| Балашовский филиал
Саратовского государственного университета
им Н. Г. Чернышевского
О. А. Кузнецов
Компьютерный практикум
по эконометрике
Часть 1
Учебно-методическое пособие
для студентов экономического
и физико-математического
факультетов
Балашов 2005
УДК 33.518
ББК 65в6
К89
Рецензенты:
Кандидат физико-математических наук, доцент
Балашовского филиала
Саратовского государственного университета
им. Н. Г. Чернышевского
М. А. Ляшко;
Кандидат педагогических наук, доцент
Балашовского филиала
Саратовского государственного
социально-экономического университета
Г. Н. Ионов.
Рекомендовано к изданию Учебно-методическим советом
Балашовского филиала Саратовского государственного университета
им. Н. Г. Чернышевского.
Кузнецов, О. А.
К89 Компьютерный практикум по эконометрике. Ч. 1 : учебно-методическое пособие для студентов экономического и физико-математического факультетов / О. А. Кузнецов. — Балашов : Изд-во «Николаев», 2005. — 84 с.
ISBN 5—94035—192—1
Настоящий компьютерный практикум предназначен для практического решения статистических и эконометрических задач. Тематики лабораторных работ полностью совпадают с тематиками учебно-методического пособия.
Практикум рассчитан на студентов экономических и физико-математических специальностей, знакомых с основными навыками работы на ЭВМ, в частности, табличного процессора Excel.
Настоящее учебно-методическое пособие соответствует Государственному образовательному стандарту по экономическим дисциплинам. Оно может быть полезно при самостоятельном решении эконометрических задач.
УДК 33.518
ББК 65в6
ISBN
5—94035—192—1
Ó О. А. Кузнецов, 2005
Оглавление
ВВЕДЕНИЕ.. 6
Глава 1. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ.. 8
Лабораторная работа № 1. 8
Основные понятия математической статистики. 8
Лабораторная работа № 2. 17
Метод наименьших квадратов. 17
Лабораторная работа № 3. 25
Свойства коэффициентов регрессии. 25
Лабораторная работа № 4. 30
Некоторые распределения. 30
Лабораторная работа № 5. 37
Проверка гипотез. 37
Лабораторная работа № 6. 40
Нелинейная регрессия. 40
Глава 2. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ.. 45
Лабораторная работа № 7. 45
Множественная регрессия. 45
Лабораторная работа № 8. 54
Спецификация переменных и проблема мультиколлинеарности. 54
Лабораторная работа № 9. 56
Фиктивные переменные и категории. 56
Лабораторная работа № 10. 61
Гетероскедастичность и взвешенный метод наименьших квадратов. 61
Лабораторная работа № 11. 68
Автокорреляция и обобщённый метод наименьших квадратов. 68
ЗАКЛЮЧЕНИЕ.. 73
БИБЛИОГРАФИЧЕСКИЙ СПИСОК.. 74
ТАБЛИЦЫ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ... 76
Лабораторные работы № 1 – 8. 76
Лабораторная работа № 9. 81
ПРЕДИСЛОВИЕ
Эконометрика как дисциплина федерального компонента по циклу общих математических и естественно-научных дисциплин впервые включена в основную образовательную программу подготовки экономистов, определенную Государственным образовательным стандартом второго поколения. Хотя в настоящее время и появилось большое количество новых учебников по данной дисциплине, имеется нехватка практических пособий, в которых излагался бы материал, способствующий наработке навыков решения эконометрических задач.
Данное учебно-методическое пособие в некоторой степени восполняет этот пробел. Оно соответствует Государственному образовательному стандарту по дисциплине «Эконометрика» для экономических специальностей вуза. При изложении материала предполагалось, что читатель изучил необходимый теоретический материал по теории вероятностей, математической статистики и эконометрики, а также имеет начальные навыки работы со стандартным программным обеспечением, в частности, с электронной таблицей Excel.
Учебно-методическое пособие состоит из введения, основного учебного материала, разбитого на две главы, и приложения. Во введении рассматривается основная структура предлагаемых лабораторных работ, обосновывается факт использования большого количества разнообразных программных продуктов и описываются методические рекомендации изучения данного пособия. Как и при изучении любой компьютерной программы, методические рекомендации заключаются в начальном чтении материала каждой лабораторной работы, а затем повторном прочтении, с выполнением всех описанных действий непосредственно за компьютером.
В первой главе содержатся лабораторные работы, предназначенные для практического решения задач парного регрессионного анализа. При этом имеются разделы, которые хотя непосредственно и не относятся к эконометрике, но содержат необходимый материал из теории вероятностей и математической статистики. В частности, это лабораторная работа № 1, в которой рассматриваются возможности вычисления параметров выборок, а также возможности генерации случайных чисел, отвечающих некоторым законам, и лабораторная работа № 4, в которой рассматриваются возможности получения параметров случайных величин, отвечающих некоторым распределениям.
Вторая глава посвящена возможностям получения параметров множественной регрессии. Здесь же рассматриваются некоторые частные случаи, а именно — эффекты гетероскедастичности и автокорреляции, которые связаны с нарушением условий Гаусса—Маркова.
В приложении располагаются таблицы исходных данных, которые необходимо самостоятельно рассмотреть.
Данное учебно-методическое пособие рассчитано в первую очередь на студентов экономических специальностей, которые изучают «Эконометрику». Однако оно может быть полезно всем, кто сталкивается с необходимостью решать практические задачи теории вероятностей и математической статистики.
ВВЕДЕНИЕ
Каждую задачу математической статистики и эконометрики можно решить «вручную», используя бумагу и ручку, либо с помощью калькулятора. Однако статистические, да и эконометрические задачи во многом однотипны и трудоёмки для решений, поэтому, вычислив один раз дисперсию или корреляцию, можно понять основные принципы и почувствовать всю рутинность данной работы. При наличии определенных навыков можно решить задачу посредством программы на каком-либо языке программирования. Но написание программы тоже достаточно трудоёмкое и творческое дело, и не каждый экономист владеет этим искусством. Для облегчения решений данных задач в настоящее время создано большое количество программных продуктов, которые позволяют обрабатывать статистические данные, а в некоторых случаях решать эконометрические задачи.
Наиболее простыми с точки зрения изучения и применения, а также наиболее распространенными, но в то же время обладающими минимальными возможностями для решения статистических задач, являются электронные таблицы
, в частности, таблица Excel
. Те статистические и эконометрические задачи, которые допускают такое решение, будут решаться нами именно в Excel. Более подробно с возможностями электронной таблицы в Excel можно ознакомиться по учебникам [3; 6; 7].
Другим классом программных продуктов, который будет использоваться в дальнейшем, являются математические пакеты, которые также как и электронные таблицы специально не предназначены для решения подобных задач, но имеют большие возможности для этого. Некоторые из основных возможностей и способы решения задач будут демонстрироваться с помощью математического пакета
MathCad
. В настоящее время он является одним из наиболее популярных пакетов подобного рода (дополнительную информацию по которому можно получить в работе [8]).
И, наконец, существует большое количество специальных пакетов, которые специально предназначены для обработки статистической информации и решения эконометрических задач. Каждый из них имеет практически одинаковый набор возможностей, но различные дополнительные инструменты и интерфейс. Среди таких пакетов можно отметить: SAS
, SPSS
, STAT
, Мезозавр
и т. д.
Мы будем изучать пакет обработки статистических данных
SPSS
, поскольку интерфейс данной программы во многом схож с интерфейсом электронной таблицы Excel. Внешний вид рабочей области имеет вид таблицы, каждая ячейка которой характеризуется названием столбца и номером строки. Работа по заданию начального вида таблиц похожа на использование конструктора в Access
. Все эти особенности пакета SPSS, позволяют быстро понять основные принципы работы всем, кто знаком с программами Microsoft Office. Для дополнительного самостоятельного изучения данного программного продукта можно порекомендовать работы [1; 9].
Данное учебно-методическое пособие содержит курс лабораторных работ, которые позволяют научиться решать эконометрические задачи, используя программные продукты. Каждая лабораторная работа содержит необходимые понятия и формулы. Данная информация является дополнительным теоретическим материалом, и ни в коем случае не может восприниматься как учебник по эконометрике. Изучить теоретическую часть можно на основании любого учебника по эконометрике, например работы [2; 4]. Название лабораторных работ совпадает с название параграфов книги [5].
Изучать данные лабораторные работы рекомендуется непосредственно работая на ЭВМ с соответствующим программным продуктом. При этом очень важно самостоятельно выполнять все описываемые действия.
Кроме обычных учебников по эконометрике, имеется огромное количество полезной информации в сети Internet. Список наиболее популярных интернет-ресурсов находится в библиографическом списке.
Глава 1. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Лабораторная работа № 1
Основные понятия математической статистики
Цель:
изучить возможности электронной таблицы Excel по обработки статистической информации.
Основные формулы и понятия:
Если
X и
Y — две произвольные случайные величины, то для них можно определить некоторые параметры, например
m
X
,m
Y
— математические ожидания;
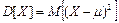 — дисперсия; — дисперсия;
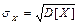 — среднеквадратичное отклонение случайной величины; — среднеквадратичное отклонение случайной величины;
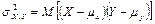 — ковариация случайных величин; — ковариация случайных величин;
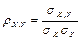 — корреляция случайных величин; — корреляция случайных величин;
Если
X дискретная случайная величина, которая принимает
n значений (х1
,х2
,...,хn
) с вероятностями (
p1
,
p2
,...,
pn
), то
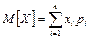 — математическое ожидание;
— математическое ожидание;
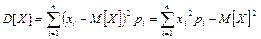 — дисперсия; — дисперсия;
Если имеется выборка (х1
,х2
,...,хn
) из генеральной совокупности, в которой каждый элемент является случайной величиной, то нельзя определить точное значение теоретических характеристик, однако можно построить точечные оценки, которые по возможности должна быть отвечать требованиям несмещённости, состоятельности и эффективности.
Основные оценки
:
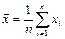 — выборочное среднее (несмещённая оценка математического ожидания
m); — выборочное среднее (несмещённая оценка математического ожидания
m);
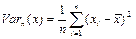 — выборочная дисперсия (смещённая оценка дисперсии); — выборочная дисперсия (смещённая оценка дисперсии);
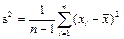 — несмещённая оценка дисперсии; — несмещённая оценка дисперсии;
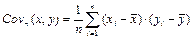 — выборочная ковариация; — выборочная ковариация;
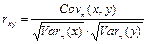 — выборочная корреляция. — выборочная корреляция.
Электронная таблица Excel
Во всех электронных таблицах имеется большое количество встроенных статистических функций. Excel не стал исключением из правил. Статистические функции, как и любые другие функции, вставляются с помощью мастера функций посредством пункта меню Вставка, Функции
или нажатием на кнопку  панели инструментов. Мастер функций выполняется в два этапа: на первом задается функция (все описываемые функции находятся в категории «Статистические»), а на втором этапе выбираются аргументы данной функции. панели инструментов. Мастер функций выполняется в два этапа: на первом задается функция (все описываемые функции находятся в категории «Статистические»), а на втором этапе выбираются аргументы данной функции.
Рассмотрим основные статистические функции. При этом необходимо отметить одну особенность. Для решения одной задачи имеется две практически одинаковые функции, например, СРЗНАЧ и СРЗНАЧА, вычисляют среднее значение в выборке. Первая функция игнорирует все ячейки, в которых содержится нечисловая информация, а вторая всем ячейкам с текстовой информацией автоматически придает значение 0. Аналогично для вычисления всех значений имеются две функции, при этом первая игнорирует все нечисловые ячейки, а вторая, заканчивающая на А, автоматически придает всем ячейкам, в которых находится текстовая или логическая информация, значение 0.
Функция ДИСПР вычисляет значение выборочной дисперсии, которая является смещённой оценкой реальной дисперсии. Иногда данное значение называют дисперсией для генеральной совокупности. Среднеквадратичное отклонение может быть вычислено как корень квадратный из дисперсии или посредством использования функции СТАНДОТКЛОН. Функция ДИСП вычисляет значения несмещённой оценкой дисперсии, которую также называют дисперсией по выборке, а для определения среднеквадратичного отклонения можно использовать функцию СТАНДОТКЛОНА. Все вышеперечисленные функции в качестве аргументов имеют один массив данных.
Функции КОВАР и КОРЕЛЛ вычисляют ковариацию и корреляцию между двумя массивами данных, а следовательно, аргументами данных функций являются два блока данных одинаковой размерности.
Рассмотрим пример использования данных функций. Исходные данные, в которых содержатся цена и спрос на некоторый товар, представлены в таблице 1.
Таблица 1
| Номер наблюдения
|
Цена
x (р.)
|
Спрос
y (тыс.шт.)
|
| 1
|
15,09р.
|
125,1779
|
| 2
|
15,21р.
|
123,8094
|
| 3
|
15,28р.
|
121,175
|
| 4
|
15,49р.
|
116,9143
|
| 5
|
15,54р.
|
119,8643
|
| 6
|
15,62р.
|
118,0681
|
| 7
|
15,70р.
|
123,5887
|
| 8
|
15,91р.
|
117,0877
|
| 9
|
15,92р.
|
116,1699
|
| 10
|
15,95р.
|
118,3436
|
| 11
|
16,31р.
|
116,2008
|
| 12
|
16,33р.
|
111,4565
|
| 13
|
16,60р.
|
115,1026
|
| 14
|
16,69р.
|
110,1056
|
| 15
|
16,76р.
|
110,0231
|
Тогда документ Excel, в котором вычисляются значение выборочного среднего, выборочных дисперсий, а также корреляции и ковариации, может иметь вид, представленный в таблице 2.
Таблица 2
| |
A
|
B
|
C
|
| 1
|
Номер наблюдения
|
Цена x (р.)
|
Спрос y (тыс.шт.)
|
| 2
|
1
|
15,09р.
|
125,1779
|
| 3
|
2
|
15,21р.
|
123,8094
|
| 4
|
3
|
15,28р.
|
121,175
|
| 5
|
4
|
15,49р.
|
116,9143
|
| 6
|
5
|
15,54р.
|
119,8643
|
| 7
|
6
|
15,62р.
|
118,0681
|
| 8
|
7
|
15,70р.
|
123,5887
|
| 9
|
8
|
15,91р.
|
117,0877
|
| 10
|
9
|
15,92р.
|
116,1699
|
Продолжение табл.
2
| 11
|
10
|
15,95р.
|
118,3436
|
| 12
|
11
|
16,31р.
|
116,2008
|
| 13
|
12
|
16,33р.
|
111,4565
|
| 14
|
13
|
16,60р.
|
115,1026
|
| 15
|
14
|
16,69р.
|
110,1056
|
| 16
|
15
|
16,76р.
|
110,0231
|
| 17
|
|
Выборочное среднее по x
|
=СРЗНАЧ(B2:B16)
|
| 18
|
|
Выборочное среднее по y
|
=СРЗНАЧ(C2:C16)
|
| 19
|
|
Выборочная дисперсия x
|
=ДИСП(B2:B16)
|
| 20
|
|
Выборочная дисперсия y
|
=ДИСП(C2:C16)
|
| 21
|
|
Ковариация
|
=КОВАР(B2:B16;C2:C16)
|
| 22
|
|
Корреляция
|
=КОРРЕЛ(B2:B16;C2:C16)
|
Вычисленные на основании этих формул значения будет равны:
Выборочное среднее по x = 15,89
Выборочное среднее по y = 117,53
Выборочная дисперсия x = 0,29
Выборочная дисперсия y = 22,34
Ковариация = –2,12
Корреляция = –0,88
Анализируя полученные результаты, можно только говорить о том, что разброс значений по y
больше, чем разброс по x
, поскольку значение дисперсии y
намного больше дисперсии x
, и зависимость между x
и y
близка к линейной убывающей зависимости, поскольку коэффициент корреляции отрицательный и по модулю близок к единице.
Основная особенность электронных таблиц заключается в том, что рабочее поле представляет собой совокупность ячеек, у каждой из которых имеется свой адрес. Функция заносится в определенную ячейку, в которую возвращается полученное значение. Для решения многих статистических и эконометрических задач использование только функций является существенным ограничением, поскольку часто результатом должно служить не одно число, а некоторый набор. С целью расширения возможностей в Excel реализованы надстройки, которые подключатся по мере необходимости и позволяют решать более специфические задачи.
Для выбора и подключения надстройки необходимо выбрать пункт меню Сервис, Надстройки
. После этого появится диалоговое окно, изображенное на рисунке 1.
Все дополнительные возможности, которые осуществляют статистический анализ данных, находятся в надстройке Пакет анализа
, поэтому данную надстройку необходимо отметить, то есть поставить галочку напротив соответствующего пункта. После нажатия на кнопку OK
ничего визуально не изменится, однако после повторного выбора пункта меню Сервис
появляется дополнительный подпункт Анализ данных
. Выбор данного пункта приводит к появлению диалогового окна (рис. 2).

Рис. 1

Рис. 2
4
Выбрав конкретный инструментарий анализа и нажав на кнопку Справка
, можно получить исчерпывающую информацию по данному инструменту от небольшой теоретической части до полного описания всей необходимой входной информации.
Инструментарий Генерация случайных чисел
позволяет сгенерировать множество значений случайной величины, имеющей какой-либо закон распределения. Выбор данного инструмента приведет к появлению диалогового окна (рис. 3):

Рис. 3
Рассмотрим вначале обязательные параметры, которые необходимо задать при работе с данной надстройкой.
Во-первых — это тип распределения. Имеется возможность выбрать Нормальное
, Равномерное
, Пуассоновское
, Биноминальное
и некоторые другие виды распределений. При этом для каждого распределения необходимо задавать свои параметры. Мы в дальнейшем будем рассматривать случайные величины, имеющие нормальное и равномерное распределение. При выборе равномерного распределения в качестве параметра необходимо задать интервал
, а при нормальном распределении необходимо задать Среднее
и Стандартное отклонение
.
Во-вторых — количество генерируемых чисел. Это можно сделать двумя способами: указать число строк и столбцов, Число переменных
— число столбцов, а Число случайных чисел —
число строк в которых разместятся сгенерированные числа. В данном случае набор случайных чисел будет помещен на новый лист. Однако часто необходимо получить набор случайных чисел в некотором диапазоне на рабочем листе. Для этого воспользуемся пунктом Параметры вывода
, который задает месторасположение генерируемых чисел. В этом случае весь указанный диапазон на исходном листе будет заполнен случайными числами. Например, указав Выходной интервал в виде $B$5:$C$11, получим 14 случайных чисел, расположенных в этих ячейках.
Кроме вида распределения и количества случайных чисел можно менять параметр — Случайное рассеивание
. В качестве значения данной опции указывается произвольное целое число. Данное значение необходимо для того, чтобы получать одинаковый набор случайных чисел.
Инструментарий Выборка
позволяет сформировать какую-либо выборку из имеющегося набора чисел, при этом Параметры вывода
имеют тот же самый смысл, то есть место, куда будет выдаваться значение. Входной интервал
задает всю генеральную совокупность, из которой будет осуществлён выбор. Метод выборки
задает способ формирования выборки: периодическая или случайная. В периодической выборке
задается период и каждое последующее число с номером кратным периоду будет скопировано в выборку. Процесс создания выборки прекратится при достижении конца входного диапазона. В случайной выборке
задается только число значений в конечной выборке, при этом любое исходное значение может быть выбрано более одного раза.
Предположим, что сгенерирована совокупность случайных чисел, отвечающая нормальному закону распределения с математическим ожиданием 0 и среднеквадратичным отклонением 1, которая содержит 100 строк и 100 столбцов, и помещена на 4-м листе. Тогда для того, чтобы выбрать 20 чисел и поместить их на новый лист можно указать параметры диалогового окна Выборка, показанные на рисунке 4.

Рис. 4
Надстройки Корреляция
и Ковариация
позволяют создавать корреляционную и ковариационную таблицы. Данные надстройки имеют одинаковые диалоговые окна и отличаются только заголовком. На рисунке 5 представлено диалоговое окно, которое появляется после выбора инструментария корреляция.

Рис. 5
Пункты Входной интервал
и Параметры вывода
задаются аналогично другим надстройкам, поэтому подробно не будем на них останавливаться. Переключатель Метки в первой строке
позволяет выдавать в сгенерированной таблице заголовки столбцов и строк.
В отличие от функций, вычисления значений корреляции и ковариации КОВАР и КОРЕЛЛ, надстройки вычисляют корреляционную и ковариационную матрицы, для произвольного количества случайных величин. Поскольку данные матрицы являются симметричными, то выводится только одна часть, при этом в корреляционной матрице на диагонали находятся единицы, а в ковариационной матрице на диагонали находятся значения дисперсий во всей генеральной совокупности.
Если для данных из таблицы 1 вызвать надстройку Ковариация
, указав входной интервал в виде диапазона A1:C16 и опцию Метка в первой строке
, а также задав некоторые параметры вывода, будет автоматически сгенерирована таблица 3.
Таблица 3
| |
Номер наблюдения
|
Цена x (р.)
|
Спрос y (тыс.шт.)
|
| Номер наблюдения
|
18,66667
|
|
|
| Цена x (р.)
|
2,248
|
0,276116
|
|
| Спрос y (тыс.шт.)
|
–17,2239
|
–2,12699
|
20,85071
|
Нетрудно заметить, что полученное в данной таблице значение ковариации –2,12699 совпадает со значением полученными нами ранее посредством функции КОВАР, а значения дисперсий 0,276116 и 20,85071 отличаются, поскольку в данной таблице вычисляется значение дисперсии по всей генеральной совокупности.
Задания для самостоятельной работы
1. Для таблицы из приложения (номер варианта соответствует номеру вашего компьютера) найдите среднее значение, смещённую и несмещённую дисперсию, среднеквадратичное отклонение в каждом столбце.
2. Получите корреляционную и ковариационную таблицу для этих же данных. Сделайте заключения об имеющихся линейных связях.
3. На одном листе Excel сгенерируйте набор из 10000 случайных чисел, имеющих равномерное распределение на интервале от 0 до 10. Найдите значение среднего и дисперсии во всей таблицы случайных чисел, которую впоследствии будем ассоциировать со всей генеральной совокупностью. Это можно сделать посредством имеющихся в Excel формул. Создайте 10 выборок из данной генеральной совокупности по 20 элементов в каждой, используя 5 раз периодическую и 5 раз случайную выборки. Поместите каждую выборку на отдельный лист. С помощью статистических функций исследуйте данные выборки, а именно, найдите выборочное среднее, несмещённую (выборочную) и смещённую (по всей генеральной совокупности) оценки дисперсии.
Замечание
Если случайная величина X
имеет равномерное распределение между значениями a
и b
, то математическое ожидание может быть вычислено по формуле 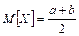 , а дисперсия , а дисперсия 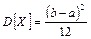 . .
Лабораторная работа № 2
Метод наименьших квадратов
Цель:
изучить возможности электронной таблицы Excel по обработке парной линейной регрессии.
Основные формулы и понятия:
у
= a
+ b
×х
+ u — модели парной линейной регрессии;
y
= а
+ b
×x — уравнение линейной регрессии;
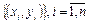 — значение наблюдений
; — значение наблюдений
;
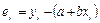 — остаток в
i-м наблюдении; — остаток в
i-м наблюдении;
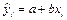 — расчетное значение у в
i-м наблюдении (точечный прогноз); — расчетное значение у в
i-м наблюдении (точечный прогноз);
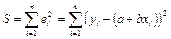 ) — суммы квадратов остатков; ) — суммы квадратов остатков;
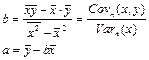 — уравнения для параметров регрессии; — уравнения для параметров регрессии;
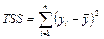 — общая сумма квадратов отклонений; — общая сумма квадратов отклонений;
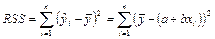 — объясненная сумма квадратов отклонений; — объясненная сумма квадратов отклонений;
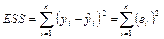 — необъясненная (остаточная) сумма квадратов отклонений; — необъясненная (остаточная) сумма квадратов отклонений;
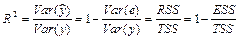 — коэффициент детерминации. — коэффициент детерминации.
Для парного регрессионного анализа выполняется условие: коэффициент детерминации R2
равен квадрату коэффициента корреляции, то есть 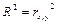
Электронная таблица Excel
Ранее изученных нами статистических функций вполне достаточно для непосредственного вычисления коэффициентов регрессии. Для нахождения значения параметра b
достаточно уметь вычислять значение ковариации и дисперсии, а для значения a
необходимы также средние значения. Эти параметры можно легко найти самостоятельно, однако в электронной таблице Excel имеется много достаточно разнородных инструментов для определения параметров регрессии. Среди них, что совершенно очевидно, имеются статистические функции, а также дополнительные средства — это надстройка и средства точечных диаграмм. Начнем рассмотрение со статистических функций.
Функция НАКЛОН возвращает наклон (коэффициент b
в уравнении линейной регрессии). При этом аргументами являются два массива, в первом из которых задаются значения зависимой переменной y
, а во втором значения регрессора x
. Значение коэффициента a
может быть найдено либо по соответствующей формуле, либо при помощи функции ОТРЕЗОК, которая имеет подобные аргументы. Функция ПРЕДСКАЗ вычисляет или предсказывает будущее значение по произвольному значению x
. Данная функция имеет три аргумента. Первый — это значение x
, а остальные имеют тот же смысл, что и в функциях НАКЛОН и ОТРЕЗОК.
К сожалению, нет специальных функций для вычисления коэффициента детерминации, а делать это на основании исходных формул достаточно затруднительно. Однако можно использовать то свойство, что коэффициент детерминации равен квадрату коэффициента корреляции.
Предположим, что исходные данные также располагаются в таблице 1, тогда в документ Excel параметры регрессии можно вычислить на основании следующих формул:
| b
=
|
= КОВАР(
C
2:
C
16;
B
2:
B
16)/ДИСПР(
B
2:
B
16)
|
| b
=
|
=НАКЛОН(
C
2:
C
16;
B
2:
B
16)
|
| a
=
|
= СРЗНАЧ(
C
2:
C
16)- НАКЛОН(
C
2:
C
16;
B
2:
B
16)* СРЗНАЧ(
B
2:
B
16)
|
| a=
|
=ОТРЕЗОК(
C
2:
C
16;
B
2:
B
16)
|
| R
2
=
|
=КОРРЕЛ(
C
2:
C
16;
B
2:
B
16)* КОРРЕЛ(
C
2:
C
16;
B
2:
B
16)
|
| Прогноз
при
x
=17
|
=ПРЕДСКАЗ(17;
C
2:
C
16;
B
2:
B
16)
|
В данном случае предлагаются два способа вычисления параметров: на основании формул НАКЛОН и ОТРЕЗОК и через исходные формулы для параметров регрессии.
Вычисленные на основании этих формул значения будут равны:
b
= –7,703
a
= 239,96
R2
= 0,7868.
При цене, равной 17, прогнозируемый спрос будет равен 109,014.
Анализируя полученные данные, можно прийти к следующим выводам:
1. Поскольку b
= –7,703, то можно предполагать, что увеличение цены на единицу в среднем уменьшает спрос на –7,703 тысячи штук, аналогично уменьшение цены на единицу увеличит спрос на –7,703 тысячи штук.
2. Значение константы в регрессионной модели равно 239,96, следовательно, именно такой должен быть спрос при цене равной нулю. Однако данное значение является во многом теоретическим и показывает только точку пересечения линии регрессии с осью oy
.
3. Регрессионная модель имеет вид: y
= 239,96 – 7,703x
.
4. Прогнозируемый спрос при цене равной 17 будет составлять 109,014 тысячи единиц.
5. Коэффициент детерминации равен 0,7868. Данное значение может быть интерпретировано следующим образом: изменение зависимой переменной, в данном случае y
на 78 %, описывается изменением независимой переменной (регрессора) x
, что говорит о достаточной обоснованности использования данной модели.
Замечание. Описанные выше функции возвращают один параметр линейной регрессии. Однако имеется функция, которая одновременно возвращает оба параметра. Это функция ЛИНЕЙН(). Более подробно с данной функцией можно ознакомится по справочной системе.
Кроме указанных функций в Excel имеется возможность построить на диаграмме линию регрессии, которая называется линией линейного тренда. Для этого необходимо задать точечную диаграмму
(диаграмма обязательно должна быть точечной), и выбрав произвольную точку в контекстном меню, можно выбрать пункт Добавить линию тренда
. Хотя термин «тренд» имеет несколько другой смысл, применительно к временным рядам, в данном случае термины «тренд» и «линия регрессии» будем отождествлять друг с другом. Выбор пункта Добавить линию тренда
приведет к появлению диалогового окна, у которого имеются две закладки — Тип
и Параметры
(рис. 6).
 
Рис. 6
На закладке Тип
необходимо выбрать один из возможных видов уравнения регрессии. Если на диаграмме имеется несколько рядов точек, то линию регрессии можно построить для любой, задав значение соответствующего параметра — Построить на ряде
.
На закладке Параметры
можно задать дополнительную информацию, которая будет присутствовать на диаграмме. Во-первых, это возможность прогнозирования, что позволит построить линии тренда вперед или назад на соответствующее число единиц. Опция Показывать уравнение на диаграмме
позволяет выдавать вид уравнения, а опция Поместить на диаграмму величину достоверности аппроксимации (
R^2)
выводит значение коэффициента детерминации. Построив точечную диаграммы для данных, заданных в таблице 1, и линию тренда, можно получить диаграмму, которая изображена на рисунке 7.
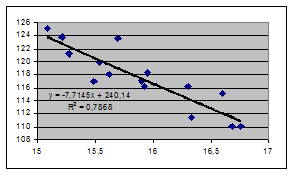
Рис. 7
В данном случае результаты полностью совпадают с полученными ранее посредством статистических функций.
Использование встроенных функций, да и точечных диаграмм, имеет определенные ограничения, поскольку нет функций, вычисляющих стандартные отклонения коэффициентов регрессии и значение детерминации. Поэтому рассмотрим дополнительные возможности, которые доступны с помощью надстройки Анализ данных
. Данная надстройка подключается с помощью пункта меню Сервис, Надстройки
и запускается на выполнение с помощью пункта меню Сервис, Анализ данных
. После выбора надстройки Регрессия
появится диалоговое окно (рис. 8).
Данное диалоговое окно имеет множество дополнительных переключателей, которые приводят к выводу большого количества дополнительной информации. Основные параметры, которые необходимо задать — это Входной интервал
Y
и Входной интервал
X
, а также Параметры вывода
. Если количество данных Y
и X
совпадает, то выдаются итоги построения модели парной регрессии (именно этот случай будем сейчас рассматривать), а если число переменных X
в несколько раз больше числа Y
, то — модель множественной регрессии. В противном случае будет выдано сообщение об ошибке. Если активизировать переключатель Метки
, то во входные интервалы для X
и Y
можно добавить ячейки с названиями, и соответствующие метки появятся в итоговой таблице, что значительно облегчит её понимание.

Рис. 8
Если Входной интервал
Y
определить как C
1:
C
16
, а В
ходной интервал
X
— B
1:
B
16
, задать некоторым образом параметры вывода, а также установить опцию Метки
, то автоматически на новом листе будет сгенерированна таблица 4.
Таблица 4
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная статистика
|
| Множественный R
|
0,887036
|
| R-квадрат
|
0,786833
|
| Нормированный
R-квадрат
|
0,770435
|
| Стандартная
ошибка
|
2,264609
|
| Наблюдения
|
15
|
| |
|
Продолжение табл.
4
| Дисперсионный анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
1
|
246,0889
|
246,0889
|
47,985
|
1,04E–05
|
| Остаток
|
13
|
66,66991
|
5,128455
|
|
|
| Итого
|
14
|
312,7588
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-
статистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
240,142
|
17,70861
|
13,56075
|
4,76E–09
|
201,8849
|
278,3991
|
| Цена x (р.)
|
–7,71453
|
1,113671
|
–6,92712
|
1,04E–05
|
–10,1205
|
–5,30859
|
Данная таблица содержит большое количество информации, поэтому будем изучать её содержимое постепенно, в нескольких последующих работах. Представленные в этой таблице данные можно условно разделить на три раздела: регрессионная статистика
, дисперсионный анализ и коэффициенты.
Весь раздел регрессионная статистика
посвящен описанию коэффициента детерминации и его различным характеристикам. В пунктах множественный
R
и R-квадрат
выводится значение коэффициента детерминации и его квадрата. Пункты меню нормированный
R-квадрат
и стандартная ошибка
будут нами рассмотрены позднее, при изучении множественной регрессии. Кроме этого выдается общее количество наблюдений.
Рассмотрим раздел дисперсионный анализ
. В столбце SS выдаются все виды сумм квадратов отклонений. В данном случае в первой строке, которая соответствует надписи Регрессия,
выдается объясненная сумма квадратов отклонений RSS
, во второй строке — Остаток
— выдается необъясненная (остаточная) сумма квадратов отклонений ESS
, в третьей строке — Итого
— выдается общая сумма квадратов отклонений TSS
.
В последнем разделе, который не имеет названия, будет интерпретироваться как раздел — коэффициенты
, содержится полная информация по коэффициентам. Рассмотрим значения, полученные в столбце Коэффициенты. Пункт Y-пересечение
выдает значение коэффициента a
. Пункт Цена x (р.)
выдает значение коэффициента b
.
Представленные в таблице значения полностью совпадают с данными, полученными посредством статистических функций и линий тренда на точечной диаграмме.
В диалоговом окне Регрессия
имеется целый раздел переключателей для получения дополнительной информации по остаткам. Например, указав опцию Остатки
, наряду со стандартной таблицей регрессии будет выдана дополнительная таблица (табл. 5) следующего вида:
Таблица 5
| ВЫВОД ОСТАТКА
|
|
| |
|
|
| Наблюдение
|
Предсказанное
Спрос y (тыс. шт.)
|
Остатки
|
| 1
|
123,7511
|
1,426776
|
| 2
|
122,7896
|
1,019821
|
| 3
|
122,2914
|
–1,11646
|
| 4
|
120,6462
|
–3,7319
|
| 5
|
120,2544
|
–0,39014
|
| 6
|
119,6494
|
–1,5813
|
| 7
|
119,0288
|
4,559903
|
| 8
|
117,4316
|
–0,34387
|
| 9
|
117,2931
|
–1,12322
|
| 10
|
117,0864
|
1,257187
|
| 11
|
114,353
|
1,847847
|
| 12
|
114,1298
|
–2,67328
|
| 13
|
112,0989
|
3,003645
|
| 14
|
111,4176
|
–1,31194
|
| 15
|
110,8662
|
–0,84306
|
В данной таблице получены результаты предсказанных значений и значения остатков отдельно для каждого наблюдения. Указав опции График подбора
, График остатков
и График нормального распределения
можно получить множество дополнительной информации и некоторые диаграммы.
Использование трех описанных нами инструментов исследования можно рассматривать как последовательные шаги в изучении парной регрессионной модели. При использовании статистических функций можно получить только уравнение регрессии и некоторый прогноз. Использование точечной диаграммы позволяет сразу увидеть уравнение регрессии, а также получить значение коэффициента детерминации. Точечная диаграмма может позволить и визуально оценить точность построенной модели. И, наконец, надстройка — Регрессия
. Используя данный инструмент можно получить полную информацию относительно регрессионной модели. Данная таблица достаточно громоздкая, могут появиться затруднения с интерпретацией полученных результатов. Поэтому рекомендуется начинать исследование модели с использования статистических функций и линии тренда на точечной диаграмме.
Задания для самостоятельной работы
1. Для начальных данных, представленных в таблице 1, найти значение параметров регрессии между y
и x
1, используя функции дисперсии, ковариации и среднего.
2. Найдите коэффициент корреляции, а также полную информацию по регрессионной модели между значениями y
и x
1, y
и x
2, y
и x
3 (данные взять из таблицы для лабораторной работы № 1—8);
3. На основании полученной информации найти лучшую регрессионную модель, то есть ту переменную, которая в большей степени влияет на y
(эта модель, в которой значение коэффициента детерминации максимально).
Лабораторная работа № 3
Свойства коэффициентов регрессии
Цель: н
аучиться использовать метод Монте-Карло для получения стандартных отклонений и проверки выполнения условий Гаусса — Маркова.
Основные формулы и понятия
Условия Гаусса — Маркова для модели
парной регрессии
:
1) случайный член регрессии в каждом наблюдении имеет нулевое математическое ожидание 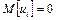 для любого
i; для любого
i;
2) дисперсия случайного члена регрессии 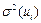 не зависит от номера наблюдения
i; не зависит от номера наблюдения
i;
3) случайные члены регрессии в разных наблюдениях не зависят друг от друга, то есть 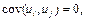 если
i
¹
j; если
i
¹
j;
4) случайный член регрессии и объясняющая переменная в каждом наблюдении независимы друг от друга, то есть 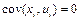 для любого
i
. для любого
i
.
Если выполняются условия Гаусса — Маркова, то параметры регрессии, найденные методом наименьших квадратов, являются несмещёнными, состоятельными и эффективными оценками.
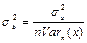 — стандартное отклонение параметра
b; — стандартное отклонение параметра
b;
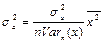 — стандартное отклонение параметра
a; — стандартное отклонение параметра
a;
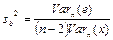 — стандартная ошибка параметра
b;
— стандартная ошибка параметра
b;
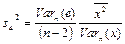 — стандартная ошибка параметра
a.
— стандартная ошибка параметра
a.
Электронная таблица Excel
В общем случае нет возможности проверить условия Гаусса — Маркова и вычислить стандартные отклонения. Поэтому рассмотрим возможности использования эксперимента по методу Монте-Карло. Простейший возможный эксперимент состоит из трех частей.
Во-первых, выбираются истинные значения a
и b
, и в каждом наблюдении выбирается значение x
.
Во-вторых, в каждом наблюдении генерируется значение u
, используя некоторый процесс генерации случайных чисел. При этом необходимо, чтобы выполнялись условия Гаусса — Маркова.
В-третьих, применяется регрессионный анализ для оценивания параметров a
и b
с использованием полученных значений y
и x
.
При этом можно видеть, являются ли а
и b
хорошими оценками a
и b
.
На первых двух шагах проводится подготовка к применению регрессионного метода. Полностью контролируем модель, которую создаем. На третьем этапе определяем, может ли поставленная нами задача решаться с помощью метода регрессии, т. е. насколько близки оценки а
и b
к истинным значениям параметров a
и b
при использовании только данных о значениях у
и x
.
Произвольно положим a
=
2 и b
=
0,5, так что истинная зависимость имеет вид:
y
= 2 + 0,5х
+ u
Предположим, что имеется 20 наблюдений и x
принимает значения от 1 до 20. Для случайной остаточной составляющей u
будем использовать случайные числа, взятые из нормально распределенной совокупности с нулевым средним и единичной дисперсией, следовательно, 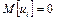 и
и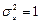 . Нам потребуется набор из 20 значений. Таблица чисел, имеющих подобное распределение, может быть генерирована с помощью надстройки Генерация случайных чисел
. При таком задании случайного воздействия u
автоматически будут выполняться условия Гаусса — Маркова. . Нам потребуется набор из 20 значений. Таблица чисел, имеющих подобное распределение, может быть генерирована с помощью надстройки Генерация случайных чисел
. При таком задании случайного воздействия u
автоматически будут выполняться условия Гаусса — Маркова.
Зная значения x
и u
в каждом наблюдении, можно вычислить значения y
,
используя уравнение. Это сделано в таблице 6.
Таблица 6
| X
|
u
|
y
|
x
|
u
|
y
|
| 1
|
0,41
|
2,91
|
11
|
–0,89
|
6,61
|
| 2
|
–0,04
|
2,96
|
12
|
–0,49
|
7,51
|
| 3
|
1,22
|
4,72
|
13
|
1,29
|
9,79
|
| 4
|
1,22
|
5,22
|
14
|
–0,59
|
8,41
|
| 5
|
–1,25
|
3,25
|
15
|
–1,28
|
8,22
|
| 6
|
–0,54
|
4,46
|
16
|
–1,39
|
8,61
|
| 7
|
0,12
|
5,62
|
17
|
0,02
|
10,52
|
| 8
|
0,19
|
6,19
|
18
|
1,17
|
12,17
|
| 9
|
–1,7
|
4,8
|
19
|
1,12
|
12,62
|
| 10
|
0,05
|
7,05
|
20
|
0,56
|
12,56
|
Теперь при оценивании регрессионной зависимости у
от x
получим:
у
= 1,95021 + 0,500932x
.
В данном случае оценка а
приняла меньшее значение по сравнению с a
, а b
немного выше по сравнению с b
.
На основании данной таблицы можно просчитать среднее отклонение для коэффициентов регрессии
. Для чего необходимо вычислить дисперсию x
, 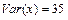 , и среднее значение из квадратов x, , и среднее значение из квадратов x,
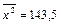 . Тогда . Тогда
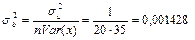 , , 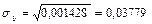 , ,
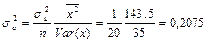 , , 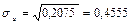 . .
Вычислить стандартные отклонения мы смогли только потому, что заранее задали все параметры модели, в частности, дисперсию случайного члена 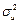 . В реальных моделях данный параметр неизвестен, поэтому необходимо воспользоваться несмещённой оценкой данного параметра . В реальных моделях данный параметр неизвестен, поэтому необходимо воспользоваться несмещённой оценкой данного параметра 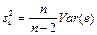 . .
После того, как вычислили стандартные отклонения, можно вычислять стандартные ошибки. Однако для этого понадобятся дисперсия остатков, для чего используя соответствующую надстройку, получим значения остатков. Возможность нахождения остатков нами была рассмотрена ранее.
В данном случае дисперсия остатков будет 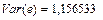 , тогда , тогда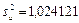 . Полученное значение оценки немного превышает значение . Полученное значение оценки немного превышает значение 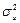 , которое мы положили равным единице, следовательно, все значения будут несколько превышать теоретические. Стандартные ошибки будут: , которое мы положили равным единице, следовательно, все значения будут несколько превышать теоретические. Стандартные ошибки будут:
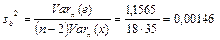 ,
, 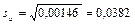 , ,
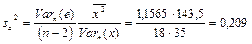 ,
, 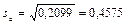 . .
Очевидно, что одного эксперимента такого типа едва ли достаточно для оценки качества метода регрессии. Он дал довольно хорошие результаты, но возможно это лишь счастливый случай. Для дальнейшей проверки повторим эксперимент с тем же истинным уравнением и с теми же значениями x
, но с новым набором случайных чисел для остаточного члена, взятых из того же распределения. Используя эти значения u
и значения x
, получим новый набор значений у
. Результаты оценивания регрессии между новыми значениями у
и x
, при различных наборах случайных величин u
, представлены в таблице 7.
Таблица 7
| Эксперимент
|
а
|
b
|
| 1
|
1,63
|
0,54
|
| 2
|
2,52
|
0,48
|
| 3
|
2,13
|
0,45
|
| 4
|
2,14
|
0,50
|
| 5
|
1,71
|
0,56
|
| 6
|
1,81
|
0,51
|
| 7
|
1,72
|
0,56
|
| 8
|
3,18
|
0,41
|
| 9
|
1,26
|
0,58
|
| 10
|
1,94
|
0,52
|
Можно заметить, что в одних случаях оценки принимают заниженные значения, а в других завышенные, однако, в целом значения а
и b
группируются вокруг истинных значений a
и b
, равных соответственно 2,00 и 0,50.
При очень большом числе повторений эксперимента можно построить таблицу частот для b
и получить аппроксимацию функции плотности вероятности. Это нормальное распределение со средним 0,50 и стандартным отклонением 0,0388.
До сих пор вся работа выполнялась с помощью стандартных функций, однако большая часть информации может быть получена, если использовать надстройку Регрессия
. Данная таблица уже рассматривалась нами ранее, но была разобрана только небольшая её часть. Выведем результаты работы надстройки Регрессии
для данных из таблицы 6.
В этом случае получим итоговую таблицу 8.
Таблица 8
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная
статистика
|
| Множественный R
|
0,951453
|
| R-квадрат
|
0,905263
|
| Нормированный
R-квадрат
|
0,9
|
| Стандартная
ошибка
|
0,984977
|
| Наблюдения
|
20
|
| |
|
| Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
1
|
166,8706
|
166,8706
|
171,9998
|
1,19E-10
|
| Остаток
|
18
|
17,46322
|
0,970179
|
|
|
| Итого
|
19
|
184,3338
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффи
циенты
|
Стандартная
ошибка
|
t-статистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
1,950211
|
0,457553
|
4,262265
|
0,000469
|
0,988927
|
2,91149
|
| X
|
0,500932
|
0,038196
|
13,11487
|
1,19E-10
|
0,420686
|
0,58117
|
В соответствующем столбце итоговой таблице имеются значения стандартных ошибок, которые полностью совпадают со значениями, полученными ранее, используя вычисления на основании исходных формул.
Задания для самостоятельной работы
1. Проведите подобные исследования, а именно получите стандартные ошибки параметров a
и b
в случае когда:
a) среднеквадратичное отклонение случайного члена регрессии u
имеет удвоенное значение, т. е. 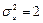 ; ;
b) имеется в два раза больше наблюдений n
= 40, при этом разность между соседними значениями x
равна 0,5;
c) имеется 20 наблюдений, но расстояние между значениями x
в два раза больше.
2. Проведите подобные исследования, взяв в качестве случайного члена регрессии u
случайную величину, имеющую равномерное распределение на отрезке от –5 до 5. Чему в данном случае будет равна дисперсия u
?
3. Будут ли нарушены условия Гаусса — Маркова, если случайная составляющая имеет:
a) равномерное распределение с параметрами между 1 и 10;
b) равномерное распределение с параметрами между –4 и 4;
c) равномерное распределение с параметрами между –2 и 4;
d) Пуассоновское распределение с параметром 2;
нормальное распределение с параметрами 0 и 10.
Лабораторная работа № 4
Некоторые распределения
Цель: изучить возможности вычисления значений функций для нормального распределения, а также распределения Стьюдента и Фишера.
Основные формулы и понятия:
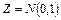 — стандартная нормально распределенная случайная величина; — стандартная нормально распределенная случайная величина;
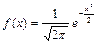 — плотность распределения; — плотность распределения;
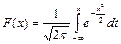 — функция распределения; — функция распределения;
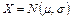 — нормально распределенная случайная величина; — нормально распределенная случайная величина;
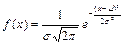 — плотность нормального распределения; — плотность нормального распределения;
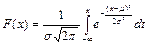 — функция нормального распределения; — функция нормального распределения;
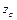 — односторонняя критическая точка с уровнем
a : — односторонняя критическая точка с уровнем
a :
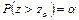 ; ;
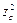 — двусторонняя критическая точка с уровнем
a : — двусторонняя критическая точка с уровнем
a :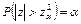 . .
Пусть случайная величина
X имеет нормальное распределение, тогда случайная величина
Y=
ex
называется логарифмически нормальной. Можно показать, что плотность распределения этой величины определяется формулой
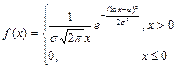
Пусть Х0
,Х1
,Х2
,... ,
Xn
имеют одно и то же нормальное распределение с параметрами
m,
s
, тогда величина
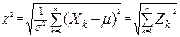 — имеет распределение хи-квадрат; — имеет распределение хи-квадрат;
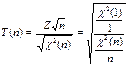 — имеет распределение Стьюдента; — имеет распределение Стьюдента;
 — односторонняя
критическая точка с уровнем
a
, — односторонняя
критическая точка с уровнем
a
,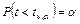 ; ;
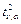 — двусторонняя критическая точек с уровнем
a: — двусторонняя критическая точек с уровнем
a:
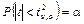 , ,
где n — число степеней свободы;
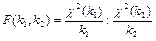 — распределение Фишера с
k1
и
k2
степенями свободы
; — распределение Фишера с
k1
и
k2
степенями свободы
;
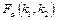 — критическая точка
с уровнем
a
: — критическая точка
с уровнем
a
: 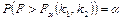 . .
Электронная таблица Excel
Для работы со случайными величинами имеется множество, на первый взгляд, очень сложных функций. Однако существуют некоторые правила, на основании которых они строятся. Например, все функции начинаются с названия распределения: НОРМ — нормальное распределение, НОРМСТ — стандартное нормальное распределение, ЛОГНОРМ — логарифмическое нормальное распределение, СТЬЮД — распределение Стьюдента и т. д. Если функция заканчивается словом РАСП, то она возвращает значение вероятность на основании некоторых параметров распределения, если ОБР, то данная функция является обратной и возвращает значение аргумента на основании вероятности, а именно возвращает значение критической точки. Хотя функции и определяются практически одинаково, в описании аргументов имеется ряд особенностей, на которых впоследствии будем останавливаться. Рассмотрим более подробно функции, которые обрабатывают распределения.
НОРМСТРАСП(z
) — возвращает значение вероятности для стандартного нормального распределения, то есть для случайной величины z
= N
(0,1). Нетрудно проверить, что значение данной функции при z = 0 будет равно 0,5. Для значений аргумента меньших, чем –8 данная функция выдает значение 0, а для больших 6 значение 1. С помощью данной функции можно проверить все табличные значения, а также построить функцию распределения нормального стандартного распределения. Функция НОРМСТОБР(вероятность) — возвращает обратное значение, на основании вероятности, то есть возвращает значение критической точки. Нетрудно проверить, что НОРМСТОБР(0,95) = 1,644853. Аналогично можно проверить все критические точки. Если вероятность =
= НОРМСТРАСП(z
), то НОРМСТОБР(вероятность) = x
. Следовательно, данные функции являются взаимнооднозначными.
Функции НОРМРАСП и НОРМОБР — определены аналогичным образом, то есть возвращают либо значение функции распределения, либо обратное значение. Однако в данных функциях используются произвольные нормальные случайные величины x
= N
(m
,s
), поэтому в качестве аргументов должны присутствовать математическое ожидание и среднеквадратичное отклонение. Однако имеются отличия. Выбор функция НОРМРАСП приводит к появлению диалогового окна (рис. 9), где помимо основных параметров распределения необходимо задать логическое значение Интегральный
. Если ввести значение Истина
, то будет вычисляться значение функции распределения, в противном случае плотность распределения. Используя данную функцию и графические возможности Excel можно легко построить графики данных функций. Функция НОРМОБР работает аналогично функции для стандартного распределения и возвращает значение критической точки.

Рис. 9
Функции ЛОГНОРМОБР и ЛОГНОРМРАСП возвращают значение функции распределения нормального логарифмического распределения и обратное значение. При работе с данными функциями необходимо помнить, что функция распределения определена только для положительных значений.
Для обработки распределения Стьюдента также имеются две функции. Функции СТЬЮДРАСП (рис. 10) на основании введенного значения x
(положительного) и числа степеней свободы выдает вероятность того, что случайная величина превзойдет данное значение x
, то есть a
= P(t
> x
). Кроме этих, стандартных для распределения Стьюдента параметров,имеется дополнительный параметр, а именно значение переменной Хвосты
. Если ввести данное значение равное 1, то всё будет вычисляться именно так, как было описано выше. Можно проверить, что значение функции СТЬЮДРАСП(0,5;10;1) равно 0,313.

Рис.
10
Однако, если значение Хвосты
равно 2, то будет подсчитана вероятность того, что, случайная величина превзойдет по модулю значение x
. Можно показать, что СТЬЮДРАСП(0,5;10;2) = 0,627. Поскольку функция плотности симметрична, то значение вероятности в первом случае в два раза меньше вероятности для второго случая.
При вызове функции СТЬЮДРАСПОБР необходимо в диалоговом окне задать только два параметра, а именно это значение вероятности и число степеней свободы, на основании которых будет вычислено значение односторонней критической точки.
Функции FРАСП и FРАСПОБР работают с распределением Фишера и запрашивают кроме стандартных аргументов значение двух степеней свободы. Если значение вероятности равно 0,05, то можно получить значения функции, например FРАСПОБР(0,05;1;1) = 161,4462, FРАСПОБР(0,05;10;100) = 1,926693. Данные функции являются обратными и нетрудно проверить, что FРАСП(0,9;5;7) = 0,529785; а FРАСПОБР(0,529;5;7) = 0,901545.
Описанных выше статистических функций Excel достаточно для вычисления значений распределений, однако мало для построения графиков как функций распределения, так и функций плотности. Поэтому кратко рассмотрим математический пакет MathCad.
Математический пакет MathCad
Для работы со случайными величинами в данном пакете имеется богатая библиотека встроенных функций, которые позволяют находить различные значения наиболее распространенных распределений. Каждое распределение представлено тремя функциями — плотность распределения, функция распределения и функция обратная к плотности распределения. Кроме этого имеется возможность генерировать выборки произвольно размера, с заданным законом распределения.
Например, для работы с нормальным распределением предназначены функции: pnorm(x,
m,
s
), dnorm(x,
m,
s
), qnorm(p,
m,
s
), rnorm(n,
m,
s
).
Функция dnorm(x,
m,
s
) возвращает значение функции плотности вероятности в точке x
, при математическом ожидании m
, и среднеквадратичное отклонение s
. Функции pnorm(x,
m,
s
) возвращает значение функции распределения; а qnorm(p,
m,
s
) такое значение x
, что F
(x
) = p
. Функция rnorm(n,
m,
s
) генерирует вектор длиной n
случайных чисел, имеющих данное распределение.
Подобное правило действует для всех встроенных функций можно интерпретировать следующим образом. Ели имеется некоторое имя некоторого распределения, то начальная буква d
означает функцию плотности, буква p
означает функцию распределения, буква q
значение критической точки. Буква r
перед именем функции позволяет генерировать вектор с заданным распределением.
Приведем список функций, предназначенных для обработки основных распределений:
· Нормальное распределение pnorm(x,
m,
s
), dnorm(x,
m,
s
), qnorm(p,
m,
s
), rnorm(n,
m,
s
).
· Логарифмически нормальное распределение plnorm(x,
m,
s
), dlnorm(x,
m,
s
), qlnorm(p,
m,
s
), rlnorm(n,
m,
s
).
· Распределение хи
-квадрат pchisd(x,
d
), dchisd (x,
d
), qchisd (p,
d
), rchisd (n,
d
).
· Распределение Стьюдента pt(x,
d
), dt(x,
d
), qt(p,
d
), rt(n,
d
).
· Распределение Фишера pF(x
,d
1
,d
2
), dF(x
,d
1
,d
2
), qF(p
,d
1
,d
2
), rF(n
,d
1
,d
2
).
· Равномерное распределение punif(x
,a
,b
), dunif(x
,a
,b
), qunif(p
,a
,b
), runif (n
,a
,b
).
Пример документа MathCad, в котором строятся графики функция плотности и распределения для стандартного нормального распределения, имеет вид:
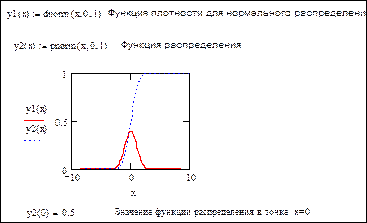
Из данного документа очевидны свойства функции плотности и распределения, а именно:
1. Функция распределения, не убывая, изменяется от 0 до 1 (пунктирная линия);
2. Функция плотности неотрицательна и ограничивает площадь равную единице (сплошная линия).
Изменяя значения математического ожидания и среднеквадратичного отклонения, можно получить различные функции плотности и распределения.
Имеется возможность также построить функции плотности распределения Стьюдента и Фишера, при этом необходимо помнить, что распределение Стьюдента имеет в качестве параметра значение степеней свободы. При увеличении данного значения функция плотность стремится снизу к функции плотности стандартного нормального распределения. Аналогичным образом можно построить соответствующие функции распределения Фишера, при этом необходимо задавать две степени свободы.
Задания для самостоятельной работы
1. Найти значения критических точек нормального распределения с вероятностями 0,9; 0,95; 0,975; 0,99.
2. Построить график функции распределения и функции плотности для нормального распределения с параметрами m
= 4, s
2
=0,3 на интервале от 0 до 8.
3. Работая с документом MathCad, построить:
a) функции плотности и функции нормального распределения
1) X
~ N
(0,1),
2) X
~ N
(5,1),
3) X
~ N
(10,0.1),
4) X
~ N
(-2,4),
5) X
~ N
(100,0.6);
b) функции плотности для распределения Стьюдента с числом степеней свободы:
1) v
= 7,
2) v
= 3,
3) v
=70,
4) v
= 15,
5) v
= 170;
c) распределение Фишера
1) k
1
= 6; k
2
= 6,
2) k
1
= 60; k
2
= 10,
3) k
1
= 100; k
2
= 6,
4) k
1
= 58; k
2
= 12,
5) k
1
= 80; k
2
= 80.
Для выполнения последнего задания необходимо активизировать внедренный документ и задать необходимые функции и аргументы.
Лабораторная работа № 5
Проверка гипотез
Цель:
научиться обосновывать умозаключения о состоятельности регрессионной модели.
Основные формулы и понятия:
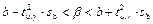 — доверительный интервал для
b; — доверительный интервал для
b;
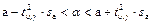 — доверительный интервал для
a; — доверительный интервал для
a;
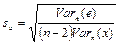 — стандартная ошибка для параметра
b; — стандартная ошибка для параметра
b;
1.
t-тест (тест Стьюдента). Тест на значимость коэффициента
b.
Нулевая гипотеза
H0:
b =
0
Альтернативная гипотеза
H1:
b
¹
0
t-статистика имеет вид:
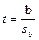
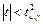 — область принятия нулевой гипотезы. — область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и регрессор признается незначимым. В противном случае принимается альтернативная гипотеза, и регрессор признаётся значимым.
2.
F-тест (тест Фишера). Тест на значимость всей регрессии.
Нулевая гипотеза
H0
:
R2
= 0
Альтернативная гипотеза
H1
:
R2
¹ 0
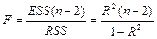
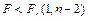 область принятия нулевой гипотезы. область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и вся регрессионная модель признается незначимой. В противном случае принимается альтернативная гипотеза, и модель признаётся значимой.
3.
t-тест (тест Стьюдента). Тест на значимость коэффициента корреляции во всей генеральной совокупности
Нулевая гипотеза
H0:
r
x,
y
= 0
Альтернативная гипотеза
H1:
r
x,
y
¹
0
t-статистика имеет вид:
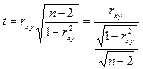
— область принятия нулевой гипотезы.
В парном регрессионном анализе результаты проверки всех трех гипотез эквивалентны.
Электронная таблица Excel
В лабораторной работе № 2 нами были проведено исследование зависимости спроса от цены на основании таблицы 1, для которой посредством надстройки была получена итоговая таблица 4 и регрессионная модель вида y
= –7,7145x
+ 240,14. Часть полученной таблицы нами уже рассматривалась.
При этом мы не учитывали, что на диалоговом окне надстройки Регрессия
(рис. 8) имеется независимый переключатель Уровень надежности
, который по умолчанию равен 95 %. Уровень надежности —
это то значение, посредством которого строятся доверительные интервалы для коэффициентов. Можно говорить о том, что Уровень надежности + Уровень значимости
= 1, то есть уровень надежности в 95 % отвечает уровню значимости в 5 % и т. д. Данное значение может быть изменено. Для этого в диалоговом окне Регрессия
необходимо отметить опцию Уровень надежности
, после чего можно поставить любое числовое значение от 0 до 100. Чаще всего используются уровни надежности в 99 % или 90 %.
В итоговой таблице имеется значения t
-тестов для каждого из коэффициентов регрессии и значение F
-теста на состоятельность регрессии. Рассмотрим данную таблицу ещё раз.
Таблица 9
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная
статистика
|
| Множественный R
|
0,887036
|
| R-квадрат
|
0,786833
|
| Нормированный
R-квадрат
|
0,770435
|
| Стандартная
ошибка
|
2,264609
|
| Наблюдения
|
15
|
Продолжение табл.
9
| |
|
| Дисперсионный анализ
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
1
|
246,0889
|
246,0889
|
47,985
|
1,04E–05
|
| Остаток
|
13
|
66,66991
|
5,128455
|
|
|
| Итого
|
14
|
312,7588
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффи
циенты
|
Стандартная
ошибка
|
t-ста
тистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
240,142
|
17,70861
|
13,56075
|
4,76E–09
|
201,8849
|
278,3991
|
| X
|
–7,71453
|
1,113671
|
–6,92712
|
1,04E–05
|
–10,1205
|
–5,30859
|
В разделе Дисперсионный анализ
выдается значение F-
теста. Данное значение равно 47,985. Однако не происходит проверки гипотезы с некоторым уровнем значимости, а находится само значение данного уровня. Поскольку, как правило, используются уровни в 5 % и 1 %, то при условии, что данное значение меньше 0,01, регрессия считается значимой, и при значении больше 0,05 — незначимой. В данном случае Значимость
F
равна 1,04E – 5 = 0,000104, то есть всю регрессионную модель можно признать значимой.
При желании можно самостоятельно найти критическое значение. Так, критическое значение с уровнем значимости 95 % можно найти по формуле FРАСПОБР(0,05;1;13) = 4,6671. Первое число степеней свободы равно числу регрессоров 1, а второе равно числу наблюдений, уменьшенному на 2, то есть 13.
В последнем разделе, где выводится значение коэффициентов, также имеется t
-статистика для каждого коэффициента, их значимость и доверительные интервалы значений. В данном случае также не производится проверка с некоторым уровнем значимости, а выдаются значения t-статистики
и P-значение
для каждого параметра.
Анализ полученных значений происходит подобным образом. Если значение меньше чем 0,01, то нулевая гипотеза отвергается, и регрессор признается значимым, если это значение больше чем 0,05, то нулевая гипотеза принимается, и соответственно регрессор признается незначимым. Как правило, эти рассуждения касаются только гипотезы H0:
b =
0. В данном случае значение статистики равно 1,04E-05, а, следовательно, регрессор можно признать значимым. При необходимости можно самостоятельно получить значения критических точек распределения Стьюдента для проверки гипотезы с некоторым уровнем значимости.
В последних двух столбцах раздела “Коэффициенты” выдаются доверительные интервалы с некоторым уровнем значимости.
Если в итоговой таблице регрессии имеются результаты о значимости коэффициентов регрессии и всей модели в целом, то гипотезу о значимости коэффициента корреляции необходимо проводить самостоятельно. (Хотя в случае парной регрессионной модели это может и не понадобиться, поскольку все гипотезы эквивалентны.)
Задания для самостоятельной работы
1. Проверить гипотезы о значимости параметров регрессии и всей регрессионной модели для данных своего варианта.
2. Найти 99 % доверительный интервал для параметров a
и b
.
3. Самостоятельно проверить гипотезу на значимость коэффициента корреляции (для этого необходимо вычислить значение соответствующей статистики, а затем проверить с критическим значением распределения Стьюдента).
Лабораторная работа № 6
Нелинейная регрессия
Цель:
научиться выбирать наилучшую регрессионную модель.
Основные формулы и понятия:
Модели нелинейной регрессии
Полиноминальная (степени
p) 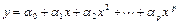
Логарифмическая 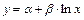
Гиперболическая
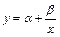
Дробно-линейная
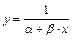
Показательная 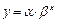
Степенная 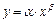
Логистическая
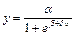
Средняя ошибка аппроксимации
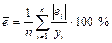 . .
Электронная таблица Excel
В электронной таблице имеются возможности получения коэффициентов и значение детерминации для логарифмической, степенной, экспоненциальной функций и полинома произвольной степени. Для этого также, как и ранее, необходимо построить точечную диаграмму, а затем вызвать контекстное меню произвольной точки. В полученном меню необходимо выбрать пункт Добавить линию тренда
, после него появится диалоговое окно (рис. 5), у которого на закладке Тип
имеется возможность выбрать соответствующую нелинейную модель. Если кроме этого отметить опции Показывать уравнение на диаграмме
и Поместить на диаграмму величину достоверности аппроксимации (
R^2,
то на графике кроме самой линии тренда появятся уравнение модели и значение коэффициента детерминации.
Например, для данных таблицы 5, построив линейную, экспоненциальную и логарифмическую модели, можно получить диаграмму, изображенную на рисунке 11:
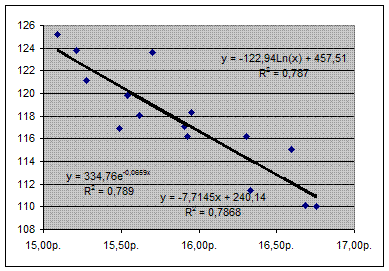
Рис. 11
То есть имеем
линейную модель: y = –7,7145x + 240,14 R2
= 0,786,
экспоненциальную модель: y = 334,76e–0,0659
x
R2
= 0,789,
логарифмическую модель: y = –122,94Ln(x) + 457,51 R2
= 0,787.
Если имеется выбор между несколькими моделями, то самый простой способ — это задавать различные уровни тренда и выбрать ту модель, у которой значение коэффициента детерминации будет максимальным.
В данном случае значения коэффициентов детерминации несильно отличаются в различных моделях, поэтому нет объективных причин выбрать наилучшую, а следовательно, необходимо проводить дополнительные исследования либо используя среднюю ошибку аппроксимации, либо множественную регрессионную модель (которую мы будем рассматривать далее).
Хотя нами и получены модели, среди которых нельзя сразу выбрать лучшую, необходимо помнить о том, что прогноз, полученный на основании каждой модели, будет различным. Как было показано ранее (лабораторная работа № 2), прогноз, в случае использования линейной модели, при x
= 17 будет равен 109,014. Прогноз, полученный на основании логарифмической модели, равен 109,1948, а на основании экспоненциальной модели — 109,1927. Эти значения получены подстановкой в уравнения моделей значения x
= 17.
Использование результатов, полученных с помощью точечной диаграммы, имеет много недостатков. Во-первых, сам набор функций достаточно ограниченный, а одна из актуальных задач современной эконометрики заключается в подборе новых, более адекватных моделей, а во-вторых, проверять гипотезы о значимости коэффициентов, да и самой регрессии в целом придется вручную. К тому же посредством точечной диаграммы можно получить модель только для парного случая.
Поэтому иногда более удобно использовать преобразования, а уже затем надстройку Регрессия
. Как мы уже знаем из теории, любая из предложенных нелинейных моделей может быть сведена к линейной либо заменой переменных, либо логарифмированием. Поэтому в таблицу исходных данных добавляют дополнительные столбцы, в которых находятся значения логарифмов, а затем строят регрессионную модель между необходимыми столбцами. Однако в этом случае нужно помнить о том, что, переходя к линейной модели, посредством логарифмирования получают изменённые значения параметров, которые затем необходимо восстанавливать.
Из экономической теории известно, что спрос является убывающей функцией цены, то есть при увеличении цены спрос убывает. Следовательно, разумной будет попытка найти лучшую модель среди убывающих функций. Имеется огромное количество функций, которые при некоторых значениях параметров являются убывающими, например, линейная, гиперболическая, показательная, с основанием меньше 1, и т. д. Рассмотрим способ построения показательной модели 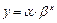 . После логарифмирования данная модель примет вид
. После логарифмирования данная модель примет вид 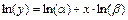 . Следовательно, для получения параметров модели необходимо значения x
задавать как и прежде, а значения y
заменить на значения логарифмов, то есть задать Входной интервал
Y
в виде D1:
D16
. В этом случае исходная таблица данных, в которой имеется дополнительный столбец, будет иметь вид (табл. 10):
. Следовательно, для получения параметров модели необходимо значения x
задавать как и прежде, а значения y
заменить на значения логарифмов, то есть задать Входной интервал
Y
в виде D1:
D16
. В этом случае исходная таблица данных, в которой имеется дополнительный столбец, будет иметь вид (табл. 10):
Таблица 10
| Номер наблюдения
|
Цена
x (р.)
|
Спрос
y (тыс. шт.)
|
ln(y)
|
| 1
|
15,09р.
|
125,1779
|
4,829736
|
| 2
|
15,21р.
|
123,8094
|
4,818744
|
| 3
|
15,28р.
|
121,175
|
4,797236
|
| 4
|
15,49р.
|
116,9143
|
4,761441
|
| 5
|
15,54р.
|
119,8643
|
4,78636
|
| 6
|
15,62р.
|
118,0681
|
4,771261
|
| 7
|
15,70р.
|
123,5887
|
4,816959
|
| 8
|
15,91р.
|
117,0877
|
4,762923
|
| 9
|
15,92р.
|
116,1699
|
4,755054
|
| 10
|
15,95р.
|
118,3436
|
4,773592
|
| 11
|
16,31р.
|
116,2008
|
4,75532
|
| 12
|
16,33р.
|
111,4565
|
4,713635
|
| 13
|
16,60р.
|
115,1026
|
4,745824
|
| 14
|
16,69р.
|
110,1056
|
4,70144
|
| 15
|
16,76р.
|
110,0231
|
4,700691
|
После вызова надстройки Регрессия
будет получена итоговая таблица (табл. 11).
Таблица 11
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная статистика
|
| Множественный R
|
0,888266
|
| R-квадрат
|
0,789016
|
| Нормированный
R-квадрат
|
0,772787
|
| Стандартная
ошибка
|
0,019221
|
| Наблюдения
|
15
|
| |
|
Продолжение табл.
11
| Дисперсионный анализ
|
|
|
|
|
|
|
Df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
1
|
0,01796
|
0,01796
|
48,61611
|
9,73E–06
|
| Остаток
|
13
|
0,004803
|
0,000369
|
|
|
| Итого
|
14
|
0,022763
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффи-
циенты
|
Стандартная
ошибка
|
t-
статистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
5,813415
|
0,1503
|
38,67869
|
8,27E–15
|
5,488711
|
6,138119
|
| Цена x (р.)
|
–0,06591
|
0,009452
|
–6,97253
|
9,73E–06
|
–0,08633
|
–0,04549
|
Используя раздел Коэффициенты
можно записать итоговую модель вид 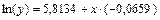 .
.
После потенцирования будет 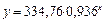 . Аналогичным образом можно построить произвольную регрессионную модель.
. Аналогичным образом можно построить произвольную регрессионную модель.
При подборе оптимальной модели кроме коэффициента детерминации можно использовать и среднюю ошибку аппроксимации. Данные вычисления достаточно очевидны, и их рекомендуется выполнить самостоятельно на основании полученных после вызова надстройки данных.
Задания для самостоятельной работы
1. Подберите наиболее подходящую модель для таблицы своего варианта.
2. Просчитайте значение средней ошибки аппроксимации для каждой модели.
3. Смоделируйте выборку, которая отвечает показательной модели.
Глава 2. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Лабораторная работа № 7
Множественная регрессия
Цель:
научиться обрабатывать множественную регрессионную модель и обосновывать её значимость и значимость каждого регрессора.
Основные формулы и понятия:
Регрессионная модель в случае двух регрессоров.
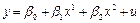 — модель, с двумя регрессорами; — модель, с двумя регрессорами;
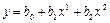 — уравнение регрессии (плоскость регрессии); — уравнение регрессии (плоскость регрессии);
Исходными данными для построения модели является выборка вида
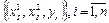 . .
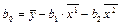
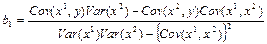
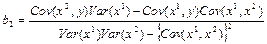 — уравнение для параметров регрессии. — уравнение для параметров регрессии.
Регрессионная модель с произвольным числом регрессоров.
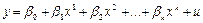 — модель множественной регрессии;
— модель множественной регрессии;
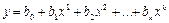 — уравнение множественной регрессии. — уравнение множественной регрессии.
Исходные данные значений регрессоров имеют вид
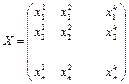 , ,
где  , ,  , , — значение
j-го регрессора в
i-м испытании. — значение
j-го регрессора в
i-м испытании.
Исходные данные значений зависимой переменной
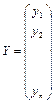
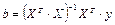 — уравнение для параметров регрессии; — уравнение для параметров регрессии;
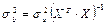 — стандартное отклонение
коэффициентов; — стандартное отклонение
коэффициентов;
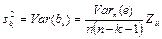 — стандартных ошибок
коэффициентов, где
— стандартных ошибок
коэффициентов, где 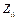 — диагональный элемент матрицы
— диагональный элемент матрицы
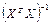 ; ;
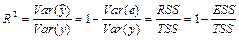 — коэффициент детерминации; — коэффициент детерминации;
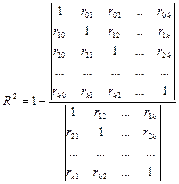 ,
,
где
rij
— парные коэффициенты корреляции между регрессорами 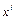 и и 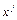 ,
a
ri
0
— парные коэффициенты корреляции между регрессором и
y; ,
a
ri
0
— парные коэффициенты корреляции между регрессором и
y;
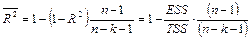 — скорректированный (нормированный) коэффициент детерминации. — скорректированный (нормированный) коэффициент детерминации.
Нулевая гипотеза
H0
:
b
i
=
0.
Альтернативная гипотеза
H1
:
b
I
¹
0.
t-статистика имеет вид:
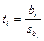 , ,
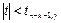 — область принятия нулевой гипотезы. — область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и регрессор xi
признается незначимым. В противном случае принимается альтернативная гипотеза, и регрессор признаётся значимым.
F-тест (тест Фишера) на значимость всей регрессии.
Нулевая гипотеза
H0
:
R2
=
0.
Альтернативная гипотеза
H1
:
R2
¹
0.
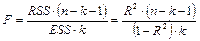 , ,
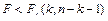 — область принятия нулевой гипотезы. — область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и вся регрессионная модель признается незначимой. В противном случае принимается альтернативная гипотеза, и модель признаётся значимой.
Математический пакет MathCad
Рассмотрение случая двух регрессоров можно опустить, поскольку в этом случае необходимо уметь вычислять средние значения, коэффициент ковариации и дисперсию. Способы получения данных параметров были изучены нами ранее (лабораторная работа № 1). Поэтому рассмотрим случай множественной регрессии.
Математический пакет MathCad содержит большое количество встроенных функций для обработки матриц, которые позволяют получить обратную и транспонированную матрицы, вычислить определителя, собственные значения и собственный вектор матрицы и т. д. Данные функции позволяют вычислить коэффициенты модели множественной регрессии и их стандартные отклонения, используя исходные формулы.
Для получения доступа к матричным функциям необходимо либо используя пункт меню Вид, Панель инструментов
активизировать панель Матрицы
, либо используя математическую панель инструментов, нажать на кнопку Векторные и матричные операции
. В любом случае появится дополнительная панель инструментов (рис. 12).

Рис. 12
Нет необходимости описывать каждую из этих кнопок, поэтому рассмотрим только необходимые в нашем случае. Первая кнопка в верхнем ряду позволяет вставить матрицу произвольной размерности, а третья позволяет получить обратную матрицу. Необходимо отметить, что все доступные функции обработки матриц можно получить, используя пункт меню Вставка, Функции
и в диалоговом окне выбрать категорию Вектора и Матрицы
.
Продемонстрируем возможности пакета по обработки матриц на примере таблицы 1, в которой наряду с данными о спросе (y
) и цене (x
1
), включены данные о ценах на некоторый подобный товар (x
2
,x
3
) и средний доход населения (x
4
). Обобщённые данные представлены в таблице 12.
Таблица 12
| Номер наблюдения
|
Цена x
1
(р.)
|
Цена на первый подобный товар x
2
(р.)
|
Цена на второй подобный товар x
3
(р.)
|
Средний доход населения x
4
(т. р.)
|
Спрос y
(тыс. шт.)
|
| 1
|
15,09р.
|
24,30р.
|
12,85р.
|
5,09
|
125,1779
|
| 2
|
15,21р.
|
26,65р.
|
12,26р.
|
5,03
|
123,8094
|
| 3
|
15,28р.
|
25,22р.
|
13,42р.
|
4,80
|
121,175
|
| 4
|
15,49р.
|
26,59р.
|
12,05р.
|
4,95
|
116,9143
|
| 5
|
15,54р.
|
26,88р.
|
12,70р.
|
4,88
|
119,8643
|
| 6
|
15,62р.
|
24,74р.
|
12,41р.
|
4,96
|
118,0681
|
| 7
|
15,70р.
|
24,42р.
|
13,83р.
|
5,10
|
123,5887
|
| 8
|
15,91р.
|
25,79р.
|
13,10р.
|
4,90
|
117,0877
|
| 9
|
15,92р.
|
24,14р.
|
13,07р.
|
4,72
|
116,1699
|
| 10
|
15,95р.
|
26,70р.
|
12,40р.
|
4,81
|
118,3436
|
| 11
|
16,31р.
|
24,66р.
|
12,82р.
|
4,95
|
116,2008
|
| 12
|
16,33р.
|
24,04р.
|
12,48р.
|
4,88
|
111,4565
|
| 13
|
16,60р.
|
25,15р.
|
13,20р.
|
5,02
|
115,1026
|
| 14
|
16,69р.
|
24,10р.
|
12,40р.
|
4,80
|
110,1056
|
| 15
|
16,76р.
|
24,49р.
|
12,01р.
|
4,85
|
110,0231
|
Учитывая, что матрица X
должна иметь на один столбец больше, чем число регрессоров, в котором находятся единицы [5, c. 69], и вектор-столбец Y
содержит значение спроса, документ MathCad может иметь следующий вид:
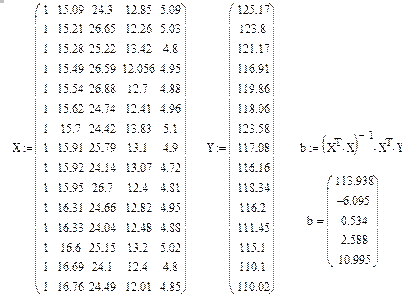
На основании полученных данных можно записать множественную модель в виде: y
= 113,938 – 6,095 x
1
+ 0,534 x
2
+ 2,588 x
3
+ 10,995 x
4
.
Сравнивая полученные данные с результатами парного регрессионного анализа (y
= 240,14 – 7,7145x), можно сделать следующие выводы:
1. Изменилось влияние цены на спрос. Если в модели парной регрессии увеличение цены на единицу приводило к уменьшению спроса на 7,714 тыс. шт., то при рассмотрении множественной модели увеличение цены на единицу приводит к уменьшению спроса на 6,095 тыс. шт. (Причина данного изменения влияния цены будет рассмотрена нами далее, при изучении проблемы лабораторной работы № 8.)
2. Изменилось значение константы. В парной модели это значение было равно 239,96, во множественной — 113,93. Именно таким должен быть спрос, при условии, что значение всех регрессоров равно нулю. Как и для случая парной регрессии, это значение является во многом теоретическим.
3. На конечный спрос влияет цена на подобные товары. Например, при увеличении на единицу цены на первый подобный товар, спрос увеличивается на 0,534, а для второго подобного товара это значение равно 2,588. То есть можно говорить о том, что второй подобный товар в большей степени влияет на спрос.
4. Кроме цен на спрос также влияет и средний доход населения. При увеличении дохода на единицу спрос увеличивается на 10,995 тыс. шт.
Полученная модель является во многом формальной, поскольку она хоть и получена на основании статистических данных, не были проверены гипотезы о значимости каждого регрессора, да и всей регрессии в целом. Трудность при работе в пакете MathCad заключается в том, что нет дополнительных встроенных возможностей для проверки гипотез, поэтому все вычисления необходимо производить вручную, создавая необходимый документ. Данная работа часто бывает затруднительна для конечного пользователя. К тому же имеется достаточно сложный механизм передачи данных между MathCad и Excel. Поэтому рассмотрим программные продукты, которые имеют необходимый для анализа множественной регрессии инструментарий.
Электронная таблица Excel
В электронной таблице Excel имеется необходимый набор матричных функций, среди них можно отметить функции: МОБР(), которая выводит обратную матрицу, МУМНОЖ(), вычисляющая произведение двух матриц, ТРАНСП(), выполняющая операцию транспортирования матрицы. Этих функций достаточно для вычисления параметров множественной регрессии, однако они являются матричными, что имеет некоторую специфику при работе с ними. Документ, в котором будут использоваться данные функции, будет выглядеть громоздким, поскольку необходимо отдельно хранить элементы выполнения каждой матричной операции. Поэтому рассмотрим другие возможности Excel.
Как и для случая парной регрессии, для множественной регрессии имеется возможность использовать ту же самую надстройку Регрессия
, однако в этом случае количество значений X
должно в несколько раз превышать количество Y
.
Перенеся таблицу 10 в Excel, в диалоговом окне надстройки Регрессия
задав Входной интервал
Y
в виде G1:G16
, а Входной интервал
X
в виде B1:
F16
и установив опцию Метки
, будет автоматически сгенерирована таблица 13.
Таблица 13
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная статистика
|
| Множественный R
|
0,963541879
|
Продолжение табл. 13
| R-квадрат
|
0,928412953
|
| Нормированный
R-квадрат
|
0,899778134
|
| Стандартная ошибка
|
1,496311516
|
| Наблюдения
|
15
|
| |
|
| Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
4
|
290,3694
|
72,59234
|
32,42252
|
1,06E–05
|
| Остаток
|
10
|
22,38948
|
2,238948
|
|
|
| Итого
|
14
|
312,7588
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффи-
циенты
|
Стандартная
ошибка
|
t-ста
тистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
113,1921888
|
36,06499
|
3,138562
|
0,010536
|
32,83438
|
193,55
|
| Цена x1
(р.)
|
–6,080773549
|
0,900492
|
–6,75273
|
5,03E–05
|
–8,08719
|
–4,07435
|
| Цена на первый
подобный товар x2
(р.)
|
0,55174938
|
0,452263
|
1,219975
|
0,250464
|
–0,45596
|
1,559454
|
| Цена на второй
подобный товар x3
(р.)
|
2,620192945
|
0,85151
|
3,077112
|
0,011698
|
0,722909
|
4,517476
|
| Средний доход
населения x4
(т. р.)
|
10,92686031
|
3,846179
|
2,840965
|
0,017519
|
2,357038
|
19,49668
|
Данная таблица нами рассматривалась уже не раз, поэтому остановимся только на том, что относится к случаю множественной регрессии. Например, в разделе Регрессионная статистика
имеется пункт Нормированный
R-квадрат
, который содержит значение скорректированного коэффициента детерминации. При включении в модель незначимого регрессора данное значение будет уменьшаться.
В разделе Коэффициенты
содержатся значения всех коэффициентов, которые совпадают со значениями, полученными посредством MathCad, а кроме этого, стандартные ошибки статистики, значимости и доверительные интервалы для коэффициентов.
На основании данной таблицы можно сделать выводы о значимости каждого регрессора и всей регрессии в целом:
1. Само уравнение регрессии является значимым, поскольку Значимость
F
равна 1,06E-05, что меньше, чем 0,01. Проверить значимость всей регрессии можно и самостоятельно, поскольку в таблице выдается значение F-статистики, а критический уровень можно, как и в парном случае, найти с помощью функции FРАСПОБР. Верхнее число степеней свободы в данном случае равно 4, а нижнее10.
2. Коэффициент b
1
является значимым при любом уровне значимости, поскольку его значимость равна 5,03E-05. Следовательно, цена на товар, а в наших обозначениях регрессор x
1
, влияет на спрос.
3. Коэффициенты b
3
, b
4
, можно признать значимыми, поскольку соответствующие значения равны 0,01169 и 0,01752, что несколько превосходит значение 0,01, но все же меньше, чем значение 0,05. Следовательно, на формирование значения спроса также влияет цена на второй подобный товар и средний доход населения.
4. Коэффициент b
2
является незначимым, поскольку соответствующее значение равно 0,25, следовательно, цена на первый подобный товар x
2
не влияет на значение спроса.
Исходя из всего вышесказанного, разумно построить регрессионную модель, в которой отсутствуют незначимые регрессоры. Для этого в электронной таблице Excel необходимо удалить тот столбец, в котором находятся значения переменой x
3
, и вызвать надстройку Регрессия
.
Таблица 14
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная статистика
|
| Множественный R
|
0,9579
|
| R-квадрат
|
0,9177
|
| Нормированный
R-квадрат
|
0,8953
|
| Стандартная ошибка
|
1,5291
|
| Наблюдения
|
15
|
| |
|
| Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
3
|
287,037
|
95,67901
|
40,91741
|
2,94E–06
|
| Остаток
|
11
|
25,72179
|
2,338345
|
|
|
| Итого
|
14
|
312,7588
|
|
|
|
| |
|
|
|
|
|
Продолжение табл.
14
|
|
Коэффи-
циенты
|
Стандартная
ошибка
|
t-ста
тистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
142,2167
|
27,6999
|
5,134194
|
0,000326
|
81,24956
|
203,1838
|
| Цена x1
(р.)
|
–6,61474
|
0,804244
|
–8,2248
|
5,01E–06
|
–8,38487
|
–4,84461
|
| Цена на второй
подобный товар x3
(р.)
|
2,240018
|
0,809838
|
2,766008
|
0,018358
|
0,457576
|
4,02246
|
| Средний доход
населения x4
(т. р.)
|
10,56105
|
3,918663
|
2,695063
|
0,02084
|
1,936122
|
19,18597
|
В данном случае, хотя значения и обычного и скорректированного (нормированного) коэффициента детерминации несколько уменьшилось по сравнению с общим случаем, все равно, модель, в которой не учитывается значения x
2
, является лучшей, поскольку в данном случае присутствуют только значимые регрессоры. Итак, наилучшая линейная множественная модель регрессии имеет вид:
y
= 142,21 – 6,61 x
1
+ 2,24 x
3
+ 10,56 x
4
.
Проанализировав данную модель, можно сделать выводы о влиянии каждого из регрессоров на значение спроса.
После нахождения значимых регрессоров и определения лучшей линейной модели, разумной является задача поиска лучшей нелинейной модели (логарифмической, степенной, показательной и т. д.). Построение подобных моделей осуществляется аналогично парному случаю (лабораторная работа № 6).
Задания для самостоятельной работы
1. Найти параметры регрессионной модели для заданий своего варианта, используя математический пакет MathCad и электронную таблицу Excel.
2. Подберите наиболее подходящую линейную модель (только значимые регрессоры).
3. Подобрать лучшую нелинейную множественную модель.
Лабораторная работа № 8
Спецификация переменных
и проблема мультиколлинеарности
Цель: научиться распознавать влияние эффекта мультиколлинеарности и находить варианты избавления от этого эффекта.
Основные формулы и понятия:
Отсутствующая переменная
:
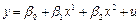 — истинная модель;
— истинная модель;
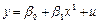 — оцениваемая модель.
— оцениваемая модель.
В этом случае
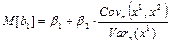
Электронная таблица Excel
Эффект мультиколлинеарности возникает тогда, когда коэффициент корреляции между регрессорами близок к единице, в то время как коэффициент корреляции между регрессором и зависимой переменной мал. Как правило, выделяют значение в 0,8.
Для анализа влияния мультиколлинеарности можно проанализировать значение ковариационной матрицы, которую можно получить, используя надстройку Корреляция
. Поскольку, как уже было определенно ранее, лучшей является модель, в которой не учитывается значения регрессора x
2
, то построим корреляционную матрицу без учета значений на первый подобный товар. Данная матрица имеет вид, изображенный в таблице 15.
Таблица 15
| |
Цена
x1
(р.)
|
Цена на подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| Цена x1
(р.)
|
1
|
|
|
|
| Цена на подобный
товар x3
(р.)
|
–0,17012
|
1
|
|
|
| Средний доход
населения x4
(т. р.)
|
–0,33828
|
0,195127
|
1
|
|
| Спрос y (тыс. шт.)
|
–0,88704
|
0,423668
|
0,555581
|
1
|
Начнем рассмотрение результатов данной таблицы с последней строки, в которой находятся частные коэффициенты корреляции зависимой переменной y
и регрессоров x
1
, x
3
, x
4
. Имеется некоторая взаимосвязь между каждым регрессором и спросом, при этом максимальное значение коэффициента корреляции равно –0,887 и говорит о существенной связи цены x
1
и спроса y
. Именно эта парная регрессионная модель строилась ранее (лабораторная работа № 2), и это значение коэффициента корреляции было получено в лабораторной работе № 1.
Все остальные коэффициенты корреляции значительно меньше, поэтому нет оснований утверждать, что присутствует эффект мультиколленеарности, однако в некоторой незначительной степени этот эффект имеет место.
Если было подтверждено наличие эффекта мультиколлинеарности, то один из возможных способов её устранения либо в укрупнении регрессоров, либо в их исключении.
На основании полученных коэффициентов частной корреляции нетрудно самостоятельно подсчитать значение коэффициента детерминации R2
, или, как его ещё иногда называют, множественного коэффициента корреляции [5, c. 73].
Рассмотрим теперь более подробно тот факт, как и почему изменяется значение коэффициентов регрессии в зависимости от того, какая модель рассматривается. Ещё раз напомним, что в парном случае модель имела вид:
y
= 239,96 – 7,703x
1
,
а во множественном случае лучшая модель будет
y
= 142,21 – 6,61 x
1
+ 2,24 x
3
+ 10,56 x
4
.
В работе [4, c. 243] рассматривается произвольный случай, когда имеется произвольное количество регрессоров, часть из которых могут оказаться лишними. Строятся статистики, которые позволяют определить наилучшую модель.
В работе [5, c. 78] рассмотрены частные случаи. Это модель с отсутствующей переменной
, когда вместо двух, реально присутствующих в модели регрессоров, рассматривается парный случай, и модель с лишней переменной
, когда исходная модель является парной, а она рассматривается как множественная. В случае лишней переменной происходит только потеря эффективности, в случае отсутствующей происходит нарушение наиболее важного свойства, а именно, нарушается несмещённость оценки. При этом показано, что математическое ожидание коэффициента в парной случае будет иметь вид
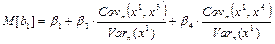 . .
Для вычисления найдем ковариационную матрицу (таблица 16).
Таблица 16
| |
Цена
x1
(р.)
|
Цена на подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y
(тыс. шт.)
|
| Цена x1
(р.)
|
0,275665
|
|
|
|
| Цена на подобный товар x3
(р.)
|
–0,04468
|
0,250289
|
|
|
| Средний доход населения x4
(т. р.)
|
–0,01923
|
0,010569
|
0,011722
|
|
| Спрос y (тыс. шт.)
|
–2,12663
|
0,967845
|
0,274663
|
20,85059
|
Используя полученные данные, нетрудно вычислить
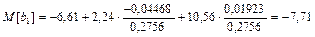 , ,
что полностью совпадает со значением, полученным в парном случае.
Если сравнивать случаи с тремя регрессорами, которая была признана нами наилучшей (таблица 12), и общим случаем (таблица 11), то очевидно, что в общем случае стандартные ошибки коэффициентов больше, а следовательно, оценки менее эффективные.
Задания для самостоятельной работы
1. Проанализировать наличие эффекта мультиколлинеарности для заданий своего варианта и рассмотреть возможности по учету и исключению;
2. Определить влияние отсутствующих и лишних переменных в регрессии.
Лабораторная работа № 9
Фиктивные переменные
и категории
Цель:
научиться использовать в модели фиктивные переменные сдвига и наклона, а также различные категории.
Основные формулы и понятия:
Фиктивная переменная
необходима для описания качественного изменения и может принимать два значения 0 и 1.
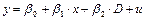 — модель с фиктивной переменной сдвига
; — модель с фиктивной переменной сдвига
;
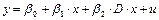 — модель с фиктивной переменной наклона
; — модель с фиктивной переменной наклона
;
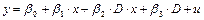 — модель с фиктивной переменной наклона и сдвига
. — модель с фиктивной переменной наклона и сдвига
.
Категория —
событие, про которое для каждого наблюдения можно определенно сказать, произошло оно в этом наблюдении или нет.
Набор категорий —
конечный набор взаимоисключающих событий, полностью исчерпывающий все возможности.
Для описания категорий необходимо ввести совокупность фиктивных переменных.
Электронная таблица Excel
До сих пор нами рассматривался только случай количественных регрессоров, поскольку значение цен и спроса являются числами. Однако может возникнуть ситуация, когда необходимо учесть некоторую специфическую информацию. Рассматривая модель спроса, можно предположить, что продаются два одинаковых продукта по одной цене, но имеющие некоторые различия. Например, наряду с уже давно продающимся чистящим порошком, поступает в продажу такой же порошок, но с новым ароматом. И имеется задача исследовать, насколько большим или меньшим спросом пользуется новая продукция. Конечно, можно построить две различные модели, и посмотреть разницу между ними, однако нас будет интересовать общая модель. В этом случае в модель необходимо вносить качественный регрессор, для чего нужно использовать фиктивную переменную. Данная переменная может принимать только два значение 0 или 1, в зависимости от отсутствия или наличия нового качества. В этом случае можно строить модель с фиктивной переменной наклона и сдвига. Работа с фиктивными переменными ни чем не отличается от построения регрессионной модели.
Поэтому рассмотрим задачу. Значение цены x
и спроса y
на два различных товара, которые мы условно назовем «обычный» и «новый», представлены в таблице 17.
Таблица 17
| Номер наблюдения
|
Вид
|
Цена x
1
(р.)
|
Спрос y
(тыс. шт.)
|
| 1
|
новый
|
15,09р.
|
125,1779
|
| 2
|
новый
|
15,21р.
|
123,8094
|
| 3
|
старый
|
15,28р.
|
121,175
|
| 4
|
старый
|
15,49р.
|
116,9143
|
| 5
|
старый
|
15,54р.
|
119,8643
|
| 6
|
старый
|
15,62р.
|
118,0681
|
| 7
|
новый
|
15,70р.
|
123,5887
|
| 8
|
новый
|
15,91р.
|
117,0877
|
| 9
|
старый
|
15,92р.
|
116,1699
|
| 10
|
новый
|
15,95р.
|
118,3436
|
| 11
|
новый
|
16,31р.
|
116,2008
|
| 12
|
старый
|
16,33р.
|
111,4565
|
| 13
|
новый
|
16,60р.
|
115,1026
|
| 14
|
старый
|
16,69р.
|
110,1056
|
| 15
|
старый
|
16,76р.
|
110,0231
|
В электронной таблице Excel имеются возможности для быстрого задания значений фиктивной переменой. Для этого необходимо вставить столбец между колонками с названиями Вид
и Цена
. Озаглавим этот столбец как Фиктивная переменная
, и для определения значений будем использовать логическую функцию ЕСЛИ. Данная функция имеет три аргумента. Первый — это логическое выражение, которое может принимать истинное или ложное значение. Вторым аргументом идет то значение, которое появляется в ячейке при истинности условия, а соответственно в третьем аргументе — значение, которое появляется в противном случае.
Выполнив данные действия, получим первые две строки таблицы 18.
Таблица 18
| Номер наблюдения
|
Вид
|
Фиктивная переменная
|
Цена
x
1
(р.)
|
Спрос y
(тыс. шт.)
|
| 1
|
новый
|
=ЕСЛИ(B2="новый";1;0)
|
15,09р.
|
125,1779
|
В столбце фиктивной переменной появится значение 1, если в предыдущем столбце находилось слово «новый», и 0 в противоположном случае. После этого необходимо значение функции, находящейся в столбце C,
скопировать во все нижние ячейки, а поскольку адресация относительная, то адрес будет меняться. Необходимо отметить, что логическая функция может иметь и другой вид:
ЕСЛИ(B2 = "обычный";0;1).
Теперь наша задача заключается в определении степени влияния фиктивной переменной. А именно, влияет ли это значение на свободный член (в этом случае при изменении качества можно говорить о том, что спрос изменится на какое-то количество) или на наклон линии регрессии (спрос изменится во сколько-то), или на оба эти значения сразу.
Вначале оценим регрессию, при условии, что фиктивная переменная влияет только на значение свободного члена. В этом случае итоговая таблица после выполнения надстройки Регрессии
, при условии, что Входной интервал
Y
задан в виде E1:
E16
, а Входной интервал
X
в виде С1:
D16
, имеет вид, изображенный в таблице 19.
Таблица 19
| ВЫВОД ИТОГОВ
|
| |
|
| Регрессионная статистика
|
| Множественный R
|
0,963696
|
| R-квадрат
|
0,928711
|
| Нормированный
R-квадрат
|
0,916830
|
| Стандартная
Ошибка
|
1,363084
|
| Наблюдения
|
15
|
| |
|
Продолжение табл.
19
| Дисперсионный анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
| Регрессия
|
2
|
290,4628387
|
145,231419
|
78,16547142
|
1,31E–07
|
| Остаток
|
12
|
22,29599593
|
1,85799966
|
|
|
| Итого
|
14
|
312,7588347
|
|
|
|
| |
|
|
|
|
|
|
|
Коэффи-
циенты
|
Стандартная
ошибка
|
t-
статистика
|
P-
значение
|
Нижние
95 %
|
Верхние
95 %
|
| Y-пересечение
|
232,0028
|
10,78827
|
21,5051052
|
5,9691E-11
|
208,49
|
255,508
|
| Фиктивная переменная
|
3,474500
|
0,7109700
|
4,8869856
|
0,00037407
|
1,9254
|
5,02357
|
| Цена x(р.)
|
-7,30442
|
0,675558
|
–10,8124125
|
1,5303E–07
|
–8,77634
|
–5,83251
|
Регрессионная модель имеет вид: y
= 232 + 3,47D
– 7,304x
Поскольку значение фиктивной переменной D
равно 1 для «нового» вида и 0 для «обычного», то данную модель можно отдельно расписать для каждого случая.
y
= 232 – 7,304x
— обычный вид,
y
= 235,47 – 7,304x
— новый вид.
Следовательно, спрос на новый вид продукции приблизительно на 3,47 тыс. ед. больше. Коэффициент детерминации равен 0,928, что намного больше, чем данное значение для парного случая.
Рассмотрим теперь возможность построения модели с фиктивной переменной наклона, для чего в качестве регрессоров значения необходимо использовать переменные x
и Dx
. Следовательно, необходимо добавить дополнительный столбец между фиктивной переменной и значениями x
, в который надо записать их произведения.
Опустим таблицу, которая генерируется надстройкой Регрессия
. Однако, самостоятельно выполнив данные операции, можно получить следующую модель: y
= 233,52 + 0,21Dx
– 7,403x
.
Аналогичным образом интерпретируя значение фиктивной переменной, можно расписать два случая:
y
= 233,52 – 7,4x —
для обычного вида продукции;
y
= 233,52 – 7,19x
— для нового вида продукции.
Выводы из полученных моделей совершенно очевидны, поскольку видна разница во влиянии цены на спрос для каждого вида продукции. Коэффициент детерминации в этом случае равен 0,929, что не намного больше соответствующего значения для фиктивной переменной сдвига, а следовательно, они обе пригодны для прогнозирования. Однако результаты использования моделей будут во многом различными. В первом случае спрос на «новый» вид продукции на 3,47 тыс. ед. больше, чем на «старый», во втором случае цена сильнее влияет на «старый» вид продукции.
При необходимости можно построить модель, в которой фиктивная переменная влияет как на наклон, так и на сдвиг.
До сих пор нами рассматривался случай, когда имеются всего два значения качества, то есть два вида продукции. Однако нередки случаи, когда необходимо проанализировать спрос для различных продуктов. Тогда необходимо вводить набор категорий
— как конечный набор взаимоисключающих событий, полностью описывающий все возможности. Предположим, что исследуется влияние цены на спрос при наличии «старой», «обычной», «новой» и «самой новой» продукции.
В этом случае для описания этих категорий необходимо вводить набор фиктивных переменных по следующему правилу.
1. Число фиктивных переменных должно быть на единицу меньше, чем число категорий. В данном случае имеется четыре категории, а следовательно, необходимо ввести три фиктивные переменные, которые мы обозначим D1, D2, D3.
2. Выбрать произвольную категорию в качестве эталонной. Именно с этой категорий в последствии будут сравниваться все остальные. Для эталонной категории необходимо, чтобы значения всех фиктивных переменных равнялись нулю.
3. Для всех остальных категорий необходимо, чтобы одна из фиктивных переменных равнялась 1, в то время как значение всех остальных равно 0.
Достаточно легко можно расставить значения фиктивных переменных, используя ту же условную функцию ЕСЛИ. При наличии четырёх различных видов продукции необходимо вставить три дополнительных столбца, в которых будут находиться фиктивные переменных. Задать логические функции можно так, как показано в таблице 20.
Таблица 20
| Номер
наблюдения
|
Вид
|
Фиктивная
переменная D1
|
Фиктивная
переменная D2
|
Фиктивная
переменная D3
|
Цена x
1
(р.)
|
Спрос
y
(тыс.шт.)
|
| 1
|
|
=ЕСЛИ(B2=
«обычный»;1;0)
|
=ЕСЛИ(B2=
«новой»;1;0)
|
=ЕСЛИ(B2=
«самой новый»;1;0)
|
15,09р.
|
125,1779
|
После копирования данных функций вниз для значения старой все фиктивные переменные будут равны нулю, для обычной — только значение первой фиктивной переменной будет равно 1 и т. д.
После этого можно вызвать надстройку Регрессия
, у которой в качестве входного интервала X, необходимо указать значения всех фиктивных переменных в и нефиктивной переменной X
, то есть задать Входной интервал
X
в виде С1:
F16
.
Полученные результаты поддаются достаточно простой интерпретации. Значение, находящееся напротив фиктивной переменной D
1, показывает, насколько изменился спрос при переходе от эталонной к первой категории, то есть насколько различен спрос между «обычной» и «новой» продукцией. Аналогично интерпретируются значения, стоящие напротив других фиктивных переменных.
Задания для самостоятельной работы
1. Для данных своего варианта подобрать наилучшее воздействие фиктивной переменной (влияние на наклон или сдвиг). При этом категории «старый» и «обычный» воспринимать как одно значение, а категории «новый» и «самый новый» — как другое.
2. Определить, насколько изменяется спрос при переходе от одной категории к другой.
Лабораторная работа № 10
Гетероскедастичность и взвешенный метод наименьших квадратов
Цель:
научиться оценивать наличие эффекта гетероскедастичности и использовать взвешенный метод наименьших квадратов.
Основные формулы и понятия:
Тест ранговой корреляции Спирмена
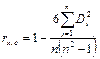 — коэффициент ранговой корреляции Спирмена, — коэффициент ранговой корреляции Спирмена,
где
x — одна из объясняющих переменных, 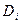 — разность между рангом
i-го наблюдения
x и рангом модуля остатка в
i-м наблюдении. — разность между рангом
i-го наблюдения
x и рангом модуля остатка в
i-м наблюдении.
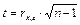 — статистика. — статистика.
Если в модели регрессии имеется более одной объясняющей переменной, то проверка гипотезы может выполняться с использованием каждой из них.
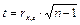 — статистика — статистика
Условие принятия гипотезы
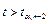 . .
Если данное условие выполняется, то нулевая гипотеза о наличии гетероскедастичности будет принята при уровне значимости a.
Тест Голдфельда — Кванта
В этом случае все наблюдения необходимо упорядочить по мере возрастания значений x. Затем построить регрессионную модель для первых m и последних m наблюдений. Соответственно обозначим через ESS1
и ESS2
необъясненную сумму квадратов отклонений в каждой регрессии. Тогда статистика имеет вид
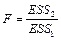 . .
Если выполняется условие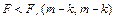 , то гипотеза об отсутствии гетероскедастичности отвергается. , то гипотеза об отсутствии гетероскедастичности отвергается.
Взвешенный метод наименьших квадратов основан на минимизации суммы:
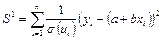 . .
Электронная таблица Excel
К сожалению, в электронной таблице нет дополнительных инструментов, которые позволяли бы проверять гипотезы и реализовывать взвешенный метод наименьших квадратов. Однако данные тесты можно реализовать вручную. Так, например, для теста ранговой корреляции Спирмена необходимо выполнить следующие действия:
1. Отсортировать данные в таблице по возрастанию значений x
, для чего необходимо выбрать пункт меню Данные, Сортировка
, а затем выбрать столбец, в котором находятся значения x
;
2. Придать каждому наблюдению ранг, для чего необходимо добавить новый столбец, в котором задать числа от 1 до n
;
3. Вызвать из пакета анализа надстройку Регрессия
, указав в диалоговом окне опцию Остатки
. После выполнения данной надстройки появится дополнительная таблица, в которой содержатся номера наблюдений, прогнозы и остатки. Тот столбец таблицы, в котором находятся остатки, необходимо перенести к исходным данным. После выполнения этих действий наша таблица будет содержать четыре столбца: ранг наблюдения, упорядоченные значения регрессора x
, значения y
и значения остатков;
4. Отсортировать данные по возрастанию модулей остатков и добавить новый столбец рангов остатков, аналогичным образом задав значения от 1 до n
;
5. В дополнительном столбце вычислить значения разности между двумя полученными рангами (это и будет значение Di
);
6. На основании формул подсчитать коэффициент ранговой корреляции и статистику;
7. Проверить гипотезу можно посредством функции, которая вычисляет значение двусторонней критической точки распределения Стьюдента (лабораторная работа № 3).
Если выполнить данные действия для таблицы 1, то получим таблицу 21.
Таблица 21
| Ранг по x
|
Ценаx1(р.)
|
Спрос y (тыс. шт.)
|
Остатки
|
Ранг по остаткам
|
Разность рангов
Di
|
Di
* Di
|
| 4
|
15,49р.
|
116,9143034
|
–3,7319
|
1
|
3
|
9
|
| 12
|
16,33р.
|
111,4565323
|
–2,67328
|
2
|
10
|
100
|
| 6
|
15,62р.
|
118,068067
|
–1,5813
|
3
|
3
|
9
|
| 14
|
16,69р.
|
110,1056432
|
–1,31194
|
4
|
10
|
100
|
| 9
|
15,92р.
|
116,169908
|
–1,12322
|
5
|
4
|
16
|
| 3
|
15,28р.
|
121,1749683
|
–1,11646
|
6
|
–3
|
9
|
| 15
|
16,76р.
|
110,023139
|
–0,84306
|
7
|
8
|
64
|
| 5
|
15,54р.
|
119,8642978
|
–0,39014
|
8
|
–3
|
9
|
| 8
|
15,91р.
|
117,0876924
|
–0,34387
|
9
|
–1
|
1
|
| 2
|
15,21р.
|
123,8094363
|
1,019821
|
10
|
–8
|
64
|
| 10
|
15,95р.
|
118,3436007
|
1,257187
|
11
|
–1
|
1
|
| 1
|
15,09р.
|
125,177912
|
1,426776
|
12
|
–11
|
121
|
| 11
|
16,31р.
|
116,2008486
|
1,847847
|
13
|
–2
|
4
|
| 13
|
16,60р.
|
115,102583
|
3,003645
|
14
|
–1
|
1
|
| 7
|
15,70р.
|
123,5886637
|
4,559903
|
15
|
–8
|
64
|
| |
|
|
|
|
Сумма
|
572
|
Следовательно, значение ранговой корреляции Спирмена будет равно
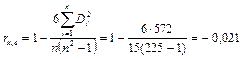
А значение статистики будет 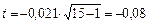
Выбрав уровень значимости 5 %, получаем критическую точку 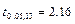 . Данное значение получено формулой СТЬЮДРАСПОБР(0,05;13). . Данное значение получено формулой СТЬЮДРАСПОБР(0,05;13).
Поскольку условие 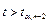 не выполняется, то гипотеза о наличии гетероскедастичности будет отклонена. не выполняется, то гипотеза о наличии гетероскедастичности будет отклонена.
Для проверки подобной гипотезы на основании теста Гольдфельда — Кванта необходимо подобным образом отсортировать наблюдения по возрастанию значения x
, а затем отдельно оценить каждую регрессионную модель для первой трети и для последней трети наблюдений, вычислив при этом объясненную сумму квадратов отклонений, получив тем самым значения. А затем просчитать статистику.
Используя вышеописанные вычисления можно, хотя это достаточно трудно, проверить модель на гетероскедастичность, однако нет принципиальных методов для реализации взвешенного метода наименьших квадратов. Поэтому рассмотрим программные пакеты, предназначенные специально для статистических вычислений. В настоящее время имеется большое количество таких программ, разнообразных как по внешнему интерфейсу, так и количеству предлагаемых возможностей. Мы остановимся на пакете SPSS for Windows поскольку интерфейс данной программы во много похож на Excel.
Пакет обработки статистических данных SPSS for Windows
Данную программу запускают, как и все программы в среде Windows, а именно либо используя ярлык, либо клавишу Пуск
, Программы
. Сразу после запуска появляется диалоговое окно, в котором предлагается выбор дальнейшей работы. Выбрав пункт Запуск введения
приводит к запуску автономной обучающей программы в формате html, в которой излагаются все основные возможности программы. Кроме этого можно задавать новые данные, запросы и источники.
Выбрав пункт меню Тип Данных,
загрузится программа, рабочее поле которой состоит из ячеек, что во многом похоже на электронную таблицу, однако имеются и принципиальные отличия, на которых мы сейчас остановимся.
В нижней части рабочего поля располагаются закладки, на которых имеются надписи Панель данных
и Вид переменных
.
Используя закладку Вид переменных
можно задать структуру, задав информацию по каждому столбцу будущей таблицы: имя переменной, тип хранящийся информации, её размер, надписи, метки, выравнивание, и т. д.
Зададим три различных переменных с именами Price (Цена), Income (Средний доход), Demand (Спрос). Задавать имена можно только английскими буквами и не более 8 символов. Выберем для них цифровой тип, количество разрядов, равное 8, и количество цифр после запятой, равное 2. Перейдя на закладку Панель данных
, получим окно (рис. 13).

Рис. 13

Рис. 14
Теперь на панели данных необходимо задать значения переменных для любого количества элементов в выборке. При необходимости можно вставить дополнительные переменные и варианты (случаи). В отличие от Excel, в котором адрес ячейки состоял из номера столбца — буквы и номера строки — цифры, в системе SPSS адрес состоит из номера случая и имени переменной. Зададим значение этих переменных аналогичные таблице 10, при этом необходимо отметить, что нельзя непосредственно копировать данные из электронной таблицы, поскольку для этого предназначены специальные механизмы подключения внешних данных.
Для получения параметров множественной регрессии необходимо выбрать пункт меню Анализ, Регрессия, Линейный
, после чего появится диалоговое окно (рис. 14).
В левой части окна находятся все числовые переменные, на основании которых можно строить регрессию. Выбрав подчиненную переменную demand, а независимые переменные price и income, получим окно (рис. 15).

Рис. 15
В левой части данного окна располагается структура полученного отчета, а в правой — компоненты.
В пункте VARIABLES ENTERED/REMOVED выдается основная информация по модели, а именно зависимые и независимые переменные и используемые методы; в MODEL SUMMARY — значение коэффициента детерминации. ANOVA — объясненная, необъясненная и общая сумма квадратов, а также значение F
-статистики. COEFFICIENT — значение коэффициентов, их стандартные ошибки, значения t-тестов и значимости.
Анализируя полученные таблицы, можно прийти к выводу, что вид полученных результатов во многом схож с той таблицей, которую генерирует Excel, с тем отличием, что таблица всегда располагается в виде нового объекта (отчета).
Данный отчет можно хранить независимо от исходной таблицы, при этом его можно сохранить с расширением spo (вывод), в отличие от данных, которые будут храниться в файле с расширением sav (стандартное расширение файлов, созданных программой SPSS).
Аналогичным образом можно построить любые варианты множественной парной регрессии, и сохранять отчеты в различных или одном файле.
Для реализации метода взвешенных наименьших квадратов необходимо задать ещё переменную, например, под именем WLS, в которой задаётся вес каждого наблюдения. После этого необходимо в диалоговом окне Линейная регрессия
перенести данную переменную в пункт вес
WLS
. В этом случае коэффициенты будут вычисляться на основании взвешенного метода наименьших квадратов.
Задания для самостоятельной работы
1. Провести исследование табличных данных (номер варианта соответствует номеру таблицы) на наличие гетероскедастичности, между значением y
и каждым регрессором отдельно, используя электронную таблицу Excel:
a) Тестом ранговой корреляции Спирмена;
b) Тестом Гольдфельда — Кванта;
2. Найти значения параметров регрессии, используя взвешенный метод наименьших квадратов и пакет обработки статистических данных SPSS:
a) взяв в качестве весов значения из столбца;
b) задав значение весов по правилу:
1) если значение x
меньше 5, то вес равен 1,
2) если значение x
меньше 10, то вес равен 4,
3) значение весов равно 7, во всех остальных случаях;
3. Сравнить полученные результаты.
Лабораторная работа № 11
Автокорреляция и обобщённый метод
наименьших квадратов
Цель:
научиться оценивать наличие эффекта автокорреляции первого порядка и использовать Кохрейна — Оркатта, а также обобщённый метод наименьших квадратов.
Основные формулы и понятия:
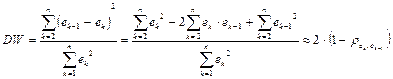
критерий Дарбина — Уотсона
.
Если
d <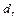 , положительная автокорреляция имеет место; , положительная автокорреляция имеет место;
если
d >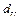 , положительной автокорреляции нет; , положительной автокорреляции нет;
если 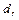 <
d< <
d<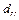 , то вывод сделать нельзя. , то вывод сделать нельзя.
Вывод об отрицательной автокорреляции делается на основании симметричных значений.
Метод Кохрейна — Оркатта устранения автокорреляции.
Предполагая, что значение автокорреляции известно, необходимо оценить модель:
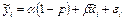 , ,
где 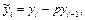 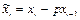 , ,
где значение параметра
p определяется из регрессионной модели вида:
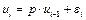 . .
Обобщённый метод наименьших квадратов основан на минимизации суммы:
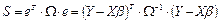 , ,
где W — корреляционная матрица случайных составляющих
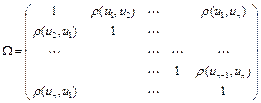
В этом случае значения параметров модели будут вычисляться по формуле:
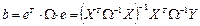 . .
Электронная таблица Excel
Для вычисления значения статистики Дарбини — Уотсона в электронной таблице Excel, так же как и для проверки теста на наличие гетероскедастичности, нет специальных средств, однако имеются достаточные возможности при реализации надстройки Регрессия
. Так, достаточно выполнить следующие действия:
1. Вызвать из пакета анализа надстройку Регрессия
, указав в диалоговом окне опцию Остатки
. После выполнения данной надстройки появится дополнительная таблица, в которой содержатся номера наблюдений, прогнозы и остатки;
2. Найти коэффициент корреляции между ei
и ei
+1
;
3. Найти значение критерия по приближенной формуле.
Кроме этого можно найти и точное значение критерия, однако полученные результаты не будут сильно отличаться. Провести анализ данных на основании значений 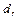 и и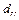 . .
Для реализации метода Кохрейна — Оркатта необходимо знать значение p
, которое, как правило, неизвестно. Его надо оценить, для чего получают параметры регрессионной модели вида: 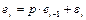 . .
Для подсчета статистики Дарби — Уотсона мы уже получали коэффициент корреляции (пункт 2). Теперь необходимо построить данную регрессионную модель, получить тем самым оценку параметра p
.
Математический пакет MathCad
Для реализации обобщённого метода наименьших квадратов можно воспользоваться возможностями данного пакета, поскольку будут незначительные отличия при вычислении параметров, основанные на использовании корреляционной матрицы. Как правило, значения данной матрицы неизвестны, поэтому их необходимо подбирать самостоятельно. Общий вид документа, реализующего обобщённый метод наименьших квадратов, имеет следующий вид
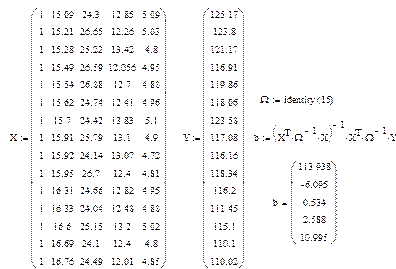
В данном примере выбрали ковариационную матрицу W как единичную (данная операция реализована посредством функции identity), при этом значение параметров b
получилось то же, что и в простом случае наименьших квадратов.
Задавая различные значения ковариационной матрицы W можно получить различные сочетания эффектов гетероскадастичности и автокорреляции. Например, если данная матрица содержит только диагональные элементы, то отсутствует эффект автокорреляции. Если при этом совпадают значения на главной диагонали, то отсутствует и эффект гетероскадастичности.
Эффекту автокорреляции первого порядка соответствует матрица W, у которой на диагоналях рядом с главной располагаются одинаковые значения. Соответственно, если значения на других диагоналях отличны от нуля, то появляется эффект автокорреляции некоторого порядка.
Задания для самостоятельной работы
1. Проанализировать значения данной таблицы на наличие эффекта автокорреляции, и при положительном ответе сравнить параметры регрессионных моделей, полученных обычным методом наименьших квадратов, методом Кохрейна — Оркатта.
2. Реализовать обобщённый метод наименьших квадратов для заданий по лабораторным работам № 1—8, при условии, что присутствуют и эффект гетероскадастичности, и эффект автокорреляции, и ковариационная матрица имеет вид:
3. Проанализировать полученные данные и обосновать отличие полученных параметров от результатов, полученных простым методом наименьших квадратов.
ЗАКЛЮЧЕНИЕ
Хороших знаний теоретического материала недостаточно для становления современного специалиста. Всё более интенсивное развитие компьютерной техники и программного обеспечения ставят новые задачи обучения. Подготовленный специалист должен не только знать теоретические основы дисциплины, но и иметь достаточные навыки для получения практических результатов, в частности, с использованием современной техники и программного обеспечения. В данной работе сделана попытка, не вдаваясь глубоко в теорию, описать основные возможности программного обеспечения для решения эконометрических задач.
Кроме знания теории и умения решать поставленные задачи современному специалисту необходимо, пожалуй, самое главное умение — анализировать полученные результаты и принимать обоснованные решения. Основные принципы анализа также представлены в данном учебно-методическом пособии.
Данное пособие предназначено для студентов экономических и физико-математических специальностей, кто изучает эконометрику. Однако эти знания могут быть полезны всем тем, кто хочет научиться решать задачи теории вероятностей и математической статистики с использованием вычислительной техники. Им будут интересны лабораторные работы № 1, 5, 7, в которых рассматриваются функции Excel, предназначенные для получения характеристик случайной величины, или системы случайных величин, а также функции определения параметров некоторых распределений. В данных работах также изложены возможности пакета MathCad для работы со случайными величинами, имеющими некоторое распределение, среди которых можно отдельно упомянуть возможность генерации случайных чисел и основные принципы работы с таблицами. В лабораторной работе № 9 изложены основные принципы работы с пакетом обработки статистических данных SPSS
.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Бююль, А. SPSS: Искусство обработки информации. Анализ статистических закономерностей и восстановление данных [Текст] / А. Бююль, П. Цефель ; пер. с нем. — М. : Диасофт, 2003.
2. Доугерти, К. Введение в эконометрику [Текст] / К. Доугерти. — М. : Инфра-М, 1999.
3. Компьютерные технологии экономико-математического моделирования[Текст] : учеб. пособие / под ред. Д. М. Дайитбегова, И. В. Орловой. — М.: ЮНИТИ, 2001.
4. Кремер, Н. Ш. Эконометрика [Текст] : учебник для вузов / Н. Ш. Кремер, Б. А. Путко. — М. : ЮНИТИ-ДАНА, 2002. — 311 c.
5. Кузнецов, О. А. Эконометрика: парная и множественная регрессия [Текст] / О. А. Кузнецов. — Балашов : Изд-во “Николаев”, 2004. — 108 c.
6. Орлова, И. В.
Экономико-математические методы и модели. Выполнение расчетов в среде EXCEL[Текст] : Практикум : учеб. пособие для вузов / И. В. Орлова. — М. : Финстатинформ, 2000. — 136 с.
7. Экономико-математические методы и прикладные модели [Текст] : учеб. пособие для вузов / В. В. Федосеев, А. Н. Гармаш и др. — М. : ЮНИТИ, 1999. — 391 с.
8. Плис, А. И. MathCad. Математический практикум для инженеров и экономистов [Текст] : учеб. пособие. — 2-е изд., перераб. и доп. / А. И. Плис, Н. А. Сливина. — М. : Финансы и статистика, 2003. — 656 с.
9. Плис, А. И Практикум по прикладной статистики в среде SPSS [Текст] : учеб. пособие : в 2 ч. Ч. 1. Классические процедуры статистики / А. И. Плис, Н. А. Сливина. — М. : Финансы и статистика, 2004. — 288 с.
10. http://www.nsu.ru/ef/tsy/ecmr/study.htm Учебные материалы по эконометрике и статистике.
11. http://www.nsu.ru/ef/tsy/ecmr/index.htm Эконометрическая страничка. Учебные материалы по эконометрике (методички, лекции, программы). Ссылки на материалы аналогичной тематики.
12. http://www.nsu.ru/ef/tsy/ecmr/soft.htm Компьютерные программы (статистика и эконометрика).
13. http://www.iet.ru/archiv/zip/nosko.zip Носко В. П. Эконометрика для начинающих. Основные понятия, элементарные методы, границы применимости, интерпретация результатов. — М., ИЭПП, 2000.
14. http://www.statsoft.ru/home/textbook/ Электронный учебник по статистике. StatSoft. Учебник помогает понять основные понятия статистики и более полно представить диапазон применения статистических методов.
15. http://jenpc.nstu.nsk.su/uchebnik2/sod-nav.htm Учебник по математической статистике.
16. http://molchanov.narod.ra/econometrics.html.
17. http://www.antorlov.chat.ru.
18. http://www.antorlov.euro.ru.
19. http://www.antorlov.nm.ru.
20. http://www.newtech.ru/~orlov.
ПРИЛОЖЕНИЕ
Таблицы для самостоятельной работы
Лабораторные работы № 1—8
| Вариант 1
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
15,09р.
|
24,30р.
|
12,85р.
|
5,09
|
125,1779
|
| 2
|
15,21р.
|
26,65р.
|
12,26р.
|
5,03
|
123,8094
|
| 3
|
15,28р.
|
25,22р.
|
13,42р.
|
4,80
|
121,175
|
| 4
|
15,49р.
|
26,59р.
|
12,05р.
|
4,95
|
116,9143
|
| 5
|
15,54р.
|
26,88р.
|
12,70р.
|
4,88
|
119,8643
|
| 6
|
15,62р.
|
24,74р.
|
12,41р.
|
4,96
|
118,0681
|
| 7
|
15,70р.
|
24,42р.
|
13,83р.
|
5,10
|
123,5887
|
| 8
|
15,91р.
|
25,79р.
|
13,10р.
|
4,90
|
117,0877
|
| 9
|
15,92р.
|
24,14р.
|
13,07р.
|
4,72
|
116,1699
|
| 10
|
15,95р.
|
26,70р.
|
12,40р.
|
4,81
|
118,3436
|
| 11
|
16,31р.
|
24,66р.
|
12,82р.
|
4,95
|
116,2008
|
| 12
|
16,33р.
|
24,04р.
|
12,48р.
|
4,88
|
111,4565
|
| 13
|
16,60р.
|
25,15р.
|
13,20р.
|
5,02
|
115,1026
|
| 14
|
16,69р.
|
24,10р.
|
12,40р.
|
4,80
|
110,1056
|
| 15
|
16,76р.
|
24,49р.
|
12,01р.
|
4,85
|
110,0231
|
| Вариант 2
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
93,82р.
|
75,98р.
|
124,14р.
|
5,093176
|
135,5503
|
| 2
|
91,01р.
|
74,26р.
|
130,59р.
|
5,031956
|
171,1037
|
| 3
|
95,96р.
|
75,51р.
|
119,98р.
|
4,79949
|
106,8294
|
| 4
|
98,99р.
|
72,00р.
|
117,02р.
|
4,95135
|
82,65364
|
| 5
|
98,85р.
|
71,31р.
|
124,77р.
|
4,877776
|
107,9813
|
| 6
|
99,58р.
|
73,48р.
|
119,30р.
|
4,961544
|
87,08134
|
| 7
|
90,14р.
|
72,40р.
|
119,50р.
|
5,098437
|
140,1648
|
| 8
|
94,07р.
|
77,10р.
|
116,61р.
|
4,899322
|
107,1392
|
| 9
|
98,63р.
|
70,25р.
|
121,64р.
|
4,722132
|
96,99346
|
| 10
|
91,39р.
|
79,16р.
|
133,30р.
|
4,810111
|
175,2817
|
| 11
|
92,45р.
|
72,07р.
|
121,98р.
|
4,948579
|
134,0831
|
| 12
|
90,45р.
|
75,34р.
|
112,02р.
|
4,884198
|
111,3925
|
| 13
|
90,32р.
|
72,00р.
|
116,68р.
|
5,01854
|
128,979
|
| 14
|
91,64р.
|
70,07р.
|
118,36р.
|
4,801321
|
124,8081
|
| 15
|
92,20р.
|
74,12р.
|
121,55р.
|
4,848674
|
132,8335
|
| Вариант 3
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
31,91р.
|
22,99р.
|
43,98р.
|
5,09р.
|
74,73
|
| 2
|
30,50р.
|
22,13р.
|
44,91р.
|
5,03р.
|
77,73
|
| 3
|
32,98р.
|
22,76р.
|
42,49р.
|
4,80р.
|
66,26
|
| 4
|
34,50р.
|
21,00р.
|
41,38р.
|
4,95р.
|
55,45
|
| 5
|
34,42р.
|
20,65р.
|
44,15р.
|
4,88р.
|
51,00
|
| 6
|
34,79р.
|
21,74р.
|
42,22р.
|
4,96р.
|
53,51
|
| 7
|
30,07р.
|
21,20р.
|
42,30р.
|
5,10р.
|
84,14
|
| 8
|
32,04р.
|
23,55р.
|
41,24р.
|
4,90р.
|
76,03
|
| 9
|
34,32р.
|
20,13р.
|
43,14р.
|
4,72р.
|
54,02
|
| 10
|
30,69р.
|
24,58р.
|
44,98р.
|
4,81р.
|
86,40
|
| 11
|
31,23р.
|
21,03р.
|
43,27р.
|
4,95р.
|
73,19
|
| 12
|
30,23р.
|
22,67р.
|
40,28р.
|
4,88р.
|
82,31
|
| 13
|
30,16р.
|
21,00р.
|
41,27р.
|
5,02р.
|
77,21
|
| 14
|
30,82р.
|
20,04р.
|
41,86р.
|
4,80р.
|
67,53
|
| 15
|
31,10р.
|
22,06р.
|
43,11р.
|
4,85р.
|
74,15
|
| Вариант 4
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
43,22р.
|
75,98р.
|
30,90р.
|
5,09
|
166,95
|
| 2
|
44,44р.
|
60,87р.
|
38,75р.
|
5,03
|
114,21
|
| 3
|
43,87р.
|
69,06р.
|
36,93р.
|
4,80
|
141,13
|
| 4
|
44,81р.
|
69,51р.
|
33,18р.
|
4,95
|
139,50
|
| 5
|
41,19р.
|
62,12р.
|
34,06р.
|
4,88
|
131,81
|
| 6
|
41,28р.
|
65,40р.
|
46,54р.
|
4,96
|
142,16
|
| 7
|
40,48р.
|
73,34р.
|
41,61р.
|
5,10
|
178,34
|
| 8
|
40,63р.
|
62,76р.
|
35,35р.
|
4,90
|
140,91
|
| 9
|
40,95р.
|
64,90р.
|
37,86р.
|
4,72
|
145,70
|
| 10
|
43,00р.
|
66,99р.
|
47,44р.
|
4,81
|
142,50
|
| 11
|
44,27р.
|
66,19р.
|
32,51р.
|
4,95
|
133,54
|
| 12
|
41,37р.
|
69,24р.
|
30,30р.
|
4,88
|
156,54
|
| 13
|
40,41р.
|
76,86р.
|
44,63р.
|
5,02
|
183,50
|
| 14
|
40,53р.
|
77,57р.
|
48,57р.
|
4,80
|
182,00
|
| 15
|
41,13р.
|
73,05р.
|
35,98р.
|
4,85
|
167,27
|
| Вариант 5
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
38,37р.
|
103,23р.
|
16,02р.
|
5,093
|
422,9505
|
| 2
|
31,30р.
|
103,39р.
|
13,17р.
|
5,032
|
436,158
|
| 3
|
33,97р.
|
113,87р.
|
18,58р.
|
4,799
|
534,9022
|
| 4
|
49,18р.
|
102,34р.
|
17,61р.
|
4,951
|
295,2635
|
| 5
|
41,26р.
|
109,05р.
|
12,41р.
|
4,878
|
251,038
|
| 6
|
39,58р.
|
107,07р.
|
14,32р.
|
4,962
|
339,7103
|
| 7
|
47,66р.
|
104,95р.
|
18,69р.
|
5,098
|
371,124
|
| 8
|
44,20р.
|
106,14р.
|
13,16р.
|
4,899
|
234,9415
|
| 9
|
32,62р.
|
116,04р.
|
18,36р.
|
4,722
|
543,2922
|
| 10
|
42,10р.
|
102,21р.
|
17,88р.
|
4,810
|
397,1158
|
| 11
|
32,90р.
|
117,34р.
|
16,07р.
|
4,949
|
494,8871
|
| 12
|
42,54р.
|
117,20р.
|
19,98р.
|
4,884
|
458,4898
|
| 13
|
38,34р.
|
113,35р.
|
11,59р.
|
5,019
|
283,1757
|
| 14
|
34,20р.
|
113,15р.
|
15,44р.
|
4,801
|
439,8954
|
| 15
|
34,42р.
|
112,66р.
|
16,68р.
|
4,849
|
478,3711
|
| |
|
|
|
|
|
| Вариант 6
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
25,73р.
|
51,96р.
|
13,98р.
|
5,093
|
132,775
|
| 2
|
21,51р.
|
48,51р.
|
14,91р.
|
5,032
|
170,105
|
| 3
|
28,95р.
|
51,02р.
|
12,49р.
|
4,799
|
100,926
|
| 4
|
33,49р.
|
44,00р.
|
11,38р.
|
4,951
|
60,666
|
| 5
|
33,27р.
|
42,61р.
|
14,15р.
|
4,878
|
60,598
|
| 6
|
34,38р.
|
46,96р.
|
12,22р.
|
4,962
|
49,481
|
| 7
|
20,22р.
|
44,81р.
|
12,30р.
|
5,098
|
188,878
|
| 8
|
26,11р.
|
54,20р.
|
11,24р.
|
4,899
|
128,269
|
| 9
|
32,95р.
|
40,51р.
|
13,14р.
|
4,722
|
69,717
|
| 10
|
22,08р.
|
58,31р.
|
14,98р.
|
4,810
|
170,243
|
| 11
|
23,68р.
|
44,13р.
|
13,27р.
|
4,949
|
153,002
|
| 12
|
20,68р.
|
50,68р.
|
10,28р.
|
4,884
|
175,995
|
| 13
|
20,49р.
|
44,01р.
|
11,27р.
|
5,019
|
177,151
|
| 14
|
22,46р.
|
40,15р.
|
11,86р.
|
4,801
|
156,506
|
| 15
|
23,29р.
|
48,24р.
|
13,11р.
|
4,849
|
152,925
|
| Вариант 7
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
13,22р.
|
37,99р.
|
8,09р.
|
5,093
|
86,71655
|
| 2
|
14,44р.
|
30,44р.
|
8,88р.
|
5,032
|
75,80126
|
| 3
|
13,87р.
|
34,53р.
|
8,69р.
|
4,799
|
81,042
|
| 4
|
14,81р.
|
34,76р.
|
8,32р.
|
4,951
|
81,18657
|
| 5
|
11,19р.
|
31,06р.
|
8,41р.
|
4,878
|
80,03161
|
| 6
|
11,28р.
|
32,70р.
|
9,65р.
|
4,962
|
82,30865432
|
| 7
|
10,48р.
|
36,67р.
|
9,16р.
|
5,098
|
99,35052
|
| 8
|
10,63р.
|
31,38р.
|
8,53р.
|
4,899
|
87,88665
|
| 9
|
10,95р.
|
32,45р.
|
8,79р.
|
4,722
|
89,09822
|
| 10
|
13,00р.
|
33,50р.
|
9,74р.
|
4,810
|
86,62127
|
| 11
|
14,27р.
|
33,09р.
|
8,25р.
|
4,949
|
82,73234
|
| 12
|
11,37р.
|
34,62р.
|
8,03р.
|
4,884
|
89,24696
|
| 13
|
10,41р.
|
38,43р.
|
9,46р.
|
5,019
|
92,89391
|
| 14
|
10,53р.
|
38,79р.
|
9,86р.
|
4,801
|
89,47333
|
| 15
|
11,13р.
|
36,53р.
|
8,60р.
|
4,849
|
88,76572
|
| Вариант 8
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
161,46р.
|
229,91р.
|
115,93р.
|
5,093
|
236,742
|
| 2
|
153,02р.
|
221,28р.
|
119,66р.
|
5,032
|
238,461
|
| 3
|
167,89р.
|
227,55р.
|
109,97р.
|
4,799
|
216,445
|
| 4
|
176,97р.
|
209,99р.
|
105,51р.
|
4,951
|
175,139
|
| 5
|
176,54р.
|
206,54р.
|
116,60р.
|
4,878
|
165,085
|
| 6
|
178,75р.
|
217,40р.
|
108,89р.
|
4,962
|
178,676
|
| 7
|
150,43р.
|
212,02р.
|
109,21р.
|
5,098
|
240,345
|
| 8
|
162,22р.
|
235,49р.
|
104,97р.
|
4,899
|
243,789
|
| 9
|
175,90р.
|
201,27р.
|
112,57р.
|
4,722
|
164,415
|
| 10
|
154,16р.
|
245,78р.
|
119,92р.
|
4,810
|
276,114
|
| 11
|
157,35р.
|
210,33р.
|
113,08р.
|
4,949
|
216,811
|
| 12
|
151,36р.
|
226,69р.
|
101,11р.
|
4,884
|
252,094
|
| 13
|
150,97р.
|
210,02р.
|
105,07р.
|
5,019
|
227,378
|
| 14
|
154,92р.
|
200,37р.
|
107,43р.
|
4,801
|
199,538
|
| 15
|
156,59р.
|
220,59р.
|
112,43р.
|
4,849
|
229,503
|
| Вариант 9
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
10,51р.
|
9,29р.
|
21,20р.
|
5,093
|
1028,181
|
| 2
|
10,31р.
|
9,78р.
|
18,17р.
|
5,032
|
1033,412
|
| 3
|
10,92р.
|
9,55р.
|
19,81р.
|
4,799
|
981,1834
|
| 4
|
11,00р.
|
9,92р.
|
19,90р.
|
4,951
|
994,5438
|
| 5
|
10,15р.
|
8,48р.
|
18,42р.
|
4,878
|
1018,348
|
| 6
|
10,16р.
|
8,51р.
|
19,08р.
|
4,962
|
1026,376
|
| 7
|
11,96р.
|
8,19р.
|
20,67р.
|
5,098
|
958,8783
|
| 8
|
11,48р.
|
8,25р.
|
18,55р.
|
4,899
|
959,321
|
| 9
|
11,87р.
|
8,38р.
|
18,98р.
|
4,722
|
925,0467
|
| 10
|
11,86р.
|
9,20р.
|
19,40р.
|
4,810
|
938,6315
|
| 11
|
11,49р.
|
9,71р.
|
19,24р.
|
4,949
|
970,6546
|
| 12
|
11,49р.
|
8,55р.
|
19,85р.
|
4,884
|
958,5316
|
| 13
|
10,72р.
|
8,16р.
|
21,37р.
|
5,019
|
1005,377
|
| 14
|
10,42р.
|
8,21р.
|
21,51р.
|
4,801
|
997,5462
|
| 15
|
10,91р.
|
8,45р.
|
20,61р.
|
4,849
|
981,2018
|
| Вариант 10
|
| Номер
наблюдения
|
Цена
x1
(р.)
|
Цена на первый подобный товар x2
(р.)
|
Цена на второй подобный товар x3
(р.)
|
Средний доход населения x4
(т. р.)
|
Спрос y (тыс.шт.)
|
| 1
|
192,56р.
|
299,70р.
|
96,02р.
|
5,093
|
152,0249
|
| 2
|
181,94р.
|
300,17р.
|
93,17р.
|
5,032
|
250,91
|
| 3
|
185,95р.
|
331,60р.
|
98,58р.
|
4,799
|
232,7626
|
| 4
|
208,78р.
|
297,01р.
|
97,61р.
|
4,951
|
8,0859
|
| 5
|
196,90р.
|
317,14р.
|
92,41р.
|
4,878
|
45,77114
|
| 6
|
194,37р.
|
311,22р.
|
94,32р.
|
4,962
|
110,6561
|
| 7
|
206,49р.
|
304,86р.
|
98,69р.
|
5,098
|
19,61478
|
| 8
|
201,30р.
|
308,41р.
|
93,16р.
|
4,899
|
3,427142
|
| 9
|
183,93р.
|
338,12р.
|
98,36р.
|
4,722
|
247,5139
|
| 10
|
198,14р.
|
296,62р.
|
97,88р.
|
4,810
|
86,62103
|
| 11
|
184,35р.
|
342,02р.
|
96,07р.
|
4,949
|
238,8057
|
| 12
|
198,80р.
|
341,61р.
|
99,98р.
|
4,884
|
93,84997
|
| 13
|
192,52р.
|
330,05р.
|
91,59р.
|
5,019
|
110,0219
|
| 14
|
186,30р.
|
329,45р.
|
95,44р.
|
4,801
|
204,7953
|
| 15
|
186,63р.
|
327,97р.
|
96,68р.
|
4,849
|
209,9875
|
Лабораторная работа № 9
| Вариант 1
|
|
Вариант 2
|
| Номер
наблюдения
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
| 1
|
новый
|
15,09р.
|
125,1779
|
|
новый
|
93,82р.
|
135,5503
|
| 2
|
самый новый
|
15,21р.
|
123,8094
|
|
самый новый
|
91,01р.
|
171,1037
|
| 3
|
старый
|
15,28р.
|
121,175
|
|
старый
|
95,96р.
|
106,8294
|
| 4
|
обычный
|
15,49р.
|
116,9143
|
|
обычный
|
98,99р.
|
82,65364
|
| 5
|
новый
|
15,54р.
|
119,8643
|
|
новый
|
98,85р.
|
107,9813
|
| 6
|
самый новый
|
15,62р.
|
118,0681
|
|
самый новый
|
99,58р.
|
87,08134
|
| 7
|
старый
|
15,70р.
|
123,5887
|
|
старый
|
90,14р.
|
140,1648
|
| 8
|
обычный
|
15,91р.
|
117,0877
|
|
обычный
|
94,07р.
|
107,1392
|
| 9
|
новый
|
15,92р.
|
116,1699
|
|
новый
|
98,63р.
|
96,99346
|
| 10
|
самый новый
|
15,95р.
|
118,3436
|
|
самый новый
|
91,39р.
|
175,2817
|
| 11
|
старый
|
16,31р.
|
116,2008
|
|
старый
|
92,45р.
|
134,0831
|
| 12
|
обычный
|
16,33р.
|
111,4565
|
|
обычный
|
90,45р.
|
111,3925
|
| 13
|
новый
|
16,60р.
|
115,1026
|
|
новый
|
90,32р.
|
128,979
|
| 14
|
старый
|
16,69р.
|
110,1056
|
|
старый
|
91,64р.
|
124,8081
|
| 15
|
старый
|
16,76р.
|
110,0231
|
|
старый
|
92,20р.
|
132,8335
|
| Вариант 3
|
|
Вариант 4
|
| Номер
наблюдения
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
| 1
|
новый
|
31,91р.
|
74,73
|
|
новый
|
43,22р.
|
166,95
|
| 2
|
самый новый
|
30,50р.
|
77,73
|
|
самый новый
|
44,44р.
|
114,21
|
| 3
|
старый
|
32,98р.
|
66,26
|
|
старый
|
43,87р.
|
141,13
|
| 4
|
обычный
|
34,50р.
|
55,45
|
|
обычный
|
44,81р.
|
139,50
|
| 5
|
новый
|
34,42р.
|
51,00
|
|
новый
|
41,19р.
|
131,81
|
| 6
|
самый новый
|
34,79р.
|
53,51
|
|
самый новый
|
41,28р.
|
142,16
|
| 7
|
старый
|
30,07р.
|
84,14
|
|
старый
|
40,48р.
|
178,34
|
| 8
|
обычный
|
32,04р.
|
76,03
|
|
обычный
|
40,63р.
|
140,91
|
| 9
|
новый
|
34,32р.
|
54,02
|
|
новый
|
40,95р.
|
145,70
|
| 10
|
самый новый
|
30,69р.
|
86,40
|
|
самый новый
|
43,00р.
|
142,50
|
| 11
|
старый
|
31,23р.
|
73,19
|
|
старый
|
44,27р.
|
133,54
|
| 12
|
обычный
|
30,23р.
|
82,31
|
|
обычный
|
41,37р.
|
156,54
|
| 13
|
новый
|
30,16р.
|
77,21
|
|
новый
|
40,41р.
|
183,50
|
| 14
|
старый
|
30,82р.
|
67,53
|
|
старый
|
40,53р.
|
182,00
|
| 15
|
старый
|
31,10р.
|
74,15
|
|
старый
|
41,13р.
|
167,27
|
| Вариант 5
|
|
Вариант 6
|
| Номер
наблюдения
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
| 1
|
новый
|
38,37р.
|
422,9505
|
|
новый
|
25,73р.
|
132,775
|
| 2
|
самый новый
|
31,30р.
|
436,158
|
|
самый новый
|
21,51р.
|
170,105
|
| 3
|
старый
|
33,97р.
|
534,9022
|
|
старый
|
28,95р.
|
100,926
|
| 4
|
обычный
|
49,18р.
|
295,2635
|
|
обычный
|
33,49р.
|
60,666
|
| 5
|
новый
|
41,26р.
|
251,038
|
|
новый
|
33,27р.
|
60,598
|
| 6
|
самый новый
|
39,58р.
|
339,7103
|
|
самый новый
|
34,38р.
|
49,481
|
| 7
|
старый
|
47,66р.
|
371,124
|
|
старый
|
20,22р.
|
188,878
|
| 8
|
обычный
|
44,20р.
|
234,9415
|
|
обычный
|
26,11р.
|
128,269
|
| 9
|
новый
|
32,62р.
|
543,2922
|
|
новый
|
32,95р.
|
69,717
|
| 10
|
самый новый
|
42,10р.
|
397,1158
|
|
самый новый
|
22,08р.
|
170,243
|
| 11
|
старый
|
32,90р.
|
494,8871
|
|
старый
|
23,68р.
|
153,002
|
| 12
|
обычный
|
42,54р.
|
458,4898
|
|
обычный
|
20,68р.
|
175,995
|
| 13
|
новый
|
38,34р.
|
283,1757
|
|
новый
|
20,49р.
|
177,151
|
| 14
|
старый
|
34,20р.
|
439,8954
|
|
старый
|
22,46р.
|
156,506
|
| 15
|
старый
|
34,42р.
|
478,3711
|
|
старый
|
23,29р.
|
152,925
|
| Вариант 7
|
|
Вариант 8
|
| Номер
наблюдения
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
| 1
|
новый
|
13,22р.
|
86,71655
|
|
новый
|
161,46р.
|
236,742
|
| 2
|
самый новый
|
14,44р.
|
75,80126
|
|
самый новый
|
153,02р.
|
238,461
|
| 3
|
старый
|
13,87р.
|
81,042
|
|
старый
|
167,89р.
|
216,445
|
| 4
|
обычный
|
14,81р.
|
81,18657
|
|
обычный
|
176,97р.
|
175,139
|
| 5
|
новый
|
11,19р.
|
80,03161
|
|
новый
|
176,54р.
|
165,085
|
| 6
|
самый новый
|
11,28р.
|
82,3086543
|
|
самый новый
|
178,75р.
|
178,676
|
| 7
|
старый
|
10,48р.
|
99,35052
|
|
старый
|
150,43р.
|
240,345
|
| 8
|
обычный
|
10,63р.
|
87,88665
|
|
обычный
|
162,22р.
|
243,789
|
| 9
|
новый
|
10,95р.
|
89,09822
|
|
новый
|
175,90р.
|
164,415
|
| 10
|
самый новый
|
13,00р.
|
86,62127
|
|
самый новый
|
154,16р.
|
276,114
|
| 11
|
старый
|
14,27р.
|
82,73234
|
|
старый
|
157,35р.
|
216,811
|
| 12
|
обычный
|
11,37р.
|
89,24696
|
|
обычный
|
151,36р.
|
252,094
|
| 13
|
новый
|
10,41р.
|
92,89391
|
|
новый
|
150,97р.
|
227,378
|
| 14
|
старый
|
10,53р.
|
89,47333
|
|
старый
|
154,92р.
|
199,538
|
| 15
|
старый
|
11,13р.
|
88,76572
|
|
старый
|
156,59р.
|
229,503
|
| Вариант 9
|
|
Вариант 10
|
| Номер
наблюдения
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
|
Вид
|
Цена
x1
(р.)
|
Спрос y (тыс.шт.)
|
| 1
|
новый
|
10,51р.
|
1028,181
|
|
новый
|
192,56р.
|
152,0249
|
| 2
|
самый новый
|
10,31р.
|
1033,412
|
|
самый новый
|
181,94р.
|
250,91
|
| 3
|
старый
|
10,92р.
|
981,1834
|
|
старый
|
185,95р.
|
232,7626
|
| 4
|
обычный
|
11,00р.
|
994,5438
|
|
обычный
|
208,78р.
|
38,0859
|
| 5
|
новый
|
10,15р.
|
1018,348
|
|
новый
|
196,90р.
|
45,77114
|
| 6
|
самый новый
|
10,16р.
|
1026,376
|
|
самый новый
|
194,37р.
|
110,6561
|
| 7
|
старый
|
11,96р.
|
958,8783
|
|
старый
|
206,49р.
|
19,61478
|
| 8
|
обычный
|
11,48р.
|
959,321
|
|
обычный
|
201,30р.
|
3,427142
|
| 9
|
новый
|
11,87р.
|
925,0467
|
|
новый
|
183,93р.
|
247,5139
|
| 10
|
самый новый
|
11,86р.
|
938,6315
|
|
самый новый
|
198,14р.
|
86,62103
|
| 11
|
старый
|
11,49р.
|
970,6546
|
|
старый
|
184,35р.
|
238,8057
|
| 12
|
обычный
|
11,49р.
|
958,5316
|
|
обычный
|
198,80р.
|
93,84997
|
| 13
|
новый
|
10,72р.
|
1005,377
|
|
новый
|
192,52р.
|
110,0219
|
| 14
|
старый
|
10,42р.
|
997,5462
|
|
старый
|
186,30р.
|
204,7953
|
| 15
|
старый
|
10,91р.
|
981,2018
|
|
старый
|
186,63р.
|
209,9875
|
|