Параллельная машина
PAGE \* MERGEFORMAT 1
Оглавление:
1. Введение
2.1. Задачи параллельных вычислений
2.2. Модель вычислений в виде графа "операции-операнды"
2.3. Описание схемы параллельного выполнения алгоритма
2.4. Показатели эффективности параллельного алгоритма
3.1. Характеристика типовых схем коммуникации в многопроцессорных вычислительных системах
3.2. Характеристики топологии сети передачи данных
4. Классификации
5. Расчёт режимов с помощью параллельных вычислений
6. Параллельные вычисления в Matlab
7. Программные инструменты параллелизма
8.1. Программно-аппаратная архитектура параллельных вычислений CUDA
8.2. Параллельные вычисления с CUDA
8.3. CUDA в электроэнергетике
9. Примеры высокопроизводительных ВС
10. Контрольные вопросы
11. Литература
1. Введение
Параллельной машиной называют набор процессоров, памяти и некоторые методы коммуникации между ними. Это может быть двухядерный процессор ноутбуке, многопроцессорный сервер или, например, кластер (суперкомпьютер).
Применение параллельных вычислительных систем является стратегическим направлением развития вычислительной техники. Это обстоятельство вызвано не только принципиальным ограничением максимально возможного быстродействия обычных последовательных ЭВМ, но и постоянным существованием вычислительных задач, для решения которых возможностей существующих средств вычислительной техники всегда оказывается недостаточно. Так, современные проблемы "большого вызова" возможностям современной науки и техники: моделирование климата, генная инженерия, проектирование интегральных схем, анализ загрязнения окружающей среды, создание лекарственных препаратов и др., - требуют для своего анализа ЭВМ с производительностью более 1000 миллиардов операций с плавающей запятой в сек. (1 террафлопс).
Организация параллельности вычислений, когда в один и тот же момент времени выполняется одновременно несколько операций обработки данных, осуществляется, в основном, введением избыточности функциональных устройств (многопроцессорности). В этом случае можно достичь ускорения процесса решения вычислительной задачи, если осуществить разделение применяемого алгоритма на информационно независимые части и организовать выполнение каждой части вычислений на разных процессорах. Подобный подход позволяет выполнять необходимые вычисления с меньшими затратами времени, и возможность получения максимального ускорения ограничивается только числом имеющихся процессоров и количеством "независимых" частей в выполняемых вычислениях.
За многие годы существования однопроцессорных систем произошло весьма четкое разделение сфер между вычислительной техникой, алгоритмическими языками и численными методами (в широком смысле этого слова). Однако, на первых порах развития высокопроизводительных вычислений появилась необходимость совместного развития всех трех перечисленных направлений.
Последние годы характеризуются скачкообразным прогрессом в развитии микроэлектроники, что ведет к постоянному совершенствованию вычислительной техники. Появилось большое количество вычислительных систем с разнообразной архитектурой, исследованы многие варианты их использования при решении возникающих задач. Среди параллельных систем различают конвейерные, векторные, матричные, систолические, спецпроцессоры и т.п. Родоначальниками параллельных систем являются ILLIAC, CRAY, CONVEX и др. В настоящее время все суперкомпьютеры являются параллельными системами.
С появлением параллельных систем возникли новые проблемы:
— как обеспечить эффективное решение задач на той или иной параллельной системе, и какими критериями эффективности следует пользоваться;
— как описать класс тех задач, которые естественно решать на данной параллельной системе, а также класс задач, не поддающихся эффективному распараллеливанию;
— как обеспечить преобразование данного алгоритма в подходящую для рассматриваемой параллельной системы форму (т.е. как распараллелить алгоритм);
— как поддержать переносимость полученной программы на систему с другой архитектурой;
— как сохранить работоспособность программы и улучшить ее характеристики при модификации данной системы; в частности, как обеспечить работоспособность программы при увеличении количества параллельных модулей.
Естественным способом решения этих проблем стало создание стандартов как для вычислительной техники (и прежде всего для элементной базы), так и для программного обеспечения. В настоящее время разрабатываются стандарты для математического обеспечения параллельных вычислительных систем; в частности, постоянно дорабатываются стандарты MPI и Open MP, а также некоторые другие.
2.1. Задачи параллельных вычислений
В настоящие время стали очень распространены параллельные компьютеры или ЭВМ. Это связано с тем, что экономически намного выгоднее делать много ядер с низкой частотой, чем одно ядро с большой частотой. В связи с этим фактом возникло новое направление – параллельные вычисления.
Они применяются в таких областях как data mining, графика, медицинская диагностика, физическое и финансовое моделирование. Все эти задачи объединяет одна общая деталь – огромный объём обрабатываемых данных. Эта деталь очень часто позволяет распараллелить обработку этих данных.
При разработке параллельных алгоритмов решения задач вычислительной математики принципиальным моментом является анализ эффективности использования параллелизма, состоящий обычно в оценке получаемого ускорения процесса вычисления. Формирование подобных оценок ускорения может осуществляться применительно к выбранному вычислительному алгоритму (оценка эффективности распараллеливания конкретного алгоритма). Другой важный подход может состоять в построении оценок максимально возможного ускорения процесса получения решения задачи конкретного типа (оценка эффективности параллельного способа решения задачи).
2.2. Модель вычислений в виде графа "операции-операнды"
Для описания существующих информационных зависимостей в выбираемых алгоритмах решения задач может быть использована модель в виде графа.
Представим множество операций, выполняемых в исследуемом алгоритме решения вычислительной задачи, и существующие между операциями информационные зависимости в виде ациклического ориентированного графа
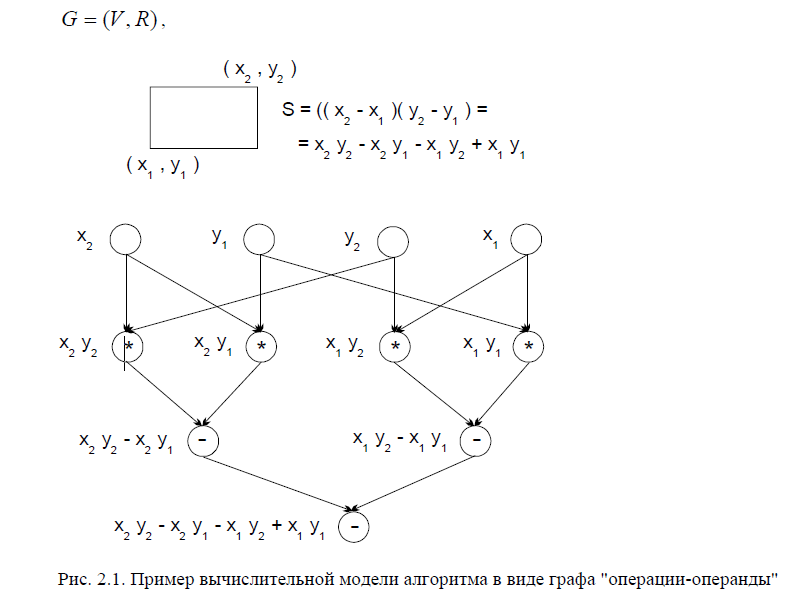
где },...,1{V=V есть множество вершин графа, представляющее выполняемые операции алгоритма, а R есть множество дуг графа (при этом дуга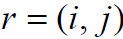 ), графу только, если операция j использует результат выполнения операции i ). Для примера на рис. 2.1 показан граф алгоритма вычисления площади прямоугольника, заданного координатами двух углов. Как можно заметить по приведенному примеру, для выполнения выбранного алгоритма решения задачи могут быть использованы разные схемы вычислений и построены соответственно разные вычислительные модели.
), графу только, если операция j использует результат выполнения операции i ). Для примера на рис. 2.1 показан граф алгоритма вычисления площади прямоугольника, заданного координатами двух углов. Как можно заметить по приведенному примеру, для выполнения выбранного алгоритма решения задачи могут быть использованы разные схемы вычислений и построены соответственно разные вычислительные модели.
В рассматриваемой вычислительной модели алгоритма вершины без входных дуг могут использоваться для задания операций ввода, а вершины без выходных дуг – для операций вывода. Обозначим через 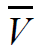 множество вершин графа без вершин ввода, а через d(G) диаметр (длину максимального пути) графа.
множество вершин графа без вершин ввода, а через d(G) диаметр (длину максимального пути) графа.
2.3. Описание схемы параллельного выполнения алгоритма
Операции алгоритма, между которыми нет пути в рамках выбранной схемы вычислений, могут быть выполнены параллельно (для вычислительной схемы на рис. 2.1, например, параллельно могут быть выполнены сначала все операции умножения, а затем первые две операции вычитания). Возможный способ описания параллельного выполнения алгоритма может состоять в следующем.
Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для параллельного выполнения вычислений необходимо задать множество
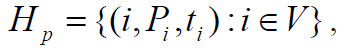
в котором для каждой операции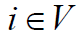 указывается номер используемого для выполнения операции процессора
указывается номер используемого для выполнения операции процессора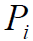 и время начала выполнения операции
и время начала выполнения операции . Для того, чтобы расписание было реализуемым, необходимо выполнение следующих требований при задании множества
. Для того, чтобы расписание было реализуемым, необходимо выполнение следующих требований при задании множества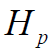 :
:
1)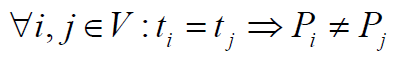 , т.е. один и тот же процессор не должен назначаться разным операциям в один и тот же момент времени,
, т.е. один и тот же процессор не должен назначаться разным операциям в один и тот же момент времени,
2)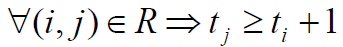 , т.е. к назначаемому моменту выполнения операции все необходимые данные уже должны быть вычислены.
, т.е. к назначаемому моменту выполнения операции все необходимые данные уже должны быть вычислены.
2.4. Показатели эффективности параллельного алгоритма
Ускорение, получаемое при использовании параллельного алгоритма для p процессоров, по сравнению с последовательным вариантом выполнения вычислений определяется :
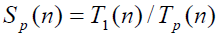
т.е. как отношение времени решения задач на скалярной ЭВМ к времени выполнения параллельного алгоритма (величина n используется для параметризации вычислительной сложности решаемой задачи и может пониматься, например, как количество входных данных задачи).
Эффективность использования параллельным алгоритмом процессоров при решении задачи определяется соотношением:
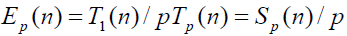
(величина эффективности определяет среднюю долю времени выполнения алгоритма, в течение которой процессоры реально используются для решения задачи).
Как следует из приведенных соотношений, в наилучшем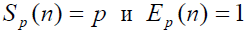 .
.
3.1. Характеристика типовых схем коммуникации в многопроцессорных вычислительных системах
Структура линий коммутации между процессорами вычислительной системы (топология сети передачи данных) определяется, как правило, с учетом возможностей эффективной технической реализации; немаловажную роль при выборе структуры сети играет и анализ интенсивности информационных потоков при параллельном решении наиболее распространенных вычислительных задач. К числу типовых топологий обычно относят следующие схемы коммуникации процессоров
полный граф (completely-connected graph or clique)– система, в которой между любой парой процессоров существует прямая линия связи; как результат, данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров;
линейка (linear array or farm) – система, в которой каждый процессор имеет линии связи только двумя соседними (с предыдущим и последующим) процессорами; такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений);
кольцо (ring) – данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки
звезда (star) – система, в которой все процессоры имеют линии связи с некоторым
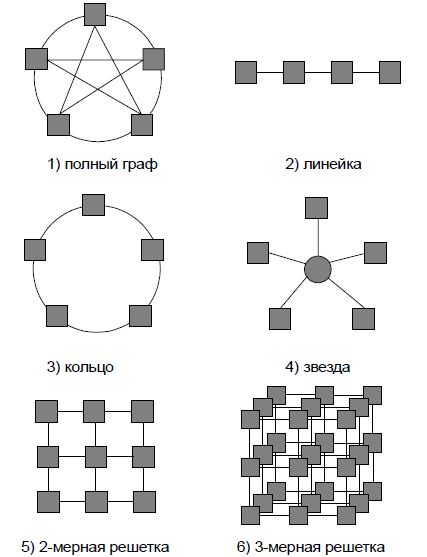
управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений;
решетка (mesh) – система, в которой граф линий связи образует прямоугольную сетку (обычно двух- или трех- мерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно используема при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных);
гиперкуб (hypercube) – данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит 2N процессоров при размерности N ); данный вариант организации сети передачи данных достаточно широко распространен в практике и характеризуется следующим рядом отличительных признаков:
два процессора имеют соединение, если двоичное представление их номеров имеет только одну различающуюся позицию;
в N -мерном гиперкубе каждый процессор связан ровно с N соседями;
N -мерный гиперкуб может быть разделен на два (N 1) -мерных гиперкуба (всего возможно различных таких разбиений); кратчайший путь между двумя любыми процессорами имеет длину, совпадающую с количеством различающихся битовых значений в номерах процессоров (данная величина известна как расстояние Хэмминга).
3.2. Характеристики топологии сети передачи данных
В качестве основных характеристик топологии сети передачи данных наиболее широко используется следующий ряд показателей:
Диаметр – показатель, определяемый как максимальное расстояние между двумя процессорами сети (под расстоянием обычно понимается величина кратчайшего пути между процессорами); данная величина может охарактеризовать максимально-необходимое время для передачи данных между процессорами, поскольку время передачи обычно прямо пропорционально длине пути;
Связность (connectivity) – показатель, характеризующий наличие разных маршрутов передачи данных между процессорами сети; конкретный вид данного показателя может быть определен, например, как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области;
Ширина бинарного деления (bisection width) – показатель, определяемый как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области одинакового размера;
стоимость – показатель, который может быть определен, например, как общее количество линий передачи данных в многопроцессорной вычислительной системе.
Для сравнения в таблице 3.1 приводятся значения перечисленных показателей для различных топологий сети передачи данных.
Таблица 3.1. Характеристики топологий сети передачи данных (p – количество процессоров)
|
Топология
|
Диаметр
|
Ширина
|
Связность Стоимость
|
|
|
|
|
бисекции
|
|
|
|
Полный граф
|
1
|
|
p 2 / 4
|
p-1
|
p(p-1)/2
|
|
|
Звезда
|
2
|
|
1
|
|
1
|
p-1
|
|
|
Полное двоичное
|
2log((p+1)/2)
|
1
|
|
1
|
p-1
|
|
|
дерево
|
|
|
|
|
|
|
|
|
Линейка
|
p-1
|
|
1
|
|
1
|
p-1
|
|
|
Кольцо
|
p/2
|
|
2
|
|
2
|
p
|
|
|
Решетка N=2
|
2(
|
p 1)
|
|
p
|
2
|
2(p- p )
|
|
|
Решетка-тор
|
2
|
p / 2
|
2
|
p
|
4
|
2p
|
|
|
N=2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Гиперкуб
|
log p
|
|
p/2
|
log p
|
(p log p)/2
|
|
|
|
|
|
|
|
|
|
|





4. Классификации
Классификация Флина:
Наибольшее распространение получила классификация вычислительных систем, предложенная в 1966 г. профессором Стенфордского университета М.Д.Флином (M.J.Flynn) - классификация Флина. Эта классификация охватывает только два классификационных признака – тип потока команд и тип потока данных.
В одиночном потоке команд в один момент времени может выполняться только одна команда. В этом случае эта единственная команда определяет в данный момент времени работу всех или, по крайней мере, многих устройств вычислительной системы.
Во множественном потоке команд в один момент времени может выполняться много команд. В этом случае каждая из таких команд определяет в данный момент времени работу только одного или лишь нескольких (но не всех) устройств вычислительной системы.
В одиночном потоке последовательно выполняются отдельные команды, во множественном потоке – группы команд.
Одиночный поток данных обязательно предполагает наличие в вычислительной системе только одного устройства оперативной памяти и одного процессора. Однако при этом процессор может быть как угодно сложным, так что процесс обработки каждой единицы информации в потоке может требовать выполнения многих команд.
Множественный поток данных состоит из многих зависимых или независимых одиночных потоков данных.
В соответствии со сказанным, все вычислительные системы делятся на четыре типа:
- SISD (ОКОД);
- MISD (МКОД);
- SIMD (ОКМД);
- MIMD (МКМД).
Вычислительная система SISD представляет собой классическую однопроцессорную ЭВМ фон-неймановской архитектуры.
На вычислительную системы MISD существуют различные точки зрения. По одной из них – за всю историю развития вычислительной техники системы MISD не были созданы. По другой точке зрения (менее распространенной, чем первая) к MISD-системам относятся векторно-конвейерные вычислительные системы. Мы будем придерживаться первой точки зрения.
Вычислительная система SIMD содержит много процессоров, которые синхронно (как правило) выполняют одну и ту же команду над разными данными.
Системы SIMD делятся на два больших класса:
- векторно-конвейерные вычислительные системы;
- векторно-параллельные вычислительные системы или матричные вычислительные системы.
Вычислительная система MIMD содержит много процессоров, которые (как правило, асинхронно) выполняют разные команды над разными данными. Подавляющее большинство современных суперЭВМ имеют архитектуру MIMD (по крайней мере, на верхнем уровне иерархии). Системы MIMD часто называют многопроцессорными системами.
Рассмотренная классификации Флина позволяет по принадлежности компьютера к классу SIMD или MIMD сделать сразу понятным базовый принцип его работы. Часто этого бывает достаточно. Недостатком классификации Флина является "переполненность" класс MIMD.
Классификация по типу строения оперативной памяти:
По типу строения оперативной памяти системы разделяются на системы с общей (разделяемой) памятью, системы с распределенной памятью и системы с физически распределенной, алогически общедоступной памятью (гибридные системы).
В вычислительных системах с общей памятью (Common Memory Systems или Shared Memory Systems) значение, записанное в память одним из процессоров, напрямую доступно для другого процессора. Общая память обычно имеет высокую пропускную способность памяти и низкую латентность памяти при передачи информации между процессорами, но при условии, что не происходит одновременного обращения нескольких процессоров к одному и тому же элементу памяти. К общей памяти доступ разных процессорами системы осуществляется, как правило, за одинаковое время. Поэтому такая память называется еще UMA-памятью (Unified Memory Access) — памятью с одинаковым временем доступа. Система с такой памятью носит название вычислительной системы с одинаковым временем доступа к памяти. Системы с общей памятью называются также сильносвязанными вычислительными системами.
В вычислительных системах с распределенной памятью (Distributed Memory Systems) каждый процессор имеет свою локальную память с локальным адресным пространством. Для систем с распределенной памятью характерно наличие большого числа быстрых каналов, которые связывают отдельные части этой памяти с отдельными процессорами. Обмен информацией между частями распределенной памяти осуществляется обычно относительно медленно. Системы с распределенной памятью называются также слабосвязанными вычислительными системами.
Вычислительные системы с гибридной памятью - (Non-Uniform Memory Access Systems) имеют память, которая физически распределена по различным частям системы, но логически разделяема (образует единое адресное пространство). Такая память называется еще логически общей (разделяемой) памятью. В отличие от UMA-систем, в NUMA-системах время доступа к различным частям оперативной памяти различно.
Заметим, что память современных параллельных систем является многоуровневой, иерархической, что порождает проблему ее когерентности.
Классификация по степени однородности:
По степени однородности различают однородные (гомогенные) и неоднородные (гетерогенные) вычислительные системы. Обычно при этом имеется в виду тип используемых процессоров.
В однородных вычислительных системах (гомогенных вычислительных системах) используются одинаковые процессоры, в неоднородных вычислительных системах (гетерогенных вычислительных системах) – процессоры различных типов. Вычислительная система, содержащая какой-либо специализированный вычислитель (например, Фурье-процессор), относится к классу неоднородных вычислительных систем.
В настоящее время большинство высокопроизводительных систем относятся к классу однородных систем с общей памятью или к классу однородных систем с распределенной памятью.
Рассмотренные классификационные признаки параллельных вычислительных систем не исчерпывают всех возможных их характеристик. Существует, например, еще разделение систем по степени согласованности режимов работы (синхронные и асинхронные вычислительные системы), по способу обработки (с пословной обработкой и ассоциативные вычислительные системы), по жесткости структуры (системы с фиксированной структурой и системы с перестраиваемой структурой), по управляющему потоку (системы потока команд -instruction flow и системы потока данных — data flow) и т.п.
Современные высокопроизводительные системы имеют, как правило, иерархическую структуру. Например, на верхнем уровне иерархии система относится к классу MIMD, каждый процессор которой представляет собой систему MIMD или систему SIMD.
Отметим также тенденцию к построению распределенных систем с программируемой структурой. В таких системах нет общего ресурса, отказ которого приводил бы к отказу системы в целом – средства управления, обработки и хранения информации распределены по составным частям системы. Такие системы обладают способностью автоматически реконфигурироваться в случае выхода из строя отдельных их частей. Средства реконфигурирования позволяют также программно перестроить систему с целью повышения эффективности решения на этой системе данной задачи или класса задач.
5. Расчёт режимов с помощью параллельных вычислений
Существует большое количество объектов, которые характеризуются значительной территориальной распределенностью пунктов контроля и управления. К таким объектам относятся магистральные нефте и газопроводы, электроэнергетические системы (ЭЭС) и другие крупно масштабные объекты. Сложность управления такими объектами обуславливается, прежде всего большими объемами обрабатываемой информации, оперативного контроля за состоянием объекта по результатам анализа параметров отельных подсистем. Мы сосредоточим внимание на решении одной из важнейших задач управления ЭЭС - на задачи расчета установившегося режима (РУР) эквивалентной электрической сети.
Обобщенная структура системы управления ЭЭС состоит из национального центра управления (НЦУ) и нескольких локальных центров управления (ЛЦУ) – рис. 1. Обмен данных и управляющих действии межу НЦУ и ЛЦУ осуществляется через каналы связи со сравнительно малой скоростью. В каждом ЛЦУ хранятся параметры подсети, управляемой им.
В настоящее время характерно использование централизованного подхода к решению такого рода задач, что является «узким» звеном, ведущим к снижению качества управления, прежде всего за счет большой временной реактивности системы, чрезмерной сложности программного обеспечения (ПО) управления данными, вынужденного использования приближенных расчетов (для уменьшения объемов обрабатываемой информации), малой живучести системы. Поэтому разработка новых перспективных подходов для повышения эффективности управления большими системами является в настоящее время весьма важной.
К основным показателям рассматриваемой эффективности относятся быстродействие, надежность получения решения и рациональная организация процессов передачи информации. Перспективный путь в этом направлении заключается: во–первых, в переходе от последовательных к параллельным вычислениям, во–вторых, в переходе от централизованной к распределенной иерархической организации вычисления.
В данном разделе реферата описывается метод распределенного параллельного вычисления РУР. Рассматриваемый метод получил название, "сетвевая МОДЕЛЬ РАСЧЕТА УСТАНОВИВШЕГОСЯ РЕЖИМА В ЭЛЕКТРОЭНЕРГЕТИЧЕСКИХ СИСТЕМАХ". Метод основан на теории Тевенена–Нортона .
Суть предлагаемого обобщения заключается в определении напряжении Vth и сопротивления Zth для всех граничных узлов подсети, а не для одного граничного узла, как в методе Тевенена–Нортона.
Метод состоит из трёх стадий, которые осуществляются на двух уровнях иерархии.
Нижний уровень выполняется компьютерами, находящими в локальных центрах управления. В этих центрах хранятся параметры своей подсети, управляемой ими.
Верхний уровень выполняется ведущим компьютером, который находится в главном центре управления. Этот компьютер содержит информацию о топологии сети в целом.
На первой стадии во всех локальных центрах строятся абстрактные схемы замещения соответствующих электрических подсетей. Абстрактная схема определяет представление каждого граничного узла в виде источника напряжения (Vth) и сопротивления (Zth) согласно модели Тевенена, или источник тока (Inor) и сопротивления (Znor) согласно модели Нортона.
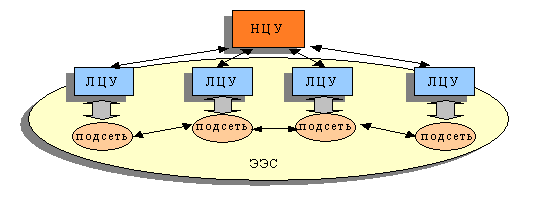
Рис.1 Обобщенная структура управления ЭЭС эквивалентов
Процесс построения эквивалентных схем граничных узлов подсети может происходить параллельно, если есть возможность параллельного вычисления. Данная стадия выполняется параллельно во всех локальных центрах, т.е., каждый локальный центр строит модель в виде абстрактной схемы замещения своей подсети. По окончании построения эквивалентных схем подсети, локальный центр посылает значения Vthи Zth каждого граничного узла ведущему компьютеру, где хранится информация о топологии сети. Понятно, что объем передаваемой информации из локальных центров ведущему относительно невелик.
Вторая стадия алгоритма начинается ведущим компьютером после получения всех значений Vth и Zth со всех граничных узлов сети. При осуществлении данной стадии строится обобщенная абстрактная модель замещения всей сети. Исходя из этой модели, решается соответствующая система линейных уравнений для того, чтобы найти напряжения в граничных узлах. Число линейных уравнений равно числу граничных узлов. После вычисления значений напряжения в граничных узлах ведущий компьютер посылает полученные значения локальным центрам.
Последняя, третья стадия алгоритма выполняется параллельно всеми вычислителями локальных центров после получения результатов от ведущего компьютера в виде напряжений на граничных узлах. Здесь вычисляются напряжения, токи и мощности внутренних узлов подсетей. Нахождение искомых значений параметров для всех внутренних узлов осуществляется путем решения системы линейных уравнений (СЛУ). Число этих уравнений равно числу внутренних узлов подсети. Рис.2 иллюстрирует предлагаемый распределенный параллельный алгоритм для решения задачи расчета установившегося режима ЭЭС.
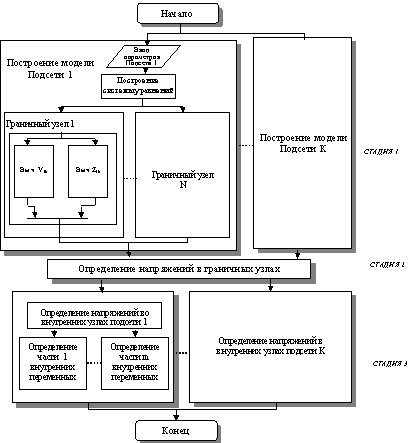
Рис.2 Схема реализации метода декомпозиционных эквивалентов
Рассматриваемый метод представляет собой аналитический подход для решения задачи РУР ЭЭС, когда объем передаваемых данных между процессами относительно не велик. Такое свойство позволяет применить этот метод в ЭЭС, для которых характерна значительная территориальная распределенность. Более того, появляется возможность эффективно использования Internet для реализации предлагаемого метода. Дополнительные свойства метода:
– равномерное распределение вычислительной нагрузки на компьютеры, управляющие ЭЭС;
– рост коэффициента ускорения параллельных вычислений с уменьшениям связности подсистем ЭЭС.
6. Параллельные вычисления в Matlab
Matlab включает несколько механизмов для проведения параллельных вычислений. Простейший подход основан на применении многопоточности и работает на системах с общей памятью. Операции с матрицами, функции линейной алгебры, вычисления преобразования Фурье и некоторые другие имеют в Matlab многопоточную реализацию, которая позволяет использовать несколько процессоров или процессорных ядер. Для применения многопоточности не требуется модифицировать программу и приобретать дополнительные лицензии.
Matlab Parallel Computing Toolbox добавляет к стандартным возможностям Matlab средства для описания параллельных циклов и распределенных массивов. Parallel Computing Toolbox работает на серверах с общей памятью и графических ускорителях.
Matlab Distributed Computing Server предназначен для запуска программ Matlab на кластере с распределенной памятью. При этом на каждом узле кластера запускается один или несколько процессов Matlab, которые обмениваются данными между собой по MPI. Distributed Computing Server может работать как на выделенном кластере Matlab, так и на разделяемом кластере под управлением системы запуска задач.
Допускается совместное использование различных подходов к параллельным вычислениям в Matlab. Например, может быть запущено несколько процессов Matlab в кластере, каждый из которых использует многопоточную функцию или GPU.
Таким образом, для проведения параллельных вычислений Matlab на ПК необходимо следующее:
– ПК с установленным Distributed Computing Server, интегрированным с системой запуска задач;
– Рабочее место пользователя с графическим интерфейсом Matlab и Parallel Computing Toolbox, который обеспечит возможность отправлять задачи в очередь задач СК для расчета.
В настоящее время существует два подхода для решения параллельных задач. Первый подход основан непосредственно на процедуре отправки задания jobmanager, в инструкциях (m - файле) которой описана последовательность команд, которые будут выполняться рабочими процессами. В этом m-файле помимо основных команд MATLAB могут быть использованы функции MPI для коммуникаций между рабочими процессами. Второй подход для решения параллельных задач основан на режиме pmode. С помощью этого режима непосредственно из командного окна MATLAB становится возможным обращение к процессам workers, просмотр их локальных переменных, обмен данными между ними. В режиме pmode команды, вводимые в рабочем окне MATLAB, будут исполняться всеми рабочими процессами, ассоциированными с соответствующим jobmanager. Режим pmode, по мнению авторов, следует использовать исключительно с двумя целями: как удобный пользовательский режим, предназначенный для первоначального знакомства с элементами параллельного программирования, для понимания многопроцессорной архитектуры и парадигмы параллельного программирования и как средство отладки параллельных программ.
7. Программные инструменты параллелизма
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Дает описание совокупности директив компилятора, библиотечных процедур и переменных окружения, которые предназначены для программирования многопоточных приложений на многопроцессорных системах с общей памятью.
POSIX Threads — стандарт POSIX реализации потоков (нитей) выполнения. Стандарт POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995) определяет API для управления потоками, их синхронизации и планирования. Реализации данного API существуют для большого числа UNIX-подобных ОС (GNU/Linux, Solaris, FreeBSD, OpenBSD, NetBSD, OS X), а также для Microsoft Windows и других ОС. Библиотеки, реализующие этот стандарт (и функции этого стандарта), обычно называются Pthreads (функции имеют приставку «pthread_»).
Windows API (англ. application programming interfaces) — общее наименование целого набора базовых функций интерфейсов программирования приложенийоперационных систем семейств Microsoft Windows корпорации «Майкрософт» и совместимой с ними свободной бесплатной операционной системы ReactOS. Является самым прямым способом взаимодействия приложений с Windows и ReactOS. Для создания программ, использующих Windows API, «Майкрософт» выпускает комплект разработчика программного обеспечения, который называется Platform SDK, и содержит документацию, набор библиотек, утилит и других инструментальных средств для разработки.
Parallel Virtual Machine (PVM) (дословно виртуальная параллельная машина) — общедоступный программный пакет, позволяющий объединять разнородный наборкомпьютеров в общий вычислительный ресурс («виртуальную параллельную машину») и предоставляющий возможности управления процессами с помощьюмеханизма передачи сообщений. Существуют реализации PVM для самых различных платформ от лаптопов до суперкомпьютеров Cray. Имеет более расширенные возможности, чем ее популярный аналог MPI, в плане контроля вычислений: присутствует специализированная консоль управления параллельной системой и ее графический эквивалент XPVM, позволяющий наглядно продемонстрировать работу всей системы.
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и суперкомпьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу. Стандартизацией MPI занимается MPI Forum. В стандарте MPI описан интерфейс передачи сообщений, который должен поддерживаться как на платформе, так и вприложениях пользователя. В настоящее время существует большое количество бесплатных и коммерческих реализаций MPI. Существуют реализации для языковФортран 77/90, Java, Си и Си++. В первую очередь MPI ориентирован на системы с распределенной памятью, то есть когда затраты на передачу данных велики, в то время как OpenMP ориентирован на системы с общей памятью (многоядерные с общим кешем). Обе технологии могут использоваться совместно, чтобы оптимально использовать в кластере многоядерные системы.
8.1. Программно-аппаратная архитектура параллельных вычислений CUDA
CUDA – это архитектура параллельных вычислений от NVIDIA, позволяющая существенно увеличить вычислительную производительность благодаря использованию GPU (графических процессоров).
На сегодняшний день продажи CUDA процессоров достигли миллионов, а разработчики программного обеспечения, ученые и исследователи широко используют CUDA в различных областях, включая обработку видео и изображений, вычислительную биологию и химию, моделирование динамики жидкостей, восстановление изображений, полученных путем компьютерной томографии, сейсмический анализ, трассировку лучей и многое другое.
8.2. Параллельные вычисления с CUDA
Направление вычислений эволюционирует от «централизованной обработки данных» на центральном процессоре до «совместной обработки» на CPU(центральное процессорное устройство) и GPU. Для реализации новой вычислительной парадигмы компания NVIDIA изобрела архитектуру параллельных вычислений CUDA, на данный момент представленную в графических процессорах GeForce, ION, Quadro и Tesla и обеспечивающую необходимую базу разработчикам ПО.
Говоря о потребительском рынке, стоит отметить, что почти все основные приложения для работы с видео уже оборудованы, либо будут оснащены поддержкой CUDA-ускорения, включая продукты от Elemental Technologies, MotionDSP и LoiLo.
Область научных исследований с большим энтузиазмом встретила технологию CUDA. К примеру, сейчас CUDA ускоряет AMBER, программу для моделирования молекулярной динамики, используемую более 60000 исследователями в академической среде и фармацевтическими компаниями по всему миру для сокращения сроков создания лекарственных препаратов.
На финансовом рынке компании Numerix и CompatibL анонсировали поддержку CUDA в новом приложении анализа риска контрагентов и достигли ускорения работы в 18 раз. Numerix используется почти 400 финансовыми институтами.
Показателем роста применения CUDA является также рост использования графических процессоров Tesla в GPU вычислениях. На данный момент более 700 GPU кластеров установлены по всему миру в компаниях из списка Fortune 500, таких как Schlumberger и Chevron в энергетическом секторе, а также BNP Paribas в секторе банковских услуг.
Благодаря относительно недавно выпущенным системам Microsoft Windows 7 и Apple Snow Leopard, вычисления на GPU займут свои позиции в секторе массовых решений. В этих новых операционных системах GPU предстанет не только графическим процессором, но также и универсальным процессором для параллельных вычислений, работающим с любым приложением.
8.3. CUDA в электроэнергетике
В энергетической сфере понятие прогнозирования тесно связано с понятием планирования. Всем участникам рынка энергетических услуг необходимо составление максимально точно- го расчета объемов электроэнергии. Потребителям знание данной величины позволит скорректировать расчет денежных средств на покупку энергетических ресурсов, энергосбытовым компаниям – снизить убытки, которые могут возникнуть из-за нехватки или, напротив, избытка запланированной для поставки электроэнергии.
Повышение точности получаемого прогноза при планировании потребления энергоресурсов должно являться одной из составляющих политики снижения издержек энергосбытовой компании и, как следствие, повышения конкурентоспособности на обновленном рынке энергетических услуг.
После изучения предметной области и обзора существующих на сегодняшний день методов построения прогноза для решения поставленной задачи было предложено использовать гибридный алгоритм, базирующийся на трех методах анализа временных рядов: фильтре Винера, нейронных сетях и эволюционном моделировании. Каждый из указанных подходов обладает своими преимуществами в преодолении указанной проблемы: фильтр Винера показывает хорошие результаты в обработке и фильтрации данных, представленных в виде временного ряда; нейронные сети помогают выявлять скрытые закономерности; эволюционное моделирование на основе мутации и естественном отборе позволяет выбрать особей, максимально удовлетворяющих заданным критериям. Объединение трех перечисленных методик призвано повысить точность работы единого гибридного алгоритма.
Было проведено тестирование трех базовых алгоритмов и разработанного гибридного подхода для построения прогноза энергопотребления. Для проведения исследования были рассмотрены показатели энергопотребления в Костромской области за 2005 год.
В качестве критерия оптимальности построенного прогноза был использован индекс Тейла:
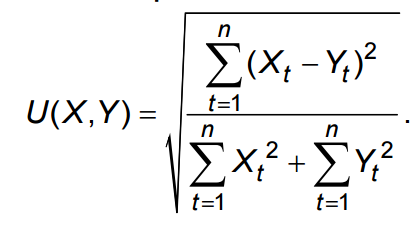
Индекс Тейла U(X, Y) измеряет несовпадение временных рядов X(t) и Y(t), и чем ближе он к нулю, тем ближе сравниваемые ряды. По результатам испытаний данный показатель при прогнозировании с помощью эволюционного моделирования составил 0,0436, фильтра Винера – 0,0329, нейронной сети – 0,0322, гибридного алгоритма – 0,0239. Анализ полученных данных показывает, что разработка гибридного алгоритма позволила решить поставленную задачу – повышение точности построения прогноза энергопотребления.
Однако достигнутый результат привел к возникновению дополнительной проблемы – увеличение временных затрат, которая может быть решена с помощью применения параллельных вычислений, в частности технологии CUDA с использованием суперкомпьютеров на базе графических ускорителей.
Параллельная реализация каждого из базовых методов принесет выгоду, однако для эффективной работы архитектуры CUDA необходим подход, при котором тысячи потоков исполняют небольшой набор одинаковых команд над собственными данными. Поэтому в данном случае для наиболее эффективного решения поставленной задачи следует максимально задействовать устройств. Каждое устройство будет последовательно выполнять параллельные версии базовых методов прогнозирования и изменять свои коэффициенты в зависимости от выбранного алгоритма оптимизации. Таким образом, предложенный гибридный алгоритм позволит максимально использовать мощности суперкомпьютера для решения задачи прогнозирования и снизить время выполнения поставленной задачи.
9. Примеры высокопроизводительных ВС
1. Система ILLIAC-IV (1974 г.) имела 64 процессора, выпол- няла 100–200 млн оп./сек с 64-разрядными словами. Память этой системы распределенная (у каждого процессора 2048 слов). Конструктивно система содержала матрицу процессоров 8 8. В этой системе команды выполнялись синхронно. Коммуникациями служили быстрые каналы, связывающие каждый процессор с четырьмя соседними процессорами. В резуль- тате получилась система, позволяющая решать довольно узкий класс задач.
2. В системе CRAY-1 (1976 г.) был использован конвейерный принцип. Система выполняла 80—140 млн оп./сек с 64-разрядными словами и имела 12 функциональных конвейерных устройств. Ре- жим работы — синхронный. Здесь имелось 8 векторных регистров по 64 слова, а также быстрые регистры, позволяющие быстро пере- страивать систему конвейеров в разнообразные цепочки с переда- чей данных через эти быстрые регистры и производить операции над векторами большой длины.
3. Система Earth-Simulator (фирма NEC, 2002 г.) — одна из последних разработок среди суперкомпьютеров (она имеет 5120 параллельных процессоров). Эта система достигла пиковой про- изводительности 40.9 триллиона операций (с плавающей точкой) в секунду (кратко 40.9 Терафлопс), а также произодительности 35.8 Терафлопс на реальных задачах линейной алгебры (из пакета LINPACK) и была мощнейшей в мире системой до 2005 года.
4. С 2005 года наиболее мощной является система BlueGene/L (фирма IBM); как отмечено выше, эта система имеет 131072 па- раллельных процессоров, достигает пиковой производительности 367 Терафлопс, а на реальных задачах ее производительность 280.6 Терафлопс.
Фирма IBM анонсировала создание суперкомпьютера Blue Gene/P, который позволит достичь пиковой производительности 3 Pflops (т.е. производительности 3 квадрильона арифметических операций с плавающей точкой в секунду), что в сто тысяч раз мощнее наиболее мощного персонального компьютера. К марту 2009 года совместными усилиями японских компаний Hitachi, NEC и Fujitsu предполагается создать суперкомпьютер со значительно большей пиковой поизводительностью, а именно — 10 Pflops.
10.Контрольные вопросы
1. В каких областях применяются параллельные вычисления?
2. Как реализуется модель вычисления в виде графа?
3. Какие задачи решаются с помощью параллельных вычислений?
4. Какие бываю показатели эффективности параллельного алгоритма?
5. Виды типовых схем коммуникации в многопроцессорных вычислительных системах?
6. Какие бывают характеристики топологии сети передачи данных?
7. Чем отличаются друг от друга разные характеристики топологии сети передачи данных?
8. Виды классификаций параллельных вычислений?
9. Как параллельные вычисления реализуются в Matlab?
10. Какие существуют виды программных инструментов параллелизма?
11.Что такое OpenMP и MPI?
12. Что использует архитектура CUDA?
13. В каких областях используется архитектура CUDA?
14. Как используется CUDA в электроэнергетике
15. Как развиваются ВС в наше время?
11. Литература
1. Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. 2003 г.
2. Воеводин В.В., Воеводин В.В.Параллельные вычисления. 2002 г.
3. http://www.math.spbu.ru/parallel/pdf/bd_algo.pdf
4. http://habrahabr.ru/post/126930/
5. http://www.wikiznanie.ru/ru-wz/index.php
6. https://ru.wikipedia.org/wiki
7. http://bigor.bmstu.ru/?cnt/?doc=Parallel/ch010101.mod/?cou=Parallel/base.cou
8.http://network-journal.mpei.ac.ru/cgi-bin/main.pl?l=ru&n=3&pa=16&ar=2
9. http://ispu.ru/files/str._47-49.pdf
10. http://www.nvidia.ru/object/cuda-parallel-computing-ru.html
Параллельная машина