Освоение методов нечеткого моделирования и разработка алгоритма для оптимизации базы правил нечеткого классификатора на основе наблюдаемых данных с помощью генетического алгоритма
red79;;;СОДЕРЖАНИЕ
ВВЕДЕНИЕ……………………………………………………………………..…4
- ЗАДАЧА КЛАССИФИКАЦИИ......………….………………….....6
- Постановка задачи классификации ………………..………..………...….6
- Методы решения задач классификации……………..…………......7
- Классификация/кластеризация в пакетах прикладных программ..8
- Критерии качества классификации…………………….…..……..………9
- НЕЧЕТКИЕ СИСТЕМЫ………..…...……....……………………..10
- Понятие нечеткой системы………………..……..…………………...….10
- Структура и этапы проектирования нечеткого классификатора…........11
- ПРОЕКТИРОВАНИЕ НЕЧЕТКОГО КЛАССИФИКАТОРА..….24
- Постановка задачи………..………………………..…………….…..……24
- Структура модели…………......……………………...………….….……24
- Управляемая данными инициализация…….…..…..………..…..………25
- Сокращение модели……………………..…………………….....…….…27
- Отбор свойств на основе межклассовой отделимости..............…27
- Упрощение базы правил………..…………………….............……28
- ИСПОЛЬЗОВАНИЕ ГЕНЕТИЧЕСКИХ АЛГОРИТМОВ ДЛЯ ОПТИМИЗАЦИИ БАЗЫ ПРАВИЛ…………………………………………….33
- Основные понятия эволюционного программирования..……..............33
- Символьная модель……………..……………………………...…..36
- Канонический генетический алгоритм.…………..…………..…..38
- Кроссовер………………………………………….…….....………38
- Мутация…...………………………………………...……….…….40
- Постановка задачи…….………………………..……..……...….....….…40
- Алгоритм генерации базы знаний…………………………….…..41
- Получение «родительского» элемента……………………...….…42
- Мутация……………………………………………………....…….42
- Нечеткие операторы………………………………………....…….43
- Условие останова………………………………………….……….45
- ОПИСАНИЕ ПРОГРАММЫ………………….………………......45
- Функциональные возможности………….….…………………………..45
- Представление данных…………………..…..….……………………….46
- Реализация………………………...…………….……………….…….....47
- Пример……………………….…..………………..….……….…………..49
ЗАКЛЮЧЕНИЕ………………………………………………………..……...…51
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ………………..………..…52
ВВЕДЕНИЕ
Кластерный анализ –это научное направление, включающее совокупность методов и средств для формирования группировок схожих данных, их интерпретации и определения принадлежности некоторого нового объекта к одной из группировок. Под кластеризацией подразумевается именно естественная группировка объектов, в то время как отнесение объекта с одной из образованных групп называют классификацией.
Особо важное место кластерный анализ занимает в тех областях науки, которые связаны с изучением массовых явление и процессов, поскольку позволяет выявить типовые объекты или осуществить структуризацию заданного множества объектов. Кластеризацию применяют для эффективного сжатия и хранения данных, поиска в базах данных, обработки изображений. Необходимость развития методов кластеризации и их использования заключается, прежде всего, в том, что такие методы помогают построить научно обоснованные классификации, выявить внутренние связи между единицами наблюдаемой совокупности.
В настоящее время существует значительное количество методов кластеризации/классификации, ориентированных на исходную информацию об объектах заданного множества. Особый класс составляют методы нечеткой классификации, поскольку позволяют подчеркнуть расплывчатый характер естественных группировок объектов. Объект одновременно принадлежит всем классам, но с различной степенью. К преимуществам методов нечеткой классификации относится использование приближенной исходной информации. Данный подход реализуется на базе нечетких систем, в которых классы объектов описываются приближенно с помощью продукционных правил. Нечеткая система, предназначенная для решения задачи классификации, называется нечетким классификатором.
Для нечетких классификаторов, как и для всех нечетких систем, актуальной является задача построения и оптимизации базы знаний, которая состоит из базы правил и базы данных, содержащей параметры лингвистических переменных, с помощью которых описываются объекты заданного множества. Критерием оптимизации является минимизация ошибок классификации для обучающей выборки. Для решения этой проблемы применимы эволюционные алгоритмы, частным случаем которых является генетический алгоритм –это алгоритм, который позволяет найти удовлетворительное решение для аналитически неразрешимых проблем через последовательный подбор и комбинирование искомых параметров с использованием механизмов, напоминающих биологическую эволюцию.
Целью дипломной работы является освоение методов нечеткого моделирования и разработка алгоритма для оптимизации базы правил нечеткого классификатора на основе наблюдаемых данных с помощью генетического алгоритма.
ГЛАВА 1. ЗАДАЧА КЛАССИФИКАЦИИ
- Постановка задачи классификации и методы ее решения
Задача классификации является важной проблемой в различных областях знаний. Существует огромное количество исследований в этой области, приведших к большому разнообразию методов, которые все больше и больше применяются на практике.
Процесс разбиения объектов заданного множества на группы близкие в некотором смысле, называется кластеризацией. Данное понятие тесно связанно с понятием классификации. Если известно количество групп, которые образуют разбиение, то кластеризация называется классификацией в широком смысле. Под классификацией в узком смысле понимается процедура отнесения заданного объекта к какой-либо группе.
Исследование методов классификации/кластеризации, основанных на знаниях, полученных от экспертов, в комбинации с наблюдаемыми данными, является перспективным направлением для решения подобных задач. Неотъемлемой частью экспертных систем, предназначенных для классификации/кластеризации, является база знаний. Именно база знаний учитывает специфику предметной области. Каждая база знаний опирается на модель представления знаний. Эффективным способом представления экспертных знаний являются продукционные правила, а экспертные системы, основанные на продукционной модели, называют продукционными.
Экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. В настоящее время появляются пакеты программ для построения нечетких экспертных систем. Они применяются в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
- Методы решения задач классификации/кластеризации
Общепринятой классификации методов кластеризации не существует, но можно выделить ряд групп подходов (некоторые методы можно отнести сразу к нескольким группам и потому предлагается рассматривать данную типизацию как некоторое приближение к реальной классификации методов кластеризации) [1]:
- Вероятностный подход. Предполагается, что каждый рассматриваемый объект относится к одному из k классов. Некоторые авторы (например, А. И. Орлов) считают, что данная группа вовсе не относится к кластеризации и противопоставляют её под названием «дискриминация», то есть выбор отнесения объектов к одной из известных групп (обучающих выборок).
- K-средних (K-means) [14]
- K-medians [15]
- EM-алгоритм
- Алгоритмы семейства FOREL [16]
- Дискриминантный анализ
- Подходы на основе систем искусственного интеллекта.
- Метод нечеткой кластеризации C-средних (C-means)
- Нейронная сеть Кохонена
- Генетический алгоритм
- Логический подход. Построение дендрограммы осуществляется с помощью дерева решений.
- Графовые алгоритмы кластеризации
- Иерархический подход. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы в свою очередь подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
- Другие методы, не вошедшие в предыдущие группы.
- Статистические алгоритмы кластеризации
- Ансамбль кластеризаторов
- Алгоритмы семейства KRAB
- Алгоритм, основанный на методе просеивания
- DBSCAN и др.
- Классификация/кластеризация в пакетах прикладных программ
В таблице 1 представлен список примеров программных пакетов, реализующих классификацию/кластеризацию.
Таблица 1 –Классификация/кластеризация в пакетах прикладных программ.
|
SAS (SAS Institute), 1982 |
Настраиваемая система для управления рисками, маркетингом. Используется для решения ряда задач: - управление маркетинговыми ресурсами - прогнозирование спроса - анализ клиентурной базы [10]. |
|
SPSS (SPSS, 1984) |
Статистический пакет для социальных наук [11]. |
|
BMDP (Dixon, 1983) |
Статистический пакет для биомедицинских приложений [12]. |
|
CLUSTAN (Wishart, 1982) |
Включает одиннадцать процедур, которые содержат семейства методов кластеризации [12]. |
|
STATISTICA |
Программный пакет для статистического анализа, реализующий функции анализа данных, управления данными, добычи и визуализации данных [11]. |
|
MATLAB |
Содержит инструмент Fuzzy Logic Toolbox, для построения и анализа нечетких множеств [11]. |
- Критерий качества классификации/кластеризации
Критерием качества классификации/кластеризации является ее точность. Оценка точности классификации может проводиться при помощи кросс-проверки. Кросс-проверка (Cross-validation) это процедура оценки точности классификации на данных из тестового множества, которое также называют кросс-проверочным множеством. Точность классификации тестового множества сравнивается с точностью классификации обучающего множества. Если классификация тестового множества дает приблизительно такие же результаты по точности, как и классификация обучающего множества, считается, что данная модель прошла кросс-проверку.
Разделение на обучающее и тестовое множества осуществляется путем деления выборки в определенной пропорции, например обучающее множество –две трети данных и тестовое –одна треть данных. Этот способ следует использовать для выборок с большим количеством примеров. Если же выборка имеет малые объемы, рекомендуется применять специальные методы, при использовании которых обучающая и тестовая выборки могут частично пересекаться [13].
ГЛАВА 2. НЕЧЕТКИЕ СИСТЕМЫ
2.1. Понятие нечеткой системы
Нечеткая система –это система, для описания которой используется аппарат теории нечетких множеств и нечеткая логика. Существуют следующие способы такого описания:
- нечеткая спецификация параметров системы (функционирование системы может быть описано алгебраическим или дифференциальным уравнением, в котором параметры являются нечеткими числами);
- нечеткое (лингвистическое) описание входных и выходных переменных системы, которое обусловлено неточной информацией, получаемой от ненадежных датчиков, или качественной информацией, получаемой от эксперта;
- нечеткое описание системы в виде совокупности если-то - правил, отражающих особенности функционирования на качественном уровне.
Нечеткая система может иметь одновременно все перечисленные атрибуты. Нечеткие системы используются для моделирования, анализа данных, прогноза или управления.
Нечеткие правила –это нечеткие продукционные правила, которые при фиксированной цели управления (например, сохранение значений управляемого параметра в некоторой области допустимых значений) описывают его стратегии на качественном уровне. Под продукцией понимается кортеж следующего вида: 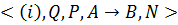 , где i –имя продукции, Q характеризует сферу применения продукции,
, где i –имя продукции, Q характеризует сферу применения продукции, 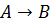 –ядро продукции (обычное прочтение ядра выглядит как: если A, то B), P –условие применимости ядра продукции или предусловие, N –постусловие продукции описывает действия и процедуры, которые необходимо выполнить после реализации B. Основной частью продукции является ядро, остальные элементы носят вспомогательный характер, поэтому в наиболее простом виде продукция может состоять лишь из имени и ядра [2].
–ядро продукции (обычное прочтение ядра выглядит как: если A, то B), P –условие применимости ядра продукции или предусловие, N –постусловие продукции описывает действия и процедуры, которые необходимо выполнить после реализации B. Основной частью продукции является ядро, остальные элементы носят вспомогательный характер, поэтому в наиболее простом виде продукция может состоять лишь из имени и ядра [2].
2.2. Структура и этапы проектирования нечеткого классификатора
Структура нечеткого классификатора представлена на рисунке 1 [2].
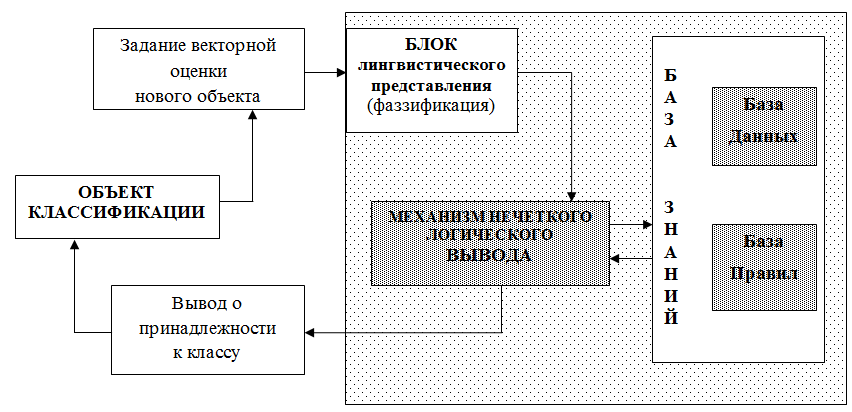
Рисунок 1 –Структура нечеткого классификатора.
Объект классификации представляет собой входную переменную, которую необходимо отнести к одному из заранее известных классов.
Блок задание векторной оценки нового объекта представляет объект классификации как вектор, состоящий из n компонент (характеристик).
В блоке лингвистического представления (фаззификации) точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности.
Механизм нечеткого логического вывода – это процесс получения нечетких заключений об объекте классификации на основе нечетких условий или предпосылок, представляющих собой информацию об объекте.
База знаний нечеткой логической системы состоит из базы правил, определяющих зависимость между входными и выходными термами-множествами, и базы данных, которая содержит функции принадлежности, показывающие степень соответствия реальных величин понятиям, определяемые термами-множествами.
В блоке вывод о принадлежности к классу определяется наиболее вероятная принадлежность объекта к одному из заданных классов.
На рисунке 2 представлен процесс проектирования нечеткого классификатора.
Рассмотрим этапы проектирования нечеткого классификатора.
ЭТАП 1. Формирование входных и/или выходных переменных
Целью введения нечеткого множества чаще всего является формализация нечетких понятий и отношений естественного языка. Данную формализацию можно выполнить, воспользовавшись понятиями нечеткой и лингвистической переменных.
Нечеткая переменная задается тройкой [5]
, U, A,
где –название переменной, U –универсальное множество (область определения ), А –нечеткое множество на U с функцией принадлежности  , описывающее ограничения на значение нечеткой переменной.
, описывающее ограничения на значение нечеткой переменной.
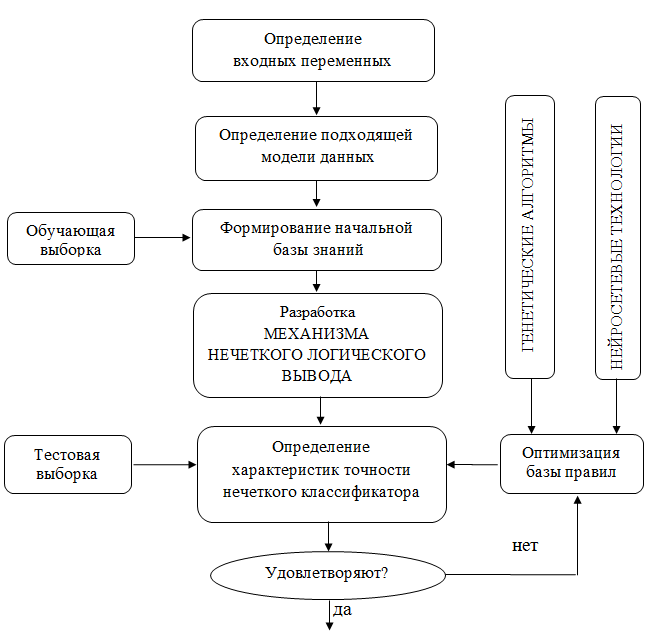
Рисунок 2 –Процесс проектирования нечеткого классификатора
Лингвистическая переменная задается кортежем [5]
<, T, U, G, M>,
где –название переменной; Т –базовое терм-множество или множество основных лингвистических значений (термов) переменной , причем каждому из них соответствует нечеткая переменная с функцией принадлежности, заданной на U; G –синтаксическое правило, описывающее процесс образования из множества Т новых значений лингвистической переменной ( называется расширенным терм-множеством); М –семантическое правило, согласно которому новые значения лингвистической переменной , полученные с помощью G, отображаются в нечеткие переменные (это может быть процедура экспертного опроса, позволяющая приписать каждому новому значению, образованному процедурой G, некоторую семантику путем формирования соответствующего нечеткого множества). Шкала U, на которой определена лингвистическая переменная, может быть числовой или нечисловой.
называется расширенным терм-множеством); М –семантическое правило, согласно которому новые значения лингвистической переменной , полученные с помощью G, отображаются в нечеткие переменные (это может быть процедура экспертного опроса, позволяющая приписать каждому новому значению, образованному процедурой G, некоторую семантику путем формирования соответствующего нечеткого множества). Шкала U, на которой определена лингвистическая переменная, может быть числовой или нечисловой.
Для обозначения лингвистических переменных используют нечеткие числа. Нечеткое число –это нечеткая переменная, определенная на числовой оси функцией принадлежности  [2,5].
[2,5].
В практических приложениях теории нечетких множеств используется большое количество различных типов функций принадлежности нечетких чисел. Основные типы функций принадлежности приведены в таблице 2 [3].
Таблица 2 –Классификация типов функций принадлежности.
|
Функции принадлежности, состоящие из прямолинейных участков |
|
Трапециевидные |
|
|
Треугольные |
|
|
Математическое представление интуитивных функций принадлежности |
|
|
Симметричная Гауссова функция |
|
|
Ассиметричная Гауссова функция |
Вводится вспомогательная переменная
где m – модальное (среднее) значение. |
|
Сигмоидальная функция |
Правая сигмоидальная функция:
где b задает координату точки k, принадлежащую нечеткому множеству со степенью 0,5; a определяет наклон функции в точке перегиба k. Левая сигмоидальная функция:
|
|
Гармоническая функция |
|
|
Полиномиальная функция (второго порядка) |
|
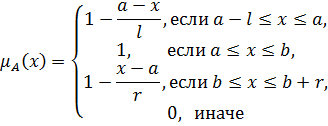
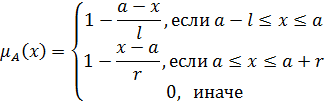
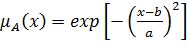 , где
, где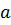 – ширина,
– ширина, 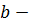 модальное значение;
модальное значение;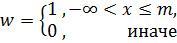
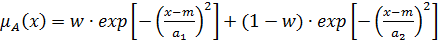 ,
,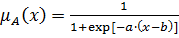 ,
,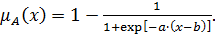
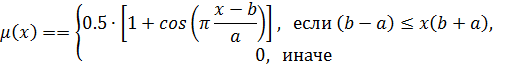
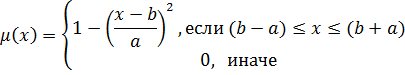
Самые простые нечеткие числа –треугольные и трапециевидные. Треугольное нечеткое число с центром в точке а можно рассматривать как нечеткое значение высказывания х приблизительно равен а, в то время как трапециевидное число обозначает нечеткое значение высказывания х находится приблизительно в интервале [a,b]. Величины l и r также называются соответственно левым и правым коэффициентами нечеткости и показывают насколько неточно (нечетко) определены границы числа. Трапециевидное нечеткое число обозначается кортежем 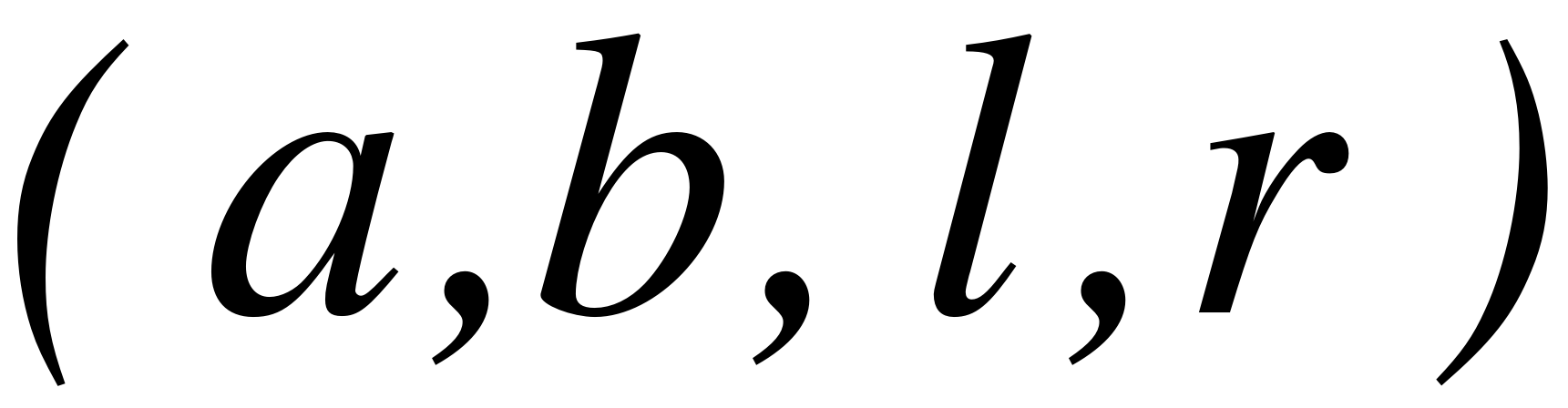 ; при
; при 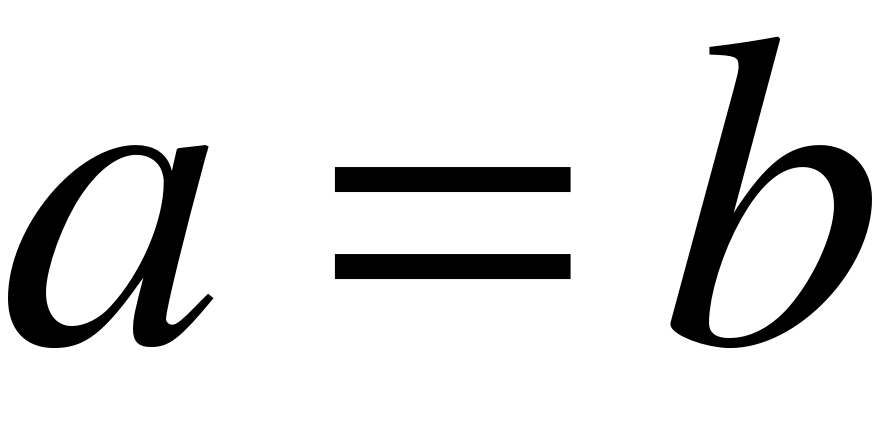 получим треугольное нечеткое числа
получим треугольное нечеткое числа 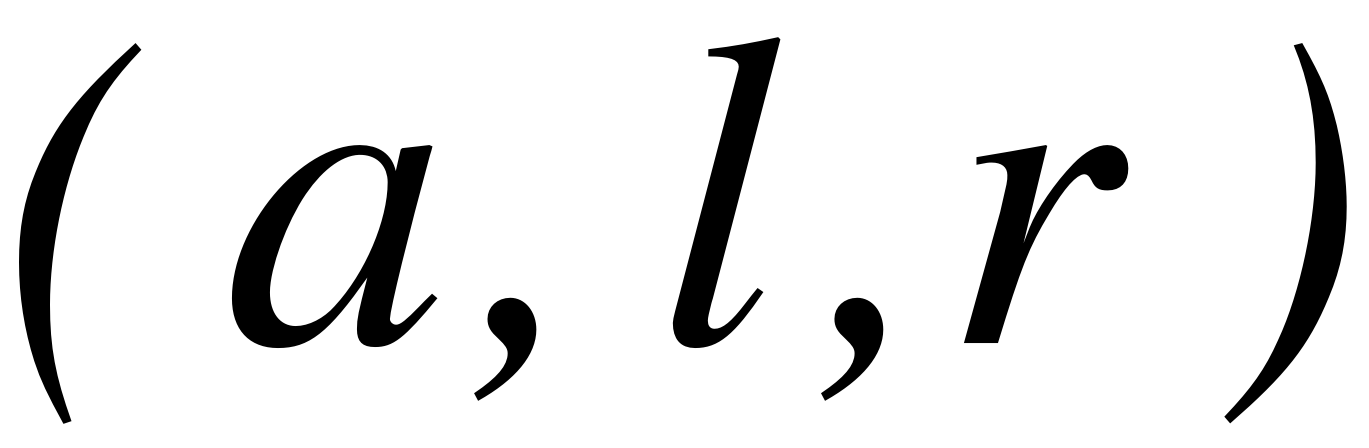 .
.
ЭТАП 2. Формирование базы правил для нечеткого классификатора
Центральным элементом нечеткой модели является база правил, поскольку именно в ней содержится информация о структуре модели. База правил содержит основную информацию о моделируемой системе или главную составляющую «интеллекта» нечеткого классификатора, и поэтому умение правильно ее формировать является очень важным условием.
Каждое правило состоит из двух частей: условной и заключительной. Антецедент или условная часть (если–часть) содержит утверждение относительно значений входных переменных, в консеквенте или заключительной части (то–части) указывается значение, которое принимает выходная переменная. Нечеткие правила если-то улучшают интерпретируемость результатов и обеспечивают более глубокое понимание сути процесса классификации.
Рассмотрим свойства, которыми могут обладать правила, базы правил и нечеткие модели [3]:
Локальный характер правил
Изменение заключения правил приводит к локальному изменению сегментов поверхности модели, прилегающих к задаваемой правилом опорной точке. На другие сегменты, не прилегающие к данной точке, изменение заключения правила либо вообще не оказывают влияния, либо влияет слабее.
Зависимость числа правил от числа содержащихся в модели нечетких множеств
С повышением уровня сложности модели (увеличение числа правил или нечетких множеств) точно так же улучшается ее способность описывать реальную систему.
Полнота модели
Нечеткая модель является полной, если с каждым входным состоянием 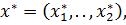 принадлежащим области X, она может связать некоторое выходное состояние
принадлежащим области X, она может связать некоторое выходное состояние 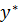 . Нечеткая модель является неполной, если с некоторыми входными состояниями
. Нечеткая модель является неполной, если с некоторыми входными состояниями 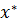 нельзя связать ни одного выходного состояния
нельзя связать ни одного выходного состояния 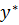 .
.
Непротиворечивость базы правил
База правил называется непротиворечивой (согласованной), если она не содержит несовместные правила, то есть правила, имеющие одинаковые условия, но разные заключения.
Связность базы правил
База правил называется связной, если в ней нет смежных правил 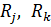 таких, что пересечение содержащихся в их заключениях нечетких множеств
таких, что пересечение содержащихся в их заключениях нечетких множеств 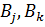 является пустым, то есть
является пустым, то есть 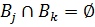 . Иными словами, для любого y, принадлежащего области значений Y выходного параметра, выполняется соотношение:
. Иными словами, для любого y, принадлежащего области значений Y выходного параметра, выполняется соотношение:
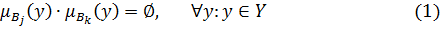
Избыточность базы правил
Иногда встречаются нечеткие модели, содержащие два или более идентичных правила (то есть правила, у которых совпадают условия и заключения). В таком случае совпадающее правило нужно либо исключить, либо заменить несколько совпадающих правил одним правилом, заключение которого соответствующим образом усилено [3].
На рисунке 3 представлена блок-схема построения базы правил на основе численных данных [4].
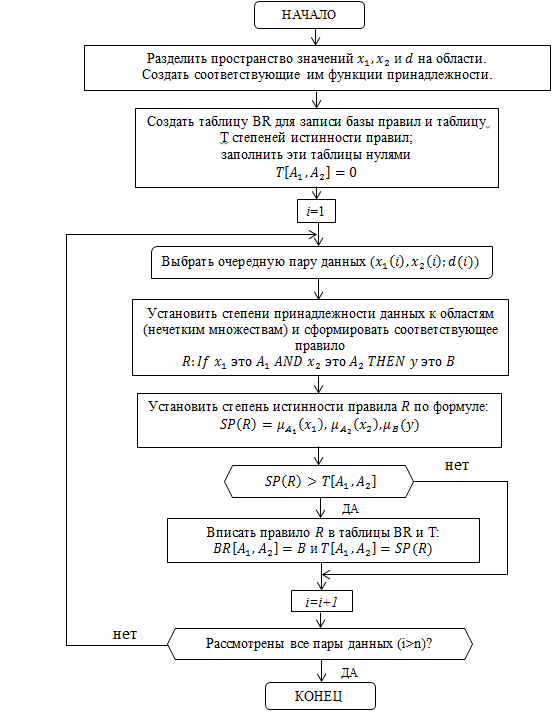
Рисунок 3 –Блок-схема построения базы правил на основе численных данных
ЭТАП 3. Разработка механизма логического вывода
Рассмотрим класс операторов пересечения и объединения, известных как треугольные нормы: t-норма 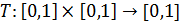 и t-конорма (s-норма)
и t-конорма (s-норма) 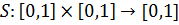 . T служит основой для определения пересечения нечетких множеств, а S – объединения нечетких множеств. Принимая во внимание свойства классических множеств, можно сформулировать следующие свойства для t-норм:
. T служит основой для определения пересечения нечетких множеств, а S – объединения нечетких множеств. Принимая во внимание свойства классических множеств, можно сформулировать следующие свойства для t-норм:
-
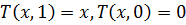 – ограниченность
– ограниченность -
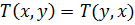 – коммутативность
– коммутативность - Если
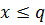 и
и 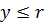 , то
, то 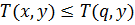 и
и 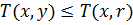 – монотонность
– монотонность -
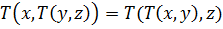 – ассоциативность
– ассоциативность
и для s-норм:
-
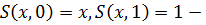 граничные условия
граничные условия -
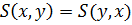 – коммутативность
– коммутативность - Если
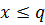 и
и 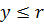 , то
, то 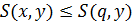 и
и 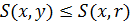 – монотонность
– монотонность -
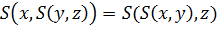 – ассоциативность
– ассоциативность
где 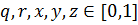 .
.
Другими словами, функция 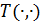 есть t-норма тогда и только тогда, когда она удовлетворяет условиям T1-T4, а
есть t-норма тогда и только тогда, когда она удовлетворяет условиям T1-T4, а 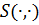 – s-норма тогда и только тогда, когда она удовлетворяет условиям S1-S4. С точки зрения алгебры, T – полугруппа в [0,1] с единицей 1, а S – с единицей 0. Наиболее важные параметры t-норм и s-норм приведены в таблице 3.
– s-норма тогда и только тогда, когда она удовлетворяет условиям S1-S4. С точки зрения алгебры, T – полугруппа в [0,1] с единицей 1, а S – с единицей 0. Наиболее важные параметры t-норм и s-норм приведены в таблице 3.
Таблица 3 – t-нормы и s-нормы
|
t-норма |
s-норма |
|
Заде |
|
|
|
|
|
Алгебраическая |
|
|
|
|
|
Лукашевич |
|
|
|
|
|
Фодор |
|
|
|
|
|
Глубокая |
|
|
|
|
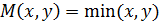
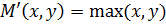
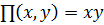
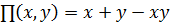
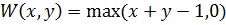
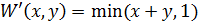
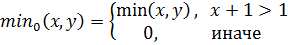
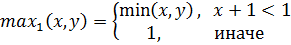
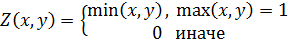
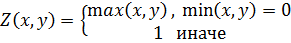
Теперь введем операцию дополнения нечеткого множества 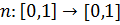 такую, что
такую, что 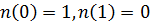 и выполняются следующие условия:
и выполняются следующие условия:
- n –строго убывающая,
- n непрерывная,
-
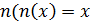 для любого
для любого 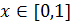 .
.
Отрицание строгое, если оно удовлетворяет условиям 1 и 2. Отрицание называется сильным, если для него также выполнено условие 3.
Функция 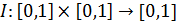 , удовлетворяющая следующим условиям, называется импликацией:
, удовлетворяющая следующим условиям, называется импликацией:
- если
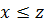 , то
, то 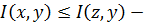 монотонность по первому аргументу;
монотонность по первому аргументу; - если
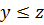 , то
, то 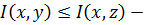 монотонность по второму аргументу;
монотонность по второму аргументу; -
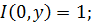
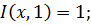
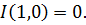
Наиболее важные нечеткие импликации представлены в таблице 4 [5].
Таблица 4 –Нечеткие импликации
|
Название |
Вид |
|
Лукашевич |
|
|
Фодор |
|
|
Райхенбах |
|
|
Клине-Динс |
|
|
Заде |
|
|
Гёдель |
|
|
Ягер |
|
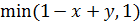
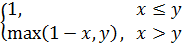
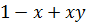
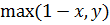
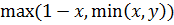
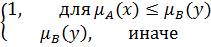
Импликация применяется для получения нечеткого логического вывода. В его основе лежат классические схемы правильных рассуждений modus ponens и modus tollens.
Классический modus ponens –это правило вывода следующего вида: если посылки 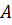 и
и 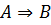 истинны, то предпосылка
истинны, то предпосылка 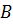 также верна, то есть
также верна, то есть 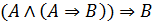 , или
, или
Предпосылка I – факт А
Предпосылка II – правило если A, то B
_________________________________
Заключение B
Нечеткая интерпретация позволяет перейти к обобщенному modus ponens, который может быть записан так:
Предпосылка I – факт А’
Предпосылка II – правило если A, то B
_________________________________
Заключение B’
где 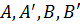 - нечеткие числа, определенные своими функциями принадлежности на множестве действительных чисел [2].
- нечеткие числа, определенные своими функциями принадлежности на множестве действительных чисел [2].
Пусть база знаний содержит набор правил:
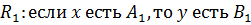
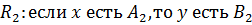
…
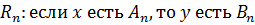
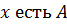
_______________________________
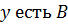
Каждому правилу 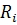 соответствует импликация
соответствует импликация 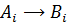 . Существует два подхода к формированию функции принадлежности заключения:
. Существует два подхода к формированию функции принадлежности заключения:
- сначала все правила агрегируются, а затем применяется композиция;
- вначале формируется заключение для каждого правила вывода, а затем применяется оператор агрегирования.
Если получившееся множество B’ является нечетким, то возникает проблема определения конкретного числового значения выходной переменной. Для этого используется процедура дефаззификации.
ЭТАП 4. Дефаззификация
Под дефаззификацией нечеткого множества B*(y), являющегося результатом вывода, понимается операция нахождения четкого значения y*, которое бы наиболее «рациональным» образом представляло это множество.
Наиболее известные методы дефаззификации [3]:
- метод среднего максимума

где 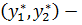 отрезок, имеющий максимальную степень принадлежности;
отрезок, имеющий максимальную степень принадлежности;
- метод первого максимума в качестве четкого значения
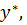 представляющего результирующее нечеткое множество-заключение, выбирается наименьшее значение
представляющего результирующее нечеткое множество-заключение, выбирается наименьшее значение 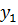 , максимизирующее его функцию принадлежности;
, максимизирующее его функцию принадлежности; - метод последнего максимума в качестве четкого значения
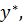 представляющего результирующее нечеткое множество-заключение, выбирается наибольшее значение
представляющего результирующее нечеткое множество-заключение, выбирается наибольшее значение 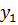 , максимизирующее его функцию принадлежности;
, максимизирующее его функцию принадлежности; - метод центра тяжести предполагает, что в качестве четкого значения
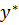 для представления результирующего нечеткого множества
для представления результирующего нечеткого множества 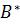 , задаваемого функцией принадлежности
, задаваемого функцией принадлежности 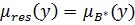 , должна выбираться координата
, должна выбираться координата 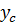 центра тяжести фигуры, ограниченной графиком этой функции. Значение координаты центра тяжести может быть найдено по формуле
центра тяжести фигуры, ограниченной графиком этой функции. Значение координаты центра тяжести может быть найдено по формуле
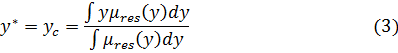
(пределы интегрирования задаются областью определения результирующего нечеткого множества-вывода 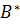 );
);
- метод высот

 .
.
ГЛАВА 3. ПРОЕКТИРОВАНИЕ НЕЧЕТКОГО
КЛАССИФИКАТОРА НА ОСНОВЕ НАБЛЮДАЕМЫХ ДАННЫХ
- Постановка задачи
Пусть имеется N объектов, каждый из которых характеризуется n свойствами, так что объекту 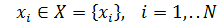 соответствует векторная оценка
соответствует векторная оценка 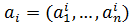 .
. 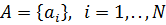 – множество векторных оценок. Требуется определить разбиение множества
– множество векторных оценок. Требуется определить разбиение множества 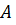 на подмножества
на подмножества 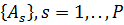 , такие что
, такие что 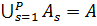 и для
и для 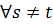 (
(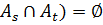 , для
, для 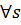
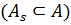 . Подмножества
. Подмножества 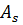 будем называть классами (или кластерами). Если разбиение определено, то для любого нового объекта необходимо определить принадлежность к определенному классу.
будем называть классами (или кластерами). Если разбиение определено, то для любого нового объекта необходимо определить принадлежность к определенному классу.
Данная задача связана с поиском на множестве векторных оценок А отношения эквивалентности Е, которое однозначно определяет искомое разбиение. Оно представляет собой фактор-множество множества А по отношению эквивалентности Е.
- Структура модели
Мы применяем нечеткие правила классификации, каждое из которых описывает один из классов 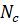 в наборе данных
в наборе данных
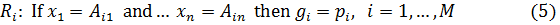
Здесь 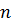 обозначает число свойств,
обозначает число свойств, 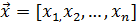 – входной вектор,
– входной вектор, 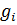 – вывод i-го правила и
– вывод i-го правила и  предшествующие нечеткие множества.
предшествующие нечеткие множества.
Шаг 1: Степень активации i-го правила вычисляется как:
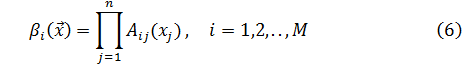
Шаг 2: Выход классификатора определяется правилом, которое имеет наивысшую степень активации:
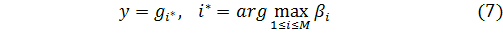
Шаг3: Предполагаем, что число классов соответствует числу правил, т.е. M=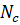 . Степень уверенности в решении дана нормализованной степенью активации правила:
. Степень уверенности в решении дана нормализованной степенью активации правила:
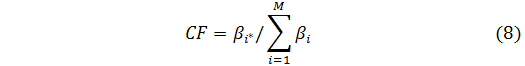
- Управляемая данными инициализация
Из К доступных пар данных 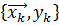 мы строим n-мерный шаблон матрицы
мы строим n-мерный шаблон матрицы 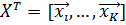 и соответствующий вектор-метку
и соответствующий вектор-метку 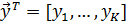 . Нечеткие антецеденты
. Нечеткие антецеденты 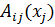 в начальной базе правил определяются алгоритмом, который изложен ниже.
в начальной базе правил определяются алгоритмом, который изложен ниже.
Функции принадлежности переменных определяются в пространстве результирующих функций, каждая из которых описывает область, где система может быть приближена единственным нечетким правилом. Это разбиение может быть реализовано итерационными методами.
Шаг 1: Предполагаем, что форма нечетких множеств может быть приближена эллипсоидами. Таким образом, каждому прототипу класса соответствует центр 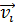 , вычисленный на основе его ковариационной матрицы
, вычисленный на основе его ковариационной матрицы 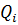

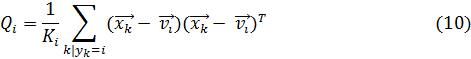
Здесь i обозначает номер класса, 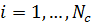 , и
, и 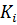 обозначает число объектов, принадлежащих i-му классу.
обозначает число объектов, принадлежащих i-му классу.
Шаг 2: Вычисляется матрица нечеткого разделения U, элементы которой 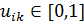 определяют степень принадлежности объекта данных
определяют степень принадлежности объекта данных 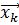 классу
классу 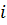 . Эта принадлежность основана на расстоянии между объектом и центром класса
. Эта принадлежность основана на расстоянии между объектом и центром класса
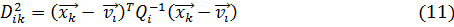
С учетом расстояния, степень принадлежности вычисляется по формуле
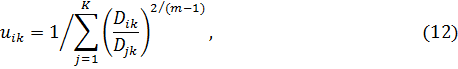
где m весовой показатель, определяющий размытость полученных разделений (m = 1,8 применяется в примере).
Строки U теперь содержат поточечные представления многомерных нечетких множеств описания классов в пространстве функций.
Шаг 3: Одномерные нечеткие множества 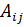 в классификации правил (1) получаются путем проектирования рядов U на входные переменные
в классификации правил (1) получаются путем проектирования рядов U на входные переменные 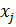 , а затем аппроксимацией проекций параметрическими функциями. Для простоты применяются треугольные нечеткие числа
, а затем аппроксимацией проекций параметрическими функциями. Для простоты применяются треугольные нечеткие числа
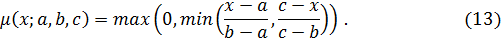
Если использовать более гладкие функции принадлежности, например, Гаусса или показательные функции, то модель будет в целом иметь более высокую точность.
- Сокращение модели
- Отбор свойств на основе межклассовой отделимости
Использование слишком большого количества признаков, характеризующих свойства классифицируемых объектов приводит к трудностям в интерпретации результатов за счет избыточности и шума. Следовательно, необходимо более обоснованно выбирать свойства, учитываемые в модели. Для этого применяется межклассовый метод отделимости Фишера, основанный на статистических свойствах маркированных данных [6]. Этот критерий основан на межклассовом и внутриклассовом разбросе или ковариационных матрицах, называемых 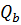 и
и 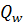 , соответственно, которые суммируются до полной матрицы разброса
, соответственно, которые суммируются до полной матрицы разброса 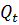 , которая является ковариацией всех обучающих данных содержащих K пар данных.
, которая является ковариацией всех обучающих данных содержащих K пар данных.
Шаг 1: Строится матрица 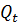
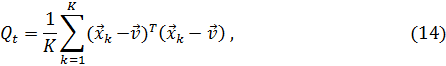
где
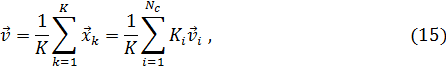
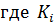 – число случаев в каждом классе.
– число случаев в каждом классе.
Общая матрица разброса может быть представлена в виде

где
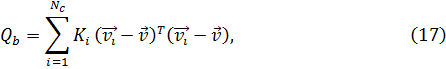

Шаг 2: Ранжирование признаков делается многократно, причем каждый раз отбрасывается последний в ранжировании признак с учетом значения критерия

где det – определитель и 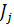 – значение критерия, включая j признаков.
– значение критерия, включая j признаков.
- Упрощение базы правил
Метод упрощения базы правил основан на мере сходства для определения количественной избыточности правил.
Под степенью сходства понимается число [5]

где 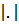 обозначает мощность множества, а
обозначает мощность множества, а 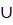 и
и 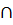 объединение и пересечение соответственно нечетких множеств. Если
объединение и пересечение соответственно нечетких множеств. Если 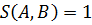 , то нечеткие множества равны или эквивалентны. S (A,B) становится 0, когда функции принадлежности не пересекаются.
, то нечеткие множества равны или эквивалентны. S (A,B) становится 0, когда функции принадлежности не пересекаются.
Нечеткие множества объединяются, когда их степень сходства превышает определяемый заранее порог 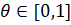 (применяется
(применяется  = 0,5).
= 0,5).
Слияние уменьшает количество лингвистических термов для входных переменных в посылке правила за счет их объединения при заданном пороге. Возможно, что это слияние приведет к тому, что получится одно нечеткое множество, носитель которого совпадет с универсальным множеством, тогда это правило исключается из базы.
Стандартные ситуации, в которых требуется объединение термов, приведены на рис. 4.
d3 cf d0 ce d9 c5 cd c8 c5
Если 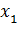 есть.. и
есть.. и 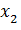 есть.. и
есть.. и 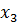 есть.. то
есть.. то 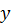 есть..
есть.. 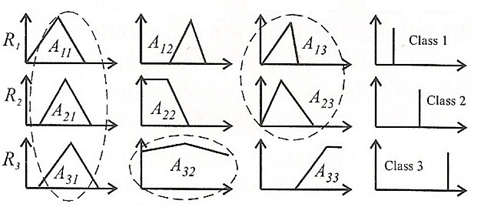
Если 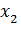 есть.. и
есть.. и  есть.. то
есть.. то  есть..
есть..
Рисунок 4 – Упрощение базы правил
Сформулируем некоторые принципы для упрощения базы правил, под которым понимается сокращения количества входных переменных или правил.
- Если существует переменная в посылках всех правил, которая принимает значения в виде нечетких множеств, которые подобны при заданном значении порога, то эта переменная является малоинформативной и может быть исключена из всех правил.
Как показано на рисунке, нечеткие множества A11, A21 и A31 подобны, следовательно, они объединяются в одно нечеткое множество, которое исключается из модели.
- Если существует такая переменная, по крайней мере, в двух правила, которая принимает значения в виде нечетких множеств, подобных при заданном значении порога, то путем объединения этих множеств формируется новое значение для данной переменной.
- Если существует переменная, принимающая значение в виде нечеткого множества, носитель которого совпадает с универсальным множеством, то такая переменная исключается из правила.
Нечеткое множество A32 является объединением множеств A12 и A22, поэтому его исключают из модели. Множества A13 и A23 сходны, поэтому они тоже объединяются.
Для упрощения базы правил нами предложен следующий алгоритм:
- Объединение по подобию основано на установлении отношения эквивалентности на множестве нечетких подмножеств, являющихся термами соответствующей лингвистической переменной.
Для каждой переменной 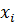 выполнить:
выполнить:
- На основе определения функции подобия [5] построить матрицу отношения подобия
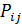 , такую, что
, такую, что

- Выбрать число
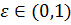 – меру подобия (чем ближе это число к 1, тем более строгим является критерий подобия).
– меру подобия (чем ближе это число к 1, тем более строгим является критерий подобия). - Преобразовать матрицу
 следующим образом:
следующим образом:
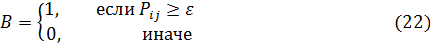
- Привести матрицу к блочно-диагональному виду путем перестановки строк и столбцов (вначале группируются одинаковые строки, а затем в том же порядке берутся столбцы).
- Объединить нечеткие множества, соответствующие отдельным блокам, так как они являются подобными.
- Исключение неинформативных свойств.
- Выполнить шаги 1.1. –.3.
- Если
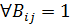 , то данное свойство исключить из правил, так как оно не информативно, то есть не влияет на конечный результат.
, то данное свойство исключить из правил, так как оно не информативно, то есть не влияет на конечный результат.
- Проверка на близость к универсальному множеству.
Для каждой переменной 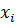 выполнить проверку:
выполнить проверку:
- Если
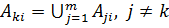 , то свойство
, то свойство 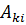 близко к универсальному множеству.
близко к универсальному множеству. - Исключить свойство
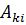 .
.
ГЛАВА 4. ИСПОЛЬЗОВАНИЕ ГЕНЕТИЧЕСКИХ
АЛГОРИТМОВ ДЛЯ ОПТИМИЗАЦИИ БАЗЫ ПРАВИЛ
- Основные понятия эволюционного программирования
Многие шаги в процессе моделирования являются субоптимальными. Например, проекция кластеров на входные переменные и их приближение треугольными нечеткими множествами представляет структурную ошибку. Другим примером является идентификация предпосылки и заключения правила. Для улучшения классификационных возможностей базы счет модификации функций принадлежностей термов предлагается использовать генетический алгоритм (ГА), который является разновидностью эволюционных алгоритмов.
К основным эволюционным алгоритмам относятся [7]:
- Генетический алгоритм, предназначенный для оптимизации функций дискретных переменных и акцентирующий внимание на рекомбинациях геномов;
- Эволюционное программирование, ориентированное на оптимизацию непрерывных функций без использования рекомбинаций;
- Эволюционная стратегия, ориентированная на оптимизацию непрерывных функций с использованием рекомбинаций;
- Генетическое программирование, использующее эволюционный метод для оптимизации компьютерных программ.
По сравнению с обычными оптимизационными методами эволюционные алгоритмы имеют следующие особенности: параллельный поиск, случайные мутации и рекомбинации уже найденных хороших решений. Они хорошо подходят как простой эвристический метод оптимизации многомерных, плохо определенных функций.
Генетический алгоритм – это новый инструмент, который появился в результате исследований Д. Холланда и его коллег. Генетические алгоритмы, описанные Д. Холландом, заимствуют в своей терминологии много из естественной генетики. Впервые генетические алгоритмы были применены к таким научным проблемам, как распознавание образов и оптимизация. Генетический алгоритм представляет собой адаптивный поисковый метод, основанный на селекции лучших элементов в популяции.
Основой для возникновения генетических алгоритмов послужила модель биологической эволюции Ч. Дарвина и методы случайного поиска. Л. Растригин отмечал [17], что случайный поиск возник как реализация простейшей модели эволюции, когда случайные мутации моделировались случайными шагами оптимального решения, а отбор – «устранением» неудачных элементов.
Эволюционный поиск с точки зрения преобразования информации – это последовательное преобразование одного конечного нечеткого множества промежуточных решений в другое. Генетические алгоритмы – это не просто случайный поиск. Они эффективно используют информацию, накопленную в процессе эволюции.
Цель генетических алгоритмов состоит в том, чтобы:
- абстрактно и формально объяснять адаптацию процессов в естественной системе и интеллектуальной исследовательской системе;
- моделировать естественные эволюционные процессы для эффективного решения задач науки и техники.
В настоящее время используется новая парадигма решений оптимизационных задач на основе генетических алгоритмов и их различных модификаций. Генетические алгоритмы осуществляют поиск баланса между эффективностью и качеством решений за счет «выживания сильнейших альтернативных решений» в неопределенных и нечетких условиях.
Генетические алгоритмы отличаются от других оптимизационных и поисковых процедур следующим [7,8,9]:
- работают в основном не с параметрами задачи, а с закодированным множеством параметров;
- осуществляют поиск не путем улучшения одного решения, а путем использования сразу нескольких альтернатив на заданном множестве решений;
- используют целевую функцию, а не ее различные приращения для оценки качества принятия решений;
- применяют не детерминированные, а вероятностные правила анализа оптимизационных задач.
Для работы генетических алгоритмов выбирают множество натуральных параметров оптимизационной проблемы и кодируют их в последовательность конечной длины в некотором алфавите. Они работают до тех пор, пока не будет выполнено заданное число генераций (итераций алгоритма) или на некоторой генерации будет получено решение определенного качества, или когда найден локальный оптимум, т.е. возникла преждевременная сходимость и алгоритм не может найти выход из этого состояния. В отличии от других методов оптимизации эти алгоритмы, как правило, анализируют различные области пространства решений одновременно и поэтому они более приспособлены к нахождению новых областей с лучшими значениями целевой функции [7].
На рисунке 5 представлена блок-схема генетического алгоритма [4].
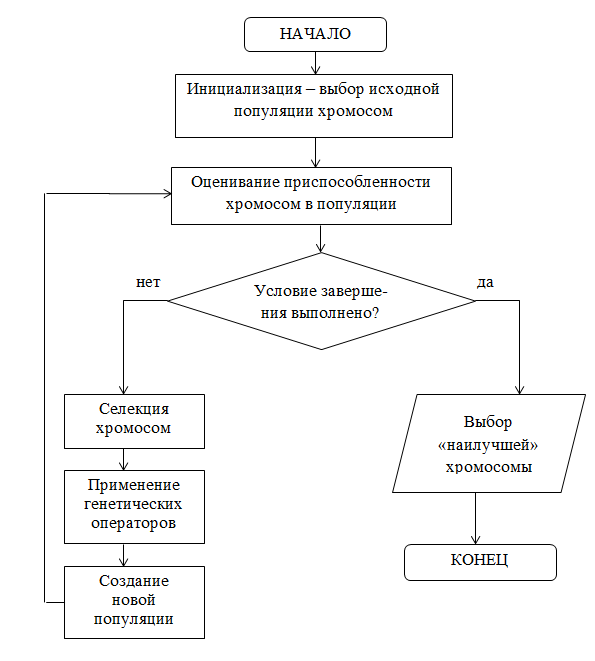
Рисунок 5 – Блок-схема генетического алгоритма
- Символьная модель
Цель оптимизации с помощью ГА состоит в том, чтобы найти лучшее возможное решение или решения задачи по одному или нескольким критериям. Чтобы реализовать генетический алгоритм, нужно сначала выбрать подходящую структуру для представления этих решений. В постановке задачи поиска экземпляр этой структуры данных представляет собой точку в пространстве поиска всех возможных решений.
Структура данных генетического алгоритма состоит из одной или более хромосом. Как правило, хромосома – это битовая строка, так что термин строка часто заменяет понятие «хромосома». В принципе, ГА не ограничены бинарными представлениями. Известны другие реализации, построенные исключительно на векторах вещественных чисел. Несмотря на то, что для многих реальных задач больше подходят строки переменной длины, в настоящее время структуры фиксированной длины наиболее распространены и изучены.
Каждая хромосома (строка) представляет собой объединение ряда подкомпонентов, называемых генами. Гены располагаются в различных позициях или локусах хромосомы, и принимают значения, называемые аллелями. В представлениях с бинарными строками, ген-бит, локус – его позиция в строке, и аллель – его значение (0 или 1). Биологический термин «генотип» относится к полной генетической модели особи и соответствует структуре в ГА. Термин «фенотип» относится к внешним наблюдаемым признакам и соответствует вектору в пространстве параметров. Чрезвычайно простой, но иллюстративный пример – задача максимизации следующей функции двух переменных:
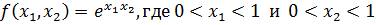
Обычно, методика кодирования реальных переменных 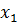 и
и 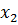 состоит в их преобразовании в двоичные целочисленные строки достаточной длины – достаточной для того, чтобы обеспечить желаемую точность. Предположим, что 10-ти разрядное кодирование достаточно для
состоит в их преобразовании в двоичные целочисленные строки достаточной длины – достаточной для того, чтобы обеспечить желаемую точность. Предположим, что 10-ти разрядное кодирование достаточно для 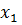 и
и 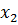 . Установить соответствие между генотипом и фенотипом закодированных особей можно, разделив соответствующее двоичное число на
. Установить соответствие между генотипом и фенотипом закодированных особей можно, разделив соответствующее двоичное число на 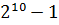 . Например, 0000000000 соответствует 0/1023 или 0, тогда как 1111111111 соответствует 1023/1023 или 1. Оптимизированная структура данных – 20-ти битная строка, представляющая конкатенацию кодировок
. Например, 0000000000 соответствует 0/1023 или 0, тогда как 1111111111 соответствует 1023/1023 или 1. Оптимизированная структура данных – 20-ти битная строка, представляющая конкатенацию кодировок 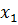 и
и 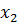 . Переменная
. Переменная 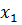 размещается в крайних левых 10-ти разрядах, тогда как
размещается в крайних левых 10-ти разрядах, тогда как 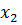 размещается в правой части генотипа особи (20-ти битной строке). Генотип – точка в 20-мерном хемминговом пространстве, исследуемом ГА. Фенотип – точка в двумерном пространстве параметров [8].
размещается в правой части генотипа особи (20-ти битной строке). Генотип – точка в 20-мерном хемминговом пространстве, исследуемом ГА. Фенотип – точка в двумерном пространстве параметров [8].
Чтобы оптимизировать структуру, используя ГА, нужно задать некоторую меру качества для каждой структуры в пространстве поиска. Для этой цели используется функция приспособленности. В функциональной максимизации, целевая функция часто сама выступает в качестве функции приспособленности; для задач минимизации, целевую функцию следует инвертировать и сместить в область положительных значений.
- Канонический генетический алгоритм
Данная модель алгоритма является классической. Она была предложена Джоном Холландом в его знаменитой работе «Адаптация в природных и искусственных средах» (1975). Часто можно встретить описание простого ГА. Он отличается от канонического тем, что использует либо рулеточный, либо турнирный отбор. Модель канонического ГА имеет следующие характеристики [8]:
- фиксированный размер популяции,
- фиксированная разрядность генов,
- пропорциональный отбор,
- особи для скрещивания выбираются случайным образом,
- одноклеточный кроссовер и одноклеточные мутации.
- Кроссовер
Оператор кроссовера (crossover operator) является основным генетическим оператором, за счет которого производится обмен генетическим материалом между особями. Кроссовер моделирует процесс скрещивания особей.
Пусть имеются две родительские особи с хромосомами 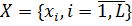 и
и 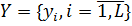 . Хромосомы, представляющие собой отображения решений, должны быть гомологичны, так как являются взаимозаменяемыми альтернативами. Случайным образом определяется точка внутри хромосомы, в которой обе хромосомы делятся на две части и обмениваются ими. Назовем эту точку точкой разрыва. Вообще говоря, в англоязычной литературе она называется точкой кроссовера (crossover point). Описанный процесс изображен на рисунке 6.
. Хромосомы, представляющие собой отображения решений, должны быть гомологичны, так как являются взаимозаменяемыми альтернативами. Случайным образом определяется точка внутри хромосомы, в которой обе хромосомы делятся на две части и обмениваются ими. Назовем эту точку точкой разрыва. Вообще говоря, в англоязычной литературе она называется точкой кроссовера (crossover point). Описанный процесс изображен на рисунке 6.
Родительские особи Потомки
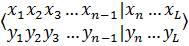
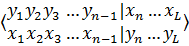
Рисунок 6 – Кроссовер
Данный тип кроссовера называется одноточечным, так как при нем родительские хромосомы разрезаются только в одной случайной точке. Также существует 2-х и n-точечный операторы кроссовера. В 2-х точечном кроссовере точек разрыва 2, а n-точечный кроссовер является своеобразным обобщением 1- и 2-точечного кросоеверов для n>2.
Кроме описанных типов кроссовера, есть еще однородный кроссовер. Его особенность заключается в том, что значение каждого бита в хромосоме потомка определяется случайным образом из соответствующих битов родителей. Для этого вводится некоторая величина 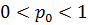 , и если случайное число больше
, и если случайное число больше 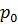 , то на n-ю позицию первого потомка попадает n-й бит первого родителя, а на n-ю позицию сторого – n-й бит второго родителя. В противном случае к первому потомку попадает бит второго родителя, а ко второму – первого. Такая операция проводится для всех битов хромосомы.
, то на n-ю позицию первого потомка попадает n-й бит первого родителя, а на n-ю позицию сторого – n-й бит второго родителя. В противном случае к первому потомку попадает бит второго родителя, а ко второму – первого. Такая операция проводится для всех битов хромосомы.
- Мутация
Оператор мутации (mutation operator) необходим для вывода популяции из локального экстремума и способствует защите от преждевременной сходимости. Это достигается за счет того, что инвертируется случайно выбранный бит в хромосоме, что показано на рисунке 7.
До мутации После мутации
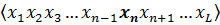
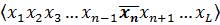
Рисунок 7 - Мутация
Так же как и кроссовер, мутация проводится не только по одной случайной точке. Можно выбирать некоторое количество точек в хромосоме для инверсии, причем их число также может быть случайным. Также можно инвертировать сразу некоторую группу подряд идущих точек. Среди рекомендаций по выбору вероятности мутации нередко можно встретить варианты 1/L или 1/N, где L – длина хромосомы, N – размер популяции.
Необходимо также отметить, что есть мнение, что оператор мутации является основным поисковым оператором и известны алгоритмы, не использующие других операторов, кроме мутации [9].
- Постановка задачи
Задача состоит в том, чтобы для заданных параметров нечеткой системы построить базу правил, которая минимизирует среднеквадратическую ошибку аппроксимации. Предполагается, что значения входных переменных задаются в виде трапециевидных нечетких чисел.
Для получения решения необходимо задать следующие параметры: t-норму, s-норму, импликацию, деффазификацию, левую и правую границы множеств, число точек в дискретном представлении нечеткого множества, число наблюдений, число итераций генетического алгоритма, число правил в искомой базе знаний.
- Алгоритм генерации базы знаний – эволюционная стратегия
Для генерации базы знаний используется эволюционная стратегия, являющаяся подклассом генетического алгоритма.
Идея эволюционных стратегий была предложена Инго Рехенбергом (Ingo Rechenberg) в 1960-70 годах. Так же, как и генетические алгоритмы, они работают с популяцией решений и основываются только на целевой функции и ограничениях. Основные отличия от классического генетического алгоритма заключаются в том, что эволюционная стратегия работает с векторами действительных чисел и использует только оператор мутации. При мутации каждому элементу вектора добавляется случайная нормально распределенная величина.
В данном алгоритме используются трапециевидные функции принадлежности. Они описываются с помощью четырех параметров и имеют два индекса i и j. Таким образом, функция принадлежности 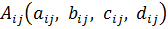 относится к i-му правилу и j-й входной переменной,
относится к i-му правилу и j-й входной переменной, 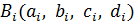 – выходная функция принадлежности для i-го правила. Функция принадлежности j-й нечеткой переменной в i-м правиле записывается следующим образом:
– выходная функция принадлежности для i-го правила. Функция принадлежности j-й нечеткой переменной в i-м правиле записывается следующим образом:
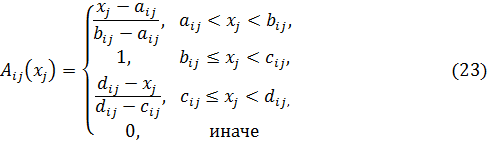
Метод кодирования нечеткой системы с двумя входами и одним выходом показан на рисунке 8.
Правило 1
|
Правило 2 |
Правило 3
|
Правило 4 |
… |
Правило n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
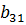
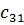
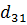
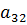
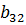
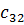
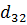
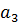
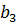
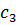
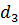
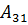
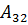
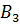
Рисунок 8 - Нечеткие правила, закодированные в хромосому.
Правило 3 на рисунке 7 означает следующее:
Если 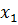 есть
есть 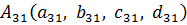 и
и 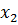 есть
есть 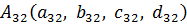 , то
, то
y есть 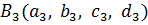
Здесь 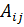 и
и 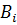 – трапециевидные функции принадлежности с четырьмя параметрами.
– трапециевидные функции принадлежности с четырьмя параметрами.
В нашей задаче один вход и один выход, поэтому правила представлены в следующем виде:
Если x есть 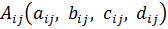 , то y есть
, то y есть 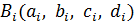 ,
,
где i – номер правила.
- Получение «родительского» элемента
Сначала создается произвольный вектор – начальная хромосома, все функции принадлежности в которой случайным образом инициализированы.
- Мутация
С помощью операции мутации создаются 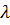 копий набора правил, где
копий набора правил, где 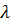 – количество потомков в популяции: некоторая часть хромосом выбирается случайным образом, и в каждой копии параметры этой выбранной части меняются добавлением нормально распределенной величины. Теперь считается ошибка для каждого элемента популяции. Лучший элемент становится родителем на следующем шаге.
– количество потомков в популяции: некоторая часть хромосом выбирается случайным образом, и в каждой копии параметры этой выбранной части меняются добавлением нормально распределенной величины. Теперь считается ошибка для каждого элемента популяции. Лучший элемент становится родителем на следующем шаге.
- Нечеткие операторы
Важно оптимизировать структуру набора правил. Неэффективные правила должны быть исключены, а похожие – объединены. Следующие операторы позволяют оптимизировать количество правил.
Отмена. Если функция принадлежности становится слишком «узкой», она не должна больше использоваться. Данный критерий записывается следующим образом:
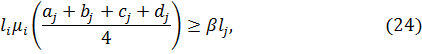
где 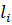 и
и 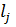 – длины медиан функций принадлежности заданных входных и выходных переменных в i-м и j-м правилах;
– длины медиан функций принадлежности заданных входных и выходных переменных в i-м и j-м правилах;
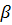 – параметр отмены. Чем он больше, тем критерий более строгий.
– параметр отмены. Чем он больше, тем критерий более строгий.
Слияние. Если две функции принадлежности, относящиеся к одной нечеткой переменной, близки друг к другу, и разница длин их медиан достаточно мала, то эти функции объединяются в одну.
Для слияния существует два критерия:
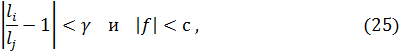
где 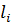 и
и 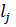 – длины медиан функций принадлежности заданных входных и выходных переменных в i-м и j-м правилах;
– длины медиан функций принадлежности заданных входных и выходных переменных в i-м и j-м правилах;
f – расстояние между центром 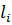 и
и 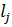 .
.
Для выполнения слияния оба критерия должны быть удовлетворены, при этом используется только один параметр 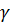 . Чем меньше значение
. Чем меньше значение 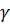 , тем критерий строже. Параметры объединенной функции принадлежности будут иметь вид:
, тем критерий строже. Параметры объединенной функции принадлежности будут иметь вид:

где 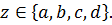
Удаление правил. При использовании метода центра тяжести для дефазификации, удаление правила влечет за собой рост ошибки. Чтобы избежать этого, мы будем увеличивать важность правила. Например, если i-е и j-е правила идентичны, то j-е правило убирается, а параметры функции принадлежности i-го правила меняются следующим образом:
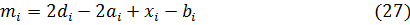
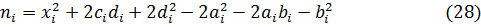


где 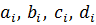 – исходные параметры трапециевидной функции принадлежности;
– исходные параметры трапециевидной функции принадлежности;
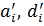 - новые значения
- новые значения 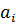 и
и 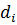 ; параметры
; параметры 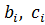 не меняются.
не меняются.
- Условие останова
Работа алгоритма представляет собой итерационный процесс, который продолжается до выполнения одного из условий останова:
- выполнение заданного числа поколений;
- прекращение улучшения популяции.
ГЛАВА 5. ОПИСАНИЕ ПРОГРАММЫ
Программа разработана в среде Microsoft Visual Studio 2012, язык программирования – C#. Язык программирования C#, созданный специально для платформы Microsoft .NET Framework, взял всё лучшее из языков C++ и Java и поэтому позволяет эффективно описать и реализовать нечеткую систему и генетический алгоритм с использованием приемов объектно-ориентированного программирования. С другой стороны, платформа .NET Framework дает возможность быстро создать удобный и красивый пользовательский интерфейс, сосредоточив тем самым всё внимание на реализации поставленной задачи.
- Функциональные возможности
Программа находит оптимальный набор правил, минимизирующий среднеквадратическую ошибку аппроксимации. В качестве тестовой была выбрана функция 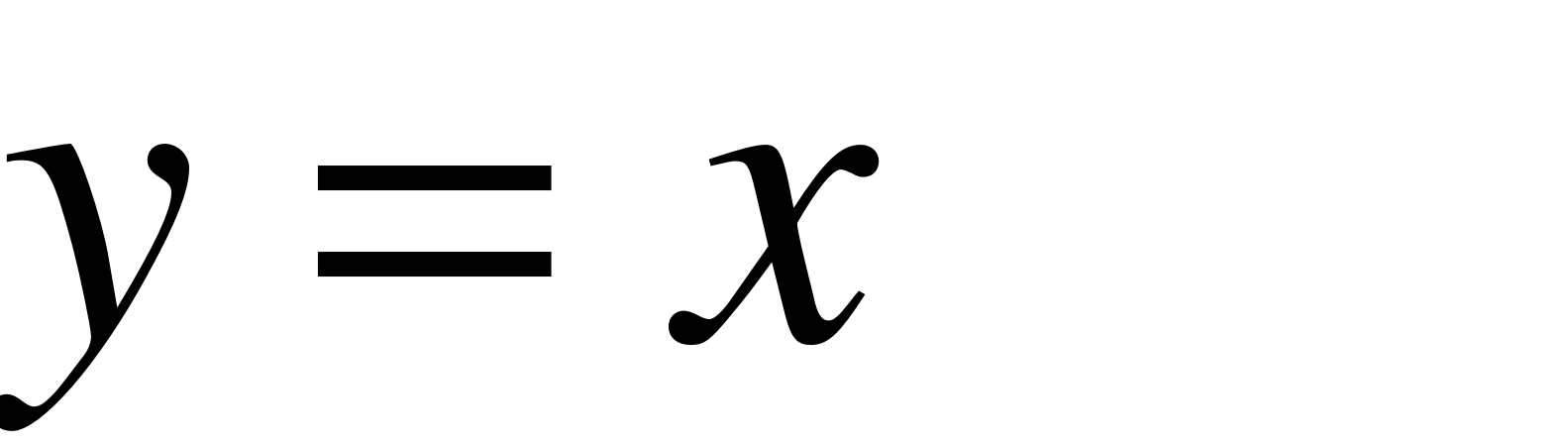 из-за того, чтобы наглядно продемонстрировать результат. Решение ищется модифицированным генетическим алгоритмом – эволюционной стратегией. Для получения результата необходимо задать следующие входные параметры:
из-за того, чтобы наглядно продемонстрировать результат. Решение ищется модифицированным генетическим алгоритмом – эволюционной стратегией. Для получения результата необходимо задать следующие входные параметры:
- t-норму
- s-норму
- импликацию
- дефазификацию
- левую и правую границы нечетких множеств
- число точек в дискретном представлении нечеткого множества
- число итераций генетического алгоритма
- число правил в искомой базе знаний
Операторы t-нормы, s-нормы, импликации и дефазификации выбираются из выпадающего списка. Реализованы следующие операторы:
- t-нормы и s-нормы: Заде, Фодор, Алгебраическая
- импликация: Фодор, Райхенбах, Клине-Динс, Заде
- дефазификация – центр тяжести (Center of Gravity – COG)
- Представление данных
Нечеткие переменные в программе представлены двумя классами: TrapezoidalVariable и DiscreteVariable.
TrapezoidalVariable представляет собой трапециевидную нечеткую переменную, задаваемую четырьмя параметрами a, b, c, d. Функция принадлежности данной переменной имеет следующий вид:
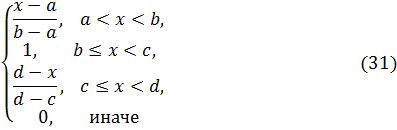
DiscreteVariable представляет собой нечеткую переменную с функцией принадлежности, заданной в конечном числе точек. Создание этого класса обусловлено тем, что в результате применения операции импликации, t- или s-нормы к трапециевидным переменным, получается переменная произвольного вида.
Классы, описанные выше, унаследованы от базового класса Variable, и реализуют общий для всех нечетких переменных интерфейс. Таким образом, в задачу не составит труда добавить новый класс, более точно описывающий какую-либо нечеткую переменную, который легко впишется в уже построенную систему.
- Реализация
В основе программы лежит следующий набор классов:
Variable
+Left
+Right
+mu()
TrapezoidalVariable
+a
+b
+c
+d
DiscreteVariable
+Points
+Step
+Set()
Defuzzification
+ CenterOfGravity()
+LeftMostMaximum()
+RightMostMaximum()
Implication
+ Fodor()
+Zade()
+Reichenbach()
+KleeneDiens()
SNorm
+Zade()
+Algebraic()+Fodor()
51
Освоение методов нечеткого моделирования и разработка алгоритма для оптимизации базы правил нечеткого классификатора на основе наблюдаемых данных с помощью генетического алгоритма