| МИнИстерство ОборонЫ УкраИнЫ
Севастопольский военно-морской ордена Красной Звезды институт имени П.С.Нахимова
Кафедра "Защиты информации"
КУРСОВАЯ РАБОТА
по дисциплине: "Теория информации"
тема: "Выбор и обоснование информационных характеристик
канала связи"
выполнила:
студентка 529 группы
И. А. Аксёненко
проверил: заведующий кафедрой "Защиты информации"
В. А. Михайлов
Севастополь
2007
ЗАДАНИЕ
Провести выбор и обоснование информационных характеристик канала связи или информационной системы путем решения десяти типовых задач.
СОДЕРЖАНИЕ
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ.. 5
ВВЕДЕНИЕ.. 6
1. ДИСКРЕТИЗАЦИЯ И ВОССТАНОВЛЕНИЕ АНАЛОГОВЫХ СИГНАЛОВ.. 8
1.1. Восстановление аналогового сигнала по дискретному, используя ряд Фурье. 8
1.1.1. Расчет и построение спектра сигнала
. 8
1.1.2. Восстановление аналогового сигнала
. 10
1.2. Восстановление аналогового сигнала по теореме Котельникова. 11
1.2.1. Расчет параметров
. 11
1.2.2. Восстановление сигнала
. 12
2. ОПРЕДЕЛЕНИЕ КОЛИЧЕСТВА ИНФОРМАЦИИ В СООБЩЕНИИ, СОДЕРЖАЩЕМ ЗАДАННЫЙ ТЕКСТ. 14
2.1. Определения количества информации в сообщении. 14
2.1.1. Определение количества информации в сообщении, написанном на алфавите с равновероятным распределением символов
. 15
2.1.2. Определение количества информации в сообщении, переданном телеграфным кодом
15
2.2. Расчет энтропии сообщения. 16
2.2.1. Расчет энтропии сообщения, написанного на алфавите с равновероятным распределением символов
. 16
2.2.2. Расчет энтропии сообщения, в котором буквы попадаются со своей вероятностью
17
3. РАСЧЕТ ПРОПУСКНОЙ СПОСОБНОСТИ
КАНАЛА СВЯЗИ БЕЗ ПОМЕХ.. 18
3.1. Построение канальной матрицы.. 18
3.2. Расчет матриц совместного появления сигналов ai
, bj
и относительных вероятностей 19
3.3. Расчет полных условных энтропий. 21
3.4. Расчет количества информации, переданной по КС.. 21
3.5. Расчет пропускной способности КС.. 22
4. СОГЛАСОВАНИЕ КАНАЛА СВЯЗИ
С ДАТЧИКОМ И ДИСПЛЕЕМ... 23
4.1. Выбор исходных данных. 23
4.2. Расчет энтропии источника. 23
4.3. Расчет ширины спектра сигнала. 24
4.4. Расчет полосы пропускания КС.. 24
4.5. Расчет энтропии приемника. 25
4.6. Определение максимальной полосы КС.. 26
4.7. Выбор ширины ПП КС.. 27
5. КОДИРОВАНИЕ ИНФОРМАЦИИ В КАНАЛЕ СВЯЗИ
БЕЗ ПОМЕХ.. 28
5.1. Оптимальное кодирование. 28
5.2. Кодирование сообщения методом Шеннона-Фано. 29
5.2.1. Разработка кода сообщения
. 29
5.2.3. Оценка кода по показателям эффективности
. 30
5.3. Кодирование сообщения методом Хаффмана. 31
5.3.1. Разработка кода сообщения
. 32
5.3.2. Оценка кода по показателям эффективности
. 34
6. РАСЧЕТ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ СИСТЕМ КОДИРОВАНИЯ ИНФОРМАЦИИ 35
6.1. Расчет показателей эффективности систем кодирования информации для помехозащищенного канала. 35
6.1.1. Расчет для сообщения, закодированного методом Шеннона-Фано
. Ошибка! Закладка не определена.
6.1.2. Расчет для сообщения, закодированного методом Хаффмана
. Ошибка! Закладка не определена.
6.2. Расчет показателей эффективности систем кодирования информации для низкого помехозащищенного канала. 37
6.2.1. Расчет для сообщения, полученного методом Шеннона-Фано
. 37
6.2.2. Расчет для сообщения, полученного методом Хаффмана
. 38
6.3. Исследование зависимости вероятностью возникновения ошибок в сообщении от вероятности возникновения ошибок в одном разряде. 39
6.3.1. Метод Шеннона-Фано
. 39
6.3.2. Метод Хаффмана
. 40
7. КОДИРОВАНИЕ ИНФОРМАЦИИ
ГРУППОВЫМ (БЛОЧНЫМ) КОДОМ... 41
7.1. Представление сообщения, закодированного методом Хаффмана, в блочной форме. 41
7.2. Разработка производящей (генераторной) матрицы.. 42
7.3. Формирование блочного кода. 44
7.4. Декодирование блочного кода в режиме обнаружения и исправления ошибок. 45
8. КОДИРОВАНИЕ ИНФОРМАЦИИ
ЦИКЛИЧЕСКИМ КОДОМ... 47
8.1. Представление сообщения, закодированного методом Хаффмана, в блочной форме. 47
8.2. Построение образующей (генераторной) матрицы.. 48
8.2.1. Выбор образующего полинома и определение контрольных разрядов
. 48
8.2.2. Построение генераторной матрицы
.. 49
8.3. Кодирование. 49
8.3.1. I способ
. 49
8.3.2. II способ
. 51
8.3.3.Проверка правильности кодирования
. 54
8.4. Проверка циклического кода на возможность исправления ошибок. 55
9. КОДИРОВАНИЕ ИНФОРМАЦИИ
СВЕРТОЧНЫМ КОДОМ... 57
9.1. Кодирование информации. 57
9.2. Декодирование информации. 59
9.2.1. Декодирование информации без ошибок
. 59
9.2.2. Проверка кода на способность обнаруживать и исправлять ошибки
. 60
10. РАСЧЕТ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ
ПОМЕХОУСТОЙЧИВЫХ КОДОВ.. 62
10.1. Расчет показателей эффективности кодов. 62
10.1.1. Расчет для кода Хаффмана
. 65
10.1.2. Расчет для блочного кода
. 66
10.1.3. Расчет для сверточного кода
. 66
10.2. Анализ зависимости qэ
= qэ
(R) 67
ПРИЛОЖЕНИЕ.. 70
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ
| АС
|
Аналоговый сигнал
|
| ГМ
|
Генераторная матрица
|
| ИМ
|
Информационная матрица
|
| КМ
|
Канальная матрица
|
| КС
|
Канал связи
|
| ПП
|
Полоса пропускания
|
| ЭВО
|
Эквивалентная вероятность ошибки
|
ВВЕДЕНИЕ
Информация наряду с материей и энергией является первичным понятием нашего мира и поэтому в строгом смысле не может быть определена. Можно лишь перечислить ее основные свойства, например такие как:
1) информация приносит сведения об окружающем мире;
2) информация не материальна, но она проявляется в форме материальных носителей, дискретных знаков или первичных сигналах;
3) знаки и первичные сигналы несут информацию только для получателя, способного распознать.
Вместе с тем слово «информация» является одним из тех терминов, которые достаточно часто встречаются во множестве обиходных ситуаций и являются интуитивно понятными каждому человеку. При этом в узком практическом смысле под
информацией
обычно понимают совокупность сведений об окружающем мире являющихся объектом хранения, передачи и преобразования.
Информация передается, и хранится в виде сообщений. Под
сообщением
понимают совокупность знаков или первичных сигналов, содержащих информацию. Иначе говоря, сообщение – это информация, представленная в какой-либо форме.
Для того чтобы сообщение можно было передать получателю, необходимо воспользоваться некоторым физическим процессом, способным с той или иной скоростью распространяться от источника к получателю сообщения. Изменяющийся во времени физический процесс, отражающий передаваемое сообщение называется сигналом
.
Сообщения могут быть функциями времени (когда информация представлена в виде первичных сигналов: речь, музыка) и не является ими (когда информация представлена в виде совокупности знаков).
Сигнал всегда является функцией времени. В данной работе рассматриваются непрерывные или аналоговые сигналы
. Они определены для всех моментов времени и могут принимать все значения из заданного диапазона. Чаще всего физические процессы, порождающие сигналы являются непрерывными. Этим и объясняется второе название сигналов данного типа – аналоговый, т.е. аналогичный порождающим процессам.
Совокупность технических средств, используемых для передачи сообщений от источника к потребителю информации, называется системой связи
. Она состоит из 5 частей:
1) Источник сообщений, создающий сообщения или последовательность сообщений, которые должны быть переданы.
2) Передатчик, который перерабатывает некоторым образом сообщения в сигналы соответственного типа, определенного характеристиками используемого канала.
3) Канал – это комплекс технических средств, обеспечивающий передачу сигналов от передатчика к приемнику.
4) Приемник обычно выполняет операцию, обратную по отношению к операции, производимой передатчиком, т.е. восстанавливается сообщение по сигналам.
5) Получатель – это лицо или аппарат, для которого предназначено сообщение. Процесс преобразования сообщения в сигнал, осуществляющийся в передатчике, и обратный ему процесс, реализующийся в приемнике, назовем соответственно кодированием и декодированием
.
Тогда круг проблем, составляющих основное содержание теории информации, можно охарактеризовать как исследование методов кодирования для экономического представления сообщений различных источников и для надежной передачи сообщений по каналам связи с шумом.
При проектировании цифровой системы передачи данных по каналу связи перед разработчиком неизбежно встает вопрос о борьбе с возникающими при передаче ошибками. Для этой цели используется кодирование информации с последующей коррекцией ошибок. Известно довольно большое разнообразие корректирующих кодов. Для оптимального выбора того или иного кода разработаны специальные методики. Основной недостаток большинства приводимых методик заключается в том, что оптимальные параметры кода ищутся только для конкретного канала связи, предполагая при этом, что в течение сеанса связи статистика канала мало отличается от принятой модели, для которой искался оптимальный код. В практических ситуациях в разных сеансах связи возможно существенное различие в параметрах канала.
В связи с этим в данной работе излагается соответствующий критерий для сравнения различных блочных кодов и приводится методика для поиска оптимальных по этому критерию параметров корректирующего кода. Из всего множества корректирующих кодов в данной работе рассматриваются только линейные блочные коды. Также приводятся несколько примеров, показывающих практическую применимость и эффективность изложенной методики.
1. ДИСКРЕТИЗАЦИЯ И ВОССТАНОВЛЕНИЕ
АНАЛОГОВЫХ СИГНАЛОВ
Исходная информация о процессе снимается с аналогового датчика. Требуется осуществить дискретизацию сигнала и подготовить его для передачи по КС. Используя ряд Котельникова, необходимо восстановить сигнал и показать работоспособность использованных методов.
1.1. Восстановление аналогового сигнала по дискретному, используя ряд Фурье
1.1.1. Расчет и построение спектра сигнала
Часто физический процесс, порождающий сигнал, развивается во времени таким образом, что значения сигнала можно измерять в любые моменты времени. Сигналы этого класса принято называть аналоговыми (континуальными). Термин «аналоговый сигнал» подчеркивает, что такой сигнал «аналогичен», полностью подобен порождающему его физическому процессу.
Одномерный аналоговый сигнал наглядно представляется своим графиком (осциллограммой), который может быть как непрерывным, так и с точками разрыва.
В данном случае аналоговый сигнал (АС) описывается выражением:
x(t) = sin (0.05wt)*cos(0.8wt) (1.1)
где w – опорная частота последовательности, образующей периодический сигнал, которая находится по формуле:
w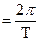 (1.2) (1.2)
Если принять Т = 100 с, график сигнала будет выглядеть следующим образом:
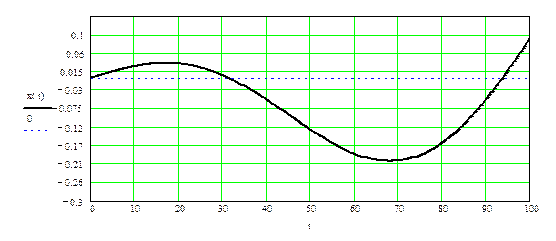 Рис. 1.1. Аналоговый сигнал Рис. 1.1. Аналоговый сигнал
Возросшие требования к радиотехническим системам заставили искать новые принципы их построения. На смену аналоговым в ряде случаев пришли импульсные системы, работа который основана на использовании дискретных сигналов. Одно из преимуществ дискретных сигналов по сравнению с аналоговыми – отсутствие необходимости воспроизводить сигнал непрерывно во все моменты времени.
При дискретизации по времени непрерывная функция x(t) преобразуется в дискретную функцию x(t*), в которой t* – дискретные значения времени. Иными словами, непрерывная функция представляется совокупностью дискретных отсчетов.
Функцию y(t), полученную в результате восстановления дискретной функции x(t*), называют воспроизводящей функцией.
 (1.3) (1.3)
Коэффициенты аj
зависят от отсчетов, а функции  являются базисными. Их выбор определяется ожидаемой формой сигнала. Чаще всего в качестве базисных функций выбирают синусоиду. В этом случае формула 1.3 представляет собой ряд Фурье в виде: являются базисными. Их выбор определяется ожидаемой формой сигнала. Чаще всего в качестве базисных функций выбирают синусоиду. В этом случае формула 1.3 представляет собой ряд Фурье в виде:
 (1.4) (1.4)
Где ai
, bi
– коэффициенты Фурье, которые рассчитываются с помощью прямого преобразования Фурье:
ai
=  (1.5) (1.5)
bi
=  (1.6) (1.6)
Итак, периодический сигнал содержит бесконечный набор гармонических колебаний, так называемых гармоник. Каждую гармонику можно описать ее амплитудой Si
и начальной фазой 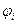 . Для этого коэффициенты ряда Фурье следует записать в виде: . Для этого коэффициенты ряда Фурье следует записать в виде:
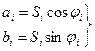
так что
Si
=  (1.7) (1.7)
Таким образом, возможно изобразить спектральную диаграмму данного сигнала, т.е. графическое изображение коэффициентов ряда Фурье:

Рис. 1.2. Спектр сигнала
1.1.2. Восстановление аналогового сигнала
Для восстановления аналогового сигнала по дискретному из построенного графика спектра сигнала необходимо выбрать количество значимых гармоник, позволяющих с заданной точностью восстановить сигнал. Обозначим его как mk
. В данном случае mk
= 3.
Исходя из этого, возможно восстановление сигнала, используя ряд Фурье:
x(t) = 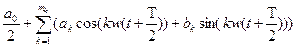 (1.8) (1.8)
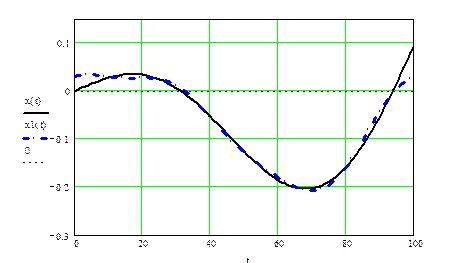
Рис. 1.3. Восстановленный сигнал
1.2. Восстановление аналогового сигнала по теореме Котельникова
1.2.1. Расчет параметров
В 1933 г. В. А. Котельников доказал теорему, которая является одним из фундаментальных положений теоретической радиотехники и других областей. Эта теорема устанавливает возможность сколь угодно точного восстановления мгновенных значений сигнала исходя из отсчетных значений, взятых через равные промежутки времени.
Теорему Котельникова принято формулировать так: произвольный сигнал, спектр которого не содержит частот выше fв
Гц, может быть полностью восстановлен, если известны отсчетные значения этого сигнала, взятые через равные промежутки времени  . Если же условия теоремы нарушаются и отсчеты во времени берутся недостаточно часто, то однозначное восстановление исходного сигнала принципиально невозможно. . Если же условия теоремы нарушаются и отсчеты во времени берутся недостаточно часто, то однозначное восстановление исходного сигнала принципиально невозможно.
Физический смысл теоремы заключается в следующем. Пусть требуется передать значение непрерывной функции x(t) с интервалом времени dt. Чем короче dt, тем точнее будет передаваться функция.
Для восстановления АС по дискретному данным методом необходимо рассчитать следующие параметры:
- ширина спектра сигнала:
Wm
= 2mk
w (1.9)
Учитывая формулу 1.2, получим:
Wm
= 0.377 рад/с
- интервал дискретизации рассчитывается по теореме Котельникова:
dt =  (1.10) (1.10)
dt = 8.333 с
- количество дискретных значений сигнала, подлежащих передаче по КС
Km
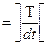 (1.11) (1.11)
Km
= 12
- значения сигнала, подлежащие передаче по КС
 (1.12) (1.12)
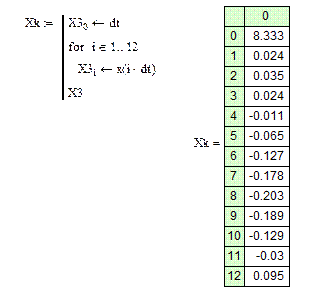
1.2.2. Восстановление сигнала
Восстановление АС осуществляется по следующей формуле Котельникова:
x(t) =  (1.13) (1.13)

Рис. 1.4. Восстановленный сигнал
Из 1.13 видно, что непрерывный сигнал x(t) представляется в виде произведений совокупностей отсчетов x(kdt) и функции времени 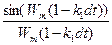 , которая называется функцией отсчетов. , которая называется функцией отсчетов.
Таким образом, функция x(t) может быть представлена своими отсчетами, снятыми с интервала времени dt. Для восстановления непрерывной функции по дискретным отсчетам необходимо использовать ряд Котельникова.
Итак, восстановление непрерывного сигнала по его дискретным значениям с заданной точностью можно осуществить двумя способами – с помощью ряда Фурье и по теореме Котельникова.
В первом случае для этого было использовано спектральное представление сигнала, выбрано число значимых гармоник. Во втором методе по теореме Котельникова был рассчитан интервал дискретизации, достаточно небольшой для восстановления сигнала с заданной точностью.
В обоих случаях при построении графиков исходного АС и восстановленного была подтверждена правильность и эффективность методов.
2. ОПРЕДЕЛЕНИЕ КОЛИЧЕСТВА ИНФОРМАЦИИ В СООБЩЕНИИ, СОДЕРЖАЩЕМ ЗАДАННЫЙ ТЕКСТ
Задано сообщение М в виде текста: <студентка 529 группы Аксененко>. Требуется:
1. определить количество информации в сообщении М для следующих случаев:
а) символы в алфавитах распределены равновероятно;
б) сообщение передается телеграфным кодом.
2. определить энтропию сообщения для случаев а) и б).
Для расчетов принять значения вероятностей появления букв, представленные в приложении.
Из анализа данного сообщения видно, что оно состоит из двух частей: буквенной М1, в которой количество знаков m1
= 27, и цифровой М2, в которой m2
=3.
2.1. Определения количества информации в сообщении
Пусть А – некоторое случайное событие, относительно которого известно, что оно может произойти с вероятностью РА
. Предположим, что до момента наступления этого события к получателю информации приходит некоторое сообщение, абсолютно точно предсказывающее исход случайного испытания. Ставится вопрос о том, какова количественная мера информации, содержащейся в данном сообщении. Впервые эту задачу поставил и решил американский инженер Хартли в конце 20-х годов. Он предложил вычислять количество информации, содержащейся в сообщении, по формуле:
 (2.1) (2.1)
где логарифм может быть взят при любом основании. В дальнейшем оказалось, что удобнее всего пользоваться двоичными логарифмами. При этом:
 (2.2) (2.2)
Хотя с физической точки зрения величина I безразмерна, ее стали измерять в условных единицах, называемых битами. Выбор двоичных логарифмов диктуется тем, что сообщение в технически реализуемых каналах связи чаще всего принимал форму отдельных групп (кодовых слов), состоящих только из двух символов, которые можно трактовать как 0 и 1. Каждая такая казалось, что уи любом основании. ле:группа кодирует, например, буквы того или иного естественного языка, из которых составляются отдельные слова.
2.1.1. Определение количества информации в сообщении, написанном на алфавите с равновероятным распределением символов
При равновероятном распределении символов в алфавите вероятность появления любой буквы Рi
=1/32. В этом случае количество информации в буквенной части сообщения
определится по формуле:
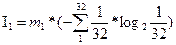 (2.1)
(2.1)
I1
= 135 бит
В цифровой части
сообщения
при равновероятном появлении цифр Pi
=1/10, количество информации в сообщении будет определяться по формуле:
 (2.2)
(2.2)
I2
= 9.96 бит
Таким образом, общее количество информации в сообщении с равновероятным появлением символов определится как:
I = I1
+ I2
(2.3)
I = 144.96 бит
Следует заметить, что подобный расчет является лишь ориентировочным, прежде всего потому, что не учитывается разница между вероятностями появления различных букв.
2.1.2. Определение количества информации в сообщении, переданном телеграфным кодом
Для расчета количества информации в данном сообщении необходимо составить вспомогательную таблицу:
Таблица 2.1
| i
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
| |
c
|
т
|
у
|
д
|
е
|
н
|
к
|
а
|
_
|
г
|
р
|
п
|
ы
|
о
|
| ni
|
2
|
2
|
2
|
1
|
3
|
3
|
3
|
2
|
3
|
1
|
1
|
2
|
1
|
1
|
| Pi
|
0.045
|
0.053
|
0.021
|
0.025
|
0.072
|
0.053
|
0.028
|
0.062
|
0.175
|
0.013
|
0.040
|
0.023
|
0.016
|
0.090
|
Расчет среднего количества информации на 1 символ
в заданном сообщении произведен по формуле:
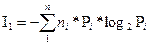 (2.4)
(2.4)
I1
= 5.9 бит
Общее количество информации в буквенной части сообщения
будет определяться как:
I11
= i*I1
(2.5)
I11
= 82.6 бит
Общее количество информации в цифровой части сообщения остается неизменным, т.к. все цифры могут попасться в сообщении также с равной вероятностью. Поэтому количество информации в цифровой части определится по формуле 2.2.
Общее количество информации в сообщении, переданном телеграфным кодом, будет определено по формуле:
I = I11
+ I2
(2.6)
I = 92.56 бит
2.2. Расчет энтропии сообщения
Понятие энтропии вводится дли измерения неопределенности состояния процесса. Исторически оно было введено в физике, математике и других точных науках. В информатике энтропия – степень неопределенности источника информации или его способности отдавать информацию. Она характеризует степень исходной неопределенности, которая присуща элементам алфавита, выбранного для передачи сообщения. Алфавит с малой энтропией, как правило, мало пригоден для практического использования.
2.2.1. Расчет энтропии сообщения, написанного на алфавите с равновероятным распределением символов
Развивая идеи Хартли, К. Шеннон ввел очень важное понятие энтропии источника – среднее значение количества информации, приходящееся на один символ алфавита. Исходя из определения, для данного случая энтропия рассчитается следующим образом:
Для буквенной части сообщения:
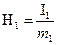 (2.7) (2.7)
Н1
= 5 бит/символ
Для цифровой части сообщения:
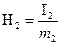 (2.8) (2.8)
Н2
= 3.32 бит/символ
Энтропия всего сообщения:
Н = Н1
+ Н2
(2.9)
Н = 8.32 бит/символ
2.2.2. Расчет энтропии сообщения, в котором буквы попадаются со своей вероятностью
Согласно тому же определению энтропии источника сообщения, в котором буквы попадаются со своей вероятностью, она определится таким же образом:
Для буквенной части сообщения:
 (2.10) (2.10)
Н11
= 3.06 бит/символ
Для цифровой части сообщения
энтропия остается неизменной, т.к. количество информации также не меняется. Она определится по формуле 2.8.
Таким образом, полная энтропия сообщения определится как:
Н = Н11
+ Н2
(2.11)
Н = 6.38 бит/символ
Таким образом, в данном пункте было определено количество информации и энтропия сообщения М для двух случаев: сообщение написано на алфавите, в котором буквы распределены с равной вероятностью, и в случае, когда сообщение написано на алфавите, в котором буквы попадаются со своей вероятностью.
Как энтропия сообщения, так и количество информации в нем меньше в том случае, когда оно написано на алфавите, буквы которого попадаются со своей вероятностью.
3. РАСЧЕТ ПРОПУСКНОЙ СПОСОБНОСТИ
КАНАЛА СВЯЗИ БЕЗ ПОМЕХ
Необходимо обосновать пропускную способность канала связи для передачи сообщения М <АКСЕНЕНКО_И> за время 10 мс.
Для расчетов принять распределение вероятностей появления букв как для художественного текста в соответствии с таблицей, приведенной в приложении.
3.1.
Построение канальной матрицы
Канальная матрица (КМ) –
квадратная матрица размером 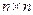 , ее элементами кроме диагональных являются вероятности появления букв передаваемого сообщения. В диагонали записывается дополнение до единицы по строке. , ее элементами кроме диагональных являются вероятности появления букв передаваемого сообщения. В диагонали записывается дополнение до единицы по строке.
Для определения размера матрицы необходимо решить неравенство:
 (3.1) (3.1)
где m – количество символов в сообщении
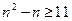
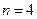
Следовательно, получаем квадратную матрицу размером  , в которую вписываем буквы сообщения. , в которую вписываем буквы сообщения.
Рис. 3.1. Канальная матрица
Элементами КМ являются сигналы bj
при условии формирования сигналов ai
, поэтому она заполняется в соответствии с таблицей, представленной в приложении.
Элементы диагонали рассчитываются следующим образом:
Р(b1
/a1
) = 1– Р(b2
/a1
) – Р(b3
/a1
)– Р(b4
/a1
) = 0.921
Р(b2
/a2
) = 1– Р(b1
/a2
) – Р(b3
/a2
) – Р(b4
/a2
) = 0.909
Р(b3
/a3
) = 1– Р(b1
/a3
) – Р(b2
/a3
) – Р(b4
/a3
) = 0.885
Р(b4
/a4
) = 1– Р(b1
/a4
) – Р(b2
/a4
) – Р(b3
/a4
) = 0.712
Таким образом, получаем заполненную КМ:
| 0.921
|
0.062
|
0.028
|
0.045
|
| 0.072
|
0.909
|
0.053
|
0.072
|
| 0.053
|
0.028
|
0.885
|
0.09
|
| 0.175
|
0.062
|
0.175
|
0.712
|
Рис. 3.2. Канальная матрица P(bj
/ai
)
3.2. Расчет матриц совместного появления сигналов ai
, bj
и относительных вероятностей
Расчет энтропии объединения базируется на знании статистических характеристик КС. Основной характеристикой КС в данном случае является матрица вероятностей взаимного появления событий P(ai
, bj
).
Элементы данной матрицы рассчитаны по следующей формуле:
P(ai
, bj
) = P(ai
)*P(bj
/ai
) (3.2)
Допустим, сигналы ai
появляются c равной вероятностью. В таком случае имеет место формула:
P(ai
) = const = 1/i (3.3)
Исходя из этого:
P(a1
) = P(a2
) = P(a3
) = P(a4
) = 1/4
Получаем матрицу P(ai
) размером  : :
Рис. 3.3. Матрица равновероятного появления сигнала ai
Таким образом, в соответствии с формулой 3.2 получаем следующую таблицу:
| 0.230
|
0.015
|
0.007
|
0.011
|
| 0.018
|
0.227
|
0.013
|
0.018
|
| 0.013
|
0.007
|
0.220
|
0.022
|
| 0.043
|
0.015
|
0.043
|
0.178
|
Рис. 3.4. Матрица совместного появления сигналов ai
, bj
Из формулы для определения вероятностей совместного появления событий можно выразить формулу для нахождения относительных вероятностей P(bj
/ai
):
 (3.4) (3.4)
Таким образом, можно построить матрицу относительных вероятностей P(bj
/ai
).
| 0.756
|
0.056
|
0.024
|
0.048
|
| 0.059
|
0.859
|
0.045
|
0.078
|
| 0.042
|
0.026
|
0.777
|
0.096
|
| 0.141
|
0.056
|
0.151
|
0.178
|
Рис. 3.6. Матрица относительных вероятностей P(bj
/ai
)
Элементы матрицы с вероятностями появления сигналов bj
, показывающей, с какой вероятностью появляются сигналы bj
в сообщении, будут рассчитываться по следующей формуле:
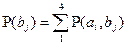 (3.5) (3.5)
Согласно этой формуле, матрица будет выглядеть следующим образом:
Рис. 3.5. Матрица вероятностей появления сигналов bj
3.3. Расчет полных условных энтропий
Если существует статистическая связь между символами алфавита источника и приемника, то энтропия приемника по отношению к источнику определится по формуле:
 (3.6) (3.6)
H(B/A) = 0.979 бит/символ
Энтропия источника по отношению к приемнику рассчитается аналогично:
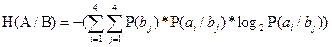 (3.7) (3.7)
H(A/B) = 1.134 бит/символ
Энтропия совместных А и В будет в таком случае найдена по следующей формуле:
 (3.8) (3.8)
H(AB) = 3.134 бит/2 символа
Размерность [бит/2 символа] означает, что взаимная энтропия представляет собой неопределенность возникновения пары символов, т.е. неопределенность на два символа.
Опираясь на формулы 3.2 и 3.4, можно показать, что энтропия появления событий АВ будет также рассчитываться как:
H(AB) = H(B) – H(A/B) (3.9)
Из данной формулы можно выразить формулы для определения энтропии источника и приемника:
H(A) = H(AB) – H(B/A) (3.10)
Н(А) = 2.155 бит/символ
H(B) = H(AB) – H(A/B) (3.11)
Н(В) = 2 бит/символ
3.4. Расчет количества информации, переданной по КС
При передаче информации одним символом снимается неопределенность Н. Если в сообщении присутствует n символов, то количество информации рассчитается по формуле:
I = nH (3.12)
Используя введенные количественные меры неопределенности, количество информации, переданной по КС, можно определить тремя способами.
1 способ
:
I(AB) = (H(A) – H(A/B)) * m (3.13)
В данном случае энтропия H(A/B) характеризует потери информации со стороны приемника.
I(AB) = 11.231 бит
2 способ
:
I(AB) = (H(B) – H(B/A)) * m (3.14)
I(AB) = 11.231 бит
Энтропия H(B/A) характеризует влияние помех.
3 способ
:
I(AB) = (H(A) + H(B) – H(AB)) * m (3.15)
I(AB) = 11.231 бит
3.5. Расчет пропускной способности КС
Кроме информационных характеристик в виде количества передаваемой информации и энтропии вводят в рассмотрение избыточность системы кодирования и динамические характеристики КС, основной из которых является пропускная способность КС, которая определяет количество информации, которая передается по КС за единицу времени.
 (3.16) (3.16)
где Т – время, за которое передается сообщение по КС
С
= 1.1 кбит/с
Итак, для определения пропускной способности КС было рассчитано количество информации в передаваемом сообщении, влияние помех на канал и потери со стороны приемника.
В данном случае для передачи сообщения, содержащего 11.2 бит, за 10 мс требуется КС с пропускной способностью 1.1 кбит/с.
4. СОГЛАСОВАНИЕ КАНАЛА СВЯЗИ
С ДАТЧИКОМ И ДИСПЛЕЕМ
Необходимо обосновать полосу пропускания КС для передачи информации от датчика, вырабатывающего сигнал, заданный в п. 1.
4.1.
Выбор исходных данных
В п. 1 для заданного источника (датчика) информации подготовлено сообщение в виде М = (dt, T, x1
, x2
, …, xn
). Из анализа значений {x1
, x2
, …, xn
} заданного сигнала, описанного выражением (1.1), необходимо определить xmin
, xmax
.

Рис. 4.1. Аналоговый сигнал
xmin
= - 0.204
xmax
= 0.095
4.2.
Расчет энтропии источника
Передаваемая информация представляет собой совокупность следующих сигналов:
1) а1
– знак числа, а1
= (0,1). Заранее указать его невозможно, поэтому, в соответствии с признаком максимальной энтропии, Р1
= 0.5.
2) а2
– количество цифр целой части числа, а2
= 0
3) а3
– число в интервале от 0 до наибольшего по абсолютной величине х, а3
= 204.
Если допустить, что цифры по КС передаются двоичным кодом, то для передачи числа 204 требуется l разрядов:
2l
= 204 (4.1)
l = 7.672
После округления в большую сторону для расчетов принято l = 8. Таким образом, а3
= [0, 204] передается с помощью двойного кода с количеством разряда, равным 8. Заранее указать значение числа невозможно, поэтому, в соответствии с принципом максимальной энтропии, Р = 1/28
.
Таким образом, передаваемая информация состоит из трех сигналов и представляет собой сложное сообщение.
При передаче сигналов их энтропия находится по формуле Шеннона:
Н 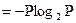 (4.2) (4.2)
H1
= - 0.5 * log2
0.5
H1
= 0.5 бит/символ
H2
= - 1*log2
1
H2
= 0 бит/символ
H3
= 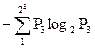
H3
= 8 бит/символ
На основании правила сложения энтропий при передаче сложного сообщения, можно найти энтропию датчика сообщения:
H(А) = H1
+ H2
+ H3
(4.3)
H(А) = 8.5 бит/символ
4.3.
Расчет ширины спектра сигнала
Любой непрерывный датчик характеризуется шириной спектра сигнала dF. В соответствии с теоремой Котельникова, для обеспечения неискаженного процесса передач необходимо показание датчика снимать с интервалом времени dt:
dF = 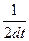 (4.4) (4.4)
Учитывая (1.9) и (1.10), ширина спектра сигнала будет равна:
dF = 0.06 Гц
4.4.
Расчет полосы пропускания КС
Необходимо рассчитать ПП КС при соотношении сигнал-шум равным 26.
В соответствии с теоремой Шеннона, для обеспечения передачи информации без искажений должно выполняться условие:
C >> R (4.5)
где R – скорость выдачи информации датчиком
С – пропускная способность КС
Т.е.
2Fkcmin
log2
(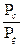 ) ) 2dF 2dF
Fkcmin
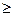 dF dF
Fkcmin
0.109 Гц
Ширина ПП должна быть тем больше, чем больше ширина спектра датчика и чем меньше соотношение мощности сигнала к мощности помехи.
4.5. Расчет энтропии приемника
В настоящее время создано большое разнообразие оконечных или периферийных устройств, с помощью которых можно представлять информацию в форме, удобной для обработки. Эта информация может наноситься на магнитные либо на бумажные носители, или представляться в виде образов на экране.
В зависимости от формы носителя разрабатываются свои методики, с помощью которых обосновываются характеристики оконечных устройств. Эти методики учитывают специфику оконечных устройств. Рассмотрим подход при разработке этих методик на примере согласования КС с черно-белым дисплеем с разрешением 800*600.
На экран монитора информация выводится в виде множества точек – пикселей. Количество пикселей, выводимых на дисплей, определяется двумя величинами – r и q. Черно-белый дисплей может, в принципе, представлять образы в виде полутонов, т.е. для каждого пикселя существует l градаций яркости. В этом случае необходимо учитывать гораздо большее количество состояний дисплея.
С другой стороны, в современных дисплеях управление разверткой луча и уровнем полутона осуществляется командами, которые представляют собой двоичные кодовые группы. Для определения количества разрядов этих кодовых групп будем считать, что луч должен выводиться равновероятно в любую точку матрицы q*r, а градации полутона могут быть также выбраны равновероятно из интервала [0, l].
Тогда количество разрядов для кодирования величин q, r, l составит:
 (4.6) (4.6)
В данном случае r = 600, q = 800, l = 8.
n1
= 9.644 бит/символ
n2
= 9.229 бит/символ
n3
= 3 бит/символ
Если считать, что все состояния дисплея равновероятны, то энтропия дисплея численно равна:
H(B) = log2
2n1 + n2 + n3
= n1
+ n2
+ n3
(4.7)
H(B) = 21.873 бит/символ
4.6. Определение максимальной полосы КС
Если на дисплей в единицу времени подается n0
фрагментов информации, то частота подачи информации на дисплей будет равна:
F =  (4.8) (4.8)
Тогда скорость вывода информации на дисплей определиться по формуле:
R = n0
H(B) =  (4.9) (4.9)
Задача согласования КС с дисплеем сводится к следующему:
R >> C (4.10)
или
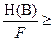 Fkcmax Fkcmax
 (4.11) (4.11)
Подставив в эту формулу выражения 4.7 и 4.8, получим:
n0
(n1
+ n2
+ n3
) Fkcmax
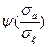
При достаточно большом соотношении сигнал-шум величина   1, следовательно, для согласования КС с дисплеем достаточно чтобы выполнялось условие: 1, следовательно, для согласования КС с дисплеем достаточно чтобы выполнялось условие:
Fkcmax
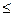 n0
(n1
+ n2
+ n3
) (4.12) n0
(n1
+ n2
+ n3
) (4.12)
В данном случае необходимо определить полосу КС при n0
= 80 зн/с:
Fkcmax
 1.75*103
Гц 1.75*103
Гц
4.7. Выбор ширины ПП КС
Для нормальной передачи информации от датчика к дисплею по КС должны выполняться два условия:
 (4.13) (4.13)
Из этой формулы следует следующее:
Fkc = Fkmax
– Fkmin
Fkc = 1.75 кГц
Таким образом, для нормальной передачи информации от датчика к дисплею по КС должны выполняться два условия:
1) Пропускная способность КС должна быть больше либо равна скорости выдачи информации датчиком.
2) Скорость вывода информации на дисплей должна быть больше либо равна пропускной способности КС.
В данном случае, исходя из формулы (4.13), видно, что достаточная ширина ПП КС составляет 1.75 кГц.
5. КОДИРОВАНИЕ ИНФОРМАЦИИ В КАНАЛЕ СВЯЗИ
БЕЗ ПОМЕХ
Необходимо закодировать заданное сообщение М <АКСЕНЕНКО_И> двумя способами:
1. методом Шеннона-Фано;
2. методом Хаффмана.
Для каждого кода требуется оценить показатель его эффективности.
Для расчетов принять значения вероятностей появления букв, представленные в приложении.
5.1. Оптимальное кодирование
Дискретный КС, работающий без помех, является самым простым техническим устройством. Для такого канала наилучшим способом кодирования является система с неравномерными кодами. При этом наиболее вероятные сообщения необходимо передавать короткими кодовыми группами. При этом основанием кода может быть любое число k.
Допустим, передаче подлежит ансамбль (1,2,3…m) с соответствующими вероятностями (Р1
, Р2
, Р3
… Рm
). Тогда количество информации
Ii
= - log2
Pi
 (5.1) (5.1)
где  = Рi = Рi
Отсюда путем некоторых преобразований можно получить выражение для определения среднего количества разрядов, которые необходимо отвести при передаче символов:
ni
=  (5.2) (5.2)
Если среднее количество разрядов не больше дроби, то кодирование оптимальное. Если нет, то говорят что кодирование неоптимальное. В настоящее время разработано множество оптимальных кодов, но классическими являются коды Шеннона-Фано и Хаффмана. Отличительной способностью этих кодов является то, что начало любой кодовой комбинации, с помощью которой кодируется символ, не совпадает с более короткой кодовой комбинацией.
5.2. Кодирование сообщения методом Шеннона-Фано
5.2.1. Разработка кода сообщения
Принцип построения оптимального кода Шеннона-Фано следующий.
Для заданного сообщения необходимо составить вспомогательную таблицу вероятностей появления букв в сообщении.
Таблица 5.1
| А
|
К
|
С
|
Е
|
Н
|
Е
|
Н
|
К
|
О
|
_
|
И
|
| 0.062
|
0.028
|
0.045
|
0.072
|
0.053
|
0.072
|
0.053
|
0.028
|
0.09
|
0.175
|
0.062
|
Все символы сообщения, входящие в ансамбль, располагаются в порядке убывания вероятности их появления, определяется сумма всех вероятностей. Чтобы кодирование было оптимальным, необходимо выполнение условия нормировки:
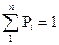 (5.1) (5.1)
Это означает, что необходимо ввести паузу, вероятность которой будет рассчитана, как:
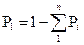
P1
= 0.26
Т.к. код Шеннона-Фано двоичный, следовательно, основание кода k = 2.
Далее все символы ансамбля разбиваются на k групп с таким расчетом, чтобы суммарные вероятности в группах были приблизительно одинаковы. Каждая из групп делится на подгруппы, чтобы в каждой из k подгрупп суммарные вероятности были бы равны. Такое разбиение осуществляется до тех пор, пока в подгруппах не останется по одному символу.
В подгруппах каждый символ или группа кодируется следующим образом. Всем символам первой подгруппы присваивается 0, всем символам второй подгруппы – 1, третьей – 2, и т.д. до k-ой группы, которой присваивается (k – 1).
По этим данным можно составить таблицу разработки кода:
Таблица 5.2
| Буква
|
Символ
|
Pi
|
1
|
2
|
3
|
4
|
5
|
аi

|
n
|
| пауза
|
а1
|
0.26
|
0
|
0
|
а1

|
2
|
| _
|
а2
|
0.175
|
0
|
1
|
0
|
а2

|
3
|
| О
|
а3
|
0.09
|
0
|
1
|
1
|
а3

|
3
|
| Е
|
а4
|
0.072
|
1
|
0
|
0
|
0
|
а4

|
4
|
| Е
|
а5
|
0.072
|
1
|
0
|
0
|
1
|
а5
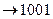
|
4
|
| А
|
а6
|
0.062
|
1
|
0
|
1
|
0
|
а6
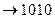
|
4
|
| И
|
а7
|
0.062
|
1
|
0
|
1
|
1
|
а7
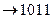
|
4
|
| Н
|
а8
|
0.053
|
1
|
1
|
0
|
0
|
а8

|
4
|
| Н
|
а9
|
0.053
|
1
|
1
|
0
|
1
|
а9

|
4
|
| С
|
а10
|
0.045
|
1
|
1
|
1
|
0
|
а10
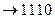
|
4
|
| К
|
а11
|
0.028
|
1
|
1
|
1
|
1
|
0
|
а11
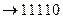
|
5
|
| К
|
а12
|
0.028
|
1
|
1
|
1
|
1
|
1
|
а12

|
5
|
Таким образом, можно окончательно записать сообщение, закодированное методом Шеннона-Фано:
0010101111011101000110010011101111110110101011
Процесс кодирования методом Шеннона-Фано обеспечивает оптимальность кода засчет того, что символам с более высокой вероятностью появления ставится в соответствие более короткая кодовая комбинация.
Обычно после разработки системы кодирования определяют среднее количество разрядов, необходимое для передачи одного символа, следующим образом:
 (5.2) (5.2)

5.2.3. Оценка кода по показателям эффективности
Для оценки качества кода необходимо знать энтропию, рассчитывающуюся по формуле Шеннона:
 (5.3) (5.3)
Н = 3.241 бит/символ
Для оптимальности кода необходимо выполнение следующего условия:
 (5.4) (5.4)
1. Расчет показателя избыточности сообщения
Расчет показателя избыточности сообщения будет осуществляться по следующей формуле:
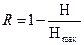 (5.5) (5.5)
где Н – энтропия сообщения, написанного на алфавите, в котором буквы распределяются со своей вероятностью
Нmax
– энтропия сообщения, написанного на алфавите, в котором буквы распределяются с равной вероятностью
Нmax
= log2
n (5.6)
В таком случае, подставив формулу (5.7) в (5.6), получим:
R = 0.096
2.Расчет показателя избыточности кода
Расчет показателя избыточности кода осуществляется по следующей формуле:
Rk  (5.7) (5.7)
Rk = 0.009
3. Расчет показателя недогруженности кода
Расчет показателя недогруженности кода осуществляется по следующей формуле:
D (5.8) (5.8)
в = 0.03
5.3. Кодирование сообщения методом Хаффмана
Код Хаффмана строится на базе кодового дерева – специального графа, отображающего запись всех возможных k-ичных n-разрядных чисел. Дерево представляет собой совокупность узлов, которые располагаются на разных уровнях.

Рис. 5.1. Кодовое дерево
5.3.1. Разработка кода сообщения
Для построения оптимального кода на базе кодового дерева необходимо учитывать следующее:
1) символ ансамбля с наибольшей вероятностью появления должен находиться в узле наименьшего порядка.
2) по крайней мере, два сообщения с минимальной вероятностью появления должны кодироваться в узлах максимального порядка.
3) если выбран узел порядка i, то все узлы более высокого порядка, связанные с ним, не могут быть использованы для кодирования.
4) для кодирования могут не использоваться узлы более высокого порядка.
При укрупнении сообщения, т.е. при переходе от улов порядка i к i – 1 количество символов, закодированных в узлах более высокого порядка, уменьшается. Однако в узлах самого высокого порядка количество закодированных символов m0
должно лежать в пределах [2,k], где k – основание кода.
При выборе k используют следующую формулу:
M = 1 + 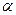 (k – 1) + (m0
– 1) (5.9) (k – 1) + (m0
– 1) (5.9)
где М – общее количество символов в алфавите
m0
– количество закодированных символов
– целое число, которое подбирается таким образом, чтобы выполнялось условие:
 (5.9) (5.9)
где k – основание кода
Если найдено m0
, то оно определяет количество закодированных символов в узлах само высокого порядка. Все остальные узлы низких порядков полностью заполняются.
Требуется построить двоичный код Хаффмана.
k = 2  m0
= 2 m0
= 2
Следовательно, в узлах самого высокого порядка количество закодированных символов равно 2.
Необходимо построить вспомогательную таблицу:
Таблица 5.3
| Буква
|
аi
|
Pi
|
|
аi

|
n
|
| |
0.579
|



     
    
   
       

      
 
  
 |
| |
0.421
|
| |
0.319
|
| пауза
|
а1
|
P1
= 0.26
|
а1
 10 10
|
2
|
| 0.23
|
| 0.191
|
| _
|
а2
|
P2
= 0.175
|
а2
000
|
3
|
| 0.144
|
| 0.124
|
| 0.106
|
| 0.101
|
| О
|
а3
|
P3
= 0.09
|
а3
111
|
3
|
| Е
|
а4
|
P4
= 0.072
|
а4
0100
|
4
|
| Е
|
а5
|
P5
= 0.072
|
а5
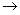 1100 1100
|
4
|
| А
|
а6
|
P6
= 0.062
|
а6
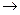 0001 0001
|
4
|
| И
|
а7
|
P7
= 0.062
|
а7
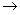 1001 1001
|
4
|
| Н
|
а8
|
P8
= 0.053
|
а8
0101
|
4
|
| Н
|
а9
|
P9
= 0.053
|
а9
1101
|
4
|
| С
|
а10
|
P10
= 0.045
|
а10
0011
|
4
|
| К
|
а11
|
P11
= 0.028
|
а11
01011
|
5
|
| К
|
а12
|
P12
= 0.028
|
а12
11011
|
5
|
Таким образом, можно окончательно записать код Хаффмана для сообщения:
1000010101100110100010111001101110111110001001
Среднее количество разрядов, необходимого для передачи одного символа рассчитается по формуле (5.3):
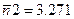
5.3.2. Оценка кода по показателям эффективности
1. Расчет показателя избыточности сообщения
Расчет показателя избыточности сообщения будет осуществляться по формуле 5.5:
R = 0.096
2. Расчет показателя избыточности кода
Расчет показателя избыточности кода осуществится по формуле (5.7):
Rk = 0.009
3. Расчет показателя недогруженности кода
Расчет показателя недогруженности кода осуществится по формуле (5.8):
в = 0.03
Исходя из расчета среднего числа разрядов, необходимых для передачи одного символа, видно, что показатель  для случая, когда сообщение кодировалось методом Хаффмана, равен показателю для случая, когда сообщение кодировалось методом Хаффмана, равен показателю  при кодировании того же сообщения методом Шеннона-Фано. Благодаря этому все показатели эффективности примененных к данному сообщению методов также будут соответственно равны. при кодировании того же сообщения методом Шеннона-Фано. Благодаря этому все показатели эффективности примененных к данному сообщению методов также будут соответственно равны.
Поэтому можно сделать вывод, что для передачи данного сообщения оба метода одинаково эффективны.
6.
РАСЧЕТ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ СИСТЕМ КОДИРОВАНИЯ ИНФОРМАЦИИ
Необходимо рассчитать показатели эффективности систем кодирования для сообщения М = (АКСЕНЕНКО_И), полученные методами Шеннона-Фано и Хаффмана при следующих исходных данных:
а) qлс
= (1+0.1*k)*10-6
- при высокой помехозащищенности
б) qлс
= (1+0.1*k)*10-2
- при низкой помехозащищенности
Исследовать зависимости Q(r), Q(q).
6.1.
Расчет показателей эффективности систем кодирования информации для помехозащищенного канала
Интуитивно ясно, какими свойствами должен обладать радиоканал, эффективно осуществляющий передачу информации от источника к потребителю. Во-первых, такой канал должен обеспечить поддержку заранее заданной скорости информационного потока. Во-вторых, нужно гарантировать невозможность ошибочного приема символов, либо свести вероятность таких ошибок к приемлемо низкому уровню.
Если бы в КС полностью отсутствовали шумы, то любые объемы информации можно было бы передать за достаточно малый отрезок времени, полностью избежав каких-либо ошибок в принятом сообщении. Неизбежное присутствие в КС помех различного происхождения в корне меняет ситуацию.
6.1.1.
Расчет для сообщения, полученного методом Шеннона-Фано
Пусть сообщение передается некоторой кодовой комбинацией с количеством разрядов n1. Из предыдущего пункта видно, что n1 = 46.
Известна вероятность возникновения ошибки в одном разряде. Будем считать, что все разряды конструктивно выполнены на одних и тех же элементах, следовательно, для каждого разряда вероятность приема кодовой комбинации кратности r:
q(r) = qr
(1 – q)n – r
(6.1)
Для данного случая примем вероятность приема ложного сигнала в одном разряде в КС при высокой помехозащищенности равную:
qлс
= 1.1 *10-6
В общем случае ошибка кратности r может появиться в одной из множества комбинаций, количество которых определяется числом сочетаний  . Тогда полная вероятность появления ошибок определится как: . Тогда полная вероятность появления ошибок определится как:

т.е.
 (6.2) (6.2)
где Q1(r) – вероятность того, что хотя бы в одном разряде будет ошибка
Ниже приведен график зависимости данной вероятности от кратности ошибок:

Рис. 6.1. Зависимость Q1 от r
6.1.2.
Расчет для сообщения, полученного методом Хаффмана
Пусть то же самое сообщение передается другой кодовой комбинацией с количеством разрядов n2. Из предыдущего пункта видно, что n2 также равно 46.
Вероятность приема ложного сигнала в одном разряде в КС при высокой помехозащищенности также равна qлс
= 1.1 *10-6
.
В таком случае
 (6.3) (6.3)
А график данной зависимости будет выглядеть следующим образом:
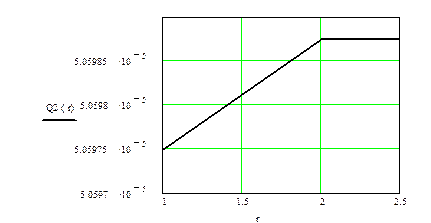
Рис. 6.2. Зависимость Q2 от r
Проанализировав график зависимости Q(r), можно сделать вывод, что учитывать ошибки кратности больше 2 нецелесообразно, следовательно, их корректирующие коды должны обнаруживать и исправлять ошибки, кратности не >3.
6.2. Расчет показателей эффективности систем кодирования информации для низкого помехозащищенного канала
6.2.1. Расчет для сообщения, полученного методом Шеннона-Фано
В данном случае будет использоваться КС с низкой помехозащищенностью, поэтому вероятность приема ложного сигнала в одном разряде будет значительно больше. Примем ее равную:
qлс
= 0.011
Количество разрядов в закодированном методом Шеннона-Фано сообщении по-прежнему равно 46, а формула зависимости вероятности возникновения хотя бы одном разряде Q3 от кратности ошибки r аналогична формуле 6.2.

Однако полученный график зависимости несколько отличается от предыдущих двух.
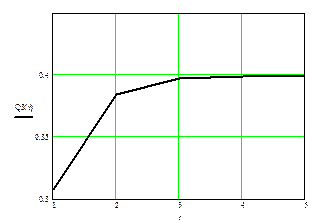
Рис. 6.3. Зависимость Q3 от r
6.2.2.
Расчет для сообщения, полученного методом Хаффмана
Для этого случая расчеты аналогичны. Количество разрядов в сообщении равно 46, вероятность ложного приема сигнала – qлс
= 0.011. формула зависимости аналогична формуле 6.3.

График зависимости в данном случае выглядит следующим образом:

Рис. 6.4. Зависимость Q3 от r
При наложении графиков 6.3 и 6.4 становится очевидным тот факт, что они полностью накладываются друг на друга.

Рис. 6.5. Зависимость Q3, Q4 от r
Из сравнения графиков зависимостей Q(r) для кодов, полученных разными методами, установлено, что оба метода одинаково эффективны с точки зрения показателя Q (вероятности возникновения ошибок при передаче сообщения).
6.3.
Исследование зависимости вероятностью возникновения ошибок в сообщении от вероятности возникновения ошибок в одном разряде
6.3.1.
Метод Шеннона-Фано
Предположим, что вероятность появления ложного сигнала в одном разряде меняется в пределах от 0 до 0.01.
Как было установлено, учитывать ошибки кратности больше 3 нецелесообразно, поэтому формула зависимости возникновения ошибок в сообщении от вероятности возникновения ошибок в одном разряде будет аналогична, однако в других пределах:
 (6.4) (6.4)

Рис. 6.6. Зависимость Q5 от q
6.3.2.
Метод Хаффмана
Формула для расчетов зависимости возникновения ошибок в сообщении, закодированном методом Хаффмана, от вероятности возникновения ошибок в одном разряде имеет тот же вид:


Рис. 6.7. Зависимость Q6 от q
При наложении графиков 6.6 и 6.7 получим:

Рис. 6.7. Зависимость Q5, Q6 от q
Существует сильная зависимость между вероятностью появления ошибки в целом сообщении и вероятностью ее появления в одном разряде, особенно при малых значениях q. При сравнительно небольших изменениях q значение Q резко возрастает. Следовательно, для передачи сообщения без искажений необходимо использовать КС с высокой помехоустойчивостью или применять корректирующие коды.
7. КОДИРОВАНИЕ ИНФОРМАЦИИ
ГРУППОВЫМ (БЛОЧНЫМ) КОДОМ
Необходимо построить групповой код, способный обнаруживать и исправлять одну ошибку при передаче сообщения М = (АКСЕНЕНКО_И), закодированного с помощью метода Хаффмана.
7.1. Представление сообщения, закодированного методом Хаффмана, в блочной форме
Задача построения кода формируется так же, как постановка общей задачи кодирования. Любое сообщение любой длины представляется в виде совокупности блоков таким образом, чтобы эти блоки могли бы сформировать квадратную матрицу.
Необходимо передать сообщение М = (АКСЕНЕНКО_И). В закодированном методом Хаффмана виде оно выглядит следующим образом:
1000010101100110100010111001101110111110001001
При этом, как было рассчитано, что количество разрядов в закодированном сообщении n2 = 46.
Для построения информационной матрицы необходимо рассчитать число m, которое равно количеству разрядов в ней.
m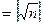 (7.1) (7.1)
m
m = 7
Таким образом, информационная матрица в блочном виде выглядит следующим образом:
A = 
7.2. Разработка производящей (генераторной) матрицы
Генераторная матрица составляется по следующей формуле:
V = (I;П) (7.2)
т.е.
n = m + k (7.3)
где I = 7 x 7 – единичная матрица с левой диагональю
П – контрольная матрица
n – количество разрядов в генераторной матрице
m – количество разрядов в информационной матрице
k – количество контрольных разрядов
Для определения количества контрольных разрядов используется понятие нижней границы Хемминга. Эта граница устанавливает связь между количеством контрольных разрядов k и количеством ошибок S, которые необходимо обнаружить и исправить. Нижняя граница Хемминга задается следующей формулой:
 (7.4) (7.4)
Если прологарифмировать обе части неравенства, то получим формулу нахождения k:
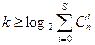 (7.5) (7.5)
Для приближенных расчетов используют формулу:
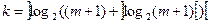 (7.6) (7.6)
Формулы 7.4 и 7.5 обосновывают количество контрольных разрядов:
k = 4
Исходя из этого, по формуле 7.3 можно найти количество разрядов в генераторной матрице:
n = 7 + 4
n = 11
Количество ошибок, которые можно обнаруживать и исправлять, определится как:
d = r + S + 1 (7.6)
d – минимальное расстояние кода, способного исправлять одну ошибку
r = 1 – кратность ошибок
S = 1 – количество ошибок, которые необходимо исправить
Для обеспечения получения кодовых комбинаций с заданным в необходимо и достаточно, чтобы вес базовой кодовой комбинации был больше либо равен d, т.е. число отличающихся разрядов любой пары базовых кодовых комбинаций не должен быть меньше d. Базовые кодовые комбинации, удовлетворяющие этим требованиям, называют базисом группового кода и записывают в виде генераторной матрицы.
Для определения веса генераторной матрицы используется следующая формула:
W  в 3 (7.5) в 3 (7.5)
d = r + S + 1
d = 3
W 3 3
В этом случае вес проверочной матрицы определится как:
Wп
W – 1
Единица отнимается по той причине, что в информационной матрице один разряд уже равен 1. Таким образом, вес проверочной матрицы равен:
Wп
2
Далее из таблицы всех возможных комбинаций необходимо выбрать те, у которых вес больше или равен 2:

Таким образом, сформируется генераторная матрица:
V = 
7.3. Формирование блочного кода
Для формирования блочного кода каждая строка информационной матрицы шифруется отдельно. Для этого используется построенная генераторная матрица. Соответствующие строки складываются по модулю 2:
1 строка: {1 0 0 0 0 1 0}
 
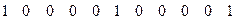
2 строка: {1 0 1 1 0 0 1}

3 строка: {1 0 1 0 0 0 1}
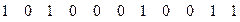
4 строка: {0 1 1 1 0 0 1}


5 строка: {1 0 1 1 1 0 1}

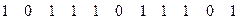
6 строка: {1 1 1 1 0 0 0}


7 строка: {1 0 0 1 1 1 1}
 
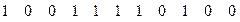
Из результатов сложения составляется закодированная информационная матрица, представленная в блочном виде, готовая к передаче:
М = 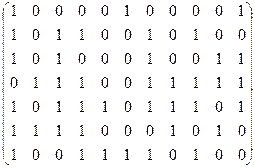
7.4. Декодирование блочного кода в режиме обнаружения и исправления ошибок
Декодирование групповых кодов осуществляется с помощью контрольной или проверочной матрицы. Структурно она представляет собой совокупность транспонированной проверочной части генераторной матрицы, дополненной единичной матрицей с левой диагональю.
Для декодирования блочного кода в режиме обнаружения и исправления ошибок необходимо построить контрольную матрицу Н.
Н =  (7.6) (7.6)
H = 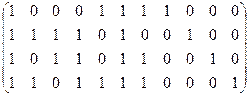
Пусть подается первая часть блочного кода (1 строка матрицы М) с запланированной ошибкой:
В =
R =  (7.7) (7.7)
где R – проверочный вектор или синдром
В – передаваемое сообщение – блок как совокупность m-шифрованных и
к – контрольных разрядов
Н – контрольная матрица
R = (2 3 2 2)
R = (0 1 0 0)
Вектор R является девятым столбцом в контрольной матрице Н. Он однозначно указывает на место ошибки переданной кодовой комбинации. Следовательно:
е = (0 0 0 0 0 0 0 0 1 0 0)
Для исправления ошибки:
 е (7.8) е (7.8)

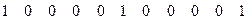
Таким образом, при кодировании сообщения групповым кодом была проверена эффективность данного метода. Алгоритм построен таким образом, чтобы была возможность обнаруживать и исправлять ошибки в переданном сообщении. Это достигается с помощью добавления избыточности в виде контрольных разрядов в каждый блок сообщения.
8. КОДИРОВАНИЕ ИНФОРМАЦИИ
ЦИКЛИЧЕСКИМ КОДОМ
Необходимо построить циклический код, способный обнаруживать и исправлять одну ошибку при передаче сообщения М = (АКСЕНЕНКО_И), закодированного с помощью метода Хаффмана.
Циклический код – это блочный код, который структурно состоит из информационной части m и проверочной части n.
В отличие от блочного кода циклический код формируется путем смещения разрядов справа налево в каждом цикле. Такой циклический сдвиг обеспечивает поиск и обнаружение ошибок краткости r также, как и в блочном коде.
8.1. Представление сообщения, закодированного методом Хаффмана, в блочной форме
Необходимо передать сообщение М = (АКСЕНЕНКО_И), закодированное методом Хаффмана:
1000010101100110100010111001101110111110001001
В пункте 7 принято, что сообщение, закодированное методом Хаффмана, в блочном виде выглядит следующим образом:
A = 
Было также определено:
r = 1
S = 1
d = 3
k = 4
8.2. Построение образующей (генераторной) матрицы
8.2.1. Выбор образующего полинома и определение контрольных разрядов
В основе теории циклических кодов лежит алгоритм поиска контрольных или проверочных групп путем использования простых полиномов. По аналогии с простыми числами простые полиномы – это полиномы, которые не могут быть представлены произведением других полиномов или, иными словами, могут делиться только на себя и на единицу. В общем случае простой полином имеет вид:
 (8.1) (8.1)
В качестве коэффициента  используются бинарные числа 0 и 1. используются бинарные числа 0 и 1.
Полиномы, с помощью которых осуществляется поиск контрольных разрядов, последующее нахождение и исправление ошибок, получили название образующие полиномы
. При использовании образующих полиномов разработаны два способа формирования циклических кодов.
Первый способ базируется на использовании генераторной матрицы.
 (8.2) (8.2)
Количество элементов проверяющей части матрицы обосновывается также, как и для групповых кодов, а сами контрольные группы определяются как остатки от деления единицы с неограниченным числом нулей на образующий полином.
Необходимо определить контрольные группы для циклического кода, способного обнаруживать и исправлять одну ошибку. Для этого понадобится образующий полином, который можно выбрать по таблице минимальных неприводимых в поле Галуа многочленов:
Таблица 8.1
| №
|
1
|
2
|
3
|
4
|
| 1
|
1
|
111
|
1011
1101
|
10011
11111
111
11001
|
| 2
|
| 3
|
| 4
|
Так как количество разрядов в контрольной группе k = 4, выберем многочлен из четвертого столбца:
P(x) = 11001
P(x) = a1
x4
+a2
x3
+a3
x0
P(x) = x4
+x3
+1
Процедура деления осуществляется до тех пор, пока кодовые группы не начнут повторяться.
 1 0 0 0 0 0 0 0 0 0 0 |1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 1 1 0 1 0
1 0 0 1
0
1 1 0 0 1
1 0 1 1
0
1 1 0 0 1
1 1 1 1
0
1 1 0 0 1
0 1 1 1
0
0 0 0 0 0
1 1 1 0
0
1 1 0 0 1
0 1 0 1
0
0 0 0 0 0
1 0 1 0
…
8.2.2. Построение генераторной матрицы
Генераторная матрица по формуле 8.2 состоит из единичной матрицы с правой диагональю и проверочной матрицы, состоящей из полученных остатков.
V = 
8.3. Кодирование
8.3.1. I способ
Сообщение М кодируется блоками путем сложения по модулю 2 соответствующих строк генераторной матрицы.
1 строка: {1 0 0 0 0 1 0}

2 строка: {1 0 1 1 0 0 1}

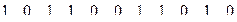
3 строка: {1 0 1 0 0 0 1}


4 строка: {0 1 1 1 0 0 1}
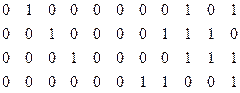
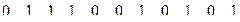
5 строка: {1 0 1 1 1 0 1}


6 строка: {1 1 1 1 0 0 0}
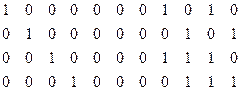
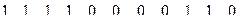
7 строка: {1 0 0 1 1 1 1}


Таким образом, формируется закодированная матрица, состоящая из результатов сложения по модулю 2:
M = 
8.3.2. II способ
Контрольные группы могут быть найдены без генераторной матрицы путем деления информационной группы или блока на образующий полином.
Необходимо выписать информационную часть кода, добавить количество нулей, равное числу контрольных разрядов, и поделить на полином.
 1 строка: 1 строка:
1 0 0 0 0 1 0 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 1 0 0 1 0
1 0 0 1 1
1 1 0 0 1
1 0 1 0 0
1 1 0 0 1
1 1 0 1 0
1 1 0 0 1
0 0 1 1 0
0 0 0 0 0
0 1 1 0 0
0 0 0 0 0
1 1 0 0 0
1 1 0 0 1
0 0 0 1
2 строка:
1 0 1 1 0 0 1 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 0 1 0 1 0
1 1 1 1 0
1 1 0 0 1
0 1 1 1 1
0 0 0 0 0
1 1 1 1 0
1 1 0 0 1
0 1 1 1 0
0 0 0 0 0
1 1 1 0 0
1 1 0 0 1
0 1 0 1 0
0 0 0 0 0
1 0 1 0
3 строка:
1 0 1 0 0 0 1 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 0 0 1 0 1
1 1 0 1 0
1 1 0 0 1
0 0 1 1 1
0 0 0 0 0
0 1 1 1 0
0 0 0 0 0
1 1 1 0 0
1 1 0 0 1
0 1 0 1 0
0 0 0 0 0
1 0 1 0 0
1 1 0 0 1
1 1 0 1
4 строка:
0 1 1 1 0 0 1 0 0 0 0 |1 1 0 0 1
0 0 0 0 0
0 1 0 1 1 0 1
1 1 1 0 0
1 1 0 0 1
0 1 0 1 1
0 0 0 0 0
1 0 1 1 0
1 1 0 0 1
1 1 1 1 0
1 1 0 0 1
0 1 1 1 0
0 0 0 0 0
1 1 1 0 0
1 1 0 0 1
0 1 0 1
5 строка:
1 0 1 1 1 0 1 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 0 1 1 0 1
1 1 1 0 0
1 1 0 0 1
0 1 0 1 1
0 0 0 0 0
1 0 1 1 0
1 1 0 0 1
1 1 1 1 0
1 1 0 0 1
0 1 1 1 0
0 0 0 0 0
1 1 1 0 0
1 1 0 0 1
0 1 0 1
6 строка:
1 1 1 1 0 0 0 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 0 1 0 1 1 0
0 1 1 1 0
0 0 0 0 0
1 1 1 0 0
1 1 0 0 1
0 1 0 1 0
0 0 0 0 0
1 0 1 0 0
1 1 0 0 1
1 1 0 1 0
1 1 0 0 1
0 0 1 1 0
0 0 0 0 0
0 1 1 0
7 строка:
1 0 0 1 1 1 1 0 0 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 1 0 0 0 0
1 0 1 0 1
1 1 0 0 1
1 1 0 0 1
1 1 0 0 1
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0
Сформированная матрица аналогична матрице, полученной первым способом:
M =
8.3.3. Проверка правильности кодирования
Для проверки правильности сформированного кода необходимо и достаточно полученную кодовую комбинацию разделить на образующий полином.
Если она делится на полином без остатка, значит, код пойдет верно, наличие остатка свидетельствует об ошибке в кодировании.
1 строка:
1 0 0 0 0 1 0 0 0 0 1 |1 1 0 0 1
1 1 0 0 1
1 1 1 1 0 0 1
1 0 0 1 1
1 1 0 0 1
1 0 1 0 0
1 1 0 0 1
1 1 0 1 0
1 1 0 0 1
0 0 1 1 0
0 0 0 0 0
0 1 1 0 0
0 0 0 0 0
1 1 0 0 1
1 1 0 0 1
0 0 0 0
5 строка:
1 0 1 1 1 0 1 0 1 0 0 |1 1 0 0 1
1 1 0 0 1
1 1 0 1 1 0 1
1 1 1 0 0
1 1 0 0 1
0 1 0 1 1
0 0 0 0 0
1 0 1 1 0
1 1 0 0 1
1 1 1 1 1
1 1 0 0 1
0 1 1 0 0
0 0 0 0 0
1 1 0 0 0
1 1 0 0 1
0 0 0 0
Т. к. вес остатка равен нулю, сообщение закодировано верно.
8.4. Проверка циклического кода на возможность исправления ошибок
Рассмотренная система кодирования позволяет обнаруживать и исправлять заданное количество ошибок. Факт существования ошибки при передаче блока по КС может быть обнаружен по остатку от деления на образующий полином. Если остаток от деления отличен от нуля, это свидетельствует о наличии ошибки.
Для поиска вектора ошибки Е используют следующий алгоритм.
Осуществляется деление принятого блока на образующий полином, определяется вес его остатка. Если величина веса W больше кратности ошибки, то осуществляется циклический сдвиг на один разряд до тех пор, пока вес остатка не будет кратен ошибке. Тогда дальнейшая работа прекращается и к деформированной кодовой группе прибавляется остаток, таким образом исправляется ошибка. После этого осуществляется сдвиг в обратном порядке на столько же разрядов, на сколько он был осуществлен при поиске остатка.
Допустим, в некотором блоке закодированного сообщения умышленно была допущена ошибка.
5 строка:
B = 
1 0 1 1 1 0 1 0 0 0 1 |1 1 0 0 1
1 1 0 0 1
1 1 0 1 1 0 1
1 1 1 0 0
1 1 0 0 1
0 1 0 1 1
0 0 0 0 0
1 0 1 1 0
1 1 0 0 1
1 1 1 1 0
1 1 0 0 1
0 1 1 1 0
0 0 0 0 0
1 1 1 0 1
1 1 0 0 1
0 1 0 0
Вес остатка равен 1, следовательно, необходимо сложить его с сообщением.

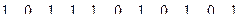
Таким образом, ошибка в блоке сообщения была исправлена.
Итак, циклический код – это блочный код, все базовые комбинации которого могут быть получены из одной путем циклического сдвига всей кодовой комбинации пошагово на один разряд справа налево. Идея построения циклических кодов базируется на использовании неприводимых в поле двоичных чисел многочленов.
В ходе проделанной работы было закодировано сообщение циклическим кодом, способным обнаружить и исправлять одну ошибку. На практике была подтверждена эффективность метода.
9. КОДИРОВАНИЕ ИНФОРМАЦИИ
СВЕРТОЧНЫМ КОДОМ
Необходимо построить сверточный код, способный обнаруживать и исправлять одну ошибку при передаче сообщения М = (АКСЕНЕНКО_И), закодированного с помощью метода Хаффмана.
9.1. Кодирование информации
Важнейшей проблемой теории помехоустойчивой передачи информации является повышение основного показателя помехоустойчивости примерно на восемь порядков.
Современные коды имеют кодовую скорость R, лежащую в диапазоне 0.2 – 0.95. Чем ближе граница, тем менее эти коды перегружены. Приближение R к 0.5 позволяет решить проблему повышения помехоустойчивости.
Для блочных кодов вся информация, подлежащая передаче, разбивается на блоки равной длины, в которых есть информационные и кодовые разряды.
I + П = Р (9.1)
где I – информационные разряды (кадры)
П – проверочные разряды
 (9.2) (9.2)
В качестве величины кодовой скорости принято R = 0.5.
Данные коды обладают самой большой избыточностью. Для надежного обнаружения и исправления ошибок сверточные коды должны обладать памятью, постоянно хранить информацию о Р кадрах. Чем больше Р, тем большими возможностями обладают коды по обнаружению и исправлению ошибок.
Р называют шагом сложения
. Он определяет допустимое количество элементов, которые могут быть поражены помехой (т.е. определяет кратность ошибки).
Одна из структурных схем кодеров приведена на рис. 9.1:

Рис. 9.1. Структурная схема дешифратора
В основе построения кодера лежит регистр сдвига. Количество разрядов этого регистра определяется как 2Р + 1. С первого и с четвертого разрядов информация поступает на сумматор, на выходе которого формируются контрольные разряды. Информационные разряды формируются на выходе седьмого разряда. Синхронный переключатель К обеспечивает поочередное подключение к выходам информационных и контрольных разрядов. Засчет этого на выходе кодера формируется сверточный код, в котором поочередно идут информационные и контрольные разряды.
Работа кодера осуществляется следующим образом: на вход подается комбинация из 0 и 1. В результате информационные разряды в регистре сдвига перемещаются от первого разряда к седьмому. В первых разрядах регистра сдвига формируются сигналы а1
, а2
, … , аi
. На выходе сумматора формируется сигнал  . Сигналы b по физическому смыслу представляют собой контрольные или проверочные разряды. Каждый информационный разряд передаваемой кодовой комбинации участвует в формировании двух контрольных разрядов: первый формируется, когда аi
находится в первой ячейке регистра сдвига; второй – когда аi
находится в четвертой ячейке. . Сигналы b по физическому смыслу представляют собой контрольные или проверочные разряды. Каждый информационный разряд передаваемой кодовой комбинации участвует в формировании двух контрольных разрядов: первый формируется, когда аi
находится в первой ячейке регистра сдвига; второй – когда аi
находится в четвертой ячейке.
Таким образом, количество информационных и контрольных разрядов всегда одинаково и следуют они так, что за каждым информационным разрядом идет контрольный..
Требуется передать сообщение, состоящее из семи разрядов: М = (1000010).
В этом случае из формулы 9.2:
m = 7
n = 14
то по формуле 7.3 k = 7
Таблица 9.1
| №
|
а1
|
а2
|
а3
|
а4
|
а5
|
а6
|
а7
|
ai
|
bj
|
| 1
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
| 2
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 3
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 4
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
| 5
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
| 6
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
| 7
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
| 8
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 9
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
| 10
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
| 11
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
| 12
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
| 13
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
Таким образом, получено закодированное сообщение:
010000010001100001000010
В исходном состоянии в ячейках регистра сдвига записана нулевая информация. С выхода кодера с седьмой ячейки снимается информационный разряд аi
. Контрольный, или проверочный, разряд bj
, который пойдет после информационного ai
, будет сниматься как сумма. После поступления первого тактового импульса в первую ячейку регистра записывается первый информационный разряд.
Из анализа видно, что на выходе кодера сначала формируется двенадцать разрядов, которые не несут полезной информации. Засчет них кодер выходит на основной режим своей работы. При декодировании сверточного кода это необходимо учитывать. Полезная информация начинает формироваться только на седьмом такте, т.е. начиная с тринадцатого разряда.
9.2. Декодирование информации
9.2.1. Декодирование информации без ошибок
Структурно декодер состоит из следующих элементов:
1. два регистра сдвига:
- информационный (с количеством ячеек 2Р+1)
- проверочный (с количеством ячеек 3Р+1)
2. четыре сумматора по модулю 2.
3. схема коррекции ошибок (СКО)
4. схема «И»
5. синхронный переключатель К, обеспечивающий запись информационных разрядов в информационный регистр, контрольных – в контрольный.
Данная структурная схема представлена на рис. 9.2:

Рис. 9.2. Структурная схема декодера
При подаче информации на декодер синхронный переключатель К направляет информационные разряды в информационные регистры сдвига, а проверочные разряды – в проверочные.
На каждом такте формируются сигналы:
 (9.3) (9.3)
А2 и В2 подаются на схему «И». С выхода после СКО снимается декодированный информационный разряд. Если в исходной последовательности, поступившей на декодер, в анализируемом разряде ошибки нет, то управляющие сигналы А2 и В2 могут принимать любые значения, кроме А2=В2=1.
Если в анализируемом разряде имеют место ошибки, то А2=В2=1. В этом случае со схемы «И» поступает управление в СКО, которая инвертирует сигнал, т.е. нуль переводит в единицу, а единицу – в нуль, и на выход декодера поступает исправленный разряд.
С помощью декодера, в принципе, возможно обнаруживать и исправлять ошибки в любом поступающем разряде.
Декодер функционирует следующим образом:
 Таблица 9.2 Таблица 9.2
| №
|
a1
|
A2
|
a3
|
a4
|
a5
|
a6
|
a7
|
b1
|
b2
|
b3
|
b4
|
b5
|
b6
|
b7
|
b8
|
b9
|
b10
|
А1
|
А2
|
В1
|
В2
|
И
|
| 1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 3
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 4
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 5
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 6
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 7
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
| 8
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 9
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 10
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
| 11
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 12
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
| 13
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
| 14
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 15
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
| 16
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
9.2.2. Проверка кода на способность обнаруживать и исправлять ошибки
Допустим, в сообщение заведомо внесена ошибкаустим, следующим образом:ать и исправлять ошибки в лю т.ализируемом разряде ошибки нет, то управляющие сигналы А2 и В2 могут :
М = 
Таблица 9.3
| №
|
a1
|
a2
|
a3
|
a4
|
a5
|
a6
|
a7
|
b1
|
b2
|
b3
|
b4
|
b5
|
b6
|
b7
|
b8
|
b9
|
b10
|
А1
|
А2
|
В1
|
В2
|
И
|
| 1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 3
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
| 4
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 5
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 6
|
0
|
0
|
0
|
1 0 0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
1
|
1
|
1
|
10
|
| 7
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
| 8
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 9
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 10
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
| 11
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| 12
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
| 13
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
| 14
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
| 15
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
| 16
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
Декодер исправил единицу на нуль и декодировал сообщение верно.
Таким образом, в результате реализации кодирования информации сверточным кодом была проверена и подтверждена эффективность данного метода. Как и другие проверенные блочные коды, он способен обнаруживать и исправлять одну ошибку. Однако отличительной особенностью данного кода является то, что информационные и контрольные разряды перемежаются при поступлении в КС. Декодер, с помощью схемы коррекции ошибок эффективно исправляет ошибки, возникшие в результате влияние помех в КС.
10. РАСЧЕТ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ
ПОМЕХОУСТОЙЧИВЫХ КОДОВ
1. Необходимо рассчитать показатели эффективности (dmin
, qэ
) кода Хаффмана, блочного и сверточного кодов для случаев:
а) канал связи с высокой помехоустойчивостью;
б) канал связи с низкой помехоустойчивостью.
2. Проанализировать зависимость qэ
= qэ
(R), где R – кодовая скорость.
Для расчетов принять:
а) КС выполнен по схеме системы передачи данных с ООС.
б) значения вероятности возникновения ошибок в одном разряде взять из п. 6.
qv
= 1.1 * 10 -6
– для КС с высокой помехоустойчивостью
qn
= 1.1 * 10 -2
– для КС с низкой помехоустойчивостью
10.1. Расчет показателей эффективности кодов
Любой код представляет собой, в конечном счете, последовательность 0 и 1. Если код некорректирующий, то все разряды являются информационными. Если код корректирующий, то в кодовой комбинации присутствуют информационные и проверочные разряды.
Вследствие большого количества разработанных кодов требуется некоторый универсальный показатель их качества. Величина dmin
, в принципе, характеризует код с точки зрения способности обнаруживать и исправлять ошибки. Однако не во всех случаях dmin
позволяет оценить качество кода. Поэтому для оценки качества системы кодирования и декодирования вводится показатель, который получил название эквивалентной вероятности ошибки. При расчете этого показателя реальная система кодирования и характеристики реального канала приводятся к двоичному симметричному каналу.
Пусть передается n–разрядная кодовая комбинация, в которой m информационных разрядов. Пусть также в канале в вероятностью Р безошибочно принимаются кодовые группы (m+k=n).
Рассмотрим другой канал – двоичный симметричный канал, в котором ошибки возникают с вероятностью qэ
. Предположим, что по нему передаются n двоичных информационных символа, но при безошибочном кодировании. Он не обнаруживает и не исправляет ошибки.
С точки зрения надежности передачи информации будем считать, что оба канала эквивалентны. Тогда можно установить связь между p и q следующим образом:
Р = (1 – q)m
(10.1)
 qэ
= 1 – qэ
= 1 –  (10.2) (10.2)
Существует достаточно много систем, в которых информация передается не только в прямом, но и в обратном направлении. Такие КС получили название дуплексных каналов.
Возможны различные способы использования таких систем для решения задач защиты информации, однако все их многообразие можно условно разделить на две группы:
- системы с информационной обратной связью;
- системы с управляющей обратной связью.
В данной работе КС выполнен по второй схеме системы передачи данных. Она выглядит следующим образом:

Рис. 10.1. Система с управляющей обратной связью
где ИИ – источник информации
АСП – анализатор сигнала переспроса
ПКС – прямой КС
ОКС – обратный КС
ДК с ОО – декодер с обнаружителем ошибок
ДСП – датчик сигнала переспроса
ПИ – приемник информации
К – переключатель
Информация от источника ИИ кодируется блоками. Каждый блок собирается в накопителе и передается по ПКС. В приемной части канала в ДК с ОО каждый принятый блок анализируется. Если ошибок не обнаружено, он передается потребителю, если ошибки обнаружены, то декодер формирует управление для запуска датчика сигнала переспроса.
Сигнал переспроса представляет собой кодовую группу, которая не участвует в формировании полезной информации. Эта кодовая группа передается по ОКС. При ее наличии на входе АСП формируется управление U2
и с накопителя через переключатель К в КС дублируется последний блок.
Основным достоинством такой схемы является то, что наблюдается существенная экономия ресурса канала. Для количественных характеристик эффективности таких каналов вводят следующие показатели:
Рпр
– вероятность безошибочной передачи кодовой комбинации
Рно
– вероятность приема кодовой комбинации с необнаруженной ошибкой
Роо
– вероятность приема кодовой комбинации с обнаруженной ошибкой
Эти вероятности можно рассчитать, если знать характеристики кода и КС. Основной характеристикой КС является вероятность q совершения ошибки при передаче одного бита информации. Тогда для симметричного КС вероятность безошибочного приема информации будет находиться по следующей формуле:
Рпр
= (1 – q)n
(10.3)
где q – вероятность приема ложного сигнала в одном разряде
 (10.4) (10.4)
где m – количество информационных разрядов
Роо
= 1 – Рпр
– Рно
(10.5)
Поскольку при исправлении ошибок организуется повторная передача блоков, то с обнаружением «забракованных» блоков могут быть запросы 1, 2, 3 и большее число раз. Но каждый запрос идет со своей вероятностью. В этом случае говорят, что формируется так называемая остаточная вероятность того, что кодовая комбинация будет передана получателю с необнаруженной ошибкой.
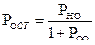 (10.6) (10.6)
Тогда Рпр
= 1 –  , и, опираясь на формулы 10.1 и 10.4, получим: , и, опираясь на формулы 10.1 и 10.4, получим:
qэ
=  (10.7) (10.7)
Скорость передачи в системе определяется не только соотношением  , но и потерей времени на повторение информации, поскольку кодовая комбинация поступает к получателю только тогда, когда не обнаружена ошибка. В этом случае кодовую скорость необходимо рассчитать по следующей формуле: , но и потерей времени на повторение информации, поскольку кодовая комбинация поступает к получателю только тогда, когда не обнаружена ошибка. В этом случае кодовую скорость необходимо рассчитать по следующей формуле:
R (10.8) (10.8)
Для двоичного кода:
R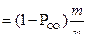 (10.9) (10.9)
10.1.1. Расчет эффективности для кода Хаффмана
Из п. 5 видно, что количество информационных разрядов в сообщении, закодированном методом Хаффмана m = 46, а контрольных k = 0.
Из формулы (10.7) следует:
 = = 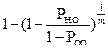
В случае, когда используется КС с низкой помехозащищенностью, вероятность появления ошибки в одном разряде qv
= 1.1 * 10 -3
.
В соответствии с формулами 10.3, 10.4, 10.5, найдены значения вероятностей:
Рпр
= 0.951
 1.421 1.421 10-14 10-14
Роо
= 0.049
Исходя из этого, по формуле 10.7 можно найти эквивалентную вероятность:
qэ
 0 0
В случае, когда используется КС с высокой помехозащищенностью, вероятность появления ошибки в одном разряде qv
= 1.1 * 10 -6
.
В соответствии с теми же формулами, найдены значения вероятностей:
Рпр
1
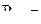 1.42110-14 1.42110-14
Роо
= 5.0610-5
Эквивалентная вероятность также стремится к нулю: qэ
0.
10.1.2. Расчет для блочного кода
Показатели эффективности для блочных кодов осуществляются аналогичным образом с той лишь разницей, что количество информационных разрядов в этом случае равно 7, а контрольных – 4.
В случае, когда используется КС с низкой помехозащищенностью, показатели эффективности будут следующими:
Рпр
= 0.988
7.81310-3
Роо
= 4.22110-3
qэ
= 0.0011
Однако в случае, когда используется КС с высокой помехозащищенностью, вероятность обнаружения ошибки в сообщении принимает отрицательное значение, что логически невозможно:
Рпр
1
 7.81310-3 7.81310-3
Роо
= – 7.810-3
qэ
= 0.0011
Можно предположить, что эта вероятность настолько мала, что становится отрицательной. Однако данным метод расчета показателей эффективности все еще требует доработки.
10.1.3. Расчет для сверточного кода
При расчете показателей эффективности сверточного кода наблюдается та же картина, что и у блочных кодов.
В случае, когда используется КС с низкой помехозащищенностью, показатели эффективности будут следующими:
Рпр
= 0.985
 7.81310-3 7.81310-3
Роо
= 7.47810-3
qэ
= 0.0011
А в случае, когда используется КС с высокой помехозащищенностью, вероятность обнаружения ошибки в сообщении также принимает отрицательное значение:
Рпр
1
 7.81310-3 7.81310-3
Роо
= – 7.79710-3
qэ
= 0.0011
10.2. Анализ зависимости qэ
= qэ
(R)
Эквивалентная вероятность ошибки напрямую связана с кодовой скоростью. Очевидно, что чем выше скорость передачи кодовой комбинации, тем больше вероятность допустить ошибку.
В соответствии с формулой 10.9 можно найти кодовые скорости для каждого метода кодирования информации и построить графики зависимости эквивалентной вероятности ошибки от кодовой скорости.
Для кода Хаффмана:
m = 46
n = 46
R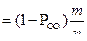
R = 0.601
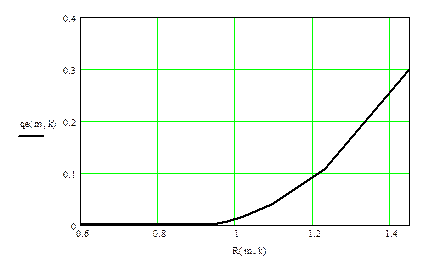
Рис. 10.2. Зависимость ЭВО от кодовой скорости для метода Хаффмана
Для блочного кода:
m = 7
n = 11
R = 0.568

Рис. 10.3. Зависимость ЭВО от кодовой скорости для блочного кода
Для сверточного кода:
m = 7
n = 14
R = 0.432

Рис. 10.4. Зависимость ЭВО от кодовой скорости для сверточного кода
Очевидно, что данный способ подсчета показателей эффективности требует доработки, т.к., судя по построенным графикам, ситуация, при которой с увеличением кодовой скорости вероятность возникновения ошибки падает, невозможна.
Таким образом, метод Хаффмана для случая, когда взят канал с низкой помехозащищенностью, наиболее эффективен.
ЗАКЛЮЧЕНИЕ
Выбор и обоснование информационных характеристик канала связи осуществляется путем определения некоторых основных параметров.
Вид требуемого КС напрямую зависит от того, какое количество информации необходимо передать. Определив этот параметр, можно выяснить, какой пропускной способностью должен обладать канал, чтобы без искажений передавать данную информацию. Немаловажно также то, как он будет согласовываться с источником информации и приемником. Для нормальной передачи сообщения были выявлены два обязательных условия:
1. Пропускная способность КС должна быть больше либо равна скорости выдачи информации датчиком.
2. Скорость вывода информации на дисплей должна быть больше либо равна пропускной способности КС.
Однако это не единственные условия, обеспечивающие передачу информации без искажений. Ошибки в передаваемых словах могут возникать вследствие природных или преднамеренных помех.
Управление правильностью (помехозащищенностью) передачи информации выполняется с помощью помехоустойчивого кодирования. Различают коды, обнаруживающие ошибки, и корректирующие коды, которые дополнительно к обнаружению еще и исправляют ошибки.
Помехоустойчивые коды позволяют по имеющейся в кодовой комбинации избыточности
обнаруживать и исправлять определённые ошибки, появление которых приводит к образованию ошибочных или запрещенных комбинаций. Кодовые слова корректирующих кодов содержат информационные и проверочные разряды. В процессе кодирования при передаче информации из информационных разрядов, в соответствии с определёнными для каждого кода правилами, формируются дополнительные символы — проверочные разряды. При декодировании из принятых кодовых слов по тем же правилам вновь формируют проверочные разряды и сравнивают их с принятыми; если они не совпадают, значит, при передаче произошла ошибка.
При рассмотрении некоторых методов была рассчитана эффективность каждого из них. Выбор кода для каждого случая необходимо согласовывать со статистической структурой рассматриваемого источника сообщений, КС и приемника.
ПРИЛОЖЕНИЕ
ТАБЛИЦЫ ЗНАЧЕНИЙ ВЕРОЯТНОСТЕЙ
ПОЯВЛЕНИЯ БУКВ РУССКОГО АЛФАВИТА
В ХУДОЖЕСТВЕННОМ ТЕКСТЕ
| А
|
0.062
|
|
И
|
0.062
|
|
Р
|
0.040
|
|
Ш
|
0.006
|
| Б
|
0.014
|
|
Й
|
0.01
|
|
С
|
0.045
|
|
Щ
|
0.003
|
| В
|
0.038
|
|
К
|
0.028
|
|
Т
|
0.053
|
|
Ъ, Ь
|
0.014
|
| Г
|
0.013
|
|
Л
|
0.035
|
|
У
|
0.021
|
|
Ы
|
0.016
|
| Д
|
0.025
|
|
М
|
0.026
|
|
Ф
|
0.002
|
|
Э
|
0.002
|
| Е
|
0.072
|
|
Н
|
0.053
|
|
Х
|
0.009
|
|
Ю
|
0.006
|
| Ж
|
0.007
|
|
О
|
0.090
|
|
Ц
|
0.004
|
|
Я
|
0.018
|
| З
|
0.016
|
|
П
|
0.023
|
|
Ч
|
0.012
|
|
пробел
|
0.175
|
|