Алгоритми мережі Ethernet/Fast Ethernet
10. Лекція: Алгоритми мережі Ethernet/Fast Ethernet
В даній лекції надано метод управління обміном CSMA/CD, який використовується в широко поширених мережах сімейства Ethernet, та який робить істотний вплив на їх особливості і характеристики. Крім того, розглядається алгоритм виявлення та коригування помилок через наведені помилки і перешкоди в одержуваних по мережі даних.
Надана оцінка продуктивності мережі (швидкість у середовищі передачі, пропускна спроможність та , що найважливіше – ефективність використання мережі)
Метод управління обміном CSMA/CD
Метод управління обміном CSMA/CD (Carrier-Sense Multiple Access with Collision Detection – множинний доступ з контролем несучої і виявленням колізій) відноситься до децентралізованих випадкових (точніше, квазівипадкових) методів. Він використовується як в звичайних мережах типа Ethernet, так і у високошвидкісних мережах (Fast Ethernet, Gigabit Ethernet). Оскільки характеристики і області вживання цих популярних на практиці мереж пов'язані саме з особливостями методу доступу, що використовується, його варто розглянути більш детально.
Спочатку про назву методу. В ранній мережі типа Alohanet, що працювала з 1970 р. на Гавайських островах, використовувався радіоканал і встановлений на супутнику ретранслятор (звідси слово "несуча" в назві методу), а також порівняльно простий метод доступу CSMA (без виявлення колізій). В мережах типа Ethernet і Fast Ethernet як несуча виступає синхросигнал, "підмішуваний" до передаваних даних так, щоб забезпечити надійну синхронізацію на приймальному кінці. Це реалізується за рахунок організації (при необхідності) додаткових примусових переходів сигналу між двома (як в коді Манчестер-II) або трьома електричними рівнями (як в коді типу 8В6Т, що використовується в сегменті Fast Ethernet 100BaseT4 на основі чотирьох неекранованих скручених пар). В порівнянні з класичним методом CSMA в методі CSMA/CD додано виявлення конфліктів (колізій) під час передачі, що підвищує швидкість доставки інформації.
При описі тимчасових діаграм мереж типу Ethernet і Fast Ethernet, а також граничних розмірів пакетів (кадрів) широко використовуються наступні терміни:
- IPG (interpacket gap, міжпакетна щілина) – мінімальний проміжок часу між пакетами, що передаються (9,6 мкс для Ethernet / 0,96 мкс для Fast Ethernet). Інша назва – міжкадровий інтервал.
- ВТ (Bit Time, час біта) – інтервал часу для передачі одного біта (100 нс для Ethernet / 10 нс для Fast Ethernet).
- PDV (Path Delay Value, значення затримки в дорозі) – час проходження сигналу між двома вузлами мережі (кругове, тобто подвоєне). Враховує сумарну затримку в кабельній системі, мережних адаптерах, повторювачах і інших мережних пристроях.
- Collision window (вікно колізій) – максимальне значення PDV для даного сегменту.
- Collision domain (область колізій, зона конфлікту) – частина мережі, на яку розповсюджується ситуація колізії, конфлікту.
- Slot time (час каналу) – максимально допустиме вікно колізій для сегменту (512• ВТ).
- Minimum frame size – мінімальний розмір кадру (512 біт).
- Maximum frame size – максимальний розмір кадру (1518 байт).
- Maximum network diameter (максимальний діаметр мережі) - максимальна допустима довжина сегменту, при якій його вікно колізій не перевищує slot time, часу каналу.
- Truncated binary exponential back (усічене двійкове експоненціальне відстрочення) – затримка перед наступною спробою передачі пакету після колізії (допускається максимум 16 спроб). Обчислюється вона по наступній формулі:
RAND(0,2min(N,10)) x 512 x ВТ
де N – значення лічильника спроб, RAND(а, b) – генератор випадкових нормально розподілених цілих чисел в діапазоні а...b, включаючи крайні значення. Діскрет зміни даного параметра дорівнює мінімальній довжині пакету або максимально допустимій подвійній затримці розповсюдження сигналу в мережі (PDV).
Алгоритм доступу до мережі
На мал. 10.1 показана структурна схема алгоритму доступу до мережі відповідно до методу CSMA/CD для одного з абонентів, що мають дані (кадри) для передачі.
На початку з кадру, призначеного для передачі, абонент (вузол) формує пакет. Далі при позначенні блоків інформації, що передаються по мережі при використовуванні алгоритму CSMA/CD, поняття "кадр" і "пакет" не розрізняються, що не зовсім правильне, але відповідає практиці, що склалася.
Якщо після підготовки пакету мережа вільна, то абонент (вузол) має право почати передачу. Але в першу чергу він повинен перевірити, чи пройшов мінімально допустимий час IPG після попередньої передачі (блок 1 на малюнку). Тільки після закінчення часу IPG абонент може почати передачу бітів свого пакету (блок 2 на малюнку).
Після передачі кожного біта абонент перевіряє наявність конфлікту (колізії) в мережі. Якщо колізій немає, передача бітів триває до закінчення пакету (блок 4 на малюнку). В цьому випадку вважається, що передача пройшла успішно.
Якщо після передачі якогось біта знайдена колізія, то передача пакету припиняється. Абонент (вузол) посилює колізію, передаючи 32-бітовий сигнал ПРОБКА (JAM) і починає готуватися до наступної спроби передачі (блок 3 на малюнку). Сигнал ПРОБКА гарантує, що факт наявності колізії знайдуть всі абоненти, що беруть участь в конфлікті.
Після передачі сигналу ПРОБКА абонент, що знайшов колізію, збільшує значення лічильника числа спроб (перед початком передачі лічильник був скинений в нуль). Максимальне число спроб передачі повинне бути не більше 16, тому якщо лічильник спроб переповнився, то спроби передати пакет припиняються. Вважається, що в цьому випадку мережа сильно перевантажена, в ній дуже багато колізій. Ця ситуація – аварійна, і обробляється вона на більш високих рівнях протоколів обміну.
Якщо ж кількість спроб не перевищила 16, то проводиться обчислення величини затримки по приведеній формулі, а потім і очікування обчисленого тимчасового інтервалу. Випадковий характер величини затримки з високим ступенем вірогідності гарантує, що у всіх абонентів, що беруть участь в конфлікті, затримки будуть різними. Потім спроба передати пакет повторюється з початку. Абонент, у якого обчислена затримка буде менше, почне наступну передачу першим і заблокує всю решту передач.
Мал. 10.1. Структурна схема алгоритму доступу до мережі відповідно до методу CSMA/CD
Якщо у момент виникнення заявки на передачу (після закінчення підготовки пакету) мережа зайнята іншим абонентом, що веде передачу, то даний абонент чекає звільнення мережі (блок 5 на малюнку). Після звільнення мережі він повинен почекати час IPG після попередньої передачі по мережі до початку власної передачі. Це пов'язано з кінцевою швидкодією вузлів, що здійснюють перевірку наявності несучої (зайнятості середовища яким-небудь передаючим абонентом).
Таким чином, виходить, що метод CSMA/CD не тільки не запобігає колізії, навпаки, він їх припускає і навіть провокує, а потім дозволяє. Наприклад, якщо заявки на передачу виникли у декількох абонентів під час зайнятості мережі, то після її звільнення всі ці абоненти одночасно почнуть передачу і утворять колізію. Колізії з'являються і у разі вільної мережі, якщо заявки на передачу виникають у декількох абонентів одночасно. В обох випадках під словом "одночасно" розуміється "в межах інтервалу подвійного проходження сигналу по мережі", тобто в межах 512-бітових інтервалів. Так само в межах 512-бітових інтервалів виявляються всі колізії в мережі.
Якщо колізія виявляється раніше 480 – бітового інтервалу, то в результаті в мережі утворюються пакети, довжина яких менше нижньої встановленої межі в 512 – бітових інтервалів (64 байти) навіть з додаванням сигналу ПРОБКА. Такі пакети (кадри) називаються карликовими (runt frames). Якщо ж колізія виявляється в кінці 512-бітового інтервалу (після 480 – бітового інтервалу), то в результаті може вийти пакет допустимої довжини (разом з сигналом ПРОБКА). Такі пакети називати карликовими не зовсім коректно. Сигнал ПРОБКА, утворюючий 32 останніх біта пакету, виступає у вигляді контрольної суми пакету. Проте вірогідність того, що ПРОБКА відповідатиме правильній контрольній сумі пакету, нескінченно мала (приблизно 1 випадок на 4,2 мільярди).
Колізії (накладення пакетів в процесі передачі) можуть і повинні виявлятися до закінчення передачі. Дійсно, аналіз прийнятого в кінці кожного пакету поля FCS, що фактично містить перешкодостійкий циклічний код CRC (Cyclic Redundancy Check), привів би до невиправданого зниження швидкості передачі.
Практично колізії виявляються або самим передаючим абонентом, або повторювателями в мережі, можливо, задовго до закінчення передачі явно зіпсованого пакету. Якщо врахувати, що довжина пакетів в локальній мережі типа Ethernet / Fast Ethernet може лежати в діапазоні від 64 до 1518 байт, те дострокове припинення передачі і звільнення лінії означає помітне підвищення ефективності використовування її пропускної спроможності.
Першою ознакою виникнення колізії є факт отримання сигналу ПРОБКА передаючим абонентом під час передачі пакету. Інші ознаки пов'язані з невірним форматом пакетів, передача яких була достроково припинена через виникнення колізії:
- довжина пакету менше 64 байт (512 біт);
- пакет має невірну контрольну суму FCS (точніше, невірний циклічний код);
- довжина пакету не кратна восьми.
Нарешті, в таких мережах як Ethernet використовується код Манчестер-II і апаратний спосіб визначення колізії, заснований на аналізі відхилення середнього значення сигналу від нуля.
Навіть при завантаженій мережі для одного абонента число підряд наступних колізій звичайно не перевищує 3. Цьому сприяє випадковий характер виникнення запиту на передачу і випадкова дискретна величина відстрочення наступної спроби передачі при виникненні колізії. Число колізій тим більше, чим більше діаметр (розмір) сегменту і чим далі розташовані один від одного абоненти з інтенсивним трафіком.
Оцінка продуктивності мережі
Питання про оцінку продуктивності мереж, що використовують випадковий метод доступу CSMA/CD, не очевидне через те, що існують декілька різних показників. Перш за все, слід згадати три зв'язані між собою показчика, характеризуючі продуктивність мережі в ідеальному випадку – за відсутності колізій і при передачі безперервного потоку пакетів, розділених тільки міжпакетним інтервалом IPG. Очевидно, такий режим реалізується, якщо один з абонентів активний і передає пакети з максимально можливою швидкістю. Неповне використовування пропускної спроможності в цьому випадку зв'язано, окрім існування інтервалу IPG, з наявністю службових полів в пакеті Ethernet (див. мал. 10.2).
Пакет максимальної довжини є якнайменше надмірним за відносною довше службовою інформацією. Він містить 12304 біт (включаючи інтервал IPG), з яких 12000 є корисними даними.
Тому максимальна швидкість передачі пакетів (або, інакше, швидкість в кабелі – wire speed) складе у разі мережі Fast Ethernet
108 бит/с х 12304 бит 8127,44 пакет/с.
Пропускна спроможність є швидкістю передачі корисної інформації і буде в даному випадку рівна
8127,44 пакет/с x 1500 байти 12,2 Мбайт/с.
Нарешті, ефективність використовування фізичної швидкості передачі мережі, у разі Fast Ethernet рівної 100 Мбіт/с, по відношенню тільки до корисних даних складе
8127,44 пакет/с x 12000 біт/ 108 бит/с 98%.
При передачі пакетів мінімальної довжини істотно зростає швидкість в кабелі, що означає всього лише факт передачі великого числа коротких пакетів. В той же час пропускна спроможність і ефективність помітно (майже в два рази) погіршуються через зростання відносної частки службової інформації.
Для реальних мереж, зокрема Fast Ethernet з великим числом активних абонентів N пропускна спроможність на рівні 12,2 Мбайт/с для якого-небудь абонента є піковим, рідко реалізованим значенням. При однаковій активності всіх абонентів середня пропускна спроможність для кожного з них складе 12,2/N Мбайт/с, а насправді може виявитися ще менше через виникнення колізій, помилок в роботі мережного устаткування і впливу перешкод (у разі роботи локальної мережі в умовах, коли кабельна система схильна впливу великих зовнішніх електромагнітних наведень). Вплив перешкод, так само як і пізніх конфліктів (late collision) в некоректних мережах, відстежується за допомогою аналізу поля FCS пакету.
Для реальних мереж більш інформативний такий показник продуктивності, як показник використовування мережі (network utilization), який є часткою у відсотках від сумарної пропускної спроможності (не поділеної між окремими абонентами). Він враховує колізії і інші чинники. Ні сервер, ні робочі станції не містять засобів для визначення показника використовування мережі, цій меті служать спеціальні, не завжди доступні через високу вартість такі апаратно-програмні засоби, як аналізатори протоколів.
Вважається, що для завантажених систем Ethernet і Fast Ethernet хорошим значенням показника використовування мережі є 30%. Це значення відповідає відсутності тривалих простоїв в роботі мережі і забезпечує достатній запас у разі пікового підвищення навантаження. Проте якщо показник використовування мережі значний час складає 80...90% і більш, то це свідчить про ресурси, що практично повністю використовуються (зараз), але не залишає резерву на майбутнє. Втім, для реальних мереж, наприклад Fast Ethernet, це швидше гіпотетична ситуація.
На мал. 10.2 приведена залежність показника використовування мережі від часу за умови, що запропоноване навантаження (offered load), тобто поточний запит на пропускну спроможність, лінійно зростає. Спочатку показник використовування мережі також лінійно підвищується, але потім конкуренція за володіння середовищем передачі породжує колізії, і даний показник досягає максимуму (точка повного навантаження на графіку). При подальшому збільшенні запропонованого навантаження показник використовування мережі починає зменшуватися, особливо різко після точки насичення. Це "погана" область роботи мережі. Вважається, що мережа працює добре, якщо і запропоноване навантаження, і показник використовування мережі високі.
Мал. 10.2. Залежність показника використовування мережі від часу при лінійному збільшенні запропонованого навантаження (1 – якнайкраща область роботи, 2 – прийнятна, 3 – погана)
Деякі автори пропонують для широко поширеного поняття "перевантаження" (overload) мереж на основі методу доступу CSMA/CD наступне визначення:
мережа переобтяжена, якщо вона не може працювати при повному навантаженні протягом 80% свого часу (при цьому 20% часу показник використовування мережі неприпустимо малий через колізії).
Після точки насичення наступає крах Ethernet (Ethernet collapse), коли зростаюче запропоноване навантаження помітно перевищує можливості мережі. Варто помітити, що реально маловірогідне, щоб запропоноване навантаження постійно збільшувалося в часі і надовго перевищувало пропускну спроможність мережі типа Fast Ethernet. Більш того, будь-який детермінований метод доступу не може забезпечити реалізацію скільки завгодно великого запропонованого навантаження, існуючого тривалий час. Якщо даний варіант детермінованого методу доступу не використовує, як і метод CSMA/CD, систему пріоритетів, то ніякий з абонентів не може захопити мережу більш ніж на час передачі одного пакету, проте передача даних окремими пакетами з довгими паузами між ними веде до зниження швидкості передачі для кожного абонента. Перевага детермінованих методів полягає в можливості простій організації системи пріоритетів, що корисне через наявність певної ієрархії в будь-якому крупному колективі.
Використовування перешкодостійких кодів для виявлення помилок в мережі
Сигнали, безпосередньо передавані по послідовних лініях (типу зкрученої пари, коаксіального кабелю або телефонної лінії), підлягають впливу ряду чинників, дія яких може привести до виникнення помилок в прийнятій інформації. Помилки можуть виникати унаслідок впливу на канал зв'язку наведень і перешкод природного або штучного походження, а також унаслідок зміни конфігурації системи передачі інформації з тимчасовим порушенням або без порушення цілісності каналу зв'язку (наприклад, у разі підключення нових абонентів до існуючої локальної інформаційної мережі). Деякі з помилок можуть бути знайдені на підставі аналізу виду прийнятого сигналу, оскільки в ньому з'являються характерні спотворення. Прикладом може служити код Манчестер-II, що використовується в мережах Ethernet. На передаючому кінці лінії цей код обов'язково містить перехід з низького електричного рівня на високий або назад в середині кожного тактового інтервалу, що вимагається для передачі одного біта інформації. Він також має середню складову, близьку до нуля. Ці властивості коду Манчестер-II можуть використовуватися для виявлення різного роду помилок. Зокрема, відмінність середньої складової сигналу від нуля є однією з ознак виникнення колізій (накладень пакетів від різних абонентів), характерних для методу доступу CSMA/CD в мережах типа Ethernet. Проте скільки-небудь серйозну систему виявлення помилок, викликаних дією перешкод з непередбачуваною поведінкою, на цій основі побудувати неможливо.
Стандартні протоколи обміну інформації в мережах передбачають введення обов'язкового поля для розміщення перешкодостійкого (коректуючого) коду. Якщо в результаті обробки прийнятого пакету виявиться невідповідність прийнятого і знов обчисленого перешкодостійкого коду, з великою часткою вірогідності можна затверджувати, що серед прийнятих біт є помилкові. Передачу такого пакету потрібно буде повторити (з розрахунку на випадковий характер перешкод).
Способи зниження числа помилок в прийнятій інформації
Є розрив між вимогами до вірності інформації, що приймається, і можливостями каналів зв'язку. Зокрема, стандартами міжнародних організацій ITU-T і МОС встановлено, що вірогідність помилки при телеграфному зв'язку не повинна перевищувати 3 x 10-5 (на знак), а при передачі даних – 10-6 (на одиничний елемент, битий). На практиці допустима вірогідність помилки при передачі даних може бути ще менше – 10-9. В той же час канали зв'язку (особливо дротяні канали великої протяжності і радіоканали) забезпечують вірогідність помилки на рівні 10-3...10-4 навіть при використовуванні фазових коректорів, регенеративних ретрансляторів і інших пристроїв, поліпшуючих якість каналів зв'язку.
Кардинальним способом зниження вірогідності помилок при прийомі є введення надмірності в передавану інформацію. В системах передачі інформації без зворотного зв'язку даний спосіб реалізується у вигляді перешкодостійкого кодування, багатократної передачі інформації або одночасної передачі інформації по декількох паралельно працюючих каналах. Перешкодостійке кодування доступніше, за інших рівних умов дозволяє обійтися меншою надмірністю і за рахунок цього підвищити швидкість передачі інформації.
Виявлення й корекція помилок
Канальний рівень повинен виявляти помилки передачі даних, пов'язані з викривленням біт у прийнятому кадру даних або із втратою кадра, і по можливості їх коректувати.
Більша частина протоколів канального рівня виконує тільки перше завдання — виявлення помилок, вважаючи, що коректувати помилки, тобто повторно передавати дані, що містили перекручену інформацію, повинні протоколи верхніх рівнів. Так працюють такі популярні протоколи локальних мереж, як Ethernet, Token Ring, FDDI і інші. Однак існують протоколи канального рівня, наприклад LLC2 або LAP-B, які самостійно вирішують завдання відновлення перекручених або загублених кадрів.
Очевидно, що протоколи повинні працювати найбільше ефективно в типових умовах роботи мережі. Тому для мереж, у яких викривлення й втрати кадрів є дуже рідкими подіями, розробляються протоколи типу Ethernet, у яких не передбачаються процедури усунення помилок. Дійсно, наявність процедур відновлення даних зажадала б від кінцевих вузлів додаткових обчислювальних витрат, які в умовах надійної роботи мережі були б надлишковими.
Напроти, якщо в мережі викривлення й втрати трапляються часто, те бажане вже на канальному рівні використовувати протокол з корекцією помилок, а не залишати цю роботу протоколам верхніх рівнів. Протоколи верхніх рівнів, наприклад транспортного або прикладного, працюючи з більшими тайм-аутами, відновлять загублені дані з великою затримкою. У глобальних мережах перших поколінь, наприклад мережах Х.25, які працювали через ненадійні канали зв'язку, протоколи канального рівня завжди виконували процедури відновлення загублених і перекручених кадрів.
Тому не можна вважати, що один протокол краще іншого тому, що він відновлює помилкові кадри, а інший протокол — немає. Кожний протокол повинен працювати в тих умовах, для яких він розроблений.
Методи виявлення помилок
Усі методи виявлення помилок засновані на передачі в складі кадра даних службової надлишкової інформації, по якій можна судити з деяким ступенем імовірності про вірогідність прийнятих даних. Цю службову інформацію прийнято називати контрольною сумою (або послідовністю контролю кадра — Frame Check Sequence, FCS).
Контрольна сума обчислюється як функція від основної інформації, причому необов'язково тільки шляхом підсумовування. Приймаюча сторона повторно обчислює контрольну суму кадра по відомому алгоритму й у випадку її збігу з контрольною сумою, обчисленою передавальною стороною, робить висновок про те, що дані були передані через мережу коректно. Існує кілька розповсюджених алгоритмів обчислення контрольної суми, що відрізняються обчислювальною складністю й здатністю виявляти помилки в даних.
Контроль по паритету являє собою найбільш простий метод контролю даних. У той же час це найменш потужний алгоритм контролю, тому що з його допомогою можна виявити тільки одиночні помилки в даних, що перевіряються. Метод полягає в підсумовуванні по модулю 2 усіх біт контрольованої інформації.
Наприклад, для даних 100101011 результатом контрольного підсумовування буде значення 1. Результат підсумовування також являє собою один біт даних, який пересилається разом з контрольованою інформацією. При викривленні у процессі пересилання будь-якого одного біта вихідних даних (або контрольного розряду) результат підсумовування буде відрізнятися від прийнятого контрольного розряду, що говорить про помилку. Однак подвійна помилка, наприклад 110101010, буде невірно прийнята за коректні дані. Тому контроль по паритету застосовується до невеликих порцій даних, як правило, до кожного байта, що дає коефіцієнт надмірності для цього методу 1/8. Метод рідко застосовується в обчислювальних мережах через його велику надмірність і невисоких діагностичних здатностей.
Вертикальний і горизонтальний контроль по паритету являє собою модифікацію описаного вище методу. Його відмінність полягає в тому, що вихідні дані розглядаються у вигляді матриці, рядка якої становлять байти даних. Контрольний розряд підраховується окремо для кожного рядка й для кожного стовпця матриці. Цей метод виявляє більшу частину подвійних помилок, однак має ще більшу надмірність. На практиці зараз також майже не застосовується.
Циклічний надлишковий контроль (Cyclic Redundancy Check, CRC) є в цей час найбільш популярним методом контролю в обчислювальних мережах (і не тільки в мережах, наприклад, цей метод широко застосовується при записі даних на диски й дискети). Метод заснований на розгляді вихідних даних у вигляді одного багаторазрядного двійкового числа.
Наприклад, кадр стандарту Ethernet, що полягає з 1024 байт, буде розглядатися як одне число, що полягає з 8192 біт. У якості контрольної інформації розглядається залишок від діллення цього числа на відомий дільник R. Звичайно в якості дільника вибирається сімнадцяти- або тридцяти трьох розрядне число, щоб залишок від розподілу мав довжину 16 розрядів (2 байт) або 32 розряда (4 байт). При одержанні\полученні кадра даних знову обчислюється залишок від розподілу на той же дільник R, але при цьому до даних кадра додається контрольна сума, що й утримується в ньому. Якщо залишок від ділення на R дорівнює нулю[Існує трохи модифікована процедура обчислення залишку, що приводить до одержання у випадку відсутності помилок відомого ненульового залишку, що є більш надійним показником коректності.], тоді робиться висновок про відсутність помилок в отриманому кадру, а якщо ні, то кадр вважається перекрученим.
Цей метод має більш високу обчислювальну складність, але його діагностичні можливості набагато вище, чим у методів контролю по паритету. Метод CRC виявляє всі одиночні помилки, подвійні помилки й помилки в непарнім числі біт. Метод має також невисокий ступінь надмірності. Наприклад, для кадра Ethernet розміром в 1024 байт контрольна інформація довжиною в 4 байт становить тільки 0,4 %.
Методи відновлення перекручених і загублених кадрів
Методи корекції помилок в обчислювальних мережах засновані на повторній передачі кадра даних у тому випадку, якщо кадр губиться й не доходить до адресата або приймач виявив у ньому викривлення інформації. Щоб переконатися в необхідності повторної передачі даних, відправник нумерує відправленні кадри й для кожного кадра очікує від приймача так званої позитивної квитанції — службового кадра, що сповіщає про те, що вихідний кадр був отриманий і дані в ньому виявилися коректними. Час цього очікування обмежене — при відправленні кожного кадра передавач запускає таймер, і, якщо по його обнуленню позитивна квитанція не отримана, кадр вважається загубленим. Приймач у випадку одержання кадра з перекрученими даними може відправити негативну квитанцію — явна вказівка на те, що даний кадр потрібно передати повторно.
Існують два підходи до організації процесу обміну квитанціями: із простоями й з організацією «вікна».
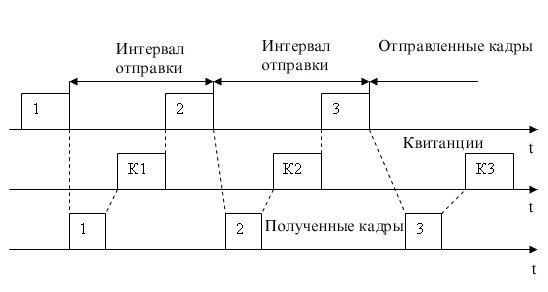
Метод із простоями (Idle Source) вимагає, щоб джерело, що послало кадр, очікувало одержання квитанції (позитивної або негативної) від приймача й тільки після цього посилало наступний кадр (або повторювало перекручений). Якщо ж квитанція не приходить протягом тайм-ауту, то кадр (або квитанція) вважається загубленим і його передача повторюється. На мал. 10.3. а видно, що в цьому випадку продуктивність обміну даними суттєво знижується, — хоча передавач і міг би послати наступний кадр відразу ж після відправлення попереднього, він зобов'язано чекати приходу квитанції. Зниження продуктивності цього методу корекції особливо помітно на низькошвидкосних каналах зв'язку, тобто в територіальних мережах.
 а
а
 б
б
 в
в
Рис. 10.3. Методи відновлення перекручених і загублених кадрів
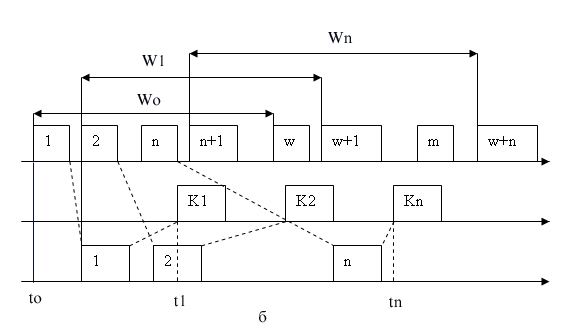
Другий метод називається методом «ковзуючого вікна» (sliding window). У цьому методі для підвищення коефіцієнта використання лінії джерелу дозволяється передати деяка кількість кадрів у безперервному режимі, тобто в максимально можливому для джерела темпі, без одержання на ці кадри позитивних відповідних квитанцій. Кількість кадрів, які дозволяється передавати таким чином, називається розміром вікна. Малюнок 10.3., б ілюструє даний метод для вікна розміром в W кадрів.
У початковий момент, коли ще не послане жодного кадра, вікно визначає діапазон кадрів з номерами від 1 до W включно. Джерело починає передавати кадри й одержувати у відповідь квитанції. Для простоти припустимо, що квитанції надходять у тій же послідовності, що й кадри, яким вони відповідають. У момент ti при одержанні першої квитанції К1 вікно зрушується на одну позицію, визначаючи новий діапазон від 2 до (W+1).
Процеси відправлення кадрів і одержання квитанцій ідуть досить незалежно друг від друга. Розглянемо довільний момент часу tn, коли джерело одержало квитанцію на кадра з номером r. Вікно зрушилося вправо й визначило діапазон дозволених до передачі кадрів від (п+1) до (W+n). Уся множина кадрів, що виходять із джерела, можна розділити на такі групи (мал. 10.3. б).
Кадри з номерами від 1 до п уже були відправлені й квитанції на них отримані, тобто вони перебувають за межами вікна ліворуч.
Кадри, починаючи з номера (п+1) і кінчаючи номером (W+n), перебувають у межах вікна й тому можуть бути відправлені не чекаючи приходу якої-небудь квитанції. Цей діапазон може бути розділений ще на два піддіапазона:
кадри з номерами від (п+1) до т, які вже відправлені, але квитанції на них ще не отримані;
кадри з номерами від m до (W+n), які поки не відправлені, хоча заборони на це немає.
Усі кадри з номерами, більшими або рівними (W+n+1), перебувають за межами вікна праворуч і тому поки не можуть бути відправлені.
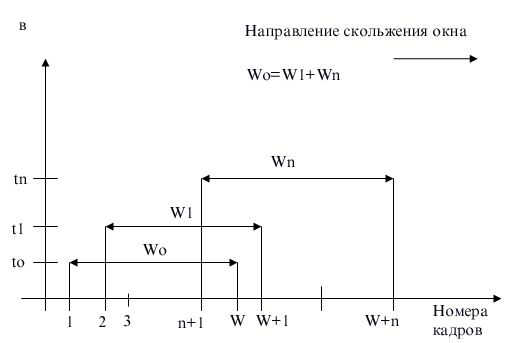
Переміщення вікна уздовж послідовності номерів кадрів показане на мал. 2.24, б. Тут to — вихідний момент, t1 і tn — моменти приходу квитанцій на перший і n-й кадр відповідно. Щораз, коли приходить квитанція, вікно зрушується вліво, але його розмір при цьому не міняється й залишається рівним W. Помітимо, що хоча в даному прикладі розмір вікна в процесі передачі залишається постійним, у реальних протоколах (наприклад, TCP) можна зустріти варіанти даного алгоритму з змінним розміром вікна.
Отже, при відправленні кадра з номером п джерелу дозволяється передати ще W-1 кадрів до одержання квитанції на кадра п, так що в мережу останнім піде кадр із номером (W+n-1). Якщо ж за цей час квитанція на кадра п так і не прийшла, то процес передачі припиняється, і після закінчення деякого тайм-ауту кадр п (або квитанція на нього) вважається загубленим, і він передається знову.
Якщо ж потік квитанцій надходить більш-менш регулярно, у межах допуску в W кадрів, то швидкість обміну досягає максимально можливої величини для даного каналу й прийнятого протоколу.
Метод ковзного вікна більш складний у реалізації, ніж метод із простоями, тому що передавач повинен зберігати в буфері всі кадри, на які поки не отримані позитивні квитанції. Крім того, потрібно відслідковувати кілька параметрів алгоритму: розмір вікна W, номер кадра, на який отримана квитанція, номер кадра, який ще можна передати до одержання нової квитанції.
Приймач може не посилати квитанції на кожний прийнятий коректний кадра. Якщо кілька кадрів прийшли майже одночасно, то приймач може послати квитанцію тільки на останній кадра. При цьому мається на увазі, що всі попередні кадри також дійшли благополучно.
Деякі методи використовують негативні квитанції. Негативні квитанції бувають двох типів — групові й вибіркові. Групова квитанція містить номер кадра, починаючи з якого потрібно повторити передачу всіх кадрів, відправлених передавачем у мережу. Вибіркова негативна квитанція вимагає повторної передачі тільки одного кадра.
Метод ковзного вікна реалізований у багатьох протоколах: LLC2, LAP-B, X.25, TCP, Novell NCP Burst Mode.
Метод із простоями є окремим випадком методу ковзучого вікна, коли розмір вікна дорівнює одиниці.
Метод ковзуючого вікна має два параметри, які можуть помітно впливати на ефективність передачі даних між передавачем і приймачем, — розмір вікна й величина тайм-ауту очікування квитанції. У надійних мережах, коли кадри спотворюються й губляться рідко, для підвищення швидкості обміну даними розмір вікна потрібно збільшувати, тому що при цьому передавач буде посилати кадри з меншими паузами. У ненадійних мережах розмір вікна слід зменшувати, тому що при частих втратах і викривленнях кадрів різко зростає обсяг удруге переданих через мережу кадрів, а виходить, пропускна здатність мережі буде витрачатися багато в чому вхолосту — корисна пропускна здатність мережі буде падати.
Вибір тайм-ауту залежить не від надійності мережі, а від затримок передачі кадрів мережею.
У багатьох реалізаціях методу ковзуючого вікна величина вікна й тайм-аут вибираються адаптивно, залежно від поточного стану мережі.
Характеристики і різновиди перешкодостійких кодів
Перешкодостійке кодування припускає введення в передаване повідомлення, разом з інформаційними, так званих перевірочних розрядів, формованих в пристроях захисту від помилок (кодерах на передаючому кінці, декодерах – на приймальному). Надмірність дозволяє відрізнити дозволену і заборонену (спотворену за рахунок помилок) комбінації при прийомі, інакше одна дозволена комбінація переходила б в іншу.
Перешкодостійкий код характеризується трійкою чисел (n, до, d0), де n – загальне число розрядів в передаваному повідомленні, включаючи перевірочні (r), k=n-r – число інформаційних розрядів, d0 – мінімальна кодова відстань між дозволеними кодовими комбінаціями, визначувана як мінімальне число біт, що розрізняються, в цих комбінаціях. Число помилок (розрядів), що знаходяться (tо) і (або) виправляються (tи), пов'язано з параметром d0 співвідношеннями:
d0 tо +1,
d0 2tи +1,
d0 tо + tи+ 1
Іноді використовуються додаткові показники надмірності, похідні від приведених вище характеристик n,k: R = r / n – відносна надмірність, v = до / n – відносна швидкість передачі.
Мал. 10.4. Класифікація перешкодостійких кодів
Існуючі перешкодостійкі коди можна розділити на ряд груп, тільки частина з яких застосовуються для виявлення помилок в передаваних по мережі пакетах (на мал. 10.4 групи, що використовуються для цієї мети, виділені потовщеними стрілками). В групі систематичних (лінійних) кодів загальною властивістю є те, що будь-яка дозволена комбінація може бути отримана в результаті лінійних операцій над лінійно-залежними векторами. Це сприяє спрощенню апаратної і програмної реалізації даних кодів, підвищує швидкість виконання необхідних операцій. Найпростішими систематичними кодами є біти парності/непарності. Вони не дозволяють знайти помилки парної кратності (тобто помилки одночасно в двох, чотирьох і т.д. бітах) і тому використовуються при невисоких вимогах до вірності даних, що приймаються (або при малій вірогідності помилок в лінії передачі). Прикладом може служити біт Parity (відповідність) в установках режимів роботи послідовного порту за допомогою команди MODE (MS DOS). Не дивлячись на обмежені можливості виявлення помилок, біти парності / непарності мають велике значення в теорії перешкодостійкого кодування. Одні з перших математично обгрунтованих і практично використаних раніше для захисту інформації в пристроях перешкодостійких кодів, що запам'ятовують, – коди Хеммінга є простою сукупністю перехресних перевірок на парність/непарність. Циклічні коди можуть розглядатися як узагальнені перевірки на парність/ непарність (див. далі).
Циклічні коди (CRC)
Циклічні коди – це сімейство перешкодостійких кодів, що включає як один з різновидів коди Хеммінга. В цілому воно забезпечує велику гнучкість з погляду можливості реалізації кодів з необхідною здатністю виявлення і виправлення помилок, визначуваною параметром d0, в порівнянні з кодами Хеммінга (для яких d0=3 або d0=4). Широке використовування циклічних кодів на практиці обумовлено також простотою реалізації відповідних кодерів і декодерів.
Основні властивості і сама назва циклічних кодів зв'язані з тим, що всі дозволені комбінації біт в передаваному повідомленні (кодові слова) можуть бути отримані шляхом операції циклічного зсуву деякого початкового кодового слова:
(a0a1…an-2an-1);
(an-1a0a1…an-2);
..........
Циклічні коди задаються за допомогою так званих поліномів (многочленів) g(x) або їх коренів, що породжують. Що породжує поліном має вигляд
G(x)=gr xr + gr-1 xr-1 + … + g0
де gi={0,1}, x=2. Крім того, вводяться поліном початкового повідомлення
u(x) = uk-1 xk-1 + uk-2 xk-2 + … +u0
і кодованого повідомлення
A(x) = an-1 xn-1 + an-2 xn-2 + … + a0
Для цих поліномів, що є по суті альтернативний запис чисел в двійковій системі счислення, визначаються операції складання, множення і розподіли, необхідні для організації кодування і декодування повідомлення. Всі операції виконуються по модулю 2.
Послідовність кодування на прикладі циклічного коду (7,4,3), g(x), що має
g(x) = x3 + x + 1, наступна:
1) інформаційна частина повідомлення записується у вигляді полінома:
u(x) = uk-1 xk-1 + uk-2 xk-2 + … +u0
В даному прикладі k=4 і для повідомлення 0111 виходить
u(x) = x2 + x + 1
2) u(x) множиться на xr, що відповідає циклічному зсуву початкового повідомлення на r розрядів вліво:
u(x) x3 = (x2 + x + 1) x3 = x5 + x4 + x3
3) отриманий многочлен ділиться на q(x):
u(x)•xr/q(x) = c(x) R(x)/q(x)
де c(x) – поліном з максимальним ступенем (k—1);
R(x) – поліном-залишок з максимальним ступенем (r-1);
– позначення порозрядної операції підсумовування по модулю 2 (що виключає АБО). Кодоване повідомлення представляється у вигляді
A(x)=u(x)xr R(x)
Таким чином, в цьому випадку
A(x) = (x5 + x4 + x3) x = x5 + x4 + x3 + x
Передаване кодоване повідомлення в звичайній двійковій формі має вигляд
0111 010
k – біт r – біт
Один з можливих варіантів апаратурної реалізації кодера для даного прикладу зображений на мал. 10.4 разом з послідовністю сигналів, підтверджуючою отримання тих же перевірочних розрядів (010) на восьмому такті (r + до + 1=8). Кодер є зсувний регістр із зворотними зв'язками, організовуваними за допомогою елементів М2 (що виключає АБО, суматор по модулю 2). Структура зворотних зв'язків повністю визначається ненульовими коефіцієнтами полінома g(x), що породжує. На перших восьми тактах ключ Кл. знаходиться у верхньому положенні, формуються перевірочні розряди. Потім ключ Кл встановлюється в нижнє положення, що відповідає розриву ланцюгів зворотних зв'язків і передачі безпосередньо в канал зв'язку або на модулятор перевірочних розрядів. Для тимчасового зберігання інформаційної частини повідомлення з метою подальшої її передачі разом з перевірочними розрядами кодер, очевидно, повинен бути доповнений зсувним регістром завдовжки у k розрядів, ключами і відповідними ланцюгами управління.
Мал. 10.5. Приклад формування циклічного коду (сигнал зворотного зв'язку відмінний від нуля на 5-у і 6-у тактах)
Проте в цілому апаратурні витрати при реалізації кодерів у разі циклічних кодів невеликі – загальне число трігерів і елементів М2 (виключаючи регістр тимчасового зберігання інформаційної частини повідомлення) не перевищує 2r і не залежить від довжини інформаційної частини повідомлення.
Двовхідний елемент М2, на один з входів якого подається в послідовній формі повідомлення, на виході формує біт парності або непарності (залежно від значення сигналу на другому вході елемента М2-0 або 1) для цього повідомлення. В схемі кодеру (мал. 10.5) елементи М2 включені між окремими трігерами зсувного регістра, причому сигнали зворотного зв'язку, що поступають на "вільні" входи елементів М2 (не пов'язані з передачею власне повідомлення через зсувний регістр), залежать як від попередніх розрядів повідомлення, так і від структури зворотних зв'язків, прийнятої в кодері. В результаті циклічний код, формований таким кодером, можна вважати сукупністю узагальнених біт парності і непарності, тип яких (парність або непарність) не визначений наперед і може динамічно мінятися від такту до такту.
Ті, що породжують, поліноми, що є так званими многочленами (діляться лише на одиницю і на самих себе), що не приводяться, табульовані для різних значень n, до і d0. Практично в комп'ютерних мережах використовуються циклічні коди довжиною в 2 або 4 байти (16 або 32 біта), а параметри n, до і d0 в явному вигляді не указуються. Це пов'язано з можливістю вибору різної довжини поля даних в пакеті на етапі встановлення і вибору параметрів з'єднання при незмінній довжині поля циклічного коду. Теоретична вірогідність помилки при прийомі у разі використовування циклічного коду не гірше pпом 1/2r, так що для виконання умови стандарту pпом 10-6 необхідне число перевірочних розрядів
r log2106 20. Окрім випадково розподілених, циклічний код дозволяє знаходити підряд наступні помилки (так звані пакети помилок) довжиною l = r або менше. Це особливо важливо у зв'язку з можливістю виникнення тривалих в часі перешкод, діючих на протяжні лінії передачі в комп'ютерних мережах.
Циклічні коди володіють здатністю виправлення помилок високої кратності (при великому значенні параметра d0) і відомі технічні рішення декодерів з виправленням помилок, проте практична реалізація таких декодерів на сучасному етапі представляється скрутною, особливо у разі широкосмугових (високошвидкісних) каналів зв'язку. В даний час більш поширені декодери з виявленням помилок. При використовуванні декодера, що знаходить, невірно прийнята інформація може ігноруватися або може бути запитана повторна передача тієї ж інформації. В останньому випадку передбачається наявність сигналу підтвердження правильності прийнятої інформації, що поступає від приймача до передавача. У міру розвитку елементної бази слід чекати появи в інтегральному виконанні декодерів циклічних кодів, здатних не тільки знаходити, але і виправляти помилки.
Окрім систем передачі інформації, циклічні коди використовуються в пристроях (ЗУ), що запам'ятовують, для виявлення можливих помилок в прочитуваній інформації. При записі файлів на диск (у тому числі при їх архівації) разом з файлами формуються і записуються відповідні циклічні коди. При читанні файлів (у тому числі при витяганні файлів з архіву) обчислені циклічні коди порівнюються із записаними і таким чином виявляються можливі помилки. Властивості циклічного коду лежать в основі сигнатурного аналізу (ефективного способу пошуку апаратних несправностей в цифрових пристроях різної складності). Варіанти практичної реалізації відповідних кодерів і сигнатурних аналізаторів мають між собою багато загального.
Слід зробити два зауваження термінології, що відносно склалася. Поняття "циклічні коди" достатньо широке, проте на практиці його звичайно використовують для позначення тільки одного різновиду, описаного вище і має в англомовній літературі назву CRC (Cyclic Redundancy Check – циклічна надмірна перевірка). Більш того, поле пакету або кадру, що фактично містить код CRC,часто називається "контрольною сумою" (FCS – контрольна сума кадру), що у принципі не вірне, оскільки контрольна сума формується інакше. Проте саме цей термін отримав широке розповсюдження.
Перспективними з погляду апаратурної реалізації представляються коди БЧХ (коди Боуза – Чаудхурі – Хоквінгема), так само, як і коди Хеммінга, що входять в сімейство циклічних кодів. Коди БЧХ не дуже великої довжини (приблизно до n=1023) оптимальні або близькі до оптимальних код, тобто забезпечують максимальне значення d0 при мінімальній надмірності. Ці коди вже знайшли практичне вживання в цифрових системах запису звуку (мови, музики), причому у варіанті, що передбачає виправлення знайдених помилок. Відносно невисокі частоти дискретизації звукових сигналів (48 або 96 кГц) не перешкоджають проведенню додаткових обчислень так жорстко, як у разі високошвидкісних мереж.
PAGE 18
Алгоритми мережі Ethernet/Fast Ethernet