Copula-Based Univariate Time Series Structural Shift Identification Test
Тест на оценку структурного сдвига в одномерных временных рядах на основе моделей «копула»
Генрих Пеникас
Аннотация
Предлагается подход к определению структурного сдвига во временных рядах в предположении нелинейной взаимосвязи лаговых компонент зависимой переменной. Копулы используются для моделирования нелинейной взаимосвязи между компонент временного ряда. Обсуждается несколько важных свойств приложения копул к временным рядам. Для определения момента сдвига применяется тест структурного сдвига в копулах. Рассматривается эмпирический пример квартальных данных о темпе прироста ВВП США за период с 1947 по 2012 гг. Показано, что предложенный подход позволяет уловить сдвиг во временном ряде, вызванном рецессией 1981-1982 гг., что не может быть идентифицировано стандартными тестами на оценку структурного сдвига во временных рядах.
Ключевые слова: копула, структурный сдвиг, Андрюс-Зивот, Колмогоров-Смирнов, ВВЛ, США.
Коды JEL: C46, C14.
Copula-Based Univariate Time Series
Structural Shift Identification Test
Henry Penikas 1
Abstract
An approach is proposed to determine structural shift in time-series assuming non-linear dependence of lagged values of dependent variable. Copulas are used to model non-linear dependence of time series components. Several nice properties of copula application to time series are discussed. To identify the break copula structural shift test is applied. Data on quarterly GDP growth rate for the US from 1947 till 2012 is used as an empirical example. It is shown that the proposed approach captures the recession of 1981-1982 as the key break date in GDP growth rate series time structure that cannot be identified by standard time series structural break tests.
Keywords: copula, structural break, Andrews-Zivot, Kolmogorov-Smirnov, GDP, US.
JEL Codes:
C46 [Modeling specific distributions],
C14 [Semiparametric and Nonparametric Methods: General].
-
Introduction
It was Wald (1947) making profound research of structural break issues. Never-the-less, the structural break test domain has attracted attention of many researchers. A lot has been done (e.g. Perron (2005) provides a comprehensive review of time series structural break tests). Recently the area of joint distributions has attracted significant importance given applications if financial risk management and actuarial science. Copula models are often used in this context when it is necessary to decompose joint distribution modeling into two steps: modeling marginal distributions and dependence (i.e. copulas themselves). As a matter of fact structural tests for copulas started being developed to research the stability of copulas during the time. Among the recent papers one might find Harvey (2008) and Brodsky et al. (2009).
The objective of the current paper is to research univariate, not multivariate time series using same copula structural shift identification approach. The paper contributes in several ways:
- The unique feature of time series in terms of copula is presented. Particularly, the stability of marginals for various lagged components of the series;
- Conventional (in copula theory) independence test is interpreted as a non-linear correlogram test;
- Copula structural break test procedure application enables to reveal shifts, missed by conventional (linear) tests on structural break identification (empirical example of US GDP is considered).
As a result the paper is organized as follows. First Section 2 is devoted to brief literature review. Second theoretical framework is given in Section 3. Then Section 4 presents the data used. Section 5 provides the results of test procedure application. Section 6 concludes.
- Literature Review
The most common structural break tests are that of Andrews-Zivot (e.g. Andrews (1993)) and Philips-Perron (cf. Perron (2005)). The idea is to consider the change in intercept and (or) trend for the linear time series model. Dummy variable approach is used to detect the moment when the change is significant to be considered as the break point.
Previous works dealing with copula structural break identification of similarly copulas comparison included Genest, Remillard (2004); Remillard, Scaillet (2006); Tsukahara (2007); Brodsky et al. (2009).
Before discussing copula models application to time series analysis it is necessary to be fair enough and mention the works of Darsow et al. (1992) and Ibragimov (2009) who already researched the properties of copulas when applied to Markov processes. Particularly, Ibragimov (2009) defines r- and m-dependence properties for copulas to be suitable for time series modeling.
- Theoretical Framework
Copulas represent a way of joint probability distribution function decomposition as it is given below in (1). Extensive overview of copulas and their properties as the linkage to triangular norms might be found in Nelsen (2006) and Alsina at al. (2006), respectively.
(1)
It is necessary to state that in case and , the following representation (2) holds given (3) that is true for large rows. In case of few observations test restrictions should be studied in greater detail.
(2)
Remark 1. Marginal distributions when decomposing time series into copula and marginal are the same.
(3)
The property (3) is of great importance for the testing procedure as it clearly states that having once modeled the marginals their relationship is fully captured by copulas that do not limit the dependence nature to linearity.
Briefly to remind the testing procedure taken from Brodsky et al. (2009).
Two empirical copulas (4) before and after potential break point l are estimated.
(4)
where and for every
(5)
is fixed and the following modification of the Kolmogorov-Smirnov statistics (6) is applied:
(6)
Then the statistics (7) takes its maximum value in the break point (8)
. (7)
, (8)
Further properties of the test statistics might be found in Brodsky et al. (2009).
Different to Brodsky et al. (2009) current paper focused on copulas applied not to a time series vector, but to a univariate time series with special attention to the dependence structure of lagged components in it. US GDP official quarterly data is taken as an example. Data description and test results follow below.
- Data Used
To apply non-linear structural break test a very common data row was chosen, i.e. US GDP ranging from 1947 to 2012 sourced from the US Bureau of Economic Analysis. Level and quarterly growth rate data is presented at figure 1 below. The total number of observations equaled to 261.
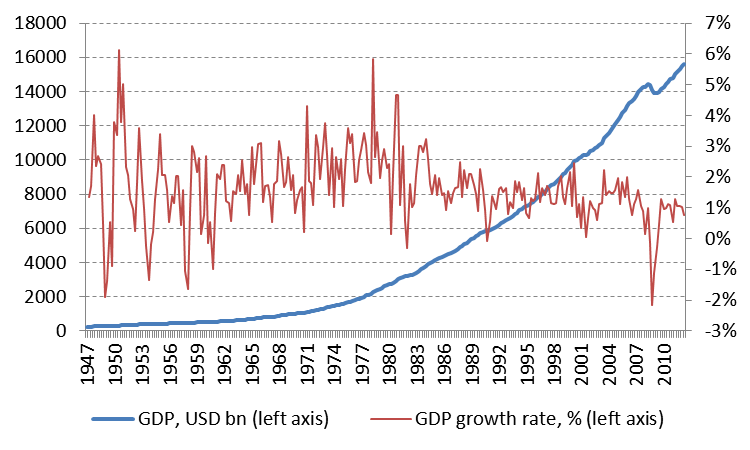
Figure . US GDP Dynamics.
Source: Bureau of Economic Analysis .
(URL: http://www.bea.gov/iTable/iTable.cfm?ReqID=9&step=1)
Quite important to note is that GDP time series is quite a low frequent and relatively nonvolatile time series compared to minute- or transaction-based financial time series. The latter are first candidates to assume non-linear dependence. Never-the-less, it was desirable to start from ordinary low frequent macroeconomic time series for test validation.
Financial time series research might well be subject of another paper where conditional heteroscedasticity might also need revision with respect to non-linearity of variance dependence on its previous values and previous squared residuals values.
GDP level-data is non-stationary is it follows solely from the visual analysis of data. That is why further analysis was proceeded with the data transformed to growth rates.
Table 1 and Figure 2 below present marginal descriptives proving marginals do not tend to differ given the discrete data. Some deviations in means only exist. This supports the fact brought in Section 3 that we might deal with the unique marginals.
Table . Marginals’ Descriptives.
|
Lag
|
0
|
-1
|
-2
|
-3
|
-4
|
-5
|
-6
|
-7
|
-8
|
-9
|
|
Min.
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
-0,022
|
|
1st Qu.
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
0,011
|
|
Median
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
|
Mean
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
0,016
|
|
3rd Qu.
|
0,021
|
0,021
|
0,021
|
0,021
|
0,021
|
0,022
|
0,022
|
0,022
|
0,022
|
0,022
|
|
Max.
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
0,061
|
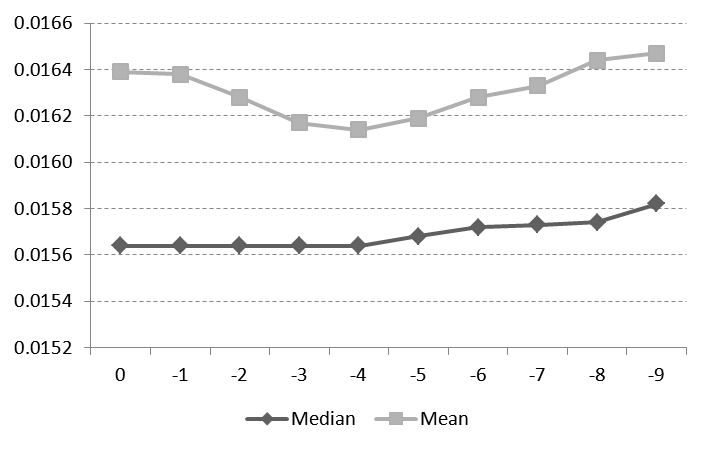
Figure . Mean and Median Values for Marginals.
Another way of data representation is the scatter plot of current GDP growth rate versus one of its lags. Example for first lag against current values is presented in figure 3. Left part (a) presents actual growth rates, whereas right part (b) shows the respective values of empirical distribution function. The latter graph brings the first hints needed for copula modeling. Though data is not rich in points like highly frequent financial time series, it still some more dispersed values in upper right corner of figure 3 (b) than that of lower left one.
Figure . Joint distribution of current GDP growth rates and its first lagged values.
- Test Realization
Testing procedure2 was twofold:
- Copula independence test suggested by Genest, Remillard (2004);
- Copula structural shift identification as proposed by Brodsky et al. (2009);
When dealing with time series analysis, traditionally one is supposed to look at the correlogram of the row to get the insights on its probable profile in terms of AR and MA components. Figure 4 illustres correlogram for US GDP growth rate series indicating the probable strong dependence of first and second lags to the current value, some jump in ACF is also observed for lags 9 and 10.
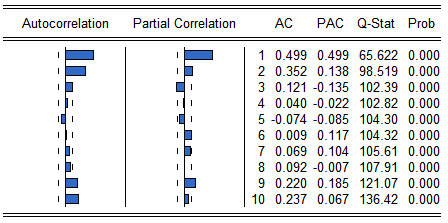
Figure . Correlograms for GDP growth rate series.
To recall correlogram brings one ideas on what are the probable (statistically significant) correlations between current values and lagged ones. But as we pointed out earlier when interested in non-linear dependence between current and lagged values, one is in need of the test whether the copula joining two values is a product copula corresponding to independence case or not.
It is exactly the question that is answered by Genest and Remillard (2004) Copula Independence Test. The test idea is to compare empirical copula to the product copula. In case the former is not statistically different from the latter, inference about independence of random variables is made. The visual test representation is Dependogram that is given in Figure 5 (reduced case) and in Annex 1 (extensive case). To comment on Figure 5 lines present the test statistics values (they are duplicated in Table 2 below for convenience), dots stand for critical values.
From the non-linear perspective (cf. Annex 1) one can also conclude about statistically significant dependence (or non-independence) case for 1st, 2nd, 9th lag that is in line with correlogram analysis. The key difference would come when searching for break point based on linearity and non-linearity assumptions.
Figure . Selected Copula Dependogram (for 1 and 2 lags)
Different to table in Annex 1 that gives one idea on bivariate copulas (i.e. pairwise dependence), Figure 5 above presents the case of a trivariate dependence, e.g. case {1,2,3}. Trivariate case analysis tests where current value of US GDP growth rate and its 1st and 2nd lag together are dependent or not. As Table 2 below shows the respective test statistics exceeds the critical value though not substantially. This implies the necessity to proceed with bivariate copula analysis with respect to time series. Never-the-less, it does not exclude application of hierarchical (cf. Okhrin et al. (2009)) or vine- (cf. Cooke et al. (2011)) copulas.
Table . Copula Independence Test Statistics Values.
|
|
subset
|
statistic
|
pvalue
|
critvalue
|
|
1
|
{1,2}
|
0.497502
|
0.00495
|
0.103565
|
|
2
|
{1,3}
|
0.363827
|
0.00495
|
0.103565
|
|
3
|
{2,3}
|
0.501566
|
0.00495
|
0.103565
|
|
4
|
{1,2,3}
|
0.009405
|
0.05445
|
0.010610
|
Our second step is to directly apply the copula structural break test to searching the break point in the time series. Figure 6 below presents the test statistics dynamics. To remember as shown in Section 3 and proven in Brodsky et al. (2009) statistics maximum corresponds to the break point. Here the bivariate3 case of is considered. The break point as summarized in table 3 below is 4th quarter of 1981.
Figure . Copula Structural Break Statistics for US GDP Growth Rate Time Series.
To give one an idea what has changed in terms of copula with the dependence for US GDP growth rate and its 1st lag Figure 7 is presented. Left part (a) of Figure 7 is more dispersed with the presence of points concentration in the right upper corner implying that Gaussian or Gumbel copulas might better descibe them. The latter is characterized by non-zero dependence of upper tails of distribution.
Figure . Scatterplots Corresponding to Copulas Before (a) and After (b) the Identified Break Date.
Inversely right part (b) of Figure 7 is less dispersed and more concentrated to lower left corner suggesting Clayton copula might be the best candidate to describe such a dependence profice. To mention Clayton copula is characterized by the non-zero dependence of lower tails of distribution (to remind Gaussian copula has zero tail dependence for both upper and lower tails of distribution).
The proposed approach is afterwards benchmarked to the conventional Andrews-Zivot test output as one may see in Table 3. All there test versions of Andrews-Zivot test were checked, including test for structural break in intercept, trend or in both.
Table . Comparison of Structural Break Tests.
|
Test Type
|
Test Specification
|
Shift Observation
|
Shift Date
|
Test Statistics
|
|
Copula
|
Kolmogorov-Smirnov
|
140
|
1981Q4
|
0.2622
|
|
Andrew-Zivot
|
Intercept
|
72
|
1964Q4
|
-10.3745
|
|
|
Trend
|
123
|
1977Q3
|
-10.3023
|
|
|
Intercept + Trend
|
96
|
1970Q4
|
-10.5476
|
Table 3 evidently shows that Andrews-Zivot linear test brings us the result of changes happening in 1964, 1970, 1977 (Annex 2 provides details for the output of testing procedure for the break point). Perhaps this is the reason for Perron to state that the problem of structural break detection and understanding is tied to the fact that the break often happens with the delay to the economic root of the structural break.
Never-the-less, it is interesting to refer to the guidance on the US history to trace what facts might underline the change. [TFC] materials suggest that the United States of America faced the first recession after Great Depression, and it was in 1973-1975 linked to the world oil crises. Thus the Andrews-Zivot test including the trend might well illustrate the delayed effect of oil crisis. Still the dates of 1964 and 1970 cannot be that explicitly explained. Not to mention the problem of reverse-engineering that having no external knowledge on economic environment one might fail to choose the correct structural break date between the three: 1964, 1970 and 1977.
What is more interesting, is that observing (and, of course, firstly assuming) non-linear nature of dependence in time series components, end of 1981 is found as the structural break date. When reverting to the US history [TFC], one may recall the events of 1981-1982 when the Iranian Revolution forced oil prices to increase once again. As one can see, the linear test for structural shift identification was unable to detect the date of 1981-1982. The latter date was the last in a sequence of crisis events, as the next recession linked with the Gulf War took place only 10 years later, i.e. in 1990-1991.
- Concluding Remarks
Current paper presented the copula structural shift test application to testing for structural shift in a univariate time series compared to conventional linear testing procedures.
The key findings are as follows:
- A nice property of time series components is noted, i.e. the equality of marginal distributions. Using copula decomposition, this property enables for copula to incorporate all dependence features (both linear and non-linear ones). Then searching for structural break in copula brings one with more information than solely dealing with the linear structural break tests.
- Copula independence test is well interpreted as a correlogram equivalent when similarly applied to time series components. Different from the correlogram, the dependogram (visual representation of copula independence test) does not distinguish between the effects on AR and MA components. Never-the-less, the inference is common as the above example have shown.
- Empirical validation of the testing procedure was done on US GDP quarterly growth rate series. Compared to Andrews-Zivot test results bringing structural shift years as 1964, 1970 and 1977, copula structural break test enabled to detect the structural change taking place after the Iranian Revolution and another oil price spike in 1981. This is considered to be the evidence of the proposed test efficiency as conventional approaches did not result in detecting this recession (as the next one was only in 1990-1991).
- References
- Alsina C., Schweiser B., Frank M. (2006): Associative Functions: Triangular Norms And Copulas. World Scientific.
- Andrews D.W.K. (1993): Tests for Parameter Instability and Structural Change with Unknown Change Point, Econometrica 61, 821-856.
- Brodsky D., Penikas H., Safaryan I. (2009): Detection of Structural Breaks in Copula Models. Applied Econometrics, 16 (4), P. 3-15.
- Cooke R., Joe H., Aas K. (2011): Vines Arise, Chapter 3 in Dependence Modeling. Vine Copula Handbook. Ed.: Kurowicka D., Joe H., World Scientific Publishing, pp. 37 – 71.
- Darsow W., Nguyen B., Olsen E. (1992): Copulas and Markov processes. Source: Illinois J. Math. Volume 36, Issue 4. P. 600-642.
- Genest Ch., Remillard B. (2004): Tests of Independence and Randomness Based on the Empirical Copula Process, Test, т. 13, № 2, 335 – 369.
- Harvey A. (2008): Dynamic Distributions and Changing Copulas, Working Paper 0839, University of Cambridge.
- Ibragimov R. (2009): Copula-Based Characterizations For Higher Order Markov Processes, Econometric Theory, 25 (3), P. 819-846.
- Nelsen R. (2006): An Introduction to Copulas. Second Edition. Springer. New York.
- Okhrin O., Okhrin Y., Schmid W. (2009): Properties of Hierarchical Archimedean Copulas, SFB 649 Discussion Paper 2009-014. http://sfb649.wiwi.hu-berlin.de/papers/pdf/SFB649DP2009-014.pdf
- Perron P. (1989): The Great Crash, the Oil Price Shock, and the Unit Root Hypothesis, Econometrica 57, 1361-1401. [cited at Astafieva A., Bessonov V., Voskoboynikov I., Lugovoi O., Turuntseva M. (2003): Analysis of Some Economic Growth Problems in Russian Transitional Economy, Working Paper. Institute of Economy in Transitional Period. Moscow, in Russian, p. 195]
- Perron P. (2005): Dealing with Structural Breaks, Palgrave Handbook of Econometrics, Vol. 1. http://sws1.bu.edu/perron/papers/dealing.pdf
- Remillard B., Scaillet O. (2009): Testing for Equality Between Two Copulas, Journal of Multivariate Analysis, № 100, 377 – 386.
- Sklar A. (1959): Fonctions de repartition a n dimensions et leurs marges. Publications de l’Institute de Statistique de l’Universite de Paris. № 8. P. 229–31.
- [TFC] How Economic Performance From 2007-2009 Compares to Other Periods in U.S. History, Teaching Financial Crises. Council for Economic Education, New York, p. 49. URL: http://tfc.councilforeconed.org/lessons.php?lid=68105
- Tsukahara H. (2005): Semiparametric estimation in copula models, Canadian Journal of Statistics, 33(3), pp.357-375.
- Wald (1947): Sequential Analysis. Courier Dover Publications. [cited at Shiryaev A.N. (1973): Statistical sequential analysis, American Mathematical Society (Translated from Russian)]
Annex 1. Copula-Based Time Series Independence Test.
Note: 1 stands for zero lag; 2 – for the first etc.; i.e. {2;10} case presents test results for first lag and ninth lag.
Annex 2. Andrews-Zivot Structural Break Test Output.
- Intercept
|
Dependent Variable: Y
|
|
Method: Least Squares
|
|
Sample(adjusted): 3 262
|
|
Included observations: 260 after adjusting endpoints
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
C
|
0.010701
|
0.001616
|
6.620455
|
0.0000
|
|
DU72
|
0.008176
|
0.002253
|
3.629600
|
0.0003
|
|
TR
|
-5.48E-05
|
1.35E-05
|
-4.055784
|
0.0001
|
|
Y(-1)
|
0.413326
|
0.056549
|
7.309130
|
0.0000
|
|
R-squared
|
0.295631
|
Mean dependent var
|
0.016243
|
|
Adjusted R-squared
|
0.287376
|
S.D. dependent var
|
0.011544
|
|
S.E. of regression
|
0.009745
|
Akaike info criterion
|
-6.408867
|
|
Sum squared resid
|
0.024311
|
Schwarz criterion
|
-6.354087
|
|
Log likelihood
|
837.1527
|
F-statistic
|
35.81521
|
|
Durbin-Watson stat
|
2.063759
|
Prob(F-statistic)
|
0.000000
|
- Trend
|
Dependent Variable: Y
|
|
Method: Least Squares
|
|
Sample(adjusted): 3 262
|
|
Included observations: 260 after adjusting endpoints
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
C
|
0.007629
|
0.001817
|
4.198986
|
0.0000
|
|
TR
|
4.88E-05
|
2.04E-05
|
2.396557
|
0.0173
|
|
DT123
|
-0.000120
|
3.46E-05
|
-3.467428
|
0.0006
|
|
Y(-1)
|
0.413901
|
0.056890
|
7.275465
|
0.0000
|
|
R-squared
|
0.292606
|
Mean dependent var
|
0.016243
|
|
Adjusted R-squared
|
0.284316
|
S.D. dependent var
|
0.011544
|
|
S.E. of regression
|
0.009766
|
Akaike info criterion
|
-6.404582
|
|
Sum squared resid
|
0.024415
|
Schwarz criterion
|
-6.349802
|
|
Log likelihood
|
836.5956
|
F-statistic
|
35.29720
|
|
Durbin-Watson stat
|
2.071036
|
Prob(F-statistic)
|
0.000000
|
- Intercept + Trend
|
Dependent Variable: Y
|
|
Method: Least Squares
|
|
Sample(adjusted): 3 262
|
|
Included observations: 260 after adjusting endpoints
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
C
|
0.009690
|
0.002202
|
4.400010
|
0.0000
|
|
DU96
|
0.006899
|
0.002558
|
2.697157
|
0.0075
|
|
TR
|
-3.63E-06
|
3.69E-05
|
-0.098266
|
0.9218
|
|
DT96
|
-7.27E-05
|
4.08E-05
|
-1.780956
|
0.0761
|
|
Y(-1)
|
0.399352
|
0.056946
|
7.012771
|
0.0000
|
|
R-squared
|
0.303651
|
Mean dependent var
|
0.016243
|
|
Adjusted R-squared
|
0.292728
|
S.D. dependent var
|
0.011544
|
|
S.E. of regression
|
0.009708
|
Akaike info criterion
|
-6.412627
|
|
Sum squared resid
|
0.024034
|
Schwarz criterion
|
-6.344153
|
|
Log likelihood
|
838.6415
|
F-statistic
|
27.79898
|
|
Durbin-Watson stat
|
2.047217
|
Prob(F-statistic)
|
0.000000
|
1 Contact author: Henry I. Penikas
Lecturer at Mathematical Economics and Econometrics Department,
Senior Research Fellow at International Laboratory of Decision Choice and Analysis,
National Research University Higher School of Economics.
E-mail: penikas@gmail.com
2 Copula independence test and copula structural break test were run in R software, whereas Andrews-Zivot test was done in EViews environment.
3 Testing up to 10-copula structural break resulted in a similar date of 1981.
12 -
Copula-Based Univariate Time Series Structural Shift Identification Test