| Национальный Технический Университет Украины
“Киевский политехнический институт”
РЕФЕРАТ ПО КУРСУ ВПКС
«Ввод-вывод в транспьютере. Передача данных по линку»
| |
Выполнил:
студент группы ЗКСМ-62 Марийко И.И
.
№ зач.кн.:
КВ-6210
Принял:
ЗайцевВ.Г.
|
Киев – 2008
Транспьютер (англ. transputer) — элемент построения многопроцессорных систем, выполненный на одном кристалле большой интегральной схемы, продукт английской компании INMOS Ltd. (ныне - подразделение SGS-Thomson Microelectronics).
Термин транспьютер происходит от слов Transistor и Computer. Такой генезис должен, по мнению разработчиков, подчеркивать возможность построения сложных вычислительных комплексов на базе транспьютеров, где их роль уподоблялась бы роли транзисторов, выступающих основным элементом при проектировании электронных схем. Другая интерпретация: trans-put-er - тот, кто передаёт, указывает на присутствие встроенных скоростных устройств ввода/вывода для обмена с соседними процессорами.
Параллельная система может создаваться из набора транспьютеров, которые функционируют независимо и взаимодействуют через последовательные каналы связи. Такие системы можно проектировать и программировать на языке Occam, основанном на концепции взаимодействующих процессов, или на других языках (например, Concurrent C, Concurrent Fortran), имеющих соответствующие средства.
Язык программирования Occam был разработан компанией INMOS на основе теории Хоара (англ. C.A.R.Hoare) о взаимодействии процессов. Occam является алголо-подобным языком высокого уровня; при этом язык оптимизирован с точки зрения эффективности его трансляции в систему команд транспьютера. Первоначально INMOS даже предлагала воспринимать Occam в качестве транспьютерного ассемблера, но позже выпустила пакет низкоуровневых средств для разработчиков компиляторов, а так же включила в Occam предписание GUY, позволяющее вставлять код на уровне процессора.
Транспьютеры успешно использовались в различных областях — от встроенных систем до суперЭВМ. В настоящее время транспьютеры не производятся, будучи вытесненными похожими разработками конкурентов, особенно Texas Instrument (TMS320) и Intel (80860). Принято считать, что концепция транспьютеров оказала заметное влияние на развитие микропроцессорной техники 80/90-х годов. Так, термин линк (link) - физический канал связи между параллельно работающими процессорами - пришёл из транспьютеров, а протокол транспьютерного линка стал стандартом IEEE.
Семейство транспьютеров спроектировано так, чтобы максимально облегчить построение параллельных архитектур из идентичных элементов с минимальным привлечением дополнительных интегральных микросхем.
Название этого элемента получено от сочетания слов «транзистор» и «компьютер».
Каждый такой элемент объединяет в одной микросхеме:
· обрабатывающий элемент
· систему связи
· память
Параллельная система может создаваться из набора транспьютеров, которые функционируют параллельно и взаимодействуют через последовательные лини связи. Такие системы можно проектировать и программировать на языке Оккам, основанном на концепции взаимодействующих процессов.
Транспьютер – это дитя технологии СБИС. Одним из важных свойств этой технологии является то, что время обмена между модулями больше, чем время обмена между компонентами одного модуля.
Для обеспечения максимальной скорости и минимального монтажа транспьютер использует двухточечные последовательные линии для прямой связи с другими транспьютерами.
Транспьютер содержит типичный процессор. В небольшой памяти хранятся 32 инструкции и обеспечивают выполнение простых последовательных программ. Кроме этого, имеются специальные инструкции, которые реализуют арифметические операции с большой точностью, и планировщик.
Так как транспьютер может обеспечивать выполнение различных параллельных процессов, он поддерживает на аппаратном уровне модель программирования языка Оккам. Планировщик транспьютера распределяет время процессора между параллельными процессами.
Внутренняя архитектура транспьютера
Транспьютер (например, IMST 414) состоит из блока памяти, процессора и системы связи, соединенных 32-рарядной шиной. К этой шине также подключен интерфейс с внешней памятью. На рисунке показана схема соединений основных блоков транспьютеров IMS T 800 и IMS T 414.
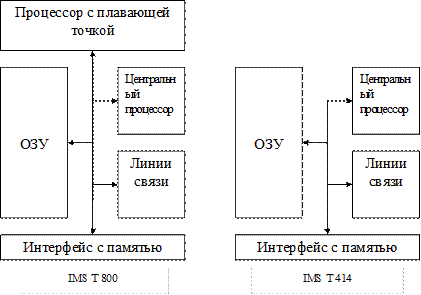
ЦП транспьютера содержит 3 регистра А, В и С для работы с целыми числами и адресами, которые формируют аппаратный стек. При записи в стек содержимое регистра В записывается в С, А – в В, и лишь после этого в регистр А заносится новое значение.
При чтении из стека извлекается значение регистра А, после чего содержимое В записывается в А, а содержимое С – в В. Процессор с плавающей точкой (ППТ) содержит трехрегистровый стек для хранения промежуточных результатов при работе с числами с ПТ (вычислительный стек). Это регистры AF, BF и CF. Работа с этим стеком аналогична предыдущему.
Адреса значений переменных с ПТ формируются в стеке ЦП и эти значения передаются между адресуемыми ячейками памяти с стеком ППТ под управлением ЦП. Так как стек ЦП используется только для хранения адресов переменных с ПТ, разрядность ЦП не зависит от разрядности ППТ. Поэтому один и тот же ППТ может использоваться как в IMS T 800, так и с IMS T 212 у которых разрядность ЦП различна.
Планировщик транспьютера поддерживает 2 уровня приоритетов. Это позволяет уменьшить время на прерывание.
Последовательная обработка
Центральный процессор содержит 6 регистров, которые используются при выполнении последовательного процесса. Этими регистрами являются:
· указатель на рабочее поле, который указывает на область памяти, где хранятся локальные переменные;
· счетчик команд
· регистр операнда, который используется для формирования операндов инструкций.

Регистры транспьютера
Регистры А, В, и С формируют вычислительный стек и являются источником и приемником для большинства арифметических и логических операций.
Для вычисления выражений используется вычислительный стек. При этом инструкции обращаются к этому стеку неявным образом. Например, инструкция add складывает два верхних элемента стека и помещает результат в верхушку стека.
Инструкции
При проектировании было учтено, что транспьютер будет программироваться на языке высокого уровня. Поэтому набор инструкций подобран для простой и эффективной компиляции. Инструкции одинакового формата, наиболее часто встречающиеся в программах. Набор инструкций не зависит от разрядности процессора, что позволяет один и тот же микрокод использовать для транспьютеров различной разрядности.
Каждая инструкция занимает 1 байт, разделенный на 2 четырехбитных поля.
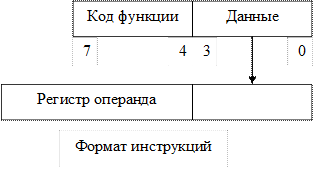
Непосредственные функции
Имеется 16 функций, у которых значение операнда находится в пределах 0 – 15. 13 из них используются для представления наиболее важных функций, выполняемых любым компьютером. Сюда входят:
| load constant
|
add constant
|
load local point
|
| load local
|
store local
|
|
| load non-local
|
store non-local
|
call
|
| jump
|
conditional jump
|
|
С помощью компактных последовательностей из таких инструкций можно осуществить эффективный доступ к структурам данных и реализовать статические связи, которые используются при реализации языков программирования сложной структуры, таких как Оккам.
Для увеличения длины операндов инструкций используются еще два кода функций. Это prefix
и negative
prefix
.
При выполнении всех инструкций четыре бита данных записываются в 4 младших разряда регистра операнда, который затем используется как операнд инструкции.
После завершения всех инструкций, кроме префиксных, регистр операнда обнуляется. При выполнении инструкции prefix
четыре бита – данные загружаются в регистр операнда, который затем сдвигается влево на 4 позиции. При инструкции negative
prefix
происходит то же самое, только до сдвига содержимое регистра операнда переводится в дополнительный код.
При использовании префиксных инструкций операнды могут быть расширены до любой длины, вплоть до разрядности регистра операнда. Другими словами, имеется возможность формировать операнды методом, не зависящим от разрядности процессора.
Косвенные функции
Кодирование косвенных функций выполнено таким образом, что наиболее часто встречающиеся операции выполняются без использования инструкции prefix
.
Сюда входят арифметические, логические операции и операции сравнения, такие как:
add
esclusive
or
greater
than
Операции, встречающиеся реже, выполняются с использованием одной префиксной операции.
Кроме того, в ряде случаев используются инструкции для работы с цветной графикой, распознаванием образов и использования кодов, корректирующих ошибки.
Эффективность кодирования
Кодирование инструкций позволяет представлять программы, написанные на языке высокого уровня в компактном виде, по сравнению с традиционным набором. Так как программа занимает меньше места в памяти, меньше времени требуется на выборку инструкций. Так как при чтении из памяти извлекается одно слово, процессор при каждом чтении извлекает несколько инструкций.
Поддержка параллелизма
Имеется микропрограммный планировщик, позволяющий параллельно выполнять любое число процессов в режиме разделения времени процессора. Это позволяет обходиться без ядра операционной системы. Но, процессор не имеет средств для динамического выделения памяти. Это отнесено на счет компилятора.
Параллельный процесс может находиться в состояниях:
Активное – выполняется
– находится в очереди ожидания на выполнение.
Пассивное – готов к вводу
– готов к выводу
– ожидает, пока не наступит указанное время.
Планировщик устроен так, что пассивные процессы не занимают процессорное время. Активные процессы находятся в списке. Это связный список рабочих областей процессов, реализованный с использованием двух регистров. Первый указывает на первый процесс из списка, другой – на последний процесс.
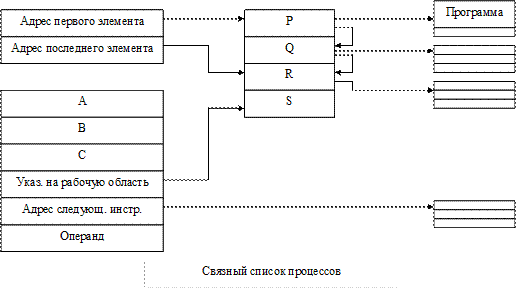
На рисунке процесс S выполняется, а процессы P, Q и R активны и ожидают выполнения.
Процесс выполняется до тех пор, пока не перейдет в режим ожидания ввода, вывода или таймера.
Как только процесс не может выполняться, его счетчик команд сохраняется в его рабочей области и выбирается следующий процесс из списка. Время переключения с процесса на процесс очень маленькое, так как при этом не нужно сохранять информацию о состоянии. Нет необходимости в сохранении и вычислительного стека.
В процессе реализованы специальные операции, поддерживающие процесс:
start
process
stop
process
Связь
Связь между процессами осуществляется с помощью каналов.
Взаимодействие между процессами является двухточечным, синхронным, небуферизированным. Для канала нет необходимости в очереди процессов и сообщений, не нужны буфера сообщений.
Канал между двумя процессами, которые выполняются на одном транспьютере, реализуется с помощью одного слова в памяти.
Канал между процессами разных транспьютеров реализуется с помощью двухточечных линий связи.
Предусмотрены операции для поддержки обмена сообщениями, важнейшими из которых являются:
Input
message
Output
message
Эти инструкции анализируют адрес канала для определения того, является ли канал внутренним или внешним. Одна и та же последовательность инструкций может использоваться как для программно-реализуемых, так и для аппаратно-реализуемых каналов. Это позволяет кодировать и компилировать процесс вне зависимости от способа реализации каналов.
Связь осуществляется, когда и вводящий и выводящий процессы готовы к обмену.
Процесс, первым инициирующий обмен, должен ждать готовности второго.
Линии связи
Связь между транспьютерами устанавливается путем соединения интерфейса связи одного транспьютера двумя однонаправленными сигнальными проводами, по которым данные передаются последовательно.
Сообщения передаются как последовательность байтов, причем на каждый переданный байт должно прийти подтверждение до посылки следующего байта.
Два провода передачи соответствуют реализации двух каналов в языке Оккам, по одному в каждом направлении.
Таймер
Часы срабатывают каждую микросекунду. С помощью инструкции read
timer
можно прочитать текущее значение процессорного таймера.
При выполнении инструкции timer input выполнение процесса приостанавливается до тех пор, пока не наступит указанное время.
Альтернативное выполнение
Процесс может переходить в режим ожидания ввода из любого канала или до наступления указанного времени. Для этого имеются специальные инструкции, которые соответствуют альтернативным инструкциям языка Оккам.
Инструкции с плавающей точкой
Базовый набор инструкций с плавающей точкой содержит набор инструкций загрузки, сохранения и арифметические инструкции.
Есть две группы таких инструкций. Одна для чисел с одинарной точностью, другая – двойной.
Адрес операнда с плавающей точкой формируется в стеке ЦП, затем операнд загружается в стек ППТ из адресуемой ячейки памяти. В стеке с плавающей точкой операнды маркируют в зависимости от того, являются ли они числами одинарной или двойной точности. Транспьютер IMS T414 на уровне микрокода поддерживает работу с 32-х разрядными числами с плавающей точкой и обеспечивает время выполнения операций с одинарной точностью около 10 мс. В транспьютере IMS T800 время существенно меньше:
| |
одинарная точность
|
двойная точность
|
| сложение
|
350 нс
|
350 нс
|
| вычитание
|
350 нс
|
350 нс
|
| умножение
|
550 нс
|
1000 нс
|
| деление
|
850 нс
|
1000 нс
|
Классическим примером МРР-систем является архитектура масштабируемой параллельной вычислительной системы PARSYTEC, на примере одной из модификаций продукции фирмы Gcel-64, построенной на транспьютерах Т-805. GCel 1/64 является мощным компьютером типа MIMD (Multiple Instractions Multiple Data) и представляет собой фактически сеть высокопроизводительных микропроцессоров (транспьютеров), каждый из которых имеет собственную память. Между процессорами можно производить обмены "память-память" с достаточно высокой скоростью. GCel 1/64 -- это конструктивно один куб. Предусмотрено наращивание мощности системы за счет увеличения числа таких кубов. Максимальное число кубов в системе 256, что эквивалентно 16384 рабочим транспьютерам.
GCel работает в связке с внешней или управляющей машиной (frontend computer). GCel 1/64 не является узлом сети ЛВС ВЦ РАН. Выход на GCel c любого компьютера локальной сети осуществляется через внешнюю машину, которая, будучи узлом сети, обеспечивает такую возможность. Внешней машиной в нашем случае является ЭВМ SPARCStation 2 фирмы SUN. Она обеспечивает интерфейс с пользователем GCel, функции загрузки процессорных узлов GCel и управления им, слежения за работой GCel (monitoring), реализует доступ к файловой системе. Системное программное обеспечение называется PARIX (PARallelunIX).
Рассмотрим возможности GCel и PARIX более подробно.
GCel 1/64 -- наименьшая аппаратная конструкция, которая может существовать самостоятельно. Будем для краткости называть ее Giga Cube (GC). GC имеет собственный конструктив, в котором размещается основное оборудование, а также система жизнеобеспечения и снабжения электропитанием.
GC состоит из 4-х кластеров. Кластер -- это своеобразный атомарный конструктивный блок. Каждый кластер содержит 17 процессорных узлов. Из них 16 основных рабочих и один дополнительный для повышения надежности системы, вступающий в работу в случае отказа любого из основных рабочих узлов. Процессорные узлы размещаются на специальной плате (processorboard). Кластер состоит из 2-х таких плат с процессорными узлами.
Каждый GC имеет еще один процессорный узел, управляющий. Если система имеет больше одного GC, то все управляющие узлы связываются между собой, образуя управляющую сеть. Назначение управляющих узлов GC: конфигурирование, начальная установка (reset), слежение за работой системы (мониторинг) и т.д. Таким образом, на GC имеется 69 процессорных узлов.
Процессорный узел содержит транспьютер, главную память объемом 4 Мбайта, специальное логическое устройство для коррекции одиночных ошибок памяти и выдачи сигнала об отказе при двойных ошибках (EDC-устройство), а также микросхемы, связанные с датчиками температуры и напряжения в сети.
В качестве процессора процессорного узла используется транспьютер Т805 фирмы INMOS, который является разновидностью RISC процессора. Это однокристальная интегральная схема с собственной памятью в 4 Кбайта (помимо главной -- объемом 4 Мбайт). Т805 имеет основной 32 разрядный процессор и процессор плавающей арифметики, работающий с 64 разрядными числами. Возможна прямая адресация к памяти объемом до 4Gбайт. Главная память транспьютерного узла 4 Мбайта. Подобно другим RISC архитектурам Т805 имеет специфическую систему команд. Код команды имеет либо 4 бита, либо находится в специальном регистре. Операнды и результат операции размещается в стеке из 3-х регистров. Команды не содержат обращения к памяти, кроме 2-х операций (записи и чтения из памяти). Транспьютер имеет специальные средства для поддержания мультипрограммирования на одном транспьютере (управление очередями, таймеры, приоритеты для процессов). Развернутой системы прерываний транспьютеры не имеют, но имеются средства реакции на некоторые внешние события -- т.н. SYSTEM SERVICES -- для приведения системы в исходное состояние (reset), проведения начальной загрузки транспьютера, получения информации об ошибках. Специальных средств защиты и управления памятью Т805 не имеет, что в некотором смысле оправдано, поскольку принятая на транспьютерах идеология параллельных вычислений предполагает, что параллелизм достигается в основном работой на нескольких транспьютерах. Многозадачность возможна, но она реализуется таким образом, что на одном транспьютере не могут работать процессы, принадлежащие разным задачам.
На одном транспьютере работают в мультипрограммном режиме только процессы пользователя (основной и подчиненные в виде т.н. (thread)) и служебные процессы их обслуживающие. Защита обеспечивается программным образом за счет жесткого распределения памяти при начальной загрузке программы. Следствием этого является то, что обычный пользователь не программирует в кодах транспьютера и на ассемблере. Важная часть работы Т805 -- это организация обменов "память-память" между транспьютерами. Каждый транспьютер имеет 4 специальных канала -- линка для такого обмена. Каждый линк имеет 2 подканала -- для ввода и для вывода. На каждом транспьютере информация в линк (или из линка) передается через специальный линковый интерфейс. Максимальная скорость обмена по линку 20 Мбит/сек (2.35 Мбайт/сек). Для реализации логического уровня связи между транспьютерами используется специальное программно настраиваемое устройство -- канальный переключатель С004 (INMOS C004 LINK CROSSBAR SWITCH).
На физическом уровне каждый транспьютер без использования С004 может быть максимально связан только с 4-мя другими транспьютерами. На логическом уровне, благодаря использованию С004, при соответствующей программной настройке, возможно иметь практически неограниченное число виртуальных логических каналов. В GCel на каждом кластере имеется 4 х С004, и каждый, из 4-х физических линков транспьютера, выходит на разные С004. С004 поддерживает скорость 20 Мбит/сек.
Физически обмены по линкам происходят синхронно. Это значит, что обмен происходит только тогда, когда на одном транспьютере выставлена команда ввода (или вывода), а на другом соответственно команда вывода (или ввода). Обмен начинается, когда выдана последняя в этой паре команда. В будущих разработках предполагается реализация на физическом уровне ассинхронных обменов. В рамках PARIX на языках высокого уровня имеются процедуры ассинхронного обмена, но они реализуются средствами эмуляции.
Как уже говорилось выше, из транспьютерных узлов строятся кластеры, четыре кластера составляют куб (GCel). На каждом кубе имеется еще один транспьютерный узел для управления. Этот управляющий узел предназначен для:
производства начальных установок для куба (процедура reset);
отслеживание внешней среды через реакцию на сигналы от температурных датчиков и датчиков уровня напряжения;
конфигурирование связей между узлами через загрузку канальных переключателей (C004) на каждом кластере.
Если система имеет несколько кубов (максимально 256), то управляющие процессорные узлы образуют управляющую сеть.
Ввод-вывод на GC осуществляется с каждого транспьютерного узла по обычным линкам. В рамках PARIX определены конкретные логические линки для ввода-вывода на каждом узле. Информация ввода-вывода передается между GC и внешней машиной по специальным линиям связи, называемым ENTRY USER или просто ENTRY. Количество таких ENTRY может быть различным и определяется в частности специальным интерфейсом, устанавливаемым на материнскую плату внешней машины. В нашем случае, мы имеем интерфейс BBK-S4, который имеет 3 ENTRY (1,2,3) и еще одну линию (0), связывающую внешнюю машину с управляющим узлом GC. Ниже мы увидим, что количество ENTRY для PARIX определяет количество одновременно решаемых задач на GC. По каналам ENTRY осуществляются операции ввода-вывода между GC и периферийными устройствами рабочих станций ЛВС ВЦ РАН.
В заключении этого раздела несколько слов о производительности вычислительной системы GCel 1/64. Физические характеристики GCel 1/64 следующие. Максимальная производительность каждого процессорного узла с транспьютером T805(30Mгц) оценивается разработчиком в 4.3 MFLOPS и 30 MIPS, максимальная скорость обмена между узлами по линкам 20Mбит/сек (2.35 Mбайт/сек). Это значит, что максимальная производительность для GCel 1/64 может быть 0.28 GFLOPS и 1.9 GMIPS. Реальная производительность GCel 1/64, естественно, меньше, она зависит от характера конкретной задачи, от качества распараллеливания данного алгоритма, от объема и характера обменов по линкам, от качества системного программного обеспечения.
PARIX -- аббревиатура от PARallel unIX. Это системное программное обеспечение, построенное на базе стандартного программного обеспечения внешней машины (в нашем случае это Solaris 1.1) и дополненное программами, обеспечивающими функционирование GCel.
PARIX -- распределенная программная система. Часть программ исполняется на внешней машине (SPARCstation 2), другая -- в транспьютерных узлах.
Пользователь на этапе записи и редактирования текстов своих программ, компиляции и получения загрузочного модуля с GCel не работает. Он пользуется стандартной unix-средой на внешней машине (редакторы текстов, NFS и т.д.), специальными кросс -- компиляторами, стандартными библиотеками, дополнительной специальной библиотекой с алгоритмами для параллельной обработки, а также специальным загрузчиком, который на внешней машине порождает загрузочный модуль для последующей загрузки транспьютерных узлов GCel.
Для ЛВС ВЦ РАН мы имеем 2 компилятора голландской фирмы ACE EXPERT -- FORTRAN-77 и C ANSY. Компиляторы на выходе порождают объектный код в соответствии с промышленным стандартом COFF/T800.
Программа, созданная компилятором и загрузчиком, предполагает, что непосредственно на процессорных узлах будет исполняться не только программа пользователя, но также подпрограммы из т.н. USER RUNTIME LIBRARY, обращение к которым имели место из программы пользователя:
программы обмена по линкам;
другие программы, использующие модель программирования PARIX;
стандартные численные подпрограммы.
Иными словами, для каждого транспьютерного узла на внешней машине подготавливается к исполнению программа в кодах транспьютера, содержащая коды алгоритма пользователя и коды тех программ из USER RUNTIME LIBRARY, которые используются данным алгоритмом.
Программа, исполняемая в процессорном узле, может запросить процедуру ввода-вывода (диск, экран, принтер). Эти процедуры реализуются через стандартный аппарат UNIXа -- RPC, о котором уже подробно говорилось выше. Процессорный узел (транспьютер) выполняет роль клиента, а в качестве сервера исполняется специальный процесс на внешней машине -- т.н. D-Server. На внешней машине может работать несколько D-Server'ов -- максимально столько, сколько мы имеем USER ENTRY (в нашем случае -- 3). Процесс "D-Server" на внешней машине образуется, когда пользователь выдает команду RUN. Внешняя машина от D-Server'а через управляющую сеть (в нашем случае, как говорилось выше, мы имеем один управляющий узел), передавая информацию через ENTRY USER 0, производит:
инсталляцию пользовательской партиции;
загрузку исходного кода в каждый узел партиции;
инициализацию пользовательских процессов на каждом процессорном узле.
В дальнейшем D-Server вступает в работу, когда через механизм RPC ему передается заказ на ввод-вывод (внешний) или возникают аварийные ситуации (ошибки в программах, нарушение внешней среды и т.д.). D-Server при исполнении соответствующих функций может порождать подчиненные процессы на внешней машине, которые в свою очередь могут быть процессами-клиентами по отношению к процессам-серверам на других машинах сети. Следует обратить внимание, что обмены по линкам между транспьютерными узлами реализуются непосредственно командами синхронных обменов транспьютера и D-Server не участвует в их реализации. Это способствует повышению общей эффективности решения задачи. То есть транспьютеры между собой обмениваются не средствами UNIX'а, а непосредственно с помощью команд обмена транспьютера Т805. D-Server в режиме RPC "разговаривает" не с самими процессами задачи, а с ядрами (kernel) PARIX'а, которые загружены в каждый процессорный узел.
Следует отметить, что архитектуры PARSYTEC и PARIX появились в реальной практике пользователей, когда уже был некоторый опыт использования транспьютеров INMOS в других архитектурах, например, вместе с обычными персональными компьютерами (PC). Для таких архитектур получили распространение свои модели программирования (Hellios с языком спецификаций CDL, MEIKOS, MACH, LINDA, EXPRESS и др.). Были разработаны специальные языки программирования для параллельной обработки (например, OCCAM).
Фирма PARSYTEC на GCel в принципе имеет возможность для поддержки большинства из сред (environment) ранних архитектур. Явно поддерживается CDL, в отношении других сред требуется программная системная настройка. Однако фирма PARSYTEC в большей мере рекомендует использование своей среды -- т.н. модель PARIX, которая предполагает программирование на языках высокого уровня (без OCCAM'а) для некоторой виртуальной среды с соблюдением определенных правил. Представители фирмы PARSYTEC утверждают, что модель PARIX станет стандартом при использовании параллельной обработки для процессов с локальной памятью.
Приведем краткое описание модели PARIX. Фактически это описание дает пользователю, разработчику программ, использующему PARSYTEC GCel 1/64, методику разработки своих параллельных алгоритмов. Следует иметь ввиду следующие особенности модели PARIX:
разрабатываемый параллельный алгоритм будет исполняться на множестве транспьютеров, называемом партицией (здесь под термином транспьютер понимается не физический процессор, как элемент транспьютерного узла с 4-мя линками, а некоторый виртуальный транспьютер с практически неограниченным числом линков). Для GCel 1/64 может быть партиция из 16 транспьютеров -- p16 или lowerleft, или lowerright, партиция из 32 транспьютеров -- p32 или upperhalf, или lowerhalf, партиция из 64 транспьютеров -- p64 или GCel, или all; в GCel 1/64 нельзя использовать партиции другой длины (кроме 16, 32, 64);
программист имеет возможность писать универсальные программы в смысле количества используемых транспьютеров (16, 32, 64), для этих целей есть стандартная процедура NPROC (), выдающая число используемых транспьютеров;
каждый транспьютер партиции имеет свою собственную память (4 Мбайта), реальный объем памяти в значительной мере зависит от числа используемых виртуальных линков;
в память каждого транспьютера будет загружена одна и та же программа. Это, пожалуй, главная особенность модели PARIX. Есть различные способы заставить исполнять различные программы на процессорах партиции при таком способе загрузки кода. Для этих целей имеются специальные процедуры: NOMPROC (), дающая ответ в виде номера транспьютера (для партиции длиной N -- номера транспьютеров от 0 до N-1), на котором выполняется данная программа. Следовательно, можно используя обычный условный оператор, реализовать работу разных ветвей программы на разных транспьютерах. С помощью NOMPOC (), а также процедуры EXECUTE, динамически загружающей предварительно скомпилированную программу, можно построить собственный план загрузки каждого узла;
каждый виртуальный транспьютер может быть связан с любым количеством других виртуальных транспьютеров, но два транспьютера могут при этом иметь только один общий линк с двумя подканалами (ввод-вывод);
при реализации собственной программы можно обмениваться массивами любой длины по линкам между транспьютерами различными способами (различными процедурами). Но при этом всегда, как и для физического транспьютера, существует правило синхронного обмена: процедура ввода на одном транспьютере соответствует процедуре вывода на связанном с ним и соответственно наоборот. Способы обменов следующие:
синхронные обмены по виртуальным линкам (Send, Recv, SendLink, RecvLink, Select);
асинхронные (точнее на GCel 1/64 псевдоасинхронные) обмены по виртуальным линкам (AInit, ASend, ARecv, ASync);
случайные синхронные обмены между транспьютерами (SendNode и RecieveNode);
для оптимальной работы транспьютеров с точки зрения обменов можно построить т.н. топологию (линия, круг, куб, гиперкуб, дерево и т.д.). Построить топологию можно с помощью стандартных процедур (MakeTorus, MakeTree и др.) и с помощью процедур построения топологии (newtop, addnewlink, freetop и др.) Последние позволяют динамически перестраивать и менять топологию;
можно запустить параллелизм (подчиненные параллельные ветви) на одном транспьютере (только в "С", но не в FORTRANе);
для реализации паралллельных алгоритмов используются обычные с точки зрения входного языка стандартные компиляторы C ANSY и FORTRAN-77, никаких дополнительных "параллельных" операторов они не содержат. Весь параллелизм достигается использованием специальных "параллельных" процедур, о некоторых таких процедурах уже говорилось выше (nomproc, nproc, execute, send, и т.д.).
На наш взгляд модель PARIX для программиста достаточно естественна. Программист имеет один общий листинг программы, что облегчает отладку. И необходимо лишь привыкнуть к некоторой специфике программистского мышления, которая заключается в том, что отдельные части программы, ветви условного оператора, например, могут исполняться не на одном процессоре, а на разных. Особо следует продумать стратегию ввода-вывода исходных данных и конечного результата. При этом надо помнить, что внешний ввод-вывод связан с работой D-Server'а, аппарата RPC и поэтому протекает довольно медленно (секунды или даже десятки секунд против миллисекунд для внутренних обменов между транспьютерами).
Часто исходные данные для параллельной программы находятся во внешнем файле. В этом случае его надо прочитать один раз на один из транспьютеров партиции, а дальше уже командами обменов разослать эти данные в полном объеме или частично по отдельным транспьютерам. Процедуру вывода данных также надо тщательно продумать. Вывод можно производить либо с каждого транспьютера партиции, либо собрать все выходные данные на одном из транспьютеров партиции, а затем, сформировав выходной файл, передать его во внешнюю память.
Впоследствии в качестве узлов в системе станут применяться процессоры Power PC, значительно превосходящие по своим параметрам транспьютерную технологию.
ЛИТЕРАТУРА
Корнеев В.В. Вычислительные системы. М. Гелиос АРВ, 2004.
Шнитман В.З. Современные высокопроизводительные компьютеры. http://www.citforum.ru.
Шнитман В.З., Кузнецов С.Д. Аппаратно-программные платформы корпоративных информационных систем. http://www.citforum.ru.
Ясинский Ф.Н., Чернышева Л.П. Многопроцессорные вычислительные системы. Архитектура. Математическое моделирование. Учебное пособие. Иваново, ИГЭУ, 1998 г. – 108 с.
Эндрюс Г.Р. Основы многопоточного, параллельного и распределенного программирования. – М.: Издательский дом «Вильямс», 2003. – 512 с.
|