Перспективность интернета как источника информационного обеспечения научных исследований
СОДЕРЖАНИЕ
Введение…………………………………………………………………………...5
- Аналитический обзор………………………………………………………….6
- История появления и развития Интернета……………………………6
- Современное состояние Интернета…………………………………..13
- Цели и задачи работы………………………………………………………...16
- Основная часть………………………………………………………………..17
- Оценка Интернета как источника информационного обеспечения научных исследований………………………………………………...17
- Способы улучшения поиска в Интернете..…………………………...21
- Интеллектуальный поиск информации………………………………24
- Развитие семантической паутины как способ повысить роль Интернета в качестве источника для исследований……………........25
Заключение.……………………………………………………………………....27
Список использованной литературы.……………………………………...........28
Приложения……………………………………………………………………...29
Введение
Интернет – одна из самых динамично развивающихся систем современности. Еще чуть более полвека назад о нем знали только ученые и был он тогда небольшой сетью со считанным количеством связанных между собой компьютеров; теперь же его услугами ежедневно пользуются миллиарды людей по всей планете.
Только вот в научной среде Всемирную сеть как источник подлинных знаний упоминают нечасто. Актуальность настоящего исследования обусловлена остро стоящей проблемой невозможности полноценного использования Интернета как источника информационного обеспечения научных исследований. Слишком много ценной для науки информации по-прежнему доступно только в бумажном формате, что затрудняет процесс обмена ею, способствует дублированию исследований в разных уголках Земли, что замедляет развитие науки.
Цель данной курсовой работы – показать перспективность Интернета как источника информационного обеспечения научных исследований. Для ее достижения необходимо выполнить следующие задачи:
- изучить историю развития Сети и ее нынешнее состояние в целом;
- оценить соответствие Интернет-ресурсов понятию «источник информационного обеспечения научных исследований»;
- исследовать пути совершенствования поиска в Сети со стороны исследователей и выделить основное направление возможного преображения Всемирной паутины, разрабатываемое учеными.
Объект исследования – Интернет; предмет исследования – оценка текущего положения и перспектив Всемирной паутины с точки зрения задействования ее в научной деятельности.
Практическая значимость работы заключается в освещении путей более качественного поиска в Сети и основного направления ее развития.
- Аналитический обзор
- История появления и развития Интернета
Идея создания сети, впоследствии получившей название Интернет, зародилась в конце 50-х годов XX века в США. В то время активно набирало обороты противостояние между 2 сверхдержавами – Советским Союзом и Соединенными Штатами – в борьбе за первенство в самых различных сферах, особенно в военно-технической отрасли. 4 октября 1957 года СССР запустил первый искусственный спутник Земли - «Спутник-1», чем вызвал широкий международный резонанс и заметно встревожил своих заокеанских противников. В результате в следующем году в качестве структурного подразделения министерства обороны США было образовано ARPA – агентство передовых исследовательских проектов, перед которым была поставлена задача сохранения военных технологий Штатов передовыми. Одним из основных проектов агентства вскоре стало создание системы передачи информации, устойчивой к целевому воздействию извне. В рамках этого направления работы в августе 1962 года американский учёный Джозеф Карл Робнетт Ликлайдер из Массачусетского технологического института (сокращенно - MIT) написал серию заметок, в которых раскрывалась сущность его концепции «Галактической сети». В ней он предвидел появление глобального взаимосвязанного набора компьютеров, с помощью которых каждый мог бы быстро получать доступ к данным и программам с любого узла – то, что по сути своей и являет собой современный Интернет.
Одной концепции для достижения результата конечно же было мало. Нужно было еще определиться с тем, как эффективно передавать данные – так, чтобы и сеть не перегружать, и не потерять ничего в процессе передачи. Этим требованиям удовлетворяла коммутация пакетов – способ доступа нескольких абонентов к общей сети, при котором информация разделяется на небольшие по размеру части (так называемые пакеты), которые передаются в сети независимо друг от друга и собираются в единое сообщение непосредственно узлом-приемником.
Преимущества таких сетей заключаются в следующем:
- по одной физической линии связи могут обмениваться данными много узлов;
- их пропускная способность используется максимально эффективно, распределяясь в соответствии с потребностями абонентов (те, кто не полностью используют свой канал связи, фактически делятся своей пропускной способностью с остальными);
- при пиковых нагрузках сеть никого не «выкидывает», а лишь снижает всем абонентам скорость передачи данных.
Разумеется, для полноценной реализации сетей со столь сложным устройством требовалось немало времени и усилий. И работа по коммутации пакетов велась не только в Америке, но и в Великобритании. В США эту тему прорабатывали в ранее упомянутом MIT, а также в стратегическом исследовательском центре RAND (г. Санта-Моника, штат Калифорния). На Туманном Альбионе исследователи сосредоточились в Национальной Физической Лаборатории (NPL) в Лондоне. Причем работа по общему для всех 3 групп направлению велась параллельно, но долгое время друг о друге они не знали. Только в 1967 году в Гатлинбурге (штат Теннеси, США) состоялась первая конференция Ассоциации вычислительной техники (ACM) по операционным системам, на которой выступили и сотрудники MIT, и представители NPL.
К тому моменту был достигнут значительный прогресс в коммутации пакетов, наметились и очертания будущей сети. Первая статья по теории пакетной коммутации была опубликована в июле 1961 года Леонардом Клейнроком из MIT, в 1964-ом вышла уже целая книга, его же. В том же 64-ом группой RAND во главе с Полом Бэраном была написана статья по сетям с коммутацией пакетов для безопасной передачи голоса в военных целях. Год спустя состоялся первый эксперимент по соединению удаленных друг от друга компьютеров. Провели его Лоренс Дж. Робертс и Томас Меррилл. Они подключили компьютер TX-2, находившийся в штате Массачусетс, к компьютеру Q-32 в Калифорнии с использованием низкоскоростной телефонной линии. В результате этого была создана первая (пусть и небольшая) широкомасштабная компьютерная сеть. Стало ясно, что общие компьютеры могут работать вместе, выполнять программы и при необходимости извлекать данные на удаленном компьютере, однако система коммутируемых телефонных линий абсолютно не подходит для этого. Уверенность Клейнрока в необходимости в пакетной коммутации была подтверждена. А в конце 1966-го Робертс отправился в ARPA для разработки концепции компьютерной сети. Дело пошло достаточно быстро, и его план сети ARPANET был опубликован уже на следующий год. В октябре же состоялась ранее упомянутая конференция, на которой с докладом по концепции сети на основе передачи пакетов выступили Дональд Дэвис и Роджер Скантлбери из NPL. Слово «пакет» было взято как раз из их работы, а предполагавшаяся скорость линии в проекте сети ARPANET была увеличена с 2,4 Кбит/с до 50 Кбит/с. Работа по ее созданию постепенно стала выходить на финишную прямую.
В августе 1968 г., как только Робертс и сообщество, финансируемое ARPA, уточнили общую структуру и характеристики для сети ARPANET, ARPA сделало заказ на разработку одного из главных компонентов – пакетных коммутаторов, которые назывались процессорами интерфейсных сообщений (IMP). В декабре того же года конкурс выиграла группа под руководством Франка Харта из компании Heart Bolt Beranek and Newman (BBN). Пока команда BBN работала над процессорами IMP вместе с Бобом Каном, который сыграл важную роль в разработке общей архитектуры сети ARPANET, Робертсом совместно с Говардом Франком и его командой в Network Analysis Corporation были существенно изменены и оптимизированы топология и экономика сети, а группой Клейнрока из Калифорнийского университета в Лос-Анджелесе (UCLA) была подготовлена сетевая измерительная система.
Поскольку Клейнрок давно начал заниматься темой коммутации пакетов и был сосредоточен на анализе, структуре и измерении, его Network Measuring Center в UCLA, стал первым узлом в сети ARPANET: 2 сентября 1969-го BBN установила там свой первый IMP и первый сервер. Проект Дуга Энгельбарта по «Дополнению интеллекта человека» (который включал NLS, первоначальную систему гипертекста) в научно-исследовательском институте Стэнфорда (SRI) предоставил второй узел. SRI поддерживал Сетевой информационный центр, который возглавляла Элизабет (Джейк) Фейнлер и включал такие функции, как обслуживание таблиц имен хостов для отображения адресов, а также каталог RFC. 29 октября в 21 час по местному времени между ними была установлена связь. Чарли Клайн пытался выполнить удалённое подключение из Лос-Анджелеса к компьютеру в Стэнфорде. Успешную передачу каждого введённого символа его коллега Билл Дювалль из Стэнфорда подтверждал по телефону. В 1-й раз сеть перестала функционировать после передачи 2 первых символов слова «LOGIN». Связь была восстановлена в 22:30, и со 2-й попытки передача полностью удалась. Именно эту дату можно считать днем рождения Интернета.
Дальнейшее развитие сети шло не менее интенсивно. К концу 1969-го к ARPANET были присоединены Университет штата Калифорния в Санта-Барбаре и Университет Юта. Одни (Глен Куллер и Бартон Фрайд) исследовали методы отображения математических функций с использованием дисплеев с блоком памяти для решения проблемы обновления по сети, другие (Роберт Тейлор и Иван Сазерленд) изучали методы представления в формате 3D по сети. С самого начала исследования в области сетевых технологий включали как работу над самой сетью, так и над тем, как использовать эту сеть. Данная традиция сохраняется и по сегодняшний день.
После этого сеть расширялась и дальше, при этом велась работа по созданию готового протокола связи между узлами. В декабре 1970 года Network Working Group (NWG), которая работала под руководством Крокера, завершила работу над созданием первоначального протокола связи между узлами сети ARPANET - протокола управления сетью (NCP). По мере того, как на узлах сети ARPANET было завершено внедрение NCP (1971-1972), пользователи сети наконец-то смогли приступить к разработке приложений. И первым таким приложением стала электронная почта. Созданная Рэем Томлинсоном из BBN программа первоначально позволяла только отправлять и читать текстовые сообщения. Но вскоре Робертс усовершенствовал ее: теперь чтение могло быть выборочным, а получаемые сообщения можно было пересылать и сохранять в файл, также появилась возможность отвечать на них. С этого момента электронная почта на несколько десятилетий закрепилась в роли крупнейшего сетевого приложения.
В октябре 1972 года Роберт Эллиот Кан организовал большую и очень успешную демонстрацию сети ARPANET на Международной конференции по компьютерной связи (ICCC). Это была первая публичная демонстрация новой сетевой технологии для широкой публики. В том же году представили и электронную почту. И тогда же Кан высказал идею создания сети с открытой архитектурой. При таком подходе выбор любой отдельной сетевой технологии уже не определялся архитектурой конкретной сети, а мог определяться произвольным образом поставщиком и затем подключался к другим сетям с использованием «межсетевой архитектуры» на метауровне. Первоначально она была лишь частью программы пакетной радиопередачи, однако впоследствии выделилась в самостоятельную программу под названием «Internetting». Работа над ней оказалась достаточно трудоемкой и многозадачной и привела к созданию нового сетевого протокола – TCP/IP.
Еще в BBN Кан стал работать над изучением и сбором принципов связи для операционных систем, чтобы последующую разработку можно было эффективно внедрить в каждой из них. А весной 1973-го он предложил Винту Серфу поработать с ним над подробным проектом протокола уже в Стэнфорде. Это было вполне оправданно, ведь Серф активно участвовал в создании NCP и мог помочь в создании интерфейсов для существовавших систем. Знания и опыт Серфа в этой области, использованные с учетом архитектурного подхода Кана, и позволили создать новый протокол – протокол управления передачей (TCP).
Первая написанная версия полученного протокола была распространена на специальном заседании Международной рабочей группы по информационно-вычислительным сетям (INWG) под председательством Серфа, которое прошло на конференции в университете Суссекса в сентябре 1973 г.
Изначально на TCP (в первую очередь, усилиями Кана) возложили слишком много работы: целый ряд транспортных услуг, начиная с абсолютно надежной последовательной доставки данных (модель виртуальной цепи) до службы дейтаграммы, в которой напрямую использовалась сетевая служба нижнего уровня, и обеспечение всех необходимых служб в Интернете. Из-за этого иногда возникали проблемы, связанные с повреждением или изменением порядка пакетов. К тому же исправление всех ошибок на уровне этого протокола оказалось не слишком целесообразным. В результате TCP разделили на 2 протокола: простой протокол IP, который обеспечивал только адресацию и пересылку отдельных пакетов, и отдельный протокол TCP, который отвечал за служебные функции, такие как управление потоком и восстановление утраченных пакетов. Для тех приложений, которым не нужны были службы TCP, был добавлен альтернативный протокол, который назывался протоколом пользовательских дейтаграмм (UDP), чтобы предотвратить прямой доступ к основной службе протокола IP.
Как только с теоретическим этапом было покончено, ARPA выдала три контракта – Стэнфорду (Серф), BBN (Рэй Томлинсон) и UCL (Петер Кирстен) на внедрение протокола TCP/IP (в статье Серфа и Кана он просто назывался TCP, хотя включал оба компонента). Команда Стэнфорда под руководством Серфа составила подробную спецификацию и примерно в течение года появились три независимые реализации TCP, которые могли взаимодействовать друг с другом. Первые реализации протокола TCP создавались для больших систем с разделением времени, таких как Tenex и TOPS 20. Когда появились первые настольные компьютеры, Дэвид Кларк и его исследовательская группа в MIT создали компактную и простую версию протокола TCP сначала для Xerox Alto (первой персональной рабочей станции, разработанной в компании Xerox PARC), а затем для компьютера IBM PC. Она могла полностью взаимодействовать с другими протоколами TCPs, однако была более адаптирована к пакету приложений и уровню производительности персонального компьютера и показала, что рабочие станции, а также большие системы с разделением времени, могут стать частью Интернета. После нескольких лет подготовки 1 января 1983 года был осуществлен единовременный переход с NCP на TCP/IP в ARPANET. С того времени за ARPANET закрепился термин Internet. До приведения в знакомое нам состояние Интернету оставалось пройти всего несколько лет развития.
В 1984 году Полом Мокапетрисом из компании USC/ISI взамен числовых адресов узлов была разработана система доменных имён (DNS). В том же году у сети ARPANET появился серьёзный соперник: Национальный научный фонд США (NSF) основал обширную межуниверситетскую сеть NSFNet, которая была составлена из более мелких сетей (включая известные тогда сети Usenet и Bitnet) и имела гораздо большую пропускную способность, чем ARPANET. К этой сети за год подключились около 10 тыс. компьютеров, название «Интернет» начало плавно переходить к NSFNet.
В 1988 году был разработан протокол Internet Relay Chat (IRC), благодаря чему в интернете стало возможно общение в реальном времени (чат).
В 1989 году в Европе, в стенах Европейского совета по ядерным исследованиям (ЦЕРН) родилась концепция Всемирной паутины. Её предложил знаменитый британский учёный Тим Бернерс-Ли, он же в течение двух лет в соавторстве с Робертом Кайо разработал протокол HTTP, язык HTML и идентификаторы URI.
В 1990 году сеть ARPANET прекратила своё существование, полностью проиграв конкуренцию NSFNet. В том же году было зафиксировано первое подключение к интернету по телефонной линии (т. н. «дозвон» - dialup access).
В 1991 году Всемирная паутина стала общедоступна в интернете, а в 1993 году появился знаменитый веб-браузер NCSA Mosaic. Всемирная паутина набирала популярность.
В 1995 году NSFNet вернулась к роли исследовательской сети, маршрутизацией всего трафика интернета теперь занимались сетевые провайдеры, а не суперкомпьютеры Национального научного фонда. А Всемирная паутина стала основным поставщиком информации в интернете, обогнав по трафику протокол пересылки файлов FTP. Был образован Консорциум Всемирной паутины (W3C). Можно сказать, что Всемирная паутина преобразила интернет и создала его современный облик. С 1996 года Всемирная паутина почти полностью подменяет собой понятие «Интернет».
В 1990-е годы интернет объединил в себе большинство существовавших тогда сетей. Объединение выглядело привлекательным благодаря отсутствию единого руководства, а также благодаря открытости технических стандартов интернета, что делало сети независимыми от бизнеса и конкретных компаний. К 1997 году в Интернете насчитывалось уже около 10 млн компьютеров, было зарегистрировано более 1 млн доменных имён. Всего за 3 десятилетия Интернет из ограниченной считанным количеством серверов сети превратился в невероятно популярное средство для обмена информацией, продолжавшее уверенное распространение по земному шару.
- Современное состояние Интернета.
На сегодняшний день Интернетом пользуется более 2,4 млрд человек, то есть более трети населения Земли, и число пользователей продолжает расти. Подключиться к Интернету можно через спутники связи, радио-каналы, кабельное телевидение, телефон, сотовую связь, специальные оптико-волоконные линии или электропровода. С 22 января 2010 года он доступен даже на борту МКС. Всемирная сеть, дополнившись работой поисковых систем (Google, Bing, Яндекс), социальных сетей (Facebook, Twitter, Вконтакте), обилием аудио и видеофайлов (YouTube), стала неотъемлемой частью жизни в развитых и развивающихся странах.
Свойства Интернета:
- Интернет является совокупностью сетей с различной географической принадлежностью, у него нет собственника;
- его нельзя выключить целиком, поскольку маршрутизаторы сетей не имеют единого внешнего управления;
- Интернет, в первую очередь, является средством открытого хранения и распространения информации. Незашифрованная информация в процессе передачи может быть перехвачена и прочитана;
- может связать каждый компьютер с любым другим, подключенным к Сети;
- распространение информации в Интернете имеет ту же природу, что и слухи в социальной среде: есть большой интерес – информация распространяется широко и быстро, нет интереса – нет распространения;
- сайты в Интернете распространяют информацию по тому же принципу, что и автоответчик телефона, то есть индивидуально, по инициативе читателя;
- чтение информации, полученной из Интернета, относится, как правило, к непубличному воспроизведению произведения. За распространение материалов в Сети в нарушение закона возможна юридическая ответственность;
- Интернет – достояние всего человечества. 3 июня 2011 года была принята резолюция ООН, признающая доступ в Интернет базовым правом человека. То есть отключение какого-то региона от Сети – нарушение прав человека.
Общепризнанного международного дня Интернета пока нет. Есть как минимум 2 даты-претендента: 4 апреля (день преставления (смерти) святого Исидора Севильского (ок. 560-636), покровителя учеников и студентов, создавшего первую в истории энциклопедию «Этимология» в 20 томах) и 17 мая (в этот день в 1991 году был утвержден стандарт для страниц WWW). В России, начиная с 1998 года, день Интернета отмечают 30 сентября.
Основные области использования Интернета:
- электронный бизнес (реклама и продажа товаров и услуг, маркетинговые исследования и т.д.);
- интернет-СМИ (новостные сайты, интернет-издания, интернет-радио и интернет-телевидение);
- распространение музыки, фильмов, литературы в Сети (зачастую нелегальное – с нарушением авторских прав);
- связь (электронная почта, IP-телефония, такие программы, как Skype, ICQ и т.п.) и общение (интернет-форумы, социальные сети, блоги) между людьми;
- краудсорсинг – передача некоторых производственных функций неопределённому кругу лиц, решение общественно значимых задач силами добровольцев, координирующих при этом свою деятельность посредством Сети (пример проекта такого рода – Википедия);
- поиск необходимой информации (через поисковые системы, такие как Google, Яндекс и т.п.).
Ключевые проблемы, связанные со Всемирной паутиной:
- интернет-зависимость (подмена человеком своей реальной жизни на виртуальную);
- интернет-цензура (не всегда обоснованное ограничение доступа к некоторым ресурсам сети);
- загруженность бесполезной информацией («мусором»).
В настоящем исследовании мы затронем роль последней из них в научной работе.
- Цели и задачи работы
Целями данной работы является изучение Интернета как источника информационного обеспечения научных исследований и выявление перспектив становления его основным источником в этой области.
Для достижения этих целей необходимо выполнить следующие задачи:
- изучить понятие «источник информационного обеспечения научных исследований» и сопоставить полученные знания о нем с имеющимися Интернет-ресурсами;
- исследовать имеющиеся пути улучшения поиска в Сети;
- рассмотреть возможности преобразования Интернета как источника информации (чтобы его можно было более активно применять в научной деятельности) на примере семантической паутины.
- Основная часть
- Оценка Интернета как источника информационного обеспечения научных исследований
Для того, чтобы оценить Всемирную Сеть с точки зрения соответствия ее ресурсов понятию «источник информационного обеспечения научных исследований», нужно сначала пояснить, что же называют информационным обеспечением и его источником в научных исследованиях.
Информационное обеспечение – предоставление информации, необходимой для осуществления какой-либо деятельности, оценки состояния чего-либо, совершенствования чего-либо, предупреждения нежелательных (опасных) ситуаций и др. В нашем случае речь идет о предоставлении информации для различных научных исследований. Соответственно, источник такого обеспечения – это различные носители информации, использованные в исследовании. Основными требованиями, предъявляемыми к нему (следовательно, и к его источникам тоже), являются:
- достоверность (характерна в первую очередь для объективной информации, опирающейся на реальные факты);
- полнота (информация содержит достаточный для принятия решений набор данных);
- релевантность (отсутствие посторонней, ненужной в работе информации);
- актуальность (соответствие предоставленной информации положению дел в настоящий момент времени);
- низкая себестоимость (при слишком высоких расходах средства на проведение исследования могут просто не выделить).
Определившись с тем, что лежит в основе понятия «источник информационного обеспечения научных исследований», мы можем смело проверить ресурсы Интернета на его соответствие требованиям к таким источникам. Для большей полноты этой оценки рассмотрим ещё и такое свойство источников информационного обеспечения как доступность – ведь чем проще путь доступа, тем удобнее работать с этим источником.
Для оценки потенциальных источников информации будем использовать матричную модель принятия решений и причин тому несколько. Во-первых, матрица предоставляет возможность наглядного отображения собранной информации об источниках. Во-вторых, данная модель дает возможность оценить каждый источник по определенным критериям, проведя, например, экспертную оценку или же руководствуясь собственным опытом и рекомендациями. В-третьих, принятие решений по такой матрице превращается в простой подсчет баллов по каждому источнику.
Для каждого источника выставляются оценки по пятибалльной шкале: лучшая оценка - 5, худшая - 1. Рекомендации по выставлению оценок следующие:
а) По достоверности: 5 - первоисточник (официальные сообщения); 4 - информационные агентства, газеты, журналы (вторичная информация - авторитетные издания); 3 - переводы, прочие издания; 2 - срочная информация со ссылкой на сомнительные источники; 1 - слухи и сплетни.
б) По полноте: 5 - полностью раскрывает суть происходящего; 4 - по возможности отражает информацию по большинству направлений; 3 - отражает информацию по главным направлениям; 2 - отражает информацию общего характера или информацию по узкому кругу вопросов; 1 - только общие слова и фразы.
в) По степени актуальности: 5 - информационное агентство; 4 - переведенные новости, газеты, ежедневные обзоры, комментарии; 3 - еженедельные и ежемесячные рассылки, аналитика; 2 - журналы, квартальные и годовые обзоры, сборники; 1 - ретроспективные сборники, старые публикации, архивы.
г) По стоимости: 5 - бесплатные; 4 - единовременные небольшие затраты; 3 - подписка в России, рассылка через Интернет; 2 - существенные затраты в России, недорогая подписка за рубежом; 1 - большие затраты за рубежом.
д) По доступности: 5 - прямой доступ; 4 - доступ с регистрацией; 3 - доступ через подписку, посещение библиотек, конференций и т.д.; 2 - доступ через границу; 1 - доступ по частным связям, каналам получения информации.
По каждому конкретному случаю полезно будет также установить уровень значимости того или иного критерия. Дело в том, что для разных случаев и разных оценок значимость тех или иных критериев может меняться, а оценка такой значимости делает модель более универсальной. Значимость также оценивается по пятибалльной шкале аналогично с оценкой критериев: самая высокая оценка - пятерка, а самая низкая - единица.
Выбор наиболее подходящего источника (источников) информации может осуществляться несколькими способами:
- по суммарному количеству баллов по всем критериям;
- по количеству баллов, набранных с учетом только одного критерия;
- по количеству баллов, набранных с учетом двух или более критериев;
Пример. Для разработки стратегии развития предприятия цветной металлургии требуется определить источники информации, которыми целесообразно пользоваться при оценке макроокружения.
Для оценки степени важности того или иного критерия для конкретного примера введем следующую градацию:
5 - необходимо;
4 - очень важно;
3 - важно;
2 - желательно;
1 - второстепенно.
Выбор источников будет осуществлен исходя из наибольшего количества баллов по всем критериям, с учетом коэффициентов значимости того или иного критерия.
Источники для оценки выберем следующие: сайт информационно-аналитического агентства Bloomberg News, еженедельный обзор мировой экономики и рынков инвестиционной фирмы "ОЛМА", электронная версия ежемесячного обзора по экономике цветной металлургии от инвестиционного банка UBS Warburg, а также газета БИКИ и годовой обзор рынка цветных металлов одной из зарубежных исследовательских компаний.
Оценки для разных источников расставим по написанным выше рекомендациям. Полученные данные сведем в следующую таблицу.
Таблица 1. Оценка источников информации.
|
Критерий
|
Bloomberg News (новости)
|
Обзор ИФ «Олма»
|
Обзор UBSW
|
Газета БИКИ
|
Годовой обзор
|
Оценка критерия
|
|
Достоверность
|
4
|
3
|
4
|
4
|
3
|
5
|
|
Полнота
|
2
|
3
|
3
|
3
|
4
|
4
|
|
Актуальность
|
5
|
4
|
3
|
2
|
2
|
2
|
|
Стоимость
|
4
|
4
|
2
|
3
|
2
|
4
|
|
Доступность
|
4
|
4
|
3
|
3
|
3
|
3
|
|
Итого
|
66
|
63
|
55
|
57
|
52
|
|
Согласно расчетам, представленным в таблице, наиболее целесообразно использовать информацию Bloomberg News или инвестиционной фирмы "ОЛМА". Если бы мы исходили только из критериев полноты и достоверности, не беря в расчет стоимость, доступность и время публикации того или иного информационного ресурса, то предпочтительными для нас стали бы газета БИКИ и еженедельный обзор инвестиционного банка UBS Warburg.
Конечно, это не означает, что пользоваться другими источниками не надо, а говорит о том, что среди прочих равных условий предпочтительными являются вышеназванные источники.
Данный пример показывает, что, даже не обладая большим опытом, данным методом вполне можно оценить имеющиеся источники информации, сравнить их и сделать свой выбор. Разумеется, подобная модель носит рекомендательный характер.
- Способы улучшения поиска в Интернете
Иметь модель оценки источников информации в Сети – безусловно полезно, но явно недостаточно. Ведь зачастую проблемы, связанные с качеством предоставляемой информации, лежат в способе поиска. Самым простым, можно даже сказать банальным, из них является простой ввод искомой фразы в поисковую строку. Процент «мусора» среди результатов таких запросов зачастую зашкаливает, как и количество времени, затрачиваемое исследователем на анализ этих результатов. Но ведь есть возможности хоть немного облегчить труд исследователя, просто в большинстве своем люди не имеют о них ни малейшего понятия. Сейчас мы их и рассмотрим.
- Использование поисковых каталогов
При первичном поиске информации целесообразно использовать поисковые каталоги. Они предоставляют доступ к меньшему количеству страниц, чем поисковые индексы, и точнее указывают на основные ресурсы Сети.
Если нужная информация ограничена лишь общей темой, можно воспользоваться услугами так называемых каталогов веб-сайтов. В отличие от поисковых машин, здесь не требуется вводить ключевые слова, достаточно определиться с общей тематикой. Каталоги часто называют рейтингами, так как ссылки упорядочены по убыванию: сначала даются ссылки на самые информационно насыщенные сайты.
Поскольку каталоги предназначены для поиска по темам, то они обычно строятся по иерархическому принципу, т. е. каждый шаг поиска - это выбор подраздела с более конкретной тематикой искомой информации. На нижнем уровне поиска пользователь получает относительно небольшой список ссылок на искомую информацию.
Примеры: https://yaca.yandex.ru, http://list.mail.ru.
- Использование языков запросов поисковых систем
Язык запросов – искусственный язык, на котором делаются запросы к базам данных и другим информационным системам, особенно к информационно-поисковым (таким, как поисковые системы). Состоит из логических операторов, префиксов обязательности, возможности учета расстояния между словами, морфологии языка, регистра слов, расширенных операторов, возможностей расширенного поиска, уточнения поиска (подробную таблицу см. в приложении).
Такие языки позволяют точнее сформулировать поисковый запрос и, как следствие, получить большее количество нужной информации по сравнению с обычным поиском. Так, если вы уверены в неделимости словосочетания, составляющего предмет поиска, можно использовать кавычки и получить источники, содержащие на своих страницах именно такую фразу. А если слово имеет достаточное количество широко употребляемых синонимов, то с использованием логического оператора «ИЛИ» (прямая вертикальная черта - |) можно провести поиск одновременно по всем этим словам. Естественно, ожидать совершенных результатов при любом подобном запросе не стоит, но при грамотном употреблении и с увеличением опыта использования искать информацию станет несколько легче.
- Поиск на специализированных ресурсах
Но наилучший путь получения информации в Сети, ориентированный именно на научные изыскания, - это использование электронных библиотек и других зарекомендовавших себя информационных ресурсов.
К числу первых относятся Российская государственная библиотека в Москве и Российская национальная библиотека в Санкт-Петербурге, обладающие широкими электронными каталогами на своих официальных сайтах (http://www.rsl.ru и http://www.nlr.ru соответственно). Правда, далеко не все из них доступны удаленно и без регистрации, зато в авторитетности таких источников сомневаться не приходится. Студентам и преподавательскому составу вузов также доступны электронные библиотеки их учебных заведениях. По объему хранящейся информации они значительно уступают крупнейшим российским библиотекам, но в то же время гораздо доступнее. Одним из ярчайших примеров безусловно является фундаментальная библиотека СПБГТИ(ТУ) (сайт - http://bibl.lti-gti.ru/). С ее помощью можно получить доступ не только к ее собственному каталогу, но и к другим российским и зарубежным порталам, подписка на которые активна в настоящий момент времени – к примеру, к таким широко известным базам научных публикаций как Scopus и Web of Science (правда, обе они англоязычные и без знания языка с ними работать будет чрезвычайно тяжело).
В числе вторых безусловная пальма первенства по степени известности у Википедии (https://ru.wikipedia.org/) – свободной общедоступной мультиязычной универсальной интернет-энциклопедии, основанной – и вот тут как раз корень ее основной проблемы как источника информации – на принципах Вики – структуру и содержимое страниц сайта может изменить практически кто угодно в любой момент времени. А это означает, что достоверность получаемых сведений гарантировать невозможно, что в серьезных научных работах просто недопустимо. Но все же сбрасывать Википедию в гору информационного «мусора» на этом основании будет несправедливо: немало статей Википедии имеют под собой достаточно авторитетные первоисточники. Перейдя по указанным на них ссылкам, нередко можно убедиться в правдивости приведенных фактов и тогда уже этот самый источник можно смело указать в своей работе. Так что если слепо не доверять всему написанному в ней, то и с ее помощью можно добавить некоторое количество информации даже в исследовательскую работу.
Резюме: как бы ни были хороши и привлекательны все перечисленные способы улучшения поиска в Сети, даже все они в совокупности на данный момент не могут сделать Интернет основным источником информации в научных исследованиях. Для реализации этой задачи нужен совсем другой, более глобальный подход к алгоритмам поиска и размещения информации в нем. Именно в этом кроется пока нереализованная перспектива Интернет-пространства в этом направлении.
- Интеллектуальный поиск информации
Понимая необходимость перемен, крупнейшие поисковые системы и учебные заведения ведущих стран мира активно ведут работу по совершенствованию поисковых систем (или созданию новых), способных к более «осмысленному» поиску информации в Сети. Отличительная особенность таких систем от распространенного в настоящее время алгоритма поиска – ориентированность не на простое совпадение слов в запросе и в источнике, а на смысловое соответствие запроса и его результатов, в связи с чем подобный поиск еще зачастую называют семантическим (от др.-греч. «» - «обозначающий»). И все же термин «интеллектуальный поиск» более полно отражает суть процесса от запроса до выдачи результатов, поскольку он не ограничивается распознаванием машиной смысла фразы, а включает в себя еще и анализ полученных данных. Такая система старается сразу выдать пользователю ответ на поставленный им вопрос. Рассмотрим одну из таких разработок – отечественную систему Нигма.РФ.
Нигма.РФ – российская интеллектуальная метапоисковая система. Создана в 2005 году при поддержке МГУ имени М. В. Ломоносова и Стэнфордского университета. За время развития обрела целый ряд полезных сервисов, а именно:
- Нигма-Математика – сервис, с помощью которого можно решить целый ряд задач от простейших вычислений до нахождения производных и интегралов от элементарных функций;
- Нигма-Химия – сервис, ориентированный на работу с различными химическими реакциями, как органическими, так и неорганическими. Поможет, к примеру, подобрать недостающее звено в реакции или просто расставить в ней коэффициенты.
- Нигма-Музыка – сервис, который существенно упрощает поиск музыкальных композиций. Результат поисковой выдачи – это список ссылок на песни с возможностью прослушать их непосредственно на странице результатов (причем переключение в случае невозможности воспроизведения того или иного файла или просто с одной песни на другую автоматическое) или скачать, не заходя предварительно на сайт, где они хранятся. При наличии регистрации можно даже загрузить на Нигму свою музыку (с определенными ограничениями).
Также Нигма может помочь уточнить запрос с помощью фильтра (своего для каждого запроса; позволяет выбрать важные темы и убрать ненужные), выдавать списки объектов в виде таблиц (если подразумевается поиск множества объектов определенной категории), стилизованные определения различных математических и физических терминов. Разумеется, и выдавать ответы на простейшие вопросы (нередко со всплывающей подсказкой) она тоже способна. Единственное «но»: то, что все эти механизмы еще требуют значительной доработки. К примеру, на вопрос «столица России» Нигма-справка не может дать ответ в итоговой выдаче, а вот на аналогичный – «столица Российской Федерации» - может. А в запросах более сложных и не предметных серьезных отличий в результатах поиска уже нет.
Что же касается таких поисковых гигантов, как Google, Яндекс и Bing, то все они уже успешно внедрили вывод информационных карточек в ответ на запросы о людях, городах и странах, и т.п., отображающих краткую справку об объекте запроса и связанные с ним объекты, перейти к поиску подробной информации о которых можно просто кликнув на соответствующее место карточки. Пока что этим все и ограничивается.
- Развитие семантической паутины как способ повысить роль Интернета в качестве источника для исследований
В настоящее время наметились 2 направления в развитии Всемирной Сети: семантическая паутина и социальная паутина. Социальная паутина рассчитана на пользователей, упорядочивающих существующую в Интернете информации. Автор полагает, что это направление с развитием технологий окончательно вымрет, хотя бы потому, что вручную или с учетом существующих программных средств систематизировать всю информацию в принципе невозможно: объемы ежедневного пополнения ею Сети слишком велики для этого. А вот у семантической паутины шансов куда больше, поскольку она рассчитана на автоматику.
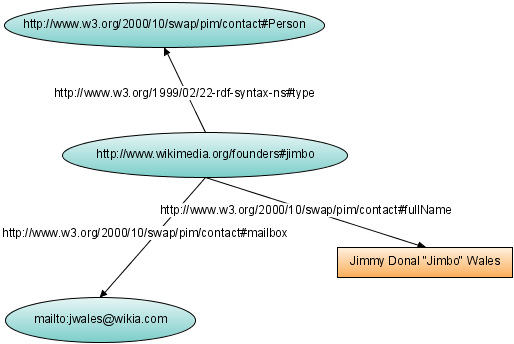
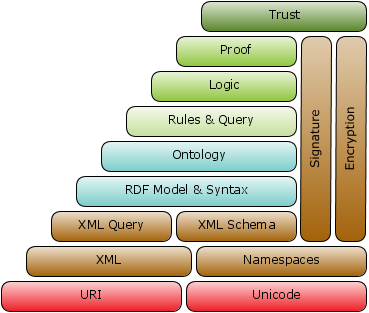
Семантическая паутина – это глобальная семантическая сеть, своеобразная надстройка над существующим сейчас Интернетом, опирающаяся на стандартизацию представления информации в том виде, который мог бы обрабатываться машинами. Идея ее создания принадлежит Тим Бернерсу-Ли, создателю и действующему главе консорциума Всемирной паутины в ее современном виде. Суть заключается в связи объектов строго определенными отношениями, представляющая собой ориентированный граф (пример см. в приложении 2). В настоящее время эта паутина базируется на URI (Uniform Resource Identifier) — унифицированном (единообразном) идентификаторе ресурсов, уникальном не только для каждой страницы, но и для любого из объектов реального мира, из абстрактных понятий – и использующем его RDF (Resource Description Framework, «среда описания ресурса») – модели, заточенной на связь URI множеством триплетов (утверждений вида «субъект-предикат-объект, составляющих в совокупности граф). Конечная цель работы – вывести Интернет на уровень глобальной распределенной базы знаний. По сути своей это будет означать появление источника, поистине всеобъемлющего, способного заменить собой в конечном итоге все существующие и стать повсеместно и регулярно употребляемым. Правда, для этого нужно решить такие проблемы, как необходимость дублирования информации (с ориентацией на человека и на машину соответственно), возможности ее строгой классификации, общедоступность просмотра и использования в таком формате и др. Удастся ли их решить и что из этого получится, покажет только время.
Заключение
Интернет – всемирная система компьютерных сетей для хранения и передачи информации. Он прошел многоэтапный и достаточно короткий по времени путь от сети ARPANET из 4 соединенных между собой компьютеров до глобального средства связи, используемого миллиардами людей ежедневно. И теперь перед ним открыты новые горизонты по активному внедрению его ресурсов в научную деятельность.
На текущий момент подавляющее число ресурсов Сети не могут стать источником информационного обеспечения научных исследований. И пока что ключевая роль в адаптации его к этой роли лежит на самих исследователях. Помочь им оценить эффективность применения в работе информации тех или иных сайтов на основе оценки соответствия требованиям, выдвигаемым к источникам информационного обеспечения научных исследований, призвана матричная модель принятия решения. Также выявлены способы улучшения поиска в Интернете, способные облегчить труд исследователя на раннем этапе его работы с виртуальными источниками информации.
В качестве основы становления Интернета не только ключевым источником информационного обеспечения научных исследований, но и наиболее употребляемым источником информации в целом признано развитие концепции семантической паутины. Определенная база у нее уже есть, однако однозначно сказать, удастся ли ей столь значительно преобразовать Сеть, на данный момент сложно: достаточное количество проблем предстоит еще разрешить для получения ответа на этот вопрос.
Список использованной литературы
- Краткий курс истории Интернета / Б. Лейнер, В. Серф, Д. Кларк и др. // Jet Info. – 1997. - № 14. – С. 4-18.
- Леонтьев, В.П. Интернет: история, возможности, программы / В.П. Леонтьев. – М. : ОЛМА Медиа Групп, 2008. - 254 с.
- Заичкин, Н.И. Экономико-математические модели и методы принятия решений в управлении производством – М.: ГУУ, 2000. – 107 с.
- Рощин, С.М. Как быстро найти нужную информацию в интернете. – М.: ДМК-Пресс, 2010. – 144 с.
- Российская энциклопедия по охране труда: в 3 т. / Рук. проекта М. Ю. Зурабов; Отв. ред. А. Л. Сафонов. – 2-е изд., перераб. и доп. — М.: НЦ ЭНАС, 2007.
- О пользе Семантической паутины / Д. Каргер // «Открытые системы» – 2014. - № 10. – С. 24-32.
- Добров, А.В. Технологии интеллектуального поиска и способы оценки их эффективности [Электронный ресурс] / А.В. Добров. Режим доступа: http://aiire.org/docs/ADobrov_2010_search_technologies.pdf. – Загл. с экрана.
Приложения
Приложение 1
Языки запросов поисковых систем
- Yandex: http://help.yandex.ru/search/query-language/qlanguage.xml
- Google: https://support.google.com/websearch/answer/2466433?hl=ru
Приложение 2
Семантическая паутина
Граф визитной карточки основателя Википедии в формате RDF:
Стек понятий Семантической паутины:
Перспективность интернета как источника информационного обеспечения научных исследований