Введение 4
Глава 1. Обзор
и сравнительный
анализ существующих
АРМ. 9
1.1 Библиотечные
системы. 18
1.1.1 РГБ (ГБЛ) 18
1.1.2 Библиотека
Администрации
Президента
Российской
Федерации
(БАПРФ). 19
1.1.3 Российская
национальная
библиотека
(РНБ). 20
1.1.4 ГПНТБ России. 20
Глава 2. Анализ
исходных данных
и выбор оптимального
инструментария
для разработки
АРМ. 22
2.1 Назначение
разрабатываемого
АРМ. 22
2.2 Определение
структурной
схемы. 22
2.3 Выбор
конкретного
программного
инструментария. 24
Глава 3. Разработка
логической
схемы. 28
3.1 Логическое
проектирование 28
3.1.1 Определение
цели создания
АРМ. 29
3.1.2 Определение
таблиц и необходимых
полей. 29
3.1.3 Определение
связей между
таблицами. 35
3.2 Разработка
таблиц. 36
3.2.1 Построение
таблиц. 36
3.2.2 Назначение
типов данных
для полей таблиц. 39
3.2.3 Создание
индексов и
связей между
таблицами 44
Глава 4. Разработка
и реализация
алгоритма 47
4.1 Разработка
алгоритма. 47
4.2 Реализация
алгоритма. 52
4.2.1 Функциональные
модули. 52
4.2.2 Модуль
идентификации
и аутентификации. 52
4.2.3 Модуль
картотеки
фондов. 53
4.2.3.1 Главная
форма 55
4.2.3.2 Просмотр 57
4.2.3.3 Поиск 61
4.2.3.4 Сортировка. 64
4.2.3.5 Фильтр 65
4.2.3.6 Новости 66
4.2.3.7 Настройка 68
4.2.3.8 Добавление 69
4.2.3.9 Изменение 71
4.2.3.10 Печать. 72
4.2.4 Модуль
картотеки
читателей. 72
4.2.4.1 Главная
форма 72
4.2.4.2 Просмотр 77
4.2.4.3 Поиск 80
4.2.4.4 Сортировка 82
4.2.4.5 Фильтр 82
4.2.4.6 Настройка 83
4.2.4.7 Добавление 84
4.2.4.8 Изменение 86
4.2.4.9 Статистика. 87
4.2.4.10 Печать. 87
4.2.5 Модуль
контроля. 87
4.2.6 Модуль
администратора. 87
Глава 5. Реализация
выбранных
решений. 89
Глава 6. Анализ
и учёт эргономических
характеристик. 92
Глава 7. Технико-экономическое
обоснование. 99
Заключение. 107
Список использованной
литературы. 109
Введение
Задача накопления,
обработки и
распространения
(обмена) информации
стояла перед
человечеством
на всех этапах
его развития.
В течение долгого
времени основными
инструментами
для ее решения
были мозг, язык
и слух человека.
Первое кардинальное
изменение
произошло с
приходом
письменности,
а затем изобретением
книгопечатания.
Поскольку в
эпоху книгопечатания
основным носителем
информации
стала бумага,
то технологию
накопления
и распространения
информации
естественно
называть “бумажной
информатикой”.
Положение
в корне изменилось
с появлением
электронных
вычислительных
машин (ЭВМ). Первые
ЭВМ использовались
как большие
автоматические
арифмометры.
Принципиально
новый шаг был
совершен, когда
от применения
ЭВМ для решения
отдельных задач
перешли к их
использованию
для комплексной
автоматизации
тех или иных
законченных
участков деятельности
человека по
переработке
информации.
Одним из
первых примеров
подобного
системного
применения
ЭВМ в мировой
практике были
так называемые
административные
системы обработки
данных: автоматизация
банковских
операций,
бухгалтерского
учета, резервирования
и оформления
билетов и т.п.
Решающее значение
для эффективности
систем подобного
рода имеет то
обстоятельство,
что они опираются
на автоматизированные
информационные
базы. Это означает,
что в памяти
ЭВМ постоянно
сохраняется
информация,
нужная для
решения тех
задач, на которые
рассчитана
система. Она
и составляет
содержимое
информационной
базы соответствующей
системы.
При решении
очередной
задачи система
нуждается во
вводе только
небольшой
порции дополнительной
информации,
- остальное
берется из
информационной
базы. Каждая
порция вновь
вводимой информации
изменяет
информационную
базу системы.
Эта база (информационная,
или база данных)
находится,
таким образом,
в состоянии
непрерывного
обновления,
отражая все
изменения,
происходящие
в реальном
объекте, с которым
имеет дело
система.
Хранение
информации
в памяти ЭВМ
придает этой
информации
принципиально
новое качество
динамичности,
т.е. способности
к быстрой перестройке
и непосредственному
ее использованию
в решаемых на
ЭВМ задачах.
Устройства
автоматической
печати, которыми
снабжены современные
ЭВМ, позволяют
в случае необходимости
быстро представить
любую выборку
из этой информации
в форме представления
на бумаге.
В преддверии
XXI века
в развитии
человеческой
цивилизации
происходят
глобальные
изменения,
ведущие к её
новому этапу
- постиндустриальному
обществу, все
шире использующему
компью-теризированные
орудия труда
и информационные
технологии.
Информация
в таком обществе
становится
одним из основных
продуктов
деятельности
человека, и
библиотекам
со своим огромным
информационным
потенциалом
предстоит войти
в процесс развития
информационной
индустрии,
обогащая содержание
и расширяя
ассортимент
производимого
ими информационного
продукта, включая
в поле деятельности
наряду с библиографической
информацией
фактографическую
и аналитическую,
а также создание
традиционной
и новой продукции
(фонды, каталоги
в бумажном и
машиночитаемом
видах, банки
данных). Всего
этого можно
достичь, если
библиотеки
уже сейчас, не
теряя времени,
приступят к
выполнению
комплексных
программ
автоматизации
библиотечных
процессов.
Традиционно
пользователи
привыкли к
мысли, что в
библиотеке
можно получить
любую информацию.
Теперь, в условиях
информационного
перенасыщения,
библиотеке
все сложнее
выполнять
основные функции:
фондообразование,
информационно-библиографическое
и абонементное
обслуживание.
Улучшить сбор,
хранение и
обеспечение
доступа к информации
библиотека
сможет только
при условии
изменения ее
технического
оснащения.
Насколько
же необходимо
обзаводиться
вычислительной
техникой, и ,
что нам могут
дать автоматизированные
библиотечно-информационные
системы (АБИС)?
Чаще всего
приводится
следующий
аргумент - повышение
скорости поиска
информации.
На самом деле
это не главное.
В конце концов,
в относительно
небольшом
массиве данных
ручной поиск
занимает не
слишком много
времени.
Более существенны
следующие
возможности:
«одноразовый
ввод данных
и многоцелевое
их использование
для поиска
документов,
печати подобранной
информации,
передачи массивов
данных другим
организациям,
подготовки
изданий и т.д.;
поиск в каталогах
других библиотек
и сводных каталогах,
который осуществляется
с дисплея своего
компьютера
в теледоступе
по каналам
связи или в
базах данных
на оптических
дисках большой
емкости, устанавливаемых
на компьютерах
в своей библиотеке;
организация
комплектования
фонда с использованием
баз данных
издающих или
книготорговых
изданий, например,
агентства
"Роспечать",
с автоматическим
формированием
заказов и учетом
их выполнения;
На практике
это означает
выполнение
автоматизированной
обработки новых
поступлений
в библиотеку;
освобождение
сотрудников
от ряда рутинных
работ по подготовке
картотек, изданий,
списков, заказов,
писем, отчетной
документации;
создание базы
данных о поступлениях;
осуществление
операций по
созданию и
копированию
тематических
архивов литературы.
Благодаря
автоматизации
можно выполнять
предметный
поиск информации
по запросам
читателей,
обслуживание
баз данных
информационных
и периодических
изданий библиотеки,
ведение массива
библиографических
описаний журнальных
статей, поиск
записей по
ключевым словам,
создание электронных
справочников,
контроль за
выданной литературой:
учет читателей
и их формуляров;
автоматическая
запись в формуляр
читателя выданной
литературы;
контроль срока
возврата книг.
А главное -
обеспечение
читателям своей
библиотеки
выхода в отечественное
и мировое
информационное
пространство.
Какие же
функции библиотеки
целесообразно
автоматизировать
?
Программное
обеспечение
в первую очередь
должно реализовать
следующие
функции АБИС:
подготовку
материалов
для библиографических
изданий, подборок
материалов
в виде списков,
фактографических
и библиографических
записей, отсортированным
по индексам
какой-либо
классификации
и алфавиту;
Глава
1. Обзор и сравнительный
анализ существующих
АРМ.
Современные
масштабы
и темпы внедрения
средств автоматизации
управления
с особой остротой
ставит задачу
проведения
комплексных
исследований,
связанных со
всесторонним
изучением и
обобщением
возникающих
при этом проблем
как практического,
так и теоретического
характера.
В последние
годы возникает
концепция
распределенных
систем управления
народным хозяйством,
где предусматривается
локальная
обработка
информации.
Для реализации
идеи распределенного
управления
необходимо
создание для
каждого уровня
управления
и каждой
предметной
области автоматизированных
рабочих мест
(АРМ) на базе
профессиональных
персональных
ЭВМ.
Анализируя
сущность АРМ,
специалисты
определяют
их чаще всего
как профессионально-ориентированные
малые вычислительные
системы, расположенные
непосредственно
на рабочих
местах специалистов
и предназначенные
для автоматизации
их работ.
Для каждого
объекта управления
нужно предусмотреть
автоматизированные
рабочие места,
соответствующие
их функциональному
назначению.
Однако принципы
создания АРМ
должны быть
общими: системность,
гибкость,
устойчивость,
эффективность.
Согласно
принципу
системности
АРМ следует
рассматривать
как системы,
структура
которых определяется
функциональным
назначением.
Принцип
гибкости означает
приспособляемость
системы к возможным
перестройкам
благодаря
модульности
построения
всех подсистем
и стандартизации
их элементов.
Принцип
устойчивости
заключается
в том, что система
АРМ должна
выполнять
основные функции
независимо
от воздействия
на нее внутренних
и возможных
внешних факторов.
Это значит,
что неполадки
в отдельных
ее частях должны
быть легко
устранимы, а
работоспособность
системы - быстро
восстановима.
Эффективность
АРМ следует
рассматривать
как интегральный
показатель
уровня реализации
приведенных
выше принципов,
отнесенного
к затратам по
созданию и
эксплуатации
системы.
Функционирование
АРМ может дать
численный
эффект только
при условии
правильного
распределения
функций и
нагрузки между
человеком и
машинными
средствами
обработки
информации,
ядром которых
является ЭВМ.
Лишь тогда
АРМ станет
средством
повышения не
только производительности
труда и эффективности
управления,
но и социальной
комфортности
специалистов.
Теперь
рассмотрим
более подробно
состояние и
перспективы
развития АРМ
на базе персональных
ЭВМ, а затем
затронем некоторые
вопросы технического
и программного
обеспечения
АРМ.
Развитие
электроники
привело к
появлению
нового класса
вычислительных
машин - персональных
ЭВМ (ПЭВМ). Главное
достоинство
ПЭВМ - сравнительно
низкая стоимость
и в то же время
высокая
производительность.
Так, например,
если проанализировать
характеристики
больших ЭВМ
начала 60-х годов,
мини-ЭВМ начала
70-х годов и ПЭВМ
80-х гг., то окажется,
что производительность
примерно
одинакова.
Низкая стоимость,
надежность,
простота
обслуживания
и эксплуатации
расширяет
сферу применения
ПЭВМ прежде
всего за счет
тех областей
человеческой
деятельности,
в которых раньше
вычислительная
техника не
использовалась
из-за высокой
стоимости,
сложности
обслуживания
и взаимодействия.
К таким областям
относится и
так называемая
учрежденческая
деятельность,
где применение
ПЭВМ позволило
реально повысить
производительность
труда специалистов,
связанных с
обработкой
информации.
Этот аспект
особенно актуален
в связи с тем,
что производительность
управленческого
труда до сих
пор росла крайне
низкими темпами.
Так за последние
30 лет она повысилась
в 2-3 раза, а в то
же время в
промышленности
- в 14-15 раз. В настоящее
время для
интенсификации
умственного
и управленческого
труда специалистов
различных
профессий
разрабатываются
и получают
широкое распространение
АРМ которые
функционируют
на базе ПЭВМ.
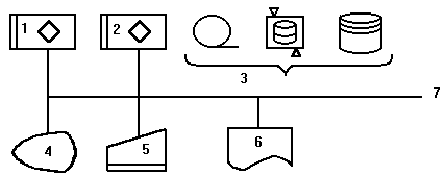
Рис 1.1 Обобщенная
схема ПЭВМ:
1-микропроцессор,
2-основная память,
3-ВЗУ, 4-дисплей,
5-клавиатура,
6-печатающее
устройство,
7-системная
магистраль.
Рассмотрим
основные
составляющие
элементы АРМ
работников
экономических
служб, управленческой
деятельности
и др., перспективы
их развития
и использования.
На рис. 1.1 представлена
общая схема
ПЭВМ, составляющей
техническую
основу АРМ.
Основным
устройством
ПЭВМ является
микропроцессор,
который обеспечивает
выполнение
различных
операций,
содержащихся
в программе.
В настоящее
время наибольшее
распространение
получили
32-разрядные
микропроцессоры,
но уже очевидно,
что скоро на
смену им придут
64-разрядные
микропроцессоры.
Разрядность
означает длину
рабочего слова
в двоичном
коде. Микропроцессоры
также различаются
по тактовой
частоте, с которой
они работают.
Чем больше
тактовая частота
и разрядность,
тем выше
производительность
процессора.
Выполнение
нескольких
десятков миллионов
операций в
секунду является
обычным делом
для ПЭВМ.
Производительность
ПЭВМ зависит
также и от
количества
памяти, с которой
она работает.
Память бывает
основная и
внешняя. Основная
память состоит
из двух компонентов:
постоянного
запоминающего
устройства
(ROM или ПЗУ) и
оперативного
запоминающего
устройства
(RAM или ОЗУ). В ОЗУ
хранится
динамическая
информация
программы и
обрабатываемые
данные. При
выключении
питания содержимое
ОЗУ теряется.
ПЗУ, как правило,
гораздо меньше
ОЗУ, информация
в нем хранится
постоянно и
ее изменение
либо вообще
невозможно,
либо возможно
только при
помощи специальных
устройств
(программаторов
ПЗУ). Емкость
памяти 8-разрядных
ЭВМ как правило
64Кб - 640Кб, 16-разрядных
- 1Мб, 32-разрядных
- 4Мб и более.
Внешние
запоминающие
устройства
(ВЗУ) также бывают
разных типов.
Ленточные
накопители
служат для
хранения информации
на магнитной
ленте. В настоящее
время могут
хранить до
нескольких
гигабайт (1Гб
= 1024 Мб) информации.
Несмотря на
то, что эти
устройства
появились
довольно давно,
они до сих пор
широко распространены,
главным образом
из-за большого
объема вмещаемых
данных, и используются
в основном
для резервного
копирования
и длительного
хранения информации.
Дисковые накопители
в настоящее
время наиболее
широко распространены.
Их можно разделить
на несколько
групп:
а) Накопители
на гибких
дисках (флоппи
дисках). Несмотря
на сравнительно
низкую емкость
дискет (от 1 до
3Мб) в настоящее
время очень
широко распространены
главным образом
из-за низкой
стоимости.
б) Накопители
на жестких
дисках
(винчестеры).Распространены
также широко,
как и накопители
на гибких дисках,
но имеют гораздо
большую скорость
передачи данных,
большую емкость
и надежность
хранения
информации.
Стоимость
винчестеров
постоянно
падает, а скорость,
надежность
и емкость (жестким
диском объемом
1-2Гб сейчас уже
никого не удивишь)
возрастают.
Все это делает
их незаменимым
атрибутом
любой современной
ПЭВМ.
в) Все большее
распространение
в настоящее
время получают
накопители
на лазерных
дисках (CD-ROM). Несмотря
на ряд недостатков
CD-ROM (небольшая
скорость передачи
данных и невозможность
перезаписи)
они занимают
все более
существенную
роль как средство
хранения информации
благодаря
тому, что могут
хранить большой
объем информации
(порядка 600Мб),
обеспечивают
высочайшую
надежность
и при этом их
себестоимость
немногим выше
стоимости
гибких дисков.
г) Существует
также целый
ряд других
ВЗУ по разным
причинам не
получивших
в настоящее
время широкого
распространения
(магнитооптические
диски, диски
Бернулли, WORM-диски
и др.). Некоторые
виды накопителей
(перфоленты,
перфокарты,
магнитные
барабаны и
пр.) сильно
устарели и в
современных
ПЭВМ вообще
не используются.
Дисплей
- основное
устройство
для отображения
информации.
Характеризуются
размером экрана,
максимальным
разрешением
и пр. Чем больше
размер экрана
и чем больше
разрешение,
тем, соответственно
больше информации
можно на нем
разместить.
Клавиатура
- основное
устройство
для ввода
информации.
Существуют
также устройства,
облегчающие
работу оператора,
такие, как мышь,
световое перо
и пр. Также для
ввода информации
широко используются
сканеры. Большое
будущее за
устройствами
распознавания
и синтеза речи,
распознавания
изображения.
Все устройства
ПЭВМ взаимодействуют
через системную
магистраль.
Однако из ВЗУ
информация
сначала должна
быть переписана
в ОЗУ и лишь
тогда, она
становиться
доступной
процессору.
Напомним,
что наиболее
эффективной
организационной
формой использования
ПЭВМ является
создание на
их базе АРМ
конкретных
специалистов
(экономистов,
статистиков,
бухгалтеров,
руководителей),
поскольку
такая форма
устраняет
психологический
барьер в отношениях
между человеком
и машиной.
Накопленный
опыт подсказывает,
что АРМ должен
отвечать следующим
требованиям:
своевременное
удовлетворение
информационной
и вычислительной
потребности
специалиста
минимальное
время ответа
на запросы
пользователя
адаптация
к уровню подготовки
пользователя
и его профессиональным
запросам
простота
освоения приемов
работы на АРМ
и легкость
общения, надежность
и простота
обслуживания
терпимость
по отношению
к пользователю
возможность
быстрого обучения
пользователя
возможность
работы в составе
вычислительной
сети.
Обобщенная
схема АРМ
представлена
на рис. 1.2.
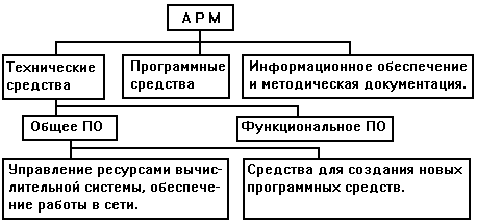
Рис 1.2. Схема
автоматизированного
рабочего места. Общее
программное
обеспечение
(ПО) обеспечивает
функционирование
вычислительной
техники, разработку
и подключение
новых программ.
Сюда входят
операционные
системы, системы
программирования
и обслуживающие
программы.
Профессиональная
ориентация
АРМ определяется
функциональной
частью ПО (ФПО).
Именно здесь
закладывается
ориентация
на конкретного
специалиста,
обеспечивается
решение задач
определенных
предметных
областей.
При разработке
ФПО очень
большое внимание
уделяется
вопросам
организации
взаимодействия
“человек-машина”.
Пользователю
интересно и
увлекательно
работать на
ЭВМ только в
том случае,
когда он чувствует,
что он занимается
полезным, серьезным
делом. В противном
случае его
ждут неприятные
ощущения.
Непрофессионал
может почувствовать
себя обойденным
и даже в чем-то
ущемленным
только потому,
что он не знает
неких “мистических”
команд, набора
символов, вследствие
чего у него
может возникнуть
глубокая досада
на все программное
обеспечение
или служителей
культа ЭВМ.
Анализ
диалоговых
систем с точки
зрения организации
этого диалога
показал, что
их можно разделить
(по принципу
взаимодействия
пользователя
и машины) на:
Применение
командного
языка в прикладных
системах это
перенос идей
построения
интерпретаторов
команд для
мини- и микро
ЭВМ. Основное
его преимущество
- простота
построения
и реализации,
а недостаток
- продолжение
их достоинств:
необходимость
запоминания
команд и их
параметров,
повторение
ошибочного
ввода, разграничение
доступности
команд на
различных
уровнях и пр.
Таким образом,
в системах с
командным
языком пользователь
должен изучать
язык взаимодействия.
Внешне противоположный
подход “человек
в мире объектов”
- отсутствуют
команды и человек
в процессе
работы “движется”
по своему объекту
с помощью клавиш
управления
курсором,
специальных
указывающих
устройств
(мышь, перо),
функциональных
комбинаций
клавиш. Диалог
в форме меню
представляет
пользователю
множества
альтернативных
действий, из
которых он
выбирает нужные.
В настоящее
время наиболее
широкое распространение
получил пользовательский
интерфейс,
сочетающий
в себе свойства
двух последних.
В нем все рабочее
пространство
экрана делится
на три части
(объекта). Первая
(обычно располагающаяся
вверху) называется
строкой или
полосой меню.
С ее помощью
пользователь
может задействовать
различные
меню, составляющие
“скелет” программы,
с их помощью
производится
доступ к другим
объектам (в
т.ч. управляющим).
Вторая часть
(обычно располагается
внизу или в
небольших
программах
может вообще
отсутствовать)
называется
строкой состояния.
С ее помощью
могут быстро
вызываться
наиболее часто
используемые
объекты или
же отображаться
какая-либо
текущая информация.
Третья часть
называется
рабочей поверхностью
(поверхностью
стола) - самая
большая. На
ней отображаются
все те объекты,
которые вызываются
из меню или
строки состояния.
Такая форма
организации
диалога человека
и машины наиболее
удобна (по крайней
мере, на сегодняшний
день ничего
лучшего не
придумано) и
все современные
программы в
той или иной
мере используют
ее. В любом случае
она должна
соответствовать
стандарту СUA
(Common User Access) фирмы IBM.
Рассмотрим
теперь два
подхода к разработке
АРМ. Первый
подход - функциональный
представляет
собой автоматизацию
наиболее типичных
функций.
Посмотрим,
как адаптируется
функциональное
ПО (ФПО) к конкретным
условиям применения.
Отметим программные
средства, которые
являются базовыми
при АРМ для
различных
профессий,
связанных с
обработкой
деловой информации
и принятием
управленческих
решений.
Первыми
появились
программные
средства для
автоматизации
труда технического
персонала,
что обусловлено,
вероятно, большой
формализацией
выполняемых
ими функций.
Наиболее типичным
примером являются
текстовые
редакторы
(процессоры).
Они позволяют
быстро вводить
информацию,
редактировать
ее, сами осуществляют
поиск ошибок,
помогают
подготовить
текст к распечатке.
Применение
текстовых
редакторов
позволят значительно
повысить
производительность
труда машинисток.
Специалистам
часто приходится
работать с
большими объемами
данных, с тем,
чтобы найти
требуемые
сведения для
подготовки
различных
документов.
Для облегчения
такого рода
работ были
созданы системы
управления
базами данных
(СУБД, DBASE, RBASE, ORACLE и др.).
СУБД позволяют
хранить большие
объемы информации,
и, что самое
главное, быстро
находить нужные
данные. Так,
например, при
работе с картотекой
постоянно
нужно перерывать
большие архивы
данных для
поиска нужной
информации,
особенно если
карточки
отсортированы
не по нужному
признаку. СУБД
справится с
этой задачей
за считанные
секунды.
Большое
число специалистов
связано также
с обработкой
различных
таблиц, так
как в большинстве
случаев экономическая
информация
представляется
в виде табличных
документов.
КЭТ (крупноформатные
электронные
таблицы) помогают
создавать
подобные
документы.
Они очень
удобны, так
как сами пересчитывают
все итоговые
и промежуточные
данные при
изменении
исходных. Поэтому
они широко
используются,
например, при
прогнозировании
объемов сбыта
и доходов.
Достаточно
большой популярностью
в учреждениях
пользуются
программные
средства АРМ
для контроля
и координации
деятельности
организации,
где вся управленческая
деятельность
описывается
как совокупность
процессов,
каждый из которых
имеет даты
начала, конца
и ответственных
исполнителей.
При этом деятельность
каждого работника
увязывается
с остальными.
таким образом
создается
план-график
работ. Пакет
может автоматически
при наступлении
срока формировать
задания исполнителям,
напоминать
о сроке завершения
работы и накапливать
данные об
исполнительской
деятельности
сотрудников.
Важную
роль в учрежденческой
деятельности
играет оперативный
обмен данными,
который занимает
до 95% времени
руководителя
и до 53% времени
специалистов.
В связи с этим
получили широкое
распространение
программные
средства типа
“электронная
почта”. Их
использование
позволяет
осуществлять
рассылку документов
внутри учреждения,
отправлять,
получать и
обрабатывать
сообщения с
различных
рабочих мест
и даже проводить
совещания
специалистов,
находящихся
на значительном
расстоянии
друг от друга.
Проблема обмена
данными тесно
связана с
организацией
работы АPM в
составе вычислительной
сети.
В настоящее
время наблюдается
тенденция к
созданию так
называемых
интегрированных
пакетов, которые
вмещают в себя
возможности
и текстовых
редакторов,
и таблиц, и
графических
редакторов.
Наличие большого
числа различных
программ для
выполнения
в сущности
одинаковых
операций -
создания и
обработки
данных обусловлено
наличием трех
различных
основных видов
информации:
числовой,
текстовой и
графической.
Для хранения
информации
чаще всего
используются
СУБД, которые
позволяют
соединять все
эти типы данных
в единое целое.
Сейчас идет
бурное развитие
двух других
видов информации:
звуковой и
видеоинформации.
Для них уже
созданы свои
редакторы и
не исключено
что в скором
времени эти
виды информации
станут неотъемлемой
частью большинства
баз данных.
Хотя современное
ФПО отвечает
почти всем
требованиям,
налагаемых
на него работниками
различных
профессий,
чего-то все
равно всегда
не хватает.
Поэтому большим
плюсом такого
ПО является
возможность
его доработки
и изменения.
Что же касается
разработки
новых программных
средств в АРМ,
то она ведется
по двум направлениям:
создание нового
ПО для новых
профессий и
специализация
ПО для существующих
профессий. В
настоящее
время наблюдается
тенденция
перехода к
созданию АРМ
профессионального
назначения.
Оно выражается
в следующем:
учет
решаемых задач
взаимодействие
с другими
сотрудниками
учет
профессиональных
привычек и
склонностей
разработка
не только ФПО,
но и специальных
технических
средств (мышь,
сеть, автоматический
набор телефонных
номеров и пр.)
Оснащение
специалистов
такими АРМ
позволяет
повысить
производительность
труда учрежденческих
работников,
сократить их
численность
и при этом
повесить скорость
обработки
экономической
информации
и ее достоверность,
что необходимо
для эффективного
планирования
и управления.
Теперь
рассмотрим
программные
комплексы для
библиотек,
которые представлены
на российском
рынке. Ведущий
разработчик
библиотечных
систем - ГИВЦ
(Главный
информационно-вычислительный
центр), выполнивший
такие разработки
АБИС, как «АС-Бибиотека»,
«АБИС-Бибиофил»,
«Библиотека
для слепых».
Также этим
делом занимается
БЕН РАН1
(«SOLAR»,
«Сочи», «DIISKAT»),
ГПНТБ России
(«АС ГПНТБ»,
«ИРБИС»2
и др.). Комплексы
программных
средств состоят
из модулей ПО
(программного
обеспечения)
автоматизированных
рабочих мест
(АРМ). То есть
создаются
АРМы, которые
обеспечивают
выполнение
следующих
функций: комплектование,
обработка,
обслуживание
абонемента
и др. В зависимости
от выбранного
комплекса
программных
средств.
С развитием
ЭК крупных
библиотек их
библиографические
ресурсы станут
доступны читателям
библиотек, не
имеющих больших
информационных
ресурсов, через
теледоступ,
а также обмен
CD-ROM.
На пути создания
систем теледоступа
стоит серьезное
препятствие
- низкое качество
отечественных
телефонных
линий, кроме
того, использование
сетей передачи
данных, электронной
почты смогут
позволить себе
немногие библиотеки
в связи с высокой
стоимостью
сетевых услуг.
Изыскиваются
возможности
вхождения
наших библиотек
в международные
информационные
сети типа INTERNET,
создается
собственная
межведомственная
библиотечная
сеть РФ LIBNET.
1.1
Библиотечные
системы.1.1.1
РГБ
(ГБЛ)
Автоматизация
в РГБ ведется
в двух направлениях:
в библиотеке
работает АС
«Информкультура»,
исполняющая
роль информационного
органа по культуре
и искусству
в РФ, а также
создается АБИС
РГБ, состоящая
из различных
банков данных,
связанных
между собой
единой концепцией
автоматизации
в плане технологии,
информационного
и лингвистического
обеспечения.
Информационная
система основана
на использовании
ЭВМ HEWLETT
PACKARD (HP) 3000/48 и персональных
компьютеров.
АС «Информкультура»
включает около
86000 записей в
составе 8
реферативно-библиографичеких
БД (банков данных):
культура
и социокультурная
деятельность
в сфере досуга;
библиотечное
дело и библиография;
музейное
дело и охрана
памятников;
общие вопросы
искусства;
изобразительное
искусство;
музыка;
эстетическое
воспитание;
культурная
жизнь стран
СНГ.
РГБ имеет
сводные каталоги
зарубежных
карт, атласов,
зарубежных
нотных изданий,
реализованных
на собственном
программном
обеспечении.
ЭК автографов
содержит
библиографические
записи и факсимильные
изображения
страниц с
дарственными
надписями,
получаемыми
путем сканирования.
РГБ совместно
с другими
библиотеками
МК РФ работает
над созданием
сводных каталогов
русской книги
1801-1917 г.г. 1.1.2
Библиотека
Администрации
Президента
Российской
Федерации
(БАПРФ).
Локальная
автоматизированная
система БАПРФ
реализована
на базе ПП
TEXTO/LOGOTEL,
ОС NetWare 3.11.
Пользователям
БАПРФ предоставлен
доступ в локальном
и удаленном
режимах к ЭК
книг и картотекам
периодики, а
также базам
данных библиотеки.
Базы данных
библиотеки
находятся
также на CD-ROM
(энциклопедии,
справочники,
международная
статистика,
экономика,
библиография
и т.п.). БАПРФ
осуществляет
широкое международное
сотрудничество
в целях реализации
взаимообмена
документами
и развития
информационных
технологий. 1.1.3
Российская
национальная
библиотека
(РНБ).
РНБ располагает
одним из крупнейших
в России книжным
фондом (31 млн.
ед. хранения).
В ней реализованы
5 локальных
сетей типа
ETHERNET.
Автоматизированная
система РНБ
в качестве
программного
обеспечения
использует
ППП ISIS
(зарубежная
разработка
комплексной
библиотечной
системы), включает
следующие
подсистемы:
Всего в
РНБ организовано
и поддерживается
5 локальных
(например,
«Авторефераты
диссертаций»,
«Иностранная
книга» и др.)
и 14 проблемно-ориентированных
БД («Храмы
С.-Петербурга»,
«Библиотеки
дореволюционной
России», «Рыночная
экономика»
и др.). 1.1.4
ГПНТБ
России.
ГПНТБ России
является сегодня
одной из самых
автоматизированных
библиотек не
только России,
но и всего бывшего
СССР. Около
200компьютеров
и станций
обеспечивают
потребности
библиотеки
в автоматизированных
технологиях.
Основное программное
средство,
применяемое
ГПНТБ России,
служит ППП
ISIS.
С 1987 г. Ведется
сводный каталог
научно-технической
литературы,
отражающей
сегодня фонды
около 600 библиотек
России и СНГ;
переведен на
средства ЛВС.
Эта сеть поддерживает
ЭК по всему
потоку поступающей
литературы
с 1993 г. и целый
ряд специализированных
тематических
баз данных:
программ,
неопубликованных
переводов,
адресно-справочных
баз данных и
электронных
изданий. Комплекс
проблемно-ориентированных
баз данных
дает пользователям
возможность
узконаправленного
поиска и заказа
литературы
по заданной
тематике или
проблеме. Комплекс
настольных
или издательских
систем, оборудованных
высокопроизводительными
лазерными
принтерами,
сканерами,
текстовыми
процессорами
и издательскими
пакетами, в
совокупности
со средствами
оперативной
полиграфии
позволяют
выпускать
печатные издания:
указатели,
каталоги,
методические
пособия и т.д.
Посещают
ГПНТБ около
500 человек в день,
книговыдача
только в читальных
залах 2.9 млн. экз.
в год. В целях
совершенствования
технологии
обслуживания
в читальных
залах внедряются
автоматизированные
системы поиска
и заказа литературы
(АСПиЗ), работающие
в локальном
и сетевом режимах.
Начата автоматизация
процесса
обслуживания
на базе специализированных
читальных
залов. Для читателя
работа АСПиЗ
ведется в двух
режимах: в
подсистеме
заказа литературы
(ПЗ) и в подсистеме
библиографического
поиска (ПБП).
ПЗ осуществляется
для читателя,
имеющего штрих
код на читательском
билете.
АСПиЗ
литературы
разработана
с использованием
штрих кодов,
которые, являясь
идентификатором
отдельного
экземпляра,
используются
для контроля
за прохождением
печатной единицы
через автоматизированную
систему. Читателю,
зарегистрированному
в системе,
достаточно
сделать отметку
о заказе в режиме
просмотра
найденной им
литературы,
чтобы перейти
в режим автоматизированного
заказа. В фонде
дежурный
библиотекарь
делает распечатку
накопившихся
заказов, подбирает
литературу
и передает на
кафедру выдачи.
Затем при помощи
сканера с каждого
экземпляра
считывается
штрих код. В
памяти машины
фиксируется
вся заказанная
литература,
при выдачи ее
сначала регистрируется
читательский
билет. На экране
монитора
высвечиваются
данные о состоянии
заказа читателя,
что исключает
возможность
выдачи чужого
заказа. При
возврате операция
считывания
штрих кода
повторяется.
Сейчас АРМ
обслуживания
читателей
(использование
штрих кодов
на книгах и
читательских
билетах) внедряется
в других библиотеках
России.
Глава
2. Анализ исходных
данных и выбор
оптимального
инструментария
для разработки
АРМ.2.1
Назначение
разрабатываемого
АРМ.Разрабатываемый
АРМ предназначен
для ввода, хранения
и обработки
информации
о библиотечных
изданиях
(монографиях,
справочниках,
сборников
статей и т.п.),
информации
о место положении
отдельных
экземпляров
(переплётов)
каждого издания,
сведений о
книгообороте
и данных о
читателях.
Реализация
такого АРМ
позволит значительно
облегчить
работу сотрудников
библиотеки:
Поможет
быстро и оперативно
получать требуемую
информацию;
Облегчит
ввод данных;
Позволит
быстро получать
отчёты;
Позволит
быстро и точно
найти или подобрать
читателю информацию
об издании.
2.2
Определение
структурной
схемы.
При разработке
нового приложения
необходимо
разработать
правильную
структуру
таблиц. Плохая
структура
приведёт к
неэффективности
и не возможности
реализации
некоторых
функций. Хорошо
продуманный
набор таблиц
не только помогает
решать текущую
задачу, но и
оставляет
задел для будущих
модернизаций
и усовершенствований,
и что ещё более
важно, значительно
сокращает
время написания
программы,
позволяет
вызывать и
обрабатывать
данные, используя
запросы и
SQL-операторы.
Базам данных
постоянно
грозит опасность
стать громоздкими,
застывшими
и чрезмерно
сложными системами.
Новые функции
порождают
новые виды
запросов к
базе данных,
это увеличивает
набор логических
связей между
её элементами.
В связи с этим
необходимо
продумывать
и использовать
простые и ясные
схемы организации
данных.
Для разработки
структура
данных используем
реляционную
модель базы
данных, которая
основана на
математических
принципах
теории множеств.
Прежде всего,
в основе теории
лежит определение
отношений
между отдельными
таблицами с
помощью связующих
полей. Теория
не требует и
не предполагает
какого-то
определённого
числа этих
отношений, но
поскольку
каждая таблица
связана ещё
хотя бы с одной,
все таблицы
в базе данных
оказываются
прямо или косвенно
связанными.
Теория так же
утверждает,
что управление
данными становится
очень простым,
если данные
организованы
согласно правилам
нормализации.
Для получения
первой нормальной
формы таблиц
не должно быть
повторяющихся
полей и составных
значений. Для
получения
второй нормальной
формы требуется
зависимость
каждого неключевого
поля от полного
набора полей
первичного
ключа. Для получения
третьей нормальной
формы таблица
должна удовлетворять
требованиям
первой и второй
нормальных
форм, а так же
для каждой
таблицы должны
быть определен
первичный
ключи, состоящий
из одного поля
или комбинации
полей, по которому
можно однозначно
определить
неключевое
поле.
Описанные
выше правила
нормализации
помогают эффективно
связывать
отношения
между собой
одним из ниже
перечисленных
способов:
Один ко
многим – когда
любой записи
в первой таблице
соответствует
несколько
записей во
второй таблице;
Один к
одному - когда
любой записи
в первой таблице
соответствует
только одна
запись во второй
таблице;
Многие
ко многим - когда
любой записи
в первой таблице
соответствует
несколько
записей во
второй и наоборот.
В большинстве
случаев между
двумя таблицами
используется
отношение
«один ко многим».
Результат
запроса к одной
или нескольким
таблицам, также
предоставляется
в виде таблицы.
Каждая таблица
должна иметь
свой ключ или
идентификатор,
уникально
определяющую
запись. В наборе
записей об
объекте возможно
наличие более
одного элемента
данных, значения
которого уникально
идентифицирует
запись об объекте.
Каждый из таких
элементов
будет являться
ключом, один
из которых
обычно выбирается
в качестве
первичного
ключа. Элементы
данных, которые
не являются
первичными
ключами, называются
атрибутами.
В записи об
объекте значения
атрибутов
идентифицируются
значениями
первичных
ключей. Также
в реляционных
базах данных
возможно объединения
информации
из разных таблиц
или запросов
на основе
совпадающих
значений
определённых
атрибутов.
Основное
преимущество
реляционной
модели - это
возможность
добавлять
новые элементы
данных, если
этого требуют
новые функции
или приложения.
Могут добавляться
и новые связи
между существующими
и вновь добавляемыми
отношениями.
В любом
случае реляционная
модель данных
удобна тем,
что в отличие
от других способна
накапливать
новые данные
и новые связи
без разрушения
старых подсистем.
2.3
Выбор
конкретного
программного
инструментария.
Система
управления
базами данных
предоставляет
полный контроль
над процессом
определения
данных, их
обработкой
и совместным
использованием.
СУБД также
существенно
облегчает
каталогизацию
и обработку
больших объемов
информации,
хранящихся
в многочисленных
таблицах.
Разнообразные
средства СУБД
обеспечивают
выполнение
трех основных
функций: определение
данных, обработку
данных и управление
данными. Все
эти функциональные
возможности
в полной мере
реализованы
в базе данных
Microsoft Visual FoxPro.
Microsoft Visual FoxPro
- это
завершённый
язык программирования,
имеющий среду
для интерактивного
выполнения
команд и выполнения
скомпилированных
программ. Это
позволяет
создавать
полностью
самостоятельные
программы,
которые можно
передавать
другим пользователям,
у которых нет
собственной
копии VFP.
В VFP
предусмотрены
все необходимые
средства для
определения
и обработки
данных, а также
для управления
ими при работе
с большими
объемами информации.
В VFP
основными
объектами
являются таблицы,
запросы, формы,
отчеты, программы
и классы. Обычно,
термин база
данных относится
только к файлам,
в которых хранятся
данные. В VFP
база данных
включает набор
таблиц, представлений
и хранимых
процедур. Ниже
приведен список
основных объектов
VFP.
Таблица
- объект, который
определяется
и используется
для хранения
данных. Каждая
таблица содержит
информацию
о субъектах
(предметах)
определенного
типа. Поля
(столбцы) служат
для хранения
различных
характеристик
субъектов, а
каждая запись
(строка) содержит
сведения о
конкретном
субъекте. Для
каждой таблицы
можно определить
первичный
ключ (одно или
несколько
полей, имеющих
уникальное
для каждой
записи значения)
и один или
несколько
индексов,
ускоряющих
доступ к данным.
Запрос
- объект, позволяющий
пользователю
получить нужные
данные из одной
или нескольких
таблиц. Для
определения
запроса можно
использовать
конструктор
отчётов или
написать инструкцию
SQL. Можно
создать запрос
на выборку,
обновление,
удаление или
добавление
данных. С помощью
запросов можно
также создавать
новые таблицы,
используя
данные из одной
или нескольких
существующих
таблиц.
Форма -
объект, предназначенный
для ввода данных,
отображения
их на экране
или управления
работой приложения.
Формы можно
использовать
для того, чтобы
реализовать
требования
пользователя
к представлению
данных таблиц
или наборов
записей запросов.
С помощью форм
можно в ответ
на некоторое
событие запустить
функцию, процедуру,
метод
формы или класса.
Отчёт - объект,
предназначенный
для форматирования,
вычисления
итогов и печати
выбранных
данных.
Класс -
объект, содержащий
набор методов,
событий и свойств,
предназначенный
для обработки
данных и событий.
Кроме того,
классы имеют
следующие
характеристики,
которые делают
их особенно
полезными для
создания
многократно
используемого,
легко поддерживаемого
кода:
Формирование
пакета
Подклассы
Наследование
В таблицах
хранятся данные,
которые можно
извлекать с
помощью запросов.
Для облегчения
проверок
целостности,
хранения информации
о связях, а так
же для хранения
запросов для
представлений,
таблицы можно
объединять
в базу данных.
Используя
формы, пользователь
может выводить
данные на экран
или изменять
их. Необходимо
заметить, что
формы и отчеты
получают данные
как непосредственно
из таблиц, так
и через запросы.
Для выполнения
нужных вычислений
и форматирования
данных, запросы
могут использовать
встроенные
функции или
функции, созданные
с помощью
VFP.
VFP
предоставляет
максимальную
свободу при
задании типа
данных (текст,
числовые данные,
даты, время,
денежные значения,
рисунки, звук,
документы,
электронные
таблицы). Также
можно задать
форматы хранения
(длина строки,
точность
представления
чисел и даты/времени)
и представления
данных для
вывода на экран
или печать.
VFP предоставляет
возможность
автоматически
проверять
правильность
отношений
между таблицами
базы данных.
Так как
VFP является
современным
приложением
Windows, в распоряжении
пользователя
оказываются
все возможности
DDE (Dynamic Data Exchange, динамический
обмен данными),
OLE (Object Linking and Embedding, связь
и внедрение
объектов) и
элементов
управления
ActiveX. DDE позволяет
выполнять
функции и
производить
обмен данными
между
VFP и любым
другим, поддерживающим
DDE
приложением
Windows. OLE является
более совершенной
технологией
Microsoft,
которая, в
частности,
позволяет
устанавливать
связи с объектами
другого приложения
или внедрять
некоторые
объекты в базу
данных
VFP. Это могут
быть рисунки,
диаграммы,
электронные
таблицы или
документы из
других приложений
Widows, поддерживающих
OLE.
VFP
воспринимает
множество
самых разнообразных
форматов данных,
включая файловые
структуры
других СУБД.
Существует
возможность
осуществления
импорта и экспорта
данных из текстовых
и электронных
таблиц.
VFP предоставляет
прямой доступ
и позволяет
обновлять
файлы
Paradox, dBase Ш,
dBase IV, Microsoft
Access и других
баз данных.
Можно также
импортировать
данные из этих
файлов в таблицы
VFP. В дополнение
к этому, VFP
может работать
с наиболее
популярными
базами данных,
поддерживающими
стандарт
ODBC (Open Database Connectivity -
открытый
доступ к данным),
включая
Microsoft SQL Server, Oracle, DB2.
Когда
возникает
необходимость
коллективного
использования
информации,
настоящая
система управления
базами данных
позволяет
защищать информацию
от несанкционированного
доступа так,
что право
просматривать
данные или
вносить в них
изменения
получают только
определенные
пользователи.
Предназначенная
для коллективного
пользования
СУБД имеет
средства, не
позволяющие
нескольким
людям одновременно
изменять одни
и те же данные.
VFP спроектирован
таким образом,
что он может
быть использован
как в качестве
самостоятельной
СУБД на отдельной
рабочей станции,
так и в сети
режима «клиент-сервер».
Поскольку в
VFP доступ
к данным могут
иметь одновременно
несколько
пользователей,
в нем предусмотрены
надежные средства
защиты и обеспечения
целостности
данных. В
VFP применяется
механизм
автоматической
блокировки
для избежания
одновременного
изменения
объекта несколькими
пользователями.
Глава
3. Разработка
логической
схемы.
Полноценное
проектирование
любого АРМ
должно осуществляться
согласно некоторым
правилам или
этапам проектирования.
Ниже приведены
основные этапы
проектирования
АРМ, в соответствии
с которыми
будет осуществляться
её дальнейшая
разработка
в среде Microsoft
Visual FoxPro:
Логическое
проектирование.
Определение
цели создания
АРМ
Определение
таблиц и необходимых
полей
Определение
связей между
таблицами
Разработка
таблиц
2.1 Построение
таблиц
Назначение
типов данных
для полей таблиц
Создание
индексов и
связей между
таблицами
3.1
Логическое
проектированиеКогда
говорят о логическом
проектировании,
употребляют
такие термины,
как сущность,
связь и атрибут.
Сущность
– это множество
однотипных
объектов, называемых
экземплярами,
при этом каждый
экземпляр
индивидуален
и отличается
от всех остальных
экземпляров.
Атрибут
– это характеристика
сущности. Атрибут
выражает одно
законченное
и определённое
свойство сущности.
При проектировании
рекомендуется
создавать
атомарные
атрибуты.
Связь
– это логическое
отношение
между сущностями,
выражающее
некоторое
ограничение
или бизнес-правило.
При
создании связей
между сущностями
в дочернюю
сущность передаются
атрибуты,
составляющие
первичный ключ
в родительской
сущности. Эти
атрибуты образуют
в дочерней
сущности внешний
ключ. 3.1.1
Определение
цели создания
АРМ.
На первом
этапе проектирования
необходимо
определить
цель создания
АРМ, основные
функции и
информацию,
которую АРМ
должен содержать,
то есть нужно
определить
основные темы
таблиц базы
данных и содержащуюся
в них информацию.
База данных
должна отвечать
требованиям
тех, кто будет
непосредственно
с ней работать.
Для этого нужно
определить
темы, которые
должны покрываться
данным АРМ,
требуемые
отчёты, проанализировать
формы в которых
в настоящий
момент используются
для хранения
и записи данных.
3.1.2
Определение
таблиц и необходимых
полей.
Одним из
наиболее сложных
этапов проектирования,
является разработка
таблиц базы
данных для
хранения информации,
так как результаты
которые должна
выдавать система
не всегда дают
полное представление
о структуре
таблиц.
При разработке,
лучше руководствоваться
следующими
основными
принципами:
Информация
в таблицах не
должна дублироваться.
Когда определённая
информация
хранится только
в одном месте,
то нет необходимости
в синхронизации
этих данных,
и обеспечит
эффективность,
и исключит
возможность
не совпадения.
Проведём
рассмотрение
этих данных.
Для ведения
библиотечных
каталогов.
Организации
поиска требуемых
изданий и
библиотечной
статистики
в базе данных
должны хранится
сведения, большая
часть которых
размещается
в аннотированных
каталожных
карточках
(рис. 3.1 ). Анализ
запросов на
литературу,
как читателей,
так и обслуживающего
персонала
библиотеки,
показывает,
что для поиска
подходящих
изданий (по
тематике, автору,
изданию и т.п.)
и отбора нужного,
следует выделять
следующие
атрибуты каталожной
карточки:
|
Д27
|
Дейт
К. Руководство
по реляционной
СУБД DB2
/ пер. с англ. И
предисловие
М.Р.Когаловского.
–М.: Финансы
и статистика,
1988. – 320 с.: ил.
|
| ISBN 5-279-00063-9 |
| Книга
американского
специалиста
в области
реляционных
баз данных
К.Дейта, автора
популярной
в СССР монографии
«Введение в
системы баз
данных», представляет
собой руководство
по СУБД фирмы
IBM DB2. Для
специалистов
по программному
обеспечению
информационных
систем и студентов
вузов. |
| ББК
32.973 |
Рис. 3.1 Аннотированная
каталожная
карточка
Автор
(фамилия и имена
(инициалы) или
псевдонимы
каждого автора
издания);
Название
(заглавие) книги;
Номер тома
(части, книги,
выпуска);
Вид издания
(сборник, монография,
справочник,…);
Составитель
(фамилия и имена
(инициалы) каждого
из составителей
издания);
Под чей
редакцией
(фамилия и имена
(инициалы) каждого
из составителей
издания);
Повторность
издания;
Издательство;
Место издания
(город);
Год выпуска;
Издательская
аннотация или
реферат;
Библиотечный
шифр;
Авторский
знак.
Библиотечный
шифр и авторский
знак используются
при составлении
каталогов и
организации
расстановки
изданий на
полках: по
содержанию
( в соответствии
с библиотечным
шифром) и по
алфавиту ( в
соответствии
с авторским
знаком).
Библиотечно-библиографическая
классификация
(ББК) распределяет
издания по
отраслям знания
в соответствии
с их содержанием.
В ней используется
цифро-буквенные
индексы ступенчатой
структуры.
К
Техника.Технические
науки.
32 Радиоэлектроника.
32.97 Вычислительная
техника.
32.973 Электронные
вычислительные
машины и устройства.
32.973.2
Электронно-вычислительные
машины и устройства
дискретного
действия. аждый из
девяти классов
(1.Марксизм-ленинизм;
2.Естественные
науки; 3.Техника.
Технические
науки; 4.Сельское
и лесное хозяйство;
5.Здравоохранение;
6/8.Общественные
и гуманитарные
науки; 9.Библиографические
пособия. Справочные
издания. Журналы.)
делится на
подклассы и
следующие
ступени деления:
Шифр ББК
используется
при выделение
хранимым изданиям
определённых
комнат, стеллажей
и полок, а также
для ведения
и составления
каталогов и
статистических
отчётов.
Авторский
знак, состоящий
из первой буква
фамилии (псевдонима)
автора или
названия издания
(для изданий
без автора) и
числа, соответствующего
слогу, наиболее
приближающегося
по написанию
к первым буквам
фамилии (названия),
упрощает расстановку
книг на полках
в алфавитном
порядке.
К объектам
и атрибутам,
позволяющим
охарактеризовать
отдельные
экземпляры
изданий (переплёты),
места их хранения
и читателей,
можно отнести:
Номер (инвентарный
номер) переплёта;
Дата приобретения
(поступления)
конкретного
переплёта;
Номер читательского
билета;
Фамилия
читателя;
Имя читателя;
Отчество
читателя;
Адрес читателя;
Телефон
читателя;
Дата выдачи
читателю
конкретного
переплёта;
Дата возврата
переплёта.
Анализ
приведённых
выше объектов
и атрибутов
позволяет
выделить сущности
проектируемой
базы данных,
приняв решение
о создании
реляционной
базы данных,
можно построить
её модель.
Каждая
таблица проектируемой
базы данных
должна содержать
информацию
на отдельную
тему, а каждое
поле таблицы
– содержать
сведения по
теме таблицы.
При разработке
надо учитывать:
Каждое поле
должно быть
связано с темой
таблицы;
Не рекомендуется
включать в
таблицу данные,
которые являются
результатом
выражения;
В таблице
должна присутствовать
вся необходимая
информация;
Информацию
следует разбивать
на наименьшие
логические
единицы.
Выделяем
следующие
таблицы и атрибуты:
Создатели
(Код_создателя,
Создатель) –
здесь хранятся
сведения об
людях, принимавших
участие в
подготовке
издания (авторах,
составителях,
редакторах).
Такое объединение
допустимо,
так как данные
о создателях
выбираются
из одного домена
(фамилии и имена)
и исключают
дублирование
данных. Так
как фамилия
и инициалы
создателя
могут быть
достаточно
большими и
будут многократно
встречается
в разных изданиях,
то их необходимо
нумеровать
и ссылаться
на эти номера.
Для этого вводим
целочисленный
атрибут Код_создателя,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового создателя.
Издательства
(Код_издательства,
Название, Город)
– здесь находятся
данные о названии
издательства
и городе, где
расположено
издательство.
Так же вводим
целочисленный
атрибут Код_издания,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового издания.
Виды издания
(Вид_издания,
Название_вида)
– здесь хранятся
данные о названии
вида издания.
Так же вводим
целочисленный
атрибут Вид_издания,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового названия
вида издания.
Раздел
(Название_раздела,
Библиотечный_код,
Код_раздела,
Код_родителя)
– здесь хранятся
данные о названии
разделов, их
коды по
библиотечно-библиографическому
классификатору
и их взаимосвязи
(ерархия). Так
же вводим
целочисленный
атрибут Код_раздела,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового раздела.
Издание
(Код_издания,
Код_раздела,
Заглавие,
Вид_издания,
Авторский_знак,
Код_издательства,
Год_издания,
Аннотация) –
здесь хранится
общая информация
об экземпляре
и его принадлежности
к разделу. Так
же вводим
целочисленный
атрибут Код_издания,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового издания.
Переплёты
(Номер_переплёта,
Код_издания,
Дата_приобретения)
– здесь хранится
информация
о конкретном
экземпляре
(переплёте),
такая как
инвентарный
номер, дата
проибретения.
Группа
(Код_группы,
Название_группы,
Код_родителя)
– здесь хранятся
данные о названии
групп читателей,
и их взаимосвязи
(ерархия). Так
же вводим
целочисленный
атрибут Код_группы,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового группы.
Читатели
(Номер_читателя,
Код_группы,
Код_фамилии,
Код_имени,
Код_отчества,
Код_города,
Код_улицы,
Дом_Квартира,
Номер_телефона,
Дата_рождения,
Дата_регистрации,
Комментарий)
– здесь хранится
информация
о читателе и
его принадлежности
к группе. Так
же вводим
целочисленный
атрибут Номер_читателя,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового читателя
и будет являться
номером читательского
билета.
Авторы
(Код_создателя,
Код_издания)
– эта таблица
является
ассоциацией
между таблицами
Создатели и
Издание.
Составители
(Код_создателя,
Код_издания)
– эта таблица
является
ассоциацией
между таблицами
Создатели и
Издание.
Редакторы
(Код_создателя,
Код_издания)
– эта таблица
является
ассоциацией
между таблицами
Создатели и
Издание.
Выдача
(Номер_переплёта,
Номер_читателя,
Дата_выдачи,
Дата_сдачи) -
эта таблица
хранит ассоциации
между таблицами
Переплёт и
Читатель.
Фамилии
(Код_фамилии,
Фамилия) – здесь
хранятся данные
о фамилиях
читателей.
Так же вводим
целочисленный
атрибут Код_фамилии,
который будет
автоматически
наращиваться
на единицу
при добавлении
новой фамилии.
Имена
(Код_имени, Имя)
– здесь хранятся
данные об именах
читателей.
Так же вводим
целочисленный
атрибут Код_имени,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового имени.
Отчества
(Код_отчества,
Отчество) –
здесь хранятся
данные об отчествах
читателей.
Так же вводим
целочисленный
атрибут Код_отчества,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового отчества.
Города
(Код_города,
Город) – здесь
хранятся данные
о названии
городов, где
проживают
читатели. Так
же вводим
целочисленный
атрибут Код_города,
который будет
автоматически
наращиваться
на единицу
при добавлении
нового города.
Улицы
(Код_улицы, Улица)
- здесь хранятся
данные о названия
улиц, где проживают
читатели. Так
же вводим
целочисленный
атрибут Код_улицы,
который будет
автоматически
наращиваться
на единицу
при добавлении
новой улицы.
Выделение
этих таблиц
позволяет
избежать
возникновения
противоречий,
снижает объём
хранимых данных
и позволяет
исключить
повторный ввод
названий.
3.1.3
Определение
связей между
таблицами.
После
распределения
данных по таблицам
и определения
полей, необходимо
выбрать схему
для связи данных
в разных таблицах.
Для этого нужно
определить
ключевые поля
и связи между
таблицами.
Описанные
выше приемы
проектирования
помогают эффективно
связывать
данные. При
создании таблиц,
в каждую новую
таблицу включается
поле, связывающее
новую и старую
таблицы. Эти
связующие поля
называются
внешними
ключами.
В хорошо
спроектированной
базе данных
использование
внешних ключей
обеспечивает
эффективность
использования
приложения.
В процессе
проектирования
нужно внимательно
следить за
созданием
внешних ключей.
Заключительный
этап логического
проектирования
базы данных
заключается
в определении
связей между
таблицами.
Задаваемые
при создании
таблиц связи
первичных
ключей с внешними
ключами используются
для объединения
данных из нескольких
таблиц.
В большинстве
случаев, как
уже описывалось
выше, таблицы
связываются
между собой
отношением
«один ко многим»,
гораздо реже
«один к одному»
и «многие ко
многим». Если
в базе данных
существует
связь между
таблицами типа
«многие ко
многим», то
необходимо
создать таблицу
пересечения,
с помощью которой
одна связь
«многие ко
многим» будет
сведена к двум
связям типа
«многие к одному».
В настоящей
базе данных
все таблицы
будут связываться
между собой
отношением
типа «многие
к одному».
Непосредственно
для работы
данного приложения
необходимо
связать данные
из таблиц с
данными о заголовках
разделов и
изданиями.
Связь между
этими таблицами
будет типа
«один ко многим»,
так как в одном
разделе может
содержаться
множество
изданий, но
любое издание
содержится
только в одном
разделе. Для
связи таблицы
Раздел
с таблицей
Издание
необходимо,
чтобы первичный
ключ этой таблицы
– Код_раздела
- присутствовал
в связанной
с ней таблице.
В таблице Издание
первичным
ключом
является Код_издания
через который
производится
связь с таблицами
Авторы,
Составители,
Редакторы
и Переплёты,
в соотношении
«один ко многим»,
так как у одного
издания может
быть несколько
авторов, составителей
и редакторов,
а так же в библиотеке
может храниться
несколько
экземпляров
данного издания.
В свою очередь
у таблицы Создатели
тоже есть первичный
ключ Код_создателя
через который
определяем
связь с таблицами
Авторы,
Составители
и Редакторы,
в отношении
«один ко многим».
Таблица Вид_издания
связана с таблицей
Издание
по первичному
ключу Вид_издания
в соотношении
«один ко многим,
так же таблица
Издательства
связана с таблицей
Издание
по первичному
ключу Код_издательства
в отношении
«один ко многим».
Таблица Переплёты
имеет первичный
ключ Номер_переплёта
по которому
связана с таблицей
Выдача
в отношении
«один ко многим».
Аналогично
таблица Группа
будет связываться
с таблицей
Читатель
отношением
типа «один ко
многим» через
первичный ключ
Код_группы,
потому как в
любой группе
может содержаться
множество
читателей, но
каждый читатель
содержится
в одной группе.
Таблица Города,
имеющая первичный
ключ Код_города
связана с таблицей
Читатель
в отношении
«один ко многим»,
аналогично
связаны таблицы
Улицы,
Фамилии,
Имена
и Отчества,
у которых
первичными
ключами являются
Код_улицы,
Код_Фамилии,
Код_имени
и Код_отчества
соответственно.
Так же таблица
Читатель,
имеющая первичный
ключ Номер_читателя,
связана с таблицей
Выдача
в отношении
«один ко многим».
3.2
Разработка
таблиц.
3.2.1
Построение
таблиц.
После
разработки
проекта приложения
можно приступать
к непосредственному
его созданию.
В
Microsoft VFP существует
три способа
создания таблицы:
Использование
мастера баз
данных для
создания всех
таблиц входящих
в базу данных,
содержащей
все требуемые
представления,
индексы, хранимые
процедуры и
связи за одну
операцию. Мастер
баз данных
создает новую
базу данных,
его нельзя
использовать
для добавления
новых таблиц,
индексов,
представлений,
связей и хранимых
процедур в
уже существующую
базу данных.
Использование
мастера таблиц
позволяет
выбрать поля
для данной
таблицы из
множества
определенных
ранее таблиц,
таких как деловые
контакты, список
личного имущества
или указать
произвольную
таблицу. Добавить
в существующую
базу данных,
назначить
типы полей,
индексы и связи.
Независимо
от метода,
примененного
для создания
таблицы, всегда
имеется возможность
использовать
режим конструктора
для дальнейшего
изменения
макета таблицы,
например, для
добавления
новых полей,
определения
типов, индексов
и связей.
В дальнейшем,
используя,
конструктор
базы данных
создаём проекты
таблиц, указываем
типы данных
и свойства
полей, определяем
индексы и
устанавливаем
связи между
таблицами,
назначаем
методы контроля
целостности.
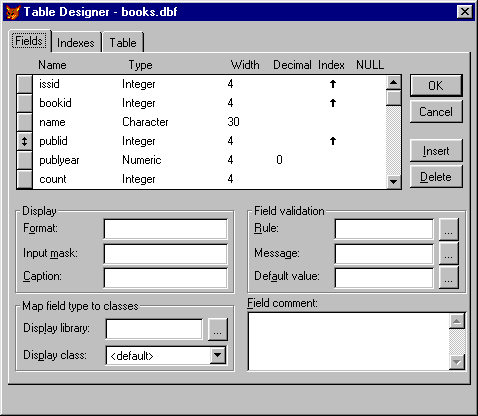
Рис.3.2 Окно
конструктора
таблиц
В верхней
части дизайнера
таблиц расположены
столбцы, в которых
вводится название
поля, тип данных,
размер поля,
наличие простого
индекса, направление
индексации
(по возрастанию,
по убыванию),
возможность
использования
значения .NULL.,
в нижней части
окна вводятся
формат поля,
формат маски
ввода, заголовок
поля, процедуры
для проверки
вводимых значений,
сообщения,
значение по
умолчанию и
комментарий
для поля.
Для оптимизации
работы с таблицами
существует
несколько
возможностей:
Проектировать
таблицы, в которых
не содержится
избыточных
данных.
Выбирать
наиболее подходящий
тип данных
для поля – это
приведёт к
уменьшению
размера таблицы
и увеличит
скорость выполнения
операций. При
описании таблицы
следует задавать
для него тип
данных наименьшего
размера, позволяющий
хранить нужные
данные.
Microsoft Visual FoxPro
поддерживает
тринадцать
типов данных:
|
Тип
данных
|
Использование
|
Размер
|
| Character |
Алфавитно-цифровые
данные |
До
254 байт |
| Currency |
Денежные
суммы |
8 байт
|
| Numeric/ Float |
Числовые
данные |
До
20 байт |
| Date |
Дата |
8 байт |
| Data/Time |
Дата-время |
8 байт |
| Double |
Числа
двойной точности
с плавающей
точкой (18 разрядов)
|
8
байт
|
| Integer |
Целые
числа |
4
байта
|
| Logical |
Логические
данные (.T./.F.)
|
1
байт
|
| Memo |
Алфавитно-числовые
данные |
Ограничено
свободным
местом на диске |
| General |
Графические
изображения,
диаграммы,
OLE объекты
|
Ограничено
свободным
местом на диске |
| Character (binary) |
Алфавитно-цифровые
данные с символами
ASCII от
0 до 255
|
Ограничено
свободным
местом на диске |
| Memo (binary) |
Алфавитно-цифровые
данные с символами
ASCII от
0 до 255
|
Ограничено
свободным
местом на диске |
3.2.2
Назначение
типов данных
для полей таблиц.
Исходя из
выше описанной
модели, определим
типы полей для
таблиц.
Для таблицы
Создатели:
Для таблицы
Издательства:
Код_издательства
– тип данных
Integer;
Название
– тип Character,
размером 30
символов;
Город –
тип Character,
размером 20
символов.
Для таблицы
Виды издания:
Для таблицы
Раздел:
Название_раздела
– тип Character,
размером 100
символов;
Библиотечный_код
– тип Character,
размером 20
символов;
Код_раздела
– тип данных
Integer;
Код_родителя
– тип данных
Integer.
Для таблицы
Издание:
Код_издания
– тип данных
Integer;
Код_раздела
– тип данных
Integer;
Заглавие
– тип Character,
размером 30
символов;
Вид_издания
– тип данных
Integer;
Код_издательства
– тип данных
Integer;
Авторский_знак
– тип Character,
размером 10
символов;
Год_издания
– тип Numeric,
размером 4
символов;
Аннотация
– тип Memo.
Для таблицы
Переплёты:
Номер_переплёта
– тип данных
Integer;
Код_издания
– тип данных
Integer;
Дата_приобретения
– тип Date.
Для Таблицы
Группа:
Код_группы
– тип данных
Integer;
Название_группы
– тип Character,
размером 30
символов;
Код_родителя
– тип данных
Integer.
Для таблицы
Читатели:
Номер_читателя
– тип данных
Integer;
Код_группы
– тип данных
Integer;
Код_фамилии
– тип данных
Integer;
Код_имени
– тип данных
Integer;
Код_отчества
– тип данных
Integer;
Код_города
– тип данных
Integer;
Код_улицы
– тип данных
Integer;
Дом_Квартира
– тип Character,
размером 20
символов;
Номер_телефона
– тип Character,
размером 15
символов;
Дата_рождения
– тип Date;
Дата_регистрации
– тип Date;
Комментарий
– тип
Memo.
Для таблицы
Авторы:
Для таблицы
Составители:
Для таблицы
Редакторы:
Для таблицы
Выдача:
Для таблицы
Фамилии:
Для таблицы
Имена:
Для таблицы
Отчества:
Для таблицы
Города:
Для Таблицы
Улицы:
На основе
выше изложенного
создадим следующую
структуру
таблиц для
использования
при разработке
АРМ.
| Раздел
(Issue.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
Id |
Integer |
4 |
Уникальный
номер раздела |
| 2 |
Bbk |
Character |
20 |
Номер
по ББК |
| 3 |
Name |
Character |
100 |
Название
раздела |
| 4 |
Parent |
Integer |
4 |
Номер
вышестоящего
раздела |
| Издания
(Books.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
IssId |
Integer |
4 |
Номер
раздела
(Issue.Id) |
| 2 |
BookId |
Integer |
4 |
Уникальный
номер книги |
| 3 |
Name |
Character |
30 |
Название
книги |
| 4 |
BookType |
Integer |
4 |
Код
вида издания |
| 5 |
PublId |
Integer |
4 |
Номер
издательства
(Publisher.PublId) |
| 6 |
PublYear |
Numeric |
4 |
Год
издания |
| 7 |
AutorId |
Character |
10 |
Авторский
знак |
| 6 |
Date |
Date |
8 |
Дата
поступления |
| 7 |
Comment |
Memo |
4 |
Аннотация |
| Создатели
(Creators.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
NameId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Name |
Character |
50 |
Значение |
| Виды
изданий (TypePubl.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
NameId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Name |
Character |
30 |
Значение |
| Авторы
(Autor.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
UniqId |
Integer |
4 |
Уникальный
номер записи |
| 2 |
BookId |
Integer |
4 |
Номер
книги
(Books.BookId) |
| 3 |
AutorId |
Integer |
4 |
Номер
автора |
| Составители
(Compilers.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
CreatorId |
Integer |
4 |
Код
создателя |
| 2 |
BookId |
Integer |
4 |
Код
издания |
| 3 |
UniqId |
Integer |
4 |
Уникальный
ключ |
| Редакторы
(Editors.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
CreatorId |
Integer |
4 |
Код
создателя |
| 2 |
BookId |
Integer |
4 |
Код
издания |
| 3 |
UniqId |
Integer |
4 |
Уникальный
ключ |
| Издательства
(Publisher.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
PublId |
Integer |
4 |
Уникальный
номер издательства |
| 2 |
PublName |
Character |
30 |
Название
издательства |
| 3 |
PublCity |
Character |
20 |
Город
издательства |
| Переплёты
(BookNum.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
BookId |
Integer |
4 |
Номер
книги
(Books.BookId) |
| 2 |
Number |
Integer |
4 |
Инвентарный
номер книги |
| 3 |
Date |
Date |
8 |
Дата
поступления
экземпляра |
| Группы
(Groups.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
Id |
Integer |
4 |
Уникальный
номер группы |
| 2 |
Name |
Character |
30 |
Название
группы |
| 3 |
Parent |
Integer |
4 |
Номер
вышестоящего
раздела |
| Читатели
(Abonents.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
GrId |
Integer |
4 |
Номер
группы (Groups.Id) |
| 2 |
AbonId |
Integer |
4 |
Уникальный
номер абонента |
| 3 |
Name1 |
Integer |
4 |
Номер
фамилии из
словаря |
| 4 |
Name2 |
Integer |
4 |
Номер
имени из словаря |
| 5 |
Name3 |
Integer |
4 |
Номер
отчества из
словаря |
| 6 |
CityId |
Integer |
4 |
Номер
города из словаря |
| 7 |
StreetId |
Integer |
4 |
Номер
улицы из словаря |
| 8 |
House_ Fl |
Character |
20 |
Номер
дома и номер
квартиры |
| 9 |
Telefon |
Character |
15 |
Номер
телефона |
| 10 |
Date1 |
Date |
8 |
Дата
рождения |
| 11 |
Date2 |
Date |
8 |
Дата
регистрации |
| 12 |
Comment |
Memo |
4 |
Комментарии
к карточке
абонента |
| Выдача
(BookUse.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
UniqId |
Integer |
4 |
Уникальный
номер записи |
| 2 |
AbonId |
Integer |
4 |
Номер
абонента
(Abonents.AbonId) |
| 3 |
Number |
Integer |
4 |
Инвентарный
номер книги
(BookNum.Number) |
| 4 |
Date1 |
Date |
8 |
Дата
выдачи книги |
| 5 |
Date2 |
Date |
8 |
Дата
сдачи книги |
| Фамилии
(Name1.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
NameId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Name |
Character |
30 |
Значение |
| Имена
(Name2.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
NameId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Name |
Character |
30 |
Значение |
| Отчества
(Name3.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
NameId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Name |
Character |
30 |
Значение |
| Города
(City.dbf) |
| № |
Название |
Тип |
Значение |
|
размер |
|
| 1 |
CityId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
City |
Character |
30 |
Значение |
| Улицы
(Streets.dbf) |
| № |
Название |
Тип |
Значение |
|
Размер |
|
| 1 |
StreetId |
Integer |
4 |
Уникальный
номер значения |
| 2 |
Street |
Character |
30 |
Значение |
3.2.3
Создание
индексов и
связей между
таблицами
Чем больше
хранится данных
в таблицах,
тем больше
индексов необходимо
для эффективного
поиска данных.
Индекс – это
внутренняя
таблица, состоящая
из двух столбцов:
значение выражения,
в котором содержатся
все поля, включенные
в индекс, и
местоположение
каждой записи
таблицы с данным
значением
индексного
выражения. Для
создания индексов
по ключевым
полям, необходимо
установить
тип индекса
Primary.
Для внешних
ключей используется
тип Regular.
Определив
необходимые
таблицы и индексы,
создадим связи
таблиц.
Как уже
было описано
выше, все таблицы
в базе данных
будут связаны
между собой
отношением
«один ко многим».
Для установления
связи между
таблицами
следует соединить
первичный ключ
таблицы, находящийся
на стороне
отношения
«один» с соответствующим
ему внешним
ключом таблицы
на стороне
отношения
«многие».
После
установки
связи, можно
определить
критерии обеспечения
целостности,
для любого
действия в
главной таблице
которое изменяет
ключевое значение,
таких как,
добавление,
удаление и
изменения.
Для изменения
и удаления
записей возможно
введения одного
из следующих
правил:
Cascade – замена
или удаление
всех записей
в подчинённой
таблице, удовлетворяющих
старому ключевому
значению главной
таблице.
Restrict –
проверяет
наличие в
подчинённой
таблице значений
удовлетворяющих
текущему значению
главного ключа,
и при их наличии
запрещает
изменения или
удаление.
Ignore –
игнорирует
ссылочную
целостность
и позволяет
изменять или
удалять значения
главного ключа.
Для добавления
записей можно
определить
только два
правила проверки:
Restrict –
запрещает
добавление,
если в главной
таблице отсутствует
запись с подходящим
ключевым значением.
Ignore
– не выполняет
никаких проверок.
Связи
таблиц показаны
на рисунке
3.3.
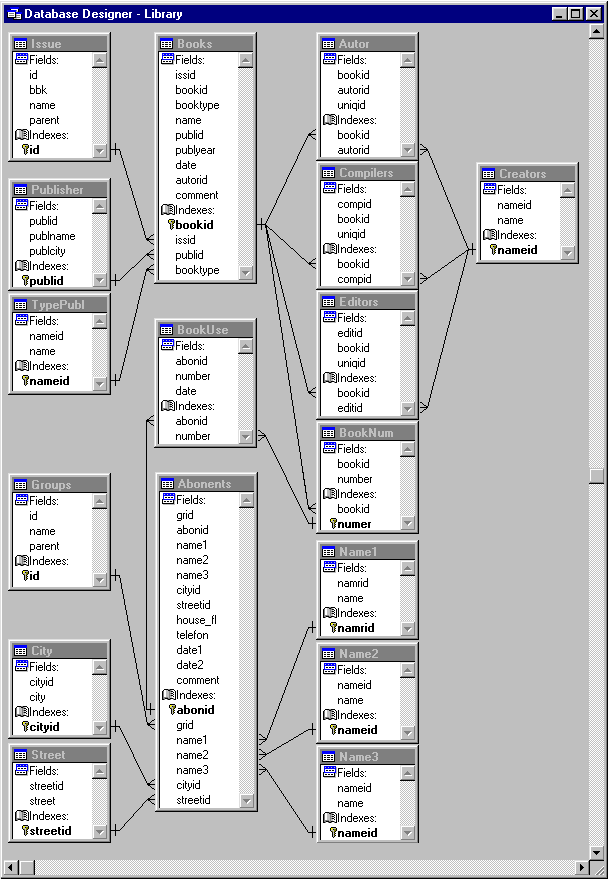
Рис.3.3 Схема
связей таблиц
Глава
4. Разработка
и реализация
алгоритма
4.1
Разработка
алгоритма.
Назначение
любой базы (в
том числе и
БРЭА) заключается
в получении
пользователем
базы необходимой
ему информации.
Кроме того,
пользователю
должны быть
предоставлены
возможности
пополнения
базы данных
вновь возникшей
информацией
и её коррекции
в случае изменения
тех или иных
компонент,
хранящихся
в базе данных.
Указанные
моменты определяют
технологический
цикл кругооборота
информации
между пользователем
и базой данных,
а также основные
направления
прохождения
информации
внутри самой
базы, иными
словами, - взаимодействие
отдельных
компонент,
составляющих
в целом базу
данных.
Сказанное
может быть
проиллюстрировано
схемой информационных
потоков БД,
представленной
на рис.4.1. От
пользователя
поступает
некоторое
множество
заданий на
выполнение
тех или иных
информационных
действий. Входные
формы воспринимают
эти задания
и инициализируют
соответствующие
запросы, которые
в свою очередь
осуществляют
поиск необходимой
информации
в таблицах,
где находятся
данные, позволяющие
выполнить
заданные действия.
Выбранная
информация
с помощью
исполнительных
частей запросов
пересылается
в выходные
формы и представляется
пользователю
для её оценки
и принятия
решения.
Обобщённо
алгоритм,
реализующий
данную технологическую
схему обработки
информации,
представляет
собой следующую
совокупность
действий:
1. Выбор
соответствующей
выходной формы
(Формаi,
i=l, ).
2. Заполнение
полей формы
(Формаi,
i=l, ).
3. Отображение
информации
на видеоконтрольном
устройстве.
4. Если необходима
твёрдая копия
полученных
данных, то Ввод
исходных
данных.
5. Анализ
исходных данных
(Формаi,
i=l, N).
6. Если исходные
данные корректны,
то переход на
пункт 4, в противном
случае - выдача
диагностического
сообщения и
переход на
пункт 1.
7. Передача
данных соответствующему
запросу (Запросij,
i=l, N; j=l, ).

Рис.
4.1 Схема
информационных
потоков АРМ
8. Анализ параметров
и условий выборки
информации.
9. Формирование
списка таблиц
для поиска
информации
(Таблицаi,...,Таблицаk,
i,
k).
10. Поиск
информации
по выбранному
списку таблиц
в соответствии
со значениями
параметров
и условиями
выборки.
11. Если
информация,
удовлетворяющая
заданным параметрам
и условиям
выборки, отсутствует,
то выдаётся
соответствующее
диагностическое
сообщение и
переход на
пункт 1. При
нахождении
необходимой
информации,
она передаётся
исполнительным
частям запросов
(Запросij,
i=l ,N; j=l , )
и переход на
пункт 9.
12. производится
её печать, в
противном
случае переход
на пункт 13.
13. Выяснение
необходимости
завершить
работу с базой
данных. Если
«Да», то переход
на пункт 14, если
«Нет», то переход
на пункт 1.
14. Конец работы.
Здесь и далее
обозначения
имеют следующий
смысл:
• N - мощность
(количество)
множества
входных форм;
• К,,
- мощности множеств
запросов,
соответствующих
входным формам
(Формаi,
i=l, N);
• -мощность
множества
таблиц;
• - мощность
множества
выходных форм.
Данный алгоритм
может быть
выражен блок-схемой,
представленной
на рис.4.2. Такое
представление
даёт возможность
более наглядного
понимания
процесса прохождения
информации.
АРМ функционирует
в следующих
режимах:
Ввод данных
в базу данных
АРМ;
Просмотр
информации
из базы данных
АРМ;
Коррекция
информации
в базе данных
АРМ;
Формирование
выходных документов.
Выбор режимов
работы осуществляется
пользователем
после инициализации
программных
модулей. Следовательно
структурная
схема будет
иметь вид показанный
на рис.


Рис. 4.2 Блок-схема
алгоритма,
реализующего
технологическую
схему обработки
информации
Рис. 4.3 Структурно-функциональная
схема АРМ
В

качестве примера
рассмотрим
блок-схему
алгоритма
функционирования
управляющего
модуля. Блок-схема
приведена на
рис.
Рис.
4.4 Блок-схема
функционирования
алгоритма
управляющего
модуля
4.2
Реализация
алгоритма.
4.2.1
Функциональные
модули.
Функционально
АРМ состоит
из следующих
модулей:
Модуль
картотеки
фондов, предназначен
для ввода/просмотра,
получения
различных
отчётов по
картотеке
фондов;
Модуль
картотеки
читателей,
предназначенный
для ввода/просмотра,
получения
различных
отчётов по
читателям;
Модуль
контроля,
обеспечивающий
контроль
достоверности
и целостности
базы данных;
Модуль
администратора,
предназначенный
для корректировки
системной
информации,
путей доступа
к базе данных,
назначения
прав доступа
для пользователей.
Доступ
к функциональным
модулям обеспечивается
через развитую
систему меню.
Вид
системы меню
представлен
на рис.4.5

Рис. 4.5
Вид системного
меню
4.2.2
Модуль
идентификации
и аутентификации.
При
доступе в программу
необходимо
производить
идентификацию
пользователя
и его прав для
доступа к функциям
программы это
диктуется тем,
что доступ к
программе будут
иметь не только
обслуживающий
персонал библиотеки,
но и читатели.
Форма демонстрирующая
этот процесс
показана на
рис. 4.6.

Рис. 4.6 Форма
ввода модуля
идентификации
и аутентификации
П
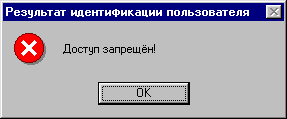
осле
ввода логина
и пароля пользователя
производится
проверка прав
доступа, в случае
наличия прав
только на чтение
выводится
сообщение
показанное
на рис. 4.7, в случае
отсутствия
прав доступа
к программе
выводится
сообщение
показанное
на рис. 4.8.
Рис. 4.7 Рис.
4.8
При
наличие прав
доступа только
на чтение некоторые
функции будут
не доступны.
Создание
новых пользователей
и назначение
прав производится
в модуле администратора.
4.2.3
Модуль
картотеки
фондов.
На рисунке
4.9 показана
структурная
схема модуля
для работы с
картотекой
фондов. Далее
рассмотрим
подробнее
данную структурную
схему.
Схема
отображает
связи функций
и возможные
переходы между
функциями,
отображает
входные и выходные
формы, позволяет
оценить возможности
данного модуля.

Р   ис.
4.9 Структурная
схема модуля
картотеки
фондов ис.
4.9 Структурная
схема модуля
картотеки
фондов
4.2.3.1
Главная форма
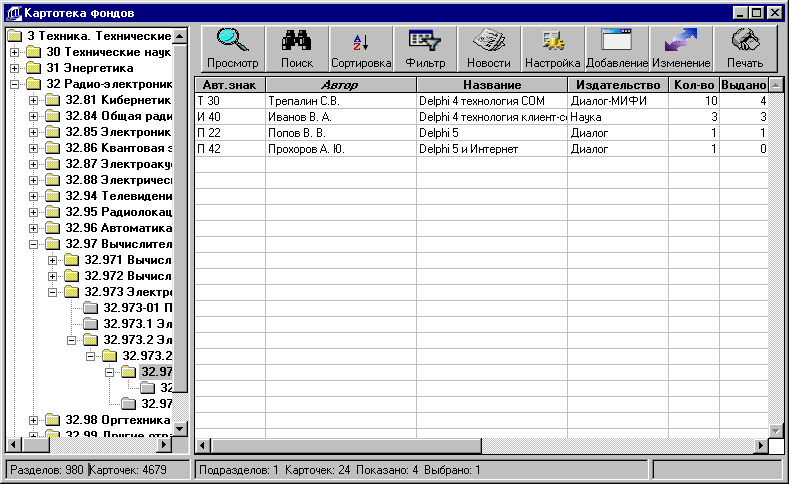 Рис.
4. 10 Главная форма
модуля картотеки
фондов Рис.
4. 10 Главная форма
модуля картотеки
фондов
На рисунке
4.10 представлена
главная форма
для работы с
картотекой
фондов. Слева
располагается
дерево разделов,
в котором
отображаются
названия разделов
и их нумерация
по ББК. Справа
находится
таблица, содержащая
список литературы
для выбранного
раздела, в ней
отображаются
следующие
данные:
Вверху
справа располагается
меню (набор
кнопок) для
выбора функций,
предусмотрены
следующие
функции:
Просмотр
библиографической
карточки;
Поиск по
выбранным
значениям
раздела или
карточки;
Сортировка
разделов и
карточек;
Наложение
фильтра на
выбранный
раздел;
Просмотр
новых поступлений;
Настройка
отображаемых
полей формы;
Добавление
новых разделов
и карточек
изданий;
Редактирование
добавленных
ранее разделов
и карточек;
Печать
библиографической
карточки.
Функции
для добавления
и изменения
информации
в картотеке
доступны только
для авторизированного
персонала
библиотеки.
В нижней
части формы
представлена
строка статуса,
в которой слева
отображается
общее количество
разделов и
общее количество
карточек изданий,
а справа количество
подразделов
в выбранном
разделе, общее
количество
карточек в этих
подразделах,
количество
карточек в
текущем разделе,
количество
выбранных
карточек изданий,
а также здесь
расположен
индикатор, в
котором при
длительных
операциях
производится
отображение
хода процесса.
Для главной
формы картотеки
фондов рассмотрим
получение
списка литературы,
для этого
используются
SQL
запрос, который
будет иметь
вид:
SELECT
Books.bookid
AS BookId,
;
Books.name
AS BookName,
;
Books.booktype
AS BookType,
;
Typepubl.name
AS
TypeName,
;
Books.publyear
AS PublYear,
;
Creators.name
AS AutorName,
;
Publisher.publname
AS PublName,
;
Publisher.publcity
AS PublCity,
;
Count(‘BookNum.Num’) AS Count, ;
Count(‘BookUse.Num’) AS UseCount, ;
Books.comment
AS Comment
;
FROM
library!Books INNER JOIN library!Autor;
INNER JOIN
library!Creators;
INNER JOIN
library!BookNum;
INNER JOIN
library!BookUse;
INNER JOIN
library!Books;
INNER JOIN
library!TypePubl ;
ON
Typepubl.nameid
=
Books.booktype ;
ON
Publisher.publid = Books.publid ;
ON
Booknum.number
=
Bookuse.number ;
ON
Books.bookid
=
Booknum.bookid ;
ON
Creators.nameid
=
Autor.autorid ;
ON
Books.bookid
=
Autor.bookid;
WHERE
Books.issid
= lnissid
AND
;
EMPTY(BookUse.Date2);
GROUP BY
Books.BookId ;
INTO CURSOR
vwBooks
Пример 4.1
SQL-запрос
получение
списка литературы.
В качестве
фильтрующего
параметра для
таблицы изданий
Books используется
уникальный
код раздела
из таблицы
Issue, а из таблицы
выдачи BookUse выбираются
записи, для
которых не
заполнена дата
возврата.
4.2.3.2 Просмотр

Рис.
4.11 Просмотр
карточки издания
На
рисунке 4.11 представлена
форма развёрнутого
просмотра со
следующей
информацией:
Данные
для формы
обеспечиваются
на основе SQL-запроса
который представлен
в примере 4.1, а
данные об авторах,
составителях,
редакторах
получают отдельными
запросами.
Рассмотрим
подробнее
запрос для
получения
списка авторов,
запрос будет
иметь следующий
вид:
SELECT
Creators.name, ;
Autor.autorid;
FROM
library!Creators INNER JOIN library!Autor ;
ON
Creators.nameid = Autor.autorid;
WHERE
Autor.bookid = lnbookid
;
INTO CURSOR
vwAutor
Пример 4.2
SQL-запрос
получение
списка авторов
В качестве
фильтрующего
параметра
используется
уникальный
код книги из
таблицы Books.
Для данной
формы предусмотрены
дополнительные
функции:
Данные функции
доступны только
для авторизированного
персонала
библиотеки.
На форме
просмотра
выданных экземпляров,
которая показана
на рисунке 4.12
доступна информация
о:

Рис. 4.12
Просмотр выданных
экземпляров
Показываются
только те экземпляры,
которые в текущий
момент являются
выданными
абоненту.
Предусмотрены
следующие
функциональные
возможности:
перехода
на карточку
абонента;
группу абонентов;
просмотр
инвентарных
номеров выданных
книг;
изменение
порядка сортировки
отображаемых
данных.
Данные
для формы получаем
SQL-запросом
следующего
вида:
SELECT
Groups.name AS GrpName, ;
Name1.name AS
Fam, ;
Name2.name
AS Name, ;
Name3.name AS
Otch, ;
BookUse.date1
AS Date, ;
COUNT('BookUse.Num')
AS Count, ;
Abonents.abonid
AS AbonId, ;
BookNum.bookid
AS BookId ;
FROM
library!BookNum INNER JOIN library!BookUse ;
INNER JOIN
library!Abonents ;
INNER JOIN
library!Groups ;
INNER JOIN
library!Name1 ;
INNER JOIN
library!Name2 ;
INNER JOIN
library!Name3 ;
ON
Name1.nameid = Abonents.name3 ;
ON
Name2.nameid = Abonents.name2 ;
ON
Name3.nameid = Abonents.name1 ;
ON
Groups.id = Abonents.grid ;
ON
Abonents.abonid = Bookuse.abonid ;
ON
Booknum.number = Bookuse.number ;
WHERE
Booknum.bookid = lnBookId ;
AND
EMPTY(Bookuse.date2) ;
GROUP BY
Abonents.abonid ;
INTO CURSOR
vwUseBook
Пример 4.3
SQL-запрос
получение
списка читателей
В качестве
элементов
фильтра используется
уникальный
код книги из
таблицы Books и
значение поля
Date2 таблицы BookUse,
которое должно
быть не заполненным,
так как определяет
дату возврата
книги в библиотеку.
На форме
просмотра
инвентарных
номеров, которая
представлена
на рис. 4.13, доступна
информация:
Для получения
данных используем
SQL-запрос:

Рис.
4.13 Просмотр
инвентарных
номеров
SELECT
Booknum.number
AS InvNum, ;
Booknum.date
AS Date ;
FROM
library!BookNum;
WHERE
Booknum.bookid = lnBookId
;
INTO CURSOR
vwInvNum
Пример 4.4
SQL-запрос получение
инвентарных
номеров
В качестве
элемента фильтра
применяется
уникальный
код книги из
таблицы Books. Для
выбранных
данных можно
изменять порядок
отображения,
установив
активный столбец
в таблице.
4.2.3.3 Поиск
На рисунке
4.14 показана форма
для ввода параметров
поиска. Поиск
по разделу
осуществляется
по следующим
значениям:
Номеру раздела
по ББК;
Названию
раздела.

Рис.
4.14 Поиск по параметру
Поиск по
карточкам
фондов осуществляется
по:
Автору;
Названию
книги;
Году издания;
Количеству
единиц хранения;
Количеству
выданных
экземпляров;
Дате добавления
в картотеку.
Поиск может
осуществляется
по любой комбинации
параметров.
В форме просмотра
результатов
поиска, показанной
на рисунке,
первыми отображаются
данные наиболее
соответствующие
введённым
значениям, те
которые удовлетворяют
логическому
условию И,
затем все которые
удовлетворяют
логическому
условию ИЛИ.

Рис.
4.15 Просмотр
результатов
поиска
В форме
просмотра
результатов
поиска, показанной
на рис. 4.15, отображается
следующая
информация:
Для формы
просмотра
результатов
поиска предусмотрены
следующие
функции:
Переход на
карточку издания;
Переход к
разделу, к которому
относится
карточка издания;
Печать
библиографической
карточки издания;
Изменение
порядка сортировки
отображаемых
данных.
4.2.3.4
Сортировка.

Рис. 4.16 Выбор
параметра
сортировки
На рисунке
4.16 показана форма
для задания
порядка отображения
записей в дереве
разделов и
списке литературы.
Для задания
порядка отображения
в дереве разделов
доступны следующие
параметры:
Номер раздела
по ББК;
Название
раздела.
Для списка
разделов:
Автор;
Составитель;
Редактор;
Название
издания;
Издательство;
Год издания;
Количество
единиц хранения;
Количество
выданных
экземпляров;
Дата добавления
в каталог.
Так же форма
предоставляет
возможность
просмотра
текущих установок.
После выбора
параметра для
сортировки,
для списка
литературы,
он отображается
в заголовке
соответствующего
столбца таблицы
изменением
шрифта надписи
на курсив.
4.2.3.5 Фильтр
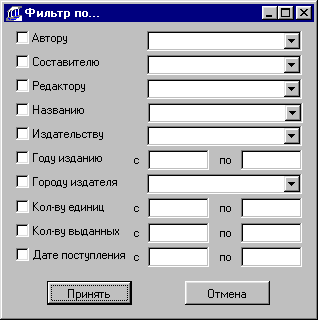
Рис. 4.17 Задание
фильтра для
раздела
На рисунке
4.17 показана форма
для задания
условий фильтрации
в списке литературы
выбранного
раздела. Фильтр
может задаваться
по следующим
параметрам:
Автору;
Составителю;
Редактору;
Названию
издания;
Издательству;
Диапазону
годов издания;
Диапазону
единиц хранения;
Диапазону
выданных
экземпляров;
Диапазону
дат занесения
в картотеку.
Фильтрация
может производиться
по любой совокупности
выбранных
параметров.
Отмеченные,
но не заполненные
параметры при
установке
фильтра не
учитываются.
Выбранные
параметры
хранятся как
массив главной
формы, а установка
фильтра производиться
командой
SET
FILTER TO [список
параметров].
Для параметров
“Автор”,
”Составитель”,
“Редактор”,
“Название
издания”,
“Издательство”
выбор значений
может производиться
как определением
списка из набора,
в котором содержатся
только уникальные
значения полученные
на основе выборок
из результата
работы запроса
показанного
в примере 4.1, так
и на основе
ручного ввода.
4.2.3.6 Новости
При
выборе пункта
“Новости”
главного окна
появляется
всплывающее
меню для выбора
типа новостей,
таких как “Новости
поступления”
и “Новости
мероприятий”.
Новости поступления
отображаются
в форме показанной
на рисунке
4.18.
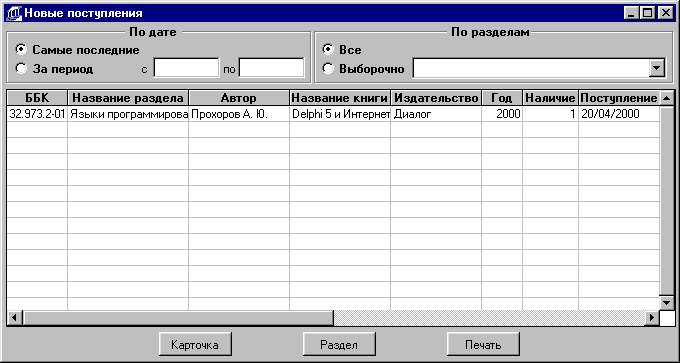
Рис.
4.18 Новости поступления
Здесь
отображается
информация
о:
При загрузке
в форме показываются
самые последние
поступления
по всем разделам,
впоследствии
настройки по
умолчанию можно
изменить, выбрав
просмотр поступлений
за период или
установив
желаемый список
разделов.
Так же в форме
предусмотрены
функции:
Перехода
на карточку
книги;
Переход на
раздел в котором
содержится
карточка;
Печати карточки
книги;
изменение
порядка сортировки
отображаемых
данных.
Отбор
информации
для формы
осуществляется
SQL-запросом
следующего
вида:
SELECT
Issue.bbk
AS BBK,
;
Issue.name
AS IssName,
;
Books.name
AS BookName,
;
Creators.name
AS AutorName,;
Publisher.publname
AS PublName,
;
Publisher.publcity
AS PublCity, ;
Books.publyear
AS PublYear,
;
COUNT(‘Booknum’)-COUNT(‘Bookuse’)
AS Count,
;
FROM
library!Issue INNER JOIN library!Books;
INNER JOIN
library!Autor;
INNER JOIN
library!Creators;
INNER JOIN
library!BookNum;
INNER JOIN
library!BookUse;
INNER JOIN
library!Books ;
ON
Publisher.publid = Books.publid ;
ON
Booknum.number
=
Bookuse.number ;
ON
Books.bookid
=
Booknum.bookid ;
ON
Creators.nameid
=
Autor.autorid ;
ON
Books.bookid
=
Autor.bookid ;
ON Issue.id
=
Books.issid;
WHERE
Books.date =>
ldDate
;
GROUP BY
Books.BookId ;
INTO CURSOR
vwNews
Пример 4.5
SQL-запрос
получение
списка новых
поступлений
В
качестве фильтрующего
параметра
используется
значение даты.
4.2.3.7 Настройка

Рис. 4.19 Настройка
отображаемых
атрубутов
На рисунке
4.19 показана форма
для настройки
выводимой
информации
в дереве разделов
и списке литературы.
Так же в форме
отображается
текущая настройка
выводимой
информации.
Для настройки
отображения
в дереве разделов
доступны следующие
пункты:
Номер раздела
по ББК;
Название
раздела.
Для списка
литературы:
Автор;
Название
книги;
Издательство;
Год издания;
Город издательства;
Количество
экземпляров
хранения;
Количество
выданных
экземпляров;
Дата занесения
в картотеку.
4.2.3.8
Добавление
При выборе
опции “Добавление”
главной
формы, появляется
всплывающее
меню для выбора
типа добавления:
“Добавить
раздел”,
“Добавить
карточку”.
При
добавлении
раздела информация
о номере раздела
по ББК и название
раздела заносится
в форме показанной
на рисунке
4.20. Раздел может
быть добавлен
в любой узел
дерева разделов,
для этого дерево
отображается
в верху формы,
по умолчанию
добавление
происходит
в текущий раздел,
выбранный в
главном окне
картотеки.
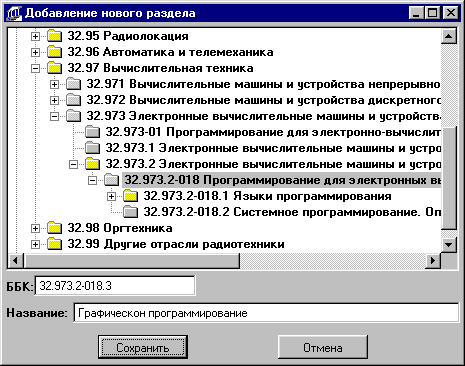
Рис. 4.20 Добавление
нового раздела
Добавление
производится
командой SQL-Insert
следующего
вида:
INSERT
INTO Issue (Id, Bbk, Name, Parent) VALUES (lnId, lcBbk, lcName,
lnParent), где
lnId - уникальный
номер нового
раздела, вычисляется
как RECCOUNT(‘Issue’)+1;
lcBbk- номер
нового раздела
по ББК;
lcName-Название
нового раздела;
lnParent-Номер
узла дерева
разделов в
который производиться
добавление.
Добавление
новой карточки
производится
в форме показанной
на рисунке
4.21.
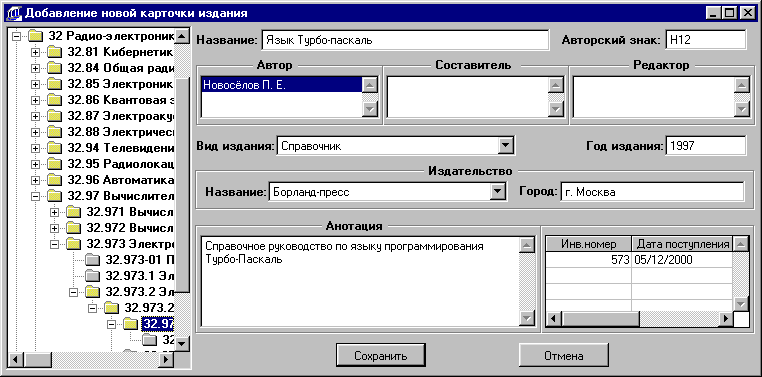
Рис. 4.21 Добавление
новой карточки
издания
Для добавления
новой карточки
необходимо
ввести следующую
информацию:
Авторский
знак;
Автора или
список авторов;
Составителя
или список
составителей;
Редактора
или список
редакторов;
Вид издания;
Год издания
Название
издания;
Издательство;
Город издательства;
Перечень
инвентарных
номеров;
Краткую
аннотацию.
Для ввода
автора (списка
авторов), составителя
(списка составителей),
редактора
(списка редакторов)
и издательства
используются
списки полученные
на основе таблиц
Creators
и Publisher
соответственно.
Добавление
производится
командами
SQL-Insert следующего
вида:
INSERT
INTO Books (IssId, BookId, Name, PublId, PublYear, Date) VALUES
(lnIssId, lnBookId, lcName, lnPublId, lnPublYear,
DATE())
INSERT INTO
BookAutor (UniqId, BookId, AutorId) VALUES (lnUniqId, lnBookId,
lnAutorId)
INSERT
INTO BookNum (BookId, Number) VALUES (lnBookId, lnNumber)
4.2.3.9 Изменение
При выборе
опции “Изменение”
главной
формы, появляется
всплывающее
меню для выбора
типа изменения:
“Изменить
раздел”,
“Изменить
карточку”.
Формы для изменения
информации
о разделе и о
карточки идентичны
формам представленным
в разделе “Добавить”.
Кроме изменения
данных о авторах,
названиях,
издательствах,
инвентарных
номерах и аннотациях,
возможно изменение
расположения
в разделах,
которое производится
выбором нового
узла из дерева
разделов. При
этом если изменение
расположения
в дереве производится
для раздела,
все карточки
находящиеся
в данном разделе
автоматически
переносятся
вместе с разделом.
Для изменения
значений в
таблице Issue
можно
применить
команду SQL-Update
имеющей вид:
UPDATE Issue
;
SET
bbk=lnbbk,
;
name=lnName, ;
parent=lnParent
;
WHERE
id=lnId
Где в качестве
элемента фильтра
применяется
уникальный
номер группы
из таблицы
Issue.
Для изменения
значений в
таблице Books необходимо
применить
несколько
аналогичных
функций.
4.2.3.10 Печать.
При
выборе этой
функции открывается
системное окно
выбора принтера,
для задания
параметров
печати, после
выбора параметров
осуществляется
печать библиографической
карточки издания.
4.2.4
Модуль
картотеки
читателей.
На рисунке
4.22 показана
структурная
схема модуля
для работы с
картотекой
читателей.
Далее рассмотрим
подробнее
данную структурную
схему.
Схема
отображает
связи функций
и возможные
переходы между
функциями,
отображает
входные и выходные
формы, позволяет
оценить возможности
данного структурного
модуля.
4.2.4.1 Главная
форма

Рис. 4.23 Главная
форма модуля
картотеки
читателей
Р
ис.
4.22 Структурная
схема модуля
картотеки
читателей

На рисунке
4.23 представлена
главная форма
для работы с
картотекой
читателей.
Слева располагается
дерево групп,
в котором
отображаются
групп читателей.
Справа находится
таблица, содержащая
список читателей
для выбранной
группы, в ней
отображаются
следующие
данные:
Фамилия, имя
и отчество
читателя;
Количество
изданий находящихся
на руках;
Количество
изданий с
просроченным
сроком сдачи;
Дата регистрации
читателя;
Дата последнего
посещения;
Дата рождения
читателя;
Телефон
читателя;
Вверху справа
располагается
меню (набор
кнопок) для
выбора функций,
предусмотрены
следующие
функции:
Просмотр
карточки читателя
с возможностью
выдачи и сдачи
изданий;
Поиск по
выбранным
значениям;
Сортировка
групп и карточек
читателей;
Наложение
фильтра на
выбранную
группу;
Настройка
отображаемых
полей формы;
Добавление
новых групп
и карточек
читателей;
Редактирование
добавленных
ранее групп
и карточек
читателей;
Формирование,
просмотр и
печать разнообразной
статистики;
Печать карточки
читателя.
В нижней
части формы
представлена
строка статуса,
в которой слева
отображается
общее количество
групп читателей
и общее количество
карточек читателей,
а справа количество
подгрупп в
выбранной
группе, общее
количество
карточек в этих
подгруппах,
количество
карточек в
текущей группе,
количество
выбранных
карточек, а
также здесь
расположен
индикатор, в
котором при
длительных
операциях
производится
отображение
хода процесса.
Для главной
формы картотеки
читателей
рассмотрим
получение
списка читателей,
для этого
используются
SQL
запрос, который
будет иметь
вид:
SELECT
Name1.name
AS Fam,
;
Name2.name
AS Name,
;
Name3.name
AS Otch,
;
Street.street
AS StreetName,
;
City.city
AS CityName, ;
Abonents.house_fl
AS House_Flat,
;
Abonents.telefon
AS Telefon,
;
Abonents.date1
AS Date1,
;
Abonents.date2
AS Date2
;
Abonents.comment
AS Comment,;
FROM
library!Name1 INNER JOIN library!Abonents;
INNER JOIN
library!Name2;
INNER JOIN
library!Name3;
INNER JOIN
library!Street;
INNER JOIN
library!City ;
ON City.cityid
= Abonents.cityid ;
ON
Street.streetid = Abonents.streetid ;
ON Name3.nameid
= Abonents.name3 ;
ON Name2.nameid
= Abonents.name2 ;
ON Name1.namrid
= Abonents.name1;
WHERE
Abonents.grid = lngrid
;
INTO CURSOR
vwAbon
Пример 4.6
SQL-запрос
получение
списка читателей
В качестве
фильтрующего
параметра для
таблицы
читателей
Abonents
используется
уникальный
код группы из
таблицы Groups.
4.2.4.2 Просмотр
На
рисунке 4.24 представлена
форма развёрнутого
просмотра со
следующей
информацией:
Фамилия,
имя и отчество
читателя;
Дата
рождения;
Адрес
читателя;
Телефон
читателя;
Примечание
к карточке
читателя;
Дата
регистрации;
Дата
последнего
посещения.
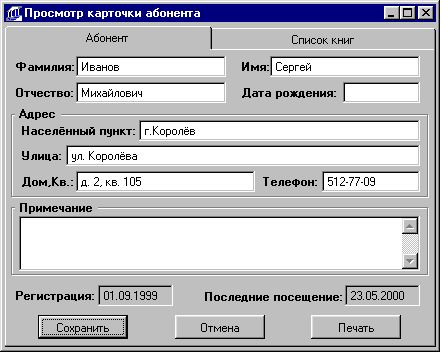
Рис. 4.24 Просмотр
карточки читателя
Данные
для формы
обеспечиваются
на основе SQL-запроса
который представлен
в примере 4.6.
Для данной
формы предусмотрены
дополнительные
функции:
На форме
просмотра
списка выданных
экземпляров,
которая показана
на рисунке
4.25, доступна
информация
о:

Рис.
4.25 Просмотр списка
изданий
По умолчанию
показываются
только те экземпляры,
которые в текущий
момент являются
выданными
абоненту.
Предусмотрены
следующие
функциональные
возможности:
Выдача
издания читателю,
с возможность
поиска по картотеке
фондов или
быстрый поиск
по инвентарному
номеру;
Приём издания
от читателя;
Просмотр
библиографической
карточки выданного
издания;
Изменение
фильтра для
просмотра,
задолженных
экземпляров
или всех изданий,
которые выдавались
читателю;
Печать списка;
Изменение
порядка сортировки
отображаемых
данных.
Данные
для формы получаем
SQL-запросом
следующего
вида:
SELECT
Bookuse.number AS BookNum, ;
Bookuse.date1
AS BookDate1, ;
Bookuse.date2
AS BookDate2 ;
FROM
library!BookNum INNER JOIN library!BookUse ;
ON
Booknum.number = Bookuse.number;
WHERE
Bookuse.abonid = lnabonid ;
INTO CURSOR
vwUseBook
Пример 4.7
SQL-запрос
получение
списка изданий
для читателя
В качестве
элементов
фильтра используется
уникальный
код читателя
таблицы Abonents.
4.2.4.3 Поиск

Рис. 4.26 Поиск
карточки читателя
На рисунке
4.26 показана форма
для ввода параметров
поиска. Поиск
может осуществляться
по группам и
по карточкам
читателей, для
этого необходимо
определить
хотя бы один
из следующих
параметров:
Поиск может
осуществляется
по любой комбинации
параметров.
Для параметров
“Название
группы”,
“Фамилия”,
“Имя”
и “Отчество”
возможен
выбор значения
из списка
формируемого
на основе таблиц
Issue,
Name1,
Name2
и Name3
соответственно.
В форме
просмотра
результатов
поиска, показанной
на рисунке,
первыми отображаются
данные наиболее
соответствующие
введённым
значениям, те
которые удовлетворяют
логическому
условию И,
затем все которые
удовлетворяют
логическому
условию ИЛИ.

Рис. 4.27 Просмотр
результатов
поиска
В форме
просмотра
результатов
поиска (рис.4.27)
отображается
следующая
информация:
Для формы
просмотра
результатов
поиска предусмотрены
следующие
функции:
Переход на
карточку читателя;
Переход к
группе, к которому
относится
карточка читателя;
Изменение
порядка сортировки
отображаемых
данных.
4.2.4.4
Сортировка
На рисунке
4.28 показана форма
для задания
порядка отображения
записей в списке
карточек читателей.
Для задания
порядка отображения
в списке читателей
доступны следующие
параметры:
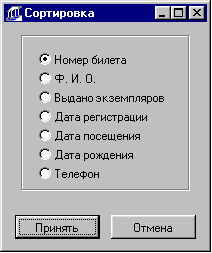
Рис.
4.28 Сортировка
карточек читателей
Так же форма
предоставляет
возможность
просмотра
текущих установок.
После выбора
параметра для
сортировки
в списке читателей,
он отображается
в заголовке
соответствующего
столбца таблицы
изменением
шрифта надписи
на курсив.
4.2.4.5 Фильтр
На рисунке
4.29 показана форма
для задания
условий фильтрации
в списке читателей
выбранной
группы. Фильтр
может задаваться
по следующим
параметрам:

Рис.
4.29 Задание фильтра
для списка
карточек читателей
Фамилии,
имени и отчеству
читателя;
Диапазону
количества
выданных
экземпляров;
Диапазону
дат регистрации;
Диапазону
дат последнего
посещения;
Диапазону
дат рождения
читателей.
Фильтрация
может производиться
по любой совокупности
выбранных
параметров.
Отмеченные,
но не заполненные
параметры при
установке
фильтра не
учитываются.
Выбранные
параметры
хранятся как
массив главной
формы картотеки
читателей, а
установка
фильтра производиться
командой
SET
FILTER TO [список
параметров].
Для параметра
“Ф.
И. О.”,
выбор значений
может производиться
как определением
списка из набора,
в котором содержатся
только уникальные
значения полученные
на основе выборок
из результата
работы запроса
показанного
в примере 4.6, так
и на основе
ручного ввода.
4.2.4.6 Настройка
На рисунке
4.30 показана форма
для настройки
выводимой
информации
в списке читателей
выбранной
группы. Так же
в форме отображается
текущая настройка
выводимой
информации.
Для настройки
отображения
доступны следующие
параметры:
Номер читательского
билета;
Фамилии,
имени и отчества;
Выданное
количество
экземпляров;

Рис. 4.30 Настройка
выводимых
атрибутов
4.2.4.7
Добавление
При выборе
опции “Добавление”,
главной
формы модуля
картотеки
читателей,
появляется
всплывающее
меню для выбора
типа добавления:
“Добавить
группу”,
“Добавить
карточку”.
При добавлении
группы, информация
о название
группы заносится
в форме показанной
на рисунке
4.31. Группа может
быть добавлен
в любой узел
дерева групп
читателей, для
этого дерево
отображается
вверху формы,
по умолчанию
добавление
происходит
в текущую группу,
выбранную в
главном окне
модуля картотеки
читателей.

Рис. 4.31 Добавление
новой группы
читателей
Добавление
производится
командой SQL-Insert
следующего
вида:
INSERT
INTO Groups (Id, Name, Parent) VALUES (lnId, lcName, lnParent),
где
lnId - уникальный
номер новой
группы, вычисляется
как
RECCOUNT(‘Groups’)+1;
lcName-Название
новой группы;
lnParent-Номер
узла дерева
групп в который
производиться
добавление.
Добавление
новой карточки
читателя производится
в форме показанной
на рисунке
4.32.
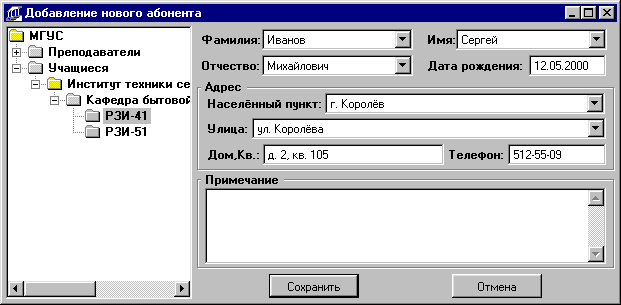
Рис.
4.32 Добавление
новой карточки
читателя
Для добавления
новой карточки
необходимо
ввести следующую
информацию:
Для ввода
фамилии, имени
и отчества
читателя используются
списки полученные
на основе таблиц
Name1, Name2 и
Name3 соответственно.
4.2.4.8 Изменение
При выборе
опции “Изменение”
главной
формы, появляется
всплывающее
меню для выбора
типа изменения:
“Изменить
группу”,
“Изменить
карточку”.
Формы для изменения
информации
о группе и информации
о карточке
читателя идентичны
формам представленным
в разделе “Добавить”.
Кроме изменения,
возможно изменение
расположения
в группах, которое
производится
выбором нового
узла из дерева
групп. При этом
если изменение
расположения
в дереве производится
для группы, все
карточки читателей
находящиеся
в данной группе
автоматически
переносятся
вместе с группой.
Для изменения
значений в
таблице Groups
можно
применить
команду SQL-Update
имеющей вид:
UPDATE Groups
;
SET
name=lnName, ;
parent=lnParent
;
WHERE
id=lnId
Где в качестве
элемента фильтра
применяется
уникальный
номер группы
из таблицы
Groups.
Для изменения
значений в
таблице Abonents
необходимо
применить
несколько
аналогичных
функций.
4.2.4.9
Статистика.
При
выборе функции
Статистика
главного окна
модуля картотеки
читателей,
появляется
всплывающее
меню для выбора
одного из возможных
видов отчёта,
таких как
“Задолженность
по группам
читателей”,
“Выдача изданий
по разделам”
и “Выдача
изданий по
группам читателей”.
4.2.4.10 Печать.
При
выборе этой
функции открывается
системное окно
выбора принтера,
для задания
параметров
печати, после
выбора параметров
осуществляется
печать карточки
читателя.
4.2.5
Модуль
контроля.
Доступ
к модулю контроля
имеет только
администратор
системы, в этом
модуле проводится
проверка корректности
базы данных,
достоверности
хранящейся
информации,
а также имеются
средства для
восстановления
таблиц, базы
данных и консистенции
информации.
4.2.6
Модуль
администратора.
Доступ
к модулю администратора
имеет только
администратор
системы, в этом
модуле производится
настройка путей
к базе данных,
создание
пользователей
и назначения
прав доступа.
Глава
5. Реализация
выбранных
решений.
После
проектирования
АРМ, разработки
таблиц, полей
и связей необходимо
еще раз просмотреть
функции подлежащие
автоматизации,
структуру базы
данных и выявить
возможные
недочеты.
Желательно
это сделать
на этапе, пока
таблицы не
заполнены
данными.
Для проверки
необходимо
создать несколько
таблиц, определить
связи между
ними и ввести
несколько
записей в каждую
таблицу, затем
осмотреть,
отвечает ли
база данных
поставленным
требованиям.
Рекомендуется
также создать
черновые выходные
формы и отчеты
и проверить.
выдают ли они
требуемую
информацию.
Кроме того,
необходимо
исключить из
таблиц все
возможные
повторения
данных.
Как указывалось
ранее, в качестве
инструментария
разработки
АРМ научно-технической
библиотеки
университета,
была выбрана
СУБД Microsoft
Visual FoxPro. Этот
выбор определяет
все особенности
компьютерной
реализации
принятых решений
по организации
информационного
обеспечения
потенциальных
пользователей.
Основой любого
АРМ являются:
• таблицы,
где хранятся
все те данные,
которые необходимы
пользователям;
• запросы,
набор возможностей
по поиску,
извлечению,
вводу и коррекции
информации;
• формы,
интерфейс между
пользователем
и программным
обеспечением
АРМ. Список
таблиц, их состав,
свойства атрибутов,
взаимосвязи
и прочие характеристики
описаны в разделах
3 и 4 данной работы.
Примеры запросов
и форм описаны
в разделе.
В процессе
выполнения
данного дипломного
проекта были
разработаны:
• перечень
таблиц (всего
17);
• состав
таблиц (суммарно
около 60
атрибутов);
• свойства
атрибутов;
• на основе
анализа доступных
источников
произведено
наполнение
таблиц реальной.
Указанные
наборы данных
являются вполне
самодостаточными
и позволяют
провести тестирование
разработанного
АРМ в полном
объёме, как в
плане проверки
вообще работоспособности
системы, так
и правильности
получаемых
результатов.
Тестирование
проводилось
методом непосредственной
имитации работы
пользователя.
Основными
критериями
верификации
(правильности)
данного программного
продукта являлись
адекватность
реакции системы
на предложенное
ей действие
и соответствие
этой реакции
эргономическим
требованиям,
изложенным
в разделе 6 данной
работы.
В процессе
тестирования
был выявлен
ряд неточностей
и некорректностей,
в частности:
• несоответствие
поля типу данных
(вместо числового
атрибута -
текстовый);
• размер
поля меньше
требуемого
(данные обрезаются
по реальному
размеру).
Эти и другие
замеченные
ошибки были
зафиксированы
и исправлены.
Результатом
тестирования,
последующей
отладки и
корректировки
базы данных
является программный
продукт, удовлетворяющий
приведенным
выше критериям.
В частности,
по классу
эргономических
требований
(ограничений),
в число которых
входит:
• время реакции
системы,
• число одновременно
оцениваемых
параметров,
• вид представляемой
информации,
• доклад о
процессе обработки
информации,
• цветовая
палитра выходных
форм,
• дружественность
интерфейса
и др.
Разрабатываемая
база данных
отвечает этим
требованиям
при условии
её реализации
на тех технических
средствах,
которые могут
обеспечить
эти характеристики.
Машинные
эксперименты
проводились
на нескольких
IBM - совместимых
компьютерах
разных поколений
и конфигураций,
а именно, PC
i486-DX, iPENTIUM-200, AMD K6-2 333, iPENTIUM II-500, AMD K7 Athlon
550.
Эти эксперименты
показали, что
на основе их
результатов
могут быть
предъявлены
определённые
требования
к техническим
и программным
средствам со
стороны разрабатываемого
АРМ. Для нормального
функционирования
базы данных
должны быть
выполнены
следующие
условия.
Технические
средства
1. Персональная
ЭВМ - совместимая
с IBM AT:
• с процессором
i486DX4-100 или выше,
• с оперативной
памятью не
менее 16 Мб,
• с объёмом
свободного
пространства
на диске не
менее 40Мб,
• с накопителем
на гибком диске.
2. Монитор
SVGA с разрешением
800*600 точек.
3. Видеокарта
с памятью не
менее 1
МБ.
4. Манипулятор
«мышь».
5. Клавиатура.
6. Принтер.
Программные
средства
1. Операционная
система
WINDOWS 95/98,
WINDOWS NT/2000.
В случае
работы в среде
локальной
вычислительной
сети необходима
соответствующая
техническая
и программная
поддержка.
По критерию
адекватности
реакции базы
данных на заданные
действия нареканий
и замечаний
нет, что свидетельствует
о правильности
выбранного
подхода к
проектированию
базы данных
и правильности
выбранного
инструментария
для её создания.
Необходимо
также отметить
тот факт, что
разработанная
база данных
является мобильным
программным
продуктом, т.е.
может быть
легко установлена
на любой
IBM - совместимой
персональной
ЭВМ.
Глава
6. Анализ и учёт
эргономических
характеристик.
ЭРГОНОМИКА
(от греч. ergon - работа
и nomos - закон), отрасль
науки, изучающая
человека (или
группу людей)
и его (их) деятельность
в условиях
производства
с целью совершенствования
орудий, условий
и процесса
труда. Основной
объект исследования
эргономики
- системы «человек
- машина», в том
числе и так
называемые
эргатические
системы.
ЭРГАТИЧЕСКАЯ
СИСТЕМА, сложная
система управления,
составным
элементом
которой является
человек-оператор
(или группа
операторов).
В конечном
итоге, результаты
эргономических
исследований
для конкретных
систем выражаются
в тех требованиях
для этих систем,
реализация
которых позволяет
человеку трудиться
как можно более
продуктивно
и в, как более
возможно, комфортных
условиях.
Современные
эргатические
системы включают
в свой состав
компьютеры
с соответствующим
программным
обеспечением,
поэтому требования
к эргономическим
параметрам
систем можно
разделить на
два больших
класса:
- требования
к техническим
средствам,
- требования
к программным
средствам.
Рассмотрение
требований
к техническим
средствам не
входит в наши
задачи, остановимся
на требованиях
к программным
средствам.
Применительно
к программному
обеспечению
можно сформулировать
некоторый
перечень требований,
в число которых,
например, входят:
- время реакции
системы,
- число одновременно
оцениваемых
параметров,
- вид представляемой
информации,
- доклад о
процессе обработки
информации,
- цветовая
палитра выходных
форм,
- дружественность
интерфейса
и др.
Время
реакции
– это время,
потребное
системе для
принятия запроса
на некоторое
действие, на
реализацию
этого действия
и на доставку
оператору
результатов
выполнения
для последующей
их оценки и
принятия решения.
В общем виде
время реакции
может быть
представлено
следующей
формулой:
Г
де:
tr
- время реакции
системы;
tпр
- время приёма
запроса
tвып
- время выполнения
tдост
- время доставки
Каждый
компонент
времени реакции
может быть
разделён на
время работы
технических
средств и время
работы программных
средств.
Очевидно,
что время реакции
не должно превышать
некоторой
заданной величины,
достаточно
ясно также, что
время работы
технических
средств в конкретном
исполнении
практически
постоянно.
Поэтому уменьшение
времени реакции
возможно только
лишь за счёт
соответствующей
организации
программного
обеспечения.
Таким образом,
эргономическое
требование
комфортного
времени реакции
системы влияет
на состав и
облик программного
обеспечения.
При табличном
проектировании
базы данных
для уменьшения
времени реакции
системы на
запрос пользователя
следует проектировать
таблицы, не
содержащие
избыточных
данных. Хорошая
структура
таблицы является
необходимым
исходным условием
для эффективного
получения и
обновления
данных. Если
всё же таблицы
содержат слишком
много данных,
следует разделить
их на связанные
таблицы, что
повысит эффективность
хранения данных.
Следует выбирать
подходящий
тип данных для
полей. Это поможет
уменьшить
размеры базы
данных и увеличит
скорость выполнения
операций связи.
При описании
поля следует
задать для него
тип данных
наименьшего
размера, позволяющий
хранить нужные
данные.
Существенное
повышение
скорости выполнения
запросов приносит
индексирование
полей, расположенных
по обе стороны
отношения, или
создание связи
между этими
полями, а также
индексирование
всех полей,
используемых
для задания
условий отбора
в запросе. Поиск
записей также
выполняется
намного быстрее,
если он ведётся
по индексированному
полю.
Нужно
заметить, что
индексы занимают
определенный
объём памяти
на диске и замедляют
операции добавления,
изменения и
удаления записей.
Однако, в большинстве
случаев выигрыш
в скорости
получения
данных перевешивает
те неудобства,
которые возникают
в этом случае
при обновлении
данных. Если
приложение
обновляет
данные очень
часто или, если
на жёстком
диске мало
свободного
места, использование
индексов можно
ограничить;
во всех остальных
случаях их
следует использовать
везде, где это
возможно.
Необходимо
отметить тот
факт, что все
эргономические
требования
определяются
психофизиологическими
особенностями
человеческого
организма.
В частности,
число одновременно
предъявленных
человеку параметров
для их оценки
(в зависимости
от их сложности)
не должно превышать
4 – 6. В противном
случае резко
повышается
вероятность
неправильного
их восприятия
и, как следствие,
- неправильного
принятия решения.
Этот фактор
необходимо
учитывать при
разработке
выходных форм.
Вид представляемой
информации.
Здесь существует
основное правило.
Информация,
представляемая
оператору на
средствах
отображения,
должна соответствовать
его профессиональному
опыту и тем
документам,
которые существовали
в данной организации
до появления
автоматизированной
обработки
данных с применением
вычислительной
техники. Т.е.
это должны быть
формализованные
таблицы, диаграммы,
графики, структурированные
сообщения и
т.д.
В разрабатываемом
АРМе в качестве
основного
метода представления
информации
выбрана технология
многооконных
форм, в которых
в соответствии
с канонами и
традициями
библиотекарского
делопроизводства
представляются
все необходимые
данные. Описания
форм и их функциональные
предназначенности
приведены в
соответствующем
разделе дипломной
работы.
Доклад
о процессе
обработки
информации.
В тех случаях,
когда время
обработки
данных существенно
превышает
заданное время
реакции, необходимо
выдавать оператору
соответствующие
сообщения.
Так, например,
установлено,
что при превышении
реального
времени реакции
над заданным
в 5-6 раз у оператора
возникает
состояние
«скуки».
(5 – 6)tзад
< tr,
При превышении
в 10 и более раз
у него возникает
состояние
«паники», т.е.
он начинает
сомневаться,
выполняется
ли вообще его
запрос или
система «зависла».
10tзад
< tr
Во избежание
подобных случаев
необходимо
выполнение
запроса «подкрашивать»
дополнительной
информацией,
например, выдавать
предполагаемую
длительность
выполнения
и бегущий таймер,
динамическую
процентную
шкалу выполнения,
звуковые сигналы
о завершении
тех или иных
этапов выполнения,
какие-либо иные
динамические
фрагменты,
свидетельствующие
о том, что процесс
выполнения
запроса происходит
в нормальном
режиме.
Так,
например, на
приведенном
рисунке
6.1 размещена
информация
о выполняемой
операции
(Копирование),
что копируется
(Описание.doc),
откуда и куда
(из 'TEXT
' в 'А:\'), процент
выполнения
(растущая
горизонтальная
диаграмма) и
сколько времени
осталось до
завершения
операции (10 сек).
Рис.6.1
При обнаружении
каких-либо
некорректностей
при выполнении
запроса необходимо
немедленно
(не откладывая
на более поздний
срок) информировать
об этом обстоятельстве
оператора.
Достаточно
эффективно
при этом использование
звуковых сигналов,
динамических
фрагментов
изображений
(мерцание, повороты
и т.д.), соответствующей
цветовой гаммы.
Цветовая
палитра выходных
форм.
Весьма важной
психофизиологической
особенностью
человека является
его восприятие
цвета.
Установлено,
что ряд цветовых
оттенков, а
особенно их
сочетание
действует на
человека как
сильнейший
раздражитель,
этот фактор
чрезвычайно
усиливает своё
воздействие
при динамической
смене цветов
(всяческие
мигания, мерцания,
вспышки и т.д.),
что неизбежно
приводит к
стрессовым
ситуациям.
И, наоборот,
другие сочетания
цветов действуют
весьма благотворно
на нервную
систему, создают
комфортные
условия для
продуктивной
длительной
работы.
Примером
хорошо продуманного
в этом плане
программного
продукта может
служить классический
NORTON COMMANDER,
который, до
появления
WINDOWS,
был обязательной
принадлежностью
каждой ПЭВМ.
Да и сейчас,
несмотря на
прекрасные
возможности
WINDOWS, его можно
встретить на
многих компьютерах.
Напротив,
подражатели,
например, VOLCOV
COMMANDER избрали
не совсем удачную
палитру цветов,
что (в сочетании
с другими факторами)
определило
их значительно
меньшую популярность.
Дружественность
интерфейса.
Понятие практически
не формализуемое,
но интуитивно
достаточно
ясное. В первую
очередь характеризуется
оптимальным
сочетанием
рассмотренных
выше факторов.
Основным
критерием
является комфортность
работы оператора,
заключающаяся,
в частности,
в отсутствии
повторов в уже
проделанной
работе, в сведении
к минимально
необходимому
числу подтверждений
и разрешений
на производство
тех или иных
операций, в
минимизации
работы с клавиатурой,
большим акцентом
работе с манипуляторами
типа «мышь»
и ему подобными.
Характеризуется
широкими
возможностями
многооконных
режимов работы,
возможностями
кратчайших
путей переходов
из одного состояния
в другое, использованием
возможностей
гипертекстовых
и гиперссылочных
свойств, хорошо
развитой системой
помощи, ненавязчивым
сервисом, защитой
от «дурака»
и т.д.
Глава
7. Технико-экономическое
обоснование.
Для наиболее
эффективного
управления
работой предприятия
необходимо
иметь достаточную
информацию
о положении
дел на предприятии
и возможность
оперативного
реагирования
на изменения
ситуации. Для
этого руководитель
предприятия
и другие ответственные
лица должны
постоянно иметь
свежую и достоверную
информацию.
Возникает
необходимость
организации
управления
работой предприятия
таким образом,
чтобы обеспечить
быструю и надежную
связь между
различными
служащими
для их слаженного
взаимодействия.
Предъявляемые
современными
условиями
требования
к системам
управления
могут быть
удовлетворены
лишь при помощи
современных
средств автоматизации
управления.
Опыт показывает,
что в наше время
для решения
этих задач не
обойтись без
помощи компьютерной
техники, позволяющей
в наиболее
удобной форме
хранить и
представлять
пользователям
интересующую
их служебную
информацию.
Однако, такие
системы требуют
для своей
работы соответствующего
программного
обеспечения,
необходимого
для обеспечения
работ отражающего
специфику
работы данного
предприятия.
Кроме того, к
такому программному
обеспечению
предъявляются
такие требования
как удобство
доступа к необходимой
информации,
простота в
обращении и
защита от
несанкционированного
доступа к
конфиденциальной
информации,
а также, защита
от порчи различного
рода программными
вирусами.
Настоящая
работа как раз
и представляет
собой подобное
программное
обеспечение
по управлению
работой предприятия
и отвечает
основным требованиям,
предъявляемым
к такого рода
программным
продуктам.
База данных
позволяет
связать всех
пользователей
локальной сети
в едином информационном
пространстве.
В целях защиты
информации
от несанкционированного
доступа к ней,
каждый из
пользователей
персонального
компьютера,
может иметь
свободный
доступ только
к информации,
необходимой
для выполнения
им его служебных
функций и получить,
при необходимости,
информацию,
не связанную
непосредственно
с его функциями,
может лишь
с ведома вышестоящего
руководства
предприятия.
Соответствующими
лицами осуществляется
обновление
информации
в соответствии
с изменением
положения
дел, такими как
поступление
или убытие
материально-технических
средств, товаров,
сырья.
При помощи
указанных
средств автоматизации
процесса управления
значительно
упрощаются
такие процессы
как документооборот
и учет на предприятии,
что значительно
уменьшает объем
бумажных документов,
поиск необходимой
документации,
восстановление
необходимых
документов
и составление
новых. Это
позволяет
облегчить
утомительную,
"бумажную",
работу.
За счет
простоты в
обращении, база
данных позволяет
использовать
при работе
со служебной
информацией
низкоквалифицированных
работников.
Хорошо спроектированная
база данных
значительно
экономит рабочее
время и повышает
эффективность
работы за счет
экономии времени
на поиск и получение
необходимой
информации.
Повышение
эффективности
работы служб,
задействованных
на предприятии,
приводит к
экономии как
людских ресурсов
в виде возможности
сокращения
числа служащих
на объекте, так
и экономии
рабочего времени
высококвалифицированных
служащих. Кроме
того, данная
система позволяет
экономию машинного
времени, а также,
возможность
использования
менее квалифицированных
работников
и высвобождение
значительного
количества
кадров с более
высокой квалификацией.
Подобный
программный
продукт может
быть реализован
в единичном
экземпляре
либо тиражирован
и реализован
некоторому
числу заказчиков.
Обычно принято
проводить
расчет экономической
эффективности
использования
разработки
для ее потребителя.
Важным
фактором, влияющим
на процесс
формирования
цены, является
конкуренция
на рынке, необходимость
учета которой
совершенно
очевидна. В
целях повышения
конкурентоспособности
продукта может
возникнуть
необходимость
снижения его
цены на рынке.
Важно заметить,
однако, что
целям повышения
конкурентоспособности
служит не только
снижение цены,
но, также, и качество
товара и его
выгодные
отличительные
признаки по
сравнению с
аналогичным
товаром конкурентов.
Наиболее
важным моментом
для разработчика,
с экономической
точки зрения,
является процесс
формирования
цены. Очевидно,
что программные
продукты представляют
собой весьма
специфичный
товар со множеством
присущих им
особенностей.
Многие их особенности
проявляются
и в методах
расчетов цены
на них. На разработку
программного
продукта средней
сложности
обычно требуются
весьма незначительные
средства. Однако,
при этом он
может дать
экономический
эффект, значительно
превышающий
эффект от
использования
достаточно
дорогостоящих
систем.
Следует
подчеркнуть,
что у программных
продуктов
практически
отсутствует
процесс физического
старения и
износа. Для них
основные затраты
приходятся
на разработку
образца, тогда
как процесс
тиражирования
представляет
собой, обычно,
сравнительно
несложную и
недорогую
процедуру
копирования
магнитных
носителей или
иных носителей,
и сопровождающей
документации.
Таким образом,
этот товар не
обладает, по
сути, рыночной
стоимостью,
формируемой
на базе общественно
необходимых
затрат труда.
Цена на
программные
продукты
устанавливается
на единицу
программной
продукции с
учетом комплексности
ее поставки.
Ее цена, обычно,
формируется
на базе нормативной
себестоимости
производства
и прибыли:
Цп=С+Пн+Нэ,
где
С —
себестоимость
единицы продукции,
руб.,
Пн—нормативная
прибыль, руб.;
Нэ —
надбавка к
цене.
Предельным
значением
цены программного
продукта является
сумма дополнительной
прибыли, полученной
потребителем
за период его
использования.
При назначении
цены следует
разделить
дополнительную
прибыль между
потребителями
данного продукта
и его собственником.
Цена на
программный
продукт может,
также, рассчитываться
и на основе
роялти. Данный
подход применяется,
когда цена
продукта возмещается
собственнику
не сразу, а по
мере получения
потребителем
дополнительного
дохода от его
использования.
Тогда цена
данного программного
продукта
складывается
из ежегодных
отчислений
дохода потребителей
в течение периода
действия соглашения,
т.е. из роялти.
Для программных
разработок
роялти составляет
3 — 5%.
Цена программного
продукта часто
складывается
из выплат целого
ряда потребителей
и распределяется
между собственниками
этого продукта
в соответствии
с количеством
заключенных
ими сделок, их
длительностью
и величиной
роялти.
Поскольку
данные о фактической
дополнительной
прибыли, в связи
с использованием
данной конкретной
программной
разработки,
могут составлять
коммерческую
тайну, и определить
ее величину
бывает порой
затруднительно
даже самому
потребителю,
постольку в
соглашениях
ставка роялти
устанавливается
в процентах
от стоимости
чистых продаж
продукции, ее
себестоимости,
валовой прибыли,
либо же определяется
в виде денежной
суммы на единицу
выпускаемой
продукции.
Наиболее
распространенным
на сегодня
методом вычисления
роялти является
ее вычисление
в процентах
от стоимости
продаж лицензионной
продукции:
Rs=(R/S)*100,
где
Rs
— ставка
роялти в процентах
от стоимости
чистых продаж;
R
— годовая сумма
роялти;
S
— годовая стоимость
чистых продаж
за вычетом
косвенных
налогов, сборов
и пошлин.
Соответственно,
валовая сумма
роялти
(Rt), выплаченная
собственнику
программного
продукта за
период действия
соглашения
(t0
— tn),
составит:
Rt=Rti=Rs*Sti
Необходимо,
также, отметить,
что одинаковым
значениям
ставки роялти
(Rs) могут
соответствовать
совершенно
различные доли
роялти в валовой
прибыли потребителя
программной
продукции и
наоборот —
одинаковая
выплата роялти
из прибыли
может производиться
при различных
ставках роялти
от стоимости
продаж. Определяющее
значение имеют
здесь различия
в нормах прибыли
к стоимости
продаж у потребителей
в различных
отраслях. Так,
например, для
получения
той же доли
прибыли потребителя
в высокорентабельных
отраслях
производства
собственнику
программных
продуктов
необходимо
устанавливать
значительно
более высокую
ставку роялти,
чем в малоприбыльных
отраслях.
Другой способ
определения
ставки роялти
основывается
на величине
годовой дополнительной
прибыли потребителя.
Годовая
дополнительная
прибыль потребителя
складывается
из величины
экономии на
капитальных
затратах, а
также, на текущих
эксплуатационных
расходах. Экономия
оценивается
либо методом
прямого расчета
годовой экономии
на основе
сравнения
производственных
показателей
двух вариантов,
либо методом
приведения
экономии на
капитальных
и текущих
затратах,
распределенной
по годам, к
текущему моменту
времени и расчету
на этой основе
среднегодовой
экономии на
предполагаемый
период действия
соглашения.
Рассчитанная
цена может
быть скорректирована
в зависимости
от степени
риска (производственного
и коммерческого),
конкуренции
со стороны
альтернативных
программных
продуктов,
монополизации
рынка продукции,
в производство
которой внедряется
новая программная
разработка.
Производственный
риск связан,
главным образом,
с тем, что потребитель
может не реализовать
тех производственных
показателей,
которых предполагалось
достичь в случае
применения
данного программного
продукта. Такая
вероятность
тем выше, чем
меньше степень
разработанности
и коммерческого
освоения нового
программного
средства. В
этом случае
коммерческое
доведение
закупленной
программной
разработки
может привести
к значительным
дополнительным
расходам, а
конкурентоспособность
альтернативных
вариантов
(более высокой
степени проработки)
— значительно
возрасти вследствие
того, что суммарные
расходы на
приобретение
программы и
ее доработку
будут слишком
высоки. Таким
образом, целесообразность
закупки программного
изделия определяется
выполнением
условия:
Рт<Ка—Кд,
где
Рт —
цена программного
продукта;
Ка —
минимальные
капиталовложения
в альтернативный
вариант;
Кд —
затраты потребителя
программного
продукта на
ее коммерческое
доведение;
По имеющимся
оценкам, вероятность
того, что доработка
и внедрение
технологии
не обеспечит
расчетных
показателей,
колеблется
от 1 — 2% в случае
передачи уже
внедренной
в серийное
производство
программной
продукции, и
до 40 — 50% для программы,
внедренной
на уровне опытного
образца. Следовательно
величина роялти
уменьшается
прямо пропорционально
росту затрат
на коммерческое
освоение
программного
продукта.
Аналогично
и влияние
коммерческого
риска, которое
выражается
в том, что покупатель
программной
продукции не
имеет гарантии
на реализацию
всей произведенной
продукции, и,
таким образом,
может не получить
расчетной
суммы дополнительной
прибыли. В этом
случае продавец
и покупатель
программного
продукта оценивают
возможную
степень риска
и вносят поправку
в ожидаемую
величину
дополнительной
прибыли. Полная
оценка степени
коммерческого
риска требует
проведения
комплексных
конъюнктурных
исследований
предполагаемого
рынка с целью
выявления
перспектив
спроса.
В условиях
расширения
рынка программных
продуктов
важным фактором,
воздействующим
на их цену,
становится
обострение
конкуренции
со стороны
альтернативных
программных
разработок.
Чем большее
количество
продавцов
программных
средств предлагает
их альтернативные
варианты, и чем
большее количество
потребителей
уже использует
или будет в
дальнейшем
использовать
данные программные
разработки,
предлагаемые
продавцом,
тем меньшая
дополнительная
прибыль потребителя
и тем быстрее
она будет
уменьшаться.
Верно, также,
и обратное —
что при уменьшении
конкуренции
дополнительная
прибыль растет.
В этой связи,
на практике,
при продаже
программной
продукции
с исключительными
правами использования
обычно устанавливается
надбавка к
базовой роялти
в размере от
25 до 50%.
Ставки
роялти — один
из двух факторов
суммы роялти
или цены, которую
получит продавец
программной
продукции от
ее реализации
на рынке. Второй
фактор связан
с периодом
платежей роялти.
Период
платежей роялти
составляет
на практике
от 5 до 10 лет. Срок
выплаты будет
больше, если
покупателю
предлагается
исключительное
право на
использование
программного
продукта или
если продукция
запатентована,
что препятствует
ее свободному
распространению
на предприятиях
конкурентов.
Достаточно
часто разрабатываемый
программный
продукт является
тиражируемой
продукцией.
Изготовление
любой тиражируемой
продукции
состоит из двух
этапов: создание
программного
продукта, который
является конечным
изделием, и
создание тиража.
Основные затраты
в этом случае
приходятся
на создание
оригинального
программного
продукта, а
создание тиража
сводится к
сравнительно
нетрудоемкому
процессу
копирования
и сопровождения,
и, быть может,
затрат на маркетинг.
Проведем
теперь расчет
стоимости
создаваемого
программного
продукта. Стоимость
продукции
включает в себя
себестоимость
и планируемую
прибыль. Себестоимость
составляется
из основной
заработной
платы разработчика,
дополнительной
заработной
платы и отчислений
на социальное
страхование.
Кроме того, в
нее входят
амортизационные
отчисления,
расходы на
электроэнергию
и на аренду
помещения.
Планируемую
прибыль примем
равной 30%.
Рассмотрим
это более подробно.
На создание
данного программного
продукта пяти
программистам
соответствующей
квалификации
требуется 6
месяцев. Исходя
из размеров
оплаты их труда,
составляющей
в месяц в среднем
3000 рублей, определяем,
что за рассматриваемый
период сумма
заработной
платы разработчикам
составит 90000
рублей. В стоимость
программного
продукта также
входит амортизация
оборудования,
которая, в данном
случае, включает
в себя амортизацию
5 компьютеров,
на которых
работают
программисты,
за период разработки.
Расходы
на арендную
плату за рассматриваемый
период, также
переносятся
на стоимость
данного программного
продукта.
Эта сумма
определяется
исходя из
годовой арендной
платы одного
квадратного
метра рабочей
площади помещения
и с учетом того,
что рабочее
место 1 программиста
занимает 6
квадратных
метров, следовательно,
требуемая
площадь составит
30 квадратных
метров.
Сложив
все вышеперечисленные
расходы, получим
сумму, которая
и будет являться
стоимостью
произведенного
программного
продукта.
В связи
со сказанным
выше, в некоторых
случаях бывает
сложно либо
нецелесообразно
проводить
подобные расчеты
и цену можно
установить
исходя из конъюнктуры
цен на аналогичную
продукцию.
Все вышеприведенные
факторы
обусловливают
значительные
преимущества
рассматриваемой
системы и, в
частности,
использования
для управления
работой объекта
локальной
компьютерной
сети. Рассмотренные
преимущества
являются основой
экономической
эффективности
разработки
и показывают
необходимость
применения
ее на практике.
Заключение.
Данная дипломная
работа посвящена
разработке
автоматизированного
рабочего места
для научно-технической
библиотеки
университета.
В процессе
разработки
данной дипломной
работы были
получены следующие
результаты:
Разработаны
17 функциональных
таблиц, предназначенных
для хранения
информации
о изданиях и
читателях. Для
каждой таблицы
определены
соответствующие
атрибуты (поля),
общее количество
которых для
всех таблиц
составило 60
наименований.
Во всех таблицах
для каждого
атрибута выбран
соответствующий
тип данных и
оптимальный
размер хранимых
в этим поле
данных.
Разработка
логической
структуры базы
данных также
включает в
себя определение
и создание
индексов для
ключевых и
неключевых
полей таблиц,
определение
и создание
связей между
таблицами,
необходимых
для работы
запросов. В
итоге получена
законченная,
достаточно
сложная логическая
структура базы
данных, состоящая
из большого
количества
таблиц, связанных
между собой
особым образом.
Для данной
структуры базы
данных, разработаны
структура и
функциональные
модули АРМ,
получен интерфейс
пользователя
позволяющие
пользователю
работать с
базой данных.
Из выше описанного
следует, что
задачи, поставленные
перед данной
работой выполнены
в полной мере.
Было проведено
технико-экономическое
обоснование
практического
внедрения
данной разработки,
проведён расчёт
стоимости
программы и
проанализирована
экономическая
эффективность
работы библиотеки
после её установки,
а именно высвобождение
кадров и значительная
экономия времени
на выполнение
тех же задач,
которые осуществлялись
ранее без
использования
данного программного
продукта.
Программные
продукты, подобные
выше описанному,
разрабатываются
в единичном
экземпляре,
с учётом пожеланий
и требований
заказчика.
Проектируемое
автоматизированное
рабочее место,
разрабатывалось
как учебное,
но при незначительных
доработках,
может быть
внедрена на
практике и
эффективно
выполнять
поставленные
задачи.
В ходе
экспериментов
было установлены
требования
для нормального
функционирования
настоящего
АРМ, для практической
установки
требуется
компьютер не
ниже i80486DX4-100,
объём оперативной
памяти, которого
должен составлять
не менее 16Mb
и свободное
место на жестком
диске около
40 Mb.
Необходимые
программные
средства –
наличие Microsoft
Windows 95/98.
Список
использованной
литературы.
Дж. Мартин
«Организация
баз данных в
вычислительных
системах»,
Мир, Москва,
1990 г.
К. Дейт «Введение
в системы управления
базами данных»,
БИНОМ, Москва,
1999 г.
А. А. Попов
«Программирование
в среде СУБД
Fox Pro 2.5»,
Радио и связь.,
Москва, 1994 г.
М. Д. Антонович
«Visual FoxPro 3 для
Windows»,
БИНОМ, Москва,
1996 г.
В. М. Владимирова,
А. С. Воронина
и др. «Стандарты
по библиотечному
делу и библиографии»,
Издательство
стандартов,
Москва, 1985 г.
В. М. Стриганов
и др. «Библиотечно-библиографическая
классификация»,
Книга, Москва,
1986 г.
М. А. Аппак
«Автоматизированные
рабочие места
на основе ПЭВМ»,
Радио и связь,
Москва, 1989 г.
В. Л. Бройдо,
В. С. Крылова
«Научные основы
организации
управления
и построения
АСУ», Высшая
школа, Москва,
1990 г.
А. Ф. Иоффе
«Персональные
ЭВМ в организационном
управлении»,
Наука, Москва,
1988 г.
«Библиотекарь»,
Журнал № 1-10 1997 г.
«Библиотекарь»,
Журнал № 6-12 1998 г.
«Библиотекарь»,
Журнал № 1-12 1999 г.
«Библиотекарь»,
Журнал № 1-3 2000 г.
Рецензия
На дипломный
проект студента
МГУС Володченко
Е. В.
Рецензент:
ст. научн. сотр.
4 ЦНИИ МО РФ ктн,
снс Уваров А.В.
Представленный
на рассмотрение
дипломный
проект на тему:
«Разработка
АРМ научно-технической
библиотеки
университета»
посвящён актуальному
вопросу из
области информационных
и компьютерных
технологий
или, точнее, их
приложений
в различных
сферах деятельности
человека.
Новизна и
целесообразность
такой работы
определяется
её направленностью
к информационным
потребностям
«пользователей»
(библиотечных
работников,
студентов,
преподавательского
состава, вообще
читателей)
библиотеки.
Объём и содержание
разделов
пояснительной
записки, полнота
разработки
основных положений,
касающихся
проектирования
логической
структуры базы
данных, форм
и запросов
пользователей
соответствуют
заданию на
дипломную
работу.
Проведенные
анализ и сравнение
с существующими
аналогами,
показывают
правильность
и обоснованность
выбранных
решений. В частности,
обоснован выбор
инструментария
для разработки
базы данных,
FoxPro. Это
обстоятельство
позволяет
положительно
судить о научно-техническом
уровне данной
работы.
Правильно
и рационально
выбраны подходы
к построению
таблиц, хранящих
значительный
объём информации
о номенклатуре
и характеристиках
печатных изданий,
являющихся
содержанием
библиотеки.
Положительной
стороной дипломного
проекта является
тот факт, что
автор не ограничился
теоретическими
построениями,
а проверил их
в машинном
эксперименте.
Проведенные
эксперименты
позволили
уточнить некоторые
неточности,
а также предложить
конкретные
рекомендации,
учитывающие
реальную
вычислительную
технику.
В этом заключается
несомненная
эффективность
выполненных
экспериментов
и ценность
полученных
результатов.
Дипломная
работа имеет
и практическую
ценность, поскольку
те таблицы,
формы и запросы,
которые были
разработаны
в ходе машинного
эксперимента,
наполнены
реальной информацией,
почерпнутой
из конкретных
источников.
Это обстоятельство
позволяет
произвести
соответствующую
репликацию
данных для
использования
их в системах,
призванных
автоматизировать
повседневную
деятельность
библиотечных
работников
и, в значительной
мере, повысить
эффективность
поиска необходимой
литературы
читателями
библиотеки.
В то же время,
работа не свободна
и от недостатков,
в частности,
не предусмотрены
формы работы
со всяческого
рода сборниками
(альманахи,
труды конференций
и т.д.), в которых
присутствует
не авторский
коллектив, а
набор независимых
авторов. Имеется
ряд терминологических
неточностей.
Однако отмеченные
недостатки
не снижают
положительного
впечатления
от работы и не
умаляют её
достоинств.
Поэтому, на
основании
изложенного,
считаю, что:
Рецензент
________________
08 июня 2000г.
Отзыв
На дипломный
проект студента
МГУС Володченко
Е. В.
Руководитель
ктн, Князев
И.И.
Представляемый
к защите дипломный
проект на тему:
«Разработка
АРМ научно-технической
библиотеки
университета»
посвящён одному
из актуальных
вопросов из
области приложений
информационных
и компьютерных
технологий
в различных
сферах деятельности
человека.
Библиотечная
деятельность
является формой
предоставления
услуг, т.е. – это
одна из форм
сервиса, таким
образом (перефразируя
известную
поговорку),
данная работа
удовлетворяет
сразу двум
«зайцам» -
обеспечение
сервиса, как
такового, так
и компьютерного.
Новизна и
целесообразность
данной работы
определяется
её направленностью
к информационным
потребностям
«пользователей»
(библиотечных
работников,
студентов,
преподавательского
состава, вообще
читателей)
библиотеки.
Объём и содержание
разделов
пояснительной
записки, полнота
разработки
основных положений,
касающихся
проектирования
логической
структуры базы
данных, форм
и запросов
пользователей
соответствуют
заданию на
дипломную
работу.
Проведенные
анализ и сравнение
с существующими
аналогами,
показывают
правильность
и обоснованность
выбранных
решений.
Правильно
и рационально
выбраны подходы
к построению
таблиц, хранящих
информацию
о печатных
изданиях, являющихся
содержанием
библиотеки.
Положительной
стороной дипломного
проекта является
тот факт, что
автор не ограничился
теоретическими
построениями,
а проверил их
в машинном
эксперименте.
В этом заключается
несомненная
эффективность
работы и ценность
полученных
результатов.
Дипломная
работа имеет
и практическую
ценность, поскольку
те таблицы,
формы и запросы,
которые были
разработаны
в ходе машинного
эксперимента,
отражают не
выдуманные,
а фактически
существующие
реалии. Это
обстоятельство
позволяет
автоматизировать
повседневную
деятельность
библиотечных
работников
и, в значительной
мере, повысить
эффективность
поиска необходимой
литературы
читателями
библиотеки.
В процессе
выполнения
дипломной
работы автор
проявил исключительную
инициативу
(порой приходилось
немного сдерживать,
ограничивая
временными
и функциональными
рамками). Вне
всякого сомнения,
при наличии
большего времени,
чем это определено
стандартами
на дипломное
проектирование,
данная работа
имела бы свой
логический
конец – законченную,
коммерчески
конкурентно-способную
продукцию.
Поэтому, на
основании
изложенного,
считаю, что:
Руководитель
________________
06 июня 2000г. |