной голографии процедура заключения нескольких страниц с данными в один и тот же объем называется мультиплексированием. Традиционно используются следующие методы мультиплексирования: по углу падения опорного пучка, по длине волны и по фазе, но, к сожалению, они требуют сложных оптических систем и толстых (толщиной в несколько миллиметров) носителей, что делает их непригодными для коммерческого применения, по крайней мере, в сфере обработки информации. Однако совсем недавно Bell Labs были изобретены три новых метода мультиплексирования: сдвиговое, апертурное и корреляционное, основанные на использовании изменения положения носителя относительно световых пучков. При этом сдвиговое и апертурное мультиплексирование используют сферический опорный пучок, а корреляционное - пучок еще более сложной формы. Кроме того, поскольку при корреляционном и сдвиговом мультиплексировании задействованы механические движущиеся элементы, время доступа при их применении будет примерно таким же, как и у обычных оптических дисков. Bell Labs удалось построить экспериментальный носитель на основе все того же ниобата лития, использующий технику корреляционного мультиплексирования, однако уже с плотностью записи около 226GB на квадратный дюйм.
Другой сложностью, возникшей на пути создания устройств голографической памяти, стал поиск подходящего материала для носителя. Большинство исследований в области голографии проводились с использованием фотореактивных материалов (главным образом, упоминавшегося выше ниобата лития), однако если они годятся для записи голографических изображений ювелирных украшений, то этого никак нельзя сказать в отношении записи информации, да еще в коммерческих устройствах: они дороги, имеют слабую чувствительность и ограниченный динамический диапазон (частотная полоса пропускания). Поэтому был разработан новый класс фотополимерных материалов, обладающих неплохими перспективами с точки зрения коммерческого применения. Фотополимеры представляют собой вещества, в которых под действием света происходят необратимые изменения, выражающиеся во флуктуациях состава и плотности. Созданные материалы имеют более продолжительный жизненный цикл (в плане хранения записанной на них информации) и устойчивы к воздействию температур, а также отличаются улучшенными оптическими характеристиками, в общем, подходят для однократной записи данных (WORM).
Еще одна проблема - сложность используемой оптической системы. Так, для голографической памяти не годятся светодиоды на базе полупроводниковых лазеров, применяемые в традиционных оптических устройствах, поскольку они обладают недостаточной мощностью, дают пучок с высокой расходимостью и, наконец, полупроводниковый лазер, генерируемый излучение в среднем диапазоне видимой области спектра, получить очень сложно. Здесь же необходим мощный лазер, дающий как можно более параллельный пучок. То же самое можно сказать и о пространственных световых модуляторах: до недавнего времени не было ни одного подобного устройства, которое можно было бы применять в системах голографической памяти. Однако времена меняются, и сегодня уже стали доступными недорогие твердотельные лазеры, появилась микроэлектромеханическая технология (MEM - Micro-Electrical Mechanical, устройства на ее основе представляют собой массивы микрозеркал размером порядка 17 микрон), как нельзя лучше подходящая на роль SLM.
Так как интерференционные шаблоны однородно заполняют весь материал, это наделяет голографическую память другим полезным свойством - высокой достоверностью записанной информации. В то время как дефект на поверхности магнитного диска или магнитной ленты разрушает важные данные, дефект в голографической среде не приводит к потере информации, а вызывает всего лишь "потускнение" голограммы. Поскольку аппаратура HDSS для изменения угла наклона луча использует акусто-оптический дефлектор (кристалл, свойства которого изменяются при прохождении через него звуковой волны), то по общим оценкам, время извлечения смежных страниц данных составит менее 10ms. Любое традиционное оптическое или магнитное устройство памяти нуждается в специальных механических средствах для доступа к данным на различных дорожках, и время этого доступа составляет несколько миллисекунд.
Пожалуй, ошибочно рассматривать устройства голографической памяти как радикально новую технологию, ибо ее основные концепции разработаны около 30 лет назад. Если что и изменилось, так это доступность ключевых компонентов для этой технологии, цены на них стали значительно ниже. Так, полупроводниковый лазер уже не является чем-то диковинным, а давным-давно уже стал стандартом. С другой стороны, SLM - это результат той же технологии, которая применяется при изготовлении LCD-экранов для ПК-блокнотов и калькуляторов, а детекторная матрица CCD позаимствована прямо из цифровой видеокамеры.
Итак, преимуществ у новой технологии более чем достаточно: кроме того, что информация сохраняется и считывается параллельно, можно достичь очень высокой скорости передачи данных и, в отдельных случаях, высокой скорости произвольного доступа. А самое главное, практически отсутствуют механические компоненты, свойственные нынешним хранителям информации (например, шпиндели с гигантским числом оборотов). Это гарантирует не только быстрый доступ (для данной технологии правильней сказать мгновенный) к данным, меньшую вероятность сбоев, но и более низкое потребление электроэнергии, поскольку сегодня жесткий диск - один из наиболее энергоемких компонентов компьютера. Правда, есть трудности с юстировкой оптики, поэтому на первых порах данные устройства, вероятно, будут все еще "бояться" сторонних "механических воздействий".
5
.3
Молекулярная память
Другой радикально иной подход в создании устройств хранения данных - молекулярный. Группа исследователей центра "W.M. Keck Center for Molecular Electronic" под руководством профессора Роберта Р. Бирга (Robert R. Birge) уже относительно давно получила прототип подсистемы памяти, использующей для запоминания цифровые биты - молекулы. Это молекулы протеина, который называется бактериородопсин (bacteriorhodopsin). Он имеет пурпурный цвет, поглощает свет и присутствует в мембране микроорганизма, называемого halobacterium halobium. Этот микроорганизм "проживает" в соляных болотах, где температура может достигать +150 °С. Когда уровень содержания кислорода в окружающей среде настолько низок, что для получения энергии невозможно использовать дыхание (окисление), он для фотосинтеза использует протеин.
Бактериородопсин был выбрал потому, что фотоцикл (последовательность структурных изменений, которые молекула претерпевает при реакции со светом) делает эту молекулу идеальным логическим запоминающим элементом типа "&" или типа переключателя из одного состояния в другое (триггер). Как показали исследования Бирга, bR-состояние (логическое значение бита "0") и Q-состояние (логическое значение бита "1") являются промежуточными состояниями молекулы и могут оставаться стабильными в течение многих лет. Это свойство, в частности, обеспечивающее удивительную стабильность протеина, и было приобретено эволюционным путем в борьбе за выживание в суровых условиях соляных болот.
По оценкам Бирга, данные, записанные на бактериородопсинном запоминающем устройстве, должны сохраняться приблизительно пять лет. Другой важной особенностью бактериородопсина является то, что эти два состояния имеют заметно отличающиеся спектры поглощения. Это позволяет легко определить текущее состояние молекулы с помощью лазера, настроенного на соответствующую частоту.
Был построен прототип системы памяти, в котором бактсриородопсин запоминает данные в трехмерной матрице. Такая матрица представляет собой кювету (прозрачный сосуд), заполненную полиакридным гелем, в который помещен протеин. Кювета имеет продолговатую форму размером 1x1x2 дюйма. Протеин, который находится в bR-состоянии, фиксируется в пространстве при полимеризации геля. Кювету окружают батарея лазеров и детекторная матрица, построенная на базе прибора, использующего принцип зарядовой инжекции (CID - Charge Injection Device), которые служат для записи и чтения данных.
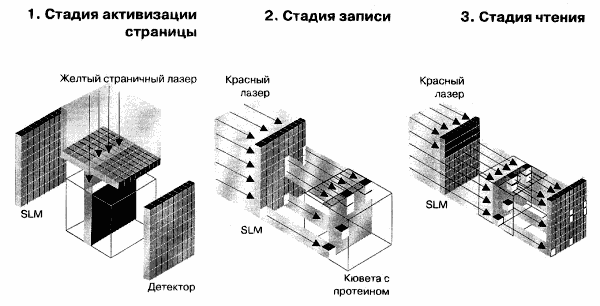
Рис.5.3.1 прибор, использующий принцип зарядовой инжекции
При записи данных сначала надо зажечь желтый "страничный" лазер - для перевода молекул в Q-состояние. Пространственный световой модулятор (SLM), который, как говорилось ранее, представляет собой LCD-матрицу, создающую маску на пути луча, вызывает возникновение активной (возбужденной) плоскости в материале внутри кюветы. Эта энергоактивная плоскость представляет собой страницу данных, которая может вмешать массив 4096x4096 bit. Перед возвратом протеина в состояние покоя (в нем он может находиться довольно длительное время, сохраняя информацию) зажигается красный, записывающий лазер, располагаемый под прямым углом по отношению к желтому. Другой SLM отображает двоичные данные и, таким образом, создает на пути луча соответствующую маску, поэтому облучению подвергнутся только определенные пятна (точки) страницы. Молекулы в этих местах перейдут в Q-состояние и будут представлять двоичную единицу. Оставшаяся часть страницы возвратится в первоначальное bR-состояние и будет представлять двоичные нули. Для того, чтобы прочитать данные, надо опять зажечь страничный лазер, который переводит читаемую страницу в Q-состояние. Это делается для того, чтобы в дальнейшем, с помощью различия в спектрах поглощения, идентифицировать двоичные нули и единицы. Через 2ms после этого страница "окунается" в низкоинтенсивный световой поток красного лазера. Низкая интенсивность нужна для того, чтобы предупредить "перепрыгивание" молекул в Q-состояние. Молекулы, представляющие двоичный нуль, поглощают красный свет, а представляющие двоичную единицу пропускают луч мимо себя. Это создает "шахматный" рисунок из светлых и темных пятен на LCD-матрице, которая захватывает страницу цифровой информации.
Для стирания данных достаточно короткого импульса синего лазера, чтобы вернуть молекулы из Q-состояния в исходное bR-состояние. Синий свет не обязательно должен идти от лазера: так можно стереть всю кювету с помощью обыкновенной ультрафиолетовой лампы. Для обеспечения целостности данных при выборочном стирании страниц применяется кэширование нескольких смежных страниц. При операциях чтения-записи также используются два дополнительных бита четности, чтобы защититься от ошибок. Страница данных может быть прочитана без разрушения до 5000 раз. Каждая страница отслеживается счетчиком, и если происходит 1024 чтения, то страница "освежается" (регенерируется) с помощью новой операции записи.
Учитывая, что молекула меняет свои состояния в пределах 1ms, суммарное время для выполнения операции чтения или записи составляет около 10ms. Однако, по аналогии с системой голографической памяти, это устройство осуществляет параллельный доступ в цикле чтения-записи, что позволяет рассчитывать на скорость до 10MBps. Предполагается, что если объединить по восемь запоминающих битовых ячеек в байт с параллельным доступом, то можно достигнуть скорости 80MBps, но для такого способа необходима соответствующая схемотехническая реализация подсистемы памяти. Некоторые версии устройств SLM выполняют страничную адресацию, которая в недорогих конструкциях используется при направлении луча на нужную страницу с помощью поворотной системы гальванических зеркал. Такой SLM обеспечивает доступ за 1ms, но и стоит соответственно в четыре раза дороже.
Сам Бирг утверждает, что предложенная им система по быстродействию близка к полупроводниковой памяти, пока не встретится страничный дефект. При обнаружении такого дефекта необходимо перенаправить луч для доступа к таким страницам с другой стороны. Теоретически, кювета, о которой уже шла речь, может вместить 1ТВ данных. Ограничения на емкость связаны, в основном, с проблемами линзовой системы и качеством протеина.
Сможет ли молекулярная память конкурировать с традиционной полупроводниковой памятью? Ее конструкция, безусловно, имеет определенные преимущества. Во-первых, она основана на протеине, который производится в большом количестве и по недорогой цене, чему способствуют достижения генной инженерии. Во-вторых, система может функционировать в более широком диапазоне температур, чем полупроводниковая память. В-третьих, данные сохраняются постоянно даже если выключить питание системы памяти, это не приведет к потере информации. И, наконец, кубики с данными, имеющие маленькие размеры, но содержащие гигабайты информации, можно помещать в архив для хранения копий (как магнитные ленты). Так как кубики не содержат движущихся частей, это удобнее, чем использование портативных жестких дисков или картриджей с магнитной лентой.
5
.4
Наноструктуры
Исследования, проведённые специалистами Университета Пердью (Уэст-Лафайетт, штат Индиана), открывают пути к созданию новых технологий производства памяти. Нанокольца - это новые наноструктуры, открытые в лабораториях университета, которые позволят повысить быстродействие памяти и плотность упаковки информации, при том, что стоимость этих решений будет приемлема для массового рынка.
Сегодня разработчики устройств хранения данных, как и вся индустрия электроники, возлагают надежды на достижения нанотехнологий. Миниатюризация компонентов до десятитысячных долей толщины человеческого волоса даёт возможность выпускать все более быстродействующие микросхемы. Но технологический процесс до сих пор находится в стадии разработки, а с уменьшением компонентов растёт стоимость их производства.
Химик из Университета Пердью Александр Вэй нашёл поразительно простое и дешёвое решение проблемы хранения данных. Исследовательская группа Вэя разработала метод создания микроскопических, диаметром значительно меньше ста нанометров, колец из частиц кобальта. Эти кольца могут сохранять намагниченность при комнатной температуре и, самое главное, формируются самостоятельно.
Кобальтовые частицы представляют собой микромагниты, которые имеют северный и южный полюса. Формирование колец происходит, когда частицы кобальта оказываются в непосредственной близости друг от друга и притягиваются под воздействием магнитных сил. Следовало полагать, что частицы соберутся в цепочку, но при определённых условиях вместо этого образуются кольца, комментирует Вэй.

Рис.5.4.1 Магнитные поля отдельных частиц нанокольца сливаются в единый поток
После образования кольца частицы кобальта ориентируются таким образом, что силовые линии их магнитных полей образуют замкнутую структуру. Таким образом, кольцо не оказывает магнитного влияния на объекты, находящиеся за его пределами, что обещает отсутствие помех для других ячеек будущей памяти. Магнитное поле в кольце может быть ориентировано в двух направлениях по часовой и против часовой стрелки, таким образом, есть возможность кодировать двоичную информацию. Предварительные исследования показали, что влиять на направленность поля можно с помощью внешних магнитных сил. Александр Вэй рассчитывает добиться этого, комбинируя нанокольца с нанопроводниками, с помощью которых возможно создавать чётко локализованные магнитные поля.
Разработка исследователей из Университета Пердью может привести к созданию новых устройств долговременного хранения информации, а также энергонезависимой оперативной памяти. Большой плюс разработки кроется в возможности функционирования при комнатной температуре и простоте получения наноколец.
Заключение
В этой курсовой работе были раскрыты нюансы оперативной памяти. Мы убедились, что эта память является одним из важнейших компонентов компьютера. Ведь именно от нее во многом зависит быстродействие компьютера, а также программное обеспечение, которое мы сможем использовать на нем. Не следует забывать и о том, что быстродействие оперативной памяти не зависит напрямую от её частоты, а скорее от структуры.
В настоящее время разработано много видов оперативной памяти: высокоскоростной и более медленной, дорогой и подешевле. Какую память следует устанавливать на компьютер, должен решать сам пользователь, в зависимости от того, какие возможности ему нужны. Но следует помнить, что быстроразвивающаяся компьютерная отрасль, в том числе программное обеспечение, предъявляют все большие требования к компьютерам, в том числе и к оперативной памяти.
Итак подведём итоги сравнения оперативной памяти:
Память DRAM:
Преимущества:
- малое число элементов на одну ячейку, откуда высокая плотность упаковки, большой объем памяти на одном кристалле;
- малое потребление мощности.
Недостатки:
- необходимость периодического перезаряда элементов памяти, а это: уменьшает быстродействие, усложняет схемы обслуживания памяти;
- при отсутствии питания стирается вся информация.
Память SRAM:
Преимущества:
- высокое быстродействие.
- отсутствие регенирации.
Недостатки:
- в связи с дороговизной память типа SRAM используется , в основном только как КЭШ L1 и L2
- маленькая плотность упаковки
Список литературы.
1. Скотт Мюллер «Модернизация и ремонт ПК», «Вильямс», Москва 2000г.
2. Михаил Гук Энциклопедия «Аппаратные средства IBM PC», «Питер» Москва 2003г.
3. Фигурнов В.Э «IBM PC для пользователя», «Инфра-М», Москва, 1998г.
4. CD disk «Referats 2002»
5. INTERNET:
5.1. www.izcity.com
5.2. www.citforum.ru
5.3. www.ixbt.com
|