СОЗДАНИЕ МОДУЛЬНЫХ ПРОГРАММ, ЭЛЕМЕНТЫ ТЕОРИИ МОДУЛЬНОГО ПРОГРАММИРОВАНИЯ
ВВЕДЕНИЕ
Программирование представляет собой сферу действий, направленную на создание программ. Программирование может рассматриваться как наука и как искусство. В свою очередь программа - это последовательность команд компью�тера, приводящая к решению задачи. Программа является результатом интеллек�туального труда, для которого характерно творчество. Программы предназначе�ны для машинной реализации задач. Задача представляет собой часть проблемы, подлежащей решению с помощью технических средств, а приложение (синоним программа) - реализованное на компьютере решение данной задачи. Таким обра�зом, можно заключить, что приложение - это программная реализация решения задачи на компьютере. В свою очередь программное обеспечение (ПО) является совокупностью программных продуктов и технической документации к ним, а программный продукт (ПП) - это комплекс взаимосвязанных программ, предна�значенный для реализации определенной задачи массового спроса. Программы являются критерием развития вычислительной техники, они делятся на утилиты (для нужд разработчиков) и программные продукты (для удовлетворения потреб�ностей пользователя).
В настоящее время при создании программных продуктов возникает ряд проблем, основными из которых являются следующие:
- Быстрая смена вычислительной техники и алгоритмических языков.
- Не стыковка ЭВМ друг с другом (VAX и IBM).
- Отсутствие полного взаимопонимания между заказчиком и исполнителем к разработанному программному продукту.
1. НОВЕЙШИЕ НАПРАВЛЕНИЯ В ОБЛАСТИ СОЗДАНИЯ ТЕХНОЛОГИЙ ПРОГРАММИ�РОВАНИЯ
В основе того или иного языка программирования лежит некоторая руко�водящая идея, оказывающая существенное влияние на стиль соответствующих
программ.
1.1. Структурное программирование
Структурное программирование - методология программирования, бази�рующаяся на системном подходе к анализу, проектированию и реализации про�граммного обеспечения. Эта методология родилась в начале 70-х годов и оказа�лась настолько жизнеспособной, что и до сих пор является основной в большом количестве проектов. Основу этой технологии составляют следующие положения:
Сложная задача разбивается на более мелкие, функционально лучше
управляемые задачи. Каждая задача имеет один вход и один выход. В этом случае
управляющий поток программы состоит из совокупности элементарных подзадач
с ясным функциональным назначением.
Простота управляющих структур, используемых в задаче. Это положе�ние означает, что логически задача должна состоять из минимальной, функцио�нально полной совокупности достаточно простых управляющих структур. В каче�стве примера такой системы можно привести алгебру логики, в которой каждая
функция может быть выражена через функционально полную систему: дизъюнк�цию, конъюнкцию и отрицание.
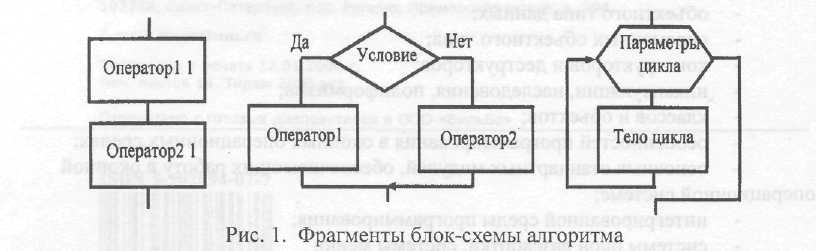
Разработка программы должна вестись поэтапно. На каждом этапе долж�но решаться ограниченное число четко поставленных задач с ясным пониманием их значения и роли в контексте всей задачи. Если такого понимания не достигает�ся, это говорит о том, что данный этап слишком велик, и его нужно разделить на более элементарные шаги. Согласно требованиям структурного программирова�ния, наиболее часто детально проработанные алгоритмы изображаются в виде блок-схемы. При их разработке используются условные обозначения согласно ГОСТу («следование», «ветвление», «цикл») (рис. 1).
1.2. Нисходящее проектирование
Метод предполагает последовательное разложение функции обработки данных на простые функциональные элементы ("сверху вниз").
В результате строится иерархическая схема, которая отражает состав и
взаимоподчиненность отдельных функций. Она носит название функциональная структура алгоритма (ФСА) приложения, в которой отражаются:
цели предметной области (цель-подцель);
состав приложений (задач обработки), обеспечивающих реализацию
поставленных целей;
характер взаимосвязи приложений с их основными характеристиками;
функции обработки данных.
Рассмотрим функциональную структуру приложения (рис. 2).
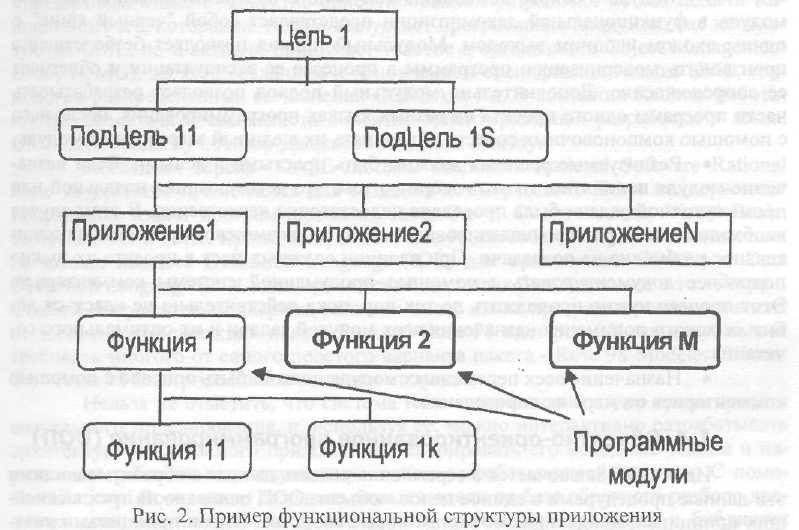
Подобная структура отражает состав и взаимосвязь функций обработки информации для реализации приложений, не раскрывая логику выполнения каж�дой отдельной функции.
Разложение должно носить строго функциональный характер, т.е. отдель�ный элемент ФСА описывает законченную содержательную функцию обработки информации, которая предполагает определенный способ реализации на про�граммном уровне.
Функции ввода/вывода информации отделяют от функций вычислитель�ной или логической обработки данных.
Некоторые функции например Ф2, ФМ далее неразложимы на состав�ляющие, они предполагают непосредственную программную реализацию. Другие функции Ф2... могут быть представлены в виде структурного объединения более простых функций, например Ф11, Ф12 .. Для всех функций-компонентов осуще�ствляется самостоятельная программная реализация, составные функции типа Ф1, ФМ реализуются как программные модули, управляющие функциями - компо�нентами, например, в виде программ-меню.
По частоте использования функции делятся на однократно выполняемые и повторяющиеся.
1.3. Концепция модульного программирования
Так же как и для структурной технологии программирования, концепцию модульного программирования можно сформулировать в виде нескольких поня�тий и положений:
Функциональная декомпозиция задачи - разбиение большой задачи на
ряд более мелких, функционально самостоятельных подзадач - модулей. Модули
связаны между собой только по входным и выходным данным.
Модуль - основа концепции модульного программирования. Каждый
модуль в функциональной декомпозиции представляет собой "черный ящик" с
одним входом и одним выходом. Модульный подход позволяет безболезненно
производить модернизацию программы в процессе ее эксплуатации и облегчает
ее сопровождение. Дополнительно модульный подход позволяет разрабатывать
части программ одного проекта на разных языках программирования, после чего
с помощью компоновочных средств объединять их в единый загрузочный модуль.
Реализуемые решения должны быть простыми и ясными. Если назна�чение модуля непонятно, то это говорит о том, что декомпозиция начальной или
промежуточной задачи была проведена недостаточно качественно. В этом случае
необходимо еще раз проанализировать задачу и, возможно, провести дополни�тельное разбиение на подзадачи. При наличии сложных мест в проекте их нужно
подробнее документировать с помощью продуманной системы комментариев.
Этот процесс нужно продолжать до тех пор, пока действительно не удастся до�биться ясного понимания назначения всех модулей задачи и их оптимального со�четания.
Назначение всех переменных модуля должно быть описано с помощью
комментариев по мере их определения.
1.4. Объектно-ориентированное программирование (ООП)
Идея ООП заключается в стремлении связать данные с обрабатывающими эти данные процедурами в единое целое - объект. ООП основано на трех важней�ших принципах, придающих объектам новые свойства. Этими принципами явля�ются инкапсуляция, наследование и полиморфизм.
Инкапсуляция - объединение в единое целое данных и алгоритмов обработки этих данных. В рамках ООП данные называются полями объекта, а алго�ритмы - объектными методами.
Наследование - свойство объектов порождать своих «потомков». Объ�ект — «потомок» автоматически наследует от «родителей» все поля и методы, мо�жет дополнять объекты новыми полями и заменять (перекрывать) методы «родителя» или дополнять их.
Полиморфизм - свойство родственных объектов (т.е. объектов, имею�щих одного общего «родителя») решать схожие по смыслу проблемы разными
способами.
1.5. CASE-системы
Представление о CASE - комплексах связано в нашем сознании с чем-то, не имеющим отношения к обычному программированию.
В Америке из-за сильнейшей конкуренции CASE-средства используются подавляющим большинством фирм - разработчиков программного обеспечения. Мощный толчок CASE-средства получили в пору внедрения объектно-ориентированной технологии разработки ПО, когда старого, проверенного време�нем метода проектирования "сверху вниз" стало явно недостаточно. К тому же появились технологии объектного моделирования Booch, OMT, UML, сами по себе весьма сложные для привязки к языкам программирования, чтобы опериро�вать ими вручную.
Сегодня лидирующей в мире CASE-системой считается Rational Rose корпорации Rational Software. Система Rational Rose нацелена на создание моду�лей с использованием языка Unified Modeling Language (UML). Кстати, UML стал стандартным языком объектно-ориентированной разработки не без подачи Ra�tional Software, которая не только выпускает программные продукты, где исполь�зуются UML, но и активно принимает участие в организации Object Management Group (OMG), занятой созданием и обновлением спецификаций языка UML, тех�нологии распределенных вычислений CORBA и т.д. В компании Rational работа�ют три создателя и евангелиста объектно-ориентированной разработки и языка UML. Это Гради Буч, Айвар Джекобсон и Джим Рамбаух.
Последняя версия CASE-системы компании Rational Software Rational Rose 98 успешно применяется для создания коммерческого ПО и поддерживает популярные языки программирования Java, Си++, Смолток, Ада, Visual Basic, Power Builder и Forte. Кроме того, пакет Rose 98 способен генерировать описания на языках Interface Definition Language (IDL) для приложений CORBA и Data Definition Language (DDL) для приложений доступа к базам данных, в том числе и Oracle 8. Разумеется, поддержка того или иного языка программирования зависит от того, о какой редакции пакета Rational Rose 98 идет речь. К примеру, нельзя требовать многого от самого простого варианта пакета - Rose 98 Modeler Edition. Зато Rose 98 Enterprise Edition оснащен от души.
Нельзя не отметить, что система Rose - признанный лидер среди средств визуального моделирования, и, используя ее, можно интерактивно разрабатывать архитектуру создаваемого приложения, генерировать его исходные тексты и па�раллельно работать над документированием разрабатываемой системы. С помо�щью Rational Rose можно создавать новые модели на базе обратного разбора дво�ичных com модулей или исходные тексты прикладных программ и библиотек классов.
Преимущества от применения Rational Rose 98 значительны:
- Сокращение цикла разработки приложения.
- Увеличение продуктивности работы программистов.
- Улучшение потребительских качеств создаваемых программ за счет
ориентации на пользователей и бизнес.
- Способность вести большие проекты и группы проектов.
- Возможность повторного использования уже созданного ПО за счет
упора на разбор их архитектуры и компонентов.
- Язык UML служит универсальным "мостиком" между разработчиками
из разных отделов.
1.6. Технологическая схема решения задач
Технологическая схема, в которой пользователь, желающий решить свою задачу на ЭВМ, обращается за консультацией к специалисту по алгоритмизации (формализации), а тот, в свою очередь, к программисту, создающему программу на основе формальной модели решаемой задачи, сейчас отходит в прошлое.
Она оказывается неэффективной по ряду причин. Например, пользователь не всегда точно знает, чего он хочет, и алгоритмист, когда формализует за�дачу, поневоле упрощает ее, теряет или отбрасывает многое из того, что пользо�ватель знает, но либо не сообщил алгоритмисту, либо опрометчиво согласился на предлагаемые упрощения. Полученная после этого модель программируется и реализуется на ЭВМ. А пользователь явно не доволен. Только теперь он понял, что ему нужно, и видит, что ему дали не то, что ему необходимо. После этого на�чинается второй раунд взаимодействия, за ним, возможно третий, четвертый и т.д.
Почему так происходит? Скорее всего, потому, что пользователь, рабо�тающий в областях, где формализация еще не проявила себя в полную силу - сей�час их принято называть плохо структурированными проблемными областями, - просто не ведает о том, какие же знания необходимо сообщить алгоритмисту о своей задаче, чтобы полностью удовлетворить и его и себя.
Возникает идея - убрать из технологической схемы алгоритмиста, сокра�тить путь пользователя к ЭВМ: пусть он теперь со своей задачей обращается прямо к программисту. Правда, для этого нужно, чтобы программист повысил свой профессиональный уровень, овладел бы "смежной" профессией алгоритми�ста. Но тогда программисты станут более дефицитными, чем сейчас, ибо требова�ния к ним резко возрастут. А ведь армия программистов и так не успевает обслу�жить всех желающих, и если темпы роста пользователей не уменьшатся, то все население земного шара будет состоять из пользователей и программистов.
Ясно, что этот путь тупиковый. К тому же он не решает основной про�блемы - прямого доступа пользователей к ЭВМ и не устраняет непонимания меж�ду пользователем и программистом, возникающим из-за отсутствия у программи�ста знаний о проблемной области пользователя, а у пользователя - о способах ре�шения задач на ЭВМ.
А что если и программиста удалить из технологической цепи пользова�тель - ЭВМ? Это можно сделать, если пользователи научатся программировать, станут профессионалами в двух областях - в своей собственной и в программиро�вании. Насколько это возможно? И сейчас существуют специалисты, овладевшие искусством программирования настолько, что сами свободно работают с вычис�лительной машиной. Но таких специалистов не много, так как овладеть двумя совершенно разными профессиями - дело нелегкое. И, как правило, в одной из них человек остается все-таки полупрофессионалом.
Есть ещё один путь приобщения специалиста к современной вычисли�тельной технике - это повышение возможностей самих ЭВМ, повышение уровня их "интеллекта". Программиста можно убрать из технологической цепи решения задачи лишь тогда, когда в самой ЭВМ появиться "автоматический програм�мист", который будет взаимодействовать с пользователем и помогать ему состав�лять программы. Так возникает идея ЭВМ нового - пятого поколения. В отличие от ЭВМ предшествующих поколений новые машины должны иметь средства для интеллектуального взаимодействия с пользователем на его профессиональном естественном языке. Другими словами, не пользователь приближается к ЭВМ, а сама ЭВМ становится интеллектуальным собеседником и помощником пользова�теля.
1.7. Индустрия искусственного интеллекта
Бум, возникший в конце семидесятых годов в искусственном интеллекте и приведший к созданию новой отрасли промышленности, не случаен. Его вызва�ли три причины:
- Угроза всеобщей мобилизации населения земного шара в программи�сты привела к идее пятого поколения ЭВМ. Но создание таких ЭВМ требует разработки средств автоматического выполнения функций алгоритмиста и программиста, то есть интеллектуальных функций по формализации задач и составлению программ для их решения. А это уже сфера искусственного интеллекта, ибо одно из толкований целей этой науки состоит как раз в утверждении, что она должна создавать методы автоматического решения задач, считающихся в человеческом понимании интеллектуальными. Это означает, что создание ЭВМ пятого поколе�ния невозможно без использования достижений, накопленных в искусственном интеллекте.
- Развитие робототехнических малолюдных или безлюдных произ�водств. На современных промышленных предприятиях происходит активное вне�дрение автоматических систем, в которых широко используются интеллектуальные роботы. Прогресс в этой области во многом зависит от того, насколько роботы могут хранить в своей памяти необходимую сумму знаний о профессии, кото�рой они овладевают.
- Необходимость передавать на ЭВМ задачи из плохо структурирован�ных проблемных областей. Именно для них нужно автоматизировать труд алго�ритмиста, его способность формализовать то, что с трудом поддается формализа�ции. Путь решения этой проблемы - формализация знаний, которые есть у профессионалов в данной проблемной области, но хранятся в их памяти в виде не� формализованных соображений, умений и навыков. Такие профессионалы явля�ются экспертами своего дела, а получаемые от них знания обычно называют экс�пертными. Если в базу знаний системы заложить знания подобного типа, то сис�тема будет называться экспертной.
ЭВМ пятого поколения, интеллектуальные роботы, экспертные системы и многие другие интеллектуальные системы обладают одним общим свойством: их работа основывается на знаниях, хранимых в базе знаний системы. Их часто так и называют - системами, основанными на знаниях.
1.8. Экспертные системы
Экспертные системы могут не только найти решение той или иной задачи, но и объяснить пользователю, как и почему оно получено. Это означает, что в экспертных системах реализована возможность "самоанализа", в них появилась возможность рассуждать о знаниях и манипулировать ими. А значит появилась и возможность иметь знания о знаниях, т.е. метазнания. С их помощью в эксперт�ных системах стала возможной оценка знаний с точки зрения их полноты и кор�ректности, а также реализация "функции любопытства", связанной с активным поиском связей между хранящимися в памяти знаниями, их классификацией и пополнением за счет разнообразных логических процедур.
В экспертных системах сделан важный шаг - знания, хранящиеся в сис�теме, стали объектом ее собственных исследований.
Потенциально человек способен к овладению любым видом интеллекту�альной деятельности. Он может научиться играть и в шахматы, и в морской бой, и в любые другие игры, ибо он обладает универсальными метапроцедурами, позво�ляющими ему создать процедуры решения конкретных интеллектуальных задач.
Развитие теории искусственного интеллекта в конце шестидесятых годов началось с осознания именно этого факта. У новой науки появился свой специфи�ческий объект исследований и моделирования - универсальные метапроцедуры программирования интеллектуальной деятельности. В их числе имеются мета�процедуры общения, обучения, анализа воспринимаемой системой информации и многие другие. Но центральное место здесь, несомненно, занимают те метапро�цедуры, которые связаны с накоплением знаний и использованием их при реше�нии интеллектуальных задач. Именно эти метапроцедуры находят свое воплоще�ние в экспертных системах.
Существующие сейчас экспертные системы принято делить на два класса: консультационные и исследовательские. Первые призваны давать советы, когда у пользователя возникает необходимость в них, а вторые - помогать исследователю решать интересующие его научные задачи.
Система общения позволяет вводить в экспертную систему информацию на естественном языке, ограниченном рамками профессиональной области, и ор�ганизует ведение диалога с пользователем. Эта система сообщает пользователю о непонятных для нее словах, о допущенных им ошибках, предлагает наборы дей�ствий, которые пользователь при желании может выполнить. Если пользователь еще не освоил "этику приема", то в дело включается блок обучения: в диалоговом режиме он постепенно обучает пользователя общению с ЭВМ, учит его решению задач, используя примеры. Пользователь может обращаться к этому учителю, ко�гда захочет - система всегда найдет время для пояснения непонятных пользовате�лю моментов.
Решатель осуществляет поиск вывода решения, нужного пользователю на основе тех знаний, которые хранятся в базе знаний системы. Он играет роль моз�гового центра системы. Чтобы функции решателя в консультационной эксперт�ной системе стали более понятными, рассмотрим конкретный пример. Предполо�жим, что в полевых условиях археолог столкнулся с находками, которые постави�ли его перед задачей датировки раскапываемого объекта. Известно, что точная датировка во многих случаях вещь весьма сложная. Она требует тщательного изучения находок, привлечения огромного по объему сравнительного материала из находок других археологов, требует от археолога умения делать правильные логические выводы, выдвигать гипотезы и отвергать их на основании найденного. При работах на раскопках рядом может не быть тех специалистов, которые могли бы оказать квалифицированную помощь. Именно для такой ситуации предназна�чена консультационная экспертная система. В ее базе знаний может храниться огромное количество накопленных ранее фактов и установленных связей между этими фактами, а также мнения (не всегда совпадающие между собой) ведущих специалистов в данной области.
Когда археолог через систему общения обращается к системе за консуль�тацией, то она может начать с того, что потребует ввести описание всех тех нахо�док (на языке, понятном системе), которыми этот археолог располагает. Получив в свое распоряжение эти описания, экспертная система начинает формировать логический вывод. От исходных фактов, введенных в нее, и с помощью тех взаи�мосвязей, которые должны существовать между фактами, она выводит гипотезы, которые не противоречат наблюдаемым фактам. Если эта гипотеза однозначна, то она сообщается пользователю. Если имеет альтернативные возможности, то экс�пертная система может задать археологу дополнительные уточняющие вопросы, например, о характере рисунков на остатках найденной керамики, которые еще не были сообщены системе. Если археолог не может сообщить системе никаких но�вых дополнительных сведений, то ему будет сообщено несколько гипотез о дати�ровке. При этом каждая гипотеза может оцениваться некоторым весом достовер�ности. Например, ответ может иметь вид: "Данный объект относится к периоду А с достоверностью 15% и к периоду В с достоверностью 85%". Если при дальней�ших раскопках будет обнаружен другой предмет, то он датируется периодом В, как наиболее вероятным. Для каждого вновь найденного предмета могут быть получены вероятности датировки, а затем все результаты могут быть проанализи�рованы совместно.
Информация в базе знаний не хранится, как зерно в элеваторе, просто сваленное в бункер. В этом случае база знаний не смогла бы обеспечить эффек�тивную работу решателя. В экспертной системе существует специальный ком�плекс средств, с помощью которых в базе знаний наводится необходимый поря�док. Информация здесь классифицируется, обобщается, оценивается ее непроти�воречивость, отдельные информационные единицы объединяются связями раз�личного типа. Другими словами, в базе знаний возникает структурированная мо�дель проблемной области, в которой отражены все ее особенности, закономерно�сти и способы решения задач. Всеми этими процедурами заведует система под�держки базы знаний.
Система объяснения - важнейшая отличительная компонента экспертных систем. К ней пользователь может обращаться с вопросами типа "Что есть X?", "Как получен У?", "Почему получен У, а не Z?" и "Зачем нужен X?". За каждым таким вопросом скрывается свой комплекс процедур, выполнение которых позво�ляет дать пользователю интересующий его ответ. Вопрос "Что есть X?" требует выдачи пользователю всей информации о X, которой система располагает, что может потребовать весьма непростых поисковых процедур в базе знаний. Эти процедуры реализуются в решателе, так как во многих случаях для ответа на во�прос пользователя надо из исходных фактов, хранящихся в базе, получить логи�ческим путем новые производные факты.
Вопрос "Как получен У?" означает, что пользователь хочет ознакомиться с тем, как рассуждала система, шаг за шагом выводя из сообщенных ей пользова�телем фактов свое заключение. Для ответа на такой вопрос система объяснения должна обратиться в решатель, в памяти которого, как на экране электронно�лучевой трубки с послесвечением, должен некоторое время сохраняться "трек" того пути, который прошел решатель.
Вопрос "Почему получен У, а не Z?" требует от экспертной системы уме�ния обосновывать отказ от гипотез. В том же решателе хранится информация об альтернативном выборе между У и Z, который один или не один раз возникал на пути поиска решения. В этих "точках разветвления" система выбирала путь, ве�дущий к У, а не тот, который вел к Z. Использованные в этот момент соображе�ния, определявшие выбор, выдаются пользователю.
Наконец ответ на вопрос "Зачем нужен X?", возникающий в ситуации, ко�гда экспертная система просит пользователя ввести в нее информацию о X, тре�бует выполнения процедур обоснования необходимости сведений о X для полу�чения решения. Эти обоснования извлекаются из модели проблемной области, хранящейся в базе знаний.
Возможны и другие типы вопросов пользователя к системе объяснения, но и приведенных достаточно, чтобы понять, сколь важна ее роль: только она де�лает выдаваемые решения понятными и обоснованными для пользователя.
Почти так же, как и консультативные, устроены исследовательские экс�пертные системы, но в них имеются еще и блоки, в которых выполняются все не�обходимые для специалиста расчеты. Можно сказать, что экспертные системы такого типа - это симбиоз ЭВМ пятого поколения и консультационных эксперт�ных систем.
1.9. Законы эволюции программного обеспечения
Проведем ассоциации компьютера с человеком. У компьютера есть орга�ны восприятия информации из внешнего мира - это клавиатура, мышь, накопите�ли на магнитных дисках. У компьютера есть органы, "переваривающие" получен�ную информацию, - это центральный процессор и оперативная память. И наконец, у компьютера есть органы речи, выдающие результаты переработки. Современ�ным компьютерам, конечно, далеко до человека. Их можно сравнить с существа�ми, взаимодействующими с внешним миром на уровне ограниченного набора безусловных рефлексов. Этот набор рефлексов образует систему машинных ко�манд. На каком бы высоком уровне мы ни общались с компьютером, в конечном итоге все сводится к скучной и однообразной последовательности машинных ко�манд. Каждая машинная команда является своего рода раздражителем для возбу�ждения того или иного безусловного рефлекса. Реакция на этот раздражитель все�гда однозначная и "зашита" в блоке микрокоманд в виде микропрограммы. Эта микропрограмма и осуществляет действия по реализации машинной команды, но уже на уровне сигналов, подаваемых на те или иные логические схемы компью�тера, управляя различными подсистемами компьютера. В этом состоит так назы�ваемый принцип микропрограммного управления. Продолжая аналогию с челове�ком, отметим: для того, чтобы компьютер правильно питался, придумано множе�ство операционных систем, компиляторов сотен языков программирования. Но все они являются по сути лишь блюдом, на котором по определенным правилам доставляется пища (программы) желудку (компьютеру). Только желудок компью�тера любит диетическую, однообразную пищу - подавай ему информацию струк�турированную, в виде строго организованных последовательностей нулей и еди�ниц, комбинации которых составляют машинный язык. Таким образом, внешне являясь полиглотом, компьютер понимает только один язык - язык машинных команд.
Программисту не нужно пытаться постичь значения различных комбина�ций двоичных чисел, т.к. еще в 50-е годы программисты стали использовать для программирования символический аналог машинного языка, который назвали языком Ассемблера. Этот язык точно отражает все особенности машинного язы�ка. Именно поэтому язык Ассемблера для каждого типа компьютера свой.
Язык программирования - это специальный язык, на котором пишут ко�манды для управления компьютером. Языки программирования созданы для того, чтобы людям было проще читать и писать для компьютера, но они затем должны транслироваться (транслятором или интерпретатором) в машинный код, который только и может исполняться компьютером. Языки программирования можно раз�делить на языки высокого уровня и языки низкого уровня.
Язык низкого уровня - это язык программирования, предназначенный для определенного типа компьютера и отражающий его внутренний машинный код. Языки низкого уровня часто называют машинно-ориентированными языками. Их сложно конвертировать для использования на компьютерах с разными централь�ными процессорами, а также довольно сложно изучать, поскольку для этого тре�буется хорошо знать принципы внутренней работы компьютера.
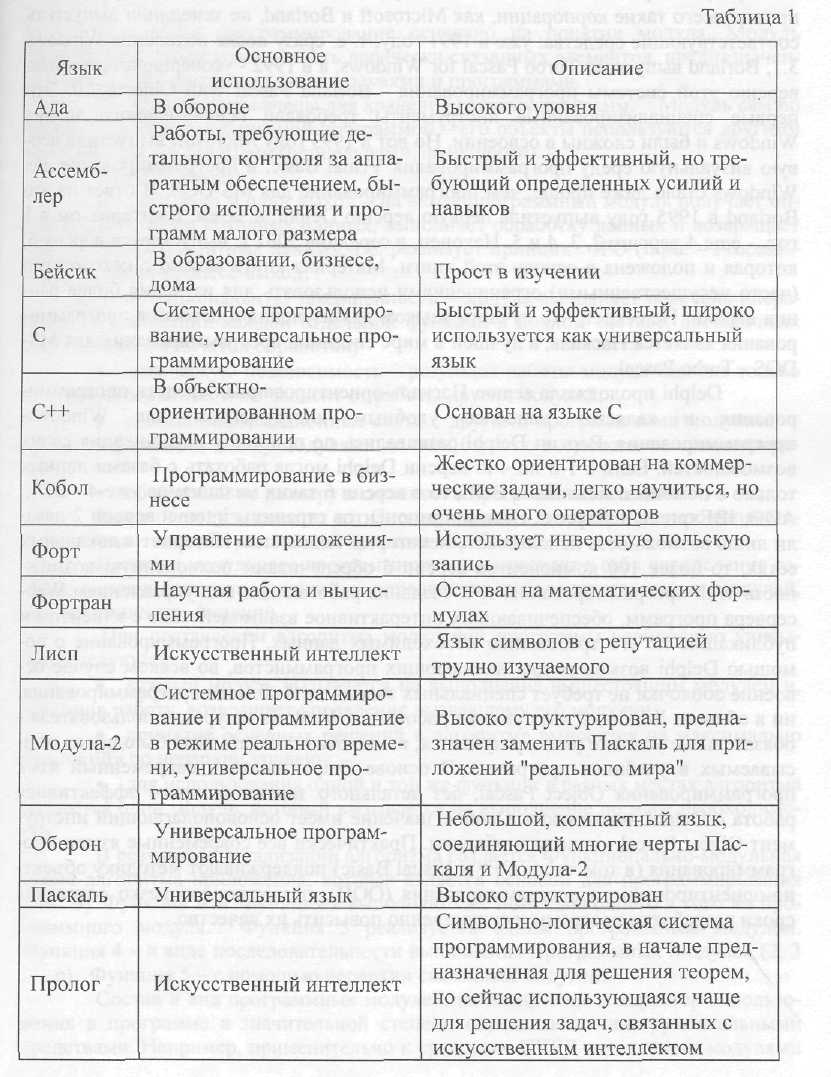
Язык высокого уровня - это язык программирования, предназначенный для удовлетворения требований программиста; он не зависит от внутренних ма�шинных кодов компьютера любого типа. Языки высокого уровня используют для решения проблем и поэтому их часто называют проблемно-ориентированными языками. Каждая команда языка высокого уровня эквивалентна нескольким командам в машинных кодах, поэтому программы, написанные на языках высокого уровня, более компактны, чем аналогичные программы в машинных кодах. Ос�новные языки программирования и области их использования приведены в таб�лице 1.
Эволюция технических средств персональных компьютеров привела к по�всеместному вытеснению старой "доброй" ОС MS-DOS значительно более мощ�ными системами Windows, программирование для которых существенно сложнее, чем программирование для MS-DOS. Разработчики систем программирования, и прежде всего такие корпорации, как Microsoft и Borland, не замедлили выпустить соответствующие средства: уже в 1991 году, т. е. сразу после появления Windows 3.1, Borland выпускает Turbo Pascal for Windows, а в 1992 - усовершенствованную версию этой системы программирования - Borland Pascal with Objects 7.0. Эти первые специализированные инструменты требовали основательного знания Windows и были сложны в освоении. Но вот в 1993 году Microsoft выпустила пер�вую визуальную среду программирования Visual Basic, и программирование для Windows стало даже проще, чем программирование для MS-DOS. В ответ на это Borland в 1995 году выпустила первую версию Delphi, а затем, с интервалом в 1 год, - еще 4 версии: 2, 3, 4 и 5. Наконец, в середине 2001 г. выпускается версия 6, которая и положена в основу этой книги. Материал книги можно с некоторыми (часто несущественными) ограничениями использовать для изучения более ран�них версий. Не секрет, что лучшим языком для изучения и освоения программи�рования является Паскаль, а лучшей в мире системой программирования для MS-DOS - Turbo Pascal.
Delphi продолжила серию Паскаль-ориентированных средств программи�рования и является наиболее удобным инструментом для Windows-программирования. Версии Delphi развивались по принципу наращивания своих возможностей. Если с 1-й по 4-ю версии Delphi могла работать с базами данных только с помощью механизма BDE, то в версии 6 таких механизмов уже 4 - BDE, ADO, IBExpress, dbExpress. Если 8 компонентов страницы internet версии 2 дава�ли лишь возможность использовать некоторые технологии Интернет в локальных сетях, то более 100 компонентов версии 6 обеспечивают полноценную возмож�ность Web-программирования, т. е. создания работающих под управлением Web-сервера программ, обеспечивающих интерактивное взаимодействие с клиентом и публикацию по его требованию необходимых данных. Программирование с по�мощью Delphi возможно для начинающих программистов, во всяком случае ос�воение оболочки не требует специальных знаний ни в области программирования, ни в области Windows, хотя умение работать с Windows на уровне пользователя -обязательное условие (если, разумеется, вы захотите создать хотя бы одну из опи�сываемых в учебнике программ). В основе Delphi заложен современный язык программирования Object Pascal, без детального знания которого эффективная работа с Delphi невозможна. Особое значение имеет основополагающий инстру�мент Object Pascal - классы и объекты. Практически все современные языки про�граммирования (в том числе C++ и Visual Basic) поддерживают методику объект�но-ориентированного программирования (ООП), позволяющую резко сократить сроки разработки программ и существенно повысить их качество.
2. СОЗДАНИЕ МОДУЛЬНЫХ ПРОГРАММ, ЭЛЕМЕНТЫ ТЕОРИИ МОДУЛЬНОГО ПРОГРАММИРОВАНИЯ
Модульное программирование основано на понятии модуля. Модуль представляет собой совокупность логически связанных элементов, предназначен�ных для использования другими модулями и программами.
Модули предназначены для хранения готовых программ. Модуль сам по себе не является выполняемой программой - его объекты используются другими программными единицами (процедурами, функциями).
Модуль имеет:
один вход и один выход - на входе программный модуль получает оп�ределенный набор исходных данных, выполняет обработку данных и возвращает
один набор результатных данных, т.е. реализует принцип IPO (Input - Process -
Output) - вход-процесс-выход;
функциональную завершенность - модуль выполняет перечень опера�ций для реализации каждой отдельной функции в полном составе, достаточных
для завершения начатой обработки;
логическую независимость - результат работы модуля зависит только
от исходных данных и не зависит от работы других модулей;
слабые информационные связи с другими программными модулями -
обмен информации между модулями должен быть по возможности минимизиро�ван;
обозримый по размеру и сложности программный элемент.
Каждый модуль состоит из Спецификации - правила использования мо�дуля и Тела - способа реализации процесса обработки.
Принцип модульного программирования включает в себя определение со�става и подчиненности функций и определение набора программных модулей, реализующих эти функции.
При составлении алгоритма модульной программы необходимо учиты�вать следующее:
каждый модуль вызывается на выполнение вышестоящим модулем и,
закончив работу, возвращает управление вызвавшему его модулю;
принятие основных решений в алгоритме выносится на максимально
«высокий» по иерархии уровень;
для использования одной и той же функции в разных местах алгоритма
создается один модуль, который вызывается на выполнение по мере необходимо�сти.
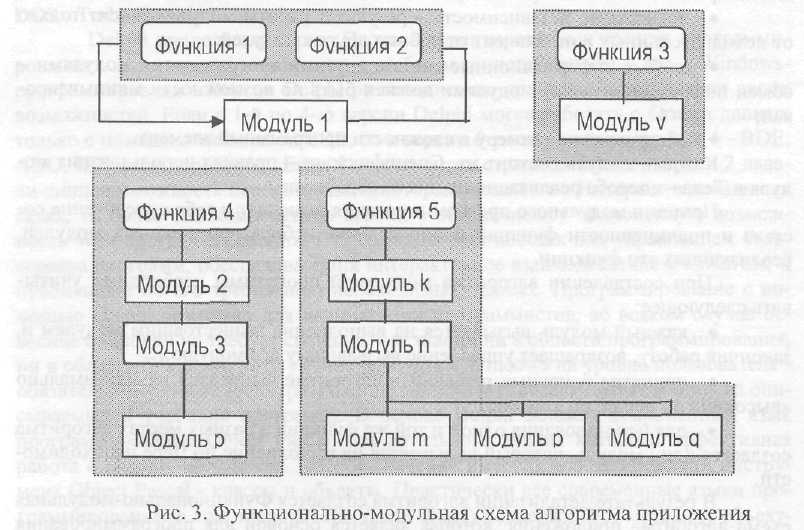
В результате детализации алгоритма создается Функционально-модульная схема алгоритма приложения, которая является основой для программирования (рис. 3). Функция 1 и Функция 2 выполняются с помощью одного и того же про�граммного модуля. Функция 3 реализуется одним программным модулем. Функция 4 - в виде последовательности выполнения Программных Модулей (2, 3 .. . р). Функция 5 - с помощью иерархии связанных модулей.
Состав и вид программных модулей, их назначение и характер использо�вания в программе в значительной степени определяются инструментальными средствами. Например, применительно к средствам СУБД отдельными модулями могут быть: Экранные формы ввода и редактирования информации БД; Отчеты генератора отчетов; Макросы; Стандартные процедуры обработки информации; Меню, обеспечивающее выбор функции обработки и др.
Стандартный Паскаль не предусматривает механизмов раздельной ком�пиляции частей программы с последующей их сборкой перед выполнением. Более того, последовательное проведение в жизнь принципа обязательного описания любого объекта перед его использованием делает фактически невозможным раз�работку разнообразных библиотек прикладных программ. Точнее, такие библио�теки в рамках стандартного Паскаля могут существовать только в виде исходных текстов, и программист, подчас, должен сам включать в программу весьма об�ширные тексты различных поддерживающих процедур, таких, как процедуры матричной алгебры, численного интегрирования, математической статистики и т.п.
Поэтому вполне понятно стремление разработчиков коммерческих ком�пиляторов Паскаля включать в язык средства, повышающие его модульность. Чаще всего таким средством является разрешение использовать внешние проце�дуры и функции, тело которых заменяется стандартной директивой EXTERNAL. Разработчики Турбо Паскаля пошли в этом направлении еще дальше, включив в язык механизм модулей.
Модуль в Паскале - это автономно компилируемая программная единица, включающая в себя различные компоненты раздела описаний (типы, константы, переменные, процедуры и функции) и, возможно, некоторые исполняемые опера�торы инициирующей части. По своей организации и характеру использования в программе модули Турбо Паскаля близки к модулям-пакетам (PACKAGE) языка программирования Ада. В них так же, как в пакетах Ады, явным образом выделя�ется некоторая «видимая» интерфейсная часть, в которой сконцентрированы опи�сания глобальных типов, констант и переменных, а также приводятся заголовки глобальных процедур и функций. Появление объектов в интерфейсной части де�лает их доступными для других модулей и основной программы. Тела процедур и функций располагаются в исполняемой части модуля, которая может быть скрыта от пользователя.
Насколько сильно изменяются свойства языка Паскаль при введении ме�ханизма модулей, свидетельствует следующее замечание его автора - Н. Вирта, сделанное им по поводу более позднего языка Модула-2: «Модули - самая важная черта, отличающая язык Модула-2 от его предшественника Паскаля».
Модули представляют собой прекрасный инструмент для разработки биб�лиотек прикладных программ и мощное средство модульного программирования. Важная особенность модулей заключается в том, что компилятор Турбо Паскаля размещает их программный код в отдельном сегменте памяти. Максимальная длина сегмента не может превышать 64 Кбайта, однако количество одновременно используемых модулей ограничивается лишь доступной памятью, что дает воз�можность создавать весьма крупные программы.
2.1. Структура модулей Паскаля
Модуль имеет следующую структуру:
UNIT <имя>;
INTERFACE
<интерфейсная часть>
IMPLEMENTATION
<исполняемая часть>
BEGIN
<инициирующая часть>
END.
Здесь UNIT - зарезервированное слово (единица); начинает заголовок мо�дуля; <имя> - имя модуля (правильный идентификатор); INTERFACE - зарезер�вированное слово (интерфейс); начинает интерфейсную часть модуля;
IMPLEMENTATION - зарезервированное слово (выполнение); начинает исполняемую часть;
BEGIN - зарезервированное слово; начинает инициирующую часть моду�ля;
конструкция BEGIN <инициирующая частъ> необязательна;
END - зарезервированное слово - признак конца модуля.
Таким образом, модуль состоит из заголовка и трех составных частей, любая из которых может быть пустой.
3. ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ
В основе того или иного языка программирования лежит некоторая руко�водящая идея, оказывающая существенное влияние на стиль соответствующих программ.
Исторически первой была идея процедурного структурирования про�грамм, в соответствии с которой программист должен был решить, какие именно процедуры он будет использовать в своей программе, а затем выбрать наилучшие алгоритмы для реализации этих процедур. Появление этой идеи было следствием недостаточной изученности алгоритмической стороны вычислительных процес�сов, столь характерной для ранних программных разработок (сороковые - пятиде�сятые годы). Типичным примером процедурно-ориентированного языка является Фортран - первый и, до сих пор, один из популярнейших языков программирова�ния. Последовательное использование идеи процедурного структурирования про�грамм привело к созданию обширных библиотек программирования, содержащих множество сравнительно небольших процедур, из которых, как из кирпичиков, можно строить «здание» программы.
По мере прогресса в области вычислительной математики акцент в про�граммировании стал смещаться с процедур в сторону организации данных. Ока�залось, что эффективная разработка сложных программ нуждается в действенных способах контроля правильности использования данных. Контроль должен осу�ществляться как на стадии компиляции, так и при прогоне программ. В против�ном случае, как показала практика, резко возрастают трудности создания круп�ных программных проектов. Отчетливое осознание этой проблемы привело к соз�данию Алгола-60, а позже - Паскаля, Модулы-2, Си и множества других языков программирования, имеющих более или менее развитые структуры типов данных. Логическим следствием развития этого направления стал модульный подход к разработке программ, характеризующийся стремлением «спрятать» данные и процедуры внутри модуля.
Начиная с языка Симула-67, в программировании наметился новый под�ход, который получил название объектно-ориентированного программирования (ООП). Его руководящая идея заключается в стремлении связать данные с обра�батывающими эти данные процедурами в единое целое - объект. Характерной чертой объектов является инкапсуляция (объединение) данных и алгоритмов их обработки, в результате чего и данные, и процедуры во многом теряют самостоя�тельное значение. Фактически, объектно-ориентированное программирование можно рассматривать как модульное программирование нового уровня, когда вместо, во многом случайного, механического объединения процедур и данных акцент делается на их смысловую связь.
Какими мощными средствами располагает объектно-ориентированное программирование наглядно демонстрирует библиотека Turbo Vision, входящая в комплект поставки Турбо Паскаля.
Следует заметить, что преимущества ООП в полной мере проявляются лишь при разработке достаточно сложных программ. Более того, инкапсуляция придает объектам совершенно особое свойство «самостоятельности», максималь�ной независимости от остальных частей программы. Правильно сконструированный объект располагает всеми необходимыми данными и процедурами их обра�ботки, чтобы успешно реализовать требуемые от него действия. Попытки исполь�зовать ООП для программирования несложных алгоритмов, связанных, например, с расчетными вычислениями по готовым формулам, чаще всего выглядят искус�ственными нагромождениями ненужных языковых конструкций. Такие програм�мы обычно не нуждаются в структуризации, расчленении алгоритма на ряд отно�сительно независимых частей. Их проще и естественнее разрабатывать традици�онными способами Паскаля. При разработке сложных диалоговых программ про�граммист вынужден структурировать программу, так как только в этом случае он может рассчитывать на успех: «критической массой» неструктурированных про�грамм является объем в 1000-1200 строк исходного текста - отладка неструктури�рованных программ большего объема обычно сталкивается с чрезмерными труд�ностями. Структурирование программы ведет, фактически, к разработке собст�венной библиотеки программирования - вот в этот момент на помощь и приходят новые средства ООП.
3.1. Основные принципы ООП
Объектно-ориентированное программирование основано на «трех китах» - трех важнейших принципах, придающих объектам новые свойства. Этими принципами являются инкапсуляция, наследование и полиморфизм.
Инкапсуляция
Инкапсуляция есть объединение в единое целое данных и алгоритмов об�работки этих данных. В рамках ООП данные называются полями объекта, а алго�ритмы - объектными методами.
Инкапсуляция позволяет в максимальной степени изолировать объект от внешнего окружения. Она существенно повышает надежность разрабатываемых программ, т.к. локализованные в объекте алгоритмы обмениваются с программой сравнительно небольшими объемами данных, причем количество и тип этих дан�ных обычно тщательно контролируются. В результате замена или модификация алгоритмов и данных, инкапсулированных в объект, как правило, не влечет за собой плохо прослеживаемых последствий для программы в целом (в целях по�вышения защищенности программ в ООП почти не используются глобальные переменные).
Другим немаловажным следствием инкапсуляции является легкость об�мена объектами, переноса их из одной программы в другую. Можно сказать, что ООП «провоцирует» разработку библиотек объектов.
Наследование
Наследование есть свойство объектов порождать своих потомков. Объект-потомок автоматически наследует от родителя все поля и методы, может допол�нять объекты новыми полями и заменять (перекрывать) методы родителя или до�полнять их.
Принцип наследования решает проблему модификации свойств объекта и придает ООП в целом исключительную гибкость. При работе с объектами про�граммист обычно подбирает объект, наиболее близкий по своим свойствам для решения конкретной задачи, и создает одного или нескольких потомков от него, которые «умеют» делать то, что не реализовано в родителе.
Последовательное проведение в жизнь принципа «наследуй и изменяй» хорошо согласуется с поэтапным подходом к разработке крупных программных проектов и во многом стимулирует такой подход.
Полиморфизм
Полиморфизм - это свойство родственных объектов (т.е. объектов, имею�щих одного общего родителя) решать схожие по смыслу проблемы разными спо�собами. В рамках ООП поведенческие свойства объекта определяются набором входящих в него методов. Изменяя алгоритм того или иного метода в потомках объекта, программист может придавать этим потомкам отсутствующие у родите�ля специфические свойства. Для изменения метода необходимо перекрыть его в потомке, т.е. объявить в потомке одноименный метод и реализовать в нем нуж�ные действия. В результате в объекте-родителе и объекте-потомке будут действо�вать два одноименных метода, имеющих разную алгоритмическую основу и, сле�довательно, придающих объектам разные свойства. Это и называется полимор�физмом объектов.
В Турбо Паскале полиморфизм достигается не только описанным выше механизмом наследования и перекрытия методов родителя, но и их виртуализа�цией (см. ниже), позволяющей родительским методам обращаться к методам по�томков.
3.2. Создание объектов
В Турбо Паскале для создания объектов используются три зарезервиро�ванных слова: object, constructor, destructor и три стандартные директивы: private, public и virtual.
Зарезервированное слово object используется для описания объекта. Опи�сание объекта должно помещаться в разделе описания типов:
type
MyObject = object
(Поля объекта}
{Методы объекта}
end ;
Если объект порождается от какого-либо родителя, имя родителя указы�вается в круглых скобках сразу за словом object:
type
MyDescendantObject = object(MyObject)
end;
Любой объект может иметь сколько угодно потомков, но только одного родителя, что позволяет создавать иерархические деревья наследования объектов.
Создадим объект-родитель TGraphObject, в рамках которого будут инкап�сулированы поля и методы, общие для всех остальных объектов:
type
TGraphObj = object
Private {Поля объекта будут скрыты от пользователя}
X,Y: Integer; {Координаты реперной точки}
Color: Word; {Цвет фигуры}
Public {Методы объекта будут доступны пользователю}
Constructor Init(aX,aY: Integer; aColor: Word);
{Создает экземпляр объекта}
Procedure Draw(aColor: Word); Virtual;
{Вычерчивает объект заданным цветом aColor}
Procedure Show;
{Показывает объект - вычерчивает его цветом Color}
Procedure Hide;
{Прячет объект - вычерчивает его цветом фона}
Procedure MoveTo(dX,dY: Integer);
{Перемещает объект в точку с координатами X+dX и Y+dY}
end; {Конец описания объекта TGraphObj}
В дальнейшем предполагается создать объекты-потомки от TGraphObj, реализующие все специфические свойства точки, линии, окружности и прямо�угольника. Каждый из этих графических объектов будет характеризоваться поло�жением на экране (поля X и Y) и цветом (поле Color). С помощью метода Draw он будет способен отображать себя на экране, а с помощью свойств «показать себя» (метод Show) и «спрятать себя» (метод Hide) сможет перемещаться по экрану (метод MoveTo). Учитывая общность свойств графических объектов, объявляем абстрактный объект TGraphObj, который не связан с конкретной графической фи�гурой. Он объединяет в себе все общие поля и методы реальных фигур и будет служить родителем для других объектов.
Директива Private в описании объекта открывает секцию описания скры�тых полей и методов. Перечисленные в этой секции элементы объекта «не видны» программисту, если этот объект он получил в рамках библиотечного ТР(/-модуля. Скрываются обычно те поля и методы, к которым программист (в его же интере�сах!) не должен иметь непосредственного доступа. В данном примере он не мо�жет произвольно менять координаты реперной точки (X.Y), т.к. это не приведет к перемещению объекта. Для изменения полей X и Y предусмотрены входящие в состав объекта методы Init и MoveTo. Скрытые поля и методы доступны в рамках той программной единицы (программы или модуля), где описан соответствую�щий объект. В дальнейшем предполагается, что программа будет использовать модуль GraphObj с описанием объектов. Скрытые поля будут доступны в модуле GraphObj, но недоступны в использующей его основной программе. Разумеется, в рамках реальной задачи создание скрытых элементов объекта вовсе необязатель�но. В данном случае они введены в объект TGraphObj лишь для иллюстрации возможностей ООП.
Директива public отменяет действие директивы private, поэтому все сле�дующие за public элементы объекта доступны в любой программной единице. Директивы private и public могут произвольным образом чередоваться в пределах одного объекта.
Вариант объявления объекта TGraphObj без использования механизма private...public:
type
TGraphObj = object
X,Y: Integer;
Color: Word;
Constructor Init(aX,aY: Integer; aColor: Word);
Procedure Draw(aColor: Word); Virtual;
Procedure Show;
Procedure Hide;
Procedure MoveTo(dX,dY: Integer);
end;
Описания полей ничем не отличаются от описания обычных переменных. Полями могут быть любые структуры данных, в том числе и другие объекты. Ис�пользуемые в примере поля X и Y содержат координату реперной (характерной) точки графического объекта, а поле Color - его цвет. Реперная точка характеризу�ет текущее положение графической фигуры на экране и, в принципе, может быть любой ее точкой.
В данном примере она совпадает с координатами точки в описываемом ниже объекте TPoint, с центром окружности в объекте TCircle, первым концом прямой в объекте TLine и с левым верхним углом прямоугольника в объекте TRect.
Для описания методов в ООП используются традиционные для Паскаля процедуры и функции, а также особый вид процедур - конструкторы и деструкто�ры. Конструкторы предназначены для создания конкретного экземпляра объекта, ведь объект - это тип данных, т.е. «шаблон», по которому можно создать сколько угодно рабочих экземпляров данных объектного типа (типа TGraphOhj, напри�мер). Зарезервированное слово constructor, используемое в заголовке конструкто�ра вместо procedure, предписывает компилятору создать особый код пролога, с помощью которого настраивается, так называемая, таблица виртуальных методов (см. ниже). Если в объекте нет виртуальных методов, в нем может не быть ни од�ного конструктора, наоборот, если хотя бы один метод описан как виртуальный (с последующим словом Virtual, см. метод Draw), в состав объекта должен входить хотя бы один конструктор, и обращение к конструктору должно предшествовать обращению к любому виртуальному методу.
Типичное действие, реализуемое конструктором, состоит в наполнении объектных полей конкретными значениями. Следует заметить, что разные экзем�пляры одного и того же объекта отличаются друг от друга только содержимым объектных полей, в то время как каждый из них использует одни и те же объект�ные методы. В данном примере конструктор Init объекта TGraphObj получает все необходимые для полного определения экземпляра данные через параметры об�ращения аХ, aY и aColor.
Процедура Draw предназначена для вычерчивания графического объекта. Эта процедура будет реализовываться в потомках объекта TGraphObj по-разному. Например, для визуализации точки следует вызвать процедуру PutPixel, для вы�черчивания линии - процедуру Line и т.д. В объекте TGraphObj процедура Draw определена как виртуальная («воображаемая»). Абстрактный объект TGraphObj не предназначен для вывода на экран, однако наличие процедуры Draw в этом объекте говорит о том, что любой потомок TGraphObj должен иметь собственный метод Draw, с помощью которого он может показать себя на экране.
При трансляции объекта, содержащего виртуальные методы, создается, так называемая, таблица виртуальных методов (ТВМ), количество элементов ко�торой равно количеству виртуальных методов объекта. В этой таблице будут хра�ниться адреса точек входа в каждый виртуальный метод. В приведенном примере ТВМ объекта TGraphObj хранит единственный элемент - адрес метода Draw. Пер�воначально элементы ТВМ не содержат конкретных адресов. Если бы был создан экземпляр объекта TGraphObj с помощью вызова его конструктора Init, код про�лога конструктора поместил бы в ТВМ нужный адрес родительского метода
Draw. Далее мы создадим несколько потомков объекта TGraphObj. Каждый из них будет иметь собственный конструктор, с помощью которого ТВМ каждого потомка настраивается так, чтобы ее единственный элемент содержал адрес нуж�ного метода Draw. Такая процедура называется поздним связыванием объекта. Позднее связывание позволяет методам родителя обращаться к виртуальным ме�тодам своих потомков и использовать их для реализации специфичных для по�томков действий.
Наличие в объекте TGraphObj виртуального метода Draw позволяет легко реализовать три других метода объекта: чтобы показать объект на экране в методе Show, вызывается Draw с цветом aColor, равным значению поля Color, а чтобы спрятать графический объект, в методе Hide вызывается Draw со значением цвета GetBkCoior, т.е. с текущим цветом фона.
Рассмотрим реализацию перемещения объекта. Если потомок TGraphObj (например, TLine) хочет переместить себя на экране, он обращается к родитель�скому методу MoveTo. В этом методе сначала с помощью Hide объект стирается с экрана, а затем с помощью Show показывается в другом месте. Для реализации своих действий и Hide, и Show обращаются к виртуальному методу Draw. По�скольку вызов MoveTo происходит в рамках объекта TLine, используется ТВМ этого объекта и вызывается его метод Draw, вычерчивающий прямую. Если бы перемешалась окружность, ТВМ содержала бы адрес метода Draw объекта TCircle, и визуализация-стирание объекта осуществлялась бы с помощью этого метода.
Чтобы описать все свойства объекта, необходимо раскрыть содержимое объектных методов, т.е. описать соответствующие процедуры и функции. Описа�ние методов производится обычным для Паскаля способом в любом месте разде�ла описаний, но после описания объекта. Например:
type
TGraphObj - object
end;
Constructor TGraphObj .Init;
begin
X:=aX;
Y:=aY; Color:=aColor
end;
Procedure TGraphObj-Draw;
begin
{Эта процедура в родительском объекте ничего не делает, поэтому экзем�пляры TGraphObj не способны отображать себя на экране. Чтобы потомки объек�та TGraphObj были способны отображать себя, они должны перекрывать этот ме�тод}
end;
Procedure TGraphObj.Show;
begin
Draw(Color)
end;
Procedure TGraphObj.Hide;
begin
Draw(GetBkColor)
end;
Procedure TGraphObj.MoveTo;
begin
Hide;
X := X+dX;
Y := Y+dY;
Show
end;
Следует отметить два обстоятельства. Во-первых, при описании методов имя метода дополняется спереди именем объекта, т.е. используется составное имя метода. Это необходимо по той простой причине, что в иерархии родственных объектов любой из методов может быть перекрыт в потомках. Составные имена четко указывают принадлежность конкретной процедуры. Во-вторых, в любом объектном методе можно использовать инкапсулированные поля объекта почти так, как если бы они были определены в качестве глобальных переменных. На�пример, в конструкторе TGraph.Init переменные в левых частях операторов при�сваивания представляют собой объектные поля и не должны заново описываться в процедуре. Более того, описание
Constructor TGraphObj.Init;
var
X,Y: Integer; {Ошибка!}
Color: Word; {Ошибка!}
begin
end;
вызовет сообщение о двойном определении переменных X, Y и Color (в этом и состоит отличие в использовании полей от глобальных переменных: глобальные переменные можно переопределять в процедурах, в то время как объектные поля переопределять нельзя).
Следует обратить внимание: абстрактный объект TGraphObj не предна�значен для вывода на экран, поэтому его метод Draw ничего не делает. Однако методы Hide, Show и MoveTo «знают» формат вызова этого метода и реализуют необходимые действия, обращаясь к реальным методам Draw своих будущих по�томков через соответствующие ТВМ. Это и есть полиморфизм объектов.
Создадим простейшего потомка от TGraphObj - объект TPoint, с помощью которого будет визуализироваться и перемещаться точка. Все основные действия, необходимые для этого, уже есть в объекте TGraphObj, поэтому в объекте TPoint перекрывается единственный метод - Draw.
type
TPoint = object(TGraphObj)
Procedure Draw(aColor); Virtual;
end;
Procedure TPoint.Draw;
begin
PutPixel(X,Y,Color) {Показываем цветом Color пиксель с координатами X иУ}
end;
В новом объекте TPoint можно использовать любые методы объекта-родителя TGraphObj. Например, вызвать метод MoveTo, чтобы переместить изо�бражение точки на новое место. В этом случае родительский метод TGraphObj.MoveTo будет обращаться к методу TPoint.Draw, чтобы спрятать и затем показать изображение точки. Такой вызов станет доступен после обраще�ния к конструктору Init объекта TPoint, который нужным образом настроит ТВМ объекта. Если вызвать TPoint.Draw до вызова Init, его ТВМ не будет содержать правильного адреса, и программа «зависнет».
Чтобы создать объект-линию, необходимо ввести два новых поля для хранения координат второго конца. Дополнительные поля требуется наполнить конкретными значениями, поэтому нужно перекрыть конструктор родительского объекта:
type
TLine - object(TGraphObj)
dX,dY: Integer; {Приращения координат второго конца}
Constructor Init(Xl,Yl5X2,Y2: Integer; aColor: Word);
Procedure Draw(aColor: Word); Virtual;
end;,
Constructor TLine.Init;
{Вызывает унаследованный конструктор TGraphObj для инициализации полей X, Y и Color. Затем инициализирует поля dX и dY}
begin
{Вызываем унаследованный конструктор}
Inherited Init(XI,Yl,aColor);
{Инициируем поля dX и dY}
dX:=X2-Xl;
dY := Y2-Y1
end;
Procedure Draw;
begin
SetColor(Color); (Устанавливаем цвет Color}
Line(X,Y,X+dX,Y+dY) {Вычерчиваем линию}
end;
В конструкторе TLine.Init для инициализации полей X, Y и Color, унасле�дованных от родительского объекта, вызывается унаследованный конструктор TGraph.Init, для чего используется зарезервированное слово inherited (англ.- унас�ледованный):
Inherited Init(XI,Yl,aColor);
С таким же успехом можно использовать и составное имя метода:
TGraphObj.Init(Xl,Yl,aColor);
Для инициализации полей dX и dY вычисляется расстояние в пикселах по горизонтали и вертикали от первого конца прямой до ее второго конца. Это по�зволяет в методе TLine.Draw вычислить координаты второго конца по координа�там первого и смещениям dX и dY. В результате простое изменение координат реперной точки X, Y в родительском методе TGraph.MoveTo перемещает всю фи�гуру по экрану.
Теперь нетрудно реализовать объект TCircle для создания и перемещения окружности:
type
TCircle = object(TGraphObj)
R: Integer; {Радиус}
Constructor Init(aX,aY,aR: Integer;
Procedure Draw(aColor: Virtual);
end;
Constructor TCircle.Init;
begin
Inherited Init(aX,aY,aCoIor);
R:=aR
end ;
aCoIor: Word)
Procedure TCircle.Draw;
begin
SetColor(aColor); (Устанавливаем цвет Color}
Circle(X,Y,R) {Вычерчиваем окружность}
end;
В объекте TRect, с помощью которого создается и перемещается прямо�угольник, учитывается то обстоятельство, что для задания прямоугольника требу�ется указать четыре целочисленных параметра, т.е. столько же, сколько для зада�ния линии. Поэтому объект TRect удобнее породить не от TGraphObj, а от TLine, чтобы использовать его конструктор Init:
type
TRect = object(TLine)
Procedure Draw(aColor: Word);
end;
Procedure TRect.Draw;
begin
SetColor(aColor);
Rectangle(X,Y,X+dX,Y+dY) {Вычерчиваем прямоугольник}
end;
Чтобы описания графических объектов не мешали созданию основной программы, нужно оформить эти описания в отдельном модуле GraphObj:
Unit GraphObj; Interface
{Интерфейсная часть модуля содержит только объявления объектов}
type
TGraphObj = object
end;
TPoint = object(TGraphObj)
end;
TLine - object(TGraphObj)
end;
TCircle = object(TGraphObj)
end;
TRect = object(TLine)
end;
Implementation
{Исполняемая часть содержит описания всех объектных методов}
Uses Graph;
Constructor TGraphObj.Init;
end.
В интерфейсной части модуля приводятся лишь объявления объектов, по�добно тому как описываются другие типы данных, объявляемые в модуле дос�тупными для внешних программных единиц. Расшифровка объектных методов помещается в исполняемую часть implementation, как если бы это были описания обычных интерфейсных процедур и функций. При описании методов можно опускать повторное описание в заголовке параметров вызова. Если они все же повторяются, они должны в точности соответствовать ранее объявленным пара�метрам в описании объекта. Например, заголовок конструктора TGraphObj.Init может быть таким:
Constructor TGraphObj.Init;
или таким:
Constructor TGraphObj.Init(aX,aY: Integer; aColor: Word);
СОЗДАНИЕ МОДУЛЬНЫХ ПРОГРАММ, ЭЛЕМЕНТЫ ТЕОРИИ МОДУЛЬНОГО ПРОГРАММИРОВАНИЯ