Базы данных. Основные понятия
Тема:
Базы данных. Основные понятия.
Объекты, атрибуты и связи.
Основные определения.
База данных – это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области (экономика, менеджмент, химия и т.д.).
В теории БД объекты называют сущностями, а данные о них – атрибутами. Целью информационной системы является не просто хранение данных об объектах, но и манипулирование этими данными, учитывая связи между объектами. Объект, атрибут и связь – фундаментальные понятия ИС.
Объект (или сущность) – это "нечто" существующее и однозначно различимое, т.е. под объектом понимается то, что имеет свое название и способ отличить один объект от другого. Объектами могут быть фирма, город, человек, химический элемент и т.д. Например, каждая компания, торгующая нефтепродуктами (Лукойл, Юкос, ТНК) – это объект. Объектами могут быть не только материальные предметы, но и более абстрактные понятия, отражающие реальный мир. Например, события, правовые нормы, философские теории и проч.
Группа подобных (объединенных по какому-либо признаку или группе признаков) объектов образует класс (набор) объектов. Например, классом могут быть фирмы, автомобили, товары и т.п. В сфере торговли – это, например, фирмы торгующие нефтепродуктами, компьютерами, сотовыми телефонами и т.д.
Каждый объект характеризуется каким-либо набором данных (свойств), которые в БД называются атрибутами.
Атрибут – это показатель (признак, свойство), который характеризует конкретный объект, с помощью числового, текстового или иного значения. При выборе атрибута необходимо приписать ему имя, а также тип данных – текстовые, числовые и т.д.
Например, при проектировании базы данных по учету поставок нефтепродуктов названию нефтепродукта можно присвоить имя Продукт и задать тип – текстовый.
Списки возможных значений атрибутов образуют классификаторы или справочники (например, список марок топлива – бензин Аи-95, бензин Аи-93, бензин Аи-76 – и есть справочник).
В дальнейшем вместо термина "атрибут" будем использовать синоним - "данное" или термин баз данных – "поле".
Модели данных и построение двумерных таблиц.
При проектировании баз данных в первую очередь решается проблема отображения объектов предметной области в абстрактные объекты моделей данных наилучшим образом (эффективным, удобным и т.п.). Т.е. построение информационной модели реального мира, в которой выделяются объекты, свойства (атрибуты) объектов и связь между объектами. Такое описание данных иногда называют логическим проектированием. Рассмотрим три типа моделей данных: иерархическую, сетевую и реляционную.
Простая двумерная структура.
Самой простым и очевидным способом организации данных является простая двумерная таблица. Примером такой таблицы (табл. 1.1) может быть телефонный справочник.
Справочник состоит из однородных объектов (номеров телефонов). Атрибутами (данными) для объекта являются: номер телефона; имя абонента; адрес абонента.
Таблица 1.1.
|
Номер
|
Имя_аб
|
Адрес
|
|
233-08-19
|
Петров Евгений
|
Садовая, 18
|
|
265-04-15
|
Дядя Коля
|
Зеленый пр-т, 10
|
|
338-15-48
|
Химчистка
|
Профсоюзная, 144
|
|
981-10-45
|
Спорттовары
|
Ленинский пр-т, 23
|
|
245-21-12
|
Кафедра ИТ
|
М.Пироговская, 1
|
|
. . .
|
. . .
|
. . .
|
Итак, базу данных образует простая двумерная таблица с фиксированным числом столбцов-данных (4) и переменным числом строк. Такое представление данных является наиболее простым и наглядным для человека и самым удобным для машины. Если поместить такие таблицы под управление, например, системы Access, можно мгновенно получить любые выборки из списка абонентов (например, только химчистки или абоненты, находящиеся на Ленинском пр-те).
Иерархическая структура данных.
В телефонном справочнике набор выбранных объектов (телефонов) описывается группой не связанных между собой данных. Но во многих случаях данные объектов связаны между собой и тогда исходная структура оказывается более сложной.
Пусть имеются две нефтеперерабатывающие компании, поставляющие топливо
(5 марок) на бензоколонки города. Мы хотим построить и поместить в память машины справочник цен, который содержит все компании, все бензоколонки, все виды топлива и их цены. Такую структуру данных можно представить себе как дерево, ствол которого – это набор объектов (рис. 1.1). В качестве корневой структуры выбрано название компании, торгующей нефтепродуктами, например, Юкос и ТНК. Далее располагаются ветви древовидной структуры, где размещены адреса бензоколонок, марки топлива на каждой бензоколонке и цена этого топлива.
Рис. 1.1. Пример иерархической базы данных.
Такая структура данных называется иерархической. Исходные элементы (фирмы) порождают следующие элементы (бензоколонки), причем эти элементы, в свою очередь, порождают следующие элементы (цены). Такое дерево можно представить в виде простой двумерной таблицы, если пройти по всем веткам дерева до каждого листочка (цены) персонально (рис 1.2). При этом каждый листочек (цена) займет отдельную строку в таблице.
|
Фирма
|
Адрес бензоколонки
|
Марка
|
Цена
|
|
ЮКОС
|
А1
|
Аи-95
|
13
|
|
ЮКОС
|
А1
|
Аи-92
|
12
|
|
ЮКОС
|
А1
|
Аи-76
|
10
|
|
ЮКОС
|
А2
|
Аи-95
|
13,1
|
|
ЮКОС
|
А2
|
Аи-92
|
12,2
|
|
ЮКОС
|
А2
|
Аи-76
|
9,9
|
|
ЮКОС
|
А3
|
Аи-95
|
13
|
|
ЮКОС
|
А3
|
Аи-92
|
12
|
|
ЮКОС
|
А3
|
Аи-76
|
10
|
|
ЮКОС
|
А3
|
ДТ
|
8,9
|
|
ТНК
|
В1
|
Аи-98
|
14
|
|
ТНК
|
В1
|
ДТ
|
9
|
|
ТНК
|
В2
|
Аи-95
|
13,2
|
|
ТНК
|
В2
|
Аи-92
|
12,1
|
|
ТНК
|
В2
|
ДТ
|
9
|
Рис. 1.2. Табличное представление данных из иерархической БД.
Очевидно, что значения некоторых данных (фирма, адрес бензоколонки) повторяются в таблице несколько раз.
Исторически БД с иерархической структурой данных относят к 1-му поколению баз данных.
Сетевая структура данных.
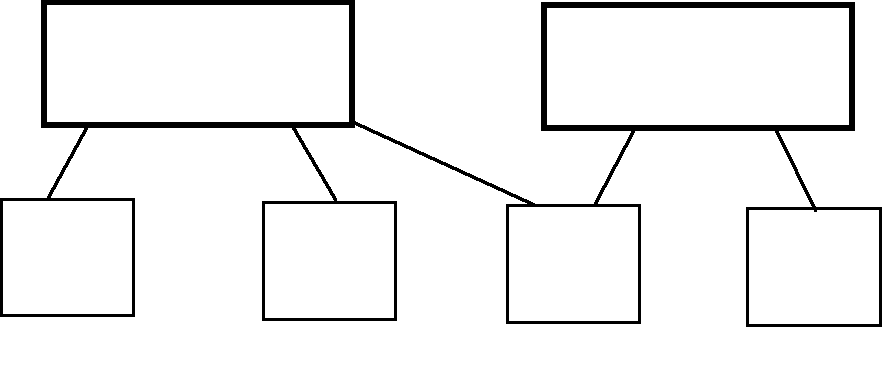
Существуют и более сложные – сетевые – структуры данных (рис 1.3), в которых каждый порожденный элемент может иметь более одного порождающего элемента (например, бензоколонка В1 может получать нефтепродукты и от ЮКОС, и от ТНК). БД с сетевой структурой тоже относятся к 1-му поколению баз данных и также могут быть преобразованы в простую двумерную таблицу.
Рис. 1.3. Сетевая база данных.
Реляционная модель данных, нормализация формы представления данных.
Реляционный подход.
Итак, сетевую и иерархическую структуру данных можно преобразовать в простую двумерную таблицу. Базы данных, которые состоят из двумерных таблиц, называют реляционными (relational database).
Реляционные базы данных – это БД 2-го поколения и появились они во 2-ой половине 70-ых годов, практически вытеснив БД 1-го поколения. Теория БД – это сложная математическая дисциплина, основы которой разработал в 70-х годах доктор Э. Кодд (США).
Основная идея реляционного подхода состоит в том, чтобы представить произвольную структуру данных в виде простой двумерной таблицы, или, как говорят, нормализовать структуру.
Подробнее процесс нормализации рассмотрим далее, а пока сформулируем основные понятия реляционных БД:
- В реляционных БД любые совокупности данных представляются в виде двумерных таблиц (в теории БД – отношений).
- Каждая таблица состоит из фиксированного числа столбцов и некоторого (переменного) количества строк. Описание столбцов, составляемое разработчиком, называют макетом таблицы.
- Столбцы таблицы называются полями (в теории БД – атрибутами), причем для каждого поля должно быть определено:
- уникальное имя поля;
- тип поля (тип данных);
- дополнительные характеристики (например, длину, формат).
- Каждая строка таблицы называется записью (в теории БД - кортежем). Число записей в таблице в процессе эксплуатации БД может как угодно меняться.
- Каждое поле может входить в несколько таблиц.
Создание БД следует начинать с ее логического проектирования, т.е. с описания предметной области. Рассмотрим реляционный подход и принципы создания БД для СУБД MS Access на простом примере учета поставок нефтепродуктов некоторой фирмы.
Построение макета таблиц БД
Пусть некоторая фирма занимается поставкой нефтепродуктов в городе (бензин, дизельное топливо). Клиентами (покупателями) фирмы являются бензоколонки, промышленные и торговые предприятия и т.п. Для учета и анализа поставок фирма может вести таблицу с именем ПОСТАВКИ и со следующими полями (табл. 1.2):
Таблица 1.2.
|
№
|
Имя поля
|
Дополнительная информация
|
Тип данных
|
-
|
Код_поставки
|
Учетный номер поставки
|
числовые
|
-
|
Клиент
|
Название фирмы-клиента
|
текстовые
|
-
|
Адрес_клиента
|
Адрес фирмы-клиента
|
текстовые
|
-
|
Телефон_клиента
|
Контактный телефон
|
текстовые
|
-
|
Продукт
|
Марка поставляемого топлива
|
текстовые
|
-
|
Объем_поставки
|
т
|
числовые
|
-
|
Дата_поставки
|
ДД.ММ.ГГГГ
|
данные типа даты
|
-
|
Цена_продукта
|
руб. / т
|
числовые
|
-
|
Стоимость_поставки
|
руб.
|
числовые
|
Каждому полю (атрибуту) приписано уникальное имя, а также тип данных (формат) - текстовые, числовые, формат даты и т.д. Например, названию нефтепродукта присвоено имя Продукт и задан тип – текстовый.
Кроме того, при заполнении БД о поставках нефтепродуктов нужно каждую марку бензина (значение поля Продукт) обозначать одинаково, например АИ-95. Если в одном случае использовать значение АИ-95, а в другом – значение Бензин_Аи-95, то при одинаковой информативности для человека, для компьютера – это совершенно разные значения поля Продукт. Процесс приспособления форматов и значений данных к нуждам автомата, т.е. уничтожение произвола в представлении данных носит название структурирования информации. Другими словами, структурирование – это просто введение каких-то соглашений о способах представления информации.
Каждая строка такой таблицы ПОСТАВКИ содержит полную информацию о конкретном заказе, а вся таблица позволяет вести учет и анализировать деятельность фирмы по объемам продукции, стоимости, датам и т.п. Таким образом, описав поля, мы разработали макет таблицы для СУБД.
Кодирование информации.
Часто вместе с наименованиями (названиями) атрибутов вводят коды – обычно это цифровые или буквенные обозначения информации. Например, табл. 1.2 можно дополнить полями с кодами Клиента и Продукта (см. табл.1.3)
Таблица 1.3.
|
№
|
Имя поля
|
Дополнительная информация
|
Тип данных
|
-
|
Код_поставки
|
Номер поставки
|
числовые
|
-
|
Клиент
|
Название фирмы-клиента
|
текстовые
|
-
|
Код_клиента
|
Числовой код
|
числовые
|
-
|
Адрес_клиента
|
Адрес фирмы-клиента
|
текстовые
|
-
|
Телефон_клиента
|
Контактный телефон
|
текстовые
|
-
|
Продукт
|
Марка поставляемого топлива
|
текстовые
|
-
|
Код_продукта
|
Числовой код
|
числовые
|
-
|
Объем_поставки
|
т
|
числовые
|
-
|
Дата_поставки
|
ДД.ММ.ГГГГ
|
данные типа даты
|
-
|
Цена_продукта
|
руб. / т
|
числовые
|
-
|
Стоимость_поставки
|
руб.
|
числовые
|
Во-первых, это уменьшит объем вводимой информации (если поле входит в несколько таблиц).
Во-вторых, позволит избежать ошибок при многократном вводе длинных названий (в примере: клиент может быть назван и Кондитерская ф-ка, и Конд. ф.).
Для расшифровки кодов в БД необходимо включить специальную таблицу (классификатор, словарь, справочник), в которой эти коды расшифровываются. Расшифровки используются при выдаче информации на печать или экран в удобочитаемой форме.
Код должен быть уникальным. Это означает, что если вы присвоили код 01 Автобазе № 3, то этот код не может принадлежать никакому другому клиенту фирмы.
Первичный ключ таблицы.
Каждая запись в таблице должна иметь первичный ключ, т.е. идентификатор, значение которого однозначно определяет эту и только эту запись. Ключ может состоять из одного (в примере Код_поставки) или нескольких полей.
Первичный ключ должен обладать двумя свойствами:
- Однозначная идентификация записи.
- Отсутствие избыточности: никакое поле нельзя удалить из ключа, не нарушив при этом свойства однозначности.
Каждое значение первичного ключа в пределах таблицы должно быть уникальным. В противном случае нельзя отличить одну запись от другой. Например, в кадровых БД, в качестве идентификатора не может использоваться ФИО, т.к. они могут повторяться, а используется табельный номер или какой-то другой индивидуальный номер (например, для абитуриентов в информационной системе "Абитуриент", действующей во всех вузах, это регистрационный номер).
Нормализация.
Вернемся к рассмотрению процесса нормализации исходной структуры данных. Уже упоминалось, что нормализация - это процесс превращения иерархической или сетевой структуры в реляционную. Существует строгая теория нормализации, но мы разберем этот процесс на простом примере макета таблицы ПОСТАВКИ.
Первичным ключом составленной таблицы является поле Код_поставки, который не повторяется в пределах таблицы и позволяет отличить одну запись от другой. Очевидно, что такие поля как Клиент и Адрес_клиента не зависят от первичного ключа, а зависят только от Кода_клиента. Поэтому следует удалить поля Клиент и Адрес_клиента из таблицы ПОСТАВКИ и включить их в классификатор (словарь) – таблицу КЛИЕНТЫ, имеющей три поля: Код_клиента, Клиент, Адрес_клиента. Аналогичным образом составляется классификатор ПРОДУКТЫ (Код_продукта, Продукт, Цена_продукта). Естественно, поля Код_продукта и Цена_продукта из таблицы ПОСТАВКИ исключаются.
Значение поля Стоимость_поставки вообще не следует включать в таблицы, т.к. она легко вычисляется как произведение цены на количество (объем).
Таким образом, в результате нормализации исходной таблицы получено три таблицы: оперативная ПОСТАВКИ и две справочные КЛИЕНТЫ и ПРОДУКТЫ (рис.1.4).
ПОСТАВКИ.
|
№
|
Имя поля
|
Дополнительная информация
|
Тип данных
|
-
|
Код_поставки
|
-
|
числовые
|
-
|
Код_клиента
|
-
|
числовые
|
-
|
Код._продукта
|
-
|
числовые
|
-
|
Объем_поставки
|
т
|
числовые
|
-
|
Дата_поставки
|
ДД.ММ.ГГГГ
|
данные типа даты
|
КЛИЕНТЫ.
|
№
|
Имя поля
|
Дополнительная информация
|
Тип данных
|
-
|
Код_клиента
|
-
|
текстовые
|
-
|
Клиент
|
-
|
числовые
|
-
|
Телефон_клиента
|
-
|
текстовые
|
-
|
Адрес_клиента
|
-
|
текстовые
|
ПРОДУКТЫ
|
№
|
Имя поля
|
Дополнительная информация
|
Тип данных
|
-
|
Код_продукта
|
-
|
текстовые
|
-
|
Продукт
|
-
|
числовые
|
-
|
Цена_продукта
|
руб. / т
|
числовые
|
Рис.1.4. Результат нормализации исходной таблицы ПОСТАВКИ.
Разбиение (декомпозиция, реорганизация) исходной структуры производится таким образом, чтобы справочные таблицы менялись достаточно редко, а основные изменения и дополнения записей приходились бы на оперативную таблицу.
Связь таблиц: главная и подчиненные таблицы.
Таблица КЛИЕНТЫ связана с таблицей ПОСТАВКИ по полю Код_клиента. Первая таблица считается главной, а вторая – подчиненной. Поле Код_клиента для первой таблицы является первичным ключом, а для второй таблицы – внешним ключом. Кроме того, вторая таблица имеет собственный первичный ключ (Код_поставки).
В таблицу КЛИЕНТЫ в принципе можно включить потенциальных клиентов и тогда каждому клиенту в подчиненной таблице ПОСТАВКИ будет соответствовать одна, несколько или ни одной записи. Такое отношение между двумя таблицами называется связью "Один-ко-многим". Реже встречается другое отношение: "Один-к-одному" (например, в кадровых таблицах каждый работник занесен в главную таблицу, но не каждый занесен в таблицу доступа к какой-либо секретной информации). Существует также отношение "Много-ко-многим", но мы его не рассматриваем.
Итак, для пары связанных таблиц (одна из которых главная, а другая подчиненная) всегда определен один из двух взаимоисключающих типов связи: "Один-ко-многим" или "Один-к-одному". Одна из функций ИС, которая обеспечивает согласованность информации в связанных таблицах, называется поддержкой целостности данных. Нельзя ввести в подчиненную таблицу ПОСТАВКИ строку с несуществующим в таблице КЛИЕНТЫ кодом клиента.
Основы алгебры логики и принципы поиска информации.
Постановка задачи.
Итак, пусть некая база данных создана и заполнена. Как выбрать из нее нужную в данный момент информацию?
Известно, что компьютер способен легко проводить расчеты (например, арифметические действия) с заданными значениями числовых данных. Однако обязанности ИС отнюдь не ограничиваются механическими расчетами по заданным формулам. Более того, многие системы вообще не предназначены для вычислений в общепринятом смысле, - например телефонный справочник. Одна из основных функций ИС – обслуживание операций поиска и выборки (а точнее – отбора) данных.
При поиске и отборе данных информационной системе приходится решать две связанные, но принципиально разные задачи.
- Если таблица невелика, система без ущерба для времени ответа может просто перебрать все записи. Однако если таблица содержит миллионы записей, простой перебор даже у мощного компьютера может занять слишком много времени. (Наверное, вы видели, как полицейские по заданному номеру автомобиля почти мгновенно получают сведения о его владельце из списка в десятки миллионов записей.) Иными словами, ИС должна находить нужную информацию, не просматривая все записи.
- Прочитав, некую строку таблицы, ИС система должна решить, удовлетворяет ли эта строка сформулированному запросу. Если да, включить строку в выборку, если нет – пропустить.
Рассмотрим один из способов решения этих задач в ИС.
Просмотр информации и индексы.
Рассмотрим первую задачу отбора данных – быстрый поиск в таблицах.
Чтобы система могла достаточно быстро найти нужные записи, таблицу следует упорядочить по значениям ключа поиска (по возрастанию или убыванию).
Рассмотрим простейший случай: найти адрес друга, телефон которого вы помните наизусть. Таблица (1.2) должна быть упорядочена по возрастанию первичного ключа – по номеру телефона. Допустим, надо найти телефон 339-18-45 в таблице из 526 строк. Система знает: (1) значения ключа (телефона) – уникальны; (2) всего в справочнике 526 записей. Прежде всего, система заглядывает в середину таблицы и читает 263 запись. Возможны три случая:
- телефон в этой записи равен искомому – запись найдена сразу;
- телефон в этой записи меньше искомого (например, 133-14-52 – значит, искомые данные находятся в верхней половине таблицы);
- телефон в этой записи больше искомого (например, 943-78-90 – значит, искомые данные находятся в нижней половине таблицы).
Таким образом, с первого захода система исключает из области поиска сразу половину таблицы. Следующая запись берется из середины верхней или нижней половины таблицы (в зависимости от результата сравнения на первом этапе) и т.д. Выполнив всего несколько шагов, система найдет искомый номер телефона или убедится, что его нет. Это самый простой метод поиска и называется он двоичным (или бинарным).
Списки телефонов можно упорядочить (сортировать) по разным ключам – по имени абонента, по категории и т.д. От ключа сортировки зависит не только время поиска по определенному запросу, но и сама возможность ответить на запрос, не перебирая все записи.
Как упорядочивают записи таблиц в информационных системах? Как правило, таблицу не трогают, но создают для нее специальный массив данных, который называется индексом.
Индекс – это набор указателей на строки таблицы, упорядоченный по значениям ключа. Каждый элемент этого набора состоит из двух частей: порядкового номера записи в таблице и значения ключа сортировки.
Например, индекс для таблицы ТЕЛЕФОНЫ при сортировке по возрастанию может выглядеть так:
|
Номер записи
|
Телефон
|
|
145
|
245-21-12
|
|
264
|
246-46-45
|
|
45
|
338-34-89
|
|
. . . .
|
. . . .
|
В разных системах индексы формируются по-разному. Мы рассмотрели частный случай индексирования – применительно к структурированным базам данных. Однако индексирование широко применяется для поиска в неструктурированных документах, например в глобальной сети Internet. В этом случае в качестве значений ключа индекса используются так называемые ключевые слова, т.е. фрагменты текста, каким-то образом отражающие содержание документа. Вместо номера записи указывается адрес документа, в котором обнаружено данное ключевое слово.
Алгебра логики.
Рассмотрим вторую задачу – отбор строк. Английский математик Дж. Буль еще в XIX веке, изучая законы логики, создал систему исчисления, называемую алгеброй логики. Основными элементами алгебры логики являются логические выражения. Элементы логического выражения соединяются знаками отношения:
|
= (равно)
|
<> (не равно)
|
|
> (больше)
|
>= (больше или равно)
|
|
< (меньше)
|
<= (меньше или равно)
|
и образуют условные выражения, например a>b.
Условные выражения (или операнды) соединяются знаками логических операций: AND, OR, XOR, EQV, IMP, NOT.
Логическая (или булева) переменная в логических выражениях может принимать только два значения: TRUE ("истина") или FALSE ("ложь").
Вычислив значение логического выражения, машина может присвоить его булевой переменной и использовать в дальнейших логических операциях.
Простой пример логического выражения (фильтра) для БД ЗАКАЗЫ: Код_клиента=02 AND Дата_поставки>=01.07.2003 (выбрать все заказы для клиента с кодом 02 сделанные за второе полугодие).
Аппарат алгебры логики лежит в основе всех механизмов отбора в информационных системах. Информация как бы фильтруется: в выборку включаются только те записи таблицы, для которых значение фильтра истинно.
Системы управления реляционными базами данных (СУБД).
Итак, мы рассмотрели основные принципы фактографических ИС:
- структурирование данных и построение двумерных таблиц;
- основы реляционного подхода;
- основы алгебры логики и принципы поиска информации.
Инструментальными средствами, позволяющими проектировать, наполнять и модифицировать базы данных, вести поиск информации, являются системы управления базами данных (СУБД).
В ИС, которые работают на ПК, большое распространение получили так называемые dBASE-подобные СУБД. Это dBASE, FoxPro, Clipper, их версии и модификации. Для пользователей существенным является то, что все эти СУБД используют одни и те же оперативные файлы с расширением .DBF, и этот формат стал на некоторое время стандартом баз данных. Характерной особенностью файла .DBF является простота и наглядность: физическое представление данных на диске в точности соответствует представлению таблицы на бумаге.
Однако в целом системы, построенные на основе файлов .DBF, следует считать устаревшими. Многие механизмы реляционных баз данных в dBASE-подобных системах не поддерживаются.
Большую популярность до сего времени имеют и другие СУБД (с другим форматом файлов) – Paradox, Clarion, db_Vista и т.д. Перечисленные системы разрабатывались для работы под MS-DOS, однако почти все они имеют версии для Windows.
Среди современных реляционных систем наиболее популярны СУБД для Windows – Access фирмы Microsoft, Approach фирмы Lotus, Paradox фирмы Borland. Многие из этих систем поддерживают технологию OLE и могут манипулировать не только числовой и текстовой информацией, но и графическими образами (рисунками, фотографиями) и даже звуковыми фрагментами и видеоклипами.
Перечисленные СУБД часто называют настольными, имея в виду сравнительно небольшой объем данных, обслуживаемых этими системами. Однако с ними работают не только индивидуальные пользователи, но и целые коллективы (особенно в локальных вычислительных сетях).
Вместе с тем, в центр современной информационной технологии постепенно перемещаются более мощные реляционные СУБД с SQL-доступом (SQL – это язык запросов). В основе этих СУБД лежит так называемая технология "клиент-сервер". Среди ведущих производителей таких систем - Oracle, Centura (Gupta), Sybase, Informix, Microsoft и другие. Появились также объектные и объектно-реляционные СУБД.
В дальнейшем Вы научитесь проектировать простейшие ИС в своей предметной области, наполнять и модифицировать базы данных, вести поиск информации и составлять отчеты в среде СУБД Access, входящей в пакет Microsoft Office. Эти знания позволят вам свободно общаться с любой профессиональной СУБД, независимо от ее конкретного вида и версии.
PAGE 9
13
12
0
8,9
9
14
13,2
12,1
9
13,1
12,2
9,9
13
12
10
Аи-95
Аи-92
Аи-76
Аи-95
Аи-92
Аи-76
Аи-95
Аи-92
Аи-76
ДТ
Аи-95
Аи-92
ДТ
B2
Аи-98
В1
ДТ
Марка и цена имеющегося топлива
Адреса бензоколонок
Фирмы, продающие топливо
ТНК
А3
А2
ЮКОС
А1
Базы данных. Основные понятия