| Федеральное агентство по образованию РФ
Государственное образовательное учреждение высшего профессионального образования
Уральский государственный университет им. А.М.Горького
Математико-механический факультет
Кафедра информатики и процессов управления
Использование подходов веб-аналитики для построения модели пользователя
| "Допущен к защите"
___________________
"__"____________2009 г.
|
|
Квалификационная работа на степень бакалавра наук
по направлению "Математика, компьютерные науки"
студента гр. КН - 401
Зуевой Анастасии Андреевны
Научный руководитель
Авербух Владимир Лазаревич
к.т.н
|
Екатеринбург
2009
РЕФЕРАТ
Зуева А.А. ИСПОЛЬЗОВАНИЕ ПОДХОДОВ ВЕБ-АНАЛИТИКИ ДЛЯ ПОСТРОЕНИЯ МОДЕЛИ ПОЛЬЗОВАТЕЛЯ, квалификационная работа на степень бакалавра наук, стр. 44, рис. 2, библ. 6 назв., приложений 4.
Ключевые слова: МОДЕЛИРОВАНИЕ ПОЛЬЗОВАТЕЛЕЙ, ВЕБ-АНАЛИТИКА, МОДЕЛЬ, ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ, МЕТРИКИ
Объект исследования – пользователь, совершающий работу в системе электронной отчетности
Цель работы – разработка методики моделирования пользователя
Рассматриваются системы электронной отчетности как специфический вид веб-ресурса. Ставится цель повышения эффективности ресурса. Разрабатывается методика построения модели веб-пользователя с применением подходов веб-аналитики. Строится модель и её графическое представление.
СОДЕРЖАНИЕ
ВВЕДЕНИЕ……………………………………………………………………4
1. Проблематика работы
1.1. Характеристика и недостатки существующих подходов………………7
1.2. Обоснование выбора объекта методики…………………………………………………………………..13
2. Постановка задачи………………………………………………………...16
3. Решение поставленной задачи.
3.1. Выбор вида модели……………………………………………………...17
3.2. Определение параметров………………………………………………..22
3.3. Представление результатов……………………………………………..29
4. Обоснование инструментария. Реализация……………………………..32
ЗАКЛЮЧЕНИЕ………………………………………………………………38
ЛИТЕРАТУРА………………………………………………………………..40
ПРИЛОЖЕНИЕ………………………………………………………………41
ВВЕДЕНИЕ
В современном мире, насыщенном информацией, становится важной не только её доступность, но также полезность и удобство представления. Во избежание информационной перегрузки, информация должна быть значимой по отношению к выполняемой задаче и знаниям субъекта. Большинство информации представлено в цифровом виде, а значит, особое внимание должно быть уделено компьютерным системам, работающим с конечными пользователями, поскольку именно пользователи являются основными потребителями и создателями цифровой информации.
Программное обеспечение на этапе разработки пишется для миллионов пользователей, в то время как в конечном итоге с ним будет работать каждый конкретный человек в отдельности. Пользователь, работающий с программой, имеет собственные ожидания и представления о том, что должна делать программа и как она должна это делать. Производители ПО заинтересованы в том, чтобы выпускать продукты, которые понравятся их потребителям, а также отслеживать свои продукты на этапе использования. Это делается для того, чтобы доработать программу в соответствии с ожиданиями пользователей, исправить возникающие ошибки и выделить, что в программе устраивает пользователя, а что нет. Очевидно, что полностью удовлетворить требованиям каждого представителя огромной аудитории невозможно. Должно существовать сбалансированное решение, устраивающее максимальное число пользователей и с позиции удобства, и с позиции эффективного выполнения поставленных задач. В то же время, современные технологии позволяют донастроить программу под нужды конкретного пользователя в процессе её использования.
В этом ключе особо следует рассматривать веб-сайты. Многие компании используют сеть Интернет для достижения своих бизнес-целей, и они напрямую заинтересованы в том, чтобы донести информацию до пользователя наилучшим образом. Веб-сайт может выполнять развлекательную, информационную, коммерческую, профессиональную и другие функции. Часто один ресурс воплощает многие из них. Программное обеспечение, как правило, предназначено для выполнения одной или ограниченного набора функций. На сайт же могут ежедневно заходить тысячи пользователей, и все они хотят видеть нечто красивое, удобное и функциональное. Конкретные ожидания посетителей определяются их целью и предназначением сайта. При этом каждый посетитель имеет свои представления о том, что они хотят получить от сайта, и эти представления могут существенно отличаться. В этом заключается специфика веб-ресурсов, и поэтому для них особенно остро стоит проблема соответствия пользовательским интересам.
Описанные вопросы – это предмет изучения дисциплины «человеко-машинное взаимодействие», одним из подразделов которой является дисциплина «моделирование пользователей». Она предоставляет инструменты, позволяющие оптимизировать процессы обмена информацией между человеком и компьютером, и позволяет взглянуть на «происходящее» с точки зрения пользователя. Строятся модели, дающие информацию о знаниях, навыках и предпочтениях пользователей. Анализируется, что следует исправить, что добавить или убрать, как должна вести себя система с конкретным пользователем. Это дает возможность сделать ресурс не оторванным от жизни, а действительно удобным и полезным.
Рассматривая взаимодействие пользователя и компьютерной системы, можно выделить два ключевых момента – отношения системы и абстрактного пользователя, взаимодействие системы с конкретным пользователем. Первый вопрос – проблема взаимодействия с абстрактным пользователем – основывается на сборе данных от большого числа пользователей, составлении статистики и выделении общих ключевых моментов во взаимодействии. Применительно к Web, этими задачами занимается веб-аналитика. Второй вопрос связан с персонализацией программного обеспечения, в частности, с персонализацией Web. Это перспективное направление, главная задача которого – приспособиться к различиям между индивидуальными пользователями и предоставить каждому из них систему, персонифицированную под его нужды. Эти задачи решает моделирование пользователей.
Два этих вопроса тесно связаны между собой. Происходит сбор информации о пользователе и её анализ. На основании полученных данных происходит оптимизация ресурса. В широком смысле, веб – аналитика и моделирование пользователей в рамках персонализации решают общий круг задач – пользователь должен быть доволен, а ресурс эффективен. Различаются только подходы для достижения этих целей. Они представляют как бы две крайности в решении проблемы, в то же время имея большое количество точек соприкосновения. Возникает естественное желание соединить подходы и создать объединенный механизм, который позволит добиться желаемых результатов с минимальными потерями. В итоге планируется разработка основных положений методики моделирования веб-пользователя, базирующейся на совместном применении двух подходов.
ПРОБЛЕМАТИКА РАБОТЫ
Характеристика и недостатки существующих подходов
Выделив два основных подхода к изучению взаимодействия пользователя и компьютерной системы, рассмотрим их ключевые характеристики и недостатки, от которых хотим избавиться.
Любая система – это более или менее сложный объект с устоявшейся, связанной структурой. Системы содержат подсистемы и включаются в надсистемы, или среды. Системы взаимодействуют с другими системами на одном уровне абстракции, со средой и своими подсистемами. Чтобы взаимодействовать с другой системой, каждая система нуждается в представлении, или модели, этого взаимодействия, которое, в свою очередь, зависит от модели самой системы и модели системы, с которой она взаимодействует. Согласно одному из определений, большинство систем, которые взаимодействуют с человеком, содержат, явно или неявно, модель того, с кем они планируют взаимодействовать, в каком – то виде. Особенно это актуально для систем, адаптирующих своё поведение под индивидуального пользователя. В самом общем случае можно сказать, что если программа может изменять своё поведение, основываясь на чем-то, зависящим от пользователя, эта программа занимается явным или неявным моделированием пользователя. Модель пользователя описывает, что пользователь «знает» о системе. Общепринятая концепция такова: вместе с моделью пользователя создается модель области знаний для системы, вместе они ведут к разработке модели взаимодействия. Эти три модели образуют пример системы моделирования пользователей. Некоторые системы останавливаются на разработке моделей привычек и предпочтений пользователя, записывая и анализируя диалог пользователя и системы. Другие системы предпочитают запрашивать интересующую их информацию у самого пользователя. Третьи делают попытку предположить цели пользователя, несмотря на то, что это достаточно трудно сделать в рамках тех данных, которые обычно предоставляет компьютерная система. Достоинства составления моделей очевидны – отбор информации, уместной для данного пользователя, экономия времени, т.к. система сама отбирает за пользователя информацию, улучшение качества работы пользователя, повышение производительности и так далее. На деле большинство моделей – это простые практические представления очень маленького числа характеристик человека. Кроме того, необходимо учитывать неприкосновенность частной жизни и этические соображения, согласно которым людям должно быть известно, какая информация о них собирается системой.
Таким образом, моделирование пользователя подразумевает представление свойств индивидуальных пользователей. Оно предполагает получение информации о пользователе путем извлечения данных из действий, совершаемых пользователем. Характер информации, запрашиваемой в каждой конкретной модели, может быть различен, также как и способы представления полученной информации. Модель, полученная в итоге, всегда является когнитивной, то есть связанной с изучением сознания, мышления. В модели отражаются навыки и знания пользователя, процесс познания, способность к обучению, особенности его поведения. Конечной целью построения модели может быть как улучшение существующей системы, так и построение новых систем, и даже их автоматическая генерация. Первоначально исследователя, разрабатывающего модель, интересуют особенности, актуальные в рамках данной системы, но набор действий, совершаемых пользователем компьютерной системы, так или иначе ограничен и для разных систем часто совпадает. В связи с этим возникают трудности с выяснением цели пользователя по набору совершаемых им действий. Мы можем предположить его цель на высоком уровне – например, если он использует программу обработки фотографий, скорее всего, его цель – это работа с фотографиями. Однако чем ниже уровень, тем более общим становится набор его действий и тем сложнее проследить его задачу. Кроме того, составитель модели может прибегнуть к помощи имеющихся подходов и алгоритмов, разработанных либо только в теории, либо для конкретных компьютерных систем со своей спецификой, своим интерфейсом, своим набором функций. Таким образом, модели пользователя могут быть различны по своему виду и структуре, раскрывать разные стороны деятельности человека, но у них есть общие недостатки. С одной стороны, большинство уже имеющихся подходов к построению моделей пользователей общие и требуют доработки для конкретного применения. Анализ производимых действий часто происходит без учета специфики системы, а построенная модель не опирается на реальность, не позволяя сделать конкретных практических выводов. Это случай, когда в модели присутствует большое количество информации, раскрывающее определенные характеристики человека, но их рассмотрение применительно к системе и оценке её эффективности не дает желаемых результатов. С другой стороны, модель часто бывает построена под конкретную систему, и для сбора данных и их обработки используются специфические методы, не применимые к другой, даже схожей системе. При анализе собранной информации часто используется методика стереотипов. Проводятся зависимости между конкретным фактом и информацией о пользователе, позволяющие глубже проанализировать пользователя на основе уже имеющихся данных. Однако такой подход может быть чреват большим количеством ошибок, так как неправильно составленный стереотип даст неверную информацию о пользователе. Моделирование пользователей – это всегда построение догадок на основе имеющейся информации, и оценить, насколько верно то или иное предположение, сложно. Ставя перед собой масштабную и полезную задачу адаптации системы под пользователя, моделирование часто отклоняется от цели или вовсе не справляется с задачей.
С развитием электронной коммерции в 90-е годы обозначилась новая сфера применения моделирования пользователя. Предложение продукта, скидки, новости о продуктах, баннеры стали разрабатывать исходя из предпочтений индивида. Появились так называемые серверы моделирования, хранившие информацию о пользователях для различных приложений, причем информацию отобранную, связанную и совместимую. Они позволяют сравнивать избирательные действия пользователей, импортировать данные из других источников, поддерживают политики секретности. Таким образом, новой тенденцией становится активное использование глобальной сети для целей моделирования, хотя она предоставляет в основном различные сервисы по обслуживанию и не используется для извлечения данных.
Этим на просторах глобальной сети занимается другая дисциплина. Веб – аналитика – это измерение, сбор, анализ и представление Интернет – данных в целях понимания и оптимизации использования веб – ресурсов. В настоящее время Интернет стал для большинства компаний таким же средством ведения бизнеса, как телефон или розничная торговля. Появилась необходимость в предоставлении отчетности. Компании хотят, чтобы средства, вложенные в развитие их веб-ресурсов, давали соразмерные результаты. Они заинтересованы в существовании оценок эффективности ведения бизнеса в Интернет и предоставлении вариантов развития и улучшения этого направления деятельности. Веб-аналитика служит этим целям. Поэтому её методы должны не только описывать использование веб-ресурсов пользователями, но и обеспечивать базу для принятия компанией решений, как веб-ресурс будет развиваться в дальнейшем. Веб – аналитика оценивает сайт в первую очередь с точки зрения прибыльности, поэтому её методы достаточно специфичны. Веб – аналитика тесно связана с оптимизацией поисковых систем, Интернет – маркетингом. Одним из методов веб – аналитики является сбор различных данных и их последующее представление в виде метрик, которые отразят требуемые характеристики взаимодействия пользователя и системы. Примером метрик могут служить ключевые показатели эффективности (КПЭ). КПЭ – это финансовая и нефинансовая система показателей, позволяющая определить и оценить прогресс по достижению поставленных целей. Согласно другому определению, КПЭ – это некоторые критерии, которые помогают понять, как соотносятся действия с заданной целью. Они выявляют успех или провал выполнения цели, которая была поставлена для организации. Важно отметить, что КПЭ - это количественные показатели. Но далеко не любая метрика является КПЭ. Необходимо учитывать, для чего предназначен веб-ресурс, зачем он был создан. Любой инструмент веб-аналитики готов предоставить в распоряжение огромное количество показателей, и результатом от его использования часто является полное непонимание, что делать с таким объемом информации и какие принимать решения. Поэтому важной является задача выделения КПЭ для конкретного бизнеса из множества существующих метрик. Хотя веб – аналитика – очень молодая дисциплина, в ней было разработано очень большое количество различных показателей и подходов к их измерению. Некоторые даже выделяют старые, традиционные КПЭ в отдельную группу и предлагают рассматривать новые показатели – ключевой анализ понимания. Понятие показателя расширяется и на качественные характеристики ресурсов, и в общем КАП считается более адаптированным к современным технологиям и лучше отражающим действительные цели и задачи посетителей. Существуют также различные мнения, какие из показателей являются наиболее значимыми. Однако в целом все они направлены на повышение эффективности ресурса, при этом под эффективностью понимается прогресс в достижении пользователем той цели, ради которой сайт существует. Упор делается на получение выгоды, а значит, аналитики заинтересованы в том, чтобы их действия по оценке действий пользователей действительно приносили результаты. Кроме того, все веб – ресурсы можно поделить на группы в зависимости от целей, которые они преследуют, а значит, в рамках одной группы технологии аналитики будут примерно одинаковые. Методы веб-аналитики имеют и собственные недостатки. Неправильно выбранные метрики сведут на нет все усилия по их вычислению и не принесут никакой полезной информации. Метрика – это представление обобщенного опыта большого числа людей, и некоторые индивидуальные характеристики неизбежно теряются. На основании веб-аналитики ресурс нельзя сделать персонализированным, можно лишь повысить его привлекательность для большинства. Основная задача веб – аналитики не предполагает построения модели пользователя как таковой, взаимодействие человека и сайта она рассматривает в основном с позиции сайта, а не с позиции пользователя. Это делает невозможным перенос готовых методик в область моделирования. В современных аналитических комплексах метрики применяются совместно с лабораторным юзабилити-тестированием, опросами и другими техниками.
Обоснование выбора объекта методики
Рассмотрение взаимодействия пользователя с веб-ресурсом представляет особый интерес. Оно выделяется не только оригинальной спецификой и наличием сформировавшихся методов изучения, но и актуальностью. Всё больше и больше сервисов представляется в формате веб-сайта, расширяется круг задач, которые пользователь решает он-лайн. В разряд веб-сервисов переходят как приложения, традиционно решавшиеся локально на компьютере пользователя, так и совершенно новые виды деятельности.
Одним из интересных нововведений являются системы электронного документооборота и их разновидность – системы сдачи электронной отчетности через Интернет. Традиционный бумажный способ обладает рядом существенных недостатков, и автоматизация процесса направлена на их устранение. Основная функциональность СЭО состоит в следующем. Пользователю предлагается заполнить набор форм через Web-интерфейс и отослать их на нужный сервер. Поскольку мы рассматриваем поведение пользователей в системе, мы не будем подробно останавливаться на описании архитектуры таких систем. Нас интересует пользовательский интерфейс, его удобство, восприятие его пользователем, а также насколько хорошо он позволяет решать стоящие перед пользователем задачи. Этот тип веб-сервиса был выбран для рассмотрения в первую очередь потому, что здесь происходит тесное и постоянное взаимодействие пользователя и сайта, которое заключается не только в переходе по ссылкам. Поэтому среди некоммерческих сайтов, в СЭО индивидуальные качества пользователя раскрываются наиболее полно. Кроме того, цель посещения заранее известна – требуется выполнить работу по заполнению форм для формирования готового документа. С одной стороны, СЭО представляет собой полноценный веб-сайт, или имеет веб-интерфейс, а с другой – является системой, в которой пользователь осуществляет свою рабочую деятельность. Необходимо оценить, насколько успешным является система, в то же время уделяя внимание поведению каждого человека, работающего в ней.
Анализируя веб-ресурсы с точки зрения моделирования пользователей, можно заметить, что их специфика создает определенные трудности в построении моделей. Если пользователей много, не имеет смысла углубляться в сбор большого количества конкретных данных, так как нет возможности рассмотреть каждый случай отдельно и выявить некоторые закономерности. Очевидно, что должен использоваться статистический подход, обобщенные величины, которые позволят судить об эффективности ресурса. Но для получения обобщенных данных нужно собрать информацию с каждого конкретного пользователя, причем сбор статистики должен происходить с позиции пользователя, учитывать его навыки, знания. Каждый пользователь хочет видеть красивый, удобный в его понимании веб-ресурс, пользователей много, и их мнения отличаются зачастую кардинально. В случае с СЭО удобство ресурса играет существенную роль, при этом в силу специфики таких систем оценить их только с помощью методов веб-аналитики нельзя. СЭО не представляет собой типичный коммерческий сайт, стандартные показатели, такие как число посетителей, источники трафика, запрос к поисковой системе, не играют для них существенной роли. В то же время, используется веб-интерфейс, и некоторые из подходов веб-аналитики как раз ориентированы на его анализ. Поэтому рациональным представляется применение сочиненного подхода веб-аналитики и моделирования пользователей для анализа таких систем. Методы веб-аналитики, ориентированные как раз на сбор информации о веб-пользователе и её дальнейший анализ, могут стать основой для дальнейшего построения модели пользователя. В рамках веб-аналитики были разработаны технологии для извлечения конкретной, имеющей смысл информации из того небольшого набора данных, которые можно получить о посетителе сайта. Известны способы, какие данные собирать, как осуществлять процесс сбора, как анализировать информацию в дальнейшем для получения выводов. Таким образом, веб-аналитика может предоставить моделированию инструментарий для построения определенных моделей пользователей – а именно, веб-пользователей, которые посещают сайты в сети Интернет. Дисциплина веб-аналитики является развивающейся, но, тем не менее, многие концепции активно применяются на практике и показывают хорошие результаты. Кроме того, разработчики этой области напрямую заинтересованы в эффективности и доходности используемых подходов. Поскольку все разработки ведутся в узкой области, с высокой вероятностью возникают методы, хорошо работающие конкретно в ней, что предположительно позволит построить модель с более высокой точностью, чем при использовании общих, абстрактных подходов.
ПОСТАНОВКА ЗАДАЧИ
Цель данной работы – разработка методики построения модели веб-пользователя с применением подходов веб-аналитики. Вопросы, на которые необходимо ответить в первую очередь – какова цель построения модели, что должна представлять собой модель, какие технологии сбора и анализа данных можно позаимствовать из веб-аналитики, каково будет представление результатов? Построение модели имеет своей первичной целью анализ удобства и повышение эффективности ресурса, это будет учитываться при создании модели. При этом под эффективностью будет пониматься способность давать хороший результат, то есть продуктивность ресурса, его результативность. Класс компьютерных систем, для которых будет разрабатываться модель – системы электронной отчетности, имеющие веб-интерфейс. Общий вид модели и её основные характеристики будут разработаны с учетом специфики системы. Главная задача – анализ пользователя – человека, который производит работу в системе электронной отчетности.
Актуальность работы связана с переходом на электронное представление информации, повсеместным использованием Интернета и широким внедрением различных систем электронного документооборота. Для успешной работы таких систем требуется их исследование и оптимизация. Кроме того, разработка методики – первый шаг к построению более сложных моделей и их практическому применению.
РЕШЕНИЕ ПОСТАВЛЕННОЙ ЗАДАЧИ
Выбор вида модели
Основные этапы построения модели можно описать следующим образом:
o Определить цели моделирования
o Проанализировать объект, выделив его известные свойства
o Проанализировать выделенные свойства с точки зрения цели моделирования
o Определить, какие из свойств следует считать существенными
o Выбрать форму представления модели
o Формализовать объект
o Проанализировать соответствие полученной модели целям моделирования
Мы определили цель моделирования пользователя как первичный анализ эффективности, удобства ресурса. Учитывая специфику системы, пользователя которой мы моделируем, а также чрезвычайную сложность самого объекта моделирования, большое количество его известных характеристик, было решено изменить порядок действий и начать с выбора вида модели. Это позволило значительно уменьшить количество признаков у объекта и определиться с тем, какие свойства следует считать существенными в данном контексте. Типы моделей выделяются в зависимости от различных характеристик, и их число достаточно велико. Модель – это некоторое упрощенное подобие реального объекта. Модель может представлять копию предмета в некотором масштабе, аналог, который по определенным параметрам схож с реальным объектом, новый объект, который отражает некоторые стороны изучаемого объекта. По способу представления модели можно разделить на материальные и информационные. Информационная модель – это совокупность информации, характеризующая свойства и состояние объекта, процесса или явления. Наиболее распространенный вид информационных моделей – дескриптивные модели, выраженные на языке описания – естественном, специальном или визуальном. Описательная модель предназначена для описания и объяснения наблюдаемых фактов или прогноза поведения объектов, в отличие от нормативной модели, предназначенной для нахождения оптимального состояния объекта. Так как модель пользователя является когнитивной по своей сути, то есть описывающей познавательные процессы, очевидно, что она должна быть информационной и дескриптивной. Описательная модель предназначена для описания и объяснения наблюдаемых фактов, прогноза поведения объектов, изображения того, как работает система и каковы её связи с внешним миром. Она отличается простотой изложения и доступностью для понимания. Модель также раскрывает наиболее общие связи и закономерности, что особенно важно, т.к. пользователь – это чрезвычайно сложная система, и узнать о нем всё и сразу невозможно. С учетом этого факта модель можно назвать оптимальной на первом этапе моделирования.
Каждого пользователя компьютерной системы можно охарактеризовать набором фактов так, что для двух пользователей наборы не будут совпадать. При этом можно использовать его психофизические характеристики, знания, опыт работы, стимул, мотивацию, особенности национальной культуры и прочее. Всё это, безусловно, влияет на то, каким образом пользователь осуществляет своё взаимодействие с системой, но носит декларативный характер, априорно задано и не зависит от конкретной системы. Эти особенности пользователя определяют его восприятие, но практически не дают представления о самой системе. На самом деле, пользователь взаимодействует с системой, и эта связь обладает определенными свойствами. И нас интересуют, в первую очередь, именно особенности взаимодействия, характер динамического процесса выполнения работы в системе. Выделив некоторые характеристики взаимодействия и рассматривая их в комплексе, мы можем понять, как именно происходит общение пользователя и системы. Основные стороны, на которые нужно сделать упор - ключевые свойства пользователя, характер связей пользователя и системы, свойства среды, которые влияют на поведение пользователя. Всё это нужно учесть в модели. Определим модель пользователя как набор параметров, которые были вычислены в процессе его деятельности. Параметры должны давать представление о пользователе с точки зрения работы с системой, о процессах, которые возникают в результате использования пользователем системы, о свойствах самой системы, оказывающих влияние на пользователя. Такой вид модели является существенно более информативным, чем простое описание априорных свойств пользователя, даёт представление о взаимодействии и характеризует саму систему. Мы получаем данные как о пользователе, так и о системе, поэтому модель не является оторванной от реальности. Модель является дескриптивной, она представляет собой описание свойств, но при этом отражает динамику происходящего процесса. Рассматривая такой подход с точки зрения соответствия нашей цели, можно предположить, что именно характеристики взаимодействия позволят оценить качество сайта, а значит, является подходящей, по крайней мере, в первом приближении.
Определив модель как набор параметров, которые вычисляются в процессе взаимодействия пользователя с системой, необходимо определить сами параметры. Для этого необходимо определить наиболее существенные свойства объекта, значимые в рамках поставленной задачи. Поскольку мы делаем упор на взаимодействие, рассмотрим, какие данные могут нам понадобиться. Хотя модель является описательной, было решено использовать в качестве параметров показатели, дающие конкретные численные значения для каждого пользователя, так как это обеспечивает удобство представления и уменьшает объем хранимых данных. Кроме того, так как информация извлекается из компьютерной системы, численная интерпретация является наиболее естественной и наглядной.
Так как наша система имеет веб – интерфейс и обладает спецификой, присущей веб – сайтам в общем, обратимся к веб – аналитике за идеями параметров. Как отмечалось ранее, веб – аналитика построена на нахождении ключевых показателей эффективности ресурса. Это количественные показатели, которые позволяют оценить прогресс по достижению пользователем поставленной задачи. Чаще всего они представляют собой средние значения, выражения в процентах, ответ на вопрос «да или нет», но могут являться и самостоятельными числовыми характеристиками. Хорошей практикой в веб – аналитике считается разработка КПЭ для каждого конкретного ресурса. Конечно, существуют общие рекомендации для различных типов ресурсов и примеры удачного использования, это учитывается аналитиками. Но то, что подходит для одного сайта, может в силу различных причин не подойти для другого. При этом изменение уже составленных и вычисляемых показателей после того, как обнаружилась их неэффективность, достаточно затратное и ресурсоёмкое. Поэтому веб – аналитики всегда проводят большую подготовительную работу по составлению параметров. Очевидно, что для нашей системы использование уже имеющихся показателей нецелесообразно, так как, во – первых, система не представляет собой стандартный узел в сети Интернет и, соответственно, лишена некоторых особенностей и для неё просто невозможно рассчитать некоторые показатели. Во-вторых, мы производим анализ с точки зрения пользователя, а веб – аналитика оценивает эффективность с позиции сайта. Таким образом, позаимствуем из веб – аналитики идею расчета количественных показателей и применим её к нашей системе.
Помимо КПЭ, в веб – аналитике используются совместно или отдельно и другие подходы. Применимо к нашей задаче следует выделить расчет плотности кликов и отслеживание движений мыши. Здесь трактовка остается неизменной – места, удостоившиеся наибольшего внимания от пользователей, должны быть подвергнуты более тщательному анализу. В некоторых системах веб – аналитики предлагается запись всех последовательных движений мышью, при этом анализ этих данных, как правило, предоставляется уже пользователю этих систем.
Определение параметров
1.
Одной из важных характеристик работы пользователя в системе электронной отчетности является равномерность распределения его времени. Под равномерностью понимается тот факт, что время, затраченное на заполнение элемента формы, зависит только от его размера. Данная характеристика позволяет оценить удобство сайта в целом. Чем равномернее работа пользователя, тем меньше затруднений у него вызывают отдельные элементы. Он работает в своем темпе и затрачивает время на заполнение форм соответственно их размерам. Если какой-то элемент вызвал у пользователя вопрос, он остановился на нем, потратил существенное количество времени на то, чтобы в нем разобраться, заполнил его и только затем продвинулся дальше. Такая ситуация может отрицательно сказаться на работе системы – свести на нет положительные впечатления от грамотно составленных элементов и увеличить общее количество времени, затраченное пользователем, хотя проблема может скрываться всего в одном или нескольких элементах.
Составим показатель, который будет характеризовать равномерность работы пользователя по времени. Определим для каждого элемента формы показатель p:
p = время, затраченное на заполнение формы / (ширина формы * высота формы)
Он характеризует относительное количество времени, затраченное на элемент, учитывая его размеры. Выделим максимальный показатель, скорее всего, это будет элемент, вызвавший наибольшие затруднения. Посчитаем среднее по всем показателям и разделим получившееся на максимальный. Это будет итоговый показатель P:
P
= Среднее p по всем элементам / максимальное p среди элементов формы
Получим число в промежутке от 0 до 1, 0<P<=1. Чем ближе получившее число к 1, тем равномернее работает пользователь в системе. Числа, близкие к 0, указывают на то, что существуют элементы, на которые пользователь затратил время, отличное от среднего. В показатель входит размер элемента, что позволяет учитывать тот факт, что на заполнение элемента большего размера у пользователя уходит больше времени, чем на заполнение меньшего. Плюсом данного показателя является ограниченная область значений. Таким образом, появляется возможность сравнения показателей для различных пользователей. Мы можем утверждать, что один пользователь работает равномернее, чем другой, если P1 > P2, т.е. показатель для первого больше, чем показатель для второго. Однако следует заметить, что данный показатель не учитывает, сколько усилий затратил пользователь, чтобы равномерно заполнить форму. Возможно, заполнение формы в нужном темпе потребовало от него значительной мобилизации ресурсов, и на самом деле элементы формы имеют существенные недостатки.
2.
Мышь является главным управляющим устройством для большинства пользователей при работе с веб-сайтами. Все действия осуществляются с использованием курсора. Системы электронной отчетности имеют свою специфику – пользователю приходится гораздо больше работать с клавиатурой, т.к. он вводит большие объемы текста. Мышь может быть задействована для выбора элемента формы, действий внутри элемента и подтверждения отправки формы. Однако некоторые пользователи предпочитают совсем не пользоваться ей, предпочитая управляющие клавиши на клавиатуре, другие наоборот, активно используют мышь. Поэтому любопытным представляется оценить, насколько при работе с формами пользователь задействует мышь. Одной из возможных оценок может быть площадь, покрываемая движением курсора мыши. Курсор мыши следует по некой траектории на веб-странице. Рассчитаем площадь выпуклой оболочки траектории движения курсора. Рассмотрим следующий показатель:
S
= Площадь / площадь страницы
Получим отношение, лежащее в полуинтервале от 0 до 1. 0 < S <=1
Мы можем сравнить показатели для различных пользователей и выяснить, насколько каждый из них задействовал мышь и кто использовал её активнее. Кроме того, этот показатель позволит нам оценить, насколько пользователь использует пространство страницы. Если пространство страницы используется существенно, возможно, формы были размещены хорошо и работа с ними является эффективной. Если показатель близок к 0, вероятно, требуется перекомпоновать элементы. Например, если большинство пользователей использует мышь, но площадь покрытия мала, может потребоваться добавление элементов в те области, которые не были охвачены. Или же элементов слишком много и следует рассредоточить их большое скопление. В любом случае, этот показатель предоставляет большое количество возможностей для дальнейшего анализа.
3.
При заполнении форм часто возникает ситуация, когда данные, которые необходимо ввести в несколько различных полей, повторяются. У пользователя есть две альтернативы – перепечатать текст заново или скопировать его в буфер, а затем вставить в нужное поле. С одной стороны, это экономит время, с другой, может указывать на недостатки системы – необходимо исследовать, зачем потребовалось вводить несколько раз одинаковые данные. Возможно, система была сконструирована таким образом, что в ней присутствуют повторяющиеся поля. Другая возможная ситуация, когда пользователю понадобится буфер – копирование какого – то объема данных из внешних источников. Допустим, пользователь имеет некие данные, необходимые для ввода, в другом файле, и он просто переносит их в систему. Однако может возникнуть ситуация, в которой какая-то часть вводимой информации уже содержится у пользователя в файлах определенной, заранее известной структуры, например, электронных таблицах или файлах бухгалтерских систем. Тогда разумным представляется организовать импорт нужных данных из внешнего файла, чтобы пользователь не тратил время на повторный ввод. Рассмотрим бинарный показатель, отвечающий за факт вставки из буфера:
F
= 0, если буфер не использовался для вставки
1, если осуществлялась вставка из буфера
Если большое количество пользователей используют буфер при работе с нашей системой, это должно послужить поводом к дальнейшему исследованию.
4.
Пожалуй, первым показателем, который приходит на ум при анализе эффективности системы, является время, которое пользователь потратил на работу с системой. Чем меньше время, проведенное за заполнением форм, тем лучше система, тем приятнее пользователям с ней работать. Хорошая ситуация, когда все пользователи системы затрачивают небольшое время на выполнение своих заданий. Однако анализ временных промежутков связан с некоторым количеством проблем. Как определить, какое количество затраченного времени является оптимальным, работают ли все пользователи в нужном темпе или, наоборот, работают слишком медленно, при каком количестве затраченного времени можно утверждать, что система не оптимальна? Так, система может состоять из полей большого размера, и соответственно, все пользователи потратят больше времени на работу. Или система состоит из полей маленького размера, но неудобно организована, и все пользователи тратят на заполнение форм больше времени, чем могли бы. Таким образом, суммарное время, прошедшее от начала работы до завершения выполнения задания, не несет для нас никакой информации, если мы не имеем какой-то точки отсчета, усредненного показателя, такого, что большее время указывает на недостатки системы. Аналогично суммарный интервал простоя - время, в течение которого пользователь не взаимодействовал с системой – не будет являться информативной характеристикой системы. Необходим другой показатель, позволяющий оценить качества системы. Например, для каждого пользователя оценим, какую часть времени он провел «в раздумьях», никак не взаимодействуя с системой. Составим показатель T1:
T
1
= Время работы / суммарное время
К нему добавим показатель T2:
T
2
= Время работы пользователя / максимальное время работы среди всех пользователей
Оба показателя принадлежать полуинтервалу от 0 до 1: 0 <T1, 2 <=1.
T1 характеризует долю времени, в течение которого пользователь совершал какие-либо действия, в суммарном времени работы с системой. Если показатель близок к 0, возможно, у пользователя во время работы возникали различные вопросы и затруднения, ему требовалось что-либо уточнить, обратиться к другим источникам или понять, что от него требуется. Это может являться недостатком системы и указывать на то, что пользователь во время работы испытывает неудобства. T2 показывает, как соотносится общее время работы пользователя с временем работы остальных пользователей. Средние значения показателя свидетельствуют о том, что пользователь работал в нормальном темпе. Значения, близкие к 1, указывают на то, что по сравнению с остальными пользователь, возможно, затратил больше времени на работу и ему стоит уделить особое внимание. Совместное рассмотрение этих двух показателей может дать дополнительные сведения. Как соотносятся время простоя и суммарное время работы? Всегда ли наибольшему времени работы соответствует наибольшая доля простоя? Отвечая на эти вопросы, мы, возможно, сможем сделать выводы об эффективности нашей системы.
5.
Каждый пользователь имеет свои отличительные особенности работы с компьютером. В том числе это проявляется и в пользовании клавиатурой. В системе электронной отчетности пользователь активно пользуется клавиатурой для ввода текста, но использует ли он дополнительные возможности клавиатуры? Этот факт может указывать на то, насколько опытным пользователем ПК является наш пользователь, т.к. служебные клавиши обычно используют те, кто знаком с их функциями. Сделав такое предположение, мы можем рассмотреть и сравнить другие показатели среди пользователей, которых мы посчитали опытными, а также сравнить их показатели с теми, кто не использует служебные клавиши в работе. Наиболее востребованными при заполнении форм являются клавиши tab для перехода между элементами формы, enter для подтверждения отправки формы, стрелки для навигации внутри текстовых полей и выбора элементов из ниспадающих списков. Рассмотрим бинарный показатель K:
K
= 0, если пользователь не пользовался служебными клавишами
1, иначе
6.
Средняя скорость набора текста (знаков в минуту.)
Набирая текст на клавиатуре, каждый пользователь нажимает на клавиши с определенной скоростью. Чем быстрее пользователь нажимает на клавиши, тем лучше он владеет навыками печати на клавиатуре. Очевидно, что при слепом наборе скорость набора текста в несколько раз выше, чем при наборе двумя пальцами. Характеристика скорости набора поможет отнести пользователя к одной из категорий по опытности пользования ПК. Составим показатель, характеризующий скорость набора:
V
= средняя по всем элементам формы скорость набора текста, знаков в минуту
Используя этот показатель совместно с показателем K
, представляется возможным достаточно точно определить, насколько опытен пользователь системы. Кроме того, можно составить по аналогии с показателем P
следующий показатель:
Vs
= V
/ максимальная скорость набора по всем элементам формы
0<V<=1
и проанализировать, как соотносятся эти два показателя, верно ли, что если согласно показателю P
пользователь испытывает затруднения в работе, то показатель V
также будет близок к 0. Можно рассмотреть показатель Vs
отдельно, как характеристику равномерности работы пользователя по скорости. Числа, близкие к 0, могут указывать на наличие некорректно сформулированных задач, которые вынудили пользователя замедлиться и тщательно обдумывать вводимые данные, или на наличие отвлекающих элементов, на которые пользователь перенес своё внимание и отвлекся от выполнения задачи.
7.
В качестве одной их характеристик системы можно рассмотреть, насколько часто ошибается пользователь при вводе данных. Возможно, это особенность пользователя, а возможно, недостаток самой системы. Если большое количество пользователей, выполняя работу, часто совершают ошибки при наборе текста, это может послужить сигналом к проверке удобства и понятности форм. Рассчитаем показатель E:
E
= Количество элементов формы, в которых пользователь не ошибался / общее количество элементов в форме
0<E<=1
Будем считать, что пользователь ошибается, когда он прерывает последовательную цепочку действий по набору текста, то есть нажимает клавиши backspace или delete, пользуется стрелками, кликает мышкой по тексту. Показатель можно рассматривать как в сочетании с показателями P
и Vs
, так и отдельно. Числа, близкие к 0, часто встречающиеся среди пользователей, по-прежнему указывают на наличие проблем в системе.
Представление результатов
После определения типа модели и составления параметров, встал вопрос о представлении результатов моделирования. Поскольку все параметры были выбраны численными, их анализ в необработанном виде мог стать несколько затруднительным. Необходимо было разработать вариант отображения параметров в более наглядном виде. Выбор пал на графическое представление данных, так как оно лучше воспринимается, выразительно, позволяет понятнее отражать большие объемы информации, способствует формированию суждений об имеющихся данных и зависимостях между ними. Для численного отображения данных стандартно используются различные схемы и графики. Был разработан похожий подход.
Поскольку имеющиеся данные отражают различных пользователей, между которыми возможно выявление некоторых взаимосвязей, было решено представить каждого пользователя в виде элемента матрицы пользователей. С одной стороны, все пользователи составляют единую совокупность, с другой, каждый из них является индивидуальным элементом со своими характеристиками. Это позволяет делать суждения как о конкретном человеке, так и о его положении в системе пользователей, о наличии общих черт между ними. Даже при небольшом наборе пользователей, учитывая количество параметров для каждого, получаем большой объем данных, который достаточно сложно интерпретировать. Представление в виде матрицы отчасти решает эту проблему – теперь каждый пользователь является элементом структуры, и становится возможным за один просмотр отразить какие-то общие характеристики. Например, возможно выяснить, все ли пользователи обладают примерно одинаковым набором свойств, имеются ли сильно выделяющиеся экземпляры, какие из параметров представлены хуже всего, а какие лучше. Такое представление отвечает требованиям наглядности и простоты восприятия. Кроме того, становится возможным первичный анализ полученных данных на основании графического представления. При разделении пользователей по группам можно расположить сгруппированные элементы в матрице рядом и отследить взаимосвязи между представлениями пользователей, принадлежащих к одной группе, и пользователей, принадлежащих к разным группам. Если же группировка не проводилась, то на основании анализа матрицы можно сгруппировать людей по различным характеристикам – например, по тому, насколько в целом у них хорошие показатели, или по оценке конкретного показателя.
Представляя каждого пользователя как элемент матрицы, необходимо каким-то образом отразить весь набор его параметров. Каждый пользователь в нашей матрице представляется в виде квадрата. Квадрат поделён на горизонтальные полосы, их количество соответствует числу параметров в модели. Каждая полоса представляет свой параметр. Так как все параметры были подобраны таким образом, чтобы их значение попадало в промежуток от 0 до 1, их решено было представить цветом с различной интенсивностью. В качестве базового цвета был выбран черный, так как его оттенки хорошо распознаются человеческим глазом. Значение параметра 0, и, соответственно, интенсивность 0, отражают негативную характеристику и представляются белым цветом. Значение 1 говорит о «хорошем» значении параметра и рисуется чёрным цветом. Все промежуточные результаты изображаются оттенками серого. Таким образом, каждый пользователь представлен в виде квадрата с горизонтальной градиентной заливкой от белого до черного. Пример графической иллюстрации работы пользователя представлен на рисунке 3.1.
Представление пользователя

Рис. 3.1
Достоинствами такого представления являются наглядность, простота, совмещенные с достаточно точной интерпретацией числовых значений. «Плохо» работавшие пользователи будут отображаться белыми квадратами, а «хорошо» работавшие – чёрными. Соблюдая для каждого пользователя порядок следования параметров, мы можем сравнить значения параметров для различных пользователей, выделить, какие параметры отображаются светлее, а какие темнее. Группировку пользователей возможно производить сразу по графической интерпретации, «на глаз», а потом сравнивать результаты с априорной группировкой. К недостаткам такого подхода можно отнести его немасштабируемость – при значительном увеличении числа пользователей матрица теряет наглядность и простоту восприятия. Однако, так как мы не ставили целью анализ большого числа статистических данных и количество проанализированных пользователей сравнительно мало, такое графическое представление удобно для использования. Таким образом, графическое представление иллюстрирует полученные параметры и позволяет наглядным образом оценить составленную модель.
ОБОСНОВАНИЕ ИНСТРУМЕНТАРИЯ. РЕАЛИЗАЦИЯ
Составив модель и выбрав её представление, необходимо протестировать полученные результаты на конкретной системе.
В качестве системы для тестирования было создано несколько веб – страниц, эмулирующих системы электронной отчетности. Каждая страница представляет собой документ в формате html. Она содержит различные текстовые поля и элементы управления для ввода данных. Пользователю предлагается ввести некоторое количество информации, заполнив формы.
Для сбора информации с веб-страницы наилучшим средством является язык сценариев Jscript. Он встроен во все браузеры и обеспечивает наилучший доступ и управление элементами страницы. JScript — это объектно-ориентированный язык программирования, предназначенный для написания сценариев, работающих как на стороне клиента, так и на стороне сервера. Он не является "полноценным" языком программирования, является интерпретируемым языком и ориентирован на использование возможностей той среды, в которой сценарии исполняются. Веб-обозреватель, работающий на компьютере-клиенте, обеспечивает среду, в которой JScript имеет доступ к объектам, которые представляют собой окна, меню, диалоги, текстовые области, фреймы и ввод-вывод в Веб-страницу. Язык является событийным, то есть сценарий на JScript реагирует на события, происходящие в момент работы пользователя с веб-страницей, на которой он размещён. Обрабатываемые события могут быть как непосредственно связаны с устройствами ввода – мышь, клавиатура, так и привязаны к конкретным элементам сайта. Такая возможность является для нас особенно важной, так как она позволяет достаточно просто реализовать сбор динамических данных со страницы. Программный код сценариев только реагирует на события и поэтому не нуждается в главной программе. Он легко встраивается внутрь html – документа или присоединяется к нему. Набор объектов, предоставляемых обозревателем, известен под названием Document Object Model (DOM). DOM – это независящая от языка и платформы объектная модель для представления документов в форматах HTML и XML. Она определяет логическую структуру документов, позволяет управлять документом и получать доступ к содержимому. С помощью DOM можно составлять документы, передвигаться по их структуре, добавлять, изменять или удалять элементы и их содержимое. При сборе информации о пользователе это средство выполняет важную роль доступа к элементам форм. Таким образом, поскольку поставленная задача предполагает сбор различной информации о пользователе, заходящем на сайт, было решено воспользоваться для реализации языком сценариев JScript.
Данные, собранные с помощью программы на JScript, необходимо в каком – то виде сохранять. В качестве формата сохраненных данных был выбран язык разметки XML, позволяющий отобразить двоичные данные в текст, читаемый человеком и анализируемый компьютером. XML (англ. eXtensible Markup Language — расширяемый язык разметки) — рекомендованный Консорциумом Всемирной паутины язык разметки, фактически представляющий собой свод общих синтаксических правил. Это текстовый формат, предназначенный для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки. XML имеет строго определённый синтаксис и требования к анализу, что позволяет ему оставаться простым, эффективным и непротиворечивым. Иерархическая структура XML подходит для описания практически любых типов документов, кроме того, XML не зависит от платформы. На основе XML также были созданы более специализированные языки разметки. Одним из преимуществ XML является возможность создания документа на основе другого документа с помощью специального языка – XSL (англ. eXtensible Stylesheet Language — расширяемый язык таблиц стилей). С помощью XSL можно трансформировать XML-документ в документ любого типа, независимо от того, является ли получаемый документ XML-документом или нет. Одним из полезных применений этой возможности является трансформация XML – документа, содержащего набор данных, в другой XML – документ, описывающий графическое представление этих данных. Визуализация данных с помощью XML становится возможным благодаря специализированному языку разметки SVG. SVG (англ. Scalable Vector Graphics — масштабируемая векторная графика) — язык разметки масштабируемой векторной графики, который предназначен для описания двухмерной векторной и смешанной векторно-растровой графики в формате XML. Таким образом, сформировав файл с данными о пользователях, мы можем легко получить требующееся графическое представление в виде матрицы.
Рассмотрим общую методику тестирования модели. Для извлечения информации о пользователе к имеющимся веб – страницам присоединяется программа на языке JScript. Посредством реакции на различные пользовательские события она собирает необходимые данные, на основании которых формирует XML-документ. Далее к исходному документу применяется трансформация XSL, которая позволяет получить графическое представление имеющихся данных. Схема тестирования приведена на рисунке 4.1.
Схема тестирования модели
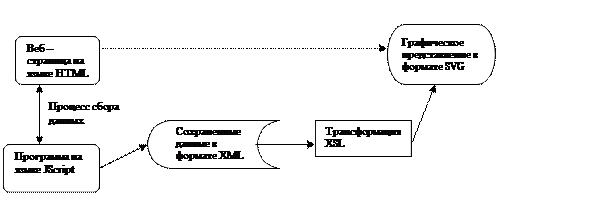
Рис. 4.1
Остановимся подробнее на каждом из этапов. После того, как сценарий прикреплен к каждой из тестируемых страниц, при их открытии он получает доступ ко всем элементам страницы. Программа на языке JScript представляет собой набор функций, являющихся обработчиками каких-либо пользовательских и системных событий. Это значит, что, как только происходит требуемое событие, вызывается отвечающая за его обработку функция. После загрузки страницы сценарий инициализирует свои переменные и назначает обработчики нужных событий для каждого из элементов формы. Отслеживая набор пользователем алфавитно-цифровых клавиш и используя события «элемент получил фокус» и «элемент потерял фокус», мы можем узнать скорость набора, время, которое пользователь уделил каждому элементу, а также время, в течение которого пользователь ничего не печатал в выделенном элементе. Это время будем считать временем простоя, требующимся для одного из параметров модели. Используя событие, возникающее, когда пользователь передвигает мышку, мы узнаем координаты движения указателя и сохраняем их для дальнейшего подсчета выпуклой оболочки траектории движения. Для определения, использовался ли буфер обмена для вставки, предусмотрено соответствующее событие. Когда пользователь печатает на клавиатуре, по кодам клавиш мы можем отследить, использовались ли служебные клавиши в процессе работы. Кроме того, следя за появлением клавиш backspace и delete, мы можем сделать вывод о совершении пользователем ошибок в процессе набора. Пока пользователь совершает какие-либо действия, данные о его активности сохраняются во внутренних переменных или во внешних файлах (для координат движения мыши). Как только пользователь покидает страницу, вызывается функция, производящая необходимые вычисления. Она считает значения всех параметров, а затем записывает их в XML-документ. Для каждой из страниц в системе формируется свой файл. Для дальнейшей обработки данных к имеющимся документам требуется применить трансформацию. Файл XSL представляет собой описание этой трансформации. XSL состоит из трех языков – XSLT – язык преобразований XML в другие типы документов или в другие XML-документы, XPath – язык определения частей и путей к элементам XML, XSL Formatting Objects (XSLFO) – язык определения показа XML. Трансформационная и форматирующая части языка XSL могут функционировать независимо друг от друга. XSLT является наиболее важной частью стандарта, так как именно он отвечает за преобразование документа. Для наших целей достаточным оказалось использование XSLT в сочетании с XPath. В процессе преобразования XSLT использует XPath для определения тех частей в документе-оригинале, которые соответствуют одному или более заранее заданным шаблонам. Когда такое соответствие обнаруживается, XSLT преобразовывает соответствующую часть в оригинале в часть документа – результата. Те части документа – оригинала, которые не соответствуют шаблону, попадают в результирующий документ немодифицированными. Кроме того, XSLT может добавлять новые элементы в выходной файл, удалять существовавшие элементы или изменять их порядок. Для того, чтобы обработать XML-документ используя XSL, необходим XML-парсер с XSL-машиной. Мы воспользовались утилитой
msxsl.exe, которая предоставляет возможность осуществления XSL-трансформаций из командной строки на основе процессора Microsoft® XSL. Она получает названия исходного файла и файла трансформации на вход и сохраняет результат в выходной файл. В нашей системе на основе XML-документа с данными создается другой XML-документ. После проведения тестирования мы получили набор XML-файлов, при этом каждый файл содержит данные по одному документу. Файл с описанием XSL-трансформации один для всех файлов с данными, так как они имеют одинаковый формат. Применяя трансформацию для каждого из XML-файлов, получим набор графических представлений для каждого из html-документов в системе. Таким образом, из имеющегося файла с данными мы получаем их готовое графическое представление.
Преимуществом подобной схемы является относительная простота реализации, связанная с тем, что использованные инструменты хорошо подходят для выполнения поставленных задач. Кроме того, следует отметить наглядность представления данных на промежуточном этапе, что делает возможным их дальнейшее использование.
ЗАКЛЮЧЕНИЕ
В рамках данной работы была разработана методика моделирования пользователя системы электронной отчетности. Были рассмотрены основные преимущества и недостатки имеющихся подходов в области моделирования пользователей, а также обоснован выбор дисциплины веб – аналитики как возможного источника информации для создания модели веб – пользователя. Был выбран тип модели, её основное наполнение, а также форма графического представления результатов. Учитывалась специфика систем электронной отчетности. Для создания модели использовались как традиционные подходы к моделированию пользователей, так и различные средства веб – аналитики. Вид модели и некоторые способы сбора данных были позаимствованы из общепринятых концепций моделирования, а основное содержание модели было разработано после ознакомления с дисциплиной веб-аналитики и её подходами к сбору и анализу данных. Для первичного испытания модели и наглядного представления методики была создана экспериментальная среда, эмулирующая систему электронной отчетности, в которой был проведен сбор данных о работе пользователей, их преобразование в пригодную для модели форму и последующее графическое представление результатов. Главной целью подобного моделирования послужила необходимость повышения эффективности работы различных веб-ресурсов, СЭО в частности, связанная с повсеместным распространением и важной ролью таких ресурсов в глобальной сети. В итоге была создана модель, которая может являться первым шагом на пути к достижению этой цели.
Одно из важнейших направлений развития данной тематики – более масштабное тестирование модели в системе с большим количеством пользователей, которое позволит оценить её практическую пригодность. Имея большую базу накопленных данных, можно понять, какие выводы позволяет сделать модель и какие направления изменения существующих систем она может предложить. На основании полученной модели могут быть оценены реальные ресурсы и предложены варианты их развития. Еще одно направление, в котором можно продолжать исследование – это применение модели к другим типам ресурсов и поиск вариантов изменения модели с учетом их специфики. Возможно также произвести обобщение модели на более широкий класс систем.
ЛИТЕРАТУРА
1. Kaushik A. Web analytics an hour a day, Wiley Publishing, 2007, стр. 1-47, 99-123
2. Devanshu Dhyani, Wee Keong Ng, Sourav S. Bhowmick A Survey of Web Metrics//ACM Computing Surveys, Vol. 34, No. 4, December 2002, стр. 469–503
3. Chi E.H., Pirolli P., Pitkow J. The Scent of a Site: A System for Analyzing and Predicting Information Scent, Usage, and Usability of a Web Site, 2000//Conference on Human Factors in Computing Systems,
Proceedings of the SIGCHI conference on Human factors in computing systems,
Netherlands, стр. 161 - 168
4. Liu B. Web DataMining Exploring Hyperlinks, catchword, and Usage Data, Springer, 2007, стр. 4-6, 449-482
5. Benyon D., Mival O. MODELS OF USERS, 2008, http://www.companions-project.org
6. Fischer G. User Modeling in Human-Computer Interaction, 2001// User Modeling and User-Adapted Interaction 11, стр. 65-86
ПРИЛОЖЕНИЕ 1
Система для тестирования модели

ПРИЛОЖЕНИЕ 2
Пример XML-файла с данными о пользователях.
<?xml version="1.0" encoding="windows-1251"?>
<?xml-stylesheet type="text/xsl" href="data.xsl"?>
<data file="prohibition.html">
<user id="1">
<p value="0.3784652278177458"/>
<t1 value="0.47940053234579333"/>
<k value="1"/>
<f value="0"/>
<e value="0"/>
<vs value="0.859375"/>
<s value="0.015342606281869474"/>
</user>
<user id="2">
<p value="0.5320904889481504"/>
<t1 value="0.1152099792099792"/>
<k value="0"/>
<f value="0"/>
<e value="0.2"/>
<vs value="0.7584135005838198"/>
<s value="0.046054973900974565"/>
</user>
<user id="3">
<p value="0.4807181505164782"/>
<t1 value="0.0773018981328887"/>
<k value="1"/>
<f value="0"/>
<e value="0.2"/>
<vs value="0.9942426926483613"/>
<s value="0.23016976938317796"/>
</user>
<user id="4">
<p value="0.3365396372529041"/>
<t1 value="0.3272328423691633"/>
<k value="1"/>
<f value="0"/>
<e value="0"/>
<vs value="0.9214330609679446"/>
<s value="0.2346418047048648"/>
</user>
</data>
ПРИЛОЖЕНИЕ 3
Пример результирующего SVG-документа.
<?xml version="1.0" encoding="UTF-16"?>
<svg version="1.1" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns="http://www.w3.org/2000/svg">
<title>User model presentation</title>
<desc>Colored matrix of rects</desc>
<defs><rect id="rect1" width="2cm" height="2cm" />
<linearGradient id="1" gradientTransform="rotate(90)">
<stop stop-color="black" stop-opacity="0.3784652278177458" offset="14.285714285714286%" />
<stop stop-color="black" stop-opacity="0.47940053234579333" offset="28.571428571428573%" />
<stop stop-color="black" stop-opacity="1" offset="42.85714285714286%" />
<stop stop-color="black" stop-opacity="0" offset="57.142857142857146%" />
<stop stop-color="black" stop-opacity="0" offset="71.42857142857143%" />
<stop stop-color="black" stop-opacity="0.859375" offset="85.71428571428572%" />
<stop stop-color="black" stop-opacity="0.015342606281869474" offset="100%" />
</linearGradient>
<linearGradient id="2" gradientTransform="rotate(90)">
<stop stop-color="black" stop-opacity="0.5320904889481504" offset="14.285714285714286%" />
<stop stop-color="black" stop-opacity="0.1152099792099792" offset="28.571428571428573%" />
<stop stop-color="black" stop-opacity="0" offset="42.85714285714286%" />
<stop stop-color="black" stop-opacity="0" offset="57.142857142857146%" />
<stop stop-color="black" stop-opacity="0.2" offset="71.42857142857143%" />
<stop stop-color="black" stop-opacity="0.7584135005838198" offset="85.71428571428572%" />
<stop stop-color="black" stop-opacity="0.046054973900974565" offset="100%" /></linearGradient>
<linearGradient id="3" gradientTransform="rotate(90)">
<stop stop-color="black" stop-opacity="0.4807181505164782" offset="14.285714285714286%" />
<stop stop-color="black" stop-opacity="0.0773018981328887" offset="28.571428571428573%" />
<stop stop-color="black" stop-opacity="1" offset="42.85714285714286%" />
<stop stop-color="black" stop-opacity="0" offset="57.142857142857146%" />
<stop stop-color="black" stop-opacity="0.2" offset="71.42857142857143%" />
<stop stop-color="black" stop-opacity="0.9942426926483613" offset="85.71428571428572%" />
<stop stop-color="black" stop-opacity="0.23016976938317796" offset="100%" />
</linearGradient>
<linearGradient id="4" gradientTransform="rotate(90)">
<stop stop-color="black" stop-opacity="0.3365396372529041" offset="14.285714285714286%" />
<stop stop-color="black" stop-opacity="0.3272328423691633" offset="28.571428571428573%" />
<stop stop-color="black" stop-opacity="1" offset="42.85714285714286%" />
<stop stop-color="black" stop-opacity="0" offset="57.142857142857146%" />
<stop stop-color="black" stop-opacity="0" offset="71.42857142857143%" />
<stop stop-color="black" stop-opacity="0.9214330609679446" offset="85.71428571428572%" />
<stop stop-color="black" stop-opacity="0.2346418047048648" offset="100%" />
</linearGradient>
</defs>
<use xlink:href="#rect1" fill="url(#1)" x="0.15cm" y="0.15cm" />
<use xlink:href="#rect1" fill="url(#2)" x="2.3cm" y="0.15cm" />
<use xlink:href="#rect1" fill="url(#3)" x="0.15cm" y="2.3cm" />
<use xlink:href="#rect1" fill="url(#4)" x="2.3cm" y="2.3cm" />
</svg>
ПРИЛОЖЕНИЕ 4
Пример графического представления результатов в виде матрицы.

|