Информационные системы
- Информационные системы
Информацией принято называть сведения, передаваемые людьми устным, письменным или любым другим способом.
Информационная система (ИС) служит для сбора и накопления информации, и ее эффективного использования для разнообразных целей. Применяя вычислительную технику можно автоматизировать информационную систему (ИС). В этом случае информация представляется в виде каких–либо формальных данных и хранится в памяти ЭВМ. Следовательно, при проектировании информационной системы (ИС) приходится решать вопросы двух аспектов: инфологического и датологического.
- Инфологический: какие сведения и для каких целей будут храниться в информационной системе.
- Датологический: как соответствующие данные будут организованны в памяти ЭВМ и как они будут обрабатываться при эксплуатации ЭВМ.
По сфере применения различают два основных класса информационных систем (ИС): информационно поисковые системы и системы обработки данных.
Информационно-поисковые системы ориентированны на извлечение некоторых подмножеств из множества хранящихся сведений в соответствии с некоторым критерием поиска. В данном случае пользователя интересует извлекаемая информация.
Пример: справочная служба 09, и т.д.
Системы обработки данных. Извлекаемая информация – это не хранимые данные, а результат обработки хранящихся данных (информационная система гостиничного хозяйства, где данные постоянно обновляются и т.д.).
- Основные понятия теории баз данных
- Предметная область
Под предметной областью (ПО) понимают часть реального мира.
По отношению к информационным системам предметная область – это та часть реального мира, о которой информационная система собирает информацию.
|
|
|
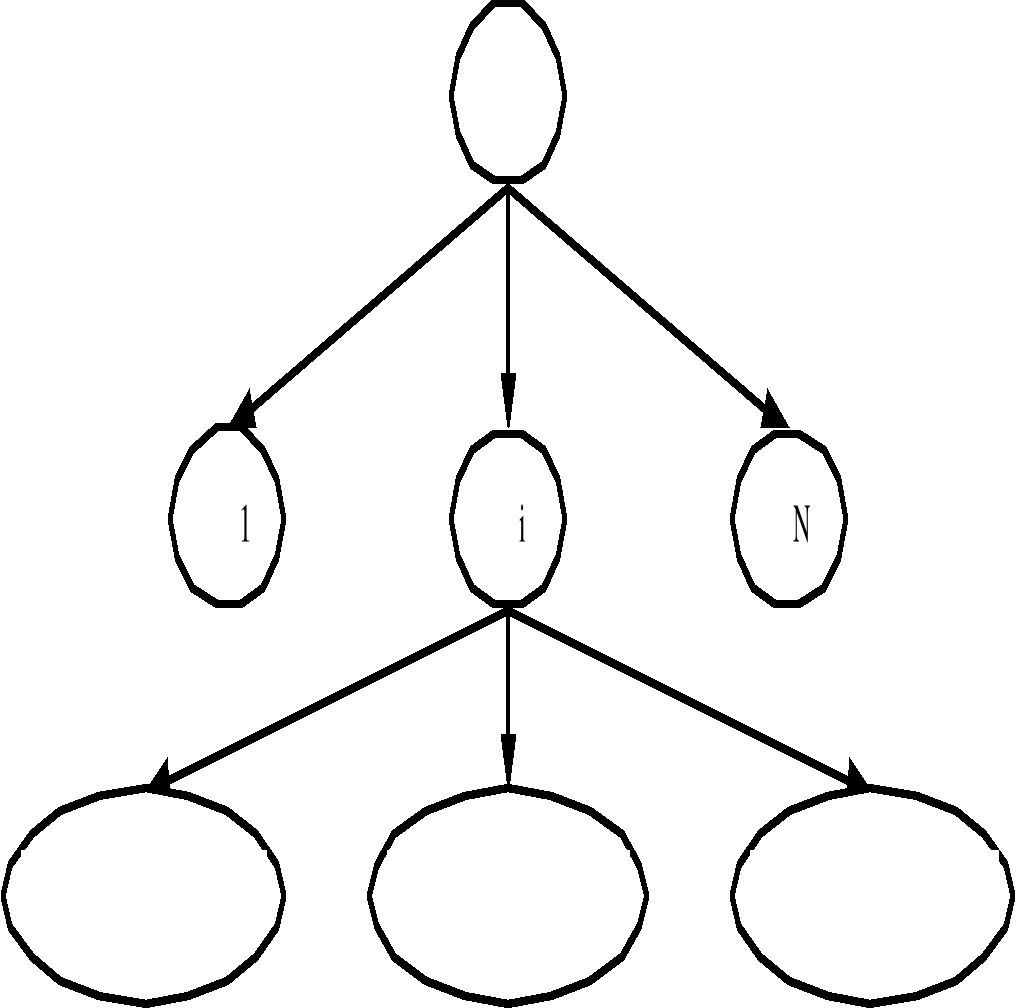
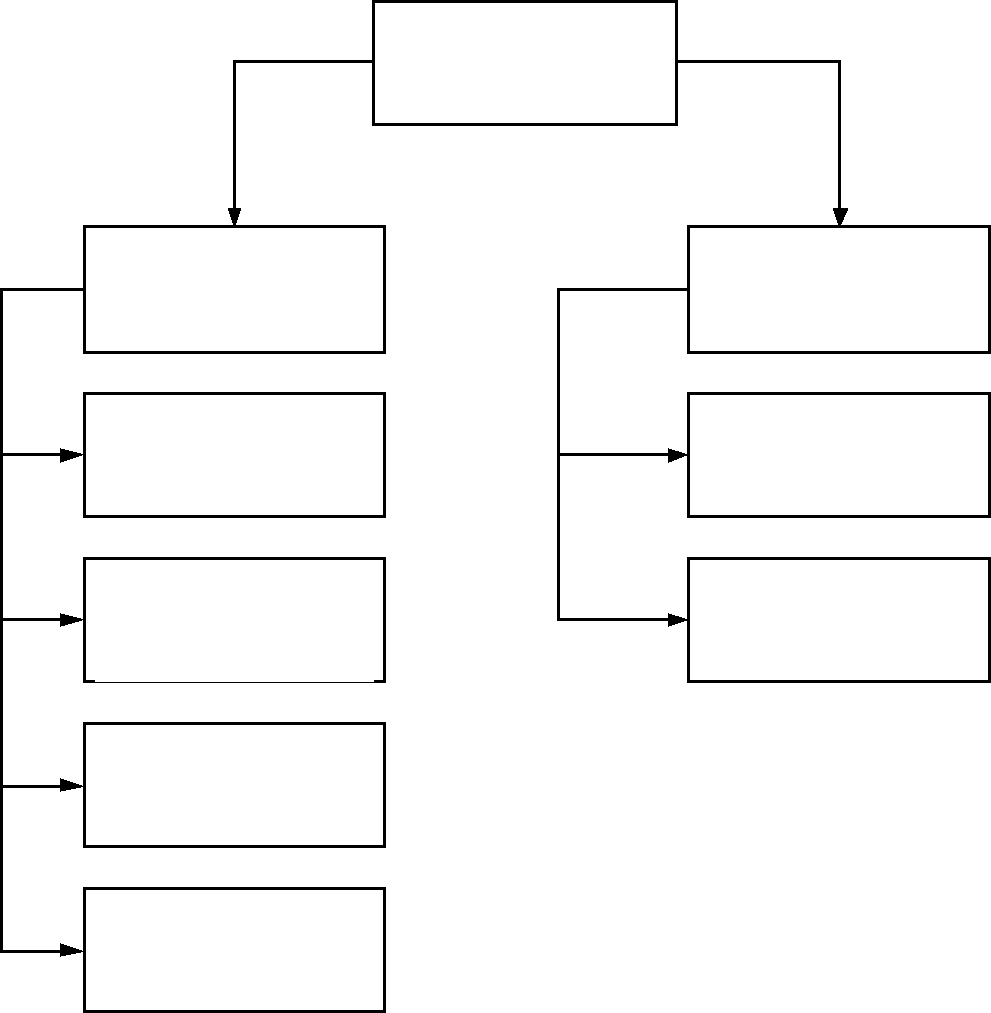
Рис. 2.1 Структура предметной области
|
Возглавляет предметную область её администратор (директор, начальник, ректор). Предметная область состоит из фрагментов (рис 2.1). Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объект, а также множеством пользователей, объединяемые единым взглядом на предметную область.
До недавнего времени автоматизировались отдельные процессы в рамках фрагментов предметной области, то есть разрабатывалось множество локальных приложений. При таком подходе одни и те же данные многократно представлялись в памяти ЭВМ, поскольку локальные приложения разрабатываются и эксплуатируются независимо друг от друга.
При переходе от автоматизации отдельных процессов предметной области к созданию автоматизированных информационных систем требуется не только увязка локальных приложений, но и качественно новый подход к организации данных. Этот подход состоит в использовании единого хранилища данных, тогда отдельные пользователи перестают быть владельцами тех или иных данных. Все данные накапливаются и хранятся централизованно.
В памяти ЭВМ создается динамически обновляемая модель предметной области, это хранилище или динамическую модель предметной области и называют базой данных.
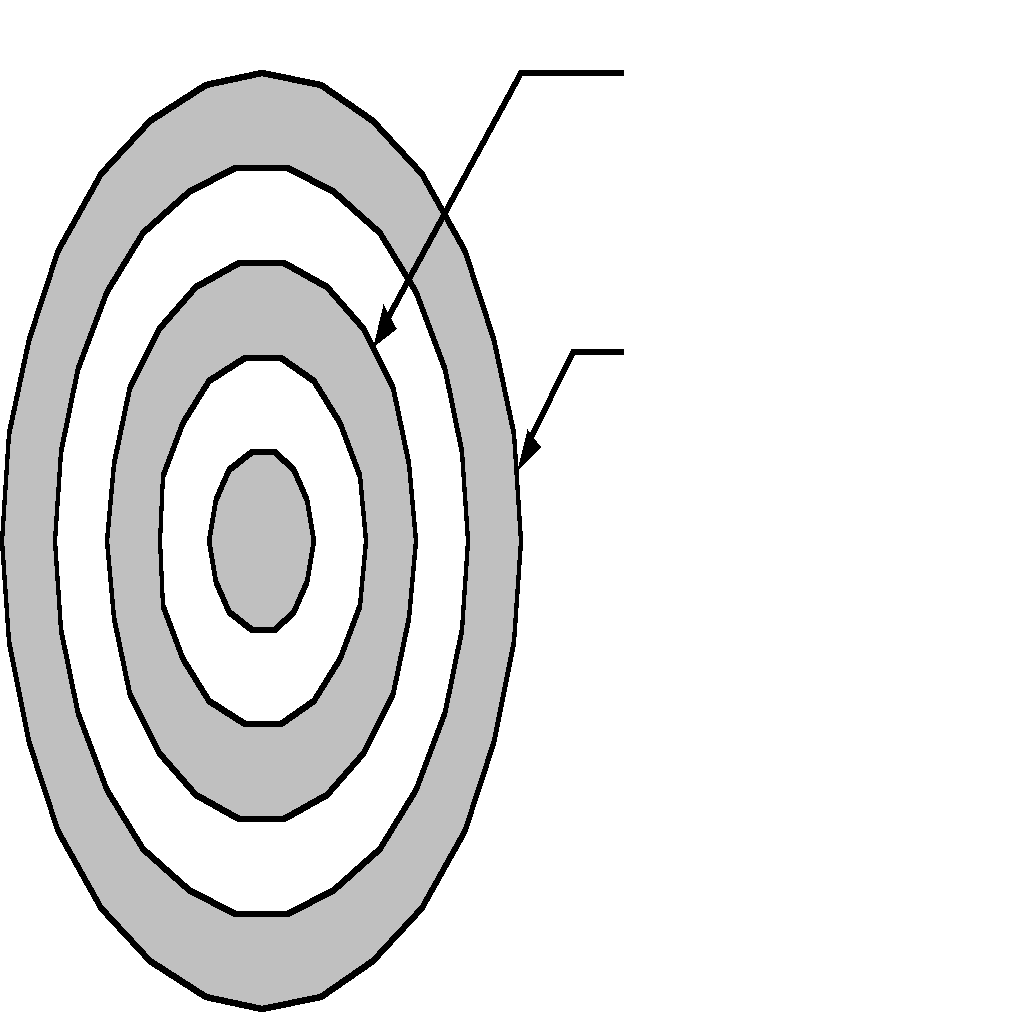
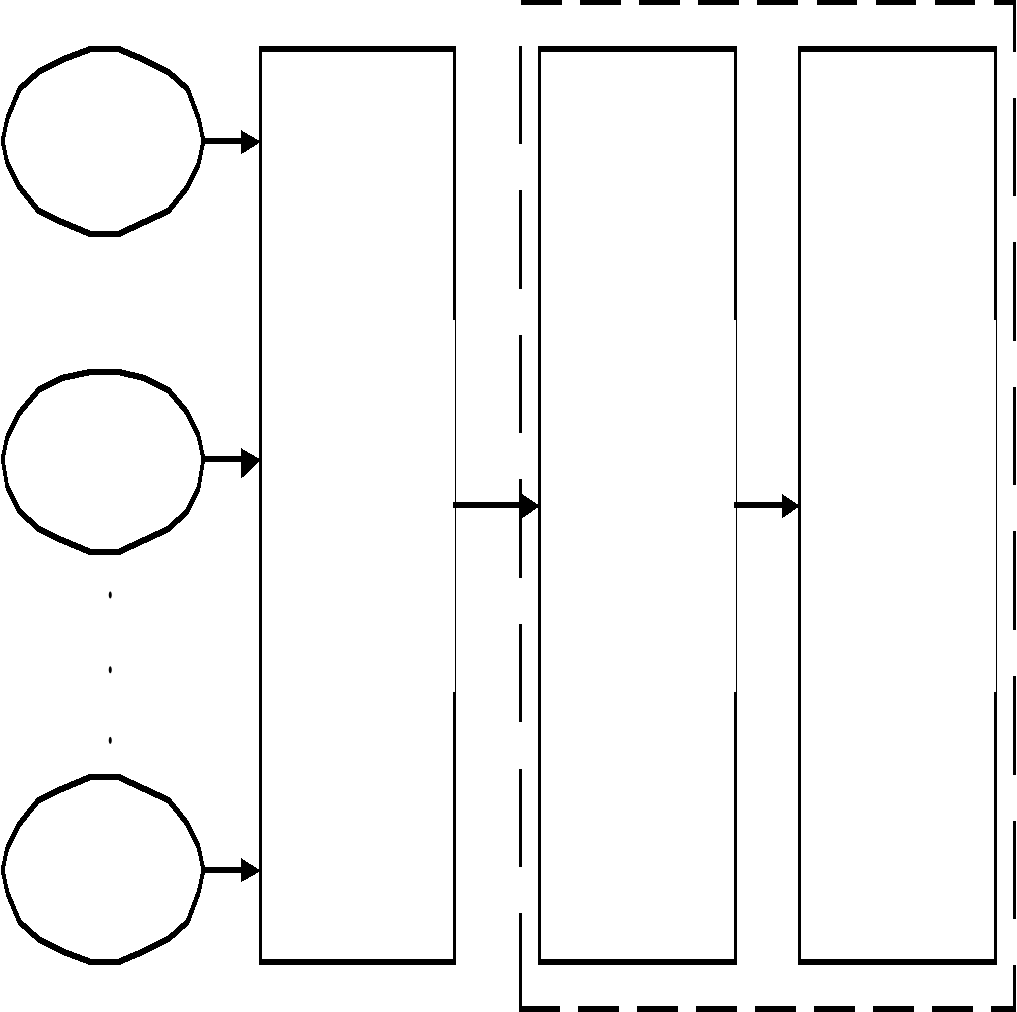
Пользователи информационных систем имеют возможность обращаться к интересующим их данным, а одни и те же данные могут быть представлены в разной форме в зависимости от потребности пользователя. Это обеспечивается использованием программной среды. Важным компонентом автоматизированной информационной системы является СУБД (система управления базой данных) (рис. 2.2).
СУБД – это набор программных модулей.
|
|
|
Рис. 2.2 Система управления базой данных (СУБД).
|
- Интеграция данных
Достоинства интеграции данных
- Интеграция обеспечивает синхронное обновление данных для всех приложений.
- Устраняется избыточность данных, что приводит к уменьшению требований к внешней памяти.
- Сокращение дублирования данных приводит к повышению достоверности данных и сокращается время на процедуру их обновления.
- Хранение данные в БД в унифицированном виде, благодаря этому разработчикам приложений не нужно задумываться над вопросами физического доступа к данным. Эти физические механизмы автоматически поддерживаются СУБД. Прикладной программист лишь подбирает подходящие типы данных и сообщает программе, в каком виде хочет их получить.
- Применение интегрированых БД обеспечивает высокий уровень независимости приложений (т.е. конкретных задач обработки данных) от организации данных.
Проблемы, связанные с интеграцией данных
|
|
|
|
В случае нескольких локальных приложений, каждый владелец сам несет полную ответственность за свои данные.
|
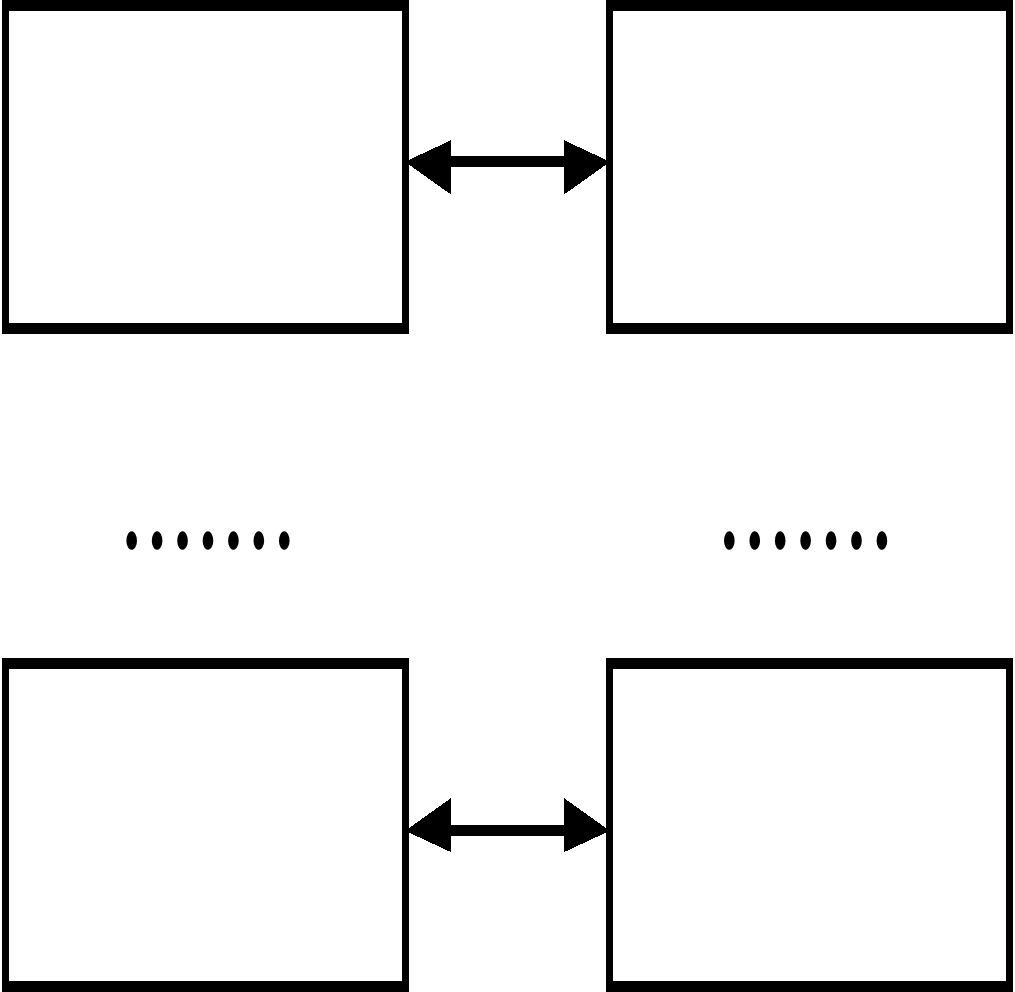
В случае глобальной базы данных владельцы данных становятся пользователями, а всю ответственность за целостность и достоверность данных несет администратор БД.
|
|
Рис. 2.3 Организация обслуживания БД.
|
Владельцы должны быть уверены в сохранности данных, а значит, возникает потребность в новом подразделении – в службе администратора БД.
- Функции администратора базы данных
- Защита данных от разрушения.
- Обеспечение достоверности данных.
- Обеспечение коллективного доступа.
- Анализ эффективности использования ресурсов БД.
Защита данных от разрушения при сбоях оборудования.
Этот вид защиты чаще всего называется обеспечением физический целостности данных. Основной способ защиты в данном случае - резервирование, т.е. периодическое копирование всех данных.
Защита от некорректных обновлений.
Некоторые обновления данных могут привести к неправильному использованию данных. Такая защита называется логической целостностью данных. Она обеспечивается:
- Ограничением доступа пользователя к данным. Отдельным пользователям может быть доступна только часть БД или часть некоторого файла.
- При описании данных некоторые методы СУБД позволяют задавать область допустимых значений и, при вводе данных система автоматически проверяет, принадлежит ли вводимое значение допустимой области.
- Кроме этого важно контролировать осмысленное сочетание значений данных, эта разновидность логической целостности называется семантической целостностью.
Защита данных от несанкционированного доступа.
Пользователю предоставляется доступ, который ограничен администратором БД за счет назначения привилегий.
Обеспечение коллективного доступа к данным.
Здесь возникают проблемы синхронизации доступа разных пользователей к одним и тем же данным. Проблемы возникают при обновлении данных. Если один пользователь обновляет какие-либо данные, некоторая часть данных должна быть заблокирована, например весь файл или отдельные записи. Для обеспечения корректного коллективного доступа используются алгоритмы типа двойной транзакции или писатель/читатель.
- Проектирование и развитие баз данных
При традиционном подходе проектирования информационных систем (ИС) (локальных приложений) организация БД диктуется потребностями конкретных пользователей, отсюда серия локальных приложений. С переходом к глобальным БД возникает новая проблема – разработка структуры данных, определение ограничения целостности и др. проблемы. Со временем БД несомненно потребует развития. Это произойдет в силу неизбежных изменений предметной области, а так же возрастающих потребностей пользователя. Стоимость соответствующих изменений БД во многом определяется качеством проектирования БД, и возможностью использования СУБД. Гибкая система позволяет избежать сложных реконструкции, при развитии и модификации БД.
- Архитектура информационной системы
- Пользователи информационной системы
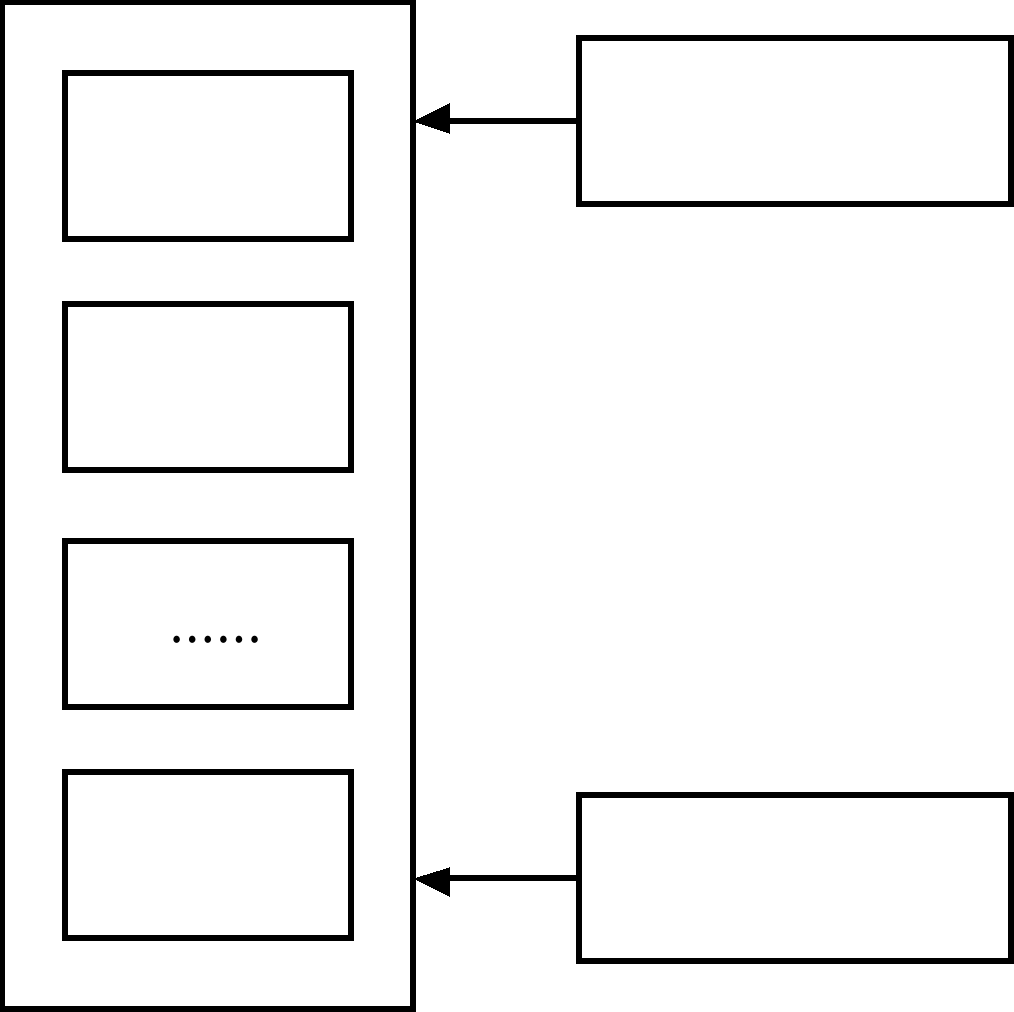
Пользователей информационной системы можно разделить на две группы: внутренних и конечных (рис. 3.1). Внутренние пользователи разрабатывают и поддерживают правильное функционирование информационной системы, а конечные пользователи - это те пользователи, ради которых и создается информационная система.
|
|
|
Рис. 3.1 Пользователи базы данных.
|
- На стадии проектирования администратор БД выступает как идеолог и конструктор системы, руководит работами по созданию программного окружения БД. На стадии эксплуатации администратор – ответственное лицо за функционирование БД. Основная задача администратора БД при эксплуатации – защита данных от разрушения, обеспечения корректного группового доступа и анализ эффективности использования ресурсов информационной системы.
- Администратор функциональных подсистем совместно с администратором БД определяет алгоритмы обработки данных.
- Системные программисты выполняют генерацию СУБД, следят за ее функционированием, разрабатывают дополнительные модули СУБД по заказу администратора.
- Задача прикладных программистов – разработка программной среды, т.е. прикладных программ.
- Косвенные конечные пользователи не общаются с ЭВМ непосредственно, они формулируют свои запросы службе администратора БД, а затем получают свои ответы на бумаге, но прежде этот ответ интерпретируется специалистами.
- Прямые конечные пользователи общаются с ИС в интерактивном режиме. Часть из них умеет обращаться к заранее разработанным приложениям и понимать получаемые ответы, другие умеют самостоятельно разрабатывать новые приложения.
Современные СУБД обладают средствами, ориентированными на конечных пользователей, которые могут разрабатывать новые приложения самостоятельно, не прибегая к услугам прикладных программистов.
- Уровни представления информационной системы.
С информационной системой работают пользователи различных категорий.
Для конечных пользователей информационная система – это хранилище информации, средство получения ответов на вопросы, возникающие в результате трудовой деятельности.
Для внутренних пользователей информационная система предоставляется в виде программных файлов и файлов данных.
Прикладные программисты оперируют файлами, записями, полями и т.д., а системные занимаются внутренним представлением данных, т.е методами физического хранения и способами доступа к данным. Можно сказать, что информационная система (ИС) имеет несколько уровней представления (рис. 3.2):
Начальный уровень
Соответствует представлениям о предметной области (ПО) конечных пользователей. Он называется уровнем локальных пользовательских представлений.
Инфологический уровень
Он представляет собой интеграцию локальных пользовательских представлений, и соответствует взгляду на предметную среду администратора БД. Администратор видит все фрагменты, все возможные связи между ними, в то время как конечный пользователь видит только ограниченные фрагменты предметной области (ПО).
Эти два уровня существуют в независимости от того, какая СУБД будет использоваться при создании информационной системы (ИС).
Концептуальный уровень
Соответствует представлению о ПО администратора БД как о совокупности файлов данных, т.е. отражает логическую организацию хранящихся в ИС данных о ПО. Этот уровень очень похож на инфологический, но его отличие состоит в том, что он ориентирован на конкретную СУБД. Описание БД на концептуальном уровне задается на языке описания данных, используемого в СУБД.
Внутренний уровень
Данный уровень рассматривает представление данных в памяти ЭВМ, а также способы доступа и хранения данных.
|
|
|
Рис. 3.2 Уровни представления информационной системы.
|
- Сетевые базы данных
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
- Структура данных сетевой модели
Основные понятия сетевых баз данных - элемент, агрегат, запись (группа), групповое отношение, база данных.
Элемент данных представляет собой наименьшую единицу структуры данных, каждому элементу приписывается уникальное имя, по которому обращаются к этому элементу при обработке данных.
Агрегат данных – есть совокупность элементов или других агрегатов.
При описании БД каждому агрегату приписывается уникальное имя, по которому к агрегату можно обратиться, как к единому целому при обработке данных.
Пример: Адрес [индекс, город, улица, дом, квартира]
Запись – это агрегат, не входящий ни в какой другой агрегат. Это основная единица обработки БД.
Следует различать тип записи и экземпляр записи:
Тип записи определяет состав ее элементов и агрегатов.
Экземпляр записи – конкретная совокупность значений элементов, составляющих запись.
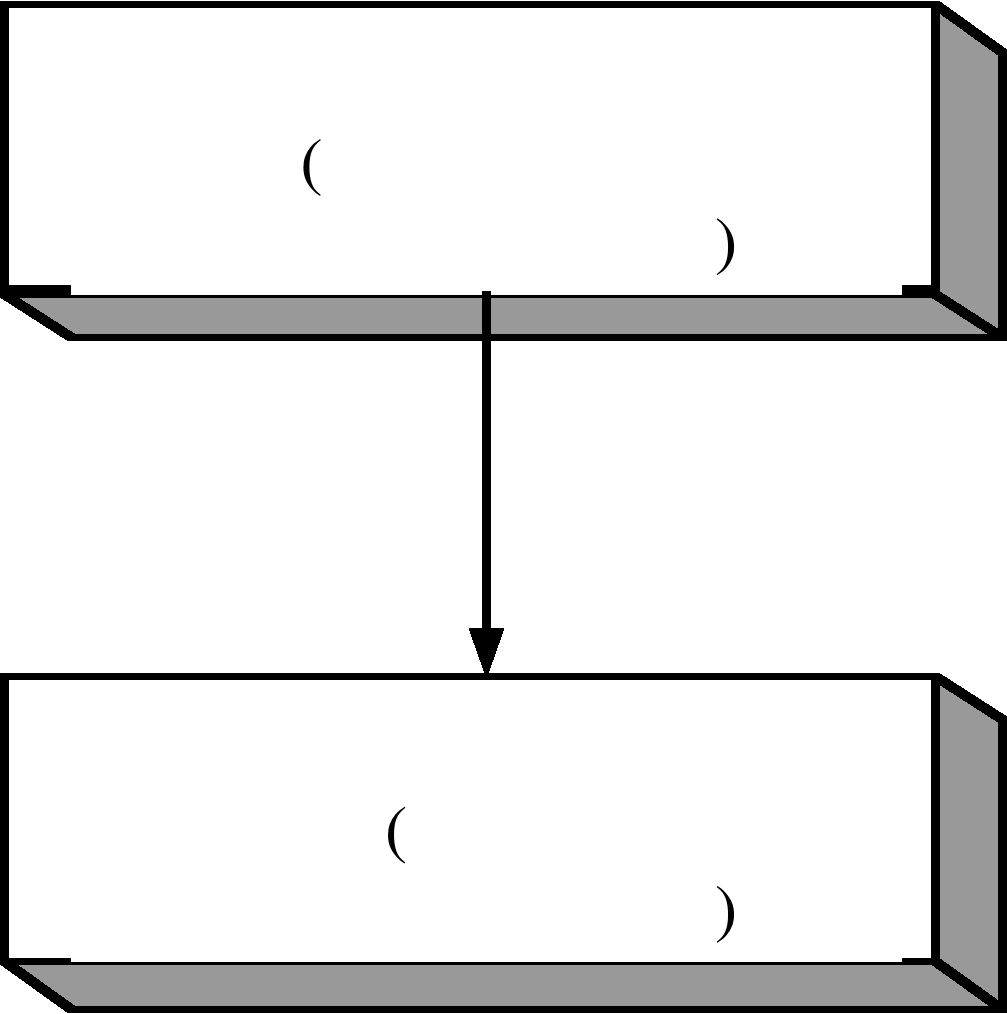
Если запись содержит несколько значений одного типа, то говорят, что в записи определен вектор (рис.4.1)
Если в каждом экземпляре записи длина вектора одинакова, то это вектор фиксированной длины (рис. 4.1), иначе – вектор переменной длины (например сведения о работах в записи жителя рис. 4.2).
|
Тип записи Житель
|

|
|

|
|
|
Вектор переменной длины
|
|
Рис. 4.1 Пример записи-вектора фиксированной длины.
|
|
Тип записи Сотрудник
|

|
|

|
|
|
Вектор фиксированной длины
|
|
Рис. 4.2 Пример записи-вектора переменной длины.
|
Один элемент или некоторая совокупность элементов могут быть описаны как первичный ключ записи. Значение первичного ключа каждой записи должно быть уникально.
Групповое отношение – это иерархическое (подчиненное) отношение между записями двух типов. Записи первого типа являются владельцами отношения, записи второго типа – членами отношения или подчиненными записями.
Групповое отношение графически изображается ориентированного, где дугами будут отношения, а вершинами типы записей. Такое изображение структуры БД называется диаграммой Бахмана. Также необходимо различать тип отношения и экземпляр отношения (рис.4.3) и (рис.4.4).
|
Диспансеризация
|
|
Поликлиника
(владелец отношения)
|
|
|
|
Житель
(член отношения)
|
|
Рис. 4.3 Тип отношения изображен с помощью диаграммы Бахмана.
|
Тип отношения – характеризуется именем отношения и определяет общие свойства для всех экземпляров данного типа отношений.
Экземпляр отношения – есть экземпляр записи-владельца отношения и множество (возможно пустое) подчиненных экземпляров записей-членов отношения.
Зарисуем пример по отношению к “Диспансеризации” (рис. 4.4):
|
Поликлиника №17
|
|

|
|
Рис. 4.4 Экземпляр отношения “Диспансеризация”.
|
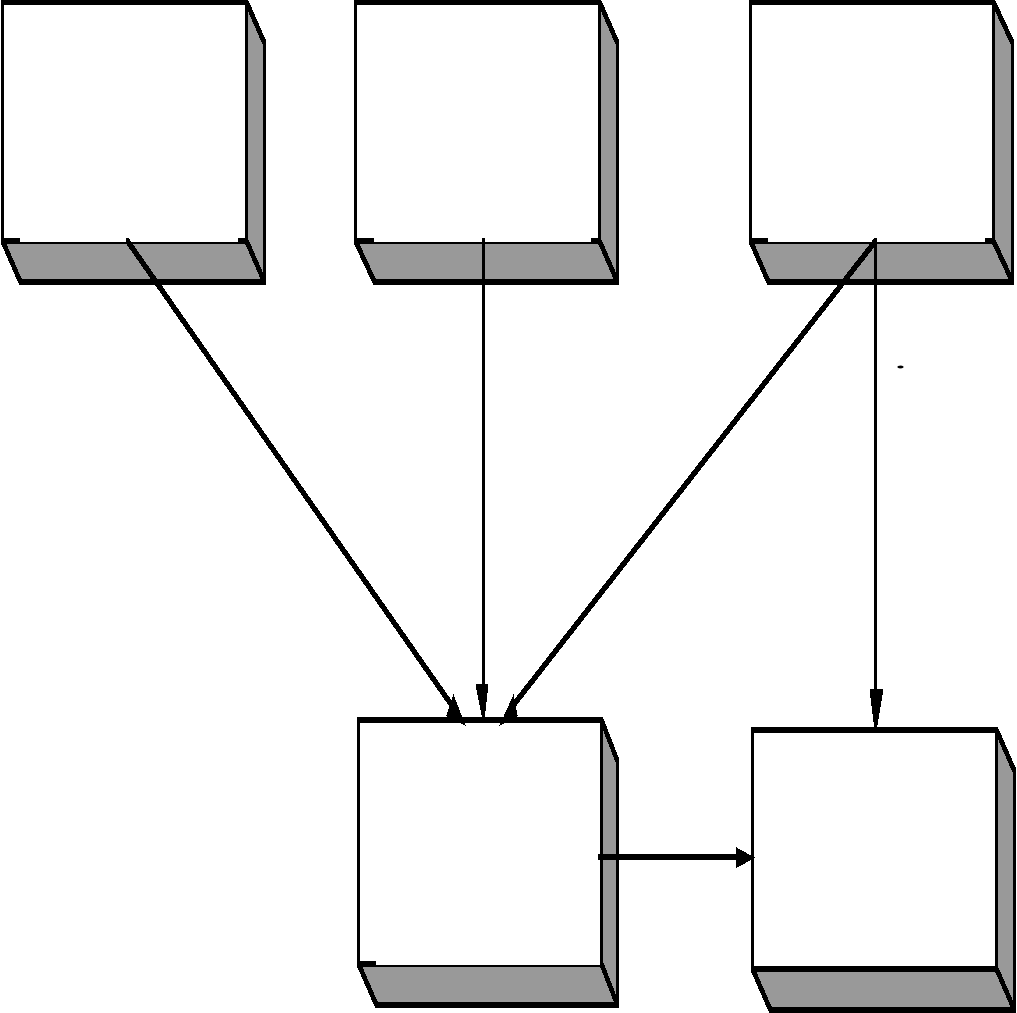
Предполагается, что экземпляр подчиненной записи может войти только в один экземпляр отношений одного типа (т.е. Иванов может стоять на учете только в поликлинике №17). Один и тот же тип записей может быть участником нескольких отношений, таким образом, в одних отношениях тип записи может быть владельцем, а в других – подчиненным (рис. 4.5).
|
|
|
Рис. 4.5 Один тип записи участвует в нескольких отношениях.
|
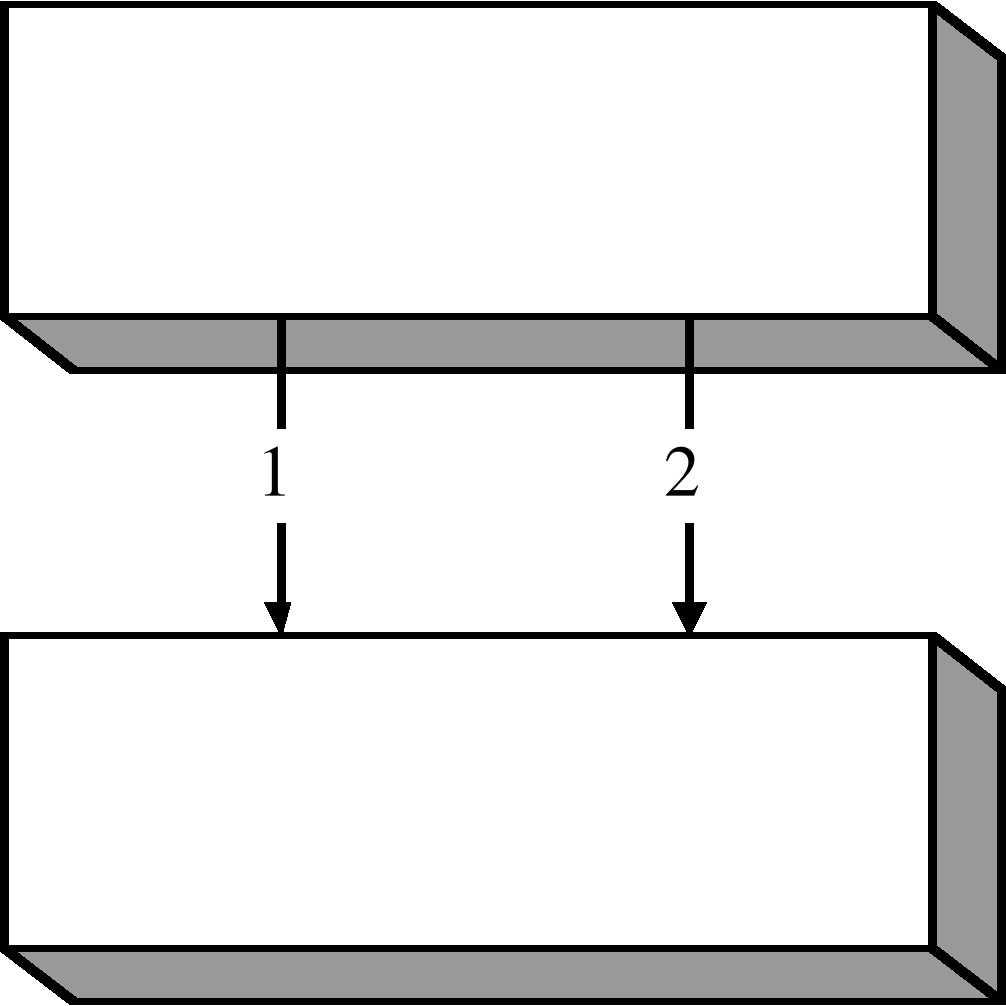
Сетевая модель данных позволяет устанавливать несколько одинаково направленных групповых отношений между двумя типами записей (рис. 4.6)
Из рисунка видно, что здесь два типа отношений – это отношение “основная работа” (1) и отношение “совместительство” (2).
Каждой организации соответствует два списка рабочих – это список основных рабочих и список совместителей. С другой стороны, каждый житель может быть связан с двумя организациями.
|
|
|
Рис. 4.6 Нескольких групповых отношений в сетевой модели данных.
|
Каждый тип группового отношения характеризуется следующими признаками.
- Способы упорядочения подчиненных записей;
- Режим включения подчиненных записей;
- Режим исключения подчиненных записей.
- Способы упорядочения подчиненных записей
Каждый экземпляр группового отношения можно рассматривать как совокупность записи владельца и списка соответствующих записей-членов. Записи-члены в списке могут быть упорядочены по-разному. Различают следующие способы:
- произвольный;
- хронологический – списки в записи располагаются в последовательности поступления их в БД, такие списки называются очереди, т.е. всякая новая запись помещается в конец списка;
- обратно хронологический – новая запись размещается в начале списка (стек, магазин);
- сортировочный, в этом случае в типе подчиненной записи выбирается ключ упорядочения, и место новой записи определяется по ключу.
- Режим включения подчиненных записей
Различают два режима включения подчиненных записей автоматический и ручной.
- Автоматический режим – подчиненная запись включается в групповое отношение одновременно с включением её в БД. Другими словами невозможно внести в БД запись, чтобы она автоматически не была закреплена за владельцем. В этом случае экземпляр-владелец должен быть помещен раньше подчиненного экземпляра в БД.
- Ручной режим – позволяет занести подчиненную запись в БД и не включать её немедленно в экземпляр группового отношения.
- Режим исключения подчиненных записей.
Режим исключения подчиненной записи зависит от класса членства записи.
Принято выделять три класса членства подчиненных записей в групповом отношении.
- Фиксированное членство – подчиненная запись жестко закрепляется за записью-владельцем и не может существовать без неё. В этом случае исключить запись из некоторого экземпляра-отношения можно только исключив её из БД. Эту запись нельзя переключить на другого владельца или оставить без владельца.
- Обязательное членство – каждая подчиненная запись, будучи однажды включенной в групповое отношение впредь будет всегда связана с какой-либо записью-владельцем. Допускается переключение записи к другому владельцу, но недопустимо существование записи без владельца. Для удаления записи владельца необходимо, чтобы она не имела подчиненных с обязательным членством. Такие подчиненные записи следует предварительно удалить либо переключить в другой экземпляр этого отношения.
- Необязательное членство – позволяет исключить подчиненную запись из группового отношения, но сохраняя её в БД, не прикрепляя к другому владельцу. При удалении записи-владельца, ее подчиненные члены сохраняются в БД, не участвуя более в этом отношении. В дальнейшем они снова могут быть включены в это отношение.
- Операции над данными в сетевой модели.
- Заполнить – позволяет занести в БД новую запись и автоматически включить эту запись в групповое отношение, где она объявлена подчиненной с автоматическим режимом включения.
- Включить в групповое отношение - позволяет существующую запись связать с записью-владельцем.
- Переключить – дает возможность изменить владельца в том же групповом отношении.
- Обновить – позволяет изменить значение элементов существующей записи. Перед обновлением существующая запись должна быть извлечена из БД.
- Извлечь Эта операция имеет несколько модификаций:
- последовательное извлечение – если сейчас извлечена запись, то эта операция извлекает следующую запись;
- извлечение по ключу – какая бы запись не была извлечена, сейчас команда извлекает запись с заданным ключом;
- извлечение с использованием отношений – извлечь подчиненного данной записи или извлечь владельца данной записи.
- Удалить – позволяет убрать из БД ненужную запись, если удаляемая запись владелец, анализируется класс членства подчиненных записей. Обязательные члены должны быть откреплены от этого владельца, фиксированные будут удалены вместе с владельцем, а необязательные останутся в БД.
- Исключить из группового отношения – позволяет разорвать связь между записью владельцем и подчиненной записью, сохраняя обе в БД.
- Ограничения целостности в сетевой модели.
Описывая конкретный тип группового отношения, администратор БД определяет, допустимы или нет экземпляры с одинаковыми значениями ключей, а также направление упорядочения (по возрастанию или по убыванию). Если ключом является фамилия, дублирование разрешено, а если – номер паспорта – нет, в таком случае информационная система должна препятствовать размещению в БД тождественных записей.
Таким образом, признак отношения и способ упорядочения позволяют создать ограничение целостности данных; одни и те же записи, являясь подчиненными в разных отношениях, могут быть упорядочены различными способами
В сетевой модели обеспечивается только поддержание целостности по ссылкам (владелец отношения - член отношения). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей.
- Иерархические базы данных
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много таких баз данных, что создает существенные проблемы с переходом, как на новую технологию БД, так и на новую технику.
- Структура данных иерархической модели
Структура данных как и в сетевой модели, определяется терминами: элемент данных, агрегат данных, запись, групповое отношение, база данных.
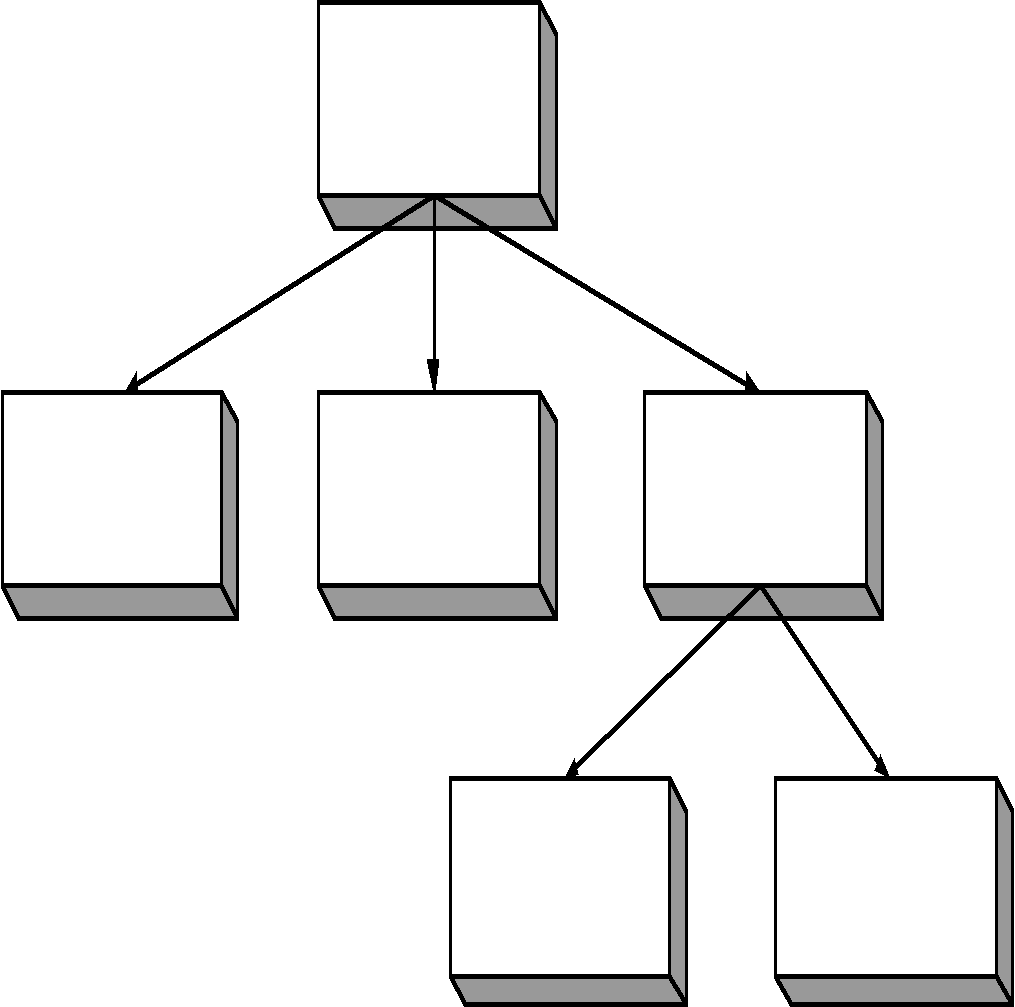
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Для графического изображения также удобно использовать диаграммы Бахмана. Отличительная черта для иерархических баз данных – ее диаграмма Бахмана будет деревом (рис. 5.1).
|
|
|
Рис. 5.1 Диаграмма Бахмана иерархической базы данных.
|
Очевидно, что количество деревьев в БД определяется числом корневых записей. Групповые отношения в иерархической модели не именуются, поскольку они определяются парой типов записей. Владелец именуется исходной записью, а член группового отношения – подчиненной.
К любой записи существует единственный путь от корневой записи. Этот путь называется иерархическим.
Для упорядочивания подчиненных записей в экземплярах групповых отношений могут использоваться разные способы (наиболее часто употребляемый - сортировка по возрастающему значению ключа).
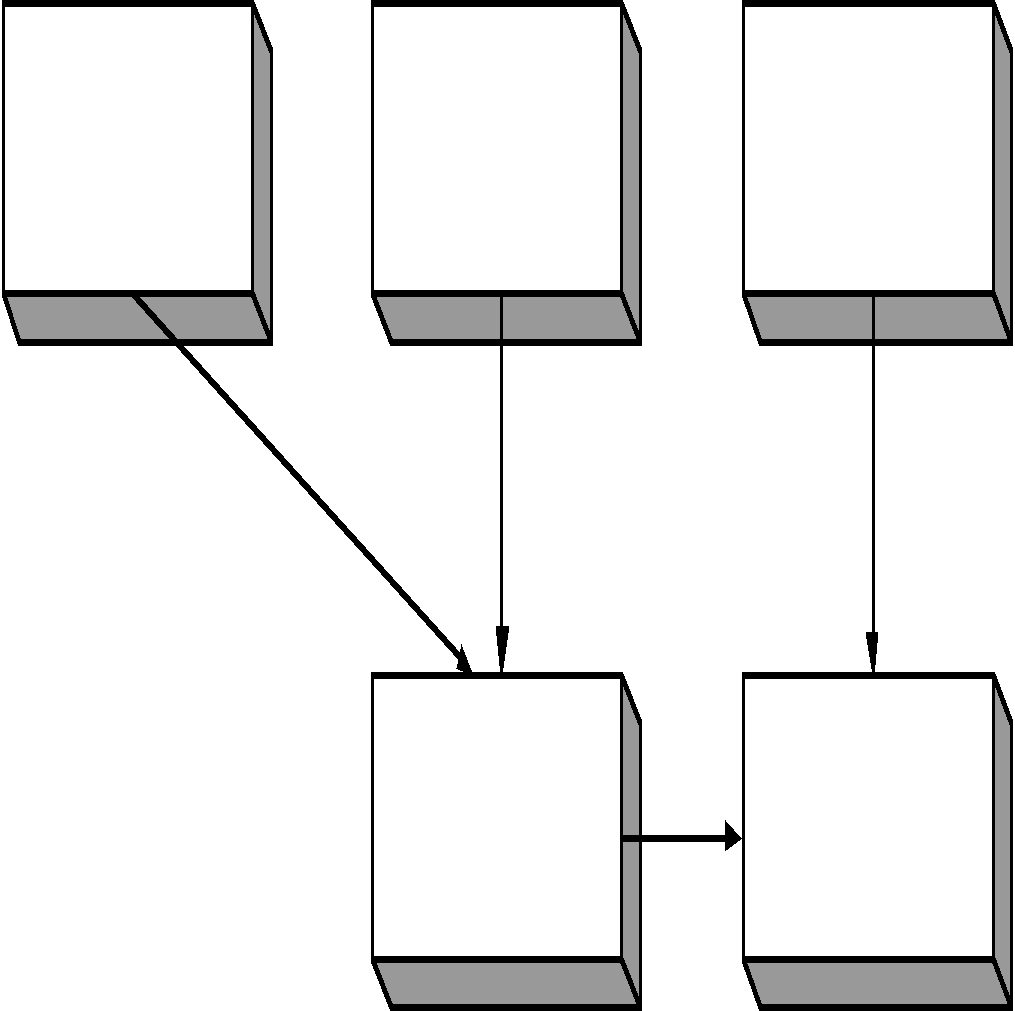
Экземпляры корневых записей должны иметь уникальные значения ключей в рамках группового отношения. Каждой записи можно поставить в соответствие полный сцепленный ключ – совокупность всех ключей от корневой записи до данной. Любую сетевую структуру можно представить иерархической моделью, при этом сетевая структура подвергается преобразованию (рис. 5.2).
|
|
|
Сетевая модель
|
|

|
|
Иерархическая модель
|
|
Рис. 5.2 Преобразование сетевой модели в иерархическую.
|
Все сведения о жителе, хранящиеся в одной записи “житель”, распределены по трем записям. Запись “Пациент” - содержит медицинские сведения, “Работник” - производственные данные, “Вкладчик” -банковские данные. Часть данных обязательно дублируется. Пример: паспортные данные, такие записи называют парными. Ответственность за поддержание соответствия между парными записями ложиться на пользователя, модель данных этого не обеспечивает. Для внесения группового отношения в иерархическую модель должен быть включен режим автоматического включения.
- Операции над данными в иерархической модели
- Запомнить – позволяет занести в БД новые записи. Для корневой записи необходим уникальный ключ. Система не допускает хранение в БД двух корневых записей с идентичными значениями ключей. Запись можно запомнить только при наличии экземпляра исходной записи.
- Обновить – изменение значений элементов предварительно извлеченной записи, ключевые значения обновляться не должны.
- Удалить – операция служит для исключения из БД некоторой записи и всех подчиненных ей.
- Извлечь Эта операция имеет несколько модификаций:
- извлечь корневую запись по ключу;
- извлечь корневую запись последовательно.
Всякая обработка БД начинается с какой-либо корневой записи. Дальнейшая обработка некорневых записей осуществляется по иерархическому пути.
|

|
Для движения по структуре служит операция извлечь следующего, т.е. понимается в смысле левостороннего обхода дерева.
Пример: для дерева изображенного на рисунке 5.3, левосторонний обход вершин следующий: A, B, C, D, E, F. Операция извлечь допускает задание условий выборки.
Пример: выбрать только мужчин в картотеке поликлиники.
|
|
Рис. 5.3 Левосторонний обход дерева.
|
|
- Ограничения целостности в иерархической модели.
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разные иерархии.
- Реляционные базы данных
Реляционная модель предложена сотрудником компании IBM Е.Ф.Коддом в 1970 г. В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название “реляционная” происходит от английского relation – “отношение”).
Домен - это семантическое понятие, которое можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
- Домен имеет уникальное имя (в пределах базы данных).
- Домен определен на некотором простом типе данных или на другом домене.
- Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена.
- Домен несет определенную смысловую нагрузку.
Например, домен D, имеющий смысл “возраст сотрудника” можно описать как следующее подмножество множества натуральных чисел:
D={nєN: n18 and n60}
Основное значение доменов состоит в том, что домены ограничивают сравнения. Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов.
Кортежи – это упорядоченная совокупность элементов доменов.
Математическое описание отношения :
пусть даны множества D1,D2,…,Dn – домены и существует ряд кортежей вида <d1, d2,…,dn>; di D, тогда декартовым произведением
D = D1•D2•D3•…•Dn называется множество всех возможных кортежей.
Пример:
D1 = { красный, синий }
D2 = { карандаш, фломастер, ручка }
D3 = { +, – }
|
D = D1•D2•D3 = {
|
<красный,
|
карандаш,
|
+>
|
|
|
<…
|
…
|
…>
|
|
|
<синий,
|
ручка,
|
–>}
|
Отношением R на доменах D1, D2,… ,D3 называется подмножество декартового произведения R D.
С точки зрения организации данных отношения удобно изображать в виде таблиц (таблица 6.1):
|
Таблица 6.1
|
|
Цвет
|
Предмет
|
Наличие
|
|
Красный
|
Карандаш
|
+
|
|
Красный
|
Карандаш
|
–
|
|
…
|
…
|
…
|
|
Синий
|
Ручка
|
–
|
Термины, которыми оперирует реляционная модель данных, имеют соответствующие “табличные” синонимы:
|
Таблица 6.2
|
|
Реляционный термин
|
Соответствующий “табличный” термин
|
|
База данных
|
Набор таблиц
|
|
Отношение
|
Таблица (файл)
|
|
Атрибут отношения
|
Наименование столбца таблицы (поле)
|
|
Кортеж отношения
|
Строка таблицы (запись)
|
|
Степень (-арность) отношения
|
Количество столбцов таблицы
|
|
Мощность отношения
|
Количество строк таблицы
|
Реляционная база данных есть совокупность отношений содержащих информацию о предметной области.
Степень отношения – это количество доменов (столбцов) образующих данное отношение, как правило, степень отношения в процессе жизненного цикла не меняется.
Мощность отношения – это количество кортежей отношения (количество строк в таблице). В общем случае она изменяется с течением времени.
Замечание.
По определению в отношении не может содержаться два идентичных кортежа. Многие реляционные СУБД допускают хранение файлов данных идентичных записей. Если в каком-либо приложении хранение идентичных записей недопустимо, программист должен позаботься об этом лично.
Расмотрим простую реляционную базы данных состоящую из трех таблиц (Таб. 6.3-6.5).
|
Таблица 6.3 “Поставщик”.
|
|
№ поставщика
|
Название поставщика
|
Город
|
|
2
|
Нормаль
|
Н.Новгород
|
|
1
|
Красная Этна
|
Н.Новгород
|
|
3
|
Уралмаш
|
Екатеринбург
|
|
4
|
Нормаль
|
Москва
|
|
Таблица 6.4 “Деталь”.
|
|
№ детали
|
Название детали
|
|
4
|
Болт 17
|
|
8
|
Шпильки
|
|
1
|
Гайка 22
|
|
2
|
Гайка 10
|
|
Таблица 6.5 “Поставщик – Деталь”.
|
|
№ поставщика
|
№ детали
|
Количество
|
|
1
|
1
|
20
|
|
1
|
2
|
10
|
|
2
|
1
|
7
|
|
3
|
8
|
20
|
БД содержит три типа информации.
- Информация о поставщиках деталей на предприятие (таблица 6.3):
номер поставщика;
наименование детали;
название города.
- Информация о деталях, используемых на предприятии (таблица 6.4):
номер детали;
наименование детали.
- Информация о номере и количестве поступления деталей от каждого поставщика (таблица 6.5)
Каждое отношение храниться в отдельном файле. Структура файла, хранящего отношение проста, то есть все записи имеют одинаковый формат.
Первичный ключ - это атрибут или набор атрибутов, значение которых однозначно указывают на конкретный кортеж отношения. Первичный ключ должен быть минимальным набором атрибутов.
Число отношений в БД и конкретные атрибуты, приписываемые каждому отношению определяются в процессе проектирования БД, который может быть довольно продолжительным. После проектирования создание БД средствами СУБД может пойти достаточно быстро.
В таблице 6.6 описаны типы данных для атрибутов БД “Поставщики и детали”.
|
Таблица 6.6 Типы Атрибутов.
|
|
Название атрибута
|
Тип атрибута
|
|
Пном
|
Числовой (3)
|
|
Пназ
|
Символьный(16)
|
|
Гор
|
Символьный(15)
|
|
Дназ
|
Символьный(10)
|
|
Штук
|
Числовой (5)
|
|
Дном
|
Числовой (5)
|
Отношения с указанными первичными ключами для данной БД:
|
Поставщик
|
(Пном, Пназ, Гор)
|
|
Деталь
|
(Дном, Дназ)
|
|
Поставщик-Деталь
|
(Пном, Дном, Штук)
|
Результатом проектирования является концептуальная модель БД.
- Цели проектирования баз данных
Наиболее важными целями проектирования являются:
- Хранение всех необходимых данных в БД, т.е. централизация данных;
- Исключение избыточности данных;
- Уменьшение количества отношений в БД;
- Нормализация отношений для решения проблем, связанных с обновлением или удалением данных.
Первым шагом в процессе проектирования является определение перечня атрибутов (столбцов), которые должны храниться в БД.
На втором шаге принимается решение о том, сколько будет отношений и какие атрибуты будут храниться в каких отношениях.
Необходимо различать дублирование данных и дублирование с избыточностью:
|
Таблица 6.7 Пример дублирования данных.
|
|
Табельный номер
|
Номер лаборатории
|
В таблице 6.7 Числа 12 и 17
дублируются, но не избыточны.
|
|
287
|
12
|
|
|
314
|
17
|
|
|
07
|
12
|
|
|
354
|
17
|
|
|
Таблица 6.8 Пример избыточного дублирования данных.
|
|
Табельный номер
|
Номер лаборатории
|
Телефон лаборатории
|
В таблице 6.8 телефон лаборатории, как видно, дублируется, и это уже избыточное дублирование.
|
|
287
|
12
|
2-17
|
|
|
314
|
17
|
4-41
|
|
|
007
|
12
|
|
|
|
354
|
17
|
|
|
Третий шаг – устранение избыточности. Полученный файл после устранения избыточности следует считать неудовлетворительным. Во-первых, пустых полей в файле следует избегать, в такой структуре хранения для записей необходимо иметь процедуру поиска. Во-вторых, могут возникнуть серьезные проблемы с удалением информации. Если удалить работника 287, то исчезнет и соответствующий номер лаборатории.
Лучший способ устранения – разбиение отношения
“Служащий – лаборатория – телефон” (таблица 6.8) на два:
“Лаборатория – телефон” (таблица 6.9)
“Служащий – лаборатория” (таблица 6.10)
|
Таблица 6.9 “Лаборатория-телефон”.
|
Таблица 6.10 “Служащий-лаборатория”.
|
|
Номер лаборатории
|
Телефон лаборатории
|
|
Табельный номер
|
Номер лаборатории
|
|
12
|
2-17
|
|
287
|
12
|
|
17
|
4-41
|
|
314
|
17
|
|
|
007
|
12
|
|
|
354
|
17
|
Разбиение отношений на два или несколько – рабочая процедура проектирования.
Разбиение отношения на два или более приводит к увеличению числа файлов, хранящихся в БД, что порождает проблемы по обработке данных, в данном случае – замедление.
Некоторые отношения порождают серьезные проблемы по удалению и обновлению информации. Проектировщик БД должен уметь находить такие отношения и “нормализовать” их. Нормализация осуществляется путем разбиения отношения на два или более мелких отношения по определенным правилам.
- Универсальные отношения
Отношение, которое включает в себя все атрибуты и содержащее все данные, предполагаемые хранить в БД, называется универсальным отношением.
Для небольших БД универсальное отношение может использоваться в качестве основного пункта при проектировании БД.
Предположим, что требуется разработать БД для начальника отдела.
Первый шаг проектирования – состоит в определении всех атрибутов, значения которых требуется хранить в БД. Эта информация берется у начальника отдела в процессе обсуждения будущей БД. В результате обсуждения выяснилось, что БД предназначена для подведения результатов работы каждого сотрудника отдела. Определился следующий набор атрибутов:
|
Сном
|
номер сотрудника (целое значение, уникальное),
|
|
Сфам
|
фамилия сотрудника (строковое значение),
|
|
Лном
|
номер лаборатории, в которой трудится данный сотрудник,
|
|
Тном
|
рабочий телефон сотрудника,
|
|
Проект
|
номер проекта, в разработке которого участвует сотрудник,
|
|
Квартал
|
период времени, в течение которого сотрудник участвовал в разработке проекта,
|
|
Вклад
|
численная характеристика, отражающая количество и качество работы с сотрудника в данном проекте и в данном квартале.
|
Второй шаг – составление таблицы по предварительно записанному набору атрибутов.
|
Таблица 6.11 Информация выбранная для хранения в базе данных
|
|
Сном
|
Сфам
|
Тном
|
Лном
|
Проект
|
Квартал
|
Вклад
|
|
289
|
Иванов
|
5-17
|
25АП
|
РКТ14
|
1990.3
|
3
|
|
|
|
|
|
Зенит
|
1990.3
|
5
|
|
|
|
|
|
ВКТ14
|
1990.4
|
2
|
|
|
|
|
|
ВТА2
|
1990.4
|
4
|
|
315
|
Николаев
|
8-29
|
4КТ
|
ВКТ14
|
1990.3
|
6
|
|
|
|
|
|
ВТА8
|
1990.4
|
7
|
|
|
|
|
|
ВКТ14
|
1990.4
|
8
|
|
429
|
Андреев
|
5-17
|
25АМ
|
Зенит
|
1990.3
|
2
|
|
|
|
|
|
ОТР6
|
1990.4
|
7
|
|
|
|
|
|
ВКТ14
|
1990.4
|
4
|
|
559
|
Зайцев
|
4-85
|
14ММ
|
ОВ77
|
1990.3
|
6
|
Хотя данные связаны в таблицу 6.11, она не может быть использована в реляционных базах данных, т.к. строки её содержат вектора значений атрибутов, что недопустимо для отношений. Такую таблицу, однако, очень легко преобразовать в отношение путем декомпозиции.
|
Таблица 6.12 Универсальное отношение базы данных “Начальник отдела”
|
|
Сном
|
Сфам
|
Тном
|
Лном
|
Проект
|
Квартал
|
Вклад
|
|
289
|
Иванов
|
5-17
|
25АП
|
РКТ14
|
1990.3
|
3
|
|
289
|
Иванов
|
5-17
|
25АП
|
Зенит
|
1990.3
|
5
|
|
289
|
Иванов
|
5-17
|
25АП
|
ВКТ14
|
1990.4
|
2
|
|
289
|
Иванов
|
5-17
|
25АП
|
ВТА2
|
1990.4
|
4
|
|
315
|
Николаев
|
8-29
|
4КТ
|
ВКТ14
|
1990.3
|
6
|
|
315
|
Николаев
|
8-29
|
4КТ
|
ВТА8
|
1990.4
|
7
|
|
315
|
Николаев
|
8-29
|
4КТ
|
ВКТ14
|
1990.4
|
8
|
|
429
|
Андреев
|
5-17
|
25АП
|
Зенит
|
1990.3
|
2
|
|
429
|
Андреев
|
5-17
|
25АП
|
ОТР6
|
1990.4
|
7
|
|
429
|
Андреев
|
5-17
|
25АП
|
ВКТ14
|
1990.4
|
4
|
|
559
|
Зайцев
|
4-85
|
14ММ
|
ОВ77
|
1990.3
|
6
|
В таблице 6.12 первичным ключом является значение трех полей Сном-Проект-Квартал. Полученная таблица – экземпляр правильного отношения.
- Проблемы, связанные с использованием единственного отношения
На первый взгляд, полученное универсальное отношение можно использовать в качестве единственного отношения проектируемой БД. Существует несколько причин, по которым не следует данное отношение использовать в качестве единственного. Различают три проблемы, связанные с использованием отношений и с выполнением определенных операций.
- проблема вставки;
- проблема обновления;
- проблема удаления.
Проблема вставки.
Если в отделе появляется новый сотрудник, то информацию о нем необходимо внести в БД. При этом значение атрибутов Проект, Квартал будут пустыми, а Вклад фактически равен нулю.
|
684
|
Сорокин
|
5-17
|
25AP
|
-
|
-
|
0
|
Как отмечалось ранее, пустых значений следует всячески избегать. Предположим, что в отношение включена новая запись о сотруднике Сорокине с пустыми полями и делается следующий запрос: “Напечатать список номеров и фамилий сотрудников, вклад которых не более 2”. В результате мы получим так называемый «черный список», в который попал и только что принятый на работу Сорокин.
|
289
|
Иванов
|
|
429
|
Андреев
|
|
687
|
Сорокин
|
В данном случае на простой вопрос мы получаем неверный ответ. Следовательно в нашей базе данных есть аномалии.
Проблема обновления.
В данном отношении большое количество избыточных данных, что чревато тем, что при исправлении данных исправлению подвергнется только одна часть данных. Рассматриваемое отношение характеризуется явной и неявной избыточностью.
Явная избыточность: фамилия сотрудника, телефон лаборатории, номер лаборатории могут появляться в отношении многократно. Если какой-либо сотрудник, на пример Иванов, перейдет на работу в другую лабораторию, соответствующие изменения необходимо сделать во всех записях, где хранится информация о данном сотруднике.
Неявная избыточность это (для нашего примера) когда один номер телефона имеют несколько сотрудников лаборатории. Например, номер 5-17 появляется в записях с фамилиями Иванов и Андреев.
Предположим возникает следующая ситуация: Начальник отдела встречает Иванова и спрашивает его – “Вы были вчера на вашем рабочем месте? Я весь день вам звонил и никто не брал трубку”. А Иванов ему отвечает “Отдел связи сменил вчера номер на 9-17”. Начальник отдела приходит к себе в кабинет и меняет во всех записях телефон Иванова на 9-17. Через некоторое время ему необходимо позвонить в лабораторию 25-AP, а телефон он не помнит, он составляет запрос вывести все не повторяющиеся записи со значением поля Лном равным 25-AP.
Ответ: 9-17 и 5-17. По какому телефону звонить если заранее известно, что в каждой лаборатории только один телефон.
Проблема удаления.
Предположим, что финансирование проекта 0В77 прекратилось и начальник удаляет все соответствующие записи. Так как в рассматриваемом отношении имеется только один кортеж с номером сотрудника 559 (это сотрудник Зайцев), который выполнял работу только по проекту 0В77, то произойдет удаление записи о сотруднике Зайцеве. Фактически мы теряем всю информацию о данном сотруднике. Рассмотренная проблема также является аномалией.
Таким образом, можно сказать, что универсальные отношения обладают аномальными свойствами и подлежат разбиению с целью ликвидации аномалий. Процесс разбиения с целью уменьшения вероятности возникновения аномалий называется декомпозицией.
- Функциональные зависимости
Пусть А и В набор атрибутов. Говорят, что В функционально зависит от А, если для каждого значения А существует только одно связанное с ним значение В.
Для конкретного отношения функциональные зависимости определяются путем анализа свойств всех атрибутов в отношении и заключения о том, как атрибуты соотносятся между собой.
- Номер сотрудника является уникальным. С номером в отношении может появиться только определенная фамилия. Отсюда получаем функциональную зависимость: СномСфам
- Если в каждой лаборатории только один телефон то получим зависимость ТномЛном.
- Так как каждый телефон обслуживает только одну лабораторию ЛномТном.
- Каждый сотрудник является работником только одной лаборатории. Тогда если в отношении появляется комбинация 315-4КТ, то вместе с 315 никакого другого значения Лном появиться не может следовательно получаем зависимость СномЛном. А так как в каждой лаборатории только один телефон можно также утверждать что, СномТном.
- Поскольку значение атрибута Вклад однозначно может быть определено, если заданы атрибуты Сном, Проект и Квартал, то получаем зависимость:
Сном, Проект, КварталВклад
|

|
Все шесть функциональных зависимостей изображены на рисунке 6.1 с помощью диаграммы функциональных зависимостей.
|
|
Рис. 6.1 Диаграмма функциональных зависимостей.
|
|
- Нормальные формы отношений
Первая нормальная форма
Атрибут называется простым, если значение его атомарно, т.е. неделимо (пример простых атрибутов: табельный номер сотрудника, фамилия сотрудника, оклад). Атрибут называется сложным, если его значение представляет собой объединение значений различных атрибутов (на Пример: атрибут Адрес [индекс, город, улица, дом, квартира]). Отношение называется отношением в первой нормальной форме, если все его атрибуты простые. Отношение “начальник отдела” находится в первой нормальной форме.
Вторая нормальная форма
Полная функциональная зависимость. Пусть А – это некоторый атрибут, Х – это набор атрибутов. Говорят, что А функционально полно зависит от Х, если Х А, Y А, где Y любое подмножество Х. Набор атрибутов Х называют детерминантом отношения. Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально полно зависит от возможного ключа. Так, отношение с зависимостью Сном, Лном, ТномСном не находится во второй нормальной форме.
Третья нормальная форма
Транзитивная зависимость. Пусть X, Y, Z – наборы атрибутов некоторого отношения.
Если XY, YZ но Y Х то XZ , тогда говорят что Z транзитивно зависит от X
Пример: транзитивной зависимости СномТном, ТномЛном СномЛном.
Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и каждый неключевой атрибут нетранзитивно зависит от ключа.
В общем случае отношение в третьей нормальной форме содержит аномалии, но если в отношении только один ключ и имеются зависимости только от ключа, оно будет свободно от аномалий.
Третья усиленная форма или нормальная форма Бойса–Кодда (НФБК)
Отношение находится в НФБК тогда и только тогда, когда отношение находится в третьей нормальной форме и каждый детерминант отношения является возможным ключом. Отношение, создаваемое для начальника отдела имеет четыре детерминанта:
|
Сном
|
|
Лном
|
|
Тном
|
|
Сфам, Проект, Квартал
|
Кодд доказал, что отношение в НФБК практически не содержит аномалий, поэтому на практике придерживаются приведения отношения в НФБК.
- Декомпозиция отношений
Декомпозиция получается приведением к получению двух отношений из одного.
Например, было R(X,Y,Z), а в результате декомпозиции получили два R1(X,Y), R2(Y,Z).
Декомпозиция аномального отношения выполняется следующим образом.
Пусть R – отношение, не находящееся в НФБК. Пусть aj зависит от ai (ai aj). Эта зависимость препятствует нахождению отношения в НФБК. Пусть ai – некоторый атрибут, детерминант, но не являющийся возможным ключем . Отношение R(a1,…,ai,…,aj) разбивают на два
R1 (a1,…,ai,…,aj-1) и R2(ai,aj)
Отношение R2 называется проекцией отношения R.
Декомпозиция считается выполненной правильно, если любой один и тот же запрос, примененный к исходному отношению и к полученным в результате декомпозиции отношениям, дает один и тот же результат.
Теория реляционных баз данных говорит, что результаты запроса будут совпадать, если декомпозиция выполнена способом, при котором соединение R1 и R2 дает в точности исходное соотношение R – это декомпозиция без потерь.
Если естественное соединение R1 и R2 в итоге дает больше кортежей, чем в R – то это декомпозиция с потерями.
Отсутствие потерь при декомпозиции отношения R(X,Y,Z) в R1(X,Y), R2(Y,Z) гарантируется при условии, что от общего атрибута (Y) функционально зависит хотя бы один атрибут из двух оставшихся.
|
Пример 1:
|
|
Таблица 6.13 R (X,Y,Z).
|
|
|
X
|
Y
|
|
|
|
Y
|
X
|
|
Y
|
Z
|
|
|
|
1
|
2
|
3
|
|
|
2
|
1
|
|
2
|
3
|
|
|
|
3
|
2
|
6
|
|
|
2
|
3
|
|
2
|
6
|
|
|
|
5
|
4
|
2
|
|
Y Х Y Z
|
|
Декомпозиция
|
|
|
|
|
Таблица 6.14 R1 (X,Y).
|
Таблица 6.15 R2 (X,Z).
|
|
X
|
Y
|
|
Y
|
Z
|
|
1
|
2
|
|
2
|
3
|
|
3
|
2
|
|
2
|
6
|
|
5
|
4
|
|
4
|
2
|
|
|
|
Соединение
|
|
Таблица 6.16 R3 (X,Y,Z).
|
|
|
|
X
|
Y
|
Z
|
|
|
|
1
|
2
|
3
|
|
|
|
1
|
2
|
6
|
лишний кортеж
|
|
|
3
|
2
|
3
|
лишний кортеж
|
|
|
3
|
2
|
6
|
|
|
|
5
|
4
|
2
|
|
|
|
|
Так как Y
|
|
X, Y
|
|
Z, то R R3.
|
|
|
|
Пример 2:
|
|
Если Y Z, то разбивая отношение R, получим, что R = R3.
|
|
Таблица 6.17 R (X,Y,Z).
|
|
|
X
|
Y
|
Z
|
|
Y
|
Z
|
Изменим строчку мешающую
|
|
|
1
|
2
|
3
|
|
2
|
3
|
зависимости Y Z
|
|
|
3
|
2
|
3
|
|
2
|
6
|
|
|
|
5
|
4
|
2
|
|
|
Декомпозиция
|
|
|
|
Таблица 6.18 R1 (X,Y).
|
Таблица 6.19 R2 (Y,Z).
|
|
X
|
Y
|
|
Y
|
Z
|
|
1
|
2
|
|
2
|
3
|
|
3
|
2
|
|
4
|
2
|
|
5
|
4
|
|
|
|
|
|
|
Соединение
|
|
Таблица 6.20 R3 (X,Y,Z).
|
|
|
X
|
Y
|
Z
|
|
|
1
|
2
|
3
|
|
|
3
|
2
|
3
|
|
|
5
|
4
|
2
|
- Избыточные функциональные зависимости. Правила вывода
Если зависимость заключает информацию, которая может быть получена из других зависимостей, то такую зависимость называют избыточной зависимостью.
Правила вывода применяются к списку функциональных зависимостей с целью избавиться от избыточных зависимостей.
Набор функциональных зависимостей, получаемый из исходного набора функциональных зависимостей удалением всех избыточных функциональных зависимостей с помощью правила вывода называется минимальным покрытием.
Избыточные функциональные зависимости следует удалять из набора по одной, каждый раз заново анализируя полученный набор функциональных зависимостей на присутствие в нем избыточных зависимостей.
Правило 1. Транзитивные зависимости
Транзитивная зависимость является избыточной (рис. 6.6).
|

|
|
Рис. 6.6 Правило 1.
|
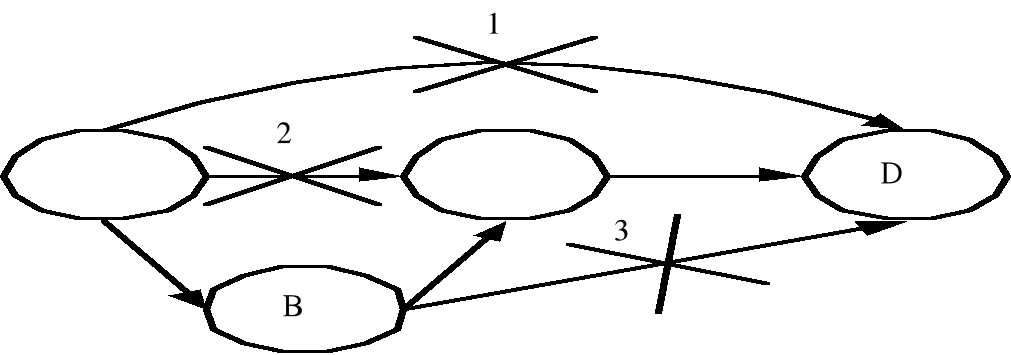
Транзитивные зависимости можно удалять, но только по одной (рис. 6.7):
|
|
|
Рис. 6.7 Удаление транзитивных зависимостей.
|
Первоначальные функциональные зависимости: AB, AC, AD, CD, BC , BD. Находим транзитивную зависимость, например: АD, и удаляем её. Затем снова анализируем ситуацию, и находим следующую избыточную функциональную зависимость (например: АС), удаляем её и так далее до тех пор, пока все транзитивные зависимости не будут удалены. В итоге получим
|

|
R1 (C,D) CD
R2 (B,C) BC
R3 (A,B) AB
|
|
Рис. 6.8 Отношения с удаленными транзитивными зависимостями.
|
Правило 2. Корректные, но избыточные зависимости
а) Если существует А В, то зависимость A,ZB – корректная, но избыточная.
б) Если существует АВ, то зависимость A,ZB,Z – корректная, но избыточная.
|
a)
|
|
б)
|

|
|
Рис. 6.9 Правило 2.
|
Правило 3. Объединение функциональных зависимостей
Объединение функциональных зависимостей.
Если АВ и АС, то АВ,С
|

|
a)
|

|
|
|
б)
|

|
|
Рис. 6.10 Правило 3: объединение функциональных зависимостей.
|
Правило 4. Декомпозиция функциональных зависимостей
Декомпозиция функциональных зависимостей.
Если АВ,С , то АВ и АС
|
|

|
|
Рис. 6.11 Правило 4: декомпозиция функциональных зависимостей.
|
Правило 5. Псевдотранзитивность
Если XY и Y,WZ то зависимость X,WZ, называется псевдотранзитивной и является избыточной функциональной зависимостью.
|
|
|
|
Рис. 6.12 Правило 5: Псевдотранзитивная зависимость.
|
Набор ФЗ, получаемый из исходного набора ФЗ удалением всех избыточных ФЗ с помощью правила вывода называется минимальным покрытием.
Избыточные ФЗ следует удалять из набора ФЗ по одной, каждый раз заново анализируя полученный набор ФЗ на присутствие в нем избыточных ФЗ.
Пример удаления избыточных зависимостей с помощью правил вывода
Для построения отношений базы данных произведем следующие действия:
- Из атрибутов предметной области сформируем универсальное отношение.
- Из универсального отношения выделим ряд функциональны зависимостей.
- Нарисуем диаграмму функциональных зависимостей.
- С помощью правил вывода проанализируем диаграмму функциональных зависимостей на наличие избыточных функциональных зависимостей.
- Удалим все избыточные зависимости по одной.
На рисунке 6.13 изображена диаграмма функциональных зависимостей универсального отношения.
|
|
A B,C
A K
A D
B,C D
B D
K C
|
|
Рис 6.13 Диаграмма функциональных зависимостей универсального отношения
|
|
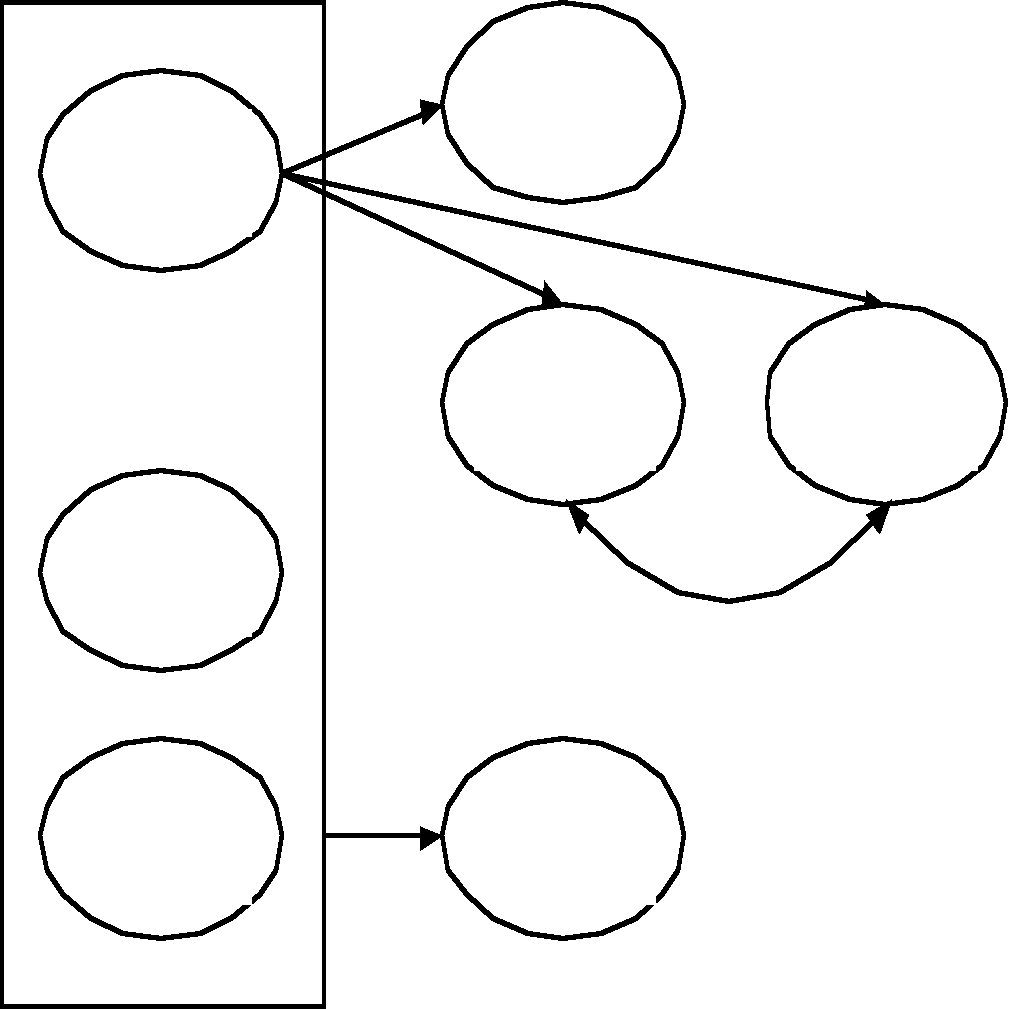
Шаг первый: Рассмотрим фрагмент
диаграммы универсального отношения.
|
По правилу 2 зависимость BC D является корректной, но избыточной. Производим ее удаление.
|
|
|
B,C D
B D
|

|
B D
|
|
Рис. 6.14 Фрагмент диаграммы B,C D, B D Рис. 6.15 Удаление избыточной зависимости B,C D
|
В результат действий первого шага получаем следующую диаграмму:
|
|
A B,C
A K
A D
B D
K C
|
|
Рис. 6.16 Диаграмма после удаления избыточной зависимости B,C D
|
|
Шаг второй: Рассмотрим фрагмент
диаграммы полученной на первом шаге.
|
По правилу 4 произведем декомпозицию зависимости A B,C на A B, A C
|
|

|
A B,C
|
|
A B
|
|
|
|
|
A C
|
|
Рис. 6.17 Фрагмент диаграммы A B,C Рис. 6.18 Декомпозиция A B,C на A B, A C
|
В результат действий второго шага получаем следующую диаграмму:
|

|
A B
A C
A D
A K
B D
K C
|
|
Рис. 6.19 Диаграмма после декомпозицию зависимости A B,C на A B, A C
|
|
Шаг третий:: Рассмотрим фрагмент диаграммы полученной на втором шаге
|
По правилу 1 зависимость A C является транзитивной и подлежит удалению.
|
|
|
A C
A K
K C
|
|
A K
K C
|
|
Рис. 6.20 Фрагмент диаграммы A C, A K, K C
|
Рис. 6.21 Удаление транзитивной зависимости A C
|
В результат действий третьего шага получаем следующую диаграмму:
|
|
A B
A D
A K
B D
K C
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 6.22 Диаграмма после удаление транзитивной зависимости A C
|
|
Шаг четвертый:: Рассмотрим фрагмент иаграммы полученной на третьем шаге
|
По правилу 1 зависимость A D транзитивная и подлежит удалению
|
|
|

|
|
A B
|
A B
|
|
A D
|
B D
|
|
B D
|
|
|
Рис. 6.23 Фрагмент диаграммы A B, A D, B D
|
Рис. 6.24 Удаление транзитивной зависимости A D
|
В результат действий четвертого шага получаем следующую диаграмму:
|
|
A B
A K
B D
K C
|
|
Рис. 6.25 Диаграмма после удаление транзитивной зависимости A D
|
|
После того как из диаграммы были удалены все избыточные зависимости, формируем следующие отношения:
|
|
R1 (B, D)
|
|
R2 (K, C)
|
|
R3 (A, B ,K)
|
- Общая схема проектирования баз данных методом декомпозиции
- Построение универсального отношения.
- Определение всех функциональных зависимостей, существующих между атрибутами универсального отношения.
- Удаление всех избыточных функциональных зависимостей.
- Определяем, находится ли отношение в НФБК, если да - проектирование закончить, если нет – отношение разбивается на два.
- Шаги 4 и 5 повторяются для всех отношений, полученных в результате декомпозиции, до тех пор пока все отношения не будут находиться в НФБК.
- Проектирование базы данных по предметной области “Начальник отдела”.
Возвратимся снова к примеру базы данных “Начальник отдела”.
|
|
|
Рис. 6.26 Универсально отношение R (Сном, Сфам, Тном, Лном, Проект, Квартал, Вклад)
|
Детерминанты не являющиеся возможными ключами:
Возможным ключом является Сфам, Проект, Квартал.
Универсальное отношенияе R (Сном, Сфам, Тном, Лном, Проект, Квартал, Вклад)
и не находится в НФБК и нуждается в декомпозиции.
Выявление функциональных зависимостей
В данном отношение содержаться следующие цепочки функциональных зависимостей:
Сном Лном Тном
Сном Тном Лном
Сном, Проект, КварталВклад
Декомпозиция универсального отношения
На рисунках 6.3-6.5 изображены диаграммы функциональных зависимостей отношений, полученых из универсального отношения в процессе его декомпозиции.
Производим декомпозицию отношения R (Сном, Сфам, Тном, Лном, Проект, Квартал, Вклад) на
R 1 (Лном, Тном) и R2 (Сном, Сфам, Лном, Проект, Квартал, Вклад).
|

|
Возможные ключи: Лном, Тном
Детерминанты: Лном, Тном
Отнонение находится в НФБК
|
|
Рис. 6.27 Отношение R 1 (Лном, Тном)
|
|

|
Возможные ключи: <Проект, Квартал, Вклад>
Детерминанты: <Проект, Квартал, Вклад>
Сном
Отношение не находится в НФБК.
|
|
Рис. 6.28 Отношение R2 (Сном, Сфам, Лном, Проект, Квартал, Вклад)
|
Произведем декомпозицию отношения R2 (Сном, Сфам, Лном, Проект, Квартал, Вклад) на
R3 (Сном, Сфам, Лном) и R4 (Сном, Проект, Квартал, Вклад).
В отношении R3 (Сном, Сфам, Лном) объединим зависимости Сном Сфам и Сном Лном в зависимость Сном Сфам, Лном.
|
|
Возможные ключи: Сном
Детерминанты: Сном
Отнонение находится в НФБК
|
|
Рис. 6.29 Отношение R3 (Сном, Сфам, Лном).
|
|
|
Возможные ключи: <Проект, Квартал, Вклад>
Детерминанты: <Проект, Квартал, Вклад>
Отнонение находится в НФБК
|
|
Рис. 6.30 Отношение R4 (Сном, Проект, Квартал, Вклад).
|
Таким образом, в результате декомпозиции мы получили следующие отношения:
R2 (Лном, Тном) – находится в НФБК
R3 (Сном, Сфам, Лном) – находится в НФБК
R4 (Сном, Проект, Квартал, Вклад) – находится в НФБК
Таблицы 6.21-6.23 демонстрируют отношения R2, R3, R4 полученные в результате декомпозиции универсального отношения R.
|
Таблица 6.21 R2.
|
Таблица 6.22 R3.
|
|
Таблица 6.23 R4.
|
|
Лном
|
Тном
|
|
Сном
|
Сфам
|
Лном
|
|
Сном
|
Проект
|
Квартал
|
Вклад
|
|
25АП
|
5-17
|
|
289
|
Иванов
|
25АП
|
|
289
|
РКТ14
|
1990,3
|
3
|
|
4КТ
|
8-29
|
|
315
|
Николаев
|
4КТ
|
|
289
|
Зенит
|
1990,3
|
5
|
|
14ММ
|
4-85
|
|
429
|
Андреев
|
25АМ
|
|
289
|
ВКТ14
|
1990,4
|
2
|
|
|
|
|
559
|
Зайцев
|
14ММ
|
|
289
|
ВТА2
|
1990,4
|
4
|
|
|
|
|
|
|
|
|
315
|
ВКТ14
|
1990,3
|
6
|
|
|
|
|
|
|
|
|
315
|
ВТА8
|
1990,4
|
7
|
|
|
|
|
|
|
|
|
315
|
ВКТ14
|
1990,4
|
8
|
|
|
|
|
|
|
|
|
429
|
Зенит
|
1990,3
|
2
|
|
|
|
|
|
|
|
|
429
|
ОТР6
|
1990,4
|
7
|
|
|
|
|
|
|
|
|
429
|
ВКТ14
|
1990,4
|
4
|
|
|
|
|
|
|
|
|
559
|
ОВ77
|
1990,3
|
6
|
Проверка на наличие аномалий в отношениях базы данных “Начальник отдела”
Присутствуют ли в этой базе данных аномалии вставки, удаления или обновления ?
Проверяем базу данных запросами взяв их из темы 6.3.
Вставка. На работу в лабораторию 25АР приняли Сорокина, его номер 687. Эта информация помещается в отношение R3 <687,Сорокин, 25АР>. Если теперь сделать запрос составить список сотрудников, вклад которых равен или меньше 2. Так как запрос будет обращен к отношению R4 будут выбранны сотрудники с табельными номерами 429, 289. После соединения таблиц мы получим ответ: Иванов и Андреев имели вклады в проекты меньше или равные трем.
Сорокина здесь нет, таким образом аномалия вставки, присутствующая в исходном отношении, устроена в результате декомпозиции.
Обновление. В исходном отношении возникла проблема при изменении телефона у Иванова на 9-17. Теперь при изменении телефона будут производится следующие действия: если мы сгенерируем запрос: из отношения R3 по табельному номеру Иванова будет определен номер лабратории в которой он работает, далее в отношения R2 изменим телефон лаборатории на 9-17. Теперь при запросе напечатать телефон лаборатории 25АР, мы получим ответ: 9-17.
Аномалия обновления, присутствующая в исходном отношении устранена в результате декомпозиции.
Удаление. Финансирование проекта ОВ77 прекращено. Информация о проекте должна быть удалена из БД. В отношении R3 нужно удалить все записи со значением Проект=ОВ77
В исходном отношении это правило к удалению из базы информации о сотруднике 559 Зайцев.
В нашем случае информация о сотрудниках храниться в R2 и не будет потеряна при удалении кортежей со значением Проект=ОВ77 из отношения R3.
Таким образом, в результате декомпозиции устранена аномалия удаления.
Цена за устранение аномалии – увеличение количества отношений. Теперь запросы к базе данных будут реализовываться более сложно, т.к. возможно понадобится прохождение цепочки из двух или трех отношений при поиске требуемых данных.
- Семантическое моделирование или проектирования баз данных методом “Сущность-связь”
Декомпозиционный метод проектирования БД, который мы рассматривали в предыдущей лекции, пригоден при условии небольшого числа атрибутов. Если количество атрибутов очень велико то, декомпозиционный метод становится излишне громоздким и проектировать БД следует, используя другие методы.
Предлагается модель данных, называемая моделью “сущность-связь” (entity-relationship model). Эта модель основывается на некоторой важной семантической информации о реальном мире. Вводится специальный диаграммный метод как средство проектирования баз данных.
- Сущности и связи
Рассмотрим простейший пример. Предположим, проектируется БД, предназначенная для хранения информации о преподавателях и курсах, которые они читают. Двумя главными объектами, или сущностями, представляющими в данном случае интерес, являются “Преподаватель” и “курс”. Между этими сущностями существует связь ЧИТАЕТ.
|
сущность
|
связь
|
сущность
|
|

|
|
Рис. 7.1 Сущности и связи
|
Связь ЧИТАЕТ, существующая между двумя сущностями ПРЕПОДАВАТЕЛЬ и КУРС может быть графически представлена несколькими способами:
Диаграмма ЕR–экземпляров:
|
|
|
Рис. 7.2 Диаграмма ER-экземпляра
|
В этом способе каждый преподаватель характеризуется номером преподавателя (НП) и каждый курс – названием курса (НК). Здесь видно, какой в точности курс читается каждым преподавателем.
Диаграмма ER–типа:
|

|
|
Рис. 7.3 Диаграмма ER-типа
|
Сущности изображаются прямоугольниками, связи в виде ромбов, ниже каждой сущности указывают атрибут или набор атрибутов, являющийся ключом сущности.
Терминология метода “Сущность-связь”
Термины, используемые в ER–методе, не могут быть определены строго, тем не менее, их необходимо определить.
Сущность определяется как некий объект, представляющий интерес для пользователей БД. Этот объект должен иметь экземпляры, отличающиеся друг от друга и допускающие однозначную идентификацию. Признак, который может помочь в отыскании сущности состоит в том, что сущность это как правило, существительное (в инфологической модели предметной области).
Связь представляет собой взаимодействие между двумя или более сущностями. При поиске сущностей следует иметь в виду, что связь, как правило, глагол (в инфологической модели ПО).
Атрибут есть свойство сущности. Например атрибутами сущности преподавателя могут быть: номер преподавателя, фамилия, телефон, должность, адрес и т.п.
Ключ сущности – это атрибут или набор атрибутов, значения которых однозначно определяют экземпляр сущности.
Ключ связи – набор ключей сущностей, соединяемых данной связью.
На первом этапе проектирования БД ER–методом необходимы только те атрибуты сущностей, которые являются их ключами. Другие атрибуты вместе с функциональными зависимостями, в которых они участвуют, будут добавлены на более поздних этапах проектирования.
- Степень связи
Важной характеристикой связи между двумя и более сущностями является степень связи. Степень связи устанавливается из описания предметной области (из инфологической модели).
|
|
Пример 1: Каждый преподаватель читает не более одного курса, и каждый курс читается не более чем одним преподавателем (т.е. могут быть преподаватели которые ничего не читают и ни кем не читаемые курсы).
|
|
не должны
|
не должны
|
|
Рис. 7.4 Диаграмма ER-экземпляра для примера 1
|
|
|
Пример 2: Каждый преподаватель читает только один курс, каждый курс читается не более чем одним преподавателем.
|
|
должны
|
не должны
|
|
Рис. 7.5 Диаграмма ER-экземпляра для примера 2
|
|

|
Пример 3: Каждый преподаватель читает не более одного курса, каждый курс читается только одним преподавателем.
|
|
не должны
|
должны
|
|
Рис. 7.6 Диаграмма ER-экземпляра для примера 3
|
|
|
Пример 4: Каждый преподаватель читает только один курс, каждый курс читается только одним преподавателем.
|
|
должны
|
должны
|
|
Рис. 7.7 Диаграмма ER-экземпляра для примера 4
|
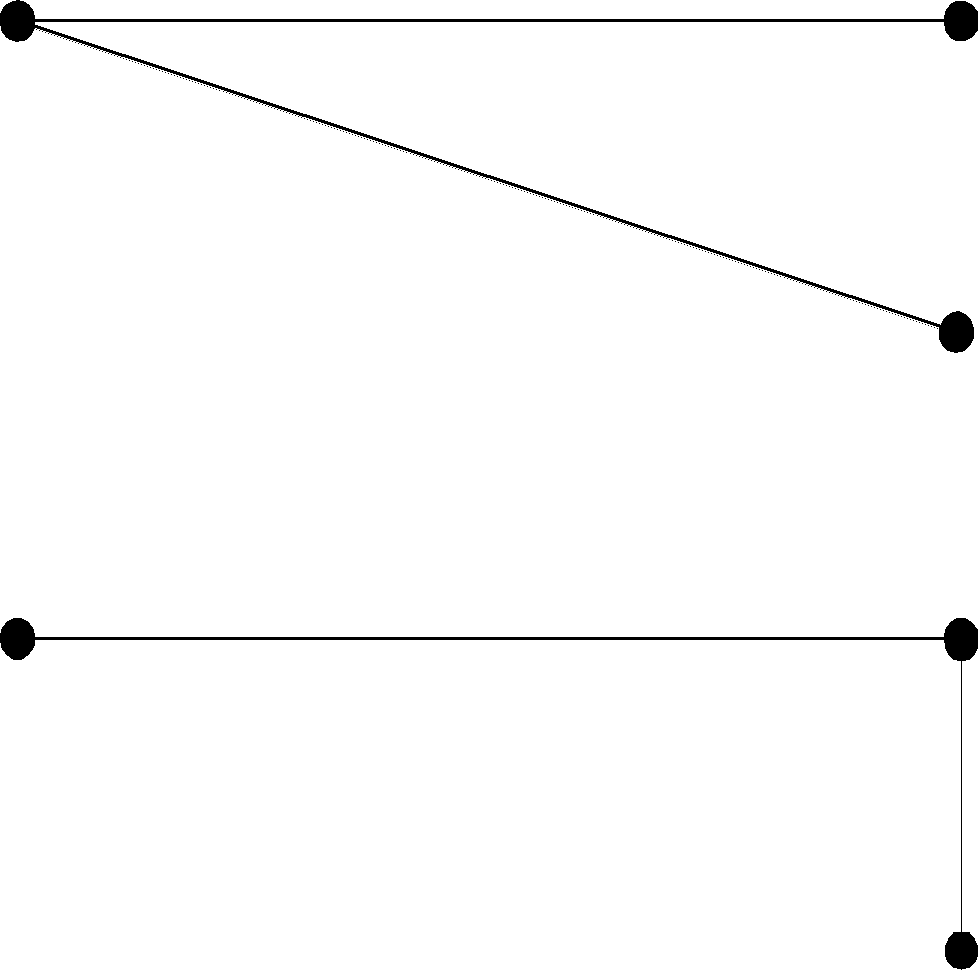
В рассмотренных примерах любой экземпляр сущности (как слева, так и справа) может быть связан максимум с одной сущностью с противоположной стороны. Такая связь определяется как связь, имеющая степень 1:1.
- Класс принадлежности сущности
Качественные различия изображенных диаграмм являются следствием того, должны или не должны все экземпляры сущности участвовать в связи.
- Если все экземпляры данной сущности должны участвовать в связи, то участие сущности называется обязательным участием.
- Если экземпляры данной сущности могут не участвовать в связи, то участие сущности называется необязательным участием.
Используется понятие класс принадлежности сущности. Класс принадлежности сущности связи является обязательным в случае обязательного участия. Класс принадлежности сущности связи является необязательным в случае необязательного участия. Класс принадлежности конкретной сущности в конкретной связи определяется из инфологической модели предметной области.
Степень связи и класс принадлежности сущности является важнейшими характеристиками, используемыми при проектировании БД ER–методом.
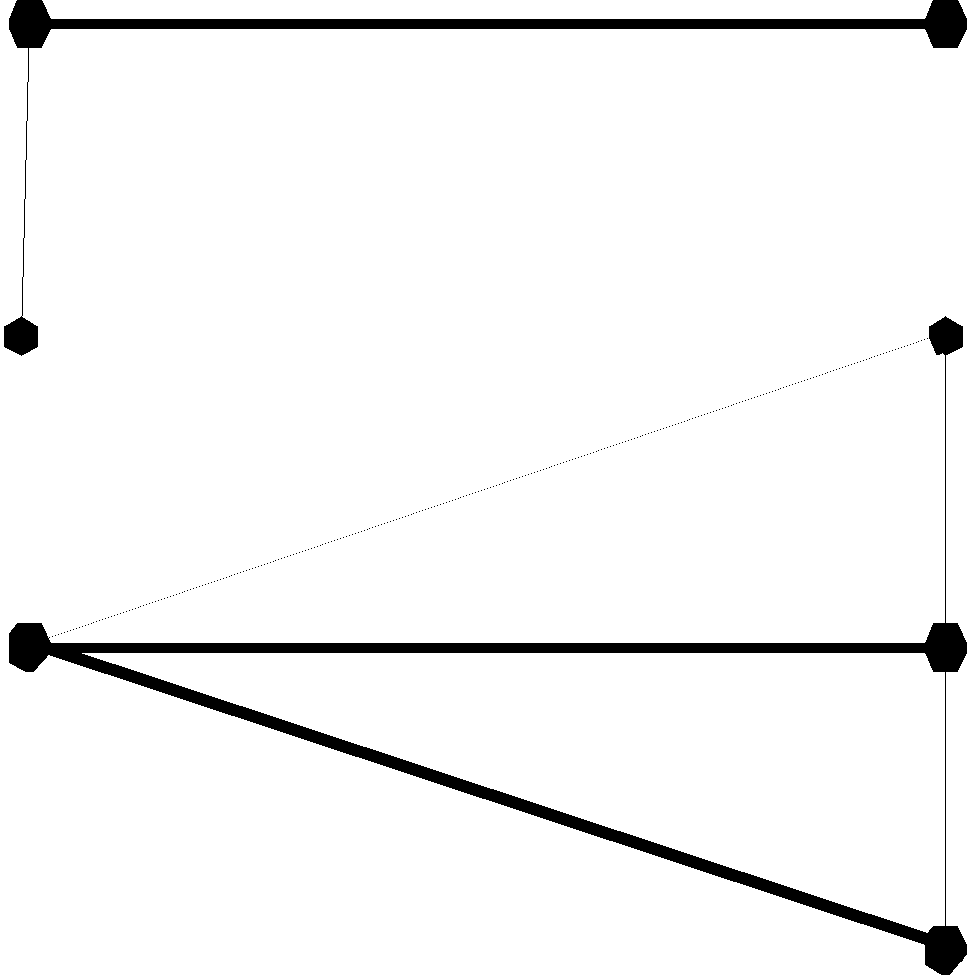
Единицы означают степень связи.
- Точка внутри прямоугольного блока означает обязательное участие сущности в данной связи (класс принадлежности обязательный).
- Точка вне прямоугольного блока означает необязательное участие сущности в данной связи (класс принадлежности не обязательный).
Примеры диаграмм ER-типа связей степени 1:1.
|

|
|
Рис. 7.8 Диаграмма ER-типа связи степени 1:1, класс принадлежности обоих сущностей необязательный
|
|

|
|
Рис. 7.9 Диаграмма ER-типа связи степени 1:1, класс принадлежности сущности необяз. - обяз.
|
|
|
|
Рис. 7.10 Диаграмма ER-типа связи степени 1:1, класс принадлежности сущности обяз. – необяз.
|
|
|
|
Рис. 7.11 Диаграмма ER-типа связи степени 1:1, класс принадлежности обоих сущностей обязательный
|
Примеры диаграмм ER-типа связей степени 1:N и N:1
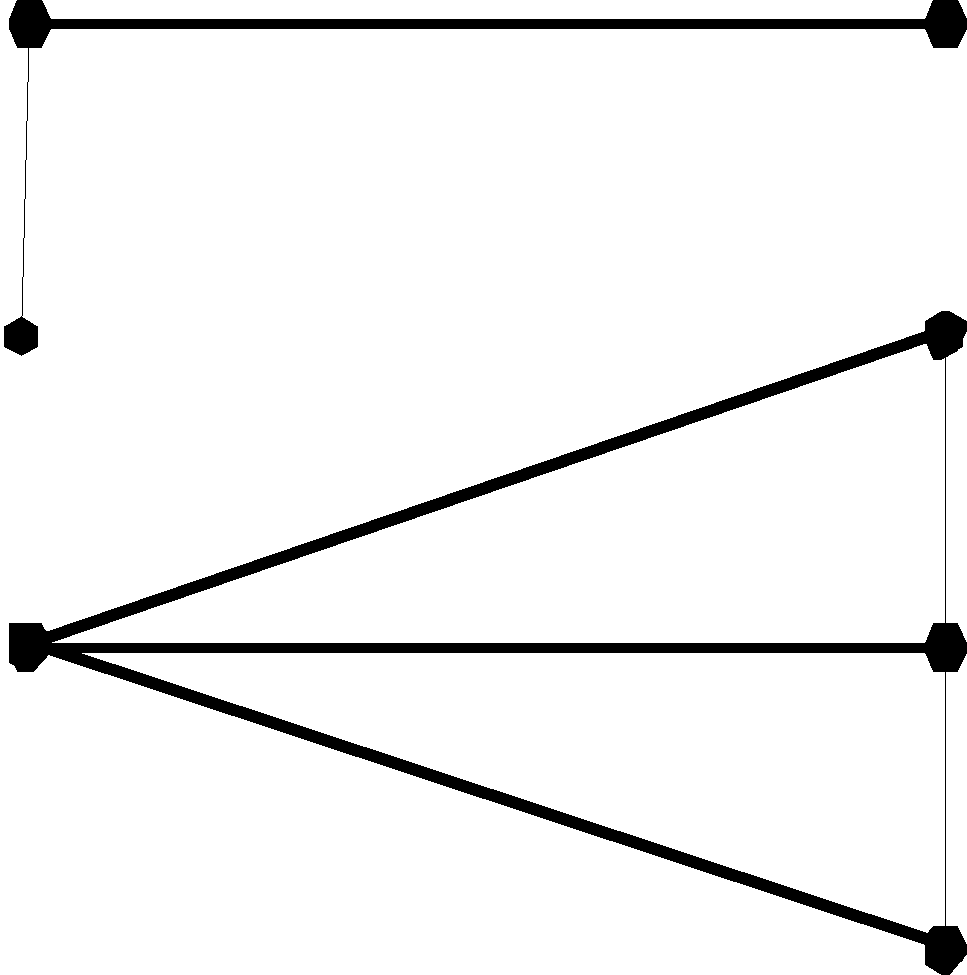
Каждый преподаватель может читать одновременно несколько курсов. Каждый курс читается не более чем одним преподавателем. Степень связи 1:N:
|

|
|
|
Рис. 7.12 Диаграмма ER-типа связи степени 1:N
|
необяз.
|
необяз.
|
|
|
|
|
Рис. 7.13 Диаграмма ER-типа связи степени 1:N
|
обяз.
|
необяз.
|
|

|
|
|
Рис. 7.14 Диаграмма ER-типа связи степени 1:N
|
необяз.
|
обяз.
|
|

|
|
|
Рис. 7.15 Диаграмма ER-типа связи степени 1:N
|
обяз.
|
обяз.
|
Каждый преподаватель читает не более одного курса, каждый курс читается более чем одним преподавателем. Степень связи N:1:
|
|

|
|
Рис. 7.16 Диаграмма ER-типа связи степени N:1
|
необяз.
|
необяз.
|
|
|
|
|
Рис. 7.17 Диаграмма ER-типа связи степени N:1
|
обяз.
|
необяз.
|
|
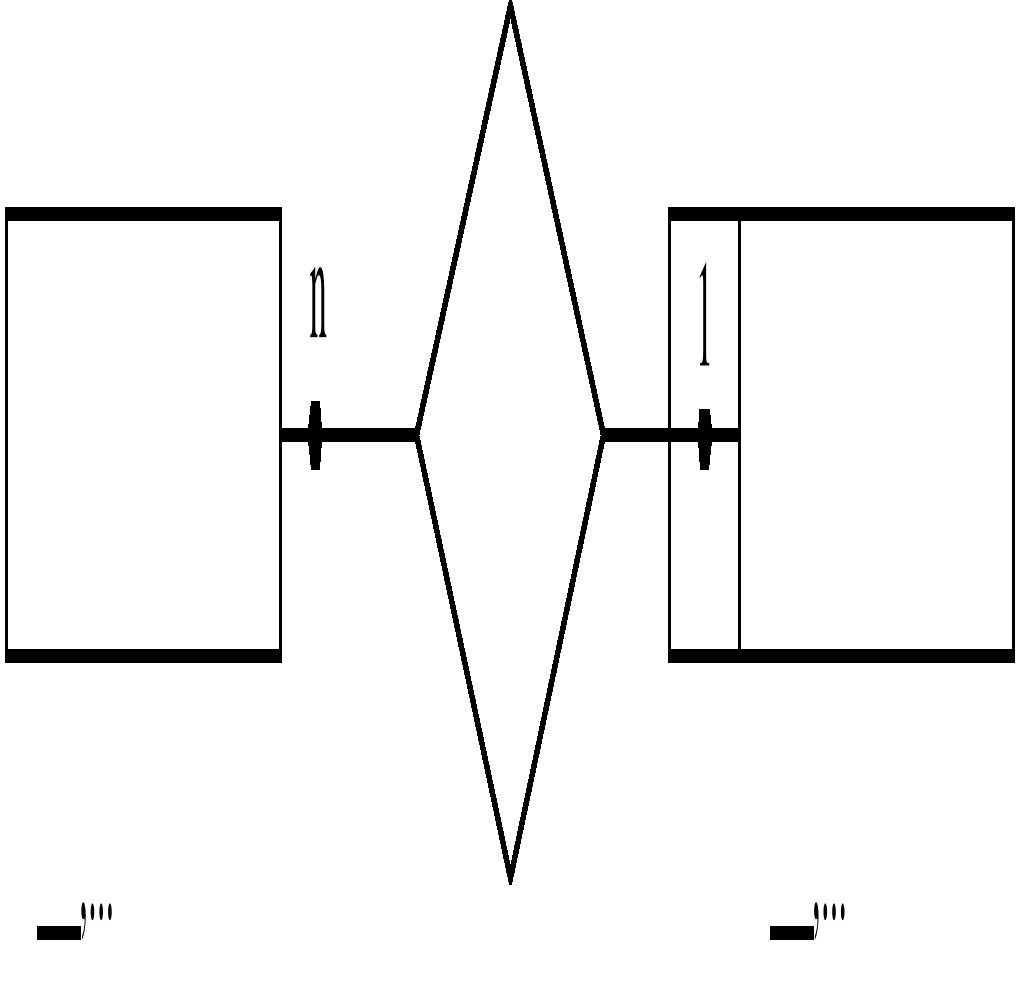
|
|
|
Рис. 7.18 Диаграмма ER-типа связи степени N:1
|
необяз.
|
обяз.
|
|
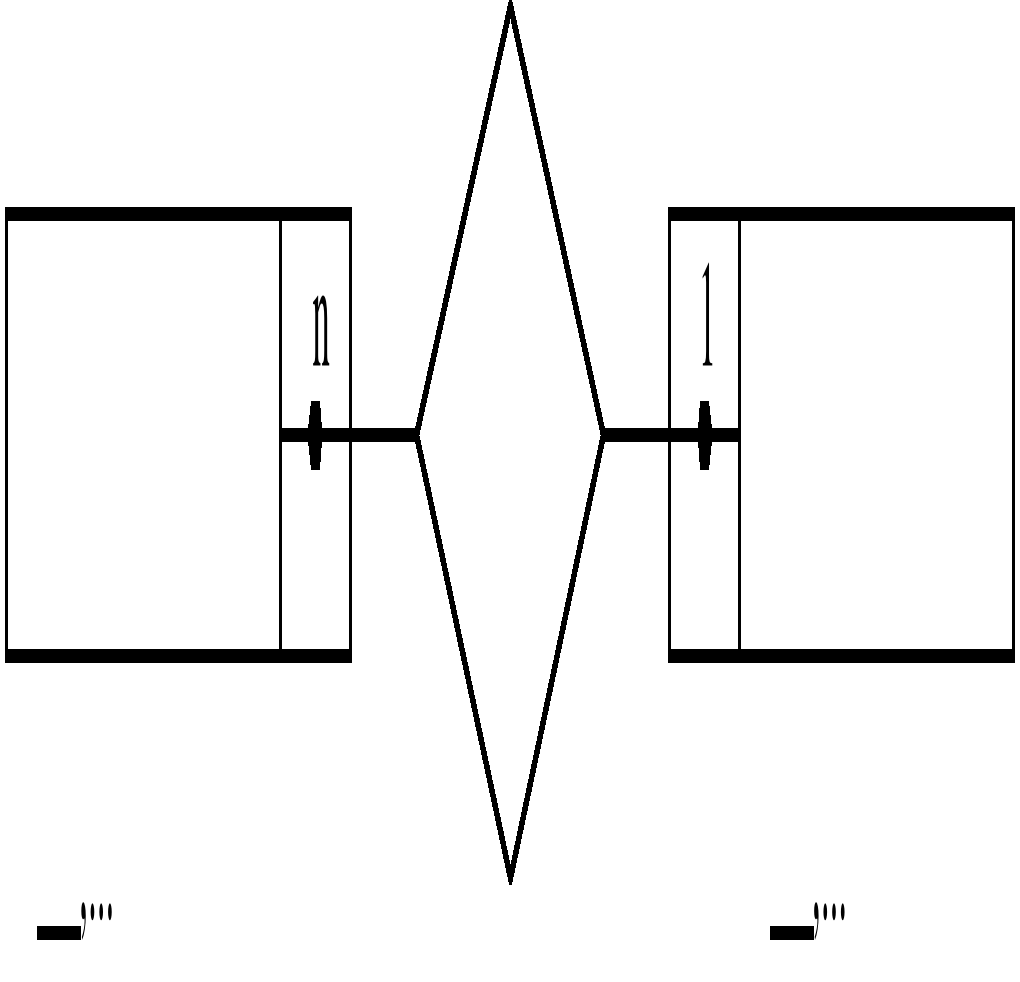
|
|
|
Рис. 7.19 Диаграмма ER-типа связи степени N:1
|
обяз.
|
обяз.
|
Примеры диаграмм ER-типа связей степени M:N
Каждый преподаватель может читать несколько курсов, каждый курс может читаться несколькими преподавателями. Степень связи M:N:
|
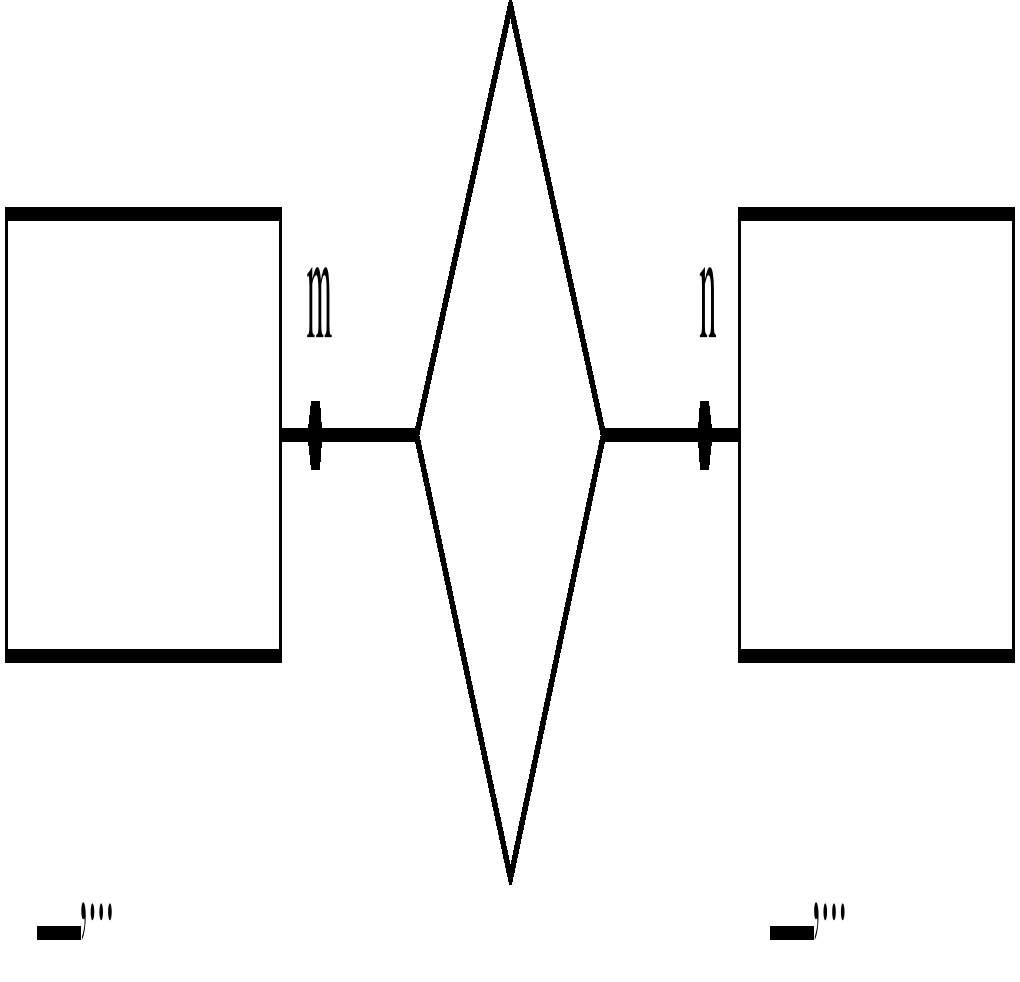
|

|
|
Рис. 7.20 Диаграмма ER-типа связи степени M:N
|
необяз.
|
необяз.
|
|
|

|
|
Рис. 7.21 Диаграмма ER-типа связи степени M:N
|
обяз.
|
необяз.
|
|
|
|
|
Рис. 7.22 Диаграмма ER-типа связи степени M:N
|
необяз.
|
обяз.
|
|

|

|
|
Рис. 7.23 Диаграмма ER-типа связи степени M:N
|
обяз.
|
обяз.
|
- Порядок или мерность связи
Связь ЧИТАЕТ, существующая между сущностями ПРЕПОДАВАТЕЛЬ и КУРС называется бинарной, поскольку она связывает две сущности. Связи между тремя или более сущностями мы будем называть связями более высокого порядка..
- Схема проектирования баз данных методом “сущность-связь”
Проектирование базы данных с помощью метода “сущность-связь” можно разбить на несколько шагов:
- Шаг 1. Построение диаграммы ER–типа, включающей все сущности и все связи, обнаруженные в результате анализа инфологической модели предметной области.
- Шаг 2. Построение набора предварительных отношений и указание предполагаемого ключа для каждого отношения.
- Шаг 3. Подготовка списка всех атрибутов и распределение этих атрибутов по полученным отношениям. Необходимо определить для каждого отношения функциональные зависимости и проверить, находятся ли эти отношения в НФБК. Если хотя бы одно отношение не находится в НФБК или некоторые атрибуты не могут логично включиться ни в одно отношение, необходимо пересмотреть диаграммы ER–типа.
- Бинарные связи со степенью связи 1: 1
Пробуем составлять предварительные отношения путем перебора всех возможных вариантов.
Рассмотрим ситуацию: Бинарная связь степень 1:1, и класс принадлежности обеих сущностей является обязательным.
|

|

|
|
Рис. 7.24 ER-диаграмма для бинарной связи “Преподаватель читает Курс” степени 1:1 и классом
принадлежности обеих сущностей обязательным
|
|
Таблица 7.1 R Универсальное отношение
|
|
НП
|
Фам.
|
Тел.
|
НК
|
V
|
В этом отношении сущность ПРЕПОДАВАТЕЛЬ дополнена двумя атрибутами – фамилия преподавателя, телефон преподавателя. Сущность КУРС дополнена атрибутом V – объем в часах.
|
|
П1
|
Иванов
|
32-22-11
|
К3
|
48
|
|
|
П2
|
Минин
|
33-98-76
|
К1
|
18
|
|
|
П3
|
Орлов
|
34-87-98
|
К4
|
54
|
|
|
П4
|
Петров
|
35-78-00
|
К2
|
36
|
|
В этом случае помещение всех атрибутов в одно отношение R (НП, Фам, Тел, НК, V) является правильным решением. Т.к. степень связи 1:1 и класс принадлежности является обязательным для обеих сущностей, гарантируется отсутствие пустых полей, а также дублирование информации.
Проверяем находится ли наше отношение в НФБК ? Да находится, так как все детерминанты являются возможными ключами.
|
Возможные ключи:
|
НП, НК, <НП, НК>
|
|
Детерминанты:
|
НП, НК, <НП, НК>
|
Правило 1.
Если связь бинарна, степени 1:1 и класс принадлежности обеих сущностей является обязательным, то требуется только одно отношение. В это отношение включаются все атрибуты обеих сущностей. Ключом данного отношения может быть ключ любой из двух сущностей.
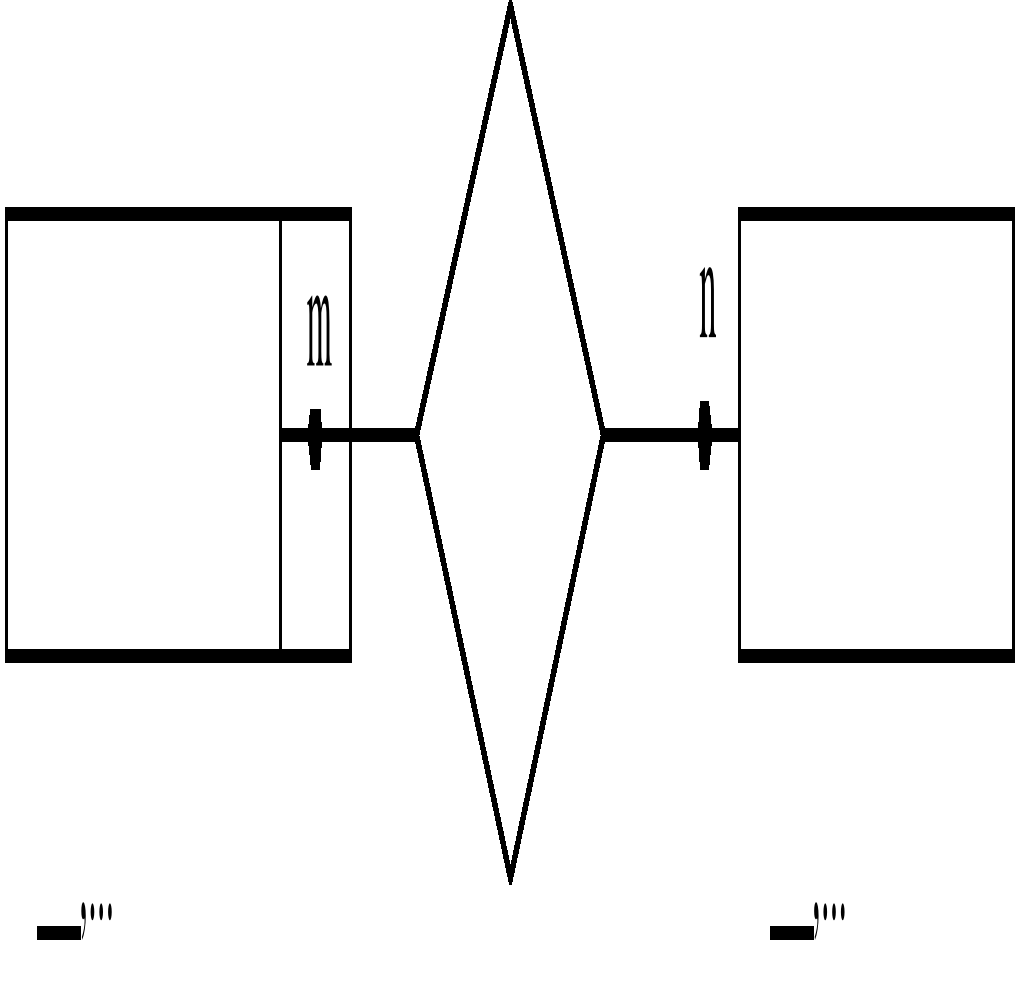
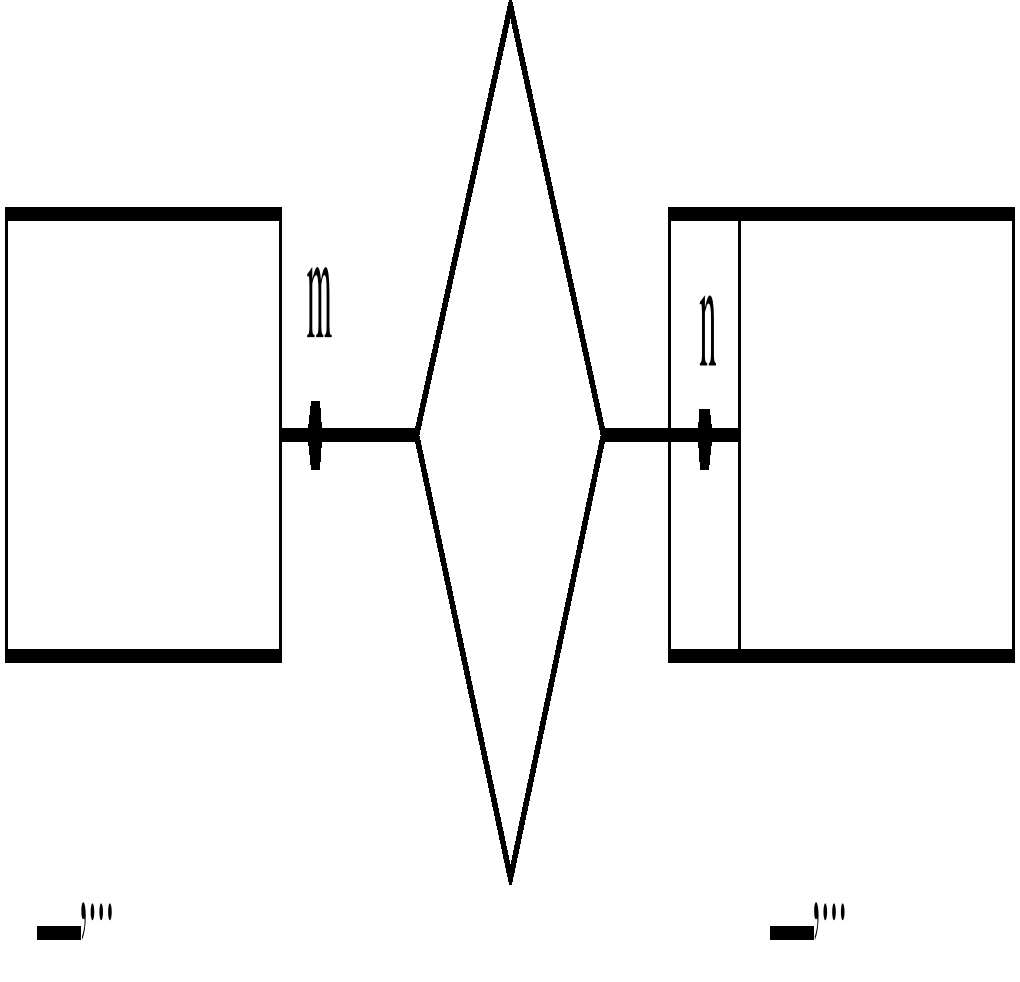
Рассмотрим ситуацию, когда класс принадлежности одной из сущностей является необязательным:
|

|
|
|
Рис. 7.25 ER-диаграмма для бинарной связи ‘Преподаватель читает Курс’ степени 1:1 и
Класс принадлежности Преподаватель – обязательным, а Курс не обязательным
|
|
Таблица 7.2 R универсальное отношение.
|
|
|
НП
|
Фам.
|
Тел.
|
НК
|
V
|
Если использовать единственное отношение, в нем могут появляться кортежи с пустыми полями (в том случае, если в реальной ситуации возникают курсы никем не читаемые). Это недопустимо.
|
|
П1
|
Иванов
|
32-22-11
|
К2
|
36
|
|
|
П2
|
Минин
|
33-98-76
|
К4
|
54
|
|
|
П3
|
Орлов
|
34-87-98
|
К1
|
18
|
|
|
-
|
-
|
-
|
К3
|
48
|
|
Попытаемся использовать для хранения информации два отношения. Первое отношение будет хранить информацию о сущности ПРЕПОДАВАТЕЛЬ, второе отношение будет хранить информацию о сущности КУРС. При этом к отношению ПРЕПОДАВАТЕЛЬ необходимо добавить еще одно поле, где будет храниться значение ключа сущности КУРС, т.е. номер курса читаемого данным преподавателем. Если мы попробуем добавить поле НП к таблице КУРС, то потерпим не удачу, так как пустые строчки не исчезнут. Данные отношения находятся в НФБК.
Преподаватель (НП, Фам, Тел., НК)
Курс (НК,V)
|
Таблица 7.3 R1
отношение “Преподаватель_НК”.
|
Таблица 7.4 R2
отношение “Курс”.
|
|
НП
|
Фам.
|
Тел.
|
НК
|
|
НК
|
V
|
|
П1
|
Иванов
|
32-22-11
|
К2
|
|
K1
|
18
|
|
П2
|
Минин
|
33-98-76
|
К4
|
|
K2
|
36
|
|
П3
|
Орлов
|
34-87-98
|
К1
|
|
K3
|
48
|
|
|
|
|
|
|
K4
|
54
|
Правило 2.
Если связь бинарна, степени 1:1 и класс принадлежности одной сущности является обязательным, а другой необязательным, информацию необходимо хранить в двух отношениях. Под каждую сущность необходимо выделить одно отношение. Кроме того, к отношению, порожденному сущностью, класс принадлежности которой является обязательным, необходимо добавить один атрибут – являющийся ключом сущности, класс принадлежности которой является необязательным.При этом ключом каждого отношения будет ключ соответствующей сущности.
Рассмотрим ситуацию, когда классы принадлежности обеих сущностей являются необязательными:
|
|

|
|
Рис. 7.26 ER-диаграмма для бинарной связи ‘Преподаватель читает Курс’ степени 1:1 и классом
принадлежности обеих сущностей необязательным
|
|
Таблица 7.5 R универсальное отношение.
|
Пустые поля возникают по двум причинам – из-за наличия курсов, никем не читаемых и из-за наличия ничего не читающих преподавателей. Отношение будет содержать аномалии Невозможно использование одного или двух отношений:
|
|
НП
|
Фам.
|
Тел.
|
НК
|
V
|
|
|
П1
|
Иванов
|
32-22-11
|
К2
|
36
|
|
|
П2
|
Минин
|
33-98-76
|
-
|
-
|
|
|
П3
|
Орлов
|
34-87-98
|
К4
|
54
|
|
|
П4
|
Петров
|
35-78-00
|
К1
|
18
|
|
|
-
|
-
|
-
|
К3
|
48
|
|
|
Таблица 7.6 R1
отношение “Преподаватель_НК”.
|
Таблица 7.7 R2
отношение “Курс_НП”.
|
|
НП
|
Фам.
|
Тел.
|
|
НК
|
|
НК
|
V
|
|
НП
|
|
П1
|
Иванов
|
32-22-11
|
|
К3
|
|
К1
|
18
|
|
П4
|
|
П2
|
Минин
|
33-98-76
|
|
-
|
|
К2
|
24
|
|
-
|
|
П3
|
Орлов
|
34-87-98
|
|
К4
|
|
К3
|
36
|
|
П1
|
|
П4
|
Петров
|
35-78-00
|
|
К1
|
|
К4
|
54
|
|
П3
|
В таб.7.6 и таб.7.7 также возникают пустые поля, если атрибут НК добавить к R1 возникнет пустое поле там, где преподаватель ни чего не читает. Если добавить атрибут НП к R2, возникнут пустые поля там, где присутствуют никем не читаемые курсы. Следовательно решение из двух отношений также неудовлетворительно. Попробуем использование трех отношений:
|
Таблица 7.8 R3
|
Таблица 7.9 R4
|
Таблица 7.10 R5
|
|
отношение “Преподаватель”.
|
отношение “Курс”.
|
отношение “Читает”.
|
|
НП
|
Фам.
|
Тел.
|
|
НК
|
V
|
|
НП
|
НК
|
|
П1
|
Иванов
|
32-22-11
|
|
К1
|
18
|
|
П1
|
К3
|
|
П2
|
Минин
|
33-98-76
|
|
К2
|
36
|
|
П3
|
К4
|
|
П3
|
Орлов
|
34-87-98
|
|
К3
|
48
|
|
П4
|
К1
|
|
П4
|
Петров
|
35-78-00
|
|
К4
|
54
|
|
|
|
Отношения Преподаватель (НП, Фам, Тел) и Курс (НК,V) находятся в НФБК. Отношение
Читает (НП, НК) содержит неповторяющиеся значения атрибутов НП и НК, и также не содержит пустых полей. В нем два детерминанта и два возможных ключа – следовательно отношение находится в НФБК.
|

|
|
Рис. 7.27 Диаграмма функциональных зависимостей R5, отношения ‘Читает’
|
Правило 3.
Если связь бинарная, степени 1:1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать для хранения информации три отношения. В первое отношение включаются все атрибуты, характеризующую первую из сущностей. Ключ ее будет являться ключом данного отношения. Во второе отношении включаются атрибуты, характеризующую вторую сущность. Ее ключ будет ключом второго отношения. Третье отношение характеризует связь. Среди своих атрибутов оно содержит ключи двух связываемых сущностей. Ключом может быть любой из этих двух атрибутов.
Пример: Проектируется база данных предназначенная для хранения информации о проводниках, которые работают на некоторых озерах и организуют рыбалку для туристов. Назовем данную базу данных “Рыболовный туризм”.
Экологи разрешили за одно озеро закреплять не более одного проводника.
А профсоюзы требуют, что бы каждый проводник обязательно обслуживал только одно озеро. Следовательно в БД могут быть озера, за которым не закреплены проводники, но не может быть проводников не прикрепленных к озеру. Интерес для БД будет представлять:
|
Фам
|
-
|
Фамилия проводника
|
|
Тном
|
-
|
Номер его телефона
|
|
Плата
|
-
|
Еженедельная оплата
|
|
Группа
|
-
|
Максимальный размер группы, которую проводник может привести на озеро
|
|
Нозера
|
-
|
Название озера
|
|
Рыба
|
-
|
Основной вид рыбы, которая водится в озере
|
|
Оценка
|
-
|
Оценка озера рыболовом
|
В данной БД сущностями будет: проводник и озеро, связи между ними: обслуживает.
|
|
|
Рис. 7.28 ER-диаграмма связи “Проводник обслуживает озеро”
|
Связь бинарная, степень связи 1:1, класс принадлежности одной сущности обязательный, а другой нет. Используем правило (2) и информацию распределяем по двум отношениям:
Проводник (Фам, Тном, Плата, Группа, Н_Озера) и Озеро (Н_Озера, Оценка, Рыба)
|

|
|
|
Рис. 7.29 Диаграмма функциональных зависимостей отношений “Проводник” и “Озеро”
|
- Бинарные связи со степенью связи 1: N
Рассмотрим ситуацию:
Преподаватель может читает несколько курсов. Каждый курс читается может читаться не более чем одним преподавателем. То есть клас принадлежности N-связанной сущности является обязательным, а односвязаной не обязательным.
|
|

|
|
Рис. 7.30 ER-диаграмма связи “Преподаватель читает курс” 1:N
|
необяз.
|
обяз.
|
|
Таблица 7.11 R универсальное отношение
|
|
НП
|
Фам
|
Тел
|
НК
|
V
|
Отношение R не состоятельно. В R присутствует избыточное дублирование информации (в полях Тел и Фам), пустоты (в полях НК и V), следовательно одной таблицы недостаточно. Отношение R содержит в себе аномалии и нуждаются в разбиении на R1 и R2
|
|
П1
|
Иванов
|
32
|
К1
|
18
|
|
|
П2
|
Минин
|
33
|
-
|
-
|
|
|
П3
|
Орлов
|
34
|
K2
|
48
|
|
|
П3
|
Орлов
|
34
|
K3
|
54
|
|
Поместим все атрибуты сущности ПРЕПОДАВАТЕЛЬ в отношение R1, а все атрибуты сущности КУРС в отношение R2 и добавим к нему атрибут НП, являющийся ключом сущности ПРЕПОДАВАТЕЛЬ.
|
Таблица 7.12 R1 отношение “Преподаватель”.
|
Таблица 7.13 R2 отношение “Курс_НП”.
|
|
НП
|
Фам
|
Тел
|
|
НК
|
V
|
НП
|
|
П1
|
Иванов
|
32
|
|
К1
|
18
|
П1
|
|
П2
|
Минин
|
33
|
|
К2
|
36
|
П3
|
|
П3
|
Орлов
|
34
|
|
K3
|
48
|
П3
|
|
П3
|
Орлов
|
34
|
|
|
|
|
Оба отношения R1 и R2 находятся в НФБК, так как все их детерминанты являются возможными ключами. В R1 это НП, а в R2 это НК и <НК, НП>.
Рассмотрим ситуацию, когда принадлежность обоих сущностей является обязательной:
|
|
|
|
Рис. 7.31 ER-диаграмма связи “Преподаватель читает курс” 1:N
|
обяз.
|
обяз.
|
|
Таблица 7.14 R Универсальное отношение.
|
|
НП
|
Фам
|
Тел
|
НК
|
V
|
В данной таблице отсутствуют пустые поля, но проблема с дублированием избыточной информации осталась, следовательно, отношение R содержит в себе аномалии и нуждаются в разбиении на R1 и R2.
|
|
П1
|
Иванов
|
32
|
К1
|
18
|
|
|
П2
|
Минин
|
33
|
К2
|
36
|
|
|
П3
|
Орлов
|
34
|
K3
|
48
|
|
|
П3
|
Орлов
|
34
|
K4
|
54
|
|
Поместим все атрибуты сущности ПРЕПОДАВАТЕЛЬ в отношение R1, а все атрибуты сущности КУРС в отношение R2 и добавим к нему атрибут НП, являющийся ключом сущности ПРЕПОДАВАТЕЛЬ.
|
Таблица 7.15 R1 отношение “Преподаватель”.
|
Таблица 7.16 R2 отношение “Курс_НП”.
|
|
НП
|
Фам
|
Тел
|
|
НК
|
V
|
НП
|
|
П1
|
Иванов
|
32
|
|
К1
|
18
|
П1
|
|
П2
|
Минин
|
33
|
|
К2
|
36
|
П2
|
|
П3
|
Орлов
|
34
|
|
K3
|
48
|
П3
|
|
П3
|
Орлов
|
34
|
|
K4
|
54
|
П3
|
Оба отношения R1 и R2 находятся в НФБК
Правило 4.
Если связь бинарная и степень ее 1:N или N:1, а класс принадлежности n–связной сущности является обязательным, то достаточно (в независимости от класса принадлежности односвязной сущности) выделить два отношения, в одно из которых включаем все атрибуты, характеризующие одну сущность, во второе хранящие другую сущность. Ключами отношения является ключи соответствующих сущностей и к отношению, содержащему в себе атрибуты n–связной сущности добавляем, как атрибут, ключ односвязной сущности.
Рассмотрим ситуацию, когда класс принадлежности обоих сущностей является необязательным:
|

|
|
|
Рис. 7.32 ER-диаграмма связи “Преподаватель читает курс” 1:N
|
необяз.
|
необяз.
|
|
Таблица 7.17 R универсальное отношение.
|
|
НП
|
Фам
|
Тел
|
НК
|
V
|
В данной таблице есть дублирование информации, а также кортежи с пустыми полями, следовательно, одним отношением не обойтись, значит, разбиваем R на два отношения R1 и R2:
|
|
П1
|
Иванов
|
32
|
К1
|
18
|
|
|
П2
|
Минин
|
32
|
К2
|
36
|
|
|
П2
|
Орлов
|
34
|
K3
|
48
|
|
|
П3
|
Орлов
|
34
|
-
|
-
|
|
|
-
|
-
|
-
|
К4
|
54
|
|
|
Таблица 7.18 R1
отношение “Преподаватель”.
|
Таблица 7.19 R2
отношение “Курс_НП”.
|
|
НП
|
Фам
|
Тел
|
|
|
НК
|
V
|
НП
|
|
П1
|
Иванов
|
32
|
|
|
К1
|
18
|
П1
|
|
П2
|
Минин
|
33
|
|
|
К2
|
36
|
П2
|
|
П3
|
Орлов
|
34
|
|
|
К3
|
48
|
П2
|
|
|
|
|
|
|
К4
|
54
|
-
|
В отношениях R1 и R2 отображенных в таблицах 7.18-7.19 нет дублирования но есть пустые поля, поэтому необходимо произвести декомпозицию отношения R на три отношения R3, R4 и R5. Отношения R3, R4 и R5 отображенные в таблицах 7.20-7.22 будут находиться в НФБК.
|
Таблица 7.20 R3
|
Таблица 7.21 R4
|
Таблица 7.22 R5
|
|
отношение “Преподаватель”.
|
отношение “Курс”.
|
отношение “Читает”.
|
|
НП
|
Фам
|
Тел
|
|
НК
|
V
|
|
НК
|
НП
|
|
П1
|
Иванов
|
32
|
|
К1
|
18
|
|
К1
|
П1
|
|
П2
|
Минин
|
33
|
|
К2
|
36
|
|
К2
|
П2
|
|
П3
|
Орлов
|
34
|
|
К3
|
48
|
|
К3
|
П2
|
|
|
|
|
|
К4
|
54
|
|
|
|
Рассмотрим ситуацию, когда класс принадлежности односвязанной сущности является обязательным, а N-связанной не обязательным.
|
|
|
|
Рис. 7.37 ER-диаграмма связи “Преподаватель читает курс” 1:N
|
обяз.
|
необяз.
|
|
Таблица 7.23 R универсальное отношение.
|
|
НП
|
Фам
|
Тел
|
НК
|
V
|
В данной таблице есть кортежи с пустыми полями, следовательно, одним отношением не обойтись, значит, разбиваем отношение R на два отношения R1 и R2:
|
|
П1
|
Иванов
|
32
|
К1
|
18
|
|
|
П2
|
Минин
|
33
|
К2
|
36
|
|
|
П2
|
Минин
|
33
|
K3
|
48
|
|
|
-
|
-
|
-
|
К4
|
54
|
|
|
Таблица 7.24 R1
отношение “Преподаватель”.
|
Таблица 7.25 R2
отношение “Курс_НП”.
|
|
НП
|
Фам
|
Тел
|
|
|
НК
|
V
|
НП
|
|
П1
|
Иванов
|
32
|
К1
|
|
К1
|
18
|
П1
|
|
П2
|
Минин
|
33
|
К2
|
|
К2
|
36
|
П2
|
|
П2
|
Минин
|
33
|
K3
|
|
К3
|
48
|
П2
|
|
|
|
|
|
К4
|
54
|
-
|
В отношениях R1 и R2 присутствует избыточное дублирование и пустые поля – следовательно решение из двух отношений является не удолетворительным. Разобъем отношение R на три отношения R3, R4 и R5 как и в предыдущем случае что показанно в таблицах 7.20-7.22.
Правило 5.
Для бинарной связи степени 1:N, N:1 с необязательным классом принадлежности n-связной сущности, то (независимо от класса принадлежности односвязной сущности) необходимо формирование трех отношений. Первое включает все атрибуты, характеризующую первую сущность. Второе включает все атрибуты, второй сущности. Третье отношение включает информацию о связи, в него будут помещенны ключи связи сущностей (возможны также и другие атрибуты). Ключами первых двух отношений будут ключи соответствующих сущностей. Ключ третьего отношения - ключ N–связной сущности.
- Бинарные связи степени M:N.
Каждый преподаватель может читать несколько курсов, каждый курс может быть читаем несколькими преподавателями:
|
|
|
|
Рис. 7.38 ER-диаграмма связи “Преподаватель читает курс” M:N
|
Составим универсальное отношение:
|
Таблица 7.21 R универсальное отношение.
|
|
НП
|
Фам
|
Тел
|
НК
|
V
|
Отношение имеет пустые поля и избыточное дублирование. Попытаемся разделить информацию из отношения R на два отношения R1 и R2. Но оба эти отношения тоже будут содержать аномалии. Разбиваем отношения R на три отношения R3, R4 и R5
|
|
П1
|
Иванов
|
32
|
К1
|
18
|
|
|
П1
|
Иванов
|
32
|
K2
|
36
|
|
|
П2
|
Минин
|
33
|
К1
|
18
|
|
|
П2
|
Минин
|
33
|
К2
|
36
|
|
|
П3
|
Орлов
|
34
|
-
|
-
|
|
|
-
|
-
|
-
|
К3
|
48
|
|
|
Таблица 7.22 R3
|
Таблица 7.23 R4
|
Таблица 7.24 R5
|
|
отношение “Преподаватель”.
|
отношение “Читает”.
|
отношение “Курс”.
|
|
НП
|
Фам
|
Тел
|
|
НП
|
НК
|
|
НК
|
V
|
|
П1
|
Иванов
|
32-22-11
|
|
П1
|
К1
|
|
К1
|
18
|
|
П2
|
Минин
|
33-98-76
|
|
П1
|
К2
|
|
K2
|
36
|
|
П3
|
Орлов
|
34-87-98
|
|
П2
|
К1
|
|
К3
|
48
|
|
|
|
|
|
П2
|
К2
|
|
|
|
Все три отношения находятся в НФБК:
Преподаватель (НП, ФАМ, ТЕЛ)
Курс (НК, V)
Читает (НП, НК)
Если рассматривать три оставшихся комбинации классов принадлежности, то становится ясно, что ни в одном случае не обойтись менее чем тремя отношениями для хранения информации.
Правило 6.
Если связь бинарная, ее степень M:N, то при любых классах принадлежности обеих сущностей для хранения информации необходимо три отношения. В двух отношениях хранится информация о сущностях. Ключами этих отношений будут ключи соответствующих сущностей. В третьем отношении хранится информация о связи. В него включаются ключевые атрибуты обеих сущностей. Ключом этого отношения будет пара этих атрибутов.
Пример проектирования с использованием связей степенью М:N
Продолжаем пример базы данных “Рыболовный туризм”. Несколько изменим ограничения накладываемые предметной области. Экологи больше не возражают, чтобы сразу несколькими проводниками обслуживалось одно озеро. Туристы, нанимающие рыбаков, интересуются видами рыб, которые водятся в озерах, самыми крупными экземплярами, пойманными за сезон в регионе и лучшей наживкой для каждого вида рыб в регионе.
|
Фам
|
-
|
Фамилия проводника
|
|
Т_ном
|
-
|
Номер телефона
|
|
Плата
|
-
|
Еженедельная оплата
|
|
Н_озера
|
-
|
Название озера
|
|
Размер
|
-
|
Максимальный размер группы
|
|
Оценка
|
-
|
Рыболовная оценка озера
|
|
Вид
|
-
|
Виды рыб
|
|
Вес
|
-
|
Вес самого большого экземпляра каждого вида
|
|
Наживка
|
-
|
Лучшая наживка для каждого вида
|
Из предметной области выделяем:
|
Сущности
|
-
|
ПРОВОДНИК, ОЗЕРО, РЫБА
|
|
Связи
|
-
|
ОБСЛУЖИВАЕТСЯ, ВОДИТСЯ
|
|

|
|
Правило 4
|
Правило 6
|
|
Рис. 7.39 Диаграммы ER-типа связей “Обслуживает” и “Водится”
|
|
Проводник
|
Озеро
|
Рыба
|
|
|
|
Рис. 7.40 Диаграммы ER-экземпляров связей “Обслуживает” и “Водится”
|
По ER-диаграмме составляем отношения:
|
для правила (4)
|
-
|
Проводник (Пфам, …,Нозеро)
|
|
|
|
Озеро (Нозеро,…)
|
|
для правила (6 )
|
-
|
Озеро (Нозеро,…)
|
|
|
|
Рыба (вид,…)
|
|
|
|
Водится (Нозеро, вид,…)
|
Далее составим отношения для всей схемы в общем:
Проводник (Фам, Тном, Плата, Размер, Нозеро)
Озеро (Нозеро, Оценка)
Рыба (Вид, Вес, Наживка)
Водится (Нозеро, Вид)
Проверяем находятся ли данные отношения в НФБК.
|

|
|
|
Рис. 7.41 Отношение “Озеро”
|
Рис7.42 Отношение “Водится”
|
|
|

|
|
Рис. 7.43 Отношение “Проводник”
|
Рис. 7.44 Отношение “Рыба”
|
Если мы проанализируем данные отношения, то обнаружим, что все они находятся в НФБК. Следовательно аномалий в базе данных “Рыболовный туризм” нет.
- Связи более высокого порядка
Рассмотрим предыдущий пример в базу данных “Рыболовный туризм”. Предположим, что туристы, нанимающие проводника, хотят знать, какую рыбу предпочитает ловить проводник.
|
Проводник
|
Озеро
|
Рыба
|
|

|
На рисунке 7.45 с помощью диаграммы ER-экземпляра показаны связи между сущностями ПРОВОДНИК, РЫБА и ОЗЕРО. Связь “Предпочитает” между сущностями ПРОВОДНИК и РЫБА показана пунктиром.
|
|
Рис. 7.45 Диаграммы ER-экземпляров связей “Обслуживает”, “Водится” и “Предпочитает”
|
|
Правило 4 (в)
|
|
|
|
Правило 4 (а)
|
Правило 6 (б)
|
|
Рис. 7.46 Диаграммы ER-типа связей “Обслуживает”, “Водится” и “Предпочитает”
|
По диаграмме ER-типа из рисунка 7.46 определяем отношения:
а) Связь бинарная, степень связи N:1 класс, принадлежности N-связанной сущности
обязательный - следовательно применяем правило номер 4.
Проводник (Фам,…,Озеро)
Озеро (Озеро,…)
б) Связь бинарная, степень связи N:M следовательно применяем правило номер 6.
Озеро (Озеро,…)
Рыба (Вид,…)
Водится (Озеро, Вид,…)
в) Связь бинарная, степень связи N:1 класс, принадлежности N-связанной сущности
обязательный следовательно применяем правило номер 4.
Проводник (Фам,…,Вид)
Рыба (Вид,…)
Проанализируем и реорганизуем полученные отношения:
- В данных отношениях есть повторяющиеся, вычеркиваем их (это Озеро,Рыба).
- Объединям два отношения проводник (Проводник (Фам,…,Озеро) и Проводник (Фам,…,Вид)) в одно Проводник (Фам,…,Озеро, Вид).
- Переписываем оставшиеся отношения дополняем их неключевыми атрибутами
- Определяем ключи отношений.
Проводник (Фам, Тном, Плата, Группа, Озеро, Вид)
Водится (Озеро, Вид)
Озеро (Озеро, Оценка)
Рыба (Вид, Вес, Наживка)
Все четыре отношения находятся в НФБК, следовательно вывод: бинарных связей в данном случае оказалось достаточно.
Усложним задачу: Дополним условия базы данных “Рыболовный туризм”.
Нам известно, что проводник может обслуживать несколько озер. Добавим к этому, что он может предпочитать ловить разную рыбу в разных озерах.
Предположим что:
|
П1
|
обслуживает
|
О1 и О2
|
|
П2
|
обслуживает
|
О2
|
|
|
|
П1
|
предпочитает
|
Р1 в О1
|
|
П1
|
предпочитает
|
Р2 в О2
|
|
П2
|
предпочитает
|
Р2 в О2
|
|
|
Попробуем решить данную проблему используя только бинарные связи. По представленным данным составим диаграмму ER-экземпляра, изображенную на рис. 7.47. Где простой линией обозначена связь “обслуживает”, волнистой – “водится”, а пунктиром “предпочитает”.
|
|
Рис. 7.47 Диаграмма ER-экземпляра усложненного “Рыболовного туризма”
|
|
Правило 6 (в)
|
|
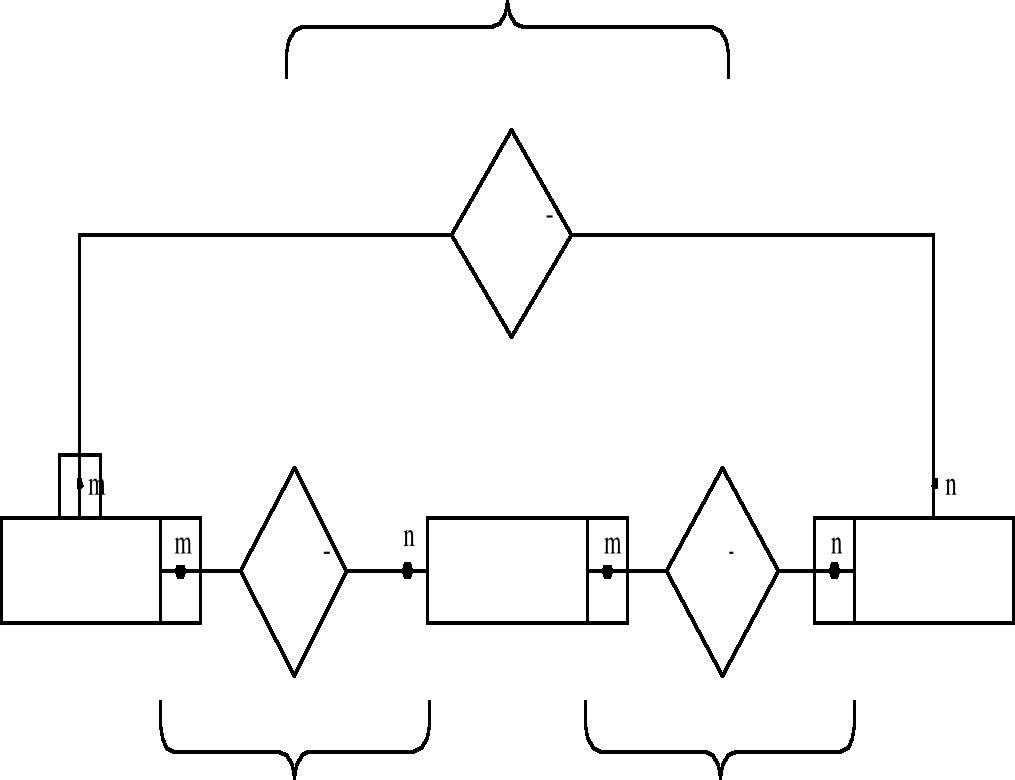
|
|
Правило 6 (а)
|
Правило 6 (б)
|
|
Рис. 7.48 Диаграмма ER-типа усложненного “Рыболовного туризма”
|
По диаграмме ER-типа из рисунка 7.48 определяем отношения:
а) Связь бинарная, степень связи N:M следовательно применяем правило номер 6
Проводник (Пфам,…)
Озеро (озеро,…)
Обслуживает (Пфам, озеро)
б) Связь бинарная, степень связи N:M следовательно применяем правило номер 6
Водится (озеро,…,вид)
Озеро (озеро,…)
Рыба (вид,…)
в) Связь бинарная, степень связи N:M следовательно применяем правило номер 6
Проводник (Пфам,…)
Рыба (вид,…)
Предпочитает (Пфам, вид,…)
Проанализируем и реорганизуем полученные отношения:
- В данных отношениях есть повторяющиеся, вычеркиваем их (это Озеро,Рыба).
- Переписываем оставшиеся отношения дополняем их неключевыми атрибутами
- Определяем ключи отношений.
Озеро (Озеро, Оценка)
Рыба (Вид, Вес, Наживка)
Проводник (Фам, Озеро, Тном, Плата, Группа)
Водится (Озеро, Вид)
Предпочитает (Фам, вид)
Все эти отношения находятся в НФБК, но отношение Предпочитает (Фам, вид) – некорректное так как из него можно сделать неверные выводы о предметной области.
Из полученных отношений можно заключить, что П1 обслуживает О1, в О1 водится Р2, П1 предпочитает ловить Р2. Из чего можно было бы сделать вывод, что П1 предпочитает ловить в О1 Р2, а это неверно. Следовательно, в данном случае только бинарными связями обойтись нельзя. Причина неудачи образования этой связи только с помощью бинарных связей заключается в следующем, что Пi проводник предпочитает ловить рыбу Рi в озере Оi т.е. здесь объединяются три сущности и такое высказывание нельзя заменить комбинациями из двух сущностей (т.е. заменить на бинарные связи).
Правильная модель должна использовать трехсторонний или трехмерный вид связи.
|

|
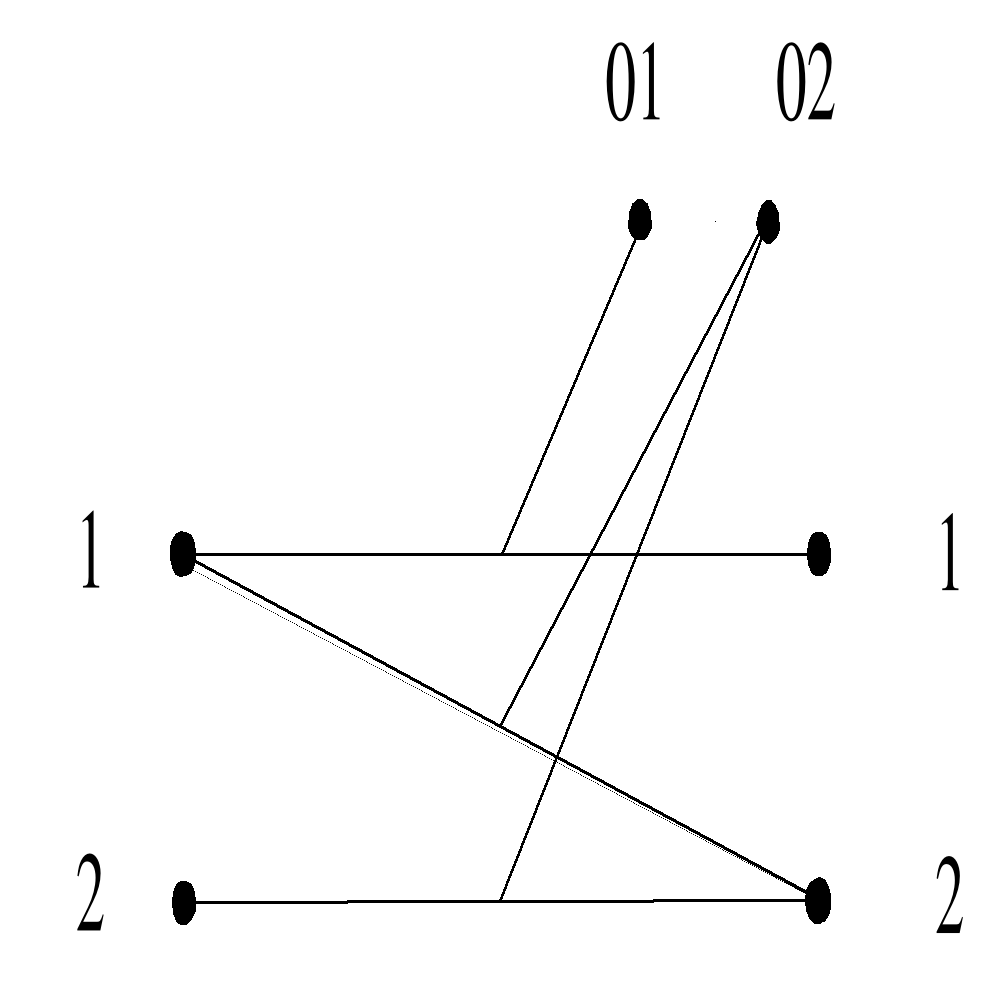
|
|
Рис. 7.49 Трехсторонний вид связи.
|
Рис. 7.50 Диаграмма ER-экземпляра связи “Предпочитает”
|
Построим диаграмму-ER типа для трехсторонней связи “Предпочитает”:
|
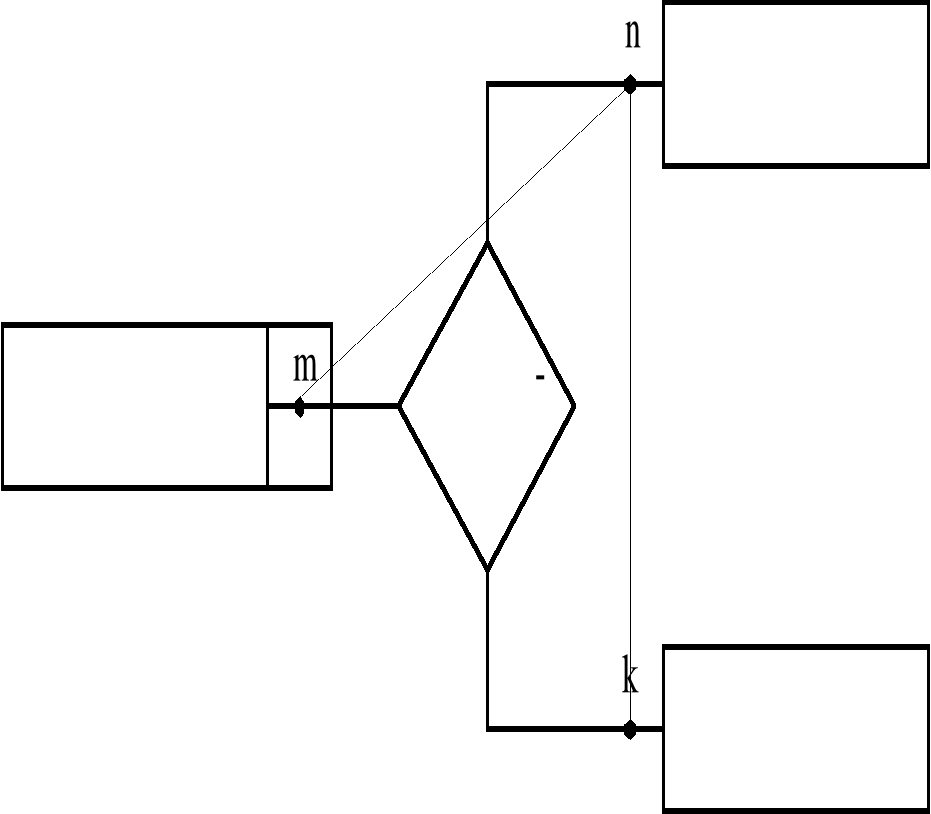
|
|
Рис. 7.51 Диаграмма ER-типа трехcторонней связи “Предпочитает”
|
Правило 7
В случае многосторонней связи (N- сторонней) необходимо использовать N+1 отношение, по одному на каждую сущность, причем ключами в этих отношениях будут ключи соответствующих сущностий. В последнем отношении будет хранится информация о связи. В него включаются ключевые атрибуты всех сущностей охваченных N–сторонней связью. Ключ в данном отношении выбирается после анализа всех атрибутов.
Пример проектирования с использованием связей более высокого порядка
Если применить правило номер 7 к рассмотренному на рисунке 7.51 примеру, то мы получим следующие отношения:
Проводник (Фам,…)
Озеро (Озеро,…)
Рыба (Вид,…)
П_О_Р (Фам, Озеро, Вид,…) – первичный ключ не может быть определен до тех пор, пока не будут рассмотрены все другие атрибуты.
Если взять атрибуты из примера, то П_О_Р будет выглядеть: П_О_Р (Пфам, Нозеро, вид), то есть в данное отношение не будут добавленны дополнительные атрибуты.
Если каждый проводник предпочитает ловить в каждом озере только один вид рыбы, то
П_О_Р (Фам, Озеро, Вид). Если проводник может указать несколько предпочтительных видов для каждого озера, то П_О_Р (Фам, Озеро, Вид).
Если проводник мог бы указать время года когда он предпочтитает данный вид рыбы в каждом озере, то тогда набор атрибутов <Фам, Озеро, Вид> не мог бы быть первичным ключом, так как возможны были бы подобные кортежи:
<Иванов, Ладога, Лещь, Осень> Иванов предпочитает ловить осенью в Ладоге леща.
<Иванов, Ладога, Лещь, Лето> Иванов предпочитает ловить летом в Ладоге леща.
- Использование ролей
В некоторых ситуациях одних сущностей и связей может оказаться недостаточно для полноценного моделирования предметной области. Одна из таких ситуаций возникает тогда, когда экземпляры некоторой сущности должны играть разные роли в деятельности предприятия.
В качестве примера предположим, что для небольшого предприятия-поставщика автомобилей необходимо хранить информацию о производственном персонале. Различают две категории служащих: Мастеров и Сборщиков. Мастера получают фиксированный оклад, в то время как у сборщиков почасовая оплата. Мастера руководят процессом сборки. У каждый мастера в подчинении от 1 до N сборщиков. У каждого сборщика должен быть только один руководитель.
Определим атрибуты представляющие для нас интерес:
|
Слфам
|
-
|
фамилия служащего
|
|
Ртел
|
-
|
рабочий телефон мастера
|
|
Дтел
|
-
|
домашний телефон служащего
|
|
Адр.сл.
|
-
|
адрес служащего
|
|
Тставка
|
-
|
почасовая тарифная ставка сборщика
|
|
Оклад
|
-
|
Месячный оклад мастера
|
|
Код.сб.
|
-
|
Код сборщика
|
|
Сф.ком
|
-
|
сфера компетенции мастера
|
Построим Диаграмма ER-типа связи “Руководит” соединяющей две сущности Мастер и Сборщик:
|
|
|
Правило 4
|
|
Рис. 7.52 Диаграмма ER-типа связи “Руководит”
|
По диаграмме ER-типа связи “Руководит” отображенной на рисунке 7.52 формируем отношения используя правило 6
Мастер (Таб.ном.маст.,…)
Сборщик (Таб.ном.сборщ.,…,Таб.ном.маст.)
С этой моделью связана проблема. Она возникает при распределени неключевых атрибутов по предварительным отношениям.
К отнощению Мастер можно однозначно отнести: Ртел, Оклад, Сф.ком.
К отнощению Сборщик можно однозначно отнести: Тставка, Код.сб.
Легко распределить почти все атрибуты, кроме Слфам, Дтел и Адр.сл.
С оставшимися атрибутами можно поступить следующим образом: разбить общие атрибуты на две части для Мастера и Сборщика, т.е. Слфам служащего = Слфам Мастера и Слфам Сборщика.
|

|
|

|
|
Рис. 7.53 Разбиение общих атрибутов Слфам, Дтел и Адр на две части
|
Но количество атрибутов увеличивается, следовательно, возникнет дублирование.
Лучшим решением данной ситуации является следующее:
- Все Мастера и Сборщики рассматриваются как служащие
- Мастера и Сборщики это те роли, которые может играть данный служащий (некоторые служащие являются Мастерами, другие Сборщиками).
- Служащий представляет собой сущность, ключом которой является табельный номер служащего (ТНС), а экземплярами данной сущности могут быть либо мастера, либо сборщики.
- Два ролевых набора Мастер и Сборщик соединяются связью “Руководит”.
На рисунке 7.54 показано использование ролей для данного примера
|

|
|
|
Правило 4
|
|
|
Рис. 7.54 Диаграмма ER-типа связи “Руководит” с использованием ролей
|
Стрелки идущие от сущности Служащий к сущностям Мастер и Сборщик, указывают на то, что сущность Служащий является исходной, а сущности Мастер и Сборщик только ролями.
Правило 8
Исходная сущность служит для генерации одного отношения, причем ключ сущности это ключ этого отношения. Ролевые элементы и связи их соединяющие, порождают такое число отношений , которое определяется ранее описанными правилами с 1 по 7, при этом в них каждая роль трактуется как обычная сущность.
Сформируем предворительные отношения для связи руководит:
Служащий (ТНС,…)
Мастер (ТНМ,…)
Сборщик (ТНСб,…,ТНМ)
Теперь без затруднений распределяем не ключевые атрибуты сущностий:
Служащий (ТНС, Слфам, Дтел, Сл.адр)
Мастер (ТНМ, Ртел, Оклад, Сф.ком)
Сборщик (ТНСб, Ставка, Код.сб, ТНМ)
Во всех отношениях один ключ, который является детерминантом, следовательно, все три отношения находятся в НФБК.
Отношение Служащий (ТНС, Слфам, Дтел, Сл.адр), полученное из исходной сущности, содержит информацию, общую для всех ее ролей ( т.е. служащих).
Отношения, полученные из ролей, содержат специфическую для каждой роли информацию. Отношения, порождаемые ролями связанны с отношением порожденным исходной сущностью через атрибут из общего домена. Т.е атрибуты ТНС, ТНМ и ТНСб принадлежат одному домену табельный номер.
Связь “Руководит” соединяет две роли одной исходной сущности, такая связь называется рекурсивной (т.е. если отбросить роль, то будет: служащий руководит служащим). Роли одной исходной сущности, могут быть связаны с другими сущностями или ролями других исходных сущностей.
Для увеличения скорости доступа при запросах можно дополнить отношение “Служащий” специальным атрибутом, для определения кем конкретно является Служащий: Мастером или Сборщиком. Служащий (ТНС, Слфам, Дтел, Сл.адр, Должность)
Пример проектирования с использованием ролей
Предположим, что необходимо спроектировать БД для детского спортивного общества (ДСО) “Буревестник”. Этой БД будут пользоваться члены Центральные совета ДСО. Центральный совет полностью контролирует деятельность ДСО. В БД должны рассматриваться следующие вопросы:
- Составление календаря для всех спортивных соревнований.
- Проверка всех спортсменов, администраторов, тренеров всех институтов, входящих в ДСО.
- Определение полного списка атрибутов исходя из анализа предметной области. Руководство определяет следующие параметры, которые имеют наибольшее значение:
- Для каждого ВУЗа, вход в ДСО: название ВУЗа, название стадиона, вместимость стадиона, число студентов, все виды спорта, культивированные данным учебным заведением
Данные по персоналу: Фамилия, Адрес, Рабочий и Домашний телефон ректора института, проректора по спорту, зав.отделения по спортивной информации и главного тренера по каждому культивированному виду спорта.
- Список всех одобренных в ДСО судей, содержащий следующую информацию: фамилия, домашний адрес, номер домашнего телефона, вид спорта который обслуживает судья, рейтинг по результатам прошлого года, соревнования следующего сезона (наступающего сезона), на которые назначен данный судья.
- Список всех студентов спортсменов, содержащий информацию: Фамилия, домашний адрес, пол, дата поступления в ВУЗ, виды спорта, которыми занимается студент, сколько лет занимался ими.
- Расписание соревнований на текущий год, содержат информацию : команда выступающая в данной встрече в роле хозяина, команда выступающая в роли гостя, даты и время встречи каждой команды, назначенные судьи, вид спорта.
- По каждому виду спорта культивированного в ДСО имеется комитет по правилам и их главный тренер, назначенного лигой в качестве представителя этого комитета.
2. Ограничения накладываемые на предметную область:
- Расписание составляется на весь наступающий сезон,
- Главный тренер тренирует только по одному виду спорта,
- Некоторые ВУЗы участвуют не во всех видах спорта, культивируемых ДСО,
- Некоторые люди имеют общие служебные телефоны.
3. Выделение сущностей:
При построении ER-диаграммы главной проблемой является выделение сущностей. Как правило множество сущностей не уникально (т.е. разные проектировщики, решая одну и туже задачу, могут выделить разные пары сущностей).
Мы будем выделять пять исходных сущностей: Судья, ВУЗ, Служащий, Вид спорта, Студент.
У сущности Служащий одна роль Главный тренер.
У сущности ВУЗ две роли ВУЗ-Гость и ВУЗ-Хозяин.
Запишем ключевые атрибуты сущностей и их ролей:
|
Н_ВУЗ
|
-
|
название ВУЗа,
|
|
Н_Х
|
-
|
название команды хозяев,
|
|
Н_Г
|
-
|
название команды гостей,
|
|
ВИД_СП
|
-
|
вид спорта,
|
|
НОМ_СТ
|
-
|
номер студента,
|
|
НОМ_СЛ
|
|
номер служащего
|
|
НОМ_ТРЕН
|
-
|
номер главного тренера,
|
|
НОМ_СУД
|
-
|
номер судьи.
|
4. Построение ER–диаграммы показанно на рисунке:
|
|
Р ис. 7.55 Диаграмма ER-типа для базы данных ДСО “Буревестник”
|
5. Сформируем отношения по правилам, чьи номера указаны в кружках:
Связь в ВУЗе работают СЛУЖАЩИЕ:
Вуз (Н_ВУЗ,…)
Служащий ( НОМ_СЛ,…,Н_ВУЗ)
Связь СТУДЕНТ учиться в ВУЗе:
Студент ( НОМ_СТ,…Н_ВУЗ)
Вуз (Н_ВУЗ,…)
Связь ВУЗ культивирует ВИД СПОРТА:
Вуз (Н_ВУЗ,…)
Вид_сп ( ВИД_СП,… )
Культивирует ( Н_ВУЗ,ВИД_СП,…)
Связь РАСПИСАНИЕ:
Судья (НОМ_СУД,…)
Вуз_гость (Н_Г,…)
Вуз_хозяин (Н_Х,…)
Расписание (НОМ_СТ,Н_Г,Н_Х,ВИД_СП,…)
Связь СТУДЕНТ занимается СПОРТОМ:
Студент (НОМ_СТ,…)
Вид спорта (ВИД_СП,…)
Участвует (ВИД_СП,НОМ_СТ,…)
Связь ГЛАВНЫЙ ТРЕНЕР тренирует ВИД СПОРТА:
Вид_сп ( ВИД_СП,… )
Тренер (НОМ_ТР,…,ВИД_СП)
Связь ГЛАВНЫЙ ТРЕНЕР является председателем по правилам данного ВИДА СПОРТА:
Вид_сп ( ВИД_СП,…,НОМ_ТР )
Тренер (НОМ_ТР,…)
Связь СУДЬЯ судит:
Судья (НОМ_СУД,…)
Вид_сп(ВИД_СП,…)
6. Вычеркиваем из полученных отношений повторяющиеся и переписываем что осталось:
Вуз (Н_ВУЗ, …)
Служащий ( НОМ_СЛ,…, Н_ВУЗ)
Студент ( НОМ_СТ, …,Н_ВУЗ)
Вид_сп ( ВИД_СП,…, НОМ_ТРЕН )
Культивирует ( Н_ВУЗ, ВИД_СП,…)
Судья (НОМ_СУД,…)
Вуз_гость (Н_Г,…)
Вуз_хозяин (Н_Х,…)
Участвует (ВИД_СП , НОМ_СТ,…)
Расписание (НОМ_СУД, Н_Г, Н_Х, ВИД_СП, …)
Тренер (НОМ_ТР,…, ВИД_СП)
7. Затем дописываем в отношения атрибуты которые оговаривались в условии:
Вуз (Н_ВУЗ, Н_СТАД, ВМЕСТ, ЧИСЛО_СТ)
Служащий ( НОМ_СЛ, Н_ВУЗ, ФАМ, АДР, ДОМ_Т, РАБ_Т, ДОЛЖНОСТЬ)
Студент ( НОМ_СТ, Н_ВУЗ, ПОЛ, ДАТА_РОЖД, ФАМ, АДР_СТ, ДАТА_ПОСТ)
Вид_сп ( ВИД_СП, НОМ_ТРЕН )
Культивирует ( Н_ВУЗ, ВИД_СП)
Судья (НОМ_СУД,ФАМ_СУД, АДР_СУД, ДТЕЛ_СУД, ВИД_СП_СУД)
Вуз_гость (Н_Г)
Вуз_хозяин (Н_Х)
Участвует (ВИД_СП , НОМ_СТ)
Расписание (НОМ_СУД, Н_Г, Н_Х, ВИД_СП, ДАТА_ВСТР, ВРЕМЯ_НАЧАЛА)
Тренер (НОМ_ТР, ВИД_СП)
Две таблицы ВУЗ Гость и ВУЗ Хозяин, не содержат ни какой полезной информации. Это является следствием того, что в модели отсутствуют атрибуты, характерные только для команды хозяев, или только для команды гостей. Поэтому эти две таблицы можно исключить. Например если бы мы хотели бы считать расходы команд за матч они были бы различными. Команда гостей должна оплачивать свое проживание, а команда хозяев оплатить банкет после матча например. Тогда в этих двух таблицах хранилась бы дополнительная информация.
Все восемь оставшихся отношений находятся в НФБК.
Рассмотрим вариант когда одну встречу могут судить несколько судей одновременно, тогда верхняя часть рисунка 7.55 выглядела бы следующим образом:
|
|
|
Рис. 7.56 Диаграмма ER-типа для связи расписание, в случае если одну встречу судят несколько судей.
|
Встреча (ID_встреча, н_гость, н_хозяин, вид_сп, дата, время),
Судит (ID_встреча, ном_с).
- Постреляционные базы данных
- Ограничения реляционных баз данных.
Появление реляционных СУБД стало важным шагом вперед по сравнению с иерархическими и сетевыми СУБД, в этих системах стали использоваться непроцедурные языки манипулирования данными и была достигнута значительная степень независимости данных от обрабатывающих программ. В то же время, выяснился ряд недостатков реляционных систем. Реляционная модель ограничена в представлении данных:
Они идеально походят для таких традиционных приложений, как системы резервирования билетов или мест в гостиницах, а также банковских систем, но их применение в системах автоматизации проектирования, интеллектуальных системах обучения и других системах, основанных на знаниях, часто является затруднительным.
Это прежде всего связано с примитивностью структур данных, лежащих в основе реляционной модели данных. Плоские нормализованные отношения универсальны и теоретически достаточны для представления данных любой предметной области. Однако в нетрадиционных приложениях в базе данных появляются сотни, если не тысячи таблиц, над которыми постоянно выполняются дорогостоящие операции соединения, необходимые для воссоздания сложных структур данных, присущих предметной области.
Другим серьезным ограничением реляционных систем являются их относительно слабые возможности по части представления семантики приложения. Самое большее, что обеспечивают реляционные СУБД,- это возможность формулирования и поддержки ограничений целостности данных.
Недостатки реляционных баз данных
- Реляционная модель данных не допускает естественного представления данных со сложной (иерархической) структурой, поскольку в ее рамках возможно моделирование лишь с помощью плоских отношений (таблиц).
- По определению в реляционной модели поля кортежа могут содержать лишь атомарные значения. Однако, в таких приложениях как САПР (системы автоматизированного проектирования), ГИС (геоинформационные системы), искусственный интеллект системы оперируют со сложно-структурированными объектами.
- В том случае, когда сложный объект удается “уложить” в реляционную базу данных, его данные распределяются, как правило, по многим таблицам. Соответственно, извлечение каждого такого объекта требует выполнения многих операций соединения, что значительно замедляет работу СУБД.
Обойти эти ограничения можно было бы в том случае, если бы реляционная модель допускала:
- возможность определения новых типов данных
- определение наборов операций, связанных с данными определенного типа
Первые работы, в которых отмечались эти и ряд других недостатков, появились уже в начале 80-х годов. В следующих разделах мы рассмотрим некоторые способы преодоления указанных недостатков.
- Системы управления базами данных следующего поколения
Кратко рассмотрим основные направления исследований и разработок в области так называемых постреляционных систем, т.е. систем, относящихся к следующему поколению.
Хотя отнесение СУБД к тому или иному классу в настоящее время может быть выполнено только условно, можно отметить три направления в области СУБД следующего поколения. Обозначим их именами наиболее характерных СУБД.
- Направление Postgres. Основная характеристика: максимальное следование (насколько это возможно с учетом новых требований) известным принципам организации СУБД (если не считать коренной переделки системы управления внешней памятью).
- Направление Exodus/Genesis. Основная характеристика: создание собственно не системы, а генератора систем, наиболее полно соответствующих потребностям приложений. Решение достигается путем создания наборов модулей со стандартизованными интерфейсами, причем идея распространяется вплоть до самых базисных слоев системы.
- Направление Starburst. Основная характеристика: достижение расширяемости системы и ее приспосабливаемости к нуждам конкретных приложений путем использования стандартного механизма управления правилами. По сути дела, система представляет собой некоторый интерпретатор системы правил и набор модулей-действий, вызываемых в соответствии с этими правилами. Можно изменять наборы правил (существует специальный язык задания правил) или изменять действия, подставляя другие модули с тем же интерфейсом.
В целом можно сказать, что СУБД следующего поколения - это прямые наследники реляционных систем. Тем не менее, различные направления систем третьего поколения стоит рассмотреть отдельно, поскольку они обладают некоторыми разными характеристиками.
Абстрактные типы данных
Одной из наиболее известных СУБД третьего поколения является система Postgres, а создатель этой системы М.Стоунбрекер. В Postgres реализованы многие интересные средства: поддерживается темпоральная модель хранения и доступа к данным (см. ниже) и в связи с этим абсолютно пересмотрен механизм журнализации изменений, откатов транзакций и восстановления БД после сбоев; обеспечивается мощный механизм ограничений целостности; поддерживаются ненормализованные отношения (работа в этом направлении началась еще в среде Ingres).
Одно свойство системы Postgres сближает ее со свойствами объектно-ориентированных СУБД. В Postgres допускается хранение в полях отношений данных абстрактных, определяемых пользователями типов. Это обеспечивает возможность внедрения поведенческого аспекта в БД, т.е. решает ту же задачу, что и ООБД, хотя, конечно, семантические возможности модели данных Postgres существенно слабее, чем у объектно-ориентированных моделей данных. Основная разница состоит в том, что системы класса Postgres не предполагают наличия языка программирования, одинаково понимаемого как внешней системой программирования, так и системой управления базами данных. Если с использованием такой системы программирования определяются типы данных, хранящихся в базе данных, то СУБД оказывается не в состоянии контролировать безопасность этих определений, т.е. то отсутствует гарантия, что при выполнении процедур абстрактных типов данных не будет разрушена сама база данных.
Заметим, что в середине 1995 г. компания Sun Microsystems объявила о выпуске нового продукта - языка и семейства интерпретаторов под названием Java. Язык Java является расширенным подмножеством языка Си++. Основные изменения касаются того, что язык является пооператорно интерпретируемым (в стиле языка Бейсик), а программы, написанные на языке Java, гарантированно безопасны (в частности, при выполнении любой программы не может быть поврежден интерпретатор). Для этого, в частности, из языка удалена арифметика над указателями. В то же время Java остается мощным объектно-ориентированным языком, включающим развитые средства определения абстрактных типов данных. Компания Sun продвигает язык Java с целью расширения возможностей службы Всемирной Паутины (World Wide Web) Internet (основная идея состоит в том, что из сервера WWW в клиенты передаются не данные, а объекты, методы которых запрограммированы на языке Java и интерпретируются на стороне клиента; этот подход, в частности, решает проблему нестандартизованного представления мультимедийной информации). Однако, интерпретируемый и безопасный язык типа Java может быть успешно применен и в системах баз данных, допускающих хранение данных с типами, определенными пользователями.
Генерация систем баз данных, ориентированных на приложения
Идея очень проста: никогда не станет возможно создать универсальную систему управления базами данных, которая будет достаточна и не избыточна для применения в любом приложении. Например, если посмотреть на использование универсальных коммерческих СУБД (например, Oracle или Informix) в российской действительности, то можно легко увидеть, что по крайней мере в 90% случаев применяется не более чем 30% возможностей системы. Тем не менее, приложение несет всю тяжесть поддерживающей его СУБД, рассчитанной на использование в наиболее общих случаях.
Поэтому очень заманчиво производить не законченные универсальные СУБД, а нечто вроде компиляторов компиляторов (сompiler compiler), позволяющих собрать систему баз данных, ориентированную на конкретное приложение (или класс приложений). Желательно уметь генерировать систему баз данных, возможности (и соответствующие накладные расходы) которой в достаточной степени соответствуют потребностям приложения. На сегодняшний день на коммерческом рынке такие “генерационные” системы отсутствуют (например, при выборе сервера системы Oracle вы не можете отказаться от каких-либо ненужных для вашего приложения его свойств или потребовать наличия некоторых дополнительных свойств). Однако существуют как минимум два экспериментальных прототипа - Genesis и Exodus.
Обе эти генерационные системы основаны прежде всего на принципах модульности и точного соблюдения установленных интерфейсов. По сути дела, системы состоят из минимального ядра (развитой файловой системы в случае Exodus) и технологического механизма программирования дополнительных модулей. В проекте Exodus этот механизм основывается на системе программирования E, которая является простым расширением Си++, поддерживающим стабильное хранение данных во внешней памяти. Вместо готовой СУБД предоставляется набор “полуфабрикатов” с согласованными интерфейсами, из которых можно сгенерировать систему, максимально отвечающую потребностям приложения.
- Ориентация на расширенную реляционную модель
Одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения. Для традиционных приложений реляционных СУБД - банковских систем, систем резервирования и т.д. - это вовсе не ограничение, а даже преимущество, позволяющее проектировать экономные по памяти БД с предельно понятной структурой. Запросы с соединениями в таких системах сравнительно редки, для динамической поддержки целостности используются соответствующие средства SQL.
Однако с появлением эффективных реляционных СУБД их стали пытаться использовать и в менее традиционных прикладных системах - САПР, системах искусственного интеллекта и т.д. Такие системы обычно оперируют сложно структурированными объектами, для реконструкции которых из плоских таблиц реляционной БД приходится выполнять запросы, почти всегда требующие соединения отношений. Осознавая эти ограничения и недостатки реляционных систем, исследователи в области баз данных выполняют многочисленные проекты, основанные на идеях, выходящих за пределы реляционной модели данных.
Расширенная реляционная модель
Постреляционная модель данных представляет собой расширенную реляционную модель, в которой отменено требование атомарности атрибутов. Поэтому постреляционную модель называют “не первой нормальной формой” (NF2) или “многомерной базой данных”. Она использует трехмерные структуры, позволяя хранить в полях таблицы другие таблицы. Тем самым расширяются возможности по описанию сложных объектов реального мира. В качестве языка запросов используется несколько расширенный SQL, позволяющий извлекать сложные объекты из одной таблицы без операций соединения.
- Объектно-ориентированные СУБД.
Направление объектно-ориентированных баз данных (ООБД) возникло сравнительно давно. Термин “объект” в программной индустрии впервые был введен в языке Simula (1967 г.) и означал какой-либо аспект моделируемой реальности. Сейчас под объектом понимается “нечто, имеющее четко определенные границы”. Одна из причин появления объектно-ориентированных СУБД потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделенного сервера базы данных крайне редки.
Пример объектно-ориентированной СУБД - ObjectStore которая обеспечивает долговременное хранение в базе данных объектов, созданных программами на языках C++ и Java.
Первой формализованной и общепризнанной моделью данных была реляционная модель Кодда. В этой модели, как и во всех следующих, выделялись три аспекта - структурный, целостный и манипуляционный. Структуры данных в реляционной модели основываются на плоских нормализованных отношениях, ограничения целостности выражаются с помощью средств логики первого порядка и, наконец, манипулирование данными осуществляется на основе реляционной алгебры или равносильного ей реляционного исчисления. Как отмечают многие исследователи, своим успехом реляционная модель данных во многом обязана тому, что опиралась на строгий математический аппарат теории множеств, отношений и логики первого порядка.
- Объектно-ориентированная парадигма.
Любая модель данных должна включать три аспекта: структурный, целостный и манипуляционный. Посмотрим, как они реализуются на основе объектно-ориентированная парадигмы программирования:
Структура:
Структура объектной модели описываются с помощью трех ключевых понятий:
- Инкапсуляция
- Наследование
- Полиморфизм
Целостность данных:
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
- автоматическое поддержание отношений наследования.
- возможность объявить некоторые поля данных и методы объекта как “скрытые”, не видимые для других объектов; такие поля и методы используются только методами самого объекта.
- создание процедур контроля целостности внутри объекта.
Средства манипулирования данными:
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
- Анализ эффективности объектно-ориентированных баз данных
Преимущества объектно-ориентированных баз данных:
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель:
- естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели “сущность-связь” в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции.
- имеется возможность определения новых типов данных и операций с ними.
Недостатки объектно-ориентированных баз данных:
- отсутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста.
- вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами:
- Расширение ОО-языков в сторону управления данными (стандарт ODMG)
- Добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
- Стандарт ODMG.
ODMG (Object Data Management Group) - консорциум поставщиков ООБД и других заинтересованных организаций, созданный в 1991 г. Его задачей является разработка стандарта на хранение объектов в базах данных. В настоящее время опубликована вторая версия стандарта, которую так и называют ODMG 2.0. Рассмотрим кратко основные положения этого документа.
Стандарт на хранение объектов ODMG 2.0 разработан на основе трех существующих стандартов: управление базами данных (SQL), объекты (стандарты OMG – Object Management Group) и стандарты на объектно-ориентированные языки программирования (C++, Smalltalk, Java).
ODMG добавляет возможности взаимодействия с базами данных в объектно-ориентированные языки программирования: определяются средства долговременного хранения объектов и расширяется семантика языка, вносятся операторы управления данными. Стандарт состоит из нескольких частей:
Объектная модель
Объектная модель - унифицированная основа всего стандарта. Она расширяет объектную модель консорциума OMG за счет введения таких свойств как связи и транзакции для обеспечения функциональности, требуемой при взаимодействии с базами данных. Ключевые концепции объектной модели ODMG:
- наделение объектов такими свойствами как атрибуты и связи
- методы объектов (поведение)
- множественное наследование
- идентификаторы объектов (ключи)
- определение таких совокупностей объектов как списки, наборы, массивы и т.д.
- блокировка объектов и изоляция доступа
- операции над базой данных
Язык описания объектов
Язык описания объектов (ODL - Object Defifnition Language) - средство определения схемы базы данных (по аналогии с DDL в реляционных СУБД). ODL является расширением IDL (Interface Definition Language - язык описания интерфейсов) модели OMG и предоставляет средства для определения объектных типов, их атрибутов, связей и методов. ODL создает слой абстрактных описаний так, что схема базы данных становится независима как от языка программирования, так и от СУБД. ODL рассматривает только описание объектных типов данных, не вдаваясь в детали реализации их методов. Это позволяет переносить схему БД между различными ODMG-совместимыми СУБД и языками программирования, а также транслировать ее в другие DDL.
Язык объектных запросов
Язык объектных запросов (OQL - Object Query Language) - SQL - подобный декларативный язык, который предоставляет эффективные средства для извлечения объектов из базы данных, включая высокоуровневые примитивы для наборов объектов и объектных структур. Синтаксис оператора SELECT, определенный SQL-92, является подмножеством OQL, это гарантирует, что SELECT- утверждения, выполняемые над реляционными таблицами, сохранят работоспособность и с наборами объектов ODMG. OQL-запросы могут вызываться из ОО-языка, точно также из OQL-запросов могут делаться обращения к процедурам, написанным на OO-языке. OQL предоставляет средства обеспечения целостности объектов (вызов объектных методов и использование собственных операторов изменения данных).
Связывание с ОО-языками
Связывание с ОО-языками. Стандарт связывания с C++, Smalltalk и Java определяет Object Manipulation Language (OML) - язык манипулирования объектами, который расширяет базовые ОО-языки средствами манипулирования и хранения объектов. Также включаются OQL, средства навигации и поддержка транзакций. Каждый ОО-язык имеет свой собственный OML, поэтому разработчик остается в одной языковой среде, ему нет необходимости разделять средства программирования и доступа к данным.
- Объектные расширения реляционных СУБД. Язык SQL-3.
Попытки совместить средства манипулирования данными реляционной модели и способы описания внешнего мира объектно-ориентированной модели получили развитие в языке SQL-3. Здесь мы рассмотрим только предлагаемые способы определения данных.
Разработчики SQL-3 считают, что характеристики объекта определяется описанием строки таблицы. Поэтому, вводится специальная возможность описания нового типа данных:
|
Create type Address (
|
number
|
char (6),
|
|
|
street
|
char (30),
|
|
|
aptno
|
integer,
|
|
|
city
|
char (30),
|
|
|
state
|
char (2),
|
|
|
Zip
|
integer);
|
На основе нового типа могут быть определены таблицы, например:
Create table Addresses of Address;
Новые типы допускается использовать и для определения столбцов (т.е. игнорируется требование атомарности атрибутов реляционной модели).
- Базы знаний
- Понятие системы баз знаний.
Аналогично СБД (система баз данных) существует понятие СБЗ - система баз знаний. Близкими понятиями являются: экспертная система - система, обеспечивающая создание и использование с помощью компьютера баз знаний экспертов; система искусственного интеллекта.
В последнее время, однако, предпочтение отдается терминам, подчеркивающим знания, а не интеллект. Такие системы демонстрируют шаблонное использование знания, а не интеллекта, которые предполагает творческий подход, нешаблонность.
Это соответствует и точному переводу английского названия таких систем - Knowledge Based Systems (KBS) - система, базирующаяся на знаниях.
Система баз знаний - система, дающая возможность использовать подходящим образом представленные знания с помощью вычислительной машины.
- Структура системы базы знаний
Компоненты Системы баз знаний (СБЗ):
- база знаний
- механизм получения решений
- интерфейс
Механизмом получения решений (inference engine - машина вывода) – это прямое использование знаний из базы знаний для решения задач – т.е. процедура поиска, планирования и решения. Механизм решения дает возможность извлекать из базы знаний ответы на вопросы, получать решения, формулируемые в терминах понятий, хранящихся в базе.
Примеры запросов:
- найти объект, удовлетворяющий заданному условию;
- какие действия нужно выполнить в такой ситуации и т.д.
Интерфейс - обеспечивает работу с базой знаний и механизмом получения решений на языке высокого уровня, приближенном к профессиональному языку специалистов в той прикладной области, к которой относится СБЗ.
Если внимательно присмотреться к тому, что реально хранится в базе данных, то можно заметить наличие трех различных видов информации. Во-первых, это информация, характеризующая структуры пользовательских данных (описание структурной части схемы базы данных). Такая информация в случае реляционной базы данных сохраняется в системных отношениях-каталогах и содержит главным образом имена базовых отношений и имена, и типы данных их атрибутов. Во-вторых, это собственно наборы кортежей пользовательских данных, сохраняемых в определенных пользователями отношениях. Наконец, в-третьих, это правила, определяющие ограничения целостности базы данных, триггеры базы данных и представляемые (виртуальные) отношения. В реляционных системах правила опять же сохраняются в системных таблицах-каталогах, хотя плоские таблицы далеко не идеально подходят для этой цели.
Экстенсиональная и интенсиональная части базы данных
Информация первого и второго вида в совокупности явно описывает объекты (сущности) реального мира, моделируемые в базе данных. Другими словами, это явные факты, предоставленные пользователями для хранения в БД. Эту часть базы данных принято называть экстенсиональной.
Информация третьего вида служит для руководства СУБД при выполнении различного рода операций, задаваемых пользователями. Ограничения целостности могут блокировать выполнение операций обновления базы данных, триггеры вызывают автоматическое выполнение специфицированных действий при возникновении специфицированных условий, определения представлений вызывают явную или косвенную материализацию представляемых таблиц при их использовании. Эту часть базы данных принято называть интенсиональной; она содержит не непосредственные факты, а информацию, характеризующую семантику предметной области.
Как видно, в реляционных базах данных наиболее важное значение имеет экстенсиональная часть, а интенсиональная часть играет в основном вспомогательную роль. В системах баз данных, основанных на правилах, эти две части как минимум равноправны.
- Активные базы данных
По определению БД называется активной, если СУБД по отношению к ней выполняет не только те действия, которые явно указывает пользователь, но и дополнительные действия в соответствии с правилами, заложенными в саму БД.
Легко видеть, что основа этой идеи содержалась в языке SQL времени System R. На самом деле, что есть определение триггера или условного воздействия, как не введение в БД правила, в соответствии с которым СУБД должна производить дополнительные действия? Плохо лишь то, что на самом деле триггеры не были полностью реализованы ни в одной из известных систем, даже и в System R. И это не случайно, потому что реализация такого аппарата в СУБД очень сложна, накладна и не полностью понятна.
Среди вопросов, ответы на которые до сих пор не получены, следующие. Как эффективно определить набор вспомогательных действий, вызываемых прямым действием пользователя? Каким образом распознавать циклы в цепочке “действие-условие-действие-...” и что делать при возникновении таких циклов? В рамках какой транзакции выполнять дополнительные условные действия и к бюджету какого пользователя относить возникающие накладные расходы?
Масса проблем не решена даже для сравнительно простого случая реализации триггеров SQL, а задача ставится уже гораздо шире. По существу, предлагается иметь в составе СУБД продукционную систему общего вида, условия и действия которой не ограничиваются содержимым БД или прямыми действиями над ней со стороны пользователя. Например, в условие может входить время суток, а действие может быть внешним, например, вывод информации на экран оператора. Практически все современные работы по активным БД связаны с проблемой эффективной реализации такой продукционной системы.
Вместе с тем, по нашему мнению, гораздо важнее в практических целях реализовать в реляционных СУБД аппарат триггеров. Заметим, что в проекте стандарта SQL3 предусматривается существование языковых средств определения условных воздействий. Их реализация и будет первым практическим шагом к активным БД (уже появились соответствующие коммерческие реализации).
- Дедуктивные базы данных
По определению, дедуктивная БД состоит из двух частей: экстенциональной, содержащей факты, и интенциональной, содержащей правила для логического вывода новых фактов на основе экстенциональной части и запроса пользователя.
Легко видеть, что при таком общем определении SQL-ориентированную реляционную СУБД можно отнести к дедуктивным системам. Действительно, что есть определенные в схеме реляционной БД представления, как не интенциональная часть БД. В конце концов не так уж важно, какой конкретный механизм используется для вывода новых фактов на основе существующих. В случае SQL основным элементом определения представления является оператор выборки языка SQL, что вполне естественно, поскольку результатом оператора выборки является порождаемая таблица. Обеспечивается и необходимая расширяемость, поскольку представления могут определяться не только над базовыми таблицами, но и над представлениями.
Основным отличием реальной дедуктивной СУБД от реляционной является то, что и правила интенциональной части БД, и запросы пользователей могут содержать рекурсию. Возможность определения рекурсивных правил и запросов дает возможность простого решения в дедуктивных базах данных проблем, которые вызывают большие проблемы в реляционных системах (например, проблемы разборки сложной детали на примитивные составляющие). С другой стороны, именно возможность рекурсии делает реализацию дедуктивной СУБД очень сложной и во многих случаях неразрешимой эффективно проблемой.
Отметим, что обычно языки запросов и определения интенциональной части БД являются логическими (поэтому дедуктивные БД часто называют логическими). Имеется прямая связь дедуктивных БД с базами знаний (интенциональную часть БД можно рассматривать как БЗ).
Какова же связь дедуктивных БД с реляционными СУБД, кроме того, что реляционная БД является вырожденным частным случаем дедуктивной? Основным является то, что для реализации дедуктивной СУБД обычно применяется реляционная система. Такая система выступает в роли хранителя фактов и исполнителя запросов, поступающих с уровня дедуктивной СУБД. Такое использование реляционных СУБД резко актуализирует задачу глобальной оптимизации запросов.
При обычном применении реляционной СУБД запросы обычно поступают на обработку по одному, поэтому нет повода для их глобальной (межзапросной) оптимизации. Дедуктивная же СУБД при выполнении одного запроса пользователя в общем случае генерирует пакет запросов к реляционной СУБД, которые могут оптимизироваться совместно.
Конечно, в случае, когда набор правил дедуктивной БД становится велик, и их невозможно разместить в оперативной памяти, возникает проблема управления их хранением и доступом к ним во внешней памяти. Здесь опять же может быть применена реляционная система, но уже не слишком эффективно. Требуются более сложные структуры данных и другие условия выборки. Известны частные попытки решить эту проблему, но общего решения пока нет.
- Инструментальные средства построения систем баз знаний.
Для создания СБЗ могут использоваться следующие средства:
- Традиционные языки программирования - C, Basic, Pascal, Lisp и др. Особо в этом ряду стоит выделит язык функционального программирования Lisp. Его основные свойства: данные представляются в виде списков, для получения решений используется рекурсия.
- Языки представления знаний (такие как Prolog) - имеют специфические средства описания знаний и встроенный механизм поиска вывода.
- Пустые оболочки экспертных систем - содержат реализации некоторого языка представления знаний и средства организации интерфейса пользователя. Позволяют практически полностью исключить обычное программирование при создании прикладной экспертной системы.
Пример: Создадим экспертную систему, с помощью которой можно отличить птицу от самолета.
|
Таблица 10.1 Массив факты
|
|
Характеристика
|
Птица
|
Самолет
|
RULES
|
В следующей таблице представлен массив факты, который фактически является в нашем случае базой знаний. В нем перечислены некоторые характеристики объектов “птица” и “самолет”, наличие данной характеристики и объекта отмечено цифрой 1, отсутствие - 0.
|
|
Крылья
|
1
|
1
|
0
|
|
|
Хвост
|
1
|
1
|
0
|
|
|
Клюв
|
1
|
0
|
1
|
|
|
Двигатель
|
0
|
1
|
-1
|
|
|
Перья
|
1
|
0
|
1
|
|
|
Шасси
|
0
|
1
|
-1
|
|
Сформируем теперь правило вывода. Для этого тем характеристикам, которые присущи обоим объектам, присвоим нулевые весовые коэффициенты. Характеристикам присущим только “птице” поставим в соответствие весовой коэффициент 1, присущим только объекту “самолет” -1. Массив RULES, содержащий правило вывода представлен в крайнем правом столбце таблицы. Тогда механизм получения решений будет иметь вид:
Массив FACTS заполняется при опросе пользователя. Нетрудно убедиться, что при полном и правильном указании всех характеристик объектов механизм получения решений дает 2 для “птицы” и -2 для “самолета”.
- Язык SQL
Язык SQL (Structured Query Language - структурированный язык запросов) основывается на некоторой смеси алгебраических и логических конструкций.
В начале 70-х годов в компании IBM была разработана экспериментальная СУБД System R на основе языка SEQUEL (Structured English Qeury Language - структурированный английский язык запросов), который можно считать непосредственным предшественником SQL. Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой пользователь, даже не имеющий навыков программирования. В 1981 году IBM объявила о своем первом, основанном на SQL программном продукте, SQL/DS. Чуть позже к ней присоединились Oracle и другие производители. Первый стандарт языка SQL был принят Американским национальным институтом стандартизации (ANSI) в 1987 (так называемый SQL level /уровень/ 1) и несколько уточнен в 1989 году (SQL level 2). Дальнейшее развитие языка поставщиками СУБД потребовало принятия в 1992 нового расширенного стандарта (ANSI SQL-92 или просто SQL-2). В настоящее время ведется работа по подготовке третьего стандарта SQL, который должен включать элементы объектно-ориентрованного доступа к данным.
- Стандарт языка доступа к БД
SQL в настоящее время является промышленным стандартом, который в большей или меньшей степени поддерживает любая СУБД, претендующая на звание “реляционной”.
Хотя SQL стандартизован, любая его версия отличается от стандарта. Бывает, что одни и те же конструкции не работают на разных платформах. Сам SQL покрывает все подмножество реляционной алгебры. И считается, что на нем можно написать любую реляционную БД.
- Классификация операторов SQL
Можно выделить следующие группы операторов:
DDL (data definition language) – операторы определения объектов БД.
|
CREATE SCHEMA
|
-
|
создать схему БД,
|
|
DROP SCHEMA
|
-
|
удалить схему БД,
|
|
CREATE TABLE
|
-
|
создать таблицу,
|
|
ALTER TABLE
|
-
|
изменить таблицу,
|
|
DROP TABLE
|
-
|
удалить таблицу,
|
|
CREATE DOMAIN
|
-
|
создать домен,
|
|
ALTER DOMAIN
|
-
|
изменить домен,
|
|
DROP DOMAIN
|
-
|
удалить домен,
|
|
CREATE COLLECTION
|
-
|
создать последовательность,
|
|
ALTER COLLECTION
|
-
|
изменить последовательность,
|
|
DROP COLLECTION
|
-
|
удалить последовательность,
|
|
CREATE VIEW
|
-
|
создать представление,
|
|
ALTER VIEW
|
-
|
изменить представление,
|
|
DROP VIEW
|
-
|
удалить представление.
|
DML (data manipulate language) – операторы манипулирования данными.
|
SELECT
|
-
|
выбрать строки из таблиц,
|
|
INSERT
|
-
|
добавить строки в таблицы,
|
|
UPDATE
|
-
|
изменить строки в таблице,
|
|
DELETE
|
-
|
удалить строки,
|
|
COMMIT
|
-
|
зафиксировать внесенные изменения,
|
|
ROLLBACK
|
-
|
откатить внесенные изменения.
|
Операторы защиты и управления данными.
|
CREATE ASSERTION
|
-
|
создать ограничение,
|
|
DROP ASSERTION
|
-
|
удалить ограничение,
|
|
GRANT
|
-
|
Предоставить привилегии пользователю или приложению на манипулирование объектами,
|
|
REVOKE
|
-
|
отменить привилегию.
|
- Операторы SQL
CREATE TABLE (создание таблиц)
CREATE TABLE <имя таблицы> (Имя столбца1, тип столбца1 [NOT NULL],…, Имя столбца n, тип столбца n [NOT NULL])
Тип столбца:
|
CHAR (m)
|
-
|
строка символов длиной m (240 – max),
|
|
NUMBER
|
-
|
числовые значения (+ или -, м.б. десятичная точка, не более 40 цифр),
|
|
NUMBER (m)
|
-
|
m – количество цифр (m<=40),
|
|
NUMBER (m,d)
|
-
|
d – количество знаков после запятой,
|
|
DATE
|
-
|
календарные даты.
|
Предположим, надо создать следующую таблицу:
|
Таблица 10.1 Таблица “Бюджет”
|
|
Номер темы
|
Название
|
Бюджет
|
|
101
|
|
250’000
|
|
102
|
|
175’000
|
|
103
|
|
95’000
|
CREATE TABLE Themes <BK> (Theme_number NUMBER (3) NOT_NULL, <BK>, Name CHAR (10), <BK>, Budget NUMBER (8,2)); <BK>
Рассмотрим еще один пример:
|
SQL> CREATE TABLE Сотрудники(
|
Таб_номер NUMBER (6),
|
|
|
Фамилия CHAR (15),
|
|
|
Должность CHAR (15),
|
|
|
Руководитель NUMBER (6),
|
|
|
Дата_приема DATE,
|
|
|
Оклад NUMBER (6,2),
|
|
|
Премия NUMBER (5,2),
|
|
|
Отдел NUMBER (3));
|
Спецификация максимальных длин не означает обязательного соответствующего расходования физической памяти БД.
INSERT INTO (Вставка записей).
Вставка записей в таблицу осуществляется с помощью оператора INSERT, который позволяет добавлять к таблицам одну или несколько записей. При добавлении одной записи оператор INSERT имеет формат:
INSERT INTO <имя таблицы>
(имя столбца 1… ,имя столбца n)
VALUES (значение 1,… ,значение n);
В результате выполнения этого оператора к таблице, имя которой указано после слова INTO, добавляется одна запись. Для добавления записи заполняются поля перечисленные в списке. Значения полей берутся из списка, расположенного после слова VALUES. Списки полей и списки значений должны соответствовать друг другу по числу и по типу их элементов. При присвоении значений для первого поля берется первое значение, для второго – второе и т. д. В команде INSERT можно указывать имена только тех столбцов в которые вводятся значения остальные столбцы остаются пустыми те принимают значение NULL.
Пример Добавляем информацию в таблицу “Сотрудники”:
INSERT INTO Сотрудники
VALUES (4954, ‘Карпов’, ‘Бухгалтер’, 7698, ‘4 NOV 86’, 120, NULL, 30);
Порядок ввода значений должен соответствовать объявленному порядку столбцов в таблице. В команде INSERT можно указывать не все столбцы, которые окажутся пустыми.
Пример:
INSERT INTO Сотрудники (ТабНомер, Фамилия, Дата приема, Отдел)
VALUES (7954, ‘Волков’ , ‘10 NOV 86’, 30);
UPDATE (Редактирование записей).
Редактирование записей – это изменение значений полей в группе записей.
Оно выполняется оператором UPDATE:
UPDATE <имя таблицы>
SET <имя столбца 1> = <выражение 1>
(<имя столбца 2> = < выражение 2>,…)
[WHERE <условие отбора>];
Во всех записях, удовлетворяющих условию отбора, изменяются значения полей. Имя столбца указывает модифицируемое поле всей совокупности записей, а выражение определяет значения, которые будут присвоены этому полю.
- Критерий отбора, указанный в операнде WHERE, не отличается от критерия, заданного в операторе SELECT. Если он не задан, то изменяются значения всех указанных полей. Критерий отбора может варьироваться от простейшего, в котором сравниваются два значения, до сложного, когда учитывается много факторов.
- Критерий отбора представляет собой логическое выражение, в котором можно использовать следующие операции:
Операции языка SQL
|
Операции сравнения
|
|
|
=
|
Равно
|
|
>
|
Больше
|
|
<
|
Меньше
|
|
>=
|
Больше или равно
|
|
<=
|
Меньше или равно
|
|
<> или !=
|
Не равно
|
|
!>
|
Не больше
|
|
!<
|
Не меньше
|
|
LIKE
|
Сравнение по шаблону
|
|
IS NULL
|
Проверка нулевого значения
|
|
IN
|
Проверка вхождения
|
|
BETWEEN
|
Проверка вхождения в диапазон
|
|
Логические операции
|
|
|
AND
|
Логическое И
|
|
OR
|
Логическое ИЛИ
|
|
NOT
|
Логическое НЕ
|
|
Круглые скобки
|
Повышение приоритета
|
Запишем ряд логических правил SQL:
- В языке SQL приоритет операций сравнения выше приоритета логических операций.
- Оператор AND означает, что общий предикат будет истинным только тогда, когда условия, связанные по “AND”, будут истинны.
- Оператор OR означает, что общий предикат будет истинным, когда хотя бы одно из условий, связанных по “OR”, будет истинным.
- Оператор NOT означает, что общий предикат будет истинным, когда условие, перед которым стоит этот оператор, будет ложным.
- В одном предикате логические операторы выполняются в следующем порядке: сначала выполняется оператор NOT, затем - AND и только после этого - оператор OR. Для изменения порядка выполнения операторов разрешается использовать скобки.
Пример. Увеличим Воронину оклад на 10:
UPDATE Сотрудники SET Оклад = Оклад * 1.1
WHERE ТабНомер = 7738;
Пример. Увеличить оклад аналитиков и экономистов отдела 20 на 15:
UPDATE Сотрудники SET Оклад = Оклад*1,15
WHERE (Должность = ‘Аналитик’ OR Должность = ‘Экономист’) AND Отдел = 20;
Если отсутствует предложение WHERE, обновляются все строки. Предложение WHERE может содержать запрос, в этом случае будут обновляться строки, удовлетворяющие этому запросу.
Пример. Увеличить оклад сотрудников, содержащихся в таблице “Список”:
UPDATE Сотрудники SET Оклад = Оклад*1,05
WHERE Фамилия IN (SELECT Фамилия FROM Список)
Предложение SET тоже может содержать запрос.
Пример. Установить оклад экономистам как у сотрудника с номером 7456:
UPDATE Сотрудники SET Оклад =
( SELECT Оклад FROM Сотрудники WHERE Табномер = 7456)
WHERE Должность = ‘Экономист’;
DELETE (Удаление записей).
Для удаления записей используется оператор DELETE, имеющий формат:
DELETE FROM <имя таблицы>
WHERE <условие отбора>;
Из таблицы, имя которой указано после слова FROM, удаляются все записи, которые удовлетворяют критерию отбора.
Пример. Удалить из таблицы “Сотрудники” запись об экономисте Воронине:
DELETE FROM Сотрудники
WHERE Табномер = 7738
Или
DELETE FROM Сотрудники
WHERE Фамилия = ‘Воронин’ AND Должность = ‘Экономист’
Оператор SELECT.
Оператор SELECT является одним из самых главных. Он выполняется над некоторыми таблицами, входящих в БД. На самом деле в БД могут быть не только постоянно хранимые таблицы, но также и временные таблицы и так называемые представления.
Представления – это просто хранящиеся в БД SELECT – выражения.
С точки зрения пользователя представление – это таблица, которая постоянно не хранится в БД, а возникает при обращении.
С точки зрения оператора SELECT, и постоянно хранимые таблицы и временные таблицы-представления выглядят совершенно одинаково. При реальном выполнении оператора SELECT система учитывает различие между хранимыми таблицами и представлениями, скрытыми от пользователя.
Результатом выполнения операции SELECT всегда является таблица.
Оператор SELECT имеет следующий формат:
SELECT [DISTINCT]
<Список полей> или *
FROM <Список таблиц>
[WHERE <Условие отбора>]
[ORDER BY <Список полей для сортировки>]
[GROUP BY <Список полей для группирования>]
[HAVING <Условие группирования>]
[UNION <Вложенный оператор SELECT>]
Выбрать все поля
SELECT *
FROM <имя таблицы>
Выбор определенных полей
SELECT <имя столбца 1>,…,<имя столбца n>
FROM <имя таблицы>
Пример. Выбрать все поля таблицы «Сотрудники»:
SELECT *
FROM Сотрудники
Пример. Выбрать определенные поля таблицы «Сотрудники»:
SELECT Табномер, Фамилия, Отдел
FROM Сотрудники
Выбор полей, удовлетворяющих некоторому условию:
SELECT <имя столбца 1>,…,<имя столбца n>
FROM <имя таблиц(ы)>
WHERE <условие отбора>;
Пример. В результате запроса выдать фамилию и отдел работы всех сотрудников с должностью ‘Заведующий’:
SELECT Отдел, Фамилия
FROM Сотрудники
WHERE Должность = “'Заведующий”
Модификатор DISTINCT (предотвращение выборки повторяющихся слов).
Дублированными являются такие строки в результирующей таблице, в которых идентичен каждый столбец.
Иногда (в зависимости от задачи) бывает необходимо устранить все повторы строк из результирующего набора. Этой цели служит модификатор DISTINCT. Данный модификатор может быть указан только один раз в списке выбираемых элементов и действует на весь список.
SELECT [DISTINCT] <имя столбца 1>,…,< имя столбца n>
FROM <имя таблиц(ы)>
WHERE <условие отбора>;
Пример. Выбрать все должности таблицы “Сотрудники”:
SELECT DISTINCT Должность
FROM Сотрудники;
ORDER BY (упорядочение строк в результате запроса).
Операнд ORDER BY содержит список полей, определяющих порядок сортировки записей результирующего набора данных. По умолчанию сортировка по каждому полю выполняется в порядке возрастания значений. Если необходимо задать для поля сортировку по убыванию, то после имени этого поля указывается описатель DESC.
ORDER BY <порядок строк> [ASC | DESC]
Операнд ORDER BY всегда должен следовать за WHERE. Порядок строк может задаваться одним из двух способов:
именами столбцов
номерами столбцов.
Столбец, определяющий порядок вывода строк, не обязательно должен присутствовать в списке выбираемых элементов (столбцов):
Пример. Упорядочить записи по табельному номеру сотрудников:
SELECT *
FROM Сотрудники
ORDER BY ТабНомер ASC | DESC;
Пример. Выдать фамилию и наименование отдела работы для всех заведующих, при этом записи упорядочить по фамилии:
SELECT Отдел, Фамилия
FROM Сотрудники
WHERE Должность = ‘Заведующий’
ORDER BY 2
Пример. Выдать все записи таблицы «Сотрудники», при этом записи упорядочить по фамилии, а затем по табельному номеру в возрастающем порядке:
SELECT *
FROM Сотрудники
ORDER BY Фамилия, ТабНомер ASC;
Использование псевдонимов (alias).
Иногда приходится выполнять запросы, в которых таблица соединяется сама с собой, или одна таблица соединяется дважды с другой таблицей. В этом случае используют псевдонимы таблицы, которые позволяют различать соединяемые копии таблиц.
Псевдонимы (алиасы или имя корреляции) вводится в разделе FROM и пишутся через пробел после имени таблицы.
Имена корреляции должны использоваться в качестве префиксов перед именем столбца и отделяться от него точкой:
Пример:
SELECT S.Фамилия, O.НомОтд
FROM Сотрудники S, Отдел O
Псевдонимы существуют не только для таблиц, но и для полей. Если в запросе указывается одно и то же поле из разных экземпляров одной таблицы, они должны быть переименованы для устранения неоднозначности в наименованиях колонок результирующей таблицы. Определение имени корреляции делается только во время выполнения запроса.
Пример:
SELECT S1.Фамилия AS Фамилия1, S2.Оклад AS ОкладМаленький
FROM Сотрудники S1, Сотрудники S2
WHERE S1.Оклад < S2.Оклад
- Арифметические выражения.
Арифметические выражения в WHERE.
В WHERE формируется условие соединения таблиц, либо условие выбора строк.
Пример:
SELECT Фамилия, Оклад, Премия
FROM Сотрудники
WHERE Премия > 0,25*Оклад
Пример. Получить список инженеров в убывающем порядке отношения Премия/Оклад:
SELECT Фамилия, Оклад, Премия, Премия/Оклад
FROM Сотрудники
ORDER BY Премия/Оклад,DESC
- Групповые функции.
К группам строк , извлеченным в результате запроса можно применить групповые функции:
AVG, COUNT, MAX, MIN, SUM
Пример. Определить средний оклад экономистов:
SELECT AVG(Оклад)
FROM Сотрудники
WHERE Должность = ‘Экономист’
Пример. Определить общий оклад и общую премию у всех инженеров:
SELECT SUM(Вклад), SUM(Премия)
FROM Сотрудники
WHERE Должность = ‘Инженер’
Групповые функции могут быть использованы в аналитических выражениях.
Пример:
SELECT AVG(Оклад+Премия)*12
FROM Сотрудники
WHERE Должность = ‘Инженер’
Пример. Определить в организации минимальные и максимальные оклады, и их разницу:
SELECT MAX(Оклад), MIN(Оклад), MAX(Оклад) - MIN(Оклад) AS Результат
Замечание. Список выборки предложения SELECT, состоящий из групповых функций, должен содержать имена столбцов, только как атрибуты групповых функций.
Пример. Получить фамилию и оклад сотрудника с максимальным окладом, используя подзапрос:
SELECT Фамилия, Оклад
FROM Сотрудники
WHERE Оклад = ( SELECT МАХ(Оклад) FROM Сотрудники)
Тот же результат выдаст и следующий запрос:
SELECT Фамилия, MAX(Оклад).
Пример. Подсчитать количество сотрудников 30-го отдела, получающих премию:
SELECT COUNT(Премия)
FROM Сотрудники
WHERE Отдел = 30 AND (Премия >0 OR Премия NOT NULL)
COUNT можно использовать со словом DISTINCT
Пример. Подсчитать количество должностей сотрудников 30-го отдела:
SELECT COUNT (DISTINCT Должность)
FROM Сотрудники
WHERE Отдел = 30
COUNT(*) подсчитывает количество строк, удовлетворяющих условиям поиска выбора.
Пример:
SELECT COUNT(*)
FROM Сотрудники
WHERE Отдел = 30
Использование агрегативных функций в запросе вместе с операндом GROUP BY.
GROUP BY служит для выборки итоговых данных по группам:
Пример. Определить средний оклад сотрудников отделов № 10, №20, №30:
SELECT AVG(Оклад)
FROM Сотрудники
GROUP BY Отдел = 10 (20,30)
GROUP BY делит таблицу на группу строк с совпадающими значениями в одном и том же столбце или столбцах.
Пример. Выбрать номера отделов и средний оклад по отделу:
SELECT Отдел AVG(Оклад)
FROM Сотрудники
GROUP BY Отдел
Если в запросе используется GROUP BY, то в предложении SELECT вместе с групповыми функциями можно указать групповой столбец, поскольку значения в групповом столбце являются атрибутом группы строк (например, у всей группы один номер отдела, так как строки группируются по отделу).
Предложение GROUP BY всегда должно следовать за WHERE, если оно есть, а если WHERE нет – то за FROM
Для распределения строк по группам можно использовать значения столбцов.
Пример:
SELECT Отдел, Должность, COUNT(*), AVG(Оклад)
FROM Сотрудники
GROUP BY Отдел, Должность
В одном запросе совместно с групповыми функциями можно использовать условия соединения таблиц. Например, добавим в предыдущий пример номер отдела и название отдела .
SELECT НазвОтд, Должность, COUNT(*), AVG(Оклад)
FROM Сотрудники, Отделы
WHERE Сотрудники.Отдел = Отделы.Отдел
GROUP BY НазвОтд, Должность
Предложение HAVING.
Может задавать условие поиска для групп (как для отдельных строк SELECT):
HAVING поле GROUP BY
Здесь сравниваются атрибуты групп
Пример. Определить среднегодовой оклад в отделе, где насчитывается более двух сотрудников:
SELECT Должность, COUNT(*), AVG(Оклад)*12
FROM Сотрудники
GROUP BY Должность
HAVING COUNT(*)>2
В данном запросе могут присутствовать как WHERE так и HAVING. Сначала применяется WHERE. Из оставшихся строк формируется группа в соответствии с GROUP BY. К полученным группам применяется предложение HAVING.
Пример. Составить список отделов, в которых работают по крайней мере два инженера:
SELECT Отдел
FROM Сотрудники
WHERE Должность = ‘Инженер’
GROUP BY Отдел
HAVING COUNT(*) > 2
Предложение HAVING может сравнивать различные атрибуты групп.
Пример. Составить список отделов, средняя премия в которых превышает 85% оклада:
SELECT Отдел, AVG(Оклад), AVG(Премия), AVG(Оклад) + 0,25
FROM Сотрудники
GROUP BY Отдел
HAVING AVG(Премия)> 0.25*AVG(Оклад)
Предложение HAVING может сравнивать атрибуты разных групп, для этого необходимо использовать подзапросы.
Пример. Получить список должностей, средний оклад которых больше среднего размера оклада заведующего:
SELECT Должность, AVG(Оклад)
FROM Сотрудники
GROUP BY Должность
HAVING AVG(Оклад) > (SELECT AVG(Оклад)
FROM Сотрудники
WHERE Должность = ‘Заведующий’)
- Вложенные запросы.
Подзапрос – это дополнительный метод манипулирования с несколькими таблицами. Это оператор SELECT, вложенный:
в предложение WHERE, HAVING или SELECT другого оператора SELECT;
в оператор INSERT, UPDATE или DELETE
в другой подзапрос.
Именно возможность вложения операторов SQL друг в друга является причиной, по которой SQL первоначально был назван Structured Query Language. Термин подзапрос часто используется для ссылки на всю совокупность операторов, которая включает один или несколько подзапросов, а также на отдельное вложение. Каждый включающий оператор – следующий по старшинству уровень в подзапросе – представляет собой внешний уровень для внутреннего подзапроса.
Упрощенный синтаксис подзапроса.
Условия поиска, относящиеся к другому запросу, также могут встречаться в предложении WHERE внешнего запроса – до или после внутреннего запроса.
|
SELECT [DISTINCT]
|
|
<Список полей> или *
|
|
FROM <Список таблиц>
|
Начало внешнего оператора SELECT
|
|
WHERE
|
|
{выражение { [NOT] IN | оператор сравнения [ANY | ALL] } | [NOT] EXISTS}
|
|
(SELECT [DISTINCT] список выбора подзапроса
|
Подзапрос
|
|
FROM <Список таблиц>
|
заключенный
|
|
WHERE условия )
|
в скобки.
|
|
|
|
[GROUP BY <Список полей для группирования>]
|
|
[HAVING <Условие группирования>]
|
|
[ORDER BY <Список полей для сортировки>]
|
Как работает подзапрос?
Подзапросы возвращают результаты внутреннего запроса во внешнее предложение и имеют две основные формы: некоррелированную и коррелированную. Первая реализуется (концептуально) “изнутри наружу”, т.е. внешний запрос выполняет то или иное действие, основываясь на результатах выполнения внутреннего запроса. Вторую форму подзапроса можно представить так: внешний оператор SQL предоставляет значения для внутреннего подзапроса, которые будут использоваться при его выполнении. Затем результаты выполнения подзапроса возвращаются на внешний запрос.
В коррелированном подзапросе внутренний запрос не может быть реализован немедленно: он ссылается на внешний запрос и выполняется поочередно для каждой строки во внешнем запросе.
Как коррелированные, так и некоррелированные запросы бывают трех типов, в зависимости от элементов в предложении WHERE внешнего запроса.
Подзапросы, которые не возвращают ни одного или возвращают несколько элементов (начинаются с IN или с оператора сравнения, содержат ключевые слова ANY или ALL).
Подзапросы, которые возвращают единственное значение (начинаются с простого оператора сравнения).
Подзапросы, которые представляют собой тест на осуществление (начинаются с EXISTS).
Пример. Найти всех сотрудников, у которых должность как у Реброва, а именно заведующий (некоррелированный подзапрос):
SELECT Фамилия, Должность
FROM Сотрудники
WHERE Должность IN (
SELECT Должность
FROM Сотрудники
WHERE Фамилия = ‘Ребров’)
Подзапросы, возвращающие набор значений.
Подзапрос может не возвращать значения или возвращать несколько значений. Эта группа включает подзапросы, начинающиеся с IN, NOT IN или оператора сравнения с ключевыми словами ANY или ALL.
Подзапросы, начинающиеся с ключевого слова IN, имеют следующую общую форму:
Начало операторов SELECT, INSERT, UPDATE, DELETE или подзапроса:
WHERE выражение [NOT] IN (подзапрос)
[Конец операторов SELECT, INSERT, UPDATE или подзапроса]
Результатом внутреннего подзапроса является список, включающий от нуля до нескольких значений.
Когда тот или иной подзапрос начинается с ключевого слова EXISTS, этот подзапрос функционирует как “тест на существование”. Ключевое слово EXISTS в предложении WHERE выполняет проверку на существование (или несуществование) данных, которые удовлетворяют критериям соответствующего подзапроса, т.е. EXISTS выполняет проверку на наличие или отсутствие “пустого набора” строк. Если подзапрос возвращает хотя бы одну строку, этот результат оценивается как “истина”. Если подзапрос возвращает пустой набор, этот результат оценивается как “ложь”.
Подзапросы, начинающиеся с ключевого слова EXISTS, имеют следующую общую форму:
Начало операторов SELECT, INSERT, UPDATE, DELETE или подзапроса
WHERE выражение [NOT] EXISTS (подзапрос)
[Конец операторов SELECT, INSERT, UPDATE или подзапроса]
В другом виде подзапросов, которые не возвращают или возвращают несколько строк, используют оператор сравнения, модифицированный ключевыми словами ANY или ALL. Подзапросы, начинающиеся с модифицированного оператора сравнения, имеют общую форму следующего вида:
Начало операторов SELECT, INSERT, UPDATE, DELETE или подзапроса
WHERE выражение оператор_сравнения [ANY | ALL] (подзапрос)
[Конец операторов SELECT, INSERT, UPDATE или подзапроса]
Что такое ANY и ALL. Если в качестве примера воспользоваться операторами сравнения “ > “, то “ > ALL” означает “больше, чем каждое значение” (другими словами, “больше, чем наибольшее значение”). Таким образом, “ > ALL (1,2,3) ” означает “больше, чем 3 ”. “ > ANY ” означает “больше, чем, по крайней мере, одно значение» (другими словами, “больше, чем наименьшее значение”). Таким образом, “ > ANY (1,2,3) ” означает “больше, чем 1”.
Таблица 10.2 иллюстрирует различие между ключевыми словами ANY и ALL.
|
Таблица 10.2 Различие между ключевыми словами ANY и ALL
|
|
ALL
|
Результат
|
ANY
|
Результат
|
|
> ALL (1,2,3)
|
>3
|
> ANY (1,2,3)
|
>1
|
|
< ALL (1,2,3)
|
<1
|
< ANY (1,2,3)
|
<3
|
|
= ALL (1,2,3)
|
=1 или =2 или =3
|
= ANY (1,2,3)
|
=1 или =2 или =3
|
Пример. Найти сведения о сотрудниках организации, зарабатывающих больше, чем любой сотрудник отдела № 30:
SELECT DISTINCT Оклад, Фамилия, Должность, Отдел
FROM Сотрудники
WHERE Оклад > ANY ( SELECT Оклад FROM Сотрудники WHERE Отдел = 30)
Подзапросы, возвращающие значения из нескольких столбцов.
Пример. Необходимо узнать фамилии сотрудников, должность и оклад которых совпадают с данными сотрудника Данина:
SELECT DISTINCT Оклад, Должность, Фамилия
FROM Сотрудники
WHERE (Должность, Оклад) = (SELECT Должность, Оклад
FROM Сотрудники WHERE Фамилия = ‘Данин’)
Составные запросы с несколькими подзапросами.
Пример. Составить список сотрудников, должность которых совпадает с должностью сотрудника Реброва или получающих столько же или более чем сотрудник Данин:
SELECT Оклад, Должность, Фамилия
FROM Сотрудники
WHERE Должность = ANY(SELECT Должность
FROM Сотрудники WHERE Фамилия = ‘Ребров’
OR Оклад >= ALL (SELECT Должность
FROM Сотрудники WHERE Фамилия = ‘Данин’)
ORDER BY Должность, Оклад
Пример. Найти фамилию и занимаемую должность всех сотрудников отдела 10, должность которых совпадает с должностью какого-либо сотрудника отдела торговли:
SELECT Должность, Фамилия
FROM Сотрудники
WHERE Должность IN (SELECT Должность
FROM Отелы, Сотрудники
WHERE Назв_отдела = ‘Торговля’ and
Сотрудники.Отдел = Отделы.Отдел)
Синхронизация повторяющихся подзапросов
Предположим, нужно найти номер отдела, фамилию и оклад сотрудников, зарабатывающих больше среднего оклада в своем отделе.
Select Отдел, Фамилия, Оклад
From Сотрудники S
Where Оклад > (Select AVG (оклад)
From Сотрудники
Where отдел = S.отдел)
В данном случае, для каждой строки первый запрос будет вложенным.
Такой механизм называется синхронизацией повторяющегося подзапроса. Псевдоним таблицы, определенный в основном запросе и встречающийся во вложенном подзапросе, сообщает СУБД о необходимости синхронизации подзапроса с основным запросом.
Последовательность действий СУБД при обработке вложенного подзапроса с синхронизацией:
В основном запросе извлекается очередная строка.
Номер отдела из этой строки передается во вложенный подзапрос и используется вместо S.отдел.
Выполняется вложенный подзапрос, который вычисляет среднюю зарплату для заданного отдела.
Средний оклад передается в основной запрос и используется в предложении Where.
Пример использования подзапросов с условием соединения.
Найти данные о сотрудниках, работающих в Твери, должность которых такая же, как у Евдокимова:
Select Фамилия, Оклад, Должность, Город
From Сотрудники, Отделы
Where Город = “Тверь” AND
Сотрудники.отдел = Отделы.отдел AND
Должность = ANY (Select Должность
From Сотрудники
Where Фамилия = “Евдокимов”)
ORDER BY Фамилия
Комбинация нескольких команд Select
Запросы и подзапросы могут комбинироваться из нескольких команд Select с помощью операторов:
- UNION – объединение. Результат выполнения – не дублирующиеся записи, полученные в результате первого и второго запроса.
- INTERSECT – пересечение. Результат – записи, полученные как в первом, так и во втором запросах.
- EXCEPT – исключение. Результат – записи, извлеченные в первом запросе за исключением записей, полученных во втором запросе.
Пример. Выдать сотрудников с фамилией Иванов и получающих больше, чем 100 рублей:
Select Фамилия, Оклад
From Сотрудники
Where Фамилия = ‘Иванов’
UNION
Select Фамилия, Оклад
From Сотрудники
Where Оклад > 100
Замечание:
Результирующие таблицы объединяемых запросов должны быть совместимы, т.е. иметь одинаковое количество столбцов и одинаковые типы столбцов в порядке их перечисления. Не требуется, чтобы объединяемые таблицы имели одинаковые имена колонок. Наименования колонок в результирующем запросе будут автоматически взяты из результатов первого запроса.
- Индексы
Служат для повышения скорости обработки таблиц. Для создания индексов существует команда CREATE INDEX:
CREATE INDEX имя ON имя таблицы (столбец1{, столбец2, …})
Достоинства: ускоряется поиск; недостатки: требуется дополнительное дисковое пространство.
Пример. Создать индекс по столбцу Фамилия для таблицы Сотрудники:
CREATE INDEX Сотр_фам ON Сотрудники (Фам):
Если таблица имеет индекс по некоторому столбцу, то этот индекс будет использоваться при поиске информации в таблице, если условие поиска содержит данные из этого столбца.
Найдем данные о сотруднике Егорове:
Select *From Сотрудники
Where Фамилия = ‘Егоров’
Индекс используется только в том случае, если проиндексированный столбец не указан в качестве аргументов функции.
- ГЛОССАРИЙ
Глоссарий представляет собой перечень понятий, используемых в курсе лекций. Отдельные термины, отсутствующие в тексте настоящего пособия, приведены здесь в целях обеспечения полноты и ясности представления.
Агрегат данных – есть совокупность элементов или других агрегатов. При описании БД каждому агрегату приписывается уникальное имя, по которому к агрегату можно обратиться, как к единому целому при обработке данных
Активная база данных – эта та база данных в которой СУБД выполняет не только те действия, которые явно указывает пользователь, но и дополнительные действия в соответствии с правилами, заложенными в саму БД.
Атрибут (Attribute) - качество вещи; материальный объект, выступающий неотъемлемой частью личности или учреждения; качественная характеристика, а также атрибут это - любое свойство, позволяющее квалифицировать, идентифицировать, измерять сущность или выражать ее состояние либо любое описание объекта или явления. Атрибут также является свойством сущности. Например атрибутами сущности преподавателя могут быть: номер преподавателя, фамилия, телефон и т.п.
атрибут Простой - это тот атрибут, чье значение атомарно, т.е. неделимо (пример простых атрибутов: табельный номер сотрудника, фамилия сотрудника, оклад).
атрибут Сложный - это тот атрибут, чье значение представляет собой объединение значений различных атрибутов.
База данных (Database) - произвольное собрание таблиц и файлов, контролируемое СУБД.
База знаний (Knowledge Based Systems – система базирующаяся на знаниях). База знаний – эта база данных позволяющая использовать представленные знания с помощью вычислительной машины. Базы знаний отличаются мощной интенциональной частью, которая содержит правила вывода новых знаний и т.д.
Групповое отношение – это иерархическое (подчиненное) отношение между записями двух типов. Где записи первого типа будут владельцами отношения, а записи второго типа будут членами отношения или подчиненными записями.
Дедуктивная база данных – эта та база данных чьи правила интенциональной части и запросы пользователей могут содержать рекурсию. В общем случае реляционная база данных является вырожденным частным случаем дедуктивной.
Декартовым произведением множеств называется множество упорядоченных кортежей вида
Декомпозиция (Decomposition) - это получение двух отношений из одного. Отношение декомпозируется (разбивается) на отношения следующего уровня детализации.
Декомпозиция без потерь – это правильно выполненная декомпозиция. Декомпозиция выполнена правильно, если любой один и тот же запрос, примененный к исходному отношению и к полученным в результате декомпозиции отношениям, дает один и тот же результат. То есть соединение R1 и R2 дает в точности исходное соотношение R.
Декомпозиция с потерями. Если естественное соединение R1 и R2 в итоге дает больше кортежей, чем в R.
Детерминант отношения - это подмножество стоящее слево в функциональной зависимости (см. Полная функциональная зависимость).
Диаграмма Бахмана – это графическое изображение структуры БД, где групповые отношения изображается дугами ориентированного графа, а типы записи вершинами.
Домен (Domain) - набор правил ввода значений, форматных ограничений и других свойств, характеризующих группу атрибутов. Другими словами домен - это подмножество значений некоторого типа данных имеющих определенный смысл. Например: список значений и диапазон.
Жесткий сбой системы (аварийный отказ аппаратуры). Жесткий сбой характеризуется повреждением внешних носителей памяти. Жесткий сбой может произойти, например, в результате поломки головок дисковых накопителей.
Журнал транзакций- это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках). Журнал транзакций содержит детали всех операций модификации данных в базе данных, в частности, старое и новое значение модифицированного объекта, системный номер транзакции, модифицировавшей объект и т.д.
Журнализация –ведение в базе данных журнала транзакций. См. журнал транзакций.
Запись (Record) – это агрегат, не входящий ни в какой другой агрегат. Это основная единица обработки БД. В СУБД реляционного типа под записью понимается строка. В СУБД, отличной от реляционной, запись это - точка входа в файл, состоящая из индивидуальных элементов данных, которые в совокупности характеризуют один из аспектов информации, циркулирующей в системе. Индивидуальные элементы хранятся в полях записи.
Избыточная зависимость – это та зависимость, которая содержит в себе ту информацию, которая может быть получена из других зависимостей.
Индекс (Index) - средство облегчения доступа к одной или нескольким строкам таблицы. Индекс может объединять значения одного или нескольких столбцов и выступать средством обеспечения их уникальности.
Индивидуальный откат транзакции. Откат индивидуальной транзакции может быть инициирован либо самой транзакцией путем подачи команды ROLLBACK, либо системой. СУБД может инициировать откат транзакции в случае возникновения какой-либо ошибки в работе транзакции (например, деление на нуль) или если эта транзакция выбрана в качестве жертвы при разрешении тупика.
Интенсиональная часть базы данных – это та часть БД, которая содержит не непосредственные факты, а информацию, характеризующую семантику предметной области.
Информация – это сведения, передаваемые людьми устным, письменным или другим способом.
Информационно-поисковые системы – это ИС ориентированные на извлечение некоторых подмножеств из множества хранящихся сведений в соответствии с некоторым критерием поиска. Пример: справочная служба 09.
IDL (Interface Definition Language) – язык описания интерфейсов, т.е. средства для определения объектных типов, связей и методов.
Inference engine – машина вывода. См. Механизм получения решений.
Ключ (Key) - любая последовательность столбцов, часто используемых для выборки строк из таблицы. См. также Уникальный идентификатор.
Ключ связи – набор ключей сущностей, соединяемых данной связью.
Ключ сущности – это атрибут или набор атрибутов, значения которых однозначно определяют экземпляр сущности.
Кортежи – это упорядоченная совокупность элементов доменов.
KBS (Knowledge Based Systems) – Система баз данных, базирующеяся на знаниях. См. Базы знаний.
Логическая целостность данных – это защита от некорректных обновлений.
Механизм получения решений (inference engine - машина вывода) – это прямое использование знаний из базы знаний для решения задач – т.е. процедура поиска, планирования и решения. Механизм решения дает возможность извлекать из базы знаний ответы на вопросы, получать решения, формулируемые в терминах понятий, хранящихся в базе.
Минимальное покрытие – это набор функциональных зависимостей, получаемый из исходного набора функциональных зависимостей удалением всех избыточных функциональных зависимостей с помощью правил.
Многомерная база данных – или база данных не впервой нормальной форме – это база данных которая позволяет хранить в полях таблиц другие таблицы.
Множество - это некоторая совокупность данных. Элементы множества можно отличать друг от друга, а также определять, принадлежит ли данный элемент данному множеству. Над множествами можно выполнять операции объединения, пересечения, разности и дополнения.
Мощность отношения – количество кортежей отношения (количество строк в таблице). В общем случае она изменяется с течением времени.
Мягкий сбой системы (аварийный отказ программного обеспечения). Мягкий сбой характеризуется утратой оперативной памяти системы. При этом поражаются все выполняющиеся в момент сбоя транзакции, теряется содержимое всех буферов базы данных. Данные, хранящиеся на диске, остаются неповрежденными. Мягкий сбой может произойти, например, в результате аварийного отключения электрического питания или в результате неустранимого сбоя процессора.
Нормализация (Normalization) - пошаговый процесс формирования описания сущности или таблицы, отличающегося: отсутствием повторяющихся групп, однородностью значений, присваиваемых атрибутам или столбцам, отчетливым именем, четкой определенностью и уникальностью строк.
Ограничение целостности – это механизм поддержания соответствия данных предметной области на основе формально описанных правил.
Объектно-ориентированные базы данных, в отличие от реляционных, хранят не записи, а объекты.
Отношение(Relation) - это подмножество декартового произведения множеств. Отношения состоят из однотипных кортежей.
Отношением степени n (n-арным отношением) называется подмножество декартового произведения множеств .
ODL (Object Definition Language) – язык описания объектов, средство определения схемы базы данных.
ODMG (Object Data Management Group) - консорциум поставщиков ООБД, в его задачи входит разработка стандартов на хранение объектов в базе данных.
OML (Object Manipulation Language) – язык манипулирования объектами.
OQL (Object Query Language) – SQL-подобный декларативный язык, предоставляющий средства для извлечения объектов из базы данных.
Первичный ключ (Primary Key) - есть атрибут или набор атрибутов, значение которых однозначно указывают на конкретный кортеж отношения. Первичный ключ должен быть минимальным набором атрибутов. Также в базе данных первичный ключ представляет собой совокупность обязательных для ввода столбцов, однозначно идентифицирующих строки таблицы.
Первичный ключ записи - это один элемент или некоторая совокупность элементов с условием, что значение первичного ключа каждой записи должно быть уникально.
Поле (Field) - средство реализации элемента данных внутри файла. Может быть в символьном, числовом формате или в формате даты, обязательным или необязательным для заполнения.
Полная функциональная зависимость. Пусть А – это некоторый атрибут, Х – это набор атрибутов. Говорят, что А функционально полно зависит от Х, если Х А, Y А, где Y любое подмножество Х. Набор атрибутов Х называют детерминантом отношения.
Полный сцепленный ключ – это совокупность всех ключей от корневой записи до искомой.
Предметная область – это та часть реального мира о которой информационная система собирает информацию.
Программа (Program) - набор машинных команд манипулирования элементами БД и реализации различных вычислительных функций.
Пустое значение (Null) - Столбец, поле или элемент данных в некоторых системах могут иметь резервное состояние, называемое "отсутствием текущего значения" - в таких случаях говорят, что они содержат пустое значение.
Реляционная база данных – это совокупность отношений содержащих информацию о предметной области.
Резервирование – это периодическое копирование всех данных.
Распределенная база данных (Distributed Database) - база данных, физически расположенная на нескольких машинах, связанных между собой посредством сети. Существенной особенностью распределенной БД является то, что пользователь (или программа) работает в ней так, словно локально обращается ко всей базе в целом. Все действия по созданию такого впечатления выполняет СУБД.
Распределенная обработка (Distributed Processing) - возможность параллельной работы нескольких машин, объединенных в распределенную сеть, в которой каждый процессор выполняет различные определенные пользователем действия.
Семантическая целостность данных – это контроль за осмысленным сочетанием значений данных.
Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм «сущность-связь».
Связь представляет собой взаимодействие между двумя или более сущностями.
Связь (Relationship) - отношение одного объекта к другому или любой вид зависимости между двумя одно- или разнотипными объектами. Имя связи имеет особое значение.
Символ (Character) - одна ячейка памяти, способная хранить один алфавитно-цифровой знак. В поле помещаются один и более символов. Одно и более полей образуют запись, одна и более записей объединяются в файл.
Система баз знаний - система, дающая возможность использовать подходящим образом представленные знания с помощью вычислительной машины.
Системы обработки данных – это те ИС, где извлекаемая информация – это не хранимые данные, а результат обработки хранящихся данных.
Степенью декартового произведения называется число множеств n, входящих в это декартово произведение.
Степень отношения – это количество доменов (столбцов) образующих данное отношение, как правило, степень отношения в процессе жизненного цикла не меняется.
Столбец (Column) - средство реализации элемента данных в таблице. Может хранить информацию в символьном и числовом формате или в формате даты; может быть необязательным или обязательным для заполнения либо средство реализации атрибута или связи.
Строка (Row) - точка входа в таблицу, состоящая из значений всех ее столбцов.
СУБД (DBMS) - система управления базой данных, набор программных модулей обычно сочетающий в себе автоматизированные средства структуризации и манипулирования данными со средствами обеспечения секретности, восстановления и сохранности информации в многопользовательском окружении.
СУРБД (RDBMS) - система управления реляционной базой данных.
Сущность (Entity) определяется как некий объект, представляющий интерес для пользователей БД. Этот объект должен иметь экземпляры, отличающиеся друг от друга и допускающие однозначную идентификацию.
Схема взаимосвязей между сущностями (Entity Relationship Diagram) - часть модели БД, созданная на стадии проектирования БД. На схеме изображаются сущности, связи между ними и характеризующие эти сущности атрибуты. См. Сущность, Атрибут. Процесс создания этой схемы называется моделированием взаимосвязей между сущностями.
Таблица (Table) - способ представления данных, объединенных в столбцы, в реляционной СУБД. Нередко выступает средством реализации сущности. В реляционной системе является логической структурой данных.
Тип записи определяет состав ее элементов и агрегатов.
Тип отношения – характеризуется именем отношения и определяет общие свойства для всех экземпляров данного типа отношений.
Темпоральная СУБД. В темпоральной СУБД при любом обновлении записи создается ее новая копия, а преведущий вариант продолжает существовать. Можно извлечь любой вариант записи, если указать момен времени, когда этот вариант был текущим. Данное свойство СУБД позволяет пересмотреть взгляд на схемы отката и журнализации транзакций.
Транзакция - это неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.
Транзитивная зависимость. Пусть X, Y, Z – наборы атрибутов некоторого отношения.
Если XY, YZ но Y Х то XZ , тогда говорят что Z транзитивно зависит от X.
Триггер – это средство языка SQL для определения так называемых условных воздействий, позволяющих автоматически поддерживать целостность базы данных при модификациях ее объектов. Условное воздействие - это каталогизированная операция модификации, для которой задано условие ее автоматического выполнения. Для каждой таблицы может быть назначена хранимая процедура без параметров, которая вызывается при выполнении оператора модификации этой таблицы (INSERT, UPDATE, DELETE). Триггеры выполняются автоматически, независимо от того, что именно является причиной модификации данных - действия человека оператора или прикладной программы.
Универсальное отношение – это отношение, которое включает в себя все атрибуты и содержащее все данные, предполагаемые хранить в БД.
Уникальный идентификатор (Unique Identifier) - любая комбинация атрибутов /или связей, всегда однозначно идентифицирующая каждое вхождение сущности. Или: Один или несколько столбцов, содержимое которых всегда определяет одну строку таблицы.
Управление доступом (Access Control) - возможность управлять выдачей отдельным пользователям или группам пользователей полномочий производить поиск, создание, модифицирование или удаление данных, хранимых в БД. Доступ может быть разрешен и запрещен владельцем данных.
Файл (File) - средство реализации БД или ее части.
Физическая целостность данных – это защита данных от разрушения при сбоях оборудования.
Формат (Format) - тип значений атрибута или столбца: символьный, дата, число и т.д.
Flat table – плоские таблицы или таблицы где все атрибуты атомарные.
Хранилище данных (Datastore) - временное или постоянное место хранения логических элементов данных/атрибутов, используемое функциями/процессами.
Хранимая процедура – это функциональные модули, которые хранятся на сервере вместе с базой данных. Для написания хранимых процедур используют процедурные расширения SQL. Эти расширения содержат логические операторы (IF ... THEN ... ELSE), операторы перехода по условию (SWITCH ... CASE ...), операторы циклов (FOR, WHILE, UNTIL) и операторы предачи управления в процедуры (CALL, RETURN). Хранимые процедуры могут быть вызваны с передачей параметров любым пользователем, имеющим на то соотвествующие права. В некоторых системах хранимые процедуры могут быть реализованы и в виде внешних по отношению к СУБД модулей на языках общего назначения, таких как C или Pascal.
Целостность данных - это механизм поддержания соответствия базы данных предметной области. В реляционной модели данных определены два базовых требования обеспечения целостности: целостность ссылок и целостность сущностей.
Целостность ссылок. Для каждого значения внешнего ключа, появляющегося в дочернем отношении, в родительском отношении должен найтись кортеж с таким же значением первичного ключа.
Целостность сущностей. Каждый кортеж любого отношения должен отличатся от любого другого кортежа этого отношения (т.е. любое отношение должно обладать первичным ключом). Поддержание целостности сущностей обеспечивается средствами системы управления базой данных (СУБД).
Экземпляр записи – конкретная совокупность значений элементов, составляющих запись.
Экземпляр отношения – есть экземпляр записи отношения и множество (возможно пустое) подчиненных экземпляров
Экстенсиональная часть базы данных – это та часть БД, которая содержит явные факты, предоставленные пользователями для хранения в БД.
Элемент данных (Data Item) представляет собой наименьшую единицу структуры данных, каждому элементу приписывается уникальное имя, по которому обращаются к этому элементу при обработке данных.
Элементарная функция (Atomic Function) - функция, не поддающаяся дальнейшей декомпозиции на согласованные и непротиворечивые подфункции.
Язык структурированных запросов (SQL) - интернациональный стандарт для систем реляционного типа, включающий, помимо обработки запросов, соглашения по определению данных, манипулированию ими, обеспечению секретности и целостности.
ОГЛАВЛЕНИЕ
|
Часть I: ИНФОРМАЦИОННЫЕ СИСТЕМЫ И
ДОРЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ…………..……..………….1
|
|
[1] Информационные системы
[2] Основные понятия теории баз данных
[2.1] Предметная область
[2.2] Интеграция данных
[2.2.1] Достоинства интеграции данных
[2.2.2] Проблемы, связанные с интеграцией данных
[2.3] Функции администратора базы данных
[2.3.1] Защита данных от разрушения при сбоях оборудования.
[2.3.2] Защита от некорректных обновлений.
[2.3.3] Защита данных от несанкционированного доступа.
[2.3.4] Обеспечение коллективного доступа к данным.
[2.4] Проектирование и развитие баз данных
[3] Архитектура информационной системы
[3.1] Пользователи информационной системы
[3.2] Уровни представления информационной системы.
[3.2.1] Начальный уровень
[3.2.2] Инфологический уровень
[3.2.3] Концептуальный уровень
[3.2.4] Внутренний уровень
[4] Сетевые базы данных
[4.1] Структура данных сетевой модели
[4.2] Способы упорядочения подчиненных записей
[4.3] Режим включения подчиненных записей
[4.4] Режим исключения подчиненных записей.
[4.5] Операции над данными в сетевой модели.
[4.6] Ограничения целостности в сетевой модели.
[5] Иерархические базы данных
[5.1] Структура данных иерархической модели
[5.2] Операции над данными в иерархической модели
[5.3] Ограничения целостности в иерархической модели.
[6] Реляционные базы данных
[6.1] Цели проектирования баз данных
[6.2] Универсальные отношения
[6.3] Проблемы, связанные с использованием единственного отношения
[6.3.1] Проблема вставки.
[6.3.2] Проблема обновления.
[6.3.3] Проблема удаления.
[6.4] Функциональные зависимости
[6.5] Нормальные формы отношений
[6.5.1] Первая нормальная форма
[6.5.2] Вторая нормальная форма
[6.5.3] Третья нормальная форма
[6.5.4] Третья усиленная форма или нормальная форма Бойса–Кодда (НФБК)
[6.6] Декомпозиция отношений
[6.7] Избыточные функциональные зависимости. Правила вывода
[6.7.1] Правило 1. Транзитивные зависимости
[6.7.2] Правило 2. Корректные, но избыточные зависимости
[6.7.3] Правило 3. Объединение функциональных зависимостей
[6.7.4] Правило 4. Декомпозиция функциональных зависимостей
[6.7.5] Правило 5. Псевдотранзитивность
[6.7.6] Пример удаления избыточных зависимостей с помощью правил вывода
[6.8] Общая схема проектирования баз данных методом декомпозиции
[6.9] Проектирование базы данных по предметной области “Начальник отдела”.
[6.9.1] Выявление функциональных зависимостей
[6.9.2] Декомпозиция универсального отношения
[6.9.3] Проверка на наличие аномалий в отношениях базы данных “Начальник отдела”
[7] Семантическое моделирование или проектирования баз данных методом “Сущность-связь”
[7.1] Сущности и связи
[7.1.1] Диаграмма ЕR–экземпляров:
[7.1.2] Диаграмма ER–типа:
[7.1.3] Терминология метода “Сущность-связь”
[7.2] Степень связи
[7.3] Класс принадлежности сущности
[7.3.1] Примеры диаграмм ER-типа связей степени 1:1.
[7.3.2] Примеры диаграмм ER-типа связей степени 1:N и N:1
[7.3.3] Примеры диаграмм ER-типа связей степени M:N
[7.4] Порядок или мерность связи
[7.5] Схема проектирования баз данных методом “сущность-связь”
[7.6] Бинарные связи со степенью связи 1: 1
[7.6.1] Правило 1.
[7.6.2] Правило 2.
[7.6.3] Правило 3.
[7.7] Бинарные связи со степенью связи 1: N
[7.7.1] Правило 4.
[7.7.2] Правило 5.
[7.8] Бинарные связи степени M:N.
[7.8.1] Правило 6.
[7.8.2] Пример проектирования с использованием связей степенью М:N
[7.9] Связи более высокого порядка
[7.9.1] Правило 7
[7.9.2] Пример проектирования с использованием связей более высокого порядка
[7.10] Использование ролей
[7.10.1] Правило 8
[7.10.2] Пример проектирования с использованием ролей
[8] Постреляционные базы данных
[8.1] Ограничения реляционных баз данных.
[8.1.1] Недостатки реляционных баз данных
[8.2] Системы управления базами данных следующего поколения
[8.2.1] Абстрактные типы данных
[8.2.2] Генерация систем баз данных, ориентированных на приложения
[8.3] Ориентация на расширенную реляционную модель
[8.3.1] Расширенная реляционная модель
[9] Объектно-ориентированные СУБД.
[9.1] Объектно-ориентированная парадигма.
[9.1.1] Структура:
[9.1.2] Целостность данных:
[9.1.3] Средства манипулирования данными:
[9.2] Анализ эффективности объектно-ориентированных баз данных
[9.2.1] Преимущества объектно-ориентированных баз данных:
[9.2.2] Недостатки объектно-ориентированных баз данных:
[9.3] Стандарт ODMG.
[9.3.1] Объектная модель
[9.3.2] Язык описания объектов
[9.3.3] Язык объектных запросов
[9.3.4] Связывание с ОО-языками
[9.4] Объектные расширения реляционных СУБД. Язык SQL-3.
[10] Базы знаний
[10.1] Понятие системы баз знаний.
[10.2] Структура системы базы знаний
[10.2.1] Компоненты Системы баз знаний (СБЗ):
[10.2.2] Экстенсиональная и интенсиональная части базы данных
[10.3] Активные базы данных
[10.4] Дедуктивные базы данных
[10.5] Инструментальные средства построения систем баз знаний.
[11] Язык SQL
[11.1] Стандарт языка доступа к БД
[11.2] Классификация операторов SQL
[11.2.1] DDL (data definition language) – операторы определения объектов БД.
[11.2.2] DML (data manipulate language) – операторы манипулирования данными.
[11.2.3] Операторы защиты и управления данными.
[11.3] Операторы SQL
[11.3.1] CREATE TABLE (создание таблиц)
[11.3.2] INSERT INTO (Вставка записей).
[11.3.3] UPDATE (Редактирование записей).
[11.3.4] Операции языка SQL
[11.3.5] DELETE (Удаление записей).
[11.3.6] Оператор SELECT.
[11.3.7] Модификатор DISTINCT (предотвращение выборки повторяющихся слов).
[11.3.8] ORDER BY (упорядочение строк в результате запроса).
[11.3.9] Использование псевдонимов (alias).
[11.4] Арифметические выражения.
[11.5] Групповые функции.
[11.5.1] Предложение HAVING.
[11.6] Вложенные запросы.
[11.6.1] Подзапросы, возвращающие набор значений.
[11.6.2] Подзапросы, возвращающие значения из нескольких столбцов.
[11.6.3] Составные запросы с несколькими подзапросами.
[11.6.4] Синхронизация повторяющихся подзапросов
[11.6.5] Комбинация нескольких команд Select
[11.7] Индексы
[12] ГЛОССАРИЙ
|
12. ГЛОССАРИЙ……………………………………………………………………..125
Информационные системы