БАЗЫ ДАННЫХ И ИХ ЗАЩИТА
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное образовательное учреждение
высшего профессионального образования
«Кубанский государственный университет»
(ФГБОУ ВПО «КубГУ»)
Кафедра функционального анализа и алгебры
БАКАЛАВРСКАЯ РАБОТА
БАЗЫ ДАННЫХ И ИХ ЗАЩИТА
Работу выполнил(а) _______________________ Черная А.А
(подпись, дата)
Факультет математики и компьютерных наук, группа 43.1
Направление 010200.62 математика и компьютерные науки
Научный руководитель ___________________ Рожков А.В.
Доктор физико – (подпись, дата)
математических наук,
профессор
Нормоконтролер ___________________ Лихарева Ю. А.
ст. лаборант (подпись, дата)
Краснодар 2015
Содержание
ВВЕДЕНИЕ
1. Обзор баз данных и их классификация
2. Математическая модель баз данных
3. Программные продукты в области баз данных
3.1. Oracle
3.2. Access
4. Язык SQL
- . Основные понятия, определения, операторы. Структура SQL
- . Реализация на открытом коде в среде MySQL Workbench 6.3
5. Защита баз данных
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ВВЕДЕНИЕ
В широком смысле понятие истории баз данных - это история любых средств, с помощью которых человечество хранило и обрабатывало данные. Базами данных, например, можно считать средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.)
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных COBOL была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Ф. Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой.
Термин база данных (англ. database) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных компанией SDC в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы.
Цель данной работы:
- Изучить виды и типы баз данных.
- Особенности их математической и алгоритмической организации.
- Конкретные программные продукты реализации баз данных.
- Освоить основы языка программирования SQL и его клона на открытом коде MySQL.
- Дать обзор средств защиты баз данных.
- Обзор баз данных и их классификация
Классификация БД по модели данных:
1. Реляционная модель данных - это абстракция данных, которая представляет данные в базу данных в виде набора таблиц, которые называются отношениями. Каждая таблица имеет имя и содержит специальный верхний ряд и конечное число строк данных. Каждая запись в верхней строке таблицы называется атрибутом. Число атрибутов в отношении называют его арностью или размером - термины, которые используются как синонимы. Имя отношения вместе с верхней строкой называется схемой.
Также существует бесконечная реляционная модель данных, которая является расширением реляционной модели данных в бесконечных таблицах.
2. Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Первые системы управления базами данных использовали иерархическую модель данных.
3. Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом. Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию. Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом. Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
4. Объектные базы данных — это модель работы с объектными данными.
Такая модель баз данных, несмотря на то, что она существует уже много лет, считается новой. И её создание открывает большие перспективы, в связи с тем, что использование объектной модели баз данных легко воспринимается пользователем, так как создается высокий уровень абстракции. Объектная модель идеально подходит для трактовки такого рода объектных данных как изображение, музыка, видео, разного вида текст.
5. Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая ООБД. Их выбор основан на 2 критериях: система должна быть объектно-ориентированной и представлять собой базу данных.
Обязательные характеристики
- Поддержка сложных объектов. В системе должна быть предусмотрена возможность создания составных объектов за счет применения конструкторов составных объектов. Необходимо, чтобы конструкторы объектов были ортогональны, то есть любой конструктор можно было применять к любому объекту.
- Поддержка индивидуальности объектов. Все объекты должны иметь уникальный идентификатор, который не зависит от значений их атрибутов.
- Поддержка типов и классов. Требуется, чтобы в ООБД поддерживалась хотя бы одна концепция различия между типами и классами. (Термин «тип» более соответствует понятию абстрактного типа данных. В языках программирования переменная объявляется с указанием ее типа. Компилятор может использовать эту информацию для проверки выполняемых с переменной операций на совместимость с ее типом, что позволяет гарантировать корректность программного обеспечения. С другой стороны класс является неким шаблоном для создания объектов и предоставляет методы, которые могут применяться к этим объектам. Таким образом, понятие «класс» в большей степени относится ко времени исполнения, чем ко времени компиляции.
- Поддержка наследования типов и классов от их предков. Подтип, или подкласс, должен наследовать атрибуты и методы от его супертипа, или суперкласса, соответственно.
- Перегрузка в сочетании с полным связыванием. Методы должны применяться к объектам разных типов. Реализация метода должна зависеть от типа объектов, к которым данный метод применяется. Для обеспечения этой функциональности связывание имен методов в системе не должно выполняться до времени выполнения программы.
- Вычислительная полнота. Язык манипулирования данными должен быть языком программирования общего назначения.
- Набор типов данных должен быть расширяемым. Пользователь должен иметь средства создания новых типов данных на основе набора предопределенных системных типов. Более того, между способами использования системных и пользовательских типов данных не должно быть никаких различий.
6. Временные, или темпоральные базы данных — это базы, хранящие данные, привязанные ко времени и имеющие средства управления такой информацией. Главное отличие темпоральных систем управления базами данных (СУБД) от обычных реляционных СУБД заключается в том, что для любого объекта, который был создан в момент времени t1 и был удален в момент времени t2, сохраняются все его состояния в этом временном интервале [t1, t2], тогда как в обычной СУБД существует только текущее на конкретный момент времени состояние объекта. Таким образом, в темпоральной базе данных хранится история изменений состояний объекта, и пользователь может получить информацию о состоянии записи в базе данных в любой момент времени из указанного промежутка.
7. Географические базы данных связаны с представлением объектов и явлений, происходящих на поверхности Земли. Географические объекты включают в себя страны, города, дороги, реки, горы, железнодорожные и телефонные линии сети, погодные условия и т. д. Представления баз данных принимают форму различных типов карт или различных видов графиков, которые выражают некоторые отношения между географическими объектами.
Пространственные базы данных включают в себя географические базы данных, но имеют более общий характер, потому что они могут быть связаны не со строго географическими явлениями. Например, пространственные базы данных могут хранить информацию об астрономической информации, такую, как галактики и звезды вселенной или макет интегральной схемы. Несмотря на это незначительное различие, термины, географические базы данных и базы пространственных данных, часто используются как взаимозаменяемые. Кроме того, термин географическая информационная система (ГИС) стал популярными вместо географической системы баз данных. Географическая информационная система или геоинформационная система (ГИС) - это информационная система, обеспечивающая сбор, хранение, обработку, анализ и отображение пространственных данных и связанных с ними непространственных, а также получение на их основе информации и знаний о географическом пространстве.
Считается, что географические или пространственные данные составляют более половины объема всей циркулирующей информации, используемой организациями, занимающимися разными видами деятельности, в которых необходим учет пространственного размещения объектов. ГИС ориентирована на обеспечение возможности принятия оптимальных управленческих решений на основе анализа пространственных данных.
Также существует пространственно-временная база данных, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
8. Базы данных изображений.
Многие приложения, такие как медицинская диагностика и военная целевая идентификация, требуют поиска от большой базы данных изображения тех изображений, которые подобны новому изображению камеры. Это требует следующих задач:
• Аффинно-инвариантная мера сходства: когда плоский объект фотографируется с разных ракурсов фотографического изображения являющимися аффинными преобразованиями друг друга. Следовательно, если изображение хранится в базе данных изображений, а другой изображение видно камерой, причем оба изображения показывают один и тот же объект, там должна быть аффинно-инвариантная мера сходства между парами изображений.
• Эффективное индексирование: эффективное индексирование важно, когда база данных изображений содержит большое количество изображений. Сочетание этих двух задач трудно. В целом компьютерное исследование видения сосредотачивается на первой и пренебрегает второй, а исследование базы данных сосредоточено на второй и пренебрегает первой.
Исследователи компьютерного зрения предложили несколько аффинно-инвариантных мер подобия между парами картинок, например, минимальная мера расстояния Хаусдорфа, геометрическая техника хеширования и подобия меры на основе наименьших квадратов расстояния. Ни одна из этих мер не приводит к эффективному индексированию.
Исследователям баз данных предлагается эффективные методы индексирования на основе следующих свойств: формы или контура, цвет и цветной гистограммы, отнести реляционные графы, которые представляют пространственные отношения между объектами с помощью графа, и различные коэффициенты сжатия изображения. Ни одно из этих свойств не является аффинно-инвариантным.
9.Геномные базы данных.
GDB (Genome Data Base) крупнейшая база данных по структуре генома человека, созданная и поддерживаемая в университете Джонса Гопкинса (Балтимор, США). Кроме известных последовательностей нуклеотидов генома человека в ней хранится вся получаемая информация о генетических маркерах, зондах и контигах, ассоциированных с генетическими заболеваниями. Проводятся работы по включению в базу данных результатов физического картирования генома. Поддерживается база данных по менделевскому наследованию у человека, которая представляет собой каталог наследуемых признаков и наследственных заболеваний человека. [20]
Классификация БД по среде физического хранения:
- БД во вторичной памяти (традиционные): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило, жёсткий диск. В оперативную память СУБД помещает лишь кэш и данные для текущей обработки;
- БД в оперативной памяти (in-memory databases): все данные находятся в оперативной памяти;
- БД в третичной памяти (tertiary databases): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило, на основе магнитных лент или оптических дисков. Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация по содержимому:
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная.
Классификация БД по степени распределённости:
- Централизованная, или сосредоточенная: БД, полностью поддерживаемая на одном компьютере.
- Распределённая: БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная: фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД
- Однородная: фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная: методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная: методом распределения данных является тиражирование.
Классификация БД по способу доступа к данным:
- БД с локальным доступом;
- БД с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем:
- файл-сервер;
- клиент-сервер.
Архитектура файл-сервер предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. Пользователи могут также создавать на рабочих станциях локальные БД, которые используются ими монопольно.
В архитектуре клиент-сервер подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) передаются по сети от сервера к клиенту.
- Математическая модель баз данных
Определение 2.1 База данных (БД) – поименованная совокупность данных, относящихся к некоторой области приложения, обладающая определенной структурой, компонентами которой могут быть любые структурные единицы данных (элементы, группы, записи, файлы), связанные между собой определенным образом. Причем эти данные могут использоваться как в одной, так и в нескольких задачах, одним или несколькими пользователями.
Определение 2.2 Модель данных — это совокупность структур данных и операций, позволяющих обрабатывать эти данные.
Определение 2.3 Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Структурные элементы БД: поле, запись, файл (таблица).
Определение 2.4 Поле - элементарная единица логической организации данных, которая соответствует неделимой единице информации -реквизиту. Для описания поля используются следующие характеристики:
- имя, например, ФИО;
- тип, например, символьный, числовой, календарный;
- длина, определяемая максимально возможным количеством символов, например, 15 байт;
- точность для числовых данных.
Определение 2.5 Запись - совокупность логически связанных полей.
Определение 2.6 Экземпляр записи - отдельная реализация записи, содержащая конкретные значения ее полей.
Определение 2.7. Файл (таблица) - совокупность экземпляров записей одной структуры.
В структуре записи файла указываются поля, значения которых являются ключами: первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Определение 2.8 Система управления базами данных (СУБД) – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Основные функции СУБД:
1.Создание БД
- определение данных,
- инициализация файлов,
- ввод данных с формально-логическим контролем (контроль типов данных);
2.Справочная функция;
3.Журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
4.Обновление данных;
5.Управление данными во внешней памяти (на дисках);
6.Управление данными в оперативной памяти с использованием дискового кэша;
7.Обеспечение целостности;
8.Обеспечение безопасности;
9.Поддержка языков БД (язык определения данных, язык манипулирования данными).
СУБД поддерживает определенную модель данных и функционирует в определенной операционной обстановке.
Определение 2.9 Обстановка – конфигурация технических средств и системно-программных средств.
Определение 2.10 Домен – это семантическое понятие, которое можно рассматривать как подмножество значений некоторого типа данных, имеющих определенный смысл.
Определение 2.11 Кортежи – это упорядоченная совокупность элементов доменов.
Определение 2.12 Первичный ключ – это атрибут или набор атрибутов, значение которых однозначно указывают на конкретный кортеж отношения. Первичный ключ должен быть минимальным набором атрибутов.
Определение 2.13 Нормализация – это удаление из таблицы повторяющихся данных путём их переноса в новые таблицы.
Определение 2.14 Алгебра множество объектов с заданной на нем совокупностью операции, замкнутых относительно этого множества, называемого основным множеством.
Определение 2. 15 Реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных.
Определение 2. 16 Предикат это утверждение, истинность которого зависит от значения переменных, входящих в него. При конкретном наборе переменных предикат превращается в обычное высказывание, о котором можно сказать истинно оно или ложно.
- Программные продукты баз данных
Рассмотрим конкретные программные продукты, относящиеся к классу СУБД. На самом общем уровне все СУБД можно разделить:
- на профессиональные, или промышленные;
- персональные (настольные).
Профессиональные (промышленные) СУБД представляют собой программную основу для разработки автоматизированных систем управления крупными экономическими объектами. На их базе создаются комплексы управления и обработки информации крупных предприятий, банков или даже целых отраслей.
Основные требования, которым должны удовлетворять профессиональные СУБД, являются:
- возможность организации совместной параллельной работы большого количества пользователей;
- масштабируемость, то есть возможность роста системы пропорционально расширению управляемого объекта;
- переносимость на различные аппаратные и программные платформы;
- устойчивость по отношению к сбоям различного рода, в том числе наличие многоуровневой системы резервирования хранимой информации;
- обеспечение безопасности хранимых данных и развитой структурированной системы доступа к ним.
3.1 Access
База данных — это средство сбора и организации информации. В базах данных могут содержаться сведения о людях, продуктах, заказах и т. д. Многие базы данных изначально представляют собой список в текстовом процессоре или электронной таблице. По мере того как список разрастается, в нем накапливаются излишние и противоречивые данные. В форме списка эти данные становится все труднее понять, а возможности поиска или извлечения подмножеств данных для просмотра весьма ограничены. Когда возникают подобные проблемы, полезно перенести информацию в базу данных, созданную с помощью системы управления базами данных (СУБД), например Office Access 2007.
Компьютерная база данных представляет собой хранилище объектов. В одной базе данных может содержаться несколько таблиц. Например, система складского учета, в которой используются три таблицы, — это не три базы данных, а одна, содержащая три таблицы. В базе данных Access таблицы сохраняются в одном файле вместе с другими объектами, такими как формы, отчеты, макросы и модули, если только база данных не предназначена специально для использования данных или кода из другого источника. Базы данных, созданные в формате Access 2007, имеют расширение имени файла ACCDB, а базы данных, созданные в более ранних форматах Access, — расширение MDB. Приложение Access 2007 можно использовать для создания файлов в более ранних форматах файлов (например, Access 2000 и Access 2002-2003).
Приложение Access предоставляет следующие возможности:
- добавление новых данных в базу данных (например, новой позиции в складскую опись);
- изменение существующих данных в базе данных (например, изменение текущего размещения позиции на складе);
- удаление сведений (например, если позиция продана или отбракована);
- организация и просмотр данных различными способами;
- совместное использование данных посредством отчетов, сообщений электронной почты, внутренней сети или Интернета.
Компоненты базы данных Access
Далее представлено краткое описание компонентов обычной базы данных Access.
Таблицы
По внешнему виду таблица базы данных сходна с электронной таблицей, в которой данные располагаются в строках и столбцах. Поэтому электронные таблицы обычно легко импортируются в таблицы базы данных. Основное различие между хранением данных в электронной таблице и в базе данных — способ организации данных.
Чтобы обеспечить наибольшую гибкость базы данных, необходимо распределить данные по таблицам так, чтобы избежать их избыточности. Например, если в базе хранятся сведения о сотрудниках, каждого из них следует один раз внести в таблицу, которая предназначена исключительно для хранения данных о сотрудниках. Данные о продуктах будут храниться в отдельной таблице, а данные о филиалах — в другой. Эта процедура называется нормализацией. То есть нормализация – это удаление из таблицы повторяющихся данных путём их переноса в новые таблицы.
Каждую строку в таблице называют записью. Запись — это место хранения отдельного элемента информации. Каждая запись состоит из одного или нескольких полей. Поля соответствуют столбцам таблицы. Например, в таблице с именем «Сотрудники» каждая запись (строка) может содержать сведения об определенном сотруднике, а каждое поле (столбец) — сведения определенного типа, например имя, фамилию, адрес и т. п. Поля должны быть определены как конкретный тип данных: текст, дата или время, число или какой-либо иной тип.
Чтобы понять, что такое записи и поля, можно представить себе библиотечный каталог с карточками. Каждая карточка в ящике картотеки соответствует записи в базе данных. Каждый элемент сведений на отдельной карточке (автор, название и т. п.) соответствует полю в базе данных.
Связи между таблицами
В нормализованной реляционной базе данных связь двух таблиц характеризуется отношениями записей типа один-к-одному, один-ко-многим, многие-к-многим. Отношение один-к-одному предполагает, что каждой записи одной таблицы соответствует одна запись в другой. Отношение один-ко-многим предполагает, что каждой записи первой таблицы соответствует много записей другой таблицы, но каждой записи второй таблицы соответствует только одна запись в первой. Соответственно, связь многие-к-многим – это связь многих записей одной таблицы ко многим записям другой.
Для двух таблиц, находящихся в отношении один-ко-многим, устанавливается связь по уникальному ключу таблицы, представляющей в отношении сторону «один», - главной таблицы в связи. Во второй таблице, представляющей в отношении сторону «многие» и называемой подчинённой, этот ключ связи может быть либо частью уникального ключа, либо не входить в состав ключа. В подчинённой таблице ключ связи называется ещё внешним ключом.
Формы
Формы иногда называются окнами ввода данных. Это интерфейсы, которые используются для работы с данными и часто содержат кнопки для выполнения различных команд. Базу данных можно создать без помощи форм, просто вводя в таблицу данные в режиме таблицы. Однако большинство пользователей баз данных предпочитают просматривать, вводить и редактировать данные таблиц при помощи форм.
Формы позволяют работать с данными в удобном формате; кроме того, в них можно добавлять функциональные элементы, например кнопки команд. Программным путем этим кнопкам можно назначить выполнение разнообразных задач, таких как определение данных, отображаемых в форме, или открытие других форм или отчетов. Например, можно создать форму с именем «Форма клиента» для работы с данными клиента. В форме клиента может присутствовать кнопка, открывающая форму заказа, в которой создается новый заказ для данного клиента.
Формы также позволяют задавать условия работы других пользователей с информацией, содержащейся в базе данных. Например, можно создать форму со строго ограниченным набором отображаемых полей и разрешенных операций. Это помогает защитить данные и гарантировать правильность их ввода.
Отчеты
Отчеты служат для сбора и представления данных, содержащихся в таблицах. Обычно отчет позволяет ответить на определенный вопрос, например: «Сколько денег было получено от каждого клиента в этом году?», «В каких городах есть клиенты нашей компании?» Каждый отчет можно отформатировать так, чтобы представить сведения в наиболее удобном виде.
Отчет можно запустить в любое время, и он всегда будет отражать текущие сведения в базе данных. Обычно отчеты форматируют для печати, но их можно также просматривать на экране, экспортировать в другую программу или отправлять в виде сообщений электронной почты.
Запросы
Запросы являются основным рабочим инструментом базы данных и могут выполнять множество различных функций. Самая распространенная функция запросов — извлечение определенных данных из таблиц. Данные, которые необходимо просмотреть, как правило, находятся в нескольких таблицах; запросы позволяют представить их в одной таблице. Кроме того, поскольку обычно не требуется просматривать все записи сразу, с помощью запросов можно, задав ряд условий, «отфильтровать» только нужные записи. Часто запросы служат источником записей для форм и отчетов.
Некоторые запросы предусматривают возможность обновления: это означает, что данные в основных таблицах можно изменять через таблицу запроса. Работая с запросом с возможностью обновления, следует помнить, что изменения фактически вносятся не только в таблицу запросов, но и в соответствующие таблицы базы данных.
Существует два основных вида запросов: запросы на выборку и запросы на изменение. Запрос на выборку просто извлекает данные и дает возможность пользоваться ими. Результаты такого запроса можно просмотреть на экране, распечатать или скопировать в буфер обмена. Кроме того, их можно использовать в качестве источника записей для формы или отчета.
Запрос на изменение, как следует из его названия, выполняет действия с данными. Запросы на изменение можно использовать для создания новых таблиц, добавления данных в существующие таблицы, обновления или удаления данных.
Макросы
Макросы в приложении Access можно рассматривать как упрощенный язык программирования, который позволяет добавлять функциональные возможности в базу данных. Например, кнопке команды в форме можно назначить макрос, который будет запускаться при нажатии этой кнопки. Макрос содержит последовательность действий для выполнения определенной задачи, например для открытия отчета, выполнения запроса или закрытия базы данных. Большинство операций с базой данных, выполняемых вручную, можно автоматизировать с помощью макросов, которые позволяют существенно экономить время.
Модули
Модули, как и макросы, являются объектами, которые можно использовать для добавления функциональных возможностей в базу данных. В то время как макросы создаются в приложении Access путем выбора макрокоманд из списка, модули пишутся на языке программирования Visual Basic для приложений (VBA). Модуль представляет собой набор описаний, операторов и процедур, которые хранятся в одном программном блоке. Модуль может быть либо модулем класса, либо стандартным модулем. Модули класса присоединяются к формам или отчетам и обычно содержат процедуры, предназначенные для формы или отчета, к которому они относятся.
Стандартные модули содержат процедуры общего назначения, не связанные ни с одним другим объектом. Стандартные модули, в отличие от модулей класса, перечисляются в группе Модули в области переходов.
3.2 Oracle
Обзор архитектуры Oracle
Система Управления Реляционными Базами Данных (СУРБД) Oracle предназначена для одновременного доступа к большим объемам хранимой информации. СУРБД складывается из двух составляющих: База Данных (информация) и экземпляр (конкретная реализация системы). База данных состоит из физических файлов, хранящихся в системе, и из логических частей (например, схема БД). Эти файлы могут быть совершенно разными, их мы рассмотрим чуть далее. Экземпляр – это способ доступа к данным, который состоит из процессов и системной памяти.
Примечание: В связи с тем, что в Oracle8 появилась система объектов, корпорация Oracle иногда называет свой продукт объектно-ориентированной СУРБД (О-СУРБД). Однако, для ясности, будем называть ее просто СУРБД.
БД Oracle состоит из двух уровней: физический и логический. Физический уровень включает файлы, которые хранятся на диске, а логический уровень представляет компоненты физического уровня. Рассмотрим эти уровни более подробно.
Физический уровень.
Физический уровень включает три категории файлов:
1) один или более файлов данных – В этих файлах хранится информация, имеющаяся в БД. Вы можете иметь как один файл данных, так и сотни таких файлов. Информация из одной таблицы может быть разбросана по нескольким файлам данных (а несколько таблиц могут делить между собой пространство файлов данных). Распределение таблиц по нескольким файлам данных может значительно увеличить производительность системы. Количество файлов данных ограничено параметром MAXDATAFILES.
2) два или более файлов журналирования операций (redo log files) – Файлы журналирования операций содержат информацию, необходимую для процесса восстановления в случае сбоя системы. Файлы журналирования операций (называемые также просто журналом операций) хранят все изменения, которые произошли в БД. С помощью журнала операций восстанавливаются те изменения, которые были произведены, но не зафиксированы перед сбоем системы. Файлы журналирования операций должны быть очень хорошо защищены против аппаратных сбоев (как на программном, так и на аппаратном уровне). Если информация журнала операций будет утеряна, то Вы не сможете восстановить систему.
3) один или более управляющих файлов – Управляющие файлы содержат информацию, необходимую для запуска экземпляра Oracle (в том числе расположение файлов данных и файлов журналирования операций). Управляющие файлы должны быть хорошо защищены. Oracle предоставляет механизм для хранения нескольких копий управляющих файлов.
Логический уровень.
Логический уровень составляют следующие элементы:
- Одно или несколько табличных пространств;
- Схема БД, состоящая из таблиц, кластеров, индексов, представлений, хранимых процедур и т.д.
Табличные пространства и файлы данных
База данных разделяется на одно или более логических частей, называемых табличными пространствами. Табличные пространства используются для логической группировки данных между собой. Например, Вы можете определить одно табличное пространство для бухгалтерских данных, а другое для складских. Сегментирование групп по табличным пространствам упрощает администрирование этих групп. Каждое табличное пространство состоит из одного или более файлов данных. Используя несколько файлов данных для одного табличного пространства, можно распределить их по разным дискам, увеличив тем самым скорость ввода-вывода и, соответственно, производительность системы.
Таким образом, БД Oracle состоит из табличных пространств, которые, в свою очередь, состоят из файлов данных. А файлы данных могут быть разбросаны по нескольким физическим дискам.
В процессе создания БД Oracle автоматически создается табличное пространство SYSTEM. Хотя для небольших баз данных может хватить этого табличного пространства, но все же следует создать дополнительные табличные пространства для пользовательских данных. В табличном пространстве SYSTEM хранится словарь данных. В словаре данных содержится информация о таблицах, индексах, кластерах и т.д.
Сегменты, экстенты и блоки данных
В СУБД Oracle контроль над дисковым пространством происходит с использованием специальных логических структур. Эти структуры следующие:
- блоки данных – Это наименьшая единица хранения данных в БД Oracle. Блок БД содержит заголовочную информацию о себе, и данные.
- экстенты – Экстент состоит из блоков данных.
- сегменты – Сегмент состоит из совокупности экстентов, содержащих определенный вид данных.
Сегменты
БД Oracle использует четыре типа сегментов:
- сегмент данных – хранит пользовательские данные.
- индексный сегмент – содержит индексы.
- сегмент отката – хранит информацию отката, используемую при возврате к предыдущему состоянию БД.
- временный (промежуточный) сегмент – создается в случае, если для выполнения SQL-выражения необходимо дополнительное рабочее пространство. Эти сегменты уничтожаются сразу после выполнения SQL-команд. Промежуточные сегменты используются также в разнообразных операциях с БД, например, при сортировке.
Экстенты
Экстенты являются строительными блоками сегментов, и, в тоже время, состоят из блоков данных. Экстенты используются для минимизации неиспользуемого (пустого) пространства хранилища. По мере увеличения количества данных в табличных пространствах, экстенты используются для хранения тех данных, которые могут разрастаться. Таким образом, несколько табличных пространств могут делить между собой пространство хранилища без предопределения разделов этих табличных пространств.
При создании табличного пространства, Вы можете указать минимальное число определения экстент, а также число экстент, добавляемых при заполнении уже определенных. Это распределение позволяет вам контролировать пространство хранилища БД.
Блоки данных
Это наименьшие единицы БД Oracle. Они физически хранятся на диске. Блоки данных на большинстве систем 2Кб (2048 байт), но Вы можете изменить этот размер на свое усмотрение для увеличения эффективности работы системы.
- Язык программирования SQL
SQL (Structured Query Language) — Структурированный Язык Запросов — стандартный язык запросов по работе с реляционными БД. Язык SQL появился после реляционной алгебры, и его прототип был разработан в конце 70-х годов в компании IBM Research. Он был реализован в первом прототипе реляционной СУБД фирмы IBM System R. В дальнейшем этот язык применялся во многих коммерческих СУБД и в силу своего широкого распространения постепенно стал стандартом «де-факто» для языков манипулирования данными в реляционных СУБД.
4.1 Основные понятия, определения, операторы. Структура SQL
В отличие от реляционной алгебры, где были представлены только операции запросов к БД, SQL является полным языком, в нем присутствуют не только операции запросов, но и операторы, соответствующие DDL — Data Definition Language — языку описания данных. Кроме того, язык содержит операторы, предназначенные для управления (администрирования) баз данных. SQL содержит разделы, представленные в таблице 4.1:
Таблица 4.1 Операторы определения данных DDL
|
Оператор
|
Смысл
|
Действие
|
|
CREATE TABLE
|
Создать таблицу
|
Создает новую таблицу в БД
|
|
DROP TABLE
|
Удалить таблицу
|
Удаляет таблицу из БД
|
|
ALTER TABLE
|
Изменить таблицу
|
Изменяет структуру существующей таблицы или ограничения целостности, задаваемые для данной таблицы
|
|
CREATE VIEW
|
Создать представление
|
Создает виртуальную таблицу, соответствующую некоторому SQL-запросу
|
|
ALTER VIEW
|
Изменить представление
|
Изменяет ранее созданное представление
|
|
DROP VIEW
|
Удалить представление
|
Удаляет ранее созданное представление
|
|
CREATE INDEX
|
Создать индекс
|
Создает индекс для некоторой таблицы для обеспечения быстрого доступа по атрибутам, входящим в индекс
|
|
DROP INDEX
|
Удалить индекс
|
Удаляет ранее созданный индекс
|
Таблица 4.2 Операторы манипулирования данными Data Manipulation Language (DMP)
|
Оператор
|
Смысл
|
Действие
|
|
DELETE
|
Удалить строки
|
Удаляет одну или несколько строк, соответствующих условиям фильтрации, из базовой таблицы. Применение оператора согласуется с принципами поддержки целостности, поэтому этот оператор не всегда может быть выполнен корректно, даже если синтаксически он записан правильно
|
|
INSERT
|
Вставить строку
|
Вставляет одну строку в базовую таблицу. Допустимы модификации оператора, при которых сразу несколько строк могут быть перенесены из одной таблицы или запроса в базовую таблицу
|
|
UPDATE
|
Обновить строку
|
Обновляет значения одного или нескольких столбцов в одной или нескольких строках, соответствующих условиям фильтрации
|
Таблица 4.3 Язык запросов Data Query Language (DQL)
|
Оператор
|
Смысл
|
Действие
|
|
SELECT
|
Выбрать строки
|
Оператор, заменяющий все операторы реляционной алгебры и позволяющий сформировать результирующее отношение, соответствующее запросу
|
Таблица 4.4 Средства управления транзакциями
|
Оператор
|
Смысл
|
Действие
|
|
COMMIT
|
Завершить транзакцию
|
Завершить комплексную взаимосвязанную обработку информации, объединенную в транзакцию
|
|
ROLLBACK
|
Откатить транзакцию
|
Отменить изменения, проведенные в ходе выполнения транзакции
|
|
'SAVEPOINT
|
Сохранить промежуточную точку выполнения транзакции
|
Сохранить промежуточное состояние БД, пометить его для того, чтобы можно было в дальнейшем к нему вернуться
|
Таблица 4.5 Средства администрирования данных
|
Оператор
|
Смысл
|
Действие
|
|
ALTER DATABASE
|
Изменить БД
|
Изменить набор основных объектов в базе данных, ограничений, касающихся всем базы данных
|
|
ALTER -DBAREA
|
Изменить область хранения БД
|
Изменить ранее созданную область хранения
|
Таблица 4.5 (продолжение)
|
Оператор
|
Смысл
|
Действие
|
|
ALTER PASSWORD
|
Изменить пароль
|
Изменить пароль для всей базы данных
|
|
CREATE DATABASE
|
Создать БД
|
Создать новую базу данных, определив основные параметры для нее
|
|
CREATE DBAREA
|
Создать область хранения
|
Создать новую область хранения и сделать ее доступной для размещения данных
|
|
DROP DATABASE
|
Удалить БД
|
Удалить существующую базу данных (только в том случае, когда вы имеете право выполнить это действие)
|
|
DROP DBAREA
|
Удалить область хранения БД
|
Удалить существующую область хранения (если в ней на настоящий момент не располагаются активные данные)
|
|
GRANT
|
Предоставить права
|
Предоставить нрава доступа на ряд действий над некоторым объектом БД
|
|
REVOKE
|
Лишить прав
|
Лишить прав доступа к некоторому объекту или некоторым действиям над объектом
|
Таблица 4.6 Программный SQL
|
Оператор
|
Смысл
|
Действие
|
|
DECLARE
|
Определяет курсор для запроса
|
Задает некоторое имя и определяет связанный с ним запрос к БД, который соответствует виртуальному набору данных
|
|
OPEN
|
Открыть курсор
|
Формирует виртуальный набор данных, соответствующий описанию указанного курсора и текущему состоянию БД
|
|
FETCH
|
Считать строку из множества строк, определенных курсором
|
Считывает очередную строку, заданную параметром команды из виртуального набора данных, соответствующего открытому курсору
|
|
CLOSE
|
Закрыть курсор
|
Прекращает доступ к виртуальному набору данных, соответствующему указанному курсору
|
|
PREPARE
|
Подготовить оператор SQL к динамическому выполнению
|
Сгенерировать план выполнения запроса, соответствующего заданному оператору SQL
|
|
Оператор
|
Смысл
|
Действие
|
|
EXECUTE
|
Выполнить оператор SQL, ранее подготовленный к динамическому выполнению
|
Выполняет ранее подготовленный план запроса
|
В коммерческих СУБД набор основных операторов расширен. В большинство СУБД включены операторы определения и запуска хранимых процедур и операторы определения триггеров.
Типы данных.
В языке SQL поддерживаются следующие типы данных:
- CHARACTER(n) или CHAR(n) — символьные строки постоянной длины в n символов. При задании данного типа под каждое значение всегда отводится n символов, и если реальное значение занимает менее, чем n символов, то СУБД автоматически дополняет недостающие символы пробелами.
- NUMERIC[(n,m)] — точные числа, здесь n — общее количество цифр в числе, m — количество цифр слева от десятичной точки.
- DECIMAL[(n,m)] — точные числа, здесь n — общее количество цифр в числе, m — количество цифр слева от десятичной точки.
- DEC[(n,m)] - то же, что и DECIMAL[(n,m)].
- INTEGER или INT — целые числа.
- SMALLINT — целые числа меньшего диапазона.
- FLOAT[(n)] — числа большой точности, хранимые в форме с плавающей точкой. Здесь n — число байтов, резервируемое под хранение одного числа. Диапазон чисел определяется конкретной реализацией.
- REAL — вещественный тип чисел, который соответствует числам с плавающей точкой, меньшей точности, чем FLOAT.
- DOUBLE PRECISION специфицирует тип данных с определенной в реализации точностью большей, чем определенная в реализации точность для REAL.
- VARCHAR(n) — строки символов переменной длины.
- NCHAR(N) — строки локализованных символов постоянной длины.
- NCHAR VARYING(n) — строки локализованных символов переменной длины.
- BIT(n) — строка битов постоянной длины.
- BIT VARYING(n) — строка битов переменной длины.
- DATE — календарная дата.
- ТIMESТАМР(точность) — дата и время.
- INTERVAL — временной интервал.
В стандарте SQL определены встроенные функции:
- BIT_LENGTH(cтpoкa) — количество битов в строке;
- САSТ(значение AS тип данных) — значение, преобразованное в заданный тип данных;
- CHAR_LENGTH(cтpoкa) — длина строки символов;
- CONVERT(cтpoкa USING функция) — строка, преобразованная в соответствии с указанной функцией;
- CURRENT_DATE - текущая дата;
- CURRENT_TIME(точность) — текущее время с указанной точностью;
- CURRENT_TIMESTAMP(точность) — текущие дата и время с указанной точностью;
- LOWER(cтpокa) — строка, преобразованная к верхнему регистру;
- OCTED_LENGTH(строка) — число байтов в строке символов;
- POSITION(первая строка IN вторая строка) — позиция, с которой начинается вхождение первой строки во вторую;
- SUBSTRING(cтpoкa FROM n FOR длина) — часть строки, начинающаяся с n-го символа и имеющая указанную длину;
- TRANSLATE(строка USING функция) — строка, преобразованная с использованием указанной функции;
- TRIM(BOTH символ FROM строка) — строка, у которой удалены все первые и последние символы;
- TRIM(LEADING символ FROM строка ) — строка, в которой удалены все первые указанные символы;
- TRIM(TRAILING символ FROM строка) — строка, в которой удалены последние указанные символы;
- UPPER(строка) — строка, преобразованная к верхнему регистру.
Оператор выбора SELECT
Язык запросов (Data Query Language) в SQL состоит из единственного оператора SELECT. Этот единственный оператор поиска реализует все операции реляционной алгебры. Кажется просто, всего один оператор. Однако писать запросы на языке SQL (грамотные запросы) сначала совсем не просто. Надо учиться, так же как надо учиться решать математические задачки или составлять алгоритмы для решения непростых комбинаторных задач. Один и тот же запрос может быть реализован несколькими способами, и, будучи все правильными, они, тем не менее, могут существенно отличаться по времени исполнения, и это особенно важно для больших баз данных.
Синтаксис оператора SELECT имеет следующий вид:
SELECT [ALL | DISTINCT] «Список полей>|*)
FROM <Список таблиц>
[WHERE <Предикат-условие выборки или соединения>]
[GROUP BY <Список полей результата>]
[HAVING <Предикат-условие для группы>]
[ORDER BY <Список полей, по которым упорядочить вывод>]
Здесь ключевое слово ALL означает, что в результирующий набор строк включаются все строки, удовлетворяющие условиям запроса. Значит, в результирующий набор могут попасть одинаковые строки. И это нарушение принципов теории отношений (в отличие от реляционной алгебры, где по умолчанию предполагается отсутствие дубликатов в каждом результирующем отношении). Ключевое слово DISTINCT означает, что в результирующий набор включаются только различные строки, то есть дубликаты строк результата не включаются в набор.
Символ *. (звездочка) означает, что в результирующий набор включаются все столбцы из исходных таблиц запроса.
В разделе FROM задается перечень исходных отношений (таблиц) запроса.
В разделе WHERE задаются условия отбора строк результата или условия соединения кортежей исходных таблиц, подобно операции условного соединения в реляционной алгебре.
В разделе GROUP BY задается список полей группировки.
В разделе HAVING задаются предикаты-условия, накладываемые на каждую группу.
В части ORDER BY задается список полей упорядочения результата, то есть список полей, который определяет порядок сортировки в результирующем отношении. Например, если первым полем списка будет указана Фамилия, а вторым Номер группы, то в результирующем отношении сначала будут собраны в алфавитном порядке студенты, и если найдутся однофамильцы, то они будут расположены в порядке возрастания номеров групп.
В выражении условий раздела WHERE могут быть использованы следующие предикаты:
- Предикаты сравнения { =, <>, >,<, >=,<= }, которые имеют традиционный смысл.
- Предикат Between A and В — принимает значения между А и В. Предикат истинен, когда сравниваемое значение попадает в заданный диапазон, включая границы диапазона. Одновременно в стандарте задан и противоположный предикат Not Between A and В, который истинен тогда, когда сравниваемое значение не попадает в заданный интервал, включая его границы.
- Предикат вхождения в множество IN (множество) истинен тогда, когда сравниваемое значение входит в множество заданных значений. При этом множество значений может быть задано простым перечислением или встроенным подзапросом. Одновременно существует противоположный предикат NOT IN (множество), который истинен тогда, когда сравниваемое значение не входит в заданное множество.
- Предикаты сравнения с образцом LIKE и NOT LIKE. Предикат LIKE требует задания шаблона, с которым сравнивается заданное значение, предикат истинен, если сравниваемое значение соответствует шаблону, и ложен в противном случае. Предикат NOT LIKE имеет противоположный смысл.
По стандарту в шаблон могут быть включены специальные символы:
- символ подчеркивания (_) — для обозначения любого одиночного символа;
- символ процента (%) — для обозначения любой произвольной последовательности символов;
- остальные символы, заданные в шаблоне, обозначают самих себя.
- Предикат сравнения с неопределенным значением IS NULL. Понятие неопределенного значения было внесено в концепции баз данных позднее. Неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. Это значение при появлении дополнительной информации в любой момент времени может быть заменено на некоторое конкретное значение. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно неопределенное значение никогда не считается равным другому неопределенному значению. Для выявления равенства значения некоторого атрибута неопределенному применяют специальные стандартные предикаты:
<имя атрибута>IS NULL и <имя атрибута> IS NOT NULL.
Если в данном кортеже (в данной строке) указанный атрибут имеет неопределенное значение, то предикат IS NULL принимает значение «Истина» (TRUE), а предикат IS NOT NULL — «Ложь» (FALSE), в противном случае предикат IS NULL принимает значение «Ложь», а предикат IS NOT NULL принимает значение «Истина».
В условиях поиска могут быть использованы все рассмотренные ранее предикаты.
Отложив на время знакомство с группировкой, рассмотрим детально первые три строки оператора SELECT:
- SELECT — ключевое слово, которое сообщает СУБД, что эта команда — запрос. Все запросы начинаются этим словом с последующим пробелом. За ним может следовать способ выборки — с удалением дубликатов (DISTINCT) или без удаления (ALL, подразумевается по умолчанию). Затем следует список перечисленных через запятую столбцов, которые выбираются запросом из таблиц, или символ '*' (звездочка) для выбора всей строки. Любые столбцы, не перечисленные здесь, не будут включены в результирующее отношение, соответствующее выполнению команды. Это, конечно, не значит, что они будут удалены или их информация будет стерта из таблиц, потому что запрос не воздействует на информацию в таблицах — он только показывает данные.
- FROM — ключевое слово, подобно SELECT, которое должно быть представлено в каждом запросе. Оно сопровождается пробелом и затем именами таблиц, используемых в качестве источника информации. В случае если указано более одного имени таблицы, неявно подразумевается, что над перечисленными таблицами осуществляется операция декартова произведения. Таблицам можно присвоить имена-псевдонимы, что бывает полезно для осуществления операции соединения таблицы с самой собою или для доступа из вложенного подзапроса к текущей записи внешнего запроса (вложенные подзапросы здесь не рассматриваются).
4.2 Реализация на открытом коде в среде MySQL Workbench 6.3.
MySQL Workbench — инструмент для визуального проектирования баз данных, интегрирующий проектирование, моделирование, создание и эксплуатацию БД в единое бесшовное окружение для системы баз данных MySQL.
Ниже представлен пример работы с языком программирования SQL на открытом коде в среде MySQL Workbench 6.3.
Создаем свою базу данных My_base при помощи оператора CREATE DATABASE:
create database My_base
В новой базе данных, используя оператор CREATE TABLE, создадим таблицы, присваивая каждому из полей необходимый тип данных:
CREATE TABLE my_base.info_actor (
actor_id INT NOT NULL AUTO_INCREMENT,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
PRIMARY KEY (actor_id)
);
CREATE TABLE my_base.id_actor_film (
actor_id INT NOT NULL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
film_id INT NOT NULL,
name_film VARCHAR(255) NOT NULL
);
Вставляем необходимые данные с помощью оператора insert из тестовой базы. При использовании оператора insert расставляем поля в таком же порядке, как и в созданной нами таблице:
insert into my_base.info_actor
SELECT actor_id,first_name,last_name
FROM sakila.actor;
Совершаем связь 2 таблиц из разных баз данных, используя вложенный select. Связь осуществим с помощью оператора join:
insert into my_base.id_actor_film
SELECT a.actor_id,first_name,last_name,b.film_id,title
FROM my_base.info_actor as a
join (SELECT distinct actor_id,film_id
from sakila.film_actor) as b on a.actor_id=b.actor_id
join sakila.film_text as d on b.film_id=d.film_id;
Проверяем наличие данных в таблице:
select * from my_base.id_actor_film
Посчитаем количество фильмов для каждого из актеров, используя функцию count, при использовании математической функции в конце запроса ставим оператор group by, для этого создадим еще одну таблицу и вставим в нее данные из таблицы my_base.id_actor_film. Для подсчета количества фильмов берем уникальные данные об актере и соответствующим ему фильмах. Для этого используем оператор select distinct, с помощью которого выгружаем неповторяющиеся данные.
CREATE TABLE my_base.kol_film (
actor_id INT NOT NULL,
kol_film real
);
insert into my_base.kol_film
select actor_id,count(film_id) kol_film
from
(select distinct actor_id,film_id
from my_base.id_actor_film) as a
group by actor_id
Создаем последнюю таблицу и заполняем ее необходимыми данными:
CREATE TABLE my_base.actor_kol_film (
actor_id INT NOT NULL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
name_film VARCHAR(255) NOT NULL,
kol_film real
);
insert into my_base.actor_kol_film
select a.actor_id,first_name,last_name,name_film,kol_film from my_base.id_actor_film a
join my_base.kol_film b on a.actor_id=b.actor_id
Просматриваем готовую таблицу:
select * from my_base.actor_kol_film
В результате написания кода на языке программирования MySQL создана база данных, таблицы, осуществлена связь между таблицами, получена таблица с необходимыми данными.
- Защита баз данных
База данных представляет собой важнейший корпоративный ресурс, который должен быть надлежащим образом защищен с помощью соответствующих средств контроля. Существуют такие опасности, как:
• похищение и фальсификация данных;
• утрата конфиденциальности (нарушение тайны);
• нарушение неприкосновенности личных данных;
• утрата целостности;
• потеря доступности.
Вопросы защиты данных часто рассматриваются вместе с вопросами
поддержки целостности данных (по крайней мере, в неформальном контексте),
хотя на самом деле это совершенно разные понятия. Термин защита
относится к защищенности данных от несанкционированного доступа, изменения или умышленного разрушения, а целостность к точности или достоверности данных. Эти термины можно определить, как показано ниже.
- Под защитой данных подразумевается предотвращение доступа к ним со стороны несанкционированных пользователей.
- Под поддержкой целостности данных подразумевается предотвращение
их разрушения при доступе со стороны санкционированных пользователей.
Другими словами, защита данных получение гарантий, что пользователям разрешено выполнять те действия, которые они пытаются выполнить, а поддержка целостности получение гарантий, что действия, которые пользователи пытаются выполнить, будут допустимыми.
Между этими понятиями есть некоторое сходство, поскольку как при обеспечении защиты данных, так и при обеспечении поддержки их целостности система вынуждена проверять, не нарушаются ли при выполняемых пользователем действиях некоторые установленные ограничения. Эти ограничения формулируются (обычно администратором базы данных) на некотором подходящем языке и сохраняются в системном каталоге. Причем в обоих случаях СУБД должна каким-то образом отслеживать все выполняемые пользователем действия и проверять их соответствие установленным ограничениям.
Эти две темы обсуждаются раздельно, так как целостность данных является фундаментальным понятием, тогда как защита данных — понятием вторичным, несмотря на его большую практическую важность (особенно в наши дни повсеместного распространения Internet, электронной коммерции и соответствующих средств доступа).
Ниже описаны многочисленные аспекты проблемы защиты данных.
- Правовые, общественные и этические аспекты (например, имеет ли некоторое лицо легальное основание запрашивать, скажем, информацию о выделенном клиенту кредите).
- Физические условия (например, запирается ли помещение с компьютерами или терминалами на замок либо оно охраняется другим способом).
- Организационные вопросы (например, каким образом на предприятии, являющемся владельцем системы, принимается решение о том, кому разрешено иметь доступ к тем или иным данным).
- Вопросы управления (например, как в случае организации защиты системы от несанкционированного доступа по схеме паролей обеспечивается секретность используемых паролей и как часто они меняются).
- Аппаратные средства защиты (например, имеет ли используемое вычислительное оборудование встроенные функции защиты, подобные ключам защиты хранимой информации или привилегированному режиму управления).
- Возможности операционной системы (например, стирает ли используемая операционная система содержимое оперативной памяти и дисковых файлов после прекращения работы с ними, и каким образом обрабатывается журнал восстановления).
- Аспекты, имеющие отношение непосредственно к самой СУБД (например, поддерживает ли используемая СУБД концепцию владельца данных).
Обычно в современных СУБД поддерживается один из двух широко распространенных методов организации защиты данных — избирательный или мандатный, а иногда оба этих метода. В обоих случаях единица данных (или объект данных), для которой организуется защита, может выбираться из широкого диапазона, от всей базы данных до конкретных компонентов отдельных кортежей. Различия между двумя указанными методами кратко описаны ниже.
В случае избирательного контроля каждому пользователю обычно предоставляются различные права доступа (иначе называемые привилегиями, или полномочиями) к разным объектам. Более того, разные пользователи, как правило, обладают разными правами доступа к одному и тому же объекту. (Например, пользователю U1 может быть разрешен доступ к объекту А, но запрещен доступ к объекту B, тогда как пользователю U2 может быть разрешен доступ к объекту B, но запрещен доступ к объекту А.) Поэтому избирательные схемы характеризуются значительной гибкостью.
В случае мандатного контроля, наоборот, каждому объекту данных назначается некоторый классификационный уровень, а каждому пользователю присваивается некоторый уровень допуска. В результате право доступа к объекту данных получают только те пользователи, которые имеют соответствующий уровень допуска. Мандатные схемы обычно имеют иерархическую структуру и поэтому являются более жесткими. (Если пользователь U1 имеет доступ к объекту А, но не имеет доступа к объекту B, то в схеме защиты объект B должен будет располагаться на более высоком уровне, чем объект А, а значит, не может существовать никакого пользователя U2, который будет иметь доступ к объекту B, но не будет иметь доступа к объекту А.)
Независимо от того, какая схема используется (избирательная или мандатная), все решения относительно предоставления пользователям прав на выполнение тех или иных операций с теми или иными объектами должны приниматься исключительно управленческим персоналом. Поэтому все эти вопросы выходят за пределы возможностей самой СУБД, и все, что она способна сделать в данной ситуации, — привести в действие решения, которые будут приняты на другом уровне. Исходя из этих соображений, можно определить приведенные ниже условия.
- Принятые организационные решения должны быть доведены до сведения системы (т.е. представлены как ограничения защиты, выраженные с помощью некоторого языка описания требований защиты) и должны быть ей постоянно доступны(храниться в системном каталоге).
- Очевидно, что в системе должны существовать определенные средства проверки поступающих запросов на получение доступа по отношению к установленным правилам защиты. (Здесь под понятием запрос на получение доступа подразумевается конкретная комбинация запрашиваемой операции, запрашиваемого объекта и запрашивающего пользователя.) Обычно такая проверка выполняется подсистемой защиты СУБД, которую иногда называют также подсистемой авторизации.
- Для принятия решения о том, какие именно установленные ограничения защиты применимы к данному запросу на получение доступа, система должна быть способна установить источник этого запроса, т.е. суметь опознать запрашивающего пользователя. Поэтому при подключении к системе от пользователя обычно требуется ввести не только свой идентификатор (чтобы указать, кто он такой), но и пароль(чтобы подтвердить, что он именно тот, за кого себя выдает). Предполагается, что пароль известен только системе и тем лицам, которые имеют право применять данный идентификатор пользователя. Процесс проверки пароля (т.е. проверки того, что пользователи являются теми, за какого себя выдают) называется аутентификацией.
Также следует отметить, что в настоящее время существуют намного более сложные методы аутентификации по сравнению с простой проверкой паролей, в которых для аутентификации применяется целый ряд биометрических устройств: приборы для чтения отпечатков пальцев, сканеры радужной оболочки, анализаторы геометрических характеристик ладони, приборы проверки голоса, устройства распознавания подписей и т.д. Все эти устройства могут эффективно использоваться для проверки "персональных характеристик, которые никто не может подделать".
Кстати, в отношении идентификаторов пользователей следует заметить, что один и тот же идентификатор может совместно применяться для целого ряда разных пользователей, входящих в состав некоторой группы. Таким образом, система может поддерживать группы пользователей (называемые также ролями), обеспечивая одинаковые права доступа для всех ее членов, например, для всех работников бухгалтерского отдела. Кроме того, операции добавления новых пользователей в группу или их удаления из нее можно выполнять независимо от операций задания привилегий доступа для этой группы на те или иные объекты.
Избирательная схема управления доступом
Следует еще раз отметить, что во многих СУБД поддерживается либо избирательная, либо мандатная схема управления доступом, либо оба типа доступа одновременно. Однако точнее все же будет сказать, что в действительности в большинстве СУБД поддерживается только избирательная схема доступа и лишь в некоторых — только мандатная. Поскольку на практике избирательная схема доступа встречается гораздо чаще.
Для определения избирательных ограничений защиты необходимо использовать некоторый язык. По вполне очевидным причинам гораздо легче указать то, что разрешается, чем то, что не разрешается. Поэтому в подобных языках обычно поддерживается определение не самих ограничений защиты, а полномочий, которые по своей сути противоположны ограничениям защиты (т.е. они разрешают какие-либо действия, а не запрещают их). Дадим краткое описание гипотетического языка определения полномочий, воспользовавшись следующим примером.
AUTHORITY SA3
GRANT RETRIEVE { S#, SNAME, CITY }, DELETE
ON S
TO Jim, Fred, Mary ;
Этот пример иллюстрирует тот факт, что в общем случае полномочия доступа включают четыре описанных ниже компонента.
1. Имя (в данном примере SA3, "suppliers authority three" — полномочия поставщика с номером 3). Устанавливаемые полномочия будут зарегистрированы в системном каталоге под этим именем.
2. Одна или несколько привилегий, задаваемых в конструкции GRANT.
3. Задаваемое в конструкции ON имя переменной отношения, к которой применяются полномочия.
4. Множество пользователей (точнее, идентификаторов пользователей), которым предоставляются указанные привилегии применительно к указанной переменной отношения, задаваемой с помощью фразы ТО.
Ниже приводится общий синтаксис оператора определения полномочий.
AUTHORITY <authority name>
GRANT <privilege commalist>
ON <relvar name>
TO <user ID commalist> ;
Мандатная схема управления доступом
Методы мандатного управления доступом применяются к тем базам данных, в которых хранимая информация имеет достаточно статичную и жесткую структуру, что свойственно, например, некоторым военным или правительственным организациям. Основная идея состоит в том, что каждому объекту данных присваивается некоторый классификационный уровень (или требуемый гриф секретности, например "Совершенно секретно", "Секретно", "Для служебного пользования" и т.д.), а каждому пользователю предоставляется уровень допуска с градациями, аналогичными существующим классификационным уровням. Предполагается, что эти уровни образуют строгую иерархическую систему (например, "Совершенно секретно" > "Секретно" > "Для служебного пользования" и т.д.). Тогда исходя из этих положений можно сформулировать два очень простых правила, впервые предложенные Беллом и Ла-Падулой.
1. Пользователь i может выполнить выборку данных объекта j только в том случае, если его уровень допуска больше классификационного уровня объекта j или равен ему {простое свойство безопасности — simple security property).
2. Пользователь i может модифицировать объект j только в том случае, если его уровень допуска равен классификационному уровню объекта j (звездное свойство — star property).
Первое правило достаточно очевидно, тогда как второе требует дополнительных пояснений. Прежде всего, следует отметить, что иным образом второе правило можно сформулировать так: "По определению любая информация, записанная пользователем i, автоматически приобретает классификационный уровень, который равен уровню допуска пользователя i". Подобное правило необходимо, например, для того, чтобы предотвратить запись секретных данных, выполняемую пользователем с уровнем допуска
"Секретно", в файл с меньшим уровнем классификации, что нарушит всю систему секретности.
Шифрование данных
Ранее предполагалось, что некий злонамеренный пользователь пытается незаконно проникнуть в базу данных с помощью обычных средств доступа, имеющихся в системе. Теперь следует рассмотреть случай, когда он пытается проникнуть в базу данных, минуя систему, т.е. физически перемещая внешние носители информации или подключаясь к линии связи. Наиболее эффективным методом борьбы с такими угрозами является шифрование данных, т.е. хранение и передача особо важных данных в зашифрованном виде.
Для изучения основных концепций шифрования данных следует ввести некоторые новые понятия. Исходные (незашифрованные) данные называются открытым текстом.
Открытый текст шифруется с помощью специального алгоритма шифрования. В качестве входных данных для такого алгоритма выступают открытый текст и ключ шифрования, а в качестве выходных— преобразованная форма открытого текста, которая называется шифрованным текстом. Детали алгоритма шифрования могут быть опубликованы, но ключ шифрования ни в коем случае не разглашается. Именно зашифрованный текст, непонятный всем, кто не обладает ключом шифрования, хранится в базе данных и передается по линии связи.
Пример 5.1. Пусть в качестве открытого текста дана следующая строка.
AS KINGFISHERS CATCH FIRE (Здесь для простоты изложения предполагается, что данные состоят только из пробелов и прописных символов.) Кроме того, допустим, что ключом шифрования является следующая строка.
ELIOT
Ниже описывается используемый алгоритм шифрования.
1. Разбить открытый текст на блоки, длина которых равна длине ключа шифрования.
AS+KI NGFIS HERS+ CATCH +FIRE
(Здесь пробелы обозначены знаком "+".)
2. Заменить каждый символ открытого текста целым числом в диапазоне 00-26, используя для пробела число 00, для А — число 01,..., для Z — число 26. В результате получится следующая строка цифр.
0119001109 1407060919 0805181900 0301200308 0006091805
3. Повторить п. 2 для ключа шифрования, в результате чего получится следующая строка цифр.
0512091520
4. Теперь значения, помещенные вместо каждого символа в каждом блоке открытого текста, просуммировать с соответствующими значениями, подставленными вместо символов ключа шифрования, и для каждой суммы из указанных двух значений определить и записать остаток от деления на 27.
5. Заменить каждое число в нижней строке п. 4 соответствующим текстовым символом.
FDIZB SSOXL MQ+GT HMBRA ERRFY
Если известен ключ шифрования, то процедура расшифровки в этом примере может быть выполнена достаточно просто. Вопрос заключается в том, насколько сложно нелегальному пользователю определить ключ шифрования, обладая открытым и зашифрованным текстами. В данном простом примере это не очень сложно выполнить, однако вполне очевидно, что можно разработать и более сложные схемы шифрования. В идеале, схема шифрования должна быть такой, чтобы усилия, затраченные на ее расшифровку, во много раз превышали полученную при этом выгоду. (Фактически это замечание применимо ко всем аспектам проблемы обеспечения безопасности, т.е. стоимость осуществления попыток взлома системы защиты должна быть значительно выше потенциальной выгоды от этого.) Конечной целью поиска таких схем следует считать схему, для которой сам ее разработчик, обладая открытым и зашифрованным вариантами одной и той же части текста, не в состоянии определить ключ и, следовательно, расшифровать другую часть зашифрованного текста.
Управление безопасностью обычно осуществляется на трех уровнях:
• уровень базы данных;
• уровень операционной системы;
• сетевой уровень.
На уровне операционной системы у администратора базы данных (АБД) должны быть права для создания и удаления относящихся к базе данных файлов. Напротив, у обычных пользователей таких прав быть не должно. Информация о безопасности на уровне операционной системы приведена в стандартной документации Oracle. Во многих крупных организациях АБД или администратор по безопасности базы данных работают в тесном контакте с администраторами вычислительной системы, чтобы координировать усилия по разработке требований и практических мероприятий, направленных на обеспечение безопасности.
В требованиях к безопасности базы данных описываются процедуры предоставления доступа к базе путем назначения каждому пользователю пары имя/пароль (username/password). В требованиях может также оговариваться ограничение объема ресурсов (дискового пространства и процессорного времени), выделяемых одному пользователю, и постулироваться необходимость аудита действий пользователей. Механизм обеспечения безопасности на уровне базы данных также обеспечивает управление доступом к конкретным объектам схемы базы данных.
ЗАКЛЮЧЕНИЕ
Практически все системы в той или иной степени связаны с функциями долговременного хранения и обработки информации. Фактически информация становится фактором, определяющим эффективность любой сферы деятельности. Увеличились информационные потоки и повысились требования к скорости обработки данных, и теперь уже большинство операций не может быть выполнено вручную, они требуют применения наиболее перспективных компьютерных технологий.
Любые административные решения требуют четкой и точной оценки текущей ситуации и возможных перспектив ее изменения. И если раньше в оценке ситуации участвовало несколько десятков факторов, которые могли быть вычислены вручную, то теперь таких факторов сотни и сотни тысяч, и ситуация меняется не в течение года, а через несколько минут, а обоснованность принимаемых решений требуется большая, потому что и реакция на неправильные решения более серьезная, более быстрая и более мощная, чем раньше. И, конечно, обойтись без информационной модели производства, хранимой в базе данных, в этом случае невозможно.
Базы данных являются наиболее распространенными ресурсами Интернет и локальных систем. Фактически любой набор данных, тем или иным образом, может быть интерпретирован как база данных. В силу этого, защита баз данных является наиболее актуальной проблемой защиты информационных ресурсов.
Актуальный в настоящее время электронный документооборот тесно связан с использованием баз данных, т.к. практически вся электронная информация организована в базы данных.
Повсеместное распространение беспроводных технологий и интернет-банкинг, интернет-бизнес и т.д. также связаны с обращением к базам данных.
Поэтому развитие технологий баз данных и их защита – в высшей степени актуальная задача, которая никогда не потеряет своей актуальности при нынешнем информационном и технологическом укладе.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Байер Д. Microsoft ASP .NET. Обеспечение безопасности. Мастер-Класс / Пер. с англ. М.: Издательство «Русская Редакция»; СПб.: Питер, 2008. – 446 стр.
- Борри Х. Firebird: руководство разработчика баз данных: Пер. с анrл. – СПб.: БХВ-�Петербург, 2006. – 1104 с.
- Гектор Гарсиа-Молина, Джеффри Д. Ульман, Дженнифер Уидом Системы баз данных. Полный курс. : Пер. с англ. – М.: Издательский дом «Вильямс», 2003. – 1088 с.
- Голованов Н.А. Современный англо-русский словарь компьютерных технологий. – М.: Бук-пресс. 2006 – 528 с.
- Гольцман В. MySQL 5.0 - Библиотека программиста: Питер; Санкт-Петербург; 2010.
- Гринвальд Р., Стаковьяк Р., Стерн Дж. Oracle 11g. Основы. 4-е изд. Пер. с англ. - СПб.: Символ-плюс, 2009. - 464 с.
- Гурвиц Г. А. Microsoft® Access 2010. Разработка приложений на реальном примере. - СПб.: БХВ-Петербург, 2010. – 496 с.: ил. + CD-ROM.
- Дейт К. Дж. Введение в системы баз данных. 8-е изд. – М.: Вильямс, 2005. – 1328 с.
- Карпова Т.С. Базы данных: модели, разработка, реализации. – СПб.: Питер, 2002. – 304 с.
- Кочергин В.И. Англо-русский толковый научно-технический словарь по системному анализу, программированию, электронике и электроприводу: В 2-х т. Т. 1. – Томск, 2008. – 652 с.
- Кочергин В.И. Англо-русский толковый научно-технический словарь по системному анализу, программированию, электронике и электроприводу: В 2-х т. Т. 2. – Томск, 2008. – 314 с.
- Кузнецов М.В., Симдянов И.В. MySQL 5 – СПб.: БХВ-Петербург, 2010 – 1024 с.: ил. + Дистрибутив на CD-ROM – (В подлиннике).
- Мизинина И. Н., Мизинина А. И., Жильцов И. В. Англо-русский и русско-английский словарь ПК: ОЛМА-ПРЕСС Образование; М.; 2006.
- Миллсап К., Хольт Д. Oracle. Оптимизация производительности. – Пер. с англ. – СПб: Символ-Плюс, 2006. – 464 с.
- НГТУ Лекции: Базы данных вместе с глоссарием. НГТУ, 2009
- Нильсен П. Microsoft SQL Server 2005. Библия пользователя.: Пер. с англ. – М.: ООО «И.Д. Вильямс», 2008. – 1232 с.
- Скембрей Дж., Шема М. Секреты хакеров. Безопасность Web-приложений – готовые решения. : Пер. с англ. – М.: Издательский дом «Вильямс», 2003. – 384 с.
- Peter Revesz Introduction to Database. From Biological to Spatio-Temporal, Springer-Verlag London Limited 2010.
- Научно-практические конференции ученых и студентов
с дистанционным участием. Коллективные монографии // Типы логических моделей баз данных – [Электронный ресурс] URL: http://sibac.info/11384
- База знаний по биологии человека. [Электронный ресурс]. – URL: http://humbio.ru/humbio/moldiagn/00008ebb.htm
- [Электронный ресурс]. – URL: http://lektor5.narod.ru/inf/inf3.htm
- [Электронный ресурс]. – URL: https://support.office.com/ru-ru/article/Основные-сведения-о-базах-данных-a849ac16-07c7-4a31-9948-3c8c94a7c204?ui=ru-RU&rs=ru-RU&ad=RU
- [Электронный ресурс]. – URL: http://do.gendocs.ru/docs/index-15097.html
- [Электронный ресурс]. – URL: https://office.live.com/start/default.aspx#
- [Электронный ресурс]. – URL: mir-oracle.com.ua/oracle-tech-info/15-oraclefromzerro/102-basictermins.html
- [Электронный ресурс]. – URL: http://bourabai.ru/einf/subd1.htm
Доклад
В широком смысле понятие истории баз данных - это история любых средств, с помощью которых человечество хранило и обрабатывало данные. Базами данных, например, можно считать средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.)
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных COBOL была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Ф. Кодда.
Термин база данных (англ. database) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных компанией SDC в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы.
Цель данной работы:
- Изучить типы баз данных. Особенности их математической и алгоритмической организации.
- Конкретные программные продукты в области баз данных.
- Получить представление о языке программирования SQL и его реализации на открытом коде MySQL.
- Получить представление о способах защиты баз данных.
Классификация БД по модели данных:
- Реляционная модель данных
- Иерархическая модель данных
- Сетевая модель данных
- Объектные базы данных
- Объектно-ориентированная база данных
- Временные, или темпоральные базы данных
- Географические базы данных
- Базы данных изображений
- Геномные базы данных
Классификация БД по среде физического хранения:
- БД во вторичной памяти (традиционные);
- БД в оперативной памяти;
- БД в третичной памяти.
Классификация по содержимому:
- Географическая;
- Историческая;
- Научная;
- Мультимедийная.
Классификация БД по степени распределённости:
- централизованная;
- распределённая;
- неоднородная;
- однородная;
- фрагментированная;
- тиражированная.
Классификация БД по способу доступа к данным:
- БД с локальным доступом;
- БД с удаленным (сетевым) доступом.
Access
В базе данных Access таблицы сохраняются в одном файле вместе с другими объектами, такими как формы, отчеты, макросы и модули, если только база данных не предназначена специально для использования данных или кода из другого источника.
Приложение Access предоставляет следующие возможности:
• добавление новых данных в базу данных (например, новой позиции в складскую опись);
• изменение существующих данных в базе данных (например, изменение текущего размещения позиции на складе);
• удаление сведений (например, если позиция продана или отбракована);
• организация и просмотр данных различными способами;
• совместное использование данных посредством отчетов, сообщений электронной почты, внутренней сети или Интернета.
Oracle
Система Управления Реляционными Базами Данных (СУРБД) Oracle предназначена для одновременного доступа к большим объемам хранимой информации. СУРБД складывается из двух составляющих: База Данных (информация) и экземпляр (конкретная реализация системы). База данных состоит из физических файлов, хранящихся в системе, и из логических частей (например, схема БД). Эти файлы могут быть совершенно разными, их мы рассмотрим чуть далее. Экземпляр – это способ доступа к данным, который состоит из процессов и системной памяти.
БД Oracle состоит из двух уровней: физический и логический. Физический уровень включает файлы, которые хранятся на диске, а логический уровень представляет компоненты физического уровня.
Язык программирования SQL
SQL (Structured Query Language) — Структурированный Язык Запросов — стандартный язык запросов по работе с реляционными БД. Язык SQL появился после реляционной алгебры, и его прототип был разработан в конце 70-х годов в компании IBM Research. Он был реализован в первом прототипе реляционной СУБД фирмы IBM System R. В дальнейшем этот язык применялся во многих коммерческих СУБД и в силу своего широкого распространения постепенно стал стандартом «де-факто» для языков манипулирования данными в реляционных СУБД.
Реализация на открытом коде в среде MySQL Workbench 6.3.
MySQL Workbench — инструмент для визуального проектирования баз данных, интегрирующий проектирование, моделирование, создание и эксплуатацию БД в единое бесшовное окружение для системы баз данных MySQL.
Язык запросов в SQL состоит из единственного оператора SELECT. Этот единственный оператор поиска реализует все операции реляционной алгебры. Один и тот же запрос может быть реализован несколькими способами, и, будучи все правильными, они, тем не менее, могут существенно отличаться по времени исполнения, и это особенно важно для больших баз данных.
В работе представлен пример работы с языком программирования SQL на открытом коде в среде MySQL Workbench 6.3.
Создаем базу данных My_base при помощи оператора CREATE DATABASE:
create database My_base
В новой базе данных, используя оператор CREATE TABLE, создадим таблицы, присваивая каждому из полей необходимый тип данных и т.д.
В результате написания кода на языке программирования MySQL создана база данных, таблицы, осуществлена связь между таблицами, получена таблица с необходимыми данными.
В работе приводится код базы данных.
База данных представляет собой важнейший корпоративный ресурс, который должен быть надлежащим образом защищен с помощью соответствующих средств контроля.
Существуют такие опасности, как:
• похищение и фальсификация данных;
• утрата конфиденциальности (нарушение тайны);
• нарушение неприкосновенности личных данных;
• утрата целостности;
• потеря доступности.
Обычно в современных СУБД поддерживается один из двух широко распространенных методов организации защиты данных — избирательный или мандатный, а иногда оба этих метода.
Для определения избирательных ограничений защиты необходимо использовать некоторый язык. По вполне очевидным причинам гораздо легче указать то, что разрешается, чем то, что не разрешается. Поэтому в подобных языках обычно поддерживается определение не самих ограничений защиты, а полномочий, которые по своей сути противоположны ограничениям защиты (т.е. они разрешают какие-либо действия, а не запрещают их).
Методы мандатного управления доступом применяются к тем базам данных, в которых хранимая информация имеет достаточно статичную и жесткую структуру, что свойственно, например, некоторым военным или правительственным организациям. Основная идея состоит в том, что каждому объекту данных присваивается некоторый классификационный уровень (или требуемый гриф секретности, например "Совершенно секретно", "Секретно", "Для служебного пользования" и т.д.), а каждому пользователю предоставляется уровень допуска с градациями, аналогичными существующим классификационным уровням. Предполагается, что эти уровни образуют строгую иерархическую систему (например, "Совершенно секретно" > "Секретно" > "Для служебного пользования" и т.д.).
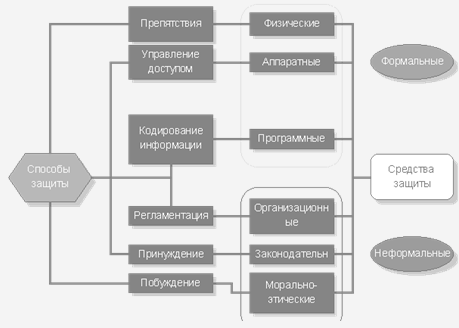
Вывод
Базы данных являются наиболее распространенными ресурсами Интернет и локальных систем. Фактически любой набор данных, тем или иным образом организованный, может быть интерпретирован как база данных. В силу этого, защита баз данных является наиболее актуальной проблемой защиты информационных ресурсов.
Актуальный в настоящее время электронный документооборот тесно связан с использованием баз данных, т.к. практически вся электронная информация организована в базы данных.
Повсеместное распространение беспроводных технологий и интернет-банкинг, интернет-бизнес и т.д. также связаны с обращением к базам данных.
Поэтому развитие технологий баз данных и их защита – в высшей степени актуальная задача, которая никогда не потеряет своей актуальности при нынешнем информационном и технологическом укладе.
БАЗЫ ДАННЫХ И ИХ ЗАЩИТА