База данных (БД)
Лекция №1
База данных (БД) – именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Для манипулирования БД разработаны системы управления базами данных (СУБД). Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Использование СУБД обеспечивает:
- минимизацию избыточности данных – в предельном случае любые данные могут храниться в одном экземпляре;
- совместное использование данных многими пользователями;
- независимость данных от программ;
- эффективность доступа к данным, как удовлетворение требований по своевременности, достоверности и др.;
- простоту работы с базой и т.д.
Обычно на СУБД возлагается выполнение следующих функций:
- описание данных;
- манипулирование данными;
- заведение базы данных;
- выполнение запросов;
- выдача отчетов;
- сервис (поддержание целостности, справочные функции, восстановление базы).
По характеру своего размещения БД могут быть централизованными или распределенными.
Централизованная БД – это БД, размещенная на одном единственном сервере.
Обзор СУБД ведущих производителей
Поскольку СУБД работает не сама по себе, а поверх определенной программно-аппаратной платформы, стоимость этой платформы играет важную роль для заказчика. Поэтому неудивительно, что крупные компании предпочитают СУБД для Unix, а средние и малые — для Windows и Linux. Чтобы удовлетворить все запросы, вендоры предлагают СУБД для всех платформ. На мировом рынке наиболее быстро растет спрос на СУБД для Linux. Однако по объему продаж у Oracle лидируют Unix-системы, на втором месте — СУБД для Windows и на третьем — для Linux, но разрыв между двумя последними платформами с каждым годом уменьшается.
Лидерами рынка СУБД на данный момент являются компании IBM, Oracle, Microsoft и Sybase.
СУБД
|
Компании
|
СУБД
|
Краткая характеристика
|
|
Зарубежные продукты
|
|
IBM
|
DB2 Universal Database
Informix
|
Мультимедийная, Web-совместимая СУБД, работает с основными версиями Unix, Linux и Windows на аппаратных платформах zSeries, iSeries, VSE и VM.
СУБД для систем масштаба предприятия и рабочей группы, обеспечивает работу с очень крупными БД в условиях дефицита ресурсов.
|
|
Microsoft
|
SQL Server
|
Реляционная СУБД для управления данными в масштабе предприятия, поддерживает технологии XML и Интернет, обладает встроенным средством анализа и извлечения данных, интегрированным с Microsoft Office, работает на платформе Windows.
|
|
Oracle
|
Oracle
|
СУБД для масштабной обработки транзакций (OLTP), хранилищ данных с высокой интенсивностью потока запросов и ресурсоемких Интернет-, приложений. Совместима с основными версиями Unix, Windows и Linux. Последняя версия поддерживает Grid-вычисления.
|
|
Sybase
|
Sybase Adaptive Server Enterprise (ASE)
Sybase Adaptive Server Anywhere (ASA)
|
СУБД масштаба предприятия для централизованной обработки критически важной информации, работает на платформах Unix и Linux.
Компактная, полноценная реляционная СУБД для рабочих групп, мобильных и встроенных вычислений.
|
|
Отечественные продукты
|
|
Рэлэкс
|
Линтер
|
Реляционная СУБД, имеющая сертификат Гостехкомиссии при Президенте РФ на соответствие 2 классу защиты информации от несанкционированного доступа, совместима с основными версиями Unix, Linux, QNX, VAX/VMS, OpenVMS, DOS, Windows, NetWare, OS/2.
|
|
СУБД с открытым исходным кодом
|
|
MySQL AB
|
MySQL
|
Компактная, быстродействующая реляционная СУБД для малых и средних предприятий, совместима с Linux, Mac OS X, Unix и Windows.
|
|
Сообщество PostgreSQL
|
PostgreSQL
|
Реляционная СУБД, имеет многие возможности, которые реализованы в крупных коммерческих продуктах, совместима с Unix, Windows и NetWare.
|
Однако некоторые задачи являются настолько требовательными к вычислительным мощностям, что даже мощнейшие из современных суперкомпьютеров не справляются. Немаловажным фактором является и стоимость оборудования (если требуется создать новую суперсистему) или стоимость машинного времени (в случае использования какого-либо суперкомпьютера). В первом случае стоимость исчисляется сотнями, во втором – десятками... миллионов долларов (евро и.т.п.).
Выходом из данной ситуации является использование распределенных баз данных.
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети.
Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределения для пользователей.
РБД состоит из набора узлов, связанных коммуникационной сетью, в которой: а) каждый узел — это полноценная СУБД сама по себе;
б) узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле.
Фундаментальный принцип создания распределённых баз данных («правило 0»): для пользователя распределённая система должна выглядеть так же, как нераспределённая система.
Фундаментальный принцип имеет следствием определённые дополнительные цели. Таких целей всего двенадцать:
1. Локальная автономность. Локальные данные должны находиться под локальным владением и управлением, включая функции безопасности, целостности, представления данных в памяти.
2. Никакой конкретный сервис не должен возлагаться на какой-либо специально выделенный центральный узел. Соблюдение этого правила, т.е. принципа децентрализации функций РаСУБД, позволяет избежать узких мест.
3. Непрерывность функционирования. Система не должна останавливаться в случае необходимости добавления нового узла или удаления в распределенной среде некоторых данных, изменения определения метаданных и даже (что довольно сложно) осуществления перехода к новой версии СУБД на отдельном узле.
4. Независимость от местоположения. Пользователи и приложения не обязаны знать о том, где физически располагаются данные.
5. Независимость от фрагментации. Фрагменты (называемые также разделами) данных должны поддерживаться и обрабатываться средствами РаСУБД таким образом, чтобы пользователи или приложения могли бы вообще ничего не знать об этом. Более того, РаСУБД должна уметь обходить при обработке запросов фрагменты, не имеющие к ним отношения (например, РаСУБД должна быть достаточно интеллектуальной, для того чтобы определять, можно ли исключить при обработке запроса тот или иной фрагмент в силу того, что запрос не содержит ссылок на хранящиеся в этом фрагменте столбцы).
6. Независимость от тиражирования. Те же принципы независимости и прозрачности относятся и к механизму тиражирования, который обсуждается ниже.
7. Распределенная обработка запросов. Обработка запросов должна производиться распределенным образом. В следующем разделе мы рассмотрим некоторые архитектурные принципы реализации РаСУБД и различные модели, в рамках которых возможна распределенная обработка запросов.
8. Управление распределенными транзакциями. На распределенные базы данных необходимо распространить механизмы управления транзакциями и управления одновременным доступом. Эта проблема включает выявление и разрешение тупиковых ситуаций, прерывания по истечении временных интервалов, фиксацию и откат распределенных транзакций, а также ряд других вопросов.
9. Независимость от оборудования. Одно и то же программное обеспечение РаСУБД должно выполняться на различных аппаратных платформах и функционировать в системе в качестве равноправного партнера. Как уже обсуждалось выше, на практике достичь этого исключительно сложно, поскольку многие поставщики поддерживают множество платформ. Это ограничение преодолевается с помощью модели многопродуктовых сред.
10. Независимость от операционных систем. Эта проблема тесно связана с предыдущей, и она также решается аналогичным образом.
11. Независимость от сети. Узлы могут быть связаны между собой с помощью множества разнообразных сетевых и коммуникационных средств. Многоуровневая модель, присущая многим современным информационным системам (например, семиуровневая модель OSI, модель TCP/IP, уровни SNA и DECnet), обеспечивает решение этой проблемы не только в среде РаБД, но и для информационных систем вообще.
12. Независимость от СУБД. Локальные СУБД должны иметь возможность участвовать в функционировании РаСУБД.
Очевидно, что, хотя крайне желательно было бы иметь системы, удовлетворяющие всем 12 правилам, нереально ожидать реализации этих требований в рамках хотя бы одного продукта даже в ближайшие годы.
Ниже определены четыре шага, необходимых для перехода к управлению распределенными базами данных и призванных обеспечить следующие возможности:
1. Удаленный запрос. Выполняется подключение к удаленному узлу и производится чтение или изменение данных на этом узле. Результат поступает на исходный узел, после чего транзакция завершается. Практически любая коммерческая СУБД в настоящее время поддерживает удаленные запросы, и такая возможность предоставляется уже в течение некоторого времени.
2. Удаленная единица работы. Это означает, что на удаленном узле можно выполнить группу запросов как атомарную единицу (транзакцию). Приложение, вообще говоря, может получать и модифицировать данные многих узлов, но каждая транзакция затрагивает данные только одного узла.
3. Распределённая единица работы при этом каждый запрос относится только к одному узлу, но запросы, составляющие распределенную единицу работы (транзакцию), могут выполняться совместно на нескольких узлах. Вся группа запросов при этом фиксируется или откатывается как одно целое.
4. Распределенный запрос. Этот шаг предусматривает возможность выполнения запросов, охватывающих множество баз данных на разных узлах. Несколько таких распределенных запросов может быть далее сгруппировано в качестве транзакции.
2. Модели распределенных баз данных
Существуют различные формы распределения данных. В одних случаях данные фрагментируются, т. е. делятся на порции, распределяемые между множеством физических ресурсов. В других случаях они тиражируются, т. е. дублируются на нескольких узлах. Позже мы обсудим различные модели фрагментации и тиражирования.
Рассмотрим каждый класс систем более подробно.
2.1. Однородные и неоднородные системы
Однородные распределенные системы баз данных относительно просты для понимания. Они имеют в своей основе один продукт СУБД, обычно с единственным языком баз данных (например, SQL с расширениями для управления распределенными данными). СУБД с поддержкой однородного распределения являются сильносвязанными системами, их встроенные средства поиска данных и средства обработки запросов оптимизированы и настроены для достижения максимальной производительности и пропускной способности. На рис. 2.1 изображена структура типичной однородной среды распределенной базы данных.
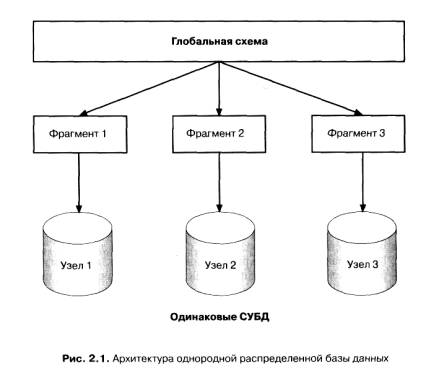
Однородные распределенные базы данных обычно проектируются методом "сверху вниз", который мы обсудим в разд. 2.2.
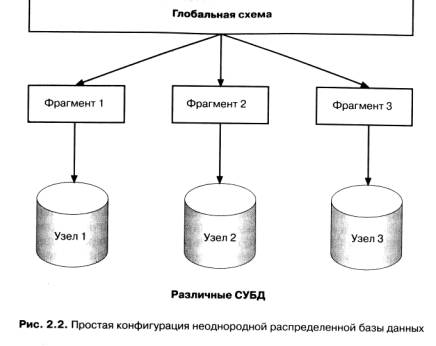
Противоположностью однородных систем РаБД являются, конечно, неоднородные распределенные системы баз данных. Неоднородные системы включают два или более существенно различающихся продукта управления данными (например, реляционные СУБД от разных поставщиков, таких, как Oracle и Digital Equipment Corp.*, или СУБД одного поставщика, но функционирующие на разных платформах и использующие различные структуры баз данных**, такие, как DB2 и SQL/DS компании IBM). На рис. 2.2 показана типичная конфигурация неоднородной распределенной базы данных. Неоднородные системы баз данных можно, в свою очередь, также подразделить на классы в широком диапазоне - от федеративных систем до различных типов систем мультибаз данных; существует и формальная таксономия неоднородных моделей.
Неоднородные распределенные системы баз данных же, напротив, чаще всего строятся "снизу вверх" с целью создать общую среду управления над существовавшими ранее разрозненными информационными ресурсами.
2.2. Методы построения распределенных баз данных
"сверху вниз" и "снизу вверх"
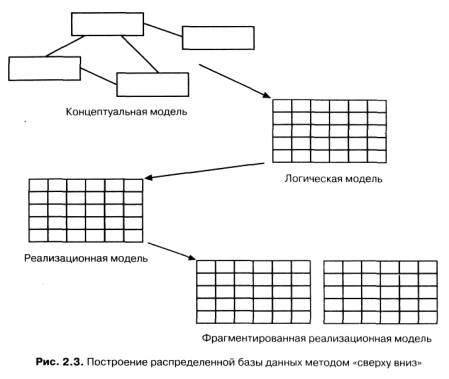
Рассмотрим сначала процесс построения распределенных баз данных методом "сверху вниз", поскольку он концептуально наиболее прост для понимания. Проектирование РаБД "сверху вниз" осуществляется в целом аналогично проектированию централизованных баз данных. В идеале оно проводится с помощью одной из формальных методологий, которые включают создание концептуальной модели базы данных, отображение ее в логическую модель данных и, наконец, создание (и настройку) специфических для конкретной СУБД структур (например, таблиц базы данных системы Rdb/VMS).
Однако при проектировании РаБД методом "сверху вниз" предполагается, что ее объекты не будут сосредоточены в одном месте, а распределятся по нескольким вычислительным системам (рис. 2.3). Распределение проводится путем фрагментации или тиражирования.
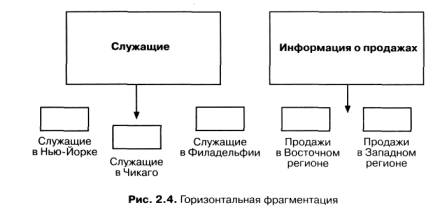
Фрагментация означает декомпозицию объектов базы данных, таких, как реляционные таблицы, на две или более частей, которые размещаются на разных компьютерных системах. Классический пример, который обычно используют для иллюстрации этого понятия, - таблица с данными о сотрудниках или о заказах на продажу, разделенная на фрагменты по географическому или другому характеристическому признаку.
На рис. 2.4 показана горизонтальная фрагментация, когда в таблице делаются горизонтальные "срезы" в соответствии со значением, скажем, какого-либо столбца таблицы. Строки данных о сотрудниках могут разбиваться на подмножества, соответствующие филиалам. Данные о продажах фрагментируются по магазинам, где эти продажи производились.
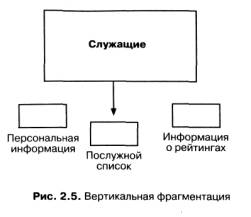
Альтернативная модель фрагментации - вертикальная - означает разбиение таблицы не по строкам, а по столбцам (рис 2.5). В этом случае некоторая часть информации о каждом сотруднике хранится в одном месте, а другая часть (относящаяся к той же таблице) - в другом.
Независимо от того, применяется горизонтальная или вертикальная фрагментация, поддерживается глобальная схема, позволяющая воссоздать из имеющихся фрагментов логически централизованную таблицу или другую структуру базы данных.
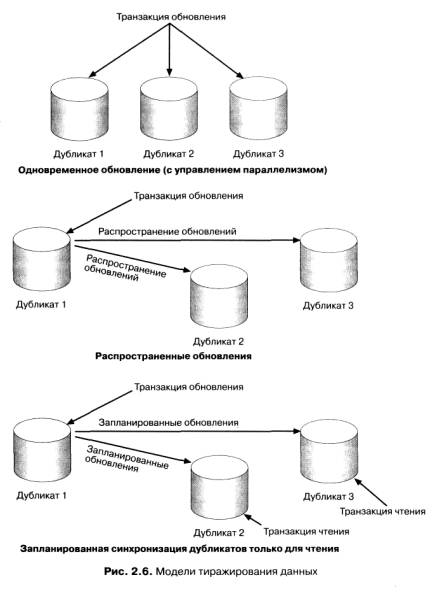
Тиражирование (или репликация) означает (как вы могли, вероятно, догадаться) создание дубликатов данных. Репликаты - это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых в соответствии с определенными в базе данных правилами поддерживается синхронизация (идентичность) с некоторой "главной" копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рис 2.6 показаны различные модели тиражирования.
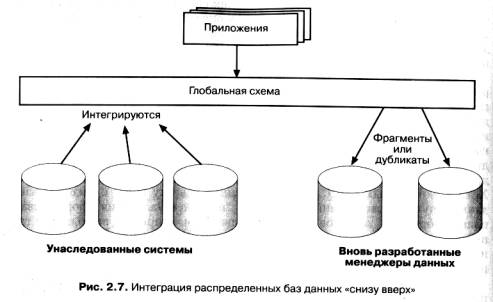
Идеология построения распределенных баз данных по принципу "сверху вниз" применима только к однородным РаБД, для которых вначале определяется глобальная схема, а затем производится распределение объектов базы данных. Такой подход оправдан при создании новых приложений, но гораздо вероятнее, что вашей организации придется решать задачу создания интегрированной среды путем объединения существующих баз данных и соответствующих информационных менеджеров, возможно, в дополнение к некоторым вновь проектируемым компонентам баз данных. В этом случае разработчики не могут позволить себе "роскошь" проектирования "сверху вниз". Здесь приходится прибегать к проектированию "снизу вверх", где основной проблемой становится объединение схем уже существующих баз данных, чтобы предоставить как новым, так и прежним приложениям доступ и к новым, и к старым ресурсам данных (рис. 2.7).
Среди многих сложных технических проблем, которые приходится при этом решать, отметим следующие:
• взаимное отображение различных моделей данных (т.е. наличие некоторого способа глобального доступа к множественным формам представления данных: к плоским файлам, к иерархическим, реляционным, объектно-ориентированным базам данных);
• управление метаданными;
• разрешение несоответствий типов данных в разных БД (элемент MOVIE_TYPE - тип фильма - в одной базе данных имеет числовое представление, а в другой - символьное).
3. Типы распределённых баз данных
1) Распределённые базы данных
2) Мультибазы данных с глобальной схемой. Система мультибаз данных — это распределённая система, которая служит внешним интерфейсом для доступа ко множеству локальных СУБД или структурируется, как глобальный уровень над локальными СУБД.
3) Федеративные базы данных. В отличие от мультибаз не располагают глобальной схемой, к которой обращаются все приложения. Вместо этого поддерживается локальная схема импорта-экспорта данных. На каждом узле поддерживается частичная глобальная схема, описывающая информацию тех удалённых источников, данные с которых необходимы для функционирования.
4) Мультибазы с общим языком доступа – распределённые среды управления с технологией «клиент-сервер»
5) Интероперабельные системы – это системы, в которых сами приложения, выполняемые в среде той или иной СУБД, ответственны за интерфейсы между различными средами приложения, независимо от того, являются они однородными или неоднородными. Системы ориентированы главным образом на обмен данными. Дальнейшее развитие этих систем является объектно-ориентированные БД.
База данных (БД)